In coding theory, the Bose–Chaudhuri–Hocquenghem codes (BCH codes) form a class of cyclic error-correcting codes that are constructed using polynomials over a finite field (also called Galois field). BCH codes were invented in 1959 by French mathematician Alexis Hocquenghem, and independently in 1960 by Raj Chandra Bose and D.K. Ray-Chaudhuri.[1][2][3] The name Bose–Chaudhuri–Hocquenghem (and the acronym BCH) arises from the initials of the inventors’ surnames (mistakenly, in the case of Ray-Chaudhuri).
One of the key features of BCH codes is that during code design, there is a precise control over the number of symbol errors correctable by the code. In particular, it is possible to design binary BCH codes that can correct multiple bit errors. Another advantage of BCH codes is the ease with which they can be decoded, namely, via an algebraic method known as syndrome decoding. This simplifies the design of the decoder for these codes, using small low-power electronic hardware.
BCH codes are used in applications such as satellite communications,[4] compact disc players, DVDs, disk drives, USB flash drives, solid-state drives,[5] quantum-resistant cryptography[6] and two-dimensional bar codes.
Definition and illustration[edit]
Primitive narrow-sense BCH codes[edit]
Given a prime number q and prime power qm with positive integers m and d such that d ≤ qm − 1, a primitive narrow-sense BCH code over the finite field (or Galois field) GF(q) with code length n = qm − 1 and distance at least d is constructed by the following method.
Let α be a primitive element of GF(qm).
For any positive integer i, let mi(x) be the minimal polynomial with coefficients in GF(q) of αi.
The generator polynomial of the BCH code is defined as the least common multiple g(x) = lcm(m1(x),…,md − 1(x)).
It can be seen that g(x) is a polynomial with coefficients in GF(q) and divides xn − 1.
Therefore, the polynomial code defined by g(x) is a cyclic code.
Example[edit]
Let q = 2 and m = 4 (therefore n = 15). We will consider different values of d for GF(16) = GF(24) based on the reducing polynomial z4 + z + 1, using primitive element α(z) = z. There are fourteen minimum polynomials mi(x) with coefficients in GF(2) satisfying

The minimal polynomials are

The BCH code with  has generator polynomial
has generator polynomial

It has minimal Hamming distance at least 3 and corrects up to one error. Since the generator polynomial is of degree 4, this code has 11 data bits and 4 checksum bits.
The BCH code with  has generator polynomial
has generator polynomial

It has minimal Hamming distance at least 5 and corrects up to two errors. Since the generator polynomial is of degree 8, this code has 7 data bits and 8 checksum bits.
The BCH code with  has generator polynomial
has generator polynomial

It has minimal Hamming distance at least 7 and corrects up to three errors. Since the generator polynomial is of degree 10, this code has 5 data bits and 10 checksum bits. (This particular generator polynomial has a real-world application, in the format patterns of the QR code.)
The BCH code with  and higher has generator polynomial
and higher has generator polynomial

This code has minimal Hamming distance 15 and corrects 7 errors. It has 1 data bit and 14 checksum bits. In fact, this code has only two codewords: 000000000000000 and 111111111111111.
General BCH codes[edit]
General BCH codes differ from primitive narrow-sense BCH codes in two respects.
First, the requirement that  be a primitive element of
be a primitive element of  can be relaxed. By relaxing this requirement, the code length changes from
can be relaxed. By relaxing this requirement, the code length changes from  to
to  the order of the element
the order of the element 
Second, the consecutive roots of the generator polynomial may run from  instead of
instead of 
Definition. Fix a finite field  where
where  is a prime power. Choose positive integers
is a prime power. Choose positive integers  such that
such that 
 and
and  is the multiplicative order of modulo
is the multiplicative order of modulo 
As before, let be a primitive  th root of unity in
th root of unity in  and let
and let  be the minimal polynomial over
be the minimal polynomial over  of
of  for all
for all 
The generator polynomial of the BCH code is defined as the least common multiple 
Note: if  as in the simplified definition, then
as in the simplified definition, then  is 1, and the order of modulo is
is 1, and the order of modulo is 
Therefore, the simplified definition is indeed a special case of the general one.
Special cases[edit]
The generator polynomial  of a BCH code has coefficients from
of a BCH code has coefficients from 
In general, a cyclic code over  with as the generator polynomial is called a BCH code over
with as the generator polynomial is called a BCH code over 
The BCH code over and generator polynomial with successive powers of as roots is one type of Reed–Solomon code where the decoder (syndromes) alphabet is the same as the channel (data and generator polynomial) alphabet, all elements of .[7] The other type of Reed Solomon code is an original view Reed Solomon code which is not a BCH code.
Properties[edit]
The generator polynomial of a BCH code has degree at most  . Moreover, if
. Moreover, if  and
and  , the generator polynomial has degree at most
, the generator polynomial has degree at most  .
.
A BCH code has minimal Hamming distance at least  .
.
A BCH code is cyclic.
Encoding[edit]
Because any polynomial that is a multiple of the generator polynomial is a valid BCH codeword, BCH encoding is merely the process of finding some polynomial that has the generator as a factor.
The BCH code itself is not prescriptive about the meaning of the coefficients of the polynomial; conceptually, a BCH decoding algorithm’s sole concern is to find the valid codeword with the minimal Hamming distance to the received codeword. Therefore, the BCH code may be implemented either as a systematic code or not, depending on how the implementor chooses to embed the message in the encoded polynomial.
Non-systematic encoding: The message as a factor[edit]
The most straightforward way to find a polynomial that is a multiple of the generator is to compute the product of some arbitrary polynomial and the generator. In this case, the arbitrary polynomial can be chosen using the symbols of the message as coefficients.

As an example, consider the generator polynomial  , chosen for use in the (31, 21) binary BCH code used by POCSAG and others. To encode the 21-bit message {101101110111101111101}, we first represent it as a polynomial over
, chosen for use in the (31, 21) binary BCH code used by POCSAG and others. To encode the 21-bit message {101101110111101111101}, we first represent it as a polynomial over  :
:

Then, compute (also over ):

Thus, the transmitted codeword is {1100111010010111101011101110101}.
The receiver can use these bits as coefficients in  and, after error-correction to ensure a valid codeword, can recompute
and, after error-correction to ensure a valid codeword, can recompute 
Systematic encoding: The message as a prefix[edit]
A systematic code is one in which the message appears verbatim somewhere within the codeword. Therefore, systematic BCH encoding involves first embedding the message polynomial within the codeword polynomial, and then adjusting the coefficients of the remaining (non-message) terms to ensure that is divisible by .
This encoding method leverages the fact that subtracting the remainder from a dividend results in a multiple of the divisor. Hence, if we take our message polynomial  as before and multiply it by
as before and multiply it by  (to «shift» the message out of the way of the remainder), we can then use Euclidean division of polynomials to yield:
(to «shift» the message out of the way of the remainder), we can then use Euclidean division of polynomials to yield:

Here, we see that  is a valid codeword. As
is a valid codeword. As  is always of degree less than
is always of degree less than  (which is the degree of ), we can safely subtract it from
(which is the degree of ), we can safely subtract it from  without altering any of the message coefficients, hence we have our as
without altering any of the message coefficients, hence we have our as

Over (i.e. with binary BCH codes), this process is indistinguishable from appending a cyclic redundancy check, and if a systematic binary BCH code is used only for error-detection purposes, we see that BCH codes are just a generalization of the mathematics of cyclic redundancy checks.
The advantage to the systematic coding is that the receiver can recover the original message by discarding everything after the first  coefficients, after performing error correction.
coefficients, after performing error correction.
Decoding[edit]
There are many algorithms for decoding BCH codes. The most common ones follow this general outline:
- Calculate the syndromes sj for the received vector
- Determine the number of errors t and the error locator polynomial Λ(x) from the syndromes
- Calculate the roots of the error location polynomial to find the error locations Xi
- Calculate the error values Yi at those error locations
- Correct the errors
During some of these steps, the decoding algorithm may determine that the received vector has too many errors and cannot be corrected. For example, if an appropriate value of t is not found, then the correction would fail. In a truncated (not primitive) code, an error location may be out of range. If the received vector has more errors than the code can correct, the decoder may unknowingly produce an apparently valid message that is not the one that was sent.
Calculate the syndromes[edit]
The received vector  is the sum of the correct codeword
is the sum of the correct codeword  and an unknown error vector
and an unknown error vector  The syndrome values are formed by considering as a polynomial and evaluating it at
The syndrome values are formed by considering as a polynomial and evaluating it at  Thus the syndromes are[8]
Thus the syndromes are[8]

for  to
to 
Since  are the zeros of
are the zeros of  of which
of which  is a multiple,
is a multiple,  Examining the syndrome values thus isolates the error vector so one can begin to solve for it.
Examining the syndrome values thus isolates the error vector so one can begin to solve for it.
If there is no error,  for all
for all  If the syndromes are all zero, then the decoding is done.
If the syndromes are all zero, then the decoding is done.
Calculate the error location polynomial[edit]
If there are nonzero syndromes, then there are errors. The decoder needs to figure out how many errors and the location of those errors.
If there is a single error, write this as  where
where  is the location of the error and
is the location of the error and  is its magnitude. Then the first two syndromes are
is its magnitude. Then the first two syndromes are

so together they allow us to calculate and provide some information about (completely determining it in the case of Reed–Solomon codes).
If there are two or more errors,

It is not immediately obvious how to begin solving the resulting syndromes for the unknowns  and
and 
The first step is finding, compatible with computed syndromes and with minimal possible  locator polynomial:
locator polynomial:

Three popular algorithms for this task are:
- Peterson–Gorenstein–Zierler algorithm
- Berlekamp–Massey algorithm
- Sugiyama Euclidean algorithm
Peterson–Gorenstein–Zierler algorithm[edit]
Peterson’s algorithm is the step 2 of the generalized BCH decoding procedure. Peterson’s algorithm is used to calculate the error locator polynomial coefficients  of a polynomial
of a polynomial

Now the procedure of the Peterson–Gorenstein–Zierler algorithm.[9] Expect we have at least 2t syndromes sc, …, sc+2t−1. Let v = t.
Factor error locator polynomial[edit]
Now that you have the  polynomial, its roots can be found in the form
polynomial, its roots can be found in the form  by brute force for example using the Chien search algorithm. The exponential
by brute force for example using the Chien search algorithm. The exponential
powers of the primitive element will yield the positions where errors occur in the received word; hence the name ‘error locator’ polynomial.
The zeros of Λ(x) are α−i1, …, α−iv.
Calculate error values[edit]
Once the error locations are known, the next step is to determine the error values at those locations. The error values are then used to correct the received values at those locations to recover the original codeword.
For the case of binary BCH, (with all characters readable) this is trivial; just flip the bits for the received word at these positions, and we have the corrected code word. In the more general case, the error weights  can be determined by solving the linear system
can be determined by solving the linear system

Forney algorithm[edit]
However, there is a more efficient method known as the Forney algorithm.
Let


And the error evaluator polynomial[10]

Finally:

where

Than if syndromes could be explained by an error word, which could be nonzero only on positions  , then error values are
, then error values are

For narrow-sense BCH codes, c = 1, so the expression simplifies to:

Explanation of Forney algorithm computation[edit]
It is based on Lagrange interpolation and techniques of generating functions.
Consider  and for the sake of simplicity suppose
and for the sake of simplicity suppose  for
for  and
and  for
for  Then
Then


We want to compute unknowns  and we could simplify the context by removing the
and we could simplify the context by removing the  terms. This leads to the error evaluator polynomial
terms. This leads to the error evaluator polynomial

Thanks to  we have
we have

Thanks to  (the Lagrange interpolation trick) the sum degenerates to only one summand for
(the Lagrange interpolation trick) the sum degenerates to only one summand for 

To get we just should get rid of the product. We could compute the product directly from already computed roots  of
of  but we could use simpler form.
but we could use simpler form.
As formal derivative

we get again only one summand in

So finally

This formula is advantageous when one computes the formal derivative of form

yielding:
where
Decoding based on extended Euclidean algorithm[edit]
An alternate process of finding both the polynomial Λ and the error locator polynomial is based on Yasuo Sugiyama’s adaptation of the Extended Euclidean algorithm.[11] Correction of unreadable characters could be incorporated to the algorithm easily as well.
Let  be positions of unreadable characters. One creates polynomial localising these positions
be positions of unreadable characters. One creates polynomial localising these positions 
Set values on unreadable positions to 0 and compute the syndromes.
As we have already defined for the Forney formula let 
Let us run extended Euclidean algorithm for locating least common divisor of polynomials  and
and 
The goal is not to find the least common divisor, but a polynomial of degree at most  and polynomials
and polynomials  such that
such that 
Low degree of guarantees, that  would satisfy extended (by
would satisfy extended (by  ) defining conditions for
) defining conditions for 
Defining  and using
and using  on the place of in the Fourney formula will give us error values.
on the place of in the Fourney formula will give us error values.
The main advantage of the algorithm is that it meanwhile computes  required in the Forney formula.
required in the Forney formula.
Explanation of the decoding process[edit]
The goal is to find a codeword which differs from the received word minimally as possible on readable positions. When expressing the received word as a sum of nearest codeword and error word, we are trying to find error word with minimal number of non-zeros on readable positions. Syndrom  restricts error word by condition
restricts error word by condition

We could write these conditions separately or we could create polynomial

and compare coefficients near powers  to
to 

Suppose there is unreadable letter on position  we could replace set of syndromes
we could replace set of syndromes  by set of syndromes
by set of syndromes  defined by equation
defined by equation  Suppose for an error word all restrictions by original set of syndromes hold,
Suppose for an error word all restrictions by original set of syndromes hold,
than

New set of syndromes restricts error vector

the same way the original set of syndromes restricted the error vector  Except the coordinate where we have
Except the coordinate where we have  an
an  is zero, if
is zero, if  For the goal of locating error positions we could change the set of syndromes in the similar way to reflect all unreadable characters. This shortens the set of syndromes by
For the goal of locating error positions we could change the set of syndromes in the similar way to reflect all unreadable characters. This shortens the set of syndromes by 
In polynomial formulation, the replacement of syndromes set by syndromes set leads to

Therefore,

After replacement of  by , one would require equation for coefficients near powers
by , one would require equation for coefficients near powers 
One could consider looking for error positions from the point of view of eliminating influence of given positions similarly as for unreadable characters. If we found  positions such that eliminating their influence leads to obtaining set of syndromes consisting of all zeros, than there exists error vector with errors only on these coordinates.
positions such that eliminating their influence leads to obtaining set of syndromes consisting of all zeros, than there exists error vector with errors only on these coordinates.
If denotes the polynomial eliminating the influence of these coordinates, we obtain

In Euclidean algorithm, we try to correct at most  errors (on readable positions), because with bigger error count there could be more codewords in the same distance from the received word. Therefore, for we are looking for, the equation must hold for coefficients near powers starting from
errors (on readable positions), because with bigger error count there could be more codewords in the same distance from the received word. Therefore, for we are looking for, the equation must hold for coefficients near powers starting from

In Forney formula, could be multiplied by a scalar giving the same result.
It could happen that the Euclidean algorithm finds of degree higher than having number of different roots equal to its degree, where the Fourney formula would be able to correct errors in all its roots, anyway correcting such many errors could be risky (especially with no other restrictions on received word). Usually after getting of higher degree, we decide not to correct the errors. Correction could fail in the case has roots with higher multiplicity or the number of roots is smaller than its degree. Fail could be detected as well by Forney formula returning error outside the transmitted alphabet.
Correct the errors[edit]
Using the error values and error location, correct the errors and form a corrected code vector by subtracting error values at error locations.
Decoding examples[edit]
Decoding of binary code without unreadable characters[edit]
Consider a BCH code in GF(24) with  and
and  . (This is used in QR codes.) Let the message to be transmitted be [1 1 0 1 1], or in polynomial notation,
. (This is used in QR codes.) Let the message to be transmitted be [1 1 0 1 1], or in polynomial notation, 
The «checksum» symbols are calculated by dividing  by and taking the remainder, resulting in
by and taking the remainder, resulting in  or [ 1 0 0 0 0 1 0 1 0 0 ]. These are appended to the message, so the transmitted codeword is [ 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0 ].
or [ 1 0 0 0 0 1 0 1 0 0 ]. These are appended to the message, so the transmitted codeword is [ 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0 ].
Now, imagine that there are two bit-errors in the transmission, so the received codeword is [ 1 0 0 1 1 1 0 0 0 1 1 0 1 0 0 ]. In polynomial notation:

In order to correct the errors, first calculate the syndromes. Taking  we have
we have 



 and
and 
Next, apply the Peterson procedure by row-reducing the following augmented matrix.
![{displaystyle left[S_{3times 3}|C_{3times 1}right]={begin{bmatrix}s_{1}&s_{2}&s_{3}&s_{4}\s_{2}&s_{3}&s_{4}&s_{5}\s_{3}&s_{4}&s_{5}&s_{6}end{bmatrix}}={begin{bmatrix}1011&1001&1011&1101\1001&1011&1101&0001\1011&1101&0001&1001end{bmatrix}}Rightarrow {begin{bmatrix}0001&0000&1000&0111\0000&0001&1011&0001\0000&0000&0000&0000end{bmatrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/01ae26421a97007762e7db564652697943f6c6dd)
Due to the zero row, S3×3 is singular, which is no surprise since only two errors were introduced into the codeword.
However, the upper-left corner of the matrix is identical to [S2×2 | C2×1], which gives rise to the solution 

The resulting error locator polynomial is  which has zeros at
which has zeros at  and
and 
The exponents of correspond to the error locations.
There is no need to calculate the error values in this example, as the only possible value is 1.
Decoding with unreadable characters[edit]
Suppose the same scenario, but the received word has two unreadable characters [ 1 0 0 ? 1 1 ? 0 0 1 1 0 1 0 0 ]. We replace the unreadable characters by zeros while creating the polynomial reflecting their positions  We compute the syndromes
We compute the syndromes  and
and  (Using log notation which is independent on GF(24) isomorphisms. For computation checking we can use the same representation for addition as was used in previous example. Hexadecimal description of the powers of are consecutively 1,2,4,8,3,6,C,B,5,A,7,E,F,D,9 with the addition based on bitwise xor.)
(Using log notation which is independent on GF(24) isomorphisms. For computation checking we can use the same representation for addition as was used in previous example. Hexadecimal description of the powers of are consecutively 1,2,4,8,3,6,C,B,5,A,7,E,F,D,9 with the addition based on bitwise xor.)
Let us make syndrome polynomial

compute

Run the extended Euclidean algorithm:
![{displaystyle {begin{aligned}&{begin{pmatrix}S(x)Gamma (x)\x^{6}end{pmatrix}}\[6pt]={}&{begin{pmatrix}alpha ^{-7}+alpha ^{4}x+alpha ^{-1}x^{2}+alpha ^{6}x^{3}+alpha ^{-1}x^{4}+alpha ^{5}x^{5}+alpha ^{7}x^{6}+alpha ^{-3}x^{7}\x^{6}end{pmatrix}}\[6pt]={}&{begin{pmatrix}alpha ^{7}+alpha ^{-3}x&1\1&0end{pmatrix}}{begin{pmatrix}x^{6}\alpha ^{-7}+alpha ^{4}x+alpha ^{-1}x^{2}+alpha ^{6}x^{3}+alpha ^{-1}x^{4}+alpha ^{5}x^{5}+2alpha ^{7}x^{6}+2alpha ^{-3}x^{7}end{pmatrix}}\[6pt]={}&{begin{pmatrix}alpha ^{7}+alpha ^{-3}x&1\1&0end{pmatrix}}{begin{pmatrix}alpha ^{4}+alpha ^{-5}x&1\1&0end{pmatrix}}\&qquad {begin{pmatrix}alpha ^{-7}+alpha ^{4}x+alpha ^{-1}x^{2}+alpha ^{6}x^{3}+alpha ^{-1}x^{4}+alpha ^{5}x^{5}\alpha ^{-3}+left(alpha ^{-7}+alpha ^{3}right)x+left(alpha ^{3}+alpha ^{-1}right)x^{2}+left(alpha ^{-5}+alpha ^{-6}right)x^{3}+left(alpha ^{3}+alpha ^{1}right)x^{4}+2alpha ^{-6}x^{5}+2x^{6}end{pmatrix}}\[6pt]={}&{begin{pmatrix}left(1+alpha ^{-4}right)+left(alpha ^{1}+alpha ^{2}right)x+alpha ^{7}x^{2}&alpha ^{7}+alpha ^{-3}x\alpha ^{4}+alpha ^{-5}x&1end{pmatrix}}{begin{pmatrix}alpha ^{-7}+alpha ^{4}x+alpha ^{-1}x^{2}+alpha ^{6}x^{3}+alpha ^{-1}x^{4}+alpha ^{5}x^{5}\alpha ^{-3}+alpha ^{-2}x+alpha ^{0}x^{2}+alpha ^{-2}x^{3}+alpha ^{-6}x^{4}end{pmatrix}}\[6pt]={}&{begin{pmatrix}alpha ^{-3}+alpha ^{5}x+alpha ^{7}x^{2}&alpha ^{7}+alpha ^{-3}x\alpha ^{4}+alpha ^{-5}x&1end{pmatrix}}{begin{pmatrix}alpha ^{-5}+alpha ^{-4}x&1\1&0end{pmatrix}}\&qquad {begin{pmatrix}alpha ^{-3}+alpha ^{-2}x+alpha ^{0}x^{2}+alpha ^{-2}x^{3}+alpha ^{-6}x^{4}\left(alpha ^{7}+alpha ^{-7}right)+left(2alpha ^{-7}+alpha ^{4}right)x+left(alpha ^{-5}+alpha ^{-6}+alpha ^{-1}right)x^{2}+left(alpha ^{-7}+alpha ^{-4}+alpha ^{6}right)x^{3}+left(alpha ^{4}+alpha ^{-6}+alpha ^{-1}right)x^{4}+2alpha ^{5}x^{5}end{pmatrix}}\[6pt]={}&{begin{pmatrix}alpha ^{7}x+alpha ^{5}x^{2}+alpha ^{3}x^{3}&alpha ^{-3}+alpha ^{5}x+alpha ^{7}x^{2}\alpha ^{3}+alpha ^{-5}x+alpha ^{6}x^{2}&alpha ^{4}+alpha ^{-5}xend{pmatrix}}{begin{pmatrix}alpha ^{-3}+alpha ^{-2}x+alpha ^{0}x^{2}+alpha ^{-2}x^{3}+alpha ^{-6}x^{4}\alpha ^{-4}+alpha ^{4}x+alpha ^{2}x^{2}+alpha ^{-5}x^{3}end{pmatrix}}.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/34d562bd03e10536d5a5c4f55c8b831b7dfec00f)
We have reached polynomial of degree at most 3, and as

we get

Therefore,

Let  Don’t worry that
Don’t worry that  Find by brute force a root of The roots are
Find by brute force a root of The roots are  and
and  (after finding for example
(after finding for example  we can divide by corresponding monom
we can divide by corresponding monom  and the root of resulting monom could be found easily).
and the root of resulting monom could be found easily).
Let

Let us look for error values using formula

where are roots of 
 We get
We get

Fact, that  should not be surprising.
should not be surprising.
Corrected code is therefore [ 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0].
Decoding with unreadable characters with a small number of errors[edit]
Let us show the algorithm behaviour for the case with small number of errors. Let the received word is [ 1 0 0 ? 1 1 ? 0 0 0 1 0 1 0 0 ].
Again, replace the unreadable characters by zeros while creating the polynomial reflecting their positions
Compute the syndromes  and
and 
Create syndrome polynomial

Let us run the extended Euclidean algorithm:

We have reached polynomial of degree at most 3, and as

we get

Therefore,

Let  Don’t worry that The root of is
Don’t worry that The root of is 
Let

Let us look for error values using formula  where are roots of polynomial
where are roots of polynomial

