Содержание
- Способы определения и продления срока службы накопителей SSD
- Как обезопасить SSD от вредного влияния и не убить диск за две недели?
- А можно несколько подробнее о S.M.A.R.T.?
- Какова продолжительность жизни SSD-диска?
- Убедитесь, что функция TRIM включена
- Отключение дефрагментации
- Отключаем файл подкачки SSD
- Спящий режим (гибернация)
- Отключение защиты
- Индексирование поиска
- Отключение индексации
- Временные файлы, кэш и журналы
- Формула расчета
- Монитор ресурсов Windows
- Утилита Process Monitor
- Что лучше всего скопировать на SSD?
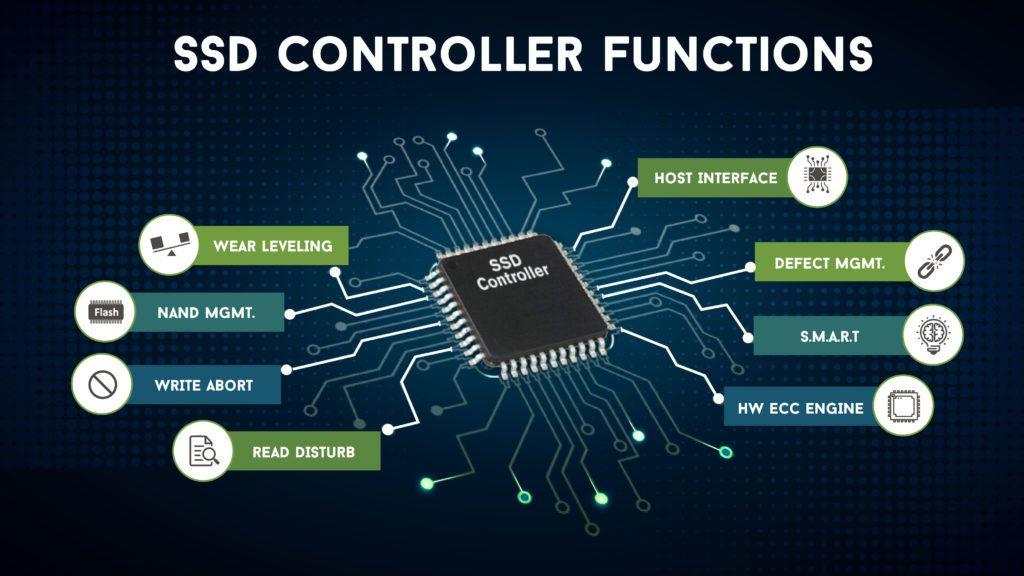
Способы определения и продления срока службы накопителей SSD

Как обезопасить SSD от вредного влияния и не убить диск за две недели?
Я только что получил свой первый SSD. И у меня работает мониторинг SSDLife в фоновом режиме. После этого я установил все программное обеспечение и протестировал SSD. Программа SSDLife сказала, что «Total Data written, GB” = 52.1 (40GB используемого пространства, 70GB — свободного).
То есть, на SSD около 40 Гб данных, при этом записано 52,1 ГБ?
Особенность твердотельного накопителя — данные записываются в блоках. Блок может содержать 256Кб: 256 * 1000 * 8 двоичных разрядов. Для изменения хотя бы одной из этих цифр, вы должны переписать весь блок. То есть, ваша операционная система видит 1 бит, но износ SSD эквивалентен 256Кб: разница в 2,048 млн раза.
Это означает, что формула (РАЗМЕР SSD) * (циклы) = общая данные, записанные на SSD до выхода из строя
это только для лучшем случае, который позволил бы вам писать данные от 1000 до 1000000 раз до отказа. Но, даже в худшем случае, это более вероятно для всех небольших циклов записи на SSD. Это подтверждается в
А можно несколько подробнее о S.M.A.R.T.?
Все когда-то видели набор определённых названий (атрибутов) и их значений, выведенных списком в соответствующем разделе или прямо в главном окне программы, как это видно на скриншоте выше. Но что они означают и как их понять? Немного вернёмся в прошлое, чтобы понять что к чему. По идее, каждый производитель вносит в продукцию что-то своё, чтобы этой уникальностью привлечь потенциального покупателя. Но вот со S.M.A.R.T. вышло несколько иначе.
В зависимости от производителя и модели накопителя набор параметров может меняться, поэтому универсальные программы могут не знать тех или иных значений, помечая их как Vendor Specific. Многие производители предоставляют в открытом доступе документацию для понимания атрибутов своих накопителей – SMART Attribute. Её можно найти на сайте производителя.
Именно поэтому и рекомендуется использовать именно фирменный софт, который в курсе всех тонкостей совместимых моделей накопителей. Кроме того, настоятельно рекомендуется использовать английский интерфейс, чтобы получить достоверную информацию о состоянии накопителя. Зачастую перевод на русский не совсем верен, что может привести в замешательство. Да и сама документация, о которой мы сказали выше, чаще всего предоставляется именно на английском.
Сейчас мы рассмотрим основные атрибуты на примере накопителя Kingston UV500. Кому интересно – читаем, кому нет – жмём PageDown пару раз и читаем заключение. Но, надеемся, вам всё же интересно – информация полезная, как ни крути. Построение текста может выглядеть необычно, но так для всех будет удобнее – не потребуется вводить лишние слова-переменные, а также именно оригинальные слова будет проще найти в отчёте о вашем накопителе.
(ID 1) Read Error Rate
– содержит частоту возникновения ошибок при чтении.
(ID 5) Reallocated Sector Count
– количество переназначенных секторов. Является, по сути, главным атрибутом. Если SSD в процессе работы находит сбойный сектор, то он может посчитать его невосполнимо повреждённым. В этом случае диск использует вместо него сектор из резервной области. Новый сектор получает логический номер LBA старого, после чего при обращении к сектору с этим номером запрос будет перенаправляться в тот, что находится в резервной области. Если ошибка единичная – это не проблема. Но если такие сектора будут появляться регулярно, то проблему можно считать критической.
(ID 9) Power On Hours
– время работы накопителя в часах, включая режим простоя и всяческих режимов энергосбережения.
(ID 12) Power Cycle Count
– количество циклов включения и отключения накопителя, включая резкие обесточивания (некорректное завершение работы).
(ID 170) Used Reserved Block Count
– количество использованных резервных блоков для замещения повреждённых.
(ID 171) Program Fail Count
– подсчёт сбоев записи в память.
(ID 172) Erase Fail Count
– подсчёт сбоев очистки ячеек памяти.
(ID 174) Unexpected Power Off Count
– количество некорректных завершений работы (сбоев питания) без очистки кеша и метаданных.
(ID 175) Program Fail Count Worst Die
– подсчёт ошибок сбоев записи в наихудшей микросхеме памяти.
(ID 176) Erase Fail Count Worst Die
– подсчёт ошибок сбоев очистки ячеек наихудшей микросхемы памяти.
(ID 178) Used Reserved Block Count worst Die
– количество использованных резервных блоков для замещения повреждённых в наихудшей микросхеме памяти.
(ID 180) Unused Reserved Block Count (SSD Total)
– количество (или процент, в зависимости от типа отображения) ещё доступных резервных блоков памяти.
Reported Uncorrectable Errors – количество неисправленных ошибок.
Temperature – температура накопителя.
On-the-Fly ECC Uncorrectable Error Count – общее количество исправляемых и неисправляемых ошибок.
Reallocation Event Count – количество операций переназначения.
Pending Sector Count – количество секторов, требующих переназначения.
UDMA CRC Error Count – счётчик ошибок, возникающих при передаче данных через SATA интерфейс.
Uncorrectable Read Error Rate – количество неисправленных ошибок для текущего периода работы накопителя.
Soft ECC Correction Rate – количество исправленных ошибок для текущего периода работы накопителя.
(ID 231) SSD Life Left
– индикация оставшегося срока службы накопителя на основе количества циклов записи/стирания информации.
(ID 241) GB Written from Interface
– объём данных в ГБ, записанных на накопитель.
(ID 242) GB Read from Interface
– объём данных в ГБ, считанных с накопителя.
(ID 250) Total Number of NAND Read Retries
– количество выполненных попыток чтения с накопителя.
