This article is to tell you the whole interpretation of the regression summary table. There are many statistical softwares that are used for regression analysis like Matlab, Minitab, spss, R etc. but this article uses python. The Interpretation is the same for other tools as well. This article needs the basics of statistics including basic knowledge of regression, degrees of freedom, standard deviation, Residual Sum Of Squares(RSS), ESS, t statistics etc.
In regression there are two types of variables i.e. dependent variable (also called explained variable) and independent variable (explanatory variable).
The regression line used here is,

The summary table of the regression is given below.
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.669
Model: OLS Adj. R-squared: 0.667
Method: Least Squares F-statistic: 299.2
Date: Mon, 01 Mar 2021 Prob (F-statistic): 2.33e-37
Time: 16:19:34 Log-Likelihood: -88.686
No. Observations: 150 AIC: 181.4
Df Residuals: 148 BIC: 187.4
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -3.2002 0.257 -12.458 0.000 -3.708 -2.693
x1 0.7529 0.044 17.296 0.000 0.667 0.839
==============================================================================
Omnibus: 3.538 Durbin-Watson: 1.279
Prob(Omnibus): 0.171 Jarque-Bera (JB): 3.589
Skew: 0.357 Prob(JB): 0.166
Kurtosis: 2.744 Cond. No. 43.4
==============================================================================
Dependent variable: Dependent variable is one that is going to depend on other variables. In this regression analysis Y is our dependent variable because we want to analyse the effect of X on Y.
Model: The method of Ordinary Least Squares(OLS) is most widely used model due to its efficiency. This model gives best approximate of true population regression line. The principle of OLS is to minimize the square of errors ( ∑ei2 ).
Number of observations: The number of observation is the size of our sample, i.e. N = 150.
Degree of freedom(df) of residuals:
Degree of freedom is the number of independent observations on the basis of which the sum of squares is calculated.
D.f Residuals = 150 – (1+1) = 148
Degree of freedom(D.f) is calculated as,
Degrees of freedom, D . f = N – K
Where, N = sample size(no. of observations) and K = number of variables + 1
Df of model:
Df of model = K – 1 = 2 – 1 = 1 ,
Where, K = number of variables + 1
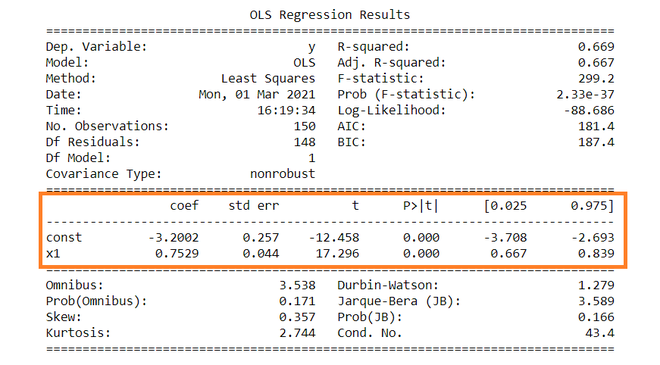
Constant term: The constant terms is the intercept of the regression line. From regression line (eq…1) the intercept is -3.002. In regression we omits some independent variables that do not have much impact on the dependent variable, the intercept tells the average value of these omitted variables and noise present in model.
Coefficient term: The coefficient term tells the change in Y for a unit change in X i.e if X rises by 1 unit then Y rises by 0.7529. If you are familiar with derivatives then you can relate it as the rate of change of Y with respect to X .
Standard error of parameters: Standard error is also called the standard deviation. Standard error shows the sampling variability of these parameters. Standard error is calculated by as –
Standard error of intercept term (b1):

Standard error of coefficient term(b2):

Here, σ2 is the Standard error of regression (SER) . And σ2 is equal to RSS( Residual Sum Of Square i.e ∑ei2 ).
t – statistics:
In theory, we assume that error term follows the normal distribution and because of this the parameters b1 and b2 also have normal distributions with variance calculated in above section.
That is ,
- b1 ∼ N(B1, σb12)
- b2 ∼ N(B2 , σb22)
Here B1 and B2 are true means of b1 and b2.
t – statistics are calculated by assuming following hypothesis –
- H0 : B2 = 0 ( variable X has no influence on Y)
- Ha : B2 ≠ 0 (X has significant impact on Y)
Calculations for t – statistics :
t = ( b1 – B1 ) / s.e (b1)
From summary table , b1 = -3.2002 and se(b1) = 0.257, So,
t = (-3.2002 – 0) / 0.257 = -12.458
Similarly, b2 = 0.7529 , se(b2) = 0.044
t = (0.7529 – 0) / 0.044 = 17.296
p – values:
In theory, we read that p-value is the probability of obtaining the t statistics at least as contradictory to H0 as calculated from assuming that the null hypothesis is true. In the summary table, we can see that P-value for both parameters is equal to 0. This is not exactly 0, but since we have very larger statistics (-12.458 and 17.296) p-value will be approximately 0.
If you know about significance levels then you can see that we can reject the null hypothesis at almost every significance level.
Confidence intervals:
There are many approaches to test the hypothesis, including the p-value approach mentioned above. The confidence interval approach is one of them. 5% is the standard significance level (∝) at which C.I’s are made.
C.I for B1 is ( b1 – t∝/2 s.e(b1) , b1 + t∝/2 s.e(b1) )
Since ∝ = 5 %, b1 = -3.2002, s.e(b1) =0.257 , from t table , t0.025,148 = 1.655,
After putting values the C.I for B1 is approx. ( -3.708 , -2.693 ). Same can be done for b2 as well.
While calculating p values we rejected the null hypothesis we can see same in C.I as well. Since 0 does not lie in any of the intervals so we will reject the null hypothesis.

R – squared value:
R2 is the coefficient of determination that tells us that how much percentage variation independent variable can be explained by independent variable. Here, 66.9 % variation in Y can be explained by X. The maximum possible value of R2 can be 1, means the larger the R2 value better the regression.
F – statistic:
F test tells the goodness of fit of a regression. The test is similar to the t-test or other tests we do for the hypothesis. The F – statistic is calculated as below –

Inserting the values of R2, n and k, F = (0.669/1) / (0.331/148) = 229.12.
You can calculate the probability of F >229.1 for 1 and 148 df, which comes to approx. 0. From this, we again reject the null hypothesis stated above.
The remaining terms are not often used. Terms like Skewness and Kurtosis tells about the distribution of data. Skewness and kurtosis for the normal distribution are 0 and 3 respectively. Jarque-Bera test is used for checking whether an error has normal distribution or not.
This article is to tell you the whole interpretation of the regression summary table. There are many statistical softwares that are used for regression analysis like Matlab, Minitab, spss, R etc. but this article uses python. The Interpretation is the same for other tools as well. This article needs the basics of statistics including basic knowledge of regression, degrees of freedom, standard deviation, Residual Sum Of Squares(RSS), ESS, t statistics etc.
In regression there are two types of variables i.e. dependent variable (also called explained variable) and independent variable (explanatory variable).
The regression line used here is,
The summary table of the regression is given below.
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.669
Model: OLS Adj. R-squared: 0.667
Method: Least Squares F-statistic: 299.2
Date: Mon, 01 Mar 2021 Prob (F-statistic): 2.33e-37
Time: 16:19:34 Log-Likelihood: -88.686
No. Observations: 150 AIC: 181.4
Df Residuals: 148 BIC: 187.4
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -3.2002 0.257 -12.458 0.000 -3.708 -2.693
x1 0.7529 0.044 17.296 0.000 0.667 0.839
==============================================================================
Omnibus: 3.538 Durbin-Watson: 1.279
Prob(Omnibus): 0.171 Jarque-Bera (JB): 3.589
Skew: 0.357 Prob(JB): 0.166
Kurtosis: 2.744 Cond. No. 43.4
==============================================================================
Dependent variable: Dependent variable is one that is going to depend on other variables. In this regression analysis Y is our dependent variable because we want to analyse the effect of X on Y.
Model: The method of Ordinary Least Squares(OLS) is most widely used model due to its efficiency. This model gives best approximate of true population regression line. The principle of OLS is to minimize the square of errors ( ∑ei2 ).
Number of observations: The number of observation is the size of our sample, i.e. N = 150.
Degree of freedom(df) of residuals:
Degree of freedom is the number of independent observations on the basis of which the sum of squares is calculated.
D.f Residuals = 150 – (1+1) = 148
Degree of freedom(D.f) is calculated as,
Degrees of freedom, D . f = N – K
Where, N = sample size(no. of observations) and K = number of variables + 1
Df of model:
Df of model = K – 1 = 2 – 1 = 1 ,
Where, K = number of variables + 1
Constant term: The constant terms is the intercept of the regression line. From regression line (eq…1) the intercept is -3.002. In regression we omits some independent variables that do not have much impact on the dependent variable, the intercept tells the average value of these omitted variables and noise present in model.
Coefficient term: The coefficient term tells the change in Y for a unit change in X i.e if X rises by 1 unit then Y rises by 0.7529. If you are familiar with derivatives then you can relate it as the rate of change of Y with respect to X .
Standard error of parameters: Standard error is also called the standard deviation. Standard error shows the sampling variability of these parameters. Standard error is calculated by as –
Standard error of intercept term (b1):
Standard error of coefficient term(b2):
Here, σ2 is the Standard error of regression (SER) . And σ2 is equal to RSS( Residual Sum Of Square i.e ∑ei2 ).
t – statistics:
In theory, we assume that error term follows the normal distribution and because of this the parameters b1 and b2 also have normal distributions with variance calculated in above section.
That is ,
- b1 ∼ N(B1, σb12)
- b2 ∼ N(B2 , σb22)
Here B1 and B2 are true means of b1 and b2.
t – statistics are calculated by assuming following hypothesis –
- H0 : B2 = 0 ( variable X has no influence on Y)
- Ha : B2 ≠ 0 (X has significant impact on Y)
Calculations for t – statistics :
t = ( b1 – B1 ) / s.e (b1)
From summary table , b1 = -3.2002 and se(b1) = 0.257, So,
t = (-3.2002 – 0) / 0.257 = -12.458
Similarly, b2 = 0.7529 , se(b2) = 0.044
t = (0.7529 – 0) / 0.044 = 17.296
p – values:
In theory, we read that p-value is the probability of obtaining the t statistics at least as contradictory to H0 as calculated from assuming that the null hypothesis is true. In the summary table, we can see that P-value for both parameters is equal to 0. This is not exactly 0, but since we have very larger statistics (-12.458 and 17.296) p-value will be approximately 0.
If you know about significance levels then you can see that we can reject the null hypothesis at almost every significance level.
Confidence intervals:
There are many approaches to test the hypothesis, including the p-value approach mentioned above. The confidence interval approach is one of them. 5% is the standard significance level (∝) at which C.I’s are made.
C.I for B1 is ( b1 – t∝/2 s.e(b1) , b1 + t∝/2 s.e(b1) )
Since ∝ = 5 %, b1 = -3.2002, s.e(b1) =0.257 , from t table , t0.025,148 = 1.655,
After putting values the C.I for B1 is approx. ( -3.708 , -2.693 ). Same can be done for b2 as well.
While calculating p values we rejected the null hypothesis we can see same in C.I as well. Since 0 does not lie in any of the intervals so we will reject the null hypothesis.
R – squared value:
R2 is the coefficient of determination that tells us that how much percentage variation independent variable can be explained by independent variable. Here, 66.9 % variation in Y can be explained by X. The maximum possible value of R2 can be 1, means the larger the R2 value better the regression.
F – statistic:
F test tells the goodness of fit of a regression. The test is similar to the t-test or other tests we do for the hypothesis. The F – statistic is calculated as below –
Inserting the values of R2, n and k, F = (0.669/1) / (0.331/148) = 229.12.
You can calculate the probability of F >229.1 for 1 and 148 df, which comes to approx. 0. From this, we again reject the null hypothesis stated above.
The remaining terms are not often used. Terms like Skewness and Kurtosis tells about the distribution of data. Skewness and kurtosis for the normal distribution are 0 and 3 respectively. Jarque-Bera test is used for checking whether an error has normal distribution or not.
1.2.1. Стандартная ошибка оценки по регрессии
Обозначается как
Sy,xи вычисляется по формуле
Sy,x=![]() .
.
Стандартная ошибка
оценки по регрессии показывает, на
сколько в среднем мы ошибаемся, оценивая
значение зависимой переменной по
найденному уравнению регрессии при
фиксированном значении независимой
переменной.
Квадрат стандартной
ошибки по регрессии является несмещенной
оценкой дисперсии ![]() 2,
2,
т.е.
![]() =
=
![]() =
=![]() .
.
Дисперсия ошибок
характеризует воздействие в модели
(1.1) неучтенных факторов и ошибок.
1.2.2. Оценка
значимости уравнения регрессии
(дисперсионный анализ регрессии)
Для оценки
значимости уравнения регрессии
устанавливают, соответствует ли выбранная
модель анализируемым данным. Для этого
используется дисперсионный анализ
регрессии. Основная его посылка – это
разложение общей суммы квадратов
отклонений
![]() на
на
составляющие. Известно, что такое
разложение имеет вид
![]() =
=![]() +
+![]() .
.
Второе слагаемое
в правой части разложения – это часть
общей суммы квадратов отклонений,
объясняемая действием случайных и
неучтенных факторов. Первое слагаемое
этого разложения – это часть общей
суммы квадратов отклонений, объясняемая
регрессионной зависимостью. Следовательно,
если регрессионная зависимость между
уихотсутствует, то
общая сумма квадратов отклонений
объясняется действием только случайных
факторов или ошибок, т.е.![]() =
=![]() .
.
В случае функциональной зависимости
между уихдействие
случайных факторов и ошибок отсутствует
и тогда![]() =
=![]() .
.
Будучи отнесенными к соответствующему
числу степеней свободы, эти суммы
называются средними квадратами отклонений
и служат оценками дисперсии![]() в
в
разных предположениях.
MSE= (![]() )/(n–2)
)/(n–2)
– остаточная дисперсия, которая является
оценкой![]() в
в
предположении отсутствия регрессионной
зависимости, аMSR= (![]() )/1
)/1
– аналогичная оценка без этого
предположения. Следовательно, если
регрессионная зависимость отсутствует,
то эти оценки должны быть близкими.
Сравниваются они на основе критерия
Фишера:F=MSR/MSE.
Расчетное значение
этого критерия сравнивается с критическим
значением F(с числом степеней свободы числителя,
равным 1, числом степеней свободы
знаменателя, равнымn–2,
и фиксированным уровнем значимости![]() ).
).
ЕслиF![]() <F, то гипотеза о не значимости
<F, то гипотеза о не значимости
уравнения регрессии не отклоняется, т.
е. признается, что уравнение регрессии
незначимо. В этом случае надо либо
изменить вид зависимости, либо пересмотреть
набор исходных данных.
При компьютерных
расчетах оценка значимости уравнения
регрессии осуществляется на основе
дисперсионного анализа регрессии в
таблицах вида:
Таблица
1.1
Дисперсионный
анализ регрессии
|
Источник вариации |
Суммы квадратов |
Степени свободы |
Средние квадраты |
F-отношение |
p-value |
|
Модель |
SSR |
1 |
MSR |
MSR/MSE |
Уровень |
|
Ошибки |
SSE |
n–2 |
MSE |
значимости |
|
|
общая |
SST |
n–1 |
Здесь p-value– это вероятность выполнения неравенстваF<F![]() ,
,
т. е. того, что расчетное значениеF-статистики попало в
область принятия гипотезы. Если эта
вероятность мала (меньше![]() ),
),
то нулевая гипотеза отклоняется.
Стандартная ошибка оценки по уравнению регрессии
Стандартная ошибка оценки, также известная как стандартная ошибка уравнения регрессии, определяется следующим образом (см. (6.23)) [c.280]
Стандартная ошибка уравнения регрессии, Эта статистика SEE представляет собой стандартное отклонение фактических значений теоретических значений У. [c.650]
Что такое стандартная ошибка уравнения регрессии ).Какие допущения лежат в основе парной регрессии 10. Что такое множественная регрессия [c.679]
Следующий этап корреляционного анализа — расчет уравнения связи (регрессии). Решение проводится обычно шаговым способом. Сначала в расчет принимается один фактор, который оказывает наиболее значимое влияние на результативный показатель, потом второй, третий и т.д. И на каждом шаге рассчитываются уравнение связи, множественный коэффициент корреляции и детерминации, /»»-отношение (критерий Фишера), стандартная ошибка и другие показатели, с помощью которых оценивается надежность уравнения связи. Величина их на каждом шаге сравнивается с предыдущей. Чем выше величина коэффициентов множественной корреляции, детерминации и критерия Фишера и чем ниже величина стандартной ошибки, тем точнее уравнение связи описывает зависимости, сложившиеся между исследуемыми показателями. Если добавление следующих факторов не улучшает оценочных показателей связи, то надо их отбросить, т.е. остановиться на том уравнении, где эти показатели наиболее оптимальны. [c.149]
Прогнозное значение ур определяется путем подстановки в уравнение регрессии ух =а + Ьх соответствующего (прогнозного) значения хр. Вычисляется средняя стандартная ошибка прогноза [c.9]
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка ть и та. [c.53]
В прогнозных расчетах по уравнению регрессии определяется предсказываемое (ур) значение как точечный прогноз ух при хр =хь т. е. путем подстановки в уравнение регрессии 5 = а + b х соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки ух, т. е. Шух, и соответственно интервальной оценкой прогнозного значения (у ) [c.57]
Чтобы понять, как строится формула для определения величин стандартной ошибки ух, обратимся к уравнению линейной регрессии ух = а + b х. Подставим в это уравнение выражение параметра а [c.57]
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения у, но и от точности прогноза значения фактора х. Его величина может задаваться на основе анализа других моделей исходя из конкретной ситуации, а также из анализа динамики данного фактора. [c.61]
В скобках указаны стандартные ошибки параметров уравнения регрессии. [c.327]
В скобках указаны стандартные ошибки параметров уравнения регрессии. Определим по этому уравнению расчетные значения >>, ,, а затем параметры уравнения регрессии (7.44). Получим следующие результаты [c.328]
На каждом шаге рассматриваются уравнение регрессии, коэффициенты корреляции и детерминации, F-критерий, стандартная ошибка оценки и другие оценочные показатели. После каждого шага перечисленные оценочные показатели сравниваются с [c.39]
Проблемы с методологией регрессии. Методология регрессии — это традиционный способ уплотнения больших массивов данных и их сведения в одно уравнение, отражающее связь между мультипликаторами РЕ и финансовыми фундаментальными переменными. Но данный подход имеет свои ограничения. Во-первых, независимые переменные коррелируют друг с другом . Например, как видно из таблицы 18,2, обобщающей корреляцию между коэффициентами бета, ростом и коэффициентами выплат для всех американских фирм, быстрорастущие фирмы обычно имеют большой риск и низкие коэффициенты выплат. Обратите внимание на отрицательную корреляцию между коэффициентами выплат и ростом, а также на положительную корреляцию между коэффициентами бета и ростом. Эта мультиколлинеарность делает мультипликаторы регрессии ненадежными (увеличивает стандартную ошибку) и, возможно, объясняет ошибочные знаки при коэффициентах и крупные изменения этих мультипликаторов в разные периоды. Во-вторых, регрессия основывается на линейной связи между мультипликаторами РЕ и фундаментальными переменными, и данное свойство, по всей вероятности, неадекватно. Анализ остаточных явлений, связанных с корреляцией, может привести к трансформациям независимых переменных (их квадратов или натуральных логарифмов), которые в большей степени подходят для объяснения мультипликаторов РЕ. В-третьих, базовая связь между мультипликаторами РЕ и финансовыми переменными сама по себе не является стабильной. Если же эта связь смещается из года в год, то прогнозы, полученные из регрессионного уравнения, могут оказаться ненадежными для более длительных периодов времени. По всем этим причинам, несмотря на полезность регрессионного анализа, его следует рассматривать только как еще один инструмент поиска подлинного значения ценности. [c.649]
На рисунке 16.6 явно просматривается четкая линейная зависимость объема частного потребления от величины располагаемого дохода. Уравнение парной линейной регрессии, оцененное по этим данным, имеет вид С= -217,6 + 1,007 Yf Стандартные ошибки для свободного члена и коэффициента парной регрессии равны, соответственно, 28,4 и 0,012, а -статистики — -7,7 и 81 9. Обе они по модулю существенно превышают 3, следовательно, их статистическая значимость весьма высока. Впрочем, несмотря на то, что здесь удалось оценить статистически значимую линейную функцию потребления, в ней нарушены сразу две предпосылки Кейнса — уровень автономного потребления С0 оказался отрицательным, а предель- [c.304]
Стандартные ошибки свободного члена и коэффициента регрессии равны, соответственно, 84,7 и 0,46 их /-статистики — (-21,4 и 36,8). По абсолютной величине /-статистики намного превышают 3, и это свидетельствует о высокой надежности оцененных коэффициентов. Коэффициент детерминации /Р уравнения равен 0,96, то есть объяснено 96% дисперсии объема потребления. И в то же время уже по рисунку видно, что оцененная рефессия не очень хоро- [c.320]
Эта стандартная ошибка S у, равная 0,65, указывает отклонение фактических данных от прогнозируемых на основании использования воздействующих факторов j i и Х2 (влияние среди покупателей бабушек с внучками и высокопрофессионального вклада Шарика). В то же время мы располагаем обычным стандартным отклонением Sn, равным 1,06 (см. табл.8), которое было рассчитано для одной переменной, а именно сами текущие значения уги величина среднего арифметического у, которое равно 6,01. Легко видеть, что S у tTa6n. В противном случае доверять полученной оценке параметра нет оснований. [c.139]
Для определения профиля посетителей магазинов местного торгового центра, не имеющих определенной цели (browsers), маркетологи использовали три набора независимых переменных демографические, покупательское поведение психологические. Зависимая переменная представляет собой индекс посещения магазина без определенной цели, индекс (browsing index). Методом ступенчатой включающей все три набора переменных, выявлено, что демографические факторы — наиболее сильные предикторы, определяющие поведение покупателей, не преследующих конкретных целей. Окончательное уравнение регрессии, 20 из 36 возможных переменных, включало все демографические переменные. В следующей таблице приведены коэффициенты регрессии, стандартные ошибки коэффициентов, а также их уровни значимости. [c.668]
Смотреть страницы где упоминается термин Стандартная ошибка уравнения регрессии
Маркетинговые исследования Издание 3 (2002) — [ c.650 ]
Лекции по дисциплине «Эконометрика» (заочное отделение) (стр. 2 )
 |
Из за большого объема этот материал размещен на нескольких страницах: 1 2 3 4 |

