Permalink
master
{{ refName }}
default
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Go to file
-
Go to file
-
Copy path
-
Copy permalink
Cannot retrieve contributors at this time
Anti-pattern
Best practice
22 lines (17 sloc)
422 Bytes
Raw
Blame
Open in GitHub Desktop
-
Open with Desktop
-
View raw
-
Copy raw contents
-
View blame
| redirect_to | code | message | title | links |
|---|---|---|---|---|
|
https://www.flake8rules.com/rules/E231.html |
E231 |
Missing whitespace after ‘,’, ‘;’, or ‘:’ |
Missing whitespace after ‘,’, ‘;’, or ‘:’ (E231) |
https://www.python.org/dev/peps/pep-0008/#pet-peeves |
There should be whitespace after the characters ,, ;, and :.
Anti-pattern
my_tuple = 1,2,3
Best practice
my_tuple = 1, 2, 3
PEP 8, иногда обозначаемый PEP8 или PEP-8, представляет собой документ, содержащий рекомендации по написанию кода на Python. Он был составлен в 2001 году Гвидо ван Россумом, Барри Варшавой и Ником Когланом. Основная цель PEP 8 – улучшить читабельность и логичность кода на Python.

PEP расшифровывается как Python Enhancement Proposal («Предложение по усовершенствованию Python»), и их несколько. PEP — это документ для сообщества, который описывает новые функции, предлагаемые для Python, и содержит такие аспекты языка, как дизайн и стиль.
В цикле из трех статей мы разберем основные принципы, изложенные в PEP 8. Эти статьи предназначены для новичков и программистов среднего уровня, поэтому мы не будем затрагивать некоторые из наиболее сложных тем. Вы можете изучить их самостоятельно, прочитав полную документацию по PEP 8 .
Из данной серии статей вы узнаете:
- как писать Python-код, соответствующий PEP8;
- какие доводы лежат в основе рекомендаций, изложенных в PEP8;
- как настроить среду разработки так, чтобы вы могли начать писать код на Python по PEP8.
“Читаемость имеет значение”, — Дзен Python
PEP 8 существует для улучшения читаемости кода Python. Но почему так важна удобочитаемость? Почему написание читаемого кода является одним из руководящих принципов языка Python?
Как сказал Гвидо ван Россум: «Код читают гораздо чаще, чем пишут». Вы можете потратить несколько минут или целый день на написание фрагмента кода для аутентификации пользователя. В дальнейшем вам не придётся его писать. Но перечитывать его вы точно будете. Этот фрагмент кода может остаться частью проекта, над которым вы работаете. Каждый раз, возвращаясь к этому файлу, вам нужно будет вспомнить, что делает этот код и зачем вы его написали. Поэтому удобочитаемость имеет большое значение.
Если вы новичок в Python, возможно, вам уже через несколько дней или недель будет трудно вспомнить, что делает фрагмент кода. Но если вы следуете PEP 8, вы можете быть уверены, что правильно назвали свои переменные . Вы будете знать, что добавили достаточно пробелов, чтобы обособить логические шаги. Вы также снабдили свой код отличными комментариями. Все это сделает ваш код будет более читабельным, а значит, к нему будет легче вернуться. Следование правилам PEP 8 для новичка может сделать изучение Python гораздо более приятной задачей.
Следование PEP 8 особенно важно, если вы претендуете на должность разработчика. Написание понятного, читаемого кода свидетельствует о профессионализме. Это скажет работодателю, что вы понимаете, как правильно структурировать свой код.
Работая над проектами, вам, скорее всего, придется сотрудничать с другими программистами. Здесь, опять же, очень важно писать читаемый код. Другие люди, которые, возможно, никогда раньше не встречали вас и не видели ваш стиль программирования, должны будут прочитать и понять ваш код. Наличие руководящих принципов, которым вы следуете и которые знаете, облегчит другим чтение вашего кода.
[python_ad_block]
Когда стоит игнорировать PEP 8
Краткий ответ на этот вопрос – никогда. Если вы строго следуете PEP 8, то можете гарантировать, что у вас будет чистый, профессиональный и читабельный код. Это принесет пользу вам, а также сотрудникам и потенциальным работодателям.
Однако некоторые рекомендации в PEP 8 неудобны в следующих случаях:
- соблюдение PEP 8 нарушает совместимость с существующим программным обеспечением
- код, связанный с тем, над чем вы работаете, несовместим с PEP 8
- код должен оставаться совместимым со старыми версиями Python
Как проверить соответствие кода PEP 8
Чтобы убедиться, что ваш код соответствует PEP 8, необходимо многое проверить. Помнить все эти правила при разработке кода может быть непросто. Особенно много времени уходит на приведение прошлых проектов к стандарту PEP 8. К счастью, есть инструменты, которые помогут ускорить этот процесс.
Существует два класса инструментов, которые можно использовать для обеспечения соответствия PEP 8: линтеры и автоформаттеры.
Линтеры
Линтеры – это программы, которые анализируют код, помечают ошибки и предлагают способы их исправления. Они особенно полезны как расширения редактора, поскольку выявляют ошибки и стилистические проблемы во время написания кода.
Вот пара лучших линтеров для кода на Python:
pycodestyle
Это инструмент для проверки вашего кода на соответствие некоторым стилевым соглашениям в PEP8.
Установите pycodestyle с помощью pip:
$ pip install pycodestyle
Вы можете запустить pycodestyle из терминала, используя следующую команду:
$ pycodestyle code.py
Результат:
code.py:1:17: E231 missing whitespace after ',' code.py:2:21: E231 missing whitespace after ',' code.py:6:19: E711 comparison to None should be 'if cond is None:'
flake8
Это инструмент, который сочетает в себе отладчик, pyflakes и pycodestyle.
Установите flake8 с помощью pip:
$ pip install flake8
Запустите flake8 из терминала, используя следующую команду:
$ flake8 code.py
Пример вывода:
code.py:1:17: E231 missing whitespace after ',' code.py:2:21: E231 missing whitespace after ',' code.py:3:17: E999 SyntaxError: invalid syntax code.py:6:19: E711 comparison to None should be 'if cond is None:'
Замечание: Дополнительная строка в выводе указывает на синтаксическую ошибку.
Также доступны расширения для Atom, Sublime Text, Visual Studio Code и VIM.
От редакции Pythonist. Рекомендуем статью «Качество кода на Python: сравнение линтеров и советы по их применению».
Автоформаттеры
Автоформаттеры – это программы, которые автоматически реорганизуют ваш код для соответствия PEP 8. Одна из таких программ — black. Она автоматически форматирует код для приведения его в соответствие с большинством правил PEP 8. Единственное, она ограничивает длину строки до 88 символов, а не до 79, как рекомендовано стандартом. Однако вы можете изменить это, добавив флаг командной строки, как в примере ниже.
Установите black с помощью pip. Для запуска требуется Python 3.6+:
$ pip install black
Его можно запустить из командной строки, как и в случае с линтерами. Допустим, вы начали со следующего кода, который не соответствует PEP 8, в файле с именем code.py:
for i in range(0,3):
for j in range(0,3):
if (i==2):
print(i,j)
Затем вы можете запустить следующую команду через командную строку:
$ black code.py reformatted code.py All done! ✨ ? ✨
code.py будет автоматически приведён к следующему виду:
for i in range(0, 3):
for j in range(0, 3):
if i == 2:
print(i, j)
Если вы хотите изменить ограничение длины строки, можно использовать флаг --line-length:
$ black --line-length=79 code.py reformatted code.py All done! ✨ ? ✨
Работа двух других автоформаттеров – autopep8 и yapf – аналогична работе black .
О том, как использовать эти инструменты, хорошо написано в статье Python Code Quality: Tools & Best Practices Александра ван Тол.
Перевод части статьи How to Write Beautiful Python Code With PEP 8.
В следующих статьях цикла про PEP 8 читайте:
- Нейминг и размещение кода
- Комментарии, пробелы, выбор методов
I’m doing code review, and seeing method declarations like that:
def __init__(self,data):
I always thought that it should be formatted like this:
def __init__(self, data):
But then I checked PEP 0008 and see no exact statement about that. There is guide about whitespace around operators, and inside parentheses, but no about comma separated list.
If it is not described in PEP8, probably there is some unwritten convention about this? Why I was convinced that this was in PEP8? Shoud PEP8 be updated?
![]()
Quill
2,7081 gold badge31 silver badges44 bronze badges
asked Jul 31, 2015 at 8:19
![]()
1
I can’t find the corresponding sentence in PEP8 as well, but I guess the reason that most people believe this rule is in PEP8 is pip pep8.
According to their document:
E231 missing whitespace after ‘,’
As most people use this as their style checker, it is easy to be convinced that the rule is really in PEP8.
answered May 6, 2016 at 4:01
![]()
Gary ShamGary Sham
5034 silver badges10 bronze badges
2
Как писать питонический код: три рекомендации и три книги
Время прочтения
15 мин
Просмотры 27K

Новички в Python часто спрашивают, как писать питонический код. Проблема — расплывчатое определение слова «питонический». Подробным материалом, в котором вы найдёте ответы на вопрос выше и три полезные книги, делимся к старту курса по Fullstack-разработке на Python.
Что значит «питонический»?
Python более 30 лет. За это время накоплен огромный опыт его применения в самых разных задачах. Этот опыт обобщался, и возникали лучшие практики, которые обычно называют «питоническим» кодом.
Философия Python раскрывается в The Zen of Python Тима Питерса, доступной в любом Python по команде import this в REPL:
>>> import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!Начинающих в Python больше всего раздражает красота Zen of Python. В Zen передаётся дух того, что значит «питонический» — и без явных советов. Вот первый принцип дзена Python: «Красивое лучше, чем уродливое». Согласен на 100%! Но как сделать красивым мой некрасивый код? Что это вообще такое — «красивый код»?
Сколь бы ни раздражала эта неоднозначность, именно она делает Zen of Python таким же актуальным, как и в 1999 году, когда Тим Питерс написал этот набор руководящих принципов. Они помогают понять, как отличать питонический и непитонический код, и дают ментальную основу принятия собственных решений.
Каким же будет определение слова «питонический»? Лучшее найденное мной определение взято из ответа на вопрос «Что означает «питонический» В этом ответе питонический код описывается так:
Код, где правилен не только синтаксис, но соблюдаются соглашения сообщества Python, а язык используется так, как он должен использоваться.
Из этого делаем два ключевых вывода:
-
Слово «питонический» связано скорее со стилем, чем с синтаксисом. Хотя идиомы Python часто имеют последствия за рамками чисто стилистического выбора, в том числе повышение производительности кода.
-
То, что считается «питоническим», определяется сообществом Python.
Итак, у нас сложилось хотя бы какое-то представление о том, что имеют в виду программисты на Python, называя код «питоническим». Рассмотрим три конкретных и доступных способа написания более питонического кода.
