Exception handling is required in any programming language to handle the runtime errors so that normal flow of the application can be maintained.
Exception normally disrupts the normal flow of the application, which is the reason why we need to use Exception handling in our application.
Exceptions are broadly classified into the following categories −
-
Checked Exception − The classes that extend Throwable class except RuntimeException and Error are known as checked exceptions e.g.IOException, SQLException etc. Checked exceptions are checked at compile-time.
One classical case is the FileNotFoundException. Suppose you had the following codein your application which reads from a file in E drive.
class Example {
static void main(String[] args) {
File file = new File("E://file.txt");
FileReader fr = new FileReader(file);
}
}
if the File (file.txt) is not there in the E drive then the following exception will be raised.
Caught: java.io.FileNotFoundException: E:file.txt (The system cannot find the file specified).
java.io.FileNotFoundException: E:file.txt (The system cannot find the file specified).
-
Unchecked Exception − The classes that extend RuntimeException are known as unchecked exceptions, e.g., ArithmeticException, NullPointerException, ArrayIndexOutOfBoundsException etc. Unchecked exceptions are not checked at compile-time rather they are checked at runtime.
One classical case is the ArrayIndexOutOfBoundsException which happens when you try to access an index of an array which is greater than the length of the array. Following is a typical example of this sort of mistake.
class Example {
static void main(String[] args) {
def arr = new int[3];
arr[5] = 5;
}
}
When the above code is executed the following exception will be raised.
Caught: java.lang.ArrayIndexOutOfBoundsException: 5
java.lang.ArrayIndexOutOfBoundsException: 5
-
Error − Error is irrecoverable e.g. OutOfMemoryError, VirtualMachineError, AssertionError etc.
These are errors which the program can never recover from and will cause the program to crash.
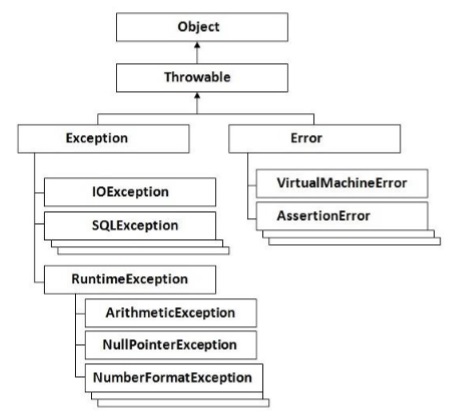
The following diagram shows how the hierarchy of exceptions in Groovy is organized. It’s all based on the hierarchy defined in Java.
Catching Exceptions
A method catches an exception using a combination of the try and catch keywords. A try/catch block is placed around the code that might generate an exception.
try {
//Protected code
} catch(ExceptionName e1) {
//Catch block
}
All of your code which could raise an exception is placed in the Protected code block.
In the catch block, you can write custom code to handle your exception so that the application can recover from the exception.
Let’s look at an example of the similar code we saw above for accessing an array with an index value which is greater than the size of the array. But this time let’s wrap our code in a try/catch block.
class Example {
static void main(String[] args) {
try {
def arr = new int[3];
arr[5] = 5;
} catch(Exception ex) {
println("Catching the exception");
}
println("Let's move on after the exception");
}
}
When we run the above program, we will get the following result −
Catching the exception Let's move on after the exception
From the above code, we wrap out faulty code in the try block. In the catch block we are just catching our exception and outputting a message that an exception has occurred.
Multiple Catch Blocks
One can have multiple catch blocks to handle multiple types of exceptions. For each catch block, depending on the type of exception raised you would write code to handle it accordingly.
Let’s modify our above code to catch the ArrayIndexOutOfBoundsException specifically. Following is the code snippet.
class Example {
static void main(String[] args) {
try {
def arr = new int[3];
arr[5] = 5;
}catch(ArrayIndexOutOfBoundsException ex) {
println("Catching the Array out of Bounds exception");
}catch(Exception ex) {
println("Catching the exception");
}
println("Let's move on after the exception");
}
}
When we run the above program, we will get the following result −
Catching the Aray out of Bounds exception Let's move on after the exception
From the above code you can see that the ArrayIndexOutOfBoundsException catch block is caught first because it means the criteria of the exception.
Finally Block
The finally block follows a try block or a catch block. A finally block of code always executes, irrespective of occurrence of an Exception.
Using a finally block allows you to run any cleanup-type statements that you want to execute, no matter what happens in the protected code. The syntax for this block is given below.
try {
//Protected code
} catch(ExceptionType1 e1) {
//Catch block
} catch(ExceptionType2 e2) {
//Catch block
} catch(ExceptionType3 e3) {
//Catch block
} finally {
//The finally block always executes.
}
Let’s modify our above code and add the finally block of code. Following is the code snippet.
class Example {
static void main(String[] args) {
try {
def arr = new int[3];
arr[5] = 5;
} catch(ArrayIndexOutOfBoundsException ex) {
println("Catching the Array out of Bounds exception");
}catch(Exception ex) {
println("Catching the exception");
} finally {
println("The final block");
}
println("Let's move on after the exception");
}
}
When we run the above program, we will get the following result −
Catching the Array out of Bounds exception The final block Let's move on after the exception
Following are the Exception methods available in Groovy −
public String getMessage()
Returns a detailed message about the exception that has occurred. This message is initialized in the Throwable constructor.
public Throwable getCause()
Returns the cause of the exception as represented by a Throwable object.
public String toString()
Returns the name of the class concatenated with the result of getMessage()
public void printStackTrace()
Prints the result of toString() along with the stack trace to System.err, the error output stream.
public StackTraceElement [] getStackTrace()
Returns an array containing each element on the stack trace. The element at index 0 represents the top of the call stack, and the last element in the array represents the method at the bottom of the call stack.
public Throwable fillInStackTrace()
Fills the stack trace of this Throwable object with the current stack trace, adding to any previous information in the stack trace.
Example
Following is the code example using some of the methods given above −
class Example {
static void main(String[] args) {
try {
def arr = new int[3];
arr[5] = 5;
}catch(ArrayIndexOutOfBoundsException ex) {
println(ex.toString());
println(ex.getMessage());
println(ex.getStackTrace());
} catch(Exception ex) {
println("Catching the exception");
}finally {
println("The final block");
}
println("Let's move on after the exception");
}
}
When we run the above program, we will get the following result −
java.lang.ArrayIndexOutOfBoundsException: 5 5 [org.codehaus.groovy.runtime.dgmimpl.arrays.IntegerArrayPutAtMetaMethod$MyPojoMetaMet hodSite.call(IntegerArrayPutAtMetaMethod.java:75), org.codehaus.groovy.runtime.callsite.CallSiteArray.defaultCall(CallSiteArray.java:48) , org.codehaus.groovy.runtime.callsite.AbstractCallSite.call(AbstractCallSite.java:113) , org.codehaus.groovy.runtime.callsite.AbstractCallSite.call(AbstractCallSite.java:133) , Example.main(Sample:8), sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method), sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57), sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) , java.lang.reflect.Method.invoke(Method.java:606), org.codehaus.groovy.reflection.CachedMethod.invoke(CachedMethod.java:93), groovy.lang.MetaMethod.doMethodInvoke(MetaMethod.java:325), groovy.lang.MetaClassImpl.invokeStaticMethod(MetaClassImpl.java:1443), org.codehaus.groovy.runtime.InvokerHelper.invokeMethod(InvokerHelper.java:893), groovy.lang.GroovyShell.runScriptOrMainOrTestOrRunnable(GroovyShell.java:287), groovy.lang.GroovyShell.run(GroovyShell.java:524), groovy.lang.GroovyShell.run(GroovyShell.java:513), groovy.ui.GroovyMain.processOnce(GroovyMain.java:652), groovy.ui.GroovyMain.run(GroovyMain.java:384), groovy.ui.GroovyMain.process(GroovyMain.java:370), groovy.ui.GroovyMain.processArgs(GroovyMain.java:129), groovy.ui.GroovyMain.main(GroovyMain.java:109), sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method), sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57), sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) , java.lang.reflect.Method.invoke(Method.java:606), org.codehaus.groovy.tools.GroovyStarter.rootLoader(GroovyStarter.java:109), org.codehaus.groovy.tools.GroovyStarter.main(GroovyStarter.java:131), sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method), sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57), sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) , java.lang.reflect.Method.invoke(Method.java:606), com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)] The final block Let's move on after the exception
This chapter covers the semantics of the Groovy programming language.
Statements
Variable definition
Variables can be defined using either their type (like String) or by using the keyword def (or var) followed by a variable name:
link:../test/SemanticsTest.groovy[]
def and var act as a type placeholder, i.e. a replacement for the type name,
when you do not want to give an explicit type.
It could be that you don’t care about the type at compile time
or are relying on type inference (with Groovy’s static nature).
It is mandatory for variable definitions to have a type or placeholder.
If left out, the type name will be deemed to refer to an existing variable (presumably declared earlier).
For scripts, undeclared variables are assumed to come from the Script binding.
In other cases, you will get a missing property (dynamic Groovy) or compile time error (static Groovy).
If you think of def and var as an alias of Object, you will understand in an instant.
Variable definitions can provide an initial value,
in which case it’s like having a declaration and assignment (which we cover next) all in one.
|
Note |
Variable definition types can be refined by using generics, like in List<String> names.To learn more about the generics support, please read the generics section. |
Variable assignment
You can assign values to variables for later use. Try the following:
link:../test/SemanticsTest.groovy[]
Multiple assignment
Groovy supports multiple assignment, i.e. where multiple variables can be assigned at once, e.g.:
link:../test/SemanticsTest.groovy[]
You can provide types as part of the declaration if you wish:
link:../test/SemanticsTest.groovy[]
As well as used when declaring variables it also applies to existing variables:
link:../test/SemanticsTest.groovy[]
The syntax works for arrays as well as lists, as well as methods that return either of these:
link:../test/SemanticsTest.groovy[]
Overflow and Underflow
If the left hand side has too many variables, excess ones are filled with null’s:
link:../test/SemanticsTest.groovy[]
If the right hand side has too many variables, the extra ones are ignored:
link:../test/SemanticsTest.groovy[]
Object destructuring with multiple assignment
In the section describing Groovy’s operators,
the case of the subscript operator has been covered,
explaining how you can override the getAt()/putAt() method.
With this technique, we can combine multiple assignments and the subscript operator methods to implement object destructuring.
Consider the following immutable Coordinates class, containing a pair of longitude and latitude doubles,
and notice our implementation of the getAt() method:
link:../test/SemanticsTest.groovy[]
Now let’s instantiate this class and destructure its longitude and latitude:
link:../test/SemanticsTest.groovy[]
-
we create an instance of the
Coordinatesclass -
then, we use a multiple assignment to get the individual longitude and latitude values
-
and we can finally assert their values.
Control structures
Conditional structures
if / else
Groovy supports the usual if — else syntax from Java
link:../test/SemanticsTest.groovy[]
Groovy also supports the normal Java «nested» if then else if syntax:
if ( ... ) { ... } else if (...) { ... } else { ... }
switch / case
The switch statement in Groovy is backwards compatible with Java code; so you can fall through cases sharing the same code for multiple matches.
One difference though is that the Groovy switch statement can handle any kind of switch value and different kinds of matching can be performed.
link:../test/SemanticsTest.groovy[]
Switch supports the following kinds of comparisons:
-
Class case values match if the switch value is an instance of the class
-
Regular expression case values match if the
toString()representation of the switch value matches the regex -
Collection case values match if the switch value is contained in the collection. This also includes ranges (since they are Lists)
-
Closure case values match if the calling the closure returns a result which is true according to the Groovy truth
-
If none of the above are used then the case value matches if the case value equals the switch value
|
Note |
When using a closure case value, the default it parameter is actually the switch value (in our example, variable x).
|
Groovy also supports switch expressions as shown in the following example:
link:../test/SemanticsTest.groovy[]
Looping structures
Classic for loop
Groovy supports the standard Java / C for loop:
link:../test/SemanticsTest.groovy[]
Enhanced classic Java-style for loop
The more elaborate form of Java’s classic for loop with comma-separate expressions
is now supported. Example:
def facts = [] def count = 5 for (int fact = 1, i = 1; i <= count; i++, fact *= i) { facts << fact } assert facts == [1, 2, 6, 24, 120]
Multi-assignment in combination with for loop
Groovy has supported multi-assignment statements since Groovy 1.6:
// multi-assignment with types def (String x, int y) = ['foo', 42] assert "$x $y" == 'foo 42'
These can now appear in for loops:
// multi-assignment goes loopy def baNums = [] for (def (String u, int v) = ['bar', 42]; v < 45; u++, v++) { baNums << "$u $v" } assert baNums == ['bar 42', 'bas 43', 'bat 44']
for in loop
The for loop in Groovy is much simpler and works with any kind of array, collection, Map, etc.
link:../test/SemanticsTest.groovy[]
|
Note |
Groovy also supports the Java colon variation with colons: for (char c : text) {}
|
while loop
Groovy supports the usual while {…} loops like Java:
link:../test/SemanticsTest.groovy[]
do/while loop
Java’s class do/while loop is now supported. Example:
// classic Java-style do..while loop def count = 5 def fact = 1 do { fact *= count-- } while(count > 1) assert fact == 120
Exception handling
Exception handling is the same as Java.
try / catch / finally
You can specify a complete try-catch-finally, a try-catch, or a try-finally set of blocks.
|
Note |
Braces are required around each block’s body. |
link:../test/SemanticsTest.groovy[]
We can put code within a ‘finally’ clause following a matching ‘try’ clause, so that regardless of whether the code in the ‘try’ clause throws an exception, the code in the finally clause will always execute:
link:../test/SemanticsTest.groovy[]
Multi-catch
With the multi catch block (since Groovy 2.0), we’re able to define several exceptions to be catch and treated by the same catch block:
try { /* ... */ } catch ( IOException | NullPointerException e ) { /* one block to handle 2 exceptions */ }
ARM Try with resources
Groovy often provides better alternatives to Java 7’s try-with-resources statement for Automatic Resource Management (ARM).
That syntax is now supported for Java programmers migrating to Groovy and still wanting to use the old style:
class FromResource extends ByteArrayInputStream { @Override void close() throws IOException { super.close() println "FromResource closing" } FromResource(String input) { super(input.toLowerCase().bytes) } } class ToResource extends ByteArrayOutputStream { @Override void close() throws IOException { super.close() println "ToResource closing" } } def wrestle(s) { try ( FromResource from = new FromResource(s) ToResource to = new ToResource() ) { to << from return to.toString() } } def wrestle2(s) { FromResource from = new FromResource(s) try (from; ToResource to = new ToResource()) { // Enhanced try-with-resources in Java 9+ to << from return to.toString() } } assert wrestle("ARM was here!").contains('arm') assert wrestle2("ARM was here!").contains('arm')
Which yields the following output:
ToResource closing FromResource closing ToResource closing FromResource closing
Power assertion
Unlike Java with which Groovy shares the assert keyword, the latter in Groovy behaves very differently. First of all,
an assertion in Groovy is always executed, independently of the -ea flag of the JVM. It makes this a first class choice
for unit tests. The notion of «power asserts» is directly related to how the Groovy assert behaves.
A power assertion is decomposed into 3 parts:
assert [left expression] == [right expression] : (optional message)
The result of the assertion is very different from what you would get in Java. If the assertion is true, then nothing
happens. If the assertion is false, then it provides a visual representation of the value of each sub-expressions of the
expression being asserted. For example:
link:../test/semantics/PowerAssertTest.groovy[]
Will yield:
Caught: Assertion failed: link:../test/semantics/PowerAssertTest.groovy[]
Power asserts become very interesting when the expressions are more complex, like in the next example:
link:../test/semantics/PowerAssertTest.groovy[]
Which will print the value for each sub-expression:
link:../test/semantics/PowerAssertTest.groovy[]
In case you don’t want a pretty printed error message like above, you can fall back to a custom error message by
changing the optional message part of the assertion, like in this example:
link:../test/semantics/PowerAssertTest.groovy[]
Which will print the following error message:
link:../test/semantics/PowerAssertTest.groovy[]
Labeled statements
Any statement can be associated with a label. Labels do not impact the semantics of the code and can be used to make
the code easier to read like in the following example:
link:../test/semantics/LabelsTest.groovy[]
Despite not changing the semantics of the labelled statement, it is possible to use labels in the break instruction
as a target for jump, as in the next example. However, even if this is allowed, this coding style is in general considered
a bad practice:
link:../test/semantics/LabelsTest.groovy[]
It is important to understand that by default labels have no impact on the semantics of the code, however they belong to the abstract
syntax tree (AST) so it is possible for an AST transformation to use that information to perform transformations over
the code, hence leading to different semantics. This is in particular what the Spock Framework
does to make testing easier.
Expressions
Expressions are the building blocks of Groovy programs that are used to reference
existing values and execute code to create new ones.
