- С русского на:
- Английский
- С английского на:
- Все языки
- Испанский
- Итальянский
- Немецкий
- Русский
- Французский
-
1
incoming error count
- подсчет входящих ошибок
Англо-русский словарь нормативно-технической терминологии > incoming error count
-
2
bit error count
Универсальный англо-русский словарь > bit error count
-
3
Incoming Error Count (IEC)
English-Russian dictionary of modern telecommunications > Incoming Error Count (IEC)
-
4
error free frame
безошибочный кадр
The receiver, maintaining a count of error free frames received, sends an acknowledgement carrying the sequence number of that first frame then adds one to the sequence number, which is the anticipated number of the next frame. — Получатель, поддерживающий счет безошибочно полученных кадров, посылает подтверждение, несущее порядковый номер этого первого кадра, задет добавляет один к порядковому номеру, который является предполагаемым номером следующего кадра.
Англо-русский универсальный дополнительный практический переводческий словарь И. Мостицкого > error free frame
-
5
count-rate meter
English-Russian big polytechnic dictionary > count-rate meter
-
6
frame count error
- ошибка подсчета числа информационных кадров
Англо-русский словарь нормативно-технической терминологии > frame count error
-
7
hole count check
English-Russian base dictionary > hole count check
-
8
frame count error
Универсальный англо-русский словарь > frame count error
-
9
frame count error
English-Russian information technology > frame count error
-
10
IEC
- подсчет входящих ошибок
- МЭК
- Международная электротехническая комиссия
- информация, просвещение, коммуникация
- внутренний контроль ошибок
информация, просвещение, коммуникация
ИПК
—
[Англо-русский глоссарий основных терминов по вакцинологии и иммунизации. Всемирная организация здравоохранения, 2009 г.]Тематики
- вакцинология, иммунизация
Синонимы
- ИПК
EN
- Information, education, communication
- IEC
МЭК
Международная электротехническая комиссия.
[ ГОСТ Р 54456-2011]Тематики
- телевидение, радиовещание, видео
EN
- International Electrotechnical Commission / Committee
- IEC
Англо-русский словарь нормативно-технической терминологии > IEC
-
11
BEC
18) NYSE. Beckman Coulter, Inc.
Универсальный англо-русский словарь > BEC
-
12
FEBE-F
Универсальный англо-русский словарь > FEBE-F
-
13
FEBE-I
Универсальный англо-русский словарь > FEBE-I
-
14
bec
18) NYSE. Beckman Coulter, Inc.
Универсальный англо-русский словарь > bec
-
15
IEC
1.
см.
Incoming Error Count
2.
см.
International Electrotechnical Commission
English-Russian dictionary of modern telecommunications > IEC
-
16
CEP
3) Военный термин: Capital Equipment Plan, Committee for Energy Policy of OECD, capability evaluation plan, circular error probable, civil emergency planning, command executive procedures, common electronic parts, concept evaluation program, current evaluation phase, custodian of enemy property, КВО, круговое вероятное отклонение, Construction Electrician
Универсальный англо-русский словарь > CEP
-
17
Cep
3) Военный термин: Capital Equipment Plan, Committee for Energy Policy of OECD, capability evaluation plan, circular error probable, civil emergency planning, command executive procedures, common electronic parts, concept evaluation program, current evaluation phase, custodian of enemy property, КВО, круговое вероятное отклонение, Construction Electrician
Универсальный англо-русский словарь > Cep
-
18
cep
3) Военный термин: Capital Equipment Plan, Committee for Energy Policy of OECD, capability evaluation plan, circular error probable, civil emergency planning, command executive procedures, common electronic parts, concept evaluation program, current evaluation phase, custodian of enemy property, КВО, круговое вероятное отклонение, Construction Electrician
Универсальный англо-русский словарь > cep
-
19
meter
Англо-русский технический словарь > meter
-
20
interrupt
English-Russian dictionary of computer science and programming > interrupt
Страницы
- Следующая →
- 1
- 2
- 3
См. также в других словарях:
-
Count Key Data — (CKD) is a disk data architecture. Each physical disk record consists of a count field, an optional key field, and a ( user ) data field with error correction/detection information appended to each field and gaps separating each field [1].… … Wikipedia
-
Count Duckula — Título Count Duckula Graf Duckula El Conde Duckula Género Serie animada Creado por Cosgrove Hall Voces de David Jason, etc País de origen … Wikipedia Español
-
Count — Count, v. i. 1. To number or be counted; to possess value or carry weight; hence, to increase or add to the strength or influence of some party or interest; as, every vote counts; accidents count for nothing. [1913 Webster] This excellent man … The Collaborative International Dictionary of English
-
error message — error ,message noun count COMPUTING a message that you get on your computer screen when you have made a mistake or something has gone wrong with the program … Usage of the words and phrases in modern English
-
error — er|ror [ erər ] noun *** 1. ) count or uncount a mistake, for example in a calculation or a decision: error in: an error in our calculations make an error: If you make a typing error, you can correct it using one of these keys.… … Usage of the words and phrases in modern English
-
Error (baseball) — In baseball [statistics] , an error is the act, in the judgment of the official scorer, of a fielder misplaying a ball in a manner that allows a batter or baserunner to reach one or more additional bases, when such an advance should have been… … Wikipedia
-
Count-Min sketch — The Count Min sketch (or CM sketch) is a probabilistic sub linear space streaming algorithm which can be used to summarize a data stream in many different ways. The algorithm was invented in 2003 by Graham Cormode and S. Muthu Muthukrishnan[1].… … Wikipedia
-
Least Count — The Least Count of any measuring equipment is the smallest quantity that can be measured accurately using that instrument.Thus Least Count indicates the degree of accuracy of measurement that can be achieved by the measuring instrument.All… … Wikipedia
-
Volusia error — The Volusia error is an example of the problems with electronic voting from the 2000 US Presidential election. Late in the night on November 7, 2000 the US election had come down to a tight race over Florida and its 25 electoral votes. Both Al… … Wikipedia
-
Standard error (statistics) — For a value that is sampled with an unbiased normally distributed error, the above depicts the proportion of samples that would fall between 0, 1, 2, and 3 standard deviations above and below the actual value. The standard error is the standard… … Wikipedia
-
Soft error — In electronics and computing, an error is a signal or datum which is wrong. Errors may be caused by a defect, usually understood either to be a mistake in design or construction, or a broken component. A soft error is also a signal or datum which … Wikipedia
На основании Вашего запроса эти примеры могут содержать грубую лексику.
На основании Вашего запроса эти примеры могут содержать разговорную лексику.
The experiment showed a decrease of classification error count by 12.15 % compared with the classifier that trained on the statistical features.
Эксперимент, поставленный на коротких научных текстах, показал снижение числа ошибок классификации на 12,15 % по сравнению с классификатором, обученным на статистических признаках.
Some days, When Internet users especially active, error count attendance external systems statistics can be 20% more (while the actual number of visitors will be more, range statistics show).
В некоторые жизнь, если пользователи интернета особенно активны, ошибка подсчёта посещаемости внешними системами статистики может сочинять 20% и более (быть этом реальное день посетителей довольно больше, чем покажет статистика).
And only in the 8th minute added by the arbitrator to the main game time visitors took advantage of a positional error count, the three went to the goalkeeper and the decisive blow was struck Andriy Yarmolenko — 1: 1.
И лишь на 8-й добавленной арбитром минуте к основному времени игры гости воспользовались позиционной ошибкой соперника, вышли втроем на голкипера и решающий удар нанес Андрей Ярмоленко — 1:1.
They proved that it is possible to combine a miniature size and a low error count with a high data transfer rate and a relatively high energy efficiency in a single device, heralding a «plasmonic breakthrough» in microelectronics that could come in the next ten years.
Они продемонстрировали сочетание малых размеров, малого числа ошибок при высокой скорости передачи данных и достаточно высокой энергоэффективности в одном устройстве, что может уже в ближайшее десятилетие обеспечить «плазмонный прорыв» в микроэлектронике.
Другие результаты
This error counts as common misspelling, unnoticed foreign spelling, an abuse of the Country Code Top-Level Domain.
Эта ошибка считается общей орфографической ошибкой, незаметным иностранным написанием, злоупотребление домена верхнего уровня с кодом страны.
I mean, tennis the winners are very important, they look better, but the unforced errors count the same.
В теннисе очень важны виннерсы , они прекрасно смотрятся со стороны, но невынужденные ошибки имеют такой же вес.
They will display average, median and 90 percentile values along with the errors count.
Приведены значения медиан, 10-й и 90-й процентилей вместе с отметками погрешностей.
Flagrant error the count can not say «no.»
Mint-made errors do not count damage received by a coin after its production.
Браком монеты не считаются повреждения, полученные монетой после ее производства.
If it is not +4, you made an error in your count.
I will commit more errors; you can count on that.
Я совершу и другие ошибки, вы можете быть в этом уверены.
Unfortunately that is within the margin of error of most quick counts.
А это в пределах ошибки подсчета запасов по самой высокой категории.
Count as error during a flashcard session. You can later repeat these cards by selecting Quiz Repeat Errors.
