Этот материал написан посетителем сайта, и за него начислено вознаграждение.
На моем десктопном компьютере установлен SSD Crucial MX-200 500Gb, на котором установлена операционная система и игры.

Где-то месяц назад игры стали ужасно лагать, зависали до 5 секунд, играть стало не возможно, компьютер иногда зависал намертво и сам перезапускался. Я начал искать причину, логично, что в первую очередь решил проверить состояние SSD Crucial MX-200 по его SMART.
рекомендации
-17% на RTX 4070 Ti в Ситилинке
Выбираем игровой ноут: на что смотреть, на чем сэкономить
3080 дешевле 70 тр — цены снова пошли вниз
Ищем PHP-программиста для апгрейда конфы
3070 Gainward Phantom дешевле 50 тр
13700K дешевле 40 тр в Регарде
16 видов <b>4070 Ti</b> в Ситилинке — все до 100 тр
3070 Ti дешевле 60 тр в Ситилинке
3070 Gigabyte Gaming за 50 тр с началом
Компьютеры от 10 тр в Ситилинке
3070 дешевле 50 тр в Ситилинке
MSI 3050 за 25 тр в Ситилинке
3060 Gigabyte Gaming за 30 тр с началом
13600K дешевле 30 тр в Регарде
4080 почти за 100тр — дешевле чем по курсу 60
-19% на 13900KF — цены рухнули
12900K за 40тр с началом в Ситилинке
RTX 4090 за 140 тр в Регарде
3060 Ti Gigabyte за 42 тр в Регарде
И обнаружил, что атрибут SMART-a 199 UltraDMA CRC Error Count (количество ошибок, возникших во время передачи данных по кабелю от материнской платы до дискретного контроллера диска) буквально за два дня вырос более чем на 2000 ошибок.

Спустя два дня

Это вполне объясняло подобное поведение компьютера.
Естественно, что в первую очередь под подозрение попал кабель SATA, но нет, если бы это было так, то я не стал бы писать статью.
Были перепробованы все кабеля SATA которые у меня только есть, для проверки также поменян кабель SATA с HDD, который у меня стоит на компьютере в качестве хранилища, кстати на нем этот атрибут равен нулю, то есть не возникло ни одной ошибки. Переподключал кабель SATA в разные порты на материнской плате, но и это ничего не дало.
После этого SSD был установлен в ноутбук, где при тех же играх и нагрузке данный атрибут SMART-a не увеличился ни на единицу, и ноутбук работал отлично.
Контроллер материнской платы компьютера я тоже исключил, так как установив на HDD стоящий в компьютере операционную систему и игры, и погоняв его с теми же нагрузками, увидел, что атрибут UltraDMA CRC Error Count не увеличился, так и остался равным нулю.
Что же тогда еще остается?
Отступление:
При замене кабелей SATA на SSD, один кабель SATA я приобрел в магазине, на всякий случай, так как думать уже не знал на что. Когда я его покупал, оговорился о данной проблеме. И от продавцов узнал для себя удивительную вещь: они авторитетно заявили, что возможно у меня стоит кабель SATA 2 и не обеспечивает необходимую пропускную способность, и нужно купить у них кабель SATA 3, и даже показали кабель на котором стоит клеймо SATA 3 (может я этого не знаю). Я возразил, сказал, что такого быть не может, что у них у всех 7 pin , и одинаковые медные проводники, и электрический сигнал распространяется одинаково. пропускная способность зависит от контроллера материнской платы и от контролера жесткого диска, а не от 7 медных проводников, которыми они соединены. И на вопрос чем они физически отличаются, внятно объяснить мне не смогли.
Что думаете вы по этому поводу напишите в комментариях.
Но я все-таки купил у них этот кабель SATA 3. Ну как вы и подумали проблему это не решило.
Дальше я принялся ковырять блок питания. По замерам мультиметра, и по данным проги «AIDA» все напряжения были в норме. Но при измерении осциллографом пульсаций по питанию, в большей мере меня интересовало питание 5 В. которым питался SSD , было выявлено наличие провалов в осциллограмме с 5 до 4,5 В.


 https://disk.yandex.ru/i/v3nlN_OmffD_hw
https://disk.yandex.ru/i/v3nlN_OmffD_hw
Расположение их по шкале времени имело случайный характер. Но казалось бы, и 4,5 В. достаточно, так как в SSD стоят свои преобразователи в более низкие напряжения. Но я все же в качестве диагностики попытался уменьшить эти пульсации и подключил прямо к разъему MOLEX к шине 5 в. электролитический конденсатор на 4000 мкФ.


