It’s well known how to pipe the standard ouput of a process into another processes standard input:
proc1 | proc2
But what if I want to send the standard error of proc1 to proc2 and leave the standard output going to its current location? You would think bash would have a command along the lines of:
proc1 2| proc2
But, alas, no. Is there any way to do this?
asked Oct 2, 2009 at 5:11
![]()
paxdiablopaxdiablo
838k230 gold badges1561 silver badges1929 bronze badges
2
There is also process substitution. Which makes a process substitute for a file.
You can send stderr to a file as follows:
process1 2> file
But you can substitute a process for the file as follows:
process1 2> >(process2)
Here is a concrete example that sends stderr to both the screen and appends to a logfile
sh myscript 2> >(tee -a errlog)
![]()
mmlb
87710 silver badges24 bronze badges
answered Mar 27, 2012 at 11:28
![]()
3
You can use the following trick to swap stdout and stderr. Then you just use the regular pipe functionality.
( proc1 3>&1 1>&2- 2>&3- ) | proc2
Provided stdout and stderr both pointed to the same place at the start, this will give you what you need.
What the x>&y bit does is to change file handle x so it now sends its data to wherever file handle y currently points. For our specific case:
3>&1creates a new handle3which will output to the current handle1(original stdout), just to save it somewhere for the final bullet point below.1>&2modifies handle1(stdout) to output to the current handle2(original stderr).2>&3-modifies handle2(stderr) to output to the current handle3(original stdout) then closes handle3(via the-at the end).
It’s effectively the swap command you see in sorting algorithms:
temp = value1;
value1 = value2;
value2 = temp;
![]()
answered Oct 2, 2009 at 5:15
![]()
paxdiablopaxdiablo
838k230 gold badges1561 silver badges1929 bronze badges
7
Bash 4 has this feature:
If `|&’ is used, the standard error of command1 is connected to command2’s standard input through the pipe; it is shorthand for 2>&1 |. This implicit redirection of the standard error is performed after any redirections specified by the command.
zsh also has this feature.
—
With other/older shells, just enter this explicitly as
FirstCommand 2>&1 | OtherCommand
![]()
answered Oct 2, 2009 at 6:14
![]()
Dennis WilliamsonDennis Williamson
338k88 gold badges371 silver badges436 bronze badges
11
Swapping is great as it solves the problem. Just in case you do not even need the original stdout, you can do it this way:
proc1 2>&1 1>/dev/null | proc2
The order is vital; you would not want:
proc1 >/dev/null 2>&1 | proc1
As this will redirect everything to /dev/null!
![]()
Chadwick
12.5k7 gold badges48 silver badges66 bronze badges
answered Dec 16, 2011 at 14:24
![]()
kccqzykccqzy
1,48814 silver badges22 bronze badges
None of these really worked very well. The best way I found do do what you wanted is:
(command < input > output) 2>&1 | less
This only works for cases where command does not need keyboard input. eg:
(gzip -d < file.gz > file) 2>&1 | less
would put gzip errors into less
answered Feb 1, 2019 at 20:22
![]()
Pipe — что это?
Pipe (конвеер) – это однонаправленный канал межпроцессного взаимодействия. Термин был придуман Дугласом Макилроем для командной оболочки Unix и назван по аналогии с трубопроводом. Конвейеры чаще всего используются в shell-скриптах для связи нескольких команд путем перенаправления вывода одной команды (stdout) на вход (stdin) последующей, используя символ конвеера ‘|’:
cmd1 | cmd2 | .... | cmdN
Например:
$ grep -i “error” ./log | wc -l
43
grep выполняет регистронезависимый поиск строки “error” в файле log, но результат поиска не выводится на экран, а перенаправляется на вход (stdin) команды wc, которая в свою очередь выполняет подсчет количества строк.
Логика
Конвеер обеспечивает асинхронное выполнение команд с использованием буферизации ввода/вывода. Таким образом все команды в конвейере работают параллельно, каждая в своем процессе.
Размер буфера начиная с ядра версии 2.6.11 составляет 65536 байт (64Кб) и равен странице памяти в более старых ядрах. При попытке чтения из пустого буфера процесс чтения блокируется до появления данных. Аналогично при попытке записи в заполненный буфер процесс записи будет заблокирован до освобождения необходимого места.
Важно, что несмотря на то, что конвейер оперирует файловыми дескрипторами потоков ввода/вывода, все операции выполняются в памяти, без нагрузки на диск.
Вся информация, приведенная ниже, касается оболочки bash-4.2 и ядра 3.10.10.
Простой дебаг
Утилита strace позволяет отследить системные вызовы в процессе выполнения программы:
$ strace -f bash -c ‘/bin/echo foo | grep bar’
....
getpid() = 13726 <– PID основного процесса
...
pipe([3, 4]) <– системный вызов для создания конвеера
....
clone(....) = 13727 <– подпроцесс для первой команды конвеера (echo)
...
[pid 13727] execve("/bin/echo", ["/bin/echo", "foo"], [/* 61 vars */]
.....
[pid 13726] clone(....) = 13728 <– подпроцесс для второй команды (grep) создается так же основным процессом
...
[pid 13728] stat("/home/aikikode/bin/grep",
...
Видно, что для создания конвеера используется системный вызов pipe(), а также, что оба процесса выполняются параллельно в разных потоках.
Много исходного кода bash и ядра
Исходный код, уровень 1, shell
Т. к. лучшая документация — исходный код, обратимся к нему. Bash использует Yacc для парсинга входных команд и возвращает ‘command_connect()’, когда встречает символ ‘|’.
parse.y:
1242 pipeline: pipeline ‘|’ newline_list pipeline
1243 { $$ = command_connect ($1, $4, ‘|’); }
1244 | pipeline BAR_AND newline_list pipeline
1245 {
1246 /* Make cmd1 |& cmd2 equivalent to cmd1 2>&1 | cmd2 */
1247 COMMAND *tc;
1248 REDIRECTEE rd, sd;
1249 REDIRECT *r;
1250
1251 tc = $1->type == cm_simple ? (COMMAND *)$1->value.Simple : $1;
1252 sd.dest = 2;
1253 rd.dest = 1;
1254 r = make_redirection (sd, r_duplicating_output, rd, 0);
1255 if (tc->redirects)
1256 {
1257 register REDIRECT *t;
1258 for (t = tc->redirects; t->next; t = t->next)
1259 ;
1260 t->next = r;
1261 }
1262 else
1263 tc->redirects = r;
1264
1265 $$ = command_connect ($1, $4, ‘|’);
1266 }
1267 | command
1268 { $$ = $1; }
1269 ;
Также здесь мы видим обработку пары символов ‘|&’, что эквивалентно перенаправлению как stdout, так и stderr в конвеер. Далее обратимся к command_connect():make_cmd.c:
194 COMMAND *
195 command_connect (com1, com2, connector)
196 COMMAND *com1, *com2;
197 int connector;
198 {
199 CONNECTION *temp;
200
201 temp = (CONNECTION *)xmalloc (sizeof (CONNECTION));
202 temp->connector = connector;
203 temp->first = com1;
204 temp->second = com2;
205 return (make_command (cm_connection, (SIMPLE_COM *)temp));
206 }
где connector это символ ‘|’ как int. При выполнении последовательности команд (связанных через ‘&’, ‘|’, ‘;’, и т. д.) вызывается execute_connection():execute_cmd.c:
2325 case ‘|’:
...
2331 exec_result = execute_pipeline (command, asynchronous, pipe_in, pipe_out, fds_to_close);
PIPE_IN и PIPE_OUT — файловые дескрипторы, содержащие информацию о входном и выходном потоках. Они могут принимать значение NO_PIPE, которое означает, что I/O является stdin/stdout.
execute_pipeline() довольно объемная функция, имплементация которой содержится в execute_cmd.c. Мы рассмотрим наиболее интересные для нас части.
execute_cmd.c:
2112 prev = pipe_in;
2113 cmd = command;
2114
2115 while (cmd && cmd->type == cm_connection &&
2116 cmd->value.Connection && cmd->value.Connection->connector == ‘|’)
2117 {
2118 /* Создание конвеера между двумя командами */
2119 if (pipe (fildes) < 0)
2120 { /* возвращаем ошибку */ }
.......
/* Выполняем первую команду из конвейера, используя в качестве
входных данных prev — вывод предыдущей команды, а в качестве
выходных fildes[1] — выходной файловый дескриптор, полученный
в результате вызова pipe() */
2178 execute_command_internal (cmd->value.Connection->first, asynchronous,
2179 prev, fildes[1], fd_bitmap);
2180
2181 if (prev >= 0)
2182 close (prev);
2183
2184 prev = fildes[0]; /* Наш вывод становится вводом для следующей команды */
2185 close (fildes[1]);
.......
2190 cmd = cmd->value.Connection->second; /* “Сдвигаемся” на следующую команду из конвейера */
2191 }
Таким образом, bash обрабатывает символ конвейера путем системного вызова pipe() для каждого встретившегося символа ‘|’ и выполняет каждую команду в отдельном процессе с использованием соответствующих файловых дескрипторов в качестве входного и выходного потоков.
Исходный код, уровень 2, ядро
Обратимся к коду ядра и посмотрим на имплементацию функции pipe(). В статье рассматривается ядро версии 3.10.10 stable.
fs/pipe.c (пропущены незначительные для данной статьи участки кода):
/*
Максимальный размер буфера конвейера для непривилегированного пользователя.
Может быть выставлен рутом в файле /proc/sys/fs/pipe-max-size
*/
35 unsigned int pipe_max_size = 1048576;
/*
Минимальный размер буфера конвеера, согласно рекомендации POSIX
равен размеру одной страницы памяти, т.е. 4Кб
*/
40 unsigned int pipe_min_size = PAGE_SIZE;
869 int create_pipe_files(struct file **res, int flags)
870 {
871 int err;
872 struct inode *inode = get_pipe_inode();
873 struct file *f;
874 struct path path;
875 static struct qstr name = {. name = “” };
/* Выделяем dentry в dcache */
881 path.dentry = d_alloc_pseudo(pipe_mnt->mnt_sb, &name);
/* Выделяем и инициализируем структуру file. Обратите внимание
на FMODE_WRITE, а также на флаг O_WRONLY, т.е. эта структура
только для записи и будет использоваться как выходной поток
в конвеере. К флагу O_NONBLOCK мы еще вернемся. */
889 f = alloc_file(&path, FMODE_WRITE, &pipefifo_fops);
893 f->f_flags = O_WRONLY | (flags & (O_NONBLOCK | O_DIRECT));
/* Аналогично выделяем и инициализируем структуру file для чтения
(см. FMODE_READ и флаг O_RDONLY) */
896 res[0] = alloc_file(&path, FMODE_READ, &pipefifo_fops);
902 res[0]->f_flags = O_RDONLY | (flags & O_NONBLOCK);
903 res[1] = f;
904 return 0;
917 }
918
919 static int __do_pipe_flags(int *fd, struct file **files, int flags)
920 {
921 int error;
922 int fdw, fdr;
/* Создаем структуры file для файловых дескрипторов конвеера
(см. функцию выше) */
927 error = create_pipe_files(files, flags);
/* Выбираем свободные файловые дескрипторы */
931 fdr = get_unused_fd_flags(flags);
936 fdw = get_unused_fd_flags(flags);
941 audit_fd_pair(fdr, fdw);
942 fd[0] = fdr;
943 fd[1] = fdw;
944 return 0;
952 }
/* Непосредственно имплементация функций
int pipe2(int pipefd[2], int flags)... */
969 SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags)
970 {
971 struct file *files[2];
972 int fd[2];
/* Создаем структуры для ввода/вывода и ищем свободные дескрипторы */
975 __do_pipe_flags(fd, files, flags);
/* Копируем файловые дескрипторы из kernel space в user space */
977 copy_to_user(fildes, fd, sizeof(fd));
/* Назначаем файловые дескрипторы указателям на структуры */
984 fd_install(fd[0], files[0]);
985 fd_install(fd[1], files[1]);
989 }
/* ...и int pipe(int pipefd[2]), которая по сути является
оболочкой для вызова pipe2 с дефолтными флагами; */
991 SYSCALL_DEFINE1(pipe, int __user *, fildes)
992 {
993 return sys_pipe2(fildes, 0);
994 }
Если вы обратили внимание, в коде идет проверка на флаг O_NONBLOCK. Его можно выставить используя операцию F_SETFL в fcntl. Он отвечает за переход в режим без блокировки I/O потоков в конвеере. В этом режиме вместо блокировки процесс чтения/записи в поток будет завершаться с errno кодом EAGAIN.
Максимальный размер блока данных, который будет записан в конвейер, равен одной странице памяти (4Кб) для архитектуры arm:
arch/arm/include/asm/limits.h:
8 #define PIPE_BUF PAGE_SIZE
Для ядер >= 2.6.35 можно изменить размер буфера конвейера:
fcntl(fd, F_SETPIPE_SZ, <size>)
Максимально допустимый размер буфера, как мы видели выше, указан в файле /proc/sys/fs/pipe-max-size.
Tips & trics
В примерах ниже будем выполнять ls на существующую директорию Documents и два несуществующих файла: ./non-existent_file и. /other_non-existent_file.
-
Перенаправление и stdout, и stderr в pipe
ls -d ./Documents ./non-existent_file ./other_non-existent_file 2>&1 | egrep “Doc|other” ls: cannot access ./other_non-existent_file: No such file or directory ./Documentsили же можно использовать комбинацию символов ‘|&’ (о ней можно узнать как из документации к оболочке (man bash), так и из исходников выше, где мы разбирали Yacc парсер bash):
ls -d ./Documents ./non-existent_file ./other_non-existent_file |& egrep “Doc|other” ls: cannot access ./other_non-existent_file: No such file or directory ./Documents -
Перенаправление _только_ stderr в pipe
$ ls -d ./Documents ./non-existent_file ./other_non-existent_file 2>&1 >/dev/null | egrep “Doc|other” ls: cannot access ./other_non-existent_file: No such file or directoryShoot yourself in the foot
Важно соблюдать порядок перенаправления stdout и stderr. Например, комбинация ‘>/dev/null 2>&1′ перенаправит и stdout, и stderr в /dev/null. -
Получение корректного кода завершения конвейра
По умолчанию, код завершения конвейера — код завершения последней команды в конвеере. Например, возьмем исходную команду, которая завершается с ненулевым кодом:
$ ls -d ./non-existent_file 2>/dev/null; echo $? 2И поместим ее в pipe:
$ ls -d ./non-existent_file 2>/dev/null | wc; echo $? 0 0 0 0Теперь код завершения конвейера — это код завершения команды wc, т.е. 0.
Обычно же нам нужно знать, если в процессе выполнения конвейера произошла ошибка. Для этого следует выставить опцию pipefail, которая указывает оболочке, что код завершения конвейера будет совпадать с первым ненулевым кодом завершения одной из команд конвейера или же нулю в случае, если все команды завершились корректно:
$ set -o pipefail $ ls -d ./non-existent_file 2>/dev/null | wc; echo $? 0 0 0 2Shoot yourself in the foot
Следует иметь в виду “безобидные” команды, которые могут вернуть не ноль. Это касается не только работы с конвейерами. Например, рассмотрим пример с grep:$ egrep “^foo=[0-9]+” ./config | awk ‘{print “new_”$0;}’Здесь мы печатаем все найденные строки, приписав ‘new_’ в начале каждой строки, либо не печатаем ничего, если ни одной строки нужного формата не нашлось. Проблема в том, что grep завершается с кодом 1, если не было найдено ни одного совпадения, поэтому если в нашем скрипте выставлена опция pipefail, этот пример завершится с кодом 1:
$ set -o pipefail $ egrep “^foo=[0-9]+” ./config | awk ‘{print “new_”$0;}’ >/dev/null; echo $? 1В больших скриптах со сложными конструкциями и длинными конвеерами можно упустить этот момент из виду, что может привести к некорректным результатам.
-
Присвоение значений переменным в конвейере
Для начала вспомним, что все команды в конвейере выполняются в отдельных процессах, полученных вызовом clone(). Как правило, это не создает проблем, за исключением случаев изменения значений переменных.
Рассмотрим следующий пример:$ a=aaa $ b=bbb $ echo “one two” | read a bМы ожидаем, что теперь значения переменных a и b будут “one” и “two” соответственно. На самом деле они останутся “aaa” и “bbb”. Вообще любое изменение значений переменных в конвейере за его пределами оставит переменные без изменений:
$ filefound=0 $ find . -type f -size +100k | while true do read f echo “$f is over 100KB” filefound=1 break # выходим после первого найденного файла done $ echo $filefound;Даже если find найдет файл больше 100Кб, флаг filefound все равно будет иметь значение 0.
Возможны несколько решений этой проблемы:- использовать
set -- $varДанная конструкция выставит позиционные переменные согласно содержимому переменной var. Например, как в первом примере выше:
$ var=”one two” $ set -- $var $ a=$1 # “one” $ b=$2 # “two”Нужно иметь в виду, что в скрипте при этом будут утеряны оригинальные позиционные параметры, с которыми он был вызван.
- перенести всю логику обработки значения переменной в тот же подпроцесс в конвейере:
$ echo “one” | (read a; echo $a;) one - изменить логику, чтобы избежать присваивания переменных внутри конвеера.
Например, изменим наш пример с find:$ filefound=0 $ for f in $(find . -type f -size +100k) # мы убрали конвейер, заменив его на цикл do read f echo “$f is over 100KB” filefound=1 break done $ echo $filefound; - (только для bash-4.2 и новее) использовать опцию lastpipe
Опция lastpipe дает указание оболочке выполнить последнюю команду конвейера в основном процессе.$ (shopt -s lastpipe; a=”aaa”; echo “one” | read a; echo $a) oneВажно, что в командной строке необходимо выставить опцию lastpipe в том же процессе, где будет вызываться и соответствующий конвейер, поэтому скобки в примере выше обязательны. В скриптах скобки не обязательны.
- использовать
Дополнительная информация
- подробное описание синтаксиса конвеера: linux.die.net/man/1/bash (секция Pipelines), или ‘man bash’ в терминале.
- логика работы конвеера: linux.die.net/man/7/pipe или ‘man 7 pipe’
- исходный код оболочки bash: ftp.gnu.org/gnu/bash, репозиторий: git.savannah.gnu.org/cgit/bash.git
- ядро Linux: www.kernel.org
Bash Streams Handbook
Learn Bash streams, pipes and redirects, from beginner to advanced.

