Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
![]()
Download Article
![]()
Download Article
After collecting data, oftentimes the first thing you need to do is analyze it. This usually entails finding the mean, the standard deviation, and the standard error of the data. This article will show you how it’s done.
Cheat Sheets
-

1
Obtain a set of numbers you wish to analyze. This information is referred to as a sample.
- For example, a test was given to a class of 5 students, and the test results are 12, 55, 74, 79 and 90.

Advertisement
-
1
Calculate the mean. Add up all the numbers and divide by the population size:[1]
- Mean (μ) = ΣX/N, where Σ is the summation (addition) sign, xi is each individual number, and N is the population size.
- In the case above, the mean μ is simply (12+55+74+79+90)/5 = 62.

-
1
Calculate the standard deviation. This represents the spread of the population.
Standard deviation = σ = sq rt [(Σ((X-μ)^2))/(N)].[2]
- For the example given, the standard deviation is sqrt[((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27.4. (Note that if this was the sample standard deviation, you would divide by n-1, the sample size minus 1.)

Advertisement
-
1
Calculate the standard error (of the mean). This represents how well the sample mean approximates the population mean. The larger the sample, the smaller the standard error, and the closer the sample mean approximates the population mean. Do this by dividing the standard deviation by the square root of N, the sample size.[3]
Standard error = σ/sqrt(n)[4]
- So for the example above, if this were a sampling of 5 students from a class of 50 and the 50 students had a standard deviation of 17 (σ = 21), the standard error = 17/sqrt(5) = 7.6.

Add New Question
-
Question
How do you find the mean given number of observations?

