Overview
This guide covers various topics related to channels, an AMQP 0-9-1-specific abstraction.
Channels cannot exist without a connection, so getting familiar with the Connections guide first
is highly recommended.
This guide covers:
- The basics of channels
- Channel lifecycle
- Channel exceptions (errors) and what they mean
- Channel resource usage
- Monitoring and metrics related to channels and how to identify common problems
- Flow control
and other topics related to connections.
The Basics
Some applications need multiple logical connections to the
broker. However, it is undesirable to keep many TCP
connections open at the same time because doing so consumes
system resources and makes it more difficult to configure
firewalls. AMQP 0-9-1 connections are multiplexed with
channels that can be thought of as «lightweight
connections that share a single TCP connection».
Every protocol operation performed by a client happens on a channel.
Communication on a particular channel is completely separate
from communication on another channel, therefore every protocol
method also carries a channel ID (a.k.a. channel number), an integer
that both the broker and clients use to figure out which channel the method is for.
A channel only exists in the context of a connection and never on its own.
When a connection is closed, so are all channels on it.
For applications that use multiple threads/processes for
processing, it is very common to open a new channel per thread/process
and not share channels between them.
Channel Lifecycle
Opening Channels
Applications open a channel right after successfully opening a connection.
Here’s a Java client example that opens a new channel with an automatically allocated channel ID
after opening a new connection:
ConnectionFactory cf = new ConnectionFactory(); Connection conn = cf.createConnection(); Channel ch = conn.createChannel(); // ... use the channel to declare topology, publish, consume
In .NET client channels are represented using the IModel interface, so the names in the API
are different:
var cf = new ConnectionFactory(); var conn = cf.newConnection(); // the .NET client calls channels "models" var ch = conn.CreateModel(); // ... use the channel to declare topology, publish, consume
Much like connections, channels are meant to be long lived. That is, there is no need to open
a channel per operation and doing so would be very inefficient, since opening a channel is a
network roundtrip.
Closing Channels
When a channel is no longer needed, it should be closed. Closing a channel will render it
unusable and schedule its resources to be reclaimed:
Channel ch = conn.createChannel(); // do some work // close the channel when it is no longer needed ch.close();
The same example using the .NET client:
// the .NET client calls channels "models" var ch = conn.CreateModel(); // do some work // close the channel when it is no longer needed ch.Close();
As mentioned above, a closed channel cannot be used. An attempt to perform an operation
on a closed channel will result in an exception that says that the channel has already been
closed.
When a channel’s connection is closed, so is the channel.
Channels and Error Handling
In the section above channels were closed by applications. There is another way a channel can
be closed: due to a protocol exception.
Certain scenarios are assumed to be recoverable («soft») errors in the protocol. They render
the channel closed but applications can open another one and try to recover or retry a number of
times. Most common examples are:
- Redeclaring an existing queue or exchange with non-matching properties
will fail with a 406 PRECONDITION_FAILED error - Accessing a resource the user is not allowed to access will fail
with a 403 ACCESS_REFUSED error - Binding a non-existing queue or a non-existing exchange will fail with a 404 NOT_FOUND error
- Consuming from a queue that does not exist will fail with a 404 NOT_FOUND error
- Publishing to an exchange that does not exist will fail with a 404 NOT_FOUND error
- Accessing an exclusive queue from a connection other than its declaring one will
fail with a 405 RESOURCE_LOCKED
Client libraries provide a way to observe and react to channel exceptions. For example, in the Java
client there is a way to register an error handler and access a channel
shutdown (closure) reason.
Any attempted operation on a closed channel will fail with an exception. Note that when RabbitMQ
closes a channel, it notifies the client of that using an asynchronous protocol method. In other words,
an operation that caused a channel exception won’t fail immediately but a channel closure event
handler will fire shortly after.
Some client libraries may use blocking operations that wait for
a response. In this case they may communicate channel exceptions differently, e.g. using
runtime exceptions, an error type, or other means appropriate for the language.
See the AMQP 0-9-1 Reference for a more complete list of
error codes.
Resource Usage
Each channel consumes a relatively small amount of memory on the client. Depending on client library’s
implementation detail it can also use a dedicated thread pool (or similar) where consumer
operations are dispatched, and therefore one or more threads (or similar).
Each channel also consumes a relatively small amount of memory on the node the client is connected to,
plus a few Erlang processes. Since a node usually serves multiple channel connections, the effects
of excessive channel usage or channel leaks will primarily be reflected in RabbitMQ nodes’ metrics
and not those of clients.
Given both of these factors, limiting the number of channels used per connection is highly recommended.
As a guideline, most applications can use a single digit number of channels per connection.
Those with particularly high concurrency rates (usually such applications are consumers)
can start with one channel per thread/process/coroutine and switch to channel pooling
when metrics suggest that the original model is no longer sustainable, e.g. because it consumes
too much memory.
See the Monitoring, Metrics and Diagnostics section to learn about how to inspect
channels, the number of channels on a connection, channel churn rate and so on.
Maximum Number of Channels per Connection
The maximum number of channels that can be open on a connection simultaneously
is negotiated by client and server at connection time. The value is configurable for
both RabbitMQ and client libraries.
On the server side, the limit is controlled using the channel_max:
# no more 100 channels can be opened on a connection at the same time channel_max = 100
Should the configured limit be exceeded, the connection will be closed with a fatal
error:
2019-02-11 16:04:06.296 [error] <0.887.0> Error on AMQP connection <0.887.0> (127.0.0.1:49956 -> 127.0.0.1:5672, vhost: '/', user: 'guest', state: running), channel 23: operation none caused a connection exception not_allowed: "number of channels opened (22) has reached the negotiated channel_max (22)"
Clients can be configured to allow fewer channels per connection. With RabbitMQ Java client,
ConnectionFactory#setRequestedChannelMax is the method that controls the limit:
ConnectionFactory cf = new ConnectionFactory(); // Ask for up to 32 channels per connection. Will have an effect as long as the server is configured // to use a higher limit, otherwise the server's limit will be used. cf.setRequestedChannelMax(32);
With RabbitMQ .NET client, use the ConnectionFactory#RequestedChannelMax
property:
var cf = new ConnectionFactory(); // Ask for up to 32 channels per connection. Will have an effect as long as the server is configured // to use a higher limit, otherwise the server's limit will be used. cf.RequestedChannelMax = 32;
The lower value of the two is used: the client cannot
be configured to allow for more channels than the server configured maximum.
Clients that attempt that will run into an error that looks like this in the logs:
2019-02-11 16:03:16.543 [error] <0.882.0> closing AMQP connection <0.882.0> (127.0.0.1:49911 -> 127.0.0.1:5672): failed to negotiate connection parameters: negotiated channel_max = 2047 is higher than the maximum allowed value (32)
Monitoring, Metrics and Diagnostics
Number of currently open channels and channel opening/closure rates are important metrics
of the system that should be monitored. Monitoring them will help detect a number of
common problems:
- Channel leaks
- High channel churn
Both problems eventually lead to node exhaustion of resources.
Individual channel metrics such as the number of unacknowledged messages
or basic.get operation rate can help identify irregularities and inefficiencies
in application behavior.
Memory Use
Monitoring systems and operators alike may need to inspect how much memory
channels consume on a node, the total
number of channels on a node and then identify how many there are on each connection.
The number of channels is displayed in the management UI on the Overview tab,
as is the number of connections.
By dividing the number of channels by the number of connections
the operator can determine an average number of channels per connection.
To find out how much memory on a node is used by channels, use rabbitmq-diagnostics memory_breakdown:
rabbitmq-diagnostics memory_breakdown -q --unit mb # => [elided for brevity] # ... # => connection_channels: 3.596 mb (2.27%) # ... # => [elided for brevity]
See the RabbitMQ Memory Use Analysis guide for details.
Channel Leaks
A channel leak is a condition under which an application repeatedly opens channels without closing them,
or at least closing only some of them.
Channel leaks eventually exhaust the node (or multiple target nodes) of RAM and CPU resources.
Relevant Metrics
Management UI’s Overview tab lists a total number of channels in all virtual hosts the current
user has access to:

To inspect the current number of channels on a connection as well as the per-connection channel limit, navigate
to the Connections tab and enable the relevant columns if they are not displayed:

Overview and individual node pages provide a chart of channel churn rate as of RabbitMQ 3.7.9.
If the rate of channel open operations is consistently higher than that of channel close operations,
this is evidence of a channel leak in one of the applications:

To find out what connection leaks channels, inspect per-connection channel count as demonstrated in this guide.
High Channel Churn
A system is said to have high channel churn when its rate of newly opened channels is consistently high and
its rate of closed channels is consistently high. This usually means that an application
uses short lived channels or channels are often closed due to channel-level exceptions.
While with some workloads this is a natural state of the system,
long lived channels should be used instead when possible.
Management UI provides a chart of channel churn rate.
Below is a chart that demonstrates a fairly low channel churn with a virtually identical number of channel open and closed
in the given period of time:

While connection and disconnection rates are system-specific, rates consistently above 100/second likely indicate a suboptimal
connection management by one or more applications and usually are worth investigating.

Note that some clients and runtimes (notably PHP) do not use long-lived connections and high connection
churn rates are expected from them unless a specialized proxy is used.
Inspecting Channels and Their State in Management UI
To inspect channels in the management UI, navigate to the Channels tab and add or remove columns
as needed:

Inspecting Channels and Their State Using CLI Tools
rabbitmqctl list_connections and rabbitmqctl list_channels are the
primary commands for inspecting per-connection channel count and channel details such as the number of
consumers, unacknowledged messages, prefetch and so on.
rabbitmqctl list_connections name channels -q # => name channels # => 127.0.0.1:52956 -> 127.0.0.1:5672 10 # => 127.0.0.1:52964 -> 127.0.0.1:5672 33
The rightmost column contains channel count on the connection.
Table headers can be suppressed:
rabbitmqctl list_connections name channels -q --no-table-headers # => 127.0.0.1:52956 -> 127.0.0.1:5672 10 # => 127.0.0.1:52964 -> 127.0.0.1:5672 33
To inspect individual channels, use rabbitmqctl list_channels:
rabbitmqctl list_channels -q # => pid user consumer_count messages_unacknowledged # => <rabbit@mercurio.3.815.0> guest 0 0 # => <rabbit@mercurio.3.820.0> guest 0 0 # => <rabbit@mercurio.3.824.0> guest 0 0 # => <rabbit@mercurio.3.828.0> guest 0 0 # => <rabbit@mercurio.3.832.0> guest 0 0 # => <rabbit@mercurio.3.839.0> guest 0 0 # => <rabbit@mercurio.3.840.0> guest 0 0
Table headers can be suppressed:
rabbitmqctl list_channels -q --no-table-headers # => <rabbit@mercurio.3.815.0> guest 0 0 # => <rabbit@mercurio.3.820.0> guest 0 0 # => <rabbit@mercurio.3.824.0> guest 0 0 # => <rabbit@mercurio.3.828.0> guest 0 0 # => <rabbit@mercurio.3.832.0> guest 0 0 # => <rabbit@mercurio.3.839.0> guest 0 0 # => <rabbit@mercurio.3.840.0> guest 0 0
It is possible to display a different set of columns:
rabbitmqctl list_channels -q --no-table-headers vhost connection number prefetch_count messages_unconfirmed # => / <rabbit@mercurio.3.799.0> 1 0 0 # => / <rabbit@mercurio.3.802.0> 1 0 0 # => / <rabbit@mercurio.3.799.0> 2 0 0 # => / <rabbit@mercurio.3.799.0> 3 0 0 # => / <rabbit@mercurio.3.802.0> 2 0 0 # => / <rabbit@mercurio.3.802.0> 3 0 0 # => / <rabbit@mercurio.3.799.0> 4 0 0 # => / <rabbit@mercurio.3.802.0> 4 0 0 # => / <rabbit@mercurio.3.799.0> 5 0 0 # => / <rabbit@mercurio.3.799.0> 6 0 0
rabbitmqctl list_channels -s vhost connection number confirm # => / <rabbit@mercurio.3.799.0> 1 false # => / <rabbit@mercurio.3.802.0> 1 false # => / <rabbit@mercurio.3.799.0> 2 false # => / <rabbit@mercurio.3.799.0> 3 false # => / <rabbit@mercurio.3.802.0> 2 false # => / <rabbit@mercurio.3.802.0> 3 false # => / <rabbit@mercurio.3.799.0> 4 false # => / <rabbit@mercurio.3.802.0> 4 false # => / <rabbit@mercurio.3.799.0> 5 false
Publisher Flow Control
Channels that publish messages can outpace other parts of the system, most likely busy queues and queues
that perform replication. When that happens, flow control is applied to
publishing channels and, in turn, connections. Channels and connections that only consume messages
are not affected.
