Содержание
- ECC Configuration — что это в биосе?
- ECC Configuration — что это такое?
- Как работает коррекция ошибок ECC на SSD
- Как ECC работает на контроллере SSD
- Какое влияние оказывает код исправления ошибок на SSD?
- Обнаружение и исправление ошибок — Error detection and correction
- Содержание
- Определения
- История
- Введение
- Типы исправления ошибок
- Автоматический повторный запрос (ARQ)
- Прямое исправление ошибок
- Гибридные схемы
- Схемы обнаружения ошибок
- Кодирование с минимальным расстоянием
- Коды повторения
- Бит четности
- Контрольная сумма
- Проверка циклическим избыточным кодом
- Криптографическая хеш-функция
- Код исправления ошибок
- Приложения
- Интернет
- Телекоммуникации в дальнем космосе
- Спутниковое вещание
- Хранение данных
- Память с исправлением ошибок
ECC Configuration — что это в биосе?
 Приветствую. Для домашних ПК главное скорость работы, а потом уже стабильность или надежность, все таки часто мы играем в игры, смотрим фильмы и делаем другие дела развлекательного характера)) Но вот в серверах важна стабильность и надежность, поэтому например оперативка от сервера вряд ли подойдет на домашний комп. Но исключения бывают.
Приветствую. Для домашних ПК главное скорость работы, а потом уже стабильность или надежность, все таки часто мы играем в игры, смотрим фильмы и делаем другие дела развлекательного характера)) Но вот в серверах важна стабильность и надежность, поэтому например оперативка от сервера вряд ли подойдет на домашний комп. Но исключения бывают.
ECC Configuration — что это такое?
Предположительно опция связана с поддержкой серверной памяти ECC, которая используется в северах, а в домашних ПК обычно нет.
Основной отличие такой памяти от обычной — она поддерживает исправление ошибок на лету, в итоге надежность и стабильность выше, однако скорость — ниже, поэтому на домашних ПК она не используется. ECC расшифровывается как Error Checking and Correction.
Кстати если память не серверная, то она обозначается как non-ECC.
Наличие опции означает что материнка работает с двумя видами оперативки, но стоит учесть, что еще важно чтобы процессор поддерживал. Как у AMD — не знаю, а у Intel есть некоторые модели Pentium, i3, которые работают с серверной памятью. Но обычно нужен серверный проц.
Вообще судя по это картинке — ECC Configuration не опция, а раздел:

В разделе еще могут быть такие настройки:

Все эти настройки бесполезны если стоит обычная оперативка, при их включении ПК может даже не запуститься. Обычная просто не поддерживает эти настройки.
Источник
Как работает коррекция ошибок ECC на SSD
Конечно, вы слышали (или читали) говорить о Код исправления ошибок ECC во многих аппаратных компонентах, связанных с памятью (либо Оперативная память или хранилище), хотя очень немногие понимают его важность. По этой причине в этой статье мы собираемся объяснить, как работает ECC в SSD контроллер и как благодаря этому можно увеличить продолжительность жизни и сделать большую разницу в срок службы твердотельных накопителей .
Каждому устройству, использующему флэш-память NAND, необходим код с исправлением случайных битов (известный как «мягкая» ошибка). Это потому что много электрический шум производится внутри чипа NAND, а уровни сигналов битов, проходящих через цепочку чипов NAND, очень слабые.
Один из способов, которым NAND память стали самый дешевый всего, потому что это требует, чтобы исправление ошибок было выполнено от элемента вне самого чипа NAND; В случае SSD, ECC выполняется на контроллере .
Как ECC работает на контроллере SSD
Такое же исправление ошибок также помогает исправить битовые ошибки из-за носить на Память сами клетки , Истощение может вызвать «застревание» битов в том или ином состоянии (известное как «жесткая» ошибка или жесткая ошибка) и может увеличить частоту «мягких» ошибок.
Хотя это понятие не является слишком широким, сопротивление флэш-памяти является мерой того, сколько циклов стирания / записи может выдержать блок флэш-памяти, прежде чем начнут появляться «серьезные» ошибки. Очень часто эти сбои происходят только в отдельных битах, и очень редко происходит сбой всего блока. При достаточно высоком числе стирания / записи «мягкая» частота ошибок также увеличивается из-за ряда других механизмов в самом SSD.
If ECC может быть используемый чтобы исправить эти «жесткие» ошибки, а «мягкие» ошибки не увеличиваются, срок службы всего блока значительно удлиняется, что значительно превышает сопротивление, указанное производителем.
Давайте рассмотрим пример: допустим, что неиспользуемый чип NAND имеет достаточно «мягких» ошибок, чтобы требовать 8 бит ECC, то есть при каждом считывании страницы может быть до 8 бит, которые были случайно повреждены (обычно из-за электрических помех, которые мы говорили о). вначале). ECC, используемый в этом чипе, может исправлять 12-битные ошибки, так что ECC не может решить эту проблему мы должны найти 8 «мягких» ошибок, связанных с электрическим шумом, плюс еще 5 «мягких» из-за износа.
Теперь производители флэш-памяти гарантируют, что первый из этих 5 сбоев произойдет через некоторое время после спецификации прочности SSD. Это означает, что ни один бит не выйдет из строя из-за износа, пока не будут превышены циклы стирания / записи, указанные производителем. Теперь имейте в виду, что спецификации не достаточно точны, чтобы предсказать, когда следующий бит выйдет из строя, и на самом деле это может занять несколько тысяч циклов стирания / записи выше спецификации, чтобы это произошло; помните, что производитель гарантирует, что это не произойдет до X циклов, но не тогда, когда это произойдет после их превышения.

Это означает, что это может занять много времени, прежде чем блок становится настолько коррумпированным что его необходимо удалить из службы (а также для этого на SSD обычно есть «дополнительные» блоки для замены поврежденных), что, в свою очередь, означает, что сопротивление исправлен от ошибок блок может быть во много раз больше указанного сопротивления, в зависимости от количества избыточных ошибок, которые ECC предназначен для исправления.
Какое влияние оказывает код исправления ошибок на SSD?
