I’ve found out a lot of similar question about this error on stackoverflow, but no one the same of my problem. I’ve build a simple page with two Regions. The first region has two select lists and the second Region has a chart who takes data from the select lists. When I open the page, Apex loads every componts Regions, items… I know in my case that initially my chart hasn’t data from the select lists and the select below return 0 rows and I get the error message:»AJAX call ORA-01403: NO DATA FOUND». When the page has been loaded, I can use the select lists and show value from the chart.
select MSO_DEVICE, nvl((case when MSO_OEE < 100 then 100 else 100 end),0) max_value, nvl((case when MSO_OEE is null
then 0
when MSO_OEE = 0
then 0
else MSO_OEE
end),0) value
FROM MES_OEE
where MSO_DEVICE = :P2_DEVICE
and MSO_DATE = :P2_DATE
order by 2 desc;
I’ve tryed to set a server condition on Chart region when P2_DEVICE and P2_DATE are null, but in this case the region not appear. In this case I would like to show the region chart with no value or value «0».
I’m beginner of apex and I’m looking for an easy way to manage this error.
Im having this Code. :P99_CAR, :P99_PARTS are Lists you can Select an ID (trough a lookup table), :P99_AMOUNT is a simple input in my form. So you select these 3 parts and want to check following code. So if PART_ID is 5, and CAR_ID is 3 and im selecting the same numbers from the list an ERROR is coming and i dont know why.
DECLARE
--Varchar(100) or Number
l_car Varchar(100);
l_part Varchar(100);
BEGIN
SELECT CAR_ID, PART_ID INTO l_car, l_part FROM CAR_PARTS WHERE CAR_ID = :P99_CAR AND PARTS_ID = :P99_PARTS;
IF l_car IS NULL OR l_parts IS NULL THEN
INSERT INTO CAR_PARTS (CAR_ID, PARTS_ID, CUR_AMOUNT) VALUES (:P99_CAR, :P99_PARTS, :P99_AMOUNT);
ELSE
UPDATE CAR_PARTS
SET CAR_ID = :P99_CAR,
PARTS_ID = :P99_PARTS,
CUR_AMOUNT = CUR_AMOUNT + :P99_AMOUNT
WHERE CAR_ID = :P99_CAR AND PARTS_ID = :P99_PARTS;
END IF;
END;
But im getting an ORA-01403 Error when Processing, and when submit this
Ajax call returned server error ORA-01403: no data found for Execute
PL/SQL Code.
I know I need to insert an Exception with that ERROR but why is it even coming?
Содержание
- Let’s Develop in Oracle
- ORA-01403: no data found
- Часть 2. Идентификация событий происходящих в Oracle PL/SQL
- Предисловие
- Введение
- Для чего это нужно?
- Архитектурное логирование событий
- Пользовательское логирование событий
- Заключение
Let’s Develop in Oracle
ORA-01403: no data found
ORA-01403: no data found
Cause: No data was found from the objects.
Action: There was no data from the objects which may be due to end of fetch
ORA-01403 is a very common error. ORA-01403 occurs with «SELECT INTO clause», which is designed to fetch only one record from a database and assign them in plsql variables. If SELECT INTO statement fails to fetch any record from database. ORA-01403 is generated.
Lets reproduce ORA-01403 with a very simple example:
In above example ORA-01403 was generated because there was no record in EMP table with EMPNO=10 causing SELECT INTO statement to return with 0 record.
SOLUTION:
When you use SELECT INTO statement, your PL/SQL code should be written to handle ORA-1403 exception. PL/SQL raises the predefined exception NO_DATA_FOUND if a SELECT INTO statement returns no rows. Following is the example which wrap up the SELECT INTO clause in proper exception handler.
In the above example, the GET_EMP_NAME function catches and handles the NO_DATA_FOUND exception and returns NULL if no record exists for empno passed as parameter .
