Introduction
This document describes details surrounding Cyclic Redundancy Check (CRC) errors observed on interface counters and statistics of Cisco Nexus switches.
Prerequisites
Requirements
Cisco recommends that you understand the basics of Ethernet switching and the Cisco NX-OS Command Line Interface (CLI). For more information, refer to one of these applicable documents:
- Cisco Nexus 9000 NX-OS Fundamentals Configuration Guide, Release 10.2(x)
- Cisco Nexus 9000 Series NX-OS Fundamentals Configuration Guide, Release 9.3(x)
- Cisco Nexus 9000 Series NX-OS Fundamentals Configuration Guide, Release 9.2(x)
- Cisco Nexus 9000 Series NX-OS Fundamentals Configuration Guide, Release 7.x
- Troubleshooting Ethernet
Components Used
The information in this document is based on these software and hardware versions:
- Nexus 9000 series switches starting from NX-OS software release 9.3(8)
- Nexus 3000 series switches starting from NX-OS software release 9.3(8)
The information in this document was created from devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, ensure that you understand the potential impact of any command.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, ensure that you understand the potential impact of any command.
Background Information
This document describes details surrounding Cyclic Redundancy Check (CRC) errors observed on interface counters on Cisco Nexus series switches. This document describes what a CRC is, how it is used in the Frame Check Sequence (FCS) field of Ethernet frames, how CRC errors manifest on Nexus switches, how CRC errors interact in Store-and-Forward switching and Cut-Through switching scenarios, the most likely root causes of CRC errors, and how to troubleshoot and resolve CRC errors.
Applicable Hardware
The information in this document is applicable to all Cisco Nexus Series switches. Some of the information in this document can also be applicable to other Cisco routing and switching platforms, such as Cisco Catalyst routers and switches.
CRC Definition
A CRC is an error detection mechanism commonly used in computer and storage networks to identify data changed or corrupted during transmission. When a device connected to the network needs to transmit data, the device runs a computation algorithm based on cyclic codes against the data that results in a fixed-length number. This fixed-length number is called the CRC value, but colloquially, it is often called the CRC for short. This CRC value is appended to the data and transmitted through the network towards another device. This remote device runs the same cyclic code algorithm against the data and compares the resulting value with the CRC appended to the data. If both values match, then the remote device assumes the data was transmitted across the network without being corrupted. If the values do not match, then the remote device assumes the data was corrupted during transmission across the network. This corrupted data cannot be trusted and is discarded.
CRCs are used for error detection across multiple computer networking technologies, such as Ethernet (both wired and wireless variants), Token Ring, Asynchronous Transfer Mode (ATM), and Frame Relay. Ethernet frames have a 32-bit Frame Check Sequence (FCS) field at the end of the frame (immediately after the payload of the frame) where a 32-bit CRC value is inserted.
For example, consider a scenario where two hosts named Host-A and Host-B are directly connected to each other through their Network Interface Cards (NICs). Host-A needs to send the sentence “This is an example” to Host-B over the network. Host-A crafts an Ethernet frame destined to Host-B with a payload of “This is an example” and calculates that the CRC value of the frame is a hexadecimal value of 0xABCD. Host-A inserts the CRC value of 0xABCD into the FCS field of the Ethernet frame, then transmits the Ethernet frame out of Host-A’s NIC towards Host-B.
When Host-B receives this frame, it will calculate the CRC value of the frame with the use of the exact same algorithm as Host-A. Host-B calculates that the CRC value of the frame is a hexadecimal value of 0xABCD, which indicates to Host-B that the Ethernet frame was not corrupted while the frame was transmitted to Host-B.
CRC Error Definition
A CRC error occurs when a device (either a network device or a host connected to the network) receives an Ethernet frame with a CRC value in the FCS field of the frame that does not match the CRC value calculated by the device for the frame.
This concept is best demonstrated through an example. Consider a scenario where two hosts named Host-A and Host-B are directly connected to each other through their Network Interface Cards (NICs). Host-A needs to send the sentence “This is an example” to Host-B over the network. Host-A crafts an Ethernet frame destined to Host-B with a payload of “This is an example” and calculates that the CRC value of the frame is the hexadecimal value 0xABCD. Host-A inserts the CRC value of 0xABCD into the FCS field of the Ethernet frame, then transmits the Ethernet frame out of Host-A’s NIC towards Host-B.
However, damage on the physical media connecting Host-A to Host-B corrupts the contents of the frame such that the sentence within the frame changes to “This was an example” instead of the desired payload of “This is an example”.
When Host-B receives this frame, it will calculate the CRC value of the frame including the corrupted payload. Host-B calculates that the CRC value of the frame is a hexadecimal value of 0xDEAD, which is different from the 0xABCD CRC value within the FCS field of the Ethernet frame. This difference in CRC values tells Host-B that the Ethernet frame was corrupted while the frame was transmitted to Host-B. As a result, Host-B cannot trust the contents of this Ethernet frame, so it will drop it. Host-B will usually increment some sort of error counter on its Network Interface Card (NIC) as well, such as the “input errors”, “CRC errors”, or “RX errors” counters.
Common Symptoms of CRC Errors
CRC errors typically manifest themselves in one of two ways:
- Incrementing or non-zero error counters on interfaces of network-connected devices.
- Packet/Frame loss for traffic traversing the network due to network-connected devices dropping corrupted frames.
These errors manifest themselves in slightly different ways depending on the device you are working with. These sub-sections go into detail for each type of device.
Received Errors on Windows Hosts
CRC errors on Windows hosts typically manifest as a non-zero Received Errors counter displayed in the output of the netstat -e command from the Command Prompt. An example of a non-zero Received Errors counter from the Command Prompt of a Windows host is here:
>netstat -e
Interface StatisticsReceived Sent
Bytes 1116139893 3374201234
Unicast packets 101276400 49751195
Non-unicast packets 0 0
Discards 0 0
Errors 47294 0
Unknown protocols 0
The NIC and its respective driver must support accounting of CRC errors received by the NIC in order for the number of Received Errors reported by the netstat -e command to be accurate. Most modern NICs and their respective drivers support accurate accounting of CRC errors received by the NIC.
RX Errors on Linux Hosts
CRC errors on Linux hosts typically manifest as a non-zero “RX errors” counter displayed in the output of the ifconfig command. An example of a non-zero RX errors counter from a Linux host is here:
$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.0.2.10 netmask 255.255.255.128 broadcast 192.0.2.255
inet6 fe80::10 prefixlen 64 scopeid 0x20<link>
ether 08:62:66:be:48:9b txqueuelen 1000 (Ethernet)
RX packets 591511682 bytes 214790684016 (200.0 GiB)
RX errors 478920 dropped 0 overruns 0 frame 0
TX packets 85495109 bytes 288004112030 (268.2 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
CRC errors on Linux hosts can also manifest as a non-zero “RX errors” counter displayed in the output of ip -s link show command. An example of a non-zero RX errors counter from a Linux host is here:
$ ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 08:62:66:84:8f:6d brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
32246366102 444908978 478920 647 0 419445867
TX: bytes packets errors dropped carrier collsns
3352693923 30185715 0 0 0 0
altname enp11s0
The NIC and its respective driver must support accounting of CRC errors received by the NIC in order for the number of RX Errors reported by the ifconfig or ip -s link show commands to be accurate. Most modern NICs and their respective drivers support accurate accounting of CRC errors received by the NIC.
CRC Errors on Network Devices
Network devices operate in one of two forwarding modes — Store-and-Forward forwarding mode, and Cut-Through forwarding mode. The way a network device handles a received CRC error differs depending on its forwarding modes. The subsections here will describe the specific behavior for each forwarding mode.
Input Errors on Store-and-Forward Network Devices
When a network device operating in a Store-and-Forward forwarding mode receives a frame, the network device will buffer the entire frame (“Store”) before you validate the frame’s CRC value, make a forwarding decision on the frame, and transmit the frame out of an interface (“Forward”). Therefore, when a network device operating in a Store-and-Forward forwarding mode receives a corrupted frame with an incorrect CRC value on a specific interface, it will drop the frame and increment the “Input Errors” counter on the interface.
In other words, corrupt Ethernet frames are not forwarded by network devices operating in a Store-and-Forward forwarding mode; they are dropped on ingress.
Cisco Nexus 7000 and 7700 Series switches operate in a Store-and-Forward forwarding mode. An example of a non-zero Input Errors counter and a non-zero CRC/FCS counter from a Nexus 7000 or 7700 Series switch is here:
switch# show interface
<snip>
Ethernet1/1 is up
RX
241052345 unicast packets 5236252 multicast packets 5 broadcast packets
245794858 input packets 17901276787 bytes
0 jumbo packets 0 storm suppression packets
0 runts 0 giants 579204 CRC/FCS 0 no buffer
579204 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
CRC errors can also manifest themselves as a non-zero “FCS-Err” counter in the output of show interface counters errors. The «Rcv-Err» counter in the output of this command will also have a non-zero value, which is the sum of all input errors (CRC or otherwise) received by the interface. An example of this is shown here:
switch# show interface counters errors
<snip>
--------------------------------------------------------------------------------
Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards
--------------------------------------------------------------------------------
Eth1/1 0 579204 0 579204 0 0
Input and Output Errors on Cut-Through Network Devices
When a network device operating in a Cut-Through forwarding mode starts to receive a frame, the network device will make a forwarding decision on the frame’s header and begin transmitting the frame out of an interface as soon as it receives enough of the frame to make a valid forwarding decision. As frame and packet headers are at the beginning of the frame, this forwarding decision is usually made before the payload of the frame is received.
The FCS field of an Ethernet frame is at the end of the frame, immediately after the frame’s payload. Therefore, a network device operating in a Cut-Through forwarding mode will already have started transmitting the frame out of another interface by the time it can calculate the CRC of the frame. If the CRC calculated by the network device for the frame does not match the CRC value present in the FCS field, that means the network device forwarded a corrupted frame into the network. When this happens, the network device will increment two counters:
- The “Input Errors” counter on the interface where the corrupted frame was originally received.
- The “Output Errors” counter on all interfaces where the corrupted frame was transmitted. For unicast traffic, this will typically be a single interface – however, for broadcast, multicast, or unknown unicast traffic, this could be one or more interfaces.
An example of this is shown here, where the output of the show interface command indicates multiple corrupted frames were received on Ethernet1/1 of the network device and transmitted out of Ethernet1/2 due to the Cut-Through forwarding mode of the network device:
switch# show interface
<snip>
Ethernet1/1 is up
RX
46739903 unicast packets 29596632 multicast packets 0 broadcast packets
76336535 input packets 6743810714 bytes
15 jumbo packets 0 storm suppression bytes
0 runts 0 giants 47294 CRC 0 no buffer
47294 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pauseEthernet1/2 is up
TX
46091721 unicast packets 2852390 multicast packets 102619 broadcast packets
49046730 output packets 3859955290 bytes
50230 jumbo packets
47294 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
CRC errors can also manifest themselves as a non-zero “FCS-Err” counter on the ingress interface and non-zero «Xmit-Err» counters on egress interfaces in the output of show interface counters errors. The «Rcv-Err» counter on the ingress interface in the output of this command will also have a non-zero value, which is the sum of all input errors (CRC or otherwise) received by the interface. An example of this is shown here:
switch# show interface counters errors
<snip>
--------------------------------------------------------------------------------
Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards
--------------------------------------------------------------------------------
Eth1/1 0 47294 0 47294 0 0
Eth1/2 0 0 47294 0 0 0
The network device will also modify the CRC value in the frame’s FCS field in a specific manner that signifies to upstream network devices that this frame is corrupt. This behavior is known as “stomping” the CRC. The precise manner in which the CRC is modified varies from one platform to another, but generally, it involves inverting the current CRC value present in the frame’s FCS field. An example of this is here:
Original CRC: 0xABCD (1010101111001101)
Stomped CRC: 0x5432 (0101010000110010)
As a result of this behavior, network devices operating in a Cut-Through forwarding mode can propagate a corrupt frame throughout a network. If a network consists of multiple network devices operating in a Cut-Through forwarding mode, a single corrupt frame can cause input error and output error counters to increment on multiple network devices within your network.
Trace and Isolate CRC Errors
The first step in order to identify and resolve the root cause of CRC errors is isolating the source of the CRC errors to a specific link between two devices within your network. One device connected to this link will have an interface output errors counter with a value of zero or is not incrementing, while the other device connected to this link will have a non-zero or incrementing interface input errors counter. This suggests that traffic egresses the interface of one device intact is corrupted at the time of the transmission to the remote device, and is counted as an input error by the ingress interface of the other device on the link.
Identifying this link in a network consisting of network devices operating in a Store-and-Forward forwarding mode is a straightforward task. However, identifying this link in a network consisting of network devices operating in a Cut-Through forwarding mode is more difficult, as many network devices will have non-zero input and output error counters. An example of this phenomenon can be seen in the topology here, where the link highlighted in red is damaged such that traffic traversing the link is corrupted. Interfaces labeled with a red «I» indicate interfaces that could have non-zero input errors, while interfaces labeled with a blue «O» indicate interfaces that could have non-zero output errors.
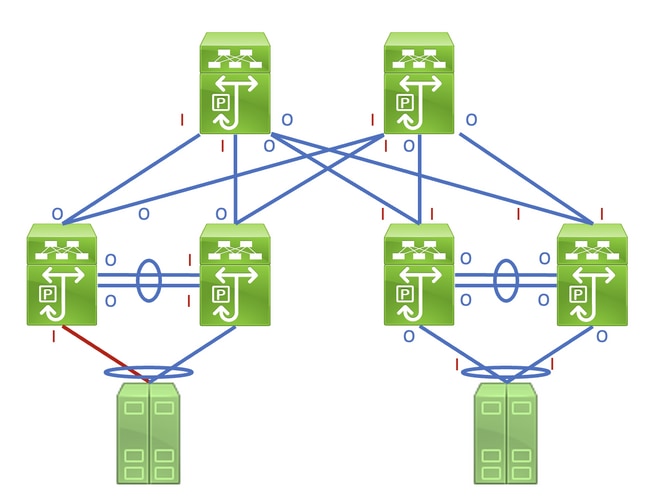
Identifying the faulty link requires you to recursively trace the «path» corrupted frames follow in the network through non-zero input and output error counters, with non-zero input errors pointing upstream towards the damaged link in the network. This is demonstrated in the diagram here.
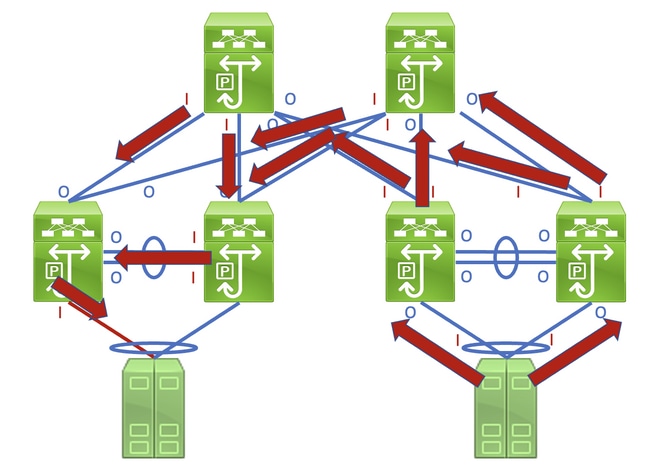
A detailed process for tracing and identifying a damaged link is best demonstrated through an example. Consider the topology here:
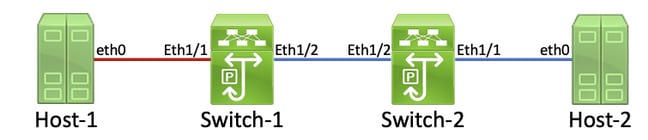
In this topology, interface Ethernet1/1 of a Nexus switch named Switch-1 is connected to a host named Host-1 through Host-1’s Network Interface Card (NIC) eth0. Interface Ethernet1/2 of Switch-1 is connected to a second Nexus switch, named Switch-2, through Switch-2’s interface Ethernet1/2. Interface Ethernet1/1 of Switch-2 is connected to a host named Host-2 through Host-2’s NIC eth0.
The link between Host-1 and Switch-1 through Switch-1’s Ethernet1/1 interface is damaged, causing traffic that traverses the link to be intermittently corrupted. However, we do not yet know that this link is damaged. We must trace the path the corrupted frames leave in the network through non-zero or incrementing input and output error counters to locate the damaged link in this network.
In this example, Host-2’s NIC reports that it is receiving CRC errors.
Host-2$ ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:50:56:84:8f:6d brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
32246366102 444908978 478920 647 0 419445867
TX: bytes packets errors dropped carrier collsns
3352693923 30185715 0 0 0 0
altname enp11s0
You know that Host-2’s NIC connects to Switch-2 via interface Ethernet1/1. You can confirm that interface Ethernet1/1 has a non-zero output errors counter with the show interface command.
Switch-2# show interface
<snip>
Ethernet1/1 is up
admin state is up, Dedicated Interface
RX
30184570 unicast packets 872 multicast packets 273 broadcast packets
30185715 input packets 3352693923 bytes
0 jumbo packets 0 storm suppression bytes
0 runts 0 giants 0 CRC 0 no buffer
0 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
TX
444907944 unicast packets 932 multicast packets 102 broadcast packets
444908978 output packets 32246366102 bytes
0 jumbo packets
478920 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
Since the output errors counter of interface Ethernet1/1 is non-zero, there is most likely another interface of Switch-2 that has a non-zero input errors counter. You can use the show interface counters errors non-zero command in order to identify if any interfaces of Switch-2 have a non-zero input errors counter.
Switch-2# show interface counters errors non-zero <snip> -------------------------------------------------------------------------------- Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards -------------------------------------------------------------------------------- Eth1/1 0 0 478920 0 0 0 Eth1/2 0 478920 0 478920 0 0 -------------------------------------------------------------------------------- Port Single-Col Multi-Col Late-Col Exces-Col Carri-Sen Runts -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port Giants SQETest-Err Deferred-Tx IntMacTx-Er IntMacRx-Er Symbol-Err -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port InDiscards --------------------------------------------------------------------------------
You can see that Ethernet1/2 of Switch-2 has a non-zero input errors counter. This suggests that Switch-2 receives corrupted traffic on this interface. You can confirm which device is connected to Ethernet1/2 of Switch-2 through the Cisco Discovery Protocol (CDP) or Link Local Discovery Protocol (LLDP) features. An example of this is shown here with the show cdp neighbors command.
Switch-2# show cdp neighbors
<snip>
Capability Codes: R - Router, T - Trans-Bridge, B - Source-Route-Bridge
S - Switch, H - Host, I - IGMP, r - Repeater,
V - VoIP-Phone, D - Remotely-Managed-Device,
s - Supports-STP-Dispute
Device-ID Local Intrfce Hldtme Capability Platform Port ID
Switch-1(FDO12345678)
Eth1/2 125 R S I s N9K-C93180YC- Eth1/2
You now know that Switch-2 is receiving corrupted traffic on its Ethernet1/2 interface from Switch-1’s Ethernet1/2 interface, but you do not yet know whether the link between Switch-1’s Ethernet1/2 and Switch-2’s Ethernet1/2 is damaged and causes the corruption, or if Switch-1 is a cut-through switch forwarding corrupted traffic it receives. You must log into Switch-1 to verify this.
You can confirm Switch-1’s Ethernet1/2 interface has a non-zero output errors counter with the show interfaces command.
Switch-1# show interface
<snip>
Ethernet1/2 is up
admin state is up, Dedicated Interface
RX
30581666 unicast packets 178 multicast packets 931 broadcast packets
30582775 input packets 3352693923 bytes
0 jumbo packets 0 storm suppression bytes
0 runts 0 giants 0 CRC 0 no buffer
0 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
TX
454301132 unicast packets 734 multicast packets 72 broadcast packets
454301938 output packets 32246366102 bytes
0 jumbo packets
478920 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
You can see that Ethernet1/2 of Switch-1 has a non-zero output errors counter. This suggests that the link between Switch-1’s Ethernet1/2 and Switch-2’s Ethernet1/2 is not damaged — instead, Switch-1 is a cut-through switch forwarding corrupted traffic it receives on some other interface. As previously demonstrated with Switch-2, you can use the show interface counters errors non-zero command in order to identify if any interfaces of Switch-1 have a non-zero input errors counter.
Switch-1# show interface counters errors non-zero <snip> -------------------------------------------------------------------------------- Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards -------------------------------------------------------------------------------- Eth1/1 0 478920 0 478920 0 0 Eth1/2 0 0 478920 0 0 0 -------------------------------------------------------------------------------- Port Single-Col Multi-Col Late-Col Exces-Col Carri-Sen Runts -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port Giants SQETest-Err Deferred-Tx IntMacTx-Er IntMacRx-Er Symbol-Err -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port InDiscards --------------------------------------------------------------------------------
You can see that Ethernet1/1 of Switch-1 has a non-zero input errors counter. This suggests that Switch-1 is receiving corrupted traffic on this interface. We know that this interface connects to Host-1’s eth0 NIC. We can review Host-1’s eth0 NIC interface statistics to confirm whether Host-1 sends corrupted frames out of this interface.
Host-1$ ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:50:56:84:8f:6d brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
73146816142 423112898 0 0 0 437368817
TX: bytes packets errors dropped carrier collsns
3312398924 37942624 0 0 0 0
altname enp11s0
The eth0 NIC statistics of Host-1 suggest the host is not transmitting corrupted traffic. This suggests that the link between Host-1’s eth0 and Switch-1’s Ethernet1/1 is damaged and is the source of this traffic corruption. Further troubleshooting will need to be performed on this link to identify the faulty component causing this corruption and replace it.
Root Causes of CRC Errors
The most common root cause of CRC errors is a damaged or malfunctioning component of a physical link between two devices. Examples include:
- Failing or damaged physical medium (copper or fiber) or Direct Attach Cables (DACs).
- Failing or damaged transceivers/optics.
- Failing or damaged patch panel ports.
- Faulty network device hardware (including specific ports, line card Application-Specific Integrated Circuits [ASICs], Media Access Controls [MACs], fabric modules, etc.),
- Malfunctioning network interface card inserted in a host.
It is also possible for one or more misconfigured devices to inadvertently causes CRC errors within a network. One example of this is a Maximum Transmission Unit (MTU) configuration mismatch between two or more devices within the network causing large packets to be incorrectly truncated. Identifying and resolving this configuration issue can correct CRC errors within a network as well.
Resolve CRC Errors
You can identify the specific malfunctioning component through a process of elimination:
- Replace the physical medium (either copper or fiber) or DAC with a known-good physical medium of the same type.
- Replace the transceiver inserted in one device’s interface with a known-good transceiver of the same model. If this does not resolve the CRC errors, replace the transceiver inserted in the other device’s interface with a known-good transceiver of the same model.
- If any patch panels are used as part of the damaged link, move the link to a known-good port on the patch panel. Alternatively, eliminate the patch panel as a potential root cause by connecting the link without using the patch panel if possible.
- Move the damaged link to a different, known-good port on each device. You will need to test multiple different ports to isolate a MAC, ASIC, or line card failure.
