CUDA error 715
Moderator: face_off
Forum rules
Please keep character renders sensibly modest, please do not post sexually explicit scenes of characters.
CUDA error 715
This thread is continue from «The video card dose not responds.» / viewtopic.php?f=45&t=68390
I try simple light scense, that only have environment light.
I meet following trouble,
How to fix this ?
CUDA error 715 on device 1: an illegal instruction was encountered
CUDA error 715 on device 2: an illegal instruction was encountered
-> failed to deallocate device memory
-> failed to deallocate device memory
CUDA error 715 on device 1: an illegal instruction was encountered
CUDA error 715 on device 2: an illegal instruction was encountered
-> could not get memory info
-> could not get memory info
CUDA error 715 on device 1: an illegal instruction was encountered
CUDA error 715 on device 2: an illegal instruction was encountered
-> failed to deallocate device memory
-> failed to deallocate device memory
CUDA error 715 on device 1: an illegal instruction was encountered
CUDA error 715 on device 2: an illegal instruction was encountered
-> could not get memory info
-> could not get memory info
CUDA error 715 on device 1: an illegal instruction was encountered
CUDA error 715 on device 2: an illegal instruction was encountered
-> failed to deallocate device memory
-> failed to unload module
CUDA error 715 on device 1: an illegal instruction was encountered
-> could not get memory info
CUDA error 715 on device 1: an illegal instruction was encountered
-> failed to unload module
Stopped logging on 15.09.18 20:30:34
reached the maximum number of consecutive runs of a slave (5) -> bailing out
- calvados
- Licensed Customer

- Posts: 79
- Joined: Sun Aug 02, 2015 1:58 am
Re: CUDA error 715
![]() by calvados » Sat Sep 15, 2018 12:25 pm
by calvados » Sat Sep 15, 2018 12:25 pm
Sorry for my Post,
Poser Version
Poser 11 Pro on Windows 10 with 32G byte memory
Nvidia Driver Version 399.24 / Windows
Network Rendering Yes
OctaneRender for Plugin version 3.05.2.88
Poser verion 11.1.0.34759
nVidia 1070(8G) * 3 / on troubled machin,
nVidia 980Ti(6G)*2 / remote machin
- calvados
- Licensed Customer
- Posts: 79
- Joined: Sun Aug 02, 2015 1:58 am
Re: CUDA error 715
![]() by face_off » Sat Sep 15, 2018 12:41 pm
by face_off » Sat Sep 15, 2018 12:41 pm
My best guess is that one of your cards is faulty. Try turning various card off to see if you can identify which is causing the issue. And try without network rendering.
Paul
-

face_off - Octane Plugin Developer
- Posts: 15151
- Joined: Fri May 25, 2012 10:52 am
- Location: Adelaide, Australia

Re: CUDA error 715
![]() by calvados » Mon Sep 17, 2018 11:05 am
by calvados » Mon Sep 17, 2018 11:05 am
Thank you for your support.
I tested lot of pattern of GPU group.
I found following result.
Case of Most Stable.
Using one GPU on Host Computer, and must be set «Kernel->Parallele Sample 1 or 2 / Pass Tracing Kernel».
Network Rendering Node has no trouble, we can use all of Network Rendering Node.
I test each GPU(3 GPUs), this result is same, therefore this trouble is not on GPU, caused by Octane Inside.
Multi GPU on Rendering Node is no reretionship with this trouble.
Case of Unstable
1. «Kernel->Parallele Sample 4 and more»
2. Use 2 or 3 GPU onHost Computer
I found that this kind of trouble occur from Octane V3.07-08.
More younger version dose not neet this trouble.
- calvados
- Licensed Customer
- Posts: 79
- Joined: Sun Aug 02, 2015 1:58 am
Re: CUDA error 715
![]() by face_off » Tue Sep 18, 2018 2:31 am
by face_off » Tue Sep 18, 2018 2:31 am
I found that this kind of trouble occur from Octane V3.07-08.
More younger version dose not neet this trouble.
You state above the problem occurs with Octane 3.07 and 3.08. However you also reported you are using the Octane 3.05.2
OctaneRender for Plugin version 3.05.2.88
So is the information you have provided accurate pls?
Paul
-
face_off - Octane Plugin Developer
- Posts: 15151
- Joined: Fri May 25, 2012 10:52 am
- Location: Adelaide, Australia
Re: CUDA error 715
![]() by calvados » Tue Sep 18, 2018 2:13 pm
by calvados » Tue Sep 18, 2018 2:13 pm
I try re-test with Octane 3.05.2, unforunary I remove old verions, and deleted this verion from your site.
Becuase, old time I meet this kind of problem, but not so offen than 3.07-08.
I can’t say it is same, I’m sorry.
Additionaly, V3.07 is better than V3.08.
Case of trouble sense, in this case V3.07 can render 1 or more pictures, but V3.08 get touble after 5 min(I feel strange this, but always same).This case use 3 GPU in main PC and Parallel Sample as 8 to 16. if 1 GPU and Parallel sample as 1-2 has no touble.
- calvados
- Licensed Customer
- Posts: 79
- Joined: Sun Aug 02, 2015 1:58 am
Re: CUDA error 715
![]() by calvados » Sun Sep 30, 2018 4:24 am
by calvados » Sun Sep 30, 2018 4:24 am
Yes, it is.
- calvados
- Licensed Customer
- Posts: 79
- Joined: Sun Aug 02, 2015 1:58 am
Re: CUDA error 715
![]() by face_off » Sun Sep 30, 2018 5:05 am
by face_off » Sun Sep 30, 2018 5:05 am
This is not related to the Poser plugin, and is an Octane or Nvidia issue. So can you pls report it to OTOY via the Support menu option above, or in the Octane Standalone release thread.
Thanks
Paul
-
face_off - Octane Plugin Developer
- Posts: 15151
- Joined: Fri May 25, 2012 10:52 am
- Location: Adelaide, Australia
Return to Poser
Who is online
Users browsing this forum: No registered users and 4 guests
Hi,
Having some issues after I bought a new GPU.
Earlier I had 2 ASUS Geforce 1060 OC 3GB, running stable for weeks. Then I also bought a ASUS Geforce 1070 OC 8GB and started getting the error:
CUDA error DRIVER ‘715’ in func ‘run_single_stream’ line 995
sometimes following error occours, at the same time. BUT not always:
CUDA error ‘an illegal instruction was encountered’ in fuc ‘cuda_lyra2rev2::run’ line 785
Thought it could be afterburner OC, but set it to factory settings. Still the same.
Upgraded Nicehash to v2.0.1.4, which installs excaviator v1.3.6a
Same issue. Miner gets error either just after startup or after 30 sec or so.
Checked GPU driver/bios….
Switched off one of the GPU’s so I only runs 1×1060 and 1×1070, then it gets more stable and have not seen an error while running a couple of hours.
Started 2 Nicehash applications. first of the runs 1060 and 1070, other application runs the last 1060.
Then error occours randomly between 1min and x hour.
The 1060’s has hyxin ram and the 1070 has Micron… -Yeah I’m so lucky!
Any good solutions to fix this?
I am writing a path tracer for GPU using CUDA 10.2. The entire program ran fine until i added a recursive call to the trace function. nvcc still compiles it, although with the warning: «Severity Code Description Project File Line Suppression State
Warning Stack size for entry function » cannot be statically determined». When the GPU reaches the point it stops and the next time CPU gets an cudaError from an API call it is cuda error 715, which is cudaErrorIllegalInstruction. I tried recreating the issue by writing another recursive kernel/function pair, and the compiler gave the same warning, but it executed expectedly. Unfortunately this means i have to dump my entire function here (if there are any questions to the functions and types used i will happily answer them):
__device__ Vec3 trace(
const Settings& settings,
const Ray& r,
const Shape* shapes,
const size_t nshapes,
uint8_t bounces,
curandState& randState) {
if (bounces >= settings.maxBounces) {
return Vec3(0.0f);
}
const Shape* shape = nullptr;
float t = inf;
bool flipNormal;
float dist;
for (size_t i = 0; i < nshapes; i++) {
if (shapes[i].intersect(r, dist, flipNormal) && dist < t) {
shape = shapes + i;
t = dist;
}
}
if (shape == nullptr)
return settings.background;
const Vec3 hitPos = r.ori + t * r.dir;
const Vec3 normal = flipNormal ? -shape->normal(hitPos) : shape->normal(hitPos);
const Vec3 hemiDir = cosineSample(normal, randState);
const Vec3 traceCol = trace(
settings,
Ray(hitPos + normal * settings.bias, hemiDir),
shapes,
nshapes,
bounces + 1,
randState
);
return shape->surface.emittance + shape->surface.color * traceCol;
}
Has anyone else had this issue and in that case, how was it fixed? I could probably redesign to a non-recursive design, although it wouldn’t be an optimal solution.
I don’t even know where to start with debugging this issue, so any ideas are greatly appreciated.

Topic: Black Screen / CUDA error 715 on line 112 (Read 4259 times)
Howdy, first post, medium long term user.
First up — great software — love it! — really useful.
I run Photoscan Standard on my MacBook and a Dell laptop without any issues, apart from super slow processing.
I have a new machine though — a PC desktop box with a decent graphics card, but i’m running into what i think is a compatibility or driver error.
specs
Win 10 for edu
Intel Xeon CPU 1.8ghz (2 processors)
32GB RAM
64 bit
NVIDIA Tesla C2075
Tesla driver ver 377.35
at first when i ran Photoscan i got the «black screen error» — i read this post on the forum, http://www.agisoft.com/forum/index.php?topic=6994.msg33739#msg33739 , and followed the steps suggested.
this is the read from the console:
2017-06-06 20:52:18 Agisoft PhotoScan Standard Version: 1.3.2 build 4195 (64 bit)
2017-06-06 20:52:18 Platform: Windows
2017-06-06 20:52:19 OpenGL Vendor: Microsoft Corporation
2017-06-06 20:52:19 OpenGL Renderer: GDI Generic
2017-06-06 20:52:19 OpenGL Version: 1.1.0
2017-06-06 20:52:19 Maximum Texture Size: 1024
2017-06-06 20:52:19 Quad Buffered Stereo: not enabled
2017-06-06 20:52:19 ARB_vertex_buffer_object: not supported
2017-06-06 20:52:19 ARB_texture_non_power_of_two: not supported
2017-06-06 20:52:51 OpenGL Vendor: Microsoft Corporation
2017-06-06 20:52:51 OpenGL Renderer: GDI Generic
2017-06-06 20:52:51 OpenGL Version: 1.1.0
2017-06-06 20:52:51 Maximum Texture Size: 1024
2017-06-06 20:52:51 Quad Buffered Stereo: not enabled
2017-06-06 20:52:51 ARB_vertex_buffer_object: not supported
2017-06-06 20:52:51 ARB_texture_non_power_of_two: not supported
i am not running WRD or any other kind of remote login — to my knowledge. so — the questions i suppose are —
why is Photoscan ignoring the installed GPU?
is the Tesla compatible with Photoscan in the first place?
what should i do next?
ALSO — when i try to run a scan with the GPU selected in preferences i get — an error — «CUDA error 715 on line 112» — when i run a scan without the GPU selected in the preferences then it runs fine — but slow.
any help would be greatly appreciated i have about 50 scans to run thru and i need to get this moving.

Logged
Hello tomburtonwood,
Unless I am mistaken, Tesla card can be used only for the computations and cannot act as OpenGL rendering device.
As for the CUDA error, can you specify the driver version and provide the full processing log from the start of the corresponding operation up to the error message (for Align Photos and Build Dense Cloud stages).
Logged
Best regards,
Alexey Pasumansky,
Agisoft LLC
Hi Alexey,
Thank you for your fast response. I did not know the Tesla does not run OpenGL — that explains a lot!
See below console — i closed Photoscan, reopened the pre-aligned file (from other machine), and reran Dense Point Cloud at High. Error msg is now «Unknown at line 195» —
2017-06-07 09:23:50 Agisoft PhotoScan Standard Version: 1.3.2 build 4195 (64 bit)
2017-06-07 09:23:50 Platform: Windows
2017-06-07 09:23:51 OpenGL Vendor: Microsoft Corporation
2017-06-07 09:23:51 OpenGL Renderer: GDI Generic
2017-06-07 09:23:51 OpenGL Version: 1.1.0
2017-06-07 09:23:51 Maximum Texture Size: 1024
2017-06-07 09:23:51 Quad Buffered Stereo: not enabled
2017-06-07 09:23:51 ARB_vertex_buffer_object: not supported
2017-06-07 09:23:51 ARB_texture_non_power_of_two: not supported
2017-06-07 09:24:10 OpenGL Vendor: Microsoft Corporation
2017-06-07 09:24:10 OpenGL Renderer: GDI Generic
2017-06-07 09:24:10 OpenGL Version: 1.1.0
2017-06-07 09:24:10 Maximum Texture Size: 1024
2017-06-07 09:24:10 Quad Buffered Stereo: not enabled
2017-06-07 09:24:10 ARB_vertex_buffer_object: not supported
2017-06-07 09:24:10 ARB_texture_non_power_of_two: not supported
2017-06-07 09:24:19 LoadProject
2017-06-07 09:24:19 Loading project…
2017-06-07 09:24:20 loaded project in 0.375 sec
2017-06-07 09:24:20 Finished processing in 0.381 sec (exit code 1)
2017-06-07 09:24:30 Checking for missing images…
2017-06-07 09:24:30 checking for missing images… done in 0.043 sec
2017-06-07 09:24:30 Finished processing in 0.044 sec (exit code 1)
2017-06-07 09:24:30 BuildDenseCloud: quality = High, depth filtering = Aggressive
2017-06-07 09:24:30 Initializing…
2017-06-07 09:24:30 Using device: Tesla C2075, 14 compute units, 5316 MB global memory, Device Compute Capability 2.0
2017-06-07 09:24:30 max work group size 1024
2017-06-07 09:24:30 max work item sizes [1024, 1024, 64]
2017-06-07 09:24:30 Using CUDA device ‘Tesla C2075’ in concurrent. (2 times)
2017-06-07 09:24:30 sorting point cloud… done in 0.828 sec
2017-06-07 09:24:31 processing matches… done in 0.286 sec
2017-06-07 09:24:31 initializing…
2017-06-07 09:24:37 selected 507 cameras from 535 in 5.333 sec
2017-06-07 09:24:37 Loading photos…
2017-06-07 09:25:27 loaded photos in 50.038 seconds
2017-06-07 09:25:27 Reconstructing depth…
2017-06-07 09:25:27 [GPU] estimating 1403x2862x640 disparity using 1403x1431x8u tiles
2017-06-07 09:25:27 [GPU] estimating 1418x4291x352 disparity using 1418x1073x8u tiles
2017-06-07 09:25:27 Error: 2017-06-07 09:25:27 GPU processing failed, switching to CPU mode
2017-06-07 09:25:27 GPU processing failed, switching to CPU mode
2017-06-07 09:25:27 [CPU] estimating 1403x2862x640 disparity using 1403x954x8u tiles
2017-06-07 09:25:27 [CPU] estimating 1418x4291x352 disparity using 1418x1073x8u tiles
Kernel failed: unknown error at line 98Error: Kernel failed: unknown error at line 98
2017-06-07 09:25:27
2017-06-07 09:25:28
2017-06-07 09:25:28 Depth reconstruction devices performance:
2017-06-07 09:25:28 — 0% done by Tesla C2075
2017-06-07 09:25:28 Total time: 0.87 seconds
2017-06-07 09:25:28
2017-06-07 09:25:28 Warning: all CUDA-capable devices are busy or unavailable
2017-06-07 09:25:29 Warning: all CUDA-capable devices are busy or unavailable
2017-06-07 09:25:29 Finished processing in 58.67 sec (exit code 0)
2017-06-07 09:25:29 Error: unknown error at line 195
i have a Quadro 4000 card. i’m going to install that on this machine and see what happens.
Thank you!
Logged
Logged
Best regards,
Alexey Pasumansky,
Agisoft LLC
Sorry NVIDIA Driver is 377.35.
the Quadro seems to have done the trick.
this is from the console — running Point Cloud now on High —
2017-06-07 10:01:34 Checking for missing images…
2017-06-07 10:01:34 checking for missing images… done in 0.036 sec
2017-06-07 10:01:34 Finished processing in 0.036 sec (exit code 1)
2017-06-07 10:01:34 BuildDenseCloud: quality = High, depth filtering = Aggressive
2017-06-07 10:01:34 Initializing…
2017-06-07 10:01:34 Using device: Quadro 4000, 8 compute units, 2048 MB global memory, Device Compute Capability 2.0
2017-06-07 10:01:34 max work group size 1024
2017-06-07 10:01:34 max work item sizes [1024, 1024, 64]
2017-06-07 10:01:34 Using device: Tesla C2075, 14 compute units, 5375 MB global memory, Device Compute Capability 2.0
2017-06-07 10:01:34 max work group size 1024
2017-06-07 10:01:34 max work item sizes [1024, 1024, 64]
2017-06-07 10:01:34 Using CUDA device ‘Tesla C2075’ in concurrent. (2 times)
2017-06-07 10:01:34 sorting point cloud… done in 0.816 sec
2017-06-07 10:01:35 processing matches… done in 0.292 sec
2017-06-07 10:01:35 initializing…
2017-06-07 10:01:40 selected 507 cameras from 535 in 5.559 sec
2017-06-07 10:01:41 Loading photos…
2017-06-07 10:02:31 loaded photos in 50.507 seconds
2017-06-07 10:02:31 Reconstructing depth…
2017-06-07 10:02:31 [GPU] estimating 1657x2184x704 disparity using 829x1092x8u tiles
2017-06-07 10:02:31 [GPU] estimating 1418x4291x352 disparity using 1418x1431x8u tiles
2017-06-07 10:02:31 [GPU] estimating 1252x2009x416 disparity using 1252x1005x8u tiles
so it seems all is good —
thank you
Logged
also it is running in compute mode.
est is 4 hours to process the scan. which is a massive improvement on prior attempts.
Logged
Hello tomburtonwood,
It seems that the problem with «all CUDA-capable devices are busy or unavailable» happens from time to time on different applications that are exploiting CUDA on NVIDIA cards. We’ll try to dig deeper, but the issue may be related to the driver behavior.
But if the issue will re-appear, please let us know.
Logged
Best regards,
Alexey Pasumansky,
Agisoft LLC
will do.
does it make sense to limited the quadro only to graphics tasks — or to run it in tandem with the Tesla for computing?
right now it is running in tandem, — with both cards computing the scan.
Logged
Hello tomburtonwood,
You can run any sample dataset on both cards with CPU disabled and check the percentage of task completed by every card. If the there is no considerable difference, it’s better to use both cards to get higher performance and faster processing.
Logged
Best regards,
Alexey Pasumansky,
Agisoft LLC
-
#1
Приветствую всех.
Народ подскажите пожалуйста уже всю голову сломал. Все фермы работают стабильно. На всех одинаковые карты 1080ti.
Но на одной ферме постоянно сыпятся ошибки. Эта ферма может проработать сутки а может час, потом перезагружается Майнер.
Характеристики фермы 6 карт 1080ti. 128 ssd, 4 гига оперативки.
Увеличил виртуальную память до 64гигов не помогло.
Куда дальше копать?
-