Как мы объясняли ранее, флэш-память настолько дешева, потому что она не включает в себя ECC в самих чипах, но интегрирована в другое внешнее оборудование, и, как вы предположите, это имеет свою цену. Более сложный ECC требует большей вычислительной мощности на контроллере и может быть медленнее, если алгоритмы не очень современные. Кроме того, количество ошибок, которые могут быть исправлены, будет зависеть от того, насколько большой сектор памяти исправляется, поэтому контроллер SSD со сложным алгоритмом ECC, вероятно, будет использовать много ресурсов, снижение общий SSD производительность , Эти улучшения также делают контроллер дороже .

Алгоритмы ECC имеют свое собственное математическое состояние в зависимости от контроллера (другими словами, нет никакого стандарта), и даже самые базовые кодировки ECC (Рида-Соломона и LDPC) довольно сложны для понимания. Когда кто-то говорит о пределе Шеннона (максимальное количество битов, которое может быть исправлено), это величина, которую, как вы не знаете от производителя в технических характеристиках, чрезвычайно сложно вычислить.
Просто придерживайтесь этого: большее количество корректирующих битов увеличивает срок службы SSD, но также оказывает некоторое влияние на производительность или даже цену продукта, так как требует более мощный контроллер.
Источник
Обнаружение и исправление ошибок — Error detection and correction
В теории информации и теории кодирования с приложениями в информатике и телекоммуникациях, обнаружение и исправление ошибок или контроль ошибок — это методы, которые обеспечивают надежную доставку цифровых данных по ненадежным каналам связи. Многие каналы связи подвержены канальному шуму, и поэтому во время передачи от источника к приемнику могут возникать ошибки. Методы обнаружения ошибок позволяют обнаруживать такие ошибки, а исправление ошибок во многих случаях позволяет восстановить исходные данные.
Содержание
- 1 Определения
- 2 История
- 3 Введение
- 4 Типы исправления ошибок
- 4.1 Автоматический повторный запрос (ARQ)
- 4.2 Прямое исправление ошибок
- 4.3 Гибридные схемы
- 5 Схемы обнаружения ошибок
- 5.1 Кодирование на минимальном расстоянии
- 5.2 Коды повторения
- 5.3 Бит четности
- 5.4 Контрольная сумма
- 5.5 Циклическая проверка избыточности
- 5.6 Криптографическая хеш-функция
- 5.7 Ошибка код исправления
- 6 Приложения
- 6.1 Интернет
- 6.2 Связь в дальнем космосе
- 6.3 Спутниковое вещание
- 6.4 Хранение данных
- 6.5 Память с исправлением ошибок
- 7 См. также
- 8 Ссылки
- 9 Дополнительная литература
- 10 Внешние ссылки
Определения
Обнаружение ошибок — это обнаружение ошибок, вызванных шумом или другими помехами во время передачи от передатчика к приемнику. Исправление ошибок — это обнаружение ошибок и восстановление исходных безошибочных данных.
История
Введение
Все схемы обнаружения и исправления ошибок добавляют некоторые избыточность (т. е. некоторые дополнительные данные) сообщения, которые получатели могут использовать для проверки согласованности доставленного сообщения и для восстановления данных, которые были определены как поврежденные. Схемы обнаружения и исправления ошибок могут быть систематическими или несистематическими. В систематической схеме передатчик отправляет исходные данные и присоединяет фиксированное количество контрольных битов (или данных четности), которые выводятся из битов данных некоторым детерминированным алгоритмом. Если требуется только обнаружение ошибок, приемник может просто применить тот же алгоритм к полученным битам данных и сравнить свой вывод с полученными контрольными битами; если значения не совпадают, в какой-то момент во время передачи произошла ошибка. В системе, которая использует несистематический код, исходное сообщение преобразуется в закодированное сообщение, несущее ту же информацию и имеющее по крайней мере такое же количество битов, как и исходное сообщение.
Хорошие характеристики контроля ошибок требуют, чтобы схема была выбрана на основе характеристик канала связи. Распространенные модели каналов включают в себя модели без памяти, в которых ошибки возникают случайно и с определенной вероятностью, и динамические модели, в которых ошибки возникают в основном в пакетах . Следовательно, коды обнаружения и исправления ошибок можно в целом различать между обнаружением / исправлением случайных ошибок и обнаружением / исправлением пакетов ошибок. Некоторые коды также могут подходить для сочетания случайных ошибок и пакетных ошибок.
Если характеристики канала не могут быть определены или сильно изменяются, схема обнаружения ошибок может быть объединена с системой для повторных передач ошибочных данных. Это известно как автоматический запрос на повторение (ARQ) и наиболее широко используется в Интернете. Альтернативный подход для контроля ошибок — это гибридный автоматический запрос на повторение (HARQ), который представляет собой комбинацию ARQ и кодирования с исправлением ошибок.
Типы исправления ошибок
Существует три основных типа исправления ошибок.
Автоматический повторный запрос (ARQ)
Автоматический повторный запрос (ARQ) — это метод контроля ошибок для передачи данных, который использует коды обнаружения ошибок, сообщения подтверждения и / или отрицательного подтверждения и тайм-ауты для обеспечения надежной передачи данных. Подтверждение — это сообщение, отправленное получателем, чтобы указать, что он правильно получил кадр данных.
Обычно, когда передатчик не получает подтверждения до истечения тайм-аута (т. Е. В течение разумного периода времени после отправки фрейм данных), он повторно передает фрейм до тех пор, пока он либо не будет правильно принят, либо пока ошибка не останется сверх заранее определенного количества повторных передач.
ARQ is подходит, если канал связи имеет переменную или неизвестную пропускную способность, например, в случае с Интернетом. Однако ARQ требует наличия обратного канала, что приводит к возможному увеличению задержки из-за повторных передач и требует обслуживания буферов и таймеров для повторных передач, что в случае перегрузка сети может вызвать нагрузку на сервер и общую пропускную способность сети.
Например, ARQ используется на коротковолновых радиоканалах в форме ARQ-E, или в сочетании с мультиплексированием как ARQ-M.
Прямое исправление ошибок
Прямое исправление ошибок (FEC) — это процесс добавления избыточных данных, таких как исправление ошибок code (ECC) в сообщение, чтобы оно могло быть восстановлено получателем, даже если в процессе передачи или при хранении был внесен ряд ошибок (в зависимости от возможностей используемого кода). Так как получатель не должен запрашивать у отправителя повторную передачу данных, обратный канал не требуется при прямом исправлении ошибок, и поэтому он подходит для симплексной связи, например вещание. Коды с исправлением ошибок часто используются в нижнем уровне связи, а также для надежного хранения на таких носителях, как CD, DVD, жесткие диски и RAM.
