The table below lists the SQL numeric error codes and their error messages. These codes are returned as the SQLCODE variable value.
Note:
While this document lists error codes as negative values, JDBC and ODBC clients always receive positive values. For example, if an ODBC or JDBC application returns error code 30, look up error code -30 in this table.
SQLCODE 0 and 100
There are two SQLCODE values that do not represent an SQL error:
SQL Error Codes 0 and 100
| Error Code | Description |
|---|---|
| 0 | Successful Completion |
| 100 | No (more) data |
-
SQLCODE=0 indicates successful completion of an SQL operation. For a SELECT statement, this usually means the successful retrieval of data from a table. However, if the SELECT performs an aggregate operation, (for example: SELECT SUM(myfield)) the aggregate operation is successful and an SQLCODE=0 is issued even when there is no data in myfield; in this case SUM returns NULL and %ROWCOUNT=1.
-
SQLCODE=100 indicates that the SQL operation was successful, but found no data to act upon. This can occur for a number of reasons. For a SELECT these include: the specified table contains no data; the table contains no data that satisfies the query criteria; or row retrieval has reached the final row of the table. For an UPDATE or DELETE these include: the specified table contains no data; or the table contains no row of data that satisfies the WHERE clause criteria. In these cases %ROWCOUNT=0.
SQLCODE -400
The SQLCODE -400 error “Fatal error occurred” is a general error. It is generated when a more specific SQLCODE error code is not available.
Retrieving SQL Message Texts
To determine the meaning of an SQLCODE numeric code, use the following ObjectScript statement:
WRITE "SQLCODE=",$SYSTEM.SQL.SQLCODE(-nnn)This SQLCODE()Opens in a new tab method can also be called as a stored procedure from ODBC or JDBC: %SYSTEM.SQL_SQLCODE(-nnn).
When possible (usually at SQL compile time), error messages include the name of the field, table, view, or other element that caused the error. Placeholders for these names are shown using the <name> syntax convention.
The %msg variable may contain an additional message error text for certain errors. For further details, refer to System Variables in the “Using Embedded SQL” chapter of Using Caché SQL.
The message texts returned are shown below in their English versions. The actual message text returned depends upon your locale setting.
For information on generating ObjectScript general errors from SQLCODE errors, refer to the %SYSTEM.ErrorOpens in a new tab class in the InterSystems Class Reference.
Table of SQL Error Codes and Messages
For ease of use, the SQL Error Codes Table has been divided into the following sub-tables:
-
Error Codes 0 and 100
-
Error Codes -1 to -99
-
Error Codes -101 to -399
-
Error Codes -400 to -500
-
WinSock Error Codes -10050 to -11002
SQL Error Codes -1 to -99
| Error Code | Description |
|---|---|
| -1 | Invalid SQL statement |
| -2 | Exponent digits missing after ‘E’ |
| -3 | Closing quote («) missing |
| -4 | A term expected, beginning with one of the following: identifier, constant, aggregate, %ALPHAUP, %EXACT, %MVR, %SQLSTRING, %SQLUPPER, %STRING, %UPPER, $$, :, +, -, (, NOT, EXISTS, or FOR |
| -5 | Column number specified in ORDER does not match SELECT list |
| -6 | ORDER BY column after UNION not found as SELECT column |
| -7 | Exponent out of range |
| -8 | Invalid DATEPART code for DATEPART(), DATENAME(), DATEADD(), or DATEDIFF() |
| -9 | Incompatible SELECT lists used in UNION |
| -10 | The SELECT list of the subquery must have exactly one item |
| -11 | A scalar expression expected, not a condition |
| -12 | A term expected, beginning with one of the following: identifier, constant, aggregate, $$, :, (, +, -, %ALPHAUP, %EXACT, %MVR, %SQLSTRING, %SQLUPPER, %STRING, or %UPPER |
| -13 | An expression other than a subquery expected here |
| -14 | A comparison operator is required here |
| -15 | A condition expected after NOT |
| -16 | Quantifier SOME expected after the FOR in the for-expression |
| -17 | A for-condition expected after the ( in the for-expression |
| -18 | IS (or IS NOT) NULL predicate can be applied only to a field |
| -19 | An aggregate function cannot be used in a WHERE or GROUP BY clause |
| -20 | Name conflict in the FROM list over label |
| -21 | Pointer->Field reference may not be modified by an INSERT or UPDATE statement |
| -22 | ORDER must specify column names, not numbers, when after ‘SELECT *’ |
| -23 | Label is not listed among the applicable tables |
| -24 | Ambiguous sort column |
| -25 | Input encountered after end of query |
| -26 | Missing FROM clause |
| -27 | Field is ambiguous among the applicable tables |
| -28 | Host variable name must begin with either % or a letter |
| -29 | Field not found in the applicable tables |
| -30 | Table or view not found |
| -31 | Field not (found/unique) in table(s) |
| -32 | Outer-join symbol ( =* or *= ) must be between two fields |
| -33 | No field(s) found for table |
| -34 | Optimizer failed to find a usable join order |
| -35 | INSERT/UPDATE/DELETE not allowed for non-updateable view |
| -36 | WITH CHECK OPTION (CHECKOPTION class parameter) not allowed for non-updateable views |
| -37 | SQL Scalar/Aggregate/Unary function not supported for Stream fields |
| -38 | No master map for table |
| -39 | No RowID field for table |
| -40 | ODBC escape extension not supported |
| -41 | An extrinsic function call must have the form ‘$$tag^routine(…)’ |
| -42 | Closing quotes («») missing following pattern match |
| -43 | Table is ambiguous within #IMPORT schema name list |
| -44 | Duplicate method or query characteristic |
| -45 | Duplicate method in ObjectScript query body |
| -46 | Required method missing in ObjectScript query body |
| -47 | Invalid method or query characteristic |
| -48 | Invalid trigger REFERENCING clause for the trigger’s event |
| -49 | Trigger REFERENCING clause cannot be specified when trigger language not SQL |
| -50 | Trigger specifies UPDATE OF <fieldlist> clause when trigger language not SQL |
| -51 | SQL statement expected |
| -52 | Cursor (Already/Was Not) DECLAREd |
| -53 | Constant or variable expected as new value |
| -54 | Array designator (last subscript omitted) expected after VALUES |
| -55 | Invalid GRANT <role> TO or REVOKE <role> FROM |
| -56 | GRANT/REVOKE Action not applicable to an object of this type |
| -57 | Trigger specifies WHEN clause when trigger language not SQL |
| -58 | Duplicate field found in trigger UPDATE OF <fieldlist> clause |
| -59 | Cannot have more than one field |
| -60 | An action (%ALTER, SELECT, UPDATE, etc.) expected |
| -61 | Cursor not updateable |
| -62 | Additional new values expected for INSERT/UPDATE |
| -63 | Data exception — invalid escape character |
| -64 | Incompatible SELECT list is used in INSERT |
| -65 | Positive integer constant or variable expected |
| -66 | Redundant fields found in SELECT list |
| -67 | Implicit join (arrow syntax) not supported in ON clause |
| -68 | Legacy outer join (=*, *=) not supported in ON clause |
| -69 | SET <field> = <value expression> not allowed with WHERE CURRENT OF <cursor> |
| -70 | Multi-Line field only valid for LIKE, Contains ([), or NULL Comparison. |
| -71 | Multi-Line field must be the left operand of the Comparison. |
| -72 | Multi-Line field not valid in ORDER BY clause |
| -73 | Aggregates not supported in ORDER BY clause |
| -74 | Duplicate <select-list> alias names found |
| -75 | <trim_spec> and/or <trim_char> required before FROM in TRIM function. |
| -76 | Cardinality mismatch between the SELECT-list and INTO-list. |
| -77 | Qualified column reference not allowed in this JOIN context. |
| -78 | Invalid transaction state. |
| -79 | Referencing key and referenced key must be the same size |
| -80 | Integer expected |
| -81 | Column Constraint expected |
| -82 | Multiple table %DESCRIPTION definitions found |
| -83 | Multiple table %FILE definitions found |
| -84 | Multiple table %NUMROWS definitions found |
| -85 | Multiple table %ROUTINE definitions found |
| -86 | Invalid field definition, no datatype defined |
| -87 | Invalid table name |
| -88 | Invalid field name |
| -89 | Invalid index name |
| -90 | Invalid view name |
| -91 | Transaction mode cannot be specified more than once |
| -92 | Level of isolation cannot be READ UNCOMMITTED or READ VERIFIED if READ WRITE specified |
| -93 | number of conditions for the DIAGNOSTICS SIZE must be exact numeric |
| -94 | Unsupported usage of OUTER JOIN |
| -95 | Operation disallowed by operation table |
| -96 | Specified level of isolation is not supported |
| -97 | Duplicate select-list names found. |
| -98 | License violation |
| -99 | Privilege violation |
SQL Error Codes -101 to -399
| Error Code | Description |
|---|---|
| -101 | Attempt to open a cursor that is already open |
| -102 | Operation (FETCH/CLOSE/UPDATE/DELETE/…) attempted on an unopened cursor |
| -103 | Positioned UPDATE or DELETE attempted, but the cursor is not positioned on any row |
| -104 | Field validation failed in INSERT, or value failed to convert in DisplayToLogical or OdbcToLogical |
| -105 | Field validation failed in UPDATE |
| -106 | Row to DELETE not found |
| -107 | Cannot UPDATE RowID or RowID based on fields |
| -108 | Required field missing; INSERT or UPDATE not allowed |
| -109 | Cannot find the row designated for UPDATE |
| -110 | Locking conflict in filing |
| -111 | Cannot INSERT into a ‘Default Only’ RowID or RowID based on field |
| -112 | Access violation |
| -113 | %THRESHOLD violation |
| -114 | One or more matching rows is locked by another user |
| -115 | Cannot INSERT/UPDATE/DELETE on a read only table |
