Challenge
During a VMware SureBackup job processing, a VM may fail to boot with the following error: An error occurred while taking a snapshot: Invalid Change Tracker Error Code.
In Task & Events of the vSphere Client, you can see the following error message: An error occurred while taking a snapshot: Invalid Change Tracker Error Code; Nested Hardware-Assisted Virtualization should be enabled when enabling VBS (Virtualization-Based Security).
To make sure the issue exists, check the job and/or task log files:
- Navigate to the following location on the Veeam Backup Server: %programdata%VeeamBackup.
- Open the folder that matches the name of the job with an issue.
- Within this folder, check the following log files:
- If the VM was started from a linked job, find the task log for the specific VM — %programdata%VeeamBackup<BackupJobName>Task.<VMName>.<GUID>.log.
- If the VM was started from the application group, find the job log file — %programdata%VeeamBackup<BackupJobName>Job.<SureBackupJobName>.log.
- Search for the following line with error: Error Nested Hardware-Assisted Virtualization should be enabled when enabling VBS (Virtualization-Based Security).
Cause
Nested Hardware-Assisted Virtualization was not enabled together with VBS (Virtualization-Based Security).
Solution
Add a registry key with the following values on the Veeam Backup Server:
Key: HKEY_LOCAL_MACHINESOFTWAREVeeamVeeam Backup and ReplicationSureBackup
Type: DWORD
Name: UseVhvEnable
Value: 0
More Information
To submit feedback regarding this article, please click this link: Send Article Feedback
To report a typo on this page, highlight the typo with your mouse and press CTRL + Enter.
Содержание
- Troubleshooting replication issues in agentless VMware VM migration
- Monitor replication status using the Azure portal
- Common Replication Errors
- Key Vault operation failed error when trying to replicate VMs
- DisposeArtefactsTimedOut
- DiskUploadTimedOut
- Encountered an error while trying to fetch changed blocks
- An internal error occurred
- Error Message: An internal error occurred. [Server Refused Connection]
- Error Message: An internal error occurred. [‘An Invalid snapshot configuration was detected.’]
- Error Message: An internal error occurred. [Generate Snapshot Hung]
- Error Message: An internal error occurred. [Failed to consolidate the disks on VM [Reasons]]
- Error Message: An internal error occurred. [Another task is already in progress]
- Error Message: An internal error occurred. [Operation not allowed in current state]
- Error Message: An internal error occurred. [Snapshot Disk size invalid]
- Error Message: An internal error occurred. [Memory allocation failed. Out of memory.]
- Error Message: An internal error occurred. [File is larger than maximum file size supported (1012384)]
- Error Message: An internal error occurred. [Cannot connect to the host (1004109)]
- Error message: An error occurred while saving the snapshot: Invalid change tracker error code
- Error message: An error occurred while taking a snapshot: Unable to open the snapshot file.
- Replication cycle failed
- Host Connection Refused
- Next Steps
Troubleshooting replication issues in agentless VMware VM migration
This article describes some common issues and specific errors that you might encounter when you replicate on-premises VMware VMs using the Migration and modernization agentless method.
When you replicate a VMware virtual machine using the agentless replication method, data from the virtual machine’s disks (vmdks) are replicated to replica managed disks in your Azure subscription. When replication starts for a VM, an initial replication cycle occurs, in which full copies of the disks are replicated. After the initial replication completes, incremental replication cycles are scheduled periodically to transfer any changes that have occurred since the previous replication cycle.
You may occasionally see replication cycles failing for a VM. These failures can happen due to reasons ranging from issues in on-premises network configuration to issues at the Azure Migrate Cloud Service backend. In this article, we will:
- Show you how you can monitor replication status and resolve errors.
- List some of the commonly occurring replication errors and suggest steps to remediate them.
Monitor replication status using the Azure portal
Use the following steps to monitor the replication status for your virtual machines:
- Go to the Servers, databases and web apps page in Azure Migrate on the Azure portal.

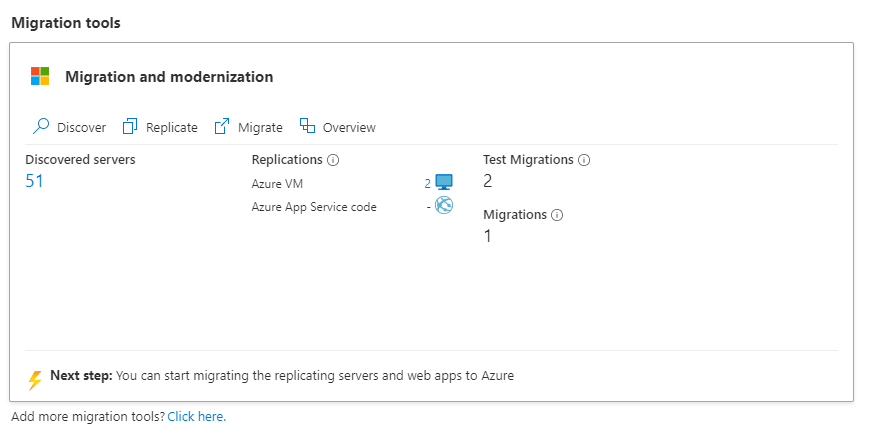
- In the Migration and modernization tile, under Replications, select the number next to Azure VM .
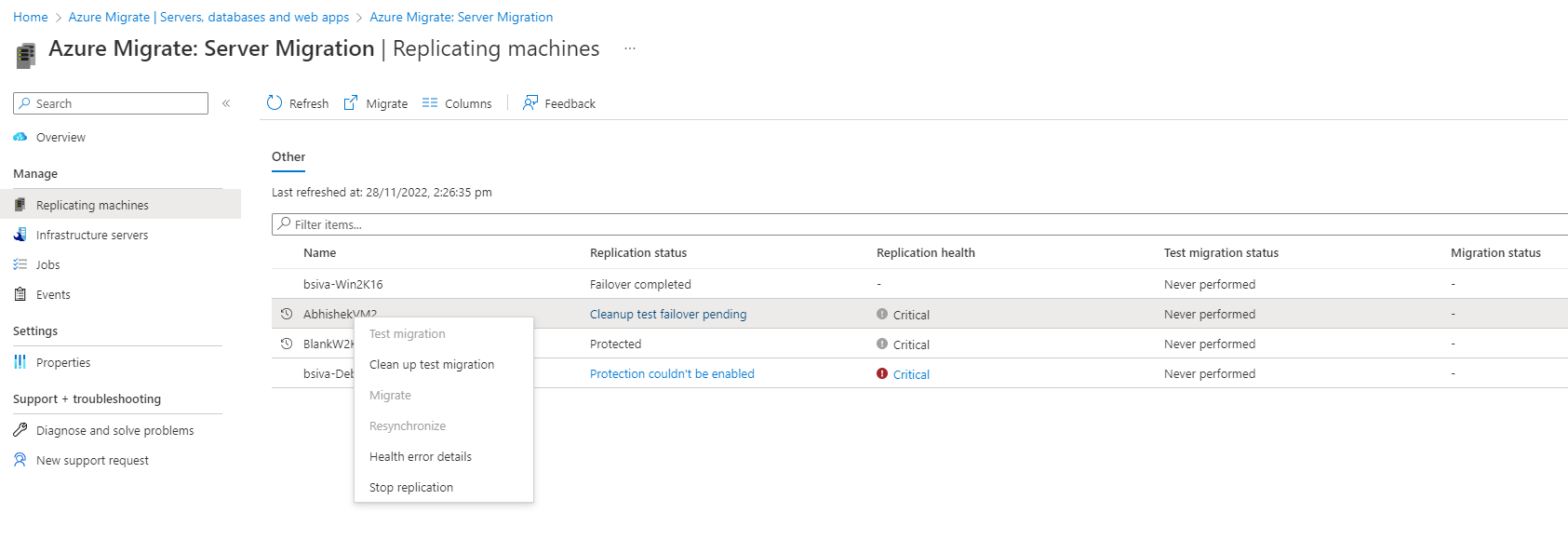
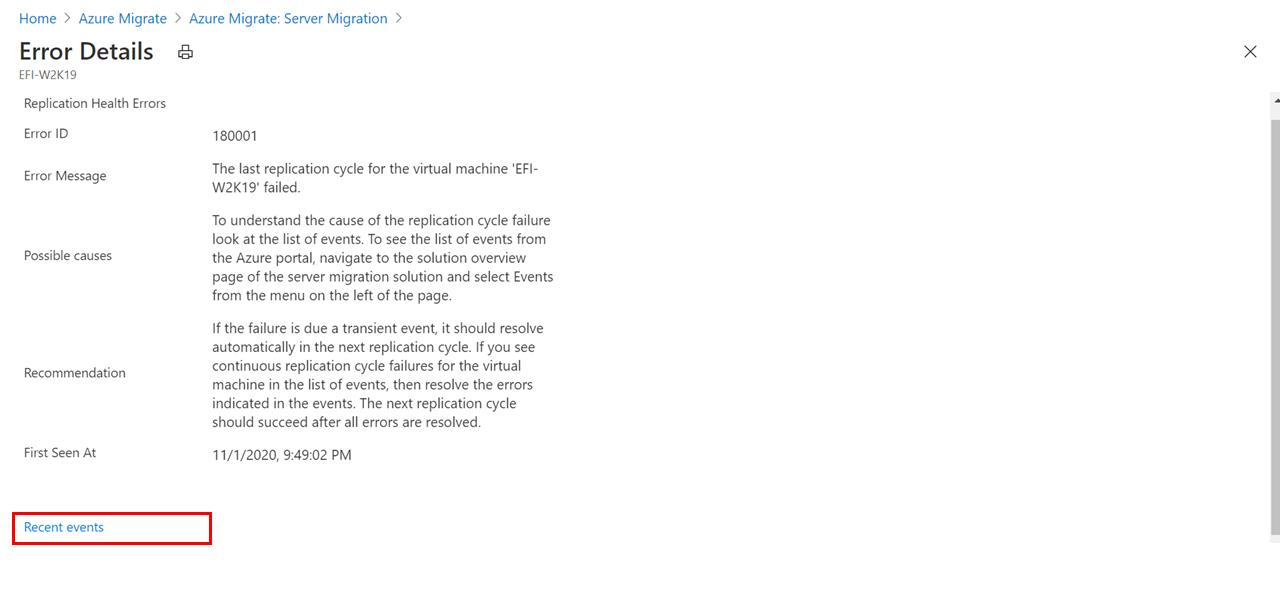
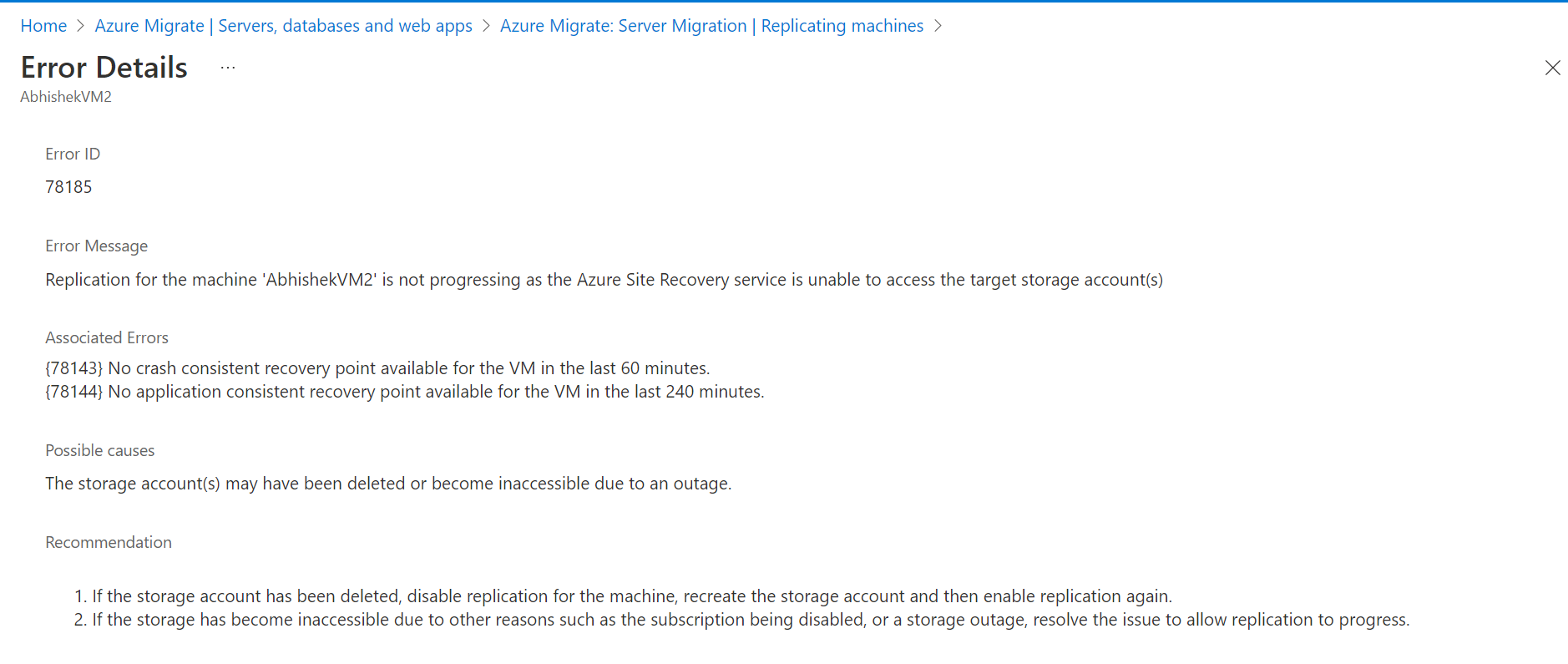
- You’ll see a list of replicating servers along with additional information such as status, health, last sync time, etc. The Replication health column indicates the current replication health of the VM. A Critical or Warning value typically indicates that the previous replication cycle for the VM failed. To get more details, right-click on the VM, and select Health error Details. The Error Details page contains information on the error and additional details on how to troubleshoot.
- Select Recent Events to see the previous replication cycle failures for the VM. In the events page, look for the most recent event of type Replication cycle failed or Replication cycle failed for disk» for the VM.
- Select the event to understand the possible causes of the error and recommended remediation steps. Use the information provided to troubleshoot and remediate the error.
Common Replication Errors
This section describes some of the common errors, and how you can troubleshoot them.
Key Vault operation failed error when trying to replicate VMs
Error: “Key Vault operation failed. Operation: Configure managed storage account, Key Vault: Key-vault-name, Storage Account: storage account name failed with the error:”
Error: “Key Vault operation failed. Operation: Generate shared access signature definition, Key Vault: Key-vault-name, Storage Account: storage account name failed with the error:”

