Is there a standard Bash tool that acts like echo but outputs to stderr rather than stdout?
I know I can do echo foo 1>&2 but it’s kinda ugly and, I suspect, error prone (e.g. more likely to get edited wrong when things change).
![]()
asked Jun 7, 2010 at 14:36
![]()
2
You could do this, which facilitates reading:
>&2 echo "error"
>&2 copies file descriptor #2 to file descriptor #1. Therefore, after this redirection is performed, both file descriptors will refer to the same file: the one file descriptor #2 was originally referring to. For more information see the Bash Hackers Illustrated Redirection Tutorial.
![]()
John Kugelman
343k67 gold badges517 silver badges565 bronze badges
answered May 8, 2014 at 18:59
![]()
Marco AurelioMarco Aurelio
20k1 gold badge16 silver badges16 bronze badges
11
You could define a function:
echoerr() { echo "$@" 1>&2; }
echoerr hello world
This would be faster than a script and have no dependencies.
Camilo Martin’s bash specific suggestion uses a «here string» and will print anything you pass to it, including arguments (-n) that echo would normally swallow:
echoerr() { cat <<< "$@" 1>&2; }
Glenn Jackman’s solution also avoids the argument swallowing problem:
echoerr() { printf "%sn" "$*" >&2; }
answered Jun 7, 2010 at 14:52
![]()
JamesJames
6,8382 gold badges16 silver badges18 bronze badges
13
Since 1 is the standard output, you do not have to explicitly name it in front of an output redirection like >. Instead, you can simply type:
echo This message goes to stderr >&2
Since you seem to be worried that 1>&2 will be difficult for you to reliably type, the elimination of the redundant 1 might be a slight encouragement to you!
![]()
Pang
9,344146 gold badges85 silver badges121 bronze badges
answered Jul 10, 2012 at 21:24
![]()
Brandon RhodesBrandon Rhodes
81.1k16 gold badges105 silver badges145 bronze badges
2
Another option
echo foo >>/dev/stderr
![]()
answered Jan 16, 2013 at 3:57
![]()
5
No, that’s the standard way to do it. It shouldn’t cause errors.
answered Jun 7, 2010 at 14:37
![]()
Matthew FlaschenMatthew Flaschen
274k50 gold badges513 silver badges537 bronze badges
6
If you don’t mind logging the message also to syslog, the not_so_ugly way is:
logger -s $msg
The -s option means: «Output the message to standard error as well as to the system log.»
answered Aug 4, 2014 at 19:15
![]()
Grzegorz LuczywoGrzegorz Luczywo
9,7021 gold badge32 silver badges22 bronze badges
2
Another option that I recently stumbled on is this:
{
echo "First error line"
echo "Second error line"
echo "Third error line"
} >&2
This uses only Bash built-ins while making multi-line error output less error prone (since you don’t have to remember to add &>2 to every line).
answered Feb 18, 2019 at 0:17
![]()
GuyPaddockGuyPaddock
1,8891 gold badge21 silver badges23 bronze badges
3
Note: I’m answering the post- not the misleading/vague «echo that outputs to stderr» question (already answered by OP).
Use a function to show the intention and source the implementation you want. E.g.
#!/bin/bash
[ -x error_handling ] && . error_handling
filename="foobar.txt"
config_error $filename "invalid value!"
output_xml_error "No such account"
debug_output "Skipping cache"
log_error "Timeout downloading archive"
notify_admin "Out of disk space!"
fatal "failed to open logger!"
And error_handling being:
ADMIN_EMAIL=root@localhost
config_error() { filename="$1"; shift; echo "Config error in $filename: $*" 2>&1; }
output_xml_error() { echo "<error>$*</error>" 2>&1; }
debug_output() { [ "$DEBUG"=="1" ] && echo "DEBUG: $*"; }
log_error() { logger -s "$*"; }
fatal() { which logger >/dev/null && logger -s "FATAL: $*" || echo "FATAL: $*"; exit 100; }
notify_admin() { echo "$*" | mail -s "Error from script" "$ADMIN_EMAIL"; }
Reasons that handle concerns in OP:
- nicest syntax possible (meaningful words instead of ugly symbols)
- harder to make an error (especially if you reuse the script)
- it’s not a standard Bash tool, but it can be a standard shell library for you or your company/organization
Other reasons:
- clarity — shows intention to other maintainers
- speed — functions are faster than shell scripts
- reusability — a function can call another function
- configurability — no need to edit original script
- debugging — easier to find the line responsible for an error (especially if you’re deadling with a ton of redirecting/filtering output)
- robustness — if a function is missing and you can’t edit the script, you can fall back to using external tool with the same name (e.g. log_error can be aliased to logger on Linux)
- switching implementations — you can switch to external tools by removing the «x» attribute of the library
- output agnostic — you no longer have to care if it goes to STDERR or elsewhere
- personalizing — you can configure behavior with environment variables
answered Mar 18, 2016 at 18:07
![]()
My suggestion:
echo "my errz" >> /proc/self/fd/2
or
echo "my errz" >> /dev/stderr
echo "my errz" > /proc/self/fd/2 will effectively output to stderr because /proc/self is a link to the current process, and /proc/self/fd holds the process opened file descriptors, and then, 0, 1, and 2 stand for stdin, stdout and stderr respectively.
The /proc/self link doesn’t work on MacOS, however, /proc/self/fd/* is available on Termux on Android, but not /dev/stderr. How to detect the OS from a Bash script? can help if you need to make your script more portable by determining which variant to use.
![]()
Sled
18.3k27 gold badges119 silver badges161 bronze badges
answered Sep 3, 2017 at 1:48
![]()
SebastianSebastian
4,1352 gold badges40 silver badges41 bronze badges
3
Don’t use cat as some have mentioned here. cat is a program
while echo and printf are bash (shell) builtins. Launching a program or another script (also mentioned above) means to create a new process with all its costs. Using builtins, writing functions is quite cheap, because there is no need to create (execute) a process (-environment).
The opener asks «is there any standard tool to output (pipe) to stderr», the short answer is : NO … why? … redirecting pipes is an elementary concept in systems like unix (Linux…) and bash (sh) builds up on these concepts.
I agree with the opener that redirecting with notations like this: &2>1 is not very pleasant for modern programmers, but that’s bash. Bash was not intended to write huge and robust programs, it is intended to help the admins to get there work with less keypresses 
And at least, you can place the redirection anywhere in the line:
$ echo This message >&2 goes to stderr
This message goes to stderr
![]()
answered Oct 9, 2014 at 13:18
![]()
return42return42
5453 silver badges10 bronze badges
4
This is a simple STDERR function, which redirect the pipe input to STDERR.
