Содержание
- Correctable memory error rate exceeded
- Dell R420 memory issue
- Popular Topics in Dell Hardware
- 11 Replies
- Read these next.
- poor wifi, school’s third floor
- Need help crafting a job posting for an IT Pro
- Snap! — AI Eye Contact, Mine Batteries, Headset-free Metaverse, D&D Betrayal
- Spark! Pro series – 13th January 2023
- R730 Messaged, «Correctable memory error rate exceeded for DIMM_A3»
- Popular Topics in Dell Hardware
- 4 Replies
- Read these next.
- poor wifi, school’s third floor
- Need help crafting a job posting for an IT Pro
- Snap! — AI Eye Contact, Mine Batteries, Headset-free Metaverse, D&D Betrayal
- Spark! Pro series – 13th January 2023
- Dell C6420 serverпѓЃ
- Documentation and softwareпѓЃ
- Dell OpenManageпѓЃ
- Booting and BIOS configurationпѓЃ
- Minimal configuration of a new server or motherboardпѓЃ
- Reconfiguring the network in BIOSпѓЃ
- C6400 Chassis System ManagementпѓЃ
- Front control panel LED colorsпѓЃ
- DellEMC System UpdateпѓЃ
- racadm commandпѓЃ
- Chassis informationпѓЃ
- C6400 firmware upgradeпѓЃ
- C6400 Chassis Power SuppliesпѓЃ
- Internal Dell informationпѓЃ
- Disk firmware upgrade without RAID controllerпѓЃ
- iDRAC Easy RestoreпѓЃ
- Memory DIMM errorsпѓЃ
- Memory retraining enhancementsпѓЃ
- Post Package Repair (PPR)пѓЃ
Correctable memory error rate exceeded

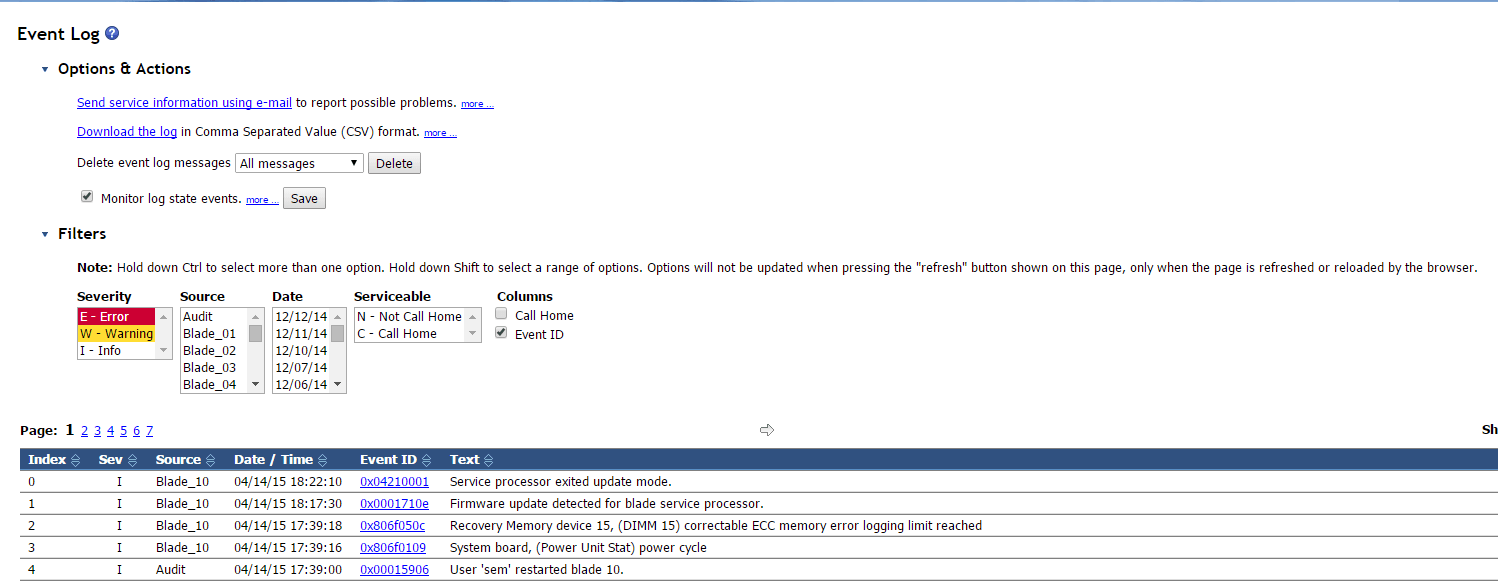
Всем привет сегодня на IBM Blade HS22 вылезла ошибка Correctable ECC memory error logging limit reached. Я расскажу как ее решить. Появляется данная проблема в журналах AMM, кто не в курсе AMM это вебинтерфейс управления корзиной с блейд серверами IBM.
Вот как выглядит данная ошибка в AMM.

Ошибка Correctable ECC memory error logging limit reached на IBM HS22-1
Ошибка Correctable ECC memory error logging limit reached, возникает с проблемой в оперативной памяти, сам IBM в первую очередь советует прошить все по максимуму, и если не поможет вытащить блейд и пере ткнуть DDR память.
и в логах эта ошибка тоже присутствует и имеет код 0x806f050c.