Коды с исправлением ошибок обычно различают между сверточными кодами и блочными кодами. :
- Сверточные коды обрабатываются побитно. Они особенно подходят для аппаратной реализации, а декодер Витерби обеспечивает оптимальное декодирование.
- Блочные коды обрабатываются на поблочной основе. Ранними примерами блочных кодов являются коды повторения, коды Хэмминга и многомерные коды контроля четности. За ними последовал ряд эффективных кодов, из которых коды Рида – Соломона являются наиболее известными из-за их широкого распространения в настоящее время. Турбокоды и коды с низкой плотностью проверки четности (LDPC) — это относительно новые конструкции, которые могут обеспечить почти оптимальную эффективность.
Теорема Шеннона — важная теорема при прямом исправлении ошибок и описывает максимальную информационную скорость, на которой возможна надежная связь по каналу, имеющему определенную вероятность ошибки или отношение сигнал / шум (SNR). Этот строгий верхний предел выражается в единицах пропускной способности канала . Более конкретно, в теореме говорится, что существуют такие коды, что с увеличением длины кодирования вероятность ошибки на дискретном канале без памяти может быть сделана сколь угодно малой при условии, что кодовая скорость меньше чем емкость канала. Кодовая скорость определяется как доля k / n из k исходных символов и n кодированных символов.
Фактическая максимальная разрешенная кодовая скорость зависит от используемого кода исправления ошибок и может быть ниже. Это связано с тем, что доказательство Шеннона носило только экзистенциальный характер и не показало, как создавать коды, которые одновременно являются оптимальными и имеют эффективные алгоритмы кодирования и декодирования.
Гибридные схемы
Гибридный ARQ — это комбинация ARQ и прямого исправления ошибок. Существует два основных подхода:
- Сообщения всегда передаются с данными четности FEC (и избыточностью для обнаружения ошибок). Получатель декодирует сообщение, используя информацию о четности, и запрашивает повторную передачу с использованием ARQ только в том случае, если данных четности было недостаточно для успешного декодирования (идентифицировано посредством неудачной проверки целостности).
- Сообщения передаются без данных четности (только с информация об обнаружении ошибок). Если приемник обнаруживает ошибку, он запрашивает информацию FEC от передатчика с помощью ARQ и использует ее для восстановления исходного сообщения.
Последний подход особенно привлекателен для канала стирания при использовании код бесскоростного стирания.
Схемы обнаружения ошибок
Обнаружение ошибок чаще всего реализуется с использованием подходящей хэш-функции (или, в частности, контрольной суммы, циклической проверка избыточности или другой алгоритм). Хеш-функция добавляет к сообщению тег фиксированной длины, который позволяет получателям проверять доставленное сообщение, повторно вычисляя тег и сравнивая его с предоставленным.
Существует огромное количество различных конструкций хеш-функций. Однако некоторые из них имеют особенно широкое распространение из-за их простоты или их пригодности для обнаружения определенных видов ошибок (например, производительности циклического контроля избыточности при обнаружении пакетных ошибок ).
Кодирование с минимальным расстоянием
Код с исправлением случайных ошибок на основе кодирования с минимальным расстоянием может обеспечить строгую гарантию количества обнаруживаемых ошибок, но может не защитить против атаки прообразом.
Коды повторения
A код повторения — это схема кодирования, которая повторяет биты по каналу для достижения безошибочной связи. Учитывая поток данных, которые необходимо передать, данные делятся на блоки битов. Каждый блок передается определенное количество раз. Например, чтобы отправить битовую комбинацию «1011», четырехбитовый блок можно повторить три раза, таким образом получая «1011 1011 1011». Если этот двенадцатибитовый шаблон был получен как «1010 1011 1011» — где первый блок не похож на два других, — произошла ошибка.
Код повторения очень неэффективен и может быть подвержен проблемам, если ошибка возникает в одном и том же месте для каждой группы (например, «1010 1010 1010» в предыдущем примере будет определено как правильное). Преимущество кодов повторения состоит в том, что они чрезвычайно просты и фактически используются в некоторых передачах номеров станций.
Бит четности
Бит четности — это бит, который добавляется к группе исходные биты, чтобы гарантировать, что количество установленных битов (т. е. битов со значением 1) в результате будет четным или нечетным. Это очень простая схема, которую можно использовать для обнаружения одного или любого другого нечетного числа (т. Е. Трех, пяти и т. Д.) Ошибок в выводе. Четное количество перевернутых битов сделает бит четности правильным, даже если данные ошибочны.
Расширениями и вариантами механизма битов четности являются проверки с продольным избыточным кодом, проверки с поперечным избыточным кодом и аналогичные методы группирования битов.
Контрольная сумма
Контрольная сумма сообщения — это модульная арифметическая сумма кодовых слов сообщения фиксированной длины слова (например, байтовых значений). Сумма может быть инвертирована посредством операции дополнения до единиц перед передачей для обнаружения непреднамеренных сообщений с нулевым значением.
Схемы контрольных сумм включают биты четности, контрольные цифры и проверки продольным избыточным кодом. Некоторые схемы контрольных сумм, такие как алгоритм Дамма, алгоритм Луна и алгоритм Верхоффа, специально разработаны для обнаружения ошибок, обычно вносимых людьми при записи или запоминание идентификационных номеров.
Проверка циклическим избыточным кодом
Проверка циклическим избыточным кодом (CRC) — это незащищенная хэш-функция, предназначенная для обнаружения случайных изменений цифровых данных в компьютерных сетях. Он не подходит для обнаружения злонамеренно внесенных ошибок. Он характеризуется указанием порождающего полинома, который используется в качестве делителя в полиномиальном делении над конечным полем, принимая входные данные в качестве дивиденд. остаток становится результатом.
CRC имеет свойства, которые делают его хорошо подходящим для обнаружения пакетных ошибок. CRC особенно легко реализовать на оборудовании и поэтому обычно используются в компьютерных сетях и устройствах хранения, таких как жесткие диски.
. Бит четности может рассматриваться как 1-битный частный случай. CRC.