378B954F-2CF2-4A2C-B14B-FC2104DE4022.jpeg
85,1 КБ · Просмотры: 337
-

CF98FA79-4C07-4B20-A4D4-A4B77FF65E17.jpeg
82,7 КБ · Просмотры: 327
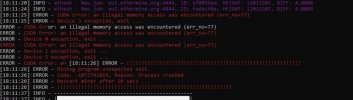
-
#2
На фото видно что ошибки начинаются с 3 девайса и со второго, но по факту там ошибки по любой карте выскакивают
-
#3
Приветствую всех.
Народ подскажите пожалуйста уже всю голову сломал. Все фермы работают стабильно. На всех одинаковые карты 1080ti.
Но на одной ферме постоянно сыпятся ошибки. Эта ферма может проработать сутки а может час, потом перезагружается Майнер.
Характеристики фермы 6 карт 1080ti. 128 ssd, 4 гига оперативки.
Увеличил виртуальную память до 64гигов не помогло.
Куда дальше копать?
Я бы увеличил подкачку до 80 на всякий, если на винде
-
#4
Увеличил виртуальную память до 64гигов не помогло.
6 карт x 11Gb = 66Gb МИНИМУМ!
-
#5
Попробуй сменить версию майнера
-
#6
Попробуй сменить версию майнера
Сейчас увеличил до 74 гигов. Если проблема сохраниться попробую другую версию Майнера.
-
#7
Ну и в любом случае проверить питание карт (разъемы). В моем случае карты вылетали или на перезагрузку выбивали. После смена всех разъемов (точнее БП для начала) — все нормализовалось. Это при нормальном драйвере и в целом стабильной системе — как написано выше.
-
#8
«Illegal memory access» — скорее всего, переразгон
-
#9
А что,на 4 гигах оперативы еще заводятся риги,что-ли?4 гига-это ультра-мало на сегодняшний день.Майнер как бы намекает,что ему не хватает памяти,виртуалка это уже вторичная причина,когда оперативы не хватает.
-
#10
Сейчас увеличил до 74 гигов. Если проблема сохраниться попробую другую версию Майнера.
Файл подкачки минимум 66 гига. Майнер обнови. Была такая беда.
Последнее редактирование: 10 Мар 2021
-
#11
А что,на 4 гигах оперативы еще заводятся риги,что-ли?4 гига-это ультра-мало на сегодняшний день.Майнер как бы намекает,что ему не хватает памяти,виртуалка это уже вторичная причина,когда оперативы не хватает.
У меня работает. Win 10 — 7 карт
-
#12
Файл подкачки минимум 54 гига. Майнер обнови. Была такая беда.
Этого мало! Файл подкачки-суммарный объем памяти всех видеокарт +10%.На 1080ти 11ГБ,дальше считай сам)
-
#13
Этого мало! Файл подкачки-суммарный объем памяти всех видеокарт +10%.На 1080ти 11ГБ,дальше считай сам)
Ошибся простите. 1080 ti там на борту 11 гигов, а я по 8 посчитал.

cps
Гений мысли
-
#14
Сейчас увеличил до 74 гигов. Если проблема сохраниться попробую другую версию Майнера.
Если не поможет, смотри на переразгон.
-
#15
Несколько недель было такое,один в один,на всех фермах одинаковый конфиг,работали долго и без проблем,потом одна начала дурить,как у вас,снизил разгон по курве и памяти,пятый день полёт нормальный,можно отвозить на базу,я думаю, что памятть диградирует помаленьку,время берёт своё.
-
#16
Несколько недель было такое,один в один,на всех фермах одинаковый конфиг,работали долго и без проблем,потом одна начала дурить,как у вас,снизил разгон по курве и памяти,пятый день полёт нормальный,можно отвозить на базу,я думаю, что памятть диградирует помаленьку,время берёт своё.
А я думаю, что даг растет, а память в порядке.
-
#17
Несколько недель было такое,один в один,на всех фермах одинаковый конфиг,работали долго и без проблем,потом одна начала дурить,как у вас,снизил разгон по курве и памяти,пятый день полёт нормальный,можно отвозить на базу,я думаю, что памятть диградирует помаленьку,время берёт своё.
Так у меня ошибки вылетают не по конкретной карте а по разным все время
-
#18
Так у меня ошибки вылетают не по конкретной карте а по разным все время
А я тебе ,что ответил,проблема один в один,как ты описал,вылеты по разным картам
-
#19
А страпы какие нибудь применены?
-
#20
А страпы какие нибудь применены?
нет, nbminer 36.1 и таблетка омой бог
Во время очередного прогона я получил вот это. Майнер каждый раз вылетает.
CUDA error in func 'search' at line 365 : an illegal memory access was encountered.
CUDA error in func 'search' at line 365 : an illegal memory access was encountered.
CUDA error in func 'search' at line 365 : an illegal memory access was encountered.
✘ 01:14:46|cudaminer1 Error CUDA mining: an illegal memory access was encountered
✘ 01:14:46|cudaminer2 Error CUDA mining: an illegal memory access was encountered
✘ 01:14:46|cudaminer4 Error CUDA mining: an illegal memory access was encountered
CUDA error in func 'search' at line 365 : an illegal memory access was encountered.
✘ 01:14:46|cudaminer3 Error CUDA mining: an illegal memory access was encountered
CUDA error in func 'search' at line 365 : an illegal memory access was encountered.
✘ 01:14:46|cudaminer0 Error CUDA mining: an illegal memory access was encountered
Это может быть связано с разгоном, вопреки моим предыдущим наблюдениям в №80. Я запускал его около 90 минут при стандартных настройках графического процессора без ошибок. Изменено на +165 ядер и +2000 памяти с помощью графического интерфейса настроек сервера nvidia x. Он работал стабильно около 2 минут и таким образом выдавал ошибку.
Я сбросил память до +1500 и начал снова. Он работал около 30 минут без проблем.
Увеличил память до +1900 только на одной карте, и ошибка возникла снова. Об этом сообщалось одновременно на обоих графических процессорах, как обычно, несмотря на изменение скорости только на одном из них.
Я могу перезапускать ethminer снова и снова с такой высокой скоростью передачи памяти, и каждый раз он дает сбой в короткие сроки.
У меня нет опыта работы с C или каким-либо аппаратным программированием низкого уровня. Поэтому я не собираюсь даже пытаться понять, что делает код.
Я надеюсь, что сообщение о том, как воспроизвести проблему, поможет кому-то найти решение или, по крайней мере, лучший способ отлова ошибок для этой воспроизводимой проблемы.
В идеале майнер обнаружил бы ошибку и перезапустился, увеличивая счетчик, показывающий количество перезапусков из-за ошибок. Есть момент, когда более высокая скорость передачи снижает производительность из-за сбоев. Но его сложно найти, когда сбои трудно обнаружить, не стоя и не наблюдая за прокручивающимся терминалом.
@shanemgrey, спасибо, что разместили это, я согласен, я подозреваю, что проблема
Согласитесь, Claymore очень хорошо справляется со сбоями, это очень удобно, особенно если вы не можете постоянно следить за майнером. Какой-то вариант перезапуска майнинга будет очень удобной функцией этого майнера.
Просто чтобы проверить, связано ли это с ОС. Мой майнер работает на Windows 7 Ultimate 64 bit и ведет себя точно так же (сбои в зависимости от уровня разгона). На моем компьютере с Windows 10 у меня есть одна карта, которая вообще не разбилась (работает 21 час). У вас такие же результаты или дело не в ОС?
@Skromniac Все еще не уверен, могу ли я воспроизвести сбои во всех ОС (Windows / Linux), когда частота слишком высока. На данный момент я заметил, что сбои становятся менее частыми (каждые 2–30 минут), когда я уменьшаю тактовую частоту. Я буду продолжать пробовать это, пока не увижу, что теперь вылетает несколько дней. Я все еще не уверен, что это полностью связано с тактовой частотой, OC усугубляет проблему, но я думаю, что это не основная причина проблемы.
Подробнее, каждый раз, когда происходит сбой, возникает ошибка драйвера ядра.
Jun 30 06:08:58 ubuntu kernel: [77905.021944] NVRM: Xid (PCI:0000:02:00): 31, Ch 0000001b, engmask 00000101, intr 10000000
Xid 31: согласно сайту драйверов Nvidia, эта ошибка возникает, когда это ошибка драйвера / приложения.
Так что это не проблема с оборудованием, что хорошо, потому что исключает проблему с оборудованием. Я пробовал другую версию драйвера и получаю такие же ошибки. Я думаю, нам нужен кто-то, кто знает, как работает майнер, чтобы взглянуть на это, может нам помочь.
Для справки: я использую Ubuntu 16.04, драйвер 64 бит, 381.22 и Cuda 8.0.
Покопавшись, я постепенно обновляюсь с версии драйвера 367.27 до 381.22. Сбои постоянны, вы их получаете независимо. Это действительно раздражает, потому что в майнере нет функции сторожевого таймера, которая могла бы перезапускаться в случае сбоя. И вы не можете присматривать за ним 24/7 или автоматически перезапускаться.
Дополнительная информация, в зависимости от версии вашего драйвера, вы получаете разные ошибки сбоя. Итак, у меня версия драйвера 381.22, у меня недопустимая ошибка памяти, но на 375.66 я получаю неопределенный сбой запуска. Все это относится к какому-то поисковому коду в библиотеке ethash для этого майнера.
@davilizh @chfast @Genoil, ребята, комментарии, пожалуйста. Очень трудно найти здесь первопричину.
@rizwansarwar
Извините, что ответил поздно.
Прочитав все ваши комментарии, проблема должна заключаться в том, что при разгоне графический процессор получает неправильные данные / инструкции. Если честно, опыта разгона gpu / mem у меня нет. Мои приблизительные мысли:
- произойдет ли ошибка снова, если мы только перегрузим тактовую память? Поскольку Ethereum привязан к памяти, я думаю, что более важно увеличить тактовую частоту памяти.
- можем ли мы разместить все структуры данных Ethereum в памяти хоста, а в видеопамять разместим только буфер dag?
- можем ли мы добавить сторожевой таймер в код, чтобы перезапустить его при возникновении ошибки?
- можем ли мы использовать cuda-gdb или cuda-memcheck, чтобы узнать, какая инструкция / данные неверны, чтобы мы могли добавить к ним защиту?
Надеюсь, это поможет для воспроизводимости — я перезапустил свою установку в пятницу и с тех пор не входил в систему через удаленный рабочий стол. Буровая установка работает нормально, без заминки. Кто-то упомянул, что проблема часто возникает, когда вы входите в систему, чтобы проверить, то есть когда основная видеокарта пытается отрендерить что-то еще (кроме майнинга).
@Skromniac
Спасибо, хорошие новости.
Если это так, мы можем добавить небольшую область разгона для основной карты и добавить большую область разгона для других. Мы даже не можем разогнать основную карту.
@davilizh
Спасибо, что вернулись. Пожалуйста, обратите внимание на мой комментарий ниже.
- Сбой происходит только при разгоне памяти. Хуже того, когда разгон приближается к пределу. Но случается все равно. Я проверил это, пытаясь постепенно снижать тактовую частоту памяти. Становится лучше, когда вы приближаетесь к штатным часам, но вы все равно получаете сбои (иногда с разницей в 12 часов).
- Наверное, хорошая идея, я не эксперт в программировании CUDA, но будет ли это снижение производительности?
- На мой взгляд, абсолютно необходимо, чтобы весь код майнера был потоком, который инициируется потоком сторожевой собаки. По возможности следует попытаться восстановить майнер.
- Извините, мои волшебные способности здесь заканчиваются, вы гуру, я просто новообращенный, пытающийся помочь и сообщить
@Skromniac Я попробую это сегодня, я постараюсь оставить видеокарту вне списка моих устройств. Надеюсь, это должно доказать, что проблема в этом.
@rizwansarwar
Спасибо за ваш ответ.
Для №2 должен быть какой-то штраф. Но пока код тщательно настроен, штраф должен быть небольшим. Но в последнее время не успеваю реализовать эту идею.
Надеюсь, что подход Skromniac может решить эту проблему.
Вот мой опыт, если это поможет.
У меня есть 2 установки: одна только с 1070 и одна с 50/50 1070 и 1060. Установка с 1060 использует —cuda-parallel-hash 4, а установка 1070 вообще не использует этот флаг. Оба работают под управлением Ubuntu 16.04.2 с версией драйвера Nvidia: 378.13.
Что касается комментария
Исходя из Claymore’s, мне пришлось сбросить тактовые частоты памяти (я не использую ядро OC), чтобы добиться некоторой стабильности. С более низкими частотами лучшее, что у меня было до сих пор, составляет около 24 часов без ошибок. Я не опустился ниже, как будто я вернусь к Claymore’s, так как он обеспечит лучший хешрейт.
У меня был аналогичный опыт с @rizwansarwar: стабильность увеличивалась, когда часы понижались, но никогда полностью не исчезали.
Не могли бы вы обновить драйвер до 384 и попробовать?
Я часами запускал код на своем GTX1060 с драйвером 384 и стандартными часами, но не могу воспроизвести проблему.
@braaad Если вы не указали cuda-parallel-hash в своей команде, то вы используете значение по умолчанию cuda-parallel-hash = 4.
@davilizh Я попробую , я могу надежно вызвать ошибку, если
@davilizh Я установил 381.22 (последнюю версию для Linux), но смог снова быстро получить ошибку, увеличив частоту на 50 МГц. Я снизил свои текущие часы немного ниже (больше, чем у меня уже было), чтобы увидеть, как это влияет на стабильность.
@braaad , не могли бы вы попробовать 384.47?
@azazhu, плохо, я дважды проверил версии после прочтения вашего комментария и понял, что 384.47 был бета-драйвером, поэтому я не видел его раньше. Взять его сейчас.
@davilizh небольшое обновление, я обновился до драйвера 384.47. Эта версия драйвера в целом более стабильна, чем все предыдущие версии. Сейчас заработала моя 6-я карта в риге, которая так и не заработала ни в одной из предыдущих версий драйвера. В журнале изменений драйвера Nvidia, похоже, исправлена ошибка с ним.
Я играл с настройками, пока то, что я наблюдал, ниже.
- Если частота памяти графического процессора с основным дисплеем не разогнана, я не получаю сбой на 384,47.
- Если частота памяти графического процессора с основным дисплеем такая же, как и у всех других карт (разогнанных), то в течение нескольких минут возникают сбои.
Поэтому я старался поддерживать частоту графического процессора с дисплеем немного ниже (от -100 до -150), чем у всех других карт. Это обеспечивает стабильность системы и ее работу на 384.47. Я скоро сообщу, если увижу сбои.
@rizwansarwar Спасибо, что поделились.
@davilizh пока 12+ часов без ошибок на одном риге — это разогнанный, а не сток. Еще слишком рано, чтобы быть уверенным на 100%, но пока выглядит хорошо.
Также следует отметить одну вещь, например, @rizwansarwar , у gpu0 должна быть более низкая частота, чем у других. Я думал, что это просто плохая карта, но, возможно, это из-за того, что это gpu0.
Надеюсь, сегодня у меня будет время обновить вторую.
@braaad Хорошие новости. Спасибо.
@rizwansarwar Привет, я не использую свою установку, но CUDA error in func 'search' at line 365 : unspecified launch failure. все равно появляется каждый раз. Водитель моей установки в настоящее время 378,78. Возможно, это проблема водителя?
@ ken8203, как ранее указывал
@davilizh Я думаю, нам следует немного следить за этим, а затем закрыть это, так как мне кажется, что проблема
Если вы не установили cuda-parallel-hash в своей команде, то вы используете значение по умолчанию cuda-parallel-hash = 4.
Не могли бы вы рассказать нам или указать на объяснение того, что именно делает этот флаг? Я немного озадачен тем, что пробовал.
На самом деле я думаю, что его следует включить в readme.md, поскольку по умолчанию используется _автоматически_ без установки флага.
Также следует отметить одну вещь, например, @rizwansarwar , у gpu0 должна быть более низкая частота, чем у других. Я думал, что это просто плохая карта, но, возможно, это из-за того, что это gpu0.
__Примечание__: _Первый_ графический процессор NVidia, подключенный к _основному_ слоту PCIe (x16).
Он не обязательно должен быть подключен к дисплею, у него все еще есть нижний предел времени памяти _ по сравнению с другими картами. При превышении определенной скорости произойдет сбой ethminer (та же ошибка).
Выиграйте 10 с бета-версией 384.47, как предлагается.
@oleng
Флаг --cuda-parallel-hash изменяет способ обработки хэшей майнером.
Это очень упрощено, но часть работы ядра cuda — это поисковая часть процесса майнинга. Он выполняет одну и ту же операцию параллельно на многих ядрах графического процессора. Когда @davilizh улучшил ядро, он добавил флаг --cuda-parallel-hash позволяющий изменять количество потоков, которые он обрабатывает одновременно.
Необходимо, чтобы какое-то значение применялось автоматически без установки флага, иначе майнер не будет работать!
Теоретически было бы лучше всего использовать как можно больше потоков, но оптимальное решение будет зависеть от оборудования. По умолчанию майнер использует 4, потому что это лучшее значение, которое
Я не думаю, что есть необходимость продвигать настройку расширенных настроек в прочтении, потому что для большинства людей их изменение, вероятно, снизит производительность. То же самое относится к флагам --cuda-block-size --cuda-grid-size и --cuda-streams . Для них установлены разумные значения по умолчанию, и я только уменьшил свои хэши, изменив их.
@jimmykl спасибо за объяснение, я чувствую, что это соответствует тому, что я подозревал.
Я не думаю, что есть необходимость продвигать настройку расширенных настроек в прочтении, потому что для большинства людей их изменение, вероятно, снизит производительность. То же самое относится к флагам
--cuda-block-size--cuda-grid-sizeи--cuda-streams. Для них установлены разумные значения по умолчанию, и я только уменьшил свои хэши, изменив их.
На самом деле мне удалось увеличить хешрейт с помощью этих флагов. Так же, как футболка любого размера подходит всем, так и настройка размера в соответствии с вашими пропорциями работает лучше. Настройка флагов под ваше оборудование работает лучше. И я считаю, что это особенно актуально при разгоне майнинга с несколькими графическими процессорами, что составляет ~ 80-90% (?) Майнеров. Есть даже различия в количестве ядер CUDA в одной и той же модельной линейке.
Думайте об этом как о предупреждении, вместо того чтобы пытаться решить, что для них хорошо.
По крайней мере, включите объяснение в --help
Да, а также увеличение частоты ядра без установки —cuda-parallel-hash также приводит к сбою ethminer.
Я сделал это в дополнение к стабильным часам памяти OC’d.
Я должен есть свои слова, авария произошла через 29 часов. Ситуация лучше, но похоже, что мы все еще сталкиваемся с ошибкой. Я бы сказал, что нам нужно найти способ воспроизвести и исправить это.
@davilizh, можете ли вы воспроизвести это в своей среде? Может быть, с разгоном вы сможете это повторить быстрее?
@rizwansarwar Я могу воспроизвести в своей среде с OC.
Как вы сказали в другом потоке (https://github.com/ethereum-mining/ethminer/issues/94#issuecomment-313800302), это, вероятно, связано с проблемой драйвера.
Вероятно, лучший способ для нас: в случае исключения, такого как «неверная инструкция», поймать его, зарегистрировать и попытаться перезапустить майнинг CUDA (из комментария chfast). Но я не знаю, как это сделать.
Я могу воспроизвести это тоже на SLI EVGA GTX 1070, думаю, мы должны обработать это в коде.
Часто такое случается и при небольшом разгоне.
Обновление: это также происходит без разгона, снижения частоты ядра и целевой мощности до 65%.
для тех, у кого все еще есть ошибка, попробуйте изменить Physix в панели управления nvidia на CPU вместо одного из GPU. Это сработало для меня.
Изменить: забудьте, это не удалось через несколько раз
Есть ли у кого-нибудь запасной майнер, который они используют тем временем, пока этот исправляется?
@feracon А пока я использую двойной
@saidmasoud Спасибо за предложение! Я проверю это!
Я также получаю этот сбой, и, похоже, он возникает только при более высоких смещениях передачи памяти (обычно около +1350 или +1400 для меня). Любопытно, что из 4 моих установок это происходит в основном на установке с EVGA GTX 1070.
Традиционный симптом разгона памяти, с которым я столкнулся, — это отказ одной карты, что имеет смысл в контексте разгона. Тем не менее, в сценарии этого потока все карты (в моем случае 6) одновременно вылетают. Итак, я согласен с тем, что разгон усугубляется, но я также думаю, что в программном обеспечении есть что-то странное и заслуживающее изучения.
Для тех, кто работает с Linux и хочет продолжать использовать ethminer, но из-за этого не доверяет процессу: просто напишите скрипт, который отслеживает вывод мощности nvidia-slip. Когда он опускается ниже 70 Вт (это порог, который я использую), вы знаете, что процесс ethminer не удался, и вы можете просто убить / перезапустить. Для меня работает как оберег. Вот соответствующий sed / cut:
/usr/bin/nvidia-smi -q -d POWER | grep "Power Draw" | sed 's/[^0-9,.]*//g' | cut -d . -f 1
@rizwansarwar Не добавив error in func 'ethash_cuda_miner::search' at line 365 или подобное? Это потому, что многие люди создают дубликаты этой проблемы и ссылаются на эту ошибку, и это может помочь им увидеть, что о ней уже сообщалось. Благодаря!
Я нашел № 94 и № 80 еще до того, как приехал сюда. Предполагая, что это основной поток для этой проблемы.
Да, пожалуйста, добавьте сюда свой отчет. Эти обманщики должны быть закрыты.
Я сделал PHP-скрипт, чтобы убить ethminer, если он перестанет хэшировать (для Linux):
#!/usr/bin/php
<?php
$start=time();
putenv("PATH=/bin:/usr/bin:/usr/local/bin");
while($line=fgets(STDIN)){
if(time()-$start<=30){ echo "[*] $line"; continue; } // ignore first 30s
if(strpos($line," 0.00MH/s")!==false){
echo "crash detected. line=$line killing ethminern";
passthru("echo "".trim(shell_exec('date'))." crash detected. killing ethminer" >> ~/ethminer.log");
passthru("killall -9 ethminer");
} else echo $line;
}
запустите ethminer в цикле и передайте его так:
while [ 1 ]; do ethminer ... 2>&1 | mine-monitor; done
Я согласен, что проблема усугубляется при использовании видеовыхода и / или выполнении других действий во время майнинга. Я использую Ubuntu 16.04 с 6 gtx 1060 (3 разных производителя), ранее разогнанными до 200/1200, теперь немного ниже, @ 85 Вт с G3900 Celeron. Я установил CUDA через официальный .deb / repo по адресу https://developer.nvidia.com/cuda-downloads, который заменил драйверы nvidia на 375.x.
Следующее, что я могу попробовать, — это майнинг без запущенного X или без подключенного монитора с использованием виртуальных мониторов.
@dhjw
Я не могу поверить в это, я цитирую кое-что, что мне написали. Но я не могу вспомнить, кто это написал.  Во всяком случае, это должно решить вашу проблему:
Во всяком случае, это должно решить вашу проблему:
вам не нужен подключенный монитор, чтобы X работал. Во время установки сохраните EDID монитора с помощью nvidia-settings, а затем используйте файл edid.bin в вашем xorg.conf, чтобы подделать X, что монитор подключен. У меня это работает на моей установке, и у X нет проблем. Вы можете добавить edid с помощью nvidia-xconfig —custom-edid =. Это сгенерирует ваш xconfig с использованием поддельного edid, после этого X должен запуститься нормально.
Я использую их, которые мне, вероятно, не понадобятся с учетом вышеизложенного: https://www.amazon.com/gp/product/B00JKFTYA8. Но они тоже могут работать.
Только что получил то, что мне кажется такой же ошибкой на Клейморе, только Клеймор восстановился.

