We have 2 node cluster, current state :
patronictl -c /etc/patroni/postgres.yml list
+———+————-+—————+———+———+————+
| Cluster | Member | Host | Role | State | Lag in MB |
+———+————-+—————+———+———+————+
| dev1 | postgresql1 | 10.144.250.41 | | running | 371.0 |
| dev1 | postgresql2 | 10.144.250.42 | Leader | running | 0.0 |
+———+————-+—————+———+———+————+
postgresql1 node was in shutdown state few hours ago and now I start it.
It can’t syncing with master with error:
cp: cannot stat ‘/data/wal_archive/000000520000012B00000081’: No such file or directory
< 2019-12-05 10:17:05.994 MSK > LOG: started streaming WAL from primary at 12B/81000000 on timeline 82
< 2019-12-05 10:17:05.994 MSK > FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000520000012B00000081 has already been removed
But it’s not true . Wal segment 000000520000012B00000081 exists on master :
[root@pgdb2 wal_archive]# ll /data/wal_archive/000000520000012B00000081
-rw——- 1 postgres postgres 16777216 Dec 4 23:38 /data/wal_archive/000000520000012B00000081
What’s wrong ?
Postgres requested WAL segment has already been removed (however it is actually in the slave’s directory)
I am using repmgr as my replication tool. On the slave I keep getting an error:
requested WAL segment has already been removed
When I check the Master indeed it is not there; however, it is in the slave’s directories both in pg_xlogs and pg_xlogs/archive_status . I can’t understand why it would be looking for this file if it’s already in the slave?
In fact it has xlogs going past the requested one. The solutions in What to do with WAL files for Postgres Slave reset are for a slightly different problem. They seem to be for a scenario where the master deletes a log file before the slave receives it. In my case it is very much present on the slave and several other files in the sequence after the one being requested.
This also tells me I do not need to increase the keep wal segments option as it didn’t seem to fall behind?
2 Answers 2
From Streaming Replication in the PostgreSQL documentation:
If you use streaming replication without file-based continuous archiving, the server might recycle old WAL segments before the standby has received them. If this occurs, the standby will need to be reinitialized from a new base backup. You can avoid this by setting wal_keep_segments to a value large enough to ensure that WAL segments are not recycled too early, or by configuring a replication slot for the standby. If you set up a WAL archive that’s accessible from the standby, these solutions are not required, since the standby can always use the archive to catch up provided it retains enough segments.
To fix the issue, you have to reinitialize the data from primary server. Remove data directory on slave:
Copy all data from the primary server:
if version is 12, Create the standby.signal file, otherwise configure replica.conf:
How long is the pg_basebackup taking? Remember that segments are generated about every 5 minutes, so if the backup takes an hour, you need at least 12 segments stored. At 2 hours, you need 24 etc., I’d set the value to about 12.2 segments/hour of backup.
Источник
Postgresql Streaming Replication Error: WAL segment removed
I want to set up PostgreSQL streaming replication, but get the following error:
Master IP : 192.168.0.30
Slave IP : 192.168.0.36
On Master:
I have created a user rep which is used solely for replication.
The relevant files inside Postgres config directory ( /opt/Postgres/9.3/data ):
I’ve restarted the postgres service.
On Slave:
I’ve stopped the postgres service, then applied the changes to the two files:
For replicating the initial database I have done:
On Master:
Internal postgres backup start command to create a backup label:
. for transferring the database data to slave:
. for internal backup stop to clean up:
On Slave:
I’ve created the following recovery.conf :
Starting the postgres service on the slave starts without any errors but is still waiting:
Meanwhile, on master:
psql command on the slave gives:
—> cd pg_log gives reason for waiting:-
How can I solve this error?
1 Answer 1
From Streaming Replication in the PostgreSQL documentation:
If you use streaming replication without file-based continuous archiving, the server might recycle old WAL segments before the standby has received them. If this occurs, the standby will need to be reinitialized from a new base backup. You can avoid this by setting wal_keep_segments to a value large enough to ensure that WAL segments are not recycled too early, or by configuring a replication slot for the standby. If you set up a WAL archive that’s accessible from the standby, these solutions are not required, since the standby can always use the archive to catch up provided it retains enough segments.
