Доброго дня.
Есть два WinServer2012Std (назовем их SRV1 и SRV2) работающие в качестве файловых помоек (шары опубликованы в DFS).
Задача — с помощью DFSR синхронизировать файлы в шарах с SRV1 на SRV2.
С помощью визардов DFSR создаю RG для одной из шар на SRV1, добавляю в качестве мембера SRV2.
Жду.
Через некоторое время в логах на SRV1 (primary):
Event id: 4004
The DFS Replication service stopped replication on the replicated folder at local path J:Share.
Additional Information:
Error: 9098 (A tombstoned content set deletion has been scheduled)
Additional context of the error:
Replicated Folder Name: Share
Replicated Folder ID: 0DFEB6CD-079B-4D60-839C-3F9F5E4BE9DA
Replication Group Name: Share
Replication Group ID: 8EE984AA-BD49-4901-B52D-CA74D7956DF8
Member ID: 501BAC61-55FC-48F2-97EB-38A702C353A5
В то же время с другой стороны на SRV2 вижу:
Event id: 4102
The DFS Replication service initialized the replicated folder at local path
J:Share and is waiting to perform initial replication. The replicated folder will remain in this state until it has received replicated data, directly or indirectly, from the designated primary member.
Additional Information:
Replicated Folder Name: Share
Replicated Folder ID: 0DFEB6CD-079B-4D60-839C-3F9F5E4BE9DA
Replication Group Name: Share
Replication Group ID: 8EE984AA-BD49-4901-B52D-CA74D7956DF8
Member ID: C2FD8726-FF60-4DBF-A085-462A0A0C3747
Все. Более ничего не происходит.
Вопрос — как запустить процесс репликации?
Содержание
- Dfs replication error 9098
- Вопрос
- Dfs replication error 9098
- Answered by:
- Question
- Answers
- All replies
- Dfs replication error 9098
- Вопрос
- Dfs replication error 9098
- Answered by:
- Question
- Answers
- All replies
- Dfs replication error 9098
- Вопрос
Dfs replication error 9098
![]()
Вопрос
![]()
![]()
Есть два WinServer2012Std (назовем их SRV1 и SRV2) работающие в качестве файловых помоек (шары опубликованы в DFS).
Задача — с помощью DFSR синхронизировать файлы в шарах с SRV1 на SRV2.
С помощью визардов DFSR создаю RG для одной из шар на SRV1, добавляю в качестве мембера SRV2.
Через некоторое время в логах на SRV1 (primary):
Event id: 4004
The DFS Replication service stopped replication on the replicated folder at local path J:Share.
Additional Information:
Error: 9098 (A tombstoned content set deletion has been scheduled)
Additional context of the error:
Replicated Folder Name: Share
Replicated Folder ID: 0DFEB6CD-079B-4D60-839C-3F9F5E4BE9DA
Replication Group Name: Share
Replication Group ID: 8EE984AA-BD49-4901-B52D-CA74D7956DF8
Member ID: 501BAC61-55FC-48F2-97EB-38A702C353A5
В то же время с другой стороны на SRV2 вижу:
Event id: 4102
The DFS Replication service initialized the replicated folder at local path J:Share and is waiting to perform initial replication. The replicated folder will remain in this state until it has received replicated data, directly or indirectly, from the designated primary member.
Additional Information:
Replicated Folder Name: Share
Replicated Folder ID: 0DFEB6CD-079B-4D60-839C-3F9F5E4BE9DA
Replication Group Name: Share
Replication Group ID: 8EE984AA-BD49-4901-B52D-CA74D7956DF8
Member ID: C2FD8726-FF60-4DBF-A085-462A0A0C3747
Все. Более ничего не происходит.
Вопрос — как запустить процесс репликации?
Источник
Dfs replication error 9098
This forum has migrated to Microsoft Q&A. Visit Microsoft Q&A to post new questions.
Answered by:
![]()
Question
![]()
![]()
Most of the fixes are to go into SysVol and Delete the DFSR Database.
Though I’m not ready to do that as its not Specific to the replica folder that is having the issue. I have three Replica Groups on the server and one works perfectly, one has 1/2 its folders in some funny state and the other 1/2 are fine. So wiping out the Database on Replica sets and folders that are working seems odd thing to do.
Is there no way to repair the DB for the folders that are not cooperating? I’ve tries removing them and then readding them (Same Name as the name is used for Namespace too) and that didn’t help.
Answers
![]()
![]()
Thanks for your reply.
According to your scenairo involve large data. You might consider to use following step to remove the data on the non replicating server and rename the folder to have a try.
- Backup Data
- Delete the replication group
- Force AD replication
- dfsrdiag pollad
- Confirm in the DFS Replication Events that there is an event 4010 stating that the replication folder has been removed.
- Rename the replicated folder in Explorer to something else
- Create a new folder which will be the new replication folder
- re enable replication between servers ensuring the correct server is set to Primary
- dfsrdiag pollad
- Monitor logs and resource monitor disk activity on the source and destination servers to confirm replication is occurring
Please refer to the article below.
Please Note: Since the web site is not hosted by Microsoft, the link may change without notice. Microsoft does not guarantee the accuracy of this information.
If it still doesn’t work, I’m afraid that you might need to consider to reset database.
Please remember to mark the replies as answers if they help and unmark them if they provide no help. If you have feedback for TechNet Subscriber Support, contact tnmff@microsoft.com.
![]()
![]()
Thanks for your post.
Could you please try with steps below to reset database on failed server:
1. Remove the failed server from replication group. Perform an AD replication to replicate the change to all members before adding it back to replication group.
2. Go to the failed server, in Windows Explorer please open the specific drive stored replicated folders.
3. Right click on the «System Volume Information» directory and select PropertiesSecurity
Note: You might need to select the option for «Show hidden files, folders or drives» and also uncheck «Hide protected operating system files» in the folders view options to be able to even see the «System Volume Information» directory.
4. Grant your user account that you’re logged in with (if a member of Administrators group this will also suffice) «Full Control» to the «System Volume Information» directory.
Note: You may get an error on setting security on some files — this is expected.
5. Open an elevated/Administrative command prompt. Switch to the » :System Volume Information» directory
6. Type the command «rmdir DFSR /s»
7. Add it back to replication group. Some files are still exist so it will not perform a full replication but just the changed ones. See if the issue could be fixed.
Please also refer to the thread discussed before.
Источник
Dfs replication error 9098
![]()
Вопрос
![]()
![]()
Есть два WinServer2012Std (назовем их SRV1 и SRV2) работающие в качестве файловых помоек (шары опубликованы в DFS).
Задача — с помощью DFSR синхронизировать файлы в шарах с SRV1 на SRV2.
С помощью визардов DFSR создаю RG для одной из шар на SRV1, добавляю в качестве мембера SRV2.
Через некоторое время в логах на SRV1 (primary):
Event id: 4004
The DFS Replication service stopped replication on the replicated folder at local path J:Share.
Additional Information:
Error: 9098 (A tombstoned content set deletion has been scheduled)
Additional context of the error:
Replicated Folder Name: Share
Replicated Folder ID: 0DFEB6CD-079B-4D60-839C-3F9F5E4BE9DA
Replication Group Name: Share
Replication Group ID: 8EE984AA-BD49-4901-B52D-CA74D7956DF8
Member ID: 501BAC61-55FC-48F2-97EB-38A702C353A5
В то же время с другой стороны на SRV2 вижу:
Event id: 4102
The DFS Replication service initialized the replicated folder at local path J:Share and is waiting to perform initial replication. The replicated folder will remain in this state until it has received replicated data, directly or indirectly, from the designated primary member.
Additional Information:
Replicated Folder Name: Share
Replicated Folder ID: 0DFEB6CD-079B-4D60-839C-3F9F5E4BE9DA
Replication Group Name: Share
Replication Group ID: 8EE984AA-BD49-4901-B52D-CA74D7956DF8
Member ID: C2FD8726-FF60-4DBF-A085-462A0A0C3747
Все. Более ничего не происходит.
Вопрос — как запустить процесс репликации?
Источник
Dfs replication error 9098
This forum has migrated to Microsoft Q&A. Visit Microsoft Q&A to post new questions.
Answered by:
![]()
Question
![]()
![]()
Most of the fixes are to go into SysVol and Delete the DFSR Database.
Though I’m not ready to do that as its not Specific to the replica folder that is having the issue. I have three Replica Groups on the server and one works perfectly, one has 1/2 its folders in some funny state and the other 1/2 are fine. So wiping out the Database on Replica sets and folders that are working seems odd thing to do.
Is there no way to repair the DB for the folders that are not cooperating? I’ve tries removing them and then readding them (Same Name as the name is used for Namespace too) and that didn’t help.
Answers
![]()
![]()
Thanks for your reply.
According to your scenairo involve large data. You might consider to use following step to remove the data on the non replicating server and rename the folder to have a try.
- Backup Data
- Delete the replication group
- Force AD replication
- dfsrdiag pollad
- Confirm in the DFS Replication Events that there is an event 4010 stating that the replication folder has been removed.
- Rename the replicated folder in Explorer to something else
- Create a new folder which will be the new replication folder
- re enable replication between servers ensuring the correct server is set to Primary
- dfsrdiag pollad
- Monitor logs and resource monitor disk activity on the source and destination servers to confirm replication is occurring
Please refer to the article below.
Please Note: Since the web site is not hosted by Microsoft, the link may change without notice. Microsoft does not guarantee the accuracy of this information.
If it still doesn’t work, I’m afraid that you might need to consider to reset database.
Please remember to mark the replies as answers if they help and unmark them if they provide no help. If you have feedback for TechNet Subscriber Support, contact tnmff@microsoft.com.
![]()
![]()
Thanks for your post.
Could you please try with steps below to reset database on failed server:
1. Remove the failed server from replication group. Perform an AD replication to replicate the change to all members before adding it back to replication group.
2. Go to the failed server, in Windows Explorer please open the specific drive stored replicated folders.
3. Right click on the «System Volume Information» directory and select PropertiesSecurity
Note: You might need to select the option for «Show hidden files, folders or drives» and also uncheck «Hide protected operating system files» in the folders view options to be able to even see the «System Volume Information» directory.
4. Grant your user account that you’re logged in with (if a member of Administrators group this will also suffice) «Full Control» to the «System Volume Information» directory.
Note: You may get an error on setting security on some files — this is expected.
5. Open an elevated/Administrative command prompt. Switch to the » :System Volume Information» directory
6. Type the command «rmdir DFSR /s»
7. Add it back to replication group. Some files are still exist so it will not perform a full replication but just the changed ones. See if the issue could be fixed.
Please also refer to the thread discussed before.
Источник
Dfs replication error 9098
![]()
Вопрос
![]()
![]()
Есть два WinServer2012Std (назовем их SRV1 и SRV2) работающие в качестве файловых помоек (шары опубликованы в DFS).
Задача — с помощью DFSR синхронизировать файлы в шарах с SRV1 на SRV2.
С помощью визардов DFSR создаю RG для одной из шар на SRV1, добавляю в качестве мембера SRV2.
Через некоторое время в логах на SRV1 (primary):
Event id: 4004
The DFS Replication service stopped replication on the replicated folder at local path J:Share.
Additional Information:
Error: 9098 (A tombstoned content set deletion has been scheduled)
Additional context of the error:
Replicated Folder Name: Share
Replicated Folder ID: 0DFEB6CD-079B-4D60-839C-3F9F5E4BE9DA
Replication Group Name: Share
Replication Group ID: 8EE984AA-BD49-4901-B52D-CA74D7956DF8
Member ID: 501BAC61-55FC-48F2-97EB-38A702C353A5
В то же время с другой стороны на SRV2 вижу:
Event id: 4102
The DFS Replication service initialized the replicated folder at local path J:Share and is waiting to perform initial replication. The replicated folder will remain in this state until it has received replicated data, directly or indirectly, from the designated primary member.
Additional Information:
Replicated Folder Name: Share
Replicated Folder ID: 0DFEB6CD-079B-4D60-839C-3F9F5E4BE9DA
Replication Group Name: Share
Replication Group ID: 8EE984AA-BD49-4901-B52D-CA74D7956DF8
Member ID: C2FD8726-FF60-4DBF-A085-462A0A0C3747
Все. Более ничего не происходит.
Вопрос — как запустить процесс репликации?
Источник
Content freshness is a fairly key concept in the life of an Active Directory/DFS guru. Most of us have seen this in action with AD replication, for example. If two DC’s aren’t replicating then at
best the AD objects & attributes are out of sync and at
worst replication will shut down completely when the disconnect continues beyond the tombstone lifetime. Systematically determining which changes should be applied becomes impossible or even problematic (think: lingering objects in this example) the longer the timeline. The fundamental idea is that directory data needs to stay fresh. If it’s been too long since the data has been synchronized it’s best to just discontinue replication. The same is true for DFS.
