Циклический
код
является разновидностью помехоустойчивых
кодов, применяется в технике передачи
дискретных сообщений. Особенности
циклических кодов заключены в двух
свойствах разрешенных кодовых комбинаций:
1. любая
из разрешенных кодовых комбинаций
циклического кода делится по модулю
два без остатка на некоторое, так
называемое «образующее двоичное число»,
определяющее помехоустойчивые свойства
кода, т.е. расстояние d![]() ;
;
2.
циклический сдвиг разрядов разрешенной
кодовой комбинации на один элемент
влево порождает другую разрешенную
кодовую комбинацию.
Например:
01011 и 10110 – две разрешенные кодовые
комбинации некоторого циклического
кода с образующим числом 1011 (d![]() =3).
=3).
Поэтому они делятся по модулю два без
остатка на образующее число:
0


 1011
1011
1011 10110 1011
0000
01
1011
10
1011
0000
1011
0000
000
000
При
этом d![]() =4
=4
>d![]() =3.
=3.
Кроме
того циклический сдвиг на один разряд
влево элементов первой комбинации
порождают вторую комбинацию.

01011 => 10110
Делимость
без остатка разрешенных кодовых
комбинаций на известное образующее
число лежит в основе операций обнаружения
и исправления ошибок при использовании
циклических кодов.
Структурная
схема СПДС, содержит кодер и декодер
циклического кода. Структура разрешенных
кодовых комбинаций циклического кода
состоит из двух частей. В начале комбинации
располагается n-проверочных
разрядов, структура которых определяется
кодерами циклического кода из условия
обеспечения делимости без остатка
формируемой разрешенной кодовой
комбинации на образующее число.
Идея
построения циклического кода (n,k)
сводится к тому, что информационную
часть кодовой комбинации G(x)
нужно преобразовать в комбинацию F(x),
которая без остатка делится на порождающий
полином Р(х) степени r=n-k.
Рассмотрим последовательность операций
построения циклического кода:
1.
Представляем информационную часть
кодовой комбинации в виде полинома
G(x).
Например информационная часть 110101.
Тогда
![]() .
.
2.
Умножаем G(x)
на одночлен
![]() ( старшую степень порождающего полинома
( старшую степень порождающего полинома
Р(х) ) и получаем![]() .
.
Пусть
у нас порождающий полином 1011![]() ,
,
тогда
![]() .
.
3. Делим
![]() на
на
порождающий полином Р(х), при этом
получаем остаток от деленияR(x).
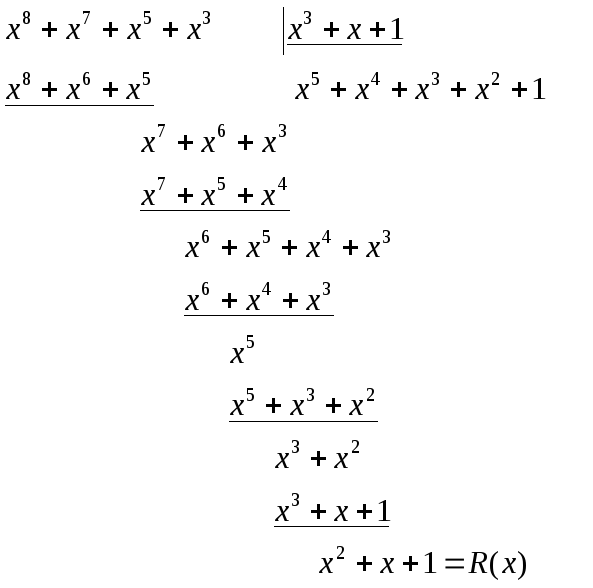
Добавим
полученный остаток R
(x)
к комбинации
![]() и
и
получим комбинацию![]() ,
,
которая будет передана в линию. Данная
комбинацияF(x)
делится без остатка на образующий
полином и представляет собой разрешенную
кодовую комбинацию циклического (n,k)
кода. На приеме производится деление
полученной кодовой комбинации на
образующий полином. Если ошибок нет, то
деление пройдет без остатка. Если при
делении получен остаток, то комбинация
принята с ошибками.
При
использовании в циклических кодах
декодирования с исправлением ошибок
остаток от деления может играть роль
синдрома. Нулевой синдром указывает на
то, что принятая комбинация является
разрешенной. Всякому ненулевому синдрому
соответствует определенная конфигурация
ошибок, которая и исправляется.
Построение
кодеров, декодеров.
Пример:
Кодер
строится на основе полинома P(x).
![]()
=> 1011
–
веса
При
построении устройства число ячеек
регистров сдвига берется по высшей
степени образующего полинома
![]() =>
=>
3 регистра сдвига; число регистров
задержки берется также по высшей степени
образующего полинома; число сумматоров
по модулю два берется по весовой части
образующего полинома минус единица =>
3-1=2m.
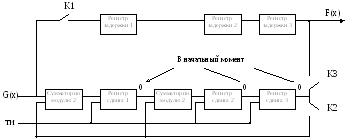
Состояния
регистров (1,2,3
– регистры; m
– сумматоры)
На
вход подается
![]() 110101000
110101000

Декодер
–
правила построения такие же, как у
кодера, но количество регистров задержки
определяется по высшей степени
информационной комбинации плюс 1
5+1=6

Деление
на образующий полином происходит за 9
тактов. Пока идет деление на образующий
полином К2 разомкнут, а К1 замкнут в
течении 6 тактов пока идет запись
информационных импульсов. После 6 такта
К1 размыкается. После 10 такта К2 замыкается
и формируется сигнал:
1. Если хотя бы в
одной ячейке регистра будет «1», то
значит произошла ошибка. Формируется
сигнал «1» и информация из регистров
сдвигов будет удаляться.
2. Если во всех
ячейках регистров сдвига будут «0», то
формируется сигнал «0» и информация
будет выдана потребителю.
Состояния
регистров

