In computing and computer programming, exception handling is the process of responding to the occurrence of exceptions – anomalous or exceptional conditions requiring special processing – during the execution of a program. In general, an exception breaks the normal flow of execution and executes a pre-registered exception handler; the details of how this is done depend on whether it is a hardware or software exception and how the software exception is implemented. Exception handling, if provided, is facilitated by specialized programming language constructs, hardware mechanisms like interrupts, or operating system (OS) inter-process communication (IPC) facilities like signals. Some exceptions, especially hardware ones, may be handled so gracefully that execution can resume where it was interrupted.
Definition[edit]
The definition of an exception is based on the observation that each procedure has a precondition, a set of circumstances for which it will terminate «normally».[1] An exception handling mechanism allows the procedure to raise an exception[2] if this precondition is violated,[1] for example if the procedure has been called on an abnormal set of arguments. The exception handling mechanism then handles the exception.[3]
The precondition, and the definition of exception, is subjective. The set of «normal» circumstances is defined entirely by the programmer, e.g. the programmer may deem division by zero to be undefined, hence an exception, or devise some behavior such as returning zero or a special «ZERO DIVIDE» value (circumventing the need for exceptions).[4] Common exceptions include an invalid argument (e.g. value is outside of the domain of a function), an unavailable resource (like a missing file, a hard disk error, or out-of-memory errors), or that the routine has detected a normal condition that requires special handling, e.g., attention, end of file.
Exception handling solves the semipredicate problem, in that the mechanism distinguishes normal return values from erroneous ones. In languages without built-in exception handling such as C, routines would need to signal the error in some other way, such as the common return code and errno pattern.[5] Taking a broad view, errors can be considered to be a proper subset of exceptions,[6] and explicit error mechanisms such as errno can be considered (verbose) forms of exception handling.[5] The term «exception» is preferred to «error» because it does not imply that anything is wrong — a condition viewed as an error by one procedure or programmer may not be viewed that way by another. Even the term «exception» may be misleading because its typical connotation of «outlier» indicates that something infrequent or unusual has occurred, when in fact raising the exception may be a normal and usual situation in the program.[7] For example, suppose a lookup function for an associative array throws an exception if the key has no value associated. Depending on context, this «key absent» exception may occur much more often than a successful lookup.[8]
A major influence on the scope and use of exceptions is social pressure, i.e. «examples of use, typically found in core libraries, and code examples in technical books, magazine articles, and online discussion forums, and in an organization’s code standards».[9]
History[edit]
The first hardware exception handling was found in the UNIVAC I from 1951. Arithmetic overflow executed two instructions at address 0, which could transfer control or fix up the result.[10]
Software exception handling developed in the 1960s and 1970s. LISP 1.5 (1958-1961)[11] allowed exceptions to be raised by the ERROR pseudo-function, similarly to errors raised by the interpreter or compiler. Exceptions were caught by the ERRORSET keyword, which returned NIL in case of an error, instead of terminating the program or entering the debugger.[12]
PL/I introduced its own form of exception handling circa 1964, allowing interrupts to be handled with ON units.[13]
MacLisp observed that ERRSET and ERR were used not only for error raising, but for non-local control flow, and thus added two new keywords, CATCH and THROW (June 1972).[14] The cleanup behavior now generally called «finally» was introduced in NIL (New Implementation of LISP) in the mid- to late-1970s as UNWIND-PROTECT.[15] This was then adopted by Common Lisp. Contemporary with this was dynamic-wind in Scheme, which handled exceptions in closures. The first papers on structured exception handling were Goodenough (1975a) and Goodenough (1975b).[16] Exception handling was subsequently widely adopted by many programming languages from the 1980s onward.
Hardware exceptions[edit]
There is no clear consensus as to the exact meaning of an exception with respect to hardware.[17] From the implementation point of view, it is handled identically to an interrupt: the processor halts execution of the current program, looks up the interrupt handler in the interrupt vector table for that exception or interrupt condition, saves state, and switches control.
IEEE 754 floating-point exceptions[edit]
Exception handling in the IEEE 754 floating-point standard refers in general to exceptional conditions and defines an exception as «an event that occurs when an operation on some particular operands has no outcome suitable for every reasonable application. That operation might signal one or more exceptions by invoking the default or, if explicitly requested, a language-defined alternate handling.»
By default, an IEEE 754 exception is resumable and is handled by substituting a predefined value for different exceptions, e.g. infinity for a divide by zero exception, and providing status flags for later checking of whether the exception occurred (see C99 programming language for a typical example of handling of IEEE 754 exceptions). An exception-handling style enabled by the use of status flags involves: first computing an expression using a fast, direct implementation; checking whether it failed by testing status flags; and then, if necessary, calling a slower, more numerically robust, implementation.[18]
The IEEE 754 standard uses the term «trapping» to refer to the calling of a user-supplied exception-handling routine on exceptional conditions, and is an optional feature of the standard. The standard recommends several usage scenarios for this, including the implementation of non-default pre-substitution of a value followed by resumption, to concisely handle removable singularities.[18][19][20]
The default IEEE 754 exception handling behaviour of resumption following pre-substitution of a default value avoids the risks inherent in changing flow of program control on numerical exceptions. For example, the 1996 Cluster spacecraft launch ended in a catastrophic explosion due in part to the Ada exception handling policy of aborting computation on arithmetic error. William Kahan claims the default IEEE 754 exception handling behavior would have prevented this.[19]
Exception support in programming languages[edit]
Software exception handling and the support provided by software tools differs somewhat from what is understood by exception handling in hardware, but similar concepts are involved. In programming language mechanisms for exception handling, the term exception is typically used in a specific sense to denote a data structure storing information about an exceptional condition. One mechanism to transfer control, or raise an exception, is known as a throw. The exception is said to be thrown. Execution is transferred to a «catch».
Programming languages differ substantially in their notion of what an exception is. Contemporary languages can roughly be divided into two groups:[9]
- Languages where exceptions are designed to be used as flow control structures: Ada, Modula-3, ML, OCaml, PL/I, Python, and Ruby fall in this category. For example, Python’s iterators throw StopIteration exceptions to signal that there are no further items produced by the iterator.[21]
- Languages where exceptions are only used to handle abnormal, unpredictable, erroneous situations: C++,[22] Java,[23] C#, Common Lisp, Eiffel, and Modula-2.
PL/I used dynamically scoped exceptions. PL/I exception handling included events that are not errors, e.g., attention, end-of-file, modification of listed variables.[citation needed]
Syntax[edit]
Many computer languages have built-in syntactic support for exceptions and exception handling. This includes ActionScript, Ada, BlitzMax, C++, C#, Clojure, COBOL, D, ECMAScript, Eiffel, Java, ML, Object Pascal (e.g. Delphi, Free Pascal, and the like), PowerBuilder, Objective-C, OCaml, PHP (as of version 5), PL/I, PL/SQL, Prolog, Python, REALbasic, Ruby, Scala, Seed7, Smalltalk, Tcl, Visual Prolog and most .NET languages.
Excluding minor syntactic differences, there are only a couple of exception handling styles in use. In the most popular style, an exception is initiated by a special statement (throw or raise) with an exception object (e.g. with Java or Object Pascal) or a value of a special extendable enumerated type (e.g. with Ada or SML). The scope for exception handlers starts with a marker clause (try or the language’s block starter such as begin) and ends in the start of the first handler clause (catch, except, rescue). Several handler clauses can follow, and each can specify which exception types it handles and what name it uses for the exception object. As a minor variation, some languages use a single handler clause, which deals with the class of the exception internally.
Also common is a related clause (finally or ensure) that is executed whether an exception occurred or not, typically to release resources acquired within the body of the exception-handling block. Notably, C++ does not provide this construct, recommending instead the Resource Acquisition Is Initialization (RAII) technique which frees resources using destructors.[24] According to a 2008 paper by Westley Weimer and George Necula, the syntax of the try…finally blocks in Java is a contributing factor to software defects. When a method needs to handle the acquisition and release of 3–5 resources, programmers are apparently unwilling to nest enough blocks due to readability concerns, even when this would be a correct solution. It is possible to use a single try…finally block even when dealing with multiple resources, but that requires a correct use of sentinel values, which is another common source of bugs for this type of problem.[25]: 8:6–8:7
Python and Ruby also permit a clause (else) that is used in case no exception occurred before the end of the handler’s scope was reached.
In its whole, exception handling code might look like this (in Java-like pseudocode):
try { line = console.readLine(); if (line.length() == 0) { throw new EmptyLineException("The line read from console was empty!"); } console.printLine("Hello %s!" % line); } catch (EmptyLineException e) { console.printLine("Hello!"); } catch (Exception e) { console.printLine("Error: " + e.message()); } else { console.printLine("The program ran successfully."); } finally { console.printLine("The program is now terminating."); }
C does not have try-catch exception handling, but uses return codes for error checking. The setjmp and longjmp standard library functions can be used to implement try-catch handling via macros.[26]
Perl 5 uses die for throw and eval {} if ($@) {} for try-catch. It has CPAN modules that offer try-catch semantics.[27]
Termination and resumption semantics[edit]
When an exception is thrown, the program searches back through the stack of function calls until an exception handler is found. Some languages call for unwinding the stack as this search progresses. That is, if function f, containing a handler H for exception E, calls function g, which in turn calls function h, and an exception E occurs in h, then functions h and g may be terminated, and H in f will handle E. This is said to be termination semantics.
Alternately, the exception handling mechanisms may not unwind the stack on entry[note 1] to an exception handler, giving the exception handler the option to restart the computation, resume or unwind. This allows the program to continue the computation at exactly the same place where the error occurred (for example when a previously missing file has become available) or to implement notifications, logging, queries and fluid variables on top of the exception handling mechanism (as done in Smalltalk). Allowing the computation to resume where it left off is termed resumption semantics.
There are theoretical and design arguments in favor of either decision. C++ standardization discussions in 1989–1991 resulted in a definitive decision to use termination semantics in C++.[28] Bjarne Stroustrup cites a presentation by Jim Mitchell as a key data point:
Jim had used exception handling in half a dozen languages over a period of 20 years and was an early proponent of resumption semantics as one of the main designers and implementers of Xerox’s Cedar/Mesa system. His message was
- “termination is preferred over resumption; this is not a matter of opinion but a matter of years of experience. Resumption is seductive, but not valid.”
He backed this statement with experience from several operating systems. The key example was Cedar/Mesa: It was written by people who liked and used resumption, but after ten years of use, there was only one use of resumption left in the half million line system – and that was a context inquiry. Because resumption wasn’t actually necessary for such a context inquiry, they removed it and found a significant speed increase in that part of the system. In each and every case where resumption had been used it had – over the ten years – become a problem and a more appropriate design had replaced it. Basically, every use of resumption had represented a failure to keep separate levels of abstraction disjoint.[16]
Exception-handling languages with resumption include Common Lisp with its Condition System, PL/I, Dylan, R,[29] and Smalltalk. However, the majority of newer programming languages follow C++ and use termination semantics.
Exception handling implementation[edit]
The implementation of exception handling in programming languages typically involves a fair amount of support from both a code generator and the runtime system accompanying a compiler. (It was the addition of exception handling to C++ that ended the useful lifetime of the original C++ compiler, Cfront.[30]) Two schemes are most common. The first, dynamic registration, generates code that continually updates structures about the program state in terms of exception handling.[31] Typically, this adds a new element to the stack frame layout that knows what handlers are available for the function or method associated with that frame; if an exception is thrown, a pointer in the layout directs the runtime to the appropriate handler code. This approach is compact in terms of space, but adds execution overhead on frame entry and exit. It was commonly used in many Ada implementations, for example, where complex generation and runtime support was already needed for many other language features. Microsoft’s 32-bit Structured Exception Handling (SEH) uses this approach with a separate exception stack.[32] Dynamic registration, being fairly straightforward to define, is amenable to proof of correctness.[33]
The second scheme, and the one implemented in many production-quality C++ compilers and 64-bit Microsoft SEH, is a table-driven approach. This creates static tables at compile time and link time that relate ranges of the program counter to the program state with respect to exception handling.[34] Then, if an exception is thrown, the runtime system looks up the current instruction location in the tables and determines what handlers are in play and what needs to be done. This approach minimizes executive overhead for the case where an exception is not thrown. This happens at the cost of some space, but this space can be allocated into read-only, special-purpose data sections that are not loaded or relocated until an exception is actually thrown.[35] The location (in memory) of the code for handling an exception need not be located within (or even near) the region of memory where the rest of the function’s code is stored. So if an exception is thrown then a performance hit – roughly comparable to a function call[36] – may occur if the necessary exception handling code needs to be loaded/cached. However, this scheme has minimal performance cost if no exception is thrown. Since exceptions in C++ are supposed to be exceptional (i.e. uncommon/rare) events, the phrase «zero-cost exceptions»[note 2] is sometimes used to describe exception handling in C++. Like runtime type identification (RTTI), exceptions might not adhere to C++’s zero-overhead principle as implementing exception handling at run-time requires a non-zero amount of memory for the lookup table.[37] For this reason, exception handling (and RTTI) can be disabled in many C++ compilers, which may be useful for systems with very limited memory[37] (such as embedded systems). This second approach is also superior in terms of achieving thread safety[citation needed].
Other definitional and implementation schemes have been proposed as well. For languages that support metaprogramming, approaches that involve no overhead at all (beyond the already present support for reflection) have been advanced.[38]
Exception handling based on design by contract[edit]
A different view of exceptions is based on the principles of design by contract and is supported in particular by the Eiffel language. The idea is to provide a more rigorous basis for exception handling by defining precisely what is «normal» and «abnormal» behavior. Specifically, the approach is based on two concepts:
- Failure: the inability of an operation to fulfill its contract. For example, an addition may produce an arithmetic overflow (it does not fulfill its contract of computing a good approximation to the mathematical sum); or a routine may fail to meet its postcondition.
- Exception: an abnormal event occurring during the execution of a routine (that routine is the «recipient» of the exception) during its execution. Such an abnormal event results from the failure of an operation called by the routine.
The «Safe Exception Handling principle» as introduced by Bertrand Meyer in Object-Oriented Software Construction then holds that there are only two meaningful ways a routine can react when an exception occurs:
- Failure, or «organized panic»: The routine fixes the object’s state by re-establishing the invariant (this is the «organized» part), and then fails (panics), triggering an exception in its caller (so that the abnormal event is not ignored).
- Retry: The routine tries the algorithm again, usually after changing some values so that the next attempt will have a better chance to succeed.
In particular, simply ignoring an exception is not permitted; a block must either be retried and successfully complete, or propagate the exception to its caller.
Here is an example expressed in Eiffel syntax. It assumes that a routine send_fast is normally the better way to send a message, but it may fail, triggering an exception; if so, the algorithm next uses send_slow, which will fail less often. If send_slow fails, the routine send as a whole should fail, causing the caller to get an exception.
send (m: MESSAGE) is -- Send m through fast link, if possible, otherwise through slow link. local tried_fast, tried_slow: BOOLEAN do if tried_fast then tried_slow := True send_slow (m) else tried_fast := True send_fast (m) end rescue if not tried_slow then retry end end
The boolean local variables are initialized to False at the start. If send_fast fails, the body (do clause) will be executed again, causing execution of send_slow. If this execution of send_slow fails, the rescue clause will execute to the end with no retry (no else clause in the final if), causing the routine execution as a whole to fail.
This approach has the merit of defining clearly what «normal» and «abnormal» cases are: an abnormal case, causing an exception, is one in which the routine is unable to fulfill its contract. It defines a clear distribution of roles: the do clause (normal body) is in charge of achieving, or attempting to achieve, the routine’s contract; the rescue clause is in charge of reestablishing the context and restarting the process, if this has a chance of succeeding, but not of performing any actual computation.