Let’s say there are two servers in a Replication Group called Server1 and Server2. When a DFS Replication group falls out of sync, changes are still being made to the files on both servers. So how do we keep track of them? In the short run, those changes can be queued up in the Staging Area of both servers and will be replicated when the communications issue is past. But what if that outage is prolonged? You could have a document on Server 1 where the file is deleted, the deletion doesn’t replicate, and meanwhile on Server2 edits continue to be made to that file. What’s DFS gonna do if the members of the DFS Replication group actually do see one another again? Does this sound familiar? It’s like the DFS version of a lingering object! In other words, content freshness is a critical aspect of replication. If the content gets stale enough – like in this scenario – you actually don’t want it to replicate. In response Microsoft’s code sets replication thresholds and shuts it down for you. In so doing, they’ve saved us from ourselves. For an even deeper dive on this, and put much more eloquently than I ever could, here is a post from the official DS Team blog on the subject – http://blogs.technet.com/b/askds/archive/2009/11/18/implementing-content-freshness-protection-in-dfsr.aspx
So what do we do if we find ourselves in this predicament???? That’s probably the reason you’re here at our blog. You’ve likely seen an event 4004 in the DFSR log that shows an error 9098 and makes the statement “A tombstoned content set deletion has been scheduled.” Content freshness is the reason this has occurred. AFTER fixing the root cause of the blockage (firewalls, DFSR in dirty shutdown, etc.) here are some options on how to get things back up and running:
Solution1: Follow the Recovery Procedure in the aforementioned DS blog post.
The specifics are already in the link. However, at a high level this essentially boils down to:
- Get a backup
- Disabling the affected member in the RG
- Force AD replication
- Enable DFS Replication again on the member.
- Force AD replication.
- The node will then go through initial sync again where it catalogs the files in the jet, so you’ll need to wait for that to complete before letting users back in.
As further evidence that this is a good course to follow, if you happen to see a 4012 in the DFSR log it suggests the very same. Picture below.

Solution2: Recreate the Replication Group. Best to consider this a second option to Solution1.
- Get a backup of the Replicated Folder on both/all nodes.
- In the DFS Console, delete the Replication Group

- Force AD Replication.

- From an elevated command prompt run DFSRDiag pollad on each of the former Replication Group members.

-
On each (former)member of the RG, delete the hidden DFSRPrivate folder.
- This holds the Staging and ConflictAndDeleted folders. You may want/need to restore some of this from backup after all is said and done if the authoritative server’s copy of the file isn’t actually the one you want.
- Where is this???? It’s in the Replicated folder. If the Replicated Folder is e:homes, then from a command prompt you can see it from e:homesdfsrprivate. You’ll need to unhide system files in order to see it in Windows Explorer.

- Recreate the Replication Group in the DFSR Console.
- DFSRDIAG pollad from each RG member, so it picks up the new configuration from Active Directory.
- This will kick off an initial sync on the Replication Group, which is going to take some time. You won’t want to let the users back in until this is complete. Keeping checking the DFSR log for a 4104 which indicates this is finished.

- As the event suggests, check the PreExisting & ConflictAndDeleted folders for any fallout and don’t be afraid to check the backups for a more relevant version of files from the old Staging folders.
Hopefully this help fill in your understanding of content freshness and why in certain circumstances the Microsoft code is actually built to halt replication. Getting out of this jam isn’t perfect and often data can be lost. However this builds the perfect business case for why you need a tool to help you monitor DFSR.
Hello,
We are getting this error on one of our DFSR shares and am not sure how to get this fixed. We have over 30 different shares replicating and all of them are fine except for one. I have tried to remove the Replication and the namespace and have recreated them
both and continue to get the same error. This is what is in the event logs on the server;
The DFS Replication service stopped replication on the replicated folder at local path E:SHARESharelocation.
Additional Information:
Error: 9098 (A tombstoned content set deletion has been scheduled)
Additional context of the error:
Replicated Folder Name: Sharelocation
Replicated Folder ID: 9BDA3E5A-8103-481F-84B2-269AE8A3BBC8
Replication Group Name: SHARE
Replication Group ID: C25E73B7-5B65-4299-A1BE-76E723443B02
Member ID: 568CC517-3329-42A4-ABAD-633CB3D1EF2E
If anyone has any suggestion on how to get this working again it would be greatly appreciated.
Here is a short summary of what I did:
Look in Event Viewer and identify all the replication groups/folders that are giving the tombstone error. Once you have them identified, go into DFS Management GUI and completely delete the replication group
associated with that folder. You do not need to delete the DFS Namespace for that folder, just the replication functionality of that namespace folder. If you have other replication groups in your DFS-R that do not get the 9098 errors, then you do not have
to do this for these folders.
Stop DFSR services (you may need to kill the service using the taskkill command if it hangs when it tries to stop).
Give yourself permissions to the hidden System Volume Information folder. If you’re account is under the domain admins group, you can simply add the security group.
This folder exists on all servers that is a member of the replication group. In my situation, 2 of the 3 servers didn’t show this folder as existing even when I enabled to see hidden folders. If this happens to you,
the server is lying to you that it’s not there. It is there. Don’t listen to it. My suggestion is to download and use the 7-zip file manager. It will see the folder and will help you set the permissions to
it as well as delete files that are longer than 256 characters, which is an issue if you do the next step from the command line).
Note, after you set the permissions, it might tell you that you still don’t have access to that folder. Just close out of 7-zip and open it back up. It should let you in that folder as well as its subfolders.
Once you have access to that folder, go ahead and delete the DFSR folder that resides underneath it. You will want to do this on all servers that has the DFSR role installed and is a member to any replication
groups. You can use the command line command «rmdir», but it fails to delete files/folders that are longer than 256 characters. This is why the 7-zip file manager is a better option to delete the DFSR folder under System Volume Information. However,
there are instances where 7-zip is unable to delete a file or folder. If you run in that scenario, use the rmdir command in an elevated command prompt. Essentially, a combination of these two will eventually clear out everything you need to clear out.
Turn DFSR services back on. This will begin the process of recreating the DFSR hash and virtual tree that you had just deleted.
Recreate the replication group that you want.
On the replication groups that you did not delete, you may get the warning: «The DFS Replication service initialized the replicated folder at local path <path> and is waiting to perform initial
replication. The replicated folder will remain in this state until it has received replicated data, directly or indirectly, from the designated primary member.»
If you do, what you need to do is run the command line to set one of the DFSR servers as the primary server for that replication group, and then once set — this
is important — you will have to go in the DFS Management GUI, click on the replication group with the associated warning, select the connections tab, and then right click the the sending member that
you just made as primary and choose «Replicate now…» This will initialize the replication and you will have to do this just that once for it to replicate here on out. You will need to do choose the «Replicate now…» option for each receiving
member that the sending member/primary member server is attached to in that replication group.
Wait about 5-10 minutes and run the dfsrdiag backlog command on each replicationgroup and see if a backlog for replication/sync gets created. Run this command each 5 to 10 minutes to see if the backlog file count value decreases. If it does, it’s syncing/replicating.
Don’t forget that when testing replication, you cannot create test files via the local path and see if it replicates. You must create it in the DFS Namespace (domainfoldershare) to see if replication works. Otherwise
you get false negatives and you think replication is still broken. Just an FYI.
Similar Messages
-
I still distribute most FCP projects via DVD. No matter which MPEG2 setting I use in Compressor 4 I get an error — even Apple’s default DVD setting. Has anybody successfully output an FCP X project to compressor and then out on a DVD?
I still distribute most FCP projects via DVD. No matter which MPEG2 setting I use in Compressor 4 I get an error — even Apple’s default DVD setting. Has anybody successfully output an FCP X project to compressor and then out on a DVD?
Anthony, thank you very much — this works, though I thought I had tried your process previously without success. I’ve tried so many things who knows. I’ve had zero luck going with the Send to Compressor or Export Using Compressor Settings under the Share menu. I’m also finding Compressor 4 to be a real dog on my system even though I have a brand new quad core machine with 8G of RAM. Prior to receiving your post I did come up with a different work process. Using Export Movie from FCP X and then loading the result in Compressor 3 works flawlessly. Thanks again!
-
Error occurred in deployment step ‘Activate Features’:EXCEPTION HAS BEEN THROWN BY THE TARGET OF AN INVOCATION?
Hi All,
While building event handler to call webservice facing «Error occurred in deployment step ‘Activate Features’:EXCEPTION HAS BEEN THROWN BY THE TARGET OF AN INVOCATION»; If comment webservice, then build successfully. How to fix this issue?
Thanks in advance!hi
if you call WCF service in feature event receiver you need to ensure that proxy is properly configured. In most cases proxy is configured via web.config file using <system.serviceModel> section, but if it is used in feature receiver it depends on how
you activate the feature:
1. if feature is added to onet.xml of custom web template which is used for creating site collection from Central Administration you will need to modify web.config file of CA
2. similar to previous but instead of site collection you try to create sub site using custom web template: in this case you will need to modify web.config of your Sharepoint web application
3. if you activate feature from timer job somehow, you will need to modify owstimer.exe.config
4. if you activate feature form powershell, most probably you will need to modify or create powershell.exe.config, but I didn’t try it
The most simple way which will work in all cases is to configure WCF proxy programmatically. See the following forum thread for details:
How can I set an HTTP Proxy (WebProxy) on a WCF client-side Service proxy.
Blog — http://sadomovalex.blogspot.com
Dynamic CAML queries via C# — http://camlex.codeplex.com -
HT1338 What’s going on with iCloud (MobileMe)? I’m able to sign in here, but I can’t access mail on my Macbook Pro, iPhone, or work computer. I always get an authorization error (user-id or passwork wrong). This has been going on for almost a week now.
What’s going on with iCloud (MobileMe)? I’m able to sign in here, but I can’t access mail on my Macbook Pro, iPhone, or work computer. I always get an authorization error (user-id or passwork wrong). This has been going on for almost a week now.
The single download means that you won’t be able to redownload it from the store without paying, either on a computer’s iTunes or an iOS device — it doesn’t stop you from copying the audiobook to your other computers or syncing it to your iOS devices, you just can’t redownload it. (I believe that they are all supplied to Apple by audible.com, so I assume that it’s them requiring the one-time download.)
You can download audiobooks on your computer’s iTunes and sync them to iOS devices, you do not have to buy them directly on the device (if you do then you can copy them back to your computer’s iTunes library by connecting the device and using the File > Devices > Transfer Purchases menu option on your computer’s iTunes).
What you are doing to sync them should work i.e.
— connecting the iPad to your Mac
— selecting the iPad on your Mac’s iTunes
— selecting its Books tab and selecting the audiobooks that you want to sync to the iPad and syncing/applying that selection.
You should then get an audiobooks option in the Music app on your iPad. If they aren’t appearing there then do they show in Settings > General > Usage > Music on the device — if you have audiobooks on the iPad then they should be listed there under an ‘audiobooks’ heading.
By ‘restart the iPad’ do you mean a soft-reset : press and hold both the sleep and home buttons for about 10 to 15 seconds (ignore the red slider), after which the Apple logo should appear — you won’t lose any content, it’s the iPad equivalent of a reboot.
You could also try closing its Music app via the iPad’s taskbar : Force an app to close in iOS.
And do a soft-reset and retry syncing.
I assume that music and other items sync ok ? -
Permissions repair: SUID file system/library/coreservices/remotemanagement/ARDAgent/contents/MacOS/ARDAgent has been modified and will not be repaired
I have a mid 2007 iMac running OS Mavericks and the hard drive is failing. When doing a disk permissions verify it shows SUID file system/library/coreservices/remotemanagement/ARDAgent/contents/MacOS/ARDAgent has been modified and will not be repaired. I do not have a backup of my system due to my external drive I use for backing up my system has stopped working. Can I repair this myself without having to reinstall the OS so I don’t loose my any of my files.
You can safely ignore that.
Disk Utility’s Repair Disk Permissions messages you can safely ignore -
HT201317 I have placed photos in my Photo Stream on my Vista PC, but cannot see them on my iPad or iMac — all set up has been done on each device. Help!
I have placed photos in my Photo Stream on my Vista PC, but cannot see them on my iPad or iMac — all set up has been done on each device. Help!
Are you putting the photos in the Uploads folder on your PC.
-
When user click «My Site clicking My Content states: There has been an error creating the personal site. etc
Hello community
Using Sharepoint 2010 Server and the UI on its intranet there is a My Site. After creating the My Site the user account that created the intranet easily can create it’s My Site, My Content and My profile. But when I logon as
a user
when I try to create the My site I get an error stating» «There has been an error creating the personal site. Contact your site administrator for more information». In the Event viewer log pasted below it says: A failure was encountered
and User cannot be found. So I check the UPS Synchronization and I can find the username in UPS «Manage User Profile» and I can logon with the username I just can’t create the My Content after clicking My Site. The funny
thing is if I click My Profile the My Profile page appears (although it is a one-way trust relationship if I use «Check Names» when I try to «Add User» to a group an error message appears stating «No match found. etc). So the
question is how come the account that created the intranet can create
My Site and create My Profile and My Content but if a regular user account logs on and clicks My Site, My Profile and get a page but clicking My Content produces that error that says: «There has been an error creating the personal site. Contact
your site administrator for more information». (Note: The output from Event Viewer is posted below)?
