I’m attempting to set up a 2-node cluster in two VMs, but I’m getting an error that I have no interfaces defined:
$ journalctl -xe
Feb 01 15:56:59 ha-node1 systemd[1]: Starting Corosync Cluster Engine...
-- Subject: Unit corosync.service has begun start-up
-- Defined-By: systemd
-- Support: http://www.ubuntu.com/support
--
-- Unit corosync.service has begun starting up.
Feb 01 15:57:00 ha-node1 corosync[11466]: [MAIN ] Corosync Cluster Engine ('2.4.4'): started and ready to provide service.
Feb 01 15:57:00 ha-node1 corosync[11466]: notice [MAIN ] Corosync Cluster Engine ('2.4.4'): started and ready to provide servic
Feb 01 15:57:00 ha-node1 corosync[11466]: [MAIN ] Corosync built-in features: dbus rdma monitoring watchdog augeas systemd xmlco
Feb 01 15:57:00 ha-node1 corosync[11466]: info [MAIN ] Corosync built-in features: dbus rdma monitoring watchdog augeas syste
Feb 01 15:57:00 ha-node1 corosync[11466]: [MAIN ] parse error in config: No interfaces defined
Feb 01 15:57:00 ha-node1 corosync[11466]: error [MAIN ] parse error in config: No interfaces defined
Feb 01 15:57:00 ha-node1 corosync[11466]: [MAIN ] Corosync Cluster Engine exiting with status 8 at main.c:1416.
Feb 01 15:57:00 ha-node1 corosync[11466]: error [MAIN ] Corosync Cluster Engine exiting with status 8 at main.c:1416.
Feb 01 15:57:00 ha-node1 systemd[1]: corosync.service: Main process exited, code=exited, status=8/n/a
Feb 01 15:57:00 ha-node1 systemd[1]: corosync.service: Failed with result 'exit-code'.
Feb 01 15:57:00 ha-node1 systemd[1]: Failed to start Corosync Cluster Engine.
Except that I do have interfaces defined (via the pcs command):
$ sudo pcs cluster auth ha-node1 ha-node2 -u hacluster -p hacluster --force
$ sudo pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force
My config:
totem {
version: 2
cluster_name: my_cluster
secauth: off
transport: udpu
}
nodelist {
node {
ring0_addr: ha-node1
nodeid: 1
}
node {
ring0_addr: ha-node2
nodeid: 2
}
}
quorum {
provider: corosync_votequorum
two_node: 1
}
logging {
to_logfile: yes
logfile: /var/log/corosync/corosync.log
to_syslog: yes
}
Here are the exact commands I ran to build from scratch. This works perfectly using LXD containers, and fails using multipass VMs:
Create two nodes
HOST:
$ multipass launch daily:cosmic --name ha-node1 Launched: ha-node1
GUEST ha-node1:
$ sudo apt update Hit:1 http://archive.ubuntu.com/ubuntu cosmic InRelease Hit:2 http://security.ubuntu.com/ubuntu cosmic-security InRelease Hit:3 http://archive.ubuntu.com/ubuntu cosmic-updates InRelease Hit:4 http://archive.ubuntu.com/ubuntu cosmic-backports InRelease Reading package lists... Done Building dependency tree Reading state information... Done All packages are up to date.
GUEST ha-node1:
$ sudo apt dist-upgrade -y Reading package lists... Done Building dependency tree Reading state information... Done Calculating upgrade... Done 0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
GUEST ha-node1:
$ sudo apt install -y pacemaker pcs corosync fence-agents ...
GUEST ha-node1:
$ echo hacluster:hacluster | sudo chpasswd
HOST:
$ multipass launch daily:cosmic --name ha-node2 Launched: ha-node2
GUEST ha-node2:
$ sudo apt update Hit:1 http://archive.ubuntu.com/ubuntu cosmic InRelease Hit:2 http://archive.ubuntu.com/ubuntu cosmic-updates InRelease Hit:3 http://archive.ubuntu.com/ubuntu cosmic-backports InRelease Hit:4 http://security.ubuntu.com/ubuntu cosmic-security InRelease Reading package lists... Done Building dependency tree Reading state information... Done All packages are up to date.
GUEST ha-node2:
$ sudo apt dist-upgrade -y Reading package lists... Done Building dependency tree Reading state information... Done Calculating upgrade... Done 0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
GUEST ha-node2:
$ sudo apt install -y pacemaker pcs corosync fence-agents ...
GUEST ha-node2:
$ echo hacluster:hacluster | sudo chpasswd
Add reciprocal host entries
GUEST ha-node1:
$ echo "10.190.245.116 ha-node2 ha-node2" | sudo tee -a /etc/hosts 10.190.245.116 ha-node2 ha-node2
GUEST ha-node2:
$ echo "10.190.245.24 ha-node1 ha-node1" | sudo tee -a /etc/hosts 10.190.245.24 ha-node1 ha-node1
http://clusterlabs.org/pacemaker/doc/en-US/Pacemaker/2.0/html/Clusters_from_Scratch/_configure_corosync.html
On one of the nodes, use pcs cluster auth to authenticate as the hacluster user
GUEST ha-node1:
$ sudo pcs cluster auth ha-node1 ha-node2 -u hacluster -p hacluster --force ha-node1: Authorized ha-node2: Authorized
Use pcs cluster setup on the same node to generate and synchronize the corosync configuration
GUEST ha-node1:
$ sudo pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug Running: /usr/sbin/corosync -v Environment: HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root Finished running: /usr/sbin/corosync -v Return value: 0 --Debug Stdout Start-- Corosync Cluster Engine, version '2.4.4' Copyright (c) 2006-2009 Red Hat, Inc. --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Destroying cluster on nodes: ha-node1, ha-node2... Running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Environment: GEM_HOME=/usr/share/pcsd/vendor/bundle/ruby HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin PCSD_DEBUG=true PCSD_NETWORK_TIMEOUT=60 SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root --Debug Input Start-- {} --Debug Input End-- Running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Environment: GEM_HOME=/usr/share/pcsd/vendor/bundle/ruby HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin PCSD_DEBUG=true PCSD_NETWORK_TIMEOUT=60 SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root --Debug Input Start-- {} --Debug Input End-- Finished running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Return value: 0 --Debug Stdout Start-- { "status": "ok", "data": { "tokens": { "ha-node1": "f79f4b48-425f-48dd-9b7c-a85233095a37", "ha-node2": "5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a" }, "ports": { "ha-node1": 2224, "ha-node2": 2224 } }, "log": [ "I, [2019-02-01T15:48:53.817665 #9900] INFO -- : PCSD Debugging enabledn", "D, [2019-02-01T15:48:53.817697 #9900] DEBUG -- : Did not detect RHEL 6n", "D, [2019-02-01T15:48:53.817708 #9900] DEBUG -- : Detected systemd is in usen", "I, [2019-02-01T15:48:53.935749 #9900] INFO -- : Running: /usr/sbin/corosync-cmapctl totem.cluster_namen", "I, [2019-02-01T15:48:53.935790 #9900] INFO -- : CIB USER: hacluster, groups: n", "D, [2019-02-01T15:48:53.942392 #9900] DEBUG -- : ["totem.cluster_name (str) = debian\n"]n", "D, [2019-02-01T15:48:53.942451 #9900] DEBUG -- : []n", "D, [2019-02-01T15:48:53.942468 #9900] DEBUG -- : Duration: 0.006589145sn", "I, [2019-02-01T15:48:53.942517 #9900] INFO -- : Return Value: 0n" ] } --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Sending HTTP Request to: https://ha-node1:2224/remote/cluster_stop Data: component=pacemaker&force=1 Finished running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Return value: 0 --Debug Stdout Start-- { "status": "ok", "data": { "tokens": { "ha-node1": "f79f4b48-425f-48dd-9b7c-a85233095a37", "ha-node2": "5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a" }, "ports": { "ha-node1": 2224, "ha-node2": 2224 } }, "log": [ "I, [2019-02-01T15:48:53.822548 #9901] INFO -- : PCSD Debugging enabledn", "D, [2019-02-01T15:48:53.822581 #9901] DEBUG -- : Did not detect RHEL 6n", "D, [2019-02-01T15:48:53.822591 #9901] DEBUG -- : Detected systemd is in usen", "I, [2019-02-01T15:48:53.937486 #9901] INFO -- : Running: /usr/sbin/corosync-cmapctl totem.cluster_namen", "I, [2019-02-01T15:48:53.937518 #9901] INFO -- : CIB USER: hacluster, groups: n", "D, [2019-02-01T15:48:53.952801 #9901] DEBUG -- : ["totem.cluster_name (str) = debian\n"]n", "D, [2019-02-01T15:48:53.952862 #9901] DEBUG -- : []n", "D, [2019-02-01T15:48:53.952880 #9901] DEBUG -- : Duration: 0.015269403sn", "I, [2019-02-01T15:48:53.952938 #9901] INFO -- : Return Value: 0n" ] } --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Sending HTTP Request to: https://ha-node2:2224/remote/cluster_stop Data: component=pacemaker&force=1 Response Code: 200 --Debug Response Start-- Stopping Cluster (pacemaker)... --Debug Response End-- Communication debug info for calling: https://ha-node1:2224/remote/cluster_stop --Debug Communication Output Start-- * Trying 127.0.1.1... * TCP_NODELAY set * Connected to ha-node1 (127.0.1.1) port 2224 (#0) * found 399 certificates in /etc/ssl/certs * ALPN, offering http/1.1 * SSL connection using TLS1.2 / ECDHE_RSA_AES_256_GCM_SHA384 * server certificate verification SKIPPED * server certificate status verification SKIPPED * common name: ha-node1 (matched) * server certificate expiration date OK * server certificate activation date OK * certificate public key: RSA * certificate version: #3 * subject: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node1 * start date: Fri, 01 Feb 2019 14:47:03 GMT * expire date: Mon, 29 Jan 2029 14:47:03 GMT * issuer: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node1 * compression: NULL * ALPN, server did not agree to a protocol > POST /remote/cluster_stop HTTP/1.1 Host: ha-node1:2224 User-Agent: PycURL/7.43.0.1 libcurl/7.61.0 GnuTLS/3.6.4 zlib/1.2.11 libidn2/2.0.5 libpsl/0.20.2 (+libidn2/2.0.4) nghttp2/1.32.1 librtmp/2.3 Accept: */* Cookie: token=f79f4b48-425f-48dd-9b7c-a85233095a37 Content-Length: 27 Content-Type: application/x-www-form-urlencoded >> component=pacemaker&force=1 * upload completely sent off: 27 out of 27 bytes < HTTP/1.1 200 OK < Content-Type: text/html;charset=utf-8 < Content-Length: 32 < X-Xss-Protection: 1; mode=block < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < Server: WEBrick/1.4.2 (Ruby/2.5.1/2018-03-29) OpenSSL/1.1.1 < Date: Fri, 01 Feb 2019 14:48:54 GMT < Connection: Keep-Alive < << Stopping Cluster (pacemaker)... * Connection #0 to host ha-node1 left intact --Debug Communication Output End-- ha-node1: Stopping Cluster (pacemaker)... Response Code: 200 --Debug Response Start-- Stopping Cluster (pacemaker)... --Debug Response End-- Communication debug info for calling: https://ha-node2:2224/remote/cluster_stop --Debug Communication Output Start-- * Trying 10.190.245.116... * TCP_NODELAY set * Connected to ha-node2 (10.190.245.116) port 2224 (#0) * found 399 certificates in /etc/ssl/certs * ALPN, offering http/1.1 * SSL connection using TLS1.2 / ECDHE_RSA_AES_256_GCM_SHA384 * server certificate verification SKIPPED * server certificate status verification SKIPPED * common name: ha-node2 (matched) * server certificate expiration date OK * server certificate activation date OK * certificate public key: RSA * certificate version: #3 * subject: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node2 * start date: Fri, 01 Feb 2019 14:48:46 GMT * expire date: Mon, 29 Jan 2029 14:48:46 GMT * issuer: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node2 * compression: NULL * ALPN, server did not agree to a protocol > POST /remote/cluster_stop HTTP/1.1 Host: ha-node2:2224 User-Agent: PycURL/7.43.0.1 libcurl/7.61.0 GnuTLS/3.6.4 zlib/1.2.11 libidn2/2.0.5 libpsl/0.20.2 (+libidn2/2.0.4) nghttp2/1.32.1 librtmp/2.3 Accept: */* Cookie: token=5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a Content-Length: 27 Content-Type: application/x-www-form-urlencoded >> component=pacemaker&force=1 * upload completely sent off: 27 out of 27 bytes < HTTP/1.1 200 OK < Content-Type: text/html;charset=utf-8 < Content-Length: 32 < X-Xss-Protection: 1; mode=block < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < Server: WEBrick/1.4.2 (Ruby/2.5.1/2018-03-29) OpenSSL/1.1.1 < Date: Fri, 01 Feb 2019 14:49:04 GMT < Connection: Keep-Alive < << Stopping Cluster (pacemaker)... * Connection #0 to host ha-node2 left intact --Debug Communication Output End-- ha-node2: Stopping Cluster (pacemaker)... Running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Environment: GEM_HOME=/usr/share/pcsd/vendor/bundle/ruby HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin PCSD_DEBUG=true PCSD_NETWORK_TIMEOUT=60 SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root --Debug Input Start-- {} --Debug Input End-- Running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Environment: GEM_HOME=/usr/share/pcsd/vendor/bundle/ruby HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin PCSD_DEBUG=true PCSD_NETWORK_TIMEOUT=60 SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root --Debug Input Start-- {} --Debug Input End-- Finished running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Return value: 0 --Debug Stdout Start-- { "status": "ok", "data": { "tokens": { "ha-node1": "f79f4b48-425f-48dd-9b7c-a85233095a37", "ha-node2": "5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a" }, "ports": { "ha-node1": 2224, "ha-node2": 2224 } }, "log": [ "I, [2019-02-01T15:49:05.167072 #9945] INFO -- : PCSD Debugging enabledn", "D, [2019-02-01T15:49:05.167111 #9945] DEBUG -- : Did not detect RHEL 6n", "D, [2019-02-01T15:49:05.167122 #9945] DEBUG -- : Detected systemd is in usen", "I, [2019-02-01T15:49:05.287033 #9945] INFO -- : Running: /usr/sbin/corosync-cmapctl totem.cluster_namen", "I, [2019-02-01T15:49:05.287076 #9945] INFO -- : CIB USER: hacluster, groups: n", "D, [2019-02-01T15:49:05.297324 #9945] DEBUG -- : ["totem.cluster_name (str) = debian\n"]n", "D, [2019-02-01T15:49:05.297380 #9945] DEBUG -- : []n", "D, [2019-02-01T15:49:05.297403 #9945] DEBUG -- : Duration: 0.010236205sn", "I, [2019-02-01T15:49:05.297450 #9945] INFO -- : Return Value: 0n" ] } --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Sending HTTP Request to: https://ha-node1:2224/remote/cluster_destroy Data: None Finished running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Return value: 0 --Debug Stdout Start-- { "status": "ok", "data": { "tokens": { "ha-node1": "f79f4b48-425f-48dd-9b7c-a85233095a37", "ha-node2": "5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a" }, "ports": { "ha-node1": 2224, "ha-node2": 2224 } }, "log": [ "I, [2019-02-01T15:49:05.176963 #9946] INFO -- : PCSD Debugging enabledn", "D, [2019-02-01T15:49:05.177001 #9946] DEBUG -- : Did not detect RHEL 6n", "D, [2019-02-01T15:49:05.177011 #9946] DEBUG -- : Detected systemd is in usen", "I, [2019-02-01T15:49:05.292809 #9946] INFO -- : Running: /usr/sbin/corosync-cmapctl totem.cluster_namen", "I, [2019-02-01T15:49:05.292868 #9946] INFO -- : CIB USER: hacluster, groups: n", "D, [2019-02-01T15:49:05.314391 #9946] DEBUG -- : ["totem.cluster_name (str) = debian\n"]n", "D, [2019-02-01T15:49:05.314461 #9946] DEBUG -- : []n", "D, [2019-02-01T15:49:05.314479 #9946] DEBUG -- : Duration: 0.021508719sn", "I, [2019-02-01T15:49:05.314539 #9946] INFO -- : Return Value: 0n" ] } --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Sending HTTP Request to: https://ha-node2:2224/remote/cluster_destroy Data: None Response Code: 200 --Debug Response Start-- Successfully destroyed cluster --Debug Response End-- Communication debug info for calling: https://ha-node1:2224/remote/cluster_destroy --Debug Communication Output Start-- * Trying 127.0.1.1... * TCP_NODELAY set * Connected to ha-node1 (127.0.1.1) port 2224 (#0) * found 399 certificates in /etc/ssl/certs * ALPN, offering http/1.1 * SSL connection using TLS1.2 / ECDHE_RSA_AES_256_GCM_SHA384 * server certificate verification SKIPPED * server certificate status verification SKIPPED * common name: ha-node1 (matched) * server certificate expiration date OK * server certificate activation date OK * certificate public key: RSA * certificate version: #3 * subject: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node1 * start date: Fri, 01 Feb 2019 14:47:03 GMT * expire date: Mon, 29 Jan 2029 14:47:03 GMT * issuer: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node1 * compression: NULL * ALPN, server did not agree to a protocol > GET /remote/cluster_destroy HTTP/1.1 Host: ha-node1:2224 User-Agent: PycURL/7.43.0.1 libcurl/7.61.0 GnuTLS/3.6.4 zlib/1.2.11 libidn2/2.0.5 libpsl/0.20.2 (+libidn2/2.0.4) nghttp2/1.32.1 librtmp/2.3 Accept: */* Cookie: token=f79f4b48-425f-48dd-9b7c-a85233095a37 < HTTP/1.1 200 OK < Content-Type: text/html;charset=utf-8 < Content-Length: 30 < X-Xss-Protection: 1; mode=block < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < Server: WEBrick/1.4.2 (Ruby/2.5.1/2018-03-29) OpenSSL/1.1.1 < Date: Fri, 01 Feb 2019 14:49:08 GMT < Connection: Keep-Alive < << Successfully destroyed cluster * Connection #0 to host ha-node1 left intact --Debug Communication Output End-- ha-node1: Successfully destroyed cluster Response Code: 200 --Debug Response Start-- Successfully destroyed cluster --Debug Response End-- Communication debug info for calling: https://ha-node2:2224/remote/cluster_destroy --Debug Communication Output Start-- * Trying 10.190.245.116... * TCP_NODELAY set * Connected to ha-node2 (10.190.245.116) port 2224 (#0) * found 399 certificates in /etc/ssl/certs * ALPN, offering http/1.1 * SSL connection using TLS1.2 / ECDHE_RSA_AES_256_GCM_SHA384 * server certificate verification SKIPPED * server certificate status verification SKIPPED * common name: ha-node2 (matched) * server certificate expiration date OK * server certificate activation date OK * certificate public key: RSA * certificate version: #3 * subject: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node2 * start date: Fri, 01 Feb 2019 14:48:46 GMT * expire date: Mon, 29 Jan 2029 14:48:46 GMT * issuer: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node2 * compression: NULL * ALPN, server did not agree to a protocol > GET /remote/cluster_destroy HTTP/1.1 Host: ha-node2:2224 User-Agent: PycURL/7.43.0.1 libcurl/7.61.0 GnuTLS/3.6.4 zlib/1.2.11 libidn2/2.0.5 libpsl/0.20.2 (+libidn2/2.0.4) nghttp2/1.32.1 librtmp/2.3 Accept: */* Cookie: token=5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a < HTTP/1.1 200 OK < Content-Type: text/html;charset=utf-8 < Content-Length: 30 < X-Xss-Protection: 1; mode=block < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < Server: WEBrick/1.4.2 (Ruby/2.5.1/2018-03-29) OpenSSL/1.1.1 < Date: Fri, 01 Feb 2019 14:49:08 GMT < Connection: Keep-Alive < << Successfully destroyed cluster * Connection #0 to host ha-node2 left intact --Debug Communication Output End-- ha-node2: Successfully destroyed cluster Running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Environment: GEM_HOME=/usr/share/pcsd/vendor/bundle/ruby HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin PCSD_DEBUG=true PCSD_NETWORK_TIMEOUT=60 SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root --Debug Input Start-- {} --Debug Input End-- Finished running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Return value: 0 --Debug Stdout Start-- { "status": "ok", "data": { "tokens": { "ha-node1": "f79f4b48-425f-48dd-9b7c-a85233095a37", "ha-node2": "5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a" }, "ports": { "ha-node1": 2224, "ha-node2": 2224 } }, "log": [ "I, [2019-02-01T15:49:08.529877 #10193] INFO -- : PCSD Debugging enabledn", "D, [2019-02-01T15:49:08.529909 #10193] DEBUG -- : Did not detect RHEL 6n", "D, [2019-02-01T15:49:08.529919 #10193] DEBUG -- : Detected systemd is in usen", "I, [2019-02-01T15:49:08.589330 #10193] INFO -- : Running: /usr/sbin/corosync-cmapctl totem.cluster_namen", "I, [2019-02-01T15:49:08.589374 #10193] INFO -- : CIB USER: hacluster, groups: n", "D, [2019-02-01T15:49:08.591461 #10193] DEBUG -- : []n", "D, [2019-02-01T15:49:08.591499 #10193] DEBUG -- : ["Failed to initialize the cmap API. Error CS_ERR_LIBRARY\n"]n", "D, [2019-02-01T15:49:08.591527 #10193] DEBUG -- : Duration: 0.002077176sn", "I, [2019-02-01T15:49:08.591555 #10193] INFO -- : Return Value: 1n", "W, [2019-02-01T15:49:08.591580 #10193] WARN -- : Cannot read config 'corosync.conf' from '/etc/corosync/corosync.conf': No such filen", "W, [2019-02-01T15:49:08.591647 #10193] WARN -- : Cannot read config 'corosync.conf' from '/etc/corosync/corosync.conf': No such file or directory - /etc/corosync/corosync.confn" ] } --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Sending 'pacemaker_remote authkey' to 'ha-node1', 'ha-node2' Sending HTTP Request to: https://ha-node1:2224/remote/put_file --Debug Input Start-- data_json=%7B%22pacemaker_remote+authkey%22%3A+%7B%22data%22%3A+%22OWE1OTgzZDgxZDZkZDdmOTVmOTBmYzhjYjY2ZWQ1NzY3ZTU3ZTU1NmFmYzBhY2U0NDVlMmM1MTQwMDRjYzk3ZQ%3D%3D%22%2C+%22type%22%3A+%22pcmk_remote_authkey%22%2C+%22rewrite_existing%22%3A+true%7D%7D --Debug Input End-- Sending HTTP Request to: https://ha-node2:2224/remote/put_file --Debug Input Start-- data_json=%7B%22pacemaker_remote+authkey%22%3A+%7B%22data%22%3A+%22OWE1OTgzZDgxZDZkZDdmOTVmOTBmYzhjYjY2ZWQ1NzY3ZTU3ZTU1NmFmYzBhY2U0NDVlMmM1MTQwMDRjYzk3ZQ%3D%3D%22%2C+%22type%22%3A+%22pcmk_remote_authkey%22%2C+%22rewrite_existing%22%3A+true%7D%7D --Debug Input End-- Finished calling: https://ha-node1:2224/remote/put_file Response Code: 200 --Debug Response Start-- {"files":{"pacemaker_remote authkey":{"code":"written","message":""}}} --Debug Response End-- Communication debug info for calling: https://ha-node1:2224/remote/put_file --Debug Communication Info Start-- * Trying 127.0.1.1... * TCP_NODELAY set * Connected to ha-node1 (127.0.1.1) port 2224 (#0) * found 399 certificates in /etc/ssl/certs * ALPN, offering http/1.1 * SSL connection using TLS1.2 / ECDHE_RSA_AES_256_GCM_SHA384 * server certificate verification SKIPPED * server certificate status verification SKIPPED * common name: ha-node1 (matched) * server certificate expiration date OK * server certificate activation date OK * certificate public key: RSA * certificate version: #3 * subject: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node1 * start date: Fri, 01 Feb 2019 14:47:03 GMT * expire date: Mon, 29 Jan 2029 14:47:03 GMT * issuer: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node1 * compression: NULL * ALPN, server did not agree to a protocol > POST /remote/put_file HTTP/1.1 Host: ha-node1:2224 User-Agent: PycURL/7.43.0.1 libcurl/7.61.0 GnuTLS/3.6.4 zlib/1.2.11 libidn2/2.0.5 libpsl/0.20.2 (+libidn2/2.0.4) nghttp2/1.32.1 librtmp/2.3 Accept: */* Cookie: token=f79f4b48-425f-48dd-9b7c-a85233095a37 Content-Length: 245 Content-Type: application/x-www-form-urlencoded >> data_json=%7B%22pacemaker_remote+authkey%22%3A+%7B%22data%22%3A+%22OWE1OTgzZDgxZDZkZDdmOTVmOTBmYzhjYjY2ZWQ1NzY3ZTU3ZTU1NmFmYzBhY2U0NDVlMmM1MTQwMDRjYzk3ZQ%3D%3D%22%2C+%22type%22%3A+%22pcmk_remote_authkey%22%2C+%22rewrite_existing%22%3A+true%7D%7D * upload completely sent off: 245 out of 245 bytes < HTTP/1.1 200 OK < Content-Type: text/html;charset=utf-8 < Content-Length: 70 < X-Xss-Protection: 1; mode=block < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < Server: WEBrick/1.4.2 (Ruby/2.5.1/2018-03-29) OpenSSL/1.1.1 < Date: Fri, 01 Feb 2019 14:49:08 GMT < Connection: Keep-Alive < << {"files":{"pacemaker_remote authkey":{"code":"written","message":""}}} * Connection #0 to host ha-node1 left intact --Debug Communication Info End-- ha-node1: successful distribution of the file 'pacemaker_remote authkey' Finished calling: https://ha-node2:2224/remote/put_file Response Code: 200 --Debug Response Start-- {"files":{"pacemaker_remote authkey":{"code":"written","message":""}}} --Debug Response End-- Communication debug info for calling: https://ha-node2:2224/remote/put_file --Debug Communication Info Start-- * Trying 10.190.245.116... * TCP_NODELAY set * Connected to ha-node2 (10.190.245.116) port 2224 (#1) * found 399 certificates in /etc/ssl/certs * ALPN, offering http/1.1 * SSL connection using TLS1.2 / ECDHE_RSA_AES_256_GCM_SHA384 * server certificate verification SKIPPED * server certificate status verification SKIPPED * common name: ha-node2 (matched) * server certificate expiration date OK * server certificate activation date OK * certificate public key: RSA * certificate version: #3 * subject: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node2 * start date: Fri, 01 Feb 2019 14:48:46 GMT * expire date: Mon, 29 Jan 2029 14:48:46 GMT * issuer: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node2 * compression: NULL * ALPN, server did not agree to a protocol > POST /remote/put_file HTTP/1.1 Host: ha-node2:2224 User-Agent: PycURL/7.43.0.1 libcurl/7.61.0 GnuTLS/3.6.4 zlib/1.2.11 libidn2/2.0.5 libpsl/0.20.2 (+libidn2/2.0.4) nghttp2/1.32.1 librtmp/2.3 Accept: */* Cookie: token=5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a Content-Length: 245 Content-Type: application/x-www-form-urlencoded >> data_json=%7B%22pacemaker_remote+authkey%22%3A+%7B%22data%22%3A+%22OWE1OTgzZDgxZDZkZDdmOTVmOTBmYzhjYjY2ZWQ1NzY3ZTU3ZTU1NmFmYzBhY2U0NDVlMmM1MTQwMDRjYzk3ZQ%3D%3D%22%2C+%22type%22%3A+%22pcmk_remote_authkey%22%2C+%22rewrite_existing%22%3A+true%7D%7D * upload completely sent off: 245 out of 245 bytes < HTTP/1.1 200 OK < Content-Type: text/html;charset=utf-8 < Content-Length: 70 < X-Xss-Protection: 1; mode=block < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < Server: WEBrick/1.4.2 (Ruby/2.5.1/2018-03-29) OpenSSL/1.1.1 < Date: Fri, 01 Feb 2019 14:49:08 GMT < Connection: Keep-Alive < << {"files":{"pacemaker_remote authkey":{"code":"written","message":""}}} * Connection #1 to host ha-node2 left intact --Debug Communication Info End-- ha-node2: successful distribution of the file 'pacemaker_remote authkey' Sending cluster config files to the nodes... Running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb send_local_configs Environment: GEM_HOME=/usr/share/pcsd/vendor/bundle/ruby HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin PCSD_DEBUG=true PCSD_NETWORK_TIMEOUT=60 SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root --Debug Input Start-- {"nodes": ["ha-node1", "ha-node2"], "force": true, "clear_local_cluster_permissions": true} --Debug Input End-- Finished running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb send_local_configs Return value: 0 --Debug Stdout Start-- { "status": "ok", "data": { "ha-node1": { "status": "ok", "result": { "pcs_settings.conf": "accepted", "tokens": "accepted" } }, "ha-node2": { "status": "ok", "result": { "pcs_settings.conf": "accepted", "tokens": "accepted" } } }, "log": [ "I, [2019-02-01T15:49:09.010607 #10209] INFO -- : PCSD Debugging enabledn", "D, [2019-02-01T15:49:09.010641 #10209] DEBUG -- : Did not detect RHEL 6n", "D, [2019-02-01T15:49:09.010656 #10209] DEBUG -- : Detected systemd is in usen", "I, [2019-02-01T15:49:09.067132 #10209] INFO -- : Running: /usr/sbin/corosync-cmapctl totem.cluster_namen", "I, [2019-02-01T15:49:09.067175 #10209] INFO -- : CIB USER: hacluster, groups: n", "D, [2019-02-01T15:49:09.069319 #10209] DEBUG -- : []n", "D, [2019-02-01T15:49:09.069359 #10209] DEBUG -- : ["Failed to initialize the cmap API. Error CS_ERR_LIBRARY\n"]n", "D, [2019-02-01T15:49:09.069394 #10209] DEBUG -- : Duration: 0.00213617sn", "I, [2019-02-01T15:49:09.069423 #10209] INFO -- : Return Value: 1n", "W, [2019-02-01T15:49:09.069448 #10209] WARN -- : Cannot read config 'corosync.conf' from '/etc/corosync/corosync.conf': No such filen", "W, [2019-02-01T15:49:09.069486 #10209] WARN -- : Cannot read config 'corosync.conf' from '/etc/corosync/corosync.conf': No such file or directory - /etc/corosync/corosync.confn", "I, [2019-02-01T15:49:09.069751 #10209] INFO -- : Sending config 'pcs_settings.conf' version 0 36dfa9387571c4c5bc22d008a40c4fe3089e2dd0 to nodes: ha-node1, ha-node2n", "I, [2019-02-01T15:49:09.069788 #10209] INFO -- : Sending config 'tokens' version 2 1d053971d7a1316c2b49835cafa305007b09aff4 to nodes: ha-node1, ha-node2n", "I, [2019-02-01T15:49:09.069948 #10209] INFO -- : SRWT Node: ha-node2 Request: set_configsn", "I, [2019-02-01T15:49:09.071662 #10209] INFO -- : SRWT Node: ha-node1 Request: set_configsn", "I, [2019-02-01T15:49:09.120520 #10209] INFO -- : Sending config response from ha-node1: {"status"=>"ok", "result"=>{"pcs_settings.conf"=>"accepted", "tokens"=>"accepted"}}n", "I, [2019-02-01T15:49:09.120603 #10209] INFO -- : Sending config response from ha-node2: {"status"=>"ok", "result"=>{"pcs_settings.conf"=>"accepted", "tokens"=>"accepted"}}n" ] } --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Environment: GEM_HOME=/usr/share/pcsd/vendor/bundle/ruby HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin PCSD_DEBUG=true PCSD_NETWORK_TIMEOUT=60 SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root --Debug Input Start-- {} --Debug Input End-- Finished running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Return value: 0 --Debug Stdout Start-- { "status": "ok", "data": { "tokens": { "ha-node1": "f79f4b48-425f-48dd-9b7c-a85233095a37", "ha-node2": "5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a" }, "ports": { "ha-node1": 2224, "ha-node2": 2224 } }, "log": [ "I, [2019-02-01T15:49:09.421365 #10228] INFO -- : PCSD Debugging enabledn", "D, [2019-02-01T15:49:09.421402 #10228] DEBUG -- : Did not detect RHEL 6n", "D, [2019-02-01T15:49:09.421413 #10228] DEBUG -- : Detected systemd is in usen", "I, [2019-02-01T15:49:09.479912 #10228] INFO -- : Running: /usr/sbin/corosync-cmapctl totem.cluster_namen", "I, [2019-02-01T15:49:09.479952 #10228] INFO -- : CIB USER: hacluster, groups: n", "D, [2019-02-01T15:49:09.482010 #10228] DEBUG -- : []n", "D, [2019-02-01T15:49:09.482049 #10228] DEBUG -- : ["Failed to initialize the cmap API. Error CS_ERR_LIBRARY\n"]n", "D, [2019-02-01T15:49:09.482075 #10228] DEBUG -- : Duration: 0.002049913sn", "I, [2019-02-01T15:49:09.482104 #10228] INFO -- : Return Value: 1n", "W, [2019-02-01T15:49:09.482129 #10228] WARN -- : Cannot read config 'corosync.conf' from '/etc/corosync/corosync.conf': No such filen", "W, [2019-02-01T15:49:09.482169 #10228] WARN -- : Cannot read config 'corosync.conf' from '/etc/corosync/corosync.conf': No such file or directory - /etc/corosync/corosync.confn" ] } --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Sending HTTP Request to: https://ha-node1:2224/remote/set_corosync_conf Data: corosync_conf=totem+%7B%0A++++version%3A+2%0A++++cluster_name%3A+my_cluster%0A++++secauth%3A+off%0A++++transport%3A+udpu%0A%7D%0A%0Anodelist+%7B%0A++++node+%7B%0A++++++++ring0_addr%3A+ha-node1%0A++++++++nodeid%3A+1%0A++++%7D%0A%0A++++node+%7B%0A++++++++ring0_addr%3A+ha-node2%0A++++++++nodeid%3A+2%0A++++%7D%0A%7D%0A%0Aquorum+%7B%0A++++provider%3A+corosync_votequorum%0A++++two_node%3A+1%0A%7D%0A%0Alogging+%7B%0A++++to_logfile%3A+yes%0A++++logfile%3A+%2Fvar%2Flog%2Fcorosync%2Fcorosync.log%0A++++to_syslog%3A+yes%0A%7D%0A ha-node1: Succeeded Response Code: 200 --Debug Response Start-- Succeeded --Debug Response End-- Communication debug info for calling: https://ha-node1:2224/remote/set_corosync_conf --Debug Communication Output Start-- * Trying 127.0.1.1... * TCP_NODELAY set * Connected to ha-node1 (127.0.1.1) port 2224 (#0) * found 399 certificates in /etc/ssl/certs * ALPN, offering http/1.1 * SSL connection using TLS1.2 / ECDHE_RSA_AES_256_GCM_SHA384 * server certificate verification SKIPPED * server certificate status verification SKIPPED * common name: ha-node1 (matched) * server certificate expiration date OK * server certificate activation date OK * certificate public key: RSA * certificate version: #3 * subject: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node1 * start date: Fri, 01 Feb 2019 14:47:03 GMT * expire date: Mon, 29 Jan 2029 14:47:03 GMT * issuer: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node1 * compression: NULL * ALPN, server did not agree to a protocol > POST /remote/set_corosync_conf HTTP/1.1 Host: ha-node1:2224 User-Agent: PycURL/7.43.0.1 libcurl/7.61.0 GnuTLS/3.6.4 zlib/1.2.11 libidn2/2.0.5 libpsl/0.20.2 (+libidn2/2.0.4) nghttp2/1.32.1 librtmp/2.3 Accept: */* Cookie: token=f79f4b48-425f-48dd-9b7c-a85233095a37 Content-Length: 522 Content-Type: application/x-www-form-urlencoded >> corosync_conf=totem+%7B%0A++++version%3A+2%0A++++cluster_name%3A+my_cluster%0A++++secauth%3A+off%0A++++transport%3A+udpu%0A%7D%0A%0Anodelist+%7B%0A++++node+%7B%0A++++++++ring0_addr%3A+ha-node1%0A++++++++nodeid%3A+1%0A++++%7D%0A%0A++++node+%7B%0A++++++++ring0_addr%3A+ha-node2%0A++++++++nodeid%3A+2%0A++++%7D%0A%7D%0A%0Aquorum+%7B%0A++++provider%3A+corosync_votequorum%0A++++two_node%3A+1%0A%7D%0A%0Alogging+%7B%0A++++to_logfile%3A+yes%0A++++logfile%3A+%2Fvar%2Flog%2Fcorosync%2Fcorosync.log%0A++++to_syslog%3A+yes%0A%7D%0A * upload completely sent off: 522 out of 522 bytes < HTTP/1.1 200 OK < Content-Type: text/html;charset=utf-8 < Content-Length: 9 < X-Xss-Protection: 1; mode=block < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < Server: WEBrick/1.4.2 (Ruby/2.5.1/2018-03-29) OpenSSL/1.1.1 < Date: Fri, 01 Feb 2019 14:49:09 GMT < Connection: Keep-Alive < << Succeeded * Connection #0 to host ha-node1 left intact --Debug Communication Output End-- Running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Environment: GEM_HOME=/usr/share/pcsd/vendor/bundle/ruby HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin PCSD_DEBUG=true PCSD_NETWORK_TIMEOUT=60 SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root --Debug Input Start-- {} --Debug Input End-- Finished running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Return value: 0 --Debug Stdout Start-- { "status": "ok", "data": { "tokens": { "ha-node1": "f79f4b48-425f-48dd-9b7c-a85233095a37", "ha-node2": "5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a" }, "ports": { "ha-node1": 2224, "ha-node2": 2224 } }, "log": [ "I, [2019-02-01T15:49:09.863117 #10243] INFO -- : PCSD Debugging enabledn", "D, [2019-02-01T15:49:09.863153 #10243] DEBUG -- : Did not detect RHEL 6n", "D, [2019-02-01T15:49:09.863164 #10243] DEBUG -- : Detected systemd is in usen", "I, [2019-02-01T15:49:09.920474 #10243] INFO -- : Running: /usr/sbin/corosync-cmapctl totem.cluster_namen", "I, [2019-02-01T15:49:09.920516 #10243] INFO -- : CIB USER: hacluster, groups: n", "D, [2019-02-01T15:49:09.922649 #10243] DEBUG -- : []n", "D, [2019-02-01T15:49:09.922689 #10243] DEBUG -- : ["Failed to initialize the cmap API. Error CS_ERR_LIBRARY\n"]n", "D, [2019-02-01T15:49:09.922718 #10243] DEBUG -- : Duration: 0.002123256sn", "I, [2019-02-01T15:49:09.922748 #10243] INFO -- : Return Value: 1n" ] } --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Sending HTTP Request to: https://ha-node2:2224/remote/set_corosync_conf Data: corosync_conf=totem+%7B%0A++++version%3A+2%0A++++cluster_name%3A+my_cluster%0A++++secauth%3A+off%0A++++transport%3A+udpu%0A%7D%0A%0Anodelist+%7B%0A++++node+%7B%0A++++++++ring0_addr%3A+ha-node1%0A++++++++nodeid%3A+1%0A++++%7D%0A%0A++++node+%7B%0A++++++++ring0_addr%3A+ha-node2%0A++++++++nodeid%3A+2%0A++++%7D%0A%7D%0A%0Aquorum+%7B%0A++++provider%3A+corosync_votequorum%0A++++two_node%3A+1%0A%7D%0A%0Alogging+%7B%0A++++to_logfile%3A+yes%0A++++logfile%3A+%2Fvar%2Flog%2Fcorosync%2Fcorosync.log%0A++++to_syslog%3A+yes%0A%7D%0A ha-node2: Succeeded Response Code: 200 --Debug Response Start-- Succeeded --Debug Response End-- Communication debug info for calling: https://ha-node2:2224/remote/set_corosync_conf --Debug Communication Output Start-- * Trying 10.190.245.116... * TCP_NODELAY set * Connected to ha-node2 (10.190.245.116) port 2224 (#0) * found 399 certificates in /etc/ssl/certs * ALPN, offering http/1.1 * SSL connection using TLS1.2 / ECDHE_RSA_AES_256_GCM_SHA384 * server certificate verification SKIPPED * server certificate status verification SKIPPED * common name: ha-node2 (matched) * server certificate expiration date OK * server certificate activation date OK * certificate public key: RSA * certificate version: #3 * subject: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node2 * start date: Fri, 01 Feb 2019 14:48:46 GMT * expire date: Mon, 29 Jan 2029 14:48:46 GMT * issuer: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node2 * compression: NULL * ALPN, server did not agree to a protocol > POST /remote/set_corosync_conf HTTP/1.1 Host: ha-node2:2224 User-Agent: PycURL/7.43.0.1 libcurl/7.61.0 GnuTLS/3.6.4 zlib/1.2.11 libidn2/2.0.5 libpsl/0.20.2 (+libidn2/2.0.4) nghttp2/1.32.1 librtmp/2.3 Accept: */* Cookie: token=5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a Content-Length: 522 Content-Type: application/x-www-form-urlencoded >> corosync_conf=totem+%7B%0A++++version%3A+2%0A++++cluster_name%3A+my_cluster%0A++++secauth%3A+off%0A++++transport%3A+udpu%0A%7D%0A%0Anodelist+%7B%0A++++node+%7B%0A++++++++ring0_addr%3A+ha-node1%0A++++++++nodeid%3A+1%0A++++%7D%0A%0A++++node+%7B%0A++++++++ring0_addr%3A+ha-node2%0A++++++++nodeid%3A+2%0A++++%7D%0A%7D%0A%0Aquorum+%7B%0A++++provider%3A+corosync_votequorum%0A++++two_node%3A+1%0A%7D%0A%0Alogging+%7B%0A++++to_logfile%3A+yes%0A++++logfile%3A+%2Fvar%2Flog%2Fcorosync%2Fcorosync.log%0A++++to_syslog%3A+yes%0A%7D%0A * upload completely sent off: 522 out of 522 bytes < HTTP/1.1 200 OK < Content-Type: text/html;charset=utf-8 < Content-Length: 9 < X-Xss-Protection: 1; mode=block < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < Server: WEBrick/1.4.2 (Ruby/2.5.1/2018-03-29) OpenSSL/1.1.1 < Date: Fri, 01 Feb 2019 14:49:09 GMT < Connection: Keep-Alive < << Succeeded * Connection #0 to host ha-node2 left intact --Debug Communication Output End-- Starting cluster on nodes: ha-node1, ha-node2... Running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Environment: GEM_HOME=/usr/share/pcsd/vendor/bundle/ruby HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin PCSD_DEBUG=true PCSD_NETWORK_TIMEOUT=60 SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root --Debug Input Start-- {} --Debug Input End-- Running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Environment: GEM_HOME=/usr/share/pcsd/vendor/bundle/ruby HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin PCSD_DEBUG=true PCSD_NETWORK_TIMEOUT=60 SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root --Debug Input Start-- {} --Debug Input End-- Finished running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Return value: 0 --Debug Stdout Start-- { "status": "ok", "data": { "tokens": { "ha-node1": "f79f4b48-425f-48dd-9b7c-a85233095a37", "ha-node2": "5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a" }, "ports": { "ha-node1": 2224, "ha-node2": 2224 } }, "log": [ "I, [2019-02-01T15:49:10.674528 #10255] INFO -- : PCSD Debugging enabledn", "D, [2019-02-01T15:49:10.674561 #10255] DEBUG -- : Did not detect RHEL 6n", "D, [2019-02-01T15:49:10.674571 #10255] DEBUG -- : Detected systemd is in usen", "I, [2019-02-01T15:49:10.794462 #10255] INFO -- : Running: /usr/sbin/corosync-cmapctl totem.cluster_namen", "I, [2019-02-01T15:49:10.794509 #10255] INFO -- : CIB USER: hacluster, groups: n", "D, [2019-02-01T15:49:10.799407 #10255] DEBUG -- : []n", "D, [2019-02-01T15:49:10.799451 #10255] DEBUG -- : ["Failed to initialize the cmap API. Error CS_ERR_LIBRARY\n"]n", "D, [2019-02-01T15:49:10.799478 #10255] DEBUG -- : Duration: 0.004887668sn", "I, [2019-02-01T15:49:10.799521 #10255] INFO -- : Return Value: 1n" ] } --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Sending HTTP Request to: https://ha-node1:2224/remote/capabilities Data: None Finished running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Return value: 0 --Debug Stdout Start-- { "status": "ok", "data": { "tokens": { "ha-node1": "f79f4b48-425f-48dd-9b7c-a85233095a37", "ha-node2": "5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a" }, "ports": { "ha-node1": 2224, "ha-node2": 2224 } }, "log": [ "I, [2019-02-01T15:49:10.683357 #10256] INFO -- : PCSD Debugging enabledn", "D, [2019-02-01T15:49:10.683394 #10256] DEBUG -- : Did not detect RHEL 6n", "D, [2019-02-01T15:49:10.683409 #10256] DEBUG -- : Detected systemd is in usen", "I, [2019-02-01T15:49:10.797184 #10256] INFO -- : Running: /usr/sbin/corosync-cmapctl totem.cluster_namen", "I, [2019-02-01T15:49:10.797218 #10256] INFO -- : CIB USER: hacluster, groups: n", "D, [2019-02-01T15:49:10.806670 #10256] DEBUG -- : []n", "D, [2019-02-01T15:49:10.806713 #10256] DEBUG -- : ["Failed to initialize the cmap API. Error CS_ERR_LIBRARY\n"]n", "D, [2019-02-01T15:49:10.806745 #10256] DEBUG -- : Duration: 0.009439062sn", "I, [2019-02-01T15:49:10.806795 #10256] INFO -- : Return Value: 1n" ] } --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Sending HTTP Request to: https://ha-node2:2224/remote/capabilities Data: None Response Code: 200 --Debug Response Start-- {"pcsd_capabilities":["booth.set-config","booth.set-config.multiple","booth.get-config","cluster.config.restore-local","cluster.create","cluster.destroy","corosync.config.get","corosync.config.set","corosync.qdevice.model.net.certificates","corosync.quorum.status","corosync.quorum.device.client","corosync.quorum.device.client.model.net.certificates","node.add","node.add.local","node.add.enable-and-start","node.remove","node.remove.local","node.remove.list","node.start-stop-enable-disable","node.start-stop-enable-disable.start-component","node.start-stop-enable-disable.stop-component","node.restart","node.attributes","node.standby","node.utilization","pcmk.acl.role","pcmk.acl.role.delete-with-users-groups-implicit","pcmk.alert","pcmk.cib.get","pcmk.constraint.location.simple","pcmk.constraint.location.simple.rule","pcmk.constraint.colocation.simple","pcmk.constraint.colocation.set","pcmk.constraint.order.simple","pcmk.constraint.order.set","pcmk.constraint.ticket.simple","pcmk.constraint.ticket.set","pcmk.properties.cluster","pcmk.properties.cluster.describe","pcmk.resource.create","pcmk.resource.delete","pcmk.resource.delete.list","pcmk.resource.update","pcmk.resource.update-meta","pcmk.resource.group","pcmk.resource.clone","pcmk.resource.master","pcmk.resource.enable-disable","pcmk.resource.manage-unmanage","pcmk.resource.manage-unmanage.list","pcmk.resource.utilization","pcmk.resource.cleanup.one-resource","pcmk.resource.refresh.one-resource","pcmk.stonith.create","pcmk.stonith.update","pcmk.stonith.levels","pcs.auth","pcs.automatic-pcs-configs-sync","pcs.permissions","pcs.daemon-ssl-cert.set","resource-agents.describe","resource-agents.list","stonith-agents.describe","stonith-agents.list","sbd","sbd-node","sbd-node.shared-block-device","status.pcmk.local-node"]} --Debug Response End-- Communication debug info for calling: https://ha-node2:2224/remote/capabilities --Debug Communication Output Start-- * Trying 10.190.245.116... * TCP_NODELAY set * Connected to ha-node2 (10.190.245.116) port 2224 (#0) * found 399 certificates in /etc/ssl/certs * ALPN, offering http/1.1 * SSL connection using TLS1.2 / ECDHE_RSA_AES_256_GCM_SHA384 * server certificate verification SKIPPED * server certificate status verification SKIPPED * common name: ha-node2 (matched) * server certificate expiration date OK * server certificate activation date OK * certificate public key: RSA * certificate version: #3 * subject: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node2 * start date: Fri, 01 Feb 2019 14:48:46 GMT * expire date: Mon, 29 Jan 2029 14:48:46 GMT * issuer: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node2 * compression: NULL * ALPN, server did not agree to a protocol > GET /remote/capabilities HTTP/1.1 Host: ha-node2:2224 User-Agent: PycURL/7.43.0.1 libcurl/7.61.0 GnuTLS/3.6.4 zlib/1.2.11 libidn2/2.0.5 libpsl/0.20.2 (+libidn2/2.0.4) nghttp2/1.32.1 librtmp/2.3 Accept: */* Cookie: token=5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a < HTTP/1.1 200 OK < Content-Type: text/html;charset=utf-8 < Content-Length: 1795 < X-Xss-Protection: 1; mode=block < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < Server: WEBrick/1.4.2 (Ruby/2.5.1/2018-03-29) OpenSSL/1.1.1 < Date: Fri, 01 Feb 2019 14:49:10 GMT < Connection: Keep-Alive < << {"pcsd_capabilities":["booth.set-config","booth.set-config.multiple","booth.get-config","cluster.config.restore-local","cluster.create","cluster.destroy","corosync.config.get","corosync.config.set","corosync.qdevice.model.net.certificates","corosync.quorum.status","corosync.quorum.device.client","corosync.quorum.device.client.model.net.certificates","node.add","node.add.local","node.add.enable-and-start","node.remove","node.remove.local","node.remove.list","node.start-stop-enable-disable","node.start-stop-enable-disable.start-component","node.start-stop-enable-disable.stop-component","node.restart","node.attributes","node.standby","node.utilization","pcmk.acl.role","pcmk.acl.role.delete-with-users-groups-implicit","pcmk.alert","pcmk.cib.get","pcmk.constraint.location.simple","pcmk.constraint.location.simple.rule","pcmk.constraint.colocation.simple","pcmk.constraint.colocation.set","pcmk.constraint.order.simple","pcmk.constraint.order.set","pcmk.constraint.ticket.simple","pcmk.constraint.ticket.set","pcmk.properties.cluster","pcmk.properties.cluster.describe","pcmk.resource.create","pcmk.resource.delete","pcmk.resource.delete.list","pcmk.resource.update","pcmk.resource.update-meta","pcmk.resource.group","pcmk.resource.clone","pcmk.resource.master","pcmk.resource.enable-disable","pcmk.resource.manage-unmanage","pcmk.resource.manage-unmanage.list","pcmk.resource.utilization","pcmk.resource.cleanup.one-resource","pcmk.resource.refresh.one-resource","pcmk.stonith.create","pcmk.stonith.update","pcmk.stonith.levels","pcs.auth","pcs.automatic-pcs-configs-sync","pcs.permissions","pcs.daemon-ssl-cert.set","resource-agents.describe","resource-agents.list","stonith-agents.describe","stonith-agents.list","sbd","sbd-node","sbd-node.shared-block-device","status.pcmk.local-node"]} * Connection #0 to host ha-node2 left intact --Debug Communication Output End-- Response Code: 200 --Debug Response Start-- {"pcsd_capabilities":["booth.set-config","booth.set-config.multiple","booth.get-config","cluster.config.restore-local","cluster.create","cluster.destroy","corosync.config.get","corosync.config.set","corosync.qdevice.model.net.certificates","corosync.quorum.status","corosync.quorum.device.client","corosync.quorum.device.client.model.net.certificates","node.add","node.add.local","node.add.enable-and-start","node.remove","node.remove.local","node.remove.list","node.start-stop-enable-disable","node.start-stop-enable-disable.start-component","node.start-stop-enable-disable.stop-component","node.restart","node.attributes","node.standby","node.utilization","pcmk.acl.role","pcmk.acl.role.delete-with-users-groups-implicit","pcmk.alert","pcmk.cib.get","pcmk.constraint.location.simple","pcmk.constraint.location.simple.rule","pcmk.constraint.colocation.simple","pcmk.constraint.colocation.set","pcmk.constraint.order.simple","pcmk.constraint.order.set","pcmk.constraint.ticket.simple","pcmk.constraint.ticket.set","pcmk.properties.cluster","pcmk.properties.cluster.describe","pcmk.resource.create","pcmk.resource.delete","pcmk.resource.delete.list","pcmk.resource.update","pcmk.resource.update-meta","pcmk.resource.group","pcmk.resource.clone","pcmk.resource.master","pcmk.resource.enable-disable","pcmk.resource.manage-unmanage","pcmk.resource.manage-unmanage.list","pcmk.resource.utilization","pcmk.resource.cleanup.one-resource","pcmk.resource.refresh.one-resource","pcmk.stonith.create","pcmk.stonith.update","pcmk.stonith.levels","pcs.auth","pcs.automatic-pcs-configs-sync","pcs.permissions","pcs.daemon-ssl-cert.set","resource-agents.describe","resource-agents.list","stonith-agents.describe","stonith-agents.list","sbd","sbd-node","sbd-node.shared-block-device","status.pcmk.local-node"]} --Debug Response End-- Communication debug info for calling: https://ha-node1:2224/remote/capabilities --Debug Communication Output Start-- * Trying 127.0.1.1... * TCP_NODELAY set * Connected to ha-node1 (127.0.1.1) port 2224 (#0) * found 399 certificates in /etc/ssl/certs * ALPN, offering http/1.1 * SSL connection using TLS1.2 / ECDHE_RSA_AES_256_GCM_SHA384 * server certificate verification SKIPPED * server certificate status verification SKIPPED * common name: ha-node1 (matched) * server certificate expiration date OK * server certificate activation date OK * certificate public key: RSA * certificate version: #3 * subject: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node1 * start date: Fri, 01 Feb 2019 14:47:03 GMT * expire date: Mon, 29 Jan 2029 14:47:03 GMT * issuer: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node1 * compression: NULL * ALPN, server did not agree to a protocol > GET /remote/capabilities HTTP/1.1 Host: ha-node1:2224 User-Agent: PycURL/7.43.0.1 libcurl/7.61.0 GnuTLS/3.6.4 zlib/1.2.11 libidn2/2.0.5 libpsl/0.20.2 (+libidn2/2.0.4) nghttp2/1.32.1 librtmp/2.3 Accept: */* Cookie: token=f79f4b48-425f-48dd-9b7c-a85233095a37 < HTTP/1.1 200 OK < Content-Type: text/html;charset=utf-8 < Content-Length: 1795 < X-Xss-Protection: 1; mode=block < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < Server: WEBrick/1.4.2 (Ruby/2.5.1/2018-03-29) OpenSSL/1.1.1 < Date: Fri, 01 Feb 2019 14:49:10 GMT < Connection: Keep-Alive < << {"pcsd_capabilities":["booth.set-config","booth.set-config.multiple","booth.get-config","cluster.config.restore-local","cluster.create","cluster.destroy","corosync.config.get","corosync.config.set","corosync.qdevice.model.net.certificates","corosync.quorum.status","corosync.quorum.device.client","corosync.quorum.device.client.model.net.certificates","node.add","node.add.local","node.add.enable-and-start","node.remove","node.remove.local","node.remove.list","node.start-stop-enable-disable","node.start-stop-enable-disable.start-component","node.start-stop-enable-disable.stop-component","node.restart","node.attributes","node.standby","node.utilization","pcmk.acl.role","pcmk.acl.role.delete-with-users-groups-implicit","pcmk.alert","pcmk.cib.get","pcmk.constraint.location.simple","pcmk.constraint.location.simple.rule","pcmk.constraint.colocation.simple","pcmk.constraint.colocation.set","pcmk.constraint.order.simple","pcmk.constraint.order.set","pcmk.constraint.ticket.simple","pcmk.constraint.ticket.set","pcmk.properties.cluster","pcmk.properties.cluster.describe","pcmk.resource.create","pcmk.resource.delete","pcmk.resource.delete.list","pcmk.resource.update","pcmk.resource.update-meta","pcmk.resource.group","pcmk.resource.clone","pcmk.resource.master","pcmk.resource.enable-disable","pcmk.resource.manage-unmanage","pcmk.resource.manage-unmanage.list","pcmk.resource.utilization","pcmk.resource.cleanup.one-resource","pcmk.resource.refresh.one-resource","pcmk.stonith.create","pcmk.stonith.update","pcmk.stonith.levels","pcs.auth","pcs.automatic-pcs-configs-sync","pcs.permissions","pcs.daemon-ssl-cert.set","resource-agents.describe","resource-agents.list","stonith-agents.describe","stonith-agents.list","sbd","sbd-node","sbd-node.shared-block-device","status.pcmk.local-node"]} * Connection #0 to host ha-node1 left intact --Debug Communication Output End-- Running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Environment: GEM_HOME=/usr/share/pcsd/vendor/bundle/ruby HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin PCSD_DEBUG=true PCSD_NETWORK_TIMEOUT=60 SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root --Debug Input Start-- {} --Debug Input End-- Running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Environment: GEM_HOME=/usr/share/pcsd/vendor/bundle/ruby HOME=/home/multipass LANG=C.UTF-8 LC_ALL=C LOGNAME=root MAIL=/var/mail/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin PCSD_DEBUG=true PCSD_NETWORK_TIMEOUT=60 SHELL=/bin/bash SUDO_COMMAND=/usr/sbin/pcs cluster setup --name my_cluster ha-node1 ha-node2 --start --enable --force --debug SUDO_GID=1001 SUDO_UID=1000 SUDO_USER=multipass TERM=xterm USER=root USERNAME=root --Debug Input Start-- {} --Debug Input End-- Finished running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Return value: 0 --Debug Stdout Start-- { "status": "ok", "data": { "tokens": { "ha-node1": "f79f4b48-425f-48dd-9b7c-a85233095a37", "ha-node2": "5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a" }, "ports": { "ha-node1": 2224, "ha-node2": 2224 } }, "log": [ "I, [2019-02-01T15:49:11.292945 #10282] INFO -- : PCSD Debugging enabledn", "D, [2019-02-01T15:49:11.292978 #10282] DEBUG -- : Did not detect RHEL 6n", "D, [2019-02-01T15:49:11.292989 #10282] DEBUG -- : Detected systemd is in usen", "I, [2019-02-01T15:49:11.410059 #10282] INFO -- : Running: /usr/sbin/corosync-cmapctl totem.cluster_namen", "I, [2019-02-01T15:49:11.410097 #10282] INFO -- : CIB USER: hacluster, groups: n", "D, [2019-02-01T15:49:11.420810 #10282] DEBUG -- : []n", "D, [2019-02-01T15:49:11.420854 #10282] DEBUG -- : ["Failed to initialize the cmap API. Error CS_ERR_LIBRARY\n"]n", "D, [2019-02-01T15:49:11.420889 #10282] DEBUG -- : Duration: 0.010702392sn", "I, [2019-02-01T15:49:11.420933 #10282] INFO -- : Return Value: 1n" ] } --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Sending HTTP Request to: https://ha-node1:2224/remote/cluster_start Data: component=corosync Finished running: /usr/bin/ruby -I/usr/share/pcsd/ /usr/share/pcsd/pcsd-cli.rb read_tokens Return value: 0 --Debug Stdout Start-- { "status": "ok", "data": { "tokens": { "ha-node1": "f79f4b48-425f-48dd-9b7c-a85233095a37", "ha-node2": "5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a" }, "ports": { "ha-node1": 2224, "ha-node2": 2224 } }, "log": [ "I, [2019-02-01T15:49:11.804998 #10288] INFO -- : PCSD Debugging enabledn", "D, [2019-02-01T15:49:11.805031 #10288] DEBUG -- : Did not detect RHEL 6n", "D, [2019-02-01T15:49:11.805041 #10288] DEBUG -- : Detected systemd is in usen", "I, [2019-02-01T15:49:11.948627 #10288] INFO -- : Running: /usr/sbin/corosync-cmapctl totem.cluster_namen", "I, [2019-02-01T15:49:11.948667 #10288] INFO -- : CIB USER: hacluster, groups: n", "D, [2019-02-01T15:49:11.950677 #10288] DEBUG -- : []n", "D, [2019-02-01T15:49:11.950713 #10288] DEBUG -- : ["Failed to initialize the cmap API. Error CS_ERR_LIBRARY\n"]n", "D, [2019-02-01T15:49:11.950739 #10288] DEBUG -- : Duration: 0.002000771sn", "I, [2019-02-01T15:49:11.954907 #10288] INFO -- : Return Value: 1n" ] } --Debug Stdout End-- --Debug Stderr Start-- --Debug Stderr End-- Sending HTTP Request to: https://ha-node2:2224/remote/cluster_start Data: component=corosync Response Code: 400 --Debug Response Start-- Starting Cluster (corosync)... Job for corosync.service failed because the control process exited with error code. See "systemctl status corosync.service" and "journalctl -xe" for details. Error: unable to start corosync --Debug Response End-- Communication debug info for calling: https://ha-node1:2224/remote/cluster_start --Debug Communication Output Start-- * Trying 127.0.1.1... * TCP_NODELAY set * Connected to ha-node1 (127.0.1.1) port 2224 (#0) * found 399 certificates in /etc/ssl/certs * ALPN, offering http/1.1 * SSL connection using TLS1.2 / ECDHE_RSA_AES_256_GCM_SHA384 * server certificate verification SKIPPED * server certificate status verification SKIPPED * common name: ha-node1 (matched) * server certificate expiration date OK * server certificate activation date OK * certificate public key: RSA * certificate version: #3 * subject: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node1 * start date: Fri, 01 Feb 2019 14:47:03 GMT * expire date: Mon, 29 Jan 2029 14:47:03 GMT * issuer: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node1 * compression: NULL * ALPN, server did not agree to a protocol > POST /remote/cluster_start HTTP/1.1 Host: ha-node1:2224 User-Agent: PycURL/7.43.0.1 libcurl/7.61.0 GnuTLS/3.6.4 zlib/1.2.11 libidn2/2.0.5 libpsl/0.20.2 (+libidn2/2.0.4) nghttp2/1.32.1 librtmp/2.3 Accept: */* Cookie: token=f79f4b48-425f-48dd-9b7c-a85233095a37 Content-Length: 18 Content-Type: application/x-www-form-urlencoded >> component=corosync * upload completely sent off: 18 out of 18 bytes < HTTP/1.1 400 Bad Request < Content-Type: text/html;charset=utf-8 < Content-Length: 221 < X-Xss-Protection: 1; mode=block < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < Server: WEBrick/1.4.2 (Ruby/2.5.1/2018-03-29) OpenSSL/1.1.1 < Date: Fri, 01 Feb 2019 14:49:11 GMT < Connection: Keep-Alive < << Starting Cluster (corosync)... Job for corosync.service failed because the control process exited with error code. See "systemctl status corosync.service" and "journalctl -xe" for details. Error: unable to start corosync * Connection #0 to host ha-node1 left intact --Debug Communication Output End-- ha-node1: Error connecting to ha-node1 - (HTTP error: 400) Response Code: 400 --Debug Response Start-- Starting Cluster (corosync)... Job for corosync.service failed because the control process exited with error code. See "systemctl status corosync.service" and "journalctl -xe" for details. Error: unable to start corosync --Debug Response End-- Communication debug info for calling: https://ha-node2:2224/remote/cluster_start --Debug Communication Output Start-- * Trying 10.190.245.116... * TCP_NODELAY set * Connected to ha-node2 (10.190.245.116) port 2224 (#0) * found 399 certificates in /etc/ssl/certs * ALPN, offering http/1.1 * SSL connection using TLS1.2 / ECDHE_RSA_AES_256_GCM_SHA384 * server certificate verification SKIPPED * server certificate status verification SKIPPED * common name: ha-node2 (matched) * server certificate expiration date OK * server certificate activation date OK * certificate public key: RSA * certificate version: #3 * subject: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node2 * start date: Fri, 01 Feb 2019 14:48:46 GMT * expire date: Mon, 29 Jan 2029 14:48:46 GMT * issuer: C=US,ST=MN,L=Minneapolis,O=pcsd,OU=pcsd,CN=ha-node2 * compression: NULL * ALPN, server did not agree to a protocol > POST /remote/cluster_start HTTP/1.1 Host: ha-node2:2224 User-Agent: PycURL/7.43.0.1 libcurl/7.61.0 GnuTLS/3.6.4 zlib/1.2.11 libidn2/2.0.5 libpsl/0.20.2 (+libidn2/2.0.4) nghttp2/1.32.1 librtmp/2.3 Accept: */* Cookie: token=5fb8ceaa-4e6e-4e5f-9290-7ffc6d89092a Content-Length: 18 Content-Type: application/x-www-form-urlencoded >> component=corosync * upload completely sent off: 18 out of 18 bytes < HTTP/1.1 400 Bad Request < Content-Type: text/html;charset=utf-8 < Content-Length: 221 < X-Xss-Protection: 1; mode=block < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < Server: WEBrick/1.4.2 (Ruby/2.5.1/2018-03-29) OpenSSL/1.1.1 < Date: Fri, 01 Feb 2019 14:49:12 GMT < Connection: Keep-Alive < << Starting Cluster (corosync)... Job for corosync.service failed because the control process exited with error code. See "systemctl status corosync.service" and "journalctl -xe" for details. Error: unable to start corosync * Connection #0 to host ha-node2 left intact --Debug Communication Output End-- ha-node2: Error connecting to ha-node2 - (HTTP error: 400) Error: unable to start all nodes ha-node1: Error connecting to ha-node1 - (HTTP error: 400) ha-node2: Error connecting to ha-node2 - (HTTP error: 400)
Содержание
- pve-cluster.service errors and corosync.service failed to start at boot time
- Gaspar
- dietmar
- Gaspar
- Corosync Parse Error In Config No Interfaces Defined
- linux — Corosync error «No interfaces defined» in a .
- parse error in config: No interfaces defined · Issue #434 .
- Starting corosync automatically on boot fails with «parse .
- 1297850 – Corosync fails to start in an ipv6 deployment
- 1441275 – NetworkManager doesn’t bring up interfaces .
- Watchdog should be started AFTER configuration validation .
- Parsers for the Corosync Cluster Engine configurations .
- corosync.conf — corosync executive configuration file
- RHEL 7 Beta で、システムの起動時に corosync を自動的に開始す …
- high availability — multicast address use in corosync .
- Corosync Parse Error In Config No Interfaces Defined Fixes & Solutions
- Error :- corosync is already running, is this node already in a cluster?!
- bpareek9694
- fiona
- bpareek9694
- fiona
- [SOLVED] After upgrade to 5.2.11 Corosync does not come up
- Jospeh Huber
- Help with cluster configuration
- Valerio Pachera
- Valerio Pachera
pve-cluster.service errors and corosync.service failed to start at boot time
Gaspar
New Member
I have this error after reboot :
I think this is happenning because of errors when pve-cluster.service is starting :
When I start manually pve-cluster, it starts correctly and corosync too.
NB: I am working with UDPU because I can’t use multicast.
Here my proxmox version :
Is anyone could help me ?

dietmar
Proxmox Staff Member
Best regards,
Dietmar
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Gaspar
New Member
Yes I didn’t use interface address because nodes are not in the same subnet. I try with one of the node’s address and with 0.0.0.0 but corosync can’t start. With this configuration it works but not at boot time.
New Member
Thank you for your answer. I work with Gaspar on this cluster.
Here is the full file:
bindnetaddr with either the public adress of the first node or 0.0.0.0 doesn’t permit the second node to join. So we removed it and the second node joined.
It works somehow, but the node cannot join automatically at boot time. We have to restart pve-cluster manually.
New Member
Apparently the network interface eth0 isn’t ready and fully configured with its address received by dhcp when pmxcfs starts.
Extracts from syslog:
By that time corosync has already read its configuration file, tried to connect and failed.
What is surprising is that it doesn’t continuously try or re-try when the NIC comes up.
We will try to postpone the start of pmxcfs until the NIC is ready.
Thank you for your attention.
Best regards,
Источник
Corosync Parse Error In Config No Interfaces Defined

We have collected for you the most relevant information on Corosync Parse Error In Config No Interfaces Defined, as well as possible solutions to this problem. Take a look at the links provided and find the solution that works. Other people have encountered Corosync Parse Error In Config No Interfaces Defined before you, so use the ready-made solutions.
linux — Corosync error «No interfaces defined» in a .
- https://unix.stackexchange.com/questions/283355/corosync-error-no-interfaces-defined-in-a-cluster-member
- Do the hostnames you have listed in your Corosync configuration resolve correctly? I would start by verifying that. # host isis.localdoamin Since, «domain», appears to be spelled incorrectly (or in a language I am ignorant of), I am going to guess that command fails?
parse error in config: No interfaces defined · Issue #434 .
- https://github.com/corosync/corosync/issues/434
- Feb 01, 2019 · Feb 01 15:57:00 ha-node1 corosync[11466]: notice [MAIN ] Corosync Cluster Engine (‘2.4.4’): started and ready to provide servic Feb 01 15:57:00 ha-node1 corosync[11466]: [MAIN ] Corosync built-in features: dbus rdma monitoring watchdog augeas systemd xmlco Feb 01 15:57:00 ha-node1 corosync[11466]: info [MAIN ] Corosync built-in features: dbus .
Starting corosync automatically on boot fails with «parse .
- https://access.redhat.com/solutions/638843
- When corosync starts on boot, it fails with «No interfaces defined» corosync starts on boot before the network interfaces have fully started Nov 14 12:17:57 node1 systemd: Started Network Manager Wait Online. Nov 14 12:17:57 node1 systemd: Starting Network is Online. Nov 14 12:17:57 node1 systemd: Reached target Network is Online.
1297850 – Corosync fails to start in an ipv6 deployment
- https://bugzilla.redhat.com/show_bug.cgi?id=1297850
- Description of problem: Corosync fails to start in an ipv6 deployment with the following error: [MAIN ] parse error in config: No interfaces defined [MAIN ] Corosync Cluster Engine exiting with status 8 at main.c:1278.
1441275 – NetworkManager doesn’t bring up interfaces .
- https://bugzilla.redhat.com/show_bug.cgi?id=1441275
- The reason why this bug is filled against NM is because Corosync depends on Requires=network-online.target After=network-online.target But in the logs, it can be seen that: Apr 11 03:57:49 gfs-i8c-04 systemd: NetworkManager-wait-online.service: main process exited, code=exited, status=1/FAILURE Apr 11 03:57:49 gfs-i8c-04 systemd: Failed to start Network …
Watchdog should be started AFTER configuration validation .
- https://github.com/corosync/corosync/issues/336
- Fail with error when it cannot find matching interface (error [MAIN ] parse error in config: No interfaces defined) when using 127.0.1.1; Or starts and runs happily even with 127.0.0.1; Also, docs basically say «use IP» yet the hostname is still accepted. But this is not a problem. Using name is perfectly ok.
Parsers for the Corosync Cluster Engine configurations .
- https://insights-core.readthedocs.io/en/latest/shared_parsers_catalog/corosync.html
- This parser reads the /etc/sysconfig/corosync file. . It exposes the corosync configuration through the parsr query interface. The parameters in the directives are referred from the manpage of corosync.conf. See man 8 corosync.conf for more info.
corosync.conf — corosync executive configuration file
- https://www.mankier.com/5/corosync.conf
- The corosync.conf instructs the corosync executive about various parameters needed to control the corosync executive. Empty lines and lines starting with # character are ignored. The configuration file consists of bracketed top level directives.
RHEL 7 Beta で、システムの起動時に corosync を自動的に開始す …
- https://access.redhat.com/ja/solutions/3015521
- システムの起動時に corosync を開始すると失敗し、No interfaces defined エラーが発生します。 システムの起動時、ネットワークインターフェイスが完全に起動する前に corosync が開始します。 Nov 14 12:17:57 node1 systemd:Started Network Manager Wait Online. Nov 14 12:17:57 node1 systemd:Starting Network is Online.
high availability — multicast address use in corosync .
- https://serverfault.com/questions/591295/multicast-address-use-in-corosync
- I’m wondering about the purpose of the multicast address in the corosync messaging software : Since we have to bind each net interface with an IP address and a …
Corosync Parse Error In Config No Interfaces Defined Fixes & Solutions
We are confident that the above descriptions of Corosync Parse Error In Config No Interfaces Defined and how to fix it will be useful to you. If you have another solution to Corosync Parse Error In Config No Interfaces Defined or some notes on the existing ways to solve it, then please drop us an email.
Источник
Error :- corosync is already running, is this node already in a cluster?!
bpareek9694
New Member
We’re facing issue of connected two clusters:-
corosync is already running, is this node already in a cluster?!
* local node address: cannot use IP ‘192.99.144.42’, it must be configured exactly once on local node!
Check if node may join a cluster failed!
How can we resolve the issue
Please Help me

fiona
Proxmox Staff Member
Best regards,
Fiona
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
bpareek9694
New Member
but when i add node to the cluster it’s shows the error 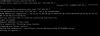
I’m just waiting over 30 min but the process are same.
Please help me to resolve the issue.
Note:- Node and Cluster both are working in debian 9.
Both are using Proxmox ve 5.4
fiona
Proxmox Staff Member
Best regards,
Fiona
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Источник
[SOLVED] After upgrade to 5.2.11 Corosync does not come up
Jospeh Huber
Active Member
first of all we use the non-subscription repos.
Today we want to upgrade to the newest version 5.2.11.
After upgrading one node it cannot join the cluster again.
The old version of the remaining running nodes is: 5.2-6.