Groovy supports many of the same kinds of expressions as Java, including:
Table 1. Expressions like Java
|
Example expression(s) |
Description |
|
|
the name of a variable, field, parameter, … |
|
|
special names |
|
|
literals |
|
|
Class literal |
|
|
parenthesised expressions |
|
|
Unary operator expressions |
|
|
Binary operator expressions |
|
|
Ternary operator expressions |
|
|
Lambda expressions |
assert 'bar' == switch('foo') { case 'foo' -> 'bar' } |
switch expressions |
Groovy also has some of its own special expressions:
Table 2. Special expressions
|
Abbreviated class literal (when not ambiguous) |
|
Groovy also expands on the normal dot-notation used in Java for member access.
Groovy provides special support for accessing hierarchical data structures by specifying the
path in the hierarchy of some data of interest.
These Groovy path expressions are known as GPath expressions.
GPath expressions
GPath is a path expression language integrated into Groovy which allows parts of nested structured data to be identified. In this
sense, it has similar aims and scope as XPath does for XML. GPath is often used in the context of processing XML, but it really applies
to any object graph. Where XPath uses a filesystem-like path notation, a tree hierarchy with parts separated by a slash /, GPath use a
dot-object notation to perform object navigation.
As an example, you can specify a path to an object or element of interest:
-
a.b.c→ for XML, yields all thecelements insidebinsidea -
a.b.c→ for POJOs, yields thecproperties for all thebproperties ofa(sort of likea.getB().getC()in JavaBeans)
In both cases, the GPath expression can be viewed as a query on an object graph. For POJOs, the object graph is most often built by the
program being written through object instantiation and composition; for XML processing, the object graph is the result of parsing
the XML text, most often with classes like XmlParser or XmlSlurper. See Processing XML
for more in-depth details on consuming XML in Groovy.
|
Tip |
When querying the object graph generated from XmlParser or XmlSlurper, a GPath expression can refer to attributes defined on elements with
|
Object navigation
Let’s see an example of a GPath expression on a simple object graph, the one obtained using java reflection. Suppose you are in a non-static method of a
class having another method named aMethodFoo
link:../test/semantics/GPathTest.groovy[]
the following GPath expression will get the name of that method:
link:../test/semantics/GPathTest.groovy[]
More precisely, the above GPath expression produces a list of String, each being the name of an existing method on this where that name ends with Foo.
Now, given the following methods also defined in that class:
link:../test/semantics/GPathTest.groovy[]
then the following GPath expression will get the names of (1) and (3), but not (2) or (0):
link:../test/semantics/GPathTest.groovy[]
Expression Deconstruction
We can decompose the expression this.class.methods.name.grep(~/.*Bar/) to get an idea of how a GPath is evaluated:
this.class-
property accessor, equivalent to
this.getClass()in Java, yields aClassobject. this.class.methods-
property accessor, equivalent to
this.getClass().getMethods(), yields an array ofMethodobjects. this.class.methods.name-
apply a property accessor on each element of an array and produce a list of the results.
this.class.methods.name.grep(…)-
call method
grepon each element of the list yielded bythis.class.methods.nameand produce a list of the results.
|
Warning |
A sub-expression like this.class.methods yields an array because this is what calling this.getClass().getMethods() in Javawould produce. GPath expressions do not have a convention where a s means a list or anything like that.
|
One powerful feature of GPath expression is that property access on a collection is converted to a property access on each element of the collection with
the results collected into a collection. Therefore, the expression this.class.methods.name could be expressed as follows in Java:
List<String> methodNames = new ArrayList<String>(); for (Method method : this.getClass().getMethods()) { methodNames.add(method.getName()); } return methodNames;
Array access notation can also be used in a GPath expression where a collection is present :
link:../test/semantics/GPathTest.groovy[]
|
Note |
array access are zero-based in GPath expressions |
GPath for XML navigation
Here is an example with an XML document and various form of GPath expressions:
link:../test/semantics/GPathTest.groovy[]
-
There is one
levelnode underroot -
There are two
sublevelnodes underroot/level -
There is one element
sublevelhaving an attributeidwith value1 -
Text value of
keyelement of firstkeyValelement of secondsublevelelement underroot/levelis ‘anotherKey’
Further details about GPath expressions for XML are in the
XML User Guide.
Promotion and coercion
Number promotion
The rules of number promotion are specified in the section on math operations.
Closure to type coercion
Assigning a closure to a SAM type
A SAM type is a type which defines a single abstract method. This includes:
Functional interfaces
link:../test/CoercionTest.groovy[]
Abstract classes with single abstract method
link:../test/CoercionTest.groovy[]
Any closure can be converted into a SAM type using the as operator:
link:../test/CoercionTest.groovy[]
However, the as Type expression is optional since Groovy 2.2.0. You can omit it and simply write:
link:../test/CoercionTest.groovy[]
which means you are also allowed to use method pointers, as shown in the following example:
link:../test/CoercionTest.groovy[]
Calling a method accepting a SAM type with a closure
The second and probably more important use case for closure to SAM type coercion is calling a method which accepts
a SAM type. Imagine the following method:
link:../test/CoercionTest.groovy[]
Then you can call it with a closure, without having to create an explicit implementation of the interface:
link:../test/CoercionTest.groovy[]
But since Groovy 2.2.0, you are also able to omit the explicit coercion and call the method as if it used a closure:
link:../test/CoercionTest.groovy[]
As you can see, this has the advantage of letting you use the closure syntax for method calls, that is to say put the
closure outside the parenthesis, improving the readability of your code.
Closure to arbitrary type coercion
In addition to SAM types, a closure can be coerced to any type and in particular interfaces. Let’s define the
following interface:
link:../test/CoercionTest.groovy[]
You can coerce a closure into the interface using the as keyword:
link:../test/CoercionTest.groovy[]
This produces a class for which all methods are implemented using the closure:
link:../test/CoercionTest.groovy[]
But it is also possible to coerce a closure to any class. For example, we can replace the interface that we defined
with class without changing the assertions:
link:../test/CoercionTest.groovy[]
Map to type coercion
Usually using a single closure to implement an interface or a class with multiple methods is not the way to go. As an
alternative, Groovy allows you to coerce a map into an interface or a class. In that case, keys of the map are
interpreted as method names, while the values are the method implementation. The following example illustrates the
coercion of a map into an Iterator:
link:../test/CoercionTest.groovy[]
Of course this is a rather contrived example, but illustrates the concept. You only need to implement those methods
that are actually called, but if a method is called that doesn’t exist in the map a MissingMethodException or an
UnsupportedOperationException is thrown, depending on the arguments passed to the call,
as in the following example:
link:../test/CoercionTest.groovy[] link:../test/CoercionTest.groovy[] link:../test/CoercionTest.groovy[] link:../test/CoercionTest.groovy[]
The type of the exception depends on the call itself:
-
MissingMethodExceptionif the arguments of the call do not match those from the interface/class -
UnsupportedOperationExceptionif the arguments of the call match one of the overloaded methods of the interface/class
String to enum coercion
Groovy allows transparent String (or GString) to enum values coercion. Imagine you define the following enum:
link:../test/CoercionTest.groovy[]
then you can assign a string to the enum without having to use an explicit as coercion:
link:../test/CoercionTest.groovy[]
It is also possible to use a GString as the value:
link:../test/CoercionTest.groovy[]
However, this would throw a runtime error (IllegalArgumentException):
link:../test/CoercionTest.groovy[]
Note that it is also possible to use implicit coercion in switch statements:
link:../test/CoercionTest.groovy[]
in particular, see how the case use string constants. But if you call a method that uses an enum with a String
argument, you still have to use an explicit as coercion:
link:../test/CoercionTest.groovy[]
Custom type coercion
It is possible for a class to define custom coercion strategies by implementing the asType method. Custom coercion
is invoked using the as operator and is never implicit. As an example,
imagine you defined two classes, Polar and Cartesian, like in the following example:
link:../test/CoercionTest.groovy[] link:../test/CoercionTest.groovy[] link:../test/CoercionTest.groovy[]
And that you want to convert from polar coordinates to cartesian coordinates. One way of doing this is to define
the asType method in the Polar class:
link:../test/CoercionTest.groovy[]
which allows you to use the as coercion operator:
link:../test/CoercionTest.groovy[]
Putting it all together, the Polar class looks like this:
link:../test/CoercionTest.groovy[] link:../test/CoercionTest.groovy[] link:../test/CoercionTest.groovy[]
but it is also possible to define asType outside of the Polar class, which can be practical if you want to define
custom coercion strategies for «closed» classes or classes for which you don’t own the source code, for example using
a metaclass:
link:../test/CoercionTest.groovy[]
Class literals vs variables and the as operator
Using the as keyword is only possible if you have a static reference to a class, like in the following code:
link:../test/CoercionTest.groovy[]
But what if you get the class by reflection, for example by calling Class.forName?
link:../test/CoercionTest.groovy[]
Trying to use the reference to the class with the as keyword would fail:
link:../test/CoercionTest.groovy[]
It is failing because the as keyword only works with class literals. Instead, you need to call the asType method:
link:../test/CoercionTest.groovy[]
Optionality
Optional parentheses
Method calls can omit the parentheses if there is at least one parameter and there is no ambiguity:
link:../test/semantics/OptionalityTest.groovy[]
Parentheses are required for method calls without parameters or ambiguous method calls:
link:../test/semantics/OptionalityTest.groovy[]
Optional semicolons
In Groovy semicolons at the end of the line can be omitted, if the line contains only a single statement.
This means that:
link:../test/semantics/OptionalityTest.groovy[]
can be more idiomatically written as:
link:../test/semantics/OptionalityTest.groovy[]
Multiple statements in a line require semicolons to separate them:
link:../test/semantics/OptionalityTest.groovy[]
Optional return keyword
In Groovy, the last expression evaluated in the body of a method or a closure is returned. This means that the return keyword is optional.
link:../test/semantics/OptionalityTest.groovy[]
Can be shortened to:
link:../test/semantics/OptionalityTest.groovy[]
Optional public keyword
By default, Groovy classes and methods are public. Therefore this class:
link:../test/semantics/OptionalityTest.groovy[]
is identical to this class:
link:../test/semantics/OptionalityTest.groovy[]
The Groovy Truth
Groovy decides whether an expression is true or false by applying the rules given below.
Boolean expressions
True if the corresponding Boolean value is true.
link:../test/semantics/TheGroovyTruthTest.groovy[]
Collections and Arrays
Non-empty Collections and arrays are true.
link:../test/semantics/TheGroovyTruthTest.groovy[]
Matchers
True if the Matcher has at least one match.
link:../test/semantics/TheGroovyTruthTest.groovy[]
Iterators and Enumerations
Iterators and Enumerations with further elements are coerced to true.
link:../test/semantics/TheGroovyTruthTest.groovy[]
Maps
Non-empty Maps are evaluated to true.
link:../test/semantics/TheGroovyTruthTest.groovy[]
Strings
Non-empty Strings, GStrings and CharSequences are coerced to true.
link:../test/semantics/TheGroovyTruthTest.groovy[]
Numbers
Non-zero numbers are true.
link:../test/semantics/TheGroovyTruthTest.groovy[]
Object References
Non-null object references are coerced to true.
link:../test/semantics/TheGroovyTruthTest.groovy[]
Customizing the truth with asBoolean() methods
In order to customize whether groovy evaluates your object to true or false implement the asBoolean() method:
link:../test/semantics/TheGroovyTruthTest.groovy[]
Groovy will call this method to coerce your object to a boolean value, e.g.:
link:../test/semantics/TheGroovyTruthTest.groovy[]
Typing
Optional typing
Optional typing is the idea that a program can work even if you don’t put an explicit type on a variable. Being a dynamic
language, Groovy naturally implements that feature, for example when you declare a variable:
link:../test/typing/OptionalTypingTest.groovy[]
-
foois declared using an explicit type,String -
we can call the
toUpperCasemethod on aString
Groovy will let you write this instead:
link:../test/typing/OptionalTypingTest.groovy[]
-
foois declared usingdef -
we can still call the
toUpperCasemethod, because the type ofaStringis resolved at runtime
So it doesn’t matter that you use an explicit type here. It is in particular interesting when you combine this feature
with static type checking, because the type checker performs type inference.
Likewise, Groovy doesn’t make it mandatory to declare the types of a parameter in a method:
link:../test/typing/OptionalTypingTest.groovy[]
can be rewritten using def as both return type and parameter types, in order to take advantage of duck typing, as
illustrated in this example:
link:../test/typing/OptionalTypingTest.groovy[]
-
both the return type and the parameter types use
def -
it makes it possible to use the method with
String -
but also with
intsince theplusmethod is defined
|
Tip |
Using the def keyword here is recommended to describe the intent of a method which is supposed to work on anytype, but technically, we could use Object instead and the result would be the same: def is, in Groovy, strictlyequivalent to using Object.
|
Eventually, the type can be removed altogether from both the return type and the descriptor. But if you want to remove
it from the return type, you then need to add an explicit modifier for the method, so that the compiler can make a difference
between a method declaration and a method call, like illustrated in this example:
link:../test/typing/OptionalTypingTest.groovy[]
-
if we want to omit the return type, an explicit modifier has to be set.
-
it is still possible to use the method with
String -
and also with
int
|
Tip |
Omitting types is in general considered a bad practice in method parameters or method return types for public APIs. While using def in a local variable is not really a problem because the visibility of the variable is limited to themethod itself, while set on a method parameter, def will be converted to Object in the method signature, making itdifficult for users to know which is the expected type of the arguments. This means that you should limit this to cases where you are explicitly relying on duck typing. |
Static type checking
By default, Groovy performs minimal type checking at compile time. Since it is primarily a dynamic language,
most checks that a static compiler would normally do aren’t possible at compile time. A method added via runtime
metaprogramming might alter a class or object’s runtime behavior. Let’s illustrate why in the
following example:
link:../test/typing/TypeCheckingTest.groovy[]
-
the
Personclass only defines two properties,firstNameandlastName -
we can create an instance of Person
-
and call a method named
formattedName
It is quite common in dynamic languages for code such as the above example not to throw any error. How can this be?
In Java, this would typically fail at compile time. However, in Groovy, it will not fail at compile time, and if coded
correctly, will also not fail at runtime. In fact, to make this work at runtime, one possibility is to rely on
runtime metaprogramming. So just adding this line after the declaration of the Person class is enough:
link:../test/typing/TypeCheckingTest.groovy[]
This means that in general, in Groovy, you can’t make any assumption about the type of an object beyond its declaration
type, and even if you know it, you can’t determine at compile time what method will be called, or which property will
be retrieved. It has a lot of interest, going from writing DSLs to testing, which is discussed in other sections of this
manual.
However, if your program doesn’t rely on dynamic features and that you come from the static world (in particular, from
a Java mindset), not catching such «errors» at compile time can be surprising. As we have seen in the previous example,
the compiler cannot be sure this is an error. To make it aware that it is, you have to explicitly instruct the compiler
that you are switching to a type checked mode. This can be done by annotating a class or a method with @groovy.transform.TypeChecked.
When type checking is activated, the compiler performs much more work:
-
type inference is activated, meaning that even if you use
defon a local variable for example, the type checker will be
able to infer the type of the variable from the assignments -
method calls are resolved at compile time, meaning that if a method is not declared on a class, the compiler will throw an error
-
in general, all the compile time errors that you are used to find in a static language will appear: method not found, property not found,
incompatible types for method calls, number precision errors, …
In this section, we will describe the behavior of the type checker in various situations and explain the limits of using
@TypeChecked on your code.
The @TypeChecked annotation
Activating type checking at compile time
The groovy.transform.TypeChecked annotation enables type checking. It can be placed on a class:
link:../test/typing/TypeCheckingTest.groovy[]
Or on a method:
link:../test/typing/TypeCheckingTest.groovy[]
In the first case, all methods, properties, fields, inner classes, … of the annotated class will be type checked, whereas
in the second case, only the method and potential closures or anonymous inner classes that it contains will be type checked.
Skipping sections
The scope of type checking can be restricted. For example, if a class is type checked, you can instruct the type checker
to skip a method by annotating it with @TypeChecked(TypeCheckingMode.SKIP):
link:../test/typing/TypeCheckingTest.groovy[]
-
the
GreetingServiceclass is marked as type checked -
so the
greetingmethod is automatically type checked -
but
doGreetis marked withSKIP -
the type checker doesn’t complain about missing properties here
In the previous example, SentenceBuilder relies on dynamic code. There’s no real Hello method or property, so the
type checker would normally complain and compilation would fail. Since the method that uses the builder is marked with
TypeCheckingMode.SKIP, type checking is skipped for this method, so the code will compile, even if the rest of the
class is type checked.
The following sections describe the semantics of type checking in Groovy.
