In process automation, you often encounter deviations from the default scenario. One way to resolve these deviations is using a BPMN error event, which allows a process model to react to errors within a task.
For example, if an invalid credit card is used in the process below, the process takes a different path than usual and uses the default payment method to collect money.
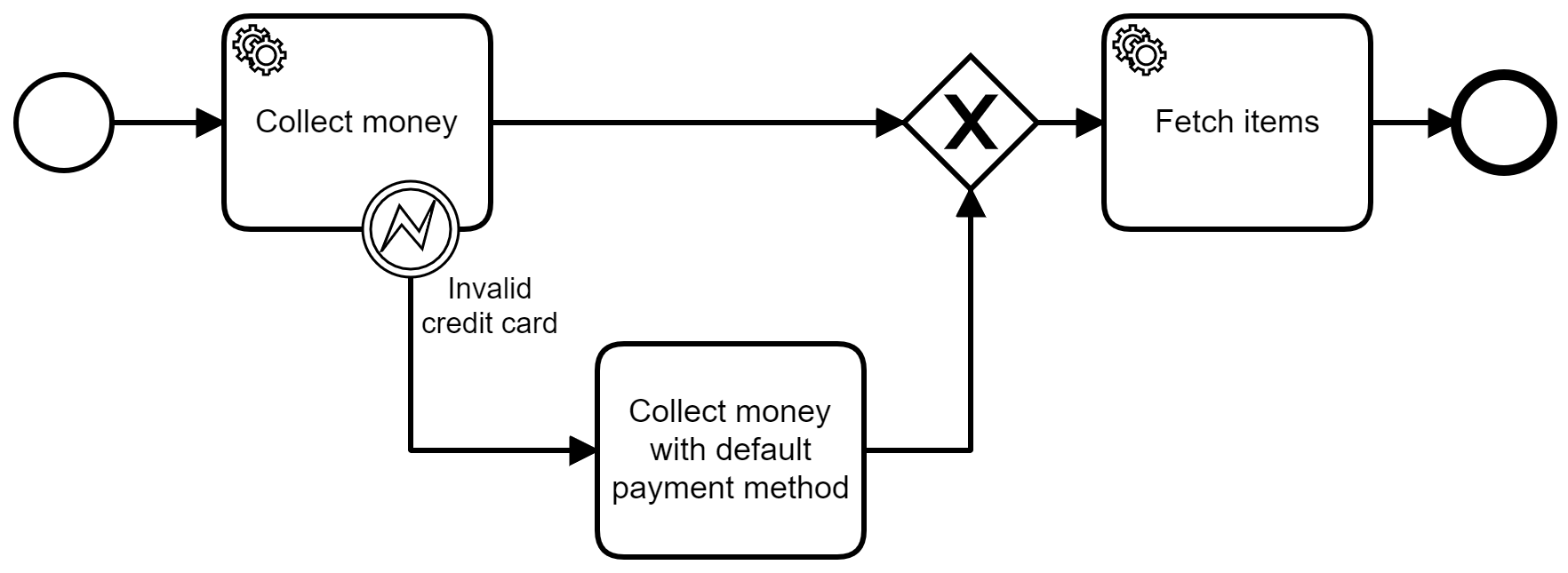
Defining the error
In BPMN, errors define possible errors that can occur. Error events are elements in the process referring to defined errors. An error can be referenced by one or more error events.
An error must define an errorCode (e.g. InvalidCreditCard). The errorCode is a string used to match a thrown error to the error catch events.
Throwing the error
An error can be thrown within the process using an error end event.
Alternatively, you can inform Zeebe that a business error occurred using a client command. This throw error client command can only be used while processing a job.
In addition to throwing the error, this also disables the job and stops it from being activated or completed by other job workers. See the gRPC command for details.
Catching the error
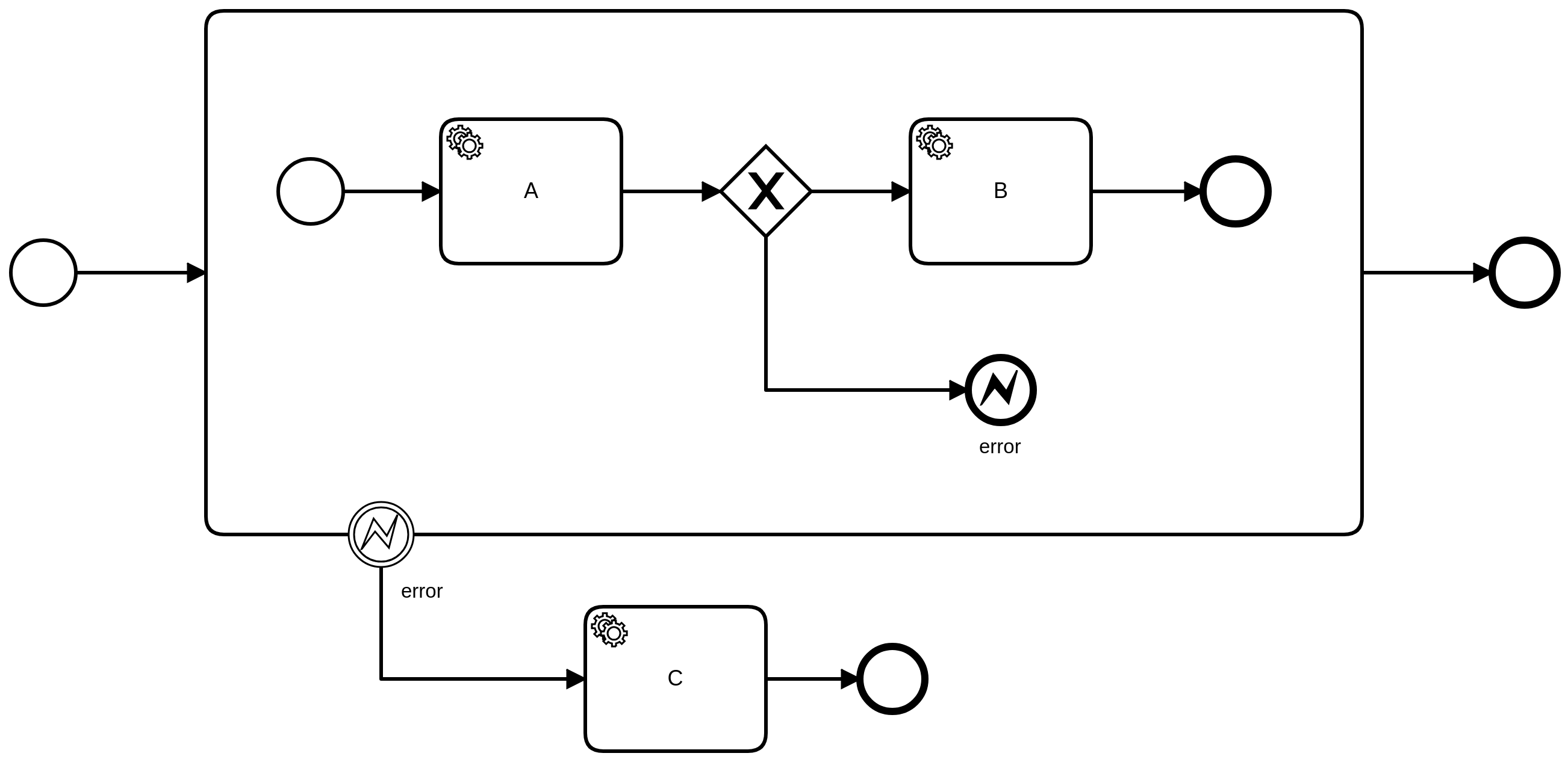
A thrown error can be caught by an error catch event, specifically using an error boundary event or an error event subprocess.
Starting at the scope where the error was thrown, the error code is matched against the attached error boundary events and error event sub processes at that level. An error is caught by the first event in the scope hierarchy matching the error code. At each scope, the error is either caught, or propagated to the parent scope.
If the process instance is created via call activity, the error can also be caught in the calling parent process instance.
Error boundary events and error event subprocesses must be interrupting. This means the process instance will not continue along the regular path, but instead follow the path that leads out of the catching error event.
If the error is thrown for a job, the associated task is terminated first. To continue the execution, the error boundary event or error event subprocess that caught the error is activated.
Unhandled errors
When an error is thrown and not caught, an incident (i.e. Unhandled error event) is raised to indicate the failure. The incident is attached to the corresponding element where the error was thrown (i.e. the task of the processed job or the error end event).
When you resolve the incident attached to a task, it ignores the error, re-enables the job, and allows it to be activated and completed by a job worker once again.
The incident attached to an error end event cannot be resolved by a user because the failure is in the process itself. The process cannot be changed to catch the error for this process instance.
Business error vs. technical error
In real life, you’ll also have to deal with technical problems that you don’t want to treat using error events.
Suppose the credit card service becomes temporarily unavailable. You don’t want to model the retrying, as you would have to add it to each and every service task. This will bloat the visual model and confuse business personnel. Instead, either retry or fall back to incidents as described above. This is hidden in the visual.
In this context, we found the terms business error and technical error can be confusing, as they emphasize the source of the error too much. This can lead to long discussions about whether a certain problem is technical or not, and if you are allowed to see technical errors in a business process model.
It’s much more important to look at how you react to certain errors. Even a technical problem can qualify for a business reaction. For example, you could decide to continue a process in the event that a scoring service is not available, and simply give every customer a good rating instead of blocking progress. The error is clearly technical, but the reaction is a business decision.
In general, we recommend talking about business reactions, which are modeled in your process, and technical reactions, which are handled generically using retries or incidents.
Additional resources
XML representation
A boundary error event:
<bpmn:error id="invalid-credit-card-error" errorCode="Invalid Credit Card" />
<bpmn:boundaryEvent id="invalid-credit-card" name="Invalid Credit Card" attachedToRef="collect-money">
<bpmn:errorEventDefinition errorRef="invalid-credit-card-error" />
</bpmn:boundaryEvent>
References
- Incidents
-
Введение в BPMN
-
Простая диаграмма BPMN
-
Использование шлюзов
-
Взаимодействие процессов
-
Официальная документация BPMN
-
-
Обзор всех видов диаграмм BPMN
-
Оркестровка
-
Действия
-
Стрелки
-
Подпроцессы
-
Шлюзы
-
События
-
Данные и артефакты
-
Практические примеры
-
Хореография
Событие BPMN с типом «Ошибка»
Автор:
Олег Борознов,
13.01.2018
Событие BPMN с типом «Ошибка» используется для моделирования возможных ошибок при выполнении процесса, а также для отображения последовательности действий по устранению этих ошибок. Графически событие BPMN «Ошибка» отображается в виде круга с триггером молнии внутри. Ниже приведены все возможные виды событий BPMN с типом «Ошибка».

BPMN не приводит какой-либо классификации возможных ошибок. Бизнес-аналитик сам выбирает какая ошибка может возникнуть в проектируемом процессе. Событие «Ошибка» может быть стартовым, промежуточным и конечным.
Стартовое событие BPMN «Ошибка»
Стартовое событие BPMN «Ошибка» используется только для запуска событийного подпроцесса. Событийный подпроцесс, начинающийся с ошибки, всегда прерывает родительский процесс.
Рассмотрим пример. На диаграмме показан развернутый подпроцесс приготовления ужина, который состоит из двух шагов: «Купить продукты» и «Приготовить еду». Дополнительно здесь предусмотрен вариант, что делать, если продукты или готовое блюдо оказались испорчены – в этом случае нужно заказать еду в ресторане. Это реализовано с помощью событийного подпроцесса «Заказ еды», который прерывает родительский процесс «Приготовление ужина».

Если блюдо или продукты во время выполнения подпроцесса «Приготовление ужина» оказались испорчены, то срабатывает стартовое прерывающее событие BPMN «Ошибка» и запускается событийный подпроцесс заказа еды в ресторане.
Промежуточное и конечное событие BPMN «Ошибка»
- Промежуточное событие BPMN «Ошибка» всегда является граничным-прерывающим. Это означает, что ошибка прерывает выполнение действия, в котором она произошла, и поток операций идет по другому маршруту.
- Конечное событие BPMN «Ошибка» показывает, что в результате выполнения процесса произошла ошибка.
Рассмотрим пример. Развернутый подпроцесс на диаграмме ниже показывает, что приготовление ужина состоит из двух задач: «Купить продукты» и «Приготовить еду». Однако, в магазине могут отсутствовать все необходимые продукты. Эта ситуация обрабатывается граничным прерывающим событием с типом «Условие». При срабатывании данного события нужно вернуть все уже положенные в корзину продукты на место и перейти к завершающему событию, которое генерирует ошибку «Нет нужных продуктов». Это событие в свою очередь обрабатывается граничным прерывающим событием «Нет нужных продуктов».