X явно то, о чем я совершенно не знаю. Мне сложно его отследить, потому что он помечен как один символ. Я могу найти множество тем на тему «Действительно ли мне нужен X» и т. Д., Но не могу найти фактическое название этой программы или ее домашнюю страницу. Заранее спасибо!
@feracon Какую версию Claymore это то, что использует? Я предполагаю, что он добавил оптимизацию CUDA из ethminer в 9.7, но я получил эту ошибку и в 9.6, когда я слишком сильно разогнался.
@jimmykl Я использую новую 9.7 с нулевым разгоном, полностью сток.
У меня такое чувство, что, возможно, в предложенной строке командного файла, которую я получил из своего FAQ по пулу, отсутствуют аргументы, которых ожидает новая версия, возможно, для новой оптимизации. Читаю сейчас. Но, по крайней мере, моя установка работает!
РЕДАКТИРОВАТЬ: Claymore’s Dual Ethereum AMD + NVIDIA GPU Miner v9.7 (Windows / Linux)
@feracon Re: Мониторинг Windows Я использую http://www.tightvnc.com и никогда не испытывал никаких проблем. Если вам нужен удаленный мониторинг, вы можете либо настроить переадресацию портов для VNC на вашем маршрутизаторе, либо запустить VPN-сервер (возможно, лучше всего для безопасности).
Re: Ошибка Claymore 9.7, тогда возможно, что он напрямую скопировал какой-то код из этой вилки и внес ту же ошибку в свой майнер … Конечно, он исправил ее, он, вероятно, не будет фиксировать ее здесь: — /
@jimmykl А, может быть. Тем не менее, для всех, у кого есть эта проблема, у Claymore может быть то же самое, но он может автоматически восстанавливаться, сохраняя вас в бизнесе. Спасибо за внимание к VNC. Я проверю это, я думаю, что он, вероятно, намного легче, чем TeamViewer.
@dhjw Спасибо!
@feracon Новый флаг оптимизации — —cuda-parallel-hash, и если он не установлен, по умолчанию используется 4, что является наиболее оптимальным для большинства карт.
@jimmykl Ага , я вижу допустимые настройки: 1, 2, 4 и 8, но люди, сообщающие о 8, отстой для некоторых 1070-х. Собираюсь поэкспериментировать и снова разогнать. Спасибо за совет.
Вот мои результаты:
GTX 1070
Ubuntu 16.04
Смещение памяти +1500
Потолок мощности 115 Вт
./ethminer -U -M —cuda-parallel-hash X:
31.10 в 1
32,36 при 2
28,87 при 3
32,42 при 4
25,86 при 5
21.60 при 6
18.59 при 7
32,22 при 8
Привет всем здесь — я новый член и рад поделиться некоторой информацией для всех.
Я протестировал несколько версий 11.0 на моем RIG1:
6 x GTX 1060 (ASUS Turbo) 6 ГБ (OC Mem 10 ГГц).
Windows 10: последняя версия
Драйвер NVidia: последняя версия
И могу подтвердить:
Все версии 11.0 имеют похожие проблемы. Иногда сообщение об ошибке отличается, но в целом у всех одна и та же проблема. Похоже, что изменения в области поиска CUDA глючны.
Я сам разработчик программного обеспечения и работал также с CUDA, но, к сожалению, у меня нет MS DevStudio 12, поэтому я не могу внести исправления. Я попытался перенести проект на MS DevStudio 2017, но это не удалось по многим причинам.
Сейчас я тестирую старую версию: ethminer-0.9.41-genoil-1.1.7, если у нее есть аналогичные проблемы с разогнанными картами, и я сообщу.
отчет:
Также версия ethminer-0.9.41-genoil-1.1.7 сообщает об ошибке поиска CUDA.
Ошибка CUDA в функции ‘ethash_cuda_miner :: search’ в строке 346: неопределенная ошибка запуска.
X 01: 25: 13 | cudaminer1 Ошибка майнинга CUDA: неопределенная ошибка запуска
Мое предложение сейчас: время выполнения программы изменяется при разгоне памяти графического процессора, я считаю, что у программного обеспечения есть общая проблема синхронизации в этой области.
ОБНОВЛЕНИЕ 1:
Я не проводил никаких дальнейших тестов, особенно с меньшим разгоном, потому что: это не имеет смысла.
Вместо этого я написал пару скриптов, которые отслеживают вывод ethminer, и если они находят слово «Ошибка», они полностью перезапускают установку. Перезагрузка занимает 3 минуты, после чего устройство снова работает на полной разогнанной скорости. Ошибка возникает относительно редко (у меня 2 раза в день).
Я остаюсь при своем мнении: это не связано с разгоном, это связано с внутренним программным обеспечением ethminer для CUDA. Потому что: он явно находится в одной определенной позиции в коде. Разная скорость разгона меняет только программное обеспечение и поведение синхронизации кода CUDA ethminer и ничего больше. Я предполагаю, что дизайнер забыл объект синхронизации в определенной позиции в коде. И этот код случайно запускает сохранение с определенной скоростью.
К сожалению, у меня нет времени просматривать весь код — примите мое мнение и мой тест с этой очень старой версией программного обеспечения как подсказку для правильного поиска и исправления. И, пожалуйста, не слишком полагайтесь на мнение «разогнан = плохо».
ОБНОВЛЕНИЕ 2:
Возможно, я понял, что: если вы используете утилиту ASUS GPU Tweak II, вам следует закрыть ее после того, как вы применили настройку. Поскольку я делаю это при запуске своей установки с помощью сценария, который запускается через 2 минуты после запуска утилиты GPU Tweak, программное обеспечение ethminer больше не сообщает об ошибках. Может быть, программа настройки время от времени выполняет параллельный доступ к графическим картам, и это вызывает ошибку? Или: я заметил, что через некоторое время утилите настройки требуется одно полное ядро процессора, чтобы сделать что-то, чего я не знаю. У меня в установке только два. Возможно, для корректной работы ethminer всегда нужен большой запас ресурсов процессора. Тогда это также может быть проблемой синхронизации программного обеспечения в ethminer.
Возможно, вы можете время от времени проверять, сильно ли ваш процессор загружен, и в это время возникает ошибка, или, может быть, вы можете проверить, работает ли ваша утилита настройки во время майнинга.
ОБНОВЛЕНИЕ 3:
Я поигрался с некоторыми настройками приоритета для ethminer.exe и понял: если я поставлю его на высокий приоритет, ошибки CUDA появятся очень скоро. Таким образом, это подчеркивает мое предположение о том, что у ethminer.exe есть проблема с асинхронизацией в целом. Может быть, кто-то использовал сообщения Boost и считает их потокобезопасными. Но они не нити экономии. Во время программирования с потоками нужно заботиться о каждой разделяемой памяти или дескрипторе. Я бы начал анализ многопоточности программного обеспечения и проверить, правильно ли спроектировано все, что связано с общей памятью.
Это конец моей статьи по этой теме 
С наилучшими пожеланиями, Матиас
имеют те же проблемы, несколько моделей 1060 после 10/20 минут сбоя, забавная часть — 3 установки 8 карт каждая клонированные диски, 1 работает без проблем, другие 2 сбоя
Я могу подтвердить, что это происходит в Ubuntu 17.10, cuda 8 с драйверами по умолчанию (я полагаю, 375,66) с 1060 и 1050Ti, оба OC +1600.
Обе карты выходят из строя одновременно, и ethminer останавливается, но остановить и запустить снова тривиально, поэтому я думаю, что сторожевой таймер — лучшее решение (кроме непосредственного обнаружения и устранения проблемы).
Раньше клеймор 9.5, казалось, работал нормально более 24 часов, но, возможно, он выходил из строя и тихо восстанавливался.
Изменить: я имел в виду Ubuntu 17.04
Согласитесь с дает сбой при запуске Claymore 9.5 и 9.7 с довольно высокими разгонами, но сторожевой таймер перезапускает майнер автоматически и не дает никаких подробностей о том, почему он разбился.
@MatthiasThoemel, не могли бы вы опубликовать свой скрипт Windows 10 для автоматической перезагрузки при ошибке?
@dhjw Спасибо за сценарий. Я использую его для автоматического перезапуска ethminer в случае сбоя. Но пока это не провалилось! (Я пытаюсь уменьшить ограничения мощности, чтобы увидеть, влияет ли это на время отказа).
@dhjw Я ловлю ложные срабатывания вашего скрипта. Не уверен, почему, но иногда после получения новой работы я получаю отчет о 0,00Mh / s без каких-либо ошибок, и, если оставить его наедине, майнер мог продолжить. Однако ваш скрипт убивает его и перезапускает. Так как я получаю это примерно раз в час или около того, я изменил скрипт, чтобы искать строку «Ошибка CUDA» вместо «0.00Mh / s», которая, надеюсь, улавливает только истинные ошибки, по-прежнему лидируя с этой проблемой.
ℹ 18:33:06|stratum Received new job #0b7eeb3f
ℹ 18:33:06|cudaminer0 set work; seed: #9e972470, target: #00000000dbe6
ℹ 18:33:06|cudaminer1 set work; seed: #9e972470, target: #00000000dbe6
m 18:33:06|ethminer Mining on PoWhash #0b7eeb3f : 0.00MH/s [A4+0:R0+0:F0]
m 18:33:10|ethminer Mining on PoWhash #0b7eeb3f : 39.06MH/s [A4+0:R0+0:F0]
m 18:33:14|ethminer Mining on PoWhash #0b7eeb3f : 39.32MH/s [A4+0:R0+0:F0]
m 18:33:18|ethminer Mining on PoWhash #0b7eeb3f : 39.58MH/s [A4+0:R0+0:F0]
Изменить: добавлен образец вывода из майнера.
Из моих 4 горнодобывающих установок только одна постоянно дает сбой. Ниже приведены журналы сбоев с этой установки на сегодняшний день, всего 8 (пока). Если порядок имеет значение, 7 из 8 сбоев начались с cudaminer3. Это интересно, потому что это говорит мне, что это определенно связано с разгоном. В то время как в прошлом я видел сбой карты и в конечном итоге требовал перезапуска ethminer, эта ошибка приводит к сбою всех карт сразу. Но основная причина все еще кажется одной плохой картой, если этот порядок действительно говорит.
В конце концов, я бы расставил приоритеты в работе с перезапуском ethminer (хотя мой сценарий Pulse отлично работает) вместо того, чтобы пытаться выяснить, почему разгон делает это.
Я уменьшил разгон на gpu3 и дам вам знать, что происходит.
miner.201707110950: ✘ 09:49:39|cudaminer3 Error CUDA mining: an illegal memory access was encountered
miner.201707110950: ✘ 09:49:39|cudaminer5 Error CUDA mining: an illegal memory access was encountered
miner.201707110950: ✘ 09:49:39|cudaminer2 Error CUDA mining: an illegal memory access was encountered
miner.201707110950: ✘ 09:49:39|cudaminer4 Error CUDA mining: an illegal memory access was encountered
miner.201707110950: ✘ 09:49:39|cudaminer0 Error CUDA mining: an illegal memory access was encountered
miner.201707110950: ✘ 09:49:39|cudaminer1 Error CUDA mining: an illegal memory access was encountered
miner.201707111324: ✘ 13:23:55|cudaminer2 Error CUDA mining: an illegal memory access was encountered
miner.201707111324: ✘ 13:23:55|cudaminer3 Error CUDA mining: an illegal memory access was encountered
miner.201707111324: ✘ 13:23:55|cudaminer0 Error CUDA mining: an illegal memory access was encountered
miner.201707111324: ✘ 13:23:55|cudaminer4 Error CUDA mining: an illegal memory access was encountered
miner.201707111324: ✘ 13:23:55|cudaminer1 Error CUDA mining: an illegal memory access was encountered
miner.201707111324: ✘ 13:23:55|cudaminer5 Error CUDA mining: an illegal memory access was encountered
miner.201707111336: ✘ 13:36:11|cudaminer3 Error CUDA mining: an illegal memory access was encountered
miner.201707111336: ✘ 13:36:11|cudaminer0 Error CUDA mining: an illegal memory access was encountered
miner.201707111336: ✘ 13:36:11|cudaminer2 Error CUDA mining: an illegal memory access was encountered
miner.201707111336: ✘ 13:36:11|cudaminer4 Error CUDA mining: an illegal memory access was encountered
miner.201707111336: ✘ 13:36:11|cudaminer5 Error CUDA mining: an illegal memory access was encountered
miner.201707111336: ✘ 13:36:11|cudaminer1 Error CUDA mining: an illegal memory access was encountered
miner.201707111448: ✘ 14:48:25|cudaminer3 Error CUDA mining: an illegal memory access was encountered
miner.201707111448: ✘ 14:48:25|cudaminer4 Error CUDA mining: an illegal memory access was encountered
miner.201707111448: ✘ 14:48:25|cudaminer5 Error CUDA mining: an illegal memory access was encountered
miner.201707111448: ✘ 14:48:25|cudaminer2 Error CUDA mining: an illegal memory access was encountered
miner.201707111448: ✘ 14:48:25|cudaminer0 Error CUDA mining: an illegal memory access was encountered
miner.201707111448: ✘ 14:48:25|cudaminer1 Error CUDA mining: an illegal memory access was encountered
miner.201707111704: ✘ 17:03:37|cudaminer3 Error CUDA mining: an illegal memory access was encountered
miner.201707111704: ✘ 17:03:37|cudaminer4 Error CUDA mining: an illegal memory access was encountered
miner.201707111704: ✘ 17:03:37|cudaminer2 Error CUDA mining: an illegal memory access was encountered
miner.201707111704: ✘ 17:03:37|cudaminer1 Error CUDA mining: an illegal memory access was encountered
miner.201707111704: ✘ 17:03:37|cudaminer0 Error CUDA mining: an illegal memory access was encountered
miner.201707111704: ✘ 17:03:37|cudaminer5 Error CUDA mining: an illegal memory access was encountered
miner.201707111814: ✘ 18:13:30|cudaminer3 Error CUDA mining: an illegal memory access was encountered
miner.201707111814: ✘ 18:13:30|cudaminer1 Error CUDA mining: an illegal memory access was encountered
miner.201707111814: ✘ 18:13:30|cudaminer2 Error CUDA mining: an illegal memory access was encountered
miner.201707111814: ✘ 18:13:30|cudaminer5 Error CUDA mining: an illegal memory access was encountered
miner.201707111814: ✘ 18:13:30|cudaminer4 Error CUDA mining: an illegal memory access was encountered
miner.201707111814: ✘ 18:13:30|cudaminer0 Error CUDA mining: an illegal memory access was encountered
miner.201707111818: ✘ 18:17:44|cudaminer3 Error CUDA mining: an illegal memory access was encountered
miner.201707111818: ✘ 18:17:44|cudaminer0 Error CUDA mining: an illegal memory access was encountered
miner.201707111818: ✘ 18:17:44|cudaminer5 Error CUDA mining: an illegal memory access was encountered
miner.201707111818: ✘ 18:17:44|cudaminer2 Error CUDA mining: an illegal memory access was encountered
miner.201707111818: ✘ 18:17:44|cudaminer1 Error CUDA mining: an illegal memory access was encountered
miner.201707111818: ✘ 18:17:44|cudaminer4 Error CUDA mining: an illegal memory access was encountered
miner.201707111919: ✘ 19:19:04|cudaminer3 Error CUDA mining: an illegal memory access was encountered
miner.201707111919: ✘ 19:19:04|cudaminer4 Error CUDA mining: an illegal memory access was encountered
miner.201707111919: ✘ 19:19:04|cudaminer5 Error CUDA mining: an illegal memory access was encountered
miner.201707111919: ✘ 19:19:04|cudaminer2 Error CUDA mining: an illegal memory access was encountered
miner.201707111919: ✘ 19:19:04|cudaminer1 Error CUDA mining: an illegal memory access was encountered
miner.201707111919: ✘ 19:19:04|cudaminer0 Error CUDA mining: an illegal memory access was encountered
Как я упоминал в другом сообщении о проблеме (№ 94), сначала он работал около 48 часов, затем у меня были эти ошибки 2 раза, каждая примерно через 1,5 часа.
Затем просто из любопытства я снизил OC на тактовой частоте памяти с +700 до +650 МГц (частота ядра +0, целевое значение мощности — 90%). Эти настройки применяются ко всем картам. Включил майнинг, и с тех пор он работает. (9 июля)
Может, это что-то значит, а может и нет, потому что я видел комментарии о сбоях на стандартных часах.
Может быть, он снова вылетит сегодня, но интересно, что это произошло 2 раза за 3 часа, а затем работает более 4 дней без каких-либо проблем.
Я второй @ aiden1408 . Вчера я увеличил OC с 1600 до 1700 (mem) и смог получить 4 ошибки за 5 минут. Раньше вылетало 2-3 раза в день.
кто-нибудь еще знает, что вызвало проблему? OC _не должно_ быть проблемой, в конце концов, это майнер.
@saidmasoud
(…) сторожевой таймер автоматически перезапускает майнер (…)
Не могли бы вы предоставить дополнительную информацию о том, как вы реализуете сторожевой таймер в этом случае?
@ piotr-dobrogost Я сам не реализовывал его, он входит в состав программного обеспечения для майнинга Claymore и включен по умолчанию. В настоящее время я использую Claymore, пока не будет исправлено решение этой проблемы.
У меня та же проблема. У меня есть 3 рига с использованием gtx 1060s pny / evga. У меня 9 PNY gtx 1060 xlr8, 6 из них работают нормально, но три из них не принимают такой же разгон, и даже когда я понижаю их OC, они вылетают сразу или через некоторое время. когда я запускаю графические процессоры без OC, они показывают «обнаружена недопустимая память», поэтому мне нужно использовать ядро -400, чтобы запустить их, но все равно происходит сбой !!!
РЕДАКТИРОВАТЬ: Между тем я решительно поддерживаю решение Orkblutts https://github.com/orkblutt/MinerLamp .
Он требует меньше системных ресурсов, работает стабильно и отлично выглядит.
Решение Powershell для сбоев CUDA
Итак, это решение PowerShell, которое уже несколько дней работает без проблем. Вы можете настроить свои карты, не беспокоясь о том, что ethminer столкнется с обсуждаемой ошибкой. Нет необходимости устанавливать дополнительное программное обеспечение или сторонние инструменты …
Не стесняйтесь совершенствоваться. Из-за тестирования скрипта у меня было несколько простоев моей установки, поэтому пожертвования очень приветствуются [0x76DC203d1cd70262459cEf56AdE865613c4b9693]
Это экран вывода:
Инструкции:
=> Создайте run.bat, но используйте вызов PowerShell для вывода файла журнала Tee — tee создает файл журнала, который в дальнейшем обрабатывается Powershell
Сохраните текст в run.bat в том же каталоге, что и ethminer. Исключите файл ps1 — и надеюсь, наслаждайтесь
« »
setx GPU_FORCE_64BIT_PTR 0
setx GPU_MAX_HEAP_SIZE 100
setx GPU_USE_SYNC_OBJECTS 1
setx GPU_MAX_ALLOC_PERCENT 100
setx GPU_SINGLE_ALLOC_PERCENT 100
powershell «./ethminer.exe —cuda-parallel-hash 4 —farm-recheck 150 -U -S eth-eu1.nanopool.org:9999 -FS eth-eu2.nanopool.org:9999 -O 0xYOURADRESS 2> & 1 | тройник log.txt «
Выход
« «
=> Это основной скрипт Powershell (не забудьте включить выполнение скрипта PowerShell в Windows). Чтобы уменьшить проблемы с памятью, скрипт открывается и через некоторое время закрывает задания (но майнинг продолжается). Вставьте текст в файл * .ps1 и сохраните его в каталоге ethminer.
« »
function JobOpen {
$ Host.UI.RawUI.CursorPosition = New-Object System.Management.Automation.Host.Coordinates 0,13
gci log.txt | % { $sb = [scriptblock]::create("get-content -wait $_") ; start-job -Name LOGSEARCH -ScriptBlock $sb }
$ null = $ (получить задание | получить задание)
# сон 1
}
function JobClose {
Stop-Job -Name LOGSEARCH
устроиться на работу | Удалить работу
[System.GC] :: Collect ()
# сон 1
}
function EthRestart {
#cls
#Write-Host "#######################################################################################################"
#$Host.UI.WriteLine($(get-job | receive-job))
stop-process -Name ethminer
sleep 2
RemoveLog
sleep 2
Start-Process .run.bat
sleep 2
}
function RemoveLog {
$ strFileName = «. log.txt»
Если (Test-Path $ strFileName) {
Удалить элемент $ strFileName -Force
} Else {
# // Файл не существует
}
}
function statOutput {
$Host.UI.RawUI.CursorPosition = New-Object System.Management.Automation.Host.Coordinates 0,0
Write-Host "Start: $orgstartdate"
$Host.UI.RawUI.CursorPosition = New-Object System.Management.Automation.Host.Coordinates 50,0
Write-Host "Nowdate: $nowdate"
$Host.UI.RawUI.CursorPosition = New-Object System.Management.Automation.Host.Coordinates 0,1
write-host "Restart: $ethstartdate"
$Host.UI.RawUI.CursorPosition = New-Object System.Management.Automation.Host.Coordinates 50,1
write-host "#Restarts: $i"
$Host.UI.RawUI.CursorPosition = New-Object System.Management.Automation.Host.Coordinates 0,2
write-host "Jobstart: $jobstartdate"
}
$ i = 0
$ s = 0
$ orgstartdate = дата получения
$ ethstartdate = дата получения
$ jobstartdate = Get-Date
$ nowdate = Дата получения
$ d = Get-Date
RemoveLog
спать 2
Пуск-процесс. Run.bat
спать 7
$ Host.UI.RawUI.CursorPosition = New-Object System.Management.Automation.Host.Coordinates 0,10
gci log.txt | % {$ sb = [блок сценария] :: create («get-content -wait $ _»); start-job -Name LOGSEARCH -ScriptBlock $ sb}
спать 1
в то время как (1) {
statOutput
if (($ nowdate — $ ethstartdate) .totalseconds -ge 15) {
$ Host.UI.RawUI.CursorPosition = New-Object System.Management.Automation.Host.Coordinates 0,20
$ Host.UI.WriteLine ($ (get-job | receive-job -Keep | select -last 1))
$ m = $ (get-job | receive-job | select -last 50 | Select-String «Ошибка майнинга CUDA»)
if($m -ne $null) {
$i++
JobClose
ethrestart
$ethstartdate= Get-Date
JobOpen
$jobstartdate=$nowdate
}
}
$ null = $ (получить задание | получить задание)
спать -м 50
$ nowdate = Дата получения
$ s ++
if ($ s -ge 6000) {
$ Host.UI.RawUI.CursorPosition = New-Object System.Management.Automation.Host.Coordinates 0,5
$ nowdate = Дата получения
Write-Host «НАЧАТЬ СБОР МУСОРА $ nowdate»
спать 1
$ nowdate = Дата получения
$ Host.UI.RawUI.CursorPosition = New-Object System.Management.Automation.Host.Coordinates 0,5
Write-Host «СБОР МУСОРА завершен $ nowdate»
$ s = 0
}
if (($ nowdate — $ jobstartdate) .totalseconds -ge 60000) {
РаботаЗакрыть
JobOpen
$ jobstartdate = $ nowdate
}
if (($ nowdate — $ ethstartdate) .totalseconds -ge 7200) {
$ i ++
РаботаЗакрыть
ethrestart
$ ethstartdate = Get-Date
JobOpen
$ jobstartdate = $ nowdate
}
}
Выход
« »
У меня такая же проблема с разогнанной GTX 1070. Я поставил +100 GPU и +1300 памяти. После этого майнер Claymore и ethminer сообщают о сбоях.
Когда я выставляю 900-1000 для памяти, сбои происходят каждые 10-15 минут, это приемлемо, но я этого не хочу; /
У меня Ubuntu 17.04, драйвер NVIDIA: 375.66 и CUDA из репозитория apt.
В настоящее время у меня +100 GPU и +1000 памяти, и у меня 185 MH / s на 6 картах.
У меня 6 x Asus ROG STRIX GTX 1070 O8G-GAMING