Type checking assignments
An object o of type A can be assigned to a variable of type T if and only if:
-
TequalsAlink:../test/typing/TypeCheckingTest.groovy[]
-
or
Tis one ofString,boolean,BooleanorClasslink:../test/typing/TypeCheckingTest.groovy[]
-
or
ois null andTis not a primitive typelink:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[]
-
or
Tis an array andAis an array and the component type ofAis assignable to the component type ofTlink:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[]
-
or
Tis an array andAis a collection or stream and the component type ofAis assignable to the component type ofTlink:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[]
-
or
Tis a superclass ofAlink:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[]
-
or
Tis an interface implemented byAlink:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[]
-
or
TorAare a primitive type and their boxed types are assignablelink:../test/typing/TypeCheckingTest.groovy[]
-
or
Textendsgroovy.lang.ClosureandAis a SAM-type (single abstract method type)link:../test/typing/TypeCheckingTest.groovy[]
-
or
TandAderive fromjava.lang.Numberand conform to the following table
Table 3. Number types (java.lang.XXX)
| T | A | Examples |
|---|---|---|
|
Double |
Any but BigDecimal or BigInteger |
link:../test/typing/TypeCheckingTest.groovy[] |
|
Float |
Any type but BigDecimal, BigInteger or Double |
link:../test/typing/TypeCheckingTest.groovy[] |
|
Long |
Any type but BigDecimal, BigInteger, Double or Float |
link:../test/typing/TypeCheckingTest.groovy[] |
|
Integer |
Any type but BigDecimal, BigInteger, Double, Float or Long |
link:../test/typing/TypeCheckingTest.groovy[] |
|
Short |
Any type but BigDecimal, BigInteger, Double, Float, Long or Integer |
link:../test/typing/TypeCheckingTest.groovy[] |
|
Byte |
Byte |
link:../test/typing/TypeCheckingTest.groovy[] |
List and map constructors
In addition to the assignment rules above, if an assignment is deemed invalid, in type checked mode, a list literal or a map literal A can be assigned
to a variable of type T if:
-
the assignment is a variable declaration and
Ais a list literal andThas a constructor whose parameters match the types of the elements in the list literal -
the assignment is a variable declaration and
Ais a map literal andThas a no-arg constructor and a property for each of the map keys
For example, instead of writing:
link:../test/typing/TypeCheckingTest.groovy[]
You can use a «list constructor»:
link:../test/typing/TypeCheckingTest.groovy[]
or a «map constructor»:
link:../test/typing/TypeCheckingTest.groovy[]
If you use a map constructor, additional checks are done on the keys of the map to check if a property of the same name
is defined. For example, the following will fail at compile time:
link:../test/typing/TypeCheckingTest.groovy[]
-
The type checker will throw an error
No such property: age for class: Personat compile time
Method resolution
In type checked mode, methods are resolved at compile time. Resolution works by name and arguments. The return type is
irrelevant to method selection. Types of arguments are matched against the types of the parameters following those rules:
An argument o of type A can be used for a parameter of type T if and only if:
-
TequalsAlink:../test/typing/TypeCheckingTest.groovy[]
-
or
Tis aStringandAis aGStringlink:../test/typing/TypeCheckingTest.groovy[]
-
or
ois null andTis not a primitive typelink:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[]
-
or
Tis an array andAis an array and the component type ofAis assignable to the component type ofTlink:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[]
-
or
Tis a superclass ofAlink:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[]
-
or
Tis an interface implemented byAlink:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[]
-
or
TorAare a primitive type and their boxed types are assignablelink:../test/typing/TypeCheckingTest.groovy[]
-
or
Textendsgroovy.lang.ClosureandAis a SAM-type (single abstract method type)link:../test/typing/TypeCheckingTest.groovy[]
-
or
TandAderive fromjava.lang.Numberand conform to the same rules as assignment of numbers
If a method with the appropriate name and arguments is not found at compile time, an error is thrown. The difference with «normal» Groovy is
illustrated in the following example:
link:../test/typing/TypeCheckingTest.groovy[]
-
printLineis an error, but since we’re in a dynamic mode, the error is not caught at compile time
The example above shows a class that Groovy will be able to compile. However, if you try to create an instance of MyService and call the
doSomething method, then it will fail at runtime, because printLine doesn’t exist. Of course, we already showed how Groovy could make
this a perfectly valid call, for example by catching MethodMissingException or implementing a custom metaclass, but if you know you’re
not in such a case, @TypeChecked comes handy:
link:../test/typing/TypeCheckingTest.groovy[]
-
printLineis this time a compile-time error
Just adding @TypeChecked will trigger compile time method resolution. The type checker will try to find a method printLine accepting
a String on the MyService class, but cannot find one. It will fail compilation with the following message:
Cannot find matching method MyService#printLine(java.lang.String)
|
Important |
It is important to understand the logic behind the type checker: it is a compile-time check, so by definition, the type checker is not aware of any kind of runtime metaprogramming that you do. This means that code which is perfectly valid without @TypeChecked willnot compile anymore if you activate type checking. This is in particular true if you think of duck typing: |
link:../test/typing/TypeCheckingTest.groovy[]
-
we define a
Duckclass which defines aquackmethod -
we define another
QuackingBirdclass which also defines aquackmethod -
quackeris loosely typed, so since the method is@TypeChecked, we will obtain a compile-time error -
even if in non type-checked Groovy, this would have passed
There are possible workarounds, like introducing an interface, but basically, by activating type checking, you gain type safety
but you loose some features of the language. Hopefully, Groovy introduces some features like flow typing to reduce the gap between
type-checked and non type-checked Groovy.
Type inference
Principles
When code is annotated with @TypeChecked, the compiler performs type inference. It doesn’t simply rely on static types, but also uses various
techniques to infer the types of variables, return types, literals, … so that the code remains as clean as possible even if you activate the
type checker.
The simplest example is inferring the type of a variable:
link:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[]
-
a variable is declared using the
defkeyword -
calling
toUpperCaseis allowed by the type checker -
calling
upperwill fail at compile time
The reason the call to toUpperCase works is because the type of message was inferred as being a String.
Variables vs fields in type inference
It is worth noting that although the compiler performs type inference on local variables, it does not perform any kind
of type inference on fields, always falling back to the declared type of a field. To illustrate this, let’s take a
look at this example:
link:../test/typing/TypeCheckingTest.groovy[]
-
someUntypedFieldusesdefas a declaration type -
someTypedFieldusesStringas a declaration type -
we can assign anything to
someUntypedField -
yet calling
toUpperCasefails at compile time because the field is not typed properly -
we can assign a
Stringto a field of typeString -
and this time
toUpperCaseis allowed -
if we assign a
Stringto a local variable -
then calling
toUpperCaseis allowed on the local variable
Why such a difference? The reason is thread safety. At compile time, we can’t make any guarantee about the type of
a field. Any thread can access any field at any time and between the moment a field is assigned a variable of some
type in a method and the time is used the line after, another thread may have changed the contents of the field. This
is not the case for local variables: we know if they «escape» or not, so we can make sure that the type of a variable is
constant (or not) over time. Note that even if a field is final, the JVM makes no guarantee about it, so the type checker
doesn’t behave differently if a field is final or not.
|
Tip |
This is one of the reasons why we recommend to use typed fields. While using def for local variables is perfectlyfine thanks to type inference, this is not the case for fields, which also belong to the public API of a class, hence the type is important. |
Collection literal type inference
Groovy provides a syntax for various type literals. There are three native collection literals in Groovy:
-
lists, using the
[]literal -
maps, using the
[:]literal -
ranges, using
from..to(inclusive),from..<to(right exclusive),from<..to(left exclusive) andfrom<..<to(full exclusive)
The inferred type of a literal depends on the elements of the literal, as illustrated in the following table:
| Literal | Inferred type |
|---|---|
link:../test/typing/TypeCheckingTest.groovy[] |
|
link:../test/typing/TypeCheckingTest.groovy[] |
|
link:../test/typing/TypeCheckingTest.groovy[] |
|
link:../test/typing/TypeCheckingTest.groovy[] |
|
link:../test/typing/TypeCheckingTest.groovy[] |
|
link:../test/typing/TypeCheckingTest.groovy[] |
|
link:../test/typing/TypeCheckingTest.groovy[] |
|
link:../test/typing/TypeCheckingTest.groovy[] |
|
As you can see, with the noticeable exception of the IntRange, the inferred type makes use of generics types to describe
the contents of a collection. In case the collection contains elements of different types, the type checker still performs
type inference of the components, but uses the notion of least upper bound.
Least upper bound
In Groovy, the least upper bound of two types A and B is defined as a type which:
-
superclass corresponds to the common super class of
AandB -
interfaces correspond to the interfaces implemented by both
AandB -
if
AorBis a primitive type and thatAisn’t equal toB, the least upper bound ofAandBis the least
upper bound of their wrapper types
If A and B only have one (1) interface in common and that their common superclass is Object, then the LUB of both
is the common interface.
The least upper bound represents the minimal type to which both A and B can be assigned. So for example, if A and B
are both String, then the LUB (least upper bound) of both is also String.
link:../test/typing/TypeCheckingTest.groovy[]
-
the LUB of
StringandStringisString -
the LUB of
ArrayListandLinkedListis their common super type,AbstractList -
the LUB of
ArrayListandListis their only common interface,List -
the LUB of two identical interfaces is the interface itself
-
the LUB of
Bottom1andBottom2is their superclassTop -
the LUB of two types which have nothing in common is
Object
In those examples, the LUB is always representable as a normal, JVM supported, type. But Groovy internally represents the LUB
as a type which can be more complex, and that you wouldn’t be able to use to define a variable for example. To illustrate this,
let’s continue with this example:
link:../test/typing/TypeCheckingTest.groovy[]
What is the least upper bound of Bottom and SerializableFooImpl? They don’t have a common super class (apart from Object),
but they do share 2 interfaces (Serializable and Foo), so their least upper bound is a type which represents the union of
two interfaces (Serializable and Foo). This type cannot be defined in the source code, yet Groovy knows about it.
In the context of collection type inference (and generic type inference in general), this becomes handy, because the type of the
components is inferred as the least upper bound. We can illustrate why this is important in the following example:
link:../test/typing/TypeCheckingTest.groovy[]
-
the
Greeterinterface defines a single method,greet -
the
Saluteinterface defines a single method,salute -
class
Aimplements bothGreeterandSalutebut there’s no explicit interface extending both -
same for
B -
but
Bdefines an additionalexitmethod -
the type of
listis inferred as «list of the LUB ofAand `B`» -
so it is possible to call
greetwhich is defined on bothAandBthrough theGreeterinterface -
and it is possible to call
salutewhich is defined on bothAandBthrough theSaluteinterface -
yet calling
exitis a compile time error because it doesn’t belong to the LUB ofAandB(only defined inB)
The error message will look like:
[Static type checking] - Cannot find matching method Greeter or Salute#exit()
which indicates that the exit method is neither defines on Greeter nor Salute, which are the two interfaces defined
in the least upper bound of A and B.
instanceof inference
In normal, non type checked, Groovy, you can write things like:
link:../test/typing/TypeCheckingTest.groovy[]
-
guard the method call with an
instanceofcheck -
make the call
The method call works because of dynamic dispatch (the method is selected at runtime). The equivalent code in Java would
require to cast o to a Greeter before calling the greeting method, because methods are selected at compile time:
link:../test/typing/TypeCheckingTest.groovy[]
However, in Groovy, even if you add @TypeChecked (and thus activate type checking) on the doSomething method, the
cast is not necessary. The compiler embeds instanceof inference that makes the cast optional.
Flow typing
Flow typing is an important concept of Groovy in type checked mode and an extension of type inference. The idea is that
the compiler is capable of inferring the type of variables in the flow of the code, not just at initialization:
link:../test/typing/TypeCheckingTest.groovy[]
-
first,
ois declared usingdefand assigned aString -
the compiler inferred that
ois aString, so callingtoUpperCaseis allowed -
ois reassigned with adouble -
calling
Math.sqrtpasses compilation because the compiler knows that at this point,ois adouble
So the type checker is aware of the fact that the concrete type of a variable is different over time. In particular,
if you replace the last assignment with:
link:../test/typing/TypeCheckingTest.groovy[]
The type checker will now fail at compile time, because it knows that o is a double when toUpperCase is called,
so it’s a type error.
It is important to understand that it is not the fact of declaring a variable with def that triggers type inference.
Flow typing works for any variable of any type. Declaring a variable with an explicit type only constrains what you
can assign to the variable:
link:../test/typing/TypeCheckingTest.groovy[]
-
listis declared as an uncheckedListand assigned a list literal of `String`s -
this line passes compilation because of flow typing: the type checker knows that
listis at this point aList<String> -
but you can’t assign a
Stringto aListso this is a type checking error
You can also note that even if the variable is declared without generics information, the type checker knows what is
the component type. Therefore, such code would fail compilation:
link:../test/typing/TypeCheckingTest.groovy[]
-
listis inferred asList<String> -
so adding an
intto aList<String>is a compile-time error
Fixing this requires adding an explicit generic type to the declaration:
link:../test/typing/TypeCheckingTest.groovy[]
-
listdeclared asList<? extends Serializable>and initialized with an empty list -
elements added to the list conform to the declaration type of the list
-
so adding an
intto aList<? extends Serializable>is allowed
Flow typing has been introduced to reduce the difference in semantics between classic and static Groovy. In particular,
consider the behavior of this code in Java:
link:../test/typing/TypeCheckingJavaTest.java[] link:../test/typing/TypeCheckingJavaTest.java[]
-
ois declared as anObjectand assigned aString -
we call the
computemethod witho -
and print the result
In Java, this code will output Nope, because method selection is done at compile time and based on the declared types.
So even if o is a String at runtime, it is still the Object version which is called, because o has been declared
as an Object. To be short, in Java, declared types are most important, be it variable types, parameter types or return
types.
In Groovy, we could write:
link:../test/typing/TypeCheckingTest.groovy[]
But this time, it will return 6, because the method which is chosen at runtime, based on the actual
argument types. So at runtime, o is a String so the String variant is used. Note that this behavior has nothing
to do with type checking, it’s the way Groovy works in general: dynamic dispatch.
In type checked Groovy, we want to make sure the type checker selects the same method at compile time, that the runtime
would choose. It is not possible in general, due to the semantics of the language, but we can make things better with flow
typing. With flow typing, o is inferred as a String when the compute method is called, so the version which takes
a String and returns an int is chosen. This means that we can infer the return type of the method to be an int, and
not a String. This is important for subsequent calls and type safety.
So in type checked Groovy, flow typing is a very important concept, which also implies that if @TypeChecked is applied,
methods are selected based on the inferred types of the arguments, not on the declared types. This doesn’t ensure 100%
type safety, because the type checker may select a wrong method, but it ensures the closest semantics to dynamic Groovy.
Advanced type inference
A combination of flow typing and least upper bound inference is used to perform
advanced type inference and ensure type safety in multiple situations. In particular, program control structures are
likely to alter the inferred type of a variable:
link:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[]
-
if
someConditionis true,ois assigned aTop -
if
someConditionis false,ois assigned aBottom -
calling
methodFromTopis safe -
but calling
methodFromBottomis not, so it’s a compile time error
When the type checker visits an if/else control structure, it checks all variables which are assigned in if/else branches
and computes the least upper bound of all assignments. This type is the type of the inferred variable
after the if/else block, so in this example, o is assigned a Top in the if branch and a Bottom in the else
branch. The LUB of those is a Top, so after the conditional branches, the compiler infers o as being
a Top. Calling methodFromTop will therefore be allowed, but not methodFromBottom.
The same reasoning exists with closures and in particular closure shared variables. A closure shared variable is a variable
which is defined outside of a closure, but used inside a closure, as in this example:
link:../test/typing/TypeCheckingTest.groovy[]
-
a variable named
textis declared -
textis used from inside a closure. It is a closure shared variable.
Groovy allows developers to use those variables without requiring them to be final. This means that a closure shared
variable can be reassigned inside a closure:
link:../test/typing/TypeCheckingTest.groovy[]
The problem is that a closure is an independent block of code that can be executed (or not) at any time. In particular,
doSomething may be asynchronous, for example. This means that the body of a closure doesn’t belong to the main control
flow. For that reason, the type checker also computes, for each closure shared variable, the LUB of all
assignments of the variable, and will use that LUB as the inferred type outside of the scope of the closure, like in
this example:
link:../test/typing/TypeCheckingTest.groovy[]
-
a closure-shared variable is first assigned a
Top -
inside the closure, it is assigned a
Bottom -
methodFromTopis allowed -
methodFromBottomis a compilation error
Here, it is clear that when methodFromBottom is called, there’s no guarantee, at compile-time or runtime that the
type of o will effectively be a Bottom. There are chances that it will be, but we can’t make sure, because it’s
asynchronous. So the type checker will only allow calls on the least upper bound, which is here a Top.
Closures and type inference
The type checker performs special inference on closures, resulting on additional checks on one side and improved fluency
on the other side.
Return type inference
The first thing that the type checker is capable of doing is inferring the return type of a closure. This is simply
illustrated in the following example:
link:../test/typing/TypeCheckingTest.groovy[]
-
a closure is defined, and it returns a string (more precisely a
GString) -
we call the closure and assign the result to a variable
-
the type checker inferred that the closure would return a string, so calling
length()is allowed
As you can see, unlike a method which declares its return type explicitly, there’s no need to declare the return type
of a closure: its type is inferred from the body of the closure.
