В предыдущем параграфе было дано описание кодов Хэмминга как циклических кодов, порождающие многочлены которых имеют корень в соответствующем расширении основного поля. Описанные коды исправляют одну ошибку. Сейчас мы возвращаемся к исправляющим две ошибки кодам над полем GF (2). Пусть длина кода имеет вид  для некоторого
для некоторого  и пусть а — примитивный элемент поля
и пусть а — примитивный элемент поля  Мы рассмотрим те даоичиые коды, для которых а и а? являются корнями порождающих многочленов, и покажем, что такие коды позволяют исправлять две ошибки.
Мы рассмотрим те даоичиые коды, для которых а и а? являются корнями порождающих многочленов, и покажем, что такие коды позволяют исправлять две ошибки.
Пусть  многочлен наименьшей степени, для которого
многочлен наименьшей степени, для которого  из
из  являются корнями. Описав процедуру декодирования, позволяющую исправлять все одиночные и двойные ошибки, мы докажем, что минимальное расстояние этого кода равно по меньшей мере 5.
являются корнями. Описав процедуру декодирования, позволяющую исправлять все одиночные и двойные ошибки, мы докажем, что минимальное расстояние этого кода равно по меньшей мере 5.
Принятое слово записывается многочленом степени  вида
вида

где  содержит не более двух ненулевых коэффициентов, поскольку мы рассматриваем случай исправления не более двух ошибок. Таким образом, или
содержит не более двух ненулевых коэффициентов, поскольку мы рассматриваем случай исправления не более двух ошибок. Таким образом, или  или с
или с  или
или  Целые числа
Целые числа  и
и  маркируют позиции, в которых произошли ошибки. Для маркировки ошибочных позиций мы будем также использовать элементы поля
маркируют позиции, в которых произошли ошибки. Для маркировки ошибочных позиций мы будем также использовать элементы поля  Элемент поля а соответствует компоненте с номером
Элемент поля а соответствует компоненте с номером  . В этой роли элементы поля называются локаторами. Обозначим —
. В этой роли элементы поля называются локаторами. Обозначим —  Так как длина кода
Так как длина кода  равна порядку элемента а, то локаторы А, и
равна порядку элемента а, то локаторы А, и  определяются однозначно. Если произошла только одна ошибка, то положим
определяются однозначно. Если произошла только одна ошибка, то положим  если ошибок не произошло, то
если ошибок не произошло, то  .
.
Пусть  Эти элементы, известные также под названием компонент синдрома, вычисляются непосредственно по принятому слову
Эти элементы, известные также под названием компонент синдрома, вычисляются непосредственно по принятому слову  Так как
Так как  являются корнями
являются корнями  то
то  Предположим, что произошли две ошибки:
Предположим, что произошли две ошибки:  Но это в точности дает систему двух уравнений относительно двух неизвестных
Но это в точности дает систему двух уравнений относительно двух неизвестных  в поле
в поле 

Если может произойти не более двух ошибок, то величина равна нулю тогда и только тогда, когда не произошло ни одной ошибки. Декодер должен продолжать работу в том случае, когда  отлично от нуля. Если выписанная система из двух нелинейных уравнений однозначно разрешима относительно
отлично от нуля. Если выписанная система из двух нелинейных уравнений однозначно разрешима относительно  то две ошибки могут быть исправлены, и минимальное расстояние рассматриваемого кода равно по меньшей мере 5.
то две ошибки могут быть исправлены, и минимальное расстояние рассматриваемого кода равно по меньшей мере 5.
Прямого очевидного способа решения такой системы нет. Один из методов состоит во введении нового многочлена, определяемого так, чтобы локаторы ошибок были его корнями:

Если мы сумеем найти коэффициенты этого многочлена, то, разложив его на линейные множители, мы сможем найти  Но над расширением поля
Но над расширением поля 

Таким образом,

если произошли одна или две ошибки. Многочлен в правой части нам известен, поскольку известны  Локаторы ошибок являются корнями этого многочлена, а корни любого многочлена над полем определяются однозначно. Следовательно, код исправляет две ошибки.
Локаторы ошибок являются корнями этого многочлена, а корни любого многочлена над полем определяются однозначно. Следовательно, код исправляет две ошибки.
Указав процедуру декодирования, мы установили, что выбранный многочлен  порождает код, исправляющий две произвольные ошибки. Практически можно использовать любую удобную процедуру декодирования, и одной из них является процедура вычисления корней выписанного выше квадратного уравнения в
порождает код, исправляющий две произвольные ошибки. Практически можно использовать любую удобную процедуру декодирования, и одной из них является процедура вычисления корней выписанного выше квадратного уравнения в  Так как всего имеется
Так как всего имеется  возможностей выбора каждого из корней, то это часто делается методом проб и ошибок. Другие схемы декодирования будут рассмотрены в следующих главах.
возможностей выбора каждого из корней, то это часто делается методом проб и ошибок. Другие схемы декодирования будут рассмотрены в следующих главах.
Рассмотренные в настоящем параграфе коды, исправляющие две ошибки, служат иллюстрацией того, как построить
циклические коды над некоторым полем, используя лежащие в большем поле корни порождающих эти коды многочленов. В гл. 7 будет рассмотрен общий случай такого построения для произвольного поля символов  и произвольного числа исправляемых ошибок.
и произвольного числа исправляемых ошибок.
In coding theory, a cyclic code is a block code, where the circular shifts of each codeword gives another word that belongs to the code. They are error-correcting codes that have algebraic properties that are convenient for efficient error detection and correction.
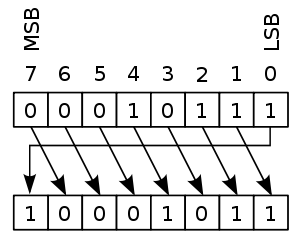
If 00010111 is a valid codeword, applying a right circular shift gives the string 10001011. If the code is cyclic, then 10001011 is again a valid codeword. In general, applying a right circular shift moves the least significant bit (LSB) to the leftmost position, so that it becomes the most significant bit (MSB); the other positions are shifted by 1 to the right.
Definition[edit]
Let  be a linear code over a finite field (also called Galois field)
be a linear code over a finite field (also called Galois field)  of block length
of block length  . is called a cyclic code if, for every codeword
. is called a cyclic code if, for every codeword  from , the word
from , the word  in
in  obtained by a cyclic right shift of components is again a codeword. Because one cyclic right shift is equal to
obtained by a cyclic right shift of components is again a codeword. Because one cyclic right shift is equal to  cyclic left shifts, a cyclic code may also be defined via cyclic left shifts. Therefore, the linear code is cyclic precisely when it is invariant under all cyclic shifts.
cyclic left shifts, a cyclic code may also be defined via cyclic left shifts. Therefore, the linear code is cyclic precisely when it is invariant under all cyclic shifts.
Cyclic codes have some additional structural constraint on the codes. They are based on Galois fields and because of their structural properties they are very useful for error controls. Their structure is strongly related to Galois fields because of which the encoding and decoding algorithms for cyclic codes are computationally efficient.
Algebraic structure[edit]
Cyclic codes can be linked to ideals in certain rings. Let ![R=A[x]/(x^{n}-1)](https://wikimedia.org/api/rest_v1/media/math/render/svg/8595f12ff1f64bc73a4e3e03851397cc877af6e2) be a polynomial ring over the finite field
be a polynomial ring over the finite field  . Identify the elements of the cyclic code
. Identify the elements of the cyclic code  with polynomials in
with polynomials in  such that
such that
 maps to the polynomial
maps to the polynomial
 : thus multiplication by
: thus multiplication by  corresponds to a cyclic shift. Then is an ideal in , and hence principal, since is a principal ideal ring. The ideal is generated by the unique monic element in of minimum degree, the generator polynomial
corresponds to a cyclic shift. Then is an ideal in , and hence principal, since is a principal ideal ring. The ideal is generated by the unique monic element in of minimum degree, the generator polynomial  .[1]
.[1]
This must be a divisor of  . It follows that every cyclic code is a polynomial code.
. It follows that every cyclic code is a polynomial code.
If the generator polynomial has degree  then the rank of the code is
then the rank of the code is  .
.
The idempotent of is a codeword  such that
such that  (that is, is an idempotent element of ) and is an identity for the code, that is
(that is, is an idempotent element of ) and is an identity for the code, that is  for every codeword
for every codeword  . If and
. If and  are coprime such a word always exists and is unique;[2] it is a generator of the code.
are coprime such a word always exists and is unique;[2] it is a generator of the code.
An irreducible code is a cyclic code in which the code, as an ideal is irreducible, i.e. is minimal in , so that its check polynomial is an irreducible polynomial.
Examples[edit]
For example, if  and
and  , the set of codewords contained in cyclic code generated by
, the set of codewords contained in cyclic code generated by  is precisely
is precisely
 .
.

It corresponds to the ideal in ![mathbb {F} _{2}[x]/(x^{3}-1)](https://wikimedia.org/api/rest_v1/media/math/render/svg/9b419295ea611763fd442a22f8f56fe8dc30c023) generated by
generated by  .
.
The polynomial is irreducible in the polynomial ring, and hence the code is an irreducible code.
The idempotent of this code is the polynomial  , corresponding to the codeword
, corresponding to the codeword  .
.
Trivial examples[edit]
Trivial examples of cyclic codes are  itself and the code containing only the zero codeword. These correspond to generators
itself and the code containing only the zero codeword. These correspond to generators  and respectively: these two polynomials must always be factors of .
and respectively: these two polynomials must always be factors of .
Over  the parity bit code, consisting of all words of even weight, corresponds to generator
the parity bit code, consisting of all words of even weight, corresponds to generator  . Again over this must always be a factor of .
