Hey,
great work with the library!
I am trying to install it, but I am getting a cuda error. I have been using pytorch the gpus wihout problems until now.
The full line reads: RuntimeError: cuda runtime error (100) : no CUDA-capable device is detected at /opt/conda/conda-bld/pytorch_1570910687650/work/aten/src/THC/THCGeneral.cpp:50
I am using python 3.7.3 and pytorch 1.3.
the output of nvidia_smi is:
Fri Nov 15 16:13:25 2019
+——————————————————————————+
| NVIDIA-SMI 418.56 Driver Version: 418.56 CUDA Version: 10.1 |
|——————————-+———————-+———————-+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|==================+======================+======================|
| 0 GeForce GTX TIT… On | 00000000:04:00.0 Off | N/A |
| 22% 41C P8 18W / 250W | 11MiB / 12212MiB | 0% Default |
+——————————-+———————-+———————-+
| 1 GeForce GTX TIT… On | 00000000:06:00.0 Off | N/A |
| 22% 38C P8 17W / 250W | 11MiB / 12212MiB | 0% Default |
+——————————-+———————-+———————-+
| 2 GeForce GTX 108… On | 00000000:07:00.0 Off | N/A |
| 31% 34C P8 8W / 250W | 1283MiB / 11178MiB | 0% Default |
+——————————-+———————-+———————-+
| 3 GeForce GTX 108… On | 00000000:08:00.0 Off | N/A |
| 31% 33C P8 8W / 250W | 10MiB / 11178MiB | 0% Default |
+——————————-+———————-+———————-+
| 4 TITAN X (Pascal) On | 00000000:0C:00.0 Off | N/A |
| 23% 35C P8 8W / 250W | 10MiB / 12196MiB | 0% Default |
+——————————-+———————-+———————-+
| 5 TITAN X (Pascal) On | 00000000:0E:00.0 Off | N/A |
| 23% 30C P8 8W / 250W | 10MiB / 12196MiB | 0% Default |
+——————————-+———————-+———————-+
+——————————————————————————+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|============================================================|
| 2 14534 C …zzi/anaconda3/envs/tmtm/bin/python3.7 1273MiB |
+——————————————————————————+
Any suggestions?
Содержание
- RuntimeError: cuda runtime error (100) : no CUDA-capable device is detected #8
- Comments
- CUDA Error: no CUDA-capable device is detected #288
- Comments
- no CUDA-capable device is detected #3265
- Comments
- System information
- Describe the problem
- nvidia-smi
- torch.cuda.device_count()
- nvcc —version
- To Reproduce
- Full Log
- ProgrammerAH
- Programmer Guide, Tips and Tutorial
- Tensorflow 2.1.0 error resolution: failed call to cuinit: CUDA_ ERROR_ NO_ DEVICE: no CUDA-capable device is detected
- How to Properly Use the GPU within a Docker Container
- Note: we have also published how to use GPUs in Docker on our blog. In this post, we walk through the steps required to access your machine’s GPU within a Docker container.
- Potential Errors in Docker
- First, Make Sure Your Base Machine Has GPU Drivers
- Next, Exposing the GPU Drivers to Docker
- Need Different base image in Dockerfile
- The Power of the NVIDIA Container Toolkit
- Update: Need CuDNN and NVCC cuda toolkit on Docker?
- Conclusion
RuntimeError: cuda runtime error (100) : no CUDA-capable device is detected #8
great work with the library!
I am trying to install it, but I am getting a cuda error. I have been using pytorch the gpus wihout problems until now.
The full line reads: RuntimeError: cuda runtime error (100) : no CUDA-capable device is detected at /opt/conda/conda-bld/pytorch_1570910687650/work/aten/src/THC/THCGeneral.cpp:50
I am using python 3.7.3 and pytorch 1.3.