Closures vs methods
It’s worth noting that return type inference is only applicable to closures. While the type checker could do the
same on a method, it is in practice not desirable: in general, methods can be overridden and it is not statically
possible to make sure that the method which is called is not an overridden version. So flow typing would actually
think that a method returns something, while in reality, it could return something else, like illustrated in the
following example:
link:../test/typing/TypeCheckingTest.groovy[]
-
class
Adefines a methodcomputewhich effectively returns aString -
this will fail compilation because the return type of
computeisdef(akaObject) -
class
BextendsAand redefinescompute, this type returning anint
As you can see, if the type checker relied on the inferred return type of a method, with flow typing,
the type checker could determine that it is ok to call toUpperCase. It is in fact an error, because a subclass can
override compute and return a different object. Here, B#compute returns an int, so someone calling computeFully
on an instance of B would see a runtime error. The compiler prevents this from happening by using the declared return
type of methods instead of the inferred return type.
For consistency, this behavior is the same for every method, even if they are static or final.
Parameter type inference
In addition to the return type, it is possible for a closure to infer its parameter types from the context. There are
two ways for the compiler to infer the parameter types:
-
through implicit SAM type coercion
-
through API metadata
To illustrate this, lets start with an example that will fail compilation due to the inability for the type checker
to infer the parameter types:
link:../test/typing/TypeCheckingTest.groovy[]
-
the
inviteIfmethod accepts aPersonand aClosure -
we call it with a
Personand aClosure -
yet
itis not statically known as being aPersonand compilation fails
In this example, the closure body contains it.age. With dynamic, not type checked code, this would work, because the
type of it would be a Person at runtime. Unfortunately, at compile-time, there’s no way to know what is the type
of it, just by reading the signature of inviteIf.
Explicit closure parameters
To be short, the type checker doesn’t have enough contextual information on the inviteIf method to determine statically
the type of it. This means that the method call needs to be rewritten like this:
link:../test/typing/TypeCheckingTest.groovy[]
-
the type of
itneeds to be declared explicitly
By explicitly declaring the type of the it variable, you can work around the problem and make this code statically
checked.
Parameters inferred from single-abstract method types
For an API or framework designer, there are two ways to make this more elegant for users, so that they don’t have to
declare an explicit type for the closure parameters. The first one, and easiest, is to replace the closure with a
SAM type:
link:../test/typing/TypeCheckingTest.groovy[]
-
declare a
SAMinterface with anapplymethod -
inviteIfnow uses aPredicate<Person>instead of aClosure<Boolean> -
there’s no need to declare the type of the
itvariable anymore -
it.agecompiles properly, the type ofitis inferred from thePredicate#applymethod signature
|
Tip |
By using this technique, we leverage the automatic coercion of closures to SAM types feature of Groovy. Whether you should use a SAM type or a Closure really depends on what you need to do. In a lot of cases, using a SAM interface is enough, especially if you consider functional interfaces as they are found in Java 8. However, closures provide features that are not accessible to functional interfaces. In particular, closures can have a delegate, and owner and can be manipulated as objects (for example, cloned, serialized, curried, …) before being called. They can also support multiple signatures (polymorphism). So if you need that kind of manipulation, it is preferable to switch to the most advanced type inference annotations which are described below. |
The original issue that needs to be solved when it comes to closure parameter type inference, that is to say, statically
determining the types of the arguments of a closure without having to have them explicitly declared, is that the Groovy
type system inherits the Java type system, which is insufficient to describe the types of the arguments.
The @ClosureParams annotation
Groovy provides an annotation, @ClosureParams which is aimed at completing type information. This annotation is primarily
aimed at framework and API developers who want to extend the capabilities of the type checker by providing type inference
metadata. This is important if your library makes use of closures and that you want the maximum level of tooling support
too.
Let’s illustrate this by fixing the original example, introducing the @ClosureParams annotation:
link:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[] link:../test/typing/TypeCheckingTest.groovy[]
-
the closure parameter is annotated with
@ClosureParams -
it’s not necessary to use an explicit type for
it, which is inferred
The @ClosureParams annotation minimally accepts one argument, which is named a type hint. A type hint is a class which
is responsible for completing type information at compile time for the closure. In this example, the type hint being used
is groovy.transform.stc.FirstParam which indicated to the type checker that the closure will accept one parameter
whose type is the type of the first parameter of the method. In this case, the first parameter of the method is Person,
so it indicates to the type checker that the first parameter of the closure is in fact a Person.
A second optional argument is named options. Its semantics depend on the type hint class. Groovy comes with
various bundled type hints, illustrated in the table below:
Table 4. Predefined type hints
| Type hint | Polymorphic? | Description and examples |
|---|---|---|
|
|
No |
The first (resp. second, third) parameter type of the method link:../test/typing/TypeCheckingHintsTest.groovy[] link:../test/typing/TypeCheckingHintsTest.groovy[] link:../test/typing/TypeCheckingHintsTest.groovy[] |
|
|
No |
The first generic type of the first (resp. second, third) parameter of the method link:../test/typing/TypeCheckingHintsTest.groovy[] Variants for |
|
|
No |
A type hint for which the type of closure parameters comes from the options string. link:../test/typing/TypeCheckingHintsTest.groovy[] This type hint supports a single signature and each of the parameter is specified as a value of the options array |
|
|
Yes |
A dedicated type hint for closures that either work on a link:../test/typing/TypeCheckingHintsTest.groovy[] This type hint requires that the first argument is a |
|
|
Yes |
Infers closure parameter types from the abstract method of some type. A signature is inferred for each abstract method. link:../test/typing/TypeCheckingHintsTest.groovy[] If there are multiple signatures like in the example above, the type checker will only be able to infer the types of |
|
|
Yes |
Infers the closure parameter types from the A single signature for a closure accepting a link:../test/typing/TypeCheckingHintsTest.groovy[] A polymorphic closure, accepting either a link:../test/typing/TypeCheckingHintsTest.groovy[] A polymorphic closure, accepting either a link:../test/typing/TypeCheckingHintsTest.groovy[] |
|
Tip |
Even though you use FirstParam, SecondParam or ThirdParam as a type hint, it doesn’t strictly mean that theargument which will be passed to the closure will be the first (resp. second, third) argument of the method call. It only means that the type of the parameter of the closure will be the same as the type of the first (resp. second, third) argument of the method call. |
In short, the lack of the @ClosureParams annotation on a method accepting a Closure will not fail compilation. If
present (and it can be present in Java sources as well as Groovy sources), then the type checker has more information
and can perform additional type inference. This makes this feature particularly interesting for framework developers.
A third optional argument is named conflictResolutionStrategy. It can reference a class (extending from
ClosureSignatureConflictResolver) that can perform additional resolution of parameter types if more than
one are found after initial inference calculations are complete. Groovy comes with a default type resolver
which does nothing, and another which selects the first signature if multiple are found. The resolver is
only invoked if more than one signature is found and is by design a post processor. Any statements which need
injected typing information must pass one of the parameter signatures determined through type hints. The
resolver then picks among the returned candidate signatures.
@DelegatesTo
The @DelegatesTo annotation is used by the type checker to infer the type of the delegate. It allows the API designer
to instruct the compiler what is the type of the delegate and the delegation strategy. The @DelegatesTo annotation is
discussed in a specific section.
Static compilation
Dynamic vs static
In the type checking section, we have seen that Groovy provides optional type checking thanks to the
@TypeChecked annotation. The type checker runs at compile time and performs a static analysis of dynamic code. The
program will behave exactly the same whether type checking has been enabled or not. This means that the @TypeChecked
annotation is neutral in regard to the semantics of a program. Even though it may be necessary to add type information
in the sources so that the program is considered type safe, in the end, the semantics of the program are the same.
While this may sound fine, there is actually one issue with this: type checking of dynamic code, done at compile time, is
by definition only correct if no runtime specific behavior occurs. For example, the following program passes type checking:
link:../test/typing/StaticCompilationIntroTest.groovy[]
There are two compute methods. One accepts a String and returns an int, the other accepts an int and returns
a String. If you compile this, it is considered type safe: the inner compute('foobar') call will return an int,
and calling compute on this int will in turn return a String.
Now, before calling test(), consider adding the following line:
link:../test/typing/StaticCompilationIntroTest.groovy[]
Using runtime metaprogramming, we’re actually modifying the behavior of the compute(String) method, so that instead of
returning the length of the provided argument, it will return a Date. If you execute the program, it will fail at
runtime. Since this line can be added from anywhere, in any thread, there’s absolutely no way for the type checker to
statically make sure that no such thing happens. In short, the type checker is vulnerable to monkey patching. This is
just one example, but this illustrates the concept that doing static analysis of a dynamic program is inherently wrong.
The Groovy language provides an alternative annotation to @TypeChecked which will actually make sure that the methods
which are inferred as being called will effectively be called at runtime. This annotation turns the Groovy compiler
into a static compiler, where all method calls are resolved at compile time and the generated bytecode makes sure
that this happens: the annotation is @groovy.transform.CompileStatic.
The @CompileStatic annotation
The @CompileStatic annotation can be added anywhere the @TypeChecked annotation can be used, that is to say on
a class or a method. It is not necessary to add both @TypeChecked and @CompileStatic, as @CompileStatic performs
everything @TypeChecked does, but in addition triggers static compilation.
Let’s take the example which failed, but this time let’s replace the @TypeChecked annotation
with @CompileStatic:
link:../test/typing/StaticCompilationIntroTest.groovy[] link:../test/typing/StaticCompilationIntroTest.groovy[] test()
This is the only difference. If we execute this program, this time, there is no runtime error. The test method
became immune to monkey patching, because the compute methods which are called in its body are linked at compile
time, so even if the metaclass of Computer changes, the program still behaves as expected by the type checker.
Key benefits
There are several benefits of using @CompileStatic on your code:
-
type safety
-
immunity to monkey patching
-
performance improvements
The performance improvements depend on the kind of program you are executing. If it is I/O bound, the difference between
statically compiled code and dynamic code is barely noticeable. On highly CPU intensive code, since the bytecode which
is generated is very close, if not equal, to the one that Java would produce for an equivalent program, the performance
is greatly improved.
|
Tip |
Using the invokedynamic version of Groovy, which is accessible to people using JDK 7 and above, the performance of the dynamic code should be very close to the performance of statically compiled code. Sometimes, it can even be faster! There is only one way to determine which version you should choose: measuring. The reason is that depending on your program and the JVM that you use, the performance can be significantly different. In particular, the invokedynamic version of Groovy is very sensitive to the JVM version in use. |
Обработка исключений требуется на любом языке программирования для обработки ошибок времени выполнения, чтобы можно было поддерживать нормальный поток приложения.
Исключение обычно нарушает нормальный поток приложения, поэтому мы должны использовать обработку исключений в нашем приложении.
Исключения широко подразделяются на следующие категории –
-
Проверенное исключение – классы, которые расширяют класс Throwable, за исключением RuntimeException и Error, известны как проверенные исключения, например ,IOException, SQLException и т. Д. Проверенные исключения проверяются во время компиляции.
Проверенное исключение – классы, которые расширяют класс Throwable, за исключением RuntimeException и Error, известны как проверенные исключения, например ,IOException, SQLException и т. Д. Проверенные исключения проверяются во время компиляции.
Одним классическим случаем является FileNotFoundException. Предположим, у вас есть следующий код в вашем приложении, который читает из файла на E-диске.
class Example { static void main(String[] args) { File file = new File("E://file.txt"); FileReader fr = new FileReader(file); } }
если файл (file.txt) отсутствует на диске E, возникает следующее исключение.
Caught: java.io.FileNotFoundException: E: file.txt (система не может найти указанный файл).
java.io.FileNotFoundException: E: file.txt (система не может найти указанный файл).
-
Непроверенное исключение – классы, которые расширяют RuntimeException, называются непроверенными исключениями, например, ArithmeticException, NullPointerException, ArrayIndexOutOfBoundsException и т. Д. Непроверенные исключения не проверяются во время компиляции, а проверяются во время выполнения.
Непроверенное исключение – классы, которые расширяют RuntimeException, называются непроверенными исключениями, например, ArithmeticException, NullPointerException, ArrayIndexOutOfBoundsException и т. Д. Непроверенные исключения не проверяются во время компиляции, а проверяются во время выполнения.
Одним классическим случаем является исключение ArrayIndexOutOfBoundsException, которое возникает, когда вы пытаетесь получить доступ к индексу массива, который больше длины массива. Ниже приведен типичный пример ошибки такого рода.
class Example { static void main(String[] args) { def arr = new int[3]; arr[5] = 5; } }
Когда приведенный выше код будет выполнен, будет сгенерировано следующее исключение.
Пойман: java.lang.ArrayIndexOutOfBoundsException: 5
java.lang.ArrayIndexOutOfBoundsException: 5
-
Ошибка – ошибка необратима, например, OutOfMemoryError, VirtualMachineError, AssertionError и т. Д.
Ошибка – ошибка необратима, например, OutOfMemoryError, VirtualMachineError, AssertionError и т. Д.
Это ошибки, которые программа никогда не сможет исправить, и это приведет к ее аварийному завершению.
Следующая диаграмма показывает, как организована иерархия исключений в Groovy. Все это основано на иерархии, определенной в Java.
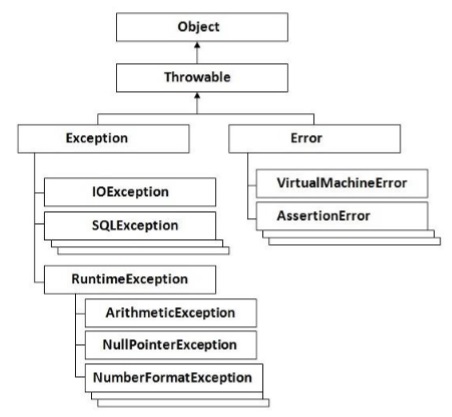
Ловить исключения
Метод перехватывает исключение, используя комбинацию ключевых слов try и catch . Вокруг кода помещается блок try / catch, который может генерировать исключение.
try { //Protected code } catch(ExceptionName e1) { //Catch block }
Весь ваш код, который может вызвать исключение, помещается в блок защищенного кода.
В блоке catch вы можете написать собственный код для обработки вашего исключения, чтобы приложение могло восстановиться после исключения.
Давайте рассмотрим пример аналогичного кода, который мы видели выше для доступа к массиву со значением индекса, превышающим размер массива. Но на этот раз давайте обернем наш код в блок try / catch.
Live Demo
class Example { static void main(String[] args) { try { def arr = new int[3]; arr[5] = 5; } catch(Exception ex) { println("Catching the exception"); } println("Let's move on after the exception"); } }
Когда мы запустим вышеуказанную программу, мы получим следующий результат –
Catching the exception Let's move on after the exception
Из приведенного выше кода мы оборачиваем неисправный код в блоке try. В блоке catch мы просто перехватываем наше исключение и выводим сообщение о том, что произошло исключение.
Многократные Пойманные Блоки
Можно иметь несколько блоков catch для обработки нескольких типов исключений. Для каждого блока catch, в зависимости от типа возникшего исключения, вы должны написать код для соответствующей обработки.
Давайте изменим приведенный выше код, чтобы он специально перехватывал исключение ArrayIndexOutOfBoundsException. Ниже приведен фрагмент кода.
Live Demo
class Example { static void main(String[] args) { try { def arr = new int[3]; arr[5] = 5; }catch(ArrayIndexOutOfBoundsException ex) { println("Catching the Array out of Bounds exception"); }catch(Exception ex) { println("Catching the exception"); } println("Let's move on after the exception"); } }
Когда мы запустим вышеуказанную программу, мы получим следующий результат –
Catching the Aray out of Bounds exception Let's move on after the exception
Из приведенного выше кода вы можете видеть, что блок перехвата ArrayIndexOutOfBoundsException перехватывается первым, потому что это означает критерии исключения.
Наконец-то блок
Блок finally следует за блоком try или блоком catch. Блок кода finally всегда выполняется независимо от возникновения исключения.
Использование блока finally позволяет запускать любые операторы типа очистки, которые вы хотите выполнить, независимо от того, что происходит в защищенном коде. Синтаксис этого блока приведен ниже.
try {
//Protected code
} catch(ExceptionType1 e1) {
//Catch block
} catch(ExceptionType2 e2) {
//Catch block
} catch(ExceptionType3 e3) {
//Catch block
} finally {
//The finally block always executes.
