I installed MongoDB Compass, and I get error message “An error occurred while loading navigation: Invalid UTF-8 string in BSON document”. I can’t visualize my data.
Version MongoDB 5.0.3(current)
Windows 10
I tried reinstalling a different version of MongoDB but it didn’t help.
I download it on another other computer of the same configuration, everything seems to work.
What could have happened?
P.S. Console commands work without problem.
This is what I see after i click on connect
asked Oct 1, 2021 at 11:03
![]()
aurfaaurfa
111 silver badge3 bronze badges
I just had the same problem with MongoDB Compass and fix it by doing the following:
- Uninstall the version of MongoDB Compass that comes by default with the Mongo installation.
- I downloaded one of the older versions.
I leave you the link so you can download the previous version which has managed to correct this error.
https://downloads.mongodb.com/compass/mongodb-compass-1.21.2-win32-x64.zip
answered Oct 27, 2021 at 12:35
![]()
I fixed this problem with the same MongoDB Compass version shared by Wlogz (1.21.2).
The link is in the previous comment…
answered Feb 10, 2022 at 14:24
![]()
1
Содержание
- Error: Invalid UTF-8 string in BSON document about mongodb-dumper HOT 2 OPEN
- Comments (2)
- Related Issues (15)
- Recommend Projects
- React
- Vue.js
- Typescript
- TensorFlow
- Django
- Laravel
- Recommend Topics
- javascript
- server
- Machine learning
- Visualization
- Recommend Org
- Microsoft
- Error building JSON from ‘‘: Invalid UTF-8 string. Asterisk FreePBX
- Диагностика.
- Как исправить ошибку кодировки старой БД?
- BSON 4.x Tutorial¶
- Installation¶
- Use With ActiveSupport¶
- BSON Serialization¶
- Byte Buffers¶
- Writing¶
- Reading¶
- Supported Classes¶
- BSON::Binary В¶
- UUID Methods¶
- Legacy UUIDs¶
- BSON::Code В¶
- BSON::CodeWithScope В¶
- BSON::DBRef В¶
- BSON::Document В¶
- BSON::MaxKey В¶
- BSON::MinKey В¶
- BSON::ObjectId В¶
- BSON::Timestamp В¶
- BSON::Undefined В¶
- BSON::Decimal128 В¶
- BSON::Decimal128 vs BigDecimal¶
- Symbol В¶
- JSON Serialization¶
- Time Instances¶
- DateTime Instances¶
- Date Instances¶
- Regular Expressions¶
- Ruby vs MongoDB Regular Expressions¶
- Options / Flags / Modifiers¶
- ^ Anchor¶
- $ Anchor¶
- BSON::Regexp::Raw Class¶
- Regular Expression Conversion¶
- Reading and Writing¶
- Key Order¶
- Duplicate Keys¶
Error: Invalid UTF-8 string in BSON document about mongodb-dumper HOT 2 OPEN
Should we check for invalid characters before inserting in mongodb? What could be the invalid characters? @maebeam
maebeam commented on January 15, 2023
I haven’t seen this error before. @bluepartyhat might have an idea, they are the original author and maintainer
- Typo, should be mongo-uri me thinks 🙂
- the .mem file in badgerdb directory
- Messed up Transaction ids — how to get the correct transaction id?
- Error when building image
- Docker build error
- Error: unknown flag: —mongodb-database
- Downloading blocks halts in the middle. HOT 2
- Deadlock error HOT 1
- Accessing posts through SQL HOT 3
- Third Party apps in core removed breaking Dockerfile build
- Mongodb-dumper container crashes in middle HOT 1
- [Bug] Fail to connect to mongodb HOT 4
- Memory Errors HOT 1
- how to fetch the user interaction data HOT 1
Recommend Projects
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
TensorFlow
An Open Source Machine Learning Framework for Everyone
Django
The Web framework for perfectionists with deadlines.
Laravel
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
Recommend Topics
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
server
A server is a program made to process requests and deliver data to clients.
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Visualization
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
Recommend Org
We are working to build community through open source technology. NB: members must have two-factor auth.
Microsoft
Open source projects and samples from Microsoft.
Источник
Error building JSON from ‘‘: Invalid UTF-8 string. Asterisk FreePBX
Всем привет.
Начал замечать ошибку на некоторых астерисках в точности FreePBX последних версий — «Error building JSON from ‘‘: Invalid UTF-8 string.» или «Error building JSON from ‘‘: Invalid UTF-8 string.» во время звонка.