This error typically occurs because the User Access Policy for the Key Vault doesn’t give the currently logged in user the necessary permissions to configure storage accounts to be Key Vault managed. To check for user access policy on the key vault, go to the Key vault page on the portal for the Key vault and select Access policies.
When the portal creates the key vault, it also adds a user access policy granting the currently logged in user permissions to configure storage accounts to be Key Vault managed. This can fail for two reasons:
The logged in user is a remote principal on the customer’s Azure tenant (CSP subscription — and the logged in user is the partner admin). The work-around in this case is to delete the key vault, sign out from the portal, and then sign in with a user account from the customer’s tenant (not a remote principal) and retry the operation. The CSP partner will typically have a user account in the customers Azure Active Directory tenant that they can use. If not, they can create a new user account for themselves in the customers Azure Active Directory tenant, sign in to the portal as the new user, and then retry the replicate operation. The account used must have either Owner or Contributor+User Access Administrator permissions granted to the account on the resource group (Migrate project resource group).
The other case where this may happen is when one user (user1) attempted to set up replication initially and encountered a failure, but the key vault has already been created (and user access policy appropriately assigned to this user). Now at a later point a different user (user2) tries to set up replication, but the Configure Managed Storage Account or Generate SAS definition operation fails as there’s no user access policy corresponding to user2 in the key vault.
Resolution: To work around this issue, create a user access policy for user2 in the key vault granting user2 permission to configure managed storage account and generate SAS definitions. User2 can do this from Azure PowerShell using the below cmdlets:
DisposeArtefactsTimedOut
Error ID: 181008
Error Message: VM: VMName. Error: Encountered timeout event ‘DisposeArtefactsTimeout’ in the state &'[‘Gateway.Service.StateMachine.SnapshotReplication.SnapshotReplicationEngine+WaitingForArtefactsDisposalPreCycle’ (‘WaitingForArtefactsDisposalPreCycle’)]’.
Possible Causes:
The component trying to replicate data to Azure is either down or not responding. The possible causes include:
- The gateway service running in the Azure Migrate appliance is down.
- The gateway service is experiencing connectivity issues to Service Bus/Event hubs/Appliance Storage account.
Identifying the exact cause for DisposeArtefactsTimedOut and the corresponding resolution:
Ensure that the Azure Migrate appliance is up and running.
Check if the gateway service is running on the appliance:
Sign in to the Azure Migrate appliance using remote desktop.
Open the Microsoft services MMC snap-in (run > services.msc), and check if the Microsoft Azure Gateway Service is running. If the service is stopped or not running, start the service. Alternatively, you can open command prompt or PowerShell and enter ‘Net Start asrgwy’.
Check for connectivity issues between Azure Migrate appliance and Appliance Storage Account:
Run the following command after downloading azcopy in the Azure Migrate appliance:
Steps to run the performance benchmark test:
Look for the appliance Storage Account in the Resource Group. The Storage Account has a name that resembles migrategwsa**********. This is the value of parameter [account] in the above command.
Search for your storage account in the Azure portal. Ensure that the subscription you use to search is the same subscription (target subscription) in which the storage account is created. Go to Containers in the Blob Service section. Select +Container and create a Container. Leave Public Access Level to the default selected value.
Go to Settings > Shared Access Signature. Select Container in Allowed Resource Type.Select Generate SAS and connection string. Copy the SAS value.
Execute the above command in Command Prompt by replacing account, container, SAS with the values obtained in steps 2, 3, and 4 respectively.
Alternatively, download the Azure Storage Explore on to the appliance and try to upload 10 blobs of
64 MB into the storage accounts. If there’s no issue, the upload should be successful.
Resolution: If this test fails, there’s a networking issue. Engage your local networking team to check connectivity issues. Typically, there can be some firewall settings that are causing the failures.
Check for connectivity issues between Azure Migrate appliance and Service Bus:
This test checks if the Azure Migrate appliance can communicate to the Azure Migrate Cloud Service backend. The appliance communicates to the service backend through Service Bus and Event Hubs message queues. To validate connectivity from the appliance to the Service Bus, download the Service Bus Explorer, try to connect to the appliance Service Bus and perform send message/receive message. If there’s no issue, this should be successful.
Steps to run the test:
- Copy the connection string from the Service Bus that got created in the Migrate Project.
- Open the Service Bus Explorer.
- Go to File then Connect.
- Paste the connection string and select Connect.
- This will open Service Bus Name Space.
- Select Snapshot Manager. Right-click on Snapshot Manager, select Receive Messages >peek, and select OK.
- If the connection is successful, you’ll see «[x] messages received» on the console output. If the connection isn’t successful, you’ll see a message stating that the connection failed.
Resolution: If this test fails, there’s a networking issue. Engage your local networking team to check connectivity issues. Typically, there can be some firewall settings that are causing the failures.
Connectivity issues between Azure Migrate appliance and Azure Key Vault:
This test checks for connectivity issues between the Azure Migrate appliance and the Azure Key Vault. The Key Vault is used to manage Storage Account access used for replication.