We get

The fact that  should not be surprising.
should not be surprising.
Corrected code is therefore [ 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0].
Citations[edit]
- ^ Reed & Chen 1999, p. 189
- ^ Hocquenghem 1959
- ^ Bose & Ray-Chaudhuri 1960
- ^ «Phobos Lander Coding System: Software and Analysis» (PDF). Archived (PDF) from the original on 2022-10-09. Retrieved 25 February 2012.
- ^ «Sandforce SF-2500/2600 Product Brief». Retrieved 25 February 2012.
- ^ http://pqc-hqc.org/doc/hqc-specification_2020-05-29.pdf[bare URL PDF]
- ^ Gill n.d., p. 3
- ^ Lidl & Pilz 1999, p. 229
- ^ Gorenstein, Peterson & Zierler 1960
- ^ Gill n.d., p. 47
- ^ Yasuo Sugiyama, Masao Kasahara, Shigeichi Hirasawa, and Toshihiko Namekawa. A method for solving key equation for decoding Goppa codes. Information and Control, 27:87–99, 1975.
References[edit]
Primary sources[edit]
- Hocquenghem, A. (September 1959), «Codes correcteurs d’erreurs», Chiffres (in French), Paris, 2: 147–156
- Bose, R. C.; Ray-Chaudhuri, D. K. (March 1960), «On A Class of Error Correcting Binary Group Codes» (PDF), Information and Control, 3 (1): 68–79, doi:10.1016/s0019-9958(60)90287-4, ISSN 0890-5401, archived (PDF) from the original on 2022-10-09
Secondary sources[edit]
- Gill, John (n.d.), EE387 Notes #7, Handout #28 (PDF), Stanford University, pp. 42–45, archived (PDF) from the original on 2022-10-09, retrieved April 21, 2010[dead link] Course notes are apparently being redone for 2012: http://www.stanford.edu/class/ee387/ Archived 2013-06-05 at the Wayback Machine
- Gorenstein, Daniel; Peterson, W. Wesley; Zierler, Neal (1960), «Two-Error Correcting Bose-Chaudhuri Codes are Quasi-Perfect», Information and Control, 3 (3): 291–294, doi:10.1016/s0019-9958(60)90877-9
- Lidl, Rudolf; Pilz, Günter (1999), Applied Abstract Algebra (2nd ed.), John Wiley
- Reed, Irving S.; Chen, Xuemin (1999), Error-Control Coding for Data Networks, Boston, MA: Kluwer Academic Publishers, ISBN 0-7923-8528-4
Further reading[edit]
- Blahut, Richard E. (2003), Algebraic Codes for Data Transmission (2nd ed.), Cambridge University Press, ISBN 0-521-55374-1
- Gilbert, W. J.; Nicholson, W. K. (2004), Modern Algebra with Applications (2nd ed.), John Wiley
- Lin, S.; Costello, D. (2004), Error Control Coding: Fundamentals and Applications, Englewood Cliffs, NJ: Prentice-Hall
- MacWilliams, F. J.; Sloane, N. J. A. (1977), The Theory of Error-Correcting Codes, New York, NY: North-Holland Publishing Company
- Rudra, Atri, CSE 545, Error Correcting Codes: Combinatorics, Algorithms and Applications, University at Buffalo, archived from the original on 2010-07-02, retrieved April 21, 2010
: Error correction code
In coding theory, the Bose–Chaudhuri–Hocquenghem codes (BCH codes) form a class of cyclic error-correcting codes that are constructed using polynomials over a finite field (also called Galois field). BCH codes were invented in 1959 by French mathematician Alexis Hocquenghem, and independently in 1960 by Raj Chandra Bose and D.K. Ray-Chaudhuri.[1][2][3] The name Bose–Chaudhuri–Hocquenghem (and the acronym BCH) arises from the initials of the inventors’ surnames (mistakenly, in the case of Ray-Chaudhuri).
One of the key features of BCH codes is that during code design, there is a precise control over the number of symbol errors correctable by the code. In particular, it is possible to design binary BCH codes that can correct multiple bit errors. Another advantage of BCH codes is the ease with which they can be decoded, namely, via an algebraic method known as syndrome decoding. This simplifies the design of the decoder for these codes, using small low-power electronic hardware.
BCH codes are used in applications such as satellite communications,[4] compact disc players, DVDs, disk drives, USB flash drives, solid-state drives,[5] quantum-resistant cryptography[6] and two-dimensional bar codes.
Definition and illustration
Primitive narrow-sense BCH codes
Given a prime number q and prime power qm with positive integers m and d such that d ≤ qm − 1, a primitive narrow-sense BCH code over the finite field (or Galois field) GF(q) with code length n = qm − 1 and distance at least d is constructed by the following method.
Let α be a primitive element of GF(qm).
For any positive integer i, let mi(x) be the minimal polynomial with coefficients in GF(q) of αi.
The generator polynomial of the BCH code is defined as the least common multiple g(x) = lcm(m1(x),…,md − 1(x)).
It can be seen that g(x) is a polynomial with coefficients in GF(q) and divides xn − 1.
Therefore, the polynomial code defined by g(x) is a cyclic code.
Example
Let q = 2 and m = 4 (therefore n = 15). We will consider different values of d for GF(16) = GF(24) based on the reducing polynomial z4 + z + 1, using primitive element α(z) = z. There are fourteen minimum polynomials mi(x) with coefficients in GF(2) satisfying
- [math]displaystyle{ m_ileft(alpha^iright) bmod left(z^4 + z + 1right) = 0. }[/math]
The minimal polynomials are
- [math]displaystyle{ begin{align}
m_1(x) &= m_2(x) = m_4(x) = m_8(x) = x^4 + x + 1, \
m_3(x) &= m_6(x) = m_9(x) = m_{12}(x) = x^4 + x^3 + x^2 + x + 1, \
m_5(x) &= m_{10}(x) = x^2 + x + 1, \
m_7(x) &= m_{11}(x) = m_{13}(x) = m_{14}(x) = x^4 + x^3 + 1.
end{align} }[/math]
The BCH code with [math]displaystyle{ d = 2, 3 }[/math] has generator polynomial
- [math]displaystyle{ g(x) = {rm lcm}(m_1(x), m_2(x)) = m_1(x) = x^4 + x + 1., }[/math]
It has minimal Hamming distance at least 3 and corrects up to one error. Since the generator polynomial is of degree 4, this code has 11 data bits and 4 checksum bits.
The BCH code with [math]displaystyle{ d=4,5 }[/math] has generator polynomial
- [math]displaystyle{ begin{align}
g(x) &= {rm lcm}(m_1(x),m_2(x),m_3(x),m_4(x)) = m_1(x) m_3(x) \
&= left(x^4 + x + 1right)left(x^4 + x^3 + x^2 + x + 1right) = x^8 + x^7 + x^6 + x^4 + 1.
end{align} }[/math]
It has minimal Hamming distance at least 5 and corrects up to two errors. Since the generator polynomial is of degree 8, this code has 7 data bits and 8 checksum bits.
The BCH code with [math]displaystyle{ d=6,7 }[/math] has generator polynomial
- [math]displaystyle{ begin{align}
g(x) &= {rm lcm}(m_1(x),m_2(x),m_3(x),m_4(x),m_5(x),m_6(x)) = m_1(x) m_3(x) m_5(x) \
&= left(x^4 + x + 1right)left(x^4 + x^3 + x^2 + x + 1right)left(x^2 + x + 1right) = x^{10} + x^8 + x^5 + x^4 + x^2 + x + 1.
end{align} }[/math]
It has minimal Hamming distance at least 7 and corrects up to three errors. Since the generator polynomial is of degree 10, this code has 5 data bits and 10 checksum bits. (This particular generator polynomial has a real-world application, in the format patterns of the QR code.)
The BCH code with [math]displaystyle{ d=8 }[/math] and higher has generator polynomial
- [math]displaystyle{ begin{align}
g(x) &= {rm lcm}(m_1(x),m_2(x),…,m_{14}(x)) = m_1(x) m_3(x) m_5(x) m_7(x)\
&= left(x^4 + x + 1right)left(x^4 + x^3 + x^2 + x + 1right)left(x^2 + x + 1right)left(x^4 + x^3 + 1right) = x^{14} + x^{13} + x^{12} + cdots + x^2 + x + 1.
end{align} }[/math]
This code has minimal Hamming distance 15 and corrects 7 errors. It has 1 data bit and 14 checksum bits. In fact, this code has only two codewords: 000000000000000 and 111111111111111.
General BCH codes
General BCH codes differ from primitive narrow-sense BCH codes in two respects.
First, the requirement that [math]displaystyle{ alpha }[/math] be a primitive element of [math]displaystyle{ mathrm{GF}(q^m) }[/math] can be relaxed. By relaxing this requirement, the code length changes from [math]displaystyle{ q^m — 1 }[/math] to [math]displaystyle{ mathrm{ord}(alpha), }[/math] the order of the element [math]displaystyle{ alpha. }[/math]
Second, the consecutive roots of the generator polynomial may run from [math]displaystyle{ alpha^c,ldots,alpha^{c+d-2} }[/math] instead of [math]displaystyle{ alpha,ldots,alpha^{d-1}. }[/math]
Definition. Fix a finite field [math]displaystyle{ GF(q), }[/math] where [math]displaystyle{ q }[/math] is a prime power. Choose positive integers [math]displaystyle{ m,n,d,c }[/math] such that [math]displaystyle{ 2leq dleq n, }[/math] [math]displaystyle{ {rm gcd}(n,q)=1, }[/math] and [math]displaystyle{ m }[/math] is the multiplicative order of [math]displaystyle{ q }[/math] modulo [math]displaystyle{ n. }[/math]
As before, let [math]displaystyle{ alpha }[/math] be a primitive [math]displaystyle{ n }[/math]th root of unity in [math]displaystyle{ GF(q^m), }[/math] and let [math]displaystyle{ m_i(x) }[/math] be the minimal polynomial over [math]displaystyle{ GF(q) }[/math] of [math]displaystyle{ alpha^i }[/math] for all [math]displaystyle{ i. }[/math]
The generator polynomial of the BCH code is defined as the least common multiple [math]displaystyle{ g(x) = {rm lcm}(m_c(x),ldots,m_{c+d-2}(x)). }[/math]
Note: if [math]displaystyle{ n=q^m-1 }[/math] as in the simplified definition, then [math]displaystyle{ {rm gcd}(n,q) }[/math] is 1, and the order of [math]displaystyle{ q }[/math] modulo [math]displaystyle{ n }[/math] is [math]displaystyle{ m. }[/math]
Therefore, the simplified definition is indeed a special case of the general one.
Special cases
- A BCH code with [math]displaystyle{ c=1 }[/math] is called a narrow-sense BCH code.
- A BCH code with [math]displaystyle{ n=q^m-1 }[/math] is called primitive.
The generator polynomial [math]displaystyle{ g(x) }[/math] of a BCH code has coefficients from [math]displaystyle{ mathrm{GF}(q). }[/math]
In general, a cyclic code over [math]displaystyle{ mathrm{GF}(q^p) }[/math] with [math]displaystyle{ g(x) }[/math] as the generator polynomial is called a BCH code over [math]displaystyle{ mathrm{GF}(q^p). }[/math]
The BCH code over [math]displaystyle{ mathrm{GF}(q^m) }[/math] and generator polynomial [math]displaystyle{ g(x) }[/math] with successive powers of [math]displaystyle{ alpha }[/math] as roots is one type of Reed–Solomon code where the decoder (syndromes) alphabet is the same as the channel (data and generator polynomial) alphabet, all elements of [math]displaystyle{ mathrm{GF}(q^m) }[/math] .[7] The other type of Reed Solomon code is an original view Reed Solomon code which is not a BCH code.
Properties
The generator polynomial of a BCH code has degree at most [math]displaystyle{ (d-1)m }[/math]. Moreover, if [math]displaystyle{ q=2 }[/math] and [math]displaystyle{ c=1 }[/math], the generator polynomial has degree at most [math]displaystyle{ dm/2 }[/math].
|
Proof |
|---|
|
Each minimal polynomial [math]displaystyle{ m_i(x) }[/math] has degree at most [math]displaystyle{ m }[/math]. Therefore, the least common multiple of [math]displaystyle{ d-1 }[/math] of them has degree at most [math]displaystyle{ (d-1)m }[/math]. Moreover, if [math]displaystyle{ q=2, }[/math] then [math]displaystyle{ m_i(x) = m_{2i}(x) }[/math] for all [math]displaystyle{ i }[/math]. Therefore, [math]displaystyle{ g(x) }[/math] is the least common multiple of at most [math]displaystyle{ d/2 }[/math] minimal polynomials [math]displaystyle{ m_i(x) }[/math] for odd indices [math]displaystyle{ i, }[/math] each of degree at most [math]displaystyle{ m }[/math]. |
A BCH code has minimal Hamming distance at least [math]displaystyle{ d }[/math].
|
Proof |
|---|
|
Suppose that [math]displaystyle{ p(x) }[/math] is a code word with fewer than [math]displaystyle{ d }[/math] non-zero terms. Then
Recall that [math]displaystyle{ alpha^c,ldots,alpha^{c+d-2} }[/math] are roots of [math]displaystyle{ g(x), }[/math] hence of [math]displaystyle{ p(x) }[/math]. This implies that [math]displaystyle{ b_1,ldots,b_{d-1} }[/math] satisfy the following equations, for each [math]displaystyle{ i in {c, dotsc, c+d-2} }[/math]:
In matrix form, we have
The determinant of this matrix equals
The matrix [math]displaystyle{ V }[/math] is seen to be a Vandermonde matrix, and its determinant is
which is non-zero. It therefore follows that [math]displaystyle{ b_1,ldots,b_{d-1}=0, }[/math] hence [math]displaystyle{ p(x) = 0. }[/math] |
A BCH code is cyclic.
|
Proof |
|---|
|
A polynomial code of length [math]displaystyle{ n }[/math] is cyclic if and only if its generator polynomial divides [math]displaystyle{ x^n-1. }[/math] Since [math]displaystyle{ g(x) }[/math] is the minimal polynomial with roots [math]displaystyle{ alpha^c,ldots,alpha^{c+d-2}, }[/math] it suffices to check that each of [math]displaystyle{ alpha^c,ldots,alpha^{c+d-2} }[/math] is a root of [math]displaystyle{ x^n-1. }[/math] This follows immediately from the fact that [math]displaystyle{ alpha }[/math] is, by definition, an [math]displaystyle{ n }[/math]th root of unity. |
Encoding
Because any polynomial that is a multiple of the generator polynomial is a valid BCH codeword, BCH encoding is merely the process of finding some polynomial that has the generator as a factor.
The BCH code itself is not prescriptive about the meaning of the coefficients of the polynomial; conceptually, a BCH decoding algorithm’s sole concern is to find the valid codeword with the minimal Hamming distance to the received codeword. Therefore, the BCH code may be implemented either as a systematic code or not, depending on how the implementor chooses to embed the message in the encoded polynomial.
Non-systematic encoding: The message as a factor
The most straightforward way to find a polynomial that is a multiple of the generator is to compute the product of some arbitrary polynomial and the generator. In this case, the arbitrary polynomial can be chosen using the symbols of the message as coefficients.
- [math]displaystyle{ s(x) = p(x)g(x) }[/math]
As an example, consider the generator polynomial [math]displaystyle{ g(x)=x^{10}+x^9+x^8+x^6+x^5+x^3+1 }[/math], chosen for use in the (31, 21) binary BCH code used by POCSAG and others. To encode the 21-bit message {101101110111101111101}, we first represent it as a polynomial over [math]displaystyle{ GF(2) }[/math]:
- [math]displaystyle{ p(x) = x^{20}+x^{18}+x^{17}+x^{15}+x^{14}+x^{13}+x^{11}+x^{10}+x^9+x^8+x^6+x^5+x^4+x^3+x^2+1 }[/math]
Then, compute (also over [math]displaystyle{ GF(2) }[/math]):
- [math]displaystyle{ begin{align}
s(x) &= p(x)g(x)\
&= left(x^{20}+x^{18}+x^{17}+x^{15}+x^{14}+x^{13}+x^{11}+x^{10}+x^9+x^8+x^6+x^5+x^4+x^3+x^2+1right)left(x^{10}+x^9+x^8+x^6+x^5+x^3+1right)\
&= x^{30}+x^{29}+x^{26}+x^{25}+x^{24}+x^{22}+x^{19}+x^{17}+x^{16}+x^{15}+x^{14}+x^{12}+x^{10}+x^9+x^8+x^6+x^5+x^4+x^2+1
end{align} }[/math]
Thus, the transmitted codeword is {1100111010010111101011101110101}.
The receiver can use these bits as coefficients in [math]displaystyle{ s(x) }[/math] and, after error-correction to ensure a valid codeword, can recompute [math]displaystyle{ p(x) = s(x)/g(x) }[/math]
Systematic encoding: The message as a prefix
A systematic code is one in which the message appears verbatim somewhere within the codeword. Therefore, systematic BCH encoding involves first embedding the message polynomial within the codeword polynomial, and then adjusting the coefficients of the remaining (non-message) terms to ensure that [math]displaystyle{ s(x) }[/math] is divisible by [math]displaystyle{ g(x) }[/math].
This encoding method leverages the fact that subtracting the remainder from a dividend results in a multiple of the divisor. Hence, if we take our message polynomial [math]displaystyle{ p(x) }[/math] as before and multiply it by [math]displaystyle{ x^{n-k} }[/math] (to «shift» the message out of the way of the remainder), we can then use Euclidean division of polynomials to yield:
- [math]displaystyle{ p(x)x^{n-k} = q(x)g(x) + r(x) }[/math]
Here, we see that [math]displaystyle{ q(x)g(x) }[/math] is a valid codeword. As [math]displaystyle{ r(x) }[/math] is always of degree less than [math]displaystyle{ n-k }[/math] (which is the degree of [math]displaystyle{ g(x) }[/math]), we can safely subtract it from [math]displaystyle{ p(x)x^{n-k} }[/math] without altering any of the message coefficients, hence we have our [math]displaystyle{ s(x) }[/math] as
- [math]displaystyle{ s(x) = q(x)g(x) = p(x)x^{n-k} — r(x) }[/math]
Over [math]displaystyle{ GF(2) }[/math] (i.e. with binary BCH codes), this process is indistinguishable from appending a cyclic redundancy check, and if a systematic binary BCH code is used only for error-detection purposes, we see that BCH codes are just a generalization of the mathematics of cyclic redundancy checks.
The advantage to the systematic coding is that the receiver can recover the original message by discarding everything after the first [math]displaystyle{ k }[/math] coefficients, after performing error correction.
Decoding
There are many algorithms for decoding BCH codes. The most common ones follow this general outline:
- Calculate the syndromes sj for the received vector
- Determine the number of errors t and the error locator polynomial Λ(x) from the syndromes
- Calculate the roots of the error location polynomial to find the error locations Xi
- Calculate the error values Yi at those error locations
- Correct the errors
During some of these steps, the decoding algorithm may determine that the received vector has too many errors and cannot be corrected. For example, if an appropriate value of t is not found, then the correction would fail. In a truncated (not primitive) code, an error location may be out of range. If the received vector has more errors than the code can correct, the decoder may unknowingly produce an apparently valid message that is not the one that was sent.
Calculate the syndromes
The received vector [math]displaystyle{ R }[/math] is the sum of the correct codeword [math]displaystyle{ C }[/math] and an unknown error vector [math]displaystyle{ E. }[/math] The syndrome values are formed by considering [math]displaystyle{ R }[/math] as a polynomial and evaluating it at [math]displaystyle{ alpha^c, ldots, alpha^{c+d-2}. }[/math] Thus the syndromes are[8]
- [math]displaystyle{ s_j = Rleft(alpha^jright) = Cleft(alpha^jright) + Eleft(alpha^jright) }[/math]
for [math]displaystyle{ j = c }[/math] to [math]displaystyle{ c + d — 2. }[/math]
Since [math]displaystyle{ alpha^{j} }[/math] are the zeros of [math]displaystyle{ g(x), }[/math] of which [math]displaystyle{ C(x) }[/math] is a multiple, [math]displaystyle{ Cleft(alpha^jright) = 0. }[/math] Examining the syndrome values thus isolates the error vector so one can begin to solve for it.
If there is no error, [math]displaystyle{ s_j = 0 }[/math] for all [math]displaystyle{ j. }[/math] If the syndromes are all zero, then the decoding is done.
Calculate the error location polynomial
If there are nonzero syndromes, then there are errors. The decoder needs to figure out how many errors and the location of those errors.
If there is a single error, write this as [math]displaystyle{ E(x) = e,x^i, }[/math] where [math]displaystyle{ i }[/math] is the location of the error and [math]displaystyle{ e }[/math] is its magnitude. Then the first two syndromes are
- [math]displaystyle{ begin{align}
s_c &= e,alpha^{c,i} \
s_{c+1} &= e,alpha^{(c+1),i} = alpha^i s_c
end{align} }[/math]
so together they allow us to calculate [math]displaystyle{ e }[/math] and provide some information about [math]displaystyle{ i }[/math] (completely determining it in the case of Reed–Solomon codes).
If there are two or more errors,
- [math]displaystyle{ E(x) = e_1 x^{i_1} + e_2 x^{i_2} + cdots , }[/math]
It is not immediately obvious how to begin solving the resulting syndromes for the unknowns [math]displaystyle{ e_k }[/math] and [math]displaystyle{ i_k. }[/math]
The first step is finding, compatible with computed syndromes and with minimal possible [math]displaystyle{ t, }[/math] locator polynomial:
- [math]displaystyle{ Lambda(x) = prod_{j=1}^t left(xalpha^{i_j} — 1right) }[/math]
Three popular algorithms for this task are:
- Peterson–Gorenstein–Zierler algorithm
- Berlekamp–Massey algorithm
- Sugiyama Euclidean algorithm
Peterson–Gorenstein–Zierler algorithm
Peterson’s algorithm is the step 2 of the generalized BCH decoding procedure. Peterson’s algorithm is used to calculate the error locator polynomial coefficients [math]displaystyle{ lambda_1 , lambda_2, dots, lambda_{v} }[/math] of a polynomial
- [math]displaystyle{ Lambda(x) = 1 + lambda_1 x + lambda_2 x^2 + cdots + lambda_v x^v . }[/math]
Now the procedure of the Peterson–Gorenstein–Zierler algorithm.[9] Expect we have at least 2t syndromes sc, …, sc+2t−1. Let v = t.
- Start by generating the [math]displaystyle{ S_{vtimes v} }[/math] matrix with elements that are syndrome values
- [math]displaystyle{ S_{v times v}=begin{bmatrix}s_c&s_{c+1}&dots&s_{c+v-1}\
s_{c+1}&s_{c+2}&dots&s_{c+v}\
vdots&vdots&ddots&vdots\
s_{c+v-1}&s_{c+v}&dots&s_{c+2v-2}end{bmatrix}.
}[/math]
- [math]displaystyle{ S_{v times v}=begin{bmatrix}s_c&s_{c+1}&dots&s_{c+v-1}\
- Generate a [math]displaystyle{ c_{v times 1} }[/math] vector with elements
- [math]displaystyle{ C_{v times 1}=begin{bmatrix}s_{c+v}\
s_{c+v+1}\
vdots\
s_{c+2v-1}end{bmatrix}.
}[/math] - [math]displaystyle{ C_{v times 1}=begin{bmatrix}s_{c+v}\
- Let [math]displaystyle{ Lambda }[/math] denote the unknown polynomial coefficients, which are given by
- [math]displaystyle{ Lambda_{v times 1} = begin{bmatrix}lambda_{v}\
lambda_{v-1}\
vdots\
lambda_{1}end{bmatrix}.
}[/math] - [math]displaystyle{ Lambda_{v times 1} = begin{bmatrix}lambda_{v}\
- Form the matrix equation
- [math]displaystyle{ S_{v times v} Lambda_{v times 1} = -C_{v times 1,} . }[/math]
- If the determinant of matrix [math]displaystyle{ S_{v times v} }[/math] is nonzero, then we can actually find an inverse of this matrix and solve for the values of unknown [math]displaystyle{ Lambda }[/math] values.
- If [math]displaystyle{ detleft(S_{v times v}right) = 0, }[/math] then follow
if [math]displaystyle{ v = 0 }[/math] then declare an empty error locator polynomial stop Peterson procedure. end set [math]displaystyle{ v leftarrow v -1 }[/math]
continue from the beginning of Peterson’s decoding by making smaller [math]displaystyle{ S_{v times v} }[/math]
- After you have values of [math]displaystyle{ Lambda }[/math], you have the error locator polynomial.
- Stop Peterson procedure.
Factor error locator polynomial
Now that you have the [math]displaystyle{ Lambda(x) }[/math] polynomial, its roots can be found in the form [math]displaystyle{ Lambda(x) = left(alpha^{i_1} x — 1right)left(alpha^{i_2} x — 1right) cdots left(alpha^{i_v} x — 1right) }[/math] by brute force for example using the Chien search algorithm. The exponential
powers of the primitive element [math]displaystyle{ alpha }[/math] will yield the positions where errors occur in the received word; hence the name ‘error locator’ polynomial.
The zeros of Λ(x) are α−i1, …, α−iv.
Calculate error values
Once the error locations are known, the next step is to determine the error values at those locations. The error values are then used to correct the received values at those locations to recover the original codeword.
For the case of binary BCH, (with all characters readable) this is trivial; just flip the bits for the received word at these positions, and we have the corrected code word. In the more general case, the error weights [math]displaystyle{ e_j }[/math] can be determined by solving the linear system
- [math]displaystyle{ begin{align}
s_c & = e_1 alpha^{c,i_1} + e_2 alpha^{c,i_2} + cdots \
s_{c+1} & = e_1 alpha^{(c + 1),i_1} + e_2 alpha^{(c + 1),i_2} + cdots \
& {} vdots
end{align} }[/math]
Forney algorithm
However, there is a more efficient method known as the Forney algorithm.
Let
- [math]displaystyle{ S(x) = s_c + s_{c+1}x + s_{c+2}x^2 + cdots + s_{c+d-2}x^{d-2}. }[/math]
- [math]displaystyle{ v leqslant d-1, lambda_0 neq 0 qquad Lambda(x) = sum_{i=0}^vlambda_i x^i = lambda_0 prod_{k=0}^{v} left(alpha^{-i_k}x — 1right). }[/math]
And the error evaluator polynomial[10]
- [math]displaystyle{ Omega(x) equiv S(x) Lambda(x) bmod{x^{d-1}} }[/math]
Finally:
- [math]displaystyle{ Lambda'(x) = sum_{i=1}^v i cdot lambda_i x^{i-1}, }[/math]
where
- [math]displaystyle{ i cdot x := sum_{k=1}^i x. }[/math]
Than if syndromes could be explained by an error word, which could be nonzero only on positions [math]displaystyle{ i_k }[/math], then error values are
- [math]displaystyle{ e_k = -{alpha^{i_k}Omegaleft(alpha^{-i_k}right) over alpha^{ccdot i_k}Lambda’left(alpha^{-i_k}right)}. }[/math]
For narrow-sense BCH codes, c = 1, so the expression simplifies to:
- [math]displaystyle{ e_k = -{Omegaleft(alpha^{-i_k}right) over Lambda’left(alpha^{-i_k}right)}. }[/math]
Explanation of Forney algorithm computation
It is based on Lagrange interpolation and techniques of generating functions.
Consider [math]displaystyle{ S(x)Lambda(x), }[/math] and for the sake of simplicity suppose [math]displaystyle{ lambda_k = 0 }[/math] for [math]displaystyle{ k gt v, }[/math] and [math]displaystyle{ s_k = 0 }[/math] for [math]displaystyle{ k gt c + d — 2. }[/math] Then
- [math]displaystyle{ S(x)Lambda(x) = sum_{j=0}^{infty}sum_{i=0}^j s_{j-i+1}lambda_i x^j. }[/math]
- [math]displaystyle{ begin{align}
S(x)Lambda(x)
&= S(x) left { lambda_0prod_{ell=1}^v left (alpha^{i_ell}x-1 right ) right } \
&= left { sum_{i=0}^{d-2}sum_{j=1}^v e_jalpha^{(c+i)cdot i_j} x^i right } left { lambda_0prod_{ell=1}^v left (alpha^{i_ell}x-1 right ) right } \
&= left { sum_{j=1}^v e_j alpha^{c i_j}sum_{i=0}^{d-2} left (alpha^{i_j} right )^i x^i right } left { lambda_0prod_{ell=1}^v left (alpha^{i_ell}x-1 right ) right } \
&= left { sum_{j=1}^v e_j alpha^{c i_j} frac{left (x alpha^{i_j} right )^{d-1}-1}{x alpha^{i_j}-1} right } left { lambda_0 prod_{ell=1}^v left (alpha^{i_ell}x-1 right ) right } \
&= lambda_0 sum_{j=1}^v e_jalpha^{c i_j} frac{ left (xalpha^{i_j} right)^{d-1}-1}{xalpha^{i_j}-1} prod_{ell=1}^v left (alpha^{i_ell}x-1 right ) \
&= lambda_0 sum_{j=1}^v e_jalpha^{c i_j} left ( left (xalpha^{i_j} right)^{d-1}-1 right ) prod_{ellin{1,cdots,v}setminus{j}} left (alpha^{i_ell}x-1 right )
end{align} }[/math]
We want to compute unknowns [math]displaystyle{ e_j, }[/math] and we could simplify the context by removing the [math]displaystyle{ left(xalpha^{i_j}right)^{d-1} }[/math] terms. This leads to the error evaluator polynomial
- [math]displaystyle{ Omega(x) equiv S(x) Lambda(x) bmod{x^{d-1}}. }[/math]
Thanks to [math]displaystyle{ vleqslant d-1 }[/math] we have
- [math]displaystyle{ Omega(x) = -lambda_0sum_{j=1}^v e_jalpha^{c i_j} prod_{ellin{1,cdots,v}setminus{j}} left(alpha^{i_ell}x — 1right). }[/math]
Thanks to [math]displaystyle{ Lambda }[/math] (the Lagrange interpolation trick) the sum degenerates to only one summand for [math]displaystyle{ x = alpha^{-i_k} }[/math]
- [math]displaystyle{ Omega left(alpha^{-i_k}right) = -lambda_0 e_kalpha^{ccdot i_k}prod_{ellin{1,cdots,v}setminus{k}} left(alpha^{i_ell}alpha^{-i_k} — 1right). }[/math]
To get [math]displaystyle{ e_k }[/math] we just should get rid of the product. We could compute the product directly from already computed roots [math]displaystyle{ alpha^{-i_j} }[/math] of [math]displaystyle{ Lambda, }[/math] but we could use simpler form.
As formal derivative
- [math]displaystyle{ Lambda'(x) = lambda_0sum_{j=1}^v alpha^{i_j}prod_{ellin{1,cdots,v}setminus{j}} left(alpha^{i_ell}x — 1right), }[/math]
we get again only one summand in
- [math]displaystyle{ Lambda’left(alpha^{-i_k}right) = lambda_0alpha^{i_k}prod_{ellin{1,cdots,v}setminus{k}} left(alpha^{i_ell}alpha^{-i_k} — 1right). }[/math]
So finally
- [math]displaystyle{ e_k = -frac{alpha^{i_k}Omega left(alpha^{-i_k}right)}{alpha^{ccdot i_k}Lambda’ left(alpha^{-i_k}right)}. }[/math]
This formula is advantageous when one computes the formal derivative of [math]displaystyle{ Lambda }[/math] form
- [math]displaystyle{ Lambda(x) = sum_{i=1}^v lambda_i x^i }[/math]
yielding:
- [math]displaystyle{ Lambda'(x) = sum_{i=1}^v i cdot lambda_i x^{i-1}, }[/math]
where
- [math]displaystyle{ icdot x := sum_{k=1}^i x. }[/math]
Decoding based on extended Euclidean algorithm
An alternate process of finding both the polynomial Λ and the error locator polynomial is based on Yasuo Sugiyama’s adaptation of the Extended Euclidean algorithm.[11] Correction of unreadable characters could be incorporated to the algorithm easily as well.
Let [math]displaystyle{ k_1, …, k_k }[/math] be positions of unreadable characters. One creates polynomial localising these positions [math]displaystyle{ Gamma(x) = prod_{i=1}^kleft(xalpha^{k_i} — 1right). }[/math]
Set values on unreadable positions to 0 and compute the syndromes.
As we have already defined for the Forney formula let [math]displaystyle{ S(x)=sum_{i=0}^{d-2}s_{c+i}x^i. }[/math]
Let us run extended Euclidean algorithm for locating least common divisor of polynomials [math]displaystyle{ S(x)Gamma(x) }[/math] and [math]displaystyle{ x^{d-1}. }[/math]
The goal is not to find the least common divisor, but a polynomial [math]displaystyle{ r(x) }[/math] of degree at most [math]displaystyle{ lfloor (d+k-3)/2rfloor }[/math] and polynomials [math]displaystyle{ a(x), b(x) }[/math] such that [math]displaystyle{ r(x)=a(x)S(x)Gamma(x)+b(x)x^{d-1}. }[/math]
Low degree of [math]displaystyle{ r(x) }[/math] guarantees, that [math]displaystyle{ a(x) }[/math] would satisfy extended (by [math]displaystyle{ Gamma }[/math]) defining conditions for [math]displaystyle{ Lambda. }[/math]
Defining [math]displaystyle{ Xi(x)=a(x)Gamma(x) }[/math] and using [math]displaystyle{ Xi }[/math] on the place of [math]displaystyle{ Lambda(x) }[/math] in the Fourney formula will give us error values.
The main advantage of the algorithm is that it meanwhile computes [math]displaystyle{ Omega(x)=S(x)Xi(x)bmod x^{d-1}=r(x) }[/math] required in the Forney formula.
Explanation of the decoding process
The goal is to find a codeword which differs from the received word minimally as possible on readable positions. When expressing the received word as a sum of nearest codeword and error word, we are trying to find error word with minimal number of non-zeros on readable positions. Syndrom [math]displaystyle{ s_i }[/math] restricts error word by condition
- [math]displaystyle{ s_i=sum_{j=0}^{n-1}e_jalpha^{ij}. }[/math]
We could write these conditions separately or we could create polynomial
- [math]displaystyle{ S(x)=sum_{i=0}^{d-2}s_{c+i}x^i }[/math]
and compare coefficients near powers [math]displaystyle{ 0 }[/math] to [math]displaystyle{ d-2. }[/math]
- [math]displaystyle{ S(x) stackrel{{0,cdots,,d-2}}{=} E(x)=sum_{i=0}^{d-2}sum_{j=0}^{n-1}e_jalpha^{ij}alpha^{cj}x^i. }[/math]
Suppose there is unreadable letter on position [math]displaystyle{ k_1, }[/math] we could replace set of syndromes [math]displaystyle{ {s_c,cdots,s_{c+d-2}} }[/math] by set of syndromes [math]displaystyle{ {t_c,cdots,t_{c+d-3}} }[/math] defined by equation [math]displaystyle{ t_i=alpha^{k_1}s_i-s_{i+1}. }[/math] Suppose for an error word all restrictions by original set [math]displaystyle{ {s_c,cdots,s_{c+d-2}} }[/math] of syndromes hold,
than
- [math]displaystyle{ t_i=alpha^{k_1}s_i-s_{i+1}=alpha^{k_1}sum_{j=0}^{n-1}e_jalpha^{ij}-sum_{j=0}^{n-1}e_jalpha^jalpha^{ij}=sum_{j=0}^{n-1}e_jleft(alpha^{k_1} — alpha^jright)alpha^{ij}. }[/math]
New set of syndromes restricts error vector
- [math]displaystyle{ f_j=e_jleft(alpha^{k_1} — alpha^jright) }[/math]
the same way the original set of syndromes restricted the error vector [math]displaystyle{ e_j. }[/math] Except the coordinate [math]displaystyle{ k_1, }[/math] where we have [math]displaystyle{ f_{k_1}=0, }[/math] an [math]displaystyle{ f_j }[/math] is zero, if [math]displaystyle{ e_j = 0. }[/math] For the goal of locating error positions we could change the set of syndromes in the similar way to reflect all unreadable characters. This shortens the set of syndromes by [math]displaystyle{ k. }[/math]
In polynomial formulation, the replacement of syndromes set [math]displaystyle{ {s_c,cdots,s_{c+d-2}} }[/math] by syndromes set [math]displaystyle{ {t_c,cdots,t_{c+d-3}} }[/math] leads to
- [math]displaystyle{ T(x) = sum_{i=0}^{d-3}t_{c+i}x^i=alpha^{k_1}sum_{i=0}^{d-3}s_{c+i}x^i-sum_{i=1}^{d-2}s_{c+i}x^{i-1}. }[/math]
Therefore,
- [math]displaystyle{ xT(x) stackrel{{1,cdots,,d-2}}{=} left(xalpha^{k_1} — 1right)S(x). }[/math]
After replacement of [math]displaystyle{ S(x) }[/math] by [math]displaystyle{ S(x)Gamma(x) }[/math], one would require equation for coefficients near powers [math]displaystyle{ k,cdots,d-2. }[/math]
One could consider looking for error positions from the point of view of eliminating influence of given positions similarly as for unreadable characters. If we found [math]displaystyle{ v }[/math] positions such that eliminating their influence leads to obtaining set of syndromes consisting of all zeros, than there exists error vector with errors only on these coordinates.
If [math]displaystyle{ Lambda(x) }[/math] denotes the polynomial eliminating the influence of these coordinates, we obtain
- [math]displaystyle{ S(x)Gamma(x)Lambda(x) stackrel{{k+v, cdots, d-2}}{=} 0. }[/math]
In Euclidean algorithm, we try to correct at most [math]displaystyle{ tfrac{1}{2}(d-1-k) }[/math] errors (on readable positions), because with bigger error count there could be more codewords in the same distance from the received word. Therefore, for [math]displaystyle{ Lambda(x) }[/math] we are looking for, the equation must hold for coefficients near powers starting from
- [math]displaystyle{ k + leftlfloor frac{1}{2} (d-1-k) rightrfloor. }[/math]
In Forney formula, [math]displaystyle{ Lambda(x) }[/math] could be multiplied by a scalar giving the same result.
It could happen that the Euclidean algorithm finds [math]displaystyle{ Lambda(x) }[/math] of degree higher than [math]displaystyle{ tfrac{1}{2}(d-1-k) }[/math] having number of different roots equal to its degree, where the Fourney formula would be able to correct errors in all its roots, anyway correcting such many errors could be risky (especially with no other restrictions on received word). Usually after getting [math]displaystyle{ Lambda(x) }[/math] of higher degree, we decide not to correct the errors. Correction could fail in the case [math]displaystyle{ Lambda(x) }[/math] has roots with higher multiplicity or the number of roots is smaller than its degree. Fail could be detected as well by Forney formula returning error outside the transmitted alphabet.
Correct the errors
Using the error values and error location, correct the errors and form a corrected code vector by subtracting error values at error locations.
Decoding examples
Decoding of binary code without unreadable characters
Consider a BCH code in GF(24) with [math]displaystyle{ d=7 }[/math] and [math]displaystyle{ g(x) = x^{10} + x^8 + x^5 + x^4 + x^2 + x + 1 }[/math]. (This is used in QR codes.) Let the message to be transmitted be [1 1 0 1 1], or in polynomial notation, [math]displaystyle{ M(x) = x^4 + x^3 + x + 1. }[/math]
The «checksum» symbols are calculated by dividing [math]displaystyle{ x^{10} M(x) }[/math] by [math]displaystyle{ g(x) }[/math] and taking the remainder, resulting in [math]displaystyle{ x^9 + x^4 + x^2 }[/math] or [ 1 0 0 0 0 1 0 1 0 0 ]. These are appended to the message, so the transmitted codeword is [ 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0 ].
Now, imagine that there are two bit-errors in the transmission, so the received codeword is [ 1 0 0 1 1 1 0 0 0 1 1 0 1 0 0 ]. In polynomial notation:
- [math]displaystyle{ R(x) = C(x) + x^{13} + x^5 = x^{14} + x^{11} + x^{10} + x^9 + x^5 + x^4 + x^2 }[/math]
In order to correct the errors, first calculate the syndromes. Taking [math]displaystyle{ alpha = 0010, }[/math] we have [math]displaystyle{ s_1 = R(alpha^1) = 1011, }[/math] [math]displaystyle{ s_2 = 1001, }[/math] [math]displaystyle{ s_3 = 1011, }[/math] [math]displaystyle{ s_4 = 1101, }[/math] [math]displaystyle{ s_5 = 0001, }[/math] and [math]displaystyle{ s_6 = 1001. }[/math]
Next, apply the Peterson procedure by row-reducing the following augmented matrix.
- [math]displaystyle{ left [ S_{3 times 3} | C_{3 times 1} right ] =
begin{bmatrix}s_1&s_2&s_3&s_4\
s_2&s_3&s_4&s_5\
s_3&s_4&s_5&s_6end{bmatrix} =
begin{bmatrix}1011&1001&1011&1101\
1001&1011&1101&0001\
1011&1101&0001&1001end{bmatrix} Rightarrow
begin{bmatrix}0001&0000&1000&0111\
0000&0001&1011&0001\
0000&0000&0000&0000
end{bmatrix} }[/math]
Due to the zero row, S3×3 is singular, which is no surprise since only two errors were introduced into the codeword.
However, the upper-left corner of the matrix is identical to [S2×2 | C2×1], which gives rise to the solution [math]displaystyle{ lambda_2 = 1000, }[/math] [math]displaystyle{ lambda_1 = 1011. }[/math]
The resulting error locator polynomial is [math]displaystyle{ Lambda(x) = 1000 x^2 + 1011 x + 0001, }[/math] which has zeros at [math]displaystyle{ 0100 = alpha^{-13} }[/math] and [math]displaystyle{ 0111 = alpha^{-5}. }[/math]
The exponents of [math]displaystyle{ alpha }[/math] correspond to the error locations.
There is no need to calculate the error values in this example, as the only possible value is 1.
Decoding with unreadable characters
Suppose the same scenario, but the received word has two unreadable characters [ 1 0 0 ? 1 1 ? 0 0 1 1 0 1 0 0 ]. We replace the unreadable characters by zeros while creating the polynomial reflecting their positions [math]displaystyle{ Gamma(x) = left(alpha^8x — 1right)left(alpha^{11}x — 1right). }[/math] We compute the syndromes [math]displaystyle{ s_1=alpha^{-7}, s_2=alpha^{1}, s_3=alpha^{4}, s_4=alpha^{2}, s_5=alpha^{5}, }[/math] and [math]displaystyle{ s_6=alpha^{-7}. }[/math] (Using log notation which is independent on GF(24) isomorphisms. For computation checking we can use the same representation for addition as was used in previous example. Hexadecimal description of the powers of [math]displaystyle{ alpha }[/math] are consecutively 1,2,4,8,3,6,C,B,5,A,7,E,F,D,9 with the addition based on bitwise xor.)
Let us make syndrome polynomial
- [math]displaystyle{ S(x)=alpha^{-7}+alpha^{1}x+alpha^{4}x^2+alpha^{2}x^3+alpha^{5}x^4+alpha^{-7}x^5, }[/math]
compute
- [math]displaystyle{ S(x)Gamma(x)=alpha^{-7}+alpha^{4}x+alpha^{-1}x^2+alpha^{6}x^3+alpha^{-1}x^4+alpha^{5}x^5+alpha^{7}x^6+alpha^{-3}x^7. }[/math]
Run the extended Euclidean algorithm:
- [math]displaystyle{ begin{align}
&begin{pmatrix}S(x)Gamma(x)\ x^6end{pmatrix} \ [6pt]
={} &begin{pmatrix}alpha^{-7} +alpha^{4}x+ alpha^{-1}x^2+ alpha^{6}x^3+ alpha^{-1}x^4+ alpha^{5}x^5 +alpha^{7}x^6+ alpha^{-3}x^7 \ x^6end{pmatrix} \ [6pt]
={} &begin{pmatrix}alpha^{7}+ alpha^{-3}x & 1\ 1 & 0end{pmatrix}
begin{pmatrix}x^6\ alpha^{-7} +alpha^{4}x +alpha^{-1}x^2 +alpha^{6}x^3 +alpha^{-1}x^4 +alpha^{5}x^5 +2alpha^{7}x^6 +2alpha^{-3}x^7end{pmatrix} \ [6pt]
={} &begin{pmatrix}alpha^{7}+ alpha^{-3}x & 1\ 1 & 0end{pmatrix}
begin{pmatrix}alpha^4 + alpha^{-5}x & 1\ 1 & 0end{pmatrix} \
&qquad begin{pmatrix}alpha^{-7}+ alpha^{4}x+ alpha^{-1}x^2+ alpha^{6}x^3+ alpha^{-1}x^4+ alpha^{5}x^5\ alpha^{-3} +left(alpha^{-7}+ alpha^{3}right)x+ left(alpha^{3}+ alpha^{-1}right)x^2+ left(alpha^{-5}+ alpha^{-6}right)x^3+ left(alpha^3+ alpha^{1}right)x^4+ 2alpha^{-6}x^5+ 2x^6end{pmatrix} \ [6pt]
={} &begin{pmatrix}left(1+ alpha^{-4}right)+ left(alpha^{1}+ alpha^{2}right)x+ alpha^{7}x^2 & alpha^{7}+ alpha^{-3}x \ alpha^4+ alpha^{-5}x & 1end{pmatrix}
begin{pmatrix}alpha^{-7}+ alpha^{4}x+ alpha^{-1}x^2+ alpha^{6}x^3+ alpha^{-1}x^4+ alpha^{5}x^5\ alpha^{-3}+ alpha^{-2}x+ alpha^{0}x^2+ alpha^{-2}x^3+ alpha^{-6}x^4end{pmatrix} \ [6pt]
={} &begin{pmatrix}alpha^{-3}+ alpha^{5}x+ alpha^{7}x^2 & alpha^{7}+ alpha^{-3}x \ alpha^4+ alpha^{-5}x & 1end{pmatrix}
begin{pmatrix}alpha^{-5}+ alpha^{-4}x & 1\ 1 & 0 end{pmatrix} \
&qquad begin{pmatrix}alpha^{-3}+ alpha^{-2}x+ alpha^{0}x^2+ alpha^{-2}x^3+ alpha^{-6}x^4\ left(alpha^{7}+ alpha^{-7}right)+ left(2alpha^{-7}+ alpha^{4}right)x+ left(alpha^{-5}+ alpha^{-6}+ alpha^{-1}right)x^2+ left(alpha^{-7}+ alpha^{-4}+ alpha^{6}right)x^3+ left(alpha^{4}+ alpha^{-6}+ alpha^{-1}right)x^4+ 2alpha^{5}x^5end{pmatrix} \ [6pt]
={} &begin{pmatrix}alpha^{7}x+ alpha^{5}x^2+ alpha^{3}x^3 & alpha^{-3}+ alpha^{5}x+ alpha^{7}x^2\ alpha^{3}+ alpha^{-5}x+ alpha^{6}x^2 & alpha^4+ alpha^{-5}xend{pmatrix}
begin{pmatrix}alpha^{-3}+ alpha^{-2}x+ alpha^{0}x^2+ alpha^{-2}x^3+ alpha^{-6}x^4\ alpha^{-4}+ alpha^{4}x+ alpha^{2}x^2+ alpha^{-5}x^3end{pmatrix}.
end{align} }[/math]
We have reached polynomial of degree at most 3, and as
- [math]displaystyle{ begin{pmatrix}-left(alpha^4+ alpha^{-5}xright) & alpha^{-3}+ alpha^{5}x+ alpha^{7}x^2\ alpha^{3}+ alpha^{-5}x+ alpha^{6}x^2 & -left(alpha^{7}x+ alpha^{5}x^2+ alpha^{3}x^3right)end{pmatrix} begin{pmatrix}alpha^{7}x+ alpha^{5}x^2+ alpha^{3}x^3 & alpha^{-3} + alpha^{5}x + alpha^{7}x^2\ alpha^{3} + alpha^{-5}x + alpha^{6}x^2 & alpha^4 + alpha^{-5}xend{pmatrix} = begin{pmatrix}1 & 0\ 0 & 1end{pmatrix}, }[/math]
we get
- [math]displaystyle{ begin{pmatrix}-left(alpha^4+ alpha^{-5}xright) & alpha^{-3}+ alpha^{5}x+ alpha^{7}x^2\ alpha^{3}+ alpha^{-5}x+ alpha^{6}x^2 & -left(alpha^{7}x+ alpha^{5}x^2+ alpha^{3}x^3right)end{pmatrix}
begin{pmatrix}S(x)Gamma(x)\ x^6end{pmatrix} = begin{pmatrix}alpha^{-3}+ alpha^{-2}x+ alpha^{0}x^2+ alpha^{-2}x^3+ alpha^{-6}x^4\ alpha^{-4}+ alpha^{4}x+ alpha^{2}x^2+ alpha^{-5}x^3end{pmatrix}. }[/math]
Therefore,
- [math]displaystyle{ S(x)Gamma(x)left(alpha^{3} + alpha^{-5}x + alpha^{6}x^2right) — left(alpha^{7}x + alpha^{5}x^2 + alpha^{3}x^3right)x^6 = alpha^{-4} + alpha^{4}x + alpha^{2}x^2 + alpha^{-5}x^3. }[/math]
Let [math]displaystyle{ Lambda(x) = alpha^{3}+ alpha^{-5}x+ alpha^{6}x^2. }[/math] Don’t worry that [math]displaystyle{ lambda_0neq 1. }[/math] Find by brute force a root of [math]displaystyle{ Lambda. }[/math] The roots are [math]displaystyle{ alpha^2, }[/math] and [math]displaystyle{ alpha^{10} }[/math] (after finding for example [math]displaystyle{ alpha^2 }[/math] we can divide [math]displaystyle{ Lambda }[/math] by corresponding monom [math]displaystyle{ left(x — alpha^2right) }[/math] and the root of resulting monom could be found easily).
Let
- [math]displaystyle{ begin{align}
Xi(x) &= Gamma(x)Lambda(x) = alpha^3 + alpha^4x^2 + alpha^2x^3 + alpha^{-5}x^4 \
Omega(x) &= S(x)Xi(x) equiv alpha^{-4} + alpha^4x + alpha^2x^2 + alpha^{-5}x^3 bmod{x^6}
end{align} }[/math]
Let us look for error values using formula
- [math]displaystyle{ e_j = -frac{Omega left(alpha^{-i_j} right)}{Xi’ left(alpha^{-i_j} right)}, }[/math]
where [math]displaystyle{ alpha^{-i_j} }[/math] are roots of [math]displaystyle{ Xi(x). }[/math] [math]displaystyle{ Xi'(x)=alpha^{2}x^2. }[/math] We get
- [math]displaystyle{ begin{align}
e_1 &=-frac{Omega(alpha^4)}{Xi'(alpha^{4})} = frac{alpha^{-4}+alpha^{-7}+alpha^{-5}+alpha^{7}}{alpha^{-5}} =frac{alpha^{-5}}{alpha^{-5}}=1 \
e_2 &=-frac{Omega(alpha^7)}{Xi'(alpha^{7})} = frac{alpha^{-4}+alpha^{-4}+alpha^{1}+alpha^{1}}{alpha^{1}}=0 \
e_3 &=-frac{Omega(alpha^{10})}{Xi'(alpha^{10})} = frac{alpha^{-4}+alpha^{-1}+alpha^{7}+alpha^{-5}}{alpha^{7}}=frac{alpha^{7}}{alpha^{7}}=1 \
e_4 &=-frac{Omega(alpha^{2})}{Xi'(alpha^{2})} = frac{alpha^{-4}+alpha^{6}+alpha^{6}+alpha^{1}}{alpha^{6}}=frac{alpha^{6}}{alpha^{6}}=1
end{align} }[/math]
Fact, that [math]displaystyle{ e_3=e_4=1, }[/math] should not be surprising.
Corrected code is therefore [ 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0].
Decoding with unreadable characters with a small number of errors
Let us show the algorithm behaviour for the case with small number of errors. Let the received word is [ 1 0 0 ? 1 1 ? 0 0 0 1 0 1 0 0 ].
Again, replace the unreadable characters by zeros while creating the polynomial reflecting their positions [math]displaystyle{ Gamma(x) = left(alpha^{8}x — 1right)left(alpha^{11}x — 1right). }[/math]
Compute the syndromes [math]displaystyle{ s_1 = alpha^{4}, s_2 = alpha^{-7}, s_3 = alpha^{1}, s_4 = alpha^{1}, s_5 = alpha^{0}, }[/math] and [math]displaystyle{ s_6 = alpha^{2}. }[/math]
Create syndrome polynomial
- [math]displaystyle{ begin{align}
S(x) &= alpha^{4} + alpha^{-7}x + alpha^{1}x^2 + alpha^{1}x^3 + alpha^{0}x^4 + alpha^{2}x^5, \
S(x)Gamma(x) &= alpha^{4} + alpha^{7}x + alpha^{5}x^2 + alpha^{3}x^3 + alpha^{1}x^4 + alpha^{-1}x^5 + alpha^{-1}x^6 + alpha^{6}x^7.
end{align} }[/math]
Let us run the extended Euclidean algorithm:
- [math]displaystyle{ begin{align}
begin{pmatrix}
S(x)Gamma(x) \
x^6
end{pmatrix}
&= begin{pmatrix}
alpha^{4} + alpha^{7}x + alpha^{5}x^2 + alpha^{3}x^3 + alpha^{1}x^4 + alpha^{-1}x^5 + alpha^{-1}x^6 + alpha^{6}x^7 \
x^6
end{pmatrix} \
&= begin{pmatrix}
alpha^{-1} + alpha^{6}x & 1 \
1 & 0
end{pmatrix} begin{pmatrix}
x^6 \
alpha^{4} + alpha^{7}x + alpha^{5}x^2 + alpha^{3}x^3 + alpha^{1}x^4 + alpha^{-1}x^5 + 2alpha^{-1}x^6 + 2alpha^{6}x^7
end{pmatrix} \
&= begin{pmatrix}
alpha^{-1} + alpha^{6}x & 1 \
1 & 0
end{pmatrix} begin{pmatrix}
alpha^{3} + alpha^{1}x & 1 \
1 & 0
end{pmatrix} begin{pmatrix}
alpha^{4} + alpha^{7}x + alpha^{5}x^2 + alpha^{3}x^3 + alpha^{1}x^4 + alpha^{-1}x^5 \
alpha^{7} + left(alpha^{-5} + alpha^{5}right)x + 2alpha^{-7}x^2 + 2alpha^{6}x^3 + 2alpha^{4}x^4 + 2alpha^{2}x^5 + 2x^6
end{pmatrix} \
&= begin{pmatrix}
left(1 + alpha^{2}right) + left(alpha^{0} + alpha^{-6}right)x + alpha^{7}x^2 & alpha^{-1} + alpha^{6}x \
alpha^{3} + alpha^{1}x & 1
end{pmatrix} begin{pmatrix}
alpha^{4} + alpha^{7}x + alpha^{5}x^2 + alpha^{3}x^3 + alpha^{1}x^4 + alpha^{-1}x^5 \
alpha^{7} + alpha^{0}x
end{pmatrix}
end{align} }[/math]
We have reached polynomial of degree at most 3, and as
- [math]displaystyle{
begin{pmatrix}
-1 & alpha^{-1} + alpha^{6}x \
alpha^{3} + alpha^{1}x & -left(alpha^{-7} + alpha^{7}x + alpha^{7}x^2right)
end{pmatrix} begin{pmatrix}
alpha^{-7} + alpha^{7}x + alpha^{7}x^2 & alpha^{-1} + alpha^{6}x \
alpha^{3} + alpha^{1}x & 1
end{pmatrix} = begin{pmatrix} 1 & 0 \ 0 & 1 end{pmatrix},
}[/math]
we get
- [math]displaystyle{
begin{pmatrix}
-1 & alpha^{-1} + alpha^{6}x \
alpha^{3} + alpha^{1}x & -left(alpha^{-7} + alpha^{7}x + alpha^{7}x^2right)
end{pmatrix}begin{pmatrix}
S(x)Gamma(x) \ x^6
end{pmatrix} = begin{pmatrix}
alpha^{4} + alpha^{7}x + alpha^{5}x^2 + alpha^{3}x^3 + alpha^{1}x^4 + alpha^{-1}x^5 \
alpha^{7} + alpha^{0}x
end{pmatrix}.
}[/math]
Therefore,
- [math]displaystyle{ S(x)Gamma(x)left(alpha^{3} + alpha^{1}xright) — left(alpha^{-7} + alpha^{7}x + alpha^{7}x^2right)x^6 = alpha^{7} + alpha^{0}x. }[/math]
Let [math]displaystyle{ Lambda(x) = alpha^{3} + alpha^{1}x. }[/math] Don’t worry that [math]displaystyle{ lambda_0 neq 1. }[/math] The root of [math]displaystyle{ Lambda(x) }[/math] is [math]displaystyle{ alpha^{3-1}. }[/math]
Let
- [math]displaystyle{ begin{align}
Xi(x) &= Gamma(x)Lambda(x) = alpha^{3} + alpha^{-7}x + alpha^{-4}x^2 + alpha^{5}x^3, \
Omega(x) &= S(x)Xi(x) equiv alpha^{7} + alpha^{0}x bmod{x^6}
end{align} }[/math]
Let us look for error values using formula [math]displaystyle{ e_j = -Omegaleft(alpha^{-i_j}right)/Xi’left(alpha^{-i_j}right), }[/math] where [math]displaystyle{ alpha^{-i_j} }[/math] are roots of polynomial [math]displaystyle{ Xi(x). }[/math]
- [math]displaystyle{ Xi'(x) = alpha^{-7} + alpha^{5}x^2. }[/math]
We get
- [math]displaystyle{ begin{align}
e_1 &= -frac{Omegaleft(alpha^4right)}{Xi’left(alpha^{4}right)}
= frac{alpha^{7} + alpha^{4}}{alpha^{-7} + alpha^{-2}}
= frac{alpha^{3}}{alpha^{3}}
= 1 \
e_2 &= -frac{Omegaleft(alpha^7right)}{Xi’left(alpha^{7}right)}
= frac{alpha^{7} + alpha^{7}}{alpha^{-7} + alpha^{4}}
= 0 \
e_3 &= -frac{Omegaleft(alpha^2right)}{Xi’left(alpha^2right)}
= frac{alpha^{7} + alpha^{2}}{alpha^{-7} + alpha^{-6}}
= frac{alpha^{-3}}{alpha^{-3}}
= 1
end{align} }[/math]
The fact that [math]displaystyle{ e_3 = 1 }[/math] should not be surprising.
Corrected code is therefore [ 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0].
Citations
- ↑ Reed & Chen 1999, p. 189
- ↑ Hocquenghem 1959
- ↑ Bose & Ray-Chaudhuri 1960
- ↑ «Phobos Lander Coding System: Software and Analysis». http://ipnpr.jpl.nasa.gov/progress_report/42-94/94V.PDF.
- ↑ «Sandforce SF-2500/2600 Product Brief». http://www.sandforce.com/index.php?id=133&parentId=2&top=1.
- ↑ http://pqc-hqc.org/doc/hqc-specification_2020-05-29.pdf
- ↑ Gill n.d., p. 3
- ↑ Lidl & Pilz 1999, p. 229
- ↑ Gorenstein, Peterson & Zierler 1960
- ↑ Gill n.d., p. 47
- ↑ Yasuo Sugiyama, Masao Kasahara, Shigeichi Hirasawa, and Toshihiko Namekawa. A method for solving key equation for decoding Goppa codes. Information and Control, 27:87–99, 1975.
References
Primary sources
- Hocquenghem, A. (September 1959), «Codes correcteurs d’erreurs» (in fr), Chiffres (Paris) 2: 147–156
- Bose, R. C.; Ray-Chaudhuri, D. K. (March 1960), «On A Class of Error Correcting Binary Group Codes», Information and Control 3 (1): 68–79, doi:10.1016/s0019-9958(60)90287-4, ISSN 0890-5401, http://repository.lib.ncsu.edu/bitstream/1840.4/2137/1/ISMS_1959_240.pdf
Secondary sources
- Gorenstein, Daniel; Peterson, W. Wesley; Zierler, Neal (1960), «Two-Error Correcting Bose-Chaudhuri Codes are Quasi-Perfect», Information and Control 3 (3): 291–294, doi:10.1016/s0019-9958(60)90877-9
- Lidl, Rudolf; Pilz, Günter (1999), Applied Abstract Algebra (2nd ed.), John Wiley
- Reed, Irving S.; Chen, Xuemin (1999), Error-Control Coding for Data Networks, Boston, MA: Kluwer Academic Publishers, ISBN 0-7923-8528-4
Further reading
- Blahut, Richard E. (2003), Algebraic Codes for Data Transmission (2nd ed.), Cambridge University Press, ISBN 0-521-55374-1
- Gilbert, W. J.; Nicholson, W. K. (2004), Modern Algebra with Applications (2nd ed.), John Wiley
- Lin, S.; Costello, D. (2004), Error Control Coding: Fundamentals and Applications, Englewood Cliffs, NJ: Prentice-Hall
- MacWilliams, F. J.; Sloane, N. J. A. (1977), The Theory of Error-Correcting Codes, New York, NY: North-Holland Publishing Company
- Rudra, Atri, CSE 545, Error Correcting Codes: Combinatorics, Algorithms and Applications, University at Buffalo, http://www.cse.buffalo.edu/~atri/courses/coding-theory/, retrieved April 21, 2010
В теории кодирования используются коды BCH или Bose – Chaudhuri– Коды Хоквенгема образуют класс циклических кодов с исправлением ошибок, которые построены с использованием полиномов над конечным полем (также называемым Поле Галуа ). Коды BCH были изобретены в 1959 году французским математиком Алексисом Хоквенгемом и независимо в 1960 году Раджем Бозом и Д. К. Рэй-Чаудхури. Название Bose – Chaudhuri – Hocquenghem (и аббревиатура BCH) происходит от инициалов фамилий изобретателей (ошибочно в случае Ray-Chaudhuri).
Одной из ключевых особенностей кодов BCH является то, что во время разработки кода существует точный контроль над количеством ошибок символов, исправляемых кодом. В частности, можно разработать двоичные коды BCH, которые могут исправлять несколько битовых ошибок. Другим преимуществом кодов BCH является легкость, с которой они могут быть декодированы, а именно с помощью алгебраического метода, известного как синдромное декодирование. Это упрощает конструкцию декодера для этих кодов с использованием небольшого маломощного электронного оборудования.
коды BCH используются в таких приложениях, как спутниковая связь, проигрыватели компакт-дисков, DVD, дисководы, твердотельные приводы, квантово-стойкая криптография и двумерные штрих-коды.
Содержание
- 1 Определение и иллюстрация
- 1.1 Примитивные узкосмысловые коды BCH
- 1.1. 1 Пример
- 1.2 Общие коды BCH
- 1.3 Особые случаи
- 1.1 Примитивные узкосмысловые коды BCH
- 2 Свойства
- 3 Кодирование
- 3.1 Несистематическое кодирование: сообщение как фактор
- 3.2 Систематическое кодирование: сообщение как префикс
- 4 Декодирование
- 4.1 Вычисление синдромов
- 4.2 Вычисление полинома местоположения ошибки
- 4.2.1 Алгоритм Петерсона – Горенштейна – Цирлера
- 4.3 Фактор полинома локатора ошибок
- 4.4 Вычисление значений ошибок
- 4.4.1 Алгоритм Форни
- 4.4.2 Объяснение вычисления алгоритма Форни
- 4.5 Декодирование на основе расширенного алгоритма Евклида
- 4.5.1 Объяснение процесса декодирования
- 4.6 Исправление ошибок
- 4.7 Примеры расшифровки
- 4.7.1 Декодирование двоичного кода без нечитаемых символов
- 4.7.2 Декодирование с нечитаемыми символами
- 4.7.3 Декодирование с нечитаемыми символами с небольшим количеством ошибок
- 5 Цитаты
- 6 Ссылки
- 6.1 Первичные источники
- 6.2 Вторичные источники
- 7 Дополнительная литература
Определение и иллюстрация
Примитивные узкосмысловые коды BCH
Дано простое число q и степень простого числа q с положительными целыми числами m и d такими, что d ≤ q — 1, примитивный узкосмысловой код BCH над конечным полем (или полем Галуа) GF (q) с длиной кода n = q — 1 и расстоянием не менее d строится следующим методом.
Пусть α будет примитивным элементом GF (q). Для любого натурального числа i пусть m i (x) будет минимальным многочленом с коэффициентами в GF (q) при α. Генераторный полином кода BCH определяется как наименьшее общее кратное g (x) = lcm (m 1 (x),…, m d — 1 (x)). Можно видеть, что g (x) — многочлен с коэффициентами из GF (q) и делит x — 1. Следовательно, полиномиальный код, определяемый g (x), является циклическим кодом.
Пример
Пусть q = 2 и m = 4 (следовательно, n = 15). Мы рассмотрим разные значения d. Для GF (16) = GF (2) на основе многочлена x + x + 1 с первообразным корнем α = x + 0 существуют минимальные многочлены m i (x) с коэффициентами в GF (2), удовлетворяющие
- mi (α i) mod (x 4 + x + 1) = 0. { displaystyle m_ {i} left ( alpha ^ {i} right) { bmod { left (x ^ {4 } + x + 1 right)}} = 0.}


Минимальные многочлены четырнадцати степеней α равны
- m 1 (x) = m 2 (x) = m 4 (x) = m 8 (х) = х 4 + х + 1, м 3 (х) = м 6 (х) = м 9 (х) = м 12 (х) = х 4 + х 3 + х 2 + х + 1, м 5 (x) = m 10 (x) = x 2 + x + 1, m 7 (x) = m 11 (x) = m 13 (x) = m 14 (x) = x 4 + x 3 + 1. { Displaystyle { begin {align} m_ {1} (x) = m_ {2} (x) = m_ {4} (x) = m_ {8} (x) = x ^ {4} + x + 1, \ m_ {3} (x) = m_ {6} (x) = m_ {9} (x) = m_ {12} (x) = x ^ {4} + x ^ {3} + x ^ {2} + x + 1, \ m_ {5} (x) = m_ {10} (x) = x ^ {2} + x + 1, \ m_ {7} (x) = m_ { 11} (x) = m_ {13} (x) = m_ {14} (x) = x ^ {4} + x ^ {3} +1. End {align}}}
Код BCH с d = 2, 3 { displaystyle d = 2,3}имеет порождающий полином
- g (x) = lcm (m 1 (x), m 2 (x)) = m 1 (х) = х 4 + x + 1. { displaystyle g (x) = { rm {lcm}} (m_ {1} (x), m_ {2} (x)) = m_ {1} (x) = x ^ {4 } + x + 1. ,}
Он имеет минимальное расстояние Хэмминга не менее 3 и исправляет до одной ошибки. Поскольку порождающий полином имеет степень 4, этот код имеет 11 бит данных и 4 бита контрольной суммы.
Код BCH с d = 4, 5 { displaystyle d = 4,5}имеет порождающий полином
- g (x) = lcm (m 1 (x), м 2 (х), м 3 (х), м 4 (х)) = м 1 (х) м 3 (х) = (х 4 + х + 1) (х 4 + х 3 + х 2 + x + 1) = x 8 + x 7 + x 6 + x 4 + 1. { displaystyle { begin {align} g (x) = { rm {lcm}} (m_ {1} (x), m_ {2} (x), m_ {3} (x), m_ {4} (x)) = m_ {1} (x) m_ {3} (x) \ = left (x ^ {4 } + x + 1 right) left (x ^ {4} + x ^ {3} + x ^ {2} + x + 1 right) = x ^ {8} + x ^ {7} + x ^ {6} + x ^ {4} +1. End {align}}}
Он имеет минимальное расстояние Хэмминга не менее 5 и исправляет до двух ошибок. Поскольку порождающий полином имеет степень 8, этот код имеет 7 бит данных и 8 битов контрольной суммы.
Код BCH с d = 6, 7 { displaystyle d = 6,7}имеет порождающий полином
- g (x) = lcm (m 1 (x), m 2 (x), m 3 (x), m 4 (x), m 5 (x), m 6 (x)) = m 1 (x) m 3 (x) m 5 (x) = ( x 4 + x + 1) (x 4 + x 3 + x 2 + x + 1) (x 2 + x + 1) = x 10 + x 8 + x 5 + x 4 + x 2 + x + 1. { Displaystyle { begin {align} g (x) = { rm {lcm}} (m_ {1} (x), m_ {2} (x), m_ {3} (x), m_ {4}) (x), m_ {5} (x), m_ {6} (x)) = m_ {1} (x) m_ {3} (x) m_ {5} (x) \ = left (x ^ {4} + x + 1 right) left (x ^ {4} + x ^ {3} + x ^ {2} + x + 1 right) left (x ^ {2} + x + 1 right) = x ^ {10} + x ^ {8} + x ^ {5} + x ^ {4} + x ^ {2} + x + 1. end {align}}}
Он имеет минимальное расстояние Хэмминга не менее 7 и исправляет до трех ошибок. Поскольку порождающий полином имеет степень 10, этот код имеет 5 бит данных и 10 битов контрольной суммы. (Этот конкретный генераторный полином имеет реальное применение в шаблонах формата QR-кода.)
Код BCH с d = 8 { displaystyle d = 8 }и выше имеет порождающий многочлен
- g (x) = lcm (m 1 (x), m 2 (x),…, m 14 (x)) = m 1 (x) m 3 (x) m 5 (x) m 7 (x) = (x 4 + x + 1) (x 4 + x 3 + x 2 + x + 1) (x 2 + x + 1) (x 4 + Икс 3 + 1) = Икс 14 + Икс 13 + Икс 12 + ⋯ + Икс 2 + Икс + 1. { Displaystyle { begin {Выровнено} g (x) = { rm {lcm}} (m_ {1 } (x), m_ {2} (x),…, m_ {14} (x)) = m_ {1} (x) m_ {3} (x) m_ {5} (x) m_ {7 } (x) \ = left (x ^ {4} + x + 1 right) left (x ^ {4} + x ^ {3} + x ^ {2} + x + 1 right) left (x ^ {2} + x + 1 right) left (x ^ {4} + x ^ {3} +1 right) = x ^ {14} + x ^ {13} + x ^ { 12} + cdots + x ^ {2} + x + 1. End {align}}}
Этот код имеет минимальное расстояние Хэмминга 15 и исправляет 7 ошибок. Он имеет 1 бит данных и 14 битов контрольной суммы. Фактически, этот код имеет только два кодовых слова: 000000000000000 и 1111111111111.
Общие коды BCH
Общие коды BCH отличаются от примитивных кодов BCH с узким смыслом в двух отношениях.
Во-первых, требование, чтобы α { displaystyle alpha}был примитивным элементом GF (qm) { displaystyle mathrm {GF} (q ^ {m})}можно расслабить. При ослаблении этого требования длина кода изменяется с qm — 1 { displaystyle q ^ {m} -1}на ord (α), { displaystyle mathrm {ord} ( alpha),}порядок элемента α. { displaystyle alpha.}
Во-вторых, последовательные корни порождающего полинома могут начинаться из α c,…, α c + d — 2 { displaystyle alpha ^ {c}, ldots, alpha ^ {c + d-2}}вместо α,…, α d — 1. { displaystyle alpha, ldots, alpha ^ {d-1}.}
Определение. Исправить конечное поле GF (q), { displaystyle GF (q),}где q { displaystyle q}— степень простого числа. Выберите целые положительные числа m, n, d, c { displaystyle m, n, d, c}так, чтобы 2 ≤ d ≤ n, { displaystyle 2 leq d leq n,}gcd (n, q) = 1, { displaystyle { rm {gcd}} (n, q) = 1,}и m { displaystyle m}— порядок умножения числа q { displaystyle q}по модулю n. { displaystyle n.}
Как и раньше, пусть α { displaystyle alpha}будет примитивом n { displaystyle n}корень -й степени из единицы в GF (qm), { displaystyle GF (q ^ {m}),}и пусть mi (x) { displaystyle m_ {i } (x)}быть минимальным многочленом над GF (q) { displaystyle GF (q)}из α i { displaystyle alpha ^ {i}}для всех i. { displaystyle i.}Генераторный полином кода BCH определяется как наименьшее общее кратное g (x) = lcm (mc (x),…, mc + d — 2 (х)). { displaystyle g (x) = { rm {lcm}} (m_ {c} (x), ldots, m_ {c + d-2} (x)).}
Примечание: если n = qm — 1 { displaystyle n = q ^ {m} -1}как в упрощенном определении, затем gcd (n, q) { displaystyle { rm { gcd}} (n, q)}равно 1, и порядок q { displaystyle q}по модулю n { displaystyle n}равно м. { displaystyle m.}Следовательно, упрощенное определение действительно является частным случаем общего.
Особые случаи
Генераторный полином g (x) { displaystyle g (x)}кода BCH имеет коэффициенты из GF (q). { displaystyle mathrm {GF} (q).}В общем, циклический код над GF (qp) { displaystyle mathrm {GF} (q ^ {p})}с g (x) { displaystyle g (x)}в качестве порождающего полинома, называется кодом BCH над GF (qp). { displaystyle mathrm {GF} (q ^ {p}).}Код BCH над GF (qm) { displaystyle mathrm {GF} (q ^ {m})}и порождающий полином g (x) { displaystyle g (x)}с последовательными степенями α { displaystyle alpha}поскольку корни — это один тип кода Рида – Соломона, где алфавит декодера (синдромов) совпадает с алфавитом канала (данные и генераторный полином), все элементы GF (qm) { displaystyle mathrm {GF} (q ^ {m})}. Другой тип кода Рида-Соломона — это исходный код Рида-Соломона, который не является кодом BCH.
Свойства
Генераторный полином кода BCH имеет степень не выше (d — 1) m { displaystyle (d-1) m}. Кроме того, если q = 2 { displaystyle q = 2}и c = 1 { displaystyle c = 1}, порождающий полином имеет степень не более dm / 2 { displaystyle dm / 2}.
| Proof |
|---|
|
Каждый минимальный многочлен mi (x) { displaystyle m_ {i} (x)} |
 из них имеет степень не более (d — 1) m { displaystyle (d-1) m }
из них имеет степень не более (d — 1) m { displaystyle (d-1) m } , то mi (x) = m 2 i (x) { displaystyle m_ {i} (x) = m_ {2i} (x)}
, то mi (x) = m 2 i (x) { displaystyle m_ {i} (x) = m_ {2i} (x)} для всех i { displaystyle i}
для всех i { displaystyle i} минимальные многочлены mi (x) { displaystyle m_ {i} (x)}
минимальные многочлены mi (x) { displaystyle m_ {i} (x)} каждый степени в большинство m { displaystyle m}
каждый степени в большинство m { displaystyle m}Код BCH имеет минимальное расстояние Хэмминга не менее d { displaystyle d}.
| Доказательство |
|---|
|
Предположим, что p (x) { displaystyle p (x)}
Напомним, что α c,…, α c + d — 2 { displaystyle alpha ^ {c}, ldots, alpha ^ {c + d-2}}
В матричной форме
Определитель этой матрицы равен
Матрица V { displaystyle V}
, который не равен нулю. Отсюда следует, что b 1,…, bd — 1 = 0, { displaystyle b_ {1}, ldots, b_ {d-1} = 0,} |

