The browser version you are using is not recommended for this site.
Please consider upgrading to the latest version of your browser by clicking one of the following links.
- Safari
- Chrome
- Edge
- Firefox
Basic Diagnostics for Correctable/Uncorrectable ECC Memory Errors with Intel® Server Boards
Documentation
Content Type
Troubleshooting
Article ID
000024007
Last Reviewed
01/10/2023
What am I seeing?
Correctable and/or Uncorrectable Error Correcting Code (ECC) events for memory modules. For example:
Mmry ECC Sensor SMI Handler Warning Memory CPU: 1, DIMM: D0 DIMM Rank: 1. — Correctable ECC / other correctable memory error — Asserted.
What is Memory Error Correction Code (ECC) Correctable Error Event?
ECC correctable error represents a threshold overflow for a given Dual In-line Memory Modules (DIMM) within a given timeframe.
How to fix it:
Memory data errors are logged as correctable or uncorrectable. Refer to the instructions below, based on the error type you encounter:
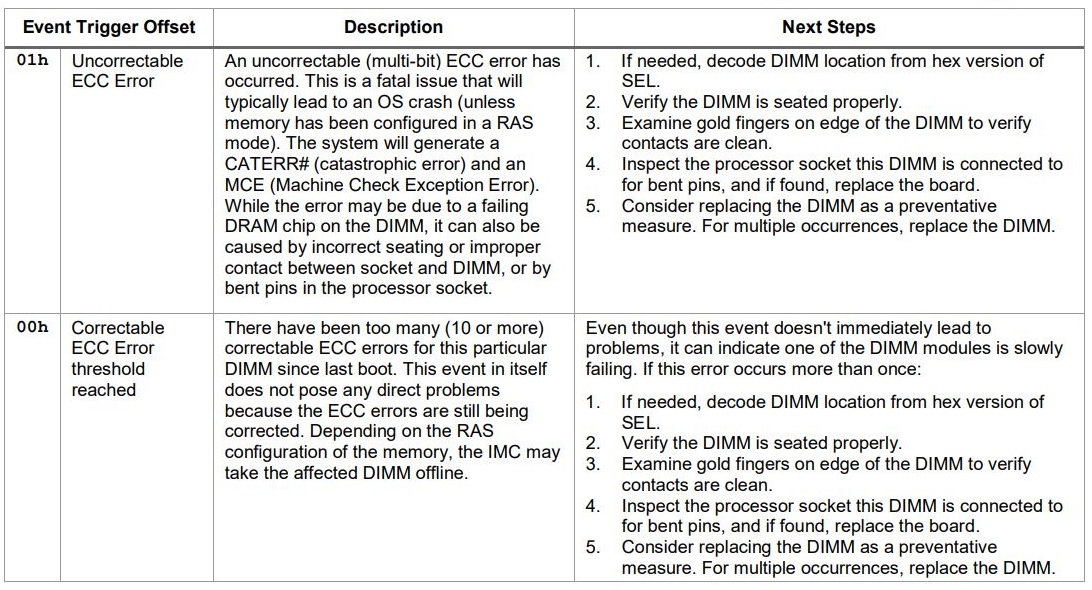
| Notes |
|
- If there is no catastrophic issue (Purple Screen of Death (PSOD) or unexpected restart) and the correctable ECC error, including Adaptative Double Device Data Correction (ADDDC) error, is less than 10 events every 24 hours for each DIMM location, which is within the threshold limit, the recommendation is to monitor the server for any recurrence of ECC error each DIMM location that triggers the event.
- If there is a catastrophic issue (Purple Screen of Death (PSOD) or unexpected restart) and the correctable ECC error, including Adaptative Double Device Data Correction (ADDDC) error, is less than 10 events every 24 hours for each DIMM location, it is recommended to re-seat each DIMM location by following the steps below:
- Power OFF the system and remove the AC power cable.
- Identify the DIMM location to re-seat. Refer to the Technical Product Specifications for your server platform to identify the DIMM location.
- Perform the re-seat of identified DIMM.
- Insert the AC power cable and power back ON the system.
- Observe for 24 hours for any recurrence of ECC error.
- If the ECC error persists with the same DIM location that was re-seated, then generate and send the SEL and Debug logs, both generated from the BMC Web Console to Intel Customer Support
- The advanced memory test (AMT) features were introduced in the BIOS and firmware stack starting with the BIOS revision 02.01.0014 for the Intel® Server Systems S2600BP, S2600WF, and S2600ST; and starting with the BIOS revision 22.01.0097 for the Intel® Server System S9200WK. For these products, recommend to enable the advanced memory test (AMT) and post package repair (PPR) features through the BIOS setup utility to perform a full check of the memory health. Refer to Chapter 5 in Memory Replacement Guideline and Advanced Memory Test for Intel® Server Products Based on Intel® 62X Chipset – White Paper for detail steps.
|
Notes |
The Error Correction Code (ECC) errors are self-correcting. Depending on the Reliability Availability Serviceability (RAS) configuration of the memory, the Integrated Memory Controller (IMC) may take the affected DIMM offline. |
|
For different Intel server platforms, there are some differences in their event definition, refer to System Event Log Troubleshooting Guide for your server platform |
|
|
Intel recommends downloading and updating the system BIOS to the latest available version for your server platform. |
|
|
If the system is an Intel® Data Center Block for Nutanix* Enterprise Cloud, rather, visit the Nutanix* Life Cycle Manager page. For a list of hardware and firmware compatibility, visit the Nutanix* Hardware and Firmware compatibility page. |
Related Products
This article applies to 221 products.
Discontinued Products
Need more help?
Give Feedback
Содержание
- Correctable ecc other correctable memory error asserted
- Uncorrectable Memory ECC
- Uncorrectable Memory ECC
- Re: Uncorrectable Memory ECC
- Re: Uncorrectable Memory ECC
- Re: Uncorrectable Memory ECC
- Re: Uncorrectable Memory ECC
- Re: Uncorrectable Memory ECC
- Re: Uncorrectable Memory ECC
- Re: Uncorrectable Memory ECC
- Re: Uncorrectable Memory ECC
- Re: Uncorrectable Memory ECC
- Solaris Troubleshooting : Deal with memory Errors – Correctable and Uncorrectable
- Correctable Memory Errors
- Uncorrectable Memory Errors
- Статистика отказов в серверной памяти
Correctable ecc other correctable memory error asserted

Всем привет сегодня на IBM Blade HS22 вылезла ошибка Correctable ECC memory error logging limit reached. Я расскажу как ее решить. Появляется данная проблема в журналах AMM, кто не в курсе AMM это вебинтерфейс управления корзиной с блейд серверами IBM.
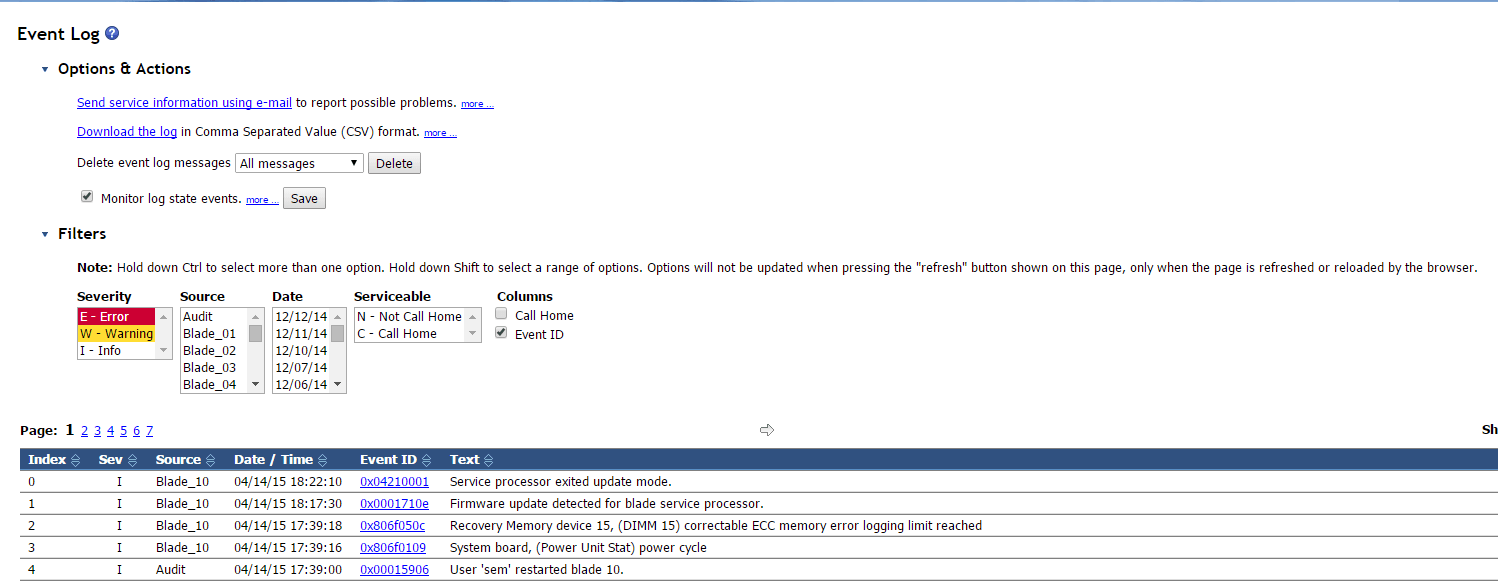
Вот как выглядит данная ошибка в AMM.

Ошибка Correctable ECC memory error logging limit reached на IBM HS22-1
Ошибка Correctable ECC memory error logging limit reached, возникает с проблемой в оперативной памяти, сам IBM в первую очередь советует прошить все по максимуму, и если не поможет вытащить блейд и пере ткнуть DDR память.
и в логах эта ошибка тоже присутствует и имеет код 0x806f050c.

Ошибка Correctable ECC memory error logging limit reached на IBM HS22-2
Я пошел первым путем решил все обновить. Ранее я вам рассказывал Как обновить все прошивки на IBM Blade HS22
После обновления видим в логах что ошибка в состоянии recovery
Ошибка Correctable ECC memory error logging limit reached на IBM HS22-11
и когда будет произведена перезагрузка после обновления вы увидите, что ошибка благополучно исчезла и все зеленое.
Как обновить все прошивки на IBM Blade HS22-10
Вот так вот просто решается Ошибка Correctable ECC memory error logging limit reached на IBM HS22.
Источник
Uncorrectable Memory ECC
Uncorrectable Memory ECC
Сообщение ServerMan » 20 май 2014, 22:05
И последняя четко в то время, когда сервер завис. Смущают следующие вещи:
1) Ошибки не только в DIMMA1, но и в DIMMA2 (а ведь это другой канал?)
2) В апреле уже было «Uncorrectable Memory ECC @ DIMMA2(CPU1)», но тогда сервер на завис.
3) В самом начале были ошибки в DIMMB1, но это было во время тестов сервера в офисе, а не ДЦ и возможно планки переставлялись.
Первая мысль поменять местами DIMMA1 и DIMMB1, DIMMA2 и DIMMB2.
Подскажите что делать?

Re: Uncorrectable Memory ECC
Сообщение Stranger03 » 21 май 2014, 11:16
Re: Uncorrectable Memory ECC
Сообщение ServerMan » 21 май 2014, 12:06
Re: Uncorrectable Memory ECC
Сообщение Stranger03 » 21 май 2014, 12:24
Re: Uncorrectable Memory ECC
Сообщение ServerMan » 21 май 2014, 12:28
А наличие Uncorrectable Memory ECC нормально или нет?
Просто на сервере 5017C-MTF с такой же памятью нет таких ошибок вообще.
Вообще на что больше похоже: на мать или память? Просто я к первому варианту больше склоняюсь пока.
На тест ночью стремно ставить, вдруг зависнет.

Re: Uncorrectable Memory ECC
Сообщение gs » 21 май 2014, 12:48
Re: Uncorrectable Memory ECC
Сообщение ServerMan » 24 май 2014, 13:51
Просто сервер рабочий и останавливать его в режим синглмод и тестить память — нет возможности.
BIOS Version : 1.1
BIOS Build Time : 07/19/2013
А биос не может быть проблемой?
Re: Uncorrectable Memory ECC
Сообщение Stranger03 » 26 май 2014, 09:55
Re: Uncorrectable Memory ECC
Сообщение gs » 26 май 2014, 14:12
Re: Uncorrectable Memory ECC
Сообщение ServerMan » 02 июн 2014, 16:45
Прошло 9 дней, больше ошибок не было. Что я сделал: вынул из сервера DIMMA1 и DIMMA2, отдав сотруднику на тест (memtest86 запущенный на 8 часов и сделавший 4 прохода ошибок не выявил!).
DIMMB1 поставил на DIMMA1, DIMMB2 на DIMMB1 — переставил чтобы исключить проблемы плохо вставленных контактов. И я правильно вставил две планки в DIMMA1 и DIMMB1, чтобы на одном канале было?
Возникает вопрос, что было? Память тесты на другом компе прошла, а та что осталась (частично в тех же слотах) проблем больше не вызывала.
Источник
Solaris Troubleshooting : Deal with memory Errors – Correctable and Uncorrectable
by Ramdev · July 29, 2022
Memory errors are quite common hardware related errors in enterprise environment, here we are going to discuss about two common types of errors ….
Correctable Memory Errors
Your system may have one or more of the following symptoms.
- The system may have received CE, ECC errors, or recoverable memory errors.
- The system may be described as having reported CPU or memory errors
- Example error messages which may have been reported are shown below:
Correctable ECC error on from a read from system memory
The following are types of main memory correctable ECC errors reported by the CPUs and also an example from a Schizo (I/O bridge chip):
Example #1: Main Memory Corrected ECC error detected by CPU3 from data read from the memory DIMM in Slot B J8000
Example #2: A Main Memory Corrected MTAG ECC error detected by CPU1 on data read from Slot A J3000
Example #3: A Main memory corrected ECC error detected by Schizo id 8
CPU correctable ECC and parity errors
CPU Correctable ECC errors are detected and corrected by the CPU module containing the fault.
An example of a CPU L2SRAM Corrected ECC error detected by CPU1 from its own L2SRAM:
There are multiple other CPU Correctable events that can be reported and these include a number of recoverable parity errors:
DPE D$ parity event
DDSPE D$ data parity event
DTSPE D$ physical tag parity event
IPE I$ parity event
IDSPE I$ data parity event
ITSPE I$ physical tag parity event
TSCE software correctable single-bit E$ tag ECC event
THCE hardware corrected single-bit E$ tag ECC event
UCC software correctable E$ ECC event
EDC hardware corrected E$ ECC event
WDC hardware corrected E$ ECC event for writeback (victimization)
CPC hardware corrected E$ ECC event for copyout (snoop request)
L3_MECC Both 16-byte data of L3 cache data access have ECC error (either correctable or uncorrectable ECC error).
L3_THCE single bit ECC error on L3 cache tag access
L3_EDC single bit ECC error on L3 cache data access for P-cache and W-cache request
L3_UCC single bit ECC error on L3 cache data access for I-cache and D-cache request
L3_CPC single bit ECC error on L3 cache data access for copyout
L3_WDC single bit ECC error on L3 cache data access for writeback
- When browsing messages files and observing console output note that [AFT0] is included in these messages, a represents the “Asynchronous Fault Trap” for correctable and recoverable errors. AFT1 is used for uncorrectable errors, AFT2 and AFT3 can be ignored in almost all cases.
- The above error messaging may change slightly depending on your kernel update patch version.
Steps to Follow to TroubleShoot:
Please validate that each troubleshooting step below is true for your environment. The steps will provide instructions or a link to a document, for validating the step and taking corrective action as necessary. The steps are ordered in the most appropriate sequence to isolate the issue and identify the proper resolution.
Please do not skip a step.
1. Verify that more than a one correctable error has been reported
A certain number of ECC correctable errors are expected to be reported by Sun Systems. There are no correctable errors where a single error is enough to require parts replacement.
2. Verify if Solaris has disabled any CPUs
Many of the correctable errors reported by the CPUs will result in the CPU being disabled (where there is more than one CPU). There are a number of ways to check is CPUs have been disabled. One method is as follows:
- Run psrinfo and check for CPUs in a state other than on-line.
- Then check the /var/adm/messages file to identify the errors which caused the fault.
- On Solaris 8 and 9 a user offlined CPU will look exactly the same as a system offlined CPU.
- With Solaris 10 a new faulted state in used for FMA/system offlined CPUs.
3. Collect Data to allow Sun Support to progress your call
Uncorrectable errors can generate very large amounts of error information in messages files. Diagnosing any fault from looking at a small number of messages, when a thousand have been reported greatly increases the chances of misdiagnosis. On the midrange and high end platforms the System Controllers capture extensive hardware level failure data which is also important.
- Collect at a minimum for diagnosis:
- /var/adm/messages
- uname -a
- To confirm that you are not hitting known error reporting bugs
- So that the correct FRU can be ordered if required:
- prtdiag -v
- Required to see what FRUs are installed.
- Also contains the OBP revision, for the OBP you can also use prtconf -V
- prtfru -x
- FRU part and serial numbers required for some FCO checks and to confirm if a FRU is RoHS or not.
- On the 3800-6900 class systems the prtfru -x output can only be collected using an explorer
- prtdiag -v
Uncorrectable Memory Errors
Your system may have one or more of the following symptoms.
- The system may have unexpectedly rebooted and cause is unknown.
- The system may have received UE, ECC errors, or recoverable memory errors.
- The system may be described as crashed, gone down, paniced, panic’d, panic’ed, panicked, rebooted, or received CPU or memory errors
- Example error messages which may have been reported are as follows:
A. Uncorrectable ECC error on from a read from system memory
Main memory uncorrectable ECC error detected by CPU3 from the bank of DIMMs in Slot A: J8100 J8101 J8201 J8200
SUNW,UltraSPARC-IV: WARNING: [AFT1] Uncorrectable system bus (UE) Event detected by CPU3 in Privileged mode at TL=0, errID 0x… AFSR 0x00100004
.000000aa AFAR 0x000000a0.0c06f1e0 Fault_PC 0x1015725c Esynd 0x00aa Slot A: J8100 J8101 J8201 J8200
SUNW,UltraSPARC-IV: [AFT1] errID 0x… Two Bits were in error
Main memory uncorrectable ECC error for a prefetch or store queue fill read.
SUNW,UltraSPARC-IV: [ID 581396 kern.warning] WARNING: [AFT1] DUE Event detected by CPU0 at TL=0, errID 0x… AFSR 0x00400000 .000000aa AFAR 0x000000a0.0c0ab1f0 Fault_PC 0xff1c1c80 Esynd 0x00aa Slot A: J8100 J8101 J8201 J8200
SUNW,UltraSPARC-IV: [ID 468316 kern.notice] [AFT1] errID 0x… Two Bits were in error
A Main memory uncorrectable ECC error detected by Schizo id 9
pcisch: WARNING: uncorrectable error detected by pci0 (safari id 00000000.00000009) during DVMA read transaction
pcisch: Transaction was a block operation.
pcisch: dvma access, Memory safari command, address 000000d0.cb1489a0, owned_in not asserted.
pcisch: AFSR=40000000.89000063 AFAR=000000d0.cb1489a0, quad word offset 00000000.00000002, Memory Module Slot D: J3100 J3101 J3201 J3200 id 9.
pcisch: mtag 0, mtag ecc syndrome 0
Uncorrectable Mtag ECC errors from main memory cause a fatal reset, domain pause or dstop depending on the platform.
B. CPU Uncorrectable ECC errors
SUNW,UltraSPARC-III+: WARNING: [AFT1] EDU Event detected by CPU1 at TL=0, errID 0x…. AFSR 0x00000018 .0000017c AFAR 0x000000a0.0c0ab1f0 Fault_PC 0x1000c19c Esynd 0x017c
SUNW,UltraSPARC-III+: [AFT1] errID 0x…. Four Bits were in error
UCU uncorrectable E$ ECC event
EDU:ST uncorrectable E$ ECC event for store merge
EDU:BLD uncorrectable E$ ECC event for block load
WDU uncorrectable E$ ECC event for writeback (victimization)
CPU uncorrectable E$ ECC event for copyout (snoop request)
L3_TUE_SH multiple-bit ECC error on L3 cache tag access due to copyback, or tag update from foreign Fireplane device, snoop request
L3_TUE multiple-bit ECC error on L3 cache tag access due to core specific tag access
L3_EDU multiple-bit ECC error on L3 cache data access for P-cache and W-cache request
L3_UCU multiple-bit ECC error on L3 cache data access for I-cache and -cache request
L3_CPU multiple-bit ECC error on L3 cache data access for copyout
L3_WDU multiple-bit ECC error on L3 cache data access for writeback
- When browsing messages files and observing console output note that [AFT1] is included in these messages, a 1 represents the “Asynchronous Fault Trap” for uncorrectable and unrecoverable errors. AFT0 is used for correctable errors, AFT2 and AFT3 can be ignored in almost all cases.
- The above error messaging may change slightly depending on your kernel update patch version.
- It is important to understand that uncorrectable ECC errors can be reported by multiple components. At no point will the corrupted data actually be used.
Источник
Статистика отказов в серверной памяти

В 2009 году, на ежегодной научной конференции SIGMETRICS, группа исследователей, работавших в Университете Торонто с данными, собранными и предоставленными для изучения компанией Google, опубликовала крайне интересный документ «DRAM Errors in the Wild: A Large-Scale Field Study» посвященный статистике отказов в серверной оперативной памяти (DRAM). Хотя подобные исследования и проводились ранее (например исследование 2007 года, наблюдавшее парк в 300 компьютеров), это было первое исследование, охватившее такой значительный парк серверов, исчисляемый тысячами единиц, на протяжении свыше двух лет, и давшее столь всеобъемлющие статистические сведения.
Отмечу также, что та же группа исследователей, во главе с аспирантом, а ныне профессором Университета Торонто, Бианкой Шрёдер (Bianca Shroeder) ранее, в 2007 году публиковала не менее интересное исследование, посвященное статистике отказов жестких дисков в датацентрах Google (краткую популярную выжимку из работы Failure Trends in a Large Disk Drive Population (pdf 242 KB), если вам скучно читать весь отчет, можно найти здесь: http://blog.aboutnetapp.ru/archives/tag/google). Кроме того, их перу принадлежит еще несколько работ, в частности об влиянии температуры и охлаждении, и о статистике отказов в оперативной памяти, вызываемой, предположительно, космическими лучами высоких энергий. Ссылки на публикации можно найти на домашней странице Шрёдер, на сервере университета.
Кратко о том, как именно происходила сборка статистических данных. Дело в том, что на протяжении довольно продолжительного времени (в опубликованной работе проанализирован период около 2,5 лет), в датацентрах Google собираются разнообразные данные мониторинга и иных событий в жизни оборудования в большой базе, данные которой в дальнейшем можно анализировать за любой желаемый промежуток времени.

(на фото, кстати, подлинный вид серверной платформы Google, именно из таких «кирпичиков» собираются гугловские кластеры, размером в многие тысячи узлов, впрочем, про них тут уже писалось)
Результаты такого анализа и представлены в опубликованной работе. И результаты во многом удивительные, заставляющие по-иному смотреть на вопросы надежности и привычные допущения в области надежности серверного оборудования.
Исследование со всей убедительностью продемонстрировало, что влияние отказов в оперативной памяти существенно недооценивается, что отказы оперативной памяти случаются куда чаще, чем до этого это было принято считать, наконец, многие допущения, например что оперативная память практически не «стареет», как «стареют», повышая вероятность отказов, компоненты с движущимися частями, такие как, например, жесткие диски, или что перегрев губительно сказывается на работе ОЗУ, являются неверными, и требуют пересмотра.
Несомненно тот факт, что в последние несколько лет, в связи со сравнительным удешевлением DRAM, и широким распространением систем серверной виртуализации, крайне охочих до объемов памяти, концентрация в одной серверной системе все больших и больших объемов ОЗУ, повышает и требования к ее надежности.
Исследование показало, что примерно каждый третий сервер (или 8% модулей памяти) в наблюдаемых датацентрах на протяжении 2,5 лет исследования встречался со сбоем в оперативной памяти. Число сбоев, зарегистрированных системой мониторинга составило свыше 4000 в год! Большая часть из них конечно была устранена использованием ECC (Error Correction Code), используемого в оперативной памяти, и более сложными его вариантами, такими как Chipkill (позволяет устранить многобитовые ошибки, например сразу в группе ячеек). Тем не менее, Uncorrectable Errors, то есть ошибки, которые не удалось исправить, и которые, почти наверняка привели к фатальным последствмяи типа BSOD или kernel panic встречаются куда чаще, чем это принято считать. А в случае использования памяти без ECC каждая из таких ошибок — это почти наверняка BSOD или kernel panic, или серьезный сбой в работе приложения. Ведь, например, очень многие хранят данные баз в памяти для ускорения ее работы.
В сравнении с ранее опубликованным исследованием, работа группы Шрёдер резко повысила «ожидания» сбоев. Так, они оценили события отказов в 25-70 тысяч сбоев на миллиард часов работы сервера, что почти в пятнадцать раз превышает более раннюю оценку, сделанную на меньшей популяции.
С отказами в результате неисправимых (uncorrectable, неисправленных ECC или Chipkill) встретились 1,3% серверов в год, или около 0,22% DIMM.
Системы, использующие «многобитные» механизмы, такие как Chipkill, имели число отказов в 4-10 раз меньше, по сравнению с обычным ECC.
Другие интересные выводы, сделанные в опубликованной работе это:
Рабочая температура, и ее повышение крайне мало коррелирует с вероятностью сбоя в DRAM. Это еще один факт, который указывает, что бытующее до сих пор в индустрии мнение о губительности повышенной температуры на полупроводники и компьютерное оборудование (мнение, основанное на исследовании 80-х годов) на сегодняшний день следует радикально пересмотреть. Это еще одно подтверждение этому факту, который уже был установлен, например в работе о жестких дисках. Парадоксальным образом там было установлено, что наименьшее количество отказов HDD наблюдалось при температурах в районе 40-45 градусов, а ее понижение количество отказов увеличивало (!).
В случае DRAM кореляция между температурой (в наблюдавшемся диапазоне около 20 градусов между самой низкой и самой высокой) и отказами была крайне незначительной.
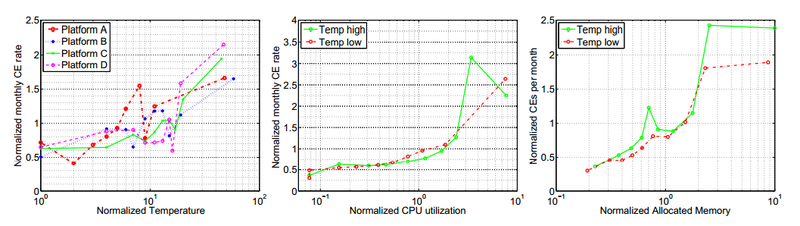
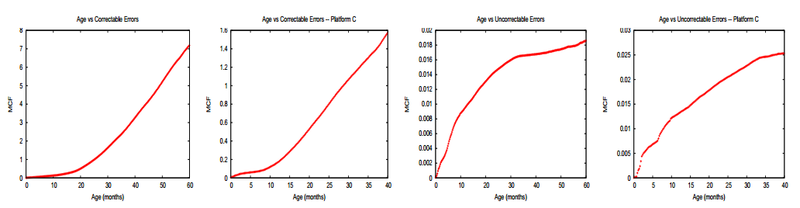
(здесь и далее на слайдах: CE — correctable errors, ошибки, зарегистрированные, но исправленные ECC, UE — uncorrectable errors)
Однако существенно коррелировали отказы с загрузкой памяти и интенсивностью обмена с ней (отчасти высокая загрузка памяти влияет и на ее температуру, конечно, но не всегда). Вполне вероятно, что интенсивный обмен и большой относительный объем заполненных данными памяти значительно повышает вероятность быстрого обнаружения сбоя.

Было установлено, что вероятность получить повторный сбой в уже ранее сбоившем модуле памяти в сотни раз выше, по сравнению с не сбоившем ранее. Это может быть вызвано как наличием плохо выявляемого технологического брака, так и тем, что отказ, например пробой заряженной частицей космических лучей, не проходит для памяти бесследно, даже если ошибка была скорректирована ECC.
70-80% случаях, когда регистрировалась неисправимая ошибка в модуле памяти, это модуль уже имел исправимый ECC или Chipkill отказ в этом или предыдущем месяце.

Было установлено, что сравнительно новые модули, выполненные с более высокой плотностью и более тонкими техпроцессами, не показывают более высокого уровня отказов. По-видимому пока в технологии DRAM технологический предел, близ которого начинаются проблемы с надежностью, пока не достигнут. В наблюдаемом парке модулей было примерно шесть разных типов и поколений памяти (DDR1, DDR2 и FBDIMM разных типов), и корреляции между высокой плотностью и числом отказов и сбоев выявлено не было.
Наконец, с пугающей ясностью был продемонстрирован эффект «старения» в модулях DRAM. Более того, в памяти он проявился куда более явно, чем, напрмер, в HDD, где порог, после которого отказы растут в разы, составил примерно 3-4 года.
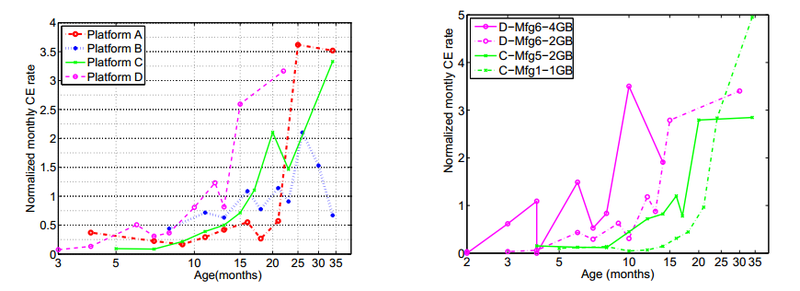
Парадоксальным образом статистика демонстрирует увеличивающиеся темпы роста correctable errors с увеличением возраста модулей, но снижающийся темп для Uncorrectable errors, однако скорее всего это просто результат плановой замены памяти в серверах, которые были замечены за сбоями.
Удивительным образом, DRAM, лишенная каких-либо движущихся частей, показывает существенный и продолжающийся рост correctable отказов уже после года-полутора эксплуатации.
Подводя итоги, хотелось бы отметить, что приведенные статистические данные заставляют пересмотреть привычные для многих, основанные на «житейском опыте» принципы построения серверных платформ и эксплуатации датацентров, и позиция «чем холоднее — тем лучше», «память не изнашивается», «если север правильно собран, то он не ломается» и «ECC DRAM — ненужная трата денег, ведь у меня десктоп работает без ECC, и ничего». И чем скорее будут изжиты подобные шапкозакидательские настроения в столь серьезной области, как построение датацентров, тем, в итоге, будет лучше.
А занимающимся темой хочу порекомендовать неизбывный источник сладости, интеллектуального упражнения и пищи для мозгов, как публикации ежегодных конференций группы USENIX, это вам, господа, не маркетинговый булшит, столь привычный нам уже всем, а настоящая серьезная наука, от которой не отмахнешься.
Источник
Модераторы: Trinity admin`s, Free-lance moderator`s
-
ServerMan
- Junior member
- Сообщения: 6
- Зарегистрирован: 20 май 2014, 21:54
- Откуда: МСК
Uncorrectable Memory ECC
Купили в августе 2013 платформу SuperMicro 1U 5018D-MTLN4F и все вроде работало, пока сегодня сервер не завис. Начали разбираться и увидели, что с самого начала в Event Log (IPMI) много ошибок:
Код: Выделить всё
1 2013/08/20 11:02:29 Chassis Intru Physical Security (Chassis Intrusion) General Chassis Intrusion - Asserted
2 2013/08/21 08:20:06 Chassis Intru Physical Security (Chassis Intrusion) General Chassis Intrusion - Asserted
3 2013/08/22 06:48:38 OEM Memory Correctable Memory ECC @ DIMMB1(CPU1) - Asserted
4 2013/08/22 07:27:17 OEM Memory Correctable Memory ECC @ DIMMB1(CPU1) - Asserted
5 2013/08/22 07:34:47 OEM Memory Correctable Memory ECC @ DIMMB1(CPU1) - Asserted
6 2013/08/22 08:18:26 Chassis Intru Physical Security (Chassis Intrusion) General Chassis Intrusion - Asserted
7 2013/08/30 14:21:44 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1) - Asserted
8 2013/09/01 05:57:58 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1) - Asserted
9 2013/09/01 22:12:37 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1) - Asserted
10 2013/09/07 08:01:50 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1) - Asserted
11 2013/09/08 20:20:13 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1) - Asserted
12 2013/09/11 19:04:47 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1) - Asserted
13 2013/09/11 23:16:25 Session Audit Invalid Username or Password
14 2013/09/11 23:16:25 Session Audit Invalid Username or Password
15 2013/09/13 06:21:32 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
16 2013/09/14 01:17:29 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
17 2013/09/14 11:06:30 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
18 2013/09/15 01:46:21 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
19 2013/09/15 12:52:32 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
20 2013/09/17 01:07:16 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
21 2013/09/17 01:49:20 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
22 2013/09/17 02:32:00 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
23 2013/09/19 02:59:14 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
24 2013/10/07 07:03:01 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
25 2013/10/19 06:17:15 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
26 2013/10/27 16:33:37 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
27 2013/11/12 18:04:05 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
28 2013/11/25 01:06:12 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
29 2013/11/25 08:36:41 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
30 2013/11/29 01:52:10 Session Audit Invalid Username or Password
31 2013/11/29 01:52:10 Session Audit Invalid Username or Password
32 2013/11/29 01:52:11 Session Audit Invalid Username or Password
33 2013/11/29 01:52:11 Session Audit Invalid Username or Password
34 2013/11/29 01:52:11 Session Audit Invalid Username or Password
35 2014/01/27 03:46:19 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
36 2014/01/28 00:57:35 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
37 2014/01/29 04:22:46 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
38 2014/01/29 18:13:15 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
39 2014/02/01 17:59:22 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
40 2014/02/01 18:06:05 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
41 2014/02/01 18:06:05 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
42 2014/02/01 18:06:07 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
43 2014/02/01 18:06:14 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
44 2014/02/02 04:44:55 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
45 2014/02/02 16:39:58 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
46 2014/02/05 11:10:56 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
47 2014/02/06 07:23:49 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
48 2014/02/09 07:24:20 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
49 2014/02/09 07:24:21 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
50 2014/02/09 07:24:21 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
51 2014/02/09 07:24:26 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
52 2014/02/09 07:24:28 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
53 2014/02/09 07:24:32 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
54 2014/02/10 04:22:23 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
55 2014/02/10 04:22:23 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
56 2014/02/12 12:17:30 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
57 2014/02/14 20:54:02 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
58 2014/02/18 14:12:33 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
59 2014/02/19 22:36:35 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
60 2014/02/25 02:00:27 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
61 2014/02/26 12:58:57 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
62 2014/02/26 12:58:57 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
63 2014/02/26 21:44:29 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
64 2014/02/27 02:51:03 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
65 2014/02/28 05:35:55 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
66 2014/03/01 21:06:47 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
67 2014/03/02 14:41:01 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
68 2014/03/02 17:31:58 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
69 2014/03/06 08:33:50 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
70 2014/03/08 02:09:46 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
71 2014/03/08 20:39:48 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
72 2014/03/09 00:47:00 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
73 2014/03/09 14:51:31 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
74 2014/03/09 17:02:56 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
75 2014/03/10 10:19:30 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
76 2014/03/10 10:19:31 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
77 2014/03/10 21:00:41 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
78 2014/03/11 04:36:52 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
79 2014/03/11 04:36:52 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
80 2014/03/12 08:45:22 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
81 2014/03/13 02:27:47 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
82 2014/03/13 09:43:43 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
83 2014/03/14 08:19:06 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
84 2014/03/15 11:18:55 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
85 2014/03/16 08:06:38 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
86 2014/03/16 09:51:34 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
87 2014/03/19 07:00:08 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
88 2014/03/22 08:02:24 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
89 2014/03/22 12:06:37 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
90 2014/03/23 20:33:31 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
91 2014/03/24 05:32:14 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
92 2014/03/24 08:17:23 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
93 2014/03/28 02:48:11 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
94 2014/04/02 21:26:48 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
95 2014/04/02 22:18:04 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
96 2014/04/02 22:18:05 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
97 2014/04/02 22:18:05 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
98 2014/04/02 22:18:05 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
99 2014/04/02 22:18:05 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
100 2014/04/02 22:18:21 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
101 2014/04/02 22:18:21 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
102 2014/04/04 13:55:35 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
103 2014/04/05 10:06:36 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
104 2014/04/06 01:42:09 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
105 2014/04/06 06:29:36 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
106 2014/04/07 04:46:09 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
107 2014/04/07 13:49:24 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
108 2014/04/07 13:49:26 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
109 2014/04/08 16:27:42 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
110 2014/04/08 17:19:35 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
111 2014/04/09 02:29:00 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
112 2014/04/09 09:21:52 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
113 2014/04/09 09:21:52 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
114 2014/04/09 09:21:52 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
115 2014/04/09 09:21:52 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
116 2014/04/09 09:21:53 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
117 2014/04/09 09:21:53 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
118 2014/04/09 09:21:53 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
119 2014/04/10 03:22:35 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
120 2014/04/10 11:13:22 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
121 2014/04/10 11:13:23 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
122 2014/04/11 13:34:51 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
123 2014/04/11 14:44:17 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
124 2014/04/11 14:44:18 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
125 2014/04/12 08:12:21 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
126 2014/04/12 08:12:21 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
127 2014/04/12 08:51:38 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
128 2014/04/12 19:02:11 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
129 2014/04/14 11:53:56 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
130 2014/04/14 22:07:02 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
131 2014/04/15 12:20:00 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
132 2014/04/18 04:28:06 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
133 2014/04/18 06:17:24 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
134 2014/04/19 07:45:58 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
135 2014/04/19 07:46:02 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
136 2014/04/19 07:46:03 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
137 2014/04/19 07:46:03 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
138 2014/04/19 07:46:04 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
139 2014/04/19 07:46:04 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
140 2014/04/19 07:46:04 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
141 2014/04/19 07:46:04 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
142 2014/04/19 07:46:04 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
143 2014/04/19 07:46:06 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
144 2014/04/19 07:46:06 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
145 2014/04/19 07:46:06 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
146 2014/04/19 07:46:07 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
147 2014/04/19 07:46:07 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
148 2014/04/19 07:46:08 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
149 2014/04/19 07:46:08 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
150 2014/04/19 07:46:08 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
151 2014/04/19 07:46:08 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
152 2014/04/19 07:46:08 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
153 2014/04/19 07:46:09 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
154 2014/04/19 07:46:09 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
155 2014/04/19 07:46:09 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
156 2014/04/19 07:46:09 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
157 2014/04/19 07:48:59 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
158 2014/04/19 07:52:16 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
159 2014/04/21 07:11:39 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
160 2014/04/22 14:29:58 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
161 2014/04/23 17:36:58 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
162 2014/04/24 12:40:47 OEM Memory Uncorrectable Memory ECC @ DIMMA2(CPU1)
163 2014/04/26 09:52:33 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
164 2014/04/27 17:09:15 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
165 2014/04/27 17:56:32 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
166 2014/04/27 21:11:31 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
167 2014/04/27 21:11:31 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
168 2014/04/29 09:37:23 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
169 2014/04/30 11:22:11 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
170 2014/05/02 01:27:06 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
171 2014/05/02 01:27:06 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
172 2014/05/02 20:06:24 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
173 2014/05/04 15:27:23 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
174 2014/05/05 11:13:51 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
175 2014/05/07 07:20:33 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
176 2014/05/07 13:16:35 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
177 2014/05/08 00:35:13 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
178 2014/05/09 13:17:57 OEM Memory Correctable Memory ECC @ DIMMA2(CPU1)
179 2014/05/16 18:44:45 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
180 2014/05/17 11:48:47 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
181 2014/05/18 01:15:36 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
182 2014/05/19 14:54:33 OEM Memory Correctable Memory ECC @ DIMMA1(CPU1)
183 2014/05/20 15:14:03 OEM Memory Uncorrectable Memory ECC @ DIMMA1(CPU1)И последняя четко в то время, когда сервер завис. Смущают следующие вещи:
1) Ошибки не только в DIMMA1, но и в DIMMA2 (а ведь это другой канал?)
2) В апреле уже было «Uncorrectable Memory ECC @ DIMMA2(CPU1)», но тогда сервер на завис.
3) В самом начале были ошибки в DIMMB1, но это было во время тестов сервера в офисе, а не ДЦ и возможно планки переставлялись.
Первая мысль поменять местами DIMMA1 и DIMMB1, DIMMA2 и DIMMB2.
Подскажите что делать?
-

Stranger03
- Сотрудник Тринити

- Сообщения: 12979
- Зарегистрирован: 14 ноя 2003, 16:25
- Откуда: СПб, Екатеринбург
- Контактная информация:
Re: Uncorrectable Memory ECC
Сообщение
Stranger03 » 21 май 2014, 11:16
ServerMan писал(а):Подскажите что делать?
Проверьте мемтестом на ночь, там видно будет. И поправьте город в профиле.
-
ServerMan
- Junior member
- Сообщения: 6
- Зарегистрирован: 20 май 2014, 21:54
- Откуда: МСК
Re: Uncorrectable Memory ECC
Сообщение
ServerMan » 21 май 2014, 12:06
На что похоже вообще это поведение по вашему опыту?
И само наличие Correctable Memory ECC это уже не нормально?
-
Stranger03
- Сотрудник Тринити
- Сообщения: 12979
- Зарегистрирован: 14 ноя 2003, 16:25
- Откуда: СПб, Екатеринбург
- Контактная информация:
Re: Uncorrectable Memory ECC
Сообщение
Stranger03 » 21 май 2014, 12:24
ServerMan писал(а):На что похоже вообще это поведение по вашему опыту?
И само наличие Correctable Memory ECC это уже не нормально?
Ну само их наличие не так критично, коррекции ошибок. Все-таки прогоните тесты, поставьте на ночь часов на 6-ть. Если там что будет, то менять по гарантии.
-
ServerMan
- Junior member
- Сообщения: 6
- Зарегистрирован: 20 май 2014, 21:54
- Откуда: МСК
Re: Uncorrectable Memory ECC
Сообщение
ServerMan » 21 май 2014, 12:28
А наличие Uncorrectable Memory ECC нормально или нет?
Просто на сервере 5017C-MTF с такой же памятью нет таких ошибок вообще.
Вообще на что больше похоже: на мать или память? Просто я к первому варианту больше склоняюсь пока…
На тест ночью стремно ставить, вдруг зависнет…
-
gs
- Сотрудник Тринити
- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
-
Контактная информация:
Re: Uncorrectable Memory ECC
Сообщение
gs » 21 май 2014, 12:48
Корректабл ошибки — это сбои, которые способна исправить ЕСС. Это плохо. Не смертельно (как анкорректабл), но при регулярном появлении очень плохо.
Виноваты могут быть как модули памяти, так и мамка/слоты, даже контакт в процессорном сокете или сам процессор (хотя последнее очень редко бывает).
В общем, запускайте мемтест, а там видно будет.
-
ServerMan
- Junior member
- Сообщения: 6
- Зарегистрирован: 20 май 2014, 21:54
- Откуда: МСК
Re: Uncorrectable Memory ECC
Сообщение
ServerMan » 24 май 2014, 13:51
Просто сервер рабочий и останавливать его в режим синглмод и тестить память — нет возможности…
BIOS Version : 1.1
BIOS Build Time : 07/19/2013
А биос не может быть проблемой?
-
Stranger03
- Сотрудник Тринити
- Сообщения: 12979
- Зарегистрирован: 14 ноя 2003, 16:25
- Откуда: СПб, Екатеринбург
- Контактная информация:
Re: Uncorrectable Memory ECC
Сообщение
Stranger03 » 26 май 2014, 09:55
ServerMan писал(а):А биос не может быть проблемой?
Врядли
-
gs
- Сотрудник Тринити
- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
- Контактная информация:
Re: Uncorrectable Memory ECC
Сообщение
gs » 26 май 2014, 14:12
А если он просто сломается — тоже будете говорить, что остановить нет возможности?
-
ServerMan
- Junior member
- Сообщения: 6
- Зарегистрирован: 20 май 2014, 21:54
- Откуда: МСК
Re: Uncorrectable Memory ECC
Сообщение
ServerMan » 02 июн 2014, 16:45
Прошло 9 дней, больше ошибок не было. Что я сделал: вынул из сервера DIMMA1 и DIMMA2, отдав сотруднику на тест (memtest86 запущенный на 8 часов и сделавший 4 прохода ошибок не выявил!).
DIMMB1 поставил на DIMMA1, DIMMB2 на DIMMB1 — переставил чтобы исключить проблемы плохо вставленных контактов. И я правильно вставил две планки в DIMMA1 и DIMMB1, чтобы на одном канале было?
Возникает вопрос, что было? Память тесты на другом компе прошла, а та что осталась (частично в тех же слотах) проблем больше не вызывала…
PS: обновил IPMI.
-
gs
- Сотрудник Тринити
- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
- Контактная информация:
Re: Uncorrectable Memory ECC
Сообщение
gs » 02 июн 2014, 16:59
Ну так может просто неконтакт?
-
ServerMan
- Junior member
- Сообщения: 6
- Зарегистрирован: 20 май 2014, 21:54
- Откуда: МСК
Re: Uncorrectable Memory ECC
Сообщение
ServerMan » 02 июн 2014, 17:05
Сейчас сервер хорошо справляется и на в два раза меньшем количестве памяти, имеет ли смысл после тестов вернуть память на место или лучше не рисковать?
-
Stranger03
- Сотрудник Тринити
- Сообщения: 12979
- Зарегистрирован: 14 ноя 2003, 16:25
- Откуда: СПб, Екатеринбург
- Контактная информация:
Re: Uncorrectable Memory ECC
Сообщение
Stranger03 » 03 июн 2014, 08:27
ServerMan писал(а):Сейчас сервер хорошо справляется и на в два раза меньшем количестве памяти, имеет ли смысл после тестов вернуть память на место или лучше не рисковать?
Это вам решать.
Вернуться в «Серверы — Решение проблем»
Перейти
- Серверы
- ↳ Серверы — Конфигурирование
- ↳ Конфигурации сервера для 1С
- ↳ Серверы — Решение проблем
- ↳ Серверы — ПО, Unix подобные системы
- ↳ Серверы — ПО, Windows система, приложения.
- ↳ Серверы — ПО, Базы Данных и их использование
- ↳ Серверы — FAQ
- Дисковые массивы, RAID, SCSI, SAS, SATA, FC
- ↳ Массивы — RAID технологии.
- ↳ Массивы — Технические вопросы, решение проблем.
- ↳ Массивы — FAQ
- Майнинг, плоттинг, фарминг (Добыча криптовалют)
- ↳ Proof Of Work
- ↳ Proof Of Space
- Кластеры — вычислительные и отказоустойчивые ( SMP, vSMP, NUMA, GRID , NAS, SAN)
- ↳ Кластеры, Аппаратная часть
- ↳ Deep Learning и AI
- ↳ Кластеры, Программное обеспечение
- ↳ Кластеры, параллельные файловые системы
- Медиа технологии, и цифровое ТВ, IPTV, DVB
- ↳ Станции видеомонтажа, графические системы, рендеринг.
- ↳ Видеонаблюдение
- ↳ Компоненты Digital TV решений
- ↳ Студийные системы, производство ТВ, Кино и рекламы
- Инфраструктурное ПО и его лицензирование
- ↳ Виртуализация
- ↳ Облачные технологии
- ↳ Резервное копирования / Защита / Сохранение данных
- Сетевые решения
- ↳ Сети — Вопросы конфигурирования сети
- ↳ Сети — Технические вопросы, решение проблем
- Общие вопросы
- ↳ Обсуждение общих вопросов
- ↳ Приколы нашего IT городка
- ↳ Регистрация на форуме
Обновлено 14.12.2016
Всем привет сегодня на IBM Blade HS22 вылезла ошибка Correctable ECC memory error logging limit reached. Я расскажу как ее решить. Появляется данная проблема в журналах AMM, кто не в курсе AMM это вебинтерфейс управления корзиной с блейд серверами IBM.
Вот как выглядит данная ошибка в AMM.