Contents
- Standard streams
- Standard input
- Standard output
- Standard error
- Redirection
- Pipelines
- Named pipes
- Command grouping
- Process Substitution
- Subshells
- Examples
- Contributing
- License
Standard streams
A data stream in the context of Bash is a communication channel between a program and the environment where the command was launched from.
There are three data standard streams that are created when a command is launched.
The three streams are:
- stdin — standard input
- stdout — standard output
- stderr — standard error
Further more:
- The standard input stream accepts text as it’s input.
- The text output from the command is sent to the shell though the standard output stream.
- Error messages from the command is sent to the shell through the standard error stream.
These data streams are treated as files meaning you read from them and write to them as if they are regular files. Files are identified by a unique number called a file descriptor, which the process uses to perform read/write operations.
When a command is launched, the first three file descriptors are allocated for the standard streams in the TTY. A TTY is the input/output environment, which is the terminal. This is different than a shell, which refers to the command-line interpreter.
Standard stream file descriptors:
- 0: stdin
- 1: stdout
- 2: stderr
File descriptor 0 is dedicated for standard input, 1 for standard output, and 2 for standard error.
File descriptors are maintained under /proc/$pid/fd where $pid is the process id. The current process can be referenced by /proc/self/fd.
The locations of these file descriptors are in /proc/self/fd/0, /proc/self/fd/1, and /proc/self/fd/2 respectively.
$ ls -la /proc/self/fd total 0 dr-x------ 2 mota mota 0 Sep 29 16:13 ./ dr-xr-xr-x 9 mota mota 0 Sep 29 16:13 ../ lrwx------ 1 mota mota 64 Sep 29 16:13 0 -> /dev/pts/9 lrwx------ 1 mota mota 64 Sep 29 16:13 1 -> /dev/pts/9 lrwx------ 1 mota mota 64 Sep 29 16:13 2 -> /dev/pts/9 lr-x------ 1 mota mota 64 Sep 29 16:13 3 -> /proc/815170/fd/ lrwx------ 1 mota mota 64 Sep 29 16:13 6 -> /dev/pts/9
example gif

