Содержание
- Evaluate OCR Output Quality with Character Error Rate (CER) and Word Error Rate (WER)
- Key concepts, examples, and Python implementation of measuring Optical Character Recognition output quality
- Contents
- Importance of Evaluation Metrics
- Error Rates and Levenshtein Distance
- Character Error Rate (CER)
- (i) Equation
- (ii) Illustration with Example
- (iii) CER Normalization
- (iv) What is a good CER value?
- Word Error Rate (WER)
- Python Example (with TesseractOCR and fastwer)
- Summing it up
- Char Error Rate¶
- Module Interface¶
- Functional Interface¶
- jiwer 2.5.1
- Навигация
- Ссылки проекта
- Статистика
- Метаданные
- Классификаторы
- Описание проекта
- JiWER: Similarity measures for automatic speech recognition evaluation
- Installation
- Usage
- pre-processing
- transforms
- Compose
- ReduceToListOfListOfWords
- ReduceToSingleSentence
- RemoveSpecificWords
- RemoveWhiteSpace
- RemovePunctuation
- RemoveMultipleSpaces
- Strip
- RemoveEmptyStrings
- ExpandCommonEnglishContractions
Evaluate OCR Output Quality with Character Error Rate (CER) and Word Error Rate (WER)
Key concepts, examples, and Python implementation of measuring Optical Character Recognition output quality
Contents
Importance of Evaluation Metrics
Great job in successfully generating output from your OCR model! You have done the hard work of labeling and pre-processing the images, setting up and running your neural network, and applying post-processing on the output.
The final step now is to assess how well your model has performed. Even if it gave high confidence scores, we need to measure performance with objective metrics. Since you cannot improve what you do not measure, these metrics serve as a vital benchmark for the iterative improvement of your OCR model.
In this article, we will look at two metrics used to evaluate OCR output, namely Character Error Rate (CER) and Word Error Rate (WER).
Error Rates and Levenshtein Distance
The usual way of evaluating prediction output is with the accuracy metric, where we indicate a match ( 1) or a no match ( 0). However, this does not provide enough granularity to assess OCR performance effectively.
We should instead use error rates to determine the extent to which the OCR transcribed text and ground truth text (i.e., reference text labeled manually) differ from each other.
A common intuition is to see how many characters were misspelled. While this is correct, the actual error rate calculation is more complex than that. This is because the OCR output can have a different length from the ground truth text.
Furthermore, there are three different types of error to consider:
- Substitution error: Misspelled characters/words
- Deletion error: Lost or missing characters/words
- Insertion error: Incorrect inclusion of character/words
The question now is, how do you measure the extent of errors between two text sequences? This is where Levenshtein distance enters the picture.
Levenshtein distance is a distance metric measuring the difference between two string sequences. It is the minimum number of single-character (or word) edits (i.e., insertions, deletions, or substitutions) required to change one word (or sentence) into another.
For example, the Levenshtein distance between “ mitten” and “ fitting” is 3 since a minimum of 3 edits is needed to transform one into the other.
The more different the two text sequences are, the higher the number of edits needed, and thus the larger the Levenshtein distance.
Character Error Rate (CER)
(i) Equation
CER calculation is based on the concept of Levenshtein distance, where we count the minimum number of character-level operations required to transform the ground truth text (aka reference text) into the OCR output.
It is represented with this formula:
- S = Number of Substitutions
- D = Number of Deletions
- I = Number of Insertions
- N = Number of characters in reference text (aka ground truth)
Bonus Tip: The denominator N can alternatively be computed with:
N = S + D + C (where C = number of correct characters)
The output of this equation represents the percentage of characters in the reference text that was incorrectly predicted in the OCR output. The lower the CER value (with 0 being a perfect score), the better the performance of the OCR model.