И наконец это решило проблему, осциллограмма выровнялась, провалы пропали, атрибут 199 UltraDMA CRC Error Count больше не увеличивается, компьютер летает, игры не лагают. Теперь выберу время, разберу блок питания и займусь им.
Надеюсь, мой случай окажется вам интересен и полезен.
Этот материал написан посетителем сайта, и за него начислено вознаграждение.
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
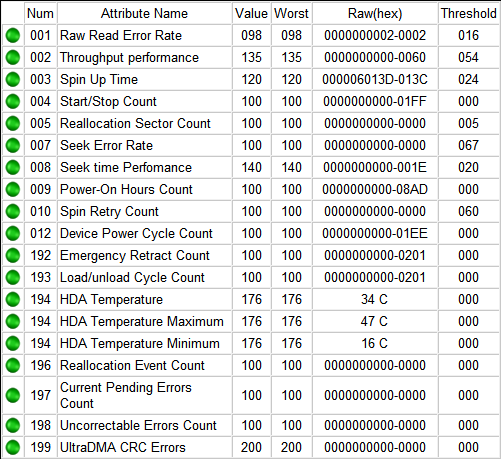
S.M.A.R.T. в HDDScan 3.3
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 10 | 11 | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | BD | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | BF | С0 | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 | СА | CB | DC | F0 | FE |
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
Атрибут: 01 Raw Read Error Rate
| Тип | текущий, может быть накапливающим для WD и старых Hitachi |
| Описание | содержит частоту возникновения ошибок при чтении с пластин |
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
| Тип | текущий |
| Описание | содержит значение средней производительности диска и измеряется в каких-то «попугаях». Обычно его ненулевое значение отмечается на винчестерах Hitachi. На них он может изменяться после изменения параметров ААМ, а может и сам по себе по неизвестному алгоритму |
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
| Тип | текущий |
| Описание | содержит время, за которое шпиндель диска в последний раз разогнался из состояния покоя до номинальной скорости. Может содержать два значения — последнее и, например, минимальное время раскрутки. Может измеряться в миллисекундах, десятках миллисекунд и т. п. — это зависит от производителя и модели диска |
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
| Тип | накапливающий |
| Описание | содержит количество раз включения диска. Бывает ненулевым на только что купленном диске, находившемся в запаянной упаковке, что может говорить о тестировании диска на заводе. Или ещё о чём-то, мне не известном  |
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
| Тип | накапливающий |
| Описание | содержит количество секторов, переназначенных винчестером в резервную область. Практически ключевой параметр в оценке состояния |
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение, а используемый вместо повреждённого сектор — переназначенным. Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при позиционировании блока магнитных головок (БМГ) |
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
| Тип | текущий |
| Описание | содержит среднюю производительность операций позиционирования головок, измеряется в «попугаях». Как и параметр 02 Throughput Performance, ненулевое значение обычно отмечается на дисках Hitachi и может изменяться после изменения параметров ААМ, а может и само по себе по неизвестному алгоритму |
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
| Тип | накапливающий |
| Описание | содержит количество часов, в течение которых винчестер был включён |
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
| Тип | накапливающий |
| Описание | содержит количество повторов запуска шпинделя, если первая попытка оказалась неудачной |
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Тип | накапливающий |
| Описание | содержит количество повторных попыток сброса накопителя (установки БМГ на нулевую дорожку) при неудачной первой попытке |
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов «включение-отключение» диска |
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
| Тип | накапливающий |
| Описание | содержит количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута |
Не говорит о здоровье накопителя.
Атрибут: 184 (B8) End-to-End Error
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче данных через кэш винчестера |
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Тип | накапливающий |
| Описание | содержит количество секторов, которые были признаны кандидатами на переназначение (см. атрибут 197) за всю историю жизни диска. Причём если сектор становится кандидатом повторно, значение атрибута тоже увеличивается |
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
| Тип | накапливающий |
| Описание | содержит количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика |
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
| Тип | накапливающий |
| Описание | содержит количество зафиксированных случаев записи при высоте полета головки выше рассчитанной — скорее всего, из-за внешних воздействий, например вибрации |
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
| Тип | текущий |
| Описание | содержит температуру винчестера для дисков Hitachi, Samsung, WD и значение «100 − [RAW-значение атрибута 194]» для Seagate |
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Тип | накапливающий |
| Описание | содержит количество критических ускорений, зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. |
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
| Тип | накапливающий |
| Описание | для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок БМГ диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т. п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi) |
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов парковки/распарковки БМГ. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (столь любимая, например, компанией Western Digital): если его содержимое превосходит (обычно — многократно) содержимое атрибута 09 — счётчик отработанных часов, — то парковка включена |
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
| Тип | текущий/накапливающий |
| Описание | содержит текущую температуру диска. Температура считывается с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера |
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
| Тип | накапливающий |
| Описание | содержит количество ошибок, которые были скорректированы аппаратными средствами ECC диска |
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
| Тип | накапливающий |
| Описание | содержит количество операций переназначения секторов |
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
| Тип | текущий |
| Описание | содержит количество секторов-кандидатов на переназначение в резервную область |
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.
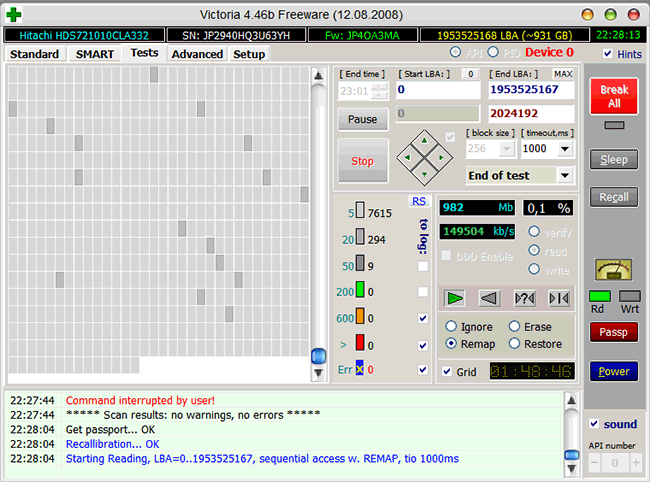
Идёт последовательное чтение с ремапом в Victoria 4.46b
В случае неудачи чтения как с remap, так и с Advanced remap, стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!
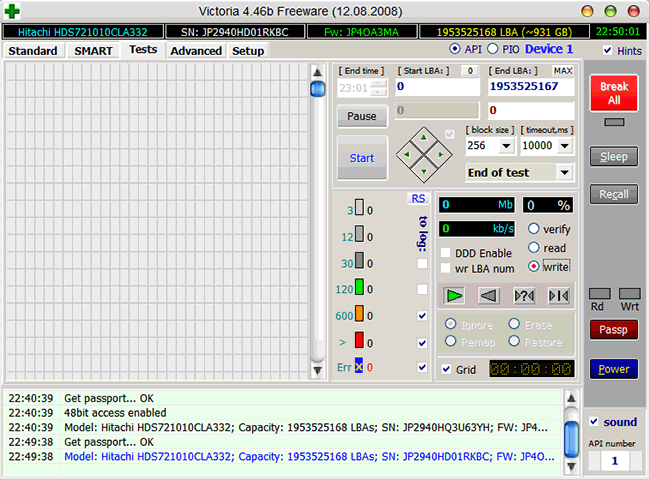
Запуск последовательной записи в Victoria 4.46b
Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Тип | текущий |
| Описание | означает то же самое, что и атрибут 197, но отличие в том, что данный атрибут содержит количество секторов-кандидатов, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой |
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
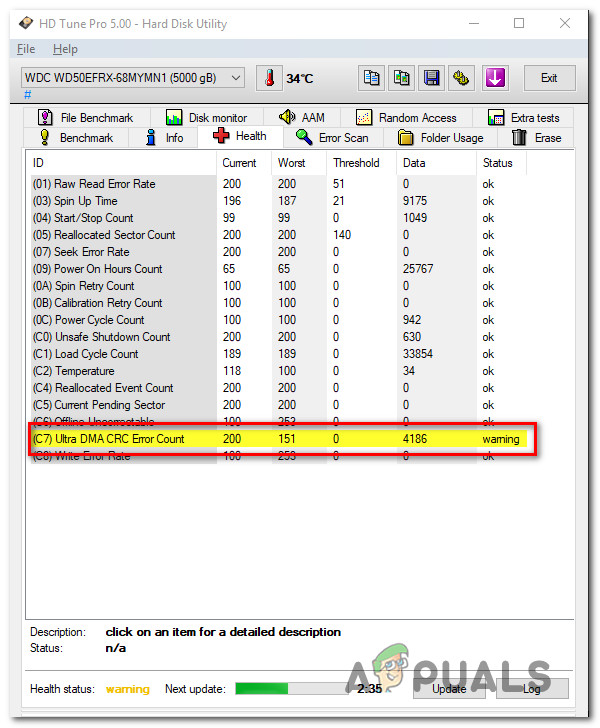
Атрибут: 199 (С7) UltraDMA CRC Error Count
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска |
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при записи |
Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать «умирающие» головки.
Атрибут: 201 (С9) Soft Read Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок чтения, произошедших по вине программного обеспечения |
Влияние на здоровье неизвестно.
Атрибут: 202 (СА) Data Address Mark Error
| Тип | неизвестно |
| Описание | содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо |
Атрибут: 203 (CB) Run Out Cancel
| Тип | текущий |
| Описание | содержит количество ошибок ECC |
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
| Тип | текущий |
| Описание | содержит измеренный в неизвестных единицах сдвиг пластин диска относительно оси шпинделя |
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
| Тип | накапливающий |
| Описание | содержит время, затраченное на позиционирование БМГ. Счётчик может содержать несколько значений в одном поле |
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
| Тип | накапливающий |
| Описание | содержит зафиксированное электроникой количество ускорений свободного падения диска, которым он подвергался, т. е., проще говоря, показывает, сколько раз диск падал |
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения:
- атрибутов 01, 07, 195 — вызывают подозрения в «болезни» у некоторых моделей дисков;
- атрибутов 10, 11, 188, 196, 199, 202 — вызывают подозрения у всех дисков;
- и, наконец, атрибутов 05, 184, 187, 197, 198, 200 — прямо говорят о неполадках.
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
![]()
Атрибут 01 в Victoria 4.46b
А так выглядит он же в «правильной» HDDScan 3.3:
![]()
Атрибут 01 в HDDScan 3.3
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина.
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:
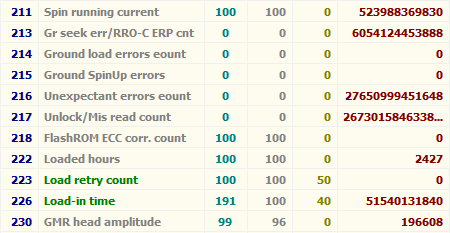
«Страшные» значения в Victoria 4.46b
Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах. При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (работает в Windows, бесплатная), CrystalDiskInfo (Windows, бесплатная), Hard Disk Sentinel (платная для Windows, бесплатная для DOS), HD Tune (Windows, платная, есть бесплатная старая версия).
И наконец, мощнейшие программы для тестирования: Victoria (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).
Содержание
- Как устранить ошибки Ultra DMA CRC Error
- Основные характеристики жесткого диска
- Технология S.M.A.R.T
- Атрибут: 199 (С7) UltraDMA CRC Error Count
- How to Fix ‘Interface CRC Error Count’ inside HD Tune
- What is Ultra DMA CRC Error Count?
- Method 1: Running the brand-specific diagnostic tool
- Method 2: Fix the Incompatibility between Samsung SSD and SATA Controller (if applicable)
- Method 3: Replace the power and SATA cable
- Method 4: Backup your HDD data
- A. Backing up the files on your HDD via Command Prompt
- B. Backing up the files on your HDD via an Imaging 3rd party software
- Method 5: Send your HDD for replacement or order a replacement
Как устранить ошибки Ultra DMA CRC Error
Одним из важнейших компонентов любого компьютерного устройства является жесткий диск, другие названия: винчестер, винт, хард, HDD и т.д. Он служит для хранения разных данных пользователя, включая документы, музыку, фотографии, а также программные продукты и файлы операционной системы. Данный узел является энергонезависимым, т.е. отключение питания не приводит к исчезновению данных.
Информация, хранящаяся на жестком диске, бывает порой ценнее самого компьютера и чтобы не потерять ее (причины утраты данных на HDD и способы восстановления), необходимо контролировать состояние винчестера. В данной статье рассматриваются причины возникновения одной из наиболее часто встречающейся проблемы в работе HDD и пути для ее устранения.
Рассмотрим характеристики винчестера, по которому оценивается устройство, а также встроенные инструментарии для контроля над состоянием его работоспособности.
Основные характеристики жесткого диска
Накопители выпускаются в разных стандартных размерах, измеримых в дюймах, так для стационарных компьютеров это значение равно 3.5 дюйма, а для ноутбуков 2.5.
Взаимодействие диска с материнской платой выполняется через интерфейс, в настоящее время в ПК используется интерфейс SATA разных версий, отличающихся скоростью передачи данных (SATA/300 – 3 Гбит/сек, SATA/600 – до 6 Гбит/сек и т.д.).
Важной характеристикой устройства является показатель емкости, определяющий максимальное количество данных, хранящихся на диске.
Чем больше скорость вращения жёсткого диска, тем быстрее возможен доступ к информации. Она составляет 5400 или 7200 об/мин (реже 10 000 или 15 0000 об/мин, но это уже специализированные HDD).
Данный узел имеет встроенную память, которая служит для ускорения его работы и устранения разницы в скоростях чтения/записи и воспроизведения. Она характеризуется объемом буфера.
Время произвольного доступа зависит от позиционирования и положения головки в начале и конце сеанса определенного участка пластины.
Надежность работы, ударостойкость, уровень шума также являются оценочными характеристиками накопителя.
Ни один другой компонент компьютера не имеет такой уникальной возможности самоанализа на наличие ошибок и статистики работы, как винчестер. Произвести оценку состояния жесткого диска и предсказать время выхода его из строя можно с помощью специальной встроенного инструмента самодиагностики.
Технология S.M.A.R.T
Инструментарий, с помощью которого можно контролировать работоспособность винчестера, получил название S.M.A.R.T, что означает самомониторинг, анализ и отчет — от заглавных букв английского варианта «Self-Monitoring, Analysis and Reporting Technology».
С учетом того, что винчестер является одним из слабых мест компьютерного устройства, возможность вовремя отслеживать изменение состояния его функционирования, позволяет быстро выявить и устранить неисправности, экономя владельцу время и деньги.
Винчестер может находиться в двух состояниях: S.M.A.R.T. Good и S.M.A.R.T. Bad. Первый вариант свидетельствует о нормальной работе устройства, второй о том, что диск находится в критическом положении. Так как переход в состояние «bad» происходит постепенно, мониторя S.M.A.R.T. можно увидеть ухудшение параметров и успеть перенести информацию на другой накопитель.
Тестирование жесткого диска выполняют специальными утилитами, которые демонстрируют атрибуты S.M.A.R.T., характеризующие состояние его «здоровья». В зависимости от модели и производителя, атрибуты имеют определенные названия (ID) и номер (NUMBER).
Примерами программ, с помощью которых можно увидеть значения S.M.A.R.T и протестировать винчестер, являются следующие: CrystalDiskInfo (бесплатная), HDDScan (бесплатная), HD Tune(бесплатная только в старой версии), Hard DiskSentinel (бесплатная только для DOS), а также Victoria (бесплатная), MHDD (бесплатная под DOS).
Вот как выглядит картинка тестирования жесткого диска с помощью программы S.M.A.R.T. в HDDScan 3.3.
- Value — показатель состояния диска во время работы. Может изменяться, уменьшаясь или увеличиваясь, или быть неизменным. Его сравнивают с атрибутом Threshold: чем меньше, тем хуже «здоровье» HDD.
- Worst — самое низкое значение, которого может достичь Value в процессе всего жизненного цикла винчестера, его также сравнивают Threshold.
- Threshold — показатель критического состояния атрибута Value: норма, если он больше чем Threshold, меньший указывает на проблему. Утилиты, оценивающие состояние диска, судят по этому атрибуту.
- RAW — один из самых важных в оценке. Объективно определить состояние HDD можно по этому показателю.
Атрибут: 199 (С7) UltraDMA CRC Error Count
Данный атрибут относится к накапливающему типу и содержит количество ошибок, которые возникают во время передачи по интерфейсному кабелю от материнской платы или дискретного контроллера к контроллеру диска.
Например, если при запуске утилиты, отображающей атрибуты S.M.A.R.T, напротив строки (C7) Ultra DMA CRC Error Count счетчик показывает значение 1234, это говорит о проблемах с HDD.
По статистике, чаще всего увеличение значения этого атрибута возникает вследствие некачественной передачи данных по интерфейсу, что приводит к автоматическому переключению режимов работы канала, на котором находится HDD, и резкому падению скорости чтения/записи.
Другой причиной может быть разгон шины PCI/PCI-E компьютерного устройства, а также нарушение контакта в SATA-разъёме на диске или на материнской плате (контроллере). В некоторых случаях растущий атрибут появляется из-за несовместимости жесткого диска и SATA-контроллера.
Устранить ошибку S.M.A.R.T UltraDMA CRC Error Count можно путем выполнения ряда следующих действий:
- замены интерфейсного кабеля SATA;
- выполнения сброса разгона шины PCI/PCI-E компьютера к заводским установкам;
- обновления BIOS материнской платы;
- очищения с помощью спирта или обыкновенной стирки (резинового ластика) контактов на разъеме жесткого диска или материнки;
- переключения SATA-кабеля на другой разъем;
- замены блока питания жесткого диска;
- проверки материнки на предмет «вздутых» конденсаторов и, при необходимости, выполнения их замены;
- замены термопасты южного моста материнки;
- замены чипсета материнской платы;
- установления перемычки на жестком диске и переключить режим работы контроллера в SATA I;
- обновления драйвера чипсета материнской платы.
Впрочем, самостоятельно делать все вышеуказанные процедуры необязательно (если нет желания), всегда можно обратиться за компьютерной помощью к специалистам.
Необходимо иметь в виду, что хорошие атрибуты S.M.A.R.T не всегда дают полную и достоверную картину отличного состояния диска, однако плохие значения точно свидетельствуют о проблемах в HDD.
Гарантировано обезопасить себя от потери ценных данных, хранящихся на жестком диске, можно только с помощью периодического резервного копирования на съемный накопитель или другой диск, тогда как тестирование винчестера на предмет обнаружения ошибок в атрибутах поможет предотвратить его внезапный выход из строя.
Источник
How to Fix ‘Interface CRC Error Count’ inside HD Tune
Some Windows users are reporting that they always end up seeing a warning (Ultra DMA CRC Error Count) when analyzing their HDD using the HD Tune utility. While some affected users are seeing this with used hard drivers, others are reporting this issue with brand new HDDs.
 Interface CRC Error Count inside HD Tune
Interface CRC Error Count inside HD Tune
What is Ultra DMA CRC Error Count?
This is a S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology) parameter that indicates the total quantity of CRC errors during UltraDMA mode. The raw value of this attribute indicates the number of errors found during data transfer in UltraDMA mode by ICRC (Interface CRC).
But keep in mind that this parameter is considered informational by most hardware vendors. Although the degradation of this parameter can be regarded as an indicator of an aging drive with potential electromechanical problems, it does NOT directly indicate imminent driver failure.
To get the complete picture of the health of your HDD, you need to pay attention to other parameters and the overall drive health.
After investigating this issue thoroughly, it turns out that there are several different underlying causes that might end up produce this particular error code:
- Generic False Positive – Keep in mind that a warning thrown around by the HD Tune utility does not necessarily mean that your HDD is failing. This utility uses generic aggregated from every manufacturer, so concerning data from one manufacturer might not be concerning for another. To get a more accurate result, you will need to run the brand-specific diagnostic tool and see if the same kind of warning occurs.
- Incompatibility between Samsung SSD and SATA Controller – If you’re encountering this issue with an SSD, chances are it’s due to a conflict between your solid-state drive and the Microsoft or AMD SATA controller driver. To fix this incompatibility, you’ll need to use Registry Editor to disable NCQ (Native Command Queue).
- Faulty SATA Cable or SATA port – As it turns out, you can also expect to encounter this type of issue if you’re dealing with a faulty SATA port or a non-congruent SATA cable. In this case, you can identify the culprit by testing the HDD on a different machine and replacing the current SATA cable.
- Failing HDD or SSD – Under certain circumstances, you can expect to see this error warning in the early stages of a failing drive. In this case, the only thing you can do is back up your data before the drive breaks up for good and start looking for a replacement.
Now that you know the very potential scenario that might cause this error code, here’s a list of methods that will help you identify and resolve the Ultra DMA CRC Error Count error:
Method 1: Running the brand-specific diagnostic tool
Keep in mind that the HD Tune Utility is a 3rd party tool that will ‘judge’ the heath of an HDD solely by comparing them against a set of generic values.
Because of this, it’s highly recommended to avoid making a decision based on HD Tune Utility alone and instead run the brand-specific diagnostic tool – The official testing tools are specifically designed for their brand products.
Depending on your HDD manufacturer, install and scan your hard drive with the proprietary diagnostic utility. To make matters easier for you, we’ve made a list of the most popular brand-specific diagnostic tools:
Note: If your HDD manufacturer is not included in the list above, search online for specific steps on your brand-specific diagnostic tool, then install and run it to see if the Ultra DMA CRC Error Count is still off.
If the manufacturer-specific diagnostic tool doesn’t raise any concerns in relation to the value of Ultra DMA CRC Error Count, then you can safely ignore the warning thrown by HD Tune.
However, if the warning is also displayed in the manufacturer-specific analysis tool, move down to the next potential fix below.
Method 2: Fix the Incompatibility between Samsung SSD and SATA Controller (if applicable)
As it turns out, the Ultra DMA CRC Error Count error is not restricted to an HDD and can also occur if you’re using an SSD.
But if you’re seeing this error with a Samsung SSD, there’s a high chance that the issue has nothing to do with a bad cable or solid-state health – It’s most likely due to an incompatibility between your Samsung SSD and your chipset Sata controller.
If you find yourself in this particular scenario, you can fix the issue and prevent this warning from appearing by disabling NCQ (Native Command Queue) in your SATA driver.
Note: This will not affect the functionality of your SATA drive.
If this scenario is applicable, the instructions below to fix the incompatibility between your Samsung SSD and the Sata Controller:
- Press Windows key + R to open up a Run dialog box. Next, inside the text box, type ‘regedit’, then press Ctrl + Shift + Enter to open up the Registry Editor with admin access. When you’re prompted by the UAC (User Account Control), click Yes to grant administrative access.
 Opening Regedit
Opening Regedit - Once you’re inside the Registry Editor, use the left-hand menu to navigate to the following locations, depending on if you’re using a Microsoft SATA Controller driver or a AMD SATA Controller driver:
 Opening Regedit
Opening RegeditNote: You can either navigate here manually or you can paste the location directly into the navigation bar
 Creating a new Dword value inside the Device menu
Creating a new Dword value inside the Device menuIf the same issue is still occurring even after following the instructions above or this scenario was not applicable, move down to the next potential fix below.
Method 3: Replace the power and SATA cable
As several affected users have confirmed, this particular issue can also be associated with a faulty SATA cable or a faulty SATA port. Because of this, the Ultra DMA CRC Error Count error can also be a symptom of a non-congruent cable.
To test this theory, you can connect your HDD to a different computer (or at least use a different SATA port + cable) if you don’t have a second machine to do some testing on.
 Example of a SATA Port on the motherboard
Example of a SATA Port on the motherboard
After you replaced the SATA port, repeat the scan inside HD Tune utility and see if the Ultra DMA CRC Error Count error is still occurring – If the issue has stopped occurring, consider taking your motherboard to an IT technician to investigate for loose pins.
On the other hand, if the issue doesn’t occur while you use a different SATA cable, you’ve just managed to identify your culprit.
In case you’ve eliminated both the SATA cable and the SATA port from the list of culprits, move down to the next potential fix below as the issue is definitely occurring due to a failing drive.
Method 4: Backup your HDD data
If you’ve previously made sure that you were right to concern yourself with the Ultra DMA CRC Error Count error, the first thing you should do is backup your data to ensure that you’re not losing anything in case the drive goes bad.
If you’re looking to back up your HDD data while you figure out which replacement to get, keep in mind that you have two ways forward – You can either backup your HDD using the built-in feature or you can use a 3rd party utility.
A. Backing up the files on your HDD via Command Prompt
If you’re comfortable with using an elevated CMD terminal, you can create a backup and save it on external storage without the need to install a 3rd party software.
But keep in mind that depending on your preferred approach, you might need to insert or plugin-compatible installation media.
If you’re comfortable with this approach, here are the instructions for backup your files from an Elevated Command prompt.
B. Backing up the files on your HDD via an Imaging 3rd party software
On the other hand, if you’re comfortable with trusting a 3rd party utility with your HDD backup, you’ll have a lot of extra features that are simply not available when creating a regular backup via Command Prompt.
You can use a 3rd party backup software to either clone or create an image of your HDD and save it externally or on the cloud. Here’s a list of the best cloning & imaging software that you should consider using.
Method 5: Send your HDD for replacement or order a replacement
If you’ve made sure that the Ultra DMA CRC Error Count warning you’re seeing is genuine and you have successfully backed up your HDD data in advance, the only thing you can do right now is to look for a replacement.
Of course, if your HDD is still protected by the warranty, you should send it in for repair right away.
But if the warranty has expired or you have the option to return it still, our recommendation is to stay away from the legacy HDD (Hard Disk Drive) and go for SSD (Solid State Drive) instead.
Although SSD is still more expensive than traditional HDD, there are much less prone to break and the speed is incomparable in favor of SSD (10x more writing and reading speeds).
If you’re in the market for an SSD, here’s our advanced guide to buying the best solid-state drive for your needs.
Источник
|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
1 |
|
|
09.10.2013, 12:18. Показов 177129. Ответов 38
Всем привет вот и я стал счастливым обладателем этой ошибки. Начну по-порядку: Была система asrock h55 core i3-540 оперативы 2гига жесткий Вестерн на 500 гб 7200 об винда хр сп 3. Начала винда капризничать постоянно пытается проверить чек диск в итоге перезагрузка и опять чек и так до бесконечности, зашел в биос поставил по умолчанию загрузилась винда. Какое-то время работает, потом ни с того ни с сего в ребут и опять ошибка ввода вывода. Когда загрузил с надцатого раза проверил hdd scan smart показал желтый кружочек в Ultra dma crc error count. При попытке сделать образ системы акронис виснет. Скопировал все данные на другой диск. Пытался менять провода без толку, какое-то время работает и вылетает система с одной и той же ошибкой. Поставил диск с другой системы форматнул предварительно проверил в hdd scan smart все зеленое. Поставил другой блок питания мощнее заменил оперативу, установил виндовс 7. Проработал комп месяц- опять сбой операции ввода вывода, проверил диск hdd scan желтый кружок на Ultra dma crc error count. Вот вопрос, это уже материнке кранты или у меня лыжи не едут. Буду признателен за ответ в чем может быть проблема?
__________________
0 |

