You first have to isolate the areas where errors might occur, and are user-visible. Then you can document them. Its that simple.
Well, simple in theory.. in practice errors can occur all over the damn place, and reporting them can turn nice code into a monster of logging, exception throwing and handling, and passing return values.
I would recommend a 2-step approach then. First is to log, log lots and lots.
Second is to determine the major components and their interfaces, and to define what major error cases these components can find themselves in. You can then log in a more visible manner when one of these errors (how you handle the error internally is up to you — exceptions or error codes make no difference here). A user will generally then see the error and go to the logs for more detailed information.
The same approach is used for web servers and your http error code example. If the user sees a 404, and reports it to support, they will look in the logs for the details of what was going on, which page was visited, when, and will glean any other info they can from where-ever else make sense, be in the DB, the network or the application.

Error codes are almost the last thing that you want to see in an API response. Generally speaking, it means one of two things — something was so wrong in your request or your handling that the API simply couldn’t parse the passed data, or the API itself has so many problems that even the most well-formed request is going to fail. In either situation, traffic comes crashing to a halt, and the process of discovering the cause and solution begins.
That being said, errors, whether in code form or simple error response, are a bit like getting a shot — unpleasant, but incredibly useful. Error codes are probably the most useful diagnostic element in the API space, and this is surprising, given how little attention we often pay them.
Today, we’re going to talk about exactly why error responses and handling approaches are so useful and important. We’ll take a look at some common error code classifications the average user will encounter, as well as some examples of these codes in action. We’ll also talk a bit about what makes a “good” error code and what makes a “bad” error code, and how to ensure your error codes are up to snuff.
The Value of Error Codes
As we’ve already said, error codes are extremely useful. Error codes in the response stage of an API is the fundamental way in which a developer can communicate failure to a user. This stage, sitting after the initial request stage, is a direct communication between client and API. It’s often the first and most important step towards not only notifying the user of a failure, but jump-starting the error resolution process.
A user doesn’t choose when an error is generated, or what error it gets — error situations often arise in instances that, to the user, are entirely random and suspect. Error responses thus are the only truly constant, consistent communication the user can depend on when an error has occurred. Error codes have an implied value in the way that they both clarify the situation, and communicate the intended functionality.
Consider for instance an error code such as “401 Unauthorized – Please Pass Token.” In such a response, you understand the point of failure, specifically that the user is unauthorized. Additionally, however, you discover the intended functionality — the API requires a token, and that token must be passed as part of the request in order to gain authorization.
With a simple error code and resolution explanation, you’ve not only communicated the cause of the error, but the intended functionality and method to fix said error — that’s incredibly valuable, especially for the amount of data that is actually returned.
HTTP Status Codes
Before we dive deeper into error codes and what makes a “good” code “good,” we need to address the HTTP Status Codes format. These codes are the most common status codes that the average user will encounter, not just in terms of APIs but in terms of general internet usage. While other protocols exist and have their own system of codes, the HTTP Status Codes dominate API communication, and vendor-specific codes are likely to be derived from these ranges.
1XX – Informational
The 1XX range has two basic functionalities. The first is in the transfer of information pertaining to the protocol state of the connected devices — for instance, 101 Switching Protocols is a status code that notes the client has requested a protocol change from the server, and that the request has been approved. The 1XX range also clarifies the state of the initial request. 100 Continue, for instance, notes that a server has received request headers from a client, and that the server is awaiting the request body.
2XX – Success
The 2XX range notes a range of successes in communication, and packages several responses into specific codes. The first three status codes perfectly demonstrate this range – 200 OK means that a GET or POST request was successful, 201 Created confirms that a request has been fulfilled and a new resource has been created for the client, and 202 Accepted means that the request has been accepted, and that processing has begun.
3XX – Redirection
The 3XX range is all about the status of the resource or endpoint. When this type of status code is sent, it means that the server is still accepting communication, but that the point contacted is not the correct point of entry into the system. 301 Moved Permanently verifies that the client request did in fact reach the correct system, but that this request and all future requests should be handled by a different URI. This is very useful in subdomains and when moving a resource from one server to another.
4XX – Client Error
The 4XX series of error codes is perhaps the most famous due to the iconic 404 Not Found status, which is a well-known marker for URLs and URIs that are incorrectly formed. Other more useful status codes for APIs exist in this range, however.
414 URI Too Long is a common status code, denoting that the data pushed through in a GET request is too long, and should be converted to a POST request. Another common code is 429 Too many Requests, which is used for rate limiting to note a client is attempting too many requests at once, and that their traffic is being rejected.
5XX – Server Error
Finally the 5XX range is reserved for error codes specifically related to the server functionality. Whereas the 4XX range is the client’s responsibility (and thus denotes a client failure), the 5XX range specifically notes failures with the server. Error codes like 502 Bad Gateway, which notes the upstream server has failed and that the current server is a gateway, further expose server functionality as a means of showing where failure is occurring. There are less specific, general failures as well, such as 503 Service Unavailable.
Making a Good Error Code
With a solid understanding of HTTP Status Codes, we can start to dissect what actually makes for a good error code, and what makes for a bad error code. Quality error codes not only communicate what went wrong, but why it went wrong.
Overly opaque error codes are extremely unhelpful. Let’s imagine that you are attempting to make a GET request to an API that handles digital music inventory. You’ve submitted your request to an API that you know routinely accepts your traffic, you’ve passed the correct authorization and authentication credentials, and to the best of your knowledge, the server is ready to respond.
You send your data, and receive the following error code – 400 Bad Request. With no additional data, no further information, what does this actually tell you? It’s in the 4XX range, so you know the problem was on the client side, but it does absolutely nothing to communicate the issue itself other than “bad request.”
This is when a “functional” error code is really not as functional as it should be. That same response could easily be made helpful and transparent with minimal effort — but what would this entail? Good error codes must pass three basic criteria in order to truly be helpful. A quality error code should include:
- An HTTP Status Code, so that the source and realm of the problem can be ascertained with ease;
- An Internal Reference ID for documentation-specific notation of errors. In some cases, this can replace the HTTP Status Code, as long as the internal reference sheet includes the HTTP Status Code scheme or similar reference material.
- Human readable messages that summarize the context, cause, and general solution for the error at hand.
Include Standardized Status Codes
First and foremost, every single error code generated should have an attached status code. While this often takes the form of an internal code, it typically takes the form of a standardized status code in the HTTP Status Code scheme. By noting the status using this very specific standardization, you not only communicate the type of error, you communicate where that error has occurred.