Всегда связан с длинным кириллическим именем в большинстве случаев в extension.
Диагностика.
Что смотреть?
Лог файл full в /var/log/asterisk/. Ищем через grep или less по «UTF-8″‘
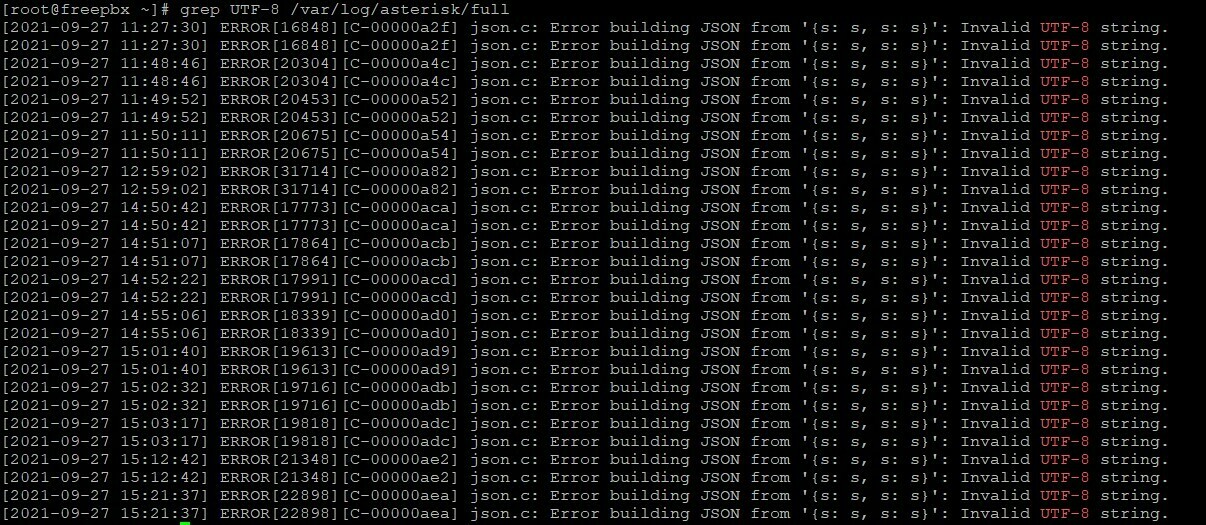 Открываем любой звонок, допустим C-00000a2f.
Открываем любой звонок, допустим C-00000a2f.
Команда:
grep C-00000a2f /var/log/asterisk/full
Находим момент где вылезает ошибка
 Видим 200 номер с кривым именем «_CALLERIDNAMEINTERNAL=Стратиенко Константи?») in new stack
Видим 200 номер с кривым именем «_CALLERIDNAMEINTERNAL=Стратиенко Константи?») in new stack
Идем в FreePBX, находим в extensions 200 номер и переименовываем в Стратиенко или просто 200, сохраняем, применяем конфиг.
После этого должна ошибка уйти, если не помогло, попробуйте удалить номер и заново его создать с уже коротким именем.
Решение этой же задачи от Alex K
В диалплане «Имя» обрезается тут:
[macro-user-callerid]
exten => s,n,Set(CALLERID(name)=$)
Не получилось исправить? Мы готовы помочь! Заполните заявку на этой странице.
Источник
Как исправить ошибку кодировки старой БД?
1300 : Invalid utf8 character string: ‘Иван Иванович Иванов’
MySQL очень старый 5.1.41, php тоже старый 5.2.17
Кодировка сервера windows-1251, БД utf8-general-ci.
- Вопрос задан более трёх лет назад
- 846 просмотров
Простой 2 комментария

1054 : Unknown column ‘Суслов РРіРѕСЂСЊ Дмитриевич’ in ‘field list’
БД теперь в cp1251_general_ci


1) я поменял mysql_escape_string на mysql_real_escape_string, т.к. mysql_real_escape_string экранирует строку с учетом текущей кодировки. почитайте в документации про нее, чтобы я не копипастил).
2) Апостроф ` поменял на одинарную ковычку, апострофом я обычно экранирую поля, таблицы, а не строки, хотя не проверял экранированные строки с апострофом.
3) Конечно надо избавляться от mysql и заменить на такие же функции mysqli, хотя где то может поломаться.