Although exceptions in Eiffel have a fairly clear philosophy, Kiniry (2006) criticizes their implementation because «Exceptions that are part of the language definition are represented by INTEGER values, developer-defined exceptions by STRING values. […] Additionally, because they are basic values and not objects, they have no inherent semantics beyond that which is expressed in a helper routine which necessarily cannot be foolproof because of the representation overloading in effect (e.g., one cannot
differentiate two integers of the same value).»[9]
Uncaught exceptions[edit]
Contemporary applications face many design challenges when considering exception handling strategies. Particularly in modern enterprise level applications, exceptions must often cross process boundaries and machine boundaries. Part of designing a solid exception handling strategy is recognizing when a process has failed to the point where it cannot be economically handled by the software portion of the process.[39]
If an exception is thrown and not caught (operationally, an exception is thrown when there is no applicable handler specified), the uncaught exception is handled by the runtime; the routine that does this is called the uncaught exception handler.[40][41] The most common default behavior is to terminate the program and print an error message to the console, usually including debug information such as a string representation of the exception and the stack trace.[40][42][43] This is often avoided by having a top-level (application-level) handler (for example in an event loop) that catches exceptions before they reach the runtime.[40][44]
Note that even though an uncaught exception may result in the program terminating abnormally (the program may not be correct if an exception is not caught, notably by not rolling back partially completed transactions, or not releasing resources), the process terminates normally (assuming the runtime works correctly), as the runtime (which is controlling execution of the program) can ensure orderly shutdown of the process.
In a multithreaded program, an uncaught exception in a thread may instead result in termination of just that thread, not the entire process (uncaught exceptions in the thread-level handler are caught by the top-level handler). This is particularly important for servers, where for example a servlet (running in its own thread) can be terminated without the server overall being affected.
This default uncaught exception handler may be overridden, either globally or per-thread, for example to provide alternative logging or end-user reporting of uncaught exceptions, or to restart threads that terminate due to an uncaught exception. For example, in Java this is done for a single thread via Thread.setUncaughtExceptionHandler and globally via Thread.setDefaultUncaughtExceptionHandler; in Python this is done by modifying sys.excepthook.
Checked exceptions[edit]
Java introduced the notion of checked exceptions,[45][46] which are special classes of exceptions. The checked exceptions that a method may raise must be part of the method’s signature. For instance, if a method might throw an IOException, it must declare this fact explicitly in its method signature. Failure to do so raises a compile-time error. According to Hanspeter Mössenböck, checked exceptions are less convenient but more robust.[47] Checked exceptions can, at compile time, reduce the incidence of unhandled exceptions surfacing at runtime in a given application.
Kiniry writes that «As any Java programmer knows, the volume of try catch code in a typical Java application is sometimes larger than the comparable code necessary for explicit formal parameter and return value checking in other languages that do not have checked exceptions. In fact, the general consensus among in-the-trenches Java programmers is that dealing with checked exceptions is nearly as unpleasant a task as writing documentation. Thus, many programmers report that they “resent” checked exceptions.».[9] Martin Fowler has written «…on the whole I think that exceptions are good, but Java checked exceptions are more trouble than they are worth.»[48] As of 2006 no major programming language has followed Java in adding checked exceptions.[48] For example, C# does not require or allow declaration of any exception specifications, with the following posted by Eric Gunnerson:[49][9][48]
«Examination of small programs leads to the conclusion that requiring exception specifications could both enhance developer productivity and enhance code quality, but experience with large software projects suggests a different result – decreased productivity and little or no increase in code quality.»
Anders Hejlsberg describes two concerns with checked exceptions:[50]
- Versioning: A method may be declared to throw exceptions X and Y. In a later version of the code, one cannot throw exception Z from the method, because it would make the new code incompatible with the earlier uses. Checked exceptions require the method’s callers to either add Z to their throws clause or handle the exception. Alternately, Z may be misrepresented as an X or a Y.
- Scalability: In a hierarchical design, each systems may have several subsystems. Each subsystem may throw several exceptions. Each parent system must deal with the exceptions of all subsystems below it, resulting in an exponential number of exceptions to be dealt with. Checked exceptions require all of these exceptions to be dealt with explicitly.
To work around these, Hejlsberg says programmers resort to circumventing the feature by using a throws Exception declaration. Another circumvention is to use a try { ... } catch (Exception e) {} handler.[50] This is referred to as catch-all exception handling or Pokémon exception handling after the show’s catchphrase «Gotta Catch ‘Em All!».[51] The Java Tutorials discourage catch-all exception handling as it may catch exceptions «for which the handler was not intended».[52] Still another discouraged circumvention is to make all exceptions subclass RuntimeException.[53] An encouraged solution is to use a catch-all handler or throws clause but with a specific superclass of all potentially thrown exceptions rather than the general superclass Exception. Another encouraged solution is to define and declare exception types that are suitable for the level of abstraction of the called method[54] and map lower level exceptions to these types by using exception chaining.
Similar mechanisms[edit]
The roots of checked exceptions go back to the CLU programming language’s notion of exception specification.[55] A function could raise only exceptions listed in its type, but any leaking exceptions from called functions would automatically be turned into the sole runtime exception, failure, instead of resulting in compile-time error.[7] Later, Modula-3 had a similar feature.[56] These features don’t include the compile time checking that is central in the concept of checked exceptions.[55]
Early versions of the C++ programming language included an optional mechanism similar to checked exceptions, called exception specifications. By default any function could throw any exception, but this could be limited by a throw clause added to the function signature, that specified which exceptions the function may throw. Exception specifications were not enforced at compile-time. Violations resulted in the global function std::unexpected being called.[57] An empty exception specification could be given, which indicated that the function will throw no exception. This was not made the default when exception handling was added to the language because it would have required too much modification of existing code, would have impeded interaction with code written in other languages, and would have tempted programmers into writing too many handlers at the local level.[57] Explicit use of empty exception specifications could, however, allow C++ compilers to perform significant code and stack layout optimizations that are precluded when exception handling may take place in a function.[35] Some analysts viewed the proper use of exception specifications in C++ as difficult to achieve.[58] This use of exception specifications was included in C++98 and C++03, deprecated in the 2012 C++ language standard (C++11),[59] and was removed from the language in C++17. A function that will not throw any exceptions can now be denoted by the noexcept keyword.
An uncaught exceptions analyzer exists for the OCaml programming language.[60] The tool reports the set of raised exceptions as an extended type signature. But, unlike checked exceptions, the tool does not require any syntactic annotations and is external (i.e. it is possible to compile and run a program without having checked the exceptions).
Dynamic checking of exceptions[edit]
The point of exception handling routines is to ensure that the code can handle error conditions. In order to establish that exception handling routines are sufficiently robust, it is necessary to present the code with a wide spectrum of invalid or unexpected inputs, such as can be created via software fault injection and mutation testing (that is also sometimes referred to as fuzz testing). One of the most difficult types of software for which to write exception handling routines is protocol software, since a robust protocol implementation must be prepared to receive input that does not comply with the relevant specification(s).
In order to ensure that meaningful regression analysis can be conducted throughout a software development lifecycle process, any exception handling testing should be highly automated, and the test cases must be generated in a scientific, repeatable fashion. Several commercially available systems exist that perform such testing.
In runtime engine environments such as Java or .NET, there exist tools that attach to the runtime engine and every time that an exception of interest occurs, they record debugging information that existed in memory at the time the exception was thrown (call stack and heap values). These tools are called automated exception handling or error interception tools and provide ‘root-cause’ information for exceptions.
Asynchronous exceptions[edit]
Asynchronous exceptions are events raised by a separate thread or external process, such as pressing Ctrl-C to interrupt a program, receiving a signal, or sending a disruptive message such as «stop» or «suspend» from another thread of execution.[61][62] Whereas synchronous exceptions happen at a specific throw statement, asynchronous exceptions can be raised at any time. It follows that asynchronous exception handling can’t be optimized out by the compiler, as it cannot prove the absence of asynchronous exceptions. They are also difficult to program with correctly, as asynchronous exceptions must be blocked during cleanup operations to avoid resource leaks.
Programming languages typically avoid or restrict asynchronous exception handling, for example C++ forbids raising exceptions from signal handlers, and Java has deprecated the use of its ThreadDeath exception that was used to allow one thread to stop another one.[63] Another feature is a semi-asynchronous mechanism that raises an asynchronous exception only during certain operations of the program. For example Java’s Thread.interrupt() only affects the thread when the thread calls an operation that throws InterruptedException.[64] The similar POSIX pthread_cancel API has race conditions which make it impossible to use safely.[65]
Condition systems[edit]
Common Lisp, Dylan and Smalltalk have a condition system[66] (see Common Lisp Condition System) that encompasses the aforementioned exception handling systems. In those languages or environments the advent of a condition (a «generalisation of an error» according to Kent Pitman) implies a function call, and only late in the exception handler the decision to unwind the stack may be taken.
Conditions are a generalization of exceptions. When a condition arises, an appropriate condition handler is searched for and selected, in stack order, to handle the condition. Conditions that do not represent errors may safely go unhandled entirely; their only purpose may be to propagate hints or warnings toward the user.[67]
Continuable exceptions[edit]
This is related to the so-called resumption model of exception handling, in which some exceptions are said to be continuable: it is permitted to return to the expression that signaled an exception, after having taken corrective action in the handler. The condition system is generalized thus: within the handler of a non-serious condition (a.k.a. continuable exception), it is possible to jump to predefined restart points (a.k.a. restarts) that lie between the signaling expression and the condition handler. Restarts are functions closed over some lexical environment, allowing the programmer to repair this environment before exiting the condition handler completely or unwinding the stack even partially.
An example is the ENDPAGE condition in PL/I; the ON unit might write page trailer lines and header lines for the next page, then fall through to resume execution of the interrupted code.
Restarts separate mechanism from policy[edit]
Condition handling moreover provides a separation of mechanism from policy. Restarts provide various possible mechanisms for recovering from error, but do not select which mechanism is appropriate in a given situation. That is the province of the condition handler, which (since it is located in higher-level code) has access to a broader view.
An example: Suppose there is a library function whose purpose is to parse a single syslog file entry. What should this function do if the entry is malformed? There is no one right answer, because the same library could be deployed in programs for many different purposes. In an interactive log-file browser, the right thing to do might be to return the entry unparsed, so the user can see it—but in an automated log-summarizing program, the right thing to do might be to supply null values for the unreadable fields, but abort with an error, if too many entries have been malformed.
That is to say, the question can only be answered in terms of the broader goals of the program, which are not known to the general-purpose library function. Nonetheless, exiting with an error message is only rarely the right answer. So instead of simply exiting with an error, the function may establish restarts offering various ways to continue—for instance, to skip the log entry, to supply default or null values for the unreadable fields, to ask the user for the missing values, or to unwind the stack and abort processing with an error message. The restarts offered constitute the mechanisms available for recovering from error; the selection of restart by the condition handler supplies the policy.
Criticism[edit]
Exception handling is often not handled correctly in software, especially when there are multiple sources of exceptions; data flow analysis of 5 million lines of Java code found over 1300 exception handling defects.[25]
Citing multiple prior studies by others (1999–2004) and their own results, Weimer and Necula wrote that a significant problem with exceptions is that they «create hidden control-flow paths that are difficult for programmers to reason about».[25]: 8:27 «While try-catch-finally is conceptually simple, it has the most complicated execution description in the language specification [Gosling et al. 1996] and requires four levels of nested “if”s in its official English description. In short, it contains a large number of corner cases that programmers often overlook.»[25]: 8:13–8:14
Exceptions, as unstructured flow, increase the risk of resource leaks (such as escaping a section locked by a mutex, or one temporarily holding a file open) or inconsistent state. There are various techniques for resource management in the presence of exceptions, most commonly combining the dispose pattern with some form of unwind protection (like a finally clause), which automatically releases the resource when control exits a section of code.
Tony Hoare in 1980 described the Ada programming language as having «…a plethora of features and notational conventions, many of them unnecessary and some of them, like exception handling, even dangerous. […] Do not allow this language in its present state to be used in applications where reliability is critical […]. The next rocket to go astray as a result of a programming language error may not be an exploratory space rocket on a harmless trip to Venus: It may be a nuclear warhead exploding over one of our own cities.»[68]
The Go developers believe that the try-catch-finally idiom obfuscates control flow,[69] and introduced the exception-like panic/recover mechanism.[70] recover() differs from catch in that it can only be called from within a defer code block in a function, so the handler can only do clean-up and change the function’s return values, and cannot return control to an arbitrary point within the function.[71] The defer block itself functions similarly to a finally clause.
Exception handling in UI hierarchies[edit]
Front-end web frameworks, such as React and Vue, have introduced error handling mechanisms where errors propagate up the UI component hierarchy, in a way that is analogous to how errors propagate up the call stack in executing code.[72][73] Here the error boundary mechanism serves as an analogue to the typical try-catch mechanism. Thus a component can ensure that errors from its child components are caught and handled, and not propagated up to parent components.
For example, in Vue, a component would catch errors by implementing errorCaptured
Vue.component('parent', { template: '<div><slot></slot></div>', errorCaptured: (err, vm, info) => alert('An error occurred'); }) Vue.component('child', { template: '<div>{{ cause_error() }}</div>' })
When used like this in markup:
<parent> <child></child> </parent>
The error produced by the child component is caught and handled by the parent component.[74]
See also[edit]
- Automated exception handling
- Exception safety
- Continuation
- Defensive programming
- Triple fault
- Option types and Result types, alternative ways of handling errors in functional programming without exceptions
- Data validation
Notes[edit]
- ^ In, e.g., PL/I, a normal exit from an exception handler unwinds the stack.
- ^ There is «zero [processing] cost» only if no exception is throw (although there will be a memory cost since memory is needed for the lookup table). There is a (potentially significant) cost if an exception is thrown (that is, if
throwis executed). Implementing exception handling may also limit the possible compiler optimizations that may be performed.
References[edit]
- ^ a b Cristian, Flaviu (1980). «Exception Handling and Software Fault Tolerance». Proc. 10th Int. Symp. On Fault Tolerant Computing (FTCS-25 reprint ed.) (6): 531–540. CiteSeerX 10.1.1.116.8736. doi:10.1109/TC.1982.1676035. OCLC 1029229019. S2CID 18345469.
- ^ Goodenough 1975b, pp. 683–684.
- ^ Goodenough 1975b, p. 684.
- ^ Black 1982, pp. 13–15.
- ^ a b Lang, Jun; Stewart, David B. (March 1998). «A study of the applicability of existing exception-handling techniques to component-based real-time software technology». ACM Transactions on Programming Languages and Systems. 20 (2): 276. CiteSeerX 10.1.1.33.3400. doi:10.1145/276393.276395. S2CID 18875882.
Perhaps the most common form of exception-handling method used by software programmers is the «return-code» technique that was popularized as part of C and UNIX.
- ^ Levin 1977, p. 5.
- ^ a b Liskov, B.H.; Snyder, A. (November 1979). «Exception Handling in CLU» (PDF). IEEE Transactions on Software Engineering. SE-5 (6): 546–558. doi:10.1109/TSE.1979.230191. S2CID 15506879. Retrieved 19 December 2021.
- ^ Levin 1977, p. 4.
- ^ a b c d e Kiniry, J. R. (2006). «Exceptions in Java and Eiffel: Two Extremes in Exception Design and Application». Advanced Topics in Exception Handling Techniques (PDF). Lecture Notes in Computer Science. Vol. 4119. pp. 288–300. doi:10.1007/11818502_16. ISBN 978-3-540-37443-5.