With slower consumers that use automatic acknowledgement mode
it is very likely that connections and channels will experience flow control when writing to
the TCP socket.
Monitoring systems can collect metrics on the number of connections in flow state.
Applications that experience flow control regularly may consider to use separate connections
to publish and consume to avoid flow control effects on non-publishing operations (e.g. queue management).
Getting Help and Providing Feedback
If you have questions about the contents of this guide or
any other topic related to RabbitMQ, don’t hesitate to ask them
on the RabbitMQ mailing list.
Help Us Improve the Docs <3
If you’d like to contribute an improvement to the site,
its source is available on GitHub.
Simply fork the repository and submit a pull request. Thank you!
|
Description of problem: rabbitmq-server throws a lot of errors on RHOSP10 during tempest run such as: Channel error on connection <0.12953.1> ([FD00:FD00:FD00:2000::12]:56390 -> [FD00:FD00:FD00:2000::15]:5672, vhost: '/', user: 'guest'), channel 1: operation basic.publish caused a channel exception not_found: "no exchange 'reply_a374c0d9d2224856b6d7bcba519b6ee8' in vhost '/'" No failover was triggered by test or tester during testing although It seems from logs that rabbitmq-server was not available for openstack services. Eventually It seems that openstack services (such as neutron agents) were able to connect to the rabbitmq-server (established connections could be seen by netstat) but were not operational (complained about messages not being replied) and many errors as pasted above were thrown in the rabbitmq log. Restarting a service or rabbitmq server seemed to help for some services such as neutron agents. The env is based on IPv6 (rabbitmq listens and connections are made to IPv6 based socket), I have not seen such errors when IPv4 was used. Version-Release number of selected component (if applicable): rabbitmq-server-3.6.3-6.el7ost.noarch python-oslo-messaging-5.10.0-5.el7ost.noarch How reproducible: Sometimes (not exact pattern) Steps to Reproduce: 1. Run full tempests suite on IPv6 based RHOSP10 until It starts failing on many tests caused by opnestack services being connected to rabbitmq but not operational. Actual results: Opnestack services such as neutron agents are connected to rabbitmq server but do not get any rabbitmq messages reply and thus are not operational. Expected results: Additional info:
I can easily reproduce the Error messages in rabbitmq log of this type: =ERROR REPORT==== 2-Dec-2016::17:12:49 === Channel error on connection <0.845.0> (10.35.169.18:60994 -> 10.35.169.13:5672, vhost: '/', user: 'guest'), channel 1: operation basic.publish caused a channel exception not_found: "no exchange 'reply_fc5a7174b2fe4c2089c6f1fdf28826b8' in vhost '/'" =ERROR REPORT==== 2-Dec-2016::17:12:49 === Channel error on connection <0.908.0> (10.35.169.18:32778 -> 10.35.169.13:5672, vhost: '/', user: 'guest'), channel 1: operation basic.publish caused a channel exception not_found: "no exchange 'reply_c243451013434ab49080ba877d386f7a' in vhost '/'" =ERROR REPORT==== 2-Dec-2016::17:12:49 === Channel error on connection <0.845.0> (10.35.169.18:60994 -> 10.35.169.13:5672, vhost: '/', user: 'guest'), channel 1: operation basic.publish caused a channel exception not_found: "no exchange 'reply_fc5a7174b2fe4c2089c6f1fdf28826b8' in vhost '/'" I do not know how severe those msgs are and whether It's a consequence of some different problem but I can see many of such messages on multiple setups (either ipv6 or ipv4 based deployments). It is present even though no failover actions are being performed. If needed I can provide a deployments for debugging.
(In reply to Marian Krcmarik from comment #2)
> If needed I can provide a deployments for debugging.
Please! If you have one handy that reproduces, it would be a big help.
I tried to reproduce the bug on latest builds and I was not that "sucessful" as two months ago, and not sure why at all. I can see the messages such as: operation basic.publish caused a channel exception not_found: "no exchange 'reply_fc5a7174b2fe4c2089c6f1fdf28826b8' in vhost '/'" But very rarely and I cannot see any rebbitmq disconnections as previously. I gonna close the bug for now and reopen If the described behaviour is reproducible again.
Hi guys, We're currently hitting this issue . I updated python-oslo-messaging and rabbitmq-server to the latest RHOSP 10 versions and we're still hitting this. Do you know which packages/process/etc caused this issue? Thank you very much, David Hill
Testing this patch [1]
[1] --- impl_rabbit.py.orig 2016-11-22 11:49:09.000000000 +0000
+++ impl_rabbit.py 2017-09-15 23:29:44.716985459 +0000
@@ -1067,11 +1067,21 @@
if not self.connection.connected:
raise self.connection.recoverable_connection_errors[0]
- while self._new_tags:
+ consume_max_retries = 2
+ while self._new_tags and consume_max_retries:
for consumer, tag in self._consumers.items():
if tag in self._new_tags:
- consumer.consume(self, tag=tag)
- self._new_tags.remove(tag)
+ try:
+ consumer.consume(tag=tag)
+ self._new_tags.remove(tag)
+ except self.connection.channel_errors as exc:
+ if exc.code == 404 and consume_max_retries:
+ consumer.declare(self)
+ self._new_tags = set(self._consumers.values())
+ consume_max_retries -= 1
+ break
+ else:
+ raise
poll_timeout = (self._poll_timeout if timeout is None
else min(timeout, self._poll_timeout))
It doesn't seem like it changing anything in this case.
This error is not totally unexpected under normal conditions. Here's roughly how it happens: - Service A creates an exchange/queue pair reply_XYZ for receiving RPC responses. These are created with auto_delete=true. - A makes an RPC call to service B. - B receives the RPC request from A, and does some work. - A stops or is disconnected from RabbitMQ for $reasons. - RabbitMQ notices there are zero consumers on reply_XYZ, and auto deletes the queue. Because the exchange is not bound to any queues now, it is also auto deleted. - B is done working, and attempts to publish to exchange reply_XYZ, but it is gone. - B will retry for some time (Offhand, I believe once per second for 60 seconds), hoping that A reconnects and re-declares the queue/exchange. During this time, you will get this error repeatedly. - Eventually either (a) A comes back, re-declares reply_XYZ, and B is able to send the reply, or (b) service B gives up after the timeout and stops trying to send the reply. So it's not necessarily indicative of a problem. It's supposed to work that way in the general case. However, it *could* be indicative of a problem, probably related to a partition, either ongoing or at some point in the past. There's not really any rule to say for sure, you have to examine the context on a case-by-case basis. Hopefully that helps clarify.
This may also be the same thing as bug 1484543, if it persists for extended periods of time (more than a minute).
We hit this issue when they did a maintenance on a network switch and bonding didn't failover to the other nic. All controllers got isolated (split brain for each host) and then , rabbitmq started exhibiting this issue: =ERROR REPORT==== 28-Apr-2018::01:30:48 === Channel error on connection <0.10376.0> (192.168.5.7:49702 -> 192.168.5.7:5672, vhost: '/', user: 'guest'), channel 1: operation basic.publish caused a channel exception not_found: "no exchange 'reply_8122e6beca9543f5b4860ad80e3619fe' in vhost '/'" Restarting rabbitmq-clone solved the problem by forcing the 3 rabbitmq cluster member to restart and then triggering all stuck connection / broken service / etc to reconnect to the AMQP service.
vhost errors (among others) also in case # 02135077: Channel error on connection <0.17098.7> (...:57542 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.17098.7> (...:57542 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.22766.7> (...:36624 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.15751.7> (...:57274 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.22766.7> (...:36624 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.15751.7> (...:57274 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.22766.7> (...:36624 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.15751.7> (...:57274 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.22766.7> (...:36624 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.15751.7> (...:57274 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.22766.7> (...:36624 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.23111.7> (...:58592 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.22766.7> (...:36624 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.23111.7> (...:58592 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.23111.7> (...:58592 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.23148.7> (...:58804 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.23189.7> (...:59240 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.23189.7> (...:59240 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.23189.7> (...:59240 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.349.2> (...:41178 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.19336.3> (...:44944 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.19336.3> (...:44944 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.24749.2> (...:43976 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.24749.2> (...:43976 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.24749.2> (...:43976 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.24749.2> (...:43976 -> ...:5672, vhost: '/', user: 'guest'), channel 1: Channel error on connection <0.20645.6> (...:55270 -> ...:5672, vhost: '/', user: 'guest'), channel 1:
This bug seems to have taken a bit of a tangent from the original issue that Marian reported. The key bit is that Marian was seeing this issue without any network disruption or failover testing. Meanwhile, the later comments seem to be more related to recovery during a network disruption / partition scenario. This is a perfectly valid concern, but we should isolate any such case and deal with them separately, otherwise we are going to mix up subtle differences. Also, these are somewhat old reports (I'm trying to clean up stale bugs) that are missing necessary data (sosreports, etc) to diagnose. So with that said, I'm going to close this one. If we still have outstanding case(s) that show a similar problem to this, feel free to open a new bug up and include as much data as possible so we can hopefully get to the bottom of it.
(In reply to Cyril Lopez from comment #23)
> Hello,
>
> We are hitting this again exactly like
> https://bugs.launchpad.net/mos/+bug/1609741
>
> Regards
> Cyril
Hey Cyril,
I am going to close this one - would you mind opening a new BZ if your customer hits this again (as per eck' suggestion)?
Thanks,
Luca
|
RabbitMQ cluster has been seen to exhibit some blocking behaviour, and becoming unreachable to external operations after being subjected to certain conditions. The logs reveal channel errors as below, which are caused by certain exchanges not being found.