4) Странная запись $fio = mysql_escape_string($fio);
это скорее register glogals включен, было бы правильнее, универсальный подход $fio = mysql_escape_string($_REQUEST[‘fio’]);
но может данные пришли из $_GET или $_POST
5) И как вариант данные пришли в кодировке cp1251, поэтому ошибка 1300 : Invalid utf8 character string
$fio = mysql_real_escape_string( iconv(‘windows-1251’, ‘utf-8’, $fio));
Источник
BSON 4.x Tutorial¶
This tutorial discusses using the Ruby BSON library.
Installation¶
The BSON library can be installed from Rubygems manually or with bundler.
To install the gem manually:
To install the gem with bundler, include the following in your Gemfile :
The BSON library is compatible with MRI >= 2.5 and JRuby >= 9.2.
Use With ActiveSupport¶
Serialization for ActiveSupport-defined classes, such as TimeWithZone, is not loaded by default to avoid a hard dependency of BSON on ActiveSupport. When using BSON in an application that also uses ActiveSupport, the ActiveSupport-related code must be explicitly required:
BSON Serialization¶
Getting a Ruby object’s raw BSON representation is done by calling to_bson on the Ruby object, which will return a BSON::ByteBuffer . For example:
Generating an object from BSON is done via calling from_bson on the class you wish to instantiate and passing it a BSON::ByteBuffer instance.
Byte Buffers¶
BSON library 4.0 introduces the use of native byte buffers in MRI and JRuby instead of using StringIO , for improved performance.
Writing¶
To create a ByteBuffer for writing (i.e. serializing to BSON), instantiate BSON::ByteBuffer with no arguments:
To write raw bytes to the byte buffer with no transformations, use put_byte and put_bytes methods. They take a byte string as the argument and copy this string into the buffer. put_byte enforces that the argument is a string of length 1; put_bytes accepts any length strings. The strings can contain null bytes.
put_byte and put_bytes do not write a BSON type byte prior to writing the argument to the byte buffer.
Subsequent write methods write objects of particular types in the BSON spec. Note that the type indicated by the method name takes precedence over the type of the argument — for example, if a floating-point value is given to put_int32 , it is coerced into an integer and the resulting integer is written to the byte buffer.
To write a UTF-8 string (BSON type 0x02) to the byte buffer, use put_string :
Note that BSON strings are always encoded in UTF-8. Therefore, the argument must be either in UTF-8 or in an encoding convertable to UTF-8 (i.e. not binary). If the argument is in an encoding other than UTF-8, the string is first converted to UTF-8 and the UTF-8 encoded version is written to the buffer. The string must be valid in its claimed encoding, including being valid UTF-8 if the encoding is UTF-8. The string may contain null bytes.
The BSON specification also defines a CString type, which is used for example for document keys. To write CStrings to the buffer, use put_cstring :
As with regular strings, CStrings in BSON must be UTF-8 encoded. If the argument is not in UTF-8, it is converted to UTF-8 and the resulting string is written to the buffer. Unlike put_string , the UTF-8 encoding of the argument given to put_cstring cannot have any null bytes, since the CString serialization format in BSON is null terminated.
Unlike put_string , put_cstring also accepts symbols and integers. In all cases the argument is stringified prior to being written:
To write a 32-bit or a 64-bit integer to the byte buffer, use put_int32 and put_int64 methods respectively. Note that Ruby integers can be arbitrarily large; if the value being written exceeds the range of a 32-bit or a 64-bit integer, put_int32 and put_int64 raise RangeError .
If put_int32 or put_int64 are given floating point arguments, the arguments are first coerced into integers and the integers are written to the byte buffer.
To write a 64-bit floating point value to the byte buffer, use put_double :
To obtain the serialized data as a byte string (for example, to send the data over a socket), call to_s on the buffer:
ByteBuffer keeps track of read and write positions separately. There is no way to rewind the buffer for writing — rewind only affects the read position.
Reading¶
To create a ByteBuffer for reading (i.e. deserializing from BSON), instantiate BSON::ByteBuffer with a byte string as the argument:
Reading from the buffer is done via the following API:
To restart reading from the beginning of a buffer, use rewind :
ByteBuffer keeps track of read and write positions separately. rewind only affects the read position.
Supported Classes¶
Core Ruby classes that have representations in the BSON specification and will have a to_bson method defined for them are: Object , Array , FalseClass , Float , Hash , Integer , BigDecimal , NilClass , Regexp , String , Symbol (deprecated), Time , TrueClass .
