Could anybody tell me how could I compute Equal Error Rate(EER) from ROC Curve in python? In scikit-learn there is method to compute roc curve and auc but could not find the method to compute EER.
from sklearn.metrics import roc_curve, auc
ANSRWER:
I think I implemented myself.
The idea of ROC EER is the intersection point between a stright line joining
(1,0) and (0,1) and the roc Curve. It is a only point where it intersects. For a straight line with a=1 and b=1, the equation would be x+y =1 (x/a +y/b =1.0) . So the intersection point would be the values of true positive rate (tpr) and false positive rate (fpr) which statisfies the following equation:
x + y - 1.0 = 0.0
Thus implemented the method as:
def compute_roc_EER(fpr, tpr):
roc_EER = []
cords = zip(fpr, tpr)
for item in cords:
item_fpr, item_tpr = item
if item_tpr + item_fpr == 1.0:
roc_EER.append((item_fpr, item_tpr))
assert(len(roc_EER) == 1.0)
return np.array(roc_EER)
So here one value is error rate and another value is accuracy.
May be somebody could help me to verify.
asked Feb 5, 2015 at 8:55
![]()
thetnathetna
6,78525 gold badges78 silver badges113 bronze badges
1
For any one else whom arrives here via a Google search. The Fran answer is incorrect as Gerhard points out. The correct code would be:
import numpy as np
from sklearn.metrics import roc_curve
fpr, tpr, threshold = roc_curve(y, y_pred, pos_label=1)
fnr = 1 - tpr
eer_threshold = threshold[np.nanargmin(np.absolute((fnr - fpr)))]
Note that this gets you the threshold at which the EER occurs not, the EER. The EER is defined as FPR = 1 — PTR = FNR. Thus to get the EER (the actual error rate) you could use the following:
EER = fpr[np.nanargmin(np.absolute((fnr - fpr)))]
as a sanity check the value should be close to
EER = fnr[np.nanargmin(np.absolute((fnr - fpr)))]
since this is an approximation.
![]()
ketza
1171 silver badge12 bronze badges
answered Sep 3, 2017 at 19:08
![]()
James S.James S.
1,10110 silver badges8 bronze badges
1
Copying form How to compute Equal Error Rate (EER) on ROC by Changjiang:
from scipy.optimize import brentq
from scipy.interpolate import interp1d
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y, y_score, pos_label=1)
eer = brentq(lambda x : 1. - x - interp1d(fpr, tpr)(x), 0., 1.)
thresh = interp1d(fpr, thresholds)(eer)
That gave me correct EER value. Also remember that in the documentation it’s written that y is True binary labels in range {0, 1} or {-1, 1}. If labels are not binary, pos_label should be explicitly given and y_score is Target scores, can either be probability estimates of the positive class, confidence values, or non-thresholded measure of decisions (as returned by “decision_function” on some classifiers).
answered Mar 29, 2018 at 11:45
![]()
ColonderColonder
1,5162 gold badges19 silver badges39 bronze badges
Equal error rate (EER) is where your false pos rate (fpr) == false neg rate (fnr) [smaller is better]
using fpr, tpr and thresholds your are getting from roc sklearn computation, you can use this function to get EER:
def compute_eer(fpr,tpr,thresholds):
""" Returns equal error rate (EER) and the corresponding threshold. """
fnr = 1-tpr
abs_diffs = np.abs(fpr - fnr)
min_index = np.argmin(abs_diffs)
eer = np.mean((fpr[min_index], fnr[min_index]))
return eer, thresholds[min_index]
answered Aug 15, 2019 at 16:55
![]()
Ehab AlBadawyEhab AlBadawy
2,7954 gold badges19 silver badges31 bronze badges
The EER is defined as FPR = 1 — PTR = FNR.
This is wrong.
Since FPR= 1-TNR (True Negative Rate) and therefore, not equal to FNR.
answered Jan 9, 2018 at 12:44
![]()
To estimate the Equal Error Rate EER you look for the point within the ROC that makes the TPR value equal to FPR value, that is, TPR-FPR=0. In other words you look for the minimum point of abs(TPR-FPR)
- First of all you need to estimate the
ROCcurve:
fpr, tpr, threshold = roc_curve(y, y_pred, pos_label=1)
- To compute the
EERin python you need only one line of code:
EER = threshold(np.argmin(abs(tpr-fpr)))
![]()
David
1,1474 gold badges21 silver badges29 bronze badges
answered Mar 13, 2017 at 10:23
![]()
FranFran
362 bronze badges
1
The EER refers to that point in a DET (Detection Error Tradeoff) curve where the FAR (False Acceptance rate) equals the FRR (False Rejection Rate).
From: Advances in Ubiquitous Computing, 2020
Replay attack detection using excitation source and system features
Madhusudan Singh, Debadatta Pati, in Advances in Ubiquitous Computing, 2020
2.4.3.1 Equal error rate and detection error tradeoff
The SV performance is generally shown by a detection error tradeoff (DET) curve and measured in terms of EER, where the false rejection rate (FRR) and false acceptance rate (FAR) are equal [49]. In false rejection, a genuine is classified as an impostor while in false acceptance, an impostor is accepted as a genuine speaker. Under a replay spoofing scenario, the replay attackers usually aim at specified (target) speakers and thereby increase the FAR of the system. Thus, under replay attacks, the FAR is a more relevant measuring parameter for evaluating the system performance. Accordingly, we have used two metrics to evaluate the system performance under both the baseline and spoofing test conditions: zero-effort false acceptance rate (ZFAR) and replay attack false acceptance rate (RFAR). ZFAR and RFAR are related to zero-effort impostor trials and replay trials, respectively.
The baseline ZFAR or equivalently the EER performance is computed by pooling all genuine and zero-effort impostor trials together. The RFAR performance is computed using the replay trials only, under replay attacks. The computation of RFAR is based on the fixed decision threshold (at EER point) of the baseline system, as shown in Fig. 2.5. As the same baseline ASV system is used for both ZFAR and RFAR computation, the difference RFAR-ZFAR directly indicates system vulnerability to replay attacks [3]. In a positive sense, it represents ASV systems’ capability to resist spoof attacks. A smaller value of RFAR-ZFAR indicates better replay detection accuracy. For a foolproof spoof-resistant (RFAR = 0) ASV system, the RFAR-ZFAR will approach to (-ZFAR). Moreover, since the same ASV system is used for both baseline and spoofing tests, the scores and decisions for all genuine trials will remain unaffected. Consequently, the FRR will remain constant, under both test conditions. Altogether, ZFAR, RFAR, and their difference RFAR-ZFAR can be used as evaluation metrics to compare the different ASV systems’ performance under a replay spoofing scenario.

Fig. 2.5. Synthetic example showing computation of ZFAR and RFAR using a decision threshold fixed at EER point (P) of the baseline system.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128168011000025
The use of WSN (wireless sensor network) in the surveillance of endangered bird species
Amira Boulmaiz, … Djemil Messadeg, in Advances in Ubiquitous Computing, 2020
9.9.2.1 Segmentation and recognition performance
To examine the performance and efficiency of the proposed segmentation method, namely TRD, we took the sound of the Ferruginous Duck with a duration just over 6 s with a sampling rate of 44.1 kHz, which gives a total number of samples of 265,250. Its time domain and spectrogram graphs are shown in Fig. 9.17A. By adding an environment noise, which leads to a SNR = 10 dB, we can get the time domain and spectrogram graphs of noisy sound shown in Fig. 9.17B. Fig. 9.17C represents the time domain graph and spectrogram of the noisy bird sound after applying the proposed tonal region detector (TRD). The samples are reducing from 265,250 down to 44,109, which represent approximately one-quarter of the total number of samples.

Fig. 9.17. The time domain graph of selected Ferruginous Duck sound in the left and his spectrogram in the right (A) in clean condition, (B) perturbed by environment noise at SNR = 10 dB, and (C) after applying the tonal region detector (TRD).
The recognition performance for different front-end/normalization setups found per each feature extraction strategy (GTECC, MFCC, PMVDR, PNCC, and MWSCC) is given in Fig. 9.18. The results are reported in terms of EER (equal error rates). The EER refers to that point in a DET (Detection Error Tradeoff) curve where the FAR (False Acceptance rate) equals the FRR (False Rejection Rate). A perfect scoring model would yield an EER of zero, so a lower EER value indicates a better performance.

