Apache – the technology that powers the web. I’m not sure if that is correct, but I think that we wouldn’t see the world wide web in its current shape without it. Launched in 1995 and since April 1996, it has been the most popular web server around the world.
Because of handling your users’ requests, Apache serves as the front application. It is crucial to understand what your server is doing, what file users are accessing, from where they came, and much, much more.
The visibility that Apache logs give you is invaluable in understanding the traffic coming to your application, the errors that happen, and the performance of the user-facing elements. Today, we will look into what the Apache web server logs are, how to interpret them, and how to analyze them easily.
What Are Apache Logs?
Apache logs are text files that contain all the information on what the Apache server is doing. They provide insight into which resources were accessed, when they were accessed, who accessed them, and metrics related to that. They also include information about the errors that happened, resource mapping process, the final resolution of the connection, and many, many more.
In general, the whole Apache logging process comes in multiple phases. First, you need to store the logs somewhere for historical analytical purposes. Second, you need to analyze the logs and parse them to retrieve useful information and metrics. And finally, you may want to graph the data as the visual representation is easier to analyze and understand for a human person.
What Is the Apache Access Log?
The Apache access logs are text files that include information about all the requests processed by the Apache server. You can expect to find information like the time of the request, the requested resource, the response code, time it took to respond, and the IP address used to request the data.
Apache Access Logs Location
The location of the Apache server access log differs depending on the operating system that you are using.
- On Red Hat, CentOS, or Fedora Linux, the access logs can be found in the
/var/log/httpd/access_logby default. - On Debian and Ubuntu, you can expect to find the Apache logs in the
/var/log/apache2/access.logand - FreeBSD will have the Apache server access logs stored in
/var/log/httpd-access.logfile.
You can configure its location using the CustomLog directive, for example:
CustomLog "/var/log/httpd-access.log"
Apache Access Log Format Configuration
Before we learn about the different log formats, let’s discuss what the Apache HTTP can do when it comes to formatting. There are two most common access log types that you can use and that the Apache server will translate to meaningful information:
- Common Log Format
- Combined Log Format
The log formatting directives are used in combination with the LogFormat option:
LogFormat "%t %h %m "%r"" custom
The above line tells that the “%t %h %m ”%r”” format should be used and assigned to an alias called custom. After that, we can use the custom alias when defining Apache logging. For example:
CustomLog "logs/my_custom_log" custom
The above section will tell Apache to write logs in the logs/my_custom_log file with the format defined by the custom alias. The above configuration will result in logging:
- time of the request thanks to the %t directive,
- remote hostname thanks to the %h directive,
- HTTP method thanks to the %m directive,
- the first line of the request surrounded by double quotes thanks to the %r directive.
Of course, there are way more directives that can be used and the complete list can be found in the mod_log_config documentation of the Apache server.
Common Log Format
The Apache Common Log Format is one of the two most common log formats used by HTTP servers. You can expect it to see its definition to look similar to the following line:
LogFormat "%h %l %u %t "%r" %>s %b" common
Here’s how an access log from that log file looks like:
10.1.2.3 - rehg [10/Nov/2021:19:22:12 -0000] "GET /sematext.png HTTP/1.1" 200 3423
As you can see the following elements are present:
- %h, resolved into 10.1.2.3 – the IP address of the remote host that made the request.
- %l, remote log name provided by identd, in our case a hyphen is provided, which is a value that we can expect to be logged in a case when the information provided by the logging directive is not found or can’t be accessed.
- %u, resolved into rehg, the user identifier determined by the HTTP authentication.
- %t, the date and time of the request with the time zone, in the above case it is [10/Nov/2021:19:22:12 -0000]
- ”%r”, the first line of the request inside double quotes, in the above case it is: “GET /sematext.png HTTP/1.1”
- %>s, the status code reported to the client. This information is crucial because it determines whether the request was successful or not.
- %b, the size of the object sent to the client, in our case the object was the sematext.png file and its size was 3423 bytes.
Combined Log Format
The Apache Combined Log Format is another format often used with access logs. It’s very similar to the Common Log Format but includes two additional headers – the referrer and the user agent. Its definition looks as follows:
LogFormat "%h %l %u %t "%r" %>s %b "%{Referer}i" "%{User-agent}i"" combined
And the example log line produced by the above log line looks like this:
10.1.2.3 - grah [12/Nov/2021:14:25:32 -0000] "GET /sematext.png HTTP/1.1" 200 3423 "http://www.sematext.com/index.html" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.74 Safari/537.36 Edg/79.0.309.43"
Custom Log Format
There is one more thing that we should discuss when it comes to Apache Server logging configuration – the CustomLog directive. We’ve already seen that configuration directive, but let’s discuss that in greater details.
Multiple Access Logs
It is possible to have multiple Apache access logs at the same time without any additional effort. We may want a limited set of information available in some files for quick scanning and the full log using the Combined Log Format if we need the complete information. For example, we could have three access log files – one that includes time, user agent, and the status code, the second that includes the time, IP address, and referrer used, and the third – the Common Log Format.
To do that we need to include multiple CustomLog sections in our configuration file:
LogFormat "%h %l %u %t "%r" %>s %b" common
CustomLog logs/agent_log "%t %{User-agent}i %>s"
CustomLog logs/referer_log "%t %h %{Referer}i"
CustomLog logs/access_log common
You can see that this time we didn’t use three separate LogFormat configuration options, but we’ve specified the apache log format in the CustomLog format line. This is also possible and very convenient when the formatting of the log lines is used only in that given file.
Conditional Logs
There are cases when you would like to write logs only when a certain condition is met. This is what Apache Server calls conditional logging. It is done by using the CustomLog directive and environment variables. For example, if you would like to log all requests accessing your PNG files in a separate file you can do that the following way:
SetEnvIf Request_URI .png$ png-image-log CustomLog "png-access.log" common env=png-image-log
Logs Rotation and Piped Logs
Depending on the logging configuration and the traffic that your Apache servers are handling, logging can be extensive. All the logs that you keep on the machine take space and if you are not using a log centralization solution like Sematext Logs, you will have to deal with space and management of logs.
Let’s talk about log rotation first. Log rotation is a process of creating a new log file that the Apache HTTP server will start writing to and renaming the old log file, so it is no longer updated. The log rotation happens when you gracefully restart the server. That means that without any kind of client requests processing interruption a new log file is created. In production environments, you would like to restart the Apache servers though.
That’s why the Apache server supports piped logs. Instead of writing the log events to a file, you use the piped logs to send the log events to a different application that will handle the log processing – for example to rotatelogs:
CustomLog "|/usr/local/apache/bin/rotatelogs /var/log/access.log 86400" common
The rotatelogs application comes with Apache server and is capable of rotating logs without the need of restarting the server. The above example will result in rotating the /var/log/access.log file every 24 hours.
How to Read Apache Access Logs
Apache server access logs are just simple text files. They can be easily opened by any tool that can read such files. On Linux-based systems, this can be the cat command-line tool or tail if you want to monitor the log lines as they go.
There are two caveats, though. The first is access policies. You may not have access to the machines running Apache HTTP server and even if you do, you may not have read access to the appropriate log directories. The second is distribution. It is not uncommon to have multiple Apache servers distributed across multiple data centers. In such a case, it is way easier to use a dedicated observability tool such as Sematext Logs that will provide not only the option to look into the raw files but also aggregated information into the key metrics derived for them.
Understanding Apache Access Logs
Our Apache access logs files are easy to read and not hard to understand either. Just remember about the patterns that you’ve used in your configuration. We’ve already covered the common patterns that you can encounter in the Apache log files. Keep in mind that understanding the log files is even easier with log analysis tools that do the parsing for you and give you an aggregated view of the data which is easier to understand.
What Is the Apache Error Log?
So far, we’ve talked about the Apache access log that gives us information on the accessed resources. But it is not the only thing that we should be interested in. We should also care about everything related to errors. In fact, the error log is the most important log file for the Apache HTTP server.
The Apache error log is where all the errors that happened during the processing of the requests. The most important thing, though, is that the error log will contain information on what went wrong during the Apache server startup and it is very likely that it will also contain hints on how to fix the issue.
Apache Errors Logs Location
Where the Apache error log is stored differs depending on the operating system on which it is running.
- On Red Hat, CentOS, or Fedora Linux, the access logs can be found in the
/var/log/httpd/error_logby default. - On Debian and Ubuntu, you can expect to find the Apache logs in the
/var/log/apache2/error.log - FreeBSD will have the Apache server access logs in
/var/log/httpd-error.logfile.
You can configure its location using the ErrorLog directive, for example:
ErrorLog "/var/log/httpd-error.log"
Apache Error Log Format Configuration
Similar to the Apache access log, you can adjust the format of the error log. The Apache error log format is configured by using the ErrorLogFormat element, for example:
ErrorLogFormat “[%{u}t] [%-m:%l] [pid %P:tid %T] [client %a] %M”
The above configuration would produce an Apache error log entry similar to the following one:
[Wed Nov 10 10:21:23.811033 2021] [core:error] [pid 22308:tid 3212342123] [client 10.1.2.3] File does not exist: /usr/local/apache2/htdocs/favicon.ico
In the above example the following formatting options were used:
- %{u}t – the current time including microseconds,
- %-m – the module that produced the error,
- %l – the level of the log event,
- %P – process identifier,
- %T – thread identifier,
- %M – the actual log message.
The full description of the available formatting options is available in the official Apache Server documentation.
Log Levels
In addition to what we discussed so far there is one other thing worth mentioning – the level of log events. The LogLevel directive allows specifying the level of log messages on a per-module basis. For example, if we would like the main log level for all events to be set to the info level but have the error level only for the rewrite module, we could have a configuration directive as follows:
LogLevel info rewrite:error
The following logging levels are described in Apache server documentation:
- emerg
- alert
- crit
- error
- warn
- notice
- info
- debug
- trace1 – trace8
The emerg one is the log event that says that the system is unstable and the trace levels are used for very low-level information logging that you can probably skip.
How to View Apache Error Logs
Viewing the Apache server error logs is just as simple as opening the text file. The error logs are not different from the access logs, so they are just simple text files. You can use whatever tools you want to look into them. But keep in mind that looking into logs from multiple Apache servers distributed across multiple data centers can be challenging. That’s why we strongly suggest using log aggregation tools, such as Sematext Logs, for that job.