|
21297 / 12107 / 653 Регистрация: 11.04.2010 Сообщений: 53,466 |
|
|
09.10.2013, 14:22 |
2 |
|
199 (C7) UltraDMA CRC Error Count — содержит количество ошибок, возникших по передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска. источник Расшифровка параметров S.M.A.R.T
1 |
|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
09.10.2013, 14:41 [ТС] |
3 |
|
да это все уже прочитано и опробовано, жесткий старый western по-новее seagate, кабели менялись переподключал к разным разъемам на мамке, единственное не чистил ластиком контакты, по-сути их надо на обоих дисках чистить, может быть проблема в материнке? да и ничего не перегревалось чисто офисный вариант. Могла как то это ошибка где то прописаться и заколбаситься в другой винт, биос по дефолту ставил ничего не разгонялось.
0 |
|
21297 / 12107 / 653 Регистрация: 11.04.2010 Сообщений: 53,466 |
|
|
09.10.2013, 14:49 |
4 |
|
Могла как то это ошибка где то прописаться и заколбаситься в другой винт нет конечно
0 |

|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
09.10.2013, 15:27 [ТС] |
5 |
|
а как узнать поточнее контроллер на материнке или нет? у меня подозрение именно в сторону материнки.
0 |
|
21297 / 12107 / 653 Регистрация: 11.04.2010 Сообщений: 53,466 |
|
|
09.10.2013, 15:40 |
6 |
|
тут только хрустальный шар вам поможет. Если вы все перепробовали, то остается материнка, логично?
1 |
|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
09.10.2013, 15:44 [ТС] |
7 |
|
Понял, спасибо за ответ, буду пробовать обновлять биос- не поможет найду мать другую, еще раз спасибо огромное.
0 |
|
21297 / 12107 / 653 Регистрация: 11.04.2010 Сообщений: 53,466 |
|
|
09.10.2013, 15:46 |
8 |
|
и вам не кашлять
1 |
") Удачи
Удачи|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
09.10.2013, 16:30 [ТС] |
9 |
|
Спасибо, да, а можно вам задать еще один вопрос, у меня на другой системе биос отображается не влезая в окно экрана по ширине-раньше этого не было, после чего стало сложно сказать. может конечо это не в той теме, но все же спасибо.
0 |
|
21297 / 12107 / 653 Регистрация: 11.04.2010 Сообщений: 53,466 |
|
|
09.10.2013, 16:39 |
10 |
|
на мониторе есть кнопочка AUTO
1 |

|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
09.10.2013, 16:47 [ТС] |
11 |
|
н-да, вторые сутки не сплю сори торможу, пора краситься в белый цвет. Спасибо.
0 |
|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
10.10.2013, 22:44 [ТС] |
12 |
|
Вот блин не везет, сегодня хотел протереть резинкой контакты на диске- не нашел соотв. отвертку. Буду искать.
0 |
|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
14.10.2013, 08:36 [ТС] |
13 |
|
Вот опять я с вопросами, скажите кто знает, ошибка Ultra dma crc error count должна сама уйти сразу или она уже никогда не уйдет и надо только флеш чистить или может есть еще какие способы. Попытался сделать образ диска на другом компе прога парагон из под доса зависла а потом выдала ошибка ввода вывода. Т.е. по всей сути все-таки диску *прощай* контакты на диске почистил.
0 |
|
21297 / 12107 / 653 Регистрация: 11.04.2010 Сообщений: 53,466 |
|
|
14.10.2013, 12:53 |
14 |
|
Ultra dma crc error count должна сама уйти нет конечно, она останется
Т.е. по всей сути все-таки диску *прощай* возможно…
0 |
|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
14.10.2013, 16:28 [ТС] |
15 |
|
спасибо
0 |
|
684 / 510 / 36 Регистрация: 23.08.2013 Сообщений: 1,243 |
|
|
14.10.2013, 19:41 |
16 |
|
Когда загрузил с надцатого раза проверил hdd scan smart показал желтый кружочек в Ultra dma crc error count. SMART надо показывать, а не рассказывать.
Вот блин не везет, сегодня хотел протереть резинкой контакты на диске- не нашел соотв. отвертку. Ищи TORX-9. Контактики под платой у WD иногда подводят — окисляются.
0 |
|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
15.10.2013, 08:50 [ТС] |
17 |
|
вот где то так Миниатюры
0 |
|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
15.10.2013, 09:46 [ТС] |
18 |
|
вот где то так спасибо за подсказку смарт выложил, отвертки нашел, протер. Добавлено через 45 минут
0 |
|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
15.10.2013, 09:49 [ТС] |
19 |
|
а вот что показывает фирменная утилита от вестерн дижитал Миниатюры
0 |
|
10 / 10 / 1 Регистрация: 09.10.2013 Сообщений: 466 |
|
|
15.10.2013, 09:58 [ТС] |
20 |
|
Какие будут советы?
0 |
- Prev
- 1
- 2
- Next
- Page 1 of 2
Recommended Posts

")
-
- Share
Ever since upgrading to the latest version, I’m getting udma crc error count on my of my drives.
I reseated the cables, didn’t work.
I bought new SAS to SATA cables, still getting them.
It’s happening to every drive. Could the Dell Perc cars be bad?
Thanks!
Sent from my iPhone using Tapatalk
- Quote
Link to comment

")
-
- Share
Chances are is just the updated reporting since 6.4.1. Once acknowledged the error counts are known and are only flagged again if they go up. The errors that you’re seeing now are most likely historic and nothing to worry about. See this thread and also the 6.4.1 release notes…
Edited March 6, 2018 by S80_UK
- Quote
Link to comment
- Author
-
- Share
Thank you! So I think it’s still ticking up. That’s why I think there is something wrong. All those drives can’t possibly bad, so I’m «guessing» it’s the SAS card? That is the only common denominator after I swapped the SAS cables.
Could the Dell PERC SAS card be the culprit for this?
OBTW, I originally thought I had a bad PSU so I swapped that out too.
Thanks!
- Quote
Link to comment

")
-
- Share
Please, read before you do anything about your current hardware. CRC errors only indicate a problem if they are increasing now! Read this post:
If you acknowledge the error, you should not get another warning UNLESS you have a new error. As @johnnie.black says even an occasional one is not a problem. In fact, you should never lose data because of a CRC error. Once the error is detected, the data will simply be resent until it received correctly. (I still have not quite figured out why they decided to highlight what is a minor problem in virtually all cases.)
Link to comment