Steps to check connectivity:
Fetch the Key Vault URI from the list of resources in the Resource Group corresponding to Azure Migrate Project.
Open PowerShell in the Azure Migrate appliance and run the following command:
This command will attempt a TCP connection and will return an output.
- In the output, check the field «TcpTestSucceeded«. If the value is «True«, there’s no connectivity issue between the Azure Migrate Appliance and the Azure Key Vault. If the value is «False», there’s a connectivity issue.
Resolution: If this test fails, there’s a connectivity issue between the Azure Migrate appliance and the Azure Key Vault. Engage your local networking team to check connectivity issues. Typically, there can be some firewall settings that are causing the failures.
DiskUploadTimedOut
Error ID: 1011
Error Message: The upload of data for disk DiskPath, DiskId of virtual machine VMName; VMId didn’t complete within the expected time.
This error typically indicates either that the Azure Migrate appliance performing the replication is unable to connect to the Azure Cloud Services, or that replication is progressing slowly causing the replication cycle to time out.
The possible causes include:
- The Azure Migrate appliance is down.
- The replication gateway service on the appliance isn’t running.
- The replication gateway service is experiencing connectivity issues to one of the following Azure service components that are used for replication: Service Bus/Event Hubs/Azure cache Storage Account/Azure Key Vault.
- The gateway service is being throttled at the vCenter level while trying to read the disk.
Identifying the root cause and resolving the issue:
Ensure that the Azure Migrate appliance is up and running.
Check if the gateway service is running on the appliance:
Sign in to the Azure Migrate appliance using remote desktop and do the following.
Open the Microsoft services MMC snap-in (run > services.msc), and check if the «Microsoft Azure Gateway Service» is running. If the service is stopped or not running, start the service. Alternatively, you can open command prompt or PowerShell and enter ‘Net Start asrgwy’.
Check for connectivity issues between Azure Migrate appliance and cache Storage Account:
Run the following command after downloading azcopy in the Azure Migrate appliance:
Steps to run the performance benchmark test:
Look for the Appliance Storage Account in the Resource Group. The Storage Account has a name that resembles migratelsa**********. This is the value of parameter [account] in the above command.
Search for your storage account in the Azure portal. Ensure that the subscription you use to search is the same subscription (target subscription) in which the storage account is created. Go to Containers in the Blob Service section. Select +Container and create a Container. Leave Public Access Level to default selected value.
Go to Settings > Shared Access Signature. Select Container in Allowed Resource Type. Select Generate SAS and connection string. Copy the SAS value.
Execute the above command in Command Prompt by replacing account, container, SAS with the values obtained in steps 2, 3, and 4 respectively.
Alternatively, download the Azure Storage Explore on to the appliance and try to upload 10 blobs of
64 MB into the storage accounts. If there’s no issue, the upload should be successful.
Resolution: If this test fails, there’s a networking issue. Engage your local networking team to check connectivity issues. Typically, there can be some firewall settings that are causing the failures.
Connectivity issues between Azure Migrate appliance and Azure Service Bus:
This test will check whether the Azure Migrate appliance can communicate to the Azure Migrate Cloud Service backend. The appliance communicates to the service backend through Service Bus and Event Hubs message queues. To validate connectivity from the appliance to the Service Bus, download the Service Bus Explorer, try to connect to the appliance Service Bus and perform send message/receive message. If there’s no issue, this should be successful.
Steps to run the test:
Copy the connection string from the Service Bus that got created in the Resource Group corresponding to Azure Migrate Project.
Open Service Bus Explorer.
Go to File > Connect.
Paste the connection string you copied in step 1, and select Connect.
This will open Service Bus namespace.
Select Snapshot Manager in namespace. Right-click on Snapshot Manager, select Receive Messages > peek, and select OK.
If the connection is successful, you’ll see «[x] messages received» on the console output. If the connection isn’t successful, you’ll see a message stating that the connection failed.
Resolution: If this test fails, there’s a connectivity issue between the Azure Migrate appliance and Service Bus. Engage your local networking team to check these connectivity issues. Typically, there can be some firewall settings that are causing the failures.
Connectivity issues between Azure Migrate appliance and Azure Key Vault:
This test checks for connectivity issues between the Azure Migrate appliance and the Azure Key Vault. The Key Vault is used to manage Storage Account access used for replication.
Steps to check connectivity:
Fetch the Key Vault URI from the list of resources in the Resource Group corresponding to Azure Migrate Project.
Open PowerShell in the Azure Migrate appliance and run the following command:
This command will attempt a TCP connection and will return an output.
- In the output, check the field «TcpTestSucceeded«. If the value is «True«, there’s no connectivity issue between the Azure Migrate Appliance and the Azure Key Vault. If the value is «False», there’s a connectivity issue.
Resolution: If this test fails, there’s a connectivity issue between the Azure Migrate appliance and the Azure Key Vault. Engage your local networking team to check connectivity issues. Typically, there can be some firewall settings that are causing the failures.
Encountered an error while trying to fetch changed blocks
Error Message: ‘Encountered an error while trying to fetch change blocks’
The agentless replication method uses VMware’s changed block tracking technology (CBT) to replicate data to Azure. CBT lets the Migration and modernization tool track and replicate only the blocks that have changed since the last replication cycle. This error occurs if changed block tracking for a replicating virtual machine is reset or if the changed block tracking file is corrupt.
This error can be resolved in the following two ways:
- If you had opted for Automatically repair replication by selecting «Yes» when you triggered replication of VM, the tool will try to repair it for you. Right-click on the VM, and select Repair Replication.
- If you didn’t opt for Automatically repair replication or the above step didn’t work for you, then stop replication for the virtual machine, reset changed block tracking on the virtual machine, and then reconfigure replication.
One such known issue that may cause a CBT reset of virtual machine on VMware vSphere 5.5 is described in VMware KB 1020128: Changed Block Tracking is reset after a storage vMotion operation in vSphere 5.x. If you are on VMware vSphere 5.5, ensure that you apply the updates described in this KB.
Alternatively, you can reset VMware changed block tracking on a virtual machine using VMware PowerCLI.
An internal error occurred
Sometimes you may hit an error that occurs due to issues in the VMware environment/API. We’ve identified the following set of errors as VMware environment-related errors. These errors have a fixed format.
Error Message: An internal error occurred. [Error message]
For example: Error Message: An internal error occurred. [An Invalid snapshot configuration was detected].
The following section lists some of the commonly seen VMware errors and how you can mitigate them.
Error Message: An internal error occurred. [Server Refused Connection]
The issue is a known VMware issue and occurs in VDDK 6.7. You need to stop the gateway service running in the Azure Migrate appliance, download an update from VMware KB, and restart the gateway service.
Steps to stop gateway service:
- Press Windows + R and open services.msc. Select Microsoft Azure Gateway Service, and stop it.
- Alternatively, you can open command prompt or PowerShell and enter ‘Net Stop asrgwy’. Ensure you wait until you get the message that service is no longer running.
Steps to start gateway service:
- Press Windows + R, open services.msc. Right-click on Microsoft Azure Gateway Service, and start it.
- Alternatively, you can open command prompt or PowerShell and enter ‘Net Start asrgwy’.
Error Message: An internal error occurred. [‘An Invalid snapshot configuration was detected.’]
If you have a virtual machine with multiple disks, you may encounter this error if you remove a disk from the virtual machine. To remediate this problem, refer to the steps in this VMware article.
Error Message: An internal error occurred. [Generate Snapshot Hung]
This issue occurs when snapshot generation stops responding. When this issue occurs, you can see create snapshot task stops at 95% or 99%. Refer to this VMware KB to overcome this issue.
Error Message: An internal error occurred. [Failed to consolidate the disks on VM [Reasons]]
When we consolidate disks at the end of replication cycle, the operation fails. Follow the instructions in the VMware KB by selecting the appropriate Reason to resolve the issue.
The following errors occur when VMware snapshot-related operations – create, delete, or consolidate disks fail. Follow the guidance in the next section to remediate the errors:
Error Message: An internal error occurred. [Another task is already in progress]
This issue occurs when there are conflicting virtual machine tasks running in the background, or when a task within the vCenter Server times out. Follow the resolution provided in the following VMware KB.
Error Message: An internal error occurred. [Operation not allowed in current state]
This issue occurs when vCenter Server management agents stop working. To resolve this issue, refer to the resolution in the following VMware KB.
Error Message: An internal error occurred. [Snapshot Disk size invalid]
This is a known VMware issue in which the disk size indicated by snapshot becomes zero. Follow the resolution given in the VMware KB.
Error Message: An internal error occurred. [Memory allocation failed. Out of memory.]
This happens when the NFC host buffer is out of memory. To resolve this issue, you need to move the VM (compute vMotion) to a different host, which has free resources.
Error Message: An internal error occurred. [File is larger than maximum file size supported (1012384)]
This happens when the file size is larger than the maximum supported file size while creating the snapshot. Follow the resolution given in the VMware KB
Error Message: An internal error occurred. [Cannot connect to the host (1004109)]
This happens when ESXi hosts can’t connect to the network. Follow the resolution given in the VMware KB.
Error message: An error occurred while saving the snapshot: Invalid change tracker error code
This error occurs when there’s a problem with the underlying datastore on which the snapshot is being stored. Follow the resolution given in the VMware KB.
Error message: An error occurred while taking a snapshot: Unable to open the snapshot file.
This error occurs when the size of the snapshot file created is larger than the available free space in the datastore where the VM is located. Follow the resolution given in this document.
Replication cycle failed
Error ID: 181008
Error Message: VM: ‘VMName’. Error: No disksnapshots were found for the snapshot replication with snapshot ID: ‘SnapshotID’.
Possible Causes:
- One or more included disks is no longer attached to the VM.
Recommendation:
- Restore the included disks to the original path using storage vMotion and try replication again.
Host Connection Refused
Error ID: 1022
Error Message: The Azure Migrate appliance is unable to connect to the vSphere host ‘%HostName;’
Possible Causes:
This may happen if:
- The Azure Migrate appliance is unable to resolve the hostname of the vSphere host.