To find the mean, add all the numbers together and divide by how many numbers there are. e.g to find the mean of 1,7,8,4,2: 1+7+8+4+2 = 22/5 = 4.4.
-
Question
The standard error is calculated as 0.2 and the standard deviation of a sample is 5kg. Can it be said to be smaller or larger than the standard deviation?
The standard error (SE) must be smaller than the standard deviation (SD), because the SE is calculating by dividing the SD by something — i.e. making it smaller.
-
Question
How can I find out the standard deviation of 50 samples?
The results of all your figures (number plus number plus number etc.) divided by quantity of samples 50 =SD.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
Calculations of the mean, standard deviation, and standard error are most useful for analysis of normally distributed data. One standard deviation about the central tendency covers approximately 68 percent of the data, 2 standard deviation 95 percent of the data, and 3 standard deviation 99.7 percent of the data. The standard error gets smaller (narrower spread) as the sample size increases.
Thanks for submitting a tip for review!
Advertisement
-
Check your math carefully. It is very easy to make mistakes or enter numbers incorrectly.
Advertisement
References
About This Article
Article SummaryX
The mean is simply the average of a set of numbers. You can work it out by adding up all the numbers and dividing the total by the amount of numbers. For example, if you wanted to find the average test score of 3 students who scored 74, 79, and 90, you’d add the 3 numbers together to get 243, then divide it by 3 to get 81. The standard error represents how well the sample mean approximates the population mean. All you need to do is divide the standard deviation by the square root of the sample size. For instance, if you were sampling 5 students from a class of 50 and the 50 students had a standard deviation of 17, you’d divide 17 by the square root of 5 to get 7.6. For more tips, including how to calculate the standard deviation, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 996,353 times.
Did this article help you?
![]()
Download Article
![]()
Download Article
After collecting data, oftentimes the first thing you need to do is analyze it. This usually entails finding the mean, the standard deviation, and the standard error of the data. This article will show you how it’s done.
Cheat Sheets
-
1
Obtain a set of numbers you wish to analyze. This information is referred to as a sample.
- For example, a test was given to a class of 5 students, and the test results are 12, 55, 74, 79 and 90.
Advertisement
-
1
Calculate the mean. Add up all the numbers and divide by the population size:[1]
- Mean (μ) = ΣX/N, where Σ is the summation (addition) sign, xi is each individual number, and N is the population size.
- In the case above, the mean μ is simply (12+55+74+79+90)/5 = 62.
-
1
Calculate the standard deviation. This represents the spread of the population.
Standard deviation = σ = sq rt [(Σ((X-μ)^2))/(N)].[2]
- For the example given, the standard deviation is sqrt[((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27.4. (Note that if this was the sample standard deviation, you would divide by n-1, the sample size minus 1.)
Advertisement
-
1
Calculate the standard error (of the mean). This represents how well the sample mean approximates the population mean. The larger the sample, the smaller the standard error, and the closer the sample mean approximates the population mean. Do this by dividing the standard deviation by the square root of N, the sample size.[3]
Standard error = σ/sqrt(n)[4]
- So for the example above, if this were a sampling of 5 students from a class of 50 and the 50 students had a standard deviation of 17 (σ = 21), the standard error = 17/sqrt(5) = 7.6.
Add New Question
-
Question
How do you find the mean given number of observations?
To find the mean, add all the numbers together and divide by how many numbers there are. e.g to find the mean of 1,7,8,4,2: 1+7+8+4+2 = 22/5 = 4.4.
-
Question
The standard error is calculated as 0.2 and the standard deviation of a sample is 5kg. Can it be said to be smaller or larger than the standard deviation?
The standard error (SE) must be smaller than the standard deviation (SD), because the SE is calculating by dividing the SD by something — i.e. making it smaller.
-
Question
How can I find out the standard deviation of 50 samples?
The results of all your figures (number plus number plus number etc.) divided by quantity of samples 50 =SD.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
Calculations of the mean, standard deviation, and standard error are most useful for analysis of normally distributed data. One standard deviation about the central tendency covers approximately 68 percent of the data, 2 standard deviation 95 percent of the data, and 3 standard deviation 99.7 percent of the data. The standard error gets smaller (narrower spread) as the sample size increases.
Thanks for submitting a tip for review!
Advertisement
-
Check your math carefully. It is very easy to make mistakes or enter numbers incorrectly.
Advertisement
References
About This Article
Article SummaryX
The mean is simply the average of a set of numbers. You can work it out by adding up all the numbers and dividing the total by the amount of numbers. For example, if you wanted to find the average test score of 3 students who scored 74, 79, and 90, you’d add the 3 numbers together to get 243, then divide it by 3 to get 81. The standard error represents how well the sample mean approximates the population mean. All you need to do is divide the standard deviation by the square root of the sample size. For instance, if you were sampling 5 students from a class of 50 and the 50 students had a standard deviation of 17, you’d divide 17 by the square root of 5 to get 7.6. For more tips, including how to calculate the standard deviation, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 996,353 times.
