| Bug #30405 | Parent: child process exited with status 4294967295 — Restarting | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Submitted: | 2004-10-11 23:39 UTC | Modified: | 2004-10-21 10:51 UTC |
|
||||||||||
| From: | joel at preacherboy dot net | Assigned: | jorton (profile) | |||||||||||
| Status: | Not a bug | Package: | Apache2 related | |||||||||||
| PHP Version: | 5.0.2 | OS: | Windows 2003 | |||||||||||
| Private report: | No | CVE-ID: | None |
Patches
Add a Patch
Pull Requests
Add a Pull Request
History
AllCommentsChangesGit/SVN commitsRelated reports
AAKH1361
Member
![]()
0
295 posts
02-08-2017, 12:44 AM —
Quote:F {rsx::thread} class std::runtime_error thrown: Invalid location (offset=0x10, location=0x66626660)
(in file C:rpcs3rpcs3EmuRSXRSXThread.cpp:135)
S {Audio Thread} XAudio 2.9 initialized
S {SPU[0x2000005] Thread (Job Manager — Job Thread)} SPU: Function detected [0x3f830-0x3f87c] (size=0x4c)
S {SPU[0x2000005] Thread (Job Manager — Job Thread)} SPU: Function detected [0x3f960-0x3f9dc] (size=0x7c)
F {SPU[0x2000005] Thread (Job Manager — Job Thread)} class std::runtime_error thrown: Unknown command GETLLAR (cmd=0xd0, lsa=0x3ef80, ea=0x2eea3f00, tag=0x0, size=0x0)
(in file C:rpcs3rpcs3EmuCellSPUThread.cpp:500)
F {SPU[0x2000004] Thread (Job Manager — Job Thread)} class std::runtime_error thrown: Unknown command GETLLAR (cmd=0xd0, lsa=0x3ef80, ea=0x2eea3f00, tag=0x0, size=0x0)
(in file C:rpcs3rpcs3EmuCellSPUThread.cpp:500)
Video:
OpenGL
Audio:
Convert to 16 bit: false
Dump to file: false
Renderer: XAudio2
Core:
Hook static functions: false
Load liblv2.sprx only: false
Load libraries:
— libadec.prx
— libcelpenc.prx
— libfs.prx
— libpngdec.prx
— libresc.prx
— librtc.prx
— libsre.prx
PPU Decoder: Interpreter (fast)
SPU Decoder: Recompiler (ASMJIT)
vlakipn
Member
![]()
0
29 posts
06-20-2017, 11:20 AM —
Video: Vulkan
Audio: OpenAl
Rest settings: Default
Managed to play untill 2nd mission. Then it stayed black. It have run arround 30fps in gameplay, while there were video cutscenes, it ran a bit slower (arround 15fps).
Intel Core i7 — 4790k @4.4 Ghz
Asus — Z97 Pro
Asus — GTX970 — Strix
16GB DDR3 @1600
Win 10 Pro x64
vlakipn
Member
![]()
0
29 posts
06-23-2017, 12:31 AM —
Retested with latest build (default settings).
Works as before, but seems something messed the text in game (menus and prologue) — some parts cant be seen (and ive noticed it with other games too — Devil May Cry HD collection).
Tested this one with default settings. Since its slow (intros lasts long) ive split it to 3 videos. 3rd one is with gameplay.
I think this one could be InGame tagged.
P.S. Im new here, but ive continuosly tested many emulators so far and i must say, you people are doing very nice job. Amazing progress. 
Intel Core i7 — 4790k @4.4 Ghz
Asus — Z97 Pro
Asus — GTX970 — Strix
16GB DDR3 @1600
Win 10 Pro x64
Ani
Administrator

![]()
16
4,024 posts
06-27-2017, 04:37 PM —
Missing test with master build and RPCS3.log file.
Desktop: Ryzen 7 5800X, Radeon RX 6800 XT, 2x8G DDR4 3600MHz, Manjaro Linux
Laptop: Ryzen 9 5900HX, Radeon RX 6700M, 2x8G DDR4 3200MHz, Manjaro Linux
Old Desktop: AMD FX-8350, Radeon R9 280X, 2x4G DDR3 1600MHz, Manjaro Linux
reznoire
Member
![]()
0
18 posts
08-07-2017, 04:56 AM —
https://ci.appveyor.com/project/kd-11/rp…/artifacts
kd-11’s latest builds fix the crash ingame after the opening boss fight, no go on master
vlakipn
Member
![]()
0
29 posts
08-09-2017, 07:15 PM —
Any way to speed up or skip videos?