Пожалуй, на этом закончим список. Конечно, для других моделей атрибутов может быть больше или меньше, но их значения в рамках производителя будут идентичны. А расшифровать значения достаточно просто и обычному пользователю, тут всё логично: увеличение количества ошибок – хуже диску, снижение резервных секторов – тоже плохо. По температуре – всё и так ясно. Каждый из вас сможет добавить что-то своё – это ожидаемо, так как полный список атрибутов очень велик, а мы перечислили лишь основные.
Какова продолжительность жизни SSD-диска?
SSD — накопители более надежны, чем жесткие диски, и должны служить до 20 лет, по крайней мере, не беря во внимание ухудшение производительности.
И это то, что мы могли бы назвать усредненным показателем. Вы можете придумать срок жизни SSD в худших случаях, если хотите. Но я могу вас заверить, что они выглядят не слишком оптимистично!
Давайте же максимизируем срок службы нашего SSD путем выравнивания износа и сводя к минимуму все эти маленькие циклы записи, используя простые и передовые технологии…
Убедитесь, что функция TRIM включена
Во-первых, нет смысла проверять и пытаться включить TRIM, если ваш ssd диск не поддерживает эту технологию. Как узнать, поддерживает ли ваш SSD-диск функцию TRIM? Самый простой способ — получить эту информацию через программку CrystalDiskInfo.
В поле Supported Features можно видеть, поддерживает ли SSD TRIM:
Следующий шаг — проверить, знакома ли ваша операционная система с функцией TRIM. В ОС Windows 7 вы можете разузнать это с помощью команды fsutil behavior query disabledeletenotify. Если результат равен нулю, операционная система использует TRIM.
В случае, если система не признает ваш диск как SSD, вы должны обнаружить и устранить неисправности. Руководствуйтесь информацией, содержащейся в диспетчере устройств и свойствах SSD. Возможно, вам нужно обновить драйверы вашего дискового контроллера для того, чтобы операционная система воспринимала накопитель как SSD.
Отключение дефрагментации
Дефрагментация предназначена для увеличения скорости доступа к данным путем уменьшения количества перемещений механической головки, расположенной внутри HDD. Но, как известно, у ССД нет движущихся частей и данная функция ему попросту не нужна. Более того, она в какой-то степени является вредной для данных видов устройств, так как фактически осуществляется перезапись данных, ввиду чего увеличивается количество проработанных циклов.
Поэтому, для увеличения срока службы SSD желательно отключить дефрагментацию.
Сделать это можно следующим путем:
- Нажимаем «Win+R» и вводим «dfrgui».
- Или же щелкаем по необходимому тому для вызова контекстного меню и открываем «Свойства».
Переходим «Сервис – Оптимизировать». В Windows 7 последний пункт будет называться «Выполнить дефрагментацию».
В следующем окне нажимаем «Изменить параметры» или «Настроить расписание».
Находим нужный раздел и убираем галочку напротив него.
Таким образом, вы сможете быстро выключить дефрагментацию и тем самым продлить жизнь SSD диску, установленному на вашем ПК.
Отключаем файл подкачки SSD
Файл подкачки (своп) необходим для улучшения быстродействия операционной системы в ресурсоемких приложениях (графические пакеты, редакторы видео, игры). Кроме того, если запущено много «тяжелых» программ и оперативная память не справляется с объемом данных, незадействованные приложения временно хранятся в свопе.
Оптимальный размер файла подкачки примерно равен 3/2 размера ОЗУ. Если у вас более 8 Гб ОЗУ, на SSD файл подкачки не нужен. Попробуйте отключить его и протестировать компьютер некоторое время. Вряд ли вы заметите какие-либо проблемы с производительностью.
Узнать объем оперативной памяти компьютера и отключить его на SSD можно в окне «Свойств системы» (Win+Pause Break).
- Откройте диалог «Быстродействие» (Мой компьютер ->Свойства системы ->Параметры быстродействия (см. предыдущую тему)).
- Во вкладке «Дополнительно» нажмите кнопку «Изменить».
- В окне виртуальная память напротив названия системного диска показан размер файла подкачки. Выбираем SSD-диск — устанавливаем опцию «Без файла подкачки» — кнопка «Задать» для применения изменений.
Спящий режим (гибернация)
Еще одна особенность, которая может вызвать проблемы — спящий режим компьютера (гибернация). Если вам действительно не нужна эта функция, рассмотрите возможность сна или выключение, потому что при гибернации ОС пишет свою память в файл гибернации, причем каждый раз, когда компьютер входит в спящий режим. Если вы решите не использовать спящий режим, отключить его можно командой
powercfg /hibernate off
выполнив ее от имени администратора. Это позволит отключить опцию спящего режима и удалить файл гибернации. Переместить файл спящего режима невозможно.
Отключение защиты
Некоторые источники говорят о том, что для продления срока службы SSD необходимо деактивировать защиту системы, однако этого не рекомендуется делать ни в коем случае. Это крайне полезная штука, которая при необходимости поможет вам восстановить ОС Windows всего за пару минут. Например, точки восстановления создаются перед установкой утилит или проведением обновлений.
Но если вы решите пренебречь своей безопасностью и деактивировать защиту, то сделать это можно следующим образом:
- Жмем правой кнопкой на «Мой Компьютер» и выбираем «Свойства».
- Переходим в «Защита системы».
После этого перезагрузите ПК.
Индексирование поиска
Большинство людей считают, что индексатор поиска необходим, так как он значительно ускоряет поиск данных на жестком диске.
Если у вас в наличии только SSD, можете спокойно отключить Индексатор поиска. Если у вас есть SSD и HDD, вы должны переместить кэш индексатора поиска на ваш жесткий диск. Это позволит избежать множества записей на диск всякий раз, когда файл сохраняется в кэше поиска.
Другой способ разобраться с индексатором — сократить места индексации до минимума, если вы точно знаете, что искать там ничего не будете.
Отключение индексации
Индексация нужна для максимального быстрого поиска файлов на ПК. Но часто ли вы пользуетесь поиском чего-либо на компьютере? Более того, прирост в быстродействии составляет не больше 10%, при этом операции чтения совершаются постоянно, что уж точно вам не нужно.
Учитывайте тот факт, что у вас и так твердотельный носитель и эти 10 процентов никак не повлияют на работу, и вы даже не заметите явных изменений.
Поэтому эту функцию можно смело отключить:
- Нажимаем на том правой кнопкой для вызова контекстного меню и заходим в «Свойства».
- Убираем галочку с пункта на разрешение индексации.
После этого индексация будет выключена.
Временные файлы, кэш и журналы
На вашем компьютере хранится гигантское количество временных файлов, кэш и журналы. Это приводит к большому количеству избыточных записей на SSD! Это зависит от того, какой браузер и другое программное обеспечение вы используете.
Например Google Earth хранит кэш образов мест, которые вы посетили, поэтому всякий раз, когда вы используете Google Earth, производится запись изображений на SSD. Давайте посмотрим в следующих главах, как найти «виновников» и в дальнейшем использовать точки соединения, когда мы не можем переместить или отключить их.
Как почистить кэш?
Формула расчета
Чтобы точно узнать, сколько живет SSD диск, необходимо воспользоваться специальной формулой расчета. Мы сделаем это на примере твердотельного накопителя с памятью типа MLC, так как именно она чаще всего используется в этих носителях. Согласно технической документации, среднее число циклов перезаписи равняется 3 000.
Если взять устройство объемом 120 Гб и в качестве среднесуточного объема записываемых данных 15 Гб, то благодаря использованию соответствующей формулы у нас получается 3000х120/15 = 24000 дней или 65 лет.
Это число теоретического характера, тем более что на практике объем записываемой информации увеличивается в 10 раз, и предварительная оценка получается 6.5 года. Но это не значит, что спустя это время накопитель придет в негодность, и не будет работать. Это зависит от интенсивности его использования, ввиду чего производители ССД в графе срока службы пишут объем записываемой информации.
Также для расчетов можно использовать специальные программы, об одной из которых мы расскажем далее.
Монитор ресурсов Windows
Давайте взглянем на встроенный монитор ресурсов в новых версиях Windows:
- Введите ‘Monitor’ Resource в стартовом меню и запустите его (или команда resmon.exe через Пуск — Выполнить).
- Перейдите во вкладку «Диск».