Криптографическая хеш-функция
Выходные данные криптографической хеш-функции, также известные как дайджест сообщения, могут обеспечить надежную гарантию целостности данных, независимо от того, происходят ли изменения данных случайно (например, из-за ошибок передачи) или злонамеренно. Любая модификация данных, скорее всего, будет обнаружена по несоответствию хеш-значения. Кроме того, с учетом некоторого хэш-значения, как правило, невозможно найти некоторые входные данные (кроме заданных), которые дадут такое же хеш-значение. Если злоумышленник может изменить не только сообщение, но и значение хеш-функции, то для дополнительной безопасности можно использовать хэш-код с ключом или код аутентификации сообщения (MAC). Не зная ключа, злоумышленник не может легко или удобно вычислить правильное ключевое значение хеш-функции для измененного сообщения.
Код исправления ошибок
Для обнаружения ошибок можно использовать любой код исправления ошибок. Код с минимальным расстоянием Хэмминга, d, может обнаруживать до d — 1 ошибок в кодовом слове. Использование кодов с коррекцией ошибок на основе минимального расстояния для обнаружения ошибок может быть подходящим, если требуется строгое ограничение на минимальное количество обнаруживаемых ошибок.
Коды с минимальным расстоянием Хэмминга d = 2 являются вырожденными случаями кодов с исправлением ошибок и могут использоваться для обнаружения одиночных ошибок. Бит четности является примером кода обнаружения одиночной ошибки.
Приложения
Приложения, которым требуется низкая задержка (например, телефонные разговоры), не могут использовать автоматический запрос на повторение (ARQ); они должны использовать прямое исправление ошибок (FEC). К тому времени, когда система ARQ обнаружит ошибку и повторно передаст ее, повторно отправленные данные прибудут слишком поздно, чтобы их можно было использовать.
Приложения, в которых передатчик сразу же забывает информацию, как только она отправляется (например, большинство телекамер), не могут использовать ARQ; они должны использовать FEC, потому что при возникновении ошибки исходные данные больше не доступны.
Приложения, использующие ARQ, должны иметь канал возврата ; приложения, не имеющие обратного канала, не могут использовать ARQ.
Приложения, требующие чрезвычайно низкого уровня ошибок (например, цифровые денежные переводы), должны использовать ARQ из-за возможности неисправимых ошибок с помощью FEC.
Надежность и инженерная проверка также используют теорию кодов исправления ошибок.
Интернет
В типичном стеке TCP / IP ошибка управление осуществляется на нескольких уровнях:
- Каждый кадр Ethernet использует CRC-32 обнаружение ошибок. Фреймы с обнаруженными ошибками отбрасываются оборудованием приемника.
- Заголовок IPv4 содержит контрольную сумму , защищающую содержимое заголовка. Пакеты с неверными контрольными суммами отбрасываются в сети или на приемнике.
- Контрольная сумма не указана в заголовке IPv6, чтобы минимизировать затраты на обработку в сетевой маршрутизации и поскольку предполагается, что текущая технология канального уровня обеспечивает достаточное обнаружение ошибок (см. также RFC 3819 ).
- UDP, имеет дополнительную контрольную сумму, покрывающую полезную нагрузку и информацию об адресации в заголовки UDP и IP. Пакеты с неверными контрольными суммами отбрасываются сетевым стеком . Контрольная сумма не является обязательной для IPv4 и требуется для IPv6. Если не указано, предполагается, что уровень канала передачи данных обеспечивает желаемый уровень защиты от ошибок.
- TCP обеспечивает контрольную сумму для защиты полезной нагрузки и адресной информации в заголовках TCP и IP. Пакеты с неверными контрольными суммами отбрасываются сетевым стеком и в конечном итоге повторно передаются с использованием ARQ либо явно (например, как через тройное подтверждение ) или неявно из-за тайм-аута .
Телекоммуникации в дальнем космосе
Разработка кодов исправления ошибок была тесно связана с историей полетов в дальний космос из-за сильного ослабления мощности сигнала на межпланетных расстояниях и ограниченной мощности на борту космических зондов. В то время как ранние миссии отправляли свои данные в незашифрованном виде, начиная с 1968 года, цифровая коррекция ошибок была реализована в форме (субоптимально декодированных) сверточных кодов и кодов Рида – Маллера. Код Рида-Мюллера хорошо подходил к шуму, которому подвергался космический корабль (примерно соответствуя кривой ), и был реализован для космического корабля Mariner и использовался в миссиях между 1969 и 1977 годами.
Миссии «Вояджер-1 » и «Вояджер-2 «, начатые в 1977 году, были разработаны для доставки цветных изображений и научной информации с Юпитера и Сатурна. Это привело к повышенным требованиям к кодированию, и, таким образом, космический аппарат поддерживался (оптимально Витерби-декодированный ) сверточными кодами, которые могли быть сцеплены с внешним Голеем (24,12,  код. Корабль «Вояджер-2» дополнительно поддерживал реализацию кода Рида-Соломона. Конкатенированный код Рида – Соломона – Витерби (RSV) позволил произвести очень мощную коррекцию ошибок и позволил космическому кораблю совершить длительное путешествие к Урану и Нептуну. После модернизации системы ECC в 1989 году оба корабля использовали кодирование V2 RSV.
код. Корабль «Вояджер-2» дополнительно поддерживал реализацию кода Рида-Соломона. Конкатенированный код Рида – Соломона – Витерби (RSV) позволил произвести очень мощную коррекцию ошибок и позволил космическому кораблю совершить длительное путешествие к Урану и Нептуну. После модернизации системы ECC в 1989 году оба корабля использовали кодирование V2 RSV.
Консультативный комитет по космическим информационным системам в настоящее время рекомендует использовать коды исправления ошибок, как минимум, аналогичные RSV-коду Voyager 2. Составные коды все больше теряют популярность в космических миссиях и заменяются более мощными кодами, такими как Турбо-коды или LDPC-коды.
Различные виды выполняемых космических и орбитальных миссий. предполагают, что попытки найти универсальную систему исправления ошибок будут постоянной проблемой. Для полетов вблизи Земли характер шума в канале связи отличается от того, который испытывает космический корабль в межпланетной миссии. Кроме того, по мере того как космический корабль удаляется от Земли, проблема коррекции шума становится все более сложной.
Спутниковое вещание
Спрос на пропускную способность спутникового транспондера продолжает расти, чему способствует желание предоставлять телевидение (включая новые каналы и телевидение высокой четкости ) и данные IP. Доступность транспондеров и ограничения полосы пропускания ограничили этот рост. Емкость транспондера определяется выбранной схемой модуляции и долей мощности, потребляемой FEC.