@reznoire — what settings did you use?
Intel Core i7 — 4790k @4.4 Ghz
Asus — Z97 Pro
Asus — GTX970 — Strix
16GB DDR3 @1600
Win 10 Pro x64
08-09-2017, 11:48 PM —
Yeah the videos are crazy slow despite it stating it’s 60 FPS
Gundark
Member
![]()
0
4 posts
08-26-2017, 10:06 PM —
There is a softlock after you rip off Charons head (the boat) and start to climb the pillars . Freeze every time.

Dante.part01.rar (Size: 1.17 MB / Downloads: 61)
Dante.part02.rar (Size: 903.51 KB / Downloads: 36)
Gundark
Member
![]()
0
4 posts
08-28-2017, 12:46 PM —
In 25709112 I’ve managed to get little further but not much. This is the screenshot where the emu froze. After Charons boat and climbing the pillars.

This post was last modified: 08-28-2017, 12:47 PM by Gundark.
pit80
Member
![]()
0
32 posts
09-13-2017, 06:55 PM —
(08-09-2017, 11:48 PM)legend80 Wrote: Yeah the videos are crazy slow despite it stating it’s 60 FPS
Any way to fix crazy slow videos? It’s really so annoying .
Проблема a disk read error occurred press может не на шутку напугать любого пользователя ПК. Проблема заключается в следующем, во время запуска Windows, система пытается считать файлы необходимые для этого действия, расположенные в скрытом разделе. Такие данные крайне важны, поэтому в случае их отсутствия или неисправности, как раз и встретим такую ошибку. Какие же варианты сложившейся ситуации поддаются исправлению, а какие нет, рассмотрим далее.

Возможные источники неисправности
Сперва следует определиться с источниками проблемы, когда пишет a disk read error occurred. Их существует немало, но некоторые легко диагностируются, поэтому приступим:
- Вирус повредил загрузочный сектор системы;
- Антивирус, что-то напутал и стёр нужные записи;
- Ошибка проявилась после неправильной установки Windows или инсталляции одной ОС поверх другой;
- Вы производили разбивку HDD на логические диски. Вообще, это не является проблемой, но при наличии битых секторов, может случиться какой-либо сбой;
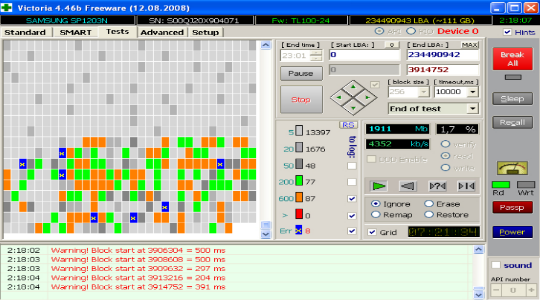
- Возможно, вы роняли системный блок/ноутбук или же сам жесткий диск;
- Отошли или перебиты шлейфы, их всего два и поэтому проверить легко;
- Вероятной причиной бывает наличие изношенного блока питания, если не достаточно напряжения, диск не сможет работать правильно;
- Иногда ломаются контролеры на материнке;
- Восстановление или откат системы, в случаи с недостаточным местом на носителе. Таким образом часть файлов перебивается, а другая остаются прежними, создавая проблемы.
- Поломка жесткого диска или наличие большого количества нестабильных секторов.
Большинство ситуаций с a disk read error occurred исправить удаётся, в основном те, что связаны с программными сбоями или шлейфами подключения.
Для начала борьбы с недугом необходим установочный диск Windows, иначе ничего не получится. Также, нужно быть готовыми, что может потребоваться полная переустановка ОС.
Читайте также: Как переустановить Windows 8 на ноутбуке?