 удовлетворяют следующим уравнениям для каждого i ∈ {c,…, c + d — 2} { displaystyle i in {c, dotsc, c + d-2 }}
удовлетворяют следующим уравнениям для каждого i ∈ {c,…, c + d — 2} { displaystyle i in {c, dotsc, c + d-2 }} :
:


 рассматривается как матрица Вандермонда, и ее определитель равен
рассматривается как матрица Вандермонда, и ее определитель равен
 , следовательно, p (x) = 0. { displaystyle p (x) = 0.}
, следовательно, p (x) = 0. { displaystyle p (x) = 0.}
Код BCH является циклическим.
| Доказательство |
|---|
|
Полиномиальный код длины n { displaystyle n} |
 Поскольку g (x) { displaystyle g (x)}
Поскольку g (x) { displaystyle g (x)} , достаточно проверить, что каждое из α c,…, α c + d — 2 { displaystyle alpha ^ {c}, ldots, alpha ^ {c + d-2}}
, достаточно проверить, что каждое из α c,…, α c + d — 2 { displaystyle alpha ^ {c}, ldots, alpha ^ {c + d-2}}Кодирование
Поскольку любой многочлен, кратный образующему многочлену, является допустимым кодовым словом BCH, кодирование BCH — это просто процесс поиска некоторого многочлена, в котором генератор является фактором.
Сам код BCH не определяет значения коэффициентов полинома; концептуально, единственная задача алгоритма декодирования BCH — найти допустимое кодовое слово с минимальным расстоянием Хэмминга до полученного кодового слова. Следовательно, код BCH может быть реализован либо как систематический код , либо нет, в зависимости от того, как разработчик решает внедрить сообщение в закодированный полином.
Несистематическое кодирование: сообщение как фактор
Самый простой способ найти многочлен, кратный генератору, — это вычислить произведение некоторого произвольного полинома и генератора. В этом случае произвольный многочлен можно выбрать, используя символы сообщения в качестве коэффициентов.
- s (x) = p (x) g (x) { displaystyle s (x) = p (x) g (x)}
В качестве примера рассмотрим порождающий полином g (x) = x 10 + x 9 + x 8 + x 6 + x 5 + x 3 + 1 { displaystyle g (x) = x ^ {10} + x ^ {9} + x ^ {8} + x ^ { 6} + x ^ {5} + x ^ {3} +1}, выбранный для использования в (31, 21) двоичном коде BCH, используемом POCSAG и другими. Чтобы закодировать 21-битное сообщение {101101110111101111101}, мы сначала представляем его как полином от GF (2) { displaystyle GF (2)}:
- p (x) = x 20 + x 18 + x 17 + x 15 + x 14 + x 13 + x 11 + x 10 + x 9 + x 8 + x 6 + x 5 + x 4 + x 3 + x 2 + 1 { displaystyle p (x) = x ^ {20 } + x ^ {18} + x ^ {17} + x ^ {15} + x ^ {14} + x ^ {13} + x ^ {11} + x ^ {10} + x ^ {9} + x ^ {8} + x ^ {6} + x ^ {5} + x ^ {4} + x ^ {3} + x ^ {2} +1}
Затем вычислите (также более GF (2) { displaystyle GF (2)}):
- s (x) = p (x) g (x) = (x 20 + x 18 + x 17 + x 15 + х 14 + х 13 + х 11 + х 10 + х 9 + х 8 + х 6 + х 5 + х 4 + х 3 + х 2 + 1) (х 10 + х 9 + х 8 + х 6 + х 5 + x 3 + 1) = x 30 + x 29 + x 26 + x 25 + x 24 + x 22 + x 19 + x 17 + x 16 + x 15 + x 14 + x 12 + x 10 + x 9 + x 8 + x 6 + x 5 + x 4 + x 2 + 1 { displaystyle { begin {align} s (x) = p (x) g (x) \ = left (x ^ {20}) + x ^ {18} + x ^ {17} + x ^ {15} + x ^ {14} + x ^ {13} + x ^ {11} + x ^ {10} + x ^ {9} + x ^ {8} + x ^ {6} + x ^ {5} + x ^ {4} + x ^ {3} + x ^ {2} +1 right) left (x ^ {10} + x ^ {9} + x ^ {8} + x ^ {6} + x ^ {5} + x ^ {3} +1 right) \ = x ^ {30} + x ^ {29} + x ^ {26} + x ^ {25} + x ^ {24} + x ^ {22} + x ^ {19} + x ^ {17} + x ^ {16} + x ^ {15} + x ^ {14} + x ^ {12 } + x ^ {10} + x ^ {9} + x ^ {8} + x ^ {6} + x ^ {5} + x ^ {4} + x ^ {2} +1 end {выровнено} }}
Таким образом, переданное кодовое слово — {1100111010010111101011101110101}.
Приемник может использовать эти биты в качестве коэффициентов в s (x) { displaystyle s (x)}и после исправления ошибок для проверки правильности кодового слова может повторно вычислить p (x) = s (x) / g (x) { displaystyle p (x) = s (x) / g (x)}
Систематическая кодировка: сообщение в виде префикса
Систематический код — это код, в котором сообщение дословно отображается где-то внутри кодового слова. Следовательно, систематическое кодирование BCH включает в себя сначала встраивание полинома сообщения в полином кодового слова, а затем настройку коэффициентов оставшихся (не связанных с сообщением) членов, чтобы гарантировать, что s (x) { displaystyle s (x)}делится на g (x) { displaystyle g (x)}.
Этот метод кодирования использует тот факт, что вычитание остатка от делимого дает результат, кратный делителю. Следовательно, если мы возьмем наш многочлен сообщения p (x) { displaystyle p (x)}, как прежде, и умножим его на xn — k { displaystyle x ^ {nk}}(чтобы «сдвинуть» сообщение с пути остатка), мы можем затем использовать евклидово деление многочленов, чтобы получить:
- p (x) xn — k = q (x) g (x) + r (x) { displaystyle p (x) x ^ {nk} = q (x) g (x) + r (x)}
Здесь мы видим, что q (x) g (x) { displaystyle q (x) g (x)}— допустимое кодовое слово. Поскольку r (x) { displaystyle r (x)}всегда имеет степень меньше n — k { displaystyle nk}(которая является степенью из g (x) { displaystyle g (x)}), мы можем безопасно вычесть его из p (x) xn — k { displaystyle p (x) x ^ { nk}}без изменения каких-либо коэффициентов сообщения, следовательно, мы имеем s (x) { displaystyle s (x)}как
- s (x) знак равно Q (Икс) г (Икс) знак равно п (Икс) Икс — К — р (Икс) { Displaystyle s (х) = д (х) г (х) = р (х) х ^ {nk} -r (x)}
Более GF (2) { displaystyle GF (2)}(то есть с двоичными кодами BCH), этот процесс неотличим от добавления циклической проверки избыточности, и если систематический двоичный код BCH используется только для целей обнаружения ошибок, мы видим, что коды BCH являются просто обобщением математики циклических проверок избыточности.
Преимущество систематического кодирования состоит в том, что получатель может восстановить исходное сообщение, отбросив все после первого k { d isplaystyle k}коэффициентов после выполнения исправления ошибок.
Декодирование
Существует множество алгоритмов декодирования кодов BCH. Наиболее распространенные из них следуют этой общей схеме:
- Вычислить синдромы s j для полученного вектора
- Определить количество ошибок t и полином локатора ошибок Λ (x) из синдромы
- Вычислить корни полинома местоположения ошибки, чтобы найти местоположения ошибки X i
- Вычислить значения ошибки Y i в этих местоположениях ошибки
- Исправить ошибки
Во время некоторых из этих шагов алгоритм декодирования может определить, что полученный вектор содержит слишком много ошибок и не может быть исправлен. Например, если подходящее значение t не найдено, коррекция не будет выполнена. В усеченном (не примитивном) коде место ошибки может быть вне допустимого диапазона. Если полученный вектор содержит больше ошибок, чем код может исправить, декодер может неосознанно выдать явно действительное сообщение, отличное от того, которое было отправлено.
Вычислить синдромы
Полученный вектор R { displaystyle R}представляет собой сумму правильного кодового слова C { displaystyle C}и неизвестный вектор ошибок E. { displaystyle E.}Значения синдрома формируются путем рассмотрения R { displaystyle R}как полинома и его оценки при α c,…, α c + d — 2. { displaystyle alpha ^ {c}, ldots, alpha ^ {c + d-2}.}Таким образом, синдромы
- sj = R (α j) = C (α j) + Е (α j) { Displaystyle s_ {j} = R left ( alpha ^ {j} right) = C left ( alpha ^ {j} right) + E left ( alpha ^ {j} right)}
для j = c { displaystyle j = c}до c + d — 2. { displaystyle c + d-2.}
Поскольку α j { displaystyle alpha ^ {j}}— это нули g (x), { displaystyle g (x),}из которых C (x) { displaystyle C (x)}кратно, C (α j) = 0. { displaystyle C left ( alpha ^ {j} right) = 0.}Таким образом, изучение значений синдрома изолирует вектор ошибок, чтобы можно было приступить к его поиску.
Если ошибки нет, s j = 0 { displaystyle s_ {j} = 0}для всех j. { displaystyle j.}Если все синдромы равны нулю, то декодирование выполнено.
Вычислить многочлен местоположения ошибки
Если есть ненулевые синдромы, значит, есть ошибки. Декодеру необходимо выяснить, сколько ошибок и где они находятся.
Если есть одна ошибка, запишите это как E (x) = exi, { displaystyle E (x) = e , x ^ {i},}где i { displaystyle i}— местоположение ошибки, а e { displaystyle e}— ее величина. Тогда первые два синдрома:
- sc = e α cisc + 1 = e α (c + 1) i = α isc { displaystyle { begin {align} s_ {c} = e , alpha ^ { c , i} \ s_ {c + 1} = e , alpha ^ {(c + 1) , i} = alpha ^ {i} s_ {c} end {align}}}
, поэтому вместе они позволяют нам вычислить e { displaystyle e}и предоставить некоторую информацию о i { displaystyle i}(полностью определяя его в случай кодов Рида – Соломона).
Если есть две или более ошибок,
- E (x) = e 1 xi 1 + e 2 xi 2 + ⋯ { displaystyle E (x) = e_ {1} x ^ {i_ { 1}} + e_ {2} x ^ {i_ {2}} + cdots ,}
Не сразу понятно, как начать решение результирующих синдромов для неизвестных ek { displaystyle e_ {k }}и ik. { displaystyle i_ {k}.}
Первым шагом является поиск, совместимый с вычисленными синдромами и с минимально возможным t, { displaystyle t,}многочлен локатора:
- Λ (Икс) знак равно ∏ J знак равно 1 T (Икс α ij — 1) { Displaystyle Lambda (x) = prod _ {j = 1} ^ {t} left (x alpha ^ {i_ {j}} -1 right)}
Два популярных алгоритма для этой задачи:
- алгоритм Петерсона – Горенштейна – Цирлера
- алгоритм Берлекампа – Месси
алгоритм Петерсона – Горенштейна – Цирлера
алгоритм Петерсона — шаг 2 обобщенной процедуры декодирования BCH. Алгоритм Петерсона используется для вычисления коэффициентов полинома локатора ошибок λ 1, λ 2,…, λ v { displaystyle lambda _ {1}, lambda _ {2}, dots, lambda _ {v} }многочлена
- Λ (x) = 1 + λ 1 x + λ 2 x 2 + ⋯ + λ vxv. { displaystyle Lambda (x) = 1 + lambda _ {1} x + lambda _ {2} x ^ {2} + cdots + lambda _ {v} x ^ {v}.}
Теперь процедура алгоритма Петерсона – Горенштейна – Цирлера. Ожидается, что у нас будет как минимум 2t синдромов s c,…, s c + 2t − 1. Пусть v = t.
- Начните с создания матрицы S v × v { displaystyle S_ {v times v}}с элементами, которые являются значениями синдрома
- S v × v = [scsc + 1 … Sc + v — 1 sc + 1 sc + 2… sc + v ⋮ ⋮ ⋱ sc + v — 1 sc + v… sc + 2 v — 2]. { Displaystyle S_ {v times v} = { begin {bmatrix} s_ {c} s_ {c + 1} dots s_ {c + v-1} \ s_ {c + 1} s_ {c + 2} dots s_ {c + v} \ vdots vdots ddots vdots \ s_ {c + v-1} s_ {c + v} dots s_ {c + 2v-2 } end {bmatrix}}.}
- S v × v = [scsc + 1 … Sc + v — 1 sc + 1 sc + 2… sc + v ⋮ ⋮ ⋱ sc + v — 1 sc + v… sc + 2 v — 2]. { Displaystyle S_ {v times v} = { begin {bmatrix} s_ {c} s_ {c + 1} dots s_ {c + v-1} \ s_ {c + 1} s_ {c + 2} dots s_ {c + v} \ vdots vdots ddots vdots \ s_ {c + v-1} s_ {c + v} dots s_ {c + 2v-2 } end {bmatrix}}.}
- Сгенерировать вектор cv × 1 { displaystyle c_ {v times 1}}с элементами
- C v × 1 = [сбн + vsc + v + 1 ⋮ sc + 2 v — 1]. { Displaystyle C_ {v times 1} = { begin {bmatrix} s_ {c + v} \ s_ {c + v + 1} \ vdots \ s_ {c + 2v-1} end { bmatrix}}.}
- C v × 1 = [сбн + vsc + v + 1 ⋮ sc + 2 v — 1]. { Displaystyle C_ {v times 1} = { begin {bmatrix} s_ {c + v} \ s_ {c + v + 1} \ vdots \ s_ {c + 2v-1} end { bmatrix}}.}
- Пусть Λ { displaystyle Lambda}обозначает неизвестные полиномиальные коэффициенты, которые задаются как
- Λ v × 1 = [λ v λ v — 1 ⋮ λ 1]. { displaystyle Lambda _ {v times 1} = { begin {bmatrix} lambda _ {v} \ lambda _ {v-1} \ vdots \ lambda _ {1} end { bmatrix}}.}
- Λ v × 1 = [λ v λ v — 1 ⋮ λ 1]. { displaystyle Lambda _ {v times 1} = { begin {bmatrix} lambda _ {v} \ lambda _ {v-1} \ vdots \ lambda _ {1} end { bmatrix}}.}
- Сформируйте матричное уравнение
- S v × v Λ v × 1 = — C v × 1. { displaystyle S_ {v times v} Lambda _ {v times 1} = — C_ {v times 1 ,}.}
- S v × v Λ v × 1 = — C v × 1. { displaystyle S_ {v times v} Lambda _ {v times 1} = — C_ {v times 1 ,}.}
- Если определитель матрицы S v × v { displaystyle S_ {v times v}}не равно нулю, тогда мы можем фактически найти обратную матрицу и найти значения неизвестного Λ { displaystyle Lambda}значений.
- Если det (S v × v) = 0, { displaystyle det left (S_ {v times v} right) = 0,}затем выполните
, если v = 0 { displaystyle v = 0}, то объявите пустой полином локатора ошибок, остановите процедуру Петерсона. конечный набор v ← v - 1 { displaystyle v leftarrow v-1}продолжить с начала декодирования Петерсона, уменьшив S v × v { displaystyle S_ {v times v} }
- После того, как у вас есть значения Λ { displaystyle Lambda}, у вас будет многочлен локатора ошибок.
- Остановить процедуру Петерсона.
 с элементами, которые являются значениями синдрома
с элементами, которые являются значениями синдрома

 с элементами
с элементами



 затем выполните
затем выполните
 , то объявите пустой полином локатора ошибок, остановите процедуру Петерсона. конечный набор v ← v - 1 { displaystyle v leftarrow v-1}
, то объявите пустой полином локатора ошибок, остановите процедуру Петерсона. конечный набор v ← v - 1 { displaystyle v leftarrow v-1}
Факторный полином локатора ошибок
Теперь, когда у вас есть многочлен Λ (x) { displaystyle Lambda (x)}, его корни можно найти в форме Λ (x) знак равно (α я 1 Икс — 1) (α я 2 Икс — 1) ⋯ (α ivx — 1) { Displaystyle Lambda (x) = left ( alpha ^ {i_ {1}} x-1 right) left ( alpha ^ {i_ {2}} x-1 right) cdots left ( alpha ^ {i_ {v}} x-1 right)}грубой силой для пример с использованием алгоритма поиска Chien. Экспоненциальные степени примитивного элемента α { displaystyle alpha}дадут позиции, где возникают ошибки в полученном слове; отсюда и название полином «локатора ошибок».
Нули Λ (x) — это α,…, α.
Расчет значений ошибок
После того, как места ошибок известны, следующим шагом будет определение значений ошибок в этих местах. Затем значения ошибок используются для исправления полученных значений в этих местах для восстановления исходного кодового слова.
Для случая двоичного BCH (со всеми читаемыми символами) это тривиально; просто переверните биты принятого слова в эти позиции, и мы получим исправленное кодовое слово. В более общем случае веса ошибок ej { displaystyle e_ {j}}могут быть определены путем решения линейной системы
- sc = e 1 α ci 1 + e 2 α ci 2 + ⋯ сбн + 1 знак равно е 1 α (с + 1) я 1 + е 2 α (с + 1) я 2 + ⋯ ⋮ { displaystyle { begin {align} s_ {c} = e_ {1} alpha ^ {c , i_ {1}} + e_ {2} alpha ^ {c , i_ {2}} + cdots \ s_ {c + 1} = e_ {1} alpha ^ { (c + 1) , i_ {1}} + e_ {2} alpha ^ {(c + 1) , i_ {2}} + cdots \ {} vdots end {выровнено}} }
алгоритм Форни
Однако существует более эффективный метод, известный как алгоритм Форни.
Пусть
- S (x) = sc + sc + 1 x + sc + 2 х 2 + ⋯ + сбн + г — 2 х г — 2. { Displaystyle S (x) = s_ {c} + s_ {c + 1} x + s_ {c + 2} x ^ {2} + cdots + s_ {c + d-2} x ^ {d-2 }.}
- v ⩽ d — 1, λ 0 ≠ 0 Λ (x) = ∑ i = 0 v λ ixi = λ 0 ∏ k = 0 v (α — ikx — 1). { displaystyle v leqslant d-1, lambda _ {0} neq 0 qquad Lambda (x) = sum _ {i = 0} ^ {v} lambda _ {i} x ^ {i} = lambda _ {0} prod _ {k = 0} ^ {v} left ( alpha ^ {- i_ {k}} x-1 right).}
И полином вычислителя ошибок
- Ом (Икс) ≡ S (Икс) Λ (Икс) mod xd — 1 { Displaystyle Omega (x) Equiv S (x) Lambda (x) { bmod {x ^ {d-1}}} }
Наконец:
- Λ ′ (x) = ∑ i = 1 vi ⋅ λ ixi — 1, { displaystyle Lambda ‘(x) = sum _ {i = 1} ^ {v} i cdot lambda _ {i} x ^ {i-1},}
где
- i ⋅ x: = ∑ k = 1 ix. { displaystyle i cdot x: = sum _ {k = 1} ^ {i} x.}
Чем, если бы синдромы можно было объяснить словом ошибки, которое может быть ненулевым только на позициях ik { displaystyle i_ {k}}, тогда значения ошибок равны
- ek = — α ik Ω (α — ik) α c ⋅ ik Λ ′ (α — ik). { displaystyle e_ {k} = — { alpha ^ {i_ {k}} Omega left ( alpha ^ {- i_ {k}} right) over alpha ^ {c cdot i_ {k} } Lambda ‘ left ( alpha ^ {- i_ {k}} right)}.}
Для кодов BCH узкого смысла c = 1, поэтому выражение упрощается до:
- ek = — Ω (α — ik) Λ ′ (α — ik). { displaystyle e_ {k} = — { Omega left ( alpha ^ {- i_ {k}} right) over Lambda ‘ left ( alpha ^ {- i_ {k}} right)}.}
Объяснение вычисления алгоритма Форни
Он основан на интерполяции Лагранжа и методах производящих функций.
Рассмотрим S (x) Λ (x), { displaystyle S (x) Lambda (x),}и для простоты предположим, что λ k = 0 { displaystyle lambda _ {k} = 0}для k>v, { displaystyle k>v,} и sk = 0 { displaystyle s_ {k} = 0}для k>+ d — 2. { displaystyle k>c + d-2.}
и sk = 0 { displaystyle s_ {k} = 0}для k>+ d — 2. { displaystyle k>c + d-2.} Тогда
Тогда
- S (x) Λ (x) = ∑ j = 0 ∞ i = 0 jsj — i + 1. { Displaystyle S (x) Lambda (x) = sum _ {j = 0} ^ { infty} sum _ {i = 0} ^ {j} s_ {j-i + 1} lambda _ { i} x ^ {j}.}
- S (x) Λ (x) = S (x) {λ 0 ∏ ℓ = 1 v (α i ℓ x — 1)} = {∑ i = 0 d — 2 ∑ j = 1 vej α (c + i) ⋅ ijxi} {λ 0 ∏ ℓ = 1 v (α i ℓ x — 1)} = {∑ j = 1 vej α cij ∑ i = 0 d — 2 (α ij) ixi} {λ 0 ∏ ℓ = 1 v (α i ℓ x — 1)} = {∑ j = 1 vej α cij (x α ij) d — 1 — 1 x α ij — 1} {λ 0 ∏ ℓ = 1 v (α i ℓ x — 1)} = λ 0 ∑ j = 1 vej α cij (x α ij) d — 1 — 1 x α ij — 1 ∏ ℓ = 1 v (α i ℓ x — 1) = λ 0 ∑ j = 1 vej α cij ( ( x α ij) d − 1 − 1) ∏ ℓ ∈ { 1, ⋯, v } ∖ { j } ( α i ℓ x − 1) {displaystyle { begin{aligned}S(x)Lambda (x)=S(x)left{lambda _{0}prod _{ell =1}^{v}left(alpha ^{i_ {ell }}x-1right)right}\=left{sum _{i=0}^{d-2}sum _{j=1}^{v}e_ {j}alpha ^{(c+i)cdot i_{j}}x^{i}right}left{lambda _{0}prod _{ell =1}^{v }left(alpha ^{i_{ell }}x-1right)right}\=left{sum _{j=1}^{v}e_{j}alpha ^{ci_{j}}sum _{i=0}^{d-2}left(a lpha ^{i_{j}}right)^{i}x^{i}right}left{lambda _{0}prod _{ell =1}^{v}left(alpha ^{i_{ell }}x-1right)right}\=left{sum _{j=1}^{v}e_{j}alpha ^{ci_{j}}{frac {left(xalpha ^{i_{j}}right)^{d-1}-1}{xalpha ^{i_{j}}-1}}right}left{lambda _{0}prod _{ell =1}^{v}left(alpha ^{i_{ell }}x-1right)right}\=lambda _{0}sum _{j=1}^{v}e_{j}alpha ^{ci_{j}}{frac {left(xalpha ^{i_{j}}right)^{d-1}-1}{xalpha ^{i_{j}}-1}}prod _{ell =1}^{v}left(alpha ^{i_{ell }}x-1right)\=lambda _{0}sum _{j=1}^{v}e_{j}alpha ^{ci_{j}}left(left(xalpha ^{i_{j}}right)^{d-1}-1right)prod _{ell in {1,cdots,v}setminus {j}}left(alpha ^{i_{ell }}x-1right)end{aligned}}}
We want to compute unknowns e j, {displaystyle e_{j},}and we could simplify the context by removing the ( x α i j) d − 1 {displaystyle left(xalpha ^{i_{j}}right)^{d-1}}terms. This leads to the error evaluator polynomial
- Ω ( x) ≡ S ( x) Λ ( x) mod x d − 1. {displaystyle Omega (x)equiv S(x)Lambda (x){bmod {x^{d-1}}}.}
Thanks to v ⩽ d − 1 {displaystyle vleqslant d-1}we have
- Ω ( x) = − λ 0 ∑ j = 1 v e j α c i j ∏ ℓ ∈ { 1, ⋯, v } ∖ { j } ( α i ℓ x − 1). {displaystyle Omega (x)=-lambda _{0}sum _{j=1}^{v}e_{j}alpha ^{ci_{j}}prod _{ell in {1,cdots,v}setminus {j}}left(alpha ^{i_{ell }}x-1right).}
Thanks to Λ {displaystyle Lambda }(the Lagrange interpolation trick) the sum degenerates to only one summand for x = α − i k {displaystyle x=alpha ^{-i_{k}}}
- Ω ( α − i k) = − λ 0 e k α c ⋅ i k ∏ ℓ ∈ { 1, ⋯, v } ∖ { k } ( α i ℓ α − i k − 1). {displaystyle Omega left(alpha ^{-i_{k}}right)=-lambda _{0}e_{k}alpha ^{ccdot i_{k}}prod _{ell in {1,cdots,v}setminus {k}}left(alpha ^{i_{ell }}alpha ^{-i_{k}}-1right).}
To get e k {displaystyle e_{k}}we just should get rid of the product. We could compute the product directly from already computed roots α − i j {displaystyle alpha ^{-i_{j}}}of Λ, {displaystyle Lambda,}but we could use simpler form.
As formal derivative
- Λ ′ ( x) = λ 0 ∑ j = 1 v α i j ∏ ℓ ∈ { 1, ⋯, v } ∖ { j } ( α i ℓ x − 1), {displaystyle Lambda ‘(x)=lambda _{0}sum _{j=1}^{v}alpha ^{i_{j}}prod _{ell in {1,cdots,v}setminus {j}}left(alpha ^{i_{ell }}x-1right),}
we get again only one summand in
- Λ ′ ( α − i k) = λ 0 α i k ∏ ℓ ∈ { 1, ⋯, v } ∖ { k } ( α i ℓ α − i k − 1). {displaystyle Lambda ‘left(alpha ^{-i_{k}}right)=lambda _{0}alpha ^{i_{k}}prod _{ell in {1,cdots,v}setminus {k}}left(alpha ^{i_{ell }}alpha ^{-i_{k}}-1right).}
So finally
- e k = − α i k Ω ( α − i k) α c ⋅ i k Λ ′ ( α − i k). {displaystyle e_{k}=-{frac {alpha ^{i_{k}}Omega left(alpha ^{-i_{k}}right)}{alpha ^{ccdot i_{k}}Lambda ‘left(alpha ^{-i_{k}}right)}}.}
This formula is advantageous when one computes the formal derivative of Λ {displaystyle Lambda }form
- Λ ( x) = ∑ i = 1 v λ i x i {displaystyle Lambda (x)=sum _{i=1}^{v}lambda _{i}x^{i}}
yielding:
- Λ ′ ( x) = ∑ i = 1 v i ⋅ λ i x i − 1, {displaystyle Lambda ‘(x)=sum _{i=1}^{v}icdot lambda _{i}x^{i-1},}
where
- i ⋅ x := ∑ k = 1 i x. {displaystyle icdot x:=sum _{k=1}^{i}x.}
Decoding based on extended Euclidean algorithm
An alternate process of finding both the polynomial Λ and the error locator polynomial is based on Yasuo Sugiyama’s adaptation of the Extended Euclidean algorithm. Correction of unreadable characters could be incorporated to the algorithm easily as well.
Let k 1,…, k k {displaystyle k_{1},…,k_{k}}be positions of unreadable characters. One creates polynomial localising these positions Γ ( x) = ∏ i = 1 k ( x α k i − 1). {displaystyle Gamma (x)=prod _{i=1}^{k}left(xalpha ^{k_{i}}-1right).}Set values on unreadable positions to 0 and compute the syndromes.
As we уже определили для формулы Форни, пусть S (x) = ∑ i = 0 d — 2 s c + i x i. { displaystyle S (x) = sum _ {i = 0} ^ {d-2} s_ {c + i} x ^ {i}.}
Давайте запустим расширенный алгоритм Евклида для определения наименьшего общего делителя многочлены S (x) Γ (x) { displaystyle S (x) Gamma (x)}и xd — 1. { displaystyle x ^ {d-1}.}Цель состоит не в том, чтобы найти наименьший общий делитель, а в том, чтобы найти многочлен r (x) { displaystyle r (x)}степени не выше ⌊ (d + k — 3) / 2 ⌋ { displaystyle lfloor (d + k-3) / 2 rfloor}и многочлены a (x), b (x) { displaystyle a (x), b (x)}такой, что r (x) = a (x) S (x) Γ (x) + б (х) хд — 1. { displaystyle r (x) = a (x) S (x) Gamma (x) + b (x) x ^ {d-1}.}Низкая степень r (x) { displaystyle r (x)}гарантирует, что a (x) { displaystyle a (x)}удовлетворяет расширенному (by Γ { displaystyle Gamma}), определяющие условия для Λ. { displaystyle Lambda.}
Определение Ξ (x) = a (x) Γ (x) { displaystyle Xi (x) = a (x) Gamma (x)}и используя Ξ { displaystyle Xi}вместо Λ (x) { displaystyle Lambda (x)}в формуле Фурни даст нам значения ошибок.
Основное преимущество алгоритма в том, что он тем временем вычисляет Ω (x) = S (x) Ξ (x) mod xd — 1 = r (x) { displaystyle Omega (x) = S (x) Xi (x) { bmod {x}} ^ {d-1} = r (x)}требуется в формуле Форни.
Объяснение процесса декодирования
Цель состоит в том, чтобы найти кодовое слово, которое минимально отличается от принятого слова на читаемых позициях. Выражая полученное слово как сумму ближайшего кодового слова и слова ошибки, мы пытаемся найти слово ошибки с минимальным количеством ненулевых символов на читаемых позициях. Синдром s i { displaystyle s_ {i}}ограничивает слово ошибки условием
- s i = ∑ j = 0 n — 1 e j α i j. { displaystyle s_ {i} = sum _ {j = 0} ^ {n-1} e_ {j} alpha ^ {ij}.}
Мы могли бы написать эти условия отдельно или мы могли бы создать многочлен
- S (x) знак равно ∑ я знак равно 0 d — 2 сбн + ixi { displaystyle S (x) = sum _ {i = 0} ^ {d-2} s_ {c + i} x ^ {i}}
и сравните коэффициенты около степеней 0 { displaystyle 0}с d — 2. { Displaystyle d-2.}
- S (x) = {0, ⋯, d — 2} E (x) = ∑ i = 0 d — 2 ∑ j = 0 n — 1 ej α ij α cjxi. { Displaystyle S (Икс) { stackrel { {0, cdots, , d-2 }} {=}} E (x) = sum _ {i = 0} ^ {d-2} sum _ {j = 0} ^ {n-1} e_ {j} alpha ^ {ij} alpha ^ {cj} x ^ {i}.}
Предположим, на позиции k есть нечитаемая буква 1, { displaystyle k_ {1},}мы могли бы заменить набор синдромов {sc, ⋯, sc + d — 2} { displaystyle {s_ {c}, cdots, s_ {c + d-2} }}по набору синдромов {tc, ⋯, tc + d — 3} { displaystyle {t_ {c}, cdots, t_ { c + d-3} }}определяется уравнением ti = α k 1 si — si + 1. { displaystyle t_ {i} = alpha ^ {k_ {1}} s_ {i} -s_ {i + 1}.}Предположим для слова ошибки все ограничения из исходного набора { sc, ⋯, sc + d — 2} { displaystyle {s_ {c}, cdots, s_ {c + d-2} }}удерживает синдромов, чем
- ti = α k 1 si — si + 1 = α k 1 ∑ j = 0 n — 1 ej α ij — ∑ j = 0 n — 1 ej α j α ij = ∑ j = 0 n — 1 ej (α k 1 — α j) α ij. { displaystyle t_ {i} = alpha ^ {k_ {1}} s_ {i} -s_ {i + 1} = alpha ^ {k_ {1}} sum _ {j = 0} ^ {n- 1} e_ {j} alpha ^ {ij} — sum _ {j = 0} ^ {n-1} e_ {j} alpha ^ {j} alpha ^ {ij} = sum _ {j = 0} ^ {n-1} e_ {j} left ( alpha ^ {k_ {1}} — alpha ^ {j} right) alpha ^ {ij}.}
Новый набор синдромов ограничивает вектор ошибок
- fj = ej (α k 1 — α j) { displaystyle f_ {j} = e_ {j} left ( alpha ^ {k_ {1}} — alpha ^ {j} right) }
точно так же, как исходный набор синдромов ограничивал вектор ошибок ej. { displaystyle e_ {j}.}За исключением координаты k 1, { displaystyle k_ {1},}, где fk 1 = 0, { displaystyle f_ {k_ {1}} = 0,}an fj { displaystyle f_ {j}}равно нулю, если ej = 0. { displaystyle e_ {j} = 0.}Для определения местоположения ошибок мы могли бы изменить набор синдромов аналогичным образом, чтобы отразить все нечитаемые символы. Это сокращает набор синдромов на k. { displaystyle k.}
В полиномиальной формулировке замена синдромов задает {sc, ⋯, sc + d — 2} { displaystyle {s_ {c}, cdots, s_ {c + d -2} }}по набору синдромов {tc, ⋯, tc + d — 3} { displaystyle {t_ {c}, cdots, t_ {c + d-3} }}приводит к
- T (x) = ∑ i = 0 d — 3 tc + ixi = α k 1 ∑ i = 0 d — 3 sc + ixi — ∑ i = 1 d — 2 сбн + ixi — 1. { Displaystyle Т (х) = сумма _ {я = 0} ^ {d-3} t_ {с + я} х ^ {я} = альфа ^ {к_ {1}} сумма _ {я = 0 } ^ {d-3} s_ {c + i} x ^ {i} — sum _ {i = 1} ^ {d-2} s_ {c + i} x ^ {i-1}.}
Следовательно,
- x T (x) = {1, ⋯, d — 2} (x α k 1 — 1) S (x). { displaystyle xT (x) { stackrel { {1, cdots, , d-2 }} {=}} left (x alpha ^ {k_ {1}} — 1 right) S ( x).}
После замены S (x) { displaystyle S (x)}на S (x) Γ (x) { displaystyle S (x) Gamma (x)}, потребуется уравнение для коэффициентов около степеней k, ⋯, d — 2. { displaystyle k, cdots, d-2.}
Можно Рассмотрите возможность поиска ошибочных позиций с точки зрения устранения влияния заданных позиций так же, как и для нечитаемых символов. Если мы нашли такие позиции v { displaystyle v}, устранение их влияния приводит к получению набора синдромов, состоящего из всех нулей, то существует вектор ошибок с ошибками только по этим координатам. Если Λ (x) { displaystyle Lambda (x)}обозначает многочлен, исключающий влияние этих координат, мы получаем
- S (x) Γ (x) Λ (x) знак равно {к + v, ⋯, d — 2} 0. { displaystyle S (x) Gamma (x) Lambda (x) { stackrel { {k + v, cdots, d-2 }} {=}} 0.}
В алгоритме Евклида мы пытаемся исправить не более 1 2 (d — 1 — k) { displaystyle { tfrac {1} {2}} (d-1- k)}ошибок (на читаемых позициях), потому что с большим количеством ошибок может быть больше кодовых слов на том же расстоянии от полученного слова. Следовательно, для Λ (x) { displaystyle Lambda (x)}, которое мы ищем, уравнение должно выполняться для коэффициентов, близких к степеням, начиная с
- k + ⌊ 1 2 (d — 1 — л) ⌋. { displaystyle k + left lfloor { frac {1} {2}} (d-1-k) right rfloor.}
В формуле Форни, Λ (x) { displaystyle Lambda (x)}можно умножить на скаляр, что даст тот же результат.
Может случиться так, что алгоритм Евклида найдет Λ (x) { displaystyle Lambda (x)}со степенью выше, чем 1 2 (d — 1 — k) { displaystyle { tfrac {1} {2}} (d-1-k)}с числом различных корней, равным его степени, где формула Фурни могла бы исправить ошибки в все его корни, в любом случае исправление такого количества ошибок может быть рискованным (особенно без других ограничений на полученное слово). Обычно после получения Λ (x) { displaystyle Lambda (x)}более высокой степени мы решаем не исправлять ошибки. Исправление может завершиться неудачно, если Λ (x) { displaystyle Lambda (x)}имеет корни с большей кратностью или число корней меньше его степени. Отказ также может быть обнаружен по формуле Форни, возвращающей ошибку вне переданного алфавита.
Исправьте ошибки
Используя значения ошибок и местоположение ошибки, исправьте ошибки и сформируйте скорректированный кодовый вектор путем вычитания значений ошибок в местах ошибки.
Примеры декодирования
Декодирование двоичного кода без нечитаемых символов
Рассмотрим код BCH в GF (2) с d = 7 { displaystyle d = 7}и g (x) = x 10 + x 8 + x 5 + x 4 + x 2 + x + 1 { displaystyle g (x) = x ^ {10} + x ^ { 8} + x ^ {5} + x ^ {4} + x ^ {2} + x + 1}. (Это используется в QR-кодах.) Пусть передаваемое сообщение будет [1 1 0 1 1], или в полиномиальной нотации M (x) = x 4 + x 3 + x + 1. { displaystyle M (x) = x ^ {4} + x ^ {3} + x + 1.}Символы «контрольной суммы» вычисляются путем деления x 10 M ( x) { displaystyle x ^ {10} M (x)}по g (x) { displaystyle g (x)}и взяв остаток, в результате x 9 + x 4 + x 2 { displaystyle x ^ {9} + x ^ {4} + x ^ {2}}или [1 0 0 0 0 1 0 1 0 0 ]. Они добавляются к сообщению, поэтому переданное кодовое слово — [1 1 0 1 1 1 0 0 0 0 1 0 1 0 0].
Теперь представьте, что при передаче есть две битовые ошибки, поэтому полученное кодовое слово равно [1 0 0 1 1 1 0 0 0 1 1 0 1 0 0]. В полиномиальной записи:
- R (x) = C (x) + x 13 + x 5 = x 14 + x 11 + x 10 + x 9 + x 5 + x 4 + x 2 { displaystyle R (x) = C (x) + x ^ {13} + x ^ {5} = x ^ {14} + x ^ {11} + x ^ {10} + x ^ {9} + x ^ {5} + x ^ {4} + x ^ {2}}
Чтобы исправить ошибки, сначала вычислите синдромы. Взяв α = 0010, { displaystyle alpha = 0010,}, мы имеем s 1 = R (α 1) = 1011, { displaystyle s_ {1} = R ( альфа ^ {1}) = 1011,}s 2 = 1001, { displaystyle s_ {2} = 1001,}s 3 = 1011, { displaystyle s_ {3} = 1011,}s 4 = 1101, { displaystyle s_ {4} = 1101,}s 5 = 0001, { displaystyle s_ {5} = 0001,}и s 6 = 1001. { displaystyle s_ {6} = 1001.}Затем примените процедуру Петерсона путем сокращения строк следующей расширенной матрицы.
- [S 3 × 3 | C 3 × 1] = [с 1 с 2 с 3 с 4 с 2 с 3 с 4 с 5 с 3 с 4 с 5 с 6] = [1011 1001 1011 1101 1001 1011 1101 0001 1011 1101 0001 1001] ⇒ [0001 0000 1000 0111 0000 0001 1011 0001 0000 0000 0000 0000] { displaystyle left [S_ {3 times 3} | C_ {3 times 1} right] = { begin {bmatrix} s_ {1} s_ {2 } s_ {3} s_ {4} \ s_ {2} s_ {3} s_ {4} s_ {5} \ s_ {3} s_ {4} s_ {5} s_ {6} end {bmatrix} } = { begin {bmatrix} 1011 1001 1011 1101 \ 1001 1011 1101 0001 \ 1011 1101 0001 1001 end {bmatrix}} Rightarrow { begin {bmatrix} 0001 0000 1000 0111 \ 0000 0001 0001 0001 0001 0001 0001 0001 0001 0001 \ 000075} к концу b строка, S 3 × 3 является сингулярной, что неудивительно, поскольку только две ошибки были введены в кодовое слово. Однако верхний левый угол матрицы идентичен [S 2 × 2 | C 2 × 1 ], что дает решение λ 2 = 1000, { displaystyle lambda _ {2} = 1000,}λ 1 = 1011. { displaystyle lambda _ {1} = 1011.}Результирующий полином локатора ошибок равен Λ (x) = 1000 x 2 + 1011 x + 0001, { displaystyle Lambda (x) = 1000x ^ {2} + 1011x + 0001,}, у которого есть нули в 0100 = α — 13 { displaystyle 0100 = alpha ^ {- 13}}и 0111 = α — 5. { displaystyle 0111 = alpha ^ {- 5}.}Показатели степени α { displaystyle alpha}соответствуют местоположениям ошибок. В этом примере нет необходимости вычислять значения ошибок, поскольку единственное возможное значение — 1.
Декодирование с нечитаемыми символами
Предположим тот же сценарий, но полученное слово содержит два нечитаемых символа [1 0 0? 1 1? 0 0 1 1 0 1 0 0]. Мы заменяем нечитаемые символы нулями при создании полинома, отражающего их позиции Γ (x) = (α 8 x — 1) (α 11 x — 1). { displaystyle Gamma (x) = left ( alpha ^ {8} x-1 right) left ( alpha ^ {11} x-1 right).}
Мы вычисляем синдромы s 1 = α — 7, s 2 = α 1, s 3 = α 4, s 4 = α 2, s 5 = α 5, { displaystyle s_ {1} = alpha ^ {- 7}, s_ {2} = alpha ^ {1}, s_ {3} = alpha ^ {4}, s_ {4} = alpha ^ {2}, s_ {5} = alpha ^ {5},}и s 6 = α — 7. { displaystyle s_ {6} = alpha ^ {- 7}.}(Использование логарифмической записи, не зависящей от изоморфизмов GF (2). Для проверки вычислений мы можем использовать то же представление для сложения, что и было использованный в предыдущем примере. Шестнадцатеричное описание степеней α { displaystyle alpha}: последовательно 1,2,4,8,3,6, C, B, 5, A, 7, E, F, D, 9 со сложением на основе побитового xor.)Сделаем синдромный многочлен
- S (x) = α — 7 + α 1 x + α 4 x 2 + α 2 x 3 + α 5 x 4 + α — 7 x 5, { displaystyle S (x) = alpha ^ {- 7} + alpha ^ {1} x + alpha ^ {4} x ^ {2} + alpha ^ {2} x ^ {3} + alpha ^ {5} x ^ {4} + alpha ^ {- 7} x ^ {5},}
вычислить
- S (x) Γ (Икс) знак равно α — 7 + α 4 Икс + α — 1 Икс 2 + α 6 Икс 3 + α — 1 Икс 4 + α 5 Икс 5 + α 7 Икс 6 + α — 3 Икс 7. { Displaystyle S (x) Gamma (x) = alpha ^ {- 7} + alpha ^ {4} x + alpha ^ {- 1} x ^ {2} + alpha ^ {6} x ^ { 3} + alpha ^ {- 1} x ^ {4} + alpha ^ {5} x ^ {5} + alpha ^ {7} x ^ {6} + alpha ^ {- 3} x ^ { 7}.}
Запустите расширенный алгоритм Евклида:
- (S (x) Γ (x) x 6) = (α — 7 + α 4 x + α — 1 x 2 + α 6 x 3 + α — 1 x 4 + α 5 x 5 + α 7 x 6 + α — 3 x 7 x 6) = (α 7 + α — 3 x 1 1 0) (x 6 α — 7 + α 4 x + α — 1 x 2 + α 6 x 3 + α — 1 x 4 + α 5 x 5 + 2 α 7 x 6 + 2 α — 3 x 7) = (α 7 + α — 3 x 1 1 0) (α 4 + α — 5 x 1 1 0) (α — 7 + α 4 x + α — 1 x 2 + α 6 x 3 + α — 1 x 4 + α 5 x 5 α — 3 + (α — 7 + α 3) x + (α 3 + α — 1) x 2 + (α — 5 + α — 6) x 3 + (α 3 + α 1) x 4 + 2 α — 6 x 5 + 2 x 6) = ((1 + α — 4) + (α 1 + α 2) x + α 7 x 2 α 7 + α — 3 x α 4 + α — 5 x 1) (α — 7 + α 4 x + α — 1 x 2 + α 6 x 3 + α — 1 x 4 + α 5 x 5 α — 3 + α — 2 x + α 0 x 2 + α — 2 x 3 + α — 6 x 4) = (α — 3 + α 5 x + α 7 x 2 α 7 + α — 3 x α 4 + α — 5 x 1) (α — 5 + α — 4 x 1 1 0) (α — 3 + α — 2 x + α 0 x 2 + α — 2 х 3 + α — 6 х 4 (α 7 + α — 7) + (2 α — 7 + α 4) x + (α — 5 + α — 6 + α — 1) x 2 + (α — 7 + α — 4 + α 6) x 3 + ( α 4 + α — 6 + α — 1) x 4 + 2 α 5 x 5) = (α 7 x + α 5 x 2 + α 3 x 3 α — 3 + α 5 x + α 7 x 2 α 3 + α — 5 x + α 6 x 2 α 4 + α — 5 x) (α — 3 + α — 2 x + α 0 x 2 + α — 2 x 3 + α — 6 x 4 α — 4 + α 4 x + α 2 x 2 + α — 5 x 3). { Displaystyle { begin {align} { begin {pmatrix} S (x) Gamma (x) \ x ^ {6} end {pmatrix}} \ [6pt] = {} { begin {pmatrix} alpha ^ {- 7} + alpha ^ {4} x + alpha ^ {- 1} x ^ {2} + alpha ^ {6} x ^ {3} + alpha ^ {- 1} x ^ {4} + alpha ^ {5} x ^ {5} + alpha ^ {7} x ^ {6} + alpha ^ {- 3} x ^ {7} \ x ^ {6} конец {pmatrix}} \ [6pt] = {} { begin {pmatrix} alpha ^ {7} + alpha ^ {- 3} x 1 \ 1 0 end {pmatrix}} { begin {pmatrix} x ^ {6} \ alpha ^ {- 7} + alpha ^ {4} x + alpha ^ {- 1} x ^ {2} + alpha ^ {6} x ^ {3} + alpha ^ {-1} x ^ {4} + alpha ^ {5} x ^ {5} +2 alpha ^ {7} x ^ {6} +2 alpha ^ {- 3} x ^ {7} end {pmatrix}} \ [6pt] = {} { begin {pmatrix} alpha ^ {7} + alpha ^ {- 3} x 1 \ 1 0 end {pmatrix}} { begin {pmatrix} alpha ^ {4} + alpha ^ {- 5} x 1 \ 1 0 end {pmatrix}} \ qquad { begin {pmatrix} alpha ^ {- 7} + alpha ^ {4} x + альфа ^ {- 1} x ^ {2} + alpha ^ {6} x ^ {3} + alpha ^ {- 1} x ^ {4} + alpha ^ {5} x ^ {5} \ alpha ^ {- 3} + left ( alpha ^ {- 7} + alpha ^ {3} right) x + left ( alpha ^ {3} + alpha ^ {- 1} right) x ^ {2} + left ( alpha ^ {- 5} + alpha ^ {- 6} right) x ^ {3} + left ( alpha ^ {3} + alpha ^ {1} right) x ^ {4} +2 alpha ^ {- 6} x ^ {5} + 2x ^ {6} end {pmatrix}} \ [6pt] = {} { begin { pmatrix} left (1+ alpha ^ {- 4} right) + left ( alpha ^ {1} + alpha ^ {2} right) x + alpha ^ {7} x ^ {2} alpha ^ {7} + alpha ^ {- 3} x \ alpha ^ {4} + alpha ^ {- 5} x 1 end {pmatrix}} { begin {pmatrix} alpha ^ {- 7 } + alpha ^ {4} x + alpha ^ {- 1} x ^ {2} + alpha ^ {6} x ^ {3} + alpha ^ {- 1} x ^ {4} + alpha ^ {5} x ^ {5} \ alpha ^ {- 3} + alpha ^ {- 2} x + alpha ^ {0} x ^ {2} + alpha ^ {- 2} x ^ {3} + alpha ^ {- 6} x ^ {4} end {pmatrix}} \ [6pt] = {} { begin {pmatrix} alpha ^ {- 3} + alpha ^ {5} x + alpha ^ {7} x ^ {2} alpha ^ {7} + alpha ^ {- 3} x \ alpha ^ {4} + alpha ^ {- 5} x 1 end {pmatrix}} { begin {pmatrix} alpha ^ {- 5} + alpha ^ {- 4} x 1 \ 1 0 end {pmatrix}} \ qquad { begin {pmatrix} alpha ^ {- 3} + alpha ^ {- 2} x + alpha ^ {0} x ^ {2} + alpha ^ {- 2} x ^ {3} + alpha ^ {- 6} x ^ {4} \ left ( альфа ^ {7} + alpha ^ {- 7} right) + left (2 alpha ^ {- 7} + alpha ^ {4} right) x + left ( alpha ^ {- 5} + alpha ^ {- 6} + alpha ^ {- 1} right) x ^ {2} + left ( alpha ^ {- 7} + alpha ^ {- 4} + alpha ^ {6} вправо) x ^ {3} + left ( alpha ^ {4} + alpha ^ {- 6} + alpha ^ {- 1} right) x ^ {4} +2 alpha ^ {5} x ^ {5} end {pmatrix}} \ [6pt] = {} { begin {pmatrix} alpha ^ {7} x + alpha ^ { 5} x ^ {2} + alpha ^ {3} x ^ {3} alpha ^ {- 3} + alpha ^ {5} x + alpha ^ {7} x ^ {2} \ альфа ^ {3} + alpha ^ {- 5} x + alpha ^ {6} x ^ {2} alpha ^ {4} + alpha ^ {- 5} x end {pmatrix}} { begin { pmatrix} alpha ^ {- 3} + alpha ^ {- 2} x + alpha ^ {0} x ^ {2} + alpha ^ {- 2} x ^ {3} + alpha ^ {- 6} x ^ {4} \ alpha ^ {- 4} + alpha ^ {4} x + alpha ^ {2} x ^ {2} + alpha ^ {- 5} x ^ {3} end {pmatrix }}. end {align}}}
Мы достигли полинома степени не выше 3, а как
- (- (α 4 + α — 5 x) α — 3 + α 5 x + α 7 x 2 α 3 + α — 5 x + α 6 x 2 — (α 7 x + α 5 x 2 + α 3 x 3)) (α 7 x + α 5 x 2 + α 3 x 3 α — 3 + α 5). Икс + α 7 Икс 2 α 3 + α — 5 Икс + α 6 Икс 2 α 4 + α — 5 Икс) = (1 0 0 1), { Displaystyle { begin {pmatrix} — left ( alpha ^ {4} + alpha ^ {- 5} x right) alpha ^ {- 3} + alpha ^ {5} x + alpha ^ {7} x ^ {2} \ alpha ^ {3} + alpha ^ {- 5} x + alpha ^ {6} x ^ {2} — left ( alpha ^ {7} x + alpha ^ {5} x ^ {2} + alpha ^ {3} x ^ {3} right) end {pmatrix}} { begin {pmatrix} alpha ^ {7} x + alpha ^ {5} x ^ {2} + alpha ^ {3} x ^ {3} alpha ^ {- 3} + alpha ^ {5} x + alpha ^ {7} x ^ {2} \ alpha ^ {3} + alpha ^ {- 5} x + alpha ^ {6} х ^ {2} а lpha ^ {4} + alpha ^ {- 5} x end {pmatrix}} = { begin {pmatrix} 1 0 \ 0 1 end {pmatrix}},}
получаем
- (- ( α 4 + α — 5 x) α — 3 + α 5 x + α 7 x 2 α 3 + α — 5 x + α 6 x 2 — (α 7 x + α 5 x 2 + α 3 x 3)) ( S (x) Γ (x) x 6) = (α — 3 + α — 2 x + α 0 x 2 + α — 2 x 3 + α — 6 x 4 α — 4 + α 4 x + α 2 x 2 + α — 5 х 3). { displaystyle { begin {pmatrix} — left ( alpha ^ {4} + alpha ^ {- 5} x right) alpha ^ {- 3} + alpha ^ {5} x + alpha ^ {7} x ^ {2} \ alpha ^ {3} + alpha ^ {- 5} x + alpha ^ {6} x ^ {2} — left ( alpha ^ {7} x + alpha ^ {5} x ^ {2} + alpha ^ {3} x ^ {3} right) end {pmatrix}} { begin {pmatrix} S (x) Gamma (x) \ x ^ { 6} end {pmatrix}} = { begin {pmatrix} alpha ^ {- 3} + alpha ^ {- 2} x + alpha ^ {0} x ^ {2} + alpha ^ {- 2} x ^ {3} + alpha ^ {- 6} x ^ {4} \ alpha ^ {- 4} + alpha ^ {4} x + alpha ^ {2} x ^ {2} + alpha ^ {-5} x ^ {3} end {pmatrix}}.}
Следовательно,
- S (x) Γ (x) (α 3 + α — 5 x + α 6 x 2) — (α 7 x + α 5 x 2 + α 3 x 3) x 6 = α — 4 + α 4 x + α 2 x 2 + α — 5 x 3. { Displaystyle S (x) Gamma (x) left ( alpha ^ {3} + alpha ^ {- 5} x + alpha ^ {6} x ^ {2} right) — left ( alpha ^ {7} x + alpha ^ {5} x ^ {2} + alpha ^ {3} x ^ {3} right) x ^ {6} = alpha ^ {- 4} + alpha ^ {4 } x + alpha ^ {2} x ^ {2} + alpha ^ {- 5} x ^ {3}.}
Пусть Λ (x) = α 3 + α — 5 x + α 6 х 2. { displaystyle Lambda (x) = alpha ^ {3} + alpha ^ {- 5} x + alpha ^ {6} x ^ {2}.}
Не волнуйтесь, что λ 0 ≠ 1. { displaystyle lambda _ {0} neq 1.}Найти корень Λ с помощью грубой силы. { displaystyle Lambda.}Корни: α 2, { displaystyle alpha ^ {2},}и α 10 { displaystyle alpha ^ {10}}(найдя, например, α 2 { displaystyle alpha ^ {2}}, мы можем разделить Λ { displaystyle Lambda}соответствующим мономом (x — α 2) { displaystyle left (x- alpha ^ {2} right)}, и корень полученного монома может быть нашел легко).Пусть
- Ξ (x) = Γ (x) Λ (x) = α 3 + α 4 x 2 + α 2 x 3 + α — 5 x 4 Ω (x) = S (x) Ξ (Икс) ≡ α — 4 + α 4 Икс + α 2 Икс 2 + α — 5 Икс 3 по модулю Икс 6 { Displaystyle { begin {align} Xi (x) = Gamma (x) Lambda (x) = alpha ^ {3} + alpha ^ {4} x ^ {2} + alpha ^ {2} x ^ {3} + alpha ^ {- 5} x ^ {4} \ Омега (x) = S (x) Xi (x) Equiv alpha ^ {- 4} + alpha ^ {4} x + alpha ^ {2} x ^ {2} + alpha ^ {- 5 } x ^ {3} { bmod {x ^ {6}}} end {align}}}
Давайте искать значения ошибок по формуле
- ej = — Ω (α — ij) Ξ ′ ( α — ij), { displaystyle e_ {j} = — { frac { Omega left ( alpha ^ {- i_ {j}} right)} { Xi ‘ left ( alpha ^ {- i_ {j}} right)}},}
где α — ij { displaystyle alpha ^ {- i_ {j}}}
— корни Ξ (x). { Displaystyle Xi (x).}Ξ ′ (x) = α 2 x 2. { displaystyle Xi ‘(x) = alpha ^ {2} x ^ {2}.}Мы получаем- e 1 = — Ω (α 4) Ξ ′ (α 4) = α — 4 + α — 7 + α — 5 + α 7 α — 5 = α — 5 α — 5 = 1 e 2 = — Ω (α 7) Ξ ′ (α 7) = α — 4 + α — 4 + α 1 + α 1 α 1 = 0 e 3 = — Ω (α 10) Ξ ′ (α 10) = α — 4 + α — 1 + α 7 + α — 5 α 7 = α 7 α 7 = 1 e 4 Знак равно — Ω (α 2) Ξ ′ (α 2) = α — 4 + α 6 + α 6 + α 1 α 6 = α 6 α 6 = 1 { Displaystyle { begin {align} e_ {1} = — { frac { Omega ( alpha ^ {4})} { Xi ‘( alpha ^ {4})}} = { frac { alpha ^ {- 4} + alpha ^ {- 7} + alpha ^ {- 5} + alpha ^ {7}} { alpha ^ {- 5}}} = { frac { alpha ^ {- 5}} { alpha ^ {- 5}}} = 1 \ e_ {2} = — { frac { Omega ( alpha ^ {7})} { Xi ‘( alpha ^ {7})}} = { frac { alpha ^ {- 4 } + alpha ^ {- 4} + alpha ^ {1} + alpha ^ {1}} { alpha ^ {1}}} = 0 \ e_ {3} = — { frac { Omega ( alpha ^ {10})} { Xi ‘( alpha ^ {10})}} = { frac { alpha ^ {- 4} + alpha ^ {- 1} + alpha ^ {7} + alpha ^ {- 5}} { alpha ^ {7}}} = { frac { alpha ^ {7}} { alpha ^ {7}}} = 1 \ e_ {4} = — { frac { Omega ( alpha ^ {2})} { Xi ‘( alpha ^ {2})}} = { frac { alpha ^ {- 4} + alpha ^ {6} + альфа ^ {6} + alpha ^ {1}} { alpha ^ {6}}} = { frac { alpha ^ {6}} { alpha ^ {6}}} = 1 end {align}}}
Факт, что e 3 = e 4 = 1, { displaystyle e_ {3} = e_ {4} = 1,}
не должно вызывать удивления.Таким образом, исправленный код — [1 1 0 1 1 1 0 0 0 0 1 0 1 0 0].
Декодирование с нечитаемыми символами с небольшим количеством ошибок
Покажем поведение алгоритма для случая с небольшим количеством ошибок. Пусть полученное слово [1 0 0? 1 1? 0 0 0 1 0 1 0 0].
Снова замените нечитаемые символы нулями при создании полинома, отражающего их положение Γ (x) = (α 8 x — 1) (α 11 x — 1). { displaystyle Gamma (x) = left ( alpha ^ {8} x-1 right) left ( alpha ^ {11} x-1 right).}
Вычислить синдромы s 1 = α 4, s 2 = α — 7, s 3 = α 1, s 4 = α 1, s 5 = α 0, { displaystyle s_ {1} = alpha ^ {4}, s_ {2} = alpha ^ {- 7}, s_ {3} = alpha ^ {1}, s_ {4} = alpha ^ {1}, s_ {5} = alpha ^ {0},}и s 6 = α 2. { displaystyle s_ {6} = alpha ^ {2}.}Создать синдромный многочлен- S (x) = α 4 + α — 7 x + α 1 x 2 + α 1 x 3 + α 0 x 4 + α 2 x 5, S (x) Γ (x) = α 4 + α 7 x + α 5 x 2 + α 3 x 3 + α 1 x 4 + α — 1 x 5 + α — 1 х 6 + α 6 х 7. { Displaystyle { begin {align} S (x) = alpha ^ {4} + alpha ^ {- 7} x + alpha ^ {1} x ^ {2} + alpha ^ {1} x ^ {3} + alpha ^ {0} x ^ {4} + alpha ^ {2} x ^ {5}, \ S (x) Gamma (x) = alpha ^ {4} + alpha ^ {7} x + alpha ^ {5} x ^ {2} + alpha ^ {3} x ^ {3} + alpha ^ {1} x ^ {4} + alpha ^ {- 1} x ^ {5} + alpha ^ {- 1} x ^ {6} + alpha ^ {6} x ^ {7}. End {align}}}
Запустим расширенный алгоритм Евклида:
- (S (x) Γ (x) x 6) = (α 4 + α 7 x + α 5 x 2 + α 3 x 3 + α 1 x 4 + α — 1 x 5 + α — 1 x 6 + α 6 x 7 x 6) = (α — 1 + α 6 x 1 1 0) (x 6 α 4 + α 7 x + α 5 x 2 + α 3 x 3 + α 1 x 4 + α — 1 x 5 + 2 α — 1 x 6 + 2 α 6 x 7) = (α — 1 + α 6 x 1 1 0) (α 3 + α 1 x 1 1 0) (α 4 + α 7 x + α 5 x 2 + α 3 x 3 + α 1 x 4 + α — 1 x 5 α 7 + (α — 5 + α 5) x + 2 α — 7 x 2 + 2 α 6 x 3 + 2 α 4 x 4 + 2 α 2 x 5 + 2 x 6) = ((1 + α 2) + (α 0 + α — 6) x + α 7 x 2 α — 1 + α 6 x α 3 + α 1 x 1) (α 4 + α 7 Икс + α 5 Икс 2 + α 3 Икс 3 + α 1 Икс 4 + α — 1 Икс 5 α 7 + α 0 Икс) { Displaystyle { begin {align} { begin {pmatrix} S (x) Gamma (x) \ x ^ {6} end {pmatrix}} = { begin {p матрица} alpha ^ {4} + alpha ^ {7} x + alpha ^ {5} x ^ {2} + alpha ^ {3} x ^ {3} + alpha ^ {1} x ^ {4 } + alpha ^ {- 1} x ^ {5} + alpha ^ {- 1} x ^ {6} + alpha ^ {6} x ^ {7} \ x ^ {6} end {pmatrix }} \ = { begin {pmatrix} alpha ^ {- 1} + alpha ^ {6} x 1 \ 1 0 end {pmatrix}} { begin {pmatrix} x ^ {6} \ альфа ^ {4} + alpha ^ {7} x + alpha ^ {5} x ^ {2} + alpha ^ {3} x ^ {3} + alpha ^ {1} x ^ {4} + alpha ^ {- 1} x ^ {5} +2 alpha ^ {- 1} x ^ {6} +2 alpha ^ {6} x ^ {7} end {pmatrix}} \ = { begin {pmatrix} alpha ^ {- 1} + alpha ^ {6} x 1 \ 1 0 end {pmatrix}} { begin {pmatrix} alpha ^ {3} + alpha ^ {1} x 1 \ 1 0 end {pmatrix}} { begin {pmatrix} alpha ^ {4} + alpha ^ {7} x + alpha ^ {5} x ^ {2} + alpha ^ {3} x ^ {3} + alpha ^ {1} x ^ {4} + alpha ^ {- 1} x ^ {5} \ alpha ^ {7} + left ( alpha ^ {- 5} + alpha ^ {5 } right) x + 2 alpha ^ {- 7} x ^ {2} +2 alpha ^ {6} x ^ {3} +2 alpha ^ {4} x ^ {4} +2 alpha ^ {2} x ^ {5} + 2x ^ {6} end {pmatrix}} \ = { begin {pmatrix} left (1+ alpha ^ {2} right) + left ( alpha ^ {0} + alpha ^ {- 6} right) x + alpha ^ {7} x ^ {2} alpha ^ {- 1} + alpha ^ {6} x \ alpha ^ {3 } + alpha ^ {1} x 1 end {pmatrix}} { begin {pmatrix} alpha ^ {4} + alpha ^ {7} x + alpha ^ {5} x ^ {2} + альфа ^ {3} x ^ {3} + alpha ^ {1} x ^ {4} + alpha ^ {- 1} x ^ {5} \ alpha ^ {7} + alpha ^ {0} x end {pmatrix}} end {align}}}
Мы достигли полинома степени не выше 3, а как
- (- 1 α — 1 + α 6 x α 3 + α 1 x — ( α — 7 + α 7 x + α 7 x 2)) (α — 7 + α 7 x + α 7 x 2 α — 1 + α 6 x α 3 + α 1 x 1) = (1 0 0 1), { displaystyle { begin {pmatrix} -1 alpha ^ {- 1} + alpha ^ {6} x \ alpha ^ {3} + alpha ^ {1} x — left ( alpha ^ { -7} + alpha ^ {7} x + alpha ^ {7} x ^ {2} right) end {pmatrix}} { begin {pmatrix} alpha ^ {- 7} + alpha ^ {7 } x + alpha ^ {7} x ^ {2} alpha ^ {- 1} + alpha ^ {6} x \ alpha ^ {3} + alpha ^ {1} x 1 end {pmatrix} } = { begin {pmatrix} 1 0 \ 0 1 end {pmatrix}},}
получаем
- (- 1 α — 1 + α 6 x α 3 + α 1 x — (α — 7 + α 7 x + α 7 x 2)) (S (x) Γ (x) x 6) = (α 4 + α 7 x + α 5 x 2 + α 3 x 3 + α 1 x 4 + α — 1 x 5 α 7 + α 0 x). { displaystyle { begin {pmatrix} -1 alpha ^ {- 1} + alpha ^ {6} x \ alpha ^ {3} + alpha ^ {1} x — left ( alpha ^ { -7} + alpha ^ {7} x + alpha ^ {7} x ^ {2} right) end {pmatrix}} { begin {pmatrix} S (x) Gamma (x) \ x ^ {6} end {pmatrix}} = { begin {pmatrix} alpha ^ {4} + alpha ^ {7} x + alpha ^ {5} x ^ {2} + alpha ^ {3} x ^ {3} + alpha ^ {1} x ^ {4} + alpha ^ {- 1} x ^ {5} \ alpha ^ {7} + alpha ^ {0} x end {pmatrix}}.}
Следовательно,
- S (x) Γ (x) (α 3 + α 1 x) — (α — 7 + α 7 x + α 7 x 2) x 6 = α 7 + α 0 x. { Displaystyle S (x) Gamma (x) left ( alpha ^ {3} + alpha ^ {1} x right) — left ( alpha ^ {- 7} + alpha ^ {7} x + alpha ^ {7} x ^ {2} right) x ^ {6} = alpha ^ {7} + alpha ^ {0} x.}
Пусть Λ (x) = α 3 + α 1 х. { displaystyle Lambda (x) = alpha ^ {3} + alpha ^ {1} x.}
Не беспокойтесь, что λ 0 ≠ 1. { displaystyle lambda _ {0} neq 1.}Корень Λ (x) { displaystyle Lambda (x)}равен α 3 — 1. { displaystyle alpha ^ {3-1}.}Пусть
- Ξ (x) = Γ (x) Λ (x) = α 3 + α — 7 x + α — 4 x 2 + α 5 Икс 3, Ом (Икс) знак равно S (Икс) Ξ (Икс) ≡ α 7 + α 0 Икс модуль Икс 6 { Displaystyle { begin {align} Xi (x) = Gamma (x) Lambda ( x) = alpha ^ {3} + alpha ^ {- 7} x + alpha ^ {- 4} x ^ {2} + alpha ^ {5} x ^ {3}, \ Omega (x) = S (x) Xi (x) Equiv alpha ^ {7} + alpha ^ {0} x { bmod {x ^ {6}}} end {align}}}
Позвольте нам найдите значения ошибок с помощью формулы ej = — Ω (α — ij) / Ξ ′ (α — ij), { displaystyle e_ {j} = — Omega left ( alpha ^ {- i_ {j}) } right) / Xi ‘ left ( alpha ^ {- i_ {j}} right),}
где α — ij { displaystyle alpha ^ {- i_ {j }}}являются корнями многочлена Ξ (x). { Displaystyle Xi (x).}- Ξ ′ (x) = α — 7 + α 5 x 2. { displaystyle Xi ‘(x) = alpha ^ {- 7} + alpha ^ {5} x ^ {2}.}
Мы получаем
- e 1 = — Ω (α 4) Ξ ′ (α 4) = α 7 + α 4 α — 7 + α — 2 = α 3 α 3 = 1 e 2 = — Ω (α 7) Ξ ′ (α 7) = α 7 + α 7 α — 7 + α 4 знак равно 0 е 3 знак равно — Ω (α 2) Ξ ′ (α 2) = α 7 + α 2 α — 7 + α — 6 = α — 3 α — 3 = 1 { displaystyle { begin {align} e_ {1} = — { frac { Omega left ( alpha ^ {4} right)} { Xi ‘ left ( alpha ^ {4} right)}} = { frac { alpha ^ {7} + alpha ^ {4}} { alpha ^ {- 7} + alpha ^ {- 2}}} = { frac { alpha ^ {3}} { alpha ^ {3}} } = 1 \ e_ {2} = — { frac { Omega left ( alpha ^ {7} right)} { Xi ‘ left ( alpha ^ {7} right)}} = { frac { alpha ^ {7} + alpha ^ {7}} { alpha ^ {- 7} + alpha ^ {4}}} = 0 \ e_ {3} = — { frac { Omega left ( alpha ^ {2} right)} { Xi ‘ left ( alpha ^ {2} right)}} = { frac { alpha ^ {7} + alpha ^ {2 }} { alpha ^ {- 7} + alpha ^ {- 6}}} = { frac { alpha ^ {- 3}} { alpha ^ {- 3}}} = 1 end {выровнено} }}
Тот факт, что e 3 = 1 { displaystyle e_ {3} = 1}
, не должен вызывать удивления.Таким образом, исправленный код — [1 1 0 1 1 1 0 0 0 0 1 0 1 0 0].
Цитаты
Ссылки
Первичные источники
- Hocquenghem, A. (сентябрь 1959 г.), «Codes correcteurs d’erreurs», Chiffres (на французском языке), Paris, 2 : 147–156
- Bose, RC ; Рэй-Чаудхури, Д.К. (март 1960), «Класс исправления ошибок двоичных групповых кодов» (PDF), Информация и управление, 3(1): 68–79, doi : 10.1016 / s0019-9958 (60) 90287-4, ISSN 0890-5401
Вторичные источники
- Джилл, Джон (nd), EE387 Notes # 7, раздаточный материал # 28 (PDF), Stanford University, стр. 42–45, получено 21 апреля 2010 г. Примечания к курсу явно переделано на 2012 год: http://www.stanford.edu/class/ee387/
- Горенштейн, Дэниел ; Петерсон, У. Уэсли ; (1960), «Коды Бозе-Чаудхури с исправлением двух ошибок являются квази-совершенными», Информация и управление, 3 (3): 291–294, doi : 10.1016 / s0019-9958 (60) 90877-9
- Лидл, Рудольф; Пильц, Гюнтер (1999), Прикладная абстрактная алгебра (2-е изд.), Джон Вили
- Рид, Ирвинг С. ; Чен, Сюэминь (1999), Кодирование с контролем ошибок для сетей передачи данных, Бостон, Массачусетс: Kluwer Academic Publishers, ISBN 0-7923-8528-4
Далее чтение
- Блахут, Ричард Э. (2003), Алгебраические коды для передачи данных (2-е изд.), Cambridge University Press, ISBN 0-521 -55374-1
- Gilbert, WJ; Николсон, В. К. (2004), Современная алгебра с приложениями (2-е изд.), John Wiley
- Lin, S.; Костелло, Д. (2004), Кодирование с контролем ошибок: основы и приложения, Englewood Cliffs, NJ: Prentice-Hall
- MacWilliams, F.J.; Sloane, NJA (1977), Теория кодов с исправлением ошибок, Нью-Йорк, Нью-Йорк: издательство North-Holland Publishing Company
- Рудра, Атри, CSE 545, Коды с исправлением ошибок: комбинаторика, Алгоритмы и приложения, Университет в Буффало, заархивировано из оригинального 02.07.2010, получено 21 апреля 2010 г.
- S (x) = α — 7 + α 1 x + α 4 x 2 + α 2 x 3 + α 5 x 4 + α — 7 x 5, { displaystyle S (x) = alpha ^ {- 7} + alpha ^ {1} x + alpha ^ {4} x ^ {2} + alpha ^ {2} x ^ {3} + alpha ^ {5} x ^ {4} + alpha ^ {- 7} x ^ {5},}
Cyclic Redundancy Check Codes
-
CRC-Code Features
-
CRC Non-Direct Algorithm
-
Example Using CRC Non-Direct Algorithm
-
CRC Direct Algorithm
-
Selected Bibliography for CRC Coding
CRC-Code Features
Cyclic redundancy check (CRC) coding is an error-control coding technique for
detecting errors that occur when a message is transmitted. Unlike block or
convolutional codes, CRC codes do not have a built-in error-correction
capability. Instead, when a communications system detects an error in a received
message word, the receiver requests the sender to retransmit the message word.
In CRC coding, the transmitter applies a rule to each message word to create
extra bits, called the checksum, or
syndrome, and then appends the checksum to the message
word. After receiving a transmitted word, the receiver applies the same rule to
the received word. If the resulting checksum is nonzero, an error has occurred,
and the transmitter should resend the message word.
Open the Error Detection and Correction library by double-clicking its icon in
the main Communications Toolbox™ block library. Open the CRC sublibrary by double-clicking on its
icon in the Error Detection and Correction library.
Communications Toolbox supports CRC Coding using Simulink® blocks, System objects, or MATLAB® objects. These CRC coding features are listed in Error Detection and Correction.
CRC Non-Direct Algorithm
The CRC non-direct algorithm accepts a binary data vector, corresponding to a
polynomial M, and appends a checksum of r bits, corresponding
to a polynomial C. The concatenation of the input vector and
the checksum then corresponds to the polynomial T =
M*xr
+ C, since multiplying by
xr corresponds to shifting the
input vector r bits to the left. The algorithm chooses the
checksum C so that T is divisible by a
predefined polynomial P of degree r,
called the generator polynomial.
The algorithm divides T by P, and sets
the checksum equal to the binary vector corresponding to the remainder. That is,
if T =
Q*P +
R, where R is a polynomial of degree
less than r, the checksum is the binary vector corresponding
to R. If necessary, the algorithm prepends zeros to the
checksum so that it has length r.
The CRC generation feature, which implements the transmission phase of the CRC
algorithm, does the following:
-
Left shifts the input data vector by r bits and
divides the corresponding polynomial by P. -
Sets the checksum equal to the binary vector of length
r, corresponding to the remainder from step
1. -
Appends the checksum to the input data vector. The result is the
output vector.
The CRC detection feature computes the checksum for its entire input vector,
as described above.
The CRC algorithm uses binary vectors to represent binary polynomials, in
descending order of powers. For example, the vector [1 1 0 1]
represents the polynomial x3 +
x2 + 1.
Note
The implementation described in this section is one of many valid
implementations of the CRC algorithm. Different implementations can yield
different numerical results.