. Again over this must always be a factor of .
Quasi-cyclic codes and shortened codes[edit]
Before delving into the details of cyclic codes first we will discuss quasi-cyclic and shortened codes which are closely related to the cyclic codes and they all can be converted into each other.
Definition[edit]
Quasi-cyclic codes:[citation needed]
An  quasi-cyclic code is a linear block code such that, for some
quasi-cyclic code is a linear block code such that, for some  which is coprime to , the polynomial
which is coprime to , the polynomial  is a codeword polynomial whenever
is a codeword polynomial whenever  is a codeword polynomial.
is a codeword polynomial.
Here, codeword polynomial is an element of a linear code whose code words are polynomials that are divisible by a polynomial of shorter length called the generator polynomial. Every codeword polynomial can be expressed in the form  , where
, where  is the generator polynomial. Any codeword
is the generator polynomial. Any codeword  of a cyclic code can be associated with a codeword polynomial, namely,
of a cyclic code can be associated with a codeword polynomial, namely,  . A quasi-cyclic code with equal to is a cyclic code.
. A quasi-cyclic code with equal to is a cyclic code.
Definition[edit]
Shortened codes:
An ![[n,k]](https://wikimedia.org/api/rest_v1/media/math/render/svg/4d9e3e5f03db243c10e64608605d156ae1885952) linear code is called a proper shortened cyclic code if it can be obtained by deleting positions from an
linear code is called a proper shortened cyclic code if it can be obtained by deleting positions from an  cyclic code.
cyclic code.
In shortened codes information symbols are deleted to obtain a desired blocklength smaller than the design blocklength. The missing information symbols are usually imagined to be at the beginning of the codeword and are considered to be 0. Therefore, − is fixed, and then is decreased which eventually decreases . It is not necessary to delete the starting symbols. Depending on the application sometimes consecutive positions are considered as 0 and are deleted.
is fixed, and then is decreased which eventually decreases . It is not necessary to delete the starting symbols. Depending on the application sometimes consecutive positions are considered as 0 and are deleted.
All the symbols which are dropped need not be transmitted and at the receiving end can be reinserted. To convert cyclic code to shortened code, set symbols to zero and drop them from each codeword. Any cyclic code can be converted to quasi-cyclic codes by dropping every th symbol where is a factor of . If the dropped symbols are not check symbols then this cyclic code is also a shortened code.
Cyclic codes for correcting errors[edit]
Now, we will begin the discussion of cyclic codes explicitly with error detection and correction. Cyclic codes can be used to correct errors, like Hamming codes as cyclic codes can be used for correcting single error. Likewise, they are also used to correct double errors and burst errors. All types of error corrections are covered briefly in the further subsections.
The (7,4) Hamming code has a generator polynomial  . This polynomial has a zero in Galois extension field
. This polynomial has a zero in Galois extension field  at the primitive element
at the primitive element  , and all codewords satisfy
, and all codewords satisfy  . Cyclic codes can also be used to correct double errors over the field . Blocklength will be equal to
. Cyclic codes can also be used to correct double errors over the field . Blocklength will be equal to  and primitive elements and
and primitive elements and  as zeros in the
as zeros in the  because we are considering the case of two errors here, so each will represent one error.
because we are considering the case of two errors here, so each will represent one error.
The received word is a polynomial of degree given as

where  can have at most two nonzero coefficients corresponding to 2 errors.
can have at most two nonzero coefficients corresponding to 2 errors.
We define the Syndrome Polynomial,  as the remainder of polynomial
as the remainder of polynomial  when divided by the generator polynomial i.e.
when divided by the generator polynomial i.e.
 as
as  .
.
For correcting two errors[edit]
Let the field elements  and
and  be the two error location numbers. If only one error occurs then is equal to zero and if none occurs both are zero.
be the two error location numbers. If only one error occurs then is equal to zero and if none occurs both are zero.
Let  and
and  .
.
These field elements are called «syndromes». Now because is zero at primitive elements and , so we can write  and
and  . If say two errors occur, then
. If say two errors occur, then
 and
and
 .
.
And these two can be considered as two pair of equations in with two unknowns and hence we can write
 and
and
 .
.
Hence if the two pair of nonlinear equations can be solved cyclic codes can used to correct two errors.
Hamming code[edit]
The Hamming(7,4) code may be written as a cyclic code over GF(2) with generator  . In fact, any binary Hamming code of the form Ham(r, 2) is equivalent to a cyclic code,[3] and any Hamming code of the form Ham(r,q) with r and q-1 relatively prime is also equivalent to a cyclic code.[4] Given a Hamming code of the form Ham(r,2) with
. In fact, any binary Hamming code of the form Ham(r, 2) is equivalent to a cyclic code,[3] and any Hamming code of the form Ham(r,q) with r and q-1 relatively prime is also equivalent to a cyclic code.[4] Given a Hamming code of the form Ham(r,2) with  , the set of even codewords forms a cyclic
, the set of even codewords forms a cyclic ![[2^{r}-1,2^{r}-r-2,4]](https://wikimedia.org/api/rest_v1/media/math/render/svg/cbf755cb5b384b44e604aa2cc03660048b528348) -code.[5]
-code.[5]
Hamming code for correcting single errors[edit]
A code whose minimum distance is at least 3, have a check matrix all of whose columns are distinct and non zero. If a check matrix for a binary code has  rows, then each column is an -bit binary number. There are possible columns. Therefore, if a check matrix of a binary code with
rows, then each column is an -bit binary number. There are possible columns. Therefore, if a check matrix of a binary code with  at least 3 has rows, then it can only have columns, not more than that. This defines a
at least 3 has rows, then it can only have columns, not more than that. This defines a  code, called Hamming code.
code, called Hamming code.
It is easy to define Hamming codes for large alphabets of size . We need to define one  matrix with linearly independent columns. For any word of size there will be columns who are multiples of each other. So, to get linear independence all non zero -tuples with one as a top most non zero element will be chosen as columns. Then two columns will never be linearly dependent because three columns could be linearly dependent with the minimum distance of the code as 3.
matrix with linearly independent columns. For any word of size there will be columns who are multiples of each other. So, to get linear independence all non zero -tuples with one as a top most non zero element will be chosen as columns. Then two columns will never be linearly dependent because three columns could be linearly dependent with the minimum distance of the code as 3.
So, there are  nonzero columns with one as top most non zero element. Therefore, a Hamming code is a
nonzero columns with one as top most non zero element. Therefore, a Hamming code is a ![[(q^{m}-1)/(q-1),(q^{m}-1)/(q-1)-m]](https://wikimedia.org/api/rest_v1/media/math/render/svg/6447e6a6ef3646859efcaa879911eae094aae869) code.
code.
Now, for cyclic codes, Let be primitive element in  , and let
, and let  . Then
. Then  and thus
and thus  is a zero of the polynomial
is a zero of the polynomial  and is a generator polynomial for the cyclic code of block length
and is a generator polynomial for the cyclic code of block length  .
.
But for  ,
,  . And the received word is a polynomial of degree given as
. And the received word is a polynomial of degree given as
where,  or
or  where
where  represents the error locations.
represents the error locations.
But we can also use  as an element of to index error location. Because
as an element of to index error location. Because  , we have
, we have  and all powers of from
and all powers of from  to
to  are distinct. Therefore, we can easily determine error location from unless
are distinct. Therefore, we can easily determine error location from unless  which represents no error. So, a Hamming code is a single error correcting code over with
which represents no error. So, a Hamming code is a single error correcting code over with  and
and  .
.
Cyclic codes for correcting burst errors[edit]
From Hamming distance concept, a code with minimum distance  can correct any
can correct any  errors. But in many channels error pattern is not very arbitrary, it occurs within very short segment of the message. Such kind of errors are called burst errors. So, for correcting such errors we will get a more efficient code of higher rate because of the less constraints. Cyclic codes are used for correcting burst error. In fact, cyclic codes can also correct cyclic burst errors along with burst errors. Cyclic burst errors are defined as
errors. But in many channels error pattern is not very arbitrary, it occurs within very short segment of the message. Such kind of errors are called burst errors. So, for correcting such errors we will get a more efficient code of higher rate because of the less constraints. Cyclic codes are used for correcting burst error. In fact, cyclic codes can also correct cyclic burst errors along with burst errors. Cyclic burst errors are defined as
A cyclic burst of length is a vector whose nonzero components are among (cyclically) consecutive components, the first and the last of which are nonzero.
In polynomial form cyclic burst of length can be described as  with
with  as a polynomial of degree
as a polynomial of degree  with nonzero coefficient
with nonzero coefficient  . Here defines the pattern and defines the starting point of error. Length of the pattern is given by deg
. Here defines the pattern and defines the starting point of error. Length of the pattern is given by deg . The syndrome polynomial is unique for each pattern and is given by
. The syndrome polynomial is unique for each pattern and is given by

A linear block code that corrects all burst errors of length or less must have at least  check symbols. Proof: Because any linear code that can correct burst pattern of length or less cannot have a burst of length or less as a codeword because if it did then a burst of length could change the codeword to burst pattern of length , which also could be obtained by making a burst error of length in all zero codeword. Now, any two vectors that are non zero in the first components must be from different co-sets of an array to avoid their difference being a codeword of bursts of length . Therefore, number of such co-sets are equal to number of such vectors which are
check symbols. Proof: Because any linear code that can correct burst pattern of length or less cannot have a burst of length or less as a codeword because if it did then a burst of length could change the codeword to burst pattern of length , which also could be obtained by making a burst error of length in all zero codeword. Now, any two vectors that are non zero in the first components must be from different co-sets of an array to avoid their difference being a codeword of bursts of length . Therefore, number of such co-sets are equal to number of such vectors which are  . Hence at least co-sets and hence at least check symbol.