Fig. 9.18. Performance comparison of alternative popular features considered in this study against GTECC in terms of EERs (%) for different values of SNR: (A) SNR = 50 dB, (B) SNR varies from 30 to 0 dB, (C) SNR varies from 0 to − 10 dB, and (D) the average values.
The training sounds data were corrupted by an additive white Gaussian noise (AWGN) with a SNR equal to 50 dB. However, the testing data were corrupted by an AWGN with a SNR that varies from − 10 to 30 dB in 5-dB steps, in order to simulate the real-world complex noisy environments. From Fig. 9.18, we can see that the proposed GTECC front-end is almost in all cases (whether in clean or noisy conditions) the most efficient in terms of EER, with or without application of a method of normalization. Moreover, GTECC postprocessed by Quantile-based cepstral dynamics normalization (GTECC-QCN) gives an average EER equal to 10.18%, which is the lowest EER compared to the other studied methods, followed by MWSCC-QCN with an average EER of 11.61% and PNCC-QCN with an average EER equal to 12.87%, then MFCC-QCN with an average EER equal to 13.78%, then PMCC-QCN with an average EER equal to 14.11%, and finally PMVDR-QCN with an average EER equal to 14.91%.
Let us consider now the performance of normalization methods used in our study for the reduction of noise in the detected segments as tonal regions in the sound of a bird. From Fig. 9.18, we can observe that spectral subtraction (SS) is less effective for reducing white Gaussian noise, especially with a SNR < 0 dB. Normalizations CMVN and CGN have relatively similar results on the Gaussian white noise with a significantly superior performance of the normalization CGN, when applied to PMVDR, in the presence of AWGN with a SNR between 0 and − 10 dB. Finally, QCN has the best performance when applied to the six methods of characterization studied namely GTECC, MFCC, PMVDR, PMCC, PNCC, and MWSCC.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128168011000098
Generative adversarial network for video anomaly detection
Thittaporn Ganokratanaa, Supavadee Aramvith, in Generative Adversarial Networks for Image-to-Image Translation, 2021
16.4.4 Performance of DSTN
We evaluate the proposed DSTN regarding accuracy and time complexity aspects. The ROC curve is used to illustrate the performance of anomaly detection at the frame level and the pixel level and analyze the experimental results with other state-of-the-art works. Additionally, the AUC and the EER are evaluated as the criteria for determining the results.
The performance of DSTN is first evaluated on the UCSD dataset, consisting of 10 and 12 videos for the UCSD Ped1 and the UCSD Ped2 with the pixel-level ground truth, by using both frame-level and pixel-level protocols. In the first stage of DSTN, patch extraction is implemented to provide the appearance features of the foreground object and its motion regarding the vector changes in each patch. The patches are extracted independently from each original image with a size of 238 × 158 pixels (UCSD Ped1) and 360 × 240 pixels (UCSD Ped2) to apply it with (w/4) × h × cp. As a result, we obtain 22 k patches from the UCSD Ped1 and 13.6 k patches from the UCSD Ped2. Then, to feed into the spatiotemporal translation model, we resize all patches to the 256 × 256 default size in both training and testing time.
During training, the input of G (the concatenation of f and fBR patches) and target data (the generated dense optical flow OFgen) are set to the same size as the default resolution of 256 × 256 pixels. The encoding and decoding modules in G are implemented differently. As in the encoder network, the image resolution is encoded from 256 → 128 → 64 → 32 → 16 → 8 → 4 → 2 → 1 to obtain the latent space representing the spatial image in one-dimensional data space. CNN effectively employs this downscale with kernels of 3 × 3 and stride s = 2. Additionally, the number of neurons corresponding to the image resolution in En is introduced in each layer from 6 → 64 → 128 → 256 → 512 → 512 → 512 → 512 → 512. In contrast, De decodes the latent space to reach the target data (the temporal representation of OFgen) with a size of 256 × 256 pixels using the same structure as En. The dropout is employed in De as noise z to remove the neuron connections using probability p = 0.5, resulting in the prevention of overfitting on the training samples. Since D needs to fluctuate G to correct the classification between real and fake images at training time, PatchGAN is then applied by inputting a patch size of 64 × 64 pixels to output the probability of class label for the object. The PatchGAN architecture is constructed from 64 → 32 → 16 → 8 → 4 → 2 → 1, which is then flattened to 512 neurons and plugged in with Fully Connection (FC) and Softmax layers. The use of PatchGAN benefits the model in terms of time complexity. This is probably because there are fewer parameters to learn on the partial image, making the model less complex and can achieve good running time for the training process. In the aspect of testing, G is specifically employed to reconstruct OFgen in order to analyze the real motion information OFfus. The image resolution for testing and training are set to the same resolution for all datasets.
The quantitative performance of DSTN is presented in Table 16.1 where we consider the DSTN with various state-of-the-art works, e.g., AMDN [15], GMM-FCN [12], Convolutional AE [14], and future frame prediction [21]. From Table 16.1 it can be observed that the DSTN overcomes most of the methods in both frame-level and pixel-level criteria since we achieve higher AUC and lower EER on the UCSD Dataset. Moreover, we show the qualitative performance of DSTN using the standard evaluation for anomaly detection research known as the ROC curves, where we vary a threshold from 0 to 1 to plot the curve of TPR against FPR. The qualitative performance of DSTN is compared with other approaches in both frame-level evaluation (see Fig. 16.20A) and pixel-level evaluation (see Fig. 16.20B) on the UCSD Ped1 and at the frame-level evaluation on the UCSD Ped2 as presented in Figs. 16.20 and 16.21, respectively. Following Figs. 16.20 and 16.21, the DSTN (circle) shows the strongest growth curve on TPR and overcomes all the competing methods in the frame and pixel level. This means that the DSTN is a reliable and effective method to be able to detect and localize the anomalies with high precision.
Table 16.1. EER and AUC comparison of DSTN with other methods on UCSD Dataset [26].
| Method | Ped1 (frame level) | Ped1 (pixel level) | Ped2 (frame level) | Ped2 (pixel level) | ||||
|---|---|---|---|---|---|---|---|---|
| EER | AUC | EER | AUC | EER | AUC | EER | AUC | |
| MPPCA | 40% | 59.0% | 81% | 20.5% | 30% | 69.3% | – | – |
| Social Force (SF) | 31% | 67.5% | 79% | 19.7% | 42% | 55.6% | 80% | – |
| SF + MPPCA | 32% | 68.8% | 71% | 21.3% | 36% | 61.3% | 72% | – |
| Sparse Reconstruction | 19% | – | 54% | 45.3% | – | – | – | – |
| MDT | 25% | 81.8% | 58% | 44.1% | 25% | 82.9% | 54% | – |
| Detection at 150fps | 15% | 91.8% | 43% | 63.8% | – | – | – | – |
| SR + VAE | 16% | 90.2% | 41.6% | 64.1% | 18% | 89.1% | – | – |
| AMDN (double fusion) | 16% | 92.1% | 40.1% | 67.2% | 17% | 90.8% | – | – |
| GMM | 15.1% | 92.5% | 35.1% | 69.9% | – | – | – | – |
| Plug-and-Play CNN | 8% | 95.7% | 40.8% | 64.5% | 18% | 88.4% | – | – |
| GANs | 8% | 97.4% | 35% | 70.3% | 14% | 93.5% | – | – |
| GMM-FCN | 11.3% | 94.9% | 36.3% | 71.4% | 12.6% | 92.2% | 19.2% | 78.2% |
| Convolutional AE | 27.9% | 81% | – | – | 21.7% | 90% | – | – |
| Liu et al. | 23.5% | 83.1% | – | 33.4% | 12% | 95.4% | – | 40.6% |
| Adversarial discriminator | 7% | 96.8% | 34% | 70.8% | 11% | 95.5% | – | – |
| AnomalyNet | 25.2% | 83.5% | – | 45.2% | 10.3% | 94.9% | – | 52.8% |
| DSTN (proposed method) | 5.2% | 98.5% | 27.3% | 77.4% | 9.4% | 95.5% | 21.8% | 83.1% |


Fig. 16.20. ROC Comparison of DSTN with other methods on UCSD Ped1 dataset: (A) frame-level evaluation and (B) pixel-level evaluation [26].