- ^ Smotherman, Mark. «Interrupts». Retrieved 4 January 2022.
- ^ McCarthy, John (12 February 1979). «History of Lisp». www-formal.stanford.edu. Retrieved 13 January 2022.
- ^ McCarthy, John; Levin, Michael I.; Abrahams, Paul W.; Edwards, Daniel J.; Hart, Timothy P. (14 July 1961). LISP 1.5 programmer’s manual (PDF). Retrieved 13 January 2022.
- ^ «The ON Statement» (PDF). IBM System/360 Operating System, PL/I Language Specifications (PDF). IBM. July 1966. p. 120. C28-6571-3.
- ^ Gabriel & Steele 2008, p. 3.
- ^ White 1979, p. 194.
- ^ a b Stroustrup 1994, p. 392.
- ^ Hyde, Randall. «Art of Assembly: Chapter Seventeen». www.plantation-productions.com. Retrieved 22 December 2021.
- ^ a b Xiaoye Li; James Demmel (1994). «Faster Numerical Algorithms via Exception Handling, IEEE Transactions on Computers, 43(8)»: 983–992.
- ^ a b W.Kahan (July 5, 2005). «A Demonstration of Presubstitution for ∞/∞» (PDF). Archived (PDF) from the original on March 10, 2012.
- ^ Hauser, John R. (March 1996). «Handling floating-point exceptions in numeric programs». ACM Transactions on Programming Languages and Systems. 18 (2): 139–174. doi:10.1145/227699.227701. S2CID 9820157.
- ^ «Built-in Exceptions — Python 3.10.4 documentation». docs.python.org. Retrieved 17 May 2022.
- ^ «Stroustrup: C++ Style and Technique FAQ». www.stroustrup.com. Archived from the original on 2 February 2018. Retrieved 5 May 2018.
- ^
Bloch, Joshua (2008). «Item 57: Use exceptions only for exceptional situations». Effective Java (Second ed.). Addison-Wesley. p. 241. ISBN 978-0-321-35668-0. - ^ Stroustrup, Bjarne. «C++ Style and Technique FAQ». www.stroustrup.com. Retrieved 12 January 2022.
- ^ a b c d Weimer, W; Necula, G.C. (2008). «Exceptional Situations and Program Reliability» (PDF). ACM Transactions on Programming Languages and Systems. Vol. 30, no. 2. Archived (PDF) from the original on 2015-09-23.
- ^ Roberts, Eric S. (21 March 1989). «Implementing Exceptions in C» (PDF). DEC Systems Research Center. SRC-RR-40. Retrieved 4 January 2022.
- ^ Christiansen, Tom; Torkington, Nathan (2003). «10.12. Handling Exceptions». Perl cookbook (2nd ed.). Beijing: O’Reilly. ISBN 0-596-00313-7.
- ^ Stroustrup 1994, 16.6 Exception Handling: Resumption vs. Termination, pp. 390–393.
- ^ «R: Condition Handling and Recovery». search.r-project.org. Retrieved 2022-12-05.
- ^ Scott Meyers, The Most Important C++ Software…Ever Archived 2011-04-28 at the Wayback Machine, 2006
- ^ D. Cameron, P. Faust, D. Lenkov, M. Mehta, «A portable implementation of C++ exception handling», Proceedings of the C++ Conference (August 1992) USENIX.
- ^ Peter Kleissner (February 14, 2009). «Windows Exception Handling — Peter Kleissner». Archived from the original on October 14, 2013. Retrieved 2009-11-21., Compiler based Structured Exception Handling section
- ^ Graham Hutton, Joel Wright, «Compiling Exceptions Correctly Archived 2014-09-11 at the Wayback Machine». Proceedings of the 7th International Conference on Mathematics of Program Construction, 2004.
- ^ Lajoie, Josée (March–April 1994). «Exception handling – Supporting the runtime mechanism». C++ Report. 6 (3).
- ^ a b Schilling, Jonathan L. (August 1998). «Optimizing away C++ exception handling». SIGPLAN Notices. 33 (8): 40–47. doi:10.1145/286385.286390. S2CID 1522664.
- ^ «Modern C++ best practices for exceptions and error handling». Microsoft. 8 March 2021. Retrieved 21 March 2022.
- ^ a b Stroustrup, Bjarne (18 November 2019). «C++ exceptions and alternatives» (PDF). Retrieved 23 March 2022.
- ^ M. Hof, H. Mössenböck, P. Pirkelbauer, «Zero-Overhead Exception Handling Using Metaprogramming Archived 2016-03-03 at the Wayback Machine», Proceedings SOFSEM’97, November 1997, Lecture Notes in Computer Science 1338, pp. 423-431.
- ^ All Exceptions Are Handled, Jim Wilcox, «All Exceptions Are Handled». Archived from the original on 2015-03-18. Retrieved 2014-12-08.
- ^ a b c Mac Developer Library, «Uncaught Exceptions Archived 2016-03-04 at the Wayback Machine»
- ^ MSDN, AppDomain.UnhandledException Event Archived 2016-03-04 at the Wayback Machine
- ^ The Python Tutorial, «8. Errors and Exceptions Archived 2015-09-01 at the Wayback Machine»
- ^ «Java Practices -> Provide an uncaught exception handler». www.javapractices.com. Archived from the original on 9 September 2016. Retrieved 5 May 2018.
- ^ PyMOTW (Python Module Of The Week), «Exception Handling Archived 2015-09-15 at the Wayback Machine»
- ^ «Google Answers: The origin of checked exceptions». Archived from the original on 2011-08-06. Retrieved 2011-12-15.
- ^ Java Language Specification, chapter 11.2. http://java.sun.com/docs/books/jls/third_edition/html/exceptions.html#11.2 Archived 2006-12-08 at the Wayback Machine
- ^ Mössenböck, Hanspeter (2002-03-25). «Advanced C#: Variable Number of Parameters» (PDF). Institut für Systemsoftware, Johannes Kepler Universität Linz, Fachbereich Informatik. p. 32. Archived (PDF) from the original on 2011-09-20. Retrieved 2011-08-05.
- ^ a b c Eckel, Bruce (2006). Thinking in Java (4th ed.). Upper Saddle River, NJ: Prentice Hall. pp. 347–348. ISBN 0-13-187248-6.
- ^ Gunnerson, Eric (9 November 2000). «C# and exception specifications». Archived from the original on 1 January 2006.
- ^ a b Bill Venners; Bruce Eckel (August 18, 2003). «The Trouble with Checked Exceptions: A Conversation with Anders Hejlsberg, Part II». Retrieved 4 January 2022.
- ^ Juneau, Josh (31 May 2017). Java 9 Recipes: A Problem-Solution Approach. Apress. p. 226. ISBN 978-1-4842-1976-8.
- ^ «Advantages of Exceptions (The Java™ Tutorials : Essential Classes : Exceptions)». Download.oracle.com. Archived from the original on 2011-10-26. Retrieved 2011-12-15.
- ^ «Unchecked Exceptions – The Controversy (The Java™ Tutorials : Essential Classes : Exceptions)». Download.oracle.com. Archived from the original on 2011-11-17. Retrieved 2011-12-15.
- ^ Bloch 2001:178 Bloch, Joshua (2001). Effective Java Programming Language Guide. Addison-Wesley Professional. ISBN 978-0-201-31005-4.
- ^ a b «Bruce Eckel’s MindView, Inc: Does Java need Checked Exceptions?». Mindview.net. Archived from the original on 2002-04-05. Retrieved 2011-12-15.
- ^ «Modula-3 — Procedure Types». .cs.columbia.edu. 1995-03-08. Archived from the original on 2008-05-09. Retrieved 2011-12-15.
- ^ a b Bjarne Stroustrup, The C++ Programming Language Third Edition, Addison Wesley, 1997. ISBN 0-201-88954-4. pp. 375-380.
- ^ Reeves, J.W. (July 1996). «Ten Guidelines for Exception Specifications». C++ Report. 8 (7).
- ^ Sutter, Herb (3 March 2010). «Trip Report: March 2010 ISO C++ Standards Meeting». Archived from the original on 23 March 2010. Retrieved 24 March 2010.
- ^ «OcamlExc — An uncaught exceptions analyzer for Objective Caml». Caml.inria.fr. Archived from the original on 2011-08-06. Retrieved 2011-12-15.
- ^ «Asynchronous Exceptions in Haskell — Marlow, Jones, Moran (ResearchIndex)». Citeseer.ist.psu.edu. Archived from the original on 2011-02-23. Retrieved 2011-12-15.
- ^ Freund, Stephen N.; Mitchell, Mark P. «Safe Asynchronous Exceptions For Python» (PDF). Retrieved 4 January 2022.
- ^ «Java Thread Primitive Deprecation». Java.sun.com. Archived from the original on 2009-04-26. Retrieved 2011-12-15.
- ^ «Interrupts (The Java™ Tutorials > Essential Java Classes > Concurrency)». docs.oracle.com. Retrieved 5 January 2022.
- ^ Felker, Rich. «Thread cancellation and resource leaks». ewontfix.com. Retrieved 5 January 2022.
- ^ What Conditions (Exceptions) are Really About (2008-03-24). «What Conditions (Exceptions) are Really About». Danweinreb.org. Archived from the original on February 1, 2013. Retrieved 2014-09-18.
- ^ «Condition System Concepts». Franz.com. 2009-07-21. Archived from the original on 2007-06-28. Retrieved 2011-12-15.
- ^ C.A.R. Hoare. «The Emperor’s Old Clothes». 1980 Turing Award Lecture
- ^ «Frequently Asked Questions». Archived from the original on 2017-05-03. Retrieved 2017-04-27.
We believe that coupling exceptions to a control structure, as in the try-catch-finally idiom, results in convoluted code. It also tends to encourage programmers to label too many ordinary errors, such as failing to open a file, as exceptional.
- ^ Panic And Recover Archived 2013-10-24 at the Wayback Machine, Go wiki
- ^ Bendersky, Eli (8 August 2018). «On the uses and misuses of panics in Go». Eli Bendersky’s website. Retrieved 5 January 2022.
The specific limitation is that recover can only be called in a defer code block, which cannot return control to an arbitrary point, but can only do clean-ups and tweak the function’s return values.
- ^ «Error Boundaries». React. Retrieved 2018-12-10.
- ^ «Vue.js API». Vue.js. Retrieved 2018-12-10.
- ^ «Error handling with Vue.js». CatchJS. Retrieved 2018-12-10.
- Black, Andrew P. (January 1982). Exception handling: The case against (PDF) (PhD). University of Oxford. CiteSeerX 10.1.1.94.5554. OCLC 123311492.
- Gabriel, Richard P.; Steele, Guy L. (2008). A Pattern of Language Evolution (PDF). LISP50: Celebrating the 50th Anniversary of Lisp. pp. 1–10. doi:10.1145/1529966.1529967. ISBN 978-1-60558-383-9.
- Goodenough, John B. (1975a). Structured exception handling. Proceedings of the 2nd ACM SIGACT-SIGPLAN symposium on Principles of programming languages — POPL ’75. pp. 204–224. doi:10.1145/512976.512997.
- Goodenough, John B. (1975). «Exception handling: Issues and a proposed notation» (PDF). Communications of the ACM. 18 (12): 683–696. CiteSeerX 10.1.1.122.7791. doi:10.1145/361227.361230. S2CID 12935051.
- Levin, Roy (June 1977). Program Structures for Exceptional Condition Handling (PDF) (PhD). Carnegie-Mellon University. DTIC ADA043449. Archived (PDF) from the original on December 22, 2021.
- Stroustrup, Bjarne (1994). The design and evolution of C++ (1st ed.). Reading, Mass.: Addison-Wesley. ISBN 0-201-54330-3.
- White, Jon L (May 1979). NIL — A Perspective (PDF). Proceedings of the 1979 Macsyma User’s Conference.
External links[edit]
- A Crash Course on the Depths of Win32 Structured Exception Handling by Matt Pietrek — Microsoft Systems Journal (1997)
- Article «C++ Exception Handling» by Christophe de Dinechin
- Article «Exceptional practices» by Brian Goetz
- Article «Object Oriented Exception Handling in Perl» by Arun Udaya Shankar
- Article «Programming with Exceptions in C++» by Kyle Loudon
- Article «Unchecked Exceptions — The Controversy»
- Conference slides Floating-Point Exception-Handling policies (pdf p. 46) by William Kahan
- Descriptions from Portland Pattern Repository
- Does Java Need Checked Exceptions?
Время прочтения
5 мин
Просмотры 9.7K
Сегодня мы приготовили перевод для тех, кто так же, как автор статьи, при изучении Документации языка программирования Swift избегает главы «Error Handling».
Из статьи вы узнаете:
- что такое оператор if-else и что с ним не так;
- как подружиться с Error Handling;
- когда стоит использовать Try! и Try?

Моя история
Когда я был младше, я начинал изучать документацию языка Swift. Я по несколько раз прочёл все главы, кроме одной: «Error Handling». Отчего-то мне казалось, что нужно быть профессиональным программистом, чтобы понять эту главу.
Я боялся обработки ошибок. Такие слова, как catch, try, throw и throws, казались бессмысленными. Они просто пугали. Неужели они не выглядят устрашающими для человека, который видит их в первый раз? Но не волнуйтесь, друзья мои. Я здесь, чтобы помочь вам.
Как я объяснил своей тринадцатилетней сестре, обработка ошибок – это всего лишь ещё один способ написать блок if-else для отправки сообщения об ошибке.
Сообщение об ошибке от Tesla Motors
Как вы наверняка знаете, у автомобилей Tesla есть функция автопилота. Но, если в работе машины по какой-либо причине происходит сбой, она просит вас взять руль в руки и сообщает об ошибке. В этом уроке мы узнаем, как выводить такое сообщение с помощью Error Handling.
Мы создадим программу, которая будет распознавать такие объекты, как светофоры на улицах. Для этого нужно знать как минимум машинное обучение, векторное исчисление, линейную алгебру, теорию вероятности и дискретную математику. Шутка.
Знакомство с оператором if-else
Чтобы максимально оценить Error Handling в Swift, давайте оглянемся в прошлое. Вот что многие, если не все, начинающие разработчики сделали бы, столкнувшись с сообщением об ошибке:
var isInControl = true
func selfDrive() {
if isInControl {
print("You good, let me ride this car for ya")
} else {
print("Hold the handlebar RIGHT NOW, or you gone die")
}
}
selfDrive() // "You good..."Проблема
Самая большая проблема заключается в удобочитаемости кода, когда блок else становится слишком громоздким. Во-первых, вы не поймёте, содержит ли сама функция сообщение об ошибке, до тех пор, пока не прочитаете функцию от начала до конца или если не назовёте ее, например, selfDriveCanCauseError, что тоже сработает.
Смотрите, функция может убить водителя. Необходимо в недвусмысленных выражениях предупредить свою команду о том, что эта функция опасна и даже может быть смертельной, если невнимательно с ней обращаться.
С другой проблемой можно столкнуться при выполнении некоторых сложных функций или действий внутри блока else. Например:
else {
print("Hold the handle bar Right now...")
// If handle not held within 5 seconds, car will shut down
// Slow down the car
// More code ...
// More code ...
}Блок else раздувается, и работать с ним – все равно что пытаться играть в баскетбол в зимней одежде (по правде говоря, я так и делаю, так как в Корее достаточно холодно). Вы понимаете, о чём я? Это некрасиво и нечитабельно.