Источник
Could not receive data from WAL stream: ERROR: requested WAL segment has already been removed
Configuration: Postgres 9.6 with a 3 cluster node. db1 is the master, db2 and db3 are replicas. WAL files are archived in AWS S3 using custom pgrsync tool. Cluster managed by patroni. The archive_command and restore_command is properly configured on all the nodes.
To simulate: On db1, do heavy writes (like vacuum a large table) and then stop db1 by sudo systemctl stop patroni ). db3 becomes the new leader. db2 requests more WAL files, which it gets via the proper restore command from AWS S3, becomes replica to db3.
Now, start db1 again by ( sudo systemctl start patroni ). But db1 (the old leader and the new to-be-replica) never comes up as a replica and gives the error message:
could not receive data from WAL stream: ERROR: requested WAL segment 0000002400053C55000000AE has already been removed.
This error message is reported by db3 (the leader), which db1 just logs it.
So, let’s see the timeline. Initially db1 was in timeline 35 (0x23) and did write the following files to archive:
db1 is stopped at this point. db3’s logs show this:
and db3 copies the following files to archives
As db3 became leader, db2 starts the process to become replica to db3 (which it successfully becomes) and here is the summary of the logs:
db1 is started now and here are the logs:
- 0000002400053C55000000AE was never written to archives by any Postgres node. The old leader (db1) copied the archive 0000002300053C55000000AE (note: 0023, not 0024) before it was stopped.
- The new leader (db3) copied 0000002200053C55000000AE (note: 0022, not 0024)
- max_wal_size is set to 1024 on all nodes.
- After db3 became the new leader, there was hardly any activity on the nodes. db3 only writes WAL files every 10 mins ( archive_timeout =600s).
- Is there any thing wrong in the configuration that makes the the old leader asking for a WAL segment, which the new leader does not have?
- How to restore the old leader (db1) at this state, without having to erase and start over?
Lots of disk space available. The problem can be simulated at will. Had tried pg_rewind on the old primary, pointing to new primary. It just said it is already on the same timeline (not exact words). Note: It was not an error message. But even after that, it was showing the same error, when starting Postgres.
We are on 9.6.19. Just a few days back 9.6.21 (and last 9.5.x release) was announced which exactly points out fix for this specific problem (Fix WAL-reading logic so that standbys can handle timeline switches correctly. This issue could have shown itself with errors like «requested WAL segment has already been removed».). However, even after upgrading to 9.6.21, the same problem exists for us.
Источник
Postgresql сломалась репликаци знаю причины не знаю как поченить стэндбай?
Добрый день.
У меня настроена каскадная репликация с одного мастера идет слейв который в свою очередь после синхронизации реплицирует на последний слейв.
OC — Ubuntu 18
СУБД — PostgreSQL 10
https://postgrespro.ru/docs/postgrespro/10/warm-standby
Проблема заключается в том что на слейвах у меня ощибка
error requested wal segment has already been removed.
Правильно ли Я понимаю что эта ошибка говорит о том что Если база с которой настроенно получение WAL уже удалила сегмент — то тут как раз репликация и встанет с ошибкой, что такого сегмента уже нет. Если его восстановить неоткуда — то необходимо копировать реплику заново. Наиболее простой способ — через pg_basebackup.
https://ru.stackoverflow.com/questions/972585/post.
В связи с этим есть вопросы:
1. Можно сделать это как то подругому ?
К примеру:
Остановить слейв скопировать с мастера папку pg_wal с файлами и запустить его ? Не станет ли слейв после этого мастером ?
Я просто не понимаю что нужно будет делать на слейве что бы он догнал мастер. Иными словами как востонавливать пошагово.
2. Могла ли данная ошибка возникнуть из-за того что Я делаю на мастере pg_basebackup -D /my_dir. Которая в свою очередь лочит базу и репликация не может пройти. Точнее она проходит но с ошибкой.