Если хотя бы в одной
ячейке регистра будет «1», то значит
произошла ошибка.
Информация из
регистров сдвигов будет удаляться. Если
во всех ячейках регистров сдвига будут
«0», то формируется сигнал «0» и информация
будет выдана потребителю.
Выбор образующего
полинома.
В
теории циклических кодов показано, что
образующий полином представляет собой
произведение так называемых минимальных
многочленов (![]() ),
),
являющихся простыми сомножителями,
(т.е. делящимися без остатка лишь на себя
и на 1).
Кроме
образующего полинома необходимо найти
и количество проверочных разрядов
r.
![]() =1
=1
если n=7,
то
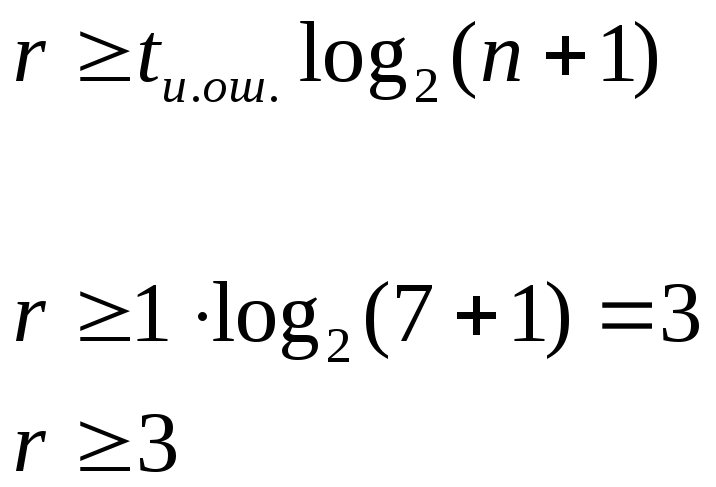
tи.ош
– число ошибок, исправляемых циклическим
кодом.
После
определения количества проверочных
разрядов
r
вычисление образующего полинома удобно
осуществить, пользуясь таблицей
минимальных многочленов.
Ниже приведена часть такой таблицы.
|
r |
Pr(x) |
Двоичная |
|
2 |
|
111 |
|
3 |
|
1011 1101 |
В частности, если
r=3,
tи.ош=1,
j=2*1-1=1,
образующий полином будет представлять
собой единственный минимальный многочлен
P(x)= x3+x+1
(первая строка, второй столбец таблицы
). Соответственно образующее число равно
1011.
Синдром циклического
кода.
Синдром циклического
кода определяется суммой по модулю 2
принятых проверочных элементов и
элементов проверочной группы,
сформированных из принятых элементов
информационной группы. В циклическом
коде для определения синдрома следует
разделить принятую кодовую комбинацию
на кодовую комбинацию порождающего
полинома. Если все элементы приняты без
ошибок, то остаток от деления R(х)
равен нулю. Если есть ошибки, то остаток
не будет равен нулю. Следовательно,
синдромом циклического кода является
многочлен R(x).
Обнаружение и исправление ошибок
производится только на основе анализа
синдрома. В зависимости от остатка
определяется элемент в котором произошла
ошибка. Для исправления ошибок необходимо
чтобы количество ненулевых остатков
равнялось количеству элементов n
( при исправлении одной ошибки ) или
числу комбинаций из n.
Соседние файлы в папке Будылдина2
- #
11.04.20152.54 Mб24ДКР рисунок Mumarev.vsd
- #
11.04.20152.49 Mб30ДКР рисунок.vsd
- #
- #
- #
- #
Вычисление
синдрома для циклических кодов является
довольно простой процедурой.
Пусть
U(x)
и r(х)
‑
полиномы, соответствующие переданному
кодовому слову и принятой последовательности.
Разделив
r(x)
на g(x),
получим
r(x)
= q(x)
g(x)
+ s(x),
(1.73)
где
— q(x)
— частное от деления, s(x)
— остаток от деления.
Если
r(x)
является кодовым полиномом, то он делится
на g(x)
без остатка, то есть s(x)
= 0.
Следовательно,
s(x)
0
является условием наличия ошибки в
принятой последовательности, то есть
синдромом принятой последовательности.
Синдром
s(x)
имеет в общем случае вид
S(x)
= S0
+ S1
x + … + Sn-
k-1
xn-k-1
. (1.74)
Очевидно,
что схема вычисления синдрома является
схемой деления, подобной схемам
кодирования рис. 1.10 или 1.11 .
При
наличии в принятой последовательности
r
хотя бы одной ошибки вектор синдрома S
будет иметь, по крайней мере, один
нулевой элемент, при этом факт наличия
ошибки легко обнаружить, объединив по
ИЛИ
выходы всех ячеек регистра синдрома.
Покажем,
что синдромный многочлен S(x)
однозначно связан с многочленом ошибки
e(x),
а
значит, с его помощью можно не только
обнаруживать, но и локализовать ошибку
в принятой последовательности.
Пусть
e(x)
= e0
+ e1
x
+ e2
x2
+ … + en-1
x
n-1
(1.75)
— полином
вектора ошибки.
Тогда
полином принятой последовательности
r(x)
= U(x)
+ e(x).
(1.76)
Прибавим
в этом выражении слева и справа U(x),
а также учтем, что
r(x)
= q(x)
g(x) + S(x), U(x) = m(x)
g(x), (1.77)
тогда
![]()
,
(1.78)
то
есть синдромный
полином S(x)
есть
остаток от
деления полинома ошибки e(x)
на порождающий полином g(x).
Отсюда следует, что по синдрому S(x)
можно однозначно определить вектор
ошибки e(x), а следовательно,
исправить эту ошибку.
На рис. 1.14 приведена схема синдромного
декодера с исправлением однократной
ошибки для циклического (7,4)-кода.
По своей структуре она подобна схеме,
приведенной на рис. 1.6, с той лишь разницей,
что вычисление синдрома принятой
последовательности производится здесь
не умножением на проверочную матрицу,
а делением на порождающий полином. При
этом она сохраняет и недостаток, присущий
всем синдромным декодерам: необходимость
иметь запоминающее устройство, ставящее
в соответствие множеству возможных
синдромов S множество векторов
ошибок e. Цикличность структуры
кода в этом случае не учитывается.
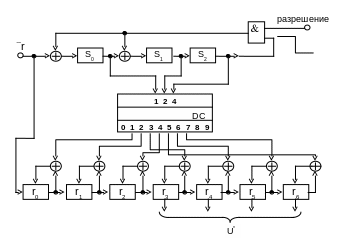
Рис.
1.14
1.3.4. Неалгебраические методы декодирования циклических кодов
Все
методы декодирования линейных блочных
кодов можно разбить на две группы:
алгебраические
и неалгебраические.
В
основе алгебраических методов лежит
решение систем уравнений, задающих
значение и расположение ошибок.
Рассмотренные синдромные декодеры
относятся именно к этой группе методов.
При
неалгебраических методах та же цель
достигается с помощью простых структурных
понятий теории кодирования, позволяющих
находить комбинации ошибок более простым
путем.
Одним
из неалгебраических методов является
декодирование с использованием алгоритма
Меггитта,
пригодного для исправления как одиночных,
так и l-кратных
ошибок (на практике l
3).
При
декодировании в соответствии с алгоритмом
Меггитта также вычисляется синдром
принятой последовательности S(x),
однако используется он иначе, нежели в
рассмотренных ранее синдромных декодерах.
Идея,
лежащая в основе декодера Меггитта,
очень проста и основывается на следующих
свойствах циклических кодов:
—
существует взаимно-однозначное
соответствие между множеством всех
исправляемых ошибок и множеством
синдромов;
—
если S(x)
— синдромный многочлен, соответствующий
многочлену ошибок е(x),
то xS(x)
mod
g(x)
— синдромный многочлен, соответствующий
x
e(x) mod (xn
+ 1).
Равенство
а(x)
= b(x) mod p(x)
читается как “а(x),
сравнимо с b(x)
по модулю р(x)”
и означает, что а(x)
и b(x)
имеют одинаковые остатки от деления на
полином p(x).
Таким
образом, второе
условие
означает, что если
комбинация ошибок циклически сдвинута
на одну позицию вправо, то для получения
нового синдрома нужно сдвинуть содержимое
регистра сдвига с обратными связями,
содержащего S(x),
также на одну позицию вправо.
Следовательно,
основным
элементом декодера Меггитта является
сдвиговый регистр. Структурная схема
декодера Меггитта для циклических кодов
произвольной длины приведена
на рис. 1.15.

Рис.
1.15
Декодер
работает следующим образом. Перед
началом работы содержимое всех разрядов
регистров равно нулю. Принимаемая
последовательность r
в
течение первых n
тактов вводится в буферный регистр и
одновременно с этим в (n—k)-разрядном
сдвиговом регистре с обратными связями
производится ее деление на порождающий
полином g(x).
Через
n
тактов
в буферном регистре оказывается принятое
слово r
,
a в регистре синдрома — остаток от
деления вектора ошибки на порождающий
полином.
Вычисленный
синдром сравнивается со всеми табличными
синдромами, и в случае совпадения с
одним из них старший разряд буферного
регистра исправляется путем прибавления
к его значению единицы.
После
этого синдромный и буферный регистры
один раз циклически сдвигаются. Это
реализует умножение S(x)
на
x
и деление на g(x).
Содержимое ячеек синдромного регистра
теперь равно остатку от деления xS(x)
на g(x)
или синдрому ошибки x
е(x) mod (Хn
+ 1).
Если
новый синдром совпадает с одним их
табличных, то исправляется очередная
ошибка и т.д. Через n
тактов
все позиции будут, таким образом,
исправлены.
Рассмотрим
работу декодера Меггитта для циклического
(7,4)-кода,
исправляющего одиночную ошибку. Схема
декодера изображена на рис. 1.16.