There are certain implications for each of the HTTP Status Code ranges, and these implications give a sense as to the responsibility for said error. 5XX errors, for instance, note that the error is generated from the server, and that the fix is necessarily something to do with server-related data, addressing, etc. 4XX, conversely, notes the problem is with the client, and specifically the request from the client or the status of the client at that moment.
By addressing error codes using a default status, you can give a very useful starting point for even basic users to troubleshoot their errors.
Give Context
First and foremost, an error code must give context. In our example above, 400 Bad Request means nothing. Instead, an error code should give further context. One such way of doing this is by passing this information in the body of the response in the language that is common to the request itself.
For instance, our error code of 400 Bad Request can easily have a JSON body that gives far more useful information to the client:
< HTTP/1.1 400 Bad Request
< Date: Wed, 31 May 2017 19:01:41 GMT
< Server: Apache/2.4.25 (Ubuntu)
< Connection: close
< Transfer-Encoding: chunked
< Content-Type: application/json
{ "error" : "REQUEST - BR0x0071" }
This error code is good, but not great. What does it get right? Well, it supplies context, for starters. Being able to see what the specific type of failure is shows where the user can begin the problem solving process. Additionally, and vitally, it also gives an internal reference ID in the form of “BR0x0071”, which can be internally referenced.
While this is an ok error code, it only meets a fraction of our requirements.
Human Readability
Part of what makes error codes like the one we just created so powerful is that it’s usable by humans and machines alike. Unfortunately, this is a very easy thing to mess up — error codes are typically handled by machines, and so it’s very tempting to simply code for the application rather than for the user of said application.
In our newly formed example, we have a very clear error to handle, but we have an additional issue. While we’ve added context, that context is in the form of machine-readable reference code to an internal error note. The user would have to find the documentation, look up the request code “BRx0071”, and then figure out what went wrong.
We’ve fallen into that trap of coding for the machine. While our code is succinct and is serviceable insomuch as it provides context, it does so at the cost of human readability. With a few tweaks, we could improve the code, while still providing the reference number as we did before:
< HTTP/1.1 400 Bad Request
< Date: Wed, 31 May 2017 19:01:41 GMT
< Server: Apache/2.4.25 (Ubuntu)
< Connection: close
< Transfer-Encoding: chunked
< Content-Type: application/json
{ "error" : "Bad Request - Your request is missing parameters. Please verify and resubmit. Issue Reference Number BR0x0071" }
With such a response, not only do you get the status code, you also get useful, actionable information. In this case, it tells the user the issue lies within their parameters. This at least offers a place to start troubleshooting, and is far more useful than saying “there’s a problem.”
While you still want to provide the issue reference number, especially if you intend on integrating an issue tracker into your development cycle, the actual error itself is much more powerful, and much more effective than simply shooting a bunch of data at the application user and hoping something sticks.
Good Error Examples
Let’s take a look at some awesome error code implementations on some popular systems.
Twitter API is a great example of descriptive error reporting codes. Let’s attempt to send a GET request to retrieve our mentions timeline.
https://api.twitter.com/1.1/statuses/mentions_timeline.jsonWhen this is sent to the Twitter API, we receive the following response:
HTTP/1.1 400 Bad Request
x-connection-hash:
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
set-cookie:
guest_id=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Date:
Thu, 01 Jun 2017 03:04:23 GMT
Content-Length:
62
x-response-time:
5
strict-transport-security:
max-age=631138519
Connection:
keep-alive
Content-Type:
application/json; charset=utf-8
Server:
tsa_b
{"errors":[{"code":215,"message":"Bad Authentication data."}]}
Looking at this data, we can generally figure out what our issue is. First, we’re told that we’ve submitted a 400 Bad Request. This tells us that the problem is somewhere in our request. Our content length is acceptable, and our response time is well within normal limits. We can see, however, that we’re receiving a unique error code that Twitter itself has denoted — “215”, with an attached message that states “Bad Authentication data”.
This error code supplies both valuable information as to why the error has occurred, and also how to rectify it. Our error lies in the fact that we did not pass any authentication data whatsoever — accordingly, error 215 is referenced, which tells us the fix is to supply said authentication data, but also gives us a number to reference on the internal documentation of the Twitter API.
For another great example, let’s look at another social network. Facebook’s Graph API allows us to do quite a lot as long as we have the proper authentication data. For the purposes of this article, all personal information will be blanked out for security purposes.
First, let’s pass a GET request to ascertain some details about a user:
https://graph.facebook.com/v2.9/me?fields=id%2Cname%2Cpicture%2C%20picture&access_token=xxxxxxxxxxxThis request should give us a few basic fields from this user’s Facebook profile, including id, name, and picture. Instead, we get this error response:
{
"error": {
"message": "Syntax error "Field picture specified more than once. This is only possible before version 2.1" at character 23: id,name,picture,picture",
"type": "OAuthException",
"code": 2500,
"fbtrace_id": "xxxxxxxxxxx"
}
}
While Facebook doesn’t directly pass the HTTP error code in the body, it does pass a lot of useful information. The “message” area notes that we’ve run into a syntax error, specifically that we’ve defined the “picture” field more than once. Additionally, this field lets us know that this behavior was possible in previous versions, which is a very useful tool to communicate to users a change in behavior from previous versions to the current.
Additionally, we are provided both a code and an fbtrace_id that can be used with support to identify specific issues in more complex cases. We’ve also received a specific error type, in this case OAuthException, which can be used to narrow down the specifics of the case even further.
Bing
To show a complex failure response code, let’s send a poorly formed (essentially null) GET request to Bing.
HTTP/1.1 200
Date:
Thu, 01 Jun 2017 03:40:55 GMT
Content-Length:
276
Connection:
keep-alive
Content-Type:
application/json; charset=utf-8
Server:
Microsoft-IIS/10.0
X-Content-Type-Options:
nosniff
{"SearchResponse":{"Version":"2.2","Query":{"SearchTerms":"api error codes"},"Errors":[{"Code":1001,"Message":"Required parameter is missing.","Parameter":"SearchRequest.AppId","HelpUrl":"httpu003au002fu002fmsdn.microsoft.comu002fen-usu002flibraryu002fdd251042.aspx"}]}}
This is a very good error code, perhaps the best of the three we’ve demonstrated here. While we have the error code in the form of “1001”, we also have a message stating that a parameter is missing. This parameter is then specifically noted as “SearchRequestAppId”, and a “HelpUrl” variable is passed as a link to a solution.
In this case, we’ve got the best of all worlds. We have a machine readable error code, a human readable summary, and a direct explanation of both the error itself and where to find more information about the error.