. Hence at least co-sets and hence at least check symbol.
This property is also known as Rieger bound and it is similar to the Singleton bound for random error correcting.
Fire codes as cyclic bounds[edit]
In 1959, Philip Fire[6] presented a construction of cyclic codes generated by a product of a binomial and a primitive polynomial. The binomial has the form  for some positive odd integer .[7] Fire code is a cyclic burst error correcting code over with the generator polynomial
for some positive odd integer .[7] Fire code is a cyclic burst error correcting code over with the generator polynomial

where  is a prime polynomial with degree not smaller than and does not divide
is a prime polynomial with degree not smaller than and does not divide  . Block length of the fire code is the smallest integer such that divides
. Block length of the fire code is the smallest integer such that divides
.
A fire code can correct all burst errors of length t or less if no two bursts and  appear in the same co-set. This can be proved by contradiction. Suppose there are two distinct nonzero bursts and of length or less and are in the same co-set of the code. So, their difference is a codeword. As the difference is a multiple of it is also a multiple of . Therefore,
appear in the same co-set. This can be proved by contradiction. Suppose there are two distinct nonzero bursts and of length or less and are in the same co-set of the code. So, their difference is a codeword. As the difference is a multiple of it is also a multiple of . Therefore,
 .
.
This shows that  is a multiple of
is a multiple of  , So
, So

for some  . Now, as
. Now, as  is less than and is less than
is less than and is less than  so
so  is a codeword. Therefore,
is a codeword. Therefore,
 .
.
Since degree is less than degree of , cannot divide . If is not zero, then also cannot divide  as is less than and by definition of , divides for no smaller than . Therefore and equals to zero. That means both that both the bursts are same, contrary to assumption.
as is less than and by definition of , divides for no smaller than . Therefore and equals to zero. That means both that both the bursts are same, contrary to assumption.
Fire codes are the best single burst correcting codes with high rate and they are constructed analytically. They are of very high rate and when and are equal, redundancy is least and is equal to  . By using multiple fire codes longer burst errors can also be corrected.
. By using multiple fire codes longer burst errors can also be corrected.
For error detection cyclic codes are widely used and are called cyclic redundancy codes.
Cyclic codes on Fourier transform[edit]
Applications of Fourier transform are widespread in signal processing. But their applications are not limited to the complex fields only; Fourier transforms also exist in the Galois field . Cyclic codes using Fourier transform can be described in a setting closer to the signal processing.
Fourier transform over finite fields[edit]
Fourier transform over finite fields
The discrete Fourier transform of vector  is given by a vector
is given by a vector  where,
where,
 =
=  where,
where,

where exp( ) is an th root of unity. Similarly in the finite field th root of unity is element
) is an th root of unity. Similarly in the finite field th root of unity is element  of order . Therefore
of order . Therefore
If  is a vector over , and be an element of of order , then Fourier transform of the vector
is a vector over , and be an element of of order , then Fourier transform of the vector  is the vector
is the vector  and components are given by
and components are given by
 =
=  where,
where,
Here is time index, is frequency and  is the spectrum. One important difference between Fourier transform in complex field and Galois field is that complex field exists for every value of while in Galois field exists only if divides
is the spectrum. One important difference between Fourier transform in complex field and Galois field is that complex field exists for every value of while in Galois field exists only if divides  . In case of extension fields, there will be a Fourier transform in the extension field if divides for some .
. In case of extension fields, there will be a Fourier transform in the extension field if divides for some .
In Galois field time domain vector is over the field but the spectrum may be over the extension field .
Spectral description of cyclic codes[edit]
Any codeword of cyclic code of blocklength can be represented by a polynomial of degree at most . Its encoder can be written as . Therefore, in frequency domain encoder can be written as  . Here codeword spectrum
. Here codeword spectrum  has a value in but all the components in the time domain are from . As the data spectrum
has a value in but all the components in the time domain are from . As the data spectrum  is arbitrary, the role of
is arbitrary, the role of  is to specify those where will be zero.
is to specify those where will be zero.
Thus, cyclic codes can also be defined as
Given a set of spectral indices,  , whose elements are called check frequencies, the cyclic code is the set of words over whose spectrum is zero in the components indexed by
, whose elements are called check frequencies, the cyclic code is the set of words over whose spectrum is zero in the components indexed by  . Any such spectrum will have components of the form
. Any such spectrum will have components of the form  .
.
So, cyclic codes are vectors in the field and the spectrum given by its inverse fourier transform is over the field and are constrained to be zero at certain components. But every spectrum in the field and zero at certain components may not have inverse transforms with components in the field . Such spectrum can not be used as cyclic codes.
Following are the few bounds on the spectrum of cyclic codes.
BCH bound[edit]
If be a factor of  for some . The only vector in of weight
for some . The only vector in of weight  or less that has consecutive components of its spectrum equal to zero is all-zero vector.
or less that has consecutive components of its spectrum equal to zero is all-zero vector.
Hartmann-Tzeng bound[edit]
If be a factor of for some , and an integer that is coprime with . The only vector in of weight or less whose spectral
components equal zero for  , where
, where  and
and  , is the all zero vector.
, is the all zero vector.
Roos bound[edit]
If be a factor of for some and  . The only vector in
. The only vector in
of weight or less whose spectral components equal to zero for  , where
, where  and
and  takes at least
takes at least  values in the range
values in the range  , is the all-zero vector.
, is the all-zero vector.
Quadratic residue codes[edit]
When the prime is a quadratic residue modulo the prime  there is a quadratic residue code which is a cyclic code of length , dimension
there is a quadratic residue code which is a cyclic code of length , dimension  and minimum weight at least
and minimum weight at least  over
over  .
.
Generalizations[edit]
A constacyclic code is a linear code with the property that for some constant λ if (c1,c2,…,cn) is a codeword then so is (λcn,c1,…,cn-1). A negacyclic code is a constacyclic code with λ=-1.[8] A quasi-cyclic code has the property that for some s, any cyclic shift of a codeword by s places is again a codeword.[9] A double circulant code is a quasi-cyclic code of even length with s=2.[9] Quasi-twisted codes and multi-twisted codes are further generalizations of constacyclic codes.[10][11]
See also[edit]
- Cyclic redundancy check
- BCH code
- Reed–Muller code
- Binary Golay code
- Ternary Golay code
- Eugene Prange
Notes[edit]
- ^ Van Lint 1998, p. 76
- ^ Van Lint 1998, p. 80
- ^ Hill 1988, pp. 159–160
- ^ Blahut 2003, Theorem 5.5.1
- ^ Hill 1988, pp. 162–163
- ^ P. Fire, E, P. (1959). A class of multiple-error-correcting binary codes for non-independent errors. Sylvania Reconnaissance Systems Laboratory, Mountain View, CA, Rept. RSL-E-2, 1959.
- ^ Wei Zhou, Shu Lin, Khaled Abdel-Ghaffar. Burst or random error correction based on Fire and BCH codes. ITA 2014: 1-5 2013.
- ^ Van Lint 1998, p. 75
- ^ a b MacWilliams & Sloane 1977, p. 506
- ^ Aydin, Nuh; Siap, Irfan; K. Ray-Chaudhuri, Dijen (2001). «The Structure of 1-Generator Quasi-Twisted Codes and New Linear Codes». Designs, Codes and Cryptography. 24 (3): 313–326. doi:10.1023/A:1011283523000. S2CID 17376783.
- ^ Aydin, Nuh; Halilović, Ajdin (2017). «A generalization of quasi-twisted codes: multi-twisted codes». Finite Fields and Their Applications. 45: 96–106. doi:10.1016/j.ffa.2016.12.002. S2CID 7694655.
References[edit]
- Blahut, Richard E. (2003), Algebraic Codes for Data Transmission (2nd ed.), Cambridge University Press, ISBN 0-521-55374-1
- Hill, Raymond (1988), A First Course In Coding Theory, Oxford University Press, ISBN 0-19-853803-0
- MacWilliams, F. J.; Sloane, N. J. A. (1977), The Theory of Error-Correcting Codes, New York: North-Holland Publishing, ISBN 0-444-85011-2
- Van Lint, J. H. (1998), Introduction to Coding Theory, Graduate Texts in Mathematics 86 (3rd ed.), Springer Verlag, ISBN 3-540-64133-5
Further reading[edit]
- Ranjan Bose, Information theory, coding and cryptography, ISBN 0-07-048297-7
- Irving S. Reed and Xuemin Chen, Error-Control Coding for Data Networks, Boston: Kluwer Academic Publishers, 1999, ISBN 0-7923-8528-4.
- Scott A. Vanstone, Paul C. Van Oorschot, An introduction to error correcting codes with applications, ISBN 0-7923-9017-2
External links[edit]
- John Gill’s (Stanford) class notes – Notes #3, October 8, Handout #9, EE 387.
- Jonathan Hall’s (MSU) class notes – Chapter 8. Cyclic codes — pp. 100 — 123
- David Terr. «Cyclic Code». MathWorld.
This article incorporates material from cyclic code on PlanetMath, which is licensed under the Creative Commons Attribution/Share-Alike License.
In coding theory, a cyclic code is a block code, where the circular shifts of each codeword gives another word that belongs to the code. They are error-correcting codes that have algebraic properties that are convenient for efficient error detection and correction.
If 00010111 is a valid codeword, applying a right circular shift gives the string 10001011. If the code is cyclic, then 10001011 is again a valid codeword. In general, applying a right circular shift moves the least significant bit (LSB) to the leftmost position, so that it becomes the most significant bit (MSB); the other positions are shifted by 1 to the right.