Fig. 16.21. ROC Comparison of DSTN with other methods on UCSD Ped2 dataset at frame-level evaluation [26].
Examples of the experimental results of DSTN on the UCSD Ped 1 and Ped 2 dataset are illustrated in Fig. 16.22 to extensively present its performance in detecting and localizing anomalies in the scene. According to Fig. 16.22, the proposed DSTN is able to detect and locate various types of abnormalities effectively with each object, e.g., (a) a wheelchair, (b) a vehicle, (c) a skateboard, and (d) a bicycle, or even more than one anomaly in the same scene, e.g., (e) bicycles, (f) a vehicle and a bicycle, and (g) a bicycle and a skateboard. However, we face the false positive problems in Fig. 16.22H a bicycle and a skateboard, where the walking person (normal event) is detected as an anomaly. Even the bicycle and the skateboard are correctly detected as anomalies in Fig. 16.22H, the false detection on the walking person makes this frame wrong anyway. The false positive anomaly detection is probably caused by a similar speed of walking to cycling in the scene.


Fig. 16.22. Examples of DSTN performance in detecting on localizing anomalies on UCSD Ped1 and Ped2 dataset: (A) a wheelchair, (B) a vehicle, (C) a skateboard, (D) a bicycle, (E) bicycles, (F) a vehicle and a bicycle, (G) a bicycle and a skateboard, and (H) a bicycle and a skateboard [26].
For the UMN dataset, the performance of DSTN is evaluated using the same settings as training parameters and network configuration on the UCSD pedestrian dataset. Table 16.2 indicates the AUC performance comparison of the DSTN with various competing works such as GANs [20], adversarial discriminator [22], AnomalyNet [23], and so on. Table 16.2 shows that the proposed DSTN achieves the best AUC results the same as Ref. [23], which outperforms all other methods. Noticeably, most of the competing methods can achieve high AUC on the UMN dataset. This is because the UMN dataset has less complexity regarding its abnormal patterns than the UCSD pedestrian and the Avenue datasets. Fig. 16.23 shows the performance of DSTN in detecting and localizing anomalies in different scenarios on the UMN dataset, including (d) an indoor and outdoors in (a), (b), and (c), where we can detect most of the individual objects in the crowded scene.
Table 16.2. AUC comparison of DSTN with other methods on UMN dataset [26].
| Method | AUC |
|---|---|
| Optical-flow | 0.84 |
| SFM | 0.96 |
| Sparse reconstruction | 0.976 |
| Commotion | 0.988 |
| Plug-and-play CNN | 0.988 |
| GANs | 0.99 |
| Adversarial discriminator | 0.99 |
| Anomalynet | 0.996 |
| DSTN (proposed method) | 0.996 |

Fig. 16.23. Examples of DSTN performance in detecting on localizing anomalies on UMN dataset, where (A), (B), and (D) contain running activity outdoors while (C) is in an indoor [26].
Apart from evaluating DSTN on the UCSD and the UMN datasets, we also assess our performance on the challenging CUHK Avenue dataset with the same parameter and configuration settings as the UCSD and the UMN datasets. Table 16.3 presents the performance comparison in terms of EER and AUC of the DSTN with other competing works [6, 12, 14, 21, 23] in which the proposed DSTN surpasses all state-of-the-art works for both protocols. We show examples of the DSTN performance in detecting and localizing various types of anomalies, e.g., (a) jumping, (b) throwing papers, (c) falling papers, and (d) grabbing a bag, on the CUHK Avenue dataset in Fig. 16.24 The DSTN can effectively detect and localize anomalies in this dataset, even in Fig. 16.24D, which contains only small movements for abnormal events (only the human head and the fallen bag are slightly moving).
Table 16.3. EER and AUC comparison of DSTN with other methods on CUHK Avenue dataset [26].
| Method | EER | AUC |
|---|---|---|
| Convolutional AE | 25.1% | 70.2% |
| Detection at 150 FPS | – | 80.9% |
| GMM-FCN | 22.7% | 83.4% |
| Liu et al. | – | 85.1% |
| Anomalynet | 22% | 86.1% |
| DSTN (proposed method) | 20.2% | 87.9% |

Fig. 16.24. Examples of DSTN performance in detecting on localizing anomalies on CUHK Avenue dataset: (A) jumping, (B) throwing papers, (C) falling papers, and (D) grabbing a bag [26].
To indicate the significance of our performance for real-time use, we then compare the running time of DSTN during testing in seconds per frame as shown in Table 16.4 with other competing methods [3–6, 15] following the environment and the computational time from Ref. [15].
Table 16.4. Running time comparison on testing measurement (seconds per frame).
| Method | CPU (GHz) | GPU | Memory (GB) | Running time | |||
|---|---|---|---|---|---|---|---|
| Ped1 | Ped2 | UMN | Avenue | ||||
| Sparse Reconstruction | 2.6 | – | 2.0 | 3.8 | – | 0.8 | – |
| Detection at 150 fps | 3.4 | – | 8.0 | 0.007 | – | – | 0.007 |
| MDT | 3.9 | – | 2.0 | 17 | 23 | – | – |
| Li et al. | 2.8 | – | 2.0 | 0.65 | 0.80 | – | – |
| AMDN (double fusion) | 2.1 | Nvidia Quadro K4000 | 32 | 5.2 | – | – | – |
| DSTN (proposed method) | 2.8 | – | 24 | 0.315 | 0.319 | 0.318 | 0.334 |
Regarding Table 16.4, we achieve a lower running time than most of the competing methods except for Ref. [6]. This is because the architecture of DSTN relies on the framework of the deep learning model using multiple layers of the convolutional neural network, which is more complex than Ref. [6] that uses the learning of a sparse dictionary and provides fewer connections. However, according to the experimental results in Tables 16.1 and 16.3, our proposed DSTN significantly provides higher AUC and lower EER with respect to the frame and the pixel level on the CUHK Avenue and the UCSD pedestrian datasets than Ref. [6]. Regarding the running time, the proposed method runs 3.17 fps for the UCSD Ped1 dataset, 3.15 fps for the UCSD Ped2 dataset, 3.15 fps for the UMN dataset, and 3 fps for the CUHK Avenue dataset. In every respect, we provide the performance comparison of the proposed DSTN with other competing works [3–6, 15] to show our performance in regard to the frame-level AUC and the running time in seconds per frame for the UCSD Ped1 and Ped2 dataset as presented in Figs. 16.25 and 16.26, respectively.

Fig. 16.25. Frame-level AUC comparison and running time on UCSD Ped1 dataset.

Fig. 16.26. Frame-level AUC comparison and running time on UCSD Ped2 dataset.
Considering Figs. 16.25 and 16.26, our proposed method achieves the best results regarding the AUC and running time aspects. In this way, we can conclude that our DSTN surpasses other state-of-the-art approaches since we reach the highest AUC values at the frame level anomaly detection and the pixel level localization and given the good computational time for real-world applications.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128235195000117
Cognitive radio evolution
Joseph MitolaIII, in Cognitive Radio Communications and Networks, 2010
20.4.2 Human Language and Machine Translation
Computer processing of human language includes both real-time speech recognition and high-performance text processing as well as machine translation. During the evolution period of Table 20.1, CRs may perceive spoken and written human language (HL) with sufficient reliability to detect, characterize, and respond appropriately to stereotypical situations, unburdening the user from the counterproductive tedium of identifying the situation for the radio. Machine translation in the cell phone may assist global travelers with greetings, hailing a taxi, understanding directions to the restaurant, and the like. Such information prosthetics may augment today’s native language facilities. With ubiquity of coverage behind it, CRA evolves toward more accurately characterizing the user’s information needs, such as via speech recognition and synthesis to interact with wearable wireless medical instruments, opening new dimensions of QoI.
Computer Speech
Computer speech technology offers opportunities for machine perception of content in well-structured audio channels such as 800 directory assistance. Although deployed with all Windows XPTM laptops, speech recognition does not appear to be in wide use for interaction with personal electronics or machine dictation. However, the technology now is mature enough to transcribe carefully spoken speech in benign acoustic environments such as a (quiet) home office, with 3–10% raw word error rates, reduced in structured utterances such as dictation to less than 2%. In situations where the speech is emotional, diffluent, heavily accented, or focused on a rare topic, the word error rates increase to about 25%, but even with these high word error rates topic spotting for geographical topics can yield 14.7% precision, improved by an order of magnitude during the past five years [767].