Ошибка Correctable ECC memory error logging limit reached на IBM HS22-2
Я пошел первым путем решил все обновить. Ранее я вам рассказывал Как обновить все прошивки на IBM Blade HS22
После обновления видим в логах что ошибка в состоянии recovery
Ошибка Correctable ECC memory error logging limit reached на IBM HS22-11
и когда будет произведена перезагрузка после обновления вы увидите, что ошибка благополучно исчезла и все зеленое.
Как обновить все прошивки на IBM Blade HS22-10
Вот так вот просто решается Ошибка Correctable ECC memory error logging limit reached на IBM HS22.
Источник
Dell R420 memory issue
Recently installed a second processor into Dell R420 server and transferred over the memory to CPU 2 slots (balanced) and now getting an error. Got one 16GB and one 8GB DIMM matching on each CPU (the DIMMS have previously worked fine with one processor).
Did a bios upgrade as part of the processor install as recommended and when starting the server it shows the correct amount of RAM (48GB) and then displays a message (DIMM Memory Test Failed B1) a message also displays on front of server ‘MEM0702 correctable memory error rate exceeded for DIMM B1, reseat DIMM’
The server still starts however need to understand how resolve this issue. I have tried the following.
— Swapped the RAM around and reseated (Always seems to be B1)
— Tried to run diagnostics on the memory but fails due to the error above
Popular Topics in Dell Hardware

Well, that is pretty clear cut — you can trust the startup diagnostics on this one. It certainly is either an actual failed RAM stick, or the system board. If it does not follow the stick, then it’s the board. With that said, the stick is about 100 times more likely, but it is also technically possible that a stick is borderline and would fail with one processor but not the other. You need more RAM to test with.
Thanks for your response, I think I am going to test with just one RAM stick in each processor and then swap.

Thanks for your response, I think I am going to test with just one RAM stick in each processor and then swap.
Good idea. Also, see if each processor has the same stepping as a mismatch can cause wierdness.
Sajiin had a similar issue:
and the conclusion was getting a new stick of memory from Dell and the problem went away.

You may have to change the memory mode in the BIOS to optimized (same-size sticks).
OK, so I have tried the following.
Swapped the memory around still reports on B1 and then sometimes on B4 (got memory in B1 and B4)
Swapped over the processors and again reporting on error on B1 (processors stepping matches)
Tried just using a single RAM in each CPU.
I am also getting an error relating to the riser board but I believe this is because there is a type for single CPU and a different riser for 2 CPU
As I say the machine boots up and if I clear the errors then it loads fine, its just this error relating to memory.
Hi,
If the riser for a 2 cpu configuration is different and you have 2 CPUs installed with a riser meant for one CPU then you might be running in to electrical paths not being correctly terminated, giving rise to reflected signals. Who knows why Dell states that a different riser must be used but if you aint using it then that might explain the wierd problems.
I dont know the banking and ram slots of the Dell R420 off the top of my head but i suggest you remove cpu2 and test all the ram individually, then add all the ram you can on the single CPU.
You might have a compound issue where you have a problem caused by 2 underlying faults. These are the sorts of problems that can drive you to madness so please try and remove that 2nd CPU!
Thanks, I have ordered a new riser to rule this out.

Brand Representative for Dell
You may also want to try to clear the hardware logs.
Put new riser in (removed the error related to riser) and I am still getting a memory error. Its now very hard to identify where the issue might be.
If you only have two sticks of RAM per CPU, why are you trying to put it in B1 + B4? (I’m assuming you’re also doing A1 + A4 as well). That’s not a supported configuration. It needs to be A1 + A2, B1 + B2.
This topic has been locked by an administrator and is no longer open for commenting.
To continue this discussion, please ask a new question.
Read these next.

poor wifi, school’s third floor
I work as a help desk technician at a high school for a school district. Teachers/students on the building’s third floor have been reporting poor wifi, with their Chromebooks/laptops etc experiencing slow connectivity and random disconnections. We hav.

Need help crafting a job posting for an IT Pro
I’d really appreciate some thoughts and advice. I’m looking to hire an IT pro to be our resident go-to for all things IT (device support, SQL Server, network admin, etc) but who also is interested in learning — or even has some experience in — the.

Snap! — AI Eye Contact, Mine Batteries, Headset-free Metaverse, D&D Betrayal
Your daily dose of tech news, in brief. Welcome to the Snap! Flashback: January 13, 1874: Adding Machine Patented (Read more HERE.) Bonus Flashback: January 13, 1990: Astronauts awakened to the song Attack of the Killer Tomatoes (Read mor.

Spark! Pro series – 13th January 2023
Happy Friday the 13th! This day has a reputation for being unlucky, but I hope that you’ll be able to turn that around and have a great day full of good luck and good fortune. Whether you’re superstitious or not, .
Источник
R730 Messaged, «Correctable memory error rate exceeded for DIMM_A3»
Received this email from my Dell idrac this morning regarding my R730 memory dimm, A3.We’ll likely replace asap but until then, will it eventually disable that dimm or will its errors potentially operations on that server?
It’s a dual ranked DDR4 32gb running at 2133mHz dimm.
Popular Topics in Dell Hardware

Correctable shouldn’t be too concerning.
The direct cause could be a few things, but replacing the dimm is the path of least resistance.
If it returns however, I’d ensure your systemrom/BIOS/microcode is current, both the newer Dells and HPEs have some advanced memory interactions.
I’ve seen this message using the ADDDC mode on Gen10 Proliants, and a lot of the errors had more to do with the memory remap setting and the system processor microcode.

Try firmware upgrade first. I’ve seen that error many times and firmware updates have cleared it. If in doubt though, replace the stick of RAM.
I’ve never actually seen a server crash or fail because of that error.

Brand Representative for Dell
As Dan ‘Glomgore’ Atchley said, I would also start with making sure the server is up to date. Afterwards I would power down the server and swap dimm A3 with another matching dimm in the server, then power back up. The reason is that when the error returns it will either stay at the original slot or follow the dimm to the new location, which will help identify if the dimm or the slot is the cause.
Let me know what you see.