Spotify
Though 5XX errors are somewhat rare in modern production environments, we do have some examples in bug reporting systems. One such report noted a 5XX error generated from the following call:
GET /v1/me/player/currently-playingThis resulted in the following error:
[2017-05-02 13:32:14] production.ERROR: GuzzleHttpExceptionServerException: Server error: `GET https://api.spotify.com/v1/me/player/currently-playing` resulted in a `502 Bad Gateway` response:
{
"error" : {
"status" : 502,
"message" : "Bad gateway."
}
}So what makes this a good error code? While the 502 Bad gateway error seems opaque, the additional data in the header response is where our value is derived. By noting the error occurring in production and its addressed variable, we get a general sense that the issue at hand is one of the server gateway handling an exception rather than anything external to the server. In other words, we know the request entered the system, but was rejected for an internal issue at that specific exception address.
When addressing this issue, it was noted that 502 errors are not abnormal, suggesting this to be an issue with server load or gateway timeouts. In such a case, it’s almost impossible to note granularly all of the possible variables — given that situation, this error code is about the best you could possibly ask for.
Conclusion
Much of an error code structure is stylistic. How you reference links, what error code you generate, and how to display those codes is subject to change from company to company. However, there has been headway to standardize these approaches; the IETF recently published RFC 7807, which outlines how to use a JSON object as way to model problem details within HTTP response. The idea is that by providing more specific machine-readable messages with an error response, the API clients can react to errors more effectively.
In general, the goal with error responses is to create a source of information to not only inform the user of a problem, but of the solution to that problem as well. Simply stating a problem does nothing to fix it – and the same is true of API failures.
The balance then is one of usability and brevity. Being able to fully describe the issue at hand and present a usable solution needs to be balanced with ease of readability and parsability. When that perfect balance is struck, something truly powerful happens.
While it might seem strange to wax philosophically about error codes, they are a truly powerful tool that go largely underutilized. Incorporating them in your code is not just a good thing for business and API developer experience – they can lead to more positive end user experience, driving continuous adoption and usage.
Some Background
REST APIs use the Status-Line part of an HTTP response message to inform clients of their request’s overarching result.
RFC 2616 defines the Status-Line syntax as shown below:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
A great amount of applications are using Restful APIs that are based on the HTTP protocol for connecting their clients. In all the calls, the server and the endpoint at the client both return a call status to the client which can be in the form of:
- The success of API call.
- Failure of API call.
In both the cases, it is necessary to let the client know so that they can proceed to the next step. In the case of a successful API call they can proceed to the next call or whatever their intent was in the first place but in the case of latter they will be forced to modify their call so that the failed call can be recovered.
RestCase
To enable the best user experience for your customer, it is necessary on the part of the developers to make excellent error messages that can help their client to know what they want to do with the information they get. An excellent error message is precise and lets the user know about the nature of the error so that they can figure their way out of it.
A good error message also allows the developers to get their way out of the failed call.
Next step is to know what error messages to integrate into your framework so that the clients on the end point and the developers at the server are constantly made aware of the situation which they are in. in order to do so, the rule of thumb is to keep the error messages to a minimum and only incorporate those error messages which are helpful.
HTTP defines over 40 standard status codes that can be used to convey the results of a client’s request. The status codes are divided into the five categories presented here:
- 1xx: Informational — Communicates transfer protocol-level information
- 2xx: Success -Indicates that the client’s request was accepted successfully.
- 3xx: Redirection — Indicates that the client must take some additional action in order to complete their request.
- 4xx: Client Error — This category of error status codes points the finger at clients.
- 5xx: Server Error — The server takes responsibility for these error status codes.

If you would ask me 5 years ago about HTTP Status codes I would guess that the talk is about web sites, status 404 meaning that some page was not found and etc. But today when someone asks me about HTTP Status codes, it is 99.9% refers to REST API web services development. I have lots of experience in both areas (Website development, REST API web services development) and it is sometimes hard to come to a conclusion about what and how use the errors in REST APIs.
There are some cases where this status code is always returned, even if there was an error that occurred. Some believe that returning status codes other than 200 is not good as the client did reach your REST API and got response.
Proper use of the status codes will help with your REST API management and REST API workflow management.
If for example the user asked for “account” and that account was not found there are 2 options to use for returning an error to the user:
-
Return 200 OK Status and in the body return a json containing explanation that the account was not found.
-
Return 404 not found status.
The first solution opens up a question whether the user should work a bit harder to parse the json received and to see whether that json contains error or not. -
There is also a third solution: Return 400 Error — Client Error. I will explain a bit later why this is my favorite solution.
It is understandable that for the user it is easier to check the status code of 404 without any parsing work to do.
I my opinion this solution is actually miss-use of the HTTP protocol
We did reach the REST API, we did got response from the REST API, what happens if the users misspells the URL of the REST API – he will get the 404 status but that is returned not by the REST API itself.
I think that these solutions should be interesting to explore and to see the benefits of one versus the other.
There is also one more solution that is basically my favorite – this one is a combination of the first two solutions, he is also gives better Restful API services automatic testing support because only several status codes are returned, I will try to explain about it.
Error handling Overview
Error responses should include a common HTTP status code, message for the developer, message for the end-user (when appropriate), internal error code (corresponding to some specific internally determined ID), links where developers can find more info. For example:
‘{ «status» : 400,
«developerMessage» : «Verbose, plain language description of the problem. Provide developers suggestions about how to solve their problems here»,
«userMessage» : «This is a message that can be passed along to end-users, if needed.»,
«errorCode» : «444444»,
«moreInfo» : «http://www.example.gov/developer/path/to/help/for/444444,
http://tests.org/node/444444»,
}’
How to think about errors in a pragmatic way with REST?
Apigee’s blog post that talks about this issue compares 3 top API providers.

No matter what happens on a Facebook request, you get back the 200 status code — everything is OK. Many error messages also push down into the HTTP response. Here they also throw an #803 error but with no information about what #803 is or how to react to it.
Twilio
Twilio does a great job aligning errors with HTTP status codes. Like Facebook, they provide a more granular error message but with a link that takes you to the documentation. Community commenting and discussion on the documentation helps to build a body of information and adds context for developers experiencing these errors.
SimpleGeo
Provides error codes but with no additional value in the payload.
Error Handling — Best Practises
First of all: Use HTTP status codes! but don’t overuse them.
Use HTTP status codes and try to map them cleanly to relevant standard-based codes.
There are over 70 HTTP status codes. However, most developers don’t have all 70 memorized. So if you choose status codes that are not very common you will force application developers away from building their apps and over to wikipedia to figure out what you’re trying to tell them.
Therefore, most API providers use a small subset.
For example, the Google GData API uses only 10 status codes, Netflix uses 9, and Digg, only 8.

