|
Joey Джоуи 1073 / 635 / 240 Регистрация: 05.05.2015 Сообщений: 3,546 Записей в блоге: 2 |
||||
|
1 |
||||
|
29.06.2015, 22:15. Показов 11083. Ответов 5 Метки нет (Все метки)
Кто в курсе, в чем ошибка. Вот код минимального приложения
Если в L»Привет, world!» убрать букву L, все нормально работает. Пример взят с сайта с уроками
0 |

|
402 / 358 / 36 Регистрация: 11.10.2010 Сообщений: 1,907 |
|
|
29.06.2015, 22:15 |
2 |
|
Joey, попробуй MessageBoxW
0 |
|
Джоуи 1073 / 635 / 240 Регистрация: 05.05.2015 Сообщений: 3,546 Записей в блоге: 2 |
|
|
29.06.2015, 22:17 [ТС] |
3 |
|
Попробовал, то же самое Добавлено через 32 секунды
0 |
|
939 / 867 / 355 Регистрация: 10.10.2012 Сообщений: 2,706 |
|
|
29.06.2015, 22:33 |
4 |
|
Решение В опции компилятора вот это добавлял:
3 |
 Сообщение было отмечено Joey как решение
Сообщение было отмечено Joey как решение
|
Max Dark шКодер самоучка 2173 / 1880 / 912 Регистрация: 09.10.2013 Сообщений: 4,135 Записей в блоге: 7 |
||||
|
29.06.2015, 22:37 |
5 |
|||
|
РешениеJoey,
макрос TEXT добавляет L перед стоками в зависимости от настроек проекта(UNICODE)
1 |
|
Джоуи 1073 / 635 / 240 Регистрация: 05.05.2015 Сообщений: 3,546 Записей в блоге: 2 |
|
|
29.06.2015, 22:52 [ТС] |
6 |
|
lss, Спасибо. Добавлено через 21 секунду Добавлено через 3 минуты
0 |
|
IT_Exp Эксперт 87844 / 49110 / 22898 Регистрация: 17.06.2006 Сообщений: 92,604 |
29.06.2015, 22:52 |
|
Помогаю со студенческими работами здесь Не срабатывает запрос, выдает ошибку «Fatal error encountered during command execution.» Invalid byte 1 of 1-byte UTF-8 sequence — ошибка (Intellij idea) Выдаёт ошибку: acos DOMAIN error,полсе нажатия окей,ещё одну ошибку pow OWERFLAW ERROR Выдаёт ошибку: acos DOMAIN error,полсе… Не могу разглядеть ошибку в программе, выдает illegal expression Искать еще темы с ответами Или воспользуйтесь поиском по форуму: 6 |
MessageBox — это макрос. В зависимости от специальных макроопределений для включения/выключения Unicode (UNICODE и _UNICODE) он превращается либо в функцию MessageBoxA (A — ASCII), либо в функцию MessageBoxW (W — wide). MessageBoxA может выводить только ASCII-символы. Грубо говоря — только английский язык. MessageBoxW предназначен для вывода Unicode-символов, куда входят и символы кириллицы.
Первый вариант решения Вашей проблемы — прямо вызывать MessageBoxW. Туда нужно передавать строки с префиксом L, так как эта функция всегда принимает широкие строки и не меняет своего поведения.
MessageBoxW(NULL, L"Привет!", L"Здравствуй!", MB_OK);
Второй вариант — включить Unicode для проекта:
#ifndef UNICODE
#define UNICODE
#endif
#ifndef _UNICODE
#define _UNICODE
#endif
#include <Windows.h>
Обратите внимание, что #include <Windows.h> должен быть обязательно после #define’ов для Unicode. Так же, макроопределения можно, и лучше так и сделать, задавать в настройках проекта, в DevC++ это должно быть в Project -> Project Options -> Parameters, там в поле C++ Compiler нужно ввести-DUNICODE и -D_UNICODE.
При таком способе нужно использовать сам макрос MessageBox и передавать в него строки при помощи _T().
MessageBox(NULL, _T("Привет!"), _T("Здравствуй!"), MB_OK);
При использовании _T программа будет работать вне зависимости от настроек Unicode. Под «работать» в данном случае я понимаю не «отображать русские символы», а «компилироваться и не падать при выводе MessageBox«. Отображать русские символы она, само собой, будет только если Unicode включен.
Thank you, Ramazan Kartal.