I’ve seen these errors so many times and never had any issues connected with them. The most apparent recommendation to eliminate this message is to update all the firmware to the latest state. Swapping the RAM sticks between slots or even servers, which is better, is another thing I would recommend doing. We had several cases where we just ignored these error messages for years (remote branch offices), and nothing ever happened.
This topic has been locked by an administrator and is no longer open for commenting.
To continue this discussion, please ask a new question.
Read these next.
poor wifi, school’s third floor
I work as a help desk technician at a high school for a school district. Teachers/students on the building’s third floor have been reporting poor wifi, with their Chromebooks/laptops etc experiencing slow connectivity and random disconnections. We hav.
Need help crafting a job posting for an IT Pro
I’d really appreciate some thoughts and advice. I’m looking to hire an IT pro to be our resident go-to for all things IT (device support, SQL Server, network admin, etc) but who also is interested in learning — or even has some experience in — the.
Snap! — AI Eye Contact, Mine Batteries, Headset-free Metaverse, D&D Betrayal
Your daily dose of tech news, in brief. Welcome to the Snap! Flashback: January 13, 1874: Adding Machine Patented (Read more HERE.) Bonus Flashback: January 13, 1990: Astronauts awakened to the song Attack of the Killer Tomatoes (Read mor.
Spark! Pro series – 13th January 2023
Happy Friday the 13th! This day has a reputation for being unlucky, but I hope that you’ll be able to turn that around and have a great day full of good luck and good fortune. Whether you’re superstitious or not, .
Источник
Dell C6420 serverпѓЃ
This page contains information about Dell PowerEdge C6420 servers deployed in our cluster.
Documentation and softwareпѓЃ
Dell Support provides C6420 information:
Dell OpenManageпѓЃ
Download the OpenManage software ISO image from the C6420_downloads page in the Systems Management download category.
Booting and BIOS configurationпѓЃ
Press F2 during start-up to enter the BIOS and firmware setup menus.
Minimal configuration of a new server or motherboardпѓЃ
At our site the following minimal settings are required for a new server or a new motherboard. Remaining settings will be configured by racadm (see the Dell R640 server page).
The Dell iDRAC9 (BMC) setup is accessed via the System Setup menu item iDRAC Settings:
In the Network page set:
NIC Selection: Dedicated
Enable IPMI over LAN to Enabled.
In the System Summary page read the NIC iDRAC MAC Address from this page for configuring the DHCP server.
Go to the System Setup menu item Device Settings and select the Integrated NIC items:
In the NIC Main Configuration Page select NIC Configuration. We use NIC port 3 (1 Gbit) as the system’s NIC.
Read the NIC Ethernet MAC Address from this page for configuring the DHCP server.
Select the Legacy Boot Protocol item PXE.
Boot Sequence menu:
Click the Boot Sequence item to move PXE boot up above the hard disk boot.
Reconfiguring the network in BIOSпѓЃ
The C6420 factory default network settings has the iDRAC9 port shared with a 1 Gbit LOM Ethernet port.
Our network configuration is designed to be:
A dedicated iDRAC9 port.
Server Ethernet port in port 2 of 10 Gbit mezzanine card.
The server Ethernet port must do PXE boot before hard disk boot.
BIOS boot (not UEFI boot).
The following procedure has been tested with BIOS 1.6.11 and iDRAC9 firmware 3.21:
During system boot press F2 to go to System Setup.
Enter iDRAC Settings:
NIC Selection: Dedicated
Thermal Profile: Maximum Performance
Go back and enter Device Settings:
Read the Ethernet MAC address of the desired port.
Go to NIC in Mezzanine 3 Port 2:
Legacy Boot Protocol: PXE
Wake on LAN: Enabled
Go back to Finish:
Reboot the system (mandatory).
During system boot press F2 to go to System Setup.
Enter System Setup:
Boot Settings:
BIOS Boot Settings:
Change Boot Sequence: NIC, then Hard drive C:
Go back to Finish:
Reboot the system (mandatory).
C6400 Chassis System ManagementпѓЃ
Front control panel LED colorsпѓЃ
The C6400 chassis front control panel LED colors are undocumented. The page Interpreting LED Colors and Blinking Patterns for the PowerEdge_VRTX product may perhaps be useful, see the Server table:
DellEMC System UpdateпѓЃ
The C6400 chassis can be managed using the Dell EMC iDRAC_Tools for Linux.
DellEMC System Update (DSU) is a script optimized update deployment tool for applying Dell Update Packages (DUP) to Dell EMC PowerEdge servers. See the DSU page https://www.dell.com/support/article/da-dk/sln310654/dell-emc-system-update-dsu?lang=en
Download the driver DELL EMC System Update, v1.8.0, filename:
and then execute it.
This will create the Yum repository file:
Install RPM packages including iDRAC_tools:
racadm commandпѓЃ
Make a soft link for the racadm command:
Chassis informationпѓЃ
Get the chassis information:
Get the chassis power information:
Inquire the system power:
Inquire thermal and fan settings:
Inquire the Thermal Profile:
Values for the ThermalProfile parameter are:
Use the set command to change the values.
C6400 firmware upgradeпѓЃ
In the C6400_drivers page find Chassis System Management firmware. Read the firmware Release Notes file.
Get the chassis information (including firmware):
You may also verify the CM chassis firmware version by:
Byte 4 — Major version (02 hex) — 02
Byte 5 — Minor version (28 hex) — 40
Install firmware updates by:
Note: It may take 5-10 minutes after upgrading before the new firmware is active on the chassis.
It is useful to loop over every 4th node using clush. For example, a list of every 4th c[001-196] node name between 1 and 196 may be generated by seq:
This can be used with clush as in this example:
C6400 Chassis Power SuppliesпѓЃ
The C6400 chassis contains two power supplies of either 1600, 2000 or 2400 W. The C6400 factory default PSU configuration is:
The PSU handle LED codes are:
Off: Input fail / System off
Solid Green: Input OK / System on
Blinking Amber: PSU failsafe failure
Blinking Green: Firmware updating
Blinking Amber: Firmware update failed
Blinking Green and Off: PSU mismatch
Internal Dell informationпѓЃ
The 1600 W PSU is special since it can be configured in 1+1 (default) redundancy mode, as well as a non-redundant 2+0 mode.
To set non-redundant 2+0 mode:
Set back to 1+1 redundant mode:
The C6400 Chassis Manager must be reset to activate a new mode by:
Disk firmware upgrade without RAID controllerпѓЃ