=ERROR REPORT==== 14-Dec-2015::16:44:40 ===
Channel error on connection <0.5462.0> (192.168.245.3:53044 -> 192.168.245.5:5672, vhost: '/', user: 'rmq_nova_user'), channel 1:
operation queue.bind caused a channel exception not_found: "no exchange 'reply_5f360ace6a4d4a9e83c9d276877e4d4b' in vhost '/'"
This also leads to some channel_termination_timeout exceptions as follows;
=CRASH REPORT==== 14-Dec-2015::16:49:05 ===
crasher:
initial call: rabbit_reader:init/4
pid: <0.7418.0>
registered_name: []
exception exit: channel_termination_timeout
in function rabbit_reader:wait_for_channel_termination/3 (src/rabbit_reader.erl, line 766)
in call from rabbit_reader:send_error_on_channel0_and_close/4 (src/rabbit_reader.erl, line 1503)
in call from rabbit_reader:terminate/2 (src/rabbit_reader.erl, line 615)
in call from rabbit_reader:handle_other/2 (src/rabbit_reader.erl, line 540)
in call from rabbit_reader:mainloop/4 (src/rabbit_reader.erl, line 502)
in call from rabbit_reader:run/1 (src/rabbit_reader.erl, line 427)
in call from rabbit_reader:start_connection/4 (src/rabbit_reader.erl, line 385)
ancestors: [<0.7416.0>,<0.2520.0>,<0.2519.0>,<0.2518.0>,rabbit_sup,
<0.634.0>]
messages: [{'EXIT',#Port<0.22137>,normal}]
links: []
dictionary: [{{channel,1},
{<0.7445.0>,{method,rabbit_framing_amqp_0_9_1}}},
{process_name,
{rabbit_reader,
<<"192.168.245.8:48658 -> 192.168.245.3:5672">>}},
{{ch_pid,<0.7445.0>},{1,#Ref<0.0.0.40007>}}]
trap_exit: true
status: running
heap_size: 2586
stack_size: 27
reductions: 7946
neighbours:
The following procedures can be carried out to reproduce this problem, assuming a Linux environment, Debian preferrably, RabbitMQ 3.4.3 or above, and preferrably Erlang 17.3;
On a 3 node cluster (NODE_A, NODE_B, NODE_C) with queue(s) decalred with HA policy set to {"ha-mode": "all", "ha-sync-mode":"automatic"} and cluster_partition_handling configured to pause_minority, apply traffic to the cluster whilst carrying out the following sequence of events, on NODE_A for example;
rabbitmqctl list_channels
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster <rabbit@NODE_B>
rabbitmqctl start_app
rabbitmqctl list_queues -q synchronised_slave_pids
sleep 2
rabbitmq-server stop
sleep 5
service rabbitmq-server start
iptables -A INPUT -s <NODE_B_IP> -p TCP -j DROP
iptables -A INPUT -s <NODE_C_IP> -p TCP -j DROP
These procedures are repeated on NODE_B and NODE_C, with NODE_B joining NODE_C, and NODE_C joining NODE_A, respectively.
Channel-oriented API reference
- Overview
- Dealing with failure
- Exceptions and promises
- Exceptions and callbacks
- Flow control
- Argument handling
- API reference
- connect
- ChannelModel and CallbackModel
- connection.close
- events
- connection.createChannel
- connection.createConfirmChannel
- Channel
- channel.close
- events
- channel.assertQueue
- channel.checkQueue
- channel.deleteQueue
- channel.purgeQueue
- channel.bindQueue
- channel.unbindQueue
- channel.assertExchange
- channel.checkExchange
- channel.deleteExchange
- channel.bindExchange
- channel.unbindExchange
- channel.publish
- channel.sendToQueue
- channel.consume
- channel.cancel
- channel.get
- channel.ack
- channel.ackAll
- channel.nack
- channel.nackAll
- channel.reject
- channel.prefetch
- channel.recover
- ConfirmChannel
- confirmChannel.publish
- confirmChannel.sendToQueue
- confirmChannel.waitForConfirms
- RabbitMQ and deletion
There are two parallel client APIs available. One uses promises, and
the other uses callbacks, mutatis mutandis. Since they present much
the same set of objects and methods, you are free to choose which you
prefer, without missing out on any features. However, they don’t mix
– a channel from the promises API has only the promise-based methods,
and likewise the callback API – so it is best to pick one and stick
with it.
The promise-based API is the “main” module in the library:
var amqp = require('amqplib');
You can access the callback-based API this way:
var amqp = require('amqplib/callback_api');
In the following I use “resolve”, “resolving” etc., to refer either to
resolving a returned promise (usually with a value); or in the
callback API, invoking a supplied callback with null as the first
argument (and usually some value as the second argument). Likewise,
“reject” etc., will mean rejecting a promise or calling the callback
with an Error as the first argument (and no value).
[^top](#top)
Overview
The client APIs are based closely on the protocol model. The general
idea is to connect, then create one or more channels on which to issue
commands, send messages, and so on. Most errors in AMQP invalidate
just the channel which had problems, so this ends up being a fairly
natural way to use AMQP. The downside is that it doesn’t give any
guidance on useful ways to use AMQP; that is, it does little beyond
giving access to the various AMQP commands.
Most operations in AMQP are RPCs, synchronous at the channel layer of
the protocol but asynchronous from the library’s point of
view. Accordingly, most methods either return promises, or accept
callbacks, yielding the server’s reply (often containing useful
information such as generated identifiers). RPCs are queued by the
channel if it is already waiting for a reply – synchronising on RPCs
in this way is implicitly required by the protocol specification.
Some methods are not RPCs – they do not have responses from the
server. These return either nothing (ack[All], nack[All], reject) or a
boolean (publish and sendToQueue); see flow
control.
[^top](#top)
Dealing with failure
Most operations in AMQP act like assertions, failing if the desired
conditions cannot be met; for example, if a queue being declared
already exists but with different properties. A failed operation will
- reject the current RPC, if there is one
- invalidate the channel object, meaning further operations will
throw an exception - reject any RPCs waiting to be sent
- cause the channel object to emit
'error' - cause the channel object to emit
'close'
Error events emitted from a channel (or a connection) have the potential to crash your application if not handled.
Since the RPCs are effectively synchronised, any such channel error is
very likely to have been caused by the outstanding RPC. However, it’s
often sufficient to fire off a number of RPCs and check only the
result for the last, since it’ll be rejected if it or any of its
predecessors fail.
The exception thrown on operations subsequent to a failure or
channel close also contains the stack at the point that the channel
was closed, in the field stackAtStateChange. This may be useful to
determine what has caused an unexpected closure.
connection.createChannel().then(function(ch) {
ch.close();
try {
ch.close();
}
catch (alreadyClosed) {
console.log(alreadyClosed.stackAtStateChange);
}
});
[^top](#top)
Exceptions and promises
Promises returned from methods are amenable to composition using, for
example, when.js’s functions:
amqp.connect().then(function(conn) {
var ok = conn.createChannel();
ok = ok.then(function(ch) {
return when.all([
ch.assertQueue('foo'),
ch.assertExchange('bar'),
ch.bindQueue('foo', 'bar', 'baz'),
ch.consume('foo', handleMessage)
]);
});
return ok;
}).then(null, console.warn);
If an exception is thrown in a promise continuation, the promise
library will redirect control to a following error continuation:
amqp.connect().then(function(conn) {
// Everything ok, but ..
throw new Error('SNAFU');
}, function(err) {
console.error('Connect failed: %s', err);
}).then(null, function(err) {
console.error('Connect succeeded, but error thrown: %s', err);
});
[^top](#top)
Exceptions and callbacks
The callback API expects callbacks that follow the convention
function(err, value) {...}. This library does not attempt to deal
with exceptions thrown in callbacks, so in general they will trigger
the last-resort 'uncaughtException' event of the process.
However, since the connection and channels are EventEmitters, they
can be bound to a domain:
var dom = domain.create();
dom.on('error', gracefullyRestart);
amqp.connect(function(err, conn) {
dom.add(conn);
//...
});
Implicit binding works for connections or channels created within a
Domain#run.
var dom = domain.create();
dom.on('error', gracefullyRestart);
dom.run(function() {
amqp.connect(function(err, conn) {
// ...
});
});
[^top](#top)
Flow control
Channels act like stream.Writable when you call
publish or sendToQueue: they return either true, meaning “keep
sending”, or false, meaning “please wait for a ‘drain’ event”.
Those methods, along with ack, ackAll, nack, nackAll, and
reject, do not have responses from the server. This means they do
not return a promise in the promises API. The ConfirmChannel does
accept a callback in both APIs, called when the server confirms the
message; as well as returning a boolean.
Argument handling
Many operations have mandatory arguments as well as optional arguments
with defaults; in general, the former appear as parameters to the
method while latter are collected in a single options parameter, to
be supplied as an object with the fields mentioned. Extraneous fields
in options are ignored, so it is often possible to coalesce the
options for a number of operations into a single object, should that
be convenient. Likewise, fields from the prototype chain are accepted,
so a common options value can be specialised by e.g., using
Object.create(common) then setting some fields.
Often, AMQP commands have an arguments table that can contain
arbitrary values, usually used by implementation-specific extensions
like
RabbitMQ’s consumer priorities. This is
accessible as the option arguments, also an object: if an API method
does not account for an extension in its stated options, you can
fall back to using the options.arguments object, though bear in mind
that the field name will usually be ‘x-something’, while the options
are just ‘something’. Values passed in options, if understood by the
API, will override those given in options.arguments.
var common_options = {durable: true, noAck: true};
ch.assertQueue('foo', common_options);
// Only 'durable' counts for queues
var bar_opts = Object.create(common_options);
bar_opts.autoDelete = true;
// "Subclass" our options
ch.assertQueue('bar', bar_opts);
var foo_consume_opts = Object.create(common_options);
foo_consume_opts.arguments = {'x-priority': 10};
ch.consume('foo', console.log, foo_consume_opts);
// Use the arguments table to give a priority, even though it's
// available as an option
var bar_consume_opts = Object.create(foo_consume_opts);
bar_consume_opts.priority = 5;
ch.consume('bar', console.log, bar_consume_opts);
// The 'priority' option will override that given in the arguments
// table
Field table values
The aforementioned arguments option, and the headers option of
publish and sendToQueue, are both a “field table” value. This is
an object with more or less arbitrary keys and values.
There are some special kinds of value that may be encoded in tables;
these are represented in JavaScript using an object, with a field
'!' giving the AMQP type. You can send these, and you may receive
them.
| Type | Example |
|---|---|
| Timestamp | {'!': 'timestamp', value: 1510443625620} |
| Decimal | {'!': 'decimal', value: {digits: 4999, places: 2}} |
Usually, numbers will be encoded as a double if they have a fractional
part, and the smallest size of integer necessary, otherwise. For
example, 12 will be encoded as a byte (int8), and 300 will be
encoded as a short (int16).
For some purposes (header matching exchanges, for example) you may
want to give a specific encoding for a number. You can use the '!'
notation above to give the specific encoding; but you will not ever
receive numbers like this – you’ll just get a number. There are
aliases for most encodings, as shown in the examples.
| Encoding | Example |
|---|---|
| signed 8-bit integer | {'!': 'int8', value: 64} |
{'!': 'byte', value: 64} |
|
| signed 16-bit integer | {'!': 'int16', value: 64} |
{'!': 'short', value: 64} |
|
| signed 32-bit integer | {"!': 'int32', value: 64} |
{'!': 'int', value: 64} |
|
| signed 64-bit integer | {'!': 'int64', value: 64} |
{'!': 'long', value: 64} |
|
| 32-bit floating point | {'!': 'float', value: 64} |
| 64-bit floating point | {'!': 'double', value: 64} |
NB AMQP only has signed integers in tables.
[^top](#top)
connect
Promises API
connect([url, [socketOptions]])
Callback API
connect([url, [socketOptions]], function(err, conn) {...})
Connect to an AMQP 0-9-1 server, optionally given an AMQP URL (see
AMQP URI syntax) and socket options. The protocol part
(amqp: or amqps:) is mandatory; defaults for elided parts are as
given in 'amqp://guest:guest@localhost:5672'. If the URI is omitted
entirely, it will default to 'amqp://localhost', which given the
defaults for missing parts, will connect to a RabbitMQ installation
with factory settings, on localhost.
auth
The auth section (guest:guest above) is treated as one section for
the purpose of default values. If nothing appears there, the defaults
will be used. If anything appears there, it will taken as giving both
the username and password (and if either is absent, it will be treated
as empty i.e., '').
Usernames and passwords should be percent-encoded.
vhost
For convenience, an absent path segment (e.g., as in the URLs just
given) is interpreted as the virtual host named /, which is present
in RabbitMQ out of the box. Per the URI specification, just a
trailing slash as in 'amqp://localhost/' would indicate the virtual
host with an empty name, which does not exist unless it’s been
explicitly created. When specifying another virtual host, remember
that its name must be escaped; so e.g., the virtual host named /foo
is '%2Ffoo'; in a full URI, 'amqp://localhost/%2Ffoo'.
tuning parameters
Further AMQP tuning parameters may be given in the query part of the
URI, e.g., as in 'amqp://localhost?frameMax=0x1000'. These are:
-
frameMax, the size in bytes of the maximum frame allowed over the
connection.0means no limit (but since frames have a size field
which is an unsigned 32 bit integer, it’s perforce2^32 - 1); I
default it to 0x1000, i.e. 4kb, which is the allowed minimum, will
fit many purposes, and not chug through Node.JS’s buffer pooling. -
channelMax, the maximum number of channels allowed. Default is
0, meaning2^16 - 1. -
heartbeat: the period of the connection heartbeat, in
seconds. Defaults to0; see heartbeating -
locale: the desired locale for error messages, I
suppose. RabbitMQ only ever usesen_US; which, happily, is the
default.