1. Подружитесь с PEP8
PEP8 — это официальное руководство по стилю кода Python. PEP расшифровывается как Python Enhancement Proposal («Предложение по улучшению Python»). Это документы, предлагающие новые особенности языка. Они образуют официальную документацию особенности языка, принятие или отклонение которой обсуждается в сообществе Python. Следование PEP8 не сделает код абсолютно «питоническим», но способствует узнаваемости кода для многих Python-разработчиков.
В PEP8 решаются вопросы, связанные с символами пробелов. Например, использование четырёх пробелов для отступа вместо символа табуляции или максимальной длиной строки: согласно PEP8, это 79 символов, хотя данная рекомендация, вероятно, самая игнорируемая.
Первое, что стоит усвоить из PEP8 новичкам, — это рекомендации и соглашения по именованию. Например, следует писать имена функций и переменных в нижнем регистре и с подчёркиваниями между словами lowercase_with_underscores:
# Correct
seconds_per_hour = 3600
# Incorrect
secondsperhour = 3600
secondsPerHour = 3600Имена классов следует писать с прописными первыми буквами слов и без пробелов, вот так: CapitalizedWords:
# Correct
class SomeThing:
pass
# Incorrect
class something:
pass
class some_thing:
passКонстанты записывайте в верхнем регистре и с подчёркиваниями между словами: UPPER_CASE_WITH_UNDERSCORES:
# Correct
PLANCK_CONSTANT = 6.62607015e-34
# Incorrect
planck_constant = 6.6260715e-34
planckConstant = 6.6260715e-34В PEP8 изложены рекомендации по пробелам: как использовать их с операторами, аргументами и именами параметров функций и для разбиения длинных строк. Хотя эти рекомендации можно освоить, годами практикуясь в чтении и написании совместимого с PEP8 кода, многое всё равно пришлось бы запоминать.
Запоминать все соглашения PEP8 не нужно: найти и устранить проблемы PEP8 в коде могут помочь такие инструменты, как flake8. Установите flake8 с помощью pip:
# Linux/macOS
$ python3 -m pip install flake8
# Windows
$ python -m pip install flake8flake8 можно использовать как приложение командной строки для просмотра файла Python на предмет нарушений стиля. Допустим, есть файл myscript.py с таким кодом:
def add( x, y ):
return x+y
num1=1
num2=2
print( add(num1,num2) )При запуске на этом коде flake8 сообщает, как и где именно нарушается стиль:
$ flake8 myscript.py
myscript.py:1:9: E201 whitespace after '('
myscript.py:1:11: E231 missing whitespace after ','
myscript.py:1:13: E202 whitespace before ')'
myscript.py:4:1: E305 expected 2 blank lines after class or function definition, found 1
myscript.py:4:5: E225 missing whitespace around operator
myscript.py:5:5: E225 missing whitespace around operator
myscript.py:6:7: E201 whitespace after '('
myscript.py:6:16: E231 missing whitespace after ','
myscript.py:6:22: E202 whitespace before ')'В каждой выводимой строке flake8 сообщается, в каком файле и в какой строке проблема, в каком столбце строки начинается ошибка, номер ошибки и её описание. Используйте эти обозначения, flake8 можно настроить на игнорирование конкретных ошибок:

Для проверки качества кода с помощью flake8 вы даже можете настроить редакторы, например VS Code. Пока вы пишете код, он постоянно проверяется на нарушения PEP8. Когда обнаруживается проблема, во flake8 под частью кода с ошибкой появляется красная волнистая линия, найденные ошибки можно увидеть во вкладке встроенного терминала Problems:

flake8 — отличный инструмент для поиска связанных с нарушением PEP8 ошибок, но исправлять их придётся вручную. А значит, будет много работы. К счастью, весь процесс автоматизируемый. Автоматически форматировать код согласно PEP можно с помощью инструмента под названием Black.
Конечно, рекомендации PEP8 оставляют много возможностей для выбора стиля, и в black многие решения принимаются за вас. Вы можете соглашаться с ними или нет. Конфигурация black минимальна.
Установите black c помощью pip:
# Linux/macOS
$ python3 -m pip install black
# Windows
$ python -m pip install blackПосле установки командой black —check можно посмотреть, будут ли black изменять файл:
$ black --check myscript.py
would reformat myscript.py
Oh no! 💥 💔 💥
1 file would be reformatted.Чтобы увидеть разницу после изменений, используйте флаг —diff:
$ black --diff myscript.py
--- myscript.py 2022-03-15 21:27:20.674809 +0000
+++ myscript.py 2022-03-15 21:28:27.357107 +0000
@@ -1,6 +1,7 @@
-def add( x, y ):
- return x+y
+def add(x, y):
+ return x + y
-num1=1
-num2=2
-print( add(num1,num2) )
+
+num1 = 1
+num2 = 2
+print(add(num1, num2))
would reformat myscript.py
All done! ✨ 🍰 ✨
1 file would be reformatted.Чтобы автоматически отформатировать файл, передайте его имя команде black:
$ black myscript.py
reformatted myscript.py
All done! ✨ 🍰 ✨
1 file reformatted.
# Show the formatted file
$ cat myscript.py
def add(x, y):
return x + y
num1 = 1
num2 = 2
print(add(num1, num2))Чтобы проверить совместимость с PEP8, снова запустите flake8 и посмотрите на вывод:
# No output from flake8 so everything is good!
$ flake8 myscript.pyПри работе с black следует иметь в виду, что максимальная длина строки по умолчанию в нём — это 88 символов. Это противоречит рекомендации PEP8 о 79 символах, поэтому при использовании black в отчёте flake8 вы увидете ошибки о длине строки.
Многие разработчики Python используют 88 знаков вместо 79, а некоторые — строки ещё длиннее. Можно настроить black на 79 символов, или flake8 — на строки большей длины.
Важно помнить, что PEP8 — это лишь набор рекомендаций, хотя многие программисты на Python относятся к ним серьёзно. PEP8 не применяется в обязательном порядке. Если в нём есть что-то, с чем вы категорически не согласны, вы вправе это игнорировать! Если же вы хотите строго придерживаться PEP8, инструменты типа flake8 и black сильно облегчат вам жизнь.
2. Избегайте циклов в стиле C
В таких языках, как C или C++, отслеживание индексной переменной при переборе массива — обычное дело. Поэтому программисты, которые перешли на Python из C или C++, при выводе элементов списка нередко пишут:
>>> names = ["JL", "Raffi", "Agnes", "Rios", "Elnor"]
>>> # Using a `while` loop
>>> i = 0
>>> while i < len(names):
... print(names[i])
... i += 1
JL
Raffi
Agnes
Rios
Elnor
>>> # Using a `for` loop
>>> for i in range(len(names)):
... print(names[i])
JL
Raffi
Agnes
Rios
ElnorВместо итерации можно перебрать все элементы списка сразу:
>>> for name in names:
... print(name)
JL
Raffi
Agnes
Rios
ElnorЭтим вторая рекомендация не ограничивается: она намного глубже простого перебора элементов списка. Такие идиомы Python, как списковые включения, встроенные функции (min(), max() и sum()) и методы объектов, может помочь вывести ваш код на новый уровень.
Отдавайте предпочтение списковым включениям, а не простым циклам for
Обработка элементов массива и сохранение результатов в новом — типичная задача программирования. Допустим, нужно преобразовать список чисел в список их квадратов. Избегая циклов в стиле C, можно написать:
>>> nums = [1, 2, 3, 4, 5]
>>> squares = []
>>> for num in nums:
... squares.append(num ** 2)
...
>>> squares
[1, 4, 9, 16, 25]Но более питонически применить списковое включение:
>>> squares = [num ** 2 for num in nums] # <-- List comprehension
>>> squares
[1, 4, 9, 16, 25]Списковые включения понять сразу может быть трудно, но они покажутся знакомыми тем, кто помнит математическую форму записи множества.
Вот так я обычно пишу списковые включения:
-
Начинаю с создания литерала пустого списка:
[]. -
Первым в списковое включение помещаю то, что обычно идёт в метод .append()при создании списка с помощью цикла for:
[num ** 2]. -
И, наконец, помещаю в конец списка заголовок цикла for:
[num ** 2 for num in nums].
Списковое включение — важное понятие, которое нужно освоить для написания идиоматичного кода Python, но ими не стоит злоупотреблять. Это не единственный вид списковых включений в Python. Далее поговорим о выражениях-генераторах и словарных включениях, вы увидите пример, когда спискового включения имеет смысл избегать.
Используйте встроенные функции, такие как min(), max() и sum()
Ещё одна типичная задача программирования — это поиск минимального или максимального значения в массиве чисел. Найти наименьшее число в списке можно с помощью for:
>>> nums = [10, 21, 7, -2, -5, 13]
>>> min_value = nums[0]
>>> for num in nums[1:]:
... if num < min_value:
... min_value = num
...
>>> min_value
-5Но более «питонически» применять встроенную функцию min():
>>> min(nums)
-5То же касается нахождения наибольшего значения в списке: вместо цикла применяется встроенная функция max():
>>> max(nums)
21Чтобы найти сумму чисел списка, написать цикл for можно, но более питонически воспользоваться sum():
>>> # Not Pythonic: Use a `for` loop
>>> sum_of_nums = 0
>>> for num in nums:
... sum_of_nums += num
...
>>> sum_of_nums
44
>>> # Pythonic: Use `sum()`
>>> sum(nums)
44Также sum() полезна при подсчёте количества элементов списка, для которых выполняется некое условие. Например, вот цикл for для подсчёта числа начинающихся с буквы A строк списка:
>>> capitals = ["Atlanta", "Houston", "Denver", "Augusta"]
>>> count_a_capitals = 0
>>> for capital in capitals:
... if capital.startswith("A"):
... count_a_capitals += 1
...
>>> count_a_capitals
2Функция sum() со списковым включением сокращает цикл for до одной строки:
>>> sum([capital.startswith("A") for capital in capitals])
2Красота! Но ещё более питонической эту строку сделает замена спискового включения на выражение-генератор. Убираем скобки списка:
>>> sum(capital.startswith("A") for capital in capitals)
2Как именно работает код? И списковое включение, и выражение-генератор возвращают итерируемый объект со значением True, если строка в списке capitals начинается с буквы A, и False — если это не так:
>>> [capital.startswith("A") for capital in capitals]
[True, False, False, True]В Python True и False — это завуалированные целые числа. True равно 1, а False — 0:
>>> isinstance(True, int)
True
>>> True == 1
True
>>> isinstance(False, int)
True
>>> False == 0
TrueКогда в sum() передаётся списковое включение или выражение-генератор, значения True и False считаются 1 и 0 соответственно. Всего два значения True и два False, поэтому сумма равна 2.
Использование sum() для подсчёта числа удовлетворяющих какому-то условию элементов списка подчёркивает важность понятия «питонический». Я нахожу такое применение sum() очень питонически. Ведь с sum() используется несколько особенностей этого языка и создаётся, на мой взгляд, лаконичный и удобный для восприятия код. Но, возможно, не каждый разработчик на Python со мной согласится.
