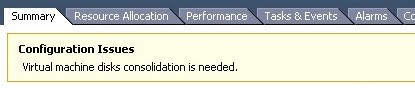
Очень часто при удалении снапшотов или консолидации дисков виртуальных машин на хостах VMWare ESXi, я сталкиваюсь с ошибкой “Unable to access a file since it is locked”. Это довольна частая проблема связана с ошибками в системе резервного копирования ВМ (я встречал проблему в Veeam, HP Data Protector, Veritas). Блокировка виртуального диска снапшота виртуальной машины не позволит вам выполнить консолидацию (Virtual machine disks consolidation is needed), Storage vMotion на другой дисковый массив, выполнить резервное копирование или удалить текущий снапшот. Иногда виртуальную машины с блокировками нельзя даже элементарно включить.
Ошибка с доступом к заблокированному файлу виртуального диска или снапшот в VMWare может выглядеть так:
Чтобы найти источник блокировки и снять ее, сначала нужно определить заблокированные файлы.

В строке RO Owner указан MAC адрес сетевой карты хоста ESXi, который заблокировал данный файл снапшота (MAC адрес выделен на скриншоте). Также обратите внимание на значение Mode:
- mode 1 – блокировка на чтение/запись (например, у включенной ВМ);
- mode 2 – обычно означает, что диск заблокирован приложением резервного копирования.
Чтобы по известному MAC адресу найти ESXi сервер, можно воспользоваться следующими командами в PowerCLI (преобразуйте полученный ранее MAC адрес в формат с двоеточиями):
Import-Module VMware.VimAutomation.Core -ErrorAction SilentlyContinue
connect-viserver vcenter1
Get-VMHost | Get-VMHostNetworkAdapter | Where-Object <$_.Mac -like «d0:67:26:ae:79:00»>| Format-List -Property *
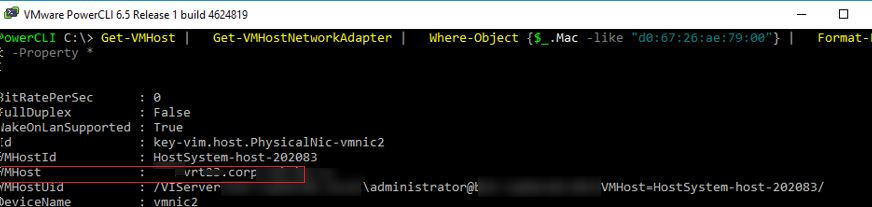
Имя ESXi хоста будет указано в поле VMHost.
Также вы можете вывести ARP таблицу прямо с хоста ESXi и получить IP и MAC адреса всех соседних серверов ESXi в сети VMkernel:
esxcli network ip neighbor list
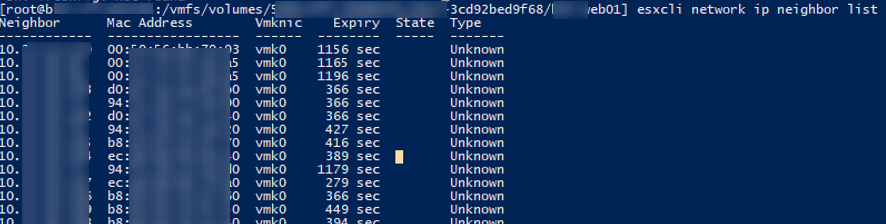
Чтобы снять блокировку с файла ВМ просто перезагрузите найденный ESXi хост (предварительно смигрируйте с него все ВМ с помощью VMotion). Если вы не можете перезагрузить хост, перезапустите службу Management Agent (hostd) в Maintenance Mode из SSH консоли хоста:
После этого попробуйте выполнить консолидацию или удалить снашот ВМ.
Чтобы исправить проблему, откройте параметры ВМ, на которой установлен прокси Veeam. Удалите из оборудования ВМ диск ВМ, файлы которой заблокированы.
Убедитесь, что вы выбрали опцию “Remove from virtual machine”, а не “Remove from virtual machine and delete files from disk”. Иначе вы можете случайно удалить ваш vmdk диск.
Источник
vCallaway
The Journey to VCDX
Error Occurred While Consolidating disks msg.fileio.lock.
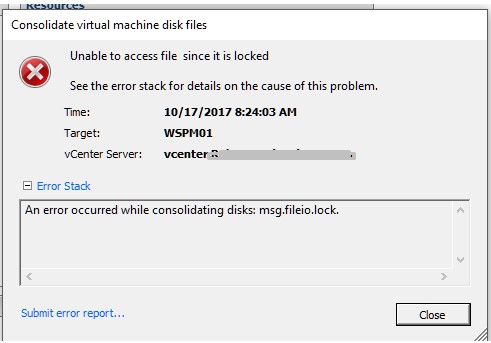
I was in vCenter the other day and noticed that one of my virtual machines had the following message/warning:
It was weird. I thought to myself, I’m the only one that has access to this vSphere environment and I haven’t taken any snapshots of this particular VM recently, so what could be the problem. I went to snapshot manager and didn’t see any snapshots listed which was odd (come to find out the snapshot DB was corrupt). I then went to ‘Snapshot Manager > Consolidate, to see if I could consolidate the VM’s after confirming there were snapshot files in the datastore (4 of them). Upon trying to consolidate the VM, it failed with the following error:
Error Occurred While Consolidating disks msg.fileio.lock.