Definition[edit]
Let be a linear code over a finite field (also called Galois field) of block length . is called a cyclic code if, for every codeword from , the word in obtained by a cyclic right shift of components is again a codeword. Because one cyclic right shift is equal to cyclic left shifts, a cyclic code may also be defined via cyclic left shifts. Therefore, the linear code is cyclic precisely when it is invariant under all cyclic shifts.
Cyclic codes have some additional structural constraint on the codes. They are based on Galois fields and because of their structural properties they are very useful for error controls. Their structure is strongly related to Galois fields because of which the encoding and decoding algorithms for cyclic codes are computationally efficient.
Algebraic structure[edit]
Cyclic codes can be linked to ideals in certain rings. Let be a polynomial ring over the finite field . Identify the elements of the cyclic code with polynomials in such that
maps to the polynomial
: thus multiplication by corresponds to a cyclic shift. Then is an ideal in , and hence principal, since is a principal ideal ring. The ideal is generated by the unique monic element in of minimum degree, the generator polynomial .[1]
This must be a divisor of . It follows that every cyclic code is a polynomial code.
If the generator polynomial has degree then the rank of the code is .
The idempotent of is a codeword such that (that is, is an idempotent element of ) and is an identity for the code, that is for every codeword . If and are coprime such a word always exists and is unique;[2] it is a generator of the code.
An irreducible code is a cyclic code in which the code, as an ideal is irreducible, i.e. is minimal in , so that its check polynomial is an irreducible polynomial.
Examples[edit]
For example, if and , the set of codewords contained in cyclic code generated by is precisely
- .
It corresponds to the ideal in generated by .
The polynomial is irreducible in the polynomial ring, and hence the code is an irreducible code.
The idempotent of this code is the polynomial , corresponding to the codeword .
Trivial examples[edit]
Trivial examples of cyclic codes are itself and the code containing only the zero codeword. These correspond to generators and respectively: these two polynomials must always be factors of .
Over the parity bit code, consisting of all words of even weight, corresponds to generator . Again over this must always be a factor of .
Quasi-cyclic codes and shortened codes[edit]
Before delving into the details of cyclic codes first we will discuss quasi-cyclic and shortened codes which are closely related to the cyclic codes and they all can be converted into each other.
Definition[edit]
Quasi-cyclic codes:[citation needed]
An quasi-cyclic code is a linear block code such that, for some which is coprime to , the polynomial is a codeword polynomial whenever is a codeword polynomial.
Here, codeword polynomial is an element of a linear code whose code words are polynomials that are divisible by a polynomial of shorter length called the generator polynomial. Every codeword polynomial can be expressed in the form , where is the generator polynomial. Any codeword of a cyclic code can be associated with a codeword polynomial, namely, . A quasi-cyclic code with equal to is a cyclic code.
Definition[edit]
Shortened codes:
An linear code is called a proper shortened cyclic code if it can be obtained by deleting positions from an cyclic code.
In shortened codes information symbols are deleted to obtain a desired blocklength smaller than the design blocklength. The missing information symbols are usually imagined to be at the beginning of the codeword and are considered to be 0. Therefore, − is fixed, and then is decreased which eventually decreases . It is not necessary to delete the starting symbols. Depending on the application sometimes consecutive positions are considered as 0 and are deleted.
All the symbols which are dropped need not be transmitted and at the receiving end can be reinserted. To convert cyclic code to shortened code, set symbols to zero and drop them from each codeword. Any cyclic code can be converted to quasi-cyclic codes by dropping every th symbol where is a factor of . If the dropped symbols are not check symbols then this cyclic code is also a shortened code.
Cyclic codes for correcting errors[edit]
Now, we will begin the discussion of cyclic codes explicitly with error detection and correction. Cyclic codes can be used to correct errors, like Hamming codes as cyclic codes can be used for correcting single error. Likewise, they are also used to correct double errors and burst errors. All types of error corrections are covered briefly in the further subsections.
The (7,4) Hamming code has a generator polynomial . This polynomial has a zero in Galois extension field at the primitive element , and all codewords satisfy . Cyclic codes can also be used to correct double errors over the field . Blocklength will be equal to and primitive elements and as zeros in the because we are considering the case of two errors here, so each will represent one error.
The received word is a polynomial of degree given as
where can have at most two nonzero coefficients corresponding to 2 errors.
We define the Syndrome Polynomial, as the remainder of polynomial when divided by the generator polynomial i.e.
as .
For correcting two errors[edit]
Let the field elements and be the two error location numbers. If only one error occurs then is equal to zero and if none occurs both are zero.
Let and .
These field elements are called «syndromes». Now because is zero at primitive elements and , so we can write and . If say two errors occur, then
and
.
And these two can be considered as two pair of equations in with two unknowns and hence we can write
and
.
Hence if the two pair of nonlinear equations can be solved cyclic codes can used to correct two errors.
Hamming code[edit]
The Hamming(7,4) code may be written as a cyclic code over GF(2) with generator . In fact, any binary Hamming code of the form Ham(r, 2) is equivalent to a cyclic code,[3] and any Hamming code of the form Ham(r,q) with r and q-1 relatively prime is also equivalent to a cyclic code.[4] Given a Hamming code of the form Ham(r,2) with , the set of even codewords forms a cyclic -code.[5]
Hamming code for correcting single errors[edit]
A code whose minimum distance is at least 3, have a check matrix all of whose columns are distinct and non zero. If a check matrix for a binary code has rows, then each column is an -bit binary number. There are possible columns. Therefore, if a check matrix of a binary code with at least 3 has rows, then it can only have columns, not more than that. This defines a code, called Hamming code.
It is easy to define Hamming codes for large alphabets of size . We need to define one matrix with linearly independent columns. For any word of size there will be columns who are multiples of each other. So, to get linear independence all non zero -tuples with one as a top most non zero element will be chosen as columns. Then two columns will never be linearly dependent because three columns could be linearly dependent with the minimum distance of the code as 3.
So, there are nonzero columns with one as top most non zero element. Therefore, a Hamming code is a code.
Now, for cyclic codes, Let be primitive element in , and let . Then and thus is a zero of the polynomial and is a generator polynomial for the cyclic code of block length .
But for , . And the received word is a polynomial of degree given as
where, or where represents the error locations.
But we can also use as an element of to index error location. Because , we have and all powers of from to are distinct. Therefore, we can easily determine error location from unless which represents no error. So, a Hamming code is a single error correcting code over with and .
Cyclic codes for correcting burst errors[edit]
From Hamming distance concept, a code with minimum distance can correct any errors. But in many channels error pattern is not very arbitrary, it occurs within very short segment of the message. Such kind of errors are called burst errors. So, for correcting such errors we will get a more efficient code of higher rate because of the less constraints. Cyclic codes are used for correcting burst error. In fact, cyclic codes can also correct cyclic burst errors along with burst errors. Cyclic burst errors are defined as
A cyclic burst of length is a vector whose nonzero components are among (cyclically) consecutive components, the first and the last of which are nonzero.
In polynomial form cyclic burst of length can be described as with as a polynomial of degree with nonzero coefficient . Here defines the pattern and defines the starting point of error. Length of the pattern is given by deg. The syndrome polynomial is unique for each pattern and is given by
A linear block code that corrects all burst errors of length or less must have at least check symbols. Proof: Because any linear code that can correct burst pattern of length or less cannot have a burst of length or less as a codeword because if it did then a burst of length could change the codeword to burst pattern of length , which also could be obtained by making a burst error of length in all zero codeword. Now, any two vectors that are non zero in the first components must be from different co-sets of an array to avoid their difference being a codeword of bursts of length . Therefore, number of such co-sets are equal to number of such vectors which are . Hence at least co-sets and hence at least check symbol.
This property is also known as Rieger bound and it is similar to the Singleton bound for random error correcting.
Fire codes as cyclic bounds[edit]
In 1959, Philip Fire[6] presented a construction of cyclic codes generated by a product of a binomial and a primitive polynomial. The binomial has the form for some positive odd integer .[7] Fire code is a cyclic burst error correcting code over with the generator polynomial
where is a prime polynomial with degree not smaller than and does not divide . Block length of the fire code is the smallest integer such that divides
.
A fire code can correct all burst errors of length t or less if no two bursts and appear in the same co-set. This can be proved by contradiction. Suppose there are two distinct nonzero bursts and of length or less and are in the same co-set of the code. So, their difference is a codeword. As the difference is a multiple of it is also a multiple of . Therefore,
.
This shows that is a multiple of , So
for some . Now, as is less than and is less than so is a codeword. Therefore,
.
Since degree is less than degree of , cannot divide . If is not zero, then also cannot divide as is less than and by definition of , divides for no smaller than . Therefore and equals to zero. That means both that both the bursts are same, contrary to assumption.
Fire codes are the best single burst correcting codes with high rate and they are constructed analytically. They are of very high rate and when and are equal, redundancy is least and is equal to . By using multiple fire codes longer burst errors can also be corrected.
For error detection cyclic codes are widely used and are called cyclic redundancy codes.
Cyclic codes on Fourier transform[edit]
Applications of Fourier transform are widespread in signal processing. But their applications are not limited to the complex fields only; Fourier transforms also exist in the Galois field . Cyclic codes using Fourier transform can be described in a setting closer to the signal processing.
Fourier transform over finite fields[edit]
Fourier transform over finite fields
The discrete Fourier transform of vector is given by a vector where,
= where,
where exp() is an th root of unity. Similarly in the finite field th root of unity is element of order . Therefore
If is a vector over , and be an element of of order , then Fourier transform of the vector is the vector and components are given by
= where,
Here is time index, is frequency and is the spectrum. One important difference between Fourier transform in complex field and Galois field is that complex field exists for every value of while in Galois field exists only if divides . In case of extension fields, there will be a Fourier transform in the extension field if divides for some .