Did this article help you?
Чтобы
судить о том, насколько точно проведенные
измерения отражают состав генеральной
совокупности, необходимо вычислить
стандартную ошибку средней арифметической
выборочной совокупности.
Стандартная
ошибка средней арифметической
характеризует степень отклонения
выборочной средней арифметической от
средней арифметической генеральной
совокупности.
Стандартная
ошибка средней арифметической вычисляется
по формуле:
![]() ,
,
где
– стандартное отклонение результатов
измерений, n
– объем выборки.
Зачастую
мы имеем дело с одной случайной выборкой
и с одной полученной при ее обработке
выборочной средней. Задача заключается
в суждении о величине неизвестной
генеральной средней по полученной
неточной величине случайной выборочной
средней.
Вычислим
среднюю ошибку найденного выборочного
среднего значения роста:
![]() 195
195
см; σ = 8,8 см;
![]() см.
см.
2,8 см
составляют не максимальную, а среднюю
возможную ошибку среднего. Отдельные
выборочные средние могут отклоняться
от генеральной как больше, так и меньше,
чем на 2,8 см.
Каковы
же пределы возможных ошибок случайной
выборки, какова ее максимальная ошибка?
Величина максимальной ошибки зависит
от величины средней ошибки и вычисляется
по формуле
![]() .
.
При
объеме выборки n
= 10:
![]() .
.
Все
случайные выборочные средние, которые
могут быть получены в подобных опытах
(в том числе и фактически полученная
выборочная средняя
![]() = 195 см), при своем варьировании около
= 195 см), при своем варьировании около
неизвестного генерального среднего в
подавляющем количестве группируются
около него так, что лишь ничтожный
процент их отклоняется от генеральной
средней более, чем на величину максимальной
ошибки.
Другими
словами, генеральная средняя определяется
как
![]() .
.
Эти пределы
колебаний значительно сужаются, если
средняя ошибка уменьшается благодаря
увеличению численности выборки.
Искомая
генеральная средняя лежит между
![]() и
и![]() .
.
Таким образом, при высокой точности
выполнения эксперимента и достаточно
большом числе измерений можно определить
среднюю арифметическую бесконечно
большого числа экспериментов.
До сих
пор мы определяли максимальную ошибку
выборочной средней, исходя из того, что
все остальные показатели известны. Если
же мы хотим достичь определенной
точности, определенного приближения к
генеральной средней, в этом случае
встает вопрос о численности выборки (о
том, сколько измерений, опытов необходимо
провести).
Допустим, что
максимальная ошибка должна быть равна
5 см. Сколько человек надо обследовать
(измерить) в нашем случае?
![]() .
.
Следовательно,
мы должны провести измерения роста у
36 баскетболистов высокого класса.
10. Достоверность различий
Следующим
важным вопросом практически для каждого
экспериментатора является умение
доказать достоверность различий между
двумя рядами признаков.
Проверку
достоверности различия двух рядов
измерений производят путем вычисления
критерия достоверности различия – t:
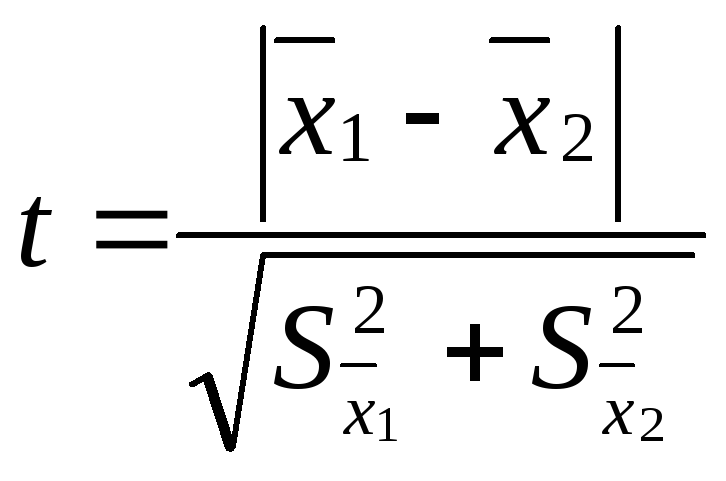 ,
,
где
![]() – средняя одной выборки;
– средняя одной выборки;![]() – средняя другой выборки;
– средняя другой выборки;![]() – средняя ошибка первой выборки;
– средняя ошибка первой выборки;![]() – второй выборки. Если t < 2, то различие
– второй выборки. Если t < 2, то различие
между двумя выборками считается
недостоверным, если t
2, то различие между двумя выборками
достоверно на 95%.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
![]()
Загрузить PDF
![]()
Загрузить PDF
Стандартной ошибкой называется величина, которая характеризует стандартное (среднеквадратическое) отклонение выборочного среднего. Другими словами, эту величину можно использовать для оценки точности выборочного среднего. Множество областей применения стандартной ошибки по умолчанию предполагают нормальное распределение. Если вам нужно рассчитать стандартную ошибку, перейдите к шагу 1.
-
1
Запомните определение среднеквадратического отклонения. Среднеквадратическое отклонение выборки – это мера рассеянности значения. Среднеквадратическое отклонение выборки обычно обозначается буквой s. Математическая формула среднеквадратического отклонения приведена выше.
-
2
Узнайте, что такое истинное среднее значение. Истинное среднее является средним группы чисел, включающим все числа всей группы – другими словами, это среднее всей группы чисел, а не выборки.
-
3
Научитесь рассчитывать среднеарифметическое значение. Среднеаримфетическое означает попросту среднее: сумму значений собранных данных, разделенную на количество значений этих данных.
-
4
Узнайте, что такое выборочное среднее. Когда среднеарифметическое значение основано на серии наблюдений, полученных в результате выборок из статистической совокупности, оно называется “выборочным средним”. Это среднее выборки чисел, которое описывает среднее значение лишь части чисел из всей группы. Его обозначают как:
-
5
Усвойте понятие нормального распределения. Нормальные распределения, которые используются чаще других распределений, являются симметричными, с единичным максимумом в центре – на среднем значении данных. Форма кривой подобна очертаниям колокола, при этом график равномерно опускается по обе стороны от среднего. Пятьдесят процентов распределения лежит слева от среднего, а другие пятьдесят процентов – справа от него. Рассеянность значений нормального распределения описывается стандартным отклонением.
-
6
Запомните основную формулу. Формула для вычисления стандартной ошибки приведена выше.
Реклама