#!/bin/bash
# *************************************************************
# This function redirect the pipe input to STDERR.
#
# @param stream
# @return string
#
function STDERR () {
cat - 1>&2
}
# remove the directory /bubu
if rm /bubu 2>/dev/null; then
echo "Bubu is gone."
else
echo "Has anyone seen Bubu?" | STDERR
fi
# run the bubu.sh and redirect you output
tux@earth:~$ ./bubu.sh >/tmp/bubu.log 2>/tmp/bubu.err
answered Feb 3, 2012 at 8:40
![]()
erselbsterselbst
1631 silver badge6 bronze badges
2
read is a shell builtin command that prints to stderr, and can be used like echo without performing redirection tricks:
read -t 0.1 -p "This will be sent to stderr"
The -t 0.1 is a timeout that disables read’s main functionality, storing one line of stdin into a variable.
answered Jan 24, 2013 at 0:16
![]()
Douglas MayleDouglas Mayle
20.7k8 gold badges42 silver badges57 bronze badges
1
Combining solution suggested by James Roth and Glenn Jackman
- add ANSI color code to display the error message in red:
echoerr() { printf "e[31;1m%se[0mn" "$*" >&2; }
# if somehow e is not working on your terminal, use u001b instead
# echoerr() { printf "u001b[31;1m%su001b[0mn" "$*" >&2; }
echoerr "This error message should be RED"
answered Jun 6, 2020 at 17:20
![]()
PolymerasePolymerase
6,06111 gold badges42 silver badges64 bronze badges
Make a script
#!/bin/sh
echo $* 1>&2
that would be your tool.
Or make a function if you don’t want to have a script in separate file.
![]()
BCS
74.1k67 gold badges185 silver badges291 bronze badges
answered Jun 7, 2010 at 14:48
![]()
n0rdn0rd
11.6k5 gold badges34 silver badges55 bronze badges
3
Here is a function for checking the exit status of the last command, showing error and terminate the script.
or_exit() {
local exit_status=$?
local message=$*
if [ "$exit_status" -gt 0 ]
then
echo "$(date '+%F %T') [$(basename "$0" .sh)] [ERROR] $message" >&2
exit "$exit_status"
fi
}
Usage:
gzip "$data_dir"
or_exit "Cannot gzip $data_dir"
rm -rf "$junk"
or_exit Cannot remove $junk folder
The function prints out the script name and the date in order to be useful when the script is called from crontab and logs the errors.
59 23 * * * /my/backup.sh 2>> /my/error.log
answered Oct 13, 2020 at 8:39
![]()
Miroslav PopovMiroslav Popov
3,2054 gold badges31 silver badges55 bronze badges
I was tasked to create an automated server hardening script and one thing that they need is a report of all the output of each command executed. I want to store the error message inside a string and append it in a text file.
Let’s say I ran this command:
/sbin/modprobe -n -v hfsplus
The output of running this in my machine would be:
FATAL: Module hfsplus not found
How can I store that error message inside a string? Any help would be greatly appreciated. Thanks!
asked May 29, 2014 at 7:25
![]()
1
you can do it by redirecting errors command:
/sbin/modprobe -n -v hfsplus 2> fileName
as a script
#!/bin/bash
errormessage=$( /sbin/modprobe -n -v hfsplus 2>&1)
echo $errormessage
or
#!/bin/bash
errormessage=`/sbin/modprobe -n -v hfsplus 2>&1 `
echo $errormessage
if you want to append the error use >> instead of >
Make sure to use 2>&1 and not 2> &1 to avoid the error
«syntax error near unexpected token `&'»
![]()
answered May 29, 2014 at 7:42
![]()
NidalNidal
8,66611 gold badges54 silver badges74 bronze badges
5
Simply to store as a string in bash script:
X=`/sbin/modprobe -n -v hfsplus 2>&1`
echo $X
This can be a bit better as you will see messages when command is executed:
TMP=$(mktemp)
/sbin/modprobe -n -v hfsplus 2>&1 | tee $TMP
OUTPUT=$(cat $TMP)
echo $OUTPUT
rm $TMP
answered May 29, 2014 at 7:47
![]()
graphitegraphite
4814 silver badges7 bronze badges
3
To return the error message in a variable, simply;
error=$(/sbin/modprobe -n -v hfsplus 2>&1 1>/dev/null)
echo $error
![]()
Prvt_Yadav
5,6227 gold badges33 silver badges48 bronze badges
answered Feb 8, 2019 at 10:56
![]()
JonathanJonathan
1701 silver badge3 bronze badges
1
Newer bash versions (I.e. bash 4.1+):
$ msg=$(ls -la nofile 2>&1)
$ echo $msg
ls: cannot access nofile: No such file or directory
$
answered Nov 4, 2017 at 10:58
![]()
I capture error like this
. ${file} 2>&1 | {
read -d "" -t 0.01 error
[ -z "$error" ] || log_warn Load completion ${file} failed: "n${error}"
}
if source failed, I will capture the error and log it.log_warn is just a simple function.
BTW, I use this in my dotfiles
answered Feb 13, 2015 at 6:22
![]()
wenerwener
4463 silver badges8 bronze badges
To append to a file use /sbin/modprobe -n -v hfsplus 2>> filename
answered May 29, 2014 at 7:44
![]()
harish.venkatharish.venkat
7,0251 gold badge24 silver badges29 bronze badges
Two tips:
Fail fast
You probably already know that you can force Bash scripts to exit immediately if
there’s an error (that is, if any command exits with a non-zero exit code)
using:
#!/usr/bin/env bash
set -e
but it’s even better to use:
so that the script:
- exits on an error (
-e, equivalent to-o errexit); - exits on an undefined variable (
-u, equivalent to-o nounset); - exits on an error in piped-together commands (
-o pipefail)1.
You can learn more about these built-ins with:
Fail noisy
Failing fast is all very well but, by default scripts fail silently offering no
debug information.
You can add:
to print each command before execution but it’s easy to add simple error
handling using trap:.
function print_error {
read line file <<<$(caller)
echo "An error occurred in line $line of file $file:" >&2
sed "${line}q;d" "$file" >&2
}
trap print_error ERR
Here we bind the print_error function to the ERR event and print out an
error message and offending line of the script (extracted using sed) to
STDERR.
Note the use of a <<< here string and the caller built-in to assign the
line and filename of the error.
So running the script:
#!/usr/bin/env bash
set -eu -o pipefail
function print_error {
read line file <<<$(caller)
echo "An error occurred in line $line of file $file:" >&2
sed "${line}q;d" "$file" >&2
}
trap print_error ERR
false
gives:
$ ./script.sh
An error occurred in line 11 of file ./test.sh:
false
There are more sophisticated ways to handle errors in Bash scripts2
but this is a concise, simple option to have to hand.
Example
Error messages are generally included in a script for debugging purposes or for providing rich user experience. Simply writing error message like this:
cmd || echo 'cmd failed'
may work for simple cases but it’s not the usual way. In this example, the error message will pollute the actual output of the script by mixing both errors and successful output in stdout.
In short, error message should go to stderr not stdout. It’s pretty simple:
cmd || echo 'cmd failed' >/dev/stderr
Another example:
if cmd; then
echo 'success'
else
echo 'cmd failed' >/dev/stderr
fi
In the above example, the success message will be printed on stdout while the error message will be printed on stderr.
A better way to print error message is to define a function:
err(){
echo "E: $*" >>/dev/stderr
}
Now, when you have to print an error:
err "My error message"
Scripting is one of the key tools for a sysadmin to manage a set of day-to-day activities such as running backups, adding users/groups, installing/updating packages, etc. While writing a script, error handling is one of the crucial things to manage.
This article shows some basic/intermediate techniques of dealing with error handling in Bash scripting. I discuss how to obtain the error codes, get verbose output while executing the script, deal with the debug function, and standard error redirection. Using these techniques, sysadmins can make their daily work easy.
[ Readers also liked: Bash command line exit codes demystified ]
Exit status
In Bash scripting, $? prints the exit status. If it returns zero, it means there is no error. If it is non-zero, then you can conclude the earlier task has some issue.