Поэтому вы просто могли бы добавить функцию в блок else вместо прямых вызовов.
else {
slowDownTheCar()
shutDownTheEngine()
}Однако при этом сохраняется первая из выделенных мной проблем, плюс нет какого-то определённого способа обозначить, что функция selfDrive() опасна и что с ней нужно обращаться с осторожностью. Поэтому предлагаю погрузиться в Error Handling, чтобы писать модульные и точные сообщения об ошибках.
Знакомство с Error Handling
К настоящему времени вы уже знаете о проблеме If-else с сообщениями об ошибках. Пример выше был слишком простым. Давайте предположим, что есть два сообщения об ошибке:
- вы заблудились
- аккумулятор автомобиля разряжается.
Я собираюсь создать enum, который соответствует протоколу Error.
enum TeslaError: Error {
case lostGPS
case lowBattery
}Честно говоря, я точно не знаю, что делает Error протокол, но при обработке ошибок без этого не обойдешься. Это как: «Почему ноутбук включается, когда нажимаешь на кнопку? Почему экран телефона можно разблокировать, проведя по нему пальцем?»
Разработчики Swift так решили, и я не хочу задаваться вопросом об их мотивах. Я просто использую то, что они для нас сделали. Конечно, если вы хотите разобраться подробнее, вы можете загрузить программный код Swift и проанализировать его самостоятельно – то есть, по нашей аналогии, разобрать ноутбук или iPhone. Я же просто пропущу этот шаг.
Если вы запутались, потерпите еще несколько абзацев. Вы увидите, как все станет ясно, когда TeslaError превратится в функцию.
Давайте сперва отправим сообщение об ошибке без использования Error Handling.
var lostGPS: Bool = true
var lowBattery: Bool = false
func autoDriveTesla() {
if lostGPS {
print("I'm lost, bruh. Hold me tight")
// A lot more code
}
if lowBattery {
print("HURRY! ")
// Loads of code
}
}Итак, если бы я запустил это:
autoDriveTesla() // "HURRY! " Но давайте используем Error Handling. В первую очередь вы должны явно указать, что функция опасна и может выдавать ошибки. Мы добавим к функции ключевое слово throws.
func autoDriveTesla() throws { ... }Теперь функция автоматически говорит вашим товарищам по команде, что autoDriveTesla – особый случай, и им не нужно читать весь блок.
Звучит неплохо? Отлично, теперь пришло время выдавать эти ошибки, когда водитель сталкивается с lostGPA или lowBattery внутри блока Else-If. Помните про enum TeslaError?
func autoDriveTesla() throws {
if lostGPS {
throw TeslaError.lostGPS
}
if lowBattery {
throw TeslaError.lowBattery
}Я вас всех поймаю
Если lostGPS равно true, то функция отправит TeslaError.lostGPS. Но что делать потом? Куда мы будем вставлять это сообщение об ошибке и добавлять код для блока else?
print("Bruh, I'm lost. Hold me tight")Окей, я не хочу заваливать вас информацией, поэтому давайте начнём с того, как выполнить функцию, когда в ней есть ключевое слово throws.
Так как это особый случай, вам необходимо добавлять try внутрь блока do при работе с этой функцией. Вы такие: «Что?». Просто последите за ходом моих мыслей ещё чуть-чуть.
do {
try autoDriveTesla()
}Я знаю, что вы сейчас думаете: «Я очень хочу вывести на экран моё сообщение об ошибке, иначе водитель умрёт».
Итак, куда мы вставим это сообщение об ошибке? Мы знаем, что функция способна отправлять 2 возможных сообщения об ошибке:
- TeslaError.lowBattery
- TeslaError.lostGPS.
Когда функция выдаёт ошибку, вам необходимо её “поймать” и, как только вы это сделаете, вывести на экран соответствующее сообщение. Звучит немного запутанно, поэтому давайте посмотрим.
var lostGPS: Bool = false
var lowBattery: Bool = true
do {
try autoDriveTesla()
} catch TeslaError.lostGPS {
print("Bruh, I'm lost. Hold me tight")
} catch TeslaError.lowBattery {
print("HURRY! ")
}
}
// Results: "HURRY! "
Теперь всё должно стать понятно. Если понятно не всё, вы всегда можете посмотреть моё видео на YouTube.
Обработка ошибок с Init
Обработка ошибок может применяться не только к функциям, но и тогда, когда вам нужно инициализировать объект. Допустим, если вы не задали имя курса, то нужно выдавать ошибку.
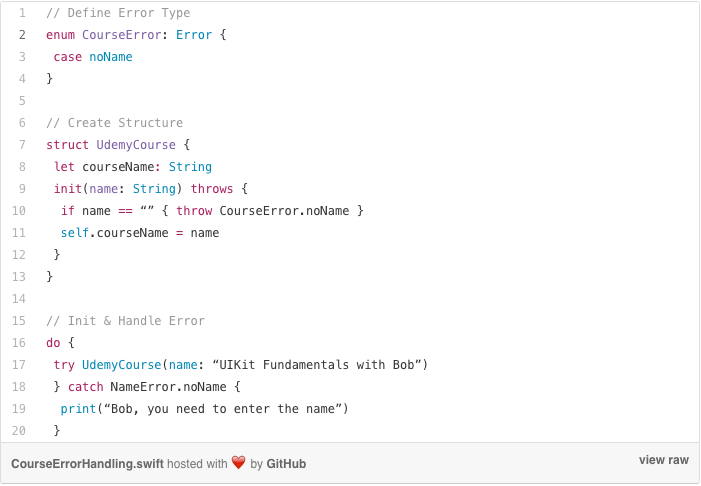
Если вы введёте tryUdemyCourse(name: «»), появится сообщение об ошибке.
Когда использовать Try! и Try?
Хорошо. Try используется только тогда, когда вы выполняете функцию/инициализацию внутри блока do-catch. Однако если у вас нет цели предупредить пользователя о том, что происходит, выводя сообщение об ошибке на экран, или как-то исправить ее, вам не нужен блок catch.
try?– что это?
Давайте начнём с try? Хотя это не рекомендуется,
let newCourse = try? UdemyCourse("Functional Programming")try? всегда возвращает опциональный объект, поэтому необходимо извлечь newCourse
if let newCourse = newCourse { ... }Если метод init выбрасывает ошибку, как, например
let myCourse = try? UdemyCourse("") // throw NameError.noNameто myCourse будет равен nil.
try! – что это?
В отличие от try? оно возвращает не опциональное значение, а обычное. Например,
let bobCourse = try! UdemyCourse("Practical POP")bobCourse не опционально. Однако, если при методе инициализации выдается ошибка вроде,
let noCourseName = try! UdemyCourse("") // throw NameError.noNameто приложение упадёт. Так же как и в случае с принудительным извлечением с помощью !, никогда не используйте его, если вы не уверены на 101% в том, что происходит.
Ну вот и всё. Теперь вы вместе со мной поняли концепцию Error Handling. Легко и просто! И не нужно становиться профессиональным программистом.
Introduction¶
Error handling is a part of the overall security of an application. Except in movies, an attack always begins with a Reconnaissance phase in which the attacker will try to gather as much technical information (often name and version properties) as possible about the target, such as the application server, frameworks, libraries, etc.
Unhandled errors can assist an attacker in this initial phase, which is very important for the rest of the attack.
The following link provides a description of the different phases of an attack.
Context¶
Issues at the error handling level can reveal a lot of information about the target and can also be used to identify injection points in the target’s features.
Below is an example of the disclosure of a technology stack, here the Struts2 and Tomcat versions, via an exception rendered to the user:
HTTP Status 500 - For input string: "null"
type Exception report
message For input string: "null"
description The server encountered an internal error that prevented it from fulfilling this request.
exception
java.lang.NumberFormatException: For input string: "null"
java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
java.lang.Integer.parseInt(Integer.java:492)
java.lang.Integer.parseInt(Integer.java:527)
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
java.lang.reflect.Method.invoke(Method.java:606)
com.opensymphony.xwork2.DefaultActionInvocation.invokeAction(DefaultActionInvocation.java:450)
com.opensymphony.xwork2.DefaultActionInvocation.invokeActionOnly(DefaultActionInvocation.java:289)
com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:252)
org.apache.struts2.interceptor.debugging.DebuggingInterceptor.intercept(DebuggingInterceptor.java:256)
com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:246)
...
note: The full stack trace of the root cause is available in the Apache Tomcat/7.0.56 logs.
Below is an example of disclosure of a SQL query error, along with the site installation path, that can be used to identify an injection point:
Warning: odbc_fetch_array() expects parameter /1 to be resource, boolean given
in D:appindex_new.php on line 188
The OWASP Testing Guide provides different techniques to obtain technical information from an application.
Objective¶
The article shows how to configure a global error handler as part of your application’s runtime configuration. In some cases, it may be more efficient to define this error handler as part of your code. The outcome being that when an unexpected error occurs then a generic response is returned by the application but the error details are logged server side for investigation, and not returned to the user.
The following schema shows the target approach:
As most recent application topologies are API based, we assume in this article that the backend exposes only a REST API and does not contain any user interface content. The application should try and exhaustively cover all possible failure modes and use 5xx errors only to indicate responses to requests that it cannot fulfill, but not provide any content as part of the response that would reveal implementation details. For that, RFC 7807 — Problem Details for HTTP APIs defines a document format.
For the error logging operation itself, the logging cheat sheet should be used. This article focuses on the error handling part.
Proposition¶
For each technology stack, the following configuration options are proposed:
Standard Java Web Application¶
For this kind of application, a global error handler can be configured at the web.xml deployment descriptor level.
We propose here a configuration that can be used from Servlet specification version 2.5 and above.
With this configuration, any unexpected error will cause a redirection to the page error.jsp in which the error will be traced and a generic response will be returned.
Configuration of the redirection into the web.xml file:
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" ns="http://java.sun.com/xml/ns/javaee"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"
version="3.0">
...
<error-page>
<exception-type>java.lang.Exception</exception-type>
<location>/error.jsp</location>
</error-page>
...
</web-app>
Content of the error.jsp file:
<%@ page language="java" isErrorPage="true" contentType="application/json; charset=UTF-8"
pageEncoding="UTF-8"%>
<%
String errorMessage = exception.getMessage();
//Log the exception via the content of the implicit variable named "exception"
//...
//We build a generic response with a JSON format because we are in a REST API app context
//We also add an HTTP response header to indicate to the client app that the response is an error
response.setHeader("X-ERROR", "true");
//Note that we're using an internal server error response
//In some cases it may be prudent to return 4xx error codes, when we have misbehaving clients
response.setStatus(500);
%>
{"message":"An error occur, please retry"}
Java SpringMVC/SpringBoot web application¶
With SpringMVC or SpringBoot, you can define a global error handler by implementing the following class in your project. Spring Framework 6 introduced the problem details based on RFC 7807.
We indicate to the handler, via the annotation @ExceptionHandler, to act when any exception extending the class java.lang.Exception is thrown by the application. We also use the ProblemDetail class to create the response object.
import org.springframework.http.HttpStatus;
import org.springframework.http.ProblemDetail;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import org.springframework.web.context.request.WebRequest;
import org.springframework.web.servlet.mvc.method.annotation.ResponseEntityExceptionHandler;
/**
* Global error handler in charge of returning a generic response in case of unexpected error situation.
*/
@RestControllerAdvice
public class RestResponseEntityExceptionHandler extends ResponseEntityExceptionHandler {
@ExceptionHandler(value = {Exception.class})
public ProblemDetail handleGlobalError(RuntimeException exception, WebRequest request) {
//Log the exception via the content of the parameter named "exception"
//...
//Note that we're using an internal server error response
//In some cases it may be prudent to return 4xx error codes, if we have misbehaving clients
//By specification, the content-type can be "application/problem+json" or "application/problem+xml"
return ProblemDetail.forStatusAndDetail(HttpStatus.INTERNAL_SERVER_ERROR, "An error occur, please retry");
}
}
References:
- Exception handling with Spring
- Exception handling with SpringBoot
ASP NET Core web application¶
With ASP.NET Core, you can define a global error handler by indicating that the exception handler is a dedicated API Controller.
Content of the API Controller dedicated to the error handling:
using Microsoft.AspNetCore.Authorization;
using Microsoft.AspNetCore.Diagnostics;
using Microsoft.AspNetCore.Mvc;
using System;
using System.Collections.Generic;
using System.Net;
namespace MyProject.Controllers
{
/// <summary>
/// API Controller used to intercept and handle all unexpected exception
/// </summary>
[Route("api/[controller]")]
[ApiController]
[AllowAnonymous]
public class ErrorController : ControllerBase
{
/// <summary>
/// Action that will be invoked for any call to this Controller in order to handle the current error
/// </summary>
/// <returns>A generic error formatted as JSON because we are in a REST API app context</returns>
[HttpGet]
[HttpPost]
[HttpHead]
[HttpDelete]
[HttpPut]
[HttpOptions]
[HttpPatch]
public JsonResult Handle()
{
//Get the exception that has implied the call to this controller
Exception exception = HttpContext.Features.Get<IExceptionHandlerFeature>()?.Error;
//Log the exception via the content of the variable named "exception" if it is not NULL
//...
//We build a generic response with a JSON format because we are in a REST API app context
//We also add an HTTP response header to indicate to the client app that the response
//is an error
var responseBody = new Dictionary<String, String>{ {
"message", "An error occur, please retry"
} };
JsonResult response = new JsonResult(responseBody);
//Note that we're using an internal server error response
//In some cases it may be prudent to return 4xx error codes, if we have misbehaving clients
response.StatusCode = (int)HttpStatusCode.InternalServerError;
Request.HttpContext.Response.Headers.Remove("X-ERROR");
Request.HttpContext.Response.Headers.Add("X-ERROR", "true");
return response;
}
}
}
Definition in the application Startup.cs file of the mapping of the exception handler to the dedicated error handling API controller:
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
namespace MyProject
{
public class Startup
{
...
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
//First we configure the error handler middleware!
//We enable the global error handler in others environments than DEV
//because debug page are useful during implementation
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
else
{
//Our global handler is defined on "/api/error" URL so we indicate to the
//exception handler to call this API controller
//on any unexpected exception raised by the application
app.UseExceptionHandler("/api/error");
//To customize the response content type and text, use the overload of
//UseStatusCodePages that takes a content type and format string.
app.UseStatusCodePages("text/plain", "Status code page, status code: {0}");
}
//We configure others middlewares, remember that the declaration order is important...
app.UseMvc();
//...
}
}
}
References:
- Exception handling with ASP.Net Core
ASP NET Web API web application¶
With ASP.NET Web API (from the standard .NET framework and not from the .NET Core framework), you can define and register handlers in order to trace and handle any error that occurs in the application.
Definition of the handler for the tracing of the error details:
using System;
using System.Web.Http.ExceptionHandling;
namespace MyProject.Security
{
/// <summary>
/// Global logger used to trace any error that occurs at application wide level
/// </summary>
public class GlobalErrorLogger : ExceptionLogger
{
/// <summary>
/// Method in charge of the management of the error from a tracing point of view
/// </summary>
/// <param name="context">Context containing the error details</param>
public override void Log(ExceptionLoggerContext context)
{
//Get the exception
Exception exception = context.Exception;
//Log the exception via the content of the variable named "exception" if it is not NULL
//...
