SUMMARY
Starting in 2.8, if the playbook has any import of an empty play then the overall execution fails completely, reporting «ERROR! Empty playbook, nothing to do».
Note that this issue also shows in the development branch.
ISSUE TYPE
- Bug Report
COMPONENT NAME
import_playbook
ANSIBLE VERSION
ansible 2.8.0b1
config file = None
configured module search path = [u'/home/centos/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python2.7/site-packages/ansible
executable location = /usr/bin/ansible
python version = 2.7.5 (default, Apr 11 2018, 07:36:10) [GCC 4.8.5 20150623 (Red Hat 4.8.5-28)]
(This issue shows in 2.8.0a1, too.)
CONFIGURATION
(no changes)
OS / ENVIRONMENT
Centos 7.5
STEPS TO REPRODUCE
inventory.ini
target ansible_connection=local
playbook.yml
--- - hosts: target tasks: - debug: msg: hello world - import_playbook: included.yml
included.yml
Run:
ansible-playbook -i inventory.ini playbook.yml -vvvv
EXPECTED RESULTS
In 2.7.9, the response is as expected (the task in playbook.yml executes):
ansible-playbook 2.7.9
config file = None
configured module search path = [u'/home/centos/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python2.7/site-packages/ansible
executable location = /usr/bin/ansible-playbook
python version = 2.7.5 (default, Apr 11 2018, 07:36:10) [GCC 4.8.5 20150623 (Red Hat 4.8.5-28)]
No config file found; using defaults
setting up inventory plugins
/home/centos/testing/inventory.ini did not meet host_list requirements, check plugin documentation if this is unexpected
/home/centos/testing/inventory.ini did not meet script requirements, check plugin documentation if this is unexpected
/home/centos/testing/inventory.ini did not meet yaml requirements, check plugin documentation if this is unexpected
Parsed /home/centos/testing/inventory.ini inventory source with ini plugin
Loading callback plugin default of type stdout, v2.0 from /usr/lib/python2.7/site-packages/ansible/plugins/callback/default.pyc
PLAYBOOK: playbook.yml *********************************************************************************************************************
1 plays in playbook.yml
PLAY [target] ******************************************************************************************************************************
TASK [Gathering Facts] *********************************************************************************************************************
task path: /home/centos/testing/playbook.yml:2
<target> ESTABLISH LOCAL CONNECTION FOR USER: centos
<target> EXEC /bin/sh -c 'echo ~centos && sleep 0'
<target> EXEC /bin/sh -c '( umask 77 && mkdir -p "` echo /home/centos/.ansible/tmp/ansible-tmp-1555948498.06-93067140766373 `" && echo ansible-tmp-1555948498.06-93067140766373="` echo /home/centos/.ansible/tmp/ansible-tmp-1555948498.06-93067140766373 `" ) && sleep 0'
Using module file /usr/lib/python2.7/site-packages/ansible/modules/system/setup.py
<target> PUT /home/centos/.ansible/tmp/ansible-local-10743KVQFNS/tmp5rKo5a TO /home/centos/.ansible/tmp/ansible-tmp-1555948498.06-93067140766373/AnsiballZ_setup.py
<target> EXEC /bin/sh -c 'chmod u+x /home/centos/.ansible/tmp/ansible-tmp-1555948498.06-93067140766373/ /home/centos/.ansible/tmp/ansible-tmp-1555948498.06-93067140766373/AnsiballZ_setup.py && sleep 0'
<target> EXEC /bin/sh -c '/usr/bin/python /home/centos/.ansible/tmp/ansible-tmp-1555948498.06-93067140766373/AnsiballZ_setup.py && sleep 0'
<target> EXEC /bin/sh -c 'rm -f -r /home/centos/.ansible/tmp/ansible-tmp-1555948498.06-93067140766373/ > /dev/null 2>&1 && sleep 0'
ok: [target]
META: ran handlers
TASK [debug] *******************************************************************************************************************************
task path: /home/centos/testing/playbook.yml:4
ok: [target] => {
"msg": "hello world"
}
META: ran handlers
META: ran handlers
PLAY RECAP *********************************************************************************************************************************
target : ok=2 changed=0 unreachable=0 failed=0
ACTUAL RESULTS
In 2.8.0b1, the response is:
ansible-playbook 2.8.0b1
config file = None
configured module search path = [u'/home/centos/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python2.7/site-packages/ansible
executable location = /usr/bin/ansible-playbook
python version = 2.7.5 (default, Apr 11 2018, 07:36:10) [GCC 4.8.5 20150623 (Red Hat 4.8.5-28)]
No config file found; using defaults
setting up inventory plugins
host_list declined parsing /home/centos/testing/inventory.ini as it did not pass it's verify_file() method
script declined parsing /home/centos/testing/inventory.ini as it did not pass it's verify_file() method
auto declined parsing /home/centos/testing/inventory.ini as it did not pass it's verify_file() method
yaml declined parsing /home/centos/testing/inventory.ini as it did not pass it's verify_file() method
Parsed /home/centos/testing/inventory.ini inventory source with ini plugin
ERROR! Empty playbook, nothing to do
In the development branch, the response is the same:
ansible-playbook 2.9.0.dev0
config file = None
configured module search path = [u'/home/centos/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module location = /home/centos/ansible/lib/ansible
executable location = /home/centos/ansible/bin/ansible-playbook
python version = 2.7.5 (default, Apr 11 2018, 07:36:10) [GCC 4.8.5 20150623 (Red Hat 4.8.5-28)]
No config file found; using defaults
setting up inventory plugins
host_list declined parsing /home/centos/testing/inventory.ini as it did not pass it's verify_file() method
script declined parsing /home/centos/testing/inventory.ini as it did not pass it's verify_file() method
auto declined parsing /home/centos/testing/inventory.ini as it did not pass it's verify_file() method
yaml declined parsing /home/centos/testing/inventory.ini as it did not pass it's verify_file() method
Parsed /home/centos/testing/inventory.ini inventory source with ini plugin
ERROR! Empty playbook, nothing to do
Обработка ошибок в плейбуках
Когда Ansible получает ненулевой код возврата от команды или сбоя от модуля,по умолчанию он прекращает выполнение на этом хосте и продолжается на других хостах.Тем не менее,в некоторых случаях вам может потребоваться иное поведение.Иногда ненулевой код возврата указывает на успех.Иногда вы хотите,чтобы сбой на одном хосте остановил выполнение на всех хостах.Ansible предоставляет инструменты и настройки,чтобы справиться с этими ситуациями и помочь вам получить поведение,вывод и отчетность вы хотите.
- Игнорирование неудачных команд
- игнорирование недоступных ошибок хоста
- Сброс недоступных хостов
- Дескрипторы и отказ
- Defining failure
- Defining “changed”
- Обеспечение успеха для командования и снаряда
-
Прерывание игры на всех хозяевах
- Прерывание первой ошибки:any_errors_fatal
- Установка максимального процента отказа
- Ошибки управления блоками
Игнорирование неудачных команд
По умолчанию Ansible прекращает выполнение задач на хосте при сбое задачи на этом хосте. Вы можете использовать ignore_errors , чтобы продолжить несмотря на сбой:
- name: Do not count this as a failure ansible.builtin.command: /bin/false ignore_errors: yes
Директива ignore_errors работает только тогда, когда задача может быть запущена и возвращает значение «сбой». Это не заставляет Ansible игнорировать ошибки неопределенных переменных, сбои соединения, проблемы с выполнением (например, отсутствующие пакеты) или синтаксические ошибки.
игнорирование недоступных ошибок хоста
Новинка в версии 2.7.