A basic example is as follows:
$ cat myscript.sh
#!/bin/bash
mkdir learning
echo $?If you run the above script once, it will print 0 because the directory does not exist, therefore the script will create it. Naturally, you will get a non-zero value if you run the script a second time, as seen below:
$ sh myscript.sh
mkdir: cannot create directory 'learning': File exists
1Best practices
It is always recommended to enable the debug mode by adding the -e option to your shell script as below:
$ cat test3.sh
!/bin/bash
set -x
echo "hello World"
mkdiir testing
./test3.sh
+ echo 'hello World'
hello World
+ mkdiir testing
./test3.sh: line 4: mkdiir: command not foundYou can write a debug function as below, which helps to call it anytime, using the example below:
$ cat debug.sh
#!/bin/bash
_DEBUG="on"
function DEBUG()
{
[ "$_DEBUG" == "on" ] && $@
}
DEBUG echo 'Testing Debudding'
DEBUG set -x
a=2
b=3
c=$(( $a + $b ))
DEBUG set +x
echo "$a + $b = $c"Which prints:
$ ./debug.sh
Testing Debudding
+ a=2
+ b=3
+ c=5
+ DEBUG set +x
+ '[' on == on ']'
+ set +x
2 + 3 = 5Standard error redirection
You can redirect all the system errors to a custom file using standard errors, which can be denoted by the number 2. Execute it in normal Bash commands, as demonstrated below:
$ mkdir users 2> errors.txt
$ cat errors.txt
mkdir: cannot create directory ‘users’: File existsMost of the time, it is difficult to find the exact line number in scripts. To print the line number with the error, use the PS4 option (supported with Bash 4.1 or later). Example below:
$ cat test3.sh
#!/bin/bash
PS4='LINENO:'
set -x
echo "hello World"
mkdiir testingYou can easily see the line number while reading the errors:
$ /test3.sh
5: echo 'hello World'
hello World
6: mkdiir testing
./test3.sh: line 6: mkdiir: command not found[ Get this free ebook: Managing your Kubernetes clusters for dummies. ]
Wrap up
Managing errors is a key skill for administrators when writing scripts. These tips should help make your life easier when troubleshooting Bash scripts or even general commands.
These few lines are not intended as a full-fledged debugging tutorial, but as hints and comments about debugging a Bash script.
Do not name your script test, for example! Why? test is the name of a UNIX®-command, and most likely built into your shell (it’s a built-in in Bash) — so you won’t be able to run a script with the name test in a normal way.
Don’t laugh! This is a classic mistake ![]()
Many people come into IRC and ask something like «Why does my script fail? I get an error!». And when you ask them what the error message is, they don’t even know. Beautiful.
Reading and interpreting error messages is 50% of your job as debugger! Error messages actually mean something. At the very least, they can give you hints as to where to start debugging. READ YOUR ERROR MESSAGES!
You may ask yourself why is this mentioned as debugging tip? Well, you would be surprised how many shell users ignore the text of error messages! When I find some time, I’ll paste 2 or 3 IRC log-snips here, just to show you that annoying fact.
Your choice of editor is a matter of personal preference, but one with Bash syntax highlighting is highly recommended! Syntax highlighting helps you see (you guessed it) syntax errors, such as unclosed quotes and braces, typos, etc.
From my personal experience, I can suggest vim or GNU emacs.
For more complex scripts, it’s useful to write to a log file, or to the system log. Nobody can debug your script without knowing what actually happened and what went wrong.
An available syslog interface is logger ( online manpage).
Insert echos everywhere you can, and print to stderr:
echo "DEBUG: current i=$i" >&2
If you read input from anywhere, such as a file or command substitution, print the debug output with literal quotes, to see leading and trailing spaces!
pid=$(< fooservice.pid) echo "DEBUG: read from file: pid="$pid"" >&2
Bash’s printf command has the %q format, which is handy for verifying whether strings are what they appear to be.
foo=$(< inputfile) printf "DEBUG: foo is |%q|n" "$foo" >&2 # exposes whitespace (such as CRs, see below) and non-printing characters
There are two useful debug outputs for that task (both are written to stderr):
Hint: These modes can be entered when calling Bash:
Here’s a simple command (a string comparison using the classic test command) executed while in set -x mode:
set -x foo="bar baz" [ $foo = test ]
That fails. Why? Let’s see the xtrace output:
+ '[' bar baz = test ']'
And now you see that it’s («bar» and «baz») recognized as two separate words (which you would have realized if you READ THE ERROR MESSAGES ). Let’s check it…
# next try [ "$foo" = test ]
xtrace now gives
+ '[' 'bar baz' = test ']'
^ ^
word markers!
(by AnMaster)
xtrace output would be more useful if it contained source file and line number. Add this assignment PS4 at the beginning of your script to enable the inclusion of that information:
export PS4='+(${BASH_SOURCE}:${LINENO}): ${FUNCNAME[0]:+${FUNCNAME[0]}(): }'
Be sure to use single quotes here!
The output would look like this when you trace code outside a function:
+(somefile.bash:412): echo 'Hello world'
…and like this when you trace code inside a function:
+(somefile.bash:412): myfunc(): echo 'Hello world'
That helps a lot when the script is long, or when the main script sources many other files.
Set flag variables with descriptive words
If you test variables that flag the state of options, such as with if [[ -n $option ]];, consider using descriptive words rather than short codes, such as 0, 1, Y, N, because xtrace will show [[ -n word ]] rather than [[ -n 1 ]] when the option is set.
Debugging commands depending on a set variable
For general debugging purposes you can also define a function and a variable to use:
debugme() {
[[ $script_debug = 1 ]] && "$@" || :
# be sure to append || : or || true here or use return 0, since the return code
# of this function should always be 0 to not influence anything else with an unwanted
# "false" return code (for example the script's exit code if this function is used
# as the very last command in the script)
}
This function does nothing when script_debug is unset or empty, but it executes the given parameters as commands when script_debug is set. Use it like this:
script_debug=1 # to turn it off, set script_debug=0 debugme logger "Sorting the database" database_sort debugme logger "Finished sorting the database, exit code $?"
Of course this can be used to execute something other than echo during debugging:
debugme set -x # ... some code ... debugme set +x
Dry-run STDIN driven commands
Imagine you have a script that runs FTP commands using the standard FTP client:
ftp user@host <<FTP cd /data get current.log dele current.log FTP
A method to dry-run this with debug output is:
if [[ $DRY_RUN = yes ]]; then sed 's/^/DRY_RUN FTP: /' else ftp user@host fi <<FTP cd /data get current.log dele current.log FTP
This can be wrapped in a shell function for more readable code.
script.sh: line 100: syntax error: unexpected end of file
Usually indicates exactly what it says: An unexpected end of file. It’s unexpected because Bash waits for the closing of a compound command:
Note: It seems that here-documents (tested on versions 1.14.7, 2.05b, 3.1.17 and 4.0) are correctly terminated when there is an EOF before the end-of-here-document tag (see redirection). The reason is unknown, but it seems to be deliberate. Bash 4.0 added an extra message for this: warning: here-document at line <N> delimited by end-of-file (wanted `<MARKER>')
script.sh: line 50: unexpected EOF while looking for matching `"' script.sh: line 100: syntax error: unexpected end of file
This one indicates the double-quote opened in line 50 does not have a matching closing quote.