Ошибка Correctable ECC memory error logging limit reached на IBM HS22-1
Ошибка Correctable ECC memory error logging limit reached, возникает с проблемой в оперативной памяти, сам IBM в первую очередь советует прошить все по максимуму, и если не поможет вытащить блейд и пере ткнуть DDR память.
и в логах эта ошибка тоже присутствует и имеет код 0x806f050c.
Ошибка Correctable ECC memory error logging limit reached на IBM HS22-2
Я пошел первым путем решил все обновить. Ранее я вам рассказывал Как обновить все прошивки на IBM Blade HS22
После обновления видим в логах что ошибка в состоянии recovery
Ошибка Correctable ECC memory error logging limit reached на IBM HS22-11
и когда будет произведена перезагрузка после обновления вы увидите, что ошибка благополучно исчезла и все зеленое.
Как обновить все прошивки на IBM Blade HS22-10
Вот так вот просто решается Ошибка Correctable ECC memory error logging limit reached на IBM HS22.
Материал сайта pyatilistnik.org
Дек 14, 2016 10:49
Статистика отказов в серверной памяти
Время прочтения
5 мин
Просмотры 46K
В 2009 году, на ежегодной научной конференции SIGMETRICS, группа исследователей, работавших в Университете Торонто с данными, собранными и предоставленными для изучения компанией Google, опубликовала крайне интересный документ «DRAM Errors in the Wild: A Large-Scale Field Study» посвященный статистике отказов в серверной оперативной памяти (DRAM). Хотя подобные исследования и проводились ранее (например исследование 2007 года, наблюдавшее парк в 300 компьютеров), это было первое исследование, охватившее такой значительный парк серверов, исчисляемый тысячами единиц, на протяжении свыше двух лет, и давшее столь всеобъемлющие статистические сведения.
Отмечу также, что та же группа исследователей, во главе с аспирантом, а ныне профессором Университета Торонто, Бианкой Шрёдер (Bianca Shroeder) ранее, в 2007 году публиковала не менее интересное исследование, посвященное статистике отказов жестких дисков в датацентрах Google (краткую популярную выжимку из работы Failure Trends in a Large Disk Drive Population (pdf 242 KB), если вам скучно читать весь отчет, можно найти здесь: http://blog.aboutnetapp.ru/archives/tag/google). Кроме того, их перу принадлежит еще несколько работ, в частности об влиянии температуры и охлаждении, и о статистике отказов в оперативной памяти, вызываемой, предположительно, космическими лучами высоких энергий. Ссылки на публикации можно найти на домашней странице Шрёдер, на сервере университета.
Кратко о том, как именно происходила сборка статистических данных. Дело в том, что на протяжении довольно продолжительного времени (в опубликованной работе проанализирован период около 2,5 лет), в датацентрах Google собираются разнообразные данные мониторинга и иных событий в жизни оборудования в большой базе, данные которой в дальнейшем можно анализировать за любой желаемый промежуток времени.
(на фото, кстати, подлинный вид серверной платформы Google, именно из таких «кирпичиков» собираются гугловские кластеры, размером в многие тысячи узлов, впрочем, про них тут уже писалось)
Результаты такого анализа и представлены в опубликованной работе. И результаты во многом удивительные, заставляющие по-иному смотреть на вопросы надежности и привычные допущения в области надежности серверного оборудования.
Исследование со всей убедительностью продемонстрировало, что влияние отказов в оперативной памяти существенно недооценивается, что отказы оперативной памяти случаются куда чаще, чем до этого это было принято считать, наконец, многие допущения, например что оперативная память практически не «стареет», как «стареют», повышая вероятность отказов, компоненты с движущимися частями, такие как, например, жесткие диски, или что перегрев губительно сказывается на работе ОЗУ, являются неверными, и требуют пересмотра.
Несомненно тот факт, что в последние несколько лет, в связи со сравнительным удешевлением DRAM, и широким распространением систем серверной виртуализации, крайне охочих до объемов памяти, концентрация в одной серверной системе все больших и больших объемов ОЗУ, повышает и требования к ее надежности.
Исследование показало, что примерно каждый третий сервер (или 8% модулей памяти) в наблюдаемых датацентрах на протяжении 2,5 лет исследования встречался со сбоем в оперативной памяти. Число сбоев, зарегистрированных системой мониторинга составило свыше 4000 в год! Большая часть из них конечно была устранена использованием ECC (Error Correction Code), используемого в оперативной памяти, и более сложными его вариантами, такими как Chipkill (позволяет устранить многобитовые ошибки, например сразу в группе ячеек). Тем не менее, Uncorrectable Errors, то есть ошибки, которые не удалось исправить, и которые, почти наверняка привели к фатальным последствмяи типа BSOD или kernel panic встречаются куда чаще, чем это принято считать. А в случае использования памяти без ECC каждая из таких ошибок — это почти наверняка BSOD или kernel panic, или серьезный сбой в работе приложения. Ведь, например, очень многие хранят данные баз в памяти для ускорения ее работы.
В сравнении с ранее опубликованным исследованием, работа группы Шрёдер резко повысила «ожидания» сбоев. Так, они оценили события отказов в 25-70 тысяч сбоев на миллиард часов работы сервера, что почти в пятнадцать раз превышает более раннюю оценку, сделанную на меньшей популяции.
С отказами в результате неисправимых (uncorrectable, неисправленных ECC или Chipkill) встретились 1,3% серверов в год, или около 0,22% DIMM.
Системы, использующие «многобитные» механизмы, такие как Chipkill, имели число отказов в 4-10 раз меньше, по сравнению с обычным ECC.
Другие интересные выводы, сделанные в опубликованной работе это:
Рабочая температура, и ее повышение крайне мало коррелирует с вероятностью сбоя в DRAM. Это еще один факт, который указывает, что бытующее до сих пор в индустрии мнение о губительности повышенной температуры на полупроводники и компьютерное оборудование (мнение, основанное на исследовании 80-х годов) на сегодняшний день следует радикально пересмотреть. Это еще одно подтверждение этому факту, который уже был установлен, например в работе о жестких дисках. Парадоксальным образом там было установлено, что наименьшее количество отказов HDD наблюдалось при температурах в районе 40-45 градусов, а ее понижение количество отказов увеличивало (!).
В случае DRAM кореляция между температурой (в наблюдавшемся диапазоне около 20 градусов между самой низкой и самой высокой) и отказами была крайне незначительной.
(здесь и далее на слайдах: CE — correctable errors, ошибки, зарегистрированные, но исправленные ECC, UE — uncorrectable errors)
Однако существенно коррелировали отказы с загрузкой памяти и интенсивностью обмена с ней (отчасти высокая загрузка памяти влияет и на ее температуру, конечно, но не всегда). Вполне вероятно, что интенсивный обмен и большой относительный объем заполненных данными памяти значительно повышает вероятность быстрого обнаружения сбоя.
Было установлено, что вероятность получить повторный сбой в уже ранее сбоившем модуле памяти в сотни раз выше, по сравнению с не сбоившем ранее. Это может быть вызвано как наличием плохо выявляемого технологического брака, так и тем, что отказ, например пробой заряженной частицей космических лучей, не проходит для памяти бесследно, даже если ошибка была скорректирована ECC.
70-80% случаях, когда регистрировалась неисправимая ошибка в модуле памяти, это модуль уже имел исправимый ECC или Chipkill отказ в этом или предыдущем месяце.
Было установлено, что сравнительно новые модули, выполненные с более высокой плотностью и более тонкими техпроцессами, не показывают более высокого уровня отказов. По-видимому пока в технологии DRAM технологический предел, близ которого начинаются проблемы с надежностью, пока не достигнут. В наблюдаемом парке модулей было примерно шесть разных типов и поколений памяти (DDR1, DDR2 и FBDIMM разных типов), и корреляции между высокой плотностью и числом отказов и сбоев выявлено не было.
Наконец, с пугающей ясностью был продемонстрирован эффект «старения» в модулях DRAM. Более того, в памяти он проявился куда более явно, чем, напрмер, в HDD, где порог, после которого отказы растут в разы, составил примерно 3-4 года.
Парадоксальным образом статистика демонстрирует увеличивающиеся темпы роста correctable errors с увеличением возраста модулей, но снижающийся темп для Uncorrectable errors, однако скорее всего это просто результат плановой замены памяти в серверах, которые были замечены за сбоями.
