Содержание
- Evaluating uncorrectable ECC errors and fallback methods
- 3 Answers 3
- Basic Diagnostics for Correctable/Uncorrectable ECC Memory Errors with Intel® Server Boards
- Correctable memory error threshold exceeded
- The memory correctable error logging limit (PFA Threshold) — Lenovo x86 Servers
- Troubleshooting
- Problem
- Resolving The Problem
- Source
- Symptom
- Affected Configurations
- Solution
- Additional Information
Evaluating uncorrectable ECC errors and fallback methods
I run a server which has just experienced an error I’ve not encountered before. It emitted a few beeps, rebooted, and got stuck at the startup screen (the part where the bios shows its logo and begins listing information) with the error:
Node0: DRAM uncorrectable ECC Error
Node1: HT Link SYNC Error
After a hard reset the system booted fine and has yet to report anything on edac-util.
My research tells me that even with ECC memory and a system in ideal conditions, an uncorrectable error is still possible and probably will likely occur during the lifespan of the system at some point; some reports suggest at least once a year or sooner.
The server runs CentOS 6.5 with several ECC modules. I am already in the process of trying to diagnose which module threw the error to make an assessment whether this is a fault or the result of something as unavoidable such as a cosmic ray.
My research also suggests that when the system halts like this, there is nowhere for a log to be written and that the only reliable way to do this is to have the system attached to another with the log being written out through a serial port.
Besides the usual edac-util, memtest, stress testing, and precautionary replacement, is there anything else I should take into consideration when addressing this error?
I was unable to find any record of this crash in any of the CentOS logs I searched, which goes along with my belief that it is not possible to log this error to a local disk. The error was only reported to me by the bios after an automatic reboot. Is it advisable to be writing system logs out to serial at all times to log these kinds of errors?
Is this kind of failure avoidable using a single system or is this only possible using an expensive enterprise solution?
What can I do to provide fallback measures in these failure cases for a single production server; as in, the production server itself does not span multiple machines but a fallback server can exist.

3 Answers 3
Well, this isn’t a fully-integrated system like an HP, Dell or IBM server, so the monitoring and reporting of such a failure isn’t going to be present or consistent.
With the systems I’ve managed, disks fail the most often, followed by RAM, power supplies, fan, system boards and CPUs.
Memory can fail. There isn’t much you can do about it.
Since you can’t really prevent ECC errors and RAM failure, just be prepared for it. Keep spares. Have physical access to your systems and maintain the warranty of your components. I definitely wouldn’t introduce «precautionary replacement» into an environment. Some of this is a function of your hardware. Do you have IPMI? Sometimes hardware logs will end up there.
This is one of the value-adds of better server hardware. Here’s a snippet from an HP ProLiant DL580 G4 server where the ECC threshold on the RAM was exceeded, then progressed to the DIMM being disabled. then finally the server crashing (ASR) and rebooting itself with the bad DIMM deactivated.

If the DIMM has uncorrectable error I’d recommend replacing it. If it is only correctable errors in a low rate you can probably live with it and in any case for correctable errors it will be harder to get a refund.
If you want to see if there is a record try to access the IPMI SEL records, with ipmitool sel elist or an equivalent tool.
The other alternative is to setup a Linux crash kernel to boot into and save the dmesg, this can also catch the information on the hardware failure.
The third alternative is to log the serial console of the server to somewhere persistent, it will also include the clues for a server crash of software or hardware kind.
This is in answer share how I stopped the system from crashing but does not address the original question. I’m still researching solutions and will share any new information I come up with as I learn it.
The system is a white box with a Supermicro H8SGL-F motherboard with 64GB (16×4) Hynix, 32GB (16×2) Viking ram. The motherboard specification says that ram modules must be installed in sets of four as the processor uses quad-channel memory controller. I threw the extra two Viking modules in to see if it worked and it did. This solution worked for months but was my first mistake.
My second mistake was that I installed the ram incorrectly. The memory slots are color-coded and interleaved for the quad-channel setup. I had the ram installed like this:
While this setup did work for several months and only starting producing a problem recently, I would not determine whether the fault was due to increased capacity causing a problem with my out-of-spec layout of whether a module actually had an issue.
As I only had one production system, I removed all of the modules and started rotating them in as pairs of two (still out of spec) and running the system at reduced capacity for several weeks. I received no crashes and there were no reports of ecc errors from edac-util. However, it’s possible that a faulty module may have been in the second slot and simply was not accessed such that it would cause a fault.