These unmatched errors occur with:
bash: test: too many arguments
You most likely forgot to quote a variable expansion somewhere. See the example for xtrace output from above. External commands may display such an error message though in our example, it was the internal test-command that yielded the error.
$ echo "Hello world!" bash: !": event not found
This is not an error per se. It happens in interactive shells, when the C-Shell-styled history expansion («!searchword«) is enabled. This is the default. Disable it like this:
set +H # or set +o histexpand
When this happens during a script function definition or on the commandline, e.g.
$ foo () { echo "Hello world"; }
bash: syntax error near unexpected token `('
you most likely have an alias defined with the same name as the function (here: foo). Alias expansion happens before the real language interpretion, thus the alias is expanded and makes your function definition invalid.
There’s a big difference in the way that UNIX® and Microsoft® (and possibly others) handle the line endings of plain text files. The difference lies in the use of the CR (Carriage Return) and LF (Line Feed) characters.
Keep in mind your script is a plain text file, and the CR character means nothing special to UNIX® — it is treated like any other character. If it’s printed to your terminal, a carriage return will effectively place the cursor at the beginning of the current line. This can cause much confusion and many headaches, since lines containing CRs are not what they appear to be when printed. In summary, CRs are a pain.
Some possible sources of CRs:
CRs can be a nuisance in various ways. They are especially bad when present in the shebang/interpreter specified with #! in the very first line of a script. Consider the following script, written with a Windows® text editor (^M is a symbolic representation of the CR carriage return character!):
#!/bin/bash^M ^M echo "Hello world"^M ...
Here’s what happens because of the #!/bin/bash^M in our shebang:
The error message can vary. If you’re lucky, you’ll get:
bash: ./testing.sh: /bin/bash^M: bad interpreter: No such file or directory
which alerts you to the CR. But you may also get the following:
: bad interpreter: No such file or directory
Why? Because when printed literally, the ^M makes the cursor go back to the beginning of the line. The whole error message is printed, but you see only part of it!
It’s easy to imagine the ^M is bad in other places too. If you get weird and illogical messages from your script, rule out the possibility that^M is involved. Find and eliminate it!
How can I find and eliminate them?
To display CRs (these are only a few examples)
To eliminate them (only a few examples)

# Append vs Truncate
# Truncate >
- Create specified file if it does not exist.
- Truncate (remove file’s content)
- Write to file
# Append >>
- Create specified file if it does not exist.
- Append file (writing at end of file).
# Redirecting both STDOUT and STDERR
File descriptors like 0 and 1 are pointers. We change what file descriptors point to with redirection. >/dev/null means 1 points to /dev/null.
First we point 1 (STDOUT) to /dev/null then point 2 (STDERR) to whatever 1 points to.
This can be further shortened to the following:
However, this form may be undesirable in production if shell compatibility is a concern as it conflicts with POSIX, introduces parsing ambiguity, and shells without this feature will misinterpret it:
NOTE: &> is known to work as desired in both Bash and Zsh.
# Redirecting standard output
> redirect the standard output (aka STDOUT) of the current command into a file or another descriptor.
These examples write the output of the ls command into the file file.txt
The target file is created if it doesn’t exists, otherwise this file is truncated.
The default redirection descriptor is the standard output or 1 when none is specified.
This command is equivalent to the previous examples with the standard output explicitly indicated:
Note: the redirection is initialized by the executed shell and not by the executed command, therefore it is done before the command execution.
# Using named pipes
Sometimes you may want to output something by one program and input it into another program, but can’t use a standard pipe.
You could simply write to a temporary file:
This works fine for most applications, however, nobody will know what tempFile does and someone might remove it if it contains the output of ls -l in that directory. This is where a named pipe comes into play:
myPipe is technically a file (everything is in Linux), so let’s do ls -l in an empty directory that we just created a pipe in:
The output is:
Notice the first character in the permissions, it’s listed as a pipe, not a file.
Now let’s do something cool.
Open one terminal, and make note of the directory (or create one so that cleanup is easy), and make a pipe.
Now let’s put something in the pipe.
You’ll notice this hangs, the other side of the pipe is still closed. Let’s open up the other side of the pipe and let that stuff through.
Open another terminal and go to the directory that the pipe is in (or if you know it, prepend it to the pipe):
You’ll notice that after hello from the other side is output, the program in the first terminal finishes, as does that in the second terminal.
Now run the commands in reverse. Start with cat < myPipe and then echo something into it. It still works, because a program will wait until something is put into the pipe before terminating, because it knows it has to get something.
Named pipes can be useful for moving information between terminals or between programs.
Pipes are small. Once full, the writer blocks until some reader reads the contents, so you need to either run the reader and writer in different terminals or run one or the other in the background:
More examples using named pipes:
Mind that first contents of file3 are displayed and then the ls -l data is displayed (LIFO configuration).
Mind that the variable $pipedata is not available for usage in the main terminal / main shell since the use of & invokes a subshell and $pipedata was only available in this subshell.
This prints correctly the value of $pipedata variable in the main shell due to the export declaration of the variable. The main terminal/main shell is not hanging due to the invocation of a background shell (&).
# Redirecting multiple commands to the same file
# Print error messages to stderr
Error messages are generally included in a script for debugging purposes or for providing rich user experience. Simply writing error message like this:
may work for simple cases but it’s not the usual way. In this example, the error message will pollute the actual output of the script by mixing both errors and successful output in stdout.
In short, error message should go to stderr not stdout. It’s pretty simple:
Another example:
In the above example, the success message will be printed on stdout while the error message will be printed on stderr.
A better way to print error message is to define a function:
Now, when you have to print an error:
# Redirection to network addresses
Bash treats some paths as special and can do some network communication by writing to /dev/{udp|tcp}/host/port. Bash cannot setup a listening server, but can initiate a connection, and for TCP can read the results at least.
For example, to send a simple web request one could do:
and the results of www.google.com‘s default web page will be printed to stdout.
Similarly
would send a UDP message containing HIn to a listener on 192.168.1.1:6666
# Redirecting STDIN
< reads from its right argument and writes to its left argument.
To write a file into STDIN we should read /tmp/a_file and write into STDIN i.e 0</tmp/a_file
Note: Internal file descriptor defaults to 0 (STDIN) for <
# Redirecting STDERR
2 is STDERR.
Definitions:
echo_to_stderr is a command that writes "stderr" to STDERR
# STDIN, STDOUT and STDERR explained
Commands have one input (STDIN) and two kinds of outputs, standard output (STDOUT) and standard error (STDERR).
For example:
STDIN
Standard input is used to provide input to a program.
(Here we’re using the read builtin (opens new window) to read a line from STDIN.)
STDOUT
Standard output is generally used for «normal» output from a command. For example, ls lists files, so the files are sent to STDOUT.
STDERR
Standard error is (as the name implies) used for error messages. Because this message is not a list of files, it is sent to STDERR.
STDIN, STDOUT and STDERR are the three standard streams. They are identified to the shell by a number rather than a name:
0 = Standard in
1 = Standard out
2 = Standard error
By default, STDIN is attached to the keyboard, and both STDOUT and STDERR appear in the terminal. However, we can redirect either STDOUT or STDERR to whatever we need. For example, let’s say that you only need the standard out and all error messages printed on standard error should be suppressed. That’s when we use the descriptors 1 and 2.
Redirecting STDERR to /dev/null
Taking the previous example,
In this case, if there is any STDERR, it will be redirected to /dev/null (a special file which ignores anything put into it), so you won’t get any error output on the shell.