Можно было бы возразить, что в этом примере нарушается один из принципов Zen of Python: «Явное лучше неявного». Ведь не очевидно, что True и False — целые числа и что sum() вообще должна работать со списком значений True и False. Чтобы освоить это применение sum(), нужно глубоко понимать встроенные типы Python.
Узнать больше о True и False как целых числах, а также о других неожиданных фактах о числах в Python можно из статьи 3 Things You Might Not Know About Numbers in Python («3 факта о числах в Python, которых вы могли не знать»).
Жёстких правил, когда называть и не называть код питоническим, нет. Всегда есть некая серая зона. Имея дело с примером кода, который может находиться в этой серой зоне, руководствуйтесь здравым смыслом. Для удобства восприятия всегда применяйте err и не бойтесь обращаться за помощью.
3. Используйте правильную структуру данных
Большая роль при написании чистого, питонического кода для конкретной задачи отводится выбору подходящей структуры данных. Python называют языком «с батарейками в комплекте». Некоторые батарейки из комплекта Python — это эффективные, готовые к применению структуры данных.
Используйте словари для быстрого поиска
Вот CSV-файл clients.csv с данными по клиентам:
first_name,last_name,email,phone
Manuel,Wilson,mwilson@example.net,757-942-0588
Stephanie,Gonzales,sellis@example.com,385-474-4769
Cory,Ali,coryali17@example.net,810-361-3885
Adam,Soto,adams23@example.com,724-603-5463Нужно написать программу, где в качестве входных данных принимается адрес электронной почты, а выводится номер телефона клиента с этой почтой, если такой клиент существует. Как бы вы это сделали?
Используя объект DictReader из модуля csv, можно прочитать каждую строку файла как словарь:
>>> import csv
>>> with open("clients.csv", "r") as csvfile:
... clients = list(csv.DictReader(csvfile))
...
>>> clients
[{'first_name': 'Manuel', 'last_name': 'Wilson', 'email': 'mwilson@example.net', 'phone': '757-942-0588'},
{'first_name': 'Stephanie', 'last_name': 'Gonzales', 'email': 'sellis@example.com', 'phone': '385-474-4769'},
{'first_name': 'Cory', 'last_name': 'Ali', 'email': 'coryali17@example.net', 'phone': '810-361-3885'},
{'first_name': 'Adam', 'last_name': 'Soto', 'email': 'adams23@example.com', 'phone': '724-603-5463'}]clients — это список словарей. Поэтому, чтобы найти клиента по адресу почты, например sellis@example.com, нужно перебрать список и сравнить почту каждого клиента с целевой почтой, пока не будет найден нужный клиент:
>>> target = "sellis@example.com"
>>> phone = None
>>> for client in clients:
... if client["email"] == target:
... phone = client["phone"]
... break
...
>>> print(phone)
385-474-4769Но есть проблема: перебор списка клиентов неэффективен. Если в файле много клиентов, на поиск клиента с совпадающим адресом почты у программы может уйти много времени. А сколько теряется времени, если такие проверки проводятся часто!
Более питонически сопоставить клиентов с их почтами, а не хранить клиентов в списке. Для этого отлично подойдёт словарное включение:
>>> with open("clients.csv", "r") as csvfile:
... # Use a `dict` comprehension instead of a `list`
... clients = {row["email"]: row["phone"] for row in csv.DictReader(csvfile)}
...
>>> clients
{'mwilson@example.net': '757-942-0588', 'sellis@example.com': '385-474-4769',
'coryali17@example.net': '810-361-3885', 'adams23@example.com': '724-603-5463'}Словарные включения очень похожи на списковые включения:
-
Я начинаю с создания пустого словаря:
{}. -
Затем помещаю туда разделённую двоеточием пару «ключ — значение»:
{row[«email»]: row[«phone»]}. -
И пишу выражение с for, которое перебирает все строки в CSV:
{row[«email»]: row[«phone»] for row in csv.DictReader(csvfile)}.
Вот это словарное включение, преобразованное в цикл for:
>>> clients = {}
>>> with open("clients.csv", "r") as csvfile:
... for row in csv.DictReader(csvfile):
... clients[row["email"]] = row["phone"]С этим словарём clients вы можете найти телефон клиента по его почте без циклов:
>>> target = "sellis@example.com"
>>> clients[target]
385-474-4769Этот код не только короче, но и намного эффективнее перебора списка циклом. Но есть проблема: если в clients нет клиента с искомой почтой, поднимается ошибка KeyError:
>>> clients["tsanchez@example.com"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'tsanchez@example.com'Поэтому, если клиент не найден, можно перехватить KeyError и вывести значение по умолчанию:
>>> target = "tsanchez@example.com"
>>> try:
... phone = clients[target]
... except KeyError:
... phone = None
...
>>> print(phone)
NoneНо более питонически применять метод словаря .get(). Если пара с ключом существует, этот метод возвращает значение пары, иначе возвращается None:
>>> clients.get("sellis@example.com")
'385-474-4769'Сравним решения выше:
import csv
target = "sellis@example.com"
phone = None
# Un-Pythonic: loop over a list
with open("clients.csv", "r") as csvfile:
clients = list(csv.DictReader(csvfile))
for client in clients:
if client["email"] == target:
phone = client["phone"]
break
print(phone)
# Pythonic: lookup in a dictionary
with open("clients.csv", "r") as csvfile:
clients = {row["email"]: row["phone"] for row in csv.DictReader(csvfile)}
phone = clients.get(target)
print(phone)Питонический код короче, эффективнее и не менее удобен для восприятия.
Используйте операции над множествами
Множества — это настолько недооценённая структура данных Python, что даже разработчики среднего уровня склонны их игнорировать, упуская возможности. Пожалуй, самое известное применение множеств в Python — это удаление повторяющихся в списке значений:
>>> nums = [1, 3, 2, 3, 1, 2, 3, 1, 2]
>>> unique_nums = list(set(nums))
>>> unique_nums
[1, 2, 3]Но множества этим не ограничиваются. Я часто применяю их для эффективной фильтрации значений итерируемого объекта. Работа множеств лучше всего видна, когда нужны уникальные значения.
Вот придуманный, но реалистичный пример. У владельца магазина есть CSV-файл клиентов с адресами их почты. Снова возьмём файл clients.csv. Есть также CSV-файл заказов за последний месяц orders.csv, тоже с адресами почты:
date,email,items_ordered
2022/03/01,adams23@example.net,2
2022/03/04,sellis@example.com,3
2022/03/07,adams23@example.net,1Владельцу магазина нужно отправить купон на скидку каждому клиенту, который в прошлом месяце ничего не заказывал. Для этого он может считать адреса почты из файлов clients.csv и orders.csv и отфильтровать их списковым включением:
>>> import csv
>>> # Create a list of all client emails
>>> with open("clients.csv", "r") as clients_csv:
... client_emails = [row["email"] for row in csv.DictReader(clients_csv)]
...
>>> # Create a list of emails from orders
>>> with open("orders.csv") as orders_csv:
... order_emails = [row["email"] for row in csv.DictReader(orders_csv)]
...
>>> # Use a list comprehension to filter the clients emails
>>> coupon_emails = [email for email in clients_emails if email not in order_emails]
>>> coupon_emails
["mwilson@example.net", "coryali17@example.net"]Код нормальный и выглядит вполне питонически. Но что, если каждый месяц клиентов и заказов будут миллионы? Тогда при фильтрации почты и определении, каким клиентам отправлять купоны, потребуется перебор всего списка client_emails. А если в файлах client.csv и orders.csv есть повторяющиеся строки? Бывает и такое.
Более питонически считать адреса почты клиентов и заказов в множествах и отфильтровать множества почтовых адресов клиентов оператором разности множеств:
>>> import csv
>>> # Create a set of all client emails using a set comprehension
>>> with open("clients.csv", "r") as clients_csv:
... client_emails = {row["email"] for row in csv.DictReader(clients_csv)}
...
>>> # Create a set of emails frp, orders using a set comprehension
>>> with open("orders.csv", "r") as orders_csv:
... order_emails = {row["email"] for row in csv.DictReader(orders_csv)}
...
>>> # Filter the client emails using set difference
>>> coupon_emails = client_emails - order_emails
>>> coupon_emails
{"mwilson@example.net", "coryali17@example.net"}Этот подход намного эффективнее предыдущего: адреса клиентов перебираются только один раз, а не два. Вот ещё одно преимущество: все повторы почтовых адресов из обоих CSV-файлов удаляются естественным образом.
Три книги, чтобы писать более питонический код
За один день писать чистый питонический код не научиться. Нужно изучить много примеров кода, пробовать писать собственный код и консультироваться с другими разработчиками Python. Чтобы облегчить вам задачу, я составил список из трёх книг, очень полезных для понимания питонического кода. Все они написаны для программистов уровня выше среднего или среднего.
Если вы новичок в Python (и тем более в программировании в целом), загляните в мою книгу Python Basics: A Practical Introduction to Python 3 («Основы Python: Практическое введение в Python 3»).
Python Tricks Дэна Бейдера
Короткая и приятная книга Дэна Бейдера Python Tricks: A Buffet of Awesome Python Features («Приёмы Python: набор потрясающих функций Python») — отличная отправная точка для начинающих и программистов, желающих больше узнать о том, как писать питонический код.
С Python Tricks вы изучите шаблоны написания чистого идиоматичного кода Python, лучшие практики для написания функций, эффективное применение функционала объектно-ориентированного программирования Python и многое другое.
Effective Python Бретта Слаткина
Effective Python («Эффективный Python») Бретта Слаткина — это первая книга, которую я прочитал после изучения синтаксиса Python. Она открыла мне глаза на возможности питонического кода.
В Effective Python содержится 90 способов улучшения кода Python. Одна только первая глава Python Thinking («Мыслить на Python») — это кладезь хитростей и приёмов, которые будут полезными даже для новичков, хотя остальная часть книги может быть для них трудной.
Fluent Python Лучано Рамальо
Если бы у меня была только одна книга о Python, это была бы книга Лучано Рамальо Fluent Python («Python. К вершинам мастерства»). Рамальо недавно обновил свою книгу до современного Python. Сейчас можно оформить предзаказ. Настоятельно рекомендую сделать это: первое издание устарело.
Полная практических примеров, чётко изложенная книга Fluent Python — отличное руководство для всех, кто хочет научиться писать питонический код. Но имейте в виду, что Fluent Python не предназначена для новичков. В предисловии к книге написано:
«Если вы только изучаете Python, эта книга будет трудной для вас».
У вас может сложиться впечатление, что в каждом скрипте на Python должны использоваться специальные методы и приёмы метапрограммирования. Преждевременная абстракция так же плоха, как и преждевременная оптимизация.
Опытные программисты на Python извлекут из этой книги большую пользу.