Рис.
1.16
Принцип
работы декодера заключается в том, что
независимо
от того, в какой позиции произошла
ошибка, осуществляется ее сдвиг в
последнюю ячейку буферного регистра с
соответствующим пересчетом синдрома
и ее исправление в этой позиции.
Полином
ошибки в старшем разряде для (7,4)-кода
Хемминга имеет вид е6
(x)
= x6,
соответствующий ему синдромный полином
S6
(x)
= 1 + x3
(
S
= (101)),
детектор ошибки настроен на это значение
синдрома.
Пусть,
например, передана последовательность
U
= (1001011),
ей соответствует кодовый полином U(x)
= 1 + x3
+ x5
+ x6.
Произошла ошибка в третьей позиции е(x)
= x3,
принятый вектор имеет вид r
= (1000011),
его полином r(x)
= 1 + x5
+ x6.
Kогда
принятая последовательность полностью
входит в буферный регистр, в регистре
синдрома оказывается синдром,
соответствующий ошибке е(x)
= x3
S3
= (110).
Поскольку он не совпадает с табличным
для е6,
на выходе детектора ошибок будет 0
и исправления не происходит.
Далее
производятся однократный циклический
сдвиг принятой последовательности в
буферном регистре, однократное деление
синдрома x∙S3
на порождающий полином в регистре с
обратными связями и проверка на совпадение
синдрома с заданным.
Последовательность
состояний регистров декодера в процессе
декодирования показана на рис. 1.17.
Рис.
1.17
Т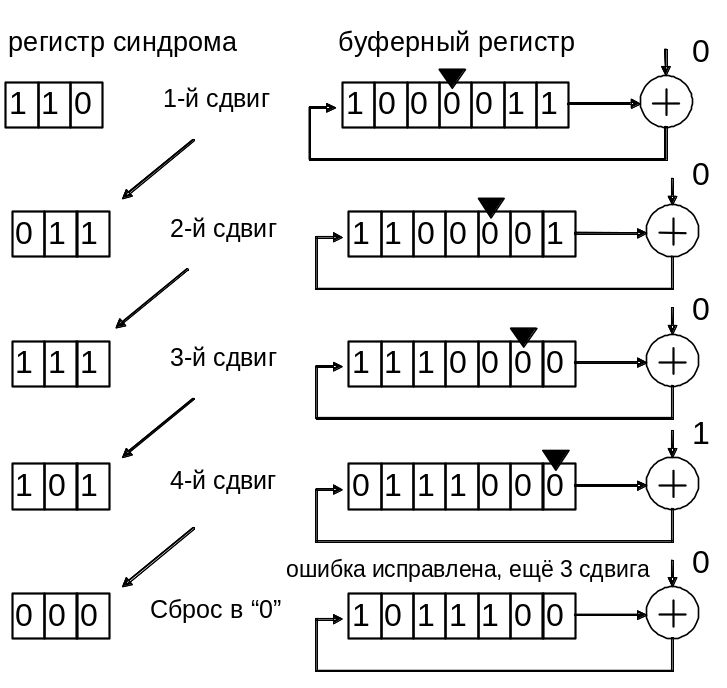
аким
образом, исправление ошибки в декодере
Меггитта осуществляется за 2n
тактов: в течение n
тактов производится ввод принятой
последовательности в буферный регистр,
в течение l
тактов
— исправление ошибки, и еще в течение
n
— l
— восстановление
буферного регистра в исходное состояние
с исправленным словом. Простота декодера
достигается увеличением времени
декодирования.
Следует
отметить, что в связи с успехами в
разработке БИС и устройств памяти в
значительной степени снимается вопрос
о размерах таблиц, связывающих значения
синдрома и вектора ошибки (для синдромных
декодеров) и даже значения кодовых слов
и принятых последовательностей (для
декодера максимального правдоподобия).
Поэтому в перспективе возможно снижение
интереса к кодам, обладающим специальной
структурой, и к методам их декодирования.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
10.06.2015684.82 Кб13P4.pdf
- #
- #
- #
- #
Макеты страниц
Синдром циклического кода, как и в любом систематическом коде, определяется суммой по модулю 2, принятых проверочных элементов и элементов проверочной группы, сформированных из принятых элементов информационной группы.
В циклическом коде для определения синдрома следует разделить принятую кодовую комбинацию на кодовую комбинацию производящего полинома Если все элементы приняты без ошибок, остаток  от деления равен нулю. Наличие ошибок приводит к тому, что
от деления равен нулю. Наличие ошибок приводит к тому, что  . Следовательно, синдромом циклического кода является многочлен
. Следовательно, синдромом циклического кода является многочлен  определения номеров элементов, в которых произошла ошибка, существует несколько методов Один из них основан на свойстве, которое заключается в том, что
определения номеров элементов, в которых произошла ошибка, существует несколько методов Один из них основан на свойстве, которое заключается в том, что  полученный при делении принятого многочлена
полученный при делении принятого многочлена  на
на  равен
равен  полученному в результате деления соответствующего многочлена ошибок
полученному в результате деления соответствующего многочлена ошибок  на
на 
Многочлен ошибок  , где
, где  — исходный многочлен циклического кода Так, если ошибка произошла в
— исходный многочлен циклического кода Так, если ошибка произошла в  то при коде
то при коде  ошибка в
ошибка в  соответствует
соответствует  и т. д. Остаток от деления
и т. д. Остаток от деления  на
на  для данного
для данного  -элементного кода всегда одинаков, он не зависит от вида передаваемой комбинации. В рассматриваемом примере
-элементного кода всегда одинаков, он не зависит от вида передаваемой комбинации. В рассматриваемом примере  Наличие ошибки в других элементах
Наличие ошибки в других элементах  приведет к другим остаткам Остатки зависят только от вида
приведет к другим остаткам Остатки зависят только от вида  и
и  . Для
. Для  будет следующее соответствие:
будет следующее соответствие:

Указанное однозначное соответствие можно использовать для определения места ошибки. Синдром не зависит от переданной кодовой комбинации, но в нем сосредоточена вся информация о наличии ошибок. Обнаружение и исправление ошибок в систематических кодах может производиться только на основе анализа синдрома.
На основании приведенного свойства существует следующий метод определения места ошибки. Сначала определяется остаток 1 (0, 1), соответствующий наличию ошибки в старшем разряде. Если ошибка произошла в следующем разряде (более низком), то такой же остаток получится в произведении принятого многочлена и  Это служит основанием для следующего приема, суть которого ясна из следующего примера.
Это служит основанием для следующего приема, суть которого ясна из следующего примера.
Пример 7.10. Предположим, задан код (11,7) в виде кодовой комбинации 10110111100 Здесь последние четыре разряда проверочные и получены на основе использования производящего многочлена  . Принята кодовая комбинация 10111111100. Определить ошибочно принятый элемент
. Принята кодовая комбинация 10111111100. Определить ошибочно принятый элемент
Вычисляем  как остаток от деления
как остаток от деления  на 10011. Произведя деление, получим 0111. Далее делим принятую комбинацию на (0,1) и получаем остаток
на 10011. Произведя деление, получим 0111. Далее делим принятую комбинацию на (0,1) и получаем остаток  Если
Если  то ошибка в старшем разряде. Если нет, то дописываем иуль и продолжаем деление. Номер ошибочно принятого разряда (отсчет слева направо) на единицу больше числа приписанных нулей, после которых остаток окажется равным 0111. Проведем процесс деления, отмечая штрихом получаемые остатки
то ошибка в старшем разряде. Если нет, то дописываем иуль и продолжаем деление. Номер ошибочно принятого разряда (отсчет слева направо) на единицу больше числа приписанных нулей, после которых остаток окажется равным 0111. Проведем процесс деления, отмечая штрихом получаемые остатки  дописываемые
дописываемые
 (1)
(1)
В данном примере для этого пришлось дописать четыре нуля. Это означает, что ошибка произошла в пятом элементе, т. е. исправленная кодовая комбинация будет иметь вид