Speaker identification technology [768] has equal error rates (equal probability of false dismissal and false alarm) of <10% for relatively small collections of speakers (<100). Such algorithms are influenced (usually corrupted) by acoustic backgrounds that distort the speaker models. Speaker recognition may be termed a soft biometric since it could be used to estimate a degree of belief that the current speaker is the usual user of the CR to align user profiles. Such speaker modeling could contribute to multifactor biometrics to deter the theft of personal information from wireless devices.
Text Understanding
Business intelligence markets are deploying text understanding technology that typically focuses on the quantitative assessment of the metrics of text documents, such as to assess and predict the performance of a business organization. Quantitative analysis of databases and spreadsheets often do not clearly establish the causal relationships needed for related business decision making. Causal cues typically are evident in the unstructured text of business documents like customer contact reports, but the extraction of those relationships historically has been excessively labor intensive. Therefore, businesses, law enforcement, and government organizations are employing text analysis to enhance their use of unstructured text for business intelligence [769], with rapidly growing markets. These products mix word sense disambiguation, named entity detection, and sentence structure analysis with business rules for more accurate business metrics than is practicable using purely statistical text mining approaches on relatively small text corpora. Google depends on the laws of very large numbers, but medium to large businesses may generate only hundreds to thousands of customer contact reports in the time interval of interest. For example, IBM’s unstructured information management architecture (UIMA) [770] text analysis analyzes small samples of text in ways potentially relevant to cognitive radio architecture evolution such as product defect detection.
In addition, Google’s recent release of the Android open handset alliance software [771] suggests a mix of statistical machine learning with at least shallow analysis of user input (e.g., for intent in the Android tool box). Google has become a popular benchmark for text processing. For example, a query tool based on ALICE (artificial linguistic Internet computer entity) is reported to improve on Google by 22% (increasing proportion of finding answers from 46% to 68%) in interactive question answering with a small sample of 21 users. Of the half of users expressing a preference, 40% preferred the ALICE-based tool (FAQchat) [772]. The commercial successful text retrieval market led by Google is stimulating research increasingly relevant to cognitive radio architecture evolution. For example, unstructured comments in wireless network service and maintenance records can yield early insight into product and service issues before they become widespread. This can lead to quicker issue resolution and lower aftermarket service and recall costs. Cognitive wireless networks (CWNs) might analyze their own maintenance records to discover operations, administration, and maintenance issues with less human oversight [773], enhancing the cost-effectiveness of cognitive devices and infrastructure compared to conventionally maintained wireless products and networks. This might entail a combination of text processing and functional description languages (FDL) such as the E3 FDL [749, 774].
The global mobility of the foundation era of Table 20.1 spurred the creation of world-phones such as GSM mobile phones that work nearly everywhere. During the evolution era, text analysis, real-time speech translation [775], text translation [776], image translation [777], and automatic identification of objects in images [778] will propel CRA evolution toward the higher layers of the protocol stack, ultimately with the user (from preferences to personal data) as the eighth layer. For example, if a future cognitive PDA knows from its most recent GPS coordinates that it is near the location of a new user’s home address and recognizes light levels consistent indoors as well as a desk and chair, then it could enable Bluetooth to check for a home computer, printer, and other peripherals. Detecting such peripherals, it could ask the user to approve sharing of data with these peripherals so that the PDA could automatically acquire information needed to assist the user, such as the user’s address book. The user could either provide permission or explain, for example, “You are my daughter’s new PDA, so you don’t need my address book. But it is OK to get hers. Her name is Barbara.” Objects prototypical of work and leisure events such as golf clubs could stimulate proactive behavior to tailor the PDA to the user, such as wallpaper of the great Scottish golf courses.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123747150000204
Human Factors
Luis M. Bergasa, … Joshua Puerta, in Intelligent Vehicles, 2018
9.1.5.3 General Observations
We begin by pointing out that one main drawback to perform a fair comparison between results obtained with different methods is the lack of a common database. Results obtained with one database could be biased by data collected and, maybe, the specific characteristics of driver environment. Performance of the algorithms depends also on data collected, CAN bus data are widely recorded, but other acquired signals could lead to achieving the best results, independently of the selected method.
A second observation is that most research papers only show the correct recognition rates to measure the goodness of the algorithm. Correct recognition performance is a vague indicator of algorithm actuation. For example, if our test set is formed by 95% samples which are labeled “normal driving” behavior and 5% samples with “aggressive driving,” a system with a constant output of “normal driving” will achieve 95% correct recognition. Even when this system is impossible to use, performance is in the state-of-the-art rates. More useful indicators to measure the performance of the algorithms are precision and recall. Precision is the fraction of retrieved instances that are relevant, let’s say “how useful the search results are,” while recall is the fraction of relevant instances that are retrieved, in other words, is “how complete the results are.” A single measure that combines both quantities is the traditional F-measure. The use of both indicators, together with F factor is highly recommended and encouraged. Other similar rates that better describe recognition performance are the false acceptance rate and false rejection rates, that can be combined to define Receiver operating characteristic (ROC) or detection error tradeoff (DET) curves. To represent recognition rate with a single quantity obtained from ROC curves, Equal Error Rate (EER) is widely used.
A third observation is that some systems increase the number of parameters when the input vector increases (e.g., adding more signals). In this case, the system may produce undesirable results. Trying to adjust one parameter may lead to an unpredictable result for other input data. Also, having more parameters to adjust requires more data in the training set, just to guarantee that enough samples are provided to the algorithm (and usually, input data are not so easy to obtain). If the training database is small, the algorithm could try to be overfitted to this training set with reduced generalization power.
A fourth observation is that the training set should be rich enough to cover a high spectrum of situations. Training with data obtained in very similar environments and testing with data obtained in other situations may lead to tricky results. Factors that have to be considered in experiment definition should include the number of drivers and experience of these drivers, drivers familiar or not with the scenario or the simulator; drivers with experience in the specific vehicle may obtain better results than novice ones.
A fifth observation is related to information extraction and feature definition. During the experimental phase a usual tradeoff should be achieved between the number of possible input signals and the cost of these signals. Since experimental data recording is expensive (drivers’ recruitment, simulator hours, vehicle consumption), a common criteria is to record “everything.” Once recorded, an initial information extraction procedure is suggested since maybe some variables could be correlated or could be combined without losing generality (but reducing processing time). In this initial procedure it is also advisable to estimate noisy signals that can be filtered or noise reduction procedure for signals that may require it.
A sixth observation is that the precise definition of classes is a complex task. Even simple classes like aggressive, calm, and normal driving have different definitions in research. Calm driving could mean optimal driving (in the sense of fuel consumption for example) or the driving condition that is more repeated or achieved in the training set. As a reference signal or indicator of driving behavior, fuel or energy consumption has been widely adopted. When this is not possible, experts in the field have been considered (e.g., in traffic safety) or the researcher directly evaluates the performance. Experts or external evaluation are preferred to avoid bias based on a priori knowledge of experiments.
A seventh observation notes that the acquisition of labeled data for a supervised driving learning process can be a costly and time-consuming task that requires the training of external evaluators. For naturalistic driving, where the driver voluntarily decides which tasks to perform at all times, the labeling process can become infeasible. However, data without known distraction states (unlabeled data) can be collected in an inexpensive way (e.g., from driver’s naturalistic driving records). In order to make use of these low cost data, semisupervised learning is proposed for model construction, due to its capability of extracting useful information from both labeled and unlabeled training data. Liu et al. (2016) investigate the benefit of semisupervised machine learning where unlabeled training data can be utilized in addition to labeled training data.
The last observation is related to implementation issues. Using onboard embedded hardware in the vehicle or smartphones as a recording and processing platform is now the state-of-the-art technology. They have enough recording space, processing power, and enough sensor devices at a very reasonable cost. They can be placed in any car to obtain naturalistic driving data using huge numbers of drivers and vehicle types. In the next years, new emergent techniques related to big data, deep learning, and data analytics will take advantage of these systems to improve intelligent vehicles’ capabilities.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128128008000096
Biometric Authentication to Access Controlled Areas Through Eye Tracking
Virginio Cantoni, … Haochen Wang, in Human Recognition in Unconstrained Environments, 2017
9.3 Methods Based on Fixation and Scanpath Analysis
The analysis of fixations and scanpaths for biometric purposes dates back to at least ten years ago, with a work in which Silver and Biggs [36] compared keystroke to eye-tracking biometrics. Although they found that models based on keystroke biometric data performed much better than those involving gaze, this work was one of the first to open the door to the use of eye tracking as an alternative identification and verification technique.