It cannot join the cluster again. (VM start reports «waiting for quorum»)
Nov 22 14:17:17 pxhost1 pmxcfs[3443]: [status] crit: cpg_initialize failed: 2
Nov 22 14:17:23 pxhost1 pmxcfs[3443]: [quorum] crit: quorum_initialize failed: 2
Nov 22 14:17:23 pxhost1 pmxcfs[3443]: [confdb] crit: cmap_initialize failed: 2
Nov 22 14:17:23 pxhost1 pmxcfs[3443]: [dcdb] crit: cpg_initialize failed: 2
Nov 22 14:17:23 pxhost1 pmxcfs[3443]: [status] crit: cpg_initialize failed: 2
The corosync service does not come up:
Nov 22 14:02:03 pxhost1 corosync[3657]: warning [MAIN ] interface section bindnetaddr is used together with nodelist. Nodelist one is going to be used.
Nov 22 14:02:03 pxhost1 corosync[3657]: warning [MAIN ] Please migrate config file to nodelist.
Nov 22 14:02:03 pxhost1 corosync[3657]: error [MAIN ] parse error in config: Multicast address family does not match bind address family
Nov 22 14:02:03 pxhost1 corosync[3657]: error [MAIN ] Corosync Cluster Engine exiting with status 8 at main.c:1416.
It seems that the corosync .conf is not compatible with corosync which is included in 5.2.11 . my config looks like that:
logging <
debug: off
to_syslog: yes
>
nodelist <
node <
name: pxhost1
nodeid: 3
quorum_votes: 1
ring0_addr: pxhost1
ring1_addr: pxhost1pm
>
node <
name: pxhost2
nodeid: 1
quorum_votes: 1
ring0_addr: pxhost2
ring1_addr: pxhost2pm
>
node <
name: pxhost5
nodeid: 2
quorum_votes: 1
ring0_addr: pxhost5
ring1_addr: pxhost5pm
>
quorum <
provider: corosync_votequorum
>
totem <
cluster_name: yyyyy-proxmox4
config_version: 4
ip_version: ipv4
rrp_mode: passive
secauth: on
version: 2
interface <
bindnetaddr: 111.222.333.121
ringnumber: 0
>
interface <
bindnetaddr: 10.0.99.0
ringnumber: 1
>
>
What can I do now?
On the cluster offline member I cannot change the file as root. it is read only and locked.
Источник
Help with cluster configuration
Valerio Pachera
Active Member
Hi, I’m configuring my first cluster following the documentation.
I have a dedicated nic for corosync on 192.168.9.0/24 network.
On the first node (192.168.9.106) I run ‘pvecm create pve-cluster-01’ and no errors were reported.
On the second node I run
On the first node
I guess the first step went wrong but i got no errors.
PS: the two dedicated nic are connected to a TP-Link TL-SG105E switch.
I enabled IGMP snooping on it.
Any suggestion?
Any log I can look at?
Looking at the man page, I think I should create the cluster on the first node by the rin0_addr option in first place.
Otherwise it would bind to another address.
Famous Member
Hi, I’m configuring my first cluster following the documentation.
I have a dedicated nic for corosync on 192.168.9.0/24 network.
On the first node (192.168.9.106) I run ‘pvecm create pve-cluster-01’ and no errors were reported.
On the second node I run
Hi,
I assume your host entry on the first node don’t point to 192.168.9.106?!
Take a look at /etc/corosync/corosync.conf on the first node.
Valerio Pachera
Active Member
@udo You are right!
Nontheless I found out that the ip address set in /etc/hosts was not matching the current server ip.
Note: the first server has been installed and configured by a third person and is already running some guests.
1) So, because I want to use a dedicated NIC, I have to specify its address alreay when I create the cluster.
Am I right?
By man, I see two options:
2) Honestly, I dont understand the ‘bindnet0_addr’ and the difference with ‘ring0_addr’.
Could you explain it please?
3) I guess it’s safe to run ‘pvecm create’ a second time right?
As of now, there are no other nodes.
Источник
Skip to navigation
Skip to main content

Infrastructure and Management
- Red Hat Enterprise Linux
- Red Hat Virtualization
- Red Hat Identity Management
- Red Hat Directory Server
- Red Hat Certificate System
- Red Hat Satellite
-
Red Hat Subscription Management
- Red Hat Update Infrastructure
- Red Hat Insights
- Red Hat Ansible Automation Platform
Cloud Computing
- Red Hat OpenShift
- Red Hat CloudForms
- Red Hat OpenStack Platform
- Red Hat OpenShift Container Platform
- Red Hat OpenShift Data Science
- Red Hat OpenShift Online
- Red Hat OpenShift Dedicated
-
Red Hat Advanced Cluster Security for Kubernetes
- Red Hat Advanced Cluster Management for Kubernetes
- Red Hat Quay
- OpenShift Dev Spaces
- Red Hat OpenShift Service on AWS
Storage
- Red Hat Gluster Storage
- Red Hat Hyperconverged Infrastructure
- Red Hat Ceph Storage
- Red Hat OpenShift Data Foundation
Runtimes
- Red Hat Runtimes
-
Red Hat JBoss Enterprise Application Platform
- Red Hat Data Grid
- Red Hat JBoss Web Server
- Red Hat Single Sign On
- Red Hat support for Spring Boot
- Red Hat build of Node.js
- Red Hat build of Thorntail
- Red Hat build of Eclipse Vert.x
- Red Hat build of OpenJDK
- Red Hat build of Quarkus
Integration and Automation
-
Red Hat Process Automation
- Red Hat Process Automation Manager
- Red Hat Decision Manager
All Products
Issue
- When
corosyncstarts on boot, it fails with «No interfaces defined» corosyncstarts on boot before the network interfaces have fully started
Nov 14 12:17:57 node1 systemd: Started Network Manager Wait Online.
Nov 14 12:17:57 node1 systemd: Starting Network is Online.
Nov 14 12:17:57 node1 systemd: Reached target Network is Online.
Nov 14 12:17:57 node1 systemd: Starting Corosync Cluster Engine...
Nov 14 12:17:57 node1 corosync[797]: [MAIN ] Corosync Cluster Engine ('2.3.2'): started and ready to provide service.
Nov 14 12:17:57 node1 corosync[797]: [MAIN ] Corosync built-in features: dbus rdma systemd xmlconf snmp pie relro bindnow
Nov 14 12:17:57 node1 corosync[797]: [MAIN ] parse error in config: No interfaces defined
Nov 14 12:17:57 node1 corosync[797]: [MAIN ] Corosync Cluster Engine exiting with status 8 at main.c:1215.
Nov 14 12:17:57 node1 network: Bringing up loopback interface: [ OK ]
Environment
- Red Hat Enterprise Linux (RHEL) 7 with the High Availability Add On
corosync.serviceenabled insystemdNetworkManager.serviceenabled insystemd
Subscriber exclusive content
A Red Hat subscription provides unlimited access to our knowledgebase, tools, and much more.
Current Customers and Partners
Log in for full access
Log In
-
#1
Hello,
I have this error after reboot :
Code:
# service corosync status
● corosync.service - Corosync Cluster Engine
Loaded: loaded (/lib/systemd/system/corosync.service; enabled)
Active: failed (Result: exit-code) since Wed 2016-05-18 11:58:55 CEST; 6min ago
Process: 1219 ExecStart=/usr/share/corosync/corosync start (code=exited, status=1/FAILURE)
May 18 11:58:55 castor corosync[1228]: [MAIN ] Corosync Cluster Engine ('2.3.5.15-e2b6b'): started and ready to provide service.
May 18 11:58:55 castor corosync[1228]: [MAIN ] Corosync built-in features: augeas systemd pie relro bindnow
May 18 11:58:55 castor corosync[1228]: [MAIN ] parse error in config: No interfaces defined
May 18 11:58:55 castor corosync[1228]: [MAIN ] Corosync Cluster Engine exiting with status 8 at main.c:1278.
May 18 11:58:55 castor corosync[1219]: Starting Corosync Cluster Engine (corosync): [FAILED]
May 18 11:58:55 castor systemd[1]: corosync.service: control process exited, code=exited status=1
May 18 11:58:55 castor systemd[1]: Failed to start Corosync Cluster Engine.
May 18 11:58:55 castor systemd[1]: Unit corosync.service entered failed state.I think this is happenning because of errors when pve-cluster.service is starting :
Code:
# service pve-cluster status
● pve-cluster.service - The Proxmox VE cluster filesystem
Loaded: loaded (/lib/systemd/system/pve-cluster.service; enabled)
Active: active (running) since Wed 2016-05-18 11:58:55 CEST; 6min ago
Process: 1190 ExecStartPost=/usr/bin/pvecm updatecerts --silent (code=exited, status=0/SUCCESS)
Process: 1126 ExecStart=/usr/bin/pmxcfs $DAEMON_OPTS (code=exited, status=0/SUCCESS)
Main PID: 1188 (pmxcfs)
CGroup: /system.slice/pve-cluster.service
└─1188 /usr/bin/pmxcfs
May 18 12:05:18 castor pmxcfs[1188]: [dcdb] crit: cpg_initialize failed: 2
May 18 12:05:18 castor pmxcfs[1188]: [status] crit: cpg_initialize failed: 2
May 18 12:05:24 castor pmxcfs[1188]: [quorum] crit: quorum_initialize failed: 2
May 18 12:05:24 castor pmxcfs[1188]: [confdb] crit: cmap_initialize failed: 2
May 18 12:05:24 castor pmxcfs[1188]: [dcdb] crit: cpg_initialize failed: 2
May 18 12:05:24 castor pmxcfs[1188]: [status] crit: cpg_initialize failed: 2
May 18 12:05:30 castor pmxcfs[1188]: [quorum] crit: quorum_initialize failed: 2
May 18 12:05:30 castor pmxcfs[1188]: [confdb] crit: cmap_initialize failed: 2
May 18 12:05:30 castor pmxcfs[1188]: [dcdb] crit: cpg_initialize failed: 2
May 18 12:05:30 castor pmxcfs[1188]: [status] crit: cpg_initialize failed: 2When I start manually pve-cluster, it starts correctly and corosync too.
NB: I am working with UDPU because I can’t use multicast.
Here my proxmox version :
Code:
# pveversion -v
proxmox-ve: 4.2-49 (running kernel: 4.4.8-1-pve)
pve-manager: 4.2-4 (running version: 4.2-4/2660193c)
pve-kernel-4.4.8-1-pve: 4.4.8-49
lvm2: 2.02.116-pve2
corosync-pve: 2.3.5-2
libqb0: 1.0-1
pve-cluster: 4.0-39
qemu-server: 4.0-74
pve-firmware: 1.1-8
libpve-common-perl: 4.0-60
libpve-access-control: 4.0-16
libpve-storage-perl: 4.0-50
pve-libspice-server1: 0.12.5-2
vncterm: 1.2-1
pve-qemu-kvm: 2.5-16
pve-container: 1.0-63
pve-firewall: 2.0-26
pve-ha-manager: 1.0-31
ksm-control-daemon: 1.2-1
glusterfs-client: 3.5.2-2+deb8u1
lxc-pve: 1.1.5-7
lxcfs: 2.0.0-pve2
cgmanager: 0.39-pve1
criu: 1.6.0-1Is anyone could help me ?
Thanks!
![]()
-
#2
Seems there are syntax error in your config («parse error in config: No interfaces defined»)
-
#3
Yes I didn’t use interface address because nodes are not in the same subnet. I try with one of the node’s address and with 0.0.0.0 but corosync can’t start. With this configuration it works but not at boot time.
Code:
cat /etc/pve/corosync.conf
totem {
version: 2
secauth: on
cluster_name: dioscures
config_version: 6
ip_version: ipv4
transport: udpu
interface {
ringnumber: 0
}
}
-
#4
Good Morning,
Thank you for your answer. I work with Gaspar on this cluster.
Here is the full file:
Code:
root@castor:~# cat /etc/corosync/corosync.conf
totem {
version: 2
secauth: on
cluster_name: dioscures
config_version: 6
ip_version: ipv4
transport: udpu
interface {
ringnumber: 0
}
}
nodelist {
node {
ring0_addr: castor
name: castor
nodeid: 1
quorum_votes: 1
}
node {
ring0_addr: pollux
name: pollux
nodeid: 2
quorum_votes: 1
}
}
quorum {
provider: corosync_votequorum
expected_votes: 1
two_node: 1
}
logging {
to_syslog: yes
debug: off
}bindnetaddr with either the public adress of the first node or 0.0.0.0 doesn’t permit the second node to join. So we removed it and the second node joined.
It works somehow, but the node cannot join automatically at boot time. We have to restart pve-cluster manually.
Code:
service pve-cluster restartBest regards,
Thierry
-
#5
Apparently the network interface eth0 isn’t ready and fully configured with its address received by dhcp when pmxcfs starts.