")
-
- Share
5 hours ago, ChaOConnor said:
So I think it’s still ticking up.
If they are still increasing then there’s still a problem, if it’s not the cables the controller is the next candidate.
- Quote
Link to comment
-
- Share
Be sure that you have not tied the sata cables together to make it ‘neat’ on the inside of the case. You should only do this if the cables are shielded and 99.9% of SATA cable made today are not! I am not sure if SAS cables are shielded or not. The problem is crosstalk between the cables. (This is a problem with any server because all of cables will have information on them during many parity operations.)
Next thing to double check is that all of the cables are firmly seated on their connectors (again, tying the cables together can contribute to a problem here.) If you are using metal locking cables, check that they have friction when you pull on the drive end. For reason, see here (And WD may not be the only manufacturer to have done this…):
https://support.wdc.com/knowledgebase/answer.aspx?ID=10477
Link to comment
- Author
-
- Share
So, fingers crossed it was the controller. I put a new SAS to SATA controller in and I haven’t had an error tick up in 3 days.
Thank you!
Link to comment

")
-
- Share
Seems several post report those error even with LSI controller ( not all confirm it is controller problem, may be fake card with bad componet build )
- Quote
Link to comment
- 3 weeks later…
")
-
- Share
I also have a LSI controller (9211-8i) and I have CRC errors on 5 drives out of 8….and counting?
Edited March 30, 2018 by yanakis
- Quote
Link to comment
-
- Share
10 hours ago, yanakis said:
I also have a LSI controller (9211-8i) and I have CRC errors on 5 drives out of 8….and counting?
If the number of errors keeps increasing there’s a problem.
- Quote
Link to comment
- 2 weeks later…
")
-
- Share
i have the same issue with a handful of drives (ie numbers continue to increase). i have even moved some to a diffferent controller (and therefore different cables) to no avail.
i think i’ll just have to turn off notification since it is flooding my email with these alerts.
steve
- Quote
Link to comment
-
- Share
29 minutes ago, evans036 said:
i think i’ll just have to turn off notification
That’s a bad idea, if it keeps increasing there’s still a problem.
- Quote
Link to comment
")
-
- Share
2 hours ago, evans036 said:
i think i’ll just have to turn off notification since it is flooding my email with these alerts.
It’s good that it’s flooding your mail — the very clear message to you is that you need to do something to solve the original problem.
You still have issues with controllers and/or disks and/or cables and/or the PSU — and the SMART data keeps ticking up because it isn’t a problem that is safe to ignore.
When the counter ticks up, you can be lucky that the drive caught the transfer error — the scary thing is that some transfers may contain errors that the drive doesn’t pick up. That means you read out — or write down — incorrect data.
- Quote
Link to comment
-
- Share
Folks really need to understand that what a CRC error is that the data going in one end of a wire is not coming out of the other end of the wire with the identical data. It is not a software failure! It is a hardware issue! And it is relativity uncommon, but it is not totally unexpected. (Otherwise, there would be no need for checking using CRC!) The error itself is correctable, and that is always done.
Better than 90% of the time, multiple error situations are cable related—Loose cables or crosstalk between cables being common causes. There could be problems in the decoding and checking hardware but again that is rare and can be a bear to figure out exactly where it is. (I have had a flakey SATA expansion card in the last six months that threw up a couple of hundred CRC errors in a few hours as well as an End-to-End error. So that possibility must always be kept in mind.)
For these reasons, each one of you who has a problem should post up in a new thread about the issues in your system. Keeping track of several different investigations with only a slight chance of any two have the same cause and solution is very confusing.
Link to comment
![]()
-
- Share
28 minutes ago, Frank1940 said:
For these reasons, each one of you who has a problem should post up in a new thread about the issues in your system. Keeping track of several different investigations with only a slight chance of any two have the same cause and solution is very confusing.
Sorry I let this get out of hand.
This thread belongs to the OP, ChaOConnor. Anybody else who wants help with this should start a separate thread for themselves.
- Quote
Link to comment
-
- Share
On 3/5/2018 at 7:54 PM, Frank1940 said:
If you acknowledge the error, you should not get another warning UNLESS you have a new error. As @johnnie.black says even an occasional one is not a problem. In fact, you should never lose data because of a CRC error. Once the error is detected, the data will simply be resent until it received correctly. (I still have not quite figured out why they decided to highlight what is a minor problem in virtually all cases.)
I skipped 6.4.1 and went to 6.5 and have two drives with crc errors. Would you mind describing how to acknowledge them? I see the crc counts in the smart listing on the affected drives’ pages highlighted in orange, but there are no buttons, etc, to acknowledge the error.
Thanks,
— Eric
- Quote
Link to comment

-
- Share
3 minutes ago, eweitzman said:
I skipped 6.4.1 and went to 6.5 and have two drives with crc errors. Would you mind describing how to acknowledge them? I see the crc counts in the smart listing on the affected drives’ pages highlighted in orange, but there are no buttons, etc, to acknowledge the error.
Thanks,
— Eric
If you click on the orange icon in the Dashboard page there is an option to acknowledge the value there.
Link to comment
- 1 month later…
-
- Share
I’m on 6.5.2 and a week ago I started getting a lot of these errors and then write errors which offlined my newest drive, only in service a month. I replaced the drive and have been fine until now I received 1 UDMA CRC error with the brand new drive. Diagnostics on the «old» new drive passed on a different system with only 3Gb/s SATA. In fact, I just RMA’d the drive and shipped it today. I had actually tried to put it back in service but as soon as unRAID booted back up it started to get UDMA CRC errors again on a different tray.
I’m running an IBM M1015 reflashed to an LSI 9211-8i. First time I’ve ever seen this kind of thing.
Since this is something that all of a sudden just started happening I’m not sure what to do. The two drives I’ve been having issues with are in a 4 slot drive cage. The other 5 drives are direct connected. The drives I’ve been having trouble with are new old stock HGST 7K4000 2TB drives. Not sure whether the cage or the controller or SAS to 4xSATA cable could be the issue? I have a shorter cable I could try.
For now it’s just a single error so nothing has gone offline again. This is still troubling.
Edited June 8, 2018 by Taddeusz
- Quote
Link to comment
-
- Share
13 minutes ago, Taddeusz said:
Not sure whether the cage or the controller or SAS to 4xSATA cable could be the issue? I have a shorter cable I could try.
Try the cable first, if it’s not that then the cage is the next most likely candidate.
- Quote
Link to comment
-
- Share
51 minutes ago, johnnie.black said:
Try the cable first, if it’s not that then the cage is the next most likely candidate.
I guess I have some digging to do this weekend.
- Quote
Link to comment
-
- Share
How is you M1015 installed? These controller gets very warm, even under idle. With rising ambient temperatures this could also be the culprit. I would highly recommend installing the Noctua NF-A4x10 FLX on top of the heat sink. If you are up for it replace the thermal compound with something better. Mine was dried up and flaky. I used a small cable tie to hold the fan in place, but others are using screws (image is not from a M1015, but results are pretty much the same) :

I leave it running at full speed, it is rather quiet and the heat sink is cool to the touch, even under load.
Try the cables first, as suggested by @johnnie.black, but maybe also consider installing the fan.
- Quote
Link to comment
-
- Share
I know that card gets hot. It just has a heatsink on it. I’ll look at putting a fan on. I’ll at least put some fresh thermal compound on there. It could probably use it.
- Quote
Link to comment
-
- Share
Well, had my newest drive offlined Friday night. Spent a lot of yesterday troubleshooting. I’ve come to the conclusion that there’s something wrong with the backplane in my drive cage. It’s a Rosewill RSV-SATA-Cage-34. I removed the backplane and rigged up some fans for cooling. Direct connected all the drives. It ran a rebuild just fine with no more UDMA CRC errors.
I tried to replace the thermal compound on my SAS card but they used thermal glue so it’s not coming off. I’ve got a couple drive cages coming but they don’t have backplanes. Also Rosewill but really low cost.
- Quote
Link to comment
- 1 month later…

")
-
- Share
Any thoughts on my post?
unRAID Disk 10 SMART health [199] Warning [UNRAID] — udma crc error count is 8731 WDC_WD20EARS
I have done cable replacements, the drive itself has 12GB free, could that be a prob?
The drive is old.
- Quote
Link to comment
-
- Share
4 hours ago, bombz said:
Any thoughts on my post?unRAID Disk 10 SMART health [199] Warning [UNRAID] — udma crc error count is 8731 WDC_WD20EARS
I have done cable replacements, the drive itself has 12GB free, could that be a prob?
The drive is old.
Both of your posts in both threads are a bit out of the wild blue wonder. (You should really have started a new thread…) The basic question that always has to be asked for any SMART 199 errors, it this: Is the count continuing to increase? The reason being that this counter can never be reset. The Error itself is a nuisance more than anything else. The error will always be automatically fixed by requesting that the data be resent until CRC code is correct. The only real problem is that it slows down the data transfer rate. If it is an occasional error, this delay is insignificant in the bigger picture. Unfortunately, you will get a warning every time unRAID reboots (and, as I recall, with the periodic status reports) unless you turn them off. (Where to do this at the moment escapes me but I think it was on the Dashboard page…)
Edited July 31, 2018 by Frank1940
Link to comment
- Prev
- 1
- 2
- Next
- Page 1 of 2
Join the conversation
You can post now and register later.
If you have an account, sign in now to post with your account.
Note: Your post will require moderator approval before it will be visible.
В сегодняшней статье:
1. Как узнать в каком состоянии мой жёсткий диск или твердотельный накопитель SSD, сколько он ещё проживёт. Как узнать состояние здоровья жёсткого диска или SSD бывшего в употреблении. Что такое S.M.A.R.T и о чём говорят его показатели: Value, Worst, Raw, Threshold?
2. Что такое бэд-блоки? Как установить — сколько сбойных секторов (бэд-блоков) на моём жёстком диске, можно ли их исправить, а самое главное, как исправить?
3. Что делать, если операционная система не загружается или зависает даже после переустановки, а жёсткий диск при работе издаёт щелчки и посторонние звуки? Почему каждый раз при загрузке Windows запускается утилита проверки диска chkdsk?
4. Как создать загрузочную флешку с программой Victoria и проверить жёсткий диск компьютера, ноутбука на бэд-блоки даже если он не загружается и так далее…
Как пользоваться одной из легендарных программ по диагностике жёстких дисков под названием Victoria!

Приветствую Вас друзья на нашем сайте remontcompa.ru! Сегодняшняя статья о программе Victoria. Скажу уверенно, данная программа самая лучшая среди утилит по диагностике и лечению жёстких дисков. Разработал сиё творение чародей первой категории Сергей Казанский.
Я очень долго и ответственно готовился к данной статье чувствуя благодарность к этой программе. Бывало Victoria спасала казалось бы уже пропавшие данные на жёстких дисках моих клиентов, друзей и знакомых (часто перед мастером НЕ стоит задача вернуть к нормальной работе неисправный жёсткий диск, а только спасти данные находящиеся на нём), а иногда возвращала к жизни и сам винчестер!
- Очень хотелось написать статью, которая помогла бы начинающим пользователям разобраться, а главное не боятся этой программы, а боятся есть чего, если пользоваться программой неосторожно, к примеру запустить бездумно сканирование в режиме Erase или ещё хуже Write , то можно удалить все данные на винте, если вы даже вовремя опомнитесь, то всё равно грохните загрузочную запись MBR и Вам не удастся в следующий раз загрузиться в операционную систему.
Друзья, невозможно всё, что я хочу рассказать и показать о программе Victoria поместить в одну статью. В результате моих стараний получилось несколько статей:
- Сегодняшняя статья. Как скачать и запустить прямо из работающей Windows программу Victoria. Что такое S.M.A.R.T. или как за пару секунд определить состояние здоровья Вашего жёсткого диска или SSD. Ещё статьи…
- Как произвести тест жёсткого диска или твердотельного накопителя SSD на наличие сбойных секторов (бэд-блоков) в программе Victoria для Windows. Как вылечить жёсткий диск.
- Как создать загрузочную флешку с программой Victoria, загрузить с неё компьютер или ноутбук (если они не загружаются нормально из-за сбойных секторов) и протестировать поверхность жёсткого диска на бэд-блоки. Как избавиться от бэд-блоков в DOS (ДОС) режиме.
- Как с помощью программы Victora произвести посекторное стирание информации с жёсткого диска и этим избавиться от сбойных секторов (бэд-блоков).
- Как обрезать на жёстком диске участок со сбойными секторами.
- Как установить точный адрес сбойного сектора в программе Victoria и исправить этот сектор.
- Как сопоставить принадлежность сбойного сектора (бэд-блока) конкретному файлу в Windows?
- Как избавить жёсткий диск ноутбука от бэд-блоков в программе Victoria
- Загрузочная флешка Live CD AOMEI PE Builder с программами для диагностики жёсткого диска: Victoria, HDDScan, CrystalDiskInfo 6.7.4, DiskMark, HDTune, DMDE
Во первых, основных версий программы Victoria две:
Первая версия позволит нам произвести диагностику и небольшой ремонт жёстких дисков прямо в работающей Windows, но хочу сказать, что диагностику винчестера с помощью этой версии произвести можно, а вот исправление сбойных секторов (ремап) часто заканчивается неудачей, да и вероятность ошибок при работе с Викторией прямо «из винды» присутствует, поэтому многие опытные пользователи и профессионалы предпочитают вторую версию программы.
Вторая версия программы Victoria будет находиться на загрузочном диске или флешке, с данного диска (флешки) мы загрузим наш стационарный компьютер или ноутбук и также проведём диагностику и если нужно лечение жёсткого диска.
Примечание: Вторая версия очень пригодится многим, так как у большинства пользователей один жёсткий диск в компьютере или тем более в ноутбуке, в этом случае можно загрузиться с диска (флешки) Виктории и работать с одним единственным винчестером.
1. Victoria на загрузочном диске очень пригодится, если из-за бэд блоков Вы не можете запустить операционную систему.
2. Если у Вас один жёсткий диск и на нём установлена операционная система и в этой же работающей операционке Вы запустите Викторию, то наверняка она откажется исправлять сбойные сектора (бэд-блоки).
Многие пользователи заметят, что зачастую хороший бэд не исправит даже Виктория, на что ответить можно так — не все бэды имеют физическую природу (разрушившийся сектор на жёстком диске), многие бэды имеют логическую природу и легко исправляются этой программой.
Примечание: все подробности о существующих бэд-блоках винчестеров, какие они бывают, логические или физические, читайте в нашей статье- Как проверить состояние жесткого диска.
Коротко лишь скажу, что физические бэды (физически разрушившийся сектор) восстановить невозможно, а логические (программные, ошибки логики сектора) восстановить можно.
Друзья, можно много говорить, но есть хорошая жизненная пословица: «Лучше один раз увидеть, чем сто раз услышать», поэтому я приведу для Вас несколько примеров работы программы Victoria.
Victoria для работы с загрузочного диска
Идём на официальный сайт программы и выбираем Victoria 3.5 Russian ISO-образ загрузочного CD-ROM.
Victoria на загрузочном диске нам тоже нужна, но работу с этой версией мы рассмотрим во вторую очередь. Если у Вас нет дисковода, тогда мы сделаем загрузочную флешку с программой Victoria.