Much more recently, Holland and Komogortsev [19] explored the possibility to exploit reading scanpaths for person identification (Fig. 9.2). Their dataset was acquired with a high-frequency eye tracker (1000 Hz) and involved 32 participants. Various eye features were exploited, among which fixation count, average fixation duration, average vectorial saccade amplitude, average horizontal saccade amplitude, and average vertical saccade amplitude. In addition, the aggregated scanpath data were calculated: scanpath length, scanpath area, regions of interest, inflection count, slope coefficients of the amplitude-duration, and main sequence relationships. The similarity was then measured with the Gaussian Cumulative Distribution Function (CDF). A weight information fusion was also conducted to combine the features. The best five top features were average fixation duration (30% EER – Equal Error Rate), fixation count (34% EER), average horizontal saccade amplitude (36% EER), average vectorial saccade velocity (37% EER), and inflection count (38% EER); the fusion technique yielded an EER of 27%.

Figure 9.2. An example of reading scanpath (reproduced from Holland and Komogortsev [19]).
Rigas et al. [34] employed the graph matching technique for identification purposes. Ten photos of faces were used as stimuli, with a 50 Hz eye tracker. A graph was constructed by clustering fixation points with the 2-round MST (Minimum Spanning Tree) technique for each subject. For the analysis, a joint MST was created. Ideally, if two MSTs come from the same subject, then the degree of overlapping is higher than those that come from two different persons. Fifteen participants were involved in eight sessions, and classification accuracy between 67.5% and 70.2% was obtained using the KNN and Support Vector Machine classifiers.
Biedert et al. [2] considered the use of task learning effects for the detection of illicit access to computers. Their basic hypothesis was that a legit user would operate a system normally, rapidly passing the “key points” of an interface without effort. On the contrary, an attacker would need to understand the interface before using it. The typical (student’s) task of checking for emails in a web based interface and receiving messages from a hypothetical supervisor was simulated. The authors assumed that a casual user would scan the interface for relevant information while the actual user would find the appropriate information more straightforwardly. To quantitatively assess this, the Relative Conditional Gaze Entropy (RCGE) approach was proposed, which analyzes the distribution of gaze coordinates.
Galdi et al. [15] and Cantoni et al. [4] carried out some studies on identification using 16 still grayscale face images as stimuli. The first study [15] involved 88 participants and data were acquired in three sessions. For the analysis, the face images were subdivided into 17 Areas of Interest (AOIs) including different parts of the face (e.g., right and left eye, mouth, nose, etc.). Feature vectors containing 17 values (one for each AOI) were then built for each tester. These values were obtained by calculating the average total fixation duration in each AOI from all 16 images. The first session was used to construct the user model, while the second and third sessions were exploited for testing purposes. Comparisons were performed by calculating the Euclidean and Cosine distances between pairs of vectors. Both single features and combined features were tried in the data analysis, and the best result was achieved with combined features with an EER of 0.361.
In addition to the dataset used in the first study [15], 34 new participants were introduced in the second study [4], one year after the first data acquisition. The same stimuli used in the first experiments were employed. Instead of manually dividing the face into AOIs, this time an automatic face normalization algorithm was applied, so that the positions and sizes of AOIs were exactly the same in all pictures. In particular, the image area was divided into a 7×6 grid (42 cells). For each cell, a weight was calculated based on the number of fixations (density) and the total fixation duration in it. As an example, Fig. 9.3 shows the density graphs of four different observers.

Figure 9.3. Density graphs of four different observers. The size of red circles indicates the weight associated with the cell (reproduced from Cantoni et al. [4]).
Weights were also calculated for arcs connecting cells, using an algorithm that merged together the different observations of the 16 different subjects’ faces. In the end, for each tester a model was created represented by two 7×6 matrices (one for the number of fixations and one for the total fixation duration) and a 42×42 adjacency matrix for the weighted paths. The similarity between the model and the test matrices was measured by building a difference matrix and then calculating the Frobenius norm of it. The developed approach was called GANT: Gaze ANalysis Technique for human identification. In the experiments, the model was constructed from 111 testers of the first study and 24 from the second study. The remaining data were divided into two groups to form the test dataset. Trials using single and combined features were conducted, and the combination of all features (density, total fixation duration, and weighted path) yielded the best ERR of 28%.
Holland and Komogortsev [20] used datasets built from both a high frequency eye tracker (1000 Hz) and a low-cost device (75 Hz). Thirty two participants provided eye data for the first eye tracker, and 173 for the second. Four features were calculated from fixations, namely: start time, duration, horizontal centroid, and vertical centroid. Seven features were derived from saccadic movements, namely: start time, duration, horizontal amplitude, horizontal mean velocity, vertical mean velocity, horizontal peak velocity, and vertical peak velocity. Five statistic methods were applied to assess the distribution between recordings, namely the Ansari–Bradley test, the Mann–Whitney U-test, the two-sample Kolmogorov–Smirnov test, the two-sample t-test, and the two-sample Cramér–von Mises test. The Weighted Mean, Support Vector Machines, Random Forest and Likelihood-Ratio classifiers were also used. An ERR of 16.5% and a rank-1 identification rate of 82.6% were obtained using the two-sample Cramér–von Mises test and the Random Forest classifier.
The data gathered from the two already quoted studies by Galdi et al. [15] and Cantoni et al. [4] were also exploited by Cantoni et al. [5] and by Galdi et al. [16] for the identification of gender and age – useful in many situations, even if not strictly biometric tasks. Two learning methods were employed, namely Adaboost and Support Vector Machines, using the feature vectors already built for testing the GANT technique. Regarding gender identification, with Adaboost the best results were obtained with the arcs feature vector, with a 53% correct classification when the observed faces were of female subjects and a 56.5% correct classification when the observed faces were of males. With SVM, still with the arcs feature vector, scores reached about 60% of correct classification for both male and female observed faces. As for age classification, with Adaboost an improvement could be noticed compared to gender (with an overall correct classification of around 55% – distinction between over and under 30). However, the performance of SVM on age categorization was not as good as gender classification, with the best result of 54.86% of correct classifications using the arcs feature vectors.
George and Routray [17] explored various eye features derived from eye fixations and saccade states in the context of the BioEye 2015 competition (of which they were the winners). The competition dataset consisted of three session recordings from 153 participants. Sessions 1 and 2 were separated by a 30 min interval, while session 3 was recorded one year later. Data were acquired with a high-frequency eye tracker (1000 Hz) and down-sampled to 250 Hz. The stimuli were a jumping point and text. Firstly, eye data were grouped into fixations and saccades. For fixations, the following features were calculated: fixation duration, standard deviation for the X coordinate, standard deviation for the Y coordinate, scanpath length, angle with the previous fixation, skewness X, skewness Y, kurtosis X, kurtosis Y, dispersion, and average velocity. For saccades, many features were used, among which saccadic duration, dispersion, mean, median, skewness. After a backward feature selection step, the chosen features became the input to a Radial Basis Function Network (RBFN). In the experiments, Session 1 data became the training dataset, and Session 2 and Session 3 data served as a testing dataset. The study yielded a 98% success rate with both stimuli with the 30 minute interval, and 94% as the best accuracy for data acquired in one year.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780081007051000099
Biometric Market Forecasts
Mark Lockie, in The Biometric Industry Report (Second Edition), 2002
3.3.4 Speaker Verification Market
The creation of computer-based systems that analyse a person’s speech patterns to provide positive authentication has been under serious development for more than a decade. So it is surprising that until recently only a handful of reference implementations have been in evidence to prove the validity of such technology in the commercial world.
Fundamentally speaker verification and identification technologies have it all to play for. After all, the systems provide one of the simplest and most natural modes of authentication and they can operate without the need for specialised equipment – a microphone is a standard accessory of any multimedia computer and verification can also be performed over standard phone lines.