- Отсортируйте Столбик ‘Процессы с дисковой активностью’ на ‘Запись (байт/с)’. Это позволит вам оценить объем записей на диск в вашей системе.
Если вы хотите получить больше данных, понадобится утилита Process Monitor.
Утилита Process Monitor
Скачаем программку Process Monitor от Microsoft Sysinternals и настроим фильтр на записи:
- и запустите утилиту.
- Нажмите на кнопку «‘Reset’ для сброса фильтра.
- Установите фильтр ‘Operation contains WRITE then Include’, затем нажмите кнопку «Add».
- Затем нажмите кнопку «Применить», а затем нажмите кнопку «OK».
- Дополнительно можно отфильтровать список по вашему SSD диску.
Теперь вы будете видеть происходящие операции записи в реальном времени. Также можно выбрать отдельный элемент и узнать подробную информацию о записи. В меню «Tools» есть «File Summary», эта команда позволяет ознакомиться со всем набором записей в разных вкладках.
Что лучше всего скопировать на SSD?
Вы должны поместить на SSD файлы, которым действительно требуются быстрая производительность. В основном это актуально для программ и игр. Размещение видеофайлов на SSD не даст заметного ускорения по сравнению с жестким диском. Это же относится к различным документам.
Изображения, фото будут загружаться быстрее в таких программах и пакетах, как Adobe Lightroom. Музыка будут проанализирована быстрее в DJ программах вроде Traktor Studio. Впрочем, текущие размеры SSD не совсем вписываются в эти задачи, так что облом.
Тем не менее, фотографии и музыка — хороший пример данных. Если вы сохраняете их единожды и не планируете редактировать, смело перемещайте эти данные на SSD.
Источник
Каждому устройству, использующему флэш-память NAND, необходим код с исправлением случайных битов (известный как «мягкая» ошибка). Это потому что много электрический шум производится внутри чипа NAND, а уровни сигналов битов, проходящих через цепочку чипов NAND, очень слабые.

Один из способов, которым NAND память стали самый дешевый всего, потому что это требует, чтобы исправление ошибок было выполнено от элемента вне самого чипа NAND; В случае SSD, ECC выполняется на контроллере .
Такое же исправление ошибок также помогает исправить битовые ошибки из-за носить на Память сами клетки , Истощение может вызвать «застревание» битов в том или ином состоянии (известное как «жесткая» ошибка или жесткая ошибка) и может увеличить частоту «мягких» ошибок.
Хотя это понятие не является слишком широким, сопротивление флэш-памяти является мерой того, сколько циклов стирания / записи может выдержать блок флэш-памяти, прежде чем начнут появляться «серьезные» ошибки. Очень часто эти сбои происходят только в отдельных битах, и очень редко происходит сбой всего блока. При достаточно высоком числе стирания / записи «мягкая» частота ошибок также увеличивается из-за ряда других механизмов в самом SSD.
If ECC может быть используемый чтобы исправить эти «жесткие» ошибки, а «мягкие» ошибки не увеличиваются, срок службы всего блока значительно удлиняется, что значительно превышает сопротивление, указанное производителем.
Давайте рассмотрим пример: допустим, что неиспользуемый чип NAND имеет достаточно «мягких» ошибок, чтобы требовать 8 бит ECC, то есть при каждом считывании страницы может быть до 8 бит, которые были случайно повреждены (обычно из-за электрических помех, которые мы говорили о). вначале). ECC, используемый в этом чипе, может исправлять 12-битные ошибки, так что ECC не может решить эту проблему мы должны найти 8 «мягких» ошибок, связанных с электрическим шумом, плюс еще 5 «мягких» из-за износа.
Теперь производители флэш-памяти гарантируют, что первый из этих 5 сбоев произойдет через некоторое время после спецификации прочности SSD. Это означает, что ни один бит не выйдет из строя из-за износа, пока не будут превышены циклы стирания / записи, указанные производителем. Теперь имейте в виду, что спецификации не достаточно точны, чтобы предсказать, когда следующий бит выйдет из строя, и на самом деле это может занять несколько тысяч циклов стирания / записи выше спецификации, чтобы это произошло; помните, что производитель гарантирует, что это не произойдет до X циклов, но не тогда, когда это произойдет после их превышения.

Это означает, что это может занять много времени, прежде чем блок становится настолько коррумпированным что его необходимо удалить из службы (а также для этого на SSD обычно есть «дополнительные» блоки для замены поврежденных), что, в свою очередь, означает, что сопротивление исправлен от ошибок блок может быть во много раз больше указанного сопротивления, в зависимости от количества избыточных ошибок, которые ECC предназначен для исправления.
Какое влияние оказывает код исправления ошибок на SSD?
Как мы объясняли ранее, флэш-память настолько дешева, потому что она не включает в себя ECC в самих чипах, но интегрирована в другое внешнее оборудование, и, как вы предположите, это имеет свою цену. Более сложный ECC требует большей вычислительной мощности на контроллере и может быть медленнее, если алгоритмы не очень современные. Кроме того, количество ошибок, которые могут быть исправлены, будет зависеть от того, насколько большой сектор памяти исправляется, поэтому контроллер SSD со сложным алгоритмом ECC, вероятно, будет использовать много ресурсов, снижение общий SSD производительность , Эти улучшения также делают контроллер дороже .

Алгоритмы ECC имеют свое собственное математическое состояние в зависимости от контроллера (другими словами, нет никакого стандарта), и даже самые базовые кодировки ECC (Рида-Соломона и LDPC) довольно сложны для понимания. Когда кто-то говорит о пределе Шеннона (максимальное количество битов, которое может быть исправлено), это величина, которую, как вы не знаете от производителя в технических характеристиках, чрезвычайно сложно вычислить.
Просто придерживайтесь этого: большее количество корректирующих битов увеличивает срок службы SSD, но также оказывает некоторое влияние на производительность или даже цену продукта, так как требует более мощный контроллер.
25.08.2012, 03:11. Показов 586781. Ответов 2

В первую очередь хочу сказать спасибо Charles Kludge и nonym4uk за помощь в написании этой статьи.
Итак, S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology — технология самоконтроля, анализа и отчётности) — технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя.
Много пользователей знает что такое S.M.A.R.T., немного меньше даже знают как его получить… Но когда встает вопрос проанализировать полученную таблицу, обычно дело стопорится. В этой статье я приведу основные значения и их расшифровку
Для любознательных
SMART производит наблюдение за основными характеристиками накопителя, каждая из которых получает оценку. Характеристики можно разбить на две группы:
параметры, отражающие процесс естественного старения жёсткого диска (число оборотов шпинделя, число премещений головок, количество циклов включения-выключения);
текущие параметры накопителя (высота головок над поверхностью диска, число переназначенных секторов, время поиска дорожки и количество ошибок поиска).
Данные хранятся в шестнадцатеричном виде, называемом «raw value», а потом пересчитываются в «value» — значение, символизирующее надёжность относительно некоторого эталонного значения. Обычно «value» располагается в диапазоне от 0 до 100 (некоторые атрибуты имеют значения от 0 до 200 и от 0 до 253).
Высокая оценка говорит об отсутствии изменений данного параметра или медленном его ухудшении. Низкая говорит о возможном скором сбое.
Значение, меньшее, чем минимальное, при котором производителем гарантируется безотказная работа накопителя, означает выход узла из строя.
Технология SMART позволяет осуществлять:
мониторинг параметров состояния;
сканирование поверхности;
сканирование поверхности с автоматической заменой сомнительных секторов на надёжные.
Следует заметить, что технология SMART позволяет предсказывать выход устройства из строя в результате механических неисправностей, что составляет около 60 % причин, по которым винчестеры выходят из строя.
Предсказать последствия скачка напряжения или повреждения накопителя в результате удара SMART не способна.
Следует отметить, что накопители НЕ МОГУТ сами сообщать о своём состоянии посредством технологии SMART, для этого существуют специальные программы.
Любая программа, показывающая S.M.A.R.T. для каждого атрибута имеет несколько значений, разберемся сначала с ними — ID, Value, Worst, Threshold и RAW. Итак:
ID (Number) — собственно, сам индикатор атрибута. Номера стандартны для значений атрибутов, но например,из-за кривизны перевода один и тот же атрибут может называться по-разному, проще орентироваться по ID, логично?