А мы поможем вам прокачать скиллы или с самого начала освоить профессию в IT, актуальную в любое время:
-
Профессия Fullstack-разработчик на Python
-
Профессия Data Scientist
Выбрать другую востребованную профессию.

PEP 8, иногда пишется как PEP8 или PEP-8, представляет собой документ, в котором содержатся рекомендации и рекомендации по написанию кода Python. Он был написан в 2001 году Гвидо ван Россумом, Барри Варшавой и Ником Когланом. Основной задачей PEP 8 является улучшение читабельности и согласованности кода Python.
PEP расшифровывается как Python Enhancement Proposal, и их несколько. PEP — это документ, который описывает новые функции, предлагаемые для Python, и документирует аспекты Python, такие как дизайн и стиль, для сообщества.
В этом руководстве изложены основные рекомендации, изложенные в PEP 8. Он предназначен для начинающих и средних программистов, и поэтому я не затронул некоторые из наиболее продвинутых тем. Вы можете узнать об этом, прочитав полную документациюPEP 8.
By the end of this tutorial, you’ll be able to:
-
Напишите код Python, соответствующий PEP 8
-
Понять обоснование руководящих принципов, изложенных в ПКП 8
-
Настройте среду разработки так, чтобы вы могли начинать писать код Python, совместимый с PEP 8
Free Bonus:5 Thoughts On Python Mastery, бесплатный курс для разработчиков Python, который показывает вам план действий и образ мышления, который вам понадобится, чтобы вывести свои навыки Python на новый уровень.
Почему нам нужен ПКП 8
«Читаемость имеет значение.»
—The Zen of Python
PEP 8 существует для улучшения читабельности кода Python. Но почему так важна читабельность? Почему написание читаемого кода является одним из руководящих принципов языка Python?
Как сказал Гвидо ван Россум: «Код читается гораздо чаще, чем пишется». Вы можете потратить несколько минут или целый день на написание фрагмента кода для обработки аутентификации пользователя. После того, как вы написали это, вы никогда не будете писать это снова. Но вам определенно придется прочитать это снова. Этот фрагмент кода может остаться частью проекта, над которым вы работаете. Каждый раз, когда вы возвращаетесь к этому файлу, вы должны помнить, что делает этот код и почему вы его написали, поэтому удобочитаемость имеет значение.
Если вы новичок в Python, может быть трудно вспомнить, что делает код через несколько дней или недель после того, как вы его написали. Если вы будете следовать PEP 8, вы можете быть уверены, что правильно назвали свои переменные. Вы будете знать, что вы добавили достаточно пробелов, чтобы легче было следовать логическим шагам в вашем коде. Вы также хорошо прокомментировали свой код. Все это будет означать, что ваш код более читабелен и к нему легче вернуться. Как новичок, следование правилам PEP 8 может сделать изучение Python гораздо более приятной задачей.
Следование PEP 8 особенно важно, если вы ищете работу по разработке. Написание четкого, читаемого кода демонстрирует профессионализм. Он скажет работодателю, что вы понимаете, как правильно структурировать свой код.
Если у вас больше опыта написания кода на Python, возможно, вам придется сотрудничать с другими. Написание читаемого кода здесь имеет решающее значение. Другим людям, которые, возможно, никогда раньше не встречали вас и не видели ваш стиль кодирования, придется читать и понимать ваш код. Наличие руководств, которые вы соблюдаете и узнаете, облегчит другим чтение вашего кода.
Соглашения об именах
«Явное лучше, чем неявное».
—The Zen of Python
Когда вы пишете код на Python, вам приходится называть множество вещей: переменные, функции, классы, пакеты и так далее. Выбор разумных имен сэкономит ваше время и энергию позже. По названию вы сможете понять, что представляет собой определенная переменная, функция или класс. Вы также избегаете использования неподходящих имен, которые могут привести к ошибкам, которые трудно отладить.
Note: Никогда не используйте однобуквенные именаl,O илиI, так как они могут быть ошибочно приняты за1 и0, в зависимости от гарнитуры :
O = 2 # This may look like you're trying to reassign 2 to zeroСтили именования
В таблице ниже приведены некоторые из распространенных стилей именования в коде Python и когда вы должны их использовать:
| Type | Соглашение об именовании | Примеры |
|---|---|---|
|
функция |
Используйте слово или слова в нижнем регистре. Для удобства чтения разделяйте слова подчеркиванием. |
|
|
переменная |
Используйте одну строчную букву, слово или слова. Для удобства чтения разделяйте слова подчеркиванием. |
|
|
Учебный класс |
Каждое слово начинайте с заглавной буквы. Не разделяйте слова подчеркиванием. Этот стиль называется «верблюжий футляр». |
|
|
метод |
Используйте слово или слова в нижнем регистре. Для удобства чтения разделяйте слова подчеркиванием. |
|
|
постоянная |
Используйте одну заглавную букву, слово или слова. Для удобства чтения разделяйте слова подчеркиванием. |
|
|
модуль |
Используйте короткие слова или слова в нижнем регистре. Для удобства чтения разделяйте слова подчеркиванием. |
|
|
пакет |
Используйте короткие слова или слова в нижнем регистре. Не разделяйте слова подчеркиванием. |
|
Вот некоторые из распространенных соглашений об именах и примеры их использования. Но для того, чтобы написать читаемый код, вы все равно должны быть осторожны с выбором букв и слов. В дополнение к выбору правильных стилей имен в вашем коде, вы также должны тщательно выбирать имена. Ниже приведены несколько советов о том, как сделать это максимально эффективно.
Как выбрать имена
Выбор имен для ваших переменных, функций, классов и т. Д. Может быть сложной задачей. При написании кода вы должны тщательно продумать свои варианты именования, так как это сделает ваш код более читабельным. Лучший способ назвать ваши объекты в Python — это использовать описательные имена, чтобы прояснить, что представляет собой объект.
При именовании переменных у вас может возникнуть соблазн выбрать простые однобуквенные имена в нижнем регистре, напримерx. Но если вы не используетеx в качестве аргумента математической функции, непонятно, что представляет собойx. Представьте, что вы сохраняете имя человека в виде строки и хотите использовать нарезку строк, чтобы по-разному форматировать его имя. Вы можете получить что-то вроде этого:
>>>
>>> # Not recommended
>>> x = 'John Smith'
>>> y, z = x.split()
>>> print(z, y, sep=', ')
'Smith, John'Это будет работать, но вам нужно будет отслеживать, что представляют собойx,y иz. Это также может сбивать с толку соавторов. Намного более ясный выбор имен был бы чем-то вроде этого:
>>>
>>> # Recommended
>>> name = 'John Smith'
>>> first_name, last_name = name.split()
>>> print(last_name, first_name, sep=', ')
'Smith, John'Точно так же, чтобы уменьшить количество набираемого текста, может быть соблазнительно использовать сокращения при выборе имен. В приведенном ниже примере я определил функциюdb(), которая принимает единственный аргументx и удваивает его:
# Not recommended
def db(x):
return x * 2На первый взгляд, это может показаться разумным выбором. db() легко может быть сокращением от double. Но представьте, что вернетесь к этому коду через несколько дней. Возможно, вы забыли, чего пытались достичь с помощью этой функции, и это затруднило бы догадаться, как вы сокращали ее.
Следующий пример намного понятнее. Если вы вернетесь к этому коду через пару дней после его написания, вы все равно сможете прочитать и понять назначение этой функции:
# Recommended
def multiply_by_two(x):
return x * 2Та же философия применима ко всем другим типам данных и объектам в Python. Всегда старайтесь использовать максимально лаконичные, но описательные имена.
Макет кода
«Красиво лучше, чем некрасиво».
—The Zen of Python
То, как вы выкладываете свой код, играет огромную роль в его читабельности. В этом разделе вы узнаете, как добавить вертикальный пробел для улучшения читабельности вашего кода. Вы также узнаете, как обрабатывать ограничение в 79 символов, рекомендованное в PEP 8.
Пустые строки
Вертикальные пробелы или пустые строки могут значительно улучшить читаемость вашего кода. Код, собранный вместе, может быть ошеломляющим и трудным для чтения. Точно так же, слишком много пустых строк в вашем коде делает его очень разреженным, и читателю может понадобиться прокрутить больше, чем необходимо. Ниже приведены три основных правила использования вертикальных пробелов.
Surround top-level functions and classes with two blank lines. Функции и классы верхнего уровня должны быть достаточно самодостаточными и обрабатывать отдельные функции. Имеет смысл поместить дополнительное вертикальное пространство вокруг них, чтобы было ясно, что они разделены:
class MyFirstClass:
pass
class MySecondClass:
pass
def top_level_function():
return NoneSurround method definitions inside classes with a single blank line. Внутри класса все функции связаны друг с другом. Рекомендуется оставлять между ними только одну строку:
class MyClass:
def first_method(self):
return None
def second_method(self):
return NoneUse blank lines sparingly inside functions to show clear steps. Иногда сложная функция должна выполнить несколько шагов перед операторомreturn. Чтобы помочь читателю понять логику внутри функции, может быть полезно оставить пустую строку между каждым шагом.
В приведенном ниже примере есть функция для расчета дисперсии списка. Это двухэтапная проблема, поэтому я обозначил каждый шаг, оставив между ними пустую строку. Перед операторомreturn также есть пустая строка. Это помогает читателю ясно увидеть, что возвращается:
def calculate_variance(number_list):
sum_list = 0
for number in number_list:
sum_list = sum_list + number
mean = sum_list / len(number_list)
sum_squares = 0
for number in number_list:
sum_squares = sum_squares + number**2
mean_squares = sum_squares / len(number_list)
return mean_squares - mean**2Если вы аккуратно используете вертикальные пробелы, это может значительно улучшить читаемость вашего кода. Это помогает читателю визуально понять, как ваш код разбивается на разделы и как эти разделы связаны друг с другом.
Максимальная длина линии и разрыв строки
PEP 8 предполагает, что строки должны быть ограничены 79 символами. Это потому, что это позволяет вам открывать несколько файлов рядом друг с другом, а также избегать переноса строк.
Конечно, сохранение утверждений длиной до 79 символов не всегда возможно. В PEP 8 изложены способы, позволяющие операторам выполнять несколько строк.
Python примет продолжение строки, если код содержится в скобках, скобках или скобках:
def function(arg_one, arg_two,
arg_three, arg_four):
return arg_oneЕсли невозможно использовать подразумеваемое продолжение, тогда вы можете использовать обратную косую черту для разбиения строк:
from mypkg import example1,
example2, example3Однако, если вы можете использовать подразумеваемое продолжение, то вам следует это сделать.
Если разрыв строки должен произойти вокруг бинарных операторов, таких как+ и*, он должен произойти до оператора. Это правило вытекает из математики. Математики сходятся во мнении, что разрыв перед двоичными операторами улучшает читабельность. Сравните следующие два примера.
