Содержание
- Как устранить ошибки Ultra DMA CRC Error
- Основные характеристики жесткого диска
- Технология S.M.A.R.T
- Атрибут: 199 (С7) UltraDMA CRC Error Count
- Блог SerZh’a
- Вы здесь
- Счетчик ошибок Ultra DMA CRC Error
- How to Fix ‘Interface CRC Error Count’ inside HD Tune
- What is Ultra DMA CRC Error Count?
- Method 1: Running the brand-specific diagnostic tool
- Method 2: Fix the Incompatibility between Samsung SSD and SATA Controller (if applicable)
- Method 3: Replace the power and SATA cable
- Method 4: Backup your HDD data
- A. Backing up the files on your HDD via Command Prompt
- B. Backing up the files on your HDD via an Imaging 3rd party software
- Method 5: Send your HDD for replacement or order a replacement
Как устранить ошибки Ultra DMA CRC Error
Одним из важнейших компонентов любого компьютерного устройства является жесткий диск, другие названия: винчестер, винт, хард, HDD и т.д. Он служит для хранения разных данных пользователя, включая документы, музыку, фотографии, а также программные продукты и файлы операционной системы. Данный узел является энергонезависимым, т.е. отключение питания не приводит к исчезновению данных.
Информация, хранящаяся на жестком диске, бывает порой ценнее самого компьютера и чтобы не потерять ее (причины утраты данных на HDD и способы восстановления), необходимо контролировать состояние винчестера. В данной статье рассматриваются причины возникновения одной из наиболее часто встречающейся проблемы в работе HDD и пути для ее устранения.
Рассмотрим характеристики винчестера, по которому оценивается устройство, а также встроенные инструментарии для контроля над состоянием его работоспособности.
Основные характеристики жесткого диска
Накопители выпускаются в разных стандартных размерах, измеримых в дюймах, так для стационарных компьютеров это значение равно 3.5 дюйма, а для ноутбуков 2.5.
Взаимодействие диска с материнской платой выполняется через интерфейс, в настоящее время в ПК используется интерфейс SATA разных версий, отличающихся скоростью передачи данных (SATA/300 – 3 Гбит/сек, SATA/600 – до 6 Гбит/сек и т.д.).
Важной характеристикой устройства является показатель емкости, определяющий максимальное количество данных, хранящихся на диске.
Чем больше скорость вращения жёсткого диска, тем быстрее возможен доступ к информации. Она составляет 5400 или 7200 об/мин (реже 10 000 или 15 0000 об/мин, но это уже специализированные HDD).
Данный узел имеет встроенную память, которая служит для ускорения его работы и устранения разницы в скоростях чтения/записи и воспроизведения. Она характеризуется объемом буфера.
Время произвольного доступа зависит от позиционирования и положения головки в начале и конце сеанса определенного участка пластины.
Надежность работы, ударостойкость, уровень шума также являются оценочными характеристиками накопителя.
Ни один другой компонент компьютера не имеет такой уникальной возможности самоанализа на наличие ошибок и статистики работы, как винчестер. Произвести оценку состояния жесткого диска и предсказать время выхода его из строя можно с помощью специальной встроенного инструмента самодиагностики.
Технология S.M.A.R.T
Инструментарий, с помощью которого можно контролировать работоспособность винчестера, получил название S.M.A.R.T, что означает самомониторинг, анализ и отчет — от заглавных букв английского варианта «Self-Monitoring, Analysis and Reporting Technology».
С учетом того, что винчестер является одним из слабых мест компьютерного устройства, возможность вовремя отслеживать изменение состояния его функционирования, позволяет быстро выявить и устранить неисправности, экономя владельцу время и деньги.
Винчестер может находиться в двух состояниях: S.M.A.R.T. Good и S.M.A.R.T. Bad. Первый вариант свидетельствует о нормальной работе устройства, второй о том, что диск находится в критическом положении. Так как переход в состояние «bad» происходит постепенно, мониторя S.M.A.R.T. можно увидеть ухудшение параметров и успеть перенести информацию на другой накопитель.
Тестирование жесткого диска выполняют специальными утилитами, которые демонстрируют атрибуты S.M.A.R.T., характеризующие состояние его «здоровья». В зависимости от модели и производителя, атрибуты имеют определенные названия (ID) и номер (NUMBER).
Примерами программ, с помощью которых можно увидеть значения S.M.A.R.T и протестировать винчестер, являются следующие: CrystalDiskInfo (бесплатная), HDDScan (бесплатная), HD Tune(бесплатная только в старой версии), Hard DiskSentinel (бесплатная только для DOS), а также Victoria (бесплатная), MHDD (бесплатная под DOS).
Вот как выглядит картинка тестирования жесткого диска с помощью программы S.M.A.R.T. в HDDScan 3.3.
- Value — показатель состояния диска во время работы. Может изменяться, уменьшаясь или увеличиваясь, или быть неизменным. Его сравнивают с атрибутом Threshold: чем меньше, тем хуже «здоровье» HDD.
- Worst — самое низкое значение, которого может достичь Value в процессе всего жизненного цикла винчестера, его также сравнивают Threshold.
- Threshold — показатель критического состояния атрибута Value: норма, если он больше чем Threshold, меньший указывает на проблему. Утилиты, оценивающие состояние диска, судят по этому атрибуту.
- RAW — один из самых важных в оценке. Объективно определить состояние HDD можно по этому показателю.
Атрибут: 199 (С7) UltraDMA CRC Error Count
Данный атрибут относится к накапливающему типу и содержит количество ошибок, которые возникают во время передачи по интерфейсному кабелю от материнской платы или дискретного контроллера к контроллеру диска.
Например, если при запуске утилиты, отображающей атрибуты S.M.A.R.T, напротив строки (C7) Ultra DMA CRC Error Count счетчик показывает значение 1234, это говорит о проблемах с HDD.
По статистике, чаще всего увеличение значения этого атрибута возникает вследствие некачественной передачи данных по интерфейсу, что приводит к автоматическому переключению режимов работы канала, на котором находится HDD, и резкому падению скорости чтения/записи.
Другой причиной может быть разгон шины PCI/PCI-E компьютерного устройства, а также нарушение контакта в SATA-разъёме на диске или на материнской плате (контроллере). В некоторых случаях растущий атрибут появляется из-за несовместимости жесткого диска и SATA-контроллера.
Устранить ошибку S.M.A.R.T UltraDMA CRC Error Count можно путем выполнения ряда следующих действий:
- замены интерфейсного кабеля SATA;
- выполнения сброса разгона шины PCI/PCI-E компьютера к заводским установкам;
- обновления BIOS материнской платы;
- очищения с помощью спирта или обыкновенной стирки (резинового ластика) контактов на разъеме жесткого диска или материнки;
- переключения SATA-кабеля на другой разъем;
- замены блока питания жесткого диска;
- проверки материнки на предмет «вздутых» конденсаторов и, при необходимости, выполнения их замены;
- замены термопасты южного моста материнки;
- замены чипсета материнской платы;
- установления перемычки на жестком диске и переключить режим работы контроллера в SATA I;
- обновления драйвера чипсета материнской платы.
Впрочем, самостоятельно делать все вышеуказанные процедуры необязательно (если нет желания), всегда можно обратиться за компьютерной помощью к специалистам.
Необходимо иметь в виду, что хорошие атрибуты S.M.A.R.T не всегда дают полную и достоверную картину отличного состояния диска, однако плохие значения точно свидетельствуют о проблемах в HDD.
Гарантировано обезопасить себя от потери ценных данных, хранящихся на жестком диске, можно только с помощью периодического резервного копирования на съемный накопитель или другой диск, тогда как тестирование винчестера на предмет обнаружения ошибок в атрибутах поможет предотвратить его внезапный выход из строя.
Источник
Блог SerZh’a
мир электронных мыслей
Вы здесь
Счетчик ошибок Ultra DMA CRC Error

Одним из самых узких мест в компьютере до сих пор остается жесткий диск. Я не говорю о твердотельных накопителях SSD, у них тоже есть свои плюсы и минусы. Сегодня речь пойдет о жестких дисках, принцип работы которых был разработан еще в прошлом веке.
Принцип до сих пор остался прежним, изменяется только технология изготовления пластин и электроники, которая контролирует все процессы, происходящие на жестком диске.Показателем здоровья жесткого диска является таблица SMART.
S.M.A.R.T. (от английского self-monitoring, analysis and reporting technology ) — технология самоконтроля, анализа и отчётности) — технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя.
Жесткий диск я купил 1,5 года назад. Хотелось поменять свой тихоходный системный диск Hitachi 500Gb, на что-то пошустрей. Выбор был невелик — Western Digital Caviar Black 1Tb SATAIII или Seagate Barracuda (ST1000DM003) 1Tb SATAIII. Выбор пал в пользу последнего. Это был первый жесткий диск на рынке с терабайтной пластиной, что сразу снимало несколько проблем: нагрев, шум, энергопотребление. Максимальная скорость чтения в HD Tune переваливала за 200 Мб/сек, когда Hitachi показывал максимум 85. Вдобавок, Seagate был в полтора раза тоньше своих собратьев!