Таким образом, если нужных продуктов в магазине не оказалось, то будет выполняться задача «Заказать еду в ресторане», и далее процесс пойдет как обычно.
|
Хотите быстро освоить BPMN? |
Error events are events which are triggered by a defined error.
Business Errors vs. Technical Errors
A BPMN error is meant for business errors — which are different than technical exceptions. So, this is different than Java exceptions — which are, by default, handled in their own way.
You might also want to check out the basics of Threading and Transactions in the User Guide first.
Defining an Error
An error event definition references an error element. The following is an example of an error end event, referencing an error declaration:
<definitions>
<error id="myError" errorCode="ERROR-OCCURED" name="ERROR-OCCURED"/>
<!-- ... -->
<process>
<!-- ... -->
<endEvent id="myErrorEndEvent">
<errorEventDefinition errorRef="myError" />
</endEvent>
</process>
</definitions>
You can trigger this error event either with a throwing error event within your process definition or from Delegation Code, see the
Throwing BPMN Errors from Delegation Code section of the User Guide for more information.
Another possibility to define an error is setting of the type (class name) of any Java Exception as error code. Example:
<definitions>
<error id="myException" errorCode="com.company.MyBusinessException"
name="myBusinessException"/>
<!-- ... -->
<process>
<!-- ... -->
<endEvent id="myErrorEndEvent">
<errorEventDefinition errorRef="myException" />
</endEvent>
</process>
</definitions>
The exception type should only be used for business exceptions and not for technical exceptions in the process.
An error event handler references the same error element to declare that it catches the error.
It is also possible to define an error message with the camunda:errorMessage extension for an error element to give further information about the error.
The referencing error event definition must specify camunda:errorMessageVariable to receive the error message. The error message can also contain expressions.
<definitions>
<error id="myError" errorCode="ERROR-OCCURED" name="ERROR-OCCURED"
camunda:errorMessage="Something went wrong: ${errorCause}" />
<!-- ... -->
<process>
<!-- ... -->
<endEvent id="myErrorEndEvent">
<errorEventDefinition errorRef="myError" camunda:errorMessageVariable="err"/>
</endEvent>
</process>
</definitions>
When the error thrown by the error end event is catched a process variable with the name err will be created that holds the evaluated message.
For External Tasks, it is also possible to define error events by using a camunda:errorEventDefinition as shown in the following example. It additionally requires an expression that must evaluate to true in order for the BPMN error to be thrown. For further details on how to use those error events, consult the External Tasks Guide.
<serviceTask id="validateAddressTask"
name="Validate Address"
camunda:type="external"
camunda:topic="AddressValidation" >
<extensionElements>
<camunda:errorEventDefinition id="addressErrorDefinition"
errorRef="addressError"
expression="${externalTask.getErrorDetails().contains('address error found')}" />
</extensionElements>
</serviceTask>
Error Start Event
An error start event can only be used to trigger an Event Sub-Process — it cannot be used to start a process instance. The error start event is always interrupting.
Three optional attributes can be added to the error start event: errorRef, camunda:errorCodeVariable and camunda:errorMessageVariable:
<definitions>
<error id="myException" errorCode="com.company.MyBusinessException" name="myBusinessException"/>
...
<process>
...
<subProcess id="SubProcess_1" triggeredByEvent="true">>
<startEvent id="myErrorStartEvent">
<errorEventDefinition errorRef="myException" camunda:errorCodeVariable="myErrorVariable"
camunda:errorMessageVariable="myErrorMessageVariable" />
</startEvent>
...
</subProcess>
...
</process>
</definitions>
- If
errorRefis omitted, the subprocess will start for every error event that occurs. - The
camunda:errorCodeVariablewill contain the error code that was specified with the error. - The
camunda:errorMessageVariablewill contain the error message that was specified with the error.
camunda:errorCodeVariable and camunda:errorMessageVariable can be retrieved like any other process variable, but only if the attribute was set.
Error End Event
When process execution arrives at an error end event, the current path of execution is ended and an error is thrown. This error can be caught by a matching intermediate error boundary event. In case no matching error boundary event is found, the execution semantics defaults to the none end event semantics.
Camunda Extensions
Error Event Definition
| Attributes |
camunda:asyncBefore, camunda:asyncAfter, camunda:errorCodeVariable, camunda:errorMessageVariable, camunda:exclusive, camunda:jobPriority |
|---|---|
| Extension Elements | camunda:inputOutput |
| Constraints | – |
Error Definition
| Attributes | camunda:errorMessage |
|---|---|
| Extension Elements | – |
| Constraints | – |
Error Boundary Event
An intermediate catching error event on the boundary of an activity, or error boundary event for short, catches errors that are thrown within the scope of the activity on which it is defined.
Defining a error boundary event makes most sense on an embedded subprocess, or a call activity, as a subprocess creates a scope for all activities inside the subprocess. Errors are thrown by error end events. Such an error will propagate its parent scopes upwards until a scope is found on which a error boundary event is defined that matches the error event definition.
When an error event is caught, the activity on which the boundary event is defined is destroyed, also destroying all current executions therein (e.g., concurrent activities, nested subprocesses, etc.). Process execution continues following the outgoing sequence flow of the boundary event.
A error boundary event is defined as a typical boundary event. As with the other error events, the errorRef references an error defined outside of the process element:
<definitions>
<error id="myError" errorCode="ERROR-OCCURED" name="name of error"/>
<!-- ... -->
<process>
<!-- ... -->
<subProcess id="mySubProcess">
<!-- ... -->
</subProcess>
<boundaryEvent id="catchError" attachedToRef="mySubProcess">
<errorEventDefinition errorRef="myError" camunda:errorCodeVariable="myErrorVariable"
camunda:errorMessageVariable="myErrorMessageVariable" />
</boundaryEvent>
</process>
</definitions>
The errorCode is used to match the errors that are caught:
- If errorRef is omitted, the error boundary event will catch any error event, regardless of the errorCode of the error.
- In case an errorRef is provided and it references an existing error, the boundary event will only catch errors with the defined error code.
- If the errorCodeVariable is set, the error code can be retrieved using this variable.
- If the errorMessageVariable is set, the error message can be retrieved using this variable.
Unhandled BPMN Error
It can happen that no catching boundary event was defined for an error event. The default behaviour in this case is to log information and end the current execution.
This behaviour can be changed with enableExceptionsAfterUnhandledBpmnError property set to true
(via the process engine configuration or the deployment descriptor) and Process Engine Exception will be thrown if unhandled BPMN Error occurs.
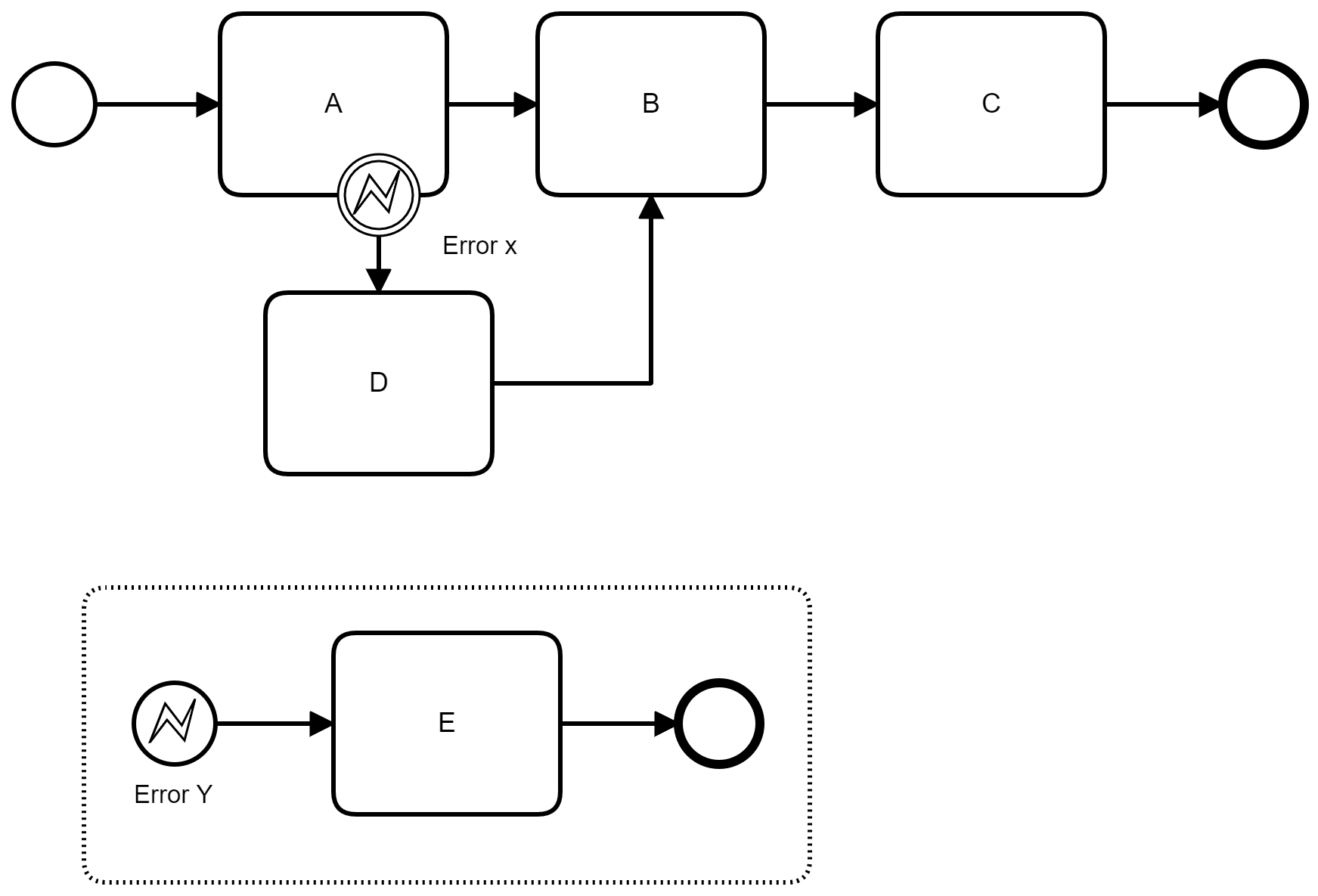
Catch and Re-Throw Pattern
An error can be handled by the error start event in the event sub process and the same error can be thrown from the event sub process to handle the error on the higher level scope (in the example below, the error thrown from the Event Subprocess is handled by the error boundary event in the Subprocess).
Additional Resources
- Error Events in the BPMN 2.0 Modeling Reference
- Incidents in the User Guide
Ошибки в BPMN допускают многие. Это и понятно — нотация кажется простой и понятной, официальная документация предназначена для программистов, а не людей. Чтобы помогать обычным людям разбираться в BPMN, я провожу онлайн-разборы диаграмм. Люди присылают диаграммы (вы тоже можете), а я рассказываю что с ними не так.
В 2018 году я провёл 10 часов таких разборов. Я пересмотрел все записи и выписал топ-25 ошибок, которые встречались и способы их лечения.
Ошибки в BPMN бывают трех видов:
- Ошибки формальные — когда диаграмма не соответствует BPMN.
- Ошибки стиля — когда схема формально правильная, но читать или модифицировать её неудобно. Стилевые предпочтения у всех свои.
- Ошибки логики — это когда схема правильная, стиль соблюден, но есть проблемы в сути того, что нарисовано.
Формальные ошибки и ошибки стиля исправить легко — не надо знать предметную область. Ошибки логики исправить сложно, нужно разбираться в каждом отдельном случае.
Схемы присылали люди, которые читали мой блог и рассылку, поэтому подготовка у респондентов моей выборки имелась.
Для тех, кто торопится
Я разработал бесплатный облачный сервис для рисования и обсуждения диаграмм с коллегами, который сам проверяет 80% ошибок. Он очень экономит время и делает обсуждение удобным. Регистрируйтесь!
Для тех, кто торопится
Я разработал бесплатный облачный сервис для рисования и обсуждения диаграмм с коллегами, который сам проверяет 80% ошибок. Он очень экономит время и делает обсуждение удобным. Регистрируйтесь!
25. НЕ BPMN (Формальная ошибка BPMN)
В диаграмме использованы символы, которых нет в BPMN. Это символы из Archimate, UML, IDEF и других нотаций.

Вот все символы BPMN.

Это Archimate

UML State machine
24-23. Пулы вместо дорожек. Дорожки вместо пулов (стилевая ошибка BPMN)
BPMN предполагает использование пулов для отображения соседнего бизнес-процесса или сущности, на которую мы повлиять не можем (Black box).

А дорожки, наоборот, показывают участников описываемого процесса:

Люди путают их: в дорожках рисуют внешние организации, а собственных сотрудников рисуют в отдельных пулах.
22. Гонка сигналов (Логическая ошибка BPMN)
Изображение взаимодействия процессов, которые могут не выполниться:

Если задача 2 будет выполняться быстрее, чем задача 1, то нижний процесс не сможет отправить сообщение. Это сообщение еще не ждёт верхний процесс.
Вылечить можно так:

Старайтесь избегать таких ситуаций по логике бизнес-процесса.
21. Возврат главного потока назад или вниз (Стилевая ошибка BPMN)
Авторы пытаются вписать процесс змейкой в формат А4.

Читать такое очень сложно. Процессы стоит рисовать строго слева-направо. А когда они перестают помещаться, то декомпозировать их или сворачивать в подпроцессы.
20. Обслуживание “главного” (Логическая ошибка BPMN)
Председатель правления, генеральный директор или еще кто-то “главный” на процессе выступают фигурой, которая сама не участвует в процессе (судя по схеме), а все участники эту фигуру обслуживают. Из-за этого схема становится перегружена этим обслуживаем.

С точки зрения бизнес-процесса “главный” такой же участник, который должен сделать свою часть работы:

19. Всё завершения в одно завершающее событие (Стилевая ошибка BPMN)
Меня учили экономить память в программах и переиспользовать функции. В случае с BPMN одно завершающее событие мешает собрать правильную статистику о самых частых окончаниях процессов. Отсутствие правильной статистики обходится дороже, чем сэкономленные байты.