Ниже приведен пример взлома перед бинарным оператором:
# Recommended
total = (first_variable
+ second_variable
- third_variable)Вы можете сразу увидеть, какая переменная добавляется или вычитается, так как оператор находится рядом с той переменной, с которой вы работаете.
Теперь давайте рассмотрим пример взлома после бинарного оператора:
# Not Recommended
total = (first_variable +
second_variable -
third_variable)Здесь сложнее увидеть, какая переменная добавляется, а какая вычитается.
Прерывание перед бинарными операторами создает более читаемый код, поэтому PEP 8 поощряет это. Код, которыйconsistently прерывается после бинарного оператора, по-прежнему соответствует PEP 8. Тем не менее, вам рекомендуется взломать перед двоичным оператором.
вдавливание
«Должен быть один — и желательно только один — очевидный способ сделать это».
—The Zen of Python
Отступы, или ведущие пробелы, чрезвычайно важны в Python. Уровень отступа строк кода в Python определяет, как операторы группируются вместе.
Рассмотрим следующий пример:
x = 3
if x > 5:
print('x is larger than 5')Операторprint с отступом сообщает Python, что он должен выполняться только в том случае, если операторif возвращаетTrue. Тот же отступ применяется к сообщению Python, какой код выполнять при вызове функции или какой код принадлежит данному классу.
Ключевыми правилами отступления, изложенными в PEP 8, являются следующие:
-
Используйте 4 последовательных пробела для обозначения отступа.
-
Предпочитаю пробелы над вкладками.
Вкладки против пространства
Как упоминалось выше, вы должны использовать пробелы вместо табуляции при отступе кода. Вы можете настроить параметры в текстовом редакторе таким образом, чтобы вместо символа табуляции выводилось 4 пробела при нажатии клавиши[.kbd .key-tab]#Tab #.
Если вы используете Python 2 и использовали комбинацию табуляции и пробелов для отступа в своем коде, вы не увидите ошибок при попытке его запустить. Чтобы помочь вам проверить согласованность, вы можете добавить флаг-t при запуске кода Python 2 из командной строки. Переводчик выдаст предупреждения, если вы не согласны с использованием табуляции и пробелов:
$ python2 -t code.py
code.py: inconsistent use of tabs and spaces in indentationЕсли вместо этого вы используете флаг-tt, интерпретатор будет выдавать ошибки вместо предупреждений, и ваш код не будет работать. Преимущество использования этого метода заключается в том, что переводчик сообщает вам, где есть несоответствия:
$ python2 -tt code.py
File "code.py", line 3
print(i, j)
^
TabError: inconsistent use of tabs and spaces in indentationPython 3 не позволяет смешивать символы табуляции и пробелы. Поэтому, если вы используете Python 3, эти ошибки выдаются автоматически:
$ python3 code.py
File "code.py", line 3
print(i, j)
^
TabError: inconsistent use of tabs and spaces in indentationВы можете написать код Python с помощью табуляции или пробелов, указывающих на отступ. Но если вы используете Python 3, вы должны соответствовать своему выбору. В противном случае ваш код не будет работать. ПКП 8 рекомендует всегда использовать 4 последовательных пробела для обозначения отступа.
Отступ после переноса строки
Если вы используете продолжения строк, чтобы длина строк не превышала 79 символов, полезно использовать отступы для улучшения читабельности. Это позволяет читателю различать две строки кода и одну строку кода, которая занимает две строки. Есть два стиля отступов, которые вы можете использовать.
Первым из них является выравнивание блока с отступом по открывающему разделителю:
def function(arg_one, arg_two,
arg_three, arg_four):
return arg_oneИногда вы можете обнаружить, что для выравнивания с начальным разделителем требуется всего 4 пробела. Это часто встречается в операторахif, которые занимают несколько строк, посколькуif, пробел и открывающая скобка составляют 4 символа. В этом случае может быть сложно определить, где начинается вложенный блок кода внутри оператораif:
x = 5
if (x > 3 and
x < 10):
print(x)В этом случае PEP 8 предоставляет две альтернативы для улучшения читабельности:
-
Добавьте комментарий после окончательного условия. Из-за подсветки синтаксиса в большинстве редакторов это отделяет условия от вложенного кода:
x = 5 if (x > 3 and x < 10): # Both conditions satisfied print(x) -
Добавьте дополнительный отступ на продолжение строки:
x = 5 if (x > 3 and x < 10): print(x)
Альтернативный стиль отступа после разрыва строки —hanging indent. Это типографский термин, означающий, что каждая строка, кроме первой в абзаце или утверждении, имеет отступ. Вы можете использовать висячий отступ для визуального представления продолжения строки кода. Вот пример:
var = function(
arg_one, arg_two,
arg_three, arg_four)Note: когда вы используете выступающий отступ, в первой строке не должно быть никаких аргументов. Следующий пример не соответствует PEP 8:
# Not Recommended
var = function(arg_one, arg_two,
arg_three, arg_four)При использовании висящего отступа добавьте дополнительный отступ, чтобы отличить продолжение строки от кода, содержащегося внутри функции. Следующий пример трудно читать, потому что код внутри функции находится на том же уровне отступа, что и продолжение строк:
# Not Recommended
def function(
arg_one, arg_two,
arg_three, arg_four):
return arg_oneВместо этого лучше использовать двойной отступ в продолжении строки. Это помогает вам различать аргументы функции и тело функции, улучшая читабельность:
def function(
arg_one, arg_two,
arg_three, arg_four):
return arg_oneКогда вы пишете код, совместимый с PEP 8, ограничение в 79 символов заставляет вас добавлять разрывы строк в ваш код. Чтобы улучшить читаемость, вы должны сделать отступ для продолжения, чтобы показать, что это продолжение. Есть два способа сделать это. Во-первых, выровнять блок с отступом по открывающему разделителю. Второе — использовать висячий отступ. Вы можете выбрать, какой метод отступа использовать после переноса строки.
Куда положить закрывающую скобку
Продолжения строк позволяют разбивать строки в скобках, скобках или скобках. Легко забыть о закрывающей скобке, но важно поместить ее куда-нибудь разумно. В противном случае, это может запутать читателя. PEP 8 предоставляет две опции для положения закрывающей скобки в подразумеваемых продолжениях строки:
-
Совместите закрывающую скобку с первым непробельным символом предыдущей строки:
list_of_numbers = [ 1, 2, 3, 4, 5, 6, 7, 8, 9 ] -
Выровняйте закрывающую фигурную скобку с первым символом строки, которая начинает конструкцию:
list_of_numbers = [ 1, 2, 3, 4, 5, 6, 7, 8, 9 ]
Вы можете выбрать, какой вариант вы используете. Но, как всегда, последовательность является ключевым фактором, поэтому старайтесь придерживаться одного из вышеуказанных методов.
«Если реализацию сложно объяснить, это плохая идея».
—The Zen of Python
Вы должны использовать комментарии, чтобы документировать код, как он написан. Важно документировать свой код, чтобы вы и все соавторы могли его понять. Когда вы или кто-то другой читает комментарий, он должен иметь возможность легко понять код, к которому относится комментарий, и то, как он вписывается в остальную часть вашего кода.
Вот несколько ключевых моментов, которые следует помнить при добавлении комментариев в код:
-
Ограничьте длину строки комментариев и строк документации до 72 символов.
-
Используйте полные предложения, начинающиеся с заглавной буквы.
-
Не забудьте обновить комментарии, если вы измените свой код.
Используйте блочные комментарии для документирования небольшого фрагмента кода. Они полезны, когда вам нужно написать несколько строк кода для выполнения одного действия, такого как импорт данных из файла или обновление записи базы данных. Они важны, так как помогают другим понять назначение и функциональность данного блока кода.
PEP 8 предоставляет следующие правила для написания комментариев к блоку:
-
Отступ блока комментариев к тому же уровню, что и код, который они описывают.
-
Каждую строку начинайте с
#, за которым следует один пробел. -
Разделите абзацы строкой, содержащей один
#.
Вот комментарий блока, объясняющий функцию циклаfor. Обратите внимание, что предложение переносится на новую строку, чтобы сохранить ограничение в 79 символов:
for i in range(0, 10):
# Loop over i ten times and print out the value of i, followed by a
# new line character
print(i, 'n')Иногда, если код очень технический, тогда необходимо использовать более одного абзаца в комментарии блока:
def quadratic(a, b, c, x):
# Calculate the solution to a quadratic equation using the quadratic
# formula.
#
# There are always two solutions to a quadratic equation, x_1 and x_2.
x_1 = (- b+(b**2-4*a*c)**(1/2)) / (2*a)
x_2 = (- b-(b**2-4*a*c)**(1/2)) / (2*a)
return x_1, x_2Если вы когда-либо сомневаетесь в том, какой тип комментария подходит, то блочные комментарии часто являются подходящим способом. Используйте их как можно больше в своем коде, но не забудьте обновить их, если вы вносите изменения в свой код!
Встроенные комментарии объясняют одно утверждение в куске кода. Они полезны, чтобы напомнить вам или объяснить другим, почему необходима определенная строка кода. Вот что говорит о них PEP 8:
-
Используйте встроенные комментарии экономно.
-
Напишите встроенные комментарии в той же строке, что и утверждение, к которому они относятся.
-
Отделяйте встроенные комментарии двумя или более пробелами из оператора.
-
Начинайте встроенные комментарии с
#и одного пробела, как комментарии блока. -
Не используйте их, чтобы объяснить очевидное.
Ниже приведен пример встроенного комментария:
x = 5 # This is an inline commentИногда встроенные комментарии могут показаться необходимыми, но вместо этого вы можете использовать лучшие соглашения об именах. Вот пример:
x = 'John Smith' # Student NameЗдесь встроенный комментарий дает дополнительную информацию. Однако использованиеx в качестве имени переменной для имени человека — плохая практика. Встроенный комментарий не нужен, если вы переименуете свою переменную:
student_name = 'John Smith'Наконец, встроенные комментарии, такие как эти, являются плохой практикой, поскольку они утверждают очевидный и загроможденный код:
empty_list = [] # Initialize empty list
x = 5
x = x * 5 # Multiply x by 5Встроенные комментарии более конкретны, чем блочные комментарии, и их легко добавить, когда они не нужны, что приводит к беспорядку. Вы можете обойтись только с помощью блочных комментариев, поэтому, если вы не уверены, что вам нужен встроенный комментарий, ваш код, скорее всего, будет соответствовать PEP 8, если вы будете придерживаться блокировки комментариев.
Строки документации
Строки документации или строки документации — это строки, заключенные в двойные (""") или одинарные (''') кавычки, которые появляются в первой строке любой функции, класса, метода или модуля. Вы можете использовать их для объяснения и документирования определенного блока кода. Существует целый PEPPEP 257, который охватывает строки документации, но в этом разделе вы получите сводку.