Bits enter the linear feedback shift register (LFSR) from the lowest index bit
to the highest index bit. The sequence of input message bits represents the
coefficients of a message polynomial in order of decreasing powers. The message
vector is augmented with r zeros to flush out the LFSR, where
r is the degree of the generator polynomial. If the
output from the leftmost register stage d(1) is a 1, then the bits in the shift
register are XORed with the coefficients of the generator polynomial. When the
augmented message sequence is completely sent through the LFSR, the register
contains the checksum [d(1) d(2) . . . d(r)]. This is an implementation of
binary long division, in which the message sequence is the divisor (numerator)
and the polynomial is the dividend (denominator). The CRC checksum is the
remainder of the division operation.
Example Using CRC Non-Direct Algorithm
Suppose the input frame is [1 1 0 0 1 1 0]', corresponding
to the polynomial M = x6
+x
5 + x2
+ x, and the generator polynomial is
P = x3 +
x2 + 1, of degree
r = 3. By polynomial division,
M*x3
= (x6 +
x3 +
x)*P +
x. The remainder is R =
x, so that the checksum is then [0 1. An extra 0 is added on the left to make the checksum have
0]'
length 3.
CRC Direct Algorithm

where
Message Block Input is m0, m1, … , mk−1
Code Word Output is c0, c1,… , cn−1=m0, m1,… ,mk−1,︸Xd0,d1, … , dn−k−1︸Y
The initial step of the direct CRC encoding occurs with the three switches in
position X. The algorithm feeds k message bits to the
encoder. These bits are the first k bits of the code word
output. Simultaneously, the algorithm sends k bits to the
linear feedback shift register (LFSR). When the system completely feeds the
kth message bit to the LFSR, the switches move to
position Y. Here, the LFSR contains the mathematical remainder from the
polynomial division. These bits are shifted out of the LFSR and they are the
remaining bits (checksum) of the code word output.
Selected Bibliography for CRC Coding
[1] Sklar, Bernard., Digital
Communications: Fundamentals and Applications, Englewood
Cliffs, NJ, Prentice Hall, 1988.
[2] Wicker, Stephen B., Error Control
Systems for Digital Communication and Storage, Upper Saddle
River, NJ, Prentice Hall, 1995.
Block Codes
-
Block-Coding Features
-
Terminology
-
Data Formats for Block Coding
-
Using Block Encoders and Decoders Within a Model
-
Examples of Block Coding
-
Notes on Specific Block-Coding Techniques
-
Shortening, Puncturing, and Erasures
-
Reed-Solomon Code in Integer Format
-
Find a Generator Polynomial
-
Performing Other Block Code Tasks
-
Selected Bibliography for Block Coding
Block-Coding Features
Error-control coding techniques detect, and possibly correct, errors that
occur when messages are transmitted in a digital communication system. To
accomplish this, the encoder transmits not only the information symbols but also
extra redundant symbols. The decoder interprets what it receives, using the
redundant symbols to detect and possibly correct whatever errors occurred during
transmission. You might use error-control coding if your transmission channel is
very noisy or if your data is very sensitive to noise. Depending on the nature
of the data or noise, you might choose a specific type of error-control
coding.
Block coding is a special case of error-control coding. Block-coding
techniques map a fixed number of message symbols to a fixed number of code
symbols. A block coder treats each block of data independently and is a
memoryless device. Communications Toolbox contains block-coding capabilities by providing Simulink blocks, System objects, and MATLAB functions.
The class of block-coding techniques includes categories shown in the diagram
below.

Communications Toolbox supports general linear block codes. It also process cyclic, BCH,
Hamming, and Reed-Solomon codes (which are all special kinds of linear block
codes). Blocks in the product can encode or decode a message using one of the
previously mentioned techniques. The Reed-Solomon and BCH decoders indicate how
many errors they detected while decoding. The Reed-Solomon coding blocks also
let you decide whether to use symbols or bits as your data.
Note
The blocks and functions in Communications Toolbox are designed for error-control codes that use an alphabet
having 2 or 2m symbols.
Communications Toolbox Support Functions. Functions in Communications Toolbox can support simulation blocks by
-
Determining characteristics of a technique, such as
error-correction capability or possible message lengths -
Performing lower-level computations associated with a technique,
such as-
Computing a truth table
-
Computing a generator or parity-check matrix
-
Converting between generator and parity-check
matrices -
Computing a generator polynomial
-
For more information about error-control coding capabilities, see Block
Codes.
Terminology
Throughout this section, the information to be encoded consists of
message symbols and the code that is produced consists
of codewords.
Each block of K message symbols is encoded into a codeword
that consists of N message symbols. K is
called the message length, N is called the codeword length,
and the code is called an [N,K]
code.
Data Formats for Block Coding
Each message or codeword is an ordered grouping of symbols. Each block in the
Block Coding sublibrary processes one word in each time step, as described in
the following section, Binary Format (All Coding Methods). Reed-Solomon coding blocks also
let you choose between binary and integer data, as described in Integer Format (Reed-Solomon Only).
Binary Format (All Coding Methods). You can structure messages and codewords as binary
vector signals, where each vector represents a
message word or a codeword. At a given time, the encoder receives an entire
message word, encodes it, and outputs the entire codeword. The message and
code signals operate over the same sample time.
This example illustrates the encoder receiving a four-bit message and
producing a five-bit codeword at time 0. It repeats this process with a new
message at time 1.
For all coding techniques except Reed-Solomon using
binary input, the message vector must have length K and the corresponding
code vector has length N. For Reed-Solomon codes with binary input, the
symbols for the code are binary sequences of length M, corresponding to
elements of the Galois field GF(2M). In this
case, the message vector must have length M*K and the corresponding code
vector has length M*N. The Binary-Input RS Encoder block and the
Binary-Output RS Decoder block use this format for messages and
codewords.
If the input to a block-coding block is a frame-based vector, it must be a
column vector instead of a row vector.
To produce sample-based messages in the binary format, you can configure
the Bernoulli Binary Generator block
so that its Probability of a zero parameter is a vector
whose length is that of the signal you want to create. To produce
frame-based messages in the binary format, you can configure the same block
so that its Probability of a zero parameter is a scalar
and its Samples per frame parameter is the length of
the signal you want to create.
Using Serial Signals
If you prefer to structure messages and codewords as scalar signals, where
several samples jointly form a message word or codeword, you can use the
Buffer and Unbuffer blocks. Buffering
involves latency and multirate processing. If your model computes error
rates, the initial delay in the coding-buffering combination influences the
Receive delay parameter in the Error Rate Calculation block.
You can display the sample times of signals in your model. On the
tab, expand . In the
section, select . Alternatively, you can
attach Probe (Simulink) blocks to connector
lines to help evaluate sample timing, buffering, and delays.
Integer Format (Reed-Solomon Only). A message word for an [N,K] Reed-Solomon code consists of M*K bits, which
you can interpret as K symbols from 0 to 2M. The
symbols are binary sequences of length M, corresponding to elements of the
Galois field GF(2M), in descending order of
powers. The integer format for Reed-Solomon codes lets you structure
messages and codewords as integer signals instead of
binary signals. (The input must be a frame-based column vector.)
Note
In this context, Simulink expects the first bit
to be the most significant bit in the symbol, as well as the smallest
index in a vector or the smallest time for a series of scalars.
The following figure illustrates the equivalence between binary and
integer signals for a Reed-Solomon encoder. The case for the decoder is
similar.
To produce sample-based messages in the integer format, you can configure
the Random Integer Generator block so that M-ary number
and Initial seed parameters are vectors of
the desired length and all entries of the M-ary number
vector are 2M. To produce frame-based messages in
the integer format, you can configure the same block so that its
M-ary number and Initial seed
parameters are scalars and its Samples per frame
parameter is the length of the signal you want to create.
Using Block Encoders and Decoders Within a Model
Once you have configured the coding blocks, a few tips can help you place them
correctly within your model:
-
If a block has multiple outputs, the first one is always the stream of
coding data.The Reed-Solomon and BCH blocks have an error counter as a second
output. -
Be sure that the signal sizes are appropriate for the mask parameters.
For example, if you use the Binary Cyclic Encoder block and set
Message length K to4,
the input signal must be a vector of length 4.You can display the size of signals in your model. On the
tab, expand
. In the
section, select
.
Examples of Block Coding
Example: Reed-Solomon Code in Integer Format. This example uses a Reed-Solomon code in integer format. It illustrates
the appropriate vector lengths of the code and message signals for the
coding blocks. It also exhibits error correction, using a simple way of
introducing errors into each codeword.

Open the model by typing doc_rscoding at the MATLAB
command line. To build the model, gather and configure these blocks:
-
Random Integer Generator,
in the Comm Sources library-
Set M-ary number to
15. -
Set Initial seed to a positive
number,randnis
chosen here. -
Check the Frame-based outputs check
box. -
Set Samples per frame to
5.
-
-
Integer-Input RS
Encoder-
Set Codeword length N to
15. -
Set Message length K to
5.
-
-
Gain (Simulink), in the
Simulink Math Operations library-
Set Gain to
[0; 0; 0; 0; 0;.
ones(10,1)]
-
-
Integer-Output RS
Decoder-
Set Codeword length N to
15. -
Set Message length K to
5.
-
-
Scope (Simulink), in the
Simulink Sinks library. Get two copies of this block. -
Add (Simulink), in the Simulink
Math Operations library-
Set List of signs to
|-+
-
Connect the blocks as shown in the preceding figure. On the
tab, in the
section, set Stop
time to 500. The
section appears on multiple
tabs.
You can display the vector length of signals in your model. On the
tab, expand . In the
section, select .
The encoder accepts a vector of length 5 (which is K in this case) and
produces a vector of length 15 (which is N in this case). The decoder does
the opposite.
Running the model produces the following scope images. The plotted error
count will vary based on the Initial Seed value used in
the Random Integer Generator block. You can adjust the axis range exactly
match that of the first scope. Right-click the plot area in the second scope
and select . On the
tab, adjust the axes limits.
Number of Errors Before Correction