Victoria для работы непосредственно в операционной системе Windows XP, 7, 8, 10
Также скачиваем на моём облаке версию для Windows.
Щёлкаем на скачанном архиве программы правой мышью и выбираем Извлечь файлы.

Файлы извлекаются в создавшуюся папку vcr43. Заходим в эту папку и обязательно запускаем от имени администратора исполняемый файл программы victoria43.exe.
Главное окно программы Victoria
В главном окне программы пройдёмся по всем вкладкам поверхностно, а затем подробно.
Standard
Выбираем начальную вкладку Standard. Если у Вас несколько жёстких дисков, то в правой части окна выделите левой мышью нужный Вам жёсткий диск и сразу в левой части окна отобразятся паспортные данные нашего жёсткого диска: где родился и женился, модель, прошивка, серийный номер, объём кэша и так далее. В нижней части ведётся лог наших действий.

Что такое S.M.A.R.T.
Затем выбираем в правой части окна нужный нам жёсткий диск, если у Вас их несколько и выделяем его левой мышью. Выберем к примеру жёсткий диск WDC WD5000AAKS-00A7B2(объём 500 ГБ).

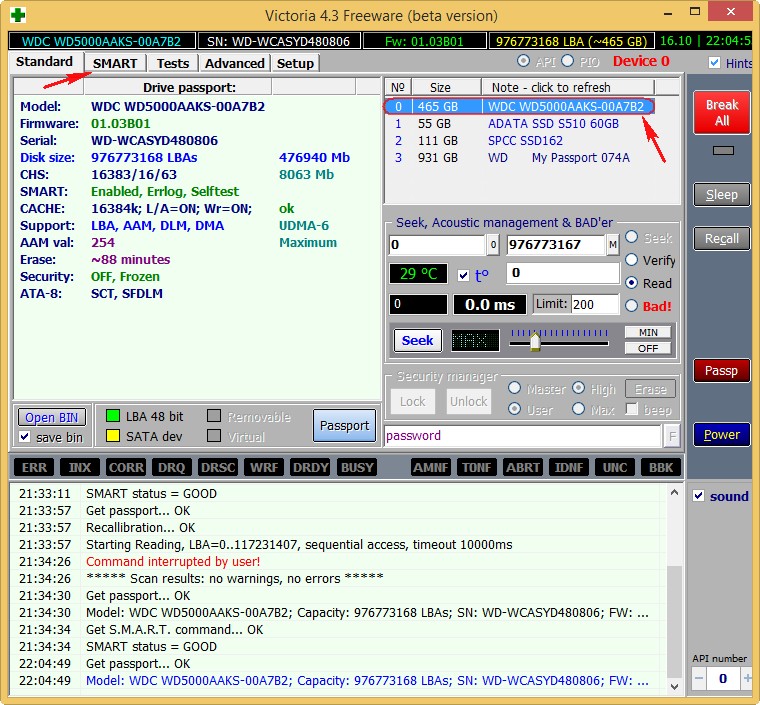
Переходим на вкладку SMART, жмем кнопку Get SMART, справа от кнопки засветится сообщение GOOD и откроется S.M.A.R.T. выбранного нами жёсткого диска.
S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology) — разработанная в 1995 году крупнейшими производители жёстких дисков усовершенствованная технология самоконтроля, анализа и отчётности винчестера.
Другими словами друзья, если посмотреть это окно, то можно узнать в каком состоянии Ваш жёсткий диск.
Обратите внимания программа Victoria подсветила красным (тревога!) цифру 8 на значении Raw, самого важного для здоровья жёсткого диска атрибута
5 Reallocated Sector Count — (remap), обозначающий число переназначенных секторов.
Примечание: значение атрибута Raw очень важно, читаем почему.
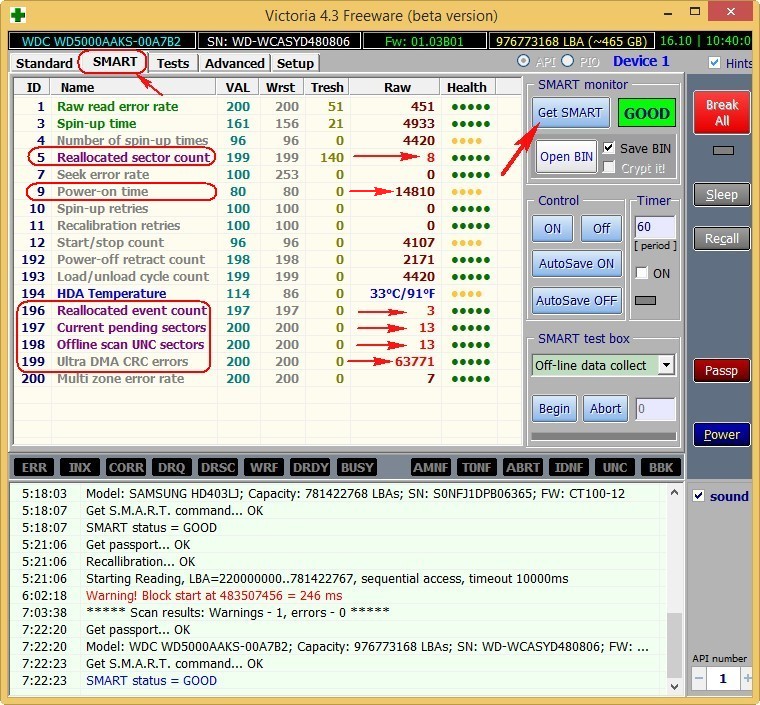
Простыми словами, если микропрограмма, встроенная в жёсткий диск, обнаружит сбойный сектор (бэд-блок), то она переназначит этот сектор сектором с резервной дорожки (процесс называется remapping). Но резервных секторов на жёстком диске не бесконечное число и программа нас предупреждает, что скоро бэд-блоки переназначать будет нечем, а это чревато потерей данных и нам надо готовиться менять жёсткий диск на новый. Забегая вперёд, скажу, что в следующей статье мы попробуем подлечить этот жёсткий диск.
9 Power-On time — общее количество отработанных жёстким диском часов 14810, не подсвечено красным, но хочу сказать, что приближение к цифре 20000 наработки в большинстве случаев связано с болезнями и нестабильной работой жёсткого диска.
Также подсвечены атрибуты:
196 Reallocation Event Count — 3. Количество операций переназначения бэд-блоков секторами с резервных дорожек (ремаппинг), учитываются как успешные, так и неуспешные операции.
197 Current Pending Sector — 13. Показатель количества нестабильных секторов реальных претендентов в бэд-блоки. Данные сектора микропрограмма жёсткого диска планирует в будущем заменить секторами из резервной области (remap), но всё же есть надежда, что в дальнейшем какой-то из этих секторов прочитается хорошо и будет исключён из списка претендентов.
198 Offline scan UNC sectors — 13. Количество реально существующих на жёстком диске не переназначенных бэдов (возможно исправимых имеющих логическую структуру — подробности далее в статье).
199 UltraDMA CRC Errors — 63771. Ошибки, возникающие при передаче информации по внешнему интерфейсу, причина — возможно перекрученный и некачественный SATA шлейф и его нужно заменить или расшатанный разъём SATA на материнской плате или на самом жёстком диске. А может сам винчестер интерфейса SATA 6 Гбит/с подключен в разъём на материнской плате SATA 3 Гбит/с, надо переподключить.
Атрибуты S.M.A.R.T и их значения. Очень важно знать!
Значения атрибутов
Val—текущее значение атрибута, оно должно быть высоким (до 255), если значение Val равно критическому Tresh или даже менее его, то это соответствует неудовлетворительной оценке параметра. К примеру в нашем случае на жёстком диске WDC WD5000AAKS-00A7B2 (500 ГБ, 7200 RPM, SATA-II) атрибут Reallocated Sector Count имеет значение Val—199, а атрибут Tresh (порог) имеет значение 140, это плохо, но значение Val—199 ещё не равно значению Tresh (порог) 140 и у нас есть время скопировать данные с этого диска и отправить его на пенсию.
Wrst—самый низкий показатель атрибута Val за всё время работы винчестера.
Tresh—пороговое значения атрибута, данное значение должно быть намного ниже значения Val (текущее значение).
Raw—«сырое значение», которое будет пересчитано в значение Value, чем меньше это значение, тем лучше. Важный показатель для оценки атрибута, представляет реальное число, исходя из которого формируется значение Value, но как именно происходит процесс формирования значения Value — это фирменный секрет каждого производителя жёсткого диска!
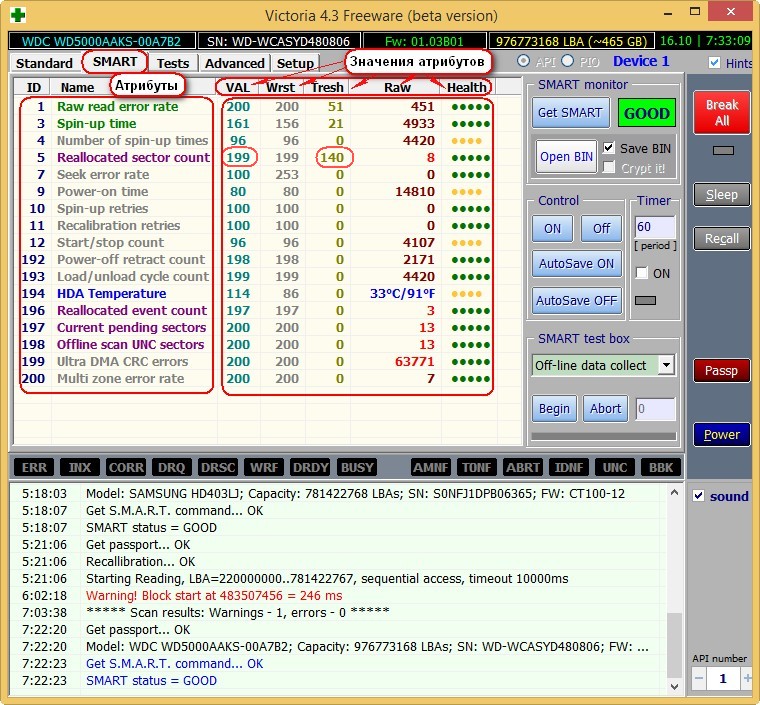
Расшифровка S.M.A.R.T.
Давайте разберёмся во всех атрибутах S.M.A.R.T, но хочу сказать, что чаще всего на «плохих» жёстких дисках неудовлетворительным будет именно этот атрибут Reallocated Sector Count (Переназначенные сектора). Это уже повод насторожиться и провести тест поверхности жёсткого диска или SSD (как это сделать узнаем далее в статье).
Друзья, для моментальной оценки здоровья жёсткого диска S.M.A.R.T я использую ещё одну простую программу на русском языке CrystalDiskInfo, обязательно скачайте и установите её себе. В ней все атрибуты указаны на русском языке!
http://crystalmark.info/download/index-e.html
Выберите Shizuku Edition (exe).
В данном окне язык программы можете выбрать русский.
Как видите, CrystalDiskInfo прямо указывает нам (подтверждая опасения «Виктории»), на жёстком диске WDC WD5000AAKS-00A7B2 (объём 500 ГБ) нехорошие значения атрибутов отвечающих за Переназначенные сектора, Нестабильные сектора, Неисправимые ошибки секторов, подсвечивая их жёлтым цветом и указывает на тех. состояние жёсткого диска одним словом «Тревога»
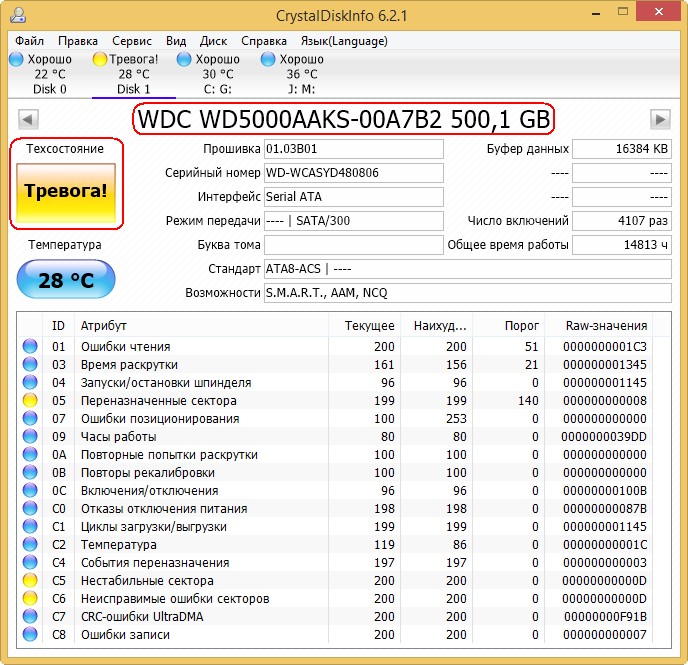
Как выглядит S.M.A.R.T неисправного жёсткого диска
А вот S.M.A.R.T неисправного жёсткого диска WDC WD500BPVT ноутбука, который мне принесли на ремонт.