-finput-charset=windows-1251 — good
As be if using several language in code ?.
For MortenMacFly.
// main.c
#define UNICODE
#include <windows.h>
//—————————————————————————
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow)
{
wchar_t capt[] = L»Sample text»;
wchar_t text_en[] = L»Hello»;
wchar_t text_ru[] = L»Привет»; // (russian string) error — converting to execution character set: Illegal byte sequence
MessageBoxExW(NULL, text_en, capt, MB_OK, 0);
MessageBoxExW(NULL, text_ru, capt, MB_OK, 0);
return 0;
}
//—————————————————————————
/*
OS — Windows Vista Ultimate x64 version 6.0.6000 (build 6000), russian (cp1251)
IDE — Code::Blocks 8.02 Build: Feb 27 2008, 20:59:09 (distrib: «codeblocks-8.02mingw-setup.exe», download: 16.03.2008)
Selected compiler — GNU GCC compiler
Project steps:
File->New->Project->Win32GUI->FrameBased
Delete default code
Insert this code (this code as sample)
Build!
Build log:
————— Build: Release in proba —————
mingw32-gcc.exe -Wall -O2 -c D:ProjectsCodeBlocksprobamain.c -o objReleasemain.o
D:ProjectsCodeBlocksprobamain.c:10:25: converting to execution character set: Illegal byte sequence
Process terminated with status 1 (0 minutes, 0 seconds)
1 errors, 0 warnings
All !
Enough information ?
*/
(Sorry, i bad speek english)
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and
privacy statement. We’ll occasionally send you account related emails.
Already on GitHub?
Sign in
to your account
Closed
ghost opened this issue
Aug 21, 2020
· 6 comments
Closed
Error when compiling on Windows 64bit
#1255
ghost opened this issue
Aug 21, 2020
· 6 comments
Comments
![]()
Describe the bug:
When I try to compile an app using fyne, I get the error:
# fyne.io/fyne/vendor/github.com/go-gl/glfw/v3.3/glfw
cc1.exe: sorry, unimplemented: 64-bit mode not compiled in
# fyne.io/fyne/vendor/github.com/go-gl/gl/v3.2-core/gl
cc1.exe: sorry, unimplemented: 64-bit mode not compiled in
Example code:
package main import ( "fyne.io/fyne/app" "fyne.io/fyne/widget" ) func main() { app := app.New() w := app.NewWindow("Hello") w.SetContent(widget.NewLabel("Hello Fyne!")) w.ShowAndRun() }
Device (please complete the following information):
- OS: Windows 64-bit
- Version: 10
- Go version: 1.15
- Fyne version: Unknown
![]()
I had this problem earlier today. Apparently it’s an issue with 64-bit version of MinGW. I solved it switching to the latest version of tdm64-gcc, as suggested here. Now I’m having the error
error: converting to execution character set: Illegal byte sequence
from go-gl/glfw but I think (hopefully) it’s unrelated
![]()
The initial error is normally seen when only a 32bit c compiler has been installed (confusingly mingW64 has both 32 and 64bit versions).
The later error probably refers to a corrupted checkout — unless you have a strange encoding on your computer. All Go files should be UTF-8.
![]()
@andydotxyz I didn’t changed any file, I just tried running the fyne_demo. Is it still possible my system is messing with the encoding? See #1257 please
![]()
It looks like you opened a new issue regarding encoding, so can this one be closed now?
![]()
I fixed this by installing mingw-w64 8.1.0 almost by accident following a tutorial on SDL2
![]()
2 participants
![]()
![]()
-
san4es
- In need of some credit

- Posts: 4
- Joined: Mon Mar 30, 2009 4:59 am
converting to execution character set: Illegal byte sequence
Добрый день!
Я начинаю осваивать wxWidgets. И сразу столкнулся с ошибкой, связанной с выводом сообщений на русском языке.
wxMessageBox(wxT(«Ошибка!»));
На такие вот строчки компилятор и ругается. Посмотрел в сети, предлагали лечить при помощи
-finput-charset=windows-1251
Однако и на это тоже я получаю ошибку:
cc1plus.exe: internal compiler error: Aborted
Я так понимаю, что вопрос не совсем связан с wxWidgets, однако помогите новичку ![]() Как всё-таки справляться с русским текстом?
Как всё-таки справляться с русским текстом?