After rotating through the ram failed to reproduce the error, I realized that I had setup the ram incorrectly. I removed the Viking modules and setup the new layout like this:
Since I made this change the system remained stable. Despite aligning to spec however, this does not confirm whether the fault is with the layout, a Viking module (since they were removed), or whether the offending module is simply one of the Hynix modules further down in the layout which is accessed infrequently enough not to fault.
Please see this answer not as a conclusion to the problem but a step I have taken to address the overall issue. I am not finished and will continue to report as I continue looking for solutions.
Also of note, the system power cycled yesterday for the first time since I set the memory to the new layout. I cannot confirm whether this was due to the memory issue being addressed or whether this is a separate issue with the power supply, so take this single incident thus far as a grain of salt.
Источник
Basic Diagnostics for Correctable/Uncorrectable ECC Memory Errors with Intel® Server Boards
Content Type Troubleshooting
Article ID 000024007
Last Reviewed 01/10/2023
What am I seeing?
Correctable and/or Uncorrectable Error Correcting Code (ECC) events for memory modules. For example:
Mmry ECC Sensor SMI Handler Warning Memory CPU: 1, DIMM: D0 DIMM Rank: 1. — Correctable ECC / other correctable memory error — Asserted.
What is Memory Error Correction Code (ECC) Correctable Error Event?
ECC correctable error represents a threshold overflow for a given Dual In-line Memory Modules (DIMM) within a given timeframe.
Memory data errors are logged as correctable or uncorrectable. Refer to the instructions below, based on the error type you encounter:
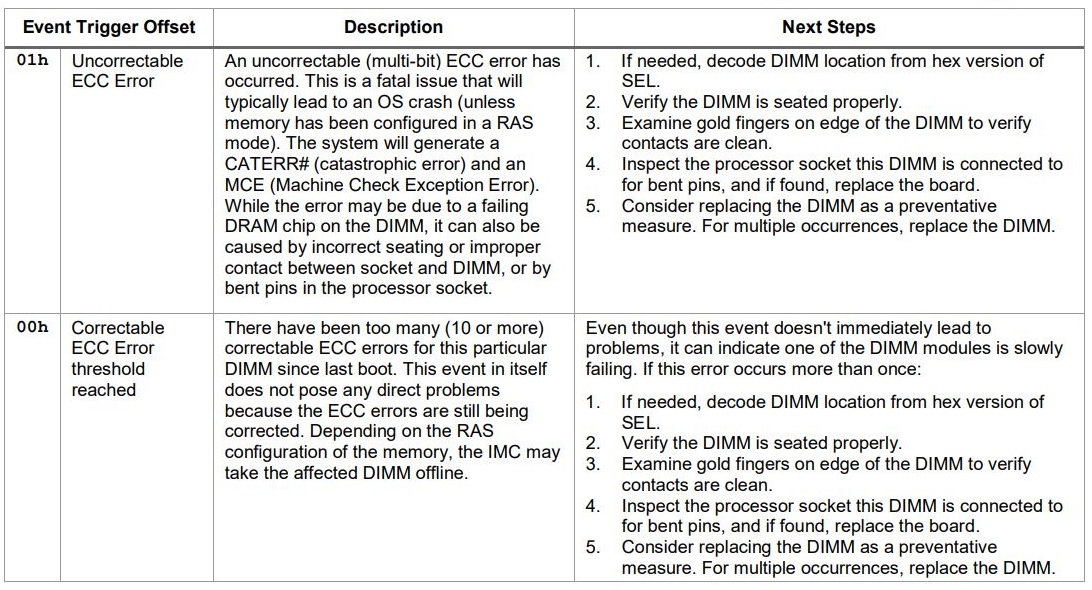
| Notes |
|
- If there is no catastrophic issue (Purple Screen of Death (PSOD) or unexpected restart) and the correctable ECC error, including Adaptative Double Device Data Correction (ADDDC) error, is less than 10 events every 24 hours for each DIMM location, which is within the threshold limit, the recommendation is to monitor the server for any recurrence of ECC error each DIMM location that triggers the event.
- If there is a catastrophic issue (Purple Screen of Death (PSOD) or unexpected restart) and the correctable ECC error, including Adaptative Double Device Data Correction (ADDDC) error, is less than 10 events every 24 hours for each DIMM location, it is recommended to re-seat each DIMM location by following the steps below:
- Power OFF the system and remove the AC power cable.
- Identify the DIMM location to re-seat. Refer to the Technical Product Specifications for your server platform to identify the DIMM location.
- Perform the re-seat of identified DIMM.
- Insert the AC power cable and power back ON the system.
- Observe for 24 hours for any recurrence of ECC error.