Value
(Current) — текущее значение атрибута в условных единицах, никому наверное неведомых . В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в уе. В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
Threshold — значение в (сюрприз!!!) уе, которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не уе, а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Теперь перейдем непосредственно к самим атрибутам.
01 (01) Raw Read Error Rate — Частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска. Для всех дисков Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5″ это — число внутренних коррекций данных, проведенных до выдачи в интерфейс, следовательно, на пугающе огромные цифры можно реагировать спокойно.
02 (02) Throughput Performance — Общая производительность диска. Если значение атрибута уменьшается, то велика вероятность, что с диском есть проблемы.
03 (03) Spin-Up Time — Время раскрутки пакета дисков из состояния покоя до рабочей скорости. Растет при износе механики (повышенное трение в подшипнике и т. п.), также может свидетельствовать о некачественном питании (например, просадке напряжения при старте диска).
04 (04) Start/Stop Count — Полное число циклов запуск-остановка шпинделя. У дисков некоторых производителей (например, Seagate) — счётчик включения режима энергосбережения. В поле raw value хранится общее количество запусков/остановок диска.
05 (05) Reallocated Sectors Count — Число операций переназначения секторов. Когда диск обнаруживает ошибку чтения/записи, он помечает сектор «переназначенным» и переносит данные в специально отведённую резервную область. Вот почему на современных жёстких дисках нельзя увидеть bad-блоки — все они спрятаны в переназначенных секторах. Этот процесс называют remapping, а переназначенный сектор — remap. Чем больше значение, тем хуже состояние поверхности дисков. Поле raw value содержит общее количество переназначенных секторов. Рост значения этого атрибута может свидетельствовать об ухудшении состояния поверхности блинов диска.
06 (06) Read Channel Margin — Запас канала чтения. Назначение этого атрибута не документировано. В современных накопителях не используется.
07 (07) Seek Error Rate — Частота ошибок при позиционировании блока магнитных головок. Чем их больше, тем хуже состояние механики и/или поверхности жёсткого диска. Также на значение параметра может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине).
08 (08) Seek Time Performance — Средняя производительность операции позиционирования магнитными головками. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
09 (09) Power-On Hours (POH) — Число часов (минут, секунд — в зависимости от производителя), проведённых во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF — mean time between failure).
10 (0А) Spin-Up Retry Count — Число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность неполадок с механической частью.
11 (0В) Recalibration Retries — Количество повторов запросов рекалибровки в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью.
12 (0С) Device Power Cycle Count — Количество полных циклов включения-выключения диска.
13 (0D) Soft Read Error Rate — Число ошибок при чтении, по вине программного обеспечения, которые не поддались исправлению. Все ошибки имеют
не механическую
природу и указывают лишь на неправильную размётку/взаимодействие с диском программ или операционной системы.
100(64) Erase/Program Cycles (для SSD) Общее количество циклов стирания/программирования для всей флэш-памяти за всё время ее существования. Твердотельный накопитель имеет ограничение на количество записей в него. Точные значения (ресурс) зависят от установленных микросхем флэш-памяти.
В накопителях Kingston — объём стёртого в гигабайтах.
103(67) Translation Table Rebuild (для SSD) Количество событий, когда внутренние таблицы адресов блоков были повреждены и впоследствии восстановлены. Raw-значение этого атрибута указывает фактическое количество событий.
170(AA) Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Иногда raw-значение содержит фактическое количество использованных резервных блоков.
170 атрибут связан с атрибутом 5, числом использованных резервных блоков.
171(AB) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов. Процесс записи технически называется «программирование флэш-памяти» — отсюда и название атрибута. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
Значение обычно идентично атрибуту 181.
172(AC) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов. Полный цикл записи флэш-памяти состоит из двух этапов. Сначала необходимо удалить память, а затем данные должны быть записаны («запрограммированы») в память. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
Идентичен атрибуту 182.
173(AD) Wear Leveller Worst Case Erase Count (для SSD) Максимальное количество операций стирания, выполняемых для одного блока флэш-памяти.
174(AE) Unexpected Power Loss (для SSD) Число неожиданных отключений питания, когда питание было потеряно до получения команды на отключение диска. На жестком диске срок службы при таких отключениях намного меньше, чем при обычном отключении. На SSD существует риск потери внутренней таблицы состояний при неожиданном завершении работы.
175(AF) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов. Процесс записи технически называется «программирование флэш-памяти», отсюда и название атрибута. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
176(B0) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов. Полный цикл записи флэш-памяти состоит из двух этапов. Сначала необходимо удалить память, а затем данные должны быть записаны («запрограммированы») в память. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
177(B1) Wear Leveling Count (для SSD)
Wear Range Delta В зависимости от производителя, максимальное количество операций стирания, выполняемых для одного блока флэш-памяти[источник не указан 269 дней] или разница между максималоьно изношенными (больше всего раз записанными) и минимально изношенными (записанными наименьшее число раз) блоками[4].
178(B2) Used Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество использованных резервных блоков.
179(B3) Used Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество использованных резервных блоков.
180(B4) Unused Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество неиспользованных резервных блоков.
181(B5) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов.
182(B6) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов.
183(B7) SATA Downshifts (для SSD) Указывает, как часто требовалось снизить скорость передачи данных SATA (с 6 Гбит/с до 3 или 1,5 Гбит/с или с 3 Гбит/с до 1,5 Гбит/с) для успешной передачи данных. Если значение атрибута уменьшается, попробуйте заменить кабель SATA.
Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1.5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута (Western Digital und Samsung).
184 (B8) End-to-End error — Назначение зависит от производителя.
У HP (часть технологии HP SMART IV) увеличивается в случае, когда после передачи данных через кэш-память чётность данных между хостом и жёстким диском не совпадает.
У Kinston это количество ошибок чтения из флэш-памяти.
185 (B9) Head Stability Стабильность головок (Western Digital).
187 (BB) Reported UNC Errors — Количество ошибок, которое накопитель сообщил хосту (интерфейсу компьютера) при любых операциях, обычно это ошибки данных на диске, которые не исправлены средствами ECC
188 (BC) Command Timeout — содержит количество операций, выполнение которых было отменено из–за превышения максимально допустимого времени ожидания отклика.Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т.д., несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате и т.д. Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
189 (BD) High Fly Writes — содержит количество зафиксированных случаев записи при высоте «полета» головки выше рассчитанной, скорее всего, из-за внешних воздействий, например, вибрации.
Для того, чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию
190 (BE) Airflow Temperature (WDC) — Температура воздуха внутри корпуса жёсткого диска. Для дисков Seagate рассчитывается по формуле (100 — HDA temperature). Для дисков
Western Digital
— (125 — HDA).
191 (BF) G-sense error rate — Количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который
фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера.
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т.к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухой.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно, если его не закрепить. Основное назначение датчика – прекратить операцию записи при вибрациях, чтобы избежать ошибок.
75
Why exactly is a «Raw Read Error Rate» of 1 considered bad? Isn’t it the lower the read error rate, the better the reads (and the less the errors)?
Your research has found that this Raw Read Error Rate is derived from the «total number of correctable and uncorrectable ECC error events». The number is normalized and treated as a percentage, so the current value represents 1%, i.e. 1% of read operations have had an issue.
Modern NAND chips explicitly mandate ECC capability because occasional bit errors on read can occur during normal operation. The requirement will specify a permissible number of bits that might be in error per NAND page read, and need correction.
In other words a read operation may occasionally incur correctable errors, and therefore this is not an indicator of pending failure.
The occurrence of uncorrectable read errors could be problematic. In theory a sector/page/block that (consistently) generates uncorrectable read errors should be identified by the integrated drive controller, marked as a bad block, and retired from use.
The Raw Read Error Rate is not as significant as the number of uncorrectable read errors (which is now available in the SMART report that you appended).
The number of uncorrectable read errors seems to be indicated in Reported Uncorrectable Errors as 0x1B3 or 435.
Compared to the total read errors of 0x1C9 or 457, that would indicate that there were only 22 (benign) correctable read errors (assuming no wrap-around), but 95% of that total are the concerning uncorrectable read errors.