Определение работоспособности жесткого диска
Простой диагностической мерой по борьбе, где ошибка a disk read error occurred не оставляет возможности получить доступ к Windows, является просмотр его отображения в БИОС. Если в нём отображается HDD правильно, то большая доля вероятности, что причина всё же в программной части, если же не определяется или показывается неправильно, то жесткий диск не исправлен. Можно попытаться восстановить его работоспособность через сервисный центр, но это актуально только для копирования важной информации с него. Итак, нужно:
- В момент запуска системы нажать Del;
- Теперь перейдите с помощью стрелочек в раздел «Advanced BIOS features»;
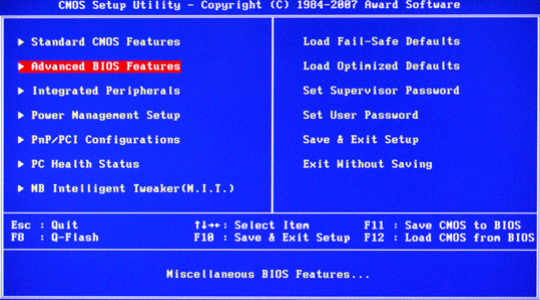
- Затем нажмите на «Hard Disk Boot Priority» или «Boot Device Priority».
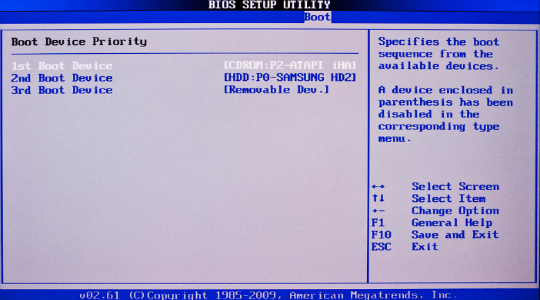
Проверьте правильность отображения наименования жесткого диска, а после этого можно проследовать дальше (в случае успеха).
Читайте также: Как зайти в BIOS в Windows 10?
Ошибка a disk read error occurred, как исправить с помощью Acronis Disk Director
Для выполнения проверки и устранения неисправности через эту программу у вас должен быть загрузочный диск Acronis, также подойдёт Paragon или другие. Теперь следует просмотреть такие разделы:
- Запуститесь через ваше приложение, делается это с помощью нажатия F9 или F8, когда показывается окно с возможностью перехода в BIOS;
- Проверьте, чтобы раздел «Зарезервировано системой» был в активном состоянии. Если это не так, то кликните правой кнопкой и выберите «Отметить как активный»;
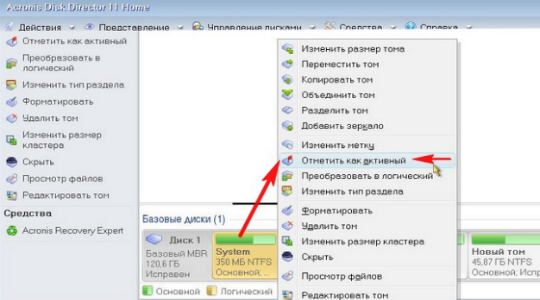
- Также проверьте наличие на диске папки Boot и файла bootmgr, они изначально скрыты, так как, являются системными. Сперва включите их отображение.
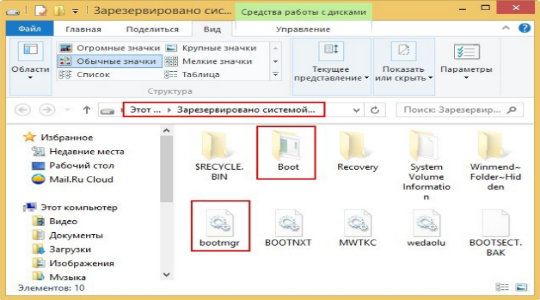
В случае отсутствия папки или файла их придется восстановить, как это сделать показано в следующем разделе.
Восстановление работы раздела загрузки
Для решения проблемы a disk read error occurred Windows 7, нужен соответствующий установочный диск с ОС, для других версий тоже самое. Процедура должна помочь системе проанализировать HDD на ошибки и, в случаи их наличия, попытаться исправить.