How many status codes should you use for your API?
When you boil it down, there are really only 3 outcomes in the interaction between an app and an API:
- Everything worked
- The application did something wrong
- The API did something wrong
Start by using the following 3 codes. If you need more, add them. But you shouldn’t go beyond 8.
- 200 — OK
- 400 — Bad Request
- 500 — Internal Server Error
Please keep in mind the following rules when using these status codes:
200 (OK) must not be used to communicate errors in the response body
Always make proper use of the HTTP response status codes as specified by the rules in this section. In particular, a REST API must not be compromised in an effort to accommodate less sophisticated HTTP clients.
400 (Bad Request) may be used to indicate nonspecific failure
400 is the generic client-side error status, used when no other 4xx error code is appropriate. For errors in the 4xx category, the response body may contain a document describing the client’s error (unless the request method was HEAD).
500 (Internal Server Error) should be used to indicate API malfunction 500 is the generic REST API error response.
Most web frameworks automatically respond with this response status code whenever they execute some request handler code that raises an exception. A 500 error is never the client’s fault and therefore it is reasonable for the client to retry the exact same request that triggered this response, and hope to get a different response.
If you’re not comfortable reducing all your error conditions to these 3, try adding some more but do not go beyond 8:
- 401 — Unauthorized
- 403 — Forbidden
- 404 — Not Found
Please keep in mind the following rules when using these status codes:
A 401 error response indicates that the client tried to operate on a protected resource without providing the proper authorization. It may have provided the wrong credentials or none at all.
403 (Forbidden) should be used to forbid access regardless of authorization state
A 403 error response indicates that the client’s request is formed correctly, but the REST API refuses to honor it. A 403 response is not a case of insufficient client credentials; that would be 401 (“Unauthorized”). REST APIs use 403 to enforce application-level permissions. For example, a client may be authorized to interact with some, but not all of a REST API’s resources. If the client attempts a resource interaction that is outside of its permitted scope, the REST API should respond with 403.
404 (Not Found) must be used when a client’s URI cannot be mapped to a resource
The 404 error status code indicates that the REST API can’t map the client’s URI to a resource.
RestCase
Conclusion
I believe that the best solution to handle errors in a REST API web services is the third option, in short:
Use three simple, common response codes indicating (1) success, (2) failure due to client-side problem, (3) failure due to server-side problem:
- 200 — OK
- 400 — Bad Request (Client Error) — A json with error more details should return to the client.
- 401 — Unauthorized
- 500 — Internal Server Error — A json with an error should return to the client only when there is no security risk by doing that.
I think that this solution can also ease the client to handle only these 4 status codes and when getting either 400 or 500 code he should take the response message and parse it in order to see what is the problem exactly and on the other hand the REST API service is simple enough.
The decision of choosing which error messages to incorporate and which to leave is based on sheer insight and intuition. For example: if an app and API only has three outcomes which are; everything worked, the application did not work properly and API did not respond properly then you are only concerned with three error codes. By putting in unnecessary codes, you will only distract the users and force them to consult Google, Wikipedia and other websites.
Most important thing in the case of an error code is that it should be descriptive and it should offer two outputs:
- A plain descriptive sentence explaining the situation in the most precise manner.
- An ‘if-then’ situation where the user knows what to do with the error message once it is returned in an API call.
The error message returned in the result of the API call should be very descriptive and verbal. A code is preferred by the client who is well versed in the programming and web language but in the case of most clients they find it hard to get the code.
As I stated before, 404 is a bit problematic status when talking about Restful APIs. Does this status means that the resource was not found? or that there is not mapping to the requested resource? Everyone can decide what to use and where 
1. Overview
REST is a stateless architecture in which clients can access and manipulate resources on a server. Generally, REST services utilize HTTP to advertise a set of resources that they manage and provide an API that allows clients to obtain or alter the state of these resources.
In this tutorial, we’ll learn about some of the best practices for handling REST API errors, including useful approaches for providing users with relevant information, examples from large-scale websites and a concrete implementation using an example Spring REST application.
2. HTTP Status Codes
When a client makes a request to an HTTP server — and the server successfully receives the request — the server must notify the client if the request was successfully handled or not.
HTTP accomplishes this with five categories of status codes:
- 100-level (Informational) – server acknowledges a request
- 200-level (Success) – server completed the request as expected
- 300-level (Redirection) – client needs to perform further actions to complete the request
- 400-level (Client error) – client sent an invalid request
- 500-level (Server error) – server failed to fulfill a valid request due to an error with server
Based on the response code, a client can surmise the result of a particular request.
3. Handling Errors
The first step in handling errors is to provide a client with a proper status code. Additionally, we may need to provide more information in the response body.
3.1. Basic Responses
The simplest way we handle errors is to respond with an appropriate status code.
Here are some common response codes:
- 400 Bad Request – client sent an invalid request, such as lacking required request body or parameter
- 401 Unauthorized – client failed to authenticate with the server
- 403 Forbidden – client authenticated but does not have permission to access the requested resource
- 404 Not Found – the requested resource does not exist
- 412 Precondition Failed – one or more conditions in the request header fields evaluated to false
- 500 Internal Server Error – a generic error occurred on the server
- 503 Service Unavailable – the requested service is not available
While basic, these codes allow a client to understand the broad nature of the error that occurred. We know that if we receive a 403 error, for example, we lack permissions to access the resource we requested. In many cases, though, we need to provide supplemental details in our responses.
500 errors signal that some issues or exceptions occurred on the server while handling a request. Generally, this internal error is not our client’s business.
Therefore, to minimize these kinds of responses to the client, we should diligently attempt to handle or catch internal errors and respond with other appropriate status codes wherever possible.
For example, if an exception occurs because a requested resource doesn’t exist, we should expose this as a 404 rather than a 500 error.
This is not to say that 500 should never be returned, only that it should be used for unexpected conditions — such as a service outage — that prevent the server from carrying out the request.
3.2. Default Spring Error Responses
These principles are so ubiquitous that Spring has codified them in its default error handling mechanism.
To demonstrate, suppose we have a simple Spring REST application that manages books, with an endpoint to retrieve a book by its ID:
curl -X GET -H "Accept: application/json" http://localhost:8082/spring-rest/api/book/1If there is no book with an ID of 1, we expect that our controller will throw a BookNotFoundException.
Performing a GET on this endpoint, we see that this exception was thrown, and this is the response body:
{
"timestamp":"2019-09-16T22:14:45.624+0000",
"status":500,
"error":"Internal Server Error",
"message":"No message available",
"path":"/api/book/1"
}Note that this default error handler includes a timestamp of when the error occurred, the HTTP status code, a title (the error field), a message if messages are enabled in the default error (and is blank by default), and the URL path where the error occurred.