Victoria из Windows. Обратите внимание на атрибут:
5 Reallocated Sector Count (переназначенные сектора), он имеет значение Val—133, а атрибут Tresh (порог) имеет значение 140, это неудовлетворительно, так как значение Val—133 не должно быть меньше предельного значения Tresh (порог) 140, то есть количество сбойных секторов будет расти, а переназначать их уже нечем, запасные сектора на резервных дорожках уже закончились.
197 Current Pending Sector — показатель количества нестабильных секторов реальных претендентов в бэд-блоки зашкалил все возможные пределы.
И самое главное, самооценка SMART status=BAD (непригоден).
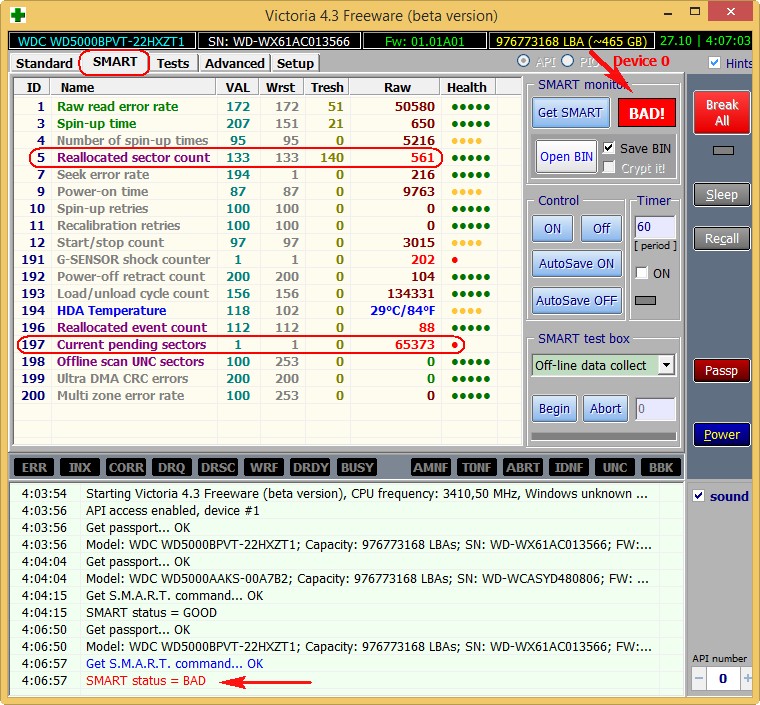
Программа CrystalDiskInfo (ссылка на скачивание чуть выше). Видим тоже самое, атрибут Переназначенные сектора (Reallocated Sector Count) имеет значение Val (текущее)—133, а атрибут Tresh (порог) имеет значение 140, программа оценила оценку тех состояния жёсткого диска как Плохо.
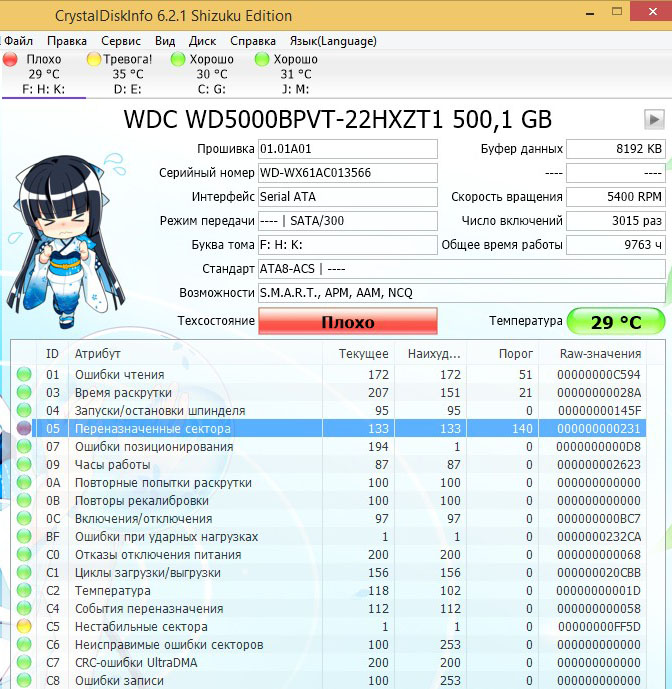
этот ноутбук ужасно тормозит, данные c него невозможно скопировать, Windows невозможно переустановить, периодически винчестер пропадает из БИОС, то есть такой жёсткий диск подлежит замене без раздумий, даже наша Victoria не сможет полностью вылечить подобный винт, так как здоровые сектора на резервных дорожках закончились и сбойные сектора переназначать уже нечем, а копирование данных с него будет настоящим приключением на неделю (обязательно напишу про это статью).
Забегая вперёд скажу, что тест этого винта в программе Victoria показал наличие 500 неисправимых сбойных секторов (бэд-блоков).
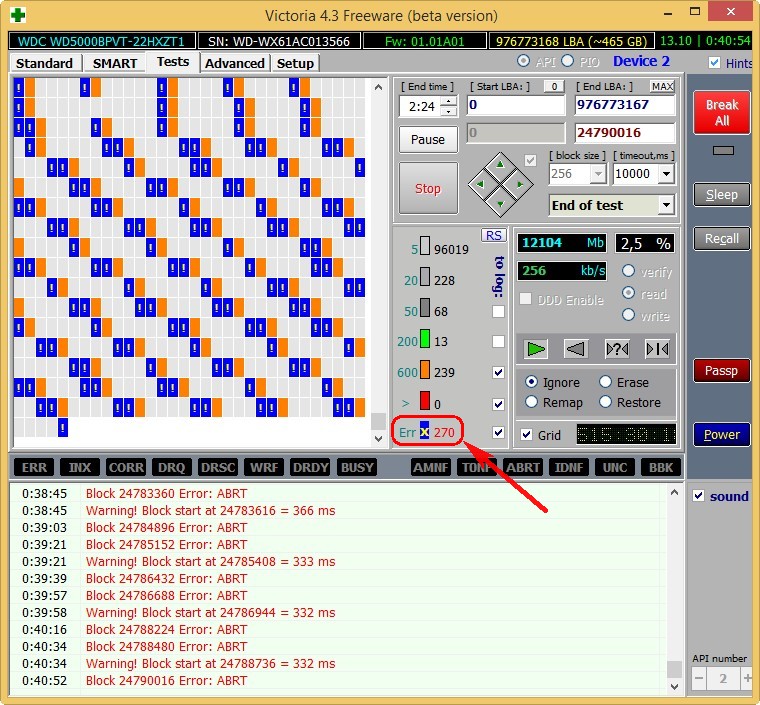
ДОС — версия программы Виктория.

Примечание: Чтобы Вам упростить жизнь, некоторые программы диагностики жёстких дисков сопоставляют каждый атрибут, хороший он или плохой, цвету значка.
Зелёный—атрибут жёсткого диска соответствует нормальному.
Жёлтый—говорит о небольшом расхождении с эталоном и на этом винте важные данные лучше не хранить, если у Вас на таком жёстком диске находится Windows, перенесите её на SSD.
Красный—говорит о значительном расхождении с эталоном и жёсткий диск нужно было менять уже вчера.
S.M.A.R.T этого же жёсткого диска WDC WD500BPVT в программе HDDScan
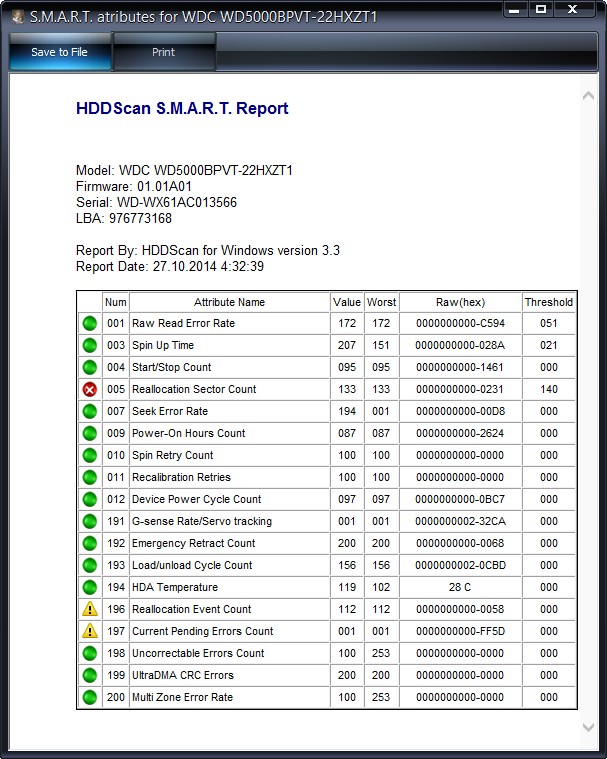
Атрибуты
001 Raw Read Error Rate—частота ошибок при чтении информации с диска
002 Spinup Time—время раскрутки дисков до рабочего состояния
003 Start/Stop Count—общее количество стартов/остановок шпинделя.
005 Reallocated Sector Count — (remap) говорит о числе переназначенных секторов. Если микропрограмма встроенная в жёсткий диск обнаружит сбойный сектор (бэд-блок), то она переназначит этот сектор сектором с резервной дорожки (процесс называется remapping). Но резервных секторов на жёстком диске не бесконечное число и программа нас предупреждает, что скоро бэд-блоки переназначать будет нечем, а это чревато потерей данных и нам надо готовиться менять жёсткий диск на новый
007 Seek Error Rate—частота ошибок при позиционировании блока головок, постоянно растущее значение, говорит о перегреве винчестера и неустойчивом положении в корзине, к примеру плохо закреплён.
009 Power-on Hours Count—число часов, проведённых во включенном состоянии.
010 Spin Retry Count—число повторных раскруток диска до рабочей скорости при неудачной первой.
012 Device Power Cycle Count—Число полных циклов включения-выключения дисков
187 Reported Uncorrectable Error—Ошибки, которые не не смогла восстановить микропрограмма винчестера, используя свои методы устранения ошибки аппаратными средствами, последствия перегрева и вибрации.
189 High Fly Writes—записывающая головка находилась над поверхностью выше, чем нужно, а значит магнитное поле было недостаточным для надежной записи носителя. Причина– вибрация (удар).
Для ноутбуков данная цифра немного выше.
190 Важные параметры касающиеся температуры. Важно, что бы температура не поднималась выше 45 градусов.
194 HDA Temperature—температура механической части жёсткого диска
195 Hardware ECC Recovered—число ошибок, которые были исправлены самим винчестером.
196 Reallocation Event Count — Количество операций переназначения бэд-блоков секторами с резервных дорожек (ремаппинг), учитываются как успешные, так и неуспешные операции.
197 Current Pending Errors Count — неисправимые ошибки секторов, тоже важный параметр, число секторов, считывание которых затруднено и сильно отличается от считывания нормального сектора. То есть, эти секторы контроллер жёсткого диска не смог прочитать с первого раза, обычно к данным секторам принадлежат софт-бэды, ещё называют программные или логические бэд-блоки (ошибка логики сектора) — при записи в сектор пользовательской информации, так же записывается служебная информация, а именно контрольная сумма сектора ECC (Error Correction Code-код коррекции ошибок), она позволяет восстанавливать данные, если они были прочитаны с ошибкой, но иногда данный код не записывается, а значит сумма пользовательских данных в секторе не совпадает с контрольной суммой ECC. К примеру так происходит при внезапном отключении компьютера из-за сбоев с электричеством, из-за этого информация в сектор жёсткого диска была записана, а контрольная сумма нет.
- Логические бэд-блоки нельзя исправить простым форматированием, так как при форматировании контроллер жёсткого диска попытается в первую очередь прочитать информацию из сбойного сектора, если ему это не удастся (в большинстве случаев), то значит не произойдёт никакой перезаписи и бэд-блок останется бэд-блоком. Исправить положение можно в программе Victoria, она принудительно впишет в сектор информацию (вылечит сектор), затем прочитает её, сравнит контрольную сумму ECC и бэд-блок станет нормальным сектором. Более подробно про все виды бэд-блоков в нашей статье Как проверить жёсткий диск.
198 Offline scan UNC sectors — Количество реально существующих на жёстком диске непереназначенных бэдов (возможно исправимых имеющих логическую структуру — подробности далее в статье).
198 Uncorrectable Errors Count—число нескорректированных ошибок при обращении к сектору, указывает на дефекты поверхности.
Reported Uncorrectable Errors — показывает число неисправленных сбойных секторов.
199 UltraDMA CRC Errors—число ошибок, возникающих при передаче информации по внешнему интерфейсу, причина- перекрученный и некачественный SATA шлейф, возможно его нужно поменять.
200 Write Error Rate—частота ошибок, происходящих при записи на винчестер, по данному показателю обычно судят о качестве поверхности накопителя и его механической части.
202 Data Address Mark Errors—расшифровки нигде не встречал, буквально Ошибка данных адресного маркера, означать может то, что знает один лишь производитель данного винчестера.
Как быстро проверить жёсткий диск или SSD на пригодность к работе?
Друзья, Вы меня часто спрашиваете: «Как быстро проверить жёсткий диск или SSD на пригодность к работе?»
Ответ: «Используйте программы: Victoria, CrystalDiskInfo, HDDScan, они сразу покажут Вам S.M.A.R.T любого жёсткого диска.
Как выглядит S.M.A.R.T абсолютно нового жёсткого диска
Во первых, смотрите как выглядит S.M.A.R.T абсолютно нового жёсткого диска WDC WD2500AAKX-00ERMA0