Параметр формально является значением Y при X = 0. Он может не иметь экономического содержания. Интерпретировать можно лишь знак при параметре . Если > 0, то относительное изменение результата происходит медленнее, чем изменение фактора. Иными словами, вариация по фактору X выше вариации для результата Y. Также считают, что включает в себя неучтенные в модели факторы.
По итогам 2008 года были собраны данные по прибыли и оборачиваемости оборотных средств 500 торговых предприятий г. Челябинска. Результаты наблюдения сведены в таблицу.
Годовая прибыль предприятия, млн. руб.
Годовая оборачиваемость оборотных средств, раз
Требуется построить зависимость прибыли предприятий от оборачиваемости оборотных средств и оценить качество полученного уравнения.
Пусть y – прибыль предприятия, x – оборачиваемость оборотных средств.
На основе исходных данных были рассчитаны следующие показатели:
Уровень доверия возьмем q=0,95 или 95%.

1. Стандартные ошибки оценок , . намного больше =0,39, следовательно, низкая точность коэффициента . очень мала по сравнению с , следовательно, высокая точность коэффициента .
2. Интервальные оценки коэффициентов уравнения регрессии.
n – 2 = 500 – 2 = 498;
α:  →
→  → очень низкая точность коэффициента;
→ очень низкая точность коэффициента;
β:  →
→  → высокая точность коэффициента.
→ высокая точность коэффициента.
3. Значимость коэффициентов регрессии.
 = >1,96 → коэффициент значим;
= >1,96 → коэффициент значим;
 = >1,96 → коэффициент значим.
= >1,96 → коэффициент значим.
4. Стандартная ошибка регрессии. Se=0,91, по сравнению со средним значением =34,5 ошибка невысокая, точность уравнения хорошая.
5. Коэффициент детерминации. R2 = rxy2=0,782=0,6084 не очень близко к 1, качество подгонки среднее.
6. Средняя ошибка аппроксимации. A=11%, качество подгонки уравнения среднее.
Экономическая интерпретация: при увеличении оборачиваемости оборотных средств предприятия на 1 раз в год средняя годовая прибыль увеличится на 5,86 млн. руб.
Тема 6. Нелинейная парная регрессия
Часто на практике между зависимой и независимыми переменными существует нелинейная форма взаимосвязи. В этом случае существует два выхода:
1) подобрать к анализируемым переменным преобразование, которое бы позволило представить существующую зависимость в виде линейной функции;
2) применить нелинейный метод наименьших квадратов.
Основные нелинейные регрессионные модели и приведение их к линейной форме
1. Экспоненциальное уравнение  .
.
Если прологарифмировать левую и правую части данного уравнения, то получится
 .
.
Это уравнение является линейным, но вместо y в левой части стоит ln y.
В данном случае параметр β1 имеет следующий экономический смысл: при увеличении переменной x на единицу переменная y в среднем увеличится примерно на 100·β% (более точно: y увеличится в  раз).
раз).
2. Логарифмическое уравнение  .
.
Переход к линейному уравнению осуществляется заменой переменной x на X=lnx..
Параметр β1 имеет следующий экономический смысл: для увеличения y на единицу необходимо увеличить переменную x в  раз, т. е. примерно на
раз, т. е. примерно на  .
.
3. Гиперболическое уравнение  .
.
В этом случае необходимо сделать замену переменных x на  . Для гиперболической зависимости нет простой интерпретации коэффициента регрессии β1.
. Для гиперболической зависимости нет простой интерпретации коэффициента регрессии β1.
4. Степенное уравнение  .
.
Прологарифмировав левую и правую части данного уравнения, получим
 .
.
Заменив соответствующие ряды их логарифмами, получится линейная регрессия.
Экономический смысл параметра β1: если значение переменной x увеличить на 1%, то y увеличится на β1%.
5. Показательное уравнение  (β1>0, β1≠1).
(β1>0, β1≠1).
Прологарифмировав левую и правую части уравнения, получим
 .
.
Проведя замены Y=ln y и B1=ln β1, получится линейная регрессия.
Экономический смысл параметра β1: при увеличении переменной x на единицу переменная y в среднем увеличится в β1 раз.
Тема 7. Множественная линейная регрессия: определение и оценка параметров
1. Понятие множественной линейной регрессии
Модель множественной линейной регрессии является обобщением парной линейной регрессии и представляет собой следующее выражение:
 , t=1. n,
, t=1. n,
где yt – значение зависимой переменной для наблюдения t,
xit – значение i-й независимой переменной для наблюдения t,
εt – значение случайной ошибки для наблюдения t,
n – число наблюдений,
m – число независимых переменных x.
2. Матричная форма записи множественной линейной регрессии
Уравнение множественной линейной регрессии можно записать в матричной форме:
 ,
,
где  ,
,  ,
,  ,
,  .
.
3. Основные предположения
2.  для всех наблюдений;
для всех наблюдений;
3.  = const для всех наблюдений;
= const для всех наблюдений;
4.  ;
;
В случае выполнения вышеперечисленных гипотез модель называется нормальной линейной регрессионной.
4. Метод наименьших квадратов
Параметры уравнения множественной регрессии оцениваются, как и в парной регрессии, методом наименьших квадратов (МНК):  .
.
Чтобы найти минимум этой функции необходимо вычислить производные по каждому из параметров и приравнять их к нулю, в результате получается система уравнений, решение которой в матричном виде следующее:
 →
→  .
.
 ,
,

5. Теорема Гаусса-Маркова
Если выполнены предположения 1-5 из пункта 3, то оценки , полученные методом наименьших квадратов, имеют наименьшую дисперсию в классе линейных несмещенных оценок, то есть являются несмещенными, состоятельными и эффективными.
Тема 8. Множественная линейная регрессия: оценка качества
1. Общая схема проверки качества парной регрессии
Адекватность модели – остатки должны удовлетворять условиям теоремы Гаусса-Маркова.
Основные показатели качества коэффициентов регрессии:
1. Стандартные ошибки оценок (анализ точности определения оценок).
2. Интервальные оценки коэффициентов уравнения регрессии (построение доверительных интервалов).
3. Значимость коэффициентов регрессии (проверка гипотез относительно коэффициентов регрессии).
Основные показатели качества уравнения регрессии в целом:
1. Стандартная ошибка регрессии Se (анализ точности уравнения регрессии).
2. Значимость уравнения регрессии в целом (проверка гипотезы относительно всех коэффициентов регрессии).
3. Коэффициент детерминации R2 (проверка качества подгонки уравнения к исходным данным).
4. Скорректированный коэффициент детерминации R2adj (проверка качества подгонки уравнения к исходным данным).
5. Средняя ошибка аппроксимации (проверка качества подгонки уравнения к эмпирическим данным).
2. Стандартные ошибки оценок
Стандартные ошибки коэффициентов регрессии – это средние квадратические отклонения коэффициентов регрессии от их истинных значений.
 ,
,
где 
 — диагональные элементы матрицы
— диагональные элементы матрицы  ,
,
 .
.
Стандартная ошибка является оценкой среднего квадратического отклонения коэффициента регрессии от его истинного значения. Чем меньше стандартная ошибка тем точнее оценка.
3. Интервальные оценки коэффициентов множественной линейной регрессии
Доверительные интервалы для коэффициентов регрессии определяются следующим образом:
1. Выбирается уровень доверия q (0,9; 0,95 или 0,99).
2. Рассчитывается уровень значимости g = 1 – q.
3. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
4. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – m – 1.
5. Рассчитывается доверительный интервал для параметра  :
:
 .
.
Доверительный интервал показывает, что истинное значение параметра с вероятностью q находится в данных пределах.
Чем меньше доверительный интервал относительно коэффициента, тем точнее полученная оценка.
4. Значимость коэффициентов регрессии
Процедура оценки значимости коэффициентов осуществляется аналогичной парной регрессии следующим образом:
1. Рассчитывается значение t-статистики для коэффициента регрессии по формуле  .
.
2. Выбирается уровень доверия q ( 0,9; 0,95 или 0,99).
3. Рассчитывается уровень значимости g = 1 – q.
4. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
5. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – m – 1.
6. Если  , то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
, то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
t-тесты обеспечивают проверку значимости предельного вклада каждой переменной при допущении, что все остальные переменные уже включены в модель.
5. Стандартная ошибка регрессии
Стандартная ошибка регрессии Se показывает, насколько в среднем фактические значения зависимой переменной y отличаются от ее расчетных значений
 .
.
Используется как основная величина для измерения качества модели (чем она меньше, тем лучше).
Значения Se в однотипных моделях с разным числом наблюдений и (или) переменных сравнимы.
6. Оценка значимости уравнения регрессии в целом
Уравнение значимо, если есть достаточно высокая вероятность того, что существует хотя бы один коэффициент, отличный от нуля.
Имеются альтернативные гипотезы:
Если принимается гипотеза H0, то уравнение статистически незначимо. В противном случае говорят, что уравнение статистически значимо.
Значимость уравнения регрессии в целом осуществляется с помощью F-статистики.
Оценка значимости уравнения регрессии в целом основана на тождестве дисперсионного анализа:
 Þ
Þ
TSS – общая сумма квадратов отклонений
ESS – объясненная сумма квадратов отклонений
RSS – необъясненная сумма квадратов отклонений
F-статистика представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы)

n – число выборочных наблюдений, m – число независимых переменных.
При отсутствии линейной зависимости между зависимой и независимой переменными F-статистика имеет F-распределение Фишера-Снедекора со степенями свободы k1 = m, k2 = n – m –1.
Процедура оценки значимости уравнения осуществляется следующим образом:
7. Рассчитывается значение F-статистики по формуле  .
.
8. Выбирается уровень доверия q ( 0,9; 0,95 или 0,99).
9. Рассчитывается уровень значимости g = 1 – q.
10. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
11. Определяется критическое значение F-статистики (Fкр) по таблицам распределения Фишера на основе g и n – m – 1.
12. Если  , то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
, то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
В парной регрессии F-статистика равна квадрату t-статистики:  , а значимость коэффициента регрессии и значимость уравнения в целом эквивалентны.
, а значимость коэффициента регрессии и значимость уравнения в целом эквивалентны.
Качество оценки уравнения можно проверить путем расчета коэффициента детерминации R2, который показывает степень соответствия найденного уравнения экспериментальным данным.
 .
.
Коэффициент R2 показывает долю дисперсии переменной y, объясненную регрессией, в общей дисперсии y.
Коэффициент детерминации лежит в пределах 0 £ R2 £ 1.
Чем ближе R2 к 1, тем выше качество подгонки уравнения к статистическим данным.
Чем ближе R2 к 0, тем ниже качество подгонки уравнения к статистическим данным.
Коэффициенты R2 в разных моделях с разным числом наблюдений и переменных несравнимы.
8. Скорректированный коэффициент детерминации R2adj
Низкое значение R2 не свидетельствует о плохом качестве модели, и может объясняться наличием существенных факторов, не включенных в модель
R2 всегда увеличивается с включением новой переменной. Поэтому его необходимо корректировать, и рассчитывают скорректированный коэффициент детерминации

Если R2adj выходит за пределы интервала [0;1], то его использовать нельзя.
Если при добавлении новой переменной в модель увеличивается не только R2, но и R2adj, то можно считать, что вклад этой переменной в повышение качества модели существенен.
9. Средняя ошибка аппроксимации
Средняя ошибка аппроксимации (средняя абсолютная процентная ошибка) – показывает в процентах среднее отклонение расчетных значений зависимой переменной от фактических значений yi