- If the damaged link involves a host, move the link to a different NIC on the host. Alternatively, connect the damaged link to a known-good host to isolate a failure of the host’s NIC.
If the malfunctioning component is a Cisco product (such as a Cisco network device or transceiver) that is covered by an active support contract, you can open a support case with Cisco TAC detailing your troubleshooting to have the malfunctioning component replaced through a Return Material Authorization (RMA).
Related Information
- Nexus 9000 Cloud Scale ASIC CRC Identification & Tracing Procedure
- Technical Support & Documentation — Cisco Systems
Contents
Introduction
This chapter presents general troubleshooting information and a discussion of tools and techniques for troubleshooting serial connections. The chapter consists of the following sections:
-
Troubleshooting Using the show interfaces serial Command
-
Using the show controllers Command
-
Using debug Commands
-
Using Extended ping Tests
-
Troubleshooting Clocking Problems
-
Adjusting Buffers
-
Special Serial Line Tests
-
Detailed Information on the show interfaces serial Command
-
Troubleshooting T1 Problems
-
Troubleshooting E1 Problems
Prerequisites
Requirements
Readers of this document should be knowledgeable of the following definitions.
-
DTE = data terminal equipment
-
CD = Carrier Detect
-
CSU = channel service unit
-
DSU = digital service unit
-
SCTE = serial clock transmit external
-
DCE = data circuit-terminating equipment
-
CTS = clear-to-send
-
DSR = data-set ready
-
SAP = Service Advertising Protocol
-
IPX = Internetwork Packet Exchange
-
FDDI = Fiber Distributed Data Interface
-
ESF = Extended Superframe Format
-
B8ZS = binary eight-zero substitution
-
LBO = Line Build Out
Components Used
This document is not restricted to specific software and hardware versions.
The information presented in this document was created from devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If you are working in a live network, ensure that you understand the potential impact of any command before using it.
Conventions
For more information on document conventions, see the Cisco Technical Tips Conventions.
Troubleshooting Using the show interfaces serial Command
The output of the show interfaces serial EXEC command displays information specific to serial interfaces. Figure 15-1 shows the output of the show interfaces serial EXEC command for a High-Level Data Link Control (HDLC) serial interface.
This section describes how to use the show interfaces serial command to diagnose serial line connectivity problems in a wide area network (WAN) environment. The following sections describe some of the important fields of the command output.
Other fields shown in the display are described in detail in the section «Detailed Information on the show interfaces serial Command,» later in this chapter.
Serial Lines: show interfaces serial Status Line Conditions
You can identify five possible problem states in the interface status line of the show interfaces serial display (see Figure 15-1):
-
Serial x is down, line protocol is down
-
Serial x is up, line protocol is down
-
Serial x is up, line protocol is up (looped)
-
Serial x is up, line protocol is down (disabled)
-
Serial x is administratively down, line protocol is down
Figure 15-1 Output of the HDLC show interface serial Command

Table 15-1: Serial Lines: show interfaces serial Status Line Conditions — This table shows the interface status conditions, possible problems associated with the conditions, and solutions to those problems.
| Status Line Condition | Possible Problem | Solution |
|---|---|---|
| Serial x is up, line protocol is up | This is the proper status line condition. No action required. | |
| Serial x is down, line protocol is down (DTE mode) |
|
|
| Serial x is up, line protocol is down (DTE mode) |
|
|
| Serial x is up, line protocol is down (DCE mode) |
|
|
| Serial x is up, line protocol is up (looped) | A loop exists in the circuit. The sequence number in the keepalive packet changes to a random number when a loop is initially detected. If the same random number is returned over the link, a loop exists. |
|
| Serial x is up, line protocol is down (disabled) |
|
|
| Serial x is administratively down, line protocol is down |
|
|
Serial Lines: Increasing Output Drops on Serial Link
Output drops appear in the output of the show interfaces serial command (see Figure 15-1) when the system is attempting to hand off a packet to a transmit buffer but no buffers are available.
Symptom: An increasing number of output drops on serial link.
Table 15-2 Serial Lines: Increasing Output Drops on Serial Link — This table outlines the possible problem that may cause this symptom and suggests solutions.
| Possible Problem | Solution |
|---|---|
| Input rate to serial interface exceeds bandwidth available on serial link |
Note: Output drops are acceptable under certain conditions. For instance, if a link is known to be overused (with no way to remedy the situation), it is often preferable to drop packets than to hold them. This is true for protocols that support flow control and can retransmit data (such as TCP/IP and Novell IPX). However, some protocols, such as DECnet and local-area transport are sensitive to dropped packets and accommodate retransmission poorly, if at all. |
Serial Lines: Increasing Input Drops on Serial Link
Input drops appear in the output of the show interfaces serial EXEC command (see Figure 15-1) when too many packets from that interface are still being processed in the system.
Symptom: An increasing number of input drops on serial link.
Table 15-3: Serial Lines: Increasing Input Drops on Serial Link — This table outlines the possible problem that may cause this symptom and suggests solutions.
| Possible Problem | Solution |
|---|---|
| Input rate exceeds the capacity of the router or input queues exceed the size of output queues |
Note: Input drop problems are typically seen when traffic is being routed between faster interfaces (such as Ethernet, Token Ring, and FDDI) and serial interfaces. When traffic is light, there is no problem. As traffic rates increase, backups start occurring. Routers drop packets during these congested periods.
|
Serial Lines: Increasing Input Errors in Excess of One Percent of Total Interface Traffic
If input errors appear in the show interfaces serial output (see Figure 15-1), there are several possible sources of those errors. The most likely sources are summarized in Table 15-4.
Note: Any input error value for cyclic redundancy check (CRC) errors, framing errors, or aborts above one percent of the total interface traffic suggests some kind of link problem that should be isolated and repaired.
Symptom: An increasing number of input errors in excess of one percent of total interface traffic.
Table 15-4: Serial Lines: Increasing Input Errors in Excess of One Percent of Total Interface Traffic
| Possible Problem | Solution |
|---|---|
The following problems can result in this symptom:
|
Note: Cisco strongly recommends not using data converters when you are connecting a router to a WAN or serial network.
|
Serial Lines: Troubleshooting Serial Line Input Errors
Table 15-5: This table describes the various types of input errors displayed by the show interfaces serial command (see Figure 15-1), possible problems that may be causing the errors and the solutions to those problems.
| Input Error Type (Field Name) | Possible Problem | Solution |
|---|---|---|
| CRC errors (CRC) | CRC errors occur when the CRC calculation does not pass-indicating that data is corrupted-for one of the following reasons:
|
|
| Framing errors (frame) | A framing error occurs when a packet does not end on an 8-bit byte boundary for one of the following reasons:
|
|
| Aborted transmission (abort) | Aborts indicate an illegal sequence of one bits (more than seven in a row). The following are possible reasons for this occurrence:
|
|
Serial Lines: Increasing Interface Resets on Serial Link
Interface resets that appear in the output of the show interfaces serial EXEC command (see Figure 15-1) are the result of missed keep-alive packets.
Symptom: An increasing number of interface resets on serial link.
Table 15-6: This table outlines the possible problems that may cause this symptom and suggests solutions.
| Possible Problem | Solution |
|---|---|
The following problems can result in this symptom:
|
When interface resets are occurring, examine other fields of the show interfaces serial command output to determine the source of the problem. Assuming that an increase in interface resets is being recorded, examine the following fields:
|
Serial Lines: Increasing Carrier Transitions Count on Serial Link
Carrier transitions appear in the output of the show interfaces serial EXEC command whenever there is an interruption in the carrier signal (such as an interface reset at the remote end of a link).
Symptom: An increasing number of carrier transitions count on serial link.
Table 15-7 outlines the possible problems that may cause this symptom and suggests solutions.
Table 15-7: Serial Lines: Increasing Carrier Transitions Count on Serial Link
| Possible Problem | Solution |
|---|---|
The following problems can result in this symptom:
|
|
Using the show controllers Command
The show controllers EXEC command is another important diagnostic tool when troubleshooting serial lines. The command syntax varies depending on the platform:
-
For serial interfaces on Cisco 7000 series routers, use the show controllers cbus EXEC command.
-
For Cisco access products, use the show controllers EXEC command.
-
For the AGS, CGS, and MGS, use the show controllers mci EXEC command.
Figure 15-2 shows the output from the show controllers cbus EXEC command. This command is used on Cisco 7000 series routers with the Fast Serial Interface Processor (FSIP) card. Check the command output to make certain that the cable to the channel service unit/digital service unit (CSU/DSU) is attached to the proper interface. You can also check the microcode version to see if it is current.
Figure 15-2: show controllers cbus Command Output

On access products such as the Cisco 2000, Cisco 2500, Cisco 3000, and Cisco 4000 series access servers and routers, use the show controllers EXEC command. Figure 15-3 shows the show controllers command output from the Basic Rate Interface (BRI) and serial interfaces on a Cisco 2503 access server. (Note that some output is not shown.)
The show controllers output indicates the state of the interface channels and whether a cable is attached to the interface. In Figure 15-3, serial interface 0 has an RS-232 DTE cable attached. Serial interface 1 has no cable attached.
Figure 15-4 shows the output of the show controllers mci command. This command is used on AGS, CGS, and MGS routers only. If the electrical interface is displayed as UNKNOWN (instead of V.35, EIA/TIA-449, or some other electrical interface type), an improperly connected cable is the likely problem. A bad applique or a problem with the internal wiring of the card is also possible. If the electrical interface is unknown, the corresponding display for the show interfaces serial EXEC command will show that the interface and line protocol are down.
Figure 15-3: show controllers Command Output

Figure 15-4: show controllers mci Command Output

Using debug Commands
The output of the various debug privileged EXEC commands provides diagnostic information relating to protocol status and network activity for many internetworking events.
 Caution: Because debugging output is assigned a high priority in the CPU process, it can render the system unusable. For this reason, use debug commands only to troubleshoot specific problems or during troubleshooting sessions with Cisco technical support staff. Moreover, it is best to use debug commands during periods of low network traffic and fewer users. Debugging during these periods decreases the likelihood that increased debug command processing overhead will affect system use. When you finish using a debug command, remember to disable it with its specific no debug command or with the no debug all command.
Caution: Because debugging output is assigned a high priority in the CPU process, it can render the system unusable. For this reason, use debug commands only to troubleshoot specific problems or during troubleshooting sessions with Cisco technical support staff. Moreover, it is best to use debug commands during periods of low network traffic and fewer users. Debugging during these periods decreases the likelihood that increased debug command processing overhead will affect system use. When you finish using a debug command, remember to disable it with its specific no debug command or with the no debug all command.
The following debug commands are useful when troubleshooting serial and WAN problems. More information about the function and output of each of these commands is provided in the Debug Command Reference publication:
-
debug serial interface— Verifies whether HDLC keepalive packets are incrementing. If they are not, a possible timing problem exists on the interface card or in the network.
-
debug x25 events— Detects X.25 events, such as the opening and closing of switched virtual circuits (SVCs). The resulting «cause and diagnostic» information is included with the event report.
-
debug lapb— Outputs Link Access Procedure, Balanced (LAPB) or Level 2 X.25 information.
-
debug arp— Indicates whether the router is sending information about or learning about routers (with ARP packets) on the other side of the WAN cloud. Use this command when some nodes on a TCP/IP network are responding but others are not.
-
debug frame-relay lmi— Obtains Local Management Interface (LMI) information useful for determining if a Frame Relay switch and a router are sending and receiving LMI packets.
-
debug frame-relay events— Determines if exchanges are occurring between a router and a Frame Relay switch.
-
debug ppp negotiation— Shows Point-to-Point Protocol (PPP) packets transmitted during PPP startup, where PPP options are negotiated.
-
debug ppp packet— Shows PPP packets being sent and received. This command displays low-level packet dumps.
-
debug ppp errors— Shows PPP errors (such as illegal or malformed frames) associated with PPP connection negotiation and operation.
-
debug ppp chap— Shows PPP Challenge Handshake Authentication Protocol (CHAP) and Password Authentication Protocol (PAP) packet exchanges.
-
debug serial packet— Shows Switched Multimegabit Data Service (SMDS) packets being sent and received. This display also prints error messages to indicate why a packet was not sent or was received erroneously. For SMDS, the command dumps the entire SMDS header and some payload data when an SMDS packet is transmitted or received.
Using Extended ping Tests
The ping command is a useful test available on Cisco internetworking devices as well as on many host systems. In TCP/IP, this diagnostic tool is also known as an Internet Control Message Protocol (ICMP) Echo Request.
Note: The ping command is particularly useful when high levels of input errors are being registered in the show interfaces serial display. See Figure 15-1.
Cisco internetworking devices provide a mechanism to automate the sending of many ping packets in sequence. Figure 15-5 illustrates the menu used to specify extended ping options. This example specifies 20 successive pings. However, when testing the components on your serial line, you should specify a much larger number, such as 1000 pings.
Figure 15-5: Extended ping Specification Menu
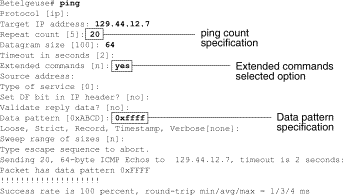
Performing Ping Tests
In general, perform serial line ping tests as follows:
-
Put the CSU or DSU into local loopback mode.
-
Configure the extended ping command to send different data patterns and packet sizes. Figure 15-6 and Figure 15-7 illustrate two useful ping tests, an all-zeros (1500-byte) ping and an all-ones (1500-byte) ping, respectively.
-
Examine the show interfaces serial command output (see Figure 15-1) and determine whether input errors have increased. If input errors have not increased, the local hardware (DSU, cable, router interface card) is probably in good condition.
Assuming that this test sequence was prompted by the appearance of a large number of CRC and framing errors, a clocking problem is likely. Check the CSU or DSU for a timing problem. See the section «Troubleshooting Clocking Problems,» later in this chapter.
-
If you determine that the clocking configuration is correct and is operating properly, put the CSU or DSU into remote loopback mode.
-
Repeat the ping test and look for changes in the input error statistics.
-
If input errors increase, there is either a problem in the serial line or on the CSU/DSU. Contact the WAN service provider and swap the CSU or DSU. If problems persist, contact your technical support representative.
Figure 15-6: ALl-Zeros 1500-Byte ping Test
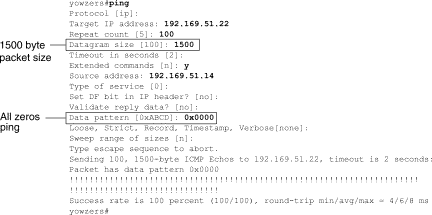
Figure 15-7 All-Ones 1500-Byte ping Test
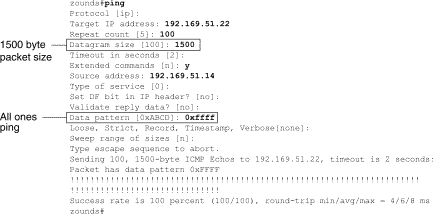
Troubleshooting Clocking Problems
Clocking conflicts in serial connections can lead either to chronic loss of connection service or to degraded performance. This section discusses the important aspects of clocking problems: clocking problem causes, detecting clocking problems, isolating clocking problems, and clocking problem solutions.
Clocking Overview
The CSU/DSU derives the data clock from the data that passes through it. In order to recover the clock, the CSU/DSU hardware must receive at least one 1-bit value for every 8 bits of data that pass through it; this is known as ones density. Maintaining ones density allows the hardware to recover the data clock reliably.
Newer T1 implementations commonly use Extended Superframe Format (ESF) framing with binary eight-zero substitution (B8ZS) coding. B8ZS provides a scheme by which a special code is substituted whenever eight consecutive zeros are sent through the serial link. This code is then interpreted at the remote end of the connection. This technique guarantees ones density independent of the data stream.
Older T1 implementations use D4-also known as Superframe Format (SF) framing and Alternate Mark Inversion (AMI) coding. AMI does not utilize a coding scheme like B8ZS. This restricts the type of data that can be transmitted because ones density is not maintained independent of the data stream.
Another important element in serial communications is serial clock transmit external (SCTE) terminal timing. SCTE is the clock echoed back from the data terminal equipment (DTE) device (for example, a router) to the data communications equipment (DCE) device (for example, the CSU/DSU).
When the DCE device uses SCTE instead of its internal clock to sample data from the DTE, it is better able to sample the data without error even if there is a phase shift in the cable between the CSU/DSU and the router. Using SCTE is highly recommended for serial transmissions faster than 64 kbps. If your CSU/DSU does not support SCTE, see the section «Inverting the Transmit Clock,» later in this chapter.
Clocking Problem Causes
In general, clocking problems in serial WAN interconnections can be attributed to one of the following causes:
-
Incorrect DSU configuration
-
Incorrect CSU configuration
-
Cables out of specification-that is, longer than 50 feet (15.24 meters) or unshielded
-
Noisy or poor patch panel connections
-
Several cables connected together in a row
Detecting Clocking Problems
To detect clocking conflicts on a serial interface, look for input errors as follows:
-
Use the show interfaces serial EXEC command on the routers at both ends of the link.
-
Examine the command output for CRC, framing errors, and aborts.
-
If either of these steps indicates errors exceeding an approximate range of 0.5 percent 2.0 percent of traffic on the interface, clocking problems are likely to exist somewhere in the WAN.
-
Isolate the source of the clocking conflicts as outlined in the following section, «Isolating Clocking Problems.»
-
Bypass or repair any faulty patch panels.
Isolating Clocking Problems
After you determine that clocking conflicts are the most likely cause of input errors, the following procedure will help you isolate the source of those errors:
-
Perform a series of ping tests and loopback tests (both local and remote), as described in the section «CSU and DSU Loopback Tests,» earlier in this chapter.
-
Determine the end of the connection that is the source of the problem, or if the problem is in the line. In local loopback mode, run different patterns and sizes in the ping tests (for example, use 1500-byte datagrams). Using a single pattern and packet size may not force errors to materialize, particularly when a serial cable to the router or CSU/DSU is the problem.
-
Use the show interfaces serial EXEC command and determine if input errors counts are increasing and where they are accumulating.
If input errors are accumulating on both ends of the connection, clocking of the CSU is the most likely problem.
If only one end is experiencing input errors, there is probably a DSU clocking or cabling problem.
Aborts on one end suggests that the other end is sending bad information or that there is a line problem.
Note: Always refer to the show interfaces serial command output (see Figure 15-1) and log any changes in error counts or note if the error count does not change.
Clocking Problem Solutions
Table 15-8 Serial Lines: Clocking Problems and Solutions: This table outlines suggested remedies for clocking problems, based on the source of the problem.
| Possible Problem | Solution |
|---|---|
| Incorrect CSU configuration |
|
| Incorrect DSU configuration |
|
| Cable to router is out of specification | If the cable is longer than 50 feet (15.24 meters), use a shorter cable. If the cable is unshielded, replace it with shielded cable. |
Inverting the Transmit Clock
If you are attempting serial connections at speeds greater than 64 kbps with a CSU/DSU that does not support SCTE, you may have to invert the transmit clock on the router. Inverting the transmit clock compensates for phase shifts between the data and clock signals.
The specific command used to invert the transmit clock varies between platforms. On a Cisco 7000 series router, enter the invert-transmit-clock interface configuration command. For Cisco 4000 series routers, use the dte-invert-txc interface configuration command.
To ensure that you are using the correct command syntax for your router, refer to the user guide for your router or access server and to the Cisco IOS configuration guides and command references.
Note: On older platforms, inverting the transmit clock may require that you move a physical jumper.
Adjusting Buffers
Excessively high bandwidth utilization (over 70percent) results in reduced overall performance and can cause intermittent failures. For example, DECnet file transmissions may be failing due to packets being dropped somewhere in the network.
If the situation is bad enough, you must increase the bandwidth of the link. However, increasing the bandwidth may not be necessary or immediately practical. One way to resolve marginal serial line overutilization problems is to control how the router uses data buffers.
Caution: In general, do not adjust system buffers unless you are working closely with a Cisco technical support representative. You can severely affect the performance of your hardware and your network if you incorrectly adjust the system buffers on your router.
Use one of the following three options to control how buffers are used:
-
Adjust parameters associated with system buffers
-
Specify the number of packets held in input or output queues (hold queues)
-
Prioritize how traffic is queued for transmission (priority output queuing)
The configuration commands associated with these options are described in the Cisco IOS configuration guides and command references.
The following section focuses on identifying situations in which these options are likely to apply and defining how you can use these options to help resolve connectivity and performance problems in serial/WAN interconnections.
Tuning System Buffers
There are two general buffer types on Cisco routers: hardware buffers and system buffers. Only the system buffers are directly configurable by system administrators. The hardware buffers are specifically used as the receive and transmit buffers associated with each interface and (in the absence of any special configuration) are dynamically managed by the system software itself.
The system buffers are associated with the main system memory and are allocated to different-size memory blocks. A useful command for determining the status of your system buffers is the show buffers EXEC command. Figure 15-8 shows the output from the show buffers command.
Figure 15-8 show buffers Command Output

In the show buffers output:
-
total— Identifies the total number of buffers in the pool, including used and unused buffers.
-
permanent— Identifies the permanent number of allocated buffers in the pool. These buffers are always in the pool and cannot be trimmed away.
-
in free list— Identifies the number of buffers currently in the pool that are available for use.
-
min— Identifies the minimum number of buffers that the Route Processor (RP) should attempt to keep in the free list:
-
The min parameter is used to anticipate demand for buffers from the pool at any given time.
-
If the number of buffers in the free list falls below the min value, the RP attempts to create more buffers for that pool.
-
-
max allowed— Identifies the maximum number of buffers allowed in the free list:
-
The max allowed parameter prevents a pool from monopolizing buffers that it doesn’t need anymore and frees this memory back to the system for further use.
-
If the number of buffers in the free list is greater than the max allowed value, the RP should attempt to trim buffers from the pool.
-
-
hits— Identifies the number of buffers that have been requested from the pool. The hits counter provides a mechanism for determining which pool must meet the highest demand for buffers.
-
misses— Identifies the number of times a buffer has been requested and the RP detected that additional buffers were required. (In other words, the number of buffers in the free list has dropped below min.) The misses counter represents the number of times the RP has been forced to create additional buffers.
-
trims— Identifies the number of buffers that the RP has trimmed from the pool when the number of buffers in the free list exceeded the number of max allowed buffers.
-
created— Identifies the number of buffers that have been created in the pool. The RP creates buffers when demand for buffers has increased until the number of buffers in the free list is less than min buffers and/or a miss occurs because of zero buffers in the free list.
-
failures— Identifies the number of failures to grant a buffer to a requester even after attempting to create an additional buffer. The number of failures represents the number of packets that have been dropped due to buffer shortage.
-
no memory— Identifies the number of failures caused by insufficient memory to create additional buffers.
The show buffers command output in Figure 15-8 indicates high numbers in the trims and created fields for large buffers. If you are receiving high numbers in these fields, you can increase your serial link performance by increasing the max free value configured for your system buffers. trims identifies the number of buffers that the RP has trimmed from the pool when the number of buffers in free list exceeded the number of max allowed buffers.