Apache Log File Management and Analysis with Sematext
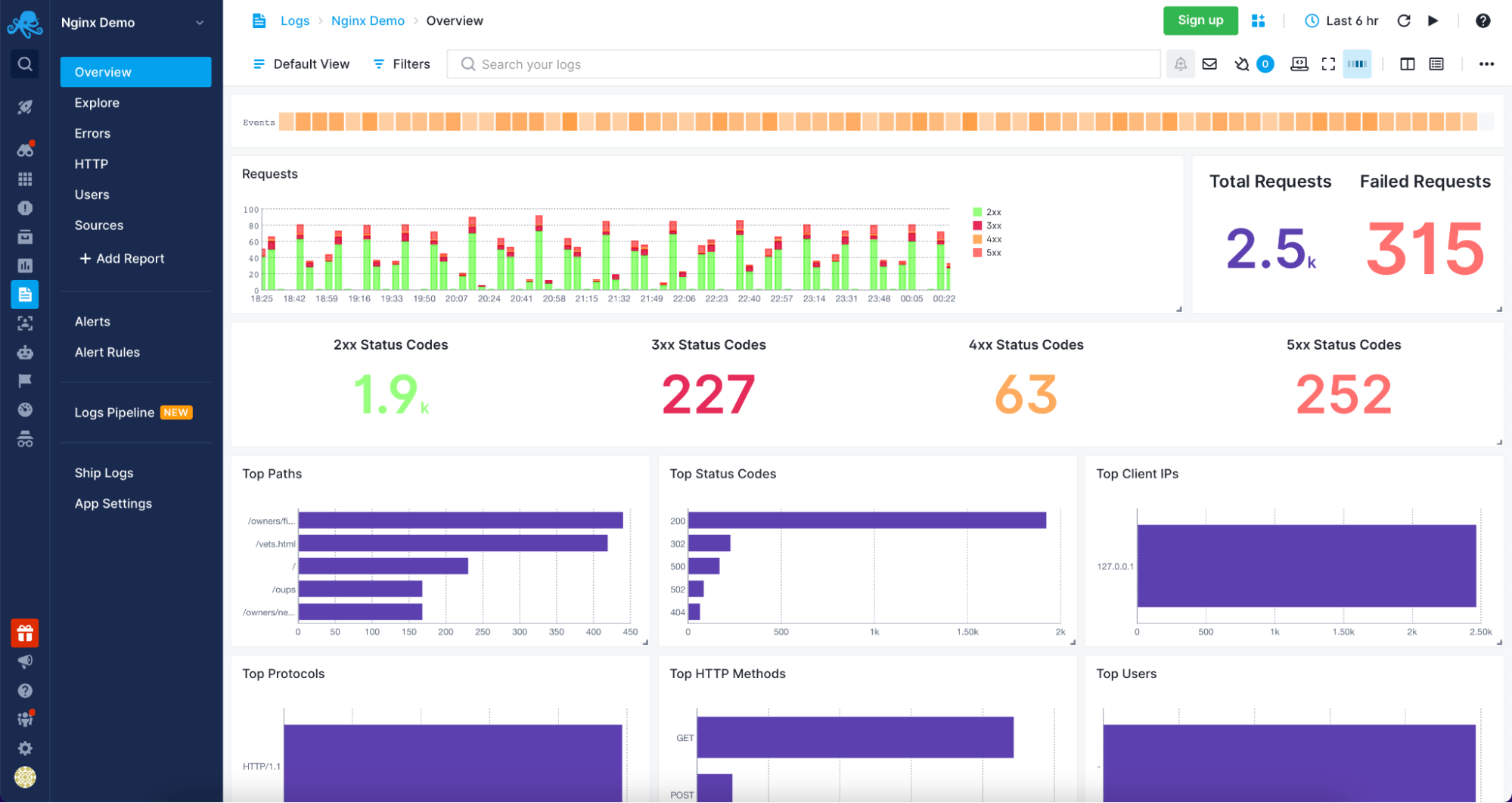
Sematext Cloud Logs – Apache Overview
Understanding and analyzing your Apache servers logs was never easier than with Sematext Logs. The only thing that you need to do is create an account with Sematext, create the Apache Logs App and install the Sematext Agent. You will be guided through the process of setting up the automatic Logs Discovery for your Logs. Your logs will be parsed and sent to the Sematext Logs giving you access to a variety of pre-built reports tailored for your Apache HTTP server.
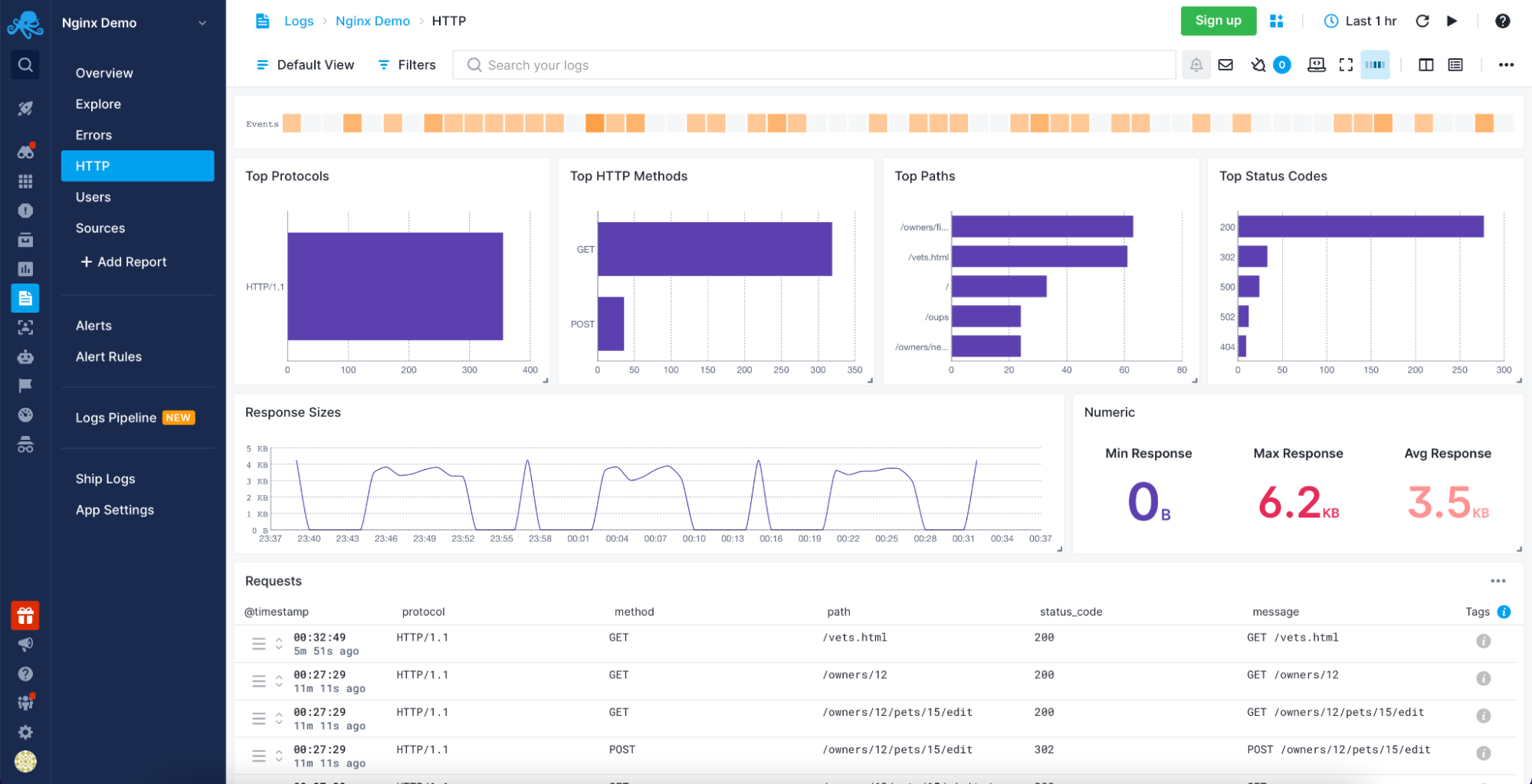
Sematext Logs – Apache HTTP Information
Sematext Logs is part of the Sematext Cloud full-stack monitoring solution providing you with all you need when it comes to observability. With Sematext Cloud, you get an overview of your Apache servers, errors report, HTTP report, including top HTTP methods and paths with an average response size visualization and requests table. You can see your users with the top User Agents used to access resources served by your Apache servers and, finally, the sources for the data. All within a single Apache Logs monitoring in Sematext Cloud.
Still not sure which open-source search engine to use? Check out this quick video comparing Apache Solr and Elasticsearch below:
Conclusion
Analyzing your Apache servers logs is invaluable in understanding the traffic coming to your application, the errors that happen, and the performance of the user-facing elements. A log management tool such as Sematext Logs does this job for you.
More than understanding server logs, knowing what resources were accessed, who accessed them, and how long it took to process the request is crucial to understanding your user’s behavior. You also need to be sure that you are aware of every error that happens so that you can react as soon as possible. Combining that with the need for distributed infrastructures to handle a large number of concurrent users and provide high availability, using an observability tool is a necessity.
Having Apache metrics and logs in the same place, being able to slice and dice them, being alerted when issues appear and having insight into every piece of your environment is no longer something good to have but need to have. All of that and more is provided by Sematext Cloud, an observability platform with dedicated Apache server logs and metrics support. Built with simplicity in mind and requiring no credit card, nothing stops you from giving it a try to see how it can improve your log management and log analysis processes.
 Обновлено: 29.01.2021
Обновлено: 29.01.2021
Опубликовано: 12.09.2018
Тематические термины: веб-сервер, nginx, Apache, PHP-FPM.
В данной статье пойдет речь о мониторинге нагрузки, именно, в контексте веб-сервера. Мы не будем особо заострять внимание на проверке производительности системы, как, например, командами top, htop, free и так далее.
Общая нагрузка на сервер
По процессам
На память
На диск
На сеть
Что грузит систему
Использование lsof
Анализ логов ошибок
Статистика
Apache
NGINX + PHP-FPM
Анализ медленных запросов
MySQL / MariaDB
PHP-FPM
Нагрузка на сервер
Анализ нагрузки стоит начать с общих метрик — потребление процессорного времени, памяти, нагрузки на сеть и дисковую систему.
Нагрузка по процессам
Проверить, нагружен ли сервер, а также понять, какой именно процесс больше всего потребляет ресурсов можно с помощью команд:
top
htop
atop
* по сути, все 3 вышеперечисленные команды выдают одну и туже информацию в разном виде. Какой-то из них может оказаться удобнее пользоваться. Утилита top встроена в систему, для использования остальных необходимо установить одноименные пакеты.
Оперативная память
Для определения объема свободной и занимаемой памяти можно воспользоваться командой:
free
* предыдущие команды тоже показывали утилизацию памяти, но кому-то команда free может показаться нагляднее.
Нагрузка на диск
Для определения нагрузки на дисковую систему, используем утилиту iotop. Сначала ее нужно установить.