Thank you
Shabeaut
Log Name: Application
Source: Microsoft-SharePoint Products-SharePoint Portal Server
Date: 7/24/2014 4:51:42 PM
Event ID: 5187
Task Category: Administration
Level: Error
Keywords:
User: NT AUTHORITYIUSR
Computer: <ServerName>.<FullQualifiedDomainName>
Description:
My Site creation failure for user ‘<DomainName><UserName>’ for site url ‘http://<MySiteHostUrl>/personal/<DomainName><UserName>’. The exception was: Microsoft.Office.Server.UserProfiles.PersonalSiteCreateException: A failure
was encountered while attempting to create the site. —> Microsoft.SharePoint.SPException: User cannot be found.
at Microsoft.SharePoint.Administration.SPSiteCollection.Add(SPContentDatabase database, SPSiteSubscription siteSubscription, String siteUrl, String title, String description, UInt32 nLCID, String webTemplate, String ownerLogin, String ownerName,
String ownerEmail, String secondaryContactLogin, String secondaryContactName, String secondaryContactEmail, String quotaTemplate, String sscRootWebUrl, Boolean useHostHeaderAsSiteName)
at Microsoft.SharePoint.SPSite.SelfServiceCreateSite(String siteUrl, String title, String description, UInt32 nLCID, String webTemplate, String ownerLogin, String ownerName, String ownerEmail, String contactLogin, String contactName, String contactEmail,
String quotaTemplate, SPSiteSubscription siteSubscription)
at Microsoft.Office.Server.UserProfiles.UserProfile.<>c__DisplayClass2.<CreateSite>b__0()
— End of inner exception stack trace —
at Microsoft.Office.Server.UserProfiles.UserProfile.<>c__DisplayClass2.<CreateSite>b__0()
at Microsoft.SharePoint.SPSecurity.<>c__DisplayClass4.<RunWithElevatedPrivileges>b__2()
at Microsoft.SharePoint.Utilities.SecurityContext.RunAsProcess(CodeToRunElevated secureCode)
at Microsoft.SharePoint.SPSecurity.RunWithElevatedPrivileges(WaitCallback secureCode, Object param)
at Microsoft.SharePoint.SPSecurity.RunWithElevatedPrivileges(CodeToRunElevated secureCode)
at Microsoft.Office.Server.UserProfiles.UserProfile.CreateSite(String strRequestUrl, Boolean bCollision, Int32 lcid).
Event Xml:
<Event xmlns=»http://schemas.microsoft.com/win/2004/08/events/event»>
<System>
<Provider Name=»Microsoft-SharePoint Products-SharePoint Portal Server» Guid=»{8b3ddd3d-2b09-4669-bf81-e2d6921feeea}» />
<EventID>5187</EventID>
<Version>14</Version>
<Level>2</Level>
<Task>1</Task>
<Opcode>0</Opcode>
<Keywords>0x4000000000000000</Keywords>
<TimeCreated SystemTime=»2014-07-24T20:51:42.494Z» />
<EventRecordID>33776</EventRecordID>
<Correlation ActivityID=»{BC4FAAA6-FA5B-4309-8C2E-0639F5BAC567}» />
<Execution ProcessID=»9600″ ThreadID=»9520″ />
<Channel>Application</Channel>
<Computer><ServerName>.<FullQualifiedDomainName></Computer>
<Security UserID=»S-1-5-17″ />
</System>
<EventData>
<Data Name=»string0″><DomainName><UserName></Data>
<Data Name=»string1″>’http://<MySiteHostUrl>/personal/<DomainName><UserName>'</Data>
<Data Name=»string2″>Microsoft.Office.Server.UserProfiles.PersonalSiteCreateException: A failure was encountered while attempting to create the site. —> Microsoft.SharePoint.SPException: User cannot be found.
at Microsoft.SharePoint.Administration.SPSiteCollection.Add(SPContentDatabase database, SPSiteSubscription siteSubscription, String siteUrl, String title, String description, UInt32 nLCID, String webTemplate, String ownerLogin, String ownerName,
String ownerEmail, String secondaryContactLogin, String secondaryContactName, String secondaryContactEmail, String quotaTemplate, String sscRootWebUrl, Boolean useHostHeaderAsSiteName)
at Microsoft.SharePoint.SPSite.SelfServiceCreateSite(String siteUrl, String title, String description, UInt32 nLCID, String webTemplate, String ownerLogin, String ownerName, String ownerEmail, String contactLogin, String contactName, String contactEmail,
String quotaTemplate, SPSiteSubscription siteSubscription)
at Microsoft.Office.Server.UserProfiles.UserProfile.<>c__DisplayClass2.<CreateSite>b__0()
— End of inner exception stack trace —
at Microsoft.Office.Server.UserProfiles.UserProfile.<>c__DisplayClass2.<CreateSite>b__0()
at Microsoft.SharePoint.SPSecurity.<>c__DisplayClass4.<RunWithElevatedPrivileges>b__2()
at Microsoft.SharePoint.Utilities.SecurityContext.RunAsProcess(CodeToRunElevated secureCode)
at Microsoft.SharePoint.SPSecurity.RunWithElevatedPrivileges(WaitCallback secureCode, Object param)
at Microsoft.SharePoint.SPSecurity.RunWithElevatedPrivileges(CodeToRunElevated secureCode)
at Microsoft.Office.Server.UserProfiles.UserProfile.CreateSite(String strRequestUrl, Boolean bCollision, Int32 lcid)</Data>
</EventData>
</Event>Make sure you enable self service site creation on the MySite web application via CA
http://technet.microsoft.com/en-us/library/cc261685(v=office.14).aspx
You mentioned trusts and people picker. I am having a bit of trouble understanding the exact issue here, but is the issue also coming up that the user in question cannot be found with people picker?
searchadforest setting to make sure SP can reach to trusted domains to find users.
«When a Web application uses Windows authentication, People Picker searches all two-way trusted forests and all two-way trusted domains. However, if you want to search from a one-way trusted forest or a one-way trusted domain, you must run the
setapppassword operation, and then run the peoplepicker-searchadforests
property.»
http://technet.microsoft.com/en-us/library/cc262051(v=office.12).aspx
http://technet.microsoft.com/en-us/library/cc263460(v=office.12).aspx
Christopher Webb | MCM: SharePoint 2010 | MCSM: SharePoint Charter | MCT | http://christophermichaelwebb.com -
Error when build cube — A duplicate attribute key has been found when processing…
Hi all,
I got an error “Errors in the OLAP storage engine: A duplicate attribute key has been found when processing: Table…” when built new cube. It looks strange in my case. I created a small example to re-produce this error as below:
I create a data source table as below
AgencyName(varchar(50))——MediaSpend(float)
OE————————————100
Œ————————————-200
Then I create a cube base on this data source with a dimension AgencyName and 1 Measure MediaSpend.
The error happened again. This look link a special case when ‘OE’ and ‘Œ’ existed in a dimension.
Do you have any ideas on this?
Thanks,Hi khoana,
Here is a similar thread about this topic for your reference, please see:
A duplicate attribute key has been found when processing:
http://social.technet.microsoft.com/Forums/en-US/sqlanalysisservices/thread/7c72639b-a050-4243-9f1d-4da906e981d5/
Regards,
Elvis Long
TechNet Community Support -
ERROR — Select a location to which a plant has been assigned
1 Message
Select a location to which a plant has been assigned (Item BOLT&NUT 4.6 COMM HEX HEAD BLK 10X170MM )
this is the error message I get any idea how to fix it?
Cheers
BHi. I presume the plants are linked correctly to the new company code in the backend, table T001K?
Also, check the entries in SRM in table BBP_LOCMAP.
Are the plants assigned to the right company codes in this table?
There is an issue if you replicate plants to SRM then change the company code assignment SRM does not get updated.
To correct BBP_LOCMAP you can use function BBP_CHANGE_ORGANIZATION.
Regards,
Dave. -
Error in virtual machine event log «disk 1 has been surprise removed»
I have setup hyper-v server 2012 on my server. there is only 1 VM running with 4 GB ram & 1.5 TB expanding hard drive.
I have found error in guest os «disk 1 has been surprise removed»
can any one tell me what is this error exactly. after this error i have checked hyper-v manager & found machine is showing
«Merge In Progress»
i never saw «disk 1 has been surprise removed»
error. is this error occur because of hyper-v server is not configured properly.
Also i have server 2008 R2 DC x64 which is working as hyper-v host. I have checked event logs of same and found following error.
«The disk signature of disk 2 is equal to the disk signature of disk 1.»
what is this.
Akshay PateI use CA-ArcServer Backup. Their technical support just verified this «warning» can be ignored.
This applies to 2008 — 2012R2. The warning is from VSS. You can disable VSS to stop the warnings, but be forewarned you will cause system instability by disabling VSS.
This is caused by the backup process (specifically imaging) that runs with CA-ArcServe and Windows Backup (and probably others). For CA-ArcServer, you can disregard the other event that coincides with the event id: 157.
I also verified my backups are working, did a file/folder restore test, and restored some emails (I run Exchange 2013 SP1 on this 2012R2 server too), which all worked fine and these restores also caused the 157 warnings.
Hope this eases someone’s mind. I get all edgy when I see errors I do not recognize or have never seen before. -
Error reads as «no stock in returns, line has been processed check mb51»
Hello Experts,
I am getting an error «no stock in returns, line has been processed check mb51» while processing the returns delivery and no material document exists in MB51 after PGI. Can anyone suggest whats missing or wrong ?
regards, sunnyHi,
Go to VL02N and check the Goods Movement Status for the Delivery under «Status» Tab. It should be C i.e. Completed. If it is not then PGI has not been done for the delivery so first do PGI and then try for Returns. -
T/ARDAgent.app/Contents/MacOS/ARDAgent» has been modified and will not be repaired.
Can anyone tell me what this means ?Warning: SUID file “System/Library/CoreServices/RemoteManagement/ARDAgent.app/Contents/MacOS/ARDAg ent” has been modified and will not be repaired.
This article Mac OS X: Disk Utility’s Repair Disk Permissions messages that you can safely ignore — Apple Support may help set your mind at ease.
-
What does this mean:»System/Library/CoreServices/RemoteManagement/ARDAgent.app/Contents/MacOS/ ARDAgent» has been modified and will not be repaired.
My computer is running well but I get this every time I repair the disk permissions, does anyone know why?:
“System/Library/CoreServices/RemoteManagement/ARDAgent.app/Contents/MacOS/ARDAge nt” has been modified and will not be repaired.ACL found but not expected on “private/var/root/Library”Repaired “private/var/root/Library”ACL found but not expected on “private/var/root/Library/Preferences”Repaired “private/var/root/Library/Preferences”
I don’t believe I’ve ever had absolutely nothing …
Thanks.That’s a permission issue caused by an Apple Remote Desktop client update. It can be ignored and it does not cause any issue, so do not worry about it. See > http://support.apple.com/kb/ts1448
-
I down loaded iMessage for mac, but when i try to register it it say the server encountered an error processing registration. please try again later, it has been doing this all night,
I down loaded the new imessage for mac from the mountain lion, free trial, but when i try to sign in it says the server encountered an error processing registration. Please try again later. I have put it on my other mac, and no problems with it, i have only brought this mac today, and just want to get it all set up
Try this:
https://discussions.apple.com/thread/3801516?tstart=0 -
ICloud Error! The maximum number of free accounts has been activated on this iPod touch.
This is seriously annoying, I’ve been going around in circles trying to get my music onto my bloody iPod. I can’t sync because it pauses @ Step 4: Waiting for changes to be applied error for ios7 devices. So my only option is to use iTunes Match and pay 40 bucks for it, but I think for iTunes match, you also need an iCloud account. Well I can’t! Because when I go to sign into my iCloud using my Apple ID, it pops up with this error: The maximum number of free accounts have been activated on this iPod touch.
I’m about to give up and kill every one of Apple’s employees.
I’m ready and open to everyones strategy at getting this fixed, thanks in advance.So I go to make a new Apple ID, then go to my newly downloaded iCloud Control Panel for PC, and it says that this is a valid Apple ID but not an iCloud ID. I figured the only way to make an iCloud ID is to make an account on my iPod… BACK TO THE START! I can’t because it gives me an error after I have created my account saying: «This device is no longer eligible for creating a free iCloud account»
WHAT IS GOING ON, fix your stuff Apple.
I was going to post this in Thickheaded Thursday, but it’s a wall of text. The short question is:
Does this mean that in 30 days my currently replicated data is going to be deleted by tombstoning? For each DFS share I created on Server 2012R2, I’m getting Event ID 4004 (error):
The DFS Replication service stopped replication on the replicated folder at local path F:SharesName.