Засчитать карточку как ошибочную. Чтобы заново пройтись по таким карточкам, выберите Тест Повторить ошибочные.
While all crew were accounted for after the muster drill, we just found an error in the Tiger count.
Вся команда была посчитана на построении, ошибка нашлась в списке Тигров.
Counter 198 (Offline Uncorrectable Sector Count) is the total count of errors when reading or writing sectors.
Счетчик 198 (Offline Unc корректируемое количество секторов) — это общее количество ошибок при чтении или записи секторов.
If we use our plan, users would have to be informed of the potential sampling error associated with population counts and how to factor it into their analysis.
Если мы воспользуемся своим планом, то пользователи информацией будут осведомлены о возможной ошибке выборки при численном учете населения, а следовательно, смогут учесть ее в своем анализе.
However, the research showed that a large proportion (56%) of the failed drives failed without recording any count in the «four strong S.M.A.R.T. warnings» identified as scan errors, reallocation count, offline reallocation and probational count.
Тем не менее исследование показало, что значительная часть (56%) неудавшихся дисков потерпела неудачу, не записав никакого количества в «четырех сильных предупреждениях SMART», идентифицированных как ошибки сканирования, количество перераспределения, автономное перераспределение и пробный счет.
As was indicated in the previous sections of this article, the above alteration of dates was apparently done because somebody had shown to Schroeder the error in his count of generations between Cain and Tuval-Cain in his first book.
Как было сказано при обсуждении первой книги, указанное изменение дат было, по-видимому, вызвано тем, что в первой книге Шрёдер ошибся в его счёте поколений от Каина до Тубал-Каина.
Amongst others you can view read error rate, start/stop count, end-to-end error, command timeout, reallocation event count and more, along with threshold, raw values, current and worst for each attribute.
Среди прочего вы можете просмотреть частоту ошибок при чтении, количество запусков/ остановок, сквозную ошибку, тайм-аут команды, количество событий перераспределения и т.д., а также пороговые, необработанные значения, текущие и худшие для каждого атрибута.
I imagine the 110,000 gas stations that keep our ICE cars humming along today will look like a rounding error when we count up the millions of electric «filling stations» that will be located in our garages and parking lots.
Я думаю, что 110000 заправочных станций, которые заставляют наши ДВС-автомобили сегодня работать, будут выглядеть как ошибка округления, когда мы подсчитаем миллионы электрических «заправочных станций», которые будут расположены в наших гаражах и на стоянках.
Результатов: 107. Точных совпадений: 4. Затраченное время: 246 мс
Documents
Корпоративные решения
Спряжение
Синонимы
Корректор
Справка и о нас
Индекс слова: 1-300, 301-600, 601-900
Индекс выражения: 1-400, 401-800, 801-1200
Индекс фразы: 1-400, 401-800, 801-1200
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
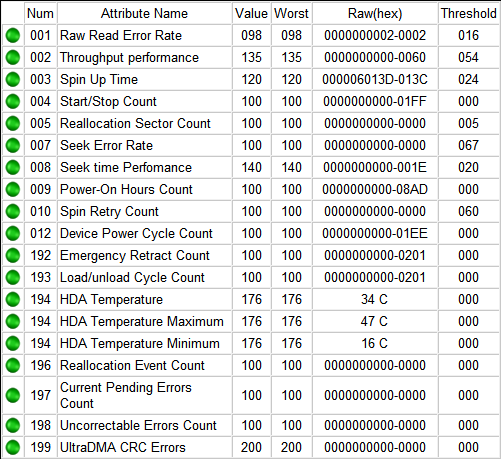
S.M.A.R.T. в HDDScan 3.3
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 10 | 11 | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | BD | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | BF | С0 | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 | СА | CB | DC | F0 | FE |
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
Атрибут: 01 Raw Read Error Rate
| Тип | текущий, может быть накапливающим для WD и старых Hitachi |
| Описание | содержит частоту возникновения ошибок при чтении с пластин |
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
| Тип | текущий |
| Описание | содержит значение средней производительности диска и измеряется в каких-то «попугаях». Обычно его ненулевое значение отмечается на винчестерах Hitachi. На них он может изменяться после изменения параметров ААМ, а может и сам по себе по неизвестному алгоритму |
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
| Тип | текущий |
| Описание | содержит время, за которое шпиндель диска в последний раз разогнался из состояния покоя до номинальной скорости. Может содержать два значения — последнее и, например, минимальное время раскрутки. Может измеряться в миллисекундах, десятках миллисекунд и т. п. — это зависит от производителя и модели диска |
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
| Тип | накапливающий |
| Описание | содержит количество раз включения диска. Бывает ненулевым на только что купленном диске, находившемся в запаянной упаковке, что может говорить о тестировании диска на заводе. Или ещё о чём-то, мне не известном  |
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
| Тип | накапливающий |
| Описание | содержит количество секторов, переназначенных винчестером в резервную область. Практически ключевой параметр в оценке состояния |
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение, а используемый вместо повреждённого сектор — переназначенным. Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при позиционировании блока магнитных головок (БМГ) |
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
| Тип | текущий |
| Описание | содержит среднюю производительность операций позиционирования головок, измеряется в «попугаях». Как и параметр 02 Throughput Performance, ненулевое значение обычно отмечается на дисках Hitachi и может изменяться после изменения параметров ААМ, а может и само по себе по неизвестному алгоритму |
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
| Тип | накапливающий |
| Описание | содержит количество часов, в течение которых винчестер был включён |
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
| Тип | накапливающий |
| Описание | содержит количество повторов запуска шпинделя, если первая попытка оказалась неудачной |
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Тип | накапливающий |
| Описание | содержит количество повторных попыток сброса накопителя (установки БМГ на нулевую дорожку) при неудачной первой попытке |
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов «включение-отключение» диска |
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
| Тип | накапливающий |
| Описание | содержит количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута |
Не говорит о здоровье накопителя.
Атрибут: 184 (B8) End-to-End Error
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче данных через кэш винчестера |
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Тип | накапливающий |
| Описание | содержит количество секторов, которые были признаны кандидатами на переназначение (см. атрибут 197) за всю историю жизни диска. Причём если сектор становится кандидатом повторно, значение атрибута тоже увеличивается |
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
| Тип | накапливающий |
| Описание | содержит количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика |
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
| Тип | накапливающий |
| Описание | содержит количество зафиксированных случаев записи при высоте полета головки выше рассчитанной — скорее всего, из-за внешних воздействий, например вибрации |
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
| Тип | текущий |
| Описание | содержит температуру винчестера для дисков Hitachi, Samsung, WD и значение «100 − [RAW-значение атрибута 194]» для Seagate |
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Тип | накапливающий |
| Описание | содержит количество критических ускорений, зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. |
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
| Тип | накапливающий |
| Описание | для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок БМГ диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т. п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi) |
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов парковки/распарковки БМГ. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (столь любимая, например, компанией Western Digital): если его содержимое превосходит (обычно — многократно) содержимое атрибута 09 — счётчик отработанных часов, — то парковка включена |
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
| Тип | текущий/накапливающий |
| Описание | содержит текущую температуру диска. Температура считывается с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера |
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
| Тип | накапливающий |
| Описание | содержит количество ошибок, которые были скорректированы аппаратными средствами ECC диска |
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
| Тип | накапливающий |
| Описание | содержит количество операций переназначения секторов |
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
| Тип | текущий |
| Описание | содержит количество секторов-кандидатов на переназначение в резервную область |
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.
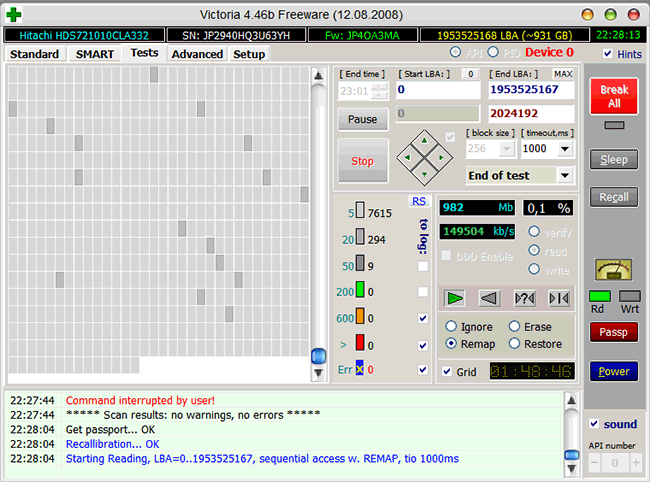
Идёт последовательное чтение с ремапом в Victoria 4.46b
В случае неудачи чтения как с remap, так и с Advanced remap, стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!