the output of nvidia_smi is:
Fri Nov 15 16:13:25 2019
+——————————————————————————+
| NVIDIA-SMI 418.56 Driver Version: 418.56 CUDA Version: 10.1 |
|——————————-+———————-+———————-+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|==================+======================+======================|
| 0 GeForce GTX TIT. On | 00000000:04:00.0 Off | N/A |
| 22% 41C P8 18W / 250W | 11MiB / 12212MiB | 0% Default |
+——————————-+———————-+———————-+
| 1 GeForce GTX TIT. On | 00000000:06:00.0 Off | N/A |
| 22% 38C P8 17W / 250W | 11MiB / 12212MiB | 0% Default |
+——————————-+———————-+———————-+
| 2 GeForce GTX 108. On | 00000000:07:00.0 Off | N/A |
| 31% 34C P8 8W / 250W | 1283MiB / 11178MiB | 0% Default |
+——————————-+———————-+———————-+
| 3 GeForce GTX 108. On | 00000000:08:00.0 Off | N/A |
| 31% 33C P8 8W / 250W | 10MiB / 11178MiB | 0% Default |
+——————————-+———————-+———————-+
| 4 TITAN X (Pascal) On | 00000000:0C:00.0 Off | N/A |
| 23% 35C P8 8W / 250W | 10MiB / 12196MiB | 0% Default |
+——————————-+———————-+———————-+
| 5 TITAN X (Pascal) On | 00000000:0E:00.0 Off | N/A |
| 23% 30C P8 8W / 250W | 10MiB / 12196MiB | 0% Default |
+——————————-+———————-+———————-+
The text was updated successfully, but these errors were encountered:
Источник
CUDA Error: no CUDA-capable device is detected #288
`0 CUDA Error: no CUDA-capable device is detected
CUDA Error: no CUDA-capable device is detected: Bad file descriptor
[darknet_ros-1] process has died [pid 15933, exit code -6, cmd /home/zaphkiel/catkin_ws/devel/lib/darknet_ros/darknet_ros __name:=darknet_ros __log:=/home/zaphkiel/.ros/log/c17b16f2-4839-11eb-aa2e-f0038c4d290f/darknet_ros-1.log].
log file: /home/zaphkiel/.ros/log/c17b16f2-4839-11eb-aa2e-f0038c4d290f/darknet_ros-1*.log
`
how can i fix this error?

The text was updated successfully, but these errors were encountered:
Hey. Same issue how to solve it?
Does nvidia-smi show you any results?
nvidia-smi no result for me
I am having this same error as well. I am using VMWare with Ubuntu 18.04. Is there a way to run darknet without needing a CUDA GPU?
I’m having the same problem, the nvidia-smi output comes out like this

If you don’t have / want to use a NVidia GPU, don’t install CUDA on your system.
Try commenting out line 17 https://github.com/leggedrobotics/darknet_ros/blob/master/darknet_ros/CMakeLists.txt#L17 of the CMakeLists.txt when you get CUDA errors but you don’t have a CUDA GPU.
If you do see output, like @leeisack , then you actually should not get this error. Try running darknet with the following environment variable set:
CUDA_VISIBLE_DEVICES=0 , this will instruct CUDA to only make the first device visible.
(In a single bash session for example, run export CUDA_VISIBLE_DEVICES=0 )
Hi, I have the same issue. nvidia-smi works, like for @leeisack, but doing hat @tomlankhorst suggested did not work. Any other suggestions?
If you don’t want to use GPU, you can delete «find_ package(CUDA QUIET)» in Cmakelists
I solved this, thank you
@leeisack could you please share how you solved it?
Well. I don’t know we build the same problem first. However, in the case of me, the driver was automatically installed when cuda was installed, but if you do this, the latest driver is installed and the version of cuda is automatically increased. So, I installed the driver and cuda by setting the correct version separately.
@leeisack
Thank you for your reply. Can you maybe share what you mean with «So, I installed the driver and cuda by setting the correct version separately.»? Maybe you can provide us with the commands you used.
i still have the same problem. 
my nvidia-smi; 
I didn’t use a special method. It was solved by installing the driver according to the gpu version I am using. It seems that cuda and cudnn are installed according to the driver. So, in my case, I wanted to install the old versions of cuda and cudnn, but since the gpu is gtx1080, relatively latest version of the driver was installed and cuda and cudnn were automatically upgraded.
As a result, it was resolved by completely removing cuda, driver, and cudnn, and installing all three by entering the desired version directly. There is nothing I can advise other than this.
Источник
no CUDA-capable device is detected #3265
System information
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): docker Ubuntu 16.04 image
- Ray installed from (source or binary): pip
- Ray version: 0.5.3
- Python version: Python 3.5.6 :: Anaconda, Inc.
- Exact command to reproduce:
Describe the problem
Trying to setup a rllib ppo agent with husky_env from Gibson Env
The script I ran can be found here
I am getting the following Error when calling agent.train() :
Gibson does the environment rendering upon environment creation, and rllib agent’s seems to invoke env_creator every time train() is called. I originally thought that was the issue but I don’t think it is the case
I tried using gpu_fraction , didn’t work. Not sure what is causing the problem.
nvidia-smi
torch.cuda.device_count()
nvcc —version
To Reproduce
Get Nvidia-Docker2
Download Gibson’s dataset
Pull Gibson’s image
Run it in Docker
replace with the absolute path to the Gibson dataset you’ve unzipped on your local machine
Add in the ray_husky.py script
Copy the ray_husky.py found here to
/mount/gibson/examples/train/ directory in the docker container.