# Syntax
- command </path/to/file # Redirect standard input to file
- command >/path/to/file # Redirect standard output to flie
- command file_descriptor>/path/to/file # Redirect output of file_descriptor to file
- command >&file_descriptor # Redirect output to file_descriptor
- command file_descriptor>&another_file_descriptor # Redirect file_descriptor to another_file_descriptor
- command <&file_descriptor # Redirect file_descriptor to standard input
- command &>/path/to/file # Redirect standard output and standard error to file
# Parameters
| Parameter | Details |
|---|---|
| internal file descriptor | An integer. |
| direction | One of >, < or <> |
| external file descriptor or path | & followed by an integer for file descriptor or a path. |
UNIX console programs have an input file and two output files (input and output streams, as well as devices, are treated as files by the OS.) These are typically the keyboard and screen, respectively, but any or all of them can be redirected to come from — or go to — a file or other program.
STDIN is standard input, and is how the program receives interactive input. STDIN is usually assigned file descriptor 0.
STDOUT is standard output. Whatever is emitted on STDOUT is considered the «result» of the program. STDOUT is usually assigned file descriptor 1.
STDERR is where error messages are displayed. Typically, when running a program from the console, STDERR is output on the screen and is indistinguishable from STDOUT. STDERR is usually assigned file descriptor 2.
The order of redirection is important
Redirects both (STDOUT and STDERR) to the file.
Redirects only STDOUT, because the file descriptor 2 is redirected to the file pointed to by file descriptor 1 (which is not the file file yet when the statement is evaluated).
Each command in a pipeline has its own STDERR (and STDOUT) because each is a new process. This can create surprising results if you expect a redirect to affect the entire pipeline. For example this command (wrapped for legibility):
will print «Python error!» to the console rather than the log file. Instead, attach the error to the command you want to capture:
Bash-скрипты: начало
Bash-скрипты, часть 2: циклы
Bash-скрипты, часть 3: параметры и ключи командной строки
Bash-скрипты, часть 4: ввод и вывод
Bash-скрипты, часть 5: сигналы, фоновые задачи, управление сценариями
Bash-скрипты, часть 6: функции и разработка библиотек
Bash-скрипты, часть 7: sed и обработка текстов
Bash-скрипты, часть 8: язык обработки данных awk
Bash-скрипты, часть 9: регулярные выражения
Bash-скрипты, часть 10: практические примеры
Bash-скрипты, часть 11: expect и автоматизация интерактивных утилит
В прошлый раз, в третьей части этой серии материалов по bash-скриптам, мы говорили о параметрах командной строки и ключах. Наша сегодняшняя тема — ввод, вывод, и всё, что с этим связано.

Вы уже знакомы с двумя методами работы с тем, что выводят сценарии командной строки:
- Отображение выводимых данных на экране.
- Перенаправление вывода в файл.
Иногда что-то надо показать на экране, а что-то — записать в файл, поэтому нужно разобраться с тем, как в Linux обрабатывается ввод и вывод, а значит — научиться отправлять результаты работы сценариев туда, куда нужно. Начнём с разговора о стандартных дескрипторах файлов.
Стандартные дескрипторы файлов
Всё в Linux — это файлы, в том числе — ввод и вывод. Операционная система идентифицирует файлы с использованием дескрипторов.
Каждому процессу позволено иметь до девяти открытых дескрипторов файлов. Оболочка bash резервирует первые три дескриптора с идентификаторами 0, 1 и 2. Вот что они означают.
0,STDIN —стандартный поток ввода.1,STDOUT —стандартный поток вывода.2,STDERR —стандартный поток ошибок.
Эти три специальных дескриптора обрабатывают ввод и вывод данных в сценарии.
Вам нужно как следует разобраться в стандартных потоках. Их можно сравнить с фундаментом, на котором строится взаимодействие скриптов с внешним миром. Рассмотрим подробности о них.
STDIN
STDIN — это стандартный поток ввода оболочки. Для терминала стандартный ввод — это клавиатура. Когда в сценариях используют символ перенаправления ввода — <, Linux заменяет дескриптор файла стандартного ввода на тот, который указан в команде. Система читает файл и обрабатывает данные так, будто они введены с клавиатуры.
Многие команды bash принимают ввод из STDIN, если в командной строке не указан файл, из которого надо брать данные. Например, это справедливо для команды cat.
Когда вы вводите команду cat в командной строке, не задавая параметров, она принимает ввод из STDIN. После того, как вы вводите очередную строку, cat просто выводит её на экран.
STDOUT
STDOUT — стандартный поток вывода оболочки. По умолчанию это — экран. Большинство bash-команд выводят данные в STDOUT, что приводит к их появлению в консоли. Данные можно перенаправить в файл, присоединяя их к его содержимому, для этого служит команда >>.
Итак, у нас есть некий файл с данными, к которому мы можем добавить другие данные с помощью этой команды:
pwd >> myfile
То, что выведет pwd, будет добавлено к файлу myfile, при этом уже имеющиеся в нём данные никуда не денутся.
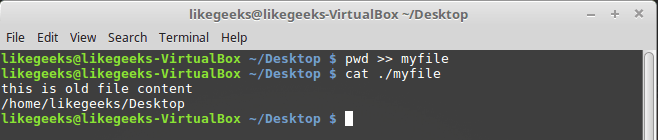
Перенаправление вывода команды в файл
Пока всё хорошо, но что если попытаться выполнить что-то вроде показанного ниже, обратившись к несуществующему файлу xfile, задумывая всё это для того, чтобы в файл myfile попало сообщение об ошибке.
ls –l xfile > myfileПосле выполнения этой команды мы увидим сообщения об ошибках на экране.

Попытка обращения к несуществующему файлу
При попытке обращения к несуществующему файлу генерируется ошибка, но оболочка не перенаправила сообщения об ошибках в файл, выведя их на экран. Но мы-то хотели, чтобы сообщения об ошибках попали в файл. Что делать? Ответ прост — воспользоваться третьим стандартным дескриптором.
STDERR
STDERR представляет собой стандартный поток ошибок оболочки. По умолчанию этот дескриптор указывает на то же самое, на что указывает STDOUT, именно поэтому при возникновении ошибки мы видим сообщение на экране.
Итак, предположим, что надо перенаправить сообщения об ошибках, скажем, в лог-файл, или куда-нибудь ещё, вместо того, чтобы выводить их на экран.
▍Перенаправление потока ошибок
Как вы уже знаете, дескриптор файла STDERR — 2. Мы можем перенаправить ошибки, разместив этот дескриптор перед командой перенаправления:
ls -l xfile 2>myfile
cat ./myfile
Сообщение об ошибке теперь попадёт в файл myfile.

Перенаправление сообщения об ошибке в файл
▍Перенаправление потоков ошибок и вывода
При написании сценариев командной строки может возникнуть ситуация, когда нужно организовать и перенаправление сообщений об ошибках, и перенаправление стандартного вывода. Для того, чтобы этого добиться, нужно использовать команды перенаправления для соответствующих дескрипторов с указанием файлов, куда должны попадать ошибки и стандартный вывод:
ls –l myfile xfile anotherfile 2> errorcontent 1> correctcontent
Перенаправление ошибок и стандартного вывода
Оболочка перенаправит то, что команда ls обычно отправляет в STDOUT, в файл correctcontent благодаря конструкции 1>. Сообщения об ошибках, которые попали бы в STDERR, оказываются в файле errorcontent из-за команды перенаправления 2>.