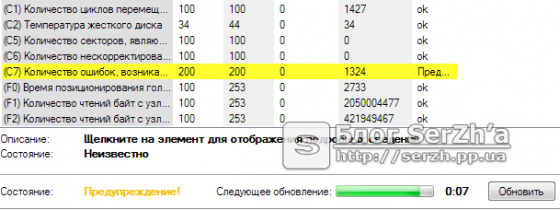
Все работало хорошо до последнего дня. Компьютер начал грузиться дольше, чем обычно. Перед загрузкой Windows каждый раз начинал запускать ScanDisk, проверяя жесткий диск на ошибки. Меня насторожило странное поведение компьютера и я решил проверить его на вирусы, загрузившись с LiveCD. Вирусов не было, поэтому я решил посмотреть на SMART дисков, чтобы удостовериться, что там все в порядке. Оказалось это не так. Напротив строки (C7) Ultra DMA CRC Error Count подсвечивалось предупреждение желтым цветом и счетчик показывал значение 1234.
В моей практике было несколько случаев, связанным с увеличением этого счетчика, но все решалось элементарной заменой интерфейсного кабеля. В данном случае это не помогло. В интернете описано много возможных путей решения этой проблемы, которые сводятся к следующему:
- Замена интерфейсного кабеля SATA (желательно с защелками);
- Возможный разгон шины PCI/PCI-E компьютера (сброс на заводские установки);
- Обновление BIOS материнской платы;
- Плохой контакт на разъеме жесткого диска или материнской платы (очистка контактов от окисления с помощью спирта или ластика);
- Переключение SATA кабеля на другой разъем;
- Нестабильное питание жесткого диска (замена блока питания);
- Перегрев южного моста материнской платы (замена термопасты);
- Деградация чипсета материнской платы;
- Несовместимость чипсета и контроллера жесткого диска;
- Смена режима работы контроллера (установка перемычек на жестком диске и переключение в режим SATA I)
- Обновление драйверов чипсета материнской платы
(C7) Ultra DMA CRC Error Count — содержит количество ошибок, возникших по передаче по интерфейсному кабелю в режиме Ultra DMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска.
Счётчик каждый раз увеличивался, когда я начинал на него записывать крупные массивы данных. Но самое интересное, что на этом компьютере у меня стоит второй жесткий диск — Western Digital Green 2Tb и когда я начинаю на него сбрасывать огромные файлы — никаких ошибок нет! Я решил поставить свой старый жесткий диск Hitachi с теми же кабелями и в тот же разъем, где были проблемы у Seagate — никаких ошибок нет.
Дальше я начал проверять все методом исключения и первое что я сделал – проверил Seagate на другом компьютере. О Чудо. Ни одной ошибки при записи! Значит, проблема с материнской платой и она все-таки деградировала за время работы?
Пока решил не делать поспешных выводов, а вытянуть материнскую плату из корпуса и хорошо все просмотреть. Внешний осмотр ничего не дал, никаких изменений я не заметил в плане вздувшихся конденсаторов или механических повреждений. Решил не отчаиваться, а попробовать прозвонить конденсаторы прибором, который я купил для ремонтов БП:

Прибор позволяет проверять электролитические конденсаторы на синусоидальном переменном токе без выпаивания из схемы. Это экономит уйму времени при ремонтах.
И мне повезло. Я нашел два конденсатора 1000mkF x 10v в районе чипсета, которые показывали обрыв. Стоят они в фильтрах стабилизаторов питания 5V. Поставил новые конденсаторы, подключил жесткий диск к материнской плате и попробовал запись на диск. Счетчик ошибок замер на значении 1340 и больше не увеличивался при любой нагрузке.
Можно сделать вывод, что по линии 5V шли сильные искажения питания, которые не давали нормально работать паре южный мост – контроллер винчестера. В свою очередь котроллер Seagate оказался очень чувствителен к таким искажениям и не мог правильно сравнивать контрольные суммы. Это привело к увеличению счетчика Ultra DMA CRC Error Count.
Если вы уже все испробовали не сдавайтесь, возможно у вас на материнской плате найдется тоже конденсатор подлежащий замене.
Источник
How to Fix ‘Interface CRC Error Count’ inside HD Tune
Some Windows users are reporting that they always end up seeing a warning (Ultra DMA CRC Error Count) when analyzing their HDD using the HD Tune utility. While some affected users are seeing this with used hard drivers, others are reporting this issue with brand new HDDs.
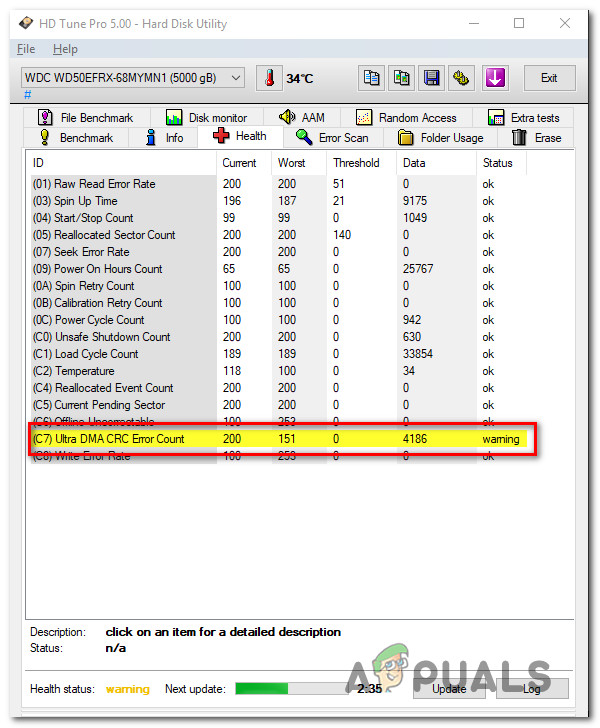 Interface CRC Error Count inside HD Tune
Interface CRC Error Count inside HD Tune
What is Ultra DMA CRC Error Count?
This is a S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology) parameter that indicates the total quantity of CRC errors during UltraDMA mode. The raw value of this attribute indicates the number of errors found during data transfer in UltraDMA mode by ICRC (Interface CRC).
But keep in mind that this parameter is considered informational by most hardware vendors. Although the degradation of this parameter can be regarded as an indicator of an aging drive with potential electromechanical problems, it does NOT directly indicate imminent driver failure.
To get the complete picture of the health of your HDD, you need to pay attention to other parameters and the overall drive health.
After investigating this issue thoroughly, it turns out that there are several different underlying causes that might end up produce this particular error code:
- Generic False Positive – Keep in mind that a warning thrown around by the HD Tune utility does not necessarily mean that your HDD is failing. This utility uses generic aggregated from every manufacturer, so concerning data from one manufacturer might not be concerning for another. To get a more accurate result, you will need to run the brand-specific diagnostic tool and see if the same kind of warning occurs.
- Incompatibility between Samsung SSD and SATA Controller – If you’re encountering this issue with an SSD, chances are it’s due to a conflict between your solid-state drive and the Microsoft or AMD SATA controller driver. To fix this incompatibility, you’ll need to use Registry Editor to disable NCQ (Native Command Queue).
- Faulty SATA Cable or SATA port – As it turns out, you can also expect to encounter this type of issue if you’re dealing with a faulty SATA port or a non-congruent SATA cable. In this case, you can identify the culprit by testing the HDD on a different machine and replacing the current SATA cable.
- Failing HDD or SSD – Under certain circumstances, you can expect to see this error warning in the early stages of a failing drive. In this case, the only thing you can do is back up your data before the drive breaks up for good and start looking for a replacement.
Now that you know the very potential scenario that might cause this error code, here’s a list of methods that will help you identify and resolve the Ultra DMA CRC Error Count error:
Method 1: Running the brand-specific diagnostic tool
Keep in mind that the HD Tune Utility is a 3rd party tool that will ‘judge’ the heath of an HDD solely by comparing them against a set of generic values.
Because of this, it’s highly recommended to avoid making a decision based on HD Tune Utility alone and instead run the brand-specific diagnostic tool – The official testing tools are specifically designed for their brand products.
Depending on your HDD manufacturer, install and scan your hard drive with the proprietary diagnostic utility. To make matters easier for you, we’ve made a list of the most popular brand-specific diagnostic tools:
Note: If your HDD manufacturer is not included in the list above, search online for specific steps on your brand-specific diagnostic tool, then install and run it to see if the Ultra DMA CRC Error Count is still off.
If the manufacturer-specific diagnostic tool doesn’t raise any concerns in relation to the value of Ultra DMA CRC Error Count, then you can safely ignore the warning thrown by HD Tune.