Connecting with an object instead of a URL
The URL can also be supplied as an object of the form:
{
protocol: 'amqp',
hostname: 'localhost',
port: 5672,
username: 'guest',
password: 'guest',
locale: 'en_US',
frameMax: 0,
heartbeat: 0,
vhost: '/',
}
in which case the values discussed above will be taken directly from
the fields. Absent fields will be given defaults as for a URL supplied
as a string.
Socket options
The socket options will be passed to the socket library (net or
tls). In an exception to the general rule, they must be fields set
on the object supplied; that is, not in the prototype chain. The
socket options is useful for supplying certificates and so on for an
SSL connection; see the SSL guide.
The socket options may also include the keys timeout and noDelay.
timeout specifies the socket timeout in milliseconds while
establishing the connection and noDelay is a boolean value that
when true sets
TCP_NODELAY on the underlying socket.
Client properties
You can specify additional client properties such as connection_name as follows…
amqp.connect('amqp://localhost', {clientProperties: {connection_name: 'myFriendlyName'}});
Result
The returned promise, or supplied callback, will either be resolved
with an object representing an open connection, or rejected with a
sympathetically-worded error (in en_US).
Supplying a malformed URI will cause connect() to throw an
exception; other problems, including refused and dropped TCP
connections, will result in a rejection.
RabbitMQ since version 3.2.0 will send a frame to notify the client of
authentication failures, which results in a rejection. RabbitMQ before
version 3.2.0, per the AMQP specification, will close the socket in
the case of an authentication failure, making a dropped connection
ambiguous (it will also wait a few seconds before doing so).
Heartbeating
If you supply a non-zero period in seconds as the heartbeat
parameter, the connection will be monitored for liveness. If the
client fails to read data from the connection for two successive
intervals, the connection will emit an error and close. It will also
send heartbeats to the server (in the absence of other data).
If you supply 0 as the heartbeat parameter (or defaults to 0), the
server value is used. This means that you can only disable heartbeat if
the server value is also 0. See
here for more details.
NOTE: Please consider NOT disabling heartbeats because they exist for a
reason.
[^top](#top)
ChannelModel and CallbackModel
These constructors represent connections in the channel APIs. They
take as an argument a connection.Connection. It is better to use
connect(), which will open the connection for you. The constructors
are exported as potential extension points.
[^top](#top)
{Channel,Callback}Model#close
Promises API
connection.close()
Callback API
connection.close([function(err) {...}])
Close the connection cleanly. Will immediately invalidate any
unresolved operations, so it’s best to make sure you’ve done
everything you need to before calling this. Will be resolved once the
connection, and underlying socket, are closed. The model will also
emit 'close' at that point.
Although it’s not strictly necessary, it will avoid some warnings in
the server log if you close the connection before exiting:
var open = amqp.connect();
open.then(function(conn) {
var ok = doStuffWithConnection(conn);
return ok.then(conn.close.bind(conn));
}).then(null, console.warn);
Note that I’m synchronising on the return value of
doStuffWithConnection(), assumed here to be a promise, so that I can
be sure I’m all done. The callback version looks like this:
amqp.connect(function(err, conn) {
if (err !== null) return console.warn(err);
doStuffWithConnection(conn, function() {
conn.close();
});
});
There it’s assumed that doStuffWithConnection invokes its second
argument once it’s all finished.
If your program runs until interrupted, you can hook into the process
signal handling to close the connection:
var open = amqp.connect();
open.then(function(conn) {
process.once('SIGINT', conn.close.bind(conn));
return doStuffWithConnection(conn);
}).then(null, console.warn);
NB it’s no good using process.on('exit', ...), since close() needs
to do I/O.
[^top](#top)
{Channel,Callback}Model events
#on('close', function() {...})
Emitted once the closing handshake initiated by #close() has
completed; or, if server closed the connection, once the client has
sent the closing handshake; or, if the underlying stream (e.g.,
socket) has closed.
In the case of a server-initiated shutdown or an error, the
'close' handler will be supplied with an error indicating the
cause. You can ignore this if you don’t care why the connection
closed; or, you can test it with
require('amqplib/lib/connection').isFatalError(err) to see if it was
a crash-worthy error.
#on('error', function (err) {...})
Emitted if the connection closes for a reason other than #close
being called or a graceful server-initiated close; such reasons
include:
- a protocol transgression the server detected (likely a bug in this
library) - a server error
- a network error
- the server thinks the client is dead due to a missed heartbeat
A graceful close may be initiated by an operator (e.g., with an admin
tool), or if the server is shutting down; in this case, no 'error'
event will be emitted.
'close' will also be emitted, after 'error'.
#on('blocked', function(reason) {...})
Emitted when a RabbitMQ server (after version 3.2.0) decides to block
the connection. Typically it will do this if there is some resource
shortage, e.g., memory, and messages are published on the
connection. See the RabbitMQ documentation for this
extension for details.
#on('unblocked', function() {...})
Emitted at some time after 'blocked', once the resource shortage has
alleviated.
[^top](#top)
{Channel,Callback}Model#createChannel
Promises API
#createChannel()
Callback API
#createChannel(function(err, channel) {...})
Resolves to an open Channel (The callback version returns the
channel; but it is not usable before the callback has been
invoked). May fail if there are no more channels available (i.e., if
there are already channelMax channels open).
[^top](#top)
{Channel,Callback}Model#createConfirmChannel
Promises API
#createConfirmChannel()
Callback API
#createConfirmChannel(function(err, channel) {...})
Open a fresh channel, switched to “confirmation mode”. See
ConfirmChannel below.
[^top](#top)
Channels
There are channel objects in each of the APIs, and these contain most
of the methods for getting things done.
new Channel(connection)
This constructor represents a protocol channel. Channels are
multiplexed over connections, and represent something like a session,
in that most operations (and thereby most errors) are scoped to
channels.
The constructor is exported from the API modules as an extension
point. When using a client API, obtain an open Channel by opening a
connection (connect() above) and calling #createChannel or
#createConfirmChannel.
[^top](#top)
Channel#close
Promises API
Channel#close()
Callback API
Channel#close([function(err) {...}])
Close a channel. Will be resolved with no value once the closing
handshake is complete.
There’s not usually any reason to close a channel rather than
continuing to use it until you’re ready to close the connection
altogether. However, the lifetimes of consumers are scoped to
channels, and thereby other things such as exclusive locks on queues,
so it is occasionally worth being deliberate about opening and closing
channels.
[^top](#top)
Channel events
#on('close', function() {...})
A channel will emit 'close' once the closing handshake (possibly
initiated by #close()) has completed; or, if its connection closes.
When a channel closes, any unresolved operations on the channel will
be abandoned (and the returned promises rejected).
#on('error', function(err) {...})
A channel will emit 'error' if the server closes the channel for any
reason. Such reasons include
- an operation failed due to a failed precondition (usually
something named in an argument not existing) - an human closed the channel with an admin tool
A channel will not emit 'error' if its connection closes with an
error.
#on('return', function(msg) {...})
If a message is published with the mandatory flag (it’s an option to
Channel#publish in this API), it may be returned to the sending
channel if it cannot be routed. Whenever this happens, the channel
will emit return with a message object (as described in #consume)
as an argument.
#on('drain', function() {...})
Like a stream.Writable, a channel will emit 'drain',
if it has previously returned false from #publish or
#sendToQueue, once its write buffer has been emptied (i.e., once it
is ready for writes again).
[^top](#top)
Channel#assertQueue
Promises API
#assertQueue([queue, [options]])
Callback API
#assertQueue([queue, [options, [function(err, ok) {...}]]])
Assert a queue into existence. This operation is idempotent given
identical arguments; however, it will bork the channel if the queue
already exists but has different properties (values supplied in the
arguments field may or may not count for borking purposes; check the
borker’s, I mean broker’s, documentation).
queue is a string; if you supply an empty string or other falsey
value (including null and undefined), the server will create a
random name for you.
options is an object and may be empty or null, or outright omitted
if it’s the last argument. The relevant fields in options are:
-
exclusive: if true, scopes the queue to the connection (defaults
to false) -
durable: if true, the queue will survive broker restarts, modulo
the effects ofexclusiveandautoDelete; this defaults to true
if not supplied, unlike the others -
autoDelete: if true, the queue will be deleted when the number of
consumers drops to zero (defaults to false) -
arguments: additional arguments, usually parameters for some kind
of broker-specific extension e.g., high availability, TTL.
RabbitMQ extensions can also be supplied as options. These typically
require non-standard x-* keys and values, sent in the arguments
table; e.g., 'x-expires'. When supplied in options, the x-
prefix for the key is removed; e.g., 'expires'. Values supplied in
options will overwrite any analogous field you put in
options.arguments.
-
messageTtl(0 <= n < 2^32): expires messages arriving in the
queue after n milliseconds -
expires(0 < n < 2^32): the queue will be destroyed after n
milliseconds of disuse, where use means having consumers, being
declared (asserted or checked, in this API), or being polled with a
#get. -
deadLetterExchange(string): an exchange to which messages
discarded from the queue will be resent. UsedeadLetterRoutingKey
to set a routing key for discarded messages; otherwise, the
message’s routing key (and CC and BCC, if present) will be
preserved. A message is discarded when it expires or is rejected or
nacked, or the queue limit is reached. -
maxLength(positive integer): sets a maximum number of messages
the queue will hold. Old messages will be discarded (dead-lettered
if that’s set) to make way for new messages. -
maxPriority(positive integer): makes the queue a priority
queue.
Resolves to the “ok” reply from the server, which includes fields for
the queue name (important if you let the server name it), a recent
consumer count, and a recent message count; e.g.,
{
queue: 'foobar',
messageCount: 0,
consumerCount: 0
}
[^top](#top)
Channel#checkQueue
Promises API
#checkQueue(queue)
Callback API
#checkQueue(queue, [function(err, ok) {...}])
Check whether a queue exists. This will bork the channel if the named
queue doesn’t exist; if it does exist, you go through to the next
round! There’s no options, unlike #assertQueue(), just the queue
name. The reply from the server is the same as for #assertQueue().
[^top](#top)
Channel#deleteQueue
Promises API
#deleteQueue(queue, [options])
Callback API
#deleteQueue(queue, [options, [function(err, ok) {...}]])
Delete the queue named. Naming a queue that doesn’t exist will result
in the server closing the channel, to teach you a lesson (except in
RabbitMQ version 3.2.0 and after1). The
options here are:
-
ifUnused(boolean): if true and the queue has consumers, it will
not be deleted and the channel will be closed. Defaults to false. -
ifEmpty(boolean): if true and the queue contains messages, the
queue will not be deleted and the channel will be closed. Defaults
to false.
Note the obverse semantics of the options: if both are true, the queue
will be deleted only if it has no consumers and no messages.
You should leave out the options altogether if you want to delete the
queue unconditionally.
The server reply contains a single field, messageCount, with the
number of messages deleted or dead-lettered along with the queue.
[^top](#top)
Channel#purgeQueue
Promises API
#purgeQueue(queue)
Callback API
#purgeQueue(queue, [function(err, ok) {...}])
Remove all undelivered messages from the queue named. Note that this
won’t remove messages that have been delivered but not yet
acknowledged; they will remain, and may be requeued under some
circumstances (e.g., if the channel to which they were delivered
closes without acknowledging them).