Bash forks a child process when launching a command and inherits the file descriptors from the parent process.
We can use $$ to get the parent process ID:
$ echo $$ 2317356 $ ps -p $$ PID TTY TIME CMD 2317356 pts/9 00:00:00 bash
example gif

Listing /proc/$$/fd will print the same information as before when using self because the $$ is expanded to the same process ID:
$ ls -la /proc/$$/fd total 0 dr-x------ 2 mota mota 0 Sep 27 19:33 ./ dr-xr-xr-x 9 mota mota 0 Sep 27 19:33 ../ lrwx------ 1 mota mota 64 Sep 27 19:33 0 -> /dev/pts/9 lrwx------ 1 mota mota 64 Sep 27 19:33 1 -> /dev/pts/9 lrwx------ 1 mota mota 64 Sep 27 19:33 2 -> /dev/pts/9 lrwx------ 1 mota mota 64 Sep 28 12:20 255 -> /dev/pts/9 lrwx------ 1 mota mota 64 Sep 27 19:33 6 -> /dev/pts/9
example gif

In the above examples, /dev/pts/9 is referencing the pseudo terminal device. A pts is a pseudo terminal device emulated by another program, such as xterm, tmux, ssh, etc.
Type the tty command to see the pts device path.
You’ll see a different number if you open up a new terminal window because it’s a new terminal device:
example gif

If we we’re on a native terminal device (non-pseudo) meaning the backend is hardware or kernel emulated (e.g. the console before launching the desktop environment), then the tty path will look something like /dev/tty1.
The file descriptor table looks like this, where the standard streams are reading/writing from the TTY.
0->/dev/pts/91->/dev/pts/92->/dev/pts/9
We can write data to the stdout file descriptor and you’ll see it be printed back at you:
$ echo "hello world" > /proc/self/fd/1 hello world
example gif

Same thing will occur if writing to the stderr file descriptor:
$ echo "hello world" > /proc/self/fd/2 hello world
example gif

We can read from from the stdin file descriptor and echo the input:
$ echo $(</proc/self/fd/0) a b c d a b c d
After running the command and typing text, press ctrl-d to stop reading from stdin. The inputed text will be printed.
example gif

If you’re not familar with the $(...) syntax, it allows you to use the result of the command as the the string argument since $() evaluates the expression. The < is the standard input redirect operator which we’ll go over in the redirection section.
symlinks
For convenience, the file descriptor path is symlinked to /dev/fd.
$ ls -l /dev/fd
lrwxrwxrwx 1 root root 13 Aug 26 23:14 /dev/fd -> /proc/self/fd
example gif

For convenience, the standard streams are symlinked to /dev/stdin, /dev/stdout, and /dev/stderr respectively.
$ ls -l /dev/std* lrwxrwxrwx 1 root root 15 Aug 26 23:14 /dev/stderr -> /proc/self/fd/2 lrwxrwxrwx 1 root root 15 Aug 26 23:14 /dev/stdin -> /proc/self/fd/0 lrwxrwxrwx 1 root root 15 Aug 26 23:14 /dev/stdout -> /proc/self/fd/1
example gif

These are the same:
/dev/stdin->/proc/self/fd/0/dev/stdout->/proc/self/fd/1/dev/stderr->/proc/self/fd/2
The symlinks are considered POSIX extensions, so they might not be available in all POSIX compliant systems.
Redirection
Redirection operators allow control of where input and output streams should go. When you see > it means redirection. The following are some of the redirect operators in Bash:
>— redirect output, overwriting target if exists>>— redirect output, appending instead of overwriting if target exists&#>— redirect file descriptor #, where # is the identifier<— redirect input
Standard streams are can be referenced by their file descriptor identifiers. An ampersand & followed by the identifier number, ie &1, references a file descriptor when redirecting.
For example:
command 1> out.log— outputs file descriptor 1 (stdout) to file.command 2> out.log— outputs file descriptor 2 (stderr) to file.command 3> out.log— outputs file descriptor 3 (a custom file descriptor) to file.
Common redirects:
1>— redirects stdout only. This is also the same as simply doing>2>— redirects stderr only2>&1— redirects stderr to stdout. The2>is redirecting the standard error output into file descriptor1which is standard out. The final output will contain both stdout and stderr output, if any.- ‘&>’ — redirect stdout and stderr. THis is also the same as the above
2>&1
For example:
command 2>&1 > out.log— says «point output of FD #2 to FD #1, and ouput FD #1 to out file».
The reason an ampersand is required is because command 2>1 would be ambiguous; it wouldn’t be clear if it was redirecting to file descriptor 1 or to a filename named 1, so the & is required to explicitly reference it as the file descriptor.
Do note that &1 (file descriptor 1) is different than a single & (run in background) and double && (AND operator). The ampersand has different meaning depending on the way it’s used.
Other redirect operators (this will be explained in later sections):
<<— «Here documents», a special-purpose code block<<<— «Here strings», a striped-down form of a here document.
Example: demonstration of the different redirect operators:
Write stdout output of ls list format to list.txt file:
$ ls
archive.zip book.pdf notes.txt
$ ls -l > list.txt
$ cat list.txt
total 0
-rw-r--r-- 1 mota mota 0 Sep 30 14:17 archive.zip
-rw-r--r-- 1 mota mota 0 Sep 30 14:17 book.pdf
-rw-r--r-- 1 mota mota 0 Sep 30 14:19 list.txt
-rw-r--r-- 1 mota mota 0 Sep 30 14:17 notes.txt
example gif