Моя установка не работает на Ubuntu, но у меня была та же проблема. Проблема впервые возникла после того, как я добавил 5-ю карту (Evga GTX 1060 6 ГБ) к уже работающему компьютеру 4 x Evga GTX 1060 6 ГБ. После некоторого теста я заметил, что пятый графический процессор имел микронную память ddr5 и использовал другую версию vbios по сравнению с другими 4 графическими процессорами. Сегодня я прошил биос графического процессора и обновил его до той же версии, что и другие. Графический процессор по-прежнему не может обрабатывать OC-ing, который я использую на устройствах с Samsung gddr, но он стабилен на уровне 50% от их значений разгона. Например, gtx 1060 с Samsung, работающим с памятью +625, с Micron, работающим с +300, оба на 80% мощности. Пока 3 часа без проблем.
До прошивки BIOS вылетал весь майнер даже при стоковом или небольшом разгоне.
Я буду отслеживать и обновлять здесь.
Надеюсь, мои выводы помогут вам в дальнейшем.
Последняя версия -dev (ethminer-0.12.0.dev1), похоже, помогает!
Обновление: к сожалению, это все еще происходит.
Мне кажется, что это слишком явно связано с разгоном. Уменьшите разгон графического процессора, который выходит из строя первым, а оставшееся можно оставить выше. У меня одна карта из 6 более чувствительна и нагревается намного быстрее, чем все остальные, даже от того же производителя. Интересно, можно ли разработать сценарий для автоматического поиска настройки, которая не дает сбоев на каждом графическом процессоре.
Изменить: я отказался от настройки «карты, которая вылетает первой», так как считаю ее неточной. Я убиваю ethminer и перезапускаю его, когда это происходит, но теперь я уменьшаю разгон только тогда, когда карта отключается.
@dhjw, так почему старая версия у меня работает без сбоев при точно таком же разгоне?
Не уверен, что @ spyrek10, но я
В моем случае проблема была (или, по крайней мере, я на это надеюсь, 48 часов без проблем) вызвана уменьшением SATA-> MOLEX в USB-переходнике с питанием, он становился очень ГОРЯЧИМ (около 70 ° C), и, например, майнер EWBF выходил через несколько секунд после запуска. Замена прямого включения SATA-> MOLEX и питания с MOLEX на блок питания решила мои проблемы (в Windows и Linux).
@dafyk У меня была такая же проблема с высокой температурой кабеля в MOLEX-SATA POWER. Я заменил провод только на sata power, работает нормально.
@orkblutt — мне очень нравится ваше решение, но по какой-то причине в моей системе происходит сбой minerlamp. Сама программа работает, но вскоре после запуска майнинга Windows сообщает, что программа перестала работать. При дальнейших попытках ethminer вообще не запустится. В вашей программе или вне ее. Мне нужно перезагрузиться.
Если разработчики читают это, я надеюсь, что функция сторожевого пса занимает первое место в списке приоритетов. Я до сих пор отказывался использовать Клеймор, потому что мне не нравится то, что он означает. Не так много гонораров, но для меня нет никаких сомнений в том, что он разорвал оптимизацию CUDA genoils. Это неверно. Затем есть влияние, которое его переключение на сервер с оплатой за разработку оказывает на серверы пула, но это дискуссия для другого места.
Ethminer — лучший майнер ETH, и не требует ничего, кроме пожертвования (которое я с радостью делаю). Только для майнинга ETH у Claymore нет никакой выгоды, кроме сторожевого пса. Я надеюсь, что у ethminer есть такой, так что мне даже не придется думать о том, чтобы заплатить ему ни цента. Спасибо за ваш тяжелый труд.
Просто последнее замечание. Я определенно смог увеличить разгон памяти на приличную величину (+100, 4×1060) с гораздо меньшим количеством сбоев, используя последние версии ethminer 0.12 dev. Мне довольно удобно оставлять майнер перезапусками с интервалом в час. Сбой происходит один или два раза в день. Я никак не мог сделать это раньше с этими часами. Может быть, эти новые карты просто мне теперь приятнее (что маловероятно), или разработчики уже занимаются этой проблемой. Я надеюсь, что это так. Сторожевой пес все равно даст необходимое спокойствие.
Спасибо @derubm. Кажется, теперь Minerlamp работает нормально. Я не возвращался к 0.11, чтобы узнать, есть ли какие-то проблемы с этой версией в моей системе. Просто забираю победу :). Отличная работа @orkblutt. Спасибо.
Привет, ребята!
Только что начал майнинг, после ответа @ michael-pesce я сделал «простой» сторожевой таймер с помощью сценария bash, и я запускаю все с супервизором (я использую его, потому что я вспомнил, что контейнеры Docker использовали его в первые дни)
Это доступно здесь:
https://github.com/joantune/ethminerWatchdog
Это сторожевой таймер Linux для Nvidia, но он может быть адаптирован для других карт.
Я запускаю его на screen пока все хорошо, прочтите Readme об этом
Привет, я тоже в той же лодке, что и все остальные.
Думаю, я попробую MinerLamp (в Windows).
Для Linux я, вероятно, попробую ethminerWatchdog от joantune, решение кажется изящным, если супервизор хорош.
Но я хотел спросить, пробовал ли кто-нибудь этот монитор на базе Python https://github.com/philon123/MinerMon ?
Также, чтобы добавить к обсуждению проблемы, может ли это быть проблема, связанная с используемой версией CUDA?
Интересно после того, как обнаружил этот выпуск №53, который репортер закрыл самостоятельно.
В Windows я заплатил относительно небольшую сумму за Awesome Miner и остался доволен.
В Ubuntu я до сих пор использую собственные сценарии, и это меня не подвело. Рад поделиться более подробной информацией, если люди заинтересованы.
поскольку этот еще не закрыт: как уже упоминали многие майнеры:
Недопустимая ошибка доступа к памяти возникает в случае карт Nvidia из-за того, что карта работает с максимальной разогнанной памятью в состоянии питания 2. Когда ваш майнер по какой-либо причине переключается в состояние P0, память получает дополнительные 200 МГц и может (или будет) стать нестабильным, что вызывает эту ошибку.
Решение без Watchdog: установите майнинг-ферму в состояние P0 (старая версия Windows Nvidiainspector, раздел 5, установите принудительное состояние P2 в «выключено») в Linux, вы должны иметь возможность сделать это уже с помощью nvidia-smi.)
.Пояснение:
Когда вы запускаете свой майнер в состоянии P0, превышение тактовой частоты памяти больше не будет появляться на максимальном уровне (зависит от марки памяти) GDDR5 (например, память Samsung: +710 в состоянии P0, +910 в состоянии P2, скорость памяти в обоих случаях: 4714 МГц в Windows (x2 в Linux для отображения)), поэтому в состоянии p2 вы будете запускать +910, затем состояние p0 будет зафиксировано, и у вас будет не +910, а +1110 — что вызывает сбой.
Если вы запускаете свою карту с самого начала с состоянием P0, она не может работать выше, чем предполагалось (+710 в моем случае, например, в состоянии P0), поэтому сбой больше не будет.
Пример инспектора Nvidia с номером версии и разделом, который необходимо изменить:
Примечание: после обновления драйвера вам необходимо снова установить состояние P0!
также: обратите внимание, что вы должны установить на 200 МГц меньше разгона, так как состояние P0 уже добавляет эти 200!
возможно, такие вещи можно будет включить в readme на правильном английском языке.
@derubm спасибо за четкий ввод!
У меня не было проблем с незаконным доступом к памяти с момента переключения в состояние P0 с помощью NVIDIA Profile Inspector 2.1.3.10 (Force P2 State -> Off). То есть в Windows 10 с одной GTX 1070.
По какой-то причине он долгое время работал стабильно с P2 на моей другой машине Windows 10 с четырьмя GTX1060. Но я думаю, что перейду на P0 и там, на всякий случай.
В Linux мне не удалось переключиться на P0, сейчас карты переходят в состояние P0, когда они простаивают, но когда я запускаю ethminer, они переходят на P2.
@ michael-pesce Мне очень интересны любые предложения по хорошим решениям, не стесняйтесь делиться своими знаниями о сценариях
В Linux он остается на уровне P2, но вы все равно можете разогнать карты до такой степени, насколько это возможно. Это зависит от каждой карты, но я получаю от 22,52 до 25,10 на GTX 1060. Обычно я устанавливаю карту немного выше, затем наблюдаю, какой хешрейт выходит из нее, чтобы определить тип памяти (~ 22-23 микрона, ~ 25 samsung), а затем уменьшать его до стабильного состояния и не отключаться.
[rig1] ethminer Speed 144,06 Mh / s gpu / 0 23,00 gpu / 1 24,94 gpu / 2 22,52 gpu / 3 24,86 gpu / 4 25,10 gpu / 5 23,65
[rig2] ethminer Speed 163,83 Mh / s gpu / 0 23,40 gpu / 1 22,76 gpu / 2 23,48 gpu / 3 23,40 gpu / 4 25,02 gpu / 5 22,92 gpu / 6 22,84
Я делаю свою конфигурацию по UUID устройства, чтобы не перепутать. Вот мой сценарий установки и файл настроек . Отправьте мне ETH на 0x5f8f7166c9920ea2d786e0810defdc611544fbfe
кто-нибудь знает, как заставить P0 State работать в Linux на GTX 1070s? большая часть / вся информация там не работает, поэтому любая ссылка будет принята с благодарностью.
По моему опыту, в Linux нормально оставаться на P2. Это не влияет на то, сколько вы можете разогнать или на скорость, которую вы получите.
У меня тоже есть в Ubuntu 16.04. Проблема с этой ошибкой (обнаружен незаконный доступ к памяти) заключается в том, что она входит в бесконечный цикл и требует завершения вручную. После перезапуска майнер нормально работает еще, скажем, 30 минут.
Почему бы не сделать счетчик для этого сообщения и, скажем, после 50 последовательных сообщений просто перезапустить майнер или выйти, чтобы мы могли перезапустить его с помощью сценария оболочки?
Чтобы перезапустить ethminer автоматически, запустите его так:
while [ 1 ]; do ethminer --farm-recheck 200 -U -F http://127.0.0.1:8080/ имя хоста 2>&1 | mine-monitor; done
Вот мой сценарий мониторинга шахты . Для этого требуется PHP и рабочая система электронной почты, такая как postfix, настроенная с помощью Gmail.
Если вы все еще получаете эти ошибки, это означает, что одна из ваших карт слишком разогнана. Когда карта в конечном итоге выходит из строя, немного уменьшите разгон и перезагрузитесь. В конце концов вы больше не должны получать ошибок.
Это мой опыт работы с 7 x ASUS GeForce DUAL-GTX1060 — O6G (редактировать: в настоящее время 9) на установке Win10 на ASRock H110 Pro BTC + с ethminer 0.12 (и Claymore в качестве короткого теста)
Сначала я тестировал только 2 карты, но это соответствует 7 (скоро я добавлю еще как минимум 2, возможно, до 5).
Я тестировал один процесс ethminer для всех графических процессоров и отдельный процесс для каждого графического процессора, а также с комбинациями типа 1 + 6 и т. Д. Лучший результат был при запуске отдельных процессов для каждого графического процессора — в случае сбоя выпадает только одна карта. . Когда какой-то графический процессор начинает выходить из строя, обычно он снова выходит из строя в течение минуты, поэтому нет смысла снова перезапускать процесс (я не проверял, даст ли перезагрузка лучший результат … Я только начал тестирование, поэтому я не зашел так далеко — мне нужно чтобы настроить несколько вещей с отложенным запуском Asus GPU Tweak II и его последующим выключением, подробнее о причине читайте ниже).
Всегда есть одна карта (обычно одна и та же), на которой ethminer выдает сообщение об ошибке.
«Ошибка CUDA в функции ‘ethash_cuda_miner :: search’ в строке 346: неопределенная ошибка запуска»
С двумя графическими процессорами он был на card0, с 7 теперь (обычно) на card1.
Монитор теперь подключен к встроенному графическому процессору Intel, поэтому теоретически RDP не должен влиять на результат, хотя мне нужно исследовать это еще немного (я использовал RDP раньше, когда проверял / тестировал вещи, поэтому я не совсем уверен, влияет ли это на исход).
Я считаю, что я довольно консервативен с OC, и я снизил скорость памяти на 200 (до 9,300) по сравнению с рекомендованными для оптимальной скорости хеширования / энергопотребления (65% — 65 градусов) на всякий случай (сообщается 22, 9MH / s / карта). Карты относятся к модели «OC», поэтому я не могу снизить скорость графического процессора ниже значения «min», указанного в интерфейсе настройки графического процессора (1.607).
К вашему сведению, я использую Asus GPU Tweak II — боль в заднице из-за некоторых сбоев, таких как сброс моих настроек каждый раз, когда что-то идет не так с графическим процессором, и настройка графического процессора работает в фоновом режиме, что означает, что я запускаю его один раз в начале и закрою это впоследствии, чтобы предотвратить это (редактировать: добавление новой карты сбрасывает значения до значений по умолчанию, поэтому необходимо устанавливать значения каждый раз, когда конфигурация графического процессора изменяется + когда что-то ломается, например, зависает ОС).
Если одна карта выходит из строя, все остальные работают стабильно (по крайней мере, в течение 8 часов, мой самый продолжительный тест).
Попытка использовать Claymore на неисправной карте приводит к тому, что ошибка переносится на карту2, а скорость хеширования для Claymore составляет около 19 MH / s. Другими словами, альтернатива 6 ethminers + 1 Claymore тоже не сработает.
Я опубликую некоторые обновления после того, как протестирую еще несколько вещей, например, что произойдет без использования RDP или Teamviewer, которые я использовал в другой системе для перезагрузки, где у меня есть 1 x AMD Vega 64 + 1 x Asus GTX 1060 6G (не OC ) и где 1060 обычно выпадает каждые 24-48 часов, поэтому я использовал Teamviewer для доступа к компьютеру из-за границы. Я не уверен, может ли сам Teamviewer быть источником каких-либо проблем (я тоже запускаю его на своей установке 7xGPU).
После последней перезагрузки я не использовал RDP, и до сих пор он работал без проблем в течение 45 минут, что многообещающе.
Я также использовал одну «установку» с двумя ASUS GeForce DUAL-GTX1060 — O6G на MacPro (2011) с Ubuntu 16.04 + ethminer Rock стабильной (это правильный английский?;)) В течение нескольких недель, хотя мне не удалось настроить память / Скорость графического процессора (только заданная мощность), поэтому она имеет в среднем 35,4 MH / s. Я планирую в конечном итоге переместить эти 2 GPU на установку ASRock.
Если я выясню, как настроить скорость памяти / графического процессора в Linux, я планирую / надеюсь выбросить Windows, поэтому любые советы приветствуются. Я погуглил несколько, с которыми не смог заставить работать (честно говоря, я пока не тратил на это так много времени — было еще несколько дел).
Редактировать 1. 2 часа спустя: нет RDP => нет ошибки (похоже).
Я только что подключил 8-й графический процессор и вернусь с обновлением. К сожалению, у меня больше нет доступных разъемов питания PCIe, и похоже, что вторичный блок питания пытается быть умным и не будет обеспечивать ток для GPU / SATA без пороговой нагрузки на разъем питания ATA … или мой новый блок питания не работает (маловероятно, но я еще не совсем уверен).
Пока есть явные признаки того, что указанная ошибка (напрямую) связана с ошибкой RDP с / для ethminer.
Редактировать 2.
После подключения 8-го графического процессора система снова стала нестабильной (без подключения RDP), поэтому несколько настроек позже (скорость памяти до 9,100) + пара перезагрузок снова стала стабильной (на один час).
Затем я нашел способ подключения скремблирования 9-го графического процессора со всех имеющихся у меня кабелей: type4 на 4 x AMP MATE-N-LOK + Molex на питание PCIe / Molex на питание sata. В то же время я заказал 20 кабелей разветвителя питания PCIe на AliExpress по 1,29 доллара за штуку, так что через 3-4 недели я смогу собрать еще 12-13 GPU с одним блоком питания для каждого (1.200 Вт).
В любом случае, вернемся к установке: первая Windows застряла, потому что я слишком рано запустил первый майнер (до того, как GPU Tweak смог полностью выключиться — я знаю нетерпение :)). Кнопка сброса и после входа в систему и запуска майнеров 9-я стала жаловаться на ошибку «нехватка памяти». Несколько позже настроек со значениями подкачки закончились на 35,000 / 45,000 МБ — мин / макс, и я смог запустить даже 9-й майнер.
Спустя 20 минут по-прежнему нет ошибок, сообщается о среднем хешрейте 22,6MH / s.
Если так и останется, я был бы более чем доволен
Изменить 3. 50 минут спустя — все еще без ошибок
Вопрос: Есть предложения по выбору между GTX1060 «normal» или «OC». Я заказал 10 OC, потому что «нормальных» не было в наличии, а предполагаемый срок доставки — несколько недель. Цена была на несколько долларов дешевле, хотя я бы остановился на «нормальных», если бы они были доступны одновременно. Теперь я больше не уверен, что предпочесть майнингу ETH.
Eit 4. Через 15,5 часов ошибок нет, счет продолжается. Текущая заявленная хешрейт: 22,4-22,5, в среднем 20,3 — 24,2 MH / s (в среднем 9: 22,4 MH / s)
Я даже снизил скорость памяти для карты без OC, и ее процесс ethminer еще не дал сбоев (в результате небольшое изменение в хассрейте, хотя, возможно, оно было выше в среднем с тех пор, в настоящее время: 23,8 MH / s)
Так что дело с моей стороны закрыто.
Редактировать 5.
ethminer на card9 выдает ошибку после 23:27 в первый раз и во второй раз примерно через 22 часа.
После второго раза я решил использовать RDP для перезапуска майнера и посмотреть, вызовет ли это более раннюю ошибку (для сравнения с ситуацией без запуска RDP). Я вернусь к вам с обновлением.
Обновление редактировать 5. Та же самая карта выпала в следующий раз через 60: 56ч (RDP использовался 2-3 раза).
Edit 6. 7 дней спустя и все еще работает …
Возьми и мои 5 копеек. На GPU начал майнить неделю назад. На данный момент у меня 14 1070ti — + OC, 2 фермы и майнинг eth с автоматическим перезапуском ethminer, если он останавливается при ошибках. Эти два сценария — не лучшее решение, они написаны с нуля, но работают нормально. Писал только для nvidia но думаю может быть переписан и для ati))
Все это протестировано на Ubuntu 16.04
Ok, Lets go!
!!! Необходимо включить nvidia coolbits, если вы хотите, чтобы настройки OC работали. Мой 13 тестировался на драйверах 381 и 387, эмулированный монитор для каждой карты требовал моей конфигурации nvidia-xconfig для 7 графических процессоров, edid.bin нашел в Google, я сделал свой из AOC 23 мес
nvidia-xconfig: файл конфигурации X, созданный nvidia-xconfig
nvidia-xconfig: версия 387.34 (buildmeister @ swio-display-x64-rhel04-15) Вт, 21 ноября, 03:31:45 PST 2017
Раздел «ServerLayout»
Идентификатор «Layout0»
Экран 0 «Экран0»
Экран 1 «Экран1» Справа от «Экран0»
Экран 2 «Экран2» Справа от «Экран1»
Экран 3 «Экран3» Справа от «Экран2»
Экран 4 «Экран4» Справа от «Экран3»
Экран 5 «Экран5» Справа от «Экран4»
Экран 6 «Экран6» Справа от «Экран5»
InputDevice «Keyboard0» «CoreKeyboard»
InputDevice «Mouse0» «CorePointer»
EndSection
Раздел «Файлы»
EndSection
Раздел «InputDevice»
# генерируется по умолчанию
Идентификатор «Mouse0»
Драйвер «мышь»
Вариант «Протокол» «авто»
Вариант «Устройство» «/ dev / psaux»
Вариант «Emulate3Buttons» «нет»
Вариант «ZAxisMapping» «4 5»
EndSection
Раздел «InputDevice»
# генерируется по умолчанию
Идентификатор «Keyboard0»
Драйвер «kbd»
EndSection
Раздел «Монитор»
Идентификатор «Monitor0»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSection
Раздел «Монитор»
Идентификатор «Монитор1»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSection
Раздел «Монитор»
Идентификатор «Монитор2»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSection
Раздел «Монитор»
Идентификатор «Монитор3»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSection
Раздел «Монитор»
Идентификатор «Монитор4»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSection
Раздел «Монитор»
Идентификатор «Монитор5»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSection
Раздел «Монитор»
Идентификатор «Монитор6»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSection
Раздел «Устройство»
Идентификатор «Device0»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID » PCI: 1 : 0: 0″
EndSection
Раздел «Устройство»
Идентификатор «Устройство1»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070»
BusID » PCI: 2 : 0: 0″
Вариант «ConnectedMonitor» «DFP-0»
Вариант «CustomEDID» «DFP-0: /etc/X11/edid.bin»
EndSection
Раздел «Устройство»
Идентификатор «Устройство2»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070»
BusID » PCI: 3 : 0: 0″
Вариант «ConnectedMonitor» «DFP-0»
Вариант «CustomEDID» «DFP-0: /etc/X11/edid.bin»
EndSection
Раздел «Устройство»
Идентификатор «Устройство3»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID » PCI: 5 : 0: 0″
Вариант «ConnectedMonitor» «DFP-0»
Вариант «CustomEDID» «DFP-0: /etc/X11/edid.bin»
EndSection
Раздел «Устройство»
Идентификатор «Device4»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID » PCI: 6 : 0: 0″
Вариант «ConnectedMonitor» «DFP-0»
Вариант «CustomEDID» «DFP-0: /etc/X11/edid.bin»
EndSection
Раздел «Устройство»
Идентификатор «Device5»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID » PCI: 7 : 0: 0″
Вариант «ConnectedMonitor» «DFP-0»
Вариант «CustomEDID» «DFP-0: /etc/X11/edid.bin»
EndSection
Раздел «Устройство»
Идентификатор «Устройство6»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070»
BusID » PCI: 8 : 0: 0″
Вариант «ConnectedMonitor» «DFP-0»
Вариант «CustomEDID» «DFP-0: /etc/X11/edid.bin»
EndSection
Раздел «Экран»
Идентификатор «Screen0»
Устройство «Device0»
Монитор «Монитор0»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSection
Раздел «Экран»
Идентификатор «Экран1»
Устройство «Device1»
Монитор «Монитор1»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSection
Раздел «Экран»
Идентификатор «Экран2»
Устройство «Устройство2»
Монитор «Монитор2»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSection
Раздел «Экран»
Идентификатор «Экран3»
Устройство «Device3»
Монитор «Монитор3»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSection
Раздел «Экран»
Идентификатор «Экран4»
Устройство «Device4»
Монитор «Монитор4»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSection
Раздел «Экран»
Идентификатор «Экран5»
Устройство «Device5»
Монитор «Монитор5»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSection
Раздел «Экран»
Идентификатор «Экран6»
Устройство «Device6»
Монитор «Монитор6»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSection
Script is for miner loop with OC settings for each GPU.
Settings apply only ones at start if they enabled
Just edit it for your needs and run thats all, main part after it
! / bin / sh
nvidia-settings -a GPUFanControlState = 0
nvidia-settings -a GPUGraphicsClockOffset [3] = — 100
nvidia-settings -a GPUMemoryTransferRateOffset [3] = 1200
nvidia-smi -pm 1
nvidia-smi -pl 155
nvidia-settings -a [gpu: 0] / GPUGraphicsClockOffset [3] = — 150
nvidia-settings -a [графический процессор: 0] / GPUMemoryTransferRateOffset [3] = 1200
nvidia-settings -a [графический процессор: 0] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 0] / GPUTargetFanSpeed = 80
nvidia-settings -a [gpu: 1] / GPUGraphicsClockOffset [3] = — 150
nvidia-settings -a [графический процессор: 1] / GPUMemoryTransferRateOffset [3] = 1450
nvidia-settings -a [графический процессор: 1] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 1] / GPUTargetFanSpeed = 80
nvidia-settings -a [gpu: 2] / GPUGraphicsClockOffset [3] = — 150
nvidia-settings -a [графический процессор: 2] / GPUMemoryTransferRateOffset [3] = 1150
nvidia-settings -a [графический процессор: 2] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 2] / GPUTargetFanSpeed = 80
nvidia-settings -a [графический процессор: 3] / GPUGraphicsClockOffset [3] = — 100
nvidia-settings -a [графический процессор: 3] / GPUMemoryTransferRateOffset [3] = 1050
nvidia-settings -a [графический процессор: 3] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 3] / GPUTargetFanSpeed = 80
nvidia-settings -a [gpu: 4] / GPUGraphicsClockOffset [3] = — 150
nvidia-settings -a [графический процессор: 4] / GPUMemoryTransferRateOffset [3] = 1050
nvidia-settings -a [графический процессор: 4] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 4] / GPUTargetFanSpeed = 80
nvidia-settings -a [графический процессор: 5] / GPUGraphicsClockOffset [3] = — 100
nvidia-settings -a [графический процессор: 5] / GPUMemoryTransferRateOffset [3] = 800
nvidia-settings -a [графический процессор: 5] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 5] / GPUTargetFanSpeed = 80
nvidia-settings -a [графический процессор: 6] / GPUGraphicsClockOffset [3] = — 100
nvidia-settings -a [графический процессор: 6] / GPUMemoryTransferRateOffset [3] = 900
nvidia-settings -a [графический процессор: 6] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 6] / GPUTargetFanSpeed = 80
пока правда; # Это зациклит ваш майнер, даже если вы убьете -9 ethminer, он запустится снова после do
# Чтобы остановить, просто CTRL + C или что угодно =)
делать
/ главная / m1 / Майнер / ethminer -U -S eth-eu2.nanopool. org: 9999 -O 0xb4983146f0047d87c63b5fdb3ef9e2bee4557ea3.M1 / [email protected]
сделанный
Thats was not so hard, the main deal is up to go !!!
While our miner script is working we will run another one
Script for monitoring
! / bin / sh
-i 5 номер GPU для мониторинга
gpu = nvidia-smi -i 5 --query-gpu=utilization.gpu --format=csv,noheader,nounits
пока правда; # Петли: =))
делать
а [$ gpu -gt 50]
делать
gpu = nvidia-smi -i 5 --query-gpu=utilization.gpu --format=csv,noheader,nounits
echo «Загрузка графического процессора $ gpu»
echo «Все хорошо $ (дата) Загрузка графического процессора $ gpu Без ошибок»
спать 10
сделанный
если [$ gpu -lt 40]
тогда
killall -9 ethminer
echo «Restart Miner GPU load $ gpu $ (date) error»
echo «Ошибка перезапуска майнера $ (дата)» >> /home/m1/Miner/ethminer.log
спать 60
gpu = nvidia-smi -i 5 --query-gpu=utilization.gpu --format=csv,noheader,nounits
fi;
сделанный
Это оно. Доделал вчера. Думаю, может быть меньше. Но ничего не нужно устанавливать, компилировать и т. Д. Всю ночь я тестировал свои графические процессоры с разгоном и мощностью — + очень быстро для проверки тактовых импульсов и + tail -f /var/log/kern.log | grep nvrm, чтобы узнать, какой графический процессор выдает ошибку без длительной остановки фермы.
Если это вам поможет. Я люблю хороший кофе)) b4983146f0047d87c63b5fdb3ef9e2bee4557ea3
Размещено
Привет, хозяин!
У меня есть небольшая установка, но в ней есть похожий xconfig (этот трюк для имитации
Монитор потребовалось время, чтобы изучить), но, возможно, значение coolbits другое,
а также значения oc. Мне нужно попробовать некоторые из ваших значений oc в gtx
1060 Я помню, например, я не мог управлять вентилятором. Я либо имел
неверное значение coolbits или просто не работает с 1060s, но есть
нет ничего лучше, чем пытаться.
Опять же, ваше решение является очень полным, поэтому спасибо, что разместили его здесь.
Как я уже сказал, у меня есть крошечная установка с одним 1060, из которого я выжимаю максимум
23,6 MH / s. Мне было интересно, сколько MH / s вы получаете с одной доски с
те конфиги oc?
В четверг, 21 декабря 2017 г., 08:29 H05ted [email protected] написал:
Возьми и мои 5 копеек. На GPU начал майнить неделю назад. На данный момент у меня 14
1070ti — + OC, 2 фермы и майнинг eth с автоматическим перезапуском ethminer, если он останавливается
об ошибках. Эти два скрипта — не лучшее решение, написанные с нуля, но
работает отлично. Написано только для nvidia, но думаю может быть переписано для ati
тоже ))Ok, Lets go!!!! Необходимо включить nvidia coolbits, если вы хотите, чтобы настройки OC работали. Шахта
13 протестировано на драйверах 381 и 387, эмулирован монитор для каждой карты
мой nvidia-xconfig conf для 7 GPU, edid.bin найти в google, я сделал свой изAOC 23 мес
nvidia-xconfig: файл конфигурации X, созданный nvidia-xconfig nvidia-xconfig:
версия 387.34 (buildmeister @ swio-display-x64-rhel04-15) Вт, 21 ноября
03:31:45 PST 2017Раздел «ServerLayout»
Идентификатор «Layout0»
Экран 0 «Экран0»
Экран 1 «Экран1» Справа от «Экран0»
Экран 2 «Экран2» Справа от «Экран1»
Экран 3 «Экран3» Справа от «Экран2»
Экран 4 «Экран4» Справа от «Экран3»
Экран 5 «Экран5» Справа от «Экран4»
Экран 6 «Экран6» Справа от «Экран5»
InputDevice «Keyboard0» «CoreKeyboard»
InputDevice «Mouse0» «CorePointer»
EndSectionРаздел «Файлы»
EndSectionРаздел «InputDevice»
генерируется по умолчанию
Идентификатор «Mouse0»
Драйвер «мышь»
Вариант «Протокол» «авто»
Вариант «Устройство» «/ dev / psaux»
Вариант «Emulate3Buttons» «нет»
Вариант «ZAxisMapping» «4 5»
EndSectionРаздел «InputDevice»
генерируется по умолчанию
Идентификатор «Keyboard0»
Драйвер «kbd»
EndSectionРаздел «Монитор»
Идентификатор «Monitor0»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSectionРаздел «Монитор»
Идентификатор «Монитор1»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSectionРаздел «Монитор»
Идентификатор «Монитор2»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSectionРаздел «Монитор»
Идентификатор «Монитор3»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSectionРаздел «Монитор»
Идентификатор «Монитор4»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSectionРаздел «Монитор»
Идентификатор «Монитор5»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSectionРаздел «Монитор»
Идентификатор «Монитор6»
VendorName «Unknown»
Название модели «Неизвестно»
HorizSync 28,0 — 33,0
VertRefresh 43,0 — 72,0
Вариант «ДПМС»
EndSectionРаздел «Устройство»
Идентификатор «Device0»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID » PCI: 1 : 0: 0″
EndSectionРаздел «Устройство»
Идентификатор «Устройство1»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070»
BusID » PCI: 2 : 0: 0″
Вариант «ConnectedMonitor» «DFP-0»
Вариант «CustomEDID» «DFP-0: /etc/X11/edid.bin»
EndSectionРаздел «Устройство»
Идентификатор «Устройство2»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070»
BusID » PCI: 3 : 0: 0″
Вариант «ConnectedMonitor» «DFP-0»
Вариант «CustomEDID» «DFP-0: /etc/X11/edid.bin»
EndSectionРаздел «Устройство»
Идентификатор «Устройство3»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID » PCI: 5 : 0: 0″
Вариант «ConnectedMonitor» «DFP-0»
Вариант «CustomEDID» «DFP-0: /etc/X11/edid.bin»
EndSectionРаздел «Устройство»
Идентификатор «Device4»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID » PCI: 6 : 0: 0″
Вариант «ConnectedMonitor» «DFP-0»
Вариант «CustomEDID» «DFP-0: /etc/X11/edid.bin»
EndSectionРаздел «Устройство»
Идентификатор «Device5»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID » PCI: 7 : 0: 0″
Вариант «ConnectedMonitor» «DFP-0»
Вариант «CustomEDID» «DFP-0: /etc/X11/edid.bin»
EndSectionРаздел «Устройство»
Идентификатор «Устройство6»
Драйвер «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070»
BusID » PCI: 8 : 0: 0″
Вариант «ConnectedMonitor» «DFP-0»
Вариант «CustomEDID» «DFP-0: /etc/X11/edid.bin»
EndSectionРаздел «Экран»
Идентификатор «Screen0»
Устройство «Device0»
Монитор «Монитор0»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSectionРаздел «Экран»
Идентификатор «Экран1»
Устройство «Device1»
Монитор «Монитор1»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSectionРаздел «Экран»
Идентификатор «Экран2»
Устройство «Устройство2»
Монитор «Монитор2»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSectionРаздел «Экран»
Идентификатор «Экран3»
Устройство «Device3»
Монитор «Монитор3»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSectionРаздел «Экран»
Идентификатор «Экран4»
Устройство «Device4»
Монитор «Монитор4»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSectionРаздел «Экран»
Идентификатор «Экран5»
Устройство «Device5»
Монитор «Монитор5»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSection
EndSectionРаздел «Экран»
Идентификатор «Экран6»
Устройство «Device6»
Монитор «Монитор6»
DefaultDepth 24
Вариант «AllowEmptyInitialConfiguration» «True»
Вариант «Coolbits» «13»
Подраздел «Дисплей»
Глубина 24
EndSubSectionEndSection
Script is for miner loop with OC settings for each GPU. Settings apply only ones at start if they enabled Just edit it for your needs and run thats all, main part after it
! / bin / sh
nvidia-settings -a GPUFanControlState = 0
nvidia-settings -a GPUGraphicsClockOffset [3] = — 100
nvidia-settings -a GPUMemoryTransferRateOffset [3] = 1200
nvidia-smi -pm 1
nvidia-smi -pl 155
nvidia-settings -a [gpu: 0] / GPUGraphicsClockOffset [3] = — 150
nvidia-settings -a [графический процессор: 0] / GPUMemoryTransferRateOffset [3] = 1200
nvidia-settings -a [графический процессор: 0] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 0] / GPUTargetFanSpeed = 80
nvidia-settings -a [gpu: 1] / GPUGraphicsClockOffset [3] = — 150
nvidia-settings -a [графический процессор: 1] / GPUMemoryTransferRateOffset [3] = 1450
nvidia-settings -a [графический процессор: 1] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 1] / GPUTargetFanSpeed = 80
nvidia-settings -a [gpu: 2] / GPUGraphicsClockOffset [3] = — 150
nvidia-settings -a [графический процессор: 2] / GPUMemoryTransferRateOffset [3] = 1150
nvidia-settings -a [графический процессор: 2] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 2] / GPUTargetFanSpeed = 80
nvidia-settings -a [графический процессор: 3] / GPUGraphicsClockOffset [3] = — 100
nvidia-settings -a [графический процессор: 3] / GPUMemoryTransferRateOffset [3] = 1050
nvidia-settings -a [графический процессор: 3] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 3] / GPUTargetFanSpeed = 80
nvidia-settings -a [gpu: 4] / GPUGraphicsClockOffset [3] = — 150
nvidia-settings -a [графический процессор: 4] / GPUMemoryTransferRateOffset [3] = 1050
nvidia-settings -a [графический процессор: 4] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 4] / GPUTargetFanSpeed = 80
nvidia-settings -a [графический процессор: 5] / GPUGraphicsClockOffset [3] = — 100
nvidia-settings -a [графический процессор: 5] / GPUMemoryTransferRateOffset [3] = 800
nvidia-settings -a [графический процессор: 5] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 5] / GPUTargetFanSpeed = 80
nvidia-settings -a [графический процессор: 6] / GPUGraphicsClockOffset [3] = — 100
nvidia-settings -a [графический процессор: 6] / GPUMemoryTransferRateOffset [3] = 900
nvidia-settings -a [графический процессор: 6] / GPUFanControlState = 1
nvidia-settings -a [вентилятор: 6] / GPUTargetFanSpeed = 80
пока правда; # Это зациклит ваш майнер, даже если вы убьете -9 ethminer it
начнется снова после того, как сделатьЧтобы остановить просто CTRL + C или что угодно =)
делать
/ главная / m1 / Майнер / ethminer -U -S eth-eu2.nanopool. org: 9999 -O
0xb4983146f0047d87c63b5fdb3ef9e2bee4557ea3.M1 / [email protected]
сделанныйThats was not so hard, the main deal is up to go !!! While our miner script is working we will run another one Script for monitoring! / bin / sh
-i 5 номер GPU для мониторинга
gpu = nvidia-smi -i 5 —query-gpu = utilization.gpu
—format = csv, noheader, nounitsпока правда; # Петли: =))
делать
а [$ gpu -gt 50]
делать
gpu = nvidia-smi -i 5 —query-gpu = utilization.gpu
—format = csv, noheader, nounits
echo «Загрузка графического процессора $ gpu»
echo «Все хорошо $ (дата) Загрузка графического процессора $ gpu Без ошибок»
спать 10
сделанный
если [$ gpu -lt 40]
тогда
killall -9 ethminer
echo «Restart Miner GPU load $ gpu $ (date) error»
echo «Ошибка перезапуска майнера $ (дата)» >> /home/m1/Miner/ethminer.log
спать 60
gpu = nvidia-smi -i 5 —query-gpu = utilization.gpu
—format = csv, noheader, nounits
fi;сделанный
Это оно. Доделал вчера. Думаю, может быть меньше. Но ничего
нужно установить, скомпилировать и т. д. Всю ночь я тестировал свои графические процессоры с разгоном и мощностью
— + очень быстро тестировать cloks и + tail -f /var/log/kern.log | grep nvrm для
посмотреть, какой графический процессор выдал ошибку без долгой остановки фермы.
Если это вам поможет. Люблю хороший кофе))
0xb4983146f0047d87c63b5fdb3ef9e2bee4557ea3
Размещено—
Вы получили это, потому что оставили комментарий.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/ethereum-mining/ethminer/issues/72#issuecomment-353278352 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/AA-DBPLj3pjf2XpPInPCCcBT1yCJI40aks5tCgjFgaJpZM4OGt11
.
Привет джоантюн
Для управления вентилятором запустите nvidia-settings -a GPUFanControlState = 1
затем nvidia-settings -a [fan: 0] / GPUTargetFanSpeed = 80 вентиляторов GPU0 отключены
попробуйте coolbits 38, я тоже искал, чтобы он работал.
Мои карты не так хороши, как хотелось бы, но каждая ~ 31.7Mhs ~ 500Sol, тестирование еще не закончено.
Я только что закончил настройку второй установки (новый майнер Asus MB — максимум 19 графических процессоров) с 3 Asus GTX 1060 OC / 1 без OC (старая партия).
H05ted вдохновил меня снова погрузиться в Linux, и он работает (мне потребуются некоторые настройки, чтобы майнер автоматически запускался после перезагрузки, но все остальное работает отлично.
Я опубликую несколько скриптов позже, но я хотел бы сделать некоторые предложения для H05ted xorg.conf
Я часами пытался изменить настройки nvidia для карты> 0, и я только что наткнулся на эту команду: sudo nvidia-xconfig -a —cool-bits = 13 —allow-empty-initial-configuration
это делает xorg.conf идеальным без последующего редактирования … и бонус в том, что nvidia-settings теперь работает для всех карт.
Я не уверен, связано ли это с установкой (apt install) xserver-xorg-dev перед перезагрузкой (запуск nvidia-xconfig пожаловался на отсутствие xorg-server, поэтому я установил его). Во всяком случае, сейчас он работает.
Как я уже писал, в будущем опубликую некоторые обновления.
Выпущен Ethereum Miner Monitor — v1.0.2 — БЕСПЛАТНО!
Это приложение на Python для мониторинга майнеров Ethereum на базе Linux и поддержания активности майнера в режиме 24/7. Если у вас есть установка для майнинга на базе Linux, но нет системы мониторинга, вы можете использовать этот автономный скрипт, чтобы ваш майнер всегда работал без ручных проверок.
Приложение постоянно проверяет, запущен ли процесс ethminer и текущее среднее значение использования графических процессоров.
Скрипт может перезапустить ethminer или перезагрузить систему.
Скрипту не нужен дополнительный пакет / модуль python, только чистый python3. Вы также можете использовать virtualenv.
Текущая версия тестировалась на Ubuntu 16.04.3 LTS (xenial) с видеокартами GeForce GTX 1070 Ti и AMD Radeon R9 290X.
Добавлена поддержка запросов AMD Utilization!
Скачать: https://github.com/xstead/ethereum-miner-monitor
xstead, а кто сейчас использует ethminer? Ты из 2015 года, чувак? )))
@ Angel996 тот, кто знает, что делает …
Evilny0, что именно? ethminer — самый медленный майнер ethash на сегодняшний день, какой смысл его использовать?
@ Angel996, если вы так уверены в этом, просто не используйте его и не очерняйте тяжелую работу по его улучшению.
Андреа Ланфранки, вы уверены в обратном? Вы говорите, что ethminer быстрее и / или более энергоэффективен, чем Claymore?
Итак, я поверил вам, я потратил некоторое время на выпуск последнего выпуска ethminer.
Пробовал на установке Ubuntu 16.04 LTS с 5x Palit 1060 Stormx 3GB Samsung. Ядро -200, память +1200.
И вот результат:
Claymore’s: ~ 23,5 Mhs на карту, ~ 116 Mhs на установку. Потребление ~ 90 Вт / карту.
Ethminer: почти 19,5 Mhs на карту, ~ 96 Mhs на установку. Потребление ~ 90 Вт / карту.
ВЕРДИКТ: Быть «убежденным» в чем-то — это хорошо, но в действительности все обстоит иначе.
@ Angel996 Мы — проект с открытым исходным кодом. Нам не платят ни за что из этого. Я думаю, это действительно здорово, что так много разработчиков внесли свой вклад в этот проект и сделали это в свое свободное время. Без таких разработчиков не было бы никаких криптовалют, потому что никто бы (и не должен) доверять закрытому исходному коду!
В своем собственном тесте я обнаружил разницу примерно в 6% с клеймором, и это цена, которую я готов заплатить за знание того, какой код выполняется на моей машине.
Не для того, чтобы кормить тролля, но вот оно:
@ Angel996 Какой на самом деле хешрейт у пула? Claymores показывает примерно на 10% больше фактического хешрейта на пуле. Ethminer показывает в пуле то же самое, что и в майнере.
Моя установка 6x 580 8GB показала ~ 180 в клейморах и ~ 168 в бассейне. При правильной настройке ethminer я получаю ~ 175MH / s как в пуле, так и в майнере. Обожаю ethminer, продолжайте в том же духе!
MariusVanDerWijden — преимущества программного обеспечения с открытым исходным кодом? Конечно. Но когда дело доходит до майнинга, все дело в зарабатывании денег. Это делает более медленные майнеры совершенно бесполезными. И, пожалуйста, не говорите мне, что вы мои в образовательных целях.
tonyaik, не смотрите на сообщенный хешрейт, вы подсчитали фактическое количество отправленных акций? У меня есть два одинаковых рига, могу провести тест, скажем, час и посмотреть.
Что такое «правильная настройка ethminer»? Я просмотрел вывод —help, я не вижу там много вариантов. OC? Я использую те же настройки, что и у Claymore’s.
@ Angel996 Да, я смотрел реальное количество акций. Лучший хешрейт в пуле и отсутствие комиссии за разработку.
—cl-local-work и global-work — вот что я имею в виду. Для меня значения по умолчанию не были оптимальными.
Параметры cl предназначены для карт AMD, о которых не идет речь (хотя они у меня тоже есть). Что касается комиссии разработчика, то здесь:
https://github.com/JuicyPasta/Claymore-No-Fee-Proxy
Поскольку протокол stratum представляет собой простой текстовый TCP-сеанс, он работает как шарм, если SSL не используется майнером.
Увидел ту же разницу с моей установкой 7x 1060.
Использование прокси без комиссии — дерьмовая вещь. Не хочу играть по правилам разработчиков, имхо не пользуйся. Во всяком случае. Я не в этой ветке.
ВЕРДИКТ: Быть «убежденным» в чем-то — это хорошо, но в действительности все обстоит иначе.
Реальность субъективна.
Я проходил одни и те же тесты снова и снова.
Для сравнения у меня есть 6x EVGA 1060 3Gb на Micron (не Samsung), и я могу выжать из каждого примерно 18,67 Mh / s. используя -200 / + 850 при 72,50 Вт с использованием Claymore (более сильное нажатие делает всю систему нестабильной и / или не отвечает), в то время как на ethminer я получаю 18,52 Mh / s, используя -200 / + 750 при 72,50 Вт (система довольно стабильна, работает для пакетов по 12 часов каждый). И да … Я ограничиваю силу, насколько могу, когда занимаюсь математикой.
Падение заявленного хешрейта не имеет ничего общего с комиссией в 1%.
Вдобавок должен сказать, что клеймор использует в среднем на 26% больше ЦП, что приводит к тому, что мои установки с не очень мощными целеронами сильно тормозят. С ethminer мои машины работают без сбоев.
Плюс … мои измерения с использованием ethermine.org показывают, что заявленный хешрейт сильно перекрывает эффективный и средний хешрейт. Те пересекающиеся линии, которых никогда не было у Клеймора. (не обращая внимания на последние 3 часа, когда у меня были проблемы с подключением.) У меня всегда было подозрение, что у Клеймора хешрейт выше, чем эффективный … но поскольку мы не можем прочитать код …