(ii) Illustration with Example
Let’s look at an example:
Several errors require edits to transform OCR output into the ground truth:
- g instead of 9 (at reference text character 3)
- Missing 1 (at reference text character 7)
- Z instead of 2 (at reference text character


With that, here are the values to input into the equation:
- Number of Substitutions (S) = 2
- Number of Deletions ( D) = 1
- Number of Insertions ( I) = 0
- Number of characters in reference text ( N) = 9
Based on the above, we get (2 + 1 + 0) / 9 = 0.3333. When converted to a percentage value, the CER becomes 33.33%. This implies that every 3rd character in the sequence was incorrectly transcribed.
We repeat this calculation for all the pairs of transcribed output and corresponding ground truth, and take the mean of these values to obtain an overall CER percentage.
(iii) CER Normalization
One thing to note is that CER values can exceed 100%, especially with many insertions. For example, the CER for ground truth ‘ ABC’ and a longer OCR output ‘ ABC12345’ is 166.67%.
It felt a little strange to me that an error value can go beyond 100%, so I looked around and managed to come across an article by Rafael C. Carrasco that discussed how normalization could be applied:
Sometimes the number of mistakes is divided by the sum of the number of edit operations ( i + s + d ) and the number c of correct symbols, which is always larger than the numerator.
The normalization technique described above makes CER values fall within the range of 0–100% all the time. It can be represented with this formula:
where C = Number of correct characters
(iv) What is a good CER value?
There is no single benchmark for defining a good CER value, as it is highly dependent on the use case. Different scenarios and complexity (e.g., printed vs. handwritten text, type of content, etc.) can result in varying OCR performances. Nonetheless, there are several sources that we can take reference from.
An article published in 2009 on the review of OCR accuracy in large-scale Australian newspaper digitization programs came up with these benchmarks (for printed text):
- Good OCR accuracy: CER 1‐2% (i.e. 98–99% accurate)
- Average OCR accuracy: CER 2-10%
- Poor OCR accuracy: CER >10% (i.e. below 90% accurate)
For complex cases involving handwritten text with highly heterogeneous and out-of-vocabulary content (e.g., application forms), a CER value as high as around 20% can be considered satisfactory.
Word Error Rate (WER)
If your project involves transcription of particular sequences (e.g., social security number, phone number, etc.), then the use of CER will be relevant.
On the other hand, Word Error Rate might be more applicable if it involves the transcription of paragraphs and sentences of words with meaning (e.g., pages of books, newspapers).
The formula for WER is the same as that of CER, but WER operates at the word level instead. It represents the number of word substitutions, deletions, or insertions needed to transform one sentence into another.
WER is generally well-correlated with CER (provided error rates are not excessively high), although the absolute WER value is expected to be higher than the CER value.
- Ground Truth: ‘my name is kenneth’
- OCR Output: ‘myy nime iz kenneth’
From the above, the CER is 16.67%, whereas the WER is 75%. The WER value of 75% is clearly understood since 3 out of 4 words in the sentence were wrongly transcribed.
Python Example (with TesseractOCR and fastwer)
We have covered enough theory, so let’s look at an actual Python code implementation.
In the demo notebook, I ran the open-source TesseractOCR model to extract output from several sample images of handwritten text. I then utilized the fastwer package to calculate CER and WER from the transcribed output and ground truth text (which I labeled manually).
Summing it up
In this article, we covered the concepts and examples of CER and WER and details on how to apply them in practice.
While CER and WER are handy, they are not bulletproof performance indicators of OCR models. This is because the quality and condition of the original documents (e.g., handwriting legibility, image DPI, etc.) play an equally (if not more) important role than the OCR model itself.
I welcome you to join me on a data science learning journey! Give this Medium page a follow to stay in the loop of more data science content, or reach out to me on LinkedIn. Have fun evaluating your OCR model!
Источник
Char Error Rate¶
Module Interface¶
Character Error Rate (CER) is a metric of the performance of an automatic speech recognition (ASR) system.