Если надо, и STDERR, и STDOUT можно перенаправить в один и тот же файл, воспользовавшись командой &>:
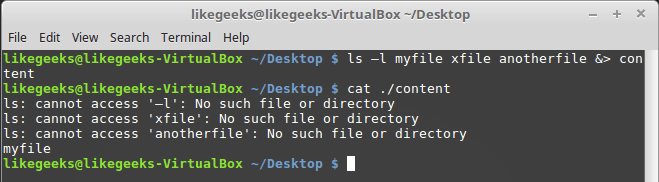
Перенаправление STDERR и STDOUT в один и тот же файл
После выполнения команды то, что предназначено для STDERR и STDOUT, оказывается в файле content.
Перенаправление вывода в скриптах
Существует два метода перенаправления вывода в сценариях командной строки:
- Временное перенаправление, или перенаправление вывода одной строки.
- Постоянное перенаправление, или перенаправление всего вывода в скрипте либо в какой-то его части.
▍Временное перенаправление вывода
В скрипте можно перенаправить вывод отдельной строки в STDERR. Для того, чтобы это сделать, достаточно использовать команду перенаправления, указав дескриптор STDERR, при этом перед номером дескриптора надо поставить символ амперсанда (&):
#!/bin/bash
echo "This is an error" >&2
echo "This is normal output"Если запустить скрипт, обе строки попадут на экран, так как, как вы уже знаете, по умолчанию ошибки выводятся туда же, куда и обычные данные.

Временное перенаправление
Запустим скрипт так, чтобы вывод STDERR попадал в файл.
./myscript 2> myfileКак видно, теперь обычный вывод делается в консоль, а сообщения об ошибках попадают в файл.
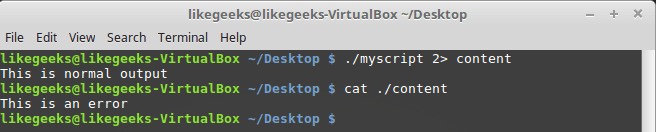
Сообщения об ошибках записываются в файл
▍Постоянное перенаправление вывода
Если в скрипте нужно перенаправлять много выводимых на экран данных, добавлять соответствующую команду к каждому вызову echo неудобно. Вместо этого можно задать перенаправление вывода в определённый дескриптор на время выполнения скрипта, воспользовавшись командой exec:
#!/bin/bash
exec 1>outfile
echo "This is a test of redirecting all output"
echo "from a shell script to another file."
echo "without having to redirect every line"Запустим скрипт.

Перенаправление всего вывода в файл
Если просмотреть файл, указанный в команде перенаправления вывода, окажется, что всё, что выводилось командами echo, попало в этот файл.
Команду exec можно использовать не только в начале скрипта, но и в других местах:
#!/bin/bash
exec 2>myerror
echo "This is the start of the script"
echo "now redirecting all output to another location"
exec 1>myfile
echo "This should go to the myfile file"
echo "and this should go to the myerror file" >&2Вот что получится после запуска скрипта и просмотра файлов, в которые мы перенаправляли вывод.
![]()
Перенаправление вывода в разные файлы
Сначала команда exec задаёт перенаправление вывода из STDERR в файл myerror. Затем вывод нескольких команд echo отправляется в STDOUT и выводится на экран. После этого команда exec задаёт отправку того, что попадает в STDOUT, в файл myfile, и, наконец, мы пользуемся командой перенаправления в STDERR в команде echo, что приводит к записи соответствующей строки в файл myerror.
Освоив это, вы сможете перенаправлять вывод туда, куда нужно. Теперь поговорим о перенаправлении ввода.
Перенаправление ввода в скриптах
Для перенаправления ввода можно воспользоваться той же методикой, которую мы применяли для перенаправления вывода. Например, команда exec позволяет сделать источником данных для STDIN какой-нибудь файл:
exec 0< myfile
Эта команда указывает оболочке на то, что источником вводимых данных должен стать файл myfile, а не обычный STDIN. Посмотрим на перенаправление ввода в действии:
#!/bin/bash
exec 0< testfile
count=1
while read line
do
echo "Line #$count: $line"
count=$(( $count + 1 ))
doneВот что появится на экране после запуска скрипта.

Перенаправление ввода
В одном из предыдущих материалов вы узнали о том, как использовать команду read для чтения данных, вводимых пользователем с клавиатуры. Если перенаправить ввод, сделав источником данных файл, то команда read, при попытке прочитать данные из STDIN, будет читать их из файла, а не с клавиатуры.
Некоторые администраторы Linux используют этот подход для чтения и последующей обработки лог-файлов.
Создание собственного перенаправления вывода
Перенаправляя ввод и вывод в сценариях, вы не ограничены тремя стандартными дескрипторами файлов. Как уже говорилось, можно иметь до девяти открытых дескрипторов. Остальные шесть, с номерами от 3 до 8, можно использовать для перенаправления ввода или вывода. Любой из них можно назначить файлу и использовать в коде скрипта.
Назначить дескриптор для вывода данных можно, используя команду exec:
#!/bin/bash
exec 3>myfile
echo "This should display on the screen"
echo "and this should be stored in the file" >&3
echo "And this should be back on the screen"
После запуска скрипта часть вывода попадёт на экран, часть — в файл с дескриптором 3.
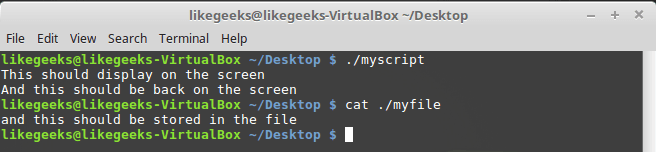
Перенаправление вывода, используя собственный дескриптор
Создание дескрипторов файлов для ввода данных
Перенаправить ввод в скрипте можно точно так же, как и вывод. Сохраните STDIN в другом дескрипторе, прежде чем перенаправлять ввод данных.
После окончания чтения файла можно восстановить STDIN и пользоваться им как обычно:
#!/bin/bash
exec 6<&0
exec 0< myfile
count=1
while read line
do
echo "Line #$count: $line"
count=$(( $count + 1 ))
done
exec 0<&6
read -p "Are you done now? " answer
case $answer in
y) echo "Goodbye";;
n) echo "Sorry, this is the end.";;
esacИспытаем сценарий.
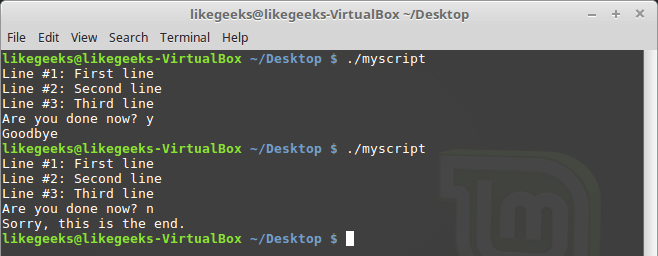
Перенаправление ввода
В этом примере дескриптор файла 6 использовался для хранения ссылки на STDIN. Затем было сделано перенаправление ввода, источником данных для STDIN стал файл. После этого входные данные для команды read поступали из перенаправленного STDIN, то есть из файла.