Тогда как делать правильно pg_basebackup что бы не ломалась реплика ?
Источник
WAL segment has already been removed error when running database backup on CloudForms
Environment
Issue
- Getting requested WAL segment 00000001000000140000004F has already been removed when running pg_basebackup on CloudForms.
Resolution
- Adjust the wal_keep_segments setting in the postgresql.conf file.
Instructions:
- SSL into your DB server CloudForms appliance
- Set wal_keep_segments to (
/4)/16MB
Please note that when calculating the that you want to keep it as low as possible, as this will take up space on the database
Root Cause
- The server recycles old WAL segments before the backup can finish.
- Depending on how long the pg_basebackup is taking it is common knowledge that the segments are generated about every 5 minutes, so if the backup takes an hour, you need at least 12 segments stored.
- Product(s)
- Red Hat Hybrid Cloud Console
- Category
- Supportability
- Tags
- cloud
- cloudforms
- database
- postgres
This solution is part of Red Hat’s fast-track publication program, providing a huge library of solutions that Red Hat engineers have created while supporting our customers. To give you the knowledge you need the instant it becomes available, these articles may be presented in a raw and unedited form.
Источник

Introduction
Various replication modes are available with PostgreSQL.
In this article, a PostgreSQL 9.6 streaming replication is implemented on Linux Ubuntu 18.04 servers, it’s very easy.
In the streaming replication mode,
the standby connects to the primary, which streams WAL records (Write Ahead Log) to the standby as they’re generated,
without waiting for the WAL file to be filled. Streaming replication allows a standby server to stay more up-to-date than
is possible with file-based log shipping.
- The standby server can be in read only mode for reporting purposes for example.
- A replication slot ensures that the needed WAL files for the standby are not removed in the primary server
before the standby server processes them. Multiple replication slots can be defined depending on the number of the standby servers.
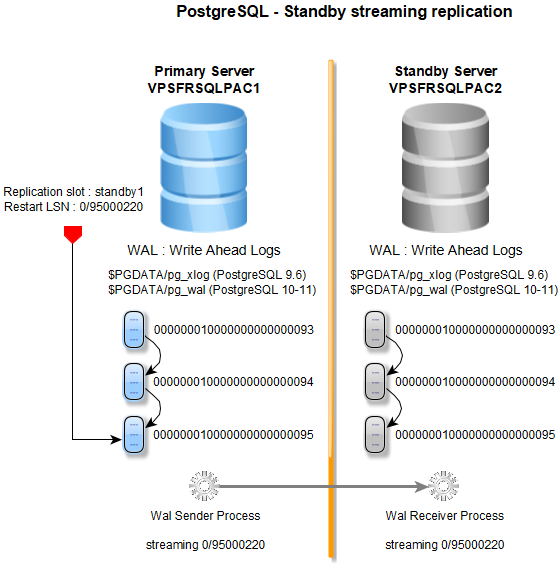
(LSN : Log Sequence Number)
The procedure below is valid for PostgreSQL 9.6, 10 and 11. For PostgreSQL version 12 and above, the setup is slightly different
and not discussed here. It is not important when configuring a PostgreSQL streaming replication, but default WAL files location is
different on PostgreSQL 9.6 and PostgreSQL 10/11.
| PostgreSQL 9.6 | $PGDATA/pg_xlog |
| PostgreSQL 10/11 | $PGDATA/pg_wal |
The context is the following : 1 primary server, 1 standby server.
VPSFRSQLPAC1Standby server :
VPSFRSQLPAC2
Binaries (PostgreSQL 9.6.15) : /opt/postgres/pgsql-9.6/bin
$PATH : /opt/postgres/pgsql-9.6/bin:$PATH
$PGLIB : /opt/postgres/pgsql-9.6/lib
Port : 30001
$PGDATA : /sqlpac/postgres/srvpg1
$CFG : /opt/postgres/dba/srvpg1/cfg
Configuration files :
$CFG/postgresql.conf
$CFG/pg_hba.conf
$CFG/pg_ident.conf
Controlling the PostgreSQL Server :
pg_ctl start|stop|restart… -D $CFGPreparing the primary server
System parameters
The primary server must be restarted, especially with PostgreSQL 9.6, to apply at least the following static parameters :
listen_addresses:*wal_level: the wal level isreplicafor streaming replication.max_replication_slots: at least 1 replication slot (1 standby). Higher values of replication slots if more standby or logical servers will be configured.max_wal_senders: at least 3 wal senders (1 standby + 2 forpg_basebackup). Higher values if more standby servers will be configured.