Вы можете игнорировать сбой задачи из-за того, что экземпляр хоста недоступен с ключевым словом ignore_unreachable . Ansible игнорирует ошибки задачи, но продолжает выполнять будущие задачи на недостижимом хосте. Например, на уровне задачи:
- name: This executes, fails, and the failure is ignored ansible.builtin.command: /bin/true ignore_unreachable: yes - name: This executes, fails, and ends the play for this host ansible.builtin.command: /bin/true
И на игровом уровне:
- hosts: all ignore_unreachable: yes tasks: - name: This executes, fails, and the failure is ignored ansible.builtin.command: /bin/true - name: This executes, fails, and ends the play for this host ansible.builtin.command: /bin/true ignore_unreachable: no
Сброс недоступных хостов
Если Ansible не может подключиться к хосту, он помечает этот хост как «НЕДОСТУПНЫЙ» и удаляет его из списка активных хостов для выполнения. Вы можете использовать meta: clear_host_errors для повторной активации всех хостов, чтобы последующие задачи могли снова попытаться связаться с ними.
Дескрипторы и отказ
Ansible runs handlers at the end of each play. If a task notifies a handler but another task fails later in the play, by default the handler does not run on that host, which may leave the host in an unexpected state. For example, a task could update a configuration file and notify a handler to restart some service. If a task later in the same play fails, the configuration file might be changed but the service will not be restarted.
Вы можете изменить это поведение с --force-handlers опций командной строки, в том числе путем force_handlers: True в пьесе, или путем добавления force_handlers = True в ansible.cfg. Когда обработчики принудительно запущены, Ansible будет запускать все обработчики уведомлений на всех хостах, даже на хостах с неудачными задачами. (Обратите внимание, что некоторые ошибки все еще могут помешать запуску обработчика, например, когда хост становится недоступным.)
Defining failure
Ansible позволяет определить, что означает «сбой» в каждой задаче, используя условие failed_when . Как и все условные операторы в Ansible, списки нескольких условий failed_when объединяются неявным оператором and , что означает, что задача завершается сбоем только при соблюдении всех условий. Если вы хотите инициировать сбой при выполнении любого из условий, вы должны определить условия в строке с явным оператором or .
Проверить на неудачу можно с помощью поиска слова или фразы в выводе команды:
- name: Fail task when the command error output prints FAILED ansible.builtin.command: /usr/bin/example-command -x -y -z register: command_result failed_when: "'FAILED' in command_result.stderr"
или на основании кода возврата:
- name: Fail task when both files are identical ansible.builtin.raw: diff foo/file1 bar/file2 register: diff_cmd failed_when: diff_cmd.rc == 0 or diff_cmd.rc >= 2
Вы также можете комбинировать несколько условий для отказа.Эта задача будет неудачной,если оба условия верны:
- name: Check if a file exists in temp and fail task if it does ansible.builtin.command: ls /tmp/this_should_not_be_here register: result failed_when: - result.rc == 0 - '"No such" not in result.stdout'
Если вы хотите, чтобы задача не выполнялась при выполнении только одного условия, измените определение failed_when на:
failed_when: result.rc == 0 or "No such" not in result.stdout
Если у вас слишком много условий для аккуратного размещения в одной строке, вы можете разделить его на многострочное значение yaml с помощью > :
- name: example of many failed_when conditions with OR ansible.builtin.shell: "./myBinary" register: ret failed_when: > ("No such file or directory" in ret.stdout) or (ret.stderr != '') or (ret.rc == 10)
Defining “changed”
Ansible позволяет вам определить, когда конкретная задача «изменила» удаленный узел, используя условное changed_when . Это позволяет вам определить, на основе кодов возврата или вывода, следует ли сообщать об изменении в статистике Ansible и должен ли запускаться обработчик или нет. Как и все условные операторы в Ansible, списки нескольких условий changed_when объединяются неявным оператором and , что означает, что задача сообщает об изменении только тогда, когда все условия соблюдены. Если вы хотите сообщить об изменении при выполнении любого из условий, вы должны определить условия в строке с явным оператором or .Например:
tasks: - name: Report 'changed' when the return code is not equal to 2 ansible.builtin.shell: /usr/bin/billybass --mode="take me to the river" register: bass_result changed_when: "bass_result.rc != 2" - name: This will never report 'changed' status ansible.builtin.shell: wall 'beep' changed_when: False
Вы также можете объединить несколько условий,чтобы отменить результат «изменено»:
- name: Combine multiple conditions to override 'changed' result ansible.builtin.command: /bin/fake_command register: result ignore_errors: True changed_when: - '"ERROR" in result.stderr' - result.rc == 2
Дополнительные примеры условного синтаксиса см. В разделе Определение ошибки .
Обеспечение успеха для командования и снаряда
В командных и оболочки модулей заботятся о кодах возврата, поэтому если у вас есть команда , чей успешный код завершения не равен нулю, то вы можете сделать это:
tasks: - name: Run this command and ignore the result ansible.builtin.shell: /usr/bin/somecommand || /bin/true
Прерывание игры на всех хозяевах
Иногда требуется, чтобы сбой на одном хосте или сбой на определенном проценте хостов прервали всю игру на всех хостах. Вы можете остановить выполнение воспроизведения после первого сбоя с помощью any_errors_fatal . Для более max_fail_percentage управления вы можете использовать max_fail_percentage, чтобы прервать выполнение после сбоя определенного процента хостов.
Прерывание первой ошибки:any_errors_fatal
Если вы устанавливаете any_errors_fatal и задача возвращает ошибку, Ansible завершает фатальную задачу на всех хостах в текущем пакете, а затем прекращает воспроизведение на всех хостах. Последующие задания и спектакли не выполняются. Вы можете избавиться от фатальных ошибок, добавив в блок раздел восстановления. Вы можете установить any_errors_fatal на уровне игры или блока:
- hosts: somehosts any_errors_fatal: true roles: - myrole - hosts: somehosts tasks: - block: - include_tasks: mytasks.yml any_errors_fatal: true
Вы можете использовать эту функцию,когда все задачи должны быть на 100% успешными,чтобы продолжить выполнение Playbook.Например,если вы запускаете сервис на машинах в нескольких центрах обработки данных с балансировщиками нагрузки для передачи трафика от пользователей к сервису,вы хотите,чтобы все балансировщики нагрузки были отключены до того,как вы остановите сервис на техническое обслуживание.Чтобы гарантировать,что любой сбой в задаче,отключающей работу балансировщиков нагрузки,остановит все остальные задачи:
--- - hosts: load_balancers_dc_a any_errors_fatal: true tasks: - name: Shut down datacenter 'A' ansible.builtin.command: /usr/bin/disable-dc - hosts: frontends_dc_a tasks: - name: Stop service ansible.builtin.command: /usr/bin/stop-software - name: Update software ansible.builtin.command: /usr/bin/upgrade-software - hosts: load_balancers_dc_a tasks: - name: Start datacenter 'A' ansible.builtin.command: /usr/bin/enable-dc
В данном примере Ansible запускает обновление программного обеспечения на передних концах только в том случае,если все балансировщики нагрузки успешно отключены.
Установка максимального процента отказа
По умолчанию,Ansible продолжает выполнять задачи до тех пор,пока есть хосты,которые еще не вышли из строя.В некоторых ситуациях,например,при выполнении скользящего обновления,вы можете прервать воспроизведение,когда достигнут определенный порог неудач.Для этого вы можете установить максимальный процент сбоев при воспроизведении:
--- - hosts: webservers max_fail_percentage: 30 serial: 10
Параметр max_fail_percentage применяется к каждому пакету, когда вы используете его с последовательным интерфейсом . В приведенном выше примере, если более 3 из 10 серверов в первой (или любой) группе серверов вышли из строя, остальная часть игры будет прервана.