- The Azure Migrate appliance is unable to connect to the vSphere host on port 902 (default port used by VMware vSphere Virtual Disk Development Kit), because TCP port 902 is being blocked on the vSphere host or by a network firewall.
Recommendations:
Ensure that the hostname of the vSphere host is resolvable from the Azure Migrate appliance.
- Sign in to the Azure Migrate appliance and open PowerShell.
- Perform an nslookup on the hostname and verify if the address is being resolved: nslookup ‘%HostName;’ .
- If the host name isn’t getting resolved, ensure that the DNS resolution of the vSphere hostnames can be performed from the Azure Migrate appliance. Alternatively, add a static host entry for each vSphere host to the hosts file(C:WindowsSystem32driversetchosts) on the appliance.
Ensure the vSphere host is accepting connections on port 902 and that the endpoint is reachable from the appliance.
- Sign in to the Azure Migrate appliance and open PowerShell.
- Use the Test-NetConnection cmdlet to validate connectivity: Test-NetConnection ‘%HostName;’ -Port 902 .
- If the tcp test doesn’t succeed, the connection is being blocked by a firewall or isn’t being accepted by the vSphere host. Resolve the network issues to allow replication to proceed.
Next Steps
Continue VM replication, and perform test migration.
Источник
If you see my first reply, I’m getting error with disk lock, and from the process DISKLIB-CBT. Workaround to clear lock for me; migrate the VM to another host. I have not had any issues with locking since. May be issues with CBT/CTK, which also may be disabled on VM level (if only occuring on some VMs, etc.). May be other underlying issues with hosts, etc.
The error I’m referring to
2021-05-16T15:38:49.953Z| vmx| | W003: DISKLIB-CBT : ChangeTrackerESX_GetMirrorCopyProgress: Failed to copy mirror: Lost previously held disk lockSince this process fail, the following snapshot request process (SnapshotPrepareTakeDoneCB) will also fail, hence the error seen in vSphere Client (my guess)
2021-05-16T15:38:49.976Z| vmx| | I005: SNAPSHOT: SnapshotPrepareTakeDoneCB: Failed to prepare block track.
2021-05-16T15:38:49.976Z| vmx| | I005: SNAPSHOT: SnapshotPrepareTakeDoneCB: Prepare phase complete (Could not get mirror copy status).I wrote a short guest post, which includes the full vmware.log for a VM, while having snapshot issues, and trying to trigger a manual snapshot (regular snapshot, via vSphere Client), which includes some more details. The relevant part is of course the warning from DISKLIB-CBT, regarding the lock.
https://vninja.net/2021/05/18/error-occurred-while-saving-snapshot-msg.changetracker.mirrorcopystatu…
I would start with verifying if it’s the same error (see the same error in the vmware.log), then go from there. If Production w/SnS, just open a SR with VMware, OFC.
Afternoon,
Had a very peculiar error message when deploying SureBackup and the internet couldn’t give me any meaningful results! So I thought time to add to the collective world of knowledge with a blog post.
Scenario:
Onboarding customer for a managed backup solution, configuring SureBackup to ensure all backups are validated prior to sending to our cloud solution (Nexus Cloud Connect if you’re interested) and two VMs were failing with an “Invalid Change Tracker Error Code”. I connected to VMware and could see that this was the message being passed to Veeam from vCenter.
Browsing the log files uncovered that this was actually a symptom of an issue, but the root cause was something completely unrelated. If you review the Task log file (Commonly C:ProgramDataVeeamBackup<BackupJobName>Task.<VMName>.<GUID>.log) , search for the word “Error” in your favourite text editor, the first line I saw was “Nested Hardware-Assisted Virtualization should be enabled when enabling VBS (Virtualization-Based Security)”.
Further reading on VBS and how it works generally and with the vSphere environment is available here and here.
Thankfully there’s a quick fix for this, open Regedit, create a key of: HKEY_LOCAL_MACHINESOFTWAREVeeamVeeam Backup and ReplicationSureBackup if it doesn’t already exist and within there we will create a new DWORD, this is to be called “UseVhvEnable” and needs to be set to a value of 0.
Once this is done, reboot your Veeam server and try to rerun your SureBackup. You should find it now works!
| title | description | author | ms.author | ms.manager | ms.topic | ms.date | ms.custom |
|---|---|---|---|---|---|---|---|
|
Troubleshoot replication issues in agentless VMware VM migration |
Get help with replication cycle failures |
piyushdhore-microsoft |
piyushdhore |
vijain |
troubleshooting |
12/12/2022 |
engagement-fy23 |
Troubleshooting replication issues in agentless VMware VM migration
This article describes some common issues and specific errors that you might encounter when you replicate on-premises VMware VMs using the Migration and modernization agentless method.
When you replicate a VMware virtual machine using the agentless replication method, data from the virtual machine’s disks (vmdks) are replicated to replica managed disks in your Azure subscription. When replication starts for a VM, an initial replication cycle occurs, in which full copies of the disks are replicated. After the initial replication completes, incremental replication cycles are scheduled periodically to transfer any changes that have occurred since the previous replication cycle.
You may occasionally see replication cycles failing for a VM. These failures can happen due to reasons ranging from issues in on-premises network configuration to issues at the Azure Migrate Cloud Service backend. In this article, we will:
- Show you how you can monitor replication status and resolve errors.
- List some of the commonly occurring replication errors and suggest steps to remediate them.
Monitor replication status using the Azure portal
Use the following steps to monitor the replication status for your virtual machines:
- Go to the Servers, databases and web apps page in Azure Migrate on the Azure portal.
- In the Migration and modernization tile, under Replications, select the number next to Azure VM .
- You’ll see a list of replicating servers along with additional information such as status, health, last sync time, etc. The Replication health column indicates the current replication health of the VM. A Critical or Warning value typically indicates that the previous replication cycle for the VM failed. To get more details, right-click on the VM, and select Health error Details. The Error Details page contains information on the error and additional details on how to troubleshoot.
- Select Recent Events to see the previous replication cycle failures for the VM. In the events page, look for the most recent event of type Replication cycle failed or Replication cycle failed for disk» for the VM.
- Select the event to understand the possible causes of the error and recommended remediation steps. Use the information provided to troubleshoot and remediate the error.





Common Replication Errors
This section describes some of the common errors, and how you can troubleshoot them.
Key Vault operation failed error when trying to replicate VMs
Error: “Key Vault operation failed. Operation: Configure managed storage account, Key Vault: Key-vault-name, Storage Account: storage account name failed with the error:”
Error: “Key Vault operation failed. Operation: Generate shared access signature definition, Key Vault: Key-vault-name, Storage Account: storage account name failed with the error:”

This error typically occurs because the User Access Policy for the Key Vault doesn’t give the currently logged in user the necessary permissions to configure storage accounts to be Key Vault managed. To check for user access policy on the key vault, go to the Key vault page on the portal for the Key vault and select Access policies.
When the portal creates the key vault, it also adds a user access policy granting the currently logged in user permissions to configure storage accounts to be Key Vault managed. This can fail for two reasons:
-
The logged in user is a remote principal on the customer’s Azure tenant (CSP subscription — and the logged in user is the partner admin). The work-around in this case is to delete the key vault, sign out from the portal, and then sign in with a user account from the customer’s tenant (not a remote principal) and retry the operation. The CSP partner will typically have a user account in the customers Azure Active Directory tenant that they can use. If not, they can create a new user account for themselves in the customers Azure Active Directory tenant, sign in to the portal as the new user, and then retry the replicate operation. The account used must have either Owner or Contributor+User Access Administrator permissions granted to the account on the resource group (Migrate project resource group).
-
The other case where this may happen is when one user (user1) attempted to set up replication initially and encountered a failure, but the key vault has already been created (and user access policy appropriately assigned to this user). Now at a later point a different user (user2) tries to set up replication, but the Configure Managed Storage Account or Generate SAS definition operation fails as there’s no user access policy corresponding to user2 in the key vault.
Resolution: To work around this issue, create a user access policy for user2 in the key vault granting user2 permission to configure managed storage account and generate SAS definitions. User2 can do this from Azure PowerShell using the below cmdlets:
$userPrincipalId = $(Get-AzureRmADUser -UserPrincipalName "user2_email_address").Id
Set-AzureRmKeyVaultAccessPolicy -VaultName "keyvaultname" -ObjectId $userPrincipalId -PermissionsToStorage get, list, delete, set, update, regeneratekey, getsas, listsas, deletesas, setsas, recover, back up, restore, purge
DisposeArtefactsTimedOut
Error ID: 181008
Error Message: VM: VMName. Error: Encountered timeout event ‘DisposeArtefactsTimeout’ in the state &'[‘Gateway.Service.StateMachine.SnapshotReplication.SnapshotReplicationEngine+WaitingForArtefactsDisposalPreCycle’ (‘WaitingForArtefactsDisposalPreCycle’)]’.
Possible Causes:
The component trying to replicate data to Azure is either down or not responding. The possible causes include:
- The gateway service running in the Azure Migrate appliance is down.
- The gateway service is experiencing connectivity issues to Service Bus/Event hubs/Appliance Storage account.
Identifying the exact cause for DisposeArtefactsTimedOut and the corresponding resolution:
-
Ensure that the Azure Migrate appliance is up and running.
-
Check if the gateway service is running on the appliance:
-
Sign in to the Azure Migrate appliance using remote desktop.
-
Open the Microsoft services MMC snap-in (run > services.msc), and check if the Microsoft Azure Gateway Service is running. If the service is stopped or not running, start the service. Alternatively, you can open command prompt or PowerShell and enter ‘Net Start asrgwy’.
-
-
Check for connectivity issues between Azure Migrate appliance and Appliance Storage Account:
Run the following command after downloading azcopy in the Azure Migrate appliance:
_azcopy bench https://[account].blob.core.windows.net/[container]?SAS_Steps to run the performance benchmark test:
-
Download azcopy.