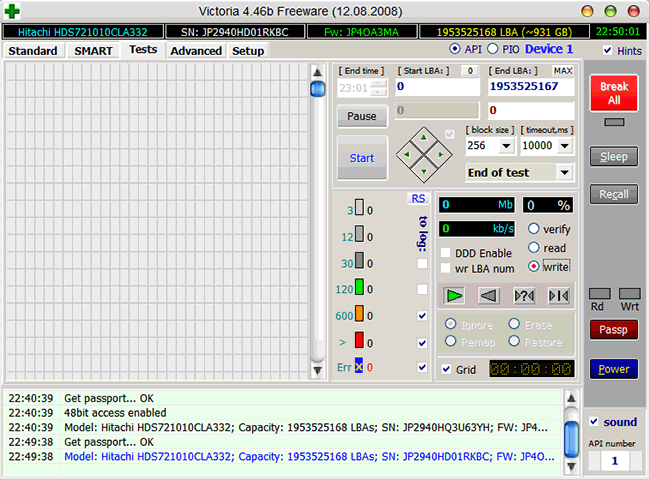
Запуск последовательной записи в Victoria 4.46b
Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Тип | текущий |
| Описание | означает то же самое, что и атрибут 197, но отличие в том, что данный атрибут содержит количество секторов-кандидатов, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой |
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
Атрибут: 199 (С7) UltraDMA CRC Error Count
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска |
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при записи |
Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать «умирающие» головки.
Атрибут: 201 (С9) Soft Read Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок чтения, произошедших по вине программного обеспечения |
Влияние на здоровье неизвестно.
Атрибут: 202 (СА) Data Address Mark Error
| Тип | неизвестно |
| Описание | содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо |
Атрибут: 203 (CB) Run Out Cancel
| Тип | текущий |
| Описание | содержит количество ошибок ECC |
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
| Тип | текущий |
| Описание | содержит измеренный в неизвестных единицах сдвиг пластин диска относительно оси шпинделя |
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
| Тип | накапливающий |
| Описание | содержит время, затраченное на позиционирование БМГ. Счётчик может содержать несколько значений в одном поле |
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
| Тип | накапливающий |
| Описание | содержит зафиксированное электроникой количество ускорений свободного падения диска, которым он подвергался, т. е., проще говоря, показывает, сколько раз диск падал |
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения:
- атрибутов 01, 07, 195 — вызывают подозрения в «болезни» у некоторых моделей дисков;
- атрибутов 10, 11, 188, 196, 199, 202 — вызывают подозрения у всех дисков;
- и, наконец, атрибутов 05, 184, 187, 197, 198, 200 — прямо говорят о неполадках.
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
![]()
Атрибут 01 в Victoria 4.46b
А так выглядит он же в «правильной» HDDScan 3.3:
![]()
Атрибут 01 в HDDScan 3.3
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина.
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:
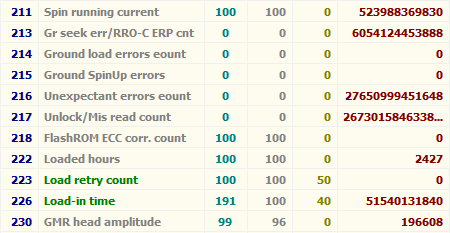
«Страшные» значения в Victoria 4.46b
Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах. При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (работает в Windows, бесплатная), CrystalDiskInfo (Windows, бесплатная), Hard Disk Sentinel (платная для Windows, бесплатная для DOS), HD Tune (Windows, платная, есть бесплатная старая версия).
И наконец, мощнейшие программы для тестирования: Victoria (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).
error — перевод на русский
/ˈɛrə/
Oh, my error.
— О, моя ошибка.
— My error.
— Моя ошибка.
Dr. Chumley, I’m afraid there’s been a serious error.
Доктор Чамли, боюсь произошла огромная ошибка.
Do you know where your fatal error lies?
Ты знаешь в чём твоя главная ошибка?
That’s your error.
Вот твоя ошибка.
Показать ещё примеры для «ошибка»…
And their error , and their … Cons .
И свои погрешности, и свои… недостатки.
The margins of error are extremely critical but if successful, there will be no more threat.
Границы погрешности в наших расчетах очень велики, но если все сработает, как мы предполагаем, угрозы жизням больше не будет.
What size margin of error are we talking about?
О какой погрешности мы говорим?
What’s your margin of error, Vaughn?
А каков предел погрешности, Вон?
Fleming is up two points, but it’s within the margin of error.
Флеминг обходит на два очка, но это не учитывая погрешности.
Показать ещё примеры для «погрешности»…
I see I’m in error.
Видимо, я ошибся.
Have I made an error in time?
Я ошибся во времени?
Well, because I made an error today.
Потому что сегодня я ошибся.
You’re right, I was in error in excluding the ring.
Вы были правы, я ошибся, исключив кольцо.
No, no, I probably made an error.
Нет-нет. Возможно, это я ошибся.
Показать ещё примеры для «ошибся»…
It will advance methodically, by trial and error… by asking a thousand questions to get one answer… by brain work and legwork.
Оно будет продвигаться постепенно, методом проб и ошибок,… задавая тысячу вопросов, получая один ответ… умственным трудом и беготней по разным местам.
So, it’s just trial and error?
Значит, это просто метод проб и ошибок?
Well, when I was an attorney, a long time ago, young man, I realised after much trial and error, that in a courtroom, whoever tells the best story wins.
Когда я был адвокатом, много-много лет назад, совсем юношей, я понял после многих проб и ошибок, что в зале суда побеждает тот, кто расскажет самую блестящую историю.
These were found by trial and error over a great deal of time.
Эти команды были найдены путём проб и ошибок в течении длительного времени.
Well, after several years of trial and error we discovered that without consciousness without human experience, emotion without life the organs failed.
После нескольких лет проб и ошибок мы обнаружили, что без сознания без человеческого опыта, без эмоций без полноценной жизни внутренние органы агнатов не способны функционировать.
Показать ещё примеры для «проб и ошибок»…
The computer cannot make an error, and assuming that I do not either, the best that could normally be hoped for would be stalemate after stalemate.
Компьютер не может ошибаться. И даже если я не ошибусь, в лучшем случае, я могу рассчитывать на серию патов.
It can only be attributable to human error.
Людям свойственно ошибаться, вот и всё.
Starfleet may be in error.
Звёздный Флот может ошибаться.
You’ve got to allow for human error.
Она человек, ей свойственно ошибаться.
No room for error this week.
На этой неделе нельзя ошибаться.
Показать ещё примеры для «ошибаться»…
Let’s assume it wasn’t human error.
Предположим, человеческий фактор тут не причем.
–Human error.
— Человеческий фактор.
–It’s not human error.
— Это не человеческий фактор.
Human error is the only other possible—
Остается только человеческий фактор.
It’s not human error.
Это не человеческий фактор.
Показать ещё примеры для «фактор»…
Count Olaf forced me to write that will and then it nearly killed me to add in all those grammatical errors.
√раф ќлаф заставил мен€ написать это завещание, и потом, мен€ чуть не убило делать все эти грамматические ошибки.
Now, about your paper, I wanted to give you the opportunity to fix some of these syntax and bookmarking errors before I post it online.
Так о вашей работе. Хотел дать вам возможность поправить грамматические ошибки и оформление ссылок, пока я не повесил работу на сайт.
In the word «sole» I found two grammatical errors.
В слове «подошвы» я нашла две грамматические ошибки.
Who cares about grammatical errors when she jumped out a window?
Кого могут заботить грамматические ошибки, когда она выбросилась из окна?
Children, disguises and grammatical errors, these are dire accusations, but they’re easily investigated.
Дети, переодевания и грамматические ошибки, это всё пустые обвинения, которые легко проверить.
Показать ещё примеры для «грамматические ошибки»…
An error in our sensors indicated that your ship was about to attack us.
Наши сенсоры ошибочно показали, что вы намерены атаковать нас.
Your perception must be in error.
Твое видение должно быть ошибочно.
If you feel that you have reached this recording in error, please check the number and try your call again.
Если вам кажется, что сообщение ошибочно, пожалуйста, проверьте номер и перезвоните.
But the syringe had been prepared in error by a student nurse.
Но шприц был ошибочно приготовлен практиканткой.
Be advised the report of an enemy gas attack was again in error.
Информация о газовой атаке опять была ошибочна.
Показать ещё примеры для «ошибочно»…
It was just, like, a stupid clerical error.
Это была просто глупая канцелярская ошибка.
However, officials now attribute the discrepancy to a simple clerical error.
Однако, представители компании говорят, что произошла обычная канцелярская ошибка.
Sounds like a clerical error.
Звучит как канцелярская ошибка.
Clerical error.
Канцелярская ошибка.
I’m afraid there has been a small clerical error.
Боюсь, закралась небольшая канцелярская ошибка.
Показать ещё примеры для «канцелярская ошибка»…
If we do, we may commit an error that has serious consequences.
И если так, то мы должны признать… ошибочность своих выводов.
—quickly saw the errors of my ways and proceeded to hurl myself at you in a very embarrassing fashion.
Я быстро увидела всю ошибочность своего пути и перешла к… ммм, просто повисла у тебя на шее, так что даже вспоминать совестно.
Vogler saw the error of his ways and repented.
Воглер понял ошибочность своих путей и раскаялся.
Others wonder if they are just giving us the opportunity to see the error of our ways and repent.
Другие считают, что они просто дают нам возможность увидеть ошибочность нашего пути и раскаяться.