This value indicates the percentage of characters that were incorrectly predicted. The lower the value, the better the performance of the ASR system with a CharErrorRate of 0 being a perfect score. Character error rate can then be computed as:

 is the number of substitutions,
is the number of substitutions,
 is the number of deletions,
is the number of deletions,
 is the number of insertions,
is the number of insertions,
 is the number of correct characters,
is the number of correct characters,
 is the number of characters in the reference (N=S+D+C).
is the number of characters in the reference (N=S+D+C).
Compute CharErrorRate score of transcribed segments against references.
kwargs¶ ( Any ) – Additional keyword arguments, see Advanced metric settings for more info.
Character error rate score
Initializes internal Module state, shared by both nn.Module and ScriptModule.
Calculate the character error rate.
Character error rate score
Store references/predictions for computing Character Error Rate scores.
preds¶ ( Union [ str , List [ str ]]) – Transcription(s) to score as a string or list of strings
target¶ ( Union [ str , List [ str ]]) – Reference(s) for each speech input as a string or list of strings
Functional Interface¶
character error rate is a common metric of the performance of an automatic speech recognition system. This value indicates the percentage of characters that were incorrectly predicted. The lower the value, the better the performance of the ASR system with a CER of 0 being a perfect score.
preds¶ ( Union [ str , List [ str ]]) – Transcription(s) to score as a string or list of strings
target¶ ( Union [ str , List [ str ]]) – Reference(s) for each speech input as a string or list of strings
Источник
jiwer 2.5.1
pip install jiwer Скопировать инструкции PIP
Выпущен: 6 сент. 2022 г.
Evaluate your speech-to-text system with similarity measures such as word error rate (WER)
Навигация
Ссылки проекта
Статистика
Метаданные
Лицензия: Apache Software License (Apache-2.0)
Требует: Python >=3.7, nikvaessen
Классификаторы
- License
- OSI Approved :: Apache Software License
- Programming Language
- Python :: 3
- Python :: 3.7
- Python :: 3.8
- Python :: 3.9
- Python :: 3.10
Описание проекта
JiWER: Similarity measures for automatic speech recognition evaluation
This repository contains a simple python package to approximate the Word Error Rate (WER), Match Error Rate (MER), Word Information Lost (WIL) and Word Information Preserved (WIP) of a transcript. It computes the minimum-edit distance between the ground-truth sentence and the hypothesis sentence of a speech-to-text API. The minimum-edit distance is calculated using the Python C module Levenshtein.
Installation
You should be able to install this package using poetry:
Or, if you prefer old-fashioned pip and you’re using Python >= 3.7 :
Usage
The most simple use-case is computing the edit distance between two strings:
Similarly, to get other measures:
You can also compute the WER over multiple sentences:
We also provide the character error rate:
pre-processing
It might be necessary to apply some pre-processing steps on either the hypothesis or ground truth text. This is possible with the transformation API:
By default, the following transformation is applied to both the ground truth and the hypothesis. Note that is simply to get it into the right format to calculate the WER.
transforms
We provide some predefined transforms. See jiwer.transformations .
Compose
jiwer.Compose(transformations: List[Transform]) can be used to combine multiple transformations.
Note that each transformation needs to end with jiwer.ReduceToListOfListOfWords() , as the library internally computes the word error rate based on a double list of words. `
ReduceToListOfListOfWords
jiwer.ReduceToListOfListOfWords(word_delimiter=» «) can be used to transform one or more sentences into a list of lists of words. The sentences can be given as a string (one sentence) or a list of strings (one or more sentences). This operation should be the final step of any transformation pipeline as the library internally computes the word error rate based on a double list of words.
ReduceToSingleSentence
jiwer.ReduceToSingleSentence(word_delimiter=» «) can be used to transform multiple sentences into a single sentence. The sentences can be given as a string (one sentence) or a list of strings (one or more sentences). This operation can be useful when the number of ground truth sentences and hypothesis sentences differ, and you want to do a minimal alignment over these lists. Note that this creates an invariance: wer([a, b], [a, b]) might not be equal to wer([b, a], [b, a]) .