The problem has historically been one of robustness and reliability limitations. This situation is gradually getting better, however. Microphone technology is constantly improving, while the cost of the sensors is comparatively inexpensive. Meanwhile, the processing power needed to analyse the voice can be packed into increasingly small, low power devices, and as signal processing technology evolves, new and efficient algorithms for extracting and compressing the key features of a speech signal are emerging.
A person’s voice is a natural indicator of identity and the principle of a speaker-based biometric system is to analyse the characteristics of that voice in order to determine whether they are sufficiently similar to characteristics stored on file as a biometric template. This process can be either in a one-to-one verification scenario, or in a one-to-many identification configuration.
Generally speaking there are three main ways that people can use a speaker verification system:
- •
-
Text dependent – This requires the user to utter a pre-determined word or phrase. Most vendors offer this type of authentication mechanism.
- •
-
Text prompted – This requires the user to utter random words or phrases from a pre-enrolled set. This is popular in corrections monitoring as it can guard against tape recordings of a person’s voice.
- •
-
Text independent – This type of system lets the user speak freely and can be very unobtrusive if the speech is verified whilst in conversation with a call centre operator. The user enrols in the system by saying a passage of text that contains several examples of all the phonemes that characterise a human voice. When a user subsequently verifies their identity they will normally need to provide a passage of speech long enough to contain clear examples of these phonemes (usually around half a minute’s worth). Obviously the more speech provided the better the probability of a correct matching decision.
No single supplier dominates the voice biometric landscape. Some suppliers use other companies’ engines in their solution offerings, while some provide the entire solution using their own verification engines. Others focus on providing the verification engines alone. Broadly speaking the landscape could be separated into solution providers and technology suppliers.
3.3.4.1 Technical Developments
All voice-based biometric systems require a user interface, software or hybrid hardware/software to convert digital speech data into templates, as well as a matching engine, which allows speech templates to be compared to one another.
There are many things a developer can do to enhance the voice signal from the user interface, which might only be capable of giving a sub-optimal voice signal. The sort of problem a vendor might have to put up with includes background and random noise, poor quality signal channels and signal coding treatments. These sorts of problem have to be considered when designing the system – so a system that operates primarily on a mobile phone network will have to look specifically at signal coding treatment, for example.
Architectures
An important choice for companies wishing to install speaker verification technology is where to place the system components in a distributed context. Some suppliers can perform the matching processes within a standalone device, such as an embedded system, while others use client server configurations, where authentication is provided remotely.
Standalone configurations could include a simple PC/microphone scenario, but it also includes embedded solutions in devices such as a mobile phone. A major advantage in this architecture is that the voice data does not leave the phone, although processing power is an issue.
Standalone solutions are not generally feasible using standard phone technology, as the addition of software to the phone handset is generally unfeasible in the majority of landline phones on the market. Such systems are best served by a server-based approach – although more severe degradation issues must be faced in this scenario.
Feature extraction
The conversion of digitised speech data into representative templates relies on some form of feature extraction process. These generally look at pitch and formant frequencies found in the voice.
The feature extraction process, while similar to that for isolated word recognition, is mainly aimed at describing and preserving information that characterises the way a person speaks rather than the words that are delivered. This process is best achieved by looking at the higher frequencies within the bandwidth.
Public telephone network infrastructures comply with a base bandwidth specification of 300Hz to 4300 Hz. This could potentially be a problem for female speakers, who often have characteristics above this upper range. However to date no serious drop in accuracy has been noted.
Clearly the amount of information extracted is proportional to the size of the speech template. Typical template sizes range anywhere from 40 bytes to tens of kilobytes. Research is still underway to try and reduce template size without compromising quality and therefore performance. The benefits of small template sizes include speedier transmission across telecommunication networks and faster database searches if the technology is used in an identification configuration.
Performance
While fingerprint, hand and face recognition biometrics are leading the way in terms of systems deployed, voice biometrics perform surprisingly well in tests. In the UK, the Communications and Electronics Security Group (CESG) carried out tests on seven biometric technologies. These showed the voice-based systems to be second to iris recognition in overall performance (where three attempts were given to access the system).
Although the performance situation is improving, it is still important for potential users to do the maths when considering rolling the system out to the population at large – in a mobile commerce scenario, for example. Even at low equal error rates (EER) a large number of users would still be falsely rejected on a regular basis and back up procedures would be necessary.
Performance can be influenced in many ways, but one important influence is that of the user interface itself. Allowing the user to speak in as natural a fashion as possible can help as it helps to reduce stress and avoids speech variations. One factor which causes increased stress in the voice is a poorly designed interactive voice response (IVR) system that leaves a caller on hold or having to wade through many levels of options. If the user has to utter too much text, this can also cause problems, as the pitch or syllable stress may vary.
Spoofing
Fooling a biometric system is possible regardless of the biometric being used – as evidenced by recent spoofing attempts, which even cracked iris recognition.
With speaker verification, the worst case scenario is if somebody replays a recording of a person’s voice into a microphone. Although there are some voice systems that claim to discriminate between live and recorded speech, they are by no means infallible.
However, in speech technologies’ favour is the ability for the system to use operational techniques that make forgery or replay attack more difficult. The simplest is to present a random subset of words taken from a full set of words taken at enrolment. However, other techniques, such as challenge/response systems can also be used.
3.3.4.2 Market Developments
Voice based biometric systems are making headway in many of the horizontal markets but the main ones include PC/Network access and financial transaction authentication. The vertical markets where speaker verification is proving most popular are the law and order, telecoms, financial services, healthcare, government and commercial sectors.
Notable contract wins over the last year have been the launch of an account access application by Banco Bradesco in Brazil; the deployment of a call centre (for PIN/Password reset) operation for the publisher Associated Mediabase; the tracking of young offenders in the community by the UK’s Home Office and a system which allows Union Pacific Railroad customers to arrange the return of empty railcars once the freight has been delivered.
Major applications
The use of speaker verification (sv) technology in law enforcement applications is one of the biggest sectors for the industry. In particular, the use of the technology to monitor parolees or young offenders (released into the community) is proving successful, with numerous roll outs in European markets, in particular. Another successful application in this sector is the monitoring of inmates.
Call centre-based applications are proving strong hunting grounds for suppliers of voice systems. A trend that is evident in this area is the combination of speech recognition and speaker verification systems in what is often referred to as a total voice solution. The advantage is that it provides customers with a 24-hour automated service, which can extend the application further than a speech recognition configuration alone. This is because speaker verification adds security to the system and so allows applications to bypass the need for a caller to speak to a call centre operator to verify identity.
The use of speaker verification in password reset operations are also proving popular. It is often reported that the most common call to a company’s help desk is because of forgotten passwords. This is an ideal application for speaker verification, which can be used to authenticate the identity of the employee and then automatically reissue a PIN or password to the caller.
Looking forward, the possible use of speaker verification technology in mobile phones or new PDA technology provides an exciting opportunity. As the third generation phones are launched over the next year, it will quickly become apparent that their functionality also brings a security headache.
This is one area where sv technology can provide an answer – although it faces hot competition from other biometrics, such as fingerprint, dynamic signature verification and iris recognition. Nevertheless there are companies that have made strong progress in the mobile phone sector, such as Domain Dynamics in the UK, which recently demonstrated the possibility of using a SIM card to perform authentication (it did this in conjunction with Schlumberger Sema and Mitsubishi).
Corporate news
From a corporate perspective an important development has been the number of integrators and value added resellers, which have now appeared on the market. This helps to spread the reach of voice biometrics into new vertical markets and new geographic locations.
Elsewhere changes have included the sale of SpeakEZ Voice Print technology from T-Netix to Speechworks International and the closing down of leading supplier Lernaut & Hauspie Speech Products – which sold its business and technology assets to ScanSoft.
In terms of technology providers, a selection of the market leaders include Nuance, VoiceVault, Speechworks, Domain Dynamics, Veritel and Persay.
3.3.4.3 Drivers
- •
-
Existing infrastructure – Most biometrics providers have to worry about providing hardware to end users of their technology. Speech based systems are in the privileged position of already having a huge infrastructure in place that is capable of supporting its requirements – namely the landline and mobile phone networks.
- •
-
Improving accuracy – This was once a significant problem for voice biometrics. Today this is improving as evidenced by tests carried out by CESG in the UK. However, in the type of application that promises the greatest future growth potential – e- and m-commerce – the accuracy will still have to improve unless many legitimate users are turned away.