In Galois field time domain vector is over the field but the spectrum may be over the extension field .
Spectral description of cyclic codes[edit]
Any codeword of cyclic code of blocklength can be represented by a polynomial of degree at most . Its encoder can be written as . Therefore, in frequency domain encoder can be written as . Here codeword spectrum has a value in but all the components in the time domain are from . As the data spectrum is arbitrary, the role of is to specify those where will be zero.
Thus, cyclic codes can also be defined as
Given a set of spectral indices, , whose elements are called check frequencies, the cyclic code is the set of words over whose spectrum is zero in the components indexed by . Any such spectrum will have components of the form .
So, cyclic codes are vectors in the field and the spectrum given by its inverse fourier transform is over the field and are constrained to be zero at certain components. But every spectrum in the field and zero at certain components may not have inverse transforms with components in the field . Such spectrum can not be used as cyclic codes.
Following are the few bounds on the spectrum of cyclic codes.
BCH bound[edit]
If be a factor of for some . The only vector in of weight or less that has consecutive components of its spectrum equal to zero is all-zero vector.
Hartmann-Tzeng bound[edit]
If be a factor of for some , and an integer that is coprime with . The only vector in of weight or less whose spectral
components equal zero for , where and , is the all zero vector.
Roos bound[edit]
If be a factor of for some and . The only vector in
of weight or less whose spectral components equal to zero for , where and takes at least values in the range , is the all-zero vector.
Quadratic residue codes[edit]
When the prime is a quadratic residue modulo the prime there is a quadratic residue code which is a cyclic code of length , dimension and minimum weight at least over .
Generalizations[edit]
A constacyclic code is a linear code with the property that for some constant λ if (c1,c2,…,cn) is a codeword then so is (λcn,c1,…,cn-1). A negacyclic code is a constacyclic code with λ=-1.[8] A quasi-cyclic code has the property that for some s, any cyclic shift of a codeword by s places is again a codeword.[9] A double circulant code is a quasi-cyclic code of even length with s=2.[9] Quasi-twisted codes and multi-twisted codes are further generalizations of constacyclic codes.[10][11]
See also[edit]
- Cyclic redundancy check
- BCH code
- Reed–Muller code
- Binary Golay code
- Ternary Golay code
- Eugene Prange
Notes[edit]
- ^ Van Lint 1998, p. 76
- ^ Van Lint 1998, p. 80
- ^ Hill 1988, pp. 159–160
- ^ Blahut 2003, Theorem 5.5.1
- ^ Hill 1988, pp. 162–163
- ^ P. Fire, E, P. (1959). A class of multiple-error-correcting binary codes for non-independent errors. Sylvania Reconnaissance Systems Laboratory, Mountain View, CA, Rept. RSL-E-2, 1959.
- ^ Wei Zhou, Shu Lin, Khaled Abdel-Ghaffar. Burst or random error correction based on Fire and BCH codes. ITA 2014: 1-5 2013.
- ^ Van Lint 1998, p. 75
- ^ a b MacWilliams & Sloane 1977, p. 506
- ^ Aydin, Nuh; Siap, Irfan; K. Ray-Chaudhuri, Dijen (2001). «The Structure of 1-Generator Quasi-Twisted Codes and New Linear Codes». Designs, Codes and Cryptography. 24 (3): 313–326. doi:10.1023/A:1011283523000. S2CID 17376783.
- ^ Aydin, Nuh; Halilović, Ajdin (2017). «A generalization of quasi-twisted codes: multi-twisted codes». Finite Fields and Their Applications. 45: 96–106. doi:10.1016/j.ffa.2016.12.002. S2CID 7694655.
References[edit]
- Blahut, Richard E. (2003), Algebraic Codes for Data Transmission (2nd ed.), Cambridge University Press, ISBN 0-521-55374-1
- Hill, Raymond (1988), A First Course In Coding Theory, Oxford University Press, ISBN 0-19-853803-0
- MacWilliams, F. J.; Sloane, N. J. A. (1977), The Theory of Error-Correcting Codes, New York: North-Holland Publishing, ISBN 0-444-85011-2
- Van Lint, J. H. (1998), Introduction to Coding Theory, Graduate Texts in Mathematics 86 (3rd ed.), Springer Verlag, ISBN 3-540-64133-5
Further reading[edit]
- Ranjan Bose, Information theory, coding and cryptography, ISBN 0-07-048297-7
- Irving S. Reed and Xuemin Chen, Error-Control Coding for Data Networks, Boston: Kluwer Academic Publishers, 1999, ISBN 0-7923-8528-4.
- Scott A. Vanstone, Paul C. Van Oorschot, An introduction to error correcting codes with applications, ISBN 0-7923-9017-2
External links[edit]
- John Gill’s (Stanford) class notes – Notes #3, October 8, Handout #9, EE 387.
- Jonathan Hall’s (MSU) class notes – Chapter 8. Cyclic codes — pp. 100 — 123
- David Terr. «Cyclic Code». MathWorld.
This article incorporates material from cyclic code on PlanetMath, which is licensed under the Creative Commons Attribution/Share-Alike License.
Основной недостаток применения групповых
линейных кодов – сложность кодирующих
и декодирующих устройств, являющихся
устройствами параллельного типа. Переход
к циклическим кодам позволяет упростить
схемную реализацию кодирующих и
декодирующих устройств за счет
многотактных способов обработки
циклических кодов с помощью сдвиговых
регистров. Таким образом, в системах,
использующих циклические коды,
«обменивают» увеличение времени
кодирования и декодирования на упрощение
аппаратуры. Циклическим кодом называют
такой групповой код, который замкнут
относительно циклической перестановки
любой кодовой комбинации этого кода,
т.е. в результате циклической перестановки
любого кодового вектора получается
кодовый вектор, принадлежащий этому же
циклическому коду.
Циклической перестановкой называется
такая перестановка, при которой все
разряды смещаются в сторону старших
разрядов, причем последний разряд
переходит на место первого.
1.2 Построение цк
Циклическим кодом называется циклического
векторное пространство, обладающее
всеми свойствами группового кода, но
замкнутого не только относительно
линейных операций, но и относительно
операции циклического сдвига. В результате
циклического сдвига любого кодового
вектора получается кодовый вектор,
принадлежащий этому же векторному
пространству. В основе циклических
кодов лежит алгебра полиномов по модулю
![]() над
над
пространственным полем (полем Галуа).
Циклическим сдвигом называется такой
сдвиг, при котором все разряды смещаются
в сторону старших разрядов, причем
последний разряд переходит на место
первого.
Пусть
![]()
Тогда после циклического сдвига получим
![]()
Математической основой построения
циклических кодов является представление
любого двоичного числа в виде полинома,
содержащего переменную Х, причем двоичные
цифры являются коэффициентами при этой
переменной.
Пример 1
В дальнейшем, если нет особых замечаний,
высшие степени пишем справа. Над такими
полиномами можно производить все
операции согласно законам алгебры.
Однако при всех операциях суммирование
производиться по модулю 2 (без переносов
в старшие разряды в отличие от
арифметического суммирования).
Вычитание, используемое при делении
полиномов, также необходимо осуществлять
по модулю два (mod2), и оно
заменяется эквивалентной операцией
суммирования поmod2.
Пример 2
Циклический код полностью задаётся
так называемым порождающим полиномом
g(x) степениk, гдеk–
число контрольных (избыточных) символов
циклического кода.
![]()
Кодовые комбинации циклического кода
строятся так, чтобы соответствующие им
полиномы делились без остатка на g(x).
С другой стороны, циклический код может
быть полностью определен многочленомh(x) степениm, гдеm–
число информационных символов циклического
кода:
![]() (1)
(1)
n– число разрядов (длина)
циклического кода (n=m+k):
Полином, соответствующий кодовой
комбинации циклического кода, имеет
вид:
![]()
Циклические коды, исправляющие одну
ошибку (![]() ),
),
либо исправляющие одну и обнаруживающие
две ошибки (![]() )
)
называются циклическими кодами Хемминга.
Для циклических кодов Хемминга имеет
место
![]()
Пример 3
Наибольший интерес представляют
систематические циклические коды, так
как они позволяют наиболее просто
реализовать кодирующие и декодирующие
устройства. Условимся в любом
систематическом циклическом коде первые
![]() символов, т.е. коэффициенты при
символов, т.е. коэффициенты при![]() всегда
всегда
выбирать в качестве проверочных символов,
а последниеmсимволов,
т.е. коэффициенты при![]() — в качестве информационных символов.
— в качестве информационных символов.
Соседние файлы в папке Теория
- #
- #
- #
- #
- #
03.07.20181.15 Mб3Теория.mht
- #
4. Циклические коды
4.1 Основные понятия
Циклическим кодом
называется линейный блоковый (n,k)-код, который характеризуется свойством
цикличности, т.е. сдвиг влево на один шаг любого разрешенного кодового слова
дает также разрешенное кодовое слово, принадлежащее этому же коду и у которого,
множество кодовых слов представляется совокупностью многочленов степени (n-1) и
менее, делящихся на некоторый многочлен g(x) степени r = n-k, являющийся
сомножителем двучлена xn+1.
Многочлен g(x) называется
порождающим.
Как следует из определения, в циклическом коде кодовые слова
представляются в виде многочленов 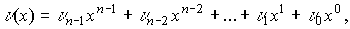
где n — длина кода;
— коэффициенты из поля GF(q).