RemoveSpecificWords
jiwer.RemoveSpecificWords(words_to_remove: List[str]) can be used to filter out certain words. As words are replaced with a character, make sure to that jiwer.RemoveMultipleSpaces , jiwer.Strip() and jiwer.RemoveEmptyStrings are present in the composition after jiwer.RemoveSpecificWords .
RemoveWhiteSpace
jiwer.RemoveWhiteSpace(replace_by_space=False) can be used to filter out white space. The whitespace characters are , t , n , r , x0b and x0c . Note that by default space ( ) is also removed, which will make it impossible to split a sentence into a list of words by using ReduceToListOfListOfWords or ReduceToSingleSentence . This can be prevented by replacing all whitespace with the space character. If so, make sure that jiwer.RemoveMultipleSpaces , jiwer.Strip() and jiwer.RemoveEmptyStrings are present in the composition after jiwer.RemoveWhiteSpace .
RemovePunctuation
jiwer.RemovePunctuation() can be used to filter out punctuation. The punctuation characters are defined as all unicode characters whose catogary name starts with P . See https://www.unicode.org/reports/tr44/#General_Category_Values.
RemoveMultipleSpaces
jiwer.RemoveMultipleSpaces() can be used to filter out multiple spaces between words.
Strip
jiwer.Strip() can be used to remove all leading and trailing spaces.
RemoveEmptyStrings
jiwer.RemoveEmptyStrings() can be used to remove empty strings.
ExpandCommonEnglishContractions
jiwer.ExpandCommonEnglishContractions() can be used to replace common contractions such as let’s to let us .
Currently, this method will perform the following replacements. Note that ␣ is used to indicate a space ( ) to get around markdown rendering constrains.
Источник
How is the OCR error rate computed? In order to answer this question, the following issues will be discussed below:
- Minimal number of errors
- Normalization
- White space
- Case folding
- Character encoding
Minimal number of errors
Computing an error rate is not so simple when the number of mistakes grows. For instance, one could argue that the character error rate between «ernest» (reference) and «nester» (output) is 6 since no character in the reference appears in «nester» at the required position. However, two identical subsequences «nest» can be aligned in both words. A subsequence of a word is any string of characters that can be obtained by just removing some of the original ones (no sorting allowed since the order of letters is essential for correct spelling). For example, «nest» is the result when the two initial characters are removed in «ernest» and «rnst» is the subsequence containing only consonants in the original word.
Clearly, there is more similarity between this pair of words than that conveyed by the 100% CER: indeed it is enough to remove 2 extra characters («er») at the beginning of the the first word and then insert the two trailing characters («er») in order to obtain the second word. With this 4 operations, the CER becomes about 67%. In contrast, the alignment of just both «er» subsequences would require 8 operations and, therefore, lead to a CER of 133%.
Therefore, the CER is computed with the minimum number of operations required to transform the reference text into the output (a number which is known as the Levenshtein distance; essentially, the larger the number, the more different both texts are). However, finding the optimal set of basic operations is not trivial, at least for lengthy and noisy outputs. Fortunately, there are computational procedures which can evaluate the minimal number automatically (see, for instance the online demo here).
As said before, in some applications swaps are a natural source of mistakes. The generalization of the Levenshtein distance including swaps of contiguous characters as a fourth basic operation (in addition to insertions, substitutions and deletions) is known as the Damerau-Levenshtein distance.
WER = (iw + sw + dw) / nw
where nw is the number of words in the reference text, sw is the number of words substituted, dw the number of words deleted and i the number of words inserted required to transform the output text into the target (among all possible transformations, that one minimizing the sum iw + sw + dw is chosen). Note that the number cw of correct words is cw = nw - dw - sw.
The character error rate is defined in a similar way as:
CER = (i + s + d) / n
but using the total number n of characters and the minimal number of character insertions i, substitutions s an deletions d required to transform the reference text into the OCR output.