However, if the warning is also displayed in the manufacturer-specific analysis tool, move down to the next potential fix below.
Method 2: Fix the Incompatibility between Samsung SSD and SATA Controller (if applicable)
As it turns out, the Ultra DMA CRC Error Count error is not restricted to an HDD and can also occur if you’re using an SSD.
But if you’re seeing this error with a Samsung SSD, there’s a high chance that the issue has nothing to do with a bad cable or solid-state health – It’s most likely due to an incompatibility between your Samsung SSD and your chipset Sata controller.
If you find yourself in this particular scenario, you can fix the issue and prevent this warning from appearing by disabling NCQ (Native Command Queue) in your SATA driver.
Note: This will not affect the functionality of your SATA drive.
If this scenario is applicable, the instructions below to fix the incompatibility between your Samsung SSD and the Sata Controller:
- Press Windows key + R to open up a Run dialog box. Next, inside the text box, type ‘regedit’, then press Ctrl + Shift + Enter to open up the Registry Editor with admin access. When you’re prompted by the UAC (User Account Control), click Yes to grant administrative access.
 Opening Regedit
Opening Regedit - Once you’re inside the Registry Editor, use the left-hand menu to navigate to the following locations, depending on if you’re using a Microsoft SATA Controller driver or a AMD SATA Controller driver:
 Opening Regedit
Opening RegeditNote: You can either navigate here manually or you can paste the location directly into the navigation bar
 Creating a new Dword value inside the Device menu
Creating a new Dword value inside the Device menuIf the same issue is still occurring even after following the instructions above or this scenario was not applicable, move down to the next potential fix below.
Method 3: Replace the power and SATA cable
As several affected users have confirmed, this particular issue can also be associated with a faulty SATA cable or a faulty SATA port. Because of this, the Ultra DMA CRC Error Count error can also be a symptom of a non-congruent cable.
To test this theory, you can connect your HDD to a different computer (or at least use a different SATA port + cable) if you don’t have a second machine to do some testing on.
 Example of a SATA Port on the motherboard
Example of a SATA Port on the motherboard
After you replaced the SATA port, repeat the scan inside HD Tune utility and see if the Ultra DMA CRC Error Count error is still occurring – If the issue has stopped occurring, consider taking your motherboard to an IT technician to investigate for loose pins.
On the other hand, if the issue doesn’t occur while you use a different SATA cable, you’ve just managed to identify your culprit.
In case you’ve eliminated both the SATA cable and the SATA port from the list of culprits, move down to the next potential fix below as the issue is definitely occurring due to a failing drive.
Method 4: Backup your HDD data
If you’ve previously made sure that you were right to concern yourself with the Ultra DMA CRC Error Count error, the first thing you should do is backup your data to ensure that you’re not losing anything in case the drive goes bad.
If you’re looking to back up your HDD data while you figure out which replacement to get, keep in mind that you have two ways forward – You can either backup your HDD using the built-in feature or you can use a 3rd party utility.
A. Backing up the files on your HDD via Command Prompt
If you’re comfortable with using an elevated CMD terminal, you can create a backup and save it on external storage without the need to install a 3rd party software.
But keep in mind that depending on your preferred approach, you might need to insert or plugin-compatible installation media.
If you’re comfortable with this approach, here are the instructions for backup your files from an Elevated Command prompt.
B. Backing up the files on your HDD via an Imaging 3rd party software
On the other hand, if you’re comfortable with trusting a 3rd party utility with your HDD backup, you’ll have a lot of extra features that are simply not available when creating a regular backup via Command Prompt.
You can use a 3rd party backup software to either clone or create an image of your HDD and save it externally or on the cloud. Here’s a list of the best cloning & imaging software that you should consider using.
Method 5: Send your HDD for replacement or order a replacement
If you’ve made sure that the Ultra DMA CRC Error Count warning you’re seeing is genuine and you have successfully backed up your HDD data in advance, the only thing you can do right now is to look for a replacement.
Of course, if your HDD is still protected by the warranty, you should send it in for repair right away.
But if the warranty has expired or you have the option to return it still, our recommendation is to stay away from the legacy HDD (Hard Disk Drive) and go for SSD (Solid State Drive) instead.
Although SSD is still more expensive than traditional HDD, there are much less prone to break and the speed is incomparable in favor of SSD (10x more writing and reading speeds).
If you’re in the market for an SSD, here’s our advanced guide to buying the best solid-state drive for your needs.
Источник
Этот материал написан посетителем сайта, и за него начислено вознаграждение.
На моем десктопном компьютере установлен SSD Crucial MX-200 500Gb, на котором установлена операционная система и игры.

Где-то месяц назад игры стали ужасно лагать, зависали до 5 секунд, играть стало не возможно, компьютер иногда зависал намертво и сам перезапускался. Я начал искать причину, логично, что в первую очередь решил проверить состояние SSD Crucial MX-200 по его SMART.
рекомендации
3060 дешевле 30тр цена — как при курсе 68
Выбираем игровой ноут: на что смотреть, на чем сэкономить
3070 Ti дешевле 60 тр — цена как при курсе 65
MSI 3060 Ti Ventus OC за 40 тр
Много 4080 от 100тр — цены в рублях не растут
3070 Gainward Phantom дешевле 50 тр
-7% на ASUS 3050 — дешевле 30 тр
5 видов 4090 в Ситилинке по норм ценам
-19% на 13900KF — цены рухнули
13700K дешевле 40 тр в Регарде
Ищем PHP-программиста для апгрейда конфы
3070 Gigabyte Gaming за 50 тр с началом
13600K дешевле 30 тр в Регарде
3070 дешевле 50 тр в Ситилинке
MSI 3050 за 25 тр в Ситилинке
3060 Gigabyte Gaming за 30 тр с началом
12900K за 40тр с началом в Ситилинке
3060 Ti Gigabyte за 40тр в Регарде
И обнаружил, что атрибут SMART-a 199 UltraDMA CRC Error Count (количество ошибок, возникших во время передачи данных по кабелю от материнской платы до дискретного контроллера диска) буквально за два дня вырос более чем на 2000 ошибок.

Спустя два дня

Это вполне объясняло подобное поведение компьютера.
Естественно, что в первую очередь под подозрение попал кабель SATA, но нет, если бы это было так, то я не стал бы писать статью.
Были перепробованы все кабеля SATA которые у меня только есть, для проверки также поменян кабель SATA с HDD, который у меня стоит на компьютере в качестве хранилища, кстати на нем этот атрибут равен нулю, то есть не возникло ни одной ошибки. Переподключал кабель SATA в разные порты на материнской плате, но и это ничего не дало.
После этого SSD был установлен в ноутбук, где при тех же играх и нагрузке данный атрибут SMART-a не увеличился ни на единицу, и ноутбук работал отлично.
Контроллер материнской платы компьютера я тоже исключил, так как установив на HDD стоящий в компьютере операционную систему и игры, и погоняв его с теми же нагрузками, увидел, что атрибут UltraDMA CRC Error Count не увеличился, так и остался равным нулю.
Что же тогда еще остается?
Отступление:
При замене кабелей SATA на SSD, один кабель SATA я приобрел в магазине, на всякий случай, так как думать уже не знал на что. Когда я его покупал, оговорился о данной проблеме. И от продавцов узнал для себя удивительную вещь: они авторитетно заявили, что возможно у меня стоит кабель SATA 2 и не обеспечивает необходимую пропускную способность, и нужно купить у них кабель SATA 3, и даже показали кабель на котором стоит клеймо SATA 3 (может я этого не знаю). Я возразил, сказал, что такого быть не может, что у них у всех 7 pin , и одинаковые медные проводники, и электрический сигнал распространяется одинаково. пропускная способность зависит от контроллера материнской платы и от контролера жесткого диска, а не от 7 медных проводников, которыми они соединены. И на вопрос чем они физически отличаются, внятно объяснить мне не смогли.
Что думаете вы по этому поводу напишите в комментариях.
Но я все-таки купил у них этот кабель SATA 3. Ну как вы и подумали проблему это не решило.
Дальше я принялся ковырять блок питания. По замерам мультиметра, и по данным проги «AIDA» все напряжения были в норме. Но при измерении осциллографом пульсаций по питанию, в большей мере меня интересовало питание 5 В. которым питался SSD , было выявлено наличие провалов в осциллограмме с 5 до 4,5 В.


 https://disk.yandex.ru/i/v3nlN_OmffD_hw
https://disk.yandex.ru/i/v3nlN_OmffD_hw
Расположение их по шкале времени имело случайный характер. Но казалось бы, и 4,5 В. достаточно, так как в SSD стоят свои преобразователи в более низкие напряжения. Но я все же в качестве диагностики попытался уменьшить эти пульсации и подключил прямо к разъему MOLEX к шине 5 в. электролитический конденсатор на 4000 мкФ.