Note
Установленный процент должен быть превышен,а не равен.Например,если серийный набор установлен на 4 и вы хотите,чтобы задача прерывала воспроизведение при сбое 2-х систем,установите max_fail_percentage на 49,а не на 50.
Ошибки управления блоками
Вы также можете использовать блоки для определения ответов на ошибки задачи. Этот подход похож на обработку исключений во многих языках программирования. См. Подробности и примеры в разделе Обработка ошибок с помощью блоков .
Ansible
-
Контроль над тем,где выполняются задачи:делегирование и местные действия.
По умолчанию Ansible собирает факты и выполняет все задачи на машинах, которые соответствуют строке hosts из вашего playbook.
-
Настройка удаленной среды
Новое в версии 1.1.
-
Использование фильтров для манипулирования данными
Фильтры позволяют преобразовывать данные JSON в разделенный URL-адрес YAML, извлекать имя хоста, получать хэш строки SHA1, добавлять несколько целых чисел и многое другое.
-
Объединение и выбор данных
Вы можете комбинировать данные из нескольких источников и типов, выбирать значения больших структур, предоставляя точный контроль над комплексом Новое в версии 2.3.
Я часто использую молекулу с драйвером докера. Есть несколько случаев, когда докер не является подходящим инструментом для тестирования доступных ролей, поэтому я хотел бы развернуть виртуальную машину в openstack.
Я создал доступную роль с помощью molecule role -r <rolename> и изменил драйвер в файле scheme.yml на openstack. Это пример моего текущего файла molle.yml:
---
dependency:
name: galaxy
driver:
name: openstack
lint:
name: yamllint
platforms:
- name: molecule-role-docker
image: CentOS7
flavor: ECS.UC1.4-4
auto_ip: true
security_groups: ssh
key_name: mykey-ci
provisioner:
name: ansible
lint:
name: ansible-lint
verifier:
name: testinfra
lint:
name: flake8
К сожалению, похоже, что отсутствует файл create.yml, который раскручивает машину:
[...]
Validation completed successfully.
--> Test matrix
└── default
├── dependency
├── create
├── prepare
└── converge
--> Scenario: 'default'
--> Action: 'dependency'
Skipping, missing the requirements file.
--> Scenario: 'default'
--> Action: 'create'
ERROR! the playbook: None could not be found
ERROR:
Если я создаю файл create.yml, сообщение об ошибке указывает на то, что файл был обнаружен пустым:
[...]
--> Scenario: 'default'
--> Action: 'create'
ERROR! Empty playbook, nothing to do
ERROR:
Итак, как мне заставить работать драйвер openstack и как создать и подготовить виртуальную машину для выполнения моих проверок?
Я использую молекулу 2.22, анзибл 2.9.4 и python 3.7.6.
Как указано в документации, я уже установил плагин молекулярного openstack: pip3 install 'molecule[openstack]'
1 ответ
Лучший ответ
Драйвер по умолчанию — докер. Вы должны создать свою роль с самого начала с помощью драйвера openstack. Это поместит для вас правильную настройку в Molle.yml, а также создаст необходимые базовые файлы в вашем сценарии по умолчанию:
molecule init role -d openstack -r my_role
Вы также можете запустить новый сценарий в существующей роли. Из корня вашей роли
molecule init scenario -d openstack -s my_scenario
1
Zeitounator
1 Фев 2020 в 03:38
В этой статье мы рассмотрим, как удаленно управлять хостами с Windows через популярную систему управления конфигурациями Ansible. Мы предполагаем, что Ansible уже установлен на вашем хосте Linux.
Содержание:
- Подготовка Windows к удаленному управления через Ansible
- Настройка Ansible для управления компьютерами Windows
- Примеры управления конфигурацией Windows из Ansible
Подготовка Windows к удаленному управления через Ansible
Ansible позволяет удаленно управлять хостами Windows со всеми поддерживаемым версиями ОС, начиная с Windows 7/Windows Server 2008 и до современных Windows 11/Windows Server 2022. В Windows должен быть установлен PowerShell 3.0 (или выше) и NET 4.0+.
Ansible использует WinRM для подключения к Windows. Поэтому вам нужно включить и настроить WinRM listener на всех управляемых хостах.
В Ansible 2.8 и выше доступна экспериментальная опция удаленного управления клиентами Windows 10 и Windows Serve 2019 через встроенный OpenSSH сервер.
- В домене AD можно централизованно настроить WinRM с помощью групповых политик;
- На отдельно стоящем хосте Windows для включения WinRM выполните команду PowerShell:
Enable-PSRemoting –Force
Если WinRM включен и настроен на хостах Windows, проверьте что с сервера Ansible на ваших серверах доступен порт TCP/5985 или TCP/5986 (если используется HTTPS).
$ nc -zv 192.168.13.122 5985

В зависимости от того. в какой среде вы будете использовать Ansible, вам нужно выбрать способ аутентификации.
- Для отдельно-стоящего компьютера или рабочей группы можно использовать HTTPS для WinRM с самоподписанными сертификатами с аутентификацией под локальной учетной записью Windows с правами администратора. Для быстрой настройки хоста Windows можно использовать готовый скрипт ConfigureRemotingForAnsible.ps1 (https://github.com/ansible/ansible/blob/devel/examples/scripts/ConfigureRemotingForAnsible.ps1);
- В моем случае все хосты Windows находятся в домене Active Directory, поэтому я буду использовать учетную запись AD для аутентификации через Ansible. В этом случае нужно настроить Kerberos аутентификацию на сервере Ansible (рассмотрено далее).
Установите необходимые пакеты для Kerberos аутентификации:
- В RHEL/Rocky Linux/CentOS через менеджер пакетов yum/dnf:
$ sudo yum -y install python-devel krb5-devel krb5-libs krb5-workstation - В Ubuntu/Debian:
$ sudo apt-get -y install python-dev libkrb5-dev krb5-user
Теперь установите пакет для python через pip:
$ sudo pip3 install requests-kerberos
Укажите настройки подключения к вашему домену в файле:
$ sudo mcedit /etc/krb5.conf
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = false
default_realm = WINITPRO.LOC
[realms]
WINITPRO.LOC = {
admin_server = dc02.winitpro.loc
kdc = dc02.winitpro.loc
}
[domain_realm]
winitpro.loc = WINITPRO.LOC
.WINITPRO.LOC = WINITPRO.LOC
Проверьте, что вы можете выполнить аутентификацию в вашем домене AD и получите тикет Kerberos:
kinit -C [email protected]
Введите пароль пользователя AD, проверьте что получен тикет.
