-
#1
Hello all, I will keep this brief and to the point. I have moved my cluster to a permanent home on a new network and am recreating my cluster. In order to do so I followed the process of removing corosync.conf and deleting all the config files. I also removed all ceph config and all vm’s are removed from all nodes.
I can create a cluster fine, but whenever I attempt to join a node to it I get the error ‘this host already contains virtual guests’ but they are all gone.
Any ideas?
![]()
mira
Proxmox Staff Member
-
#2
Are there any files left in ‘/etc/pve/qemu-server’ or ‘/etc/pve/lxc’ on the node you want to join?
-
#3
Are there any files left in ‘/etc/pve/qemu-server’ or ‘/etc/pve/lxc’ on the node you want to join?
In /etc/pve/nodes/ I found that there was a directory for each of the old nodes(i.e. /etc/pve/nodes/node1/qemu-server/ and inside found the vm .conf files i.e. 101.conf. I removed those and then the join worked properly.
Thank you for the quick response and help!
-
#4
I have the same issue. I removed the 101.conf and 102.conf and when I try again to add the server to the cluster I receive the same error * this host already contains virtual guests
Any ideeas?
![]()
mira
Proxmox Staff Member
-
#5
Please post the output of ls /etc/pve/qemu-server and ls /etc/pve/lxc as well as ls /etc/pve/nodes
-
#6
@mira
The server that will join the cluster:
root@pmx2:~# ls /etc/pve/qemu-server
root@pmx2:~# ls /etc/pve/lxc
100.conf
root@pmx2:~# ls /etc/pve/nodes
pmx2
root@pmx2:~#
The server that hosts the cluster:
root@proxmox:~# ls /etc/pve/qemu-server
root@proxmox:~# ls /etc/pve/lxc
101.conf 102.conf 105.conf 106.conf 107.conf 108.conf 110.conf
root@proxmox:~# ls /etc/pve/nodes
proxmox
root@proxmox:~#
![]()
mira
Proxmox Staff Member
-
#7
You already have a container on that node. If you want to keep it, make a backup. Then delete the container, join the node to the cluster and restore the container.
-
#8
@mira may I ask on what node? On the pmx2 one? Or on the host node.
![]()
mira
Proxmox Staff Member
-
#9
On the one you want to join, as the error message mentions. You can’t join a node to a cluster if the node has guests.
-
#10
hello I have some problem,
I have two node the first have a lot VM and the host name is Proxmox
On the proxmox host I have make a cluster.
now I’d like to join another node named proxmox2 but when i try there is error:
* this host already contains virtual guests
below result of command:
root@proxmox:~# ls /etc/pve/qemu-server
100.conf 101.conf 102.conf 103.conf 104.conf 105.conf 106.conf 110.conf 112.conf
root@proxmox:~# ls /etc/pve/lxc
root@proxmox:~# ls /etc/pve/nodes
proxmox
root@proxmox:~#
root@proxmox2:~# ls /etc/pve/qemu-server
root@proxmox2:~# ls /etc/pve/lxc
root@proxmox2:~# ls /etc/pve/nodes
proxmox2
root@proxmox2:~#
what can I d for fix ?
![]()
mira
Proxmox Staff Member
-
#11
You can backup all your VMs on that node. Afterwards remove them from the node and join the node to the cluster. Once everything is working you can restore the VMs on the node.
Please make sure the backups are working before you delete the VMs.
-
#12
each night node backs up to nas
-
#13
On the one you want to join, as the error message mentions. You can’t join a node to a cluster if the node has guests.
This is a bad design. Consider making it possible to join when guests exist on the joining node.
Last edited: Dec 27, 2020
-
#14
This is a bad design. Consider making it possible to join when guests exist on the joining node.
I also don’t understand why this limitation.
Will this ever be overcome?
![]()
mira
Proxmox Staff Member
-
#16
No, this won’t be changed.
One of the reasons why this limitation exists, is that there can be a conflict of VM/CT IDs.
-
#17
No, this won’t be changed.
One of the reasons why this limitation exists, is that there can be a conflict of VM/CT IDs.
yes, I know this, but PVE team can compare what’s in the cluster and what’s in the new joining node, rename VM/CT IDs and disk names to not be what’s in the cluster, so when joining it’s unique.
Only workaround is to backup every VM/CT and restore after joining (oh, and dealing with VM/CT IDs)
-
#18
That’s what i did to sort this out:
— stop all the VMs on the joining node
— move the VMs descriptors within /etc/pve/nodes/[NODENAME]/qemu-server to /home/_cluster_bck
— join the cluster
— copy the backup VMs descriptors back to /etc/pve/nodes/[NODENAME]/qemu-server
done =)
![]()
-
#19
yes, I know this, but PVE team can compare what’s in the cluster and what’s in the new joining node, rename VM/CT IDs and disk names to not be what’s in the cluster, so when joining it’s unique.
Only workaround is to backup every VM/CT and restore after joining (oh, and dealing with VM/CT IDs)
it’s not that easy — changing guest IDs involves storage operations, storage config entries can also conflict, as could stuff like CPU models, firewall groups, backup jobs — and that’s just from the top of my head without actually thinking through all the corner cases that might pop up.
you can already trivially work around this limitation manually if you know what you are doing (backup relevant content from /etc/pve, remove guest configs, join, restore content as needed), but there is so much that can go wrong that this will not be automated. 99% of the time a node is freshly installed, then joined to an existing cluster while empty.
-
#20
Sure thing Fabian, I wouldn’t do this in production that’s for sure.. But see here I’ve just made some stupid mistakes (rm -r /etc/pve/nodes/) while reconfiguring the cluster etc and well all the VMs were locally hosted or on NFS.. And I needed a few VMs to control underneath hardware, hence not much of a choice… in my home lab setup this hasn’t gave me any issues really..
And sure thing, backup, backup backup..
Size:
a
a
a
2021 June 04
Что за СС на панели задач?

Это?
Camtasia.
Screen recorder.
2021 June 05
скорее всего кривая цепочка сертификатов
а еще я редирекчу 443 на 8006
Доброго дня, есть два сервера H1 H2 оба сервера расположены в hetzner(железные) на H2 был инициализирован кластер, все VM расположены на H1, при добавлении в кластер H1 получаю ошибку
detected the following error(s):
* this host already contains virtual guests
TASK ERROR: Check if node may join a cluster failed!
что требуется еще очистить, я не могу понять, на H2 нет VM?
Добавляемые в кластер должны быть чистые
Надо на h1 инициировать кластер
this host already contains virtual guests
написано же 🙂
Выключи виртуалки все.
Сохрани конфы всех виртуалок в отдельное место…. Удали в каталоге pve файлы conf, которые сохранил.
Если винты обозваны везде одинаково, то добавишь в кластер без проблем… Потом верни конфы файлы от виртуалок, в нужную папку ноды Н* , в pve каталоге и будет счастье
Сам собирал 3 ноды так в кластер..
И номера VM должны быть на обоих сервера РАЗНЫЕ
Привет
Проблема решена,
Все работает
ESET blokiruet SSL
Нужно было отключить проверки в nod 32 SSL.
Да, по этой ошибке гуглится толкьо одно решение, думал есть альтернативы без отключения VM в кластере
так создавай кластер на правильной машине
присоединяй пустую к кластеру, а не наоборот

crimsonCoder
4 дня назад
So does a proxmox cluster increase availability and stability or reduce the time for task completion by separating out the tasks, like, let’s say, machine learning and data science calculations? Or is it both tasks are separated across the node, and high availability is there by design?

HAMBURG GHETTO RAP
1 месяц назад
didnt work at all bro, im quiting my IT job now

enticed2zeitgeist
2 месяца назад
Incredible. How is promox free and open!
How the hell can it do this while the VM is active. At what point in time does the virtual kernel leave one CPU and start on the other?

haider khan
3 месяца назад
Great sir, I have one confusion, I changes IP for one of them server, then cluster will break or not, can you explain litle bit more?

Meer Hassan
4 месяца назад
according this tutorial when i am trying to join a cluster i am getting this error message below,
(detected the following error(s):
* this host already contains virtual guests
TASK ERROR: Check if node may join a cluster failed!)
How Can i solved this problem?? need some advice….
Thanks in Advance…

Fuseteam ꧂
5 месяцев назад
Hmmm so we don’t need to set up corosync and passwordless login between the two uhh three?

iBlaze🏳️🌈⃠
5 месяцев назад
Thats nice, thanks

Nya Nates
5 месяцев назад
Nice vid. I’m trying to set up a similar PM cluster but one of them can’t join. QQ: Do all the nodes in a Proxmox cluster need to be at the same version? Not the case with these 2x.

Roger Ramirez
8 месяцев назад
thank you, very cool and informative!!!

le chaldon
8 месяцев назад
I plan on working my way through these videos and creating ansible playbooks/roles for these tasks in proxmox. How difficult do you think that will be to achieve clustering+ha in ansible and has anyone already done it? Is there a role to automate this deployment?

Tokoia Oben
10 месяцев назад
Thank you very much. You created second network (brides) on the pve2 and pve3 to match the network settings on the pve1, is that requirement b4 you that live migrate ? I have several VMs on one server and each VM assinged to different vlan. Creating other vlan networks on other servers (or pves) is not possible since I have only few intherfaces on the node.

Muhammad Ejaz
10 месяцев назад
Thanks for sharing such a great experience. very nice explanation. Sir Please include class on Replication (live and scheduled replication). Related to Clustering please tell me can we share resources of servers in clusters (i.e CPU, RAM or HDDs) in case one server utilizing full resources and we need to increase it CPUs or RAM can we take these from other server in the cluster??? or this can be done by some other method? I really appreciate your Hard work. Thanks

Psionic P.
10 месяцев назад
Why are you using a bridge for cluster network?

Brian Thomas
11 месяцев назад
Hello. Great video. Question: What benefits would you have on putting Proxmox on different devices? Aside from high availability.

Somchai Sichon
11 месяцев назад
How to access promox cluster in case of the Primary server failed ?

Jordan
11 месяцев назад
Jay, is it possible to migrate a VM that is using shared storage, onto another nodes local storage?

Wallis Short
1 год назад
Hi Jay — really enjoying your videos. Just clarification on the cluster — You actually have to apply an IP address for each network you create for the bridge. You created networks and you didnt set up the cluster in a different network but rather created the cluster in the mgmnt network and not cluster network. I have 4 networks (mgmnt, cluster, VM’s and Ceph) and I followed your example but found I couldn’t add in the cluster network as it needed an IP address and not network address. If you see your vmbr1 bridge under networks it has an IP address and not a network address. As soon as I changed mine, i could add in the cluster network and all worked fine — Just my 2c 

Voice of Treason
1 год назад
I think the novelty of the matrix in the terminal scripts really wore off by now

mohammed saif
1 год назад
Do i need to keep identical hardware for the migration support.

Jason Li
1 год назад
Love it. Thanks so much for the help.
Время прочтения
13 мин
Просмотры 104K
За последние несколько лет я очень тесно работаю с кластерами Proxmox: многим клиентам требуется своя собственная инфраструктура, где они могут развивать свой проект. Именно поэтому я могу рассказать про самые распространенные ошибки и проблемы, с которыми также можете столкнуться и вы. Помимо этого мы конечно же настроим кластер из трех нод с нуля.

Proxmox кластер может состоять из двух и более серверов. Максимальное количество нод в кластере равняется 32 штукам. Наш собственный кластер будет состоять из трех нод на мультикасте (в статье я также опишу, как поднять кластер на уникасте — это важно, если вы базируете свою кластерную инфраструктуру на Hetzner или OVH, например). Коротко говоря, мультикаст позволяет осуществлять передачу данных одновременно на несколько нод. При мультикасте мы можем не задумываться о количестве нод в кластере (ориентируясь на ограничения выше).
Сам кластер строится на внутренней сети (важно, чтобы IP адреса были в одной подсети), у тех же Hetzner и OVH есть возможность объединять в кластер ноды в разных датацентрах с помощью технологии Virtual Switch (Hetzner) и vRack (OVH) — о Virtual Switch мы также поговорим в статье. Если ваш хостинг-провайдер не имеет похожие технологии в работе, то вы можете использовать OVS (Open Virtual Switch), которая нативно поддерживается Proxmox, или использовать VPN. Однако, я рекомендую в данном случае использовать именно юникаст с небольшим количеством нод — часто возникают ситуации, где кластер просто “разваливается” на основе такой сетевой инфраструктуры и его приходится восстанавливать. Поэтому я стараюсь использовать именно OVH и Hetzner в работе — подобных инцидентов наблюдал в меньшем количестве, но в первую очередь изучайте хостинг-провайдера, у которого будете размещаться: есть ли у него альтернативная технология, какие решения он предлагает, поддерживает ли мультикаст и так далее.
Установка Proxmox
Proxmox может быть установлен двумя способами: ISO-инсталлятор и установка через shell. Мы выбираем второй способ, поэтому установите Debian на сервер.
Перейдем непосредственно к установке Proxmox на каждый сервер. Установка предельно простая и описана в официальной документации здесь.
Добавим репозиторий Proxmox и ключ этого репозитория:
echo "deb http://download.proxmox.com/debian/pve stretch pve-no-subscription" > /etc/apt/sources.list.d/pve-install-repo.list
wget http://download.proxmox.com/debian/proxmox-ve-release-5.x.gpg -O /etc/apt/trusted.gpg.d/proxmox-ve-release-5.x.gpg
chmod +r /etc/apt/trusted.gpg.d/proxmox-ve-release-5.x.gpg # optional, if you have a changed default umaskОбновляем репозитории и саму систему:
apt update && apt dist-upgradeПосле успешного обновления установим необходимые пакеты Proxmox:
apt install proxmox-ve postfix open-iscsiЗаметка: во время установки будет настраиваться Postfix и grub — одна из них может завершиться с ошибкой. Возможно, это будет вызвано тем, что хостнейм не резолвится по имени. Отредактируйте hosts записи и выполните apt-get update
С этого момента мы можем авторизоваться в веб-интерфейс Proxmox по адресу https://<внешний-ip-адрес>:8006 (столкнетесь с недоверенным сертификатом во время подключения).
Изображение 1. Веб-интерфейс ноды Proxmox
Установка Nginx и Let’s Encrypt сертификата
Мне не очень нравится ситуация с сертификатом и IP адресом, поэтому я предлагаю установить Nginx и настроить Let’s Encrypt сертификат. Установку Nginx описывать не буду, оставлю лишь важные файлы для работы Let’s encrypt сертификата:
/etc/nginx/snippets/letsencrypt.conf
location ^~ /.well-known/acme-challenge/ {
allow all;
root /var/lib/letsencrypt/;
default_type "text/plain";
try_files $uri =404;
}
Команда для выпуска SSL сертификата:
certbot certonly --agree-tos --email sos@livelinux.info --webroot -w /var/lib/letsencrypt/ -d proxmox1.domain.name
Конфигурация сайта в NGINX
upstream proxmox1.domain.name {
server 127.0.0.1:8006;
}
server {
listen 80;
server_name proxmox1.domain.name;
include snippets/letsencrypt.conf;
return 301 https://$host$request_uri;
}
server {
listen 443 ssl;
server_name proxmox1.domain.name;
access_log /var/log/nginx/proxmox1.domain.name.access.log;
error_log /var/log/nginx/proxmox1.domain.name.error.log;
include snippets/letsencrypt.conf;
ssl_certificate /etc/letsencrypt/live/proxmox1.domain.name/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/proxmox1.domain.name/privkey.pem;
location / {
proxy_pass https://proxmox1.domain.name;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504;
proxy_redirect off;
proxy_buffering off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
Не забываем после установки SSL сертификата поставить его на автообновление через cron:
0 */12 * * * /usr/bin/certbot -a ! -d /run/systemd/system && perl -e 'sleep int(rand(3600))' && certbot -q renew --renew-hook "systemctl reload nginx"Отлично! Теперь мы можем обращаться к нашему домену по HTTPS.
Заметка: чтобы отключить информационное окно о подписке, выполните данную команду:
sed -i.bak "s/data.status !== 'Active'/false/g" /usr/share/javascript/proxmox-widget-toolkit/proxmoxlib.js && systemctl restart pveproxy.serviceСетевые настройки
Перед подключением в кластер настроим сетевые интерфейсы на гипервизоре. Стоит отметить, что настройка остальных нод ничем не отличается, кроме IP адресов и названия серверов, поэтому дублировать их настройку я не буду.
Создадим сетевой мост для внутренней сети, чтобы наши виртуальные машины (в моем варианте будет LXC контейнер для удобства) во-первых, были подключены к внутренней сети гипервизора и могли взаимодействовать друг с другом. Во-вторых, чуть позже мы добавим мост для внешней сети, чтобы виртуальные машины имели свой внешний IP адрес. Соответственно, контейнеры будут на данный момент за NAT’ом у нас.
Работать с сетевой конфигурацией Proxmox можно двумя способами: через веб-интерфейс или через конфигурационный файл /etc/network/interfaces. В первом варианте вам потребуется перезагрузка сервера (или можно просто переименовать файл interfaces.new в interfaces и сделать перезапуск networking сервиса через systemd). Если вы только начинаете настройку и еще нет виртуальных машин или LXC контейнеров, то желательно перезапускать гипервизор после изменений.
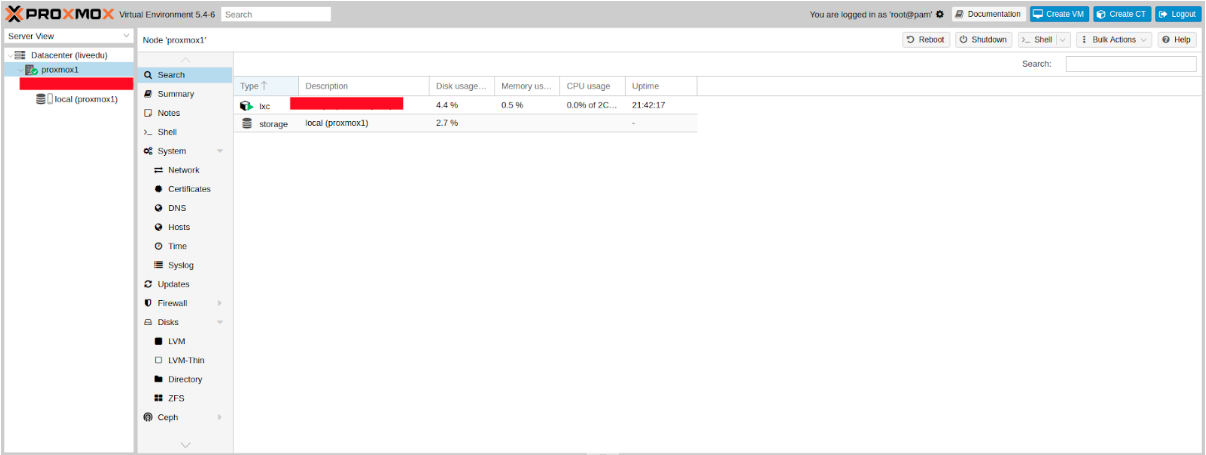
Теперь создадим сетевой мост под названием vmbr1 во вкладке network в веб-панели Proxmox.
Изображение 2. Сетевые интерфейсы ноды proxmox1
Изображение 3. Создание сетевого моста

Изображение 4. Настройка сетевой конфигурации vmbr1
Настройка предельно простая — vmbr1 нам нужен для того, чтобы инстансы получали доступ в Интернет.
Теперь перезапускаем наш гипервизор и проверяем, создался ли интерфейс:

Изображение 5. Сетевой интерфейс vmbr1 в выводе команды ip a
Заметьте: у меня уже есть интерфейс ens19 — это интерфейс с внутренней сетью, на основе ее будет создан кластер.
Повторите данные этапы на остальных двух гипервизорах, после чего приступите к следующему шагу — подготовке кластера.
Также важный этап сейчас заключается во включении форвардинга пакетов — без нее инстансы не будут получать доступ к внешней сети. Открываем файл sysctl.conf и изменяем значение параметра net.ipv4.ip_forward на 1, после чего вводим следующую команду:
sysctl -pВ выводе вы должны увидеть директиву net.ipv4.ip_forward (если не меняли ее до этого)
Настройка Proxmox кластера
Теперь перейдем непосредственно к кластеру. Каждая нода должна резолвить себя и другие ноды по внутренней сети, для этого требуется изменить значения в hosts записях следующих образом (на каждой ноде должна быть запись о других):
172.30.0.15 proxmox1.livelinux.info proxmox1
172.30.0.16 proxmox2.livelinux.info proxmox2
172.30.0.17 proxmox3.livelinux.info proxmox3
Также требуется добавить публичные ключи каждой ноды к остальным — это требуется для создания кластера.
Создадим кластер через веб-панель:
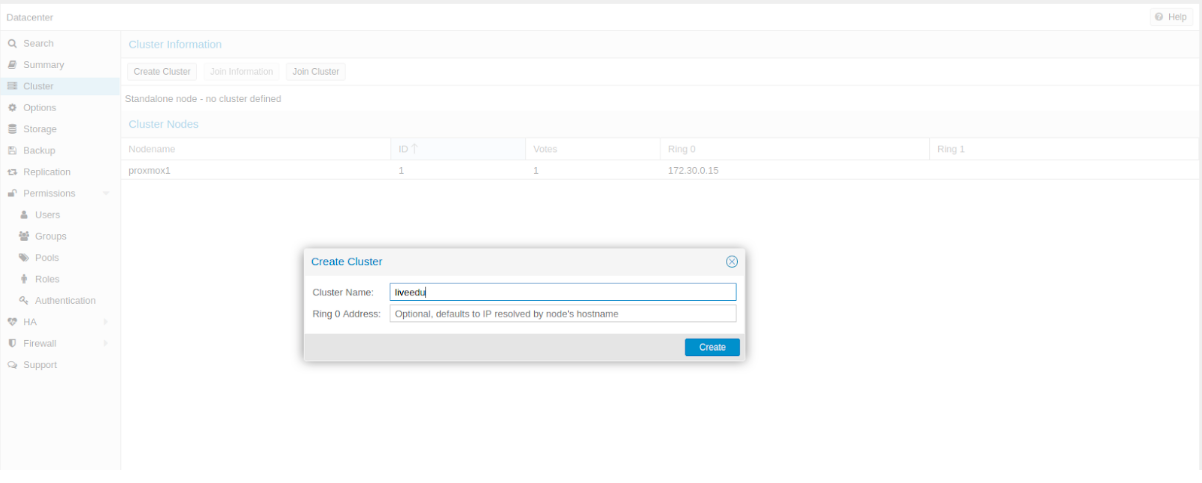
Изображение 6. Создание кластера через веб-интерфейс
После создания кластера нам необходимо получить информацию о нем. Переходим в ту же вкладку кластера и нажимаем кнопку “Join Information”:
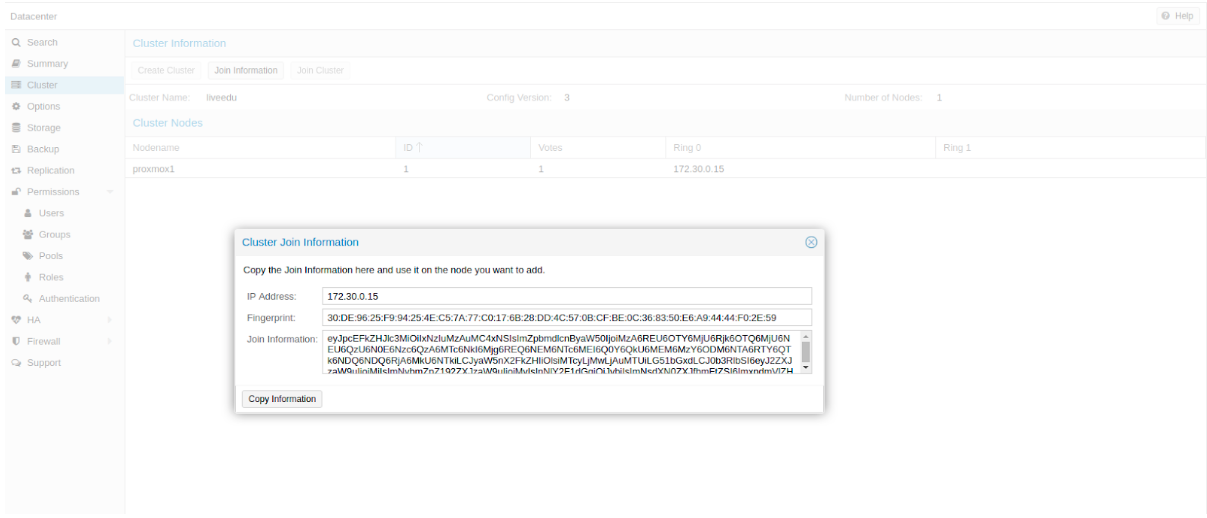
Изображение 7. Информация о созданном кластере
Данная информация пригодится нам во время присоединения второй и третьей ноды в кластер. Подключаемся к второй ноде и во вкладке Cluster нажимаем кнопку “Join Cluster”:
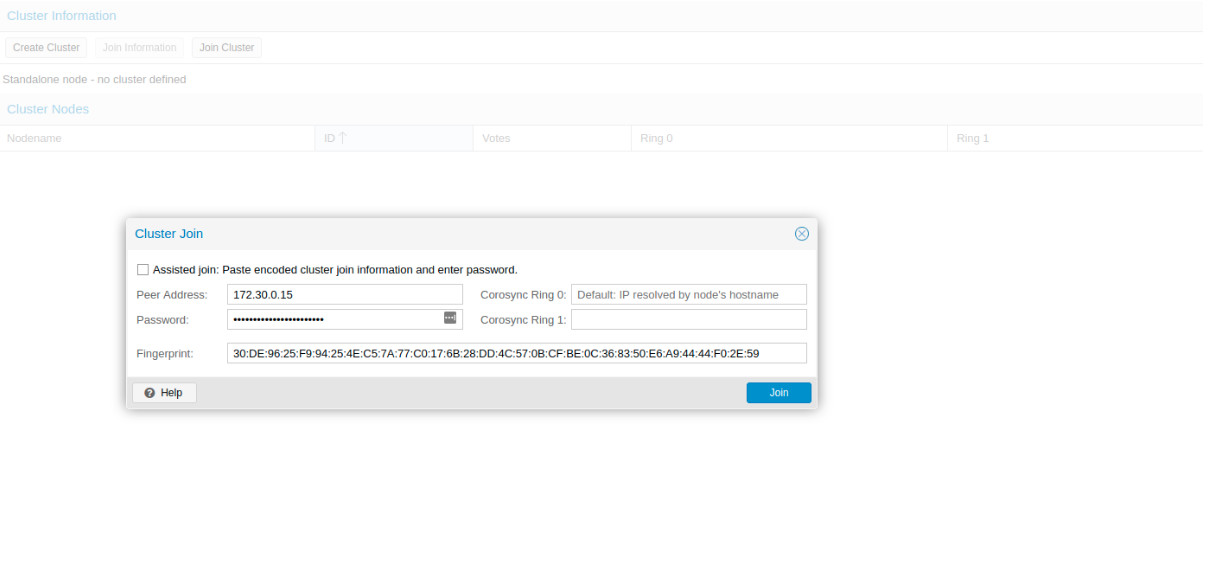
Изображение 8. Подключение к кластеру ноды
Разберем подробнее параметры для подключения:
- Peer Address: IP адрес первого сервера (к тому, к которому мы подключаемся)
- Password: пароль первого сервера
- Fingerprint: данное значение мы получаем из информации о кластере
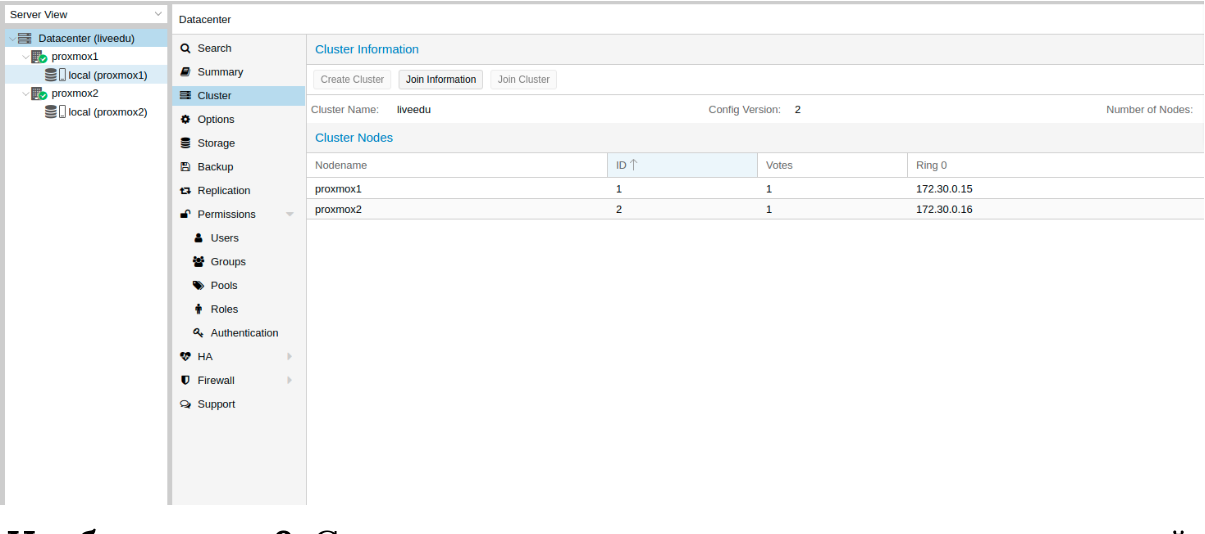
Изображение 9. Состояние кластера после подключения второй ноды
Вторая нода успешно подключена! Однако, такое бывает не всегда. Если вы неправильно выполните шаги или возникнут сетевые проблемы, то присоединение в кластер будет провалено, а сам кластер будет “развален”. Лучшее решение — это отсоединить ноду от кластера, удалить на ней всю информацию о самом кластере, после чего сделать перезапуск сервера и проверить предыдущие шаги. Как же безопасно отключить ноду из кластера? Для начала удалим ее из кластера на первом сервере:
pvecm del proxmox2После чего нода будет отсоединена от кластера. Теперь переходим на сломанную ноду и отключаем на ней следующие сервисы:
systemctl stop pvestatd.service
systemctl stop pvedaemon.service
systemctl stop pve-cluster.service
systemctl stop corosync
systemctl stop pve-cluster
Proxmox кластер хранит информацию о себе в sqlite базе, ее также необходимо очистить:
sqlite3 /var/lib/pve-cluster/config.db
delete from tree where name = 'corosync.conf';
.quit
Данные о коросинке успешно удалены. Удалим оставшиеся файлы, для этого необходимо запустить кластерную файловую систему в standalone режиме:
pmxcfs -l
rm /etc/pve/corosync.conf
rm /etc/corosync/*
rm /var/lib/corosync/*
rm -rf /etc/pve/nodes/*
Перезапускаем сервер (это необязательно, но перестрахуемся: все сервисы по итогу должны быть запущены и работать корректно. Чтобы ничего не упустить делаем перезапуск). После включения мы получим пустую ноду без какой-либо информации о предыдущем кластере и можем начать подключение вновь.
Установка и настройка ZFS
ZFS — это файловая система, которая может использоваться совместно с Proxmox. С помощью нее можно позволить себе репликацию данных на другой гипервизор, миграцию виртуальной машины/LXC контейнера, доступ к LXC контейнеру с хост-системы и так далее. Установка ее достаточно простая, приступим к разбору. На моих серверах доступно три SSD диска, которые мы объединим в RAID массив.
Добавляем репозитории:
nano /etc/apt/sources.list.d/stretch-backports.list
deb http://deb.debian.org/debian stretch-backports main contrib
deb-src http://deb.debian.org/debian stretch-backports main contrib
nano /etc/apt/preferences.d/90_zfs
Package: libnvpair1linux libuutil1linux libzfs2linux libzpool2linux spl-dkms zfs-dkms zfs-test zfsutils-linux zfsutils-linux-dev zfs-zed
Pin: release n=stretch-backports
Pin-Priority: 990
Обновляем список пакетов:
apt updateУстанавливаем требуемые зависимости:
apt install --yes dpkg-dev linux-headers-$(uname -r) linux-image-amd64Устанавливаем сам ZFS:
apt-get install zfs-dkms zfsutils-linuxЕсли вы в будущем получите ошибку fusermount: fuse device not found, try ‘modprobe fuse’ first, то выполните следующую команду:
modprobe fuseТеперь приступим непосредственно к настройке. Для начала нам требуется отформатировать SSD и настроить их через parted:
Настройка /dev/sda
parted /dev/sda
(parted) print
Model: ATA SAMSUNG MZ7LM480 (scsi)
Disk /dev/sda: 480GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 4296MB 4295MB primary raid
2 4296MB 4833MB 537MB primary raid
3 4833MB 37,0GB 32,2GB primary raid
(parted) mkpart
Partition type? primary/extended? primary
File system type? [ext2]? zfs
Start? 33GB
End? 480GB
Warning: You requested a partition from 33,0GB to 480GB (sectors 64453125..937500000).
The closest location we can manage is 37,0GB to 480GB (sectors 72353792..937703087).
Is this still acceptable to you?
Yes/No? yes
Аналогичные действия необходимо произвести и для других дисков. После того, как все диски подготовлены, приступаем к следующему шагу:
zpool create -f -o ashift=12 rpool /dev/sda4 /dev/sdb4 /dev/sdc4
Мы выбираем ashift=12 из соображений производительности — это рекомендация самого zfsonlinux, подробнее про это можно почитать в их вики: github.com/zfsonlinux/zfs/wiki/faq#performance-considerations
Применим некоторые настройки для ZFS:
zfs set atime=off rpool
zfs set compression=lz4 rpool
zfs set dedup=off rpool
zfs set snapdir=visible rpool
zfs set primarycache=all rpool
zfs set aclinherit=passthrough rpool
zfs inherit acltype rpool
zfs get -r acltype rpool
zfs get all rpool | grep compressratio
Теперь нам надо рассчитать некоторые переменные для вычисления zfs_arc_max, я это делаю следующим образом:
mem =`free --giga | grep Mem | awk '{print $2}'`
partofmem=$(($mem/10))
echo $setzfscache > /sys/module/zfs/parameters/zfs_arc_max
grep c_max /proc/spl/kstat/zfs/arcstats
zfs create rpool/data
cat > /etc/modprobe.d/zfs.conf << EOL
options zfs zfs_arc_max=$setzfscache
EOL
echo $setzfscache > /sys/module/zfs/parameters/zfs_arc_max
grep c_max /proc/spl/kstat/zfs/arcstatsВ данный момент пул успешно создан, также мы создали сабпул data. Проверить состояние вашего пула можно командой zpool status. Данное действие необходимо провести на всех гипервизорах, после чего приступить к следующему шагу.
Теперь добавим ZFS в Proxmox. Переходим в настройки датацентра (именно его, а не отдельной ноды) в раздел «Storage», кликаем на кнопку «Add» и выбираем опцию «ZFS», после чего мы увидим следующие параметры:
ID: Название стораджа. Я дал ему название local-zfs
ZFS Pool: Мы создали rpool/data, его и добавляем сюда.
Nodes: указываем все доступные ноды
Данная команда создает новый пул с выбранными нами дисками. На каждом гипервизоре должен появится новый storage под названием local-zfs, после чего вы сможете смигрировать свои виртуальные машины с локального storage на ZFS.
Репликация инстансов на соседний гипервизор
В кластере Proxmox есть возможность репликации данных с одного гипервизора на другой: данный вариант позволяет осуществлять переключение инстанса с одного сервера на другой. Данные будут актуальны на момент последней синхронизации — ее время можно выставить при создании репликации (стандартно ставится 15 минут). Существует два способа миграции инстанса на другую ноду Proxmox: ручной и автоматический. Давайте рассмотрим в первую очередь ручной вариант, а в конце я предоставлю вам Python скрипт, который позволит создавать виртуальную машину на доступном гипервизоре при недоступности одного из гипервизоров.
Для создания репликации необходимо перейти в веб-панель Proxmox и создать виртуальную машину или LXC контейнер. В предыдущих пунктах мы с вами настроили vmbr1 мост с NAT, что позволит нам выходить во внешнюю сеть. Я создам LXC контейнер с MySQL, Nginx и PHP-FPM с тестовым сайтом, чтобы проверить работу репликации. Ниже будет пошаговая инструкция.
Загружаем подходящий темплейт (переходим в storage —> Content —> Templates), пример на скриншоте:
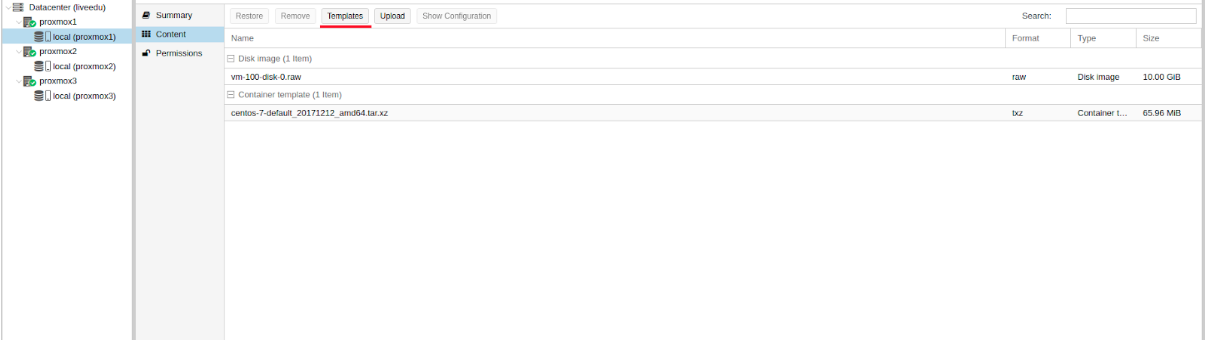
Изображение 10. Local storage с шаблонами и образами ВМ
Нажимаем кнопку “Templates” и загружаем необходимый нам шаблон LXC контейнера:
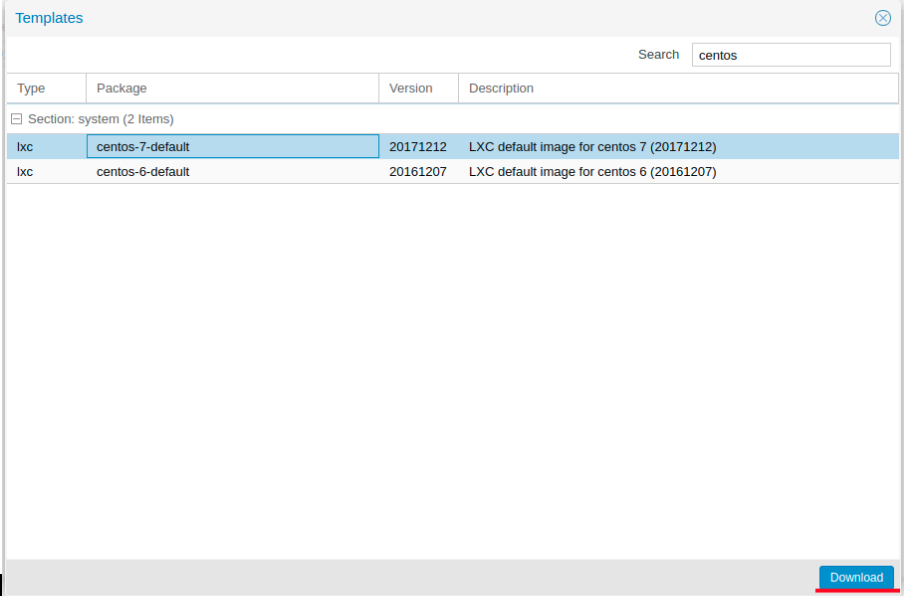
Изображение 11. Выбор и загрузка шаблона
Теперь мы можем использовать его при создании новых LXC контейнеров. Выбираем первый гипервизор и нажимаем кнопку “Create CT” в правом верхнем углу: мы увидим панель создания нового инстанса. Этапы установки достаточно просты и я приведу лишь конфигурационный файл данного LXC контейнера:
arch: amd64
cores: 3
memory: 2048
nameserver: 8.8.8.8
net0: name=eth0,bridge=vmbr1,firewall=1,gw=172.16.0.1,hwaddr=D6:60:C5:39:98:A0,ip=172.16.0.2/24,type=veth
ostype: centos
rootfs: local:100/vm-100-disk-1.raw,size=10G
swap: 512
unprivileged:
Контейнер успешно создан. К LXC контейнерам можно подключаться через команду pct enter , я также перед установкой добавил SSH ключ гипервизора, чтобы подключаться напрямую через SSH (в PCT есть небольшие проблемы с отображением терминала). Я подготовил сервер и установил туда все необходимые серверные приложения, теперь можно перейти к созданию репликации.
Кликаем на LXC контейнер и переходим во вкладку “Replication”, где создаем параметр репликации с помощью кнопки “Add”:
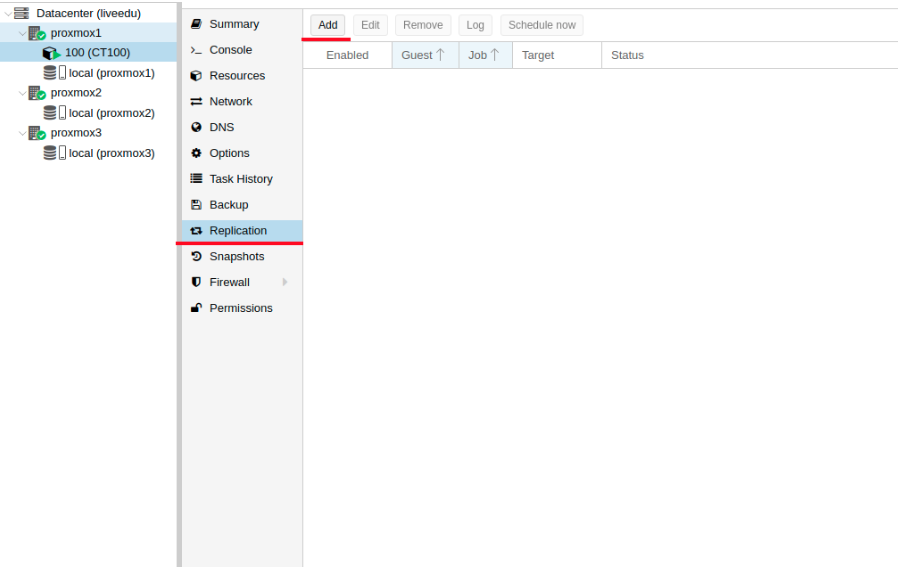
Изображение 12. Создание репликации в интерфейсе Proxmox

Изображение 13. Окно создания Replication job
Я создал задачу реплицировать контейнер на вторую ноду, как видно на следующем скриншоте репликация прошла успешно — обращайте внимание на поле “Status”, она оповещает о статусе репликации, также стоит обращать внимание на поле “Duration”, чтобы знать, сколько длится репликация данных.

Изображение 14. Список синхронизаций ВМ
Теперь попробуем смигрировать машину на вторую ноду с помощью кнопки “Migrate”
Начнется миграция контейнера, лог можно просмотреть в списке задач — там будет наша миграция. После этого контейнер будет перемещен на вторую ноду.
Ошибка “Host Key Verification Failed”
Иногда при настройке кластера может возникать подобная проблема — она мешает мигрировать машины и создавать репликацию, что нивелирует преимущества кластерных решений. Для исправления этой ошибки удалите файл known_hosts и подключитесь по SSH к конфликтной ноде:
/usr/bin/ssh -o 'HostKeyAlias=proxmox2' root@172.30.0.16
Примите Hostkey и попробуйте ввести эту команду, она должна подключить вас к серверу:
/usr/bin/ssh -o 'BatchMode=yes' -o 'HostKeyAlias=proxmox2' root@172.30.0.16
Особенности сетевых настроек на Hetzner
Переходим в панель Robot и нажимаем на кнопку “Virtual Switches”. На следующей странице вы увидите панель создания и управления интерфейсов Virtual Switch: для начала его необходимо создать, а после “подключить” выделенные сервера к нему. В поиске добавляем необходимые сервера для подключения — их не не нужно перезагружать, только придется подождать до 10-15 минут, когда подключение к Virtual Switch будет активно.
После добавления серверов в Virtual Switch через веб-панель подключаемся к серверам и открываем конфигурационные файлы сетевых интерфейсов, где создаем новый сетевой интерфейс:
auto enp4s0.4000
iface enp4s0.4000 inet static
address 10.1.0.11/24
mtu 1400
vlan-raw-device enp4s0Давайте разберем подробнее, что это такое. По своей сути — это VLAN, который подключается к единственному физическому интерфейсу под названием enp4s0 (он у вас может отличаться), с указанием номера VLAN — это номер Virtual Switch’a, который вы создавали в веб-панели Hetzner Robot. Адрес можете указать любой, главное, чтобы он был локальный.
Отмечу, что конфигурировать enp4s0 следует как обычно, по сути он должен содержать внешний IP адрес, который был выдан вашему физическому серверу. Повторите данные шаги на других гипервизорах, после чего перезагрузите на них networking сервис, сделайте пинг до соседней ноды по IP адресу Virtual Switch. Если пинг прошел успешно, то вы успешно установили соединение между серверами по Virtual Switch.
Я также приложу конфигурационный файл sysctl.conf, он понадобится, если у вас будут проблемы с форвардингом пакетом и прочими сетевыми параметрами:
net.ipv6.conf.all.disable_ipv6=0
net.ipv6.conf.default.disable_ipv6 = 0
net.ipv6.conf.all.forwarding=1
net.ipv4.conf.all.rp_filter=1
net.ipv4.tcp_syncookies=1
net.ipv4.ip_forward=1
net.ipv4.conf.all.send_redirects=0
Добавление IPv4 подсети в Hetzner
Перед началом работ вам необходимо заказать подсеть в Hetzner, сделать это можно через панель Robot.
Создадим сетевой мост с адресом, который будет из этой подсети. Пример конфигурации:
auto vmbr2
iface vmbr2 inet static
address ip-address
netmask 29
bridge-ports none
bridge-stp off
bridge-fd 0Теперь переходим в настройки виртуальной машины в Proxmox и создаем новый сетевой интерфейс, который будет прикреплен к мосту vmbr2. Я использую LXC контейнер, его конфигурацию можно изменять сразу же в Proxmox. Итоговая конфигурация для Debian:
auto eth0
iface eth0 inet static
address ip-address
netmask 26
gateway bridge-addressОбратите внимание: я указал 26 маску, а не 29 — это требуется для того, чтобы сеть на виртуальной машине работала.
Добавление IPv4 адреса в Hetzner
Ситуация с одиночным IP адресом отличается — обычно Hetzner дает нам дополнительный адрес из подсети сервера. Это означает, что вместо vmbr2 нам требуется использоваться vmbr0, но на данный момент его у нас нет. Суть в том, что vmbr0 должен содержать IP адрес железного сервера (то есть использовать тот адрес, который использовал физический сетевой интерфейс enp2s0). Адрес необходимо переместить на vmbr0, для этого подойдет следующая конфигурация (советую заказать KVM, чтобы в случае чего возобновить работу сети):
auto enp2s0
iface enp2s0 inet manual
auto vmbr0
iface vmbr0 inet static
address ip-address
netmask 255.255.255.192
gateway ip-gateway
bridge-ports enp2s0
bridge-stp off
bridge-fd 0
Перезапустите сервер, если это возможно (если нет, перезапустите сервис networking), после чего проверьте сетевые интерфейсы через ip a:
2: enp2s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master vmbr0 state UP group default qlen 1000
link/ether 44:8a:5b:2c:30:c2 brd ff:ff:ff:ff:ff:ff
Как здесь видно, enp2s0 подключен к vmbr0 и не имеет IP адрес, так как он был переназначен на vmbr0.
Теперь в настройках виртуальной машины добавляем сетевой интерфейс, который будет подключен к vmbr0. В качестве gateway укажите адрес, прикрепленный к vmbr0.
В завершении
Надеюсь, что данная статья пригодится вам, когда вы будете настраивать Proxmox кластер в Hetzner. Если позволит время, то я расширю статью и добавлю инструкцию для OVH — там тоже не все очевидно, как кажется на первый взгляд. Материал получился достаточно объемным, если найдете ошибки, то, пожалуйста, напишите в комментарии, я их исправлю. Всем спасибо за уделенное внимание.
Автор: Илья Андреев, под редакцией Алексея Жадан и команды «Лайв Линукс»

21.11.2017
12:50:25
https://habrahabr.ru/post/154235/
![]() Google
Google
 Dmitry
Dmitry
21.11.2017
12:50:50
dd без опции direct показывает лишь скорость кеша — не более. В некоторых конфигурациях вы можете получать линейную скорость без кеша выше, чем с кешем. В некоторых вы будете получать сотни мегабайт в секунду, при линейной производительности в единицы мегабайт.
 Konstantin
Konstantin
21.11.2017
12:52:23

вот я включил барьер, заметно куда более. Это нормальная разница?
Dmitry
21.11.2017
12:53:14
что пишет дд и куда в твоем случае?
Konstantin
21.11.2017
12:53:59
это графики kvm дисков и Postgres, не дд
Dmitry
21.11.2017
12:56:57
ну с nobarrier будет быстрее явно
Konstantin
21.11.2017
12:57:01

т.е. там и нагрузки то нет
Dmitry
21.11.2017
12:57:19
![]() Google
Google
Dmitry
21.11.2017
12:57:29
нормально что такая разница?
Konstantin
21.11.2017
12:57:36
базы просто ложатся при небольшой записи
транзакции до 1-3сек из-за IOwait
я перенёс вирт диск на локальное хранилище, за BBU, там можно выключить барьер то, а вот с цефом я не пойму.. много кешей, я запутался
![]() Ecklory
Ecklory
22.11.2017
09:07:57
Доброго времени суток.
У кого-то есть знакомые юристы/адвокаты специализирующиеся в IT? Есть пара вопросов, могу озвучить сюда.
Сорян, что не по теме
Dmitry
22.11.2017
09:11:10
лучше поискать там, где народу поболе
![]() Ecklory
Ecklory
22.11.2017
09:11:41
https://pastebin.com/Kqrk0fji
Dmitry
22.11.2017
09:46:52
заплатите пару тысяч лойеру за консультацию и взьебите этих мудаков
![]() Ecklory
Ecklory
22.11.2017
09:48:35
не надо по чатам ходить
На самом деле… дали вполне хороший совет. Запись устного диалога, при этом в начале разговора уведомить собеседника о том, что идёт запись. В дальнейшем запись приложить к делу.
Dmitry
22.11.2017
09:49:24
![]() Ecklory
Ecklory
22.11.2017
09:50:11
Да и там работают очень грамотные люди, уже работал с ними
 Andrey
Andrey
22.11.2017
09:50:35
![]() Ecklory
Ecklory
22.11.2017
09:51:33
![]() Google
Google
 Александр
Александр
22.11.2017
09:53:47
Какой демон отвечате в проксе за веб?
Я уже задавал такой вопрос помоему
Dmitry
22.11.2017
09:54:05
Александр
22.11.2017
09:54:34
 Georgii
Georgii
22.11.2017
09:56:58
 Nick
Nick
22.11.2017
09:57:05
Georgii
22.11.2017
09:57:42
по проксмоксу, ктонибудь давал клиентам дуступ к морде ? или там с бесопасностью совсем плохо ?
или в личный кабинет через api прикручивать
Nick
22.11.2017
09:58:21
«нас все время кидает подрядчик, но мы даем ему новые заказы и платим деньги по устным договоренностям»
Смешно
![]() Ecklory
Ecklory
22.11.2017
09:59:05
Nick
22.11.2017
10:00:21
Дуло пистолета, например… это точно к УК относится
Если в договоре не прописана ответственность исполнителя — то максимум, что вы можете сделать — это вернуть деньги, если контора еще жива. Да и то шансов не много. А если нет договора и деньги платились на частное лицо, например — то шансы, мягко говоря, ничтожны
Презерватив придуман чтобы не думать о последствиях. Договор придуман для того же самого. Если презерватив плохой — это все может плохо кончится
![]() Ecklory
Ecklory
22.11.2017
10:04:03
Nick
22.11.2017
10:04:04
Если это частное лицо и выплаты были после апреля — то до подачи декларации ндфл3 он имеет полное право жить спокойно аж до апреля следующего года…
Это по поводу налогов
На счет мошенничества — возможно и прокатит, не знаю. Но всякие стоны про упущенную прибыль — это в пользу бедных. Короче на юристов придется потратиться
![]() Ecklory
Ecklory
22.11.2017
10:17:12
@UnixGuru
Спасибо за советы/ответы. Учту
 Artem
Artem
22.11.2017
10:17:59
![]() Google
Google
Artem
22.11.2017
10:18:09
подскажите как чекнуть версию овирта на хосте ?
обновялся кто с 3й на 4ю версию ?
Александр
22.11.2017
10:22:40
Artem
22.11.2017
10:23:06
думаю обновится гна актуальную версию
есть где то 3.1 в клатсере
![]() Admin
Admin
Artem
22.11.2017
10:23:24
вот и думаю гладко ли пройдет все
![]() Alexander
Alexander
22.11.2017
16:56:16
как убить «залипшую» вм?
«залипла» в статусе » in shutdown»
virsh destroy не отрабатывает. pid этой визит в статусе zombie
Georgii
22.11.2017
17:18:23
![]() Dan
Dan
22.11.2017
17:18:43
хотя если там zstate то все плохо
 Старый
Старый
22.11.2017
17:19:16
![]() Dan
Dan
22.11.2017
17:20:14
только что наткнулся на баг с qemu и внутренними снепшотами, думаю скоро починят, разрабы слегка шокированы этим глюком
Старый
22.11.2017
17:20:49
![]() Dan
Dan
22.11.2017
17:22:03
Старый
22.11.2017
17:22:30
![]() Google
Google
Старый
22.11.2017
17:23:01
на центоси у меня оракл нормально не поднялся
![]() Dan
Dan
22.11.2017
17:23:24
![]() Alexander
Alexander
22.11.2017
17:29:13
![]() Dan
Dan
22.11.2017
17:31:58
@alexk24 если родителя нет то процесс должен унаследовать инит
![]() Alexander
Alexander
22.11.2017
17:41:18
![]() Dan
Dan
22.11.2017
17:46:30
![]() Stanislav
Stanislav
22.11.2017
18:04:57
Andrey
23.11.2017
13:54:18
Ребят, я тут похоже сотворил хуйню. Было 2 сервака с пятым проксом
Я собрал из них кластер и на одном из серверов пропали все вирты из списка, но я вижу их в списке процессов в шеле.
Реально ли это поправить?
![]() Yaroslav
Yaroslav
23.11.2017
13:55:12
Andrey
23.11.2017
13:55:50
 Roman
Roman
23.11.2017
13:56:01
![]() Yaroslav
Yaroslav
23.11.2017
13:56:13
может веб-морда отвалилась.
Andrey
23.11.2017
13:57:06
root@prox2:~# pvecm add prox1.somelocalnetwork
detected the following error(s):
* this host already contains virtual guests
root@prox2:~# pvecm add prox1.somelocalnetwork -f
The authenticity of host ‘prox1.somelocalnetwork (10.0.0.16)’ can’t be established.
ECDSA key fingerprint is SHA256:ihPhZnFiembLDWCgEFfw3T5tvv4qAmbajWrcqzqyPHk.
Are you sure you want to continue connecting (yes/no)? yes
root@prox1.somelocalnetwork’s password:
copy corosync auth key
stopping pve-cluster service
backup old database
waiting for quorum…OK
generating node certificates
merge known_hosts file
restart services
successfully added node ‘prox2’ to cluster.
Roman
23.11.2017
13:59:53
при вводе в кластер очевидно затерлись конфиги из
/etc/pve/qemu-server/
из можно было бы легко восстановить, если взять из бэкапа
ну а без бэкапа, слажна…