The server reply contains a single field, messageCount, containing
the number of messages purged from the queue.
[^top](#top)
Channel#bindQueue
Promises API
#bindQueue(queue, source, pattern, [args])
Callback API
#bindQueue(queue, source, pattern, [args, [function(err, ok) {...}]])
Assert a routing path from an exchange to a queue: the exchange named
by source will relay messages to the queue named, according to the
type of the exchange and the pattern given. The RabbitMQ
tutorials give a good account of how routing works in
AMQP.
args is an object containing extra arguments that may be required
for the particular exchange type (for which, see
your server’s documentation). It may be omitted if
it’s the last argument, which is equivalent to an empty object.
The server reply has no fields.
[^top](#top)
Channel#unbindQueue
Promises API
#unbindQueue(queue, source, pattern, [args])
Callback API
#unbindQueue(queue, source, pattern, [args, [function(err, ok) {...}]])
Remove a routing path between the queue named and the exchange named
as source with the pattern and arguments given. Omitting args is
equivalent to supplying an empty object (no arguments). Beware:
attempting to unbind when there is no such binding may result in a
punitive error (the AMQP specification says it’s a connection-killing
mistake; RabbitMQ before version 3.2.0 softens this to a channel
error, and from version 3.2.0, doesn’t treat it as an error at
all1. Good ol’ RabbitMQ).
[^top](#top)
Channel#assertExchange
Promises API
#assertExchange(exchange, type, [options])
Callback API
#assertExchange(exchange, type, [options, [function(err, ok) {...}]])
Assert an exchange into existence. As with queues, if the exchange
exists already and has properties different to those supplied, the
channel will ‘splode; fields in the arguments object may or may not be
‘splodey, depending on the type of exchange. Unlike queues, you must
supply a name, and it can’t be the empty string. You must also supply
an exchange type, which determines how messages will be routed through
the exchange.
NB There is just one RabbitMQ extension pertaining to exchanges in
general (alternateExchange); however, specific exchange types may
use the arguments table to supply parameters.
The options:
-
durable(boolean): if true, the exchange will survive broker
restarts. Defaults to true. -
internal(boolean): if true, messages cannot be published
directly to the exchange (i.e., it can only be the target of
bindings, or possibly create messages ex-nihilo). Defaults to false. -
autoDelete(boolean): if true, the exchange will be destroyed
once the number of bindings for which it is the source drop to
zero. Defaults to false. -
alternateExchange(string): an exchange to send messages to if
this exchange can’t route them to any queues. -
arguments(object): any additional arguments that may be needed
by an exchange type.
The server reply echoes the exchange name, in the field exchange.
[^top](#top)
Channel#checkExchange
Promises API
#checkExchange(exchange)
Callback API
#checkExchange(exchange, [function(err, ok) {...}])
Check that an exchange exists. If it doesn’t exist, the channel will
be closed with an error. If it does exist, happy days.
[^top](#top)
Channel#deleteExchange
Promises API
#deleteExchange(name, [options])
Callback API
#deleteExchange(name, [options, [function(err, ok) {...}]])
Delete an exchange. The only meaningful field in options is:
ifUnused(boolean): if true and the exchange has bindings, it
will not be deleted and the channel will be closed.
If the exchange does not exist, a channel error is raised (RabbitMQ
version 3.2.0 and after will not raise an
error1).
The server reply has no fields.
[^top](#top)
Channel#bindExchange
Promises API
#bindExchange(destination, source, pattern, [args])
Callback API
#bindExchange(destination, source, pattern, [args, [function(err, ok) {...}]])
Bind an exchange to another exchange. The exchange named by
destination will receive messages from the exchange named by
source, according to the type of the source and the pattern
given. For example, a direct exchange will relay messages that have
a routing key equal to the pattern.
NB Exchange to exchange binding is a RabbitMQ extension.
The server reply has no fields.
[^top](#top)
Channel#unbindExchange
Promises API
#unbindExchange(destination, source, pattern, [args])
Callback API
#unbindExchange(destination, source, pattern, [args, [function(err, ok) {...}]])
Remove a binding from an exchange to another exchange. A binding with
the exact source exchange, destination exchange, routing key
pattern, and extension args will be removed. If no such binding
exists, it’s – you guessed it – a channel error, except in
RabbitMQ >= version 3.2.0, for which it succeeds
trivially1.
[^top](#top)
Channel#publish
Promises and callback APIs
#publish(exchange, routingKey, content, [options])
NOTE: Does not return a promise in the promises API; see
flow control
Publish a single message to an exchange. The mandatory parameters are:
-
exchangeandroutingKey: the exchange and routing key, which
determine where the message goes. A special case is sending''as
the exchange, which will send directly to the queue named by the
routing key;#sendToQueuebelow is equivalent to this special
case. If the named exchange does not exist, the channel will be
closed. -
content: a buffer containing the message content. This will be
copied during encoding, so it is safe to mutate it once this method
has returned.
The remaining parameters are provided as fields in options, and are
divided into those that have some meaning to RabbitMQ and those that
will be ignored by RabbitMQ but passed on to consumers. options may
be omitted altogether, in which case defaults as noted will apply.
The “meaningful” options are a mix of fields in BasicDeliver (the
method used to publish a message), BasicProperties (in the message
header frame) and RabbitMQ extensions which are given in the headers
table in BasicProperties.
Used by RabbitMQ and sent on to consumers:
-
expiration(string): if supplied, the message will be discarded
from a queue once it’s been there longer than the given number of
milliseconds. In the specification this is a string; numbers
supplied here will be coerced to strings for transit. -
userId(string): If supplied, RabbitMQ will compare it to the
username supplied when opening the connection, and reject messages
for which it does not match. -
CC(string or array of string): an array of routing keys as
strings; messages will be routed to these routing keys in addition
to that given as theroutingKeyparameter. A string will be
implicitly treated as an array containing just that string. This
will override any value given forCCin theheaders
parameter. NB The property namesCCandBCCare
case-sensitive. -
priority(positive integer): a priority for the message; ignored
by versions of RabbitMQ older than 3.5.0, or if the queue is not a
priority queue (seemaxPriority
above). -
persistent(boolean): If truthy, the message will survive broker
restarts provided it’s in a queue that also survives
restarts. Corresponds to, and overrides, the property
deliveryMode. -
deliveryMode(boolean or numeric): Either1or falsey, meaning
non-persistent; or,2or truthy, meaning persistent. That’s just
obscure though. Use the optionpersistentinstead.
Used by RabbitMQ but not sent on to consumers:
-
mandatory(boolean): if true, the message will be returned if it
is not routed to a queue (i.e., if there are no bindings that match
its routing key). -
BCC(string or array of string): likeCC, except that the value
will not be sent in the message headers to consumers.
Not used by RabbitMQ and not sent to consumers:
immediate(boolean): in the specification, this instructs the
server to return the message if it is not able to be sent
immediately to a consumer. No longer implemented in RabbitMQ, and
if true, will provoke a channel error, so it’s best to leave it
out.
Ignored by RabbitMQ (but may be useful for applications):
-
contentType(string): a MIME type for the message content -
contentEncoding(string): a MIME encoding for the message content -
headers(object): application specific headers to be carried
along with the message content. The value as sent may be augmented
by extension-specific fields if they are given in the parameters,
for example, ‘CC’, since these are encoded as message headers; the
supplied value won’t be mutated. -
correlationId(string): usually used to match replies to
requests, or similar -
replyTo(string): often used to name a queue to which the
receiving application must send replies, in an RPC scenario (many
libraries assume this pattern) -
messageId(string): arbitrary application-specific identifier for
the message -
timestamp(positive number): a timestamp for the message -
type(string): an arbitrary application-specific type for the
message -
appId(string): an arbitrary identifier for the originating
application
#publish mimics the stream.Writable interface in
its return value; it will return false if the channel’s write buffer
is ‘full’, and true otherwise. If it returns false, it will emit a
'drain' event at some later time.
[^top](#top)
Channel#sendToQueue
Promises and callback APIs
#sendToQueue(queue, content, [options])
NOTE: Does not return a promise in the promises API; see
flow control
Send a single message with the content given as a buffer to the
specific queue named, bypassing routing. The options and return
value are exactly the same as for #publish.
[^top](#top)
Channel#consume
Promises API
#consume(queue, function(msg) {...}, [options])
Callback API
#consume(queue, function(msg) {...}, [options, [function(err, ok) {...}]])
Set up a consumer with a callback to be invoked with each message.
Options (which may be omitted if the last argument):
-
consumerTag(string): a name which the server will use to
distinguish message deliveries for the consumer; mustn’t be already
in use on the channel. It’s usually easier to omit this, in which
case the server will create a random name and supply it in the
reply. -
noLocal(boolean): in theory, if true then the broker won’t
deliver messages to the consumer if they were also published on this
connection; RabbitMQ doesn’t implement it though, and will ignore
it. Defaults to false. -
noAck(boolean): if true, the broker won’t expect an
acknowledgement of messages delivered to this consumer; i.e., it
will dequeue messages as soon as they’ve been sent down the
wire. Defaults to false (i.e., you will be expected to acknowledge
messages). -
exclusive(boolean): if true, the broker won’t let anyone else
consume from this queue; if there already is a consumer, there goes
your channel (so usually only useful if you’ve made a ‘private’
queue by letting the server choose its name). -
priority(integer): gives a priority to the consumer; higher
priority consumers get messages in preference to lower priority
consumers. See this RabbitMQ extension’s
documentation -
arguments(object): arbitrary arguments. Go to town.
The server reply contains one field, consumerTag. It is necessary to
remember this somewhere if you will later want to cancel this consume
operation (i.e., to stop getting messages).
The message callback supplied in the second argument will be invoked
with message objects of this shape:
{
content: Buffer,
fields: Object,
properties: Object
}
The message content is a buffer containing the bytes published.
The fields object has a handful of bookkeeping values largely of
interest only to the library code: deliveryTag, a serial number for
the message; consumerTag, identifying the consumer for which the
message is destined; exchange and routingKey giving the routing
information with which the message was published; and, redelivered,
which if true indicates that this message has been delivered before
and been handed back to the server (e.g., by a nack or recover
operation).
The properties object contains message properties, which are all the
things mentioned under #publish as options that are
transmitted. Note that RabbitMQ extensions (just CC, presently) are
sent in the headers table so will appear there in deliveries.
If the consumer is cancelled by RabbitMQ,
the message callback will be invoked with null.
[^top](#top)
Channel#cancel
Promises API
#cancel(consumerTag)
Callback API
#cancel(consumerTag, [function(err, ok) {...}])
This instructs the server to stop sending messages to the consumer
identified by consumerTag. Messages may arrive between sending this
and getting its reply; once the reply has resolved, however, there
will be no more messages for the consumer, i.e., the message callback
will no longer be invoked.
The consumerTag is the string given in the reply to #consume,
which may have been generated by the server.
[^top](#top)
Channel#get
Promises API
#get(queue, [options])
Callback API
#get(queue, [options, [function(err, msgOrFalse) {...}]])
Ask a queue for a message, as an RPC. This will be resolved with
either false, if there is no message to be had (the queue has no
messages ready), or a message in the same shape as detailed in
#consume.
Options:
noAck(boolean): if true, the message will be assumed by the server
to be acknowledged (i.e., dequeued) as soon as it’s been sent over
the wire. Default is false, that is, you will be expected to
acknowledge the message.
[^top](#top)
Channel#ack
Promises and callback APIs
#ack(message, [allUpTo])
NOTE: Does not return a promise in the promises API, or accept a callback in the callback API.
Acknowledge the given message, or all messages up to and including the
given message.
If a #consume or #get is issued with noAck: false (the default),
the server will expect acknowledgements for messages before forgetting
about them. If no such acknowledgement is given, those messages may be
requeued once the channel is closed.
If allUpTo is true, all outstanding messages prior to and including
the given message shall be considered acknowledged. If false, or
omitted, only the message supplied is acknowledged.