In coding theory, a cyclic code is a block code, where the circular shifts of each codeword gives another word that belongs to the code. They are error-correcting codes that have algebraic properties that are convenient for efficient error detection and correction.
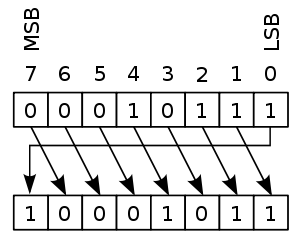
If 00010111 is a valid codeword, applying a right circular shift gives the string 10001011. If the code is cyclic, then 10001011 is again a valid codeword. In general, applying a right circular shift moves the least significant bit (LSB) to the leftmost position, so that it becomes the most significant bit (MSB); the other positions are shifted by 1 to the right.
Definition[edit]
Let  be a linear code over a finite field (also called Galois field)
be a linear code over a finite field (also called Galois field)  of block length
of block length  . is called a cyclic code if, for every codeword
. is called a cyclic code if, for every codeword  from , the word
from , the word  in
in  obtained by a cyclic right shift of components is again a codeword. Because one cyclic right shift is equal to
obtained by a cyclic right shift of components is again a codeword. Because one cyclic right shift is equal to  cyclic left shifts, a cyclic code may also be defined via cyclic left shifts. Therefore, the linear code is cyclic precisely when it is invariant under all cyclic shifts.
cyclic left shifts, a cyclic code may also be defined via cyclic left shifts. Therefore, the linear code is cyclic precisely when it is invariant under all cyclic shifts.
Cyclic codes have some additional structural constraint on the codes. They are based on Galois fields and because of their structural properties they are very useful for error controls. Their structure is strongly related to Galois fields because of which the encoding and decoding algorithms for cyclic codes are computationally efficient.
Algebraic structure[edit]
Cyclic codes can be linked to ideals in certain rings. Let ![R=A[x]/(x^{n}-1)](https://wikimedia.org/api/rest_v1/media/math/render/svg/8595f12ff1f64bc73a4e3e03851397cc877af6e2) be a polynomial ring over the finite field
be a polynomial ring over the finite field  . Identify the elements of the cyclic code
. Identify the elements of the cyclic code  with polynomials in
with polynomials in  such that
such that
 maps to the polynomial
maps to the polynomial
 : thus multiplication by
: thus multiplication by  corresponds to a cyclic shift. Then is an ideal in , and hence principal, since is a principal ideal ring. The ideal is generated by the unique monic element in of minimum degree, the generator polynomial
corresponds to a cyclic shift. Then is an ideal in , and hence principal, since is a principal ideal ring. The ideal is generated by the unique monic element in of minimum degree, the generator polynomial  .[1]
.[1]
This must be a divisor of  . It follows that every cyclic code is a polynomial code.
. It follows that every cyclic code is a polynomial code.
If the generator polynomial has degree  then the rank of the code is
then the rank of the code is  .
.
The idempotent of is a codeword  such that
such that  (that is, is an idempotent element of ) and is an identity for the code, that is
(that is, is an idempotent element of ) and is an identity for the code, that is  for every codeword
for every codeword  . If and
. If and  are coprime such a word always exists and is unique;[2] it is a generator of the code.
are coprime such a word always exists and is unique;[2] it is a generator of the code.
An irreducible code is a cyclic code in which the code, as an ideal is irreducible, i.e. is minimal in , so that its check polynomial is an irreducible polynomial.
Examples[edit]
For example, if  and
and  , the set of codewords contained in cyclic code generated by
, the set of codewords contained in cyclic code generated by  is precisely
is precisely
 .
.

It corresponds to the ideal in ![mathbb {F} _{2}[x]/(x^{3}-1)](https://wikimedia.org/api/rest_v1/media/math/render/svg/9b419295ea611763fd442a22f8f56fe8dc30c023) generated by
generated by  .
.
The polynomial is irreducible in the polynomial ring, and hence the code is an irreducible code.
The idempotent of this code is the polynomial  , corresponding to the codeword
, corresponding to the codeword  .
.
Trivial examples[edit]
Trivial examples of cyclic codes are  itself and the code containing only the zero codeword. These correspond to generators
itself and the code containing only the zero codeword. These correspond to generators  and respectively: these two polynomials must always be factors of .
and respectively: these two polynomials must always be factors of .
Over  the parity bit code, consisting of all words of even weight, corresponds to generator
the parity bit code, consisting of all words of even weight, corresponds to generator  . Again over this must always be a factor of .
. Again over this must always be a factor of .
Quasi-cyclic codes and shortened codes[edit]
Before delving into the details of cyclic codes first we will discuss quasi-cyclic and shortened codes which are closely related to the cyclic codes and they all can be converted into each other.
Definition[edit]
Quasi-cyclic codes:[citation needed]
An  quasi-cyclic code is a linear block code such that, for some
quasi-cyclic code is a linear block code such that, for some  which is coprime to , the polynomial
which is coprime to , the polynomial  is a codeword polynomial whenever
is a codeword polynomial whenever  is a codeword polynomial.
is a codeword polynomial.
Here, codeword polynomial is an element of a linear code whose code words are polynomials that are divisible by a polynomial of shorter length called the generator polynomial. Every codeword polynomial can be expressed in the form  , where
, where  is the generator polynomial. Any codeword
is the generator polynomial. Any codeword  of a cyclic code can be associated with a codeword polynomial, namely,
of a cyclic code can be associated with a codeword polynomial, namely,  . A quasi-cyclic code with equal to is a cyclic code.
. A quasi-cyclic code with equal to is a cyclic code.
Definition[edit]
Shortened codes:
An ![[n,k]](https://wikimedia.org/api/rest_v1/media/math/render/svg/4d9e3e5f03db243c10e64608605d156ae1885952) linear code is called a proper shortened cyclic code if it can be obtained by deleting positions from an
linear code is called a proper shortened cyclic code if it can be obtained by deleting positions from an  cyclic code.
cyclic code.
In shortened codes information symbols are deleted to obtain a desired blocklength smaller than the design blocklength. The missing information symbols are usually imagined to be at the beginning of the codeword and are considered to be 0. Therefore, − is fixed, and then is decreased which eventually decreases . It is not necessary to delete the starting symbols. Depending on the application sometimes consecutive positions are considered as 0 and are deleted.
is fixed, and then is decreased which eventually decreases . It is not necessary to delete the starting symbols. Depending on the application sometimes consecutive positions are considered as 0 and are deleted.
All the symbols which are dropped need not be transmitted and at the receiving end can be reinserted. To convert cyclic code to shortened code, set symbols to zero and drop them from each codeword. Any cyclic code can be converted to quasi-cyclic codes by dropping every th symbol where is a factor of . If the dropped symbols are not check symbols then this cyclic code is also a shortened code.
Cyclic codes for correcting errors[edit]
Now, we will begin the discussion of cyclic codes explicitly with error detection and correction. Cyclic codes can be used to correct errors, like Hamming codes as cyclic codes can be used for correcting single error. Likewise, they are also used to correct double errors and burst errors. All types of error corrections are covered briefly in the further subsections.
The (7,4) Hamming code has a generator polynomial  . This polynomial has a zero in Galois extension field
. This polynomial has a zero in Galois extension field  at the primitive element
at the primitive element  , and all codewords satisfy
, and all codewords satisfy  . Cyclic codes can also be used to correct double errors over the field . Blocklength will be equal to
. Cyclic codes can also be used to correct double errors over the field . Blocklength will be equal to  and primitive elements and
and primitive elements and  as zeros in the
as zeros in the  because we are considering the case of two errors here, so each will represent one error.
because we are considering the case of two errors here, so each will represent one error.
The received word is a polynomial of degree given as