1.Теперь вставьте диск или флеш накопитель и запустите его;
2.Нажмите на ссылке «Восстановление системы»;
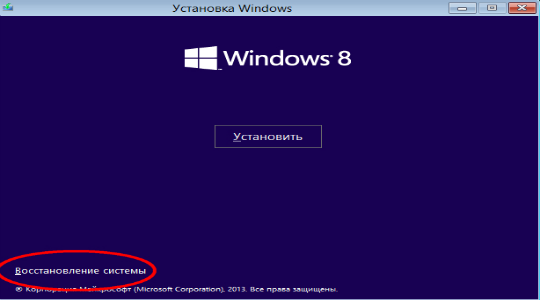
3.Далее пройдите в раздел «Диагностика»;
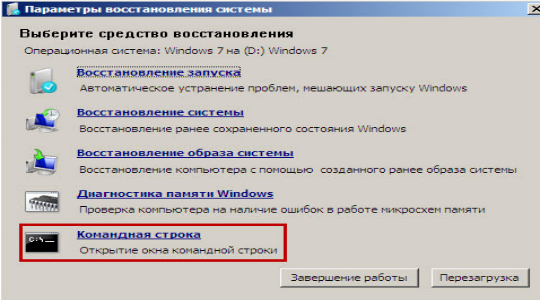
4.Теперь «Дополнительные параметры»;
5.Затем выберите пункт «Командная строка»;
6.Сперва нужно запустить блокнот, благодаря которому мы сможем узнать распределение букв для логических дисков. Для этого:
- Введите notepad.exe и нажмите ввод;
- Клик по вкладке «Файл» и выберите опцию «Открыть»;
- В «Мой компьютер» важно запомнить или записать, буквы для разделов «Зарезервировано системой», содержащий файлы Windows и загрузочный сектор.
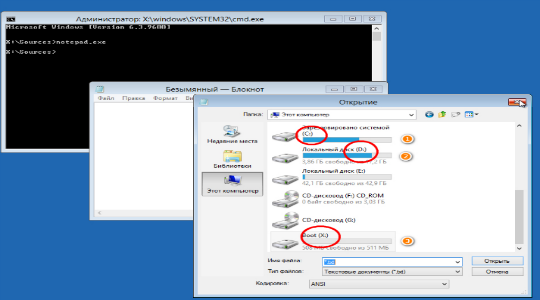
7.Для восстановления файлов Windows нужно ввести команду bcdboot С:/Windows, где C – это буква соответствующего раздела;
8.Для произведения проверки зарезервированной области введите поочерёдно chkdsk D: /r и chkdsk D: /f, где D – буква вашего раздела и она может отличаться.
9.Затем выполните пункт 8 для раздела, который содержит Windows.
10.Если проверка прошла успешно, следует восстановить MBR записи с помощью следующих команд bootrec.exe /fixmbr и bootrec.exe /fixboot;
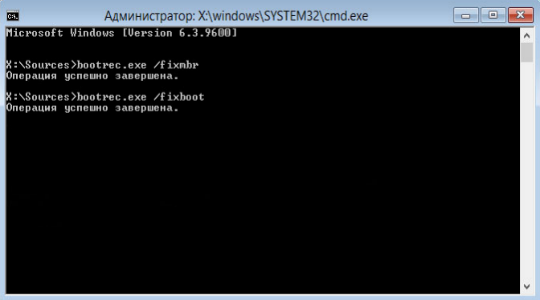
11.В конце необходимо провести поиск ОС и включить их в список загрузки, с помощью bootrec.exe /rebuildBcd.
Читайте также: Как преобразовать диск gpt в mbr?
Вероятно, что после показанных действий ошибка исчезнет, но Windows так и не захочет запускаться (не часто, но бывает). Тогда после исправления ошибки a disk read error occurred что делать очевидно, просто переустановить систему заново. Лучше сначала перекинуть все файлы на другой диск и отформатировать изначальный HDD и после установить чистую Windows.
Если у Вас остались вопросы по теме «Как исправить ошибку a disk read error occurred?», то можете задать их в комментариях
![]()
I have tried setting JsonSerializerOptions.AllowTrailingCommas but that didn’t make a difference. If it would do what I expect it still wouldn’t help if the JSON isn’t followed by a comma.
![]()
@ericwj can you share your input JSON payload that is causing the issue and also the .NET object model you are deserializing to?
Also, what version of dotnet sdk are you using (share the output of dotnet --info)? Can you try with preview 9 bits (or latest nightly)?