They’re sure to see the error of their ways one day.
Когда-нибудь до них дойдёт ошибочность их пути.
Показать ещё примеры для «ошибочность»…
Отправить комментарий
Некоторые пользователи Windows сообщают, что они всегда видят предупреждение (Ultra DMA CRC Error Count) при анализе жесткого диска с помощью утилиты HD Tune. В то время как некоторые затронутые пользователи видят это с использованными жесткими драйверами, другие сообщают об этой проблеме с новыми жесткими дисками.
Счетчик ошибок CRC интерфейса внутри HD Tune
Что такое счетчик ошибок CRC Ultra DMA?
Это параметр SMART (технология самоконтроля, анализа и отчетности), который указывает общее количество ошибок CRC в режиме UltraDMA. Необработанное значение этого атрибута указывает количество ошибок, обнаруженных ICRC (интерфейс CRC) во время передачи данных в режиме UltraDMA.
Но имейте в виду, что этот параметр считается информационным у большинства производителей оборудования. Хотя ухудшение этого параметра можно рассматривать как индикатор устаревания привода с потенциальными электромеханическими проблемами, оно НЕ указывает напрямую на неизбежный отказ драйвера.
Чтобы получить полную картину состояния вашего жесткого диска, вам нужно обратить внимание на другие параметры и общее состояние накопителя.
После тщательного изучения этой проблемы выясняется, что существует несколько различных основных причин, которые могут привести к возникновению этого конкретного кода ошибки:
- Общий ложноположительный результат — имейте в виду, что предупреждение, выдаваемое утилитой HD Tune, не обязательно означает, что ваш жесткий диск выходит из строя. Эта утилита использует обобщенные данные от каждого производителя, поэтому данные от одного производителя могут не иметь значения для другого. Чтобы получить более точный результат, вам нужно будет запустить диагностический инструмент для конкретной марки и посмотреть, появляется ли такое же предупреждение.
- Несовместимость между SSD Samsung и контроллером SATA. Если вы столкнулись с этой проблемой с SSD, скорее всего, это связано с конфликтом между твердотельным накопителем и драйвером контроллера SATA Microsoft или AMD. Чтобы исправить эту несовместимость, вам нужно использовать редактор реестра, чтобы отключить NCQ (собственная очередь команд).
- Неисправный кабель SATA или порт SATA. Как оказалось, вы также можете ожидать столкнуться с проблемой этого типа, если имеете дело с неисправным портом SATA или несовместимым кабелем SATA. В этом случае вы можете определить виновника, протестировав жесткий диск на другом компьютере и заменив текущий кабель SATA.
- Отказ жесткого диска или твердотельного накопителя — при определенных обстоятельствах вы можете ожидать увидеть это предупреждение об ошибке на ранних стадиях отказа диска. В этом случае единственное, что вы можете сделать, — это создать резервную копию данных до того, как диск выйдет из строя навсегда, и начать поиск замены.
Теперь, когда вы знаете очень потенциальный сценарий, который может вызвать этот код ошибки, вот список методов, которые помогут вам определить и устранить ошибку счетчика ошибок CRC Ultra DMA:
Метод 1. Запуск диагностического инструмента для конкретной марки
Имейте в виду, что HD Tune Utility — это сторонний инструмент, который будет «оценивать» состояние жесткого диска исключительно путем сравнения их с набором общих значений.
Из-за этого настоятельно рекомендуется избегать принятия решений, основанных только на HD Tune Utility, и вместо этого запускать диагностический инструмент для конкретной марки — официальные инструменты тестирования специально разработаны для продуктов их брендов.
В зависимости от производителя жесткого диска установите и просканируйте жесткий диск с помощью специальной диагностической утилиты. Чтобы упростить вам задачу, мы составили список самых популярных инструментов диагностики для конкретных брендов:
Примечание. Если производитель вашего жесткого диска не включен в список выше, поищите в Интернете конкретные шаги с помощью диагностического инструмента для вашего бренда, затем установите и запустите его, чтобы проверить, не отключен ли счетчик ошибок CRC Ultra DMA.
Если диагностический инструмент, специфичный для производителя, не вызывает никаких опасений в отношении значения Ultra DMA CRC Error Count, вы можете спокойно игнорировать предупреждение, выдаваемое HD Tune.
Однако, если предупреждение также отображается в инструменте анализа, зависящем от производителя, перейдите к следующему потенциальному исправлению ниже.
Метод 2: устранение несовместимости между SSD Samsung и контроллером SATA (если применимо)
Как оказалось, ошибка Ultra DMA CRC Error Count не ограничивается жестким диском и также может возникать, если вы используете SSD.
Но если вы видите эту ошибку с SSD Samsung, высока вероятность, что проблема не связана с плохим кабелем или работоспособностью твердотельного накопителя — скорее всего, это связано с несовместимостью между вашим SSD Samsung и контроллером Sata вашего чипсета. .
Если вы оказались в этом конкретном сценарии, вы можете решить проблему и предотвратить появление этого предупреждения, отключив NCQ (собственная очередь команд) в драйвере SATA.
Примечание. Это не повлияет на работу вашего диска SATA.
Если этот сценарий применим, приведенные ниже инструкции по устранению несовместимости между твердотельным накопителем Samsung и контроллером Sata:
- Нажмите клавишу Windows + R, чтобы открыть диалоговое окно «Выполнить». Затем в текстовом поле введите «regedit», затем нажмите Ctrl + Shift + Enter, чтобы открыть редактор реестра с правами администратора. Когда вам будет предложено UAC (Контроль учетных записей пользователей), нажмите Да, чтобы предоставить административный доступ.
Открытие Regedit
- Как только вы войдете в редактор реестра, используйте левое меню для перехода к следующим местоположениям, в зависимости от того, используете ли вы драйвер контроллера Microsoft SATA или драйвер контроллера AMD SATA: Расположение контроллера Microsoft SATA: HKEY_LOCAL_MACHINE SYSTEM CurrentControlSet Services storahci Parameters Device Расположение драйвера контроллера AMD SATA:[HKEY_LOCAL_MACHINE SYSTEM CurrentControlSet services amd_sata Parameters Device
[HKEY_LOCAL_MACHINESYSTEMCurrentControlSetservicesamd_sataParametersDeviceПримечание. Вы можете перейти сюда вручную или вставить местоположение прямо в панель навигации.
- Как только вы окажетесь в нужном месте, щелкните правой кнопкой мыши «Устройство», затем выберите «Создать»> «Значение Dword (32-бит)» в появившемся контекстном меню.
Создание нового значения Dword в меню устройства
- Затем назовите вновь созданный DWORD NcqDisabled, если вы используете драйвер Microsoft SATA Controller, или назовите его AmdSataNCQDisabled, если вы используете драйвер AMD SATA Controller.
- Наконец, дважды щелкните DWORD, который вы только что создали, затем установите для Base значение Hexadecimal и значение 1, чтобы отключить NCQ и предотвратить такую же несовместимость с созданием ошибки Ultra DMA CRC Error Count.
Если та же проблема все еще возникает даже после выполнения приведенных выше инструкций или этот сценарий неприменим, перейдите к следующему потенциальному исправлению ниже.
Способ 3. Замените кабель питания и SATA.
Как подтвердили несколько затронутых пользователей, эта конкретная проблема также может быть связана с неисправным кабелем SATA или неисправным портом SATA. Из-за этого ошибка счетчика ошибок CRC Ultra DMA также может быть признаком несовместимого кабеля.
Чтобы проверить эту теорию, вы можете подключить свой жесткий диск к другому компьютеру (или, по крайней мере, использовать другой порт SATA + кабель), если у вас нет второй машины для тестирования.
Пример порта SATA на материнской плате
После замены порта SATA повторите сканирование внутри утилиты HD Tune и посмотрите, возникает ли ошибка счетчика ошибок CRC Ultra DMA. Если проблема перестала возникать, подумайте о том, чтобы обратиться к ИТ-специалисту с материнской платой для исследования на предмет ослабленных контактов.
С другой стороны, если проблема не возникает, когда вы используете другой кабель SATA, вам просто удалось идентифицировать виновника.
Если вы исключили и кабель SATA, и порт SATA из списка виновных, перейдите к следующему потенциальному исправлению ниже, поскольку проблема определенно возникает из-за неисправного диска.
Метод 4: сделайте резервную копию данных жесткого диска
Если вы ранее убедились, что были правы, обеспокоившись ошибкой Ultra DMA CRC Error Count, первое, что вам следует сделать, это сделать резервную копию своих данных, чтобы убедиться, что вы ничего не потеряете в случае выхода диска из строя.
Если вы хотите создать резервную копию данных жесткого диска, пока решаете, какую замену получить, имейте в виду, что у вас есть два пути вперед: вы можете сделать резервную копию жесткого диска с помощью встроенной функции или использовать стороннюю утилиту. .
A. Резервное копирование файлов на жестком диске через командную строку
Если вам удобно использовать терминал CMD с повышенными правами, вы можете создать резервную копию и сохранить ее на внешнем хранилище без необходимости установки стороннего программного обеспечения.