Does this mean my SSD is about to fail imminently? It has been working fine since I bought my laptop years ago…
If you think that the drive is «working fine», then that could mean that the drive was able to recover from those errors by retrying successfully and/or remapping was successful. (Note that the SMART report indicates that 9 blocks have been retired so far during this drive’s lifetime.)
At the very least you could backup your data from that drive, and regularity monitor the SMART report for changes.
With almost 20,000 hours of use, there’s no way to determine when these errors occurred.
But you could try to generate fresh read errors by scanning the entire drive, either using the SMART long/extended test or using a Linux command such as sudo dd if=/dev/sdX of=/dev/null. The first test is a lot faster but would only increment the SMART statistics, whereas the later test could also abort on a read error and thus provide a LBA of a problem area.
If you do not encounter more read errors, then that could be reassuring.
Note that the SMART report indicates the current value of 98% for Percent Lifetime Used indicates that only 2% of the expected lifetime has been used. The raw value of 2 indicates that neither of the two salient end-of-life indicators (average block wear and available spare blocks) are problematic.
Why exactly is a «Raw Read Error Rate» of 1 considered bad? Isn’t it the lower the read error rate, the better the reads (and the less the errors)?
Your research has found that this Raw Read Error Rate is derived from the «total number of correctable and uncorrectable ECC error events». The number is normalized and treated as a percentage, so the current value represents 1%, i.e. 1% of read operations have had an issue.
Modern NAND chips explicitly mandate ECC capability because occasional bit errors on read can occur during normal operation. The requirement will specify a permissible number of bits that might be in error per NAND page read, and need correction.
In other words a read operation may occasionally incur correctable errors, and therefore this is not an indicator of pending failure.
The occurrence of uncorrectable read errors could be problematic. In theory a sector/page/block that (consistently) generates uncorrectable read errors should be identified by the integrated drive controller, marked as a bad block, and retired from use.
The Raw Read Error Rate is not as significant as the number of uncorrectable read errors (which is now available in the SMART report that you appended).
The number of uncorrectable read errors seems to be indicated in Reported Uncorrectable Errors as 0x1B3 or 435.
Compared to the total read errors of 0x1C9 or 457, that would indicate that there were only 22 (benign) correctable read errors (assuming no wrap-around), but 95% of that total are the concerning uncorrectable read errors.
Does this mean my SSD is about to fail imminently? It has been working fine since I bought my laptop years ago…
If you think that the drive is «working fine», then that could mean that the drive was able to recover from those errors by retrying successfully and/or remapping was successful. (Note that the SMART report indicates that 9 blocks have been retired so far during this drive’s lifetime.)
At the very least you could backup your data from that drive, and regularity monitor the SMART report for changes.
With almost 20,000 hours of use, there’s no way to determine when these errors occurred.
But you could try to generate fresh read errors by scanning the entire drive, either using the SMART long/extended test or using a Linux command such as sudo dd if=/dev/sdX of=/dev/null. The first test is a lot faster but would only increment the SMART statistics, whereas the later test could also abort on a read error and thus provide a LBA of a problem area.
If you do not encounter more read errors, then that could be reassuring.
Note that the SMART report indicates the current value of 98% for Percent Lifetime Used indicates that only 2% of the expected lifetime has been used. The raw value of 2 indicates that neither of the two salient end-of-life indicators (average block wear and available spare blocks) are problematic.
Технология S.M.A.R.T. позволяет считывать сохраняемые в служебной области жесткого диска сведения, необходимые для оценки его состояния. Расшифровка термина такова: Self – сам, Monitoring – контроль, Analysis – анализ, Reporting Technology – технология отчетов. Как и для чего использовать S.M.A.R.T., детально рассмотрено в данной статье. Проверить звук микрофона онлайн.

Содержание
- Для чего нужна эта технология
- Программы для просмотра S.M.A.R.T.
- CrystalDiskInfo
- AIDA64
- Victoria
- HDDScan
- Speccy
- Сложности при сканировании
- Значение атрибутов S.M.A.R.T.
- 01 Raw Read Error Rate
- 02 Throughput Performance
- 03 Spin-Up Time
- 04 Number of Spin-Up Times (Start/Stop Count)
- 05 Reallocated Sector Count
- 07 Seek Error Rate
- 08 Seek Time Performance
- 09 Power On Hours Count (Power-on Time)
- 10 (0A) Spin Retry Count
- 11 (0B) Calibration Retry Count (Recalibration Retries)
- 12 (0C) Power Cycle Count
- 183 (B7) SATA Downshift Error Count
- 184 (B8) End-to-End Error
- 187 (BB) Reported Uncorrected Sector Count (UNC Error)
- 188 (BC) Command Timeout
- 189 (BD) High Fly Writes
- 190 (BE) Airflow Temperature
- 191 (BF) G-Sensor Shock Count (Mechanical Shock)
- 192 (C0) Power Off Retract Count (Emergency Retry Count)
- 193 (C1) Load/Unload Cycle Count
- 194 (C2) Temperature (HDA Temperature, HDD Temperature)
- 195 (C3) Hardware ECC Recovered
- 196 (C4) Reallocated Event Count
- 197 (C5) Current Pending Sector Count
- 198 (C6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
- 199 (C7) UltraDMA CRC Error Count
- 200 (C8) Write Error Rate (MultiZone Error Rate)
- 201 (C9) Soft Read Error Rate
- 202 (CA) Data Address Mark Error
- 203 (CB) Run Out Cancel
- 220 (DC) Disk Shift
- 240 (F0) Head Flying Hours
- 254 (FE) Free Fall Event Count
- Предсказание поломки диска в командной строке
- Определение статуса диска
- Прогнозируемый сбой
- Предсказание в Windows PowerShell
- Анализ в приложении Системный монитор
- Что делать с ошибками S.M.A.R.T.
- Прекратите использование сбойного HDD
- Восстановите удаленные данные диска
- Просканируйте диск на наличие битых секторов
- Снизьте температуру диска
- Произведите дефрагментацию жесткого диска
- Приобретите новый жесткий диск
- Как сбросить S.M.A.R.T ошибку и стоит ли это делать?
Для чего нужна эта технология
Все современные жесткие диски оснащены S.M.A.R.T.-блоком, ответственным за отслеживание и сохранение информации об их основных параметрах: нагревание винчестера в процессе работы, скорость вращения, время позиционирования магнитных головок, предназначенных для записи и считывания данных. Также отслеживаются сбои, возникающие при эксплуатации накопителя. Инструкция как сделать тест веб камеры.
В случае обнаружения на дисковой поверхности битых секторов производится их замещение резервными блоками. Использование данной технологии позволяет своевременно предвидеть выход из строя винчестера и заранее позаботиться об его замене на исправное дисковое устройство. Пользователь может, не дожидаясь окончательной поломки жесткого диска, создать резервную копию всех хранящихся на нем файлов. В таком случае потери информации можно больше не опасаться.
Программы для просмотра S.M.A.R.T.
Ряд производителей HDD выпускают также утилиты собственной разработки, предназначенные для получения информации от S.M.A.R.T. Они максимально адаптированы для работы с носителями определенных моделей. Но такой софт разработан не для всех винчестеров, да и его возможностей иногда оказывается недостаточно для всесторонней оценки состояния накопителя.
В качестве альтернативы можно использовать один из многочисленных программных продуктов, созданных сторонними разработчиками. Далее мы рассмотрим несколько хорошо зарекомендовавших себя приложений, предоставляющих доступ к S.M.A.R.T.
CrystalDiskInfo

CrystalDiskInfo – бесплатное приложение для просмотра параметров S.M.A.R.T. и оценки тенденции их изменений. Интерфейс утилиты полностью русифицирован (язык можно переключить с помощью меню). Температура винчестера или твердотельного накопителя показывается в системном трее (внизу экрана справа). Программа позволяет построить график, на котором будут наглядно отображены изменения, произошедшие за последний месяц с носителем информации. В случае необходимости приложение может быть запущено с задержкой. С помощью CrystalDiskInfo пользователю удобно изменить режим работы жесткого диска: установить максимально возможную скорость либо включить режим экономии электроэнергии (при этом также уменьшится издаваемый HDD шум). Помимо этого, разработчиками реализована поддержка внешних HDD и карманов, а также RAID-массивов Intel.