Как видим, все показатели накопителя в отличном состоянии и отработал он ноль часов (параметр 9 Power-On Time)
Теперь берём почти новый жёсткий диск WDC WD2500AAKX-001CA0 и смотрим S.M.A.R.T, как видим, винчестер практически в идеальном состоянии, хотя и отработал уже 8000 часов (параметр 9 Power-On Time)

Victoria
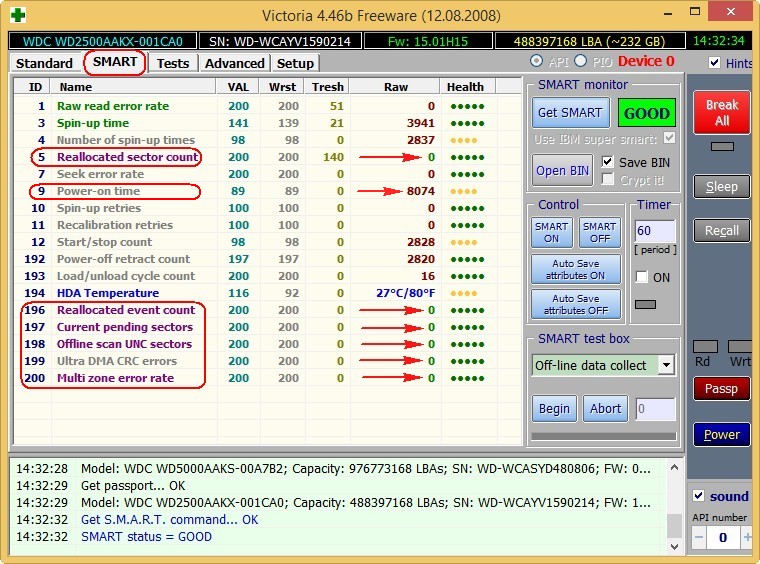
Тест поверхности жёсткого диска!
В правой части окна программы отметьте пункт Ignor и пункт read и нажмите Start. Этим Вы запустите простой тест поверхности жёсткого диска без исправления ошибок. Данный тест не принесёт никаких отрицательных и положительных воздействий на жёсткий диск, но зато по окончании теста Вы будете знать в каком состоянии находится Ваш винчестер..
Результаты теста отличные. Ни одного блока с задержкой более 30 мc!

CrystalDiskInfo
HDDScan

Жёсткий диск SAMSUNG HD403LJ (372 ГБ) из недавней статьи Как перенести Windows 7, 8, 8,1 на SSD с помощью программы Acronis True Image.
На нём были бэд-блоки и мне пришлось переносить с него Windows 8 на SSD, после успешного переноса, хозяин (мой одноклассник) подарил мне этот винт и Victoria вскоре вернула его к жизни после «записи по всей поляне» (алгоритм Write). Прежний хозяин забирать вылеченный винчестер отказался.

Результаты теста чуть хуже. 3 блока с задержкой более 200 мс и 1 блок с задержкой 600 мс (возможно кандидат в бэды).
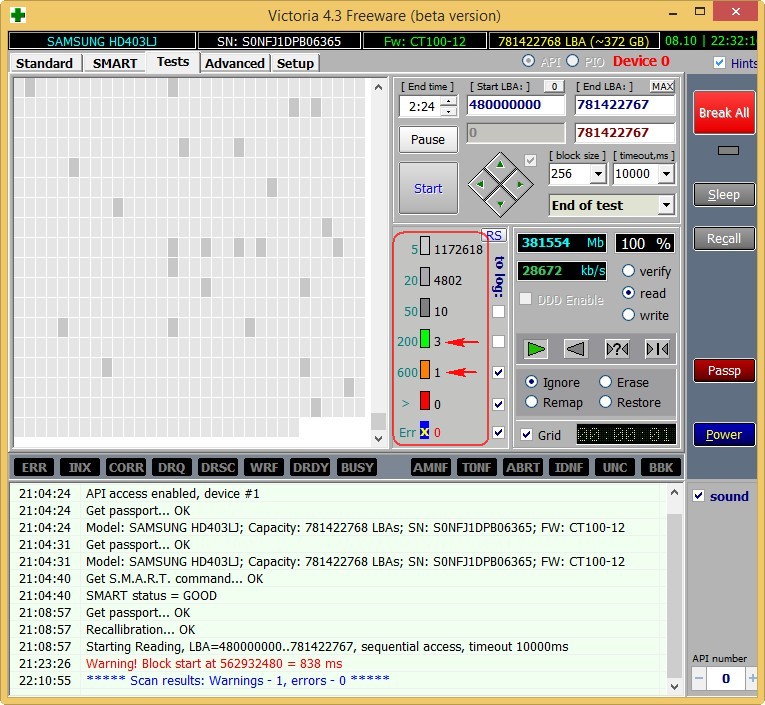
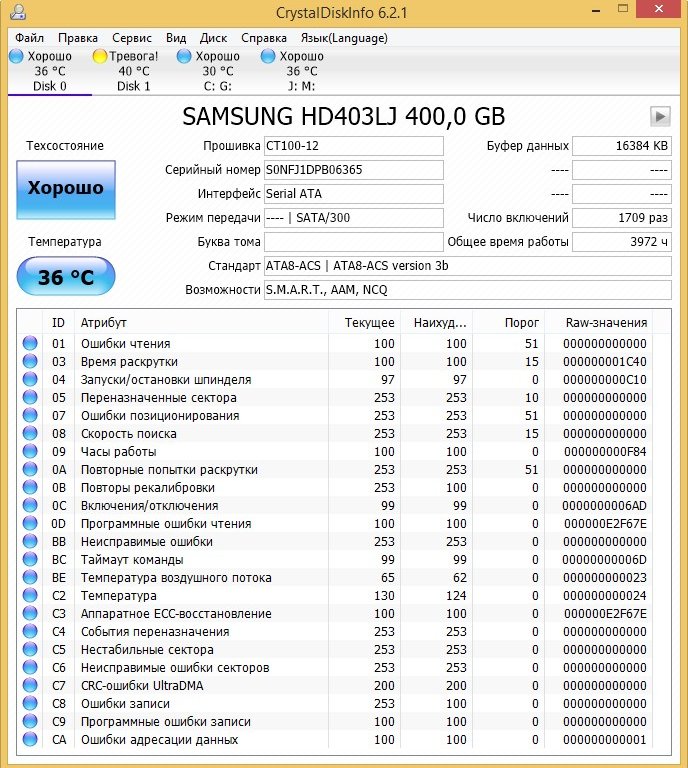

Не вполне исправный жёсткий диск MAXTOR STM3250310AS (250 ГБ, 7200 RPM, SATA-II) ему 8 лет (ветеран) и он всё ещё работает, правда я его берегу, храню на нём только файлы неважных данных.

Хоть явных бэдов на нём и нет, видим, что атрибут 5 Reallocated Sector Count — (remap), обозначающий число переназначенных секторов критический и скоро бэды переназначать будет нечем.
9 Power-On time — общее количество отработанных жёстким диском часов 23668, это очень много, обычно проблемы у жёстких дисков начинаются после 20000 часов отработки.
Также неважнецкий атрибут 199 UltraDMA CRC Errors — 63771,ошибки, возникающие при передаче информации по внешнему интерфейсу, причина — некачественный шлейф SATA шлейф и его нужно заменить (не всегда дело в этом).
Результаты теста ещё хуже. 71 блок с задержкой более 200 мс и 1 блок с задержкой 600 мс (возможно кандидат в бэды).
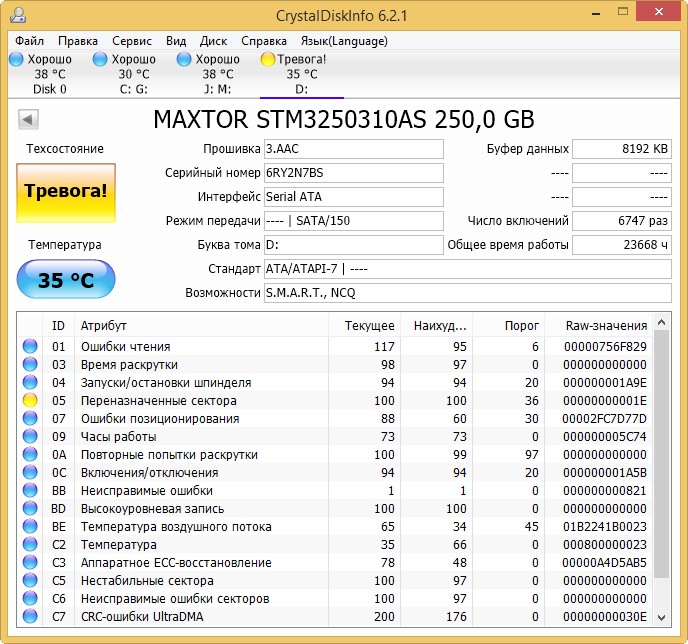
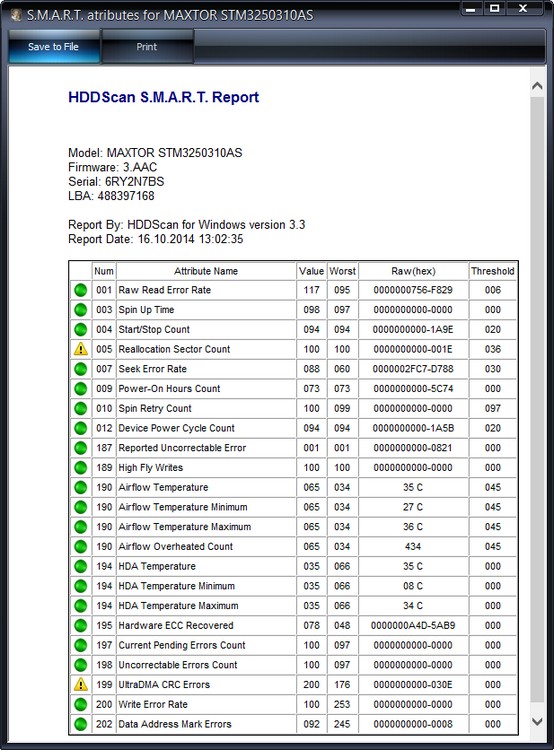
Жёсткий диск ST3200826AS (200 ГБ, 7200 RPM, SATA). Винту около трёх лет и полёт пока нормальный.