Но имейте в виду, что в зависимости от вашего предпочтительного подхода вам может потребоваться вставить установочный носитель, совместимый с плагинами.
Если вас устраивает такой подход, вот инструкции по резервному копированию файлов из командной строки с повышенными правами.
Б. Резервное копирование файлов на жестком диске с помощью стороннего программного обеспечения для обработки изображений.
С другой стороны, если вам удобно доверять стороннюю утилиту для резервного копирования жесткого диска, у вас будет много дополнительных функций, которые просто недоступны при создании регулярной резервной копии через командную строку.
Вы можете использовать стороннее программное обеспечение для резервного копирования, чтобы клонировать или создать образ жесткого диска и сохранить его на внешнем сервере или в облаке. Вот список лучших программ для клонирования и обработки изображений, которые вам следует рассмотреть.
Метод 5: отправьте жесткий диск на замену или закажите замену
Если вы убедились, что предупреждение Ultra DMA CRC Error Count, которое вы видите, является подлинным, и заранее успешно создали резервную копию данных жесткого диска, единственное, что вы можете сделать прямо сейчас, — это поискать замену.
Конечно, если на ваш жесткий диск по-прежнему распространяется гарантия, вам следует сразу же отправить его в ремонт.
Но если срок гарантии истек или у вас есть возможность вернуть его, мы рекомендуем держаться подальше от устаревшего жесткого диска (жесткого диска) и вместо этого выбрать SSD (твердотельный накопитель).
Хотя SSD по-прежнему дороже традиционных жестких дисков, они гораздо менее подвержены поломкам, а скорость несопоставима с SSD (в 10 раз больше скорости записи и чтения).
Если вы ищете твердотельный накопитель, вот наше расширенное руководство по покупке лучшего твердотельного накопителя для ваших нужд.

Восстановить жесткий диск, используя специальные программы. Они позволяют протестировать винчестер, а также исправить незначительные неисправности. Зачастую, этого вполне достаточно для продолжения плодотворной работы. Из статьи вы узнаете об одной из них под названием Victoria.
Проверка жесткого диска программой Victoria полностью бесплатна. Также программа обладает множеством функций и рассчитана не только на профессионалов, но также и на неопытных пользователей. Итак, сейчас вы узнаете, как проверить жесткий диск программой Victoria.
Технология S.M.A.R.T.
Все современные накопители на жестких магнитных дисках поддерживают технологию самотестирования, анализа состояния, и накопления статистических данных об ухудшении собственных характеристик S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology). Основы S.M.A.R.T. были разработаны в 1995 г. совместными усилиями ведущих производителями жестких дисков.
В процессе совершенствования оборудования накопителей, возможности технологии также дорабатывались, и после стандарта SMART появился SMART II, затем — SMART III, который, очевидно, тоже не станет последним.
Жесткий диск в процессе своего функционирования постоянно отслеживает определенные параметры своего состояния и отражает их в специальных характеристиках — атрибутах (Attribute), сохраняющихся, как правило, в специально выделенной части дисковой поверхности, доступной только внутренней микропрограмме накопителя — служебной зоне. Данные атрибутов могут быть считаны специальным программным обеспечением.
Атрибуты идентифицируются своим цифровым номером, большинство из которых одинаково интерпретируется накопителями разных моделей. Некоторые атрибуты могут быть определены конкретным производителем оборудования, и поддерживаться только отдельными моделями накопителей.
Атрибуты состоят из нескольких полей, каждое из которых имеет определенный смысл. Обычно, программы считывания S.M.A.R.T. выдают расшифровку атрибутов в виде:
- Attribute — имя атрибута
- ID — идентификатор атрибута
- Value — текущее значение атрибута
- Threshold — минимальное пороговое значения атрибута
- Worst — самое низкое значение атрибута за все время работы накопителя
- Raw — абсолютное значение атрибута
- Type (необязательно) — тип атрибута — характеризует производительность (PR — Performance-related), характеризует сбои (ER — Error rate), счетчик событий (EC — Events count), определено производителем или не используется (SP — Self-preserve);
Для анализа состояния накопителя, пожалуй, самым важным значением атрибута является Value — условное число (обычно от 0 до 100 или до 253), заданное производителем. Значение Value изначально установлено на максимум при производстве накопителя и уменьшается в случае ухудшения его параметров. Для каждого атрибута существует пороговое значение, до достижения которого, производитель гарантирует его работоспособность — поле Threshold. Если значение Value приближается или становится меньше значения Threshold, — накопитель пора менять. Перечень атрибутов и их значения жестко не стандартизированы и определяются изготовителем накопителя, но наиболее важные из них интерпретируются одинаково. Например, атрибут с идентификатором 5 (Reallocated sector count) будет характеризовать число забракованных и переназначенных из резервной области секторов диска, и для устройств производства компании Seagate, и для Western Digital, Samsung, Maxtor.
Жесткий диск не имеет возможности, по собственной инициативе, передать данные SMART потребителю. Их считывание выполняется специальным программным обеспечением.
В настройках большинства современных BIOS материнских плат имеется пункт позволяющий запретить или разрешить считывание и анализ атрибутов SMART в процессе выполнения тестов оборудования перед выполнением начальной загрузки системы. Включение опции позволяет подпрограмме тестирования оборудования BIOS считать значения критических атрибутов и, при превышении порога, предупредить об этом пользователя. Как правило, без особой детализации:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Выполнение подпрограммы BIOS приостанавливается, чтобы привлечь внимание:
Press F1 to Resume
Таким образом, без установки или запуска дополнительного программного обеспечения, имеется возможность вовремя определить критическое состояние накопителя (при включении данной опции) средствами Базовой Системы Ввода-Вывода (BIOS).
Анализ данных S.M.A.R.T. жесткого диска
Для получения данных SMART в среде операционной системы могут использоваться специальные программы, в частности, практически все утилиты для тестирования оборудования жестких дисков.
Одной из самых популярных программ для тестирования жестких дисков является Victoria Сергея Казанского.
На сайте автора найдете последнюю версию программы, а также массу полезной информации, в том числе и подробное описание работы с Victoria.
Программа Victoria имеет две разновидности — для работы в среде DOS и, для работы в среде Windows. DOS-версия может напрямую работать с контроллером жесткого диска и обладает значительно большими возможностями по сравнению с версией для Windows.
Назначение, основные возможности и порядок использования программы найдете на сайте автора
Программа проста в использовании и позволяет оценить техническое состояние накопителя, выполнить его тестирование и некоторые настройки — уровня шума, производительности, физического объема. Режимы тестирования поверхности накопителя позволяют принудительно избавиться от сбойных секторов с помощью режима Remap нескольких видов. Вызов меню тестирования выполняется по нажатию клавиши F4 (SCAN). Пользователь имеет возможность задать.
область тестирования
Start LBA :0 — начало области (по умолчанию — 0)
End LBA :14680064 — конец области (по умолчанию — номер последнего блока диска)
Режим тестирования
Линейное чтение — последовательное чтение от начального блока до конечного
Случайное чтение — номер считываемого блока формируется случайным образом.
BUTTERFLY чтение — выполняется чтение блоков, начиная от граничных номеров (начала и конца), к центру области тестирования.
Изменение режима выполняется по нажатию клавиши «пробел»
Режим обработки ошибок
Этот пункт позволяет выполнить скрытие дефектных блоков, с использованием переназначения (ремап) из резервной области. Выбор режима выполняется клавишей «пробел». Выбранный метод работы с дефектами отображается в правом верхнем углу экрана, под часами, а также в нижней строке в момент запуска теста. Изменить режим можно в и в процессе выполнения сканирования.
Ignore Bad Blocks — программа не будет выполнять никаких действий при обнаружении ошибки.
BB = RESTORE DATA — программа попытается восстановить данные из поврежденных секторов.
BB = Classic REMAP — выполняется запись в поврежденный сектор для вызова процедуры переназначения.
BB = Advanced REMAP — улучшенный алгоритм скрытия сбойных блоков. Используется, когда не помогает классический ремап. Программа выполняет специальную последовательность операций с целью формирования признака кандидата на ремап (атрибут 197) у сбойного блока. Затем выполняется 10-кратная запись, обрабатываемая микропрограммой накопителя как обычная обработка кандидата на ремап — если есть ошибка, выполняется переназначение, если нет ошибки — блок считается нормальным и удаляется из кандидатов на ремап. Данный режим позволяет выполнить скрытие сбойных блоков без потери пользовательских данных. Конечно, только в случаях, когда накопитель технически исправен и есть свободное место в резервной области для переназначения.
BB = Fujitsu Remap — выполнение специфических алгоритмов, основанных на недокументированных возможностях некоторых моделей накопителей Fujitsu
BB = Erase 256 sect — при обнаружении сбойного сектора выполняется перезаписывание блока из 256 секторов. Пользовательские данные не сохраняются.

В процессе работы с программой можно вызвать контекстную справку клавишей F1
Расшифровка кодов ошибок в Victoria:
BBK (Bad Block Detected) — Найден бэд-блок.