klist

Настройка Ansible для управления компьютерами Windows
Теперь добавьте все ваши хосты Windows в инвентаризационный файл ansible:
$ sudo mcedit /etc/ansible/hosts
msk-rds2.winitpro.loc msk-rds3.winitpro.loc wks-t1122h2.winitpro.loc [windows_all:vars] ansible_port=5985 [email protected] ansible_connection=winrm ansible_winrm_transport=kerberos ansible_winrm_scheme=http ansible_winrm_server_cert_validation=ignore
Проверьте, что все ваши Windows хосты (в моем списке два Windows Server 2019 и один компьютер Windows 11) доступны из Ansible:
$ ansible windows_all -m win_ping
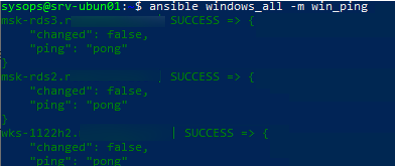
В моем случае все хосты вернули ошибку:
"msg": "kerberos: Bad HTTP response returned from server. Code 500", "unreachable": true

Причина в том, что в этом примере для WinRM подключения используется протокол HTTP вместо HTTPS. Чтобы игнорировать ошибку, нужно разрешить незашифрованный трафик на хостах Windows:
Set-Item -Path WSMan:localhostServiceAllowUnencrypted -Value true
Теперь через Ansible вы можете выполнить произвольную команду на всех хостах. Например, я хочу сбросить DNS кеш на всех хостах Windows:
$ ansible windows_all -m win_shell -a "ipconfig /flushdns"
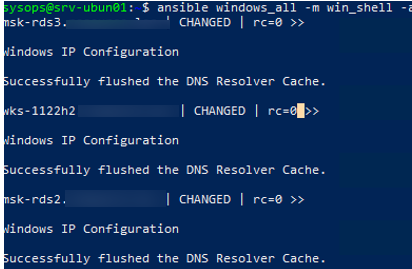
Команда успешно отработала везде.
Примеры управления конфигурацией Windows из Ansible
Теперь вы можете запускать плейбуки Ansible на ваших хостах Windows.
Например, вам нужно через Ansible выполнить PowerShell скрипт на всех хостах (в этом примере мы с помощью PowerShell получим текущие настройки DNS на хостах). Создайте файл плейбука:
$ sudo mcedit /etc/ansible/playbooks/win-exec-powershell.yml
---
- name: win_powershell_exec
hosts: windows_all
tasks:
- name: check DNS
win_shell: |
Get-DnsClientServerAddress -InterfaceIndex (Get-NetAdapter|where Status -eq "Up").ifindex -ErrorAction SilentlyContinue
register: command_output
- name: command output
ansible.builtin.debug:
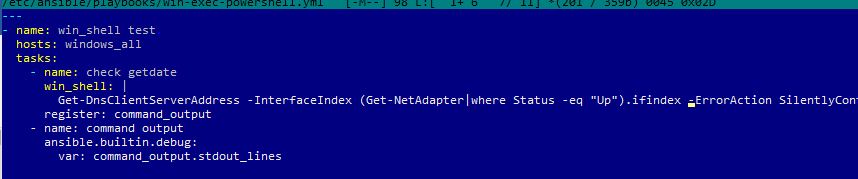
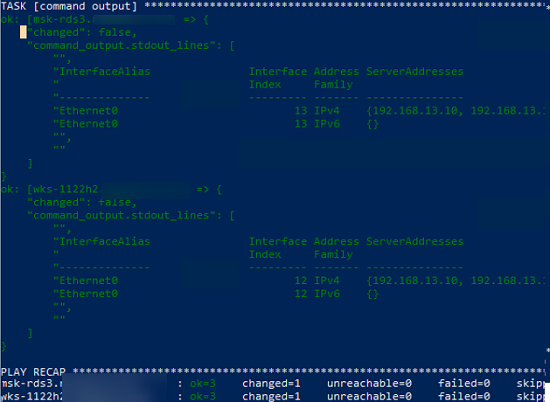
Выполните плейбук:
$ ansible-playbook /etc/ansible/playbooks/win-exec-powershell.yml
В данном примере плейбук отработал на всех Windows хостах и вернул текущие настройки DNS.
Далее рассмотрим несколько типовых плейбуков Absible, для стандартных задач управления хостами Windows.
Скопировать файл:
- name: Copy a single file
win_copy:
src: /home/sysops/files/test.ps1"
dest: C:Temptest.ps1
Создать файл:
- name: Create file
win_file:
path: C:Tempfile.txt
state: touch
Удалить файл:
- name: Delete file
win_file:
path: C:Tempfile.txt
state: absent
Создать параметр реестра:
- name: Create reg dword
win_regedit:
path: HKLM:SOFTWAREMicrosoftWindowsCurrentVersionPoliciesDataCollection
name: AllowTelemetry
data: 0
type: dword
Установить программу из MSI:
Установить программу из MSI:
- name: Install MSI package
win_package:
path: C:Distradobereader.msi
arguments:
- /install
- /passive
- /norestart
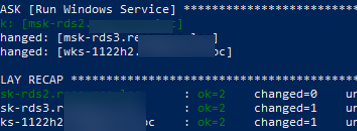
Запустить службу Windows:
- name: Run Windows Service
win_service:
name: wuauserv
state: started
Установить роль Windows Server:
- name: Install Windows Feature
win_feature:
name: SNMP-Service
state: present
Открыть порт в файерволе:
- name: Open SMTP Port п
win_firewall_rule:
name: port 25
localport: 25
action: allow
direction: in
protocol: tcp
state: present
enabled: yes
Выполнить PowerShell скрипт:
- name: Run PowerShell Script win_command: powershell.exe -ExecutionPolicy ByPass -File C:/temp/powershellscript.ps1
В этой статье мы рассмотрели, как управлять конфигурацией компьютеров Windows через Ansible. Если ваши хосты Windows не добавлены в домен Active Directory (находятся в рабочей группе), то удаленное управление конфигурацией хостов Windows через Ansible может быть неплохой альтернативной настройке с помощью доменных групповых политик.
Можно установить Ansible в подсистеме WSL на Windows. Это позволит запускать плейбуки без развертывания отдельного Linux хоста под ansible.
Вы можете включить режим отладки, чтобы получить больше информации, чем дает вам -v* . Для этого просто экспортируйте ANSIBLE_DEBUG=1 чтобы включить его.
Нам, вероятно, понадобится дополнительная информация, чтобы попытаться помочь вам с этим, что, надеюсь, предоставят журналы отладки. Такое количество хостов действительно требует одновременного подключения, вы работаете параллельно или блоками?
need_info
Хм, на что ставите вилки? Одновременный доступ к большому количеству хостов может занять много ресурсов — также стоит проверить / var / log / messages.
Вы можете попробовать wait_for_connection как способ проверить, что все ваши хосты доступны. Это приятно, поскольку он знает тип подключения, поэтому он работает, даже если у вас смешанный инвентарь, скажем, Windows и хосты Linux.
Привет, он подключается максимум к 10 хостам одновременно, это конфигурация:
[defaults]
host_key_checking = False
timeout = 20
retry_files_save_path = /home/ansible/retry/
# Do not put more jobs here, or ssh will fail
# Anything more than 10 kills this poor server
forks = 10
remote_user = root
log_path=/var/log/ansible.log
[ssh_connection]
retries=3
pipelining=True
Мне удалось найти «блок хостов», содержащий тот, который, вероятно, вызывает это зависание, поэтому теперь я удаляю все больше и больше хостов из этого временного файла в надежде определить тот, который вызывает это.
Я предполагаю, что он может зависнуть от DNS-запроса? Возможно, один из этих хостов не существует, и из-за неправильной настройки DNS-сервера запрос будет длиться вечно? Понятия не имею, но совершенно уверен, что никакой подробной информации нет даже в журнале отладки, я постараюсь предоставить ее в ближайшее время. Я вижу несколько строк отладки, затем вижу зеленый ок: [имя хоста], а затем ничего навсегда, ни одной строки отладки или подробной информации, просто зависает.