-
1
Рассчитайте выборочное среднее. Чтобы найти стандартную ошибку, сначала нужно определить среднеквадратическое отклонение (поскольку среднеквадратическое отклонение s входит в формулу для вычисления стандартной ошибки). Начните с нахождения средних значений. Выборочное среднее выражается как среднее арифметическое измерений x1, x2, . . . , xn. Его рассчитывают по формуле, приведенной выше.
- Допустим, например, что вам нужно рассчитать стандартную ошибку выборочного среднего результатов измерения массы пяти монет, указанных в таблице:
Вы сможете рассчитать выборочное среднее, подставив значения массы в формулу:
- Допустим, например, что вам нужно рассчитать стандартную ошибку выборочного среднего результатов измерения массы пяти монет, указанных в таблице:
-
2
Вычтите выборочное среднее из каждого измерения и возведите полученное значение в квадрат. Как только вы получите выборочное среднее, вы можете расширить вашу таблицу, вычтя его из каждого измерения и возведя результат в квадрат.
- Для нашего примера расширенная таблица будет иметь следующий вид:
-
3
Найдите суммарное отклонение ваших измерений от выборочного среднего. Общее отклонение – это сумма возведенных в квадрат разностей от выборочного среднего. Чтобы определить его, сложите ваши новые значения.
- В нашем примере нужно будет выполнить следующий расчет:
Это уравнение дает сумму квадратов отклонений измерений от выборочного среднего.
- В нашем примере нужно будет выполнить следующий расчет:
-
4
Рассчитайте среднеквадратическое отклонение ваших измерений от выборочного среднего. Как только вы будете знать суммарное отклонение, вы сможете найти среднее отклонение, разделив ответ на n -1. Обратите внимание, что n равно числу измерений.
- В нашем примере было сделано 5 измерений, следовательно n – 1 будет равно 4. Расчет нужно вести следующим образом:
-
5
Найдите среднеквадратичное отклонение. Сейчас у вас есть все необходимые значения для того, чтобы воспользоваться формулой для нахождения среднеквадратичного отклонения s.
- В нашем примере вы будете рассчитывать среднеквадратичное отклонение следующим образом:
Следовательно, среднеквадратичное отклонение равно 0,0071624.
Реклама
- В нашем примере вы будете рассчитывать среднеквадратичное отклонение следующим образом:





-
1
Чтобы вычислить стандартную ошибку, воспользуйтесь базовой формулой со среднеквадратическим отклонением.
- В нашем примере вы сможете рассчитать стандартную ошибку следующим образом:
Таким образом в нашем примере стандартная ошибка (среднеквадратическое отклонение выборочного среднего) составляет 0,0032031 грамма.
- В нашем примере вы сможете рассчитать стандартную ошибку следующим образом:

Советы
- Стандартную ошибку и среднеквадратическое отклонение часто путают. Обратите внимание, что стандартная ошибка описывает среднеквадратическое отклонение выборочного распределения статистических данных, а не распределения отдельных значений
- В научных журналах понятия стандартной ошибки и среднеквадратического отклонения несколько размыты. Для объединения двух величин используется знак ±.
Реклама
Об этой статье
Эту страницу просматривали 48 427 раз.
Была ли эта статья полезной?
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
Что такое Стандартная ошибка?
Стандартная ошибка (SE) статистики – это приблизительное стандартное отклонение статистической выборки. Стандартная ошибка – это статистический термин, который измеряет точность, с которой выборочное распределение представляет генеральную совокупность с помощью стандартного отклонения. В статистике выборочное среднее отклоняется от фактического среднего для генеральной совокупности; это отклонение представляет собой стандартную ошибку среднего.
Ключевые моменты
- Стандартная ошибка – это приблизительное стандартное отклонение статистической выборки.
- Стандартная ошибка может включать вариацию между вычисленным средним для генеральной совокупности и тем, которое считается известным или принимаемым как точное.
- Чем больше точек данных участвует в расчетах среднего, тем меньше стандартная ошибка.
Понимание стандартной ошибки
Термин «стандартная ошибка» используется для обозначения стандартного отклонения различных статистических данных выборки, таких как среднее или медианное значение. Например, «стандартная ошибка среднего» относится к стандартному отклонению распределения выборочных средних, взятых из генеральной совокупности. Чем меньше стандартная ошибка, тем более репрезентативной будет выборка для генеральной совокупности.
Связь между стандартной ошибкой и стандартным отклонением такова, что для данного размера выборки стандартная ошибка равна стандартному отклонению, деленному на квадратный корень из размера выборки. Стандартная ошибка также обратно пропорциональна размеру выборки; Чем больше размер выборки, тем меньше стандартная ошибка, поскольку статистика приближается к фактическому значению.
Стандартная ошибка считается частью выводимой статистики. Он представляет собой стандартное отклонение среднего значения в наборе данных. Это служит мерой вариации случайных величин, обеспечивая измерение спреда. Чем меньше разброс, тем точнее набор данных.
Краткая справка
Стандартная ошибка и стандартное отклонение – это меры изменчивости, в то время как меры центральной тенденции включают среднее значение, медианное значение и т. Д.
Требования к стандартной ошибке
Когда производится выборка из генеральной совокупности , обычно рассчитывается среднее или среднее значение. Стандартная ошибка может включать разброс между вычисленным средним для генеральной совокупности и тем, которое считается известным или принимаемым как точное. Это помогает компенсировать любые случайные неточности, связанные со сбором пробы.
В случаях, когда собирается несколько образцов, среднее значение каждой выборки может незначительно отличаться от других, создавая разброс между переменными. Этот разброс чаще всего измеряется как стандартная ошибка, учитывающая различия между средними значениями в наборах данных.
Чем больше точек данных участвует в расчетах среднего, тем меньше стандартная ошибка. Когда стандартная ошибка мала, данные считаются более репрезентативными для истинного среднего значения. В случаях, когда стандартная ошибка велика, данные могут иметь некоторые заметные отклонения.
Стандартное отклонение – это представление разброса каждой точки данных. Стандартное отклонение используется для определения достоверности данных на основе количества точек данных, отображаемых на каждом уровне стандартного отклонения. Стандартные ошибки больше служат способом определения точности образца или точности нескольких образцов путем анализа отклонения в пределах средних.

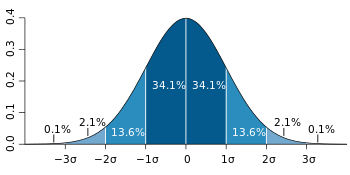
Для значения, полученного с помощью несмещенного нормально распределенный ошибка, приведенное выше показывает долю выборок, которая будет находиться между 0, 1, 2 и 3 стандартными отклонениями выше и ниже фактического значения.
В стандартная ошибка (SE)[1][2] из статистика (обычно оценка параметр ) это стандартное отклонение своего выборочное распределение[3] или оценка этого стандартного отклонения. Если статистика является выборочным средним, она называется стандартная ошибка среднего (SEM).[2]
В выборочное распределение среднего значения совокупности генерируется путем повторного отбора проб и регистрации полученных средних значений. Это формирует распределение различных средств, и это распределение имеет свои собственные иметь в виду и отклонение. Математически дисперсия полученного распределения выборки равна дисперсии генеральной совокупности, деленной на размер выборки. Это связано с тем, что по мере увеличения размера выборки средние значения выборки сгруппируются ближе к среднему значению генеральной совокупности.
Следовательно, соотношение между стандартной ошибкой среднего и стандартным отклонением таково, что для данного размера выборки стандартная ошибка среднего равна стандартному отклонению, деленному на квадратный корень размера выборки.[2] Другими словами, стандартная ошибка среднего — это мера разброса выборочных средних вокруг среднего по генеральной совокупности.
В регрессивный анализ, термин «стандартная ошибка» относится либо к квадратному корню из приведенная статистика хи-квадрат, или стандартная ошибка для определенного коэффициента регрессии (как, например, доверительные интервалы ).
Стандартная ошибка среднего
численность населения
Стандартная ошибка среднего (SEM) может быть выражена как:[2]