Use the buffers max free number global configuration command to increase the number of free system buffers. The value you configure should be approximately 150 percent of the figure indicated in the total field of the show buffers command output. Repeat this process until the show buffers output no longer indicates trims and created buffers.
If the show buffers command output shows a large number of failures in the (no memory) field (see the last line of output in Figure 15-8), you must reduce the usage of the system buffers or increase the amount of shared or main memory (physical RAM) on the router. Call your technical support representative for assistance.
Implementing Hold Queue Limits
Hold queues are buffers used by each router interface to store outgoing or incoming packets. Use the hold-queue interface configuration command to increase the number of data packets queued before the router will drop packets. Increase these queues by small increments (for instance, 25 percent) until you no longer see drops in the show interfaces output. The default output hold queue limit is 100 packets.
Note: The hold-queue command is used for process-switched packets and periodic updates generated by the router.
Use the hold-queue command to prevent packets from being dropped and to improve serial-link performance under the following conditions:
-
You have an application that cannot tolerate drops and the protocol is able to tolerate longer delays. DECnet is an example of a protocol that meets both criteria. Local-area transport (LAT) does not because it does not tolerate delays.
-
The interface is very slow. Bandwidth is low or anticipated utilization is likely to sporadically exceed available bandwidth.
Note: When you increase the number specified for an output hold queue, you may need to increase the number of system buffers. The value used depends on the size of the packets associated with the traffic anticipated for the network.
Using Priority Queuing to Reduce Bottlenecks
Priority queuing is a list-based control mechanism that allows traffic to be prioritized on an interface-by-interface basis. Priority queuing involves two steps:
-
Create a priority list by protocol type and level of priority.
-
Assign the priority list to a specific interface.
Both of these steps use versions of the priority-list global configuration command. In addition, further traffic control can be applied by referencing access-list global configuration commands from priority-list specifications. For examples of defining priority lists and for details about command syntax associated with priority queuing, refer to the Cisco IOS configuration guides and command references.
Note: Priority queuing automatically creates four hold queues of varying size. This overrides any hold queue specification included in your configuration.
Use priority queuing to prevent packets from being dropped and to improve serial link performance under the following conditions:
-
When the interface is slow, there is a variety of traffic types being transmitted, and you want to improve terminal traffic performance.
-
If you have a serial link that is intermittently experiencing very heavy loads (such as file transfers occurring at specific times) priority queuing will help select which types of traffic should be discarded at high traffic periods.
In general, start with the default number of queues when implementing priority queues. After enabling priority queuing, monitor output drops with the show interfaces serial EXEC command. If you notice that output drops are occurring in the traffic queue you have specified to be high priority, increase the number of packets that can be queued (using the queue-limit keyword option of the priority-list global configuration command). The default queue-limit arguments are 20 packets for the high-priority queue, 40 for medium, 60 for normal, and 80 for low.
Note: When bridging Digital Equipment Corporation (DEC) LAT traffic, the router must drop very few packets, or LAT sessions can terminate unexpectedly. A high-priority queue depth of about 100 (specified with the queue-limit keyword) is a typical working value when your router is dropping output packets and the serial lines are subjected to about 50 percent bandwidth utilization. If the router is dropping packets and is at 100 percent utilization, you need another line.
Another tool to relieve congestion when bridging DEC LAT is LAT compression. You can implement LAT compression with the interface configuration command bridge-group group lat-compression.
Special Serial Line Tests
In addition to the basic diagnostic capabilities available on routers, a variety of supplemental tools and techniques can be used to determine the conditions of cables, switching equipment, modems, hosts, and remote internetworking hardware. For more information, consult the documentation for your CSU, DSU, serial analyzer, or other equipment.
CSU and DSU Loopback Tests
If the output of the show interfaces serial EXEC command indicates that the serial line is up but the line protocol is down, use the CSU/DSU loopback tests to determine the source of the problem. Perform the local loop test first, and then the remote test. Figure 15-9 illustrates the basic topology of the CSU/DSU local and remote loopback tests.
Figure 15-9: CSU/DSU Local and Remote Loopback Tests

Note: These tests are generic in nature and assume attachment of the internetworking system to a CSU or DSU. However, the tests are essentially the same for attachment to a multiplexer with built-in CSU/DSU functionality. Because there is no concept of a loopback in X.25 or Frame Relay packet-switched network (PSN) environments, loopback tests do not apply to X.25 and Frame Relay networks.
CSU and DSU Local Loopback Tests for HDLC or PPP Links
Listed below is a general procedure for performing loopback tests in conjunction with built-in system diagnostic capabilities:
-
Place the CSU/DSU in local loop mode (refer to your vendor documentation). In local loop mode, the use of the line clock (from the T1 service) is terminated, and the DSU is forced to use the local clock.
-
Use the show interfaces serial EXEC command to determine if the line status changes from «line protocol is down» to «line protocol is up (looped),» or if it remains down.
-
If the line protocol comes up when the CSU or DSU is in local loopback mode, this suggests that the problem is occurring on the remote end of the serial connection. If the status line does not change state, there is a possible problem in the router, connecting cable, or CSU/DSU.
-
If the problem appears to be local, use the debug serial interface privileged EXEC command.
-
Take the CSU/DSU out of local loop mode. When the line protocol is down, the debug serial interface command output will indicate that keepalive counters are not incrementing.
-
Place the CSU/DSU in local loop mode again. This should cause the keepalive packets to begin to increment. Specifically, the values for mineseen and yourseen keepalives will increment every 10 seconds. This information will appear in the debug serial interface output.
If the keepalives do not increment, there may be a timing problem on the interface card or on the network. For information on correcting timing problems, see the section «Troubleshooting Clocking Problems,» earlier in this chapter.
If the keepalives do not increment, there may be a timing problem on the interface card or on the network. For information on correcting timing problems, see the section «Troubleshooting Clocking Problems,» earlier in this chapter.
-
Check the local router, CSU/DSU hardware, and any attached cables. Make certain that the cables are within the recommended lengths-no more than 50 feet (15.24 meters) or 25 feet (7.62 meters) for a T1 link. Make certain the cables are attached to the proper ports. Swap faulty equipment as necessary.
Figure 15-10 shows the output from the debug serial interface command for an HDLC serial connection, with missed keepalives causing the line to go down and the interface to reset.
Figure 15-10: debug serial interface Command Output

CSU and DSU Remote Loopback Tests for HDLC or PPP Links
If you determine that the local hardware is functioning properly but you still encounter problems when attempting to establish connections over the serial link, try using the remote loopback test to isolate the problem cause.
Note: This remote loopback test assumes that HDLC encapsulation is being used and that the preceding local loop test was performed immediately before this test.
The following steps are required to perform loopback testing:The following steps are required to perform loopback testing:
-
Put the remote CSU or DSU into remote loopback mode (refer to the vendor documentation).
-
Using the show interfaces serial EXEC command, determine if the line protocol remains up with the status line indicating «Serial x is up, line protocol is up (looped),» or if it goes down with the status line indicating «line protocol is down.»
-
If the line protocol remains up (looped), the problem is probably at the remote end of the serial connection (between the remote CSU/DSU and the remote router). Perform both local and remote tests at the remote end to isolate the problem source.
-
If the line status changes to «line protocol is down» when remote loopback mode is activated, make sure that ones density is being properly maintained. The CSU/DSU must be configured to use the same framing and coding schemes used by the leased-line or other carrier service (for example, ESF and B8ZS).
-
If problems persist, contact your WAN network manager or the WAN service organization.
Detailed Information on the show interfaces serial Command
The following sub-sections cover the show interfaces serial command’s parameters, syntax description, sample output display, and field descriptions.
show interfaces serial Parameters
To display information about a serial interface, use the show interfaces serial privileged EXEC command:
show interfaces serial [number] [accounting] show interfaces serial [number [:channel-group] [accounting] (Cisco 4000 series) show interfaces serial [slot | port [:channel-group]] [accounting] (Cisco 7500 series) show interfaces serial [type slot | port-adapter | port] [serial] (ports on VIP cards in the Cisco 7500 series) show interfaces serial [type slot | port-adapter | port] [:t1-channel] [accounting | crb] (CT3IP in Cisco 7500 series)
Syntax Description
-
number-Optional. Port number.
-
accounting-Optional. Displays the number of packets of each protocol type that have been sent through the interface.
-
:channel-group -Optional. On the Cisco 4000 series with an NPM or a Cisco 7500 series with a MIP, specifies the T1 channel-group number in the range of 0 to 23, defined with the channel-group controller configuration command.
-
slot -Refers to the appropriate hardware manual for slot information.
-
port -Refers to the appropriate hardware manual for port information.
-
port-adapter -Refers to the appropriate hardware manual for information about port adapter compatibility.
-
:t1-channel -Optional. For the CT3IP, the T1 channel is a number between 1 and 28.
-
T1 channels on the CT3IP are numbered 1 to 28 rather than the more traditional zero-based scheme (0 to 27) used with other Cisco products. This is to ensure consistency with Telco numbering schemes for T1 channels within channelized T3 equipment.
-
crb-Optional. Shows interface routing and bridging information.
Command Mode
Privileged EXEC
Usage Guidelines
This command first appeared in Cisco IOS Release 10.0 for the Cisco 4000 series. It first appeared in Cisco IOS Release 11.0 for the Cisco 7000 series, and it was modified in Cisco IOS Release 11.3 to include the CT3IP.
Sample Displays
The following is sample output from the show interfaces command for a synchronous serial interface:
Router# show interfaces serial
Serial 0 is up, line protocol is up
Hardware is MCI Serial
Internet address is 150.136.190.203, subnet mask is 255.255.255.0
MTU 1500 bytes, BW 1544 Kbit, DLY 20000 usec, rely 255/255, load 1/255
Encapsulation HDLC, loopback not set, keepalive set (10 sec)
Last input 0:00:07, output 0:00:00, output hang never
Output queue 0/40, 0 drops; input queue 0/75, 0 drops
Five minute input rate 0 bits/sec, 0 packets/sec
Five minute output rate 0 bits/sec, 0 packets/sec
16263 packets input, 1347238 bytes, 0 no buffer
Received 13983 broadcasts, 0 runts, 0 giants
2 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored, 2 abort
1 carrier transitions
22146 packets output, 2383680 bytes, 0 underruns
0 output errors, 0 collisions, 2 interface resets, 0 restarts
Field Description
Table 15-9: show interfaces serial Field Descriptions — this table describes significant fields shown in the output.
| Field | Description |
|---|---|
| Serial…is {up | down}…is administratively down | Indicates whether the interface hardware is currently active (carrier detect is present) or whether it has been taken down by an administrator. |
| line protocol is {up | down} | Indicates whether the software processes that handle the line protocol consider the line usable (that is, keepalives are successful) or whether it has been taken down by an administrator. |
| line protocol is {up | down} | Indicates whether the software processes that handle the line protocol consider the line usable (that is, keepalives are successful) or whether it has been taken down by an administrator. |
| Hardware is | Specifies the hardware type. |
| Internet address is | Specifies the internet address and subnet mask. |
| MTU | Maximum transmission unit of the interface. |
| BW | Indicates the value of the bandwidth parameter that has been configured for the interface (in kilobits per second). The bandwidth parameter is used to compute IGRP metrics only. If the interface is attached to a serial line with a line speed that does not match the default (1536 or 1544 for T1 and 56 for a standard synchronous serial line), use the bandwidth command to specify the correct line speed for this serial line. |
| DLY | Delay of the interface in microseconds. |
| rely | Reliability of the interface as a fraction of 255 (255/255 is 100 percent reliability), calculated as an exponential average over five minutes. |
| load | Reliability of the interface as a fraction of 255 (255/255 is 100 percent reliability), calculated as an exponential average over five minutes. |
| Encapsulation | Encapsulation method assigned to the interface. |
| loopback | Indicates whether loopback is set. |
| keepalive | Indicates whether keepalives are set. |
| Last input | Number of hours, minutes, and seconds since the last packet was successfully received by an interface. Useful for knowing when a dead interface failed. |
| Last output | Number of hours, minutes, and seconds since the last packet was successfully transmitted by an interface.Number of hours, minutes, and seconds since the last packet was successfully transmitted by an interface. |
| output hang | Number of hours, minutes, and seconds (or never) since the interface was last reset because of a transmission that took too long. When the number of hours in any of the last fields exceeds 24, the number of days and hours is printed. If that field overflows, asterisks are printed. |
| Output queue, drops input queue, drops | Number of packets in output and input queues. Each number is followed by a slash, the maximum size of the queue, and the number of packets because the queue is full. |
| 5 minute input rate 5 minute output rate | Average number of bits and packets transmitted per second in the past five minutes. The five-minute input and output rates should be used only as an approximation of traffic per second during a given five-minute period. These rates are exponentially weighted averages with a time constant of five minutes. A period of four time constants must pass before the average will be within 2 percent of the instantaneous rate of a uniform stream of traffic over that period. |
| packets input | Total number of error-free packets received by the system. |
| bytes | Total number of bytes, including data and MAC encapsulation, in the error-free packets received by the system. |
| no buffer | Number of received packets discarded because there was no buffer space in the main system. Compare with ignored count. Broadcast storms on Ethernet networks and bursts of noise on serial lines are often responsible for no input buffer events. |
| Received… broadcasts | Total number of broadcast or multicast packets received by the interface. |
| runts | Number of packets that are discarded because they are smaller than the medium’s minimum packet size. |
| giants | Number of packets that are discarded because they exceed the medium’s maximum packet size. |
| input errors | Total number of no buffer, runts, giants, CRCs, frame, overrun, ignored, and abort counts. Other input-related errors can also increment the count, so this sum may not balance with the other counts. |
| CRC | Cyclic redundancy check generated by the originating station or far-end device does not match the checksum calculated from the data received. On a serial link, CRCs usually indicate noise, gain hits, or other transmission problems on the data link. |
| frame | Number of packets received incorrectly having a CRC error and a noninteger number of octets. On a serial line, this is usually the result of noise or other transmission problems. |
| overrun | Number of times the serial receiver hardware was unable to hand received data to a hardware buffer because the input rate exceeded the receiver’s ability to handle the data. |
| ignored | Number of received packets ignored by the interface because the interface hardware ran low on internal buffers. Broadcast storms and bursts of noise can cause the ignored count to be increased. |
| abort | Illegal sequence of one bits on a serial interface. This usually indicates a clocking problem between the serial interface and the data link equipment. |
| carrier transitions | Number of times the carrier detect signal of a serial interface has changed state. For example, if data carrier detect (DCD) goes down and comes up, the carrier transition counter will increment two times. Indicates modem or line problems if the carrier detect line is changing state often. |
| packets output | Total number of messages transmitted by the system. |
| bytes output | Total number of bytes, including data and MAC encapsulation, transmitted by the system. |
| underruns | Number of times that the transmitter has been running faster than the router can handle. This may never be reported on some interfaces. |
| output errors | Sum of all errors that prevented the final transmission of datagrams out of the interface being examined. Note that this may not balance with the sum of the enumerated output errors because some datagrams can have more than one error, and others can have errors that do not fall into any of the specifically tabulated categories. |
| collisions | Number of messages retransmitted due to an Ethernet collision. This usually is the result of an overextended LAN (that is, Ethernet or transceiver cable too long, more than two repeaters between stations, or too many cascaded multiport transceivers). Some collisions are normal. However, if your collision rate climbs to around 4 percent or 5 percent, you should consider verifying that there is no faulty equipment on the segment and/or moving some existing stations to a new segment. A packet that collides is counted only once in output packets. |
| interface resets | Number of times an interface has been completely reset. This can happen if packets queued for transmission were not sent within several seconds’ time. On a serial line, this can be caused by a malfunctioning modem that is not supplying the transmit clock signal, or by a cable problem. If the system notices that the carrier detect line of a serial interface is up but the line protocol is down, it periodically resets the interface in an effort to restart it. Interface resets can also occur when an interface is looped back or shut down. |
| restarts | Number of times the controller was restarted because of errors. |
| alarm indications, remote alarms, rx LOF, rx LOS | Number of CSU/DSU alarms, and number of occurrences of receive loss of frame and receive loss of signal. |
| BER inactive, NELR inactive, FELR inactive | Status of G.703-E1 counters for bit error rate (BER) alarm, near-end loop remote (NELR), and far-end loop remote (FELR). Note that you cannot set the NELR or FELR. |
Troubleshooting T1
This section describes the techniques and procedures for troubleshooting T1 circuits for dial-in customers.
Troubleshooting Using the show controller t1 Command
This command displays the controller status that is specific to the controller hardware. The information displayed is generally useful for diagnostic tasks performed by technical support personnel only.
The NMP (Network Management Processor) or MIP (MultiChannel Interface Processor) can query the port adapters to determine their current status. Issue a show controller t1 command to display statistics about the T1 link.
If you specify a slot and port number, statistics for each 15-minute period will be displayed. The show controller t1 EXEC command provides information to logically troubleshoot physical layer and data link layer problems. This section describes how to logically troubleshoot using the show controller t1 command.
Most T1 errors are caused by misconfigured lines. Ensure that linecoding, framing and clock source are configured according to what the service provider recommends.
show controller t1 Conditions
The T1 controller can be in one of the following three states.
-
Administratively down
-
Down
-
Up
Is the T1 Controller Administratively Down?
The controller is administratively down when it has been manually shut down. You should restart the controller to correct this error.
-
Enter enable mode.
maui-nas-03>en Password: maui-nas-03#
-
Enter global configuration mode.
maui-nas-03#configure terminal Enter configuration commands, one per line. End with CNTL/Z. maui-nas-03(config)#
-
Enter controller configuration mode.
maui-nas-03(config)#controller t1 0 maui-nas-03(config-controlle)#
-
Restart controller.
maui-nas-03(config-controlle)#shutdown maui-nas-03(config-controlle)#no shutdown
Is the Line Up?
If the T1 controller and line are not up, check to see if one of the following messages appears in the show controller t1 EXEC output:
-
Receiver has loss of frame
-
Receiver has loss of signal
If T1 Receiver Has Loss of Frame:
Follow these steps if T1 Receiver Has Loss of Frame:
-
Check to see if the framing format configured on the port matches the framing format of the line. You can check the framing format of the controller from the running configuration or the show controller t1 command output.
To change the framing format use the framing {SF | ESF} command in the controller configuration mode as shown below:
maui-nas-03#configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
maui-nas-03(config)#controller t1 0 maui-nas-03(config-controlle)#framing esf
-
Try the other framing format to see if the alarm clears.
-
Change the line buildout setting using the cablelength {long | short} command.
Line build out (LBO) compensates for the loss in decibels based on the distance from the device to the first repeater in the circuit. A longer distance from the device to the repeater requires that the signal strength on the circuit be boosted to compensate for loss over that distance.
Consult your service provider and the Cisco IOSÒ Command Reference for details on buildout settings.
If this does not fix the problem, proceed to the «If T1 Receiver Has Loss of Signal» section below.
If T1 Receiver Has Loss of Signal:
Follow these steps if T1 Receiver Has Loss of Signal:
-
Make sure that the cable between the interface port and the T1 service provider’s equipment (or T1 terminal equipment) is connected correctly. Check to see if the cable is hooked up to the correct ports. Correct the cable connections if necessary.
-
Check cable integrity. Look for breaks or other physical abnormalities in the cable. Ensure that the pinouts are set correctly. If necessary, replace the cable.
-
Check the cable connectors. A reversal of the transmit and receive pairs or an open receive pair can cause errors. Set the receive pair to lines 1 & 2. Set the transmit pair to lines 4 & 5.
The pins on a RJ-45 jack are numbered from 1 through 8. Pin 1 is the leftmost pin when looking at the jack with the metal pins facing you. Refer to the figure below.
Figure 15-10: RJ-45 Cable

-
Try using a rollover cable.
Run the show controller t1 EXEC command after each step to check if the controller exhibits any errors.
Check to see if the line is in loopback mode from the show controller t1 output. A line should be in loopback mode only for testing purposes.
To turn off loopback, use the no loopback command in the controller configuration mode as shown below:
maui-nas-03(config-controlle)#no loopback
If the Controller Displays Any Alarms:
Check the show controller command output to see if there are alarms displayed by the controller.
We will now discuss various alarms and the procedure necessary to correct them.
Receive (RX) Alarm Indication Signal (AIS) (Blue):
A received Alarm Indication Signal (AIS) means there is an alarm occurring on the line upstream of the equipment connected to the port.
-
Check to see if the framing format configured on the port matches the framing format of the line. If not, change the framing format on the controller to match that of the line.
-
Contact your service provider to check for mis-configuration within the Telco.
Receive (Rx) Remote Alarm Indication (RAI) (Yellow):
A received RAI means that the far-end equipment has a problem with the signal it is receiving from its upstream equipment.
-
Insert an external loopback cable into the port. To create a loopback plug refer to the section «Creating a Loopback Plug,» later in the chapter.
-
Check to see if there are any alarms. If you do not see any alarms, then the local hardware is probably in good condition. In that case:
-
Check the cabling. See the section «If T1 Receiver Has Loss of Signal» for more information.
-
Check the settings at the remote end and verify that they match your port settings.
-
If the problem persists, contact your service provider.
-
-
Remove the loopback plug and reconnect your T1 line.
-
Check the cabling. See the section «If T1 Receiver Has Loss of Signal» for more information.
-
Power-cycle the router.
-
Connect the T1 line to a different port. Configure the port with the same settings as that of the line. If the problem does not persist, then the fault lies with the one port:
-
Reconnect the T1 line to the original port.
-
Proceed to the «Troubleshooting T1 Error Events» section.
If the problem persists, then:
-
-
Perform a hardware loop test as described in the section «Performing Hardware Loopback Plug Test.»
-
Replace the T1 controller card.
-
Proceed to the «Troubleshooting T1 Error Events» section.
Transmitter Sending Remote Alarm (Red):
A Red alarm is declared when the CSU cannot synchronize with the framing pattern on the T1 line.
-
Check to see if the framing format configured on the port matches the framing format of the line. If not change the framing format on the controller to match that of the line.
-
Check the settings at the remote end and verify that they match your port settings.
-
Contact your service provider.
Transmit(Tx) Remote Alarm Indication (RAI) (Yellow):
A transmitted RAI at the interface indicates that the interface has a problem with the signal it is receiving from the far-end equipment.
-
Check the settings at the remote end and verify that they match your port settings.
-
A transmit RAI should be accompanied by some other alarm that indicates the nature of the problem the T1 port/card is having with the signal from the far-end equipment.
Troubleshoot that condition to resolve the transmit RAI.
Transmit(Tx) AIS (Blue):
Follow the steps below to correct the Transmit (Tx) AIS (Blue).
-
Check to see if the framing format configured on the port matches the framing format of the line. If not, correct the mismatch.
-
Power-cycle the router.
-
Connect the T1 line to a different port. Configure the port with the same settings as that of the line.
-
Perform a hardware loop test as described in the section «Performing Hardware Loopback Plug Test.»
-
Replace the T1 controller card.
-
Proceed to the «Troubleshooting T1 Error Events» section.