Наиболее важные правила, применяемые к строкам документации, следующие:
-
Окружите строки документации тремя двойными кавычками с каждой стороны, как в
"""This is a docstring""". -
Напишите их для всех общедоступных модулей, функций, классов и методов.
-
Поместите
""", который завершает многострочную строку документации, на отдельной строке:def quadratic(a, b, c, x): """Solve quadratic equation via the quadratic formula. A quadratic equation has the following form: ax**2 + bx + c = 0 There always two solutions to a quadratic equation: x_1 & x_2. """ x_1 = (- b+(b**2-4*a*c)**(1/2)) / (2*a) x_2 = (- b-(b**2-4*a*c)**(1/2)) / (2*a) return x_1, x_2 -
Для однострочных строк документации оставьте
"""в одной строке:def quadratic(a, b, c, x): """Use the quadratic formula""" x_1 = (- b+(b**2-4*a*c)**(1/2)) / (2*a) x_2 = (- b-(b**2-4*a*c)**(1/2)) / (2*a) return x_1, x_2
Пробелы в выражениях и утверждениях
«Разреженный лучше, чем плотный.»
—The Zen of Python
Пробелы могут быть очень полезны в выражениях и утверждениях при правильном использовании. Если пробелов недостаточно, код может быть трудным для чтения, так как все это объединено. Если пробелов слишком много, может быть сложно визуально объединить связанные термины в утверждении.
Пробелы вокруг бинарных операторов
Окружите следующие двоичные операторы одним пробелом с каждой стороны:
-
Операторы присваивания (
=,+=,-=и т. Д.) -
Сравнения (
==,!=,>,<.>=,<=) и (is,is not,in,not in) -
Логические значения (
and,not,or)
Note: когда= используется для присвоения значения по умолчанию аргументу функции, не окружайте его пробелами.
# Recommended
def function(default_parameter=5):
# ...
# Not recommended
def function(default_parameter = 5):
# ...Когда в операторе более одного оператора, добавление одного пробела до и после каждого оператора может показаться запутанным. Вместо этого лучше всего добавлять пробелы вокруг операторов с самым низким приоритетом, особенно при выполнении математических манипуляций. Вот пара примеров:
# Recommended
y = x**2 + 5
z = (x+y) * (x-y)
# Not Recommended
y = x ** 2 + 5
z = (x + y) * (x - y)Вы также можете применить это к операторамif, где есть несколько условий:
# Not recommended
if x > 5 and x % 2 == 0:
print('x is larger than 5 and divisible by 2!')В приведенном выше примере операторand имеет самый низкий приоритет. Поэтому может быть более понятным выражениеif, как показано ниже:
# Recommended
if x>5 and x%2==0:
print('x is larger than 5 and divisible by 2!')Вы можете выбрать более понятный вариант с оговоркой, что вы должны использовать одинаковое количество пробелов по обе стороны от оператора.
Следующее недопустимо:
# Definitely do not do this!
if x >5 and x% 2== 0:
print('x is larger than 5 and divisible by 2!')В срезах двоеточия действуют как бинарные операторы. Поэтому применяются правила, изложенные в предыдущем разделе, и с каждой стороны должно быть одинаковое количество пробелов. Допустимы следующие примеры фрагментов списка:
list[3:4]
# Treat the colon as the operator with lowest priority
list[x+1 : x+2]
# In an extended slice, both colons must be
# surrounded by the same amount of whitespace
list[3:4:5]
list[x+1 : x+2 : x+3]
# The space is omitted if a slice parameter is omitted
list[x+1 : x+2 :]Таким образом, вы должны окружить большинство операторов пробелами. Однако есть некоторые оговорки к этому правилу, например, в аргументах функций или когда вы объединяете несколько операторов в одном операторе.
Когда избегать добавления пробелов
В некоторых случаях добавление пробела может затруднить чтение кода. Слишком много пробелов может сделать код слишком разреженным и трудным для понимания. В PEP 8 приведены очень четкие примеры, когда пробелы неуместны.
Самое важное место, чтобы избежать добавления пробелов, находится в конце строки. Это известно какtrailing whitespace. Он невидим и может привести к ошибкам, которые трудно отследить.
В следующем списке перечислены некоторые случаи, когда следует избегать добавления пробелов:
-
Сразу внутри скобок, скобок или фигурных скобок:
# Recommended my_list = [1, 2, 3] # Not recommended my_list = [ 1, 2, 3, ] -
Перед запятой, точкой с запятой или двоеточием:
x = 5 y = 6 # Recommended print(x, y) # Not recommended print(x , y) -
Перед открывающей скобкой, которая запускает список аргументов вызова функции:
def double(x): return x * 2 # Recommended double(3) # Not recommended double (3) -
Перед открывающей скобкой, которая начинает индекс или срез:
# Recommended list[3] # Not recommended list [3] -
Между запятой и закрывающей скобкой:
# Recommended tuple = (1,) # Not recommended tuple = (1, ) -
Для выравнивания операторов присваивания:
# Recommended var1 = 5 var2 = 6 some_long_var = 7 # Not recommended var1 = 5 var2 = 6 some_long_var = 7
Убедитесь, что в вашем коде нет пробелов в конце. В других случаях PEP 8 препятствует добавлению лишних пробелов, например непосредственно в скобках, а также перед запятыми и двоеточиями. Вы также никогда не должны добавлять лишние пробелы для выравнивания операторов.
Рекомендации по программированию
«Простое лучше, чем сложное».
—The Zen of Python
Вы часто обнаружите, что есть несколько способов выполнить подобное действие в Python (и любом другом языке программирования в этом отношении). В этом разделе вы увидите некоторые предложения, которые предлагает PEP 8 для устранения этой неоднозначности и сохранения согласованности.
Don’t compare boolean values to True or False using the equivalence operator. Вам часто нужно будет проверять, является ли логическое значение Истинным или Ложным. При этом интуитивно понятно сделать это с помощью заявления, подобного приведенному ниже:
# Not recommended
my_bool = 6 > 5
if my_bool == True:
return '6 is bigger than 5'Использование оператора эквивалентности== здесь не требуется. bool может принимать только значенияTrue илиFalse. Достаточно написать следующее:
# Recommended
if my_bool:
return '6 is bigger than 5'Этот способ выполнения оператораif с логическим значением требует меньше кода и проще, поэтому PEP 8 поощряет его.
Use the fact that empty sequences are falsy in if statements. Если вы хотите проверить, пуст ли список, у вас может возникнуть соблазн проверить длину списка. Если список пуст, его длина равна0, что эквивалентноFalse при использовании в инструкцииif. Вот пример:
# Not recommended
my_list = []
if not len(my_list):
print('List is empty!')Однако в Python любой пустой список, строка или кортеж равенfalsy. Поэтому мы можем предложить более простую альтернативу вышесказанному:
# Recommended
my_list = []
if not my_list:
print('List is empty!')Хотя оба примера будут выводитьList is empty!, второй вариант проще, поэтому PEP 8 поддерживает его.
Use is not rather than not ... is in if statements. Если вы пытаетесь проверить, имеет ли переменная определенное значение, есть два варианта. Первый — оценить операторif с помощьюx is not None, как в примере ниже:
# Recommended
if x is not None:
return 'x exists!'Второй вариант — оценитьx is None, а затем получить операторif на основе результатаnot:
# Not recommended
if not x is None:
return 'x exists!'Хотя оба варианта будут оценены правильно, первый проще, поэтому PEP 8 поощряет его.
Don’t use if x: when you mean if x is not None:. Иногда у вас может быть функция с аргументами, которые по умолчанию равныNone. Распространенной ошибкой при проверке, присвоено ли такому аргументуarg другое значение, является использование следующего:
# Not Recommended
if arg:
# Do something with arg...Этот код проверяет, чтоarg правдиво. Вместо этого вы хотите проверить, чтоarg равноnot None, поэтому было бы лучше использовать следующее:
# Recommended
if arg is not None:
# Do something with arg...Ошибка здесь заключается в предположении, чтоnot None и truthy эквивалентны. Вы могли бы установитьarg = []. Как мы видели выше, пустые списки в Python оцениваются как ложные. Таким образом, несмотря на то, что аргументarg был назначен, условие не выполняется, и поэтому код в теле оператораif не будет выполнен.
Use .startswith() and .endswith() instead of slicing. Если вы пытались проверить, была ли строкаword префиксом или суффиксом со словомcat, может показаться разумным использоватьlist slicing. Однако нарезка списка подвержена ошибкам, и вам необходимо жестко указать количество символов в префиксе или суффиксе. Кто-то, менее знакомый с нарезкой списков в Python, также не понимает, чего вы пытаетесь достичь:
# Not recommended
if word[:3] == 'cat':
print('The word starts with "cat"')Однако это не так удобно, как использование.startswith():
# Recommended
if word.startswith('cat'):
print('The word starts with "cat"')Точно так же тот же принцип применяется, когда вы проверяете суффиксы. В приведенном ниже примере показано, как проверить, заканчивается ли строка наjpg:
# Not recommended
if file_name[-3:] == 'jpg':
print('The file is a JPEG')Несмотря на то, что результат верный, обозначения немного неуклюжи и трудны для чтения. Вместо этого вы можете использовать.endswith(), как в примере ниже:
# Recommended
if file_name.endswith('jpg'):
print('The file is a JPEG')Как и в большинстве этих рекомендаций по программированию, целью является удобочитаемость и простота. В Python есть много разных способов выполнить одно и то же действие, поэтому рекомендации по выбору методов полезны.
Когда игнорировать PEP 8
Краткий ответ на этот вопрос никогда не бывает. Если вы будете следовать PEP 8 к письму, вы можете гарантировать, что у вас будет чистый, профессиональный и читаемый код. Это принесет пользу вам, а также сотрудникам и потенциальным работодателям.
Однако некоторые рекомендации в PEP 8 неудобны в следующих случаях:
-
Если соблюдение PEP 8 нарушит совместимость с существующим программным обеспечением
-
Если код, над которым вы работаете, не соответствует PEP 8
-
Если код должен оставаться совместимым со старыми версиями Python
Советы и подсказки, чтобы помочь вашему коду следовать PEP 8
Нужно помнить, что ваш код соответствует требованиям PEP 8. Может быть непросто запомнить все эти правила при разработке кода. Особенно много времени требуется для обновления предыдущих проектов, чтобы они соответствовали требованиям PEP 8. К счастью, есть инструменты, которые могут помочь ускорить этот процесс. Существует два класса инструментов, которые можно использовать для обеспечения соответствия требованиям PEP 8: линтеры и автоформаторы.
Линтер
Линтеры — это программы, которые анализируют код и отмечают ошибки. Они дают предложения о том, как исправить ошибку. Линтеры особенно полезны при установке в качестве расширений для вашего текстового редактора, поскольку они отмечают ошибки и стилистические проблемы во время написания. В этом разделе вы увидите схему работы линтеров со ссылками на расширения текстового редактора в конце.