It’s an error to supply a message that either doesn’t require
acknowledgement, or has already been acknowledged. Doing so will
errorise the channel. If you want to acknowledge all the messages and
you don’t have a specific message around, use #ackAll.
[^top](#top)
Channel#ackAll
Promises and callback APIs
#ackAll()
NOTE: Does not return a promise in the promises API, or accept a callback in the callback API.
Acknowledge all outstanding messages on the channel. This is a “safe”
operation, in that it won’t result in an error even if there are no
such messages.
[^top](#top)
Channel#nack
Promises and callback APIs
#nack(message, [allUpTo, [requeue]])
NOTE: Does not return a promise in the promises API, or accept a callback in the callback API.
Reject a message. This instructs the server to either requeue the
message or throw it away (which may result in it being dead-lettered).
If allUpTo is truthy, all outstanding messages prior to and including
the given message are rejected. As with #ack, it’s a channel-ganking
error to use a message that is not outstanding. Defaults to false.
If requeue is truthy, the server will try to put the message or
messages back on the queue or queues from which they came. Defaults to
true if not given, so if you want to make sure messages are
dead-lettered or discarded, supply false here.
This and #nackAll use a RabbitMQ-specific
extension.
[^top](#top)
Channel#nackAll
Promises and callback APIs
#nackAll([requeue])
NOTE: Does not return a promise in the promises API, or accept a callback in the callback API.
Reject all messages outstanding on this channel. If requeue is
truthy, or omitted, the server will try to re-enqueue the messages.
[^top](#top)
Channel#reject
Promises and callback APIs
#reject(message, [requeue])
NOTE: Does not return a promise in the promises API, or accept a callback in the callback API.
Reject a message. Equivalent to #nack(message, false, requeue), but
works in older versions of RabbitMQ (< v2.3.0) where #nack does not.
[^top](#top)
Channel#prefetch
Promises and callback APIs
#prefetch(count, [global])
NOTE: Does not return a promise in the promises API, or accept a callback in the callback API.
Set the prefetch count for this channel. The count given is the
maximum number of messages sent over the channel that can be awaiting
acknowledgement; once there are count messages outstanding, the
server will not send more messages on this channel until one or more
have been acknowledged. A falsey value for count indicates no such
limit.
NB RabbitMQ v3.3.0 changes the meaning of prefetch (basic.qos) to
apply per-consumer, rather than per-channel. It will apply to
consumers started after the method is called. See
rabbitmq-prefetch.
Use the global flag to get the per-channel behaviour. To keep life
interesting, using the global flag with an RabbitMQ older than
v3.3.0 will bring down the whole connection.
[^top](#top)
Channel#recover
Promises API
#recover()
Callback API
#recover([function(err, ok) {...}])
Requeue unacknowledged messages on this channel. The server will reply
(with an empty object) once all messages are requeued.
[^top](#top)
ConfirmChannel
A channel which uses “confirmation mode” (a
RabbitMQ extension).
On a channel in confirmation mode, each published message is ‘acked’
or (in exceptional circumstances) ‘nacked’ by the server, thereby
indicating that it’s been dealt with.
A confirm channel has the same methods as a regular channel, except
that #publish and #sendToQueue accept a callback as an additional
argument. See examples and method signature below.
var open = require('amqplib').connect();
open.then(function(c) {
c.createConfirmChannel().then(function(ch) {
ch.sendToQueue('foo', new Buffer('foobar'), {},
function(err, ok) {
if (err !== null)
console.warn('Message nacked!');
else
console.log('Message acked');
});
});
});
Or, with the callback API:
require('amqplib/callback_api').connect(function(err, c) {
c.createConfirmChannel(function(err, ch) {
ch.sendToQueue('foo', new Buffer('foobar'), {}, function(err, ok) {
if (err !== null) console.warn('Message nacked!');
else console.log('Message acked');
});
});
});
There are, broadly speaking, two uses for confirms. The first is to be
able to act on the information that a message has been accepted, for
example by responding to an upstream request. The second is to rate
limit a publisher by limiting the number of unconfirmed messages it’s
allowed.
new ConfirmChannel(connection)
This constructor is a channel that uses confirms. It is exported as an
extension point. To obtain such a channel, use connect to get a
connection, then call #createConfirmChannel.
[^top](#top)
ConfirmChannel#publish
Promises and callback APIs
#publish(exchange, routingKey, content, options, function(err, ok) {...})
NOTE: Does not return a promise and stil expects a callback in the promises API; see
flow control
options argument must be supplied, at least as an empty object.
[^top](#top)
ConfirmChannel#sendToQueue
Promises and callback APIs
#sendToQueue(queue, content, options, function(err, ok) {...})
NOTE: Does not return a promise and stil expects a callback in the promises API; see
flow control
options argument must be supplied, at least as an empty object.
[^top](#top)
ConfirmChannel#waitForConfirms
Promises API
#waitForConfirms()
Callback API
#waitForConfirms(function(err) {...})
Resolves the promise, or invokes the callback, when all published
messages have been confirmed. If any of the messages has been nacked,
this will result in an error; otherwise the result is no value. Either
way, the channel is still usable afterwards. It is also possible to
call waitForConfirms multiple times without waiting for previous
invocations to complete.
[^top](#top)
RabbitMQ and deletion
RabbitMQ version 3.2.0 makes queue and exchange deletions (and unbind)
effectively idempotent, by not raising an error if the exchange,
queue, or binding does not exist.
This does not apply to preconditions given to the operations. For
example deleting a queue with {ifEmpty: true} will still fail if
there are messages in the queue.
[^top](#top)
Another reason in my case was that by mistake I acknowledged a message twice. This lead to RabbitMQ errors in the log like this after the second acknowledgment.
=ERROR REPORT==== 11-Dec-2012::09:48:29 ===
connection <0.6792.0>, channel 1 - error:
{amqp_error,precondition_failed,"unknown delivery tag 1",'basic.ack'}
After I removed the duplicate acknowledgement then the errors went away and the channel did not close anymore and also the AlreadyClosedException were gone.
I’d like to add this information for other users who will be searching for this topic
Another possible reason for Receiving a Channel Closed Exception is when Publishers and Consumers are accessing Channel/Queue with different queue declaration/settings
Publisher
channel.queueDeclare("task_queue", durable, false, false, null);
Worker
channel.queueDeclare("task_queue", false, false, false, null);
From RabbitMQ Site
RabbitMQ doesn't allow you to redefine an existing queue with different parameters and will return an error to any program that tries to do that
An AMQP channel is closed on a channel error. Two common things that can cause a channel error:
- Trying to publish a message to an exchange that doesn’t exist
- Trying to publish a message with the immediate flag set that doesn’t have a queue with an active consumer set
I would look into setting up a ShutdownListener on the channel you’re trying to use to publish a message using the addShutdownListener() to catch the shutdown event and look at what caused it.
Apparently, there are many reasons for the AMQP connection and/or channels to close abruptly. In my case, there was too many unacknowledged messages on the queue because the consumer didn’t specify the prefetch_count so the connection was getting terminated every ~1min. Limiting the number of unacknowledged messages by setting the consumer’s prefetch count to a non-zero value fixed the problem.
channel.basicQos(100);
При тестировании очереди TTL в RABBITMQ сегодня возникает ошибка, сообщение об ошибке выглядит следующим образом:
Exception in thread “main” java.io.IOException
at com.rabbitmq.client.impl.AMQChannel.wrap(AMQChannel.java:124)
at com.rabbitmq.client.impl.AMQChannel.wrap(AMQChannel.java:120)
at com.rabbitmq.client.impl.AMQChannel.exnWrappingRpc(AMQChannel.java:142)
at com.rabbitmq.client.impl.ChannelN.queueDeclare(ChannelN.java:958)
at com.rabbitmq.client.impl.recovery.AutorecoveringChannel.queueDeclare(AutorecoveringChannel.java:333)
at com.fu.rabbitemq.ttl.Producer.main(Producer.java:27)
Caused by: com.rabbitmq.client.ShutdownSignalException: channel error; protocol method: #method<channel.close>(reply-code=406, reply-text=PRECONDITION_FAILED — inequivalent arg ‘x-message-ttl’ for queue ‘queue_ttl_1’ in vhost ‘/’: received the value ‘10000’ of type ‘signedint’ but current is none, class-id=50, method-id=10)
at com.rabbitmq.utility.ValueOrException.getValue(ValueOrException.java:66)
at com.rabbitmq.utility.BlockingValueOrException.uninterruptibleGetValue(BlockingValueOrException.java:36)
at com.rabbitmq.client.impl.AMQChannel$BlockingRpcContinuation.getReply(AMQChannel.java:443)
at com.rabbitmq.client.impl.AMQChannel.privateRpc(AMQChannel.java:263)
at com.rabbitmq.client.impl.AMQChannel.exnWrappingRpc(AMQChannel.java:136)
… 3 more
Caused by: com.rabbitmq.client.ShutdownSignalException: channel error; protocol method: #method<channel.close>(reply-code=406, reply-text=PRECONDITION_FAILED — inequivalent arg ‘x-message-ttl’ for queue ‘queue_ttl_1’ in vhost ‘/’: received the value ‘10000’ of type ‘signedint’ but current is none, class-id=50, method-id=10)
at com.rabbitmq.client.impl.ChannelN.asyncShutdown(ChannelN.java:515)
at com.rabbitmq.client.impl.ChannelN.processAsync(ChannelN.java:340)
at com.rabbitmq.client.impl.AMQChannel.handleCompleteInboundCommand(AMQChannel.java:162)
at com.rabbitmq.client.impl.AMQChannel.handleFrame(AMQChannel.java:109)
at com.rabbitmq.client.impl.AMQConnection.readFrame(AMQConnection.java:676)
at com.rabbitmq.client.impl.AMQConnection.access$300(AMQConnection.java:48)
at com.rabbitmq.client.impl.AMQConnection$MainLoop.run(AMQConnection.java:603)
at java.lang.Thread.run(Thread.java:748)
решение
После расследования оказалось, что на сервере уже есть очередь queue_ttl_1 на сервере, и эта очередь не является очередью TTL, поэтому его снова найдут.