Troubleshooting T1 Error Events
The show controller t1 EXEC command provides error messages that can be used to troubleshoot problems. We will now discuss several error messages and how to correct the errors.
To see if the error counters are increasing, execute the show controller t1 command repeatedly. Note the values of the counters for the current interval.
Consult your service provider for framing and linecoding settings. A good rule of thumb is to use B8ZS linecoding with ESF framing and AMI linecoding with SF framing.
Slip Secs Counter is increasing:
The presence of slips on a T1 line indicates a clocking problem. The T1 provider (Telco) will provide the clocking to which the Customer Premises Equipment (CPE) should be synchronized.
-
Verify that the clock source is derived from the network. This can be ascertained by looking for Clock Source is Line Primary.
Note: If there are multiple T1s into an access server, only one can be the primary, while the other T1s derive the clock from the primary. In that case verify that the T1 line designated as the primary clock source is configured correctly.
-
Set the T1 clock source correctly from the controller configuration mode.
maui-nas-03(config-controlle)#clock source line primary
Framing Loss Seconds Counter is Increasing:
Follow these steps when the Framing Loss Seconds Counter is Increasing.
-
Check to see if the framing format configured on the port matches the framing format of the line. You can check this by looking for the Framing is {ESF|SF} in the show controller t1 output.
-
To change the framing format use the framing {SF | ESF} command in the controller configuration mode as shown below:
maui-nas-03(config-controlle)#framing esf
-
Change the line buildout using the cablelength {long | short} command.
Consult your service provider and the Cisco IOSÒ Command Reference for details on buildout settings.
Line Code Violations are increasing:
Follow these steps when Line Code Violations are increasing.
-
Check to see if the linecoding configured on the port matches the framing format of the line. You can check this by looking for the Line Code is {B8ZS|AMI} in the show controller t1 output.
-
To change the linecoding, use the linecode {ami | b8zs} command in the controller configuration mode as shown below:
maui-nas-03(config-controlle)#linecode b8zs
-
Change the line buildout using the cablelength {long | short} command.
Consult your service provider and the Cisco IOS® Command Reference for details on buildout settings.
Verifying that ISDN Switch Type and PRI-Group are Configured Correctly
Use the show running-config command to see if ISDN switch type and the PRI-group timeslots are configured correctly. Contact your service provider for correct values.
To change the ISDN switch type and PRI-group:
maui-nas-03#configure terminal maui-nas-03(config)#isdn switch-type primary-5ess maui-nas-03(config)#controller t1 0 maui-nas-03(config-controlle)#pri-group timeslots 1-24
Verifying the Signaling Channel
If the error counters do not increase but the problem persists, verify that the signaling channel is up and configured correctly.
-
Run the show interface serial x:23 command, where x should be replaced by the interface number.
-
Check to see if the interface is up. If the interface is not up, use the no shutdown command to bring the interface up.
maui-nas-03#config terminal Enter configuration commands, one per line. End with CNTL/Z. maui-nas-03(config)#interface serial 0:23 maui-nas-03(config-if)#no shutdown
-
Ensure that encapsulation is PPP. If the interface is not using PPP then use the encapsulation ppp command in the interface configuration mode to correct it.
maui-nas-03(config-if)#encapsulation ppp
-
Check to see if loopback is set. Loopback should be set only for testing purposes. Use the no loopback command to remove loopbacks.
maui-nas-03(config-if)#no loopback
-
Power-cycle the router.
-
If the problem persists, contact your service provider or Cisco TAC
Troubleshooting a PRI
Whenever troubleshooting a PRI, you need to check to see if the T1 is running cleanly on both ends. If Layer 1 problems have been resolved, as described above, consider Layer 2 and Layer 3 problems.
Troubleshooting Using the show isdn status Command
The show isdn status command is used to display a snapshot of all ISDN interfaces. It displays the status of Layers 1, 2 and 3.
-
Verify that Layer 1 is active.
The Layer 1 status should always say ACTIVE unless the T1 is down. If show isdn status indicates that Layer 1 is DEACTIVATED, then there is a problem with the physical connectivity on the T1 line. See the section «Is the T1 Controller T1 Down?»
Also verify that the T1 is not administratively down. Use the no shutdown command to bring the T1 controller up.
-
Check to see if the Layer 2 State is MULTIPLE_FRAME_ESTABLISHED
The desired Layer 2 state is Multiple_Frame_Established, which indicates that we are exchanging layer 2 frames and have finished Layer 2 initialization.
If Layer 2 is not Multiple_Frame_Established , use the show controller t1 EXEC command to diagnose the problem. Refer to the Troubleshooting using the show controller t1 Command section in this chapter.
Since show isdn status is a snapshot of the current status, it is possible that layer 2 is bouncing up and down despite indicating Mulitple_Frame_Established. Use debug isdn q921 to verify that layer 2 is stable.
The debug isdn q921 command displays data link layer (layer 2) access procedures that are taking place at the router on the D-channel.
Ensure that you are configured to view debug messages by using the logging console or terminal monitor command as necessary.
Note: In a production environment, verify that console logging is disabled. Enter the show logging command. If logging is enabled, the access server may intermittently freeze up as soon as the console port gets overloaded with log messages. Enter the no logging console command.
Note: If debug isdn q921 is turned on and you do not receive any debug outputs, place a call or reset the controller to get debug outputs.
-
Verify that Layer 2 is stable.
You should observe the debug outputs for messages indicating that the service is not bouncing up and down. If you see the following types of debug outputs, the line is not stable.
Mar 20 10:06:07.882: %ISDN-6-LAYER2DOWN: Layer 2 for Interface Se0:23, TEI 0 changed to down Mar 20 10:06:09.882: %LINK-3-UPDOWN: Interface Serial0:23, changed state to down Mar 20 10:06:21.274: %DSX1-6-CLOCK_CHANGE: Controller 0 clock is now selected as clock source Mar 20 10:06:21.702: %ISDN-6-LAYER2UP: Layer 2 for Interface Se0:23, TEI 0 changed to up Mar 20 10:06:22.494: %CONTROLLER-5-UPDOWN: Controller T1 0, changed state to up Mar 20 10:06:24.494: %LINK-3-UPDOWN: Interface Serial0:23, changed state to up
If Layer 2 does not appear to be stable, see «Troubleshooting T1 Error Events,» earlier in this chapter.
-
Verify that you are seeing only SAPI messages in both transmit (TX) and Receive (RX) sides.
Mar 20 10:06:52.505: ISDN Se0:23: TX -> RRf sapi = 0 tei = 0 nr = 0 Mar 20 10:06:52.505: ISDN Se0:23: RX <- RRf sapi = 0 tei = 0 nr = 0 Mar 20 10:07:22.505: ISDN Se0:23: TX -> RRp sapi = 0 tei = 0 nr = 0 Mar 20 10:07:22.509: ISDN Se0:23: RX <- RRp sapi = 0 tei = 0 nr = 0 Mar 20 10:07:22.509: ISDN Se0:23: TX -> RRf sapi = 0 tei = 0 nr = 0 Mar 20 10:07:22.509: ISDN Se0:23: RX <- RRf sapi = 0 tei = 0 nr = 0
-
Verify that you are not seeing SABME messages, which indicates that Layer 2 is trying to reinitialize. This is usually seen when we are transmitting poll requests (RRp) and not getting a response from the switch (RRf) or vice-versa. Below are example of SABME messages.
Mar 20 10:06:21.702: ISDN Se0:23: RX <- SABMEp sapi = 0 tei = 0 Mar 20 10:06:22.494: ISDN Se0:23: TX -> SABMEp sapi = 0 tei = 0
If you are seeing SABME messages, use the show running-config command to see if ISDN switch type and the PRI-group timeslots are configured correctly. Contact your service provider for correct values.
To change the ISDN switch type and PRI-group:
maui-nas-03#configure terminal maui-nas-03(config)#isdn switch-type primary-5ess maui-nas-03(config)#controller t1 0 maui-nas-03(config-controlle)#pri-group timeslots 1-24
-
Verify that the D-channel is up using the show interfaces serial x:23 command.
If the D-channel is not up, then use no shutdown command to bring it up:
maui-nas-03(config)#interface serial 0:23 maui-nas-03(config-if)#no shutdown
-
Check to see if encapsulation is PPP. If not, use the encapsulation ppp command to set encapsulation.
maui-nas-03(config-if)#encapsulation ppp
-
Check to see if the interface is in loopback mode. For normal operation, the interface should not be in loopback mode.
maui-nas-03(config-if)#no loopback
-
Power-cycle the router.
-
If the problem persists, contact your service provider or the Cisco TAC.
Performing Hardware Loopback Plug Test
The Hardware loopback plug test can be used to test whether the router has any faults. If a router passes a hardware loopback plug test, then the problem exists elsewhere on the line.
Create a Loopback Plug:
Follow these steps to create a loopback plug.
-
Use wire cutters to cut a working RJ-45 or RJ-48 cable so that there are five inches of cable and the connector is attached to it.
-
Strip the wires.
-
Twist together the wires from pins 1 and 4.
-
Twist together the wires from pins 2 and 5.
The pins on a RJ-45/48 jack are numbered from 1 through 8. Pin 1 is the left-most pin when looking at the jack with the metal pins facing you.
Performing the Loopback Plug Test
Follow these steps to perform the loopback plug test.
-
Insert the plug into the T1 port in question.
-
Save your router configuration using the write memory command.
maui-nas-03#write memory Building configuration... [OK]
-
Set the encapsulation to HDLC
maui-nas-03#config terminal Enter configuration commands, one per line. End with CNTL/Z. maui-nas-03(config)#interface serial 0 maui-nas-03(config-if)#enc maui-nas-03(config-if)#encapsulation HDLC maui-nas-03(config-if)#^Z
-
Use the show running-config command to see if the interface has an IP address.
If the interface does not have an IP address, obtain a unique address and assign it to the interface with a subnet mask of 255.255.255.0.
maui-nas-03(config)#ip address 172.22.53.1 255.255.255.0
-
Clear the interface counters using the clear counters command.
maui-nas-03#clear counters Clear "show interfaces" counters on all interfaces [confirm] maui-nas-03#
-
Perform the extended ping test as described in the «Using Extended ping Tests,» section earlier in this chapter.
Troubleshooting E1
This section describes the techniques and procedures for troubleshooting E1 circuits for dial-in customers.
Troubleshooting Using the show controller e1 Command
This command displays the controller status that is specific to the controller hardware. The information displayed is generally useful for diagnostic tasks performed by technical support personnel only.
The NMP or MIP can query the port adapters to determine their current status. Issue a show controller e1 command to display statistics about the E1 link. If you specify a slot and port number, statistics for each 15 minute period will be displayed.
The show controller e1 EXEC command provides information to logically troubleshoot physical layer and data link layer problems. This section describes how to logically troubleshoot using the show controller e1 command.
Most E1 errors are caused by misconfigured lines. Ensure that linecoding, framing, clock source and line termination (balanced or unbalanced) are configured according to what the service provider recommends.
show controller e1 Conditions
The E1 controller can be in one of the following three states.
-
Administratively down
-
Down
-
Up
Is the E1 Controller Administratively Down?
The controller is administratively down when it has been manually shut down. You should restart the controller to correct this error.
-
Enter enable mode.
maui-nas-03>enable Password: maui-nas-03#
-
Enter global configuration mode.
maui-nas-03#configure terminal Enter configuration commands, one per line. End with CNTL/Z. maui-nas-03(config)#
-
Enter controller configuration mode.
maui-nas-03(config)#controller e1 0 maui-nas-03(config-controlle)#
-
Restart controller.
maui-nas-03(config-controlle)#shutdown maui-nas-03(config-controlle)#no shutdown
Is the Line Up?
If the E1 line is not up, check to see that the line configuration is correct and matches the settings of the remote end.
-
Check the framing of the line and the remote end. For E1 lines, the framing is either CRC4 or noCRC4
-
Check the linecoding of the line and the remote end. The linecoding is either AMI or HDB3.
-
Check to see if the line termination is set for balanced or unbalanced (75-ohm or 120-ohm).
Consult your service provider for more information regarding the correct settings. Make any changes as necessary to both local or remote end-devices.
If the E1 controller and line are not up, check to see if one of the following messages appears in the show controller e1 EXEC output:
-
Receiver has loss of frame
-
Receiver has loss of signal
If E1 Receiver Has Loss of Frame:
Follow these steps if E1 receiver has loss of frame.
-
Check to see if the framing format configured on the port matches the framing format of the line. You can check the framing format of the controller from the running configuration or the show controller e1 command output.
To change the framing format, use the framing {CRC4 | no CRC4} command in the controller configuration mode as shown below:
maui-nas-03#configure terminal Enter configuration commands, one per line. End with CNTL/Z. maui-nas-03(config)#controller E1 0 maui-nas-03(config-controlle)#framing CRC4
-
Try the other framing format to see if the alarm clears.
If this does not fix the problem, proceed to the «If E1 Receiver Has Loss of Signal» section below.
-
Check the framing format on the remote end.
-
Check the linecoding on the remote end.
If E1 Receiver Has Loss of Signal:
Follow these steps if E1 receiver has loss of signal
-
Make sure that the cable between the interface port and the E1 service provider’s equipment (or E1 terminal equipment) is connected correctly. Check to see if the cable is hooked up to the correct ports. Correct the cable connections if necessary.
-
Check cable integrity. Look for breaks or other physical abnormalities in the cable. Ensure that the pinouts are set correctly. If necessary, replace the cable.
-
Check the cable connectors. A reversal of the transmit and receive pairs or an open receive pair can cause errors. Set the receive pair to lines 1 & 2. Set the transmit pair to lines 4 & 5.
The pins on a RJ-48 jack are numbered from 1 through 8. Pin 1 is the leftmost pin when looking at the jack with the metal pins facing you. Refer to the following figure for more information.
Figure 15-11: RJ-45 Cable
-
Try using a rollover cable.
-
Check to see if there are far-end block errors. If so, the problem exists with the receive lead on the local end. Contact the TAC for more assistance.
Run the show controller e1 EXEC command after each step to check if the controller exhibits any errors.
If the Line is in Loopback Mode:
Check to see if the line is in loopback mode from the show controller e1 output. A line should be in loopback mode only for testing purposes.
To turn off loopback, use the no loopback command in the controller configuration mode as shown below:
maui-nas-03(config-controlle)#no loopback
If the Controller Displays Any Alarms:
Check the show controller command output to see if there are alarms displayed by the controller.
We will now discuss various alarms and the procedure necessary to correct them.
Receiver (Rx) Has Remote Alarm:
A received remote alarm means there is an alarm occurring on the line upstream of the equipment connected to the port.
-
Check to see if the framing format configured on the port matches the framing format of the line. If not, change the framing format on the controller to match that of the line.
-
Check the linecoding setting on the remote-end equipment. Contact your service provider for the correct settings. Correct any misconfigurations as necessary.
-
Insert an external loopback cable into the port. To create a loopback plug, see the section «Performing Hardware Loopback Plug Test,» earlier in the chapter.
-
Check to see if there are any alarms. If you do not see any alarms, then the local hardware is probably in good condition. In that case:
-
Check the cabling. Refer to the section «If E1 Receiver Has Loss of Signal» for more information.
-
Check the settings at the remote end and verify that they match your port settings.
-
If the problem persists, contact your service provider.
-
-
Remove the loopback plug and reconnect your E1 line.
-
Check the cabling. See the section «If E1 Receiver Has Loss of Signal» for more information.
-
Power-cycle the router.
-
Connect the E1 line to a different port. Configure the port with the same settings as that of the line. If the problem does not persist, then the fault lies with the one port:
-
Reconnect the E1 line to the original port.
-
Proceed to the «Troubleshooting E1 Error Events» section.
If the problem persists, then:
-
-
Perform a hardware loop test as described in the section «Performing Hardware loopback Plug Test»
-
Replace the E1 controller card.
-
Proceed to the «Troubleshooting E1 Error Events» section.
Transmitter Sending Remote Alarm (Red):
A Red alarm is declared when the CSU cannot synchronize with the framing pattern on the E1 line.
-
Check to see if the framing format configured on the port matches the framing format of the line. If not change the framing format on the controller to match that of the line.
-
Check the settings at the remote end and verify that they match your port settings.
-
Insert an external loopback cable into the port. To create a loopback plug, see the section «Performing Hardware Loopback Plug Test,» earlier in the chapter.
-
Check to see if there are any alarms. If you do not see any alarms, then the local hardware is probably in good condition. In that case:
-
Check the cabling. Refer to the section «If E1 Receiver Has Loss of Signal» for more information.
-
If the problem persists, contact your service provider.
-
-
Connect the E1 line to a different port. Configure the port with the same settings as that of the line. If the problem does not persist, then the fault lies with the one port.
-
Reconnect the E1 line to the original port.
-
Proceed to the «Troubleshooting E1 Error Events» section.
If the problem persists, then:
-
-
Perform a hardware loop test as described in the section «Performing Hardware Loopback Plug Test.»
-
Replace the E1 controller card.
-
Proceed to the «Troubleshooting E1 Error Events» section.
-
Contact your service provider.
Troubleshooting E1 Error Events
The show controller e1 EXEC command provides error messages that can be used to troubleshoot problems. We will now discuss several error messages and how to correct the errors.
To see if the error counters are increasing, execute the show controller e1 command repeatedly. Note the values of the counters for the current interval. Consult your service provider for framing and linecoding settings.
Slip Secs Counter is increasing:
The presence of slips on E1 lines indicates a clocking problem. The E1 provider (Telco) will provide the clocking to which the Customer Premises Equipment (CPE) should be synchronized.
-
Verify that the clock source is derived from the network. This can be ascertained by looking for Clock Source is Line Primary.
Note: If there are multiple E1s in an access server, only one can be the primary, while the other E1s derive the clock from the primary. In that case, verify that the E1 line designated as the primary clock source is configured correctly.
-
Set the E1 clock source correctly from the controller configuration mode.
maui-nas-03(config-controlle)#clock source line primary
Framing Loss Seconds Counter is Increasing:
Follow these steps when framing loss seconds counter is increasing:
-
Check to see if the framing format configured on the port matches the framing format of the line. You can check this by looking for the Framing is {CRC4|no CRC4} in the show controller e1 output.
-
To change the framing format use the framing {CRC4 | no CRC4} command in the controller configuration mode as shown below:
maui-nas-03(config-controlle)#framing crc4
Line Code Violations are Increasing:
Follow these steps when line code violations are increasing.
-
Check to see if the linecoding configured on the port matches the framing format of the line. You can check this by looking for the Line Code is {AMI/HDB3} in the show controller e1 output.
-
To change the linecoding, use the linecode {ami | hdb3} command in the controller configuration mode as shown below:
maui-nas-03(config-controlle)#linecode ami
Verifying that ISDN Switch Type and PRI-Group are Configured Correctly
Use the show running-config command to check if ISDN switch type and the PRI-group timeslots are configured correctly. Contact your service provider for correct values.
To change the ISDN switch type and PRI-group:
maui-nas-03#configure terminal maui-nas-03(config)#isdn switch-type primary-net5 maui-nas-03(config)#controller e1 0 maui-nas-03(config-controlle)#pri-group timeslots 1-31
Verifying the Signaling Channel
If the error counters do not increase but the problem persists, verify that the signaling channel is up and configured correctly.
-
Run the show interface serial x:15 command, where x should be replaced by the interface number.
-
Check to see if the interface is up. If the interface is not up, use the no shutdown command to bring the interface up.
maui-nas-03#config terminal Enter configuration commands, one per line. End with CNTL/Z. maui-nas-03(config)#interface serial 0:15 maui-nas-03(config-if)#no shutdown
-
Ensure that encapsulation is PPP. If the interface is not using PPP, then use the encapsulation ppp command in the interface configuration mode to correct it.
maui-nas-03(config-if)#encapsulation ppp
-
Check to see if loopback is set. Loopback should be set only for testing purposes. Use the no loopback command to remove loopbacks.
maui-nas-03(config-if)#no loopback
-
Power-cycle the router.
-
If the problem persists, contact your service provider or the Cisco TAC.
Troubleshooting a PRI
When troubleshooting a PRI, you need to determine if the E1 is running cleanly on both ends. If Layer 1 problems have been resolved as described above, consider Layer 2 and Layer 3 problems.
Troubleshooting Using the show isdn status Command
The show isdn status command is used to display a snapshot of all ISDN interfaces. It displays the status of Layers 1, 2 and 3.
-
Verify that Layer 1 is active.
The Layer 1 status should always say ACTIVE unless the E1 is down.
If show isdn status indicates that Layer 1 is DEACTIVATED, then there is a problem with the physical connectivity on the E1 line. See the section «Is the E1 Controller Administratively Down?»
Also verify that the E1 is not administratively down. Use the no shutdown command to bring the E1 controller up.
-
Check to see if the Layer 2 State is MULTIPLE_FRAME_ESTABLISHED.
The desired Layer 2 state is Multiple_Frame_Established, which indicates the startup protocol between ISDN switch and end-device has been established and we are exchanging Layer 2 frames.
If Layer 2 is not Multiple_Frame_Established, use the show controller e1 EXEC command to diagnose the problem. See «Troubleshooting Using the show controller e1 Command» section in this chapter and the «Troubleshooting E1 Error Events» section.
Because show isdn status is a snapshot of the current status, it is possible that Layer 2 is bouncing up and down despite indicating Mulitple_Frame_Established. Use the debug isdn q921 command to verify that Layer 2 is stable.
Using debug q921
The debug isdn q921 command displays data link layer (Layer 2) access procedures that are taking place at the router on the D-channel.
Ensure that you are configured to view debug messages by using the logging console or terminal monitor command as necessary.
Note: In a production environment, verify that console logging is disabled. Enter the show logging command. If logging is enabled, the access server may intermittently freeze up as soon as the console port gets overloaded with log messages. Enter the no logging console command.
Note: If debug isdn q921 is turned on and you do not receive any debug outputs, place a call or reset the controller to get debug outputs.
-
Verify that Layer 2 is stable. You should observe the debug outputs for messages indicating that the service is not bouncing up and down. If you see the following types of debug outputs, the line is not stable.
Mar 20 10:06:07.882: %ISDN-6-LAYER2DOWN: Layer 2 for Interface Se0:15, TEI 0 changed to down Mar 20 10:06:09.882: %LINK-3-UPDOWN: Interface Serial0:15, changed state to down Mar 20 10:06:21.274: %DSX1-6-CLOCK_CHANGE: Controller 0 clock is now selected as clock source Mar 20 10:06:21.702: %ISDN-6-LAYER2UP: Layer 2 for Interface Se0:15, TEI 0 changed to up Mar 20 10:06:22.494: %CONTROLLER-5-UPDOWN: Controller E1 0, changed state to up Mar 20 10:06:24.494: %LINK-3-UPDOWN: Interface Serial0:15, changed state to up
If Layer 2 does not appear to be stable, see «Troubleshooting E1 Error Events,» earlier in this chapter.
-
Verify that you are seeing only SAPI messages in both transmit (TX) and Receive (RX) sides.