Additional Information: Error: 9098 (A tombstoned content set deletion has been scheduled) Additional context of the error:
Replicated Folder Name: Name Replicated Folder ID: 611915A0-A36B-4BF8-A3AC-5EC4208D8BA0 Replication Group Name: Name Replication Group ID: 4828BE3E-9F9C-4AEE-B1CB-88306235F95C Member ID: 50E0A471-7D5E-4DD6-9761-CC9B852AE64F
This is followed immediately by Event ID 2002, then another 4004, then 4002, then 4102, and after a while, 4104.
Now, let me lead you through the steps that led up this:
-
Created DFS root domain.extroot
-
Created DFS shares
-
Created replication groups (but did not associate them with the corresponding DFS share)
-
Stopped replication
-
Removed replication groups
-
Removed replication partner that was being written to
-
Started replication
-
In each share, deleted DFSRPrivate
-
Waited a couple weeks, no issues
-
Recreated DFS Shares
-
Created replication groups, associated with corresponding DFS shares
This is when the Event ID set listed above starts happening. I have verified that the replicated folder ID in 4004 matches the objectGUID for each respective content set in ADSIEdit for each share. I know that replication is complete for all shares, because running
wmic /namespace:rootmicrosoftdfs path dfsrreplicatedfolderinfo get replicatedfoldername,state
All folders are listed as 4.
I’d like to know ahead of time if I did something wrong here, and if I should stop replication, remove RGroups and partners, then remove the DFSroot from System Volume Information (which I did NOT do before). I really don’t want to walk in next month to find content being deleted. Or is this just a «suck it up buttercup, use your MSDN ticket»?
I hope I was able to frame this so that you can follow, I tried to be as detailed as I could. Thanks folks.
Почему не проходит репликация dfs в windows server?
Есть два сервера SRV1 и SRV2
SRV1 физический сервер с Windows 2008 r2
SRV2 виртуальная машина(VMWARE esx 5.5) c Windows 2012 r2
На SRV1 поднята роль DFS и между серверами настроена реплика. С SRV1 идет в одну сторону реплика на SRV2
Собственно сама проблема. Репликация на проходит. Точнее она проходила какое-то время, сейчас не идет. При запуске диагностического отчета все ОК.
- Вопрос задан более трёх лет назад
- 3110 просмотров

alexq2: Исходя из этих строк лога:
20160317 08:45:32.521 8940 CFAD 8716 Config::AdConfig::GetComputer [CLUSTER] This computer is a cluster node. Get list of owned VCOs.
20160317 08:45:32.521 8940 CLUS 4280 Cluster::ClusterUtil::GetVcoList [CLUSTER] Searching for locally owned VCOs
20160317 08:45:32.521 8940 CFAD 8779 Config::AdConfig::GetComputer [CLUSTER] Cluster service is not installed or configured. Skipping the VCO polling.
20160317 08:45:32.521 8940 ADWR 1293 Config::AdWriter::CreateSysVolObjects [SYSVOL] IsDc:1 isSysVolCreated:0
У вас есть недоделанный кластер сервер DC3 у вас состоит в этом кластере?
И ещё вопрос у вас реплика AD между DC1 и DC3 проходит?
Ещё как радикальный вариант можете удалить полностью DFS с DC3 перегрузить и заново установить DFS и настроить реплику.
Выявляем неполадки с репликацией Active Directory
Как устранить четыре общие проблемы репликации
Один из механизмов Active Directory (AD), с которым могут быть связаны всевозможные затруднения, это репликация. Репликация – критически важный процесс в работе одного или более доменов или контроллеров домена (DC), и не важно, находятся они на одном сайте или на разных. Неполадки с репликацией могут привести к проблемам с аутентификацией и доступом к сетевым ресурсам. Обновления объектов AD реплицируются на контроллеры домена, чтобы все разделы были синхронизированы. В крупных компаниях использование большого количества доменов и сайтов – обычное дело. Репликация должна происходить внутри локального сайта, так же как дополнительные сайты должны сохранять данные домена и леса между всеми DC.
В этой статье речь пойдет о методах выявления проблем с репликацией в AD. Кроме того, я покажу, как находить и устранять неисправности и работать с четырьмя наиболее распространенными ошибками репликации AD:
- Error 2146893022 (главное конечное имя неверно);
- Error 1908 (не удалось найти контроллер домена);
- Error 8606 (недостаточно атрибутов для создания объекта);
- Error 8453 (доступ к репликации отвергнут).
Вы также узнаете, как анализировать метаданные репликации с помощью таких инструментов, как AD Replication Status Tool, встроенная утилита командной строки RepAdmin.exe и Windows PowerShell.
Для всестороннего рассмотрения я буду использовать лес Contoso, который показан на рисунке. В таблице 1 перечислены роли, IP-адреса и настройки DNS-клиента для компьютеров данного леса.
.jpg) |
| Рисунок. Архитектура леса |
.jpg)
Для обнаружения неполадок с репликацией AD запустите AD Replication Status Tool на рабочей станции администратора в корневом домене леса. Например, вы открываете этот инструмент из системы Win8Client, а затем нажимаете кнопку Refresh Replication Status для уверенности в четкой коммуникации со всеми контроллерами домена. В таблице Discovery Missing Domain Controllers на странице Configuration/Scope Settings инструмента можно увидеть два недостающих контроллера домена, как показано на экране 1.
.jpg) |
| Экран 1. Два недостающих контроллера домена |
В таблице Replication Status Collection Details вы можете проследить статус репликации контроллеров домена, которые никуда не пропадали, как показано на экране 2.
.jpg) |
| Экран 2. Статус репликации контроллеров домена |
Пройдя на страницу Replication Status Viewer, вы обнаружите некоторые ошибки в репликации. На экране 3 видно, что возникает немалое число ошибок репликации, возникающих в лесу Contoso. Из пяти контроллеров домена два не могут видеть другие DC, а это означает, что репликация не будет происходить на контроллерах домена, которые не видны. Таким образом, пользователи, подключающиеся к дочерним DC, не будут иметь доступ к самой последней информации, что может привести к проблемам.
.jpg) |
| Экран 3. Ошибки репликации, возникающие в лесу Contoso |
Поскольку ошибки репликации все же возникают, полезно задействовать утилиту командной строки RepAdmin.exe, которая помогает получить отчет о состоянии репликации по всему лесу. Чтобы создать файл, запустите следующую команду из Cmd.exe:
Проблема с двумя DC осталась, соответственно вы увидите два вхождения LDAP error 81 (Server Down) Win32 Err 58 на экране, когда будет выполняться команда. Мы разберемся с этими ошибками чуть позже. А теперь откройте ShowRepl.csv в Excel и выполните следующие шаги:
- Из меню Home щелкните Format as table и выберите один из стилей.
- Удерживая нажатой клавишу Ctrl, щелкните столбцы A (Showrepl_COLUMNS) и G (Transport Type). Правой кнопкой мыши щелкните в этих столбцах и выберите Hide.
- Уменьшите ширину остальных столбцов так, чтобы был виден столбец K (Last Failure Status).
- Для столбца I (Last Failure Time) нажмите стрелку вниз и отмените выбор 0.
- Посмотрите на дату в столбце J (Last Success Time). Это последнее время успешной репликации.
- Посмотрите на ошибки в столбце K (Last Failure Status). Вы увидите те же ошибки, что и в AD Replication Status Tool.
Таким же образом вы можете запустить средство RepAdmin.exe из PowerShell. Для этого сделайте следующее:
1. Перейдите к приглашению PowerShell и введите команду
2. В появившейся сетке выберите Add Criteria, затем Last Failure Status и нажмите Add.
3. Выберите подчеркнутое слово голубого цвета contains в фильтре и укажите does not equal.
4. Как показано на экране 4, введите 0 в поле, так, чтобы отфильтровывалось все со значением 0 (успех) и отображались только ошибки.
.jpg) |
| Экран 4. Задание фильтра |
Теперь, когда вы знаете, как проверять статус репликации и обнаруживать ошибки, давайте посмотрим, как выявлять и устранять четыре наиболее распространенные неисправности.
Исправление ошибки AD Replication Error -2146893022
Итак, начнем с устранения ошибки -2146893022, возникающей между DC2 и DC1. Из DC1 запустите команду Repadmin для проверки статуса репликации DC2:
На экране 5 показаны результаты, свидетельствующие о том, что репликация перестала выполняться, поскольку возникла проблема с DC2: целевое основное имя неверно. Тем не менее, описание ошибки может указать ложный путь, поэтому приготовьтесь копать глубже.
.jpg) |
| Экран 5. Проблема с DC2 — целевое основное имя неверно |
Во-первых, следует определить, есть ли базовое подключение LDAP между системами. Для этого запустите следующую команду из DC2:
На экране 5 видно, что вы получаете сообщение об ошибке LDAP. Далее попробуйте инициировать репликацию AD с DC2 на DC1:
И на этот раз отображается та же ошибка с главным именем, как показано на экране 5. Если открыть окно Event Viewer на DC2, вы увидите событие с Event ID 4 (см. экран 6).
.jpg) |
| Экран 6. Сообщение о событии с Event ID 4 |
Выделенный текст в событии указывает на причину ошибки. Это означает, что пароль учетной записи компьютера DC1 отличается от пароля, который хранится в AD для DC1 в Центре распределения ключей – Key Distribution Center (KDC), который в данном случае запущен на DC2. Значит, следующая наша задача – определить, соответствует ли пароль учетной записи компьютера DC1 тому, что хранится на DC2. В командной строке на DC1 введите две команды:
Далее откройте файлы dc1objmeta1.txt и dc1objmeta2.txt, которые были созданы, и посмотрите на различия версий для dBCSPwd, UnicodePWD, NtPwdHistory, PwdLastSet и lmPwdHistory. В нашем случае файл dc1objmeta1.txt показывает версию 19, тогда как версия в файле dc1objmeta2.txt – 11. Таким образом, сравнивая эти два файла, мы видим, что DC2 содержит информацию о старом пароле для DC1. Операция Kerberos не удалась, потому что DC1 не смог расшифровать билет службы, представленный DC2.
KDC, запущенный на DC2, не может быть использован для Kerberos вместе с DC1, так как DC2 содержит информацию о старом пароле. Чтобы решить эту проблему, вы должны заставить DC2 использовать KDC на DC1, чтобы завершить репликацию. Для этого вам, в первую очередь, необходимо остановить службу KDC на DC2:
Теперь требуется начать репликацию корневого раздела Root:
Следующим вашим шагом будет запуск двух команд Repadmin /showobjmeta снова, чтобы убедиться в том, что версии совпадают. Если все хорошо, вы можете перезапустить службу KDC:
Обнаружение и устранение ошибки AD Replication Error 1908
Теперь, когда мы устранили ошибку -2146893022, давайте перейдем к ошибке репликации AD 1908, где DC1, DC2 и TRDC1 так и не удалось выполнить репликацию из ChildDC1. Решить проблему можно следующим образом. Используйте Nltest.exe для создания файла Netlogon.log, чтобы выявить причину ошибки 1908. Прежде всего, включите расширенную регистрацию на DC1, запустив команду:
Теперь, когда расширенная регистрация включена, запустите репликацию между DC – так все ошибки будут зарегистрированы. Этот шаг поможет запустить три команды для воспроизведения ошибок. Итак, во-первых, запустите следующую команду на DC1:
Результат, показанный на экране 7, говорит о том, что репликация не состоялась, потому что DC домена не может быть найден.
.jpg) |
| Экран 7. Репликация не состоялась, потому что DC домена не может быть найден |
Во-вторых, из DC1 попробуйте определить местоположение KDC в домене child.root.contoso.com с помощью команды:
Результаты на экране 7 свидетельствуют, что такого домена нет. В-третьих, поскольку вы не можете найти KDC, попытайтесь установить связь с любым DC в дочернем домене, используя команду:
В очередной раз результаты говорят о том, что нет такого домена, как показано на экране 7.
Теперь, когда вы воспроизвели все ошибки, просмотрите файл Netlogon.log, созданный в папке C:Windowsdebug. Откройте его в «Блокноте» и найдите запись, которая начинается с DSGetDcName function called. Обратите внимание, что записей с таким вызовом будет несколько. Вам нужно найти запись, имеющую те же параметры, что вы указали в команде Nltest (Dom:child и Flags:KDC). Запись, которую вы ищете, будет выглядеть так:
Вы должны просмотреть начальную запись, равно как и последующие, в этом потоке. В таблице 2 представлен пример потока 3372. Из этой таблицы следует, что поиск DNS записи KDC SRV в дочернем домене был неудачным. Ошибка 1355 указывает, что заданный домен либо не существует, либо к нему невозможно подключиться.