AIDA64

С помощью данного приложения можно получить информацию обо всех аппаратных компонентах системы и их технических характеристиках, а также выполнить их тестирование. Для просмотра информации о жестком диске следует перейти к разделу «Меню» в левой части окна и щелчком по треугольнику слева открыть подменю «Хранение данных». В его нижней части присутствует пункт «SMART», именно его и нужно выбрать. В правой секции окна вверху появится список всех установленных в системе жестких дисков. Остается выбрать только нужный накопитель и щелкнуть мышью по соответствующей строке. Сведения о выбранном диске будут отображены в секции ниже.
AIDA64 – условно-бесплатное приложение, период безвозмездного пользования которым ограничен 30 днями. Чтобы иметь возможность работать с ним и дальше, необходимо купить лицензию.
Victoria

Victoria – одна из лучших утилит для диагностики и восстановления неисправностей жестких дисков. Существует 2 версии программы: для запуска с загрузочного носителя и для работы непосредственно в среде Windows. В последнем случае для корректной работы приложения его следует запускать от имени администратора (соответствующую команду можно выбрать из его контекстного меню посредством щелчка по значку правой кнопкой мыши). Для загрузки с внешнего носителя потребуется предварительно создать загрузочный USB-диск или CD (DVD) и записать на него образ приложения.
После того, как Victoria запустится, на вкладке «Standard» в правой половине окна вверху выбираем тестируемый HDD и жмем на кнопку «Passport» для обновления сведений о нем. В самом низу окна отобразится информация о модели винчестера, его вместимости в дорожках и серийном номере. Затем можно переходить на вкладку “SMART”. Для считывания данных нажимаем на кнопку «Get SMART» в правой секции окна вверху.
При всех своих прочих достоинствах программа бесплатна. Также следует отметить, что ее новейшие версии поддерживают работу со S.M.A.R.T.-данными SSD-накопителей.
HDDScan
Отличительной особенностью утилиты является предельная простота в использовании. Достаточно выбрать из списка «Select Drive» жесткий диск и нажать на кнопку «S.M.A.R.T.», как на экране появится новое окно с подобной информацией о жестком диске. Разработчиками предусмотрена возможность менять некоторые из этих параметров (AAM, APM и др.). И за все это платить ничего не надо.
Speccy

С помощью бесплатного приложения Speccy с поддержкой русского языка можно получить сведения об установленных в компьютере комплектующих и их технических характеристиках. Предусмотрена возможность сохранения этой информации в виде подробного отчета.
Из меню в левой части экрана выбираем «Хранение данных», и в правой части окна приложения появятся сведения сразу обо всех установленных на машине пользователя жестких дисках. Если информация сразу не будет выведена на экран, надо подождать несколько секунд до завершения ее считывания.
Сложности при сканировании
Как правило, при проверке жестких дисков никаких проблем не возникают. Сканирование невозможно только для старых моделей винчестеров, не поддерживающих S.M.A.R.T.-технологию, или самотестирование которых отключено. Но тут уж ничего не поделать.
Определенные проблемы возникнут и в случае подключения винчестера в AHCI-режиме, поскольку данные S.M.A.R.T. в такой ситуации прочесть нельзя. Об этом выводится соответствующее сообщение на экран (например, может отображаться надпись «Non ATA». Чтобы обойти данное ограничение, необходимо загрузить BIOS и перейти на вкладку «Config > Serial ATA (SATA) > SATA Controller Mode Option». Вместо AHCI нужно выбрать Compatibility и сохранить изменения. Когда тестирование закончено, следует вернуться к прежней настройке.
Значение атрибутов S.M.A.R.T.
Для каждого из атрибутов программа тестирования отобразит следующие сведения (в зависимости от приложения они могут несколько отличаться от приведенного здесь списка):
- наименование;
- номер;
- пороговое значение;
- текущее значение;
- графический индикатор состояния на момент тестирования;
- динамика зарегистрированных изменений;
- приблизительная дата окончательной поломки накопителя.
Здесь следует обратить внимание на цвета индикаторов атрибутов. Зеленый цвет говорит о том, что соответствующий ему показатель в норме. Если же какие-то атрибуты попали в желтую зону, ситуацию следует расценивать как тревожную. В случае же окраски индикатора в красный цвет состояние винчестера критическое, и полностью сломаться он может в любой момент.
Рассмотрим каждый из S.M.A.R.T.-атрибутов жесткого диска.
01 Raw Read Error Rate
Этот показатель используется для определения числа ошибок, возникающих при считывании данных с винчестера. Его значения могут интерпретироваться по-разному в зависимости от модели устройства. Для одних производителей идеалом считается нулевое значение, для других же – чем больше, тем лучше.
02 Throughput Performance
Отображает среднее значение производительности накопителя. Строгих норм для него не существует. Для диагностики HDD практически бесполезен.
03 Spin-Up Time
Позволяет установить время, необходимое винчестеру для раскрутки. Сам по себе данный параметр мало что значит. Его следует оценивать только с учетом заявленных технических характеристик конкретного жесткого диска.
04 Number of Spin-Up Times (Start/Stop Count)
Показывает, сколько раз производилось включение жесткого диска за весь период его эксплуатации. Может использоваться для получения косвенной оценки длительности и интенсивности использования устройства.
05 Reallocated Sector Count
Один из важнейших атрибутов, позволяющий определить физическое состояние винчестера. Показывает количество сбойных секторов, замененных на исправные из резервной области. Такая замена называется ремапом. Ремап производится автоматически в случае, если чтение информации с какого-либо участка диска сильно затруднено или невозможно. При этом поврежденный сектор помечается как неисправный, чтобы операционная система больше не пыталась его использовать.
Надо понимать, что резервная область не безгранична, и когда возможности резервирования будут исчерпаны, начнется необратимое разрушение жесткого диска. Число резервных секторов у разных моделей винчестеров различно. Но максимальное их количество не превышает нескольких тысяч (чаще всего не больше тысячи).
07 Seek Error Rate
Отображает данные, с помощью которых можно определить частоту появления сбоев в ходе позиционирования блока магнитных головок. Во многом схож с атрибутом Raw Read Error Rate. Отличие состоит в том, что для дисков Hitachi нормальным считается только нулевое значение. На дисках Seagate, Samsung SpinPoint F1 и более новых его моделей, а также Fujitsu 2.5’’ этот показатель вообще не стоит учитывать.
08 Seek Time Performance
Показывает среднее значение производительности операций позиционирования дисковых головок. Никаких предельных значений для него не предусмотрено.
09 Power On Hours Count (Power-on Time)
С помощью этого параметра мы можем узнать, сколько часов отработал жесткий диск с начала его использования.
10 (0A) Spin Retry Count
Позволяет определить, сколько раз производились повторные запуски шпинделя с момента первой неудачной попытки его старта. Однако рост данного показателя не всегда означает физическую неисправность винчестера. В большинстве случаев проблема связана с плохим контактом HDD с блоком питания или недостаточным количеством получаемой устройством электроэнергии. Если значение атрибута не превышает 2, то все в порядке. В противном случае следует проверить блок питания и его контакт с жестким диском.
11 (0B) Calibration Retry Count (Recalibration Retries)
Здесь отображается число повторных попыток произвести сброс носителя информации (в результате такой процедуры магнитные головки устанавливаются на нулевую дорожку) после того, как была зарегистрирована первая неудачная попытка. Если значение атрибута нулевое, проблемы отсутствуют, если нет – устройство, скорее всего, неисправно.
12 (0C) Power Cycle Count
Отмечается общее число циклов «включение-отключение» винчестера.
183 (B7) SATA Downshift Error Count
В этом параметре хранится информация о том, сколько попыток понижения режима SATA завершилось неудачей. Дело в том, что при выявлении определенных ошибок HDD может попытаться переключиться на работу в режиме с меньшей скоростью. Такое переключение завершится неудачей, если контроллер по каким-либо причинам откажется выполнять поступившую команду. Но в любом случае к здоровью накопителя это отношения не имеет.
184 (B8) End-to-End Error
Дает возможность оценить, сколько всего ошибок возникло в процессе передачи информации через кэш жесткого диска за все время его использования. О проблеме с устройством может свидетельствовать любое ненулевое значение.