Mar 20 10:06:52.505: ISDN Se0:15: TX -> RRf sapi = 0 tei = 0 nr = 0 Mar 20 10:06:52.505: ISDN Se0:15: RX <- RRf sapi = 0 tei = 0 nr = 0 Mar 20 10:07:22.505: ISDN Se0:15: TX -> RRp sapi = 0 tei = 0 nr = 0 Mar 20 10:07:22.509: ISDN Se0:15: RX <- RRp sapi = 0 tei = 0 nr = 0 Mar 20 10:07:22.509: ISDN Se0:15: TX -> RRf sapi = 0 tei = 0 nr = 0 Mar 20 10:07:22.509: ISDN Se0:15: RX <- RRf sapi = 0 tei = 0 nr = 0
-
Verify that you are not seeing SABME messages, which indicates that Layer 2 is trying to reinitialize. This is usually seen when we are transmitting poll requests (RRp) and not getting a response from the switch (RRf) or vice-versa. Below are example of SABME messages. We should get a response from ISDN switch for our SABME messages (UA frame received).
Mar 20 10:06:21.702: ISDN Se0:15: RX <- SABMEp sapi = 0 tei = 0 Mar 20 10:06:22.494: ISDN Se0:15: TX -> SABMEp sapi = 0 tei = 0
If you are seeing SABME messages, use the show running-config command to check if ISDN switch type and the PRI-group timeslots are configured correctly. Contact your service provider for correct values.
To change the ISDN switch type and PRI-group:
maui-nas-03#configure terminal maui-nas-03(config)#isdn switch-type primary-net5 maui-nas-03(config)#controller e1 0 maui-nas-03(config-controlle)#pri-group timeslots 1-31
-
Verify that the D-channel is up using the show interfaces serial x:15 command.
If the D-channel is not up, then use the no shutdown command to bring it up:
maui-nas-03(config)#interface serial 0:15 maui-nas-03(config-if)#no shutdown
-
Check to see if encapsulation is PPP. If not use the encapsulation ppp command to set encapsulation.
maui-nas-03(config-if)#encapsulation ppp
-
Check to see if the interface is in loopback mode. For normal operation, the interface should not be in loopback mode.
maui-nas-03(config-if)#no loopback
-
Power-cycle the router.
-
If the problem persists, contact your service provider or the Cisco TAC.
Related Information
- Technical Support — Cisco Systems
Contents
Introduction
This document describes how to resolve fabric errors reported in the Cisco Nexus 7000 platform. A troubleshoot of fabric Cyclic Redundancy Checksums (CRCs) involves the collection of data, data analysis, and an elimination process in order to isolate the problem component. This document covers the most common types of fabric CRC errors.
Fabric CRC Detection Overview
Here is a high-level diagram of a Nexus 7018 fabric module with M1 linecards:

The previous image gives an overview of the components involved when a packet traverses a fabric module. Stage 1 (S1), Stage 2 (S2), and Stage 3 (S3) are the three stages of the Nexus 7000 fabric, Octopus is the queue engine, Santa Cruz (SC) is the fabric ASIC, and Instance 1 and 2 are the two SC instances on the XBAR. This document considers only one XBAR. Please remember that most of the Nexus 7000 Series switches have three or more XBARs installed.
With the assumption that a unidirectional flow from Module 1 (M1) to Module 2 (M2) is present, the ingress Octopus-1 on M1 performs error checks on packets it receives from the south, and the egress Octopus-1 on M2 from the north. If CRC is detected in S3, a problem might have happened in S1 or S2 also, since no CRC check is performed in those stages. So, the devices involved in the path are the ingress Octopus, chassis, crossbar fabric, and egress Octopus.
In M1/Fab1 architecture, CRCs are detected only on the egress linecard (S3).
Here is a sample error message:
%OC_USD-SLOT1-2-RF_CRC: OC1 received packets with
CRC error from MOD 15 through XBAR slot 1/inst 1
This is reported by M1, which indicates that it received packets with the wrong CRC from Module 15 (M15) via XBAR slot 1/instance 1.
Understand the Different Fabric CRC Errors
This section describes four of the most common types of fabric CRC Errors.
- CRC error with a single source module, receive module, and XBAR instance:
%OC_USD-SLOT1-2-RF_CRC: OC1 received packets with
CRC error from MOD 15 through XBAR slot 1/inst 1This means that the module in slot 1 detected a CRC error from M15 through XBAR slot 1/instance 1. The module where the CRC errors originate is referred to as the ingress module (M15 in this case), and the module that reported the problem is the egress module (M1). XBAR 1 is the cross bar in which the packet was received. There are two instances per XBAR. In this case, M1 detected CRC errors from M15 through XBAR slot 1 instance 1.
- CRC error with a single source module, receive module, but no XBAR instance:
%OC_USD-SLOT4-2-RF_CRC: OC2 received packets with
CRC error from MOD 1In this message, Module 4 (M4) reported the CRC error from M1. Notice that the XBAR information is missing. The system is unable to ascertain the XBAR that the packet traversed. There are many reasons, but the most common ones are: The information in the fabric header of the packet might be corrupt, so the source module cannot be determined; the XBAR that was traversed is removed from the system since the error incremented. Thus, it was not reported in the hourly syslog message.
- CRC error with no receive module:
%OC_USD-2-RF_CRC: OC1 received packets with
CRC error from MOD 16 through XBAR slot 1/inst 1In this instance, a device detected a CRC from Module 16 (M16) through XBAR 1. There is, however, no receiver module. When the Supervisor (SUP) detects a CRC that comes from the fabric module, the slot information is not logged. When you do not see slot information, then the SUP detected the problem. This does not mean that the SUP is bad. Just as when the module reports the problem, there are multiple components that might have caused the problem: M16, the chassis (not as likely), XBAR 1, or the SUP.
- CRC error with multiple possible source modules:
%OC_USD-SLOT6-2-RF_CRC: OC2 received packets with
CRC error from MOD 11 or 12 or 14 or 15 or 16 or 17 or 18The source module is gleaned from the ingress Octopus that sourced the bad packet. The driver that raises an interrupt in order to log this error message does not always know the ingress Octopus from which the bad packet originated. This is because some of the bits used in order to represent the ingress Octopus are not used. If the system determines multiple modules have these unused bits turned on, the system must assume that any one of them might be the source, which causes the error message to include all of those modules. The system found that Module 13 (M13) cannot have this conflict due to those bits not being used; thus, it is not logged as a potential source.
Fabric CRC Troubleshoot Approach
New linecards (M2) and fabric module 2 (FAB2) detect CRCs in S1, S2, or S3. When you investigate in detail and find patterns in the failure and log messages, it helps isolate the faulty component.
Here are some questions to ask:
- Was the error message a one-time event, or have multiple CRC error messages been logged?
- How frequently are the CRC error messages logged? (Every hour, once a day, once a month?)
- Do the CRC errors ALL come from the same ingress module?
- Are the CRC errors ALL reported on the same egress module?
- Are the CRC errors from multiple ingress modules AND reported on multiple egress modules?
- If multiple modules report CRC errors, is there a common source module or XBAR module?
Answers to the these questions allow you to approach the troubleshoot procedure from an angle that is more likely to lead to faster resolution.
General CRC Troubleshoot Guidelines
This section establishes a general framework used in order to troubleshoot these issues.
- Find the common modules (including XBARs) that are reported in the fabric CRC error messages.
- After you find the common modules, pick the most likely cause of the problem, shut down (in case of XBAR), move it to a known slot that works, reseat, and replace it while you monitor in order to verify if the problem goes away. Shut down, reseat, and replace modules one at a time. This makes it easier to isolate the faulty part.
- When you shutdown, move, reseat, or replace a part, look for any changes in the problem symptoms. You might have to revise your action plan after you learn more from each step taken.
- If multiple parts are replaced and the problem still persists, then:
- The new parts might be bad.
- Multiple XBARs might be bad.
- A bad chassis slot might be the cause.
Case Studies
This section provides examples of how to troubleshoot similar problems.
Ingress Module Corrupts the Packets
Logs
%OC_USD-SLOT1-2-RF_CRC: OC2 received packets with CRC error from MOD 7
%OC_USD-SLOT3-2-RF_CRC: OC2 received packets with CRC error from MOD 7
%OC_USD-SLOT1-2-RF_CRC: OC2 received packets with CRC error from MOD 7
%OC_USD-SLOT3-2-RF_CRC: OC2 received packets with CRC error from MOD 7
%OC_USD-SLOT1-2-RF_CRC: OC2 received packets with CRC error from MOD 7
%OC_USD-SLOT3-2-RF_CRC: OC2 received packets with CRC error from MOD 7
Problem
For a few hours, CRC errors are seen on M1 and Module 3 (M3) that come from Module 7 (M7) only.
Probable Cause of the Problem
There is a bad or mis-seated XBAR that corrupts packets headed to M7, or M7 is bad or mis-seated.
Faulty Component Isolation Process
- Shutdown the XBARs one-by-one while you monitor in order to verfiy if the problem is resolved.
- Reseat the ingress M7 while you monitor.
- Replace the M7 while you monitor.
If you have three XBARs installed, it gives you N+1 redundancy. Therefore, you are able to shut them down one at a time (never shut down more than one at any given time) with only minimal impact in order to see if the problem is resolved. Enter these commands in order to complete this process:
N7K(config)# poweroff xbar 1<monitor>
N7K(config)# no poweroff xbar 1
N7K(config)# poweroff xbar 2<monitor>
N7K(config)# no poweroff xbar 2
N7K(config)# poweroff xbar 3
N7K(config)# no poweroff xbar 3
In this particular case study, the problem was not resolved when the XBARs were shut down.
As there are two modules that report CRC errors, it is unlikely that those two modules (M1 & M3) are the cause. The next step is to reseat M7 (ingress module), because it is most likely the faulty component. Mis-seated linecards might cause this problem, and it is recommended to reseat the module before replacement.
In this case study, CRC errors continued to increment on the fabric module after a reseat of M7. Contact the Cisco Technical Assistance Center (TAC) at this point (or before this point) in order to replace M7 since a reseat does not resolve the problem.
In this case study, the replacement of M7 stopped the fabric CRC error messages, and resolved the packet loss.
Mis-Seated XBAR Injects Corrupt Packets
Logs
%OC_USD-SLOT11-2-RF_CRC: CRC error from MOD 12 through XBAR slot 3/inst 1
%OC_USD-SLOT12-2-RF_CRC: CRC error from MOD 12 through XBAR slot 3/inst 1
%OC_USD-SLOT13-2-RF_CRC: CRC error from MOD 12 through XBAR slot 3/inst 1
%OC_USD-SLOT15-2-RF_CRC: CRC error from MOD 12 through XBAR slot 3/inst 1
%OC_USD-SLOT2-2-RF_CRC: CRC error from MOD 12 through XBAR slot 3/inst 1
%OC_USD-SLOT4-2-RF_CRC: CRC error from MOD 12 through XBAR slot 3/inst 1
%OC_USD-SLOT5-2-RF_CRC: CRC error from MOD 12 through XBAR slot 3/inst 1
%OC_USD-SLOT6-2-RF_CRC: CRC error from MOD 12 through XBAR slot 3/inst 1
%OC_USD-SLOT7-2-RF_CRC: CRC error from MOD 12 through XBAR slot 3/inst 1
%OC_USD-SLOT8-2-RF_CRC: CRC error from MOD 12 through XBAR slot 3/inst 1
Problem
Multiple modules report CRC errors from Module 12 (M12) that go through XBAR 3.
Probable Cause of the Problem
XBAR 3 is bad or mis-seated, or M12 is mis-seated or faulty.
Faulty Component Isolation Process
- Shutdown XBAR 3 while you monitor.
- Reseat the ingress M12 while you monitor.
- Replace M12 while you monitor.
In this case, XBAR 3 is shut down with the procedure previously described (in the first case study), and monitored for further errors. It was found that errors ceased when XBAR 3 was shut down. At this point, XBAR 3 is reseated, and care is taken in order to ensure that no pins are bent on the midplane and that the module is properly inserted. After XBAR 3 is reenabled, the problem never reoccurs. This problem is attributed to a mis-seated XBAR module.
Faulty Egress Module Corrupts Packets from the Fabric
Logs
%OC_USD-SLOT6-2-RF_CRC: OC1 received packets with CRC error from
MOD 1 or 2 or 7 or 13 or 17 through XBAR
slot 1/inst 1 and slot 2/inst 1 and slot 3/inst 1%OC_USD-SLOT6-2-RF_CRC: OC2 received packets with CRC error from
MOD 1 or 2 or 3 or 7 or 15 or 17 through XBAR
slot 2/inst 1 and slot 3/inst 1%OC_USD-SLOT6-2-RF_CRC: OC1 received packets with CRC error from
MOD 1 or 2 or 5 or 7 or 16 or 17 through XBAR
slot 1/inst 1 and slot 2/inst 1 and slot 3/inst 1
Problem
Module 6 (M6) reports packets with CRC errors received from multiple linecards and XBARs.
Probable Cause of the Problem
M6 is mis-seated or bad.
Faulty Component Isolation Process
- Reseat M6 while you monitor.
- Replace M6 while you monitor.
M6 is the most-likely cause of this issue because it is the one common modules in all of the error messages. Of all the modules listed in the error messages, the one that most consistently appears is M6. Therefore, attempt to reseat M6 in order to see if the issue is resolved before you replace it.
In this case, M6 is reseated, but the errors still persist. So, you must open a Cisco TAC case in order to have M6 replaced. After M6 is replaced, the errors are not reported.
Troubleshoot Commands
Here is a list of the commands used in order to troubleshoot/debug:
- show clock
- show mod xbar
- show hardware fabric-utilization detail
- show hardware fabric-utilization detail timestamp
- show hardware internal xbar-driver all event-history errors
- show hardware internal xbar-driver all event-history msgs
- show system internal xbar-client internal event-history msgs
- show system internal xbar all
- show module internal event-history xbar 1
- show module internal activity xbar 1
- show module internal event-history xbar 2
- show module internal activity xbar 2
- show module internal event-history xbar 3
- show module internal activity xbar 3
- show module internal event-history xbar 4
- show module internal activity xbar 4
- show module internal event-history xbar 5
- show module internal activity xbar 5
- show logging onboard internal xbar
- show logging onboard internal octopus
- show tech detail
![]() Re: Ошибки на портах типа: input errors, CRC
Re: Ошибки на портах типа: input errors, CRC
Mr_skvish писал(а):
cable-diagnostics используем встроенный в Cisco. Да и отдельно lan-tester’ом прозванивали (ерунда конечно, но что есть). Линия в норме. Линию мерили от и до. Что касается кабеля, он точно не говеный)
Если бы вы флюком промеряли я бы не усомнился, а так ошибка в линии 99%. Я не сильно разбирался в этом тестере, но не думаю что встроенный в Cisco умеет мерять всякие наводки типа next/fext и т.д. Вдруг где кабель силовой рядом?
Может быть ошибка конкретного порта, но элементарно проверяется же, втыкаете в порт с ошибками CRC напрямую комп и смотрите есть ли ошибки, желательно прогнать чем нибудь типо iperf, иногда ошибки вылезают только на высоких скоростях ( но это скорее в случае линии). Если ошибок нет на конкретном порту, то точно ошибка в линии. Согласование портов проверили по скоростям и дуплексу?
Вот Cisco troubleshooting ethernet guide, в котором четко написано почему могут быть CRC ошибки.
http://www.cisco.com/en/US/docs/interne … r1904.html
Indicates that the cyclic redundancy checksum generated by the originating LAN station or far-end device does not match the checksum calculated from the data received. On a LAN, this usually indicates noise or transmission problems on the LAN interface or the LAN bus itself. A high number of CRCs is usually the result of collisions or a station transmitting bad data.
Так что другой причины быть не может, и почему такие ошибки возникают в официальном гайде четко описано, раз моим словам не верите. Так что не разделяю вашей уверенности в том, что с линией все ок, ошибку надо искать именно там.
Часть 1 Часть 2
Содержание
Самые распространенные команды по устранению неполадок портов и интерфейсов для CatOS и Cisco IOS
Основные сведения о выходных данных счетчиков портов и интерфейсов для CatOS и Cisco IOS
Команды Show Port для CatOS и Show Interfaces для Cisco IOS
Команды Show Mac для CatOS и Show Interfaces Counters для Cisco IOS
Команды Show Counters для CatOS и Show Counters Interface для Cisco IOS
Команда Show Controller Ethernet-Controller для Cisco IOS
Команда Show Top для CatOS
Распространенные сообщения о системных ошибках
Сообщения об ошибках в модулях WS-X6348
%PAGP-5-PORTTO / FROMSTP и %ETHC-5-PORTTO / FROMSTP
%SPANTREE-3-PORTDEL_FAILNOTFOUND
%SYS-4-PORT_GBICBADEEPROM: / %SYS-4-PORT_GBICNOTSUPP
Команда отклонена: [интерфейс] не является коммутационным портом
Основные сведения о выходных данных счетчиков портов и интерфейсов для CatOS и Cisco IOS
На большинстве коммутаторов имеется механизм отслеживания пакетов и ошибок, происходящих в интерфейсах и портах. Распространенные команды, используемые для нахождения сведений этого типа, описываются в разделе Самые распространенные команды по устранению неполадок портов и интерфейсов для CatOS и Cisco IOS данного документа.
Примечание: На различных платформах и выпусках счетчики могут быть реализованы по-разному. Хотя значения счетчиков весьма точны, однако конструктивно они не являются очень точными. Для сбора точных статистических данных о трафике предлагается использовать анализатор сетевых пакетов для мониторинга нужных входящих и исходящих интерфейсов.
Чрезмерное количество ошибок обычно указывает на проблему. В полудуплексном режиме нормальной является регистрация некоторого количества ошибок соединения в счетчиках FCS, выравнивания, пакетов с недопустимо малой длиной и конфликтов. Обычно один процент ошибок по отношению ко всему трафику является приемлемым для полудуплексных соединений. Если количество ошибок по отношению к входящим пакетам превысило два или три процента, может стать заметным спад производительности.
В полудуплексных средах коммутатор и подключенное устройство могут одновременно обнаружить канал и начать передачу, что приводит к конфликту. Конфликты могут вызвать появление пакетов с недопустимо малой длиной, последовательности FCS и ошибки выравнивания, так как кадр не полностью копируется в канал, что приводит к фрагментации кадра.
В дуплексном режиме значение счетчиков ошибок последовательности FCS, контрольной суммы CRC, выравнивания и пакетов с недопустимо малой длиной должно быть минимальным. Если соединение работает в режиме полного дуплекса, счетчик конфликтов неактивен. Если показания счетчиков ошибок последовательности FCS, контрольной суммы CRC, выравнивания или пакетов с недопустимо малой длиной увеличиваются, проверьте соответствие дуплексных режимов. Для определения дуплексного режима вы можете обратиться в компанию выполняющую регулярное обслуживание сетевых устройств и компьютеров вашей организации. Несоответствие дуплексных режимов возникает, когда коммутатор работает в дуплексном режиме, а подключенное устройство — в полудуплексном, или наоборот. Следствиями несоответствия дуплексных режимов являются чрезвычайно медленная передача, периодические сбои подключения и потеря связи. Другие возможные причины ошибок канала передачи данных в полнодуплексном режиме — дефекты кабелей, неисправные порты коммутатора, программные или аппаратные неполадки сетевой платы. Дополнительные сведения см. в разделе Распространенные проблемы портов и интерфейсов данного документа.
Команды Show Port для CatOS и Show Interfaces для Cisco IOS
Команда show port {mod/port} используется в ОС CatOS в модуле Supervisor. Альтернатива этой команды — команда show port counters {mod/port}, которая отображает только счетчики ошибок портов. Описание выходных данных счетчиков ошибок см. в таблице 1.
Switch> (enable) sh port counters 3/1 Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize ----- ---------- ---------- ---------- ---------- --------- 3/1 0 0 0 0 0 Port Single-Col Multi-Coll Late-Coll Excess-Col Carri-Sen Runts Giants ----- ---------- ---------- ---------- ---------- --------- --------- --------- 3/1 0 0 0 0 0 0 0
Команда show interfaces card-type {slot/port} — эквивалентная команда для Cisco IOS в модуле Supervisor. Альтернативой данной команды (для коммутаторов серии Catalyst 6000, 4000, 3550, 2970 2950/2955 и 3750) является команда show interfaces card-type {slot/port} counters errors , которая отображает счетчики ошибок интерфейсов.
Примечание: Для коммутаторов серии 2900/3500XL используйте только команду show interfaces card-type {slot/port} с командной show controllers Ethernet-controller .
Router#sh interfaces fastEthernet 6/1 FastEthernet6/1 is up, line protocol is up (connected) Hardware is C6k 100Mb 802.3, address is 0009.11f3.8848 (bia 0009.11f3.8848) MTU 1500 bytes, BW 100000 Kbit, DLY 100 usec, reliability 255/255, txload 1/255, rxload 1/255 Encapsulation ARPA, loopback not set Full-duplex, 100Mb/s input flow-control is off, output flow-control is off ARP type: ARPA, ARP Timeout 04:00:00 Last input 00:00:14, output 00:00:36, output hang never Last clearing of "show interface" counters never Input queue: 0/2000/0/0 (size/max/drops/flushes); Total output drops: 0 Queueing strategy: fifo Output queue :0/40 (size/max) 5 minute input rate 0 bits/sec, 0 packets/sec 5 minute output rate 0 bits/sec, 0 packets/sec
Команда show interfaces выдает на экран выходные данные до описанной здесь точки (по порядку):
-
up, line protocol is up (connected) — Первое «up» относится к состоянию физического уровня интерфейса. Сообщение «line protocol up» показывает состояние уровня канала передачи данных для данного интерфейса и означает, что интерфейс может отправлять и принимать запросы keepalive.
-
MTU – максимальный размер передаваемого блока данных (MTU) составляет 1500 байт для Ethernet по умолчанию (максимальный размер блока данных кадра).
-
Full-duplex, 100Mb/s (полнодуплексный, 100 Мбит/с) — текущая скорость и режим дуплексирования для данного интерфейса. Но это не позволяет узнать, использовалось ли для этого автоматическое согласование.
-
Последние входные, выходные данные — число часов, минут и секунд с момента последнего успешного приема или передачи интерфейсом пакета. Полезно знать время отказа заблокированного интерфейса.
-
Последнее обнуление счетчиков «show interface» — время последнего применения команды clear counters после последней перезагрузки коммутатора. Команда clear counters используется для сброса статистики интерфейса.
Примечание: Переменные, которые могут повлиять на маршрутизацию (например, на загрузку и надежность), не очищаются вместе со счетчиками.
-
Очередь входа — число пакетов в очереди входа. Size/max/drops = текущее число кадров в очереди/максимальное число кадров в очереди (до начала потерь кадров)/фактическое число потерянных кадров из-за превышения максимального числа кадров. Сбросы используется для подсчета выборочного отбрасывания пакетов на коммутаторах серии Catalyst 6000 с ОС Cisco IOS. (Счетчик сбросов может использоваться, но его показания не увеличиваются на коммутаторах серии Catalyst 4000 с Cisco IOS.) Выборочное отбрасывание пакетов — механизм быстрого отбрасывания пакетов с низким приоритетом в случае перегрузки ЦПУ, чтобы сохранить некоторые вычислительные ресурсы для пакетов с высоким приоритетом.