-
Look for the appliance Storage Account in the Resource Group. The Storage Account has a name that resembles migrategwsa**********. This is the value of parameter [account] in the above command.
-
Search for your storage account in the Azure portal. Ensure that the subscription you use to search is the same subscription (target subscription) in which the storage account is created. Go to Containers in the Blob Service section. Select +Container and create a Container. Leave Public Access Level to the default selected value.
-
Go to Settings > Shared Access Signature. Select Container in Allowed Resource Type.Select Generate SAS and connection string. Copy the SAS value.
-
Execute the above command in Command Prompt by replacing account, container, SAS with the values obtained in steps 2, 3, and 4 respectively.
Alternatively, download the Azure Storage Explore on to the appliance and try to upload 10 blobs of ~64 MB into the storage accounts. If there’s no issue, the upload should be successful.
Resolution: If this test fails, there’s a networking issue. Engage your local networking team to check connectivity issues. Typically, there can be some firewall settings that are causing the failures.
-
-
Check for connectivity issues between Azure Migrate appliance and Service Bus:
This test checks if the Azure Migrate appliance can communicate to the Azure Migrate Cloud Service backend. The appliance communicates to the service backend through Service Bus and Event Hubs message queues. To validate connectivity from the appliance to the Service Bus, download the Service Bus Explorer, try to connect to the appliance Service Bus and perform send message/receive message. If there’s no issue, this should be successful.
Steps to run the test:
- Copy the connection string from the Service Bus that got created in the Migrate Project.
- Open the Service Bus Explorer.
- Go to File then Connect.
- Paste the connection string and select Connect.
- This will open Service Bus Name Space.
- Select Snapshot Manager. Right-click on Snapshot Manager, select Receive Messages > peek, and select OK.
- If the connection is successful, you’ll see «[x] messages received» on the console output. If the connection isn’t successful, you’ll see a message stating that the connection failed.
Resolution: If this test fails, there’s a networking issue. Engage your local networking team to check connectivity issues. Typically, there can be some firewall settings that are causing the failures.
-
Connectivity issues between Azure Migrate appliance and Azure Key Vault:
This test checks for connectivity issues between the Azure Migrate appliance and the Azure Key Vault. The Key Vault is used to manage Storage Account access used for replication.
Steps to check connectivity:
-
Fetch the Key Vault URI from the list of resources in the Resource Group corresponding to Azure Migrate Project.
-
Open PowerShell in the Azure Migrate appliance and run the following command:
_test-netconnection Key Vault URI -P 443_This command will attempt a TCP connection and will return an output.
- In the output, check the field «TcpTestSucceeded«. If the value is «True«, there’s no connectivity issue between the Azure Migrate Appliance and the Azure Key Vault. If the value is «False», there’s a connectivity issue.
Resolution: If this test fails, there’s a connectivity issue between the Azure Migrate appliance and the Azure Key Vault. Engage your local networking team to check connectivity issues. Typically, there can be some firewall settings that are causing the failures.
-
DiskUploadTimedOut
Error ID: 1011
Error Message: The upload of data for disk DiskPath, DiskId of virtual machine VMName; VMId didn’t complete within the expected time.
This error typically indicates either that the Azure Migrate appliance performing the replication is unable to connect to the Azure Cloud Services, or that replication is progressing slowly causing the replication cycle to time out.
The possible causes include:
- The Azure Migrate appliance is down.
- The replication gateway service on the appliance isn’t running.
- The replication gateway service is experiencing connectivity issues to one of the following Azure service components that are used for replication: Service Bus/Event Hubs/Azure cache Storage Account/Azure Key Vault.
- The gateway service is being throttled at the vCenter level while trying to read the disk.
Identifying the root cause and resolving the issue:
-
Ensure that the Azure Migrate appliance is up and running.
-
Check if the gateway service is running on the appliance:
-
Sign in to the Azure Migrate appliance using remote desktop and do the following.
-
Open the Microsoft services MMC snap-in (run > services.msc), and check if the «Microsoft Azure Gateway Service» is running. If the service is stopped or not running, start the service. Alternatively, you can open command prompt or PowerShell and enter ‘Net Start asrgwy’.
-
-
Check for connectivity issues between Azure Migrate appliance and cache Storage Account:
Run the following command after downloading azcopy in the Azure Migrate appliance:
_azcopy bench https://[account].blob.core.windows.net/[container]?SAS_Steps to run the performance benchmark test:
-
Download azcopy
-
Look for the Appliance Storage Account in the Resource Group. The Storage Account has a name that resembles migratelsa**********. This is the value of parameter [account] in the above command.
-
Search for your storage account in the Azure portal. Ensure that the subscription you use to search is the same subscription (target subscription) in which the storage account is created. Go to Containers in the Blob Service section. Select +Container and create a Container. Leave Public Access Level to default selected value.
-
Go to Settings > Shared Access Signature. Select Container in Allowed Resource Type. Select Generate SAS and connection string. Copy the SAS value.
-
Execute the above command in Command Prompt by replacing account, container, SAS with the values obtained in steps 2, 3, and 4 respectively.
Alternatively, download the Azure Storage Explore on to the appliance and try to upload 10 blobs of ~64 MB into the storage accounts. If there’s no issue, the upload should be successful.
Resolution: If this test fails, there’s a networking issue. Engage your local networking team to check connectivity issues. Typically, there can be some firewall settings that are causing the failures.
-
-
Connectivity issues between Azure Migrate appliance and Azure Service Bus:
This test will check whether the Azure Migrate appliance can communicate to the Azure Migrate Cloud Service backend. The appliance communicates to the service backend through Service Bus and Event Hubs message queues. To validate connectivity from the appliance to the Service Bus, download the Service Bus Explorer, try to connect to the appliance Service Bus and perform send message/receive message. If there’s no issue, this should be successful.
Steps to run the test:
-
Copy the connection string from the Service Bus that got created in the Resource Group corresponding to Azure Migrate Project.
-
Open Service Bus Explorer.
-
Go to File > Connect.
-
Paste the connection string you copied in step 1, and select Connect.
-
This will open Service Bus namespace.
-
Select Snapshot Manager in namespace. Right-click on Snapshot Manager, select Receive Messages > peek, and select OK.
If the connection is successful, you’ll see «[x] messages received» on the console output. If the connection isn’t successful, you’ll see a message stating that the connection failed.
Resolution: If this test fails, there’s a connectivity issue between the Azure Migrate appliance and Service Bus. Engage your local networking team to check these connectivity issues. Typically, there can be some firewall settings that are causing the failures.
-
-
Connectivity issues between Azure Migrate appliance and Azure Key Vault:
This test checks for connectivity issues between the Azure Migrate appliance and the Azure Key Vault. The Key Vault is used to manage Storage Account access used for replication.
Steps to check connectivity:
-
Fetch the Key Vault URI from the list of resources in the Resource Group corresponding to Azure Migrate Project.
-
Open PowerShell in the Azure Migrate appliance and run the following command:
_test-netconnection Key Vault URI -P 443_This command will attempt a TCP connection and will return an output.
- In the output, check the field «TcpTestSucceeded«. If the value is «True«, there’s no connectivity issue between the Azure Migrate Appliance and the Azure Key Vault. If the value is «False», there’s a connectivity issue.
Resolution: If this test fails, there’s a connectivity issue between the Azure Migrate appliance and the Azure Key Vault. Engage your local networking team to check connectivity issues. Typically, there can be some firewall settings that are causing the failures.
-
Encountered an error while trying to fetch changed blocks
Error Message: ‘Encountered an error while trying to fetch change blocks’
The agentless replication method uses VMware’s changed block tracking technology (CBT) to replicate data to Azure. CBT lets the Migration and modernization tool track and replicate only the blocks that have changed since the last replication cycle. This error occurs if changed block tracking for a replicating virtual machine is reset or if the changed block tracking file is corrupt.
This error can be resolved in the following two ways:
- If you had opted for Automatically repair replication by selecting «Yes» when you triggered replication of VM, the tool will try to repair it for you. Right-click on the VM, and select Repair Replication.
- If you didn’t opt for Automatically repair replication or the above step didn’t work for you, then stop replication for the virtual machine, reset changed block tracking on the virtual machine, and then reconfigure replication.
One such known issue that may cause a CBT reset of virtual machine on VMware vSphere 5.5 is described in VMware KB 1020128: Changed Block Tracking is reset after a storage vMotion operation in vSphere 5.x. If you are on VMware vSphere 5.5, ensure that you apply the updates described in this KB.
Alternatively, you can reset VMware changed block tracking on a virtual machine using VMware PowerCLI.
An internal error occurred
Sometimes you may hit an error that occurs due to issues in the VMware environment/API. We’ve identified the following set of errors as VMware environment-related errors. These errors have a fixed format.
Error Message: An internal error occurred. [Error message]
For example: Error Message: An internal error occurred. [An Invalid snapshot configuration was detected].
The following section lists some of the commonly seen VMware errors and how you can mitigate them.
Error Message: An internal error occurred. [Server Refused Connection]
The issue is a known VMware issue and occurs in VDDK 6.7. You need to stop the gateway service running in the Azure Migrate appliance, download an update from VMware KB, and restart the gateway service.
Steps to stop gateway service:
- Press Windows + R and open services.msc. Select Microsoft Azure Gateway Service, and stop it.
- Alternatively, you can open command prompt or PowerShell and enter ‘Net Stop asrgwy’. Ensure you wait until you get the message that service is no longer running.
Steps to start gateway service:
- Press Windows + R, open services.msc. Right-click on Microsoft Azure Gateway Service, and start it.
- Alternatively, you can open command prompt or PowerShell and enter ‘Net Start asrgwy’.
Error Message: An internal error occurred. [‘An Invalid snapshot configuration was detected.’]
If you have a virtual machine with multiple disks, you may encounter this error if you remove a disk from the virtual machine. To remediate this problem, refer to the steps in this VMware article.