Append new stdout output of ls showing hidden files to same list.txt file:
$ ls -a . .. archive.zip book.pdf .cache .config notes.txt $ ls -a >> list.txt $ cat list.txt total 0 -rw-r--r-- 1 mota mota 0 Sep 30 14:17 archive.zip -rw-r--r-- 1 mota mota 0 Sep 30 14:17 book.pdf -rw-r--r-- 1 mota mota 0 Sep 30 14:19 list.txt -rw-r--r-- 1 mota mota 0 Sep 30 14:17 notes.txt . .. archive.zip book.pdf .cache .config list.txt notes.txt
example gif

Search for particular filenames and write errors from stderr to errors.txt file:
$ ls *.json ls: cannot access '*.json': No such file or directory $ ls *.json 2> errors.txt $ cat errors.txt ls: cannot access '*.json': No such file or directory
example gif

Read errors.txt file as input to the less command:
$ less < errors.txt ls: cannot access '*.json': No such file or directory errors.txt (END)
example gif

Standard input
stdin (standard input) is an input stream where input data is sent to. The program reads the stream data as input for the program. stdin is a file descriptor we can write to. In most cases the standard input is input from the keyboard.
The stdin file descriptor is located at /proc/self/fd/0 but we can use the symlink /dev/stdin as well.
Data to be sent to program as input is redirected with <:
Example: Read stdin as input for bash script:
program.sh:
while read line do echo "hello $line" done < /dev/stdin
Create file with names:
$ printf "alicenbobn" > file.txt
Run program:
$ chmod +x program.sh
$ ./program.sh < file.txt
hello alice
hello bob
example gif

Example: For stdin demonstration purposes, you can send file data as input to the echo command by reading the file into a subshell and using the result as the echo arguments:
$ echo "hello world" > file.txt $ echo $(< file.txt) hello world
example gif

Standard output
stdout (standard output) is an output stream where data is sent to and then outputted by the terminal. stdout is a file descriptor we can write to.
The stdout file descriptor is located at /proc/self/fd/1 but we can use the symlink /dev/stdout as well.
The standard output of a program is redirect with 1> or simply just >:
The above is the same as command 1> stdout.log
Example: Redirect stdout to a file:
$ echo "hello world" > stdout.log $ cat stdout.log hello world
example gif

Trying to write to a file that can’t be opened for writing will make the command fail:
$ touch stdout.log $ chmod -w stdout.log $ echo "hello world" > stdout.log bash: stdout.log: Permission denied
example gif

Sometimes when we aren’t interested in the program stdout output, we can redirected to /dev/null to silence the output. This device file acts like a black hole for data streams.
Standard error
stderr (standard error) is an output stream where error data is sent to and then outputted by the terminal. stderr is a file descriptor we can write to.
The stderr file descriptor is located at /proc/self/fd/2 but we can use the symlink /dev/stderr as well.
The standard error of a program is redirect with 2>:
Example: Redirect stdout to the stderr file descriptor. stderr messages are outputted to the terminal:
$ echo "hello world" > /dev/stderr hello world
example gif

Example: Redirect the standard error messages to a file.
Redirecting with only > captures stdout and not stderr:
$ ls /foo > out.log ls: cannot access '/foo': No such file or directory $ cat out.log
example gif

We use 2> to redirect stderr only:
$ ls /foo 2> out.log $ cat out.log ls: cannot access '/foo': No such file or directory
example gif

Of course now the following won’t write anything to the file because there is no error:
$ ls /home 2> out.log
mota/
$ cat out.log
example gif

We can use 2>&1 to redirect stderr to stdout, and then redirect stdout to the file with > (or >> to append):
$ ls /home > out.log 2>&1 $ cat out.log mota/ $ ls /foo >> out.log 2>&1 $ cat out.log mota/ ls: cannot access '/foo': No such file or directory
example gif

Alternatively, we can redirect stdout to stderr with 1>&2 (or simply >&2), and then redirect stderr to the file with 2> (or 2>> to append):
$ ls /home 2> out.log 1>&2 $ cat out.log mota/ $ ls /foo 2>> out.log 1>&2 $ cat out.log mota/ ls: cannot access '/foo': No such file or directory
example gif

Since > is shorthand for 1>, we can replace 1>&2 with >&2 and it’ll work the same.
Order is important!
The following is what probably seems more intuitive but it won’t work as you’d expect:
$ ls /foo 2>&1 > out.log ls: cannot access '/foo': No such file or directory $ cat out.log
example gif

It didn’t write to the file, and the reason is because stderr was made a copy of stdout before stdout was redirected to the file. It’s assigning the right operand to the left operand by copy and not by reference.
Basically the above example is redirecting stderr to whatever stdout currently is (the TTY screen in this case) and then redirects stdout to the file.
Moving the stderr redirect operator 2>&1 to after the stdout > part correctly copies the error stream to the output stream which is redirecting to the file.
Shorthand
We already learned about the > shorthand for 1>. There’s another shorthand for redirecting stderr to stdout to a file or file descriptor. The redirection > file 2>&1 can be shorthanded to &>
$ ls /home &> out.log $ cat out.log mota/ $ ls /foo &>> out.log $ cat out.log mota/ ls: cannot access '/foo': No such file or directory
example gif

Pipelines
Using the | pipe operator allows you to send the output of one program as input to another program.
A basic example is filtering output of a program. For example, to only display files that end in .txt
$ ls archive.zip book.pdf data.txt My_Notes.txt $ ls | grep ".txt$" data.txt My_Notes.txt
example gif

You can chain multiple commands creating a pipeline:
command 1 | command 2 | command3
Example: Add additional lowercase command:
$ ls | grep ".txt$" | tr '[A-Z]' '[a-z]' data.txt my_notes.txt
example gif

It’s important to note that the commands in pipelines, ie cmd1 | cmd2 | cmd3, are all launched in parallel and not ran sequentially. The inputs and outputs are configured appropriately for each program
For running a series of commands in sequential order then use the following operators:
&&— run command if the last one did not fail (zero exit status code)||— run command if the last one failed (non-zero exit status code);— run command regardless of the last exit code
&&
The AND operator && (double ampersand) is used for separating commands and only running the command if the previous on succeeds:
Example: Continue if condition is true. The test command returns exit code 0 if the condition is true.
$ test 2 -lt 5 && echo "yes" yes
example gif

If the test condition is false then the circuit breaks because the exit code is non-zero and the execution order doesn’t reach the echo command:
$ test 7 -lt 5 && echo "yes"
example gif

You can chain as many commands as you need:
command1 && command2 && command3
It’s important to not confuse the && double ampersand with a single & ampersand since they do very different things. The single ampersand is used for launching the command list in the background. See «&» section.
||
The OR operator || (double pipe) is used for separating commands and only running the command if the previous one failed:
Example: Continue if condition is false. The test command returns a non-zero exit code if the condition is false.
$ test 7 -lt 5 || echo "yes" yes
example gif

If the test condition is true and exit code is 0 then the execution will stop at the OR statement:
$ test 2 -lt 5 || echo "yes"
example gif

;
Commands separated by a ; are executed sequentially: one after another.
The shell waits for the finish of each command.
# command2 will be executed after command1
command1 ; command2
&
The single ampersand is used for launching a command or command list in a new subshell in the background. The operator & must be at the end of the command:
Example: Run program in background. This command is will be immediately launched in the background and after 5 seconds it will display a desktop notification:
$ sleep 5 && notify-send "hello world" & [1] 2481042
example gif

After running a command with & you’ll see the job ID and process ID returned. Run jobs to see the list of running processes launched in the background.
$ jobs [1]+ Running sleep 5 && notify-send "hello world" &
example gif