-
Общее число выходных сбросов – количество пакетов, сброшенных из-за заполнения очереди выхода. Типичной причиной этого может быть коммутация трафика из канала с высокой пропускной способностью в канал с меньшей пропускной способностью, либо коммутация трафика из нескольких входных каналов в один выходной канал. Например, если большой объем пульсирующего трафика поступает в гигабитный интерфейс и переключается на интерфейс 100 Мбит/с, это может вызвать увеличение отбрасывания исходящего трафика на интерфейсе 100 Мбит/с. Это происходит потому, что очередь выхода на указанном интерфейсе переполняется избыточным трафиком из-за несоответствия скорости входящей и исходящей полосы пропускания.
-
Очередь выхода — число пакетов в очереди выхода. Size/max означает текущее число кадров в очереди/максимальное количество кадров, которое может находиться в очереди до заполнения, после чего начинается отбрасывание кадров.
-
Пятиминутная скорость ввода/вывода – средняя скорость ввода и вывода, которая наблюдалась интерфейсом за последние пять минут. Чтобы получить более точные показания за счет указания более короткого периода времени (например, для улучшения обнаружения всплесков трафика), выполните команду интерфейса load-interval <секунды>.
В остальной части выходных данных команды show interfaces отображаются показания счетчиков ошибок, которые аналогичны или эквивалентны показаниям счетчиков ошибок в CatOS.
Команда show interfaces card-type {slot/port} counters errors эквивалентна команде Cisco IOS для отображения счетчиков портов для CatOS. Описание выходных данных счетчиков ошибок см. в таблице 1.
Router#sh interfaces fastEthernet 6/1 counters errors
Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards Fa6/1
0 0 0 0 0 0
Port Single-Col Multi-Col Late-Col Excess-Col Carri-Sen Runts Giants Fa6/1
0 0 0 0 0 0 0
Таблица 1.
Сведения о счетчиках ошибок CatOS содержатся в выходных данных команды show port или show port counters для коммутаторов серии Cisco Catalyst 6000, 5000 и 4000. Сведения о счетчиках ошибок Cisco IOS содержатся в выходных данных команды show interfaces или show interfaces card-type x/y counters errors для коммутаторов серии Catalyst 6000 и 4000
|
Счетчики (в алфавитном порядке) |
Описание и распространенные причины увеличения значений счетчиков ошибок |
|---|---|
|
Align-Err |
Описание: CatOS sh port и Cisco IOS sh interfaces counters errors. Количество ошибок выравнивания определяется числом полученных кадров, которые не заканчиваются четным числом октетов и имеют неверную контрольную сумму CRC. Распространенные причины: они обычно являются результатом несоответствия дуплексных режимов или физической проблемы (такой как прокладка кабелей, неисправный порт или сетевая плата). При первом подключении кабеля к порту могут возникнуть некоторые из этих ошибок. Кроме того, если к порту подключен концентратор, ошибки могут вызвать конфликты между другими устройствами концентратора. Исключения для платформы: ошибки выравнивания не подсчитываются в Catalyst 4000 Series Supervisor I (WS-X4012) или Supervisor II (WS-X4013). |
|
Перекрестные помехи |
Описание: Cisco IOS sh interfaces счетчик. Счетчик CatOS, указывающий на истечение срока таймера передачи сбойных пакетов. Сбойный пакет — это кадр длиной свыше 1518 октетов (без кадрирующих битов, но с октетами FCS), который не заканчивается четным числом октетов (ошибка выравнивания) или содержит серьезную ошибку FCS). |
|
Carri-Sen |
Описание: CatOS sh port и Cisco IOS sh interfaces counters errors. Значение счетчика Carri-Sen (контроль несущей) увеличивается каждый раз, когда контроллер Ethernet собирается отослать данные по полудуплексному соединению. Контроллер обнаруживает провод и перед передачей проверяет, не занят ли он. Распространенные причины: это нормально для полудуплексного сегмента Ethernet. |
|
конфликты |
Описание: Cisco IOS sh interfaces счетчик. Число конфликтов, произошедших до того, как интерфейс успешно передал кадр носителю. Распространенные причины: это нормальное явление для полудуплексных интерфейсов, но не для полнодуплексных интерфейсов. Быстрый рост числа конфликтов указывает на высокую загрузку соединения или возможное несоответствие дуплексных режимов с присоединенным устройством. |
|
CRC |
Описание: Cisco IOS sh interfaces счетчик. Значение данного счетчика увеличивается, когда контрольная сумма CRC, сгенерированная исходящей станцией ЛВС или устройством на дальнем конце, не соответствует контрольной сумме, рассчитанной по принятым данным. Распространенные причины: обычно это означает проблемы с шумами или передачей в интерфейсе ЛВС или самой ЛВС. Большое значение счетчика CRC обычно является результатом конфликтов, но может указывать на физическую неполадку (такую как проводка кабелей, неправильный интерфейс или неисправная сетевая плата) или несоответствие дуплексных режимов. |
|
deferred |
Описание: Cisco IOS sh interfaces счетчик. Число кадров, успешно переданных после ожидания освобождения носителя. Распространенные причины: они обычно наблюдаются в полудуплексных средах, в которых несущая уже используется при попытке передачи кадра. |
|
pause input |
Описание: Cisco IOS show interfaces счетчик. Приращение значения счетчика «pause input» означает, что подключенное устройство запрашивает приостановку трафика, когда его буфер приема почти заполнен. Распространенные причины: приращение показаний этого счетчика служит в информационных целях, так как коммутатор принимает данный кадр. Передача пакетов с запросом приостановки прекращается, когда подключенное устройство способно принимать трафик. |
|
input packetswith dribble condition |
Описание: Cisco IOS sh interfaces счетчик. Битовая ошибка указывает, что кадр слишком длинный. Распространенные причины: приращение показаний счетчика ошибок в кадрах служит в информационных целях, так как коммутатор принимает данный кадр. |
|
Excess-Col |
Описание: CatOS sh port и Cisco IOS sh interfaces counters errors. Количество кадров, для которых передача через отдельный интерфейс завершилась с ошибкой из-за чрезмерного числа конфликтов. Избыточный конфликт возникает, когда для некоторого пакета конфликт регистрируется 16 раз подряд. Затем пакет отбрасывается. Распространенные причины: чрезмерное количество конфликтов обычно обозначает, что нагрузку на данный сегмент необходимо разделить между несколькими сегментами, но может также указывать на несоответствие дуплексных режимов с присоединенным устройством. На интерфейсах, сконфигурированных в качестве полнодуплексных, конфликты наблюдаться не должны. |
|
FCS-Err |
Описание: CatOS sh port и Cisco IOS sh interfaces counters errors. Число кадров допустимого размера с ошибками контрольной последовательности кадров (FCS), но без ошибок кадрирования. Распространенные причины: обычно это указывает на физическую проблему (такую как прокладка кабелей, неисправный порт или сетевая плата), однако также может означать несоответствие дуплексных режимов. |
|
кадр |
Описание: Cisco IOS sh interfaces счетчик. Число неправильно принятых пакетов с ошибками контрольной суммы CRC и нецелым числом октетов (ошибка выравнивания). Распространенные причины: обычно это вызвано конфликтами или физической проблемой (например, проводкой кабелей, неисправным портом или сетевой платой), а также может указывать на несоответствие дуплексных режимов. |
|
Кадры с недопустимо большой длиной |
Описание: CatOS sh port и Cisco IOS sh interfaces и sh interfaces counters errors. Полученные кадры, размеры которых превышают максимально допускаемые стандартом IEEE 802.3 (1518 байт для сетей Ethernet без поддержки jumbo-кадров) и обладают неверной последовательностью FCS. Распространенные причины: во многих случаях это следствие поврежденной сетевой интерфейсной платы. Попробуйте найти проблемное устройство и удалить его из сети. Исключения для платформ: коммутаторы серии Catalyst Cat4000 с Cisco IOS версии, предшествующей 12.1(19)EW, показания счетчика кадров с недопустимо большой величиной увеличиваются в случае кадра размером > 1518 байтов. После версии 12.1(19)EW кадры giant в выходных данных команды show interfaces учитываются только в случае приема кадра размером > 1518 байтов с неверной последовательностью FCS. |
|
ignored |
Описание: Cisco IOS sh interfaces счетчик. Количество полученных пакетов, проигнорированных интерфейсом из-за недостатка места во внутренних буферах оборудования интерфейса. Распространенные причины: широковещательный шторм и всплески помех могут вызвать рост показаний данного счетчика. |
|
Ошибки ввода |
Описание: Cisco IOS sh interfaces счетчик. Распространенные причины: в счетчике учитываются ошибки кадров, кадры с недопустимо маленькой или недопустимо большой величиной, кадры, отброшенные из-за переполнения буфера, несоответствия значения контрольной суммы CRC или перегрузки, а также проигнорированные пакеты. Другие ошибки, относящиеся к входным данным, также могут увеличивать количество ошибок ввода; некоторые датаграммы могут содержать несколько ошибок. Поэтому эта сумма может не совпадать с суммой перечисленных ошибок ввода. Также см. раздел Ошибки ввода в интерфейсе уровня 3, подключенном к порту коммутатора уровня 2. |
|
Late-Col |
Описание: CatOS sh port и Cisco IOS sh interfaces и sh interfaces counters errors. Количество обнаруженных конфликтов в определенном интерфейсе на последних этапах процесса передачи. Для порта со скоростью 10 Мбит/с это позднее, чем время передачи 512 битов для пакета. В системе со скоростью передачи данных 10 Мбит/с 512 битовых интервалов соответствуют 51,2 микросекунды. Распространенные причины: это ошибка, в частности, может указывать на несоответствие дуплексных режимов. В сценарии с несоответствием дуплексных режимов на стороне с полудуплексным режимом наблюдается поздний конфликт. Во время передачи со стороны с полудуплексным режимом на стороне с дуплексным режимом выполняется одновременная передача без ожидания своей очереди, что приводит к возникновению позднего конфликта. Поздние конфликты также могут указывать на слишком большую длину кабеля или сегмента Ethernet. На интерфейсах, сконфигурированных в качестве полнодуплексных, конфликты наблюдаться не должны. |
|
lost carrier |
Описание: Cisco IOS sh interfaces счетчик. Число потерь несущей во время передачи. Распространенные причины: проверьте исправность кабеля. Проверьте физическое соединение на обеих сторонах. |
|
Multi-Col |
Описание: CatOS sh port и Cisco IOS sh interfaces counters errors. Число множественных конфликтов произошедших до того, как порт успешно передал кадр носителю. Распространенные причины: это нормальное явление для полудуплексных интерфейсов, но не для полнодуплексных интерфейсов. Быстрый рост числа конфликтов указывает на высокую загрузку соединения или возможное несоответствие дуплексных режимов с присоединенным устройством. |
|
no buffer |
Описание: Cisco IOS sh interfaces счетчик. Число принятых пакетов, которые отвергнуты из-за отсутствия буферного пространства. Распространенные причины: сравните со счетчиком пропущенных пакетов. Часто такие ошибки вызываются широковещательными штормами. |
|
Отсутствует несущая |
Описание: Cisco IOS sh interfaces счетчик. Сколько раз несущая отсутствовала во время передачи. Распространенные причины: проверьте исправность кабеля. Проверьте физическое соединение на обеих сторонах. |
|
Out-Discard |
Описание: количество исходящих пакетов, которые выбраны для отбрасывания несмотря на отсутствие ошибок Распространенные причины: одна возможная причина отбрасывания таких пакетов — освобождение буферного пространства. |
|
output buffer failuresoutput buffers swapped out |
Описание: Cisco IOS sh interfaces счетчик. Число буферов с ошибками и число выгруженных буферов. Распространенные причины: порт размещает пакеты в буфере Tx, когда скорость поступающего в порт трафика высока и порт не может обработать такой объем трафика. Порт начинает пропускать пакеты в случае заполнения буфера Tx, при этом увеличиваются значения счетчиков недогрузок и сбоев выходных буферов. Увеличение значений счетчиков сбоев выходных буферов может означать, что порты работают с минимальными настройками скорости и/или дуплексного режима, или через порт проходит слишком большой объем трафика. Например, рассмотрите сценарий, в котором гигабайтный многоадресный поток пересылается 24 портам с пропускной способностью 100 Мбит/с. Если выходной интерфейс перегружен, обычно наблюдаются сбои выходного буфера, число которых растет вместе с числом выходящих отброшенных пакетов (Out-Discards). Сведения об устранении неполадок см. в разделе Отложенные кадры (Out-Lost или Out-Discard) данного документа. |
|
output errors |
Описание: Cisco IOS sh interfaces счетчик. Сумма всех ошибок, препятствовавших целевой передаче датаграмм от заданного интерфейса. |
|
overrun (переполнение) |
Описание: сколько раз аппаратному оборудованию приемника не удалось поместить принятые данные в аппаратный буфер. Распространенные причины: входящая скорость трафика превысила способность приемника к обработке данных. |
|
packets input/output |
Описание: Cisco IOS sh interfaces счетчик. Общее количество безошибочных пакетов, полученных и переданных на данном интерфейсе. Мониторинг приращений показаний этих счетчиков полезен при проверке правильного прохождения трафика через интерфейс. Счетчик байтов включает эти данные и инкапсуляцию MAC-адресов в безошибочные пакеты, принятые и переданные системой. |
|
Rcv-Err |
Описание: CatOS show port или show port counters и Cisco IOS (только для коммутаторов серии Catalyst 6000) «sh interfaces counters error». Распространенные причины: см. исключения для платформ. Исключения для платформ: коммутаторы серии Catalyst 5000 rcv-err = сбои буферов приема. Например, кадры недопустимо маленькой или недопустимо большой величины или ошибки последовательности FCS (FCS-Err) не приводят к увеличению значения счетчика rcv-err. Значение счетчика rcv-err для 5K увеличивается только в случае избыточного трафика. В отличие от коммутаторов серии Catalyst 5000 на коммутаторах серии Catalyst 4000 значение rcv-err равно сумме всех ошибок приема, т.е. значение счетчика rcv-err увеличивается в случае регистрации таких ошибок, как прием интерфейсом кадров с недопустимо маленькой или недопустимо большой величиной или ошибки последовательности FCS. |
|
Кадры с недопустимо маленькой величиной |
Описание: CatOS sh port и Cisco IOS sh interfaces и sh interfaces counters errors. Принятые кадры с размером меньше минимального размера кадра IEEE 802.3 (64 байта для Ethernet) и неверной контрольной суммой CRC. Распространенные причины: это может быть вызвано несоответствием дуплексных режимов и физическими проблемами, такими как неисправный кабель, порт или сетевая плата на присоединенном устройстве. Исключения для платформ: на коммутаторах серии Catalyst 4000 с Cisco IOS версии, предшествующей версии 12.1(19)EW, кадры с недопустимо маленькой величиной — это кадры размера undersize. Undersize = кадр < 64 байтов. Значение счетчика кадров с недопустимо маленькой величиной увеличивается при получении кадра размером менее 64 байтов. После версии 12.1(19)EW кадр с недопустимо маленькой величиной = фрагмент. Фрагмент — это кадр < 64 байта с неверной контрольной суммой CRC. В результате значение счетчика кадров с недопустимо маленькой величиной увеличивается в show interfacesвместе со счетчиком фрагментов в show interfaces counters errors при получении кадра < 64 байтов с неверной контрольной суммой CRC. |
|
Single-Col |
Описание: CatOS sh port и Cisco IOS sh interfaces counters errors. Число конфликтов, произошедших до того, как интерфейс успешно передал кадр носителю. Распространенные причины: это нормальное явление для полудуплексных интерфейсов, но не для полнодуплексных интерфейсов. Быстрый рост числа конфликтов указывает на высокую загрузку соединения или возможное несоответствие дуплексных режимов с присоединенным устройством. |
|
underruns |
Описание: сколько раз скорость передатчика превышала возможности коммутатора. Распространенные причины: это может происходить в случае высокой пропускной способности, когда через интерфейс проходит большой объем пульсирующего трафика от многих других интерфейсов одновременно. В случае недогрузки возможен сброс интерфейса. |
|
Undersize |
Описание: CatOS sh port и Cisco IOS sh interfaces counters errors. Полученные фреймы с размером меньше минимального размера фрейма в стандарте IEEE 802.3, равного 64 байтам (без битов кадрирования, но с октетами FCS), но хорошо сформированных во всем остальном. Распространенные причины: проверьте устройство, отправляющее такие кадры. |
|
Xmit-Err |
Описание: CatOS sh port и Cisco IOS sh interfaces counters errors. Это указывает на заполнение внутреннего буфера отправки (Tx). Распространенные причины: часто ошибки Xmit-Err возникают из-за передачи трафика из канала с высокой пропускной способностью в канал с меньшей пропускной способностью или трафика из нескольких входящих каналов в один исходящий. Например, если большой объем пульсирующего трафика поступает в гигабитный интерфейс и переключается на интерфейс на 100 Мбит/с, на 100-мегабитном интерфейсе это может вызывать приращение значения счетчика Xmit-Err. Это происходит потому, что выходной буфер заданного интерфейса переполняется избыточным трафиком из-за несоответствия скорости входящей и исходящей полосы пропускания. |
Команды Show Mac для CatOS и Show Interfaces Counters для Cisco IOS
Команда show mac {mod/port} полезна при использовании CatOS в модуле Supervisor для отслеживания входящего и исходящего трафика данного порта в соответствии с показаниями счетчиков приема (Rcv) и передачи (Xmit) для трафика одноадресной, многоадресной и широковещательной рассылки. Эти выходные данные получены от Catalyst 6000, использующего CatOS:
Console> (enable) sh mac 3/1 Port Rcv-Unicast Rcv-Multicast Rcv-Broadcast-------- -------------------- -------------------- --------------------3/1 177 256272 3694Port Xmit-Unicast Xmit-Multicast Xmit-Broadcast-------- -------------------- -------------------- --------------------3/1 30 680377 153Port Rcv-Octet Xmit-Octet-------- -------------------- --------------------3/1 22303565 48381168 MACDely-Exced MTU-Exced In-Discard Out-Discard-------- ---------- ---------- ---------- -----------3/1 0 0 233043 17Port Last-Time-Cleared----- --------------------------3/1 Sun Jun 1 2003, 12:22:47
В данной команде также используются следующие счетчики ошибок: Dely-Exced, MTU-Exced, In-Discard и Out-Discard.
-
Dely-Exced — количество кадров, отклоненных данным портом из-за чрезмерной задержки передачи данных через коммутатор. Показания данного счетчика растут только при очень интенсивном использовании порта.
-
MTU Exceed — это показатель того, что одно из устройств на данном порту или сегменте передает объем данных больше, чем разрешено размером кадра (1518 байт для сети Ethernet без поддержки jumbo-кадров).
-
In-Discard – результат обработки допустимых входящих кадров, которые были отброшены, поскольку их коммутация не требовалась. Это может быть нормальным, если концентратор подключен к порту и два устройства на данном концентраторе обмениваются данными. Порт коммутатора продолжает видеть данные, но не переключает его (так как в таблице CAM отображается MAC-адрес обоих устройств, связанных с одним и тем же портом). Поэтому трафик отбрасывается. Значение данного счетчика также увеличивается в случае порта, настроенного в качестве магистрали, если данная магистраль блокирует некоторые сети VLAN, или в случае порта, который является единственным членом некоторой сети VLAN.
-
Out-Discard (Число отбрасываемых исходящих пакетов) – число исходящих пакетов, которые выбраны для отбрасывания несмотря на отсутствие ошибок. Одна из возможных причин отбрасывания таких пакетов — освобождение буферного пространства.
-
In-Lost — на коммутаторах серии Catalyst 4000; этот счетчик представляет собой сумму всех пакетов с ошибками, полученных данным портом. С другой стороны на коммутаторах серии Catalyst 5000 счетчик In-Lost отслеживает сумму всех сбоев буферов приема.
-
Out-Lost — на коммутаторах серии Catalyst 4000 и 5000 учитываются исходящие кадры, которые были потеряны до пересылки (из-за недостатка буферного пространства). Обычно это вызывается перегрузкой порта.
Команда show interfaces card-type {slot/port} counters используется при выполнении Cisco IOS в модуле Supervisor.
Команда show counters [mod/port] предоставляет еще более подробную статистику для портов и интерфейсов. Эта команда доступна для CatOS, а эквивалентная ей команда show counters interface card-type {slot/port} была введена в Cisco IOS версии 12.1(13)E только для коммутаторов серии Catalyst 6000. Эти команды отображают 32- и 64-разрядные счетчики ошибок для каждого порта или интерфейса. Дополнительные сведения см. в документации по командам CatOS show counters.