Error Message: An internal error occurred. [Generate Snapshot Hung]
This issue occurs when snapshot generation stops responding. When this issue occurs, you can see create snapshot task stops at 95% or 99%. Refer to this VMware KB to overcome this issue.
Error Message: An internal error occurred. [Failed to consolidate the disks on VM [Reasons]]
When we consolidate disks at the end of replication cycle, the operation fails. Follow the instructions in the VMware KB by selecting the appropriate Reason to resolve the issue.
The following errors occur when VMware snapshot-related operations – create, delete, or consolidate disks fail. Follow the guidance in the next section to remediate the errors:
Error Message: An internal error occurred. [Another task is already in progress]
This issue occurs when there are conflicting virtual machine tasks running in the background, or when a task within the vCenter Server times out. Follow the resolution provided in the following VMware KB.
Error Message: An internal error occurred. [Operation not allowed in current state]
This issue occurs when vCenter Server management agents stop working. To resolve this issue, refer to the resolution in the following VMware KB.
Error Message: An internal error occurred. [Snapshot Disk size invalid]
This is a known VMware issue in which the disk size indicated by snapshot becomes zero. Follow the resolution given in the VMware KB.
Error Message: An internal error occurred. [Memory allocation failed. Out of memory.]
This happens when the NFC host buffer is out of memory. To resolve this issue, you need to move the VM (compute vMotion) to a different host, which has free resources.
Error Message: An internal error occurred. [File is larger than maximum file size supported (1012384)]
This happens when the file size is larger than the maximum supported file size while creating the snapshot. Follow the resolution given in the VMware KB
Error Message: An internal error occurred. [Cannot connect to the host (1004109)]
This happens when ESXi hosts can’t connect to the network. Follow the resolution given in the VMware KB.
Error message: An error occurred while saving the snapshot: Invalid change tracker error code
This error occurs when there’s a problem with the underlying datastore on which the snapshot is being stored. Follow the resolution given in the VMware KB.
Error message: An error occurred while taking a snapshot: Unable to open the snapshot file.
This error occurs when the size of the snapshot file created is larger than the available free space in the datastore where the VM is located. Follow the resolution given in this document.
Replication cycle failed
Error ID: 181008
Error Message: VM: ‘VMName’. Error: No disksnapshots were found for the snapshot replication with snapshot ID: ‘SnapshotID’.
Possible Causes:
- One or more included disks is no longer attached to the VM.
Recommendation:
- Restore the included disks to the original path using storage vMotion and try replication again.
Host Connection Refused
Error ID: 1022
Error Message: The Azure Migrate appliance is unable to connect to the vSphere host ‘%HostName;’
Possible Causes:
This may happen if:
- The Azure Migrate appliance is unable to resolve the hostname of the vSphere host.
- The Azure Migrate appliance is unable to connect to the vSphere host on port 902 (default port used by VMware vSphere Virtual Disk Development Kit), because TCP port 902 is being blocked on the vSphere host or by a network firewall.
Recommendations:
Ensure that the hostname of the vSphere host is resolvable from the Azure Migrate appliance.
- Sign in to the Azure Migrate appliance and open PowerShell.
- Perform an
nslookupon the hostname and verify if the address is being resolved:nslookup '%HostName;'. - If the host name isn’t getting resolved, ensure that the DNS resolution of the vSphere hostnames can be performed from the Azure Migrate appliance. Alternatively, add a static host entry for each vSphere host to the hosts file(C:WindowsSystem32driversetchosts) on the appliance.
Ensure the vSphere host is accepting connections on port 902 and that the endpoint is reachable from the appliance.
- Sign in to the Azure Migrate appliance and open PowerShell.
- Use the
Test-NetConnectioncmdlet to validate connectivity:Test-NetConnection '%HostName;' -Port 902. - If the tcp test doesn’t succeed, the connection is being blocked by a firewall or isn’t being accepted by the vSphere host. Resolve the network issues to allow replication to proceed.
Next Steps
Continue VM replication, and perform test migration.
Обновлено 15.03.2022

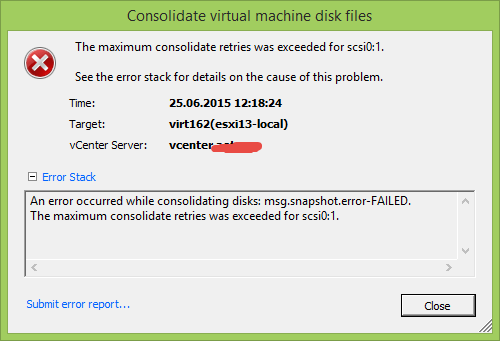
Всем привет сегодня расскажу как решается ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5. Когда вы делаете бэкапы с помощью veeam или делаете снапшоты, вы можете получить у виртуальной машины вот такой статус Ошибка virtual machine disks consolidation is needed в ESXI 5.x.x, она решалась просто, но есть случаи когда консолидация не проходит и выходит ошибка, рассматриваемая ниже.
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-00
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded выходит когда асинхронная консолидация заканчивается с ошибкой. Происходит это, когда виртуальная машина генерирует данные быстрее, чем скорость консолидации. Смотрим что делать.
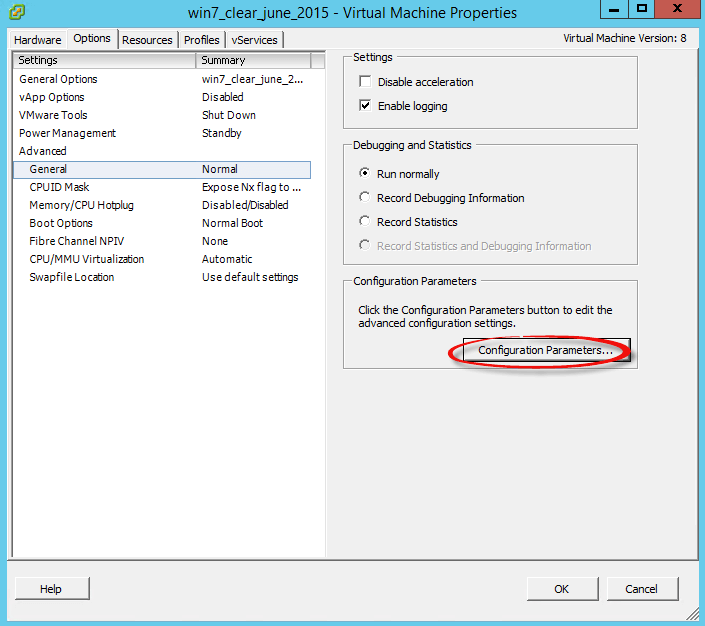
Выключаем виртуальную машину, щелкаем правой кнопкой мыши и выбираем Edit settings. Переходим на вкладку Options-General и нажимаем кнопку Configuration Parlameters
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-01
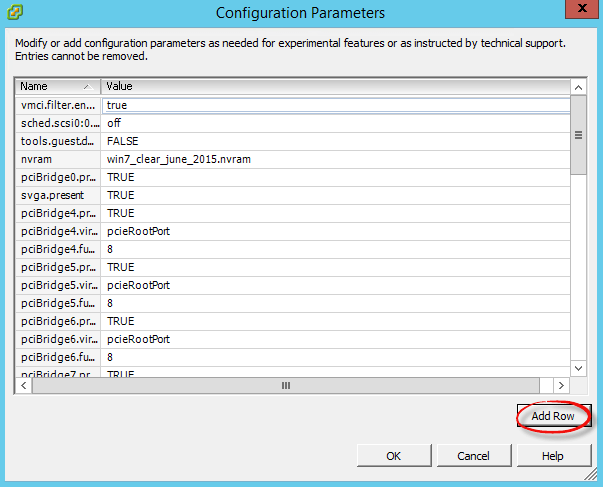
Далее нам нужно добавить новой поле, жмем Add row
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-02
И добавляем параметр snapshot.asyncConsolidate.forceSync и значение True
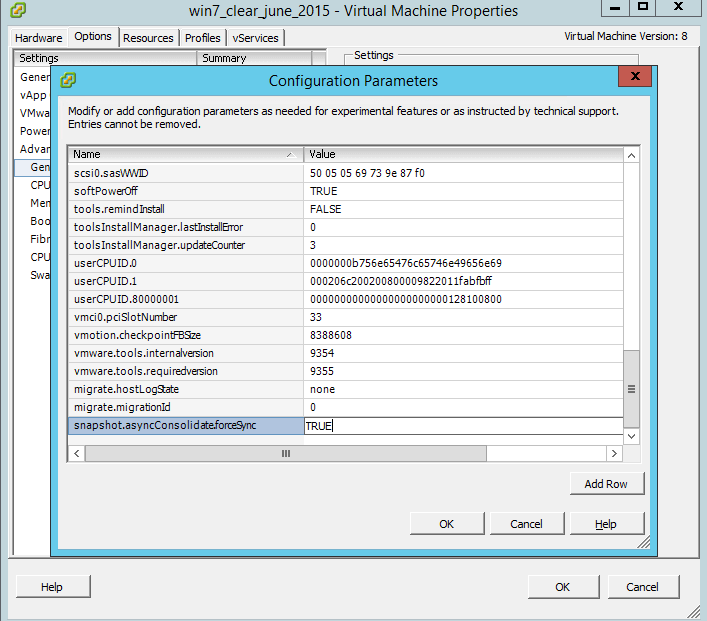
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-03
Для того чтобы увеличить временной лимит на консолидацию снапшота. Создадим новое поле
snapshot.maxConsolidateTime со значением 30
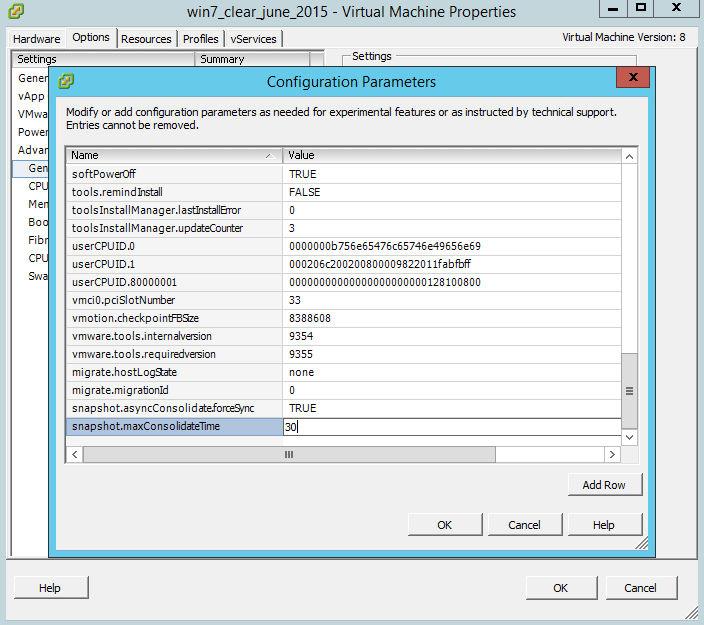
Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-04
Для того чтобы не выключать виртуальную машину и решить данную проблему, нужно воспользоваться PowerCLI и ввести такую команду
get-vm virtual_machine_name | New-AdvancedSetting -Name snapshot.asyncConsolidate.forceSync -Value TRUE -Confirm:$False

Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5-06
Где virtual_machine_name имя нужной виртуальной машины.