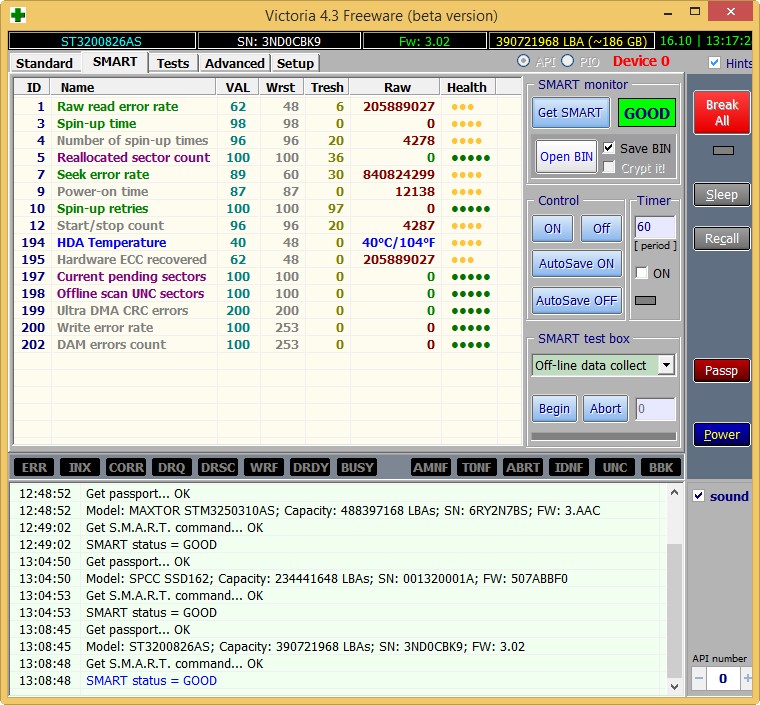
Результаты теста. 6 блоков с задержкой более 200 мс.
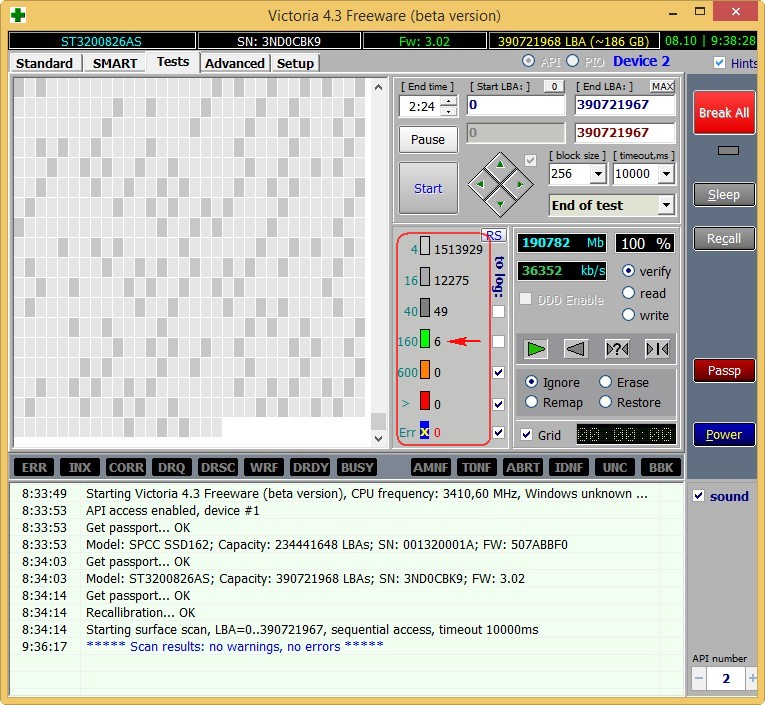
Новый твердотельный накопитель SSD SPCC SSD162

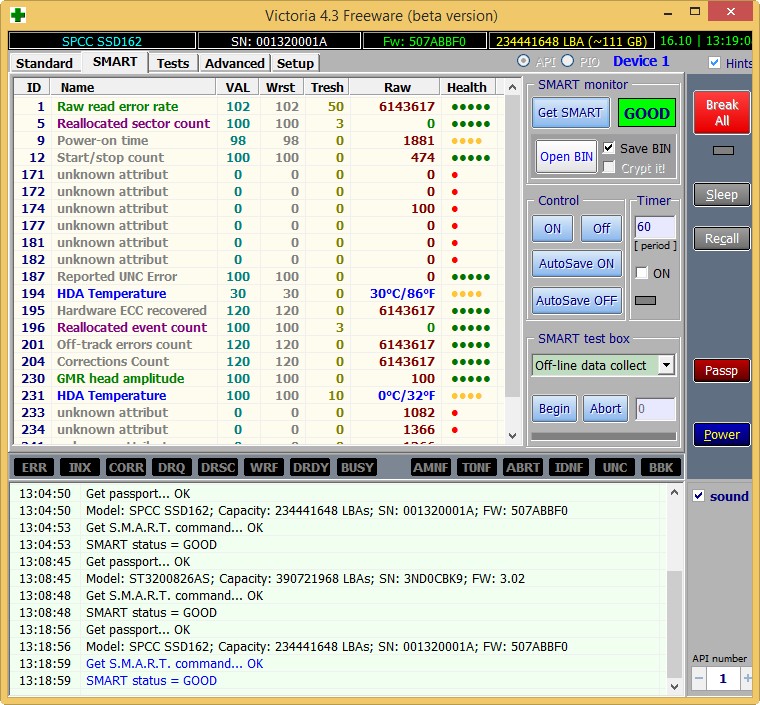
Тест
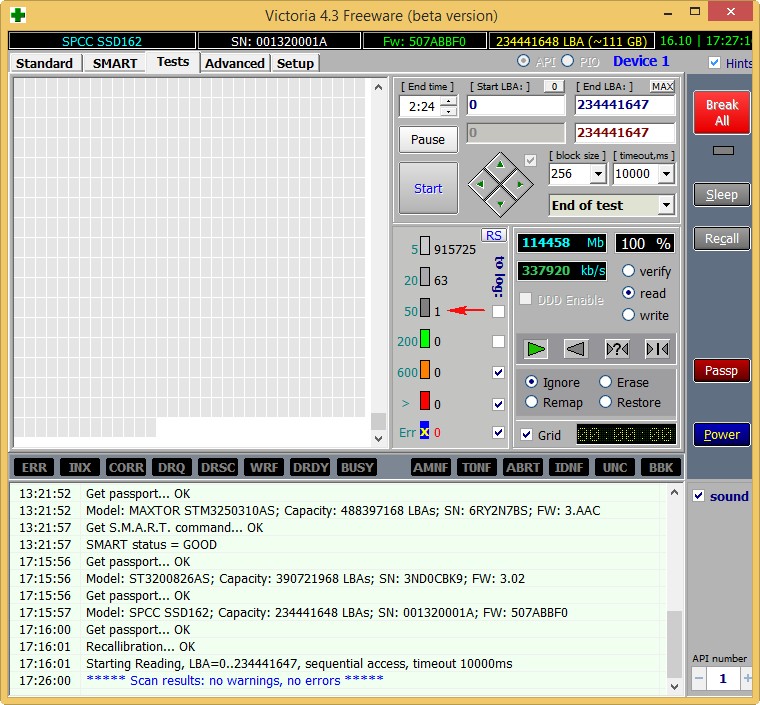
Под конец статьи проверим мой самый старый твердотельный накопитель SSD — ADATA S510 60GB (60 ГБ, SATA-III)
Ему уже третий год, но работает он отменно, жалко что объём всего 60 ГБ, но когда я его покупал больше и не было, а стоил он около двухсот баксов.

![]()
При включении компьютера ОС загружается нормально. Но через некоторое время начинаются зависания программ, замедленное реагирование на команды. Порой весьма значительное. Например, хочу закрыть браузер. Нажимаю на соотвествующую кнопку… Программа закрывается порой через минуту. Тестировал HDD программой «HD Tune Pro 5.00-Hard Disk Utilty.» Скриншот прилагаю. Значение «DATA» подросло. Было-5657. Стало-5888. Также тестировал программой Виктория. В том числе и в загружочном режиме. «Битых» секторов нет. Всячески менял и переустанавливал шлейф HDD. У меня есть 2-а HDD. На каждом установлена своя ОС. На одном XP? надругом-Windows 8. (скрин тестирования второго диска также прилагаю).
В интернете нашел такой текст:
«Практика, собранная статистика и изучение журналов ошибок SMART показывают: в большинстве случаев ошибки CRC возникают при сильном завышении частоты PCI (больше номинальных 33.6 MHz), сильно перекрученом кабеле, а также — по вине драйверов ОС, которые не соблюдают требований к передачи/приему данных в режимах UltraDMA.».
1.Что такое «сильное завышение частоты PCI». Как проверить и, в случае необходимости исправить.
2.Что значит «драйвера ОС не соблюдают требований к приему/передаче данных. Как проверить и исправить.
Сегодня при запуске система вылетела в «синий экран». Текст:
Check to make sure any new hardware or Suftware is properly installed. If this is a new installation, ask your hardware or software manufacturer for any windows updates you might need.
Примерно неделю назад установил программу «Планета Земля» от гугла. Все работало. Больше ничего не ставил.
![]()
Можно фотографии диспетчера задач, именно вкладки процессы и быстродействие.
И посмотри чтобы в биосе подключение жёсткого диска было SATA3, если у тебя подключён через SATA, бывает что жёсткий диск не переключает автоматически если у тебя жёсткий диск с индексом SE.
![]()
Атрибут: 199 (С7) UltraDMA CRC Error Count
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
![]()
Этот текст я уже вида=ел в сети.
![]()
Можно фотографии диспетчера задач, именно вкладки процессы и быстродействие.
Можно
![]()
Система работает нормально. Посмотри загруженность диска.
И посмотри чтобы в биосе подключение жёсткого диска было SATA3, если у тебя подключён через SATA, бывает что жёсткий диск не переключает автоматически если у тебя жёсткий диск с индексом SE.
![]()
Что такое «загруженность диска» Если наличие свободного от информации места- то его более чем достаточно. Недавно переставлял ОС и отформатировал весь HDD.
В BIOS-вкладка «Main». Диск подключен SATA4. Если критично- как переподключить?
![]()
DaliL сказал(а)
Что такое «загруженность диска» Если наличие свободного от информации места- то его более чем достаточно. Недавно переставлял ОС и отформатировал весь HDD.
В BIOS-вкладка «Main». Диск подключен SATA4. Если критично- как переподключить?
В диспетчере задач посмотри загруженность.
![]()
![]()
DaliL сказал(а)
Загрузка ЦП от 10 до 50%
Самого жёсткого диска. Вообщем советую на другом компьютере проверить через HD Tune Pro 5.00-Hard Disk Utilty, если такая же ошибка то меняй жёсткий диск. Либо только остаётся попробовать поменять блок питания или возможно материнская плата у тебя не правильно выдаёт напряжение на SATA кабель.

не проще проверить на другом кабеле и сата разъеме или sata контроллер pc-e поставить
Явно проблема в материнке и кабеле.
![]()
Блок питания сменил недавно. Как проверить напряжение, которое выдает мать на SATA кабель?
![]()
Что это значит: В интернете нашел такой текст:
«Практика, собранная статистика и изучение журналов ошибок SMART показывают: в большинстве случаев ошибки CRC возникают при сильном завышении частоты PCI (больше номинальных 33.6 MHz), сильно перекрученом кабеле, а также — по вине драйверов ОС, которые не соблюдают требований к передачи/приему данных в режимах UltraDMA.».
DaliL сказал(а)
Как проверить напряжение, которое выдает мать на SATA кабель?
если менял кабель и не работает, пробуй на sata pc-e контроллере
какая материнка?
Мой Компьютер—>Управление—>Управление дисками посмотри инициализацию диска.
В биосе попрбуй в режиме ide запустить
![]()
все что ты посоветовал- сделаю. Но у меня все больше и больше крепнет уверенность, что неисправность в материнку. как проверит «драйвера ОС, которые не соблюдают требований к передачи/приему данных в режимах UltraDMA.».
Обновить материнку, можно даже вытащить батарейку и поновой все установить.
Можно прошивку поменять на последнюю на материнке
![]()
Обновить материнку, можно даже вытащить батарейку и поновой все установить.
имеешь в иду BIOS? Если да, то батарейку уже вытаскивал и все настраивал по новой.
прошей биос материнки на последний.