Our C6420 servers have a SATA SSD disk connected to a simple S140 HBA controller. The Linux firmware update xxx.BIN file apparently can only update firmwares on disks connected to a PERC RAID controller.
The alternative is to upgrade the disk firmware through the iDRAC9 controller using the above racadm command together with the upgrade file in Windows 32-bit .EXE format.
NOTE: This upgrade does not work in a non-interactive crontab job. You have to run the racadm command from an interactive shell, which also includes ssh and clush commands.
iDRAC Easy RestoreпѓЃ
See the iDRAC9 User’s Guide:
After you replace the motherboard on your server, Easy Restore allows you to automatically restore the following data:
System Service Tag
UEFI Diagnostics application
System configuration settings—BIOS, iDRAC, and NIC
Easy Restore uses the Easy Restore flash memory to back up the data. When you replace the motherboard and power on the system, the BIOS queries the iDRAC and prompts you to restore the backed-up data. The first BIOS screen prompts you to restore the Service Tag, licenses, and UEFI diagnostic application. The second BIOS screen prompts you to restore system configuration settings. If you choose not to restore data on the first BIOS screen and if you do not set the Service Tag by another method, the first BIOS screen is displayed again. The second BIOS screen is displayed only once.
Memory DIMM errorsпѓЃ
In the BMC and iDRAC event log there may be DIMM errors such as:
Correctable memory error rate exceeded for DIMM_XX
Warning — MEM0701- “Correctable memory error rate exceeded for DIMM_XX.”
Critical — MEM0702 — “Correctable memory error rate exceeded for DIMM_XX.”
NOTE: Do not swap DIMM modules as the first action!
According to the internal Dell KB QNA44643, with BIOS 2.1.x and newer there is a memory “self healing” operation performed during reboot, see the QNA44643 What is DDR4 Self-healing on Dell PowerEdge Servers with Intel Xeon Scalable Processors. See also the paper Memory Errors and Dell EMC PowerEdge YX4X Server Memory RAS Features.
Memory retraining enhancementsпѓЃ
Memory retraining which happens during boot, optimizes the signal timing/margining for each DIMM/slot for best access. Timing characteristics of a DIMM may change for several different reasons:
Changes in Server memory configuration
Different operating temperatures of the Server or DIMM
General age of the DIMM
Post Package Repair (PPR)пѓЃ
Post Package Repair (PPR) — The second “self-healing’ memory enhancement, results in repairing a failing memory location on a DIMM by disabling the location/address at the hardware layer enabling a spare memory row to be used instead. The exact number of spare memory rows available depends on the DRAM device, and DIMM size.
Note: Message ID MEM8000 (Correctable memory error logging disabled for a memory device at location DIMM_XX) by itself, will not result in a PPR being scheduled for the next reboot. This message ID is expected to result in a PPR being scheduled for the next reboot starting with the BIOS version AFTER 2.3.10 (February 2020).
After the reboot, verify that the PPR operation was successfully performed. An example of a successful PPR operation will be similar to:
Message ID MEM9060 — “The Post-Package Repair operation is successfully completed on the Dual In-line memory Module (DIMM) device that was failing earlier.”
A DIMM replacement for these correctable memory errors is not necessary unless the PPR operation failed after the reboot. An example of a failing PPR message is:
Critical — Message ID UEFI10278 — “Unable to complete the Post Package Repair (PPR) operation because of an issue in the DIMM memory slot X.”
Источник
Обновлено 14.12.2016
Всем привет сегодня на IBM Blade HS22 вылезла ошибка Correctable ECC memory error logging limit reached. Я расскажу как ее решить. Появляется данная проблема в журналах AMM, кто не в курсе AMM это вебинтерфейс управления корзиной с блейд серверами IBM.
Вот как выглядит данная ошибка в AMM.
Ошибка Correctable ECC memory error logging limit reached на IBM HS22-1
Ошибка Correctable ECC memory error logging limit reached, возникает с проблемой в оперативной памяти, сам IBM в первую очередь советует прошить все по максимуму, и если не поможет вытащить блейд и пере ткнуть DDR память.
и в логах эта ошибка тоже присутствует и имеет код 0x806f050c.
Ошибка Correctable ECC memory error logging limit reached на IBM HS22-2
Я пошел первым путем решил все обновить. Ранее я вам рассказывал Как обновить все прошивки на IBM Blade HS22
После обновления видим в логах что ошибка в состоянии recovery
Ошибка Correctable ECC memory error logging limit reached на IBM HS22-11
и когда будет произведена перезагрузка после обновления вы увидите, что ошибка благополучно исчезла и все зеленое.
Как обновить все прошивки на IBM Blade HS22-10
Вот так вот просто решается Ошибка Correctable ECC memory error logging limit reached на IBM HS22.
Материал сайта pyatilistnik.org
Дек 14, 2016 10:49
The memory correctable error logging limit (PFA Threshold) — Lenovo x86 Servers
Troubleshooting
Problem
In some cases, the system reports excessive correctable single bit errors. This might cause the system to reach the limited PFA threshold. User will see the following message in the System Event Log (SEL) in Intelligent Platform Management Interface (IPMI): 04/09/2015 02:30:01 Memory device (replaceable memory devices, e.g. DIMM/SIMM) (Memory — DIMM 24): Assertion: Correctable ECC / other correctable memory error logging limit reached. (where PFA = Predictive Failure Analysis)
Resolving The Problem
Source
RETAIN Tip: H214565
Symptom
In some cases, the system reports excessive correctable single bit errors. This might cause the system to reach the limited PFA threshold. User will see the following message in the System Event Log (SEL) in Intelligent Platform Management Interface (IPMI):
04/09/2015 02:30:01 Memory device (replaceable memory devices, e.g. DIMM/SIMM) (Memory — DIMM 24): Assertion: Correctable ECC / other correctable memory error logging limit reached.
(where PFA = Predictive Failure Analysis)
Affected Configurations
The system may be any of the following Lenovo x86 servers:
- Lenovo Flex System x240 M5 Compute Node, type 9532, any model, any AC1
- Lenovo NeXtScale nx360 M5, type 5465, any model
- Lenovo NeXtScale nx360 M5, type 5467, any model
- Lenovo System x3500 M5, type 5464, any model
- Lenovo System x3550 M5, type 5463, any model
- Lenovo System x3650 M5, type 5462, any model This tip is not software specific.
This tip is not option specific.
The following system BIOS or UEFI level(s) are affected:Â Â Â
