Обновлено 15.03.2022

Всем привет сегодня расскажу как решается ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5. Когда вы делаете бэкапы с помощью veeam или делаете снапшоты, вы можете получить у виртуальной машины вот такой статус Ошибка virtual machine disks consolidation is needed в ESXI 5.x.x, она решалась просто, но есть случаи когда консолидация не проходит и выходит ошибка, рассматриваемая ниже.
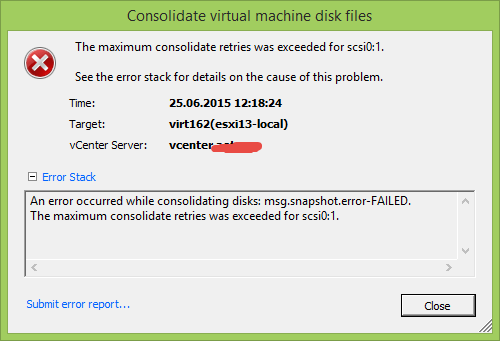
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-00
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded выходит когда асинхронная консолидация заканчивается с ошибкой. Происходит это, когда виртуальная машина генерирует данные быстрее, чем скорость консолидации. Смотрим что делать.
Выключаем виртуальную машину, щелкаем правой кнопкой мыши и выбираем Edit settings. Переходим на вкладку Options-General и нажимаем кнопку Configuration Parlameters
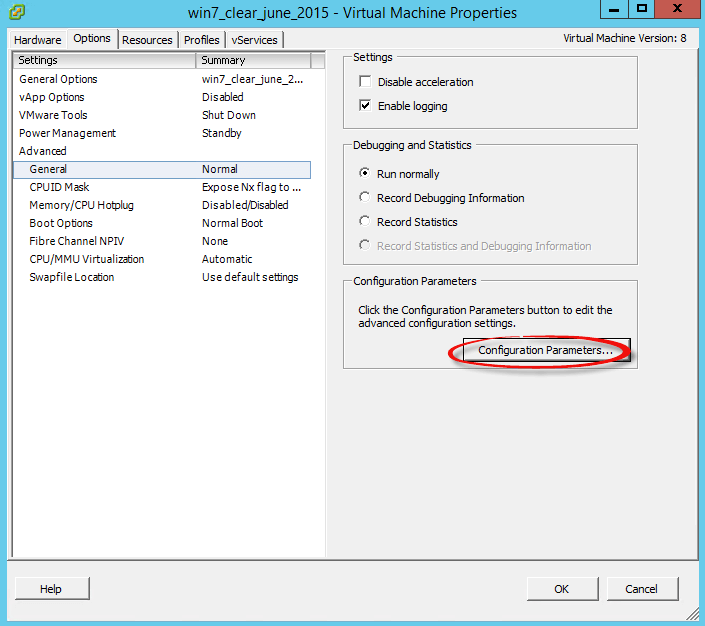
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-01
Далее нам нужно добавить новой поле, жмем Add row
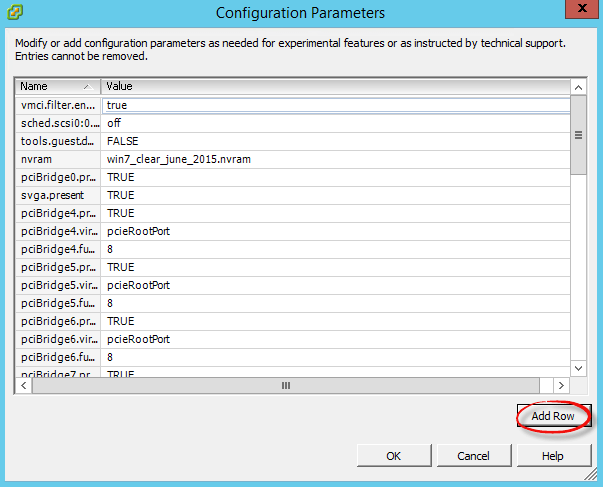
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-02
И добавляем параметр snapshot.asyncConsolidate.forceSync и значение True
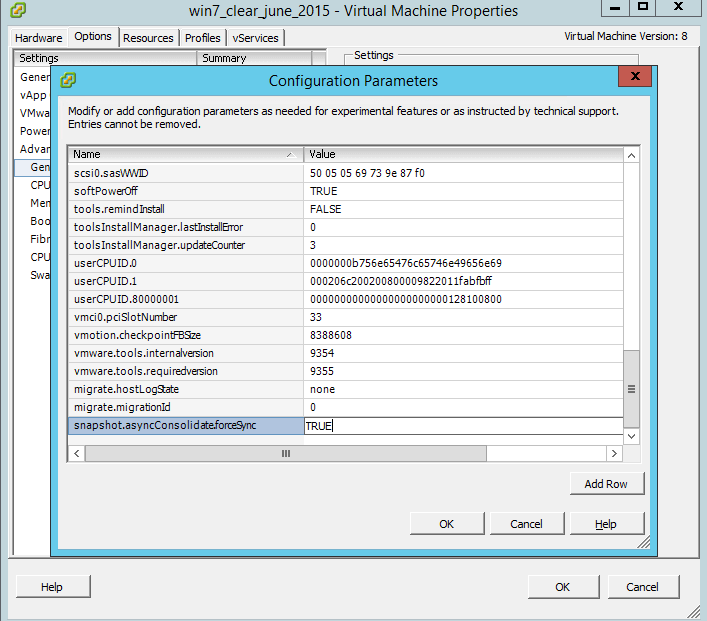
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-03
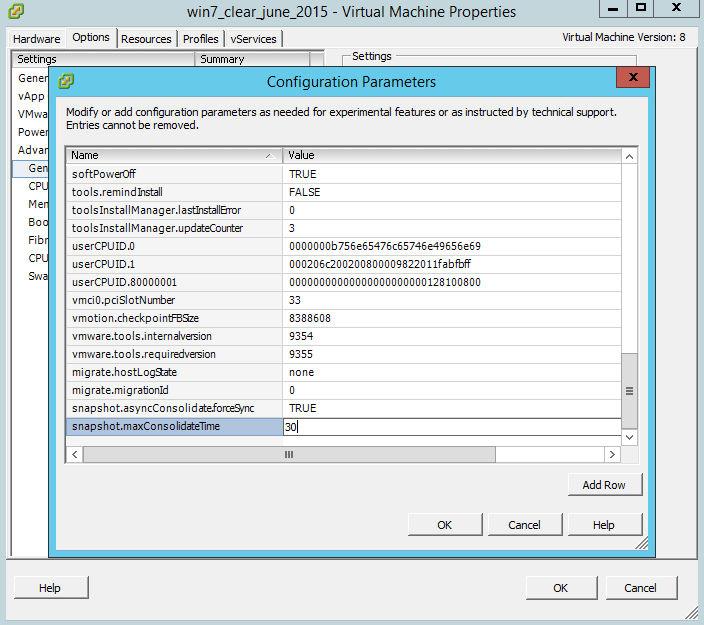
Для того чтобы увеличить временной лимит на консолидацию снапшота. Создадим новое поле
snapshot.maxConsolidateTime со значением 30
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-04
Для того чтобы не выключать виртуальную машину и решить данную проблему, нужно воспользоваться PowerCLI и ввести такую команду
get-vm virtual_machine_name | New-AdvancedSetting -Name snapshot.asyncConsolidate.forceSync -Value TRUE -Confirm:$False

Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-06
Где virtual_machine_name имя нужной виртуальной машины.
Вот так вот просто решается Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5.
Материал сайта pyatilistnik.org
Всем привет сегодня расскажу как решается ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5. Когда вы делаете бэкапы с помощью veeam или делаете снапшоты, вы можете получить у виртуальной машины вот такой статус Ошибка virtual machine disks consolidation is needed в ESXI 5.x.x, она решалась просто, но есть случаи когда консолидация не проходит и выходит ошибка, рассматриваемая ниже.
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-00
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded выходит когда асинхронная консолидация заканчивается с ошибкой. Происходит это, когда виртуальная машина генерирует данные быстрее, чем скорость консолидации. Смотрим что делать.
Выключаем виртуальную машину, щелкаем правой кнопкой мыши и выбираем Edit settings. Переходим на вкладку Options-General и нажимаем кнопку Configuration Parlameters
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-01
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-02
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-03
Для того чтобы увеличить временной лимит на консолидацию снапшота. Создадим новое поле
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-04
Для того чтобы не выключать виртуальную машину и решить данную проблему, нужно воспользоваться PowerCLI и ввести такую команду
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-06
Где virtual_machine_name имя нужной виртуальной машины.
Очень часто при удалении снапшотов или консолидации дисков виртуальных машин на хостах VMWare ESXi, я сталкиваюсь с ошибкой “Unable to access a file since it is locked”. Это довольна частая проблема связана с ошибками в системе резервного копирования ВМ (я встречал проблему в Veeam, HP Data Protector, Veritas). Блокировка виртуального диска снапшота виртуальной машины не позволит вам выполнить консолидацию (Virtual machine disks consolidation is needed), Storage vMotion на другой дисковый массив, выполнить резервное копирование или удалить текущий снапшот. Иногда виртуальную машины с блокировками нельзя даже элементарно включить.
Ошибка с доступом к заблокированному файлу виртуального диска или снапшот в VMWare может выглядеть так:
Чтобы найти источник блокировки и снять ее, сначала нужно определить заблокированные файлы.