И последнее, но не менее важное: ethminer можно использовать бесплатно без ваших «читов» (которые в ближайшем будущем вполне могут обойти Claymore’s). И это открытый исходный код: возможность читать код и быть уверенным, что за кулисами не происходит ничего нежелательного или неожиданного, очень ценится.
ВЕРДИКТ: выносить абсолютный вердикт — всегда не лучшая идея.
И я останавливаюсь здесь.
tonyak >> Claymores показывает примерно на 10% больше фактического хешрейта на пуле.
Это абсолютно НЕ правда! Сообщенный хешрейт отправляется в пул, чтобы люди действительно могли сравнить реальный хешрейт с сообщенным. Здесь я использовал установку 4x 1060 1x 1050ti 20 часов подряд. Полученные результаты:
Средний хешрейт за последние 6 часов: 105,3 Mh / s
Последний отчетный хешрейт: 106,2 Mh / s.
Пул — eth.nanopool.org. Небольшая разница на самом деле составляет 1% от комиссии Клеймора. Это также хороший способ проверить, не крадет ли пул доли. Вероятно, ваш опыт связан с фактом кражи акций, а не с неверным сообщением Claymore о хешрейте.
_AndreaLanfranchi >> Для сравнения у меня есть 6x EVGA 1060 4Gb на Micron (не на Samsung), и я могу выжать из каждого примерно 18,67 Mh / s. с использованием -200 / + 850 при 72,50 Вт с использованием Claymore (более сильное нажатие делает всю систему нестабильной и / или не отвечает) _
Я могу высказать вердикт, потому что построил много ригов. Я делаю это для себя, а также за деньги для других людей.
Микронная память тоже довольно быстрая, она должна дать вам около 21 mh / s (по крайней мере!). Если ваша система становится нестабильной / не отвечает при дальнейшем OC, проблема не в графическом процессоре, а в вашем источнике питания или проводке. Поскольку превышение предела OC должно выдавать ошибку «GPU отключен от шины», установка не должна зависать или перестать отвечать. Уменьшая тактовые частоты и играя с ограничением мощности, вы просто получаете стабильность системы в качестве компромисса вместо обеспечения стабильного питания вашего оборудования.
Если вы используете преобразователи питания SATA -> 6PIN, откажитесь от них. Припаяйте качественные толстые провода прямо к блоку питания, и вы удивитесь, насколько лучше будет работать ваша установка. Я прошел через это.
В качестве альтернативы вы можете попробовать удалить 5 графических процессоров и запустить свою систему на 1 графическом процессоре. Посмотри, сможешь ли ты лучше разобраться. Я уверен, что вы можете (поскольку графический процессор получает больше мощности). Кроме того, упоминание о том, что система перестает отвечать, предполагает, что ваш ЦП / материнская плата / память недостаточно мощны из-за слишком большого количества графических процессоров в вашей установке или, опять же, из-за плохой проводки.
ОБНОВИТЬ:
Я попробовал это на установке с 2x 1060 Hynix и 2x GTX 970 Hynix.
Клеймора:
GPU0 18,473 Mh / s, GPU1 18,465 Mh / s, GPU2 10,292 Mh / s, GPU3 10,536 Mh / s
Этминер:
gpu / 0 18,60 gpu / 1 18,60 gpu / 2 10,49 gpu / 3 10,49
Это даже немного быстрее. )) Очень интересно. Кроме того, это может быть подсказкой для разработчиков ethminer. Как хешрейт соотносится со скоростью памяти?
ps GTX 970 раньше была намного быстрее (до 21 mhs), но они стали значительно медленнее после определенной эпохи ethash: ((
4x1080ti evga
Windows
16 гб оперативной памяти
Этот код появился сегодня дважды. Оба раза я входил в систему через vnc. Похоже, что это вызвало это.
70% мощности
149 разгон
499 разгон памяти
Я сталкиваюсь с такими же проблемами, когда пытаюсь использовать GPU в keras.
InternalError: CUDA runtime implicit initialization on GPU:0 failed. Status: an illegal memory access was encountered
Была ли эта страница полезной?
0 / 5 — 0 рейтинги
Ошибки Видеокарты При Майнинге
Самое полное собрание ошибок в майнинге на Windows, HiveOS и RaveOS и их быстрых и спокойных решений
Can’t find nonce with device CUDA_ERROR_LAUNCH_FAILED