Команда Show Controller Ethernet-Controller для Cisco IOS
На коммутаторах серии Catalyst 3750, 3550, 2970, 2950/2955, 2940 и 2900/3500XL используйте команду «show controller ethernet-controller» для отображения выходных данных счетчика трафика и счетчика ошибок, которые аналогичны выходным данным команд sh port, sh interface, sh mac и show counters для коммутаторов серии Catalyst 6000, 5000 и 4000.
|
Счетчик |
Описание |
Возможные причины |
|---|---|---|
|
Переданные кадры |
||
|
Отброшенные кадры |
Общее количество кадров, попытка передачи которых прекращена из-за недостатка ресурсов. В это общее количество входят кадры всех типов назначения. |
Отбрасывание кадров вызвано чрезмерной нагрузкой трафиком данного интерфейса. Если в этом поле наблюдается рост числа пакетов, уменьшите нагрузку на данный интерфейс. |
|
Устаревшие кадры |
Число кадров, передача которых через коммутатор заняла более двух секунд. По этой причине они были отброшены коммутатором. Это случается только в условиях экстремально высокой нагрузки. |
Отбрасывание кадров вызвано чрезмерной нагрузкой трафиком данного коммутатора. Если в этом поле наблюдается рост числа пакетов, уменьшите нагрузку на данный коммутатор. Может потребоваться изменение топологии сети, чтобы снизить нагрузку трафиком данного коммутатора. |
|
Deferred frames (отложенные кадры) |
Общее число кадров, первая попытка передачи которых была отложена из-за трафика в сетевом носителе. В это общее число входят только кадры, которые в последствии передаются без ошибок и конфликтов. |
Отбрасывание кадров вызвано чрезмерной нагрузкой трафика, направленного к данному коммутатору. Если в этом поле наблюдается рост числа пакетов, уменьшите нагрузку на данный коммутатор. Может потребоваться изменение топологии сети, чтобы снизить нагрузку трафика на данный коммутатор. |
|
Collision frames (кадры с конфликтами) |
В счетчиках кадров с конфликтами содержится число пакетов, одна попытка передачи которых была неудачной, а следующая — успешной. Это означает, что в случае увеличения значения счетчика кадров с конфликтами на 2, коммутатор дважды неудачно пытался передать пакет, но третья попытка была успешной. |
Отбрасывание кадров вызвано чрезмерной нагрузкой трафиком данного интерфейса. Если в этих полях наблюдается рост числа пакетов, уменьшите нагрузку на данный интерфейс. |
|
Excessive collisions (частые конфликты) |
Значение счетчика частых конфликтов возрастает после возникновения 16 последовательных поздних конфликтов. Через 16 попыток отправки пакета, он отбрасывается, а значение счетчика возрастает. |
Увеличение значения этого счетчика указывает на проблему с проводкой, чрезмерно загруженную сеть или несоответствие дуплексных режимов. Чрезмерная загрузка сети может быть вызвана совместным использованием сети Ethernet слишком большим числом устройств. |
|
Late collisions (поздние конфликты) |
Поздний конфликт возникает, когда два устройства передают одновременно, но конфликт не обнаруживается ни одной из сторон соединения. Причина этого заключается в том, что время передачи сигнала с одного конца сети к другому превышает время, необходимое, чтобы поместить целый пакет в сеть. Два устройства, вызвавшие поздний конфликт, никогда не видят пакет, отправляемый другим устройством, пока он не будет полностью помещен в сеть. Поздние конфликты обнаруживаются передатчиком только после истечения первого временного интервала для передачи 64 байтов. Это связано с тем, что конфликты обнаруживаются только при передаче пакетов длиннее 64 байтов. |
Поздние конфликты являются следствием неправильной прокладки кабелей или несовместимого числа концентраторов в сети. Неисправные сетевые платы также могут вызывать поздние конфликты. |
|
Хорошие кадры (1 конфликт) |
Общее число кадров, которые испытали только один конфликт, а затем были успешно переданы. |
Конфликты в полудуплексной среде — обычное ожидаемое поведение. |
|
Хорошие кадры (> 1 конфликта) |
Общее число кадров, которые испытали от 2 до 15 конфликтов включительно, а затем были успешно переданы. |
Конфликты в полудуплексной среде — обычное ожидаемое поведение. По мере приближения к верхнему пределу данного счетчика для таких кадров возрастает риск превышения 15 конфликтов и причисления к частым конфликтам. |
|
Отброшенные кадры сети VLAN |
Число кадров, отброшенных интерфейсом из-за задания бита CFI. |
Биту Canonical Format Indicator (CFI) в TCI кадра 802.1q задается значение 0 для канонического формата кадра Ethernet. Если биту CFI задано значение 1, это указывает на наличие поля сведений о маршрутизации (RIF) или неканонического кадра Token Ring, который отброшен. |
|
Received Frames (принятые кадры) |
||
|
No bandwidth frames (кадры с недостатком пропускной способности) |
Только 2900/3500XL. Количество раз, которое порт принимал пакеты из сети, но у коммутатора не было ресурсов для его принятия. Это случается только в условиях высокой нагрузки, но может произойти и в случае всплесков трафика на нескольких портах. Таким образом, небольшое число в поле «No bandwidth frames» – не повод для беспокойства. (Оно должно оставаться намного меньше одного процента принятых кадров.) |
Отбрасывание кадров вызвано чрезмерной нагрузкой трафиком данного интерфейса. Если в этом поле наблюдается рост числа пакетов, уменьшите нагрузку на данный интерфейс. |
|
No buffers frames (кадры без буфера) |
Только 2900/3500XL. Количество раз, которое порт принимал пакеты из сети, но у коммутатора не было ресурсов для его принятия. Это случается только в условиях высокой нагрузки, но может произойти и в случае всплесков трафика на нескольких портах. Таким образом, небольшое число в поле «No buffers frames» – не повод для беспокойства. (Оно должно оставаться намного меньше одного процента принятых кадров.) |
Отбрасывание кадров вызвано чрезмерной нагрузкой трафиком данного интерфейса. Если в этом поле наблюдается рост числа пакетов, уменьшите нагрузку на данный интерфейс. |
|
No dest, unicast (одноадресные пакеты без назначения) |
Это число одноадресных пакетов, которые не были пересланы данным портом другим портам. |
Ниже дается краткое описание случаев, когда значение счетчиков «No dest» (unicast, multicast и broadcast) может возрастать.
|
|
No dest, multicast (многоадресные пакеты без назначения) |
Это число многоадресных пакетов, которые не были пересланы данным портом другим портам. |
|
|
No dest,broadcast (широковещательные пакеты без назначения) |
Это число широковещательных пакетов, которые не были пересланы данным портом другим портам. |
|
|
Alignment errors (ошибки выравнивания) |
Ошибки выравнивания определяются числом полученных кадров, которые не заканчиваются четным количеством октетов и имеют неверную контрольную сумму CRC. |
Ошибки выравнивания вызываются неполным копированием кадра в канал, что приводит к фрагментированным кадрам. Ошибки выравнивания являются результатом конфликтов при несоответствии дуплексных режимов, неисправном оборудовании (сетевой плате, кабеле или порте), или подключенное устройство генерирует кадры, не завершающиеся октетом, или с неверной последовательностью FCS. |
|
FCS errors (ошибки FCS) |
Число ошибок последовательности FCS соответствует числу кадров, принятых с неверной контрольной суммой (CRC) в кадре Ethernet. Такие кадры отбрасываются и не передаются на другие порты. |
Ошибки FCS являются результатом конфликтов в случае несоответствия дуплексных режимов, неисправного оборудования (сетевая плата, кабель или порт) или кадров с неверной последовательностью FCS, формируемых подключенным устройством. |
|
Undersize frames (неполномерные кадры) |
Это общее число принятых пакетов с длиной менее 64 октетов (без битов кадрирования, но с октетами FCS) и допустимым значением FCS. |
Это указывает на поврежденный кадр, сформированный подключенным устройством. Убедитесь, что подключенное устройство функционирует правильно. |
|
Oversize frames (кадры избыточного размера) |
Число принятых портом из сети пакетов с длиной более 1514 байтов. |
Это может указывать на сбой оборудования либо проблемы конфигурации режима магистрального соединения для dot1q или ISL. |
|
Collision fragments (фрагменты с конфликтами) |
Общее число кадров с длиной менее 64 октетов (без битов кадрирования, но с октетами FCS) и неверным значением FCS. |
Увеличение значения этого счетчика указывает на то, что порты настроены на полудуплексный режим. Установите в настройках дуплексный режим. |
|
Overrun frames (кадры с переполнением) |
Количество раз, которое оборудованию приемника не удалось поместить принятые данные в аппаратный буфер. |
Входящая скорость трафика превысила способность приемника к обработке данных. |
|
VLAN filtered frames (кадры, отфильтрованные по сети VLAN) |
Общее число кадров, отфильтрованных по типу содержащейся в них информации о сети VLAN. |
Порт можно настроить на фильтрацию кадров с тегами 802.1Q. При получении кадра с тегом 802.1Q он фильтруется, а значение счетчика увеличивается. |
|
Source routed frames (кадры с маршрутом источника) |
Общее число полученных кадров, которые были отброшены из-за задания бита маршрута источника в адресе источника собственного кадра. |
Этот тип маршрутизации источников определен только для Token Ring и FDDI. Спецификация IEEE Ethernet запрещает задание этого бита в кадрах Ethernet. Поэтому коммутатор отбрасывает такие кадры. |
|
Valid oversize frames (допустимые кадры избыточного размера) |
Общее число полученных кадров с длиной, превышающей значение параметра System MTU, но с правильными значениями FCS. |
В данном случае собирается статистика о кадрах с длиной превышающей настроенное значение параметра System MTU, размер которых можно увеличить с 1518 байтов до размера, разрешенного для инкапсуляции Q-in-Q или MPLS. |
|
Symbol error frames (кадры с ошибками символа) |
В Gigabit Ethernet (1000 Base-X) используется кодирование 8B/10B для преобразования 8-битных данных из MAC-подуровня (уровень 2) в 10-битный символ для отправки по проводу. Когда порт получает символ, он извлекает 8-битные данные из данного символа (10 битов). |
Символьная ошибка означает, что интерфейс обнаружил прием неопределенного (недопустимого) символа. Небольшое число символьных ошибок можно игнорировать. Большое число символьных ошибок может указывать на неисправность устройства, кабеля или оборудования. |
|
Invalid frames, too large (недопустимые кадры, слишком большие) |
Кадры с недопустимо большой величиной или полученные кадры с неверной последовательностью FCS, размер которых превышает размер максимального кадра в IEEE 802.3 (1518 байт для сетей Ethernet без поддержки jumbo-кадров). |
В большинстве случаев это является следствием поврежденной сетевой интерфейсной платы. Попробуйте найти проблемное устройство и удалить его из сети. |
|
Invalid frames, too small (недопустимые кадры, слишком маленькие) |
Кадры с недопустимо маленькой величиной или кадры, размером менее 64 байта (с битами FCS, но без заголовка кадра) и недопустимым значением FCS или ошибкой выравнивания. |
Это может произойти из-за несоответствия дуплексных режимов и физических проблем, таких как неисправный кабель, порт или сетевая плата на подключенном устройстве. |
Команда Show Top для CatOS
Команда show top позволяет собирать и анализировать данные о каждом физическом порте коммутатора. Данная команда для каждого физического порта отображает следующие данные:
-
уровень загрузки порта (Uti %)
-
число входящих и исходящих байтов (Bytes)
-
число входящих и исходящих пакетов (Pkts)
-
число входящих и исходящих пакетов широковещательной рассылки (Bcst)
-
число входящих и исходящих пакетов многоадресной рассылки (Mcst)
-
число ошибок (Error)
-
число ошибок переполнения буфера (Overflow)
Примечание: При вычислении уровня загрузки порта данная команда объединяет строки Tx и Rx в один счетчик, а также определяет пропускную способность в дуплексном режиме при вычислении процента загруженности. Например, порт Gigabit Ethernet работает в дуплексном режиме с пропускной способностью 2000 Мбит/с.
Число ошибок (in Errors) представляет сумму всех пакетов с ошибками, полученных данным портом.
Переполнение буфера означает, что порт принимает больше трафика, чем может быть сохранено в его буфере. Это может быть вызвано пульсирующим трафиком, а также переполнением буферов. Предлагаемое действие — уменьшить скорость передачи исходного устройства.
Также см. значения счетчиков «In-Lost» и «Out-Lost» в выходных данных команды show mac .
Распространенные сообщения о системных ошибках
В Cisco IOS иногда используется различный формат для системных сообщений. Для сравнения можно проверить системные сообщения CatOS и Cisco IOS. Описание выпусков используемого программного обеспечения см. в руководстве Сообщения и процедуры восстановления. Например, можно прочитать документ Сообщения и процедуры восстановления для ПО CatOS версии 7.6 и сравнить его с содержимым документа Сообщения и процедуры восстановления для выпусков Cisco IOS 12.1 E.
Сообщения об ошибках в модулях WS-X6348
Просмотите следующие сообщения об ошибках.
-
Coil Pinnacle Header Checksum (контрольная сумма заголовка Coil/Pinnacle)
-
Ошибка состояния компьютера Coil Mdtif
-
Ошибка контрольной суммы пакета Coil Mdtif.
-
Ошибка «Coil Pb Rx Underflow»
-
Ошибка четности Coil Pb Rx
Можно проверить наличие в сообщениях системного журнала одной из описанных ниже ошибок.
%SYS-5-SYS_LCPERR5:Module 9: Coil Pinnacle Header Checksum Error - Port #37
При появлении этого типа сообщений или в случае сбоя группы портов 10/100 в модулях WS-X6348 см. в следующих документах дальнейшие советы по устранению неполадок в зависимости от используемой операционной системы.
%PAGP-5-PORTTO / FROMSTP и %ETHC-5-PORTTO / FROMSTP
В CatOS используйте команду show logging buffer для просмотра сохраненных сообщений журнала. Для Cisco IOS используйте команду show logging .
Протокол PAgP выполняет согласование каналов EtherChannel между коммутаторами. Если устройство присоединяется или покидает порт моста, на консоли отображается информационное сообщение. В большинстве случае появление этого сообщение совершенно нормально, однако при появлении таких сообщений на портах, которые по каким-то причинам не участвуют в переброске, требуется дополнительное изучение. Для изучения консольных сообщений всегда можно обратиться в IT-аутсорсинговую компанию, которая специализируется на обслуживании сетевого оборудования.
В программном обеспечении CatOS версии 7.x или выше «PAGP-5» изменено на «ETHC-5», чтобы сделать данное сообщение более понятным.
Это сообщение характерно для коммутаторов серии Catalyst 4000, 5000 и 6000 с ПО CatOS. Для коммутаторов с ПО Cisco IOS нет сообщений об ошибках, эквивалентных данному.
%SPANTREE-3-PORTDEL_FAILNOTFOUND
Это сообщение не указывает на проблему с коммутатором. Оно обычно возникает вместе с сообщениями %PAGP-5-PORTFROMSTP.
Протокол PAgP выполняет согласование каналов EtherChannel между коммутаторами. Если устройство присоединяется или покидает порт моста, на консоли отображается информационное сообщение. В большинстве случае появление этого сообщение совершенно нормально и не требует, каких-либо действий вроде аудита IT-инфраструктуры, однако при появлении таких сообщений на портах, которые по каким-то причинам не участвуют в переброске, требуется дополнительное изучение.
Это сообщение характерно для коммутаторов серии Catalyst 4000, 5000 и 6000 с ПО CatOS. Для коммутаторов с ПО Cisco IOS нет сообщений об ошибках, эквивалентных данному.
%SYS-4-PORT_GBICBADEEPROM: / %SYS-4-PORT_GBICNOTSUPP
Наиболее распространенная причина появления этого сообщения заключается в установке несертифицированного стороннего (не Cisco) конвертера GBIC в модуль Gigabit Ethernet. У такого конвертера GBIC нет памяти Cisco SEEPROM, что приводит к созданию сообщения об ошибке.
GBIC-модули WS-G5484, WS-G5486 и WS-G5487, используемые с WS-X6408-GBIC, также могут вызвать появление таких сообщений об ошибках, однако реальных проблем с данными платами и GBIC-модулями нет, а для программного обеспечения есть обновленное исправление.
Команда отклонена: [интерфейс] не является коммутационным портом
В коммутаторах, поддерживающих и интерфейсы L3, и коммутационные порты L2, сообщение Команда отклонена: [интерфейс] не является коммутационным портом отображается при попытке ввода команды, относящейся к уровню2, для порта, который настроен в качестве интерфейса уровня 3.
Чтобы преобразовать данный интерфейс из режима уровня 3 в режим уровня 2, выполните команду настройки интерфейса switchport. После применения этой команды настройте для данного порта требуемые свойства уровня 2.
Часть 4
В данной статье производится описание порядка диагностики и поиска ошибок на портах коммутатора.
В примере используется коммутатор Cisco Catalyst C4948
Для диагностики ошибок на портах коммутатора Cisco необходимо подключиться к консоли
коммутатора через утилиту telnet, используя консольный порт (прямое подключение)
или по IP-адресу.
Следующим шагом мы переходим в привилегированный режим редактирования конфигурации Enable (en).
C4948> enable
или
C4948> en
Следующей командой мы можем посмотреть счетчики ошибок по всем портам коммутатора:
C4948# sh interfaces counters errors
или по одному порту gi1/33
C4948# sh interfaces gi1/33 counters errors
Вывод команды
Port CrcAlign-Err Dropped-Bad-Pkts Collisions Symbol-Err
Gi1/33 0 0 0 0
Port Undersize Oversize Fragments Jabbers
Gi1/33 0 0 0 0
Port Single-Col Multi-Col Late-Col Excess-Col
Gi1/33 0 0 0 0
Port Deferred-Col False-Car Carri-Sen Sequence-Err
Gi1/33 0 0 0 0
Приведем описание наиболее важных счетчиков
| Счетчик | Описание | Возможная причина |
|---|---|---|
| CrcAlign-Err | Количество ошибок выравнивания определяется числом полученных кадров, которые не заканчиваются четным числом октетов и имеют неверную контрольную сумму CRC | Данные ошибки обычно являются результатом несоответствия дуплексных режимов или физической проблемы (такой как прокладка кабелей, неисправный порт или сетевая плата). При первом подключении кабеля к порту могут возникнуть некоторые из этих ошибок. Кроме того, если к порту подключен концентратор, ошибки могут вызвать конфликты между другими устройствами концентратора |
| Collisions | В счетчиках кадров с конфликтами содержится число пакетов, одна попытка передачи которых была неудачной, а следующая — успешной. Это означает, что в случае увеличения значения счетчика кадров с конфликтами на 2, коммутатор дважды неудачно пытался передать пакет, но третья попытка была успешной | Отбрасывание кадров вызвано чрезмерной нагрузкой трафиком данного интерфейса. Если в этих полях наблюдается рост числа пакетов, уменьшите нагрузку на данный интерфейс |
| Undersize | Это общее число принятых пакетов с длиной менее 64 октетов (без битов кадрирования, но с октетами FCS) и допустимым значением FCS | Указывает на поврежденный кадр, сформированный подключенным устройством. Убедитесь, что подключенное устройство функционирует правильно |
| Oversize | Число принятых портом из сети пакетов с длиной более 1514 байтов2 | Это может указывать на сбой оборудования либо проблемы конфигурации режима магистрального соединения для dot1q или ISL |
| Fragment | Общее число кадров с длиной менее 64 октетов (без битов кадрирования, но с октетами FCS) и неверным значением FCS | Увеличение значения этого счетчика указывает на то, что порты настроены на полудуплексный режим. Установите в настройках дуплексный режим |
| Single-Col | Число конфликтов, произошедших до того, как интерфейс успешно передал кадр носителю | Нормальное явление для полудуплексных интерфейсов, но не для полнодуплексных интерфейсов. Быстрый рост числа конфликтов указывает на высокую загрузку соединения или возможное несоответствие дуплексных режимов с присоединенным устройством |
| Multi-Col | Число множественных конфликтов произошедших до того, как порт успешно передал кадр носителю | Нормальное явление для полудуплексных интерфейсов, но не для полнодуплексных интерфейсов. Быстрый рост числа конфликтов указывает на высокую загрузку соединения или возможное несоответствие дуплексных режимов с присоединенным устройством |
| Late-Col | Количество обнаруженных конфликтов в определенном интерфейсе на последних этапах процесса передачи. Для порта со скоростью 10 Мбит/с это позднее, чем время передачи 512 битов для пакета. В системе со скоростью передачи данных 10 Мбит/с 512 битовых интервалов соответствуют 51,2 микросекунды | Ошибка, в частности, может указывать на несоответствие дуплексных режимов. В сценарии с несоответствием дуплексных режимов на стороне с полудуплексным режимом наблюдается поздний конфликт. Во время передачи со стороны с полудуплексным режимом на стороне с дуплексным режимом выполняется одновременная передача без ожидания своей очереди, что приводит к возникновению позднего конфликта. Поздние конфликты также могут указывать на слишком большую длину кабеля или сегмента Ethernet. На интерфейсах, сконфигурированных в качестве полнодуплексных, конфликты наблюдаться не должны |
| Excess-Col | Количество кадров, для которых передача через отдельный интерфейс завершилась с ошибкой из-за чрезмерного числа конфликтов. Избыточный конфликт возникает, когда для некоторого пакета конфликт регистрируется 16 раз подряд. Затем пакет отбрасывается | Чрезмерное количество конфликтов обычно обозначает, что нагрузку на данный сегмент необходимо разделить между несколькими сегментами, но может также указывать на несоответствие дуплексных режимов с присоединенным устройством. На интерфейсах, сконфигурированных в качестве полнодуплексных, конфликты наблюдаться не должны |
| Deferred-Col | Общее число кадров, первая попытка передачи которых была отложена из-за трафика в сетевом носителе | Отбрасывание кадров вызвано чрезмерной нагрузкой трафика, направленного к данному коммутатору. Если в этом поле наблюдается рост числа пакетов, уменьшите нагрузку на данный коммутатор. Может потребоваться изменение топологии сети, чтобы снизить нагрузку трафика на данный коммутатор |
| Carri-Sen | Счетчик увеличивается каждый раз, когда контроллер Ethernet собирается отослать данные по полудуплексному соединению. Контроллер обнаруживает провод и перед передачей проверяет, не занят ли он | Нормально для полудуплексного сегмента Ethernet |
Далее проверяем, включено ли обнаружение отключения из-за ошибки на порту коммутатора:
C4948# sh errdisable detect
Вывод команды
ErrDisable Reason Detection Mode
----------------- --------- ----
arp-inspection Enabled port
bpduguard Enabled port
channel-misconfig Enabled port
community-limit Enabled port
dhcp-rate-limit Enabled port
dtp-flap Enabled port
ekey Enabled port
gbic-invalid Enabled port
inline-power Enabled port
invalid-policy Enabled port
l2ptguard Enabled port
link-flap Enabled port
link-monitor-failure Enabled port
lsgroup Enabled port
oam-remote-failure Enabled port
mac-limit Enabled port
pagp-flap Enabled port
port-mode-failure Enabled port
pppoe-ia-rate-limit Enabled port
psecure-violation Enabled port/vlan
security-violation Enabled port
sfp-config-mismatch Enabled port
storm-control Enabled port
udld Enabled port
unicast-flood Enabled port
vmps Enabled port
где, по умолчанию, в колонке Detection все значения должны быть Enabled
Смотрим порты которые находятся в состоянии ошибки errdisable (порт
автоматически отключен операционной системой коммутатора, так как порт
обнаружен в состоянии ошибки):
C4948# sh errdisable recovery
Вывод команды:
ErrDisable Reason Timer Status
----------------- --------------
arp-inspection Disabled
bpduguard Disabled
channel-misconfig Disabled
dhcp-rate-limit Disabled
dtp-flap Disabled
gbic-invalid Disabled
inline-power Disabled
l2ptguard Disabled
link-flap Disabled
mac-limit Disabled
link-monitor-failure Disabled
oam-remote-failure Disabled
pagp-flap Disabled
port-mode-failure Disabled
pppoe-ia-rate-limit Disabled
psecure-violation Disabled
security-violation Disabled
sfp-config-mismatch Disabled
storm-control Disabled
udld Disabled
unicast-flood Disabled
vmps Disabled
Timer interval: 300 seconds
Interfaces that will be enabled at the next timeout:
где в колонке ErrDisable Reason отображается причина перехода порта в состояние errdisable.
В нашем случае портов в состоянии errdisable не обнаружено.
Просмотр подробной информации о настройках и состоянии порта коммутатора:
C4948# sh interfaces gigabitEthernet 1/33
Вывод команды
GigabitEthernet1/33 is up, line protocol is up (connected)
Hardware is Gigabit Ethernet Port, address is 8843.e1a1.7f60 (bia 8843.e1a1.7f60)
MTU 1500 bytes, BW 100000 Kbit, DLY 100 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Full-duplex, 100Mb/s, link type is auto, media type is 10/100/1000-TX
input flow-control is off, output flow-control is off
ARP type: ARPA, ARP Timeout 04:00:00
Last input never, output never, output hang never
Last clearing of "show interface" counters never
Input queue: 0/2000/0/0 (size/max/drops/flushes); Total output drops: 0
Queueing strategy: fifo
Output queue: 0/40 (size/max)
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 22000 bits/sec, 18 packets/sec
249311846 packets input, 197650705208 bytes, 0 no buffer
Received 146 broadcasts (0 multicasts)
0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored
0 input packets with dribble condition detected
413450928 packets output, 82056436068 bytes, 0 underruns
0 output errors, 0 collisions, 0 interface resets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier
0 output buffer failures, 0 output buffers swapped out
Как видно из вывода команды, ошибок на порте коммутатора не обнаружено.