Run: python ray_husky.py
Full Log
The text was updated successfully, but these errors were encountered:
Источник
ProgrammerAH
Programmer Guide, Tips and Tutorial
Tensorflow 2.1.0 error resolution: failed call to cuinit: CUDA_ ERROR_ NO_ DEVICE: no CUDA-capable device is detected
today in the use of keras-gpu in jupyter notebook error, at first did not pay attention to the console output, only from jupyter see error messages. So, check the solution, roughly divided into two, one version back, two specified running equipment. Because I felt that it was not the version problem, I still used the latest version without going back, so I tried the second method to solve the problem, that is, the program was designed to run the device, and the program could run without error. I accidentally noticed the console output and found that the CPU was running?Then found that the name of the specified device error, resulting in the system can not find the device, so first query the name of the device and then specify the device, to solve the problem.
- cudatoolkit = 10.1.243
- cudnn = 7.6.5
- tensorflow – gpu = 2.1.0
- keras – gpu = 2.3.1
Jupyter notebook print error:
Jupyter notebook console print error: failed call to cuInit: CUDA_ERROR_NO_DEVICE: no cuda-capable device is detected 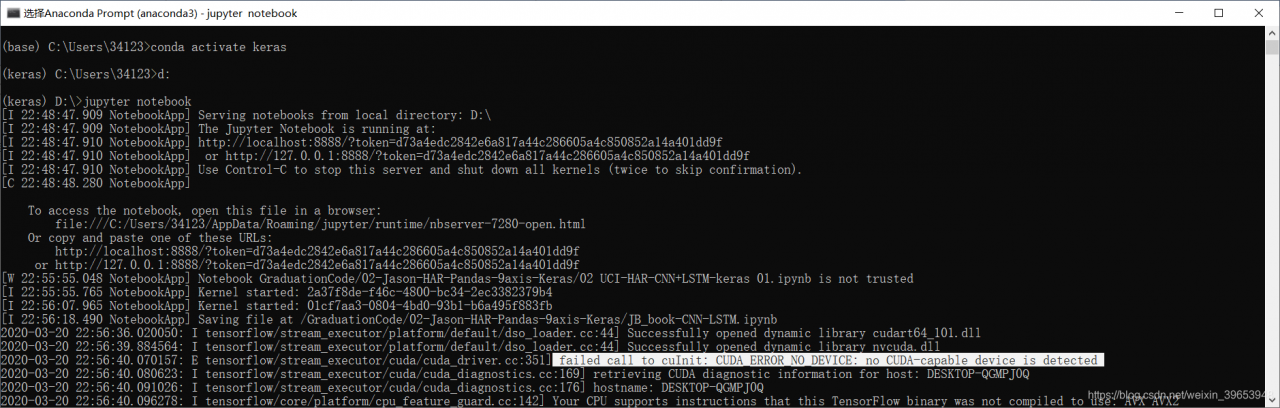
- to view native GPU/CPU information
- can see that the native device has GPU, so use the following statement to specify the name of the running device:
The attention! = The following must be the device name, each person’s device name may be different, do not copy, must first use the command query, then specify!
- to view the currently loaded device:
Источник
How to Properly Use the GPU within a Docker Container
Note: we have also published how to use GPUs in Docker on our blog. In this post, we walk through the steps required to access your machine’s GPU within a Docker container.
Configuring the GPU on your machine can be immensely difficult. The configuration steps change based on your machine’s operating system and the kind of NVIDIA GPU that your machine has. To add another layer of difficulty, when Docker starts a container — it starts from almost scratch. Certain things like the CPU drivers are pre-configured for you, but the GPU is not configured when you run a docker container. Luckily, you have found the solution explained here. It is called the NVIDIA Container Toolkit!
Potential Errors in Docker
When you attempt to run your container that needs the GPU in Docker, you might receive any of the following errors.
Error: Docker does not find Nvidia drivers
Error: tensorflow cannot access GPU in Docker
Error: pytorch cannot access GPU in Docker
Error: keras cannot access GPU in Docker
You may receive many other errors indicating that your Docker container cannot access the machine’s GPU. In any case, if you have any errors that look like the above, you have found the right place here.
First, Make Sure Your Base Machine Has GPU Drivers
You must first install NVIDIA GPU drivers on your base machine before you can utilize the GPU in Docker. As previously mentioned, this can be difficult given the plethora of distribution of operating systems, NVIDIA GPUs, and NVIDIA GPU drivers. The exact commands you will run will vary based on these parameters. Here are some resources that you might find useful to configure the GPU on your base machine.