Ошибка майнера Can’t find nonce
Ошибка говорит о том, что майнер не может найти нонс и сразу же сам предлагает решение — уменьшить разгон. Особенно начинающие майнеры стараются выжать из видеокарты максимум — разгоняют слишком сильно по ядру или памяти. В таком разгоне видеокарта даже может запуститься, но потом выдавать ошибки как указано ниже. Помните, лучше — стабильная отправка шар на пул, чем гонка за цифрами в майнере.
Зарабатывай на чужих сделках на бирже BingX. Подробнее — тут.
Phoenixminer Connection to API server failed — что делать?

Ошибка Connection to API server failed
Такая ошибка встречается на PhoenixMiner на операционной систему HiveOS. Она говорит о том, что майнинг-ферма/риг не может подключиться к серверу статистики. Что делать для ее решения:
- Введите команду net-test и запомните/запишите сервер с низким пингом. После чего смените его в веб интерфейсе Hive (на воркере) и перезагрузите ваш риг.
- Если это не помогло, выполните команду dnscrypt -i && sreboot
Phoenixminer CUDA error in CudaProgram.cu:474 : the launch timed out and was terminated (702)

Ошибка майнера Phoenixminer CUDA error in CudaProgram
Эта ошибка, как и в первом случае, говорит о переразгоне карты. Откатите видеокарту до заводских настроек и постепенно поднимайте разгон до тех пор, пока не будет ошибки.
UNABLE TO ENUM CUDA GPUS: INVALID DEVICE ORDINAL

Ошибка майнера Unable to enum CUDA GPUs: invalid device ordinal
Проверяем драйвера видеокарты и саму видеокарту на работоспособность (как она отмечена в диспетчере устройств, нет ли восклицательных знаков).
Если все ок, то проверяем райзера. Часто бывает, что именно райзер бывает причиной такой ошибки.
UNABLE TO ENUM CUDA GPUS: INSUFFICIENT CUDA DRIVER: 5000

Ошибка майнера Unable to enum CUDA GPUs: Insufficient CUDA driver: 5000
Аналогично предыдущей ошибке — проверяем драйвера видеокарты и саму видеокарту на работоспособность (как она отмечена в диспетчере устройств, нет ли восклицательных знаков).
NBMINER MINING PROGRAM UNEXPECTED EXIT.CODE: -1073740791, REASON: PROCESS CRASHED

Ошибка майнера NBMINER MINING PROGRAM UNEXPECTED EXIT.CODE: -1073740791, REASON: PROCESS CRASHED
Ошибка code 1073740791 nbminer возникает, если ваш риг/майнинг-ферма собраны из солянки Nvidia+AMD. В этом случае разделите майнинг на два .bat файла (или полетника, если вы на HiveOS). Один — с картами AMD, другой с картами Nvidia.
NBMINER CUDA ERROR: OUT OF MEMORY (ERR_NO=2) — как исправить?