| -116 | Cardinality mismatch on INSERT/UPDATE between values list and number of table columns. |
| -117 | Aggregates not supported in views |
| -118 | Unknown or non-unique User or Role |
| -119 | UNIQUE or PRIMARY KEY constraint failed uniqueness check upon INSERT |
| -120 | UNIQUE or PRIMARY KEY constraint failed uniqueness check upon UPDATE |
| -121 | FOREIGN KEY constraint failed referential check upon INSERT of row in referencing table |
| -122 | FOREIGN KEY constraint failed referential check upon UPDATE of row in referencing table |
| -123 | FOREIGN KEY constraint failed referential check upon UPDATE of row in referenced table |
| -124 | FOREIGN KEY constraint failed referential check upon DELETE of row in referenced table |
| -125 | UNIQUE or PRIMARY KEY Constraint failed uniqueness check upon creation of the constraint |
| -126 | REVOKE with RESTRICT failed. |
| -127 | FOREIGN KEY Constraint failed referential check upon creation of the constraint |
| -128 | Argument to scalar function %OBJECT() must be a stream field |
| -129 | Illegal value for SET OPTION locale property |
| -130 | Before Insert trigger failed |
| -131 | After Insert trigger failed |
| -132 | Before Update trigger failed |
| -133 | After Update trigger failed |
| -134 | Before Delete trigger failed |
| -135 | After Delete trigger failed |
| -136 | View’s WITH CHECK OPTION validation failed in INSERT |
| -137 | View’s WITH CHECK OPTION validation failed in UPDATE |
| -138 | Cannot INSERT/UPDATE a value for a read only field |
| -139 | Concurrency failure on update: row versions not the same |
| -140 | Invalid length parameter passed to the SUBSTRING function |
| -141 | Invalid input value passed to the CONVERT function |
| -142 | Cardinality mismatch between the view-column-list and view query’s SELECT clause |
| -143 | ORDER BY not valid in a view’s query |
| -144 | A subquery is not allowed in an insert statement’s set/values clause |
| -145 | SQLPREVENTFULLSCAN class parameter is 1 for this table. Query that performs full scan of data map is not allowed |
| -146 | Unable to convert date input to a valid logical date value |
| -147 | Unable to convert time input to a valid logical time value |
| -148 | CREATE VIEW, ALTER VIEW, or a view’s query may not contain host variable references |
| -149 | SQL Function encountered an error |
| -150 | Optimistic concurrency locking for a class definition failed |
| -151 | Index is not found within tables used by this statement |
| -152 | Index is ambiguous within tables used by this statement |
| -161 | References to an SQL connection must constitute a whole subquery |
| -162 | SQL Connection is not defined |
| -201 | Table or view name not unique |
| -220 | Gateway query error |
| -221 | Gateway query GetConnection() failed |
| -222 | Gateway query AllocStatement() failed |
| -223 | Gateway query Prepare() failed |
| -225 | Gateway query BindParameters() failed |
| -226 | Gateway query Execute() failed |
| -227 | Gateway query Fetch() failed |
| -228 | Gateway query GetData() failed |
| -241 | Parallel query queue error |
| -242 | Parallel query run-time error |
| -300 | DDL not allowed on this table definition |
| -301 | No Savepoint name |
| -302 | Savepoint names starting with «SYS» are reserved |
| -303 | No implicit conversion of Stream value to non-Stream field in UPDATE assignment is supported |
| -304 | Attempt to add a NOT NULL field with no default value to a table which contains data |
| -305 | Attempt to make field required when the table has one or more rows where the column value is NULL |
| -306 | Column with this name already exists |
| -307 | Primary key already defined for this table |
| -308 | Identity column already defined for this table |
| -309 | The left operand of %CONTAINS is not a property that supports the %Text interface |
| -310 | Foreign key references non-existent table |
| -311 | Foreign key with same name already defined for this table |
| -312 | Invalid schema name. Must use delimited identifiers to reference this schema name |
| -313 | Condition expression not supported for Stream fields |
| -314 | Foreign key references non-unique key/column collection |
| -315 | Constraint or Key not found |
| -316 | Foreign key references non-existent key/column collection |
| -317 | Cannot DROP Constraint — One or more Foreign Key constraints reference this Unique constraint |
| -319 | Referenced table has no primary key defined |
| -320 | Cannot DROP table — One or more Foreign Key constraints reference this table |
| -321 | Cannot DROP view — One or more views reference this view |
| -322 | Cannot DROP column — column is defined on one or more indexes or constraints |
| -324 | Index with this name already defined for this table |
| -325 | Index cannot be dropped because it is the IDKEY index and the table has data |
| -333 | No such index defined |
| -334 | Index name is ambiguous. Index found in multiple tables. |
| -340 | No such database (namespace) defined |
| -341 | Database file already exists |
| -342 | Cannot delete system namespace |
| -343 | Invalid database name |
| -344 | Cannot drop database that you are currently using or connected to |
| -350 | An unexpected error occurred executing SqlComputeCode |
| -356 | SQL Function (function stored procedure) is not defined to return a value |
| -357 | SQL Function (function stored procedure) is not defined as a function procedure |
| -358 | SQL Function (function stored procedure) name not unique |
| -359 | SQL Function (function stored procedure) not found |
| -360 | Class not found |
| -361 | Method or Query name not unique |
| -362 | Method or Query not found |
| -363 | Trigger not found |
| -364 | Trigger with same EVENT, TIME, and ORDER already defined |
| -365 | Trigger name not unique |
| -366 | Schema name mismatch between trigger name and table name |
| -370 | SQL CALL, more arguments specified than defined in the stored procedure |
| -371 | :HVar = CALL … Specified for a procedure which does not return a value |
| -372 | Support for extrinsic function calls are disabled |
| -373 | An extrinsic function call may not call a % routine |
| -374 | Cannot alter the datatype of a field to/from a stream type when the table contains data |
| -375 | Cannot ROLLBACK to unestablished savepoint |
| -376 | Unsupported CAST target specified |
| -377 | Field appears more than once in assignment list of insert or update statement |
| -378 | Datatype mismatch, explicit CAST is required |
| -380 | Invalid or Missing argument to scalar function |
| -381 | Too many arguments to scalar function |
SQL Error Codes -400 to -500
| Error Code | Description |
|---|---|
| -400 | Fatal error occurred |
| -401 | Fatal Connection error |
| -402 | Invalid Username/Password |
| -405 | Unable to read from communication device |
| -406 | Unable to Write to Server |
| -407 | Unable to Write to Server Master |
| -408 | Unable to start server |
| -409 | Invalid server function |
| -410 | Invalid Directory |
| -411 | No stream object defined for field |
| -412 | General stream error |
| -413 | Incompatible client/server protocol |
| -415 | Fatal error occurred within the SQL filer |
| -416 | CacheInfo Error |
| -417 | Security Error |
| -422 | SELECT request processed via ODBC, JDBC, or Dynamic SQL cannot contain an INTO clause |
| -425 | Error processing stored procedure request |
| -426 | Error preparing stored procedure |
| -427 | Invalid stored procedure name |
| -428 | Stored procedure not found |
| -429 | Invalid number of input/output parameters for stored procedure |
| -430 | Cannot initialize procedure context |
| -431 | Stored procedure parameter type mismatch |
| -432 | Function returned multiple rows when only a single value is expected |
| -450 | Request timed out due to user timeout |
| -451 | Unable to receive server message |
| -452 | Message sequencing error |
| -453 | Error in user initialization code |
| -454 | Error sending external interrupt request |
| -459 | Kerberos authentication failure |
| -460 | General error |
| -461 | Communication link failure |
| -462 | Memory allocation failure |
| -463 | Invalid column number |
| -464 | Function sequence error |
| -465 | Invalid string or buffer length |
| -466 | Invalid parameter number |
| -467 | Column type out of range |
| -468 | Fetch type out of range |
| -469 | Driver not capable |
| -470 | Option value changed |
| -471 | Duplicate cursor name |
| -472 | A collection-valued property was expected |
| -478 | Query recompiled: Result Set mismatch |
| -500 | Fetch row count limit reached |
WinSock Error Codes -10050 to -11002
| Error Code | Description |
|---|---|
| -10050 | WinSock: Network is down |
| -10051 | WinSock: Network is unreachable |
| -10052 | WinSock: Net dropped connection or reset |
| -10054 | WinSock: Connection reset by peer (due to timeout or reboot) |
| -10055 | WinSock: No buffer space available |
| -10056 | WinSock: Socket is already connected |
| -10057 | WinSock: Socket is not connected |
| -10058 | WinSock: Cannot send after socket shutdown |
| -10060 | WinSock: Connection timed out |
| -10061 | WinSock: Connection refused |
| -10064 | WinSock: Host is down |
| -10065 | WinSock: No route to host |
| -10070 | WinSock: Stale NFS file handle |
| -10091 | WinSock: Network subsystem is unavailable |
| -10092 | WinSock: WINSOCK DLL version out of range |
| -10093 | WinSock: Successful WSASTARTUP not yet performed |
| -11001 | WinSock: Host not found |
| -11002 | WinSock: Nonauthoritative host not found |
Время прочтения
16 мин
Просмотры 35K
Привет, Хабр! Представляю вашему вниманию перевод статьи «Error and Transaction Handling in SQL Server. Part One – Jumpstart Error Handling» автора Erland Sommarskog.