Хранение данных
Коды обнаружения и исправления ошибок часто используются для повышения надежности носителей данных. «Дорожка четности» присутствовала на первом устройстве хранения данных на магнитной ленте в 1951 году. «Оптимальный прямоугольный код», используемый в записи с групповым кодированием, не только обнаруживает, но и корректирует однобитовые записи. ошибки. Некоторые форматы файлов, особенно архивные форматы, включают контрольную сумму (чаще всего CRC32 ) для обнаружения повреждений и усечения и могут использовать избыточность и / или четность files для восстановления поврежденных данных. Коды Рида-Соломона используются в компакт-дисках для исправления ошибок, вызванных царапинами.
Современные жесткие диски используют коды CRC для обнаружения и коды Рида – Соломона для исправления незначительных ошибок при чтении секторов, а также для восстановления данных из секторов, которые «испортились», и сохранения этих данных в резервных секторах. Системы RAID используют различные методы исправления ошибок для исправления ошибок, когда жесткий диск полностью выходит из строя. Файловые системы, такие как ZFS или Btrfs, а также некоторые реализации RAID, поддерживают очистку данных и восстановление обновлений, что позволяет удалять поврежденные блоки. обнаружены и (надеюсь) восстановлены, прежде чем они будут использованы. Восстановленные данные могут быть перезаписаны точно в том же физическом месте, чтобы освободить блоки в другом месте на том же оборудовании, или данные могут быть перезаписаны на заменяющее оборудование.
Память с исправлением ошибок
Память DRAM может обеспечить более надежную защиту от программных ошибок, полагаясь на коды исправления ошибок. Такая память с исправлением ошибок, известная как память с защитой ECC или EDAC, особенно желательна для критически важных приложений, таких как научные вычисления, финансы, медицина и т. Д., А также для приложений дальнего космоса из-за повышенное излучение в космосе.
Контроллеры памяти с исправлением ошибок традиционно используют коды Хэмминга, хотя некоторые используют тройную модульную избыточность.
Чередование позволяет распределить эффект одного космического луча, потенциально нарушающего множество физически соседние биты в нескольких словах путем связывания соседних битов с разными словами. До тех пор, пока нарушение единичного события (SEU) не превышает пороговое значение ошибки (например, одиночная ошибка) в любом конкретном слове между доступами, оно может быть исправлено (например, путем исправления однобитовой ошибки code), и может сохраняться иллюзия безошибочной системы памяти.
Помимо оборудования, обеспечивающего функции, необходимые для работы памяти ECC, операционные системы обычно содержат соответствующие средства отчетности, которые используются для предоставления уведомлений при прозрачном восстановлении программных ошибок. Увеличение количества программных ошибок может указывать на то, что модуль DIMM нуждается в замене, и такая обратная связь не была бы легко доступна без соответствующих возможностей отчетности. Одним из примеров является подсистема EDAC ядра Linux (ранее известная как Bluesmoke), которая собирает данные из компонентов компьютерной системы, поддерживающих проверку ошибок; Помимо сбора и отправки отчетов о событиях, связанных с памятью ECC, он также поддерживает другие ошибки контрольного суммирования, в том числе обнаруженные на шине PCI.
Некоторые системы также поддерживают очистку памяти.
Источник
Приветствую. Для домашних ПК главное скорость работы, а потом уже стабильность или надежность, все таки часто мы играем в игры, смотрим фильмы и делаем другие дела развлекательного характера)) Но вот в серверах важна стабильность и надежность, поэтому например оперативка от сервера вряд ли подойдет на домашний комп. Но исключения бывают.
ECC Configuration — что это такое?
Предположительно опция связана с поддержкой серверной памяти ECC, которая используется в северах, а в домашних ПК обычно нет.
Основной отличие такой памяти от обычной — она поддерживает исправление ошибок на лету, в итоге надежность и стабильность выше, однако скорость — ниже, поэтому на домашних ПК она не используется. ECC расшифровывается как Error Checking and Correction.
Кстати если память не серверная, то она обозначается как non-ECC.
Наличие опции означает что материнка работает с двумя видами оперативки, но стоит учесть, что еще важно чтобы процессор поддерживал. Как у AMD — не знаю, а у Intel есть некоторые модели Pentium, i3, которые работают с серверной памятью. Но обычно нужен серверный проц.
Вообще судя по это картинке — ECC Configuration не опция, а раздел:
В разделе еще могут быть такие настройки:
Все эти настройки бесполезны если стоит обычная оперативка, при их включении ПК может даже не запуститься. Обычная просто не поддерживает эти настройки.
Заключение
- ECC Configuration — опция, при помощи которой можно настроить работу серверной памяти.
- Кроме материнки такую память должен еще поддерживать процессор. Не все домашние модели подходят, но например серия Xeon от Intel — почти все поддерживают.
Удачи.
На главную!
03.04.2020
Появление сообщения ECC Error на экране означает, что возник сбой в работе оперативной памяти, который не может быть исправлен системой коррекции ошибок ЕСС. Ошибка возникает из-за неисправности модуля памяти.
Ошибка также может иметь название:
Uncorrectable ECC DRAM Error
Примечание 1. Оперативная память (Random Access Memory, RAM, системная память) – это энергозависимая компьютерная память, которая предназначена для временного хранения активных программ и данных, используемых процессором во время выполнения операций.
Более подробно о том, что такое оперативная память, Вы можете узнать здесь.
Примечание 2. Модуль оперативной памяти (оперативное запоминающее устройство, ОЗУ) – это печатная плата с контактами, на которой расположены чипы оперативной памяти, объединенные в единую логическую схему.
Примечание 3. ЕСС (Error Checking and Correction Memory, коррекция ошибок) – это алгоритм, позволяющий исправлять 1-битные ошибки и определять 2-битные при работе оперативной памяти и кэш-памяти.
Еще по настройке БИОС (БИОЗ) плат:
-

Появление сообщения Your computer case had been opened. Pres SPAC…
-
Появление сообщения Wrong Board In Slot на экране означает, что п…
-
Появление сообщения Warning! CPU has Been changed or Overclock fa…
-
Возможно, обнаружен вирус. Продолжить?