После очень долгой отладки и тестирования серверов один за другим я выяснил, какой из них вызывает это. Его DNS в порядке, он отвечает, и я могу использовать ssh, но есть некоторая проблема:
12502 1506511086.24143: starting run
12502 1506511086.42742: Loading CacheModule 'memory' from /usr/lib/python2.7/site-packages/ansible/plugins/cache/memory.py
12502 1506511086.63981: Loading CallbackModule 'default' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/default.py
12502 1506511086.64073: Loading CallbackModule 'actionable' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/actionable.py (found_in_cache=False, class_only=True)
12502 1506511086.64109: Loading CallbackModule 'context_demo' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/context_demo.py (found_in_cache=False, class_only=True)
12502 1506511086.64146: Loading CallbackModule 'debug' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/debug.py (found_in_cache=False, class_only=True)
12502 1506511086.64166: Loading CallbackModule 'default' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/default.py (found_in_cache=False, class_only=True)
12502 1506511086.64226: Loading CallbackModule 'dense' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/dense.py (found_in_cache=False, class_only=True)
12502 1506511086.67297: Loading CallbackModule 'foreman' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/foreman.py (found_in_cache=False, class_only=True)
12502 1506511086.68313: Loading CallbackModule 'hipchat' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/hipchat.py (found_in_cache=False, class_only=True)
12502 1506511086.68376: Loading CallbackModule 'jabber' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/jabber.py (found_in_cache=False, class_only=True)
12502 1506511086.68409: Loading CallbackModule 'json' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/json.py (found_in_cache=False, class_only=True)
12502 1506511086.68476: Loading CallbackModule 'junit' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/junit.py (found_in_cache=False, class_only=True)
12502 1506511086.68511: Loading CallbackModule 'log_plays' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/log_plays.py (found_in_cache=False, class_only=True)
12502 1506511086.68598: Loading CallbackModule 'logentries' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/logentries.py (found_in_cache=False, class_only=True)
12502 1506511086.68675: Loading CallbackModule 'logstash' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/logstash.py (found_in_cache=False, class_only=True)
12502 1506511086.68789: Loading CallbackModule 'mail' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/mail.py (found_in_cache=False, class_only=True)
12502 1506511086.68823: Loading CallbackModule 'minimal' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/minimal.py (found_in_cache=False, class_only=True)
12502 1506511086.68855: Loading CallbackModule 'oneline' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/oneline.py (found_in_cache=False, class_only=True)
12502 1506511086.68892: Loading CallbackModule 'osx_say' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/osx_say.py (found_in_cache=False, class_only=True)
12502 1506511086.68932: Loading CallbackModule 'profile_tasks' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/profile_tasks.py (found_in_cache=False, class_only=True)
12502 1506511086.68973: Loading CallbackModule 'selective' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/selective.py (found_in_cache=False, class_only=True)
12502 1506511086.69006: Loading CallbackModule 'skippy' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/skippy.py (found_in_cache=False, class_only=True)
12502 1506511086.69063: Loading CallbackModule 'slack' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/slack.py (found_in_cache=False, class_only=True)
12502 1506511086.69186: Loading CallbackModule 'syslog_json' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/syslog_json.py (found_in_cache=False, class_only=True)
12502 1506511086.69221: Loading CallbackModule 'timer' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/timer.py (found_in_cache=False, class_only=True)
12502 1506511086.69256: Loading CallbackModule 'tree' from /usr/lib/python2.7/site-packages/ansible/plugins/callback/tree.py (found_in_cache=False, class_only=True)
12502 1506511086.69296: in VariableManager get_vars()
12502 1506511086.71899: Loading FilterModule 'core' from /usr/lib/python2.7/site-packages/ansible/plugins/filter/core.py
12502 1506511086.71980: Loading FilterModule 'ipaddr' from /usr/lib/python2.7/site-packages/ansible/plugins/filter/ipaddr.py
12502 1506511086.72396: Loading FilterModule 'json_query' from /usr/lib/python2.7/site-packages/ansible/plugins/filter/json_query.py
12502 1506511086.72433: Loading FilterModule 'mathstuff' from /usr/lib/python2.7/site-packages/ansible/plugins/filter/mathstuff.py
12502 1506511086.72655: Loading TestModule 'core' from /usr/lib/python2.7/site-packages/ansible/plugins/test/core.py
12502 1506511086.72845: Loading TestModule 'files' from /usr/lib/python2.7/site-packages/ansible/plugins/test/files.py
12502 1506511086.72880: Loading TestModule 'mathstuff' from /usr/lib/python2.7/site-packages/ansible/plugins/test/mathstuff.py
12502 1506511086.73542: done with get_vars()
12502 1506511086.73603: in VariableManager get_vars()
12502 1506511086.73665: Loading FilterModule 'core' from /usr/lib/python2.7/site-packages/ansible/plugins/filter/core.py (found_in_cache=True, class_only=False)
12502 1506511086.73686: Loading FilterModule 'ipaddr' from /usr/lib/python2.7/site-packages/ansible/plugins/filter/ipaddr.py (found_in_cache=True, class_only=False)
12502 1506511086.73702: Loading FilterModule 'json_query' from /usr/lib/python2.7/site-packages/ansible/plugins/filter/json_query.py (found_in_cache=True, class_only=False)
12502 1506511086.73717: Loading FilterModule 'mathstuff' from /usr/lib/python2.7/site-packages/ansible/plugins/filter/mathstuff.py (found_in_cache=True, class_only=False)
12502 1506511086.73765: Loading TestModule 'core' from /usr/lib/python2.7/site-packages/ansible/plugins/test/core.py (found_in_cache=True, class_only=False)
12502 1506511086.73783: Loading TestModule 'files' from /usr/lib/python2.7/site-packages/ansible/plugins/test/files.py (found_in_cache=True, class_only=False)
12502 1506511086.73799: Loading TestModule 'mathstuff' from /usr/lib/python2.7/site-packages/ansible/plugins/test/mathstuff.py (found_in_cache=True, class_only=False)
12502 1506511086.73921: done with get_vars()
PLAY [all:!ignored] **********************************************************************************************************************************************************************************************************************************
12502 1506511086.81512: Loading StrategyModule 'linear' from /usr/lib/python2.7/site-packages/ansible/plugins/strategy/linear.py
12502 1506511086.82241: getting the remaining hosts for this loop
12502 1506511086.82263: done getting the remaining hosts for this loop
12502 1506511086.82282: building list of next tasks for hosts
12502 1506511086.82297: getting the next task for host in-terminal01.prod.domain.tld
12502 1506511086.82315: done getting next task for host in-terminal01.prod.domain.tld
12502 1506511086.82330: ^ task is: TASK: Gathering Facts
12502 1506511086.82345: ^ state is: HOST STATE: block=0, task=0, rescue=0, always=0, run_state=ITERATING_SETUP, fail_state=FAILED_NONE, pending_setup=True, tasks child state? (None), rescue child state? (None), always child state? (None), did rescue? False, did start at task? False
12502 1506511086.82360: done building task lists
12502 1506511086.82376: counting tasks in each state of execution
12502 1506511086.82390: done counting tasks in each state of execution:
num_setups: 1
num_tasks: 0
num_rescue: 0
num_always: 0
12502 1506511086.82405: advancing hosts in ITERATING_SETUP
12502 1506511086.82418: starting to advance hosts
12502 1506511086.82432: getting the next task for host in-terminal01.prod.domain.tld
12502 1506511086.82448: done getting next task for host in-terminal01.prod.domain.tld
12502 1506511086.82462: ^ task is: TASK: Gathering Facts
12502 1506511086.82478: ^ state is: HOST STATE: block=0, task=0, rescue=0, always=0, run_state=ITERATING_SETUP, fail_state=FAILED_NONE, pending_setup=True, tasks child state? (None), rescue child state? (None), always child state? (None), did rescue? False, did start at task? False
12502 1506511086.82492: done advancing hosts to next task
12502 1506511086.83078: getting variables
12502 1506511086.83098: in VariableManager get_vars()
12502 1506511086.83157: Loading FilterModule 'core' from /usr/lib/python2.7/site-packages/ansible/plugins/filter/core.py (found_in_cache=True, class_only=False)
12502 1506511086.83176: Loading FilterModule 'ipaddr' from /usr/lib/python2.7/site-packages/ansible/plugins/filter/ipaddr.py (found_in_cache=True, class_only=False)
12502 1506511086.83193: Loading FilterModule 'json_query' from /usr/lib/python2.7/site-packages/ansible/plugins/filter/json_query.py (found_in_cache=True, class_only=False)
12502 1506511086.83209: Loading FilterModule 'mathstuff' from /usr/lib/python2.7/site-packages/ansible/plugins/filter/mathstuff.py (found_in_cache=True, class_only=False)
12502 1506511086.83247: Loading TestModule 'core' from /usr/lib/python2.7/site-packages/ansible/plugins/test/core.py (found_in_cache=True, class_only=False)
12502 1506511086.83263: Loading TestModule 'files' from /usr/lib/python2.7/site-packages/ansible/plugins/test/files.py (found_in_cache=True, class_only=False)
12502 1506511086.83281: Loading TestModule 'mathstuff' from /usr/lib/python2.7/site-packages/ansible/plugins/test/mathstuff.py (found_in_cache=True, class_only=False)
12502 1506511086.83394: done with get_vars()
12502 1506511086.83421: done getting variables
12502 1506511086.83438: sending task start callback, copying the task so we can template it temporarily
12502 1506511086.83453: done copying, going to template now
12502 1506511086.83470: done templating
12502 1506511086.83484: here goes the callback...