Если код построен над полем GF(2), то
коэффициенты принимают значения 0 или 1 и код называется двоичным.
Пример. Если кодовое слово циклического кода 
то соответствующий
ему многочлен 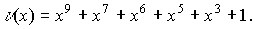
Например, если код
построен над полем GF(q)=GF(23), которое является расширением GF(2)
по модулю неприводимого многочлена f(z)=z3+z+1, а элементы этого поля
имеют вид, представленный в таблице 3,
| 0 | 000 | 0 | a3 | 011 | Z+1 |
| a0 | 001 | 1 | a4 | 110 | Z2+Z |
| a1 | 010 | Z | a5 | 111 | Z2+Z+1 |
| a2 | 100 | Z2 | a6 | 101 | Z2+1 |
то
коэффициенты 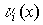 принимают значения
принимают значения
элементов этого поля и поэтому они сами отображаются в виде многочленов
следующего вида 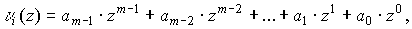
где m — степень многочлена, по которому получено расширение поля GF(2);
ai — коэффициенты, принимающие значение элементов GF(2), т.е. 0 и
1.
Такой код называется q-ным.
Длина циклического кода
называется примитивной и сам код называется примитивным, если его длина
n=qm-1 над GF(q).
Если длина кода меньше длины примитивного кода,
то код называется укороченным или непримитивным.
Как следует
из определения общее свойство кодовых слов циклического кода — это их делимость
без остатка на некоторый многочлен g(x), называемый порождающим.
Результатом деления двучлена xn+1 на многочлен g(x)
является проверочный многочлен h(x).
При декодировании
циклических кодов используются многочлен ошибок e(x) и синдромный многочлен
S(x).
Многочлен ошибок степени не более (n-1) определяется из выражения
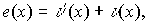
где 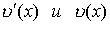 —
—
многочлены, отображающие соответственно принятое (с ошибкой) и переданное
кодовые слова.
Ненулевые коэффициенты в е(x) занимают позиции, которые
соответствуют ошибкам.
Пример.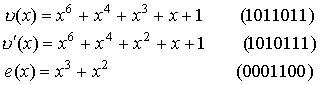
Синдромный многочлен, используемый при декодировании циклического
кода, определяется как остаток от деления принятого кодового слова на
порождающий многочлен, т.е. 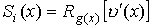
или 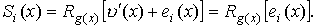
Следовательно, синдромный многочлен зависит непосредственно от многочлена
ошибок е(х).Это положение используется при построении таблицы
синдромов, применяемой в процессе декодирования. Эта таблица содержит список
многочленов ошибок (см. первый столбец стандартного расположения кода в разделе
2.4) и список соответствующих синдромов, определяемых из выражения 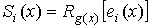 (см.
(см.
таблицу 4).
| (x) | S(x) |
| 1 | Rg(x)[1] |
| X | Rg(x)[x] |
| X2 | Rg(x)[x2] |
| · | · |
| · | · |
| · | · |
| X+1 | Rg(x)[x+1] |
| X2+1 | Rg(x)[x2+1] |
| · | · |
| · | · |
| · | · |
В процессе
декодирования по принятому кодовому слову вычисляется синдром, затем в таблице
находится соответствующий многочлен е(х), суммирование которого с принятым
кодовым словом дает исправленное кодовое слово, т.е. 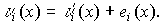
Перечисленные
многочлены 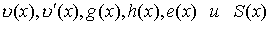 можно складывать,
можно складывать,
умножать и делить, используя известные правила алгебры, но с приведением
результата по mod 2, а затем по mod xn+1, если степень результата
превышает степень (n-1).
Примеры.
Допустим,
что длина кода n=7, то результат приводим по mod x7+1.
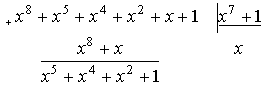
При
построении и декодировании циклических кодов в результате деления многочленов
обычно необходимо иметь не частное, а остаток от деления.
Поэтому
рекомендуется более простой способ деления, используя не многочлены, а только
его коэффициенты (вариант 2 в примере).
- Пример.
- 1.
- 2.
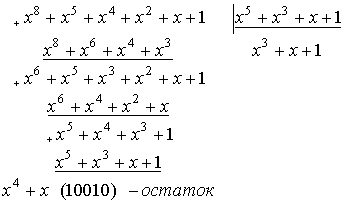

4.2 Матричное задание кодов
Циклический
код может быть задан порождающей и проверочной матрицами. Для их построения
достаточно знать порождающий g(x) и проверочный h(x) многочлены.
Для несистематического циклического кода матрицы строятся
циклическим сдвигом порождающего и проверочного многочленов, т.е. путем их
умножения на x 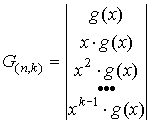 и
и 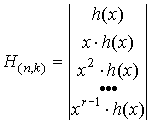
При построении
матрицы H(n,k) старший коэффициент многочлена h(x) располагается
справа.
Пример. Для циклического (7,4)-кода с порождающим многочленом
g(x)=x3+x+1 матрицы G(n,k) и H(n,k) имеют вид:
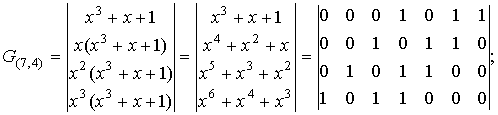
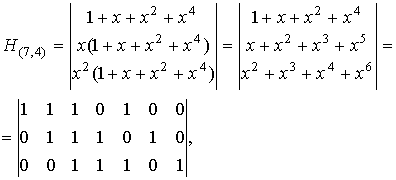
где 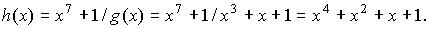
Для систематического циклического кода матрица G(n,k)
определяется из выражения 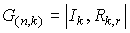
где
Ik — единичная матрица;
Rk,r — прямоугольная
матрица.
Строки матрицы Rk,r определяются из выражений 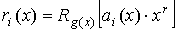 или
или 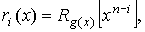
где
ai(x) — значение i-той строки матрицы Ik;
i — номер
строки матрицы Rk,r.
Пример. Матрица G(n,k) для
(7,4)-кода на основе порождающего многочлена g(x)=x3+x+1, строится в
следующей последовательности 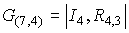
 или
или 
Определяется
R4,3, используя 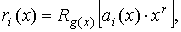
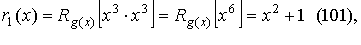 так как
так как 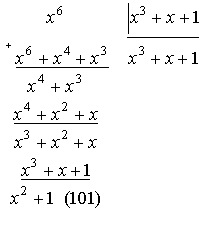
Аналогичным способом
определяется 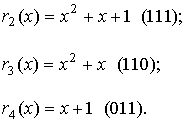
В результате получаем 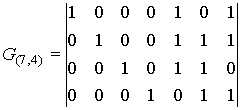 или
или 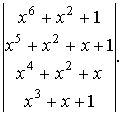
Используя выражение
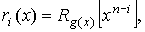
получим тот же результат.
Строки матрицы G(n,k) можно определить
непосредственно из выражения 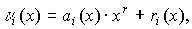 где
где 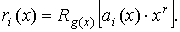
Проверочная матрица в систематическом виде строится на основе
матрицы G(n,k), а именно: 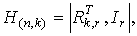
где
Ir — единичная матрица;  — матрица из
— матрица из
G(n,k) в транспонированном виде.
Пример. Для (7,4)-кода
матрица H(n,k) будет иметь вид: 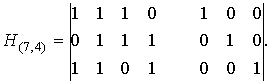
Одна из основных
задач, стоящих перед разработчиками устройств защиты от ошибок при передаче
дискретных сообщений по каналам связи является выбор порождающего многочлена
g(x) для построения циклического кода, обеспечивающего требуемое минимальное
кодовое расстояние для гарантийного обнаружения и исправления t-кратных ошибок.
Существуют специальные таблицы по выбору g(x) в зависимости от предъявляемых
требований к корректирующим возможностям кода. Однако у каждого циклического
кода имеются свои особенности формирования g(x). Поэтому при изучении конкретных
циклических кодов будут рассматриваться соответствующие способы построения g(x).
4.3 Коды БЧХ
Одним из классов
циклических кодов, способных исправлять многократные ошибки, являются коды БЧХ.
Примитивным кодом БЧХ, исправляющим tu ошибок,
называется код длиной n=qm-1 над GF(q), для которого элементы 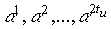 являются
являются
корнями порождающего многочлена.
Здесь a —
примитивный элемент GF(qm).
Порождающий многочлен
определяется из выражения 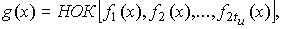 где
где
f1(x),f2(x)…- минимальные многочлены корней g(x).
Число проверочных элементов кода БЧХ удовлетворяет соотношению 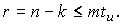
Пример. Определить значение порождающего многочлена для построения
примитивного кода БЧХ над GF(2) длины 31, исправляющего двух кратные ошибки
(tu=2).
Исходя из определения кода БЧХ корнями многочлена g(x)
являются: 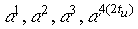 , где a — примитивный элемент GF(qm)=GF(25).
, где a — примитивный элемент GF(qm)=GF(25).
Порождающий многочлен определяется из выражения 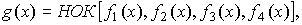 где f1(x),
где f1(x),
f2(x), f3(x), f4(x) — минимальные многочлены
корней соответственно 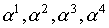 .
.
Примечание.
Минимальный многочлен элемента b поля
GF(qm) определяется из выражения  , где
, где 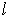 — наименьшее целое
— наименьшее целое
число, при котором 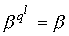 .
.