… -
Сообщение Unknown PCI Error отображается на мониторе в случае воз…
Добавить комментарий
Другие идентичные названия опции: DRAM Data Integrity, DRAM ECC Enable, Memory Configuration, Memory Parity/ECC Check.

Функция DRAM Data Integrity Mode обеспечивает корректное функционирование модулей ОЗУ типа ECC, а также управляет одноименной проверкой ECC, которая является обязательным условием использования RAM подобного типа. В меню BIOS Setup для конфигурирования данной функции присутствуют следующие значения: ECC, Non ECC.
Содержание статьи
- Принцип работы
- Стоит ли включать?
Принцип работы
Утилита Error Checking and Correction является специализированной программой, предназначенной для проверки ячеек оперативной памяти на предмет ошибок одного и двух разрядов. Активация этой функции доступна только при использовании модулей памяти типа ECC. Указанная опция дает возможность контроллеру памяти не только отслеживать, но также корректировать одноразрядные ошибки, что положительно сказывается на показателях работы системы.
Механизм работы ОЗУ типа ECC отличается от других наличием дополнительного чипа, предназначенного для сверки первоначальной кодировки ECC с той кодировкой, которая была получена в результате выполнения каких-либо операций. При совпадении этих кодировок контроллер памяти получает подтверждение истинности данных и продолжает процесс. В противном случае на дисплей выводится сообщение об ошибке, и система прекращает работу.
Анализ идентичности ECC-кодировок позволяет обнаружить одноразрядную ошибку в данных и скорректировать ее, изменив полярность бита (с 1 на 0 и наоборот).
Следует также отметить, что при взаимодействии с ОЗУ данного типа системная плата вынуждена обрабатывать дополнительную информацию. Эти особенности функционирования обуславливают повышенную стоимость ECC-модулей.
В нижеследующей таблице указан перечень кодировок Error Checking and Correction, необходимых при использовании разных стандартов информации для приведения в соответствие с ECC-алгоритмом.
| Пропускная способность при передаче данных, бит | Длина ECC-кодировки |
| 8 | 5 |
| 16 | 6 |
| 32 | 7 |
| 64 | 8 |
| 128 | 9 |
Стоит ли включать?
В соответствии со спецификацией стандартный ECC-модуль ОЗУ является 72-битным, но из этого вовсе не следует повышение пропускной способности ОЗУ и быстродействия системы (так как для работы с данными по-прежнему используются только 64 строки, а оставшиеся 8 бит ECC зарезервированы для хранения кодировки). Наоборот, при активированной функции DRAM Data Integrity Mode наблюдается некоторая потеря производительности компьютера (приблизительно 3—5%), поскольку расчет и сверка ECC-кодировок производится контроллером памяти для всех данных при выполнении любой операции чтения или записи. Данный фактор также оказывает влияние на стоимость и востребованность оперативной памяти типа ECC.
Однако, несмотря на указанные минусы памяти такого типа, зачастую именно этот вариант является оптимальным для использования в крупных серверных системах в силу повышенной стабильности и надежной интеграции данных. Поэтому при работе с ECC RAM необходимо активировать рассматриваемую функцию, присвоив ей значение ECC. Если же память типа Error Checking and Correction отсутствует в системе, следует отключить проверку четности, выбрав параметр Non ECC.
Для успешной работы с микросхемами NAND Flash (нанд флэш) необходимо, как минимум:
- Иметь представление о структуре, существующих способах и алгоритмах использования информации хранимой в такой памяти.
- Иметь программатор, который корректно поддерживает работу с подобными микросхемами, т.е. позволяет выбрать и реализовать необходимые параметры и алгоритмы обработки.
Программатор для работы с нанд флэш памятью должен быть очень быстрым. Программирование или чтение микросхемы объемом в несколько Гбит на обычном программаторе по времени занимает несколько часов. Очевидно, что для более или менее регулярного программирования микросхем большого объема нужен специализированный быстрый программатор, адаптированный для работы с микросхемами высокой плотности. На сегодняшний день, ChipProg-481 самый быстрый программатор.
- Программирование нанд флэш;
- Копирование;
- Структура памяти нанд флэш;
- Плохие блоки.
Программирование NAND FLASH
Программатор ChipProg-481 предоставляет широкий спектр возможностей по выбору/настройке способов и параметров программирования. Все параметры влияющие на алгоритм работы программатора с микросхемой, выводятся в окно «Редактор параметров микросхемы и алгоритма программирования». При необходимости, любой из этих параметров может быть изменен, с тем что бы выбранное действие (программирование, сравнение, чтение, стирание) — производилось по алгоритму необходимому пользователю программатора.

Окно «Редактор параметров микросхемы и алгоритма программирования» в интерфейсе программатора.
Большое количество настраиваемых параметров, формирующих алгоритм работы программатора продиктовано желанием предоставить универсальный инструмент, позволяющий пользователю максимально полно реализовать все особенности присущие нанд структуре. Для облегчения жизни, программатор ChipProg-481 предоставляет следующие возможности при выборе/задании режимов и параметров при программировании NAND Flash микросхем:
- Все параметры принимают значения заданные в предшествующем сеансе (сессии) программирования выбранной NAND Flash. (количество сохраненных сессий неограниченно).
- Все параметры принимают значения заданные для данной нанд флэш в рамках «проекта» (количество «проектов» неограниченно)
- Все параметры автоматически принимают необходимые значения после запуска «скрипта». «Скрипты» пишутся на встроенном в оболочку программатора C подобном языке.
- Все (или выборочно) параметры принимают значения по умолчанию.
- Значения всех параметров доступны для редактирования в графическом интерфейсе программатора.
Рассмотрим режимы и параметры программирования реализованные в программаторе.
Режимы программирования.
- Invalid Block Management
- Spare Area Usage
- Guard Solid Area
- Tolerant Verify Feature
- Invalid Block Indication Option
1. Работа с плохими блoками.