TASK [Gathering Facts] ********************************************************************************************************************************************************************************************************************************************************
12502 1506511086.83515: sending task start callback
12502 1506511086.83530: entering _queue_task() for in-terminal01.prod.domain.tld/setup
12502 1506511086.83694: worker is 1 (out of 1 available)
12502 1506511086.83772: exiting _queue_task() for in-terminal01.prod.domain.tld/setup
12502 1506511086.83840: done queuing things up, now waiting for results queue to drain
12502 1506511086.83859: waiting for pending results...
12511 1506511086.84236: running TaskExecutor() for in-terminal01.prod.domain.tld/TASK: Gathering Facts
12511 1506511086.84316: in run()
12511 1506511086.84379: calling self._execute()
12511 1506511086.85119: Loading Connection 'ssh' from /usr/lib/python2.7/site-packages/ansible/plugins/connection/ssh.py
12511 1506511086.85207: Loading ShellModule 'csh' from /usr/lib/python2.7/site-packages/ansible/plugins/shell/csh.py
12511 1506511086.85264: Loading ShellModule 'fish' from /usr/lib/python2.7/site-packages/ansible/plugins/shell/fish.py
12511 1506511086.85346: Loading ShellModule 'powershell' from /usr/lib/python2.7/site-packages/ansible/plugins/shell/powershell.py
12511 1506511086.85381: Loading ShellModule 'sh' from /usr/lib/python2.7/site-packages/ansible/plugins/shell/sh.py
12511 1506511086.85423: Loading ShellModule 'sh' from /usr/lib/python2.7/site-packages/ansible/plugins/shell/sh.py (found_in_cache=True, class_only=False)
12511 1506511086.85479: Loading ActionModule 'normal' from /usr/lib/python2.7/site-packages/ansible/plugins/action/normal.py
12511 1506511086.85500: starting attempt loop
12511 1506511086.85516: running the handler
12511 1506511086.85572: ANSIBALLZ: Using lock for setup
12511 1506511086.85589: ANSIBALLZ: Acquiring lock
12511 1506511086.85606: ANSIBALLZ: Lock acquired: 29697296
12511 1506511086.85624: ANSIBALLZ: Creating module
12511 1506511087.15592: ANSIBALLZ: Writing module
12511 1506511087.15653: ANSIBALLZ: Renaming module
12511 1506511087.15678: ANSIBALLZ: Done creating module
12511 1506511087.15765: _low_level_execute_command(): starting
12511 1506511087.15786: _low_level_execute_command(): executing: /bin/sh -c '/usr/bin/python && sleep 0'
12511 1506511087.16363: Sending initial data
12511 1506511089.69186: Sent initial data (103646 bytes)
12511 1506511089.69246: stderr chunk (state=3):
>>>mux_client_request_session: session request failed: Session open refused by peer
ControlSocket /home/ansible/.ansible/cp/170b9dc5f6 already exists, disabling multiplexing
<<<
Здесь он висит навсегда. Я заменил домен этой компании на «domain.tld», фактическое доменное имя другое.
Это все еще ошибка в Ansible, по крайней мере в том смысле, что Ansible должен выдавать какое-то подробное сообщение об ОШИБКЕ, которое позволит пользователю узнать, какой хост вызывает зависание, чтобы этот хост можно было удалить из файла инвентаризации без необходимости сложного исследования того, что пошло не так.
Также веду большую инвентаризацию (более 2400), наблюдая похожие ошибки и выполняя те же длительные процедуры устранения неполадок в надежде найти многословие журнала, которое укажет мне лучшее направление.
ansible 2.4.1.0
python version = 2.7.5 (default, May 3 2017, 07:55:04) [GCC 4.8.5 20150623 (Red Hat 4.8.5-14)]
Видеть, как он доходит до конца пьесы, и не получать фьютекс и закрывающие запросы. Из основной работы, которая показывает проблему:
21:39:26 stat("/var/lib/awx/projects/<job>/host_vars", 0x7ffd4ce0dfd0) = -1 ENOENT (No such file or directory)
21:39:26 stat("/var/lib/awx/.cache/facts/<host>", 0x7ffd4ce0dae0) = -1 ENOENT (No such file or directory)
21:39:26 stat("/var/lib/awx/.cache/facts/<host>", 0x7ffd4ce0dcf0) = -1 ENOENT (No such file or directory)
21:39:26 select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
21:39:26 select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
... infinite Timeout
От успешной работы:
21:39:39 stat("/var/lib/awx/projects/<job>/host_vars", 0x7ffd4ce0dfd0) = -1 ENOENT (No such file or directory)
21:39:39 stat("/var/lib/awx/.cache/facts/<host>", 0x7ffd4ce0dae0) = -1 ENOENT (No such file or directory)
21:39:39 stat("/var/lib/awx/.cache/facts/<host>", 0x7ffd4ce0dcf0) = -1 ENOENT (No such file or directory)
21:39:39 select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
21:39:39 select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
21:39:39 futex(0x7fb178001390, FUTEX_WAKE_PRIVATE, 1) = 1
21:39:39 futex(0x1e9d090, FUTEX_WAKE_PRIVATE, 1) = 1
21:39:39 futex(0x1e9d090, FUTEX_WAIT_PRIVATE, 0, NULL) = 0
21:39:39 futex(0x1e9d090, FUTEX_WAIT_PRIVATE, 0, NULL) = 0
21:39:39 futex(0x1e9d090, FUTEX_WAIT_PRIVATE, 0, NULL) = 0
21:39:39 futex(0x1e9d090, FUTEX_WAIT_PRIVATE, 0, NULL) = 0
21:39:39 futex(0x7f15690, FUTEX_WAKE_PRIVATE, 1) = 1
21:39:39 futex(0x1e9d090, FUTEX_WAKE_PRIVATE, 1) = 1
21:39:39 futex(0x711f9e0, FUTEX_WAIT_PRIVATE, 0, NULL) = -1 EAGAIN (Resource temporarily unavailable)
21:39:39 close(7) = 0
... continues to close and wrap up
@benapetr / @jmighion, как вы, ребята, решили основную проблему? Попытка найти обходной путь, когда возникают подобные проблемы
Это может произойти по нескольким причинам. Я никогда не говорил, что нашел решение. Теоретически вы можете запустить playbook вручную в цикле на каждом хосте отдельно, чтобы выяснить, какой из них вызывает проблемы, а затем вам нужно исследовать этот хост.