.jpg)
Поскольку вы пытаетесь подключиться к Child.root.contoso.com, следующий ваш шаг – выполнить для него команду ping из DC1. Скорее всего, вы получите сообщение о том, что хост не найден. Информация из файла Netlogon.log и ping-тест указывают на возможные проблемы в делегировании DNS. Свои подозрения вы можете проверить, сделав тест делегирования DNS. Для этого выполните следующую команду на DC1:
На экране 8 показан пример файла Dnstest.txt. Как вы можете заметить, это проблема DNS. Считается, что IP-адрес 192.168.10.1 – адрес для DC1.
.jpg) |
| Экран 8. Пример файла Dnstest.txt |
Чтобы устранить проблему DNS, сделайте следующее:
1. На DC1 откройте консоль управления DNS.
2. Разверните Forward Lookup Zones, разверните root.contoso.com и выберите child.
3. Щелкните правой кнопкой мыши (как в родительской папке) на записи Name Server и выберите пункт Properties.
4. Выберите lamedc1.child.contoso.com и нажмите кнопку Remove.
5. Выберите Add, чтобы можно было добавить дочерний домен сервера DNS в настройки делегирования.
6. В окне Server fully qualified domain name (FQDN) введите правильный сервер childdc1.child.root.contoso.com.
7. В окне IP Addresses of this NS record введите правильный IP-адрес 192.168.10.11.
8. Дважды нажмите кнопку OK.
9. Выберите Yes в диалоговом окне, где спрашивается, хотите ли вы удалить связующую запись (glue record) lamedc1.child.contoso.com [192.168.10.1]. Glue record – это запись DNS для полномочного сервера доменных имен для делегированной зоны.
10. Используйте Nltest.exe для проверки, что вы можете найти KDC в дочернем домене. Примените опцию /force, чтобы кэш Netlogon не использовался:
11. Протестируйте репликацию AD из ChildDC1 на DC1 и DC2. Это можно сделать двумя способами. Один из них – выполнить команду
Другой подход заключается в использовании оснастки Active Directory Sites и Services консоли Microsoft Management Console (MMC), в этом случае правой кнопкой мыши щелкните DC и выберите Replicate Now, как показано на экране 9. Вам нужно это сделать для DC1, DC2 и TRDC1.
.jpg) |
| Экран 9. Использование оснастки Active Directory Sites и?Services |
После этого вы увидите диалоговое окно, как показано на экране 10. Не учитывайте его, нажмите OK. Я вкратце расскажу об этой ошибке.
.jpg) |
| Экран 10. Ошибка при репликации |
Когда все шаги выполнены, вернитесь к AD Replication Status Tool и обновите статус репликации на уровне леса. Ошибки 1908 больше быть не должно. Ошибка, которую вы видите, это ошибка 8606 (недостаточно атрибутов для создания объекта), как отмечалось на экране 10. Это следующая трудность, которую нужно преодолеть.
Устранение ошибки AD Replication Error 8606
Устаревший объект (lingering object) – это объект, который присутствует на DC, но был удален на одном или нескольких других DC. Ошибка репликации AD 8606 и ошибка 1988 в событиях Directory Service – хорошие индикаторы устаревших объектов. Важно учитывать, что можно успешно завершить репликацию AD и не регистрировать ошибку с DC, содержащего устаревшие объекты, поскольку репликация основана на изменениях. Если объекты не изменяются, то реплицировать их не нужно. По этой причине, выполняя очистку устаревших объектов, вы допускаете, что они есть у всех DC (а не только DCs logging errors).
Чтобы устранить проблему, в первую очередь убедитесь в наличии ошибки, выполнив следующую команду Repadmin на DC1:
Вы увидите сообщение об ошибке, как показано на экране 11. Кроме того, вы увидите событие с кодом в Event Viewer DC1 (см. экран 12). Обратите внимание, что событие с кодом 1988 только дает отчет о первом устаревшем объекте, который вам вдруг встретился. Обычно таких объектов много.
.jpg) |
| Экран 11. Ошибка из-за наличия устаревшего объекта |
.jpg) |
| Экран 12. Событие с кодом 1988 |
Вы должны скопировать три пункта из информации об ошибке 1988 в событиях: идентификатор globally unique identifier (GUID) устаревшего объекта, сервер-источник (source DC), а также уникальное, или различающееся, имя раздела – distinguished name (DN). Эта информация позволит определить, какой DC имеет данный объект.
Прежде всего, используйте GUID объекта (в данном случае 5ca6ebca-d34c-4f60-b79c-e8bd5af127d8) в следующей команде Repadmin, которая отправляет результаты в файл Objects.txt:
Если вы откроете файл Objects.txt, то увидите, что любой DC, который возвращает метаданные репликации для данного объекта, содержит один или более устаревших объектов. DC, не имеющие копии этого объекта, сообщают статус 8439 (уникальное имя distinguished name, указанное для этой операции репликации, недействительно).
Затем вам нужно, используя GUID объект Directory System Agent (DSA) DC1, идентифицировать все устаревшие объекты в разделе Root на DC2. DSA предоставляет доступ к физическому хранилищу информации каталога, находящейся на жестком диске. В AD DSA – часть процесса Local Security Authority. Для этого выполните команду:
В Showrepl.txt GUID объект DSA DC1 появляется вверху файла и выглядит следующим образом:
Ориентируясь на эту информацию, вы можете применить следующую команду, чтобы удостовериться в существовании устаревших объектов на DC2, сравнив его копию раздела Root с разделом Root DC1.
Далее вы можете просмотреть журнал регистрации событий Directory Service на DC2, чтобы узнать, есть ли еще какие-нибудь устаревшие объекты. Если да, то о каждом будет сообщаться в записи события 1946. Общее число устаревших объектов для проверенного раздела будет отмечено в записи события 1942.
Вы можете удалить устаревшие объекты несколькими способами. Предпочтительно использовать ReplDiag.exe. В качестве альтернативы вы можете выбрать RepAdmin.exe.
Используем ReplDiag.exe. С вашей рабочей станции администратора в корневом домене леса, а в нашем случае это Win8Client, вы должны выполнить следующие команды:
Первая команда удаляет объекты. Вторая команда служит для проверки успешного завершения репликации (иными словами, ошибка 8606 больше не регистрируется). Возвращая команды Repadmin /showobjmeta, вы можете убедиться в том, что объект был удален из всех, что объект был удален DC. Если у вас есть контроллер только для чтения read-only domain controller (RODC) и он содержал данный устаревший объект, вы заметите, что он все еще там находится. Дело в том, что текущая версия ReplDiag.exe не удаляет объекты из RODC. Для очистки RODC (в нашем случае, ChildDC2) выполните команду:
После этого просмотрите журнал событий Directory Service на ChildDC2 и найдите событие с кодом 1939. На экране 13 вы видите уведомление о том, что устаревшие объекты были удалены.
.jpg) |
| Экран 13. Сообщение об удалении устаревших объектов |
Используем RepAdmin.exe. Другой способ, позволяющий удалить устаревшие объекты – прибегнуть к помощи RepAdmin.exe. Сначала вы должны удалить устаревшие объекты главных контроллеров домена (reference DC) с помощью кода, который видите в листинге 1. После этого необходимо удалить устаревшие объекты из всех остальных контроллеров домена (устаревшие объекты могут быть показаны или на них могут обнаружиться ссылки на нескольких контроллерах домена, поэтому убедитесь, что вы удалили их все). Необходимые для этой цели команды приведены в листинге 2.
Как видите, использовать ReplDiag.exe гораздо проще, чем RepAdmin.exe, поскольку вводить команд вам придется намного меньше. Ведь чем больше команд, тем больше шансов сделать опечатку, пропустить команду или допустить ошибку в командной строке.
Устранение ошибки AD Replication Error 8453
Предыдущие ошибки репликации AD были связаны с невозможностью найти другие контроллеры домена. Ошибка репликации AD с кодом состояния 8453 возникает, когда контроллер домена видит другие DC, но не может установить с ними связи репликации.
Например, предположим, что ChildDC2 (RODC) в дочернем домене не уведомляет о себе как о сервере глобального каталога – Global Catalog (GC). Для получения статуса ChildDC2 запустите следующие команды на ChildDC2:
Данная команда отправляет результаты Repl.txt. Если вы откроете этот текстовый файл, то увидите вверху следующее:
Если вы внимательно посмотрите на раздел Inbound Neighbors, то увидите, что раздел DC=treeroot,DC=fabrikam,DC=com отсутствует, потому что он не реплицируется. Взгляните на кнопку файла – вы увидите ошибку:
Эта ошибка означает, что ChildDC2 не может добавить связь репликации (replication link) для раздела Treeroot. Как показано на экране 14, данная ошибка также записывается в журнал регистрации событий Directory Services на ChildDC2 как событие с кодом 1926.
.jpg) |
| Экран 14. Отсутствие связи репликации |
Здесь вам нужно проверить, нет ли проблем, связанных с безопасностью. Для этого используйте DCDiag.exe:
На экране 15 показан фрагмент вывода DCDiag.exe.
.jpg) |
| Экран 15. Фрагмент вывода DCDiag.exe |
Как видите, вы получаете ошибку 8453, потому что группа безопасности Enterprise Read-Only Domain Controllers не имеет разрешения Replicating Directory Changes.
Чтобы решить проблему, вам нужно добавить отсутствующую запись контроля доступа – missing access control entry (ACE) в раздел Treeroot. В этом вам помогут следующие шаги:
1. На TRDC1 откройте оснастку ADSI Edit.
2. Правой кнопкой мыши щелкните DC=treeroot,DC=fabrikam,DC=com и выберите Properties.
3. Выберите вкладку Security.
4. Посмотрите разрешения на этот раздел. Отметьте, что нет записей для группы безопасности Enterprise Read-Only Domain Controllers.
6. В окне Enter the object names to select наберите ROOTEnterprise Read-Only Domain Controllers.
7. Нажмите кнопку Check Names, затем выберите OK, если указатель объектов (object picker) разрешает имя.
8. В диалоговом окне Permissions для Enterprise Read-Only Domain Controllers снимите флажки Allow для следующих разрешений
*Read domain password & lockout policies («Чтение политики блокировки и пароля домена»)
*Read Other domain parameters
9. Выберите флажок Allow для разрешения Replicating Directory Changes, как показано на экране 16. Нажмите OK.
10. Вручную запустите Knowledge Consistency Checker (KCC), чтобы немедленно сделать перерасчет топологии входящей репликации на ChildDC2, выполнив команду
.jpg) |
| Экран 16. Включение разрешения Replicating Directory Change |
Данная команда заставляет KCC на каждом целевом сервере DC незамедлительно делать перерасчет топологии входящей репликации, добавляя снова раздел Treeroot.
Состояние репликации критически важно
Репликация во всех отношениях в лесу AD имеет решающее значение. Следует регулярно проводить ее диагностику, чтобы изменения были видны всем контроллерам домена, иначе могут возникать различные проблемы, в том числе связанные с аутентификацией. Проблемы репликации нельзя обнаружить сразу. Поэтому если вы пренебрегаете мониторингом репликации (в крайнем случае, периодически делайте проверку), то рискуете столкнуться с трудностями в самый неподходящий момент. Моей задачей было показать вам, как проверять статус репликации, обнаруживать ошибки и в то же время как справиться с четырьмя типичными проблемами репликации AD.
Листинг 1. Команды для удаления устаревших объектов из Reference DC
Листинг 2. Команды для удаления устаревших объектов из остальных DC
источники:
http://www.osp.ru/winitpro/2014/11/13043633
DFS Replication is really cool, it tends to work really well for us and it has saved our bacon many times already when used in combination to Namespaces.
This week, one of our servers went down (Window Server 2012 R2) unexpectedly due to a blue screen error which turned out to be memory related. The result, I had a bit of a nightmare on my hands as I had to patiently wait for RAID to rebuild then Replication stopped working after that. Luckily, our other replicated server kept things going whilst I worked on the fault but It seemed that the replication had managed to somehow become corrupted and no longer function.
I kept seeing logged events in the event log:
The DFS Replication service stopped replication on the replicated folder at local path W:DeploymentShare. Additional Information: Error: 9098 (A tombstoned content set deletion has been scheduled) Additional context of the error: Replicated Folder Name: DeploymentShare Replicated Folder ID: 3B11214C-1B97-44D4-B5A3-27563F64007B Replication Group Name: DeploymentShare Replication Group ID: 40EAC201-204F-44E9-95F3-2B1810B4958C Member ID: 486E2ABE-3275-4E4B-9CC7-8C1911EA47E4
and this one also:
The DFS Replication service stopped replication on the replicated folder at local path M:DeploymentShare. Additional Information: Error: 9073 (Content set initialization is pending journal wrap task to resume journal read) Additional context of the error: Replicated Folder Name: DeploymentShare Replicated Folder ID: 8F880E6D-F6E6-42A5-8E29-7F07B9DC7D73 Replication Group Name: Deployment Share Replication Group ID: 06C43A27-6E9F-408E-AD5B-2A69E69A4F79 Member ID: 76F9B906-3323-450A-A607-6E57B7A4CC1F
I could also see that the DfsrPrivateStaging folder had a number of files in the Content Set but nothing was replicating. I created a simple text document on Server A and it never arrived at Server B.