UNCR (Uncorrectable Error) — Неисправимая ошибка. Не удалось скорректировать данные избыточным кодом, блок признан нечитаемым. Может быть как следствием нарушения контрольной суммы данных (софтовый Bad Block), так и неисправностью HDD;
IDNF (ID Not Found) — Не найден идентификатор сектора. Обычно говорит о разрушении микрокода или формата низкого (физического уровня) HDD . У исправных HDD такая ошибка выдается при попытке обратиться к несуществующему адресу физического сектора;
ABRT (Aborted Command) — HDD отверг команду в результате неисправности, или команда не поддерживается данным HDD (пароль, устаревшая или слишком новая модель и т.д.)
T0NF (Track 0 Not Found) — не найдена нулевая дорожку, невозможно выполнить рекалибровку на стартовый цилиндр рабочей области. На современных HDD говорит о неисправности микрокода или магнитных головок;
AMNF (Address Mark Not Found) — адресный маркер не найден, невозможно прочитать сектор, обычно в результате неисправности тракта чтения или дефекта поверхности.
Версия Victoria For Windows обладает более скромными возможностями по настройке накопителя и выбору режимов тестирования, и на данный момент не имеет поддержки русского языка , однако ей проще пользоваться и имеющихся возможностей вполне достаточно для считывания таблицы SMART и оценки технического состояния накопителя.
Программа не требует установки, просто скачайте ее по ссылке на странице загрузки сайта автора.
Программа должна выполняться под учетной записью с павами администратора. В среде Windows 7 / 8 необходимо использовать контекстное меню «Запуск от имени администратора».
Для анализа состояния SMART-атрибутов выбираем режим работы через программный интерфейс Windows — включаем кнопку API в правой верхней части основного окна. Затем выбираем накопитель для проверки — нажимаем на кнопку Standard в основном меню программы и подсвечиваем мышкой нужный диск в окне со списком. В информационном окне будет отображен паспорт накопителя — модель, версию аппаратной прошивки, серийный номер, размер и т.п. Для получения данных SMART выбираем пункт меню SMART и жмем кнопку «Get SMART». Результат будет отображен в информационном окне программы.

Краткое описание атрибутов
- 001 ( 1 ) Raw Read Error Rate — абсолютное значение ошибок считывания. Существует некоторые отличия в формировании значения данного атрибута разными производителями. Из практики могу сказать, что накопители Seagate могут иметь гигантское значение RAW этого атрибута, реально будучи в хорошем состоянии, а накопители Western Digital могут иметь его нулевым, имея критические показатели по другим характеристикам. Некоторые модели вообще могут не поддерживать данный атрибут.
- 003 ( 3 ) Spin Up Time — Среднее время раскрутки шпинделя диска от 0 RPM до рабочей скорости.
- 004 ( 4 ) Start/Stop Count — Количество циклов запуск/останов шпинделя.
- 005 ( 5 ) Reallocated Sector Count — Количество переназначенных секторов. Современные накопители имеют довольно большую (тысячи секторов) резервную область поверхности накопителя для использования ее в случае ухудшения характеристик секторов из основной зоны. Если накопитель обнаруживает проблемы с записью/считыванием какого — либо сектора, то он автоматически перемещает его данные в резервную область, а данный сектор помечается как «переназначенный». Часто этот процесс называют «remapping», или «automatic defect reassignment», он выполняется микропрограммой накопителя и для пользователя (операционной системы) невидим. Поле raw value содержит общее количество переназначенных секторов. Даже некритическое, но большое значение этого поля, может привести к снижению скорости обмена данными, поскольку накопитель выполняет дополнительную операцию установки головок на дорожки резервной области, обычно расположенной в конце диска.
- 007 ( 7 ) Seek Error Rate — Частота появления ошибок позиционирования блока магнитных головок (БМГ) . Накопитель контролирует правильность установки головок на требуемую дорожку поверхности. В случае, когда установка выполнилась неверно, фиксируется ошибка и операция повторяется. Для данного накопителя причиной большого числа ошибок явился перегрев.
- 008 ( 8 ) Seek Time Performance — средняя скорость позиционирования магнитных головок. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
- 009 ( 9 ) Power-On Hours — Количество часов во включенном состоянии. Достижение предельного значения этого атрибута означает выработку накопителем заданной производителем наработки на отказ (MTBF — Mean Time Between Failures).
- 010 ( 0A ) Spin Retry Count — Количество повторных попыток старта шпинделя. После включения питания, накопитель раскручивает диски и контролирует достижение рабочей скорости вращения для данного устройства ( например 5400 , 7200, 10000 об/мин.) за определенное время. В случае неудачи — увеличивается счетчик повторов и повторяется попытка старта.
- 011 ( 0B ) Recalibration Retries — количество попыток рекалибровки, в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью накопителя. Кроме того, увеличение абсолютного значения данного атрибута может быть вызвано тем, что процедура рекалибровки используется внутренней микропрограммой накопителя для коррекции других типов ошибок.
- 012 ( 0C ) Device Power Cycle Count — Количество циклов включения/выключения диска.
- 184 ( B8 ) End-to-End error — Данный атрибут — часть технологии HP SMART IV — означает, что после передачи данных через буферную память чётность данных между контроллером компьютера и жестким диском не совпадает.
- 187 ( BB ) Reported Uncorrectable Error — Характеризует количество ошибок, которые не были исправлены микропрограммой накопителя.
- 188 ( BC ) Command Timeout Количество прерванных операций в связи с отсутствием ответа от накопителя. Обычно это значение атрибута должно быть равно нулю, и, если значение гораздо выше нуля, то, возможными причинами могут быть проблемы с питанием или окислением контактов интерфейсного кабеля.
- 189 ( BD ) High Fly Writes — Если высота полета головки над магнитной поверхностью, даже на короткое время превысит оптимальную, то записанные ею данные, в дальнейшем, могут не прочитаться. Современные накопители используют специально разработанную технологию контроля высоты полета головок, позволяющую не выполнять запись данных при неоптимальной высоте. В счетчик данного атрибута добавляется единица, а запись выполняется после установки нормальной высоты полета. Повышенное значение данного атрибута может быть вызвано внешними ударами или вибрациями, ненормальной температурой, ухудшением характеристик магнитной поверхности или головки.
- 190 ( BE ) Airflow Temperature — температура окружающей среды блока магнитных головок. Для различных моделей HDD данный атрибут отсутствует и используются атрибуты 194 или 231.
- 191 (BF ) Mechanical Shock — количество механических ударов. Вместо данного атрибута может использоваться атрибут 221.
- 192 ( C0 ) Power-off retract count — количество циклов выключений или аварийных отказов (включений/выключений питания накопителя).
- 193 ( C1 ) Load/Unload Cycle — количество циклов перемещения блока магнитных головок в зону парковки.
- 194 ( C2 ) HDA Temperature — температура самого накопителя (HDA — Hard Disk Assembly). В данном атрибуте хранятся показания встроенного температурного датчика, которым обычно служит одна из магнитных головок (как правило — нижняя ). Данные, записанные в полях атрибута отображают текущую, минимальную и максимальную температуру. Поле Worst показывает наихудшую, достигнутую за время работы накопителя, температуру (можно установить факт перегрева и его степень), Raw value — текущую температуру. Некоторые модели накопителей могут поддерживать атрибут 205 ( CD ) Thermal asperity rate (TAR) фиксирующий количество опасных перепадов температуры. В некоторых моделях накопителей вместо атрибута 194 может использоваться атрибут 231.
- 195 ( C3 ) Hardware ECC recovered — характеризует количество ошибок считывания, исправленных оборудованием накопителя с применением кода коррекции ошибок. Подобные ошибки не требуют повторного считывания сектора, и не приводят к потере скорости обмена данными, но большое их количество говорит об ухудшении параметров тракта считывания.
- 196 ( C4 ) Reallocation Event Count — Число событий переназначения сбойных секторов. В поле Raw value данного атрибута хранится общее число попыток переноса данных из нестабильных секторов в резервную область. Учитываются как успешные, так и неуспешные попытки.
- 197 ( C5 ) Current Pending Sector Count — Текущее количество нестабильных секторов. Поле Raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает кандидатами на переназначение в резервную область (remap). Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка кандидатов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped).
- 198 ( C6 ) Uncorrectable Sector Count — Счетчик некорректируемых ошибок. Это ошибки, которые не были исправлены внутренними средствами коррекции оборудования накопителя. Может быть вызвано неисправностью отдельных элементов или отсутствием свободных секторов в резервной области диска, когда возникла необходимость переназначения.
- 199 ( C7 ) UltraDMA CRC Error Count — Счетчик ошибок, возникших при передаче данных в режиме UltraDMA . Аппаратные средства контроля передачи данных из накопителя в оперативную память обнаружили ошибку контрольной суммы. Нередко этот тип ошибки связан не столько с оборудованием накопителя, сколько с неисправным интерфейсным кабелем, нестабильным питанием, разгоном частоты шины PCI, перегревом микросхем чипсета материнской платы и т.п.
- 200 ( C8 ) Write Error Rate ( Multi-Zone Error Rate ) — Характеризует наличие ошибок при записи данных. Может быть вызвано ухудшением состояния поверхности, головок или характеристик тракта записи данных. Чем ниже значение Value, тем опаснее использовать такой накопитель.