Please try the nightly SDK/runtime with the fix to verify it works (https://github.com/dotnet/core-sdk#installers-and-binaries), or wait till preview 9 ships. Alternatively, you could reference the latest S.T.Json NuGet package. For example:
<ItemGroup> <PackageReference Include="System.Text.Json" Version="4.6.0-preview9.19413.13" /> <PackageReference Include="System.Text.Encodings.Web" Version="4.6.0-preview9.19413.13" /> </ItemGroup>
If your scenarios is the following (and you want to just read the first json object), then that is not supported today. We only support reading a single JSON object:
File containing more than one payload isn’t supported:
{ ... some json...}, { ... another json ... }
This is also how the underlying Utf8JsonReader behaves (which is where the exception you observed is coming from).
string json = "{}," byte[] input = Encoding.UTF8.GetBytes(jsonString); var reader = new Utf8JsonReader(input, new JsonReaderOptions() { AllowTrailingCommas = true }); while (reader.Read()) ; // After EndObject throws System.Text.Json.JsonReaderException : ',' is invalid after a single JSON value. Expected end of data. LineNumber: 0 | BytePositionInLine: 2
![]()
Yes I am trying to read in a streaming fashion, so there is JSON following other JSON. The files can become fairly big.
I think I might be able to use a Pipe and an Utf8JsonReader to do the job.
Although it is quite a lot of code overhead, working with SequencePosition is awkward and JsonSerializer.Deserialize<T>(ref reader, ...) will throw exceptions as long as the buffer isn’t valid yet while I search for the next '}'. Wouldn’t it be better if there was a bool TryDeserialize<T> anyway?
![]()
Wouldn’t it be better if there was a
bool TryDeserialize<T>anyway?
What would you expect TryDeserialize to do/return in your scenario where you have multiple json payloads within the file and it fails to deserialize? The deserialize call today throws, so I don’t see returning false in the Try* API would help all that much. cc @steveharter
I think I might be able to use a
Pipeand anUtf8JsonReaderto do the job.
Although it is quite a lot of code overhead, working withSequencePositionis awkward
Yep, that’s true. Let me think about the scenario you presented and get back to you (I want to see how much effort is required if a motivated dev wants to support this case via the low-level reader). If you already have a pipe/utf8jsonreader-based implementation that works, please share.
![]()
A quick and dirty implementation that works as long as the input is okay is here.
What would you expect TryDeserialize to do/return in your scenario where you have multiple json payloads within the file and it fails to deserialize?
I would like it to return false or some error status and not throw, because exceptions are wicked expensive. Something like this:
class JsonSerializer { public static bool TryDeserialize<T>( ref Utf8JsonReader reader, out T result, JsonSerializerOptions options); }
The pipe reader code will search for [, { and their closing counterparts, where any unbalanced object tags will cause an exception calling JsonSerializer.Deserialize<T>. A naive way is just to try to deserialize for any } found, hoping it will match the first opening brace in the JSON remaining at that point, at the cost of a try...catch if the braces aren’t balanced. Less naive might be to balance {‘s with }‘s, but that comes at the cost of more calls to ReadOnlySequence<byte>.PositionOf(byte) or yet higher code complexity and more awkward SequencePosition math and comparisons.
I don’t immediately see the need for SequencePosition in favor of plain ints or longs at all, can the tracking of the _object field not be avoided by just having overloads that take some integral offset? Or it has to become something proper that is comparable and has suitable operators defined. But then still I don’t see why I have to deal with them and drag that _object field along.
I seriously don’t think using the Utf8JsonReader directly — that is, without calling into JsonSerializer — is beneficial except if performance is supercritical and you have to deserialize a lot of JSON. I don’t think I might ever go that route except in a rare case when the schema is very, very limited and the volume to read/write justifies the effort.
![]()
Given this is currently by-design, and requires some thinking/design work to support this feature, moving to 5.0.