И наконец это решило проблему, осциллограмма выровнялась, провалы пропали, атрибут 199 UltraDMA CRC Error Count больше не увеличивается, компьютер летает, игры не лагают. Теперь выберу время, разберу блок питания и займусь им.
Надеюсь, мой случай окажется вам интересен и полезен.
Этот материал написан посетителем сайта, и за него начислено вознаграждение.
Первую часть этого материала можно прочитать здесь.
Технология S.M.A.R.T. родилась в далеком 1995 году, так что возраст у нее почтенный. Предполагалось, что атрибуты SMART (давайте для простоты писать аббревиатуру без точек), формируемые микропрограммой жесткого диска, позволят программно оценивать состояние накопителя, а также дадут механизм для предсказания выхода его из строя. Последнее в те времена было достаточно актуально: срок жизни дисков в серверах, например, исчислялся годом-полутора, и знать, когда готовить замену, было нелишним.
Со временем многое поменялось: что-то отмерло, какие-то стороны развились сильнее (например, контроль механики диска). Первоначальный набор из десятка простейших атрибутов усложнился и разросся в несколько раз, порой менялся их смысл, многие производители ввели собственные атрибуты с не всегда ясным функционалом. Появилась масса программ для анализа SMART (как правило, невысокого качества, но с эффектным интерфейсом, да еще и за деньги) и т.п.
Так что не мешает описать современное состояние SMART. Начнем с критически важных атрибутов, ухудшение которых почти всегда свидетельствует о проблемах с накопителем. Именно их первым делом смотрят ремонтники при диагностике HDD.
- #01 Raw Read Error Rate — частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска. Для всех дисков Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5″ это — число внутренних коррекций данных, проведенных ДО выдачи в интерфейс; на пугающе огромные цифры можно не обращать внимания.
- #03 Spin-Up Time — время раскрутки пакета пластин из состояния покоя до рабочей скорости. Растет при износе механики (повышенное трение в подшипнике и т.п.), также может свидетельствовать о некачественном питании (например, просадке напряжения при старте диска).
- #05 Reallocated Sectors Count — число операций переназначения секторов. Когда диск обнаруживает ошибку чтения/записи, он помечает сектор переназначенным и переносит данные в резервную область. Вот почему на современных HDD нельзя увидеть bad-блоки — все они спрятаны в переназначенных секторах. Этот процесс называют remapping, на жаргоне — ремап. Поле Raw Value атрибута содержит общее количество переназначенных секторов. Чем оно больше, тем хуже состояние поверхности диска.
- #07 Seek Error Rate — частота ошибок при позиционировании блока магнитных головок (БМГ). Рост этого атрибута свидетельствует о низком качестве поверхности или о поврежденной механике накопителя. Также может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине).
- #10 Spin-Up Retry Count — число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. Если значение атрибута растет, то велика вероятность проблем с механикой.
- #196 Reallocation Event Count — число операций переназначения. В поле Raw Value атрибута хранится общее число попыток переноса информации со сбойных секторов в резервную область диска (она, как правило, не слишком велика — несколько тысяч секторов). Учитываются как успешные, так и неудачные операции.
- #197 Current Pending Sector Count — текущее число нестабильных секторов. Здесь хранится число секторов, являющихся кандидатами на замену. Они не были еще определены как плохие, но считывание с них происходит с затруднениями (например, не с первого раза). Если «подозрительный» сектор будет в дальнейшем считываться успешно, то он исключается из числа кандидатов. В случае же повторных ошибочных чтений накопитель попытается восстановить его и выполнить ремап.
- #198 Uncorrectable Sector Count — число секторов, при чтении которых возникают неисправимые (внутренними средствами) ошибки. Рост этого атрибута указывает на серьезные дефекты поверхности или на проблемы с механикой накопителя.
- #220 Disk Shift — сдвиг пакета пластин относительно оси шпинделя. В основном возникает из-за сильного удара или падения диска. Единица измерения неизвестна, но при сильном росте атрибута диск не жилец.
Также следует принимать во внимание и информационные атрибуты, способные много чего поведать об «истории» диска.
- #02 Throughput Performance — средняя производительность диска. Если значение атрибута уменьшается, то велика вероятность, что у накопителя есть проблемы.
- #04 Start/Stop Count — число циклов запуск-остановка шпинделя. У дисков некоторых производителей (например, Seagate) — счетчик включения режима энергосбережения.
- #08 Seek Time Performance — средняя производительность операции позиционирования головок. Снижение значения этого атрибута свидетельствует о неполадках в механике привода головок (в первую очередь о замедленном позиционировании).
- #09 Power-On Hours (POH) — время, проведённое во включенном состоянии. Показывает общее время работы диска, единица измерения зависит от модели (не только 1 час, но и 30 мин, и даже 1 минута).
- #11 Recalibration Retries — число повторов рекалибровки в случае, если первая попытка была неудачной. Рост этого атрибута указывает на проблемы с механикой диска.
- #12 Device Power Cycle Count — число полных циклов включения-выключения диска.
- #13 Soft Read Error Rate — частота появления «программных» ошибок при чтении данных. Сюда можно отнести ошибки программного обеспечения, драйверов, файловой системы, неверную разметку диска — в общем, почти все, что не относится к аппаратной части.
- #190 Airflow Temperature — температура воздуха внутри корпуса HDD. Для дисков Seagate атрибут выдается в нормировке 100º минус температура (тем самым критический нагрев соответствует значению 45), а модели Western Digital используют нормировку 125º минус температура.
- #191 G—sense error rate — число ошибок, возникших из-за внешних нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера.
- #192 Power—off retract count — число зафиксированных повторов включения/выключения питания накопителя.
- #193 Load/Unload Cycle Count — число циклов перемещения БМГ в специальную парковочную зону/в рабочее положение.
- #194 HDA temperature — температура механической части диска, в просторечии банки (HDA — Hard Disk Assembly). Информация снимается со встроенного термодатчика, которым служит одна из магнитных головок, обычно нижняя в банке. В битовых полях атрибута фиксируются текущая, минимальная и максимальная температура. Не все программы, работающие со SMART, правильно разбирают эти поля, так что к их показаниям стоит относиться критично.
- #195 Hardware ECC Recovered — число ошибок, скорректированных аппаратной частью диска. Сюда входят ошибки чтения, ошибки позиционирования, ошибки передачи по внешнему интерфейсу. На дисках с SATA-интерфейсом значение нередко ухудшается при повышении частоты системной шины — SATA очень чувствителен к разгону.
- #199 UltraDMA (Ultra ATA) CRC Error Count — число ошибок, возникающих при передаче данных по внешнему интерфейсу в режиме UltraDMA (нарушения целостности пакетов и т.п.). Рост этого атрибута свидетельствует о плохом (мятом, перекрученном) кабеле и плохих контактах. Также подобные ошибки появляются при разгоне шины PCI, сбоях питания, сильных электромагнитных наводках, а иногда и по вине драйвера.
- #200 Write Error Rate/ Multi-Zone Error Rate — частота появления ошибок при записи данных. Показывает общее число ошибок записи на диск. Чем больше значение атрибута, тем хуже состояние поверхности и механики накопителя.
Как видим, большинство «интересных» атрибутов отражает функционирование механики накопителя. Технология SMART действительно позволяет предсказывать выход диска из строя в результате механических неисправностей, что, по статистике, составляет около 60% всех отказов. Полезен и мониторинг температур: перегрев головок резко ускоряет их деградацию, так что превышение опасного порога (45-55º в зависимости от модели) — сигнал срочно улучшить охлаждение диска.
Вместе с тем не следует переоценивать возможности SMART. Современные диски нередко «дохнут» на фоне отличных атрибутов, что связано с тонкими процессами дефект-менеджмента в условиях высокой плотности записи и не всегда, мягко говоря, качественных компонентов (разнобой в отдаче головок сегодня — обычное дело). Тем более SMART не способен предсказать последствия таких «форс-мажоров», как скачок напряжения, перегрев платы электроники или повреждение накопителя от удара.
Практически у всех атрибутов наибольший интерес представляет поле Raw Value: «сырые» значения наиболее информативны. Их нормировка (степень приближения к абстрактному порогу) часто ничего не дает и только запутывает дело. Поэтому и программы, полагающиеся на эти проценты, нельзя считать вполне надежными. Типичный случай для них — ложные тревоги. Программа сообщает, что новый, недавно установленный накопитель того и гляди «склеит ласты». А все дело в том, что в начале эксплуатации некоторые атрибуты SMART быстро меняются и примитивная экстраполяция приводит к пугающим пользователя прогнозам.
Я советую бесплатную программу HDDScan — она корректно понимает все атрибуты, в том числе и новые, правильно разбирает температурные показатели. Отчет выводится в виде аккуратной xml-таблицы с цветовой индикацией, которую можно сохранить или распечатать.