Разумнее нарисовать схему так:

18. Переход в межпроцессное взаимодействие там, где это не нужно. (Стилевая ошибка BPMN )
Эта ошибка BPMN характерна для людей, которые некоторое время уже изучают тему. Такие люди знают, что межпроцессное взаимодействие можно организовать с помощью сообщений:

Такое отображение только усложняет схему и не отличается от такого:

17. Одна задача для множественной обработки (Логическая ошибка BPMN)
В BPMN есть элементы, показывают итерирование по набору сущностей.
Аналитики делают задачу, в названии которой пишут массовую операцию:

Это нормально, но при обработке исключительных случаев ВНУТРИ обработки заказа могут возникнуть проблемы. Поэтому такой квадратик можно развернуть как подпроцесс, работающий по массиву:

16. Инструкция, а не процесс (Логическая ошибка BPMN)
BPMN предназначен для моделирования бизнес-процессов, а не человеческих инструкций. BPMN важно наличие задачи, а не способ выполнения.

Такие задачи можно рисовать одним кубиком:

15. Страх “сложных” символов (Стилевая ошибка BPMN )
Достигнув определённого понимания инструментов и почувствовав в нём уверенность, авторы начинают решать все задачи имеющимися инструментами.

Такие схемы можно отрисовывать, используя богатые возможности BPMN:

14. Использование conditional flow (стилевая ошибка BPMN )
BPMN позволяет на потоки управления навешивать условия.

Использование таких символов скрывает суть процесса и переносит её в текстовую форму. Лучше такие условия отрисовывать в явном виде через развилку.

13. Одна развилка для сборка и разведения токенов (стилевая ошибка BPMN)
Нотация настоятельно рекомендует не использовать одну развилку и для сведения и для разведения потоков управления:

Лечится просто:

12. Сверху вниз (стилевая ошибка BPMN)
Известная проблема всех, кто рисовал алгоритмы в институте.

В BPMN схемы моделируются слева направо. Некоторые редакторы, например https://bpmn.io/ не дают размещать пулы или дорожки вертикально.
11. Передать информацию, получить информацию (логическая ошибка BPMN)
Для отображения факта передачи информации не надо ставить задачи:

Сам поток управления и означает факт передачи информации.
Нужно рисовать вот так:

10. Текст вместо символов (стилевая ошибка BPMN)
Много комментариев, которые можно выразить символами BPMN.

Нужно прокачиваться, чтобы лучше знать возможности BPMN.

9. Неверное использование бизнес-правил (стилевая ошибка BPMN)
Символ бизнес-правил напоминает таблицу, поэтому люди вставляют его туда, где предполагается работа с таблицами:

Бизнес-правила нужно использовать тогда, когда есть много вариантов выбора дальнейшего развития процесса.

8. Разный уровень задач на процессе (логическая ошибка BPMN )
Это ситуация, когда на одной схеме задачи совершенно разного операционного уровня:

Явные правила я пока не придумал, поэтому такие моменты нужно чувствовать.
7.Техника, а не бизнес-процесс (логическая ошибка BPMN)
BPMN, позволяет описывать любые процессы, в том числе и технологические. Но мельчить не стоит, это создаст неудобства для модификации и обсуждения задач с бизнесом:

Не вырождайте бизнесовое действие в технологическое, пишите явно что происходит:

6. Много стрелок виз квадратиков (стилевая ошибка BPMN)
Когда вы вставляете много стрелок в квадратик, вы можете сконфузить читателя — легко подумать, что 2 стрелки должны прийти вместе:

Используйте развилки для гарантированного и явного описания логики процесса.

5. Не сходятся токены (формальная ошибка BPMN )
Это одна из неявных особенностей BPMN: по схемам движутся токены и их количество меняется в зависимости от пройденных элементов. Нужно уметь в голове проигрывать такие путешествия токенов.

Развилка №2 никогда не пропустит процесс дальше, т.к. ждёт 3 токена на вход (потому что 3 входящих потока), но И/ИЛИ развилка между Task 2 и Task 3 запустит токен только по одному из потоков. Исправляется тем, что мы добавляем исключающую развилку, который “соберёт” токены, перед тем, как их вставить в развилку №2.

4. Перепутаны потоки (формальная ошибка BPMN )
Почему-то коллеги любят сменить в одной дорожке поток управления на поток сообщений, или наоборот:

- Потоки управления можно использовать только внутри пула или дорожки — они не могут пересекать границы пула.
- Потоки сообщения можно использовать только за пределами пула или дорожки — они не могут находится в одном пуле или дорожке.
- Поток ассоциаций вообще используется только для улучшения читаемости схем и не имеет определяет поведение процесса.
3. Элементы ничем не заканчиваются (стилистическая ошибка BPMN )
BPMN формально разрешает брошенные элементы:

Но это просто отвратительно — у читателя сразу масса вопросов. Где завершение? Забыли нарисовать? Почему есть начало, но нет завершения?
Старайтесь чтобы из задачи всегда был выход.

2. Задачи на клиента (стилистическая ошибка BPMN)
В BPMN есть концепция blackbox — это пул, отражающий сущность, устройство которой мы знать не хотим или не можем. В 99% такой сущностью является клиент. Это значит, что мы не можем поставить клиенту задачу. Мы можем только реагировать на действия (или бездействие) клиента .

Это довольно сильно меняет наш процесс, мы полагаемся только на свои силы и на те вещи, на которые можем влиять:

1. События используются c ошибками(формальная ошибка в BPMN)
Самая частая ошибка, что неудивительно — событий много. Если вы не знаете как работает событие, лучше не используйте его.
События отправки и приема сообщений из-за конвертика воспринимаются как задача нотификации по е-мейлу. А на самом деле — эти символы используются для организации межпроцессного взаимодействия.
В этот пост все события уже не поместятся, ждите следующий.