These fields provide a client or developer with information to help troubleshoot the problem and also constitute a few of the fields that make up standard error handling mechanisms.
Also note that Spring automatically returns an HTTP status code of 500 when our BookNotFoundException is thrown. Although some APIs will return a 500 status code or other generic ones, as we will see with the Facebook and Twitter APIs, for all errors for the sake of simplicity, it is best to use the most specific error code when possible.
In our example, we can add a @ControllerAdvice so that when a BookNotFoundException is thrown, our API gives back a status of 404 to denote Not Found instead of 500 Internal Server Error.
3.3. More Detailed Responses
As seen in the above Spring example, sometimes a status code is not enough to show the specifics of the error. When needed, we can use the body of the response to provide the client with additional information.
When providing detailed responses, we should include:
- Error – a unique identifier for the error
- Message – a brief human-readable message
- Detail – a lengthier explanation of the error
For example, if a client sends a request with incorrect credentials, we can send a 401 response with this body:
{
"error": "auth-0001",
"message": "Incorrect username and password",
"detail": "Ensure that the username and password included in the request are correct"
}The error field should not match the response code. Instead, it should be an error code unique to our application. Generally, there is no convention for the error field, expect that it be unique.
Usually, this field contains only alphanumerics and connecting characters, such as dashes or underscores. For example, 0001, auth-0001 and incorrect-user-pass are canonical examples of error codes.
The message portion of the body is usually considered presentable on user interfaces. Therefore, we should translate this title if we support internationalization. So if a client sends a request with an Accept-Language header corresponding to French, the title value should be translated to French.
The detail portion is intended for use by developers of clients and not the end user, so the translation is not necessary.
Additionally, we could also provide a URL — such as the help field — that clients can follow to discover more information:
{
"error": "auth-0001",
"message": "Incorrect username and password",
"detail": "Ensure that the username and password included in the request are correct",
"help": "https://example.com/help/error/auth-0001"
}Sometimes, we may want to report more than one error for a request.
In this case, we should return the errors in a list:
{
"errors": [
{
"error": "auth-0001",
"message": "Incorrect username and password",
"detail": "Ensure that the username and password included in the request are correct",
"help": "https://example.com/help/error/auth-0001"
},
...
]
}And when a single error occurs, we respond with a list containing one element.
Note that responding with multiple errors may be too complicated for simple applications. In many cases, responding with the first or most significant error is sufficient.
3.4. Standardized Response Bodies
While most REST APIs follow similar conventions, specifics usually vary, including the names of fields and the information included in the response body. These differences make it difficult for libraries and frameworks to handle errors uniformly.
In an effort to standardize REST API error handling, the IETF devised RFC 7807, which creates a generalized error-handling schema.
This schema is composed of five parts:
- type – a URI identifier that categorizes the error
- title – a brief, human-readable message about the error
- status – the HTTP response code (optional)
- detail – a human-readable explanation of the error
- instance – a URI that identifies the specific occurrence of the error
Instead of using our custom error response body, we can convert our body:
{
"type": "/errors/incorrect-user-pass",
"title": "Incorrect username or password.",
"status": 401,
"detail": "Authentication failed due to incorrect username or password.",
"instance": "/login/log/abc123"
}Note that the type field categorizes the type of error, while instance identifies a specific occurrence of the error in a similar fashion to classes and objects, respectively.
By using URIs, clients can follow these paths to find more information about the error in the same way that HATEOAS links can be used to navigate a REST API.
Adhering to RFC 7807 is optional, but it is advantageous if uniformity is desired.
4. Examples
The above practices are common throughout some of the most popular REST APIs. While the specific names of fields or formats may vary between sites, the general patterns are nearly universal.
4.1. Twitter
Let’s send a GET request without supplying the required authentication data:
curl -X GET https://api.twitter.com/1.1/statuses/update.json?include_entities=trueThe Twitter API responds with an error with this body:
{
"errors": [
{
"code":215,
"message":"Bad Authentication data."
}
]
}This response includes a list containing a single error, with its error code and message. In Twitter’s case, no detailed message is present, and a general error — rather than a more specific 401 error — is used to denote that authentication failed.
Sometimes a more general status code is easier to implement, as we’ll see in our Spring example below. It allows developers to catch groups of exceptions and not differentiate the status code that should be returned. When possible, though, the most specific status code should be used.
4.2. Facebook
Similar to Twitter, Facebook’s Graph REST API also includes detailed information in its responses.
Let’s perform a POST request to authenticate with the Facebook Graph API:
curl -X GET https://graph.facebook.com/oauth/access_token?client_id=foo&client_secret=bar&grant_type=bazWe receive this error:
{
"error": {
"message": "Missing redirect_uri parameter.",
"type": "OAuthException",
"code": 191,
"fbtrace_id": "AWswcVwbcqfgrSgjG80MtqJ"
}
}Like Twitter, Facebook also uses a generic error — rather than a more specific 400-level error — to denote a failure. In addition to a message and numeric code, Facebook also includes a type field that categorizes the error and a trace ID (fbtrace_id) that acts as an internal support identifier.
5. Conclusion
In this article, we examined some of the best practices of REST API error handling:
- Providing specific status codes
- Including additional information in response bodies
- Handling exceptions in a uniform manner
While the details of error handling will vary by application, these general principles apply to nearly all REST APIs and should be adhered to when possible.
Not only does this allow clients to handle errors in a consistent manner, but it also simplifies the code we create when implementing a REST API.
The code referenced in this article is available over on GitHub.
I’m looking for guidance on good practices when it comes to return errors from a REST API. I’m working on a new API so I can take it any direction right now. My content type is XML at the moment, but I plan to support JSON in future.
I am now adding some error cases, like for instance a client attempts to add a new resource but has exceeded his storage quota. I am already handling certain error cases with HTTP status codes (401 for authentication, 403 for authorization and 404 for plain bad request URIs). I looked over the blessed HTTP error codes but none of the 400-417 range seems right to report application specific errors. So at first I was tempted to return my application error with 200 OK and a specific XML payload (ie. Pay us more and you’ll get the storage you need!) but I stopped to think about it and it seems to soapy (/shrug in horror). Besides it feels like I’m splitting the error responses into distinct cases, as some are http status code driven and other are content driven.
So what is the industry recommendations? Good practices (please explain why!) and also, from a client pov, what kind of error handling in the REST API makes life easier for the client code?