OS: WinXP, compiler: GCC 3.4.5, wxWidgets 2.8.10
-
van_user
- Experienced Solver
- Posts: 55
- Joined: Wed Jun 11, 2008 9:28 pm
- Location: UA
Re: converting to execution character set: Illegal byte sequ
Post
by van_user » Mon Mar 30, 2009 7:24 am
san4es wrote:И сразу столкнулся с ошибкой, связанной с выводом сообщений на русском языке.
wxMessageBox(wxT(«Ошибка!»));
На такие вот строчки компилятор и ругается.
Будет лучше если ты еще выложишь лог компилятора. У меня диалоги с русскими буквами нормально работают без специальных параметров в configure.
И исходник у тебя, судя по всему, небольшой — выложи и его.
Win XP (SP0), mingw, wx 2.9.0
-
borr_1
- Super wx Problem Solver
- Posts: 362
- Joined: Wed Mar 07, 2007 8:10 am
- Location: Russia, Shakhty
Post
by borr_1 » Mon Mar 30, 2009 7:26 am
Среда разработки какая? Надеюсь у тебя файл исходник в кодировке UTF-8?
-
san4es
- In need of some credit
- Posts: 4
- Joined: Mon Mar 30, 2009 4:59 am
Re: converting to execution character set: Illegal byte sequ
Post
by san4es » Mon Mar 30, 2009 4:43 pm
IDE — CodeBlocks
Код такой:
Code: Select all
if(wxFile::Exists(wxT("MGI.xml")))
{
mgi_bib_db = new XMLBiblioDB(wxT("MGI.xml"));
bDBLoaded = true;
}else
{
wxMessageBox(wxT("Ошибка! Отсутствует файл базы данных!"));
bDBLoaded = false;
}Build log:
Code: Select all
-------------- Build: Release in wxBiblio ---------------
Compiling: wxBiblioMain.cpp
C:backupProgrammingwxBibliowxBiblioMain.cpp:97:1: converting to execution character set: Illegal byte sequence
C:backupProgrammingwxBibliowxBiblioMain.cpp:134:1: converting to execution character set: Illegal byte sequence
Process terminated with status 1 (0 minutes, 7 seconds)
2 errors, 0 warningsOS: WinXP, compiler: GCC 3.4.5, wxWidgets 2.8.10
-
borr_1
- Super wx Problem Solver
- Posts: 362
- Joined: Wed Mar 07, 2007 8:10 am
- Location: Russia, Shakhty
Post
by borr_1 » Tue Mar 31, 2009 4:31 am
А по второму вопросу — если стоит wxUSE_UNICODE в дефинесах. Все исходники должны быть в UTF-8 а не в win1251
Как собиралось wxWidgets с ключом Unicode=1?
-
san4es
- In need of some credit
- Posts: 4
- Joined: Mon Mar 30, 2009 4:59 am
Post
by san4es » Tue Mar 31, 2009 5:23 am
borr_1 wrote:А по второму вопросу — если стоит wxUSE_UNICODE в дефинесах. Все исходники должны быть в UTF-8 а не в win1251
Как собиралось wxWidgets с ключом Unicode=1?
Да, собирал с Unicode=1, для проекта в CodeBlocks тоже указал Unicode. А насчёт исходников — значит ли это, что надо конвертнуть исходник в UTF-8 для надёжности, поскольку я его редактировал и наверное внёс win1251?
OS: WinXP, compiler: GCC 3.4.5, wxWidgets 2.8.10
-
borr_1
- Super wx Problem Solver
- Posts: 362
- Joined: Wed Mar 07, 2007 8:10 am
- Location: Russia, Shakhty
Post
by borr_1 » Tue Mar 31, 2009 8:03 am
В CodeBlocks смотри в меню Edit->File Encoding
-
san4es
- In need of some credit
- Posts: 4
- Joined: Mon Mar 30, 2009 4:59 am
Post
by san4es » Tue Mar 31, 2009 12:30 pm
borr_1 wrote:В CodeBlocks смотри в меню Edit->File Encoding
Спасибо, помогло!