а) На системы Debian / Ubuntu:
apt-get install iotop
б) На системы Red Hat / CentOS:
yum install iotop
После выполняем следующую команду:
iotop
Сетевая активность
Для измерения нагрузки на сеть необходимо установить утилиту nload.
а) В CentOS / Red Hat:
yum install nload
б) В Ubuntu / Debian:
apt-get install nload
После установки, запускаем утилиту командой:
nload -ni eth0
* в данном примере будет запущена статистика для использования сетевого интерфейса eth0.
Что грузит систему
Даже, если мы увидим, что на веб-сервере заканчивается оперативная память или загружен процессор, мы не сможем найти источник проблемы, которым, чаще всего, является некорректно работающий скрипт. Поэтому, определяем, какой файл на сервере вызывает нагрузку.
Использование lsof
lsof — утилита командной строки, которая отображает какие файлы используются процессами. Она позволит определить, к каким скриптам идет обращение со стороны веб-сервера. Для начала, необходимо установить lsof.
а) В CentOS / Red Hat:
yum install lsof
б) В Ubuntu / Debian:
apt-get install lsof
Теперь можно выполнить следующие команды:
lsof -c httpd
lsof -c php-fpm
* первая команда покажет, к каким файлам обращается apache, вторая — php-fpm (часто можно увидеть в связке с nginx).
Анализ error-логов
Анализ логов ошибок позволит не только обнаружить проблемы в работе сайта, но и найти причину его медленной работы. По умолчанию, логи находятся в каталоге /var/log. Если мы не меняли расположение логов, запускаем следующие команды:
tail -f /var/log/nginx/error.log
* лог ошибок nginx.
tail -f /var/log/php-fpm/error.log
* лог ошибок php-fpm.
tail -f /var/log/httpd/error_log
* лог ошибок apache в CentOS.
tail -f /var/log/apache2/error_log
* лог ошибок apache в Ubuntu.
В первую очередь, нужно обратить внимание на повторяющиеся ошибки — они могут быть причиной проблем. Лучше всего, добиться полного отсутствия ошибок, внеся исправления в работу сайта. Возможно, это устранит проблемы производительности.
Статистика веб-сервера
Для веб-серверов можно воспользоваться служебной страницей просмотра статуса. Она может показать статистику запросов к веб-серверу.
Apache
Для Apache необходим модуль mod_status, который идет в комплекте с данным веб-сервером. Проверить подключение модуля можно в конфигурационном файле httpd.conf (в разных Linux системах может находится в различных каталогах).
По умолчанию, server-status не активен. Создаем конфигурационный файл.
Для CentOS / Red Hat:
vi /etc/httpd/conf.d/server-status.conf
Для Ubuntu / Debian:
vi /etc/apache2/sites-enabled/server-status.conf
* где 2 — используемая версия apache.
В открытый конфигурационный файл добавим:
ExtendedStatus on
<VirtualHost *:80>
servername 111.111.111.111
<Location /server-status>
Sethandler server-status
</Location>
</VirtualHost>
<Location /server-status>
SetHandler server-status
</Location>
* где 111.111.111.111 — IP-адрес нашего веб-сервера; 80 — порт, на котором слушает apache.
* в данном примере мы прописали два варианта просмотра статистики: первый — обращение в браузере к серверу по IP-адресу + /server-status; второй — обращение к любому сайту + /server-status. Разные способы оправданы для разных настроек самих сайтов и используемых CMS.
Проверим корректность внесенных данных и перезапустим веб-сервер apache:
apachectl configtest
systemctl restart httpd || systemctl restart apache2
Теперь открываем браузер и вводим название сайта + /server-status, например, http://www.dmosk.ru/server-status. Или обращаемся к серверу по IP-адресу, например, http://111.111.111.111/server-status.
NGINX + PHP-FPM
Открываем конфигурационный файл nginx:
vi /etc/nginx/nginx.conf
В секцию http добавляем:
…
server {
listen 80;
server_name 111.111.111.111;
location /server-status {
stub_status on;
}
}
…
* где 111.111.111.111 — IP-адрес нашего веб-сервера.
Проверяем корректность настройки и перезапускаем nginx:
nginx -t
systemctl restart nginx
Открываем браузер и заходим на страницу 111.111.111.111/server-status. Мы должны увидеть статистику использования сервера:

Теперь настроим статистику для php-fpm. В конфигурационном файле nginx в нашу директиву server добавим:
vi /etc/nginx/nginx.conf
…
server {
listen 80;
server_name 78.110.63.31;
location /server-status {
stub_status on;
}
location /status {
access_log off;
include fastcgi_params;
#fastcgi_pass unix:/var/run/php-fpm/php5-fpm.sock;
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
}
…
* обратите внимание на закомментированную строку и строку под ней. В зависимости от того, как настроен php-fpm (слушает на порту или через сокетный файл) необходимо настроить nginx. В данном примере подразумевается, что php-fpm слушает на 9000 порту.
Открываем конфигурационный файл php-fpm:
vi /etc/php-fpm.d/www.conf
Снимаем комментарий со следующей строки:
pm.status_path = /status
Проверяем настройку nginx, перезапускаем его и php-fpm:
nginx -t
systemctl restart nginx
systemctl restart php-fpm
Открываем браузер и заходим на страницу 111.111.111.111/server-status. Мы должны увидеть статистику использования сервера:

Долгие запросы
С помощью длительных запросов к веб-серверу или СУБД можно сделать выводы о том, что является узким местом в работе сервиса.
MySQL / MariDB
Для начала, воспользуемся инструкцией, чтобы настроить ведение лога медленных запросов (для MySQL или MariaDB).
После, воспользовавшись статистикой, находим неоптимальные запросы. В одних случаях необходимо будет переписать сам запрос, в других — создать индексы базы данных.
PHP-FPM
Открываем конфигурационный файл:
vi /etc/php-fpm.d/www.conf
Редактируем следующие параметры:
request_slowlog_timeout = 10s
slowlog = /var/log/php-fpm/www-slow.log
* request_slowlog_timeout определяет время, в течение которого должен выполняться запрос, чтобы он считался медленным; slowlog — путь до лога, куда будет сохранена информация о медленных запросах.
Перезапускаем сервис:
systemctl restart php-fpm
Непрерывный просмотр лога можно запустить командой:
tail -f /var/log/php-fpm/www-slow.log
♒ Скрипты для анализа логов веб сервера
- Подробности
- Просмотров: 9087
- Что такое, как расшифровывается, что хранится в логах веб сервера апача
- На что смотреть, что анализировать из логов веб сервера
- Записки и систематизация скриптов анализа и обработки лог- файлов.
Анализ логов — краеугольный наш к увеличению стабильности и скорости работы сайта, уменьшения количества ошибок. Ведь исправив пиковые элементы мы решим главные задачи — 20% времени занимают 80 процентов эффекта.
Я перерыл кучу информации в интернете в поисках программ веб анализатора, к сожалению найти что ли достойное или удобное не представилось возможным, там где что-то было интересное требовалось как минимум 40$, и выше, при этом все рано часть вещей оставалась не освещена. Плюс при этом функционал как правило не мог дать что то отличное от веб-аналитики, и не решал реальных задач поиска причин нагрузок.
Цитаты объясняющие сложность проблемы:
Когда один пользователь заходит на сайт, процессы же не только на PHP создаются. Помимо этого загружаются CSS, JavaScript, графика и т.д. И если их очень много, при большом количестве пользователей суммарное кол-во процессов может быть большим.
Картинки, стили и скрипты – это “статическое содержимое”. Оно не изменяется с течением времени, и на такие обращения нужно меньше всего ресурсов (процессорное время практически не используется, памяти нужно минимальное количество).
Динамическое содержимое — это лишние запросы к БД и затраты процессорного времени на выполнение.
Основные причины, по которым сайт сильно нагружает хостинг:
- вывод последних комментариев (обычно ставят на отображение 10 последних = 10 запросов к БД),
- вывод последних новостей в блоке,
- вывод самых комментируемых новостей,
- другие супер интересные установленных виджеты — плагины,
- множественные лишние запросы в самом шаблоне, которые можно заменить на статическое содержимое, необходимо найти “плохой” плагин или модуль, и обновить, починить, заменить или даже отключить его.
- львиную долю задач можно и нужно решать напрямую — редактируя шаблон.
Теория — при обработке статических файлов apache использует около 2-3 Мб на процесс, для динамиких файлов (php, cgi) — от 16 до 32 Мб.
Процесс PHP есть 2 Мб — не бывает такого, любая копия скрипта будет забирать как минимум 4-6 Мб, причем даже состоящего всего из пару — тройки строк кода.
Если скрипт тяжелый, и тем более с ошибками то ему одному не хватит ОЗУ, если только статика на сервера — без проблем пара сотен пользователей в день.
При небольшой посещаемости не будет заметной разницы между apache2 и nginx, однако nginx — меньше потребляет при той же производительности.
memory_limit в php — например 256 Мб делим на 10 проектов по 2 Мбайта, получается по 12,8 человек на каждом сайте одновременно или 128-онлайн на 1.
На VPS все ресурсы «наши»: сервер, интерпретатор и панель управления — забирают у вас вашу оплаченную память. При нехватке памяти VPS (оперативной + своп) сервер не виснит, а сразу — 500 ошибка — отказ обслуживания для клиента.
ап..
Рекомендация: периодически сохраняйте логи вашего сервера у себя, хотя бы раз в месяц, часто позволяет отследить многие тенденции, так как как правило логи у хостера хранятся всего 7 дней, максимум что я видел 1 месяц.