Если A ≤ 10%, то качество подгонки уравнения считается хорошим. Чем меньше значение A, тем лучше.
10. Использование показателей качества коэффициентов и уравнения регрессии для интерпретации и корректировки модели
В случае незначимости уравнения, необходимо устранить ошибки модели. Наиболее распространенными являются следующие ошибки:
— неправильно выбран вид функции регрессии;
— в модель включены незначимые регрессоры;
— в модели отсутствуют значимые регрессоры.
После устранения ошибок требуется заново оценить параметры уравнения и его качество, продолжая этот процесс до тех пор, пока качество уравнения не станет удовлетворительным. Если после поделанных процедур, мы не достигли требуемого уровня значимости, то необходимо устранять другие ошибки (спецификации, классификации, наблюдения и т. д., см. тему 3, п. 6).
11. Интерпретация множественной линейной регрессии
Коэффициент регрессии при переменной xi показывает, на сколько увеличится среднее значение зависимой переменной y при увеличении xi на 1, при условии постоянства других переменных.
В апреле 2006 года были собраны данные по стоимости 200 двухкомнатных квартир в Металлургическом районе г. Челябинска, их жилой площади, площади кухни и расстоянии до центра города (пл. Революции). Результаты наблюдения сведены в таблицу.
Оценка результатов линейной регрессии
Введение
Модель линейной регрессии
Итак, пусть есть несколько независимых случайных величин X1, X2, . Xn (предикторов) и зависящая от них величина Y (предполагается, что все необходимые преобразования предикторов уже сделаны). Более того, мы предполагаем, что зависимость линейная, а ошибки рапределены нормально, то есть 
где I — единичная квадратная матрица размера n x n.
Итак, у нас есть данные, состоящие из k наблюдений величин Y и Xi и мы хотим оценить коэффициенты. Стандартным методом для нахождения оценок коэффициентов является метод наименьших квадратов. И аналитическое решение, которое можно получить, применив этот метод, выглядит так: 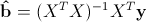
где b с крышкой — оценка вектора коэффициентов, y — вектор значений зависимой величины, а X — матрица размера k x n+1 (n — количество предикторов, k — количество наблюдений), у которой первый столбец состоит из единиц, второй — значения первого предиктора, третий — второго и так далее, а строки соответствуют имеющимся наблюдениям.
Функция summary.lm() и оценка получившихся результатов
Теперь рассмотрим пример построения модели линейной регрессии в языке R:
Таблица gala содержит некоторые данные о 30 Галапагосских островах. Мы будем рассматривать модель, где Species — количество разных видов растений на острове линейно зависит от нескольких других переменных.
Рассмотрим вывод функции summary.lm().
Сначала идет строка, которая напоминает, как строилась модель.
Затем идет информация о распределении остатков: минимум, первая квартиль, медиана, третья квартиль, максимум. В этом месте было бы полезно не только посмотреть на некоторые квантили остатков, но и проверить их на нормальность, например тестом Шапиро-Уилка.
Далее — самое интересное — информация о коэффициентах. Здесь потребуется немного теории.
Сначала выпишем следующий результат: 
при этом сигма в квадрате с крышкой является несмещенной оценкой для реальной сигмы в квадрате. Здесь b — реальный вектор коэффициентов, а эпсилон с крышкой — вектор остатков, если в качестве коэффициентов взять оценки, полученные методом наименьших квадратов. То есть при предположении, что ошибки распределены нормально, вектор коэффициентов тоже будет распределен нормально вокруг реального значения, а его дисперсию можно несмещенно оценить. Это значит, что можно проверять гипотезу на равенство коэффициентов нулю, а следовательно проверять значимость предикторов, то есть действительно ли величина Xi сильно влияет на качество построенной модели.
Для проверки этой гипотезы нам понадобится следующая статистика, имеющая распределение Стьюдента в том случае, если реальное значение коэффициента bi равно 0: 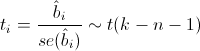
где
 — стандартная ошибка оценки коэффициента, а t(k-n-1) — распределение Стьюдента с k-n-1 степенями свободы.
— стандартная ошибка оценки коэффициента, а t(k-n-1) — распределение Стьюдента с k-n-1 степенями свободы.
Теперь все готово для продолжения разбора вывода функции summary.lm().
Итак, далее идут оценки коэффициентов, полученные методом наименьших квадратов, их стандартные ошибки, значения t-статистики и p-значения для нее. Обычно p-значение сравнивается с каким-нибудь достаточно малым заранее выбранным порогом, например 0.05 или 0.01. И если значение p-статистики оказывается меньше порога, то гипотеза отвергается, если же больше, ничего конкретного, к сожалению, сказать нельзя. Напомню, что в данном случае, так как распределение Стьюдента симметричное относительно 0, то p-значение будет равно 1-F(|t|)+F(-|t|), где F — функция распределения Стьюдента с k-n-1 степенями свободы. Также, R любезно обозначает звездочками значимые коэффициенты, для которых p-значение достаточно мало. То есть, те коэффициенты, которые с очень малой вероятностью равны 0. В строке Signif. codes как раз содержится расшифровка звездочек: если их три, то p-значение от 0 до 0.001, если две, то оно от 0.001 до 0.01 и так далее. Если никаких значков нет, то р-значение больше 0.1.
В нашем примере можно с большой уверенностью сказать, что предикторы Elevation и Adjacent действительно с большой вероятностью влияют на величину Species, а вот про остальные предикторы ничего определенного сказать нельзя. Обычно, в таких случаях предикторы убирают по одному и смотрят, насколько изменяются другие показатели модели, например BIC или Adjusted R-squared, который будет разобран далее.
Значение Residual standart error соответствует просто оценке сигмы с крышкой, а степени свободы вычисляются как k-n-1.
А теперь самая важные статистики, на которые в первую очередь стоит смотреть: R-squared и Adjusted R-squared: 
где Yi — реальные значения Y в каждом наблюдении, Yi с крышкой — значения, предсказанные моделью, Y с чертой — среднее по всем реальным значениям Yi. 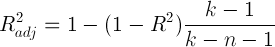
Начнем со статистики R-квадрат или, как ее иногда называют, коэффициента детерминации. Она показывает, насколько условная дисперсия модели отличается от дисперсии реальных значений Y. Если этот коэффициент близок к 1, то условная дисперсия модели достаточно мала и весьма вероятно, что модель неплохо описывает данные. Если же коэффициент R-квадрат сильно меньше, например, меньше 0.5, то, с большой долей уверенности модель не отражает реальное положение вещей.
Однако, у статистики R-квадрат есть один серьезный недостаток: при увеличении числа предикторов эта статистика может только возрастать. Поэтому, может показаться, что модель с большим количеством предикторов лучше, чем модель с меньшим, даже если все новые предикторы никак не влияют на зависимую переменную. Тут можно вспомнить про принцип бритвы Оккама. Следуя ему, по возможности, стоит избавляться от лишних предикторов в модели, поскольку она становится более простой и понятной. Для этих целей была придумана статистика скорректированный R-квадрат. Она представляет собой обычный R-квадрат, но со штрафом за большое количество предикторов. Основная идея: если новые независимые переменные дают большой вклад в качество модели, значение этой статистики растет, если нет — то наоборот уменьшается.
Для примера рассмотрим ту же модель, что и раньше, но теперь вместо пяти предикторов оставим два:
Как можно увидеть, значение статистики R-квадрат снизилось, однако значение скорректированного R-квадрат даже немного возросло.
Теперь проверим гипотезу о равенстве нулю всех коэффициентов при предикторах. То есть, гипотезу о том, зависит ли вообще величина Y от величин Xi линейно. Для этого можно использовать следующую статистику, которая, если гипотеза о равенстве нулю всех коэффициентов верна, имеет распределение Фишера c n и k-n-1 степенями свободы: 
Значение F-статистики и p-значение для нее находятся в последней строке вывода функции summary.lm().
Заключение
В этой статье были описаны стандартные методы оценки значимости коэффициентов и некоторые критерии оценки качества построенной линейной модели. К сожалению, я не касался вопроса рассмотрения распределения остатков и проверки его на нормальность, поскольку это увеличило бы статью еще вдвое, хотя это и достаточно важный элемент проверки адекватности модели.
Очень надеюсь что мне удалось немного расширить стандартное представление о линейной регрессии, как об алгоритме который просто оценивает некоторый вид зависимости, и показать, как можно оценить его результаты.
источники:
http://pandia.ru/text/78/101/1285-2.php
http://habr.com/ru/post/195146/
АКТУАЛЬНОСТЬ ТЕМЫ
Общие положения
Про регрессионный анализ вообще, и его применение в DataScience написано очень много. Есть множество учебников, монографий, справочников и статей по прикладной статистике, огромное количество информации в интернете, примеров расчетов. Можно найти множество кейсов, реализованных с использованием средств Python. Казалось бы — что тут еще можно добавить?
Однако, как всегда, есть нюансы:
1. Регрессионный анализ — это прежде всего процесс, набор действий исследователя по определенному алгоритму: «подготовка исходных данных — построение модели — анализ модели — прогнозирование с помощью модели». Это ключевая особенность. Не представляет особой сложности сформировать DataFrame исходных данных и построить модель, запустить процедуру из библиотеки statsmodels. Однако подготовка исходных данных и последующий анализ модели требуют гораздо больших затрат человеко-часов специалиста и строк программного кода, чем, собственно, построение модели. На этих этапах часто приходится возвращаться назад, корректировать модель или исходные данные. Этому, к сожалению, во многих источниках, не удаляется достойного внимания, а иногда — и совсем не уделяется внимания, что приводит к превратному представлению о регрессионном анализе.
2. Далеко не во всех источниках уделяется должное внимание интерпретации промежуточных и финальных результатов. Специалист должен уметь интерпретировать каждую цифру, полученную в ходе работы над моделью.
3. Далеко не все процедуры на этапах подготовки исходных данных или анализа модели в источниках разобраны подробно. Например, про проверку значимости коэффициента детерминации найти информацию не представляет труда, а вот про проверку адекватности модели, построение доверительных интервалов регрессии или про специфические процедуры (например, тест Уайта на гетероскедастичность) информации гораздо меньше.
4. Своеобразная сложность может возникнуть с проверкой статистических гипотез: для отечественной литературы по прикладной статистике больше характерно проверять гипотезы путем сравнения расчетного значения критерия с табличным, а в иностранных источниках чаще определяется расчетный уровень значимости и сравнивается с заданным (чаще всего 0.05 = 1-0.95). В разных источниках информации реализованы разные подходы. Инструменты python (прежде всего библиотеки scipy и statsmodels) также в основном оперируют с расчетным уровнем значимости.
5. Ну и, наконец, нельзя не отметить, что техническая документация библиотеки statsmodels составлена, на мой взгляд, далеко не идеально: информация излагается путано, изобилует повторами и пропусками, описание классов, функций и свойств выполнено фрагментарно и количество примеров расчетов — явно недостаточно.
Поэтому я решил написать ряд обзоров по регрессионному анализу средствами Python, в которых акцент будет сделан на практических примерах, алгоритме действий исследователя, интерпретации всех полученных результатов, конкретных методических рекомендациях. Буду стараться по возможности избегать теории (хотя совсем без нее получится) — все-таки предполагается, что специалист DataScience должен знать теорию вероятностей и математическую статистику, хотя бы в рамках курса высшей математики для технического или экономического вуза.
В данном статье остановимся на самои простом, классическом, стереотипном случае — простой линейной регрессии (simple linear regression), или как ее еще принято называть — парной линейной регрессионной модели (ПЛРМ) — в ситуации, когда исследователя не подстерегают никакие подводные камни и каверзы — исходные данные подчиняются нормальному закону, в выборке отсутствуют аномальные значения, отсутствует ложная корреляция. Более сложные случаи рассмотрим в дальнейшем.
Для построение регрессионной модели будем пользоваться библиотекой statsmodels.
В данной статье мы рассмотрим по возможности полный набор статистических процедур. Некоторые из них (например, дескриптивная статистика или дисперсионный анализ регрессионной модели) могут показаться избыточными. Все так, но эти процедуры улучшают наше представление о процессе и об исходных данных, поэтому в разбор я их включил, а каждый исследователь сам вправе для себя определить, потребуются ему эти процедуры или нет.
Краткий обзор источников
Источников информации по корреляционному и регрессионному анализу огромное количество, в них можно просто утонуть. Поэтому позволю себе просто порекомендовать ряд источников, на мой взгляд, наиболее полезных:
-
Кобзарь А.И. Прикладная математическая статистика. Для инженеров и научных работников. — М.: ФИЗМАТЛИТ, 2006. — 816 с.
-
Львовский Е.Н. Статистические методы построения эмпирических формул. — М.: Высшая школа, 1988. — 239 с.
-
Фёрстер Э., Рёнц Б. Методы корреляционного и регрессионного анализа / пер с нем. — М.: Финансы и статистика, 1983. — 302 с.
-
Афифи А., Эйзен С. Статистический анализ. Подход с использованием ЭВМ / пер с англ. — М.: Мир, 1982. — 488 с.
-
Дрейпер Н., Смит Г. Прикладной регрессионный анализ. Книга 1 / пер.с англ. — М.: Финансы и статистика, 1986. — 366 с.
-
Айвазян С.А. и др. Прикладная статистика: Исследование зависимостей. — М.: Финансы и статистика, 1985. — 487 с.
-
Прикладная статистика. Основы эконометрики: В 2 т. 2-е изд., испр. — Т.2: Айвазян С.А. Основы эконометрики. — М.: ЮНИТИ-ДАНА, 2001. — 432 с.
-
Магнус Я.Р. и др. Эконометрика. Начальный курс — М.: Дело, 2004. — 576 с.
-
Носко В.П. Эконометрика. Книга 1. — М.: Издательский дом «Дело» РАНХиГС, 2011. — 672 с.
-
Брюс П. Практическая статистика для специалистов Data Science / пер. с англ. — СПб.: БХВ-Петербург, 2018. — 304 с.
-
Уатт Дж. и др. Машинное обучение: основы, алгоритмы и практика применения / пер. с англ. — СПб.: БХВ-Петербург, 2022. — 640 с.
Прежде всего следует упомянуть справочник Кобзаря А.И. [1] — это безусловно выдающийся труд. Ничего подобного даже близко не издавалось. Всем рекомендую иметь под рукой.
Есть очень хорошее практическое пособие [2] — для начинающих и практиков.>
Добротная работа немецких авторов [3]. Все разобрано подробно, обстоятельно, с примерами — очень хорошая книга. Примеры приведены из области экономики.
Еще одна добротная работа — [4], с примерами медико-биологического характера.
Работа [5] считается одним из наиболее полных изложений прикладного регрессионного анализа.
Более сложные работы — [6] (классика жанра), [7], [8], [9] — выдержаны на достаточно высоком математическом уровне, примеры из экономической области.
Свежие работы [10] (с примерами на языке R) и [11] (с примерами на python).
Cтатьи
Статей про регрессионный анализ в DataScience очень много, обращаю внимание на некоторые весьма полезные из них.
Серия статей «Python, корреляция и регрессия», охватывающая весь процесс регрессионного анализа:
-
первичная обработка данных, визуализация и корреляционный анализ;
-
регрессия;
-
теория матриц в регрессионном анализе, проверка адекватности, мультиколлинеарность;
-
прогнозирование с помощью регрессионных моделей.
Очень хороший обзор «Интерпретация summary из statsmodels для линейной регрессии». В этой статье даны очень полезные ссылки:
-
Statistical Models
-
Interpreting Linear Regression Through statsmodels .summary()
Статья «Регрессионные модели в Python».
Основные предпосылки (гипотезы) регрессионного анализа
Очень кратко — об этом написано тысячи страниц в учебниках — но все же вспомним некоторые основы теории.
Проверка исходных предпосылок является очень важным моментом при статистическом анализе регрессионной модели. Если мы рассматриваем классическую линейную регрессионную модель вида:
![]()
то основными предпосылками при использовании обычного метода наименьших квадратов (МНК) для оценки ее параметров являются:
-
Среднее значение (математическое ожидание) случайной составляющей равно нулю:
![]()
-
Дисперсия случайной составляющей является постоянной:
![]()
В случае нарушения данного условия мы сталкиваемся с явлением гетероскедастичности.
-
Значения случайной составляющей статистически независимы (некоррелированы) между собой:
![]()
В случае нарушения данного условия мы сталкиваемся с явлением автокорреляции.
-
Условие существования обратной матрицы
![]()
что эквивалентно одному из двух следующих условий:

то есть число наблюдений должно превышать число параметров.
-
Значения случайной составляющей некоррелированы со значениями независимых переменных:
![]()
-
Случайная составляющая имеет нормальный закон распределения (с математическим ожиданием равным нулю — следует из условия 1):
![]()
Более подробно — см.: [3, с.90], [4, с.147], [5, с.122], [6, с.208], [7, с.49], [8, с.68], [9, с.88].
Кроме гетероскедастичности и автокорреляции возможно возникновение и других статистических аномалий — мультиколлинеарности, ложной корреляции и т.д.
Доказано, что оценки параметров, полученные с помощью МНК, обладают наилучшими свойствами (несмещенность, состоятельность, эффективность) при соблюдении ряда условий:
-
выполнение приведенных выше исходных предпосылок регрессионного анализа;
-
число наблюдений на одну независимую переменную должно быть не менее 5-6;
-
должны отсутствовать аномальные значения (выбросы).
Кроме обычного МНК существуют и другие его разновидности (взвешенный МНК, обобщенный МНК), которые применяются при наличии статистических аномалий. Кроме МНК применяются и другие методы оценки параметров моделей. В этом обзоре мы эти вопросы рассматривать не будем.
Алгоритм проведения регрессионного анализа
Алгоритм действий исследователя при построении регрессионной модели (полевые работы мы, по понятным причинам, не рассматриваем — считаем, что исходные данные уже получены):
-
Подготовительный этап — постановка целей и задач исследования.
-
Первичная обработка исходных данных — об этом много написано в учебниках и пособиях по DataScience, сюда могут относится:
-
выявление нерелевантных признаков (признаков, которые не несут полезной информации), нетипичных данных (выбросов), неинформативных признаков (имеющих большое количество одинаковых значений) и работа с ними (удаление/преобразование);
-
выделение категориальных признаков;
-
работа с пропущенными значениями;
-
преобразование признаков-дат в формат datetime и т.д.
-
Визуализация исходных данных — предварительный графический анализ.
-
Дескриптивная (описательная) статистика — расчет выборочных характеристик и предварительные выводы о свойствах исходных данных.
-
Исследование закона распределения исходных данных и, при необходимости, преобразование исходных данных к нормальному закону распределения.
-
Выявление статистически аномальных значений (выбросов), принятие решения об их исключении.
Этапы 4, 5 и 6 могут быть при необходимости объединены.
-
Корреляционный анализ — исследование корреляционных связей между исходными данными; это разведка перед проведением регрессионного анализа.
-
Построение регрессионной модели:
-
выбор моделей;
-
выбор методов;
-
оценка параметров модели.
-
Статистический анализ регрессионной модели:
-
оценка ошибок аппроксимации (error metrics);
-
анализ остатков (проверка нормальности распределения остатков и гипотезы о равенстве нулю среднего значения остатков);
-
проверка адекватности модели;
-
проверка значимости коэффициента детерминации;
-
проверка значимости коэффициентов регрессии;
-
проверка мультиколлинеарности (для множественных регрессионных моделей; вообще мультиколлинеарные переменные выявляются еще на стадии корреляционного анализа);
-
проверка автокорреляции;
-
проверка гетероскедастичности.
Этапы 8 и 9 могут быть при необходимости повторяться несколько раз.
-
Сравнительный анализ нескольких регрессионных моделей, выбор наилучшей (при необходимости).
-
Прогнозирование с помощью регрессионной модели и оценка качества прогноза.
-
Выводы и рекомендации.
Само собой, этот алгоритм не есть истина в последней инстанции — в зависимости от особенностей исходных данных и вида модели могут возникать дополнительные задачи.
Применение пользовательских функций
Далее в обзоре мной будут использованы несколько пользовательских функций для решения разнообразных задач. Все эти функции созданы для облегчения работы и уменьшения размера программного кода. Данные функции загружается из пользовательского модуля my_module__stat.py, который доступен в моем репозитории на GitHub. Лично мне так удобнее работать, хотя каждый исследователь сам формирует себе инструменты по душе — особенно в части визуализации. Желающие могут пользоваться этими функциями, либо создать свои.
Итак, вот перечень данных функций:
-
graph_scatterplot_sns — функция позволяет построить точечную диаграмму средствами seaborn и сохранить график в виде png-файла;
-
graph_hist_boxplot_probplot_XY_sns — функция позволяет визуализировать исходные данные для простой линейной регрессии путем одновременного построения гистограммы, коробчатой диаграммы и вероятностного графика (для переменных X и Y) средствами seaborn и сохранить график в виде png-файла; имеется возможность выбирать, какие графики строить (h — hist, b — boxplot, p — probplot);
-
descriptive_characteristics — функция возвращает в виде DataFrame набор статистических характеристики выборки, их ошибок и доверительных интервалов;
-
detecting_outliers_mad_test — функция выполняет проверку наличия аномальных значений (выбросов) по критерию наибольшего абсолютного отклонения (более подробно — см.[1, с.547]);
-
norm_distr_check — проверка нормальности распределения исходных данных с использованием набора из нескольких статистических тестов;
-
corr_coef_check — функция выполняет расчет коэффициента линейной корреляции Пирсона, проверку его значимости и расчет доверительных интервалов; об этой функции я писал в своей статье.
-
graph_regression_plot_sns — — функция позволяет построить график регрессионной модели.
Ряд пользовательских функций мы создаем в процессе данного обзора (они тоже включены в пользовательский модуль my_module__stat.py):
-
regression_error_metrics — расчет ошибок аппроксимации регрессионной модели;
-
ANOVA_table_regression_model — вывод таблицы дисперсионного анализа регрессионной модели;
-
regression_model_adequacy_check — проверка адекватности регрессионной модели по критерию Фишера;
-
determination_coef_check — проверка значимости коэффициента детерминации по критерию Фишера;
-
regression_coef_check — проверка значимости коэффициентов регрессии по критеирю Стьюдента;
-
Goldfeld_Quandt_test, Breush_Pagan_test, White_test — проверка гетероскедастичности с использование тестов Голдфелда-Квандта, Бриша-Пэгана и Уайта соответственно;
-
regression_pair_predict — функция для прогнозирования с помощью парной регрессионной модели: рассчитывает прогнозируемое значение переменной Y по заданной модели, а также доверительные интервалы среднего и индивидуального значения для полученного прогнозируемого значения Y;
-
graph_regression_pair_predict_plot_sns — прогнозирование: построение графика регрессионной модели (с доверительными интервалами) и вывод расчетной таблицы с данными для заданной области значений X.
ПОСТАНОВКА ЗАДАЧИ
В качестве примера рассмотрим практическую задачу из области экспертизы промышленной безопасности — калибровку ультразвукового прибора для определения прочности бетона.
Итак, суть задачи: при обследовании несущих конструкций зданий и сооружений эксперт определяет прочность бетона с использованием ультразвукового прибора «ПУЛЬСАР-2.1», для которого необходимо предварительно построить градуировочную зависимость. Заключается это в следующем — производятся замеры с фиксацией следующих показателей:
-
X — показания ультразвукового прибора «ПУЛЬСАР-2.1» (м/с)
-
Y — результаты замера прочности бетона (методом отрыва со скалыванием) склерометром ИПС-МГ4.03.
Предполагается, что между показателями X и Y имеется линейная регрессионная зависимость, которая позволит прогнозировать прочность бетона на основании измерений, проведенных прибором «ПУЛЬСАР-2.1».
Были выполнены замеры фактической прочности бетона конструкций для бетонов одного вида с одним типом крупного заполнителя, с единой технологией производства. Для построения были выбраны 14 участков (не менее 12), включая участки, в которых значение косвенного показателя максимальное, минимальное и имеет промежуточные значения.
Настройка заголовков отчета:
# Общий заголовок проекта
Task_Project = 'Калибровка ультразвукового прибора "ПУЛЬСАР-2.1" nдля определения прочности бетона'
# Заголовок, фиксирующий момент времени
AsOfTheDate = ""
# Заголовок раздела проекта
Task_Theme = ""
# Общий заголовок проекта для графиков
Title_String = f"{Task_Project}n{AsOfTheDate}"
# Наименования переменных
Variable_Name_X = "Скорость УЗК (м/с)"
Variable_Name_Y = "Прочность бетона (МПа)"
# Константы
INCH = 25.4 # мм/дюйм
DecPlace = 5 # number of decimal places - число знаков после запятой
# Доверительная вероятность и уровень значимости:
p_level = 0.95
a_level = 1 - p_level Подключение модулей и библиотек:
# Стандартные модули и библиотеки
import os # загрузка модуля для работы с операционной системой
import sys
import platform
print('{:<35}{:^0}'.format("Текущая версия Python: ", platform.python_version()), 'n')
import math
from math import * # подключаем все содержимое модуля math, используем без псевдонимов
import numpy as np
#print ("Текущая версия модуля numpy: ", np.__version__)
print('{:<35}{:^0}'.format("Текущая версия модуля numpy: ", np.__version__))
from numpy import nan
import scipy as sci
print('{:<35}{:^0}'.format("Текущая версия модуля scipy: ", sci.__version__))
import scipy.stats as sps
import pandas as pd
print('{:<35}{:^0}'.format("Текущая версия модуля pandas: ", pd.__version__))
import matplotlib as mpl
print('{:<35}{:^0}'.format("Текущая версия модуля matplotlib: ", mpl.__version__))
import matplotlib.pyplot as plt
import seaborn as sns
print('{:<35}{:^0}'.format("Текущая версия модуля seaborn: ", sns.__version__))
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.graphics.api as smg
import statsmodels.stats.api as sms
from statsmodels.compat import lzip
print('{:<35}{:^0}'.format("Текущая версия модуля statsmodels: ", sm.__version__))
import statistics as stat # module 'statistics' has no attribute '__version__'
import sympy as sym
print('{:<35}{:^0}'.format("Текущая версия модуля sympy: ", sym.__version__))
# Настройки numpy
np.set_printoptions(precision = 4, floatmode='fixed')
# Настройки Pandas
pd.set_option('display.max_colwidth', None) # текст в ячейке отражался полностью вне зависимости от длины
pd.set_option('display.float_format', lambda x: '%.4f' % x)
# Настройки seaborn
sns.set_style("darkgrid")
sns.set_context(context='paper', font_scale=1, rc=None) # 'paper', 'notebook', 'talk', 'poster', None
# Настройки Mathplotlib
f_size = 8 # пользовательская переменная для задания базового размера шрифта
plt.rcParams['figure.titlesize'] = f_size + 12 # шрифт заголовка
plt.rcParams['axes.titlesize'] = f_size + 10 # шрифт заголовка
plt.rcParams['axes.labelsize'] = f_size + 6 # шрифт подписей осей
plt.rcParams['xtick.labelsize'] = f_size + 4 # шрифт подписей меток
plt.rcParams['ytick.labelsize'] = f_size + 4
plt.rcParams['legend.fontsize'] = f_size + 6 # шрифт легенды
# Пользовательские модули и библиотеки
Text1 = os.getcwd() # вывод пути к текущему каталогу
#print(f"Текущий каталог: {Text1}")
sys.path.insert(1, "D:REPOSITORYMyModulePython")
from my_module__stat import *ФОРМИРОВАНИЕ ИСХОДНЫХ ДАННЫХ
Показания ультразвукового прибора «ПУЛЬСАР-2.1» (м/с):
X = np.array([
4416, 4211, 4113, 4110, 4122,
4427, 4535, 4311, 4511, 4475,
3980, 4490, 4007, 4426
])Результаты замера прочности бетона (методом отрыва со скалыванием) прибором ИПС-МГ4.03:
Y = np.array([
34.2, 35.1, 31.5, 30.8, 30.0,
34.0, 35.4, 35.8, 38.0, 37.7,
30.0, 37.8, 31.0, 35.2
])Запишем данные в DataFrame:
calibrarion_df = pd.DataFrame({
'X': X,
'Y': Y})
display(calibrarion_df)
calibrarion_df.info()Сохраняем данные в csv-файл:
calibrarion_df.to_csv(
path_or_buf='data/calibrarion_df.csv',
mode='w+',
sep=';')Cоздаем копию исходной таблицы для работы:
dataset_df = calibrarion_df.copy()ВИЗУАЛИЗАЦИЯ ДАННЫХ
Границы значений переменных (при построении графиков):
(Xmin_graph, Xmax_graph) = (3800, 4800)
(Ymin_graph, Ymax_graph) = (25, 45)# Пользовательская функция
graph_scatterplot_sns(
X, Y,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=Ymin_graph, Ymax=Ymax_graph,
color='orange',
title_figure=Task_Project,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
s=100,
file_name='graph/scatterplot_XY_sns.png')
Существует универсальный набор графиков — гистограмма, коробчатая диаграмма, вероятностный график — которые позволяют исследователю сделать предварительные выводы о свойствах исходных данных.
Так как объем выборки невелик (n=14), строить гистограммы распределения переменных X и Y не имеет смысла, поэтому ограничимся построением коробчатых диаграмм и вероятностных графиков:
# Пользовательская функция
graph_hist_boxplot_probplot_XY_sns(
data_X=X, data_Y=Y,
data_X_min=Xmin_graph, data_X_max=Xmax_graph,
data_Y_min=Ymin_graph, data_Y_max=Ymax_graph,
graph_inclusion='bp', # выбираем для построения виды графиков: b - boxplot, p - probplot)
data_X_label=Variable_Name_X,
data_Y_label=Variable_Name_Y,
title_figure=Task_Project,
file_name='graph/hist_boxplot_probplot_XY_sns.png') 
Для сравнения характера распределений переменных X и Y возможно также построить совмещенную коробчатую диаграмму по стандартизованным данным:
# стандартизуем исходные данные
standardize_df = lambda X: ((X - np.mean(X))/np.std(X))
dataset_df_standardize = dataset_df.copy()
dataset_df_standardize = dataset_df_standardize.apply(standardize_df)
display(dataset_df_standardize)
# построим график
fig, axes = plt.subplots(figsize=(210/INCH, 297/INCH/2))
axes.set_title("Распределение стандартизованных переменных X и Y", fontsize = 16)
sns.boxplot(
data=dataset_df_standardize,
orient='h',
width=0.5,
ax=axes)
plt.show()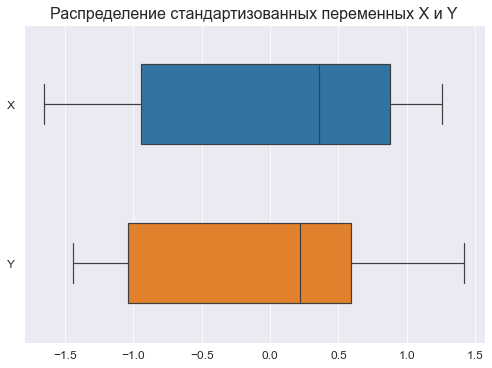
Графический анализ позволяет сделать следующие выводы:
-
Отсутствие выбросов на коробчатых диаграммах свидетельствует об однородности распределения переменных.
-
Смещение медианы вправо на коробчатых диаграммах свидетельствует о левосторонней асимметрии распределения.
ДЕСКРИПТИВНАЯ (ОПИСАТЕЛЬНАЯ СТАТИСТИКА)
Собственно говоря, данный этап требуется проводить далеко не всегда, однако с помощью статистических характеристик выборки мы тоже можем сделать полезные выводы.
Описательная статистика исходных данных средствами библиотеки Pandas — самый простой вариант:
dataset_df.describe()
Описательная статистика исходных данных средствами библиотеки statsmodels — более развернутый вариант, с большим количеством показателей:
from statsmodels.stats.descriptivestats import Description
result = Description(
dataset_df,
stats=["nobs", "missing", "mean", "std_err", "ci", "ci", "std", "iqr", "mad", "coef_var", "range", "max", "min", "skew", "kurtosis", "mode",
"median", "percentiles", "distinct", "top", "freq"],
alpha=a_level,
use_t=True)
display(result.summary())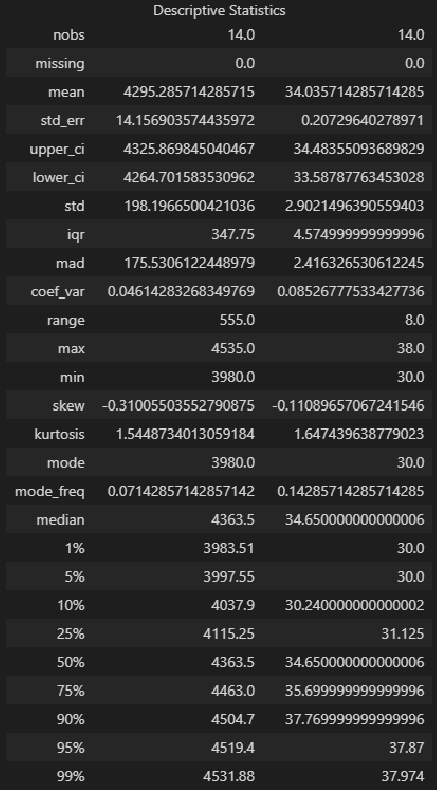
Описательная статистика исходных данных с помощью пользовательской функции descriptive_characteristics:
# Пользовательская функция
descriptive_characteristics(X)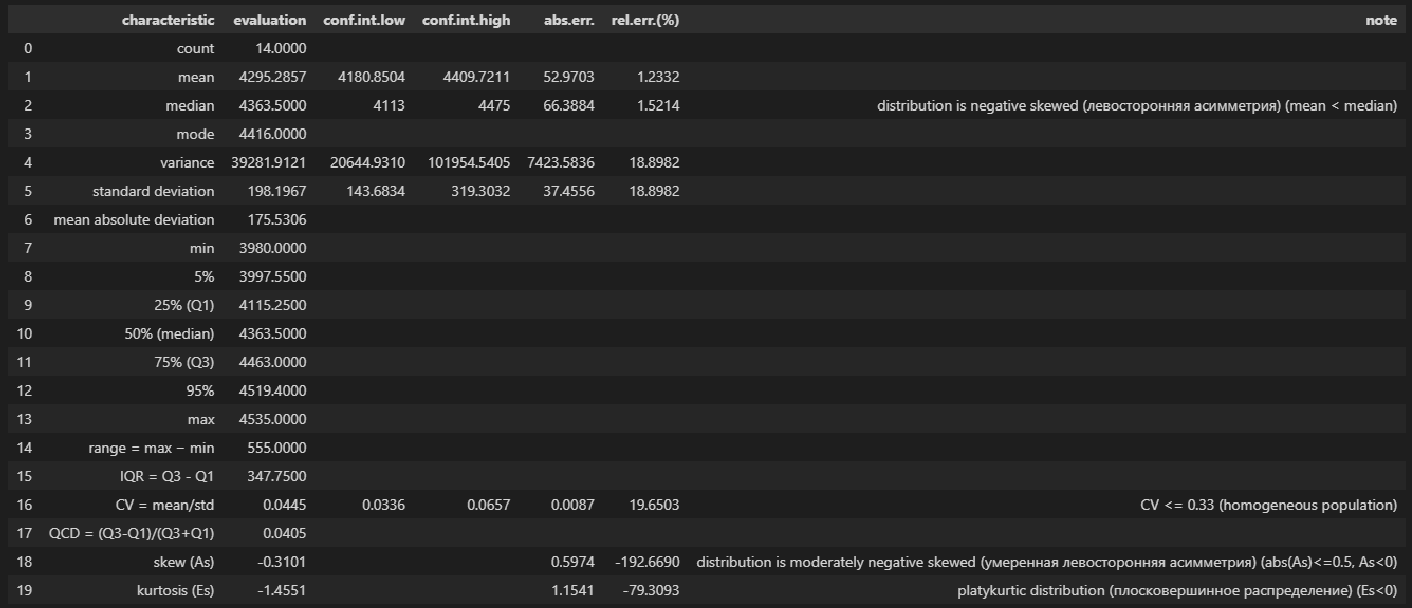
Выводы:
-
Сравнение показателей среднего арифметического (mean) и медианы (median) свидетельствует о левосторонней асимметрии (т.к.mean < median).
-
Значение коэффициента вариации CV = 0.0445 и доверительный интервал для него 0.0336 ≤ CV ≤ 0.0657 свидетельствует об однородности исходных данных (т.к. CV ≤ 0.33).
-
Значение показателя асимметрии skew (As) = -0.3101 свидетельствует об умеренной левосторонней асимметрии распределении (т.к. |As| ≤ 0.5, As < 0).
-
Значение показателя эксцесса kurtosis (Es) = -1.4551 свидетельствует о плосковершинном распределении (platykurtic distribution) (т.к. Es < 0).
# Пользовательская функция
descriptive_characteristics(Y)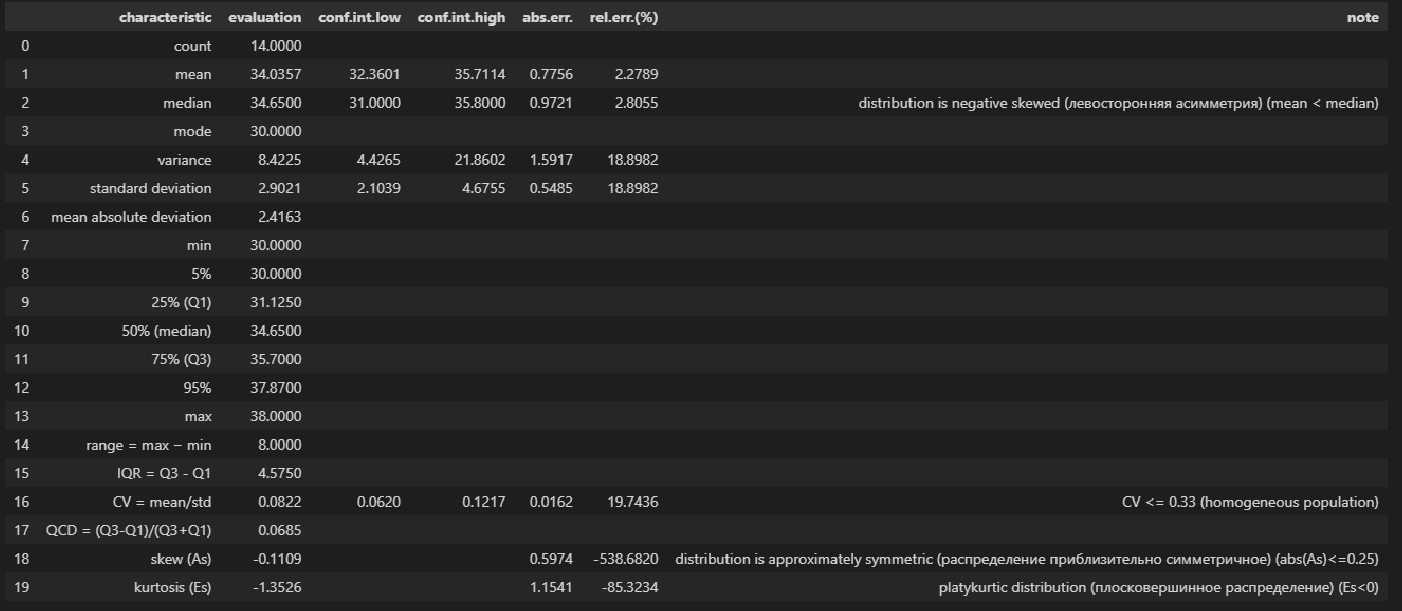
Выводы:
-
Сравнение показателей среднего арифметического (mean) и медианы (median) свидетельствует о левосторонней асимметрии (т.к.mean < median).
-
Значение коэффициента вариации CV = 0.0822 и доверительный интервал для него 0.06202 ≤ CV ≤ 0.1217 свидетельствует об однородности исходных данных (т.к. CV ≤ 0.33).
-
Значение показателя асимметрии skew (As) = -0.1109 свидетельствует о приблизительно симметричном распределении (т.к. |As| ≤ 0.25).
-
Значение показателя эксцесса kurtosis (Es) = -1.3526 свидетельствует о плосковершинном распределении (platykurtic distribution) (т.к. Es < 0).
ПРОВЕРКА НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ
Для проверки нормальности распределения использована пользовательская функция norm_distr_check, которая объединяет в себе набор стандартных статистических тестов проверки нормальности. Все тесты относятся к стандартному инструментарию Pyton (библиотека scipy, модуль stats), за исключением теста Эппса-Палли (Epps-Pulley test); о том, как реализовать этот тест средствами Pyton я писал в своей статье https://habr.com/ru/post/685582/.
Примечание: для использования функции norm_distr_check в каталог с ipynb-файлом необходимо поместить папку table c файлом Tep_table.csv, который содержит табличные значения статистики критерия Эппса-Палли.
# пользовательская функция
norm_distr_check(X)
# Пользовательская функция
norm_distr_check (Y)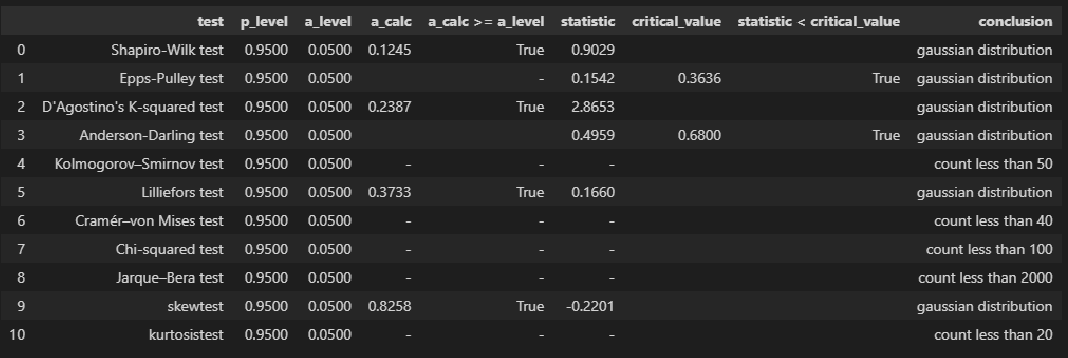
Вывод: большинство статистических тестов позволяют принять гипотезу о нормальности распределения переменных X и Y.