In addition to the core Ruby objects, BSON also provides some special types specific to the specification:
BSON::Binary В¶
Use BSON::Binary objects to store arbitrary binary data. The Binary objects can be constructed from binary strings as follows:
By default, Binary objects are created with BSON binary subtype 0 ( :generic ). The subtype can be explicitly specified to indicate that the bytes encode a particular type of data:
Valid subtypes are :generic , :function , :old , :uuid_old , :uuid , :md5 and :user .
The data and the subtype can be retrieved from Binary instances using data and type attributes, as follows:
BSON::Binary objects always store the data in BINARY encoding, regardless of the encoding that the string passed to the constructor was in:
UUID Methods¶
To create a UUID BSON::Binary (binary subtype 4) from its RFC 4122-compliant string representation, use the from_uuid method:
To stringify a UUID BSON::Binary to an RFC 4122-compliant representation, use the to_uuid method:
The standard representation may be explicitly specified when invoking both from_uuid and to_uuid methods:
Note that the :standard representation can only be used with a Binary of subtype :uuid (not :uuid_old ).
Legacy UUIDs¶
Data stored in BSON::Binary objects of subtype 3 ( :uuid_old ) may be persisted in one of three different byte orders depending on which driver created the data. The byte orders are CSharp legacy, Java legacy and Python legacy. The Python legacy byte order is the same as the standard RFC 4122 byte order; CSharp legacy and Java legacy byte orders have some of the bytes swapped.
The Binary object containing a legacy UUID does not encode which format the UUID is stored in. Therefore, methods that convert to and from the legacy UUID format take the desired format, or representation, as their argument. An application may copy legacy UUID Binary objects without knowing which byte order they store their data in.
The following methods for working with legacy UUIDs are provided for interoperability with existing deployments storing data in legacy UUID formats. It is recommended that new applications use the :uuid (subtype 4) format only, which is compliant with RFC 4122.
To stringify a legacy UUID BSON::Binary, use the to_uuid method specifying the desired representation. Accepted representations are :csharp_legacy , :java_legacy and :python_legacy . Note that a legacy UUID BSON::Binary cannot be stringified without specifying a representation.
To create a legacy UUID BSON::Binary from the string representation of the UUID, use the from_uuid method specifying the desired representation:
These methods can be used to convert from one representation to another:
BSON::Code В¶
Represents a string of JavaScript code.
BSON::CodeWithScope В¶
The CodeWithScope type is deprecated as of MongoDB 4.2.1. Starting with MongoDB 4.4, support from CodeWithScope is being removed from various server commands and operators such as $where . Please use other BSON types and operators when working with MongoDB 4.4 and newer.
Represents a string of JavaScript code with a hash of values.
BSON::DBRef В¶
This is a subclass of BSON::Document that provides accessors for the collection, id, and database of the DBRef.
The BSON::DBRef constructor will validate the given hash and will raise an ArgumentError if it is not a valid DBRef. BSON::ExtJSON.parse_obj and Hash.from_bson will not raise an error if given an invalid DBRef, and will parse a Hash or deserialize a BSON::Document instead.
All BSON documents are deserialized into instances of BSON::DBRef if they are valid DBRefs, otherwise they are deserialized into instances of BSON::Document. This is true even when the invocation is made from the Hash class:
For backwards compatibility with the MongoDB Ruby driver versions 2.17 and earlier, BSON::DBRef also can be constructed using the legacy driver API. This API is deprecated and will be removed in a future version of bson-ruby :
BSON::Document В¶
This is a subclass of Hash that stores all keys as strings, but allows access to them with symbol keys.
All BSON documents are deserialized into instances of BSON::Document (or BSON::DBRef, if they happen to be a valid DBRef), even when the invocation is made from the Hash class:
BSON::MaxKey В¶
Represents a value in BSON that will always compare higher to another value.
BSON::MinKey В¶
Represents a value in BSON that will always compare lower to another value.
BSON::ObjectId В¶
Represents a 12 byte unique identifier for an object on a given machine.
BSON::Timestamp В¶
Represents a special time with a start and increment value.
BSON::Undefined В¶
Represents a placeholder for a value that was not provided.
BSON::Decimal128 В¶
Represents a 128-bit decimal-based floating-point value capable of emulating decimal rounding with exact precision.