}
Давайте изменим наш код выше и добавим блок finally. Ниже приведен фрагмент кода.
class Example { static void main(String[] args) { try { def arr = new int[3]; arr[5] = 5; } catch(ArrayIndexOutOfBoundsException ex) { println("Catching the Array out of Bounds exception"); }catch(Exception ex) { println("Catching the exception"); } finally { println("The final block"); } println("Let's move on after the exception"); } }
Когда мы запустим вышеуказанную программу, мы получим следующий результат –
Catching the Array out of Bounds exception The final block Let's move on after the exception
Ниже приведены методы исключения, доступные в Groovy.
public String getMessage ()
Возвращает подробное сообщение об исключении, которое произошло. Это сообщение инициализируется в конструкторе Throwable.
public Throwable getCause ()
Возвращает причину исключения в виде объекта Throwable.
public String toString ()
Возвращает имя класса, объединенного с результатом getMessage ()
public void printStackTrace ()
Печатает результат toString () вместе с трассировкой стека в System.err, поток вывода ошибок.
public StackTraceElement [] getStackTrace ()
Возвращает массив, содержащий каждый элемент в трассировке стека. Элемент с индексом 0 представляет вершину стека вызовов, а последний элемент в массиве представляет метод в нижней части стека вызовов.
public Throwable fillInStackTrace ()
Заполняет трассировку стека этого объекта Throwable текущей трассировкой стека, добавляя к любой предыдущей информации в трассировке стека.
пример
Ниже приведен пример кода с использованием некоторых методов, приведенных выше:
Live Demo
class Example { static void main(String[] args) { try { def arr = new int[3]; arr[5] = 5; }catch(ArrayIndexOutOfBoundsException ex) { println(ex.toString()); println(ex.getMessage()); println(ex.getStackTrace()); } catch(Exception ex) { println("Catching the exception"); }finally { println("The final block"); } println("Let's move on after the exception"); } }
Когда мы запустим вышеуказанную программу, мы получим следующий результат –
Содержание
- Groovy — Exception Handling
- Groovy Fundamentals For Testers — Step By Step
- Groovy Programming Fundamentals for Java Developers
- Catching Exceptions
- Multiple Catch Blocks
- Finally Block
- public String getMessage()
- public Throwable getCause()
- public String toString()
- public void printStackTrace()
- public StackTraceElement [] getStackTrace()
- public Throwable fillInStackTrace()
- Example
- Semantics
- 1. Statements
- 1.1. Variable definition
- 1.2. Variable assignment
- 1.2.1. Multiple assignment
- 1.2.2. Overflow and Underflow
- 1.2.3. Object destructuring with multiple assignment
- 1.3. Control structures
- 1.3.1. Conditional structures
- 1.3.2. Looping structures
- 1.3.3. Exception handling
- 1.3.4. try / catch / finally
- 1.3.5. Multi-catch
- 1.3.6. ARM Try with resources
- 1.4. Power assertion
- 1.5. Labeled statements
- 2. Expressions
- 2.1. GPath expressions
- 2.1.1. Object navigation
- 2.1.2. Expression Deconstruction
- 2.1.3. GPath for XML navigation
- 3. Promotion and coercion
- 3.1. Number promotion
- 3.2. Closure to type coercion
- 3.2.1. Assigning a closure to a SAM type
- 3.2.2. Calling a method accepting a SAM type with a closure
- 3.2.3. Closure to arbitrary type coercion
- 3.3. Map to type coercion
- 3.4. String to enum coercion
- 3.5. Custom type coercion
- 3.6. Class literals vs variables and the as operator
- 4. Optionality
- 4.1. Optional parentheses
- 4.2. Optional semicolons
- 4.3. Optional return keyword
- 4.4. Optional public keyword
- 5. The Groovy Truth
- 5.1. Boolean expressions
- 5.2. Collections and Arrays
- 5.3. Matchers
- 5.4. Iterators and Enumerations
- 5.5. Maps
- 5.6. Strings
- 5.7. Numbers
- 5.8. Object References
- 5.9. Customizing the truth with asBoolean() methods
- 6. Typing
- 6.1. Optional typing
- 6.2. Static type checking
- 6.2.1. The @TypeChecked annotation
- 6.2.2. Type checking assignments
- 6.2.3. List and map constructors
- 6.2.4. Method resolution
- 6.2.5. Type inference
- 6.2.6. Closures and type inference
- 6.3. Static compilation
- 6.3.1. Dynamic vs static
- 6.3.2. The @CompileStatic annotation
- 6.3.3. Key benefits
- 7. Type checking extensions
- 7.1. Writing a type checking extension
- 7.1.1. Towards a smarter type checker
- 7.1.2. The extensions attribute
- 7.1.3. A DSL for type checking
- 7.1.4. Type checking extensions API
Groovy — Exception Handling

Groovy Fundamentals For Testers — Step By Step
52 Lectures 8 hours

Groovy Programming Fundamentals for Java Developers
49 Lectures 2.5 hours
Exception handling is required in any programming language to handle the runtime errors so that normal flow of the application can be maintained.
Exception normally disrupts the normal flow of the application, which is the reason why we need to use Exception handling in our application.
Exceptions are broadly classified into the following categories −
Checked Exception − The classes that extend Throwable class except RuntimeException and Error are known as checked exceptions e.g.IOException, SQLException etc. Checked exceptions are checked at compile-time.
One classical case is the FileNotFoundException. Suppose you had the following codein your application which reads from a file in E drive.
if the File (file.txt) is not there in the E drive then the following exception will be raised.
Caught: java.io.FileNotFoundException: E:file.txt (The system cannot find the file specified).
java.io.FileNotFoundException: E:file.txt (The system cannot find the file specified).
Unchecked Exception − The classes that extend RuntimeException are known as unchecked exceptions, e.g., ArithmeticException, NullPointerException, ArrayIndexOutOfBoundsException etc. Unchecked exceptions are not checked at compile-time rather they are checked at runtime.
One classical case is the ArrayIndexOutOfBoundsException which happens when you try to access an index of an array which is greater than the length of the array. Following is a typical example of this sort of mistake.
When the above code is executed the following exception will be raised.
Caught: java.lang.ArrayIndexOutOfBoundsException: 5
Error − Error is irrecoverable e.g. OutOfMemoryError, VirtualMachineError, AssertionError etc.
These are errors which the program can never recover from and will cause the program to crash.
The following diagram shows how the hierarchy of exceptions in Groovy is organized. It’s all based on the hierarchy defined in Java.

Catching Exceptions
A method catches an exception using a combination of the try and catch keywords. A try/catch block is placed around the code that might generate an exception.
All of your code which could raise an exception is placed in the Protected code block.
In the catch block, you can write custom code to handle your exception so that the application can recover from the exception.
Let’s look at an example of the similar code we saw above for accessing an array with an index value which is greater than the size of the array. But this time let’s wrap our code in a try/catch block.
When we run the above program, we will get the following result −
From the above code, we wrap out faulty code in the try block. In the catch block we are just catching our exception and outputting a message that an exception has occurred.
Multiple Catch Blocks
One can have multiple catch blocks to handle multiple types of exceptions. For each catch block, depending on the type of exception raised you would write code to handle it accordingly.
Let’s modify our above code to catch the ArrayIndexOutOfBoundsException specifically. Following is the code snippet.
When we run the above program, we will get the following result −
From the above code you can see that the ArrayIndexOutOfBoundsException catch block is caught first because it means the criteria of the exception.
Finally Block
The finally block follows a try block or a catch block. A finally block of code always executes, irrespective of occurrence of an Exception.
Using a finally block allows you to run any cleanup-type statements that you want to execute, no matter what happens in the protected code. The syntax for this block is given below.
Let’s modify our above code and add the finally block of code. Following is the code snippet.
When we run the above program, we will get the following result −
Following are the Exception methods available in Groovy −
public String getMessage()
Returns a detailed message about the exception that has occurred. This message is initialized in the Throwable constructor.
public Throwable getCause()
Returns the cause of the exception as represented by a Throwable object.
public String toString()
Returns the name of the class concatenated with the result of getMessage()
public void printStackTrace()
Prints the result of toString() along with the stack trace to System.err, the error output stream.
public StackTraceElement [] getStackTrace()
Returns an array containing each element on the stack trace. The element at index 0 represents the top of the call stack, and the last element in the array represents the method at the bottom of the call stack.
public Throwable fillInStackTrace()
Fills the stack trace of this Throwable object with the current stack trace, adding to any previous information in the stack trace.
Example
Following is the code example using some of the methods given above −
When we run the above program, we will get the following result −
Источник
Semantics
This chapter covers the semantics of the Groovy programming language.
1. Statements
1.1. Variable definition
Variables can be defined using either their type (like String ) or by using the keyword def (or var ) followed by a variable name:
def and var act as a type placeholder, i.e. a replacement for the type name, when you do not want to give an explicit type. It could be that you don’t care about the type at compile time or are relying on type inference (with Groovy’s static nature). It is mandatory for variable definitions to have a type or placeholder. If left out, the type name will be deemed to refer to an existing variable (presumably declared earlier). For scripts, undeclared variables are assumed to come from the Script binding. In other cases, you will get a missing property (dynamic Groovy) or compile time error (static Groovy). If you think of def and var as an alias of Object , you will understand in an instant.
Variable definitions can provide an initial value, in which case it’s like having a declaration and assignment (which we cover next) all in one.
Variable definition types can be refined by using generics, like in List names . To learn more about the generics support, please read the generics section.
1.2. Variable assignment
You can assign values to variables for later use. Try the following:
1.2.1. Multiple assignment
Groovy supports multiple assignment, i.e. where multiple variables can be assigned at once, e.g.:
You can provide types as part of the declaration if you wish:
As well as used when declaring variables it also applies to existing variables:
The syntax works for arrays as well as lists, as well as methods that return either of these:
1.2.2. Overflow and Underflow
If the left hand side has too many variables, excess ones are filled with null’s:
If the right hand side has too many variables, the extra ones are ignored:
1.2.3. Object destructuring with multiple assignment
In the section describing Groovy’s operators, the case of the subscript operator has been covered, explaining how you can override the getAt() / putAt() method.
With this technique, we can combine multiple assignments and the subscript operator methods to implement object destructuring.
Consider the following immutable Coordinates class, containing a pair of longitude and latitude doubles, and notice our implementation of the getAt() method:
Now let’s instantiate this class and destructure its longitude and latitude:
123
| we create an instance of the Coordinates class |
| then, we use a multiple assignment to get the individual longitude and latitude values |
| and we can finally assert their values. |
1.3. Control structures
1.3.1. Conditional structures
if / else
Groovy supports the usual if — else syntax from Java
Groovy also supports the normal Java «nested» if then else if syntax:
switch / case
The switch statement in Groovy is backwards compatible with Java code; so you can fall through cases sharing the same code for multiple matches.
One difference though is that the Groovy switch statement can handle any kind of switch value and different kinds of matching can be performed.
Switch supports the following kinds of comparisons:
Class case values match if the switch value is an instance of the class
Regular expression case values match if the toString() representation of the switch value matches the regex
Collection case values match if the switch value is contained in the collection. This also includes ranges (since they are Lists)
Closure case values match if the calling the closure returns a result which is true according to the Groovy truth
If none of the above are used then the case value matches if the case value equals the switch value
When using a closure case value, the default it parameter is actually the switch value (in our example, variable x ).
Groovy also supports switch expressions as shown in the following example:
1.3.2. Looping structures
Classic for loop
Groovy supports the standard Java / C for loop:
Enhanced classic Java-style for loop
The more elaborate form of Java’s classic for loop with comma-separate expressions is now supported. Example:
Multi-assignment in combination with for loop
Groovy has supported multi-assignment statements since Groovy 1.6:
These can now appear in for loops:
for in loop
The for loop in Groovy is much simpler and works with any kind of array, collection, Map, etc.
Groovy also supports the Java colon variation with colons: for (char c : text) <>
while loop
Groovy supports the usual while <…>loops like Java:
do/while loop
Java’s class do/while loop is now supported. Example:
1.3.3. Exception handling
Exception handling is the same as Java.
1.3.4. try / catch / finally
You can specify a complete try-catch-finally , a try-catch , or a try-finally set of blocks.
Braces are required around each block’s body.
We can put code within a ‘finally’ clause following a matching ‘try’ clause, so that regardless of whether the code in the ‘try’ clause throws an exception, the code in the finally clause will always execute:
1.3.5. Multi-catch
With the multi catch block (since Groovy 2.0), we’re able to define several exceptions to be catch and treated by the same catch block:
1.3.6. ARM Try with resources
Groovy often provides better alternatives to Java 7’s try -with-resources statement for Automatic Resource Management (ARM). That syntax is now supported for Java programmers migrating to Groovy and still wanting to use the old style:
Which yields the following output:
1.4. Power assertion
Unlike Java with which Groovy shares the assert keyword, the latter in Groovy behaves very differently. First of all, an assertion in Groovy is always executed, independently of the -ea flag of the JVM. It makes this a first class choice for unit tests. The notion of «power asserts» is directly related to how the Groovy assert behaves.
A power assertion is decomposed into 3 parts:
The result of the assertion is very different from what you would get in Java. If the assertion is true, then nothing happens. If the assertion is false, then it provides a visual representation of the value of each sub-expressions of the expression being asserted. For example:
Power asserts become very interesting when the expressions are more complex, like in the next example:
Which will print the value for each sub-expression:
In case you don’t want a pretty printed error message like above, you can fallback to a custom error message by changing the optional message part of the assertion, like in this example:
Which will print the following error message:
1.5. Labeled statements
Any statement can be associated with a label. Labels do not impact the semantics of the code and can be used to make the code easier to read like in the following example:
Despite not changing the semantics of the labelled statement, it is possible to use labels in the break instruction as a target for jump, as in the next example. However, even if this is allowed, this coding style is in general considered a bad practice:
It is important to understand that by default labels have no impact on the semantics of the code, however they belong to the abstract syntax tree (AST) so it is possible for an AST transformation to use that information to perform transformations over the code, hence leading to different semantics. This is in particular what the Spock Framework does to make testing easier.
2. Expressions
Expressions are the building blocks of Groovy programs that are used to reference existing values and execute code to create new ones.
Groovy supports many of the same kinds of expressions as Java, including:
the name of a variable, field, parameter, …
this , super , it
foo + bar , bar * baz
(Integer x, Integer y) → x + y
Groovy also has some of its own special expressions:
Abbreviated class literal (when not ambiguous)
literal list expressions
literal map expressions
Groovy also expands on the normal dot-notation used in Java for member access. Groovy provides special support for accessing hierarchical data structures by specifying the path in the hierarchy of some data of interest. These Groovy path expressions are known as GPath expressions.
2.1. GPath expressions
GPath is a path expression language integrated into Groovy which allows parts of nested structured data to be identified. In this sense, it has similar aims and scope as XPath does for XML. GPath is often used in the context of processing XML, but it really applies to any object graph. Where XPath uses a filesystem-like path notation, a tree hierarchy with parts separated by a slash / , GPath use a dot-object notation to perform object navigation.
As an example, you can specify a path to an object or element of interest:
a.b.c → for XML, yields all the c elements inside b inside a
a.b.c → for POJOs, yields the c properties for all the b properties of a (sort of like a.getB().getC() in JavaBeans)
In both cases, the GPath expression can be viewed as a query on an object graph. For POJOs, the object graph is most often built by the program being written through object instantiation and composition; for XML processing, the object graph is the result of parsing the XML text, most often with classes like XmlParser or XmlSlurper. See Processing XML for more in-depth details on consuming XML in Groovy.
When querying the object graph generated from XmlParser or XmlSlurper, a GPath expression can refer to attributes defined on elements with the @ notation:
a[«@href»] → map-like notation : the href attribute of all the a elements
a.’@href’ → property notation : an alternative way of expressing this
a.@href → direct notation : yet another alternative way of expressing this
2.1.1. Object navigation
Let’s see an example of a GPath expression on a simple object graph, the one obtained using java reflection. Suppose you are in a non-static method of a class having another method named aMethodFoo
the following GPath expression will get the name of that method:
More precisely, the above GPath expression produces a list of String, each being the name of an existing method on this where that name ends with Foo .
Now, given the following methods also defined in that class:
then the following GPath expression will get the names of (1) and (3), but not (2) or (0):
2.1.2. Expression Deconstruction
We can decompose the expression this.class.methods.name.grep(
/.*Bar/) to get an idea of how a GPath is evaluated:
property accessor, equivalent to this.getClass() in Java, yields a Class object.
property accessor, equivalent to this.getClass().getMethods() , yields an array of Method objects.
apply a property accessor on each element of an array and produce a list of the results.
call method grep on each element of the list yielded by this.class.methods.name and produce a list of the results.
A sub-expression like this.class.methods yields an array because this is what calling this.getClass().getMethods() in Java would produce. GPath expressions do not have a convention where a s means a list or anything like that.
One powerful feature of GPath expression is that property access on a collection is converted to a property access on each element of the collection with the results collected into a collection. Therefore, the expression this.class.methods.name could be expressed as follows in Java:
Array access notation can also be used in a GPath expression where a collection is present :
array access are zero-based in GPath expressions
2.1.3. GPath for XML navigation
Here is an example with a XML document and various form of GPath expressions:
1234
| There is one level node under root |
| There are two sublevel nodes under root/level |
| There is one element sublevel having an attribute id with value 1 |
| Text value of key element of first keyVal element of second sublevel element under root/level is ‘anotherKey’ |
Further details about GPath expressions for XML are in the XML User Guide.
3.1. Number promotion
The rules of number promotion are specified in the section on math operations.