- If the ECC error persists with the same DIM location that was re-seated, then generate and send the SEL and Debug logs, both generated from the BMC Web Console to Intel Customer Support
- The advanced memory test (AMT) features were introduced in the BIOS and firmware stack starting with the BIOS revision 02.01.0014 for the Intel® Server Systems S2600BP, S2600WF, and S2600ST; and starting with the BIOS revision 22.01.0097 for the Intel® Server System S9200WK. For these products, recommend to enable the advanced memory test (AMT) and post package repair (PPR) features through the BIOS setup utility to perform a full check of the memory health. Refer to Chapter 5 in Memory Replacement Guideline and Advanced Memory Test for Intel® Server Products Based on Intel® 62X Chipset – White Paper for detail steps.
The Error Correction Code (ECC) errors are self-correcting. Depending on the Reliability Availability Serviceability (RAS) configuration of the memory, the Integrated Memory Controller (IMC) may take the affected DIMM offline.
For different Intel server platforms, there are some differences in their event definition, refer to System Event Log Troubleshooting Guide for your server platform
Intel recommends downloading and updating the system BIOS to the latest available version for your server platform.
If the system is an Intel® Data Center Block for Nutanix* Enterprise Cloud, rather, visit the Nutanix* Life Cycle Manager page. For a list of hardware and firmware compatibility, visit the Nutanix* Hardware and Firmware compatibility page.
Источник
Correctable memory error threshold exceeded

Всем привет сегодня на IBM Blade HS22 вылезла ошибка Correctable ECC memory error logging limit reached. Я расскажу как ее решить. Появляется данная проблема в журналах AMM, кто не в курсе AMM это вебинтерфейс управления корзиной с блейд серверами IBM.
Вот как выглядит данная ошибка в AMM.

Ошибка Correctable ECC memory error logging limit reached на IBM HS22-1
Ошибка Correctable ECC memory error logging limit reached, возникает с проблемой в оперативной памяти, сам IBM в первую очередь советует прошить все по максимуму, и если не поможет вытащить блейд и пере ткнуть DDR память.
и в логах эта ошибка тоже присутствует и имеет код 0x806f050c.

Ошибка Correctable ECC memory error logging limit reached на IBM HS22-2
Я пошел первым путем решил все обновить. Ранее я вам рассказывал Как обновить все прошивки на IBM Blade HS22
После обновления видим в логах что ошибка в состоянии recovery
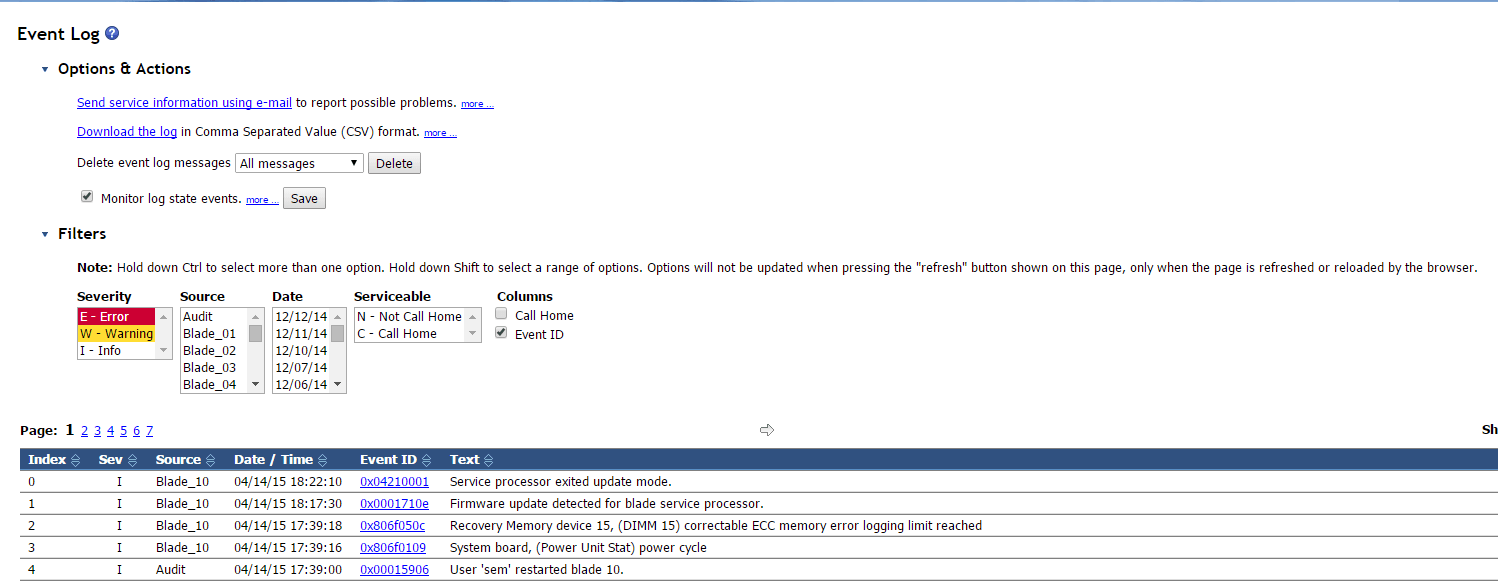
Ошибка Correctable ECC memory error logging limit reached на IBM HS22-11
и когда будет произведена перезагрузка после обновления вы увидите, что ошибка благополучно исчезла и все зеленое.