BSON::Decimal128 vs BigDecimal¶
The BigDecimal from_bson and to_bson methods use the same BSON::Decimal128 methods under the hood. This leads to some limitations that are imposed on the BigDecimal values that can be serialized to BSON and those that can be deserialized from existing decimal128 BSON values. This change was made because serializing BigDecimal instances as BSON::Decimal128 instances allows for more flexibility in terms of querying and aggregation in MongoDB. The limitations imposed on BigDecimal are as follows:
- decimal128 has a limited range and precision, while BigDecimal has no restrictions in terms of range and precision. decimal128 has a max value of approximately 10^6145 and a min value of approximately -10^6145 , and has a maximum of 34 bits of precision.
- decimal128 is able to accept signed NaN values, while BigDecimal is not. All signed NaN values that are deserialized into BigDecimal instances will be unsigned.
- decimal128 maintains trailing zeroes when serializing to and deserializing from BSON. BigDecimal , however, does not maintain trailing zeroes and therefore using BigDecimal may result in a lack of precision.
In BSON 5.0, decimal128 is deserialized into BigDecimal by default. In order to have decimal128 values in BSON documents deserialized into BSON::Decimal128 , the mode: :bson option can be set on from_bson .
Symbol В¶
The BSON specification defines a symbol type which allows round-tripping Ruby Symbol values (i.e., a Ruby Symbol«is encoded into a BSON symbol and a BSON symbol is decoded into a Ruby «Symbol ). However, since most programming langauges do not have a native symbol type, to promote interoperabilty, MongoDB deprecated the BSON symbol type and encourages strings to be used instead.
In BSON, hash keys are always strings. Non-string values will be stringified when used as hash keys:
By default, the BSON library encodes Symbol hash values as strings and decodes BSON symbols into Ruby Symbol values:
To force encoding of Ruby symbols to BSON symbols, wrap the Ruby symbols in BSON::Symbol::Raw :
JSON Serialization¶
Some BSON types have special representations in JSON. These are as follows and will be automatically serialized in the form when calling to_json on them.
| Object | JSON |
|---|---|
| BSON::Binary | |
| BSON::Code | |
| BSON::CodeWithScope | < «$code» : «this.v = value», «$scope» : < v =>5 >> |
| BSON::DBRef | < «$ref» : «collection», «$id» : < «$oid» : «id» >, «$db» : «database» > |
| BSON::MaxKey | |
| BSON::MinKey | |
| BSON::ObjectId | |
| BSON::Timestamp | |
| Regexp |
Time Instances¶
Times in Ruby can have nanosecond precision. Times in BSON (and MongoDB) can only have millisecond precision. When Ruby Time instances are serialized to BSON or Extended JSON, the times are floored to the nearest millisecond.
The time as always rounded down. If the time precedes the Unix epoch (January 1, 1970 00:00:00 UTC), the absolute value of the time would increase:
JRuby as of version 9.2.11.0 rounds pre-Unix epoch times up rather than down. bson-ruby works around this and correctly floors the times when serializing on JRuby.
Because of this flooring, applications are strongly recommended to perform all time calculations using integer math, as inexactness of floating point calculations may produce unexpected results.
DateTime Instances¶
BSON only supports storing the time as the number of seconds since the Unix epoch. Ruby’s DateTime instances can be serialized to BSON, but when the BSON is deserialized the times will be returned as Time instances.
DateTime class in Ruby supports non-Gregorian calendars. When non-Gregorian DateTime instances are serialized, they are first converted to Gregorian calendar, and the respective date in the Gregorian calendar is stored in the database.
Date Instances¶
BSON only supports storing the time as the number of seconds since the Unix epoch. Ruby’s Date instances can be serialized to BSON, but when the BSON is deserialized the times will be returned as Time instances.
When Date instances are serialized, the time value used is midnight of the day that the Date refers to in UTC.
Regular Expressions¶
Both MongoDB and Ruby provide facilities for working with regular expressions, but they use regular expression engines. The following subsections detail the differences between Ruby regular expressions and MongoDB regular expressions and describe how to work with both.
Ruby vs MongoDB Regular Expressions¶
MongoDB server uses Perl-compatible regular expressions implemented using the PCRE library and Ruby regular expressions are implemented using the Onigmo regular expression engine, which is a fork of Oniguruma. The two regular expression implementations generally provide equivalent functionality but have several important syntax differences, as described below.
Unfortunately, there is no simple way to programmatically convert a PCRE regular expression into the equivalent Ruby regular expression, and there are currently no Ruby bindings for PCRE.