1. Введение
Эта статья – первая в серии из трёх статей, посвященных обработке ошибок и транзакций в SQL Server. Её цель – дать вам быстрый старт в теме обработки ошибок, показав базовый пример, который подходит для большей части вашего кода. Эта часть написана в расчете на неопытного читателя, и по этой причине я намеренно умалчиваю о многих деталях. В данный момент задача состоит в том, чтобы рассказать как без упора на почему. Если вы принимаете мои слова на веру, вы можете прочесть только эту часть и отложить остальные две для дальнейших этапов в вашей карьере.
С другой стороны, если вы ставите под сомнение мои рекомендации, вам определенно необходимо прочитать две остальные части, где я погружаюсь в детали намного более глубоко, исследуя очень запутанный мир обработки ошибок и транзакций в SQL Server. Вторая и третья части, так же, как и три приложения, предназначены для читателей с более глубоким опытом. Первая статья — короткая, вторая и третья значительно длиннее.
Все статьи описывают обработку ошибок и транзакций в SQL Server для версии 2005 и более поздних версий.
1.1 Зачем нужна обработка ошибок?
Почему мы обрабатываем ошибки в нашем коде? На это есть много причин. Например, на формах в приложении мы проверяем введенные данные и информируем пользователей о допущенных при вводе ошибках. Ошибки пользователя – это предвиденные ошибки. Но нам также нужно обрабатывать непредвиденные ошибки. То есть, ошибки могут возникнуть из-за того, что мы что-то упустили при написании кода. Простой подход – это прервать выполнение или хотя бы вернуться на этап, в котором мы имеем полный контроль над происходящим. Недостаточно будет просто подчеркнуть, что совершенно непозволительно игнорировать непредвиденные ошибки. Это недостаток, который может вызвать губительные последствия: например, стать причиной того, что приложение будет предоставлять некорректную информацию пользователю или, что еще хуже, сохранять некорректные данные в базе. Также важно сообщать о возникновении ошибки с той целью, чтобы пользователь не думал о том, что операция прошла успешно, в то время как ваш код на самом деле ничего не выполнил.
Мы часто хотим, чтобы в базе данных изменения были атомарными. Например, задача по переводу денег с одного счета на другой. С этой целью мы должны изменить две записи в таблице CashHoldings и добавить две записи в таблицу Transactions. Абсолютно недопустимо, чтобы ошибки или сбой привели к тому, что деньги будут переведены на счет получателя, а со счета отправителя они не будут списаны. По этой причине обработка ошибок также касается и обработки транзакций. В приведенном примере нам нужно обернуть операцию в BEGIN TRANSACTION и COMMIT TRANSACTION, но не только это: в случае ошибки мы должны убедиться, что транзакция откачена.
2. Основные команды
Мы начнем с обзора наиболее важных команд, которые необходимы для обработки ошибок. Во второй части я опишу все команды, относящиеся к обработке ошибок и транзакций.
2.1 TRY-CATCH
Основным механизмом обработки ошибок является конструкция TRY-CATCH, очень напоминающая подобные конструкции в других языках. Структура такова:
BEGIN TRY
<обычный код>
END TRY
BEGIN CATCH
<обработка ошибок>
END CATCH
Если какая-либо ошибка появится в <обычный код>, выполнение будет переведено в блок CATCH, и будет выполнен код обработки ошибок.
Как правило, в CATCH откатывают любую открытую транзакцию и повторно вызывают ошибку. Таким образом, вызывающая клиентская программа понимает, что что-то пошло не так. Повторный вызов ошибки мы обсудим позже в этой статье.
Вот очень быстрый пример:
BEGIN TRY
DECLARE @x int
SELECT @x = 1/0
PRINT 'Not reached'
END TRY
BEGIN CATCH
PRINT 'This is the error: ' + error_message()
END CATCH
Результат выполнения: This is the error: Divide by zero error encountered.
Мы вернемся к функции error_message() позднее. Стоит отметить, что использование PRINT в обработчике CATCH приводится только в рамках экспериментов и не следует делать так в коде реального приложения.
Если <обычный код> вызывает хранимую процедуру или запускает триггеры, то любая ошибка, которая в них возникнет, передаст выполнение в блок CATCH. Если более точно, то, когда возникает ошибка, SQL Server раскручивает стек до тех пор, пока не найдёт обработчик CATCH. И если такого обработчика нет, SQL Server отправляет сообщение об ошибке напрямую клиенту.
Есть одно очень важное ограничение у конструкции TRY-CATCH, которое нужно знать: она не ловит ошибки компиляции, которые возникают в той же области видимости. Рассмотрим пример:
CREATE PROCEDURE inner_sp AS
BEGIN TRY
PRINT 'This prints'
SELECT * FROM NoSuchTable
PRINT 'This does not print'
END TRY
BEGIN CATCH
PRINT 'And nor does this print'
END CATCH
go
EXEC inner_spВыходные данные:
This prints
Msg 208, Level 16, State 1, Procedure inner_sp, Line 4
Invalid object name 'NoSuchTable'Как можно видеть, блок TRY присутствует, но при возникновении ошибки выполнение не передается блоку CATCH, как это ожидалось. Это применимо ко всем ошибкам компиляции, таким как пропуск колонок, некорректные псевдонимы и тому подобное, которые возникают во время выполнения. (Ошибки компиляции могут возникнуть в SQL Server во время выполнения из-за отложенного разрешения имен – особенность, благодаря которой SQL Server позволяет создать процедуру, которая обращается к несуществующим таблицам.)
Эти ошибки не являются полностью неуловимыми; вы не можете поймать их в области, в которой они возникают, но вы можете поймать их во внешней области. Добавим такой код к предыдущему примеру:
CREATE PROCEDURE outer_sp AS
BEGIN TRY
EXEC inner_sp
END TRY
BEGIN CATCH
PRINT 'The error message is: ' + error_message()
END CATCH
go
EXEC outer_spТеперь мы получим на выходе это:
This prints
The error message is: Invalid object name 'NoSuchTable'.На этот раз ошибка была перехвачена, потому что сработал внешний обработчик CATCH.
2.2 SET XACT_ABORT ON
В начало ваших хранимых процедур следует всегда добавлять это выражение:
SET XACT_ABORT, NOCOUNT ONОно активирует два параметра сессии, которые выключены по умолчанию в целях совместимости с предыдущими версиями, но опыт доказывает, что лучший подход – это иметь эти параметры всегда включенными. Поведение SQL Server по умолчанию в той ситуации, когда не используется TRY-CATCH, заключается в том, что некоторые ошибки прерывают выполнение и откатывают любые открытые транзакции, в то время как с другими ошибками выполнение последующих инструкций продолжается. Когда вы включаете XACT_ABORT ON, почти все ошибки начинают вызывать одинаковый эффект: любая открытая транзакция откатывается, и выполнение кода прерывается. Есть несколько исключений, среди которых наиболее заметным является выражение RAISERROR.
Параметр XACT_ABORT необходим для более надежной обработки ошибок и транзакций. В частности, при настройках по умолчанию есть несколько ситуаций, когда выполнение может быть прервано без какого-либо отката транзакции, даже если у вас есть TRY-CATCH. Мы видели такой пример в предыдущем разделе, где мы выяснили, что TRY-CATCH не перехватывает ошибки компиляции, возникшие в той же области. Открытая транзакция, которая не была откачена из-за ошибки, может вызвать серьезные проблемы, если приложение работает дальше без завершения транзакции или ее отката.
Для надежной обработки ошибок в SQL Server вам необходимы как TRY-CATCH, так и SET XACT_ABORT ON. Среди них инструкция SET XACT_ABORT ON наиболее важна. Если для кода на промышленной среде только на нее полагаться не стоит, то для быстрых и простых решений она вполне подходит.
Параметр NOCOUNT не имеет к обработке ошибок никакого отношения, но включение его в код является хорошей практикой. NOCOUNT подавляет сообщения вида (1 row(s) affected), которые вы можете видеть в панели Message в SQL Server Management Studio. В то время как эти сообщения могут быть полезны при работе c SSMS, они могут негативно повлиять на производительность в приложении, так как увеличивают сетевой трафик. Сообщение о количестве строк также может привести к ошибке в плохо написанных клиентских приложениях, которые могут подумать, что это данные, которые вернул запрос.
Выше я использовал синтаксис, который немного необычен. Большинство людей написали бы два отдельных выражения:
SET NOCOUNT ON
SET XACT_ABORT ONМежду ними нет никакого отличия. Я предпочитаю версию с SET и запятой, т.к. это снижает уровень шума в коде. Поскольку эти выражения должны появляться во всех ваших хранимых процедурах, они должны занимать как можно меньше места.
3. Основной пример обработки ошибок
После того, как мы посмотрели на TRY-CATCH и SET XACT_ABORT ON, давайте соединим их вместе в примере, который мы можем использовать во всех наших хранимых процедурах. Для начала я покажу пример, в котором ошибка генерируется в простой форме, а в следующем разделе я рассмотрю решения получше.
Для примера я буду использовать эту простую таблицу.
CREATE TABLE sometable(a int NOT NULL,
b int NOT NULL,
CONSTRAINT pk_sometable PRIMARY KEY(a, b))Вот хранимая процедура, которая демонстрирует, как вы должны работать с ошибками и транзакциями.
CREATE PROCEDURE insert_data @a int, @b int AS
SET XACT_ABORT, NOCOUNT ON
BEGIN TRY
BEGIN TRANSACTION
INSERT sometable(a, b) VALUES (@a, @b)
INSERT sometable(a, b) VALUES (@b, @a)
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
DECLARE @msg nvarchar(2048) = error_message()
RAISERROR (@msg, 16, 1)
RETURN 55555
END CATCHПервая строка в процедуре включает XACT_ABORT и NOCOUNT в одном выражении, как я показывал выше. Эта строка – единственная перед BEGIN TRY. Все остальное в процедуре должно располагаться после BEGIN TRY: объявление переменных, создание временных таблиц, табличных переменных, всё. Даже если у вас есть другие SET-команды в процедуре (хотя причины для этого встречаются редко), они должны идти после BEGIN TRY.
Причина, по которой я предпочитаю указывать SET XACT_ABORT и NOCOUNT перед BEGIN TRY, заключается в том, что я рассматриваю это как одну строку шума: она всегда должна быть там, но я не хочу, чтобы это мешало взгляду. Конечно же, это дело вкуса, и если вы предпочитаете ставить SET-команды после BEGIN TRY, ничего страшного. Важно то, что вам не следует ставить что-либо другое перед BEGIN TRY.
Часть между BEGIN TRY и END TRY является основной составляющей процедуры. Поскольку я хотел использовать транзакцию, определенную пользователем, я ввел довольно надуманное бизнес-правило, в котором говорится, что если вы вставляете пару, то обратная пара также должна быть вставлена. Два выражения INSERT находятся внутри BEGIN и COMMIT TRANSACTION. Во многих случаях у вас будет много строк кода между BEGIN TRY и BEGIN TRANSACTION. Иногда у вас также будет код между COMMIT TRANSACTION и END TRY, хотя обычно это только финальный SELECT, возвращающий данные или присваивающий значения выходным параметрам. Если ваша процедура не выполняет каких-либо изменений или имеет только одно выражение INSERT/UPDATE/DELETE/MERGE, то обычно вам вообще не нужно явно указывать транзакцию.
В то время как блок TRY будет выглядеть по-разному от процедуры к процедуре, блок CATCH должен быть более или менее результатом копирования и вставки. То есть вы делаете что-то короткое и простое и затем используете повсюду, не особо задумываясь. Обработчик CATCH, приведенный выше, выполняет три действия:
- Откатывает любые открытые транзакции.
- Повторно вызывает ошибку.
- Убеждается, что возвращаемое процедурой значение отлично от нуля.
Эти три действия должны всегда быть там. Мы можете возразить, что строка
IF @@trancount > 0 ROLLBACK TRANSACTIONне нужна, если нет явной транзакции в процедуре, но это абсолютно неверно. Возможно, вы вызываете хранимую процедуру, которая открывает транзакцию, но которая не может ее откатить из-за ограничений TRY-CATCH. Возможно, вы или кто-то другой добавите явную транзакцию через два года. Вспомните ли вы тогда о том, что нужно добавить строку с откатом? Не рассчитывайте на это. Я также слышу читателей, которые возражают, что если тот, кто вызывает процедуру, открыл транзакцию, мы не должны ее откатывать… Нет, мы должны, и если вы хотите знать почему, вам нужно прочитать вторую и третью части. Откат транзакции в обработчике CATCH – это категорический императив, у которого нет исключений.
Код повторной генерации ошибки включает такую строку:
DECLARE @msg nvarchar(2048) = error_message()Встроенная функция error_message() возвращает текст возникшей ошибки. В следующей строке ошибка повторно вызывается с помощью выражения RAISERROR. Это не самый простой способ вызова ошибки, но он работает. Другие способы мы рассмотрим в следующей главе.
Замечание: синтаксис для присвоения начального значения переменной в DECLARE был внедрен в SQL Server 2008. Если у вас SQL Server 2005, вам нужно разбить строку на DECLARE и выражение SELECT.
Финальное выражение RETURN – это страховка. RAISERROR никогда не прерывает выполнение, поэтому выполнение следующего выражения будет продолжено. Пока все процедуры используют TRY-CATCH, а также весь клиентский код обрабатывает исключения, нет повода для беспокойства. Но ваша процедура может быть вызвана из старого кода, написанного до SQL Server 2005 и до внедрения TRY-CATCH. В те времена лучшее, что мы могли делать, это смотреть на возвращаемые значения. То, что вы возвращаете с помощью RETURN, не имеет особого значения, если это не нулевое значение (ноль обычно обозначает успешное завершение работы).
Последнее выражение в процедуре – это END CATCH. Никогда не следует помещать какой-либо код после END CATCH. Кто-нибудь, читающий процедуру, может не увидеть этот кусок кода.
После прочтения теории давайте попробуем тестовый пример:
EXEC insert_data 9, NULLРезультат выполнения:
Msg 50000, Level 16, State 1, Procedure insert_data, Line 12
Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.Давайте добавим внешнюю процедуру для того, чтобы увидеть, что происходит при повторном вызове ошибки:
CREATE PROCEDURE outer_sp @a int, @b int AS
SET XACT_ABORT, NOCOUNT ON
BEGIN TRY
EXEC insert_data @a, @b
END TRY
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
DECLARE @msg nvarchar(2048) = error_message()
RAISERROR (@msg, 16, 1)
RETURN 55555
END CATCH
go
EXEC outer_sp 8, 8Результат работы:
Msg 50000, Level 16, State 1, Procedure outer_sp, Line 9
Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Мы получили корректное сообщение об ошибке, но если вы посмотрите на заголовки этого сообщения и на предыдущее поближе, то можете заметить проблему:
Msg 50000, Level 16, State 1, Procedure insert_data, Line 12
Msg 50000, Level 16, State 1, Procedure outer_sp, Line 9Сообщение об ошибке выводит информацию о расположении конечного выражения RAISERROR. В первом случае некорректен только номер строки. Во втором случае некорректно также имя процедуры. Для простых процедур, таких как наш тестовый пример, это не является большой проблемой. Но если у вас есть несколько уровней вложенных сложных процедур, то наличие сообщения об ошибке с отсутствием указания на место её возникновения сделает поиск и устранение ошибки намного более сложным делом. По этой причине желательно генерировать ошибку таким образом, чтобы можно было определить нахождение ошибочного фрагмента кода быстро, и это то, что мы рассмотрим в следующей главе.
4. Три способа генерации ошибки
4.1 Использование error_handler_sp
Мы рассмотрели функцию error_message(), которая возвращает текст сообщения об ошибке. Сообщение об ошибке состоит из нескольких компонентов, и существует своя функция error_xxx() для каждого из них. Мы можем использовать их для повторной генерации полного сообщения, которое содержит оригинальную информацию, хотя и в другом формате. Если делать это в каждом обработчике CATCH, это будет большой недостаток — дублирование кода. Вам не обязательно находиться в блоке CATCH для вызова error_message() и других подобных функций, и они вернут ту же самую информацию, если будут вызваны из хранимой процедуры, которую выполнит блок CATCH.
Позвольте представить вам error_handler_sp:
CREATE PROCEDURE error_handler_sp AS
DECLARE @errmsg nvarchar(2048),
@severity tinyint,
@state tinyint,
@errno int,
@proc sysname,
@lineno int
SELECT @errmsg = error_message(), @severity = error_severity(),
@state = error_state(), @errno = error_number(),
@proc = error_procedure(), @lineno = error_line()
IF @errmsg NOT LIKE '***%'
BEGIN
SELECT @errmsg = '*** ' + coalesce(quotename(@proc), '<dynamic SQL>') +
', Line ' + ltrim(str(@lineno)) + '. Errno ' +
ltrim(str(@errno)) + ': ' + @errmsg
END
RAISERROR('%s', @severity, @state, @errmsg)Первое из того, что делает error_handler_sp – это сохраняет значение всех error_xxx() функций в локальные переменные. Я вернусь к выражению IF через секунду. Вместо него давайте посмотрим на выражение SELECT внутри IF:
SELECT @errmsg = '*** ' + coalesce(quotename(@proc), '<dynamic SQL>') +
', Line ' + ltrim(str(@lineno)) + '. Errno ' +
ltrim(str(@errno)) + ': ' + @errmsgЦель этого SELECT заключается в форматировании сообщения об ошибке, которое передается в RAISERROR. Оно включает в себя всю информацию из оригинального сообщения об ошибке, которое мы не можем вставить напрямую в RAISERROR. Мы должны обработать имя процедуры, которое может быть NULL для ошибок в обычных скриптах или в динамическом SQL. Поэтому используется функция COALESCE. (Если вы не понимаете форму выражения RAISERROR, я рассказываю о нем более детально во второй части.)
Отформатированное сообщение об ошибке начинается с трех звездочек. Этим достигаются две цели: 1) Мы можем сразу видеть, что это сообщение вызвано из обработчика CATCH. 2) Это дает возможность для error_handler_sp отфильтровать ошибки, которые уже были сгенерированы один или более раз, с помощью условия NOT LIKE ‘***%’ для того, чтобы избежать изменения сообщения во второй раз.
Вот как обработчик CATCH должен выглядеть, когда вы используете error_handler_sp:
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
EXEC error_handler_sp
RETURN 55555
END CATCHДавайте попробуем несколько тестовых сценариев.
EXEC insert_data 8, NULL
EXEC outer_sp 8, 8Результат выполнения:
Msg 50000, Level 16, State 2, Procedure error_handler_sp, Line 20
*** [insert_data], Line 5. Errno 515: Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.
Msg 50000, Level 14, State 1, Procedure error_handler_sp, Line 20
*** [insert_data], Line 6. Errno 2627: Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Заголовки сообщений говорят о том, что ошибка возникла в процедуре error_handler_sp, но текст сообщений об ошибках дает нам настоящее местонахождение ошибки – как название процедуры, так и номер строки.
Я покажу еще два метода вызова ошибок. Однако error_handler_sp является моей главной рекомендацией для читателей, которые читают эту часть. Это — простой вариант, который работает на всех версиях SQL Server начиная с 2005. Существует только один недостаток: в некоторых случаях SQL Server генерирует два сообщения об ошибках, но функции error_xxx() возвращают только одну из них, и поэтому одно из сообщений теряется. Это может быть неудобно при работе с административными командами наподобие BACKUPRESTORE, но проблема редко возникает в коде, предназначенном чисто для приложений.
4.2. Использование ;THROW
В SQL Server 2012 Microsoft представил выражение ;THROW для более легкой обработки ошибок. К сожалению, Microsoft сделал серьезную ошибку при проектировании этой команды и создал опасную ловушку.
С выражением ;THROW вам не нужно никаких хранимых процедур. Ваш обработчик CATCH становится таким же простым, как этот:
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
;THROW
RETURN 55555
END CATCHДостоинство ;THROW в том, что сообщение об ошибке генерируется точно таким же, как и оригинальное сообщение. Если изначально было два сообщения об ошибках, оба сообщения воспроизводятся, что делает это выражение еще привлекательнее. Как и со всеми другими сообщениями об ошибках, ошибки, сгенерированные ;THROW, могут быть перехвачены внешним обработчиком CATCH и воспроизведены. Если обработчика CATCH нет, выполнение прерывается, поэтому оператор RETURN в данном случае оказывается не нужным. (Я все еще рекомендую оставлять его, на случай, если вы измените свое отношение к ;THROW позже).
Если у вас SQL Server 2012 или более поздняя версия, измените определение insert_data и outer_sp и попробуйте выполнить тесты еще раз. Результат в этот раз будет такой:
Msg 515, Level 16, State 2, Procedure insert_data, Line 5
Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.
Msg 2627, Level 14, State 1, Procedure insert_data, Line 6
Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Имя процедуры и номер строки верны и нет никакого другого имени процедуры, которое может нас запутать. Также сохранены оригинальные номера ошибок.
В этом месте вы можете сказать себе: действительно ли Microsoft назвал команду ;THROW? Разве это не просто THROW? На самом деле, если вы посмотрите в Books Online, там не будет точки с запятой. Но точка с запятой должны быть. Официально они отделяют предыдущее выражение, но это опционально, и далеко не все используют точку с запятой в выражениях T-SQL. Более важно, что если вы пропустите точку с запятой перед THROW, то не будет никакой синтаксической ошибки. Но это повлияет на поведение при выполнении выражения, и это поведение будет непостижимым для непосвященных. При наличии активной транзакции вы получите сообщение об ошибке, которое будет полностью отличаться от оригинального. И еще хуже, что при отсутствии активной транзакции ошибка будет тихо выведена без обработки. Такая вещь, как пропуск точки с запятой, не должно иметь таких абсурдных последствий. Для уменьшения риска такого поведения, всегда думайте о команде как о ;THROW (с точкой с запятой).
Нельзя отрицать того, что ;THROW имеет свои преимущества, но точка с запятой не единственная ловушка этой команды. Если вы хотите использовать ее, я призываю вас прочитать по крайней мере вторую часть этой серии, где я раскрываю больше деталей о команде ;THROW. До этого момента, используйте error_handler_sp.
4.3. Использование SqlEventLog
Третий способ обработки ошибок – это использование SqlEventLog, который я описываю очень детально в третьей части. Здесь я лишь сделаю короткий обзор.
SqlEventLog предоставляет хранимую процедуру slog.catchhandler_sp, которая работает так же, как и error_handler_sp: она использует функции error_xxx() для сбора информации и выводит сообщение об ошибке, сохраняя всю информацию о ней. Вдобавок к этому, она логирует ошибку в таблицу splog.sqleventlog. В зависимости от типа приложения, которое у вас есть, эта таблица может быть очень ценным объектом.
Для использования SqlEventLog, ваш обработчик CATCH должен быть таким:
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
EXEC slog.catchhandler_sp @@procid
RETURN 55555
END CATCH@@procid возвращает идентификатор объекта текущей хранимой процедуры. Это то, что SqlEventLog использует для логирования информации в таблицу. Используя те же тестовые сценарии, получим результат их работы с использованием catchhandler_sp:
Msg 50000, Level 16, State 2, Procedure catchhandler_sp, Line 125
{515} Procedure insert_data, Line 5
Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.
Msg 50000, Level 14, State 1, Procedure catchhandler_sp, Line 125
{2627} Procedure insert_data, Line 6
Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Как вы видите, сообщение об ошибке отформатировано немного не так, как это делает error_handler_sp, но основная идея такая же. Вот образец того, что было записано в таблицу slog.sqleventlog:
| logid | logdate | errno | severity | logproc | linenum | msgtext |
| 1 | 2015-01-25 22:40:24.393 | 515 | 16 | insert_data | 5 | Cannot insert … |
| 2 | 2015-01-25 22:40:24.395 | 2627 | 14 | insert_data | 6 | Violation of … |
Если вы хотите попробовать SqlEventLog, вы можете загрузить файл sqleventlog.zip. Инструкция по установке находится в третьей части, раздел Установка SqlEventLog.
5. Финальные замечания
Вы изучили основной образец для обработки ошибок и транзакций в хранимых процедурах. Он не идеален, но он должен работать в 90-95% вашего кода. Есть несколько ограничений, на которые стоит обратить внимание:
- Как мы видели, ошибки компиляции не могут быть перехвачены в той же процедуре, в которой они возникли, а только во внешней процедуре.
- Пример не работает с пользовательскими функциями, так как ни TRY-CATCH, ни RAISERROR нельзя в них использовать.
- Когда хранимая процедура на Linked Server вызывает ошибку, эта ошибка может миновать обработчик в хранимой процедуре на локальном сервере и отправиться напрямую клиенту.
- Когда процедура вызвана как INSERT-EXEC, вы получите неприятную ошибку, потому что ROLLBACK TRANSACTION не допускается в данном случае.
- Как упомянуто выше, если вы используете error_handler_sp или SqlEventLog, мы потеряете одно сообщение, когда SQL Server выдаст два сообщения для одной ошибки. При использовании ;THROW такой проблемы нет.
Я рассказываю об этих ситуациях более подробно в других статьях этой серии.
Перед тем как закончить, я хочу кратко коснуться триггеров и клиентского кода.
Триггеры
Пример для обработки ошибок в триггерах не сильно отличается от того, что используется в хранимых процедурах, за исключением одной маленькой детали: вы не должны использовать выражение RETURN (потому что RETURN не допускается использовать в триггерах).
С триггерами важно понимать, что они являются частью команды, которая запустила триггер, и в триггере вы находитесь внутри транзакции, даже если не используете BEGIN TRANSACTION.
Иногда я вижу на форумах людей, которые спрашивают, могут ли они написать триггер, который не откатывает в случае падения запустившую его команду. Ответ таков: нет способа сделать это надежно, поэтому не стоит даже пытаться. Если в этом есть необходимость, по возможности не следует использовать триггер вообще, а найти другое решение. Во второй и третьей частях я рассматриваю обработку ошибок в триггерах более подробно.
Клиентский код
У вас должна быть обработка ошибок в коде клиента, если он имеет доступ к базе. То есть вы должны всегда предполагать, что при любом вызове что-то может пойти не так. Как именно внедрить обработку ошибок, зависит от конкретной среды.
Здесь я только обращу внимание на важную вещь: реакцией на ошибку, возвращенную SQL Server, должно быть завершение запроса во избежание открытых бесхозных транзакций:
IF @@trancount > 0 ROLLBACK TRANSACTIONЭто также применимо к знаменитому сообщению Timeout expired (которое является не сообщением от SQL Server, а от API).
6. Конец первой части
Это конец первой из трех частей серии. Если вы хотели изучить вопрос обработки ошибок быстро, вы можете закончить чтение здесь. Если вы настроены идти дальше, вам следует прочитать вторую часть, где наше путешествие по запутанным джунглям обработки ошибок и транзакций в SQL Server начинается по-настоящему.
… и не забывайте добавлять эту строку в начало ваших хранимых процедур:
SET XACT_ABORT, NOCOUNT ONВ статье рассказывается:
- Суть и причины возникновения ошибки установки соединения с базой данных
- Первые шаги устранения ошибки установки соединения
- 3 способа устранения ошибки установки соединения с БД
- Дополнительные методы устранения ошибки установки соединения с БД
- Профилактика возникновения ошибки установки соединения с базой данных
-

Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Ошибка установки соединения с базой данных — довольно частое явление на WordPress, которое может быть вызвано различными причинами. При первом появлении она может добавить седых волос владельцу сайта, ведь доступ к ресурсу будет невозможен, включая и его «админку», и при недостатке знаний ставит в тупик.
Не стоит паниковать и сильно переживать, ошибка установки соединения может быть исправлена относительно простыми методами. В нашей статье мы расскажем, почему возникает данная неисправность, как можно ее устранить, и что делать, чтобы снизить риск ее повторного появления.
Суть и причины возникновения ошибки установки соединения с базой данных
Чтобы понять, что означает “Ошибка установки соединения с базой данных” (Error establishing a database connection) разберемся, как работает WordPress и выясним, что такое база данных.
WordPress – одна из самых популярных CMS – систем., т.е. систем управления контентом. Это программное обеспечение, позволяющее добавлять, удалять и редактировать содержание вашего сайта без знаний языков программирования. Вся информация о контенте хранится в базе данных.
База данных — это и есть совокупность информации, организованная так, чтобы при необходимости компьютер смог ее найти и обработать. Все сведения о вашем WordPress сайте хранится в базе данных на серверах вашего хостинг- провайдера. Любое действие на сайте приводит кому, что WordPress посылает запрос на нужную информацию в базу данных. Если запрос успешно обработан, то пользователь получает нужную информацию.

Одним из наиболее важных файлов в WordPress является wp-config.php файл. Он находится в корневой директории и содержит сведения о конфигурации вашего сайта, в том числе и информацию о подключении к базе данных. Важно, чтобы эта информация была прописана в строго определенном порядке:
- Database Name — Имя базы данных
- Database Username — Имя пользователя базы данных
- Database Password — Пароль пользователя базы данных
- Database Host — Сервер базы данных
Таким образом, в большинстве случаев “Ошибка установки соединения с базой данных” возникает, если информация, описанная выше, указана не верно. Кроме того, ошибка может быть вызвана повреждением базы данных или перегруженностью сервера.
Первые шаги устранения ошибки установки соединения
Рассмотрим основные причины ошибки установки соединения с базой данных и способы их устранения.
Скачать файл
Прежде всего, настоятельно рекомендуем создать резервную копию всей важной информации и обновлять ее после каждого значимого изменения. Тогда вы гарантированно не потеряете данные. А в случае серьезной ошибки и восстановления базы данных, не столкнетесь с необходимостью создания сайта с нуля. Для создания резервной копии используются плагины Duplicator или All-in-One WP Migration.
Есть много программных модулей для резервного копирования, но они не смогут вам помочь при отсутствии доступа в админку.
В такой ситуации нужен плагин ISPmanager или другой модуль, который поможет, управляя хостингом, сделать полное резервное копирование сайта.

При возникновении сложностей стоит воспользоваться технической поддержкой, которая есть на всех платных хостингах. Здесь вам окажут квалифицированную помощь с созданием резервной копии.
3 способа устранения ошибки установки соединения с БД
Проверка памяти сервера
Предположим, вы проверили учетные данные в фале wp-config.php и убедились в их корректности. Следующим шагом следует проверить сервер на наличие памяти. Довольно часто ошибка соединения возникает из-за перегруженности сервера. Если сервер хостинг-провайдера испытывает трудности, то и ваш сайт WordPress будет замедляться.
В первую очередь удостоверимся, что MySQL работает, и памяти для обработки данных WordPress достаточно.
Подключитесь к удаленному серверу через SSH, используя IP-адрес сервера:
ssh 8host@ <server IP>
Затем убедимся, работает ли MySQL с помощью утилиты netstat. Она позволяет отслеживать проблемы, связанные с производительностью сети. Чтобы увидеть список TCP-портов, которые прослушиваются, и имена программ, используйте команду:
sudo netstat -plt
где флаги –p, –l и –t означают program (программы), listening (прослушивание) и TCP соответственно.
В результате выполнения команды вы увидите список. Найдите в нем mysqld – это сервер MySQL:
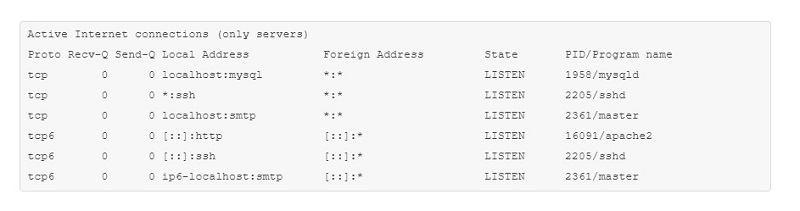
Если вы видите его в списке, значит, сервер MySQL работает и прослушивает соединения. В противном случае нужно попробовать ручной запуск сервера. Следующая команда полностью перегружает MySQL:
sudo systemctl start mysql
Заметьте, что в некоторых версиях и дистрибутивах Linux используется mysqld или mysql-server, а не mysql. Попробуйте разные варианты, чтобы определить, какой из них применяется в вашей системе.
После выполнения этой команды сервер запустится. Проверьте это с помощью sudo netstat -plt, как описано ранее.
По какой причине сервер MySQL может завершить работу? Эта система очень эффективна и производительна, но не всегда стабильна. Если количество одновременно выполняемых задач велико, то она существенно замедляется. Чтобы минимизировать возможные проблемы, нужно следить за объемом доступной памяти.

Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Уже скачали 18728 ![]()
Проверьте log-файлы и ищите в них сообщения об ошибках. Для поиска используйте команду zgrep:
zgrep -a «allocate memory» /var/log/mysql/error.log*
В результате выполнения данной команды вы увидите все log-файлы, содержащие error.log и ‘allocate memory’. Поиск будет выполняться по файлам в директории /var/log/mysql/.
На выводе вы можете увидеть подобную строку:
2017-04-11T17:38:22.604644Z 0 [ERROR] InnoDB: Cannot allocate memory for the buffer pool
Это значит, что для корректной работы MySQL не хватает памяти. Именно это и является причиной ошибки подключения к базе данных. Если вы видите не одну такую строку, а несколько, значит, проблема нехватки памяти регулярная. Решается она переносом данных на более мощный сервер. Если сайт размещен на облачном сервере, то хостинг-провайдер в большинстве случаев может обновить сервер быстро и с минимальным простоем.


Читайте также
Если команда zgrep не выдала списка log-файлов, то сервер не испытывает проблем с нехваткой памяти. Значит проблемы установки соединения с базой данных может быть связана неверными учетными данными MySQL.
Проверка учётных данных MySQL
Если вы поменяли хостинг-провайдера или переместили установку WordPress на новый сервер, то информация в файле wp-config.php становится неактуальной. Вам необходимо поменять соответствующие строки в файле, иначе подключение к базе данных будет невозможно.
Чтобы найти этот файл используйте команду find:
sudo find / -name «wp-config.php»
Данная команда будет искать файл с указанным именем в корневой папке. Если он будет найден, то на выходе вы увидите путь к найденному файлу:
/var/www/html/wp-config.php
Чтобы открыть его в текстовом редакторе nano, напишите:
sudo nano /var/www/html/wp-config.php
В результате вы увидите файл с большим количеством строк. Первыми строками как раз и будут те, что описывают подключение к базе данных:
/** The name of the database for WordPress */
define(‘DB_NAME’, ‘database_name’);
/** MySQL database username */
define(‘DB_USER’, ‘database_username’);
/** MySQL database password */
define(‘DB_PASSWORD’, ‘database password’);

Вместо ‘database_name’, ‘database_username’ и ‘database_password’ должны быть указаны корректные данные о вашей БД. При необходимости отредактируйте их. На забудьте сохранить файл и выйти из редактора, нажатием CTRL-O, CTRL-X.
Чтобы убедиться, что проблема решена, попробуйте подключиться к базе данных. Для этого наберите команду:
mysqlshow -u database_username -p
Затем введите пароль. Если имя пользователя или пароль не верные, то вы увидите ошибку Access denied. В противном случае на экран будет выведена информация обо всех базах данных, к которым у вас есть доступ.
+———————+
|Databases |
+———————+
| information_schema |
| database_name |
+———————+
Если вы видите имя нужной базы данных в списке, то в файле wp-config.php указаны корректные данные. Теперь можно перезапустить WordPress сайт.
Если после этого ошибка подключения к базе данных не исчезла, то переходите к третьему шагу.
![]()
Точный инструмент «Колесо компетенций»
Для детального самоанализа по выбору IT-профессии
![]()
Список грубых ошибок в IT, из-за которых сразу увольняют
Об этом мало кто рассказывает, но это должен знать каждый
![]()
Мини-тест из 11 вопросов от нашего личного психолога
Вы сразу поймете, что в данный момент тормозит ваш успех
Регистрируйтесь на бесплатный интенсив, чтобы за 3 часа начать разбираться в IT лучше 90% новичков.
Только до 13 февраля
Осталось 17 мест
Восстановление базы данных WordPress
Случается, что база данных WordPress оказывается поврежденной. Причин, по которым такое происходит, может быть несколько:
- неудачное обновление;
- сбой базы данных;
- некорректный плагин.
Непосредственно на сайте в таком случае вы все также увидите сообщение — «ошибка установки соединения с базой данных».
Попытаемся восстановить БД. Откройте файл wp-config.php с помощью текстового редактора:
sudo nano /var/www/html/wp-config.php
Вставьте в файл строку:
define(‘WP_ALLOW_REPAIR’, true);
Таким образом включается функция восстановления базы данных. Сохраните файл и закройте его.
Затем откройте браузер и перейдите по следующему URL:
http://www.example.com/wp-admin/maint/repair.php
Не забудьте заменить www.example.com на URL вашего сайта или укажите IP.
Тогда вы увидите следующее сообщение на экране:
WordPress can automatically look for some common database problems and repair them.
Выберите вариант Repair Database. В появившейся странице вы увидите процент проверенных и восстановленных данных.
После восстановления вернитесь к файлу wp-config.php. Удалите из него функцию, ответственную за восстановление базы данных. Это необходимо сделать из соображений безопасности, иначе доступ к восстановлению БД будет у всех.

Если после восстановления базы данных WordPress все еще выдает ошибку о проблеме соединения, восстановите базу данных из бэкапа (резервной копии).
Если же после проверки на странице с результатами вы не увидели исправлений, то ошибка соединения с базой данных не связана с самой базой данных.
Описанные выше способы устранения ошибки соединения зачастую достаточны для решения проблемы. В редких случаях причиной могут быть также вредоносные программы и атаки.
Дополнительные методы устранения ошибки установки соединения с БД
Следующие способы устранения ошибки установки соединения с базой данных категорически не рекомендуется использовать начинающим администраторам WordPress! Переходите к ним только в том случае, если не помогли методы, описанные ранее. Не используйте их, если у вас нет валидной резервной копии вашего сайта!

Читайте также
- Обновление настройки в wp_options
Некоторые пользователи отмечали, что ошибка была устранена после выполнения запроса к БД через phpMyAdmin:
[sql]UPDATE wp_options SET option_value=’ http://your_site.ru’ WHERE option_name=’siteurl’;[/sql]
Где вместо ’your_site.ru ‘укажите URL вашего сайта.
- Подключение к базе данных с правами root
Если вы используете виртуальный сервер и можете воспользоваться root правами, то попробуйте подключиться к БД через файл test.php. В случае успеха, попробуйте также подключиться к БД вашего сайта через файл wp-config.php. Затем проверьте работу сайта.
Работать на сервере под учётной записью root – большая ошибка. Обязательно создайте нового пользователя через phpMyAdmin. Не забудьте внести в wp-config.php файл логин и пароль созданного пользователя.
Профилактика возникновения ошибки установки соединения с базой данных
Никто не застрахован от ошибки установки соединения с базой данных при работе с Вордпресс. Однако, вы можете минимизировать шанс остановки сайта, если будете следовать следующим рекомендациям:
- Тщательно выбирайте хостинг-провайдера, который подходит именно для работы с CMS WordPress. Он должен иметь хорошую техподдержку, обеспечивать высокую скорость и стабильность. Зачастую проблемы в работе сайта связаны именно с хостингом.
- Регулярно делайте бэкап. Вы можете самостоятельно выбрать один из плагинов, например, UpdraftPlus, Duplicator или All-in-One WP Migration.
К сожалению, если вы не имеете доступ в панель управления сайта, то вы не сможете воспользоваться резервной копией. Тогда вам нужно будет воспользоваться программным обеспечением для управления хостингом. Например, ISPmanager. Он позволит вам сделать полную резервную копию сайта.
Если вы не хотите самостоятельно делать бэкап, можете обратиться в техподдержку хостинг-провайдера. Они предложат вам программу для резервного копирования.
Prisma Client error types
Prisma Client throws different kinds of errors. The following lists the exception types, and their documented data fields:
PrismaClientKnownRequestError
Prisma Client throws a PrismaClientKnownRequestError exception if the query engine returns a known error related to the request — for example, a unique constraint violation.
| Property | Description |
|---|---|
code |
A Prisma-specific error code. |
meta |
Additional information about the error — for example, the field that caused the error: { target: [ 'email' ] } |
message |
Error message associated with error code. |
clientVersion |
Version of Prisma Client (for example, 2.19.0) |
PrismaClientUnknownRequestError
Prisma Client throws a PrismaClientUnknownRequestError exception if the query engine returns an error related to a request that does not have an error code.
| Property | Description |
|---|---|
message |
Error message associated with error code. |
clientVersion |
Version of Prisma Client (for example, 2.19.0) |
PrismaClientRustPanicError
Prisma Client throws a PrismaClientRustPanicError exception if the underlying engine crashes and exits with a non-zero exit code. In this case, the Prisma Client or the whole Node process must be restarted.
| Property | Description |
|---|---|
message |
Error message associated with error code. |
clientVersion |
Version of Prisma Client (for example, 2.19.0) |
PrismaClientInitializationError
Prisma Client throws a PrismaClientInitializationError exception if something goes wrong when the query engine is started and the connection to the database is created. This happens either:
- When
prisma.$connect()is called OR - When the first query is executed
Errors that can occur include:
- The provided credentials for the database are invalid
- There is no database server running under the provided hostname and port
- The port that the query engine HTTP server wants to bind to is already taken
- A missing or inaccessible environment variable
- The query engine binary for the current platform could not be found (
generatorblock)
| Property | Description |
|---|---|
errorCode |
A Prisma-specific error code. |
message |
Error message associated with error code. |
clientVersion |
Version of Prisma Client (for example, 2.19.0) |
PrismaClientValidationError
Prisma Client throws a PrismaClientValidationError exception if validation fails — for example:
- Missing field — for example, an empty
data: {}property when creating a new record - Incorrect field type provided (for example, setting a
Booleanfield to"Hello, I like cheese and gold!")
| Property | Description |
|---|---|
message |
Error message. |
clientVersion |
Version of Prisma Client (for example, 2.19.0) |
Error codes
Common
P1000
«Authentication failed against database server at P1001
«Can’t reach database server at P1002
«The database server at P1003
«Database {database_file_name} does not exist at {database_file_path}» «Database «Database P1008
«Operations timed out after P1009
«Database P1010
«User P1011
«Error opening a TLS connection: {message}» P1012
Note: If you get error code P1012 after you upgrade Prisma to version 4.0.0 or later, see the version 4.0.0 upgrade guide. A schema that was valid before version 4.0.0 might be invalid in version 4.0.0 and later. The upgrade guide explains how to update your schema to make it valid. «{full_error}» Possible P1012 error messages: P1013
«The provided database string is invalid. {details}» P1014
«The underlying {kind} for model P1015
«Your Prisma schema is using features that are not supported for the version of the database. P1016
«Your raw query had an incorrect number of parameters. Expected: P1017
«Server has closed the connection.» Prisma Client (Query Engine)
P2000
«The provided value for the column is too long for the column’s type. Column: {column_name}» P2001
«The record searched for in the where condition ( P2002
«Unique constraint failed on the {constraint}» P2003
«Foreign key constraint failed on the field: P2004
«A constraint failed on the database: P2005
«The value P2006
«The provided value P2007
«Data validation error P2008
«Failed to parse the query P2009
«Failed to validate the query: P2010
«Raw query failed. Code: P2011
«Null constraint violation on the {constraint}» P2012
«Missing a required value at P2013
«Missing the required argument P2014
«The change you are trying to make would violate the required relation ‘{relation_name}’ between the P2015
«A related record could not be found. {details}» P2016
«Query interpretation error. {details}» P2017
«The records for relation P2018
«The required connected records were not found. {details}» P2019
«Input error. {details}» P2020
«Value out of range for the type. {details}» P2021
«The table P2022
«The column P2023
«Inconsistent column data: {message}» P2024
«Timed out fetching a new connection from the connection pool. (More info: http://pris.ly/d/connection-pool (Current connection pool timeout: {timeout}, connection limit: {connection_limit})» P2025
«An operation failed because it depends on one or more records that were required but not found. {cause}» P2026
«The current database provider doesn’t support a feature that the query used: {feature}» P2027
«Multiple errors occurred on the database during query execution: {errors}» P2028
«Transaction API error: {error}» P2030
«Cannot find a fulltext index to use for the search, try adding a @@fulltext([Fields…]) to your schema» P2031
«Prisma needs to perform transactions, which requires your MongoDB server to be run as a replica set. See details: https://pris.ly/d/mongodb-replica-set» P2033
«A number used in the query does not fit into a 64 bit signed integer. Consider using P2034
«Transaction failed due to a write conflict or a deadlock. Please retry your transaction» Prisma Migrate (Migration Engine)
P3000
«Failed to create database: {database_error}» P3001
«Migration possible with destructive changes and possible data loss: {migration_engine_destructive_details}» P3002
«The attempted migration was rolled back: {database_error}» P3003
«The format of migrations changed, the saved migrations are no longer valid. To solve this problem, please follow the steps at: https://pris.ly/d/migrate» P3004
«The P3005
«The database schema is not empty. Read more about how to baseline an existing production database: https://pris.ly/d/migrate-baseline» P3006
«Migration P3007
«Some of the requested preview features are not yet allowed in migration engine. Please remove them from your data model before using migrations. (blocked: {list_of_blocked_features})» P3008
«The migration P3009
«migrate found failed migrations in the target database, new migrations will not be applied. Read more about how to resolve migration issues in a production database: https://pris.ly/d/migrate-resolve P3010
«The name of the migration is too long. It must not be longer than 200 characters (bytes).» P3011
«Migration P3012
«Migration P3013
«Datasource provider arrays are no longer supported in migrate. Please change your datasource to use a single provider. Read more at https://pris.ly/multi-provider-deprecation» P3014
«Prisma Migrate could not create the shadow database. Please make sure the database user has permission to create databases. Read more about the shadow database (and workarounds) at https://pris.ly/d/migrate-shadow. Original error: {error_code} P3015
«Could not find the migration file at {migration_file_path}. Please delete the directory or restore the migration file.» P3016
«The fallback method for database resets failed, meaning Migrate could not clean up the database entirely. Original error: {error_code} P3017
«The migration {migration_name} could not be found. Please make sure that the migration exists, and that you included the whole name of the directory. (example: «20201207184859_initial_migration»)» P3018
«A migration failed to apply. New migrations cannot be applied before the error is recovered from. Read more about how to resolve migration issues in a production database: https://pris.ly/d/migrate-resolve Migration name: {migration_name} Database error code: {database_error_code} Database error: P3019
«The datasource provider P3020
«The automatic creation of shadow databases is disabled on Azure SQL. Please set up a shadow database using the P3021
«Foreign keys cannot be created on this database. Learn more how to handle this: https://pris.ly/d/migrate-no-foreign-keys» P3022
«Direct execution of DDL (Data Definition Language) SQL statements is disabled on this database. Please read more here about how to handle this: https://pris.ly/d/migrate-no-direct-ddl» prisma db pull
P4000
«Introspection operation failed to produce a schema file: {introspection_error}» P4001
«The introspected database was empty.» P4002
«The schema of the introspected database was inconsistent: {explanation}» Data Proxy
Because Data Proxy connections operate differently from local database connections, error codes are different from regular ones. In general, all Data Proxy-related errors start with P5000
This request could not be understood by the server P5001
This request must be retried P5002
The datasource provided is invalid: P5003
Requested resource does not exist P5004
The feature is not yet implemented: P5005
Schema needs to be uploaded P5006
Unknown server error P5007
Unauthorized, check your connection string P5008
Usage exceeded, retry again later P5009
Request timed out P5010
Cannot fetch data from service P5011
Request parameters are invalid.
You see error P5000 when the server cannot understand the request. In comparison, P5011 indicates that the server understands the request but rejects it due to failed validation checks, such as parameters being out of range. P5012
Engine version is not supported P5013
Engine not started: healthcheck timeout P5014
Unknown engine startup error (contains message and logs) P5015
Interactive transaction error:
{database_host}, the provided database credentials for {database_user} are not valid. Please make sure to provide valid database credentials for the database server at {database_host}.»
{database_host}:{database_port} Please make sure your database server is running at {database_host}:{database_port}.»
{database_host}:{database_port} was reached but timed out. Please try again. Please make sure your database server is running at {database_host}:{database_port}. «
{database_name}.{database_schema_name} does not exist on the database server at {database_host}:{database_port}.»{database_name} does not exist on the database server at {database_host}:{database_port}.»
{time}«
{database_name} already exists on the database server at {database_host}:{database_port}«
{database_user} was denied access on the database {database_name}«
{} is missing.»{} takes {} arguments, but received {}.»{} is missing in attribute @{}.»{} is missing in data source block {}.»{} is missing in generator block {}.»@{}: {}»@{} is defined twice.»{} could not be defined because another model with this name exists: {}«{} is a reserved scalar type name and can not be used.»{} cannot be defined because a {} with that name already exists.»{} is already defined in {}.»{} is already specified as unnamed argument.»{} is already specified.»{} is already defined on model {}.»{} in model {} can’t be a list. The current connector does not support lists of primitive types.»{} is declared multiple times. With the current connector index names have to be globally unique.»{} is already defined on enum {}.»@{}.»{}.»{}.»{}. Please specify a different database as shadow database.»{} is not known. Expected one of: {}»{} is not a valid value for {}.»{} is neither a built-in type, nor refers to another model, custom type, or enum.»{} is not a built-in type.»{}.»{}: {}.»{}: {}»{} in model {}: {}»{datasource}: {message}»»{}: {}»
{model} does not exist.»
Database version: {database_version}
Errors:
{errors}»
{expected}, actual: {actual}.»
{model_name}.{argument_name} = {argument_value}) does not exist»
{field_name}«
{database_error}«
{field_value} stored in the database for the field {field_name} is invalid for the field’s type»
{field_value} for {model_name} field {field_name} is not valid»
{database_error}«
{query_parsing_error} at {query_position}«
{query_validation_error} at {query_position}«
{code}. Message: {message}«
{path}«
{argument_name} for field {field_name} on {object_name}.»
{model_a_name} and {model_b_name} models.»
{relation_name} between the {parent_name} and {child_name} models are not connected.»
{table} does not exist in the current database.»
{column} does not exist in the current database.»
BigInt as field type if you’re trying to store large integers»
{database_name} database is a system database, it should not be altered with prisma migrate. Please connect to another database.»
{migration_name} failed to apply cleanly to the shadow database.
{error_code}Error:
{inner_error}»
{migration_name} is already recorded as applied in the database.»
{details}»
{migration_name} cannot be rolled back because it was never applied to the database. Hint: did you pass in the whole migration name? (example: «20201207184859_initial_migration»)»
{migration_name} cannot be rolled back because it is not in a failed state.»
{inner_error}»
{inner_error}»
{database_error} «
{provider} specified in your schema does not match the one specified in the migration_lock.toml, {expected_provider}. Please remove your current migration directory and start a new migration history with prisma migrate dev. Read more: https://pris.ly/d/migrate-provider-switch»
shadowDatabaseUrl datasource attribute.
Read the docs page for more details: https://pris.ly/d/migrate-shadow»
P5xxx.
prisma:// protocol when --data-proxy is used
beforeExit event is not yet supported