Виды логов access_ssl_log, разница access_ssl_log access_ssl_log.processed access_log.processed
♳ I) ПРО ЛОГИ
1) access_log — лог досупа (данные за последний час)
- access_log
- access_ssl_log
Пример:
217.27.154.74 — — [30/Oct/2015:13:38:31 +0300] «GET /images/stories/b/1/Hard-Disk.jpg HTTP/1.0» 200 286 «http://www.web.ru/informatsiya/kak.html» «Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36 OPR/32.0.1948.69»
78.25.64.74 — — [30/Oct/2015:13:38:36 +0300] «GET /informatsiya/zamena-na-plate.html HTTP/1.0» 200 56996 «-» «Mozilla/5.0 (Linux; U; Android 2.3.6; ru-ru; GT-S5660 Build/GINGERBREAD) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1»
✎ Расшифровка: С IP адреса 78.25.64.74 30 октября 2015 в 13-38 дня по московскому времени запросили по протоколу HTTP/1.0, методом GET страницу «/informatsiya/zamena-na-plate.html» сайта. Успешно, о чем свидетельствует 200. Ответ занял 56996 байта. В скобках браузер и ОС: Mobile Safari — Android 2.3.6

2) _processing — транзакции обрабатываются (в основном в нем хранятся интересные нам данные — в основном архив)
- access_ssl_log.processed
- access_log.processed
- access_log.processed.1.gz
2.92.86.203 — — [06/Aug/2015:21:09:18 +0300] «GET /media/system/js/mootools.js HTTP/1.1» 200 20296 «http://www.web.ru/acpi/cpu.html» «Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.125 Safari/537.36»
2.93.56.15 — — [06/Aug/2015:18:57:16 +0300] «GET /images/stories/informatsiya/Kak/uznat.jpg HTTP/1.1» 200 34075 «http://www. web.ru/informatsiya/kak.html» «Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.107 Safari/537.36 OPR/31.0.1889.99»
3) error_log — лог ошибок
- error_log
[Fri Nov 06 18:06:33 2015] [error] [client 31.173.84.230] File does not exist: /var/www/vhosts/u7.hosting.ru/ web.ru /apple-touch-icon.png
[Fri Nov 06 18:11:52 2015] [warn] [client 207.46.13.140] mod_fcgid: can’t apply process slot for
[Fri Nov 06 21:55:15 2015] [error] [client 109.188.125.10] ModSecurity: Warning. Matched phrase «/109.188.125.10/» at TX:ip_boundary. [file «/etc/httpd/modsecurity.d/activated_rules/modsecurity_slr_10_ip_reputation.conf»] [line «17»] [id «2200000»] [msg «SLR: Client IP in Blacklist.»] [tag «REPUTATION/MALICIOUS»] [hostname «www.veb.ru»] …
(проблема с недостатком слотов — ошибки в скриптах в их выполнении)

менее интересно
4) proxy_access_log — фиксирует то что использует ресурсы с нашего сайта отдельным запросом — как например:
- proxy_access_ssl_log — тоже самое только по протоколу SSL
- proxy_error_log — с кривыми запросами
a) что используется — берется доп запросом, пример:
93.81.145.180 — — [30/Oct/2015:12:16:27 +0300] «GET /images/thumbnails/images/stories/informatsiya-o/reductor/reductor2015-485×183.jpg HTTP/1.1» 200 17461 «http://dmitry-anapa.ru/» «Opera/9.80 (Windows NT 5.2; U; YB/5.0.3; ru) Presto/2.2.15 Version/10.10»
b) кто берет
c) может брать не только внешние ресурсы- сайты ну и «сами у себя» (для нас это как правило менее интересно)
95.82.202.246 — — [30/Oct/2015:12:55:35 +0300] «GET /components/com_jcomments/images/smiles/wink.gif HTTP/1.1» 200 738 «http://www.test.ru/informatsiya/kak-obnovit.html» «Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36»
5) access_log.webstat, access_ssl_log.webstat — нет доступа — используется скриптом статистики, нам мало интересен.
6) не интересен — xferlog_regular.processed — записи о всех изменениях, внесенных с помощью FTP, xferlog_regular.processed — это журнал FTP-доступа сервера.
6) mail.log — лог работы сервера по оправке почты — писем/
mail() on [/var/www/vhosts/u5.hosting.ru/veb.net/libraries/phpmailer/phpmailer.php:755]: To:
Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра.
— Headers: Date: Thu, 5 Nov 2015 12:37:26 +0300 Return-Path:
Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра.
From: =?utf-8?B?0KHQutCw0LfQutC4INC00LvRjyDQtNC10YLQtdC5?= <support@ veb.net > Reply-To: =?utf-8?B?0KHQutCw0LfQutC4INC00LvRjyDQtNC10YLQtdC5?= <
Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра.
> Message-ID: <
Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра.
> X-Priority: 3 X-Mailer: PHPMailer 5.2.1 (http://code.google.com/a/apache-extras.org/p/phpmailer/) MIME-Version: 1.0 Content-Transfer-Encoding: 8bit Content-Type: text/html; charset=»utf-8″
SSL сертификат (модуль поддержки SSL в Apache)
SSL (англ. secure sockets layer — уровень защищённых сокетов) — криптографический протокол, который подразумевает более безопасную связь. Он использует асимметричную криптографию для аутентификации ключей обмена, симметричное шифрование для сохранения конфиденциальности, коды аутентификации сообщений для целостности сообщений.
Протокол SSL обеспечивает защищенный обмен данных за счет двух следующих элементов:
- Аутентификация
- Шифрование
SSL использует асимметричную криптографию для аутентификации ключей обмена, симметричный шифр для сохранения конфиденциальности, коды аутентификации сообщений для целостности сообщений.
Протокол SSL предоставляет «безопасный канал», который имеет три основных свойства:
- Канал является частным. Шифрование используется для всех сообщений после простого диалога, который служит для определения секретного ключа.
- Канал аутентифицирован. Серверная сторона диалога всегда аутентифицируется, а клиентская делает это опционно.
- Канал надежен. Транспортировка сообщений включает в себя проверку целостности.
Преимуществом SSL является то, что он независим от прикладного протокола. Протоколы приложений (HTTP, FTP, TELNET и т.д.) могут работать поверх протокола SSL совершенно прозрачно, т.е. SSL может согласовывать алгоритм шифрования и ключ сессии, а также аутентифицировать сервер до того, как приложение примет или передаст первый байт сообщения.
____________________________
♴ II. Основы синтаксиса и команд консоли шелл (очень похожа на MS DOC, lunix):
Для анализа нужно скачать на официальном сайте шелловский бесплатный крошечный клиент putty.exe, заходим на сервер под вашим основным логином — паролем аккаунта


✦ dir — листинг, просмотр содержимого текущего каталога

Примечание:
1. Что бы не набирать команду или тем более последовательность из команд длинной в целую строку — их можно просто копировать со страницы сайта, выделяешь строку команд, жмешь например CTRL+C, а в черном командном интерфейсе шелл — клиента просто щелкаем Правой кнопкой мышки (CTRL +V — здесь не работает) — строка сама вставляется, остается подправить вид-название лог-файла если нужно, его расположение (например обрабатывать и во всех подпаках — «*/» , и просто нажать ENTER.
2. Для повтора введенной команды стоя в интерфейсе клиента — можно стрелочками «вверх» — «вниз» перебрать вводимые ранее команды.
✦ cd .. — переход в предыдущий каталог;
✦ cd -переносит вас в ваш домашний каталог
✦ Кнопка на клавиатуре Print Screen — для остановки вывода листингов строк, «q» и «c» — для выхода- остановки
cd logs

Скрипты
Вне зависимости где находимся:
— по всем доменам — под папкам cat */access_log
— по всему cat * (- всем логам сразу — большая нагрузка — и долго)
— по всем логам *log*
-Топ пользователей по количеству процессов:
ps auxwww|awk ‘{print($1)}’| sort| uniq -c | sort -n |tail
Сколько чего запрашивается из ресурсов
ps auxwww|awk ‘{print($11)}’| sort| uniq -c | sort -n |tail
✦ — top .. по ссылке ниже..
✦ Команда cat (сокращенно от «concatenate») является одной из наиболее часто используемой командой в Linux Unix-подобных операционных системах. Команда cat позволяет создать один или несколько файлов, просмотреть содержание файлов, объединять файлы и перенаправлять вывод в терминал или файлы.
✦ uniq — утилита Unix, с помощью которой можно вывести или отфильтровать повторяющиеся строк
Опции программы имеют следующие значения:
-u Выводить только те строки, которые не повторяются на входе.
-d Выводить только те строки, которые повторяются на входе.
-c Перед каждой строкой выводить число повторений этой строки на входе и один пробел.
✦ tail — утилита в UNIX, выводящая несколько (по умолчанию 10) последних строк из файла.
Ключ -n <количество строк> (или просто -<количество строк>) позволяет изменить количество выводимых строк
✦ sort — UNIX‐утилита, выводящая сортированное
-n, —numeric-sort сравнивать численные значения строк
-r, —reverse обратить результаты сравнения
✦ AWK — язык построчного разбора и обработки входного потока (например, текстового файла) — рассматривает входной поток как список записей. Каждая запись делится на поля.По умолчанию разделителем записей является символ новой строки. Разделителем полей — символ пробела или табуляции. Каждая запись поочерёдно сравнивается со всеми шаблонами, и каждый раз когда она соответствует шаблону, выполняется указанное действие.
________________
♵ III. Все логи
По размеру отсортированы — по мере важности — объема данных в них:
- access_log.processed
- access_log
- proxy_access_log
(в 10 раз меньше по размеру)
- access_ssl_log
- access_ssl_log.processed
- proxy_access_ssl_log
- proxy_error_log
- error_log
.gz
- access_log.processed.1.gz
(в 10 раз меньше по размеру — сжат в архив)
- access_ssl_log.processed.1.gz
- error_log.1.gz
✑ Команды текущего лог-файла (обычно за текущии сутки или их часть) (текущей папки — текущего домена)
✑ MAX количество запросов с IP — команда которая выведет список IP-адресов, с которых наблюдается наибольшее количество запросов:
cat access_log.processed | awk ‘{print $1}’ | sort | uniq -c | sort -n | tail
cat access_log | awk ‘{print $1}’ | sort | uniq -c | sort -n | tail
cat proxy_access_log | awk ‘{print $1}’ | sort | uniq -c | sort -n | tail
(✑Для всех поддоменов- под папок внутри данной папки)
cat */access_log.processed | awk ‘{print $1}’ | sort | uniq -c | sort -n | tail
cat */access_log | awk ‘{print $1}’ | sort | uniq -c | sort -n | tail
cat */proxy_access_log | awk ‘{print $1}’ | sort | uniq -c | sort -n | tail

✑ Анализ по сжатым -архивным лог — файлам веб сервера (обычно 7 дней) за все дни (кроме текущего дня — см. чуть выше), текущий домен-каталог
zcat access_log.processed.*.** | awk ‘{print $1}’ | sort | uniq -c | sort -n | tail
все каталоги домены
==================================================
zcat */access_log.processed.*.** | awk ‘{print $1}’ | sort | uniq -c | sort -n | tail
==================================================
- access_log.processed.1.gz
Логи за прошедшие дни хранятся в заархивированном виде для их просмотра с помощь указанных вами команд необходимо использовать утилиту zcat вместо cat.