where  can have at most two nonzero coefficients corresponding to 2 errors.
can have at most two nonzero coefficients corresponding to 2 errors.
We define the Syndrome Polynomial,  as the remainder of polynomial
as the remainder of polynomial  when divided by the generator polynomial i.e.
when divided by the generator polynomial i.e.
 as
as  .
.
For correcting two errors[edit]
Let the field elements  and
and  be the two error location numbers. If only one error occurs then is equal to zero and if none occurs both are zero.
be the two error location numbers. If only one error occurs then is equal to zero and if none occurs both are zero.
Let  and
and  .
.
These field elements are called «syndromes». Now because is zero at primitive elements and , so we can write  and
and  . If say two errors occur, then
. If say two errors occur, then
 and
and
 .
.
And these two can be considered as two pair of equations in with two unknowns and hence we can write
 and
and
 .
.
Hence if the two pair of nonlinear equations can be solved cyclic codes can used to correct two errors.
Hamming code[edit]
The Hamming(7,4) code may be written as a cyclic code over GF(2) with generator  . In fact, any binary Hamming code of the form Ham(r, 2) is equivalent to a cyclic code,[3] and any Hamming code of the form Ham(r,q) with r and q-1 relatively prime is also equivalent to a cyclic code.[4] Given a Hamming code of the form Ham(r,2) with
. In fact, any binary Hamming code of the form Ham(r, 2) is equivalent to a cyclic code,[3] and any Hamming code of the form Ham(r,q) with r and q-1 relatively prime is also equivalent to a cyclic code.[4] Given a Hamming code of the form Ham(r,2) with  , the set of even codewords forms a cyclic
, the set of even codewords forms a cyclic ![[2^{r}-1,2^{r}-r-2,4]](https://wikimedia.org/api/rest_v1/media/math/render/svg/cbf755cb5b384b44e604aa2cc03660048b528348) -code.[5]
-code.[5]
Hamming code for correcting single errors[edit]
A code whose minimum distance is at least 3, have a check matrix all of whose columns are distinct and non zero. If a check matrix for a binary code has  rows, then each column is an -bit binary number. There are possible columns. Therefore, if a check matrix of a binary code with
rows, then each column is an -bit binary number. There are possible columns. Therefore, if a check matrix of a binary code with  at least 3 has rows, then it can only have columns, not more than that. This defines a
at least 3 has rows, then it can only have columns, not more than that. This defines a  code, called Hamming code.
code, called Hamming code.
It is easy to define Hamming codes for large alphabets of size . We need to define one  matrix with linearly independent columns. For any word of size there will be columns who are multiples of each other. So, to get linear independence all non zero -tuples with one as a top most non zero element will be chosen as columns. Then two columns will never be linearly dependent because three columns could be linearly dependent with the minimum distance of the code as 3.
matrix with linearly independent columns. For any word of size there will be columns who are multiples of each other. So, to get linear independence all non zero -tuples with one as a top most non zero element will be chosen as columns. Then two columns will never be linearly dependent because three columns could be linearly dependent with the minimum distance of the code as 3.
So, there are  nonzero columns with one as top most non zero element. Therefore, a Hamming code is a
nonzero columns with one as top most non zero element. Therefore, a Hamming code is a ![[(q^{m}-1)/(q-1),(q^{m}-1)/(q-1)-m]](https://wikimedia.org/api/rest_v1/media/math/render/svg/6447e6a6ef3646859efcaa879911eae094aae869) code.
code.
Now, for cyclic codes, Let be primitive element in  , and let
, and let  . Then
. Then  and thus
and thus  is a zero of the polynomial
is a zero of the polynomial  and is a generator polynomial for the cyclic code of block length
and is a generator polynomial for the cyclic code of block length  .
.
But for  ,
,  . And the received word is a polynomial of degree given as
. And the received word is a polynomial of degree given as
where,  or
or  where
where  represents the error locations.
represents the error locations.
But we can also use  as an element of to index error location. Because
as an element of to index error location. Because  , we have
, we have  and all powers of from
and all powers of from  to
to  are distinct. Therefore, we can easily determine error location from unless
are distinct. Therefore, we can easily determine error location from unless  which represents no error. So, a Hamming code is a single error correcting code over with
which represents no error. So, a Hamming code is a single error correcting code over with  and
and  .
.
Cyclic codes for correcting burst errors[edit]
From Hamming distance concept, a code with minimum distance  can correct any
can correct any  errors. But in many channels error pattern is not very arbitrary, it occurs within very short segment of the message. Such kind of errors are called burst errors. So, for correcting such errors we will get a more efficient code of higher rate because of the less constraints. Cyclic codes are used for correcting burst error. In fact, cyclic codes can also correct cyclic burst errors along with burst errors. Cyclic burst errors are defined as
errors. But in many channels error pattern is not very arbitrary, it occurs within very short segment of the message. Such kind of errors are called burst errors. So, for correcting such errors we will get a more efficient code of higher rate because of the less constraints. Cyclic codes are used for correcting burst error. In fact, cyclic codes can also correct cyclic burst errors along with burst errors. Cyclic burst errors are defined as
A cyclic burst of length is a vector whose nonzero components are among (cyclically) consecutive components, the first and the last of which are nonzero.
In polynomial form cyclic burst of length can be described as  with
with  as a polynomial of degree
as a polynomial of degree  with nonzero coefficient
with nonzero coefficient  . Here defines the pattern and defines the starting point of error. Length of the pattern is given by deg
. Here defines the pattern and defines the starting point of error. Length of the pattern is given by deg . The syndrome polynomial is unique for each pattern and is given by
. The syndrome polynomial is unique for each pattern and is given by

A linear block code that corrects all burst errors of length or less must have at least  check symbols. Proof: Because any linear code that can correct burst pattern of length or less cannot have a burst of length or less as a codeword because if it did then a burst of length could change the codeword to burst pattern of length , which also could be obtained by making a burst error of length in all zero codeword. Now, any two vectors that are non zero in the first components must be from different co-sets of an array to avoid their difference being a codeword of bursts of length . Therefore, number of such co-sets are equal to number of such vectors which are
check symbols. Proof: Because any linear code that can correct burst pattern of length or less cannot have a burst of length or less as a codeword because if it did then a burst of length could change the codeword to burst pattern of length , which also could be obtained by making a burst error of length in all zero codeword. Now, any two vectors that are non zero in the first components must be from different co-sets of an array to avoid their difference being a codeword of bursts of length . Therefore, number of such co-sets are equal to number of such vectors which are  . Hence at least co-sets and hence at least check symbol.
. Hence at least co-sets and hence at least check symbol.
This property is also known as Rieger bound and it is similar to the Singleton bound for random error correcting.
Fire codes as cyclic bounds[edit]
In 1959, Philip Fire[6] presented a construction of cyclic codes generated by a product of a binomial and a primitive polynomial. The binomial has the form  for some positive odd integer .[7] Fire code is a cyclic burst error correcting code over with the generator polynomial
for some positive odd integer .[7] Fire code is a cyclic burst error correcting code over with the generator polynomial

where  is a prime polynomial with degree not smaller than and does not divide
is a prime polynomial with degree not smaller than and does not divide  . Block length of the fire code is the smallest integer such that divides
. Block length of the fire code is the smallest integer such that divides
.
A fire code can correct all burst errors of length t or less if no two bursts and  appear in the same co-set. This can be proved by contradiction. Suppose there are two distinct nonzero bursts and of length or less and are in the same co-set of the code. So, their difference is a codeword. As the difference is a multiple of it is also a multiple of . Therefore,
appear in the same co-set. This can be proved by contradiction. Suppose there are two distinct nonzero bursts and of length or less and are in the same co-set of the code. So, their difference is a codeword. As the difference is a multiple of it is also a multiple of . Therefore,
 .
.
This shows that  is a multiple of
is a multiple of  , So
, So