В строке RO Owner указан MAC адрес сетевой карты хоста ESXi, который заблокировал данный файл снапшота (MAC адрес выделен на скриншоте). Также обратите внимание на значение Mode:
- mode 1 – блокировка на чтение/запись (например, у включенной ВМ);
- mode 2 – обычно означает, что диск заблокирован приложением резервного копирования.
Чтобы по известному MAC адресу найти ESXi сервер, можно воспользоваться следующими командами в PowerCLI (преобразуйте полученный ранее MAC адрес в формат с двоеточиями):
Import-Module VMware.VimAutomation.Core -ErrorAction SilentlyContinue
connect-viserver vcenter1
Get-VMHost | Get-VMHostNetworkAdapter | Where-Object <$_.Mac -like «d0:67:26:ae:79:00»>| Format-List -Property *
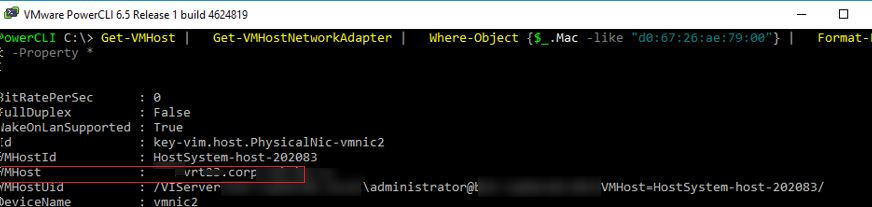
Имя ESXi хоста будет указано в поле VMHost.
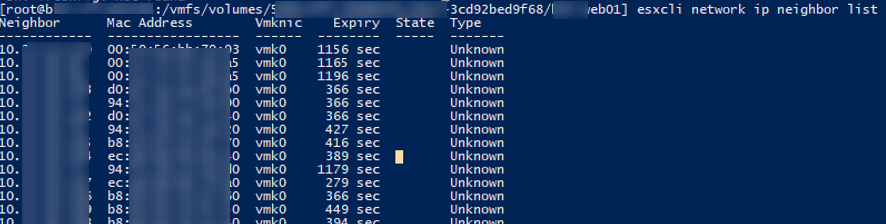
Также вы можете вывести ARP таблицу прямо с хоста ESXi и получить IP и MAC адреса всех соседних серверов ESXi в сети VMkernel:
esxcli network ip neighbor list
Чтобы снять блокировку с файла ВМ просто перезагрузите найденный ESXi хост (предварительно смигрируйте с него все ВМ с помощью VMotion). Если вы не можете перезагрузить хост, перезапустите службу Management Agent (hostd) в Maintenance Mode из SSH консоли хоста:
После этого попробуйте выполнить консолидацию или удалить снашот ВМ.
Чтобы исправить проблему, откройте параметры ВМ, на которой установлен прокси Veeam. Удалите из оборудования ВМ диск ВМ, файлы которой заблокированы.
Убедитесь, что вы выбрали опцию “Remove from virtual machine”, а не “Remove from virtual machine and delete files from disk”. Иначе вы можете случайно удалить ваш vmdk диск.
Источник
Записки ИТ специалиста.
An error occurred while consolidating disks: msg.snapshot.error-DISKLOCKED.
Проверяя состояния виртуальных машин на VMware VCenter обнаружил, что на одна из ВМ помечена желтым треугольником с восклицательным знаком. Во вкладке Summary висела запись «Virtual machine disks consolidation is needed»
Консолидация жестких дисков через клиент vCenter дало ошибку.
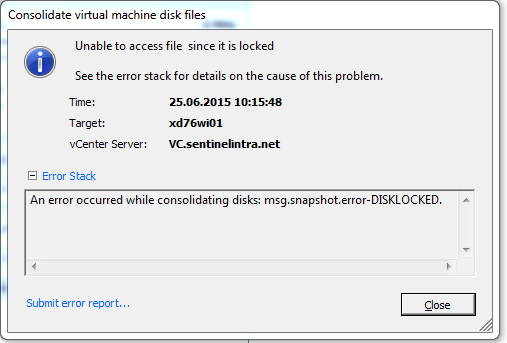
Что-то блокирует доступ к файл. Резервная копия ВМ делается с помощью Veeam. Смотрю выполнение задания РК.
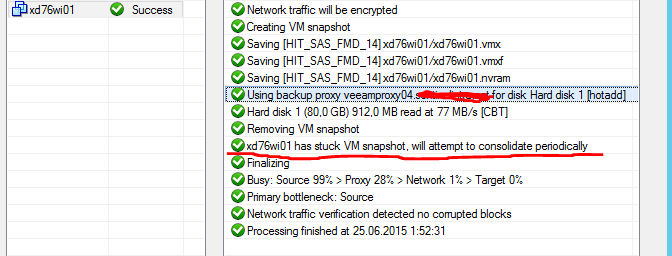
Вижу, что в РК участвовал сервер veeamproxy04, через него шло РК единственного диска ВМ XD76wi01. Так же в этом задании отмечено, что требуется консолидация дисков. Сам Veeam сделать это не смог.
Смотрю в свойства ВМ veeamprox04
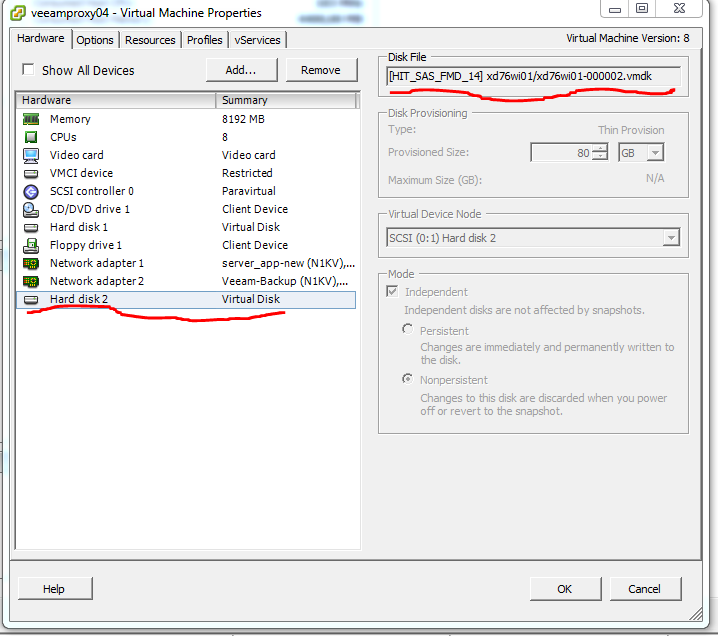
Вижу, что примаплен диск, от ВМ xd76wi01, с которой проблемы. Видимо произошел сбой и после РК диск не был отмаплен. Делаем это вручную
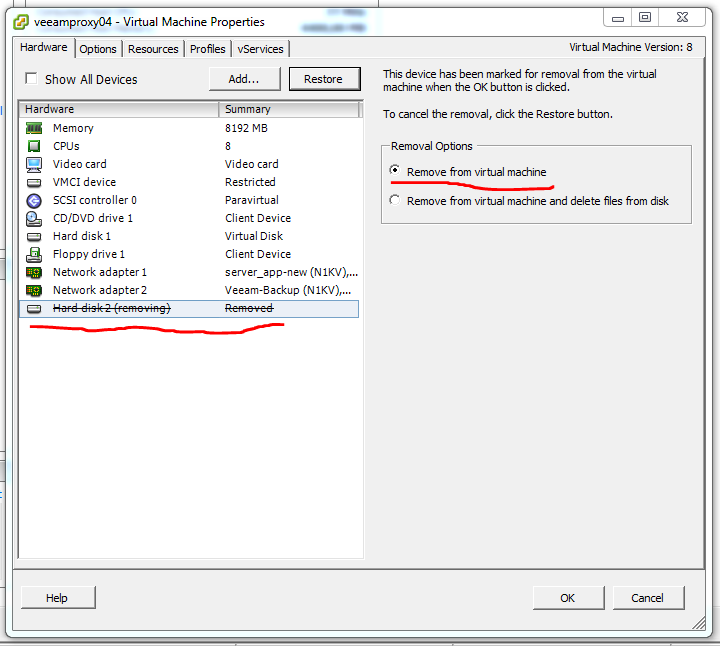
Нажимаем кнопку «Remove», выбираем пункт «Remove from virtual machine»
После этого консолидация дисков прошла успешно.
Источник
Tech Kiranangal
Technical Blogs Created For Server/Desktop/Network Virtualization
Thursday, October 8, 2020
VMware vSphere 6.x: An error occurred while consolidating disks: msg.snapshot.error-DISKLOCKED -SOLVED
Unable to Power on Virtual Machine. It gives below Symptoms.
1. While attempting to power on giving below error.
«Power On virtual machine:Failed to lock the file
See the error stack for details on the cause of this problem.
Time: 10/9/2020 6:37:25 AM
vCenter Server: MYVCENTER.MYDOMAIN.COM
An error was received from the ESX host while powering on VM MYVM001.
Failed to start the virtual machine.
Cannot open the disk ‘/vmfs/volumes/594d0000-d290000-500-00000000002/MYVM001/MYVM001-000002.vmdk’ or one of the snapshot disks it depends on.
Failed to lock the file»

VMware vSphere 6.x: An error occurred while consolidating disks: msg.snapshot.error-DISKLOCKED