After the command has completed and exited, the status will change to done:
$ jobs [1]+ Done sleep 5 && notify-send "hello world"
Use the -l flag to list the process ID as well:
$ jobs -l [1]+ 2481042 Done sleep 5 && notify-send "hello world"
If the command hasn’t completed yet, you can bring to the foreground with the fg command:
$ fg 1 sleep 5 && notify-send "hello world"
example gif

Notice how there’s no & at the end because the process is no longer running in the background.
Example: Launch bash scripts or executible files in the background:
$ cat > program.sh sleep 5 && notify-send "hello world" ^D $ chmod +x program.sh $ ./program.sh &
example gif

Named pipes
The mkfifo allows us to create a special type of file, a FIFO file, which can be opened for writing and reading and behave similar to a pipe. These files are referred to as named pipes.
The difference between a FIFO file and a regular file is that the FIFO file must be opened on both ends at the same time to let the program continue with input or output operations. The data is passed internally through the kernel without writing it to the file system (the file size is always 0 bytes). This means reading from the FIFO file will be blocked until it’s opened for writing, and writing to it will be blocked will until it’s opened for reading.
Example: create a named piped for writing and reading
First we create the named pipe with mkfifo:
Listing the file information shows us that it’s a pipe because the file type letter in the attributes is p
$ ls -l mypipe prw-r--r-- 1 mota mota 0 Oct 25 02:14 mypipe
In one terminal, we redirect some standard output to the named pipe:
$ echo "hello world" > mypipe
Notice how it appears to hang after running the command. The pipe is blocked until another process reads from the pipe.
In another terminal, redirect standard input of the pipe into cat to read and print the contents that were sent to the pipe in the first terminal. This also unblocks the pipe since both ends are simultaneously opened.
$ cat < mypipe
hello world
example gif

The FIFO device file is on disk so we have to manually delete it if we’re done using it:
Another option is to create FIFO files in /tmp which will get automatically wiped after a restart.
Command grouping
Commands can be grouped using curly braces {...}
$ { command; command; command; }
Important! there must be a space separating the command and the curly brace and the last command needs to be terminated by a semicolon for the group to be executed correctly.
Another way to group commands is by using a subshell (...).
$ (command; command; command)
Grouping with subshells does not require the space separation and last command semicolon as like grouping with curly braces. There are differences in grouping using a subshell and subshells are explained further in the subshells section
Grouping commands is useful for managing redirection. For example, we can redirect the output of multiple programs to a single location without adding redudant redirects.
For context:
$ ls data.json list.txt $ cat list.txt archive.zip book.pdf
example gif

We can take file write redirects like these:
$ date > out.log $ ls >> out.log $ cat list.txt >> out.log $ cat out.log Sat Oct 10 09:35:06 PM PDT 2020 data.json list.txt out.log archive.zip book.pdf
example gif

Group them to simplify things:
$ { date; ls; cat list.txt; } > out.log
$ cat out.log
Sat Oct 10 09:35:06 PM PDT 2020
data.json
list.txt
out.log
archive.zip
book.pdf
example gif

A command group can be piped to another command as if it were a single standard input:
$ { date; ls; cat list.txt; } | tail -n+2 | sort
archive.zip
book.pdf
data.json
list.txt
example gif

Similarly, grouping can be done with a subshell:
$ (date; ls; cat list.txt) | tail -n+2 | sort archive.zip book.pdf data.json list.txt
example gif

pipefail
By default, a bash pipeline’s exit status code will be whichever exit code the last command returned, meaning a non-zero exit code is not preserved throughout the pipeline.
Example: here we have a program that has a failing pipeline however the exit code is 0. The last exit code can be read from the variable $?.
$ cat > program.sh ls /foo | tee out.log; echo $? echo "done" ^D $ chmod +x program.sh $ ./program.sh ls: cannot access '/foo': No such file or directory 0 done
example gif

The bash set builtin command allows us to configure shell options. One important option is the set -o pipefail option which causes the pipeline’s exit code to be preserved if a command fails in the pipeline:
$ cat > program.sh set -o pipefail ls /foo | tee out.log; echo $? echo "done" ^D $ chmod +x program.sh $ ./program.sh ls: cannot access '/foo': No such file or directory 2 done
example gif

The ls man page mentions the following reasons for exit status codes:
0— if OK1— if minor problems2— if serious trouble
Notice how the last echo command still got executed after the pipeline failed. We can combine the pipefail option with the set -e (errexit) option to immediately exit the script if any command fails:
$ cat > program.sh set -eo pipefail ls /foo | tee out.log; echo $? echo "done" ^D $ chmod +x program.sh $ ./program.sh ls: cannot access '/foo': No such file or directory
example gif

The program exited immediately after the failing ls command and didn’t print any commands after it.
Process Substitution
Process substitution allows us to run a program and write to another program as if it were a file. The syntax for process substitution is >(command) for writing to the program as an output file or <(command) for using the program as an input file.
<(command)— for programs that produce standard output>(command)— for programs that intake standard input
The operator <() or >() creates a temporary file descriptor that manages reading and writing the substituted program.
It’s important that theres no space between the < or > and the parentheses ( otherwise it would result in an error. Although it looks similar, process substitution is different than command grouping or subshells.
Example: Print the file descriptor created by process substitution:
We can use the echo command to view the result of the expansion:
$ echo <(date) /dev/fd/63
example gif

Example: Print the contents of the file created by process substitution:
$ cat <(date)
Sat Oct 10 12:56:18 PM PDT 2020
example gif

Example: command tee stdout to cat
The tee command accepts only files to write to but using process substitution we can write the output to cat. This results in the date command being printed and the cat command printing the date as well.
$ date | tee >(cat) Sat Oct 10 01:27:15 PM PDT 2020 Sat Oct 10 01:27:15 PM PDT 2020
example gif

Example: send command stderr to substituted file while also logging stdout and stderr:
command 2> tee >(cat >&2)
The >() operator substitute the tee command as a file and within that process substitution the cat command is substituted as a file so tee can write to it. The 2> operator sends only stderr to outer substituted file. The operator >&2 copies stdout to stderr.
If there is no stderr from the command then nothing is sent to the tee substituted file:
$ ls /home 2> >(tee >(cat >&2)) mota/
example gif

If there is stderr from the command then the tee process substitution will process it and log it:
$ ls /foo 2> >(tee >(cat >&2)) ls: cannot access '/foo': No such file or directory ls: cannot access '/foo': No such file or directory
example gif

Subshells
A subshell executes commands in a child copy of the current shell. The environment is copied to the new instance of the shell when running subshelled commands. The copy of the environment is deleted once the subshell exits so changes, such as environment variables assignments, in the subhsell are lost when it exits. Command grouping is preferred to subshells in most cases because it’s faster and uses less memory.
Wrap the command(s) in parentheses (...) to launch them in a subshell:
Example: running a command in a subshell:
Notice how the second environment variable echo is not printed because the variable was set in the subshell environment:
$ (FOO=bar; echo $FOO); echo $FOO bar
example gif

Example: using process substitution to get around subshell caveats:
As an example, the read command can be used for caching input. The read input is copied to the $REPLY environment variable.
$ read hello world $ echo $REPLY hello world
example gif

However if we pipe a string to the read command, it will not print the string as expected after reading it:
$ echo "hello world" | read $ echo $REPLY
example gif

This is because read command is launched in a subshell when it’s in a pipeline and the REPLY variable copy is lost after it exits. Commands in pipelines are executed in subshell and any variable assignments will not be available after the subshell terminates.
We can use process substitution to get around this problem so a subshell doesn’t to be initialized:
$ read < <(echo "hello world") $ echo $REPLY hello world
example gif

Examples
The following are various examples utilizing bash pipelines and redirections:
Pipe only on stderr
# will echo message only if command is not found $ command -v mycommand &>/dev/null || echo "command not found"
Echo to stderr
Copy stderr file descriptor #1 to stdout file descriptor #2:
echo "this will go to stderr" 1>&2
example gif

You can omit the 1 since > is the same as 1>:
echo "this will go to stderr" >&2
example gif

To make it more readable, the redirect can be moved to the front:
>&2 echo "this will go to stderr"
example gif

Diff two commands
Diff the output of two commands using process substitution:
diff <(command) <(command)
Example 1:
$ diff <(xxd file1.bin) <(xxd file2.bin)
Example 2:
$ diff <(printf "foonbar/nquxn") <(printf "foonbaznquxn")
example gif