}
}
}
Definition of the handler for the management of the error in order to return a generic response:
using Newtonsoft.Json;
using System;
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
using System.Web.Http;
using System.Web.Http.ExceptionHandling;
namespace MyProject.Security
{
/// <summary>
/// Global handler used to handle any error that occurs at application wide level
/// </summary>
public class GlobalErrorHandler : ExceptionHandler
{
/// <summary>
/// Method in charge of handle the generic response send in case of error
/// </summary>
/// <param name="context">Error context</param>
public override void Handle(ExceptionHandlerContext context)
{
context.Result = new GenericResult();
}
/// <summary>
/// Class used to represent the generic response send
/// </summary>
private class GenericResult : IHttpActionResult
{
/// <summary>
/// Method in charge of creating the generic response
/// </summary>
/// <param name="cancellationToken">Object to cancel the task</param>
/// <returns>A task in charge of sending the generic response</returns>
public Task<HttpResponseMessage> ExecuteAsync(CancellationToken cancellationToken)
{
//We build a generic response with a JSON format because we are in a REST API app context
//We also add an HTTP response header to indicate to the client app that the response
//is an error
var responseBody = new Dictionary<String, String>{ {
"message", "An error occur, please retry"
} };
// Note that we're using an internal server error response
// In some cases it may be prudent to return 4xx error codes, if we have misbehaving clients
HttpResponseMessage response = new HttpResponseMessage(HttpStatusCode.InternalServerError);
response.Headers.Add("X-ERROR", "true");
response.Content = new StringContent(JsonConvert.SerializeObject(responseBody),
Encoding.UTF8, "application/json");
return Task.FromResult(response);
}
}
}
}
Registration of the both handlers in the application WebApiConfig.cs file:
using MyProject.Security;
using System.Web.Http;
using System.Web.Http.ExceptionHandling;
namespace MyProject
{
public static class WebApiConfig
{
public static void Register(HttpConfiguration config)
{
//Register global error logging and handling handlers in first
config.Services.Replace(typeof(IExceptionLogger), new GlobalErrorLogger());
config.Services.Replace(typeof(IExceptionHandler), new GlobalErrorHandler());
//Rest of the configuration
//...
}
}
}
Setting customErrors section to the Web.config file within the csharp <system.web> node as follows.
<configuration>
...
<system.web>
<customErrors mode="RemoteOnly"
defaultRedirect="~/ErrorPages/Oops.aspx" />
...
</system.web>
</configuration>
References:
-
Exception handling with ASP.Net Web API
-
ASP.NET Error Handling
Sources of the prototype¶
The source code of all the sandbox projects created to find the right setup to use is stored in this GitHub repository.
Appendix HTTP Errors¶
A reference for HTTP errors can be found here RFC 2616. Using error messages that do not provide implementation details is important to avoid information leakage. In general, consider using 4xx error codes for requests that are due to an error on the part of the HTTP client (e.g. unauthorized access, request body too large) and use 5xx to indicate errors that are triggered on server side, due to an unforeseen bug. Ensure that applications are monitored for 5xx errors which are a good indication of the application failing for some sets of inputs.
Error handling is the process of responding to and recovering from error conditions in your program. Swift provides first-class support for throwing, catching, propagating, and manipulating recoverable errors at runtime.
Some operations aren’t guaranteed to always complete execution or produce a useful output. Optionals are used to represent the absence of a value, but when an operation fails, it’s often useful to understand what caused the failure, so that your code can respond accordingly.
As an example, consider the task of reading and processing data from a file on disk. There are a number of ways this task can fail, including the file not existing at the specified path, the file not having read permissions, or the file not being encoded in a compatible format. Distinguishing among these different situations allows a program to resolve some errors and to communicate to the user any errors it can’t resolve.
Representing and Throwing Errors¶
In Swift, errors are represented by values of types that conform to the Error protocol. This empty protocol indicates that a type can be used for error handling.
Swift enumerations are particularly well suited to modeling a group of related error conditions, with associated values allowing for additional information about the nature of an error to be communicated. For example, here’s how you might represent the error conditions of operating a vending machine inside a game:
- enum VendingMachineError: Error {
- case invalidSelection
- case insufficientFunds(coinsNeeded: Int)
- case outOfStock
- }
Throwing an error lets you indicate that something unexpected happened and the normal flow of execution can’t continue. You use a throw statement to throw an error. For example, the following code throws an error to indicate that five additional coins are needed by the vending machine:
- throw VendingMachineError.insufficientFunds(coinsNeeded: 5)
Handling Errors¶
When an error is thrown, some surrounding piece of code must be responsible for handling the error—for example, by correcting the problem, trying an alternative approach, or informing the user of the failure.
There are four ways to handle errors in Swift. You can propagate the error from a function to the code that calls that function, handle the error using a do—catch statement, handle the error as an optional value, or assert that the error will not occur. Each approach is described in a section below.
When a function throws an error, it changes the flow of your program, so it’s important that you can quickly identify places in your code that can throw errors. To identify these places in your code, write the try keyword—or the try? or try! variation—before a piece of code that calls a function, method, or initializer that can throw an error. These keywords are described in the sections below.
Note
Error handling in Swift resembles exception handling in other languages, with the use of the try, catch and throw keywords. Unlike exception handling in many languages—including Objective-C—error handling in Swift doesn’t involve unwinding the call stack, a process that can be computationally expensive. As such, the performance characteristics of a throw statement are comparable to those of a return statement.
Propagating Errors Using Throwing Functions¶
To indicate that a function, method, or initializer can throw an error, you write the throws keyword in the function’s declaration after its parameters. A function marked with throws is called a throwing function. If the function specifies a return type, you write the throws keyword before the return arrow (->).
- func canThrowErrors() throws -> String
- func cannotThrowErrors() -> String
A throwing function propagates errors that are thrown inside of it to the scope from which it’s called.
Note
Only throwing functions can propagate errors. Any errors thrown inside a nonthrowing function must be handled inside the function.
In the example below, the VendingMachine class has a vend(itemNamed:) method that throws an appropriate VendingMachineError if the requested item isn’t available, is out of stock, or has a cost that exceeds the current deposited amount:
- struct Item {
- var price: Int
- var count: Int
- }
- class VendingMachine {
- var inventory = [
- «Candy Bar»: Item(price: 12, count: 7),
- «Chips»: Item(price: 10, count: 4),
- «Pretzels»: Item(price: 7, count: 11)
- ]
- var coinsDeposited = 0
- func vend(itemNamed name: String) throws {
- guard let item = inventory[name] else {
- throw VendingMachineError.invalidSelection
- }
- guard item.count > 0 else {
- throw VendingMachineError.outOfStock
- }
- guard item.price <= coinsDeposited else {
- throw VendingMachineError.insufficientFunds(coinsNeeded: item.price — coinsDeposited)
- }
- coinsDeposited -= item.price
- var newItem = item
- newItem.count -= 1
- inventory[name] = newItem
- print(«Dispensing (name)«)
- }
- }
The implementation of the vend(itemNamed:) method uses guard statements to exit the method early and throw appropriate errors if any of the requirements for purchasing a snack aren’t met. Because a throw statement immediately transfers program control, an item will be vended only if all of these requirements are met.
Because the vend(itemNamed:) method propagates any errors it throws, any code that calls this method must either handle the errors—using a do—catch statement, try?, or try!—or continue to propagate them. For example, the buyFavoriteSnack(person:vendingMachine:) in the example below is also a throwing function, and any errors that the vend(itemNamed:) method throws will propagate up to the point where the buyFavoriteSnack(person:vendingMachine:) function is called.
- let favoriteSnacks = [
- «Alice»: «Chips»,
- «Bob»: «Licorice»,
- «Eve»: «Pretzels»,
- ]
- func buyFavoriteSnack(person: String, vendingMachine: VendingMachine) throws {
- let snackName = favoriteSnacks[person] ?? «Candy Bar»
- try vendingMachine.vend(itemNamed: snackName)
- }
In this example, the buyFavoriteSnack(person: vendingMachine:) function looks up a given person’s favorite snack and tries to buy it for them by calling the vend(itemNamed:) method. Because the vend(itemNamed:) method can throw an error, it’s called with the try keyword in front of it.
Throwing initializers can propagate errors in the same way as throwing functions. For example, the initializer for the PurchasedSnack structure in the listing below calls a throwing function as part of the initialization process, and it handles any errors that it encounters by propagating them to its caller.
- struct PurchasedSnack {
- let name: String
- init(name: String, vendingMachine: VendingMachine) throws {
- try vendingMachine.vend(itemNamed: name)
- self.name = name
- }
- }
Handling Errors Using Do-Catch¶
You use a do—catch statement to handle errors by running a block of code. If an error is thrown by the code in the do clause, it’s matched against the catch clauses to determine which one of them can handle the error.
Here is the general form of a do—catch statement:
- do {
- try expression
- statements
- } catch pattern 1 {
- statements
- } catch pattern 2 where condition {
- statements
- } catch pattern 3, pattern 4 where condition {
- statements
- } catch {
- statements
- }
You write a pattern after catch to indicate what errors that clause can handle. If a catch clause doesn’t have a pattern, the clause matches any error and binds the error to a local constant named error. For more information about pattern matching, see Patterns.
For example, the following code matches against all three cases of the VendingMachineError enumeration.
- var vendingMachine = VendingMachine()
- vendingMachine.coinsDeposited = 8
- do {
- try buyFavoriteSnack(person: «Alice», vendingMachine: vendingMachine)
- print(«Success! Yum.»)
- } catch VendingMachineError.invalidSelection {
- print(«Invalid Selection.»)
- } catch VendingMachineError.outOfStock {
- print(«Out of Stock.»)
- } catch VendingMachineError.insufficientFunds(let coinsNeeded) {
- print(«Insufficient funds. Please insert an additional (coinsNeeded) coins.»)
- } catch {
- print(«Unexpected error: (error).»)
- }
- // Prints «Insufficient funds. Please insert an additional 2 coins.»
In the above example, the buyFavoriteSnack(person:vendingMachine:) function is called in a try expression, because it can throw an error. If an error is thrown, execution immediately transfers to the catch clauses, which decide whether to allow propagation to continue. If no pattern is matched, the error gets caught by the final catch clause and is bound to a local error constant. If no error is thrown, the remaining statements in the do statement are executed.
The catch clauses don’t have to handle every possible error that the code in the do clause can throw. If none of the catch clauses handle the error, the error propagates to the surrounding scope. However, the propagated error must be handled by some surrounding scope. In a nonthrowing function, an enclosing do—catch statement must handle the error. In a throwing function, either an enclosing do—catch statement or the caller must handle the error. If the error propagates to the top-level scope without being handled, you’ll get a runtime error.
For example, the above example can be written so any error that isn’t a VendingMachineError is instead caught by the calling function:
- func nourish(with item: String) throws {
- do {
- try vendingMachine.vend(itemNamed: item)
- } catch is VendingMachineError {
- print(«Couldn’t buy that from the vending machine.»)
- }
- }
- do {
- try nourish(with: «Beet-Flavored Chips»)
- } catch {
- print(«Unexpected non-vending-machine-related error: (error)«)
- }
- // Prints «Couldn’t buy that from the vending machine.»
In the nourish(with:) function, if vend(itemNamed:) throws an error that’s one of the cases of the VendingMachineError enumeration, nourish(with:) handles the error by printing a message. Otherwise, nourish(with:) propagates the error to its call site. The error is then caught by the general catch clause.
Another way to catch several related errors is to list them after catch, separated by commas. For example:
- func eat(item: String) throws {
- do {
- try vendingMachine.vend(itemNamed: item)
- } catch VendingMachineError.invalidSelection, VendingMachineError.insufficientFunds, VendingMachineError.outOfStock {
- print(«Invalid selection, out of stock, or not enough money.»)
- }
- }
The eat(item:) function lists the vending machine errors to catch, and its error text corresponds to the items in that list. If any of the three listed errors are thrown, this catch clause handles them by printing a message. Any other errors are propagated to the surrounding scope, including any vending-machine errors that might be added later.
Converting Errors to Optional Values¶
You use try? to handle an error by converting it to an optional value. If an error is thrown while evaluating the try? expression, the value of the expression is nil. For example, in the following code x and y have the same value and behavior:
- func someThrowingFunction() throws -> Int {
- // …
- }
- let x = try? someThrowingFunction()
- let y: Int?
- do {
- y = try someThrowingFunction()
- } catch {
- y = nil
- }
If someThrowingFunction() throws an error, the value of x and y is nil. Otherwise, the value of x and y is the value that the function returned. Note that x and y are an optional of whatever type someThrowingFunction() returns. Here the function returns an integer, so x and y are optional integers.
Using try? lets you write concise error handling code when you want to handle all errors in the same way. For example, the following code uses several approaches to fetch data, or returns nil if all of the approaches fail.
- func fetchData() -> Data? {
- if let data = try? fetchDataFromDisk() { return data }
- if let data = try? fetchDataFromServer() { return data }
- return nil
- }
Disabling Error Propagation¶
Sometimes you know a throwing function or method won’t, in fact, throw an error at runtime. On those occasions, you can write try! before the expression to disable error propagation and wrap the call in a runtime assertion that no error will be thrown. If an error actually is thrown, you’ll get a runtime error.
For example, the following code uses a loadImage(atPath:) function, which loads the image resource at a given path or throws an error if the image can’t be loaded. In this case, because the image is shipped with the application, no error will be thrown at runtime, so it’s appropriate to disable error propagation.
- let photo = try! loadImage(atPath: «./Resources/John Appleseed.jpg»)
Specifying Cleanup Actions¶
You use a defer statement to execute a set of statements just before code execution leaves the current block of code. This statement lets you do any necessary cleanup that should be performed regardless of how execution leaves the current block of code—whether it leaves because an error was thrown or because of a statement such as return or break. For example, you can use a defer statement to ensure that file descriptors are closed and manually allocated memory is freed.
A defer statement defers execution until the current scope is exited. This statement consists of the defer keyword and the statements to be executed later. The deferred statements may not contain any code that would transfer control out of the statements, such as a break or a return statement, or by throwing an error. Deferred actions are executed in the reverse of the order that they’re written in your source code. That is, the code in the first defer statement executes last, the code in the second defer statement executes second to last, and so on. The last defer statement in source code order executes first.
- func processFile(filename: String) throws {
- if exists(filename) {
- let file = open(filename)
- defer {
- close(file)
- }
- while let line = try file.readline() {
- // Work with the file.
- }
- // close(file) is called here, at the end of the scope.
- }
- }
The above example uses a defer statement to ensure that the open(_:) function has a corresponding call to close(_:).
Note
You can use a defer statement even when no error handling code is involved.
Порядок выполнения и обработка ошибок
- « Предыдущая статья
- Следующая статья »
JavaScript поддерживает компактный набор инструкций, особенно управляющих инструкций, которые вы можете использовать, чтобы реализовать интерактивность в вашем приложении. В данной главе даётся обзор этих инструкций.
Более подробная информация об инструкциях, рассмотренных в данной главе, содержится в справочнике по JavaScript. Точка с запятой (;) используется для разделения инструкций в коде.
Любое выражение (expression) в JavaScript является также инструкцией (statement). Чтобы получить более подробную информацию о выражениях, прочитайте Выражения и операторы.
Инструкция block
Инструкция block является фундаментальной и используется для группировки других инструкций. Блок ограничивается фигурными скобками:
{ statement_1; statement_2; ... statement_n; }
Блок обычно используется с управляющими инструкциями (например, if, for, while).
В вышеприведённом примере { x++; } является блоком.
Обратите внимание: в JavaScript отсутствует область видимости блока до ECMAScript2015. Переменные, объявленные внутри блока, имеют область видимости функции (или скрипта), в которой находится данный блок, вследствие чего они сохранят свои значения при выходе за пределы блока. Другими словами, блок не создаёт новую область видимости. «Автономные» (standalone) блоки в JavaScript могут продуцировать полностью отличающийся результат, от результата в языках C или Java. Например:
var x = 1;
{
var x = 2;
}
console.log(x); // выведет 2
В вышеприведённом примере инструкция var x внутри блока находится в той же области видимости, что и инструкция var x перед блоком. В C или Java эквивалентный код выведет значение 1.
