 |
|
|||
| AleXxX_lag
14.01.21 — 20:01 |
Привет всем! Подскажите плиз как победить ошибку CBynaryData: ошибка кодирования/декодирования. |
||
| Волшебник
1 — 14.01.21 — 20:17 |
пишется Binary |
||
| AleXxX_lag
2 — 14.01.21 — 20:32 |
Волшебник,буква в букву написано. скриншот как приложить? |
||
| Сказочный
3 — 14.01.21 — 21:32 |
Звони в 1С отчетность, они помогут |
||
|
Anttonnio 4 — 10.02.21 — 12:36 |
Задал такой вопрос Калуге Астрал и они ответили следующее: Здравствуйте! Попробуйте установить локаль ru_RU.CP1251, например, для Ubuntu вызовами:
sudo /usr/share/locales/install-language-pack ru_RU.CP1251 И это помогло=) |
| |
|
TurboConf — расширение возможностей Конфигуратора 1С |
ВНИМАНИЕ! Если вы потеряли окно ввода сообщения, нажмите Ctrl-F5 или Ctrl-R или кнопку «Обновить» в браузере.
Тема не обновлялась длительное время, и была помечена как архивная. Добавление сообщений невозможно.
Но вы можете создать новую ветку и вам обязательно ответят!
Каждый час на Волшебном форуме бывает более 2000 человек.
Содержание
- Обработка ошибок, возникающих при обмене данными в распределенной информационной базе
- Общие ошибки, возникающие при работе с XML
- Ситуации, возникающие при обмене данными в рамках распределенной информационной базы
- Ошибки на клиенте при работе с сервером 1С на Linux. Часть 2
- Оглавление:
- Ошибка загрузки библиотеки libfontconfig.so
- Не печатается документ с штрихкодом. Ошибка (EObjectNotFound)
- Проблема с кодировкой в загружаемом файле в 1С
- РеКС — друг в мире компьютеров
- Приведение простых типов к типу Строка
- Функция Формат
- Сериализация и десериализация
- Сериализация 1С
- Ошибка кодирования и декодирования в неанглийском имени сжатого файла
- 36 ответов
Обработка ошибок, возникающих при обмене данными в распределенной информационной базе
Общие ошибки, возникающие при работе с XML
Сообщение обмена данными является документом XML, поэтому имеет смысл описать возможные ошибки, которые могут возникнуть во время чтения/записи сообщений обмена данными при использовании средств чтения/записи данных XML, предоставляемых платформой «1С:Предприятие 8». При работе с данными в формате XML может возникать множество различных ситуаций, однако в данной статье будут рассмотрены только те, которые так или иначе имеют отношение к обмену данными в рамках распределенной информационной базы.
Значение URI пространства имен должно соответствовать рекомендации Namespaces in XML (см. http://www.w3.org/TR/REC-xml-names)
Производится попытка записи в XML значения, для типа которого не определена процедура записи в XML. Или производится попытка чтения из XML значения неизвестного типа или типа, для которого не определена процедура чтения из XML.
Ситуации, возникающие при обмене данными в рамках распределенной информационной базы
Источник
Ошибки на клиенте при работе с сервером 1С на Linux. Часть 2

Администраторы и пользователи при работе в сервером 1C установленном на Linux часто сталкиваются с ошибками которые не встречаются на ОС MS Wndows. Связано это с тем что первоначально программа 1С Предприятие долгое время была ориентированна только на работу с ОС Windows и ее портировании на ОС Linux началось сравнительно недавно. Из-за особенностей архитектуры операционной системы Linux, некоторые моменты, которые под ОС Windows были само собой разумеющимися и не вызывали вопросов, тут требуют определенной настройки. Рассмотрим наиболее часто встречающиеся ошибки при работе клиентов с сервером на ОС Linux.
Оглавление:
Ошибка загрузки библиотеки libfontconfig.so
Пример полного текста ошибки:
Описание:
Не запускается база в режиме 1С:Предприятия.
Решение:
Установим недостающие пакеты:
Не печатается документ с штрихкодом. Ошибка (EObjectNotFound)
Пример полного текста ошибки:
Описание:
Не печатается документ с штрихкодом. Текст ошибки может быть связан с получением отраслевой лицензии(для отраслевых конфигураций).
Решение:
Установим недостающие пакеты(в нашем случае нужна была только libpng12):
Проблема с кодировкой в загружаемом файле в 1С
Пример полного текста ошибки:
Пример вывода сообщения об ошибке в программе 1С:

А это пример некорректного отображения символов:

Описание:
При загрузке данных из файла символы преобразовываются некорректно.
Источник
РеКС — друг в мире компьютеров
Приведение простых типов к типу Строка
Приведение простого типа к строке происходит неявным вызовом функции Строка(), которая использует текущие региональные настройки среды пользователя ОС, и поэтому в различных системах и различных сеансах может возвращать различные результаты, что самом по себе не приемлемо во многих задачах. Приведение к строке сложных типов вообще не дает представление о содержании, а содержит только краткое имя типа.
Функция Формат
| Сообщение об ошибке | Описание ошибки |
| Возможные пути исправления ошибки | |
| Не установлен MS XML Core Services 4.0 | На компьютере не установлен Microsoft XML Core Services 4.0, используемый «1С:Предприятием 8» для работы с XML |
| Установить Microsoft XML Core Services 4.0. При установке «1С:Предприятия 8» Microsoft XML Core Services 4.0 устанавливается автоматически | |
| Ошибка разбора XML | Ошибка, возникающая при синтаксическом анализе данных XML в процессе чтения. Все ошибки, определенные в SAX2, трансформируются в данную ошибку, генерируемую платформой «1С:Предприятие 8» |
| Проверить правильность оформления и синтаксис данных XML (см. http://www.w3.org/TR/REC-xml). | |
| Ошибочный порядок записи XML | Методы записи содержимого документа XML вызываются в неправильном порядке. Например, запись атрибута вызывается после записи текста элемента. |
| Выявить и исправить места некорректного порядка вызова методов | |
| Текст XML содержит недопустимые символы | Записываемый текст XML содержит недопустимые символы. |
| Текст XML должен соответствовать требованиям, изложенным в главе 2.2 рекомендации XML (см. http://www.w3.org/TR/REC-xml#charsets) | |
| Недопустимое имя XML | Записываемое имя XML содержит недопустимые символы. |
| Имя XML должно соответствовать требованиям, изложенным в главе 2.3 рекомендации XML (см. http://www.w3.org/TR/REC-xml#NT-Name) | |
| Пустое значение URI допустимо только для пространства имен по умолчанию | Производится попытка записать соответствие пространства имен, в котором URI пространства имен, представленному пустой строкой, соответствует непустой префикс. |
| вид Форматной Строки | Формат( ) | = | Описание |
|---|---|---|---|
| — | (1234567.89) (0) |
1 234 567,89 | Отсутствие строки форматирования эквивалентно функции Строка(…) |
| ЧЦ (ND) (число цифр) |
(1234567.89,»ЧЦ=10;») (1234567.89,»ЧЦ=7;») (1234567.89,»ЧЦ=6;») |
1 234 568 1 234 568 999 999 |
общее число отображаемых десятичных разрядов целой и дробной частей. Исходное число округляется при этом в соответствии с правилами округления Окр15как20. Если указан этот параметр, то для отображения дробной части числа обязательно указание параметра ЧДЦ, иначе дробная часть отображаться не будет. |
| ЧВН () (число вывод нуля) |
(1234567.89,»ЧЦ=9;ЧВН=;») (1234567.89,»ЧЦ=6;ЧВН=;») |
001 234 568 999 999 |
если параметр указан, лидирующие нули выводятся. Если не указан — лидирующие нули не выводятся. Значение параметра игнорируется. |
| ЧН (NZ) (число ноль) |
(0,»ЧН=;») (0,»ЧН=;ЧЦ=9;») (0,»ЧЦ=9;ЧН=;ЧВН=;») |
0 0 000 000 000 |
строка, представляющая нулевое значение числа. Если не задано, то представление в виде пустой строки. Если задано «ЧН=», то в виде «0». Не используется для числовых полей ввода. |
| ЧРГ (NGS) (число разделитель групп) |
(1234567.89,»ЧРГ=;») (1234567.89,»ЧРГ= «) (1234567.89,»ЧРГ=+;») (1234567.89,»ЧРГ=0;») |
1 234 567,89 1 234`567,89 1+234+567,89 102340567,89 |
символ-разделитель групп целой части числа. Если в качестве разделителя использовать пустую строку, то в этом случае разделителем будет символ неразрывного пробела. |
| ЧГ (NG) число группа |
(1234567.89,»ЧГ=;») (1234567.89,»ЧГ=0;») (1234567.89,»ЧГ=3;») (1234567.89,»ЧГ=3,2;») |
1234567,89 1234567,89 1234 567,89 12 34 567,89 |
порядок группировки разрядов числа. В качестве значения указываются числа, через запятую, обозначающие количество группируемых разрядов справа налево. Имеют смысл только два первых числа. Первое из них указывает первичную группировку, то есть ту, которая будет использована для наименее значимых разрядов целой части числа. Если второе число не указано, то будут сгруппированы только наименее значимые разряды. Если в качестве второго числа задан 0, то для всех разрядов целой части числа будет применено значение указанное для первичной группировки. Если в качестве второго числа используется значение, отличное от 0, то это значение будет использовано для группировки всех разрядов, кроме уже сгруппированных наименее значимых. |
| ЧРД (NDS) число разделитель дробной части |
(1234567.89,»ЧРД=;») (1234567.89,»ЧРД=.;») (1234567.89,»ЧРД=:;») |
1 234 567,89 1 234 567.89 1 234 567:89 |
символ-разделитель целой и дробной части. |
| ЧДЦ (NFD) число десятичные цифры |
(1234567.89,»ЧДЦ=0;») (1234567.89,»ЧДЦ=1;») (1234567.89,»ЧДЦ=3;») |
1 234 567 1 234 567,9 1 234 567,890 |
число десятичных разрядов в дробной части. Исходное число округляется при этом в соответствии с правилами округления Окр15как20. |
| ЧО (NN) число отрицательные |
(-1234567.89,»ЧО=0″) (-1234567.89,»ЧО=1″) (-1234567.89,»ЧО=2″) (-1234567.89,»ЧО=3″) (-1234567.89,»ЧО=4″) |
(1 234 567,89) -1 234 567,89 — 1 234 567,89 1 234 567,89- 1 234 567,89 — |
представление отрицательных чисел. |
| ЧС (NS) число сдвиг |
(1234567.89,»ЧС=0;») (1234567.89,»ЧС=1;») (1234567.89,»ЧС=9;») (1234567.89,»ЧС=-6;») |
1 234 567,89 123 456,789 0,00123456789 1 234 567 890 000 |
сдвиг разрядов: положительный — деление, отрицательный — умножение. Другими словами, это означает, что исходное число будет умножено или поделено на 10*С, где С — значение параметра по модулю. |
| ЧФ (NF) число формат |
(1234567.89,»ЧФ=’Ч штук’;») (12345.89,»ЧФ=’Вес: Ч’;») (123,»ЧФ=’ЧЧЧ’;») |
1 234 567,89 штук Вес: 12 345,89 123123123 |
шаблон форматирования числа. В строке можно использовать символ Ч(N) для указания позиции, в которую нужно вывести число. Число выводится с учетом остальных параметров, заданных в форматной строке. Остальные символы выводятся как есть. Символы, находящиеся между двойными или одинарными кавычками выводятся как есть. Шаблон форматирования не применяется к числу 0 (за исключением случая наличия в формате строки параметра «ЧН=»). |
| Форматирование типа Булево | |||
| БЛ (BF) булево Ложь |
(Истина,»БЛ=Неправда;») (Ложь,»БЛ=Неправда;») |
Да Неправда |
строка, представляющая логическое значение Ложь. |
| БИ (BT) булево Истина |
(Истина,»БИ=Правда;») (Ложь,»БИ=Правда;») |
Правда Нет |
строка, представляющая логическое значение Истина. |
| БИ=;БЛ=; булево Истина и Ложь |
(Истина,»БИ=Свет;БЛ=Тьма») (Ложь,»БИ=Свет;БЛ=Тьма») |
Свет Тьма |
комбинированная форматная строка для типа Булево |
| Полезные комбинированные форматные строки | |||
| ЧГ=;ЧН=; ноль и числа без групп |
(0,»ЧГ=;ЧН=;») (1234567,89,»ЧГ=;ЧН=;») |
0 -1234567,89 |
отменяет числовые группы и выводит «0» для обычного отображения и экспорта в Ecxel |
| ЧРД=.;ЧГ=0;ЧН=; точка, ноль, без групп |
(0,»ЧРД=.;ЧГ=0;ЧН=;») (1234567.89,»ЧРД=.;ЧГ=0;ЧН=;») |
0 1234567.89 |
использует десятичную точку, отменяет числовые группы и выводит «0» для вычисления в формулах, для обмена данными и сериализации |
Для преобразования к строке типа Дата используют другие виды форматных строк:
| вид Форматной Строки | Формат( ) | = | Описание |
|---|---|---|---|
| — | (‘00010101000000’) (‘20060504010203’) |
01.02.2003 4:05:06 | Отсутствие строки форматирования эквивалентно функции Строка(…) |
| ДФ (DF) (дата формат) |
(‘20030201040506’, «ДФ=’дддд дд.ММ.гггг ЧЧ:мм:сс’») (‘20030201040506’, «ДФ=»»ддд дд ММММ гггг’г.’»»») (‘20030201040506’, «ДФ=’д.М.г Ч:м:с’») |
суббота 01.02.2003 04:05:06 Сб 01 февраля 2003г. 1.2.3 4:5:6 |
формат даты позволяет задать произвольный способ преобразоания
Важно! Порядок следования опций форматной строки для ДЛФ (ДВ или ДДВ) не может быть изменен. При комбинировании ДФ и ДЛФ, приоритет получает ДФ, а ДЛФ игнорируется. |
| ДП (DE) (дата пустая) |
(‘00010101000000’, «ДЛФ=Д;ДП=’без даты’») (‘20030201040506’, «ДЛФ=Д;ДП=’без даты’») |
без даты 01.02.2003 |
формат пустой даты устанавливает текст представления пустой даты |
Сериализация и десериализация
Понятие сериализации данных применяется, когда некоторые данные некоторого типа необходимо преобразовать в строковую последовательность, но не с целью представления, а для передачи средствами какого-либо потока. После прохождения сериализованной строковой последовательностью потока она должна быть точно преобразована к первоначальному или эквивалентному типу с эквивалентным значением.
Сериализация 1С
Платформа 1С реализует собственный формат сериализации, который может быть использован в модулях с компиляцией &НаСервере парой функций прямого и обратного преобразования:
Пример сериализации реквизита типа СписокЗначений:
Источник
Ошибка кодирования и декодирования в неанглийском имени сжатого файла
У меня есть rar-файл. После извлечения он генерирует файл с китайским именем, который показан в Nautilus как:
В терминале это показано как:
Содержимое rar-файла, указанного в unrar, является correct:
Файл не может быть открыт, если я не изменю его имя на что-то вроде 1.djvu.
Мне было интересно, почему персонажи не отображаются правильно с китайским именем сжатого файла, в то время как я могу создать каталог или файл с китайским именем?
Как мне это сделать?
36 ответов
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: cd /path/to/directory/ Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: unrar x filename.rar Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: cd /path/to/directory/ Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: unrar x filename.rar Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: cd /path/to/directory/ Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: unrar x filename.rar Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: cd /path/to/directory/ Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: unrar x filename.rar Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: cd /path/to/directory/ Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: unrar x filename.rar Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: cd /path/to/directory/ Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: unrar x filename.rar Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Похоже, что имя файла создает другую кодировку символов, чем ваша среда. Символ ѧ (CYRILLIC SMALL LETTER LITTLE YUS), скорее всего, не является частью китайского имени файла.
Есть ли у вас информация об операционной системе и языковых настройках, в которой был создан файл? Вы знаете, какие кодировки символов являются общими для кодирования китайских имен файлов?