Лучшие линтеры для кода Python:
-
pycodestyle— это инструмент для проверки вашего кода Python на соответствие некоторым стилевым соглашениям в PEP 8.Установите
pycodestyle, используяpip:$ pip install pycodestyleВы можете запустить
pycodestyleиз терминала, используя следующую команду:$ pycodestyle code.py code.py:1:17: E231 missing whitespace after ',' code.py:2:21: E231 missing whitespace after ',' code.py:6:19: E711 comparison to None should be 'if cond is None:' -
flake8— это инструмент, который объединяет отладчикpyflakesсpycodestyle.Установите
flake8, используяpip:Запустите
flake8из терминала, используя следующую команду:$ flake8 code.py code.py:1:17: E231 missing whitespace after ',' code.py:2:21: E231 missing whitespace after ',' code.py:3:17: E999 SyntaxError: invalid syntax code.py:6:19: E711 comparison to None should be 'if cond is None:'Также показан пример вывода.
Note: дополнительная строка вывода указывает на синтаксическую ошибку.
Autoformatters
Автоформаторы — это программы, которые автоматически реорганизуют ваш код в соответствии с PEP 8. Однажды такой программой являетсяblack, которая автоматически форматирует код, следуяmost правил в PEP 8. Одно большое отличие состоит в том, что он ограничивает длину строки до 88 символов, а не до 79. Однако вы можете перезаписать это, добавив флаг командной строки, как вы увидите в примере ниже.
Установитеblack, используяpip. Для запуска требуется Python 3.6+:
Его можно запустить через командную строку, как и с линтерами. Допустим, вы начали со следующего кода, который не соответствует PEP 8, в файле с именемcode.py:
for i in range(0,3):
for j in range(0,3):
if (i==2):
print(i,j)Затем вы можете запустить следующую команду через командную строку:
$ black code.py
reformatted code.py
All done! ✨ 🍰 ✨code.py будет автоматически переформатирован, чтобы выглядеть так:
for i in range(0, 3):
for j in range(0, 3):
if i == 2:
print(i, j)Если вы хотите изменить ограничение длины строки, вы можете использовать флаг--line-length:
$ black --line-length=79 code.py
reformatted code.py
All done! ✨ 🍰 ✨Два других автоформатора,autopep8 иyapf, выполняют действия, аналогичные тем, что делаетblack.
Заключение
Теперь вы знаете, как писать высококачественный читаемый код Python, используя инструкции, изложенные в PEP 8. Несмотря на то, что рекомендации могут показаться педантичными, следование им может реально улучшить ваш код, особенно когда дело доходит до обмена вашим кодом с потенциальными работодателями или сотрудниками.
В этом уроке вы узнали:
-
Что такое PEP 8 и почему он существует
-
Почему вы должны стремиться написать PEP 8-совместимый код
-
Как написать код, совместимый с PEP 8
Кроме того, вы также узнали, как использовать линтеры и автоформаторы для проверки вашего кода на соответствие рекомендациям PEP 8.
Если вы хотите узнать больше о PEP 8, вы можете прочитатьfull documentation или посетитьpep8.org, который содержит ту же информацию, но был хорошо отформатирован. В этих документах вы найдете остальные рекомендации по PEP 8, не описанные в этом руководстве.
|
palachevskiy 0 / 0 / 0 Регистрация: 15.05.2020 Сообщений: 9 |
||||
|
1 |
||||
|
15.05.2020, 16:57. Показов 7149. Ответов 4 Метки нет (Все метки)
./solution.py:3:12: E203 whitespace before ‘:’
__________________
0 |

|
5403 / 3827 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
|
|
15.05.2020, 17:05 |
2 |
|
отфармотировать по стандарту PEP8 Может, сначала сдашь русский? И еще: ты видел, что люди выкладывают сюда код в тегах Python кода, а не тупой нечитабельной лапшой?
1 |
|
Просто Лис
4830 / 3152 / 991 Регистрация: 17.05.2012 Сообщений: 9,186 Записей в блоге: 9 |
|
|
15.05.2020, 17:28 |
3 |
|
PyCharm -> ctrl+L
0 |
|
unfindable_404
683 / 466 / 204 Регистрация: 22.03.2020 Сообщений: 1,051 |
||||
|
15.05.2020, 17:54 |
4 |
|||
|
Дело не в PEP8. Код, который вы запускаете, поддерживается только Python3.8. Но вы запускаете его на Python более старой версии. Отсюда и ошибки. Я поправил.
2 |
|
Нарушитель
14040 / 8228 / 2485 Регистрация: 21.10.2017 Сообщений: 19,708 |
|
|
16.05.2020, 18:38 |
5 |
|
PyCharm -> ctrl+L Ctrl+Alt+L
2 |

")
A linter is an automated tool that enforces common style guidelines and best practices. It is every developer’s best friend. If you are not using one, you are missing out.
Linters are not a Python-only thing. They are commonly used in any software development project regardless of the language.
This is all it takes to fix a piece of Python code with autopep8 linter:
autopep8 --in-place --aggressive --aggressive Desktop/example.py
Commonly used linters in Python are flake8 and autopep8.
In this guide, you are going to learn how to help write cleaner and more readable code.
The Problem
Writing code is a brain-heavy task. There are many things you need to focus on at the same time.
One aspect that gets overlooked constantly is the readability of the code. When your code finally works it is tempting to ditch it as if you never had to come back at it again. But this is never the case. You or one of your teammates will most definitely have to look at that piece of code in the future. As a developer, it is thus your responsibility to write as readable code as possible.
The Solution
One of the easiest ways to write cleaner code is by using a linter as a code quality assistant.
A linter is a code analyzer that helps you write correctly formatted code that follows best practices. A linter inspects each line of code and points out any styling issues it detects.
Commonly a linter finds:
- Syntax errors, such as incorrect indentations.
- Structural issues, such as unused variables.
- Best practice violations, such as too long lines.
Linters are flexible tools. Some linters even make it possible to auto-fix the styling errors on the fly. This can save you a lot of time.
How to Use a Linter in Python
Linters can be installed as separate tools that you can interact with using the command line. Also, a common way to use one is to integrate it with your favorite code editor, such as VSCode. This way the linter shows warnings in the code editor in real-time.
Now that you understand what a linter is and what problem it solves, it is time to get our hands dirty.
- First, you are going to learn how to use a Python linter called flake8 via command line.
- Then you are going to see how to use a linter called autopep8 that also fixes the listing issues.
- Finally, you are going integrate flake8 into Visual Studio Code to show styling issues in the code editor.
Flake8 Linter in Python
When speaking about Python linters, you commonly hear flake8 mentioned first. It is a really common Python linter that is easy to install and use.
Installation
If you are on Mac or Windows, open up a command line window and run the following command:
pip install flake8
Wait for a couple of seconds for the installation to complete.
When the installation is completed, you are all set. Next, let’s take a look at how you can use the tool to point out the styling issues in your code.
Usage
Flake8 works such that it analyzes your code and displays all the issues. Then it is up to you to actually fix the issues. When you have fixed an issue, re-analyzing the code file does not show that issue in the result again.
To make flake8 analyze your code, run the following command in a command-line window:
flake8 <path_to_file>
Where you replace <path_to_file> with the correct path to the code file you want to analyze.
For example:
flake8 /Desktop/script.py
Analyzes a file called script.py on the Desktop.
Example in Real Life
Feel free to follow this worked-out example where you use flake8 to fix styling issues in a code file.
- Create and open a file called example.py on your desktop.
- Open up a command line window and navigate to desktop.
- Copy-paste following code into the example.py file:
import math, sys;
def example1():
####This is a long comment. This should be wrapped to fit within 72 characters.
some_tuple=( 1,2, 3,'a' );
some_variable={'long':'Long code lines should be wrapped within 79 characters.',
'other':[math.pi, 100,200,300,9876543210,'This is a long string that goes on'],
'more':{'inner':'This whole logical line should be wrapped.',some_tuple:[1,
20,300,40000,500000000,60000000000000000]}}
return (some_tuple, some_variable)
This piece of code is valid in Python, but it has a lot of styling/best practice issues. To expose these issues, run the following command in the command line:
flake8 example.py
(Notice how the path of the file is the name of the file because you are working in the same directory as the file.)
As a result, you see a lengthy output in the command line window:
example.py:1:1: F401 'sys' imported but unused
example.py:1:12: E401 multiple imports on one line
example.py:1:17: E703 statement ends with a semicolon
example.py:3:1: E302 expected 2 blank lines, found 1
example.py:4:5: E265 block comment should start with '# '
example.py:4:80: E501 line too long (83 > 79 characters)
example.py:5:15: E225 missing whitespace around operator
example.py:5:17: E201 whitespace after '('
example.py:5:21: E231 missing whitespace after ','
example.py:5:26: E231 missing whitespace after ','
example.py:5:31: E202 whitespace before ')'
example.py:5:33: E703 statement ends with a semicolon
example.py:6:18: E225 missing whitespace around operator
example.py:6:26: E231 missing whitespace after ':'
example.py:6:80: E501 line too long (84 > 79 characters)
example.py:7:5: E128 continuation line under-indented for visual indent
example.py:7:12: E231 missing whitespace after ':'
example.py:7:26: E231 missing whitespace after ','
example.py:7:30: E231 missing whitespace after ','
example.py:7:34: E231 missing whitespace after ','
example.py:7:45: E231 missing whitespace after ','
example.py:7:80: E501 line too long (83 > 79 characters)
example.py:8:5: E122 continuation line missing indentation or outdented
example.py:8:11: E231 missing whitespace after ':'
example.py:8:20: E231 missing whitespace after ':'
example.py:8:65: E231 missing whitespace after ','
example.py:8:76: E231 missing whitespace after ':'
example.py:9:5: E128 continuation line under-indented for visual indent
example.py:9:7: E231 missing whitespace after ','
example.py:9:11: E231 missing whitespace after ','
example.py:9:17: E231 missing whitespace after ','
example.py:9:27: E231 missing whitespace after ','
example.py:10:39: W292 no newline at end of file
These are all the linting issues found in the code. To get rid of these issues, read what each line suggests and fix the issues. After addressing all these issues, your code should look like this:
import math
def example1():
# This is a long comment. This should be wrapped to fit within 72
# characters.
some_tuple = (1, 2, 3, 'a')
some_variable = {
'long': 'Long code lines should be wrapped within 79 characters.',
'other': [
math.pi,
100,
200,
300,
9876543210,
'This is a long string that goes on'],
'more': {
'inner': 'This whole logical line should be wrapped.',
some_tuple: [
1,
20,
300,
40000,
500000000,
60000000000000000]}}
return (some_tuple, some_variable)
To verify that you fixed all the issues, run flake8 example.py again. If the output is empty, you are all set.
Awesome! Now you understand how linting works and how to use one in your project.