187 (BB) Reported Uncorrected Sector Count (UNC Error)
Означает число секторов, которые в скором времени подлежат переназначению. Иногда сектор повторно может определяться как кандидат на переназначение, что также приводит к увеличению значения атрибута. Если в этой строке не ноль (особенно когда атрибут 197 тоже не равен нулю), с винчестером начали происходить деструктивные изменения.
188 (BC) Command Timeout
Сохраняет данные о том, сколько операций пришлось прервать в связи с превышением предельно допустимого периода ожидания. Любое значение больше нуля свидетельствует о наличии таких сбоев. Но не всегда это связано с неисправностью жесткого диска. Проблема может возникнуть также при использовании некачественных кабелей, плохих переходников, поврежденных контактов, несовместимости с контроллером SATA/PATA на системной плате. В Windows такая ошибка может проявляться появлением «синего экрана смерти».
189 (BD) High Fly Writes
Показывает, сколько было зарегистрировано процессов записи на носитель, когда скорость головки превышала рассчитанную величину. Основной причиной этого явления является внешнее влияние (толчки, удары, вибрация). Однако каких-либо стандартов по данному пункту нет.
190 (BE) Airflow Temperature
Выводит на экран температуру жесткого диска в момент тестирования. Нагревание выше +55 – +60ºC негативно отражается на работе устройства. В таком случае полезно будет установить дополнительное охлаждение.
191 (BF) G-Sensor Shock Count (Mechanical Shock)
По этому параметру можно определить число критических ускорений головки HDD. Причинами их появления могут стать падания накопителя либо удары по его корпусу. Но даже если такие ускорения были зарегистрированы датчиками устройства, это еще не значит, что он был поврежден. Состояние HDD нужно оценивать с учетом значений других атрибутов. Также следует отметить, что у жестких дисков Samsung данный параметр можно не смотреть, поскольку его датчики могут реагировать едва ли не на движение воздуха.
192 (C0) Power Off Retract Count (Emergency Retry Count)
Отображаемая в соответствующей строке информация зависит от модели устройства. Здесь может выводиться или общее количество операций парковок магнитных головок, производящихся при появлении аварийных ситуаций, или число циклов включения/выключения устройства за все время его работы.
193 (C1) Load/Unload Cycle Count
Показывает суммарное количество циклов парковки и распарковки магнитных головок накопителя. С помощью этого параметра мы можем узнать, активирована ли автоматическая парковка HDD. Если значение атрибута 192 превышает значение атрибута 09, это означает, что автоматическая парковка включена и используется.
194 (C2) Temperature (HDA Temperature, HDD Temperature)
Выводит температуру винчестера в момент считывания информации из S.M.A.R.T. Также может содержать сведения о минимальной и максимальной температурах устройства, зарегистрированных за период его эксплуатации. Нужно убедиться, что жесткий диск не перегревается (предельно допустимая температура составляет +55ºC).
195 (C3) Hardware ECC Recovered
Позволяет определить общее количество ошибок, обработанных аппаратными средствами ECC HDD. Является аналогом атрибутов 01 и 07.
196 (C4) Reallocated Event Count
Один из наиболее значимых атрибутов для определения реального состояния винчестера. Чем выше его значение, тем хуже обстоят дела. Но для того, чтобы дать объективную оценку состояния устройства, следует учитывать значения и остальных параметров.
Данный показатель находится в тесной связи с атрибутом 05. Если один из них начал ухудшаться, негативные перемены обычно начинают происходить и с другим. Если же перемены затрагивают только атрибут 196, это означает, что в ходе выполнения ремапа оказалось, что проблемы с сектором обусловлены нарушением логической структуры, а не физической неисправностью, и были устранены средствами жесткого диска.
Иногда возникает ситуация, когда значение атрибута 05 больше аналогичного показателя у атрибута 196. В таком случае был выполнен ремап нескольких секторов одновременно.
197 (C5) Current Pending Sector Count
Выводит информацию о количестве секторов, подлежащих перераспределению. Но не всегда они имеют физическую неисправность. Перераспределяются только кандидаты, получившие статус bad, а сектора со статусом soft (логическая ошибка) после их исправления снова становятся пригодными для использования.
198 (C6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
Во многом схож с атрибутом 197. Основное отличие заключается в том, что атрибут 198 показывает зафиксированное число кандидатов на ремап, выявленных в процессе оффлайн-тестирования (оно запускается во время простоя).
199 (C7) UltraDMA CRC Error Count
Этот показатель позволяет определить, сколько ошибок произошло в ходе выполнения операций передачи информации по интерфейсному кабелю, осуществляемых в режиме UltraDMA. Если наблюдается тенденция к росту параметра, это может свидетельствовать о некачественном или поврежденном шлейфе передачи данных, работе шин PCI/PCI-E в режиме разгона или плохом подключении кабеля SATA к соответствующему разъему на материнской плате или винчестере.
При появлении таких ошибок HDD может быть автоматически переключен в режим PIO, следствием чего станет ощутимое снижение его производительности. В большинстве случаев проблема решается переподключением интерфейсного кабеля или заменой его на новый.
200 (C8) Write Error Rate (MultiZone Error Rate)
Данный параметр отвечает за количество ошибок, зарегистрированных при выполнении записи на информационный носитель. Если их число неуклонно возрастает, жесткий диск уже нельзя считать надежным устройствам. В первую очередь это относится к накопителям WD. Для них высокие значения атрибута 200 могут означать скорый выход из строя пишущей головки.
201 (C9) Soft Read Error Rate
Показывает, сколько ошибок возникает в ходе считывания информации.
202 (CA) Data Address Mark Error
Высокие значения этого показателя свидетельствуют о проблемах, возникающих при работе винчестера.
203 (CB) Run Out Cancel
Здесь фиксируется количество ошибок ECC.
220 (DC) Disk Shift
Позволяет узнать значение сдвига пластин по отношению к оси шпинделя накопителя.
240 (F0) Head Flying Hours
Атрибут можно использовать для оценки времени, которое требуется для позиционирования головки. Позволяет отслеживать состояние блока магнитных головок.
254 (FE) Free Fall Event Count
Регистрирует факты падения жесткого диска и предоставляет возможность определить их количество. Если здесь не нулевое значение, это повод для беспокойства, поскольку в таком случае нельзя исключать физическое повреждение HDD.
Предсказание поломки диска в командной строке
Проверить винчестер на наличие неисправностей с использованием командной строки можно двумя способами. Это определение статуса диска и получение информации о его прогнозируемом сбое.
Определение статуса диска
Для того, чтобы проверить S.M.A.R.T. жесткого диска с помощью командной строки, следует придерживаться такой последовательности действий:
- Запустить системное приложение «Командная строка» с административными правами. Найти ярлык командной строки можно в меню «Пуск». Для того, выполнить запуск приложения с привилегированными правами доступа в Windows 10, нужно кликнуть по его ярлыку правой кнопкой мыши, перейти в меню «Дополнительно» и активировать команду «Запуск от имени администратора».
- После того, как окно консоли появится на экране, ввести в него команду wmic diskdrive get status.
- Подтвердить выполнение команды нажатием клавиши «Enter».
- Подождать пару секунд окончания выполнения команды. Результаты проверки отобразятся в столбце «Status». Если с установленными в компьютере дисками все нормально, везде будет стоять «OK». При выявлении ошибок статус может иметь значения «bad», «unknown» или «caution».
Прогнозируемый сбой
Чтобы заранее предсказать вероятную поломку винчестера, пользователю следует придерживаться такого алгоритма:
- Выполнить запуск командной строки в режиме администратора (как это делается, описано в предыдущем разделе).
- Ввести в консоль команду wmic /namespace:\rootwmi path MSStorageDriver_FailurePredictStatus.
- Подтвердить выполнение операции нажатием на «Enter».
- Дождаться вывода результата на экран. Нужная нам информация будет находиться в столбце «PredictFailure». Если результат тестирования – «FALSE», накопитель функционирует нормально. Значение «TRUE» свидетельствует о серьезных проблемах с HDD, в такой ситуации можно ожидать его скорую поломку. Также следует обратить внимание на столбец «Reason», особенно если в нем отображается число больше нуля. Значение выводимого здесь числового кода у разных производителей винчестеров может расшифровываться по-разному.