Заключение
Вышло логично — самые неочевидные вещи с первого взгляда — самые частые ошибки в BPMN. Но теперь вы про них знаете и можете избегать в своих схемах.
Напишите в комментарии — какие еще сложности у вас возникают при моделировании в BPMN? О каких ошибках я забыл?
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
| title | weight | menu | ||||||
|---|---|---|---|---|---|---|---|---|
|
Error Handling |
280 |
|
Error Handling Strategies
There are a couple of basic strategies to handle errors and exceptions within processes. The decision which strategy to use depends on:
- Technical vs. Business Errors: Does the error have some business meaning and causes an alternative process flow (like «item not on stock») or is it a technical malfunction (like «network currently down»)?
- Explicit error handling or generic approach: For some situations you want to explicitly model what should happen in case of an error (typically for business errors). For a lot of situations you don’t want to do that but have some generic mechanism which applies for errors, simplifying your process models (typical for technical errors, imagine you would have to model network outage on every task were it might possibly occur? You wouldn’t be able to recognize your business process any more).
In the context of the process engine, errors are normally raised as Java exceptions which you have to handle. Let’s have a look at how to handle them.
Transaction Rollbacks
The standard handling strategy is that exceptions are thrown to the client, meaning that the current transaction is rolled back. This means that the process state is rolled back to the last wait state. This behavior is described in detail in the [Transactions in Processes]({{< ref «/user-guide/process-engine/transactions-in-processes.md» >}}) section of the [User Guide]({{< ref «/user-guide/_index.md» >}}). Error handling is delegated to the client by the engine.
Let’s show this in a concrete example: the user gets an error dialog on the frontend stating that the stock management software is currently not reachable due to network errors. To perform a retry, the user might have to click the same button again. Even if this is often not desired it is still a simple strategy applicable in a lot of situations.
Async and Failed Jobs
If you don’t want the exception being shown to the user, one option is to make service calls, which might cause an error, async (as described in [Transactions in Processes]({{< ref «/user-guide/process-engine/transactions-in-processes.md» >}})). In that case the exception is stored in the process engine database and the [Job]({{< ref «/user-guide/process-engine/the-job-executor.md» >}}) in the background is marked as failed (to be more precise, the exception is stored and some retry counter is decremented).
In the example above this means that the user will not see an error but an «everything successful» dialog. The exception is stored on the job. Now either a clever retry strategy will automatically re-trigger the job later on (when the network is available again) or an operator needs to have a look at the error and trigger an additional retry. This is shown later in more detail.
This strategy is pretty powerful and applied often in real-life projects, however, it still hides the error in the BPMN diagram, so for business errors which you want to be visible in the process diagram, it would be better to use [Error Events]({{< relref «#bpmn-2-0-error-event» >}}).
Catch Exception and use Data Based XOR-Gateway
If you call Java Code which can throw an exception, you can catch the exception within the Java Delegate, CDI Bean or whatsoever. Maybe it is already sufficient to log some information and go on, meaning that you ignore the error. More often you write the result into a process variable and model an XOR-Gateway later in the process flow to take a different path if that error occurs.
In that case you model the error handling explicitly in the process model but you make it look like a normal result and not like an error. From a business perspective it is not an error but a result, so the decision should not be made lightly. A rule of thumb is that results can be handled this way, exceptional errors should not. However, the BPMN perspective does not always have to match the technical implementation.
Example:
{{< img src=»../img/error-result-xor.png» title=»Error Result XOR» >}}
We trigger a «check data completeness» task. The Java Service might throw a «DataIncompleteException». However, if we check for completeness, incomplete data is not an exception, but an expected result, so we prefer to use an XOR-Gateway in the process flow which evaluates a process variable, e.g., «#{dataComplete==false}».
BPMN 2.0 Error Event
The BPMN 2.0 error event gives you the possibility to explicitly model errors, tackling the use case of business errors. The most prominent example is the «intermediate catching error event», which can be attached to the boundary of an activity. Defining a boundary error event makes most sense on an embedded subprocess, a call activity or a Service Task. An error will cause the alternative process flow to be triggered:
{{< img src=»../img/bpmn.boundary.error.event.png» title=»Error Boundary Event» >}}
See the [Error Events]({{< ref «/reference/bpmn20/events/error-events.md» >}}) section of the [BPMN 2.0 Implementation Reference]({{< ref «/reference/bpmn20/_index.md» >}}) and the [Throwing Errors from Delegation Code]({{< ref «/user-guide/process-engine/delegation-code.md#throw-bpmn-errors-from-delegation-code» >}}) section of the [User Guide]({{< ref «/user-guide/_index.md» >}}) for more information.
BPMN 2.0 Compensation and Business Transactions
BPMN 2.0 transactions and compensations allow you to model business transaction boundaries (however, not in a technical ACID manner) and make sure already executed actions are compensated during a rollback. Compensation means to make the effect of the action invisible, e.g. book in goods if you have previously booked out the goods. See the [BPMN Compensation event]({{< ref «/reference/bpmn20/events/cancel-and-compensation-events.md» >}}) and the [BPMN Transaction Subprocess]({{< ref «/reference/bpmn20/subprocesses/transaction-subprocess.md» >}}) sections of the [BPMN 2.0 Implementation Reference]({{< ref «/reference/bpmn20/_index.md» >}}) for details.
Monitoring and Recovery Strategies
In case the error occurred, different recovery strategies can be applied.
Let the User Retry
As mentioned above, the simplest error handling strategy is to throw the exception to the client, meaning that the user has to retry the action himself. How he does that is up to the user, normally reloading the page or clicking again.
Retry Failed Jobs
If you use Jobs (async), you can leverage Cockpit as monitoring tool to handle failed jobs, in this case no end user sees the exception. Then you normally see failures in cockpit when the retries are depleted (see the [Failed Jobs]({{< ref «/user-guide/process-engine/the-job-executor.md#failed-jobs» >}}) section of the [Web Applications]({{< ref «/webapps/cockpit/_index.md» >}}) for more information).
See the [Failed Jobs in Cockpit]({{< ref «/webapps/cockpit/bpmn/failed-jobs.md» >}}) section of the [Web Applications]({{< ref «/webapps/cockpit/_index.md» >}}) for more details.
If you don’t want to use Cockpit, you can also find the failed jobs via the API yourself:
List<Job> failedJobs = processEngine.getManagementService().createJobQuery().withException().list(); for (Job failedJob : failedJobs) { processEngine.getManagementService().setJobRetries(failedJob.getId(), 1); }
Explicit Modeling
Of course you can always explicitly model a retry mechanism as pointed out in Where is the retry in BPMN 2.0:
{{< img src=»../img/retry.png» title=»Retry Mechanism» >}}
We would recommend to limit it to cases where you want to see it in the process diagram for a good reason. We prefer asynchronous continuation, as it doesn’t bloat your process diagram and basically can do the same thing with even less runtime overhead, as «walking» through the modeled loop involves additional action, e.g., writing an audit log.
User Tasks for Operations
We often see something like this in projects:
{{< img src=»../img/error-handling-user-task.png» title=»User Task Error Handling» >}}
Actually this is a valid approach in which you assign errors to an operator as User Tasks and model what options he has to solve the problem. However, this is a strange mixture: We want to handle a technical error we but add it to our business process model. Where do we stop? Do we have to model it on every Service Task now?
Having a failed jobs list instead of using the «normal» task list feels like a more natural approach for this situation, which is why we normally recommend the other possibility and do not consider this to be best practice.
Exception codes
Sometimes an API call doesn’t succeed because a problem occurs. The Java programming model uses exceptions
to handle these situations. Exceptions that occur on the process engine’s application level are
of the type {{< javadocref page="org/camunda/bpm/engine/ProcessEngineException.html" text="ProcessEngineException" >}}.
Here are two examples of everyday situations in which the engine throws a ProcessEngineException:
- You cannot start a process instance since the variable’s value is too long.
- Two users in parallel complete the same task.
You can read the exception message to understand the reason for a ProcessEngineException. However,
sometimes the message of the top-level exception is too generic. In these situations, the cause might
contain a more insightful exception message. Traversing through exception causes might be tedious.
Also, causes are unavailable when an error occurs on the REST API level.
While reading the error message might help users to understand the root cause of the problem,
evaluating exception messages in an automated way is not a good idea since:
- The message might change with newer versions.
- Relying on fragments of the message can be error-prone.
This is why we introduced static exception codes your business logic can rely on to determine specific
problems and react accordingly.
You can access error codes via Java as well as [REST API]({{< ref «/reference/rest/overview/_index.md#exception-codes» >}}).
Built-in codes
We identified common situations in which the engine throws an exception and assigned a built-in
error code to the exception. You can look up the built-in codes in the Categories, ranges, and codes section.
Custom codes
Sometimes you may want to assign codes to specific errors Camunda hasn’t covered so far.
You can either define custom codes from delegation code or by registering your custom ExceptionCodeProvider.
Delegation code
Learn more on how to assign a custom error code to an exception in the documentation about [Delegation Code]({{< ref «/user-guide/process-engine/delegation-code.md#exception-codes» >}}).
Configuration
You can configure the exception error codes feature in your [process engine configuration]({{< ref «/reference/deployment-descriptors/tags/process-engine.md#exception-codes» >}}):
- To disable the exception codes feature entirely, set the flag
disableExceptionCode
in your process engine configuration totrue. - To disable the built-in exception code provider, set the flag
disableBuiltinExceptionCodeProvider
in your process engine configuration totrue. Disabling the built-in exception code
provider allows overriding the reserved code range with your custom exception codes.
Register a Custom Code Provider
With the help of a [ProcessEnginePlugin]({{< ref «/user-guide/process-engine/process-engine-plugins.md» >}}) you can register a custom {{< javadocref page="org/camunda/bpm/engine/impl/errorcode/ExceptionCodeProvider.html" text="ExceptionCodeProvider" >}}:
engineConfig.setCustomExceptionCodeProvider(new ExceptionCodeProvider() { @Override public Integer provideCode(ProcessEngineException processEngineException) { // Put your business logic here to determine the // error code in case a process engine exception was thrown. return 22_222; } @Override public Integer provideCode(SQLException sqlException) { // Put your business logic here to determine the // error code in case a sql exception was thrown. return 33_333; } });
{{< note title=»Heads-up!» class=»info» >}}
If your custom error code violates the reserved code range, it will be overridden with 0 unless you disable the built-in code provider.
{{< /note >}}
Categories, ranges, and codes
In the table below, you will find an overview of all categories, ranges, and codes:
| Category | Range | Code | Description | Safe to retry |
|---|---|---|---|---|
| Fallback | 0 | All errors with no code assigned. | ||
| Engine | [1, 9999] | 1 | OptimisticLockingException/CrdbTransactionRetryException |
X |
| Persistence | [10000, 19999] | 10,000 | Deadlock situation occurred. | X |
| 10,001 | A foreign key constraint was violated. | |||
| 10,002 | The column size is too small. | |||
| Custom | [20000, 39999] | E.g., 22,222 | E.g., custom JavaDelegate validation error. |
Reserved code range
The codes <= 19,999 and >= 40,000 are reserved for built-in codes. If you disable the built-in code provider,
you can also use the reserved code range for your custom codes.
| title | weight | menu | ||||||
|---|---|---|---|---|---|---|---|---|
|
Error Handling |
280 |
|
Error Handling Strategies
There are a couple of basic strategies to handle errors and exceptions within processes. The decision which strategy to use depends on:
- Technical vs. Business Errors: Does the error have some business meaning and causes an alternative process flow (like «item not on stock») or is it a technical malfunction (like «network currently down»)?
- Explicit error handling or generic approach: For some situations you want to explicitly model what should happen in case of an error (typically for business errors). For a lot of situations you don’t want to do that but have some generic mechanism which applies for errors, simplifying your process models (typical for technical errors, imagine you would have to model network outage on every task were it might possibly occur? You wouldn’t be able to recognize your business process any more).
In the context of the process engine, errors are normally raised as Java exceptions which you have to handle. Let’s have a look at how to handle them.
Transaction Rollbacks
The standard handling strategy is that exceptions are thrown to the client, meaning that the current transaction is rolled back. This means that the process state is rolled back to the last wait state. This behavior is described in detail in the [Transactions in Processes]({{< ref «/user-guide/process-engine/transactions-in-processes.md» >}}) section of the [User Guide]({{< ref «/user-guide/_index.md» >}}). Error handling is delegated to the client by the engine.
Let’s show this in a concrete example: the user gets an error dialog on the frontend stating that the stock management software is currently not reachable due to network errors. To perform a retry, the user might have to click the same button again. Even if this is often not desired it is still a simple strategy applicable in a lot of situations.
Async and Failed Jobs
If you don’t want the exception being shown to the user, one option is to make service calls, which might cause an error, async (as described in [Transactions in Processes]({{< ref «/user-guide/process-engine/transactions-in-processes.md» >}})). In that case the exception is stored in the process engine database and the [Job]({{< ref «/user-guide/process-engine/the-job-executor.md» >}}) in the background is marked as failed (to be more precise, the exception is stored and some retry counter is decremented).