Failed to open file ‘MYVM001-delta.vmdk’; Requested flags 0x4008, world: 1197120 [vmx-vthread-8], (Existing flags 0x4008, world: 43796 [unknown]): Busy
4. Command «vmkfstools -e vmfs/volumes/00000003-000230-000b-0123211000/VM001-000001.vmdk» shows below output.
Failed to open disk link /vmfs/volumes/5b4d1233-3e1234-1f5b-0123211000/VM001-000001.vmdk :Failed to lock the file (16392)Disk chain is not consistent : Failed to lock the file (16392)
5. virtual machine disk descriptor file shows normal and CID chain is not broken.
The VMDK or Delta VMDK is locked by one of the esxi in the cluster. Even if we move the VM in the particular Host, VM will fail to power on or consolidate disk.
To identify which disk is locked, refer the /var/log/vmkernal.log
Identify the ESXI host which is currently have lock on the Delta vmdk or VMDK with below command.
[root@I-MY-ESXI-01:/vmfs/volumes/152525252-26252526122-ED3455555555/MYVM001] vmfsfilelockinfo -p MYVM001-000001-delta.vmdk -v 172.11.13.3 -u administrator@vsphere.local
vmfsfilelockinfo Version 1.0
Looking for lock owners on «MYVM001-000001-delta.vmdk»
«MYVM001-000001-delta.vmdk» is locked in Exclusive mode by host having mac address [’00:20:b2:01:10:01′]
Found 2 ESX hosts from Virtual Center Server.
Searching on Host MY-ESXI-01.MYCOM.MYDOMAIN.COM
Searching on Host MY-ESXI-02.MYCOM.MYDOMAIN.COM
MAC Address : 00:20:b2:01:10:01
Host owning the lock on the vmdk is MY-ESXI-02.MYCOM.MYDOMAIN.COM, lockMode : Exclusive
Total time taken : 0.38 seconds.
Above output saying, disk is locked by MY-ESXI-02.MYCOM.MYDOMAIN.COM with MAC Address 00:20:b2:01:10:01.
Steps to Clear ESXi Lock:
1. Put the host in maintenance.
2. reboot the host.
Lock will be cleared during ESXi reboot and we will be able to power on or consolidate snapshot of VM.
Источник
Veeam R&D Forums
Technical discussions about Veeam products and related data center technologies
ESX 5.5: An error occurred while consolidating disks
ESX 5.5: An error occurred while consolidating disks
Post by pgitdept » Feb 07, 2014 11:48 am 7 people like this post
I thought I’d share some information regarding an issue we’ve been experiencing since moving to ESX 5.5 and Veeam 7 R2a. Background: We’ve been running Veeam for just shy of 4 years. Our Veeam server was a 2008R2 box and it backed up a 3 host ESX 5.1 cluster. Now, some of our VM’s are rather large. in the region of 8TB+ large (although using a bunch of 2TB VMDK’s). The size of these VM’s has never been an issue and things have been running really well.
So, we now have some servers that just cannot fit within the 2TB limit. In fact, we have to allow for a 11TB drive on one of our servers (this is the lowest granularity we can achieve). So, we built a ESXi 5.5 cluster on new hosts as soon as it was available, built and tested some large VM’s (Windows and RHEL) along with two new Veeam 7 servers (Windows 2012R2). Initial testing was good: backups and restore from both disk and tape, good. We’re good to go!
In addition to these new servers we needed to accomodate our existing VM’s and so needed to upgrade our 5.1 hosts. To do this we moved them into the new 5.5 vCenter and upgraded the hosts without much incident. This new cluster is served by the new Veeam servers and so we knew/accepted that we’d have to do full backups to begin with. This wasn’t a concern as we probably don’t run active fulls as often as we’d like because of VM’s are so big.
On the whole this has been going well, but we did find that two of our older servers had the vSphere yellow warning triangle on them — once after the full seed, the other a few days after it’s initial seed. Each of these servers are about 4TB in size and contain 3 or 4 disks. That size is usual here and many other servers of that size or larger worked correctly. The yellow triangle was the ‘VM needs it’s disks consolidating’ message with no snaps present in Snapshot Manager. When trying to consolidate we got the following message:
Error: An error occurred while consolidating disks: msg.snapshot.error-FAILED. The maximum consolidate retries was exceeded for scsix:x.
We have spoken to VMWare, had the logs dug into and they couldn’t understand why this was happening. We could take and remove snaps after, but couldn’t avoid one disk from each server working on a snapshot. Next, on one of the servers, which has little change, we shutdown, manually deleted the snap and connected to the flat disk. Once we took and removed another snapshot. consolidation was needed again. VMware seemed to indicate that we might need to shutdown and clone the disk to remedy this. This wasn’t something we could entertain, as this issue may present itself of any of our disks and these are production servers that cannot afford days of cloning time. Imagine cloning a 11TB disk.
So it was starting to look fairly helpless, until Veeam identified the following in the log (VMWare did highlight this, but didn’t spend too much time :
2014-01-16T04:17:27.495Z| vcpu-0| I120: DISKLIB-LIB : Free disk space is less than imprecise space neeeded for combine (0x96a3b800
2014-01-16T04:17:40.173Z| vcpu-0| I120: SnapshotVMXConsolidateHelperProgress: Stunned for 13 secs (max = 12 secs). Aborting consolidate.
2014-01-16T04:17:40.173Z| vcpu-0| I120: DISKLIB-LIB :DiskLibSpaceNeededForCombineInt: Cancelling space needed for combine calculation
2014-01-16T04:17:40.174Z| vcpu-0| I120: DISKLIB-LIB : DiskLib_SpaceNeededForCombine: failed to get space for combine operation: Operation was canceled (33).
2014-01-16T04:17:40.174Z| vcpu-0| I120: DISKLIB-LIB : Combine: Failed to get (precise) space requirements.
2014-01-16T04:17:40.174Z| vcpu-0| I120: DISKLIB-LIB : Failed to combine : Operation was canceled (33).
2014-01-16T04:17:40.174Z| vcpu-0| I120: SNAPSHOT: SnapshotCombineDisks: Failed to combine: Operation was canceled (33).
2014-01-16T04:17:40.178Z| vcpu-0| I120: DISKLIB-CBT : Shutting down change tracking for untracked fid 9428050.
2014-01-16T04:17:40.178Z| vcpu-0| I120: DISKLIB-CBT : Successfully disconnected CBT node.
2014-01-16T04:17:40.211Z| vcpu-0| I120: DISKLIB-VMFS : «/vmfs/volumes/50939781-d365a9b0-5523-001b21badd94/ / -000002-delta.vmdk» : closed.
2014-01-16T04:17:40.213Z| vcpu-0| I120: DISKLIB-VMFS : «/vmfs/volumes/50939781-d365a9b0-5523-001b21badd94/ / -flat.vmdk» : closed.
2014-01-16T04:17:40.213Z| vcpu-0| I120: SNAPSHOT: Snapshot_ConsolidateWorkItem failed: Operation was canceled (5) 2014-01-16T04:17:40.213Z| vcpu-0| I120: SnapshotVMXConsolidateOnlineCB: Synchronous consolidate failed for disk node: scsi0:2. Adding it to skip list.
We can see that there is a process that calculates if there is enough space free for consolidation and if this process does not complete in 12 or less seconds, it aborts the consolidate operation. After speaking to VMWare we found that we couldn’t extend this timer — it’s hardcoded. Veeam suggested that this precise calculation is only needed if there is less free space available in the datastore than the size of the disk that needs consolidation. So we extended the LUN and datastore so we had enough free space and ran the consolidate task again. This time it worked instantly and has continued to work for the last few days.
So I guess we have a work-around for the issue — to extend the datastore. Obviously this isn’t ideal when we might be speaking about 11TB VMDK’s (22TB datastore!!).
We still don’t know why this happened, or should I say why it didn’t happen before. The VM hasn’t changed in size for months and we never had this issue on 5.1 or Veeam 6.5. It’s on the same backend storage and the datastore latency hasn’t really risen. I’m guessing something must have changed in connection with vSphere 5.5 snapshotting and this has made it less tolerant of our environment.
Anyway, I just thought I’d post this in-case anyone else experiences this or similar issues or has any further insight into this issue.
Источник
VMware Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded

Сегодня рассмотрим, как решается ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded. Когда вы делаете бэкапы с помощью veeam или создаете и удаляете снапшоты, вы можете получить у виртуальной машины статус: Ошибка virtual machine disks consolidation is needed. Задача по исправлению несложная(нужно консолидировать диски), но есть случаи когда консолидация не проходит и выходит ошибка, рассматриваемая ниже.

Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded случается когда асинхронная консолидация заканчивается с ошибкой. Происходит это, когда виртуальная машина генерирует данные быстрее, чем скорость консолидации. Смотрим, что делать.
Исправляем ошибку An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded
Выключаем виртуальную машину, щелкаем по ней правой кнопкой мыши и выбираем Edit settings. Переходим на вкладку Options-General и нажимаем кнопку Configuration Parameters
Далее нам нужно добавить новую строку, жмем Add row
И добавляем параметр snapshot.asyncConsolidate.forceSync и значение True
Для того чтобы увеличить временной лимит на консолидацию снапшота, создадим строку snapshot.maxConsolidateTime со значением 30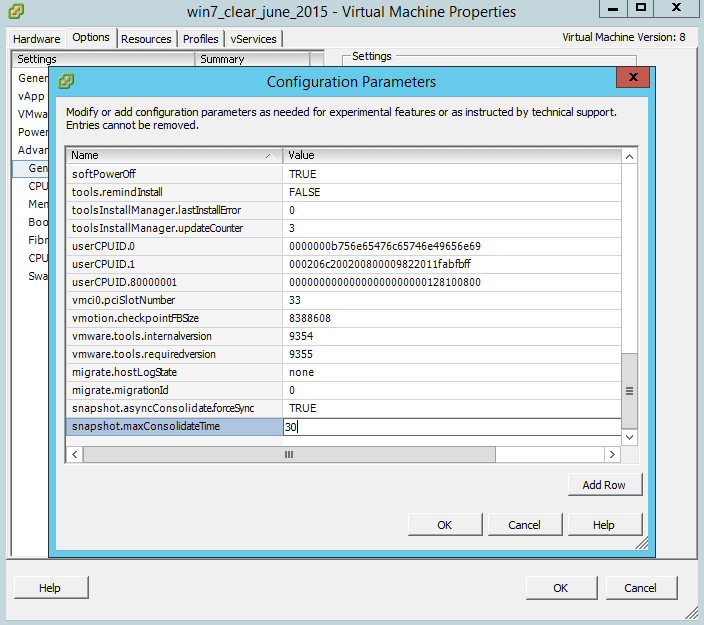
Для того чтобы не выключать виртуальную машину и решить данную проблему, нужно воспользоваться PowerCLI и ввести такую команду
|
get-vm virtual_machine_name | New-AdvancedSetting -Name snapshot.asyncConsolidate.forceSync -Value TRUE -Confirm:$False |