Solution
This behavior was corrected in the following UEFI firmware releases:
- nx360M5 — the108j-1.20
- x3650M5 — tce106k-1.10
- x3550M5 — tbe106k-1.10
- x3500M5 — tae106j-1.11
- x240M5Â — c4e106j-1.10
The file is available by selecting the appropriate Product Group, type of System, Product name, Product machine type, and Operating system on IBM Support’s Fix Central web page, at the following URL:Â Â Â Â
Additional Information
The new Intel Memory Reference Code (MRC) provides better margin on handling the memory corruption. It helps the additional memory setup margin that reduces the higher frequencies of the memory correctable bit error. The new Intel MRC is incorporated in the UEFI firmware. The system updates with UEFI will improve the storm of the memory correctable error. Before the fix was available, it was strongly recommended to follow the memory problem determination in the installation guide.
Источник
Special considerations for resolving 0X806F010C 0X806F030C 0X806F050C Memory events — IBM BladeCenter
Troubleshooting
Problem
There are number of advanced features implemented in the memory subsystem of IBM’s BladeCenter Architecture which actively monitor Dual In-Line Modules (DIMMs). If memory errors are detected, the BladeCenter system will log one (1) of the following events: 0x806F010C — uncorrectable ECC memory error 0x806F030C — memory scrub failed (Power On Self Test (POST) MRC/Training error) 0x806F050C — correctable ECC memory error logging limit reached (where: ECC = Error Correction Code) In addition, to maintain the highest levels of system availability, if a memory error is detected during POST or memory configuration, the server can disable the memory bank containing the failed memory DIMM automatically and continue operating with reduced memory capacity.
Resolving The Problem
Source
RETAIN tip: H21455
Symptom
There are number of advanced features implemented in the memory subsystem of IBM’s BladeCenter Architecture which actively monitor Dual In-Line Modules (DIMMs). If memory errors are detected, the Advanced Management Module (AMM) will log one of the following events. Similar messages will be logged in the IMM/IMMv2 event log of the server:
0x806F030C — memory scrub failed (Power On Self Test (POST) MRC/Training error)
0x806F050C — correctable ECC memory error logging limit reached
(where: ECC = Error Correction Code)
Respectively System UEFI or POST diagnostic error codes will be generated when the server starts up or while the server is running and the memory error is detected:
[W.58001] The PFA Threshold limit (correctable error logging limit) has been exceeded on DIMM number percent at address percent. MC5 Status contains percent and MC5 Misc contains percent.
[S.51003] An uncorrectable memory error was detected in DIMM slot percent on rank percent.
[S.51003] An uncorrectable memory error was detected on processor percent channel percent. The failing DIMM within the channel could not be determined.
[S.51003] An uncorrectable memory error has been detected during POST.
[S.58008] A DIMM has failed the POST memory test.
In addition, to maintaining the highest levels of system availability, if a memory error is detected during Power On Self Test (POST) or memory configuration, the server can disable the memory bank containing the failed memory DIMM automatically and continue operating with reduced memory capacity.
Affected configurations
The system may be any of the following IBM servers:
- BladeCenter HS22, type 1911, any model
- BladeCenter HS22, type 1936, any model
- BladeCenter HS22, type 7809, any model, any any
- BladeCenter HS22, type 7870, any model
- BladeCenter HS22V, type 1949, any model
- BladeCenter HS22V, type 7871, any model
- BladeCenter HS23, type 1929, any model
- BladeCenter HS23, type 7875, any model
- BladeCenter HS23, type 7875 E5-xxxxV2, any model
- BladeCenter HS23E, type 8038, any model
- BladeCenter HS23E, type 8039, any model
- BladeCenter HX5, type 1909, any model
- BladeCenter HX5, type 1910, any model
- BladeCenter HX5, type 7872, any model
- BladeCenter HX5, type 7873, any model
This tip is not software specific.
This tip is not option specific.
The following system BIOS or UEFI level(s) are affected: Refer to fix section for affected list of FW
Workaround
Following are the minimum system firmware build levels that should be running on an IBM BladeCenter servers prior to replacement of memory DIMMs for memory scrub and correctable/uncorrectable ECC memory error events:
BladeCenter HS23 imm2_1aoo50c-3.60 uefi_tke136v-1.50
BladeCenter HS23E imm2_1aoo50d-3.65 uefi_ahe136a-1.40
BladeCenter HX5 imm_yuoof7c-1.41 uefi_hie179b-1.79
BladeCenter HS22 imm_yuoof7c-1.41 uefi_p9e159a-1.20
BladeCenter HS22V imm_yuoof7c-1.41 uefi_p9e159a-1.20
(where: IMM = Integrated Management Module)
(where: UEFI = Unified Extensible Firmware Interface)
The file is available by selecting the appropriate Product Group, type of System, Product name, Product machine type, and Operating system on IBM Support’s Fix Central web page, at the following URL:
After the latest system firmware build is applied to the blade server the user should re-enable the memory bank manually using the F1 Setup menu in the UEFI if DIMMs where disabled due to memory errors.
Refer to IBM BladeCenter Information Center or Problem Determination and Service Guide (PDSG) for steps related to the specific blade server that should be followed when taking actions for device specific events:
IMPORTANT: It should be noted that updating system firmware to the code levels listed in this document may not resolve all the memory subsystem issues but should address all memory issues known by IBM.
Additional information
System Unified Extensible Firmware versions listed in this document contain memory reference code updates as well as memory refresh and threshold optimization for predictive failure alerts (PFA), which will result in significant reduction in the rate of superfluous PFA alerts.
Источник
RETAIN Tip H212293 Special considerations for resolving 0X806F010C 0X806F030C 0X806F050C memory events — System x
Troubleshooting
Problem
There are a number of advanced features implemented in the memory subsystem of IBM’s System x Server Architecture which actively monitor Dual In-Line Modules (DIMMs). If memory errors are detected, the Integrated Management Module (IMM) or IMMv2 of theserver will log messages similar to:
Resolving The Problem
Source
RETAIN tip: H212293
Symptom