Хороший пример проблемы, которая может вызвать это, — отключение монтирования NFS, которое может зависнуть даже при выполнении команды «df».
Извините, не помню, как нашел решение. Я думаю, что наш висел на устройстве, к которому мы пытались подключиться, но, честно говоря, не могу сказать. Однако мы больше не решаем проблему.
https://github.com/ansible/ansible/issues/30411#issuecomment -360766621
Хороший пример проблемы, которая может вызвать это, — отключение монтирования NFS, которое может зависнуть даже при команде> «df».
Это была моя проблема. Ни один параметр ansible.cfg (ни тайм-аут fact_caching_timeout) не помог мне прервать процесс. Спасибо огромное!
ИМО, это может привести к ошибке / тайм-ауту на управляющей машине.
У меня была аналогичная проблема, я установил pipelining с True на False , запустил playbook (успешно после этого изменения), а затем вернулся к True после чего последующие прогоны playbook также работали правильно.
Изменить: @benapetr : Спасибо! На самом деле это была основная проблема. Папка монтируется через SSHFS через обратный SSH-туннель (для отправки с управляющей машины ansible). После ручного подключения через SSH к целевой машине и размонтирования umount -l ... проблема исчезла.
Похоже, у меня аналогичная проблема с ansible и монтированием nfs на цели. lsof, df, ansible .. все висит.
Установка конвейерной обработки на false в ansible.cfg не помогла.
@jeroenflvr : В моем случае монтирование sshfs зависает (также при вызове команды монтирования вручную). Я перешел на монтирование CIFS / samba через обратный туннель SSH и теперь он работает без зависаний. Кажется, что это частично связано с плавлением, но не с анзиблем.
не имеет значения, вызвано ли зависание на целевом хосте предохранителем, nfs или чем-то еще, это все еще ошибка Ansible в том смысле, что 1 целевой хост не может заблокировать всю игру для всех других хостов.
Должен быть какой-то тайм-аут или реализован внутренний сторожевой таймер, который убивал бы playbook для неправильного поведения и сломанных машин. 1 сломанная машина из 5000 не должна ломать Ansible для всех 5000 машин.
@benapetr да, когда- разобраться . не как ошибка, а как проблема дизайна, такие зависания являются большой чумой, и ни одно «исправление» не решит их по-настоящему. Я иногда использовал его с 2011 года, и ИМО, так будет всегда, пока, наконец, кто-то не примет, что что-то должно быть сделано на более высоком уровне.
То же самое для меня.
У меня шесть хостов MacOS, и я запускаю:
ansible-playbook tcmacagents.yml -f 6
Он висит на первом этапе «Сбор фактов». Всегда на одном хосте (tcmacagent5):
« `ЗАДАЧ [Сбор Факты] * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
хорошо: [tcmacagent1]
хорошо: [tcmacagent2]
хорошо: [tcmacagent6]
хорошо: [tcmacagent3]
хорошо: [tcmacagent4]
strace:
```[pid 24072] select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
[pid 24072] wait4(24211, 0x7ffc608410a4, WNOHANG, NULL) = 0
[pid 24072] wait4(24211, 0x7ffc608410d4, WNOHANG, NULL) = 0
[pid 24072] select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
[pid 24072] wait4(24211, 0x7ffc608410a4, WNOHANG, NULL) = 0
[pid 24072] wait4(24211, 0x7ffc608410d4, WNOHANG, NULL) = 0
[pid 24072] select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
[pid 24072] wait4(24211, 0x7ffc608410a4, WNOHANG, NULL) = 0
[pid 24072] wait4(24211, 0x7ffc608410d4, WNOHANG, NULL) = 0
[pid 24072] select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
[pid 24072] wait4(24211, 0x7ffc608410a4, WNOHANG, NULL) = 0
[pid 24072] wait4(24211, 0x7ffc608410d4, WNOHANG, NULL) = 0
[pid 24072] select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
[pid 24072] wait4(24211, 0x7ffc608410a4, WNOHANG, NULL) = 0
[pid 24072] wait4(24211, 0x7ffc608410d4, WNOHANG, NULL) = 0
[pid 24072] select(0, NULL, NULL, NULL, {0, 1000}) = 0 (Timeout)
Как я могу это исправить? Что не так с моим tcmacagent5?
# ansible --version
ansible 2.5.0
Если это монтирование, и его нельзя использовать (коснитесь файла или чего-то еще), перемонтируйте его. В моей особой ситуации я всегда возвращал виртуальную машину к моментальному снимку для тестирования, и дескриптор NFS не совпадает с этой виртуальной машиной, поэтому он находится в устаревшем состоянии
Мы также наблюдали зависание Ansible без каких-либо сообщений об ошибке при запуске playbooks на 23 хостах с forks=25 . Мы используем Ansible 2.2.3.0, но имеем ту же проблему с Ansible 2.5.3. Мы запускаем наши плейбуки из macOS 10.12.6, используя Python 2.7.15. С forks=5 я не вижу проблемы. Мы также не видим проблемы при использовании transport=paramiko (и forks=25 ).
У нас такая же проблема. Playbook случайно зависает во время воспроизведения без сообщений об ошибках. После нажатия ctrl + c пьеса продолжается.
Для меня это тоже проблема, когда я использую ansible 2.16.1. Я думаю, что это чаще всего происходит на этапе сбора фактов, когда df зависает (в моем случае). должен быть механизм для сбора фактов с возможностью исключения некоторых его частей (?), … просто thoguht.
У меня такая же проблема, какой-то тайм-аут (в основном приостановка воспроизведения без ошибок)
Я использую плагин подключения kubectl ansible для подключения моих модулей kubernetes и запуска playbook на этих хостах (3 модуля). это очень медленно, например, для запуска каждого модуля на удаленном хосте требуется 8 секунд, а пауза в середине плейбука выглядит странно без каких-либо ошибок или массажа
Как может столь серьезный вопрос оставаться нерешенным так долго?
Ни у кого нет времени работать над исправлением?
@pillarsdotnet : в конце концов я переключился на монтирование CIFS / samba, и проблем с зависанием нет.
Я вижу эту проблему, когда сеть вообще не монтируется. Просто обычные экземпляры AWS под управлением Ubuntu 18.
Хорошо, после проверки того, на каком сеансе ssh он застрял, выяснилось, что в моем случае это было вечно, потому что не удалось подключиться к зеркалам. Конечно, любой другой процесс зависания может / будет делать то же самое. Реальная проблема, которую нужно решить, — это таймауты в целом
@strarsis вы также можете просто использовать мягкое крепление вместо жесткого (которое говорит ему блокировать! на @tuxick , проблема в том, что для удаленных таймаутов нет обработки ошибок. Ручное исправление тривиальных тайм-аутов в окружающем окружении, чтобы автоматизация могла управлять им … ПОЧЕМУ ДАЖЕ ОБСУЖДАЕТСЯ?