The second plot is the number of errors that the decoder detected while
trying to recover the message. Often the number is five because the Gain
block replaces the first five symbols in each codeword with zeros. However,
the number of errors is less than five whenever a correct codeword contains
one or more zeros in the first five places.
The first plot is the difference between the original message and the
recovered message; since the decoder was able to correct all errors that
occurred, each of the five data streams in the plot is zero.
Notes on Specific Block-Coding Techniques
Although the Block Coding sublibrary is somewhat uniform in its look and feel,
the various coding techniques are not identical. This section describes special
options and restrictions that apply to parameters and signals for the coding
technique categories in this sublibrary. Coding techniques discussed below
include — Generic Linear Block code, Cyclic code, Hamming code, BCH code, and
Reed-Solomon code.
Generic Linear Block
Codes
Encoding a message using a generic linear block code requires a generator
matrix. Decoding the code requires the generator matrix and possibly a truth
table. To use the Binary Linear Encoder and Binary Linear Decoder blocks, you
must understand the Generator matrix and
Error-correction truth table parameters.
Generator Matrix — The process of encoding a message into
an [N,K] linear block code is determined by a K-by-N generator matrix
G. Specifically, a 1-by-K message vector
v is encoded into the 1-by-N codeword vector
vG. If G has the form
[Ik, P] or
[P, Ik], where
P is some K-by-(N-K) matrix and
Ik is the K-by-K identity matrix,
G is said to be in standard form.
(Some authors, such as Clark and Cain [2], use the first standard form, while others, such as Lin and Costello [3], use the second.) The linear block-coding blocks in this product require the
Generator matrix mask parameter to be in standard
form.
Decoding Table — A decoding table tells a decoder how to
correct errors that may have corrupted the code during transmission. Hamming
codes can correct any single-symbol error in any codeword. Other codes can
correct, or partially correct, errors that corrupt more than one symbol in a
given codeword.
The Binary Linear Decoder block allows
you to specify a decoding table in the Error-correction truth
table parameter. Represent a decoding table as a matrix with N
columns and 2N-K rows. Each row gives a correction
vector for one received codeword vector.
You can avoid specifying a decoding table explicitly, by setting the
Error-correction truth table parameter to
0. When Error-correction truth table
is 0, the block computes a decoding table using the syndtable function.
Cyclic Codes
For cyclic codes, the codeword length N must have the form
2M-1, where M is an integer greater than or equal
to 3.
Generator Polynomials — Cyclic codes have special
algebraic properties that allow a polynomial to determine the coding process
completely. This so-called generator polynomial is a degree-(N-K) divisor of the
polynomial xN-1. Van Lint [5] explains how a generator polynomial determines a cyclic code.
The Binary Cyclic Encoder and Binary Cyclic Decoder blocks allow
you to specify a generator polynomial as the second mask parameter, instead of
specifying K there. The blocks represent a generator polynomial using a vector
that lists the coefficients of the polynomial in order of
ascending powers of the variable. You can find
generator polynomials for cyclic codes using the cyclpoly function.
If you do not want to specify a generator polynomial, set the second mask
parameter to the value of K.
Hamming Codes
For Hamming codes, the codeword length N must have the form
2M-1, where M is an integer greater than or equal
to 3. The message length K must equal N-M.
Primitive Polynomials — Hamming codes rely on algebraic
fields that have 2M elements (or, more generally,
pM elements for a prime number
p). Elements of such fields are named relative
to a distinguished element of the field that is called a
primitive element. The minimal polynomial of a
primitive element is called a primitive polynomial. The
Hamming Encoder and Hamming Decoder blocks allow you to
specify a primitive polynomial for the finite field that they use for
computations. If you want to specify this polynomial, do so in the second mask
parameter field. The blocks represent a primitive polynomial using a vector that
lists the coefficients of the polynomial in order of
ascending powers of the variable. You can find
generator polynomials for Galois fields using the gfprimfd function.
If you do not want to specify a primitive polynomial, set the second mask
parameter to the value of K.
BCH Codes
BCH codes are cyclic error-correcting codes that are constructed using finite
fields. For these codes, the codeword length N must have the form
2M-1, where M is an integer from 3 to 9. The
message length K is restricted to particular values that depend on N. To see
which values of K are valid for a given N, see the comm.BCHEncoder
System object™ reference page. No known analytic formula describes the
relationship among the codeword length, message length, and error-correction
capability for BCH codes.
Narrow-Sense BCH Codes
The narrow-sense generator polynomial is LCM[m_1(x), m_2(x), …, m_2t(x)],
where:
-
LCM represents the least common multiple,
-
m_i(x) represents the minimum polynomial corresponding to
αi, α is a root of the default primitive
polynomial for the field GF(n+1), -
and t represents the error-correcting capability of the code.
Reed-Solomon Codes
Reed-Solomon codes are useful for correcting errors that occur in bursts. In
the simplest case, the length of codewords in a Reed-Solomon code is of the form
N= 2M-1, where the 2M is
the number of symbols for the code. The error-correction capability of a
Reed-Solomon code is floor((N-K)/2), where K is the length of
message words. The difference N-K must be even.
It is sometimes convenient to use a shortened Reed-Solomon code in which N is
less than 2M-1. In this case, the encoder appends
2M-1-N zero symbols to each message word and
codeword. The error-correction capability of a shortened Reed-Solomon code is
also floor((N-K)/2). The Communications Toolbox Reed-Solomon blocks can implement shortened Reed-Solomon
codes.
Effect of Nonbinary Symbols — One difference between
Reed-Solomon codes and the other codes supported in this product is that
Reed-Solomon codes process symbols in GF(2M) instead
of GF(2). M bits specify each symbol. The nonbinary nature of the Reed-Solomon
code symbols causes the Reed-Solomon blocks to differ from other coding blocks
in these ways:
-
You can use the integer format, via the Integer-Input RS Encoder and
Integer-Output RS Decoder
blocks. -
The binary format expects the vector lengths to be an integer multiple
of M*K (not K) for messages and the same integer M*N (not N) for
codewords.
Error Information — The Reed-Solomon decoding blocks
(Binary-Output RS Decoder and Integer-Output RS Decoder) return
error-related information during the simulation. The second output signal
indicates the number of errors that the block detected in the input codeword. A
-1 in the second output indicates that the block detected more errors than it
could correct using the coding scheme.
Shortening, Puncturing, and Erasures
Many standards utilize punctured codes, and digital receivers can easily
output erasures. BCH and RS performance improves significantly in fading
channels where the receiver generates erasures.
A punctured codeword has only parity symbols removed, and
a shortened codeword has only information symbols removed.
A codeword with erasures can have those erasures in either information symbols
or parity symbols.
Reed Solomon Examples with Shortening, Puncturing, and
Erasures
In this section, a representative example of Reed Solomon coding with
shortening, puncturing, and erasures is built with increasing complexity of
error correction.
Encoder Example with Shortening and
Puncturing
The following figure shows a representative example of a (7,3) Reed Solomon
encoder with shortening and puncturing.
In this figure, the message source outputs two information symbols, designated
by I1I2. (For a BCH example, the
symbols are binary bits.) Because the code is a shortened (7,3) code, a zero
must be added ahead of the information symbols, yielding a three-symbol message
of 0I1I2. The modified message
sequence is RS encoded, and the added information zero is then removed, which
yields a result of
I1I2P1P2P3P4.
(In this example, the parity bits are at the end of the codeword.)
The puncturing operation is governed by the puncture vector, which, in this
case, is 1011. Within the puncture vector, a 1 means that the
symbol is kept, and a 0 means that the symbol is thrown away.
In this example, the puncturing operation removes the second parity symbol,
yielding a final vector of
I1I2P1P3P4.
Decoder Example with Shortening and
Puncturing
The following figure shows how the RS decoder operates on a shortened and
punctured codeword.
This case corresponds to the encoder operations shown in the figure of the RS
encoder with shortening and puncturing. As shown in the preceding figure, the
encoder receives a (5,2) codeword, because it has been shortened from a (7,3)
codeword by one symbol, and one symbol has also been punctured.
As a first step, the decoder adds an erasure, designated by E, in the second
parity position of the codeword. This corresponds to the puncture vector 1011.
Adding a zero accounts for shortening, in the same way as shown in the preceding
figure. The single erasure does not exceed the erasure-correcting capability of
the code, which can correct four erasures. The decoding operation results in the
three-symbol message DI1I2. The
first symbol is truncated, as in the preceding figure, yielding a final output
of I1I2.
Decoder Example with Shortening, Puncturing, and
Erasures
The following figure shows the decoder operating on the punctured, shortened
codeword, while also correcting erasures generated by the receiver.
In this figure, demodulator receives the
I1I2P1P3P4
vector that the encoder sent. The demodulator declares that two of the five
received symbols are unreliable enough to be erased, such that symbols 2 and 5
are deemed to be erasures. The 01001 vector, provided by an external source,
indicates these erasures. Within the erasures vector, a 1 means that the symbol
is to be replaced with an erasure symbol, and a 0 means that the symbol is
passed unaltered.
The decoder blocks receive the codeword and the erasure vector, and perform
the erasures indicated by the vector 01001. Within the erasures vector, a 1
means that the symbol is to be replaced with an erasure symbol, and a 0 means
that the symbol is passed unaltered. The resulting codeword vector is
I1EP1P3E,
where E is an erasure symbol.
The codeword is then depunctured, according to the puncture vector used in the
encoding operation (i.e., 1011). Thus, an erasure symbol is inserted between
P1 and P3, yielding a codeword
vector of
I1EP1EP3E.
Just prior to decoding, the addition of zeros at the beginning of the
information vector accounts for the shortening. The resulting vector is
0I1EP1EP3E,
such that a (7,3) codeword is sent to the Berlekamp algorithm.
This codeword is decoded, yielding a three-symbol message of
DI1I2 (where D refers to a
dummy symbol). Finally, the removal of the D symbol from the message vector
accounts for the shortening and yields the original
I1I2 vector.
For additional information, see the Reed-Solomon Coding with Erasures, Punctures, and Shortening
MATLAB example or the Reed-Solomon Coding with Erasures, Punctures, and Shortening in Simulink
example.
Reed-Solomon Code in Integer Format
To open an example model that uses a Reed-Solomon code in integer format, type
doc_rscoding at the MATLAB command line. For more information about the model, see Example: Reed-Solomon Code in Integer Format
Find a Generator Polynomial
To find a generator polynomial for a cyclic, BCH, or Reed-Solomon code, use
the cyclpoly, bchgenpoly, or
rsgenpoly function, respectively. The commands
genpolyCyclic = cyclpoly(15,5) % 1+X^5+X^10 genpolyBCH = bchgenpoly(15,5) % x^10+x^8+x^5+x^4+x^2+x+1 genpolyRS = rsgenpoly(15,5)
find generator polynomials for block codes of different types. The output is
below.
genpolyCyclic =
1 0 0 0 0 1 0 0 0 0 1
genpolyBCH = GF(2) array.
Array elements =
1 0 1 0 0 1 1 0 1 1 1
genpolyRS = GF(2^4) array. Primitive polynomial = D^4+D+1 (19 decimal)
Array elements =
1 4 8 10 12 9 4 2 12 2 7
The formats of these outputs vary:
-
cyclpolyrepresents a generator polynomial using
an integer row vector that lists the polynomial’s coefficients in order
of ascending powers of the variable. -
bchgenpolyandrsgenpoly
represent a generator polynomial using a Galois row vector that lists
the polynomial’s coefficients in order of
descending powers of the variable. -
rsgenpolyuses coefficients in a Galois field
other than the binary field GF(2). For more information on the meaning
of these coefficients, see How Integers Correspond to Galois Field Elements and Polynomials over Galois Fields.
Nonuniqueness of Generator Polynomials
Some pairs of message length and codeword length do not uniquely determine the
generator polynomial. The syntaxes for functions in the example above also
include options for retrieving generator polynomials that satisfy certain
constraints that you specify. See the functions’ reference pages for details
about syntax options.
Algebraic Expression for Generator
Polynomials
The generator polynomials produced by bchgenpoly and
rsgenpoly have the form
(X — Ab)(X — Ab+1)…(X — Ab+2t-1),
where A is a primitive element for an appropriate Galois field, and b and t are
integers. See the functions’ reference pages for more information about this
expression.
Performing Other Block Code Tasks
This section describes functions that compute typical parameters associated
with linear block codes, as well as functions that convert information from one
format to another.
-
Error Correction Versus Error Detection for
Linear Block CodesYou can use a linear block code to detect
dmin -1 errors or to
correct t = [12(dmin−1)] errors.If you compromise the error correction capability of a code, you
can detect more than t errors. For example, a
code with dmin = 7 can
correct t = 3 errors or it can detect up to 4
errors and correct up to 2 errors. -
Finding the Error-Correction
CapabilityThe
bchgenpolyand
rsgenpolyfunctions can return an optional
second output argument that indicates the error-correction
capability of a BCH or Reed-Solomon code. For example, the
commands[g,t] = bchgenpoly(31,16); t t = 3find that a [31, 16] BCH code can correct up to three errors in
each codeword. -
Finding Generator and Parity-Check
MatricesTo find a parity-check and generator matrix for a Hamming code
with codeword length2^m-1, use the
hammgenfunction as below.
mmust be at least three.[parmat,genmat] = hammgen(m); % Hamming
To find a parity-check and generator matrix for a cyclic code, use
thecyclgenfunction. You must provide the
codeword length and a valid generator polynomial. You can use the
cyclpolyfunction to produce one possible
generator polynomial after you provide the codeword length and
message length. For example,[parmat,genmat] = cyclgen(7,cyclpoly(7,4)); % Cyclic -
Converting Between Parity-Check and
Generator MatricesThe
gen2parfunction converts a generator
matrix into a parity-check matrix, and vice versa. The reference
page forgen2parcontains examples to
illustrate this.
Selected Bibliography for Block Coding
[1] Berlekamp, Elwyn R., Algebraic Coding
Theory, New York, McGraw-Hill, 1968.
[2] Clark, George C. Jr., and J. Bibb Cain,
Error-Correction Coding for Digital
Communications, New York, Plenum Press, 1981.
[3] Lin, Shu, and Daniel J. Costello, Jr.,
Error Control Coding: Fundamentals and
Applications, Englewood Cliffs, NJ, Prentice-Hall,
1983.
[4] Peterson, W. Wesley, and E. J. Weldon, Jr.,
Error-Correcting Codes, 2nd ed., Cambridge, MA,
MIT Press, 1972.
[5] van Lint, J. H., Introduction to Coding
Theory, New York, Springer-Verlag, 1982.
[6] Wicker, Stephen B., Error Control
Systems for Digital Communication and Storage, Upper Saddle
River, NJ, Prentice Hall, 1995.
[7] Gallager, Robert G., Low-Density
Parity-Check Codes, Cambridge, MA, MIT Press,
1963.
[8] Ryan, William E., “An introduction to
LDPC codes,” Coding and Signal Processing for Magnetic
Recoding Systems (Vasic, B., ed.), CRC Press,
2004.
Convolutional Codes
-
Convolutional Code Features
-
Polynomial Description of a Convolutional Code
-
Trellis Description of a Convolutional Code
-
Create and Decode Convolutional Codes
-
Design a Rate-2/3 Feedforward Encoder Using MATLAB
-
Design a Rate 2/3 Feedforward Encoder Using Simulink
-
Puncture a Convolutional Code Using MATLAB
-
Implement a Systematic Encoder with Feedback Using Simulink
-
Soft-Decision Decoding
-
Tailbiting Encoding Using Feedback
Encoders -
Selected Bibliography for Convolutional Coding
Convolutional Code Features
Convolutional coding is a special case of error-control coding. Unlike a block
coder, a convolutional coder is not a memoryless device. Even though a
convolutional coder accepts a fixed number of message symbols and produces a
fixed number of code symbols, its computations depend not only on the current
set of input symbols but on some of the previous input symbols.
Communications Toolbox provides convolutional coding capabilities as Simulink blocks, System objects, and MATLAB functions. This product supports feedforward and feedback
convolutional codes that can be described by a trellis structure or a set of
generator polynomials. It uses the Viterbi algorithm to implement hard-decision
and soft-decision decoding.
The product also includes an a posteriori probability
decoder, which can be used for soft output decoding of convolutional
codes.
For background information about convolutional coding, see the works listed in
Selected Bibliography
for Convolutional Coding.
Block Parameters for Convolutional
Coding
To process convolutional codes, use the Convolutional Encoder, Viterbi Decoder, and/or APP Decoder blocks in the
Convolutional sublibrary. If a mask parameter is required in both the encoder
and the decoder, use the same value in both blocks.
The blocks in the Convolutional sublibrary assume that you use one of two
different representations of a convolutional encoder:
-
If you design your encoder using a diagram with shift registers and
modulo-2 adders, you can compute the code generator polynomial matrix
and subsequently use thepoly2trellisfunction (in
Communications Toolbox) to generate the corresponding trellis structure mask
parameter automatically. For an example, see Design a Rate 2/3 Feedforward Encoder Using Simulink. -
If you design your encoder using a trellis diagram, you can construct
the trellis structure in MATLAB and use it as the mask parameter.
For more information about these representations, see Polynomial
Description of a Convolutional Code and Trellis Description of
a Convolutional Code.
Using the Polynomial Description in
Blocks
To use the polynomial description with the Convolutional Encoder, Viterbi Decoder, or APP Decoder blocks, use the utility
function poly2trellis from Communications Toolbox. This function accepts a polynomial description and converts it
into a trellis description. For example, the following command computes the
trellis description of an encoder whose constraint length is 5 and whose
generator polynomials are 35 and 31:
trellis = poly2trellis(5,[35 31]);
To use this encoder with one of the convolutional-coding blocks, simply place
a poly2trellis command such as
in the Trellis structure parameter field.
Polynomial Description of a Convolutional Code
A polynomial description of a convolutional encoder describes the connections
among shift registers and modulo 2 adders. For example, the figure below depicts
a feedforward convolutional encoder that has one input, two outputs, and two
shift registers.
A polynomial description of a convolutional encoder has either two or three
components, depending on whether the encoder is a feedforward or feedback
type:
-
Constraint
lengths -
Generator
polynomials -
Feedback connection
polynomials (for feedback encoders only)
Constraint Lengths. The constraint lengths of the encoder form a vector whose length is the
number of inputs in the encoder diagram. The elements of this vector
indicate the number of bits stored in each shift register,
including the current input bits.
In the figure above, the constraint length is three. It is a scalar
because the encoder has one input stream, and its value is one plus the
number of shift registers for that input.
Generator Polynomials. If the encoder diagram has k inputs and n outputs, the code generator
matrix is a k-by-n matrix. The element in the ith row and jth column
indicates how the ith input contributes to the jth output.
For systematic bits of a systematic feedback encoder,
match the entry in the code generator matrix with the corresponding element
of the feedback connection vector. See Feedback Connection Polynomials below for details.
In other situations, you can determine the (i,j) entry in the matrix as
follows:
-
Build a binary number representation by placing a 1 in each spot
where a connection line from the shift register feeds into the
adder, and a 0 elsewhere. The leftmost spot in the binary number
represents the current input, while the rightmost spot represents
the oldest input that still remains in the shift register. -
Convert this binary representation into an octal representation by
considering consecutive triplets of bits, starting from the
rightmost bit. The rightmost bit in each triplet is the least
significant. If the number of bits is not a multiple of three, place
zero bits at the left end as necessary. (For example, interpret
1101010 as 001 101 010 and convert it to 152.)
For example, the binary numbers corresponding to the upper and lower
adders in the figure above are 110 and 111, respectively. These binary
numbers are equivalent to the octal numbers 6 and 7, respectively, so the
generator polynomial matrix is [6 7].
Note
You can perform the binary-to-octal conversion in MATLAB by using code like
str2num(dec2base(bin2dec('110'),8)).
For a table of some good convolutional code generators, refer to [2] in the section Selected Bibliography for Block Coding, especially that book’s
appendices.
Feedback Connection Polynomials. If you are representing a feedback encoder, you need a vector of feedback
connection polynomials. The length of this vector is the number of inputs in
the encoder diagram. The elements of this vector indicate the feedback
connection for each input, using an octal format. First build a binary
number representation as in step 1 above. Then convert the binary
representation into an octal representation as in step 2 above.
If the encoder has a feedback configuration and is also systematic, the
code generator and feedback connection parameters corresponding to the
systematic bits must have the same values.
Use Trellis Structure for Rate 1/2 Feedback Convolutional Encoder
Create a trellis structure to represent the rate 1/2 systematic convolutional encoder with feedback shown in this diagram.
This encoder has 5 for its constraint length, [37 33] as its generator polynomial matrix, and 37 for its feedback connection polynomial.
The first generator polynomial is octal 37. The second generator polynomial is octal 33. The feedback polynomial is octal 37. The first generator polynomial matches the feedback connection polynomial because the first output corresponds to the systematic bits.
The binary vector [1 1 1 1 1] represents octal 37 and corresponds to the upper row of binary digits in the diagram. The binary vector [1 1 0 1 1] represents octal 33 and corresponds to the lower row of binary digits in the diagram. These binary digits indicate connections from the outputs of the registers to the two adders in the diagram. The initial 1 corresponds to the input bit.
Convert the polynomial to a trellis structure by using the poly2trellis function. When used with a feedback polynomial, poly2trellis makes a feedback connection to the input of the trellis.
trellis = poly2trellis(5,[37 33],37)
trellis = struct with fields:
numInputSymbols: 2
numOutputSymbols: 4
numStates: 16
nextStates: [16x2 double]
outputs: [16x2 double]
Generate random binary data. Convolutionally encode the data by using the specified trellis structure. Decode the coded data by using the Viterbi algorithm with the specified trellis structure, 34 for its traceback depth, truncated operation mode, and hard decisions.
data = randi([0 1],70,1); codedData = convenc(data,trellis); tbdepth = 34; % Traceback depth for Viterbi decoder decodedData = vitdec(codedData,trellis,tbdepth,'trunc','hard');
Verify the decoded data has zero bit errors.
Using the Polynomial Description in MATLAB. To use the polynomial description with the functions
convenc and vitdec, first
convert it into a trellis description using the
poly2trellis function. For example, the command
below computes the trellis description of the encoder pictured in the
section Polynomial
Description of a Convolutional Code.
trellis = poly2trellis(3,[6 7]);
The MATLAB structure trellis is a suitable input
argument for convenc and
vitdec.
Trellis Description of a Convolutional Code
A trellis description of a convolutional encoder shows how each possible input
to the encoder influences both the output and the state transitions of the
encoder. This section describes trellises, and how to represent
trellises in MATLAB, and gives an example of a MATLAB
trellis.
The figure below depicts a trellis for the convolutional encoder from the
previous section. The encoder has four states (numbered in binary from 00 to
11), a one-bit input, and a two-bit output. (The ratio of input bits to output
bits makes this encoder a rate-1/2 encoder.) Each solid arrow shows how the
encoder changes its state if the current input is zero, and each dashed arrow
shows how the encoder changes its state if the current input is one. The octal
numbers above each arrow indicate the current output of the encoder.
As an example of interpreting this trellis diagram, if the encoder is in the
10 state and receives an input of zero, it outputs the code symbol 3 and changes
to the 01 state. If it is in the 10 state and receives an input of one, it
outputs the code symbol 0 and changes to the 11 state.
Note that any polynomial description of a convolutional encoder is equivalent
to some trellis description, although some trellises have no corresponding
polynomial descriptions.
Specifying a Trellis in MATLAB. To specify a trellis in MATLAB, use a specific form of a MATLAB structure called a trellis structure. A trellis structure must
have five fields, as in the table below.
Fields of a Trellis Structure for a Rate k/n Code
| Field in Trellis Structure |
Dimensions | Meaning |
|---|---|---|
numInputSymbols
|
Scalar | Number of input symbols to the encoder: 2k |
numOutputsymbols
|
Scalar | Number of output symbols from the encoder: 2n |
numStates
|
Scalar | Number of states in the encoder |
nextStates
|
numStates-by-2kmatrix |
Next states for all combinations of current state and current input |
outputs
|
numStates-by-2kmatrix |
Outputs (in octal) for all combinations of current state and current input |
Note
While your trellis structure can have any name, its fields must have
the exact names as in the table. Field names are
case sensitive.
In the nextStates matrix, each entry is an integer
between 0 and numStates-1. The element in the ith row and
jth column denotes the next state when the starting state is i-1 and the
input bits have decimal representation j-1. To convert the input bits to a
decimal value, use the first input bit as the most significant bit (MSB).
For example, the second column of the nextStates matrix
stores the next states when the current set of input values is {0,…,0,1}.
To learn how to assign numbers to states, see the reference page for
istrellis.
In the outputs matrix, the element in the ith row and
jth column denotes the encoder’s output when the starting state is i-1 and
the input bits have decimal representation j-1. To convert to decimal value,
use the first output bit as the MSB.
How to Create a MATLAB Trellis Structure. Once you know what information you want to put into each field, you can
create a trellis structure in any of these ways:
-
Define each of the five fields individually, using
structurename.fieldnamenotation. For
example, set the first field of a structure called
susing the command below. Use additional
commands to define the other fields.The reference page for the
istrellisfunction
illustrates this approach. -
Collect all field names and their values in a single
structcommand. For example:s = struct('numInputSymbols',2,'numOutputSymbols',2,... 'numStates',2,'nextStates',[0 1;0 1],'outputs',[0 0;1 1]); -
Start with a polynomial description of the encoder and use the
poly2trellisfunction to convert it to a
valid trellis structure. For more information , see Polynomial Description of a Convolutional Code.
To check whether your structure is a valid trellis structure, use the
istrellis function.
Example: A MATLAB Trellis Structure. Consider the trellis shown below.
To build a trellis structure that describes it, use the command
below.
trellis = struct('numInputSymbols',2,'numOutputSymbols',4,... 'numStates',4,'nextStates',[0 2;0 2;1 3;1 3],... 'outputs',[0 3;1 2;3 0;2 1]);
The number of input symbols is 2 because the trellis diagram has two types
of input path: the solid arrow and the dashed arrow. The number of output
symbols is 4 because the numbers above the arrows can be either 0, 1, 2, or
3. The number of states is 4 because there are four bullets on the left side
of the trellis diagram (equivalently, four on the right side). To compute
the matrix of next states, create a matrix whose rows correspond to the four
current states on the left side of the trellis, whose columns correspond to
the inputs of 0 and 1, and whose elements give the next states at the end of
the arrows on the right side of the trellis. To compute the matrix of
outputs, create a matrix whose rows and columns are as in the next states
matrix, but whose elements give the octal outputs shown above the arrows in
the trellis.
Create and Decode Convolutional Codes
The functions for encoding and decoding convolutional codes are
convenc and vitdec. This section
discusses using these functions to create and decode convolutional codes.
Encoding. A simple way to use convenc to create a convolutional
code is shown in the commands below.
% Define a trellis. t = poly2trellis([4 3],[4 5 17;7 4 2]); % Encode a vector of ones. x = ones(100,1); code = convenc(x,t);
The first command converts a polynomial description of a feedforward
convolutional encoder to the corresponding trellis description. The second
command encodes 100 bits, or 50 two-bit symbols. Because the code rate in
this example is 2/3, the output vector code contains 150
bits (that is, 100 input bits times 3/2).
To check whether your trellis corresponds to a catastrophic convolutional
code, use the iscatastrophic function.
Hard-Decision Decoding. To decode using hard decisions, use the vitdec
function with the flag 'hard' and with
binary input data. Because the output of
convenc is binary, hard-decision decoding can use
the output of convenc directly, without additional
processing. This example extends the previous example and implements
hard-decision decoding.
Define a trellis. t = poly2trellis([4 3],[4 5 17;7 4 2]); Encode a vector of ones. code = convenc(ones(100,1),t); Set the traceback length for decoding and decode using vitdec. tb = 2; decoded = vitdec(code,t,tb,'trunc','hard'); Verify that the decoded data is a vector of 100 ones. isequal(decoded,ones(100,1))
Soft-Decision Decoding. To decode using soft decisions, use the vitdec
function with the flag 'soft'. Specify the number,
nsdec, of soft-decision bits and use input data
consisting of integers between 0 and 2^nsdec-1.
An input of 0 represents the most confident 0, while an input of
2^nsdec-1 represents the most confident 1. Other
values represent less confident decisions. For example, the table below
lists interpretations of values for 3-bit soft decisions.
Input Values for 3-bit Soft Decisions
| Input Value | Interpretation |
|---|---|
| 0 | Most confident 0 |
| 1 | Second most confident 0 |
| 2 | Third most confident 0 |
| 3 | Least confident 0 |
| 4 | Least confident 1 |
| 5 | Third most confident 1 |
| 6 | Second most confident 1 |
| 7 | Most confident 1 |
Implement Soft-Decision Decoding Using
MATLAB
The script below illustrates decoding with 3-bit soft decisions. First it
creates a convolutional code with convenc and adds
white Gaussian noise to the code with awgn. Then, to
prepare for soft-decision decoding, the example uses
quantiz to map the noisy data values to appropriate
decision-value integers between 0 and 7. The second argument in
quantiz is a partition vector that determines which
data values map to 0, 1, 2, etc. The partition is chosen so that values near
0 map to 0, and values near 1 map to 7. (You can refine the partition to
obtain better decoding performance if your application requires it.)
Finally, the example decodes the code and computes the bit error rate. When
comparing the decoded data with the original message, the example must take
the decoding delay into account. The continuous operation mode of
vitdec causes a delay equal to the traceback
length, so msg(1) corresponds to
decoded(tblen+1) rather than to
decoded(1).
s = RandStream.create('mt19937ar', 'seed',94384); prevStream = RandStream.setGlobalStream(s); msg = randi([0 1],4000,1); % Random data t = poly2trellis(7,[171 133]); % Define trellis. % Create a ConvolutionalEncoder System object hConvEnc = comm.ConvolutionalEncoder(t); % Create an AWGNChannel System object. hChan = comm.AWGNChannel('NoiseMethod', 'Signal to noise ratio (SNR)',... 'SNR', 6); % Create a ViterbiDecoder System object hVitDec = comm.ViterbiDecoder(t, 'InputFormat', 'Soft', ... 'SoftInputWordLength', 3, 'TracebackDepth', 48, ... 'TerminationMethod', 'Continuous'); % Create a ErrorRate Calculator System object. Account for the receive % delay caused by the traceback length of the viterbi decoder. hErrorCalc = comm.ErrorRate('ReceiveDelay', 48); ber = zeros(3,1); % Store BER values code = step(hConvEnc,msg); % Encode the data. hChan.SignalPower = (code'*code)/length(code); ncode = step(hChan,code); % Add noise. % Quantize to prepare for soft-decision decoding. qcode = quantiz(ncode,[0.001,.1,.3,.5,.7,.9,.999]); tblen = 48; delay = tblen; % Traceback length decoded = step(hVitDec,qcode); % Decode. % Compute bit error rate. ber = step(hErrorCalc, msg, decoded); ratio = ber(1) number = ber(2) RandStream.setGlobalStream(prevStream);
The output is below.
number =
5
ratio =
0.0013
Implement Soft-Decision Decoding Using Simulink. This example creates a rate 1/2 convolutional code. It uses a quantizer
and the Viterbi Decoder block to perform soft-decision decoding. To open the
model, enter doc_softdecision at the MATLAB command line. For a description of the model, see Overview
of the Simulation.
Defining the Convolutional Code
The feedforward convolutional encoder in this example is depicted
below.
The encoder’s constraint length is a scalar since the encoder has one
input. The value of the constraint length is the number of bits stored in
the shift register, including the current input. There are six memory
registers, and the current input is one bit. Thus the constraint length of
the code is 7.
The code generator is a 1-by-2 matrix of octal numbers because the encoder
has one input and two outputs. The first element in the matrix indicates
which input values contribute to the first output, and the second element in
the matrix indicates which input values contribute to the second
output.
For example, the first output in the encoder diagram is the modulo-2 sum
of the rightmost and the four leftmost elements in the diagram’s array of
input values. The seven-digit binary number 1111001 captures this
information, and is equivalent to the octal number 171. The octal number 171
thus becomes the first entry of the code generator matrix. Here, each
triplet of bits uses the leftmost bit as the most significant bit. The
second output corresponds to the binary number 1011011, which is equivalent
to the octal number 133. The code generator is therefore
[171 133].
The Trellis structure parameter in the Convolutional
Encoder block tells the block which code to use when processing data. In
this case, the poly2trellis function, in
Communications Toolbox, converts the constraint length and the pair of octal numbers
into a valid trellis structure.
While the message data entering the Convolutional Encoder block is a
scalar bit stream, the encoded data leaving the block is a stream of binary
vectors of length 2.
Mapping the Received Data
The received data, that is, the output of the AWGN Channel block, consists
of complex numbers that are close to -1 and 1. In order to reconstruct the
original binary message, the receiver part of the model must decode the
convolutional code. The Viterbi Decoder block in this model expects its
input data to be integers between 0 and 7. The demodulator, a custom
subsystem in this model, transforms the received data into a format that the
Viterbi Decoder block can interpret properly. More specifically, the
demodulator subsystem
-
Converts the received data signal to a real signal by removing its
imaginary part. It is reasonable to assume that the imaginary part
of the received data does not contain essential information, because
the imaginary part of the transmitted data is zero (ignoring small
roundoff errors) and because the channel noise is not very
powerful. -
Normalizes the received data by dividing by the standard deviation
of the noise estimate and then multiplying by -1. -
Quantizes the normalized data using three bits.
The combination of this mapping and the Viterbi Decoder block’s decision
mapping reverses the BPSK modulation that the BPSK Modulator Baseband block
performs on the transmitting side of this model. To examine the demodulator
subsystem in more detail, double-click the icon labeled Soft-Output BPSK
Demodulator.
Decoding the Convolutional Code
After the received data is properly mapped to length-2 vectors of 3-bit
decision values, the Viterbi Decoder block decodes it. The block uses a
soft-decision algorithm with 23 different input
values because the Decision type parameter is
Soft Decision and the Number of
soft decision bits parameter is 3.
Soft-Decision Interpretation of
Data
When the Decision type parameter is set to
Soft Decision, the Viterbi Decoder block
requires input values between 0 and 2b-1, where
b is the Number of soft decision
bits parameter. The block interprets 0 as the most confident
decision that the codeword bit is a 0 and interprets
2b-1 as the most confident decision that the
codeword bit is a 1. The values in between these extremes represent less
confident decisions. The following table lists the interpretations of the
eight possible input values for this example.
| Decision Value | Interpretation |
|---|---|
| 0 | Most confident 0 |
| 1 | Second most confident 0 |
| 2 | Third most confident 0 |
| 3 | Least confident 0 |
| 4 | Least confident 1 |
| 5 | Third most confident 1 |
| 6 | Second most confident 1 |
| 7 | Most confident 1 |
Traceback and Decoding Delay
The traceback depth influences the decoding delay. The decoding delay is the number of zero symbols that precede the first decoded symbol in the output.
-
For the continuous operating mode, the decoding delay is equal to the number of
traceback depth symbols. -
For the truncated or terminated operating mode, the decoding delay is zero. In
this case, the traceback depth must be less than or equal to the number of symbols
in each input.
Traceback Depth Estimate
As a general estimate, a typical traceback depth value is approximately two
to three times (ConstraintLength – 1) / (1 –
coderate). The constraint length of the code, ConstraintLength,
is equal to (log2(trellis.numStates) +
1). The coderate is equal to (K / N) ×
(length(PuncturePattern) /
sum(PuncturePattern).
K is the number of input symbols, N
is the number of output symbols, and PuncturePattern is the puncture
pattern vector.
For example, applying this general estimate, results in these approximate
traceback depths.
-
A rate 1/2 code has a traceback depth of 5(ConstraintLength – 1).
-
A rate 2/3 code has a traceback depth of 7.5(ConstraintLength – 1).
-
A rate 3/4 code has a traceback depth of 10(ConstraintLength – 1).
-
A rate 5/6 code has a traceback depth of 15(ConstraintLength – 1).
The Traceback depth parameter in the Viterbi Decoder block represents
the length of the decoding delay. Some hardware implementations offer
options of 48 and 96. This example chooses 48 because that is closer to the
estimated target for a rate ½ code with a constraint length of 7.
Delay in Received Data
The Receive delay parameter of the Error Rate Calculation block is
nonzero because a given message bit and its corresponding recovered bit are
separated in time by a nonzero amount of simulation time. The
Receive delay parameter tells the block which
elements of its input signals to compare when checking for errors.
In this case, the Receive delay value is equal to the Traceback depth
value (48).
Comparing Simulation Results with Theoretical
Results
This section describes how to compare the bit error rate in this
simulation with the bit error rate that would theoretically result from
unquantized decoding. The process includes these steps
-
Computing Theoretical Bounds for the Bit
Error RateTo calculate theoretical bounds for the bit error rate
Pb of the
convolutional code in this model, you can use this estimate
based on unquantized-decision decoding:In this estimate,
cd is the sum of
bit errors for error events of distance d,
and f is the free distance of the code. The
quantity Pd is the
pairwise error probability, given bywhere R is the code rate of 1/2, and
erfcis the
MATLAB complementary error function, defined byValues for the coefficients
cd and the free
distance f are in published articles such
as «Convolutional Codes with Optimum Distance Spectrum» [3]. The free distance for this code is
f = 10.The following commands calculate the values of
Pb for
Eb/N0
values in the range from 1 to 4, in increments of 0.5:EbNoVec = [1:0.5:4.0]; R = 1/2; % Errs is the vector of sums of bit errors for % error events at distance d, for d from 10 to 29. Errs = [36 0 211 0 1404 0 11633 0 77433 0 502690 0,... 3322763 0 21292910 0 134365911 0 843425871 0]; % P is the matrix of pairwise error probilities, for % Eb/No values in EbNoVec and d from 10 to 29. P = zeros(20,7); % Initialize. for d = 10:29 P(d-9,:) = (1/2)*erfc(sqrt(d*R*10.^(EbNoVec/10))); end % Bounds is the vector of upper bounds for the bit error % rate, for Eb/No values in EbNoVec. Bounds = Errs*P;
-
Simulating Multiple Times to Collect Bit
Error RatesYou can efficiently vary the simulation parameters by using
thesim(Simulink) function to
run the simulation from the MATLAB command line. For example, the following code
calculates the bit error rate at bit energy-to-noise ratios
ranging from 1 dB to 4 dB, in increments of 0.5 dB. It collects
all bit error rates from these simulations in the matrix
BERVec. It also plots the bit error rates
in a figure window along with the theoretical bounds computed in
the preceding code fragment.Note
To simulate the model, enter
doc_softdecisionat the MATLAB command line. Then execute these commands,
which might take a few minutes.% Plot theoretical bounds and set up figure. figure; semilogy(EbNoVec,Bounds,'bo',1,NaN,'r*'); xlabel('Eb/No (dB)'); ylabel('Bit Error Rate'); title('Bit Error Rate (BER)'); l = legend('Theoretical bound on BER','Actual BER'); l.AutoUpdate = 'off'; axis([1 4 1e-5 1]); hold on; BERVec = []; % Make the noise level variable. set_param('doc_softdecision/AWGN Channel',... 'EsNodB','EbNodB+10*log10(1/2)'); % Simulate multiple times. for n = 1:length(EbNoVec) EbNodB = EbNoVec(n); sim('doc_softdecision',5000000); BERVec(n,:) = BER_Data; semilogy(EbNoVec(n),BERVec(n,1),'r*'); % Plot point. drawnow; end hold off;Note
The estimate for
Pb assumes
that the decoder uses unquantized data, that is, an
infinitely fine quantization. By contrast, the simulation in
this example uses 8-level (3-bit) quantization. Because of
this quantization, the simulated bit error rate is not quite
as low as the bound when the signal-to-noise ratio is
high.The plot of bit error rate against signal-to-noise ratio
follows. The locations of your actual BER points might vary
because the simulation involves random numbers.
Design a Rate-2/3 Feedforward Encoder Using MATLAB
The example below uses the rate 2/3 feedforward encoder depicted in this
schematic. The accompanying description explains how to determine the trellis
structure parameter from a schematic of the encoder and then how to perform
coding using this encoder.
Determining Coding Parameters. The convenc and vitdec functions
can implement this code if their parameters have the appropriate
values.
The encoder’s constraint length is a vector of length 2 because the
encoder has two inputs. The elements of this vector indicate the number of
bits stored in each shift register, including the current input bits.
Counting memory spaces in each shift register in the diagram and adding one
for the current inputs leads to a constraint length of [5 4].
To determine the code generator parameter as a 2-by-3 matrix of octal
numbers, use the element in the ith row and jth column to indicate how the
ith input contributes to the jth output. For example, to compute the element
in the second row and third column, the leftmost and two rightmost elements
in the second shift register of the diagram feed into the sum that forms the
third output. Capture this information as the binary number 1011, which is
equivalent to the octal number 13. The full value of the code generator
matrix is [23 35 0; 0 5 13].
To use the constraint length and code generator parameters in the
convenc and vitdec functions,
use the poly2trellis function to convert those
parameters into a trellis structure. The command to do this is below.
trel = poly2trellis([5 4],[23 35 0;0 5 13]); % Define trellis.
Using the Encoder. Below is a script that uses this encoder.
len = 1000; msg = randi([0 1],2*len,1); % Random binary message of 2-bit symbols trel = poly2trellis([5 4],[23 35 0;0 5 13]); % Trellis % Create a ConvolutionalEncoder System object hConvEnc = comm.ConvolutionalEncoder(trel); % Create a ViterbiDecoder System object hVitDec = comm.ViterbiDecoder(trel, 'InputFormat', 'hard', ... 'TracebackDepth', 34, 'TerminationMethod', 'Continuous'); % Create a ErrorRate Calculator System object. Since each symbol represents % two bits, the receive delay for this object is twice the traceback length % of the viterbi decoder. hErrorCalc = comm.ErrorRate('ReceiveDelay', 68); ber = zeros(3,1); % Store BER values code = step(hConvEnc,msg); % Encode the message. ncode = rem(code + randerr(3*len,1,[0 1;.96 .04]),2); % Add noise. decoded = step(hVitDec, ncode); % Decode. ber = step(hErrorCalc, msg, decoded);
convenc accepts a vector containing 2-bit symbols and
produces a vector containing 3-bit symbols, while
vitdec does the opposite. Also notice that
biterr ignores the first 68 elements of
decoded. That is, the decoding delay is 68, which is
the number of bits per symbol (2) of the recovered message times the
traceback depth value (34) in the vitdec function. The
first 68 elements of decoded are 0s, while subsequent
elements represent the decoded messages.
Design a Rate 2/3 Feedforward Encoder Using Simulink
This example uses the rate 2/3 feedforward convolutional encoder depicted in
the following figure. The description explains how to determine the coding
blocks’ parameters from a schematic of a rate 2/3 feedforward encoder. This
example also illustrates the use of the Error Rate Calculation block with a
receive delay.
How to Determine Coding Parameters. The Convolutional Encoder and Viterbi Decoder blocks can
implement this code if their parameters have the appropriate values.
The encoder’s constraint length is a vector of length 2 since the encoder
has two inputs. The elements of this vector indicate the number of bits
stored in each shift register, including the current input bits. Counting
memory spaces in each shift register in the diagram and adding one for the
current inputs leads to a constraint length of [5 4].
To determine the code generator parameter as a 2-by-3 matrix of octal
numbers, use the element in the ith row and jth column to indicate how the
ith input contributes to the jth output. For example, to compute the element
in the second row and third column, notice that the leftmost and two
rightmost elements in the second shift register of the diagram feed into the
sum that forms the third output. Capture this information as the binary
number 1011, which is equivalent to the octal number 13. The full value of
the code generator matrix is [27 33 0; 0 5 13].
To use the constraint length and code generator parameters in the
Convolutional Encoder and Viterbi Decoder blocks, use the
poly2trellis function to convert those parameters
into a trellis structure.
How to Simulate the Encoder. The following model simulates this encoder.

To open the completed model, enter doc_convcoding at
the MATLAB command line. To build the model, gather and configure these
blocks:
-
Bernoulli Binary
Generator, in the Comm Sources library-
Set Probability of a zero to
.5. -
Set Initial seed to any positive
integer scalar, preferably the output of therandn
function. -
Set Sample time to
.5. -
Check the Frame-based outputs check
box. -
Set Samples per frame to
2.
-
-
Convolutional
Encoder-
Set Trellis structure to
poly2trellis([5 4],[23 35 0; 0 5.
13])
-
-
Binary Symmetric Channel,
in the Channels library-
Set Error probability to
0.02. -
Set Initial seed to any positive
integer scalar, preferably the output of therandn
function. -
Clear the Output error vector check
box.
-
-
Viterbi Decoder
-
Set Trellis structure to
poly2trellis([5 4],[23 35 0; 0 5.
13]) -
Set Decision type to
Hard decision.
-
-
Error Rate Calculation,
in the Comm Sinks library-
Set Receive delay to
68. -
Set Output data to
Port. -
Check the Stop simulation check
box. -
Set Target number of errors to
100.
-
-
Display (Simulink), in the
Simulink Sinks library-
Drag the bottom edge of the icon to make the display big
enough for three entries.
-
Connect the blocks as shown in the preceding figure. On the
tab, in the
section, set Stop
time to inf. The
section appears on multiple
tabs.
Notes on the Model. You can display the matrix size of signals in your model. On the
tab, expand . In the
section, select .
The encoder accepts a 2-by-1 column vector and produces a 3-by-1 column
vector, while the decoder does the opposite. The Samples per
frame parameter in the Bernoulli Binary Generator block is 2
because the block must generate a message word of length 2.
The Receive delay parameter in the Error Rate
Calculation block is 68, which is the vector length (2) of the recovered
message times the Traceback depth value (34) in the
Viterbi Decoder block. If you examine the transmitted and received signals
as matrices in the MATLAB workspace, you see that the first 34 rows of the recovered
message consist of zeros, while subsequent rows are the decoded messages.
Thus the delay in the received signal is 34 vectors of length 2, or 68
samples.
Running the model produces display output consisting of three numbers: the
error rate, the total number of errors, and the total number of comparisons
that the Error Rate Calculation block makes during the simulation. (The
first two numbers vary depending on your Initial seed
values in the Bernoulli Binary Generator and Binary Symmetric Channel
blocks.) The simulation stops after 100 errors occur, because
Target number of errors is set to
100 in the Error Rate Calculation block. The error
rate is much less than 0.02, the Error
probability in the Binary Symmetric Channel block.
Puncture a Convolutional Code Using MATLAB
This example processes a punctured convolutional code. It begins by generating
30,000 random bits and encoding them using a rate-3/4 convolutional encoder with
a puncture pattern of [1 1 1 0 0 1]. The resulting vector contains 40,000 bits,
which are mapped to values of -1 and 1 for transmission. The punctured code,
punctcode, passes through an additive white Gaussian
noise channel. Then vitdec decodes the noisy vector using
the 'unquant' decision type.
Finally, the example computes the bit error rate and the number of bit
errors.
len = 30000; msg = randi([0 1], len, 1); % Random data t = poly2trellis(7, [133 171]); % Define trellis. % Create a ConvolutionalEncoder System object hConvEnc = comm.ConvolutionalEncoder(t, ... 'PuncturePatternSource', 'Property', ... 'PuncturePattern', [1;1;1;0;0;1]); % Create an AWGNChannel System object. hChan = comm.AWGNChannel('NoiseMethod', 'Signal to noise ratio (SNR)',... 'SNR', 3); % Create a ViterbiDecoder System object hVitDec = comm.ViterbiDecoder(t, 'InputFormat', 'Unquantized', ... 'TracebackDepth', 96, 'TerminationMethod', 'Truncated', ... 'PuncturePatternSource', 'Property', ... 'PuncturePattern', [1;1;1;0;0;1]); % Create a ErrorRate Calculator System object. hErrorCalc = comm.ErrorRate; berP = zeros(3,1); berPE = berP; % Store BER values punctcode = step(hConvEnc,msg); % Length is (2*len)*2/3. tcode = 1-2*punctcode; % Map "0" bit to 1 and "1" bit to -1 hChan.SignalPower = (tcode'*tcode)/length(tcode); ncode = step(hChan,tcode); % Add noise. % Decode the punctured code decoded = step(hVitDec,ncode); % Decode. berP = step(hErrorCalc, msg, decoded);% Bit error rate % Erase the least reliable 100 symbols, then decode release(hVitDec); reset(hErrorCalc) hVitDec.ErasuresInputPort = true; [dummy idx] = sort(abs(ncode)); erasures = zeros(size(ncode)); erasures(idx(1:100)) = 1; decoded = step(hVitDec,ncode, erasures); % Decode. berPE = step(hErrorCalc, msg, decoded);% Bit error rate fprintf('Number of errors with puncturing: %dn', berP(2)) fprintf('Number of errors with puncturing and erasures: %dn', berPE(2))
Implement a Systematic Encoder with Feedback Using Simulink
This section explains how to use the Convolutional Encoder block to implement
a systematic encoder with feedback. A code is systematic if
the actual message words appear as part of the codewords. The following diagram
shows an example of a systematic encoder.
To implement this encoder, set the Trellis structure
parameter in the Convolutional Encoder block to poly2trellis(5, [37. This setting corresponds to
33], 37)
-
Constraint length:
5 -
Generator polynomial pair:
[37 33] -
Feedback polynomial:
37
The feedback polynomial is represented by the binary vector [1 1 1 1 1],
corresponding to the upper row of binary digits. These digits indicate
connections from the outputs of the registers to the adder. The initial 1
corresponds to the input bit. The octal representation of the binary number
11111 is 37.
To implement a systematic code, set the first generator polynomial to be the
same as the feedback polynomial in the Trellis structure
parameter of the Convolutional Encoder block. In this example, both polynomials
have the octal representation 37.
The second generator polynomial is represented by the binary vector [1 1 0
1 1], corresponding to the lower row of binary digits. The octal number
corresponding to the binary number 11011 is 33.
For more information on setting the mask parameters for the Convolutional
Encoder block, see Polynomial
Description of a Convolutional Code.
Soft-Decision Decoding
This example creates a rate 1/2 convolutional code. It uses a quantizer and
the Viterbi Decoder block to perform soft-decision decoding. This description
covers these topics:
-
Overview of the Simulation
-
Defining the Convolutional Code
-
Mapping the Received Data
-
Decoding the Convolutional Code
-
Delay in Received Data
-
Comparing Simulation Results with Theoretical Results
Overview of the Simulation. The model is in the following figure. To open the model, enter
doc_softdecision at the MATLAB command line. The simulation creates a random binary message
signal, encodes the message into a convolutional code, modulates the code
using the binary phase shift keying (BPSK) technique, and adds white
Gaussian noise to the modulated data in order to simulate a noisy channel.
Then, the simulation prepares the received data for the decoding block and
decodes. Finally, the simulation compares the decoded information with the
original message signal in order to compute the bit error rate. The
Convolutional encoder is configured as a rate 1/2 encoder. For every 2 bits,
the encoder adds another 2 redundant bits. To accommodate this, and add the
correct amount of noise, the Eb/No (dB) parameter of
the AWGN block is in effect halved by subtracting 10*log10(2). The
simulation ends after processing 100 bit errors or
107 message bits, whichever comes
first.
Defining the Convolutional Code. The feedforward convolutional encoder in this example is depicted
below.
The encoder’s constraint length is a scalar since the encoder has one
input. The value of the constraint length is the number of bits stored in
the shift register, including the current input. There are six memory
registers, and the current input is one bit. Thus the constraint length of
the code is 7.
The code generator is a 1-by-2 matrix of octal numbers because the encoder
has one input and two outputs. The first element in the matrix indicates
which input values contribute to the first output, and the second element in
the matrix indicates which input values contribute to the second
output.
For example, the first output in the encoder diagram is the modulo-2 sum
of the rightmost and the four leftmost elements in the diagram’s array of
input values. The seven-digit binary number 1111001 captures this
information, and is equivalent to the octal number 171. The octal number 171
thus becomes the first entry of the code generator matrix. Here, each
triplet of bits uses the leftmost bit as the most significant bit. The
second output corresponds to the binary number 1011011, which is equivalent
to the octal number 133. The code generator is therefore
[171 133].
The Trellis structure parameter in the Convolutional
Encoder block tells the block which code to use when processing data. In
this case, the poly2trellis function, in
Communications Toolbox, converts the constraint length and the pair of octal numbers
into a valid trellis structure.
While the message data entering the Convolutional Encoder block is a
scalar bit stream, the encoded data leaving the block is a stream of binary
vectors of length 2.
Mapping the Received Data. The received data, that is, the output of the AWGN Channel block, consists
of complex numbers that are close to -1 and 1. In order to reconstruct the
original binary message, the receiver part of the model must decode the
convolutional code. The Viterbi Decoder block in this model expects its
input data to be integers between 0 and 7. The demodulator, a custom
subsystem in this model, transforms the received data into a format that the
Viterbi Decoder block can interpret properly. More specifically, the
demodulator subsystem
-
Converts the received data signal to a real signal by removing its
imaginary part. It is reasonable to assume that the imaginary part
of the received data does not contain essential information, because
the imaginary part of the transmitted data is zero (ignoring small
roundoff errors) and because the channel noise is not very
powerful. -
Normalizes the received data by dividing by the standard deviation
of the noise estimate and then multiplying by -1. -
Quantizes the normalized data using three bits.
The combination of this mapping and the Viterbi Decoder block’s decision
mapping reverses the BPSK modulation that the BPSK Modulator Baseband block
performs on the transmitting side of this model. To examine the demodulator
subsystem in more detail, double-click the icon labeled Soft-Output BPSK
Demodulator.
Decoding the Convolutional Code. After the received data is properly mapped to length-2 vectors of 3-bit
decision values, the Viterbi Decoder block decodes it. The block uses a
soft-decision algorithm with 23 different input
values because the Decision type parameter is
Soft Decision and the Number of
soft decision bits parameter is 3.
Soft-Decision Interpretation of
Data
When the Decision type parameter is set to
Soft Decision, the Viterbi Decoder block
requires input values between 0 and 2b-1, where
b is the Number of soft decision
bits parameter. The block interprets 0 as the most confident
decision that the codeword bit is a 0 and interprets
2b-1 as the most confident decision that the
codeword bit is a 1. The values in between these extremes represent less
confident decisions. The following table lists the interpretations of the
eight possible input values for this example.
| Decision Value | Interpretation |
|---|---|
| 0 | Most confident 0 |
| 1 | Second most confident 0 |
| 2 | Third most confident 0 |
| 3 | Least confident 0 |
| 4 | Least confident 1 |
| 5 | Third most confident 1 |
| 6 | Second most confident 1 |
| 7 | Most confident 1 |
Traceback and Decoding Delay
The Traceback depth parameter in the Viterbi Decoder
block represents the length of the decoding delay. Typical values for a
traceback depth are about five or six times the constraint length, which
would be 35 or 42 in this example. However, some hardware implementations
offer options of 48 and 96. This example chooses 48 because that is closer
to the targets (35 and 42) than 96 is.
Delay in Received Data. The Receive delay parameter of the Error Rate Calculation block is
nonzero because a given message bit and its corresponding recovered bit are
separated in time by a nonzero amount of simulation time. The
Receive delay parameter tells the block which
elements of its input signals to compare when checking for errors.
In this case, the Receive delay value is equal to the Traceback depth
value (48).
Comparing Simulation Results with Theoretical Results. This section describes how to compare the bit error rate in this
simulation with the bit error rate that would theoretically result from
unquantized decoding. The process includes a few steps, described in these
sections:
Computing Theoretical Bounds for the Bit Error
Rate
To calculate theoretical bounds for the bit error rate
Pb of the convolutional code
in this model, you can use this estimate based on unquantized-decision
decoding:
In this estimate, cd is the
sum of bit errors for error events of distance d, and
f is the free distance of the code. The quantity
Pd is the pairwise error
probability, given by
where R is the code rate of 1/2, and erfc is the MATLAB complementary error function, defined by
Values for the coefficients cd
and the free distance f are in published articles such
as «Convolutional Codes with Optimum Distance Spectrum» [3]. The free distance for this code is
f = 10.
The following commands calculate the values of
Pb for
Eb/N0
values in the range from 1 to 4, in increments of 0.5:
EbNoVec = [1:0.5:4.0]; R = 1/2; % Errs is the vector of sums of bit errors for % error events at distance d, for d from 10 to 29. Errs = [36 0 211 0 1404 0 11633 0 77433 0 502690 0,... 3322763 0 21292910 0 134365911 0 843425871 0]; % P is the matrix of pairwise error probilities, for % Eb/No values in EbNoVec and d from 10 to 29. P = zeros(20,7); % Initialize. for d = 10:29 P(d-9,:) = (1/2)*erfc(sqrt(d*R*10.^(EbNoVec/10))); end % Bounds is the vector of upper bounds for the bit error % rate, for Eb/No values in EbNoVec. Bounds = Errs*P;
Simulating Multiple Times to Collect Bit Error
Rates
You can efficiently vary the simulation parameters by using the sim (Simulink) function to run the
simulation from the MATLAB command line. For example, the following code calculates the
bit error rate at bit energy-to-noise ratios ranging from 1 dB to 4 dB, in
increments of 0.5 dB. It collects all bit error rates from these simulations
in the matrix BERVec. It also plots the bit error rates
in a figure window along with the theoretical bounds computed in the
preceding code fragment.
Note
To open the model, enter doc_softdecision at the
MATLAB command line. Then execute these commands, which might
take a few minutes.
Note
The estimate for Pb
assumes that the decoder uses unquantized data, that is, an infinitely
fine quantization. By contrast, the simulation in this example uses
8-level (3-bit) quantization. Because of this quantization, the
simulated bit error rate is not quite as low as the bound when the
signal-to-noise ratio is high.
The plot of bit error rate against signal-to-noise ratio follows. The
locations of your actual BER points might vary because the simulation
involves random numbers.
Tailbiting Encoding Using Feedback Encoders
This example demonstrates Tailbiting encoding using feedback encoders. For
feedback encoders, the ending state depends on the entire block of data. To
accomplish tailbiting, you must calculate for a given information vector (of N
bits), the initial state, that leads to the same ending state after the block of
data is encoded.
This is achieved in two steps:
-
The first step is to determine the zero-state response for a given
block of data. The encoder starts in the all-zeros state. The whole
block of data is input and the output bits are ignored. After N
bits, the encoder is in a state
XN
[zs]. From this state, we calculate the
corresponding initial state
X0 and initialize the
encoder with X0. -
The second step is the actual encoding. The encoder starts with
the initial state X0, the
data block is input and a valid codeword is output which conforms to
the same state boundary condition.
Refer to [8] for a theoretical calculation of the initial state
X0 from
XN
[zs] using state-space formulation. This is a
one-time calculation which depends on the block length and in practice could be
implemented as a look-up table. Here we determine this mapping table by
simulating all possible entries for a chosen trellis and block length.
To open the model, enter doc_mtailbiting_wfeedback at the
MATLAB command line.
function mapStValues = getMapping(blkLen, trellis)
% The function returns the mapping value for the given block
length and trellis to be used for determining the initial
state from the zero-state response.
% All possible combinations of the mappings
mapStValuesTab = perms(0:trellis.numStates-1);
% Loop over all the combinations of the mapping entries:
for i = 1:length(mapStValuesTab)
mapStValues = mapStValuesTab(i,:);
% Model parameterized for the Block length
sim('mtailbiting_wfeedback');
% Check the boundary condition for each run
% if ending and starting states match, choose that mapping set
if unique(out)==0
return
end
end
Selecting the returned mapStValues for the Table
data parameter of the Direct Lookup Table block in the Lookup subsystem will perform tailbiting
(n-D)
encoding for the chosen block length and trellis.
Selected Bibliography for Convolutional Coding
[1] Clark, George C. Jr., and J. Bibb Cain,
Error-Correction Coding for Digital
Communications, New York, Plenum Press, 1981.
[2] Gitlin, Richard D., Jeremiah F. Hayes, and Stephen
B. Weinstein, Data Communications Principles, New
York, Plenum Press, 1992.
[3] Frenger, P., P. Orten, and T. Ottosson. “Convolutional Codes with Optimum Distance Spectrum.” IEEE Communications Letters 3, no. 11 (November 1999): 317–19. https://doi.org/10.1109/4234.803468.
Linear Block Codes
-
Represent Words for Linear Block Codes
-
Configure Parameters for Linear Block Codes
-
Create and Decode Linear Block Codes
Represent Words for Linear Block Codes
The cyclic, Hamming, and generic linear block code functionality in this
product offers you multiple ways to organize bits in messages or codewords.
These topics explain the available formats:
-
Use MATLAB to Create Messages and Codewords in Binary Vector
Format -
Use MATLAB to Create Messages and Codewords in Binary Matrix
Format -
Use MATLAB to Create Messages and Codewords in Decimal Vector
Format
To learn how to represent words for BCH or Reed-Solomon codes, see Represent Words for BCH Codes or Represent Words for Reed-Solomon Codes.
Use MATLAB to Create Messages and Codewords in Binary Vector
Format. Your messages and codewords can take the form of vectors containing 0s and
1s. For example, messages and codes might look like msg
and code in the lines below.
n = 6; k = 4; % Set codeword length and message length % for a [6,4] code. msg = [1 0 0 1 1 0 1 0 1 0 1 1]'; % Message is a binary column. code = encode(msg,n,k,'cyclic'); % Code will be a binary column. msg' code'
The output is below.
ans =
Columns 1 through 5
1 0 0 1 1
Columns 6 through 10
0 1 0 1 0
Columns 11 through 12
1 1
ans =
Columns 1 through 5
1 1 1 0 0
Columns 6 through 10
1 0 0 1 0
Columns 11 through 15
1 0 0 1 1
Columns 16 through 18
0 1 1
In this example, msg consists of 12 entries, which are
interpreted as three 4-digit (because k = 4)
messages. The resulting vector code comprises three
6-digit (because n = 6) codewords, which are
concatenated to form a vector of length 18. The parity bits are at the
beginning of each codeword.
Use MATLAB to Create Messages and Codewords in Binary Matrix
Format. You can organize coding information so as to emphasize the grouping of
digits into messages and codewords. If you use this approach, each message
or codeword occupies a row in a binary matrix. The example below illustrates
this approach by listing each 4-bit message on a distinct row in
msg and each 6-bit codeword on a distinct row in
code.
n = 6; k = 4; % Set codeword length and message length. msg = [1 0 0 1; 1 0 1 0; 1 0 1 1]; % Message is a binary matrix. code = encode(msg,n,k,'cyclic'); % Code will be a binary matrix. msg code
The output is below.
msg =
1 0 0 1
1 0 1 0
1 0 1 1
code =
1 1 1 0 0 1
0 0 1 0 1 0
0 1 1 0 1 1
Note
In the binary matrix format, the message matrix must have
k columns. The corresponding code matrix has
n columns. The parity bits are at the beginning
of each row.
Use MATLAB to Create Messages and Codewords in Decimal Vector
Format. Your messages and codewords can take the form of vectors containing
integers. Each element of the vector gives the decimal representation of the
bits in one message or one codeword.
Note
If 2^n or 2^k is very large, you
should use the default binary format instead of the decimal format. This
is because the function uses a binary format internally, while the
roundoff error associated with converting many bits to large decimal
numbers and back might be substantial.
Note
When you use the decimal vector format, encode
expects the leftmost bit to be the least
significant bit.
The syntax for the encode command must mention the
decimal format explicitly, as in the example below. Notice that
/decimal is appended to the fourth argument in the
encode command.
n = 6; k = 4; % Set codeword length and message length. msg = [9;5;13]; % Message is a decimal column vector. % Code will be a decimal vector. code = encode(msg,n,k,'cyclic/decimal')
The output is below.
Note
The three examples above used cyclic coding. The formats for messages
and codes are similar for Hamming and generic linear block codes.
Configure Parameters for Linear Block Codes
This subsection describes the items that you might need in order to process
[n,k] cyclic, Hamming, and generic linear block codes. The table below lists the
items and the coding techniques for which they are most relevant.
Parameters Used in Block Coding Techniques
Generator Matrix. The process of encoding a message into an [n,k] linear block code is
determined by a k-by-n generator matrix G. Specifically, the 1-by-k message
vector v is encoded into the 1-by-n codeword vector vG. If G has the form
[Ik P] or
[P Ik], where P is some k-by-(n-k) matrix and
Ik is the k-by-k identity matrix, G is said to be
in standard form. (Some authors, e.g., Clark and Cain
[2], use the first standard form, while others, e.g., Lin and Costello [3], use the second.) Most functions in this toolbox assume that a generator
matrix is in standard form when you use it as an input argument.
Some examples of generator matrices are in the next section, Parity-Check Matrix.
Parity-Check Matrix. Decoding an [n,k] linear block code requires an (n-k)-by-n parity-check
matrix H. It satisfies
GHtr = 0 (mod
2), where Htr denotes the matrix transpose of H,
G is the code’s generator matrix, and this zero matrix is k-by-(n-k). If
G = [Ik P] then
H = [-Ptr In-k].
Most functions in this product assume that a parity-check matrix is in
standard form when you use it as an input argument.
The table below summarizes the standard forms of the generator and
parity-check matrices for an [n,k] binary linear block code.
| Type of Matrix |
Standard Form |
Dimensions |
|---|---|---|
| Generator | [Ik P] or [P Ik] |
k-by-n |
| Parity-check | [-P'In-k] or [In-k -P '] |
(n-k)-by-n |
Ik is the identity matrix of size k and the
' symbol indicates matrix transpose. (For
binary codes, the minus signs in the parity-check
form listed above are irrelevant; that is, -1 = 1 in the binary
field.)
Examples
In the command below, parmat is a parity-check matrix
and genmat is a generator matrix for a Hamming code in
which
[n,k] = [23-1, n-3] = [7,4].
genmat has the standard form
[P Ik].
[parmat,genmat] = hammgen(3)
parmat =
1 0 0 1 0 1 1
0 1 0 1 1 1 0
0 0 1 0 1 1 1
genmat =
1 1 0 1 0 0 0
0 1 1 0 1 0 0
1 1 1 0 0 1 0
1 0 1 0 0 0 1
The next example finds parity-check and generator matrices for a [7,3]
cyclic code. The cyclpoly function is mentioned below
in Generator Polynomial.
genpoly = cyclpoly(7,3);
[parmat,genmat] = cyclgen(7,genpoly)
parmat =
1 0 0 0 1 1 0
0 1 0 0 0 1 1
0 0 1 0 1 1 1
0 0 0 1 1 0 1
genmat =
1 0 1 1 1 0 0
1 1 1 0 0 1 0
0 1 1 1 0 0 1
The example below converts a generator matrix for a [5,3] linear block
code into the corresponding parity-check matrix.
genmat = [1 0 0 1 0; 0 1 0 1 1; 0 0 1 0 1];
parmat = gen2par(genmat)
parmat =
1 1 0 1 0
0 1 1 0 1
The same function gen2par can also convert a
parity-check matrix into a generator matrix.
Generator Polynomial. Cyclic codes have algebraic properties that allow a polynomial to
determine the coding process completely. This so-called generator
polynomial is a degree-(n-k) divisor of the polynomial
xn-1. Van Lint [5] explains how a generator polynomial determines a cyclic code.
The cyclpoly function produces generator polynomials
for cyclic codes. cyclpoly represents a generator
polynomial using a row vector that lists the polynomial’s coefficients in
order of ascending powers of the variable. For example,
the command
genpoly = cyclpoly(7,3)
genpoly =
1 0 1 1 1
finds that one valid generator polynomial for a [7,3] cyclic code is
1 + x2 + x3 + x4.
Use Decoding Table in MATLAB
A decoding table tells a decoder how to correct errors that might have corrupted the code during transmission. Hamming codes can correct any single-symbol error in any codeword. Other codes can correct, or partially correct, errors that corrupt more than one symbol in a given codeword.
This toolbox represents a decoding table as a matrix with n columns and 2^(n—k) rows. Each row gives a correction vector for one received codeword vector. A Hamming decoding table has n+1 rows. The syndtable function generates a decoding table for a given parity-check matrix.
This example uses a Hamming decoding table to correct an error in a received message. The hammgen function produces the parity-check matrix and the syndtable function produces the decoding table. To determine the syndrome, the transpose of the parity-check matrix is multiplied on the left by the received codeword. The decoding table helps determine the correction vector. The corrected codeword is the sum (modulo 2) of the correction vector and the received codeword.
Set parameters for a [7,4] Hamming code.
m = 3; n = 2^m-1; k = n-m;
Produce a parity-check matrix and decoding table.
parmat = hammgen(m); trt = syndtable(parmat);
Specify a vector of received data.
Calculate the syndrome, and then display the decimal and binary value for the syndrome.
syndrome = rem(recd * parmat',2); syndrome_int = bit2int(syndrome',m); % Convert to decimal. disp(['Syndrome = ',num2str(syndrome_int),... ' (decimal), ',num2str(syndrome),' (binary)'])
Syndrome = 3 (decimal), 0 1 1 (binary)
Determine the correction vector by using the decoding table and syndrome, and then compute the corrected codeword by using the correction vector.
corrvect = trt(1+syndrome_int,:)
corrvect = 1×7
0 0 0 0 1 0 0
correctedcode = rem(corrvect+recd,2)
correctedcode = 1×7
1 0 0 1 0 1 1
Create and Decode Linear Block Codes
The functions for encoding and decoding cyclic, Hamming, and generic linear
block codes are encode and decode.
This section discusses how to use these functions to create and decode generic linear block
codes, cyclic codes, and
Hamming
codes.
Generic Linear Block Codes. Encoding a message using a generic linear block code requires a generator
matrix. If you have defined variables msg,
n, k, and
genmat, either of the commands
code = encode(msg,n,k,'linear',genmat); code = encode(msg,n,k,'linear/decimal',genmat);
encodes the information in msg using the
[n,k] code that the generator
matrix genmat determines. The /decimal
option, suitable when 2^n and 2^k are
not very large, indicates that msg contains nonnegative
decimal integers rather than their binary representations. See Represent Words for Linear Block Codes or the reference page
for encode for a description of
the formats of msg and code.
Decoding the code requires the generator matrix and possibly a decoding
table. If you have defined variables code,
n, k, genmat,
and possibly also trt, then the commands
newmsg = decode(code,n,k,'linear',genmat); newmsg = decode(code,n,k,'linear/decimal',genmat); newmsg = decode(code,n,k,'linear',genmat,trt); newmsg = decode(code,n,k,'linear/decimal',genmat,trt);
decode the information in code, using the
[n,k] code that the generator
matrix genmat determines. decode
also corrects errors according to instructions in the decoding table that
trt represents.
Example: Generic Linear Block
Coding
The example below encodes a message, artificially adds some noise, decodes
the noisy code, and keeps track of errors that the decoder detects along the
way. Because the decoding table contains only zeros, the decoder does not
correct any errors.
n = 4; k = 2; genmat = [[1 1; 1 0], eye(2)]; % Generator matrix msg = [0 1; 0 0; 1 0]; % Three messages, two bits each % Create three codewords, four bits each. code = encode(msg,n,k,'linear',genmat); noisycode = rem(code + randerr(3,4,[0 1;.7 .3]),2); % Add noise. trt = zeros(2^(n-k),n); % No correction of errors % Decode, keeping track of all detected errors. [newmsg,err] = decode(noisycode,n,k,'linear',genmat,trt); err_words = find(err~=0) % Find out which words had errors.
The output indicates that errors occurred in the first and second words.
Your results might vary because this example uses random numbers as
errors.
Cyclic Codes. A cyclic code is a linear block code with the property that cyclic shifts
of a codeword (expressed as a series of bits) are also codewords. An
alternative characterization of cyclic codes is based on its generator
polynomial, as mentioned in Generator Polynomial and discussed in [5].
Encoding a message using a cyclic code requires a generator polynomial. If
you have defined variables msg, n,
k, and genpoly, then either of the
commands
code = encode(msg,n,k,'cyclic',genpoly); code = encode(msg,n,k,'cyclic/decimal',genpoly);
encodes the information in msg using the
[n,k] code determined by the
generator polynomial genpoly. genpoly
is an optional argument for encode. The default
generator polynomial is cyclpoly(n,k). The
/decimal option, suitable when 2^n
and 2^k are not very large, indicates that
msg contains nonnegative decimal integers rather than
their binary representations. See Represent Words for Linear Block Codes or the reference page
for encode for a description of
the formats of msg and code.
Decoding the code requires the generator polynomial and possibly a
decoding table. If you have defined variables code,
n, k, genpoly,
and trt, then the commands
newmsg = decode(code,n,k,'cyclic',genpoly); newmsg = decode(code,n,k,'cyclic/decimal',genpoly); newmsg = decode(code,n,k,'cyclic',genpoly,trt); newmsg = decode(code,n,k,'cyclic/decimal',genpoly,trt);
decode the information in code, using the
[n,k] code that the generator
matrix genmat determines. decode
also corrects errors according to instructions in the decoding table that
trt represents. genpoly is an
optional argument in the first two syntaxes above. The default generator
polynomial is cyclpoly(n,k).
Example
You can modify the example in Generic Linear Block Codes
so that it uses the cyclic coding technique, instead of the linear block
code with the generator matrix genmat. Make the changes
listed below:
-
Replace the second line by
genpoly = [1 0 1]; % generator poly is 1 + x^2 -
In the fifth and ninth lines (
encodeand
decodecommands), replace
genmatbygenpolyand
replace'linear'by
'cyclic'.
Another example of encoding and decoding a cyclic code is on the reference
page for encode.
Hamming Codes. The reference pages for encode and decode contain examples of
encoding and decoding Hamming codes. Also, the section Use Decoding Table in MATLAB illustrates error
correction in a Hamming code.
Hamming Codes
-
Create a Hamming Code in Binary Format Using Simulink
-
Reduce the Error Rate Using a Hamming Code
Create a Hamming Code in Binary Format Using Simulink
This example shows very simply how to use an encoder and decoder. It
illustrates the appropriate vector lengths of the code and message signals for
the coding blocks. Because the Error Rate Calculation block accepts
only scalars or frame-based column vectors as the transmitted and received
signals, this example uses frame-based column vectors throughout. (It thus
avoids having to change signal attributes using a block such as Convert 1-D to 2-D.)