Normalizaton
Since the number of mistakes can be larger than the length of the reference text and lead to rates large than 100% (for example, a ground-truth document with 100 character and a lengthy OCR output which contains 120 wrong characters give a 120% error rate and a negative accuracy), sometimes the number of mistakes is divided by the sum (i + s + d + c ) of the number of edit operations (i + s + d) and the number c of correct symbols, which is always larger than the numerator.
White space
Blank or white space plays an important role in any text, since it separates words (e.g., it is quite different to read «mangoes» instead of «man goes»), and it must be therefore considered while computing the character error rate. In order to understand a text, it is however not so relevant the length of the white space. Therefore, contiguous spaces are often considered to be equivalent to a single one, that is, the CER between «were wolf» (with a double blank between both words) with respect to the reference text «werewolf» is 0.125.
It is worth however to note that white space is not a character like the others: when the alignment between texts allows to replace white space with a printable character, it leads sometimes to weird results. For example, when comparing «bad man» and «batman», the deletion of d and substitution of the white-space with t has identical Levenshtein cost (two operations) than the deletion of the white-space plus the replacement of the d with a t (also two operations). However, the second option seems a more natural transformation. This behavior can be minimized if the substitution of white space with printable characters is not allowed.
In contrast, the computation of word error rated does not need to take care of white space since the text is pre-processed by a word tokenizer and blanks only matter in this step. Some care must be just taken when defining a word, since the definition may have a slight influence in word counting. For example, very often «I.B.M.» will be split into three different words by many tokenizers.
Case folding
Clearly, case matters in OCR: for example, «white house» and «White House» will probably refer to two different meanings. Therefore, the CER when «white house» is obtained instead of «White House» is not 0 but rather 0.18 (18%). However, in the context of information retrieval (whose objective is to find all attestations of a word or expression), case is often neglected (so that capitalized words in titles are equivalent to non-capitalized ones in normal paragraphs). This suggests that WER should not count as mistakes the substitution of one uppercase letter by the correspondong lowercase one.
Text encoding
Unfortunately, there is a large number of alternative encodings for text files (such as ASCII, ISO-8859-9, UTF8, Windows-1252) and the tool makes its best to guess the format used for every input file.
XML files customarily include the declaration of the encoding in the very fist line:
<?xml version="1.0" encoding="utf-8"?>
and this provides a method to detect automatically the character set which was employed to create the file.
Also HTML files often contain metainformation like the following line
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
which informs on the character set used.
However, these metadata are not compulsory and may be missing. Furhtermore, in the case of text files (such as those whose nae end with the extension .txt) there is no information about encoding. In all cases where the encoding is not declared in the document, the software makes a guess which should work in most cases (at least for long enough files) but can lead occasionally to unexpected results.
Notes:
|
Project description
A PyPI package for fast word/character error rate (WER/CER) calculation
- fast (cpp implementation)
- sentence-level and corpus-level WER/CER scores
Installation
pip install fastwer
Example
import fastwer hypo = ['This is an example .', 'This is another example .'] ref = ['This is the example :)', 'That is the example .'] # Corpus-Level WER: 40.0 fastwer.score(hypo, ref) # Corpus-Level CER: 25.5814 fastwer.score(hypo, ref, char_level=True) # Sentence-Level WER: 40.0 fastwer.score_sent(hypo[0], ref[0]) # Sentence-Level CER: 22.7273 fastwer.score_sent(hypo[0], ref[0], char_level=True)
Contact
Changhan Wang (wangchanghan@gmail.com)
Download files
Download the file for your platform. If you’re not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Release 1.7.1
The Word Error Rate (WER) and Character Error Rate (CER) indicate the amount of text in a handwriting that the applied HTR model did not read correctly. A CER of 10% means that every tenth character (and these are not only letters, but also punctuations, spaces, etc.) was not correctly identified. The accuracy rate would therefore be 90 %. A good HTR model should recognize 95% of a handwriting correctly, the CER is not more than 5%. This is roughly the value that is achieved today with “dirty” OCR for fracture fonts. Incidentally, an accuracy rate of 95% also corresponds to the expectations formulated in the DFG’s Practical Rules on Digitization.