куда
- σ это стандартное отклонение населения.
- п — размер (количество наблюдений) выборки.
Оценивать
Поскольку стандартное отклонение населения редко известно, стандартная ошибка среднего обычно оценивается как стандартное отклонение выборки деленное на квадратный корень из размера выборки (при условии статистической независимости значений в выборке).

куда
- s это стандартное отклонение выборки (т. е. основанная на выборке оценка стандартного отклонения генеральной совокупности), и
- п — размер (количество наблюдений) выборки.
Образец
В тех контекстах, где стандартная ошибка среднего значения определяется не как стандартное отклонение выборки, а как его оценка, это оценка, обычно указываемая как ее значение. Таким образом, стандартное отклонение среднего значения часто определяется как:

Примечание: стандартная ошибка и стандартное отклонение малых выборок, как правило, систематически занижают стандартную ошибку генеральной совокупности и стандартное отклонение. В частности, стандартная ошибка среднего составляет предвзятый оценщик стандартной ошибки генеральной совокупности. При n = 2 занижение составляет около 25%, но для n = 6 занижение составляет всего 5%. Гурланд и Трипати (1971) предлагают поправку и уравнение для этого эффекта.[4] Сокал и Рольф (1981) приводят уравнение поправочного коэффициента для небольших выборокп < 20.[5] Видеть объективная оценка стандартного отклонения для дальнейшего обсуждения.
Практический результат: Для уменьшения неопределенности в оценке среднего значения в два раза требуется получить в четыре раза больше наблюдений в выборке; уменьшение стандартной ошибки в десять раз требует в сто раз больше наблюдений.
Производные
Формула может быть получена из отклонение суммы независимых случайных величин.[6]
Независимые и одинаково распределенные случайные величины со случайным размером выборки
Бывают случаи, когда образец берут, не зная заранее, сколько наблюдений будет приемлемым по тому или иному критерию. В таких случаях размер выборки  случайная величина, вариация которой добавляет к вариации
случайная величина, вариация которой добавляет к вариации  так что,
так что,
- [7]

Если имеет распределение Пуассона, тогда  с оценщиком
с оценщиком  . Следовательно, оценка
. Следовательно, оценка  становится
становится  , приводя к следующей формуле для стандартной ошибки:
, приводя к следующей формуле для стандартной ошибки:

(поскольку стандартное отклонение — это квадратный корень из дисперсии)
Приближение Стьюдента при σ значение неизвестно
Во многих практических приложениях истинная ценность σ неизвестно. В результате нам нужно использовать распределение, которое учитывает этот разброс возможных σ ‘s. Если известно, что истинное базовое распределение является гауссовым, хотя и с неизвестным σ, то полученное оцененное распределение следует t-распределению Стьюдента. Стандартная ошибка — это стандартное отклонение t-распределения Стьюдента. Т-распределения немного отличаются от гауссовых и меняются в зависимости от размера выборки. Небольшие выборки с большей вероятностью недооценивают стандартное отклонение совокупности и имеют среднее значение, которое отличается от истинного среднего значения совокупности, а t-распределение Стьюдента учитывает вероятность этих событий с несколько более тяжелыми хвостами по сравнению с гауссовым. Для оценки стандартной ошибки t-распределения Стьюдента достаточно использовать стандартное отклонение выборки «s» вместо σ, и мы могли бы использовать это значение для вычисления доверительных интервалов.
Примечание: В Распределение вероятностей студента хорошо аппроксимируется распределением Гаусса, когда размер выборки превышает 100. Для таких выборок можно использовать последнее распределение, которое намного проще.
Предположения и использование
Пример того, как  используется, чтобы сделать доверительные интервалы неизвестного среднего значения в генеральной совокупности. Если выборочное распределение нормально распределенный, выборочное среднее, стандартная ошибка и квантили нормального распределения можно использовать для расчета доверительных интервалов для истинного среднего значения по совокупности. Следующие выражения можно использовать для расчета верхнего и нижнего 95% доверительных интервалов, где
используется, чтобы сделать доверительные интервалы неизвестного среднего значения в генеральной совокупности. Если выборочное распределение нормально распределенный, выборочное среднее, стандартная ошибка и квантили нормального распределения можно использовать для расчета доверительных интервалов для истинного среднего значения по совокупности. Следующие выражения можно использовать для расчета верхнего и нижнего 95% доверительных интервалов, где  равно выборочному среднему, равна стандартной ошибке для выборочного среднего, и 1.96 это приблизительное значение 97,5 процентиль точка нормальное распределение:
равно выборочному среднему, равна стандартной ошибке для выборочного среднего, и 1.96 это приблизительное значение 97,5 процентиль точка нормальное распределение:
- Верхний предел 95% и
- Нижний предел 95%