There are a number of advanced features implemented in the memory subsystem of IBM’s System x Server Architecture which actively monitor Dual In-Line Modules (DIMMs). If memory errors are detected, the Integrated Management Module (IMM) or IMMv2 of the server will log messages similar to:
0x806F010C — Uncorrectable ECC memory error.
0x806F030C — Memory scrub failed (Power On Self Test (POST) MRC/Training error).
0x806F050C — Correctable ECC memory error logging limit reached.
(where: ECC = Error Correction Code)
Respectively System UEFI or POST diagnostic error codes will be generated when the server starts up or while the server is running and the memory error is detected:
W.58001] The PFA Threshold limit (correctable error logging limit) has been exceeded on DIMM number percent at address percent. MC5 Status contains percent and MC5 Misc contains percent.
[S.51003] An uncorrectable memory error was detected in DIMM slot percent on rank percent.
[S.51003] An uncorrectable memory error was detected on processor percent channel percent. The failing DIMM within the channel could not be determined.
[S.51003] An uncorrectable memory error has been detected during POST.
[S.58008] A DIMM has failed the POST memory test.
In addition, to maintaining the highest levels of system availability, if a memory error is detected during POST or memory configuration, the server can disable the memory bank containing the failed memory DIMM automatically and continue operating with reduced memory capacity.
Affected configurations
The system may be any of the following IBM servers:
- System x3100 M4, type 2582, any model
- System x3250 M4, type 2583, any model
- System x3300 M4, type 7382, any model
- System x3400 M3, type 7378, any model
- System x3400 M3, type 7379, any model
- System x3500 M3, type 7380, any model
- System x3500 M4, type 7383, any model
- System x3500 M4, type 7383 E5-xxxxV2, any model
- System x3550 M3, type 4254, any model
- System x3550 M3, type 7944, any model
- System x3550 M4, type 5459, any model
- System x3550 M4, type 7914, any model
- System x3550 M4, type 7914 E5-xxxxV2, any model
- System x3620 M3, type 7376, any model
- System x3630 M3, type 7377, any model
- System x3630 M4, type 7158, any model
- System x3630 M4, type 7158 E5-xxxxV2, any model
- System x3650 M3, type 4255, any model
- System x3650 M3, type 5454, any model
- System x3650 M3, type 7945, any model
- System x3650 M4 BD, type 5466, any model
- System x3650 M4 HD, type 5460, any model
- System x3650 M4, type 7915, any model
- System x3650 M4, type 7915 E5-xxxxV2, any model
- System x3690 X5, type 7147, any model
- System x3690 X5, type 7148, any model
- System x3690 X5, type 7149, any model
- System x3690 X5, type 7192, any model
- System x3750 M4, type 8722, any model
- System x3750 M4, type 8733, any model
- System x3750 M4, type 8752, any model
- System x3850 X5, type 7143, any model
- System x3850 X5, type 7145, any model
- System x3850 X5, type 7146, any model
- System x3850 X5, type 7191, any model
- System x3950 X5, type 7143, any model
- System x3950 X5, type 7145, any model
- iDataPlex dx360 M3 Server, type 6391, any model
- iDataPlex dx360 M4 2U chassis, type 7913, any model
- iDataPlex dx360 M4 server, type 7912, any model
- iDataPlex dx360 M4 server, type 7912 E5-xxxxV2, any model
This tip is not software specific.
This tip is not option specific.
The following system BIOS or UEFI level(s) are affected: Refer to fix section for affected list of FW
Solution
Following are the minimum system firmware build levels that should be running on an IBM System x servers prior to replacement of memory DIMMs for memory scrub and correctable/uncorrectable ECC memory error events:
| System x3750 M4 | imm2_1aoo40z-2.50 | uefi_koe136s-1.40 |
| System x3650 M4 | imm2_1aoo40z-2.50 | uefi_vve134m-1.50 |
| System x3630 M4 | imm2_1aoo40z-2.50 | uefi_bee128e-1.42 |
| System x3550 M4 | imm2_1aoo40z-2.50 | uefi_d7e134e-1.50 |
| System x3300 M4 | imm2_1aoo40z-2.50 | uefi_yae128e-1.23 |
| System x3250 M4 | imm2_1aoo40z-2.50 | uefi_jqe152f-1.03 |
| System x3100 M4 | imm2_1aoo40z-2.50 | uefi_jqe152f-1.03 |
| iDataPlex dx360 M4 | imm2_1aoo48l-3.30 | uefi_tde134e-1.31 |
| System x3500 M4 | imm2_1aoo40z-2.50 | uefi_y5e134f-1.50 |
| iDataPlex dx360 M4 | imm2_1aoo48l-3.30 | uefi_tde134e-1.31 |
| System x3690 X5 | imm_yuoof7a-1.40 | uefi_mle179a-1.79 |
| System x3850 X5 | imm_yuoog2c-1.42 | uefi_g0e181b-1.81 |
| System x3950 X5 | imm_yuoog2c-1.42 | uefi_g0e181b-1.81 |
| System x3650 M3 | imm_yuoof7a-1.40 | uefi_d6e159a-1.17 |
| System x3630 M3 | imm_yuoof7a-1.40 | uefi_hse123a-1.12 |
| System x3620 M3 | imm_yuoof7a-1.40 | uefi_hse123a-1.12 |
| System x3550 M3 | imm_yuoof7a-1.40 | uefi_d6e159a-1.17 |
| System x3500 M3 | imm_yuoof7a-1.40 | uefi_y4e159a-1.14 |
| System x3400 M3 | imm_yuoof7a-1.40 | uefi_y4e159a-1.14 |
| iDataPlex dx360 M3 | imm_yuoof7a-1.40 | uefi_tme159a-1.20 |
| (where: IMM = Integrated Management Module) | ||
| (where: UEFI = Unified Extensible Firmware Interface) |
The file is available by selecting the appropriate Product Group, type of System, Product name, Product machine type, and Operating system on IBM Support’s Fix Central web page, at the following URL:
After the latest system firmware build is applied to the server the user should re-enable the memory bank manually using the F1 Setup menu in the UEFI if DIMMs where disabled due to memory errors.
Refer to IBM System x Information Center or Problem Determination and Service Guide (PDSG) for steps related to the specific server that should be followed when taking actions for device specific events:
IMPORTANT: It should be noted that updating system firmware to the code levels listed in this document may not resolve all the memory subsystem issues but should address all memory issues known by IBM.
Additional information
System Unified Extensible Firmware versions listed in this document contain memory reference code updates as well as memory refresh and threshold optimization for predictive failure alerts (PFA) which will result in significant reduction in the rate of superfluous PFA alerts.
Источник
Recently, some readers reported that the limit of logged memory errors has reached Dimm 5.
Approved
The software to fix your PC is just a click away — download it now.
Problem
Approved
The ASR Pro repair tool is the solution for a Windows PC that’s running slowly, has registry issues, or is infected with malware. This powerful and easy-to-use tool can quickly diagnose and fix your PC, increasing performance, optimizing memory, and improving security in the process. Don’t suffer from a sluggish computer any longer — try ASR Pro today!