One interesting thing about ORA-01403 is that if I use same «get_emp_name» function in SQL Statement even without exception handling, ORA-01403 will not be generated as in sql no data found quite simply means «no data found», stop. Let me show you this behavior by following example:
This is all I want to cover for ORA-01403 (NO_DATA_FOUND). I hope you have enjoyed reading this. Please put your feedback in comment box.
Источник
Часть 2. Идентификация событий происходящих в Oracle PL/SQL
Предисловие
Убедительная просьба, рассматривать данный текст только как продолжение к статье о «Событийной модели логирования». Эта статья будет полезна тем, у кого уже реализовано логирование событий в БД и кто хотел бы осуществлять сбор статистики и начать проводить аналитику этих событий. Только представьте, что ваша БД сможет информировать вас о критичных сбоях системы, накапливать информацию о событиях в БД (кол-во повторений, период повторений и т.д.). И всё это без использования стороннего ПО силами одного PL/SQL.
Введение
В этом цикле статей будет показано как реализованный функционал «логирования» позволяет фиксировать факт возникновения не только ошибок (сообщение с типом «Error»), но и сообщений с предупреждением (тип «Warning»), информативных сообщений (с типом «Info») и т.д., поэтому, в рамках данных статей введём термин — «Модель логирования событий» (далее по тексту — «модель») или коротко «Логирование событий», где под «событием» подразумевается некоторое ожидаемое действие, возникшее в ходе штатной/внештатной работы алгоритма.
Модель логирования позволяет реализовать:
Единый подход в обработке и хранении событий (статья)
Собственную нумерацию и идентификацию событий происходящих в БД
Единый мониторинг событий (статья в разработке)
Анализ событий происходящих в БД (статья в разработке)
Описанные выше характеристики указаны в порядке нумерации и каждый следующий пункт (шаг) есть улучшение и усложнение существующей модели. Описание этой модели будет сложно выполнить в рамках одной статьи, поэтому опишем их последовательно. В этой (второй) статье создадим собственную нумерацию кодов для событий, а также создадим функционал идентификации событий происходящих в БД.
Для чего это нужно?
Для начала давайте рассмотрим пример. Вы реализовали логирование ошибок в вашей БД. С течением времени в ваш лог «прилетают» самые разнообразные ошибки. Предположим, имеются две ошибки вида «no_data_found» возникшие в двух разных процедурах при двух разных запросах (select). Первая ошибка возникла при попытке найти «email» клиента, что в принципе не является критичной ошибкой. Вторая ошибка возникла при попытке найти номер лицевого счета клиента, что вполне может являться критичной ошибкой. При этом если мы посмотрим в таблицу лога (из статьи), то увидим, что указанные ошибки будут храниться с одинаковым кодом 1403 (ORA-01403) в столбце msgcode. Более того, текст указанных ошибок будет практически аналогичным (текст полученный с помощью функции SQLERRM) за исключением имен объектов, на которых произошла ошибка. Для того чтобы понять является ли критичной конкретная ошибка, разработчику необходимо вникать в текст ошибки, смотреть в каком объекте возникла ошибка и на основе этой информации сделать вывод о срочности исправления. При этом, если мы сможем задать более четкое описание ошибки отличное от текста Oracle (SQLERRM), то это позволит упростить понимание причин возникновения и способов решения ошибки.
Как должно быть (в идеале)
Не найдена запись в таблице содержащей адреса электронной почты клиентов
ORA-01403: данные не найдены
USR0001: Не найден адрес электронной почты клиента (идентификатор клиента)
Не найдена запись в таблице содержащей лицевые счета клиентов
ORA-01403: данные не найдены
USR0002: Не найден лицевой счет клиента (идентификатор клиента)
Из этого примера видно, что одна и та же ошибка «no_data_found» (ORA-01403: данные не найдены) может иметь совершенно разное значение с точки зрения бизнес логики, а значит нам необходимо разработать механизм, который позволит идентифицировать каждое событие происходящее в БД как отдельное событие с нашим внутренним уникальным кодом и текстом события (отличную от Oracle). Таким образом мы решаем две проблемы:
1) В месте возникновения ошибки мы устанавливаем уникальный код ошибки. В будущем это позволяет достаточно быстро найти место возникновения ошибки. Также, наличие уникальных кодов позволяет нам произвести точечный подсчет повторений и на основании этой информации принять решение об устранении данной ошибки.