![]()
gorn
4,9677 gold badges30 silver badges46 bronze badges
asked Jun 3, 2009 at 3:39
![]()
Remus RusanuRemus Rusanu
286k40 gold badges430 silver badges565 bronze badges
5
So at first I was tempted to return my application error with 200 OK and a specific XML payload (ie. Pay us more and you’ll get the storage you need!) but I stopped to think about it and it seems to soapy (/shrug in horror).
I wouldn’t return a 200 unless there really was nothing wrong with the request. From RFC2616, 200 means «the request has succeeded.»
If the client’s storage quota has been exceeded (for whatever reason), I’d return a 403 (Forbidden):
The server understood the request, but is refusing to fulfill it. Authorization will not help and the request SHOULD NOT be repeated. If the request method was not HEAD and the server wishes to make public why the request has not been fulfilled, it SHOULD describe the reason for the refusal in the entity. If the server does not wish to make this information available to the client, the status code 404 (Not Found) can be used instead.
This tells the client that the request was OK, but that it failed (something a 200 doesn’t do). This also gives you the opportunity to explain the problem (and its solution) in the response body.
What other specific error conditions did you have in mind?
answered Jun 3, 2009 at 4:08
![]()
Rich ApodacaRich Apodaca
27.9k16 gold badges101 silver badges127 bronze badges
9
The main choice is do you want to treat the HTTP status code as part of your REST API or not.
Both ways work fine. I agree that, strictly speaking, one of the ideas of REST is that you should use the HTTP Status code as a part of your API (return 200 or 201 for a successful operation and a 4xx or 5xx depending on various error cases.) However, there are no REST police. You can do what you want. I have seen far more egregious non-REST APIs being called «RESTful.»
At this point (August, 2015) I do recommend that you use the HTTP Status code as part of your API. It is now much easier to see the return code when using frameworks than it was in the past. In particular, it is now easier to see the non-200 return case and the body of non-200 responses than it was in the past.
The HTTP Status code is part of your api
-
You will need to carefully pick 4xx codes that fit your error conditions. You can include a rest, xml, or plaintext message as the payload that includes a sub-code and a descriptive comment.
-
The clients will need to use a software framework that enables them to get at the HTTP-level status code. Usually do-able, not always straight-forward.
-
The clients will have to distinguish between HTTP status codes that indicate a communications error and your own status codes that indicate an application-level issue.
The HTTP Status code is NOT part of your api
-
The HTTP status code will always be 200 if your app received the request and then responded (both success and error cases)
-
ALL of your responses should include «envelope» or «header» information. Typically something like:
envelope_ver: 1.0 status: # use any codes you like. Reserve a code for success. msg: "ok" # A human string that reflects the code. Useful for debugging. data: ... # The data of the response, if any.
-
This method can be easier for clients since the status for the response is always in the same place (no sub-codes needed), no limits on the codes, no need to fetch the HTTP-level status-code.
Here’s a post with a similar idea: http://yuiblog.com/blog/2008/10/15/datatable-260-part-one/
Main issues:
-
Be sure to include version numbers so you can later change the semantics of the api if needed.
-
Document…
![]()
shA.t
16.4k5 gold badges53 silver badges111 bronze badges
answered Jun 3, 2009 at 4:13
![]()
Larry KLarry K
46.9k14 gold badges84 silver badges138 bronze badges
6
Remember there are more status codes than those defined in the HTTP/1.1 RFCs, the IANA registry is at http://www.iana.org/assignments/http-status-codes. For the case you mentioned status code 507 sounds right.
answered Jun 3, 2009 at 5:46
![]()
Julian ReschkeJulian Reschke
39.2k8 gold badges92 silver badges96 bronze badges
11
As others have pointed, having a response entity in an error code is perfectly allowable.
Do remember that 5xx errors are server-side, aka the client cannot change anything to its request to make the request pass. If the client’s quota is exceeded, that’s definitly not a server error, so 5xx should be avoided.
answered Jun 4, 2009 at 13:54
![]()
SerialSebSerialSeb
6,66122 silver badges28 bronze badges
2
There are two sorts of errors. Application errors and HTTP errors. The HTTP errors are just to let your AJAX handler know that things went fine and should not be used for anything else.
5xx Server Error
500 Internal Server Error
501 Not Implemented
502 Bad Gateway
503 Service Unavailable
504 Gateway Timeout
505 HTTP Version Not Supported
506 Variant Also Negotiates (RFC 2295 )
507 Insufficient Storage (WebDAV) (RFC 4918 )
509 Bandwidth Limit Exceeded (Apache bw/limited extension)
510 Not Extended (RFC 2774 )
2xx Success
200 OK
201 Created
202 Accepted
203 Non-Authoritative Information (since HTTP/1.1)
204 No Content
205 Reset Content
206 Partial Content
207 Multi-Status (WebDAV)
However, how you design your application errors is really up to you. Stack Overflow for example sends out an object with response, data and message properties. The response I believe contains true or false to indicate if the operation was successful (usually for write operations). The data contains the payload (usually for read operations) and the message contains any additional metadata or useful messages (such as error messages when the response is false).
answered Jun 3, 2009 at 9:21
![]()
aleembaleemb
30.8k18 gold badges98 silver badges114 bronze badges
1
Agreed. The basic philosophy of REST is to use the web infrastructure. The HTTP Status codes are the messaging framework that allows parties to communicate with each other without increasing the HTTP payload. They are already established universal codes conveying the status of response, and therefore, to be truly RESTful, the applications must use this framework to communicate the response status.
Sending an error response in a HTTP 200 envelope is misleading, and forces the client (api consumer) to parse the message, most likely in a non-standard, or proprietary way. This is also not efficient — you will force your clients to parse the HTTP payload every single time to understand the «real» response status. This increases processing, adds latency, and creates an environment for the client to make mistakes.
answered Nov 21, 2013 at 17:38
![]()
KingzKingz
4,9363 gold badges35 silver badges24 bronze badges
4
Please stick to the semantics of protocol. Use 2xx for successful responses and 4xx , 5xx for error responses — be it your business exceptions or other. Had using 2xx for any response been the intended use case in the protocol, they would not have other status codes in the first place.
answered Apr 14, 2016 at 6:42
![]()
rahil008rahil008
1731 silver badge7 bronze badges
Don’t forget the 5xx errors as well for application errors.
In this case what about 409 (Conflict)? This assumes that the user can fix the problem by deleting stored resources.
Otherwise 507 (not entirely standard) may also work. I wouldn’t use 200 unless you use 200 for errors in general.
answered Jun 3, 2009 at 15:38
![]()
Kathy Van StoneKathy Van Stone
25.3k3 gold badges31 silver badges40 bronze badges
If the client quota is exceeded it is a server error, avoid 5xx in this instance.
answered May 6, 2010 at 0:02
![]()
2
Join the DZone community and get the full member experience.