Удивительным образом, DRAM, лишенная каких-либо движущихся частей, показывает существенный и продолжающийся рост correctable отказов уже после года-полутора эксплуатации.
Подводя итоги, хотелось бы отметить, что приведенные статистические данные заставляют пересмотреть привычные для многих, основанные на «житейском опыте» принципы построения серверных платформ и эксплуатации датацентров, и позиция «чем холоднее — тем лучше», «память не изнашивается», «если север правильно собран, то он не ломается» и «ECC DRAM — ненужная трата денег, ведь у меня десктоп работает без ECC, и ничего». И чем скорее будут изжиты подобные шапкозакидательские настроения в столь серьезной области, как построение датацентров, тем, в итоге, будет лучше.
А занимающимся темой хочу порекомендовать неизбывный источник сладости, интеллектуального упражнения и пищи для мозгов, как публикации ежегодных конференций группы USENIX, это вам, господа, не маркетинговый булшит, столь привычный нам уже всем, а настоящая серьезная наука, от которой не отмахнешься.
О LENOVO
+
О LENOVO
-
Наша компания
-
Новости
-
Контакт
-
Соответствие продукта
-
Работа в Lenovo
-
Общедоступное программное обеспечение Lenovo
КУПИТЬ
+
КУПИТЬ
-
Где купить
-
Рекомендованные магазины
-
Стать партнером
Поддержка
+
Поддержка
-
Драйверы и Программное обеспечение
-
Инструкция
-
Инструкция
-
Поиск гарантии
-
Свяжитесь с нами
-
Поддержка хранилища
РЕСУРСЫ
+
РЕСУРСЫ
-
Тренинги
-
Спецификации продуктов ((PSREF)
-
Доступность продукта
-
Информация об окружающей среде
©
Lenovo.
|
|
|
|
-
#1
Hi,
I got my Hardware for my new freenas build. The board is an Supermicro X10SL7-F with 32 gig of Samsung Memory (M391B1G73QH0-YK0). CPU is an Xeon E3-1230.
I know assembled the whole build and started the burn-in tests. Memtest now ran for 50h+ and reported no errors, but when I check my SEL I find four messages saying:
Code:
Assertion: Memory| Event = Correctable ECC@DIMMB1(CPU1)
I played arround a bit and found out that this error seems to accour from time to time when I reboot the system. It never occoured while running the memtest. Is one of my modules (DIMMB1) faulty?

-
#2
Could be. Could also be bad power (sounds more likely if it only happens at boot).

-
#3
Swap your RAM around and see if the failure follows the stick of RAM or if it remains at DIMMB1. If the problem moves then it is likely a faulty stick of RAM. If it remains then it could be the power supply (the easiest thing to replace) or possibly the motherboard. Also, ensure your BIOS is setup for the RAM properly (speed, timing, etc…)
-
#4
Swap your RAM around and see if the failure follows the stick of RAM or if it remains at DIMMB1. If the problem moves then it is likely a faulty stick of RAM. If it remains then it could be the power supply (the easiest thing to replace) or possibly the motherboard. Also, ensure your BIOS is setup for the RAM properly (speed, timing, etc…)
I was thinking that it might follow the DIMM, if it’s a marginal (on the «working» side) one and bad power is causing this.
@Harsesis — what PSU are you using?
-
#5
Hi,
thanks for your response! The PSU I’m using is a new Seasonic G450. I will then start checking the BIOS (changed nothing here), than swapping the DIMM’s, if that does not make any difference I could change the PSU (should have laying arround some older ones).
-
#6
Well, Seasonic does reduce the probability of it being the PSU — always a possibility, though.
-
#7
So I checked the BIOS and I’m not 100% confident wheather the settings are corret. Futhermore I dont know how I can change them. Is there a way to change the timings? I’ve made a screenshot of the current settings, you can find it here. The datasheet of the ram can be found here. When I understand the datasheet correctly the settings of tRCDmin, tRPmin and tRASmin are wrong and should be 13.75-13.75-35?
I also swaped DIMMB1 and DIMMA1 on the board. After restarting there was no error in the SEL, but after booting into Memtest86+ version 5.01 a new error appeared in the SEL. Know it is reporting the error from DIMMA1. So there are tow things going on:
— the error moves with the (possibly faulty) DIMM
— the error occours when the systems loads memtest86
So what do you beleve, should I simply contact the vendor and RMA the possibly faulty DIMM?
-
#8
Manually set your RAM speed to 1333 MHz and that should take care of the timings, which actually look fine for 1600 MHz but if the RAM is actually being pushed up to 1600 MHz, you are safer manually dialing it down.
As to your DIMM modules, I’d reseat them again. Just be careful to not physically break them.
As for RMA, try the above steps first. Your system may not be as stable running the RAM in a turbo speed situation.
-
#9
With setting the RAM speed you mean setting the memory frequency limiter? Expecting this would help is this the proper way of dealing with it? I mean the modules are specified as 1600, shouldent they deliver that?
I did not quite understand your comment on the RMA. What do you mean with the system could be instable in turbo speed situations? How can I check this and what could be the reason for this?
-
#10
Since everything is supposed to support DDR3-1600, not running at that speed is plentiful reason to RMA. No need to keep marginal stuff around, even if it stabilizes with a workaround.
-
#11
So you would go for RMA now? Or is there anything else I could try? Did one of you take a look at my BIOS timing settings? Still not sure if they are correct and if not how I can change them in BIOS…
-
#12
So you would go for RMA now? Or is there anything else I could try? Did one of you take a look at my BIOS timing settings? Still not sure if they are correct and if not how I can change them in BIOS…
That’s taken care of automatically with SPD. CL11 sounds right, too.
I’d just try a different PSU first. If everything stays the same, RMA the DIMM.
-
#13
So good news, I just dicided to order one extra DIMM and replace the other one with this. I allready got my new DIMM today and up to now it seems to work just fine. I decieded to do it this way as I can just reovke the new or one DIMM of the old order without any cost. That was the fastest way and I dont have to do the RMA procedure.
If anything changes and surprisingly new errors would occour I will let you know! Thank you all for you help!
Server Products
Data Center Products including boards, integrated systems, Intel® Xeon® Processors, RAID Storage; and Intel® Xeon® Processors
The Intel sign-in experience is changing in February to support enhanced security controls. If you sign in, click here for more information.
- Intel Communities
- Product Support Forums
- Server Products
- what does correctable ecc asserted explicily mean?
More actions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
I have «correctable ecc asserted» warning in the bmc of my server. This event probably lead to the server status light turned amber and blink. I wonder is this event mean only one bit error occurred in the dimm or the number of error occurred in that dimm exceeded the threshold? If it is the first case, I think it is ok, and won’t lead to any server health problem. I hope someone can help me with this!
- ECC Memory
-
All forum topics -
Previous topic -
Next topic
8 Replies
Hello Mr. Guo,
In regards to your question the BMC error messages could change from board to board and even with the firmware version. Could you please specify what board/chassis model you have on your server and what BIOS version is it currently running?
Regards
Jose H.
board:s2600cw2r
BIOS01010022
ME030103043
BMC015010802
FRUSDR114
thank you for your help!
No. I saw this in the even log.
Sorry for this late reply, but I was on a business trip last week.
Mr. Guo,
Do you mind to share that event log file here? I would like to take a look at it.
Jose H.
Hello Mr. Guo,
Let me share with you the following info in regards to Correctable Error Correcting Code (ECC) or other correctable memory error for memory modules
- Decode DIMM error(s) using the https://www.intel.com/content/www/us/en/support/server-products/000023940.html System Information Retrieval Utility.
- Verify the DIMM is seated properly.
- Examine gold fingers on edge of the DIMM to ensure that the contacts are clean.
- Inspect the processor socket DIMM for any bent contacts/pins. If you find bent contacts/pins, replace the board.
- Consider replacing the DIMM as a preventive measure if the correctable error becomes uncorrectable.
Hope this helps.
Jose H.
Hello Mr. Guo,
Do you have updates in regards to this?
Just let me know.
Jose H.
Hello Mr. Guo,
I will proceed to mark this thread as closed. If you have further questions just create a new topic and we will be glad to assist you.
Regards
Jose H.
![]()
-
All forum topics -
Previous topic -
Next topic