2) Дополнительный «читаемый» текст позволяет сильно упростить понимание ошибки. В таблице выше показано, как одна и та же ошибка может запутать или разъяснить пользователю сведения об ошибке.
Надеюсь мне удалось объяснить зачем необходимо кодировать события в таблице логов. Далее по тексту, будут введены термины «Архитектурный лог» и «Пользовательский лог». На примере процедуры поиска активного номера телефона клиента будет показано как и зачем создано разделение на архитектурный и пользовательский лог.
Архитектурное логирование событий
Давайте рассмотрим пример, имеется процедура поиска активного номера телефона принадлежащего конкретному клиенту (для примера его Предположим, что при постановке задачи для разработчика не было описания каких-либо особых условий т.е. по условиям задачи предполагалось, что для конкретного пользователя (id = 43, идентификатор передается в качестве параметра) в таблице client_telnumbers всегда будет хотя бы одна запись с номером телефона клиента и признаком «активный» (значение поля enddate равно дате 31.12.5999 23:59:59, что означает что номер используется клиентом. В случае, любой другой даты в указанном поле означает, что номер перестал быть активным и более не используется), поэтому наша процедура будет выглядеть примерно так:
Исходный код демонстрационной процедуры
Важно! Представленный код является примерным (примитивным) и служит только для демонстрации логирования в рамках данной статьи. В своих статьях я не выкладываю текст кода из реально действующих БД. Надеюсь, вы понимаете, что в реальности указанная процедура написана гораздо сложнее.
*Исходный код других используемых объектов смотрите в Git
Если мы будем использовать логирование ошибок как показано в предыдущей статье, то с течением времени обнаружим, что идентифицировать ошибки из данной процедуры будет сложно. Поэтому для всех ошибок попадающих в обработку исключения «WHEN OTHERS» реализована процедура pkg_msglog.p_log_archerr, которая при первом возникновении ошибки автоматически присваивает ей уникальный код и сохраняет ошибку в таблице лога. В дальнейшем, при повторении данной ошибки процедура найдет ранее созданный код и использует его при логировании в таблице лога.
В итоге, после добавления блока «архитектурного» логирования (строки с 18 по 24), наша процедура будет выглядеть следующим образом:
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
На этапе написания текста процедуры разработчик не всегда может предугадать возникновение той или иной ошибки (если честно, не всегда есть на это время), поэтому на начальном этапе ему достаточно «отлавливать» абсолютно все ошибки возникающие в данной процедуре с помощью оператора «WHEN OTHERS». Таким образом мы можем ввести новый термин (в рамках данного цикла статей), «Архитектурные логирование» — это логирование всех ошибок, возникновение которых не предполагается при штатной работе алгоритма. Для функционала «Архитектурных ошибок» были созданы объекты: отдельный справочник ошибок messagecodes_arch и процедура pkg_msglog.p_log_archerr создания записи в таблице лога для указанного типа ошибок.
Исходный код таблицы
Ограничение в таблице на комбинацию (Имя объекта, код ошибки SQLCODE). При первом появлении ошибки создается запись в таблице и генерируется код ошибки «SYS0000» + счетчик ошибок. При повторном появлении указанной ошибки будет взят уже сгенерированный ранее код ошибки.
 рис. Пример содержимого таблицы messagecodes_arch
рис. Пример содержимого таблицы messagecodes_arch
*Исходный код других используемых объектов смотрите в Git
Обратите внимание, что при использовании описанной модели «архитектурного» логирования у вас появляется функционал позволяющий максимально быстро реагировать на первое появление ошибки (в конкретной функции/процедуре). Для этого необходимо реализовать отдельный мониторинг архитектурных ошибок, который постараюсь продемонстрировать в следующей (третьей) статье. Использование процедуры pkg_msglog.p_log_archerr не требует каких-либо действий кроме описания входных параметров.