![]()
msftgits
transferred this issue from dotnet/corefx
Feb 1, 2020
![]()
I ran into this issue myself and ended up working around it by making a custom Stream class that has some minimal understanding of JSON syntax and, provided the JSON is valid, can determine when it has reached the end of a JSON value. One thing I ran into, though, is that in some cases, the end of the JSON value is detectable only by reading a character that isn’t part of the value, and if Deserialize simply returned at that point, that character would be lost, since generic Stream doesn’t have a way to «push back» a character to allow a future call to reread it. My custom Stream takes this into account, storing this potential «pushed back» character. But, this is a really messy solution, and I don’t see a way to integrate partial reads of the source data into the existing model for Deserialize without running into this problem. But, a thought that occurred to me is that perhaps JsonSerializer could present a method specifically for deserializing a JSON array into an IEnumerable or IAsyncEnumerable, yielding each item as it is deserialized. Lacking a full async deserialization infrastructure, each of those items will have to be fully deserialized in order to be returned (e.g. even if it contains a nested array, that nested array cannot itself be returned piecemeal), but that is its own extremely difficult problem to solve in a way that I believe doing this at the top level is not. A method as proposed would basically need to itself recognize [, ], and ,, and then would need internally to have a Deserialize method that could return a «push back» character and also use one passed back in from a previous call, instead of requiring that the end of the value coincide with the end of the stream.
![]()
Actually if it were only being used by the enumerate-array-elements method it wouldn’t need to support receiving a pushback character, as the character in question would always be either , or ] and would be consumed by the outer method.
![]()
In case it is not obvious, specifically, if the value being deserialized is a string, an object or an array, then the character that tells you you are at the end of the JSON value is a part of the value itself and no further character needs to be read. But, if it is a number, you only know that you’re past the end of the number once you read the first character that isn’t part of the number. Technically speaking, when reading true, false or null, the last letter of the word, with well-formed JSON, unambiguously marks the end of value, but if the value is read up until a clear «end of identifier», that end is also past the end of the JSON value.
![]()
@logiclrd — You’re making things hard on yourself. Assuming you’ve got some sort of delegating stream which is buffering the contents, you don’t bother to rewind the stream, you just don’t move the offending characters into the buffer (or rather, don’t mark them as part of the buffer).
- Assume the current character may be invalid (ie,
,followed immediately by,). - Seek until either start-of-object (
{) or start-of-array ([) is found.- Mark which it was.
- have the relevant stream methods consider this «start of stream» (ie,
CopyToconsiders it index 0)
- As the stream is consumed, increment a count for additional starts of the same type, and decrement for counts of the same type (you don’t have to consider starts/ends of the other type).
- Obviously, skip starts/ends inside of strings. This means you need to keep track of string starts/ends too.
- When the count is 0, consider it end-of-stream.
This unfortunately iterates over the stream an extra time (but only once), but is simple to implement and doesn’t require messing around with states of readers.
![]()
This unfortunately iterates over the stream an extra time (but only once)
CanSeek is not always true. This is not a general solution. In my specific case, the underlying stream is a TCP connection. The entire purpose of my implementation is to avoid buffering and yield elements of the array as they arrive, and I think that would be a very useful thing to have in general. 
![]()
I have had a similar issue. I solved it by deleting the file before writing serialized JSON in it. If not do the deletion, the System.Text.Json.JsonSerializer will overwrite the file and leave the previous extra data unchanged.
I hope my experience could solve the issue for someone else.
![]()
It’s good to point this out in case people with corrupt data end up on this issue by searching for the error message, but I want to make it clear that this issue isn’t about corrupt data, but about a design limitation in System.Text.Json that makes it impossible to intentionally decode a JSON value from the middle of a stream.
Note that there is another approach you can use: call stream.SetLength(stream.Position) after serializing to it but before closing the file.
![]()
I ran into a similar issue with my json:
{«StorageIdentifier»:»aafb1460-8a30-49f4-89be-5ccf2651248d»,»Subscription»:»c728de4b-07f3-488f-b9eb-58508281525b»}
I can’t figure out what is the problem
![]()
Duplicate of #33030, specifically the discussion about SupportMultipleContent-like functionality.
![]()
This does not seem like a duplicate of #33030. #33030 is about reading multiple independent JSON documents in succession from a stream, while this one is about reading a part of a single JSON document.
![]()
![]()
At the very least the other one is the duplicate — it is three quarters of a year newer than this issue.
Looks like about the same although I think SupportMultipleContent is misleading. Can you just make it stop parsing when it’s done please?