Как обновить все прошивки на IBM Blade HS22-10
Вот так вот просто решается Ошибка Correctable ECC memory error logging limit reached на IBM HS22.
Источник
The memory correctable error logging limit (PFA Threshold) — Lenovo x86 Servers
Troubleshooting
Problem
In some cases, the system reports excessive correctable single bit errors. This might cause the system to reach the limited PFA threshold. User will see the following message in the System Event Log (SEL) in Intelligent Platform Management Interface (IPMI): 04/09/2015 02:30:01 Memory device (replaceable memory devices, e.g. DIMM/SIMM) (Memory — DIMM 24): Assertion: Correctable ECC / other correctable memory error logging limit reached. (where PFA = Predictive Failure Analysis)
Resolving The Problem
Source
RETAIN Tip: H214565
Symptom
In some cases, the system reports excessive correctable single bit errors. This might cause the system to reach the limited PFA threshold. User will see the following message in the System Event Log (SEL) in Intelligent Platform Management Interface (IPMI):
04/09/2015 02:30:01 Memory device (replaceable memory devices, e.g. DIMM/SIMM) (Memory — DIMM 24): Assertion: Correctable ECC / other correctable memory error logging limit reached.
(where PFA = Predictive Failure Analysis)
Affected Configurations
The system may be any of the following Lenovo x86 servers:
- Lenovo Flex System x240 M5 Compute Node, type 9532, any model, any AC1
- Lenovo NeXtScale nx360 M5, type 5465, any model
- Lenovo NeXtScale nx360 M5, type 5467, any model
- Lenovo System x3500 M5, type 5464, any model
- Lenovo System x3550 M5, type 5463, any model
- Lenovo System x3650 M5, type 5462, any model This tip is not software specific.
This tip is not option specific.
The following system BIOS or UEFI level(s) are affected:Â Â Â
Solution
This behavior was corrected in the following UEFI firmware releases:
- nx360M5 — the108j-1.20
- x3650M5 — tce106k-1.10
- x3550M5 — tbe106k-1.10
- x3500M5 — tae106j-1.11
- x240M5Â — c4e106j-1.10
The file is available by selecting the appropriate Product Group, type of System, Product name, Product machine type, and Operating system on IBM Support’s Fix Central web page, at the following URL:Â Â Â Â
Additional Information
The new Intel Memory Reference Code (MRC) provides better margin on handling the memory corruption. It helps the additional memory setup margin that reduces the higher frequencies of the memory correctable bit error. The new Intel MRC is incorporated in the UEFI firmware. The system updates with UEFI will improve the storm of the memory correctable error. Before the fix was available, it was strongly recommended to follow the memory problem determination in the installation guide.
Источник
Adblock
detector
1. Reseat the DIMM.
2. Update the system ROM to the latest version. For more information, see Updating firmware or system
ROM on page 114.
3. If the issue still exists, then replace the DIMM.
For more information, see the Server maintenance and service guide on page 125.
Symptom
•
Performance is degraded.
•
The memory LED is amber.
•
ECC errors occur with no other symptoms.
Cause
•
The DIMM is not installed or seated properly.
•
The DIMM has failed.
Action
1. Update the system ROM to the latest version. For more information, see Updating firmware or system
ROM on page 114.
2. Replace the DIMM. For more information, see the Server maintenance and service guide on page 125.
Processor issues
Troubleshooting the processor
Symptom
A POST error message or an IML message is received.
Cause
•
One or more processors are not supported by the server.
•
The processor configuration is not supported by the server.
•
The server ROM is not current.
•
A processor is not seated properly.
•
A processor has failed.
Action
1. Be sure each processor is supported by the server and is installed as directed in the server
documentation. The processor socket requires very specific installation steps and only supported
processors should be installed. For processor requirements, see the Server user guide on page 125.
2. Be sure the server ROM is current.
3. Be sure you are not mixing processor stepping, core speeds, or cache sizes if this is not supported on the
server. For more information, see the Product QuickSpecs on page 107.