После чтения файла мы возвращаем STDIN в исходное состояние, перенаправляя его в дескриптор 6. Теперь, для того, чтобы проверить, что всё работает правильно, скрипт задаёт пользователю вопрос, ожидает ввода с клавиатуры и обрабатывает то, что введено.
Закрытие дескрипторов файлов
Оболочка автоматически закрывает дескрипторы файлов после завершения работы скрипта. Однако, в некоторых случаях нужно закрывать дескрипторы вручную, до того, как скрипт закончит работу. Для того, чтобы закрыть дескриптор, его нужно перенаправить в &-. Выглядит это так:
#!/bin/bash
exec 3> myfile
echo "This is a test line of data" >&3
exec 3>&-
echo "This won't work" >&3После исполнения скрипта мы получим сообщение об ошибке.

Попытка обращения к закрытому дескриптору файла
Всё дело в том, что мы попытались обратиться к несуществующему дескриптору.
Будьте внимательны, закрывая дескрипторы файлов в сценариях. Если вы отправляли данные в файл, потом закрыли дескриптор, потом — открыли снова, оболочка заменит существующий файл новым. То есть всё то, что было записано в этот файл ранее, будет утеряно.
Получение сведений об открытых дескрипторах
Для того, чтобы получить список всех открытых в Linux дескрипторов, можно воспользоваться командой lsof. Во многих дистрибутивах, вроде Fedora, утилита lsof находится в /usr/sbin. Эта команда весьма полезна, так как она выводит сведения о каждом дескрипторе, открытом в системе. Сюда входит и то, что открыли процессы, выполняемые в фоне, и то, что открыто пользователями, вошедшими в систему.
У этой команды есть множество ключей, рассмотрим самые важные.
-pПозволяет указатьIDпроцесса.-dПозволяет указать номер дескриптора, о котором надо получить сведения.
Для того, чтобы узнать PID текущего процесса, можно использовать специальную переменную окружения $$, в которую оболочка записывает текущий PID.
Ключ -a используется для выполнения операции логического И над результатами, возвращёнными благодаря использованию двух других ключей:
lsof -a -p $$ -d 0,1,2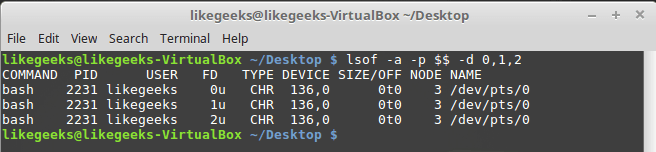
Вывод сведений об открытых дескрипторах
Тип файлов, связанных с STDIN, STDOUT и STDERR — CHR (character mode, символьный режим). Так как все они указывают на терминал, имя файла соответствует имени устройства, назначенного терминалу. Все три стандартных файла доступны и для чтения, и для записи.
Посмотрим на вызов команды lsof из скрипта, в котором открыты, в дополнение к стандартным, другие дескрипторы:
#!/bin/bash
exec 3> myfile1
exec 6> myfile2
exec 7< myfile3
lsof -a -p $$ -d 0,1,2,3,6,7Вот что получится, если этот скрипт запустить.
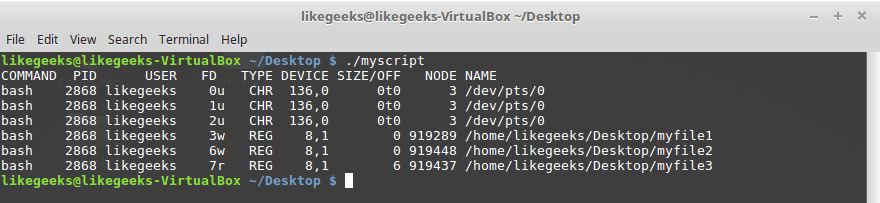
Просмотр дескрипторов файлов, открытых скриптом
Скрипт открыл два дескриптора для вывода (3 и 6) и один — для ввода (7). Тут же показаны и пути к файлам, использованных для настройки дескрипторов.
Подавление вывода
Иногда надо сделать так, чтобы команды в скрипте, который, например, может исполняться как фоновый процесс, ничего не выводили на экран. Для этого можно перенаправить вывод в /dev/null. Это — что-то вроде «чёрной дыры».
Вот, например, как подавить вывод сообщений об ошибках:
ls -al badfile anotherfile 2> /dev/nullТот же подход используется, если, например, надо очистить файл, не удаляя его:
cat /dev/null > myfileИтоги
Сегодня вы узнали о том, как в сценариях командной строки работают ввод и вывод. Теперь вы умеете обращаться с дескрипторами файлов, создавать, просматривать и закрывать их, знаете о перенаправлении потоков ввода, вывода и ошибок. Всё это очень важно в деле разработки bash-скриптов.
В следующий раз поговорим о сигналах Linux, о том, как обрабатывать их в сценариях, о запуске заданий по расписанию и о фоновых задачах.
Уважаемые читатели! В этом материале даны основы работы с потоками ввода, вывода и ошибок. Уверены, среди вас есть профессионалы, которые могут рассказать обо всём этом то, что приходит лишь с опытом. Если так — передаём слово вам.
Bash, or the Bourne-Again Shell, is a powerful command-line interface (CLI) that is commonly used in Linux and Unix systems. When working with Bash, it is important to understand how to handle errors that may occur during the execution of commands. In this article, we will discuss various ways to understand and ignore errors in Bash. Bash scripting is a powerful tool for automating and simplifying various tasks in Linux and Unix systems. However, errors can occur during the execution of commands and can cause scripts to fail. In this article, we will explore the various ways to understand and handle errors in Bash. We will look at ways to check the exit status code and error messages of commands, as well as techniques for ignoring errors when necessary. By understanding and properly handling errors, you can ensure that your Bash scripts run smoothly and achieve the desired outcome.
Step-by-step approach for understanding and ignoring errors in Bash:
Step 1: Understand how errors are generated in Bash.
- When a command is executed, it returns an exit status code.
- A successful command will have an exit status of 0, while a failed command will have a non-zero exit status.
- Error messages are generated when a command returns a non-zero exit status code.
Step 2: Check the exit status code of a command.
- To check the exit status code of a command, you can use the $? variable, which holds the exit status of the last executed command.
- For example, after executing the command ls non_existent_directory, you can check the exit status code by running echo $? The output
- will be non-zero (e.g., 2) indicating that the command failed.
Step 3: Check the error message of a command.
- To check the error message of a command, you can redirect the standard error output (stderr) to a file or to the standard output (stdout) using the 2> operator.
- For example, you can redirect the stderr of the command ls non_existent_directory to a file by running ls non_existent_directory 2> error.log. Then you can view the error message by running cat error.log.
Step 4: Use the set -e command.
- The set -e command causes the script to exit immediately if any command exits with a non-zero status. This can be useful for detecting and handling errors early on in a script.
- For example, if you run set -e followed by ls non_existent_directory, the script will exit immediately with an error message.
Step 5: Ignore errors when necessary.
- To ignore errors, you can use the command || true construct. This construct allows you to execute a command, and if it returns a non-zero exit status, the command following the || operator (in this case, true) will be executed instead.
- For example, you can run rm non_existent_file || true to remove a file that does not exist without exiting with an error.
- Another way to ignore errors is to use the command 2> /dev/null construct, which redirects the standard error output (stderr) of a command to the null device, effectively ignoring any error messages.