Open this model by entering doc_hamming at the
MATLAB command line. To build the model, gather and configure these
blocks:
-
Bernoulli Binary Generator, in
the Comm Sources library-
Set Probability of a zero to
.5. -
Set Initial seed to any positive integer
scalar, preferably the output of therandn
function. -
Check the Frame-based outputs check
box. -
Set Samples per frame to
4.
-
-
Hamming Encoder, with default
parameter values -
Hamming Decoder, with default
parameter values -
Error Rate Calculation, in
the Comm Sinks library, with default parameter values
Connect the blocks as in the preceding figure. You can display the vector
length of signals in your model. On the tab,
expand . In the
section, select . After updating the diagram, if necessary, press
Ctrl+D to compile the model and check error statistics.
The connector lines show relevant signal attributes. The connector lines are
double lines to indicate frame-based signals, and the annotations next to the
lines show that the signals are column vectors of appropriate sizes.
Reduce the Error Rate Using a Hamming Code
This section describes how to reduce the error rate by adding an
error-correcting code. This figure shows model that uses a Hamming code.

To open a complete version of the model, enter doc_hamming
at the MATLAB prompt.
Building the Hamming Code Model
You can build the Hamming code model by following these steps:
-
Type
doc_channelat the MATLAB command line to open the channel noise model.
Then save the model as
my_hammingin the folder where you keep your
work files. -
From the Simulink Library Browser drag the Hamming Encoder and
Hamming Decoder blocks
from the Error Detection and Correction/Block sublibrary into the
model window. -
Click the right border of the model and drag it to the right to
widen the model window. -
Move the Binary Symmetric Channel,
Error Rate Calculation,
and Display (Simulink) blocks to
the right by clicking and dragging. -
Create enough space between the Bernoulli Binary Generator
and Binary Symmetric Channel
blocks to fit the Hamming Encoder between
them. -
Click and drag the Hamming Encoder block on top of
the line between the Bernoulli Binary Generator
block and the Binary Symmetric Channel block, to the
right of the branch point, as shown in the following figure. Then
release the mouse button. The Hamming Encoder block should
automatically connect to the line from the Bernoulli Binary
Generator block to the Binary Symmetric
Channel block. -
Move blocks again to create enough space between the Binary Symmetric Channel
and the Error Rate Calculation
blocks to fit the Hamming Decoder between
them. -
Click and drag the Hamming Decoder block on top of
the line between the Binary Symmetric Channel block
and the Error Rate Calculation block.

The model should now resemble this figure.

Using the Hamming Encoder and Decoder
Blocks
The Hamming Encoder block encodes the data before it is sent
through the channel. The default code is the [7,4] Hamming code, which encodes
message words of length 4 into codewords of length 7. As a result, the block
converts frames of size 4 into frames of size 7. The code can correct one error
in each transmitted codeword.
For an [n,k] code, the input to the Hamming Encoder block must consist of
vectors of size k. In this example, k = 4.
The Hamming Decoder block decodes the data after it is sent
through the channel. If at most one error is created in a codeword by the
channel, the block decodes the word correctly. However, if more than one error
occurs, the Hamming Decoder block might decode
incorrectly.
To learn more about block coding features, see Block Codes.
Setting Parameters in the Hamming Code
Model
Double-click the Bernoulli Binary Generator block and make the
following changes to the parameter settings in the block’s dialog box, as shown
in the following figure:
-
Set Samples per frame to
4. This converts the output of the block into
frames of size 4, in order to meet the input requirement of the
Hamming Encoder Block. See Sample-Based and Frame-Based Processing for more
information about frames.Note
Many blocks, such as the Hamming Encoder block,
require their input to be a vector of a specific size. If you
connect a source block, such as the Bernoulli Binary
Generator block, to one of these blocks, set
Samples per frame to the required
value. For this model the Samples per frame
parameter of the Bernoulli Binary Generator block
must be a multiple of the Message Length K
parameter of the Hamming Encoder block.
Labeling the Display Block
You can change the label that appears below a block to make it more
informative. For example, to change the label below the Display block to
'Error Rate Display', first select the label with the
mouse. This causes a box to appear around the text. Enter the changes to the
text in the box.
Running the Hamming Code Model
To run the model, select >
. The model terminates after 100 errors occur.
The error rate, displayed in the top window of the Display block, is
approximately .001. You get slightly different results if you change the
Initial seed parameters in the model or run a
simulation for a different length of time.
You expect an error rate of approximately .001 for the following reason: The
probability of two or more errors occurring in a codeword of length 7 is
1 – (0.99)7 –
7(0.99)6(0.01) = 0.002
If the codewords with two or more errors are decoded randomly, you expect
about half the bits in the decoded message words to be incorrect. This indicates
that .001 is a reasonable value for the bit error rate.
To obtain a lower error rate for the same probability of error, try using a
Hamming code with larger parameters. To do this, change the parameters
Codeword length and Message length
in the Hamming Encoder and Hamming
Decoder block dialog boxes. You also have to make the appropriate
changes to the parameters of the Bernoulli Binary Generator block
and the Binary Symmetric Channel block.
Displaying Frame Sizes
You can display the sizes of data frames in different parts in your model. On
the tab, expand . In the section,
select . The line leading out of the
Bernoulli Binary Generator block is labeled
[4x1], indicating that its output consists of column
vectors of size 4. Because the Hamming Encoder block uses a [7,4]
code, it converts frames of size 4 into frames of size 7, so its output is
labeled [7x1].

Adding a Scope to the Model
To display the channel errors produced by the Binary Symmetric
Channel block, add a Scope block to the model. This
is a good way to see whether your model is functioning correctly. The example
shown in the following figure shows where to insert the Scope
block into the model.
To build this model from the one shown in the figure Reduce the Error Rate Using a Hamming Code, follow these steps:
-
Drag the following blocks from the Simulink Library Browser into
the model window:-
Relational
Operator (Simulink) block, from the Simulink Logic and Bit
Operations library -
Scope (Simulink)
block, from the Simulink Sinks library -
Two copies of the Unbuffer block,
from the Buffers sublibrary of the Signal Management library
in DSP System Toolbox™
-
-
Double-click the Binary Symmetric Channel block to
open its dialog box, and select Output error
vector. This creates a second output port for the
block, which carries the error vector. -
Double-click the Scope block, under
> , set Number of input
ports to2. Select
Layout and highlight two blocks
vertically. Click OK. -
Connect the blocks as shown in the preceding figure.
Setting Parameters in the Expanded
Model
Make the following changes to the parameters for the blocks you added to the model.
-
Error Rate Calculation Block –
Double-click the Error Rate Calculation block and clear the box next
to Stop simulation in the block’s dialog
box. -
Scope Block – The Scope (Simulink) block
displays the channel errors and uncorrected errors. To configure the block,-
Double-click the Scope block, select
>
. -
Select the Time tab and set
Time span to
5000. -
Select the Logging tab and set
Limit data points to last to
30000. -
Click OK.
-
The scope should now appear as shown.

-
To configure the axes, follow these steps:
-
Right-click the vertical axis at the left side
of the upper scope. -
In the context menu, select
. -
Set Y-limits (Minimum) to
-1. -
Set Y-limits (Maximum) to
2, and click
OK. -
Repeat the same steps for the vertical axis of
the lower scope. -
Widen the scope window until it is roughly
three times as wide as it is high. You can do this
by clicking the right border of the window and
dragging the border to the right, while pressing
the left-mouse button.
-
-
-
Relational Operator – Set
Relational Operator to
~=in the block’s dialog box. The
Relational Operator block compares the transmitted signal, coming
from the Bernoulli Random Generator block, with the received signal,
coming from the Hamming Decoder block. The block outputs a 0 when
the two signals agree and a 1 when they disagree.
Observing Channel Errors with the
Scope
When you run the model, the scope displays the error data. At the end of each
5000 time steps, the scope appears as shown this figure. The scope then clears
the displayed data and displays the next 5000 data points.
The upper scope shows the channel errors generated by the Binary Symmetric Channel block. The
lower scope shows errors that are not corrected by channel coding.
Click the Stop button on the toolbar at the top of the
model window to stop the scope.
You can see individual errors by zooming in on the scope. First click the
middle magnifying glass button at the top left of the Scope
window. Then click one of the lines in the lower scope. This zooms in
horizontally on the line. Continue clicking the lines in the lower scope until
the horizontal scale is fine enough to detect individual errors. A typical
example of what you might see is shown in the figure below.
The wider rectangular pulse in the middle of the upper scope represents two
1s. These two errors, which occur in a single codeword, are not corrected. This
accounts for the uncorrected errors in the lower scope. The narrower rectangular
pulse to the right of the upper scope represents a single error, which is
corrected.
When you are done observing the errors, select
>
.
Export Data to MATLAB explains how to send the error data to the
MATLAB workspace for more detailed analysis.
BCH Codes
-
Represent Words for BCH Codes
-
Parameters for BCH Codes
-
Create and Decode BCH Codes
-
Algorithms for BCH and RS Errors-only Decoding
Represent Words for BCH Codes
A message for an [n,k] BCH code must be
a k-column binary Galois field array. The code that
corresponds to that message is an n-column binary Galois
field array. Each row of these Galois field arrays represents one word.
The example below illustrates how to represent words for a [15, 11] BCH
code.
msg = [1 0 0 1 0; 1 0 1 1 1]; % Messages in a Galois array
obj = comm.BCHEncoder;
c1 = step(obj, msg(1,:)');
c2 = step(obj, msg(2,:)');
cbch = [c1 c2].'
The output is
Columns 1 through 5
1 0 0 1 0
1 0 1 1 1
Columns 6 through 10
0 0 1 1 1
0 0 0 0 1
Columns 11 through 15
1 0 1 0 1
0 1 0 0 1
Parameters for BCH Codes
BCH codes use special values of n and
k:
-
n, the codeword length, is an integer of the form
2m-1 for some integer
m > 2. -
k, the message length, is a positive integer less
thann. However, only some positive integers less
thannare valid choices fork.
See the BCH Encoder block reference
page for a list of some valid values ofk
corresponding to values ofnup to 511.
Create and Decode BCH Codes
The BCH Encoder and BCH Decoder System objects create and decode BCH codes, using the
data described in Represent Words for BCH Codes and Parameters for BCH Codes.
The topics are
-
Example: BCH Coding Syntaxes
-
Detect and Correct Errors in a BCH Code Using MATLAB
Example: BCH Coding Syntaxes. The example below illustrates how to encode and decode data using a
[15, 5] BCH code.
n = 15; k = 5; % Codeword length and message length msg = randi([0 1],4*k,1); % Four random binary messages % Simplest syntax for encoding enc = comm.BCHEncoder(n,k); dec = comm.BCHDecoder(n,k); c1 = step(enc,msg); % BCH encoding d1 = step(dec,c1); % BCH decoding % Check that the decoding worked correctly. chk = isequal(d1,msg) % The following code shows how to perform the encoding and decoding % operations if one chooses to prepend the parity symbols. % Steps for converting encoded data with appended parity symbols % to encoded data with prepended parity symbols c11 = reshape(c1, n, []); c12 = circshift(c11,n-k); c1_prepend = c12(:); % BCH encoded data with prepended parity symbols % Steps for converting encoded data with prepended parity symbols % to encoded data with appended parity symbols prior to decoding c21 = reshape(c1_prepend, n, []); c22 = circshift(c21,k); c1_append = c22(:); % BCH encoded data with appended parity symbols % Check that the prepend-to-append conversion worked correctly. d1_append = step(dec,c1_append); chk = isequal(msg,d1_append)
The output is below.
Detect and Correct Errors in a BCH Code Using MATLAB. The following example illustrates the decoding results for a corrupted
code. The example encodes some data, introduces errors in each codeword, and
attempts to decode the noisy code using the BCH
Decoder
System object.
n = 15; k = 5; % Codeword length and message length [gp,t] = bchgenpoly(n,k); % t is error-correction capability. nw = 4; % Number of words to process msgw = randi([0 1], nw*k, 1); % Random k-symbol messages enc = comm.BCHEncoder(n,k,gp); dec = comm.BCHDecoder(n,k,gp); c = step(enc, msgw); % Encode the data. noise = randerr(nw,n,t); % t errors per codeword noisy = noise'; noisy = noisy(:); cnoisy = mod(c + noisy,2); % Add noise to the code. [dc, nerrs] = step(dec, cnoisy); % Decode cnoisy. % Check that the decoding worked correctly. chk2 = isequal(dc,msgw) nerrs % Find out how many errors have been corrected.
Notice that the array of noise values contains binary values, and that the
addition operation c + noise takes place in the
Galois field GF(2) because c is a Galois field array in
GF(2).
The output from the example is below. The nonzero value of
ans indicates that the decoder was able to correct
the corrupted codewords and recover the original message. The values in the
vector nerrs indicate that the decoder corrected
t errors in each codeword.
Excessive Noise in BCH Codewords
In the previous example, the BCH Decoder
System object corrected all the errors. However, each BCH code has a finite
error-correction capability. To learn more about how the BCH Decoder
System object behaves when the noise is excessive, see the analogous
discussion for Reed-Solomon codes in Excessive Noise in Reed-Solomon Codewords.
Algorithms for BCH and RS Errors-only Decoding
Overview. The errors-only decoding algorithm used for BCH and RS codes can be
described by the following steps (sections 5.3.2, 5.4, and 5.6 in [2]).
-
Calculate the first 2t terms of the infinite
degree syndrome polynomial, S(z). -
If those 2t terms of S(z) are all equal to 0, then the code has no errors ,
no correction needs to be performed, and the decoding algorithm
ends. -
If one or more terms of S(z) are nonzero, calculate the error locator
polynomial, Λ(z), via the Berlekamp
algorithm. -
Calculate the error evaluator polynomial, Ω(z), via
-
Correct an error in the codeword according to
where eim is the error magnitude in the imth position in the codeword, m
is a value less than the error-correcting capability of the code, Ω(z) is the error magnitude polynomial,
Λ'(z) is the formal derivative [5] of the error locator polynomial, Λ(z), and α
is the primitive element of the Galois field of the code.
Further description of several of the steps is given in the following
sections.
Syndrome Calculation. For narrow-sense codes, the 2t terms of S(z) are calculated by evaluating the received codeword at
successive powers of α (the field’s primitive element) from 0 to
2t-1. In other words, if we assume one-based indexing
of codewords C(z) and the syndrome polynomial S(z), and that codewords are of the form [c1 c1 … cN], then each term Si of S(z) is given as
Error Locator Polynomial Calculation. The error locator polynomial, Λ(z), is found using the
Berlekamp algorithm. A complete description of this algorithm is found in
[2], but we summarize the algorithm as follows.
We define the following variables.
| Variable | Description |
|---|---|
| n | Iterator variable |
| k | Iterator variable |
| L | Length of the feedback register used to generate the first 2t terms of S(z) |
| D(z) | Correction polynomial |
| d | Discrepancy |
The following diagram shows the iterative procedure (i.e., the Berlekamp
algorithm) used to find Λ(z).
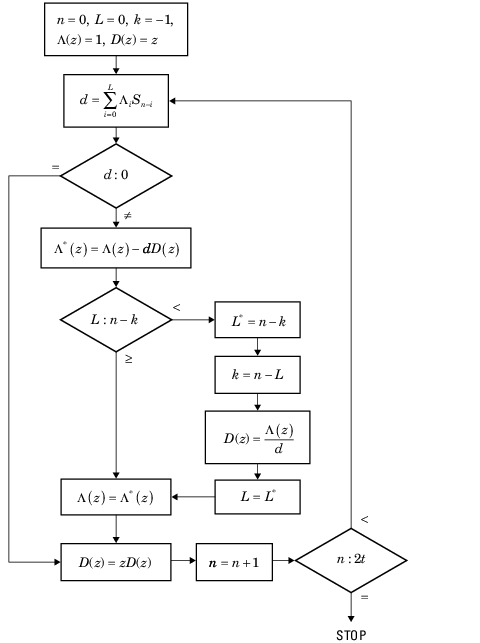
Error Evaluator Polynomial Calculation. The error evaluator polynomial, Ω(z), is simply the convolution of Λ(z) and S(z).
Reed-Solomon Codes
-
Represent Words for Reed-Solomon Codes
-
Parameters for Reed-Solomon Codes
-
Create and Decode Reed-Solomon Codes
-
Find a Generator Polynomial
-
Reed Solomon Examples with Shortening, Puncturing, and Erasures
Represent Words for Reed-Solomon Codes
This toolbox supports Reed-Solomon codes that use m-bit symbols instead of
bits. A message for an [n,k] Reed-Solomon
code must be a k-column Galois field array in the field
GF(2m). Each array entry must be an integer
between 0 and 2m-1. The code corresponding to that
message is an n-column Galois field array in
GF(2m). The codeword length n
must be between 3 and 2m-1.
The example below illustrates how to represent words for a [7,3] Reed-Solomon
code.
n = 7; k = 3; % Codeword length and message length m = 3; % Number of bits in each symbol msg = [1 6 4; 0 4 3]; % Message is a Galois array. obj = comm.RSEncoder(n, k); c1 = step(obj, msg(1,:)'); c2 = step(obj, msg(2,:)'); c = [c1 c2].'
The output is
C =
1 6 4 4 3 6 3
0 4 3 3 7 4 7
Parameters for Reed-Solomon Codes
This section describes several integers related to Reed-Solomon codes and
discusses how to find generator
polynomials.
Allowable Values of Integer Parameters. The table below summarizes the meanings and allowable values of some
positive integer quantities related to Reed-Solomon codes as supported in
this toolbox. The quantities n and k
are input parameters for Reed-Solomon functions in this toolbox.
| Symbol | Meaning | Value or Range |
|---|---|---|
| m | Number of bits per symbol | Integer between 3 and 16 |
n
|
Number of symbols per codeword | Integer between 3 and 2m-1 |
k |
Number of symbols per message | Positive integer less thann, such thatn-k is even |
| t | Error-correction capability of the code |
(n-k)/2 |
Generator Polynomial. The rsgenpoly function produces generator polynomials
for Reed-Solomon codes. rsgenpoly represents a
generator polynomial using a Galois row vector that lists the polynomial’s
coefficients in order of descending powers of the
variable. If each symbol has m bits, the Galois row vector is in the field
GF(2m). For example, the command
r = GF(2^4) array. Primitive polynomial = D^4+D+1 (19 decimal)
Array elements =
1 6 8
finds that one generator polynomial for a [15,13] Reed-Solomon code is
X2 + (A2 + A)X + (A3),
where A is a root of the default primitive polynomial for GF(16).
Algebraic Expression for Generator
Polynomials
The generator polynomials that rsgenpoly produces
have the form
(X — Ab)(X — Ab+1)…(X — Ab+2t-1),
where b is an integer, A is a root of the primitive polynomial for the
Galois field, and t is (n-k)/2. The default value of b is
1. The output from rsgenpoly is the result of
multiplying the factors and collecting like powers of X. The example below
checks this formula for the case of a [15,13] Reed-Solomon code, using
b = 1.
n = 15; a = gf(2,log2(n+1)); % Root of primitive polynomial f1 = [1 a]; f2 = [1 a^2]; % Factors that form generator polynomial f = conv(f1,f2) % Generator polynomial, same as r above.
Create and Decode Reed-Solomon Codes
The RS Encoder and RS Decoder System objects create and decode Reed-Solomon codes,
using the data described in Represent Words for Reed-Solomon Codes and Parameters for Reed-Solomon Codes.
This section illustrates how to use the RS and
EncoderRS Decoder System
objects. The topics are
-
Reed-Solomon Coding Syntaxes in MATLAB
-
Detect and Correct Errors in a Reed-Solomon Code Using MATLAB
-
Excessive Noise in Reed-Solomon Codewords
-
Create Shortened Reed-Solomon Codes
Reed-Solomon Coding Syntaxes in MATLAB. The example below illustrates multiple ways to encode and decode data
using a [15,13] Reed-Solomon code. The example shows that you can
-
Vary the generator polynomial for the code, using
rsgenpolyto produce a different generator
polynomial. -
Vary the primitive polynomial for the Galois field that contains
the symbols, using an input argument in
gf. -
Vary the position of the parity symbols within the codewords,
choosing either the end (default) or beginning.
This example also shows that corresponding syntaxes of the RS Encoder and RS System objects use the same input arguments, except
Decoder
for the first input argument.
m = 4; % Number of bits in each symbol n = 2^m-1; k = 13; % Codeword length and message length msg = randi([0 m-1],4*k,1); % Four random integer messages % Simplest syntax for encoding hEnc = comm.RSEncoder(n,k); hDec = comm.RSDecoder(n,k); c1 = step(hEnc, msg); d1 = step(hDec, c1); % Vary the generator polynomial for the code. release(hEnc), release(hDec) hEnc.GeneratorPolynomialSource = 'Property'; hDec.GeneratorPolynomialSource = 'Property'; hEnc.GeneratorPolynomial = rsgenpoly(n,k,19,2); hDec.GeneratorPolynomial = rsgenpoly(n,k,19,2); c2 = step(hEnc, msg); d2 = step(hDec, c2); % Vary the primitive polynomial for GF(16). release(hEnc), release(hDec) hEnc.PrimitivePolynomialSource = 'Property'; hDec.PrimitivePolynomialSource = 'Property'; hEnc.GeneratorPolynomialSource = 'Auto'; hDec.GeneratorPolynomialSource = 'Auto'; hEnc.PrimitivePolynomial = [1 1 0 0 1]; hDec.PrimitivePolynomial = [1 1 0 0 1]; c3 = step(hEnc, msg); d3 = step(hDec, c3); % Check that the decoding worked correctly. chk = isequal(d1,msg) & isequal(d2,msg) & isequal(d3,msg) % The following code shows how to perform the encoding and decoding % operations if one chooses to prepend the parity symbols. % Steps for converting encoded data with appended parity symbols % to encoded data with prepended parity symbols c31 = reshape(c3, n, []); c32 = circshift(c31,n-k); c3_prepend = c32(:); % RS encoded data with prepended parity symbols % Steps for converting encoded data with prepended parity symbols % to encoded data with appended parity symbols prior to decoding c34 = reshape(c3_prepend, n, []); c35 = circshift(c34,k); c3_append = c35(:); % RS encoded data with appended parity symbols % Check that the prepend-to-append conversion worked correctly. d3_append = step(hDec,c3_append); chk = isequal(msg,d3_append)
The output is
Detect and Correct Errors in a Reed-Solomon Code Using MATLAB. The example below illustrates the decoding results for a corrupted code.
The example encodes some data, introduces errors in each codeword, and
attempts to decode the noisy code using the RS
Decoder
System object.
m = 3; % Number of bits per symbol n = 2^m-1; k = 3; % Codeword length and message length t = (n-k)/2; % Error-correction capability of the code nw = 4; % Number of words to process msgw = randi([0 n],nw*k,1); % Random k-symbol messages hEnc = comm.RSEncoder(n,k); hDec = comm.RSDecoder(n,k); c = step(hEnc, msgw); % Encode the data. noise = (1+randi([0 n-1],nw,n)).*randerr(nw,n,t); % t errors per codeword noisy = noise'; noisy = noisy(:); cnoisy = gf(c,m) + noisy; % Add noise to the code under gf(m) arithmetic. [dc nerrs] = step(hDec, cnoisy.x); % Decode the noisy code. % Check that the decoding worked correctly. isequal(dc,msgw) nerrs % Find out how many errors hDec corrected.
The array of noise values contains integers between 1 and
2^m, and the addition operation
c + noise takes place in the Galois field
GF(2^m) because c is a Galois
field array in GF(2^m).
The output from the example is below. The nonzero value of
ans indicates that the decoder was able to correct
the corrupted codewords and recover the original message. The values in the
vector nerrs indicates that the decoder corrected
t errors in each codeword.
Excessive Noise in Reed-Solomon Codewords. In the previous example, RS Encoder
System object corrected all of the errors. However, each Reed-Solomon code
has a finite error-correction capability. If the noise is so great that the
corrupted codeword is too far in Hamming distance from the correct codeword,
that means either
-
The corrupted codeword is close to a valid codeword
other than the correct codeword. The
decoder returns the message that corresponds to the other
codeword. -
The corrupted codeword is not close enough to any codeword for
successful decoding. This situation is called a decoding
failure. The decoder removes the symbols in parity
positions from the corrupted codeword and returns the remaining
symbols.
In both cases, the decoder returns the wrong message. However, you can
tell when a decoding failure occurs because RS
Decoder
System object also returns a value of -1 in its second
output.
To examine cases in which codewords are too noisy for successful decoding,
change the previous example so that the definition of
noise is
noise = (1+randi([0 n-1],nw,n)).*randerr(nw,n,t+1); % t+1 errors/row
Create Shortened Reed-Solomon Codes. Every Reed-Solomon encoder uses a codeword length that equals
2m-1 for an integer m. A shortened
Reed-Solomon code is one in which the codeword length is not
2m-1. A shortened
[n,k] Reed-Solomon code implicitly
uses an [n1,k1] encoder, where
-
n1 = 2m — 1,
where m is the number of bits per symbol -
k1 = k + (n1 —
n)
The RS Encoder
System object supports shortened codes using the same syntaxes it uses for
nonshortened codes. You do not need to indicate explicitly that you want to
use a shortened code.
hEnc = comm.RSEncoder(7,5); ordinarycode = step(hEnc,[1 1 1 1 1]'); hEnc = comm.RSEncoder(5,3); shortenedcode = step(hEnc,[1 1 1 ]');
How the RS Encoder
System Object Creates a Shortened Code
When creating a shortened code, the RS
Encoder
System object performs these steps:
-
Pads each message by prepending zeros
-
Encodes each padded message using a Reed-Solomon encoder having an
allowable codeword length and the desired error-correction
capability -
Removes the extra zeros from the nonparity symbols of each
codeword
The following example illustrates this process.
n = 12; k = 8; % Lengths for the shortened code m = ceil(log2(n+1)); % Number of bits per symbol msg = randi([0 2^m-1],3*k,1); % Random array of 3 k-symbol words hEnc = comm.RSEncoder(n,k); code = step(hEnc, msg); % Create a shortened code. % Do the shortening manually, just to show how it works. n_pad = 2^m-1; % Codeword length in the actual encoder k_pad = k+(n_pad-n); % Messageword length in the actual encoder hEnc = comm.RSEncoder(n_pad,k_pad); mw = reshape(msg,k,[]); % Each column vector represents a messageword msg_pad = [zeros(n_pad-n,3); mw]; % Prepend zeros to each word. msg_pad = msg_pad(:); code_pad = step(hEnc,msg_pad); % Encode padded words. cw = reshape(code_pad,2^m-1,[]); % Each column vector represents a codeword code_eqv = cw(n_pad-n+1:n_pad,:); % Remove extra zeros. code_eqv = code_eqv(:); ck = isequal(code_eqv,code); % Returns true (1).
Find a Generator Polynomial
To find a generator polynomial for a cyclic, BCH, or Reed-Solomon code, use
the cyclpoly, bchgenpoly, or
rsgenpoly function, respectively. The commands
genpolyCyclic = cyclpoly(15,5) % 1+X^5+X^10 genpolyBCH = bchgenpoly(15,5) % x^10+x^8+x^5+x^4+x^2+x+1 genpolyRS = rsgenpoly(15,5)
find generator polynomials for block codes of different types. The output is
below.
genpolyCyclic =
1 0 0 0 0 1 0 0 0 0 1
genpolyBCH = GF(2) array.
Array elements =
1 0 1 0 0 1 1 0 1 1 1
genpolyRS = GF(2^4) array. Primitive polynomial = D^4+D+1 (19 decimal)
Array elements =
1 4 8 10 12 9 4 2 12 2 7
The formats of these outputs vary:
-
cyclpolyrepresents a generator polynomial using
an integer row vector that lists the polynomial’s coefficients in order
of ascending powers of the variable. -
bchgenpolyandrsgenpoly
represent a generator polynomial using a Galois row vector that lists
the polynomial’s coefficients in order of
descending powers of the variable. -
rsgenpolyuses coefficients in a Galois field
other than the binary field GF(2). For more information on the meaning
of these coefficients, see How Integers Correspond to Galois Field Elements and Polynomials over Galois Fields.
Nonuniqueness of Generator Polynomials. Some pairs of message length and codeword length do not uniquely determine
the generator polynomial. The syntaxes for functions in the example above
also include options for retrieving generator polynomials that satisfy
certain constraints that you specify. See the functions’ reference pages for
details about syntax options.
Algebraic Expression for Generator Polynomials. The generator polynomials produced by bchgenpoly and
rsgenpoly have the form
(X — Ab)(X — Ab+1)…(X — Ab+2t-1),
where A is a primitive element for an appropriate Galois field, and b and t
are integers. See the functions’ reference pages for more information about
this expression.
Reed Solomon Examples with Shortening, Puncturing, and Erasures
In this section, a representative example of Reed Solomon coding with
shortening, puncturing, and erasures is built with increasing complexity of
error correction.
Encoder Example with Shortening and Puncturing. The following figure shows a representative example of a (7,3) Reed
Solomon encoder with shortening and puncturing.
In this figure, the message source outputs two information symbols,
designated by I1I2. (For a BCH
example, the symbols are simply binary bits.) Because the code is a
shortened (7,3) code, a zero must be added ahead of the information symbols,
yielding a three-symbol message of
0I1I2. The modified
message sequence is then RS encoded, and the added information zero is
subsequently removed, which yields a result of
I1I2P1P2P3P4.
(In this example, the parity bits are at the end of the codeword.)
The puncturing operation is governed by the puncture vector, which, in
this case, is 1011. Within the puncture vector, a 1 means that the symbol is
kept, and a 0 means that the symbol is thrown away. In this example, the
puncturing operation removes the second parity symbol, yielding a final
vector of
I1I2P1P3P4.
Decoder Example with Shortening and Puncturing. The following figure shows how the RS encoder operates on a shortened and
punctured codeword.
This case corresponds to the encoder operations shown in the figure of the
RS encoder with shortening and puncturing. As shown in the preceding figure,
the encoder receives a (5,2) codeword, because it has been shortened from a
(7,3) codeword by one symbol, and one symbol has also been punctured.
As a first step, the decoder adds an erasure, designated by E, in the
second parity position of the codeword. This corresponds to the puncture
vector 1011. Adding a zero accounts for shortening, in the same way as shown
in the preceding figure. The single erasure does not exceed the
erasure-correcting capability of the code, which can correct four erasures.
The decoding operation results in the three-symbol message
DI1I2. The first symbol is
truncated, as in the preceding figure, yielding a final output of
I1I2.
Encoder Example with Shortening, Puncturing, and Erasures. The following figure shows the decoder operating on the punctured,
shortened codeword, while also correcting erasures generated by the
receiver.
In this figure, demodulator receives the
I1I2P1P3P4
vector that the encoder sent. The demodulator declares that two of the five
received symbols are unreliable enough to be erased, such that symbols 2 and
5 are deemed to be erasures. The 01001 vector, provided by an external
source, indicates these erasures. Within the erasures vector, a 1 means that
the symbol is to be replaced with an erasure symbol, and a 0 means that the
symbol is passed unaltered.
The decoder blocks receive the codeword and the erasure vector, and
perform the erasures indicated by the vector 01001. Within the erasures
vector, a 1 means that the symbol is to be replaced with an erasure symbol,
and a 0 means that the symbol is passed unaltered. The resulting codeword
vector is
I1EP1P3E,
where E is an erasure symbol.
The codeword is then depunctured, according to the puncture vector used in
the encoding operation (i.e., 1011). Thus, an erasure symbol is inserted
between P1 and P3, yielding a
codeword vector of
I1EP1EP3E.
Just prior to decoding, the addition of zeros at the beginning of the
information vector accounts for the shortening. The resulting vector is
0I1EP1EP3E,
such that a (7,3) codeword is sent to the Berlekamp algorithm.
This codeword is decoded, yielding a three-symbol message of
DI1I2 (where D refers to a
dummy symbol). Finally, the removal of the D symbol from the message vector
accounts for the shortening and yields the original
I1I2 vector.
For additional information, see the Reed-Solomon Coding with Erasures, Punctures, and Shortening in Simulink
example.
LDPC Codes
Low-Density Parity-Check (LDPC) codes are linear error control codes with:
-
Sparse parity-check matrices
-
Long block lengths that can attain performance near the Shannon limit
(see LDPC Encoder and LDPC Decoder)
Communications Toolbox performs LDPC Coding using Simulink blocks and MATLAB objects.
The decoding process is done iteratively. If the number of iterations is too
small, the algorithm may not converge. You may need to experiment with the number of
iterations to find an appropriate value for your model. For details on the decoding
algorithm, see Decoding
Algorithm.
Unlike some other codecs, you cannot connect an LDPC decoder directly to the
output of an LDPC encoder, because the decoder requires log-likelihood ratios (LLR).
Thus, you may use a demodulator to compute the LLRs.