In the DFS Management console, I created a Diagnostic Health report and it reported the same errors found in the event log.
Here is how I (eventually) resolved this matter without losing any data:
Open a command prompt on both Member servers
Type in to each server:
NET STOP DFSR
This will stop the replication service from trying to replicate.
Next, go into Explorer on both servers and show hidden files.
Go into the Disks that contain the Replicated folders (i.e. W: Drive)
Right click on “System Volume Information” and select “Properties” from the context menu.
Go to the “Security” tab and click “Edit…”
We need to give ourselves access to this folder so click on “Add…”
Type in your administrative user name or simply use “Domain Admins” if you choose.
Tick the “Full Control” -> “Allow” check box and click “OK”
Click “OK” again to return to Explorer.
Next, we need to return to our CMD window and type the following:
rmdir "W:System Volume InformationDFSR" /s
This will remove the DFS Replication database information for this drive. Doing this will force DFS to re-generate a new set.
Note: If this command reports any errors about filenames being too long, you may need to delete files manually using a filemanager that is able to delete file paths longer than 255 chars. I used 7-Zip’s File Manager which is handy for doing this. In 7-Zip, browse to where the folder is stored and hold SHIFT whilst clicking Delete. That folder should now delete ok.Once these folders have been removed from both Member servers, we can go ahead and start the DFSR services again. In our CMD prompt, type:
NET START DFSR
Watch the event logs! You should see something along these lines within about 10-15 mins:
The DFS Replication service initialized the replicated folder at local path W:DeploymentShare and is waiting to perform initial replication. The replicated folder will remain in this state until it has received replicated data, directly or indirectly, from the designated primary member. Additional Information: Replicated Folder Name: DeploymentShare Replicated Folder ID: 8F880E6D-F6E6-42A5-8E29-7F07B9DC7D73 Replication Group Name: Deployment Share Replication Group ID: 06C43A27-6E9F-408E-AD5B-2A69E69A4F79 Member ID: 79E1C694-787F-47A5-9566-AE087FC4F7F3
You should also start to see items re-appearing in the DfsrPrivateStaging folder in those 15 mins.
This worked like this for one of my Replication Groups, but one other troublesome replication group still didn’t propagate the staging folder after 30 mins of waiting so here is what I had to do:
First of all, I checked to see if DFS knew which Member was Primary by typing in the following command in our CMD prompt on one of the member servers:
dfsradmin membership list /RGName:"Distribution Share" /attr:ALL >%USERPROFILE%Desktopmembers.txt
This command kindly dropped a text file on my server desktop and I noticed that in the “IsPrimary” field, neither of my member servers were Primary. Both were saying “No”.
So then I nominated the surviving member server (not the one that crashed) to be the Primary by typing in the following command:
dfsradmin membership set /RGName:"Distribution Share" /RFName:"Distribution" /MemName:WDS2 /IsPrimary:Yes
Once DFS found a primary member for the Replication Group, it pretty much immediately started filling the Staging area with files and things started moving along nicely. We also got a very promising event logged in the event log:
The DFS Replication service initialized the replicated folder at local path W:Distribution and is waiting to perform initial replication. The replicated folder will remain in this state until it has received replicated data, directly or indirectly, from the designated primary member. Additional Information: Replicated Folder Name: Distribution Replicated Folder ID: 8C7E9497-452F-4574-9B4F-23759686392A Replication Group Name: Distribution Share Replication Group ID: A064B665-2F5B-4ED6-9C4A-236043697A79 Member ID: 82C9C73E-6882-4E3B-BDA7-A2E09213450E
I could then see a bit later that things were going very well (albeit I maybe need to review my staging quota) when this event was logged:
The DFS Replication service has detected that the staging space in use for the replicated folder at local path W:Distribution is above the high watermark. The service will attempt to delete the oldest staging files. Performance may be affected.
Additional Information:
Staging Folder: W:DistributionDfsrPrivateStagingContentSet{8C7E9497-452F-4574-9B4F-23759686392A}-{82C9C73E-6882-4E3B-BDA7-A2E09213450E}
Configured Size: 10240 MB
Space in Use: 9216 MB
High Watermark: 90%
Low Watermark: 60%
Replicated Folder Name: Distribution
Replicated Folder ID: 8C7E9497-452F-4574-9B4F-23759686392A
Replication Group Name: Distribution Share
Replication Group ID: A064B665-2F5B-4ED6-9C4A-236043697A79
Thankfully, our replication is now back to full operation again. Did this help you? I’d love to hear from you. Please comment below.
Rick
Почему не проходит репликация dfs в windows server?
Есть два сервера SRV1 и SRV2
SRV1 физический сервер с Windows 2008 r2
SRV2 виртуальная машина(VMWARE esx 5.5) c Windows 2012 r2
На SRV1 поднята роль DFS и между серверами настроена реплика. С SRV1 идет в одну сторону реплика на SRV2
Собственно сама проблема. Репликация на проходит. Точнее она проходила какое-то время, сейчас не идет. При запуске диагностического отчета все ОК.
- Вопрос задан более трёх лет назад
- 3109 просмотров
alexq2: Исходя из этих строк лога:
20160317 08:45:32.521 8940 CFAD 8716 Config::AdConfig::GetComputer [CLUSTER] This computer is a cluster node. Get list of owned VCOs.
20160317 08:45:32.521 8940 CLUS 4280 Cluster::ClusterUtil::GetVcoList [CLUSTER] Searching for locally owned VCOs
20160317 08:45:32.521 8940 CFAD 8779 Config::AdConfig::GetComputer [CLUSTER] Cluster service is not installed or configured. Skipping the VCO polling.
20160317 08:45:32.521 8940 ADWR 1293 Config::AdWriter::CreateSysVolObjects [SYSVOL] IsDc:1 isSysVolCreated:0
У вас есть недоделанный кластер сервер DC3 у вас состоит в этом кластере?
И ещё вопрос у вас реплика AD между DC1 и DC3 проходит?
Ещё как радикальный вариант можете удалить полностью DFS с DC3 перегрузить и заново установить DFS и настроить реплику.
Поддержка транзакций в указанном диспетчере ресурсов не запущена
Пользователи жаловались на невозможность добавлять, редактировать или удалять запланированные задачи в Windows 10. Каждый раз, когда они пытаются выполнить любое из этих действий, они получают следующее сообщение об ошибке:
Поддержка транзакций в указанном диспетчере ресурсов не запущена или была отключена из-за ошибки.
Приведенное выше сообщение об ошибке связано с Центром обновления Windows, так как вы также можете не установить обновления. К счастью, решить эту проблему несложно, и в этом руководстве мы покажем вам, как это сделать.
Поддержка транзакций в указанном диспетчере ресурсов не запущена
Аномалия, когда вы испытываете указанную выше ошибку, заключается в том, что она говорит, что работает в службах диспетчера задач, несмотря на то, что планировщик задач не открывается. Мы исправим эту проблему, используя следующие решения:
- Очистите все содержимое каталога TxR.
- Сбросьте диспетчер транзакционных ресурсов с помощью fsutil.
- Замените жесткий диск.
Продолжайте читать это руководство, чтобы получить полную информацию о вышеуказанных исправлениях.
1]Очистить все содержимое каталога TxR

Откройте проводник Windows и включите просмотр скрытых файлов. Для этого перейдите в Вид меню и проверьте Скрытые предметы флажок, который он показывает.
Затем щелкните адресную строку, введите следующий адрес и нажмите ENTER:
Это подводит вас к TxR папка. нажмите CTRL + A комбинация, чтобы выбрать все в этом каталоге и использовать CTRL + X чтобы все это вырезать.
Затем перейдите в другой каталог и нажмите CTRL + V чтобы вставить файлы в это новое место. Теперь вы можете выйти из проводника.
2]Сбросить диспетчер транзакционных ресурсов с помощью fsutil
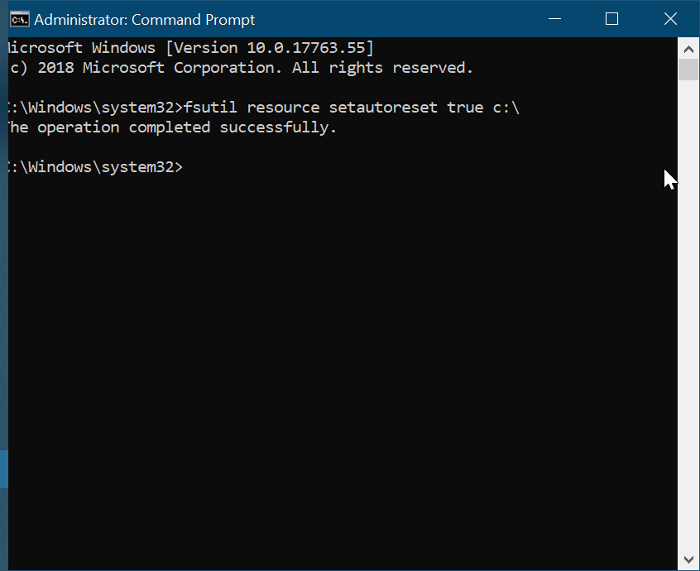
Первым шагом этого решения является открытие командной строки от имени администратора.
Для этого нажмите кнопку Window и найдите cmd. Щелкните правой кнопкой мыши командную строку и выберите Запуск от имени администратора.
Введите следующую команду и нажмите клавишу ВВОД, чтобы запустить ее.
ПРИМЕЧАНИЕ: Приведенная выше команда с использованием C . Однако вы должны изменить это на букву вашего системного диска.
Наконец, выйдите из командной строки и перезагрузите компьютер.
3]Замените жесткий диск
Если вы получаете ошибку на виртуальной машине, а два других исправления не решают проблему, это может означать, что ошибка связана с аппаратной проблемой на вашем жестком диске.
Плохой диск (RAID 1) может вызвать эту ошибку, потому что виртуальная машина не может видеть привод. Таким образом, замена жесткого диска может быть последним решением.
Удаление неправильно выведенного из строя сервера Exchange
Бывают случаи, когда сервер исчез/перезалился/потерялся без удаления на нём Exchange, но остался в системе. Избавиться от него и его хвостов одной кнопкой, к сожалению, не получится.
Есть два пути для удаления следов:
- Через режим восстановления
- Через ручное удаление, с подчисткой схемы
Я являюсь категорическим противником второго варианта. Никогда не знаешь, всплывёт где-нибудь когда-нибудь или нет. Поэтому, делюсь удалением через восстановление.
Берём такую же операционную систему, как и на потерянном сервере. Производим установку Exchange через командую строку с использованием ключа /Mode:RecoverServer.
После установки, перезагружаемся и запускаем удаление:
После удаления, у меня подчистились все хвосты неправильно удалённого сервера Exchange.

Возможные ошибки
Сервер может не установиться до конца. Это не страшно. Если была пройдена проверка перед установкой, установка началась и какие-то из компонентов установились, но потом на чём-нибудь свалилось в ошибку — всё ок. Можно перезагрузиться и запустить удаление. В моих случаях происходило полное удаление сервера.
Ошибка «The language pack bundle could not be found or is corrupt.»
На этапе проверки, перед установкой, возникла следующая ошибка:
Эта ошибка решилась удалением на сервере ветки реестра: HKEY_LOCAL_MACHINESOFTWAREMicrosoftExchangeServerv15Lanaguage Packs
 HKEY_LOCAL_MACHINESOFTWAREMicrosoftExchangeServerv15Lanaguage Packs
HKEY_LOCAL_MACHINESOFTWAREMicrosoftExchangeServerv15Lanaguage Packs
Описание решения есть у Микрософт: https://support.microsoft.com/ru-ru/help/3069005/error-when-you-try-to-install-exchange-server-2013-in-recoverserver-mo
Ошибка: После того, как установка свалилась, не стартует удаление/установка Exchange.
Мне помогло удаление под веткой HKEY_LOCAL_MACHINESOFTWAREMicrosoftExchangeServerv15* всех значений Action и Watermark:

 (3 оценок, среднее: 5,00 из 5)
(3 оценок, среднее: 5,00 из 5)
 Загрузка.
Загрузка.
источники:
http://zanz.ru/podderzhka-tranzakczij-v-ukazannom-dispetchere-resursov-ne-zapushhena/
http://bgelov.ru/microsoft-exchange/udalenie-nepravilno-vyvedennogo-iz-stroya-servera-exchange/
Почему не проходит репликация dfs в windows server?
Есть два сервера SRV1 и SRV2
SRV1 физический сервер с Windows 2008 r2
SRV2 виртуальная машина(VMWARE esx 5.5) c Windows 2012 r2
На SRV1 поднята роль DFS и между серверами настроена реплика. С SRV1 идет в одну сторону реплика на SRV2
Собственно сама проблема. Репликация на проходит. Точнее она проходила какое-то время, сейчас не идет. При запуске диагностического отчета все ОК.