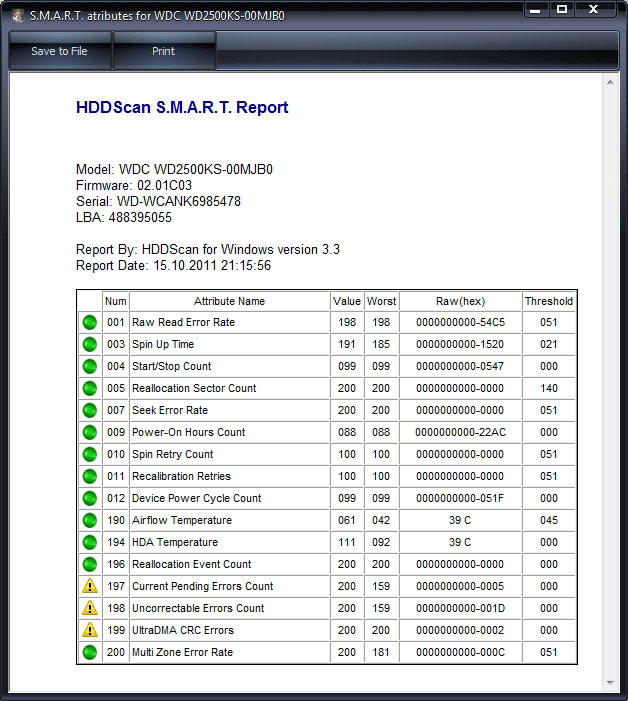
SMART диска WD пятилетнего возраста. О его близкой кончине свидетельствуют ненулевые значения атрибутов 1 и 200 (для WD они особенно чреваты), а также тот факт, что после ремапа атрибут 197 снова растет. Это значит, что возможности исправления дефектов исчерпаны
Крайне полезна у HDDScan возможность считывать SMART у внешних накопителей, столь распространенных сегодня. Практически ни одна другая программа этого не умеет, ведь на пути данных стоит контроллер, преобразующий интерфейс PATA/SATA в USB или FireWire. Автор целенаправленно работал в этом направлении, и ему удалось охватить широкий спектр контроллеров. Не забыты и диски с интерфейсом SCSI, до сих пор широко применяемые в серверах (атрибуты у них особые — например, выводится общее число записанных или считанных байтов за всю жизнь накопителя).
Функционал HDDScan полностью отвечает потребностям ремонтника. Когда первичную диагностику принесенного внешнего диска можно провести, не разбирая корпус, — это удобно, экономит время, а порой и сохраняет гарантию.
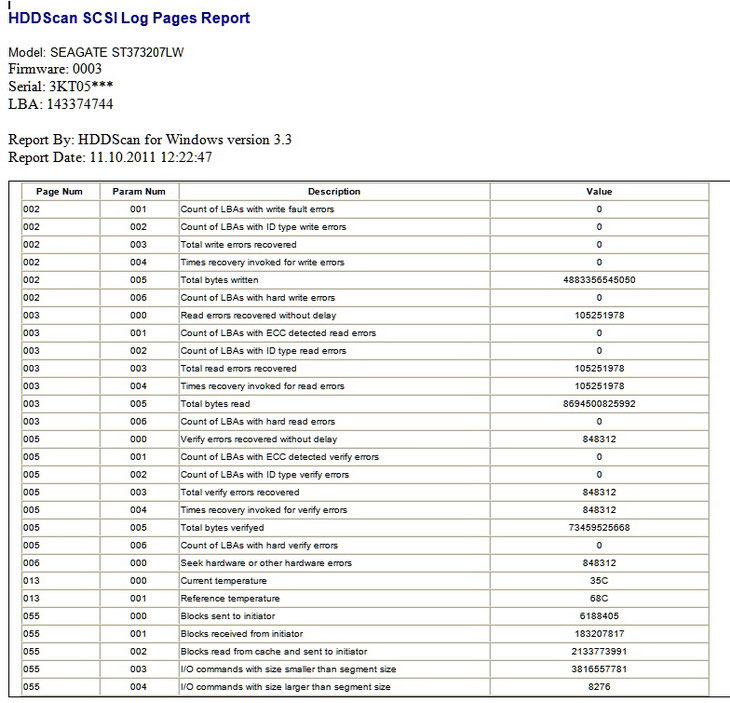
SMART, снятый со SCSI-диска. Здесь исторически сложились совсем другие атрибуты
⇡#Барьеры HDD
Механика давно стала ахиллесовой пятой HDD, и даже не столько из-за чувствительности к ударам и вибрации (это еще можно компенсировать), сколько из-за медлительности. Самые быстрые «дерганья» блоком магнитных головок (2-3 мс у лучших серверных моделей) в тысячи раз уступают скоростям электроники.
И принципиально ничего тут не улучшишь. Поднимать скорость вращения пакета дисков некуда, 15000 об./мин уже предел. Японцы несколько лет назад подступались к 20000 об./мин (вполне гироскопная скорость), но в итоге отказались — не выдерживают материалы, конструкция получается слишком дорогая и для массового производства слабо пригодная. В малых же сериях винчестеры выйдут золотыми, такие никто не купит — это не гироскопы, которые заменить нечем.
Выходит, уткнулись в барьер. Механику на кривой козе не объедешь. Единственный выход — поднимать плотность записи, поперечную и продольную. Продольная плотность (вдоль дорожки) влияет на производительность накопителя, т.е. на поток данных к остальным узлам компьютера. Но все равно, даже достигнутые 100-130 Мбайт/с — это для нынешних компьютеров слишком мало. Например, рядовая оперативная память (DRAM) имеет реальную производительность около 3 Гбайт/с, а кеш процессора — еще больше. Разница на порядки, и она сильно сказывается на общем быстродействии. Конечно, никто не требует от энергонезависимого накопителя, емкость которого в сотни раз превышает DRAM, такой же производительности. Но даже простое удвоение было бы заметно любому пользователю.
Поперечная плотность записи — это густота дорожек на пластине, в современных HDD она превышает 10000 на 1 миллиметр. Получается, что сама дорожка имеет ширину менее 100 нм (между прочим, нанотехнологии в чистом виде). Это позволяет резко поднять емкость в расчете на одну поверхность, а также ускоряет позиционирование за счет изощренных алгоритмов (их разработка потянула бы на пару докторских диссертаций).
Как итог, за последние годы емкость и производительность HDD значительно выросли. Все это стало возможным благодаря технологии перпендикулярной записи, которая существует уже более 20 лет, но до массового внедрения дозрела только в 2007 году. Причем емкость тогда выросла даже сильнее, чем требуется: первые терабайтные диски встретили вялый отклик пользователей. Народ просто не понимал, куда приспособить таких монстров, тем более что они поначалу строились на пяти пластинах, были капризными, шумными и горячими (речь о тогдашних флагманах Hitachi).
Потом, конечно, люди разобрались, торренты заработали в полную силу, да и количество пластин поуменьшилось. В то же время плотность записи выросла до 500-750 Гбайт на пластину (имеются в виду диски настольного сегмента с форм-фактором 3,5″). Вот-вот в массовое производство пойдут терабайтные пластины, что даст возможность выпустить винчестеры объемом до 4 Тбайт (больше четырех пластин в стандартном корпусе высотой 26,1 мм не уместить; хитачевские пятипластинные первенцы большого развития не получили).

Трехтерабайтный диск WD Caviar Green WD30EZRX, наиболее емкий на сегодня. Имеет четырехпластинный дизайн, выпускается ровно год (с 20 октября 2010 г.). Как полагается, весной и летом дешевел, но в последние дни резко подорожал из-за наводнения в Таиланде (там расположены сборочные заводы WD, и стихия блокировала подвоз комплектующих)
Увы, скорость позиционирования выросла, мягко говоря, несильно, а у массовых моделей так вообще осталась на прежнем уровне, а то и упала в угоду… тишине. Маркетологи доказали, что потребитель голосует кошельком за гигабайты в расчете на один доллар, а не за миллисекунды доступа. Поэтому и небыстры дешевые диски по сравнению с породистыми серверными собратьями. Медлительность хорошо проявляется в скорости загрузки ОС, когда надо читать с диска большое количество мелких файлов, разбросанных по пластинам. Здесь главную роль играет скорость вращения шпинделя и мощный привод БМГ, дающий возможность больших ускорений.
Между прочим, «быстрые» диски легко отличить даже на вес — они заметно тяжелее «медленных». Полноразмерная банка с утолщенными стенками, способствующая геометрической стабильности и подавлению вибраций, скоростной шпиндельный двигатель, мощные магниты позиционера, двухслойная крышка повышенной жесткости — все это прибавляет такому накопителю десятки и сотни граммов. Еще больше отрыв в серверных моделях на 15000 об./мин, где пластины уменьшенного размера окружены внушительным объемом литого алюминия, а общий вес «харда» доходит до килограмма.