3.2. Closure to type coercion
3.2.1. Assigning a closure to a SAM type
A SAM type is a type which defines a single abstract method. This includes:
Any closure can be converted into a SAM type using the as operator:
However, the as Type expression is optional since Groovy 2.2.0. You can omit it and simply write:
which means you are also allowed to use method pointers, as shown in the following example:
3.2.2. Calling a method accepting a SAM type with a closure
The second and probably more important use case for closure to SAM type coercion is calling a method which accepts a SAM type. Imagine the following method:
Then you can call it with a closure, without having to create an explicit implementation of the interface:
But since Groovy 2.2.0, you are also able to omit the explicit coercion and call the method as if it used a closure:
As you can see, this has the advantage of letting you use the closure syntax for method calls, that is to say put the closure outside of the parenthesis, improving the readability of your code.
3.2.3. Closure to arbitrary type coercion
In addition to SAM types, a closure can be coerced to any type and in particular interfaces. Let’s define the following interface:
You can coerce a closure into the interface using the as keyword:
This produces a class for which all methods are implemented using the closure:
But it is also possible to coerce a closure to any class. For example, we can replace the interface that we defined with class without changing the assertions:
3.3. Map to type coercion
Usually using a single closure to implement an interface or a class with multiple methods is not the way to go. As an alternative, Groovy allows you to coerce a map into an interface or a class. In that case, keys of the map are interpreted as method names, while the values are the method implementation. The following example illustrates the coercion of a map into an Iterator :
Of course this is a rather contrived example, but illustrates the concept. You only need to implement those methods that are actually called, but if a method is called that doesn’t exist in the map a MissingMethodException or an UnsupportedOperationException is thrown, depending on the arguments passed to the call, as in the following example:
The type of the exception depends on the call itself:
MissingMethodException if the arguments of the call do not match those from the interface/class
UnsupportedOperationException if the arguments of the call match one of the overloaded methods of the interface/class
3.4. String to enum coercion
Groovy allows transparent String (or GString ) to enum values coercion. Imagine you define the following enum:
then you can assign a string to the enum without having to use an explicit as coercion:
It is also possible to use a GString as the value:
However, this would throw a runtime error ( IllegalArgumentException ):
Note that it is also possible to use implicit coercion in switch statements:
in particular, see how the case use string constants. But if you call a method that uses an enum with a String argument, you still have to use an explicit as coercion:
3.5. Custom type coercion
It is possible for a class to define custom coercion strategies by implementing the asType method. Custom coercion is invoked using the as operator and is never implicit. As an example, imagine you defined two classes, Polar and Cartesian , like in the following example:
And that you want to convert from polar coordinates to cartesian coordinates. One way of doing this is to define the asType method in the Polar class:
which allows you to use the as coercion operator:
Putting it all together, the Polar class looks like this:
but it is also possible to define asType outside of the Polar class, which can be practical if you want to define custom coercion strategies for «closed» classes or classes for which you don’t own the source code, for example using a metaclass:
3.6. Class literals vs variables and the as operator
Using the as keyword is only possible if you have a static reference to a class, like in the following code:
But what if you get the class by reflection, for example by calling Class.forName ?
Trying to use the reference to the class with the as keyword would fail:
It is failing because the as keyword only works with class literals. Instead, you need to call the asType method:
4. Optionality
4.1. Optional parentheses
Method calls can omit the parentheses if there is at least one parameter and there is no ambiguity:
Parentheses are required for method calls without parameters or ambiguous method calls:
4.2. Optional semicolons
In Groovy semicolons at the end of the line can be omitted, if the line contains only a single statement.
This means that:
can be more idiomatically written as:
Multiple statements in a line require semicolons to separate them:
4.3. Optional return keyword
In Groovy, the last expression evaluated in the body of a method or a closure is returned. This means that the return keyword is optional.
Can be shortened to:
4.4. Optional public keyword
By default, Groovy classes and methods are public . Therefore this class:
is identical to this class:
5. The Groovy Truth
Groovy decides whether an expression is true or false by applying the rules given below.
5.1. Boolean expressions
True if the corresponding Boolean value is true .
5.2. Collections and Arrays
Non-empty Collections and arrays are true.
5.3. Matchers
True if the Matcher has at least one match.
5.4. Iterators and Enumerations
Iterators and Enumerations with further elements are coerced to true.
5.5. Maps
Non-empty Maps are evaluated to true.
5.6. Strings
Non-empty Strings, GStrings and CharSequences are coerced to true.
5.7. Numbers
Non-zero numbers are true.
5.8. Object References
Non-null object references are coerced to true.
5.9. Customizing the truth with asBoolean() methods
In order to customize whether groovy evaluates your object to true or false implement the asBoolean() method:
Groovy will call this method to coerce your object to a boolean value, e.g.:
6. Typing
6.1. Optional typing
Optional typing is the idea that a program can work even if you don’t put an explicit type on a variable. Being a dynamic language, Groovy naturally implements that feature, for example when you declare a variable:
12
| foo is declared using an explicit type, String |
| we can call the toUpperCase method on a String |
Groovy will let you write this instead:
12
| foo is declared using def |
| we can still call the toUpperCase method, because the type of aString is resolved at runtime |
So it doesn’t matter that you use an explicit type here. It is in particular interesting when you combine this feature with static type checking, because the type checker performs type inference.
Likewise, Groovy doesn’t make it mandatory to declare the types of a parameter in a method:
can be rewritten using def as both return type and parameter types, in order to take advantage of duck typing, as illustrated in this example:
123
| both the return type and the parameter types use def |
| it makes it possible to use the method with String |
| but also with int since the plus method is defined |
Using the def keyword here is recommended to describe the intent of a method which is supposed to work on any type, but technically, we could use Object instead and the result would be the same: def is, in Groovy, strictly equivalent to using Object .
Eventually, the type can be removed altogether from both the return type and the descriptor. But if you want to remove it from the return type, you then need to add an explicit modifier for the method, so that the compiler can make a difference between a method declaration and a method call, like illustrated in this example:
123
| if we want to omit the return type, an explicit modifier has to be set. |
| it is still possible to use the method with String |
| and also with int |
Omitting types is in general considered a bad practice in method parameters or method return types for public APIs. While using def in a local variable is not really a problem because the visibility of the variable is limited to the method itself, while set on a method parameter, def will be converted to Object in the method signature, making it difficult for users to know which is the expected type of the arguments. This means that you should limit this to cases where you are explicitly relying on duck typing.
6.2. Static type checking
By default, Groovy performs minimal type checking at compile time. Since it is primarily a dynamic language, most checks that a static compiler would normally do aren’t possible at compile time. A method added via runtime metaprogramming might alter a class or object’s runtime behavior. Let’s illustrate why in the following example:
123
| the Person class only defines two properties, firstName and lastName |
| we can create an instance of Person |
| and call a method named formattedName |
It is quite common in dynamic languages for code such as the above example not to throw any error. How can this be? In Java, this would typically fail at compile time. However, in Groovy, it will not fail at compile time, and if coded correctly, will also not fail at runtime. In fact, to make this work at runtime, one possibility is to rely on runtime metaprogramming. So just adding this line after the declaration of the Person class is enough:
This means that in general, in Groovy, you can’t make any assumption about the type of an object beyond its declaration type, and even if you know it, you can’t determine at compile time what method will be called, or which property will be retrieved. It has a lot of interest, going from writing DSLs to testing, which is discussed in other sections of this manual.
However, if your program doesn’t rely on dynamic features and that you come from the static world (in particular, from a Java mindset), not catching such «errors» at compile time can be surprising. As we have seen in the previous example, the compiler cannot be sure this is an error. To make it aware that it is, you have to explicitly instruct the compiler that you are switching to a type checked mode. This can be done by annotating a class or a method with @groovy.transform.TypeChecked .
When type checking is activated, the compiler performs much more work:
type inference is activated, meaning that even if you use def on a local variable for example, the type checker will be able to infer the type of the variable from the assignments
method calls are resolved at compile time, meaning that if a method is not declared on a class, the compiler will throw an error
in general, all the compile time errors that you are used to find in a static language will appear: method not found, property not found, incompatible types for method calls, number precision errors, …
In this section, we will describe the behavior of the type checker in various situations and explain the limits of using @TypeChecked on your code.
6.2.1. The @TypeChecked annotation
Activating type checking at compile time
The groovy.transform.TypeChecked annotation enables type checking. It can be placed on a class:
In the first case, all methods, properties, fields, inner classes, … of the annotated class will be type checked, whereas in the second case, only the method and potential closures or anonymous inner classes that it contains will be type checked.
Skipping sections
The scope of type checking can be restricted. For example, if a class is type checked, you can instruct the type checker to skip a method by annotating it with @TypeChecked(TypeCheckingMode.SKIP) :
1234
| the GreetingService class is marked as type checked |
| so the greeting method is automatically type checked |
| but doGreet is marked with SKIP |
| the type checker doesn’t complain about missing properties here |
In the previous example, SentenceBuilder relies on dynamic code. There’s no real Hello method or property, so the type checker would normally complain and compilation would fail. Since the method that uses the builder is marked with TypeCheckingMode.SKIP , type checking is skipped for this method, so the code will compile, even if the rest of the class is type checked.
The following sections describe the semantics of type checking in Groovy.
6.2.2. Type checking assignments
An object o of type A can be assigned to a variable of type T if and only if:
or T is one of String , boolean , Boolean or Class
or o is null and T is not a primitive type
or T is an array and A is an array and the component type of A is assignable to the component type of T
or T is an array and A is a collection or stream and the component type of A is assignable to the component type of T
or T is a superclass of A
or T is an interface implemented by A
or T or A are a primitive type and their boxed types are assignable
or T extends groovy.lang.Closure and A is a SAM-type (single abstract method type)
or T and A derive from java.lang.Number and conform to the following table
Table 3. Number types (java.lang.XXX)
Any but BigDecimal or BigInteger
Any type but BigDecimal, BigInteger or Double
Any type but BigDecimal, BigInteger, Double or Float
Any type but BigDecimal, BigInteger, Double, Float or Long
Any type but BigDecimal, BigInteger, Double, Float, Long or Integer
6.2.3. List and map constructors
In addition to the assignment rules above, if an assignment is deemed invalid, in type checked mode, a list literal or a map literal A can be assigned to a variable of type T if:
the assignment is a variable declaration and A is a list literal and T has a constructor whose parameters match the types of the elements in the list literal
the assignment is a variable declaration and A is a map literal and T has a no-arg constructor and a property for each of the map keys
For example, instead of writing:
You can use a «list constructor»:
or a «map constructor»:
If you use a map constructor, additional checks are done on the keys of the map to check if a property of the same name is defined. For example, the following will fail at compile time:
| T | A | Examples |
|---|---|---|
1
The type checker will throw an error No such property: age for class: Person at compile time
6.2.4. Method resolution
In type checked mode, methods are resolved at compile time. Resolution works by name and arguments. The return type is irrelevant to method selection. Types of arguments are matched against the types of the parameters following those rules:
An argument o of type A can be used for a parameter of type T if and only if:
or T is a String and A is a GString
or o is null and T is not a primitive type
or T is an array and A is an array and the component type of A is assignable to the component type of T
or T is a superclass of A
or T is an interface implemented by A
or T or A are a primitive type and their boxed types are assignable
or T extends groovy.lang.Closure and A is a SAM-type (single abstract method type)
or T and A derive from java.lang.Number and conform to the same rules as assignment of numbers
If a method with the appropriate name and arguments is not found at compile time, an error is thrown. The difference with «normal» Groovy is illustrated in the following example:
1
printLine is an error, but since we’re in a dynamic mode, the error is not caught at compile time
The example above shows a class that Groovy will be able to compile. However, if you try to create an instance of MyService and call the doSomething method, then it will fail at runtime, because printLine doesn’t exist. Of course, we already showed how Groovy could make this a perfectly valid call, for example by catching MethodMissingException or implementing a custom meta-class, but if you know you’re not in such a case, @TypeChecked comes handy:
1
printLine is this time a compile-time error
Just adding @TypeChecked will trigger compile time method resolution. The type checker will try to find a method printLine accepting a String on the MyService class, but cannot find one. It will fail compilation with the following message:
Cannot find matching method MyService#printLine(java.lang.String)
It is important to understand the logic behind the type checker: it is a compile-time check, so by definition, the type checker is not aware of any kind of runtime metaprogramming that you do. This means that code which is perfectly valid without @TypeChecked will not compile anymore if you activate type checking. This is in particular true if you think of duck typing:
1234
| we define a Duck class which defines a quack method |
| we define another QuackingBird class which also defines a quack method |
| quacker is loosely typed, so since the method is @TypeChecked , we will obtain a compile-time error |
| even if in non type-checked Groovy, this would have passed |
There are possible workarounds, like introducing an interface, but basically, by activating type checking, you gain type safety but you loose some features of the language. Hopefully, Groovy introduces some features like flow typing to reduce the gap between type-checked and non type-checked Groovy.
6.2.5. Type inference
Principles
When code is annotated with @TypeChecked , the compiler performs type inference. It doesn’t simply rely on static types, but also uses various techniques to infer the types of variables, return types, literals, … so that the code remains as clean as possible even if you activate the type checker.
The simplest example is inferring the type of a variable:
123
| a variable is declared using the def keyword |
| calling toUpperCase is allowed by the type checker |
| calling upper will fail at compile time |
The reason the call to toUpperCase works is because the type of message was inferred as being a String .
Variables vs fields in type inference
It is worth noting that although the compiler performs type inference on local variables, it does not perform any kind of type inference on fields, always falling back to the declared type of a field. To illustrate this, let’s take a look at this example:
12345678
| someUntypedField uses def as a declaration type |
| someTypedField uses String as a declaration type |
| we can assign anything to someUntypedField |
| yet calling toUpperCase fails at compile time because the field is not typed properly |
| we can assign a String to a field of type String |
| and this time toUpperCase is allowed |
| if we assign a String to a local variable |
| then calling toUpperCase is allowed on the local variable |
Why such a difference? The reason is thread safety. At compile time, we can’t make any guarantee about the type of a field. Any thread can access any field at any time and between the moment a field is assigned a variable of some type in a method and the time is is used the line after, another thread may have changed the contents of the field. This is not the case for local variables: we know if they «escape» or not, so we can make sure that the type of a variable is constant (or not) over time. Note that even if a field is final, the JVM makes no guarantee about it, so the type checker doesn’t behave differently if a field is final or not.
This is one of the reasons why we recommend to use typed fields. While using def for local variables is perfectly fine thanks to type inference, this is not the case for fields, which also belong to the public API of a class, hence the type is important.
Collection literal type inference
Groovy provides a syntax for various type literals. There are three native collection literals in Groovy:
lists, using the [] literal
maps, using the [:] literal
ranges, using from..to (inclusive), from.. (right exclusive), from (left exclusive) and from (full exclusive)
The inferred type of a literal depends on the elements of the literal, as illustrated in the following table:
java.util.List be careful, a GString is not a String !
java.util.LinkedHashMap be careful, the key is a GString !
groovy.lang.Range : uses the type of the bounds to infer the component type of the range
As you can see, with the noticeable exception of the IntRange , the inferred type makes use of generics types to describe the contents of a collection. In case the collection contains elements of different types, the type checker still performs type inference of the components, but uses the notion of least upper bound.
Least upper bound
In Groovy, the least upper bound of two types A and B is defined as a type which:
superclass corresponds to the common super class of A and B
interfaces correspond to the interfaces implemented by both A and B
if A or B is a primitive type and that A isn’t equal to B , the least upper bound of A and B is the least upper bound of their wrapper types
If A and B only have one (1) interface in common and that their common superclass is Object , then the LUB of both is the common interface.
The least upper bound represents the minimal type to which both A and B can be assigned. So for example, if A and B are both String , then the LUB (least upper bound) of both is also String .
123456
| the LUB of String and String is String |
| the LUB of ArrayList and LinkedList is their common super type, AbstractList |
| the LUB of ArrayList and List is their only common interface, List |
| the LUB of two identical interfaces is the interface itself |
| the LUB of Bottom1 and Bottom2 is their superclass Top |
| the LUB of two types which have nothing in common is Object |
In those examples, the LUB is always representable as a normal, JVM supported, type. But Groovy internally represents the LUB as a type which can be more complex, and that you wouldn’t be able to use to define a variable for example. To illustrate this, let’s continue with this example:
What is the least upper bound of Bottom and SerializableFooImpl ? They don’t have a common super class (apart from Object ), but they do share 2 interfaces ( Serializable and Foo ), so their least upper bound is a type which represents the union of two interfaces ( Serializable and Foo ). This type cannot be defined in the source code, yet Groovy knows about it.
In the context of collection type inference (and generic type inference in general), this becomes handy, because the type of the components is inferred as the least upper bound. We can illustrate why this is important in the following example:
123456789
| the Greeter interface defines a single method, greet |
| the Salute interface defines a single method, salute |
| class A implements both Greeter and Salute but there’s no explicit interface extending both |
| same for B |
| but B defines an additional exit method |
| the type of list is inferred as «list of the LUB of A and `B`» |
| so it is possible to call greet which is defined on both A and B through the Greeter interface |
| and it is possible to call salute which is defined on both A and B through the Salute interface |
| yet calling exit is a compile time error because it doesn’t belong to the LUB of A and B (only defined in B ) |
The error message will look like:
which indicates that the exit method is neither defines on Greeter nor Salute , which are the two interfaces defined in the least upper bound of A and B .
instanceof inference
In normal, non type checked, Groovy, you can write things like:
12
| guard the method call with an instanceof check |
| make the call |
The method call works because of dynamic dispatch (the method is selected at runtime). The equivalent code in Java would require to cast o to a Greeter before calling the greeting method, because methods are selected at compile time:
However, in Groovy, even if you add @TypeChecked (and thus activate type checking) on the doSomething method, the cast is not necessary. The compiler embeds instanceof inference that makes the cast optional.
Flow typing
Flow typing is an important concept of Groovy in type checked mode and an extension of type inference. The idea is that the compiler is capable of inferring the type of variables in the flow of the code, not just at initialization:
1234
| first, o is declared using def and assigned a String |
| the compiler inferred that o is a String , so calling toUpperCase is allowed |
| o is reassigned with a double |
| calling Math.sqrt passes compilation because the compiler knows that at this point, o is a double |
So the type checker is aware of the fact that the concrete type of a variable is different over time. In particular, if you replace the last assignment with:
The type checker will now fail at compile time, because it knows that o is a double when toUpperCase is called, so it’s a type error.
It is important to understand that it is not the fact of declaring a variable with def that triggers type inference. Flow typing works for any variable of any type. Declaring a variable with an explicit type only constrains what you can assign to the variable:
123
| list is declared as an unchecked List and assigned a list literal of `String`s |
| this line passes compilation because of flow typing: the type checker knows that list is at this point a List |
| but you can’t assign a String to a List so this is a type checking error |
You can also note that even if the variable is declared without generics information, the type checker knows what is the component type. Therefore, such code would fail compilation:
12
| list is inferred as List |
| so adding an int to a List is a compile-time error |
Fixing this requires adding an explicit generic type to the declaration:
123
| list declared as List and initialized with an empty list |
| elements added to the list conform to the declaration type of the list |
| so adding an int to a List is allowed |
Flow typing has been introduced to reduce the difference in semantics between classic and static Groovy. In particular, consider the behavior of this code in Java:
123
| o is declared as an Object and assigned a String |
| we call the compute method with o |
| and print the result |
In Java, this code will output Nope , because method selection is done at compile time and based on the declared types. So even if o is a String at runtime, it is still the Object version which is called, because o has been declared as an Object . To be short, in Java, declared types are most important, be it variable types, parameter types or return types.
In Groovy, we could write:
But this time, it will return 6 , because the method which is chosen is chosen at runtime, based on the actual argument types. So at runtime, o is a String so the String variant is used. Note that this behavior has nothing to do with type checking, it’s the way Groovy works in general: dynamic dispatch.
In type checked Groovy, we want to make sure the type checker selects the same method at compile time, that the runtime would choose. It is not possible in general, due to the semantics of the language, but we can make things better with flow typing. With flow typing, o is inferred as a String when the compute method is called, so the version which takes a String and returns an int is chosen. This means that we can infer the return type of the method to be an int , and not a String . This is important for subsequent calls and type safety.
So in type checked Groovy, flow typing is a very important concept, which also implies that if @TypeChecked is applied, methods are selected based on the inferred types of the arguments, not on the declared types. This doesn’t ensure 100% type safety, because the type checker may select a wrong method, but it ensures the closest semantics to dynamic Groovy.
Advanced type inference
A combination of flow typing and least upper bound inference is used to perform advanced type inference and ensure type safety in multiple situations. In particular, program control structures are likely to alter the inferred type of a variable:
1234
| if someCondition is true, o is assigned a Top |
| if someCondition is false, o is assigned a Bottom |
| calling methodFromTop is safe |
| but calling methodFromBottom is not, so it’s a compile time error |
When the type checker visits an if/else control structure, it checks all variables which are assigned in if/else branches and computes the least upper bound of all assignments. This type is the type of the inferred variable after the if/else block, so in this example, o is assigned a Top in the if branch and a Bottom in the else branch. The LUB of those is a Top , so after the conditional branches, the compiler infers o as being a Top . Calling methodFromTop will therefore be allowed, but not methodFromBottom .
The same reasoning exists with closures and in particular closure shared variables. A closure shared variable is a variable which is defined outside of a closure, but used inside a closure, as in this example:
12
| a variable named text is declared |
| text is used from inside a closure. It is a closure shared variable. |
Groovy allows developers to use those variables without requiring them to be final. This means that a closure shared variable can be reassigned inside a closure:
The problem is that a closure is an independent block of code that can be executed (or not) at any time. In particular, doSomething may be asynchronous, for example. This means that the body of a closure doesn’t belong to the main control flow. For that reason, the type checker also computes, for each closure shared variable, the LUB of all assignments of the variable, and will use that LUB as the inferred type outside of the scope of the closure, like in this example:
1234
| a closure-shared variable is first assigned a Top |
| inside the closure, it is assigned a Bottom |
| methodFromTop is allowed |
| methodFromBottom is a compilation error |
Here, it is clear that when methodFromBottom is called, there’s no guarantee, at compile-time or runtime that the type of o will effectively be a Bottom . There are chances that it will be, but we can’t make sure, because it’s asynchronous. So the type checker will only allow calls on the least upper bound, which is here a Top .
6.2.6. Closures and type inference
The type checker performs special inference on closures, resulting on additional checks on one side and improved fluency on the other side.
Return type inference
The first thing that the type checker is capable of doing is inferring the return type of a closure. This is simply illustrated in the following example:
123
| a closure is defined, and it returns a string (more precisely a GString ) |
| we call the closure and assign the result to a variable |
| the type checker inferred that the closure would return a string, so calling length() is allowed |
As you can see, unlike a method which declares its return type explicitly, there’s no need to declare the return type of a closure: its type is inferred from the body of the closure.
It’s worth noting that return type inference is only applicable to closures. While the type checker could do the same on a method, it is in practice not desirable: in general, methods can be overridden and it is not statically possible to make sure that the method which is called is not an overridden version. So flow typing would actually think that a method returns something, while in reality, it could return something else, like illustrated in the following example:
123
| class A defines a method compute which effectively returns a String |
| this will fail compilation because the return type of compute is def (aka Object ) |
| class B extends A and redefines compute , this type returning an int |
As you can see, if the type checker relied on the inferred return type of a method, with flow typing, the type checker could determine that it is ok to call toUpperCase . It is in fact an error, because a subclass can override compute and return a different object. Here, B#compute returns an int , so someone calling computeFully on an instance of B would see a runtime error. The compiler prevents this from happening by using the declared return type of methods instead of the inferred return type.
For consistency, this behavior is the same for every method, even if they are static or final.
Parameter type inference
In addition to the return type, it is possible for a closure to infer its parameter types from the context. There are two ways for the compiler to infer the parameter types:
through implicit SAM type coercion
through API metadata
To illustrate this, lets start with an example that will fail compilation due to the inability for the type checker to infer the parameter types:
123
| the inviteIf method accepts a Person and a Closure |
| we call it with a Person and a Closure |
| yet it is not statically known as being a Person and compilation fails |
In this example, the closure body contains it.age . With dynamic, not type checked code, this would work, because the type of it would be a Person at runtime. Unfortunately, at compile-time, there’s no way to know what is the type of it , just by reading the signature of inviteIf .
Explicit closure parameters
To be short, the type checker doesn’t have enough contextual information on the inviteIf method to determine statically the type of it . This means that the method call needs to be rewritten like this:
1
the type of it needs to be declared explicitly
By explicitly declaring the type of the it variable, you can workaround the problem and make this code statically checked.
Parameters inferred from single-abstract method types
For an API or framework designer, there are two ways to make this more elegant for users, so that they don’t have to declare an explicit type for the closure parameters. The first one, and easiest, is to replace the closure with a SAM type:
12
| declare a SAM interface with an apply method |
| inviteIf now uses a Predicate |
instead of a Closure 3 there’s no need to declare the type of the it variable anymore 4 it.age compiles properly, the type of it is inferred from the Predicate#apply method signature
By using this technique, we leverage the automatic coercion of closures to SAM types feature of Groovy. The question whether you should use a SAM type or a Closure really depends on what you need to do. In a lot of cases, using a SAM interface is enough, especially if you consider functional interfaces as they are found in Java 8. However, closures provide features that are not accessible to functional interfaces. In particular, closures can have a delegate, and owner and can be manipulated as objects (for example, cloned, serialized, curried, …) before being called. They can also support multiple signatures (polymorphism). So if you need that kind of manipulation, it is preferable to switch to the most advanced type inference annotations which are described below.
The original issue that needs to be solved when it comes to closure parameter type inference, that is to say, statically determining the types of the arguments of a closure without having to have them explicitly declared, is that the Groovy type system inherits the Java type system, which is insufficient to describe the types of the arguments.
The @ClosureParams annotation
Groovy provides an annotation, @ClosureParams which is aimed at completing type information. This annotation is primarily aimed at framework and API developers who want to extend the capabilities of the type checker by providing type inference metadata. This is important if your library makes use of closures and that you want the maximum level of tooling support too.
Let’s illustrate this by fixing the original example, introducing the @ClosureParams annotation:
12
| the closure parameter is annotated with @ClosureParams |
| it’s not necessary to use an explicit type for it , which is inferred |
The @ClosureParams annotation minimally accepts one argument, which is named a type hint. A type hint is a class which is responsible for completing type information at compile time for the closure. In this example, the type hint being used is groovy.transform.stc.FirstParam which indicated to the type checker that the closure will accept one parameter whose type is the type of the first parameter of the method. In this case, the first parameter of the method is Person , so it indicates to the type checker that the first parameter of the closure is in fact a Person .
A second optional argument is named options. Its semantics depend on the type hint class. Groovy comes with various bundled type hints, illustrated in the table below:
Table 4. Predefined type hints
FirstParam
SecondParam
ThirdParam
The first (resp. second, third) parameter type of the method
FirstParam.FirstGenericType
SecondParam.FirstGenericType
ThirdParam.FirstGenericType
The first generic type of the first (resp. second, third) parameter of the method
Variants for SecondGenericType and ThirdGenericType exist for all FirstParam , SecondParam and ThirdParam type hints.
A type hint for which the type of closure parameters comes from the options string.
This type hint supports a single signature and each of the parameter is specified as a value of the options array using a fully-qualified type name or a primitive type.
A dedicated type hint for closures that either work on a Map.Entry single parameter, or two parameters corresponding to the key and the value.
This type hint requires that the first argument is a Map type, and infers the closure parameter types from the map actual key/value types.
Infers closure parameter types from the abstract method of some type. A signature is inferred for each abstract method.
If there are multiple signatures like in the example above, the type checker will only be able to infer the types of the arguments if the arity of each method is different. In the example above, firstSignature takes 2 arguments and secondSignature takes 1 argument, so the type checker can infer the argument types based on the number of arguments. But see the optional resolver class attribute discussed next.
Infers the closure parameter types from the options argument. The options argument consists of an array of comma-separated non-primitive types. Each element of the array corresponds to a single signature, and each comma in an element separate parameters of the signature. In short, this is the most generic type hint, and each string of the options map is parsed as if it was a signature literal. While being very powerful, this type hint must be avoided if you can because it increases the compilation times due to the necessity of parsing the type signatures.
A single signature for a closure accepting a String :
A polymorphic closure, accepting either a String or a String, Integer :
A polymorphic closure, accepting either a T or a pair T,T :
| Type hint | Polymorphic? | Description and examples |
|---|---|---|
Even though you use FirstParam , SecondParam or ThirdParam as a type hint, it doesn’t strictly mean that the argument which will be passed to the closure will be the first (resp. second, third) argument of the method call. It only means that the type of the parameter of the closure will be the same as the type of the first (resp. second, third) argument of the method call.
In short, the lack of the @ClosureParams annotation on a method accepting a Closure will not fail compilation. If present (and it can be present in Java sources as well as Groovy sources), then the type checker has more information and can perform additional type inference. This makes this feature particularly interesting for framework developers.
A third optional argument is named conflictResolutionStrategy. It can reference a class (extending from ClosureSignatureConflictResolver ) that can perform additional resolution of parameter types if more than one are found after initial inference calculations are complete. Groovy comes with the a default type resolver which does nothing, and another which selects the first signature if multiple are found. The resolver is only invoked if more than one signature is found and is by design a post processor. Any statements which need injected typing information must pass one of the parameter signatures determined through type hints. The resolver then picks among the returned candidate signatures.
@DelegatesTo
The @DelegatesTo annotation is used by the type checker to infer the type of the delegate. It allows the API designer to instruct the compiler what is the type of the delegate and the delegation strategy. The @DelegatesTo annotation is discussed in a specific section.
6.3. Static compilation
6.3.1. Dynamic vs static
In the type checking section, we have seen that Groovy provides optional type checking thanks to the @TypeChecked annotation. The type checker runs at compile time and performs a static analysis of dynamic code. The program will behave exactly the same whether type checking has been enabled or not. This means that the @TypeChecked annotation is neutral with regards to the semantics of a program. Even though it may be necessary to add type information in the sources so that the program is considered type safe, in the end, the semantics of the program are the same.
While this may sound fine, there is actually one issue with this: type checking of dynamic code, done at compile time, is by definition only correct if no runtime specific behavior occurs. For example, the following program passes type checking:
There are two compute methods. One accepts a String and returns an int , the other accepts an int and returns a String . If you compile this, it is considered type safe: the inner compute(‘foobar’) call will return an int , and calling compute on this int will in turn return a String .
Now, before calling test() , consider adding the following line:
Using runtime metaprogramming, we’re actually modifying the behavior of the compute(String) method, so that instead of returning the length of the provided argument, it will return a Date . If you execute the program, it will fail at runtime. Since this line can be added from anywhere, in any thread, there’s absolutely no way for the type checker to statically make sure that no such thing happens. In short, the type checker is vulnerable to monkey patching. This is just one example, but this illustrates the concept that doing static analysis of a dynamic program is inherently wrong.
The Groovy language provides an alternative annotation to @TypeChecked which will actually make sure that the methods which are inferred as being called will effectively be called at runtime. This annotation turns the Groovy compiler into a static compiler, where all method calls are resolved at compile time and the generated bytecode makes sure that this happens: the annotation is @groovy.transform.CompileStatic .
6.3.2. The @CompileStatic annotation
The @CompileStatic annotation can be added anywhere the @TypeChecked annotation can be used, that is to say on a class or a method. It is not necessary to add both @TypeChecked and @CompileStatic , as @CompileStatic performs everything @TypeChecked does, but in addition triggers static compilation.
Let’s take the example which failed, but this time let’s replace the @TypeChecked annotation with @CompileStatic :
This is the only difference. If we execute this program, this time, there is no runtime error. The test method became immune to monkey patching, because the compute methods which are called in its body are linked at compile time, so even if the metaclass of Computer changes, the program still behaves as expected by the type checker.
6.3.3. Key benefits
There are several benefits of using @CompileStatic on your code:
The performance improvements depend on the kind of program you are executing. If it is I/O bound, the difference between statically compiled code and dynamic code is barely noticeable. On highly CPU intensive code, since the bytecode which is generated is very close, if not equal, to the one that Java would produce for an equivalent program, the performance is greatly improved.
Using the invokedynamic version of Groovy, which is accessible to people using JDK 7 and above, the performance of the dynamic code should be very close to the performance of statically compiled code. Sometimes, it can even be faster! There is only one way to determine which version you should choose: measuring. The reason is that depending on your program and the JVM that you use, the performance can be significantly different. In particular, the invokedynamic version of Groovy is very sensitive to the JVM version in use.
7. Type checking extensions
7.1. Writing a type checking extension
7.1.1. Towards a smarter type checker
Despite being a dynamic language, Groovy can be used with a static type checker at compile time, enabled using the @TypeChecked annotation. In this mode, the compiler becomes more verbose and throws errors for, example, typos, non-existent methods,… This comes with a few limitations though, most of them coming from the fact that Groovy remains inherently a dynamic language. For example, you wouldn’t be able to use type checking on code that uses the markup builder:
In the previous example, none of the html , head , body or p methods exist. However if you execute the code, it works because Groovy uses dynamic dispatch and converts those method calls at runtime. In this builder, there’s no limitation about the number of tags that you can use, nor the attributes, which means there is no chance for a type checker to know about all the possible methods (tags) at compile time, unless you create a builder dedicated to HTML for example.
Groovy is a platform of choice when it comes to implement internal DSLs. The flexible syntax, combined with runtime and compile-time metaprogramming capabilities make Groovy an interesting choice because it allows the programmer to focus on the DSL rather than on tooling or implementation. Since Groovy DSLs are Groovy code, it’s easy to have IDE support without having to write a dedicated plugin for example.