в 10 раз меньше по размеру access_ssl_log.processed.1.gz (протокол пока еще юзается мало кем):
zcat */ access_ssl_log.processed.*.** | awk ‘{print $1}’ | sort | uniq -c | sort -n | tail
zcat */ access_ssl_log.processed.*.** | awk ‘{print $1}’ | sort | uniq -c | sort -n | tail
error_log.1.gz:
zcat */error_log.*.** | awk ‘{print $1}’ | sort | uniq -c | sort -n | tail
zcat */error_log.*.** | awk ‘{print $1}’ | sort | uniq -c | sort -n | tail
✑ Далее можно посмотреть какие запросы шли с IP-адреса — смотрим кто с таким IP что и как запрашивал наибольшее количество раз (как правило просто про парсил — про сканировал сайт):
cat */access_log | grep 5.142.18.18
zcat */ access_ssl_log.processed.*.** | grep 188.165.15.206
=======================================
(логи от этого ip) последних от 100 до 150:
zcat */access_log.processed.*.** | grep 37.140.192.45 | tail -n +101 | head -n 50
первых 50:
zcat */access_log.processed.*.** | grep 37.140.192.45 | tail -50
=======================================
Вариант сортировки, блок из:
cat */access_log | grep 5.142.18.18 | tail -n +101 | head -n 10
Синтаксис:
- cat file | tail -n +N | head -n (M-N+1), выводятся строки 101 – 110 файла,
- tail -n +101 : игнорирует строки до указанного номера, потом начинает выводить строки, начиная с него,
- head -n 10 : выводит первые 10 строк, т.е. с 101 до 110, оставшиеся – игнорирует.
✑ Далее — выясняем что за айпишник, кто- что — зачем заходит к нам, парсят-скачивают нас.
На любом удобном вам сайте, от
- https://www.nic.ru/whois/?query=66.102.9.11
- https://www.reg.ru/whois/?dname=66.102.9.11
- http://whatismyipaddress.com/ip
- и тд..
При этом часто бывает так что ip вроде бы принадлежит например Микрософт, а ы логах при запросе в предыдущем примере видно что юзер агент вовсе не бот микрософта.. а какой нибудь адройд… вероятно — просто подмена ip или прокси. Поэтому данная проверка в любом случае идет после предыдущей, в которой убеждаемся какой IP кем является в сигнатуре и что делает.
Полученные IP:
- 35103 37.140.192.237
- 37379 66.102.9.122
- 37393 66.102.9.112
- 37555 66.102.9.11
Полученные пояснения от сервисов к некоторым айпишкам:
- Hostname: spider-5-255-253-155.yandex.com
- ISP: YANDEX LLC
- Organization: YANDEX LLC
далее:
- General IP InformationIP: 66.102.9.11
- Hostname: google-proxy-66-102-9-11.google.com
- Organization: Google
- Services: Confirmed proxy server
- Type: Corporate
- Assignment: Static IP
- State/Region: California
- City: Mountain View
далее:
- General IP InformationIP: 168.63.139.43
- ISP: Microsoft Corp
- Organization: Microsoft Azure
- Services: Confirmed proxy server
- Type: Broadband
- Assignment: Static IP
- Country: United States
Итог, прокси гугла, сервер микрософт, бот яндекса… но не всегда. если тупо парсят из Брянска, Тулы — то пробуем банить ссылка на тхагес- варианты бана по ip, клиенту — сигнатуре.
____________________
♶ IV. Пройдемся с краткими пояснениями по другим наиболее интересным данным типичного формата лога:
✰ Домены — 11 по счету:
cat */access_log | awk ‘{print $11}’ | sort | uniq -c | sort -n | tail
или обработать сжатые архивы за прошедшие дни:
zcat */access_log.processed.*.** | awk ‘{print $11}’ | sort | uniq -c | sort -n | tail
- 9709 «http://www.veb101.ru/templates/online/css/template.css»
- 10711 «http://www.veb.ru/informatsiya/nastroyk.html»
- 12077 «http://www.veb.ru/components/com_jcomments/tpl/default/style.css?v=21»
- 12869 «http://veb101.ru/pushkin/ge.html»
- 16790 «http://www.veb.ru/informatsiya/kak.html»
- 16997 «http://veb101.ru/templates/duo/css/church.css»
- 23845 «http://veb101.ru/pushkin/tavar.html»

✰Платформа система клиента
cat */access_log | awk ‘{print $13}’ | sort | uniq -c | sort -n | tail
- 1948 (J2ME/MIDP;
- 2856 (Mobile;
- 2936 (Macintosh;
- 3557 (Android;
- 3704
- 7951 (compatible;
- 15359 (iPad;
- 17364 (iPhone;
- 79135 (Linux;
- 238890 (Windows
✰ Ответ занял 283 байта
cat */access_log | awk ‘{print $10}’ | sort | uniq -c | sort -n | tail
- 8234 295
- 8518 284
- 8653 292
- 9251 296
- 9278 282
- 11425 285
- 11848 289
- 12934 293
- 17801 288
- 19986 286
✰ Коды ответов сколько (не точно)
cat */access_log | awk ‘{print $9}’ | sort | uniq -c | sort -n | tail
- 6 206
- 17 503
- 18 303
- 37 301
- 62 500
- 173 401
- 1167 404
- 1830 304
- 3418 403
- 373016 200
✰ Картинки, скрипты — конкретные файлы — наиболее запрашиваемые на сервере — уменьшить объем — оптимизировать их в первую очередь:
cat */access_log | awk ‘{print $7}’ | sort | uniq -c | sort -n | tail

✰ Время максимальной нагрузки на сайте — наибольших количеств запросов:
cat */access_log | awk ‘{print $4}’ | sort | uniq -c | sort -n | tail
✰ От куда — и куда идут 404:
cat */access_log | grep 404
141.0.13.98 — — [07/Nov/2015:00:03:36 +0300] «GET /components/com_jcomments/images/smiles/arrow.gif HTTP/1.0» 404 290 «http://veb.net/stikhotvoreniya/marshak.html» «Opera/9.80 (Android; Opera Mini/7.6.40234/37.7011; U; ru) Presto/2.12.423 Version/12.16»
Перевод см. ссылку в низу:
✰ Позволяет узнать, какие ссылки не работают сейчас?
После будет искать для запросов, в результате которых 404 ответ, а затем отсортировать их по количеству запросов в URL. Вы получите самый посещаемый 404 страниц
awk ‘($9 ~ /404/)’ */access_log | awk ‘{print $7}’ | sort | uniq -c | sort -rn
✰ Аналогично, для 502 (плохой-шлюз) мы можем запустить следующую команду:
awk ‘($9 ~ /502/)’ */access_log.processed | awk ‘{print $7}’ | sort | uniq -c | sort -r
✰ 404 для PHP файлов — в основном попытки взлома
awk ‘($9 ~ /404/)’ */access_log.processed | awk -F» ‘($2 ~ «^GET .*.php»)’ | awk ‘{print $7}’ | sort | uniq -c | sort -r | head -n 20
✰ Самые популярные URLS
awk -F» ‘{print $2}’ */access_log.processed | awk ‘{print $2}’ | sort | uniq -c | sort
(без r — выводит в конце наиболее запрашиваемые)
✰ Ссылки
awk -F» ‘($2 ~ «ref»){print $2}’ */access_log.processed | awk ‘{print $2}’ | sort | uniq -c | sort
______________________
☑ Тонкая FastCGI-буферов:
Источник: https://rtcamp.com/tutorials/nginx/tweaking-fastcgi-buffers
a) Максимальный размер отклика
awk ‘($9 ~ /200/)’ access.log | awk ‘{print $10}’ | sort -nr | head -n 1
b) Средний размер отклика
echo $(( `awk ‘($9 ~ /200/)’ */access_log.processed | awk ‘{print $10}’ | awk ‘{s+=$1} END {print s}’` / `awk ‘($9 ~ /200/)’ */access_log.processed | wc -l` ))
c) Поэтому мы используем:
fastcgi_buffers 32 32k; fastcgi_buffer_size 32k;
Еще команды для анализа логов — http://eddmann.com/posts/processing-apache-and-nginx-access-logs/
______________
☑ Команда вывода количество запущенных процессов владельцами (ориентировочно — приблизительно можно оценить количество аккаунтов на хостинге)
-Топ пользователей по количеству процессов:
ps auxwww|awk ‘{print($1)}’| sort| uniq -c | sort -n |tail
- 4 u011114
- 4 u9111116
- 5 apache
- 5 u0011115
- 16 nginx
- 20 u111115
- 35 postfix
- 429 root
429=70 акков (по 3-20 сайтов на акк) 
☑ Сколько чего чем запрашивается из ресурсов (top — потребителей) на сервере
ps auxwww|awk ‘{print($11)}’| sort| uniq -c | sort -n |tail
____________________
♷ V. Про память сервера, пока просто статистика,есть что сказать подскажите куда смотреть что с чем связано что кого тянет:
ОЗУ — оперативной памяти сервера
- cat /proc/meminfo
- vmstat -s
- cat /proc/mdstat
♸ VI. Список работающих в системе процессов и информации о них
top — консольная команда, которая выводит список работающих в системе процессов и информации о них. По умолчанию она в реальном времени сортирует их по нагрузке на процессор.
Чтобы выйти из программы top, нужно нажать клавишу [q].
Программа с частотой обновления в 2с показывает текущую активность процессов в виде таблицы. Стандартные колонки:
- PID — идентификатор процесса
- USERNAME — пользователь, от которого запущен процесс
- THR — количество потоков, запущенных процессом
- PRI — текущий приоритет процесса
- NICE — приоритет, выставленный командой nice. От 0 (наивысший) до 20.
- SIZE — размер процесса (данные, стек и т. д.) в килобайтах
- RES — текущее использование оперативной памяти
- STATE — текущее состояние («START», «RUN» (только в этом состоянии показывает текущую нагрузку программы на процессор), «SLEEP», «STOP», «ZOMB», «WAIT» или «LOCK»)
- C — номер процессора, на котором идет выполнение (доступен только на SMP системах)
- TIME — время использования процессора в секундах
- VIRT — полный объем виртуальной памяти, которую занимает процесс
- CPU — процент доступного времени процессора, которое использовала запущенная программа
- WCPU — усредненное значение CPU
- COMMAND — команда, запустившая процесс.
Чтобы выйти из программы top, нужно нажать клавишу [q].
Наиболее полезные интерактивные команды, которые можно использовать в top:
- [1] Отобразить всю статистику по всем ядрам.
- [c] Абсолютный путь расположения модуля команды и её аргументы.
- [M] Сортировать по объёму используемой памяти.
- [P] Сортировать по загрузке процессора.
- [u] Сортировать по имени пользователя.
- [z] Подсветить работающие процессы.
- [Z] Выбрать цвет подсветки.
- [h] Вывести справку о программе.
- [n] Изменить число отображаемых процессов. Вам предлагается ввести число.
- [r] Изменить приоритет процесса.
- [k] Уничтожить процесс. Программа запрашивает у вас код процесса и сигнал, который будет ему послан.
- [Пробел] Немедленно обновить содержимое экрана.