- Вопрос задан более трёх лет назад
- 3110 просмотров
alexq2: Исходя из этих строк лога:
20160317 08:45:32.521 8940 CFAD 8716 Config::AdConfig::GetComputer [CLUSTER] This computer is a cluster node. Get list of owned VCOs.
20160317 08:45:32.521 8940 CLUS 4280 Cluster::ClusterUtil::GetVcoList [CLUSTER] Searching for locally owned VCOs
20160317 08:45:32.521 8940 CFAD 8779 Config::AdConfig::GetComputer [CLUSTER] Cluster service is not installed or configured. Skipping the VCO polling.
20160317 08:45:32.521 8940 ADWR 1293 Config::AdWriter::CreateSysVolObjects [SYSVOL] IsDc:1 isSysVolCreated:0
У вас есть недоделанный кластер сервер DC3 у вас состоит в этом кластере?
И ещё вопрос у вас реплика AD между DC1 и DC3 проходит?
Ещё как радикальный вариант можете удалить полностью DFS с DC3 перегрузить и заново установить DFS и настроить реплику.
Выявляем неполадки с репликацией Active Directory
Как устранить четыре общие проблемы репликации
Один из механизмов Active Directory (AD), с которым могут быть связаны всевозможные затруднения, это репликация. Репликация – критически важный процесс в работе одного или более доменов или контроллеров домена (DC), и не важно, находятся они на одном сайте или на разных. Неполадки с репликацией могут привести к проблемам с аутентификацией и доступом к сетевым ресурсам. Обновления объектов AD реплицируются на контроллеры домена, чтобы все разделы были синхронизированы. В крупных компаниях использование большого количества доменов и сайтов – обычное дело. Репликация должна происходить внутри локального сайта, так же как дополнительные сайты должны сохранять данные домена и леса между всеми DC.
В этой статье речь пойдет о методах выявления проблем с репликацией в AD. Кроме того, я покажу, как находить и устранять неисправности и работать с четырьмя наиболее распространенными ошибками репликации AD:
- Error 2146893022 (главное конечное имя неверно);
- Error 1908 (не удалось найти контроллер домена);
- Error 8606 (недостаточно атрибутов для создания объекта);
- Error 8453 (доступ к репликации отвергнут).
Вы также узнаете, как анализировать метаданные репликации с помощью таких инструментов, как AD Replication Status Tool, встроенная утилита командной строки RepAdmin.exe и Windows PowerShell.
Для всестороннего рассмотрения я буду использовать лес Contoso, который показан на рисунке. В таблице 1 перечислены роли, IP-адреса и настройки DNS-клиента для компьютеров данного леса.
|
| Рисунок. Архитектура леса |
Для обнаружения неполадок с репликацией AD запустите AD Replication Status Tool на рабочей станции администратора в корневом домене леса. Например, вы открываете этот инструмент из системы Win8Client, а затем нажимаете кнопку Refresh Replication Status для уверенности в четкой коммуникации со всеми контроллерами домена. В таблице Discovery Missing Domain Controllers на странице Configuration/Scope Settings инструмента можно увидеть два недостающих контроллера домена, как показано на экране 1.
|
| Экран 1. Два недостающих контроллера домена |
В таблице Replication Status Collection Details вы можете проследить статус репликации контроллеров домена, которые никуда не пропадали, как показано на экране 2.
|
| Экран 2. Статус репликации контроллеров домена |
Пройдя на страницу Replication Status Viewer, вы обнаружите некоторые ошибки в репликации. На экране 3 видно, что возникает немалое число ошибок репликации, возникающих в лесу Contoso. Из пяти контроллеров домена два не могут видеть другие DC, а это означает, что репликация не будет происходить на контроллерах домена, которые не видны. Таким образом, пользователи, подключающиеся к дочерним DC, не будут иметь доступ к самой последней информации, что может привести к проблемам.
|
| Экран 3. Ошибки репликации, возникающие в лесу Contoso |
Поскольку ошибки репликации все же возникают, полезно задействовать утилиту командной строки RepAdmin.exe, которая помогает получить отчет о состоянии репликации по всему лесу. Чтобы создать файл, запустите следующую команду из Cmd.exe:
Проблема с двумя DC осталась, соответственно вы увидите два вхождения LDAP error 81 (Server Down) Win32 Err 58 на экране, когда будет выполняться команда. Мы разберемся с этими ошибками чуть позже. А теперь откройте ShowRepl.csv в Excel и выполните следующие шаги:
- Из меню Home щелкните Format as table и выберите один из стилей.
- Удерживая нажатой клавишу Ctrl, щелкните столбцы A (Showrepl_COLUMNS) и G (Transport Type). Правой кнопкой мыши щелкните в этих столбцах и выберите Hide.
- Уменьшите ширину остальных столбцов так, чтобы был виден столбец K (Last Failure Status).
- Для столбца I (Last Failure Time) нажмите стрелку вниз и отмените выбор 0.
- Посмотрите на дату в столбце J (Last Success Time). Это последнее время успешной репликации.
- Посмотрите на ошибки в столбце K (Last Failure Status). Вы увидите те же ошибки, что и в AD Replication Status Tool.
Таким же образом вы можете запустить средство RepAdmin.exe из PowerShell. Для этого сделайте следующее:
1. Перейдите к приглашению PowerShell и введите команду
2. В появившейся сетке выберите Add Criteria, затем Last Failure Status и нажмите Add.
3. Выберите подчеркнутое слово голубого цвета contains в фильтре и укажите does not equal.
4. Как показано на экране 4, введите 0 в поле, так, чтобы отфильтровывалось все со значением 0 (успех) и отображались только ошибки.
|
| Экран 4. Задание фильтра |
Теперь, когда вы знаете, как проверять статус репликации и обнаруживать ошибки, давайте посмотрим, как выявлять и устранять четыре наиболее распространенные неисправности.
Исправление ошибки AD Replication Error -2146893022
Итак, начнем с устранения ошибки -2146893022, возникающей между DC2 и DC1. Из DC1 запустите команду Repadmin для проверки статуса репликации DC2:
На экране 5 показаны результаты, свидетельствующие о том, что репликация перестала выполняться, поскольку возникла проблема с DC2: целевое основное имя неверно. Тем не менее, описание ошибки может указать ложный путь, поэтому приготовьтесь копать глубже.
|
| Экран 5. Проблема с DC2 — целевое основное имя неверно |
Во-первых, следует определить, есть ли базовое подключение LDAP между системами. Для этого запустите следующую команду из DC2:
На экране 5 видно, что вы получаете сообщение об ошибке LDAP. Далее попробуйте инициировать репликацию AD с DC2 на DC1:
И на этот раз отображается та же ошибка с главным именем, как показано на экране 5. Если открыть окно Event Viewer на DC2, вы увидите событие с Event ID 4 (см. экран 6).
|
| Экран 6. Сообщение о событии с Event ID 4 |
Выделенный текст в событии указывает на причину ошибки. Это означает, что пароль учетной записи компьютера DC1 отличается от пароля, который хранится в AD для DC1 в Центре распределения ключей – Key Distribution Center (KDC), который в данном случае запущен на DC2. Значит, следующая наша задача – определить, соответствует ли пароль учетной записи компьютера DC1 тому, что хранится на DC2. В командной строке на DC1 введите две команды:
Далее откройте файлы dc1objmeta1.txt и dc1objmeta2.txt, которые были созданы, и посмотрите на различия версий для dBCSPwd, UnicodePWD, NtPwdHistory, PwdLastSet и lmPwdHistory. В нашем случае файл dc1objmeta1.txt показывает версию 19, тогда как версия в файле dc1objmeta2.txt – 11. Таким образом, сравнивая эти два файла, мы видим, что DC2 содержит информацию о старом пароле для DC1. Операция Kerberos не удалась, потому что DC1 не смог расшифровать билет службы, представленный DC2.
KDC, запущенный на DC2, не может быть использован для Kerberos вместе с DC1, так как DC2 содержит информацию о старом пароле. Чтобы решить эту проблему, вы должны заставить DC2 использовать KDC на DC1, чтобы завершить репликацию. Для этого вам, в первую очередь, необходимо остановить службу KDC на DC2:
Теперь требуется начать репликацию корневого раздела Root:
Следующим вашим шагом будет запуск двух команд Repadmin /showobjmeta снова, чтобы убедиться в том, что версии совпадают. Если все хорошо, вы можете перезапустить службу KDC:
Обнаружение и устранение ошибки AD Replication Error 1908
Теперь, когда мы устранили ошибку -2146893022, давайте перейдем к ошибке репликации AD 1908, где DC1, DC2 и TRDC1 так и не удалось выполнить репликацию из ChildDC1. Решить проблему можно следующим образом. Используйте Nltest.exe для создания файла Netlogon.log, чтобы выявить причину ошибки 1908. Прежде всего, включите расширенную регистрацию на DC1, запустив команду:
Теперь, когда расширенная регистрация включена, запустите репликацию между DC – так все ошибки будут зарегистрированы. Этот шаг поможет запустить три команды для воспроизведения ошибок. Итак, во-первых, запустите следующую команду на DC1:
Результат, показанный на экране 7, говорит о том, что репликация не состоялась, потому что DC домена не может быть найден.
|
| Экран 7. Репликация не состоялась, потому что DC домена не может быть найден |
Во-вторых, из DC1 попробуйте определить местоположение KDC в домене child.root.contoso.com с помощью команды:
Результаты на экране 7 свидетельствуют, что такого домена нет. В-третьих, поскольку вы не можете найти KDC, попытайтесь установить связь с любым DC в дочернем домене, используя команду:
В очередной раз результаты говорят о том, что нет такого домена, как показано на экране 7.
Теперь, когда вы воспроизвели все ошибки, просмотрите файл Netlogon.log, созданный в папке C:Windowsdebug. Откройте его в «Блокноте» и найдите запись, которая начинается с DSGetDcName function called. Обратите внимание, что записей с таким вызовом будет несколько. Вам нужно найти запись, имеющую те же параметры, что вы указали в команде Nltest (Dom:child и Flags:KDC). Запись, которую вы ищете, будет выглядеть так:
Вы должны просмотреть начальную запись, равно как и последующие, в этом потоке. В таблице 2 представлен пример потока 3372. Из этой таблицы следует, что поиск DNS записи KDC SRV в дочернем домене был неудачным. Ошибка 1355 указывает, что заданный домен либо не существует, либо к нему невозможно подключиться.
Поскольку вы пытаетесь подключиться к Child.root.contoso.com, следующий ваш шаг – выполнить для него команду ping из DC1. Скорее всего, вы получите сообщение о том, что хост не найден. Информация из файла Netlogon.log и ping-тест указывают на возможные проблемы в делегировании DNS. Свои подозрения вы можете проверить, сделав тест делегирования DNS. Для этого выполните следующую команду на DC1:
На экране 8 показан пример файла Dnstest.txt. Как вы можете заметить, это проблема DNS. Считается, что IP-адрес 192.168.10.1 – адрес для DC1.
|
| Экран 8. Пример файла Dnstest.txt |
Чтобы устранить проблему DNS, сделайте следующее:
1. На DC1 откройте консоль управления DNS.
2. Разверните Forward Lookup Zones, разверните root.contoso.com и выберите child.
3. Щелкните правой кнопкой мыши (как в родительской папке) на записи Name Server и выберите пункт Properties.
4. Выберите lamedc1.child.contoso.com и нажмите кнопку Remove.
5. Выберите Add, чтобы можно было добавить дочерний домен сервера DNS в настройки делегирования.
6. В окне Server fully qualified domain name (FQDN) введите правильный сервер childdc1.child.root.contoso.com.
7. В окне IP Addresses of this NS record введите правильный IP-адрес 192.168.10.11.
8. Дважды нажмите кнопку OK.
9. Выберите Yes в диалоговом окне, где спрашивается, хотите ли вы удалить связующую запись (glue record) lamedc1.child.contoso.com [192.168.10.1]. Glue record – это запись DNS для полномочного сервера доменных имен для делегированной зоны.
10. Используйте Nltest.exe для проверки, что вы можете найти KDC в дочернем домене. Примените опцию /force, чтобы кэш Netlogon не использовался:
11. Протестируйте репликацию AD из ChildDC1 на DC1 и DC2. Это можно сделать двумя способами. Один из них – выполнить команду
Другой подход заключается в использовании оснастки Active Directory Sites и Services консоли Microsoft Management Console (MMC), в этом случае правой кнопкой мыши щелкните DC и выберите Replicate Now, как показано на экране 9. Вам нужно это сделать для DC1, DC2 и TRDC1.
|
| Экран 9. Использование оснастки Active Directory Sites и?Services |
После этого вы увидите диалоговое окно, как показано на экране 10. Не учитывайте его, нажмите OK. Я вкратце расскажу об этой ошибке.
|
| Экран 10. Ошибка при репликации |
Когда все шаги выполнены, вернитесь к AD Replication Status Tool и обновите статус репликации на уровне леса. Ошибки 1908 больше быть не должно. Ошибка, которую вы видите, это ошибка 8606 (недостаточно атрибутов для создания объекта), как отмечалось на экране 10. Это следующая трудность, которую нужно преодолеть.
Устранение ошибки AD Replication Error 8606
Устаревший объект (lingering object) – это объект, который присутствует на DC, но был удален на одном или нескольких других DC. Ошибка репликации AD 8606 и ошибка 1988 в событиях Directory Service – хорошие индикаторы устаревших объектов. Важно учитывать, что можно успешно завершить репликацию AD и не регистрировать ошибку с DC, содержащего устаревшие объекты, поскольку репликация основана на изменениях. Если объекты не изменяются, то реплицировать их не нужно. По этой причине, выполняя очистку устаревших объектов, вы допускаете, что они есть у всех DC (а не только DCs logging errors).
Чтобы устранить проблему, в первую очередь убедитесь в наличии ошибки, выполнив следующую команду Repadmin на DC1:
Вы увидите сообщение об ошибке, как показано на экране 11. Кроме того, вы увидите событие с кодом в Event Viewer DC1 (см. экран 12). Обратите внимание, что событие с кодом 1988 только дает отчет о первом устаревшем объекте, который вам вдруг встретился. Обычно таких объектов много.
|
| Экран 11. Ошибка из-за наличия устаревшего объекта |
|
| Экран 12. Событие с кодом 1988 |
Вы должны скопировать три пункта из информации об ошибке 1988 в событиях: идентификатор globally unique identifier (GUID) устаревшего объекта, сервер-источник (source DC), а также уникальное, или различающееся, имя раздела – distinguished name (DN). Эта информация позволит определить, какой DC имеет данный объект.
Прежде всего, используйте GUID объекта (в данном случае 5ca6ebca-d34c-4f60-b79c-e8bd5af127d8) в следующей команде Repadmin, которая отправляет результаты в файл Objects.txt:
Если вы откроете файл Objects.txt, то увидите, что любой DC, который возвращает метаданные репликации для данного объекта, содержит один или более устаревших объектов. DC, не имеющие копии этого объекта, сообщают статус 8439 (уникальное имя distinguished name, указанное для этой операции репликации, недействительно).
Затем вам нужно, используя GUID объект Directory System Agent (DSA) DC1, идентифицировать все устаревшие объекты в разделе Root на DC2. DSA предоставляет доступ к физическому хранилищу информации каталога, находящейся на жестком диске. В AD DSA – часть процесса Local Security Authority. Для этого выполните команду:
В Showrepl.txt GUID объект DSA DC1 появляется вверху файла и выглядит следующим образом:
Ориентируясь на эту информацию, вы можете применить следующую команду, чтобы удостовериться в существовании устаревших объектов на DC2, сравнив его копию раздела Root с разделом Root DC1.
Далее вы можете просмотреть журнал регистрации событий Directory Service на DC2, чтобы узнать, есть ли еще какие-нибудь устаревшие объекты. Если да, то о каждом будет сообщаться в записи события 1946. Общее число устаревших объектов для проверенного раздела будет отмечено в записи события 1942.
Вы можете удалить устаревшие объекты несколькими способами. Предпочтительно использовать ReplDiag.exe. В качестве альтернативы вы можете выбрать RepAdmin.exe.
Используем ReplDiag.exe. С вашей рабочей станции администратора в корневом домене леса, а в нашем случае это Win8Client, вы должны выполнить следующие команды:
Первая команда удаляет объекты. Вторая команда служит для проверки успешного завершения репликации (иными словами, ошибка 8606 больше не регистрируется). Возвращая команды Repadmin /showobjmeta, вы можете убедиться в том, что объект был удален из всех, что объект был удален DC. Если у вас есть контроллер только для чтения read-only domain controller (RODC) и он содержал данный устаревший объект, вы заметите, что он все еще там находится. Дело в том, что текущая версия ReplDiag.exe не удаляет объекты из RODC. Для очистки RODC (в нашем случае, ChildDC2) выполните команду:
После этого просмотрите журнал событий Directory Service на ChildDC2 и найдите событие с кодом 1939. На экране 13 вы видите уведомление о том, что устаревшие объекты были удалены.
|
| Экран 13. Сообщение об удалении устаревших объектов |
Используем RepAdmin.exe. Другой способ, позволяющий удалить устаревшие объекты – прибегнуть к помощи RepAdmin.exe. Сначала вы должны удалить устаревшие объекты главных контроллеров домена (reference DC) с помощью кода, который видите в листинге 1. После этого необходимо удалить устаревшие объекты из всех остальных контроллеров домена (устаревшие объекты могут быть показаны или на них могут обнаружиться ссылки на нескольких контроллерах домена, поэтому убедитесь, что вы удалили их все). Необходимые для этой цели команды приведены в листинге 2.
Как видите, использовать ReplDiag.exe гораздо проще, чем RepAdmin.exe, поскольку вводить команд вам придется намного меньше. Ведь чем больше команд, тем больше шансов сделать опечатку, пропустить команду или допустить ошибку в командной строке.
Устранение ошибки AD Replication Error 8453
Предыдущие ошибки репликации AD были связаны с невозможностью найти другие контроллеры домена. Ошибка репликации AD с кодом состояния 8453 возникает, когда контроллер домена видит другие DC, но не может установить с ними связи репликации.
Например, предположим, что ChildDC2 (RODC) в дочернем домене не уведомляет о себе как о сервере глобального каталога – Global Catalog (GC). Для получения статуса ChildDC2 запустите следующие команды на ChildDC2:
Данная команда отправляет результаты Repl.txt. Если вы откроете этот текстовый файл, то увидите вверху следующее:
Если вы внимательно посмотрите на раздел Inbound Neighbors, то увидите, что раздел DC=treeroot,DC=fabrikam,DC=com отсутствует, потому что он не реплицируется. Взгляните на кнопку файла – вы увидите ошибку:
Эта ошибка означает, что ChildDC2 не может добавить связь репликации (replication link) для раздела Treeroot. Как показано на экране 14, данная ошибка также записывается в журнал регистрации событий Directory Services на ChildDC2 как событие с кодом 1926.
|
| Экран 14. Отсутствие связи репликации |
Здесь вам нужно проверить, нет ли проблем, связанных с безопасностью. Для этого используйте DCDiag.exe:
На экране 15 показан фрагмент вывода DCDiag.exe.
|
| Экран 15. Фрагмент вывода DCDiag.exe |
Как видите, вы получаете ошибку 8453, потому что группа безопасности Enterprise Read-Only Domain Controllers не имеет разрешения Replicating Directory Changes.
Чтобы решить проблему, вам нужно добавить отсутствующую запись контроля доступа – missing access control entry (ACE) в раздел Treeroot. В этом вам помогут следующие шаги:
1. На TRDC1 откройте оснастку ADSI Edit.
2. Правой кнопкой мыши щелкните DC=treeroot,DC=fabrikam,DC=com и выберите Properties.
3. Выберите вкладку Security.
4. Посмотрите разрешения на этот раздел. Отметьте, что нет записей для группы безопасности Enterprise Read-Only Domain Controllers.
6. В окне Enter the object names to select наберите ROOTEnterprise Read-Only Domain Controllers.
7. Нажмите кнопку Check Names, затем выберите OK, если указатель объектов (object picker) разрешает имя.
8. В диалоговом окне Permissions для Enterprise Read-Only Domain Controllers снимите флажки Allow для следующих разрешений
*Read domain password & lockout policies («Чтение политики блокировки и пароля домена»)
*Read Other domain parameters
9. Выберите флажок Allow для разрешения Replicating Directory Changes, как показано на экране 16. Нажмите OK.
10. Вручную запустите Knowledge Consistency Checker (KCC), чтобы немедленно сделать перерасчет топологии входящей репликации на ChildDC2, выполнив команду
|
| Экран 16. Включение разрешения Replicating Directory Change |
Данная команда заставляет KCC на каждом целевом сервере DC незамедлительно делать перерасчет топологии входящей репликации, добавляя снова раздел Treeroot.
Состояние репликации критически важно
Репликация во всех отношениях в лесу AD имеет решающее значение. Следует регулярно проводить ее диагностику, чтобы изменения были видны всем контроллерам домена, иначе могут возникать различные проблемы, в том числе связанные с аутентификацией. Проблемы репликации нельзя обнаружить сразу. Поэтому если вы пренебрегаете мониторингом репликации (в крайнем случае, периодически делайте проверку), то рискуете столкнуться с трудностями в самый неподходящий момент. Моей задачей было показать вам, как проверять статус репликации, обнаруживать ошибки и в то же время как справиться с четырьмя типичными проблемами репликации AD.
Листинг 1. Команды для удаления устаревших объектов из Reference DC
Листинг 2. Команды для удаления устаревших объектов из остальных DC
источники:
http://www.osp.ru/winitpro/2014/11/13043633
Content freshness is a fairly key concept in the life of an Active Directory/DFS guru. Most of us have seen this in action with AD replication, for example. If two DC’s aren’t replicating then at
best the AD objects & attributes are out of sync and at
worst replication will shut down completely when the disconnect continues beyond the tombstone lifetime. Systematically determining which changes should be applied becomes impossible or even problematic (think: lingering objects in this example) the longer the timeline. The fundamental idea is that directory data needs to stay fresh. If it’s been too long since the data has been synchronized it’s best to just discontinue replication. The same is true for DFS.
Let’s say there are two servers in a Replication Group called Server1 and Server2. When a DFS Replication group falls out of sync, changes are still being made to the files on both servers. So how do we keep track of them? In the short run, those changes can be queued up in the Staging Area of both servers and will be replicated when the communications issue is past. But what if that outage is prolonged? You could have a document on Server 1 where the file is deleted, the deletion doesn’t replicate, and meanwhile on Server2 edits continue to be made to that file. What’s DFS gonna do if the members of the DFS Replication group actually do see one another again? Does this sound familiar? It’s like the DFS version of a lingering object! In other words, content freshness is a critical aspect of replication. If the content gets stale enough – like in this scenario – you actually don’t want it to replicate. In response Microsoft’s code sets replication thresholds and shuts it down for you. In so doing, they’ve saved us from ourselves. For an even deeper dive on this, and put much more eloquently than I ever could, here is a post from the official DS Team blog on the subject – http://blogs.technet.com/b/askds/archive/2009/11/18/implementing-content-freshness-protection-in-dfsr.aspx
So what do we do if we find ourselves in this predicament???? That’s probably the reason you’re here at our blog. You’ve likely seen an event 4004 in the DFSR log that shows an error 9098 and makes the statement “A tombstoned content set deletion has been scheduled.” Content freshness is the reason this has occurred. AFTER fixing the root cause of the blockage (firewalls, DFSR in dirty shutdown, etc.) here are some options on how to get things back up and running:
Solution1: Follow the Recovery Procedure in the aforementioned DS blog post.
The specifics are already in the link. However, at a high level this essentially boils down to:
- Get a backup
- Disabling the affected member in the RG
- Force AD replication
- Enable DFS Replication again on the member.
- Force AD replication.
- The node will then go through initial sync again where it catalogs the files in the jet, so you’ll need to wait for that to complete before letting users back in.
As further evidence that this is a good course to follow, if you happen to see a 4012 in the DFSR log it suggests the very same. Picture below.
Solution2: Recreate the Replication Group. Best to consider this a second option to Solution1.
- Get a backup of the Replicated Folder on both/all nodes.
- In the DFS Console, delete the Replication Group
- Force AD Replication.
- From an elevated command prompt run DFSRDiag pollad on each of the former Replication Group members.
-
On each (former)member of the RG, delete the hidden DFSRPrivate folder.
- This holds the Staging and ConflictAndDeleted folders. You may want/need to restore some of this from backup after all is said and done if the authoritative server’s copy of the file isn’t actually the one you want.
- Where is this???? It’s in the Replicated folder. If the Replicated Folder is e:homes, then from a command prompt you can see it from e:homesdfsrprivate. You’ll need to unhide system files in order to see it in Windows Explorer.
- Recreate the Replication Group in the DFSR Console.
- DFSRDIAG pollad from each RG member, so it picks up the new configuration from Active Directory.
- This will kick off an initial sync on the Replication Group, which is going to take some time. You won’t want to let the users back in until this is complete. Keeping checking the DFSR log for a 4104 which indicates this is finished.
- As the event suggests, check the PreExisting & ConflictAndDeleted folders for any fallout and don’t be afraid to check the backups for a more relevant version of files from the old Staging folders.
Hopefully this help fill in your understanding of content freshness and why in certain circumstances the Microsoft code is actually built to halt replication. Getting out of this jam isn’t perfect and often data can be lost. However this builds the perfect business case for why you need a tool to help you monitor DFSR.