Значения
минимальных многочленов будут следующими: 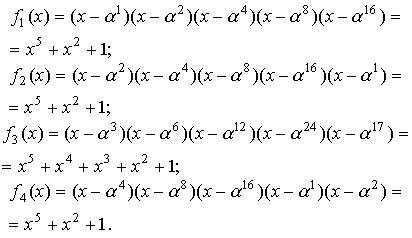
Так как f1(x)=
f2(x)= f4(x), то 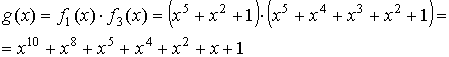
На
практике при определении значений порождающего многочлена пользуются специальной
таблицей минимальных многочленов (см. таблицу 8 приложения), и выражением для
порождающего многочлена 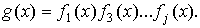 При этом работа
При этом работа
осуществляется в следующей последовательности.
По заданной длине кода n и
кратности исправляемых ошибок tu определяют:
— из выражения
n=2m-1 значение параметра m, который является максимальной степенью
сомножителей g(x);
— из выражения j=2tu-1 максимальный порядок
минимального многочлена, входящего в число сомножителей g(x).
— пользуясь
таблицей минимальных многочленов, определяется выражение для g(x) в зависимости
от m и j. Для этого из колонки, соответствующей параметру m, выбираются
многочлены с порядками от 1 до j, которые в результате перемножения дают
значение g(x).
Примечание.
В выражении для g(x) содержаться минимальные
многочлены только для нечетных степеней a, так как
обычно соответствующие им минимальные многочлены четных степеней a имеют аналогичные выражения.
Например, минимальные
многочлены элементов 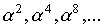 соответствуют
соответствуют
минимальному многочлену элемента a1,
минимальные многочлены элементов 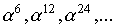 соответствуют
соответствуют
минимальному многочлену a3 и т.п.
Пример. Определить значение порождающего многочлена для построения
примитивного кода БЧХ над GF(2) длины 31, обеспечивающего tu=3.
Определяем значения m и j. 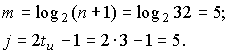
Из таблицы
минимальных многочленов в соответствии с m=5 и j=5 получаем 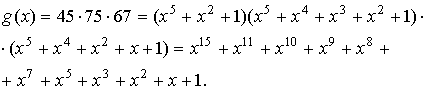
Заданные исходные
данные: n и tu или k и tu для построения циклического кода
часто приводят к выбору завышенного значения m и как следствие этого к
неоправданному увеличению длины кода. Такое положение снижает эффективность
полученного кода, так как часть информационных разрядов вообще не используется.
Пример. Требуется построить циклический код, исправляющий двух
кратные ошибки, если длина информационной части кода k=40.
Согласно
выражению для примитивного кода n=2m-1, ближайшая длина кода равна
63, для которой m=6, а r=mtu=12. Следовательно, код будет иметь n=63,
k=51. Неиспользованных информационных разрядов будет 11(51-40).
Подобное
несоответствие в ряде случаев можно устранить, применяя непримитивный код БЧХ.
Непримитивным кодом БЧХ, исправляющим tu ошибок,
называется код длины n над GF(q), для которого элементы 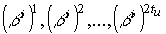 являются корнями
являются корнями
порождающего многочлена.
Здесь bi-непримитивный элемент GF(qm), а
длина кода n равна порядку элемента bi.
Примечание.
Порядком элемента bi
является наименьшее n, для которого 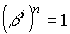 .
.
Пример.
Порядок элемента b3 поля GF(26)
равен 21, так как 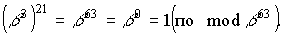 .
.
Порождающий многочлен непримитивного кода БЧХ, по аналогии с
примитивным кодом, определяется из выражения 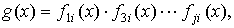
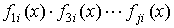 — минимальные многочлены
— минимальные многочлены
элементов 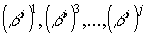 поля
поля
GF(qm), которые являются корнями g(x); i — степень непримитивного
элемента b.
Пример. Определить значение g(x)
для построения непримитивного кода БЧХ над GF(2) длины n=20, исправляющего двух
кратные ошибки.
Из таблицы непримитивных элементов GF(2m) (см.
таблицу 7 приложения) выбираем поле, элемент b которого
имеет порядок больший, но близкий к заданному n.
Такими являются
GF(26) и b3, порядок которого
n=21.
Так как j=2tu-1=2(2-1=3, то выражение для g(x) будет иметь
вид 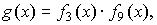
где f3(x) и f9(x) — минимальные многочлены элементов
b3 и b9
поля GF(26).
Значения этих многочленов следующие: 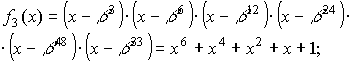
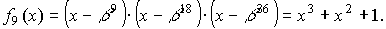
Выражения для
f3(x) и f9(x) можно определить из таблицы минимальных
многочленов, используя для этого параметр m выбранного поля GF(2m) и
порядковые номера сомножителей g(x).
Для рассмотренного примера m=6, а
порядковые номера равны 3 и 9. Поэтому 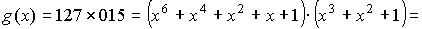
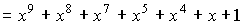 .
.
4.4 Способы кодирования
Задача кодирования
заключается в формировании по информационным словам a(x) кодовых слов u(x) циклического (n,k)-кода, который по своей структуре
может быть несистематическим и систематическим.
Формирование
кодовых слов несистематического кода заключается в умножении многочлена a(x),
отображающего информационную последовательность длины k, на порождающий
многочлен, т.е. u(x)=a(x)(g(x). Формирование кодовых
слов систематического кода заключается в преобразовании информационной
последовательности a(x) в соответствии с выражением u(x)=a(x)·xr+r(x).
Проверочная последовательность r(x) определяется двумя способами:
при использовании «классического» способа кодирования 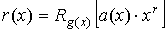 ;
;
при использовании
способа кодирования, рекомендованного МККТТ 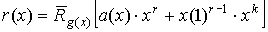 ,
,
где
x(1)r-1 — единичный многочлен степени (r-1).
Указанные выше
математические операции выполняют кодеры несистематического и систематического
кодов.
4.5 Способы декодирования с обнаружением ошибок
Процедура декодирования
циклического кода с обнаружением ошибок, по аналогии с процессом кодирования,
использует два способа:
— при кодировании «классическим»
способом декодирование основано на использовании свойства делимости без остатка
кодового многочлена u(x) циклического (n,k)-кода на
порождающий многочлен g(x). Поэтому алгоритм декодирования включает в себя
деление принятого кодового слова, описываемого многочленом 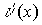 на g(x), вычисление и
на g(x), вычисление и
анализ остатка r(x). Если r(x)=0, то принятое кодовое слово считается
неискаженным. Если r(x)№0, то принятое кодовое слово
стирается и формируется сигнал «ошибка».
— при кодировании
способом МККТТ декодирование основано на свойстве получения определенного
контрольного остатка R0(x) при делении принятого кодового многочлена
u(x) на порождающий многочлен. Поэтому, если полученный
при делении остаток 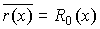 , то принятое кодовое
, то принятое кодовое
слово считается неискаженным. Если остаток 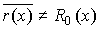 , то принятое кодовое
, то принятое кодовое
слово стирается и формируется сигнал «ошибка».
Значение контрольного остатка
определяется из выражения 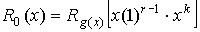 .
.
4.6 Способы декодирования с исправлением ошибок
и схемная реализация декодирующих устройств
и схемная реализация декодирующих устройств
Декодирование циклического
кода в режиме исправления ошибок можно осуществлять различными способами. Ниже
излагаются два способа, являющиеся наиболее простыми.
В
основу первого способа положено использование таблицы синдромов (декодирования),
в которой каждому многочлену или образцу ошибок ei(x), соответствует
определенный синдром Si(x), представляющий остаток от деления
принятого кодового слова 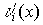 и соответствующего ему
и соответствующего ему
ei(x) на g(x). Процедура декодирования следующая. Принятое кодовое
слово делится на g(x),
определяется Si(x) и соответствующий ему многочлен ei(x),
а затем суммируется с
ei(x). В результате получаем исправленное кодовое слово, т.е. 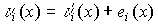 .
.
В состав декодера входят: вычислитель
синдрома (ВС), два регистра сдвига RG1 и RG2, постоянное запоминающее устройство
(ПЗУ), котороесодержит 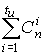 слова длины n,
слова длины n,
соответствующие многочленам ошибок ei(x).
Принятое кодовое слово
поступает на вход вычислителя синдрома, где осуществляется деление его на g(x) и
формирование Si(x), и одновременно — на вход RG2, где
накапливается. Синдром Si(x) используется в качестве адреса, по
которому из ПЗУ в регистр RG1 записывается ei(x), соответствующий
синдрому Si(x). Перечисленные операции завершаются за n тактов. В
течение последующих n тактов происходит поэлементное суммирование содержимого
RG2 и RG1, т.е. операция , и исправление ошибок.
В основе второго способа исправления ошибок, позволяющего
значительно сократить объем используемых табличных синдромов и существенно
упростить схему декодера, лежат следующие положения:
1. Синдром
Si(x), соответствующий принятому кодовому слову равен остатку от
деления на g(x), а также остатку
от деления соответствующего многочлена ошибок ei(x) на g(x), т.е. 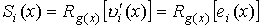 .
.
2.
Если Si(x) соответствует и ei(x), то
x( Si(x) является синдромом, который соответствует  и
и  или
или 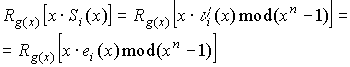 .
.
3.
При исправлении ошибок используются синдромы образцов ошибок только с ненулевым
коэффициентом в старшем разряде.