Также, набрав следующую команду, можно посмотреть статус и используемые протоколы на портах коммутатора:
C4948# sh interfaces counters protocol status
или по определенному порту:
C4948# sh interfaces gi1/33 counters protocol status
Вывод команды:
Protocols allocated:
GigabitEthernet1/33: Other, IP, Spanning Tree, CDP
где
| Протокол | Описание |
|---|---|
IP |
Маршрутизируемый протокол сетевого уровня стека TCP/IP. |
Spanning Tree (STP) |
Канальный протокол связующего дерева. Основной задачей STP является устранение петель в топологии произвольной сети Ethernet, в которой есть один или более сетевых мостов, связанных избыточными соединениями. |
CDP |
Проприетарный протокол второго уровня, разработанный компанией Cisco Systems, позволяющий обнаруживать подключённое сетевое оборудование Cisco, его название, версию IOS и IP-адреса. |
Problem
This document will describe the methods used to determine the source of frames with CRC (cyclic redundancy check) errors, or bit errors from external devices. This document does not cover methods to determine if CRC errors are sourced within a switch, which is a rare condition. The net result of a frame with a CRC error will typically cause the frame to be discarded, either within the switch itself or by the destination device. Regardless of where a CRC frame is discarded, the result is an IO operation will have to be retried which causes some degree of negative impact on performance.
Resolving The Problem
This document assumes the reader does not necessarily have access to various management applications, but does have command line interface access to the switch. Once the root source of CRCs has been determined, the means to correct this situation will be provided in another document titled “How to resolve CRC errors”.
The method to determine the source of frames with CRC errors on Cisco switches is simple and somewhat easier to identify when compared to the methods used with Brocade switches. Cisco switches have the operational characteristic in which the switch will discard a frame detected to have a CRC error at the point of error detection. For external facing switch ports, this means that frames with CRCs are detected, and discarded, by the switch port’s receiver.
There are two commands available to find the source of frames with CRCs. The commands are:
· show interface
· show interface counters
The output of both commands is reasonably similar to each other. For illustration purposes, the following example is from the show interface counters command.
show interface counter
fc1/1
5 minutes input rate 8888736 bits/sec, 1111092 bytes/sec, 624 frames/sec
5 minutes output rate 2855360 bits/sec, 356920 bytes/sec, 400 frames/sec
424107878 frames input, 642308273224 bytes
0 class-2 frames, 0 bytes
424107878 class-3 frames, 642308273224 bytes
0 class-f frames, 0 bytes
0 discards, 0 errors, 36 CRC/FCS
0 unknown class, 0 too long, 0 too short
471089499 frames output, 574867395548 bytes
0 class-2 frames, 0 bytes
471089499 class-3 frames, 574867395548 bytes
0 class-f frames, 0 bytes
0 discards, 0 errors
<output has been truncated>
In this example, port fc1/1 has received 36 frames which contain a CRC error which was the point where the frames were discarded. Since frames with CRC errors are discarded on the ingress side of a port, notice that the output information does not have a counter for frames with CRCs. In this example the device attached to port fc1/1 or the pathway from the attached device port is the root source of the CRC errors. This could be a device such as a host or storage system port or it could be another switch.
[{«Product»:{«code»:»STTQ3Y»,»label»:»Cisco MDS 9513 Multiplayer Director»},»Business Unit»:{«code»:»BU054″,»label»:»Systems w/TPS»},»Component»:»—«,»Platform»:[{«code»:»»,»label»:»N/A»}],»Version»:»All Versions»,»Edition»:»»,»Line of Business»:{«code»:»»,»label»:»»}}]
In this post, I would like share an interesting issue that we came across on one of our core ASR9K devices. We were getting reports of intermittent packet loss for traffic that load balanced across a pair of redundant Cisco ASR9K devices. Every hop between between source and destination was verified for any routing and switching issues with no luck.
So, a deeper investigation began to rule out any internal issues and that is when we came across increment in fabric crossbar CRC errors.
SLOT0:
show controllers fabric crossbar statistics instance 0 location 0/0/cpu0 | in "Port|CRC" Port statistics for xbar:0 port:7 Packet CRC Error Count : 1226275 Port statistics for xbar:0 port:8 Port statistics for xbar:0 port:9 Packet CRC Error Count : 1225809 Port statistics for xbar:0 port:11 Packet CRC Error Count : 1225330 Port statistics for xbar:0 port:12 Packet CRC Error Count : 1225903 Port statistics for xbar:0 port:14 Packet CRC Error Count : 569923 Port statistics for xbar:0 port:15 Packet CRC Error Count : 568892 Port statistics for xbar:0 port:16 Packet CRC Error Count : 910746 Packet CRC Error Count : 1 Port statistics for xbar:0 port:17 Packet CRC Error Count : 909642 Packet CRC Error Count : 3 Port statistics for xbar:0 port:24
On slot 0, CRC errors were incrementing for ports 7,9,11,12,14,15,16,17
#### 5.1.1 system with RSP440 and Typhoon LC in slot 0-4 ####
Following table shows logical-to-physical LC mapping in 9010 chassis.
——————————————————————–
Physical-Slot Logical-slot
======================================
0 0
1 1
2 2
3 3
4 RSP
5 RSP
6 4
7 5
8 6
9 7
#show controllers fabric crossbar link-status instance 0 location 0/0/cpu0 PORT Remote Slot Remote Inst Logical ID Status ====================================================== 00 00 02 1 Up <=== Local port. FIA instance 2 (no CRC) 01 00 01 1 Up <=== Local port. FIA instance 1 (no CRC) 02 00 01 0 Up <=== Local port. FIA instance 1 (no CRC) 03 00 00 0 Up <=== Local port. FIA instance 0 (no CRC) 04 00 00 1 Up <=== Local port. FIA instance 0 (no CRC) 05 00 03 1 Up <=== Local port. FIA instance 3 (no CRC) 07 05 00 1 Up <=== Remote, 5 is RSP (CRC incrementing) 08 00 03 0 Up <=== Local port. FIA instance 3 (no CRC) 09 04 00 1 Up <=== Remote, 4 is RSP (CRC incrementing) 11 05 00 0 Up <=== Remote, 5 is RSP (CRC incrementing) 12 04 00 0 Up <=== Remote, 4 is RSP (CRC incrementing) 14 04 01 1 Up <=== Remote, 4 is RSP (CRC incrementing) 15 05 01 1 Up <=== Remote, 5 is RSP (CRC incrementing) 16 04 01 0 Up <=== Remote, 4 is RSP (CRC incrementing) 17 05 01 0 Up <=== Remote, 5 is RSP (CRC incrementing) 24 00 02 0 Up <=== Local port. FIA instance 2 (no CRC)
All ports on LC0 with incrementing CRC errors pointed towards RSP0 or 1 (4 or 5 remote slot) which indicated LC0 was not generating these errors.
SLOT1:
sh controllers fabric crossbar statistics instance 0 loc 0/1/CPU0 | i "xbar|Error" Port statistics for xbar:0 port:7 Internal Error Count: 1481 Packet CRC Error Count : 31547 Port statistics for xbar:0 port:9 Internal Error Count: 1490 Packet CRC Error Count : 32122 Port statistics for xbar:0 port:11 Internal Error Count: 1491 Packet CRC Error Count : 31818 Port statistics for xbar:0 port:12 Internal Error Count: 1486 Packet CRC Error Count : 31695 Port statistics for xbar:0 port:14 Internal Error Count: 1474 Packet CRC Error Count : 19183 Port statistics for xbar:0 port:15 Internal Error Count: 1473 Packet CRC Error Count : 19018 Port statistics for xbar:0 port:16 Internal Error Count: 1472 Packet CRC Error Count : 18981 Port statistics for xbar:0 port:17 Internal Error Count: 1470 Packet CRC Error Count : 18975 Packet CRC Error Count : 3
On slot 1, CRC errors were incrementing for ports 7,9,11,12,14,15,17 and all those pointed towards RSP0 or RSP1 which was same as slot 0.
SLOT 2:
#show controllers fabric crossbar link-status instance 0 location 0/2/cpu0 Port statistics for xbar:0 port:0 Packet CRC Error Count : 165916259 Packet CRC Error Count : 51 Port statistics for xbar:0 port:24 Packet CRC Error Count : 165974573 Packet CRC Error Count : 104 #show controllers fabric crossbar link-status instance 0 location 0/2/cpu0 PORT Remote Slot Remote Inst Logical ID Status ====================================================== 00 02 02 1 Up <=== Local port. FIA instance 2 (CRC incrementing) 01 02 01 1 Up 02 02 01 0 Up 03 02 00 0 Up 04 02 00 1 Up 05 02 03 1 Up 07 05 00 1 Up 08 02 03 0 Up 09 04 00 1 Up 11 05 00 0 Up 12 04 00 0 Up 14 04 01 1 Up 15 05 01 1 Up 16 04 01 0 Up 17 05 01 0 Up 24 02 02 0 Up <=== Local port. FIA instance 2 (CRC incrementing)
Above stats from LC2 clearly indicated that the issue is with slot 0/2 since the errors traced to be incrementing locally.
In majority of the cases, the CRC is nothing but a memory corruption in the FPGA that is resolved by reloading impacted LC. Sometimes, the memory corruption can be permanent failure and in that case only LC replacement can take care of the issue.
Reload of the LC2 fixed the errors in our case but we had it replaced anyway to avoid re-occurrence.
Commands:
Fabric: show controllers fabric crossbar statis instance 0 loc 0/0/CPU0 | I "xbar|Error" show controllers fabric fia stats location 0/0/CPU0 | i drop show controllers fabric fia drops ingress location 0/0/CPU0 | ex 0 show controllers fabric crossbar link-status instance 0 loca 0/0/cpu0 show controllers fabric ltrace crossbar location 0/0/cpu0 | I link_retrain show controllers fabric fia bridge ddr-status loc <RSP> show controllers fabric fia <drops|errors> <ingress|egress> loc <RSP> show controllers fabric fia link-status loc <RSP>
NP issues: show controller np ports all loc 0/0/cpU0 show controller np count np0 location 0/X/CPU0 show controller np fabric-counters <rx|tx> <np> loca LC LPTS issues: show lpts pifib hardware police location 0/0/CPU0 show lpts bindings brief show lpts pifib hardware entry bri location 0/7/cpu0
Resources:
https://supportforums.cisco.com/document/12153086/asr9000xr-understanding-fabric-and-troubleshooting-commands
http://www.cisco.com/c/en/us/support/docs/routers/asr-9000-series-aggregation-services-routers/116727-troubleshoot-punt-00.html
http://d2zmdbbm9feqrf.cloudfront.net/2013/usa/pdf/BRKSPG-2904.pdf
In the following table you see descriptions and causes of error counters
| Counters (in alphabetical order) | Description and Common Causes of Incrementing Error Counters |
| Align-Err | Description: CatOS sh port and Cisco IOS sh interfaces counters errors. Alignment errors are a count of the number of frames received that don’t end with an even number of octets and have a bad Cyclic Redundancy Check (CRC). Common Causes: These are usually the result of a duplex mismatch or a physical problem (such as cabling, a bad port, or a bad NIC). When the cable is first connected to the port, some of these errors can occur. Also, if there is a hub connected to the port, collisions between other devices on the hub can cause these errors. Platform Exceptions: Alignment errors are not counted on the Catalyst 4000 Series Supervisor I (WS-X4012) or Supervisor II (WS-X4013). |
| babbles | Description: Cisco IOS sh interfaces counter. CatOS counter indicating that the transmit jabber timer expired. A jabber is a frame longer than 1518 octets (which exclude framing bits, but include FCS octets), which does not end with an even number of octets (alignment error) or has a bad FCS error. |
| Carri-Sen | Description: CatOS sh port and Cisco IOS sh interfaces counters errors. The Carri-Sen (carrier sense) counter increments every time an Ethernet controller wants to send data on a half duplex connection. The controller senses the wire and checks if it is not busy before transmitting. Common Causes: This is normal on an half duplex Ethernet segment. |
| collisions | Descriptions: Cisco IOS sh interfaces counter. The number of times a collision occurred before the interface transmitted a frame to the media successfully. Common Causes: Collisions are normal for interfaces configured as half duplex but must not be seen on full duplex interfaces. If collisions increase dramatically, this points to a highly utilized link or possibly a duplex mismatch with the attached device. |
| CRC | Description: Cisco IOS sh interfaces counter. This increments when the CRC generated by the originating LAN station or far-end device does not match the checksum calculated from the data received. Common Causes: This usually indicates noise or transmission problems on the LAN interface or the LAN itself. A high number of CRCs is usually the result of collisions but can also indicate a physical issue (such as cabling, bad interface or NIC) or a duplex mismatch. |
| deferred | Description: Cisco IOS sh interfaces counter. The number of frames that have been transmitted successfully after they wait because the media was busy. Common Causes: This is usually seen in half duplex environments where the carrier is already in use when it tries to transmit a frame. |
| pause input | Description: Cisco IOS show interfaces counter. An increment in pause input counter means that the connected device requests for a traffic pause when its receive buffer is almost full. Common Causes: This counter is incremented for informational purposes, since the switch accepts the frame. The pause packets stop when the connected device is able to receive the traffic. |
| input packetswith dribble condition | Description: Cisco IOS sh interfaces counter. A dribble bit error indicates that a frame is slightly too long. Common Causes: This frame error counter is incremented for informational purposes, since the switch accepts the frame. |
| Excess-Col | Description: CatOS sh port and Cisco IOS sh interfaces counters errors. A count of frames for which transmission on a particular interface fails due to excessive collisions. An excessive collision happens when a packet has a collision 16 times in a row. The packet is then dropped. Common Causes: Excessive collisions are typically an indication that the load on the segment needs to be split across multiple segments but can also point to a duplex mismatch with the attached device. Collisions must not be seen on interfaces configured as full duplex. |
| FCS-Err | Description: CatOS sh port and Cisco IOS sh interfaces counters errors. The number of valid size frames with Frame Check Sequence (FCS) errors but no framing errors. Common Causes: This is typically a physical issue (such as cabling, a bad port, or a bad Network Interface Card (NIC)) but can also indicate a duplex mismatch. |
| frame | Description: Cisco IOS sh interfaces counter. The number of packets received incorrectly that has a CRC error and a non-integer number of octets (alignment error). Common Causes: This is usually the result of collisions or a physical problem (such as cabling, bad port or NIC) but can also indicate a duplex mismatch. |
| Giants | Description: CatOS sh port and Cisco IOS sh interfaces and sh interfaces counters errors. Frames received that exceed the maximum IEEE 802.3 frame size (1518 bytes for non-jumbo Ethernet) and have a bad Frame Check Sequence (FCS). Common Causes: In many cases, this is the result of a bad NIC. Try to find the offending device and remove it from the network. Platform Exceptions: Catalyst Cat4000 Series that run Cisco IOS Previous to software Version 12.1(19)EW, the giants counter incremented for a frame > 1518bytes. After 12.1(19)EW, a giant in show interfaces increments only when a frame is received >1518bytes with a bad FCS. |
| ignored | Description: Cisco IOS sh interfaces counter. The number of received packets ignored by the interface because the interface hardware ran low on internal buffers. Common Causes: Broadcast storms and bursts of noise can cause the ignored count to be increased. |
| Input errors | Description: Cisco IOS sh interfaces counter. Common Causes: This includes runts, giants, no buffer, CRC, frame, overrun, and ignored counts. Other input-related errors can also cause the input errors count to be increased, and some datagrams can have more than one error. Therefore, this sum cannot balance with the sum of enumerated input error counts. Also refer to the section Input Errors on a Layer 3 Interface Connected to a Layer 2 Switchport. |
| Late-Col | Description: CatOS sh port and Cisco IOS sh interfaces and sh interfaces counters errors. The number of times a collision is detected on a particular interface late in the transmission process. For a 10 Mbit/s port this is later than 512 bit-times into the transmission of a packet. Five hundred and twelve bit-times corresponds to 51.2 microseconds on a 10 Mbit/s system. Common Causes: This error can indicate a duplex mismatch among other things. For the duplex mismatch scenario, the late collision is seen on the half duplex side. As the half duplex side is transmitting, the full duplex side does not wait its turn and transmits simultaneously which causes a late collision. Late collisions can also indicate an Ethernet cable or segment that is too long. Collisions must not be seen on interfaces configured as full duplex. |
| lost carrier | Description: Cisco IOS sh interfaces counter. The number of times the carrier was lost in transmission. Common Causes: Check for a bad cable. Check the physical connection on both sides. |
| Multi-Col | Description: CatOS sh port and Cisco IOS sh interfaces counters errors. The number of times multiple collisions occurred before the interface transmitted a frame to the media successfully. Common Causes: Collisions are normal for interfaces configured as half duplex but must not be seen on full duplex interfaces. If collisions increase dramatically, this points to a highly utilized link or possibly a duplex mismatch with the attached device. |
| no buffer | Description: Cisco IOS sh interfaces counter. The number of received packets discarded because there is no buffer space. Common Causes: Compare with ignored count. Broadcast storms can often be responsible for these events. |
| no carrier | Description: Cisco IOS sh interfaces counter. The number of times the carrier was not present in the transmission. Common Causes: Check for a bad cable. Check the physical connection on both sides. |
| Out-Discard | Description: The number of outbound packets chosen to be discarded even though no errors have been detected. Common Causes: One possible reason to discard such a packet can be to free up buffer space. |
| output buffer failuresoutput buffers swapped out | Description: Cisco IOS sh interfaces counter. The number of failed buffers and the number of buffers swapped out. Common Causes: A port buffers the packets to the Tx buffer when the rate of traffic switched to the port is high and it cannot handle the amount of traffic. The port starts to drop the packets when the Tx buffer is full and thus increases the underruns and the output buffer failure counters. The increase in the output buffer failure counters can be a sign that the ports are run at an inferior speed and/or duplex, or there is too much traffic that goes through the port. As an example, consider a scenario where a 1gig multicast stream is forwarded to 24 100 Mbps ports. If an egress interface is over-subscribed, it is normal to see output buffer failures that increment along with Out-Discards. For troubleshooting information, see the Deferred Frames (Out-Lost or Out-Discard) section of this document. |
| output errors | Description: Cisco IOS sh interfaces counter. The sum of all errors that prevented the final transmission of datagrams out of the interface. Common Cause: This issue is due to the low Output Queue size. |
| overrun | Description: The number of times the receiver hardware was unable to hand received data to a hardware buffer. Common Cause: The input rate of traffic exceeded the ability of the receiver to handle the data. |
| packets input/output | Description: Cisco IOS sh interfaces counter. The total error free packets received and transmitted on the interface. Monitoring these counters for increments is useful to determine whether traffic flows properly through the interface. The bytes counter includes both the data and MAC encapsulation in the error free packets received and transmitted by the system. |
| Rcv-Err | Description: CatOS show port or show port counters and Cisco IOS (for the Catalyst 6000 Series only) sh interfaces counters error. Common Causes: See Platform Exceptions. Platform Exceptions: Catalyst 5000 Series rcv-err = receive buffer failures. For example, a runt, giant, or an FCS-Err does not increment the rcv-err counter. The rcv-err counter on a 5K only increments as a result of excessive traffic. On Catalyst 4000 Series rcv-err = the sum of all receive errors, which means, in contrast to the Catalyst 5000, that the rcv-err counter increments when the interface receives an error like a runt, giant or FCS-Err. |
| Runts | Description: CatOS sh port and Cisco IOS sh interfaces and sh interfaces counters errors. The frames received that are smaller than the minimum IEEE 802.3 frame size (64 bytes for Ethernet), and with a bad CRC. Common Causes: This can be caused by a duplex mismatch and physical problems, such as a bad cable, port, or NIC on the attached device. Platform Exceptions: Catalyst 4000 Series that run Cisco IOS Previous to software Version 12.1(19)EW, a runt = undersize. Undersize = frame < 64bytes. The runt counter only incremented when a frame less than 64 bytes was received. After 12.1(19EW, a runt = a fragment. A fragment is a frame < 64 bytes but with a bad CRC. The result is the runt counter now increments in show interfaces, along with the fragments counter in show interfaces counters errors when a frame <64 bytes with a bad CRC is received. Cisco Catalyst 3750 Series Switches In releases prior to Cisco IOS 12.1(19)EA1, when dot1q is used on the trunk interface on the Catalyst 3750, runts can be seen on show interfaces output because valid dot1q encapsulated packets, which are 61 to 64 bytes and include the q-tag, are counted by the Catalyst 3750 as undersized frames, even though these packets are forwarded correctly. In addition, these packets are not reported in the appropriate category (unicast, multicast, or broadcast) in receive statistics. This issue is resolved in Cisco IOS release 12.1(19)EA1 or 12.2(18)SE or later. |
| Single-Col | Description: CatOS sh port and Cisco IOS sh interfaces counters errors. The number of times one collision occurred before the interface transmitted a frame to the media successfully. Common Causes: Collisions are normal for interfaces configured as half duplex but must not be seen on full duplex interfaces. If collisions increase dramatically, this points to a highly utilized link or possibly a duplex mismatch with the attached device. |
| throttles | Description: Cisco IOS show interfaces. The number of times the receiver on the port is disabled, possibly because of buffer or processor overload. If an asterisk (*) appears after the throttles counter value, it means that the interface is throttled at the time the command is run. Common Causes: Packets which can increase the processor overload include IP packets with options, expired TTL, non-ARPA encapsulation, fragmentation, tunelling, ICMP packets, packets with MTU checksum failure, RPF failure, IP checksum and length errors. |
| underruns | Description: The number of times that the transmitter has been that run faster than the switch can handle. Common Causes: This can occur in a high throughput situation where an interface is hit with a high volume of bursty traffic from many other interfaces all at once. Interface resets can occur along with the underruns. |
| Undersize | Description: CatOS sh port and Cisco IOS sh interfaces counters errors . The frames received that are smaller than the minimum IEEE 802.3 frame size of 64 bytes (which excludes framing bits, but includes FCS octets) that are otherwise well formed. Common Causes: Check the device that sends out these frames. |
| Xmit-Err | Description: CatOS sh port and Cisco IOS sh interfaces counters errors. This is an indication that the internal send (Tx) buffer is full. Common Causes: A common cause of Xmit-Err can be traffic from a high bandwidth link that is switched to a lower bandwidth link, or traffic from multiple inbound links that are switched to a single outbound link. For example, if a large amount of bursty traffic comes in on a gigabit interface and is switched out to a 100Mbps interface, this can cause Xmit-Err to increment on the 100Mbps interface. This is because the output buffer of the interface is overwhelmed by the excess traffic due to the speed mismatch between the inbound and outbound bandwidths. |
Source