Join For Free
What do you do when everything goes wrong with your RESTful API? You have many ways to indicate an API call failure, including the built-in status codes included in HTTP. Use these best practices to help developers with their API integration.
Good Error Codes and Messages
Nothing is more frustrating than running into an error code that doesn’t tell you anything about the problem. You want readable, understandable error messages that provide developers with the necessary resources to continue forward.
Don’t Skimp on the Help
Do you have documentation or knowledge base articles that walk developers through the solution to an error message? Include the links for a convenient reference. If you don’t have any documentation, now’s a good time to go back and write all your error codes up.
Client Needs to Rely on Graceful Error Handling
The end user working with your API integrates it as a single piece of a much larger whole. If errors show up on their end, they need detailed error messages to promote a good user experience.
Tell Clients If They Can’t Solve the Problem
You may have developers who assume that they caused a particular error if they don’t have any other information to go off of. They try everything to fix it when it ends up being a problem on your side. Indicate whether an error is caused by something the end user controls or if they need to wait for you to address the issue.
How to Choose the Right Type of Error Codes
You might find it handy that the HTTP protocol includes more than 70 status codes, but you need to narrow that list down to the ones you actually need. Keeping it simple is harder than it sounds. You don’t have a one-size-fits-all set of status codes that work for every RESTful API you develop. The type of data you have, the ways the client interacts with it and how your server handles the data all have an impact on your selection. Start with the bare basics, such as:
- 200 OK.
- 400 Bad Request.
- 500 Internal Server Error.
Pay close attention to the way you interact with the API once you create this list. Every time you encounter a situation that aligns with an HTTP status code, include it with the other messages. A few common options include:
- 401 Unauthorized.
- 403 Forbidden.
There’s no right or wrong number of status codes to incorporate in your API. Be prepared to work in more as the need arises. Edge cases and other unusual scenarios fall under the common sense rules. Stick to the spirit of REST error handling practices and give the client sufficient detail.
API
Editor’s note: We’ve got an updated eBook on the topics covered in this blog series: Web API Design: The Missing Link.
In previous discussions about pragmatic REST API design, I talked about simplyfing associations, using the HTTP ? to hide complexities and optional parameters, choosing plural nouns and concrete names, and more.
What about errors in the context of RESTful API best practices? Many software developers, including myself, don’t always like to think about exceptions and error handling but it is a very important piece of the puzzle for any software developer, and especially for API designers.
Why is good error design especially important for API designers?
Bottom line, it’s about making your APIs intuitive and making developers successful.
First, developers learn to write code through errors. The «test-first» concepts of the extreme programming model and the more recent «test driven development» models represent a body of best practices that have evolved because this is such an important and natural way for developers to work.
From the perspective of the developer consuming your Web API, everything at the other side of that interface is a black box. Errors therefore become a key tool providing context and visibility into how to use an API.
Secondly, in addition to when they’re developing their applications, developers depend on well-designed errors at the critical times when they are troubleshooting and resolving issues after the applications they’ve built using your APIs are in the hands of their users.
How to think about errors in a pragmatic way with REST?
Let’s take a look at how three top APIs approach it.

Facebook
No matter what happens on a Facebook request, you get back the 200 status code — everything is OK. Many error messages also push down into the HTTP response. Here they also throw an #803 error but with no information about what #803 is or how to react to it.
Twilio
Twilio does a great job aligning errors with HTTP status codes. Like Facebook, they provide a more granular error message but with a link that takes you to the documentation. Community commenting and discussion on the documentation helps to build a body of information and adds context for developers experiencing these errors.
SimpleGeo
Provides error codes but with no additional value in the payload.
A couple of best practices
Use HTTP status codes
Use HTTP status codes and try to map them cleanly to relevant standard-based codes.
There are over 70 HTTP status codes. However, most developers don’t have all 70 memorized. So if you choose status codes that are not very common you will force application developers away from building their apps and over to wikipedia to figure out what you’re trying to tell them.
Therefore, most API providers use a small subset. For example, the Google GData API uses only 10 status codes, Netflix uses 9, and Digg, only 8.

How many status codes should you use for your API?
When you boil it down, there are really only 3 outcomes in the interaction between an app and an API:
- Everything worked
- The application did something wrong
- The API did something wrong
Start by using the following 3 codes. If you need more, add them. But you shouldn’t go beyond 8.
- 200 — OK
- 404 — Not Found
- 500 — Internal Server Error
If you’re not comfortable reducing all your error conditions to these 3, try picking among these additional 5:
- 201 — Created
- 304 — Not Modified
- 400 — Bad Request
- 401 — Unauthorized
- 403 — Forbidden
(Check out this good Wikipedia entry for all HTTP Status codes.)
It is important that the code that is returned can be consumed and acted upon by the application’s business logic — for example, in an if-then-else, or a case statement.
Make messages returned in the payload as verbose as possible
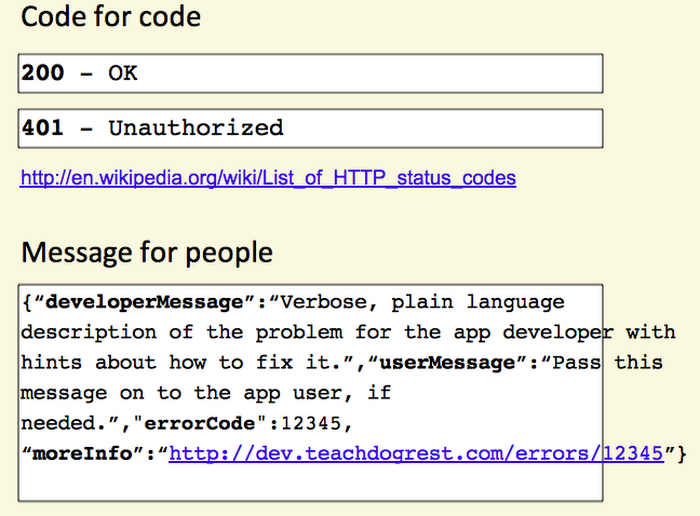
Be verbose.
Use plain language descriptions.
Add as many hints as your API team can think of about what’s causing an error.
I highly recommend you add a link in your description to more information, like Twilio does.