The error LED is on on the chassis and on the BladeCenter on the front information panel of the HS22 blade. The well-known name of the Advanced Control Module (AMM) system indicates that a new error has occurred “Correctable ECC Memory Error. Registration limits reached ”. AMM fixes the following errors: Nineteen E Blade_05 12/08/09 11:29:06 (Octane012) Recordable memory error limit reached 28 E Blade_05 12.08.09, 11:29:05 (Octane012) Recoverable memory error affecting transfer limit on DIMM 5. ReachedMemory errors can occur with the following BladeCenter HS22 configuration: – CPU-C announces [Activate] – Temperature setting [Normal] doubles the refresh rate. – Lots of Gigabyte Samsung (gb) VLP DIMMs installed, option part number 44T1488, part number (FRU) 44T1498.
Resolve The Problem
Source
Symptom
The error LED is on on the front and front information panels of the BladeCenter HS22. Advanced Management Module (AMM) system status indicates the presence ofe errors “Correctable ECC space error”. The registration limit has been reached. ” AMM logs the following errors:
19 E Blade_05 12.08.09 11:29:06 (Oktan012)
Recordable memory error limit reached
20 E Blade_05 12.08.09 11:29:05 (Oktan012)
Recoverable memory error log management achieved on DIMM 5
– 4 gigabyte (GB) Samsung DIMMs installed, option selection from 44T1488, part number (FRU) 44T1498.
Affected Configurations
- BladeCenter HS22 Type Any 1936 Model
- BladeCenter HS22 Type 7870 Any Model
This is not a real program.
This offer does not apply to this option.