OS: WinXP, compiler: GCC 3.4.5, wxWidgets 2.8.10
-
SmileGobo
- Earned some good credits
- Posts: 111
- Joined: Wed Jul 30, 2008 8:01 am
- Location: Russia/MO
- Contact:
Post
by SmileGobo » Thu Apr 02, 2009 4:50 pm
Немного не в тему вопрос. Как с длинной строк кириллических символов обстоит дело? у меня не юникодная сборка и на некоторые строки у меня Length() выдает ноль.
win xp sp2; CodeBlocks/mingw/wxWidgets 2.8.9/wxFormBuilder
web-программирование:PHP,js/Ajax
-
Kolya
- Experienced Solver
- Posts: 85
- Joined: Mon Dec 11, 2006 11:35 am
- Location: /dev/null
Post
by Kolya » Fri Apr 03, 2009 8:52 am
SmileGobo wrote:Как с длинной строк кириллических символов обстоит дело? у меня не юникодная сборка и на некоторые строки у меня Length() выдает ноль.
Значит эти строки пустые
-
SmileGobo
- Earned some good credits
- Posts: 111
- Joined: Wed Jul 30, 2008 8:01 am
- Location: Russia/MO
- Contact:
Post
by SmileGobo » Fri Apr 03, 2009 7:25 pm
В том то и дело что нет. Это так странно ведет себя строка после использования Trim().
win xp sp2; CodeBlocks/mingw/wxWidgets 2.8.9/wxFormBuilder
web-программирование:PHP,js/Ajax
-
Kolya
- Experienced Solver
- Posts: 85
- Joined: Mon Dec 11, 2006 11:35 am
- Location: /dev/null
Post
by Kolya » Fri Apr 03, 2009 11:40 pm
SmileGobo wrote:В том то и дело что нет. Это так странно ведет себя строка после использования Trim().
Тогда пример в студию! ![]()
И исходники функции есть же, можно в отладке посмотреть.
Code: Select all
// some compilers (VC++ 6.0 not to name them) return true for a call to
// isspace('xEA') in the C locale which seems to be broken to me, but we have
// to live with this by checking that the character is a 7 bit one - even if
// this may fail to detect some spaces (I don't know if Unicode doesn't have
// space-like symbols somewhere except in the first 128 chars), it is arguably
// still better than trimming away accented letters
inline int wxSafeIsspace(wxChar ch) { return (ch < 127) && wxIsspace(ch); }
// trims spaces (in the sense of isspace) from left or right side
wxString& wxString::Trim(bool bFromRight)
{
// first check if we're going to modify the string at all
if ( !empty() &&
(
(bFromRight && wxSafeIsspace(GetChar(length() - 1))) ||
(!bFromRight && wxSafeIsspace(GetChar(0u)))
)
)
{
if ( bFromRight )
{
// find last non-space character
reverse_iterator psz = rbegin();
while ( (psz != rend()) && wxSafeIsspace(*psz) )
psz++;
// truncate at trailing space start
erase(psz.base(), end());
}
else
{
// find first non-space character
iterator psz = begin();
while ( (psz != end()) && wxSafeIsspace(*psz) )
psz++;
// fix up data and length
erase(begin(), psz);
}
}
return *this;
}
Может быть wxSafeIsspace считает эти символы пробельными, а может быть эти символы изначально были пробельными. Отладка покажет. Если нет, то желательно воспроизвести эту проблему на примере minimal, что идет в составе библиотеки.
-
borr_1
- Super wx Problem Solver
- Posts: 362
- Joined: Wed Mar 07, 2007 8:10 am
- Location: Russia, Shakhty
Post
by borr_1 » Sat Apr 04, 2009 5:27 am
И исходники функции есть же, можно в отладке посмотреть.
С этого места поподробнее. Если я имею gdb отладчик и wxWidgets уже скомпилированную как динамическая библ. Как я могу в ней что-то отладить?
-
Kolya
- Experienced Solver
- Posts: 85
- Joined: Mon Dec 11, 2006 11:35 am
- Location: /dev/null
Post
by Kolya » Sat Apr 04, 2009 12:42 pm
borr_1 wrote:Если я имею gdb отладчик и wxWidgets уже скомпилированную как динамическая библ. Как я могу в ней что-то отладить?
Я gdb не использовал, но насколько я знаю он позволяет загружать отладочную информацию. А вот в случае будет ли он работать в отладке динамических библиотек ничего не скажу.
Если не получится отладить, то можно скопировать исходники в приложение и там проверить.