Начиная с ECMAScript 6, оператор let позволяет объявить переменную в области видимости блока. Чтобы получить более подробную информацию, прочитайте let.
Условные инструкции
Условная инструкция — это набор команд, которые выполняются, если указанное условие является истинным. JavaScript поддерживает две условные инструкции: if...else и switch.
Инструкция if…else
Используйте оператор if для выполнения инструкции, если логическое условия истинно. Используйте опциональный else, для выполнения инструкции, если условие ложно. Оператор if выглядит так:
if (condition) {
statement_1;
} else {
statement_2;
}
Здесь condition может быть любым выражением, вычисляемым как истинное (true) или ложное (false). Чтобы получить более подробную информацию о значениях true и false, прочитайте Boolean. Если условие оценивается как true, то выполняется statement_1, в противном случае — statement_2. Блоки statement_1 и statement_2 могут быть любыми блоками, включая также вложенные инструкции if.
Также вы можете объединить несколько инструкций, пользуясь else if для получения последовательности проверок условий:
if (condition_1) { statement_1;} else if (condition_2) { statement_2;} else if (condition_n) { statement_n; } else { statement_last;}
В случае нескольких условий только первое логическое условие, которое вычислится истинным (true), будет выполнено. Используйте блок ({ ... }) для группировки нескольких инструкций. Применение блоков является хорошей практикой, особенно когда используются вложенные инструкции if:
if (condition) {
statement_1_runs_if_condition_is_true;
statement_2_runs_if_condition_is_true;
} else {
statement_3_runs_if_condition_is_false;
statement_4_runs_if_condition_is_false;
}
Нежелательно использовать простые присваивания в условном выражении, т.к. присваивание может быть спутано с равенством при быстром просмотре кода. Например, не используйте следующий код:
Если вам нужно использовать присваивание в условном выражении, то распространённой практикой является заключение операции присваивания в дополнительные скобки. Например:
if ( (x = y) ) { /* ... */ }
Ложные значения
Следующие значения являются ложными:
falseundefinednull0NaN- пустая строка (
"")
Все остальные значения, включая все объекты, будут восприняты как истина при передаче в условное выражение.
Не путайте примитивные логические значения true и false со значениями true и false объекта Boolean. Например:
var b = new Boolean(false);
if (b) // это условие true
if (b == true) // это условие false
В следующем примере функция checkData возвращает true, если число символов в объекте Text равно трём; в противном случае функция отображает окно alert и возвращает false.
function checkData() {
if (document.form1.threeChar.value.length == 3) {
return true;
} else {
alert("Enter exactly three characters. " +
document.form1.threeChar.value + " is not valid.");
return false;
}
}
Инструкция switch
Инструкция switch позволяет сравнить значение выражения с различными вариантами и при совпадении выполнить соответствующий код. Инструкция имеет следующий вид:
switch (expression) {
case label_1:
statements_1
[break;]
case label_2:
statements_2
[break;]
...
default:
statements_default
[break;]
}
Сначала производится поиск ветви case с меткой label, совпадающей со значением выражения expression. Если совпадение найдено, то соответствующий данной ветви код выполняется до оператора break, который прекращает выполнение switch и передаёт управление дальше. В противном случае управление передаётся необязательной ветви default и выполняется соответствующий ей код. Если ветвь default не найдена, то программа продолжит выполняться со строчки, следующей за инструкцией switch. По соглашению ветвь default является последней ветвью, но следовать этому соглашению необязательно.
Если оператор break отсутствует, то после выполнения кода, который соответствует выбранной ветви, начнётся выполнение кода, который следует за ней.
В следующем примере если fruittype имеет значение "Bananas", то будет выведено сообщение "Bananas are $0.48 a pound." и оператор break прекратит выполнение switch. Если бы оператор break отсутствовал, то был бы также выполнен код, соответствующий ветви "Cherries", т.е. выведено сообщение "Cherries are $3.00 a pound.".
switch (fruittype) {
case "Oranges":
console.log("Oranges are $0.59 a pound.");
break;
case "Apples":
console.log("Apples are $0.32 a pound.");
break;
case "Bananas":
console.log("Bananas are $0.48 a pound.");
break;
case "Cherries":
console.log("Cherries are $3.00 a pound.");
break;
case "Mangoes":
console.log("Mangoes are $0.56 a pound.");
break;
case "Papayas":
console.log("Mangoes and papayas are $2.79 a pound.");
break;
default:
console.log("Sorry, we are out of " + fruittype + ".");
}
console.log("Is there anything else you'd like?");
Инструкции обработки исключений
Инструкция throw используется, чтобы выбросить исключение, а инструкция try...catch, чтобы его обработать.
Типы исключений
Практически любой объект может быть выброшен как исключение. Тем не менее, не все выброшенные объекты создаются равными. Обычно числа или строки выбрасываются как исключения, но часто более эффективным является использование одного из типов исключений, специально созданных для этой цели:
- Исключения ECMAScript
DOMException(en-US) иDOMError(en-US)
Инструкция throw
Используйте инструкцию throw, чтобы выбросить исключение. При выбросе исключения нужно указать выражение, содержащее значение, которое будет выброшено:
throw expression;
Вы можете выбросить любое выражение, а не только выражения определённого типа. В следующем примере выбрасываются исключения различных типов:
throw "Error2"; // string
throw 42; // number
throw true; // boolean
throw { toString: function() { return "I'm an object!"; } }; // object
Примечание: Вы можете выбросить объект как исключение. Вы можете обращаться к свойствам данного объекта в блоке catch.
Примечание: В следующем примере объект UserException выбрасывается как исключение:
function UserException (message) {
this.message = message;
this.name = "UserException";
}
UserException.prototype.toString = function () {
return this.name + ': "' + this.message + '"';
}
throw new UserException("Value too high");
Инструкция try…catch
Инструкция try...catch состоит из блока try, который содержит одну или несколько инструкций, и блок catch, которые содержит инструкции, определяющие порядок действий при выбросе исключения в блоке try. Иными словами, если в блоке try будет выброшено исключение, то управление будет передано в блок catch. Если в блоке try не возникнет исключений, то блок catch будет пропущен. Блок finally будет выполнен после окончания работы блоков try и catch, вне зависимости от того, было ли выброшено исключение.
В следующем примере вызывается функция getMonthName, которая возвращает название месяца по его номеру. Если месяца с указанным номером не существует, то функция выбросит исключение "InvalidMonthNo", которое будет перехвачено в блоке catch:
function getMonthName(mo) {
mo = mo - 1; // Adjust month number for array index (1 = Jan, 12 = Dec)
var months = ["Jan","Feb","Mar","Apr","May","Jun","Jul",
"Aug","Sep","Oct","Nov","Dec"];
if (months[mo]) {
return months[mo];
} else {
throw "InvalidMonthNo"; //throw keyword is used here
}
}
try { // statements to try
monthName = getMonthName(myMonth); // function could throw exception
}
catch (e) {
monthName = "unknown";
logMyErrors(e); // pass exception object to error handler -> your own
}
Блок catch
Используйте блок catch, чтобы обработать исключения, сгенерированные в блоке try.
catch (catchID) { statements }
JavaScript создаёт идентификатор catchID, которому присваивается перехваченное исключение, при входе в блок catch; данный идентификатор доступен только в пределах блока catch и уничтожается при выходе из него.
В следующем примере выбрасывается исключение, которое перехватывается в блоке catch:
try {
throw "myException"
} catch (e) {
console.error(e);
}
Блок finally
Блок finally содержит код, который будет выполнен после окончания работы блоков try и catch, но до того, как будет выполнен код, который следует за инструкцией try...catch. Блок finally выполняется вне зависимости от того, было ли выброшено исключение. Блок finally выполняется даже в том случае, если исключение не перехватывается в блоке catch.
В следующем примере открывается файл, затем в блоке try происходит вызов функции writeMyFile, который может выбросить исключение. Если возникает исключение, то оно обрабатывается в блоке catch. В любом случае файл будет закрыт функцией closeMyFile, вызов которой находится в блоке finally.
openMyFile();
try {
writeMyFile(theData);
} catch(e) {
handleError(e);
} finally {
closeMyFile();
}
Если блок finally возвращает значение, то данное значение становится возвращаемым значением всей связки try-catch-finally. Значения, возвращаемые блоками try и catch, будут проигнорированы.
function f() {
try {
console.log(0);
throw "bogus";
} catch(e) {
console.log(1);
return true; // приостанавливается до завершения блока `finally`
console.log(2); // не выполняется
} finally {
console.log(3);
return false; // заменяет предыдущий `return`
console.log(4); // не выполняется
}
// `return false` выполняется сейчас
console.log(5); // не выполняется
}
f(); // отображает 0, 1, 3 и возвращает `false`
Замена возвращаемых значений блоком finally распространяется в том числе и на исключения, которые выбрасываются или перевыбрасываются в блоке catch:
function f() {
try {
throw "bogus";
} catch(e) {
console.log('caught inner "bogus"');
throw e; // приостанавливается до завершения блока `finally`
} finally {
return false; // заменяет предыдущий `throw`
}
// `return false` выполняется сейчас
}
try {
f();
} catch(e) {
// Не выполняется, т.к. `throw` в `catch `заменяется на `return` в `finally`
console.log('caught outer "bogus"');
}
// В результате отображается сообщение caught inner "bogus"
// и возвращается значение `false`
Вложенные инструкции try...catch
Вы можете вкладывать инструкции try...catch друг в друга. Если внутренняя инструкция try...catch не имеет блока catch, то она должна иметь блок finally, кроме того исключение будет перехвачено во внешнем блоке catch. Для получения большей информации ознакомьтесь с вложенными try-блоками.
Использование объекта Error
В зависимости от типа ошибки вы можете использовать свойства name и message, чтобы получить более подробную информацию. Свойство name содержит название ошибки (например, DOMException или Error), свойство message — описание ошибки.
Если вы выбрасываете собственные исключения, то чтобы получить преимущество, которое предоставляют эти свойства (например, если ваш блок catch не делает различий между вашими исключениями и системными), используйте конструктор Error. Например:
function doSomethingErrorProne () {
if ( ourCodeMakesAMistake() ) {
throw ( new Error('The message') );
} else {
doSomethingToGetAJavascriptError();
}
}
try {
doSomethingErrorProne();
} catch (e) {
console.log(e.name); // 'Error'
console.log(e.message); // 'The message' или JavaScript error message
}
Объект Promise
Начиная с ECMAScript2015, JavaScript поддерживает объект Promise, который используется для отложенных и асинхронных операций.
Объект Promise может находиться в следующих состояниях:
- ожидание (pending): начальное состояние, не выполнено и не отклонено.
- выполнено (fulfilled): операция завершена успешно.
- отклонено (rejected): операция завершена с ошибкой.
- заданный (settled): промис выполнен или отклонен, но не находится в состоянии ожидания.

Загрузка изображения при помощи XHR
Простой пример использования объектов Promise и XMLHttpRequest для загрузки изображения доступен в репозитории MDN promise-test на GitHub. Вы также можете посмотреть его в действии. Каждый шаг прокомментирован, что позволяет вам разобраться в архитектуре Promise и XHR. Здесь приводится версия без комментариев:
function imgLoad(url) {
return new Promise(function(resolve, reject) {
var request = new XMLHttpRequest();
request.open('GET', url);
request.responseType = 'blob';
request.onload = function() {
if (request.status === 200) {
resolve(request.response);
} else {
reject(Error('Image didn't load successfully; error code:'
+ request.statusText));
}
};
request.onerror = function() {
reject(Error('There was a network error.'));
};
request.send();
});
}
- « Предыдущая статья
- Следующая статья »
This computer programming article is available in pseudocode and Ada.
Error handling techniques[edit source]
This chapter describes various error handling techniques. First the technique is described, then its use is shown with an example function and a call to that function. We use the √ function which should report an error condition when called with a negative parameter.
Return code[edit source]
function √ (X : in Float) : Float
begin
if (X < 0) :
return -1
else
calculate root from x
fi
end
C := √ (A2 + B2) if C < 0 then error handling else normal processing fi
Our example make use of the fact that all valid return values for √ are positive and therefore -1 can be used as an error indicator. However this technique won’t work when all possible return values are valid and no return value is available as error indicator.
Error (success) indicator parameter[edit source]
An error condition is returned via additional out parameter. Traditionally the indicator is either a boolean with «true = success» or an enumeration with the first element being «Ok» and other elements indicating various error conditions.
function √ (
X : in Float;
Success : out Boolean ) : Float
begin
if (X < 0) :
Success := False
else
calculate root from x
Success := True
fi
end
C := √ (A2 + B2, Success) if not Success then error handling else normal processing fi
This technique does not look very nice in mathematical calculations.
Global variable[edit source]
An error condition is stored inside a global variable. This variable is then read directly or indirectly via a function.
function √ (X : in Float) : Float
begin
if (X < 0) :
Float_Error := true
else
calculate root from x
fi
end
Float_Error := false C := √ (A2 + B2) if Float_Error then error handling else normal processing fi
As you can see from the source the problematic part of this technique is choosing the place at which the flag is reset. You could either have the callee or the caller do that.
Also this technique is not suitable for multithreading.
Exceptions[edit source]
The programming language supports some form of error handling. This ranges from the classic ON ERROR GOTO ... from early Basic dialects to the try ... catch exceptions handling from modern object oriented languages.
The idea is always the same: you register some part of your program as error handler to be called whenever an error happens. Modern designs allow you to define more than one handler to handle different types of errors separately.
Once an error occurs the execution jumps to the error handler and continues there.
function √ (X : in Float) : Float
begin
if (X < 0) :
raise Float_Error
else
calculate root from x
fi
end
try: C := √ (A2 + B2) normal processing when Float_Error: error handling yrt
The great strength of exceptions handling is that it can block several operations within one exception handler. This eases up the burden of error handling since not every function or procedure call needs to be checked independently for successful execution.
Design by Contract[edit source]
In Design by Contract (DbC) functions must be called with the correct parameters. This is the caller’s part of the contract. If the types of actual arguments match the types of formal arguments, and if the actual arguments have values that make the function’s preconditions True, then the subprogram gets a chance to fulfill its postcondition. Otherwise an error condition occurs.
Now you might wonder how that is going to work. Let’s look at the example first:
function √ (X : in Float) : Float
pre-condition (X >= 0)
post-condition (return >= 0)
begin
calculate root from x
end
C := √ (A2 + B2)
As you see the function demands a precondition of X >= 0 — that is the function can only be called when X ≥ 0. In return the function promises as postcondition that the return value is also ≥ 0.
In a full DbC approach, the postcondition will state a relation that fully describes the value that results when running the function, something like result ≥ 0 and X = result * result. This postcondition is √’s part of the contract. The use of assertions, annotations, or a language’s type system for expressing the precondition X >= 0 exhibits two important aspects of Design by Contract:
- There can be ways for the compiler, or analysis tool, to help check the contracts. (Here for example, this is the case when
X ≥ 0follows from X’s type, and √’s argument when called is of the same type, hence also ≥ 0.) - The precondition can be mechanically checked before the function is called.
The 1st aspect adds to safety: No programmer is perfect. Each part of the contract that needs to be checked by the programmers themselves has a high probability for mistakes.