Предсказание в Windows PowerShell
Windows PowerShell – встроенный расширяемый инструмент автоматизации, предоставляемый компанией «Microsoft». Чтобы предсказать с его помощью возможные неполадки, нужно выполнить следующие шаги:
- Произвести запуск приложения «Windows PowerShell». В Windows 10 проще всего это сделать с помощью меню «Опытного пользователя». Процедура запуска такова: после щелчка правой кнопкой мыши по кнопке «Пуск» откройте это самое меню и выберите в нем команду «Windows PowerShell (администратор)».
- Введите в консоль команду Get-WmiObject -namespace rootwmi –class SStorageDriver_FailurePredictStatus.
- Нажмите «Enter».
- После того, как команда будет выполнена, на экране отобразится отчет в виде таблицы. В ней будет присутствовать информация обо всех установленных в компьютере дисках. Нас прежде всего интересует значение строки «PredictFailure». Если здесь стоит «FALSE», за судьбу жесткого диска можно пока не переживать. «TRUE» свидетельствует о серьезных проблемах с устройством и предсказывает ему скорую утрату работоспособности. О неисправностях может говорить и ненулевое значение строки «Reason» (что означает то или иное число, можно уточнить, обратившись в службу поддержки производителя HDD).
Анализ в приложении Системный монитор
В отличие от рассмотренных ранее предустановленных в систему приложений, «Системный монитор» работает не в консольном, а в графическом режиме. Для оценки состояния винчестера пользователю потребуется:
- Запустить программу «Системный монитор». Для этого нужно щелкнуть на кнопку «Пуск и открыть панель поиска, в которую ввести запрос «Системный монитор». Искомое приложение будет показано в разделе «Лучшее соответствие». Останется только произвести по нему щелчок левой кнопкой мыши.
- В левой секции появившегося окна щелчком по стрелке слева открыть раздел группы «Сборщиков данных». Ниже будут показаны вложенные в него элементы.
- Открыть подраздел «Системные».
- Перейти на вкладку «System Diagnostics (Диагностика системы)». Вызвать ее контекстное меню щелчком правой кнопки мыши. Выбрать в нем строку «Пуск».
- Еще раз развернуть вложенные элементы и открыть раздел «Отчеты».
- Найти подраздел «Системные» и раскрыть его.
- Развернуть содержимое подраздела «System Diagnostics» и изучить его содержимое.
- Кликнуть мышью по диагностическому отчету, наименование которого соответствует кодовому имени компьютера.
- Через некоторое время детальный отчет будет выведен в правой части окна. В нем следует открыть раздел «Предупреждения», а затем в таблице «Базовые системные проверки» в графе «Тесты» щелкнуть по кнопке с плюсом (она располагается около пункта «Проверка диска»).
- Ознакомиться с содержанием строки «Проверка SMART – предсказания сбоя». Если в колонке «Отказ» стоит нулевое значение, а в колонке «Описание» отображается надпись «Выполнена», то проблем с жестким диском не выявлено.
Что делать с ошибками S.M.A.R.T.
Ответ на этот вопрос зависит от характера проблем с винчестером и степени его неисправности.
Прекратите использование сбойного HDD
Если на жестком диске уже появились битые сектора, это говорит о его значительном износе. Фактически он уже начал рассыпаться, и остановить этот процесс невозможно. Дальнейшее использование такого HDD чревато потерей данных. Поскольку причина этого – физическая неисправность устройства, восстановить их скорее всего не получится.
Восстановите удаленные данные диска
Информация с носителя может исчезать и вследствие логических ошибок (они могут возникать при повреждении файловой системы. В таком случае пропавшие в результате сбоя данные подлежат восстановлению (если они не были перезаписаны другими данными), поскольку физические повреждения на жестком диске отсутствуют. Их можно восстановить, например, с помощью программы R-Studio, которая позволяет спасти информацию даже с удаленных или отформатированных разделов.
Просканируйте диск на наличие битых секторов
Проверить HDD на битые сектора можно с помощью стандартных средств Windows. Для этого необходимо перейти к нужному диску (или разделу), вызвать его контекстное меню и открыть пункт «Свойства». Затем на вкладке «Сервис» кликнуть по кнопке «Выполнить проверку» и в открывшемся окне поставить галочки «Автоматически исправлять системные ошибки» и «Проверять и восстанавливать поврежденные сектора». Возможно, потребуется перезагрузка компьютера после нажатия кнопки «Запуск». Проверка очень объемных винчестеров может длиться до нескольких часов. После завершения процедуры логические ошибки будут исправлены, а bad-сектора подвергнуты ремапу (если их резерв еще не исчерпан).

Сканирование может быть выполнено и рядом сторонних приложений. Для этого отлично подходит программа Victoria. Чтобы полностью проверить весь винчестер на битые сектора, следует на вкладке «Standard» выбрать HDD, а затем перейти на вкладку «Tests» и нажать там кнопку «Start». Количество найденных сбойных секторов будет отображаться в процессе сканирования справа от синего прямоугольника, обозначенного «Err». Цифры рядом с красным и оранжевым прямоугольниками – это еще рабочие сектора, но скорость доступа к ним очень низкая (небольшое их количество может находиться даже на новом винчестере). Полная проверка может продолжаться несколько часов.
Снизьте температуру диска
Перегрев жесткого диска может оказывать негативное влияние на работу его механических компонентов и электроники. Поэтому при подъеме его температуры до 55ºC и выше ему требуется дополнительное охлаждение. Для снижения температуры устройства можно установить в корпус компьютера еще один вентилятор. Также существуют специальные вентиляторы, предназначенные для охлаждения винчестеров. Наконец, температуру накопителя можно немного понизить, если отключить установленные в корпус ПК устройства, выделяющие тепло, без которых можно некоторое время обойтись (например, второй HDD или видеокарта в случае наличия в системной плате интегрированной видеокарты).
Произведите дефрагментацию жесткого диска
Замедление скорости чтения и записи на диск зачастую обусловлено высокой степенью фрагментации хранящихся на нем файлов. Сильная фрагментация файловой системы может способствовать ускоренному износу блока магнитных головок. Это приведет к дополнительным проблемам, связанным с ухудшением показателей их позиционирования, а также с ростом температуры накопителя (поскольку файлы разбиваются на фрагменты, зачастую расположенные друг от друга на значительном удалении, магнитным головкам приходится выполнять дополнительные перемещения, что увеличивает выделение тепла).
SSD-диски дефрагментировать не нужно, т.к. в них нет движущихся пластин и головок, в отличии от HDD.
Для предотвращения этих проблем следует выполнить дефрагментацию диска. Для этого нужно зайти в его свойства (путем вызова контекстного меню), перейти на вкладку «Сервис» и нажать на кнопку «Оптимизировать» (в Windows 10). Затем установить курсор на нужный диск или раздел и уже в этом окне кликнуть по кнопке «Оптимизировать». Обычно процедура оптимизации продолжается несколько минут.
Приобретите новый жесткий диск
Если количество сбойных секторов превышает резерв для их переназначения, приближается к этому показателю или неуклонно возрастает, следует позаботиться о покупке нового винчестера. После покупки надо как можно быстрее установить на него операционную систему и скопировать всю информацию, пока ее считывание еще возможно.
Как сбросить S.M.A.R.T ошибку и стоит ли это делать?
Информацию, записанную в S.M.A.R.T. HDD, в принципе можно удалить. После того, как все данные о накопителе будут сброшены, его S.M.A.R.T. станет выглядеть как у совершенно нового диска, котором еще не начали пользоваться. Конечно же, физические проблемы от этого никуда не исчезнут. Но такой возможностью иногда полезно воспользоваться (и не только недобросовестным продавцам бывших в употреблении винчестеров), если, например, сектора, обозначенные как кандидаты на ремап, оказались физически исправными, а такой статус они получили в результате логических проблем с файловой системой.
Данную операцию можно выполнить при помощи специальных приложений. Одной из таких программ является DRevitalize (с некоторыми моделями винчестеров она не работает). После запуска этой утилиты следует выбрать подлежащий обнулению HDD и нажать на кнопку «Start». Далее выбираем пункт «Features menu and firmware data», после чего жмем по строке «Clear defect reassign list» и подтверждаем выполнение операции. Через несколько секунд можно будет перейти на «SMART Reset Attribute Values» и нажать «ОК». Если после проведения этих манипуляций обновление S.M.A.R.T. не произойдет, следует выполнить перезапуск компьютера.