Где virtual_machine_name имя нужной виртуальной машины.
Вот так решается проблема с ошибкой An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в VMware VSphere.
Возможно вас заинтересуют еще статьи в рубрике, посвященной виртуализации VMware или вы найдете что-то полезное в рубрике Скачать.
Problem:
Unable to Power on Virtual Machine. It gives below Symptoms.
1. While attempting to power on giving below error.
«Power On virtual machine:Failed to lock the file
See the error stack for details on the cause of this problem.
Time: 10/9/2020 6:37:25 AM
Target: MYVM001
vCenter Server: MYVCENTER.MYDOMAIN.COM
Error Stack
An error was received from the ESX host while powering on VM MYVM001.
Failed to start the virtual machine.
Cannot open the disk ‘/vmfs/volumes/594d0000-d290000-500-00000000002/MYVM001/MYVM001-000002.vmdk’ or one of the snapshot disks it depends on.
Failed to lock the file»
2. Virtual Machine showing warning » Consolidation Needed». But unable to perform snapshot consolidation. It gives below error.
3. /var/log/vmkernal.log shows below error.
Failed to open file ‘MYVM001-delta.vmdk’; Requested flags 0x4008, world: 1197120 [vmx-vthread-8], (Existing flags 0x4008, world: 43796 [unknown]): Busy
4. Command «vmkfstools -e vmfs/volumes/00000003-000230-000b-0123211000/VM001-000001.vmdk» shows below output.
Failed to open disk link /vmfs/volumes/5b4d1233-3e1234-1f5b-0123211000/VM001-000001.vmdk :Failed to lock the file (16392)Disk chain is not consistent : Failed to lock the file (16392)
5. virtual machine disk descriptor file shows normal and CID chain is not broken.
Reason:
The VMDK or Delta VMDK is locked by one of the esxi in the cluster. Even if we move the VM in the particular Host, VM will fail to power on or consolidate disk.
To identify which disk is locked, refer the /var/log/vmkernal.log
Solution:
Identify the ESXI host which is currently have lock on the Delta vmdk or VMDK with below command.
[root@I-MY-ESXI-01:/vmfs/volumes/152525252-26252526122-ED3455555555/MYVM001] vmfsfilelockinfo -p MYVM001-000001-delta.vmdk -v 172.11.13.3 -u administrator@vsphere.local
### -v <vcenter IP>
### -u <vCenter credential>
Output:
vmfsfilelockinfo Version 1.0
Looking for lock owners on «MYVM001-000001-delta.vmdk»
«MYVM001-000001-delta.vmdk» is locked in Exclusive mode by host having mac address [’00:20:b2:01:10:01′]
——————————————————————
Found 2 ESX hosts from Virtual Center Server.
——————————————————————
Searching on Host MY-ESXI-01.MYCOM.MYDOMAIN.COM
Searching on Host MY-ESXI-02.MYCOM.MYDOMAIN.COM
MAC Address : 00:20:b2:01:10:01
Host owning the lock on the vmdk is MY-ESXI-02.MYCOM.MYDOMAIN.COM, lockMode : Exclusive
Total time taken : 0.38 seconds.
Above output saying, disk is locked by MY-ESXI-02.MYCOM.MYDOMAIN.COM with MAC Address 00:20:b2:01:10:01.
Steps to Clear ESXi Lock:
1. Put the host in maintenance.
2. reboot the host.
Lock will be cleared during ESXi reboot and we will be able to power on or consolidate snapshot of VM.
Hi All,
Case: #00510773
I thought I’d share some information regarding an issue we’ve been experiencing since moving to ESX 5.5 and Veeam 7 R2a. Background: We’ve been running Veeam for just shy of 4 years. Our Veeam server was a 2008R2 box and it backed up a 3 host ESX 5.1 cluster. Now, some of our VM’s are rather large… in the region of 8TB+ large (although using a bunch of 2TB VMDK’s). The size of these VM’s has never been an issue and things have been running really well.
So, we now have some servers that just cannot fit within the 2TB limit. In fact, we have to allow for a 11TB drive on one of our servers (this is the lowest granularity we can achieve). So, we built a ESXi 5.5 cluster on new hosts as soon as it was available, built and tested some large VM’s (Windows and RHEL) along with two new Veeam 7 servers (Windows 2012R2). Initial testing was good: backups and restore from both disk and tape, good. We’re good to go!
In addition to these new servers we needed to accomodate our existing VM’s and so needed to upgrade our 5.1 hosts. To do this we moved them into the new 5.5 vCenter and upgraded the hosts without much incident. This new cluster is served by the new Veeam servers and so we knew/accepted that we’d have to do full backups to begin with. This wasn’t a concern as we probably don’t run active fulls as often as we’d like because of VM’s are so big.
On the whole this has been going well, but we did find that two of our older servers had the vSphere yellow warning triangle on them — once after the full seed, the other a few days after it’s initial seed. Each of these servers are about 4TB in size and contain 3 or 4 disks. That size is usual here and many other servers of that size or larger worked correctly. The yellow triangle was the ‘VM needs it’s disks consolidating’ message with no snaps present in Snapshot Manager. When trying to consolidate we got the following message:
Error: An error occurred while consolidating disks: msg.snapshot.error-FAILED. The maximum consolidate retries was exceeded for scsix:x.
We have spoken to VMWare, had the logs dug into and they couldn’t understand why this was happening. We could take and remove snaps after, but couldn’t avoid one disk from each server working on a snapshot. Next, on one of the servers, which has little change, we shutdown, manually deleted the snap and connected to the flat disk. Once we took and removed another snapshot… consolidation was needed again. VMware seemed to indicate that we might need to shutdown and clone the disk to remedy this. This wasn’t something we could entertain, as this issue may present itself of any of our disks and these are production servers that cannot afford days of cloning time. Imagine cloning a 11TB disk. ![]()
So it was starting to look fairly helpless, until Veeam identified the following in the log (VMWare did highlight this, but didn’t spend too much time :
2014-01-16T04:17:27.495Z| vcpu-0| I120: DISKLIB-LIB : Free disk space is less than imprecise space neeeded for combine (0x96a3b800 < 0x9b351000, in sectors). Getting precise space needed for combine…
2014-01-16T04:17:40.173Z| vcpu-0| I120: SnapshotVMXConsolidateHelperProgress: Stunned for 13 secs (max = 12 secs). Aborting consolidate.
2014-01-16T04:17:40.173Z| vcpu-0| I120: DISKLIB-LIB :DiskLibSpaceNeededForCombineInt: Cancelling space needed for combine calculation
2014-01-16T04:17:40.174Z| vcpu-0| I120: DISKLIB-LIB : DiskLib_SpaceNeededForCombine: failed to get space for combine operation: Operation was canceled (33).
2014-01-16T04:17:40.174Z| vcpu-0| I120: DISKLIB-LIB : Combine: Failed to get (precise) space requirements.
2014-01-16T04:17:40.174Z| vcpu-0| I120: DISKLIB-LIB : Failed to combine : Operation was canceled (33).
2014-01-16T04:17:40.174Z| vcpu-0| I120: SNAPSHOT: SnapshotCombineDisks: Failed to combine: Operation was canceled (33).
2014-01-16T04:17:40.178Z| vcpu-0| I120: DISKLIB-CBT : Shutting down change tracking for untracked fid 9428050.
2014-01-16T04:17:40.178Z| vcpu-0| I120: DISKLIB-CBT : Successfully disconnected CBT node.
2014-01-16T04:17:40.211Z| vcpu-0| I120: DISKLIB-VMFS : «/vmfs/volumes/50939781-d365a9b0-5523-001b21badd94/<SERVERNAME>/<SERVERNAME>-000002-delta.vmdk» : closed.
2014-01-16T04:17:40.213Z| vcpu-0| I120: DISKLIB-VMFS : «/vmfs/volumes/50939781-d365a9b0-5523-001b21badd94/<SERVERNAME>/<SERVERNAME>-flat.vmdk» : closed.
2014-01-16T04:17:40.213Z| vcpu-0| I120: SNAPSHOT: Snapshot_ConsolidateWorkItem failed: Operation was canceled (5) 2014-01-16T04:17:40.213Z| vcpu-0| I120: SnapshotVMXConsolidateOnlineCB: Synchronous consolidate failed for disk node: scsi0:2. Adding it to skip list.
We can see that there is a process that calculates if there is enough space free for consolidation and if this process does not complete in 12 or less seconds, it aborts the consolidate operation. After speaking to VMWare we found that we couldn’t extend this timer — it’s hardcoded. Veeam suggested that this precise calculation is only needed if there is less free space available in the datastore than the size of the disk that needs consolidation. So we extended the LUN and datastore so we had enough free space and ran the consolidate task again. This time it worked instantly and has continued to work for the last few days.
So I guess we have a work-around for the issue — to extend the datastore. Obviously this isn’t ideal when we might be speaking about 11TB VMDK’s (22TB datastore!!).
We still don’t know why this happened, or should I say why it didn’t happen before… The VM hasn’t changed in size for months and we never had this issue on 5.1 or Veeam 6.5. It’s on the same backend storage and the datastore latency hasn’t really risen. I’m guessing something must have changed in connection with vSphere 5.5 snapshotting and this has made it less tolerant of our environment.
Anyway, I just thought I’d post this in-case anyone else experiences this or similar issues or has any further insight into this issue.
Thanks
Adrian
Очень часто при удалении снапшотов или консолидации дисков виртуальных машин на хостах VMWare ESXi, я сталкиваюсь с ошибкой “Unable to access a file since it is locked”. Это довольна частая проблема связана с ошибками в системе резервного копирования ВМ (я встречал проблему в Veeam, HP Data Protector, Veritas). Блокировка виртуального диска снапшота виртуальной машины не позволит вам выполнить консолидацию (Virtual machine disks consolidation is needed), Storage vMotion на другой дисковый массив, выполнить резервное копирование или удалить текущий снапшот. Иногда виртуальную машины с блокировками нельзя даже элементарно включить.
Ошибка с доступом к заблокированному файлу виртуального диска или снапшот в VMWare может выглядеть так:
Unable to access file since it is locked. An error occurred while consolidating disks: One or more disks are busy.
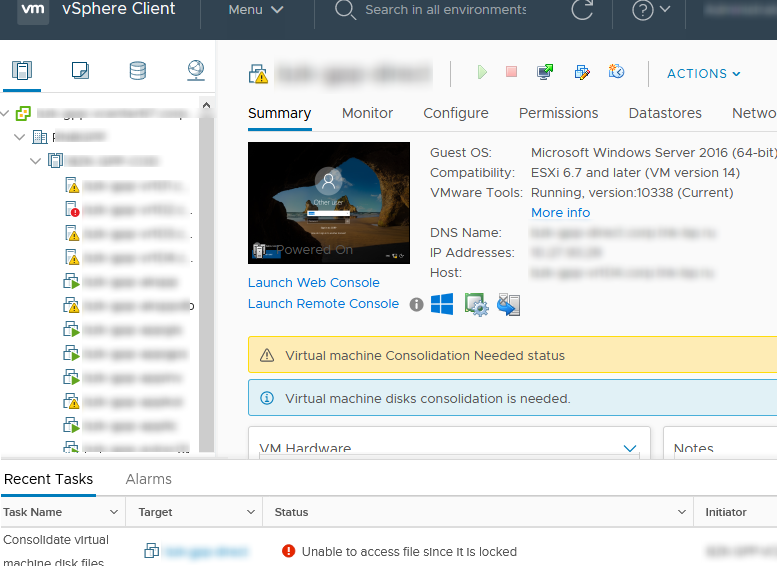
Так же вы можете увидеть такую ошибку:
An error occurred while consolidating disks: msg.snapshot.error-DISKLOCKED.
Чаще всего ошибка “Unable to access file since it is locked” появляется:
- Когда некоторые файлы включенной виртуальной машины содержат метки блокировки другими хостаим ESXi;
- При добавлении виртуальных дисков в appliance резервного копирования во время неудачных сессий создания бэкапа;
Чтобы найти источник блокировки и снять ее, сначала нужно определить заблокированные файлы.
- С помощью SSH клиента подключитесь к хосту ESXi, на котором зарегистрирована проблемная ВМ;
- Перейдите в каталог с файлами виртуальной машины:
cd /vmfs/volumes/VMFS_DATASTORE_NAME/LOCKED_VM - Найдите ошибки консолидации, блокировки файлов в журнале vmware.log:
cat vmware.log | grep lock - В логе должны содержаться примерно такие ошибки:
VigorSnapshotManagerConsolidateCallback: snapshotErr = Failed to lock the file (5:4008) 2020-01-13T05:07:11.432Z| vmx| I125: DISK: Cannot open disk "/vmfs/volumes/5121c3ff-230b21a-41aa-21d92b219221/msk-web01/msk-web01_1-000002.vmdk": Failed to lock the file (16392). 2020-01-13T05:07:11.432Z| Worker#1| I125: DISKLIB-LIB : Failed to open '/vmfs/volumes/5121c3ff-230b21a-41aa-21d92b219221/msk-web01/msk-web01-000002.vmdk' with flags 0xa Failed to lock the file (16392). 2020-01-13T05:07:11.432Z| Worker#1| I125: DISK: Cannot open disk "/vmfs/volumes/5121c3ff-230b21a-41aa-21d92b219221/msk-web01/msk-web01-000002.vmdk": Failed to lock the file (16392). 2020-01-13T05:07:11.432Z| vmx| I125: [msg.fileio.lock] Failed to lock the file