Extracts from syslog:
Code:
May 18 10:12:50 castor kernel: [ 14.031771] IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready
May 18 10:12:50 castor pmxcfs[1163]: [quorum] crit: quorum_initialize failed: 2
May 18 10:12:52 castor corosync[1230]: [MAIN ] parse error in config: No interfaces defined
May 18 10:12:52 castor ntpd_intres[1110]: host name not found: 0.debian.pool.ntp.org
May 18 10:12:53 castor kernel: [ 17.587743] IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready
May 18 10:12:53 castor dhclient: bound to {public IP address} -- renewal in 2147483648 seconds.
May 18 10:12:56 castor pmxcfs[1163]: [quorum] crit: quorum_initialize failed: 2
May 18 10:12:58 castor ntpd_intres[1110]: DNS 0.debian.pool.ntp.org -> 195.154.174.209By that time corosync has already read its configuration file, tried to connect and failed.
What is surprising is that it doesn’t continuously try or re-try when the NIC comes up.
We will try to postpone the start of pmxcfs until the NIC is ready.
Thank you for your attention.
Best regards,
Thierry
-
#6
Ok I found a solution, I don’t know if it’s the better one :
I change the file /etc/systemd/system/multi-user.target.wants/corosync.service
Code:
root@castor:~# diff -u corosync.service.old corosync.service.new
--- corosync.service.old 2016-05-18 17:44:53.249169049 +0200
+++ corosync.service.new 2016-05-18 17:45:50.849885682 +0200
@@ -11,6 +11,8 @@
[Service]
ExecStart=/usr/share/corosync/corosync start
ExecStop=/usr/share/corosync/corosync stop
+Restart=on-failure
+RestartSec=5s
Type=forkingWatchdog should be started AFTER configuration validation, not BEFORE, else it can cause reboot loop. #336
Comments
XANi commented Apr 6, 2018
2.4.2 from Debian
Currently, loading bad config will cause server to hard reboot in some cases. For example. corosync died with
Yet coresync managed to set up watchdog before getting to that point so server hard-resetted before it was even possible to check what is wrong (it was deployed via CM so I wasn’t even logged on server). And then it caused a reboot loop.
Aside from that the error message is incorrect, problem in question was some bad /etc/hosts entries after install (debian added 127.0.1.1 hostname.example.com hostname there and node address was specified as host). So it probably should be changed to something along the lines of «I can’t find myself in nodelist»
The text was updated successfully, but these errors were encountered:
jfriesse commented Apr 9, 2018
@XANi Thank you for the report. Could you please share «bad config» (please remove sensitive information)? I would like to test what exactly is happening.
Thank you,
Honza
XANi commented Apr 9, 2018 •
Okay so the config was not actually «bad», it was one that run perfectly fine on different server that was set up by a different admin. Just that config + bad /etc/hosts produced that failure. It is a 2 node cluster with
Same thing happened with fqdn. And yes I am aware that just using IPs would be better idea but like I said, I’ve inherited config (and probably finally I will just use IPs), but the «you got bad config, therefore I will hard reboot your machine in infinity isn’t exactly nice way of signalling it.
Also, docs basically say «use IP» yet the hostname is still accepted.
To replicate, add 127.0.1.1 hq-puppet1.example.com hq-puppet1 in the /etc/hosts of first node (and have hardware watchdog or VM with watchdog enabled)
jfriesse commented Apr 9, 2018
@XANi Could you please paste complete config and not just snip? Because I’m unable to reproduce the issue, because corosync will ether:
- Fail with error when it cannot find matching interface ( error [MAIN ] parse error in config: No interfaces defined ) when using 127.0.1.1
- Or starts and runs happily even with 127.0.0.1
Also, docs basically say «use IP» yet the hostname is still accepted.
But this is not a problem. Using name is perfectly ok.
Источник
pve-cluster.service errors and corosync.service failed to start at boot time
Gaspar
New Member
I have this error after reboot :
I think this is happenning because of errors when pve-cluster.service is starting :
When I start manually pve-cluster, it starts correctly and corosync too.
NB: I am working with UDPU because I can’t use multicast.
Here my proxmox version :
Is anyone could help me ?
dietmar
Proxmox Staff Member
Best regards,
Dietmar
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Gaspar
New Member
Yes I didn’t use interface address because nodes are not in the same subnet. I try with one of the node’s address and with 0.0.0.0 but corosync can’t start. With this configuration it works but not at boot time.
New Member
Thank you for your answer. I work with Gaspar on this cluster.
Here is the full file:
bindnetaddr with either the public adress of the first node or 0.0.0.0 doesn’t permit the second node to join. So we removed it and the second node joined.
It works somehow, but the node cannot join automatically at boot time. We have to restart pve-cluster manually.
New Member
Apparently the network interface eth0 isn’t ready and fully configured with its address received by dhcp when pmxcfs starts.
Extracts from syslog:
By that time corosync has already read its configuration file, tried to connect and failed.
What is surprising is that it doesn’t continuously try or re-try when the NIC comes up.
We will try to postpone the start of pmxcfs until the NIC is ready.
Thank you for your attention.
Best regards,
Источник
[SOLVED] After upgrade to 5.2.11 Corosync does not come up
Jospeh Huber
Active Member
first of all we use the non-subscription repos.
Today we want to upgrade to the newest version 5.2.11.
After upgrading one node it cannot join the cluster again.
The old version of the remaining running nodes is: 5.2-6.
It cannot join the cluster again. (VM start reports «waiting for quorum»)
Nov 22 14:17:17 pxhost1 pmxcfs[3443]: [status] crit: cpg_initialize failed: 2
Nov 22 14:17:23 pxhost1 pmxcfs[3443]: [quorum] crit: quorum_initialize failed: 2
Nov 22 14:17:23 pxhost1 pmxcfs[3443]: [confdb] crit: cmap_initialize failed: 2
Nov 22 14:17:23 pxhost1 pmxcfs[3443]: [dcdb] crit: cpg_initialize failed: 2
Nov 22 14:17:23 pxhost1 pmxcfs[3443]: [status] crit: cpg_initialize failed: 2
The corosync service does not come up:
Nov 22 14:02:03 pxhost1 corosync[3657]: warning [MAIN ] interface section bindnetaddr is used together with nodelist. Nodelist one is going to be used.
Nov 22 14:02:03 pxhost1 corosync[3657]: warning [MAIN ] Please migrate config file to nodelist.
Nov 22 14:02:03 pxhost1 corosync[3657]: error [MAIN ] parse error in config: Multicast address family does not match bind address family
Nov 22 14:02:03 pxhost1 corosync[3657]: error [MAIN ] Corosync Cluster Engine exiting with status 8 at main.c:1416.
It seems that the corosync .conf is not compatible with corosync which is included in 5.2.11 . my config looks like that:
logging <
debug: off
to_syslog: yes
>
nodelist <
node <
name: pxhost1
nodeid: 3
quorum_votes: 1
ring0_addr: pxhost1
ring1_addr: pxhost1pm
>
node <
name: pxhost2
nodeid: 1
quorum_votes: 1
ring0_addr: pxhost2
ring1_addr: pxhost2pm
>
node <
name: pxhost5
nodeid: 2
quorum_votes: 1
ring0_addr: pxhost5
ring1_addr: pxhost5pm
>
quorum <
provider: corosync_votequorum
>
totem <
cluster_name: yyyyy-proxmox4
config_version: 4
ip_version: ipv4
rrp_mode: passive
secauth: on
version: 2
interface <
bindnetaddr: 111.222.333.121
ringnumber: 0
>
interface <
bindnetaddr: 10.0.99.0
ringnumber: 1
>
>
What can I do now?
On the cluster offline member I cannot change the file as root. it is read only and locked.
Источник
Error :- corosync is already running, is this node already in a cluster?!
bpareek9694
New Member
We’re facing issue of connected two clusters:-
corosync is already running, is this node already in a cluster?!
* local node address: cannot use IP ‘192.99.144.42’, it must be configured exactly once on local node!
Check if node may join a cluster failed!
How can we resolve the issue
Please Help me
fiona
Proxmox Staff Member
Best regards,
Fiona
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
bpareek9694
New Member
but when i add node to the cluster it’s shows the error
I’m just waiting over 30 min but the process are same.
Please help me to resolve the issue.
Note:- Node and Cluster both are working in debian 9.
Both are using Proxmox ve 5.4
fiona
Proxmox Staff Member
Best regards,
Fiona
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Источник
Help with cluster configuration
Valerio Pachera
Active Member
Hi, I’m configuring my first cluster following the documentation.
I have a dedicated nic for corosync on 192.168.9.0/24 network.
On the first node (192.168.9.106) I run ‘pvecm create pve-cluster-01’ and no errors were reported.
On the second node I run
On the first node
I guess the first step went wrong but i got no errors.
PS: the two dedicated nic are connected to a TP-Link TL-SG105E switch.
I enabled IGMP snooping on it.
Any suggestion?
Any log I can look at?
Looking at the man page, I think I should create the cluster on the first node by the rin0_addr option in first place.
Otherwise it would bind to another address.
Famous Member
Hi, I’m configuring my first cluster following the documentation.
I have a dedicated nic for corosync on 192.168.9.0/24 network.
On the first node (192.168.9.106) I run ‘pvecm create pve-cluster-01’ and no errors were reported.
On the second node I run
Hi,
I assume your host entry on the first node don’t point to 192.168.9.106?!
Take a look at /etc/corosync/corosync.conf on the first node.
Valerio Pachera
Active Member
@udo You are right!
Nontheless I found out that the ip address set in /etc/hosts was not matching the current server ip.
Note: the first server has been installed and configured by a third person and is already running some guests.
1) So, because I want to use a dedicated NIC, I have to specify its address alreay when I create the cluster.
Am I right?
By man, I see two options:
2) Honestly, I dont understand the ‘bindnet0_addr’ and the difference with ‘ring0_addr’.
Could you explain it please?
3) I guess it’s safe to run ‘pvecm create’ a second time right?
As of now, there are no other nodes.
Источник
Определение multicast (Ругается corosync)
Модератор: SLEDopit
-
Enar
- Сообщения: 300
Определение multicast
Здравствуйте, подскажите пожалуйста мне при настройке corosync нужно указать multicast адрес для двух сетей, на адреса привиденные в примерах найденных в интернете corosync ругается. Ни где не могу найти как определить правильный мультикаст адрес, подскажите пожалуйста.
Вывод corosync если нужен:
Код: Выделить всё
[....] Starting corosync daemon: corosyncAug 14 10:55:12 corosync [MAIN ] Corosync Cluster Engine ('1.4.2'): started and ready to provide service.
Aug 14 10:55:12 corosync [MAIN ] Corosync built-in features: nss
Aug 14 10:55:12 corosync [MAIN ] Successfully read main configuration file '/etc/corosync/corosync.conf'.
Aug 14 10:55:12 corosync [MAIN ] parse error in config: No multicast address specified
Aug 14 10:55:12 corosync [MAIN ] Corosync Cluster Engine exiting with status 8 at main.c:1708.
failed!-
Enar
- Сообщения: 300
Re: Определение multicast
Сообщение
Enar » 15.08.2013 08:09
Вот из corosync.conf
Код: Выделить всё
interface {
ringnumber: 0
bindnetaddr: 172.16.0.0
mcastaddr: 239.255.42.1
mcastport: 5405
}
interface {
ringnumber: 1
bindnetaddr: 172.16.1.0
mcastaddr: 239.255.42.2
mcastport: 5405
}systemctl status corosync (version: 2.4.5) report error:
parse error in config: No interfaces defined
Signed-off-by: Zhao Heming <heming.zhao@xxxxxxxx>
---
test/lib/test-corosync-conf | 9 +++++++++
1 file changed, 9 insertions(+)
diff --git a/test/lib/test-corosync-conf b/test/lib/test-corosync-conf
index ccc958f1d1..e04be73998 100644
--- a/test/lib/test-corosync-conf
+++ b/test/lib/test-corosync-conf
@@ -3,6 +3,13 @@ totem {
version: 2
secauth: off
cluster_name: test
+ interface {
+ ingnumber: 0
+ bindnetaddr: 127.0.0.1
+ mcastaddr: 239.255.255.100
+ mcastport: 5405
+ ttl: 1
+ }
}
nodelist {
node {
@@ -12,6 +19,8 @@ nodelist {
}
quorum {
provider: corosync_votequorum
+ expected_votes: 1
+ two_node: 0
}
logging {
to_syslog: yes
--
2.24.0
_______________________________________________
linux-lvm mailing list
linux-lvm@xxxxxxxxxx
https://www.redhat.com/mailman/listinfo/linux-lvm
read the LVM HOW-TO at http://tldp.org/HOWTO/LVM-HOWTO/