♹ VII. Про Advanced Web Statistics
На счет сервисов и служб анализатор логов предоставляемых хостингом — как можно видеть они мало чем по информации отличаются от метрики и аналитики (т.е. реальной картины нагрузки, запросов не дает) — если по ошибкам 404 -ответам там еще есть кое-что, то по другим моментам одни общии тенденции, с минимумом подробности, и отсутствием возможности делать срезы, как обрабатывать, выбирать.
Например типичный анализатор лога: Advanced Web Statistics






При этом метрика и аналитик отражают лишь реальных посетителей — т.е. от силы 1/3 от показанной «нагрузки» анализатором логов — т.е. от всех запросов (посетители + пауки, боты, парсеры и тд.)
ps. Данная страница не может не содержать ошибок и опечаток — это просто записки что бы не забыть.. есть что дополнить — исправить пишите в комментариях! Буду рад!
Добавить комментарий
Nginx — один из наиболее известных веб-серверов. Давайте разберемся о чем могут рассказать логи Nginx и как их удобнее анализировать.
При возникновении каких либо ошибок или же нежелательной активности на сайте первым делом стоит оценить масштаб трагедии:
- как часто сервер отвечает 500-ым кодом?
- как часто запрашивается отдельный URL?
- с какого IP адреса идет наибольшая активность?
- и так далее..
В этом всем поможет нам nginx-access.lognginx-error.log
Анализ nginx-access.log
Вывести строки содержащие ответы сервера с 50x кодами. На самом деле можно указывать различные варианты поискового текста:
grep "HTTP/1.1" 50" logs/nginx-access.log
Тоже самое, что и выше только выводит количество найденых строк:
grep "HTTP/1.1" 50" logs/nginx-access.log | wc -l
Вывести строки содержащие ответы сервера с 50x кодами из архивных файлов за май месяц:
zgrep "HTTP/1.1" 50" logs/nginx-access.log-202005*
Найти текст во всех файлах с именем nginx-access.log
find . -name "nginx-access.log" -exec grep "fields" {} ;
Вывести топ 20 самых «активных» IP адресов:
cat logs/nginx-access.log | awk -F" '{print $8}' | awk '{print $1}' | sort -n | uniq -c | sort -nr | head -20
Вывести топ 20 самых часто запрашиваемых URL адресов:
cat logs/nginx-access.log | awk '{print $7}' | sort -n | uniq -c | sort -nr | head -20
Вывести топ 20 самых активных User-Agent’ов:
cat logs/nginx-access.log | awk -F" '{print $6}' | sort -n | uniq -c | sort -nr | head -20
Использование GoAccess
Open-source анализатор логов, который может быть доступен как через командную строку, так и через браузер (об этом недавно узнал). Подробная информация размещена на официальном сайте — goaccess.io. У нас на работе она запускается следующим образом:
goaccess -p /etc/goaccess.conf -f logs/nginx-access.log
, где содержимое /etc/goaccess.conf
time-format %H:%M:%S
date-format %d/%b/%Y
log-format %^ - %^ [%d:%t %^] "%r" %s %b "%R" "%u" %T "%h,%^"
В общем, GoAccess освобождает вас от выполнения этих длинных и непонятных команд для получения самых активных IP адресов, самых популярных URL и так далее. Запуск в одну команду и порядка 15 секций данных для анализа.
Анализ nginx-error.log
На рабочих серверах редко приходилось обращаться к этому файлу. Обычно только за информацией о нехватке PHP воркеров 128 worker_connections are not enough
grep "worker_connections are not enough" logs/nginx-error.log
PHP logs are not just about errors. You can use logs to track the performance of API calls and function calls, or to count the occurrence of significant events in your applications (e.g., logins, signups, and downloads). Whether you’re operating a microservices architecture or a monolith, implementing a comprehensive PHP logging strategy will allow you to track critical changes in your applications and optimize their performance.
PHP and its available logging libraries give you many options for where to send and store your logs. As you’ll see in this post, storing your PHP logs in a central file is simple and gives you the greatest flexibility for processing and analyzing your logs later on. When you use a specialized tool to tail your log file and forward your logs to a central log management solution, your application code isn’t burdened with the overhead of buffering logs and handling network errors.
In this post, you’ll learn how to:
- configure the PHP system logger to automatically log errors
- use native PHP functions to log custom errors
- expand your logging capabilities with the Monolog logging library
- capture PHP exceptions and arbitrary events
How PHP creates logs
The PHP system logger creates logs automatically when the execution of your code produces an error. Additionally, you can create logs by calling PHP’s logging functions as you need to log custom errors and arbitrary events in your application. In this section, we’ll look at how logs are created and routed by each of these mechanisms.
The PHP system logger
You can configure the PHP system logger by using the error_reporting directive in PHP’s configuration file, php.ini, to designate the types of errors PHP will automatically log. This directive uses a set of predefined constants and bitwise operators to express what types of events to include and exclude from logs. For example, you would use this directive to log all errors:
PHP’s display_errors configuration directive gives you the option of displaying log messages in the browser. In a production environment, you should always set display_errors to Off for security reasons. However, in a development environment, you might want to display warnings and errors directly in the browser so developers can easily see information about the application’s status.
The PHP system logger routes logs in different ways depending on the value of the error_log configuration directive in php.ini:
- If
error_lognames a file, PHP writes its logs to that file. - If
error_logis set tosyslog, PHP sends logs to the OS logger. This is usuallysyslogor the newerrsyslog(which implements the syslog protocol) on Linux, orEvent Logon Windows. - If
error_logis unset, PHP creates logs using the Server API (SAPI). The SAPI used depends on your platform. As an example, a LAMP setup usesapacheas a SAPI, and logs are written to Apache’s error log.
To maximize the logging data available and to give yourself options for centralizing, processing, and analyzing your logs later, add the following configuration to your php.ini. (In PHP .ini files, a semicolon indicates the start of a comment.)
; Log all errors
error_reporting = E_ALL
; Don't display any errors in the browser
display_errors = Off
; Write all logs to this file:
error_log = my_file.log
Now your PHP logs are written to the my_file.log file we specified in the error_log directive above.
PHP’s logging functions
You can log any event you choose by explicitly calling PHP’s error_log() or syslog() function within your code. These functions create logs containing the message string you provide. The syslog() function will use the configuration in your rsyslog.conf file to write log messages. The error_log() function routes it to the file specified by the error_log configuration directive. The following example sends a message to the PHP system logger:
<?php
error_log("An error has occurred.");
The PHP system logger automatically adds a timestamp to each log, so each time this code runs, a line like the one below will be appended to our my_file.log file:
[15-Apr-2019 20:25:11 UTC] An error has occurred.
If no value is provided for the error_log configuration item in php.ini, logs are generated by the SAPI, and their format depends on the SAPI in use. For example, on a LAMP server with Apache’s default logging configuration, the example code shown above adds the following line to Apache’s error log (e.g., /var/log/apache2/error.log):
[Mon Apr 15 20:25:11.950260 2019] [php7:notice] [pid 26154] [client 123.123.123.123:57728] An error has occurred.
PHP’s error_log() and syslog() functions provide more options for configuring where your logs are sent. For example, when you call error_log(), you can provide a path to the file where the message should be logged that is different from the one defined by the error_log directive. For information about the advanced routing capabilities of PHP’s error_log() and syslog() functions, see the PHP documentation. In this article, we will focus on logging to a file, since this gives you the ability to forward and process your logs, as we described above.
Centralizing and storing your logs
So far, we’ve looked at PHP’s system logger and native logging functions. These mechanisms don’t provide much flexibility when you want to customize how your logs are formatted or routed, but they make it easy to get started writing logs to a local file. You can also process your logs with an external service. Consider a strategy that combines writing logs to a local file and forwarding them to an external service to aggregate, analyze, and monitor your logs. This way, you can offload log processing and long-term storage and aggregate logs from all your hosts in a single platform. You can troubleshoot an incident much more efficiently if you don’t have to manually log into each of your servers to view logs.
When you use a log management and analytics platform like Datadog, we recommend using JSON-formatted logs. This makes it easy to process, search, filter, and monitor your logs. To make it easy to create JSON logs and route them to a file, we recommend that you use the Monolog logging library. In the next section we will cover how to use the Monolog library to format your logs as JSON and automatically add metadata to all your logs.
The Monolog logging library
Monolog is one of the most widely used PHP logging libraries. It provides all the functionality of PHP’s native logging functions, and makes it easy to create PHP logs in different formats. You can easily differentiate logs within a single application by categorizing them in channels, and you can send your logs to databases, message queues, and external collaboration tools.
Monolog is available in the Packagist repository, and the examples in this section assume you’ve installed Monolog using Composer. If you already have Composer installed, all you need to do is issue this command to add Monolog to your project:
composer require monolog/monolog
In this section, we’ll look at some of the Monolog features that you can use to enhance your PHP logging. We’ll show you how to:
- create and organize logs using loggers and channels
- route logs using Monolog handlers
- use formatters to create JSON-formatted logs
- use processors to log uniform data
- assign appropriate log levels to events of different types
Loggers and channels
To start using Monolog, you need to create a logger—an instance of Monolog’s Logger class:
<?php
// Load dependencies required by Composer (including Monolog):
require_once "vendor/autoload.php";
// Use Monolog's `Logger` namespace:
use MonologLogger;
$logger = new Logger('transactions');
This code creates a logger object named $logger and gives it a channel name of transactions.
Monolog uses channels to differentiate logs that have been routed to the same destination but that contain data about different categories of events. Each time you create a logger, you need to provide a channel name. You can create multiple loggers within your application and use each one to log events related to a category of activity, such as purchases or user accounts. Because each logger’s channel value is associated with the logs it creates (as an object within a JSON-formatted log, for example), channels give you more latitude to use metadata to differentiate your logs.
Handlers
Monolog’s handlers determine how PHP will act on the log messages sent to each logger. The StreamHandler is Monolog’s basic means of writing logs to a file. Numerous other handlers are available so you can easily send logs to the service of your choice.
Once you’ve created a logger, you use it by defining one or more handlers and pushing them onto the Logger object. For each handler you create, you provide information about how it should route the log (e.g., a filename), and a minimum log level at which the handler should be triggered. By pushing multiple handlers onto a logger, you can use it to log different types of events to different destinations.
The following code illustrates pushing a handler on to the logger ($logger) we created above. It then calls Monolog’s info method to trigger the handler and log a message to the file /var/log/monolog/php.log:
<?php
require_once "vendor/autoload.php";
use MonologLogger;
use MonologHandlerStreamHandler;
$logger = new Logger('transactions');
// Declare a new handler and store it in the $logstream variable
// This handler will be triggered by events of log level INFO and above
$logstream = new StreamHandler('/var/log/monolog/php.log', Logger::INFO);
// Push the $logstream handler onto the Logger object
$logger->pushHandler($logstream);
$logger->info('A notable event has occurred.');
This logger creates logs in Monolog’s default format, but it’s easy to make Monolog structure your logs in a useful format. In the next sections of this post, we’ll look at the benefits you gain when you use the JsonFormatter to create your logs.