$CFG/postgresql.conf
listen_addresses = '*'
wal_level=replica
max_replication_slots=3
max_wal_senders=3With PostgreSQL 10 and 11, the default values are already adjusted for replication. However, check the settings.
| PostgreSQL 10 / 11 | Default values |
|---|---|
wal_level |
replica |
postgres@vpsfrsqlpac1$ pg_ctl restart -D $CFGReplication role
Create a role with the replication privilege, this role will be used by the standby server to connect to the primary
server :
create role repmgr with replication login encrypted password '***********';Add the role in the primary server file pg_hba.conf with the standby IP address server, this will allow connections from the standby server.
Don’t forget to manage existing firewall rules.
$CFG/pg_hba.conf
host replication repmgr 51.xxx.xxx.xxx/32 md5Here, SSL connections are not implemented.
Reload the configuration :
postgres@vpsfrsqlpac1$ pg_ctl reload -D $CFGReplication slot
Create a replication slot in the primary server.
select * from pg_create_physical_replication_slot('standby1');slot_name | xlog_position -----------+--------------- standby1 | (1 row)select slot_name, restart_lsn from pg_replication_slots;slot_name | restart_lsn -----------+------------- standby1 | (1 row)
The replication slot (restart_lsn) will be initialized during the primary server backup
with pg_basebackup.
Starting with PostgreSQL 11, it is not mandatory to create manually the replication slot, this one can be created and initialized with
pg_basebackup.
Primary server backup (pg_basebackup)
The primary server backup is performed with pg_basebackup.
postgres@vpsfrsqlpac1$ pg_basebackup -D /sqlpac/postgres/backup/srvpg1
-X stream
--write-recovery-conf
--slot=standby1
--dbname="host=localhost user=postgres port=30001"Starting with,PostgreSQL 11, add the argument --create-slot if the replication slot has not been previously created.
With the option --slot giving the replication slot name : that way, it is guaranteed the primary server does not remove
any necessary WAL data in the time between the end of the base backup and the start of streaming replication.
When the backup is completed, the replication slot standby1 is then defined :
select slot_name, restart_lsn from pg_replication_slots;slot_name | restart_lsn -----------+------------- standby1 | 0/33000000
The option --write-recovery-conf (or -R) writes a file recovery.conf in the root backup directory.
This file will prevent any user error when starting the standby server, this file indeed indicates a standby server, and the slot name
is given :
/sqlpac/postgres/backup/srvpg1/recovery.conf
standby_mode = 'on'
primary_conninfo = 'user=postgres host=localhost port=30001 sslmode=prefer sslcompression=1 krbsrvname=postgres'
primary_slot_name = 'standby1'Standby server activation
Install the primary server backup previously performed in the standby data directory ($PGDATA).
recovery.conf
Be sure the file recovery.conf is installed in the standby server root data directory
with the option standby_mode = 'on' and the replication slot name.
Update the connection info parameters to the primary server in this file.