Version: ESXi 5.5
My initial thought was hmmm…
Then I thought about what might be creating VM snapshots and of course that would be the image based backup solution that I run which is NetBackup. I head over to my NetBackup appliance and notice that there are failures for this particular VM. So I assume that the file(s) is locked by NetBackup.
To confirm that, I went into the hostd.log file on the host that it was sitting on and start reviewing the logs. Of course it says it can’t have access to the disk yet it doesn’t show me who’s locking it.
After Googling around I didn’t find much information or success on getting these VM files unlocked.
I tried finding the lock using these helpful KB’s.
All I received back was an odd error which yielded no results on my Google search. After trying to figure out what I needed to do I thought, let me see if I can vMotion this to another machine and see if I can unlock these file(s) that way.
vMotion was a success, but the following consolidation effort still failed. My next thought was to shutdown the VM and the Netbackup Appliance. But before I did that, I thought that may not be the best option. Because if I shut down the VM, and it still has a lock on the file, then I’ll be stuck unable to power it back on.
So I basically was nervous to do a Storage vMotion to help release the lock so I punted to GSS (VMware Support). After initial troubleshooting these were the following steps that we laid out for a solution.
From GSS:
- We confirmed that the snapshot database is corrupt. This is why snapshot manager is not showing any active snapshots.
- We confirmed that the current snapshot chain and its data is consistent. The VM and its snapshots are in a healthy state, besides the missing database.
- A consolidation would be successful in the VM’s current state if not for the stale locks.
- Consolidation of the VM is failing due to stale locked files. We are getting error: “Inappropriate ioctl for device”
- We checked for a mounted ISO or file but there was no there.
At this point we have a couple of options to try and remediate this issue. Starting with least impactful first.
1) Attempt to Storage VMotion the VM to a different datastore. The hope here is that it will move all active files over to the new datastore which would remove the lock and allow us to consolidate.
–The only problem I see with this is that it might attempt to delete some of the old files after the Svmotion and we will get the same error about files being locked – The hope is that the svmotion would still be successful, it would just fail on the second part (removing the old files) and we could clean that up manually.
2) We can do a rolling reboot of the ESXi hosts in the cluster. This should release and stale locks and allow us to run the consolidation. This is a little more impactful because we have to migrate a lot of VM’s around.
3) As a last resort, we can essentially do a force clone of the vmdk and attach that to the existing VM. This will consolidate the snapshots during the process but would require us to shutdown the VM.
At the end of the day, I used Storage vMotion to move the VM to another datastore, and then I was able to successfully consolidate the virtual machine. After that was completed, I immediately performed a new backup that was successful. Waited 2 days to see if the old files on the previous datastore were being modified (old snapshots) and they weren’t which led me to successfully removing those files to save space.
I hope this helps someone down the road. Thanks for reading!
Источник
VMware vSphere: Locked Disks, Snapshot Consolidation Errors, and ‘msg.fileio.lock’
A reoccurring issue this one, and usually due to a failed backup. In my case, this was due to a failure of a Veeam Backup & Replication disk backup job which had, effectively, failed to remove it’s delta disks following a backup run. As a result, a number of virtual machines reported disk consolidation alerts and, due to the locked vmdks, I was unable to consolidate the snapshots or Storage vMotion the VM to a different datastore. A larger and slightly more pressing concern that arose (due to the size and amount of delta disks being held) meant the underlying datastore had blown it’s capacity, taking a number of VMs offline.
So, how do we identify a) the locked file, b) the source of the lock, and c) resolve the locked vmdks and consolidate the disks?
 Disk consolidation required.
Disk consolidation required. 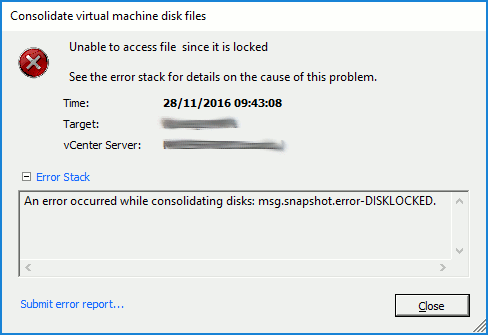 Manual attempts at consolidating snapshots fail with either DISKLOCKED errors…
Manual attempts at consolidating snapshots fail with either DISKLOCKED errors… 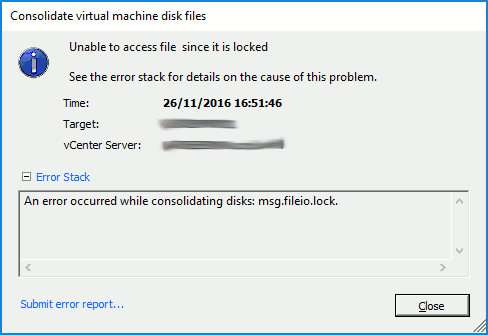 …and/or ‘msg.fileio.lock’ errors.
…and/or ‘msg.fileio.lock’ errors. 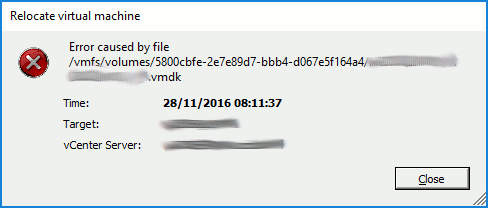 Storage vMotion attempts fail, identifying the locked file.
Storage vMotion attempts fail, identifying the locked file.
Identify the Locked File
As a first step, we’ll need to check the hostd.log to try and identify what is happening during the above tasks. To do this, SSH to the ESXi host hosting the VM in question, and launch the hostd.log.