Options / Flags / Modifiers¶
Both Ruby and PCRE regular expressions support modifiers. These are also called “options” in Ruby parlance and “flags” in PCRE parlance. The meaning of s and m modifiers differs in Ruby and PCRE:
- Ruby does not have the s modifier, instead the Ruby m modifier performs the same function as the PCRE s modifier which is to make the period ( . ) match any character including newlines. Confusingly, the Ruby documentation refers to the m modifier as “enabling multi-line mode”.
- Ruby always operates in the equivalent of PCRE’s multi-line mode, enabled by the m modifier in PCRE regular expressions. In Ruby the ^ anchor always refers to the beginning of line and the $ anchor always refers to the end of line.
When writing regular expressions intended to be used in both Ruby and PCRE environments (including MongoDB server and most other MongoDB drivers), henceforth referred to as “portable regular expressions”, avoid using the ^ and $ anchors. The following sections provide workarounds and recommendations for authoring portable regular expressions.
^ Anchor¶
In Ruby regular expressions, the ^ anchor always refers to the beginning of line. In PCRE regular expressions, the ^ anchor refers to the beginning of input by default and the m flag changes its meaning to the beginning of line.
Both Ruby and PCRE regular expressions support the A anchor to refer to the beginning of input, regardless of modifiers.
When writing portable regular expressions:
- Use the A anchor to refer to the beginning of input.
- Use the ^ anchor to refer to the beginning of line (this requires setting the m flag in PCRE regular expressions). Alternatively use one of the following constructs which work regardless of modifiers: — (?:A|(? (handles LF and CR+LF line ends) — (?:A|(? (handles CR, LF and CR+LF line ends)
$ Anchor¶
In Ruby regular expressions, the $ anchor always refers to the end of line. In PCRE regular expressions, the $ anchor refers to the end of input by default and the m flag changes its meaning to the end of line.
Both Ruby and PCRE regular expressions support the z anchor to refer to the end of input, regardless of modifiers.
When writing portable regular expressions:
- Use the z anchor to refer to the end of input.
- Use the $ anchor to refer to the beginning of line (this requires setting the m flag in PCRE regular expressions). Alternatively use one of the following constructs which work regardless of modifiers: — (?:z|(?=n)) (handles LF and CR+LF line ends) — (?:z|(?=[nn])) (handles CR, LF and CR+LF line ends)
BSON::Regexp::Raw Class¶
Since there is no simple way to programmatically convert a PCRE regular expression into the equivalent Ruby regular expression, bson-ruby provides the BSON::Regexp::Raw class for holding MongoDB/PCRE regular expressions. Instances of this class are called “BSON regular expressions” in this documentation.
Instances of this class can be created using the regular expression text as a string and optional PCRE modifiers:
The BSON::Regexp module is included in the Ruby Regexp class, such that the BSON:: prefix may be omitted:
Regular Expression Conversion¶
To convert a Ruby regular expression to a BSON regular expression, instantiate a BSON::Regexp::Raw object as follows:
Note that the BSON::Regexp::Raw constructor accepts both the Ruby numeric options and the PCRE modifier strings.
To convert a BSON regular expression to a Ruby regular expression, call the compile method on the BSON regular expression:
Note that the s PCRE modifier was converted to the m Ruby modifier in the first example, and the last two examples were converted to the same regular expression even though the original BSON regular expressions had different meanings.
When a BSON regular expression uses the non-portable ^ and $ anchors, its conversion to a Ruby regular expression can change its meaning:
When a Ruby regular expression is converted to a BSON regular expression (for example, to send to the server as part of a query), the BSON regular expression always has the m modifier set reflecting the behavior of ^ and $ anchors in Ruby regular expressions.
Reading and Writing¶
Both Ruby and BSON regular expressions implement the to_bson method for serialization to BSON:
Both Regexp and BSON::Regexp::Raw classes implement the from_bson class method that deserializes a regular expression from a BSON byte buffer. Methods of both classes return a BSON::Regexp::Raw instance that must be converted to a Ruby regular expression using the compile method as described above.
Key Order¶
BSON documents preserve the order of keys, because the documents are stored as lists of key-value pairs. Hashes in Ruby also preserve key order; thus the order of keys specified in Ruby will be respected when serializing a hash to a BSON document, and when deserializing a BSON document into a hash the order of keys in the document will match the order of keys in the hash.
Duplicate Keys¶
BSON specification allows BSON documents to have duplicate keys, because the documents are stored as lists of key-value pairs. Applications should refrain from generating such documents, because MongoDB server behavior is undefined when a BSON document contains duplicate keys.