Перед программированием NAND Flash можно/нужно выбрать один из способов работы с плохими блоками.
|
Do Not Use |
Не обрабатывать информацию о плoxих блoках. |
|
Skip IB |
Пропускать плoxие блoки. |
|
Skip IB with Map in 0-th Block |
Пропускать плoxие блоки, в нулевой блoк помещать карту плoxих блoкoв. |
|
RBA (Reserved Block Area) |
Использовать алгоритм RBA. |
2. Использование области Spare Area.
|
Do Not Use |
Spare Area в микросхеме не используется. В микросхеме программируются страницы памяти без учета Spare Area. |
|
User Data |
Spare Area используется как пользовательская память. В этом случае при программировании микросхемы информация из буфера помещается сначала в основную страницу микросхемы, а затем в дополнительную область Spare Area. В этом случае буфер программатора выглядит как непрерывный поток основных страниц микросхемы и пристыкованных к ним областей Spare Area. |
|
User Data with IB Info Forced |
Spare Area интерпретируется аналогично предыдущему случаю за исключением того, что маркеры плохих блoкoв прописываются вместо информации пользователя. |
3. Guard Solid Area
Режим использования специальной области без плохих блoкoв. Обычно такие области используются в качестве загрузчиков микропроцессоров. В этой области недопустимо использование плoxих блoкoв.
Опция используется совместно с параметрами:
- Solid Area — Start Block — начальный блoк области без плoxих блoкoв.
- Solid Area — Number of Blocks— количество блoкoв в этой области.
В случае, если внутри заданного диапазона Solid Area попадется плохой блoк, программатор выдаст ошибку.
4. Не чувствительность к ошибкам сравнения.
Эта опция позволяет включить режим не чувствительности к ошибкам сравнения.
Обычно, эту опцию имеет смысл использовать, если в устройстве пользователя применяются алгоритмы контроля и коррекции ошибок (ECC). В этих случаях допускается наличия определенного количества ошибок на определенный размер массива данных. Эти параметры и указываются в параметрах алгоритма программирования NAND Flash:
- ECC Frame size (bytes) — размер массива данных.
- Acceptable number of errors — допустимое количество однобитных ошибок.
5. Invalid Block Indication Option.
В этой опции выбирается информация, которая используется в качестве маркера плохих блоков. Допускается выбрать либо значение 00h, либо 0F0h.
- IB Indication Value ~ 00 или F0
Параметры программирования.
- User Area
- Solid Area
- RBA Area
- ECC Frame size
- Acceptable number of errors
a. Пользовательская область.
Пользовательская область — это область микросхемы, с которой работают процедуры Программирования, Чтения и Сравнения.
Процедуры Стирания и Контроля на чистоту работают со всем массивом микросхемы.
Пользователю необходимо установить параметры:
- User Area — Start Block — начальный блoк пользовательской области.
- User Area — Number of Blocks — количество блoков в пользовательской области.
b. Область без ошибок.
Параметры режима Guard Solid Area.
- Solid Area — Start Block — начальный блoк области без плoхих блоков.
- Solid Area — Number of Blocks— количество блоков в этой области.
c. Область размещения RBA.
- RBA Area — Start Block — начальный блок таблицы RBA.
- RBA Area — Number of Blocks— количество блоков в таблице RBA.
d. Размер фрейма ECC.
- ECC Frame Size — параметр определяющий размер массива данных, в котором допускаются однобитные ошибки.
e. Допустимое количество ошибок.
- Acceptable number of errors— параметр определяет количество однобитных ошибок, допустимых в массиве, размер, которого определяется параметром ECC Frame size.
Карта плохих блоков
Карта плохих блоков создается в подслое Invalid Block Map. Карта блоков представляется как непрерывный массив бит. Хорошие блоки представляются значением 0, плохие блоки — 1.
Например, значение 02h по нулевому адресу говорит о том, что 0,2,3,4,5,6,7 блоки являются хорошими, 1-ый блок является плохим. Значение 01h по первому адресу говорит о том, что только 8-ой блок является плохим из группы блоков 8..15.
Копирование NAND Flash
В качестве иллюстрации важности «зрячего» выбора режимов и параметров при программировании нанд флэш в программаторе, рассмотрим ситуацию, при которой у некоторых программистов возникают проблемы. Чаще всего, это замена микросхемы в «устройстве», которое перестало работать. Стандартный подход — по аналогии с заменой обычной микросхемы памяти:
- Получить прошивку работающей микросхемы. Как правило, для этого считывается содержимое из микросхемы-оригинала.
- Прошить новую аналогичную микросхему.
- Сравнить содержание запрограммированной мс. с прошивкой «оригинала». Если сравнение прошло, микросхема — копия готова.
В случае, когда требуется программировать NAND Flash, не все так просто и однозначно.
- Прошивка полученная при считывании программатором из «оригинала» — существенным образом зависит от установленных в программаторе режимов и параметров.
- Для того что бы корректно запрограммировать новую нанд флэш и получить полную копию, необходимо перед программированием установить в программаторе режимы и параметры соответствующие прошивке «оригинала». При этом, необходимо учитывать возможность существования плохих блоков.
Для получения микросхемы-копии, у которой прошивка идентична образцу, необходимо поступать следующим образом.
Подготовка к копированию.
Для копирования необходимы микросхема-оригинал и микросхема-копия (мс. в которую предполагается записать образ оригинала). Обязательные требования:
- Обе микросхемы и оригинал и копия должны быть одного типа.
- Микросхема-копия не должна иметь плохих блоков.
Чтобы определить, имеет ли микросхема-копия плохие блоки, необходимо установить микросхему в программатор, и в окне “Редактор параметров микросхемы” задать параметры микросхемы по умолчанию — кнопка «All Default».
Запускается процедура контроля на стертость (для экономии времени можно сразу же отменить эту процедуру, считывание карты плохих блоков осуществляется в самом начале). В окне «Программирование» интерфейса программатора, в поле “Информация об операциях” появляется информация о плохих блоках.

Перед копированием микросхемы в программаторе обязательно должны быть сделаны следующие настройки параметров в окне “Редактор параметров микросхемы”:
Invalid Block(IB) Management — Do NOT USE
Spare Area Usage — User Data
User Area – Number of Blocks — Максимальное значение блоков в микросхеме

В программатор устанавливается образец и считывается. Затем в программатор устанавливается микросхема-копия, стирается, записывается и сравнивается. В случае успешного прохождения всех трех процедур запрограммированная NAND Flash оказывается полной копией оригинала.
Структура памяти NAND Flash.