![]()
At the very least the other one is the duplicate — it is three quarters of a year newer than this issue.
I should point out that me closing this or the other issue is not assigning credit — we just need to keep a focused backlog. It just happens that the other issue was triaged ahead of time and as such contains more recent information. I would recommend upvoting the other issue or contributing to the conversation there.
Looks like about the same although I think SupportMultipleContent is misleading. Can you just make it stop parsing when it’s done please?
Why do you think it’s misleading? The default behavior is to fail on trailing data and we’re not changing that. We can discuss adding an optional flag for disabling this, just like Json.NET is doing.
![]()
I should point out that me closing this or the other issue is not assigning credit
Thats fine.
Why do you think it’s misleading? The default behavior is to fail on trailing data and we’re not changing that.
I think the name SupportMultipleContent is. I totally understand most use cases need to fail for trailing bytes. My point is that I started reading at some random point in a stream and it didn’t care about that either. It also shouldn’t care what follows, JSON which I read as ‘multiple content’, newline, or emoji, or 0xdeadbeef or 0xcc, or an access violation.
![]()
Sure, this is not an API proposal, it’s merely pointing out the name of the feature in Json.NET
![]()
I still feel like these are fundamentally not the same issue.
The other issue is about allowing parsing in situations where the source data is not syntactically valid JSON, because it is smushing multiple documents together. This issue is about making the parsing of JSON arrays piecewise — it’s still a single, valid document, I just don’t want to parse the whole thing in one call. But, I want the parsing state preserved so that I can go back to it and get the next piece.
These are not the same functionality.
EDIT: I thought I was commenting on a related issue that I had encountered. Rereading the top of this thread, @ericwj is not coming at this from quite the same place I am, and my issue was a comment further down the thread.
![]()
Just looking through how this works, I also think this issue should be reopened, over this request: TryDeserialize overloads.
Although neither the , nor the end-of-lines in #33030 are really a problem when the reading is from a span and the objects being read are known to be fairly small and can hence be definitely fully in the span such that Utf8JsonReader will happily succeed calling JsonSerializer.Deserialize<T>(ref Utf8JsonReader), stuff gets very cumbersome when the reading is from a stream like in this original issue’s comment. Most of these scenario’s get even more complicated when reading arbitrary objects, asynchronously. And one reason why I struggle to get anything custom implemented is because all I can do is try and catch and that just stinks for being…smelly, and for performing very badly for no reason.
In the former case, with small objects, in spans, or single read results, @logiclrd is also helped using the pair Utf8JsonReader.CurrentState and new UTf8JsonReader(Span/Sequence, bool, JsonReaderState). But this is seriously unworkable as a general solution over the lack of TryDeserialize on JsonSerializer and it is also just a lot of code — which would lead to #33030, but I can imagine whatever solution you create for that, someone will have some special requirements and still want to hand roll something and hence stumble on the limited performance of catches/second possible.
![]()
EDIT: I thought I was commenting on a related issue that I had encountered. Rereading the top of this thread, @ericwj is not coming at this from quite the same place I am, and my issue was a comment further down the thread.
@logiclrd is this presumably related to #30405 (comment)? I’m not sure I entirely understand the first part of the post, so I would recommend creating a new issue containing a reproduction of the behavior so we can make a recommendation. Regarding the second part, .NET 6 does ship with a DeserializeAsyncEnumerable method for streaming root-level JSON arrays.
![]()
@ericwj a related request was discussed in #54557 (comment). Per design guidelines Try- methods are only permitted to return false for one and only one failure mode. So a method that’s equivalent to doing catch { return false; } would most likely not be accepted since it’s collapsing a large number of failure modes.
![]()
Mm, DeserializeAsyncEnumerable I believe does cover my usage. It only applies to arrays at the root, but that’s precisely my situation.
![]()
@ericwj a related request was discussed (…) design guidelines (…)
This too is not an API proposal.
I’d be fine with error codes, preferably the most reasonable ones defined in an enum while there is a whole series of errors for which its fine to still throw in this case, too — like out of memory, etc. but also say invalid characters for the current JavaScript decoder.
Other than that, for the use case at the start of the article, all that would be needed is bool TryDeserialize<T> which returns false only in one or two specific cases, primarily when there is not enough data available.