The system has the warning label described above.
Solution
Choose one of two implementation methods to fix my mistakes:
Method 1:
- Start the server blade in this dedicated F1 system setup and boot management screen. Highlight System Preferences. Click and enter the memory. Select thermal mode and change the market setting to ‘manufacturer ost ”.
- Press the full Esc key twice to open System Setup, Startup and Administration, then select Save Settings, but also exit setup.
- Follow the instructions on the adjacent screen to exit all “configuration utilities”.
- Disable the panel for these changes to take effect and be modified.
Switching from “normal” to actual “performance” mode affects how the current onboard dual memory modules (DIMMs) are updated. This will cause the DIMM temperature warning to appear, which will occur at a much lower temperature of 10 degrees. This may have no effect in most standard data centers.
2:
method
- Immediately start the server blade from the F1 System Configuration and Startup Control screen. Highlight System Preferences, press Enter and select Processors. Select CPU C-States, then change the required value to “Disable”.
- Press the Escape key several times to access System Configuration, Completelinen boot and administration “, then select” Save settings “and exit the settings.
- Follow the information on the screen next to “Configuration Utility”.
- Lightly light the blade to make the change happen over and over.
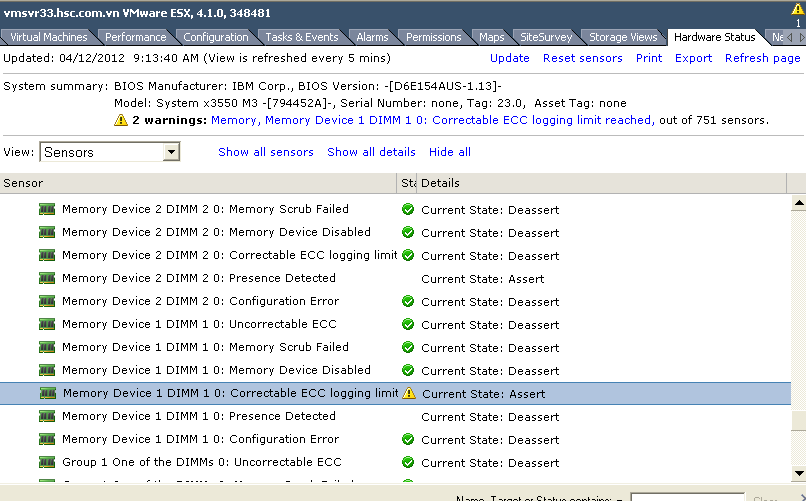
If the indicator is still on after making changes, turn it off in one of the following ways:
- Using the whole IPMItool application (which is also a third party application for Windows and Linux):
- impitool sel doc (to check if there are any log messages)
- ipmitool salt purifier
- ipmitool sel report (to check if the log is empty here)
- Restart IMM. This can be done using the AMM GUI (select Server Blade Tasks, Power / Reboot, and Restart Blade Management Processor for Corresponding Server Blade), also known as the ASU Power Tool (asu rebootimm ).
- Turn this blade off completely and then turn it on again (do not restart a particular blade). This can be done with Via AMM or locally on the slide.
Additional information
This error message usually indicates a clearly defective DIMM, however the detected Samsung DIMMs are in a very, very rare condition that can cause a false failure. By implementing one of the recommended workarounds above, you should avoid the “ECC Corrected Memory Log Limit Reached” error.
Note. A fake error “Recoverable ECC Memory Error Logging Limit Reached” does not mean that the DIMMs are defective.
The software to fix your PC is just a click away — download it now.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Problem
The Error Light Emitting Diode (LED) is illuminated on the chassis and the BladeCenter HS22 blade server front information panel. The Advanced Management Module (AMM) system status indicates that there is a «correctable ECC memory error logging limit reached» error. The AMM logs the following errors:
19 E Blade_05 12/08/09, 11:29:06 (octans012)
Correctable memory error logging limit reached
20 E Blade_05 12/08/09, 11:29:05 (octans012)
Correctable memory error logging limitreached on DIMM 5
The memory errors occur in the following BladeCenter HS22 configuration:
— CPU-C states [Enable]
— Thermal Mode [Normal] double refresh rate
— 4 Gigabyte (GB) Samsung VLP DIMMs installed, Option part number 44T1488, replacement part number (FRU) 44T1498.
Resolving The Problem
Source
RETAIN tip: H196525
Symptom
The Error Light Emitting Diode (LED) is illuminated on the chassis and the BladeCenter HS22 blade server front information panel. The Advanced Management Module (AMM) system status indicates that there is a «correctable ECC memory error logging limit reached» error. The AMM logs the following errors:
19 E Blade_05 12/08/09, 11:29:06 (octans012)
Correctable memory error logging limit reached
20 E Blade_05 12/08/09, 11:29:05 (octans012)
Correctable memory error logging limit reached on DIMM 5
The memory errors occur in the following BladeCenter HS22 configuration:
— CPU-C states [Enable]
— Thermal Mode [Normal] double refresh rate
— 4 Gigabyte (GB) Samsung VLP DIMMs installed, Option part number 44T1488, replacement part number (FRU) 44T1498.
Affected configurations
The system may be any of the following IBM servers:
- BladeCenter HS22, Type 1936, any model
- BladeCenter HS22, Type 7870, any model
This tip is not software specific.
This tip is not option specific.
The system has the symptom described above.
Solution
Choose one of the following two (2) methods to resolve the errors:
Method 1:
Change Thermal Mode setting (preferred method)
- Boot the blade into the F1 «System Configuration and Boot Management» screen. Highlight «System Settings.» Press Enter and select Memory. Select Thermal Mode and change the setting to «Performance.»
- Press the Esc key twice to get to «System Configuration and Boot Management» and then select Save Settings and Exit Setup.
- Follow the instructions on the next screen to exit the «Setup Utility.»
- Power the blade off for the changes to take effect and restart.
Changing «Normal» mode to «Performance» mode affects the way that the Dual In-Line Memory Modules (DIMMs) are refreshed. This results in a DIMM temperature warning message occurring at a 10 degree lower temperature. This causes no impact in most industry standard data centers.
Method 2:
Disable CPU C-State
- Boot the blade into the F1 «System Configuration and Boot Management» screen. Highlight System Settings, press Enter, and select Processors. Select CPU C-States, and then change the setting to «Disable.»
- Press the Esc key twice to get to «System Configuration and Boot Management» and then select Save Settings and Exit Setup.
- Follow the instructions on the next screen to exit the «Setup Utility.
- Power the blade off for the changes to take effect and restart.
If the LED stays on after the changes have been made, do one of the following to turn it off:
-
Using the IPMItool application (which is a third party application available for Windows and Linux):
- impitool sel list (to verify the log contains messages)
- ipmitool sel clear
- ipmitool sel list (to verify the log is now empty)
- Restart the IMM. This can be done via the AMM GUI interface (select Blade Tasks, Power/Restart, and Restart Blade System Mgmt Processor for the appropriate blade) or with the ASU command line tool (asu rebootimm).
- Fully power the blade off, then power it back on (do not restart the blade). This can be done with the AMM or locally at the blade.
Additional information
This error message usually indicates a failing DIMM, however, a very rare condition has been identified with Samsung DIMMs that can cause a false error. By implementing either of the recommended Workaround s above, the false «correctable ECC memory logging limit reached» error should not occur.
Note: The false «correctable ECC memory error logging limit reached» error does not indicate defective DIMMs.
[{«Type»:»HW»,»Business Unit»:{«code»:»BU054″,»label»:»Systems w/TPS»},»Product»:{«code»:»HW21Q»,»label»:»BladeCenter HS Series Server (7809-H22)»},»Platform»:[{«code»:»PF025″,»label»:»Platform Independent»}],»Line of Business»:{«code»:»LOB18″,»label»:»Miscellaneous LOB»}}]