- 201 ( C9 ) Soft Read Error Rate — количество некорректируемых ошибок чтения, обнаруженных программным обеспечением.
- 202 ( CA ) Data Address Mark Errors — количество некорректируемых ошибок при чтении собственного адреса сектора.
- 203 ( CB ) Run Out Cancel — количество ошибок, зафиксированных при выполнении коррекции данных.
- 204 ( CC ) Soft ECC Correction — количество ошибок, исправленных внутренней микропрограммой накопителя.
- 205 ( CD ) Thermal Asperity Rate — общее количество проблем, вызванных повышенной температурой.
- 206 ( CE ) Flying Height — высота полета головок над поверхностью диска.
- 207 ( CF ) Spin High Current — ток, необходимый для раскручивания двигателя.
- 208 ( D0 ) Spin Buzz — количество повторных попыток запуска двигателя из-за пониженного тока.
- 209 ( D1 ) Offline Seek Performance — производительность, определенная при выполнении внутренних тестов накопителя.
- 210 ( D2 ) Vibration During Write — вибрации, зафиксированные при выполнении операций записи.
- 211 ( D3 ) Shock During Write — удары, зафиксированные при выполнении операций записи.
- 220 ( DC ) Disk Shift — смещение блока дисков относительно вертикальной оси шпинделя. В основном возникает из-за сильного удара или падения накопителя и как правило, является сигналом для его замены.
- 221 ( DD ) G-Sense Error Rate— количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера. Обычно довольно точно характеризует условия эксплуатации ноутбуков — большое значение атрибута говорит о резких толчках и падениях при работе устройства.
- 222 ( DE ) Loaded Hours — количество часов, отработанных накопителем.
- 223 ( DF ) Load/Unload Retry Count — количество операций ввода/вывода головок в зону данных.
- 226 ( E0 ) Load-in Time — общее время нахождения головок в зоне данных.
- 228 ( E4 ) Power-Off Retract Cycle — Количество автоматических парковок магнитных головок при пропадании питания.
- 230 ( E6 ) GMR Head Amplitude — Амплитуда перемещения головок между операциями.
- 231 ( E7 ) Hard Disk Temperature — температура, зафиксированная внутренними датчиками накопителя.
Современные накопители поддерживают не только формирование атрибутов S.M.A.R.T, но и ведут дополнительные журналы статистики, а также поддерживают протокол SCT (SMART Command Transport), обеспечивающий считывание данных журналов. Журнал статистики устройства — это доступный только для чтения журнал SMART, передаваемый накопителем при получении команд READ LOG EXT, READ LOG DMA EXT или SMART READ LOG. В журналах отображается информация о выполнении встроенных тестов S.M.A.R.T ( self-test ), статистика ошибок, номера сбойных блоков LBA и т.п.
Ремап (Remap) и проверка поверхности жесткого диска
Удивительно, как долго могут существовать ошибочные представления о жестких дисках и их правильной эксплуатации. В частности, даже неплохие специалисты в области компьютерной техники, бывает, рекомендуют выполнять в среде ОС Windows полное форматирование поверхности вместо быстрого, или даже низкоуровневое форматирование. Что касается последнего, свою лепту в путаницу с форматированием вносят и некоторые производители программного обеспечения, выпускающие программы для «низкоуровневого форматирования», которые ничего не форматируют. Низкоуровневое форматирование (Low Level Format) — это разметка поверхности диска специальной служебной информацией, в соответствии с геометрией накопителя, выполняемой специальной командой посылаемой накопителю. В стандарте ST506/412, который предшествовал современному стандарту ATA (AT attachment) имелась команда 50h (Format Track), при выполнении которой производилась разметка дорожки адресными маркерами, в соответствии с геометрией диска, т.е. в соответствии с номером цилиндра, номером головки и количеством секторов на дорожке. В дальнейшем, при записи данных, эта часть информации никогда не изменялась. При выполнении команды записи данных в сектор, накопитель никогда и ничего не записывает в ту область дорожки, которая является служебной и была создана при низкоуровневом форматировании дорожек поверхности специально для этого предназначенной командой 50h.
В современных накопителях стандарта ATA команды низкоуровневого форматирования вообще отсутствуют, а рекламируемые некоторыми производителями программы для выполнения данной операции являются простыми «стиралками» данных, выполняющими запись в область данных секторов. Нет, и не может быть, никаких программ для выполнения настоящего низкоуровневого форматирования в среде любой операционной системы. Любое подобное «низкоуровневое» форматирование — это высокоуровневое форматирование логической структуры пользовательских данных.
Что же касается полного форматирования в среде Windows, то по сравнению с быстрым, сразу создающим пустое оглавление, оно просто добавляет проверку поверхности диска перед тем, как выполнить то же самое, что делает быстрое форматирование. Что также не имеет смысла, поскольку проверка и отбраковка нестабильных секторов выполняется средствами аппаратной реализации технологии S.M.A.R.T накопителя, которая с данной задачей справляется гораздо эффективнее автоматически и в непрерывном режиме. Полное форматирование имело смысл на старых дисках, которые не могли выполнять замену нестабильных секторов на сектора из резервной зоны, и такие сектора сразу становились дефектными блоками ( Bad Block ), которые исключались из файловой структуры при форматировании с проверкой поверхности. Существует также утверждение, что при полном форматировании выполняется стирание всей поверхности диска. Это тоже не соответствует действительности, что легко проверяется любыми программами мониторинга обращений к диску , например, утилитой Disk Monitor из пакета Sysinternals Suite. Программа показывает, что при полном форматировании выполняется чтение поверхности, и небольшое количество операций записи, выполняемой после проверки поверхности при формировании пустого оглавления, в самом конце работы. И даже из того факта, что существую программы для восстановления данных после форматирования ( любого, в том числе и полного ) вполне логично следует вывод – никакого стирания данных не происходит.
При записи жесткий диск не проверяет, что и как было записано в область данных сектора, кроме случаев, когда предварительная диагностика, которой накопитель занимается все «свободное время», не пометила в соответствующих журналах эти сектора, как проблемные, или кандидаты на переназначение, что отражается в атрибуте 197 SMART (Current Pending Sectors).
Кандидат — это сектор (или группа секторов), который не был считан за стандартное время и с установленным числом повторов. В режиме простоя, запустится программа самотестирования, которая попытается считать данные с применением дополнительных режимов. Если сектор будет успешно считан — программа самодиагностики попытается записать данные обратно, и если запись выполнится успешно, то из кандидатов такой сектор удалится. Если же записанная на то же место информация не будет нормально считываться, то выполнится переназначение сектора (Remap), данные запишутся в сектор из специально для этого предназначенной резервной области (spare area). В дальнейшем, всегда вместо этого сбойного сектора будут считываться данные из резервной области. А сектор-кандидат на переназначение, не исправленный программой самотестирования, увеличит значение атрибута 198 (Offline Scan UNC Sectors). Убрать такой «бед» можно только перезаписью. Но если резервная область закончилась, то все последующие кандидаты на переназначение превратятся в реальные «плохие секторы» (Bad Blocks). В этом случае программы полного форматирования и проверки поверхности могут исключить сбойный сектор из логической структуры диска, однако, использовать накопитель с закончившейся резервной областью — это очень рискованная идея, которая обязательно закончится потерей данных. Использовать такой диск можно разве что для опасных экспериментов, хранения некритичных данных, или выбросить его на помойку.
При возникновении плохих блоков (Bad Block) нередко возникает необходимость проверки принадлежности сбойного участка конкретному файлу. Для этих целей можно воспользоваться консольной утилитой NFI.EXE (NTFS File Sector Information Utility) из состава пакета Support Tools от Microsoft. Скачать 10кб
Формат командной строки
nfi.exe Диск Номер логического сектора
Подсказку по использованию NFI.EXE можно получить по команде nfi.exe /?
Букву логического диска можно задавать без двоеточия. Номер логического сектора — это номер сектора относительно начала логического диска. Обратите внимание на тот факт, что программы сканирования работают со всей поверхностью физического диска и используют нумерацию секторов, не привязанную к его логической структуре. А номер сектора, задаваемый в качестве параметра утилиты NFI.EXE — это номер сектора логического диска (раздела), и он отличается величиной смещения начального сектора раздела от начала диска. Значение номеров начальных секторов логических дисков можно получить нажав кнопку View part data вкладки «Advanced» программы Victoria For Windows.
nfi.exe C: 655234 — выдать имя файла, которому принадлежит сектор 655234
nfi.exe C: 0xBF5E34 — то же самое, но номер сектора задан в шестнадцатеричной системе счисления
В результате выполнения команды будет выдано сообщение
***Logical sector 12541492 (0xbf5e34) on drive C is in file number 49502.
WINDOWS system32 D3DCompiler_38.dll
Т.е. интересующий нас сбойный сектор принадлежит файлу D3DCompiler_38.dll в каталоге Windowssystem32. В случае, когда сбойные блоки принадлежат системным файлам Windows, возможно появление синих экранов смерти или зависаний системы с перезагрузкой. В большинстве случаев, информация о наличии сбоев дисковой подсистемы, будет отображаться в системном журнале Windows.