The benefit of the former variant would be that much higher levels of customizations can be achieved at very high performance. Would still need to instruct it to succeed without error if all that is wrong is that data follows the JSON, whatever how long the valid part is.
![]()
Given the scenario where you just want a single value, I’d probably take the approach of passing in a JsonPath (e.g. «$.MyObject.MyPropertyToReturn» to a helper like:
static async Task<byte[]> GetJsonFromPath(Stream utf8Json, string jsonPath, JsonSerializerOptions options); // Return the raw bytes to be deserialized in any way (serializer, node, element)
or a helper that directly deserializes those bytes using the serializernodeelement which will avoid an extra byte[] allocation:
static async Task<TValue> GetValueFromPath(Stream utf8Json, string jsonPath, JsonSerializerOptions options); // Return the value from the serializer.
Similar JsonPath functionality was proposed with #31068 and also in #55827 where I said I’ll provide a sample to do this with V6 code, however Stream+SingleValue wasn’t mentioned (which complicates things).
Some options for Stream:
- Drain: drain the Stream to the end, like the existing implementation for JsonDocumentJsonElementNode. Not performant if there is a bunch of data past the requested JsonPath.
- Single-use: read from the Stream only to the requested value (plus whatever the Stream reads to fill up the current smallish buffer) and then assume the Stream will be disposed. Since there will likely be some read but unprocessed bytes after the requested JSON value, it wouldn’t be possible to do another ReadAsync on the Stream again to perform another SerializeDeserialize since the unprocessed bytes are no longer known by the Stream.
- Multiple-use: extend Single-use to support multiple SerializeDeserialize by keeping track of the unprocessed bytes. One way to support that is to add a «JsonCursor» abstraction that can be used with new SerializeDeserialize methods. JsonCursor would contain a reference to the Stream and maintain the reader and unprocessed bytes for multiple calls to SerializeDeserialize.
All options would have minimal processing of the unneeded values — e.g. values that are not the target JsonPath will not be deserialized.
I can work on the sample now if there’s interest, but would like to know if «drain» is acceptable or not.
![]()
No thank you @steveharter, repeatedly parsing is unacceptable for the problems described in this issue and in #33030.
![]()
OK I’ll work on a prototype; since it involves async+Stream the prototype may need to change internal STJ code instead of just an add-on sample.
![]()
msftbot
bot
locked as resolved and limited conversation to collaborators
Dec 1, 2021
APAR status
-
Closed as fixed if next.
Error description
-
Customer attempts Live Update on a PowerHA cluster node where a Resource Group with VGs is not Online. (The VGs will be varyonvg concurrent passive.) The LKU fails with messages like this -- Moving workload to surrogate LPAR. 1430-030 An error occurred while moving the workload. 1430-045 The live update operation failed. Cleanup action is started.
Local fix
-
n/a
Problem summary
-
Customer attempts Live Update on a PowerHA cluster node where a Resource Group with VGs is not Online. (The VGs will be varyonvg concurrent passive.) The LKU fails with messages like this Moving workload to surrogate LPAR. 1430-030 An error occurred while moving the workload. 1430-045 The live update operation failed. Cleanup action is started.
Problem conclusion
Temporary fix
Comments
APAR Information
-
APAR number
IJ30405
-
Reported component name
POWERHA SYSMIR
-
Reported component ID
5765H3900
-
Reported release
723
-
Status
CLOSED FIN
-
PE
NoPE
-
HIPER
NoHIPER
-
Submitted date
2021-01-20
-
Closed date
2021-01-20
-
Last modified date
2021-01-20
-
APAR is sysrouted FROM one or more of the following:
IJ29044
-
APAR is sysrouted TO one or more of the following:
Fix information
-
Fixed component name
POWERHA SYSMIR
-
Fixed component ID
5765H3900
Applicable component levels
[{«Business Unit»:{«code»:»BU058″,»label»:»IBM Infrastructure w/TPS»},»Product»:{«code»:»SSLM9V»,»label»:»PowerHA SystemMirror Standard Edition for AIX»},»Platform»:[{«code»:»PF053″,»label»:»Power Systems»}],»Version»:»723″,»Line of Business»:{«code»:»LOB57″,»label»:»Power»}}]