Вот так вот просто решается Ошибка An error occurred while consolidating disks msg.snapshot.error-failed. the maximum consolidate retries was exceeded в ESXI 5.5.
Материал сайта pyatilistnik.org
Guest Post #
Info

This is a guest post by Espen Ødegaard, Senior Systems Consultant for Proact. #
You can find him on Twitter and LinkedIn. Espen is usually found in vmkernel.log, esxtop, sexigraf or vSAN Observer. Or eating, he eats a lot.
I recently ran into a strange issue in my home lab, running ESXi 7.0.2, build 17867351 where Veeam Backup & Replication v10 reported the following error:
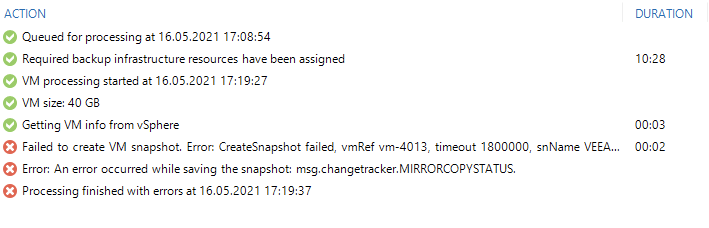
Veeam Backup & Replication Log entries #
16.05.2021 17:34:50 :: Failed to create VM snapshot. Error: CreateSnapshot failed, vmRef vm-4013, timeout 1800000, snName VEEAM BACKUP TEMPORARY SNAPSHOT, snDescription Please do not delete this snapshot. It is being used by Veeam Backup., memory False, quiesce False
The same error could also be seen in vCenter:
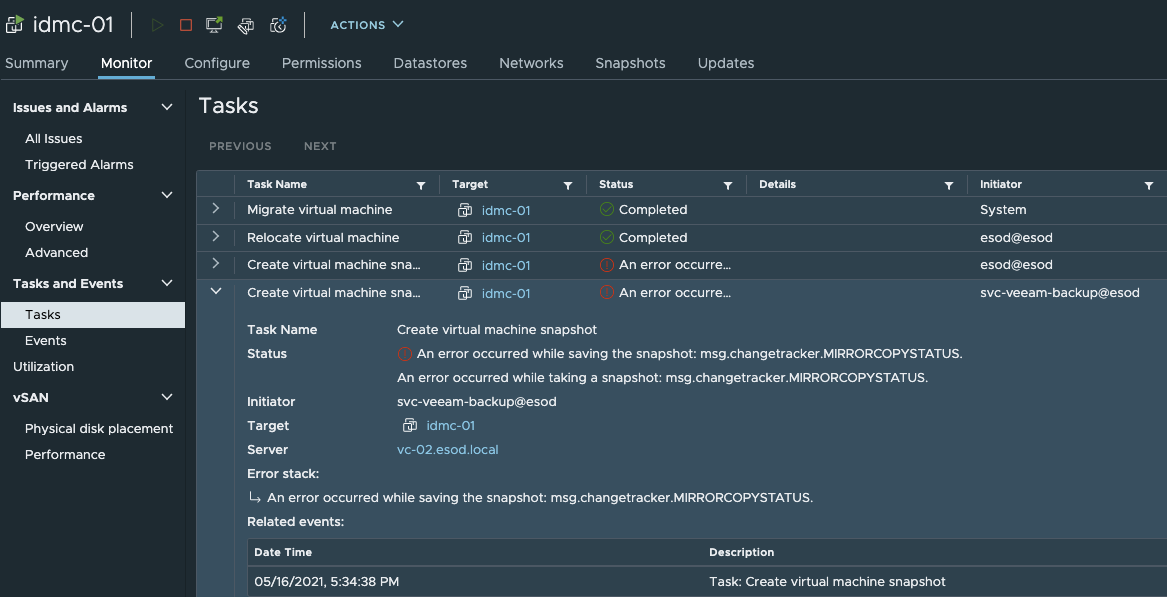
vCenter Log entries #
16.05.2021 17:34:56 :: Error: An error occurred while saving the snapshot: msg.changetracker.MIRRORCOPYSTATUS.
Findings #
The same issue arrises when manually creating a snapshot in vCenter, so it does not seem to be Veeam Backup & Replication specific.
A quick look into vmware.log for the affected VM:
Full vmware.log for the affected VM #
2021-05-16T15:38:49.395Z| vmx| | I005: VigorTransportProcessClientPayload: opID=knxctxhk-242836-auto-57dh-h5:70044488-3a-9f-6432 seq=54938: Receiving Snapshot.Take request.
2021-05-16T15:38:49.397Z| vmx| | I005: SnapshotVMX_TakeSnapshot start: 'VM Snapshot 16%2f05%2f2021, 17:38:44', deviceState=0, lazy=0, quiesced=1, forceNative=0, tryNative=1, saveAllocMaps=0
2021-05-16T15:38:49.665Z| vmx| | I005: DISKLIB-LIB_CREATE : DiskLibCreateCreateParam: vmfsSparse grain size is set to 1 for '/vmfs/volumes/vsan:52b2da12ab7803d1-77d0a7d9896eb6ac/80f04160-c378-5f8b-871e-a4ae111c7980/idmc-01-000001.vmdk'
2021-05-16T15:38:49.852Z| vmx| | I005: DISKLIB-CBT :ChangeTrackerESX_CreateMirror: Created mirror node /vmfs/devices/svm/6d1716-25d0ef6-cbtmirror.
2021-05-16T15:38:49.953Z| vmx| | W003: DISKLIB-CBT : ChangeTrackerESX_GetMirrorCopyProgress: Failed to copy mirror: Lost previously held disk lock
2021-05-16T15:38:49.953Z| vmx| | I005: DISKLIB-LIB_BLOCKTRACK : DiskLibBlockTrackMirrorProgress: Failed to get mirror status of block track info file /vmfs/volumes/vsan:52b2da12ab7803d1-77d0a7d9896eb6ac/80f04160-c378-5f8b-871e-a4ae111c7980/idmc-01-ctk.vmdk.
2021-05-16T15:38:49.953Z| vmx| | I005: DISKLIB-CBT :ChangeTrackerESX_DestroyMirror: Destroyed mirror node 6d1716-25d0ef6-cbtmirror.
2021-05-16T15:38:49.976Z| vmx| | I005: SNAPSHOT: SnapshotPrepareTakeDoneCB: Failed to prepare block track.
2021-05-16T15:38:49.976Z| vmx| | I005: SNAPSHOT: SnapshotPrepareTakeDoneCB: Prepare phase complete (Could not get mirror copy status).
2021-05-16T15:38:49.976Z| vmx| | I005: SnapshotVMXPrepareTakeDoneCB: Prepare phase failed: Could not get mirror copy status (5).
2021-05-16T15:38:49.976Z| vmx| | I005: SnapshotVMXTakeSnapshotComplete: Done with snapshot 'VM Snapshot 16%2f05%2f2021, 17:38:44': 0
2021-05-16T15:38:49.977Z| vmx| | I005: SnapshotVMXTakeSnapshotComplete: Snapshot 0 failed: Could not get mirror copy status (5).
2021-05-16T15:38:49.977Z| vmx| | I005: VigorTransport_ServerSendResponse opID=knxctxhk-242836-auto-57dh-h5:70044488-3a-9f-6432 seq=54938: Completed Snapshot request with messages.
And there I found the locking issue:
2021-05-16T15:38:49.953Z| vmx| | W003: DISKLIB-CBT : ChangeTrackerESX_GetMirrorCopyProgress: Failed to copy mirror: Lost previously held disk lock
Resolution/workaround #
Since the lock is held locally by the ESXi host, I just did a vMotion of the VM (to another host in my cluster), to clear the lock and re-issue it by another host. After completing a vMotion of the affected VM, it now completed successfully (and backup is now working again). My lab is running vSAN, so this does not seem related to VMware KB 2107795: Troubleshooting issues resulting from locked virtual disks.
The root cause of the issue is still unknown, but a vMotion cleared the lock and backups have now been running successfully for a few days since the original issue appeared. Hopefully it stays that way!