Если вы знаете кодировку имен файлов, вы можете использовать convmv (не установленный по умолчанию), чтобы преобразовать его в используемую вами кодировку (скорее всего, UTF- 8).
У меня была та же проблема с rar-файлом, который содержал имена с кириллическими буквами. Я смог исправить это, переустановив unrar, как это предлагается здесь:
Оказалось, что по умолчанию версия с открытым исходным кодом rar & amp; Утилиты unrar установлены в Ubuntu: «unrar 0.0.1 Copyright (C) 2004 Ben Asselstine, Jeroen Dekkers».
После переустановки unrar фактическая версия его установлена из репозитория «ограниченного» (проприетарного программного обеспечения) (обратите внимание, что это должно быть включено в настройках вашего обновления ): «UNRAR 5.40 freeware Copyright (c) 1993-2016 Александр Рошаль»
Эта версия обрабатывает символы Unicode, по крайней мере, она работала для меня с кириллическими буквами.
Обратите внимание, что удаление open исходная версия rar / unrar также устранила проблему с программным обеспечением GUI:
Похоже, что имя файла создает другую кодировку символов, чем ваша среда. Символ ѧ (CYRILLIC SMALL LETTER LITTLE YUS), скорее всего, не является частью китайского имени файла.
Есть ли у вас информация об операционной системе и языковых настройках, в которой был создан файл? Вы знаете, какие кодировки символов являются общими для кодирования китайских имен файлов?
Если вы знаете кодировку имен файлов, вы можете использовать convmv (не установленный по умолчанию), чтобы преобразовать его в используемую вами кодировку (скорее всего, UTF- 8).
У меня была та же проблема с rar-файлом, который содержал имена с кириллическими буквами. Я смог исправить это, переустановив unrar, как это предлагается здесь:
Оказалось, что по умолчанию версия с открытым исходным кодом rar & amp; Утилиты unrar установлены в Ubuntu: «unrar 0.0.1 Copyright (C) 2004 Ben Asselstine, Jeroen Dekkers».
После переустановки unrar фактическая версия его установлена из репозитория «ограниченного» (проприетарного программного обеспечения) (обратите внимание, что это должно быть включено в настройках вашего обновления ): «UNRAR 5.40 freeware Copyright (c) 1993-2016 Александр Рошаль»
Эта версия обрабатывает символы Unicode, по крайней мере, она работала для меня с кириллическими буквами.
Обратите внимание, что удаление open исходная версия rar / unrar также устранила проблему с программным обеспечением GUI:
Похоже, что имя файла создает другую кодировку символов, чем ваша среда. Символ ѧ (CYRILLIC SMALL LETTER LITTLE YUS), скорее всего, не является частью китайского имени файла.
Есть ли у вас информация об операционной системе и языковых настройках, в которой был создан файл? Вы знаете, какие кодировки символов являются общими для кодирования китайских имен файлов?
Если вы знаете кодировку имен файлов, вы можете использовать convmv (не установленный по умолчанию), чтобы преобразовать его в используемую вами кодировку (скорее всего, UTF- 8).
У меня была та же проблема с rar-файлом, который содержал имена с кириллическими буквами. Я смог исправить это, переустановив unrar, как это предлагается здесь:
Оказалось, что по умолчанию версия с открытым исходным кодом rar & amp; Утилиты unrar установлены в Ubuntu: «unrar 0.0.1 Copyright (C) 2004 Ben Asselstine, Jeroen Dekkers».
После переустановки unrar фактическая версия его установлена из репозитория «ограниченного» (проприетарного программного обеспечения) (обратите внимание, что это должно быть включено в настройках вашего обновления ): «UNRAR 5.40 freeware Copyright (c) 1993-2016 Александр Рошаль»
Эта версия обрабатывает символы Unicode, по крайней мере, она работала для меня с кириллическими буквами.
Обратите внимание, что удаление open исходная версия rar / unrar также устранила проблему с программным обеспечением GUI:
Похоже, что имя файла создает другую кодировку символов, чем ваша среда. Символ ѧ (CYRILLIC SMALL LETTER LITTLE YUS), скорее всего, не является частью китайского имени файла.
Есть ли у вас информация об операционной системе и языковых настройках, в которой был создан файл? Вы знаете, какие кодировки символов являются общими для кодирования китайских имен файлов?
Если вы знаете кодировку имен файлов, вы можете использовать convmv (не установленный по умолчанию), чтобы преобразовать его в используемую вами кодировку (скорее всего, UTF- 8).
У меня была та же проблема с rar-файлом, который содержал имена с кириллическими буквами. Я смог исправить это, переустановив unrar, как это предлагается здесь:
Оказалось, что по умолчанию версия с открытым исходным кодом rar & amp; Утилиты unrar установлены в Ubuntu: «unrar 0.0.1 Copyright (C) 2004 Ben Asselstine, Jeroen Dekkers».
После переустановки unrar фактическая версия его установлена из репозитория «ограниченного» (проприетарного программного обеспечения) (обратите внимание, что это должно быть включено в настройках вашего обновления ): «UNRAR 5.40 freeware Copyright (c) 1993-2016 Александр Рошаль»
Эта версия обрабатывает символы Unicode, по крайней мере, она работала для меня с кириллическими буквами.
Обратите внимание, что удаление open исходная версия rar / unrar также устранила проблему с программным обеспечением GUI:
Похоже, что имя файла создает другую кодировку символов, чем ваша среда. Символ ѧ (CYRILLIC SMALL LETTER LITTLE YUS), скорее всего, не является частью китайского имени файла.
Есть ли у вас информация об операционной системе и языковых настройках, в которой был создан файл? Вы знаете, какие кодировки символов являются общими для кодирования китайских имен файлов?
Если вы знаете кодировку имен файлов, вы можете использовать convmv (не установленный по умолчанию), чтобы преобразовать его в используемую вами кодировку (скорее всего, UTF- 8).
у меня была такая же проблема с rar-файл, содержащий имена с русскими буквами. Я был в состоянии исправить это путем переустановки unrar, как это предложено здесь:
оказалось, что по умолчанию с открытым исходным кодом версия rar & [F4] и коммунальных услуг устанавливается в Ubuntu: «распаковка 0.0.1 Авторское право (C) 2004 Бен Asselstine, Йерун Деккерс». Эта версия не обрабатывает не-ASCII символы.
после переустановки unrar актуальная версия он установлен с «ограниченным» (проприетарное программное обеспечение) репозиторий (обратите внимание, что это должно быть включено в обновление настройки): «распаковка 5.40 бесплатные программы Авторское право (C) 1993-2016 Александр Рошаль»
эта версия обрабатывает символы в кодировке Юникод, по крайней мере, это сработало для меня с русскими буквами.
обратите внимание, что удаление открытым исходным кодом варианте rar/unrar на, также Исправлена ошибка с графическим программным обеспечением:
Источник
Содержание
- Как так получилось, что мой скрипт работает на моем компьютере, но при размещении на моем raspberry pi он продолжает выдавать ошибки кодирования/декодирования?
- Cbynarydata ошибка кодирования декодирования 1c linux
- 1с Тонкий клиент linux
- Порядок установки 1c тонкого клиента
- Распространенная ошибка с пакетом libwebkitgtk в 1с
- Первый вариант
- Вариант второй для Debian 10
- Ошибки со шрифтом 1с
- Ошибка расшифровки файла
- Возникновение ошибок
- Обновление криптопровайдеров
- Пошаговая инструкция по обновлению криптопровайдера
- Другие причины возникновения ошибок
- Проверка версии криптопровайдера
- Обновление 1С
- Права пользователя, отправляющего отчетность
- Техническая поддержка Калуга-Астрал
- Настройка криптографии
- Рекомендации Бухэксперт8
- Полный список рекомендаций 1С
- Похожие публикации
- Карточка публикации
- Все комментарии (1)
- Добавить комментарий Отменить ответ
- Содержание
- проблема
- анализ проблемы
- Посмотреть кодировку страницы
- Кодировка и декодирование текста
- Вернуться к вопросу
- задача решена
- Проблема кодирования Python3
- Возвышенная проблема конфигурации
- Введение
- Кодирование строковых переменных
- Кодировка скрипта
- Кодировка пи-файла
- Кодировка окна дисплея
- В заключение
- Другие производные
Как так получилось, что мой скрипт работает на моем компьютере, но при размещении на моем raspberry pi он продолжает выдавать ошибки кодирования/декодирования?
У меня есть простой сценарий для учебных целей. Он собирает информацию о погоде с веб-сайта, обмен валюты с другого веб-сайта и мировые новости с помощью API Reddit. Затем он упаковывает все это в электронное письмо и отправляет его. Когда я запускаю этот скрипт на своем компьютере (макбуке, чего бы это ни стоило), он просто работает как шарм, ноль проблем, никаких проблем. Но когда я размещаю свой скрипт и запускаю его на своем Raspberry Pi, начинаются все проблемы, в основном проблемы с кодировкой/декодированием.
Полный код слишком длинный, но в основном у меня есть несколько переменных:
этот содержит информацию о погоде, которую я кодирую в utf-8, учитывая, что символ градуса вызывал проблемы и не отображался на экране должным образом:
теперь у меня есть список reddit.posts , который представляет собой список заголовков, пока все хорошо, здесь та же проблема, поэтому я решил преобразовать его в utf-8, чтобы предотвратить любые проблемы в будущем:
[x.encode(‘utf-8’) for x in reddit.posts]
Все идет нормально. Когда приходит время представить эту информацию, я упаковываю ее в электронное письмо как часть содержимого HTML. Я запускаю этот скрипт со своего компьютера, и он отлично работает, ошибок кодирования нет, и все символы отображаются правильно.
Но мое удивление заключается в том, что этот код, который отлично работает на моем Mac, когда я отправляю его на свой Raspberry Pi, начинает выдавать массу сумасшедших ошибок:
UnicodeEncodeError: ‘ascii’ codec can’t encode character u’xb0′ in position 353: ordinal not in range(128)
ВСЕ ВРЕМЯ. Я попытался снова декодировать строки в utf-8, поэтому в одном случае код будет примерно таким (упрощением):
Но постоянно выдает ошибки.
Что меня действительно сбило с толку, так это то, что он отлично работает на моем ноутбуке, но выдает ошибки в малине.
Что здесь не так, ребята, это сводит меня с ума.
U+00B0 — знак градуса. Это указывает на то, что кодировка не UTF-8, как вы предполагаете, а Latin-9 или Windows-1252 или совместимая. Разве вы не можете использовать правильную библиотеку HTTP, которая автоматически правильно декодирует в соответствии с заголовком Content-Type?
Источник
Cbynarydata ошибка кодирования декодирования 1c linux
У меня есть rar-файл. После извлечения он генерирует файл с китайским именем, который показан в Nautilus как:
ѧ. . ѧ .2008.djvu (неверная кодировка)
В терминале это показано как:
Содержимое rar-файла, указанного в unrar, является correct:
$ unrar l 近代组合学.王天明.大连理工大学出版 社.2008.rar UNRAR 3.93 freeware Copyright (c) 1993-2010 Alexander Roshal Archive 近代组合学.王天明.大连理工大学出版社.2008.rar Name Size Packed Ratio Date Time Attr CRC Meth Ver ——————————————————————————- 近代组合学.王天明.大连理工大学出版社.2008.djvu 6190416 6187189 99% 03-06-11 10:33 . A. 98320D40 m3g 2.9 ——————————————————————————- 1 6190416 6187189 99%
Файл не может быть открыт, если я не изменю его имя на что-то вроде 1.djvu.
Мне было интересно, почему персонажи не отображаются правильно с китайским именем сжатого файла, в то время как я могу создать каталог или файл с китайским именем?
Как мне это сделать?
Спасибо и привет!
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Благодаря! Это решает проблему. Но как я могу заставить GUI распознавать китайские кодировки? – Tim 11 June 2011 в 01:54
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: cd /path/to/directory/ Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: unrar x filename.rar Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: cd /path/to/directory/ Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: unrar x filename.rar Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: cd /path/to/directory/ Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: unrar x filename.rar Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: cd /path/to/directory/ Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: unrar x filename.rar Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: cd /path/to/directory/ Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: unrar x filename.rar Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
Откройте терминал. Перейдите в каталог, содержащий файл: cd /path/to/directory/ Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если имеется несколько вариантов. Запустите программу unrar для распаковки filename.rar: unrar x filename.rar Здесь вы можете использовать также заполнение табуляции для имени файла. Содержимое архива будет видно в текущем каталоге.
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
- Откройте терминал .
- Перейдите в каталог, содержащий файл: cd / path / to / directory / Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если есть несколько вариантов.
- Запустите программу unrar , чтобы распаковать filename.rar : unrar x filename.rar Здесь вы можете использовать для заполнения имени вкладки.
- Содержимое архива будет отображаться в текущем каталоге. [ ! d9]
Возможно, программа графического архива не понимает китайский язык. Попробуйте извлечь архив с помощью командной строки:
- Откройте терминал .
- Перейдите в каталог, содержащий файл: cd / path / to / directory / Вы можете использовать клавишу Tab для завершения имен файлов и имен каталогов. Дважды нажмите «Tab», чтобы получить список возможных завершений в случае, если есть несколько вариантов.
- Запустите программу unrar , чтобы распаковать filename.rar : unrar x filename.rar Здесь вы можете использовать для заполнения имени вкладки.
- Содержимое архива будет отображаться в текущем каталоге. [ ! d9]
Благодаря! Это решает проблему. Но как я могу заставить GUI распознавать китайские кодировки? – Tim 11 June 2011 в 01:54
Похоже, что имя файла создает другую кодировку символов, чем ваша среда. Символ ѧ (CYRILLIC SMALL LETTER LITTLE YUS), скорее всего, не является частью китайского имени файла.
Есть ли у вас информация об операционной системе и языковых настройках, в которой был создан файл? Вы знаете, какие кодировки символов являются общими для кодирования китайских имен файлов?
Если вы знаете кодировку имен файлов, вы можете использовать convmv (не установленный по умолчанию), чтобы преобразовать его в используемую вами кодировку (скорее всего, UTF- 8).
Благодаря! Я предполагаю, что он был создан в Windows. Из Википедии китайскими кодировками являются китайский Guobiao: GB 2312, GBK (код Microsoft 936) и GB 18030. – Tim 11 June 2011 в 01:48
Оказалось, что по умолчанию версия с открытым исходным кодом rar & amp; Утилиты unrar установлены в Ubuntu: «unrar 0.0.1 Copyright (C) 2004 Ben Asselstine, Jeroen Dekkers».
После переустановки unrar фактическая версия его установлена из репозитория «ограниченного» (проприетарного программного обеспечения) (обратите внимание, что это должно быть включено в настройках вашего обновления ): «UNRAR 5.40 freeware Copyright (c) 1993-2016 Александр Рошаль»
Эта версия обрабатывает символы Unicode, по крайней мере, она работала для меня с кириллическими буквами.
Обратите внимание, что удаление open исходная версия rar / unrar также устранила проблему с программным обеспечением GUI:
unrar —enable-charset x $1
Похоже, что имя файла создает другую кодировку символов, чем ваша среда. Символ ѧ (CYRILLIC SMALL LETTER LITTLE YUS), скорее всего, не является частью китайского имени файла.
Есть ли у вас информация об операционной системе и языковых настройках, в которой был создан файл? Вы знаете, какие кодировки символов являются общими для кодирования китайских имен файлов?
Если вы знаете кодировку имен файлов, вы можете использовать convmv (не установленный по умолчанию), чтобы преобразовать его в используемую вами кодировку (скорее всего, UTF- 8).
Благодаря! Я предполагаю, что он был создан в Windows. Из Википедии китайскими кодировками являются китайский Guobiao: GB 2312, GBK (код Microsoft 936) и GB 18030. – Tim 11 June 2011 в 01:48
$ sudo apt-get remove rar $ sudo apt-get remove unrar $ sudo apt-get install unrar
Оказалось, что по умолчанию версия с открытым исходным кодом rar & amp; Утилиты unrar установлены в Ubuntu: «unrar 0.0.1 Copyright (C) 2004 Ben Asselstine, Jeroen Dekkers».
После переустановки unrar фактическая версия его установлена из репозитория «ограниченного» (проприетарного программного обеспечения) (обратите внимание, что это должно быть включено в настройках вашего обновления ): «UNRAR 5.40 freeware Copyright (c) 1993-2016 Александр Рошаль»
Эта версия обрабатывает символы Unicode, по крайней мере, она работала для меня с кириллическими буквами.
Обратите внимание, что удаление open исходная версия rar / unrar также устранила проблему с программным обеспечением GUI:
unrar —enable-charset x $1
Похоже, что имя файла создает другую кодировку символов, чем ваша среда. Символ ѧ (CYRILLIC SMALL LETTER LITTLE YUS), скорее всего, не является частью китайского имени файла.
Есть ли у вас информация об операционной системе и языковых настройках, в которой был создан файл? Вы знаете, какие кодировки символов являются общими для кодирования китайских имен файлов?
Если вы знаете кодировку имен файлов, вы можете использовать convmv (не установленный по умолчанию), чтобы преобразовать его в используемую вами кодировку (скорее всего, UTF- 8).
Благодаря! Я предполагаю, что он был создан в Windows. Из Википедии китайскими кодировками являются китайский Guobiao: GB 2312, GBK (код Microsoft 936) и GB 18030. – Tim 11 June 2011 в 01:48
$ sudo apt-get remove rar $ sudo apt-get remove unrar $ sudo apt-get install unrar
Оказалось, что по умолчанию версия с открытым исходным кодом rar & amp; Утилиты unrar установлены в Ubuntu: «unrar 0.0.1 Copyright (C) 2004 Ben Asselstine, Jeroen Dekkers».
После переустановки unrar фактическая версия его установлена из репозитория «ограниченного» (проприетарного программного обеспечения) (обратите внимание, что это должно быть включено в настройках вашего обновления ): «UNRAR 5.40 freeware Copyright (c) 1993-2016 Александр Рошаль»
Эта версия обрабатывает символы Unicode, по крайней мере, она работала для меня с кириллическими буквами.
Обратите внимание, что удаление open исходная версия rar / unrar также устранила проблему с программным обеспечением GUI:
unrar —enable-charset x $1
Похоже, что имя файла создает другую кодировку символов, чем ваша среда. Символ ѧ (CYRILLIC SMALL LETTER LITTLE YUS), скорее всего, не является частью китайского имени файла.
Есть ли у вас информация об операционной системе и языковых настройках, в которой был создан файл? Вы знаете, какие кодировки символов являются общими для кодирования китайских имен файлов?
Если вы знаете кодировку имен файлов, вы можете использовать convmv (не установленный по умолчанию), чтобы преобразовать его в используемую вами кодировку (скорее всего, UTF- 8).
Благодаря! Я предполагаю, что он был создан в Windows. Из Википедии китайскими кодировками являются китайский Guobiao: GB 2312, GBK (код Microsoft 936) и GB 18030. – Tim 11 June 2011 в 01:48
$ sudo apt-get remove rar $ sudo apt-get remove unrar $ sudo apt-get install unrar
Оказалось, что по умолчанию версия с открытым исходным кодом rar & amp; Утилиты unrar установлены в Ubuntu: «unrar 0.0.1 Copyright (C) 2004 Ben Asselstine, Jeroen Dekkers».
После переустановки unrar фактическая версия его установлена из репозитория «ограниченного» (проприетарного программного обеспечения) (обратите внимание, что это должно быть включено в настройках вашего обновления ): «UNRAR 5.40 freeware Copyright (c) 1993-2016 Александр Рошаль»
Эта версия обрабатывает символы Unicode, по крайней мере, она работала для меня с кириллическими буквами.
Обратите внимание, что удаление open исходная версия rar / unrar также устранила проблему с программным обеспечением GUI:
unrar —enable-charset x $1
Похоже, что имя файла создает другую кодировку символов, чем ваша среда. Символ ѧ (CYRILLIC SMALL LETTER LITTLE YUS), скорее всего, не является частью китайского имени файла.
Есть ли у вас информация об операционной системе и языковых настройках, в которой был создан файл? Вы знаете, какие кодировки символов являются общими для кодирования китайских имен файлов?
Если вы знаете кодировку имен файлов, вы можете использовать convmv (не установленный по умолчанию), чтобы преобразовать его в используемую вами кодировку (скорее всего, UTF- 8).
Благодаря! Я предполагаю, что он был создан в Windows. Из Википедии китайскими кодировками являются китайский Guobiao: GB 2312, GBK (код Microsoft 936) и GB 18030. – Tim 11 June 2011 в 01:48
$ sudo apt-get remove rar $ sudo apt-get remove unrar $ sudo apt-get install unrar
оказалось, что по умолчанию с открытым исходным кодом версия rar & [F4] и коммунальных услуг устанавливается в Ubuntu: «распаковка 0.0.1 Авторское право (C) 2004 Бен Asselstine, Йерун Деккерс». Эта версия не обрабатывает не-ASCII символы.
после переустановки unrar актуальная версия он установлен с «ограниченным» (проприетарное программное обеспечение) репозиторий (обратите внимание, что это должно быть включено в обновление настройки): «распаковка 5.40 бесплатные программы Авторское право (C) 1993-2016 Александр Рошаль»
эта версия обрабатывает символы в кодировке Юникод, по крайней мере, это сработало для меня с русскими буквами.
обратите внимание, что удаление открытым исходным кодом варианте rar/unrar на, также Исправлена ошибка с графическим программным обеспечением:

1с Тонкий клиент linux
1c thin-client или 1с тонкий клиент. Устанавливаем в Debian 10 и в дистрибутивах на его основе, использующие deb пакеты.
Уже не первый раз приходится обновлять тонкий клиент 1с на новую версию. Если в операционной системе windows это все сводится к простому нажатию Далее, Далее и ОК, то в системах Linux как правило возникают нюансы.
Порядок установки 1c тонкого клиента
Для установки тонкого клиента в системах Linux использующих deb пакеты как правило необходимо установить два пакета.
Первым ставим пакет самого клиента, а затем ставим языковый пакет. Пакет содержащий переводы, языки отличные от английского.

Хочу напомнить, если вы используете debin 10, то для установки пакета используйте командную строку
команда будет выглядеть так
Если будете устанавливать с помощью приложения GDebi, то вначале запустите его, а потом из его меню выберите пакет для установки.

Для этого выберите пункт файл, затем открыть и в открывшемся окне выберите нужный пакет.
Распространенная ошибка с пакетом libwebkitgtk в 1с
Как правило многие столкнутся с ошибкой в зависимостях с пакетом libwebkitgtk на момент написания статьи его версия 3.0 и полное го название libwebkitgtk-3.0
Последняя цифра это, как уже догадались, его версия.
Ошибка выглядит так

Соответственно, чтоб решить эту проблему нужно добавить репозиторий с этим пакетом и установить его.
Первый вариант
Подойдет для дистрибутивов Ubuntu и Mint
Подключаем репозиторий с этим пакетом, для этого в терминале откроем sources.list идобавим его туда.
Открываем файл sources.list командой в терминале, с помощью редактора nano
В конец добавляем строчку нашего репозитория
Выглядеть это будет так

Затем сохраняем сочетанием клавиш Ctrl+O и закрываем Ctrl+x
Далее традиционно обновляемся
Ну и затем ставим пакет

Просто откройте снова его через терминал в редакторе nano
Не забудьте сохранить файл сочетанием клавиш Ctrl+O и закрываем Ctrl+x
Далее ставим наш клиент 1с, ошибок не должно быть, не забываем про пакет с поддержкой языков.
Вариант второй для Debian 10
Если у вас Debian 10 то добавьте в список репозиториев репозиторий stretch.
Откройте файл репозиториев в терминале при помощи редактора nano
Добавьте в конец репозиторий
Не забываем после изменений сохранить Ctrl+O и закрыть Ctrl+x
Далее традиционно обновимся
sudo apt update
Теперь поставим, недостающий пакет именно из того репозитория который указали
После ставим наш пакет 1с с тонким клиентом и его языковый пакет.
Ошибки со шрифтом 1с
Как правило после установки тонкого клиента многим не нравится шрифт.
Иногда не корректно отображается шрифт.
Для решения этих вопросов необходимо до установить пакеты с нужными шрифтами.
Порядок установки и их название описаны в статье по первоначальным настройкам debian и настройкам debian10.
Многие организации используют в программе дополнительный сервис 1С-Отчетность . С помощью него они обмениваются отчетами и прочим электронным документооборотом с контролирующими органами непосредственно из 1С без использования сторонних программ, что очень удобно. Но усложнение программы, как всегда бывает, приводит к новым ошибкам, с которыми нужно уметь справляться.
Прочитав статью, вы:
- Получите важную информацию на 2019 год от оператора 1С-Отчетность Калуга Астрал .
- Узнаете, какие ошибки возникают при обмене электронного документооборота.
- Изучите рекомендации по исправлению ошибок, полученных при попытке расшифровать файл. Это самая распространенная ошибка в 1С-Отчетности .
Ошибка расшифровки файла
Список возможных ошибок 1С-Отчетности можно посмотреть здесь. PDF
- Не расшифровано.
- Не найден сертификат. Ошибка расшифровки файла документа при распаковке пакета.
22 ноября 2018 года оператор 1С-Отчетности распространил следующую информацию для партнеров 1С и пользователей, сдающих отчетность в ПФР Москвы и Московской области.
Если вы сдаете отчетность в ПФР Москвы и Московской области, то вы гарантированно получите указанную ошибку.

Возникновение ошибок
Использование криптопровайдеров ниже версий VipNet 4.2 или КриптоПро CSP 4.0 повлечет возникновение ошибок при обработке документов на стороне ПФР.
Обновление криптопровайдеров
Для исключения технических проблем при работе с ПФР, необходимо обновить криптопровайдеры до версий: VipNet 4.2 или КриптоПро CSP 4.0 и выше.
Пошаговая инструкция по обновлению криптопровайдера
Шаг 1. Откройте криптопровайдер, щелкнув мышкой по иконке VipNet СSP .

Шаг 2. Проверьте версию криптопровайдера VipNet в нижнем левом углу открывшейся формы.

Шаг 3. Обновите версию криптопровайдера по инструкции оператора Калуга Астрал, если:
- сдаете отчетность в ПФР Москвы и Московской области;
- версия вашего криптопровайдера VipNet ниже 4.2.

Другие причины возникновения ошибок
Проверка версии криптопровайдера

Обновление 1С
Второе не менее важное правило: перед глубоким погружением в проблему выполните две несложных проверки в1С:
- проверьте на актуальность релиз вашей 1С;
- уточните права пользователя, отправляющего отчетность.
Отправка отчетности всегда должна выполняться на актуальной версии 1С. Проверьте текущий релиз вашей программы на сайте поддержки пользователей и обновите конфигурацию, если установленный релиз вашей программы не актуальный.
Разработчики вносят изменения в 1С, подключают новые модули, поэтому соответствие релиза программы актуальному перед отправкой отчетности необходимое условие успешной сдачи отчетности.
Права пользователя, отправляющего отчетность
Пользователи, работающие с 1С-Отчетность , должны иметь права:
- Право на защищенный документооборот с контролирующими органами;
- Полные права.
Если с отчетностью работает пользователь не с полными правами, ему необходимо добавить право на защищенный документооборот, например, в Конфигураторе : меню Администрирование — Пользователи на вкладке Прочее .

Если работать с отчетностью стал новый пользователь и у него стала выходить ошибка, а у прежнего пользователя все было нормально — дело, скорее всего. в правах нового пользователя.
Если проверки выполнены, а ошибка осталась — переходите к поиску решения проблемы с помощью:
- технической поддержки Калуга-Астрал;
- самостоятельной настройки криптографии.
Техническая поддержка Калуга-Астрал
Корректность шифровки передаваемого файла сначала проверяет оператор, т.е. компания Калуга-Астрал, после успешной проверки оператором файлы отсылаются непосредственному адресату получения, например, в ПФР.
При возникновении проблем с передачей отчетности, в том числе по расшифровке переданного файла, можно перезвонить непосредственно оператору Калуга-Астрал и попросить помощи:
Техническая поддержка компании работает круглосуточно и успешно устраняет проблемы, связанные с передачей файлов по сервису 1 С-Отчетность , удаленно подключаясь к компьютеру пользователя.
Дозвониться до оператора совсем несложно, в отличие от горячей линии 1С, и работа по решению проблем оператором выполняется без задержек — в момент обращения.
Обратиться в техподдержку Калуга-Астрал один из самых простых вариантов решить проблемы. Работа выполняется профессионально и бесплатно в рамках приобретенного сервиса 1С:Отчетность .
На сайте оператора собраны все возможные ошибки и пути их устранения. Это настоящая библиотека «скорой помощи» пользователю. Мы очень рекомендуем в нее заглядывать:
Настройка криптографии
Поскольку проблема носит чисто технический характер и может быть вызвана множеством причин, рассмотреть которые в одной статье очень сложно, мы дадим в этой части статьи:
- свои экспертные рекомендации, которые помогали нам решить проблему у наших клиентов;
- общий список рекомендации 1С, включающий работу с ОС и 1С одновременно.
Рекомендации Бухэксперт8
Если все технические рекомендации, указанные выше, выполнены, переходим к проверке состояния файлов сертификатов и их настроек в учетной записи документооборота 1С.
Как зайти в настройки учетной записи документооборота?
В разных конфигурациях откройте вкладку Список заявлений : справочник Организации — ЭДО — Список заявлений .

Откройте список заявлений и проверьте, чтобы не было «красноты».

Перейдите на вкладку Служебная информация , откройте графу Учетная запись — результат и выполните команду Открыть (щелкнув мышкой по двум квадратикам).

В открывшемся окне можно:
- проверить параметры настройки;
- обновить сертификаты контролирующих органов по нажатию кнопки Настроить автоматически сейчас ;
- проверить параметры доступа к серверу;
- проверить цифровые сертификаты ответственных лиц организации;
- выбрать пользователей системы 1С, которым будет предоставлен доступ к сервису 1С-Отчетность .

После выполнения каждой инструкции нажимайте кнопки Обменяться и Расшифровать . Проблема может решиться после любого выполненного шага.
Если предложенные шаги не привели к решению проблемы — переустановите криптопровайдер.
Полный список рекомендаций 1С
Полный список рекомендаций 1С для устранения ошибки в операционной системе:
- Повторно выполнить настройку криптографии на компьютере.
- Переустановить личный сертификат.
- Провести тестирование контейнера закрытого ключа, связанного с сертификатом.
- Сбросить пароль на контейнер закрытого ключа.
- Повторно перенести контейнер закрытого ключа в реестр при необходимости.
Действия по исправлению ошибки в 1С:
- Пометить на удаление имя сертификата ЭЦП, и поставив префикс Не использовать , чтобы не спутать с новым элементом справочника.
- Добавить сертификат из хранилища сертификатов, для которого была проведена повторная установка.
- Провести Тест настроек сертификата .
- Указать новый элемент справочника Сертификаты ЭЦП в Соглашении.
- Провести Тест настроек соглашения .
Получите еще секретный бонус и полный доступ к справочной системе БухЭксперт8 на 14 дней бесплатно
Похожие публикации
- Контроль дебиторской и кредиторской задолженности — одно из важных направлений..Иногда при работе с программой 1С может возникнуть ошибка СУБД.Для передачи покупателям счетов-фактур в формате ЭДО типовыми средствами 1С.
Карточка публикации
Все комментарии (1)
Спасибо,за ваш кладезь знаний,которыми вы охотно делитесь с нами,чем облегчаете нам работу и экономите наше время.
Добавить комментарий Отменить ответ
Для отправки комментария вам необходимо авторизоваться.
Вы можете задать еще вопросов
Доступ к форме «Задать вопрос» возможен только при оформлении полной подписки на БухЭксперт8
Вы можете оформить заявку от имени Юр. или Физ. лица Оформить заявку
Нажимая кнопку «Задать вопрос», я соглашаюсь с
регламентом БухЭксперт8.ру >>
Спасибо,очень ждем семинара,вернее Марину Аркадьевну,в её изложении все просто и понятно.
Надежда Владимировна В. (Нижневартовск, Ханты-Мансийский авт. окр.)
Содержание
Вы можете задать еще вопросов
Доступ к форме «Задать вопрос» возможен только при оформлении полной подписки на БухЭксперт8
Вы можете оформить заявку от имени Юр. или Физ. лица Оформить заявку
Нажимая кнопку «Задать вопрос», я соглашаюсь с
регламентом БухЭксперт8.ру >>
В последнее время сканеры python слишком часто сталкиваются с проблемами кодирования, пожалуйста, оставьте запись в блоге для записи.

проблема
Очень распространенный код сканера, код выглядит так:
Цель на самом деле очень проста, то есть сканировать содержимое цепочки, но после этого выполнения возвращаемые результаты, все содержимое, относящееся к китайскому, будут искажены, например
Такие данные можно назвать бесполезными.
анализ проблемы
Проблема здесь очевидна, то есть неправильная кодировка текста, приводящая к искаженным символам.
Посмотреть кодировку страницы
От заголовка просканированной целевой страницы используется страница utf-8 Кодировать.
Поэтому для окончательного кодирования мы также должны использовать utf-8 для обработки, то есть для окончательной обработки текста, использовать utf-8 для декодирования, то есть: decode(‘utf-8’)
Кодировка и декодирование текста
Процесс кодирования и декодирования Python похож на это, Исходный файл ===》 кодировать (метод кодирования) ===》 декодировать (метод декодирования) , В значительной степени, это не рекомендуется
Это способ жестко обрабатывать кодировку текста. Тем не менее, при определенных обстоятельствах, это не большая проблема, чтобы быть ленивым, но это больше рекомендуется использовать encode с участием decode Способ обработки текста.
Вернуться к вопросу
Самая большая проблема сейчас — это кодирование исходного файла, мы используем его обычно requests , Он будет автоматически угадывать метод кодирования исходного файла, а затем перекодировать в Unicode Кодирование, но, в конце концов, это программа, которую можно угадать неправильно, поэтому если вы угадываете неправильно, нам нужно вручную указать метод кодирования. Официальное описание документа выглядит следующим образом:
Итак, нам нужно проверить requests Что именно возвращает метод кодирования?
Печатные результаты являются следующими:
Другими словами, исходный файл использует ISO-8859-1 Кодировать Baidu ISO-8859-1 , Результаты приведены ниже:
ISO8859-1, обычно называется Latin-1. Latin-1 включает в себя дополнительные символы, которые необходимы для написания всех западноевропейских языков.
задача решена
Нашел этот материал, проблема решена очень хорошо, пока вы указываете код, вы можете правильно печатать на китайском. код шоу, как показано ниже:
Результат печати очевиден, и китайский отображается правильно.
Другой способ заключается в декодировании и кодировании исходного файла, код выглядит следующим образом:
другой: ISO-8859-1 ака latin1 , использование latin1 Это нормально сделать результат декодирования.
Проблема кодирования Python3
Я взял несколько потоков байтов из Интернета и хотел их распечатать. Произошла следующая ошибка:
UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘xbb’ in position 8530: illegal multibyte sequence
Мало того, следующий код был найден в html домашней странице Baidu:
Это показывает, что веб-страница действительно использует utf-8, почему возникает ошибка?
В python3 есть здравый смысл в кодировании
1. Символы — это символы Юникода, а строки — массивы символов Юникода.
Если вы тестируете с помощью следующего кода,
Вы обнаружите, что результатом является Истина, которой достаточно, чтобы объяснить эквивалентность между ними.
2. Стр. В байты, называемые кодированием, байты в стр., Называемые декодированием, так как приведенный выше код предназначен для декодирования захваченного байтового потока в массив Юникод
После тестирования со следующим кодом
Это действительно дало ошибку: UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘xbb’ in position 0: illegal multibyte sequence
В Интернете я нашел таблицу кодирования UTF-8 и обнаружил, что форма специального символа »UTF-8 — это c2bb, а юникод -« u00bb », почему его нельзя декодировать. , ,
Результат неверный: UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘xbb’ in position 0: illegal multibyte sequence
Оказывается, функция print () имеет свои ограничения и не может печатать все символы Юникода полностью.
Зная причину, я нашел решение в Google -8 ‘сделаю
После запуска не сообщается об ошибке, но есть много искаженных символов (английский отображается нормально, китайский искажен)! ! После другого броска выяснилось, что это проблема с консолью. В частности, когда я запускаю скрипт под cmd, там будут искаженные символы, но под IDLE это нормально.
Исходя из этого, я предполагаю, что cmd не очень хорошо совместим с utf8, и IDLE может даже работать под IDLE, даже «менять кодировку по умолчанию для стандартного вывода» не нужно, поскольку по умолчанию используется utf8. Если вы должны запустить его под cmd, то измените кодировку, например, я изменил на «gb18030», он может отображаться нормально:
Наконец, прикрепите имена некоторых обычно используемых китайских кодировок и назначьте их кодировке соответственно, вы можете увидеть различные эффекты:

Возвышенная проблема конфигурации

Введение
Мне никогда не нравилось использовать командную строку, поэтому в технологических инновациях в конце прошлого года я использовал TkInter для разработки небольших инструментов. В результате потребовалось много времени, чтобы научиться пользоваться TkInter UI.
Недавно я хотел разобраться с инструментом, использовать командную строку, а затем распространять инструмент как исполняемый файл. Обнаружены проблемы кодирования в начале работы.
В скрипте присутствуют следующие коды, используемые для получения пользователем интерактивного ввода ip.
В первой строке файла скрипта я добавил следующий код
Но когда консоль окон выполнена, появляются искаженные символы. Это немного озадачивает, потому что я всегда был на python, и китайский код добавляется в заголовок файла.
При поиске было обнаружено, что это произошло из-за кодировки cp936 по умолчанию, используемой в Windows cmd. Теперь, когда вы знаете, как использовать эту кодировку, измените кодировку на следующую:
Но получил следующую ошибку:
Озадаченный. Как ленивый больной раком, я хочу обойтись. Используйте следующий метод для кодирования отдельных строк.
Это важно для нормального вывода китайского языка в cmd. Но проблема приближается. В моем скрипте есть сотни строк кода на китайском языке. Я пишу это везде, мне лень, но я наказан.
На этот раз через поиск. Постепенно обнаружил причину проблемы. Это потому, что Python имеет несколько уровней кодирования. Они есть:
- Кодировка на уровне строки
- Кодирование на уровне сценария
- кодировка уровня py файла
- Кодировка окна дисплея
Кодирование строковых переменных
Для транскодирования одной строки вы можете использовать: encode() Кодируется для отображения. Обычно строка не может быть напрямую преобразована из одной кодировки в другую кодировку. Обычно необходимо декодировать в Unicode, а затем перекодировать строку Unicode. Например, приведенный выше пример.
Кодировка скрипта
Кодировка пи-файла
Кодировка py-файлов по умолчанию — ANSI. Но вы также можете использовать utf-8, кодировку Unicode.
Кодировка окна дисплея
В вышеуказанных случаях китайцы не ошибутся на этапе эксплуатации. Однако эти китайские иероглифы могут отображаться неправильно. Может ли это отображаться нормально, Есть также решения по кодированию, поддерживаемые окном дисплея , Например, китайский язык в cmd поддерживает GBK и cp936, поэтому строки в коде должны быть закодированы для этих двух, прежде чем их можно будет отобразить.
Когда кодировка файла py является ANSI. Добавить, если не указано в коде ** — -coding:utf-8 — — **, когда в коде появляется китайский, при запуске скрипта. Следующая ошибка появится
В заключение
Из приведенного выше теста можно сделать несколько выводов:
- Кодирование имеет иерархическую структуру. Кодировка файла влияет на кодировку содержимого сценария, а кодировка содержимого сценария определяет кодировку строки.
- Когда отображение строки устанавливает кодировку. Кодировка строки символов — это кодировка, устанавливаемая дисплеем, в этом случае кодировка файла и сценария не работает. Когда строка символов не отображает установленную кодировку, применяется кодирование верхнего уровня.
- Поэтому при установке этих трех кодов необходимо убедиться, что эти три кода могут быть преобразованы. В противном случае произойдут перечисленные выше ошибки.
Другие производные
Есть много вещей, которые можно сказать о кодировке символов. Друзья, которые хотят знать, могут обратиться к информации следующих великих богов.
Источник
Я ищу немного помощи с моими функциями кодирования/декодирования на кросс-платформах. В настоящее время код работает в ОС Windows, но не работает в Linux. В настоящее время он не проверен на Mac.
void tradingDialog::on_SaveKeys_clicked()
{
// Encryption properties store iv and password information
EncryptionProperties props;// Generate a 256 bit random IV from 4 separate 64 bit numbers
props.iv = crypto_random();
props.iv2 = crypto_random();
props.iv3 = crypto_random();
props.iv4 = crypto_random();// What cipher function do we require?
props.cipher = Algorithm::AES;// Qstring to string
string password = ui->PasswordInput->text().toUtf8().constData();
// the password used for encryption / decryption
props.password = string(password);/*========== The main cryptostreampp usage ==========*/
boost::filesystem::path pathAPI = GetDataDir() / "APIcache.txt";
// Create a stream in output mode to create a brand new file called apicache.txt
//CryptoStreamPP stream(pathAPI.string(), props, std::ios::out | std::ios::binary | std::ios::trunc);
CryptoStreamPP stream(pathAPI.string(), props, std::ios::out | std::ios::binary | std::ios::trunc);// ------------------------------------------------------
// NOTE:
// After creating the stream, there will be a short pause
// as the key stream is initialized. This accounts for
// one million iterations of PBKDF2
// ------------------------------------------------------// write to the stream as you would a normal fstream. Normally
// you would write a buffer of char data. In this example,
// we write a string which is basically the same thing.
// Stream operator support to be properly added in future.// qstrings to utf8, add to byteArray and convert to const char for stream
const QByteArray byteArray = (ui->ApiKeyInput->text().toUtf8() + ui->SecretKeyInput->text().toUtf8());
const char *API = byteArray.constData();stream.write(API, 64);
// make sure stream is flushed before closing it
stream.flush();
stream.close();
}void tradingDialog::on_LoadKeys_clicked()
{
// Encryption properties store iv and password information
EncryptionProperties props;// Generate a 256 bit random IV from 4 separate 64 bit numbers
props.iv = crypto_random();
props.iv2 = crypto_random();
props.iv3 = crypto_random();
props.iv4 = crypto_random();// What cipher function do we require?
props.cipher = Algorithm::AES;// Qstring to string
string password = ui->PasswordInput->text().toUtf8().constData();
// the password used for encryption / decryption
props.password = string(password);boost::filesystem::path pathAPI = GetDataDir() / "APIcache.txt";
// Create a stream in input mode to open a file named APIcache.txt
CryptoStreamPP stream(pathAPI.string(), props, std::ios::in | std::ios::binary);// Read in a buffer of data
{
QString Key = "";
stream.seekg(0);
char buffer[33];
stream.read(buffer, 32);
buffer[32] = '';// Should print out "api key 32 digit"
Key = buffer;
ui->ApiKeyInput->setText(Key);
}stream.flush();
// now seek to digit 32 and read in api secret
{
QString Secret = "";
stream.seekg(32);
char buffer[33];
stream.read(buffer, 32);
buffer[32] = '';// Should print out "api secret 32 digit"
Secret = buffer;
ui->SecretKeyInput->setText(Secret);
}stream.flush();
stream.close();
}
При печати «пароль» и «API» в «on_SaveKeys_clicked()». Оба правильные.
При печати «password» в «on_LoadKeys_clicked()» это правильно.
При печати «Ключ» в «on_LoadKeys_clicked()» это неверно.
При печати «Секрет» в «on_LoadKeys_clicked()» это неверно.
CryptoStreamPP можно найти на странице https://github.com/benhj/CryptoStreamPP/tree/master/cryptostreampp
Администраторы и пользователи при работе в сервером 1C установленном на Linux часто сталкиваются с ошибками которые не встречаются на ОС MS Wndows. Связано это с тем что первоначально программа 1С Предприятие долгое время была ориентированна только на работу с ОС Windows и ее портировании на ОС Linux началось сравнительно недавно. Из-за особенностей архитектуры операционной системы Linux, некоторые моменты, которые под ОС Windows были само собой разумеющимися и не вызывали вопросов, тут требуют определенной настройки. Рассмотрим наиболее часто встречающиеся ошибки при работе клиентов с сервером на ОС Linux.
Оглавление:
1. Ошибка загрузки библиотеки libfontconfig.so
2. Не печатается документ с штрихкодом. (EObjectNotFound)
3. Проблема с кодировкой в загружаемом файле в 1С
4. На сервере отсутствуют шрифты из состава Microsoft Core Fonts
5. Ошибка доступа к файлу Read-only file system
Ошибка загрузки библиотеки libfontconfig.so
Пример полного текста ошибки:
Ошибка загрузки библиотеки libfontconfig.so по причине: Библиотека не обнаружена.
Часть функций будет недоступна.
Обратитесь к разделу справочной системы «1С:Предприятие - Работа пользователя –
Особенности работы в Linux – Внешние библиотеки»
Описание:
Не запускается база в режиме 1С:Предприятия.
Решение:
Установим недостающие пакеты:
|
yum install ImageMagick freetype libgsf glib unixODBC libusb libicu freetype expat libpng12 -y |
Не печатается документ с штрихкодом. Ошибка (EObjectNotFound)
Пример полного текста ошибки:
(EObjectNotFound) Object «СЗК_ЗащищеннаяОбработка» is not found
Описание:
Не печатается документ с штрихкодом. Текст ошибки может быть связан с получением отраслевой лицензии(для отраслевых конфигураций).
Решение:
Установим недостающие пакеты(в нашем случае нужна была только libpng12):
|
yum install libicu freetype expat libpng12 |
Проблема с кодировкой в загружаемом файле в 1С
Пример полного текста ошибки:
Ошибка загрузки библиотеки libgsf-1.so по причине: Библиотека не обнаружена. Часть функций будет недоступна.
Пример вывода сообщения об ошибке в программе 1С:
А это пример некорректного отображения символов:
Описание:
При загрузке данных из файла символы преобразовываются некорректно.
Решение:
Установим недостающие пакеты(в данном случае необходима была libgsf):
|
yum install ImageMagick freetype libgsf glib unixODBC libusb libicu freetype expat libpng12 -y |
На официальном сайте информационно-технологического сопровождения 1С:Предприятия есть статья о особенность работы 1С под ОС Linux, в которой подробно описано какие библиотеки, шрифты и прочее должны быть установлены для работы с 1С.
На сервере отсутствуют шрифты из состава Microsoft Core Fonts
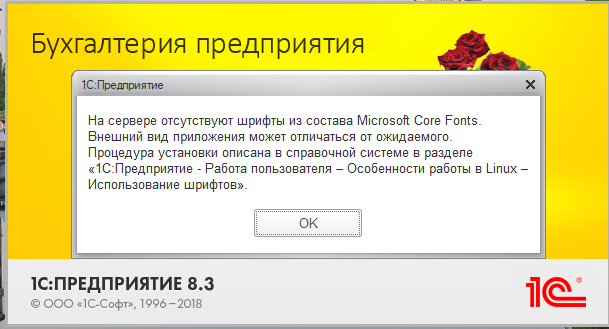
Пример полного текста ошибки:
На сервере отсутствуют шрифты из состава Microsoft Core Fonts.
Внешний вид приложения может отличаться от ожидаемого.
Процедура установки описана в справочной системе в разделе
«1С:Предприятие – Работа пользователя-Особенности работы в Linux – использование шрифтов».
В веб-клиенте это сообщение выглядит так:
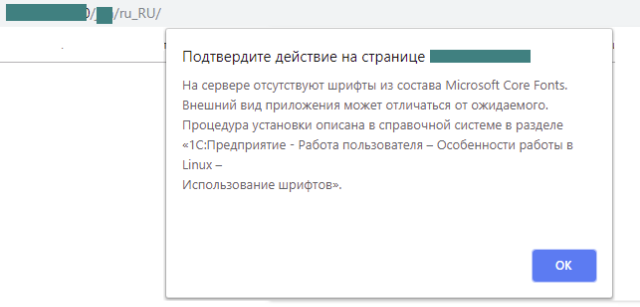
В клиенте 1С Предприятие так:
Описание:
При первичном запуске 1С:Предприятия выдается сообщение «На сервере отсутствуют шрифты».
Это не мешает дальнейшему запуску системы. И при последующих запусках ошибка не появляется.
Решение:
Нам понадобятся пакеты шрифтов:
- fontconfig-2.10.95-11.el7.x86_64.rpm;
- msttcorefonts-2.5-1.rpm
Выполним установку пакетов.
|
yum localinstall fontconfig-2.10.95-11.el7.x86_64.rpm yum localinstall msttcorefonts-2.5-1.rpm |
Ошибка доступа к файлу Read-only file system
Пример полного текста ошибки:
Ошибка доступа к файлу /home/usr1cv8/.1cv8/1C/1cv8/reg_1541/snccntx0114ae32-dd36-1e86-005056b7219:
Read-only file system
Пример окна с ошибкой: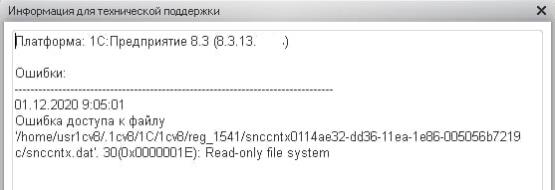
Описание:
Возникновение данной ошибки возможно, например, при миграции серверов между хостами.
Решение:
1. Выполним перезагрузку сервера
2. Если проблема не ушла – выполним перемонтирование дисков.
Добрый день, дело вот в чем.. из Клиент-банка(Строй-кредит) выгружаем выписки, файл формируется в формате *.txt.. но при загрузке в 1с, файл не загружается,ошибка при чтении файла, данне не видит, или не верная кодировка…в той же базе еще 3 клиент-банка, они загружаются без проблем.
отладчик или приглашенный специалист вас спасет
А что будет делать спеуиалист?
Как ругается Нуф-Нуф на автора — я услышал  А как ругается 1С на файл?
А как ругается 1С на файл? 
Специалист посмотрит на файл и выставит в обработке загрузки нужную кодировку
Пока что «неверная» кодировка — это всего лишь предположение автора…
Указанный файл не является файлом обмена или неверно указана кодировка! Уверена, что это кодировка не верна
для конкретно этого клиент банка?
Возможно, в самом клиенте нужно выставлять и настраивать. Я же сказал: _специалист_ _посмотрит_
Если мне память не изменяет, то для работы с клиент-банком нужно выбрать формат файла обмена. Как правило он соответсвует наименованию банка или его используемой клиентской системы. Так? Может быть Вы «не то» указываете?
Или версия обмена уже «не та»?
а блокно-то открывает? визуальные отличия от выгрузок из «нормальных» банк-клиентов есть?
Денис, ну право-же, не тормози, — лучше помоги. Была-бы возможность у автора — сама бы обратилась к специалистам А так обращается к нам, — специалистам широкого профиля
А ещё можно сравнить заголовки с предыдущими файлами обмена (те которое прошли нормально)…
Так я а) не вижу её файла , б) плохо знаком с 8-кой. Поэтому могу давать только общие советы.
Открой файл в ворде и торкни меню Файл-Свойства. Там кодировка будет указана. Расскажи нам
а в обработке в 1С какая кодировка задана? Посмотри в настройке.
открывает, они используют банк-клиент i-bank2
а кб наверно выгружает в досе …
Если честно не могу там найти кодировку, имя MS-DOS не то..
+19 i-bank2 — я так подозреваю, что это ИКБ, посему там выписки формируются в виндусявой кодировке. А в простом КБ в ДОС, как предположение, потому что у нас так.
я загружаю и с кодировкой DOS b Windows
nfr yb c rfrjq rjlbhjdrjq yt pfuhe;ftncz
ой, ни с какой кодировкой не загружается
поясните, пожалуйста, в Вашей программе КБ дается право выбора, в какой кодировке выгружать? или файл просто выгружается и все?
а если самой настройке клиент-банка поменять кодировку?
А Белочка не че такая, я бы тебе помог.
Просто файл выгружается, программа кажется совсем простой..
в нашем КБ нет такой функции, просто выгружается *.txt файл в ДОС-кодировке. а почему тогда Вы говорите, что ни в какой кодировке не загружается, если Вы выгружаете в той, которую задал КБ?
А где Вы кодировку указываете(выбираете)? Там что выбор ограниченный — всего два вида?
Во первых что за конфа, во вторых в самом банк клиенте когда выгружаешь ессть выбор кодировки, во вторых есть выбор самой программы.
Поиграйся ручками не бойся.
я, наверно, опять туплю, простите, рано мне в 1с еще:) наверно, в отчете дается право выбора, да?
в нашем нету( но если совсем извратиться, можно написать отчет по перекодировке и подпихивать виндусявые выписки:)
Конфигурация БП8.1, релиз, в самом банк клиенте нет возможности выбора кодировки, по крайней мере я не видила, просто выгружаешь файл..программа по названию совпадает, с выбранной, если конечно нет двух одинаковых программ
Вы просто не видете настройки. Они есть такого быть не может
Посмотрел. В обработке «1спредприятие — клиент банка» — справа внизу еззь кнопока Настройка. Там можно указать , какая кодировка будет использоваться для загрузки.
а я говорю — может:) другой вопрос, что помимо выгрузки в файл есть выгрузки в DBF и в формате 1С, но это уже другая песня =)
Что, уже вопрос благополучно решили? А спасибо где? Хочу спасибо всем
Ыыы… я горько плакаю… без слов… кажется всё уже сказано было
Тэги:
Комментарии доступны только авторизированным пользователям
Содержание
- Обработка ошибок, возникающих при обмене данными в распределенной информационной базе
- Общие ошибки, возникающие при работе с XML
- Ситуации, возникающие при обмене данными в рамках распределенной информационной базы
- Ошибки на клиенте при работе с сервером 1С на Linux. Часть 2
- Оглавление:
- Ошибка загрузки библиотеки libfontconfig.so
- Не печатается документ с штрихкодом. Ошибка (EObjectNotFound)
- Проблема с кодировкой в загружаемом файле в 1С
Обработка ошибок, возникающих при обмене данными в распределенной информационной базе
При организации обмена данными в рамках распределенной информационной базы могут возникать различные ситуации, приводящие к сообщениям об ошибках. Однако не все подобные ситуации являются ошибками в чистом виде: некоторые из них могут быть отнесены к штатным ситуациям, соответствующим протоколу обмена данными, некоторые — к неадаптированности конфигурации для работы в рамках распределенной информационной базе.
Общие ошибки, возникающие при работе с XML
Сообщение обмена данными является документом XML, поэтому имеет смысл описать возможные ошибки, которые могут возникнуть во время чтения/записи сообщений обмена данными при использовании средств чтения/записи данных XML, предоставляемых платформой «1С:Предприятие 8». При работе с данными в формате XML может возникать множество различных ситуаций, однако в данной статье будут рассмотрены только те, которые так или иначе имеют отношение к обмену данными в рамках распределенной информационной базы.
Значение URI пространства имен должно соответствовать рекомендации Namespaces in XML (см. http://www.w3.org/TR/REC-xml-names)
Производится попытка записи в XML значения, для типа которого не определена процедура записи в XML. Или производится попытка чтения из XML значения неизвестного типа или типа, для которого не определена процедура чтения из XML.
При обмене данными в рамках распределенной информационной базы используются штатные механизмы записи/чтения XML — ситуации, связанные с передачей некорректных данных, могут возникать только вследствие искажения сообщения обмена данными. В таком случае необходимо получить новое сообщение обмена данными от информационной базы — источника сообщения.
Если же сообщение содержит корректные данные и ошибка возникает в процессе считывания данных из базы данных (для последующего изменения их данными из сообщения обмена), то необходимо проверить наличие прав пользователя, от имени которого производится чтения сообщения обмена.
Также необходимо удостовериться, что в процессе чтения сообщения не возникает блокировки данных (например, чтение производится в рамках транзакции, а данные заблокированы другим пользователем), можно предпринять попытку чтения сообщения в монопольном режиме доступа к информационной базе.
Если вышеперечисленные способы не привели к устранению ошибки, то необходимо проверить целостность данных информационной базы
Ситуации, возникающие при обмене данными в рамках распределенной информационной базы
| Сообщение об ошибке | Описание ошибки |
| Возможные пути исправления ошибки | |
| Не установлен MS XML Core Services 4.0 | На компьютере не установлен Microsoft XML Core Services 4.0, используемый «1С:Предприятием 8» для работы с XML |
| Установить Microsoft XML Core Services 4.0. При установке «1С:Предприятия 8» Microsoft XML Core Services 4.0 устанавливается автоматически | |
| Ошибка разбора XML | Ошибка, возникающая при синтаксическом анализе данных XML в процессе чтения. Все ошибки, определенные в SAX2, трансформируются в данную ошибку, генерируемую платформой «1С:Предприятие 8» |
| Проверить правильность оформления и синтаксис данных XML (см. http://www.w3.org/TR/REC-xml). | |
| Ошибочный порядок записи XML | Методы записи содержимого документа XML вызываются в неправильном порядке. Например, запись атрибута вызывается после записи текста элемента. |
| Выявить и исправить места некорректного порядка вызова методов | |
| Текст XML содержит недопустимые символы | Записываемый текст XML содержит недопустимые символы. |
| Текст XML должен соответствовать требованиям, изложенным в главе 2.2 рекомендации XML (см. http://www.w3.org/TR/REC-xml#charsets) | |
| Недопустимое имя XML | Записываемое имя XML содержит недопустимые символы. |
| Имя XML должно соответствовать требованиям, изложенным в главе 2.3 рекомендации XML (см. http://www.w3.org/TR/REC-xml#NT-Name) | |
| Пустое значение URI допустимо только для пространства имен по умолчанию | Производится попытка записать соответствие пространства имен, в котором URI пространства имен, представленному пустой строкой, соответствует непустой префикс. |
| Переопределение пространства имен по умолчанию для текущего элемента XML недопустимо | Текущий записываемый элемент не относится ни к какому пространству имен. Поэтому для него недопустимо определение непустого пространства имен по умолчанию. |
| Переопределение пространства имен по умолчанию для элемента, не относящегося ни к какому пространству имен -запрещено | |
| Ошибка преобразования данных XML | Ошибка возникает вследствие нарушения структуры передаваемых данных. При чтении данных XML платформой производится автоматическое определение типа получаемых данных, кроме случаев, когда тип данных указан при вызове операции чтения. Если структура данных XML не соответствует структуре данных, определяемых типом, то будет сгенерировано данное сообщение об ошибке. |
| При обмене данными в рамках распределенной информационной базы используются штатные механизмы записи/чтения XML. Данная ошибка является следствием искажения сообщения обмена. Необходимо повторно получить сообщение от информационной базы — источника сообщения | |
| Значения данного типа не могут быть представлены в XML | |
| Ошибка может возникнуть при участии в обмене информационных баз, имеющих различные конфигурации. Однако при обмене данными в рамках распределенной информационной базы поддерживается идентичность конфигураций информационных баз, участвующих в обмене. Данная ошибка является следствием искажения сообщения обмена. Необходимо повторно получить сообщение от информационной базы — источника сообщения | |
| Ошибка данных XML | Ошибка возникает при получении некорректных данных из источника XML или же в случаях неудачного считывания из базы данных содержимого объекта, данные которого должны быть прочитаны из источника XML: блокировка объекта или же отсутствие прав на чтение данного объекта. Например, чтение существующего элемента справочника: если элемент справочника является группой, а было прочитано то, что является элементом, будет сгенерирована данная ошибка. |
В случае чтения сообщения обмена данными от подчиненного узла в главном узле данная ситуация является штатной и означает наличие изменений конфигурации, которые еще не были получены в подчиненном узле — источнике сообщения.
Если же чтение сообщения от главного узла производится в подчиненном узле, то данная ситуация является следствием изменения конфигурации в подчиненном узле. Необходимо удостовериться, что обмен производится в правильно настроенной распределенной информационной базе (создание подчиненных узлов производилось при помощи рекомендованных способов) и в процессе работы не производилось изменения конфигурации подчиненной информационной базы (изменение в штатном режиме невозможно). Изменения конфигурации подчиненного узла может быть осуществлено только после отключения информационной базы от распределенной информационной базы — установка значения главного узла в Неопределено . В случае несанкционированного изменения конфигурации в подчиненном узле необходимо восстановить соответствие конфигураций путем полной загрузки конфигурации из главного узла
| Сообщение об ошибке | Описание ошибки |
| Возможные пути исправления ошибки | |
| Узел не является узлом распределенной ИБ | При вызове одного из методов встроенного языка, относящегося к распределенной ИБ, значение переданного параметра — узла плана обмена — не принадлежит плану обмена с установленным признаком «Распределенная информационная база». |
| Необходимо убедиться в правильности передаваемого в метод параметра | |
| Запись сообщения обмена данными не начата | В метод записи изменения данных передан в качестве параметра объект ЗаписьСообщенияОбмена , у которого не был вызван метод НачатьЗапись или был вызван метод завершения записи ( ПрерватьЗапись , ЗакончитьЗапись ). |
| Убедиться, что вызов записи изменений вызывается в рамках процесса записи объекта ЗаписьСообщенияОбмена | |
| Чтение сообщения обмена данными не начато | В метод чтения изменения данных передан в качестве параметра объект ЧтениеСообщенияОбмена , у которого не был вызван метод НачатьЧтение или был вызван метод завершения записи ( ПрерватьЧтение , ЗакончитьЧтение ). |
| Убедиться, что вызов чтения изменений вызывается в рамках процесса чтения объекта ЧтениеСообщенияОбмена . | |
| Номер сообщения распределенной ИБ должен быть больше номера ранее принятого сообщения | Производится попытка чтения старого (возможно, уже принятого) сообщения обмена данными. |
| Необходимо произвести синхронизации номера принятого сообщения в текущем узле распределенной ИБ и номера отправленного сообщения в узле — источнике сообщения обмена данными. Этого можно достичь при помощи непосредственного изменения соответствующих реквизитов у узлов плана обмена, по которому осуществляется работа, или выполнить запись необходимого количества сообщений обмена данными в узле — источнике сообщения | |
| Начальный образ может быть выгружен только во вновь созданную или пустую ИБ | По указанному месторасположению начального образа уже существует другая информационная база. |
| Необходимо убедиться, что при создании начального образа указано место, в котором не существует информационной базы | |
| Ошибка формата представления изменений | Структура и порядок следования элементов сообщения обмена данными не соответствуют требуемому. |
| При обмене данными в рамках распределенной информационной базы используются штатные механизмы записи/чтения XML. Данная ошибка является следствием искажения сообщения обмена данными. Необходимо повторно получить сообщение от информационной базы — источника сообщения | |
| Попытка приема изменений от неизвестной конфигурации | При попытке чтения сообщения обмена данными в рамках распределенной информационной базы обнаружено несоответствие конфигураций источника и приемника сообщения. |
| По всей видимости, сообщение обмена было записано для информационной базы, имеющей конфигурацию, отличную от данной. Подобная ситуация может произойти в случае ручной настройки распределенной информационной базы. Если подчиненный узел распределенной информационной базы создавался путем объединения конфигурации информационной базы и конфигурации главного узла, то внутренняя идентификация объектов метаданных не будет соответствовать конфигурации главного узла, что приводит к данной ошибке. Рекомендуется создавать информационные базы подчиненных узлов либо при помощи создания начального образа, либо при помощи полной загрузки конфигурации в информационную базу | |
| Искажены изменения конфигурации! | При попытке чтения сообщения обмена данными обнаружены искажения в передаваемых изменениях конфигурации. |
| Необходимо получить от источника сообщения новое сообщение обмена данными | |
| Конфигурация узла распределенной ИБ не соответствует ожидаемой! | Конфигурация текущей информационной базы была изменена по отношению к конфигурации информационной базы источника сообщения. |
| Изменения конфигурации не могут быть получены из подчиненного узла распределенной ИБ | При чтении сообщения обмена, полученного от подчиненного узла, в нем обнаружены изменения конфигурации. |
| Подобная ситуация может возникнуть если имеет место искажение сообщения обмена, либо обмен производится в распределенной информационной базе с незавершенным процессом перестроения иерархии узлов. Необходимо убедится, что сообщение обмена получено без искажений и правильно заполнены узлы соответствующего плана обмена в обоих узлах распределенной информационной базы (источнике и приемнике сообщения). | |
| Из главного узла распределенной ИБ получены изменения конфигурации. Необходимо выполнить обновление конфигурации базы данных. Обновление может быть выполнено в режиме Конфигуратор |
Из главного узла получены изменения конфигурации. |
| Необходимо запустить систему в режиме Конфигуратор , произвести обновление конфигурации базы данных, после чего повторить чтение данного сообщения обмена в режиме 1С:Предприятие для завершения чтения сообщения. | |
| Данные не входят в состав плана обмена | При чтении сообщения обмена обнаружены данные, не входящие в состав плана обмена. |
| При обмене данными в рамках распределенной информационной базы используются штатные механизмы записи/чтения XML. Данная ошибка является следствием искажения сообщения обмена. Необходимо повторно получить сообщение от информационной базы — источника сообщения |
При чтении сообщения обмена производится автоматическая запись полученных изменений данных в информационную базу. Если в процессе записи данных происходит ошибка, то процесс чтения сообщения прерывается. Для определения в процедурах записи элементов данных (объектов и наборов записей) режима записи после загрузки из сообщения обмена существует свойство Загрузка . Для корректной работы в рамках распределенной информационной базы процедуры записи элементов данных должны быть написаны с учетом произвольного порядка загрузки данных из сообщений обмена (например, не должны выполняться проверки связанной с записываемым элементом данных информации.
Источник
Ошибки на клиенте при работе с сервером 1С на Linux. Часть 2
Администраторы и пользователи при работе в сервером 1C установленном на Linux часто сталкиваются с ошибками которые не встречаются на ОС MS Wndows. Связано это с тем что первоначально программа 1С Предприятие долгое время была ориентированна только на работу с ОС Windows и ее портировании на ОС Linux началось сравнительно недавно. Из-за особенностей архитектуры операционной системы Linux, некоторые моменты, которые под ОС Windows были само собой разумеющимися и не вызывали вопросов, тут требуют определенной настройки. Рассмотрим наиболее часто встречающиеся ошибки при работе клиентов с сервером на ОС Linux.
Оглавление:
Ошибка загрузки библиотеки libfontconfig.so
Пример полного текста ошибки:
Описание:
Не запускается база в режиме 1С:Предприятия.
Решение:
Установим недостающие пакеты:
Не печатается документ с штрихкодом. Ошибка (EObjectNotFound)
Пример полного текста ошибки:
Описание:
Не печатается документ с штрихкодом. Текст ошибки может быть связан с получением отраслевой лицензии(для отраслевых конфигураций).
Решение:
Установим недостающие пакеты(в нашем случае нужна была только libpng12):
Проблема с кодировкой в загружаемом файле в 1С
Пример полного текста ошибки:
Пример вывода сообщения об ошибке в программе 1С:
А это пример некорректного отображения символов:
Описание:
При загрузке данных из файла символы преобразовываются некорректно.
Источник