In a lot of cases, DSL engines are written in Groovy (or Java) then user code is executed as scripts, meaning that you have some kind of wrapper on top of user logic. The wrapper may consist, for example, in a GroovyShell or GroovyScriptEngine that performs some tasks transparently before running the script (adding imports, applying AST transforms, extending a base script,…). Often, user written scripts come to production without testing because the DSL logic comes to a point where any user may write code using the DSL syntax. In the end, a user may just ignore that what they write is actually code. This adds some challenges for the DSL implementer, such as securing execution of user code or, in this case, early reporting of errors.
For example, imagine a DSL which goal is to drive a rover on Mars remotely. Sending a message to the rover takes around 15 minutes. If the rover executes the script and fails with an error (say a typo), you have two problems:
first, feedback comes only after 30 minutes (the time needed for the rover to get the script and the time needed to receive the error)
second, some portion of the script has been executed and you may have to change the fixed script significantly (implying that you need to know the current state of the rover…)
Type checking extensions is a mechanism that will allow the developer of a DSL engine to make those scripts safer by applying the same kind of checks that static type checking allows on regular groovy classes.
The principle, here, is to fail early, that is to say fail compilation of scripts as soon as possible, and if possible provide feedback to the user (including nice error messages).
In short, the idea behind type checking extensions is to make the compiler aware of all the runtime metaprogramming tricks that the DSL uses, so that scripts can benefit the same level of compile-time checks as a verbose statically compiled code would have. We will see that you can go even further by performing checks that a normal type checker wouldn’t do, delivering powerful compile-time checks for your users.
7.1.2. The extensions attribute
TheВ @TypeChecked annotation supports an attribute namedВ extensions . This parameter takes an array of strings corresponding to a list of type checking extensions scripts. Those scripts are found atВ compile time on classpath. For example, you would write:
In that case, theВ foo methods would be type checked with the rules of the normal type checker completed by those found in theВ myextension.groovy script. Note that while internally the type checker supports multiple mechanisms to implement type checking extensions (including plain old java code), the recommended way is to use those type checking extension scripts.
7.1.3. A DSL for type checking
The idea behind type checking extensions is to use a DSL to extend the type checker capabilities. This DSL allows you to hook into the compilation process, more specifically the type checking phase, using an «event-driven» API. For example, when the type checker enters a method body, it throws aВ beforeVisitMethod event that the extension can react to:
Imagine that you have this rover DSL at hand. A user would write:
If you have a class defined as such:
The script can be type checked before being executed using the following script:
123
| a compiler configuration adds the @TypeChecked annotation to all classes |
| use the configuration in a GroovyShell |
| so that scripts compiled using the shell are compiled with @TypeChecked without the user having to add it explicitly |
Using the compiler configuration above, we can applyВ @TypeChecked transparently to the script. In that case, it will fail at compile time:
Now, we will slightly update the configuration to include the «extensions» parameter:
Then add the following to your classpath:
Here, we’re telling the compiler that if an unresolved variable is found and that the name of the variable is robot, then we can make sure that the type of this variable is Robot .
7.1.4. Type checking extensions API
The type checking API is a low level API, dealing with the Abstract Syntax Tree. You will have to know your AST well to develop extensions, even if the DSL makes it much easier than just dealing with AST code from plain Java or Groovy.
Events
The type checker sends the following events, to which an extension script can react:
Event name
Called When
Called after the type checker finished initialization
Источник
1. Catch an exception
2. Multiple capture blocks
3. finally block
Any programming language requires exception handling to handle run-time errors so that the application’s normal flow can be maintained.
Exceptions often break the normal flow of the application, which is why we need to use exception handling in our applications.
Exceptions fall broadly into the following categories —
-
Detect exceptions
—
Classes that extend the Throwable class (except RuntimeException and Error) are called Check exceptions egIOEx, SQLException, and so on. T
he checked exception is checked at compile time.
A typical case is FileNotFoundEx.
Suppose you have the following code in your application, which reads from the files in the E disk.
class Example {
static void main(String[] args) {
File file = new File("E://file.txt");
FileReader fr = new FileReader(file);
}
}
If the file .txt is not on the E disk, the following exception is thrown.
Crawl: java.io.FileNotFoundException: E:’file.txt (the system could not find the specified file).
java.io.FileNotFoundException: E:file.txt (the specified file could not be found).
-
Uncensored
exceptions — Classes that extend RuntimeException are called uncensored exceptions, such as
ArithmeticException, NullPointerException, ArrayIndexOutOfBoundsException, etc. E
xceptions that are not checked are not checked during the compilation period, but are checked at runtime.
A typical scenario is ArrayIndexOutOfBoundsException, which occurs when you try to access an array index larger than the number of group leaders.
The following is a typical example of this error.
class Example {
static void main(String[] args) {
def arr = new int[3];
arr[5] = 5;
}
}
When the above code executes, the following exception is thrown.
Grab: java.lang.ArrayIndexOutOfBoundsException: 5
java.lang.ArrayIndexOutOfBoundsException:5
-
Error
— The
error could not be recovered. O
utOfMemoryError, VirtualMachineError, AssertionError, etc.
These are errors that the program can never recover and will cause the program to crash.
The following illustration shows how to organize the exception hierarchy in Groovy.
It is based on the hierarchy defined in Java.
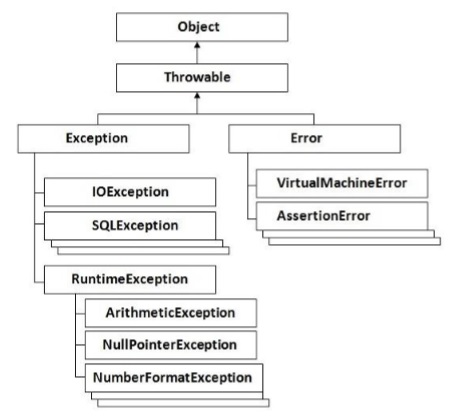
Catch an exception
Method captures exceptions using a combination of try and catch keywords.
Try / catch blocks are placed around code that may generate exceptions.
try {
//Protected code
} catch(ExceptionName e1) {
//Catch block
}
All code that might throw an exception is placed in a protected block of code.
In the catch block, you can write custom code to handle exceptions so that applications can recover from exceptions.
Let’s look at a similar code example, where we see an array with an index value greater than the size of the array.
But this time let’s wrap our code in a try/catch block.
class Example {
static void main(String[] args) {
try {
def arr = new int[3];
arr[5] = 5;
} catch(Exception ex) {
println("Catching the exception");
}
println("Let's move on after the exception");
}
}
When we run the program above, we will get the following results —
Catching the exception Let's move on after the exception
From the code above, we wrap the wrong code in the try block.
In the catch block, we just catch our exception and output a message that an exception has already occurred.
Multiple capture blocks
You can have multiple catch blocks to handle multiple types of exceptions.
For each catch block, depending on the type of exception thrown, you will write code to handle it accordingly.
Let’s modify the code above to capture ArrayIndexOutOfBoundsException.
The following is a snipper.
class Example {
static void main(String[] args) {
try {
def arr = new int[3];
arr[5] = 5;
}catch(ArrayIndexOutOfBoundsException ex) {
println("Catching the Array out of Bounds exception");
}catch(Exception ex) {
println("Catching the exception");
}
println("Let's move on after the exception");
}
}
When we run the program above, we will get the following results —
Catching the Aray out of Bounds exception Let's move on after the exception
From the above code, you can see that the ArrayIndexOutOfBoundsEx catch block was first caught because it means the standard of the exception.
finally block
The
final block follows the try block or catch block.
The finally block of code is always executed regardless of the exception.
Use the find block to run any cleanup type statement you want to execute, regardless of what happens in the protected code.
The syntax of the block is as follows.
try {
//Protected code
} catch(ExceptionType1 e1) {
//Catch block
} catch(ExceptionType2 e2) {
//Catch block
} catch(ExceptionType3 e3) {
//Catch block
} finally {
//The finally block always executes.
}
Let’s modify the code above us and add the findy block.
The following is a snipper.
class Example {
static void main(String[] args) {
try {
def arr = new int[3];
arr[5] = 5;
} catch(ArrayIndexOutOfBoundsException ex) {
println("Catching the Array out of Bounds exception");
}catch(Exception ex) {
println("Catching the exception");
} finally {
println("The final block");
}
println("Let's move on after the exception");
}
}
When we run the program above, we will get the following results —
Catching the Array out of Bounds exception The final block Let's move on after the exception
Here’s the exception method provided in Groovy —
public String getMessage()
Returns a detailed message that an exception has occurred.
This message is initialized in the Throwable constructor.
public Throwable getCause()
Returns the reason for the exception represented by the Throwable object.
public String toString()
Returns the name of the class that is connected to the result of getMessage().
public void printStackTrace()
Print the results of toString() with the stack trace to System.err, the error output stream.
public StackTraceElement [] getStackTrace()
Returns an array that contains each element on the stack trace.
The element at index 0 represents the top of the call stack, and the last element in the array represents the method at the bottom of the call stack.
public Throwable fillInStackTrace()
Use the current stack trace to populate the stack trace of this Thisrowable object and add any previous information to the stack trace.
Example
Here’s an example of code that uses some of the methods given above —
class Example {
static void main(String[] args) {
try {
def arr = new int[3];
arr[5] = 5;
}catch(ArrayIndexOutOfBoundsException ex) {
println(ex.toString());
println(ex.getMessage());
println(ex.getStackTrace());
} catch(Exception ex) {
println("Catching the exception");
}finally {
println("The final block");
}
println("Let's move on after the exception");
}
}
When we run the program above, we will get the following results —
java.lang.ArrayIndexOutOfBoundsException: 5 5 [org.codehaus.groovy.runtime.dgmimpl.arrays.IntegerArrayPutAtMetaMethod$MyPojoMetaMet hodSite.call(IntegerArrayPutAtMetaMethod.java:75), org.codehaus.groovy.runtime.callsite.CallSiteArray.defaultCall(CallSiteArray.java:48) , org.codehaus.groovy.runtime.callsite.AbstractCallSite.call(AbstractCallSite.java:113) , org.codehaus.groovy.runtime.callsite.AbstractCallSite.call(AbstractCallSite.java:133) , Example.main(Sample:8), sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method), sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57), sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) , java.lang.reflect.Method.invoke(Method.java:606), org.codehaus.groovy.reflection.CachedMethod.invoke(CachedMethod.java:93), groovy.lang.MetaMethod.doMethodInvoke(MetaMethod.java:325), groovy.lang.MetaClassImpl.invokeStaticMethod(MetaClassImpl.java:1443), org.codehaus.groovy.runtime.InvokerHelper.invokeMethod(InvokerHelper.java:893), groovy.lang.GroovyShell.runScriptOrMainOrTestOrRunnable(GroovyShell.java:287), groovy.lang.GroovyShell.run(GroovyShell.java:524), groovy.lang.GroovyShell.run(GroovyShell.java:513), groovy.ui.GroovyMain.processOnce(GroovyMain.java:652), groovy.ui.GroovyMain.run(GroovyMain.java:384), groovy.ui.GroovyMain.process(GroovyMain.java:370), groovy.ui.GroovyMain.processArgs(GroovyMain.java:129), groovy.ui.GroovyMain.main(GroovyMain.java:109), sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method), sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57), sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) , java.lang.reflect.Method.invoke(Method.java:606), org.codehaus.groovy.tools.GroovyStarter.rootLoader(GroovyStarter.java:109), org.codehaus.groovy.tools.GroovyStarter.main(GroovyStarter.java:131), sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method), sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57), sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) , java.lang.reflect.Method.invoke(Method.java:606), com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)] The final block Let's move on after the exception

Exception handling is required in any programming language to handle the runtime errors so that normal flow of the application can be maintained.
Exception normally disrupts the normal flow of the application, which is the reason why we need to use Exception handling in our application.
Exceptions are broadly classified into the following categories −
- Checked Exception − The classes that extend Throwable class except RuntimeException and Error are known as checked exceptions e.g.IOException, SQLException etc. Checked exceptions are checked at compile-time.
One classical case is the FileNotFoundException. Suppose you had the following codein your application which reads from a file in E drive.
class Example {
static void main(String[] args) {
File file = new File("E://file.txt");
FileReader fr = new FileReader(file);
}
}
if the File (file.txt) is not there in the E drive then the following exception will be raised.
Caught: java.io.FileNotFoundException: E:file.txt (The system cannot find the file specified).
java.io.FileNotFoundException: E:file.txt (The system cannot find the file specified).
- Unchecked Exception − The classes that extend RuntimeException are known as unchecked exceptions, e.g., ArithmeticException, NullPointerException, ArrayIndexOutOfBoundsException etc. Unchecked exceptions are not checked at compile-time rather they are checked at runtime.
One classical case is the ArrayIndexOutOfBoundsException which happens when you try to access an index of an array which is greater than the length of the array. Following is a typical example of this sort of mistake.
class Example {
static void main(String[] args) {
def arr = new int[3];
arr[5] = 5;
}
}
When the above code is executed the following exception will be raised.
Caught: java.lang.ArrayIndexOutOfBoundsException: 5
java.lang.ArrayIndexOutOfBoundsException: 5
- Error − Error is irrecoverable e.g. OutOfMemoryError, VirtualMachineError, AssertionError etc.
These are errors which the program can never recover from and will cause the program to crash.
The following diagram shows how the hierarchy of exceptions in Groovy is organized. It’s all based on the hierarchy defined in Java.

Catching Exceptions
A method catches an exception using a combination of the try and catch keywords. A try/catch block is placed around the code that might generate an exception.
try {
//Protected code
} catch(ExceptionName e1) {
//Catch block
}
All of your code which could raise an exception is placed in the Protected code block.
In the catch block, you can write custom code to handle your exception so that the application can recover from the exception.
Let’s look at an example of the similar code we saw above for accessing an array with an index value which is greater than the size of the array. But this time let’s wrap our code in a try/catch block.
class Example {
static void main(String[] args) {
try {
def arr = new int[3];
arr[5] = 5;
} catch(Exception ex) {
println("Catching the exception");
}
println("Let's move on after the exception");
}
}
When we run the above program, we will get the following result −
Catching the exception Let's move on after the exception
From the above code, we wrap out faulty code in the try block. In the catch block we are just catching our exception and outputting a message that an exception has occurred.
Multiple Catch Blocks
One can have multiple catch blocks to handle multiple types of exceptions. For each catch block, depending on the type of exception raised you would write code to handle it accordingly.
Let’s modify our above code to catch the ArrayIndexOutOfBoundsException specifically. Following is the code snippet.
class Example {
static void main(String[] args) {
try {
def arr = new int[3];
arr[5] = 5;
}catch(ArrayIndexOutOfBoundsException ex) {
println("Catching the Array out of Bounds exception");
}catch(Exception ex) {
println("Catching the exception");
}
println("Let's move on after the exception");
}
}
When we run the above program, we will get the following result −
Catching the Aray out of Bounds exception Let's move on after the exception
From the above code you can see that the ArrayIndexOutOfBoundsException catch block is caught first because it means the criteria of the exception.
Finally Block
The finally block follows a try block or a catch block. A finally block of code always executes, irrespective of occurrence of an Exception.
Using a finally block allows you to run any cleanup-type statements that you want to execute, no matter what happens in the protected code. The syntax for this block is given below.
try {
//Protected code
} catch(ExceptionType1 e1) {
//Catch block
} catch(ExceptionType2 e2) {
//Catch block
} catch(ExceptionType3 e3) {
//Catch block
} finally {
//The finally block always executes.
}
Let’s modify our above code and add the finally block of code. Following is the code snippet.
class Example {
static void main(String[] args) {
try {
def arr = new int[3];
arr[5] = 5;
} catch(ArrayIndexOutOfBoundsException ex) {
println("Catching the Array out of Bounds exception");
}catch(Exception ex) {
println("Catching the exception");
} finally {
println("The final block");
}
println("Let's move on after the exception");
}
}
When we run the above program, we will get the following result −
Catching the Array out of Bounds exception The final block Let's move on after the exception
Following are the Exception methods available in Groovy −
public String getMessage()
Returns a detailed message about the exception that has occurred. This message is initialized in the Throwable constructor.
public Throwable getCause()
Returns the cause of the exception as represented by a Throwable object.
public String toString()
Returns the name of the class concatenated with the result of getMessage()
public void printStackTrace()
Prints the result of toString() along with the stack trace to System.err, the error output stream.
public StackTraceElement [] getStackTrace()
Returns an array containing each element on the stack trace. The element at index 0 represents the top of the call stack, and the last element in the array represents the method at the bottom of the call stack.
public Throwable fillInStackTrace()
Fills the stack trace of this Throwable object with the current stack trace, adding to any previous information in the stack trace.
Example
Following is the code example using some of the methods given above −
class Example {
static void main(String[] args) {
try {
def arr = new int[3];
arr[5] = 5;
}catch(ArrayIndexOutOfBoundsException ex) {
println(ex.toString());
println(ex.getMessage());
println(ex.getStackTrace());
} catch(Exception ex) {
println("Catching the exception");
}finally {
println("The final block");
}
println("Let's move on after the exception");
}
}
Next Topic:-Click Here