Поэтому при реализации
этого способа множество всех образцов ошибок разбивается на классы
эквивалентности. Каждый класс представляет циклический сдвиг одного образца
ошибок, а синдром этого класса соответствует образцу ошибок с ненулевым старшим
разрядом. Если вычисленный синдром принадлежит одному из классов эквивалентности
образцов исправляемых ошибок, то старший символ кодового слова исправляется.
Затем принятое слово и синдром циклически сдвигается, а процесс нахождения в
предыдущей по старшинству позиции повторяется.
Для исправления ошибок,
принадлежащих данному классу эквивалентности, нужно произвести n циклических
сдвигов.
Простейшим является декодер Меггитта. В состав декодера
входят: вычислитель синдрома, осуществляющий деление кодового слова на g(x)
и формирование соответствующего синдрома; блок декодеров (ДК), который настроен
на синдромы всех образцов исправляемых ошибок с ненулевыми старшими разрядами;
регистр сдвига RG.
При поступлении на вход схемы кодового слова его
символы заполняют регистр RG, а в вычислителе формируется соответствующий
синдром Si(x). Вычисленный синдром сравнивается со всеми табличными
синдромами, заложенными в схему блока ДК, и в случае совпадения с одним из них
на его выходе формируется сигнал, который исправляет ошибочный символ,
находящийся в старшем разряде регистра. После этого содержимое вычислителя и RG
циклически сдвигается на один шаг. Этот сдвиг реализует операции 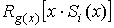 и . Если
и . Если
новый синдром совпадает с одним из табличных синдромов, то это означает, что
произошла ошибка во втором по старшинству символе кодового слова, который,
перейдя в старший разряд RG, исправляется. Затем производится новый циклический
сдвиг на одну позицию и новая проверка на совпадение синдромов. После повторения
этого процесса n раз в RG будет сформировано исправленное кодовое слово.
Введение обратной связи для RG не обязательно, так как в процессе исправления
ошибок символы кодового слова поступают на выход декодера.
Пример. Рассмотрим схему и работу декодера Меггитта
циклического (15,7)-кода, обеспечивающего исправление одиночных и двойных
ошибок, с g(x)=x8+ x7+ x6+ x4+1 (см.
рисунок 8).
Блок декодеров настраивается на 15 синдромов, которые
представлены в таблице 5 и соответствуют классам эквивалентности с образцами
ошибок в старшем разряде.
| № | е(х) | S(x) | № | е(х) | S(x) |
|---|---|---|---|---|---|
| 1 | x14 | x7+ x6+x5+ x3 |
9 | x14+ x6 | |
| 2 | x14+ x13 | x7+ x4+x3+ x2 |
10 | x14+ x5 | x7+ x6+x3 |
| 3 | x14+ x12 | x7+ x6+x4+ x |
11 | x14+ x4 | x7+ x6+x5+ x4+x3 |
| 4 | x14+ x11 | 12 | x14+ x3 | x7+ x6+x5 |
|
| 5 | x14+ x10 | 13 | x14+ x2 | x7+ x6+x5+ x3+x2 |
|
| 6 | x14+ x9 | 14 | x14+ x1 | x7+ x6+x5+ x3+x |
|
| 7 | x14+ x8 | 15 | x14+ x0 | x7+ x6+x5+ x3+0 |
|
| 8 | x14+ x7 |
Допустим, что
ошибки в 3 и 5 разрядах, т.е. им соответствует многочлен ошибки
e(x)=x12+x10.
При поступлении на вход декодера
искаженного кодового слова он заполняет регистр и в вычислителе формируется
синдром 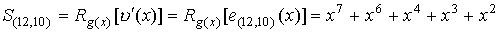 .
.
Блок декодеров не
реагирует на этот синдром.
Затем происходит сдвиг кодового слова в RG, а в
BC формируется новый синдром 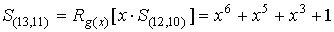 .
.
Блок декодеров и в
этом случае не срабатывает.
При следующем сдвиге кодового слова в RG первый
искаженный разряд занимает старшую позицию в RG, а в BC формируется синдром 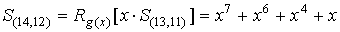 , от
, от
которого срабатывает БДК. В результате исправляется первая ошибка.
Следующим
сдвиг приводит к формированию синдрома 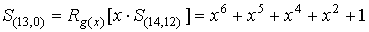 .
.
Этот синдром
соответствует многочлену ошибки e(x)=x13+x0, т.к. первый
искаженный разряд по обратной связи должен занять младшую позицию RG.
На
синдром S(13,0) блок декодеров не реагирует.
При следующем сдвиге
кодового слова в RG второй искаженный разряд занимает старшую позицию в RG, а в
BC формируется синдром 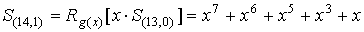 , от которого срабатывает
, от которого срабатывает
БДК. В результате исправляется вторая ошибка в кодовом слове.
4.7 Коды Рида-Соломона (РС)
Коды РС
являются недвоичными циклическими кодами, символы кодовых слов которых берутся
из конечного поля GF(q). Здесь q степень некоторого простого числа, например
q=2m.
Допустим, что РС-код построен над GF(8), которое является
расширением поля GF(2) по модулю примитивного многочлена f(z)=z3+z+1.
В этом случае символы кодовых слов кода будут иметь значения, представленные в
таблице 6.
| 000 | 0 | 0 | 011 | z+1 | a3 |
| 001 | 1 | a0 | 110 | z2+z | a4 |
| 010 | z | a1 | 111 | z2+z+1 | a5 |
| 100 | z2 | a2 | 101 | z2+1 | a6 |
Кодовые слова РС-кода
отображаются в виде многочленов 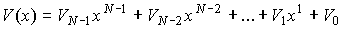 ,
,
где N — длина кода;
Vi — q-ичные коэффициенты (символы кодовых слов), которые могут
принимать любое значение из GF(q).
Эти коэффициенты как это следует из
таблицы, также отображаются многочленами с двоичными коэффициентами 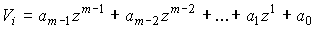 . Коды РС являются максимальными, т.к. при длине кода N и
. Коды РС являются максимальными, т.к. при длине кода N и
информационной последовательности k они обладают наибольшим кодовым расстоянием
d=N-k+1.
Порождающим многочленом g(x) РС-кода является делитель двучлена
xN+1 степени меньшей N с коэффициентами из GF(q) при условии, что
элементы  этого поля являются
этого поля являются
корнями g(x). Здесь  — примитивный элемент
— примитивный элемент
GF(q).
На основе этого определения, а также теоремы Безу,
выражение для порождающего многочлена РС-кода будет иметь вид 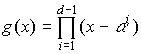 .
.
Степень g(x) равна d-1=N-k=R.
В РС-кодах принадлежность кодовых слов
данному коду определяется выполнением d-1 уравнений в соответствии с выражением
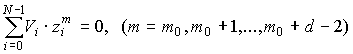
(*),
где Vi — символы-коэффициенты из GF(q);
z0,
z1… zN-1 — ненулевые элементы GF(q).
Элементы
z0, z1… zN-1 называются локаторами, т.е.
указывающими на номер позиции символа кодового слова.
Например, указателем i
— позиции является локатор zi или элемент ai
GF(q).
Так как все локаторы должны быть различны и причем ненулевыми, то их
число в GF(q) равно q-1. Следовательно, такое количество символов должно быть в
кодовых словах кода.Поэтому обычно длина РС-кода определяется из
выражения N=q-1.
Пример. Допустим, что длина РС-кода равна N, кодовое
расстояние d=3, то в соответствии с (*) проверочными уравнениями будут 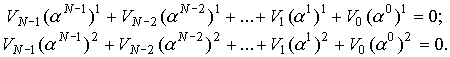
Свойства РС-кодов.
1. Циклический сдвиг кодовых слов, символы которых принимают значение из
GF(q), порождает новые кодовые слова этого же кода.
2. Сумма по mod2 двух и
более кодовых слов дает кодовое слово, принадлежащее этому же коду.
3.
Кодовое расстояние РС-кода определяется не по двоичным элементам, а по q-ичным
символам.
4. В РС-коде, исправляющем tu ошибок порождающий
многочлен определяется из выражения 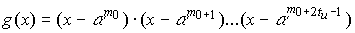 . Обычно m0
. Обычно m0
принимают равным 1. Однако, с помощью разумного выбора значения m0,
иногда можно упростить схему кодера.
5. Корректирующие способности РС-кода
определяются его кодовым расстоянием. 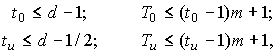
где T0 и
Tu — длина пакетов, в которых обнаруживаются и исправляются ошибки.
Обнаружение ошибок в кодовых словах состоит в проверке условий ((), т.е.
определении синдрома 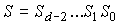 , элементы которого
, элементы которого
определяются из выражения 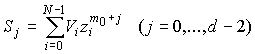 .
.
Пример. Требуется сформировать кодовое слово РС-кода над
GF(23), соответствующее двоичной информационной последовательности
a(1,0)=000000011100101.
Так как m=3, то каждый q-ичный символ кода состоит
из трех двоичных элементов. Поэтому с учетом таблицы 6 a(x)=a3x2+ a2x+a6.
Определяем параметры кода.
N=q-1=7; k=5; R=2; d=N-k+1=3; 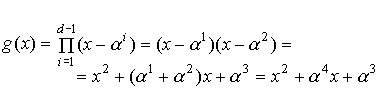 .
.
Кодовое слово формируется в соответствии с выражением. 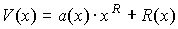 ,
,
где
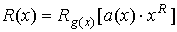 .
.
В
результате  или в двоичной форме
или в двоичной форме
V(1,0)=000.000.011.100.101.101.101.