- •
-
Increased number of VARs/integrators – the increased number of VARs and integrators will bring speech-based biometrics to the market in applications so far untapped.
- •
-
Call centre automation – Increasingly the use of sv technology to process callers to call centres is being introduced. This trend is likely to continue as the need to give customers greater functionality increases along with the continual pressure to cut call centre operation costs.
- •
-
m-commerce opportunities – the emergence of commerce opportunities on mobile phones will provide a future growth opportunity for sv technology. The technology could also be used to cut down on mobile phone theft – as phones that only respond to authenticated users emerge.
3.3.4.4 Detractors
- •
-
Accuracy – As detailed above, the accuracy of speaker verification technology must still be improved in order for the greatest potential markets to be tapped. In particular accuracy is dependent on establishing clever user interfaces and systems to enable the user to speak as naturally as possible.
- •
-
Competing technologies – The speaker verification market faces stiff competition in markets such as m-commerce from other biometrics, such as fingerprint, and verification techniques, such as PINs and passwords.
- •
-
Slow adoption – Apart from a few exceptions, mobile phone operators have been slow to answer the security challenge, instead focusing on other challenges such as the roll out of new generation networks, increased phone functionality, bluetooth and so on.
3.3.4.5 Outlook
No other biometric has the advantage of an infrastructure quite as established as that of voice biometric technology and this could prove to be a winning formula over the years to come. Now that accuracy and robustness problems appear to be resolved, there is every chance this biometric will do well. In particular, call centre applications are expected to provide a great boost in short-term growth, with e-and m-commerce opportunities emerging in the next three years.
From a revenue perspective, in 2002 the amount of money created by the industry stood at US$13.9 million, some 5% of the total market. This is expected to keep at a similar market share to 2006, which is impressive considering the strong growth of other technologies such as fingerprint, face and iris recognition.

Figure 3.7. Revenue Forecast for Voice Verification Technology 2000–2006 (US$ million)
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781856173940500086
Touch-based continuous mobile device authentication: State-of-the-art, challenges and opportunities
Ahmad Zairi Zaidi, … Ali Safaa Sadiq, in Journal of Network and Computer Applications, 2021
3.5.3 Equal error rate (EER)
An equal error rate (EER) measures the trade-off between security and usability (Meng et al., 2018a,b), and it is the most used performance evaluation metric in biometric-based authentication scheme (Chang et al., 2018). EER is the value when FAR equals FRR (Khan et al., 2016). EER measures the overall accuracy of a continuous authentication schemes and its comparative performance with other schemes (Teh et al., 2016). EER is also used to measure the overall performance of an authentication scheme regardless of parameters used (Murmuria et al., 2015). It is worth to note that varying the threshold of decision value of a classifier is usually used to obtain ERR (Al-Rubaie and Chang, 2016). Eq. (3) shows the calculation of EER.
(3)EER=FAR+FRR2
where the difference between FAR and FRR should have the smallest value based on the variation of thresholds (Smith-Creasey and Rajarajan, 2017). Lower EER indicates a more secure and useable authentication scheme. Therefore, a smaller EER is preferred (Nguyen et al., 2017). In the case of continuous authentication scheme, it can detect illegitimate users better, and the legitimate users do not have to be locked out frequently (Smith-Creasey and Rajarajan, 2019). EER of 0 indicates a perfect classification (Palaskar et al., 2016). However, in reality, it is unrealistic to achieve a perfect authentication accuracy as the classifier may not be able to accurately classify all touch strokes.
Read full article
URL:
https://www.sciencedirect.com/science/article/pii/S1084804521001740
Monozygotic twin face recognition: An in-depth analysis and plausible improvements
Vinusha Sundaresan, S. Amala Shanthi, in Image and Vision Computing, 2021
2.3 Investigation on the performance achieved
The most often used reliable measures of performance were the recognition rate and the Equal Error Rate (EER). The recognition rate was employed as the performance measure, while the system operated in the identification mode. In contrast, the EER was used to evaluate a system that operated in the verification mode. Recognition rate merely implies the count of subjects, who are precisely identified from the given image collection by the recognition system. In contrast, EER reveals the measure of the system, where the False Acceptance Rate (FAR) and the False Rejection Rate (FRR) equals. Here, FAR and FRR indicate the errors that are produced from the face recognition system. For instance, consider the individuals of a twin pair as A and B. FAR denotes the measure that twin A is falsely identified, when B is actually the claimed identity in the twin pair. In the other case, FRR denotes the measure that twin A is falsely rejected (B is falsely identified), when A is actually the claimed identity in the twin pair. These two errors occur very often, when it comes to twin discrimination. Specifically, when FAR dominates FRR, it represents a very crucial security issue in applications because an imposter is being admitted in place of a genuine individual. On the contrary, the Verification Rate (VR) and accuracy denote the measure that the claimed identity is correctly identified. Hence, the performance of current face recognition systems has been evaluated by either one of the following measures: (i) EER, (ii) Recognition rate, (iii) Accuracy and (iv) VR at % FAR. For the recognition system to be efficient, recognition rate, accuracy and VR must be higher. On the contrary, EER and FAR must be possibly small. Table 5 reveals the performances values, which were achieved using various twin recognition approaches of the past. On considering EER, the lowest achieved value fell in the range (0.01, 0.04) at 90% confidence interval [15]. However, the number of twins considered for the experimentation was small, when compared to the most recent works. Further, it should be noted that illumination, expression and time-lapse between image acquisitions strongly affected the EER performance. It was evident from [19], as stated in Table 5. Moreover, on considering the VR at % FAR, the performance from past research was comparatively small and it was not beyond 90%. This is in contrast to the most recent works, which produced higher recognition rates as high as 99.45% and 100% for uncontrolled and controlled illuminations, respectively [23]. However, this increase was achieved at the cost of computation complexity and the use of so many traits, feature extraction algorithms and their resultant combinations. Further, the accuracy measure was also small, not exceeding 90%, even with the use of deep learning architectures [24]. Hence, the research to attain higher recognition rates and reduced EERs in twin recognition is still necessitated.
Table 5. Year-wise existing research and performances.
| Year | Author [citation] | Performance metric | Best performance values achieved |
|---|---|---|---|
| 2011 | Phillips et al. [15] | EER | At 90% confidence interval and neutral expression:
|
| 2011 | Klare et al. [16] | True Accept Rate (TAR) at % FAR |
|
| 2012 | Srinivas et al. [17] | EER |
|
| 2013 | Juefei-Xu and Savvides [18] | VR at % FAR |
|
| 2014 | Paone et al. [19] | EER | Change of minimum EER from same day to one-year time-lapse for the best performing algorithm:
|
| 2015 | Le et al. [20] | Recognition Rate | For ND-TWINS-2009-2010 dataset with smiling-no glass condition, the average recognition rate was as high as:
|
| 2017 | Afaneh et al. [21] | EER |
|
| 2018 | Toygar et al. [22] | Recognition Rate | Maximum Recognition Rate = 75% (Fusing Right Profile Face and Right Ear) |
| 2019 | Toygar et al. [23] | Recognition Rate, EER | Maximum Recognition Rate = 100% (controlled illumination) Maximum Recognition Rate = 99.45% (uncontrolled illumination) Minimum EER = 0.54% (controlled illumination) Minimum EER = 1.63% (uncontrolled illumination) |
| 2019 | Ahmad et al. [24] | Accuracy, EER | Average Accuracy = 87.2% EER Range was between 1.4% and 9.3% |
Read full article
URL:
https://www.sciencedirect.com/science/article/pii/S0262885621002365
Abnormal behavior recognition for intelligent video surveillance systems: A review
Amira Ben Mabrouk, Ezzeddine Zagrouba, in Expert Systems with Applications, 2018
4.2 Evaluation metrics
Several metrics are provided to evaluate a video surveillance system. The two commonly used criteria are the Equal Error Rate (EER) and the Area Under Roc curve (AUC). Those two criteria are derived from the Receiver Operating Characteristic (ROC) Curve which is highly used for performance comparison. EER is the point on the ROC curve where the false positive rate (normal behavior is considered as abnormal) is equal to the false negative rate (abnormal behavior is identified as normal). For a good recognition algorithm, the EER should be as small as possible. Conversely, a system is considered having good performances if the value of the AUC is high. An other used recognition measure is the accuracy (A) which corresponds to the fraction of the correctly classified behaviors. In Table 7, we summarize the performance evaluation of previous interesting papers whose results are available.