for some  . Now, as
. Now, as  is less than and is less than
is less than and is less than  so
so  is a codeword. Therefore,
is a codeword. Therefore,
 .
.
Since degree is less than degree of , cannot divide . If is not zero, then also cannot divide  as is less than and by definition of , divides for no smaller than . Therefore and equals to zero. That means both that both the bursts are same, contrary to assumption.
as is less than and by definition of , divides for no smaller than . Therefore and equals to zero. That means both that both the bursts are same, contrary to assumption.
Fire codes are the best single burst correcting codes with high rate and they are constructed analytically. They are of very high rate and when and are equal, redundancy is least and is equal to  . By using multiple fire codes longer burst errors can also be corrected.
. By using multiple fire codes longer burst errors can also be corrected.
For error detection cyclic codes are widely used and are called cyclic redundancy codes.
Cyclic codes on Fourier transform[edit]
Applications of Fourier transform are widespread in signal processing. But their applications are not limited to the complex fields only; Fourier transforms also exist in the Galois field . Cyclic codes using Fourier transform can be described in a setting closer to the signal processing.
Fourier transform over finite fields[edit]
Fourier transform over finite fields
The discrete Fourier transform of vector  is given by a vector
is given by a vector  where,
where,
 =
=  where,
where,

where exp( ) is an th root of unity. Similarly in the finite field th root of unity is element
) is an th root of unity. Similarly in the finite field th root of unity is element  of order . Therefore
of order . Therefore
If  is a vector over , and be an element of of order , then Fourier transform of the vector
is a vector over , and be an element of of order , then Fourier transform of the vector  is the vector
is the vector  and components are given by
and components are given by
 =
=  where,
where,
Here is time index, is frequency and  is the spectrum. One important difference between Fourier transform in complex field and Galois field is that complex field exists for every value of while in Galois field exists only if divides
is the spectrum. One important difference between Fourier transform in complex field and Galois field is that complex field exists for every value of while in Galois field exists only if divides  . In case of extension fields, there will be a Fourier transform in the extension field if divides for some .
. In case of extension fields, there will be a Fourier transform in the extension field if divides for some .
In Galois field time domain vector is over the field but the spectrum may be over the extension field .
Spectral description of cyclic codes[edit]
Any codeword of cyclic code of blocklength can be represented by a polynomial of degree at most . Its encoder can be written as . Therefore, in frequency domain encoder can be written as  . Here codeword spectrum
. Here codeword spectrum  has a value in but all the components in the time domain are from . As the data spectrum
has a value in but all the components in the time domain are from . As the data spectrum  is arbitrary, the role of
is arbitrary, the role of  is to specify those where will be zero.
is to specify those where will be zero.
Thus, cyclic codes can also be defined as
Given a set of spectral indices,  , whose elements are called check frequencies, the cyclic code is the set of words over whose spectrum is zero in the components indexed by
, whose elements are called check frequencies, the cyclic code is the set of words over whose spectrum is zero in the components indexed by  . Any such spectrum will have components of the form
. Any such spectrum will have components of the form  .
.
So, cyclic codes are vectors in the field and the spectrum given by its inverse fourier transform is over the field and are constrained to be zero at certain components. But every spectrum in the field and zero at certain components may not have inverse transforms with components in the field . Such spectrum can not be used as cyclic codes.
Following are the few bounds on the spectrum of cyclic codes.
BCH bound[edit]
If be a factor of  for some . The only vector in of weight
for some . The only vector in of weight  or less that has consecutive components of its spectrum equal to zero is all-zero vector.
or less that has consecutive components of its spectrum equal to zero is all-zero vector.
Hartmann-Tzeng bound[edit]
If be a factor of for some , and an integer that is coprime with . The only vector in of weight or less whose spectral
components equal zero for  , where
, where  and
and  , is the all zero vector.
, is the all zero vector.
Roos bound[edit]
If be a factor of for some and  . The only vector in
. The only vector in
of weight or less whose spectral components equal to zero for  , where
, where  and
and  takes at least
takes at least  values in the range
values in the range  , is the all-zero vector.
, is the all-zero vector.
Quadratic residue codes[edit]
When the prime is a quadratic residue modulo the prime  there is a quadratic residue code which is a cyclic code of length , dimension
there is a quadratic residue code which is a cyclic code of length , dimension  and minimum weight at least
and minimum weight at least  over
over  .
.
Generalizations[edit]
A constacyclic code is a linear code with the property that for some constant λ if (c1,c2,…,cn) is a codeword then so is (λcn,c1,…,cn-1). A negacyclic code is a constacyclic code with λ=-1.[8] A quasi-cyclic code has the property that for some s, any cyclic shift of a codeword by s places is again a codeword.[9] A double circulant code is a quasi-cyclic code of even length with s=2.[9] Quasi-twisted codes and multi-twisted codes are further generalizations of constacyclic codes.[10][11]
See also[edit]
- Cyclic redundancy check
- BCH code
- Reed–Muller code
- Binary Golay code
- Ternary Golay code
- Eugene Prange
Notes[edit]
- ^ Van Lint 1998, p. 76
- ^ Van Lint 1998, p. 80
- ^ Hill 1988, pp. 159–160
- ^ Blahut 2003, Theorem 5.5.1
- ^ Hill 1988, pp. 162–163
- ^ P. Fire, E, P. (1959). A class of multiple-error-correcting binary codes for non-independent errors. Sylvania Reconnaissance Systems Laboratory, Mountain View, CA, Rept. RSL-E-2, 1959.
- ^ Wei Zhou, Shu Lin, Khaled Abdel-Ghaffar. Burst or random error correction based on Fire and BCH codes. ITA 2014: 1-5 2013.
- ^ Van Lint 1998, p. 75
- ^ a b MacWilliams & Sloane 1977, p. 506
- ^ Aydin, Nuh; Siap, Irfan; K. Ray-Chaudhuri, Dijen (2001). «The Structure of 1-Generator Quasi-Twisted Codes and New Linear Codes». Designs, Codes and Cryptography. 24 (3): 313–326. doi:10.1023/A:1011283523000. S2CID 17376783.
- ^ Aydin, Nuh; Halilović, Ajdin (2017). «A generalization of quasi-twisted codes: multi-twisted codes». Finite Fields and Their Applications. 45: 96–106. doi:10.1016/j.ffa.2016.12.002. S2CID 7694655.
References[edit]
- Blahut, Richard E. (2003), Algebraic Codes for Data Transmission (2nd ed.), Cambridge University Press, ISBN 0-521-55374-1
- Hill, Raymond (1988), A First Course In Coding Theory, Oxford University Press, ISBN 0-19-853803-0
- MacWilliams, F. J.; Sloane, N. J. A. (1977), The Theory of Error-Correcting Codes, New York: North-Holland Publishing, ISBN 0-444-85011-2
- Van Lint, J. H. (1998), Introduction to Coding Theory, Graduate Texts in Mathematics 86 (3rd ed.), Springer Verlag, ISBN 3-540-64133-5
Further reading[edit]
- Ranjan Bose, Information theory, coding and cryptography, ISBN 0-07-048297-7
- Irving S. Reed and Xuemin Chen, Error-Control Coding for Data Networks, Boston: Kluwer Academic Publishers, 1999, ISBN 0-7923-8528-4.
- Scott A. Vanstone, Paul C. Van Oorschot, An introduction to error correcting codes with applications, ISBN 0-7923-9017-2
External links[edit]
- John Gill’s (Stanford) class notes – Notes #3, October 8, Handout #9, EE 387.
- Jonathan Hall’s (MSU) class notes – Chapter 8. Cyclic codes — pp. 100 — 123
- David Terr. «Cyclic Code». MathWorld.
This article incorporates material from cyclic code on PlanetMath, which is licensed under the Creative Commons Attribution/Share-Alike License.
In coding theory, a cyclic code is a block code, where the circular shifts of each codeword gives another word that belongs to the code. They are error-correcting codes that have algebraic properties that are convenient for efficient error detection and correction.