- Additionally, you can use the command 2>&1 >/dev/null construct to ignore both standard error and standard output.
- You can also use the command || : construct which allows you to execute a command and if it returns a non-zero exit status, the command following the || operator (in this case, 🙂 will be executed instead. The: command is a no-op command that does nothing, effectively ignoring the error.
Practical Explanation for Understanding Errors
First, let’s examine how errors are generated in Bash. When a command is executed, it returns an exit status code. This code indicates whether the command was successful (exit status 0) or not (non-zero exit status). For example, the following command attempts to list the files in a directory that does not exist:
$ ls non_existent_directory ls: cannot access 'non_existent_directory': No such file or directory

As you can see, the command generated an error message and returned a non-zero exit status code. To check the exit status code of a command, you can use the $? variable, which holds the exit status of the last executed command.
$ echo $? 2
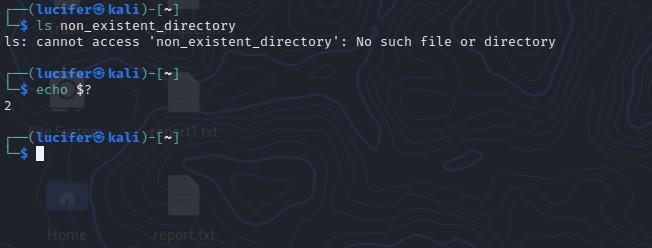
In addition to the exit status code, you can also check the standard error output (stderr) of a command to understand errors. This can be done by redirecting the stderr to a file or to the standard output (stdout) using the 2> operator.
For example, the following script will redirect the stderr of a command to a file:
$ ls non_existent_directory 2> error.log $ cat error.log ls: cannot access 'non_existent_directory': No such file or directory

You can also redirect the stderr to the stdout using the 2>&1 operator, which allows you to see the error message along with the standard output of the command.
$ ls non_existent_directory 2>&1 ls: cannot access 'non_existent_directory': No such file or directory

Another useful tool for understanding errors is the set -e command, which causes the script to exit immediately if any command exits with a non-zero status. This can be useful for detecting and handling errors early on in a script.
$ set -e $ ls non_existent_directory # as soon as you hit enter this will exit shell and will close the terminal.
After this command script will exit from the shell if the exit code is nonzero.
Practical Explanation for Ignoring Errors
While it is important to handle errors in Bash scripts, there may be certain situations where you want to ignore errors and continue running the script. In this section, we will discuss different methods for ignoring errors in Bash and provide examples of how to implement them.
Heredoc
Heredoc is a feature in Bash that allows you to specify a string or command without having to escape special characters. This can be useful when you want to ignore errors that may occur while executing a command. The following example demonstrates how to use Heredoc to ignore errors.
#!/bin/bash # Example of ignoring errors using Heredoc # The `command` will fail but it will not stop execution cat <<EOF | while read line; do echo $line done command that will fail EOF # Rest of the script
In this example, the command that is inside the Heredoc will fail, but the script will not stop execution. This is because the output of the command is piped to the while loop, which reads the output and ignores the error.
Pipefail
The pipe fails option in Bash can be used to change the behavior of pipelines so that the exit status of the pipeline is the value of the last (rightmost) command to exit with a non-zero status or zero if all commands exit successfully. This can be useful when you want to ignore errors that may occur while executing multiple commands in a pipeline. The following example demonstrates how to use the pipe fail option to ignore errors.
#!/bin/bash # Example of ignoring errors using pipefail # The `command1` will fail but it will not stop execution set -o pipefail command1 | command2 # Rest of the script
In this example, command1 will fail, but command2 will continue to execute, and the script will not stop execution.
Undefined Variables
By default, Bash will stop the execution of a script if an undefined variable is used. However, you can use the -u option to ignore this behavior and continue running the script even if an undefined variable is used. The following example demonstrates how to ignore undefined variables.
#!/bin/bash # Example of ignoring undefined variables set +u echo $undefined_variable # Rest of the script
In this example, the script will not stop execution when an undefined variable is used.
Compiling and Interpreting
When compiling or interpreting a script, errors may occur. However, these errors can be ignored by using the -f option when running the script. The following example demonstrates how to ignore errors when compiling or interpreting a script.
#!/bin/bash # Example of ignoring errors when compiling or interpreting bash -f script.sh # Rest of the script
In this example, the script will continue to run even if there are errors during the compilation or interpretation process.
Traps
A trap is a way to execute a command or a set of commands when a specific signal is received by the script. This can be useful when you want to ignore errors and run a cleanup command instead. The following example demonstrates how to use a trap to ignore errors.
#!/bin/bash
# Example of ignoring errors using a trap
# Set a trap to run the cleanup function when an error occurs
trap cleanup ERR
# Function to run when an error occurs
cleanup() {
echo "Cleaning up before exiting..."
}
# Command that will cause an error
command_that_will_fail
# Rest of the script
In this example, when the command_that_will_fail causes an error, the script will execute the cleanup function instead of stopping execution. This allows you to perform any necessary cleanup before exiting the script.
Examples of Bash for Error Handling:
Example 1: Error Handling Using a Conditional Condition
One way to handle errors in Bash is to use a conditional statement. The following example demonstrates how to check for a specific error and handle it accordingly.
#!/bin/bash # Example of error handling using a conditional condition file=example.txt if [ ! -f $file ]; then echo "Error: $file does not exist" exit 1 fi # Rest of the script
In this example, we check if the file “example.txt” exists using the -f option of the [ command. If the file does not exist, the script will print an error message and exit with a status code of 1. This allows the script to continue running if the file exists and exit if it does not.
Example 2: Error Handling Using the Exit Status Code
Another way to handle errors in Bash is to check the exit status code of a command. Every command in Bash returns an exit status code when it completes, with a code of 0 indicating success and any other code indicating an error. The following example demonstrates how to check the exit status code of a command and handle it accordingly.
#!/bin/bash # Example of error handling using the exit status code command1 if [ $? -ne 0 ]; then echo "Error: command1 failed" exit 1 fi # Rest of the script
In this example, the script runs the command “command1” and then checks the exit status code using the special variable $?. If the exit status code is not 0, the script will print an error message and exit with a status code of 1.
Example 3: Stop the Execution on the First Error
When running a script, it can be useful to stop the execution on the first error that occurs. This can be achieved by using the set -e command, which tells Bash to exit the script if any command exits with a non-zero status code.
#!/bin/bash # Stop execution on the first error set -e command1 command2 command3 # Rest of the script
In this example, if any of the commands “command1”, “command2” or “command3” fail, the script will exit immediately.
Example 4: Stop the Execution for Uninitialized Variable
Another way to stop execution on error is if an uninitialized variable is used during script execution. This can be achieved by using the set -u command, which tells Bash to exit the script if any uninitialized variable is used.
#!/bin/bash # Stop execution for uninitialized variable set -u echo $uninitialized_variable # Rest of the script
In this example, if the uninitialized_variable is not defined, the script will exit immediately.
Conclusion
In conclusion, understanding and ignoring errors in Bash is an important aspect of working with the command-line interface. By checking the exit status code of a command, its associated error message, and redirecting the stderr to a file or the stdout, you can understand what went wrong. And by using the command || true, command 2> /dev/null, command 2>&1 >/dev/null, and command || : constructs, you can ignore errors when necessary. It’s always a good practice to test these constructs in a testing environment before using them in production.