Read full article
URL:
https://www.sciencedirect.com/science/article/pii/S0957417417306334
· Introduction of the evaluation index EER(Equal Error Rate)
In-depth learning articles generally use Error probabilities such as EER(Equal Error Rate) as an objective criterion for measuring classifiers, and the RECEIVER Operating Characteristic (ROC) curve explains how to calculate EER.
Here is a brief introduction to the EER calculation
EER (Average error probability) is a biometric security system algorithm used to pre-determine its error acceptance rate and its error rejection rate threshold. When the rates are equal, the common value is called the equal error rate. This value indicates that the proportion of false acceptances is equal to the proportion of false rejections. The lower the iso-error rate, the higher the accuracy of biometric identification system.
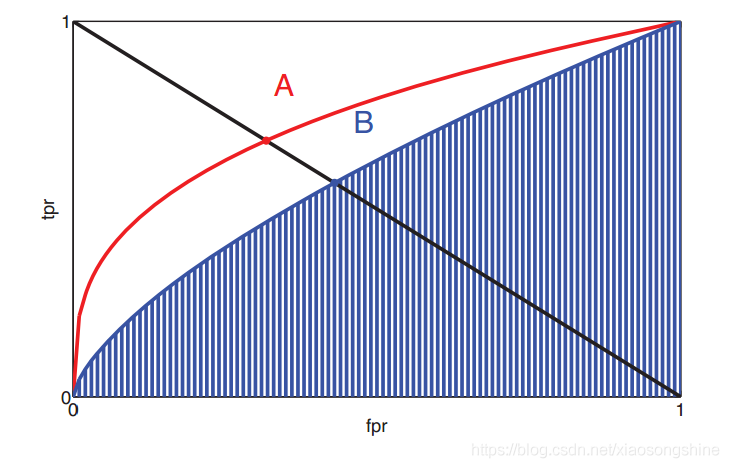
Use other ROC evaluation criteria
AUC (area under thecurve), also is the area under the ROC curve, the greater the classifier, the better, the maximum value is 1, the blue stripes in the graph area is the blue curve corresponding AUCEER (equal error rate), that is, the value of the FPR = FNR, due to the FNR = 1 – TPR, can draw A from (0, 1) to (1, 0) in A straight line, finding the intersection point, in the figure A and B two points.
Read More:
Оценка качества Биометрических систем
Работа
биометрической системы идентификации
пользователя (БСИ) описывается техническими
и ценовыми параметрами. Качество работы
БСИ характеризуется процентом ошибок
при прохождении процедуры допуска. В
БСИ различают ошибки трех видов:
-
FRR
(False Rejection Rate)ошибка первого рода—
вероятность принять «своего» за
«чужого». Обычно в коммерческих
системах эта ошибка выбирается равной
примерно 0,01, поскольку считается, что,
разрешив несколько касаний для «своих»,
можно искусственным способом улучшить
эту ошибку. В ряде случаев (скажем, при
большом потоке, чтобы не создавать
очередей) требуется улучшение FRR до
0,001-0,0001. В системах, присутствующих на
рынке, FRR обычно находится в диапазоне
0,025-0,01. -
FAR
(False Acceptance Rate)ошибка второго рода— вероятность принять «чужого» за
«своего». В представленных на рынке
системах эта ошибка колеблется в
основном от 10-3до 10-6, хотя
есть решения и с FAR = 10-9. Чем больше
данная ошибка, тем грубее работает
система и тем вероятнее проникновение
«чужого»; поэтому в системах с
большим числом пользователей или
транзакций следует ориентироваться
на малые значения FAR.
-
EER
(Equal Error Rates)– равная вероятность
(норма) ошибок первого и второго рода.
Биометрические
технологии
основаны на биометрии, измерении
уникальных характеристик отдельно
взятого человека. Это могут быть как
уникальные признаки, полученные им с
рождения, например: ДНК, отпечатки
пальцев, радужная оболочка глаза; так
и характеристики, приобретённые со
временем или же способные меняться с
возрастом или внешним воздействием,
например: почерк, голос или походка.
Все
биометрические системы работают
практически по одинаковой схеме.
Во-первых, система запоминает образец
биометрической характеристики (это и
называется процессом записи). Во время
записи некоторые биометрические системы
могут попросить сделать несколько
образцов для того, чтобы составить
наиболее точное изображение биометрической
характеристики. Затем полученная
информация обрабатывается и
преобразовывается в математический
код. Кроме того, система может попросить
произвести ещё некоторые действия для
того, чтобы «приписать» биометрический
образец к определённому человеку.
Например, персональный идентификационный
номер (PIN) прикрепляется к определённому
образцу, либо смарт-карта, содержащая
образец, вставляется в считывающее
устройство. В таком случае, снова делается
образец биометрической характеристики
и сравнивается с представленным образцом.
Идентификация по любой биометрической
системе проходит четыре стадии:
-
Запись
– физический или поведенческий образец
запоминается системой; -
Выделение
– уникальная информация выносится из
образца и составляется биометрический
образец; -
Сравнение
– сохраненный образец сравнивается с
представленным; -
Совпадение/несовпадение
— система решает, совпадают ли
биометрические образцы, и выносит
решение.
Подавляющее
большинство людей считают, что в памяти
компьютера хранится образец отпечатка
пальца, голоса человека или картинка
радужной оболочки его глаза. Но на самом
деле в большинстве современных систем
это не так. В специальной базе данных
хранится цифровой код длиной до 1000 бит,
который ассоциируется с конкретным
человеком, имеющим право доступа. Сканер
или любое другое устройство, используемое
в системе, считывает определённый
биологический параметр человека. Далее
он обрабатывает полученное изображение
или звук, преобразовывая их в цифровой
код. Именно этот ключ и сравнивается с
содержимым специальной базы данных для
идентификации личности [19].
Преимущества
биометрической идентификации состоит
в том, что биометрическая защита дает
больший эффект по сравнению, например,
с использованием паролей, смарт-карт,
PIN-кодов, жетонов или технологии
инфраструктуры открытых ключей. Это
объясняется возможностью биометрии
идентифицировать не устройство, но
человека.
Обычные
методы защиты чреваты потерей или кражей
информации, которая становится открытой
для незаконных пользователей.
Исключительный биометрический
идентификатор, например, отпечатки
пальцев, является ключом, не подлежащим
потере [18].
Соседние файлы в папке ГОСЫ
- #
- #
- #
- #
- #
- #
- #
- #
- #
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
1
branch
0
tags
Code
-
Use Git or checkout with SVN using the web URL.
-
Open with GitHub Desktop
-
Download ZIP
Latest commit
Files
Permalink
Failed to load latest commit information.
Type
Name
Latest commit message
Commit time
python-compute-eer
Simple Python script to compute equal error rate (EER) for machine learning model evaluation.
Reference: https://stackoverflow.com/questions/28339746/equal-error-rate-in-python
Code:
import numpy as np import sklearn.metrics """ Python compute equal error rate (eer) ONLY tested on binary classification :param label: ground-truth label, should be a 1-d list or np.array, each element represents the ground-truth label of one sample :param pred: model prediction, should be a 1-d list or np.array, each element represents the model prediction of one sample :param positive_label: the class that is viewed as positive class when computing EER :return: equal error rate (EER) """ def compute_eer(label, pred, positive_label=1): # all fpr, tpr, fnr, fnr, threshold are lists (in the format of np.array) fpr, tpr, threshold = sklearn.metrics.roc_curve(label, pred, positive_label) fnr = 1 - tpr # the threshold of fnr == fpr eer_threshold = threshold[np.nanargmin(np.absolute((fnr - fpr)))] # theoretically eer from fpr and eer from fnr should be identical but they can be slightly differ in reality eer_1 = fpr[np.nanargmin(np.absolute((fnr - fpr)))] eer_2 = fnr[np.nanargmin(np.absolute((fnr - fpr)))] # return the mean of eer from fpr and from fnr eer = (eer_1 + eer_2) / 2 return eer
Sample usage:
from compute_eer import compute_eer label = [1, 1, 0, 0, 1] prediction = [0.3, 0.1, 0.4, 0.8, 0.9] eer = compute_eer(label, prediction) print('The equal error rate is {:.3f}'.format(eer))