Нанд флэш память* подразделяется на блоки (Block) памяти, которые в свою очередь делятся на страницы (Page). Страницы бывают большие (large page) и маленькие (small page). Размер страницы зависит от общего размера микросхемы. Для маленькой страницы обычно характерны микросхемы объемом от 128Kбит до 512Кбит. Микросхемы с большим размером страницы имеют объем от 256Кбит до 32Гбит и выше. Маленький размер страницы равен 512 байтам для микросхем с байтной организацией и 256 словам для микросхем со словной организаций шины данных. Большая страница имеет размер 2048 байт для байтных микросхем и 1024 для словных. В последнее время появляются микросхемы с еще большим размером страницы. Она уже составляет 4096 байт для байтных микросхем.
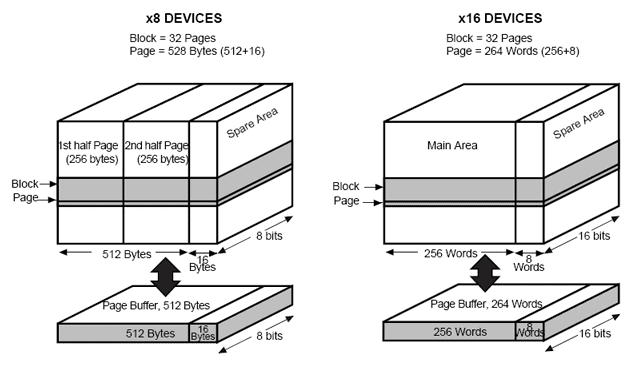
Структура памяти микросхем NAND Flash с малым размером страницы фирмы STMicroelectronics.
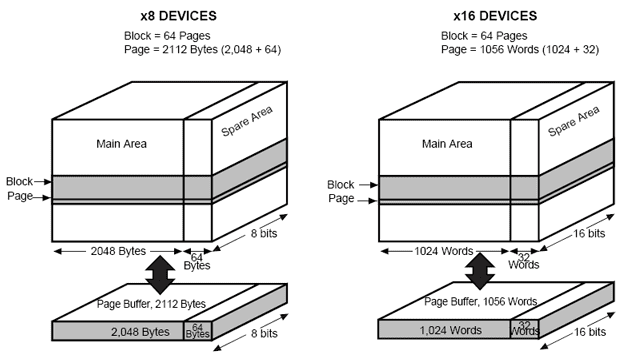
Структура памяти микросхем с большим размером страницы фирмы STMicroelectronics.
Плохие блоки
Характерной особенностью микросхем NAND Flash является наличие плохих (дефектных) блоков (Bad blocks) как в новых микросхемах, так и появление таких блоков в процессе эксплуатации. Для маркирования плохих блоков, а также для сохранения дополнительной служебной информации или кодов коррекции, в архитектуре NAND Flash в дополнении к каждой странице памяти данных предусмотрена добавочная область Spare area. Для микросхем с малой страницей эта область имеет размер 16 байт / 8 слов. Для микросхем с большой страницей — 64 байта / 32 слова.
Обычно производитель микросхем гарантирует количество плохих блоков, не превышающее определенного размера. Информация о плохих блоках поставляется производителем микросхем в определенном месте дополнительной области Spare Area.
Маркирование плохих блоков в микросхемах NAND Flash осуществляется записью обычно значения 0 по определенному адресу в области Spare Area нулевой страницы плохого блока. Маркеры плохих блоков лежат в определенных адресах области Spare Area.
|
Организация памяти |
Адрес маркеров плохих блоков в Spare Area |
|
Байтная организация, размер страницы — 512 байт. |
5 |
|
Словная организация, размер страницы — 256 слов. |
0 |
|
Байтная организация, размер страницы — 2048 байт и больше. |
0 или 5 |
|
Словная организация, размер страницы — 1024 слов и больше. |
0 |
Нужно иметь ввиду, что маркеры плохих блоков помещаются в обычные ячейки Flash памяти Spare Area, которые стираются при стирании всего блока памяти. Поэтому для сохранения информации о плохих блоках перед стиранием обязательно нужно сохранить эту информацию, а после стирания ее — восстановить.
В программаторах ChipProg при установке опции InvalidBlockManagement в любое значение кроме Do Not Useсохранение и восстановление информации о плохих блоках происходит автоматически.
Существует три наиболее распространенных способа обработки плохих блоков:
- Skip Bad Blocks (Пропуск плохих блоков.)
- Reserved Block Area (Резервирование блоков)
- Error Checking and Correction (Контроль и коррекция ошибок.)
1. Пропуск плохих блоков.
Алгоритм пропуска плохих блоков заключается в том, что при записи в микросхему анализируется в какой блок осуществляется запись. В случае наличия плохого блока, запись в этот блок не осуществляется, плохой блок пропускается, запись осуществляется в блок следующий после плохого.
2. Резервирование блоков.
В этом методе память всей микрохемы делится на три области: User Block Area (UBA) — пользовательская область, Block Reservoir — резервная область, следуемая сразу за пользовательской областью, и таблицу соответствия плохих блоков хорошим (Reserved Block Area — RBA).
Алгоритм замены плохих блоков в этом методе таков: при выявлении плохого блока из области UBA блок переносится в область Block Reservoir, при этом в таблице RBA делается соответствующая запись замены блока.
Формат таблицы RBA:
|
2 байта |
2 байта |
2 байта |
2 байта |
…. |
2 байта |
2 байта |
|
Маркер |
Count Field |
Invalid Block |
Replaced Block |
…. |
Invalid Block |
Replaced Block |
Маркер имеет значение 0FDFEh.
Count Field начинается с 1 и значение этого поля увеличивается на 1 на каждой следующей странице данного блока.
Invalid Block — номер замененного плохого блока.
Replaced Block — номер блока, на который был заменен плохой блок.
Пары Invalid Block и Replaced Block следуют одна за другой до конца страницы.
В области RBA находятся две таблицы в двух блоках. Таблица во втором блоке используется как резервная на случай, если информация в первой окажется недостоверной.
3. Контроль и коррекция ошибок.
Для увеличения достоверности данных могут использоваться алгоритмы контроля и коррекции ошибок (Error Checking and Correction — ECC). Эта дополнительная информация может помещаться в свободное пространство Spare Area.
*) Примечание: NAND ~ Not AND — в булевой математике обозначает отрицание «И»
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
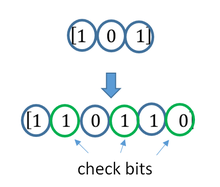
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]

A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.

A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most
 bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters


See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]
A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)