Высокопроизводительный диск WD Raptor со скоростью вращения шпинделя 10 000 об./мин. При емкости 150 Гбайт весит 740 г (массовые модели той же емкости — 400-500 г). Обратите внимание на размер магнитов и толщину стенок
С удешевлением твердотельных SSD, использующихся, в первую очередь, под операционную систему, нужда в высокопроизводительных HDD стала снижаться, а сами они постепенно выделяются в особый сегмент рынка (такова, например, «черная» серия у WD). Подобными дисками комплектуются профессиональные рабочие станции с ресурсоемкими приложениями, критичными к скорости доступа. Рядовые же пользователи брать достаточно дорогие накопители не торопятся, предпочитая объем производительности.
На другом конце спектра — популярные «зеленые» модели с намеренно замедленным вращением шпинделя (5400-5900 об./мин вместо 7200) и небыстрым позиционированием головок. Дешевые, тихие, холодные и достаточно надежные, эти винчестеры идеально подходят для хранения мультимедийных данных в домашних компьютерах, внешних корпусах и сетевых хранилищах. На наших прилавках все эти Green и LP сильно потеснили другие линейки, так что в мелких «точках» порой ничего больше и не найдешь.
⇡#Расточительность магнитной записи
Намагниченность доменов жесткого диска, как и в середине двадцатого века, меняют с помощью магнитной головки, поле которой возбуждается переменным электрическим током и действует на магнитный слой через зазор. Также эта технология требует быстрого вращения пластин, прецизионного контроля положения головки и т.д. Двигатель и позиционер жесткого диска, а также управляющая ими электроника потребляют заметную мощность, да и стоят немало. Но главное — на само возбуждение магнитного поля тратится очень много энергии.
Расточительность стандартного метода магнитной записи трудно оценить, работая на персональном компьютере. Жесткие диски массовых серий даже при активной работе потребляют менее 10 Вт, что на фоне прочих комплектующих (100 Вт и более) почти незаметно. Но ваши взгляды сразу переменятся после посещения серверной комнаты какого-нибудь крупного банка, а чтобы получить впечатлений на всю оставшуюся жизнь, достаточно подойти к дисковой стойке суперкомпьютера. В шуме сотен и тысяч жестких дисков, обдувающих их вентиляторов и прецизионных кондиционеров становится понятно, сколько энергии в глобальном масштабе тратится на такую работу.
Недаром для систем хранения данных энергоэффективность в списке характеристик выходит на первый план. Вот уже и Google переводит свои дата-центры на баржи в море (вот где настоящие офшоры!). Оказывается, охлаждение СХД забортной водой радикально сокращает операционные затраты, в первую очередь за счет экономии на кондиционерах.
⇡#О питании жестких дисков
Будет ли работать обычная 220-вольтовая лампочка от 230 В? Конечно, будет. А от 240 В? Тоже. Вопрос — сколько она протянет? Понятно, что меньше или существенно меньше — это зависит от конкретной лампочки. Ей суждена яркая, но короткая жизнь.
Примерно та же ситуация и с жесткими дисками. Наивные производители проектировали их, полагаясь на стандартные +5 В и +12 В. Однако в типичном компьютерном блоке питания (БП) стабилизируется лишь линия 5 В. К чему же это приводит?
При высокой нагрузке на процессор (а современные «камни» потребляют немало) и недостаточной мощности БП линия 5 В проседает, и система стабилизации отрабатывает это дело, повышая напряжение до номинального значения. Одновременно повышается и напряжение 12 В (из-за отсутствия стабилизации по нему). В результате и так нестойкий к нагреву HDD работает еще и при повышенном напряжении, которое подается на самые греющиеся узлы — микросхему управления двигателем (на жаргоне ремонтников — «крутилка») и привод головок (т.н. «звуковая катушка»). Итог — смотри рассуждение о лампочке.


Сгоревшая «крутилка» на плате как результат повышенного напряжения и плохого охлаждения. Нередко микросхема сгорает в буквальном смысле, с пиротехническими эффектами и выгоранием дорожек на плате. Такое ремонту не подлежит
Отсюда советы по блоку питания. Чем больше его мощность, тем лучше (в разумных пределах: запас более 30-35% по отношению к реальному потреблению снижает КПД блока, так что вы будете греть комнату). Менее мощный, но фирменный БП лучше более мощного, но безродно-китайского. Помните — разгоняют не только процессоры. В первом приближении, 420 «китайских» ватт эквивалентны 300 «правильным».
По-хорошему, надо бы еще учитывать возраст БП: после 2-3 лет эксплуатации его реальная мощность заметно снижается, а выходные напряжения дрейфуют. Разумеется, в некачественных изделиях, работающих на честном китайском слове, процессы старения выражены гораздо резче. Хорошо еще, если подобный блок тихо умрет сам, а не утащит за собой в агонии половину системного блока!
Максимально допустимым считается 12,6 В (+5% от номинала). Однако у многих дисков c ростом напряжения наблюдается нелинейно-резкий нагрев упомянутых выше узлов — «крутилки» и «катушки». Поэтому я рекомендую строже контролировать БП с помощью внешнего вольтметра (датчики на материнской плате, измеряющие напряжение для BIOS и программ типа AIDA, могут быть весьма неточны).
Измерять напряжение лучше всего на разъемах Molex и обязательно под полной нагрузкой: процессор занят вычислениями с плавающей точкой, видеокарта — выводом динамичной трехмерной графики, а диск — дефрагментацией. При 12,2-12,4 В стоит призадуматься, 12,4-12,6 В — поволноваться, 12,6-13 В — бить тревогу, а в случае 13 В и выше — копить деньги на новый диск или положить гарантийный талон на видное место…

Конденсаторы (2200 мкФ, 25 В), напаянные на цепи питания HDD (желтый провод — +12 В, красный — +5 В, черный — земля). В данном случае они уменьшают пульсации напряжения, от которых блок питания издает раздражающий высокочастотный писк
Если напряжение по линии 12 В сильно завышено, а вы не боитесь паяльника и способны отличить транзистор от диода, то можете включить последний в разрыв питания HDD (напомню, линии 12 В соответствует желтый провод). Диод сыграет роль ограничителя — на его p-n переходе упадут «лишние» 0,2-0,7 В (в зависимости от типа диода), и диску станет полегче. Только диод надо брать достаточно мощный, чтобы он выдерживал пусковой ток в 2-3 А.
И без фанатизма: результирующее напряжение не должно опускаться ниже 11,7 В. В противном случае возможна неустойчивая работа диска (множественные рестарты) и даже порча данных. А некоторые модели (в частности, Seagate 7200.10 и 7200.11) могут вообще не запуститься.
⇡#Миграция с флеш
Память NAND Flash появилась много позднее, чем HDD, и переняла ряд его технологий — взять хотя бы коды ECC. Далее оба направления развивались параллельно и сравнительно независимо. Но в последнее время наметился и обратный процесс: миграция технологий с флеш-памяти на жесткие диски. Конкретно речь идет о выравнивании износа.
Как известно, любой флеш-чип имеет ограниченный ресурс по числу стираний-записей в одну ячейку. В какой-то момент стереть ее уже не удается, и она навсегда застывает с последним записанным значением. Поэтому контроллер считает количество записей в каждую страницу и в случае превышения копирует ее на менее изношенное место. В дальнейшем вся работа ведется с новым участком (этим заведует транслятор), а старая страница остается как есть и не используется. Данная технология получила название Wear Leveling. Так вот, износ есть и в жестких дисках, но там он механический и температурный. Если магнитная головка все время висит над одной дорожкой (скажем, постоянно изменяется тот или иной файл), то растет вероятность повреждения дорожки при случайных толчках или вибрации диска (например, от соседних накопителей в корзине). Головка может коснуться пластины и повредить магнитный слой со всеми вытекающими печальными последствиями. Даже если вредного контакта нет, неподвижная головка локально нагревается и пусть обратимо, но деградирует. Запись в данное место происходит менее надежно, растет вероятность последующего неустойчивого считывания (а при современных огромных плотностях записи любое отклонение параметров губительно).
Эти соображения достаточно очевидны, и прошивка серверных дисков с интерфейсом SCSI/SAS (а они весьма горячи) давно научилась перемещать головки в простое, дабы они не перегревались. Но еще лучше вместе с головкой «перебрасывать» и информацию по пластине — в этом случае описанные эффекты подавляются максимально, а надежность накопителя растет. Вот Western Digital и ввел подобный механизм в новых моделях VelociRaptor. Это дорогие высокопроизводительные диски со скоростью вращения шпинделя 10000 об./мин и пятилетней гарантией, так что Wear Leveling там уместен.


VelociRaptor снаружи и внутри. Привлекает внимание мощный радиатор. Пластины же имеют уменьшенный диаметр — это характерно для современных скоростных дисков.
Кроме того, вся линейка VelociRaptor нацелена на использование в высоконагруженных системах, в первую очередь серверах, где запись на диск ведется очень интенсивно и зачастую в одни и те же файлы (типичный пример — логи транзакций). Массовым «ширпотребным» дискам высокие нагрузки не грозят, греются они тоже умеренно, так что подобный изыск там вряд ли появится. Впрочем, поживем — увидим.
⇡#Аdvanced Format и его применение
Вот уже более 20 лет все жесткие диски имеют одинаковый размер физического сектора: 512 байт. Это минимальная порция записи на диск, позволяющая гибко управлять распределением дискового пространства. Однако с ростом объема HDD все сильнее стали проявляться недостатки такого подхода — в первую очередь неэффективное использование емкости магнитной пластины, а также высокие накладные расходы при организации потока данных.
Поэтому диски большой емкости (терабайт и выше) стали производиться по технологии Advanced Format, которая оперирует «длинными» физическими секторами в 4096 байт. Разметка магнитных пластин под AF весьма выгодна для производителя: меньше межсекторных промежутков, выше полезная емкость дорожки и всей пластины (а это, наряду с магнитными головками, самый дорогой компонент HDD). Именно Advanced Format позволил выпустить на рынок недорогие винчестеры, столь популярные ныне у потребителей аудио- и видеоконтента. AF-дисками емкостью 1-3 Тбайт комплектуются не только компьютеры, но и масса внешних накопителей, сетевых хранилищ и медиаплееров.

Один из первых дисков 3,5″ с Advanced Format, выпущенный в 2009 г
Но даром ничего не дается, новые диски уже начинают приносить в ремонт. Похоже, надежность все-таки просела. Ведь единичный сбой диска или дефект поверхности портит теперь в 8 раз больше данных пользователя, чем обычно. При физическом секторе в 4 Кбайт и эмуляции «коротких» секторов в 512 байт не будет читаться от 1 до 8 секторов. Операционная система на это реагирует понятно как: авария, все пропало! В итоге мелкая проблема на пластинах вырастает для пользователя в зависание или чего еще хуже.
Я считаю, на дисках с AF не стоит держать ОС, прикладные программы и базы данных со множеством мелких файлов. Пока что их удел — мультимедийные данные, некритичные к выпадениям.
⇡#Что стоит почитать о жестких дисках
В первую очередь рекомендую заглянуть на форум HARDW.net. Его раздел «Накопители информации» посещает множество профессиональных ремонтников и энтузиастов (почти 40 тыс. участников). Там можно найти ответы практически по любой теме, связанной с HDD, за исключением самых новых «нераскопанных» моделей. Начните с подраздела «Песочница»: на простые (в понимании профессионалов) вопросы там отвечают подробно и содержательно, а не отшивают, как в других местах, — «несите к ремонтнику».
Еще больше информации, правда, на английском языке, можно найти на портале HDDGURU. Помимо ремонтно-диагностического ПО и статей по отдельным вопросам (например, как поменять головки у диска), там есть международный форум ремонтников, а также огромный архив ресурсов по HDD (firmware, документация, фото и т.п.). Портал прививает широкий взгляд на вещи, он будет интересен подготовленным и мотивированным людям. Во всяком случае, в закрытых конференциях ремонтников ссылки на него пробегают постоянно.
Сошлюсь и на свою статью «Как продлить жизнь жестким дискам» в трех частях. Она дает начальные сведения по обращению с HDD, и хотя написана более трех лет назад, устарела мало — диски за это время принципиально не изменились, разве что стали еще менее надежными из-за свирепой экономии. Производители, застигнутые мировым кризисом, снижали свои затраты по всем направлениям, что и послужило причиной ряда громких провалов 2008-2009 гг. Об одном из них речь пойдет в продолжении этого материала, которое выйдет в ближайшее время.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
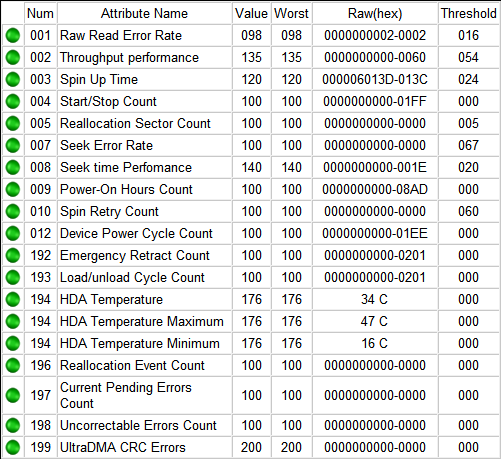
S.M.A.R.T. в HDDScan 3.3
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 10 | 11 | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | BD | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | BF | С0 | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 | СА | CB | DC | F0 | FE |
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
Атрибут: 01 Raw Read Error Rate
| Тип | текущий, может быть накапливающим для WD и старых Hitachi |
| Описание | содержит частоту возникновения ошибок при чтении с пластин |
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
| Тип | текущий |
| Описание | содержит значение средней производительности диска и измеряется в каких-то «попугаях». Обычно его ненулевое значение отмечается на винчестерах Hitachi. На них он может изменяться после изменения параметров ААМ, а может и сам по себе по неизвестному алгоритму |
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
| Тип | текущий |
| Описание | содержит время, за которое шпиндель диска в последний раз разогнался из состояния покоя до номинальной скорости. Может содержать два значения — последнее и, например, минимальное время раскрутки. Может измеряться в миллисекундах, десятках миллисекунд и т. п. — это зависит от производителя и модели диска |
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
| Тип | накапливающий |
| Описание | содержит количество раз включения диска. Бывает ненулевым на только что купленном диске, находившемся в запаянной упаковке, что может говорить о тестировании диска на заводе. Или ещё о чём-то, мне не известном  |
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
| Тип | накапливающий |
| Описание | содержит количество секторов, переназначенных винчестером в резервную область. Практически ключевой параметр в оценке состояния |
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение, а используемый вместо повреждённого сектор — переназначенным. Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при позиционировании блока магнитных головок (БМГ) |
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
| Тип | текущий |
| Описание | содержит среднюю производительность операций позиционирования головок, измеряется в «попугаях». Как и параметр 02 Throughput Performance, ненулевое значение обычно отмечается на дисках Hitachi и может изменяться после изменения параметров ААМ, а может и само по себе по неизвестному алгоритму |
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
| Тип | накапливающий |
| Описание | содержит количество часов, в течение которых винчестер был включён |
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
| Тип | накапливающий |
| Описание | содержит количество повторов запуска шпинделя, если первая попытка оказалась неудачной |
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Тип | накапливающий |
| Описание | содержит количество повторных попыток сброса накопителя (установки БМГ на нулевую дорожку) при неудачной первой попытке |
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов «включение-отключение» диска |
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
| Тип | накапливающий |
| Описание | содержит количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута |
Не говорит о здоровье накопителя.
Атрибут: 184 (B8) End-to-End Error
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче данных через кэш винчестера |
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Тип | накапливающий |
| Описание | содержит количество секторов, которые были признаны кандидатами на переназначение (см. атрибут 197) за всю историю жизни диска. Причём если сектор становится кандидатом повторно, значение атрибута тоже увеличивается |
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
| Тип | накапливающий |
| Описание | содержит количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика |
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
| Тип | накапливающий |
| Описание | содержит количество зафиксированных случаев записи при высоте полета головки выше рассчитанной — скорее всего, из-за внешних воздействий, например вибрации |
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
| Тип | текущий |
| Описание | содержит температуру винчестера для дисков Hitachi, Samsung, WD и значение «100 − [RAW-значение атрибута 194]» для Seagate |
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Тип | накапливающий |
| Описание | содержит количество критических ускорений, зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. |
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
| Тип | накапливающий |
| Описание | для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок БМГ диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т. п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi) |
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов парковки/распарковки БМГ. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (столь любимая, например, компанией Western Digital): если его содержимое превосходит (обычно — многократно) содержимое атрибута 09 — счётчик отработанных часов, — то парковка включена |
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
| Тип | текущий/накапливающий |
| Описание | содержит текущую температуру диска. Температура считывается с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера |
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
| Тип | накапливающий |
| Описание | содержит количество ошибок, которые были скорректированы аппаратными средствами ECC диска |
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
| Тип | накапливающий |
| Описание | содержит количество операций переназначения секторов |
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
| Тип | текущий |
| Описание | содержит количество секторов-кандидатов на переназначение в резервную область |
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.
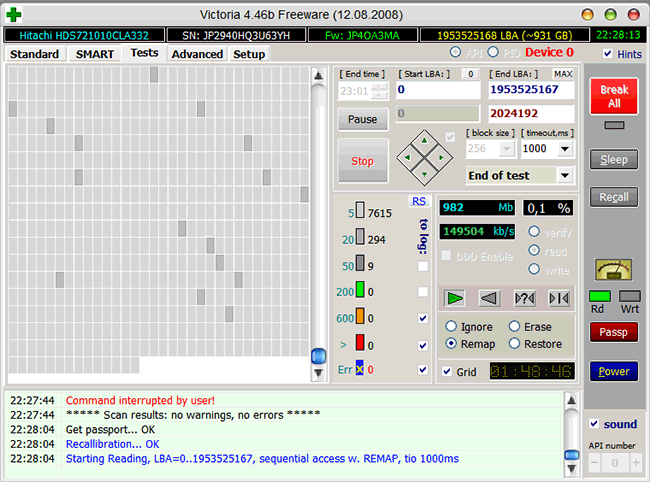
Идёт последовательное чтение с ремапом в Victoria 4.46b
В случае неудачи чтения как с remap, так и с Advanced remap, стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!
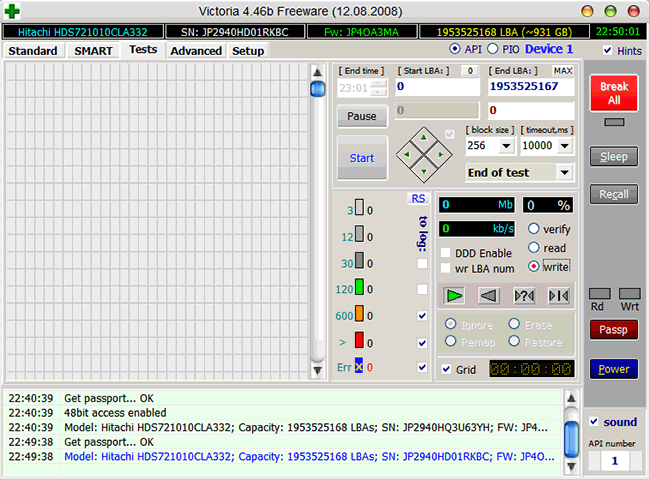
Запуск последовательной записи в Victoria 4.46b
Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Тип | текущий |
| Описание | означает то же самое, что и атрибут 197, но отличие в том, что данный атрибут содержит количество секторов-кандидатов, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой |
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
Атрибут: 199 (С7) UltraDMA CRC Error Count
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска |
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при записи |
Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать «умирающие» головки.
Атрибут: 201 (С9) Soft Read Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок чтения, произошедших по вине программного обеспечения |
Влияние на здоровье неизвестно.
Атрибут: 202 (СА) Data Address Mark Error
| Тип | неизвестно |
| Описание | содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо |
Атрибут: 203 (CB) Run Out Cancel
| Тип | текущий |
| Описание | содержит количество ошибок ECC |
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
| Тип | текущий |
| Описание | содержит измеренный в неизвестных единицах сдвиг пластин диска относительно оси шпинделя |
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
| Тип | накапливающий |
| Описание | содержит время, затраченное на позиционирование БМГ. Счётчик может содержать несколько значений в одном поле |
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
| Тип | накапливающий |
| Описание | содержит зафиксированное электроникой количество ускорений свободного падения диска, которым он подвергался, т. е., проще говоря, показывает, сколько раз диск падал |
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения:
- атрибутов 01, 07, 195 — вызывают подозрения в «болезни» у некоторых моделей дисков;
- атрибутов 10, 11, 188, 196, 199, 202 — вызывают подозрения у всех дисков;
- и, наконец, атрибутов 05, 184, 187, 197, 198, 200 — прямо говорят о неполадках.
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
![]()
Атрибут 01 в Victoria 4.46b
А так выглядит он же в «правильной» HDDScan 3.3:
![]()
Атрибут 01 в HDDScan 3.3
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина.
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:
«Страшные» значения в Victoria 4.46b
Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах. При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (работает в Windows, бесплатная), CrystalDiskInfo (Windows, бесплатная), Hard Disk Sentinel (платная для Windows, бесплатная для DOS), HD Tune (Windows, платная, есть бесплатная старая версия).
И наконец, мощнейшие программы для тестирования: Victoria (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).
Одним из самых узких мест в компьютере до сих пор остается жесткий диск. Я не говорю о твердотельных накопителях SSD, у них тоже есть свои плюсы и минусы. Сегодня речь пойдет о жестких дисках, принцип работы которых был разработан еще в прошлом веке.
Принцип до сих пор остался прежним, изменяется только технология изготовления пластин и электроники, которая контролирует все процессы, происходящие на жестком диске.Показателем здоровья жесткого диска является таблица SMART.
S.M.A.R.T. (от английского self-monitoring, analysis and reporting technology ) — технология самоконтроля, анализа и отчётности) — технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя.
Жесткий диск я купил 1,5 года назад. Хотелось поменять свой тихоходный системный диск Hitachi 500Gb, на что-то пошустрей. Выбор был невелик — Western Digital Caviar Black 1Tb SATAIII или Seagate Barracuda (ST1000DM003) 1Tb SATAIII. Выбор пал в пользу последнего. Это был первый жесткий диск на рынке с терабайтной пластиной, что сразу снимало несколько проблем: нагрев, шум, энергопотребление. Максимальная скорость чтения в HD Tune переваливала за 200 Мб/сек, когда Hitachi показывал максимум 85. Вдобавок, Seagate был в полтора раза тоньше своих собратьев!
Все работало хорошо до последнего дня. Компьютер начал грузиться дольше, чем обычно. Перед загрузкой Windows каждый раз начинал запускать ScanDisk, проверяя жесткий диск на ошибки. Меня насторожило странное поведение компьютера и я решил проверить его на вирусы, загрузившись с LiveCD. Вирусов не было, поэтому я решил посмотреть на SMART дисков, чтобы удостовериться, что там все в порядке. Оказалось это не так. Напротив строки (C7) Ultra DMA CRC Error Count подсвечивалось предупреждение желтым цветом и счетчик показывал значение 1234.
В моей практике было несколько случаев, связанным с увеличением этого счетчика, но все решалось элементарной заменой интерфейсного кабеля. В данном случае это не помогло. В интернете описано много возможных путей решения этой проблемы, которые сводятся к следующему:
- Замена интерфейсного кабеля SATA (желательно с защелками);
- Возможный разгон шины PCI/PCI-E компьютера (сброс на заводские установки);
- Обновление BIOS материнской платы;
- Плохой контакт на разъеме жесткого диска или материнской платы (очистка контактов от окисления с помощью спирта или ластика);
- Переключение SATA кабеля на другой разъем;
- Нестабильное питание жесткого диска (замена блока питания);
- Перегрев южного моста материнской платы (замена термопасты);
- Деградация чипсета материнской платы;
- Несовместимость чипсета и контроллера жесткого диска;
- Смена режима работы контроллера (установка перемычек на жестком диске и переключение в режим SATA I)
- Обновление драйверов чипсета материнской платы
(C7) Ultra DMA CRC Error Count — содержит количество ошибок, возникших по передаче по интерфейсному кабелю в режиме Ultra DMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска.
Счётчик каждый раз увеличивался, когда я начинал на него записывать крупные массивы данных. Но самое интересное, что на этом компьютере у меня стоит второй жесткий диск — Western Digital Green 2Tb и когда я начинаю на него сбрасывать огромные файлы — никаких ошибок нет! Я решил поставить свой старый жесткий диск Hitachi с теми же кабелями и в тот же разъем, где были проблемы у Seagate — никаких ошибок нет!!!
Дальше я начал проверять все методом исключения и первое что я сделал – проверил Seagate на другом компьютере. О Чудо!!! Ни одной ошибки при записи! Значит, проблема с материнской платой и она все-таки деградировала за время работы?
Пока решил не делать поспешных выводов, а вытянуть материнскую плату из корпуса и хорошо все просмотреть. Внешний осмотр ничего не дал, никаких изменений я не заметил в плане вздувшихся конденсаторов или механических повреждений. Решил не отчаиваться, а попробовать прозвонить конденсаторы прибором, который я купил для ремонтов БП:
Прибор позволяет проверять электролитические конденсаторы на синусоидальном переменном токе без выпаивания из схемы. Это экономит уйму времени при ремонтах.
И мне повезло. Я нашел два конденсатора 1000mkF x 10v в районе чипсета, которые показывали обрыв. Стоят они в фильтрах стабилизаторов питания 5V. Поставил новые конденсаторы, подключил жесткий диск к материнской плате и попробовал запись на диск. Счетчик ошибок замер на значении 1340 и больше не увеличивался при любой нагрузке.
Можно сделать вывод, что по линии 5V шли сильные искажения питания, которые не давали нормально работать паре южный мост – контроллер винчестера. В свою очередь котроллер Seagate оказался очень чувствителен к таким искажениям и не мог правильно сравнивать контрольные суммы. Это привело к увеличению счетчика Ultra DMA CRC Error Count.
Если вы уже все испробовали не сдавайтесь, возможно у вас на материнской плате найдется тоже конденсатор подлежащий замене.
Удачи!