Once you have worked through those steps, you will know you are successful by running the nvidia-smi command and viewing an output like the following.
Now that we can assure we have successfully assure that the NVIDIA GPU drivers are installed on the base machine, we can move one layer deeper to the Docker container.
Next, Exposing the GPU Drivers to Docker
In order to get Docker to recognize the GPU, we need to make it aware of the GPU drivers. We do this in the image creation process. Docker image creation is a series of commands that configure the environment that our Docker container will be running in.
The Brute Force Approach — The brute force approach is to include the same commands that you used to configure the GPU on your base machine. When docker builds the image, these commands will run and install the GPU drivers on your image and all should be well. The brute force approach will look something like this in your Dockerfile (Code credit to stack overflow):
The Downsides of the Brute Force Approach — First of all, every time you rebuild the docker image you will have to reinstall the image, slowing down development. Second, if you decide to lift the docker image off of the current machine and onto a new one that has a different GPU, operating system, or you would like new drivers — you will have to re-code this step every time for each machine. This kind of defeats the purpose of build a Docker image. Third, you might not remember the commands to install the drivers on your local machine, and there you are back at configuring the GPU again inside of Docker.
The Best Approach — The best approach is to use the NVIDIA Container Toolkit. The NVIDIA Container Toolkit is a docker image that provides support to automatically recognize GPU drivers on your base machine and pass those same drivers to your Docker container when it runs. So if you are able to run nvidia-smi, on your base machine you will also be able to run it in your Docker container (and all of your programs will be able to reference the GPU). In order to use the NVIDIA Container Toolkit, you simply pull the NVIDIA Container Toolkit image at the top of your Dockerfile like so — nano Dockerfile:
This is all the code you need to expose GPU drivers to Docker. In that Dockerfile we have imported the NVIDIA Container Toolkit image for 10.2 drivers and then we have specified a command to run when we run the container to check for the drivers. Now we build the image like so with docker build . -t nvidia-test:
Now we run the container from the image by using the command docker run — gpus all nvidia-test. Keep in mind, we need the — gpus all or else the GPU will not be exposed to the running container.
From this base state, you can develop your app accordingly. In my case, I use the NVIDIA Container Toolkit to power experimental deep learning frameworks. The layout of a fully built Dockerfile might look something like the following (where /app/ contains all of the python files):
The above Docker container trains and evaluates a deep learning model based on specifications using the base machines GPU. Pretty cool!
Need Different base image in Dockerfile
Let’s say you have been relying on a different base image in your Dockerfile. Then, you can install NVIDIA container runtime.
Now you can run other base images with nvidia container runtime (here we run ubuntu base).
Now that you have you written your image to pass through the base machine’s GPU drivers, you will be able to lift the image off the current machine and deploy it to containers running on any instance that you desire.
The nvidia/cuda:10.2-base will only get you nvidia-smi. If you need cuDNN or nvcc —version you can pull from other NVIDIA Docker base images, namely: nvidia/cuda:10.2-devel-ubuntu18.0. (gets you nvcc cuda toolkit) and nvidia/cuda:10.2-cudnn7-devel-ubuntu18.04. (gets you cuDNN).
Conclusion
Congratulations! Now you know how to expose GPU Drivers to your running Docker container using the NVIDIA Container Toolkit.
Want to use your new Docker capabilities to do something awesome? You might enjoy our other posts on training a state of the art object detection model, training a state of the art image classification model, or simply by looking into some free computer vision data!
Источник
I have been using their algorithm for days and I tried several, but none of them gave me this error until now.
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-5-dbd18151b569> in <module>()
1 from demo import load_checkpoints
2 generator, kp_detector = load_checkpoints(config_path='config/vox-256.yaml',
----> 3 checkpoint_path='/content/gdrive/My Drive/first-order-motion-model/vox-cpk.pth.tar')
10 frames
/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py in _lazy_init()
188 raise AssertionError(
189 "libcudart functions unavailable. It looks like you have a broken build?")
--> 190 torch._C._cuda_init()
191 # Some of the queued calls may reentrantly call _lazy_init();
192 # we need to just return without initializing in that case.
RuntimeError: cuda runtime error (100) : no CUDA-capable device is detected at /pytorch/aten/src/THC/THCGeneral.cpp:47
![]()
talonmies
69.9k34 gold badges189 silver badges262 bronze badges
asked Sep 11, 2020 at 22:57
![]()
You have not enabled GPU on your notebook, enable it in Runtime > Change runtime.
answered Sep 24, 2020 at 19:10
![]()
Walid GhalemWalid Ghalem
2061 gold badge2 silver badges10 bronze badges