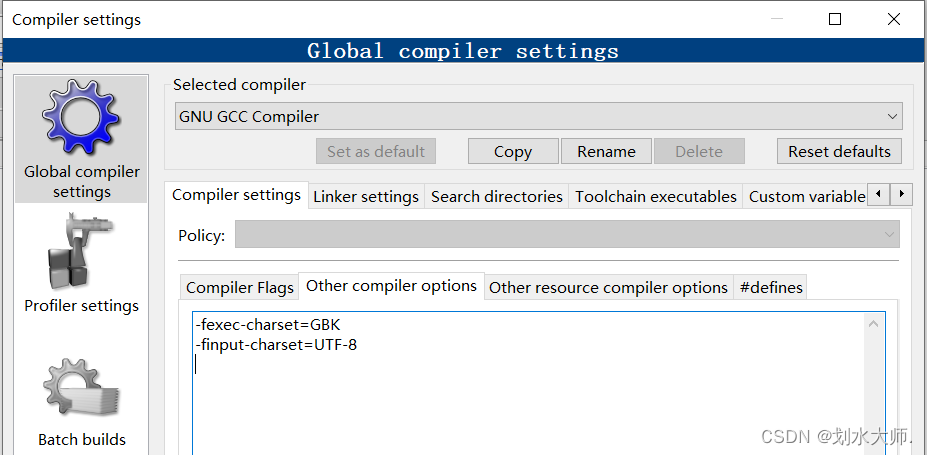
Today, after writing a program, I found that the compiler always reports an error: error converting to execution character set illegal byte sequence. When compiling by default, it is parsed according to UTF-8, and when the character set is not specified, it is always treated as UTF-8. So you have to add the following in settings->compiler->Global compiler settings->Other options:
-fexec-charset=GBK
-finput-charset=UTF-8
The former represents the encoding interpretation format of the input file during compilation, and the latter represents the encoding format used for the display of the generated execution file during execution.
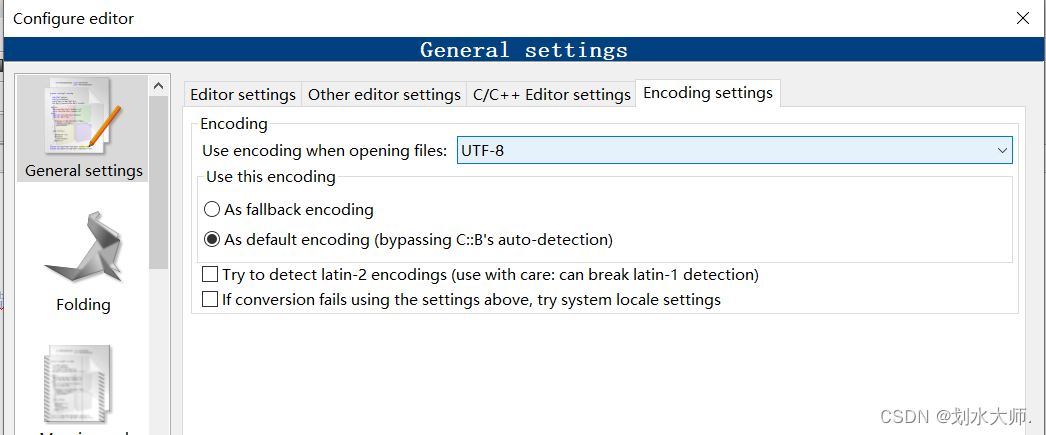
At the same time. In settings -> Editor-> gernal settings-> Other settings, set the file encoding format saved by default to UTF-8, and keep the encoding formats of both sides the same.
But after I did this, I found it useless… Later, I found that my program didn’t know when it was changed to ANSI format, so it had been either compiled incorrectly or Chinese garbled.
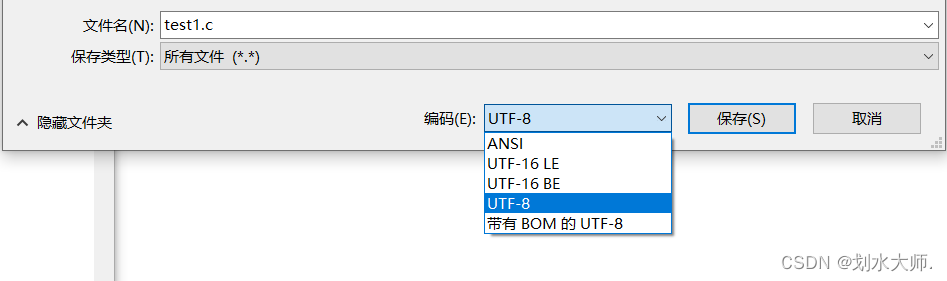
To solve this problem, you can open the code file with notepad and select the file – & gt; How to select the encoding format of UTF-8 to save as.