Ошибка майнера NBMINER CUDA ERROR: OUT OF MEMORY (ERR_NO=2)
Одна из самых распространённых ошибок на Windows — нехватка памяти, в данном случае на майнере Nbminer, но встречается и в майнере Nicehash. Чтобы ее исправить — надо увеличить файл подкачки. Файл подкачки должен быть равен сумме гб всех видеокарт в риге плюс 10% запаса. Как увеличить файл подкачки — читаем тут.
GMINER ERROR ON GPU: OUT OF MEMORY STOPPED MINING ON GPU0

Ошибка майнера GMINER ERROR ON GPU: OUT OF MEMORY STOPPED MINING ON GPU0
В данном случае скорее всего виноват не файл подкачки, а переразгон по видеокарте, которая идет под номером 0. Сбавьте разгон и ошибка должна пропасть.
Socket error. the remote host closed the connection, в майнере Nbminer

Socket error. the remote host closed the connection
Также может быть описана как «ERROR — Failed to establish connection to mining pool: Socket operation timed out».
Сетевой конфликт — проверьте соединение рига с интернетом. Перегрузите роутер.
Также может быть, что провайдер закрывает соединение с пулом. Смените пул, попробуйте VPN или измените адреса DNS на внешнего провайдера, например cloudflare 1.1.1.1, 1.0.0.1
Server not responded on share, на майнере Gminer

Server not responded on share
Такая ошибка говорит о том, что у вас что-то с подключением к интернету, что критично для Gminer. Попробуйте сделать рестарт роутера и отключить watchdog на майнере.
DAG has been damaged check overclocking settings, в майнере Gminer
Также в этой ошибке может быть указано Device not responding, check overclocking settings.
Ошибка говорит о переразгоне, попробуйте сначала убавить его.
Если это не помогло, смените майнер — Gminer никогда не славился работой с видеокартами AMD. Мы рекомендуем поменять майнер на Teamredminer, а если вам критична поддержка майнером одновременно Nvidia и AMD видеокарт, то используйте Lolminer.
Если смена майнера не поможет, переставьте видеодрайвер.
Если и это не поможет, то нужно тестировать эту карту отдельно в слоте X16.
ERROR: Can’t start T-Rex, failed to initialize device map: can’t get busid, code -6
Ошибки настройки памяти с кодом -6 обычно указывают на проблему с драйвером.
Если у вас Windows, используйте программу DDU (DisplayDriverUninstaller), чтобы полностью удалить все драйверы Nvidia.
Перезагрузите систему.
Установите новый драйвер прямо с сайта Nvidia.
Перезагрузите систему снова.
Если у вас HiveOS/RaveOS — накатите чистый образ системы. Чтобы наверняка.
TREX: Can’t unlock GPU
Полный текст ошибки:
TREX: Can’t unlock GPU [ID=1, GPU #1], error code 15
WARN: Miner is going to shutdown…
WARN: NVML: can’t get fan speed for GPU #1, error code 15
WARN: NVML: can’t get power for GPU #1, error code 15
WARN: NVML: can’t get mem/core clock for GPU #1, error code 17
Решение:
- Проверьте все кабельные соединения видеокарты и райзера, особенно кабеля питания.
- Если с первый пунктом все ок, попробуйте поменять райзер на точно рабочий.
- Если ошибка остается, вставьте видеокарту в разъем х16 напрямую в материнскую плату.
CAN’T START MINER, FAILED TO INITIALIZE DEVIS MAP, CAN’T GET BUSID, CODE -6

Ошибка майнера CAN’T START MINER, FAILED TO INITIALIZE DEVIS MAP, CAN’T GET BUSID, CODE -6
В конкретном случае была проблема в блоке питания, он не держал 3 видеокарты. После замены блока питания ошибка пропала.
Если вы уверены, что ваш мощности вашего блока питания достаточно, попробуйте сменить майнер.
Зарабатывай на чужих сделках на бирже BingX. Подробнее — тут.
ОШИБКА 511 ГРАДУСОВ НА ВИДЕОКАРТА

Ошибка 511 градусов видеокарта
Ошибка 511 говорит о неисправности райзера или питания карты. Проверьте все соединения. Для выявления неисправности рекомендуется запустить систему с одной картой. Протестировать, и затем добавлять по одной карте.
GPU driver error, no temps в HiveOS — что делать?
Вероятнее всего, вы получили эту ошибку, майнив на HiveOS. Причин ее появления может быть несколько — как софтовая, так и аппаратная (например райзер).
Можно попробовать обойтись малой кровью и вбить в HiveOS команду:
hive-replace -y —stable
Система по новой накатит стабильную версию HiveOS.
Если ошибка не уйдет — проверьте райзер.
GPU are lost, rebooting
Это не ошибка, а ее последствие. Что узнать какая ошибка приводит к перезагрузке карт, сделайте следующее:
Включите сохранение логов (по умолчанию они выключены) командой
logs-on
И перезагрузите риг.
После того как ошибка повторится можно будет скачать логи командами ниже.
Вы можете использовать следующую команду, чтобы загрузить логи майнера прямо с панели мониторинга;
message file «miner.log» -f=/var/log/miner/minername/minername.log
Итак, скажем, например, мне нужны логи TeamRedMiner
message file «teamredminer.log» -f=/var/log/miner/teamredminer/teamredminer.log
Отправленная командная строка будет выделена синим цветом. Загружаемый файл будет отображаться белым цветом. Нажав на него, вы сможете его скачать.
Эта команда позволит скачать лог системы
message file «syslog» -f=/var/log/syslog
exitcode=3 в HiveOS

Вероятнее всего, вы получили эту ошибку, майнив на HiveOS. Причин ее появления может быть несколько — как софтовая, так и аппаратная (например райзер).
Можно попробовать обойтись малой кровью и вбить в HiveOS команду:
hive-replace -y —stable
Система по новой накатит стабильную версию HiveOS.
Если ошибка не уйдет — проверьте райзер.
exitcode=1 в HiveOS
Данная ошибка возникает когда есть проблема с датой в биосе материнской платы (сбитое время) и (или) есть проблема с интернетом.
Если сбито время, то удаленно вы не сможете подключиться.
Тем не менее, обновление драйверов Nvidia должно пройти командой:
nvidia-driver-update —list
gpu fault detected 146
Скорее всего вы пытаетесь майнить с помощью Phoenix miner. Решения два:
- Откатитесь на более старую версию, например на 5.4с
- (Рекомендуемый вариант) Используйте Trex для видеокарт Nvidia и TeamRedMiner для AMD.
Waiting interface to come up — не работает VPN на HiveOS

Waiting interface to come up
Начните с логов, чтобы понять какая именно ошибка вызывает эту проблему.
Команды для получения логов:
systemctl status openvpn@client
journalctl -u openvpn@client -e —no-pager -n 100
Как узнать ip адрес воркера hive os

Как узнать ip адрес воркера hive os
Самое простое — зайти в воркера и прокрутить страницу ниже видеокарт. Там будет указан Remote IP — это и есть внешний IP.
Альтернативный вариант — вы можете проверить ваш внешний айпи адрес hive через консоль Hive Shell:
Выполните одну из команд:
curl 2ip.ru
wget -qO- eth0.me
wget -qO- ipinfo.io/ip
wget -qO- ipecho.net/plain
wget -qO- icanhazip.com
wget -qO- ipecho.net
wget -qO- ident.me
Repository update failed в HiveOS

Иногда встречается на HiveOS. Полный текст ошибки:
Some index files failed to download. They have been ignored, or old ones used instead.
Repository update failed
------------------------------------------------------
> Restarting autofan and watchdog
> Starting miners
Miner screen is already running
Run miner or screen -r to resume screen
Upgrade failedРешение:
- Выполнить команду apt update && selfupgrade -f
- Если не сработала и она, то 99.9%, что разработчики HiveOS уже знают об этой проблеме и решают ее. Попробуйте выполнить обновление через некоторое время.
Rave os не запускается. Boot aborted Rave os

Перепроверьте все настройки ПК и БИОСа материнской платы:
— Установите загрузочное устройство HDD/SSD/M2/USB в зависимости от носителя с ОС.
— Включите 4G decoding.
— Установите поддержку PCIe на Auto.
— Включите встроенную графику.
— Установите предпочтительный режим загрузки Legacy mode.
— Отключите виртуализацию.
Если после данных настроек не определяется часть карт, то выполните следующие настройки в BIOS (после каждого пункта требуется полная перезагрузка):
— Отключите 4G decoding
— Перезагрузка
— Отключите CSM
— Перезагрузка
— Включите 4G decoding, установите PCI-E Gen2/3, а при отсутствии Gen2/3, можно выбрать Gen1
Failed to allocate memory Raveos
Эта же ошибка может называться как:
failed to allocate initramfs memory bailing out, failed to load idlinux c.32
или
failed to allocate memory for kernel boot parameter block
или
failed to allocate initramfs memory raveos bailing
Но решение у нее одно — вы должны правильно настроить БИОС материнской платы.
gpu_driver_fault, GPU #0 fault в RaveOS

gpu_driver_fault, GPU #0 fault в RaveOS
В большинстве случаев эта проблема решается уменьшением разгона (особенно по памяти) на конкретной видеокарте (на скрине это карта номер 0).
Если уменьшение разгона не помогает, то попробуйте обновить драйвера.
Если обновление драйверов не привело к решению проблемы, то попробуйте поменять райзер на этой карте на точно работающий.
Если и это не помогает, перепроверьте все кабельные соединения и мощность блока питания, хватает ли его для вашей конфигурации.
Gpu driver fault. All tasks have been stopped. Worker will be rebooted after 5 minutes в RaveOS

Gpu driver fault. All tasks have been stopped. Worker will be rebooted after 5 minutes
Что приводит к появлению этой ошибки? Вероятно, вы переразогнали видеокарту (часто сильно гонят по памяти), сбавьте разгон. На скрине видно, что проблему дает именно GPU под номером 1 — начните с нее.
Вторая частая причина — нехватка питания БП на систему с видеокартами. Учтите, что сама система потребляет не менее 100 вт, каждый райзер еще закладывайте 50 вт. БП должно хватать с запасом в 20%.
Miner restarted after error RaveOS
Смотрите логи майнера, там будет указана конкретная ошибка, которая приводит к miner restarted. После этого найдите ее на этой странице и исправьте. Проблема уйдет.
Miner restart limit reached. Worker rebooting by flag auto в RaveOS
Аналогично предыдущему пункту — смотрите логи майнера, там будет указана конкретная ошибка, которая приводит к рестарту воркера. Пофиксите ту ошибку — уйдет и эта проблема.
Miner cannot be started, ОС RaveOS
Непосредственно перед этой ошибкой обычно пишется еще другая, которая и вызывает эту проблему. Но если ничего нет, то:
- Поставьте майнер на паузу, перезагрузите риг и в консоли выполните команды clear-miners clear-logs и fix-fs. Запустите майнинг.
- Если ошибка не ушла, перепишите образ RaveOS.
Overclock can’t be applied в RaveOS
Эта ошибка означает, что значения разгона между собой конфликтуют или выходят за пределы допустимых. Перепроверьте их. Скиньте разгон на стоковый и попробуйте еще раз.
В редких случаях причиной этой ошибки также становится райзер.
Error installing hive miners

Error installing hive miners
Можно попробовать обойтись малой кровью и вбить в HiveOS команду:
hive-replace -y —stable
Система по новой накатит стабильную версию HiveOS.
Если ошибка не уйдет — физически перезапишите образ. Если у вас флешка, то скорее всего она умерла. Купите SSD.
Warning: Nvidia settings applied with errors
Переразгон. Снизьте значения частот ядра и памяти. После этого перезагрузите риг.
Nvtool error или Danger: nvtool error
Скорее всего при установке драйвера появилась проблема с модулем nvtool
Попробуйте переустановить драйвер Nvidia командой через Hive shell:
nvidia-driver-update версия_драйвера —force
Или попробуйте обновить систему полностью командой из Hive shell:
hive-replace -y —stable

nvtool error
Перестал отображаться кулер видеокарты HiveOS

0% скорости вращения кулера.
Это может произойти по нескольким причинам:
- кулер действительно не крутится
- датчик оборотов отключен или сломан
- видеокарта слишком агрессивно работает (высокий разгон)
- неисправен райзер или одно из его частей
ERROR: parsing JSON failed
Необходимо выполнить на риге локально (с клавиатурой и монитором) следующую команду:
net-test
Данная команда покажет ваше текущее состояние подключения к разным зеркалам API серверов HiveOS.
Посмотрите, к какому API у вас наименьшая задержка (ping), и когда воркер снова появится в панели, измените стандартное зеркало на то, что ближе к вам.
После смены зеркала, в обязательном порядке перезагрузите ваш воркер.
Изменить сервер API вы можете командой nano /hive-config/rig.conf
После смены нажмите ctrl + o и ентер для того чтобы сохранить файл.
После этого выйдите в консоль командой ctrl + x, f10 и выполните команду hello
NVML: can’t get fan speed for GPU #5, error code 999 hive os
Проблема с скоростью кулеров на GPU 5
0% скорости вращения кулера / ошибки в целом
Это может произойти по нескольким причинам:
— кулер действительно не крутится
— датчик оборотов отключен или сломан
— видеокарта слишком агрессивно работает (высокий разгон)
Начните с визуальной проверки карты и ее кулера.
Can’t get power for GPU #2
Как правило эта ошибка встречается рядом вместе с другими:
Attribute ‘GPUGraphicsClockOffset’ was already set to 0
Attribute ‘GPUMemoryTransferRateOffset’ was already set to 2200
Attribute ‘GPUFanControlState’ (hive1660s_ETH:0[gpu:2]) assigned value
0.
20211029 12:40:50 WARN: NVML: can’t get fan speed for GPU #2, error code 999
20211029 12:40:50 WARN: NVML: can’t get power for GPU #2, error code 999
20211029 12:40:50 WARN: NVML: can’t get mem/core clock for GPU #2, error code 999
Решение:
Проверьте корректность установки драйвера на видеокарте.
Убедитесь что нет проблем с драйвером, если все в порядке, то попробуйте другой параметр разгона. Например уменьшить разгон по памяти.
GPU1 search error: unspecified launch failure
Уменьшите разгон и проверьте контакты райзера
Warning: Autofan: unable to set fan speed, rebooting
Найдите логи майнера, посмотрите какие ошибки майнер пишет в логах. Например:
kernel: [12112.410046][ T7358] NVRM: GPU at PCI:0000:0c:00: GPU-236e3bef-2e03-6cdb-0518-7ac01eb8736d
kernel: [12112.410049][ T7358] NVRM: Xid (PCI:0000:0c:00): 62, pid=7317, 0000(0000) 00000000 00000000
kernel: [12112.433831][ T7358] NVRM: Xid (PCI:0000:0c:00): 45, pid=7317, Ch 00000010
CRON[21094]: (root) CMD (command -v debian-sa1 > /dev/null && debian-sa1 1 1)
Исходя из логов, мы видим что есть проблема с видеокартой на слоте PCIE 0c:00 (под номером Gpu пишется номер PCIE слота) с ошибками 45 и 62
Коды ошибок (других, которые также могут быть там) и что с ними делать:
• 13, 43, 45: ошибки памяти, снизить MEM
• 8, 31, 32, 61, 62: снизить CORE, возможно и MEM
• 79: снизить CORE, проверить райзер
Ошибка Kernel-Power код 41
Проверьте все провода (от БП до карт, от БП до райзеров), возможно где-то идёт оплавление. Если визуальный осмотр показал, что все ок, то ошибка программная и вам нужно переустановить Windows.
Danger: hive-replace -y —stable (failed, exitcode=137)
Очень редкая ошибка, которая вылезла в момент удаленного обновления образа HiveOS. Она не встречается в тематических майнинг группах и сайтах. Не поверите что произошло.
На балконе, где стоял риг, поселилась семья голубей. Они засрали риг, в прямом смысле, из-за этого он постоянно уходил в оффлайн. После полной продувки материнской платы и видеокарт проблема решилась сама.
MALFUNCTION HIVEOS

Malfunction — неисправность. Причин и решений может быть несколько:
- Вам следует переустановить видео драйвер;
- Если драйвер не помог, тогда отключайте все GPU и поочередно вставляйте по 1 шт, и смотрите вызовет ли какая-то видеокарта подобную ошибку или нет. Если да, то возможно это райзер.
- Неисправен носитель, на который записана Hive OS, запишите образ еще раз.
Не нашли своей ошибки? Помогите сделать мир майнинга лучше. Отправьте ее по этой форме и мы обновим наш гайд в самое ближайшее время.