This is a post in the Guest Post series. Posts in this series:
- My Experience: VCP-DCV for vSphere 7.x 2V0-21.20 Exam —
4 Jan, 2023 - Leveling Up: My First VMUG Presentation —
22 Dec, 2022 - My First VMware Explore —
2 Dec, 2022 - Expired VMware vCenter certificates —
8 Aug, 2022 - Hot Add NVMe Device Caused PSOD on ESXi —
8 Sep, 2021 - Upgrading to ESXi 7.0 build 18426014 U2c. ESXi stuck in Not responding from vCenter —
24 Aug, 2021 - ESXi 7.0 SD Card/USB Drive Issue Temporary Workaround —
1 Jun, 2021 - Searching vCenter Tasks and Events via PowerShell and GridView —
19 May, 2021 - ESXi 7.0 U2a Potentially Killing USB and SD drives! —
18 May, 2021 - ESXi: Error Occurred While Saving Snapshot Msg.changetracker —
18 May, 2021 - The Curious Case of the Intel Microcode Part #2 — It Gets Better — Then Worse —
14 Jan, 2018 - The Curious Case of the Intel Microcode —
9 Jan, 2018 - Relax and virtualize it! —
15 Oct, 2015 - HP Proliant DL380p Gen8 «Decompressed MD5» error —
13 Aug, 2015
- Upgrading to ESXi 7.0 build 18426014 U2c. ESXi stuck in Not responding from vCenter —
24 Aug, 2021 - ESXi 7.0 SD Card/USB Drive Issue Temporary Workaround —
1 Jun, 2021 - Searching vCenter Tasks and Events via PowerShell and GridView —
19 May, 2021 - ESXi 7.0 U2a Potentially Killing USB and SD drives! —
18 May, 2021 - VMware vSAN 7.0 Update 2 Announced —
9 Mar, 2021
Post last updated on May 19, 2021: New guest post from Espen: Searching vCenter Tasks and Events via PowerShell
null
Иногда может возникнуть ситуация требующая удаления snapshot’ов вручную, из за различных ошибок не позволяющих выполнить удаление/консолидацию через графический/web интерфейс vmware.
Подобные проблемы могут возникнуть, например, в случае возникновения ошибок при процессе репликации средствами Veeam, как в нашем случае.
Для того, чтобы восстановить рабочее состояние виртуальной машины, необходимо:
-
зайти через CLI в каталог с виртуальной машиной и посмотреть на наличие файлов snapshot’ов и delta-дисков на файловой системе
/vmfs/volumes/9619731d-7db0f1c5-998f-00157812468ad/MYVIRTUALMACHINE_replica_1 # ls -l total 131951640 -rw------- 1 root root 34836 Dec 12 17:41 MYVIRTUALMACHINE-Snapshot18.vmsn -rw------- 1 root root 34836 Dec 13 17:42 MYVIRTUALMACHINE-Snapshot20.vmsn -rw------- 1 root root 8684 Dec 13 17:41 MYVIRTUALMACHINE.nvram -rw------- 1 root root 1101 Dec 13 17:59 MYVIRTUALMACHINE.vmsd -rwx------ 1 root root 6077 Dec 13 17:59 MYVIRTUALMACHINE.vmx -rw------- 1 root root 3500 Dec 13 17:41 MYVIRTUALMACHINE.vmxf -rw------- 1 root root 372736 Dec 13 17:42 MYVIRTUALMACHINE_1-000001-delta.vmdk -rw------- 1 root root 327 Dec 13 17:42 MYVIRTUALMACHINE_1-000001.vmdk -rw------- 1 root root 3070603264 Dec 13 17:41 MYVIRTUALMACHINE_1-000010-delta.vmdk -rw------- 1 root root 343 Dec 13 17:59 MYVIRTUALMACHINE_1-000010.vmdk -rw------- 1 root root 193273528320 Dec 13 17:59 MYVIRTUALMACHINE_1-flat.vmdk -rw------- 1 root root 521 Dec 13 17:59 MYVIRTUALMACHINE_1.vmdk
-
Посмотреть и, в случае необходимости, отредактировать файл с информацией о snapshot’ах виртуальной машины .vmsd
.encoding = "UTF-8" snapshot.lastUID = "20" snapshot.current = "20" snapshot0.uid = "18" snapshot0.filename = "MYVIRTUALMACHINE-Snapshot18.vmsn" snapshot0.displayName = "Restore Point 12.12.2016 20:05:19" snapshot0.description = "<RPData PointTime=|225247857609617387904|22 WorkingSnapshotTime=|2252 snapshot0.createTimeHigh = "344953" snapshot0.createTimeLow = "-1653115076" snapshot0.numDisks = "1" snapshot0.disk0.fileName = "MYVIRTUALMACHINE_1.vmdk" snapshot0.disk0.node = "scsi0:0" snapshot1.uid = "20" snapshot1.filename = "MYVIRTUALMACHINE-Snapshot20.vmsn" snapshot1.parent = "18" snapshot1.displayName = "Restore Point 13.12.2016 20:04:59" snapshot1.description = "<RPData PointTime=|225247858473417387904|22 WorkingSnapshotTime=|2252 snapshot1.createTimeHigh = "344973" snapshot1.createTimeLow = "-1122050657" snapshot1.numDisks = "1" snapshot1.disk0.fileName = "MYVIRTUALMACHINE_1-000010.vmdk" snapshot1.disk0.node = "scsi0:0" snapshot.numSnapshots = "2"
-
Проверить наличие объектов на файловой системе описанных в filename и корректность
занимаемых этими файлами размеров(может быть пустой/битый vmdk файл). — прим. безусловно в случае ошибок типа Consolidate failed for VM MYVIRTUALMACHINE with error: vim.fault.FileLocked или vim.vm.Snapshot.remove: vim.fault.FileNotFound
-
Если требуется руками удалить неактуальный снапшот, то нужно удалить строчки с данным снапшотом и последующими снапшотами (в примере если мы хотим убрать некорректный snapshot1 с uid 20 мы должны удалить все строчки начинающиеся с snapshot1, если были бы последующие, у которых в цепочке взаимосвязей,указанных в параметре parent значился бы данный снапшот,их так же следовало бы удалить).
-
[Если на пункте 4 потребовалось изменение файла .vmsd]
После изменить на UID последнего снапшота.
snapshot.lastUID = "20" snapshot.current = "20"
В нашем случае на snapshot0 с UID 18
snapshot.lastUID = "18" snapshot.current = "18"
-
[Если на пункте 4 потребовалось изменение файла .vmsd]
Изменить информаци о количестве снапшотов
snapshot.numSnapshots = "1"
-
[Если на пункте 4 потребовалось изменение файла .vmsd]
Если требуется удалить всю информацию о снапшотах, нужно очистить содержимое данного файла.
-
[Если на пункте 4 потребовалось изменение файла .vmsd]
Чтобы изменения были восприняты гипервизором/vsphere необходимо перерегистрировать виртуальную машину в Inventory [1][2]
Исспользуемый источник: Understanding virtual machine snapshots in VMware ESXi and ESX
P.S. Возможные ошибки
Ошибка quiesce
Error: An error occurred while saving the snapshot: Failed to quiesce the virtual machine. 2016-12-13T15:20:46.251+03:00 [02752 error 'vmsnapshot' opID=0D3F1714-00000060-b1] [VmMo::ConsolidateDisks] Consolidate failed for VM MYVIRTUALMACHINE with error: vim.fault.InvalidSnapshotFormat
Ошибки vim.fault.FileLocked
2016-12-13T16:59:00.941+03:00 [02736 error 'vmsnapshot' opID=0D3F1714-00000386-8b] [VmMo::ConsolidateDisks] Consolidate failed for VM MYVIRTUALMACHINE with error: vim.fault.FileLocked
2016-12-13T16:59:01.945+03:00 [02736 info 'Default' opID=0D3F1714-00000386-8b] [VpxLRO] -- ERROR task-74490 -- vm-13111 -- vim.VirtualMachine.consolidateDisks: vim.fault.FileLocked:
--> Result:
--> (vim.fault.FileLocked) {
--> dynamicType = <unset>,
--> faultCause = (vmodl.MethodFault) null,
--> faultMessage = (vmodl.LocalizableMessage) [
--> (vmodl.LocalizableMessage) {
--> dynamicType = <unset>,
--> key = "msg.snapshot.vigor.consolidate.error",
--> arg = (vmodl.KeyAnyValue) [
--> (vmodl.KeyAnyValue) {
--> dynamicType = <unset>,
--> key = "1",
--> value = "msg.snapshot.error-DUPLICATEDISK",
--> }
--> ],
--> message = "An error occurred while consolidating disks: One of the disks in this virtual machine is already in use by a virtual machine or by a snapshot.",
Ошибки NOTFOUND
2016-12-13T16:32:32.741+03:00 [05584 info 'Default' opID=0D3F1714-00000310-9c] [VpxLRO] -- ERROR task-74486 -- vm-13109 -- vim.vm.Snapshot.revert: vim.fault.InvalidSnapshotFormat:
--> Result:
--> (vim.fault.InvalidSnapshotFormat) {
--> dynamicType = <unset>,
--> faultCause = (vmodl.MethodFault) null,
--> faultMessage = (vmodl.LocalizableMessage) [
--> (vmodl.LocalizableMessage) {
--> dynamicType = <unset>,
--> key = "msg.snapshot.vigor.revert.error",
--> arg = (vmodl.KeyAnyValue) [
--> (vmodl.KeyAnyValue) {
--> dynamicType = <unset>,
--> key = "1",
--> value = "msg.snapshot.error-NOTFOUND",
--> }
--> ],
--> message = "An error occurred while reverting to a snapshot: A required file was not found.",
--> }
--> ],
--> msg = "Detected an invalid snapshot configuration."
--> }
2016-12-13T16:32:24.034+03:00 [02736 info 'Default' opID=0D3F1714-0000030B-ea] [VpxLRO] -- ERROR task-74485 -- vm-13109 -- vim.vm.Snapshot.remove: vim.fault.FileNotFound:
--> Result:
--> (vim.fault.FileNotFound) {
--> dynamicType = <unset>,
--> faultCause = (vmodl.MethodFault) null,
--> file = "[]",
--> msg = "File [] was not found",
--> }
--> Args: