Содержание
- Форум UPgrade
- Как побороть UNC сектора на HDD?
- Как побороть UNC сектора на HDD?
- PC-3000 Forum
- TOSHIBA MQ02ABF050
- TOSHIBA MQ02ABF050
- Re: TOSHIBA MQ02ABF050
- Re: TOSHIBA MQ02ABF050
- Re: TOSHIBA MQ02ABF050
- Re: TOSHIBA MQ02ABF050
- Re: TOSHIBA MQ02ABF050
- Defoult.ru
- Сложный компьютер простыми словами
- Тестирование жесткого диска (HDD)
- Как работает сканирование?
- Как разобраться в результатах скана?
- Расшифровка ошибок mhdd:
- PC-3000 Forum
- Seagate ST3500418AS Sector Reading problem
- Seagate ST3500418AS Sector Reading problem
- Re: Seagate ST3500418AS Sector Reading problem
- Re: Seagate ST3500418AS Sector Reading problem
- Re: Seagate ST3500418AS Sector Reading problem
- Re: Seagate ST3500418AS Sector Reading problem
Форум UPgrade
Официальный форум журнала UPgrade и портала upweek.ru
Как побороть UNC сектора на HDD?
Как побороть UNC сектора на HDD?
Сообщение DarkWave » 24 окт 2007, 22:26
Недавно решил достать из шкафа старый (относительно старый, покупался года три назад) жесткий диск Samsung SP1614C объемом 160 гигобайт, который лежал там около года, хотел туда слить архив музыки, но сначала решил проверить его на бэдблоки с помощью программы MHDD 4.6. Бэдов обнаружено не было, но есть сектора UNC (как я понял это неправильная контрольнаясумма при считывании данных), сначала их было 50 штук, но на следующий день их стало 24.
Ни erase, ни scan+erase waits не помогают, а при scan+remap вывешывается флаг ERR и проверка останавливается, помогает только ресет.
Показания SMART снятые с помощью программы Dalas 2.0.0.10
Модель: SAMSUNG SP1614C
S/N: S01XJ20Y121812
————————————————————————————————
| № | Название атрибута | Порог | Значение | Худшее | Внутренний формат |
| — | —————————— | ———- | ———- | ———- | ——————
| 1 | Raw Read Error Rate. | 51 | 100 | 100 | 49 |
| 2 | Spin Up Time. | 25 | 100 | 100 | 5696 |
| 3 | Start/Stop Count. | 0 | 99 | 99 | 1269 |
| 4 | Reallocated Sector Count. | 11 | 100 | 100 | 2 |
| 5 | Seek Error Rate. | 51 | 100 | 100 | 0 |
| 6 | Seek Time Performance. | 15 | 100 | 100 | 0 |
| 7 | Power On Hours Count. | 0 | 100 | 100 | 226743 |
| 8 | Spin Retry Count. | 51 | 100 | 100 | 0 |
| 9 | Recalibration Retries. | 0 | 100 | 100 | 0 |
| 10 | Drive Power Cycle Count. | 0 | 100 | 100 | 655 |
| 11 | Temperature. | 0 | 169 | 70 | 23°C |
| 12 | ECC On The Fly Count. | 0 | 100 | 100 | 15603161 |
| 13 | Reallocation Event Count. | 0 | 88 | 88 | 26 |
| 14 | Current Pending Sector Count.. | 0 | 100 | 100 | 0 |
| 15 | Uncorrectable Sector Count. | 0 | 100 | 100 | 0 |
| 16 | Ultra ATA CRC Error Rate. | 0 | 200 | 200 | 0 |
| 17 | Write Error Rate. | 51 | 100 | 100 | 0 |
| 18 | TA Counter Detected. | 51 | 100 | 99 | 48 |
————————————————————————————————
Отчет сканирования поврхности:
Model: SAMSUNG SP1614C FW: SW100-34
s/n: S01XJ20Y121812
Начальный LBA. 0
Конечный LBA. 312581807
Error UNC : 2366464
Error UNC : 2367488
Error UNC : 2369536
Error UNC : 2377728
Error UNC : 2378752
Error UNC : 2379776
Error UNC : 2380800
Error UNC : 2415872
Error UNC : 2416896
Error UNC : 2417920
Error UNC : 2418688
Error UNC : 2419712
Error UNC : 2420736
Error UNC : 2423040
Error UNC : 2424064
Error UNC : 2424832
Error UNC : 2440960
Error UNC : 2441728
Error UNC : 2442752
Error UNC : 2445056
Error UNC : 2446080
Error UNC : 2447104
Error UNC : 2447872
Error UNC : 2448896
Warning >500 : 6270464
Error Time : 13607936
Error Time : 42466560
Error Time : 53996544
Error Time : 58932992
Error Time : 60913920
Error Time : 72628480
Error Time : 77446912
Error Time : 77699584
Error Time : 89125632
Error Time : 96212736
Error Time : 96561152
Error Time : 152763648
Error Time : 163001344
Error Time : 237753088
Error Time : 238595328
Error Time : 244640768
Error Time : 245261056
Error Time : 287148544
Error Time : 288102400
Последний проверенный LBA..312581807
Минимальная скорость. 1,2 MB/c
Максимальная скорость. 56,7 MB/c
Предупреждений. 1
Ошибок. 43
Общее время прохождения. 01:04:30
Источник
PC-3000 Forum
TOSHIBA MQ02ABF050
![]()
TOSHIBA MQ02ABF050
Post by redlabs » 21.02.17, 12:54
i got a TOSHIBA MQ02ABF050 in which is not reading sector what could be the problem
![]()
Re: TOSHIBA MQ02ABF050
Post by redlabs » 22.02.17, 08:26
anyone can help

Re: TOSHIBA MQ02ABF050
Post by Amarbir[CDR-Labs] » 22.02.17, 11:39
![]()
Re: TOSHIBA MQ02ABF050
Post by redlabs » 02.03.17, 10:59
we don’t did anything as of now
Zone table. : Zone table read error; Device Error Detected 51/20 ( )
G-List reading error. : G-List read error; Device Error Detected 51/26 (TON;ABR; )
When try to read sector found error below
Read sector (0-1) ext error device error detected «AMN;(bit5);UNC;BBK
and we did selecting other modal and trying clear G-list and rest the password and clear the SMART
![]()
Re: TOSHIBA MQ02ABF050
Post by redlabs » 02.03.17, 11:02
if i select ABF model find the log below
Zone table. : Ok
Cyl num. : 208 403
Head num. : 2
Vendor. : TOSHIBA
Model. : MQ02ABF050
Microcode. : HDF01K0G
Defects in G-List. : 0
CP Avalable. : 33,34,44,56,92,95,98,9A,9C,A2,A5,A7,A8,A9,AA,AD,AE,B1,B3,BB,BF,C1,C5,C6,C7,C8,C9,CB,CD,D0,D1,D3,D4,D6,D7,D9,DA,DB,DC,DD,EF,F1,F3,
![]()
Re: TOSHIBA MQ02ABF050
Post by redlabs » 05.03.17, 15:07
Источник
Defoult.ru
Сложный компьютер простыми словами
Тестирование жесткого диска (HDD)

Купил новый жестки диск (HDD) или есть подозрение что твой старенький HDD уже не тот, – настоятельно рекомендую проверить его на наличие бэдов.
Бэд, бэды, бэд-сектор, бэд-блок – (от англ. “bad” – плохой) – сбойный, нечитаемый, ненадежный, ненадежный файл, сектор диска.
Ссылки на программу:
- Оффициальный сайт Mhdd (на русском)
- Скачать последнюю версию iso образа (на момент написания статью версия 4.6) mhdd32ver4.6iso
Приведу пошаговую инструкцию по тестированию HDD на примере программы MHDD. Программа при должном умении и опыте дает шанс исправить некоторые бэды, по незнанию лучше ничего не пытаться исправить. А вот проверить исправность диска – довольно просто и безболезненно, об этом и напишу.
- Запиши образ на дискдискетуфлешку.
- Диагностируемый накопитель IDE должен быть переключен в режим MASTER. Все устройства SLAVE должны быть отключены. Поэтому, проверь в каком режиме жесткий диск (в качестве примера смотри рисунок)

Внимание: Никогда не запускайте MHDD с накопителя, который находится на том же физическом IDE канале (кабеле), к которому (к кабелю, к каналу) подключается тестируемый накопитель. Вы будете иметь значительные повреждения данных на обоих накопителях! В связи с этим, по умолчанию, MHDD не работает с каналом PRIMARY, так как у большинства пользователей именно там находится MHDD.
Иными словами – IDE устройства (жесткий диск и CD-Rom) не должны находиться на одном кабеле (как на изображении).
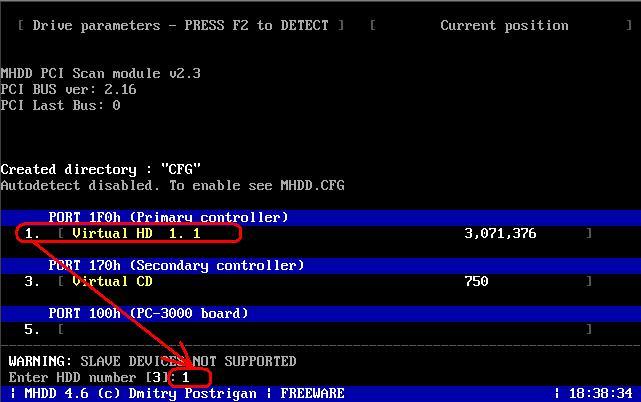
Через несколько секунд на мониторе появится окно, где нужно выбрать номер тестируемого HDD. В этом примере жесткий диск находится под номером 1, его и выберем. Жмем ентер!
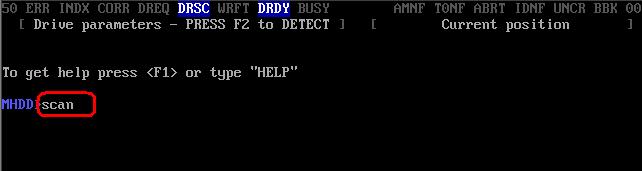
Для подготовки к тестированию нужно нажать либо F4, либо написать scan и нажать ентер.
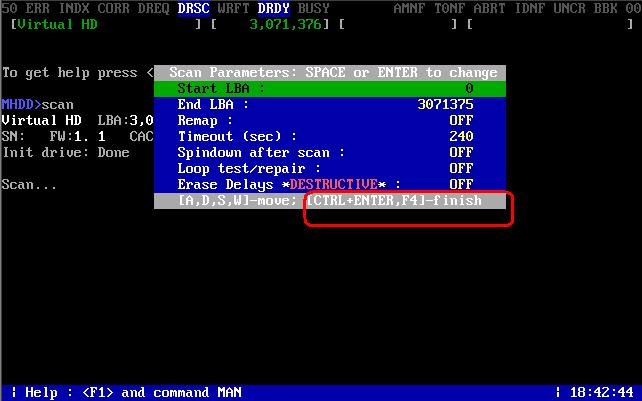
Появится окно параметров сканирования, оставим все значения как есть. Для запуска тестирования жмем CTRL+ENTER или F4
Далее начнется сканирование жесткого диска на наличие ошибок. Особое внимание следует обратить табличную часть справа.
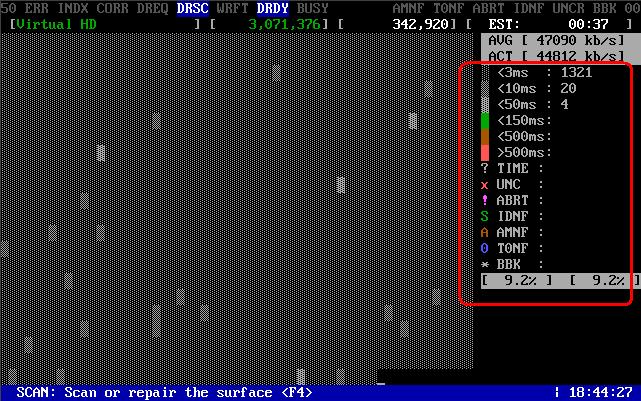
Как работает сканирование?
- MHDD посылает команду VERIFY SECTORS с номером LBA (номер сектора) и номером секторов в качестве параметров
- Накопитель поднимает флаг BUSY(диск блокируется)
- MHDD запускает таймер (таймер замеряет время блокировки диска,т.е. когда он был BUSY или по-русски – занят!)
- После того, как накопитель выполнил команду, он опускает флаг BUSY
- MHDD вычисляет затраченное накопителем время и выводит соответствующий блок на экран ( табличная часть справа ). Если встретилась ошибка (bad block), программа выводит соответствующую букву, которая описывает ошибку.
MHDD повторяет шаги 1—5 до конечного сектора.
Как разобраться в результатах скана?
Наличие красных (>500ms) блоков на полностью здоровом накопителе недопустимо. Я бью тревогу когда появляются зеленые блоки ( ). Можно попытаться исправить эти блоки стиранием всей поверхности диска (естественно все данные будут потеряны) и, если это не помогло – можно делать выводы (накопитель перестал быть достаточно надёжным).
Буквенно-символьные блоки говорят о наличии BAD блоков на поверхности.
Расшифровка ошибок mhdd:
- UNC (Uncorrectable Data Error) – Не удалось скорректировать данные избыточным кодом, блок признан нечитаемым. Может быть как следствием нарушения контрольной суммы данных, так и следствием физического повреждения HDD;
- ABRT (Aborted Command) – hdd отверг команду в результате неисправности, или команда не поддерживается данным HDD (возможно установлен пароль, устаревшая или слишком новая модель…).
- IDNF (ID Not Found) – Не идентифицирован сектор. Обычно говорит о разрушении микрокода или формата нижнего уровня HDD. У исправных винчестеров такая ошибка выдается при попытке обратиться к несуществующему адресу (проблема в том, что в современных винтах сектора не всегда имеются заголовки);
- AMNF (Address Mark Not Found) – невозможно прочитать сектор, обычно в результате серьезной аппаратной проблемы (например, на HDD Toshiba, Maxtor – говорит о неисправности магнитных головок);
- T0NF (Track 0 Not Found) – невозможно выполнить рекалибровку на стартовый цилиндр рабочей области. На современных HDD говорит о неисправности микрокода или магнитных головок;
- BBK (Bad Block Detected) – Найден бэд-блок. Ошибка устарела;
Подробнее об этих ошибках можно узнать в описании ATA-стандарта на сайте www.t13.org (но найти там нужный документ -нудное дело ).
Исправить буквенно-символьные блоки можно (только осторожно и 100% гарантии нет):
- Полная очистка поверхности командой erase.
- Если это не помогло, то scan с включенной опцией EraseWaits.
- Если Bad блоки так и не исчезли, следует запустить scan с включенной опцией Remap.
И самое главное. Перед тем как что-то пытаться исправить подумай трижды! Сохрани исправную информацию (все сотрется)! Почитай дополнительную информацию:
З.Ы. ПОМНИ! Если что-то не знаешьне понимаешьне уверен – не пытайся сам исправлять, можно все угробить!
Источник
PC-3000 Forum
Seagate ST3500418AS Sector Reading problem
Moderator: Nick_TS
![]()
Seagate ST3500418AS Sector Reading problem
Post by betty » 03.10.14, 07:26
I have the segate 500GB with model ST3500418AS FW CC33. Problem is that I can’t access total sector.It shows full capacity. It can possible smart reset, i can access terminal mode,m0,6,2. 22 etc. But when i try to use translator recovery there have giving error on sector reading. Also i try to read sector through sector edit menu, i can’t read the sector. error of 48bit showing. But if i use option » utility and then » transit split data» yes/no . then press yes i can read the data.
but in DE i used the same utility. even though i can’t get full data.
Any one can give any idea. to solve the problem..
![]()
Re: Seagate ST3500418AS Sector Reading problem
Post by AJ2008 » 03.10.14, 10:09
This is the problem, translator is incomplete because it was rebuilt using slip list only and not NRG list which is also a dependency for translator to load properly. Did you save entries from NRG before you apply this command?
![]()
Re: Seagate ST3500418AS Sector Reading problem
Post by betty » 04.10.14, 06:07
First Thanks AJ2008,
I had save the HDD resources. That has some module have reading problem. ie module 0027,0028,29,30,31,32,2C,2D .And it shows in terminal following message.
Starting LBA of RW Request=0001869F Length=FFFFFFFF
ProcessRWError -Read- at LBA 0001869F Sense Code=43110081
Unrecoverable Error Reported
(H) SATA Reset
SSPSaveSettings
SSPRestoreSettings
Send Status: COMRESET seen
(S) SATA Reset
Send Status: COMRESET seen
Starting LBA of RW Request=0001161C Length=FFFFFFFF
ProcessRWError -Read- at LBA 0001161C Sense Code=43110081
Unrecoverable Error Reported
Starting LBA of RW Request=0001161C Length=FFFFFFFF
ProcessRWError -Read- at LBA 0001161C Sense Code=43110081
Unrecoverable Error Reported
Starting LBA of RW Request=0001161C Length=FFFFFFFF
ProcessRWError -Read- at LBA 0001161C Sense Code=43110081
Unrecoverable Error Reported
Starting LBA of RW Request=0001161C Length=FFFFFFFF
ProcessRWError -Read- at LBA 0001161C Sense Code=43110081
Unrecoverable Error Reported
Starting LBA of RW Request=0001161C Length=FFFFFFFF
ProcessRWError -Read- at LBA 0001161C Sense Code=43110081
Unrecoverable Error Reported
Starting LBA of RW Request=0001161D Length=FFFFFFFF
ProcessRWError -Read- at LBA 0001161D Sense Code=43110081
Unrecoverable Error Reported
Starting LBA of RW Request=0001161D Length=FFFFFFFF
ProcessRWError -Read- at LBA 0001161D Sense Code=43110081
Unrecoverable Error Reported
Starting LBA of RW Request=0001161D Length=FFFFFFFF
ProcessRWError -Read- at LBA 0001161D Sense Code=43110081
Unrecoverable Error Reported
Starting LBA of RW Request=0001161E Length=FFFFFFFF
ProcessRWError -Read- at LBA 0001161E Sense Code=43110081
Unrecoverable Error Reported
Starting LBA of RW Request=0001161E Length=FFFFFFFF
ProcessRWError -Read- at LBA 0001161E Sense Code=43110081
Unrecoverable Error Reported
And also i tried to recover the translation recovery proccess. But after some time it shows
HDD ID reading.
Detecting defects hiding cmd type.
G-List erase.
Detecting Phys Sct Size.
Result. : 512
Start scanning.
«Fork» searching: 1055901 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect E7:1:32F(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect E7:1:32F(1)! Tech state 0x72, 0x03110081
LBA : 1055901
«Fork» searching: 1055902 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect E7:1:330(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect E7:1:330(1)! Tech state 0x72, 0x03110081
LBA : 1055902
«Fork» searching: 1055903 — 976773167
Verify sectors ext error Device error detected «UNC»
And One more thing is that first 5 digit sector can access. ie 99999 or 55555 . But when i try to access 6 digit it shows «48bit error»
I hope that you can help .
![]()
Re: Seagate ST3500418AS Sector Reading problem
Post by betty » 05.10.14, 08:31
the same hdd have new problem. model,fw,serial is showing as it is.. but the capacity is 0 mb. Also we can access the terminal. And when we are doing» clear
Smart (N1) it shows the following message.
Init SMART Fail
LED:000000CC FAddr:0024EA75
LED:000000CC FAddr:0024EA75
Any body can give any idea

Re: Seagate ST3500418AS Sector Reading problem
Post by pclab » 05.10.14, 12:33
I have a similar problem with a ST9500325AS.
I hear no clicks.
It’s well detected, can read all resources without any problem.
But When I try to read sectors, I get Read Error 48-bit Device error detected UNC.
But sometimes the same sector can be read.
On PC3K, head test is OK, but on DDI, the head’s show failures, altough I could already imaged a piece of the drive.
I have tried to clear G-List, SMART and translator regen, but the same happens.
Translator Recovery does this:
«Fork» searching: 11 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0:B(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0:B(1)! Tech state 0x72, 0x03110081
LBA : 11
«Fork» searching: 12 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0:C(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0:C(1)! Tech state 0x72, 0x03110081
LBA : 12
«Fork» searching: 13 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0(1)! Tech state 0x72, 0x03110081
LBA : 13
«Fork» searching: 14 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0:20(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0:20(1)! Tech state 0x72, 0x03110081
LBA : 32
«Fork» searching: 33 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0:21(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0:21(1)! Tech state 0x72, 0x03110081
LBA : 33
«Fork» searching: 34 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0:23(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0:23(1)! Tech state 0x72, 0x03110081
LBA : 35
«Fork» searching: 36 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0:24(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0:24(1)! Tech state 0x72, 0x03110081
LBA : 36
«Fork» searching: 37 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0:30(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0:30(1)! Tech state 0x72, 0x03110081
LBA : 48
«Fork» searching: 49 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0:34(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0:34(1)! Tech state 0x72, 0x03110081
LBA : 52
«Fork» searching: 53 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0:35(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0:35(1)! Tech state 0x72, 0x03110081
LBA : 53
«Fork» searching: 54 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0:36(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0:36(1)! Tech state 0x72, 0x03110081
LBA : 54
«Fork» searching: 55 — 976773167
HDD power supply switching OFF/ON.
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0:3F(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0:3F(1)! Tech state 0x72, 0x03110081
LBA : 63
«Fork» searching: 64 — 976773167
Verify sectors ext error Device error detected «UNC»
PRd: Err Rd Ph Sect 0:0:40(1)! Tech state 0x72, 0x03110081
Surface scanning error (UNC) : PRd: Err Rd Ph Sect 0:0:40(1)! Tech state 0x72, 0x03110081
LBA : 64
If I selected the option Read/Write Options — Use utility and I can read the sectors without the UNC faillure. I can image the drive like this, but the speed is 1kb/s. It will take forever.
Any idea how to speed it up?
Thanks
Источник
|
0 / 0 / 0 Регистрация: 08.03.2013 Сообщений: 10 |
|
|
1 |
|
|
28.04.2013, 06:14. Показов 18869. Ответов 4
Сканирую HDD прог. MHDD 4.6 есть ошибка UNC допустим в 614602, делаю сканирование с REMAP, сектор закрывают синим, делаю опять сканирование ошибка вылазит на следующем секторе 614603
__________________
0 |

|
33 / 33 / 0 Регистрация: 07.12.2011 Сообщений: 237 |
|
|
28.04.2013, 07:11 |
2 |
|
MHDD так помечает убитый сектор, который восстановить не удастся. Было-бы хорошо увидеть смарт харда.
0 |
|
0 / 0 / 0 Регистрация: 08.03.2013 Сообщений: 10 |
|
|
28.04.2013, 07:20 [ТС] |
3 |
|
MHDD так помечает убитый сектор, который восстановить не удастся. Было-бы хорошо увидеть смарт харда. сам первый раз такое вижу, обычно закроешь и нормально винда стартует [ WDC WD3200BPVT-22ZEST0 (WD-WX21AC0H1981) ] 01 Raw Read Error Rate 51 196 196 10026 OK: Значение нормальное
0 |

|
Клюг 7673 / 3188 / 382 Регистрация: 03.05.2011 Сообщений: 8,380 |
|
|
28.04.2013, 15:29 |
4 |
|
BF Mechanical Shock 0 1 1 12010 OK: Всегда пройдено No comments.
0 |
|
0 / 0 / 0 Регистрация: 08.03.2013 Сообщений: 10 |
|
|
29.04.2013, 06:16 [ТС] |
5 |
|
No comments. Значит все его на свалку, или мона что то сделать?
0 |
|
IT_Exp Эксперт 87844 / 49110 / 22898 Регистрация: 17.06.2006 Сообщений: 92,604 |
29.04.2013, 06:16 |
|
5 |
Купил новый жестки диск (HDD) или есть подозрение что твой старенький HDD уже не тот, – настоятельно рекомендую проверить его на наличие бэдов.
Бэд, бэды, бэд-сектор, бэд-блок – (от англ. “bad” – плохой) – сбойный, нечитаемый, ненадежный, ненадежный файл, сектор диска.
Ссылки на программу:
- Оффициальный сайт Mhdd (на русском)
- Скачать последнюю версию iso образа (на момент написания статью версия 4.6) mhdd32ver4.6iso
Приведу пошаговую инструкцию по тестированию HDD на примере программы MHDD. Программа при должном умении и опыте дает шанс исправить некоторые бэды, по незнанию лучше ничего не пытаться исправить!!!. А вот проверить исправность диска – довольно просто и безболезненно, об этом и напишу. ![]()
- Запиши образ на дискдискетуфлешку.
- Диагностируемый накопитель IDE должен быть переключен в режим MASTER. Все устройства SLAVE должны быть отключены. Поэтому, проверь в каком режиме жесткий диск (в качестве примера смотри рисунок)

Внимание: Никогда не запускайте MHDD с накопителя, который находится на том же физическом IDE канале (кабеле), к которому (к кабелю, к каналу) подключается тестируемый накопитель. Вы будете иметь значительные повреждения данных на обоих накопителях! В связи с этим, по умолчанию, MHDD не работает с каналом PRIMARY, так как у большинства пользователей именно там находится MHDD.
Иными словами – IDE устройства (жесткий диск и CD-Rom) не должны находиться на одном кабеле (как на изображении).

- Перезагрузи компьютер и убедись что он загружается с образа, который ты записал, а не с жесткого диска. (загрузка носителей выставляется в БИОСе, если не понятно – пиши в комментариях).
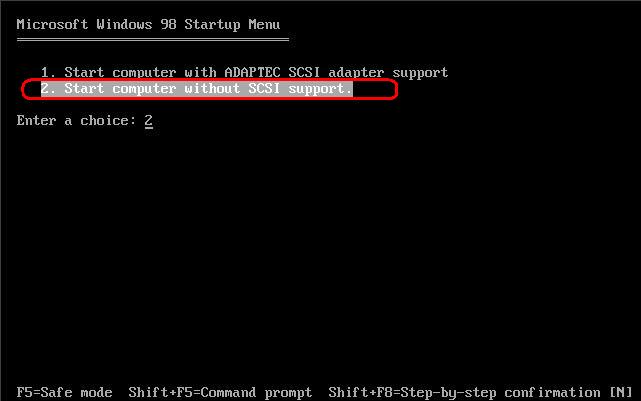
- После загрузки с образа, появится следующий экран (см. изображение ниже). Для доступа к SCSI-устройствам MHDD использует DOS ASPI драйвер. Если вы не планируете работать с накопителями SCSI — значит, вам не нужен этот драйвер. Поэтому выберем параметр загрузки по-умолчанию (пункт 2).
- Через несколько секунд на мониторе появится окно, где нужно выбрать номер тестируемого HDD. В этом примере жесткий диск находится под номером 1, его и выберем. Жмем ентер!
- Для подготовки к тестированию нужно нажать либо F4, либо написать scan и нажать ентер.
- Появится окно параметров сканирования, оставим все значения как есть. Для запуска тестирования жмем CTRL+ENTER или F4
- Далее начнется сканирование жесткого диска на наличие ошибок. Особое внимание следует обратить табличную часть справа.
Как работает сканирование?
- MHDD посылает команду VERIFY SECTORS с номером LBA (номер сектора) и номером секторов в качестве параметров
- Накопитель поднимает флаг BUSY (диск блокируется)
- MHDD запускает таймер (таймер замеряет время блокировки диска,т.е. когда он был BUSY или по-русски – занят!)
- После того, как накопитель выполнил команду, он опускает флаг BUSY
- MHDD вычисляет затраченное накопителем время и выводит соответствующий блок на экран (табличная часть справа). Если встретилась ошибка (bad block), программа выводит соответствующую букву, которая описывает ошибку.
MHDD повторяет шаги 1—5 до конечного сектора.
Как разобраться в результатах скана?
Наличие красных (>500ms) блоков на полностью здоровом накопителе недопустимо. Я бью тревогу когда появляются зеленые блоки (<150ms). Можно попытаться исправить эти блоки стиранием всей поверхности диска (естественно все данные будут потеряны) и, если это не помогло – можно делать выводы (накопитель перестал быть достаточно надёжным).
Буквенно-символьные блоки говорят о наличии BAD блоков на поверхности.
Расшифровка ошибок mhdd:
- UNC (Uncorrectable Data Error) – Не удалось скорректировать данные избыточным кодом, блок признан нечитаемым. Может быть как следствием нарушения контрольной суммы данных, так и следствием физического повреждения HDD;
- ABRT (Aborted Command) – hdd отверг команду в результате неисправности, или команда не поддерживается данным HDD (возможно установлен пароль, устаревшая или слишком новая модель…).
- IDNF (ID Not Found) – Не идентифицирован сектор. Обычно говорит о разрушении микрокода или формата нижнего уровня HDD. У исправных винчестеров такая ошибка выдается при попытке обратиться к несуществующему адресу (проблема в том, что в современных винтах сектора не всегда имеются заголовки);
- AMNF (Address Mark Not Found) – невозможно прочитать сектор, обычно в результате серьезной аппаратной проблемы (например, на HDD Toshiba, Maxtor – говорит о неисправности магнитных головок);
- T0NF (Track 0 Not Found) – невозможно выполнить рекалибровку на стартовый цилиндр рабочей области. На современных HDD говорит о неисправности микрокода или магнитных головок;
- BBK (Bad Block Detected) – Найден бэд-блок. Ошибка устарела;
Подробнее об этих ошибках можно узнать в описании ATA-стандарта на сайте www.t13.org (но найти там нужный документ -нудное дело ![]() ).
).
Исправить буквенно-символьные блоки можно (только осторожно и 100% гарантии нет):
- Полная очистка поверхности командой erase.
- Если это не помогло, то scan с включенной опцией EraseWaits.
- Если Bad блоки так и не исчезли, следует запустить scan с включенной опцией Remap.
И самое главное!!! Перед тем как что-то пытаться исправить подумай трижды! Сохрани исправную информацию (все сотрется)! Почитай дополнительную информацию:
- Сайт MHDD
- Документация MHDD на русском языке
- Часто задаваемые вопросы по MHDD и ответы на них
З.Ы. ПОМНИ! Если что-то не знаешьне понимаешьне уверен – не пытайся сам исправлять, можно все угробить! ![]()
Удачи!
Недавно решил достать из шкафа старый (относительно старый, покупался года три назад) жесткий диск Samsung SP1614C объемом 160 гигобайт, который лежал там около года, хотел туда слить архив музыки, но сначала решил проверить его на бэдблоки с помощью программы MHDD 4.6. Бэдов обнаружено не было, но есть сектора UNC (как я понял это неправильная контрольнаясумма при считывании данных), сначала их было 50 штук, но на следующий день их стало 24.
Ни erase, ни scan+erase waits не помогают, а при scan+remap вывешывается флаг ERR и проверка останавливается, помогает только ресет.
Показания SMART снятые с помощью программы Dalas 2.0.0.10
Модель: SAMSUNG SP1614C
S/N: S01XJ20Y121812
————————————————————————————————
| № | Название атрибута | Порог | Значение | Худшее | Внутренний формат |
| — | —————————— | ———- | ———- | ———- | ——————
| 1 | Raw Read Error Rate……….. | 51 | 100 | 100 | 49 |
| 2 | Spin Up Time……………… | 25 | 100 | 100 | 5696 |
| 3 | Start/Stop Count………….. | 0 | 99 | 99 | 1269 |
| 4 | Reallocated Sector Count…… | 11 | 100 | 100 | 2 |
| 5 | Seek Error Rate…………… | 51 | 100 | 100 | 0 |
| 6 | Seek Time Performance……… | 15 | 100 | 100 | 0 |
| 7 | Power On Hours Count………. | 0 | 100 | 100 | 226743 |
| 8 | Spin Retry Count………….. | 51 | 100 | 100 | 0 |
| 9 | Recalibration Retries……… | 0 | 100 | 100 | 0 |
| 10 | Drive Power Cycle Count……. | 0 | 100 | 100 | 655 |
| 11 | Temperature………………. | 0 | 169 | 70 | 23°C |
| 12 | ECC On The Fly Count………. | 0 | 100 | 100 | 15603161 |
| 13 | Reallocation Event Count…… | 0 | 88 | 88 | 26 |
| 14 | Current Pending Sector Count.. | 0 | 100 | 100 | 0 |
| 15 | Uncorrectable Sector Count…. | 0 | 100 | 100 | 0 |
| 16 | Ultra ATA CRC Error Rate…… | 0 | 200 | 200 | 0 |
| 17 | Write Error Rate………….. | 51 | 100 | 100 | 0 |
| 18 | TA Counter Detected……….. | 51 | 100 | 99 | 48 |
————————————————————————————————
Отчет сканирования поврхности:
Model: SAMSUNG SP1614C FW: SW100-34
s/n: S01XJ20Y121812
Начальный LBA………….0
Конечный LBA…………..312581807
Error UNC : 2366464
Error UNC : 2367488
Error UNC : 2369536
Error UNC : 2377728
Error UNC : 2378752
Error UNC : 2379776
Error UNC : 2380800
Error UNC : 2415872
Error UNC : 2416896
Error UNC : 2417920
Error UNC : 2418688
Error UNC : 2419712
Error UNC : 2420736
Error UNC : 2423040
Error UNC : 2424064
Error UNC : 2424832
Error UNC : 2440960
Error UNC : 2441728
Error UNC : 2442752
Error UNC : 2445056
Error UNC : 2446080
Error UNC : 2447104
Error UNC : 2447872
Error UNC : 2448896
Warning >500 : 6270464
Error Time : 13607936
Error Time : 42466560
Error Time : 53996544
Error Time : 58932992
Error Time : 60913920
Error Time : 72628480
Error Time : 77446912
Error Time : 77699584
Error Time : 89125632
Error Time : 96212736
Error Time : 96561152
Error Time : 152763648
Error Time : 163001344
Error Time : 237753088
Error Time : 238595328
Error Time : 244640768
Error Time : 245261056
Error Time : 287148544
Error Time : 288102400
Последний проверенный LBA..312581807
Минимальная скорость…….1,2 MB/c
Максимальная скорость……56,7 MB/c
Предупреждений………….1
Ошибок…………………43
Общее время прохождения….01:04:30
Что можно сделать с UNC секторами?
Последний раз редактировалось DarkWave 25 окт 2007, 15:12, всего редактировалось 1 раз.
When running smartctl on your hard drive, you often get a plethora of information that can be hard to interpret for unexperienced users. This post attempts to provide aid in interpreting what the technical reasons behind the error messages are. If you’re looking for advice on whether to replace your hard drive, the only guidance I can give you is it might fail any time, so better backup your data, but it might also run for many years to come.. Furthermore, this article does not describe basic SMART WHEN_FAILED checking but rather interpretation of more subtle signs of possibly impending HDD failures.
One example that is particularly hard to interpret is the device error log storing the last few errors, for example
Error 8910 occurred at disk power-on lifetime: 7257 hours (302 days + 9 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 41 1a 00 33 96 61 Error: UNC at LBA = 0x01963300 = 26620672 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 60 08 18 00 33 96 40 00 03:09:52.125 READ FPDMA QUEUED 60 88 10 50 06 11 40 00 03:09:52.125 READ FPDMA QUEUED 60 08 08 60 ac 5e 40 00 03:09:52.113 READ FPDMA QUEUED 60 08 00 48 cf 6d 40 00 03:09:52.099 READ FPDMA QUEUED 60 90 f0 b0 ef e5 40 00 03:09:52.065 READ FPDMA QUEUED
Obviously, the first line shows when this error occured. The other lines, however, are not as obvious. Let’s examine the next section:
After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 41 1a 00 33 96 61 Error: UNC at LBA = 0x01963300 = 26620672
While this section also shows the content of some registers while the error occured, the interesting part of it is the error description Error: UNC at LBA = 0x01963300 = 26620672.
A LBA is a logical block address, i.e. some logical address on the hard drive. It is shown in both hexadecimal form 0x01963300 and in decimal form 26620672. In order to convert it to a byte address, you need to multiply it by the value listed at the head of the smartctloutput:
Sector Size: 512 bytes logical/physical
In almost any case, this value is 512 bytes, so in this example the byte offset would be 26620672 * 512 = 13629784064 = 12.69 GiB. In some cases it might be helpful to look up this address in a tool like GParted to see in which partition the error occured in. Also see this smartmontools HOWTO describing this process in detail.
UNC errors
The error message now tells us than an error called UNC occured at this LBA. UNC is shorthand for UNCorrectable, which means the data which has been read from the hard drive at this LBA was damaged and could not be corrected.
Hard drives not only store your data by itself, but automatically compute a so-called error-correction code (ECC). While there are many subtypes of those mathematical codes, they have one aspect in common: Given a set of bytes (e.g. the ones stored on the hard drive) which might be slightly damaged (i.e. some 0-bits are now-1 bits or vice versa) and and the matching ECC code (constituting of a few extra bytes) a suitable decoder can recover a limited number of bit errors. In most cases, ECC codes can also detect errors – for example, one specific ECC code might be able to correct one bit flip in two bytes, but it can detect up to three bitflips in two bytes.
If there are more bitflips than the ECC can recover (but not more than it can detect), this results in an unrecoverable error – the UNC. If there are more bitflips than the ECC can detect, anything might happen: Usually, the data that is computed from the ECC will be damaged, or no error might be detected at all.
Note that this explanation is highly simplified. For example, ECC codes are not stored as bytes separate from the data, but instead a mathematical function is computed on the data, resulting in a set of bytes that is larger that the original dataset – containing both the data itself plus the error-recovery extra data. In other words, the ECC data plus the data itself are mixed together.
This has multiple consequences for the interpretation. Firstly, this means that physically the data could be read, yet it does not seem to be correct. This means
Other error messages
While UNC errors occur reasonably often, there are other, more rare errors that you can’t find too much documentation about.
There is one definitive source for all smartctl error messages: The smartmontools source code.
We can find the error descriptions in ataprint.cpp (also see the GPL license information in the source tarball):
const char *abrt = "ABRT"; // ABORTED const char *amnf = "AMNF"; // ADDRESS MARK NOT FOUND const char *ccto = "CCTO"; // COMMAND COMPLETION TIMED OUT const char *eom = "EOM"; // END OF MEDIA const char *icrc = "ICRC"; // INTERFACE CRC ERROR const char *idnf = "IDNF"; // ID NOT FOUND const char *ili = "ILI"; // MEANING OF THIS BIT IS COMMAND-SET SPECIFIC const char *mc = "MC"; // MEDIA CHANGED const char *mcr = "MCR"; // MEDIA CHANGE REQUEST const char *nm = "NM"; // NO MEDIA const char *obs = "obs"; // OBSOLETE const char *tk0nf = "TK0NF"; // TRACK 0 NOT FOUND const char *unc = "UNC"; // UNCORRECTABLE const char *wp = "WP"; // WRITE PROTECTED
Realistically, you’ll only encounter a few of these errors even if you are working with hard disks professionally. Some of these errors like MC, MCR or NM are also related to hot-swapping of hard drives and do not neccessarily represent errors related to hard drive health itself.
One important error is ICRC – the interface CRC error. This means that there are errors being detected on the IDE/SATA or PCIe bus the hard drive is connected to. Although this is rare and might be caused by the HDD itself, it might mean that your chipset (the hardware controlling e.g. SATA) is damaged – in this case, replacing the hard drive would not fix the issue. Possibly there is also an intermittent cable connection.
How severe are those errors?
Over the life of most hard drives, especially consumer models, errors will occur – more often so in portable devices where high acceleration forces are more like to be encountered.
What separates a good hard drive from one at the end of its life (excluding those that fail without warning) is often the frequency of new errors. If you look at the total lifetime of the HDD, i.e. Power_On_Hours or similar:
9 Power_On_Hours 0x0032 082 082 000 Old_age Always - 8586
and compare the value (in this case 8586) with the lifetime at the last error,
Error 8911 occurred at disk power-on lifetime: 7257 hours
in this case, 7257, you can see over a thousand HDD operational hours have passed since the last error. This indicates that there is no mechanical defect which could result in destruction of the hard drive but rather a couple of defective or damaged sectors. UNC errors do not even neccessarily mean that the sectors are physically damaged.
Often hard drive errors are triggered when a files that are accessed very rarely (such as archived video files that are only opened every few years). When there are enough bit flips in such files for any reason, this can result in a larger number of HDD errors appearing at once.
Another indicator is the total number of errors the hard drive has encountered, i.e. 8911 in
Error 8911 occurred at disk power-on lifetime: 7257 hours
or in
ATA Error Count: 8911 (device log contains only the most recent five errors)
While this number is not shown for all hard drives, a very high number or a number which is growing rapidly indicates there is some physical issue with the drive. Issues relating to only a few bad sectors induce a sudden jump in the error counter, but after that. Note, however, that there can be other reasons for a high error counter, for example a bad or intermittent physical connection to the hard drive.
Also see this previous post on how to fix bad HDD sectors.
-
Berkut
Junior
misha2
southman
у вас тут своя атмосфера
-
S
Member

- Звідки: Киев

Повідомлення
27.11.2012 20:01
southman:ССД-диск дорого стоит, логично, что за восстановление можно просить больше — это 2)

Не логично — должны быть банальные человекочасы какого то «паяльника» 6 разряда. Как оно и есть заграницей в банальном СЦ.
-
misha2
Member

- Звідки: APK

Повідомлення
27.11.2012 20:46
S
А вы считаете что восстановление данных с современных ССД — простая задача ? Для сравнения — восстановление инфы с HDD в Москве от 400 до 1200 $, а восстановление с SSD от 2000 $. И сама стоимость всего одного аппаратного комплекса примерно 25 000 грн. Не считая стороннего софта , материалов и инструментов.
Хотелось бы видеть как вы «паяльником 6 разряда» вытаскивали б инфу. ![]()
Да и за границей я работал в RMA WD. Так что я могу конкретно говорить о сложности и стоимости работ.
Помню случай в Ontrack Recovery — утопленный винт на восстановление инфы, стоимость работы составила — 12 000$. ![]()
А вы «банальные человеко-часы»…И в большинстве «банальных СЦ» в Европе почти не берутся за восстановление инфы с сильно повреждённых накопителей. А наши делают.
-
S
Member
- Звідки: Киев
Повідомлення
28.11.2012 01:51
misha2
СНГ не показатель.
Наши если и делают то как правило хуже, не имеют ни знаний ни оборудования и цены себе не сложат. При чем в любой области куда не сунься.
-
misha2
Member
- Звідки: APK
Повідомлення
28.11.2012 08:48
S:misha2
СНГ не показатель.
Наши если и делают то как правило хуже, не имеют ни знаний ни оборудования и цены себе не сложат. При чем в любой области куда не сунься.
Всё в точности до наоборот. Там как раз нет специалистов местных. Лучшее оборудование выпускается в Ростове и весь мир пользуется. Разработчиком и вообщем-то автором канадского Atola Inside является Д. Постригань (автор MHDD) из Киева. В Германии, Франции, Англии, Голландии (список можно длинный накатать) в практически всех СЦ по винтом работают русские и украинцы в подавляющем большинстве. И я не сам попёрся в Чехию, а меня пригласили поработать. Так что как раз самые лучшие специалисты — только наши. Даже китайцы тырят винторемонтный софт у наших разработчиков. ![]()
-
southman
Member

- Звідки: Киев

Повідомлення
28.11.2012 10:51
S:Не логично — должны быть банальные человекочасы
там смайлик видели вот такой? ![]() — а он был)))
— а он был)))
ЗЫ: кстати, вот ровно сейчас на данные попала Тошиба (MK3276GSXN), ушатали в ноуте — по СМАРТу видно — реаллоков под завязку, G-shock вот такой ![]() , и при этом читает через пень.
, и при этом читает через пень.
Но (!!!) ЭТО, блин, сила, а не винт! Он как трактор, нет — как танк, часов 5 уже на скане, тормозит, но вычитывать удается, ошибок не так и много. Не отваливается с интерфейса — что главное.
В общем, запас терпения и пару утилит — все что нужно и немного удачи и везения. Другой сигейт или WD бы уже бы отвалился с ABRT.
-
S
Member
- Звідки: Киев
Повідомлення
28.11.2012 11:27
southman:там смайлик видели вот такой?
С развитием сферы услуг в этой области и появлением жесткой конкуренции этот смайлик там появится не сомневайтесь. Хотя учитывая последние облачные тенденции решение вопроса скорее всего придет с другой стороны.
Добавлено через 11 минут 4 секунды:
misha2:Всё в точности до наоборот. Там как раз нет специалистов местных.
Там есть вменяемые инструкции придерживаясь которых и используя и простые дешевые решения резервного копирования большая часть пользователей избегает контакта с подобными «чудо» спецами.
-
misha2
Member
- Звідки: APK
Повідомлення
28.11.2012 12:51
Абсолютно нет. Всё так же как и у нас. Несут и юсб-винты с залипшимии головами, и просто винты с проблемами БМГ и поверхностей.
А то что «как бы вменяемые» инструкции есть, то попроуйте их применить к юсб-винту у которого не хватило питания в порту и не сработала аварийная парковка голов. Или внезапный отказ всего БМГ у винта, например стоящего на сервере в массиве с вашими «облачными решениями и инструкциями» и самой главное — с вашей резервно тщательно (следуя инструкциям) закопированной инфой. ![]()
-
S
Member
- Звідки: Киев
Повідомлення
28.11.2012 13:16
misha2:Или внезапный отказ всего БМГ у винта, например стоящего на сервере в массиве
по горячему вИнул вИкинул вставил новый и превед — даже нажимать ничего не надо да и в нормальных массивах RAID контроллеров тоже два.
misha2:и самой главное — с вашей резервно тщательно (следуя инструкциям) закопированной инфой.
отдал на гарантию/выкиныл битую медиа и работаешь с копией коих обычно две разнесенные по площадкам в разных концах города.
misha2:А то что «как бы вменяемые» инструкции есть, то попроуйте их применить к юсб-винту у которого не хватило питания в порту и не сработала аварийная парковка голов.
очевидно же работать со стационарным винтом/массивом/облаком а на юсб хдд/флешку делать только копию — подохло новый носитель — еще одна копия.
-
misha2
Member
- Звідки: APK
Повідомлення
28.11.2012 13:42
В мой практике было немало случаев, когда вылетал весь массив и аппаратно или случаи вылетов винтов вместе с бэкапами.
Если б такой класс специалистов не был бы нужен и востребован — их бы и не существовало… Разве что в «облачных решениях». ![]()
А тема то про тошку . И может хватит флеймить ? ![]()
А то что вам не нужен такой специалист — то я просто рад за вас. ![]()
-
S
Member
- Звідки: Киев
Повідомлення
28.11.2012 13:46
misha2:А то что вам не нужен такой специалист — то я просто рад за вас.
Меня просто очень злит когда берутся деньги ни за что. Не может быть цена програмно-апаратного комплекса 25 тыс грн., а цена за восстановление инфы с одного ссд 16 тыс грн. как тут выше указали.
-
misha2
Member
- Звідки: APK
Повідомлення
28.11.2012 14:24
Вот Эпосовский прайс :
Восстановление информации с жестких дисков
Объем HDD Стоимость
До 200 Гбайт от 1200 грн.
От 200 до 500 Гбайт от 1550 грн.
500 Гбайт и более от 1900 грн.
пункта с ССД я к сожалению не увидел. В R-Lab (Москва) я сам читал что в среднем от 2000 $.
Стоимость оборудовния по восстановлению инфы с ССД и флэшек — http://forensictools.com.ua/category.php?id_category=12″ target=»_blank.
Видим что стоимость самого оборудования и плюс софт ~ 23 000 грн (~7 500$).
Стоимость оборудования Acelab — http://www.acelab.ru/dep.pc/price.php» target=»_blank
№_________Наименование_______________Описание____________________________________________________________________Цена/р с НДС
8__________PC-3000 Flash (SSD Edition)_____Программно-аппаратный комплекс для восстановления данных с Flash накопителей и SSD_____39 950
то есть примерно 1200$ без доставки и стоимости компа. В общих затратах и выйдет 2000$ и выше.
И обязательно наличие опыта и знаний. (Это тоже немалого стоит).
А вы говорили — «паяльник 6 разряда». ![]() Он столько не стоит.
Он столько не стоит.
-
S
Member
- Звідки: Киев
Повідомлення
28.11.2012 14:31
misha2:Видим что стоимость самого оборудования и плюс софт
Цена в 2 тыс долл была бы еще как то оправдана при стоимости оборудования в 250-400 тыс долл что бы тихо мирно окупиться лет за 5.
misha2:А вы говорили — «паяльник 6 разряда».
Операция выполняется в любом случае рутинная научных изысканий проводить каждый раз не требуется потому справился бы.
-
misha2
Member
- Звідки: APK
Повідомлення
28.11.2012 14:38
S:
Операция выполняется в любом случае рутинная научных изысканий проводить каждый раз не требуется потому справился бы.
Да нуу ? ![]() Это вы так думаете. А спросите-ка у тех кто этим занимается.
Это вы так думаете. А спросите-ка у тех кто этим занимается. ![]() А раз сами справитесь — то может стоило б заняться самому этим, при таких-то ценах ?
А раз сами справитесь — то может стоило б заняться самому этим, при таких-то ценах ? ![]()
-
andrey.nk
Member

- Звідки: Николаев

Повідомлення
28.11.2012 16:26
S
зачем ты влез? Когда специалисты спорили, было любо-дорого смотреть, а ты только помоями облить пытаешься человека, который тебе ничего не навязывает.
-
S
Member
- Звідки: Киев
Повідомлення
28.11.2012 19:58
misha2:Да нуу ?
не мой профиль.
andrey.nk:зачем ты влез? Когда специалисты спорили, было любо-дорого смотреть, а ты только помоями облить пытаешься человека, который тебе ничего не навязывает.
сходи сходи к специалистам
-
misha2
Member
- Звідки: APK
Повідомлення
01.12.2012 12:59
Винт получил, подключил. Не хотел давать готовность и определяться. Сразу стало ясно что проблема с БМГ (блоком головок). Проверка модулей в СА выявила дефекты в самой СА —
Чтение модулей
13 ALIST………………………….. : Гол.: 0, Ошибка чтения сектора (c: 2,h:0,s: 257); Device Error Detected 51/40 (UNC)
71 SCT_DATA……………………….. : Гол.: 0, Ошибка чтения сектора (c:20,h:0,s: 4); Device Error Detected 51/40 (UNC)
37 SMART………………………….. : Гол.: 0, Ошибка чтения сектора (c:20,h:0,s: 5); Device Error Detected 51/40 (UNC)
93 IN_SITU………………………… : Гол.: 0, Ошибка чтения сектора (c:20,h:0,s: 837); Device Error Detected 51/40 (UNC)Запись модулей
Из папки………………………….. : <HDD Profile>DataModulesHead01
13 ALIST………………………….. : Гол.: 0, Ошибка записи сектора (c: 2,h:0,s: 257,num: 1); Device Error Detected 51/04 (ABR)
37 SMART………………………….. : Гол.: 0, Ошибка записи сектора (c:20,h:0,s: 5,num: 1); Device Error Detected 51/04 (ABR)
93 IN_SITU………………………… : Гол.: 0, Ошибка записи сектора (c:20,h:0,s: 837,num: 1); Device Error Detected 51/04 (ABR)
Это подтверждение — что винт всё-таки имел аппаратные проблемы. И восстановить софтово инфу с него — не получилось бы.
P.S. Более того начало диска не читаемо по головам 00 и 01.
-
southman
Member
- Звідки: Киев
Повідомлення
01.12.2012 13:16
misha2 Хорошая работа ![]()
Если бэды в СА, интересно как будут обстоять дела с юзер-зоной…
-
misha2
Member
- Звідки: APK
Повідомлення
01.12.2012 13:32
Пока что прочитано ~ 40 Гб с конца диска ( с ЛБА 1 953 525 167 к началу). Полёт нормальный. ![]()
Мешает 0-я голова —
Тест головок
Указанные головки………………….. : 0,1,2,3
Ошибка записи сектора (c:62,h:0,s: 1); Device Error Detected 51/04 (ABR)
Ошибка записи сектора (c:62,h:0,s: 2); Device Error Detected 51/04 (ABR)
Head : 1………………………….. : Ok
Head : 2………………………….. : Ok
Head : 3………………………….. : Ok
-
Gnok
Member

- Звідки: UK

Повідомлення
02.12.2012 09:45
Очень жду и надеюсь на положительный результат Вашей работы.
И всё-таки не даёт покоя мне вопрос: как он так взял и внезапно издох. Ни бедов не было никогда, ни синьки. Просто в один прекрасный момент запоролся.

Тема: Винту хана? (Прочитано 18112 раз)
0 Пользователей и 1 Гость просматривают эту тему.
Вот мой SMART:
Что такое Reported UNC error? Моему диску хана?
Хард Samsung SP2004C
Добавлено позже:
ОМГ.. Reported UNC Error — это общее количество непрочитанных секторов.. точно хана..
А почему тогда Reallocated sector count = 0? Они ж вроде должны были тогда переназначаться
« Последнее редактирование: 04 Август 2010, 18:41:34 от Qwentor »

Qwentor,
Reported UNC error — общее количество непрочитанных секторов, почитал информационные источники и выяснил, эта ошибка убивает загрузку системы.
Способ решения проблемы — замена харда. 
У меня на втором диске (320gb) плохие значения reallocated sector count, из за неё операционные системы постепенно рушатся, диск годен только для хранения инфы. 
диск годен только для хранения инфы
Но ведь информация на таком диске тоже может повредиться? Так что получается только для хранения не особо ценной инфы, которую можно восстановить из других источников, типа фильмов и музыки..
Пока все ценное сбросил на болванки
Но ведь информация на таком диске тоже может повредиться? Так что получается только для хранения не особо ценной инфы, которую можно восстановить из других источников, типа фильмов и музыки..
Он у меня уже больше года живёт, ошибки происходят только если использовать его как основной для операционки, образы консольных игр всегда храню на втором диске.
Мда, все равно менять, т.к. он ща системный и единственный.
А вот тогда интересно можно ли из SATA диска сделать съемный с USB?
На днях скачал программу Hard Drive Inspector она показала довольно странный результат, все параметры почти идеальны:

Даже не верится… 
если диск хоть как-то определяется виндой то спасти его можно hdd regeniratorом — единственная прога по делу, закрывает убитые сектора, а остальные проги по сути своей лишь информеры.
если диск хоть как-то определяется виндой то спасти его можно hdd regeniratorом — единственная прога по делу, закрывает убитые сектора, а остальные проги по сути своей лишь информеры.
Это для вас, школоты, привыкшей к ГУЮ и мышке. А для нас, спецов, есть еще HDDSPEED, PC3000 и еще с десяток программ. И я не говорю за прожки от производителей и станка от ACE Labs (дорого, да, но у меня есть :3). И вот именно они ПО ДЕЛУ.
Может подскажите и мне заодно. вот купил 3 дня назад винт сигейт. что это такое hardware ecc rocovered ?
этот пункт растет через каждые 5 секунд,если обновлять. чем это опасно???
это я уже прочитал википедии. а чем оно чревато для винта в дальнейшем? или этот просто справочный параметр в данном случае?
Ну так там написано же «Критический параметр — красный фон строки. Индикатор возможной скорой поломки устройства».
У «hardware ecc recovered» как раз красная строчка.
Бум ждать ,пока гайки с него посыпятся . не нести же мне его сдавать по гарантии, потому что в виктории так показывает. А вообще хотелось бы услышать ответ от более компетентных людей.
не нести же мне его сдавать по гарантии, потому что в виктории так показывает
Именно поэтому и нужно нести и сдавать по гарантии. А то потом будет поздно.
Так и прийти и сказать: в Victoria показывает плохой SMART. Если сервисники нормальные — проверят, убедятся и поменяют.
Упс. Сорри, я не посмотрел, что на скрине SMART — GOOD.
Тогда сначала советую убедиться что с винтом нормально.
Качаем Victoria под DOS (никаких Win-версий) и запускаем в тест с параметром Ignore bad blocks. Будет хоть один bad block — несем где купили и просим замены.
« Последнее редактирование: 26 Август 2010, 16:45:47 от Noise_Unit »
скачал и запустил викторию. запускаю тест f4, пишет-рекалибровка-error! и вообще на все пишет -либо еррор, либо винт отказался чегот о там….
П.С. а на смарте уже показало 2 красных точки .прямо на глазах растет.
MHDD – бесплатная программа для низкоуровневой проверки жестких дисков на наличие битых секторов и ошибок. Программа поддерживает работу с жесткими дисками через наиболее распространенные интерфейсы: IDE, Serial ATA, SCSI.
При помощи программы MHDD, записанной на загрузочную флэшку или CD/DVD, можно просканировать жесткий диск на ошибки не загружая Windows. Это очень удобно в том случае, когда нет возможности подключить HDD к компьютеру с рабочим жестким диском и исправной ОС. Утилита может работать с жесткими дисками любых производителей благодаря тому, что взаимодействие осуществляется через стандартные порты ATA и определенный набор команд, определенных в спецификации ATA.
Как пользоваться программой MHDD.
- Выбираем в BIOS или BOOT MENU (загрузочном меню) устройство, с котрого будет производится загрузка — USB или CD/DVD.
- После загрузки программа попытается найти подключенные жесткие диски и выведит на экран список того, что было найдено.
 Для выбора жесткого диска на проверку битых секторов необходимо ввести цифру, соответствующую ему в списке, и нажать Enter.
Для выбора жесткого диска на проверку битых секторов необходимо ввести цифру, соответствующую ему в списке, и нажать Enter. - После этого необходимо нажать F2, чтобы определить параметры жесткого диска. Для получения расширенной информации о жестком диске будет предложено нажать Shift+F2. После того как параметры жесткого диска определены можно приступать к проверке жесткого диска на ошибки — нажимаем клавишу F4.
- Появится окно, в котором будет предложено установить параметры сканирования жесткого диска. Start LBA — адрес начального блока.
End LBA — адрес конечного блока.
Remap — это функция позволяет найти нерабочие сектора жесткого диска и заменить их на работоспособные.
Timout (sec) — задает время на выполнение операции с жестким диском.
Spindown after scan — останавливает жесткий диск после сканирования.
Loop test/repair — проводить сканирование/восстановление циклично.
Erase Delays — стирает сектора в которых обнаружены задержки чтения.Поменять значение параметра можно нажав клавишу Enter. - Установив нужные параметры, нажимаем еще раз F4 для запуска сканирования.
- Запустим режим сканирования со стиранием секторов , в которых есть задержка чтения — Erase Delays: ON.После завершения, запустим повторное сканирование и не меняя параметров проверим состояние диска. Если битые сектора остались, то MHDD их не удалось затереть и в таком случае эти сектора нужно заменить рабочими. Для этого нужно запустить сканирование с параметром Remap: ON
 Для выбора жесткого диска на проверку битых секторов необходимо ввести цифру, соответствующую ему в списке, и нажать Enter.
Для выбора жесткого диска на проверку битых секторов необходимо ввести цифру, соответствующую ему в списке, и нажать Enter. После того как параметры жесткого диска определены можно приступать к проверке жесткого диска на ошибки — нажимаем клавишу F4.
После того как параметры жесткого диска определены можно приступать к проверке жесткого диска на ошибки — нажимаем клавишу F4. Start LBA — адрес начального блока.
Start LBA — адрес начального блока.
Расшифровка ошибок MHDD.
В процессе проверки поверхности диска программой блоки секторов закрашиваются квадратиками. Чем светлее квадратик тем больше времени было потрачено на чтение этого блока. Цветными квадратиками отмечаются блоки с высокой задержкой чтения. У блоков отмеченных зеленым цветом задержка чтения еще в пределах нормы — менее 150 мс, а красные блоки сигнализируют о том, что начал формироваться BAD block (плохой блок). ? TIME и UNC по сути означают уже сформированные BAD блоки.
х UNC (Uncorrectable Data Error). Не удалось скорректировать данные избыточным кодом, блок признан нечитаемым. Может быть как следствием нарушения контрольной суммы данных, так и следствием физического повреждения HDD;
! ABRT (Aborted Command). Винт отверг команду в результате неисправности, или команда не поддерживается данным HDD (пароль, устаревшая или слишком новая модель итд.).
S IDNF (ID Not Found). Не идентифицирован сектор. Обычно говорит о разрушении микрокода или формата нижнего уровня HDD. У исправных винчестеров такая ошибка выдается при попытке обратиться к несуществующему адресу.
A AMNF (Address Mark Not Found). Невозможно прочитать сектор, обычно в результате серьезной аппаратной проблемы (например, на HDD Toshiba, Maxtor — говорит о неисправности магнитных головок);
0 T0NF (Track 0 Not Found). Невозможно выполнить рекалибровку на стартовый цилиндр рабочей области. На современных HDD говорит о неисправности микрокода или магнитных головок;
* BBK (Bad Block Detected). Найден бэд-блок. Устарело;
Индикация режимов работы жесткого диска HDD.
(Первоисточник — стандарт ATA/ATAPI)
BUSY (Busy). Винт занят обработкой команды или «завис». В то время, пока горит эта лампочка, все остальные индикаторы считаются недействительными, и винчестер может реагировать только на команду «Reset» (F3).
DRDY (Drive Ready). Винт готов к приему команды;
WRFT (Write Fault). Ошибка записи. Устарело. По новому стандарту, и, следовательно, на новых HDD: «Device Fault» — неисправность устройства;
DRSC (Drive Seek Complete). Винт успешно закончил установку головки на трек; Устарело. На новых назначение зависит от предшествующей команды.
DRQ (Data Request). Винт готов к обмену данными через интерфейс;
INX (Index). Зажигается при каждом обороте диска. На некоторых винчестерах уже не используется, или может выдавать неверный результат.
CORR коррекция. Устарело и на новых HDD не применяется.
ERR (Error) Произошла ошибка. В регистре ошибок можно узнать код ошибки.