Formatters
Monolog allows you to define a custom log format, or you can choose an existing formatter to determine how your log messages appear. Monolog formatters are available to meet different logging requirements, and you can choose the one that best suits your needs.
Monolog’s JSONFormatter helps you structure your log data and lets you include any arbitrary data you require. This can make it easy to store multi-line errors in a single log line. You can also store information unique to each session by logging the PHP session array. JSON-formatted logs are easy for log management solutions to parse, so you can search, filter, and analyze your application’s data to track errors, usage, and performance trends.
The sample code below creates JSON logs with a channel value of transactions.
<?php
require_once "vendor/autoload.php";
use MonologLogger;
use MonologHandlerStreamHandler;
use MonologFormatterJsonFormatter;
$logger = new Logger('transactions');
$logstream = new StreamHandler('/var/log/monolog/php.log', Logger::INFO);
// Apply Monolog's built-in JsonFormatter
$logstream->setFormatter(new JsonFormatter());
$logger->pushHandler($logstream);
$logger->info('Transaction complete');
When PHP executes this code, a log is added to the specified file—/var/log/monolog/php.log—that looks like this:
{
"message": "Transaction complete",
"context": [],
"level": 200,
"level_name": "INFO",
"channel": "transactions",
"datetime": {
"date": "2019-02-14 17:19:11.332526",
"timezone_type": 3,
"timezone": "UTC"
},
"extra": []
}
To isolate these logs from those created by other loggers in your application, you can use a log management solution to filter your data and view only logs from the transactions channel.
Notice that Monolog automatically adds two arrays to this log—context and extra. You can use these arrays to enrich your logs and provide more information about the activity you’re logging. In the next section, we’ll look at how to create and populate these arrays.
Processors
The context and extra arrays give you options for easily adding metadata to each log. You can use them to store any data that’s useful to you. We recommend using context to log the high-cardinality data that varies between sessions, and extra to log global metadata that’s common to all requests. In this section we’ll illustrate how you can use the two arrays to store different kinds of data.
You can use a Monolog processor to define metadata to be added to each log’s context and extra arrays. Processors make it easy to include the same information consistently across all the logs created by a single logger. The following example defines a Monolog processor to include context and extra data:
<?php
require_once "vendor/autoload.php";
use MonologLogger;
use MonologHandlerStreamHandler;
use MonologFormatterJsonFormatter;
$logger = new Logger('transactions');
$logstream = new StreamHandler('/var/log/monolog/php.log', Logger::INFO);
$logstream->setFormatter(new JsonFormatter());
$logger->pushHandler($logstream);
$logger->pushProcessor(function ($record) {
$record['extra']['env'] = 'staging';
$record['extra']['version'] = '1.1';
$record['context'] = array('user' => $_SESSION["user"], 'customerID' => $_SESSION["customerID"], 'checkoutValue' => $_SESSION["checkoutValue"], 'sku_array' => $_SESSION["sku"]);
return $record;
});
$logger->info('Transaction complete');
In the resulting log, both the context and extra arrays are populated.
{
"message": "Transaction complete",
"context": {
"user": "user@example.com",
"customerID": 12102,
"checkoutValue": "17.39",
"sku_array": [468, 116]
},
"level": 200,
"level_name": "INFO",
"channel": "transactions",
"datetime": {
"date": "2019-04-16 15:46:16.531986",
"timezone_type": 3,
"timezone": "UTC"
},
"extra": {
"env": "staging",
"version": "1.1"
}
}
You can also pass context array data as an argument to the method you use to create the log. The example below illustrates passing the log message and context data in a single call:
$logger->info('Transaction complete', array('user' => $_SESSION["user"], 'customerID' => $_SESSION["customerID"], 'checkoutValue' => $_SESSION["checkoutValue"], 'sku_array' => $_SESSION["sku"]));
Log levels
PHP’s error_log() function assumes all messages describe errors within your application, but Monolog allows you to log other types of PHP events as well. Monolog supports eight different log levels—the same ones defined in the syslog protocol—so that each log carries metadata that conveys the severity of the event being logged.
When you call the Monolog function to create a log, you specify the log’s level. This way, you
can log the types of events (e.g., debug, error, or alert) you need to know about. For example, to log an event whose log level is error, you would call the logger’s error method as shown below:
$logger->error('Transaction failed');
Of course, you don’t want to have to revise your code during an outage to log debug messages. Instead you can configure your application to log events of all levels, and use a log management solution to filter logs downstream to isolate certain kinds of events.
Expanding your logging coverage
Because PHP logging is flexible, you have options in how much to log and how to handle your logs. In this section, we’ll look at how PHP exceptions work and how to capture them. We’ll also show you how to expand your logging to capture useful information about different types of events—not just errors.
Centralize and organize your PHP logging for easier analysis with Datadog.
Catch and log exceptions
Like many other languages, PHP uses exceptions to accommodate unintended behavior by your application. An exception is an object PHP creates (or throws) when the execution of your PHP script reaches an unintended state.
Exceptions should be caught when they occur—governed by code that addresses the exceptional case. The exception handler—the code that catches the exception—defines PHP’s behavior and output when faced with an exception. PHP does not automatically log exceptions when they are thrown, so you should create exception handlers that log useful information about the exception.
The code below shows an example of a basic exception handling strategy. The checkUsername function validates the length of the string passed to it, then throws exceptions under certain conditions. The function is called from within a try block, and a catch block handles any exceptions and logs the details.
<?php
require_once "vendor/autoload.php";
use MonologLogger;
use MonologHandlerStreamHandler;
use MonologFormatterJsonFormatter;
$logger = new Logger('signups');
$logstream = new StreamHandler('/var/log/monolog/php.log', Logger::INFO);
$logstream->setFormatter(new JsonFormatter());
$logger->pushHandler($logstream);
function checkUsername($username) {
if (strlen($username) < 4) {
throw new Exception("Username $username is not long enough.");
} else if (strlen($username) > 12) {
throw new Exception("Username $username is too long.");
}
// $username is OK
}
try {
checkUsername('me');
} catch (exception $e) {
$message_string = "{$e->getMessage()} (file: {$e->getFile()}, line: {$e->getLine()})";
$logger->error($message_string);
}
When PHP throws an exception, it creates an exception object (named $e in the example above) that is available for the exception handler to use. The exception object contains properties, such as the file and lines of code that have caused the unintended state, that describe the state of the application. It also provides methods you can use to access those properties (such as getMessage() in the example above). You can use an exception handler to access the data contained in the exception object and log details of the exception.
The code above will append a line like this one to the file /var/log/monolog/php.log:
{
"message": "Username me is not long enough. (file: /var/www/html/checkUsername.php, line: 17)",
"context": [],
"level": 400,
"level_name": "ERROR",
"channel": "signups",
"datetime": {
"date": "2019-04-11 20:33:45.500634",
"timezone_type": 3,
"timezone": "UTC"
},
"extra": []
}
Better than logging only the message returned by the exception’s getMessage() method, you should log the exception object itself. The PHP logging standard that Monolog implements, PSR-3, states that a logged exception must be in the exception element of the context array. To log the whole exception object, change the $logger->error() call in the previous example to look like this instead:
$logger->error("checkUsername failed", array('exception' => $e));
When you log the exception object, all the information it contains is recorded in the log as JSON, as shown in this example log:
{
"message": "checkUsername failed",
"context": {
"exception": {
"class": "Exception",
"message": "Username me is not long enough.",
"code": 0,
"file": "/var/www/html/checkUsername.php:16"
}
},
"level": 400,
"level_name": "ERROR",
"channel": "signups",
"datetime": {
"date": "2019-04-24 15:01:17.656613",
"timezone_type": 3,
"timezone": "UTC"
},
"extra": []
}
If you use a log management service, you can use the exception object’s data to view, filter, and analyze your logs.
Catch unhandled exceptions
If your code doesn’t include a handler for a particular exception, PHP will generate a fatal error and halt execution. To prevent this, you can use PHP’s set_exception_handler() function to define your own default exception handler. This way you can avoid the fatal error caused by an unhandled exception, and you can capture the exception in your logs. The example below uses set_exception_handler() to catch and log any unhandled exceptions.
<?php
require_once "vendor/autoload.php";
use MonologLogger;
use MonologHandlerStreamHandler;
use MonologFormatterJsonFormatter;
$logger = new Logger('signups');
$logstream = new StreamHandler('/var/log/monolog/php.log', Logger::INFO);
$logstream->setFormatter(new JsonFormatter());
$logger->pushHandler($logstream);
// Define default behavior if an exception isn't caught:
set_exception_handler( function($e) {
$uncaught_log = new Logger('uncaught');
$uncaught_logstream = new StreamHandler('/var/log/monolog/php.log', Logger::ERROR);
$uncaught_logstream->setFormatter(new JsonFormatter());
$uncaught_log->pushHandler($uncaught_logstream);
$uncaught_log->error("Uncaught exception", array('exception' => $e));
});
// Declare an empty class
class myClass {
// empty
}
// Try to call a non-existent function
try {
myClass::myFunction();
} catch (Exception $e) {
$logger->error("Call to myFunction failed", array('exception' => $e));
}
In this code, set_exception_handler() processes the exception thrown when the nonexistent myFunction() is called. It serves as the default exception handler, and will process any uncaught exceptions throughout the script (any of which would otherwise have caused a PHP fatal error).
When this code is executed, it logs an exception like the one below:
{
"message": "Uncaught exception",
"context": {
"exception": {
"class": "Error",
"message": "Call to undefined method myClass::myFunction()",
"Code": 0,
"file": "/var/www/html/test_exception_handler.php:30"
}
},
"level": 400,
"level_name": "ERROR",
"channel": "uncaught",
"datetime": {
"date": "2019-04-11 19:20:20.241717",
"timezone_type": 3,
"timezone": "UTC"
},
"extra": []
}
Note that it does not log the Call to myFunction failed error from the catch block. The code in the catch block would execute if myFunction() threw an exception, but in this case PHP throws an exception when we try to call the nonexistent myFunction(). Since that exception is uncaught, it gets processed by the function defined in set_exception_handler().
Log events (not just errors)
In addition to the errors the PHP system logger records automatically, you can log custom events such as API calls to and from your application. Logging these events allows you to monitor your application’s performance and usage trends. In an application made up of microservices, pretty much everything will be an API call, and you can add custom logging code around any calls worthy of attention. The example below calculates the response time of an API call, then uses Monolog to log the result.