Also, unlike other decoders, it is possible (although rare) that the output of the
LDPC decoder does not satisfy all parity checks.
Galois Field Computations
A Galois field is an algebraic field that has a finite number
of members. Galois fields having 2m members are used in
error-control coding and are denoted GF(2m). This section
describes how to work with fields that have 2m members,
where m is an integer between 1 and 16. The subsections in this section are as
follows.
-
Galois Field Terminology
-
Representing Elements of Galois Fields
-
Arithmetic in Galois Fields
-
Logical Operations in Galois Fields
-
Matrix Manipulation in Galois Fields
-
Linear Algebra in Galois Fields
-
Signal Processing Operations in Galois Fields
-
Polynomials over Galois Fields
-
Manipulating Galois Variables
-
Speed and Nondefault Primitive Polynomials
-
Selected Bibliography for Galois Fields
If you need to use Galois fields having an odd number of elements, see Galois Fields of Odd Characteristic.
For more details about specific functions that process arrays of Galois field
elements, see the online reference pages in the documentation for MATLAB or for Communications Toolbox software.
Note
Please note that the Galois field objects do not support the copy method.
MATLAB functions whose generalization to Galois fields is straightforward to
describe do not have reference pages in this manual because the entries would be
identical to those in the MATLAB documentation.
Galois Field Terminology
The discussion of Galois fields in this document uses a few terms that are not
used consistently in the literature. The definitions adopted here appear in van
Lint [4]:
-
A primitive element of
GF(2m) is a cyclic generator of the group
of nonzero elements of GF(2m). This means
that every nonzero element of the field can be expressed as the
primitive element raised to some integer power. -
A primitive polynomial for
GF(2m) is the minimal polynomial of some
primitive element of GF(2m). It is the
binary-coefficient polynomial of smallest nonzero degree having a
certain primitive element as a root in
GF(2m). As a consequence, a primitive
polynomial has degree m and is irreducible.
The definitions imply that a primitive element is a root of a corresponding
primitive polynomial.
Representing Elements of Galois Fields
-
Section Overview
-
Creating a Galois field array
-
Example: Creating Galois Field Variables
-
Example: Representing Elements of GF(8)
-
How Integers Correspond to Galois Field Elements
-
Example: Representing a Primitive Element
-
Primitive Polynomials and Element Representations
Section Overview. This section describes how to create a Galois field
array, which is a MATLAB expression that represents the elements of a Galois field.
This section also describes how MATLAB technical computing software interprets the numbers that you
use in the representation, and includes several examples.
Creating a Galois field array. To begin working with data from a Galois field GF(2^m),
you must set the context by associating the data with crucial information
about the field. The gf function performs this
association and creates a Galois field array in MATLAB. This function accepts as inputs
-
The Galois field data,
x, which is a
MATLAB array whose elements are integers between 0 and
2^m-1. -
(Optional) An integer,
m,
that indicatesxis in the field
GF(2^m). Valid values ofm
are between 1 and 16. The default is 1, which means that the field
is GF(2). -
(Optional) A positive integer that indicates
which primitive polynomial for GF(2^m) you are
using in the representations inx. If you omit
this input argument,gfuses a default
primitive polynomial for GF(2^m). For information
about this argument, see Primitive Polynomials and Element Representations.
The output of the gf function is a variable that
MATLAB recognizes as a Galois field array, rather than an array of
integers. As a result, when you manipulate the variable, MATLAB works within the Galois field you have specified. For example,
if you apply the log function to a Galois field array,
MATLAB computes the logarithm in the Galois field and
not in the field of real or complex numbers.
When MATLAB Implicitly Creates a Galois field
array
Some operations on Galois field arrays require multiple arguments. If you
specify one argument that is a Galois field array and another that is an
ordinary MATLAB array, MATLAB interprets both as Galois field arrays in the same field. It
implicitly invokes the gf function on the ordinary
MATLAB array. This implicit invocation simplifies your syntax because
you can omit some references to the gf function. For an
example of the simplification, see Example: Addition and Subtraction.
Example: Creating Galois Field Variables. The code below creates a row vector whose entries are in the field GF(4),
and then adds the row to itself.
x = 0:3; % A row vector containing integers m = 2; % Work in the field GF(2^2), or, GF(4). a = gf(x,m) % Create a Galois array in GF(2^m). b = a + a % Add a to itself, creating b.
The output is
a = GF(2^2) array. Primitive polynomial = D^2+D+1 (7 decimal)
Array elements =
0 1 2 3
b = GF(2^2) array. Primitive polynomial = D^2+D+1 (7 decimal)
Array elements =
0 0 0 0
The output shows the values of the Galois field arrays named
a and b. Each output section
indicates
-
The field containing the variable, namely, GF(2^2) = GF(4).
-
The primitive polynomial for the field. In this case, it is the
toolbox’s default primitive polynomial for GF(4). -
The array of Galois field values that the variable contains. In
particular, the array elements inaare exactly
the elements of the vectorx, and the array
elements inbare four instances of the zero
element in GF(4).
The command that creates b shows how, having defined
the variable a as a Galois field array, you can add
a to itself by using the ordinary
+ operator. MATLAB performs the vectorized addition operation in the field GF(4).
The output shows that
-
Compared to
a,bis in the
same field and uses the same primitive polynomial. It is not
necessary to indicate the field when defining the sum,
b, because MATLAB remembers that information from the definition of the
addends,a. -
The array elements of
bare zeros because the
sum of any value with itself, in a Galois field of
characteristic two, is zero. This result differs from
the sumx + x, which represents an addition
operation in the infinite field of integers.
Example: Representing Elements of GF(8). To illustrate what the array elements in a Galois field array mean, the
table below lists the elements of the field GF(8) as integers and as
polynomials in a primitive element, A. The table should help you interpret a
Galois field array like
gf8 = gf([0:7],3); % Galois vector in GF(2^3)
| Integer Representation | Binary Representation | Element of GF(8) |
|---|---|---|
| 0 | 000 | 0 |
| 1 | 001 | 1 |
| 2 | 010 | A |
| 3 | 011 | A + 1 |
| 4 | 100 | A2 |
| 5 | 101 | A2 + 1 |
| 6 | 110 | A2 + A |
| 7 | 111 | A2 + A + 1 |
How Integers Correspond to Galois Field Elements. Building on the GF(8) example
above, this section explains the interpretation of array elements
in a Galois field array in greater generality. The field
GF(2^m) has 2^m distinct elements,
which this toolbox labels as 0, 1, 2,…, 2^m-1. These
integer labels correspond to elements of the Galois field via a polynomial
expression involving a primitive element of the field. More specifically,
each integer between 0 and 2^m-1 has a binary
representation in m bits. Using the bits in the binary
representation as coefficients in a polynomial, where the least significant
bit is the constant term, leads to a binary polynomial whose order is at
most m-1. Evaluating the binary polynomial at a primitive
element of GF(2^m) leads to an element of the
field.
Conversely, any element of GF(2^m) can be expressed as
a binary polynomial of order at most m-1, evaluated at a
primitive element of the field. The m-tuple of
coefficients of the polynomial corresponds to the binary representation of
an integer between 0 and 2^m.
Below is a symbolic illustration of the correspondence of an integer
X, representable in binary form, with a Galois field
element. Each bk is either zero or
one, while A is a primitive element.
Example: Representing a Primitive Element. The code below defines a variable alph that represents
a primitive element of the field GF(24).
m = 4; % Or choose any positive integer value of m. alph = gf(2,m) % Primitive element in GF(2^m)
The output is
alph = GF(2^4) array. Primitive polynomial = D^4+D+1 (19 decimal)
Array elements =
2
The Galois field array alph represents a primitive
element because of the correspondence among
-
The integer 2, specified in the
gf
syntax -
The binary representation of 2, which is 10 (or 0010 using four
bits) -
The polynomial A + 0, where A is a primitive element in this field
(or 0A3 + 0A2
+ A + 0 using the four lowest powers of A)
Primitive Polynomials and Element Representations. This section builds on the discussion in Creating a Galois field array by describing how to specify your own
primitive polynomial when you create a Galois field array. The topics
are
If you perform many computations using a nondefault primitive polynomial,
see Speed and Nondefault Primitive Polynomials.
Specifying the Primitive
Polynomial
The discussion in How Integers Correspond to Galois Field Elements refers to a
primitive element, which is a root of a primitive polynomial of the field.
When you use the gf function to create a Galois field
array, the function interprets the integers in the array with respect to a
specific default primitive polynomial for that field, unless you explicitly
provide a different primitive polynomial. A list of the default primitive
polynomials is on the reference page for the gf function.
To specify your own primitive polynomial when creating a Galois field
array, use a syntax like
c = gf(5,4,25) % 25 indicates the primitive polynomial for GF(16).
instead of
c1= gf(5,4); % Use default primitive polynomial for GF(16).
The extra input argument, 25 in this case, specifies
the primitive polynomial for the field GF(2^m) in a way
similar to the representation described in How Integers Correspond to Galois Field Elements. In this case,
the integer 25 corresponds to a binary representation of 11001, which in
turn corresponds to the polynomial
D4 + D3 + 1.
Note
When you specify the primitive polynomial, the input argument must
have a binary representation using exactly m+1 bits,
not including unnecessary leading zeros. In other words, a primitive
polynomial for GF(2^m) always has order
m.
When you use an input argument to specify the primitive polynomial, the
output reflects your choice by showing the integer value as well as the
polynomial representation.
d = GF(2^4) array. Primitive polynomial = D^4+D^3+1 (25 decimal)
Array elements =
1 2 3
Note
After you have defined a Galois field array, you cannot change the
primitive polynomial with respect to which MATLAB interprets the array elements.
Finding Primitive
Polynomials
You can use the primpoly function to find primitive
polynomials for GF(2^m) and the
isprimitive function to determine whether a
polynomial is primitive for GF(2^m). The code below
illustrates.
m = 4; defaultprimpoly = primpoly(m) % Default primitive poly for GF(16) allprimpolys = primpoly(m,'all') % All primitive polys for GF(16) i1 = isprimitive(25) % Can 25 be the prim_poly input in gf(...)? i2 = isprimitive(21) % Can 21 be the prim_poly input in gf(...)?
The output is below.
Primitive polynomial(s) =
D^4+D^1+1
defaultprimpoly =
19
Primitive polynomial(s) =
D^4+D^1+1
D^4+D^3+1
allprimpolys =
19
25
i1 =
1
i2 =
0
Effect of Nondefault Primitive Polynomials on
Numerical Results
Most fields offer multiple choices for the primitive polynomial that helps
define the representation of members of the field. When you use the
gf function, changing the primitive polynomial
changes the interpretation of the array elements and, in turn, changes the
results of some subsequent operations on the Galois field array. For
example, exponentiation of a primitive element makes it easy to see how the
primitive polynomial affects the representations of field elements.
a11 = gf(2,3); % Use default primitive polynomial of 11. a13 = gf(2,3,13); % Use D^3+D^2+1 as the primitive polynomial. z = a13.^3 + a13.^2 + 1 % 0 because a13 satisfies the equation nz = a11.^3 + a11.^2 + 1 % Nonzero. a11 does not satisfy equation.
The output below shows that when the primitive polynomial has integer
representation 13, the Galois field array satisfies a
certain equation. By contrast, when the primitive polynomial has integer
representation 11, the Galois field array fails to
satisfy the equation.
z = GF(2^3) array. Primitive polynomial = D^3+D^2+1 (13 decimal)
Array elements =
0
nz = GF(2^3) array. Primitive polynomial = D^3+D+1 (11 decimal)
Array elements =
6
The output when you try this example might also include a warning about
lookup tables. This is normal if you did not use the
gftable function to optimize computations involving
a nondefault primitive polynomial of 13.
Arithmetic in Galois Fields
-
Section Overview
-
Example: Addition and Subtraction
-
Example: Multiplication
-
Example: Division
-
Example: Exponentiation
-
Example: Elementwise Logarithm
Section Overview. You can perform arithmetic operations on Galois field arrays by using
familiar MATLAB operators, listed in the table below. Whenever you operate on
a pair of Galois field arrays, both arrays must be in the same Galois field.
| Operation | Operator |
|---|---|
| Addition | +
|
| Subtraction | -
|
| Elementwise multiplication | .*
|
| Matrix multiplication | *
|
| Elementwise left division | ./
|
| Elementwise right division | .
|
| Matrix left division | /
|
| Matrix right division | |
| Elementwise exponentiation | .^
|
| Elementwise logarithm | log()
|
| Exponentiation of a square Galois matrix by a scalar integer |
^
|
For multiplication and division of polynomials over a Galois field, see
Addition and Subtraction of Polynomials.
Example: Addition and Subtraction. The code below adds two Galois field arrays to create an addition table
for GF(8). Addition uses the ordinary + operator. The
code below also shows how to index into the array addtb
to find the result of adding 1 to the elements of GF(8).
m = 3; e = repmat([0:2^m-1],2^m,1); f = gf(e,m); % Create a Galois array. addtb = f + f' % Add f to its own matrix transpose. addone = addtb(2,:); % Assign 2nd row to the Galois vector addone.
The output is below.
addtb = GF(2^3) array. Primitive polynomial = D^3+D+1 (11 decimal)
Array elements =
0 1 2 3 4 5 6 7
1 0 3 2 5 4 7 6
2 3 0 1 6 7 4 5
3 2 1 0 7 6 5 4
4 5 6 7 0 1 2 3
5 4 7 6 1 0 3 2
6 7 4 5 2 3 0 1
7 6 5 4 3 2 1 0
As an example of reading this addition table, the (7,4) entry in the
addtb array shows that gf(6,3)
plus gf(3,3) equals gf(5,3).
Equivalently, the element A2+A plus the element
A+1 equals the element A2+1. The equivalence
arises from the binary representation of 6 as 110, 3 as 011, and 5 as
101.
The subtraction table, which you can obtain by replacing
+ by -, is the same as
addtb. This is because subtraction and addition are
identical operations in a field of characteristic two.
In fact, the zeros along the main diagonal of addtb
illustrate this fact for GF(8).
Simplifying the Syntax
The code below illustrates scalar expansion and the implicit creation of a
Galois field array from an ordinary MATLAB array. The Galois field arrays h and
h1 are identical, but the creation of
h uses a simpler syntax.
g = gf(ones(2,3),4); % Create a Galois array explicitly. h = g + 5; % Add gf(5,4) to each element of g. h1 = g + gf(5*ones(2,3),4) % Same as h.
The output is below.
h1 = GF(2^4) array. Primitive polynomial = D^4+D+1 (19 decimal)
Array elements =
4 4 4
4 4 4
Notice that 1+5 is reported as 4 in the Galois field. This is true because
the 5 represents the polynomial expression A2+1,
and 1+(A2+1) in GF(16) is
A2. Furthermore, the integer that represents
the polynomial expression A2 is 4.
Example: Multiplication. The example below multiplies individual elements in a Galois field array
using the .* operator. It then performs matrix
multiplication using the * operator. The elementwise
multiplication produces an array whose size matches that of the inputs. By
contrast, the matrix multiplication produces a Galois scalar because it is
the matrix product of a row vector with a column vector.
m = 5; row1 = gf([1:2:9],m); row2 = gf([2:2:10],m); col = row2'; % Transpose to create a column array. ep = row1 .* row2; % Elementwise product. mp = row1 * col; % Matrix product.
Multiplication Table for GF(8)
As another example, the code below multiplies two Galois vectors using
matrix multiplication. The result is a multiplication table for
GF(8).
m = 3;
els = gf([0:2^m-1]',m);
multb = els * els' % Multiply els by its own matrix transpose.
The output is below.
multb = GF(2^3) array. Primitive polynomial = D^3+D+1 (11 decimal)
Array elements =
0 0 0 0 0 0 0 0
0 1 2 3 4 5 6 7
0 2 4 6 3 1 7 5
0 3 6 5 7 4 1 2
0 4 3 7 6 2 5 1
0 5 1 4 2 7 3 6
0 6 7 1 5 3 2 4
0 7 5 2 1 6 4 3
Example: Division. The examples below illustrate the four division operators in a Galois
field by computing multiplicative inverses of individual elements and of an
array. You can also compute inverses using inv or using
exponentiation by -1.
Elementwise Division
This example divides 1 by each of the individual elements in a Galois
field array using the ./ and .
operators. These two operators differ only in their sequence of input
arguments. Each quotient vector lists the multiplicative inverses of the
nonzero elements of the field. In this example, MATLAB expands the scalar 1 to the size of nz
before computing; alternatively, you can use as arguments two arrays of the
same size.
m = 5; nz = gf([1:2^m-1],m); % Nonzero elements of the field inv1 = 1 ./ nz; % Divide 1 by each element. inv2 = nz . 1; % Obtain same result using . operator.
Matrix Division
This example divides the identity array by the square Galois field array
mat using the / and
operators. Each quotient matrix is the
multiplicative inverse of mat. Notice how the transpose
operator (') appears in the equivalent operation using
. For square matrices, the sequence of transpose
operations is unnecessary, but for nonsquare matrices, it is
necessary.
m = 5; mat = gf([1 2 3; 4 5 6; 7 8 9],m); minv1 = eye(3) / mat; % Compute matrix inverse. minv2 = (mat' eye(3)')'; % Obtain same result using operator.
Example: Exponentiation. The examples below illustrate how to compute integer powers of a Galois
field array. To perform matrix exponentiation on a Galois field array, you
must use a square Galois field array as the base and an ordinary (not
Galois) integer scalar as the exponent.
Elementwise Exponentiation
This example computes powers of a primitive element, A, of a Galois field.
It then uses these separately computed powers to evaluate the default
primitive polynomial at A. The answer of zero shows that A is a root of the
primitive polynomial. The .^ operator exponentiates each
array element independently.
m = 3; av = gf(2*ones(1,m+1),m); % Row containing primitive element expa = av .^ [0:m]; % Raise element to different powers. evp = expa(4)+expa(2)+expa(1) % Evaluate D^3 + D + 1.
The output is below.
evp = GF(2^3) array. Primitive polynomial = D^3+D+1 (11 decimal)
Array elements =
0
Matrix Exponentiation
This example computes the inverse of a square matrix by raising the matrix
to the power -1. It also raises the square matrix to the powers 2 and
-2.
m = 5; mat = gf([1 2 3; 4 5 6; 7 8 9],m); minvs = mat ^ (-1); % Matrix inverse matsq = mat^2; % Same as mat * mat matinvssq = mat^(-2); % Same as minvs * minvs
Example: Elementwise Logarithm. The code below computes the logarithm of the elements of a Galois field
array. The output indicates how to express each nonzero
element of GF(8) as a power of the primitive element. The logarithm of the
zero element of the field is undefined.
gf8_nonzero = gf([1:7],3); % Vector of nonzero elements of GF(8) expformat = log(gf8_nonzero) % Logarithm of each element
The output is
expformat =
0 1 3 2 6 4 5
As an example of how to interpret the output, consider the last entry in
each vector in this example. You can infer that the element
gf(7,3) in GF(8) can be expressed as either
-
A5, using the last element of
expformat -
A2+A+1, using the binary representation
of 7 as 111. See Example: Representing Elements of GF(8) for more
details.
Logical Operations in Galois Fields
-
Section Overview
-
Testing for Equality
-
Testing for Nonzero Values
Section Overview. You can apply logical tests to Galois field arrays and obtain a logical
array. Some important types of tests are testing for the equality of two
Galois field arrays and testing for nonzero
values in a Galois field array.
Testing for Equality. To compare corresponding elements of two Galois field arrays that have the
same size, use the operators == and
~=. The result is a logical array, each element of which
indicates the truth or falsity of the corresponding elementwise comparison.
If you use the same operators to compare a scalar with a Galois field array,
MATLAB technical computing software compares the scalar with each
element of the array, producing a logical array of the same size.
m = 5; r1 = gf([1:3],m); r2 = 1 ./ r1; lg1 = (r1 .* r2 == [1 1 1]) % Does each element equal one? lg2 = (r1 .* r2 == 1) % Same as above, using scalar expansion lg3 = (r1 ~= r2) % Does each element differ from its inverse?
The output is below.
lg1 =
1 1 1
lg2 =
1 1 1
lg3 =
0 1 1
Comparison of isequal and ==
To compare entire arrays and obtain a logical scalar
result rather than a logical array, use the built-in
isequal function. However,
isequal uses strict rules for its comparison, and
returns a value of 0 (false) if you compare
-
A Galois field array with an ordinary MATLAB array, even if the values of the underlying array
elements match -
A scalar with a nonscalar array, even if all elements in the array
match the scalar
The example below illustrates this difference between
== and isequal.
m = 5; r1 = gf([1:3],m); r2 = 1 ./ r1; lg4 = isequal(r1 .* r2, [1 1 1]); % False lg5 = isequal(r1 .* r2, gf(1,m)); % False lg6 = isequal(r1 .* r2, gf([1 1 1],m)); % True
Testing for Nonzero Values. To test for nonzero values in a Galois vector, or in the columns of a
Galois field array that has more than one row, use the
any or all function. These two
functions behave just like the ordinary MATLAB functions any and
all, except that they consider only the underlying
array elements while ignoring information about which Galois field the
elements are in. Examples are below.
m = 3; randels = gf(randi([0 2^m-1],6,1),m); if all(randels) % If all elements are invertible invels = randels . 1; % Compute inverses of elements. else disp('At least one element was not invertible.'); end alph = gf(2,4); poly = 1 + alph + alph^3; if any(poly) % If poly contains a nonzero value disp('alph is not a root of 1 + D + D^3.'); end code = [0:4 4 0; 3:7 4 5] if all(code,2) % Is each row entirely nonzero? disp('Both codewords are entirely nonzero.'); else disp('At least one codeword contains a zero.'); end
Matrix Manipulation in Galois Fields
-
Basic Manipulations of Galois Field Arrays
-
Basic Information About Galois Field Arrays
Basic Manipulations of Galois Field Arrays. Basic array operations on Galois field arrays are in the table below. The
functionality of these operations is analogous to the MATLAB operations having the same syntax.
| Operation | Syntax |
|---|---|
| Index into array, possibly using colon operator instead of a vector of explicit indices |
a(vector) ora(vector,vector1), wherevector and/orvector1 can be« :» instead of a vector |
| Transpose array | a'
|
| Concatenate matrices | [a,b] or[a;b]
|
| Create array having specified diagonal elements |
diag(vector)or diag(vector,k)
|
| Extract diagonal elements | diag(a) ordiag(a,k)
|
| Extract lower triangular part | tril(a) ortril(a,k)
|
| Extract upper triangular part | triu(a) ortriu(a,k)
|
| Change shape of array | reshape(a,k1,k2)
|
The code below uses some of these syntaxes.
m = 4; a = gf([0:15],m); a(1:2) = [13 13]; % Replace some elements of the vector a. b = reshape(a,2,8); % Create 2-by-8 matrix. c = [b([1 1 2],1:3); a(4:6)]; % Create 4-by-3 matrix. d = [c, a(1:4)']; % Create 4-by-4 matrix. dvec = diag(d); % Extract main diagonal of d. dmat = diag(a(5:9)); % Create 5-by-5 diagonal matrix dtril = tril(d); % Extract upper and lower triangular dtriu = triu(d); % parts of d.
Basic Information About Galois Field Arrays. You can determine the length of a Galois vector or the size of any Galois
field array using the length and
size functions. The functionality for Galois field
arrays is analogous to that of the MATLAB operations on ordinary arrays, except that the output
arguments from size and length are
always integers, not Galois field arrays. The code below illustrates the use
of these functions.
m = 4; e = gf([0:5],m); f = reshape(e,2,3); lne = length(e); % Vector length of e szf = size(f); % Size of f, returned as a two-element row [nr,nc] = size(f); % Size of f, returned as two scalars nc2 = size(f,2); % Another way to compute number of columns
Positions of Nonzero Elements
Another type of information you might want to determine from a Galois
field array are the positions of nonzero elements. For an ordinary
MATLAB array, you might use the find function.
However, for a Galois field array, you should use find
in conjunction with the ~= operator, as
illustrated.
x = [0 1 2 1 0 2]; m = 2; g = gf(x,m); nzx = find(x); % Find nonzero values in the ordinary array x. nzg = find(g~=0); % Find nonzero values in the Galois array g.
Linear Algebra in Galois Fields
-
Inverting Matrices and Computing Determinants
-
Computing Ranks
-
Factoring Square Matrices
-
Solving Linear Equations
Inverting Matrices and Computing Determinants. To invert a square Galois field array, use the inv
function. Related is the det function, which computes
the determinant of a Galois field array. Both inv and
det behave like their ordinary MATLAB counterparts, except that they perform computations in the
Galois field instead of in the field of complex numbers.
Note
A Galois field array is singular if and only if its determinant is
exactly zero. It is not necessary to consider roundoff errors, as in the
case of real and complex arrays.
The code below illustrates matrix inversion and determinant
computation.
m = 4; randommatrix = gf(randi([0 2^m-1],4,4),m); gfid = gf(eye(4),m); if det(randommatrix) ~= 0 invmatrix = inv(randommatrix); check1 = invmatrix * randommatrix; check2 = randommatrix * invmatrix; if (isequal(check1,gfid) & isequal(check2,gfid)) disp('inv found the correct matrix inverse.'); end else disp('The matrix is not invertible.'); end
The output from this example is either of these two messages, depending on
whether the randomly generated matrix is nonsingular or singular.
inv found the correct matrix inverse. The matrix is not invertible.
Computing Ranks. To compute the rank of a Galois field array, use the
rank function. It behaves like the ordinary
MATLAB
rank function when given exactly one input argument.
The example below illustrates how to find the rank of square and nonsquare
Galois field arrays.
m = 3; asquare = gf([4 7 6; 4 6 5; 0 6 1],m); r1 = rank(asquare); anonsquare = gf([4 7 6 3; 4 6 5 1; 0 6 1 1],m); r2 = rank(anonsquare); [r1 r2]
The output is
The values of r1 and r2 indicate
that asquare has less than full rank but that
anonsquare has full rank.
Factoring Square Matrices. To express a square Galois field array (or a permutation of it) as the
product of a lower triangular Galois field array and an upper triangular
Galois field array, use the lu function. This function
accepts one input argument and produces exactly two or three output
arguments. It behaves like the ordinary MATLAB
lu function when given the same syntax. The example
below illustrates how to factor using lu.
tofactor = gf([6 5 7 6; 5 6 2 5; 0 1 7 7; 1 0 5 1],3); [L,U]=lu(tofactor); % lu with two output arguments c1 = isequal(L*U, tofactor) % True tofactor2 = gf([1 2 3 4;1 2 3 0;2 5 2 1; 0 5 0 0],3); [L2,U2,P] = lu(tofactor2); % lu with three output arguments c2 = isequal(L2*U2, P*tofactor2) % True
Solving Linear Equations. To find a particular solution of a linear equation in a Galois field, use
the or / operator on Galois field
arrays. The table below indicates the equation that each operator addresses,
assuming that A and B are previously
defined Galois field arrays.
| Operator | Linear Equation | Syntax | Equivalent Syntax Using |
|---|---|---|---|
Backslash ( |
A * x = B |
x = A B |
Not applicable |
Slash (/) |
x * A = B |
x = B / A |
x = (A'B')' |
The results of the syntax in the table depend on characteristics of the
Galois field array A:
-
If
Ais square and nonsingular, the output
xis the unique solution to the linear
equation. -
If
Ais square and singular, the syntax in the
table produces an error. -
If
Ais not square, MATLAB attempts to find a particular solution. If
A'*AorA*A'is a singular
array, or ifAis a matrix, where the rows
outnumber the columns, that represents an overdetermined system, the
attempt might fail.
Note
An error message does not necessarily indicate that the linear
equation has no solution. You might be able to find a solution by
rephrasing the problem. For example, gf([1 2; 0 0],3) gf([1; produces an error but the mathematically equivalent
0],3)
gf([1 2],3) gf([1],3) does not. The first
syntax fails because gf([1 2; 0 0],3) is a singular
square matrix.
Example: Solving Linear Equations
The examples below illustrate how to find particular solutions of linear
equations over a Galois field.
m = 4; A = gf(magic(3),m); % Square nonsingular matrix Awide=[A, 2*A(:,3)]; % 3-by-4 matrix with redundancy on the right Atall = Awide'; % 4-by-3 matrix with redundancy at the bottom B = gf([0:2]',m); C = [B; 2*B(3)]; D = [B; B(3)+1]; thesolution = A B; % Solution of A * x = B thesolution2 = B' / A; % Solution of x * A = B' ck1 = all(A * thesolution == B) % Check validity of solutions. ck2 = all(thesolution2 * A == B') % Awide * x = B has infinitely many solutions. Find one. onesolution = Awide B; ck3 = all(Awide * onesolution == B) % Check validity of solution. % Atall * x = C has a solution. asolution = Atall C; ck4 = all(Atall * asolution == C) % Check validity of solution. % Atall * x = D has no solution. notasolution = Atall D; ck5 = all(Atall * notasolution == D) % It is not a valid solution.
The output from this example indicates that the validity checks are all
true (1), except for ck5, which is
false (0).
Signal Processing Operations in Galois Fields
-
Section Overview
-
Filtering
-
Convolution
-
Discrete Fourier Transform
Section Overview. You can perform some signal-processing operations on
Galois field arrays, such as filtering, convolution, and
the discrete Fourier
transform.
This section describes how to perform these operations.
Other information about the corresponding operations for ordinary real
vectors is in the Signal Processing Toolbox™ documentation.
Filtering. To filter a Galois vector, use the filter function.
It behaves like the ordinary MATLAB
filter function when given exactly three input
arguments.
The code and diagram below give the impulse response of a particular
filter over GF(2).
m = 1; % Work in GF(2). b = gf([1 0 0 1 0 1 0 1],m); % Numerator a = gf([1 0 1 1],m); % Denominator x = gf([1,zeros(1,19)],m); y = filter(b,a,x); % Filter x. figure; stem(y.x); % Create stem plot. axis([0 20 -.1 1.1])
Convolution. Communications Toolbox software offers two equivalent ways to convolve a pair of
Galois vectors:
-
Use the
convfunction, as described in Multiplication and Division of Polynomials. This works
because convolving two vectors is equivalent to multiplying the two
polynomials whose coefficients are the entries of the
vectors. -
Use the
convmtxfunction to compute the
convolution matrix of one of the vectors, and then multiply that
matrix by the other vector. This works because convolving two
vectors is equivalent to filtering one of the vectors by the other.
The equivalence permits the representation of a digital filter as a
convolution matrix, which you can then multiply by any Galois vector
of appropriate length.
Tip
If you need to convolve large Galois vectors, multiplying by the
convolution matrix might be faster than using
conv.
Example
Computes the convolution matrix for a vector b in
GF(4). Represent the numerator coefficients for a digital filter, and then
illustrate the two equivalent ways to convolve b with
x over the Galois field.
m = 2; b = gf([1 2 3]',m); n = 3; x = gf(randi([0 2^m-1],n,1),m); C = convmtx(b,n); % Compute convolution matrix. v1 = conv(b,x); % Use conv to convolve b with x v2 = C*x; % Use C to convolve b with x.
Discrete Fourier Transform. The discrete Fourier transform is an important tool in digital signal
processing. This toolbox offers these tools to help you process discrete
Fourier transforms:
-
fft, which transforms a Galois vector -
ifft, which inverts the discrete Fourier
transform on a Galois vector -
dftmtx, which returns a Galois field array
that you can use to perform or invert the discrete Fourier transform
on a Galois vector
In all cases, the vector being transformed must be a Galois vector of
length 2m-1 in the field
GF(2m). The following example illustrates the
use of these functions. You can check, using the
isequal function, that y equals
y1, z equals
z1, and z equals
x.
m = 4; x = gf(randi([0 2^m-1],2^m-1,1),m); % A vector to transform alph = gf(2,m); dm = dftmtx(alph); idm = dftmtx(1/alph); y = dm*x; % Transform x using the result of dftmtx. y1 = fft(x); % Transform x using fft. z = idm*y; % Recover x using the result of dftmtx(1/alph). z1 = ifft(y1); % Recover x using ifft.
Tip
If you have many vectors that you want to transform (in the same
field), it might be faster to use dftmtx once and
matrix multiplication many times, instead of using
fft many times.
Polynomials over Galois Fields
-
Section Overview
-
Addition and Subtraction of Polynomials
-
Multiplication and Division of Polynomials
-
Evaluating Polynomials
-
Roots of Polynomials
-
Roots of Binary Polynomials
-
Minimal Polynomials
Section Overview. You can use Galois vectors to represent polynomials in an indeterminate
quantity x, with coefficients in a Galois field. Form the representation by
listing the coefficients of the polynomial in a vector in order of
descending powers of x. For example, the vector
represents the polynomial Ax3 +
1x2 + 0x + (A+1), where
-
A is a primitive element in the field
GF(24). -
x is the indeterminate quantity in the polynomial.
You can then use such a Galois vector to perform arithmetic with, evaluate, and
find roots of
polynomials. You can also find minimal
polynomials of elements of a Galois field.
Addition and Subtraction of Polynomials. To add and subtract polynomials, use + and
- on equal-length Galois vectors that represent the
polynomials. If one polynomial has lower degree than the other, you must pad
the shorter vector with zeros at the beginning so the two vectors have the
same length. The example below shows how to add a degree-one and a
degree-two polynomial.
lin = gf([4 2],3); % A^2 x + A, which is linear in x linpadded = gf([0 4 2],3); % The same polynomial, zero-padded quadr = gf([1 4 2],3); % x^2 + A^2 x + A, which is quadratic in x % Can't do lin + quadr because they have different vector lengths. sumpoly = [0, lin] + quadr; % Sum of the two polynomials sumpoly2 = linpadded + quadr; % The same sum
Multiplication and Division of Polynomials. To multiply and divide polynomials, use conv and
deconv on Galois vectors that represent the
polynomials. Multiplication and division of polynomials is equivalent to
convolution and deconvolution of vectors. The deconv
function returns the quotient of the two polynomials as well as the
remainder polynomial. Examples are below.
m = 4; apoly = gf([4 5 3],m); % A^2 x^2 + (A^2 + 1) x + (A + 1) bpoly = gf([1 1],m); % x + 1 xpoly = gf([1 0],m); % x % Product is A^2 x^3 + x^2 + (A^2 + A) x + (A + 1). cpoly = conv(apoly,bpoly); [a2,remd] = deconv(cpoly,bpoly); % a2==apoly. remd is zero. [otherpol,remd2] = deconv(cpoly,xpoly); % remd is nonzero.
The multiplication and division operators in Arithmetic in Galois Fields
multiply elements or matrices, not polynomials.
Evaluating Polynomials. To evaluate a polynomial at an element of a Galois field, use
polyval. It behaves like the ordinary MATLAB
polyval function when given exactly two input
arguments. The example below evaluates a polynomial at several elements in a
field and checks the results using .^ and
.* in the field.
m = 4; apoly = gf([4 5 3],m); % A^2 x^2 + (A^2 + 1) x + (A + 1) x0 = gf([0 1 2],m); % Points at which to evaluate the polynomial y = polyval(apoly,x0) a = gf(2,m); % Primitive element of the field, corresponding to A. y2 = a.^2.*x0.^2 + (a.^2+1).*x0 + (a+1) % Check the result.
The output is below.
y = GF(2^4) array. Primitive polynomial = D^4+D+1 (19 decimal)
Array elements =
3 2 10
y2 = GF(2^4) array. Primitive polynomial = D^4+D+1 (19 decimal)
Array elements =
3 2 10
The first element of y evaluates the polynomial at
0 and, therefore, returns the polynomial’s constant
term of 3.
Roots of Polynomials. To find the roots of a polynomial in a Galois field, use the
roots function on a Galois vector that represents
the polynomial. This function finds roots that are in the same field that
the Galois vector is in. The number of times an entry appears in the output
vector from roots is exactly its multiplicity as a root
of the polynomial.
Note
If the Galois vector is in GF(2m), the
polynomial it represents might have additional roots in some extension
field GF((2m)k).
However, roots does not find those additional roots
or indicate their existence.
The examples below find roots of cubic polynomials in GF(8).
p = 3; m = 2; field = gftuple([-1:p^m-2]',m,p); % List of all elements of GF(9) % Use default primitive polynomial here. polynomial = [1 0 1 1]; % 1 + x^2 + x^3 rts =gfroots(polynomial,m,p) % Find roots in exponential format % Check that each one is actually a root. for ii = 1:3 root = rts(ii); rootsquared = gfmul(root,root,field); rootcubed = gfmul(root,rootsquared,field); answer(ii)= gfadd(gfadd(0,rootsquared,field),rootcubed,field); % Recall that 1 is really alpha to the zero power. % If answer = -Inf, then the variable root represents % a root of the polynomial. end answer
Roots of Binary Polynomials. In the special case of a polynomial having binary coefficients, it is also
easy to find roots that exist in an extension field. This is because the
elements 0 and 1 have the same
unambiguous representation in all fields of characteristic two. To find
roots of a binary polynomial in an extension field, apply the
roots function to a Galois vector in the extension
field whose array elements are the binary coefficients of the
polynomial.
The example below seeks the roots of a binary polynomial in various
fields.
gf2poly = gf([1 1 1],1); % x^2 + x + 1 in GF(2) noroots = roots(gf2poly); % No roots in the ground field, GF(2) gf4poly = gf([1 1 1],2); % x^2 + x + 1 in GF(4) roots4 = roots(gf4poly); % The roots are A and A+1, in GF(4). gf16poly = gf([1 1 1],4); % x^2 + x + 1 in GF(16) roots16 = roots(gf16poly); % Roots in GF(16) checkanswer4 = polyval(gf4poly,roots4); % Zero vector checkanswer16 = polyval(gf16poly,roots16); % Zero vector
The roots of the polynomial do not exist in GF(2), so
noroots is an empty array. However, the roots of the
polynomial exist in GF(4) as well as in GF(16), so roots4
and roots16 are nonempty.
Notice that roots4 and roots16 are
not equal to each other. They differ in these ways:
-
roots4is a GF(4) array, while
roots16is a GF(16) array. MATLAB keeps track of the underlying field of a Galois field
array. -
The array elements in
roots4and
roots16differ because they use
representations with respect to different primitive polynomials. For
example,2(which represents a primitive element)
is an element of the vectorroots4because the
default primitive polynomial for GF(4) is the same polynomial that
gf4polyrepresents. On the other hand,
2is not an element of
roots16because the primitive element of
GF(16) is not a root of the polynomial that
gf16polyrepresents.
Minimal Polynomials. The minimal polynomial of an element of GF(2m)
is the smallest degree nonzero binary-coefficient polynomial having that
element as a root in GF(2m). To find the minimal
polynomial of an element or a column vector of elements, use the
minpol function.
The code below finds that the minimal polynomial of
gf(6,4) is
D2 + D + 1 and then checks
that gf(6,4) is indeed among the roots of that polynomial
in the field GF(16).
m = 4; e = gf(6,4); em = minpol(e) % Find minimal polynomial of e. em is in GF(2). emr = roots(gf([0 0 1 1 1],m)) % Roots of D^2+D+1 in GF(2^m)
The output is
em = GF(2) array.
Array elements =
0 0 1 1 1
emr = GF(2^4) array. Primitive polynomial = D^4+D+1 (19 decimal)
Array elements =
6
7
To find out which elements of a Galois field share the same minimal
polynomial, use the cosets function.
Manipulating Galois Variables
-
Section Overview
-
Determining Whether a Variable Is a Galois Field Array
-
Extracting Information from a Galois Field Array
-
Use Field Extension Suffixes Appended to Galois Field Array Variables
Section Overview. This section describes techniques for manipulating Galois variables or for
transferring information between Galois field arrays and ordinary
MATLAB arrays.
Note
These techniques are particularly relevant if you write MATLAB file functions that process Galois field arrays. For an
example of this type of usage, enter edit gf/conv in
the Command Window and examine the first several lines of code in the
editor window.
Determining Whether a Variable Is a Galois Field Array. To find out whether a variable is a Galois field array rather than an
ordinary MATLAB array, use the isa function. An
illustration is below.
mlvar = eye(3); gfvar = gf(mlvar,3); no = isa(mlvar,'gf'); % False because mlvar is not a Galois array yes = isa(gfvar,'gf'); % True because gfvar is a Galois array
Extracting Information from a Galois Field Array. To extract the array elements, field order, or primitive polynomial from a
variable that is a Galois field array, append a suffix to the name of the
variable. The table below lists the exact suffixes, which are independent of
the name of the variable.
| Information | Suffix | Output Value |
|---|---|---|
| Array elements | .x |
MATLAB array of type uint16 thatcontains the data values from the Galois field array. |
| Field order | .m |
Integer of type double that indicatesthat the Galois field array is in GF( 2^m). |
| Primitive polynomial | .prim_poly |
Integer of type uint32 that representsthe primitive polynomial. The representation is similar to the description in How Integers Correspond to Galois Field Elements. |
Note
If the output value is an integer data type and you want to convert it
to double for later manipulation, use the
double function.
Use Field Extension Suffixes Appended to Galois Field Array Variables
Extract information from Galois field arrays by using field extension suffixes.
Array elements (.x)
Convert a Galois field array to doubles.
a = GF(2) array. Array elements = 1 0
b = double(a.x) % a.x is in uint16
Field Order (.m)
Check that e solves its own minimal polynomial. Create empr as a Galois field array in a field order extension field (.m) by using a vector of binary coefficients of a polynomial (emp.x).
e = gf(6,4); % An element of GF(16) emp = minpol(e); % Minimal polynomial is in GF(2) empr = roots(gf(emp.x,e.m)) % Find roots of emp in GF(16)
empr = GF(2^4) array. Primitive polynomial = D^4+D+1 (19 decimal) Array elements = 6 7
Primitive polynomial (.prim_poly)
Check that the primitive element gf(2,m) is really a root of the primitive polynomial for the field by confirming the output vector includes 2. Retrieve the primitive polynomial for the field and convert it to a binary vector representation having the appropriate number of bits.
primpoly_int = double(e.prim_poly); mval = e.m; primpoly_vect = gf(int2bit(primpoly_int,mval+1)',mval); containstwo = roots(primpoly_vect)
containstwo = GF(2^4) array. Primitive polynomial = D^4+D+1 (19 decimal) Array elements = 2 3 4 5
Speed and Nondefault Primitive Polynomials
Primitive Polynomials and Element Representations describes how to represent elements of a
Galois field with respect to a primitive polynomial of your choice. This section
describes how you can increase the speed of computations involving a Galois
field array that uses a primitive polynomial other than the default primitive
polynomial. The technique is recommended if you perform many such
computations.
The mechanism for increasing the speed is a data file,
userGftable.mat, that some computational functions use to
avoid performing certain computations repeatedly. To take advantage of this
mechanism for your combination of field order (m) and
primitive polynomial (prim_poly):
-
Navigate in the MATLAB application to a folder to which you have write
permission. You can use either thecdfunction or
the Current Folder feature to navigate. -
Define
mandprim_polyas
workspace variables. For example:m = 3; prim_poly = 13; % Examples of valid values
-
Invoke the
gftablefunction:gftable(m,prim_poly); % If you previously defined m and prim_poly
The function revises or creates userGftable.mat in your
current working folder to include data relating to your combination of field
order and primitive polynomial. After you initially invest the time to invoke
gftable, subsequent computations using those values of
m and prim_poly should be
faster.
Note
If you change your current working directory after invoking
gftable, you must place
userGftable.mat on your MATLAB path to ensure that MATLAB can see it. Do this by using the addpath
command to prefix the directory containing
userGftable.mat to your MATLAB path. If you have multiple copies of
userGftable.mat on your path, use
which('userGftable.mat','-all') to find out where
they are and which one MATLAB is using.
To see how much gftable improves the speed of your
computations, you can surround your computations with the
tic and toc functions. See the
gftable reference page for an
example.
Selected Bibliography for Galois Fields
[1] Blahut, Richard E., Theory and Practice
of Error Control Codes, Reading, MA, Addison-Wesley, 1983,
p. 105.
[2] Lang, Serge, Algebra, Third
Edition, Reading, MA, Addison-Wesley, 1993.
[3] Lin, Shu, and Daniel J. Costello, Jr.,
Error Control Coding: Fundamentals and
Applications, Englewood Cliffs, NJ, Prentice-Hall, 1983.
[4] van Lint, J. H., Introduction to Coding
Theory, New York, Springer-Verlag, 1982.
[5] Wicker, Stephen B., Error Control
Systems for Digital Communication and Storage, Upper Saddle
River, NJ, Prentice Hall, 1995.
Galois Fields of Odd Characteristic
A Galois field is an algebraic field having
pm elements, where p is prime and m is a positive
integer. This section describes how to work with Galois fields in which p is
odd. To work with Galois fields having an even number of
elements, see Galois Field
Computations. The subsections in this section are as follows.
-
Galois Field Terminology
-
Representing Elements of Galois Fields
-
Default Primitive Polynomials
-
Converting and Simplifying Element Formats
-
Arithmetic in Galois Fields
-
Polynomials over Prime Fields
-
Other Galois Field Functions
-
Selected Bibliography for Galois Fields
Galois Field Terminology
Throughout this section, p is an odd prime number and m is a positive integer.
Also, this document uses a few terms that are not used consistently in the
literature. The definitions adopted here appear in van Lint [5].
-
A primitive element of
GF(pm) is a cyclic generator of the group
of nonzero elements of GF(pm). This means
that every nonzero element of the field can be expressed as the
primitive element raised to some integer power. Primitive elements are
called A throughout this section. -
A primitive polynomial for
GF(pm) is the minimal polynomial of some
primitive element of GF(pm). As a
consequence, it has degree m and is irreducible.
Representing Elements of Galois Fields
-
Section Overview
-
Exponential Format
-
Polynomial Format
-
List of All Elements of a Galois Field
-
Nonuniqueness of Representations
Section Overview. This section discusses how to represent Galois field elements using this
toolbox’s exponential
format and polynomial
format. It also describes a way to list all
elements of the Galois field, because some functions use such a
list as an input argument. Finally, it discusses the nonuniqueness of
representations of Galois field elements.
The elements of GF(p) can be represented using the integers from 0 to
p-1.
When m is at least 2, GF(pm) is called an
extension field. Integers alone cannot represent the elements of
GF(pm) in a straightforward way. MATLAB technical computing software uses two main conventions for
representing elements of GF(pm): the exponential
format and the polynomial format.
Note
Both the exponential format and the polynomial format are relative to
your choice of a particular primitive element A of
GF(pm).
Exponential Format. This format uses the property that every nonzero element of
GF(pm) can be expressed as
Ac for some integer c between 0 and
pm-2. Higher exponents are not needed,
because the theory of Galois fields implies that every nonzero element of
GF(pm) satisfies the equation
xq-1 = 1 where
q = pm.
The use of the exponential format is shown in the table below.
| Element of GF(pm) |
MATLAB Representation of the Element |
|---|---|
| 0 | -Inf |
| A0 = 1 | 0
|
| A1 | 1
|
| … | … |
Aq-2 whereq = pm
|
q-2
|
Although -Inf is the standard exponential
representation of the zero element, all negative integers are equivalent to
-Inf when used as input
arguments in exponential format. This equivalence can be useful; for
example, see the concise line of code at the end of the section Default Primitive Polynomials.
Note
The equivalence of all negative integers and -Inf
as exponential formats means that, for example, -1 does
not represent A-1,
the multiplicative inverse of A. Instead, -1 represents the zero element
of the field.
Polynomial Format. The polynomial format uses the property that every element of
GF(pm) can be expressed as a polynomial in A
with exponents between 0 and m-1, and coefficients in GF(p). In the
polynomial format, the element
A(1) + A(2) A + A(3) A2 + … + A(m) Am-1
is represented in MATLAB by the vector
[A(1) A(2) A(3) ... A(m)]
Note
The Galois field functions in this toolbox represent a polynomial as a
vector that lists the coefficients in order of
ascending powers of the variable. This is the
opposite of the order that other MATLAB functions use.
List of All Elements of a Galois Field. Some Galois field functions in this toolbox require an argument that lists
all elements of an extension field GF(pm). This
is again relative to a particular primitive element A of
GF(pm). The proper format for the list of
elements is that of a matrix having pm rows, one
for each element of the field. The matrix has m columns, one for each
coefficient of a power of A in the polynomial format shown in Polynomial Format above. The first row contains only zeros
because it corresponds to the zero element in
GF(pm). If k is between 2 and
pm, then the kth row specifies the polynomial
format of the element Ak-2.
The minimal polynomial of A aids in the computation of this matrix,
because it tells how to express Am in terms of
lower powers of A. For example, the table below lists the elements of
GF(32), where A is a root of the primitive
polynomial 2 + 2x + x2. This
polynomial allows repeated use of the substitution
A2 = -2 — 2A = 1 + A
when performing the computations in the middle column of the table.
Elements of GF(9)
| Exponential Format | Polynomial Format | Row of MATLAB Matrix of Elements |
|---|---|---|
| A-Inf | 0 | 0 0
|
| A0 | 1 | 1 0
|
| A1 | A | 0 1 |
| A2 | 1+A | 1 1 |
| A3 | A + A2 = A + 1 + A = 1 + 2A | 1 2 |
| A4 | A + 2A2 = A + 2 + 2A = 2 | 2 0 |
| A5 | 2A | 0 2 |
| A6 | 2A2 = 2 + 2A | 2 2 |
| A7 | 2A + 2A2 = 2A + 2 + 2A = 2 + A | 2 1 |
Example
An automatic way to generate the matrix whose rows are in the third column
of the table above is to use the code below.
p = 3; m = 2;
% Use the primitive polynomial 2 + 2x + x^2 for GF(9).
prim_poly = [2 2 1];
field = gftuple([-1:p^m-2]',prim_poly,p);
The gftuple function is discussed in more detail in
Converting and Simplifying Element Formats.
Nonuniqueness of Representations. A given field has more than one primitive element. If two primitive
elements have different minimal polynomials, then the corresponding matrices
of elements will have their rows in a different order. If the two primitive
elements share the same minimal polynomial, then the matrix of elements of
the field is the same.
Note
You can use whatever primitive element you want, as long as you
understand how the inputs and outputs of Galois field functions depend
on the choice of some primitive polynomial. It is
usually best to use the same primitive polynomial throughout a given
script or function.
Other ways in which representations of elements are not unique arise from
the equations that Galois field elements satisfy. For example, an
exponential format of 8 in GF(9) is really the same as an exponential format
of 0, because
A8 = 1 = A0
in GF(9). As another example, the substitution mentioned just before the
table Elements of GF(9) shows that the
polynomial format [0 0 1] is really the same as the polynomial format [1
1].
Default Primitive Polynomials
This toolbox provides a default primitive polynomial for
each extension field. You can retrieve this polynomial using the
gfprimdf function. The command
prim_poly = gfprimdf(m,p); % If m and p are already defined
produces the standard row-vector representation of the default minimal
polynomial for GF(pm).
For example, the command below shows that the default primitive polynomial for
GF(9) is 2 + x + x2,
not the polynomial used in List of All Elements of a Galois Field.
To generate a list of elements of GF(pm) using the
default primitive polynomial, use the command
field = gftuple([-1:p^m-2]',m,p);
Converting and Simplifying Element Formats
-
Converting to Simplest Polynomial Format
-
Example: Generating a List of Galois Field Elements
-
Converting to Simplest Exponential Format
Converting to Simplest Polynomial Format. The gftuple function produces the simplest polynomial
representation of an element of GF(pm), given
either an exponential representation or a polynomial representation of that
element. This can be useful for generating the list of elements of
GF(pm) that other functions require.
Using gftuple requires three arguments: one
representing an element of GF(pm), one indicating
the primitive polynomial that MATLAB technical computing software should use when computing the
output, and the prime p. The table below indicates how
gftuple behaves when given the first two arguments
in various formats.
Behavior of gftuple Depending on Format of
First Two Inputs
| How to Specify Element | How to Indicate Primitive Polynomial |
What gftuple Produces |
|---|---|---|
| Exponential format; c = any integer | Integer m > 1 | Polynomial format of Ac, where A is a root of the default primitive polynomial for GF(pm) |
Example: tp = = 6
|
||
| Exponential format; c = any integer | Vector of coefficients of primitive polynomial | Polynomial format of Ac, where A is a root of the given primitive polynomial |
Example:polynomial = gfprimdf(2,3); tp = = 6
|
||
| Polynomial format of any degree | Integer m > 1 | Polynomial format of degree < m, using default primitive polynomial for GF(pm) to simplify |
Example: tp =
|
||
| Polynomial format of any degree | Vector of coefficients of primitive polynomial | Polynomial format of degree < m, using the given primitive polynomial for GF(pm) to simplify |
Example:polynomial = gfprimdf(2,3); tp = gftuple([0
|
The four examples that appear in the table above all produce the same
vector tp = [2, 1], but their different inputs to
gftuple correspond to the lines of the table. Each
example expresses the fact that
A6 = 2+A, where A is a root of the
(default) primitive polynomial
2 + x+ x2 for
GF(32).
Example
This example shows how gfconv and
gftuple combine to multiply two polynomial-format
elements of GF(34). Initially,
gfconv multiplies the two polynomials, treating the
primitive element as if it were a variable. This produces a high-order
polynomial, which gftuple simplifies using the
polynomial equation that the primitive element satisfies. The final result
is the simplest polynomial format of the product.
p = 3; m = 4; a = [1 2 0 1]; b = [2 2 1 2]; notsimple = gfconv(a,b,p) % a times b, using high powers of alpha simple = gftuple(notsimple,m,p) %Highest exponent of alpha is m-1
The output is below.
notsimple =
2 0 2 0 0 1 2
simple =
2 1 0 1
Example: Generating a List of Galois Field Elements. This example applies the conversion functionality to the task of
generating a matrix that lists all elements of a Galois field. A matrix that
lists all field elements is an input argument in functions such as
gfadd and gfmul. The variables
field1 and field2 below have the
format that such functions expect.
p = 5; % Or any prime number m = 4; % Or any positive integer field1 = gftuple([-1:p^m-2]',m,p); prim_poly = gfprimdf(m,p); % Or any primitive polynomial % for GF(p^m) field2 = gftuple([-1:p^m-2]',prim_poly,p);
Converting to Simplest Exponential Format. The same function gftuple also produces the simplest
exponential representation of an element of
GF(pm), given either an exponential
representation or a polynomial representation of that element. To retrieve
this output, use the syntax
[polyformat, expformat] = gftuple(...)
The input format and the output polyformat are as in
the table Behavior of gftuple Depending on Format of First Two Inputs. In
addition, the variable expformat contains the simplest
exponential format of the element represented in
polyformat. It is simplest in
the sense that the exponent is either -Inf or a number
between 0 and pm-2.
Example
To recover the exponential format of the element 2 + A that the
previous section considered, use the commands below. In this case,
polyformat contains redundant information, while
expformat contains the desired result.
[polyformat, expformat] = gftuple([2 1],2,3)
polyformat =
2 1
expformat =
6
This output appears at first to contradict the information in the table
Elements of GF(9) , but in fact it does
not. The table uses a different primitive element; two plus that primitive
element has the polynomial and exponential formats shown below.
prim_poly = [2 2 1]; [polyformat2, expformat2] = gftuple([2 1],prim_poly,3)
The output below reflects the information in the bottom line of the
table.
polyformat2 =
2 1
expformat2 =
7
Arithmetic in Galois Fields
-
Section Overview
-
Arithmetic in Prime Fields
-
Arithmetic in Extension Fields
Section Overview. You can add, subtract, multiply, and divide elements of Galois fields
using the functions gfadd, gfsub,
gfmul, and gfdiv,
respectively. Each of these functions has a mode for prime fields and
a mode for extension
fields.
Arithmetic in Prime Fields. Arithmetic in GF(p) is the same as arithmetic modulo p. The functions
gfadd, gfmul,
gfsub, and gfdiv accept two
arguments that represent elements of GF(p) as integers between 0 and p-1.
The third argument specifies p.
Example: Addition Table for GF(5)
The code below constructs an addition table for GF(5). If
a and b are between 0 and 4, then
the element gfp_add(a+1,b+1) represents the sum
a+b in GF(5). For example, gfp_add(3,5) = because 2+4 is 1 modulo 5.
1
p = 5; row = 0:p-1; table = ones(p,1)*row; gfp_add = gfadd(table,table',p)
The output for this example follows.
gfp_add =
0 1 2 3 4
1 2 3 4 0
2 3 4 0 1
3 4 0 1 2
4 0 1 2 3
Other values of p produce tables for different prime
fields GF(p). Replacing gfadd by
gfmul, gfsub, or
gfdiv produces a table for the corresponding
arithmetic operation in GF(p).
Arithmetic in Extension Fields. The same arithmetic functions can add elements of
GF(pm) when m > 1, but the
format of the arguments is more complicated than in the case above. In
general, arithmetic in extension fields is more complicated than arithmetic
in prime fields; see the works listed in Selected Bibliography for Galois Fields for details about how the arithmetic operations work.
When working in extension fields, the functions
gfadd, gfmul,
gfsub, and gfdiv use the first
two arguments to represent elements of GF(pm) in
exponential format. The third argument, which is required, lists all
elements of GF(pm) as described in List of All Elements of a Galois Field. The result is in
exponential format.
Example: Addition Table for GF(9)
The code below constructs an addition table for
GF(32), using exponential formats relative to
a root of the default primitive polynomial for GF(9). If
a and b are between -1 and 7, then
the element gfpm_add(a+2,b+2) represents the sum of
Aa and Ab in
GF(9). For example, gfpm_add(4,6) = 5 because
A2 + A4 = A5
Using the fourth and sixth rows of the matrix field,
you can verify that
A2 + A4 = (1 + 2A) + (2 + 0A) = 3 + 2A = 0 + 2A = A5
modulo 3.
p = 3; m = 2; % Work in GF(3^2). field = gftuple([-1:p^m-2]',m,p); % Construct list of elements. row = -1:p^m-2; table = ones(p^m,1)*row; gfpm_add = gfadd(table,table',field)
The output is below.
gfpm_add =
-Inf 0 1 2 3 4 5 6 7
0 4 7 3 5 -Inf 2 1 6
1 7 5 0 4 6 -Inf 3 2
2 3 0 6 1 5 7 -Inf 4
3 5 4 1 7 2 6 0 -Inf
4 -Inf 6 5 2 0 3 7 1
5 2 -Inf 7 6 3 1 4 0
6 1 3 -Inf 0 7 4 2 5
7 6 2 4 -Inf 1 0 5 3
Note
If you used a different primitive polynomial, then the tables would
look different. This makes sense because the ordering of the rows and
columns of the tables was based on that particular choice of primitive
polynomial and not on any natural ordering of the elements of
GF(9).
Other values of p and m produce
tables for different extension fields GF(p^m). Replacing
gfadd by gfmul,
gfsub, or gfdiv produces a
table for the corresponding arithmetic operation in
GF(p^m).
Polynomials over Prime Fields
-
Section Overview
-
Cosmetic Changes of Polynomials
-
Polynomial Arithmetic
-
Characterization of Polynomials
-
Roots of Polynomials
Section Overview. A polynomial over GF(p) is a polynomial whose coefficients are elements of
GF(p). Communications Toolbox software provides functions for
-
Changing polynomials in cosmetic
ways -
Performing polynomial
arithmetic -
Characterizing polynomials as primitive or
irreducible -
Finding roots of
polynomials in a Galois fieldNote
The Galois field functions in this toolbox represent a
polynomial over GF(p) for odd values of p as a vector that lists
the coefficients in order of ascending
powers of the variable. This is the opposite of the order that
other MATLAB functions use.
Cosmetic Changes of Polynomials. To display the traditionally formatted polynomial that corresponds to a
row vector containing coefficients, use gfpretty. To
truncate a polynomial by removing all zero-coefficient terms that have
exponents higher than the degree of the polynomial, use
gftrunc. For example,
polynom = gftrunc([1 20 394 10 0 0 29 3 0 0]) gfpretty(polynom)
The output is below.
polynom =
1 20 394 10 0 0 29 3
2 3 6 7
1 + 20 X + 394 X + 10 X + 29 X + 3 X
Note
If you do not use a fixed-width font, then the spacing in the display
might not look correct.
Polynomial Arithmetic. The functions gfadd and gfsub
add and subtract, respectively, polynomials over GF(p). The
gfconv function multiplies polynomials over GF(p).
The gfdeconv function divides polynomials in GF(p),
producing a quotient polynomial and a remainder polynomial. For example, the
commands below show that
2 + x + x2 times
1 + x over the field GF(3) is
2 + 2x2 + x3.
a = gfconv([2 1 1],[1 1],3) [quot, remd] = gfdeconv(a,[2 1 1],3)
The output is below.
a =
2 0 2 1
quot =
1 1
remd =
0
The previously discussed functions gfadd and
gfsub add and subtract, respectively, polynomials.
Because it uses a vector of coefficients to represent a polynomial,
MATLAB does not distinguish between adding two polynomials and adding
two row vectors elementwise.
Characterization of Polynomials. Given a polynomial over GF(p), the gfprimck function
determines whether it is irreducible and/or primitive. By definition, if it
is primitive then it is irreducible; however, the reverse is not necessarily
true. The gfprimdf and gfprimfd
functions return primitive polynomials.
Given an element of GF(pm), the
gfminpol function computes its minimal polynomial
over GF(p).
Example
For example, the code below reflects the irreducibility of all minimal
polynomials. However, the minimal polynomial of a nonprimitive element is
not a primitive polynomial.
p = 3; m = 4; % Use default primitive polynomial here. prim_poly = gfminpol(1,m,p); ckprim = gfprimck(prim_poly,p); % ckprim = 1, since prim_poly represents a primitive polynomial. notprimpoly = gfminpol(5,m,p); cknotprim = gfprimck(notprimpoly,p); % cknotprim = 0 (irreducible but not primitive) % since alpha^5 is not a primitive element when p = 3. ckreducible = gfprimck([0 1 1],p); % ckreducible = -1 since the polynomial is reducible.
Roots of Polynomials. Given a polynomial over GF(p), the gfroots function
finds the roots of the polynomial in a suitable extension field
GF(pm). There are two ways to tell
MATLAB the degree m of the extension field
GF(pm), as shown in the following table.
Formats for Second Argument of
gfroots
| Second Argument | Represents |
|---|---|
| A positive integer | m as in GF(pm). MATLAB uses the default primitive polynomial in its computations. |
| A row vector | A primitive polynomial for GF(pm). Here m is the degree of this primitive polynomial. |
Example: Roots of a Polynomial in
GF(9)
The code below finds roots of the polynomial
1 + x2 + x3
in GF(9) and then checks that they are indeed roots. The exponential format
of elements of GF(9) is used throughout.
p = 3; m = 2; field = gftuple([-1:p^m-2]',m,p); % List of all elements of GF(9) % Use default primitive polynomial here. polynomial = [1 0 1 1]; % 1 + x^2 + x^3 rts =gfroots(polynomial,m,p) % Find roots in exponential format % Check that each one is actually a root. for ii = 1:3 root = rts(ii); rootsquared = gfmul(root,root,field); rootcubed = gfmul(root,rootsquared,field); answer(ii)= gfadd(gfadd(0,rootsquared,field),rootcubed,field); % Recall that 1 is really alpha to the zero power. % If answer = -Inf, then the variable root represents % a root of the polynomial. end answer
The output shows that A0 (which equals 1),
A5, and A7 are
roots.
roots =
0
5
7
answer =
-Inf -Inf -Inf
See the reference page for gfroots to see how
gfroots can also provide you with the polynomial
formats of the roots and the list of all elements of the field.
Other Galois Field Functions
See the online reference pages for information about these other Galois field
functions in Communications Toolbox software:
-
gfcosets, which produces
cyclotomic cosets -
gffilter, which filters
data using GF(p) polynomials -
gfprimfd, which finds
primitive polynomials -
gfrank, which computes the
rank of a matrix over GF(p) -
gfrepcov, which converts
one binary polynomial representation to another
Selected Bibliography for Galois Fields
[1] Blahut, Richard E., Theory and
Practice of Error Control Codes, Reading, Mass.,
Addison-Wesley, 1983.
[2] Lang, Serge, Algebra,
Third Edition, Reading, Mass., Addison-Wesley, 1993.
[3] Lin, Shu, and Daniel J. Costello, Jr.,
Error Control Coding: Fundamentals and
Applications, Englewood Cliffs, N.J., Prentice-Hall, 1983.
[4] van Lint, J. H., Introduction to
Coding Theory, New York, Springer-Verlag, 1982.
- Download source files — 3.12 Kb
Introduction
BCH error correction codes are block-based error correcting codes with a wide range of applications in digital communications and storage. BCH codes are used to correct errors in many systems including:
- Storage devices (including tape, Compact Disk, DVD, barcodes etc.)
- Wireless or mobile communications (including cellular telephones, microwave links, pager etc.)
- Satellite communications
- Digital television / DVB
- High-speed modems such as ADSL, xDSL, etc.
The BCH encoder takes a block of digital data and adds extra «redundant» bits. Errors occur during transmission or storage due to a number of reasons (for example, noise or interference, scratches on a CD, etc.). The BCH decoder processes each block of data and attempts to correct the errors and recover the original data. The number and type of errors that can be corrected depends on the characteristics of the BCH code.
BCH encoding and decoding can be carried out either in software or in special-purpose hardware.
Finite (Galois) field arithmetic
BCH codes are based on a special area of mathematics known as Galois fields or finite fields. A finite field has the property that the arithmetic operations (+,-,x,/ etc.) on field elements always have a result in the field. A BCH encoder or decoder needs to carry out these arithmetic operations. These operations require special hardware or software functions to implement.
Generator polynomial
A BCH codeword is generated using a special polynomial. All valid codewords are exactly divisible by the generator polynomial. The general form of the generator polynomial is:
g(x) = (x - a<SUP>i</SUP>) (x - a<SUP>i+1</SUP>) .... (x - a<SUP>i+2t</SUP>)
and the codeword is constructed using:
c(x) = g(x) . i(x)
where g(x) is the generator polynomial, i(x) is the information block, c(x) is a valid codeword and a is a primitive element of the field.
One of my projects was to implement the POCSAG protocol that is used in pagers for a simple communication. The protocol requires some error correction codes that can easily recover lost data from redundant data. For this, the creators decided to use BCH ECC. The protocol consists of codewords. Every codeword contains 21 bits of data (original), 10 bits of redundant data (for error correcting) and 1 bit of parity. In this case, we use BCH 21,31 to implement codewords of POCSAG.
I have tried to give a brief introduction to BCH and you can find more useful information from articles and books on error correction codes, concepts, and the mathematics required. Also Dr. Dobbs journal published a very useful series of articles on Reed-Solomon and BCH. I found a few articles in this field such as those that are introduced in the «The Error Correcting Codes (ECC) Page», but unfortunately none of them works right. There are some bugs in the codes and they return wrong results. Then, I decided to write my own code.
Note that we have used binary BCH for POCSAG.
CBCHEncoder
CBCHEncoder is a simple class for computing BCH ECC for a set of data. You give the class a 32 bit integer or an array of integers for encoding. The class treats the first 21 bits as the original data and adds the encoded 10 bits at the end of the integer. Below is the class interface:
class CBCHEncoder { public: int GetEncodedData(); int* GetEncodedDataPtr(); void SetData(int* pData); void SetData(int iData); void Encode(); CBCHEncoder(); virtual ~CBCHEncoder(); private: void InitializeEncoder(); void ComputeGeneratorPolynomial(); void GenerateGf(); int m, n, k, t, d; int length; int p[6]; int alpha_to[32], index_of[32], g[11]; int recd[32], data[21], bb[11]; int Mr[31]; };
Using the class is very simple. Just create an instance of the class such as m_bch as follows:
CBCHEncoder m_bch; m_bch.SetData(0x23c5FFFF); m_bch.Encode(); int iEncodedData=m_bch.GetEncodedData();
Note that the class itself generates the Galois Field GF(2**m) and then computes the generator polynomial of the BCH code (see InitializeEncoder(), private member function of the class).
Encode() is the heart of the class. Here is its body:
void CBCHEncoder::Encode() { int h, i, j=0, start=0, end=(n-k); for (i = 0; i < n; i++) Mr[i] = 0; for (h=0; h < k; ++h) Mr[h] = data[h]; while (end < n) { for (i=end; i>start-2; --i) { if (Mr[start] != 0) { Mr[i]^=g[j]; ++j; } else { ++start; j = 0; end = start+(n-k); break; } } } j = 0; for (i = start; i < end; ++i) { bb[j]=Mr[i]; ++j; } }
Acknowledgements
I should thank my cousin Mohammad and also Mohammad Shahmohammadi one of my best friends who helped me in writing/debugging the code. Most of the code is taken from the Reed-Solomon implementation from the ECC Homepage.
Enjoy!
I was born in Shiraz, Iran. A beautiful city that’s famous for its weather, poets, ancient culture.
Got my high school diploma from QHS — Quebec High School.
Studied Computer Eng. at the University of New Brunswick (Canada) & Continued at Shiraz University.
Graduated from the University, school of Engineering: 2004.
Masters program, IT, e-Commerce at the electronic University of Shiraz.
Masters in IT Management at UTM, Malaysia.
Masters in Computer Science (Machine Learning) at University of Alberta
Currently in Edmonton, AB Canada!
|
284 |
14 |
ERROR-CORRECTING CODES |
||
|
TABLE 14.13. Decoding Using Syndromes and Coset Leaders |
||||
|
Word received u |
100110010 |
100100101 |
111101100 |
000111110 |
|
Syndrome Hu |
01000 |
00000 |
10111 |
10011 |
|
Coset leader e |
010000000 |
000000000 |
000000011 |
001101000 |
|
Code word u + e |
110110010 |
100100101 |
111101111 |
001010110 |
|
Message |
0010 |
0101 |
1111 |
0110 |
The (9,4)-code in Example 14.15 will, by Corollary 14.7, detect single, double, and triple errors. Hence it will correct any single error. It will not detect all errors involving four digits or correct all double errors, because 000000000 and 100001110 are two code words of Hamming distance 4 apart. For example, if the received word is 100001000, whose syndrome is 00101, Table 14.12 would decode this as 100001110 rather than 000000000; both these code words differ from the received word by a double error.
Example 14.16. Decode 100110010, 100100101, 111101100, and 000111110 using the parity check matrix in Example 14.11 and the coset leaders in Table 14.12.
|
Solution. Table 14.13 illustrates the decoding process. |
The most powerful class of error-correcting codes known to date were discovered around 1960 by Hocquenghem and independently by Bose and Chaudhuri. For any positive integers m and t, with t < 2m−1, there exists a Bose–Chaudhuri–Hocquenghem (BCH) code of length n = 2m − 1 that will correct any combination of t or fewer errors. These codes are polynomial codes with a generator p(x) of degree mt and have message length at least n − mt.
A t—error-correcting BCH code of length n = 2m − 1 has a generator polynomial p(x) that is constructed as follows. Take a primitive element α in the Galois field GF(2m). Let pi (x) Z2[x] be the irreducible polynomial with αi as a root, and define
p(x) = lcm(p1(x), p2(x), . . . , p2t (x)).
It is clear that α, α2, α3, . . . , α2t are all roots of p(x). By Exercise 11.56, [pi (x)]2 = pi (x2) and hence α2i is a root of pi (x). Therefore,
p(x) = lcm(p1(x), p3(x), . . . , p2t −1(x)).
Since GF(2m) is a vector space of degree m over Z2, for any β = αi , the elements 1, β, β2, . . . , βm are linearly dependent. Hence β satisfies a polynomial of degree at most m in Z2[x], and the irreducible polynomial pi (x) must also
have degree at most m. Therefore,
deg p(x) deg p1(x) · deg p3(x) · · · deg p2t −1(x) mt.
Example 14.17. Find the generator polynomials of the t-error-correcting BCH codes of length n = 15 for each value of t less than 8.
Solution. Let α be a primitive element of GF (16), where α4 + α + 1 = 0. We repeatedly refer back to the elements of GF (16) given in Table 11.4 when performing arithmetic operations in GF(16) = Z2(α).
We first calculate the irreducible polynomials pi (x) that have αi as roots. We only need to look at the odd powers of α. The element α itself is the root of
|
x4 |
+ x + 1. Therefore, p1(x) = x |
4 |
x |
+ 1. |
|
|
+ 3 |
|||||
|
If the polynomial p3(x) contains α |
as a root, it also contains |
||||
|
(α3)2 = α6, (α6)2 = α12, |
(α12)2 = α24 = α9, and (α9)2 = α18 = α3. |
Hence
p3(x) = (x − α3)(x − α6)(x − α12)(x − α9)
=(x2 + (α3 + α6)x + α9)(x2 + (α12 + α9)x + α21)
=(x2 + α2x + α9)(x2 + α8x + α6)
=x4 + (α2 + α8)x3 + (α9 + α10 + α6)x2 + (α17 + α8)x + α15
=x4 + x3 + x2 + x + 1.
The polynomial p5(x) has roots α5, α10, and α20 = α5. Hence
p5(x) = (x − α5)(x − α10)
= x2 + x + 1.
The polynomial p7(x) has roots α7, α14, α28 = α13, α26 = α11, and α22 = α7. Hence
p7(x) = (x − α7)(x − α14)(x − α13)(x − α11)
=(x2 + αx + α6)(x2 + α4x + α9)
=x4 + x3 + 1.
Now every power of α is a root of one of the polynomials p1(x), p3(x), p5(x), or p7(x). For example, p9(x) contains α9 as a root, and therefore, p9(x) = p3(x).
The BCH code that corrects one error is generated by p(x) = p1(x) = x4 + x + 1.
The BCH code that corrects two errors is generated by
p(x) = lcm(p1(x), p3(x)) = (x4 + x + 1)(x4 + x3 + x2 + x + 1).