Удалите очередь и повторно запустите код. Бегите правильно следующим образом: 
I’m trying to start rabbitmq, yet it seems to crash upon start and producing errors:
handshake_error,opening,amqp_error,internal_error and refused for user:
rabbitmq | 2019-08-14 15:10:16.053 [info] <0.244.0>
rabbitmq | Starting RabbitMQ 3.7.16 on Erlang 22.0.7
rabbitmq | Copyright (C) 2007-2019 Pivotal Software, Inc.
rabbitmq | Licensed under the MPL. See https://www.rabbitmq.com/
rabbitmq |
rabbitmq | ## ##
rabbitmq | ## ## RabbitMQ 3.7.16. Copyright (C) 2007-2019 Pivotal Software, Inc.
rabbitmq | ########## Licensed under the MPL. See https://www.rabbitmq.com/
rabbitmq | ###### ##
rabbitmq | ########## Logs: <stdout>
rabbitmq |
rabbitmq | Starting broker...
rabbitmq | 2019-08-14 15:10:16.054 [info] <0.244.0>
rabbitmq | node : rabbit@rabbitmq
rabbitmq | home dir : /var/lib/rabbitmq
rabbitmq | config file(s) : /etc/rabbitmq/rabbitmq.conf
rabbitmq | cookie hash : AIlteC+QMYJQCC1CZZToPg==
rabbitmq | log(s) : <stdout>
rabbitmq | database dir : /var/lib/rabbitmq/mnesia/rabbit@rabbitmq
rabbitmq | 2019-08-14 15:10:16.065 [info] <0.244.0> Running boot step pre_boot defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.065 [info] <0.244.0> Running boot step rabbit_core_metrics defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.066 [info] <0.244.0> Running boot step rabbit_alarm defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.105 [info] <0.252.0> Memory high watermark set to 12065 MiB (12651329945 bytes) of 30163 MiB (31628324864 bytes) total
rabbitmq | 2019-08-14 15:10:16.194 [info] <0.262.0> Enabling free disk space monitoring
rabbitmq | 2019-08-14 15:10:16.194 [info] <0.262.0> Disk free limit set to 50MB
rabbitmq | 2019-08-14 15:10:16.198 [info] <0.244.0> Running boot step code_server_cache defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.198 [info] <0.244.0> Running boot step file_handle_cache defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.199 [info] <0.267.0> Limiting to approx 1048476 file handles (943626 sockets)
rabbitmq | 2019-08-14 15:10:16.199 [info] <0.268.0> FHC read buffering: OFF
rabbitmq | 2019-08-14 15:10:16.199 [info] <0.268.0> FHC write buffering: ON
rabbitmq | 2019-08-14 15:10:16.201 [info] <0.244.0> Running boot step worker_pool defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.201 [info] <0.245.0> Will use 8 processes for default worker pool
rabbitmq | 2019-08-14 15:10:16.201 [info] <0.245.0> Starting worker pool 'worker_pool' with 8 processes in it
rabbitmq | 2019-08-14 15:10:16.202 [info] <0.244.0> Running boot step database defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.203 [info] <0.244.0> Waiting for Mnesia tables for 30000 ms, 9 retries left
rabbitmq | 2019-08-14 15:10:16.274 [info] <0.244.0> Waiting for Mnesia tables for 30000 ms, 9 retries left
rabbitmq | 2019-08-14 15:10:16.274 [info] <0.244.0> Peer discovery backend rabbit_peer_discovery_classic_config does not support registration, skipping registration.
rabbitmq | 2019-08-14 15:10:16.274 [info] <0.244.0> Running boot step database_sync defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.274 [info] <0.244.0> Running boot step codec_correctness_check defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.274 [info] <0.244.0> Running boot step external_infrastructure defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.275 [info] <0.244.0> Running boot step rabbit_registry defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.275 [info] <0.244.0> Running boot step rabbit_auth_mechanism_cr_demo defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.275 [info] <0.244.0> Running boot step rabbit_queue_location_random defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.275 [info] <0.244.0> Running boot step rabbit_event defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.275 [info] <0.244.0> Running boot step rabbit_auth_mechanism_amqplain defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.275 [info] <0.244.0> Running boot step rabbit_auth_mechanism_plain defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.275 [info] <0.244.0> Running boot step rabbit_exchange_type_direct defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.276 [info] <0.244.0> Running boot step rabbit_exchange_type_fanout defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.276 [info] <0.244.0> Running boot step rabbit_exchange_type_headers defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.276 [info] <0.244.0> Running boot step rabbit_exchange_type_topic defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.276 [info] <0.244.0> Running boot step rabbit_mirror_queue_mode_all defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.276 [info] <0.244.0> Running boot step rabbit_mirror_queue_mode_exactly defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.276 [info] <0.244.0> Running boot step rabbit_mirror_queue_mode_nodes defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.276 [info] <0.244.0> Running boot step rabbit_priority_queue defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.276 [info] <0.244.0> Priority queues enabled, real BQ is rabbit_variable_queue
rabbitmq | 2019-08-14 15:10:16.276 [info] <0.244.0> Running boot step rabbit_queue_location_client_local defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.277 [info] <0.244.0> Running boot step rabbit_queue_location_min_masters defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.277 [info] <0.244.0> Running boot step kernel_ready defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.277 [info] <0.244.0> Running boot step rabbit_sysmon_minder defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.277 [info] <0.244.0> Running boot step rabbit_epmd_monitor defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.281 [info] <0.244.0> Running boot step guid_generator defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.286 [info] <0.244.0> Running boot step rabbit_node_monitor defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.286 [info] <0.324.0> Starting rabbit_node_monitor
rabbitmq | 2019-08-14 15:10:16.287 [info] <0.244.0> Running boot step delegate_sup defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.287 [info] <0.244.0> Running boot step rabbit_memory_monitor defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.287 [info] <0.244.0> Running boot step core_initialized defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.287 [info] <0.244.0> Running boot step upgrade_queues defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.307 [info] <0.244.0> Running boot step rabbit_connection_tracking defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.307 [info] <0.244.0> Running boot step rabbit_connection_tracking_handler defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.307 [info] <0.244.0> Running boot step rabbit_exchange_parameters defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.307 [info] <0.244.0> Running boot step rabbit_mirror_queue_misc defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.308 [info] <0.244.0> Running boot step rabbit_policies defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.308 [info] <0.244.0> Running boot step rabbit_policy defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.308 [info] <0.244.0> Running boot step rabbit_queue_location_validator defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.308 [info] <0.244.0> Running boot step rabbit_vhost_limit defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.309 [info] <0.244.0> Running boot step recovery defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.346 [info] <0.578.0> Making sure data directory '/var/lib/rabbitmq/mnesia/rabbit@rabbitmq/msg_stores/vhosts/628WB79CIFDYO9LJI6DKMI09L' for vhost '/' exists
rabbitmq | 2019-08-14 15:10:16.348 [error] <0.579.0> CRASH REPORT Process <0.579.0> with 0 neighbours crashed with reason: no match of right hand value {error,{not_a_dets_file,"/var/lib/rabbitmq/mnesia/rabbit@rabbitmq/msg_stores/vhosts/628WB79CIFDYO9LJI6DKMI09L/recovery.dets"}} in rabbit_recovery_terms:open_table/1 line 197
rabbitmq | 2019-08-14 15:10:16.349 [error] <0.578.0> Unable to recover vhost <<"/">> data. Reason {badmatch,{error,{{{badmatch,{error,{not_a_dets_file,"/var/lib/rabbitmq/mnesia/rabbit@rabbitmq/msg_stores/vhosts/628WB79CIFDYO9LJI6DKMI09L/recovery.dets"}}},[{rabbit_recovery_terms,open_table,1,[{file,"src/rabbit_recovery_terms.erl"},{line,197}]},{rabbit_recovery_terms,init,1,[{file,"src/rabbit_recovery_terms.erl"},{line,177}]},{gen_server,init_it,2,[{file,"gen_server.erl"},{line,374}]},{gen_server,init_it,6,[{file,"gen_server.erl"},{line,342}]},{proc_lib,init_p_do_apply,3,[{file,"proc_lib.erl"},{line,249}]}]},{child,undefined,rabbit_recovery_terms,{rabbit_recovery_terms,start_link,[<<"/">>]},transient,30000,worker,[rabbit_recovery_terms]}}}}
rabbitmq | Stacktrace [{rabbit_recovery_terms,start,1,[{file,"src/rabbit_recovery_terms.erl"},{line,53}]},{rabbit_queue_index,start,2,[{file,"src/rabbit_queue_index.erl"},{line,502}]},{rabbit_variable_queue,start,2,[{file,"src/rabbit_variable_queue.erl"},{line,483}]},{rabbit_priority_queue,start,2,[{file,"src/rabbit_priority_queue.erl"},{line,92}]},{rabbit_amqqueue,recover,1,[{file,"src/rabbit_amqqueue.erl"},{line,238}]},{rabbit_vhost,recover,1,[{file,"src/rabbit_vhost.erl"},{line,72}]},{rabbit_vhost_process,init,1,[{file,"src/rabbit_vhost_process.erl"},{line,56}]},{gen_server2,init_it,6,[{file,"src/gen_server2.erl"},{line,554}]}]
rabbitmq | 2019-08-14 15:10:16.350 [error] <0.578.0> CRASH REPORT Process <0.578.0> with 0 neighbours exited with reason: no match of right hand value {error,{{{badmatch,{error,{not_a_dets_file,"/var/lib/rabbitmq/mnesia/rabbit@rabbitmq/msg_stores/vhosts/628WB79CIFDYO9LJI6DKMI09L/recovery.dets"}}},[{rabbit_recovery_terms,open_table,1,[{file,"src/rabbit_recovery_terms.erl"},{line,197}]},{rabbit_recovery_terms,init,1,[{file,"src/rabbit_recovery_terms.erl"},{line,177}]},{gen_server,init_it,2,[{file,"gen_server.erl"},{line,374}]},{gen_server,init_it,6,[{file,"gen_server.erl"},{line,342}]},{proc_lib,init_p_do_apply,3,[{file,"proc_lib.erl"},{line,...}]}]},...}} in gen_server2:init_it/6 line 589
rabbitmq | 2019-08-14 15:10:16.350 [error] <0.576.0> Supervisor {<0.576.0>,rabbit_vhost_sup_wrapper} had child rabbit_vhost_process started with rabbit_vhost_process:start_link(<<"/">>) at undefined exit with reason {badmatch,{error,{{{badmatch,{error,{not_a_dets_file,"/var/lib/rabbitmq/mnesia/rabbit@rabbitmq/msg_stores/vhosts/628WB79CIFDYO9LJI6DKMI09L/recovery.dets"}}},[{rabbit_recovery_terms,open_table,1,[{file,"src/rabbit_recovery_terms.erl"},{line,197}]},{rabbit_recovery_terms,init,1,[{file,"src/rabbit_recovery_terms.erl"},{line,177}]},{gen_server,init_it,2,[{file,"gen_server.erl"},{line,374}]},{gen_server,init_it,6,[{file,"gen_server.erl"},{line,342}]},{proc_lib,init_p_do_apply,3,[{file,"proc_lib..."},...]}]},...}}} in context start_error
rabbitmq | 2019-08-14 15:10:16.350 [warning] <0.244.0> Unable to initialize vhost data store for vhost '/'. The vhost will be stopped for this node. Reason: {shutdown,{failed_to_start_child,rabbit_vhost_process,{badmatch,{error,{{{badmatch,{error,{not_a_dets_file,"/var/lib/rabbitmq/mnesia/rabbit@rabbitmq/msg_stores/vhosts/628WB79CIFDYO9LJI6DKMI09L/recovery.dets"}}},[{rabbit_recovery_terms,open_table,1,[{file,"src/rabbit_recovery_terms.erl"},{line,197}]},{rabbit_recovery_terms,init,1,[{file,"src/rabbit_recovery_terms.erl"},{line,177}]},{gen_server,init_it,2,[{file,"gen_server.erl"},{line,374}]},{gen_server,init_it,6,[{file,"gen_server.erl"},{line,342}]},{proc_lib,init_p_do_apply,3,[{file,"proc_lib.erl"},{line,249}]}]},{child,undefined,rabbit_recovery_terms,{rabbit_recovery_terms,start_link,[<<"/">>]},transient,30000,worker,[rabbit_recovery_terms]}}}}}}
rabbitmq | 2019-08-14 15:10:16.351 [info] <0.244.0> Running boot step empty_db_check defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.351 [info] <0.244.0> Running boot step rabbit_looking_glass defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.351 [info] <0.244.0> Running boot step rabbit_core_metrics_gc defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.351 [info] <0.244.0> Running boot step background_gc defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.351 [info] <0.244.0> Running boot step connection_tracking defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.351 [info] <0.244.0> Setting up a table for connection tracking on this node: tracked_connection_on_node_rabbit@rabbitmq
rabbitmq | 2019-08-14 15:10:16.352 [info] <0.244.0> Setting up a table for per-vhost connection counting on this node: tracked_connection_per_vhost_on_node_rabbit@rabbitmq
rabbitmq | 2019-08-14 15:10:16.352 [info] <0.244.0> Running boot step routing_ready defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.352 [info] <0.244.0> Running boot step pre_flight defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.352 [info] <0.244.0> Running boot step notify_cluster defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.352 [info] <0.244.0> Running boot step networking defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.354 [warning] <0.589.0> Setting Ranch options together with socket options is deprecated. Please use the new map syntax that allows specifying socket options separately from other options.