The 2nd aspect is important for optimization — when the contract can be checked at compile time, no runtime check is needed. You might not have noticed but if you think about it:  is never negative, provided the exponentiation operator and the addition operator work in the usual way.
is never negative, provided the exponentiation operator and the addition operator work in the usual way.
We have made 5 nice error handling examples for a piece of code which never fails. And this is the great opportunity for controlling some runtime aspects of DbC: You can now safely turn checks off, and the code optimizer can omit the actual range checks.
DbC languages distinguish themselves on how they act in the face of a contract breach:
- True DbC programming languages combine DbC with exception handling — raising an exception when a contract breach is detected at runtime, and providing the means to restart the failing routine or block in a known good state.
- Static analysis tools check all contracts at analysis time and demand that the code written in such a way that no contract can ever be breached at runtime.
Language overview[edit | edit source]
This list gives an overview of the standard or primary behavior and error handling techniques used in various programming languages. This does not mean that other techniques or behavior are not possible in the programming languages named.
| Language | Technique | null | / 0 | array | int | float | type |
|---|---|---|---|---|---|---|---|
| Ada Book of the Month September 2005 | exceptions/DbC1 | handled | handled | handled | handled | handled | handled |
| C | return/var | crash | crash | fault | fault2 | fault | fault2 |
| C++ | exceptions | crash | crash | fault | fault2 | fault | fault2 |
| Python | exceptions | handled | handled | handled | handled | handled | handled |
| SPARK | DbC | handled | handled | handled | handled | handled | handled |
| Error Types | |||||||
| null | null pointer or nil element access. | ||||||
| / 0 | division by 0. | ||||||
| array | out of bound array access. | ||||||
| int | out of bound integer range/overflow. | ||||||
| float | out of bound floating point calculations. | ||||||
| type | out of bound type conversions. | ||||||
| Handled by | |||||||
| handled | the error is handled by the language in a proper manner — for example with the use of error or exception handlers. | ||||||
| fault | the program continues to run in an undefined or faulty manner. | ||||||
| crash | program crashes. | ||||||
| Technique | |||||||
| DbC | The Language uses Design by Contract to avoid error condition. | ||||||
| exceptions | Language raises an exception or uses a similar technique when an error condition appears. | ||||||
| return | Language uses an return code to indicate an error condition. | ||||||
| var | Language uses one or more global variables to indicate an error condition. |
1 : Ada supports a very limited form of DbC through its strong typing system.
2 : In C and C++ the behavior is defined and sometimes intentionally used however in this comparison we consider unintentional use.
This is the thirty-seventh installment in a series of articles about fundamental object-oriented (O-O) concepts and related object-oriented technologies. The material presented in these articles is based on material from the second edition of my book, The Object-Oriented Thought Process, 2nd edition. The Object-Oriented Thought Process is intended for anyone who needs to understand basic object-oriented concepts and technologies before jumping directly into the code. Click here to start at the beginning of the series.
In keeping with the code examples used in the previous articles, Java will be the language used to implement the concepts in code. One of the reasons that I like to use Java is because you can download the Java compiler for personal use at the Sun Microsystems Web site http://java.sun.com/. You can download the standard edition, J2SE 5.0, at http://java.sun.com/j2se/1.5.0/download.jsp to compile and execute these applications. I often reference the Java J2SE 5.0 API documentation and I recommend that you explore the Java API further. Code listings are provided for all examples in this article as well as figures and output (when appropriate). See the first article in this series for detailed descriptions for compiling and running all the code examples (http://www.developer.com/design/article.php/3304881).
The code examples in this series are meant to be a hands-on experience. There are many code listings and figures of the output produced from these code examples. Please boot up your computer and run these exercises as you read through the text.
For the past several months, you have been exploring various issues regarding object integrity, security, and performance. In this month’s article, you review a concept that I touched on briefly earlier in the series error handling. In this article, you will cover the basic concepts of error handling with the intent of delving much deeper into this topic in future articles.
It is important to realize that this article’s focus is on error handling and not specifically on exceptions. Although exceptions are the true objects (as with all objects, the Exception class inherits from the Object class), Exceptions are not the only technique for error handling. In fact, the terminology can get a bit tricky. Technically, errors and exceptions are defined as two totally separate entities in the Java programming specification. Both errors and exceptions inherit from a class called Throwable, as seen in Diagram 1.
Diagram 1: The Throwable inheritance tree.
Although you often hear the terms ‘catching an exception‘ or ‘handling an error‘ used quite often, you don’t often hear the term ‘Throwable’ used in many places (although you may well hear someone refer to throwing an exception).
This is why the terminology may get a bit confusing when discussing error handling. Error handling has always been a major part of programming; however, throwing and catching Exceptions are somewhat newer concepts. In any case, what exactly does Throwable mean and how does it relate to Errors and Exceptions?
The definition from the Java API specifications describes the Throwable class as follows:
The Throwable class is the superclass of all errors and exceptions in the Java language. Only objects that are instances of this class (or one of its subclasses) are thrown by the Java Virtual Machine or can be thrown by the Java throw statement. Similarly, only this class or one of its subclasses can be the argument type in a catch clause.

Diagram 2: An Object with two References and two Objects (different content)
At this point, the application loses control of the process and is aborted. Control returns to the operating system. You can see this by observing the output in Figure 1.

Figure 1: Generating an Error—Ignoring the problem
This scenario is not a happy ending for the user. How many times have you been using a software application when the application crashed? Although this used to be a more common occurrence several years ago, it is still an unwelcome situation. And, when a situation such as this does occur, the results can be anywhere from annoying to devastating. When an application has an uncontrolled abort, there is a distinct possibility that data will be lost or corrupted. One of the cardinal rules pertaining to software applications is that an application should avoid an uncontrolled abort (crash) at all costs. If an application continuously crashes, users are very likely to stop using (buying) the product.
If you do make the effort to detect the problem, you might as well figure out how to handle it; if you are going to ignore the problem, why bother detecting it in the first place? The bottom line is that you should not ignore the problem. If you do not handle your errors, the application will eventually terminate ungracefully or continue in a mode that can be considered an unstable (unsafe) state. In the latter case, you might not even know you are getting incorrect results for some period of time—and this can be dangerous.
Checking for Problems and Terminating the Application Gracefully
If you decide to check for potential problems and exit the application when a problem is detected, the application can, at least, display a message indicating that you have a problem and what action is being taken.
Detecting a problem and then gracefully exiting means that the application identifies a problem, cleans up the mess as best as possible, and then decides to terminate the application. This is not a crash. Rather than allowing the operating system to indiscriminately abort the application, the application (via the programmer) remains in control of the process. Then, the programmer simply decides that it is better, and/or safer, to exit the application.
This strategy allows the programmer to code clean-up methods that can perform important functions such as saving or closing files, sending messages, and putting the system in a safe-state. Consider an elevator system. If there is a fire alarm anomaly, you would want all the elevators to either proceed to the first floor, or at least open the doors at the closest floor. If the application simply crashes, there could be people left stranded in the elevators during a fire. This is all well and good; however, you better let the user know what is happening.
If you exit the application without letting the user know, the code may in fact terminate gracefully (meaning no crash); however, the user is left staring at the computer screen, shaking his/her head and wondering what just happened.
Although gracefully exiting the application when an anomaly is detected is a far superior option to ignoring the problem, it is by no means optimal. However, this does allow the system to clean up things and put itself in a more stable state, such as closing files.
// Class ErrorHandling
public class ErrorHandling {
public static void main(String[] args) {
int a = 0;
int b = 0;
int c = 0;
if (b != 0) { // catch the divide by zero
c = a / b;
} else {
System.out.println("Error: Divide by zero");
System.exit(0); //abort under control
}
}
}
Listing 2: Generating an Error—Ignoring the exception
With the if statement, in the case of the code in Listing 2, you check to make sure that a division by zero never happens. When a division by zero is detected, the code is skipped and an error is printed. Diagram 3 shows the program flow in this situation. Note that the operating system eventually gets control of the process back; however, the application exits while in control and gives control back to the operating system voluntarily.

Diagram 3: An Object with two References and two Objects (different content)
The output produced when the code in Listing 2 is executed is presented in Figure 2. As you can see, the user is not shown the exception messages coming directly from the operating system. The users view what the programmer decides to show them.

Figure 2: Generating an Error—Catching the problem and aborting
Checking for Problems and Attempting to Recover
Checking for potential problems, catching the mistake, and attempting to recover is a far superior solution than simply checking for problems and gracefully exiting. In this case, the problem is detected by the code, and the application attempts to fix itself. This works well in certain situations. You could prompt the user to re-enter until an appropriate value is determined. Listing 3 is one solution—but not necessarily the best.
import java.io.*;
// Class ErrorHandling
public class ErrorHandling {
public static void main(String[] args) throws Exception {
int a = 0;
int b = 0;
int c = 0;
b = getInput();
while (b == 0) { // catch the divide by zero
System.out.println("Error: Divide by zero. Please reenter.");
b = getInput();
}
c = a / b;
System.out.println("c = " + c);
}
public static int getInput() throws Exception {
int x;
BufferedReader stdin =
new BufferedReader(new InputStreamReader(System.in), 1);
System.out.print("Please Enter Number:");
String s1 = stdin.readLine();
x = Integer.parseInt(s1); // string to double
System.out.println("x = " + x);
return (x);
}
}
Listing 3: Generating an Error—Catching the problem and handling it.
Note that the code in red is in place to re-prompt the user for valid input. Also presented in red, note that you are ignoring the required exception detection. The anomaly is detected so that no division takes place with a zero denominator. Rather than terminate, the application can continue. In theory, the operating system does not come in to play, as seen in Diagram 4.

Diagram 4: Generating an Error—Catching the problem and handling it.
In this case, the user is kept informed by an error message indicating what the problem is and then is asked to re-enter a valid value, as seen in Figure 3. It is important to make sure that the messages to the user are specific and clear.

Figure 3: Generating an Error—Catching the problem and handling it.
Despite the fact that this type of error handling is not necessarily object-oriented in nature, I believe that it has a valid place in OO design. Throwing an exception (discussed in the next section) can be expensive in terms of overhead (you will learn about the cost of exception handling in a later article). Thus, although exceptions are a great design choice, you will still want to consider other error handling techniques, depending on your design and performance needs.
Although this means of error checking is preferable to the previous solutions, it still has a few potentially limiting problems. It is not always easy to determine where a problem first appears. And, it might take a while for the problem to be detected. It is always important to design error handling into the class right from the start.
Throwing an Exception
Most OO languages provide a feature called exceptions. In the most basic sense, exceptions are unexpected events that occur within a system. Exceptions provide a way to detect problems and then handle them. In Java, C#, and C++, exceptions are handled by the keywords catch and throw. This might sound like a baseball game, but the key here is that a specific block of code is written to handle a specific exception. This solves the problem of trying to figure out where the problem started and unwinding the code to the proper point. Here is how the code for a try/catch block looks:
try {
// Business/program logic
} catch(Exception e) {
// Code executed when exception occurs
}
If an exception is thrown within the try block, the catch block will handle it. When an exception is thrown while the code in the try block is executing, the following occurs:
- The execution of the try block is terminated.
- The catch clauses are checked to determine whether an appropriate catch block for the offending exception was included. (There might be more than one catch clause per try block.)
- If none of the catch clauses handle the offending exception, it is passed to the next higher-level try block. (If the exception is not caught in the code, the system ultimately catches it and the results are unpredictable.)
- If a catch clause is matched (the first match encountered), the statements in the catch clause are executed.
- Execution then resumes with the statement following the try block.
Listing 4 an example of how an exception is caught by using the code from the previous examples:
import java.io.*;
// Class ErrorHandling
public class ErrorHandling {
public static void main(String[] args) throws Exception {
int a = 9;
int b = 0;
int c = 0;
b = getInput();
try {
c = a / b;
} catch(Exception e) {
System.out.println("n*** Exception Caught");
System.out.print("*** System Message : ");
System.out.println(e.getMessage());
System.out.println("*** Exiting application ...n");
}
System.out.println("c = " + c);
}
public static int getInput() throws Exception {
int x;
BufferedReader stdin =
new BufferedReader(new InputStreamReader(System.in), 1);
System.out.print("Please Enter Number:");
String s1 = stdin.readLine();
x = Integer.parseInt(s1); // string to double
return (x);
}
}
Listing 4: Generating an Error—Catching the exception.
Exception Granularity
You can catch exceptions at various levels of granularity. You can catch all exceptions or just check for specific exceptions, such as arithmetic exceptions. If your code does not catch an exception, the Java runtime will—and it won’t be happy about it!
In this example, as you have already seen, the division by zero within the try block will cause an arithmetic exception. If an exception is actually generated (thrown) outside a try block, the program would most likely have been terminated. However, because the exception was thrown within a try block, the catch block is checked to see whether the specific exception (in this case, an arithmetic exception) was planned for.

Diagram 5: Generating an Error—Catching the exception.
As seen in Diagram 5, the operating system and the application are, in effect, working together to handle the problems. Although the operating system (or Virtual Machine) does actually generate the exceptions, the application detects them and can handle them as desired. Figure 4 shows what the user sees from the various messages printed after the exception is handled.

Figure 4: Generating an Error—Catching the exception.
Conclusion
It is almost certain that every system will encounter unforeseen problems. Thus, it is not a good idea to simply ignore potential errors. The developer of a good class (or any code, for that matter) anticipates potential errors and includes code to handle these conditions when they are encountered.
The rule of thumb is that the application should never crash. When an error is encountered, the system should either fix itself and continue, or exit gracefully without losing any data that’s important to the user.
It’s a good idea to use a combination of the methods described here to make your program as bulletproof for your user as possible.
References
- www.sun.com
- http://java.sun.com/j2se/1.5.0/docs/api/
- Java Primer Plus: Supercharging Web Applications With the Java Programming Language. Tyma, Torol, Downing. ISBN: 157169062X
- Object-oriented design in Java. Stephen Gilbert; Bill McCarty. ISBN: 1571691340
About the Author
Matt Weisfeld is a faculty member at Cuyahoga Community College (Tri-C) in Cleveland, Ohio. Matt is a member of the Information Technology department, teaching programming languages such as C++, Java, C#, and .NET as well as various web technologies. Prior to joining Tri-C, Matt spent 20 years in the information technology industry, gaining experience in software development, project management, business development, corporate training, and part-time teaching. Matt holds an MS in computer science and an MBA in project management. Besides The Object-Oriented Thought Process, which is now in its second edition, Matt has published two other computer books, and more than a dozen articles in magazines and journals such as Dr. Dobb’s Journal, The C/C++ Users Journal, Software Development Magazine, Java Report, and the international journal Project Management. Matt has presented at conferences throughout the United States and Canada.
Don’t you hate it when you see an uncaughtException error pop up and crash your Node.js app?
Yeah… I feel you. Can anything be worse? Oh yeah, sorry, unhandledRejection I didn’t see you there. What a nightmare you are. 😬
I maintain all Node.js open-source repos at Sematext. A few of them can help you out with error handling, but more about that further down.
Here at Sematext, we take error handling seriously! I want to share a bit of that today.
I want to guide you through what I’ve learned so far about error handling in Node.js while working on open-source projects. Hopefully, it’ll help you improve your code, make it more robust, and ultimately help you step up your bug hunting, and help improve your general developer experience.
I don’t want you to have to stay up late and burn the midnight oil troubleshooting bugs. Ah! About that, here’s an epic song I really like!
What Is Error Handling in Node.js
I’ve heard a ton of my fellow developers say error handling in Node.js is way too hard. Well, I can’t lie. It’s not easy. But, I have to be fair and say it’s not that hard either once you set up centralized error handling.