If 00010111 is a valid codeword, applying a right circular shift gives the string 10001011. If the code is cyclic, then 10001011 is again a valid codeword. In general, applying a right circular shift moves the least significant bit (LSB) to the leftmost position, so that it becomes the most significant bit (MSB); the other positions are shifted by 1 to the right.
Definition[edit]
Let be a linear code over a finite field (also called Galois field) of block length . is called a cyclic code if, for every codeword from , the word in obtained by a cyclic right shift of components is again a codeword. Because one cyclic right shift is equal to cyclic left shifts, a cyclic code may also be defined via cyclic left shifts. Therefore, the linear code is cyclic precisely when it is invariant under all cyclic shifts.
Cyclic codes have some additional structural constraint on the codes. They are based on Galois fields and because of their structural properties they are very useful for error controls. Their structure is strongly related to Galois fields because of which the encoding and decoding algorithms for cyclic codes are computationally efficient.
Algebraic structure[edit]
Cyclic codes can be linked to ideals in certain rings. Let be a polynomial ring over the finite field . Identify the elements of the cyclic code with polynomials in such that
maps to the polynomial
: thus multiplication by corresponds to a cyclic shift. Then is an ideal in , and hence principal, since is a principal ideal ring. The ideal is generated by the unique monic element in of minimum degree, the generator polynomial .[1]
This must be a divisor of . It follows that every cyclic code is a polynomial code.
If the generator polynomial has degree then the rank of the code is .
The idempotent of is a codeword such that (that is, is an idempotent element of ) and is an identity for the code, that is for every codeword . If and are coprime such a word always exists and is unique;[2] it is a generator of the code.
An irreducible code is a cyclic code in which the code, as an ideal is irreducible, i.e. is minimal in , so that its check polynomial is an irreducible polynomial.
Examples[edit]
For example, if and , the set of codewords contained in cyclic code generated by is precisely
- .
It corresponds to the ideal in generated by .
The polynomial is irreducible in the polynomial ring, and hence the code is an irreducible code.
The idempotent of this code is the polynomial , corresponding to the codeword .
Trivial examples[edit]
Trivial examples of cyclic codes are itself and the code containing only the zero codeword. These correspond to generators and respectively: these two polynomials must always be factors of .
Over the parity bit code, consisting of all words of even weight, corresponds to generator . Again over this must always be a factor of .
Quasi-cyclic codes and shortened codes[edit]
Before delving into the details of cyclic codes first we will discuss quasi-cyclic and shortened codes which are closely related to the cyclic codes and they all can be converted into each other.
Definition[edit]
Quasi-cyclic codes:[citation needed]
An quasi-cyclic code is a linear block code such that, for some which is coprime to , the polynomial is a codeword polynomial whenever is a codeword polynomial.
Here, codeword polynomial is an element of a linear code whose code words are polynomials that are divisible by a polynomial of shorter length called the generator polynomial. Every codeword polynomial can be expressed in the form , where is the generator polynomial. Any codeword of a cyclic code can be associated with a codeword polynomial, namely, . A quasi-cyclic code with equal to is a cyclic code.
Definition[edit]
Shortened codes:
An linear code is called a proper shortened cyclic code if it can be obtained by deleting positions from an cyclic code.
In shortened codes information symbols are deleted to obtain a desired blocklength smaller than the design blocklength. The missing information symbols are usually imagined to be at the beginning of the codeword and are considered to be 0. Therefore, − is fixed, and then is decreased which eventually decreases . It is not necessary to delete the starting symbols. Depending on the application sometimes consecutive positions are considered as 0 and are deleted.
All the symbols which are dropped need not be transmitted and at the receiving end can be reinserted. To convert cyclic code to shortened code, set symbols to zero and drop them from each codeword. Any cyclic code can be converted to quasi-cyclic codes by dropping every th symbol where is a factor of . If the dropped symbols are not check symbols then this cyclic code is also a shortened code.
Cyclic codes for correcting errors[edit]
Now, we will begin the discussion of cyclic codes explicitly with error detection and correction. Cyclic codes can be used to correct errors, like Hamming codes as cyclic codes can be used for correcting single error. Likewise, they are also used to correct double errors and burst errors. All types of error corrections are covered briefly in the further subsections.
The (7,4) Hamming code has a generator polynomial . This polynomial has a zero in Galois extension field at the primitive element , and all codewords satisfy . Cyclic codes can also be used to correct double errors over the field . Blocklength will be equal to and primitive elements and as zeros in the because we are considering the case of two errors here, so each will represent one error.
The received word is a polynomial of degree given as
where can have at most two nonzero coefficients corresponding to 2 errors.
We define the Syndrome Polynomial, as the remainder of polynomial when divided by the generator polynomial i.e.
as .
For correcting two errors[edit]
Let the field elements and be the two error location numbers. If only one error occurs then is equal to zero and if none occurs both are zero.
Let and .
These field elements are called «syndromes». Now because is zero at primitive elements and , so we can write and . If say two errors occur, then
and
.
And these two can be considered as two pair of equations in with two unknowns and hence we can write
and
.
Hence if the two pair of nonlinear equations can be solved cyclic codes can used to correct two errors.
Hamming code[edit]
The Hamming(7,4) code may be written as a cyclic code over GF(2) with generator . In fact, any binary Hamming code of the form Ham(r, 2) is equivalent to a cyclic code,[3] and any Hamming code of the form Ham(r,q) with r and q-1 relatively prime is also equivalent to a cyclic code.[4] Given a Hamming code of the form Ham(r,2) with , the set of even codewords forms a cyclic -code.[5]
Hamming code for correcting single errors[edit]
A code whose minimum distance is at least 3, have a check matrix all of whose columns are distinct and non zero. If a check matrix for a binary code has rows, then each column is an -bit binary number. There are possible columns. Therefore, if a check matrix of a binary code with at least 3 has rows, then it can only have columns, not more than that. This defines a code, called Hamming code.
It is easy to define Hamming codes for large alphabets of size . We need to define one matrix with linearly independent columns. For any word of size there will be columns who are multiples of each other. So, to get linear independence all non zero -tuples with one as a top most non zero element will be chosen as columns. Then two columns will never be linearly dependent because three columns could be linearly dependent with the minimum distance of the code as 3.
So, there are nonzero columns with one as top most non zero element. Therefore, a Hamming code is a code.
Now, for cyclic codes, Let be primitive element in , and let . Then and thus is a zero of the polynomial and is a generator polynomial for the cyclic code of block length .
But for , . And the received word is a polynomial of degree given as
where, or where represents the error locations.
But we can also use as an element of to index error location. Because , we have and all powers of from to are distinct. Therefore, we can easily determine error location from unless which represents no error. So, a Hamming code is a single error correcting code over with and .
Cyclic codes for correcting burst errors[edit]
From Hamming distance concept, a code with minimum distance can correct any errors. But in many channels error pattern is not very arbitrary, it occurs within very short segment of the message. Such kind of errors are called burst errors. So, for correcting such errors we will get a more efficient code of higher rate because of the less constraints. Cyclic codes are used for correcting burst error. In fact, cyclic codes can also correct cyclic burst errors along with burst errors. Cyclic burst errors are defined as