Even with a good CER, the word error rate can be high. The WER shows how good the exact reproduction of the words in the text is. As a rule, the WER is three to four times higher than the CER and is proportional to it. The value of the WER is not particularly meaningful for the quality of the model, because unlike characters, words are of different lengths and do not allow a clear comparison (a word is already incorrectly recognized if just one letter in it is not correct). That is why the WER is rarely used to characterize the value of a model.
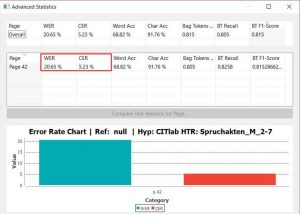
The WER, however, gives clues to an important aspect. Because when I perform a text recognition with the aim of later performing a full text search in my document, the WER shows me the exact success rate that I can expect in my search. The search is for words or parts of words. So no matter how good my CER is: with a WER of 10%, potentially every tenth search term cannot be found.
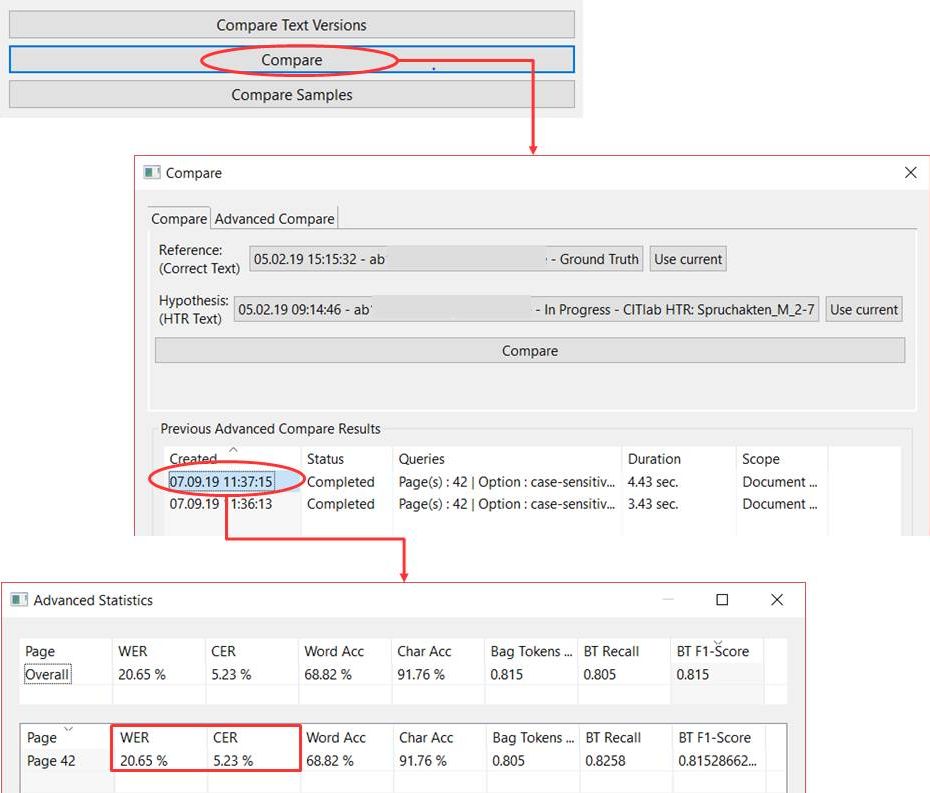
Tips & Tools
The easiest way to display the CER and WER is to use the Compare function under Tools. Here you can compare one or more pages of a Ground Truth version with an HTR text to estimate the quality of the model.