|
286 |
14 ERROR-CORRECTING CODES |
This least common multiple is the product because p1(x) and p3(x) are different irreducible polynomials. Hence p(x) = x8 + x7 + x6 + x4 + 1.
The BCH code that corrects three errors is generated by
p(x) = lcm(p1(x), p3(x), p5(x))
=(x4 + x + 1)(x4 + x3 + x2 + x + 1)(x2 + x + 1)
=x10 + x8 + x5 + x4 + x2 + x + 1.
The BCH code that corrects four errors is generated by
p(x) = lcm(p1(x), p3(x), p5(x), p7(x))
= p1(x) · p3(x) · p5(x) · p7(x)
|
x15 + 1 |
14 |
||||
|
xi . |
|||||
|
= x |
+ |
1 |
= |
i |
|
|
= |
|||||
|
0 |
This polynomial contains all the elements of GF (16) as roots, except for 0 and 1. Since p9(x) = p3(x), the five-error-correcting BCH code is generated by
p(x) = lcm(p1(x), p3(x), p5(x), p7(x), p9(x))
= (x15 + 1)/(x + 1),
and this is also the generator of the sixand seven-error-correcting BCH codes. These results are summarized in Table 14.14.
For example, the two-error-correcting BCH code is a (15, 7)-code with generator polynomial x8 + x7 + x6 + x4 + 1. It contains seven message digits and eight check digits.
The seven-error-correcting code generated by (x15 + 1)/(x + 1) has message length 1, and the two code words are the sequence of 15 zeros and the sequence of 15 ones. Each received word can be decoded by majority rule to give the
TABLE 14.14. Construction of t-Error-Correcting BCH Codes of Length 15
|
Roots of |
Degree, |
Degp(x) = 15 − k |
Message |
||||||||||||
|
t |
p2t −1(x) |
p2t −1(x) |
p(x) |
Length, k |
|||||||||||
|
1 |
α, α2, α4, α8 |
4 |
p1(x) |
4 |
11 |
||||||||||
|
2 |
α3 |
, α6, α12, α9 |
4 |
p1(x)p3(x) |
8 |
7 |
|||||||||
|
3 |
α5 |
, α10 |
2 |
p1(x)p3(x)p5(x) |
10 |
5 |
|||||||||
|
4 |
7 |
14 |
α13 |
, α11 |
4 |
(x15 |
+ 1 |
)/(x |
+ 1 |
) |
14 |
1 |
|||
|
α9 |
, α3 |
7 |
, |
6 |
12 |
15 |
|||||||||
|
5 |
α11 |
, α14 |
, α13 |
4 |
(x15 |
+ 1)/(x |
+ 1) |
14 |
1 |
||||||
|
, α , α , α |
(x |
)/(x |
) |
||||||||||||
|
6 |
α13 |
, α11 |
, α |
7 |
, α |
14 |
4 |
(x |
15 |
+ 1 |
+ 1 |
14 |
1 |
||
|
7 |
α |
, α |
4 |
+ 1)/(x |
+ 1) |
14 |
1 |
message 1, if the word contains more 1’s than 0’s, and to give the message 0 otherwise. It is clear that this will correct up to seven errors.
We now show that the BCH code given at the beginning of this section does indeed correct t errors.
Lemma 14.18. The minimum Hamming distance between code words of a linear code is the minimum number of ones in the nonzero code words.
|
Proof. If v1 and v2 are code words, then, since the code is |
linear, v1 − v2 |
|
is also a code word. The Hamming distance between v1 and v2 |
is equal to the |
number of 1’s in v1 − v2. The result now follows because the zero word is always a code word, and its Hamming distance from any other word is the number of 1’s in that word.
Theorem 14.19. If t < 2m−1, the minimum distance between code words in the BCH code given in at the beginning of this section is at least 2t + 1, and hence this code corrects t or fewer errors.
Proof. Suppose that the code contains a code polynomial with fewer than 2t + 1 nonzero terms,
v(x) = v1xr1 + · · · + v2t xr2t where r1 < · · · < r2t .
This code polynomial is divisible by the generator polynomial p(x) and hence has roots α, α2, α3, . . . , α2t . Therefore, if 1 i 2t,
v(αi ) = v1αir1 + · · · + v2t αir2t
= αir1 (v1 + · · · + v2t αir2t −ir1 ).
Put si = ri − r1 so that the elements v1, . . . , v2t satisfy the following linear equations:
|
v1 |
+ |
v2αs2 |
|
v1 |
+ |
v2α2s2 |
|
. |
||
|
. |
||
|
. |
||
|
v1 |
+ |
v2α2t s2 |
+ · · · + v2t αs2t + · · · + v2t α2s2t
.
.
.
+ · · · + v2t α2t s2t
The coefficient matrix is nonsingular because its determinant is the Vandermonde determinant:
|
1 |
αs2 |
||
|
1 |
α2s2 |
||
|
det |
. |
||
|
. |
|||
|
. |
|||
|
1 |
α |
|
· · · |
α2s2t |
||||||
|
αs2t |
|||||||
|
. |
= |
− |
= |
||||
|
. |
2t |
(αsi |
αsj ) 0. |
||||
|
. |
|||||||
|
2 |
|||||||
|
· · · |
α |
2t s2t |
|||||
|
i>j |
|||||||
This is the approved revision of this page, as well as being the most recent.
In [[codin15}}). We will consider different values of }}
its minimal polynomial over is

The minimal polynomials of the first fourteen powers of are




The BCH code with  has generator polynomial
has generator polynomial

It has minimal Hamming distance at least 3 and corrects up to one error. Since the generator polynomial is of degree 4, this code has 11 data bits and 4 checksum bits.
The BCH code with  has generator polynomial
has generator polynomial

It has minimal Hamming distance at least 5 and corrects up to two errors. Since the generator polynomial is of degree 8, this code has 7 data bits and 8 checksum bits.
The BCH code with  has generator polynomial
has generator polynomial

It has minimal Hamming distance at least 7 and corrects up to three errors. Since the generator polynomial is of degree 10, this code has 5 data bits and 10 checksum bits.
(This particular generator polynomial has a real-world application, in the format patterns of the QR code.)
The BCH code with  and higher has generator polynomial
and higher has generator polynomial

This code has minimal Hamming distance 15 and corrects 7 errors. It has 1 data bit and 14 checksum bits. In fact, this code has only two codewords: 000000000000000 and 111111111111111.
Contents
- 1 General BCH codes
- 2 Special cases
- 3 Properties
- 4 Encoding
-
5 Decoding
- 5.1 Calculate the syndromes
-
5.2 Calculate the error location polynomial
- 5.2.1 Peterson–Gorenstein–Zierler algorithm
- 5.3 Factor error locator polynomial
-
5.4 Calculate error values
- 5.4.1 Forney algorithm
- 5.4.2 Explanation of Forney algorithm computation
-
5.5 Decoding based on extended Euclidean algorithm
- 5.5.1 Explanation of the decoding process
- 5.6 Correct the errors
-
5.7 Decoding examples
- 5.7.1 Decoding of binary code without unreadable characters
- 5.7.2 Decoding with unreadable characters
- 5.7.3 Decoding with unreadable characters with a small number of errors
- 6 Citations
- 7 Source
- 8 See Also on BitcoinWiki
General BCH codes[edit]
General BCH codes differ from primitive narrow-sense BCH codes in two respects.
First, the requirement that  be a primitive element of
be a primitive element of  can be relaxed. By relaxing this requirement, the code length changes from
can be relaxed. By relaxing this requirement, the code length changes from  to
to  the order of the element
the order of the element 
Second, the consecutive roots of the generator polynomial may run from  instead of
instead of 
Definition. Fix a finite field  where
where  is a prime power. Choose positive integers
is a prime power. Choose positive integers  such that
such that 
 and
and  is the multiplicative order of modulo
is the multiplicative order of modulo 
As before, let be a primitive  th root of unity in
th root of unity in  and let
and let  be the minimal polynomial over
be the minimal polynomial over  of
of  for all
for all 
The generator polynomial of the BCH code is defined as the least common multiple 
Note: if  as in the simplified definition, then
as in the simplified definition, then  is 1, and the order of modulo is
is 1, and the order of modulo is 
Therefore, the simplified definition is indeed a special case of the general one.
Special cases[edit]
The generator polynomial  of a BCH code has coefficients from
of a BCH code has coefficients from 
In general, a cyclic code over  with as the generator polynomial is called a BCH code over
with as the generator polynomial is called a BCH code over 
The BCH code over with as the generator polynomial is called a Reed–Solomon code. In other words, a Reed–Solomon code is a BCH code where the decoder alphabet is the same as the channel alphabet.
Properties[edit]
The generator polynomial of a BCH code has degree at most  . Moreover, if
. Moreover, if  and
and  , the generator polynomial has degree at most
, the generator polynomial has degree at most  .
.
Each minimal polynomial has degree at most .
Therefore, the least common multiple of  of them has degree at most .
of them has degree at most .
Moreover, if  then
then  for all
for all  .
.
Therefore, is the least common multiple of at most  minimal polynomials for odd indices
minimal polynomials for odd indices  each of degree at most .
each of degree at most .
A BCH code has minimal Hamming distance at least  .
.
Suppose that  is a code word with fewer than non-zero terms. Then
is a code word with fewer than non-zero terms. Then

Recall that are roots of  hence of .
hence of .
This implies that  satisfy the following equations, for each
satisfy the following equations, for each  :
:

In matrix form, we have

The determinant of this matrix equals

The matrix  is seen to be a Vandermonde matrix, and its determinant is
is seen to be a Vandermonde matrix, and its determinant is

which is non-zero. It therefore follows that  hence
hence 
A BCH code is cyclic.
A polynomial code of length is cyclic if and only if its generator polynomial divides 
Since is the minimal polynomial with roots  it suffices to check that each of is a root of
it suffices to check that each of is a root of
This follows immediately from the fact that is, by definition, an th root of unity.
Encoding[edit]
Decoding[edit]
There are many algorithms for decoding BCH codes. The most common ones follow this general outline:
- Calculate the syndromes sj for the received vector
- Determine the number of errors t and the error locator polynomial Λ(x) from the syndromes
- Calculate the roots of the error location polynomial to find the error locations Xi
- Calculate the error values Yi at those error locations
- Correct the errors
During some of these steps, the decoding algorithm may determine that the received vector has too many errors and cannot be corrected. For example, if an appropriate value of t is not found, then the correction would fail. In a truncated (not primitive) code, an error location may be out of range. If the received vector has more errors than the code can correct, the decoder may unknowingly produce an apparently valid message that is not the one that was sent.
Calculate the syndromes[edit]
The received vector  is the sum of the correct codeword
is the sum of the correct codeword  and an unknown error vector
and an unknown error vector 
The syndrome values are formed by considering as a polynomial and evaluating it at 
Thus the syndromes are

for  to
to 
Since  are the zeros of of which
are the zeros of of which
 is a multiple,
is a multiple, 
Examining the syndrome values thus isolates the error vector so one can begin to solve for it.
If there is no error,  for all
for all 
If the syndromes are all zero, then the decoding is done.
Calculate the error location polynomial[edit]
If there are nonzero syndromes, then there are errors. The decoder needs to figure out how many errors and the location of those errors.
If there is a single error, write this as 
where is the location of the error and  is its magnitude. Then the first two syndromes are
is its magnitude. Then the first two syndromes are


so together they allow us to calculate and provide some information about (completely determining it in the case of Reed–Solomon codes).
If there are two or more errors,

It is not immediately obvious how to begin solving the resulting syndromes for the unknowns  and
and 
First step is finding locator polynomial
-
compatible with computed syndromes and with minimal possible
 compatible with computed syndromes and with minimal possible
compatible with computed syndromes and with minimal possible 
Two popular algorithms for this task are:
- Peterson–Gorenstein–Zierler algorithm
- Berlekamp–Massey algorithm
Peterson–Gorenstein–Zierler algorithm[edit]
Peterson’s algorithm is the step 2 of the generalized BCH decoding procedure. Peterson’s algorithm is used to calculate the error locator polynomial coefficients  of a polynomial
of a polynomial

Now the procedure of the Peterson–Gorenstein–Zierler algorithm. Expect we have at least 2t syndromes sc,…,sc+2t−1.
Let v = t.
- Start by generating the matrix with elements that are syndrome values
 matrix with elements that are syndrome values
matrix with elements that are syndrome values
- Generate a vector with elements
 vector with elements
vector with elements
- Let denote the unknown polynomial coefficients, which are given by

- Form the matrix equation

if
 then
declare an empty error locator polynomial
stop Peterson procedure.
end
set
then
declare an empty error locator polynomial
stop Peterson procedure.
end
set  continue from the beginning of Peterson's decoding by making smaller
continue from the beginning of Peterson's decoding by making smaller - After you have values of , you have with you the error locator polynomial.
- Stop Peterson procedure.
Factor error locator polynomial[edit]
Now that you have the  polynomial, its roots can be found in the form
polynomial, its roots can be found in the form  by brute force for example using the Chien search algorithm. The exponential
by brute force for example using the Chien search algorithm. The exponential
powers of the primitive element will yield the positions where errors occur in the received word; hence the name ‘error locator’ polynomial.
The zeros of Λ(x) are α−i1, …, α−iv.
Calculate error values[edit]
Once the error locations are known, the next step is to determine the error values at those locations. The error values are then used to correct the received values at those locations to recover the original codeword.
For the case of binary BCH, (with all characters readable) this is trivial; just flip the bits for the received word at these positions, and we have the corrected code word. In the more general case, the error weights  can be determined by solving the linear system
can be determined by solving the linear system

Forney algorithm[edit]
However, there is a more efficient method known as the Forney algorithm.
Let


And the error evaluator polynomial

Finally:

where

Than if syndromes could be explained by an error word, which could be nonzero only on positions  , then error values are
, then error values are

For narrow-sense BCH codes, c = 1, so the expression simplifies to:

Explanation of Forney algorithm computation[edit]
It is based on Lagrange interpolation and techniques of generating functions.
Consider  and for the sake of simplicity suppose
and for the sake of simplicity suppose  for
for  and
and  for
for  Then
Then


We want to compute unknowns  and we could simplify the context by removing the
and we could simplify the context by removing the  terms. This leads to the error evaluator polynomial
terms. This leads to the error evaluator polynomial

Thanks to  we have
we have

Thanks to  (the Lagrange interpolation trick) the sum degenerates to only one summand for
(the Lagrange interpolation trick) the sum degenerates to only one summand for 

To get we just should get rid of the product. We could compute the product directly from already computed roots  of
of  but we could use simpler form.
but we could use simpler form.
As formal derivative

we get again only one summand in

So finally

This formula is advantageous when one computes the formal derivative of form

yielding:
where
Decoding based on extended Euclidean algorithm[edit]
An alternate process of finding both the polynomial Λ and the error locator polynomial is based on Yasuo Sugiyama’s adaptation of the Extended Euclidean algorithm. Correction of unreadable characters could be incorporated to the algorithm easily as well.
Let  be positions of unreadable characters. One creates polynomial localising these positions
be positions of unreadable characters. One creates polynomial localising these positions 
Set values on unreadable positions to 0 and compute the syndromes.
As we have already defined for the Forney formula let 
Let us run extended Euclidean algorithm for locating least common divisor of polynomials  and
and 
The goal is not to find the least common divisor, but a polynomial  of degree at most
of degree at most  and polynomials
and polynomials  such that
such that 
Low degree of guarantees, that  would satisfy extended (by
would satisfy extended (by  ) defining conditions for
) defining conditions for 
Defining  and using
and using  on the place of in the Fourney formula will give us error values.
on the place of in the Fourney formula will give us error values.
The main advantage of the algorithm is that it meanwhile computes  required in the Forney formula.
required in the Forney formula.
Explanation of the decoding process[edit]
The goal is to find a codeword which differs from the received word minimally as possible on readable positions. When expressing the received word as a sum of nearest codeword and error word, we are trying to find error word with minimal number of non-zeros on readable positions. Syndrom  restricts error word by condition
restricts error word by condition

We could write these conditions separately or we could create polynomial

and compare coefficients near powers  to
to 

Suppose there is unreadable letter on position  we could replace set of syndromes
we could replace set of syndromes  by set of syndromes
by set of syndromes  defined by equation
defined by equation  Suppose for an error word all restrictions by original set of syndromes hold,
Suppose for an error word all restrictions by original set of syndromes hold,
than

New set of syndromes restricts error vector

the same way the original set of syndromes restricted the error vector  Note, that except the coordinate where we have
Note, that except the coordinate where we have  an
an  is zero, if
is zero, if  For the goal of locating error positions we could change the set of syndromes in the similar way to reflect all unreadable characters. This shortens the set of syndromes by
For the goal of locating error positions we could change the set of syndromes in the similar way to reflect all unreadable characters. This shortens the set of syndromes by 
In polynomial formulation, the replacement of syndromes set by syndromes set leads to

Therefore,

After replacement of  by , one would require equation for coefficients near powers
by , one would require equation for coefficients near powers 
One could consider looking for error positions from the point of view of eliminating influence of given positions similarly as for unreadable characters. If we found  positions such that eliminating their influence leads to obtaining set of syndromes consisting of all zeros, than there exists error vector with errors only on these coordinates.
positions such that eliminating their influence leads to obtaining set of syndromes consisting of all zeros, than there exists error vector with errors only on these coordinates.
If denotes the polynomial eliminating the influence of these coordinates, we obtain

In Euclidean algorithm, we try to correct at most  errors (on readable positions), because with bigger error count there could be more codewords in the same distance from the received word. Therefore, for we are looking for, the equation must hold for coefficients near powers starting from
errors (on readable positions), because with bigger error count there could be more codewords in the same distance from the received word. Therefore, for we are looking for, the equation must hold for coefficients near powers starting from

In Forney formula, could be multiplied by a scalar giving the same result.
It could happen that the Euclidean algorithm finds of degree higher than having number of different roots equal to its degree, where the Fourney formula would be able to correct errors in all its roots, anyway correcting such many errors could be risky (especially with no other restrictions on received word). Usually after getting of higher degree, we decide not to correct the errors. Correction could fail in the case has roots with higher multiplicity or the number of roots is smaller than its degree. Fail could be detected as well by Forney formula returning error outside the transmitted alphabet.
Correct the errors[edit]
Using the error values and error location, correct the errors and form a corrected code vector by subtracting error values at error locations.
Decoding examples[edit]
Decoding of binary code without unreadable characters[edit]
Consider a BCH code in GF(24) with  and
and  . (This is used in QR codes.) Let the message to be transmitted be [1 1 0 1 1], or in polynomial notation,
. (This is used in QR codes.) Let the message to be transmitted be [1 1 0 1 1], or in polynomial notation, 
The «checksum» symbols are calculated by dividing  by and taking the remainder, resulting in
by and taking the remainder, resulting in  or [ 1 0 0 0 0 1 0 1 0 0 ]. These are appended to the message, so the transmitted codeword is [ 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0 ].
or [ 1 0 0 0 0 1 0 1 0 0 ]. These are appended to the message, so the transmitted codeword is [ 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0 ].
Now, imagine that there are two bit-errors in the transmission, so the received codeword is [ 1 0 1 1 1 0 0 0 1 0 1 0 0 ]. In polynomial notation:

In order to correct the errors, first calculate the syndromes. Taking  we have
we have 



 and
and 
Next, apply the Peterson procedure by row-reducing the following augmented matrix.
![left [ S_{3 times 3} | C_{3 times 1} right ] =
begin{bmatrix}s_1&s_2&s_3&s_4\
s_2&s_3&s_4&s_5\
s_3&s_4&s_5&s_6end{bmatrix} =
begin{bmatrix}1011&1001&1011&1101\
1001&1011&1101&0001\
1011&1101&0001&1001end{bmatrix} Rightarrow
begin{bmatrix}0001&0000&1000&0111\
0000&0001&1011&0001\
0000&0000&0000&0000end{bmatrix}](https://en.bitcoinwiki.org/upload/en/images/math/d/a/3/da3e42dcac8419e6b07afa7ec1dbd6ec.png)
Due to the zero row, is singular, which is no surprise since only two errors were introduced into the codeword.
However, the upper-left corner of the matrix is identical to , which gives rise to the solution 

The resulting error locator polynomial is  which has zeros at
which has zeros at  and
and 
The exponents of correspond to the error locations.
There is no need to calculate the error values in this example, as the only possible value is 1.
Decoding with unreadable characters[edit]
Suppose the same scenario, but the received word has two unreadable characters [ 1 0 ? 1 1 ? 0 0 1 0 1 0 0 ]. We replace the unreadable characters by zeros while creating the polynom reflecting their positions  We compute the syndromes
We compute the syndromes  and
and  (Using log notation which is independent on GF(24) isomorphisms. For computation checking we can use the same representation for addition as was used in previous example. Hexadecimal description of the powers of are consecutively 1,2,4,8,3,6,C,B,5,A,7,E,F,D,9 with the addition based on bitwise xor.)
(Using log notation which is independent on GF(24) isomorphisms. For computation checking we can use the same representation for addition as was used in previous example. Hexadecimal description of the powers of are consecutively 1,2,4,8,3,6,C,B,5,A,7,E,F,D,9 with the addition based on bitwise xor.)
Let us make syndrome polynomial

compute

Run the extended Euclidean algorithm:
![begin{align}
begin{pmatrix}S(x)Gamma(x)\ x^6end{pmatrix} &= begin{pmatrix}alpha^{-7} +alpha^{4}x+ alpha^{-1}x^2+ alpha^{6}x^3+ alpha^{-1}x^4+alpha^{5}x^5 +alpha^{7}x^6+ alpha^{-3}x^7 \ x^6end{pmatrix} \ [6pt]
&=begin{pmatrix}alpha^{7}+alpha^{-3}x&1\ 1&0end{pmatrix} begin{pmatrix}x^6\ alpha^{-7} +alpha^{4}x +alpha^{-1}x^2 +alpha^{6}x^3 +alpha^{-1}x^4 +alpha^{5}x^5 +2alpha^{7}x^6 +2alpha^{-3}x^7end{pmatrix} \ [6pt]
&=begin{pmatrix}alpha^{7}+alpha^{-3}x&1\ 1&0end{pmatrix} begin{pmatrix}alpha^4+alpha^{-5}x&1\ 1&0end{pmatrix} times \
&qquad times begin{pmatrix} alpha^{-7}+alpha^{4}x+alpha^{-1}x^2+alpha^{6}x^3+alpha^{-1}x^4+alpha^{5}x^5\ alpha^{-3} +(alpha^{-7}+alpha^{3})x+(alpha^{3}+alpha^{-1})x^2+(alpha^{-5}+alpha^{-6})x^3+(alpha^3+alpha^{1})x^4+ 2alpha^{-6}x^5+ 2x^6end{pmatrix} \ [6pt]
&=begin{pmatrix}(1+alpha^{-4})+(alpha^{1}+alpha^{2})x+alpha^{7}x^2&alpha^{7}+alpha^{-3}x \ alpha^4+alpha^{-5}x&1end{pmatrix} begin{pmatrix} alpha^{-7} +alpha^{4}x +alpha^{-1}x^2+ alpha^{6}x^3+alpha^{-1}x^4+alpha^{5}x^5\ alpha^{-3}+alpha^{-2}x+alpha^{0}x^2+ alpha^{-2}x^3+alpha^{-6}x^4end{pmatrix} \ [6pt]
&=begin{pmatrix}alpha^{-3}+alpha^{5}x+alpha^{7}x^2&alpha^{7}+alpha^{-3}x \ alpha^4+alpha^{-5}x&1end{pmatrix} begin{pmatrix}alpha^{-5}+alpha^{-4}x&1\ 1&0 end{pmatrix} times \
&qquad times begin{pmatrix} alpha^{-3}+alpha^{-2}x+alpha^{0}x^2+ alpha^{-2}x^3+alpha^{-6}x^4\ (alpha^{7}+alpha^{-7})+ (2alpha^{-7}+alpha^{4})x+ (alpha^{-5}+alpha^{-6}+alpha^{-1})x^2+ (alpha^{-7}+alpha^{-4}+alpha^{6})x^3+ (alpha^{4}+alpha^{-6}+alpha^{-1})x^4+ 2alpha^{5}x^5end{pmatrix} \ [6pt]
&=begin{pmatrix} alpha^{7}x+alpha^{5}x^2+alpha^{3}x^3&alpha^{-3}+alpha^{5}x+alpha^{7}x^2\ alpha^{3}+alpha^{-5}x+alpha^{6}x^2&alpha^4+alpha^{-5}xend{pmatrix}
begin{pmatrix} alpha^{-3}+alpha^{-2}x+alpha^{0}x^2+ alpha^{-2}x^3+alpha^{-6}x^4\ alpha^{-4}+alpha^{4}x+alpha^{2}x^2+ alpha^{-5}x^3end{pmatrix}.
end{align}](https://en.bitcoinwiki.org/upload/en/images/math/9/8/b/98bc35296a2d1ad38cfdd11ef2a1322c.png)
We have reached polynomial of degree at most 3, and as

we get

Therefore,

Let  Don’t worry that
Don’t worry that  Find by brute force a root of The roots are
Find by brute force a root of The roots are  and
and  (after finding for example
(after finding for example  we can divide by corresponding monom
we can divide by corresponding monom  and the root of resulting monom could be found easily).
and the root of resulting monom could be found easily).
Let


Let us look for error values using formula

where are roots of 
 We get
We get

Fact, that  should not be surprising.
should not be surprising.
Corrected code is therefore [ 1 0 1 1 0 0 1 0 1 0 0].
Decoding with unreadable characters with a small number of errors[edit]
Let us show the algorithm behaviour for the case with small number of errors. Let the received word is [ 1 0 ? 1 1 ? 0 0 0 1 0 1 0 0 ].
Again, replace the unreadable characters by zeros while creating the polynom reflecting their positions
Compute the syndromes  and
and 
Create syndrome polynomial


Let us run the extended Euclidean algorithm:

We have reached polynomial of degree at most 3, and as

we get

Therefore,

Let  Don’t worry that The root of is
Don’t worry that The root of is 
Let


Let us look for error values using formula  where are roots of polynomial
where are roots of polynomial 
We get

The fact that  should not be surprising.
should not be surprising.
Corrected code is therefore [ 1 0 1 1 0 0 0 1 0 1 0 0].
Citations[edit]
Source[edit]
http://wikipedia.org/
See Also on BitcoinWiki[edit]
- Wallet features
- Uc bitcoin
- Legality of bitcoin by country or territory
- Proof of Ownership
- Tipping