In the example above this means that the user will not see an error but an «everything successful» dialog. The exception is stored on the job. Now either a clever retry strategy will automatically re-trigger the job later on (when the network is available again) or an operator needs to have a look at the error and trigger an additional retry. This is shown later in more detail.
This strategy is pretty powerful and applied often in real-life projects, however, it still hides the error in the BPMN diagram, so for business errors which you want to be visible in the process diagram, it would be better to use [Error Events]({{< relref «#bpmn-2-0-error-event» >}}).
Catch Exception and use Data Based XOR-Gateway
If you call Java Code which can throw an exception, you can catch the exception within the Java Delegate, CDI Bean or whatsoever. Maybe it is already sufficient to log some information and go on, meaning that you ignore the error. More often you write the result into a process variable and model an XOR-Gateway later in the process flow to take a different path if that error occurs.
In that case you model the error handling explicitly in the process model but you make it look like a normal result and not like an error. From a business perspective it is not an error but a result, so the decision should not be made lightly. A rule of thumb is that results can be handled this way, exceptional errors should not. However, the BPMN perspective does not always have to match the technical implementation.
Example:
{{< img src=»../img/error-result-xor.png» title=»Error Result XOR» >}}
We trigger a «check data completeness» task. The Java Service might throw a «DataIncompleteException». However, if we check for completeness, incomplete data is not an exception, but an expected result, so we prefer to use an XOR-Gateway in the process flow which evaluates a process variable, e.g., «#{dataComplete==false}».
BPMN 2.0 Error Event
The BPMN 2.0 error event gives you the possibility to explicitly model errors, tackling the use case of business errors. The most prominent example is the «intermediate catching error event», which can be attached to the boundary of an activity. Defining a boundary error event makes most sense on an embedded subprocess, a call activity or a Service Task. An error will cause the alternative process flow to be triggered:
{{< img src=»../img/bpmn.boundary.error.event.png» title=»Error Boundary Event» >}}
See the [Error Events]({{< ref «/reference/bpmn20/events/error-events.md» >}}) section of the [BPMN 2.0 Implementation Reference]({{< ref «/reference/bpmn20/_index.md» >}}) and the [Throwing Errors from Delegation Code]({{< ref «/user-guide/process-engine/delegation-code.md#throw-bpmn-errors-from-delegation-code» >}}) section of the [User Guide]({{< ref «/user-guide/_index.md» >}}) for more information.
BPMN 2.0 Compensation and Business Transactions
BPMN 2.0 transactions and compensations allow you to model business transaction boundaries (however, not in a technical ACID manner) and make sure already executed actions are compensated during a rollback. Compensation means to make the effect of the action invisible, e.g. book in goods if you have previously booked out the goods. See the [BPMN Compensation event]({{< ref «/reference/bpmn20/events/cancel-and-compensation-events.md» >}}) and the [BPMN Transaction Subprocess]({{< ref «/reference/bpmn20/subprocesses/transaction-subprocess.md» >}}) sections of the [BPMN 2.0 Implementation Reference]({{< ref «/reference/bpmn20/_index.md» >}}) for details.
Monitoring and Recovery Strategies
In case the error occurred, different recovery strategies can be applied.
Let the User Retry
As mentioned above, the simplest error handling strategy is to throw the exception to the client, meaning that the user has to retry the action himself. How he does that is up to the user, normally reloading the page or clicking again.
Retry Failed Jobs
If you use Jobs (async), you can leverage Cockpit as monitoring tool to handle failed jobs, in this case no end user sees the exception. Then you normally see failures in cockpit when the retries are depleted (see the [Failed Jobs]({{< ref «/user-guide/process-engine/the-job-executor.md#failed-jobs» >}}) section of the [Web Applications]({{< ref «/webapps/cockpit/_index.md» >}}) for more information).
See the [Failed Jobs in Cockpit]({{< ref «/webapps/cockpit/bpmn/failed-jobs.md» >}}) section of the [Web Applications]({{< ref «/webapps/cockpit/_index.md» >}}) for more details.
If you don’t want to use Cockpit, you can also find the failed jobs via the API yourself:
List<Job> failedJobs = processEngine.getManagementService().createJobQuery().withException().list(); for (Job failedJob : failedJobs) { processEngine.getManagementService().setJobRetries(failedJob.getId(), 1); }
Explicit Modeling
Of course you can always explicitly model a retry mechanism as pointed out in Where is the retry in BPMN 2.0:
{{< img src=»../img/retry.png» title=»Retry Mechanism» >}}
We would recommend to limit it to cases where you want to see it in the process diagram for a good reason. We prefer asynchronous continuation, as it doesn’t bloat your process diagram and basically can do the same thing with even less runtime overhead, as «walking» through the modeled loop involves additional action, e.g., writing an audit log.
User Tasks for Operations
We often see something like this in projects:
{{< img src=»../img/error-handling-user-task.png» title=»User Task Error Handling» >}}
Actually this is a valid approach in which you assign errors to an operator as User Tasks and model what options he has to solve the problem. However, this is a strange mixture: We want to handle a technical error we but add it to our business process model. Where do we stop? Do we have to model it on every Service Task now?
Having a failed jobs list instead of using the «normal» task list feels like a more natural approach for this situation, which is why we normally recommend the other possibility and do not consider this to be best practice.
Exception codes
Sometimes an API call doesn’t succeed because a problem occurs. The Java programming model uses exceptions
to handle these situations. Exceptions that occur on the process engine’s application level are
of the type {{< javadocref page="org/camunda/bpm/engine/ProcessEngineException.html" text="ProcessEngineException" >}}.
Here are two examples of everyday situations in which the engine throws a ProcessEngineException:
- You cannot start a process instance since the variable’s value is too long.
- Two users in parallel complete the same task.
You can read the exception message to understand the reason for a ProcessEngineException. However,
sometimes the message of the top-level exception is too generic. In these situations, the cause might
contain a more insightful exception message. Traversing through exception causes might be tedious.
Also, causes are unavailable when an error occurs on the REST API level.
While reading the error message might help users to understand the root cause of the problem,
evaluating exception messages in an automated way is not a good idea since:
- The message might change with newer versions.
- Relying on fragments of the message can be error-prone.
This is why we introduced static exception codes your business logic can rely on to determine specific
problems and react accordingly.
You can access error codes via Java as well as [REST API]({{< ref «/reference/rest/overview/_index.md#exception-codes» >}}).
Built-in codes
We identified common situations in which the engine throws an exception and assigned a built-in
error code to the exception. You can look up the built-in codes in the Categories, ranges, and codes section.
Custom codes
Sometimes you may want to assign codes to specific errors Camunda hasn’t covered so far.
You can either define custom codes from delegation code or by registering your custom ExceptionCodeProvider.
Delegation code
Learn more on how to assign a custom error code to an exception in the documentation about [Delegation Code]({{< ref «/user-guide/process-engine/delegation-code.md#exception-codes» >}}).
Configuration
You can configure the exception error codes feature in your [process engine configuration]({{< ref «/reference/deployment-descriptors/tags/process-engine.md#exception-codes» >}}):
- To disable the exception codes feature entirely, set the flag
disableExceptionCode
in your process engine configuration totrue. - To disable the built-in exception code provider, set the flag
disableBuiltinExceptionCodeProvider
in your process engine configuration totrue. Disabling the built-in exception code
provider allows overriding the reserved code range with your custom exception codes.
Register a Custom Code Provider
With the help of a [ProcessEnginePlugin]({{< ref «/user-guide/process-engine/process-engine-plugins.md» >}}) you can register a custom {{< javadocref page="org/camunda/bpm/engine/impl/errorcode/ExceptionCodeProvider.html" text="ExceptionCodeProvider" >}}:
engineConfig.setCustomExceptionCodeProvider(new ExceptionCodeProvider() { @Override public Integer provideCode(ProcessEngineException processEngineException) { // Put your business logic here to determine the // error code in case a process engine exception was thrown. return 22_222; } @Override public Integer provideCode(SQLException sqlException) { // Put your business logic here to determine the // error code in case a sql exception was thrown. return 33_333; } });
{{< note title=»Heads-up!» class=»info» >}}
If your custom error code violates the reserved code range, it will be overridden with 0 unless you disable the built-in code provider.
{{< /note >}}
Categories, ranges, and codes
In the table below, you will find an overview of all categories, ranges, and codes:
| Category | Range | Code | Description | Safe to retry |
|---|---|---|---|---|
| Fallback | 0 | All errors with no code assigned. | ||
| Engine | [1, 9999] | 1 | OptimisticLockingException/CrdbTransactionRetryException |
X |
| Persistence | [10000, 19999] | 10,000 | Deadlock situation occurred. | X |
| 10,001 | A foreign key constraint was violated. | |||
| 10,002 | The column size is too small. | |||
| Custom | [20000, 39999] | E.g., 22,222 | E.g., custom JavaDelegate validation error. |
Reserved code range
The codes <= 19,999 and >= 40,000 are reserved for built-in codes. If you disable the built-in code provider,
you can also use the reserved code range for your custom codes.
<<предыдущая содержание следующая>>
Структура BPMN
- 8.1. Пакет Infrastructure
- 8.1.1 Класс Definitions
- 8.1.2 Класс Import
- 8.1.2 Пакет Foundation
- 8.2. Пакет Foundation
- 8.2.1. Base Element
- 8.2.2. Documentation
- 8.2.3. Extensibility
- 8.2.4. Ссылки на внешние объекты
- 8.2.5. Корневой элемент
- 8.2.6. Представление XML-схем для пакета Foundation (Foundation Package)
- 8.3. Общие элементы (Common Elements)
- 8.3.1. Артефакты (Artifacts)
- 8.3.2. Корреляция (Correlation)
- 8.3.3. Ошибка (Error)
- 8.3.4. Эскалация (Escalation)
- 8.3.5. События (Events)
- 8.3.6. Выражения (Expressions)
- 8.3.7. Элемент Потока (Flow Element)
- 8.3.8. Контейнер Элементов Потока (Flow Elements Container)
- 8.3.9. Шлюзы (Gateways)
- 8.3.10. Определение компонента (Item Definition)
- 8.3.11. Сообщение (Message)
- 8.3.12. Ресурсы (Resources)
- 8.3.13. Поток Операций (Sequence Flow)
- 8.3.14. Представление XML-схем для Пакета Общий (Common Package)
- 8.4. Пакет Сервис (Services)
- 8.4.1. Интерфейс (Interface)
- 8.4.2. Конечная Точка (EndPoint)
- 8.4.3. Операция (Operation)
- 8.4.4. Представление XML-схемы для Пакета Сервис (Service Package)
В следующих подразделах содержится описание элементов BPMN, которые МОГУТ добавляться на диаграммы разных типов (Процесс (Process), Взаимодействие (Collaboration), и Хореография (Choreography)).
8.3.1 Артефакты (Artifacts)
Для разработчиков моделей в BPMN предусмотрена возможность внесения дополнительной информации о Процессе (Process). Такая информация не связана непосредственно с Потоками Операций (Sequence Flow) или Потоками Сообщений (Message Flow) этого Процесса.
В данном документе представлено три типа стандартных Артефактов: Ассоциация (Association), Группа (Group) и Текстовая Аннотация (Text Annotation), что, однако, не исключает возможности добавления других Артефактов в последующих версиях спецификации (т.е. в будущем МОГУТ БЫТЬ добавлены новые Артефакты). Разработчики моделей или инструменты моделирования МОГУТ расширять диаграммы BPMN, добавляя при этом на Диаграммы собственные типы Артефактов. Любой искусственно добавленный Артефакт ДОЛЖЕН соответствовать правилам соединения с Потоком Операций и Потоком Сообщений (см. ниже). Для соединения Артефактов с Элементами Потока (Flow Objects) используется Ассоциация (Association) (для получения более подробной информации см. таблицу 7.2).
На фигуре 8.8 отображена диаграмма класса Artifacts. Артефакт хранится либо во Взаимодействии (Collaboration), либо в элементе FlowElementsContainer (Процесса (Process) или Хореографии (Choreography)). 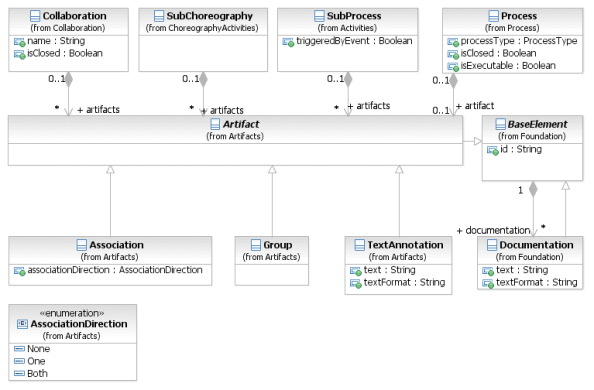
Фигура 8.8 – Метамодель Артефакта
Общие определения для Артефактов
В следующих подразделах представлена информация об определениях, общих для всех Артефактов.
Соединение Артефакта с Потоком Операций
Для получения более подробной информации об элементах BPMN, которые МОГУТ являться как источниками, так и целями Потоков Операций (Sequence Flow), см. подраздел 7.5.1.
- Артефакты НЕ ДОЛЖНЫ являться целями Потоков Операций.
- Артефакты НЕ ДОЛЖНЫ служить источниками Потоков Операций.
Соединение Артефакта с Потоком Сообщений
Для получения более подробной информации об элементах BPMN, которые МОГУТ являться как источниками, так и целями Потоков Сообщений (Message Flow), см. подраздел 7.5.2.
- Артефакты НЕ ДОЛЖНЫ являться целями Потоков Сообщений.
- Артефакты НЕ ДОЛЖНЫ служить источниками Потоков Сообщений.
Ассоциация (Association)
Ассоциация (Association) используется для установки соответствия между какой-либо информацией и Артефактом и Элементами Потока (Flow Objects). Текстовые и графические элементы, не являющиеся Элементами Потока, также могут быть ассоциированы с Элементами Потока и каким-либо Потоком операций. Ассоциация используется и для отображения Действия (Activity) компенсации. Для получения более подробной информации о компенсации см. раздел 10.6.
- Ассоциация должна быть выполнена пунктирной линией (см. фигуру 8.9).
- Текст, цвет, размер, а также линии, используемые для изображения Ассоциации, ДОЛЖНЫ соответствовать правилам, указанным в разделе «Использование Текста, Цвета и Линий в Моделировании Диаграмм».
![]()
Фигура 8.9 – Ассоциация (Association)
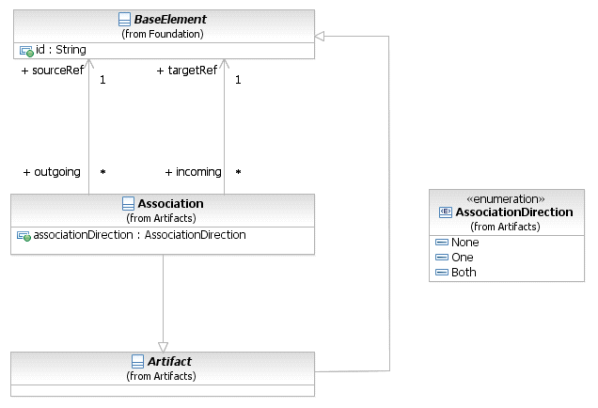
Фигура 8.10 – Диаграмма класса Association
Для того чтобы отобразить направление Ассоциации, необходимо следовать правилам:
- Графический элемент Ассоциация МОЖЕТ отображаться со стрелкой (см. фигуру 8.11).
- Ассоциация может иметь одно (1) или два направления.
![]()
Фигура 8.11 – Направленная Ассоциация
Обратите внимание, что описанная в BPMN 1.2 направленная Ассоциация использовалась для отображения того, каким образом Объекты Данных (Data Object) входили в Действия (Activity) или выходили из них. В BPMN 2.0 для этого используется Ассоциация Данных (Data Association) (для получения более подробной информации см. фигуру 10.64). При добавлении на диаграмму Ассоциации Данных используется та же нотация, что и для добавления направленной Ассоциации (см. фигуру 8.11).
Ассоциация используется для соединения указанного пользователем текста (Аннотации (Annotation)) с Элементами Потока (Flow Objects) (см. фигуру 8.12).