Для выполнения тестирования поверхности накопителя с принудительным переназначением (ремапом) сбойных секторов можно воспользоваться программами тестирования HDD, алгоритм работы которых специально разработан таким образом, чтобы «заставить» внутреннюю микропрограмму накопителя выполнить переназначение нестабильного участка.
Так, например, подобные алгоритмы будут использоваться, в упоминаемой выше программе Victoria, если выбран режим тестирования поверхности с выполнением операций восстановления или переназначения (Classic Remap, Advanced Remap :). Изначально режим выполнения теста установлен в Ignore Bad Blocks

Нажатие пробела изменяет режим обработки сбоев. При выполнении такого вида тестирования накопителя, пользовательские данные остаются в сохранности.
Добавлю, что режим Advanced Remap, хотя и является наиболее эффективным, на практике может приводить к «зависанию» микропрограммы на некоторых моделях HDD, выйти из которого можно только с использованием принудительного сброса (режим Reset, клавиша F3). После чего можно продолжить тестирование. Если в режиме Advanced Remap таймауты происходят слишком часто, имеет смысл перейти к использованию классического ремапа.
Для программы Victoria For Windows переназначение сбойных секторов включается установками режима выполнения теста в правой части основного окна. По умолчанию установлен режим Ignore — ничего не делать при обнаружении сбоя, а нужно установить режим Remap

Раздражает, когда какой-то сайт не загружается и отзывается непонятными ошибками. Обычно они сопровождаются одним из десятков HTTP-кодов, которые как раз намекают на характер сбоя, а также его вероятные причины.
В этом материале поговорим об ошибке 400 Bad Request. Почему она появляется и как ее исправить.
Чуть подробнее об ошибке 400
Как и другие коды, начинающиеся на четверку, 400 Bad Request говорит о том, что возникла проблема на стороне пользователя. Зачастую сервер отправляет ее, когда появившаяся неисправность не подходит больше ни под одну категорию ошибок.
Стоит запомнить — код 400 напрямую связан с клиентом (браузером, к примеру) и намекает на то, что отправленный запрос со стороны пользователя приводит к сбою еще до того, как его обработает сервер (вернее, так считает сам сервер).
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Из-за чего всплывает Bad Request?
Есть 4 повода для возникновения ошибки сервера 400 Bad Request при попытке зайти на сайт:
- Некорректно настроенные HTTP-заголовки в запросе со стороны клиента. Некоторые приложения и сайты мониторят заголовки на предмет наличия в них чего-нибудь подозрительного. Если ваш запрос не соответствует ожиданиям сервера, то высока вероятность появления ошибки 400 (но это не всегда вина пользователя).
- Такой же сбой появляется, если клиент пытается загрузить на сервер файл слишком большого размера. Это происходит, потому что на большинстве сайтов есть ограничения по размеру загружаемых данных. Причем ограничение может быть как в 2 гигабайта, так и в 600 килобайт.
- Еще ошибка 400 появляется, когда пользователь пытается получить доступ к несуществующей странице. То есть в браузер банально ввели ссылку с опечаткой, некорректным доменом или поддоменом.
- Устаревшие или измененные куки-файлы. Сервер может воспринять подмену куки-файлов как попытку атаковать или воспользоваться дырой в безопасности. Поэтому такие запросы сходу блокируются.
Читайте также


Исправляем ошибку 400 Bad Request на стороне клиента
Так как ошибка 400 в 99 случаев из 100 возникает на стороне клиента, начнем с соответствующих методов. Проверим все элементы, участвующие в передаче запроса со стороны клиента (браузера).
Проверяем адрес сайта
Банальщина, но необходимая банальщина. Перед тем как бежать куда-то жаловаться и предпринимать более серьезные шаги, повнимательнее взгляните на ссылку в адресной строке. Может, где-то затесалась опечатка или вы случайно написали большую букву вместо маленькой. Некоторые части адреса чувствительны к регистру.
А еще стоит поискать запрашиваемую страницу через поисковик, встроенный в сайт. Есть вероятность, что конкретная страница куда-то переехала, но сервер не может показать подходящий HTTP-код в духе 404 Not Found. Если, конечно, сам сайт работает.
Сбрасываем параметры браузера
Этот метод срабатывает, если сервер отказывается принимать запросы из-за «битых» куки или других данных. Дело в том, что сайт использует куки-файлы, чтобы хранить информацию о пользователе у него же в браузере. При входе конкретного человека на ресурс, он пытается распознать куки и сравнить информацию с той, что уже есть на сервере.
Иногда случается, что куки-файлы одного или нескольких пользователей вступают в конфликт. В таком случае надо открыть настройки браузера, а потом удалить весь кэш, куки и прочие связанные элементы.
В зависимости от браузера процесс удаления куки-файлов может немного отличаться. В Chrome это работает так:
- Открываем настройки браузера.
- Переходим в раздел «Конфиденциальность и безопасность».
- Выбираем «Файлы cookie и другие данные».
- Нажимаем на кнопку «Удалить все».


Для чистки cookies можно использовать стороннюю программу в духе CCleaner или CleanMyPC.
Загружаем файл подходящего размера
Если ошибка 400 Bad Request появляется при попытке загрузить на сайт какой-нибудь файл, то стоит попробовать загрузить файл поменьше. Иногда вебмастера ленятся грамотно настроить ресурс, и вместо понятного объяснения вроде «Загружаемые файлы не должны быть размером больше 2 мегабайт» люди получают Bad Request. Остается только гадать, какой там у них лимит.
Устраняем проблемы, связанные с Windows и сторонним софтом
Помимо браузера, на работу сети могут влиять другие программные продукты (экраны, защищающие от «непонятных подключений»). И вирусы. Да и сама Windows может стать проблемой. Почти любой ее компонент. Поэтому надо бы проделать следующее:
- Повторно установить NET.Framework. Желательно перед этим удалить предыдущую версию.
- Установить какой-нибудь приличный антивирус (а лучше два) и запустить глубокую проверку систему. Возможно, подключению и входу на ресурс мешает вредоносная программа.
- Если у вас уже установлен антивирус, то, наоборот, попробуйте его отключить. Иногда встроенные в них экраны проверки подключений блокируют работу браузера целиком или отдельных страниц. Лучше выдать браузеру больше прав на выполнение своих задач или установить антивирус, который более лояльно относится к установленному на компьютере софту.
- Еще надо поменять параметры брандмауэра. Его можно разыскать в панели управления Windows. Там надо добавить в список исключений ваш браузер. Тогда брандмауэр не будет мешать подключению к запрашиваемому сайту.
- Почистить Windows от программного мусора. Можно пройтись приложением CCleaner.
- Обновить драйверы для сетевых устройств.
- Обновить Windows или просканировать систему на наличие погрешностей в системных компонентах.
Ищем проблему на стороне сервера
Если что-то происходит на стороне ресурса, то это редко заканчивается ошибкой 400. Но все-таки есть несколько сценариев, при которых клиента обвиняют в сбое зря, а настоящая вина лежит на сервере.
Проверяем требования к HTTP-заголовкам
Пока настраиваешь сайт, несложно допустить ошибку или даже парочку. Возможно, требования к HTTP-заголовком указаны некорректно, и сервер ожидает запросы с ошибками, которые по объективным причинам не может распознать адекватно. Тогда администратору стоит перепроверить ожидаемые заголовки на своем сайте или в приложении.
Удаляем свежие обновления и плагины
Иногда ошибка 400 Bad Request появляется после обновления CMS или установки новых плагинов. Если у вас она появилась из-за этого, то наиболее логичное решение — откатиться до более ранней версии CMS и удалить все новые плагины.
Главное, перед этим сделать резервную копию данных. И перед установкой обновлений тоже стоило бы.
Проверяем состояние базы данных
Некоторые сторонние расширения для того же WordPress получают полный доступ к ресурсу и имеют право вносить изменения даже в подключенную базу данных. Если после удаления свежих плагинов ошибка 400 никуда не исчезла и появляется у всех, кто пытается зайти на сайт, стоит проверить, в каком состоянии находится база данных. Нужно вручную проверить все записи на наличие подозрительных изменений, которые могли быть сделаны установленными расширениями.
Исправляем ошибки в коде и скриптах
Ничего из вышеперечисленного не помогло? Тогда осталось проверить свой код и работающие скрипты. Лучше провести дебаггинг вручную и не надеяться на помощь компьютера. Сделать копию приложения или сайта, потом пошагово проверить каждый отрезок кода в поисках ошибок.
В крайнем случае придется кричать «полундра» и звать на помощь техподдержку хостинга. Возможно, возникли сложности на их стороне. Тогда вообще ничего не надо будет делать. Просто ждать, пока все исправят за вас.
На этом все. Основные причины появления 400 Bad Request разобрали. Как ее лечить — тоже. Теперь дело за вами. Пользуйтесь полученной информацией, чтобы больше не пришлось мучиться в попытках зайти на нужный ресурс.