Record SSH session
Use tee to record an SSH session:
ssh user@server | tee /path/to/file
Example:
$ ssh root@example.com | tee session.log # after exiting server $ cat session.log
example gif

Split pipe into multiple streams
Split a pipe into two separate pipes using tee and process substitution:
Example 1: echo text and reverse the text in second stream:
$ echo "split this pipe" | tee >(rev) split this pipe epip siht tilps
You’re not limited to just one; add as many additional streams as you like:
$ echo "split this pipe" | tee >(rev) >(tr ' ' '_') >(tr a-z A-Z) split this pipe SPLIT THIS PIPE split_this_pipe epip siht tilps
example gif

Example 2: Run command and copy output to clipboard:
$ echo "hello world" | tee >(copy) hello world
Send text to another terminal
Echo text from one TTY to another TTY:
Example:
Terminal 1
Terminal 2
$ echo "this will show up in terminal 1" > /dev/pts/39
example gif

Pipe terminal output to another terminal
Pipe stdout and stderr output of current TTY to another TTY:
$ exec &> >(tee >(cat > /dev/pts/{id}))
Example:
Terminal 1
Terminal 2
$ exec &> >(tee >(cat > /dev/pts/39))
example gif

Another way is to use the script command. The script command allows you to record terminal sessions. Here we specify the TTY as the output file:
script -q /dev/pts/{id} command
Example:
Terminal 1:
Terminal 2:
$ script -q /dev/pts/12 bash
example gif

Read pipe into variable
$ read varname < <(command)
Example:
$ read myvar < <(echo "hello world") $ echo $myvar hello world
example gif

Pipe to file descriptor
command | tee /dev/fd/{id}
Example:
$ echo "hello world" | tee /dev/fd/3
However, the above won’t work on all systems. The cross-platform compatible way is to use process substitution:
$ command > >(tee >(cat >&3))
Read stdin line by line in Bash
Set stdin as input file:
while read line do echo "echo: $line" done < /dev/stdin
Example:
example gif

Read command output as line by line in Bash
while read line do echo "$line" done < <(command)
Example:
while true; do date; sleep 1; done > stream.log
while read line do echo "$line" done < <(tail -n0 -f stream.log)
example gif

Another way of reading command output line by line:
command | while read line do echo "$line" done
Example:
tail -n0 -f stream.log | while read line do echo "$line" done
example gif

Pipe terminal to another computer’s terminal
Pipe your terminal to an open TCP socket file descriptor:
$ exec 3<>/dev/tcp/{hostname}/{port} && exec &> >(tee >(cat >&3))
Example:
Terminal 1
Terminal 2
$ exec 3<>/dev/tcp/127.0.0.1/1337 && exec &> >(tee >(cat >&3))
example gif

Alternatively, you can use netcat to pipe your terminal:
$ exec &> >(nc 127.0.0.1 1337)
example gif

Redirect the output of multiple commands
{ command1; command2; command3; } > stdout.log 2> stderr.log
Example:
$ { date ; echo "ok"; >&2 echo "error!"; } > stdout.log 2> stderr.log
$ cat stdout.log
Sat 29 Aug 2020 11:16:39 AM PDT
$ cat stderr.log
error!
example gif

Stream audio
Stream audio to terminal audio player:
curl -s {http-stream-url} | mpv -
Example: Streaming mp3 audio from somafm to mpv player:
$ curl -s http://ice1.somafm.com/defcon-128-mp3 | mpv -
example gif

Example: Using afplay player (preinstalled on macOS). Note afplay doesn’t support streaming so we create a file descriptor to stream to.
$ exec 3<> /tmp/file.mp3 && curl -s http://ice1.somafm.com/defcon-128-mp3 | tee >&3 | (sleep 1; afplay /tmp/file.mp3)
Example: using ffplay player (preinstalled on Fedora):
$ curl -s http://ice1.somafm.com/defcon-128-mp3 | ffplay -nodisp -
Example: Using youtube-dl to get the m3u8 playlist url for mpv to stream:
$ youtube-dl -f best -g https://www.youtube.com/watch?v=dQw4w9WgXcQ | xargs -I % curl -s % | mpv --no-video -
example gif

Stream directory contents to remote server
Server:
nc -l -s 0.0.0.0 -p 1337 | tar xf -
Client:
tar cf - /some/directory | nc {hostname} 1337
Example: pipe all content from current client directory to server:
Server:
$ nc -l -p 1337 | tar xf -
Client:
tar cf - . | nc 127.0.0.1 1337
example gif

A thing to note is that it’d be very easy to for someone to stream all your home directory contents (SSH keys, AWS credentials, etc) if they’re able to run this command on your machine! Only run trusted software and monitor outgoing HTTP requests using something like OpenSnitch.
Take webcam picture on mouse move
Example: trigger a webcam picture to be taken when mouse movement events is read from /dev/input/mouse0, and wait 10 seconds before listening for another mouse event again:
while true; do sudo cat /dev/input/mouse0 | read -n1; streamer -q -o cam.jpeg -s 640x480 > /dev/null 2>&1; sleep 10; done
example gif

Group commands with OR
Group commands with OR operator to try different commands until one succeeds and pipe the result to the next command:
$ ( command || command || command ) | command
Example: attempt to deflate a gzipped file and pipe text to less:
$ echo "hello world" > stream.log; gzip stream.log; FILE=stream.log.gz $ ( zcat $FILE || gzcat $FILE || bzcat2 $FILE ) | less hello world
example gif

Writing standard input to a file
$ cat > file.txt
hello world
^D
$ cat file.txt
hello world
example gif

It’s the same thing using the - argument in cat to indicate that you want to read from stdin, e.g. cat - > file.txt
Concatenating files with standard input in between
Example: With cat can use the - in place of a file name to read from stdin. Press ctrl-d to exit the stdin prompt:
$ echo "hello" > 1.txt $ echo "world" > 3.txt $ cat 1.txt - 3.txt > all.txt earth ^D $ cat all.txt hello earth world
example gif

Send commands to terminal through a named pipe
Example: Set standard input of terminal to FIFO file
In terminal 1, create a FIFO file and replace terminal standard input by using exec:
$ mkfifo myfifo $ exec < myfifo
In terminal 2, write to the FIFO file and see the command being executed in the first terminal. However, the first terminal will close right away. This is because the writer closed the FIFO and the reading process received EOF.
example gif

We can create a file descriptor with an open connection to the FIFO pipe to prevent the terminal from closing when writing commands to it.
In temrinal 1, run exec again to replace standard input:
In terminal 2, use exec to create a custom file descriptor 3 and redirect the standard output to the named pipe. Now we can echo commands to this file descriptor and the first terminal will execute them and remain opened.
$ exec 3> myfifo $ echo "ls -l" >&3
example gif

Use the FD close operator {fd}>&- with exec to close the file descriptor opened for writing to the FIFO:
example gif

Filter input for reading with process substitution
In this example, we’ll create a program that will intake a filtered output of ls -l and print a formatted string.
Print long form of ls:
$ ls -l total 8 -rw-r--r-- 1 mota mota 2247 Oct 10 19:51 book.pdf -rw-r--r-- 1 mota mota 465 Oct 10 19:51 data.txt
Strip out first line:
$ ls -l | tail -n+2
-rw-r--r-- 1 mota mota 2247 Oct 10 19:51 book.pdf
-rw-r--r-- 1 mota mota 465 Oct 10 19:51 data.txt
Print only the size and filename columns:
$ ls -l | tail -n+2 | awk '{print $5 " " $9}' 2247 book.pdf 465 data.txt
Now that we know what filter pipeline we’ll use, let’s create a program that reads line by line the output of the pipeline through process substitution as standard input and prints a formatted string for every line:
program.sh
while read size filename; do cat << EOF $filename is $size bytes EOF done < <(ls -l | tail -n+2 | awk '{print $5 " " $9}')
$ ./program.sh book.pdf is 2247 bytes data.txt is 465 bytes
example gif