Фигура 8.12 – Ассоциация, применяемая к Текстовой Аннотации
Элемент Association наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5). Таблица 8.20 содержит информацию о дополнительных атрибутах и ассоциациях элемента Association.
Таблица 8.20 – Атрибуты и ассоциации элемента Association
| Название атрибута | Описание/использование |
| associationDirection: AssociationDirection = None {None | One | Both} | Данный атрибут указывает на то, будет ли Ассоциация иметь направление (т.е. будет ли отображаться со стрелкой). Значением по умолчанию является «None» (подразумевает отсутствие стрелки). Значение «One» используется для указания того, что Ассоциация ДОЛЖНА БЫТЬ направлена к Элементу, являющемуся Источником. Значение «Both» указывает на то, что стрелка ДОЛЖНА отображаться на обоих концах графического элемента Ассоциация. |
| sourceRef: BaseElement | Определяет элемент BaseElement, от которого направлена Ассоциация. |
| targetRef: BaseElement | Определяет элемент BaseElement, к которому направлена Ассоциация. |
Группа (Group)
Элемент Группа (Group) является Артефактом, служащим в качестве неформального механизма отображения группы элементов на диаграмме. Такая группировка связана со значением CategoryValue соответствующего элемента. Это означает, что Группа представляет собой визуальное отображение конкретного значения CategoryValue.
Примечание: Значение CategoryValue также может быть выделено другими способами, например, цветом, выбранным разработчиком модели или инструментом моделирования.
- Группа представляет собой прямоугольник с закругленными краями, который ДОЛЖЕН БЫТЬ выполнен жирным пунктиром (см. фигуру 8.13).
- Текст, цвет, размер, а также линии, используемые для изображения Группы, ДОЛЖНЫ соответствовать правилам, указанным в разделе «Использование Текста, Цвета и Линий в Моделировании Диаграмм».

Фигура 8.13 – Артефакт типа Группа
Как и Артефакт, Группа не является Действием (Activity) или одним из Элементов Потока (Flow Object), поэтому данный графический элемент не может быть соединен с Потоком Операций (Sequence Flow) или с Потоком Сообщений (Message Flow). Ограничения использования Пулов (Pool) и Дорожек (Lane) не распространяются на использование Групп. Это означает, что для объединения элементов Диаграммы Группа может простираться за границы Пула (см. фигуру 8.14). В таком качестве Группа используется для отображения Действий (Activity), являющихся частью масштабных взаимоотношений типа B2B (business-to-business).
Фигура 8.14 – Группа, объединяющая Действия из разных Пулов
Группы обычно используются для выделения областей Диаграммы, при этом на их использование не налагается никаких ограничений (применяемых по отношению к Подпроцессу (Sub-Process)). Выделенная область (сгруппированные элементы) Диаграммы может быть разделена в целях создания отчетности и произведения анализа. Группы не оказывают влияния на ход Процесса (Process).
На фигуре 8.15 отображена диаграмма класса Group.
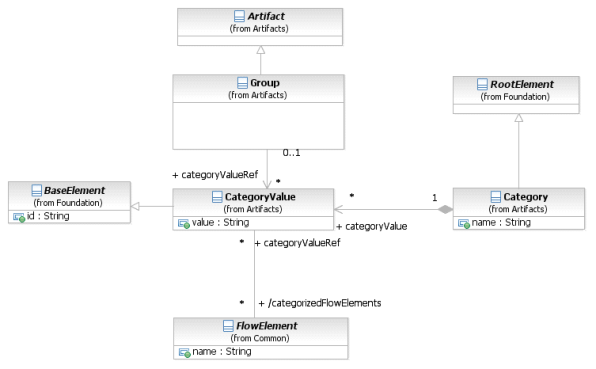
Фигура 8.15 – Диаграмма классов элемента Group
Элемент Group наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5) посредством связи с элементом Atrifact. Таблица 8.21 содержит информацию о дополнительных ассоциациях элемента Group.
Таблица 8.21 – Ассоциации элемента Group
| Название атрибута | Описание/использование |
| categoryValueRef: Category- Value [0..1] | Данный атрибут указывает значение categoryValueRef, которое представлено Группой. Для получения более подробной информации об элементах Category CategoryValue см. следующий подраздел. Название Группы состоит из названия элемента Category и значения CategoryValue, разделенных знаком «.» (точкой). Значения CategoryValue назначаются на графические элементы, расположенные внутри Группы. |
Категория (Category)
Категории, семантика для которых определяется пользователем, могут использоваться для документирования или анализа. К примеру, элементы FlowElements могут быть разбиты на категории, включающие ориентированные на заказчика элементы и элементы, ориентированные на поддержку. Кроме того, для каждой из Категорий могут быть подсчитаны стоимость и время выполнения Действий (Activity).
Группы являются одним из способов, при помощи которых Категории объектов отображаются на диаграмме. Это означает, что Группа является визуальным отображением конкретного значения CategoryValue. Графические элементы, заключенные в Группы, назначаются на конкретное значение CategoryValue данной Группы. Значение CategoryValue, перед которым указано название Категории и стоит разделитель «:», отображается на диаграмме в качестве названия Группы. Обратите внимание, что Категории могут быть выделены другими способами, например, цветом, выбранным разработчиком модели или инструментом моделирования. На диаграмме одна Категория может использоваться в нескольких Группах.
Элемент Category наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5) посредством связи с элементом RootElement. Таблица 8.22 содержит информацию о дополнительных ассоциациях элемента Category.
Таблица 8.22 – Ассоциации элемента Category
| Название атрибута | Описание/использование |
| name: string | Описательное имя элемента. |
| categoryValue: CategoryValue [0..*] | Посредством атрибута categoryValue указывается одно или более значений элемента Category. К примеру, если Category означает «Регион», то для неё могут быть установлены следующие значения: «север», «юг», «запад», «восток». |
Элемент CategoryValue наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5). Таблица 8.23 содержит информацию о дополнительных атрибутах и ассоциациях элемента CategoryValue.
Таблица 8.23 – Атрибуты и ассоциации элемента CategoryValue
| Название атрибута | Описание/использование |
| value: string | Посредством данного атрибута устанавливается значение элемента CategoryValue. |
| category: Category [0..1] | Данный атрибут используется для определения Категории как таковой и содержит значение CategoryValue (для получения более подробной информации о Категории см. Описание выше). |
| categorizedFlowElements: FlowElement [0..*] | Посредством данного атрибута указываются все элементы (например, События (Events), Действия (Activities), Шлюзы (Gateways) и Артефакты (Artifacts)), заключенные в Группу. |
Текстовая Аннотация (Text Annotation)
Текстовая Аннотация представляет собой механизм, при помощи которого разработчик модели может добавлять на Диаграмму BPMN дополнительную информацию, являющуюся важной для конечного пользователя Диаграммы.
- Текстовая Аннотация представляет собой негерметичный прямоугольник, который ДОЛЖЕН БЫТЬ выполнен одинарной жирной линией (см. фигуру 8.16).
- Текст, цвет, размер, а также линии, используемые для изображения Текстовой Аннотации, ДОЛЖНЫ соответствовать правилам, указанным в разделе «Использование Текста, Цвета и Линий в Моделировании Диаграмм».
Графический элемент Текстовая Аннотация может быть присоединен к определенному элементу на Диаграмме при помощи Ассоциации (Association), однако, он не оказывает влияния на ход Процесса. Текст, ассоциированный с Аннотацией, может располагаться в пределах данного графического элемента.