Таким образом мы можем создать базовый шаблон процедуры (функции), использование которого позволит вам гарантированно отлавливать все архитектурные ошибки в вашем коде.
Шаблон процедуры/функции с архитектурным логированием
Рекомендую использовать данный шаблон для построения «Событийной модели логирования».
*Исходный код других используемых объектов смотрите в Git
В рамках событийной модели логирования, предполагается, что все архитектурные ошибки будут исправляться отдельной задачей т.е. основная цель это устранить повторное появление ошибок с кодом «SYS****» в таблице лога. В указанной задаче вам необходимо либо устранить причины возникновения данной ошибки, либо добавить отдельную обработку ошибки отличную от «when others», которую в дальнейшем будем назвать «пользовательское» логирование (в рамках данного цикла статей).
Пользовательское логирование событий
Предположим, что однажды в нашей процедуре get_telnumber произошла «архитектурная ошибка». В частности, для конкретного пользователя в таблице client_telnumbers хранится два номера телефона с признаком «активный». В таком случае, процедура «упадёт» с ошибкой «ORA-01422: too_many_rows». При этом, наш функционал архитектурного логирования сгенерировал новый код ошибки «SYS0061» и создал запись в таблице лога.
 рис. Код архитектурной ошибки SYS0061
рис. Код архитектурной ошибки SYS0061
Самое важно в такой ситуации это не откладывать «на потом» исправление архитектурных ошибок. В идеале, необходимо создать отдельную задачу (баг) и в рамках неё устранить ошибку.
Предположим ,что была создана отдельная задача для устранения ошибки и назначена разработчику. В рамках этой задачи, разработчик совместно с технологом, аналитиком и др. коллегами пришел к выводу, что указанная ошибка носит систематический характер, является некорректной работой системы и требует исправления. В качестве мер исправления было решено добавить обработку события «too_many_rows» с последующим логированием события в таблице лога и выводом текста ошибки для пользователя.
Для этого в процедуре get_telnumber добавлено исключение (exception) «too_many_rows» пользовательского логирования. Также, был создан справочник пользовательских ошибок отличный от архитектурного справочника, тем что в него все записи добавляются разработчиком «вручную». Наверное это самое слабое место во всей архитектуре логирования. Предполагается, что разработчик должен описать исключение (exception) и создать для него уникальный код ошибки. Также, желательно к указанной ошибке сформулировать читаемый текст ошибки (для своих коллег, пользователя, техподдержки и т.д.), что бывает иногда очень сложным (из личного опыта).
Таблица пользовательских ошибок и процедура их «регистрации» будет выглядеть следующим образом:
Исходный код таблицы пользовательских ошибок и процедуры регистрации
Регистрация пользовательских ошибок производится процедурой p_insert_msgcode. На вход подается код и текст ошибки. В случае, если по указанному коду нет записей в справочнике messagecodes, то создается новая запись (производится регистрация). В случае, если по коду ошибки найдена запись, то производится сравнение текстов ошибки, в случае расхождений производится обновление текста, иначе работа процедуры завершается без изменений. Таким образом мы всегда можем корректировать текст ошибок.
Обратите внимание, что текст ошибок имеет параметризацию т.е. для ошибки в тексте имеются специальные символы $1, $2, $3 и т.д. Например, рассмотрим ошибку «USR0003» с текстом «Для клиента найдено два и более активных номеров телефона!» при вызове функции f_get_errcode на вход подаётся код ошибки и параметры ошибки. Далее, функция по коду ошибки найдет строку, в тексте ошибки заменит подстроку «$1» на значение параметра to_char(p_userid) т.е. подставит значение to_char(p_userid).
В случае если в тексте ошибки будут два и более спецсимвола $1, $2, $3 и т.д., то параметры передаются с использованием символа-разделителя «;».
Итого, содержимое справочника пользовательских ошибок будет выглядеть следующим образом:
 рис. Пример содержимого справочника пользовательских ошибок
рис. Пример содержимого справочника пользовательских ошибок
*Исходный код других используемых объектов смотрите в Git
После того, как мы «зарегистрировали» пользовательскую ошибку «USR0003» и добавив отдельную обработку пользовательского логирования (строки с 19 по 28), наша процедура get_telnumber будет выглядеть следующим образом:
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
При повторном возникновении ошибки «too_many_rows» обработка события пройдет по нашему сценарию «пользовательского» логирования. Таким образом мы можем ввести второй термин (в рамках данного цикла статей), «Пользовательские логирование» — это логирование всех ошибок, возникновение которых предполагается и ожидается при нештатной работе алгоритма. В итоге, пользователь получит читаемый текст ошибки с кодом «USR0003», также, мы же всегда сможем подсчитать количество ошибок с указанным кодом. В случае большого количества ошибок у нас на руках будет «живая» статистика частоты возникновения ошибки и их количества, что позволит нам выйти на руководство с предложением по доработке/оптимизации процесса.
Давайте рассмотрим еще один пример (кейс из реального случая), в момент когда процедура get_telnumber по id клиента находит один «активный» номер телефона иногда возникает ситуация, что номер телефона не принадлежит мобильному оператору. Ситуации бывают разные иногда указанный номер мог быть номером городской телефонной сети, иногда номером международного оператора, а иногда вообще набор из нескольких цифр и т.д. Основным требованием от бизнес-заказчика было использование номера телефона российских операторов мобильной связи. Поэтому было решено добавить проверку соответствия найденного номера некому «корректному» шаблону (строки с 18 по 29). В случае обнаружения некорректного номера, логировать данное событие отдельным кодом «USR0004» и типом «WRN». Добавим функцию проверки корректности номера телефона, если номер соответствует шаблону (требованиям), то вернем номер телефона, иначе пустое значение.
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
После сбора статистических данных по конкретной ошибке с кодом «USR0004», руководству стало понятно, что ошибка актуальна и количество ошибок с течением времени не только не уменьшается, а наоборот растет с линейной прогрессией. В дальнейшем, были выявлены источники «кривых» данных и были установлены внутренние требования по первичной обработке номера телефона клиентов. В итоге, со временем количество ошибок уменьшилось до нуля. И этого нельзя было добиться до тех пор, пока у всех участвующих лиц не возникло понимание о масштабе проблемы.
Выполняя самый банальный запрос в таблицу лога с группировкой по типу сообщения (msgtype), имени объекта (objname) и вашему внутреннему коду ошибки (msgcode) за отдельный квартал, вы сможете увидеть реальную картинку частоты возникновения той или иной ошибки. Как только в вашей БД появляется ошибка с большим количеством повторений вы всегда сможете выявить это событие и принять решение об устранении.
Исходный код запроса
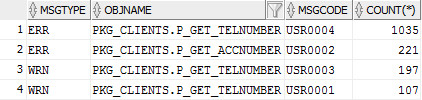 рис. Пример результата запроса с группировкой
рис. Пример результата запроса с группировкой
*Исходный код других используемых объектов смотрите в Git
Заключение
В заключении наверное скажу банальную вещь, о том что ваша БД является сложным механизмом ежесекундно выполняющая рутинные операции. Прямо сейчас в БД могут происходить различные ошибки. Критичные, которые вы исправляете практически сразу или некритичные, о которых вы можете вообще не знать. И если у вас нет информации о подобных ошибках, то возникает вопрос: «Нужно ли их вообще исправлять? Или можно подождать до тех пор, пока проблема не всплывёт?». Вопрос наверное «риторический».
Я же данной статьёй хотел показать один из способов ведения логирования с кодированием отдельных событий. Данный метод требует некоторых «обязательств» от разработчика и в нынешнее время этого тяжело добиться. В следующей статье постараюсь показать один из способов мониторинга ошибок основанный напрямую по кодам ошибок созданных в текущей статье.
Источник
In my previous articles, I have given the proper idea of different oracle errors, which are frequently come. In this article, I will try to explain the most common error, which has been searched on google approximately 10 k times per month. ORA-01403 is coming when PLSQL variable does not found any data. ORERR utility may provide the information of this error, which is ‘No data found’ error. Most of the time developer forget to handle this error in PLSQL code. There might be different possible reasons for this error.

Cause and resolution of this error :
The main cause of this error is variable does not found any data. In this article I will try to give different causes for this error.
![]()
1.Select Into clause does not found any data :
This is the base reason of this error. This error will come when variable does not found any data.kindly check the following example for the same.
Example :
DECLARE
V_SRNUM VARCHAR2(20);
BEGIN
SELECT SR_NUM
INTO V_SRNUM
FROM S_SRV_REQ
WHERE ROW_ID = ‘124’;
DBMS_OUTPUT.PUT_LINE(V_SRNUM);
END;
Output :
ORA-01403: no data found
ORA-06512: at line 4
01403. 00000 – “no data found”
*Cause:
*Action:
Resolution of this error :
Handle the exception :
To resolve this error PLSQL developer needs to handle the given exception carefully. So the code will be changed as follows :
DECLARE
V_SRNUM VARCHAR2(20);
BEGIN
SELECT SR_NUM
INTO V_SRNUM
FROM S_SRV_REQ
WHERE ROW_ID = ‘124’;
DBMS_OUTPUT.PUT_LINE(V_SRNUM);
Exception WHEN NO_DATA_FOUND THEN
dbms_output.put_line(‘Exception came’);
END;
2.Use of UTL_FILE package :
When you are using UTL_FILE package this error will occur.There was an attempt to read past the end of file when using the UTL_FILE package.
Resolution of this error :
Fix the code stop running prior to reading end of file.
3.Logical standby :
There might be the possible cause of using LOGICAL STANDBY statement. Previous use of Skip rule on DML operations causing a data mismatch. In this case simply skip the transaction and restart the apply process.
ORA-01403: no data found
ORA-01403: no data found
Cause: No data was found from the objects.
Action: There was no data from the objects which may be due to end of fetch
Reference: Oracle Documentation
ORA-01403 is a very common error. ORA-01403 occurs with «SELECT INTO clause», which is designed to fetch only one record from a database and assign them in plsql variables. If SELECT INTO statement fails to fetch any record from database. ORA-01403 is generated.
Lets reproduce ORA-01403 with a very simple example:
SQL> create or replace function get_emp_name(p_empno emp.empno%type)
2 return varchar2
3 as
4 l_ename emp.ename%type;
5 begin
6 select ename
7 into l_ename
8 from emp
9 where empno = p_empno;
10
11 return l_ename;
12 end;
13 /
Function created.
SQL> declare
2 l_ename emp.ename%type;
3 begin
4 l_ename := get_emp_name(10);
5 dbms_output.put_line('l_ename :' || l_ename);
6 end;
7 /
declare
*
ERROR at line 1:
ORA-01403: no data found
ORA-06512: at "SCOTT.GET_EMP_NAME", line 6
ORA-06512: at line 4
In above example ORA-01403 was generated because there was no record in EMP table with EMPNO=10 causing SELECT INTO statement to return with 0 record.
SOLUTION:
When you use SELECT INTO statement, your PL/SQL code should be written to handle ORA-1403 exception. PL/SQL raises the predefined exception NO_DATA_FOUND if a SELECT INTO statement returns no rows. Following is the example which wrap up the SELECT INTO clause in proper exception handler.
SQL> create or replace function get_emp_name(p_empno emp.empno%type)
2 return varchar2
3 as
4 l_ename emp.ename%type;
5 begin
6 select ename
7 into l_ename
8 from emp
9 where empno = p_empno;
10
11 return l_ename;
12 exception
13 when NO_DATA_FOUND then
14 -- exception handling logic goes here
15 return null;
16 end;
17 /
Function created.
SQL> set serveroutput on
SQL> declare
2 l_ename emp.ename%type;
3 begin
4 l_ename := get_emp_name(10);
5 dbms_output.put_line('l_ename :' || l_ename);
6 end;
7 /
l_ename :
PL/SQL procedure successfully completed.
In the above example, the GET_EMP_NAME function catches and handles the NO_DATA_FOUND exception and returns NULL if no record exists for empno passed as parameter .
One interesting thing about ORA-01403 is that if I use same «get_emp_name» function in SQL Statement even without exception handling, ORA-01403 will not be generated as in sql no data found quite simply means «no data found», stop. Let me show you this behavior by following example:
SQL> create or replace function get_emp_name(p_empno emp.empno%type)
2 return varchar2
3 as
4 l_ename emp.ename%type;
5 begin
6 select ename
7 into l_ename
8 from emp
9 where empno = p_empno;
10
11 return l_ename;
12 end;
13 /
Function created.
SQL> select get_emp_name(10) from dual;
GET_EMP_NAME(10)
--------------------------------------------------
SQL>
This is all I want to cover for ORA-01403 (NO_DATA_FOUND). I hope you have enjoyed reading this. Please put your feedback in comment box.
Related Posts:
— ORA-06502: invalid LOB locator specified
— ORA-01422: exact fetch returns more than requested number of rows
— ORA-01489: result of string concatenation is too long
— ORA-01439: column to be modified must be empty to change datatype
— ORA-01830 date format picture ends before converting entire input string
— ORA-01460 unimplemented or unreasonable conversion requested
April 30, 2021
I got ” ORA-01403: no data found ” error in Oracle database.
ORA-01403: no data found
Details of error are as follows.
ORA-01403 no data found Cause: In a host language program, all records have been fetched. The return code from the fetch was +4, indicating that all records have been returned from the SQL query. Action: Terminate processing for the SELECT statement
no data found
This ORA-01403 errors are related with the host language program, all records have been fetched. The return code from the fetch was +4, indicating that all records have been returned from the SQL query.
Mostly you can get this error during SELECT INTO statement usage and no rows were returned.
Or You have referenced uninitialized row in table.
You can terminate processing for the SELECT statement.
Or if you want to avoid ORA-01403, your PL/SQL code has to contain exceptions ,
Do you want to learn Oracle Database for Beginners, then read the following articles.
Oracle Tutorial | Oracle Database Tutorials for Beginners ( Junior Oracle DBA )
1,556 views last month, 1 views today
About Mehmet Salih Deveci

I am Founder of SysDBASoft IT and IT Tutorial and Certified Expert about Oracle & SQL Server database, Goldengate, Exadata Machine, Oracle Database Appliance administrator with 10+years experience.I have OCA, OCP, OCE RAC Expert Certificates I have worked 100+ Banking, Insurance, Finance, Telco and etc. clients as a Consultant, Insource or Outsource.I have done 200+ Operations in this clients such as Exadata Installation & PoC & Migration & Upgrade, Oracle & SQL Server Database Upgrade, Oracle RAC Installation, SQL Server AlwaysOn Installation, Database Migration, Disaster Recovery, Backup Restore, Performance Tuning, Periodic Healthchecks.I have done 2000+ Table replication with Goldengate or SQL Server Replication tool for DWH Databases in many clients.If you need Oracle DBA, SQL Server DBA, APPS DBA, Exadata, Goldengate, EBS Consultancy and Training you can send my email adress [email protected].- -Oracle DBA, SQL Server DBA, APPS DBA, Exadata, Goldengate, EBS ve linux Danışmanlık ve Eğitim için [email protected] a mail atabilirsiniz.