ПРОВЕРКА АНОМАЛЬНЫХ ЗНАЧЕНИЙ (ВЫБРОСОВ)
Статистическую проверку аномальных значений (выбросов) не стоит путать с проверкой выбросов, которая проводится на этапе первичной обработки результатов наблюдений. Последняя проводится с целью отсеять явные ошибочные данные (например, в результате неправильно поставленной запятой величина показателя может увеличиться/уменьшиться на порядок); здесь же мы говорим о статистической проверке данных, которые уже прошли этап первичной обработки.
Имеется довольно много критериев для проверки аномальных значений (подробнее см.[1]); вообще данная процедура довольно неоднозначная:
-
критерии зависят от вида распределения;
-
мало данных о сравнительной мощности этих критериев;
-
даже в случае принятии гипотезы о нормальном распределении в выборке могут быть обнаружены аномальные значения и пр.
Кроме существует дилемма: если какие-то значения в выборке признаны выбросами — стоит или не стоит исследователю исключать их? Ведь каждое значение несет в себе информацию, причем иногда весьма ценную, а сильно отклоняющиеся от основного массива данные (которые не являются выбросами в смысле первичной обработки, но являются статистическим значимыми аномальными значениями) могут кардинально изменить статистический вывод.
В общем, о задаче выявления аномальных значений (выбросов) можно написать отдельно, а пока, в данном разборе, ограничимся проверкой аномальных значений по критерию наибольшего максимального отклонения (см.[1, с.547]) с помощью пользовательской функции detecting_outliers_mad_test. Данные функция возвращает DataFrame, которые включает список аномальных значений со следующими признаками:
-
value — проверяемое значение из выборки;
-
mad_calc и mad_table — расчетное и табличное значение статистики критерия;
-
outlier_conclusion — вывод (выброс или нет).
Обращаю внимание, что критерий наибольшего максимального отклонения можно использовать только для нормально распределенных данных.
# пользовательская функция
print("Проверка наличия выбросов переменной X:n")
result = detecting_outliers_mad_test(X)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])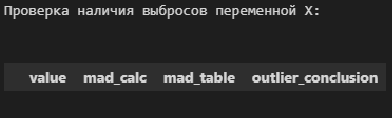
# пользовательская функция
print("Проверка наличия выбросов переменной Y:n")
result = detecting_outliers_mad_test(Y)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])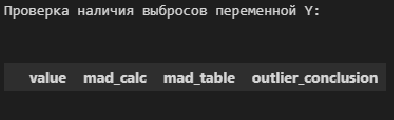
Вывод: в случае обеих переменных X и Y список пуст, следовательно, аномальных значений (выбросов) не выявлено.
КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Корреляционный анализ — это разведка перед построением регрессионной модели.
Выполним расчет коэффициента линейной корреляции Пирсона, проверку его значимости и построение доверительных интервалов с помощью пользовательской функции corr_coef_check (про эту функцию более подробно написано в моей статье https://habr.com/ru/post/683442/):
# пользовательская функция
display(corr_coef_check(X, Y, scale='Evans'))
Выводы:
-
Значение коэффициента корреляции coef_value = 0.8900 свидетельствует о весьма сильной корреляционной связи (по шкале Эванса).
-
Коэффициент корреляции значим по критерию Стьюдента: t_calc ≥ t_table, a_calc ≤ a_level.
-
Доверительный интервал для коэффициента корреляции: 0.6621 ≤ coef_value ≤ 0.9625.
РЕГРЕССИОННЫЙ АНАЛИЗ
Предварительная визуализация
python позволяет выполнить предварительную визуализацию, например, с помощью функции jointplot библиотеки seaborn:
fig = plt.figure(figsize=(297/INCH, 210/INCH))
axes = sns.jointplot(
x=X, y=Y,
kind='reg',
ci=95)
plt.show()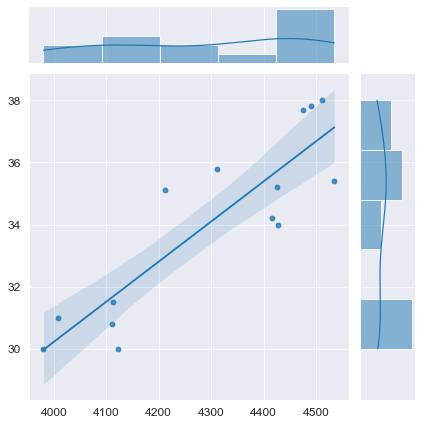
Построение модели
Выполним оценку параметров и анализ простой линейной регрессии (simple linear regression), используя библиотеку statsmodels (https://www.statsmodels.org/) и входящий в нее модуль линейной регрессии Linear Regression (https://www.statsmodels.org/stable/regression.html).
Данный модуль включает в себя классы, реализующие различные методы оценки параметров моделей линейной регрессии, в том числе:
-
класс OLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.OLS.html#statsmodels.regression.linear_model.OLS) — Ordinary Least Squares (обычный метод наименьших квадратов).
-
класс WLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.WLS.html#statsmodels.regression.linear_model.WLS) — Weighted Least Squares (метод взвешенных наименьших квадратов) (https://en.wikipedia.org/wiki/Weighted_least_squares), применяется, если имеет место гетероскедастичность данных (https://ru.wikipedia.org/wiki/Гетероскедастичность).
-
класс GLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.GLS.html#statsmodels.regression.linear_model.GLS) — Generalized Least Squares (обобщенный метод наименьших квадратов) (https://en.wikipedia.org/wiki/Generalized_least_squares), применяется, если существует определенная степень корреляции между остатками в модели регрессии.
-
класс GLSAR (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.GLSAR.html#statsmodels.regression.linear_model.GLSAR) — Generalized Least Squares with AR covariance structure (обобщенный метод наименьших квадратов, ковариационная структура с автокорреляцией — экспериментальный метод)
-
класс RecurciveLS (https://www.statsmodels.org/stable/examples/notebooks/generated/recursive_ls.html) — Recursive least squares (рекурсивный метод наименьших квадратов) (https://en.wikipedia.org/wiki/Recursive_least_squares_filter)
-
классы RollingOLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.rolling.RollingOLS.html#statsmodels.regression.rolling.RollingOLS) и RollingWLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.rolling.RollingWLS.html#statsmodels.regression.rolling.RollingWLS) — скользящая регрессия (https://www.statsmodels.org/stable/examples/notebooks/generated/rolling_ls.html, https://help.fsight.ru/ru/mergedProjects/lib/01_regression_models/rolling_regression.htm)
и т.д.
Так как исходные данные подчиняются нормальному закону распределения и аномальные значения (выбросы) отсутствуют, воспользуемся для оценки параметров обычным методом наименьших квадратов (класс OLS):
model_linear_ols = smf.ols(formula='Y ~ X', data=dataset_df)
result_linear_ols = model_linear_ols.fit()
print(result_linear_ols.summary())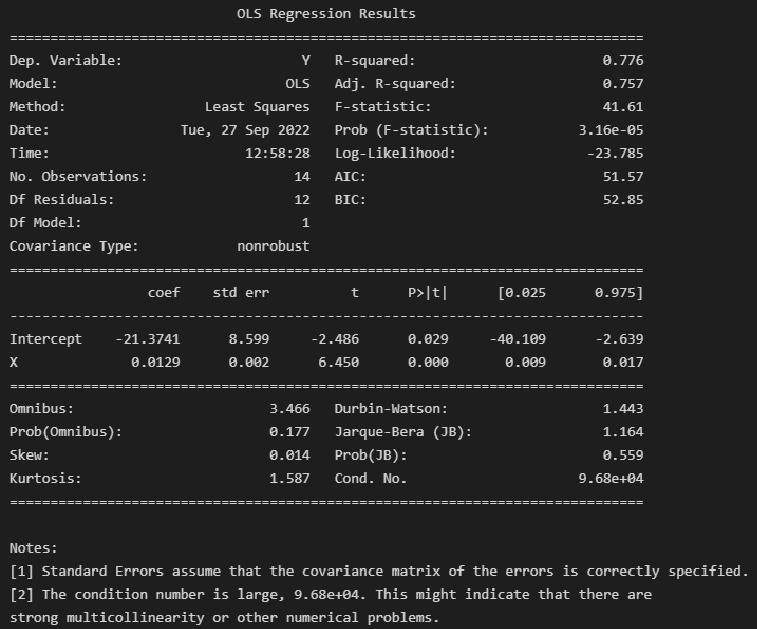
Альтернативная форма выдачи результатов:
print(result_linear_ols.summary2())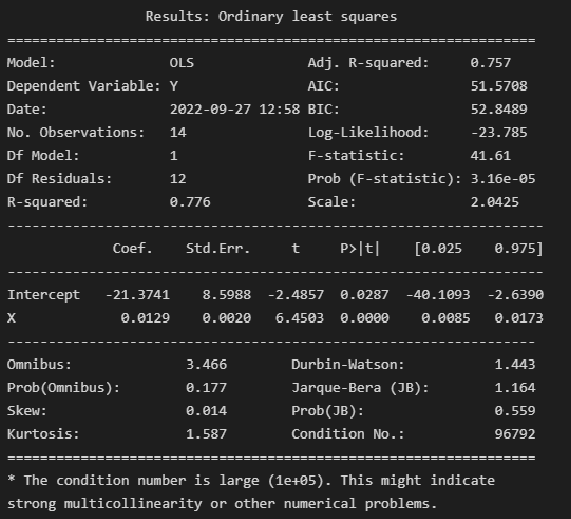
Результаты построения модели мы получаем как класс statsmodels.regression.linear_model.RegressionResults (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.html#statsmodels.regression.linear_model.RegressionResults).
Экспресс-выводы, которые мы можем сразу сделать из результатов построения модели:
-
Коэффициенты регрессии модели Y = b0 + b1∙X:
-
Intercept = b0 = -21.3741
-
b1 = 0.0129
-
-
Коэффициент детерминации R-squared = 0.776, его скорректированная оценка Adj. R-squared = 0.757 — это означает, что регрессионная модуль объясняет 75.75% вариации переменной Y.
-
Проверка значимости коэффициента детерминации:
-
расчетное значение статистики критерия Фишера: F-statistic = 41.61
-
расчетный уровень значимости Prob (F-statistic) = 3.16e-05
-
так как значение Prob (F-statistic) < 0.05, то нулевая гипотеза R-squared = 0 НЕ ПРИНИМАЕТСЯ, т.е. коэффициент детерминации ЗНАЧИМ
-
-
Проверка значимости коэффициентов регрессии:
-
расчетный уровень значимости P>|t| не превышает 0.05 — это означает, что оба коэффициента регрессии значимы
-
об этом же свидетельствует то, что доверительный интервал для обоих коэффициентов регрессии ([0.025; 0.975]) не включает в себя точку 0
Также в таблице результатов содержится прочая информация по коэффициентам регрессии: стандартная ошибка Std.Err. расчетное значение статистики критерия Стьюдента t для проверки гипотезы о значимости.
-
-
Анализ остатков модели:
-
Тест Omnibus — про этот тест подробно написано в https://en.wikipedia.org/wiki/Omnibus_test, https://medium.com/swlh/interpreting-linear-regression-through-statsmodels-summary-4796d359035a, http://work.thaslwanter.at/Stats/html/statsModels.html.
Расчетное значение статистики критерия Omnibus = 3.466 — по сути расчетное значение F-критерия (см. https://en.wikipedia.org/wiki/Omnibus_test).
Prob(Omnibus) = 0.177 — показывает вероятность нормального распределения остатков (значение 1 указывает на совершенно нормальное распределение).
Учитывая, что в дальнейшем мы проверим нормальность распределения остатков по совокупности различных тестов, в том числе с достаточно высокой мощностью, и все тесты позволят принять гипотезу о нормальном распределении — в данном случае к тесту Omnibus возникают вопросы. С этим тестом нужно разбираться отдельно.
-
Skew = 0.014 и Kurtosis = 1.587 — показатели асимметрии и эксцесса остатков свидетельствуют, что распределение остатков практически симметричное, островершинное.
-
проверка нормальности распределения остатков по критерию Харке-Бера: расчетное значение статистики критерия Jarque-Bera (JB) = 1.164 и расчетный уровень значимости Prob(JB) = 0.559. К данным результатам также возникают вопросы, особенно, если учесть, что критерий Харке-Бера является асимптотическим, расчетное значение имеет распределение хи-квадрат, поэтому данный критерий рекомендуют применять только для больших выборок (см. https://en.wikipedia.org/wiki/Jarque–Bera_test). Проверку нормальности распределения остатков модели лучше проводить с использованием набора стандартных статистических тестов python (см. далее).
-
-
Проверка автокорреляции по критерию Дарбина-Уотсона: Durbin-Watson = 1.443.
Мы не будем здесь разбирать данный критерий, так как явление автокорреляции больше характерно для данных, выражаемых в виде временных рядов. Однако, для грубой оценки считается, что при расчетном значении статистики криетрия Дарбина=Уотсона а интервале [1; 2] автокорреляция отсутствует (см.https://en.wikipedia.org/wiki/Durbin–Watson_statistic).
Более подробно про критерий Дарбина-Уотсона — см. [1, с.659].
Прочая информация, которую можно извлечь из результатов построения модели:
-
Covariance Type — тип ковариации, подробнее см. https://habr.com/ru/post/681218/, https://towardsdatascience.com/simple-explanation-of-statsmodel-linear-regression-model-summary-35961919868b#:~:text=Covariance type is typically nonrobust,with respect to each other.
-
Scale — масштабный коэффициент для ковариационной матрицы (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.scale.html#statsmodels.regression.linear_model.RegressionResults.scale), равен величине Mean squared error (MSE) (cреднеквадратической ошибке), об подробнее см. далее, в разделе про ошибки аппроксимации моделей.
-
Показатели сравнения качества различных моделей:
-
Log-Likelihood — логарифмическая функция правдоподобия, подробнее см. https://en.wikipedia.org/wiki/Likelihood_function#Log-likelihood, https://habr.com/ru/post/433804/
-
AIC — информационный критерий Акаике (Akaike information criterion), подробнее см. https://en.wikipedia.org/wiki/Akaike_information_criterion
-
BIC — информационный критерий Байеса (Bayesian information criterion), подробнее см. https://en.wikipedia.org/wiki/Bayesian_information_criterion
В данной статье мы эти показатели рассматривать не будем, так как задача выбора одной модели из нескольких перед нами не стоит.
-
-
Число обусловленности Cond. No = 96792 используется для проверки мультиколлинеарности (считается, что мультиколлинеарность есть, если значение Cond. No > 30) (см. http://work.thaslwanter.at/Stats/html/statsModels.html). В нашем случае парной регрессионной модели о мультиколлинеарности речь не идет.
Далее будем извлекать данные из стандартного набора выдачи результатов и анализировать их более подробно. Последующие этапы вовсе не обязательно проводить в полном объеме при решении задач, но здесь мы рассмотрим их подробно.
Параметры и уравнение регрессионной модели
Извлечем параметры полученной модели — как свойство params модели:
print('Параметры модели: n', result_linear_ols.params, type(result_linear_ols.params))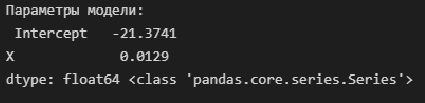
Имея параметры модели, можем формализовать уравнение модели Y = b0 + b1*X:
b0 = result_linear_ols.params['Intercept']
b1 = result_linear_ols.params['X']
Y_calc = lambda x: b0 + b1*xГрафик регрессионной модели
Для построения графиков регрессионных моделей можно воспользоваться стандартными возможностями библиотек statsmodels, seaborn, либо создать пользовательскую функцию — на усмотрение исследователя:
1. Построение графиков регрессионных моделей с использованием библиотеки statsmodels
С помощью функции statsmodels.graphics.plot_fit (https://www.statsmodels.org/stable/generated/statsmodels.graphics.regressionplots.plot_fit.html#statsmodels.graphics.regressionplots.plot_fit) — отображается график Y and Fitted vs.X (фактические и расчетные значения Y с доверительным интервалом для каждого значения Y):
fig, ax = plt.subplots(figsize=(297/INCH, 210/INCH))
fig = sm.graphics.plot_fit(
result_linear_ols, 'X',
vlines=True, # это параметр отвечает за отображение доверительных интервалов для Y
ax=ax)
ax.set_ylabel(Variable_Name_Y)
ax.set_xlabel(Variable_Name_X)
ax.set_title(Task_Project)
plt.show()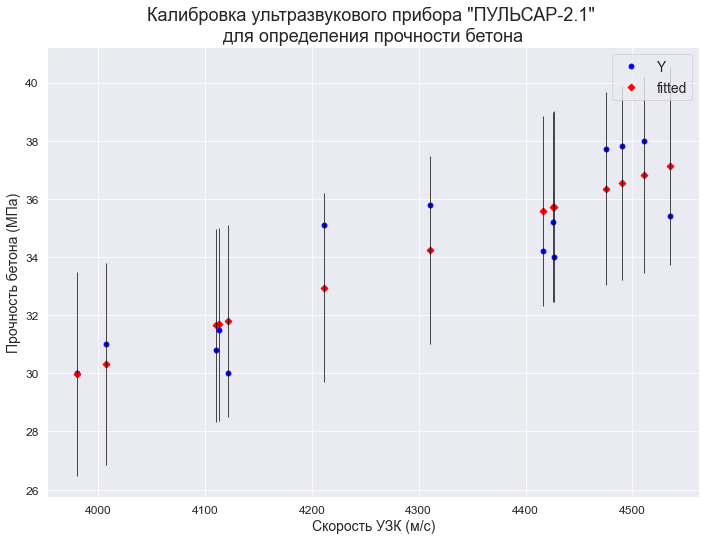
С помощью функции statsmodels.graphics.plot_regress_exog (https://www.statsmodels.org/stable/generated/statsmodels.graphics.regressionplots.plot_regress_exog.html#statsmodels.graphics.regressionplots.plot_regress_exog) — отображается область 2х2, которая содержит:
-
предыдущий график Y and Fitted vs.X;
-
график остатков Residuals versus X;
-
график Partial regression plot — график частичной регрессии, пытается показать эффект добавления другой переменной в модель, которая уже имеет одну или несколько независимых переменных (более подробно см. https://en.wikipedia.org/wiki/Partial_regression_plot);
-
график CCPR Plot (Component-Component plus Residual Plot) — еще один способ оценить влияние одной независимой переменной на переменную отклика, принимая во внимание влияние других независимых переменных (более подробно — см. https://towardsdatascience.com/calculating-price-elasticity-of-demand-statistical-modeling-with-python-6adb2fa7824d, https://www.kirenz.com/post/2021-11-14-linear-regression-diagnostics-in-python/linear-regression-diagnostics-in-python/).
fig = plt.figure(figsize=(297/INCH, 210/INCH))
sm.graphics.plot_regress_exog(result_linear_ols, 'X', fig=fig)
plt.show()
2. Построение графиков регрессионных моделей с использованием библиотеки seaborn
Воспользуемся модулем regplot библиотеки seaborn (https://seaborn.pydata.org/generated/seaborn.regplot.html). Данный модуль позволяет визуализировать различные виды регрессии:
-
линейную
-
полиномиальную
-
логистическую
-
взвешенную локальную регрессию (LOWESS — Locally Weighted Scatterplot Smoothing) (см. http://www.machinelearning.ru/wiki/index.php?title=Алгоритм_LOWESS, https://www.statsmodels.org/stable/generated/statsmodels.nonparametric.smoothers_lowess.lowess.html)
Более подробно про модуль regplot можно прочитать в статье: https://pyprog.pro/sns/sns_8_regression_models.html.
Есть более совершенный модуль lmplot (https://seaborn.pydata.org/generated/seaborn.lmplot.html), который объединяет в себе regplot и FacetGrid, но мы его здесь рассматривать не будем.
# создание рисунка (Figure) и области рисования (Axes)
fig = plt.figure(figsize=(297/INCH, 420/INCH/1.5))
ax1 = plt.subplot(2,1,1)
ax2 = plt.subplot(2,1,2)
# заголовок рисунка (Figure)
title_figure = Task_Project
fig.suptitle(title_figure, fontsize = 18)
# заголовок области рисования (Axes)
title_axes_1 = 'Линейная регрессионная модель'
ax1.set_title(title_axes_1, fontsize = 16)
# график регрессионной модели
order_mod = 1 # порядок модели
#label_legend_regr_model = 'фактические данные'
sns.regplot(
#data=dataset_df,
x=X, y=Y,
#x_estimator=np.mean,
order=order_mod,
logistic=False,
lowess=False,
robust=False,
logx=False,
ci=95,
scatter_kws={'s': 30, 'color': 'red'},
line_kws={'color': 'blue'},
#label=label_legend_regr_model,
ax=ax1)
ax1.set_ylabel(Variable_Name_Y)
ax1.legend()
# график остатков
title_axes_2 = 'График остатков'
ax2.set_title(title_axes_2, fontsize = 16)
sns.residplot(
#data=dataset_df,
x=X, y=Y,
order=order_mod,
lowess=False,
robust=False,
scatter_kws={'s': 30, 'color': 'darkorange'},
ax=ax2)
ax2.set_xlabel(Variable_Name_X)
plt.show()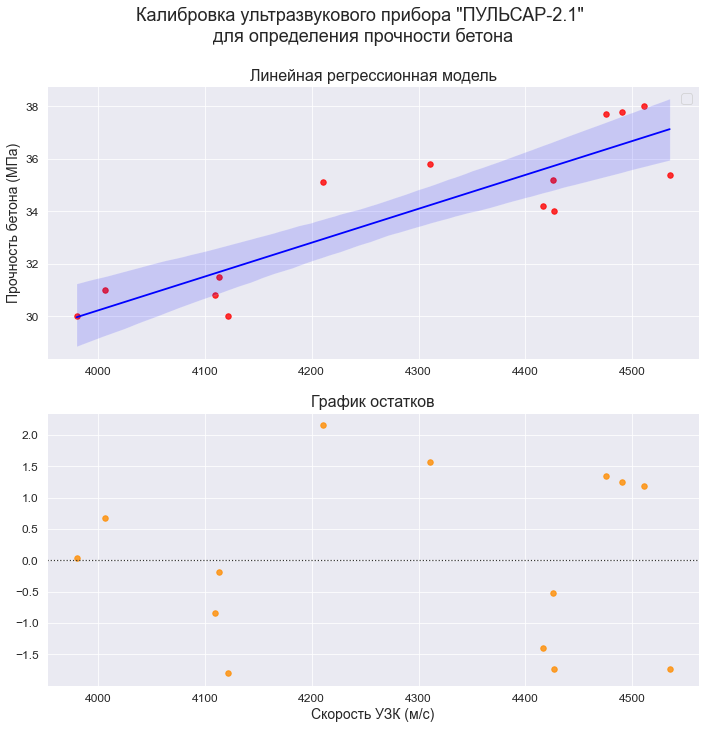
3. Построение графиков регрессионных моделей с помощью пользовательской функции
# Пользовательская функция
graph_regression_plot_sns(
X, Y,
regression_model=Y_calc,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=Ymin_graph, Ymax=Ymax_graph,
title_figure=Task_Project,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X',
s=80,
file_name='graph/regression_plot_lin.png')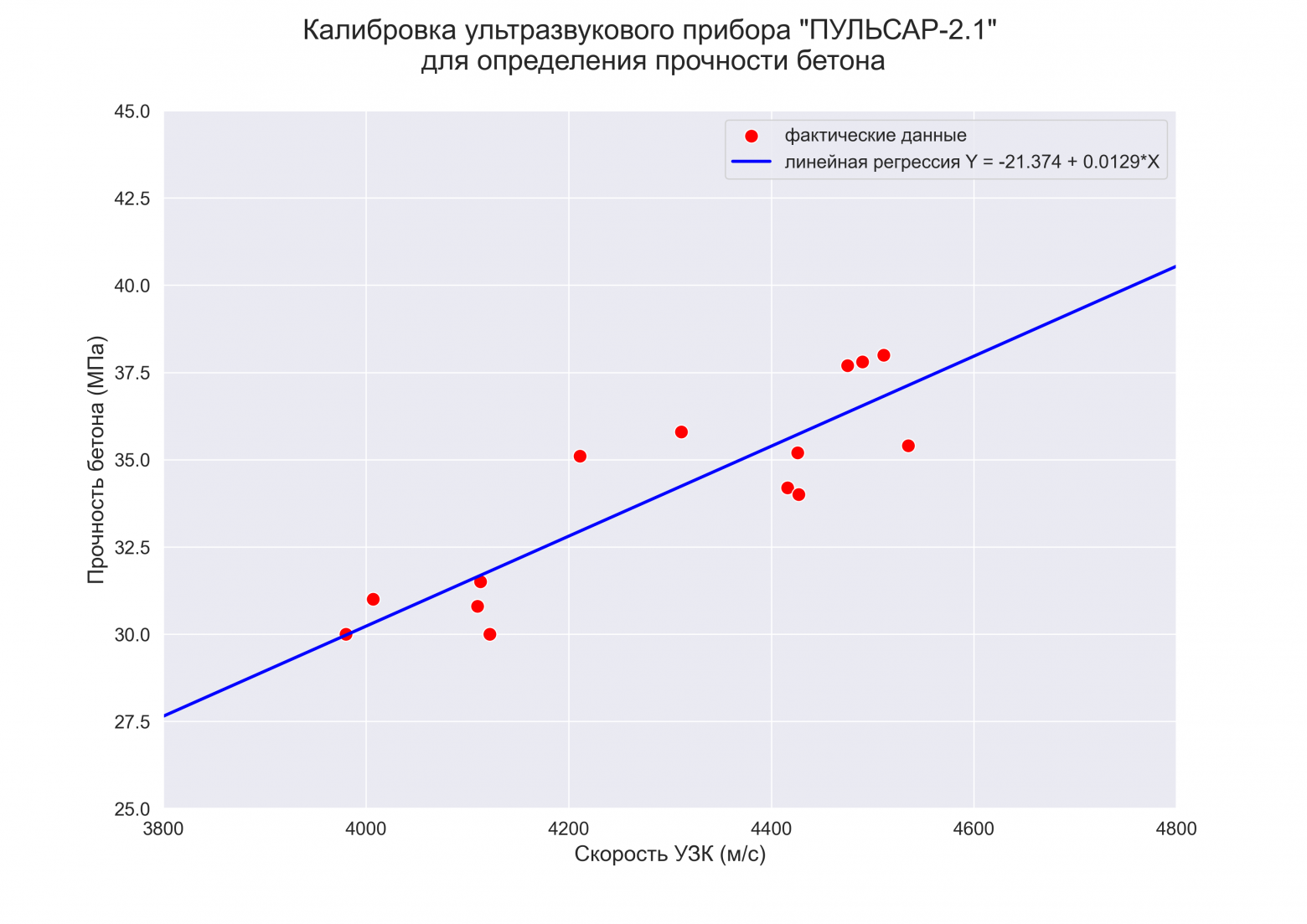
Статистический анализ регрессионной модели
1. Расчет ошибки аппроксимации (Error Metrics)
Ошибки аппроксимации (Error Metrics) позволяют получить общее представление о качестве модели, а также позволяют сравнивать между собой различные модели.
Создадим пользовательскую функцию, которая рассчитывает основные ошибки аппроксимации для заданной модели:
-
Mean squared error (MSE) или Mean squared deviation (MSD) — среднеквадратическая ошибка (https://en.wikipedia.org/wiki/Mean_squared_error):