Фигура 8.16 – Текстовая Аннотация
Элемент Text Annotation наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5). Таблица 8.24 содержит информацию о дополнительных атрибутах элемента Text Annotation.
Таблица 8.24 – Атрибуты элемента Text Annotation
| Название атрибута | Описание/использование |
| text: string | Данный атрибут представляет собой текст, который разработчик модели желает сообщить конечному пользователю Диаграммы. |
| textFormat: string | Посредством данного атрибута указывается формат текста. Его значение ДОЛЖНО БЫТЬ указано в формате MIME-тип. Значением по умолчанию является «text/plain». |
Представление XML-схемы для Артефактов
Таблица 8.25 — XML-схема для элемента Artifact
Таблица 8.26 — XML-схема для элемента Association
name=»association» type=»tAssociation» substitutionGroup=»artifact»/>
name=»tAssociation»>
<xsd:extension base=»tArtifact»>
name=»sourceRef» type=»xsd:QName» use=»required»/>
name=»targetRef» type=»xsd:QName» use=»required»/>
name=»associationDirection» type=»tAssociationDirection» default=»None»/>
name=»tAssociationDirection»>
base=»xsd:string»>
value=»None»/>
value=»One»/>
value=»Both»/>
Таблица 8.27 — XML-схема для элемента Category
name=»category» type=»tCategory» substitutionGroup=»rootElement»/>
name=»tCategory»>
base=»tRootElement»>
<xsd:element ref=»categoryValue» minOccurs=»0″ maxOccurs=»unbounded»/>
name=»name» type=»xsd:string»/>
Таблица 8.28 — XML-схема для элемента CategoryValue
name=»categoryValue» type=»tCategoryValue»/>
name=»tCategoryValue»>
base=»tBaseElement»>
name=»value» type=»xsd:string» use=»optional»/>
Таблица 8.29 — XML-схема для элемента Group
name=»group» type=»tGroup» substitutionGroup=»artifact»/>
name=»tGroup»>
base=»tArtifact»>
<xsd:attribute name=»categoryValueRef» type=»xsd:QName» use=»optional»/>
Таблица 8.30 — XML-схема для элемента Text Annotation
name=»textAnnotation» type=»tTextAnnotation» substitutionGroup=»artifact»/>
name=»tTextAnnotation»>
base=»tArtifact»>
ref=»text» minOccurs=»0″ maxOccurs=»1″/>
name=»textFormat» type=»xsd:string» default=»textplain»/>
8.3.2 Корреляция (Correlation)
Выполнение Бизнес-Процесса может осуществляться в течение нескольких дней или даже месяцев, сопровождаясь асинхронным общением через Сообщения (Message). В то же время параллельно могут выполняться множество экземпляров (instance) конкретного Процесса, к примеру, множество экземпляров процесса заказа, каждый из которых представляет собой отдельно взятый заказ. Корреляция используется для установки соответствия между каким-либо Сообщением и исходящим Обменом сообщениями (Conversation) двух различных экземпляров Процесса. BPMN позволяет использовать данные из существующих Сообщений для установки такой корреляции. К примеру, в процессе заказа каждый отдельно взятый экземпляр этого процесса может быть идентифицирован посредством относящегося к нему атрибута ordered или customerID, а не путем запроса технических данных о корреляции.
Суть Корреляции заключается в ассоциировании Сообщения с Задачей типа Отправка (Send Task) или Задачей типа Получение (Receive Task), что также называется маршрутизацией экземпляра (instance routing). Корреляция особенно важна, когда для осуществления маршрутизации экземпляра не может быть использована поддержки инфраструктура. Обратите внимание, что такая ассоциация может просматриваться на различных уровнях моделирования, т.е. во Взаимодействии (Collaboration (Conversation)), Хореографии (Choreography) и Процессе (Process). Однако собственно корреляция выполняется в ходе выполнения процесса (к примеру, на одном из уровней Процесса). Посредством корреляций описывается набор утверждений, касаемых Сообщения (как правило, передаваемых приложением данных). Эти утверждения должны быть удовлетворены, иначе Сообщение не будет ассоциировано с обособленной Задачей Отправка или Задачей Получение. Кроме того, любая Задача Отправка и любая Задача Получение может участвовать в одном или более Обменах сообщениями (Conversation). К тому же Задача такого типа идентифицирует Сообщение, которое она отсылает, и, таким образом, устанавливает связь с одним или несколькими Ключами Корреляции — CorrelationKeys.
Существуют два механизма неэксклюзивной корреляции:
- Корреляция, основанная на ключах. В данном случае между Сообщениями, которые были отправлены и получены в ходе Обмена сообщениями (Conversation), устанавливается логическая корреляция посредством одного или более общих ключей CorrelationKeys. Это означает, что в любом Сообщении, которое отсылается или принимается в ходе Обмена сообщениями (Conversation), должно храниться значение по-меньшей мере одного экземпляра CorrelationKey, входящее в передаваемые им данные. Посредством CorrelationKey указывается ключ (составной) (key/composite key). Сообщение, которое отсылается или принимается первым, инициализирует один или более экземпляров CorrelationKey, ассоциированных с Обменом сообщениями (Conversation). Другими словами, оно указывает значения для экземпляров CorrelationProperty, являющихся полями/частичными ключами (fields/partial keys) элементов CorrelationKey. CorrelationKey может быть использован лишь в случае, если Сообщение оказало влияние на все поля CorrelationProperty ключа, содержащего значение. Если следующее Сообщение получает экземпляр CorrelationKey (с учетом, что данный CorrelationKey был уже инициализирован в Обмене сообщениями (Conversation)), то значение CorrelationKey, содержащееся в Сообщении, ДОЛЖНО соответствовать значению CorrelationKey, содержащемуся в Обмене сообщениями. Если же следующее Сообщение получает экземпляр CorrelationKey, ассоциированный с Обменом сообщениями (Conversation), однако, предварительно не инициализированный, то значение CorrelationKey становится ассоциированным с Обменом сообщениями. Поскольку в Обмен сообщениями (Conversation) могут входить различные Сообщения, его структура также может быть разной, а каждое значение Свойства Корреляции — CorrelationProperty — сопровождается количеством правил извлечения (CorrelationPropertyRetrievalExpression) для соответствующих частичных ключей, соответствующим количеству Сообщений.
- Корреляция, основанная на контексте. В данном случае контекст Процесса (например, Объекты данных (Data Object) или Свойства (Properties)) могут динамически воздействовать на критерии соответствия. Это означает, что CorrelationKey может быть дополнен CorrelationSubscription, относящимся к Процессу. CorrelationSubscription объединяет столько элементов CorrelationPropertyBindings, сколько CorrelationProperties содержится в данном CorrelationKey. CorrelationPropertyBinding связан с конкретным CorrelationProperty, а также ссылается на Формальное Выражение — FormalExpression, которое указывает на правило динамического извлечения, действующее поверх контекста Процесса. В ходе выполнения процесса экземпляр CorrelationKey для отдельно взятого Обмена сообщениями (Conversation) распространяется (и динамически обновляется), исходя из контекста Процесса и используя FormalExpressions (формальные выражения). В этом смысле изменения в контексте Процесса могут менять условия корреляции.
Корреляция может быть использована в Потоках Сообщений (Message Flows), входящих в состав Взаимодействия (Collaboration) и Хореографии (Choreography) (для получения более подробной информации см. Главы 9 и 11 соответственно). Ключи, используемые в Потоках Сообщений, представляют собой ключи контейнеров или группировок Потоков Сообщений, представленными в виде Взаимодействия, Хореографии, Точек Обмена Сообщениями (Conversation Nodes) и Действий Хореографии (Choreography Activities). Результатом могут стать множественные CorrelationKeys, используемые в том же самом Потоке Сообщений (возможно, из-за многочисленных слоев ограничения). В частности, вызовы Взаимодействия и Хореографии представляют собой особые Точки Обмена Сообщениями (Conversation Nodes) и Действия Хореографии соответственно. Они рассматриваются в качестве ограничений, необходимых для корреляции. Значения CorrelationKeys, заданные в вызывающем операторе, используются в Потоках Сообщений вызываемого Взаимодействия или вызываемой Хореографии.
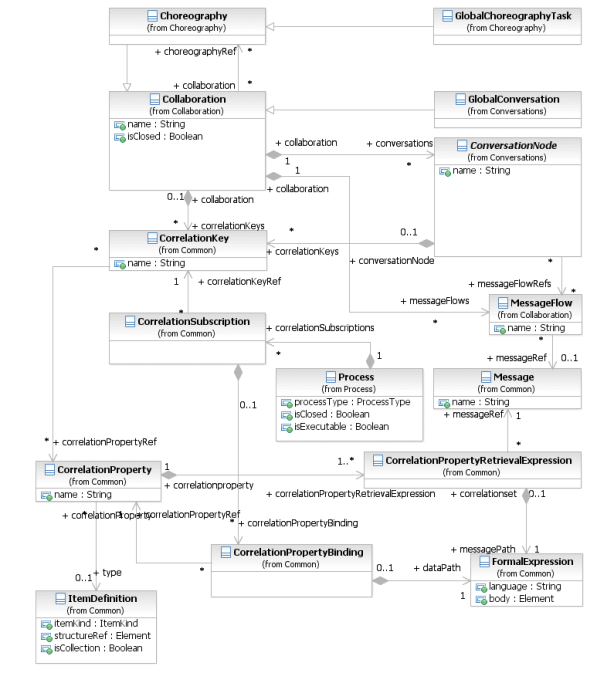
Фигура 8.17 – Диаграмма классов элемента Correlation
Ключ Корреляции (CorrelationKey)
Ключ Корреляции (CorrelationKey) представляет собой составной ключ из одного или более Свойств Корреляции (CorrelationProperties), который главным образом определяет извлечение Выражений (Expressions) поверх Сообщений. В результате каждое Свойство Корреляции выступает в роли частичного ключа корреляции. В любом Сообщении, которое отсылается или принимается как часть какого-то Обмена сообщениями (Conversation), Свойства Корреляции должны указывать выражение CorrelationPropertyRetrievalExpression, которое устанавливает связь (ссылку) между Формальным Выражением (FormalExpression) и передаваемыми Сообщением данными. Это означает, что для каждого Сообщения, используемого в Обмене Сообщениями, существует Выражение (Expression), которое извлекает соответствующие данные, передаваемые в Сообщении.
Элемент CorrelationKey наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5). Таблица 8.31 содержит информацию о дополнительных ассоциациях элемента CorrelationKey.
Таблица 8.31 – Ассоциации элемента CorrelationKey
| Название атрибута | Описание/использование |
| name: string [0..1] | Указывает название элемента CorrelationKey. |
| correlationPropertyRef: CorrelationProperty [0..*] | Свойства корреляции (CorrelationProperties), представляющие собой частичные ключи данного Ключа Корреляции (CorrelationKey). |
Основанная на ключах Корреляция (Key-based Correlation)
Основанная на ключах корреляция представляет собой простую и эффективную форму корреляции, при которой для идентификации Обмена Сообщениями (Conversation) используются один или несколько ключей. Любое входящее Сообщение (Message) должно быть противопоставлено Ключу Корреляции (CorrelationKey) путем извлечения Свойств Корреляции (CorrelationProperties) из этого Сообщения в соответствии с выражением CorrelationPropertyRetrievalExpression. При этом для данного Обмена Сообщениями выполняется сравнение составного ключа с экземпляром Ключа Корреляции (CorrelationKey). Смысл заключается в использовании объединенного «токена» (token), как отправляемого, так и получаемого, а также исходящих (outgoing) и входящих (incoming) Сообщений. Сообщения ассоциируются с каким-либо Обменом Сообщениями (Conversation) в том случае, если составной ключ, извлеченный из передаваемых данных, соответствует Ключу Корреляции (CorrelationKey), инициализированному для данного Обмена Сообщениями.
Задача Отправка (Send Task) или Задача получение (Receive Task), стоящая первой в составе Обмена Сообщениями (Conversation), ДОЛЖНА распространить по-меньшей мере один из экземпляров Ключа Корреляции (CorrelationKey) за счет извлечения значений из Свойств Корреляции (CorrelationProperties) в соответствии с выражением CorrelationPropertyRetrievalExpression, содержащимся в предварительно переданном или полученном Сообщении. Затем распространенные в Обмене Сообщениями экземпляры Ключа Корреляции (CorrelationKey) используются для описываемой процедуры согласования, когда составной ключ извлекается из входящих Сообщений и используется для идентификации соответствующего Обмена Сообщениями (Conversation). Когда такие, не способные к инициации Сообщения являются источникам значений для Ключей Корреляции (CorrelationKey), ассоциированных с Обменом Сообщениями, однако, ещё не распространенных, тогда извлеченные значения будут ассоциированы с экземпляром данного Обмена Сообщениями.
Элемент CorrelationProperty наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5) посредством связи с элементом RootElement. Таблица 8.32 содержит информацию о дополнительных ассоциациях элемента CorrelationProperty.
Таблица 8.32 – Ассоциации элемента CorrelationProperty
| Название атрибута | Описание/использование |
| name: string [0..1] | Указывает название элемента CorrelationProperty. |
| type: string [0..1] | Указывает тип элемента CorrelationProperty. |
| correlationPropertyRetrieval- Expression: CorrelationPropertyRetrieval- Expression [1..*] | Представляет собой выражение CorrelationPropertyRetrievalExpressions для данного Ключа Корреляции (CorrelationKey), представляющее, в свою очередь, ассоциации Формальных Выражений (FormalExpressions), или путей извлечения, с Сообщениями, входящими в состав данного Обмена Сообщениями (Conversation). |
Элемент CorrelationPropertyRetrievalExpression наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5). Таблица 8.33 содержит информацию о дополнительных ассоциациях элемента CorrelationPropertyRetrievalExpressions.
Таблица 8.33 – Ассоциации элемента CorrelationPropertyRetrievalExpression
| Название атрибута | Описание/использование |
| messagePath: FormalExpression | Формальное Выражение (FormalExpression), определяющее то, каким образом Свойство Корреляции (CorrelationProperty) извлекается из передаваемых в Сообщении данных. |
| messageRef: Message | Конкретное Сообщение, из которого Формальное Выражение (FormalExpression) извлекает Свойство Корреляции (CorrelationProperty). |
Основанная на контексте Корреляция (Context-based Correlation)
По сравнению с корреляцией, основанной на ключах, корреляция, основанная на контексте, является более точной. В дополнении к скрытому распространению экземпляра Ключа Корреляции (CorrelationKey), начиная с первого отправленного или полученного Сообщения (Message), добавляется ещё один механизм установления связи между Ключом Корреляции (CorrelationKey) и контекстом Процесса. Это означает, что Процесс МОЖЕТ предоставить Подписку на Корреляцию (CorrelationSubscription), которая по отношению к Ключу Корреляции (CorrelationKey) выполняет функцию специального дубликата. В данном случае Обмен сообщениями (Conversation) МОЖЕТ дополнительно ссылаться на данные контекста Процесса, которые скрыто обновляются. Это позволяет определить, является ли получение Сообщения необходимым или нет. В ходе выполнения экземпляр Ключа Корреляции (CorrelationKey) хранит составной ключ, значение которого динамически высчитывается, исходя из контекста Процесса, а также автоматически обновляется, независимо от того, когда изменяются расположенные ниже Объекты Данных (Data Object) или Свойства (Properties).
Элементы CorrelationPropertyBindings представляют собой частичные ключи Подписки на корреляцию (CorrelationSubscription), каждый из которых относится к какому-то Свойству корреляции (CorrelationProperty) соответствующего Ключа Корреляции (CorrelationKey). Посредством Формального выражения (FormalExpression) определяется то, каким образом, исходя из контекста Процесса, распространяется и обновляется экземпляр Свойства Корреляции (CorrelationProperty) в ходе выполнения.
Элемент CorrelationSubscription наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5). Таблица 8.34 содержит информацию о дополнительных ассоциациях элемента CorrelationSubscription.
Таблица 8.34 – Ассоциации элемента CorrelationSubscription
| Название атрибута | Описание/использование |
| correlationKeyRef: CorrelationKey | Ключ Корреляции (CorrelationKey), на который ссылается элемент CorrelationSubscription. |
| correlationPropertyBinding: CorrelationPropertyBinding [0..*] | Связь со Свойствами Корреляции (CorrelationProperties) и Формальными Выражениями (FormalExpressions) (правила извлечения поверх контекста Процесса). |
Элемент CorrelationPropertyBinding наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5). Таблица 8.35 содержит информацию о дополнительных ассоциациях элемента CorrelationPropertyBinding.
Таблица 8.35 – Ассоциации элемента CorrelationPropertyBinding
| Название атрибута | Описание/использование |
| dataPath: FormalExpression | Формальное Выражение (FormalExpression), определяющее правило извлечения поверх контекста Процесса. |
| correlationPropertyRef: CorrelationProperty | Свойства Корреляции (CorrelationProperties), на которые ссылается данный элемент CorrelationPropertyBinding. |
В ходе выполнения механизм корреляции работает следующим образом: когда создается экземпляр Процесса, экземпляры Ключа Корреляции (CorrelationKey) во всех Обменах Сообщениями (Conversations) инициализируются вместе с некоторыми начальными значениями, посредством которых указывается корреляция с любым входящим Сообщением (Message) данных Обменов Сообщениями. Свойство Подписки (SubscriptionProperty) обновляется независимо от того, когда меняется любой Объект Данных (Data Objects) или Свойство (Properties), на которые в соответствующем Формальном Выражении (FormalExpression) есть ссылка. В результате, входящее Сообщение противопоставлено экземпляру Ключа Корреляции (CorrelationKey). Дальше, по ходу следования маршрута Процесса, Свойства Подписки (SubscriptionProperties) опять-таки могут изменить (в том числе, и скрыто) критерии корреляции. В качестве альтернативы может быть использован установленный механизм получения первой Задачи Отправка (Send Task) или Задачи Получение (Receive Task), используемых для распространения экземпляра Ключа Корреляции (CorrelationKey).
Представление XML-схемы для Корреляции (Correlation)
Таблица 8.36 – XML-схема для элемента Correlation Key
name=»correlationKey» type=»tCorrelationKey»/>
name=»tCorrelationKey»>
base=»tBaseElement»>
name=»correlationPropertyRef» type=»xsd:QName»
minOccurs=»0″ maxOccurs=»unbounded»/>
name=»name» type=»xsd:String» use=»optional»/>
Таблица 8.37 – XML-схема для элемента Correlation Property
name=»correlationProperty» type=»tCorrelationProperty» substitutionGroup=»rootElement»/>
name=»tCorrelationProperty»>
base=»tRootElement»>