A cyclic burst of length is a vector whose nonzero components are among (cyclically) consecutive components, the first and the last of which are nonzero.
In polynomial form cyclic burst of length can be described as with as a polynomial of degree with nonzero coefficient . Here defines the pattern and defines the starting point of error. Length of the pattern is given by deg. The syndrome polynomial is unique for each pattern and is given by
A linear block code that corrects all burst errors of length or less must have at least check symbols. Proof: Because any linear code that can correct burst pattern of length or less cannot have a burst of length or less as a codeword because if it did then a burst of length could change the codeword to burst pattern of length , which also could be obtained by making a burst error of length in all zero codeword. Now, any two vectors that are non zero in the first components must be from different co-sets of an array to avoid their difference being a codeword of bursts of length . Therefore, number of such co-sets are equal to number of such vectors which are . Hence at least co-sets and hence at least check symbol.
This property is also known as Rieger bound and it is similar to the Singleton bound for random error correcting.
Fire codes as cyclic bounds[edit]
In 1959, Philip Fire[6] presented a construction of cyclic codes generated by a product of a binomial and a primitive polynomial. The binomial has the form for some positive odd integer .[7] Fire code is a cyclic burst error correcting code over with the generator polynomial
where is a prime polynomial with degree not smaller than and does not divide . Block length of the fire code is the smallest integer such that divides
.
A fire code can correct all burst errors of length t or less if no two bursts and appear in the same co-set. This can be proved by contradiction. Suppose there are two distinct nonzero bursts and of length or less and are in the same co-set of the code. So, their difference is a codeword. As the difference is a multiple of it is also a multiple of . Therefore,
.
This shows that is a multiple of , So
for some . Now, as is less than and is less than so is a codeword. Therefore,
.
Since degree is less than degree of , cannot divide . If is not zero, then also cannot divide as is less than and by definition of , divides for no smaller than . Therefore and equals to zero. That means both that both the bursts are same, contrary to assumption.
Fire codes are the best single burst correcting codes with high rate and they are constructed analytically. They are of very high rate and when and are equal, redundancy is least and is equal to . By using multiple fire codes longer burst errors can also be corrected.
For error detection cyclic codes are widely used and are called cyclic redundancy codes.
Cyclic codes on Fourier transform[edit]
Applications of Fourier transform are widespread in signal processing. But their applications are not limited to the complex fields only; Fourier transforms also exist in the Galois field . Cyclic codes using Fourier transform can be described in a setting closer to the signal processing.
Fourier transform over finite fields[edit]
Fourier transform over finite fields
The discrete Fourier transform of vector is given by a vector where,
= where,
where exp() is an th root of unity. Similarly in the finite field th root of unity is element of order . Therefore
If is a vector over , and be an element of of order , then Fourier transform of the vector is the vector and components are given by
= where,
Here is time index, is frequency and is the spectrum. One important difference between Fourier transform in complex field and Galois field is that complex field exists for every value of while in Galois field exists only if divides . In case of extension fields, there will be a Fourier transform in the extension field if divides for some .
In Galois field time domain vector is over the field but the spectrum may be over the extension field .
Spectral description of cyclic codes[edit]
Any codeword of cyclic code of blocklength can be represented by a polynomial of degree at most . Its encoder can be written as . Therefore, in frequency domain encoder can be written as . Here codeword spectrum has a value in but all the components in the time domain are from . As the data spectrum is arbitrary, the role of is to specify those where will be zero.
Thus, cyclic codes can also be defined as
Given a set of spectral indices, , whose elements are called check frequencies, the cyclic code is the set of words over whose spectrum is zero in the components indexed by . Any such spectrum will have components of the form .
So, cyclic codes are vectors in the field and the spectrum given by its inverse fourier transform is over the field and are constrained to be zero at certain components. But every spectrum in the field and zero at certain components may not have inverse transforms with components in the field . Such spectrum can not be used as cyclic codes.
Following are the few bounds on the spectrum of cyclic codes.
BCH bound[edit]
If be a factor of for some . The only vector in of weight or less that has consecutive components of its spectrum equal to zero is all-zero vector.
Hartmann-Tzeng bound[edit]
If be a factor of for some , and an integer that is coprime with . The only vector in of weight or less whose spectral
components equal zero for , where and , is the all zero vector.
Roos bound[edit]
If be a factor of for some and . The only vector in
of weight or less whose spectral components equal to zero for , where and takes at least values in the range , is the all-zero vector.
Quadratic residue codes[edit]
When the prime is a quadratic residue modulo the prime there is a quadratic residue code which is a cyclic code of length , dimension and minimum weight at least over .
Generalizations[edit]
A constacyclic code is a linear code with the property that for some constant λ if (c1,c2,…,cn) is a codeword then so is (λcn,c1,…,cn-1). A negacyclic code is a constacyclic code with λ=-1.[8] A quasi-cyclic code has the property that for some s, any cyclic shift of a codeword by s places is again a codeword.[9] A double circulant code is a quasi-cyclic code of even length with s=2.[9] Quasi-twisted codes and multi-twisted codes are further generalizations of constacyclic codes.[10][11]
See also[edit]
- Cyclic redundancy check
- BCH code
- Reed–Muller code
- Binary Golay code
- Ternary Golay code
- Eugene Prange
Notes[edit]
- ^ Van Lint 1998, p. 76
- ^ Van Lint 1998, p. 80
- ^ Hill 1988, pp. 159–160
- ^ Blahut 2003, Theorem 5.5.1
- ^ Hill 1988, pp. 162–163
- ^ P. Fire, E, P. (1959). A class of multiple-error-correcting binary codes for non-independent errors. Sylvania Reconnaissance Systems Laboratory, Mountain View, CA, Rept. RSL-E-2, 1959.
- ^ Wei Zhou, Shu Lin, Khaled Abdel-Ghaffar. Burst or random error correction based on Fire and BCH codes. ITA 2014: 1-5 2013.
- ^ Van Lint 1998, p. 75
- ^ a b MacWilliams & Sloane 1977, p. 506
- ^ Aydin, Nuh; Siap, Irfan; K. Ray-Chaudhuri, Dijen (2001). «The Structure of 1-Generator Quasi-Twisted Codes and New Linear Codes». Designs, Codes and Cryptography. 24 (3): 313–326. doi:10.1023/A:1011283523000. S2CID 17376783.
- ^ Aydin, Nuh; Halilović, Ajdin (2017). «A generalization of quasi-twisted codes: multi-twisted codes». Finite Fields and Their Applications. 45: 96–106. doi:10.1016/j.ffa.2016.12.002. S2CID 7694655.
References[edit]
- Blahut, Richard E. (2003), Algebraic Codes for Data Transmission (2nd ed.), Cambridge University Press, ISBN 0-521-55374-1
- Hill, Raymond (1988), A First Course In Coding Theory, Oxford University Press, ISBN 0-19-853803-0
- MacWilliams, F. J.; Sloane, N. J. A. (1977), The Theory of Error-Correcting Codes, New York: North-Holland Publishing, ISBN 0-444-85011-2
- Van Lint, J. H. (1998), Introduction to Coding Theory, Graduate Texts in Mathematics 86 (3rd ed.), Springer Verlag, ISBN 3-540-64133-5
Further reading[edit]
- Ranjan Bose, Information theory, coding and cryptography, ISBN 0-07-048297-7
- Irving S. Reed and Xuemin Chen, Error-Control Coding for Data Networks, Boston: Kluwer Academic Publishers, 1999, ISBN 0-7923-8528-4.
- Scott A. Vanstone, Paul C. Van Oorschot, An introduction to error correcting codes with applications, ISBN 0-7923-9017-2
External links[edit]
- John Gill’s (Stanford) class notes – Notes #3, October 8, Handout #9, EE 387.
- Jonathan Hall’s (MSU) class notes – Chapter 8. Cyclic codes — pp. 100 — 123
- David Terr. «Cyclic Code». MathWorld.
This article incorporates material from cyclic code on PlanetMath, which is licensed under the Creative Commons Attribution/Share-Alike License.