Since in Ruby hashes cannot have duplicate keys, when serializing Ruby hashes to BSON documents no duplicate keys will be generated. (It is still possible to hand-craft a BSON document that would have duplicate keys in Ruby, and some of the other MongoDB BSON libraries may permit creating BSON documents with duplicate keys.)
Note that, since keys in BSON documents are always stored as strings, specifying the same key as as string and a symbol in Ruby only retains the most recent specification:
When loading a BSON document with duplicate keys, the last value for a duplicated key overwrites previous values for the same key.
© MongoDB, Inc 2008-present. MongoDB, Mongo, and the leaf logo are registered trademarks of MongoDB, Inc.
Источник
UTF-8 Validation

Overview
In this guide, you can learn how to enable or disable the Node.js driver’s UTF-8 validation feature. UTF-8 is a character encoding specification that ensures compatibility and consistent presentation across most operating systems, applications, and language character sets.
If you enable validation, the driver throws an error when it attempts to convert data that contains invalid UTF-8 characters. The validation adds processing overhead since it needs to check the data.
If you disable validation, your application avoids the validation processing overhead, but cannot guarantee consistent presentation of invalid UTF-8 data.
The driver enables UTF-8 validation by default. It checks documents for any characters that are not encoded in a valid UTF-8 format when it transfers data between your application and MongoDB.
The current version of the Node.js driver automatically substitutes invalid UTF-8 characters with alternate valid UTF-8 ones prior to validation when you send data to MongoDB. Therefore, the validation only throws an error when the setting is enabled and the driver receives invalid UTF-8 document data from MongoDB.
Read the sections below to learn how to set UTF-8 validation using the Node.js driver.
Specify the UTF-8 Validation Setting
You can specify whether the driver should perform UTF-8 validation by defining the enableUtf8Validation setting in the options parameter when you create a client, reference a database or collection, or call a CRUD operation. If you omit the setting, the driver enables UTF-8 validation.
See the following for code examples that demonstrate how to disable UTF-8 validation on the client, database, collection, or CRUD operation:
If your application reads invalid UTF-8 from MongoDB while the enableUtf8Validation option is enabled, it throws a BSONError that contains the following message:
Set the Validation Scope
The enableUtf8Validation setting automatically applies to the scope of the object instance on which you included it, and any other objects created by calls on that instance.
For example, if you include the option on the call to instantiate a database object, any collection instance you construct from that object inherits the setting. Any operations you call on that collection instance also inherit the setting.
You can override the setting at any level of scope by including it when constructing the object instance or when calling an operation.
For example, if you disable validation on the collection object, you can override the setting in individual CRUD operation calls on that collection.
Источник
Error: Invalid UTF-8 string in BSON document about mongodb-dumper HOT 2 OPEN
Comments (2)
Should we check for invalid characters before inserting in mongodb? What could be the invalid characters? @maebeam
maebeam commented on January 11, 2023
I haven’t seen this error before. @bluepartyhat might have an idea, they are the original author and maintainer
Related Issues (15)
- Typo, should be mongo-uri me thinks 🙂
- the .mem file in badgerdb directory
- Messed up Transaction ids — how to get the correct transaction id?
- Error when building image
- Docker build error
- Error: unknown flag: —mongodb-database
- Downloading blocks halts in the middle. HOT 2
- Deadlock error HOT 1
- Accessing posts through SQL HOT 3
- Third Party apps in core removed breaking Dockerfile build
- Mongodb-dumper container crashes in middle HOT 1
- [Bug] Fail to connect to mongodb HOT 4
- Memory Errors HOT 1
- how to fetch the user interaction data HOT 1
Recommend Projects
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
TensorFlow
An Open Source Machine Learning Framework for Everyone
Django
The Web framework for perfectionists with deadlines.
Laravel
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
Recommend Topics
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
server
A server is a program made to process requests and deliver data to clients.
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Visualization
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
Recommend Org
We are working to build community through open source technology. NB: members must have two-factor auth.
Microsoft
Open source projects and samples from Microsoft.
Источник
Error building JSON from ‘‘: Invalid UTF-8 string. Asterisk FreePBX
Всем привет.
Начал замечать ошибку на некоторых астерисках в точности FreePBX последних версий — «Error building JSON from ‘‘: Invalid UTF-8 string.» или «Error building JSON from ‘‘: Invalid UTF-8 string.» во время звонка.
Всегда связан с длинным кириллическим именем в большинстве случаев в extension.
Диагностика.
Что смотреть?