<xsd:element ref=»correlationPropertyRetrievalExpression»
minOccurs=»1″ maxOccurs=»unbounded»/>
name=»name» type=»xsd:String» use=»optional»/>
<xsd:attribute name=»type» type=»xsd:QName»/>
Таблица 8.38 – XML-схема для элемента Correlation Property Binding
name=»correlationPropertyBinding» type=»tCorrelationPropertyBinding»/>
<xsd:complexType name=»tCorrelationPropertyBinding»>
<xsd:extension base=»tBaseElement»>
name=»dataPath» type=»tFormalExpression» minOccurs=»1″ maxOccurs=»1″/>
name=»correlationPropertyRef» type=»xsd:QName» use=»required»/>
Таблица 8.39 – XML-схема для элемента Correlation Property Retrieval Expression
name=»correlationPropertyRetrievalExpression» type=»tCorrelationPropertyRetrievalExpression»/>
name=»tCorrelationPropertyRetrievalExpression»>
base=»tBaseElement»>
name=»messagePath» type=»tFormalExpression» minOccurs=»1″ maxOccurs=»1″/>
name=»messageRef» type=»xsd:QName» use=»required»/>
Таблица 8.40 – XML-схема для элемента Correlation Subscription
name=»correlationSubscription» type=»tCorrelationSubscription»/>
name=» tCorrelationSubscription «>
base=»tBaseElement»>
name=»process» type=»xsd:QName» use=»required»/>
ref=»correlationKeyRef» minOccurs=»1″ maxOccurs=»1″/>
<xsd:element name=»correlationPropertyBinding» type=»xsd:QName»
minOccurs=»0″ maxOccurs=»unbounded»/>
8.3.3 Ошибка (Error)
Ошибка (Error) представляет собой содержимое События типа Ошибка (Error Event) либо Ошибку (Fault) при сбое Операции (Operation). Посредством класса ItemDefinition указывается структура Ошибки (Error). Ошибка генерируется тогда, когда в ходе обработки Действия (Activity) возникает критическая проблема, либо когда выполнение Операции завершается ошибкой.
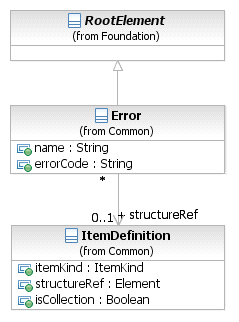
Фигура 8.18 – Диаграмма классов элемента Error
Элемент Error наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5) посредством его связи с элементом RootElement. Таблица 8.41 содержит информацию о дополнительных атрибутах и ассоциациях элемента Error.
Таблица 8.41 – Атрибуты и ассоциации элемента Error
| Название атрибута | Описание/использование |
| structureRef : ItemDefinition [0..1] | Используется для определения полезной нагрузки Ошибки. |
| name : string | Описательное имя Ошибки. |
| errorCode: string | Для Конечных Событий (End Event): Если результатом является Ошибка, то ДОЛЖЕН предоставляться errorCode (в данном случае значение атрибута processType Процесса равно «executable»). Инициирует Ошибку. Для Промежуточных Событий (Intermediate Event) в составе стандартного потока операций: Если триггер является Ошибкой, то ДОЛЖЕН быть введен errorCode (в данном случае значение атрибута processType Процесса равно «executable»). Инициирует Ошибку. Для Промежуточных Событий (Intermediate Event), присоединенных к границе Действия (Activity): Если триггер является Ошибкой, то МОЖЕТ БЫТЬ введен errorCode. Событие данного типа обрабатывает (catch) Ошибку. В случае если значение errorCode не введено, то Событие ДОЛЖНО инициироваться любой ошибкой. В случае если значение errorCode все же введено, то Событие ДОЛЖНО инициироваться лишь соответствующей Ошибкой, указанной в errorCode. |
8.3.4 Эскалация (Escalation)
Эскалация (Escalation) возникает в момент, когда Процесс каким-либо образом должен отреагировать на происходящее. Класс ItemDefinition используется для определения структуры Эскалации.
Фигура 8.19 – Диаграмма классов элемента Escalation
Элемент Escalation наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5) посредством его связи с элементом RootElement. Таблица 8.42 содержит информацию о дополнительных ассоциациях элемента Escalation.
Таблица 8.42 – Атрибуты и ассоциации элемента Escalation
| Название атрибута | Описание/использование |
| structureRef : ItemDefinition [0..1] | Используется для определения полезной нагрузки Эскалации. |
| name : string | Описательное имя Эскалации. |
| escalationCode: string | Для Конечных Событий (End Event): Если результатом является Эскалация, то ДОЛЖЕН предоставляться escalationCode (в данном случае значение атрибута processType Процесса равно «executable»). Инициирует Эскалацию. Для Промежуточных Событий (Intermediate Event) в составе стандартного потока операций: Если триггер является Эскалацией, то ДОЛЖЕН быть введен escalationCode (в данном случае значение атрибута processType Процесса равно «executable»). Инициирует Эскалацию. Для Промежуточных Событий (Intermediate Event), присоединенных к границе Действия (Activity): Если триггер является Эскалацией, то МОЖЕТ БЫТЬ введен errorCode. Событие данного типа обрабатывает (catch) Эскалацию. В случае, если значение escalationCode не введено, то Событие ДОЛЖНО инициироваться любой Эскалацией. В случае, если значение escalationCode все же введено, то Событие ДОЛЖНО инициироваться лишь соответствующей Эскалацией, указанной в escalationCode. |
8.3.5 События (Events)
Событие (Event) – это то, что происходит в течение Процесса. Событие оказывает влияние на ход Процесса и чаще всего имеет причину (cause) или оказывает воздействие (impact). Сам термин «событие» является достаточно объемным и подразумевает многие явления, происходящие в Процессе. Начало выполнения Действия, его завершение, смена статуса документа, прибывшее Сообщение и т.д., — все это может подходить под категорию «события». Однако в BPMN существуют ограничения использования Событий. Таким образом, Событиями BPMN могут называться лишь те события, которые оказывают влияние на последовательность Действий Процесса или время их выполнения.
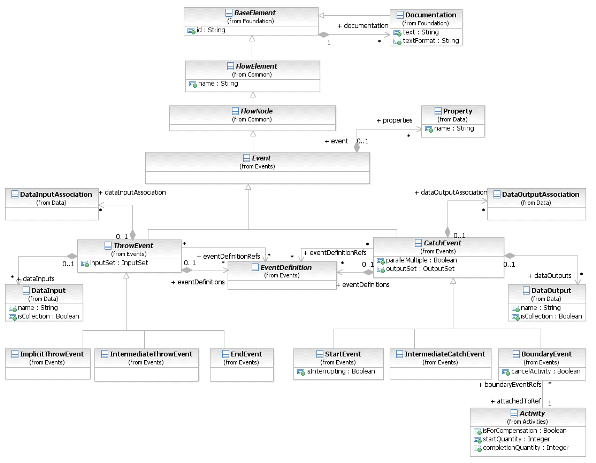
Фигура 8.20 – Диаграмма классов элемента Event
Элемент Event наследует атрибуты и ассоциации элемента FlowElement (см. таблицу 8.44), однако, не может иметь каких-либо дополнительных атрибутов и ассоциаций.
Информацию о типах Событий (Стартовое, Промежуточное, Конечное) см. в подразделе 10.4.5.
8.3.6. Выражения (Expressions)
Класс Expression используется для определения Выражения (Expression) в виде текста на естественном языке. Такие Выражения являются неисполняемыми. Текст на естественном языке вводится с использованием атрибута documentation, заимствованного из элемента BaseElement.
Элемент Expression наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5), однако, не может иметь каких-либо дополнительных атрибутов и ассоциаций.
Выражения используются довольно во многих местах модели BPMN. С их помощью добывается информация из различных элементов (как правило, из элементов, содержащих данные). Наиболее распространенный пример использования Выражений – это моделирование решений, когда условные Выражения (conditional Expressions) используются для определения направления маршрутов в соответствии с определенными критериями.
BPMN поддерживает использование недостаточно определенных Выражений, в которых логика представлена в виде описательного текста на естественном языке разработчика модели. Язык также поддерживает формальные Выражения (formal Expressions), в которых логика является исполняемой и описана с использованием конкретного языка Выражений.
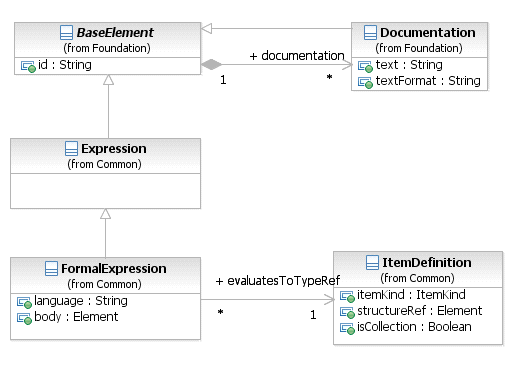
Фигура 8.21 – Диаграмма классов элемента Expression
Класс Expression
Класс Expression (выражений) используется для определения Выражения (Expression) в виде текста на естественном языке. Такие Выражения являются неисполняемыми и считаются недостаточно определенными.
Выражение (Expression) может использоваться двумя способами: оно может содержаться там же, где и используется, либо оно может быть указано на одном из уровней Процесса, куда к нему ведет ссылка из места, где оно должно быть использовано.
Элемент Expression наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5), однако, не может иметь каких-либо дополнительных атрибутов и ассоциаций.
Класс Formal Expression
Класс FormalExpression (формальных выражений) используется для определения исполняемых Выражений (Expression) с использованием конкретного языка Выражений. В качестве дополнения к основному требованию определения таких Выражений также может быть использовано описание на естественном языке.
Язык Выражений, использующийся по умолчанию для определения всех Выражений, указывается в элементе Definitions посредством атрибута expressionLanguage, хотя для определения какого-либо Формального Выражения, использующего этот атрибут, указанный по умолчанию язык может быть изменен.
Элемент FormalExpression наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5) посредством его связи с элементом Expression. Таблица 8.43 содержит информацию о дополнительных атрибутах и ассоциациях элемента FormalExpression.
Таблица 8.43 – Атрибуты и ассоциации элемента FormalExpression
| Название атрибута | Описание/использование |
| language: string [0..1] | Отменяет язык Выражений (Expression language), указанный в Definitions. Язык ДОЛЖЕН иметь формат UML. |
| body: Element | Тело Выражения. Обратите внимание, что данный атрибут не является значимым в случае, если для замены использован язык XML Schema. Напротив, сложным типом FormalExpression поддерживается смешанное наполнение. Тело Выражения определяется как наполнение элемента. Пример: count(../dataObject[id=»CustomerRecord_1″]/emailAddress) > 0 |
| evaluatesToTypeRef: ItemDefinition | Тип объекта, возвращаемый Выражением при вычислении. К примеру, условные Выражения (conditional Expressions) вычисляются как булевские (boolean). |
8.3.7 Элемент Потока (Flow Element)
FlowElement представляет собой абстрактный суперкласс для всех элементов, входящих в состав потоков Процесса — так называемых Узлов Потока (FlowNodes, см. соотв. пункт раздела 8.3.13). Узлы Потока состоят из Действий (Activities, см. раздел 10.2), Действий Хореографии (Choreography Activities, см. раздел 11.4), Шлюзов (Gateways, см. раздел 10.5), Событий (Events, см. раздел 10.4), Объектов Данных (Data Objets, см. раздел 10.3.1), Ассоциаций Данных (Data Association, см. соотв. пункт раздела 10.3.2), Потоков Операций (Sequence Flow, см. раздел 8.3.13).
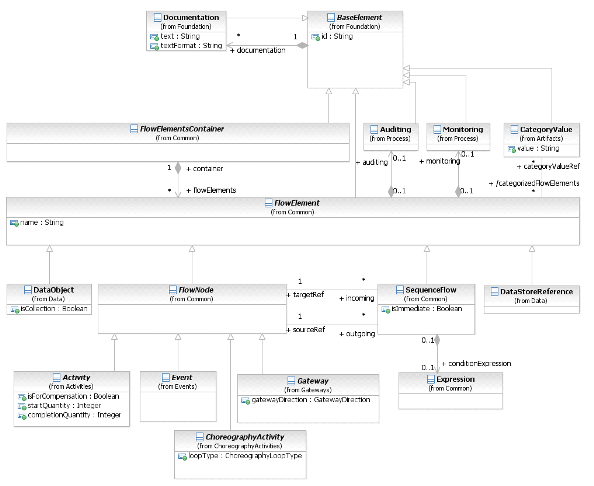
Фигура 8.22 – Диаграмма класса элемента FlowElement
Элемент FlowElement наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5). Таблица 8.44 содержит информацию о дополнительных атрибутах и ассоциациях элемента FlowElement.
Таблица 8.44 – Атрибуты и ассоциации элемента FlowElement
| Название атрибута | Описание/использование |
| name: string [0..1] | Описательное имя элемента. |
| categoryValueRef: Category- Value [0..*] | Ссылка на Значения Категории (Category Values), ассоциированные с данным Элементом Потока (Flow Element). |
| auditing: Auditing [0..1] | Метод указания свойств проверки. Данный атрибут может использоваться только для Процесса. |
| monitoring: Monitoring [0..1] | Метод указания свойств мониторинга. Данный атрибут может использоваться только для Процесса. |
8.3.8 Контейнер Элементов Потока (Flow Elements Container)
Элемент FlowElementsContainer представляет собой абстрактный суперкласс для диаграмм BPMN (видов) и служит для определения расширенного набора элементов, отображаемых на диаграммах. В основном, Контейнер Элементов Потока содержит такие Элементы Потока, как События (Events, см. раздел 10.4), Шлюзы (Gateways, см. раздел 10.5), Потоки Операций (Sequence Flow, см. раздел 8.3.13), Действия (Activities, см. раздел 10.2) и Действия Хореографии (Choreography Activities, см. раздел 11.4).
Действий (Activities, см. раздел 10.2), Действий Хореографии (Choreography Activities, см. раздел 11.4), Шлюзов (Gateways, см. раздел 10.5), Событий (Events, см. раздел 10.4), Объектов Данных (Data Objets, см. раздел 10.3.1), Ассоциаций Данных (Data Association, см. соотв. пункт раздела 10.3.2), Потоков Операций (Sequence Flow, см. раздел 8.3.13).
BPMN выделяет четыре (4) типа Контейнеров Элементов Потока (см. фигуру 8.23): Процесс (Process), Подпроцесс (Sub-Process), Хореография (Choreography) и Подхореография (Sub-Choreography).
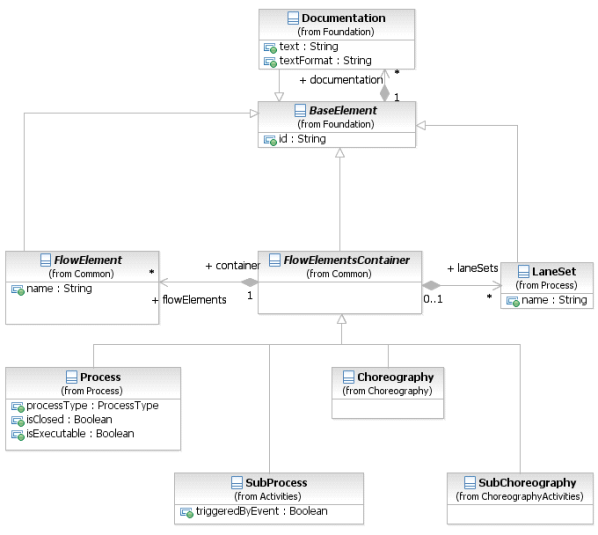
Фигура 8.23 – Диаграмма классов элемента FlowElementContainers
Элемент FlowElementsContainer наследует атрибуты и ассоциации элемента BaseElement (см. таблицу 8.5). Таблица 8.45 содержит информацию о дополнительных ассоциациях элемента FlowElementsContainer.
Таблица 8.45 – Ассоциации элемента FlowElementsContainer
| Название атрибута | Описание/использование |
| flowElements: Flow Element [0..*] | Данная ассоциация используется для указания конкретных элементов потока (flow elements), содержащихся в Контейнере Элементов Потока. Элементами Потока являются: События, Шлюзы, Потоки Операций, Действия, Объекты Данных, Ассоциации Данных и Действия Хореографии. Обратите внимание:
|
| laneSets: LaneSet [0..*] | Данный атрибут служит для определения списка элементов LaneSets, используемых в Контейнере Элементов Потока. LaneSets не используются в Хореографиях и Подхореографиях. |
<<предыдущая содержание следующая>>
Данные материалы предназначены исключительно для ознакомления в личных целях.Любое воспроизведение, копирование, а так же коммерческое и некоммерческое использование материалов должно согласовываться с авторами материалов (elma@elewise.ru). Допускается использование материалов сайта без уведомления авторов, но с явным указанием источника.
Errors are inherently part of software development. They can happen because of several reasons. One common definition of a software error is a mismatch between the program and its specification. In other words, we can say, a program has an error when the program does not do what the end-user expects. In this blog post, we want to share few concepts about dealing with errors in BPMN and of course in Camunda.
BPMN uses the error event to handle the occurrence of errors during the execution of a certain activity or at a certain point in the flow of a process. There are few basic considerations
- The error event can appear as an
- start event only for event sub-processes (catching type)
- intermediate attached event (catching type)
- end event (throwing type)
There is only place to throw an error, at the end of a flow. The reasoning behind is, an error cuts the normal flow of a process, and it does not make sense to continue until the error is handled. Handling an error can only be done in an activity coming from an attached event, or inside one event sub-process.
Let’s now imagine the following situation, an activity needs to handle many errors. If this is the case for several activities in a process, the result is:
- one error attached event is required for each error to be handled
A direct consequence of the previous statement is that the process gets cluttered. So what can be done to avoid cluttering the process?
One thing to understand is that in BPMN two types of errors are recognized, and each type can be dealt better with specific symbols and behaviors of a given BPMN engine, in our case the Camunda Platform engine, the following table can help visualize the possibilities.
| Type of error | Definition | Handling |
| Business Errors | Should be handled in the logic of the process | With symbols: Error, Escalation |
| Technical Errors | Should be handled by the engine as error in the implementation i.e. code, connection, infrastructure, etc. | As incident in the Camunda engine |
Now, how can technical and business error be set apart? By answering the following question: Does the error have some business meaning and causes an alternative process flow (like “item not on stock” in an inventory process) or is it a technical malfunction in the infrastructure or code (like “network currently down”)?
When we let technical errors be handled by the engine, such as in the case of incidents, nothing is to be done in the process diagram, reducing the need to add explicit error events. But there are still many other business errors that might occur and clutter the model.
One possible solution is, using an event sub-process that can distinguished between all business errors. However doing this with plain BPMN is a real challenge. With Camunda BPMN Platform there is the possibility to implement the mentioned solution, it requires the use of the class:
org.camunda.bpm.engine.delegate.BpmnErrorThe class provides a constructor where we can define a code and a message:
BpmnError(String errorCode, String message)with the errorCode and the message, a creative approach inside a event sub-process can be implemented.
The first step is that the activity that contains the possible errors, does the actual throwing proactively i.e. checking in code the conditions that produce the business errors and the throwing them as in the following code snippet:
if (some variable checkings and so on ...) {
throw new org.camunda.bpm.engine.delegate.BpmnError("GenericError", "errorB");
}The second step is, having an event sub-process catching always the same errorCode and then distinguishing the errors using the message variable together with a X-OR gateway that redirects the flow to specific remedy actions. Important here is that using the properties panel of the Camunda modeler, we need to configure the start event of the event sub-process to define the name of the message variable field.
Using this approach will reduce the need to add one error attached event for each possible error to handle, effectively reducing the cluttering in the model. The model keeps its readability by having a general error handling mechanism, and if required, activities can still have single error attached events for special cases.
Putting everything together in a model the solution looks like this:
An example made for educational purposes with javascript can be found in the following github repository:
GitHub – bassgelo/BPMNErrorHandlingDemo: BPMN Error Handling Demo
Written by
Gerardo Manzano
Engineering Manager at JIT