As you probably noticed, fixing all the issues manually in this particular piece of code took a while. But there is a way to automate this whole process. You can use another type of linter that not only detects issues but also fixes them. In the next chapter, you are going to learn how to use a linter called autopep8 that fixes all the styling issues for you
Autopep8 – Auto-Fix Code Style Issues
Autopep8 is a Python linter that analyzes your code and fixes styling/formatting issues.
Installation
Installing autopep8 is simple. If you are on Mac or Windows, open up a command line window and run the following command:
pip install autopep8
After the installation completes, you are ready to use autopep8.
Usage
To make autopep8 fix your code styling issues, run the following command in the command line window:
autopep8 --in-place --aggressive --aggressive <path_to_file>
Where you replace the <path_to_file> with the actual path to the file you want to fix.
For example, if you have a file called script.py on the Desktop, you can fix the styling issues in it by:
autopep8 --in-place --aggressive --aggressive Desktop/script.py
Example
Feel free to follow this worked-out example where you use autopep8 to fix formatting issues in your code.
- Create and open a file called example.py on your desktop.
- Open up a command line window and navigate to desktop.
- Copy-paste the same code as in the previous example into the example.py file:
import math, sys;
def example1():
####This is a long comment. This should be wrapped to fit within 72 characters.
some_tuple=( 1,2, 3,'a' );
some_variable={'long':'Long code lines should be wrapped within 79 characters.',
'other':[math.pi, 100,200,300,9876543210,'This is a long string that goes on'],
'more':{'inner':'This whole logical line should be wrapped.',some_tuple:[1,
20,300,40000,500000000,60000000000000000]}}
return (some_tuple, some_variable)
This is all valid Python code. However, it has multiple style/best practice issues. To fix these issues, use autopep8 by running the following command in the command line:
autopep8 --in-place --aggressive --aggressive example.py
Now if you look at the example.py file, you can see it is formatted nicely:
import math
import sys
def example1():
# This is a long comment. This should be wrapped to fit within 72
# characters.
some_tuple = (1, 2, 3, 'a')
some_variable = {
'long': 'Long code lines should be wrapped within 79 characters.',
'other': [
math.pi,
100,
200,
300,
9876543210,
'This is a long string that goes on'],
'more': {
'inner': 'This whole logical line should be wrapped.',
some_tuple: [
1,
20,
300,
40000,
500000000,
60000000000000000]}}
return (some_tuple, some_variable)
This saves time as you do not have to go through the list of issues and fix them one by one. This is super handy if you want to make your code look nice and clean with ease.
So far you have learned how to use linters to both show and fix styling issues in your code with a single command.
Chances are that you are using a code editor when writing code. It is useful to know that most of the code editors allow integrating a linter to them to show the linting errors in the editor.
Let’s take a look at an example of how to integrate the flake8 linter in Visual Studio Code, a really common code editor.
Integrate a Python Linter in VSCode
Visual Studio Code, which is one of the most popular code editors to date, can be made support Python linters.
In this example, I show you how to integrate flake8 linter in Visual Studio Code to warn about code formatting issues in real-time.
- Open up a new Visual Studio Code window.
- Press Command + Shift + P (⇧⌘P). This opens a search bar.
- Type Python: Select Linter into the search bar and hit enter.
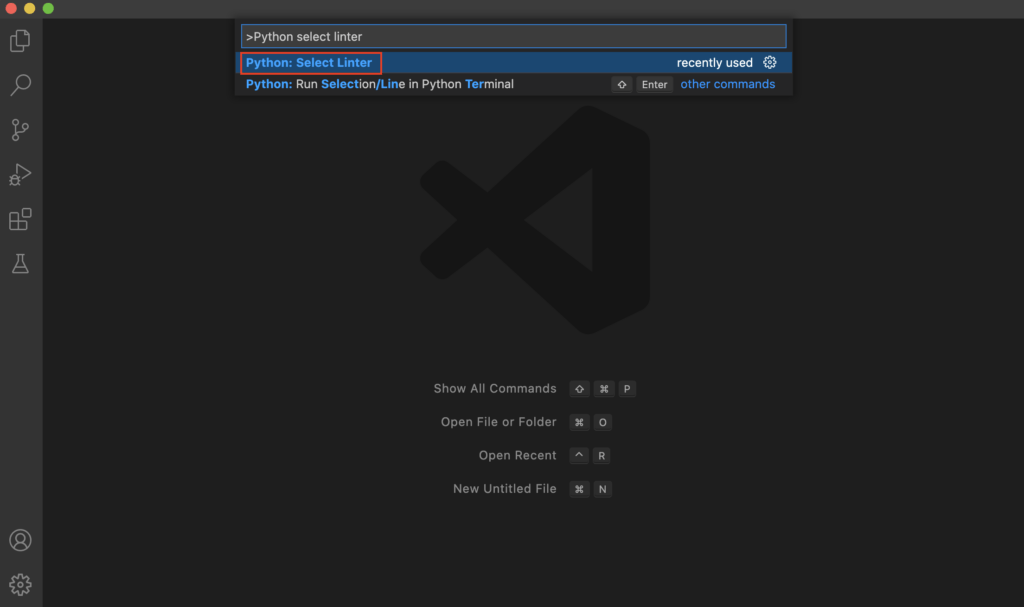
This opens up a list of linters that Visual Studio Code currently supports.
Choose the flake8 option.
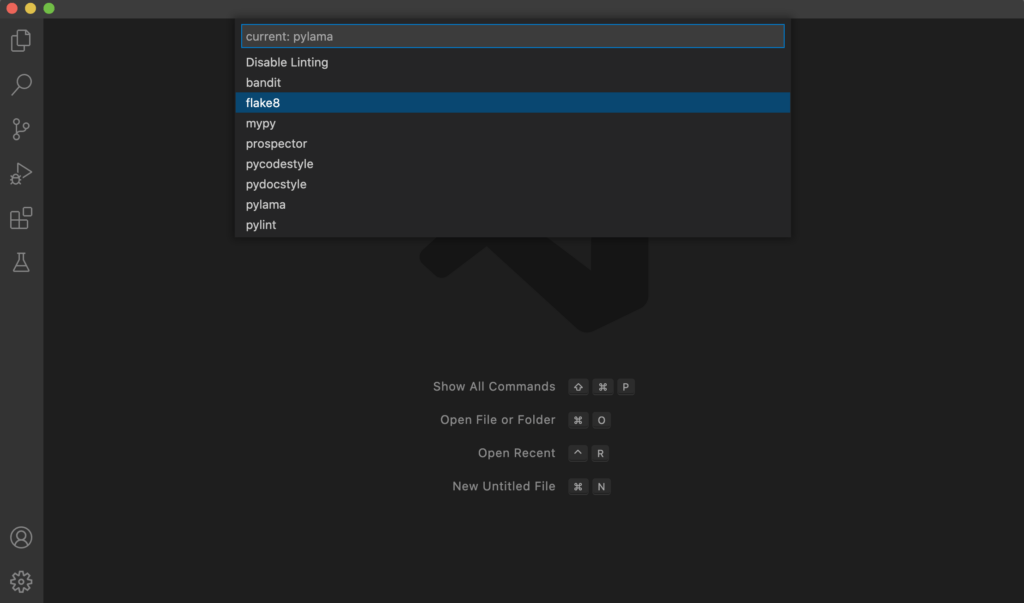
Now that the linter is defined you can open up any Python code file. However, if you have not installed flake8 yet, you see this error:

To proceed, just click “Install”. This installs flake8 on your system so that VSCode can use it.
Now the linter is activated and you should be able to see code issues directly in the VSCode editor.
For example, copy-paste the following code into a Python file and open the file with Visual Studio Code:
import math, sys;
def example1():
####This is a long comment. This should be wrapped to fit within 72 characters.
some_tuple=( 1,2, 3,'a' );
some_variable={'long':'Long code lines should be wrapped within 79 characters.',
'other':[math.pi, 100,200,300,9876543210,'This is a long string that goes on'],
'more':{'inner':'This whole logical line should be wrapped.',some_tuple:[1,
20,300,40000,500000000,60000000000000000]}}
return (some_tuple, some_variable)
You are going to see a lot of red. These are the styling issues picked up by the flake8 linter.
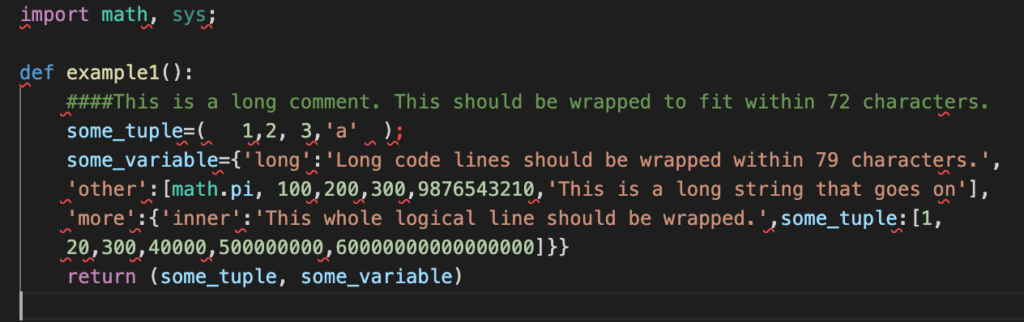
If you hover over any red error, you see a modal that describes the styling issue.
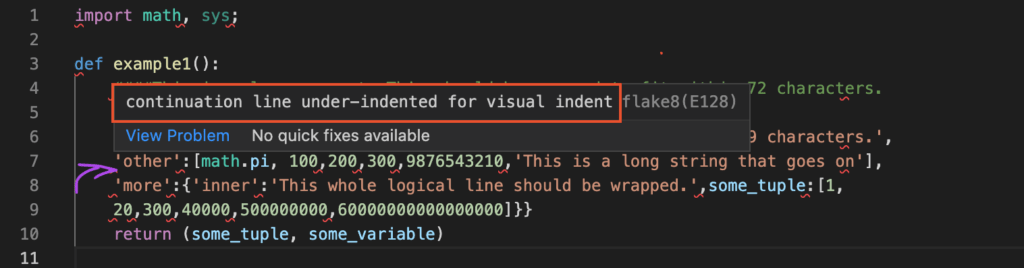
This is useful as now you get real-time feedback about the code styling mistakes you make. Now it is up to you to fix these issues and make the code look readable.
Conclusion
Today you learned about linters in Python.
To recap, a linter is a code analyzer that helps you write clean code that follows style guides and best practices. Any software developer should use a linter in their projects. A linter is very easy to install and use. A popular choice as a Python linter is flake8.
You can use a linter that warns you about styling issues. Commonly you can couple one of these with your favorite code editor to see the issues in real-time.
Alternatively, you can use a linter that not only shows the issues but also fixes them by running a command from the command line. An example of this is the autopep8 linter.
Thanks for reading.
Happy coding!
Further Reading
50 Python Interview Questions
About the Author
- I’m an entrepreneur and a blogger from Finland. My goal is to make coding and tech easier for you with comprehensive guides and reviews.