-
Root mean square error (RMSE) или Root mean square deviation (RMSD) — квадратный корень из MSE (https://en.wikipedia.org/wiki/Root-mean-square_deviation):
![]()
-
Mean absolute error (MAE) — средняя абсолютная ошибка (https://en.wikipedia.org/wiki/Mean_absolute_error):

-
Mean squared prediction error (MSPE) — среднеквадратическая ошибка прогноза (среднеквадратическая ошибка в процентах) (https://en.wikipedia.org/wiki/Mean_squared_prediction_error):
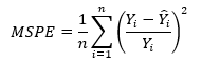
-
Mean absolute percentage error (MAPE) — средняя абсолютная ошибка в процентах (https://en.wikipedia.org/wiki/Mean_absolute_percentage_error):

Про выбор метрики см. также https://machinelearningmastery.ru/how-to-select-the-right-evaluation-metric-for-machine-learning-models-part-2-regression-metrics-d4a1a9ba3d74/.
# Пользовательская функция
def regression_error_metrics(model, model_name=''):
model_fit = model.fit()
Ycalc = model_fit.predict()
n_fit = model_fit.nobs
Y = model.endog
MSE = (1/n_fit) * np.sum((Y-Ycalc)**2)
RMSE = sqrt(MSE)
MAE = (1/n_fit) * np.sum(abs(Y-Ycalc))
MSPE = (1/n_fit) * np.sum(((Y-Ycalc)/Y)**2)
MAPE = (1/n_fit) * np.sum(abs((Y-Ycalc)/Y))
model_error_metrics = {
'MSE': MSE,
'RMSE': RMSE,
'MAE': MAE,
'MSPE': MSPE,
'MAPE': MAPE}
result = pd.DataFrame({
'MSE': MSE,
'RMSE': RMSE,
'MAE': MAE,
'MSPE': "{:.3%}".format(MSPE),
'MAPE': "{:.3%}".format(MAPE)},
index=[model_name])
return model_error_metrics, result
(model_error_metrics, result) = regression_error_metrics(model_linear_ols, model_name='linear_ols')
display(result)
В литературе по прикладной статистике нет единого мнения о допустимом размере относительных ошибок аппроксимации: в одних источниках допустимой считается ошибка 5-7%, в других она может быть увеличена до 8-10%, и даже до 15%.
Вывод: модель хорошо аппроксимирует фактические данные (относительная ошибка аппроксимации MAPE = 3.405% < 10%).
2. Дисперсионный анализ регрессионной модели (ДАРМ)
ДАРМ не входит в стандартную форму выдачи результатов Regression Results, однако я решил написать здесь о нем по двум причинам:
-
Именно анализ дисперсии регрессионной модели, разложение этой дисперсии на составляющие дает фундаментальное представление о сути регрессии, а термины, используемые при ДАРМ, применяются на последующих этапах анализа.
-
С терминами ДАРМ в литературе по прикладной статистике имеется некоторая путаница, в разных источниках они могут именоваться по-разному (см., например, [8, с.52]), поэтому, чтобы двигаться дальше, необходимо определиться с понятиями.
При ДАРМ общую вариацию результативного признака (Y) принято разделять на две составляющие — вариация, обусловленная регрессией и вариация, обусловленная отклонениями от регрессии (остаток), при этом в разных источниках эти термины могут именоваться и обозначаться по-разному, например:
-
Вариация, обусловленная регрессией — может называться Explained sum of squares (ESS), Sum of Squared Regression (SSR) (https://en.wikipedia.org/wiki/Explained_sum_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684), Sum of squared deviations (SSD).
-
Вариация, обусловленная отклонениями от регрессии (остаток) — может называться Residual sum of squares (RSS), Sum of squared residuals (SSR), Squared estimate of errors, Sum of Squared Error (SSE) (https://en.wikipedia.org/wiki/Residual_sum_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684); в отчественной практике также применяется термин остаточная дисперсия.
-
Общая (полная) вариация — может называться Total sum of squares (TSS), Sum of Squared Total (SST) (https://en.wikipedia.org/wiki/Partition_of_sums_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684).
Как видим, путаница знатная:
-
в разных источниках под SSR могут подразумеваться различные показатели;
-
легко перепутать показатели ESS и SSE;
-
в библиотеке statsmodel также есть смешение терминов: для показателя Explained sum of squares используется свойство ess, а для показателя Sum of squared (whitened) residuals — свойство ssr.
Мы будем пользоваться системой обозначений, принятой в большинстве источников — SSR (Sum of Squared Regression), SSE (Sum of Squared Error), SST (Sum of Squared Total). Стандартная таблица ДАРМ в этом случае имеет вид:

Примечания:
-
Здесь приведена таблица ДАРМ для множественной линейной регрессионной модели (МЛРМ), в нашем случае при ПЛРМ мы имеем частный случай p=1.
-
Показатели Fcalc-ad и Fcalc-det — расчетные значения статистики критерия Фишера при проверке адекватности модели и значимости коэффициента детерминации (об этом — см.далее).
Более подробно про дисперсионный анализ регрессионной модели — см.[4, глава 3].
Класс statsmodels.regression.linear_model.RegressionResults позволяет нам получить данные для ANOVA (см. https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.html#statsmodels.regression.linear_model.RegressionResults) как свойства класса:
-
Сумма квадратов, обусловленная регрессией / SSR (Sum of Squared Regression) — свойство ess.
-
Сумма квадратов, обусловленная отклонением от регрессии / SSE (Sum of Squared Error) — свойство ssr.
-
Общая (полная) сумма квадратов / SST (Sum of Squared Total) — свойство centered_tss.
-
Кол-во наблюдений / Number of observations — свойство nobs.
-
Число степеней свободы модели / Model degrees of freedom — равно числу переменных модели (за исключением константы, если она присутствует — свойство df_model.
-
Среднеквадратичная ошибка модели / Mean squared error the model — сумма квадратов, объясненная регрессией, деленная на число степеней свободы регрессии — свойство mse_model.
-
Среднеквадратичная ошибка остатков / Mean squared error of the residuals — сумма квадратов остатков, деленная на остаточные степени свободы — свойство mse_resid.
-
Общая среднеквадратичная ошибка / Total mean squared error — общая сумма квадратов, деленная на количество наблюдений — свойство mse_total.
Также имеется модуль statsmodels.stats.anova.anova_lm, который позволяет получить результаты ДАРМ (нескольких типов — 1, 2, 3):
# тип 1
print('The type of Anova test: 1')
display(sm.stats.anova_lm(result_linear_ols, typ=1))
# тип 2
print('The type of Anova test: 2')
display(sm.stats.anova_lm(result_linear_ols, typ=2))
# тип 3
print('The type of Anova test: 3')
display(sm.stats.anova_lm(result_linear_ols, typ=3))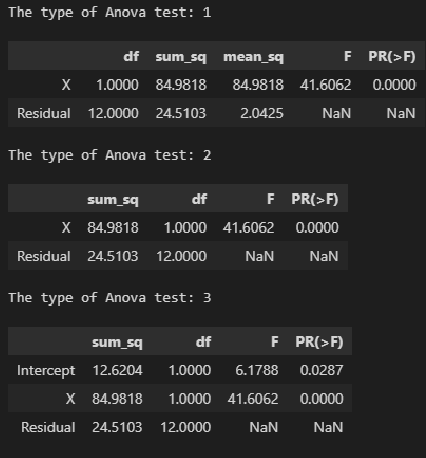
На мой взгляд, форма таблица результатов statsmodels.stats.anova.anova_lm не вполне удобна, поэтому сформируем ее самостоятельно, для чего создадим пользовательскую функцию ANOVA_table_regression_model:
# Пользовательская функция
def ANOVA_table_regression_model(model_fit):
n = int(model_fit.nobs)
p = int(model_fit.df_model)
SSR = model_fit.ess
SSE = model_fit.ssr
SST = model_fit.centered_tss
result = pd.DataFrame({
'sources_of_variation': ('regression (SSR)', 'deviation from regression (SSE)', 'total (SST)'),
'sum_of_squares': (SSR, SSE, SST),
'degrees_of_freedom': (p, n-p-1, n-1)})
result['squared_error'] = result['sum_of_squares'] / result['degrees_of_freedom']
R2 = 1 - result.loc[1, 'sum_of_squares'] / result.loc[2, 'sum_of_squares']
F_calc_adequacy = result.loc[2, 'squared_error'] / result.loc[1, 'squared_error']
F_calc_determ_check = result.loc[0, 'squared_error'] / result.loc[1, 'squared_error']
result['F-ratio'] = (F_calc_determ_check, F_calc_adequacy, '')
return result
result = ANOVA_table_regression_model(result_linear_ols)
display(result)
print(f"R2 = 1 - SSE/SST = {1 - result.loc[1, 'sum_of_squares'] / result.loc[2, 'sum_of_squares']}")
print(f"F_calc_adequacy = MST / MSE = {result.loc[2, 'squared_error'] / result.loc[1, 'squared_error']}")
print(f"F_calc_determ_check = MSR / MSE = {result.loc[0, 'squared_error'] / result.loc[1, 'squared_error']}")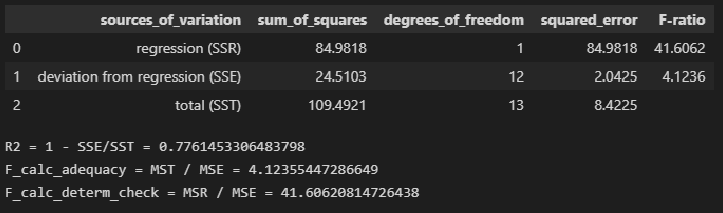
ДАРМ позволяет визуализировать вариацию:
fig, axes = plt.subplots(figsize=(210/INCH, 297/INCH/1.5))
axes.pie(
(result.loc[0, 'sum_of_squares'], result.loc[1, 'sum_of_squares']),
labels=(result.loc[0, 'sources_of_variation'], result.loc[1, 'sources_of_variation']),
autopct='%.1f%%',
startangle=60)
plt.show()
На основании данных ДАРМ мы рассчитали ряд показателей (R2, Fcalc-ad и Fcalc-det), которые будут использоваться в дальнейшем.
3. Анализ остатков (проверка нормальности распределения остатков и гипотезы о равенстве нулю среднего значения остатков)
Проверка нормальности распределения остатков — один их важнейших этапов анализа регрессионной модели. Требование нормальности распределения остатков не требуется для отыскания параметров модели, но необходимо в дальнейшем для проверки статистических гипотез с использованием критериев Фишера и Стьюдента (проверка адекватности модели, значимости коэффициента детерминации, значимости коэффициентов регрессии) и построения доверительных интервалов [5, с.122].
Остатки регрессионной модели:
print('Остатки регрессионной модели:n', result_linear_ols.resid, type(result_linear_ols.resid))
res_Y = np.array(result_linear_ols.resid)statsmodels может выдавать различные преобразованные виды остатков (см. https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.resid_pearson.html, https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.wresid.html).
График остатков:
# Пользовательская функция
graph_scatterplot_sns(
X, res_Y,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=-3.0, Ymax=3.0,
color='red',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=18,
x_label=Variable_Name_X,
y_label='ΔY = Y - Ycalc',
s=75,
file_name='graph/residuals_plot_sns.png')
Проверка нормальности распределения остатков:
# Пользовательская функция
graph_hist_boxplot_probplot_sns(
data=res_Y,
data_min=-2.5, data_max=2.5,
graph_inclusion='bp',
data_label='ΔY = Y - Ycalc',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=16,
file_name='graph/residuals_hist_boxplot_probplot_sns.png') 
norm_distr_check(res_Y)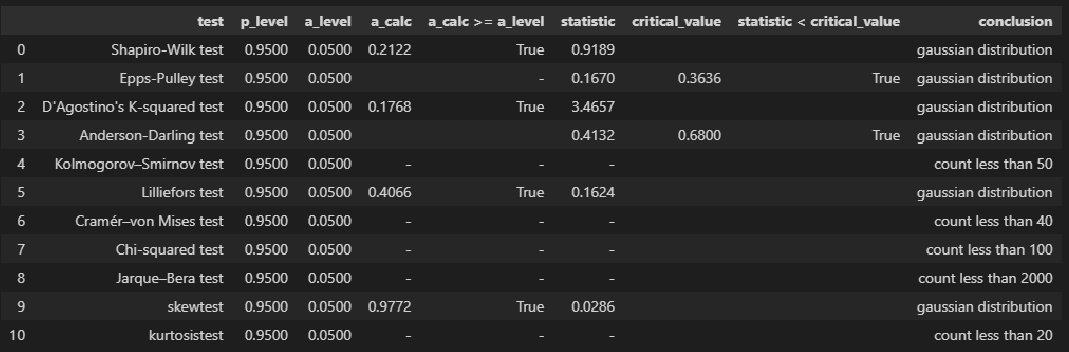
Вывод: большинство статистических тестов позволяют принять гипотезу о нормальности распределения остатков.
Проверка гипотезы о равенстве нулю среднего значения остатков — так как остатки имеют нормальное распределение, воспользуемся критерием Стьюдента (функция scipy.stats.ttest_1samp, https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html):
sps.ttest_1samp(res_Y, popmean=0)![]()
Вывод: так как расчетный уровень значимости превышает заданный (0.05), то нулевая гипотеза о равенстве нулю остатков ПРИНИМАЕТСЯ.
4. Проверка адекватности модели
Суть проверки адекватности регрессионной модели заключается в сравнении полной дисперсии MST и остаточной дисперсии MSE — проверяется гипотеза о равенстве этих дисперсий по критерию Фишера. Если дисперсии различаются значимо, то модель считается адекватной. Более подробно про проверку адекватности регрессионной — см.[1, с.658], [2, с.49], [4, с.154].
Для проверки адекватности регрессионной модели создадим пользовательскую функцию regression_model_adequacy_check:
def regression_model_adequacy_check(
model_fit,
p_level: float=0.95,
model_name=''):
n = int(model_fit.nobs)
p = int(model_fit.df_model) # Число степеней свободы регрессии, равно числу переменных модели (за исключением константы, если она присутствует)
SST = model_fit.centered_tss # SST (Sum of Squared Total)
dfT = n-1
MST = SST / dfT
SSE = model_fit.ssr # SSE (Sum of Squared Error)
dfE = n - p - 1
MSE = SSE / dfE
F_calc = MST / MSE
F_table = sci.stats.f.ppf(p_level, dfT, dfE, loc=0, scale=1)
a_calc = 1 - sci.stats.f.cdf(F_calc, dfT, dfE, loc=0, scale=1)
conclusion_model_adequacy_check = 'adequacy' if F_calc >= F_table else 'adequacy'
# формируем результат
result = pd.DataFrame({
'SST': (SST),
'SSE': (SSE),
'dfT': (dfT),
'dfE': (dfE),
'MST': (MST),
'MSE': (MSE),
'p_level': (p_level),
'a_level': (a_level),
'F_calc': (F_calc),
'F_table': (F_table),
'F_calc >= F_table': (F_calc >= F_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'adequacy_check': (conclusion_model_adequacy_check),
},
index=[model_name]
)
return result
regression_model_adequacy_check(result_linear_ols, p_level=0.95, model_name='linear_ols')
Вывод: модель является АДЕКВАТНОЙ.
5. Коэффициент детерминации и проверка его значимости
Различают несколько видов коэффициента детерминации:
-
Собственно обычный коэффициент детерминации:

Его значение может быть получено как свойство rsquared модели.
-
Скорректированный (adjusted) коэффициент детерминации — используется для того, чтобы была возможность сравнивать модели с разным числом признаков так, чтобы число регрессоров (признаков) не влияло на статистику R2, при его расчете используются несмещённые оценки дисперсий:


Его значение может быть получено как свойство rsquared_adj модели.
-
Обобщённый (extended) коэффициент детерминации — используется для сравнения моделей регрессии со свободным членом и без него, а также для сравнения между собой регрессий, построенных с помощью различных методов: МНК, обобщённого метода наименьших квадратов (ОМНК), условного метода наименьших квадратов (УМНК), обобщённо-условного метода наименьших квадратов (ОУМНК). В данном разборе ПЛРМ рассматривать этот коэффициент мы не будем.
Более подробно с теорией вопроса можно ознакомиться, например: http://www.machinelearning.ru/wiki/index.php?title=Коэффициент_детерминации), а также в [7].
Значения коэффициента детерминации и скорректированного коэффициента детерминации, извлеченные с помощью свойств rsquared и rsquared_adj модели.
print('R2 =', result_linear_ols.rsquared)
print('R2_adj =', result_linear_ols.rsquared_adj)
Значимость коэффициента детерминации можно проверить по критерию Фишера [3, с.201-203; 8, с.83].
Расчетное значение статистики критерия Фишера может быть получено с помощью свойства fvalue модели:
print(f"result_linear_ols.fvalue = {result_linear_ols.fvalue}")![]()
Расчетный уровень значимости при проверке гипотезы по критерию Фишера может быть получено с помощью свойства f_pvalue модели:
print(f"result_linear_ols.f_pvalue = {result_linear_ols.f_pvalue}")![]()
Можно рассчитать уровень значимости самостоятельно (так сказать, для лучшего понимания и общей демонстрации возможностей) — для этого воспользуемся библиотекой scipy, модулем распределения Фишера scipy.stats.f, свойством cdf (функция распределения):
df1 = int(result_linear_ols.df_model)
df2 = int(result_linear_ols.nobs - result_linear_ols.df_model - 1)
F_calc = result_linear_ols.fvalue
a_calc = 1 - sci.stats.f.cdf(F_calc, df1, df2, loc=0, scale=1)
print(a_calc)![]()
Как видим, результаты совпадают.
Табличное значение статистики критерия Фишера получить с помощью Regression Results нельзя. Рассчитаем его самостоятельно — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.f, свойством ppf (процентные точки):
F_table = sci.stats.f.ppf(p_level, df1, df2, loc=0, scale=1)
print(F_table)![]()
Для удобства создадим пользовательскую функцию determination_coef_check для проверки значимости коэффициента детерминации, которая объединяет все вышеперечисленные расчеты:
# Пользовательская функция
def determination_coef_check(
model_fit,
p_level: float=0.95):
a_level = 1 - p_level
R2 = model_fit.rsquared
R2_adj = model_fit.rsquared_adj
n = model_fit.nobs # объем выборки
p = model_fit.df_model # Model degrees of freedom. The number of regressors p. Does not include the constant if one is present.
F_calc = R2 / (1 - R2) * (n-p-1)/p
df1 = int(p)
df2 = int(n-p-1)
F_table = sci.stats.f.ppf(p_level, df1, df2, loc=0, scale=1)
a_calc = 1 - sci.stats.f.cdf(F_calc, df1, df2, loc=0, scale=1)
conclusion_determ_coef_sign = 'significance' if F_calc >= F_table else 'not significance'
# формируем результат
result = pd.DataFrame({
'notation': ('R2'),
'coef_value (R)': (sqrt(R2)),
'coef_value_squared (R2)': (R2),
'p_level': (p_level),
'a_level': (a_level),
'F_calc': (F_calc),
'df1': (df1),
'df2': (df2),
'F_table': (F_table),
'F_calc >= F_table': (F_calc >= F_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'significance_check': (conclusion_determ_coef_sign),
'conf_int_low': (''),
'conf_int_high': ('')
},
index=['Coef. of determination'])
return result
determination_coef_check(
result_linear_ols,
p_level=0.95)
Вывод: коэффициент детерминации ЗНАЧИМ.
6. Коэффициенты регрессии и проверка их значимости
Ранее мы уже извлекли коэффициенты регрессии как параметры модели b0 и b1 (как свойство params модели). Также можно получить их значения, как свойство bse модели:
print(b0, b1)
print(result_linear_ols.bse, type(result_linear_ols.bse))
Значимость коэффициентов регрессии можно проверить по критерию Стьюдента [3, с.203-212; 8, с.78].
Расчетные значения статистики критерия Стьюдента могут быть получены с помощью свойства tvalues модели:
print(f"result_linear_ols.tvalues = n{result_linear_ols.tvalues}")
Расчетные значения уровня значимости при проверке гипотезы по критерию Стьюдента могут быть получены с помощью свойства pvalues модели:
print(f"result_linear_ols.pvalues = n{result_linear_ols.pvalues}")
Доверительные интервалы для коэффициентов регрессии могут быть получены с помощью свойства conf_int модели:
print(result_linear_ols.conf_int(), 'n')
Можно рассчитать уровень значимости самостоятельно (как ранее для критерия Фишера — для лучшего понимания и общей демонстрации возможностей) — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.t, свойством cdf (функция распределения):
t_calc = result_linear_ols.tvalues
df = int(result_linear_ols.nobs - result_linear_ols.df_model - 1)
a_calc = 2*(1-sci.stats.t.cdf(abs(t_calc), df, loc=0, scale=1))
print(a_calc)![]()
Как видим, результаты совпадают.
Табличные значения статистики критерия Стьюдента получить с помощью Regression Results нельзя. Рассчитаем их самостоятельно — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.t, свойством ppf (процентные точки):
t_table = sci.stats.t.ppf((1 + p_level)/2 , df)
print(t_table)![]()
Для удобства создадим пользовательскую функцию regression_coef_check для проверки значимости коэффициентов регрессии, которая объединяет все вышеперечисленные расчеты:
def regression_coef_check(
model_fit,
notation_coef: list='',
p_level: float=0.95):
a_level = 1 - p_level
# параметры модели (коэффициенты регрессии)
model_params = model_fit.params
# стандартные ошибки коэффициентов регрессии
model_bse = model_fit.bse
# проверка гипотезы о значимости регрессии
t_calc = abs(model_params) / model_bse
n = model_fit.nobs # объем выборки
p = model_fit.df_model # Model degrees of freedom. The number of regressors p. Does not include the constant if one is present.
df = int(n - p - 1)
t_table = sci.stats.t.ppf((1 + p_level)/2 , df)
a_calc = 2*(1-sci.stats.t.cdf(t_calc, df, loc=0, scale=1))
conclusion_ = ['significance' if elem else 'not significance' for elem in (t_calc >= t_table).values]
# доверительный интервал коэффициента регрессии
conf_int_low = model_params - t_table*model_bse
conf_int_high = model_params + t_table*model_bse
# формируем результат
result = pd.DataFrame({
'notation': (notation_coef),
'coef_value': (model_params),
'std_err': (model_bse),
'p_level': (p_level),
'a_level': (a_level),
't_calc': (t_calc),
'df': (df),
't_table': (t_table),
't_calc >= t_table': (t_calc >= t_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'significance_check': (conclusion_),
'conf_int_low': (conf_int_low),
'conf_int_high': (conf_int_high),
})
return result
regression_coef_check(
result_linear_ols,
notation_coef=['b0', 'b1'],
p_level=0.95)
Вывод: коэффициенты регрессии b0 и b1 ЗНАЧИМЫ.
7. Проверка гетероскедастичности
Для проверка гетероскедастичности statsmodels предлагает нам следующие инструменты:
-
тест Голдфелда-Квандта (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_goldfeldquandt.html#statsmodels.stats.diagnostic.het_goldfeldquandt) — теорию см. [8, с.178], также https://ru.wikipedia.org/wiki/Тест_Голдфелда_—_Куандта.
-
тест Бриша-Пэгана (Breush-Pagan test) (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_breuschpagan.html#statsmodels.stats.diagnostic.het_breuschpagan) — теорию см.[8, с.179], также https://en.wikipedia.org/wiki/Breusch–Pagan_test.
-
тест Уайта (White test) (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_white.html#statsmodels.stats.diagnostic.het_white) — теорию см.[8, с.177], а также https://ru.wikipedia.org/wiki/Тест_Уайта.
Тест Голдфелда-Квандта (Goldfeld–Quandt test)
# тест Голдфелда-Квандта (Goldfeld–Quandt test)
test = sms.het_goldfeldquandt(result_linear_ols.resid, result_linear_ols.model.exog)
test_result = lzip(['F_calc', 'p_calc'], test) # распаковка результатов теста
# расчетное значение статистики F-критерия
F_calc_tuple = test_result[0]
F_calc = F_calc_tuple[1]
print(f"Расчетное значение статистики F-критерия: F_calc = {round(F_calc, DecPlace)}")
# расчетный уровень значимости
p_calc_tuple = test_result[1]
p_calc = p_calc_tuple[1]
print(f"Расчетное значение доверительной вероятности: p_calc = {round(p_calc, DecPlace)}")
#a_calc = 1 - p_value
#print(f"Расчетное значение уровня значимости: a_calc = 1 - p_value = {round(a_calc, DecPlace)}")
# вывод
if p_calc < a_level:
conclusion_GQ_test = f"Так как p_calc = {round(p_calc, DecPlace)} < a_level = {round(a_level, DecPlace)}" +
", то дисперсии в подвыборках отличаются значимо, т.е. гипотеза о наличии гетероскедастичности ПРИНИМАЕТСЯ"
else:
conclusion_GQ_test = f"Так как p_calc = {round(p_calc, DecPlace)} >= a_level = {round(a_level, DecPlace)}" +
", то дисперсии в подвыборках отличаются незначимо, т.е. гипотеза о наличии гетероскедастичности ОТВЕРГАЕТСЯ"
print(conclusion_GQ_test)
Для удобства создадим пользовательскую функцию Goldfeld_Quandt_test:
def Goldfeld_Quandt_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_goldfeldquandt(model_fit.resid, model_fit.model.exog)
test_result = lzip(['F_statistic', 'p_calc'], test) # распаковка результатов теста
# расчетное значение статистики F-критерия
F_calc_tuple = test_result[0]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости
p_calc_tuple = test_result[1]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('Goldfeld–Quandt test'),
'p_level': (p_level),
'a_level': (a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
Goldfeld_Quandt_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Тест Бриша-Пэгана (Breush-Pagan test)
# тест Бриша-Пэгана (Breush-Pagan test)
name = ["Lagrange multiplier statistic", "p-value", "f-value", "f p-value"]
test = sms.het_breuschpagan(result_linear_ols.resid, result_linear_ols.model.exog)
lzip(name, test)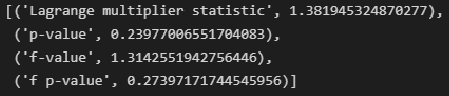
Для удобства создадим пользовательскую функцию Breush_Pagan_test:
def Breush_Pagan_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_breuschpagan(model_fit.resid, model_fit.model.exog)
name = ['Lagrange_multiplier_statistic', 'p_calc_LM', 'F_statistic', 'p_calc']
test_result = lzip(name, test) # распаковка результатов теста
# расчетное значение статистики теста множителей Лагранжа
LM_calc_tuple = test_result[0]
Lagrange_multiplier_statistic = LM_calc_tuple[1]
# расчетный уровень значимости статистики теста множителей Лагранжа
p_calc_LM_tuple = test_result[1]
p_calc_LM = p_calc_LM_tuple[1]
# расчетное значение F-статистики гипотезы о том, что дисперсия ошибки не зависит от x
F_calc_tuple = test_result[2]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости F-статистики
p_calc_tuple = test_result[3]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('Breush-Pagan test'),
'p_level': (p_level),
'a_level': (a_level),
'Lagrange_multiplier_statistic': (Lagrange_multiplier_statistic),
'p_calc_LM': (p_calc_LM),
'p_calc_LM < a_level': (p_calc_LM < a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
Breush_Pagan_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Тест Уайта (White test)
# тест Уайта (White test)
name = ["Lagrange multiplier statistic", "p-value", "f-value", "f p-value"]
test = sms.het_white(result_linear_ols.resid, result_linear_ols.model.exog)
lzip(name, test)
Для удобства создадим пользовательскую функцию White_test:
def White_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_white(model_fit.resid, model_fit.model.exog)
name = ['Lagrange_multiplier_statistic', 'p_calc_LM', 'F_statistic', 'p_calc']
test_result = lzip(name, test) # распаковка результатов теста
# расчетное значение статистики теста множителей Лагранжа
LM_calc_tuple = test_result[0]
Lagrange_multiplier_statistic = LM_calc_tuple[1]
# расчетный уровень значимости статистики теста множителей Лагранжа
p_calc_LM_tuple = test_result[1]
p_calc_LM = p_calc_LM_tuple[1]
# расчетное значение F-статистики гипотезы о том, что дисперсия ошибки не зависит от x
F_calc_tuple = test_result[2]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости F-статистики
p_calc_tuple = test_result[3]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('White test'),
'p_level': (p_level),
'a_level': (a_level),
'Lagrange_multiplier_statistic': (Lagrange_multiplier_statistic),
'p_calc_LM': (p_calc_LM),
'p_calc_LM < a_level': (p_calc_LM < a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
White_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Объединим результаты всех тестов гетероскедастичность в один DataFrame:
Goldfeld_Quandt_test_df = Goldfeld_Quandt_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Breush_Pagan_test_df = Breush_Pagan_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
White_test_df = White_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
heteroscedasticity_tests_df = pd.concat([Breush_Pagan_test_df, White_test_df, Goldfeld_Quandt_test_df])
display(heteroscedasticity_tests_df)
Выводы
Итак, мы провели статистический анализ регрессионной модели и установили:
-
исходные данные имеют нормальное распределение;
-
между переменными имеется весьма сильная корреляционная связь;
-
регрессионная модель хорошо аппроксимирует фактические данные;
-
остатки модели имеют нормальное распределение;
-
регрессионная модель адекватна по критерию Фишера;
-
коэффициент детерминации значим по критеию Фишера;
-
коэффициенты регрессии значимы по критерию Стьюдента;
-
гетероскедастичность отсутствует.
Применительно к рассматриваемой задаче выполнять проверку автокорреляции не имеет особого смысла из-за особенностей исходных данных (результаты замеров прочности бетона на разных участках здания).
Про статистический анализ регрессионных моделей с помощью statsmodels— см. еще https://www.statsmodels.org/stable/examples/notebooks/generated/regression_diagnostics.html.
Доверительные интервалы регрессионной модели
Для регрессионных моделей определяют доверительные интервалы двух видов [3, с.184-192; 4, с.172; 8, с.205-209]:
-
Доверительный интервал средних значений переменной Y.
-
Доверительный интервал индивидуальных значений переменной Y.
При этом размер доверительного интервала для индивидуальных значений больше, чем для средних значений.
Доверительные интервалы регрессионных моделей (ДИРМ) могут быть найдены разными способами:
-
непосредственно путем расчетов по формулам (см., например, https://habr.com/ru/post/558158/);
-
с использованием инструментария библиотеки statsmodels (см., например, https://www.stackfinder.ru/questions/17559408/confidence-and-prediction-intervals-with-statsmodels).
Разбререм более подробно способ с использованием библиотеки statsmodels. Прежде всего, с помощью свойства summary_table класса statsmodels.stats.outliers_influence.OLSInfluence (https://www.statsmodels.org/stable/generated/statsmodels.stats.outliers_influence.OLSInfluence.html?highlight=olsinfluence) мы можем получить таблицу данных, содержащую необходимую нам информацию:
-
Dep Var Population — фактические значения переменной Y;
-
Predicted Value — предсказанные значения переменной Y по по регрессионной модели;
-
Std Error Mean Predict — среднеквадратическая ошибка предсказанного среднего;
-
Mean ci 95% low и Mean ci 95% upp — границы доверительного интервала средних значений переменной Y;
-
Predict ci 95% low и Predict ci 95% upp — границы доверительного интервала индивидуальных значений переменной Y;
-
Residual — остатки регрессионной модели;
-
Std Error Residual — среднеквадратическая ошибка остатков;
-
Student Residual — стьюдентизированные остатки (подробнее см. http://statistica.ru/glossary/general/studentizirovannie-ostatki/);
-
Cook’s D — Расстояние Кука (Cook’s distance) — оценивает эффект от удаления одного (рассматриваемого) наблюдения; наблюдение считается выбросом, если Di > 4/n (более подробно — см.https://translated.turbopages.org/proxy_u/en-ru.ru.f584ceb5-63296427-aded8f31-74722d776562/https/en.wikipedia.org/wiki/Cook’s_distance, http://www.machinelearning.ru/wiki/index.php?title=Расстояние_Кука).
from statsmodels.stats.outliers_influence import summary_table
st, data, ss2 = summary_table(result_linear_ols, alpha=0.05)
print(st, 'n', type(st))
В нашем случае критическое значение расстояния Кука равно:
print(f'D_crit = 4/n = {4/result_linear_ols.nobs}')![]()
то есть выбросов, смещающих оценки коэффициентов регрессии, не наблюдается.
Мы получили данные как класс statsmodels.iolib.table.SimpleTable. Свойство data преобразует данные в список. Далее для удобства работы преобразуем данные в DataFrame:
st_data_df = pd.DataFrame(st.data)Будем использовать данный DataFrame в дальнейшем, несколько преобразуем его:
-
изменим наименование столбцов (с цифр на названия показателей из таблицы summary_table)
-
удалим строки с текстовыми значениями
-
изменим индекс
-
добавим новый столбец — значения переменной X
-
отсортируем по возрастанию значений переменной X (это необходимо, чтобы графики границ доверительных интервалов выглядели как линии)
st_df = st_data_df.copy()
# изменим наименования столбцов
str = st_df.iloc[0,0:] + ' ' + st_df.iloc[1,0:]
st_df = st_df.rename(str, axis='columns')
# удалим строки 0, 1
st_df = st_df.drop([0,1])
# изменим индекс
st_df = st_df.set_index(np.arange(0, result_linear_ols.nobs))
# добавим новый столбец - значения переменной X
st_df.insert(1, 'X', X)
# отсортируем по возрастанию значений переменной X
st_df = st_df.sort_values(by='X')
display(st_df)
С помощью полученных данных мы можем построить график регрессионной модели с доверительными интервалами:
# создание рисунка (Figure) и области рисования (Axes)
fig, axes = plt.subplots(figsize=(297/INCH, 210/INCH))
# заголовок рисунка (Figure)
title_figure = Task_Project
fig.suptitle(title_figure, fontsize = 16)
# заголовок области рисования (Axes)
title_axes = 'Линейная регрессионная модель'
axes.set_title(title_axes, fontsize = 14)
# фактические данные
sns.scatterplot(
x=st_df['X'], y=st_df['Dep Var Population'],
label='фактические данные',
s=50,
color='red',
ax=axes)
# график регрессионной модели
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X'
sns.lineplot(
x=st_df['X'], y=st_df['Predicted Value'],
label=label_legend_regr_model,
color='blue',
ax=axes)
# доверительный интервал средних значений переменной Y
Mean_ci_low = st_df['Mean ci 95% low']
plt.plot(
st_df['X'], Mean_ci_low,
color='magenta', linestyle='--', linewidth=1,
label='доверительный интервал средних значений Y')
Mean_ci_upp = st_df['Mean ci 95% upp']
plt.plot(
st_df['X'], Mean_ci_upp,
color='magenta', linestyle='--', linewidth=1)
# доверительный интервал индивидуальных значений переменной Y
Predict_ci_low = st_df['Predict ci 95% low']
plt.plot(
st_df['X'], Predict_ci_low,
color='orange', linestyle='-.', linewidth=2,
label='доверительный интервал индивидуальных значений Y')
Predict_ci_upp = st_df['Predict ci 95% upp']
plt.plot(
st_df['X'], Predict_ci_upp,
color='orange', linestyle='-.', linewidth=2)
axes.set_xlabel(Variable_Name_X)
axes.set_ylabel(Variable_Name_Y)
axes.legend(prop={'size': 12})
plt.show()
Однако, мы получили данные о границах доверительных интервалов регрессионной модели только в пределах области фактических значений переменной X. Как быть, если мы хотим распространить прогноз за пределы этой области?
Прогнозирование
Под прогнозированием мы в данном случае будем понимать определение значений переменной Y и доверительных интервалов для ее средних и индивидуальных значений при заданном X. По сути, нам предстоит построить аналог рассмотренной выше таблицы summary_table, только с другими значениями X, причем эти значения могут выходить за пределы тех значений, которые использовались нами для построения регрессии.
Методика расчета доверительных интервалов регрессионных моделей разобрана в статье «Python, корреляция и регрессия: часть 4» (https://habr.com/ru/post/558158/), всем рекомендую ознакомиться.
Найти прогнозные значения Y не представляет труда, так как ранее мы уже формализовали модель в виде лямбда-функции, а вот для построения доверительных интервалов придется выполнить расчеты по формулам. Для этого создадим пользовательскую функцию regression_pair_predict, которая в случае парной регрессии (pair regression) для заданного значения X возвращает:
-
прогнозируемое по регрессионной модели значение y_calc
-
доверительный интервал [y_calc_mean_ci_low, y_calc_mean_ci_upp] средних значений переменной Y
-
доверительный интервал [y_calc_predict_ci_low, y_calc_predict_ci_upp] индивидуальных значений переменной Y
Алгоритм расчета доверительных интервалов для множественной регрессии (multiple regression) отличается и в данном обзоре не рассматривается (рассмотрим в дальнейшем).
Про прогнозирование с помощью регрессионных моделей — см.также:
-
https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.predict.html?highlight=predict#statsmodels.regression.linear_model.RegressionResults.predict
-
How to Make Predictions Using Regression Model in Statsmodels
-
https://www.statsmodels.org/stable/examples/notebooks/generated/predict.html
def regression_pair_predict(
x_in,
model_fit,
regression_model,
p_level: float=0.95):
a_level = 1 - p_level
X = pd.DataFrame(model_fit.model.exog)[1].values # найти лучшее решение
Y = model_fit.model.endog
# вспомогательные величины
n = int(result_linear_ols.nobs)
SSE = model_fit.ssr # SSE (Sum of Squared Error)
dfE = n - p - 1
MSE = SSE / dfE # остаточная дисперсия
Xmean = np.mean(X)
SST_X = np.sum([(X[i] - Xmean)**2 for i in range(0, n)])
t_table = sci.stats.t.ppf((1 + p_level)/2 , dfE)
S2_y_calc_mean = MSE * (1/n + (x_in - Xmean)**2 / SST_X)
S2_y_calc_predict = MSE * (1 + 1/n + (x_in - Xmean)**2 / SST_X)
# прогнозируемое значение переменной Y
y_calc=regression_model(x_in)
# доверительный интервал средних значений переменной Y
y_calc_mean_ci_low = y_calc - t_table*sqrt(S2_y_calc_mean)
y_calc_mean_ci_upp = y_calc + t_table*sqrt(S2_y_calc_mean)
# доверительный интервал индивидуальных значений переменной Y
y_calc_predict_ci_low = y_calc - t_table*sqrt(S2_y_calc_predict)
y_calc_predict_ci_upp = y_calc + t_table*sqrt(S2_y_calc_predict)
result = y_calc, y_calc_mean_ci_low, y_calc_mean_ci_upp, y_calc_predict_ci_low, y_calc_predict_ci_upp
return resultСравним результаты расчета доверительных интервалов разными способами — с использованием функции regression_pair_predict и средствами statsmodels, для этого сформируем DaraFrame с новыми данными:
regression_pair_predict_df = pd.DataFrame(
[regression_pair_predict(elem, result_linear_ols, regression_model=Y_calc) for elem in st_df['X'].values],
columns=['y_calc', 'y_calc_mean_ci_low', 'y_calc_mean_ci_upp', 'y_calc_predict_ci_low', 'y_calc_predict_ci_upp'])
regression_pair_predict_df.insert(0, 'X', st_df['X'].values)
display(regression_pair_predict_df)
Видим, что результаты расчетов идентичны, следовательно мы можем использовать функцию regression_pair_predict для прогнозирования.
def graph_regression_pair_predict_plot_sns(
model_fit,
regression_model_in,
Xmin=None, Xmax=None, Nx=10,
Ymin_graph=None, Ymax_graph=None,
title_figure=None, title_figure_fontsize=18,
title_axes=None, title_axes_fontsize=16,
x_label=None,
y_label=None,
label_fontsize=14, tick_fontsize=12,
label_legend_regr_model='', label_legend_fontsize=12,
s=50, linewidth_regr_model=2,
graph_size=(297/INCH, 210/INCH),
result_output=True,
file_name=None):
# фактические данные
X = pd.DataFrame(model_fit.model.exog)[1].values # найти лучшее решение
Y = model_fit.model.endog
X = np.array(X)
Y = np.array(Y)
# границы
if not(Xmin) and not(Xmax):
Xmin=min(X)
Xmax=max(X)
Xmin_graph=min(X)*0.99
Xmax_graph=max(X)*1.01
else:
Xmin_graph=Xmin
Xmax_graph=Xmax
if not(Ymin_graph) and not(Ymax_graph):
Ymin_graph=min(Y)*0.99
Ymax_graph=max(Y)*1.01
# формируем DataFrame данных
Xcalc = np.linspace(Xmin, Xmax, num=Nx)
Ycalc = regression_model_in(Xcalc)
result_df = pd.DataFrame(
[regression_pair_predict(elem, model_fit, regression_model=regression_model_in) for elem in Xcalc],
columns=['y_calc', 'y_calc_mean_ci_low', 'y_calc_mean_ci_upp', 'y_calc_predict_ci_low', 'y_calc_predict_ci_upp'])
result_df.insert(0, 'x_calc', Xcalc)
# заголовки графика
fig, axes = plt.subplots(figsize=graph_size)
fig.suptitle(title_figure, fontsize = title_figure_fontsize)
axes.set_title(title_axes, fontsize = title_axes_fontsize)
# фактические данные
sns.scatterplot(
x=X, y=Y,
label='фактические данные',
s=s,
color='red',
ax=axes)
# график регрессионной модели
sns.lineplot(
x=Xcalc, y=Ycalc,
color='blue',
linewidth=linewidth_regr_model,
legend=True,
label=label_legend_regr_model,
ax=axes)
# доверительный интервал средних значений переменной Y
Mean_ci_low = result_df['y_calc_mean_ci_low']
plt.plot(
result_df['x_calc'], Mean_ci_low,
color='magenta', linestyle='--', linewidth=1,
label='доверительный интервал средних значений Y')
Mean_ci_upp = result_df['y_calc_mean_ci_upp']
plt.plot(
result_df['x_calc'], Mean_ci_upp,
color='magenta', linestyle='--', linewidth=1)
# доверительный интервал индивидуальных значений переменной Y
Predict_ci_low = result_df['y_calc_predict_ci_low']
plt.plot(
result_df['x_calc'], Predict_ci_low,
color='orange', linestyle='-.', linewidth=2,
label='доверительный интервал индивидуальных значений Y')
Predict_ci_upp = result_df['y_calc_predict_ci_upp']
plt.plot(
result_df['x_calc'], Predict_ci_upp,
color='orange', linestyle='-.', linewidth=2)
axes.set_xlim(Xmin_graph, Xmax_graph)
axes.set_ylim(Ymin_graph, Ymax_graph)
axes.set_xlabel(x_label, fontsize = label_fontsize)
axes.set_ylabel(y_label, fontsize = label_fontsize)
axes.tick_params(labelsize = tick_fontsize)
#axes.tick_params(labelsize = tick_fontsize)
axes.legend(prop={'size': label_legend_fontsize})
plt.show()
if file_name:
fig.savefig(file_name, orientation = "portrait", dpi = 300)
if result_output:
return result_df
else:
return
graph_regression_pair_predict_plot_sns(
model_fit=result_linear_ols,
regression_model_in=Y_calc,
Xmin=Xmin_graph-300, Xmax=Xmax_graph+200, Nx=25,
Ymin_graph=Ymin_graph-5, Ymax_graph=Ymax_graph+5,
title_figure=Task_Project, title_figure_fontsize=16,
title_axes='Линейная регрессионная модель', title_axes_fontsize=14,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X',
s=50,
result_output=True,
file_name='graph/regression_plot_lin.png')

Выводы и рекомендации
Исследована зависимость показаний ультразвукового прибора «ПУЛЬСАР-2.1» (X) и результатов замера прочности бетона (методом отрыва со скалыванием) склерометром ИПС-МГ4.03 (Y).
Между переменными имеется весьма сильная линейная корреляционная связь. Получена регрессионная модель:
Y = b0 + b1∙X = -21.3741 + 0.0129∙X
Модель хорошо аппроксимирует фактические данные, является адекватной, значимой и может использоваться для предсказания прочности бетона.
Также построен график прогноза с доверительными интервалами.
ИТОГИ
Итак, мы рассмотрели все этапы регрессионного анализа в случае простой линейной регрессии (simple linear regression) с использованием библиотеки statsmodels на конкретном практическом примере; подробно остановились на статистическом анализа модели с проверкой гипотез; также предложен ряд пользовательских функций, облегчающих работу исследователя и уменьшающих размер программного кода.
Конечно, мы разобрали далеко не все вопросы анализа регрессионных моделей и возможности библиотеки statsmodels применительно к simple linear regression, в частности статистики влияния (Influence Statistics), инструмент Leverage, анализ стьюдентизированных остатков и пр. — это темы для отдельных обзоров.
Исходный код находится в моем репозитории на GitHub.
Надеюсь, данный обзор поможет специалистам DataScience в работе.