Contributing
Pull requests are welcome!
For contributions please create a new branch and submit a pull request for review.
Resources
- GNU Bash Manual — Redirections
- Advanced Bash-Scripting Guide: Process Substitution
- Introduction to Linux — I/O redirection
- The Linux Command Line
- Bash One-Liners Explained: All about redirections
- Bash Redirection Cheat Sheet
License
MIT @ Miguel Mota
Bash, or the Bourne-Again Shell, is a powerful command-line interface (CLI) that is commonly used in Linux and Unix systems. When working with Bash, it is important to understand how to handle errors that may occur during the execution of commands. In this article, we will discuss various ways to understand and ignore errors in Bash. Bash scripting is a powerful tool for automating and simplifying various tasks in Linux and Unix systems. However, errors can occur during the execution of commands and can cause scripts to fail. In this article, we will explore the various ways to understand and handle errors in Bash. We will look at ways to check the exit status code and error messages of commands, as well as techniques for ignoring errors when necessary. By understanding and properly handling errors, you can ensure that your Bash scripts run smoothly and achieve the desired outcome.
Step-by-step approach for understanding and ignoring errors in Bash:
Step 1: Understand how errors are generated in Bash.
- When a command is executed, it returns an exit status code.
- A successful command will have an exit status of 0, while a failed command will have a non-zero exit status.
- Error messages are generated when a command returns a non-zero exit status code.
Step 2: Check the exit status code of a command.
- To check the exit status code of a command, you can use the $? variable, which holds the exit status of the last executed command.
- For example, after executing the command ls non_existent_directory, you can check the exit status code by running echo $? The output
- will be non-zero (e.g., 2) indicating that the command failed.
Step 3: Check the error message of a command.
- To check the error message of a command, you can redirect the standard error output (stderr) to a file or to the standard output (stdout) using the 2> operator.
- For example, you can redirect the stderr of the command ls non_existent_directory to a file by running ls non_existent_directory 2> error.log. Then you can view the error message by running cat error.log.
Step 4: Use the set -e command.
- The set -e command causes the script to exit immediately if any command exits with a non-zero status. This can be useful for detecting and handling errors early on in a script.
- For example, if you run set -e followed by ls non_existent_directory, the script will exit immediately with an error message.
Step 5: Ignore errors when necessary.
- To ignore errors, you can use the command || true construct. This construct allows you to execute a command, and if it returns a non-zero exit status, the command following the || operator (in this case, true) will be executed instead.
- For example, you can run rm non_existent_file || true to remove a file that does not exist without exiting with an error.
- Another way to ignore errors is to use the command 2> /dev/null construct, which redirects the standard error output (stderr) of a command to the null device, effectively ignoring any error messages.
- Additionally, you can use the command 2>&1 >/dev/null construct to ignore both standard error and standard output.
- You can also use the command || : construct which allows you to execute a command and if it returns a non-zero exit status, the command following the || operator (in this case, 🙂 will be executed instead. The: command is a no-op command that does nothing, effectively ignoring the error.
Practical Explanation for Understanding Errors
First, let’s examine how errors are generated in Bash. When a command is executed, it returns an exit status code. This code indicates whether the command was successful (exit status 0) or not (non-zero exit status). For example, the following command attempts to list the files in a directory that does not exist:
$ ls non_existent_directory ls: cannot access 'non_existent_directory': No such file or directory

As you can see, the command generated an error message and returned a non-zero exit status code. To check the exit status code of a command, you can use the $? variable, which holds the exit status of the last executed command.
$ echo $? 2
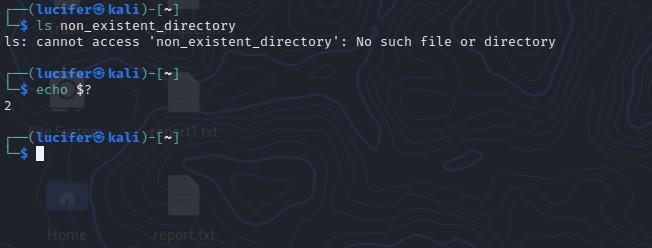
In addition to the exit status code, you can also check the standard error output (stderr) of a command to understand errors. This can be done by redirecting the stderr to a file or to the standard output (stdout) using the 2> operator.
For example, the following script will redirect the stderr of a command to a file:
$ ls non_existent_directory 2> error.log $ cat error.log ls: cannot access 'non_existent_directory': No such file or directory

You can also redirect the stderr to the stdout using the 2>&1 operator, which allows you to see the error message along with the standard output of the command.
$ ls non_existent_directory 2>&1 ls: cannot access 'non_existent_directory': No such file or directory