- API Management
- Apigee
- Google Cloud
- Developers & Practitioners
| title | description | ms.date | ms.topic | ms.assetid |
|---|---|---|---|---|
|
Modern C++ best practices for exceptions and error handling |
How Modern C++ supports exceptional programming styles over error codes. |
08/24/2020 |
conceptual |
a6c111d0-24f9-4bbb-997d-3db4569761b7 |
Modern C++ best practices for exceptions and error handling
In modern C++, in most scenarios, the preferred way to report and handle both logic errors and runtime errors is to use exceptions. It’s especially true when the stack might contain several function calls between the function that detects the error, and the function that has the context to handle the error. Exceptions provide a formal, well-defined way for code that detects errors to pass the information up the call stack.
Use exceptions for exceptional code
Program errors are often divided into two categories: Logic errors that are caused by programming mistakes, for example, an «index out of range» error. And, runtime errors that are beyond the control of programmer, for example, a «network service unavailable» error. In C-style programming and in COM, error reporting is managed either by returning a value that represents an error code or a status code for a particular function, or by setting a global variable that the caller may optionally retrieve after every function call to see whether errors were reported. For example, COM programming uses the HRESULT return value to communicate errors to the caller. And the Win32 API has the GetLastError function to retrieve the last error that was reported by the call stack. In both of these cases, it’s up to the caller to recognize the code and respond to it appropriately. If the caller doesn’t explicitly handle the error code, the program might crash without warning. Or, it might continue to execute using bad data and produce incorrect results.
Exceptions are preferred in modern C++ for the following reasons:
-
An exception forces calling code to recognize an error condition and handle it. Unhandled exceptions stop program execution.
-
An exception jumps to the point in the call stack that can handle the error. Intermediate functions can let the exception propagate. They don’t have to coordinate with other layers.
-
The exception stack-unwinding mechanism destroys all objects in scope after an exception is thrown, according to well-defined rules.
-
An exception enables a clean separation between the code that detects the error and the code that handles the error.
The following simplified example shows the necessary syntax for throwing and catching exceptions in C++.
#include <stdexcept> #include <limits> #include <iostream> using namespace std; void MyFunc(int c) { if (c > numeric_limits< char> ::max()) throw invalid_argument("MyFunc argument too large."); //... } int main() { try { MyFunc(256); //cause an exception to throw } catch (invalid_argument& e) { cerr << e.what() << endl; return -1; } //... return 0; }
Exceptions in C++ resemble ones in languages such as C# and Java. In the try block, if an exception is thrown it will be caught by the first associated catch block whose type matches that of the exception. In other words, execution jumps from the throw statement to the catch statement. If no usable catch block is found, std::terminate is invoked and the program exits. In C++, any type may be thrown; however, we recommend that you throw a type that derives directly or indirectly from std::exception. In the previous example, the exception type, invalid_argument, is defined in the standard library in the <stdexcept> header file. C++ doesn’t provide or require a finally block to make sure all resources are released if an exception is thrown. The resource acquisition is initialization (RAII) idiom, which uses smart pointers, provides the required functionality for resource cleanup. For more information, see How to: Design for exception safety. For information about the C++ stack-unwinding mechanism, see Exceptions and stack unwinding.
Basic guidelines
Robust error handling is challenging in any programming language. Although exceptions provide several features that support good error handling, they can’t do all the work for you. To realize the benefits of the exception mechanism, keep exceptions in mind as you design your code.
-
Use asserts to check for errors that should never occur. Use exceptions to check for errors that might occur, for example, errors in input validation on parameters of public functions. For more information, see the Exceptions versus assertions section.
-
Use exceptions when the code that handles the error is separated from the code that detects the error by one or more intervening function calls. Consider whether to use error codes instead in performance-critical loops, when code that handles the error is tightly coupled to the code that detects it.
-
For every function that might throw or propagate an exception, provide one of the three exception guarantees: the strong guarantee, the basic guarantee, or the nothrow (noexcept) guarantee. For more information, see How to: Design for exception safety.
-
Throw exceptions by value, catch them by reference. Don’t catch what you can’t handle.
-
Don’t use exception specifications, which are deprecated in C++11. For more information, see the Exception specifications and
noexceptsection. -
Use standard library exception types when they apply. Derive custom exception types from the
exceptionClass hierarchy. -
Don’t allow exceptions to escape from destructors or memory-deallocation functions.
Exceptions and performance
The exception mechanism has a minimal performance cost if no exception is thrown. If an exception is thrown, the cost of the stack traversal and unwinding is roughly comparable to the cost of a function call. Additional data structures are required to track the call stack after a try block is entered, and additional instructions are required to unwind the stack if an exception is thrown. However, in most scenarios, the cost in performance and memory footprint isn’t significant. The adverse effect of exceptions on performance is likely to be significant only on memory-constrained systems. Or, in performance-critical loops, where an error is likely to occur regularly and there’s tight coupling between the code to handle it and the code that reports it. In any case, it’s impossible to know the actual cost of exceptions without profiling and measuring. Even in those rare cases when the cost is significant, you can weigh it against the increased correctness, easier maintainability, and other advantages that are provided by a well-designed exception policy.
Exceptions versus assertions
Exceptions and asserts are two distinct mechanisms for detecting run-time errors in a program. Use assert statements to test for conditions during development that should never be true if all your code is correct. There’s no point in handling such an error by using an exception, because the error indicates that something in the code has to be fixed. It doesn’t represent a condition that the program has to recover from at run time. An assert stops execution at the statement so that you can inspect the program state in the debugger. An exception continues execution from the first appropriate catch handler. Use exceptions to check error conditions that might occur at run time even if your code is correct, for example, «file not found» or «out of memory.» Exceptions can handle these conditions, even if the recovery just outputs a message to a log and ends the program. Always check arguments to public functions by using exceptions. Even if your function is error-free, you might not have complete control over arguments that a user might pass to it.
C++ exceptions versus Windows SEH exceptions
Both C and C++ programs can use the structured exception handling (SEH) mechanism in the Windows operating system. The concepts in SEH resemble the ones in C++ exceptions, except that SEH uses the __try, __except, and __finally constructs instead of try and catch. In the Microsoft C++ compiler (MSVC), C++ exceptions are implemented for SEH. However, when you write C++ code, use the C++ exception syntax.
For more information about SEH, see Structured Exception Handling (C/C++).
Exception specifications and noexcept
Exception specifications were introduced in C++ as a way to specify the exceptions that a function might throw. However, exception specifications proved problematic in practice, and are deprecated in the C++11 draft standard. We recommend that you don’t use throw exception specifications except for throw(), which indicates that the function allows no exceptions to escape. If you must use exception specifications of the deprecated form throw( type-name ), MSVC support is limited. For more information, see Exception Specifications (throw). The noexcept specifier is introduced in C++11 as the preferred alternative to throw().
See also
How to: Interface between exceptional and non-exceptional code
C++ language reference
C++ Standard Library