rabbitmq | 2019-08-14 15:10:16.355 [info] <0.603.0> started TCP listener on [::]:5672
rabbitmq | 2019-08-14 15:10:16.355 [info] <0.244.0> Running boot step direct_client defined by app rabbit
rabbitmq | 2019-08-14 15:10:16.449 [info] <0.8.0> Server startup complete; 0 plugins started.
rabbitmq | completed with 0 plugins.
rabbitmq | 2019-08-14 15:10:18.598 [info] <0.607.0> accepting AMQP connection <0.607.0> (10.0.0.69:44814 -> 10.0.0.138:5672)
rabbitmq | 2019-08-14 15:10:18.599 [info] <0.610.0> accepting AMQP connection <0.610.0> (10.0.0.69:44812 -> 10.0.0.138:5672)
rabbitmq | 2019-08-14 15:10:18.600 [info] <0.614.0> accepting AMQP connection <0.614.0> (10.0.0.69:44820 -> 10.0.0.138:5672)
rabbitmq | 2019-08-14 15:10:18.600 [info] <0.617.0> accepting AMQP connection <0.617.0> (10.0.0.69:44818 -> 10.0.0.138:5672)
rabbitmq | 2019-08-14 15:10:18.656 [error] <0.607.0> Error on AMQP connection <0.607.0> (10.0.0.69:44814 -> 10.0.0.138:5672, vhost: 'none', user: 'guest', state: opening), channel 0:
rabbitmq | {handshake_error,opening,
rabbitmq | {amqp_error,internal_error,
rabbitmq | "access to vhost '/' refused for user 'guest': vhost '/' is down",
rabbitmq | 'connection.open'}}
Please advise.
related articles:Building Rabbitmq Server High Available Clusters

Specific error message:
2018-05-04 11:21:48.116 ERROR 60848 --- [.168.0.202:8001] o.s.a.r.c.CachingConnectionFactory : Channel shutdown: connection error
2018-05-04 11:21:48.116 ERROR 60848 --- [.168.0.202:8001] o.s.a.r.c.CachingConnectionFactory : Channel shutdown: connection error
2018-05-04 11:21:48.125 INFO 60848 --- [nge.consumer1-8] o.s.a.r.l.SimpleMessageListenerContainer : Restarting [email protected]: tags=[{amq.ctag-d_wIlZIGxM3f0fsxkmYQfA=my_test_exchange.consumer1}], channel=Cached Rabbit Channel: AMQChannel(amqp://[email protected]:8001/,1), conn: [email protected] Shared Rabbit Connection: [email protected] [delegate=amqp://[email protected]:8001/, localPort= 56258], acknowledgeMode=AUTO local queue size=0
2018-05-04 11:21:48.126 INFO 60848 --- [nge.consumer1-9] o.s.a.r.c.CachingConnectionFactory : Attempting to connect to: [manager1:8001]
2018-05-04 11:21:48.393 INFO 60848 --- [nge.consumer1-9] o.s.a.r.c.CachingConnectionFactory : Created new connection: rabbitConnectionFactory#2b8bd14b:12/[email protected] [delegate=amqp://[email protected]:8001/, localPort= 56260]
2018-05-04 11:21:49.059 INFO 60848 --- [nge.consumer1-8] o.s.a.r.l.SimpleMessageListenerContainer : Restarting [email protected]: tags=[{amq.ctag-T1HyrOd5Ykr_VQZDwxRslA=stream_exchange.consumer1}], channel=Cached Rabbit Channel: AMQChannel(amqp://[email protected]:8001/,2), conn: [email protected] Shared Rabbit Connection: [email protected] [delegate=amqp://[email protected]:8001/, localPort= 56260], acknowledgeMode=AUTO local queue size=0
Spring boot Configure Rabbitmq (using a Haproxy load balancing):
spring:
application:
name: stream-rabbitmq-producer
rabbitmq:
host: manager1
port: 8001
username: admin
password: admin123456
Recently, when using the Rabbitmq cluster (Haproxy load balancing), frequent appearances of error messages, but the message can be normal consumption, if only the single-machine version Rabbitmq is used (not using haproxy), there is no error.
I have been troubled by this problem for a long time, Google found a lot of information, nor did it find a solution, unintentional to find an article:RabbitMQ and HAProxy: a timeout issue
The article says that if you use Haproxy to configure Rabbitmq, you will encounter a client connection timeout problem.
Why do you have this problem? Because Haproxy is configured with client connection timeout parameters (timeout client ms), If the client connection exceeds the configured parameter, then Haproxy will delete this client connection.
Rabbitmq client uses permanent connection to the agent, never timeout, why do you have problems?Because if Rabbitmq is in a non-active state within a period of time, then Haproxy will automatically turn off the connection (a little pit).
How do you solve this problem? We saw Haproxy provided aclitcpkaParameter configuration, it can send from the clientTCP keepalivedata pack.
We use it, but it is found to have the above problem after it is configured.
why?
[…]the exact behaviour of tcp keep-alive is determined by the underlying OS/Kernel configuration[…]
What do you mean? it meansTCP keepaliveThe delivery of the packet depends on the operating system / kernel configuration.
We can use the command to view (in the server where Haproxy is located)tcp_keepalive_timeConfiguration):
[[email protected] ~]# cat /proc/sys/net/ipv4/tcp_keepalive_time
7200
tcp_keepalive_timeDefault configuration time 2 hours, indicating sendingTCP keepaliveThe interval between packets is 2 hours, or it is sent every 2 hours.TCP keepalivedata pack.
It’s clear, let’s configure it in Haproxy.clitcpkaParameters, but because the system is sentTCP keepaliveThe interval between packets is too long, far exceeding Haproxytimeout clientTimeout (default seems to be 2 seconds), so the client connection is deleted by Haproxy ruthlessly, and then constantly rebuilt.
Said so much, how should we solve this problem?
Two options:
- Modify system
tcp_keepalive_timeConfigure, interval is below Haproxy configurationtimeout clientTimeout (because it is possible to affect other system services, not recommended). - Modify Haproxy
timeout clientTimeout, configuration is greater than the systemtcp_keepalive_timeInterval (recommended)
Because of the systemtcp_keepalive_timesendTCP keepaliveThe data package interval is 2 hours, so we will be in Haproxytimeout clientTimeout, set to 3 hours:
timeout client 3h
timeout server 3h
A complete example configuration:
[[email protected] ~]# cat /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local0 info
global
log 127.0.0.1 local1 notice
daemon
global
maxconn 4096
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
option abortonclose
maxconn 4096
timeout connect 5000ms
timeout client 3000ms
global
timeout server 3000ms
balance roundrobin
listen private_monitoring
bind 0.0.0.0:8000
mode http
option httplog
stats refresh 5s
stats uri /stats
stats realm Haproxy
stats auth admin:admin
listen rabbitmq_admin
bind 0.0.0.0:8002
server manager1 manager1:15672
server manager2 manager2:15672
server manager3 manager3:15672
listen rabbitmq_cluster
bind 0.0.0.0:8001
mode tcp
option tcplog
balance roundrobin
timeout client 3h
timeout server 3h
server manager1 manager1:5672 check inter 5000 rise 2 fall 3
server manager2 manager2:5672 check inter 5000 rise 2 fall 3
server manager3 manager3:5672 check inter 5000 rise 2 fall 3
Run Haproxy and then the Rabbitmq test successfully:

In a conversation, parties greet each other, exchange verbal banter, and
eventually continue on their way. A similar form of communication occurs
over low-level TCP connections exposing lightweight channels in RabbitMQ.
This article examines how clients, consumers, and brokers pass information in
RabbitMQ.
RabbitMQ was originally developed to support AMQP 0.9.1 which is the «core»
protocol supported by the RabbitMQ broker. Here are the
channels
used to send messages over
TCP connections.
What is a connection?
A connection (TCP) is a link between the client and the broker, that performs
underlying networking tasks including initial authentication, IP resolution,
and networking.

What is a channel?
Connections can multiplex over a single TCP connection, meaning that
an application can open «lightweight connections» on a single connection.
This «lightweight connection» is called a channel. Each connection can
maintain a set of underlying channels.
Many applications needs to
have multiple connections to the broker, and instead of having
many connections an application can reuse the connection, by instead, create
and delete channels. Keeping many TCP connections open at the same time is
not desired, as they consume system resources. The handshake process for a
connection is also quite complex and
requires at least 7 TCP packets or more if TLS is used.
A channel acts as a virtual connection inside a TCP connection.
A channel reuses a connection, forgoing the need to reauthorize and open a
new TCP stream. Channels allow you to use resources more efficiently (more
about this later in this article).
Every AMQP protocol-related operation occurs over a channel.

A connection is created by opening a physical TCP connection to the target
server. The client resolves the hostname to one or more IP addresses before
sending a handshake. The receiving server then authenticates the client.
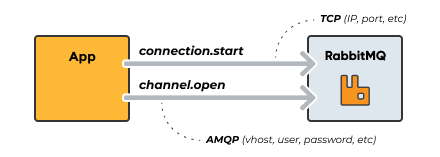
To send a message or manage queues, a connection is created with the broker
before establishing a channel through a client. The channel packages the
messages and handles protocol operations. Clients send messages through
the channel’s
basic_publish
method. Queue creation and maintenance also occur here, such as AMQP commands
like
queue.create
and
exchange.create
are all sent over AMQP, on a channel.
Closing a connection closes all associated channels.
Publish a message to the RabbitMQ broker
We will look at a simple example from the Python library
Pika.
- As with all clients, you establish a TCP connection.
-
After that, a logical channel is created for sending data or performing
other operations (like the creation of a queue). You provide authorization
information when instantiating a
BlockingConnection
since the broker verifies this information on a per-connection basis. - A message is routed to the queue, over the channel.
- The connection is closed (and so the are all channels in the connection).
connection = pika.BlockingConnection(connection_parameters)
channel = connection.channel()
channel.basic_publish(exchange="my_exchange",
routing_key="my_route",
body= bytes("test_message")
)
connection.close()
Configuring the number of channels
We recommend to use the operator limit for connections and
channels.
Use
channel_max
to configure the max amount of allowed channels on a
connection. This variable corresponds to
rabbit.channel_max
in the new config format. Exceeding this limit results in a fatal error.
Use
connections_max
to configure the max amount of allowed connections.
A common question we get is how many channels one should have per RabbitMQ
connection, or how many channels is optimal. It’s hard to give an answer to
that since it always depends on the setup. Ideally, you should establish
one connection per process with a dedicated channel given to each new thread.
Setting
channel_max
to 0 means «unlimited». This could be a dangerous move, since applications
sometimes have channel leaks.
Avoiding connection and channel leaks
Two common user mistakes are channel and connection leaks, when a client
opens millions of connections/channels, causing RabbitMQ to crash due to memory issues.
To help catch these issues early, CloudAMQP provides alarms that can be
enabled.
Often, a channel or connection leak is the result of failing to close either
when finished.
Recommendations for connections and channels
Here follow some recommendations of how to use, and not to use connections
and channels.
Use long-lived connection
Each channel consumes a relatively small amount of memory on the client,
compared to a connection. Too many connections can be a heavy burden on the
RabbitMQ server memory usage. Try to keep long-lived connections and instead
open and close channels more frequently, if required.
We recommend that each process only creates one TCP connection and uses
multiple channels in that connection for different threads.
Separate the connections for publishers and consumers
Use at least one connection for publishing and one for consuming for each
app/service/process.
RabbitMQ can apply back pressure on the TCP connection
when the publisher is sending too many messages for the server to handle. If
you consume on the same TCP connection, the server might not receive the
message acknowledgments from the client, thus affecting the consumer
performance. With a lower consume speed, the server will be overwhelmed.
Don’t share channels between threads
Use one channel per thread in your application, and make sure that you don’t
share channels between threads as most clients don’t make channels
thread-safe.
CloudAMQP allows you to scale your instances to meet demand while providing
mechanisms to troubleshoot leaks. If you have any questions, you can reach out
to us at
support@cloudamqp.com