4. If the server has only one processor installed, reseat the processor. If the issue is resolved after you restart
the server, the processor was not installed properly.
5. If the server has only one processor installed, replace it with a known functional processor. If the issue is
resolved after you restart the server, the original processor failed.
6. If the server has multiple processors installed, test each processor:
a. Remove all but one processor from the server. Replace each with a processor terminator board or
blank, if applicable to the server.
b. Replace the remaining processor with a known functional processor. If the issue is resolved after you
restart the server, a fault exists with one or more of the original processors. Install each processor one
90
Correctable memory error threshold exceeded
О LENOVO
+
О LENOVO
-
Наша компания
-
Новости
-
Контакт
-
Соответствие продукта
-
Работа в Lenovo
-
Общедоступное программное обеспечение Lenovo
КУПИТЬ
+
КУПИТЬ
-
Где купить
-
Рекомендованные магазины
-
Стать партнером
Поддержка
+
Поддержка
-
Драйверы и Программное обеспечение
-
Инструкция
-
Инструкция
-
Поиск гарантии
-
Свяжитесь с нами
-
Поддержка хранилища
РЕСУРСЫ
+
РЕСУРСЫ
-
Тренинги
-
Спецификации продуктов ((PSREF)
-
Доступность продукта
-
Информация об окружающей среде
©
Lenovo.
|
|
|
|
Posted by billhungerford 2021-06-04T13:24:51Z
Received this email from my Dell idrac this morning regarding my R730
memory dimm, A3.We’ll likely replace asap but until then, will it
eventually disable that dimm or will its errors potentially operations
on that server?
It’s a dual ranked DDR4 32gb running at 2133mHz dimm.
Thanks
4 Replies
-
Correctable shouldn’t be too concerning.
The direct cause could be a few things, but replacing the dimm is the path of least resistance.If it returns however, I’d ensure your systemrom/BIOS/microcode is current, both the newer Dells and HPEs have some advanced memory interactions.
I’ve seen this message using the ADDDC mode on Gen10 Proliants, and a lot of the errors had more to do with the memory remap setting and the system processor microcode.
Was this post helpful?
thumb_up
thumb_down
-
Try firmware upgrade first. I’ve seen that error many times and firmware updates have cleared it. If in doubt though, replace the stick of RAM.
I’ve never actually seen a server crash or fail because of that error.
1 found this helpful
thumb_up
thumb_down
-

Brand Representative for Dell
tabasco
Billhungerford,
As
Dan ‘Glomgore’ Atchley said, I would also start with making sure the server is up to date. Afterwards I would power down the server and swap dimm A3 with another matching dimm in the server, then power back up. The reason is that when the error returns it will either stay at the original slot or follow the dimm to the new location, which will help identify if the dimm or the slot is the cause.
Let me know what you see.
Was this post helpful?
thumb_up
thumb_down
-
I’ve seen these errors so many times and never had any issues connected with them. The most apparent recommendation to eliminate this message is to update all the firmware to the latest state. Swapping the RAM sticks between slots or even servers, which is better, is another thing I would recommend doing. We had several cases where we just ignored these error messages for years (remote branch offices), and nothing ever happened.
Was this post helpful?
thumb_up
thumb_down


0
1
Есть древний сервер HP DL580 G5 с CentOS 7. В последнее время в сислог стали спамиться сообщения:
[2164864.727076] EDAC MC0: 1 CE Read error on unknown memory (branch:0 channel:1 slot:4 page:0x0 offset:0x0 grain:0 syndrome:0x4ccd1d10 — DRAM-Bank=1 RAS=4464 CAS=2732, Err=0x2000 (Correctable Non-Mirrored Demand Data ECC)))
Вроде очевидно, что какая-то планка памяти потихоньку выходит из строя. Но проблема в том, что памяти «branch:0 channel:1 slot:4» просто не существует:
$awk ‘{print $0}’ /sys/devices/system/edac/mc/mc0/dimm*/dimm_location
branch 0 channel 0 slot 0
branch 0 channel 1 slot 2
branch 0 channel 1 slot 3
branch 1 channel 0 slot 0
branch 1 channel 0 slot 1
branch 0 channel 0 slot 1
branch 1 channel 1 slot 0
branch 1 channel 1 slot 1
branch 0 channel 0 slot 2
branch 0 channel 0 slot 3
branch 0 channel 1 slot 0
branch 0 channel 1 slot 1
Если это действительно сбойная память, как ее найти? Очень не хочется лезть в сервер и вынимать планки по одной, там все очень неудобно сделано. Если же это не память, то что?