Another useful tool for understanding errors is the set -e command, which causes the script to exit immediately if any command exits with a non-zero status. This can be useful for detecting and handling errors early on in a script.
$ set -e $ ls non_existent_directory # as soon as you hit enter this will exit shell and will close the terminal.
After this command script will exit from the shell if the exit code is nonzero.
Practical Explanation for Ignoring Errors
While it is important to handle errors in Bash scripts, there may be certain situations where you want to ignore errors and continue running the script. In this section, we will discuss different methods for ignoring errors in Bash and provide examples of how to implement them.
Heredoc
Heredoc is a feature in Bash that allows you to specify a string or command without having to escape special characters. This can be useful when you want to ignore errors that may occur while executing a command. The following example demonstrates how to use Heredoc to ignore errors.
#!/bin/bash # Example of ignoring errors using Heredoc # The `command` will fail but it will not stop execution cat <<EOF | while read line; do echo $line done command that will fail EOF # Rest of the script
In this example, the command that is inside the Heredoc will fail, but the script will not stop execution. This is because the output of the command is piped to the while loop, which reads the output and ignores the error.
Pipefail
The pipe fails option in Bash can be used to change the behavior of pipelines so that the exit status of the pipeline is the value of the last (rightmost) command to exit with a non-zero status or zero if all commands exit successfully. This can be useful when you want to ignore errors that may occur while executing multiple commands in a pipeline. The following example demonstrates how to use the pipe fail option to ignore errors.
#!/bin/bash # Example of ignoring errors using pipefail # The `command1` will fail but it will not stop execution set -o pipefail command1 | command2 # Rest of the script
In this example, command1 will fail, but command2 will continue to execute, and the script will not stop execution.
Undefined Variables
By default, Bash will stop the execution of a script if an undefined variable is used. However, you can use the -u option to ignore this behavior and continue running the script even if an undefined variable is used. The following example demonstrates how to ignore undefined variables.
#!/bin/bash # Example of ignoring undefined variables set +u echo $undefined_variable # Rest of the script
In this example, the script will not stop execution when an undefined variable is used.
Compiling and Interpreting
When compiling or interpreting a script, errors may occur. However, these errors can be ignored by using the -f option when running the script. The following example demonstrates how to ignore errors when compiling or interpreting a script.
#!/bin/bash # Example of ignoring errors when compiling or interpreting bash -f script.sh # Rest of the script
In this example, the script will continue to run even if there are errors during the compilation or interpretation process.
Traps
A trap is a way to execute a command or a set of commands when a specific signal is received by the script. This can be useful when you want to ignore errors and run a cleanup command instead. The following example demonstrates how to use a trap to ignore errors.
#!/bin/bash
# Example of ignoring errors using a trap
# Set a trap to run the cleanup function when an error occurs
trap cleanup ERR
# Function to run when an error occurs
cleanup() {
echo "Cleaning up before exiting..."
}
# Command that will cause an error
command_that_will_fail
# Rest of the script
In this example, when the command_that_will_fail causes an error, the script will execute the cleanup function instead of stopping execution. This allows you to perform any necessary cleanup before exiting the script.
Examples of Bash for Error Handling:
Example 1: Error Handling Using a Conditional Condition
One way to handle errors in Bash is to use a conditional statement. The following example demonstrates how to check for a specific error and handle it accordingly.
#!/bin/bash # Example of error handling using a conditional condition file=example.txt if [ ! -f $file ]; then echo "Error: $file does not exist" exit 1 fi # Rest of the script
In this example, we check if the file “example.txt” exists using the -f option of the [ command. If the file does not exist, the script will print an error message and exit with a status code of 1. This allows the script to continue running if the file exists and exit if it does not.
Example 2: Error Handling Using the Exit Status Code
Another way to handle errors in Bash is to check the exit status code of a command. Every command in Bash returns an exit status code when it completes, with a code of 0 indicating success and any other code indicating an error. The following example demonstrates how to check the exit status code of a command and handle it accordingly.
#!/bin/bash # Example of error handling using the exit status code command1 if [ $? -ne 0 ]; then echo "Error: command1 failed" exit 1 fi # Rest of the script
In this example, the script runs the command “command1” and then checks the exit status code using the special variable $?. If the exit status code is not 0, the script will print an error message and exit with a status code of 1.
Example 3: Stop the Execution on the First Error
When running a script, it can be useful to stop the execution on the first error that occurs. This can be achieved by using the set -e command, which tells Bash to exit the script if any command exits with a non-zero status code.
#!/bin/bash # Stop execution on the first error set -e command1 command2 command3 # Rest of the script
In this example, if any of the commands “command1”, “command2” or “command3” fail, the script will exit immediately.
Example 4: Stop the Execution for Uninitialized Variable
Another way to stop execution on error is if an uninitialized variable is used during script execution. This can be achieved by using the set -u command, which tells Bash to exit the script if any uninitialized variable is used.
#!/bin/bash # Stop execution for uninitialized variable set -u echo $uninitialized_variable # Rest of the script
In this example, if the uninitialized_variable is not defined, the script will exit immediately.
Conclusion
In conclusion, understanding and ignoring errors in Bash is an important aspect of working with the command-line interface. By checking the exit status code of a command, its associated error message, and redirecting the stderr to a file or the stdout, you can understand what went wrong. And by using the command || true, command 2> /dev/null, command 2>&1 >/dev/null, and command || : constructs, you can ignore errors when necessary. It’s always a good practice to test these constructs in a testing environment before using them in production.
According to «Linux: The Complete Reference 6th Edition» (pg. 44), you can pipe only STDERR using the |& redirection symbols.
I’ve written a pretty simple script to test this:
#!/bin/bash
echo "Normal Text."
echo "Error Text." >&2
I run this script like this:
./script.sh |& sed 's:^:t:'
Presumably, only the lines printed to STDERR will be indented. However, it doesn’t actually work like this, as I see:
Normal Text.
Error Text.
What am I doing wrong here?
asked Nov 10, 2011 at 23:21
![]()
Naftuli KayNaftuli Kay
37.4k84 gold badges216 silver badges308 bronze badges
I don’t know what text your book uses, but the bash manual is clear (if you’re a little familiar with redirections already):
If
|&is used, command1’s standard error, in addition to its standard output, is connected to command2’s standard input through the pipe; it is shorthand for2>&1 |. This implicit redirection of the standard error to the standard output is performed after any redirections specified by the command.
So if you don’t want to mix standard output and standard error, you’ll have to redirect standard output somewhere else. See How to grep standard error stream (stderr)?
{ ./script.sh 2>&1 >&3 | sed 's:^:t:'; } 3>&1
Both fd 1 and 3 of script.sh and sed will point to the original stdout destination however. If you want to be a good citizen, you can close those fd 3 which those commands don’t need:
{ ./script.sh 2>&1 >&3 3>&- | sed 's:^:t:' 3>&-; } 3>&1
bash and ksh93 can condense the >&3 3>&- to >&3- (fd move).
![]()
answered Nov 10, 2011 at 23:34
![]()
2
|& pipes stderr to stdin, like 2>&1 |, so the next program will get both on stdin.
$cat test.sh
#!/bin/bash
echo "Normal Text."
echo "Error Text." >&2
$./test.sh | sed 's:^:t:'
Error Text.
Normal Text.
$ ./test.sh |& sed 's:^:t:'
Normal Text.
Error Text.
![]()
Lesmana
26.1k20 gold badges77 silver badges84 bronze badges
answered Nov 10, 2011 at 23:33
![]()
KevinKevin
39.2k16 gold badges86 silver badges112 bronze badges
2
|& in bash is just a (not terribly portable) shortcut for 2>&1 |, so you should see every line indented.
![]()
Lesmana
26.1k20 gold badges77 silver badges84 bronze badges
answered Nov 10, 2011 at 23:31
![]()
jw013jw013
49.1k9 gold badges132 silver badges141 bronze badges
So I have a script like this:
somecommad | grep --invert-match something
I’d like to be able to conditionally run a different command if somecommand fails. Here’s what I tried:
somecommand | grep --invert-match something || {
echo 'Oops'
}
But that didn’t work (the grep wasn’t executed). What is the proper way to do this?
asked Oct 21, 2021 at 1:05
![]()
2
@steeldriver mentioned in the comments that PIPESTATUS might work. I tried it, and it worked well. Here’s what I did:
somecommand | grep --invert-match something
if [ "${PIPESTATUS[0]}" != "0" ]; then
echo 'Oops'
fi
It runs the command as before, but then I have an if statement to look at the PIPESTATUS array. I only care about the first element, so that is the one I look at. I check it it failed (if the exit code is not 0), and it it did fail, run echo 'Oops'
answered Oct 21, 2021 at 1:31
![]()
cocomaccocomac
2,6153 gold badges14 silver badges43 bronze badges
3
Another way, depending on the exact behaviour needed, is to use the pipefail option:
The exit status of a pipeline is the exit status of the last command
in the pipeline, unless thepipefailoption is enabled (see The Set
Builtin).
Ifpipefailis enabled, the pipeline’s return status is the value of
the last (rightmost) command to exit with a non-zero status, or zero
if all commands exit successfully.
So, if you don’t care which of somecommand or grep failed, as long as one of those did fail:
set -o pipefail
if ! somecommand | grep --invert-match something; then
echo 'Oops'
fi
answered Oct 21, 2021 at 10:25
![]()
murumuru
189k52 gold badges460 silver badges711 bronze badges
Kyle’s Unix/Linux command does the job of switching the STDERR with the STDOUT; however the explanation is not quite right. The redirecting operators do not do any copying or duplicating, they just redirect the flow to a different direction.
Rewriting Kyle’s command by temporary moving the 3>&1 to the end, would make it easier to understand the concept:
find /var/log 1>&2 2>&3 3>&1
Written this way though, Linux would display an error because &3 does not exist yet as it is located before 3>&1. 3>something is a way to declare (define) that we are going to use a third pipe, so it has to be located before we flow water into that pipe, for instance the way Kyle wrote it. Try this other way just for fun:
((echo "STD1"; anyerror "bbbb"; echo "STD2" ) 3>&1 4>&2 1>&4 2>&3) > newSTDOUT 2> newSTDERR
Not having a way to do copies is a shame. You cannot do things like «3>&1 3>&2» in the same command, because Linux will only use the first one found and dismisses the second.
I have not (yet) found a way to send both the error and the regular output to a file and also send a copy of the error to the standar output with one command. For instace, I have a cron job that I want both outputs (error and standard) go to a log file and let the error also go out to make an email message sent to my blackBerry. I can do it with two commands using «tee» but the error does not show in the right order among the regular output line in the file. This is the ugly way I resolved the problem:
((echo "STD1"; sdfr "bbbb"; echo "STD2" ) 3>&1 1>&2 2>&3 | tee -a log1 ) 2>> log1
Note that I have to use log1 twice and I have to append in both cases, the firs one using the «-a» option for the «tee» command and the second one using «>>».
Doing a cat log1 you get the following:
STD1
STD2
-bash: sdfr: command not found
Notice that the error does not show in the second line as it should.
Seeing «Broken pipe» in this situation is rare, but normal.
When you run type rvm | head -1, bash executes type rvm in one process, head -1 in another.1 The stdout of type is connected to the «write» end of a pipe, the stdin of head to the «read» end. Both processes run at the same time.
The head -1 process reads data from stdin (usually in chunks of 8 kB), prints out a single line (according to the -1 option), and exits, causing the «read» end of the pipe to be closed. Since the rvm function is quite long (around 11 kB after being parsed and reconstructed by bash), this means that head exits while type still has a few kB of data to write out.
At this point, since type is trying to write to a pipe whose other end has been closed – a broken pipe – the write() function it caled will return an EPIPE error, translated as «Broken pipe». In addition to this error, the kernel also sends the SIGPIPE signal to type, which by default kills the process immediately.
(The signal is very useful in interactive shells, since most users do not want the first process to keep running and trying to write to nowhere. Meanwhile, non-interactive services ignore SIGPIPE – it would not be good for a long-running daemon to die on such a simple error – so they find the error code very useful.)
However, signal delivery is not 100% immediate, and there may be cases where write() returns EPIPE and the process continues to run for a short while before receiving the signal. In this case, type gets enough time to notice the failed write, translate the error code and even print an error message to stderr before being killed by SIGPIPE. (The error message says «-bash: type:» since type is a built-in command of bash itself.)
This seems to be more common on multi-CPU systems, since the type process and the kernel’s signal delivery code can run on different cores, literally at the same time.
It would be possible to remove this message by patching the type builtin (in bash’s source code) to immediately exit when it receives an EPIPE from the write() function.
However, it’s nothing to be concerned about, and it is not related to your rvm installation in any way.