$PGDATA : /sqlpac/postgres/srvpg1/recovery.conf
standby_mode = 'on'
primary_conninfo = 'user=repmgr host=vpsfrsqlpac1 port=30001 password=************'
primary_slot_name = 'standby1'postgresql.conf
If read only connections are allowed, check the parameter hot_standby is set to on on the standby server
(on by default starting with PostgreSQL 10):
$CFG/postgresql.conf
hot_standby = onStarting the standby server
Now the standby server can be started.
postgres@vpsfrsqlpac2$ pg_ctl start -D $CFGWhen there is no error, in the standby server log file :
LOG: entering standby mode
LOG: redo starts at 0/33000028
LOG: consistent recovery state reached at 0/34000000
LOG: database system is ready to accept read only connections
LOG: started streaming WAL from primary at 0/34000000 on timeline 1The standby server is in recovery mode :
postgres@vpsfrsqlpac2$ psql -p30001select pg_is_in_recovery();pg_is_in_recovery ------------------- t
If the replication slot has not been defined and the needed WAL files removed in the primary server, an error occurs :
FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000010000000000000010 has already been removedTesting replication
Create a table heartbeat in the primary server, this table will be updated every minute :
postgres@vpsfrsqlpac1$ psql -p30001create table heartbeat ( reptimestamp timestamp ); insert into heartbeat values (now()); select * from heartbeat;reptimestamp ---------------------------- 2019-11-22 09:04:36.399274
Check the replication to the standby server :
postgres@vpsfrsqlpac2$ psql -p30001select * from heartbeat;reptimestamp ---------------------------- 2019-11-22 09:04:36.399274
Pause / Resume replication
To pause/resume replication, on the standby server :
postgres@vpsfrsqlpac2$ psql -p30001| PostgreSQL 9.6 | PostgreSQL 10 / 11 | |
|---|---|---|
| Pause replication |
|
|
| Resume replication |
|
|
| Replication paused ? |
|
|
Essential replication informations
This article does not deal with replication monitoring, however below the essential informations about the replication state.
Standby server : pg_stat_wal_receiver
In the standby, use the view pg_stat_wal_receiver :
postgres@vpsfrsqlpac2$ psql -p30001x on; select * from pg_stat_wal_receiver;-[ RECORD 1 ]---------+----------------------------------------------------- pid | 2262 status | streaming receive_start_lsn | 0/97000000 receive_start_tli | 1 received_lsn | 0/99000920 received_tli | 1 last_msg_send_time | 2019-11-22 18:17:46.355579+01 last_msg_receipt_time | 2019-11-22 18:17:46.355835+01 latest_end_lsn | 0/99000760 latest_end_time | 2019-11-22 18:15:46.232277+01 slot_name | standby1 conninfo | user=repmgr password=******** dbname=replication host=vpsfrsqlpac1 port=30001 …
The WAL receiver process id is 2262 :
postgres@vpsfrsqlpac2$ ps -ef | grep 'postgres' | grep 2262postgres 2262 32104 0 18:35 ? 00:00:04 postgres: wal receiver process streaming 0/99000920
Primary server : pg_stat_replication and pg_replication_slots
In the primary server, use pg_stat_replication and pg_replication_slots :
postgres@vpsfrsqlpac1$ psql -p30001x on; select * from pg_stat_replication;-[ RECORD 1 ]----+----------------------------- pid | 6247 usesysid | 16384 usename | repmgr application_name | walreceiver client_addr | 51.xxx.xxx.xxx client_hostname | client_port | 41354 backend_start | 2019-11-22 09:35:42.41099+01 backend_xmin | state | streaming sent_location | 0/99000920 write_location | 0/99000920 flush_location | 0/99000920 replay_location | 0/99000840 sync_priority | 0 sync_state | asyncx on; select * from pg_replication_slots;-[ RECORD 1 ]-------+----------- slot_name | standby1 plugin | slot_type | physical datoid | database | active | t active_pid | 6247 xmin | catalog_xmin | restart_lsn | 0/99000920 confirmed_flush_lsn |
The WAL sender process id is 6247 :
postgres@vpsfrsqlpac1$ ps -ef | grep 'postgres' | grep 6247postgres 6247 5576 0 18:35 ? 00:00:00 postgres: wal sender process repmgr 51.xxx.xxx.xxx(41354) streaming 0/99000920
Conclusion
Installing a streaming replication with PostgreSQL 9.6 is very easy, maybe one of the easiest replication architecture.
Do not forget replication slots ! Only replication slots guarantee standby servers won’t run out of sync from the primary server.