В частности, стандартная ошибка статистика выборки (Такие как выборочное среднее ) — фактическое или расчетное стандартное отклонение выборочного среднего в процессе, в котором оно было получено. Другими словами, это фактическое или расчетное стандартное отклонение выборочное распределение статистики выборки. Обозначение стандартной ошибки может быть любым из SE, SEM (для стандартной ошибки измерение или же иметь в виду) или SE.
Стандартные ошибки обеспечивают простые меры неопределенности значения и часто используются, потому что:
- во многих случаях, если известна стандартная ошибка нескольких отдельных величин, то стандартная ошибка некоторых функция количества можно легко рассчитать;
- когда распределение вероятностей значения известно, его можно использовать для расчета точного доверительный интервал;
- когда распределение вероятностей неизвестно, Чебышев или Неравенства Высочанского – Петунина. может использоваться для расчета консервативного доверительного интервала; и
- как размер образца стремится к бесконечности Центральная предельная теорема гарантирует, что выборочное распределение среднего асимптотически нормальный.
Стандартная ошибка среднего значения по сравнению со стандартным отклонением
В научно-технической литературе экспериментальные данные часто суммируются либо с использованием среднего значения и стандартного отклонения выборочных данных, либо среднего значения со стандартной ошибкой. Это часто приводит к путанице в отношении их взаимозаменяемости. Однако среднее значение и стандартное отклонение равны описательная статистика, тогда как стандартная ошибка среднего описывает процесс случайной выборки. Стандартное отклонение данных выборки — это описание вариации в измерениях, тогда как стандартная ошибка среднего — это вероятностное утверждение о том, как размер выборки обеспечит лучшую границу оценок среднего генеральной совокупности в свете центрального предела. теорема.[8]
Проще говоря, стандартная ошибка выборочного среднего — это оценка того, насколько далеко среднее значение выборки может отличаться от среднего по генеральной совокупности, тогда как стандартное отклонение выборки — это степень, в которой отдельные лица в выборке отличаются от среднего по выборке.[9] Если стандартное отклонение генеральной совокупности конечно, стандартная ошибка среднего значения выборки будет стремиться к нулю с увеличением размера выборки, потому что оценка генерального среднего будет улучшаться, в то время как стандартное отклонение выборки будет приближаться к стандарту генеральной совокупности. отклонение по мере увеличения размера выборки.
Расширения
Поправка на конечную совокупность
Приведенная выше формула для стандартной ошибки предполагает, что размер выборки намного меньше размера генеральной совокупности, так что совокупность может считаться фактически бесконечной по размеру. Обычно это имеет место даже в случае конечных популяций, потому что большую часть времени люди в первую очередь заинтересованы в управлении процессами, которые создали существующую конечную популяцию; это называется аналитическое исследование, следующий У. Эдвардс Деминг. Если люди заинтересованы в управлении существующей конечной совокупностью, которая не будет меняться со временем, то необходимо внести поправку в размер популяции; это называется перечислительное исследование.
Когда фракция отбора проб большой (примерно 5% и более) в перечислительное исследование, оценка стандартной ошибки должна быть скорректирована путем умножения на «поправку на конечную совокупность»:[10][11]

что для больших N:

чтобы учесть дополнительную точность, полученную за счет выборки, близкой к большему проценту населения. Эффект FPC заключается в том, что ошибка становится нулевой, когда размер выборки п равна численности населения N.
Поправка на корреляцию в выборке

Ожидаемая ошибка в среднем А для образца п точки данных с коэффициентом смещения выборкиρ. Непредвзятый стандартная ошибка сюжеты как ρ = 0 диагональная линия с логарифмическим уклоном −½.
Если значения измеряемой величины А не являются статистически независимыми, но были получены из известных мест в пространстве параметровИкс, несмещенная оценка истинной стандартной ошибки среднего (фактически поправка на часть стандартного отклонения) может быть получена путем умножения вычисленной стандартной ошибки выборки на коэффициентж:

где коэффициент смещения выборки ρ — широко используемый Оценка Прейса – Винстена из автокорреляция -коэффициент (величина от -1 до +1) для всех пар точек выборки. Эта приблизительная формула предназначена для выборки среднего и большого размера; Справочник дает точные формулы для любого размера выборки и может применяться к сильно автокоррелированным временным рядам, таким как котировки акций Уолл-стрит. Более того, эта формула работает как для положительных, так и для отрицательных значений ρ.[12] Смотрите также объективная оценка стандартного отклонения для дальнейшего обсуждения.
Смотрите также
- Иллюстрация центральной предельной теоремы
- Допустимая погрешность
- Вероятная ошибка
- Стандартная ошибка средневзвешенного значения
- Среднее значение выборки и ковариация выборки
- Стандартная ошибка медианы
- Дисперсия
Рекомендации
- ^ «Список вероятностных и статистических символов». Математическое хранилище. 2020-04-26. Получено 2020-09-12.
- ^ а б c d Альтман, Дуглас Дж. Блэнд, Дж. Мартин (2005-10-15). «Стандартные отклонения и стандартные ошибки». BMJ: Британский медицинский журнал. 331 (7521): 903. ISSN 0959-8138. ЧВК 1255808. PMID 16223828.
- ^ Эверит, Б. С. (2003). Кембриджский статистический словарь. ЧАШКА. ISBN 978-0-521-81099-9.
- ^ Гурланд, Дж; Трипати RC (1971). «Простое приближение для объективной оценки стандартного отклонения». Американский статистик. 25 (4): 30–32. Дои:10.2307/2682923. JSTOR 2682923.
- ^ Сокаль; Рольф (1981). Биометрия: принципы и практика статистики в биологических исследованиях (2-е изд.). п.53. ISBN 978-0-7167-1254-1.
- ^ Хатчинсон, Т. Основы статистических методов, на 41 странице. Аделаида: Рамсби. ISBN 978-0-646-12621-0.
- ^ Корнелл, Дж. Р., и Бенджамин, К. А., Вероятность, статистика и решения для инженеров-строителей, Макгроу-Хилл, Нью-Йорк, 1970 г., ISBN 0486796094С. 178–9.
- ^ Барде, М. (2012). «Что использовать для выражения изменчивости данных: стандартное отклонение или стандартная ошибка среднего?». Перспектива. Clin. Res. 3 (3): 113–116. Дои:10.4103/2229-3485.100662. ЧВК 3487226. PMID 23125963.
- ^ Вассертхайль-Смоллер, Сильвия (1995). Биостатистика и эпидемиология: учебник для медицинских работников (Второе изд.). Нью-Йорк: Спрингер. С. 40–43. ISBN 0-387-94388-9.
- ^ Иссерлис, Л. (1918). «О значении среднего, рассчитанном по выборке». Журнал Королевского статистического общества. 81 (1): 75–81. Дои:10.2307/2340569. JSTOR 2340569. (Уравнение 1)
- ^ Бонди, Уоррен; Злот, Уильям (1976). «Стандартная ошибка среднего и разница между средними для конечных совокупностей». Американский статистик. 30 (2): 96–97. Дои:10.1080/00031305.1976.10479149. JSTOR 2683803. (Уравнение 2)
- ^ Бенс, Джеймс Р. (1995). «Анализ коротких временных рядов: поправка на автокорреляцию». Экология. 76 (2): 628–639. Дои:10.2307/1941218. JSTOR 1941218.
Стандартная ошибка
Стандартная ошибка — это стандартное отклонение выборочного распределения статистики. Этот термин также может использоваться для оценки (хорошего предположения) этого стандартного отклонения, взятого из выборки всей группы.
Среднее значение некоторой части группы (называемой выборкой) является обычным способом оценки среднего значения для всей группы. Часто бывает слишком сложно или стоит слишком много денег, чтобы измерить всю группу. Но если измерить другую выборку, то ее среднее значение будет немного отличаться от первой выборки. Стандартная ошибка среднего — это способ узнать, насколько близка средняя по выборке к средней по всей группе. Это способ узнать, насколько вы можете быть уверены в среднем значении по выборке.
В реальных измерениях истинное значение стандартного отклонения среднего для всей группы обычно неизвестно. Поэтому термин стандартная ошибка часто используется для обозначения близкого к истинному значению для всей группы. Чем больше измерений в выборке, тем ближе к истинному значению для всей группы.
![]()
Для значения, отобранного с несмещенной нормально распределенной ошибкой, выше показана доля выборок, которые будут находиться в пределах 0, 1, 2 и 3 стандартных отклонений выше и ниже фактического значения.
Как найти стандартную ошибку среднего значения
Один из способов найти стандартную ошибку среднего — это множество выборок. Сначала находят среднее значение для каждой выборки. Затем находят среднее и стандартное отклонение этих средних по выборкам. Стандартное отклонение для всех средних по выборке и есть стандартная ошибка среднего. Это может быть большой объем работы. Иногда иметь большое количество образцов слишком сложно или стоит слишком много денег.
Другой способ найти стандартную ошибку среднего — использовать уравнение, для которого нужна только одна выборка. Стандартная ошибка среднего обычно оценивается по стандартному отклонению для выборки из всей группы (стандартное отклонение выборки), деленному на квадратный корень из размера выборки.
S E x ¯ = s n {displaystyle SE_{bar {x}} ={frac {s}{sqrt {n}}}} 
где
s — стандартное отклонение выборки (т.е. выборочная оценка стандартного отклонения популяции), и
n — количество измерений в выборке.
Насколько большой должна быть выборка, чтобы оценка стандартной ошибки среднего была близка к фактической стандартной ошибке среднего для всей группы? В выборке должно быть не менее шести измерений. Тогда стандартная ошибка среднего для выборки будет находиться в пределах 5% от стандартной ошибки среднего, если бы измерялась вся группа.
Исправления для некоторых случаев
Существует еще одно уравнение, которое можно использовать, если количество измерений составляет 5% или более от всей группы:
Существуют специальные уравнения, которые необходимо использовать, если образец имеет менее 20 измерений.
Иногда выборка поступает из одного места, хотя вся группа может быть рассредоточена. Кроме того, иногда выборка может быть сделана за короткий промежуток времени, когда вся группа охватывает более длительный период. В этом случае числа в выборке не являются независимыми. Тогда используются специальные уравнения, чтобы попытаться исправить это.
Полезность
Практический результат: Можно быть более уверенным в среднем значении, если провести больше измерений в выборке. Тогда стандартная ошибка среднего значения будет меньше, поскольку стандартное отклонение делится на большее число. Однако, чтобы сделать неопределенность (стандартную ошибку среднего) среднего значения в два раза меньше, размер выборки (n) должен быть в четыре раза больше. Это происходит потому, что стандартное отклонение делится на квадратный корень из размера выборки. Чтобы сделать неопределенность на одну десятую больше, размер выборки (n) должен быть в сто раз больше!
Стандартные ошибки легко вычисляются и часто используются, потому что:
- Если известна стандартная ошибка нескольких отдельных величин, то во многих случаях можно легко рассчитать стандартную ошибку некоторой функции этих величин;
- Если вероятностное распределение значения известно, его можно использовать для расчета хорошего приближения к точному доверительному интервалу; и
- Если распределение вероятности неизвестно, для оценки доверительного интервала можно использовать другие уравнения
- Когда размер выборки становится очень большим, принцип центральной предельной теоремы показывает, что числа в выборке очень похожи на числа во всей группе (они имеют нормальное распределение).
Относительная стандартная ошибка
Относительная стандартная ошибка (RSE) — это стандартная ошибка, деленная на среднее значение. Это число меньше единицы. Умножение его на 100% дает его в процентах от среднего значения. Это помогает показать, является ли неопределенность важной или нет. Например, рассмотрим два исследования доходов домохозяйств, в результате которых среднее значение по выборке составляет $50 000. Если стандартная ошибка одного опроса составляет $10 000, а другого — $5 000, то относительные стандартные ошибки равны 20% и 10% соответственно. Опрос с меньшей относительной стандартной ошибкой лучше, потому что он имеет более точное измерение (неопределенность меньше).
На самом деле, люди, которым необходимо знать средние значения, часто решают, насколько мала должна быть неопределенность, прежде чем они решат использовать информацию. Например, Национальный центр статистики здравоохранения США не сообщает среднее значение, если относительная стандартная ошибка превышает 30%. NCHS также требует не менее 30 наблюдений для того, чтобы оценка была представлена в отчете. []
Пример
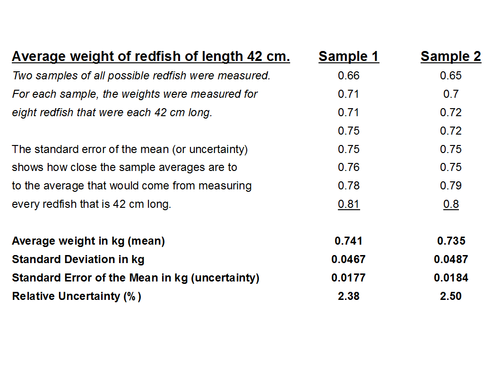
Например, в воде Мексиканского залива водится много красной рыбы. Чтобы узнать, сколько в среднем весит красноперка длиной 42 см, невозможно измерить всех красноперок длиной 42 см. Вместо этого можно измерить некоторых из них. Рыба, которую измеряют, называется образцом. В таблице показан вес двух образцов красноперки длиной 42 см. Средний (средний) вес первого образца составляет 0,741 кг. Средний (средний) вес второго образца — 0,735 кг, что немного отличается от первого образца. Каждое из этих средних значений немного отличается от среднего значения, которое было бы получено при измерении каждой красной рыбы длиной 42 см (что в любом случае невозможно).
Неопределенность среднего значения можно использовать для того, чтобы узнать, насколько близки средние значения выборок к среднему значению, которое было бы получено в результате измерения всей группы. Неопределенность среднего оценивается как стандартное отклонение для выборки, деленное на квадратный корень из числа выборок минус один. Из таблицы видно, что неопределенности в средних для двух выборок очень близки друг к другу. Кроме того, относительная неопределенность — это неопределенность среднего значения, деленная на среднее значение, умноженное на 100%. Относительная неопределенность в данном примере составляет 2,38% и 2,50% для двух образцов.
Зная неопределенность среднего, можно узнать, насколько близко выборочное среднее к среднему, которое было бы получено в результате измерения всей группы. Среднее по всей группе находится между а) средним по выборке плюс неопределенность в среднем и б) средним по выборке минус неопределенность в среднем. В данном примере средний вес всей красноперки длиной 42 см в Мексиканском заливе, как ожидается, составит 0,723-0,759 кг по первой выборке и 0,717-0,753 по второй выборке.
![]()
.jpg)
![]()
Пример красной рыбы (также известной как красный барабан, Sciaenops ocellatus), используемой в примере.