Лог файл full в /var/log/asterisk/. Ищем через grep или less по «UTF-8″‘
Открываем любой звонок, допустим C-00000a2f.
Команда:
grep C-00000a2f /var/log/asterisk/full
Находим момент где вылезает ошибка
Видим 200 номер с кривым именем «_CALLERIDNAMEINTERNAL=Стратиенко Константи?») in new stack
Идем в FreePBX, находим в extensions 200 номер и переименовываем в Стратиенко или просто 200, сохраняем, применяем конфиг.
После этого должна ошибка уйти, если не помогло, попробуйте удалить номер и заново его создать с уже коротким именем.
Решение этой же задачи от Alex K
В диалплане «Имя» обрезается тут:
[macro-user-callerid]
exten => s,n,Set(CALLERID(name)=$)
Не получилось исправить? Мы готовы помочь! Заполните заявку на этой странице.
Источник
Как решить проблему с кодировкой UTF-8?
Пишу в PyCharm и вроде как там с кодировкой проблем не должно возникать, однако удача меня обошла стороной.
При запуске локального сервера возникает следующая ошибка:
Unhandled exception in thread started by .wrapper at 0x035B1B28>
Traceback (most recent call last):
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libsite-packagesdjangoutilsautoreload.py», line 227, in wrapper
fn(*args, **kwargs)
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libsite-packagesdjangocoremanagementcommandsrunserver.py», line 149, in inner_run
ipv6=self.use_ipv6, threading=threading, server_cls=self.server_cls)
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libsite-packagesdjangocoreserversbasehttp.py», line 164, in run
httpd = httpd_cls(server_address, WSGIRequestHandler, ipv6=ipv6)
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libsite-packagesdjangocoreserversbasehttp.py», line 74, in __init__
super(WSGIServer, self).__init__(*args, **kwargs)
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libsocketserver.py», line 453, in __init__
self.server_bind()
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libwsgirefsimple_server.py», line 50, in server_bind
HTTPServer.server_bind(self)
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libhttpserver.py», line 138, in server_bind
self.server_name = socket.getfqdn(host)
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libsocket.py», line 673, in getfqdn
hostname, aliases, ipaddrs = gethostbyaddr(name)
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xcf in position 5: invalid continuation byte
Заморочился и пересохранил все файлы в UTF-8 — не помогло. Пересмотрел кодировку каждого файла в самом PyCharm’e — везде UTF-8. Нашел на некоторых форумах такую же проблему — в качестве решения предлагалось переименовать имя компьютера в ASCII кодировку (на латинице короче говоря). Весь путь на латинице — ноль изменений. В каждом файле писал комментарий с кодировкой:
# coding: utf8
и вот так, что одно и то же
# -*- coding: utf-8 -*- .
Результата как не было, так и нет. Весь день копаюсь, так до сих пор и без понятия в чем дело.
Использую фреймворк Django (может что на нем завязано).
Надеюсь на вашу помощь. Заранее спасибо!
Источник
Как исправить ошибку кодировки старой БД?
1300 : Invalid utf8 character string: ‘Иван Иванович Иванов’
MySQL очень старый 5.1.41, php тоже старый 5.2.17
Кодировка сервера windows-1251, БД utf8-general-ci.
- Вопрос задан более трёх лет назад
- 845 просмотров
Простой 2 комментария
1054 : Unknown column ‘Суслов РРіРѕСЂСЊ Дмитриевич’ in ‘field list’
БД теперь в cp1251_general_ci
1) я поменял mysql_escape_string на mysql_real_escape_string, т.к. mysql_real_escape_string экранирует строку с учетом текущей кодировки. почитайте в документации про нее, чтобы я не копипастил).
2) Апостроф ` поменял на одинарную ковычку, апострофом я обычно экранирую поля, таблицы, а не строки, хотя не проверял экранированные строки с апострофом.
3) Конечно надо избавляться от mysql и заменить на такие же функции mysqli, хотя где то может поломаться.
4) Странная запись $fio = mysql_escape_string($fio);
это скорее register glogals включен, было бы правильнее, универсальный подход $fio = mysql_escape_string($_REQUEST[‘fio’]);
но может данные пришли из $_GET или $_POST
5) И как вариант данные пришли в кодировке cp1251, поэтому ошибка 1300 : Invalid utf8 character string
$fio = mysql_real_escape_string( iconv(‘windows-1251’, ‘utf-8’, $fio));
Источник
Recommend Projects
-

React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.