- В этом примере видно, что заблокирован файл
msk-web01_1-000002.vmdk
; - С помощью следующей команды можно вывести текущую цепочку снапшотов начиная с указанного, до flat диска:
vmkfstools -qv10 msk-web01_1-000002.vmdk - Теперь выведем информацию о снапшоте, и его владельце (RO owner):
vmkfstools -D msk-web01-000001-delta.vmdkLock [type 10c000021 offset 242835456 v 856, hb offset 3153920 gen 3, mode 1, owner 5cbac61a-4b6e32b7-0480-d06726ae7900 mtime 5199410 num 0 gblnum 0 gblgen 0 gblbrk 0] RO Owner[0] HB Offset 3153920 5cbac61a-4b6e32b7-0480-d06726ae7900 Addr <4, 532, 83>, gen 859, links 1, type reg, flags 0, uid 0, gid 0, mode 600

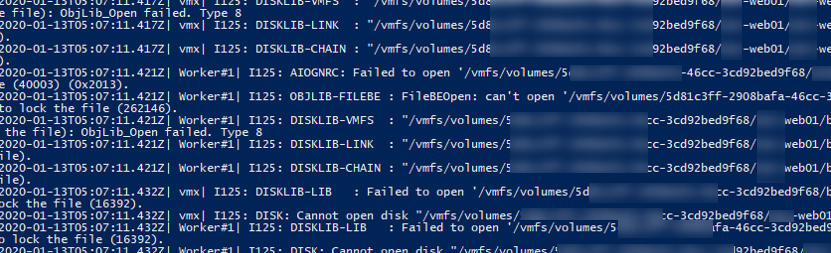
В строке RO Owner указан MAC адрес сетевой карты хоста ESXi, который заблокировал данный файл снапшота (MAC адрес выделен на скриншоте). Также обратите внимание на значение Mode:
- mode 1 – блокировка на чтение/запись (например, у включенной ВМ);
- mode 2 – обычно означает, что диск заблокирован приложением резервного копирования.
Чтобы по известному MAC адресу найти ESXi сервер, можно воспользоваться следующими командами в PowerCLI (преобразуйте полученный ранее MAC адрес в формат с двоеточиями):
Import-Module VMware.VimAutomation.Core -ErrorAction SilentlyContinue
connect-viserver vcenter1
Get-VMHost | Get-VMHostNetworkAdapter | Where-Object {$_.Mac -like "d0:67:26:ae:79:00"} | Format-List -Property *
Имя ESXi хоста будет указано в поле VMHost.
Также вы можете вывести ARP таблицу прямо с хоста ESXi и получить IP и MAC адреса всех соседних серверов ESXi в сети VMkernel:
esxcli network ip neighbor list
Чтобы снять блокировку с файла ВМ просто перезагрузите найденный ESXi хост (предварительно смигрируйте с него все ВМ с помощью VMotion). Если вы не можете перезагрузить хост, перезапустите службу Management Agent (hostd) в Maintenance Mode из SSH консоли хоста:
services.sh restart
После этого попробуйте выполнить консолидацию или удалить снашот ВМ.
Ошибка “Unable to access file since it is locked” довольно часто возникает в Veeam Backup & Replication при использовании прокси-сервера Veeam. Из-за ошибок при резервном копировании Veeam может не отключить корректно диск виртуальной машины.
Чтобы исправить проблему, откройте параметры ВМ, на которой установлен прокси Veeam. Удалите из оборудования ВМ диск ВМ, файлы которой заблокированы.
Убедитесь, что вы выбрали опцию “Remove from virtual machine”, а не “Remove from virtual machine and delete files from disk”. Иначе вы можете случайно удалить ваш vmdk диск.
You all know what I’m talking about. Haven’t you ever attempted some operation on a vSphere VM – VMotion, disk consolidation, etc. and received a vCenter error stating the operation failed because of some lock on the VM’s vmdk?
After receiving an email from my backup software (Veeam) that one of my VMs needed disk consolidation, I went into vCenter & attempted to do so. Upon performing the task, vCenter returned an error:
An error occurred while consolidating disks: msg.snapshot.error-DISKLOCKED
Or, something like this error, as well:

I then went into Veeam to see if the backup job this VM was in failed. It did…at least just this particular problem VM in the backup job. I then specifically looked at the error for this VM in the backup job (“Error: Failed to open VDDK disk [[datastore-name] VM-directory/VM-name-000014.vmdk] ( is read-only mode – [true] ) Failed to open virtual disk Logon attempt with parameters [VC/ESX: [vcenter-name];Port: 443;Login: [domainuser];VMX Spec: [moref=vm-101];Snapshot mor: [snapshot-17944];Transports: [nbd];Read Only: [true]] failed because of the following errors: Failed to open disk for read. Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}. ”), and noticed this is an error I’m familiar with. This error is typical when a VM’s vmdk is attached to a Veeam Proxy VM during backup and, upon the backup job completion, the vmdk doesn’t get removed from the Veeam Proxy VM. This is most common when using Veeam’s “hotadd” backup mode. In checking all my Proxy VMs, there was no stray vmdk attached to them, so I was a bit puzzled.
I next went into the Datastore this problem VM was on & looked at the VM’s directory. To my surprise, there were 16 delta files! (hence why I received a notification this problem VM needed consolidated) Well, I couldn’t consolidate as noted above due to a file lock, so to try to remove the lock I attempted a VMotion of this problem VM. vCenter again returned an error:

This was better information because it let me know the explicit disk (the parent vmdk & not any of its subsequent deltas) that was locked. After a bit more digging through Google and some VMware KB’s (specifically, these 2 posts – http://kb.vmware.com/kb/1003656 and http://vknowledge.net/2013/07/01/disk-consolidation-unable-to-access-file/ ), I was able to lock down what object/device had a lock on the VM. To find the lock, open an SSH session to the ESXi Host the problem VM currently resides on then run this command:
vmkfstools -D /vmfs/volumes/48fbd8e5-c04f6d90-1edb-001cc46b7a18/VM-directory/problem-vm.vmdk
When running the command, make sure to use the UUID of the Datastore as shown above and not the Datastore alias/friendly name (i.e. vmfs01). When you run the command, there will be output like the sample below:
Lock [type 10c00001 offset 48226304 v 386, hb offset 3558400
Aug 24 16:15:52 esxhost vmkernel: gen 37, mode 0, owner 4a84acc3-786ebaf4-aaf9-001a6465b7b0 mtime 221688]
Aug 24 16:15:52 esxhost vmkernel: 10:20:00:22.731 cpu5:1040)Addr <4, 96, 156>, gen 336, links 1, type reg, flags 0x0, uid 0, gid 0, mode 100600
Take note of the text after the word “owner”, specifically the red highlighted text above. Those 12 digits represent a MAC Address and that is the key. That MAC Address represents the MAC of a network adapter of the ESXi Host that the problem VM lock originates from. To find that MAC, simply go into vCenter > Configuration tab > Network Adapters (in the ‘Hardware’ box) and look at the MAC for each Adapter on each Host. Once you find the MAC, there is your culprit… i.e. the Host holding the lock on the problem VM’s vmdk. Once found, you’ll need to either restart the management agents on the Host, or migrate VMs off the Host and perform a reboot. The lock should then be disengaged from the problem VM disk and tasks can be completed as normal (migration, consolidation, etc.).
Last week I had a customer with a VM that required virtual disk consolidation, however when he attempted to perform this from the vSphere client it would run for hours and unfortunately fail:
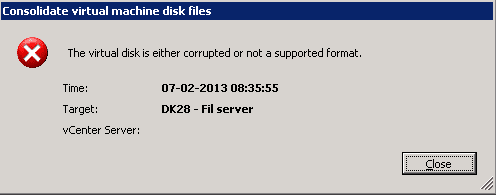
The virtual disk is either corrupted or not a supported format.
I waited till we could get a service window on the VM, performed a shutdown and re-ran the disk consolidation. Still the same error message!
I then used command vim-cmd vmsvc/getallvms to quickly locate the volume containing the VM:

Then checked if there was any locks on the vmdk file:

I have highlighted the line showing us there is a RO (Read-Only) lock on the VMDK file. This is most likely what is causing the disk consolidation to fail. The last part of the line 0026b9564d86 is the mac address of the host locking the file.
Lets lookup if the host running the VM currently is also the host locking the file:

The mac address matched up and a quick Google search revealed the following VMware Knowledge Base article.
As suggested in the article I then performed a vMotion of the VM to a different host and re-tried the disk consolidation.
Finally it finished without errors!
As always, if this helped you please leave a comment! 🙂
Incoming search terms:
- An error occurred while consolidating disks: msg fileio lock
- An error occurred while consolidating disks: msg snapshot error-DISKLOCKED
- msg fileio lock
- msg snapshot error-DISKLOCKED
- virtual machine disks consolidation is needed
- the virtual disk is either corrupted or not a supported format
- An error occurred while consolidating disks: msg snapshot error-NOTFOUND
- an error occurred while consolidating disks msg fileio lock
- An error occurred while consolidating disks: Failed to lock the file