What is an error anyhow? It’s a way to see bugs in your code. Following this logic, error handling is a way to find these bugs and solve them as quickly as humanly possible.
From this explanation, it’s obvious the hard part is setting up a good base for your error handling. It’s all about keeping you sane at the end of the day. Handling errors properly means developing a robust codebase and reducing development time by finding bugs and errors easily.
Why Do You Need Error Handling
Why? For your own sanity. You want to make bug fixing less painful. It helps you write cleaner code. It centralizes all errors and lets you enable alerting and notifications so you know when and how your code breaks.
Types of Errors: Operational vs. Programmer Errors
Would you believe me when I said not all errors are caused by humans? Don’t get me wrong, most still are, but not all of them! Errors can be Operational and Programmer errors.
Operational Errors
Operational errors represent runtime problems. These errors are expected in the Node.js runtime and should be dealt with in a proper way. This does not mean the application itself has bugs. It means they need to be handled properly. Here’s a list of common operational errors:
- failed to connect to server
- failed to resolve hostname
- invalid user input
- request timeout
- server returned a 500 response
- socket hang-up
- system is out of memory
Programmer Errors
Programmer errors are what we call bugs. They represent issues in the code itself. Here’s a common one for Node.js, when you try reading a property of an undefined object. It’s a classic case of programmer error. Here are a few more:
- called an asynchronous function without a callback
- did not resolve a promise
- did not catch a rejected promise
- passed a string where an object was expected
- passed an object where a string was expected
- passed incorrect parameters in a function
Now you understand what types of errors you’ll be facing, and how they are different. Operational errors are part of the runtime and application while programmer errors are bugs you introduce in your codebase.
Now you’re thinking, why do we divide them into two categories? It’s simple really.
Do you want to restart your app if there’s a user not found error? Absolutely not. Other users are still enjoying your app. This is an example of an operational error.
What about failing to catch a rejected promise? Does it make sense to keep the app running even when a bug threatens your app? No! Restart it.
What Is an Error Object?
The error object is a built-in object in the Node.js runtime. It gives you a set of info about an error when it happens. The Node.js docs have a more in-depth explanation.
A basic error looks like this:
const error = new Error("An error message")
console.log(error.stack)
It has an error.stack field that gives you a stack trace showing where the error came from. It also lists all functions that were called before the error occurred. The error.stack field is optimal to use while debugging as it prints the error.message as well.
How Do You Handle Errors in Node.js: Best Practices You Should Follow
From my experience, there are a few best practices that will make it easier to handle errors in Node.js.
You can handle errors in callbacks. There are some serious drawbacks to using callbacks because it creates a nested “callback hell”. It’s notoriously hard to debug and fix errors if you need to look for them in nested functions.
A better way is to use async/await and try-catch statements, or .catch() errors in promises.
Let me show you what I mean.
1. Use Custom Errors to Handle Operational Errors
With the async/await pattern you can write code that looks synchronous, but actually is asynchronous.
const anAsyncTask = async () => {
try {
const user = await getUser()
const cart = await getCart(user)
return cart
} catch (error) {
console.error(error)
} finally {
await cleanUp()
}
}
This pattern will clean up your code and avoid the dreaded callback hell.
You can use the built-in Error object in Node.js as I mentioned above, as it gives you detailed info about stack traces.
However, I also want to show you how to create custom Error objects with more meaningful properties like HTTP status codes and more detailed descriptions.
Here’s a file called baseError.js where you set the base for every custom error you’ll use.
// baseError.js
class BaseError extends Error {
constructor (name, statusCode, isOperational, description) {
super(description)
Object.setPrototypeOf(this, new.target.prototype)
this.name = name
this.statusCode = statusCode
this.isOperational = isOperational
Error.captureStackTrace(this)
}
}
module.exports = BaseError
Also create an httpStatusCodes.js file to keep a map of all status codes you want to handle.
// httpStatusCodes.js
const httpStatusCodes = {
OK: 200,
BAD_REQUEST: 400,
NOT_FOUND: 404,
INTERNAL_SERVER: 500
}
module.exports = httpStatusCodes
Then, you can create an api404Error.js file, and extend the BaseError with a custom error for handling 404s.
// api404Error.js
const httpStatusCodes = require('./httpStatusCodes')
const BaseError = require('./baseError')
class Api404Error extends BaseError {
constructor (
name,
statusCode = httpStatusCodes.NOT_FOUND,
description = 'Not found.',
isOperational = true
) {
super(name, statusCode, isOperational, description)
}
}
module.exports = Api404Error
How do you use it? Throw it in your code when you want to handle 404 errors.
const Api404Error = require('./api404Error')
...
const user = await User.getUserById(req.params.id)
if (user === null) {
throw new Api404Error(`User with id: ${req.params.id} not found.`)
}
...
You can duplicate this code for any custom error, 500, 400, and any other you want to handle.
2. Use a Middleware
Once you have a set of custom errors, you can configure centralized error handling. You want to have a middleware that catches all errors. There you can decide what to do with them and where to send them if they need to notify you via an alert notification.
In your API routes you’ll end up using the next() function to forward errors to the error handler middleware.
Let me show you.
...
app.post('/user', async (req, res, next) => {
try {
const newUser = User.create(req.body)
} catch (error) {
next(error)
}
})
...
The next() function is a special function in Express.js middlewares that sends values down the middleware chain. At the bottom of your routes files you should have a .use() method that uses the error handler middleware function.
const { logError, returnError } = require('./errorHandler')
app.use(logError)
app.use(returnError)
The error handler middleware should have a few key parts. You should check if the error is operational, and decide which errors to send as alert notifications so you can debug them in more detail. Here’s what I suggest you add to your error handler.
function logError (err) {
console.error(err)
}
function logErrorMiddleware (err, req, res, next) {
logError(err)
next(err)
}
function returnError (err, req, res, next) {
res.status(err.statusCode || 500).send(err.message)
}
function isOperationalError(error) {
if (error instanceof BaseError) {
return error.isOperational
}
return false
}
module.exports = {
logError,
logErrorMiddleware,
returnError,
isOperationalError
}
3. Restart Your App Gracefully to Handle Programmer Errors
Everything I’ve explained so far has been related to operational errors. I’ve shown how to gracefully handle expected errors and how to send them down the middleware chain to a custom error handling middleware.
Let’s jump into programmer errors now. These errors can often cause issues in your apps like memory leaks and high CPU usage. The best thing to do is to crash the app and restart it gracefully by using the Node.js cluster mode or a tool like PM2. I wrote another article where I describe in detail how to detect Node.js memory leaks using various solutions.
4. Catch All Uncaught Exceptions
When unexpected errors like these happen, you want to handle it immediately by sending a notification and restarting the app to avoid unexpected behavior.
const { logError, isOperationalError } = require('./errorHandler')
...
process.on('uncaughtException', error => {
logError(error)
if (!isOperationalError(error)) {
process.exit(1)
}
})
...
5. Catch All Unhandled Promise Rejections
Promise rejections in Node.js only cause warnings. You want them to throw errors, so you can handle them properly.
It’s good practice to use fallback and subscribe to:
process.on('unhandledRejection', callback)
This lets you throw an error properly.
Here’s what the error handling flow should look like.
...
const user = User.getUserById(req.params.id)
.then(user => user)
// missing a .catch() block
...
// if the Promise is rejected this will catch it
process.on('unhandledRejection', error => {
throw error
})
process.on('uncaughtException', error => {
logError(error)
if (!isOperationalError(error)) {
process.exit(1)
}
})
6. Use a Centralized Location for Logs and Error Alerting
I recently wrote a detailed tutorial about Node.js logging best practices you should check out.
The gist of it is to use structured logging to print errors in a formatted way and send them for safekeeping to a central location, like Sematext Logs, our log management tool.
It’ll help with your sanity and persist the logs over time, so you can go back and troubleshoot issues whenever things break.
To do this, you should use loggers like winston and morgan. Additionally, you can add winston-logsene to send the logs to Sematext right away.
First, create a setup for winston and winston-logsene. Create a loggers directory and a logger.js file. Paste this into the file.
// logger.js
const winston = require('winston')
const Logsene = require('winston-logsene')
const options = {
console: {
level: 'debug',
handleExceptions: true,
json: false,
colorize: true
},
logsene: {
token: process.env.LOGS_TOKEN,
level: 'debug',
type: 'app_logs',
url: 'https://logsene-receiver.sematext.com/_bulk'
}
}
const logger = winston.createLogger({
levels: winston.config.npm.levels,
transports: [
new winston.transports.Console(options.console),
new Logsene(options.logsene)
],
exitOnError: false
})
module.exports = logger
The good thing with this is that you get JSON formatted logs you can analyze to get more useful information about your app. You’ll also get all logs forwarded to Sematext. This will alert you whenever errors occur. That’s pretty awesome!
Furthermore, you should add an httpLogger.js file in the loggers directory and add morgan and morgan-json to print out access logs. Paste this into the httpLogger.js:
const morgan = require('morgan')
const json = require('morgan-json')
const format = json({
method: ':method',
url: ':url',
status: ':status',
contentLength: ':res[content-length]',
responseTime: ':response-time'
})
const logger = require('./logger')
const httpLogger = morgan(format, {
stream: {
write: (message) => {
const {
method,
url,
status,
contentLength,
responseTime
} = JSON.parse(message)
logger.info('HTTP Access Log', {
timestamp: new Date().toString(),
method,
url,
status: Number(status),
contentLength,
responseTime: Number(responseTime)
})
}
}
})
module.exports = httpLogger
In your app.js file you can now require both the logger.js and httpLogger.js, and use the logger instead of console.log().
// app.js
const logger = require('./loggers/logger')
const httpLogger = require('./loggers/httpLogger')
...
app.use(httpLogger)
...
In your errorHandler.js you can now replace all console.error() statements with logger.error() to persist the logs in Sematext.
// errorHandler.js
const logger = require('../loggers/logger')
const BaseError = require('./baseError')
function logError (err) {
logger.error(err)
}
function logErrorMiddleware (err, req, res, next) {
logError(err)
next(err)
}
function returnError (err, req, res, next) {
res.status(err.statusCode || 500).send(err.message)
}
function isOperationalError(error) {
if (error instanceof BaseError) {
return error.isOperational
}
return false
}
module.exports = {
logError,
logErrorMiddleware,
returnError,
isOperationalError
}
That’s it. You now know how to properly handle errors!
However, I do want to cover how to deliver errors. Should you be throwing them, passing errors in callback functions or promise rejections, or emit an “error” event via an EventEmitter.
How to Deliver Errors: Function Patterns
Let’s go over the four main ways to deliver an error in Node.js:
- throw the error (making it an exception).
- pass the error to a callback, a function provided specifically for handling errors and the results of asynchronous operations
- pass the error to a reject Promise function
- emit an “error” event on an EventEmitter
We’ve talked about how to handle errors, but when you’re writing a new function, how do you deliver errors to the code that called your function?
Throwing Errors
When you throw an error it unwinds the entire function call stack ignoring any functions you have on the stack. It gets delivered synchronously, in the same context where the function was called.
If you use a try-catch block you can handle the error gracefully. Otherwise, the app usually crashes, unless you have a fallback for catching Uncaught Exceptions as I explained above.
Here’s an example of throwing an error and handling it in a try-catch block:
const getUserWithAsyncAwait = async (id) => {
try {
const user = await getUser(id)
if (!user) {
throw new 404ApiError('No user found.')
}
return user
} catch (error) {
// handle the error
logError(error)
}
}
const user = await getUserWithAsyncAwait(1)
...
Using Callback
Callbacks are the most basic way of delivering an error asynchronously. The user passes you a function – the callback, and you invoke it sometime later when the asynchronous operation completes. The usual pattern is that the callback is invoked as callback(err, result), where only one of err and result is non-null, depending on whether the operation succeeded or failed.
Callbacks have been around for ages. It’s the oldest way of writing asynchronous JavaScript code. It’s also the oldest way of delivering errors asynchronously.
You pass a callback function as a parameter to the calling function, which you later invoke when the asynchronous function completes executing.
The usual pattern looks like this:
callback(err, result)
The first parameter in the callback is always the error.
Inside the callback function, you’ll then first check if the error exists and only if it’s a non-null value you continue executing the callback function.
function getUserWithCallback(id, callback) {
getUser(id, function(user) {
if (!user) {
return callback(new 404ApiError('No user found.'))
}
callback(null, user)
})
}
getUserWithCallback(1, function(err, user) {
if (err) {
// handle the error
logError(error)
}
const user = user
...
})
Using Promises
Promises have replaced callbacks as the new and improved way of writing asynchronous code.
This pattern has become the new norm since Node.js version 8 that included async/await out of the box. Asynchronous code can be written to look like synchronous code. Catch errors can be done by using try-catch.
function getUserWithPromise(id) {
return new Promise((resolve, reject) => {
getUser(id, function(user) {
if (!user) {
return reject(new 404ApiError('No user found.'))
}
resolve(user)
})
})
}
getUserWithPromise(1)
.then(user => {
const user = user
...
})
.catch(err => {
logError(error)
})
Using EventEmitter
Ready for some more complicated use cases?
In some cases, you can’t rely on promise rejection or callbacks. What if you’re reading files from a stream. Or, fetching rows from a database and reading them as they arrive. A use case I see on a daily basis is streaming log lines and handling them as they’re coming in.
You can’t rely on one error because you need to listen for error events on the EventEmitter object.
In this case, instead of returning a Promise, your function would return an EventEmitter and emit row events for each result, an end event when all results have been reported, and an error event if any error is encountered.
Here’s a code sample from Logagent, an open-source log shipper I maintain. The socket value is an EventEmitter object.
net.createServer(socket => {
...
socket
.on('data', data => {
...
})
.on('end', result => {
…
})
.on('error', console.error) // handle multiple errors
}
Throw, Callback, Promises, or EventEmitter: Which Pattern Is the Best?
Now, we’ve finally come to the verdict, when should you throw errors, and when do you use promise rejections or EventEmitters?
For operational errors, you should use Promise rejections or a try-catch block with async/await. You want to handle these errors asynchronously. It works well and is widely used.
If you have a more complicated case like I explained above, you should use an event emitter instead.
You want to explicitly throw errors if unwinding the whole call stack is needed. This can mean when handling programmer errors and you want the app to restart.
How to Write Functions for Efficient Error Handling
Whatever you do, choose one way to deliver operational errors. You can throw errors and deliver them synchronously, or asynchronously by using Promise rejections, passing them in callbacks, or emitting errors on an EventEmitter.
After setting up centralized error handling, the next logical step is to use a central location for your logs that also gives you error alerting.
Sematext Logs provides log management and error alerting to help analyze logs and debug and fix errors and exceptions. Definitely check it out and try it yourself. But you can also take a look at the lists where we compare the best log management tools, log analysis software, and cloud logging services available today.
Closing Thoughts
In this tutorial, I wanted to give you a way to handle the dreaded unhandledException and unhandledRejection errors in Node.js apps. I hope it was useful to you and that you’ll use what you learned today in your own apps.
Alongside this, I also explained a few best practices about error handling, like how to set up centralized error handling with middlewares and use a central location for your error logs. Don’t forget that logging frameworks like winston and morgan are crucial for this to work.
Lastly, I explained a few different ways of delivering errors, either with throw or with Promise .reject(), callback functions or the .on(‘error’) event on an EventEmitter.
I’ve tried to share all the knowledge I’ve gained over the last few years while maintaining open-source repos to keep you from making the same mistakes I’ve made in the past. Best of luck!
If you ever need alerting, error handling, and log management for your production apps, check us out.