<?php
require_once "vendor/autoload.php";
use MonologLogger;
use MonologHandlerStreamHandler;
use MonologFormatterJsonFormatter;
$logger = new Logger('APIperformance');
$logstream = new StreamHandler('/var/log/monolog/php.log', Logger::INFO);
$logstream->setFormatter(new JsonFormatter());
$logger->pushHandler($logstream);
function myAPIcall() {
$curl = curl_init();
$url = 'http://dummy.restapiexample.com/api/v1/employees';
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$result = curl_exec($curl);
curl_close($curl);
return $result;
}
$logger->pushProcessor(function ($record) {
$record['extra']['env'] = 'staging';
$record['extra']['version'] = '1.1';
return $record;
});
$start = microtime(TRUE); // A timestamp before the call
$result = myAPIcall();
$end = microtime(TRUE); // Another timestamp after the call
// Log the call duration as a readable string
// and include the context array
$logger->info("myAPIcall took " . ($end - $start) . " seconds.", array('duration' => ($end - $start)), array('user' => $_SESSION["user"], 'customerID' => $_SESSION["customerID"], 'checkoutValue' => $_SESSION["checkoutValue"], 'sku_array' => $_SESSION["sku"]));
Each time this function runs, your logs collect data on the performance of the API call, which you can visualize in a service like Datadog:
In addition to logging API calls, you can expand your logging coverage to capture logins and logouts, as well as other user activity such as signups and transactions.
With all your logs aggregated in one place, Datadog’s Log Analytics makes it easy for you to visualize log data. For example, you can see your aggregated log volume, grouped by channel to understand the amount of activity across the different areas of your application.
From this view, you can export the graph to a dashboard or click to see individual logs. You can even create a monitor to alert on your log data, so you can automatically be notified of any unusual activity captured in your application logs.
For further information about using Monolog and Datadog, see our documentation.
Do more with your PHP logs
PHP logging offers a lot of flexibility that enables you to capture the right information and make it available for troubleshooting and monitoring. Once you’ve configured your applications to log all the information that might be useful to you, you can send your logs to a monitoring platform for in-depth analysis and collaborative troubleshooting. If you’re not already using Datadog to collect and analyze your logs, you can start with a free, full-featured 14-day trial.
Веб-серверы Apache могут генерировать много логов.
Эти логи содержат различную информацию, такую как HTTP-запросы, которые Apache обработал и ответил, и другие действия, специфичные для Apache.
Анализ журналов является важной частью администрирования Apache и обеспечения его правильной работы.
В этом руководстве мы рассмотрим различные параметры ведения журналов, представленные в Apache, и способы их интерпретации.
Вы узнаете, как анализировать логи, которые создает Apache, и как настроить параметры ведения журналов, чтобы предоставить вам наиболее релевантные данные о том, что делает Apache.
В этом руководстве вы узнаете как:
- Настроить и понять ведение журналов веб-сервера Apache
- Каковы уровни журнала Apache
- Как интерпретировать форматирование логов Apache и их значение
- Каковы наиболее распространенные файлы конфигурации логгирования Apache
- Как расширить конфигурацию логгирования, чтобы включить форензику
Содержание
- Логи Apache и их расположение
- Форматирование логов Apache
- Настройка логов Apache
- Директивы логов
- Модули логов Apache
- Заключение
Логи Apache и их расположение
Apache создает два разных файла журнала:
- access.log хранит информацию обо всех входящих запросах на подключение к Apache. Каждый раз, когда пользователь посещает ваш сайт, это будет зарегистрирован здесь. Каждая страница, которую запрашивает пользователь, также будет зарегистрирована как отдельная запись.
- error.log хранит информацию об ошибках, с которыми Apache сталкивается на протяжении всей своей работы. В идеале этот файл должен оставаться относительно пустым.
Расположение файлов журналов может зависеть от того, какую версию Apache вы используете и какой дистрибутив Linux вы используете.
Apache также может быть настроен для хранения этих файлов в другом месте, отличном от заданного по умолчанию.
Но по умолчанию вы сможете найти журналы доступа и ошибок в одном из следующих каталогов:
- /var/log/apache/
- /var/log/apache2/
- /etc/httpd/logs/
Форматирование логов Apache
Apache позволяет вам настраивать, какая информация регистрируется и как представляется каждая запись в журнале, что мы рассмотрим позже в этом руководстве.
Обычный формат, которым следует Apache для представления записей журнала:
"%h %l %u %t "%r" %>s %O "%{Referer}i" "%{User-Agent}i""
Вот как можно интерпретировать это форматирование:
- %h –IP-адрес клиента.
- %l –Это «идентификатор» на клиенте, который используется для идентификации. Это поле обычно пустое и представляется как дефис.
- %u – Идентификатор пользователя клиента, если использовалась HTTP-аутентификация. Если нет, в записи журнала ничего для этого поля не будет отображаться.
- %t –Отметка времени записи в журнале.
- %r –Строка запроса от клиента. Этот параметр покажет, какой метод HTTP был использован (например, GET или POST), какой файл был запрошен и какой протокол HTTP был использован.
- %>s –Код состояния, который был возвращен клиенту. Коды 4xx (например, 404, страница не найдена) указывают на ошибки клиента, а коды 5xx (например, 500, внутренняя ошибка сервера) указывают на ошибки сервера. Другие числа должны указывать успешную работу (например, 200, ОК) или что-то еще, например, перенаправление (например, 301).
- %O –Размер файла (включая заголовки) в байтах, который был запрошен.
- ”%{Referer}i”– Ссылка на ссылку. Параметр говорит о том, как пользователь перешел на вашу страницу (по внутренней или внешней ссылке).
- ”%{User-Agent}i” – Содержит информацию о подключающемся веб-браузере клиента и операционной системе.
Типичная запись в журнале access.log будет выглядеть примерно так:
10.10.220.3 - - [17/Dec/2019:23:05:32 -0500] "GET /products/index.php HTTP/1.1" 200 5015 "http://example.com/products/index.php" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36"
Журнал ошибок ( error.log )немного более прост и легко интерпретируется.
Вот как может выглядеть типичная запись:
[Mon Dec 16 06:29:16.613789 2019] [php7:error] [pid 2095] [client 10.10.244.61:24145] script '/var/www/html/settings.php' not found or unable to stat
Это хороший способ узнать, сколько ошибок 404 встречают ваши посетители, и может помочь вам найти некоторые неработающие ссылки на вашем сайте.
Что еще более важно, эти логи могут предупредить вас о пропавших ресурсах или потенциальных проблемах с сервером.
В приведенном выше примере показана страница * .php, которая была запрошена, но отсутствует на сервере.
Настройка логов Apache
Ведение логов в Apache очень настраиваемо и может быть изменено с помощью пары файлов конфигурации.
В Ubuntu и Debian основной файл конфигурации для ведения журнала Apache находится здесь:
- /etc/apache2/apache2.conf
Поскольку вы можете запускать несколько веб-сайтов (называемых виртуальными хостами) из одного экземпляра Apache, вы также можете настроить каждый из них для отдельного ведения и журналов доступа и ошибок.
Чтобы определить, как должны называться эти отдельные файлы журналов и где их сохранять, настройте этот файл:
- /etc/apache2/sites-available/000-default.conf
На CentOS, RHEL и Fedora два файла конфигурации находятся, соответственно, в следующих местах:
- /etc/httpd/conf/httpd.conf
- /etc/httpd/conf.d/ (поместите дополнительные конфигурации VirtualHost в этот каталог)
Директивы логов
Существует несколько различных директив, которые можно настроить внутри этих файлов, но это основные из них, о которых вам следует позаботиться, если вы хотите настроить логи Apache:
- CustomLog – определяет, где хранится файл журнала доступа.
- ErrorLog – определяет, где хранится файл журнала ошибок.
- LogLevel – Определяет, насколько серьезным должно быть событие, чтобы его можно было зарегистрировать (подробнее см. Ниже).
- LogFormat – Определяет, как должна быть отформатирована каждая запись в журнале доступа (подробнее см. Ниже).
LogLevel по умолчанию настроен на warn, что означает, что он будет записывать в журнал error.log предупреждения или более серьезные события.
Если ваш журнал ошибок заполняется множеством безобидных предупреждающих сообщений, вы можете увеличить его до error, и система будет сообщать только об ошибках или более серьезных проблемах.
Другие варианты включают (в порядке серьезности)crit, alert, и emerg.
Apache рекомендует использовать уровень как минимум crit.
В целях отладки вы можете временно настроить LogLevel на debug, но имейте в виду, что вы можете получить громоздкое количество записей в журнале ошибок (error.log).
LogFormat позволяет вам настроить внешний вид записей в журнале доступа ( acces.log ).
Если вы считаете, что пример записи в access.log (из приведенного выше примера логов Apache) немного сбивает с толку, вы не одиноки в этом мнении.
Apache позволяет вам настроить формат записей журнала, дабы вы могли настроить их более логичным способом.
Вы также можете использовать эту настройку, чтобы исключить определенную информацию, которая может оказаться неактуальной.
Модули логов Apache
Настройка логов, которую мы пока показываем в этом руководстве, относится к модулю Apache mod_log_config.
Чтобы расширить функциональность логов, вы можете загрузить другие модули Apache.
Они могут предоставить вам некоторые дополнительные возможности, которые недоступны с настройками по умолчанию.
mod_log_forensic начинает запись перед запросом (когда заголовки получены впервые) и снова регистрируется после запроса.
Это означает, что для каждого запроса создаются две записи журнала, что позволяет администратору более точно измерять время ответа.
Определите местоположение вашего журнала форензики с помощью директивы CustomLog.
Например:
CustomLog ${APACHE_LOG_DIR}/forensic.log forensic
mod_logio записывает количество байтов, отправленных и полученных от каждого запроса.
Он предоставляет очень точную информацию, поскольку он также учитывает данные, присутствующие в заголовке и теле каждого запроса, а также дополнительные данные, которые требуются для зашифрованных соединений SSL / TLS.
Добавьте %I и O% % к директиве LogFormat, чтобы использовать дополнительные данные, предоставленные этим модулем.
Так же есть и другие модули; это лишь два из самых полезных.
Заключение
В этой статье мы увидели, как анализировать и интерпретировать acces.log и error.log Apache.
Мы также узнали, как настроить ведение журнала в файлах конфигурации Apache, чтобы сделать данные журнала более актуальными.
Вооружившись этими знаниями, вы сможете быстрее выявлять проблемы и решать их.
Помните, что функциональность логов в Apache может быть расширена с помощью других модулей, хотя это необходимо только в крайних случаях, которые требуют расширенной отладки.