While the log is being displayed, jump back to either the vSphere Client for Windows (C#) or vSphere Web Client and re-run a snapshot consolidation (Virtual Machine > Snapshot > Consolidate). Keep an eye on the hostd.log output while the snapshot consolidation task attempts to run, as any/all file lock errors will be displayed. In my instance, the file-lock error detailed in the Storage vMotion screenshot above is confirmed via the hostd.log output (below), and clearly shows the locked disk in question.
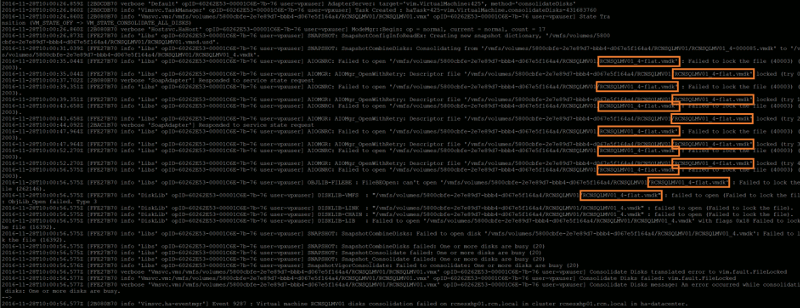 File lock errors, detailed via the hostd.log, should be fairly easy to identify, and will enable you to identify the locked vmdk.
File lock errors, detailed via the hostd.log, should be fairly easy to identify, and will enable you to identify the locked vmdk.
Identify the Source of the Locked File
Next, we need to identify which ESXi host is holding the lock on the vmdk by using vmkfstools.
We are specifically interested in the ‘RO Owner’, which (in the below example) shows both the lock itself and the MAC address of the offending ESXi host (in this example, ending ‘f1:64:09’).

The MAC address shown in the above output can be used to identify the ESXi host via vSphere.
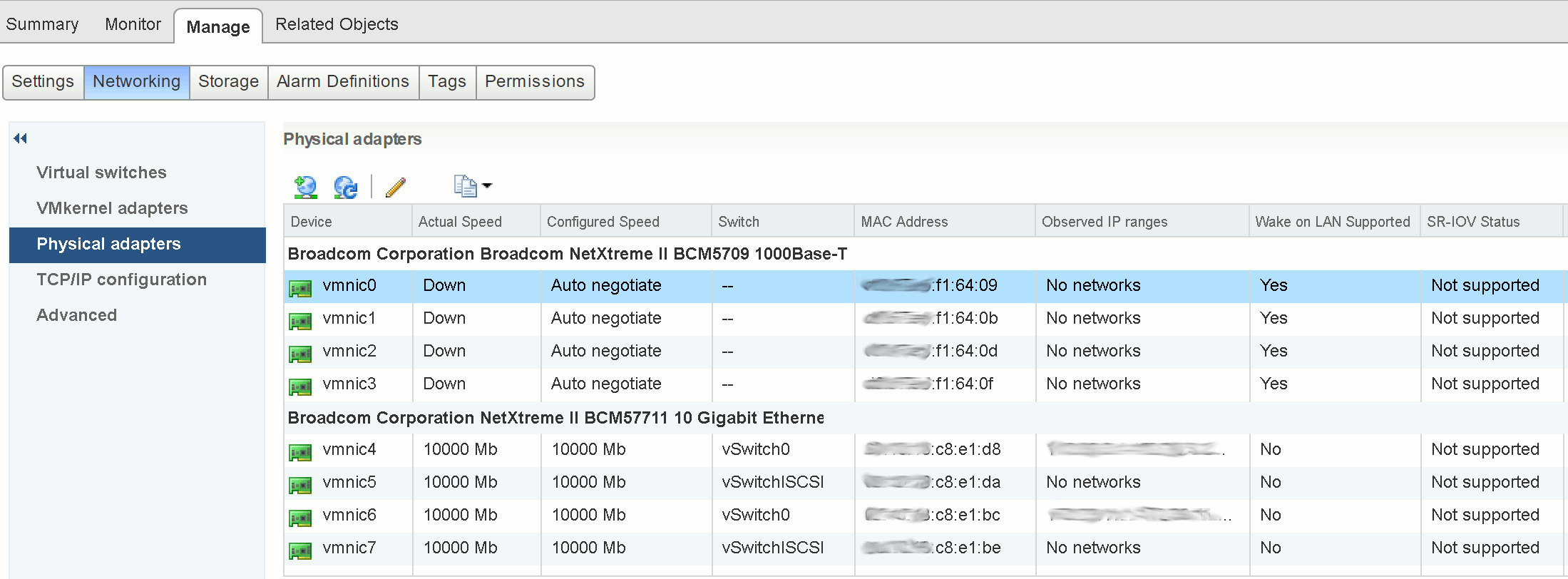
Resolve the Locked VMDKs and Consolidate the Disks
Now the host has been identified, place in Maintenance Mode and restart the Management Agent/host daemon service (hostd) via the below command.

Following a successful restart of the hostd service, re-run the snapshot consolidation. This should now complete without any further errors and, once complete, any underlying datastore capacity issues (such as in my case) should be cleared.
For more information, an official VMware KB is available by clicking here.
Источник
An error occurred while consolidating disks msg fileio lock

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I’m currently facing an issue in which two VMs require disk consolidation after being backed up by Veeam but a file lock remains on the files. I get the message » An error occurred while consolidating disks: msg.fileio.lock. » when I try to consolidate. When looking at the host servers ESXI logs I can see this error:
AIOGNRC: Failed to open ‘/vmfs/volumes/*Datastore*/*VM*/*VM*-flat.vmdk’ : Failed to lock the file (40003) (0x2013).
AIOMgr_OpenWithRetry: Descriptor file ‘/vmfs/volumes/*Datastore*/*VM*/*VM*-flat.vmdk’ locked (try 2)
From what I’ve seen elsewhere a common solution to this is to vMotion the VM in question to a new datastore. Unfortunately this is going to be complicated for me because we don’t have the full license to allow a powered on migration, and one of the affected VMs is the VCenter Appliance itself. So if I power down the Appliance to try and perform the migration I will lose access to the vSphere console and the individual host won’t be able to perform the move on its own.
So my questions are:
Is there an alternative to the Storage vMotion to unlock the files?
Is there a better way of doing the migration? I have seen that Veeam’s Quick Migration might work but again I don’t know how that will interact with the vCenter Appliance being the one moved.
Источник
An error occurred while consolidating disks msg fileio lock
So I am in an situation that for some reason we have a lot of deltas and the server needed disk consolidation done.
But when I go to start it it gives me the following error
«An error occurred while consolidating disks: msg.fileio.lock.»
Now I did see the following article https://kb.vmware.com/s/article/2107795 but am a bit lost on how to the steps
Also I did find this following article as well https://kb.vmware.com/s/article/1027876 that I could clone the latest delta file to a new vmdk
Would this clone be in essence the latest vmdk as if I did do the consolidation?
The other issue is the amount of free space, which is currently at about 500GB. and the machine consists of 2 hdd, 1 — 147GB and 1 — 500gb
I forgot to mention this is on ESXI 5.5 as well

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Could you migrate the VM to another hypervisor? That fixes the locked error sometimes.
Also creating a snapshot and then consolidate fixes it. Sometimes .

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
To start of with, check if any of the VM disks are mounted on the backup proxy VM. If yes, unmount them unless there is an active backup running for the VM.
If this does not help, you need to navigate to the VM folder from the host on which the VM is currently running (folders if the VM disks spans across multiple folders/datastores) and run . For the flat vmdk’s that report as busy, run to determine the lock owner. Then, follow the KB VMware Knowledge Base to identify the MAC address of the host holding the lock and reboot the host in case it is a stale lock.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You might want to investigate if there are any lock on any of the vm’s file.
Regarding your query for VMware Knowledge Base your understanding is correct . However depending on the size of all deltas vmdk please make sure that you have enough space on the destination datastore where you are cloning the vmdk to.
Clone the virtual hard disk from its current snapshot delta point using the vmkfstools -i command.
# vmkfstools -i /vmfs/volumes/Storage1/examplevm/examplevm-000003.vmdk /vmfs/volumes/Storage2/examplevm_clone.vmdk
You see output similar to:
Destination disk format: VMFS thick
Cloning disk ‘/vmfs/volumes/Storage1 (3)/examplevm/examplevm-000003.vmdk’.
Clone: 100% done.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@aleex42 — Cannot do that unfortunatley, as only single host, cannot migrate. But will try to create a new snapshot and remove
@SupreetK — We use HPE VMX Explorer for vm backups but I do not see that anything is mounted there, but will double check
I have looked at that article you linked, which I did in my initial post as well, but I am at a loss on what I am looking for in the logs, it says to look at last consolidate/power-on process, but not sure how that is worded in the logs. But have had rebooted the host prior to trying to consolidate
@concord0007 — ok good to know. I may need to do that ultimately if i cannot find why I cannot do it normally
Источник
Очень часто при удалении снапшотов или консолидации дисков виртуальных машин на хостах VMWare ESXi, я сталкиваюсь с ошибкой “Unable to access a file since it is locked”. Это довольна частая проблема связана с ошибками в системе резервного копирования ВМ (я встречал проблему в Veeam, HP Data Protector, Veritas). Блокировка виртуального диска снапшота виртуальной машины не позволит вам выполнить консолидацию (Virtual machine disks consolidation is needed), Storage vMotion на другой дисковый массив, выполнить резервное копирование или удалить текущий снапшот. Иногда виртуальную машины с блокировками нельзя даже элементарно включить.
Ошибка с доступом к заблокированному файлу виртуального диска или снапшот в VMWare может выглядеть так:
Unable to access file since it is locked. An error occurred while consolidating disks: One or more disks are busy.
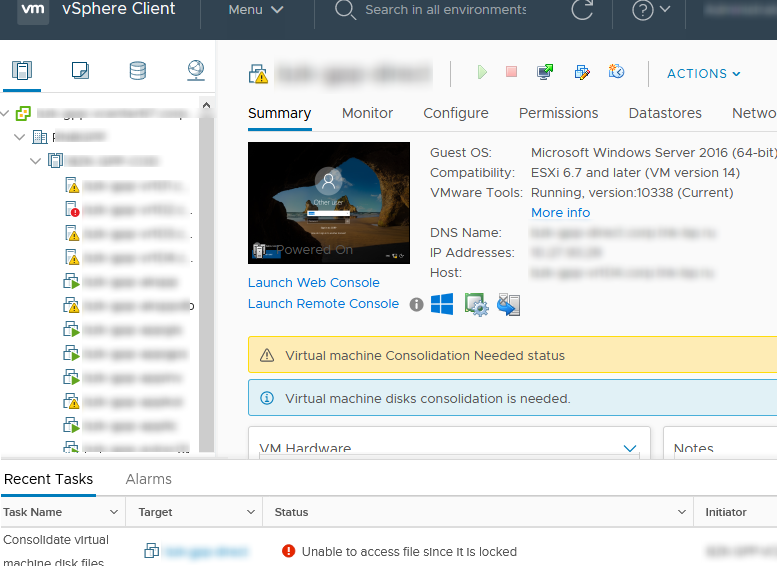
Так же вы можете увидеть такую ошибку:
An error occurred while consolidating disks: msg.snapshot.error-DISKLOCKED.
Чаще всего ошибка “Unable to access file since it is locked” появляется:
- Когда некоторые файлы включенной виртуальной машины содержат метки блокировки другими хостаим ESXi;
- При добавлении виртуальных дисков в appliance резервного копирования во время неудачных сессий создания бэкапа;
Чтобы найти источник блокировки и снять ее, сначала нужно определить заблокированные файлы.
- С помощью SSH клиента подключитесь к хосту ESXi, на котором зарегистрирована проблемная ВМ;
- Перейдите в каталог с файлами виртуальной машины:
cd /vmfs/volumes/VMFS_DATASTORE_NAME/LOCKED_VM - Найдите ошибки консолидации, блокировки файлов в журнале vmware.log:
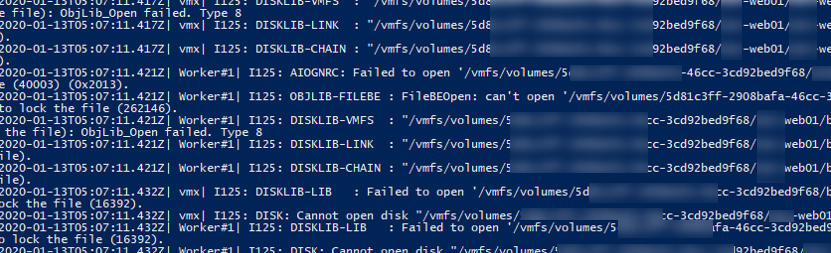
cat vmware.log | grep lock - В логе должны содержаться примерно такие ошибки:
VigorSnapshotManagerConsolidateCallback: snapshotErr = Failed to lock the file (5:4008) 2020-01-13T05:07:11.432Z| vmx| I125: DISK: Cannot open disk "/vmfs/volumes/5121c3ff-230b21a-41aa-21d92b219221/msk-web01/msk-web01_1-000002.vmdk": Failed to lock the file (16392). 2020-01-13T05:07:11.432Z| Worker#1| I125: DISKLIB-LIB : Failed to open '/vmfs/volumes/5121c3ff-230b21a-41aa-21d92b219221/msk-web01/msk-web01-000002.vmdk' with flags 0xa Failed to lock the file (16392). 2020-01-13T05:07:11.432Z| Worker#1| I125: DISK: Cannot open disk "/vmfs/volumes/5121c3ff-230b21a-41aa-21d92b219221/msk-web01/msk-web01-000002.vmdk": Failed to lock the file (16392). 2020-01-13T05:07:11.432Z| vmx| I125: [msg.fileio.lock] Failed to lock the file

- В этом примере видно, что заблокирован файл
msk-web01_1-000002.vmdk
; - С помощью следующей команды можно вывести текущую цепочку снапшотов начиная с указанного, до flat диска:
vmkfstools -qv10 msk-web01_1-000002.vmdk - Теперь выведем информацию о снапшоте, и его владельце (RO owner):
vmkfstools -D msk-web01-000001-delta.vmdkLock [type 10c000021 offset 242835456 v 856, hb offset 3153920 gen 3, mode 1, owner 5cbac61a-4b6e32b7-0480-d06726ae7900 mtime 5199410 num 0 gblnum 0 gblgen 0 gblbrk 0] RO Owner[0] HB Offset 3153920 5cbac61a-4b6e32b7-0480-d06726ae7900 Addr <4, 532, 83>, gen 859, links 1, type reg, flags 0, uid 0, gid 0, mode 600

В строке RO Owner указан MAC адрес сетевой карты хоста ESXi, который заблокировал данный файл снапшота (MAC адрес выделен на скриншоте). Также обратите внимание на значение Mode:
- mode 1 – блокировка на чтение/запись (например, у включенной ВМ);
- mode 2 – обычно означает, что диск заблокирован приложением резервного копирования.
Чтобы по известному MAC адресу найти ESXi сервер, можно воспользоваться следующими командами в PowerCLI (преобразуйте полученный ранее MAC адрес в формат с двоеточиями):
Import-Module VMware.VimAutomation.Core -ErrorAction SilentlyContinue
connect-viserver vcenter1
Get-VMHost | Get-VMHostNetworkAdapter | Where-Object {$_.Mac -like "d0:67:26:ae:79:00"} | Format-List -Property *
Имя ESXi хоста будет указано в поле VMHost.
Также вы можете вывести ARP таблицу прямо с хоста ESXi и получить IP и MAC адреса всех соседних серверов ESXi в сети VMkernel:
esxcli network ip neighbor list
Чтобы снять блокировку с файла ВМ просто перезагрузите найденный ESXi хост (предварительно смигрируйте с него все ВМ с помощью VMotion). Если вы не можете перезагрузить хост, перезапустите службу Management Agent (hostd) в Maintenance Mode из SSH консоли хоста:
services.sh restart
После этого попробуйте выполнить консолидацию или удалить снашот ВМ.
Ошибка “Unable to access file since it is locked” довольно часто возникает в Veeam Backup & Replication при использовании прокси-сервера Veeam. Из-за ошибок при резервном копировании Veeam может не отключить корректно диск виртуальной машины.
Чтобы исправить проблему, откройте параметры ВМ, на которой установлен прокси Veeam. Удалите из оборудования ВМ диск ВМ, файлы которой заблокированы.
Убедитесь, что вы выбрали опцию “Remove from virtual machine”, а не “Remove from virtual machine and delete files from disk”. Иначе вы можете случайно удалить ваш vmdk диск.
Reading Time: 3 minutes
A reoccurring issue this one, and usually due to a failed backup. In my case, this was due to a failure of a Veeam Backup & Replication disk backup job which had, effectively, failed to remove it’s delta disks following a backup run. As a result, a number of virtual machines reported disk consolidation alerts and, due to the locked vmdks, I was unable to consolidate the snapshots or Storage vMotion the VM to a different datastore. A larger and slightly more pressing concern that arose (due to the size and amount of delta disks being held) meant the underlying datastore had blown it’s capacity, taking a number of VMs offline.
So, how do we identify a) the locked file, b) the source of the lock, and c) resolve the locked vmdks and consolidate the disks?
Identify the Locked File
As a first step, we’ll need to check the hostd.log to try and identify what is happening during the above tasks. To do this, SSH to the ESXi host hosting the VM in question, and launch the hostd.log.
tail -f /var/log/hostd.log
While the log is being displayed, jump back to either the vSphere Client for Windows (C#) or vSphere Web Client and re-run a snapshot consolidation (Virtual Machine > Snapshot > Consolidate). Keep an eye on the hostd.log output while the snapshot consolidation task attempts to run, as any/all file lock errors will be displayed. In my instance, the file-lock error detailed in the Storage vMotion screenshot above is confirmed via the hostd.log output (below), and clearly shows the locked disk in question.
Identify the Source of the Locked File
Next, we need to identify which ESXi host is holding the lock on the vmdk by using vmkfstools.
vmkfstools -D /vmfs/volumes/volume-name/vm-name/locked-vm-disk-name.vmdk
We are specifically interested in the ‘RO Owner’, which (in the below example) shows both the lock itself and the MAC address of the offending ESXi host (in this example, ending ‘f1:64:09’).
The MAC address shown in the above output can be used to identify the ESXi host via vSphere.
Resolve the Locked VMDKs and Consolidate the Disks
Now the host has been identified, place in Maintenance Mode and restart the Management Agent/host daemon service (hostd) via the below command.
/etc/init.d/hostd restart
Following a successful restart of the hostd service, re-run the snapshot consolidation. This should now complete without any further errors and, once complete, any underlying datastore capacity issues (such as in my case) should be cleared.
For more information, an official VMware KB is available by clicking here.
Veeam backup was sending this error/warning email.
VM on vCenter.com needs snapshot consolidation, but all automatic snapshot consolidation attempts have failed.
Most likely reason is a virtual disk being locked by some external process. Please troubleshoot the locking issue, and initiate snapshot consolidation manually in vSphere Client.
I tried consolidating the disk manually via right clicking on the machine -> Spnapshots -> Consolidate and then I got the disk locked error “An error occurred while consolidating disks: msg.fileio.lock”
After many hours of trouble shooting suggested by VMware here https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2107795 and a lot of other places i.e. checking what locks the disk vis SSH-ing to ESXi hosts and using the vmfkstools -D command and no luck. Nothing from within the VMware infrastructure was locking it. It turned out to be one of the Veeam proxy servers. They attach the vmdk disks of the VM that they are backing up to themselves during the backup process. If there is an issue with the backup process and the vmdk being backed up does not remove itself from the Veeam proxy VM then it locks it and you will receive the error.
To resolve this you need to go to the Veeam proxy server VM under VMware -> right click -> Edit settings and remove the Hard Disk of the VM that is stuck. Make sure that you select “Remove from virtual machine” and not “Remove from virtual machine and delete files from disk”. The article that was useful for me in this case was from Veeam kb located here https://www.veeam.com/kb1775
Hope this helps someone.
I was in vCenter the other day and noticed that one of my virtual machines had the following message/warning:
It was weird. I thought to myself, I’m the only one that has access to this vSphere environment and I haven’t taken any snapshots of this particular VM recently, so what could be the problem. I went to snapshot manager and didn’t see any snapshots listed which was odd (come to find out the snapshot DB was corrupt). I then went to ‘Snapshot Manager > Consolidate, to see if I could consolidate the VM’s after confirming there were snapshot files in the datastore (4 of them). Upon trying to consolidate the VM, it failed with the following error:
Error Occurred While Consolidating disks msg.fileio.lock.
Version: ESXi 5.5
My initial thought was hmmm…
Then I thought about what might be creating VM snapshots and of course that would be the image based backup solution that I run which is NetBackup. I head over to my NetBackup appliance and notice that there are failures for this particular VM. So I assume that the file(s) is locked by NetBackup.
To confirm that, I went into the hostd.log file on the host that it was sitting on and start reviewing the logs. Of course it says it can’t have access to the disk yet it doesn’t show me who’s locking it.
After Googling around I didn’t find much information or success on getting these VM files unlocked.
I tried finding the lock using these helpful KB’s.
https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2136521
https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=10051
All I received back was an odd error which yielded no results on my Google search. After trying to figure out what I needed to do I thought, let me see if I can vMotion this to another machine and see if I can unlock these file(s) that way.
vMotion was a success, but the following consolidation effort still failed. My next thought was to shutdown the VM and the Netbackup Appliance. But before I did that, I thought that may not be the best option. Because if I shut down the VM, and it still has a lock on the file, then I’ll be stuck unable to power it back on.
So I basically was nervous to do a Storage vMotion to help release the lock so I punted to GSS (VMware Support). After initial troubleshooting these were the following steps that we laid out for a solution.
From GSS:
- We confirmed that the snapshot database is corrupt. This is why snapshot manager is not showing any active snapshots.
- We confirmed that the current snapshot chain and its data is consistent. The VM and its snapshots are in a healthy state, besides the missing database.
- A consolidation would be successful in the VM’s current state if not for the stale locks.
- Consolidation of the VM is failing due to stale locked files. We are getting error: “Inappropriate ioctl for device”
- We checked for a mounted ISO or file but there was no there.
At this point we have a couple of options to try and remediate this issue. Starting with least impactful first.
1) Attempt to Storage VMotion the VM to a different datastore. The hope here is that it will move all active files over to the new datastore which would remove the lock and allow us to consolidate.
–The only problem I see with this is that it might attempt to delete some of the old files after the Svmotion and we will get the same error about files being locked – The hope is that the svmotion would still be successful, it would just fail on the second part (removing the old files) and we could clean that up manually.
2) We can do a rolling reboot of the ESXi hosts in the cluster. This should release and stale locks and allow us to run the consolidation. This is a little more impactful because we have to migrate a lot of VM’s around.
3) As a last resort, we can essentially do a force clone of the vmdk and attach that to the existing VM. This will consolidate the snapshots during the process but would require us to shutdown the VM.
At the end of the day, I used Storage vMotion to move the VM to another datastore, and then I was able to successfully consolidate the virtual machine. After that was completed, I immediately performed a new backup that was successful. Waited 2 days to see if the old files on the previous datastore were being modified (old snapshots) and they weren’t which led me to successfully removing those files to save space.
I hope this helps someone down the road. Thanks for reading!
Last week I had a customer with a VM that required virtual disk consolidation, however when he attempted to perform this from the vSphere client it would run for hours and unfortunately fail:
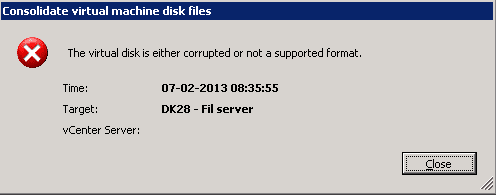
The virtual disk is either corrupted or not a supported format.
I waited till we could get a service window on the VM, performed a shutdown and re-ran the disk consolidation. Still the same error message!
I then used command vim-cmd vmsvc/getallvms to quickly locate the volume containing the VM:

Then checked if there was any locks on the vmdk file:

I have highlighted the line showing us there is a RO (Read-Only) lock on the VMDK file. This is most likely what is causing the disk consolidation to fail. The last part of the line 0026b9564d86 is the mac address of the host locking the file.
Lets lookup if the host running the VM currently is also the host locking the file:

The mac address matched up and a quick Google search revealed the following VMware Knowledge Base article.
As suggested in the article I then performed a vMotion of the VM to a different host and re-tried the disk consolidation.
Finally it finished without errors!
As always, if this helped you please leave a comment! 🙂
Incoming search terms:
- An error occurred while consolidating disks: msg fileio lock
- An error occurred while consolidating disks: msg snapshot error-DISKLOCKED
- msg fileio lock
- msg snapshot error-DISKLOCKED
- virtual machine disks consolidation is needed
- the virtual disk is either corrupted or not a supported format
- An error occurred while consolidating disks: msg snapshot error-NOTFOUND
- an error occurred while consolidating disks msg fileio lock
- An error occurred while consolidating disks: Failed to lock the file
Hey, I had this issue for some days and actually was a real headache because the problem was more than the normal consolidate situation.
Let me explain, I had a Virtual Machine that the Datastore that was inside starting getting full. After a browse of the Datastore I saw that the server had a lot of delta/ctk vmdks around 11 except the 2 running hard drives of the Virtual Machine.
In order to troubleshoot the issue I started with the classic investigation about consolidation failures. First of all I wanted to see the processes that my Virtual Machine is running so (Take a note of the vmx-vthread-7 and vmx-vthread-8):
~# ps -s | grep -i VMNAME
19484255 vmm0:VMNAME RUN NONE 0-11
19484257 vmm1:VMNAME RUN NONE 0-11
19484258 vmm2:VMNAME READY NONE 0-11
19484259 vmm3:VMNAME RUN NONE 0-11
19484260 19484254 vmx-vthread-7:VMNAME WAIT UFUTEX 0-11 /bin/vmx
19484261 19484254 vmx-vthread-8:VMNAME WAIT UFUTEX 0-11 /bin/vmx
19484262 19484254 vmx-mks:VMNAME WAIT UPOL 0-11 /bin/vmx
19484263 19484254 vmx-svga:VMNAME WAIT SEMA 0-11 /bin/vmx
19484264 19484254 vmx-vcpu-0:VMNAME RUN NONE 0-11 /bin/vmx
19484265 19484254 vmx-vcpu-1:VMNAME RUN NONE 0-11 /bin/vmx
19484266 19484254 vmx-vcpu-2:VMNAME RUN NONE 0-11 /bin/vmx
19484267 19484254 vmx-vcpu-3:VMNAME RUN NONE 0-11 /bin/vmx
After seeing this, it was really strange the two vmx-vthread I told you above, so I wanted to see if there is anything for these threads in the vmkernel logs:
~ # cat /var/log/vmkernel.log | grep vmx-vthread-*
2016-01-19T11:13:29.616Z cpu2:269957)FSS: 5914: Failed to open file ‘VMNAME-000011-delta.vmdk’; Requested flags 0x40001, world: 269957 [vpxa-worker] (Existing flags 0x4008, world: 19484260 [vmx-vthread-7:VMNAME]): Busy
2016-01-19T11:13:37.394Z cpu7:269957)FSS: 5914: Failed to open file ‘VMNAME_9-000008-delta.vmdk’; Requested flags 0x40001, world: 269957 [vpxa-worker] (Existing flags 0x4008, world: 19484261 [vmx-vthread-8:VMNAME]): Busy
The output was the thing I wanted to see (not exactly) but there is something to investigate little bit further, so we are good.
I saw that two of the delta.vmdk files couldn’t be opened because they were busy. Note: most of the times from my experience busy means lock, but anyway I had to see more in order to understand who is locking these two vmdks.
In order to see the “busy”thing if it is locked I had to find first who is locking these files, so you check the Virtual Machines in the current host.
~ # vim-cmd vmsvc/getallvms
Vmid Name File Guest OS Version Annotation
1 VMNAME02 [customer-data-fr1-pa-03] VMNAME02/VMNAME02.vmx windows7Server64Guest vmx-09
2 VMNAME12 [customer-data-fr1-pa-01] VMNAME12/VMNAME12.vmx winNetEnterpriseGuest vmx-09
22 VMNAME [customer-data-fr1-pa-02] VMNAME/VMNAME.vmx windows8Server64Guest vmx-09
23 VMNAME07 [customer-data-fr1-pa-01] VMNAME07/VMNAME07.vmx windows7Server64Guest vmx-09
24 VMNAME17 [customer-data-fr1-pa-06] VMNAME17/VMNAME17.vmx winNetEnterpriseGuest vmx-09
The Virtual Machine I want to check is the VMNAME so I see that is inside customer-data-fr1-pa-02. Lets check there if there is anything locked and who is locking these files. Run the vmkfstools with the flat.vmdk:
~ # vmkfstools -D /vmfs/volumes/customer-data-fr1-pa-02/VMNAME/VMNAME-flat.vmdk
Lock [type 10c00001 offset 13895680 v 2175, hb offset 3694592
gen 13777, mode 2, owner 00000000-00000000-0000-000000000000 mtime 979023
num 2 gblnum 0 gblgen 0 gblbrk 0]
RO Owner[0] HB Offset 3309568 5630b2a6-c21df93e-32f1-e41f13b64614
RO Owner[1] HB Offset 3694592 562f9f68-e125dcdc-adb9-5cf3fcb6ad78
Addr <4, 13, 41>, gen 85, links 1, type reg, flags 0, uid 0, gid 0, mode 600
len 107374182400, nb 51200 tbz 18110, cow 0, newSinceEpoch 51200, zla 3, bs 2097152
So I see that there are two owners that they are locking these files based on the MAC Address, actually they are both of my hosts in this cluster.
In order to see the MAC addresses of a host you just run: ~# esxcfg-nics -l
Now, if we had the lock only to one of the two hosts the things will be more easy because normally you could just vMotion the Virtual Machine to the other host and try consolidate again, 99% this works like a charm without a problem.
But that was really strange, the first thing I thought that maybe my TSM Data Manager Virtual Machine failed to unmount a disk during the backup, but the thing is that 1 of the 2 locking vmdks was actually a normal VMDK but not one of the two I had attached to my Virtual Machine.
Okay, wait a moment, after a search to RVTools I saw that this vmdk was attached to another Virtual Machine (don’t ask me why). So after some confirmations, I removed the virtual disk from the other Virtual Machine, I migrated the VMNAME virtual machine to the ESXi host was locking him and voila, my Virtual Machine consolidated without problem.
These things reminds me always of PEBKAC, Enjoy! 🙂

Published by anksos
Geek@IBM and The Big Lebowski fan!
View all posts by anksos
Published
January 25, 2016January 25, 2016
Issue :
You encounter below error while consolidating VM or powering
ON a VM :
An error occurred while consolidating disks: msg.snapshot.error-DISKLOCKED
An error occurred while consolidating disks: msg.fileio.lock.
Consolidation failed for disk node ‘scsi0:0’: msg.fileio.lock
Unable to access a file filename since it is locked
Unable to access virtual machine configuration
A general system error occurred: vim.fault.G-enericVmC-onfigFault
Cause :
- The common reason would be a powered on virtual machine contains locks on all files in use by the owning ESXi host to facilitate read and write access.
- Other locks may be created by hot-adding disks to snapshot based backup appliances during the backup process.
- Failure to create a lock / start a virtual machine can occur if an unsupported disk format is used or if a lock is already present.
Solutions
Solution 1 : vMotion the
virtual machine
vMotion the virtual machine to a
different host and try to consolidate/power on.
If the above is not successful
storage vMotion the virtual machine to a different datastore.
Solution 2 : Restart the
management agents on the particular host the VM is running on.
SSH into the ESXi host and run the
command services.sh restart
Solution 3 : Restart the ESXi
host.
Shutdown the affected VM. vMotion
all other working VMs to a different host and restart the ESXi host.
Solution 4 : Unregister the virtual machine from the host &
re-register the virtual machine on the host holding the lock.
Solution 5 : Clone the VMDK files to a different datastore using
PowerCLI, create new Virtual Machine, attach the cloned VMDKs’.