(часть «df» сборки может выйти из строя законно, или модуль «yum» может выйти из строя … даже система может выйти из строя, если мы не сможем придумать что-то менее печальное. но чего не может быть, так это зависания всего run_ против env)
Да, если я не смогу придумать обходной путь, я официально порекомендую нам перейти от анзибля к более зрелой системе автоматизации.
@tuxick Итак, я должен заменить это:
- name: Something that might hang
module:
param: data
option: value
с этим:
- name: Something that might hang
block:
- module:
param: data
option: value
async: '{{ async_timeout|default(1000) }}'
register: 'something_that_might_hang'
- async_status:
jid: '{{ something_that_might_hang.ansible_job_id }}'
register: '{{ something_that_might_hang_result }}'
retries: '{{ async_retries|default(30) }}'
until: 'something_that_might_hang_result is defined and
"finished" in something_that_might_hang_result and
something_that_might_hang_result.finished'
when: 'something_that_might_hang.ansible_job_id is defined'
Я пока придерживался простого «async: 300», но, конечно, он может выглядеть лучше :). Мне интересно, должна ли какая-то форма тайм-аута быть встроена в модули, которые могут страдать от таких проблем. В любом случае, только те, которые я когда-либо видел, продолжались вечно, были nfs и yum.
Большинство зависаний, которые я вижу, связаны с pip.
Фактически, вышеуказанный шаблон не работает, с ошибкой, указывающей, что предложение when не может быть оценено, потому что переменная в предложении register не определена.
(обновленный шаблон …)
Простой способ избежать зависаний, если вы можете определить потенциально зависающие задачи.
Замените это:
- name: Something that might hang
module:
param: data
option: value
с этим:
- name: Something that might hang
module:
param: data
option: value
async: '{{ async_timeout|default(1000) }}'
poll: '{{ async_poll|default(10) }}'
Я должен согласиться с тем, что мы сталкивались с этой проблемой несколько раз, когда у нас более 1000 серверов в инвентаре, и это похоже на клиентов. У каждого модуля должен быть тайм-аут, который должен просто перейти к следующему хосту или задаче, если что-то застряло на xx минут. Каждый раз нам приходится сокращать количество хостов в инвентаре и запускать задания снова и снова. К тому времени, когда мы дойдем до последнего набора, проблема будет решена с плохим хостом, и мы не сможем понять, что пошло не так.
У меня такая же проблема с фактом с ansible 2.5.1
Я использовал ограниченный факт gather_subset = network, которого мне достаточно, так как мне нужна только информация об ip, ядре и ОС для установки моих group_vars, похоже, все в порядке
но похоже, что некоторые модули используют lsof, например, zypper, я думаю, у меня застрял playbook, который застрял, глядя на prcesses, узнаю lsof -n -FpcuLRftkn0, после его убийства playbook начинает возобновляться 
когда дело доходит до обновления большого количества серверов, это настоящая боль
Итак, мы изучаем несколько вещей, которые могут помочь: # 47684 добавляет новое событие для обратных вызовов, чтобы показать, на каком хосте запускается задача, затем вы можете сравнить с завершенными хостами, чтобы выяснить, какой из них завис.
Другая линия атаки — # 49398, которая в большинстве случаев пытается справиться с основным подозреваемым / виновником, запрашивая информацию о монтировании, это надеется как ускорить процесс, отказаться от заблокированных проверок и сообщить либо полную информацию, либо причину, по которой мы не смогли (тайм-аут или фактическая ошибка).
Привет,
эта проблема существует и в анзибле 2.6
ansible 2.6.11
config file = None
configured module search path = [u'/home/pkolze/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module location = /home/pkolze/.virtualenvs/ansible26/local/lib/python2.7/site-packages/ansible
executable location = /home/pkolze/.virtualenvs/ansible26/bin/ansible
python version = 2.7.13 (default, Sep 26 2018, 18:42:22) [GCC 6.3.0 20170516]
с моей стороны, проблема вызвана oom:
[2507.235957] Недостаточно памяти: завершите процесс 14022 (ansible-playboo), набрав 393 балла, или принесите в жертву ребенка.
[2507.238181] Прерванный процесс 14022 (ansible-playboo) total-vm: 408724kB, anon- rss: 175508kB , file- rss: 732kB
определенно не имеет отношения к анзиблю
мои 2 цента
когда я запускаю команду с wait_for и тайм-аутом, тайм-аут не работает, если соединение с хостом разорвано. в этом примере он работал два часа и должен умереть через 60 минут. соединение с хостом разрывается из-за перезагрузки. было бы хорошо, если бы тайм-аут обрабатывал разорванное соединение, если нет другого варианта.
- name: "Wait until Softnas Update completes. This can take 15-45 mins"
wait_for:
path: /tmp/softnas-update.status
search_regex: "^OK. SoftNAS software update to version.*completed at.*$"
timeout: 3600
when: update_file.stat.exists and softnas_runupdate
Спасибо, что поделились, это круто!
@pillarsdotnet Кажется, что ansible не поддерживает include_tasks с until (https://github.com/ansible/ansible/issues/17098). Как ты заставил его работать в файле /tasks/again.yml ? (Я тестировал с ansible 2.7.8)
@lucasbasquerotto — Я думаю, это не работает, как я ожидал. Надо переосмыслить это. Благодарю.
@pillarsdotnet Мне удалось заставить его работать, again.yml (с использованием диапазона от 0 до количества повторных попыток) и добавив время ожидания в loop.yml (чтобы _sleep_ на каждой итерации ):
_again.yml: _
- name: 'retries'
set_fact:
watch_retries: '{{ watch_timeout / watch_poll }}'
- name: 'checking {{ watch_job }} status until finished'
include_tasks: 'loop.yml'
loop: "{{ range(0, watch_retries | int, 1) | list }}"
_loop.yml: _
...
- wait_for:
timeout: '{{ watch_poll | int }}'
when: not watch_status.finished
...
Просто убедитесь, что количество повторных попыток не слишком велико, иначе он может вернуть ошибку о памяти или что-то в этом роде (потому что ansible сделает каждое включение до фактического запуска цикла), поэтому, если тайм-аут равен 3600, сделайте опрос как 10 ( вместо 1), так что включение будет выполнено 360 раз (вместо 3600).
Другое дело, что если длительное задание выполняется с каким-то пользователем, вызов async_status в loop.yml должен быть тем же пользователем (важно помнить об этом при запуске с become: yes ).
Просто наткнулся на эту проблему при попытке использовать модуль сценария для одного из моих сценариев подготовки. Нет проблем в более раннем использовании модуля сценария (в той же книге), но по какой-то причине на этом он завис навсегда.
Затем я попытался изменить модуль сценария на копирование сценария на мой /usr/bin/ а затем запустить его с модулем оболочки, который работал.
небольшое смягчение, это позволяет увидеть, какие хосты запущены # 53819
Та же проблема при использовании ansible в докере.
ansible 2.7.8
config file = None
configured module search path = ['/home/jenkins/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/local/lib/python3.7/site-packages/ansible
executable location = /usr/local/bin/ansible
python version = 3.7.2 (default, Mar 5 2019, 06:22:51) [GCC 6.3.0 20170516]
Я столкнулся с этой проблемой при развертывании на одни и те же виртуальные машины (все они являются клонами одной и той же машины). Некоторые из них клонируют публичное репо, а другие просто вешают
У меня такая же проблема с одиночной задачей. Вот результат с ANSIBLE_DEBUG=1 (немного отредактирован)
< TASK [myrole : Set Admnistrator SSH key] >
----------------------------------------------------
^__^
(oo)_______
(__) )/
||----w |
|| ||
task path: /home/kvaps/git/myrepo/myproject/roles/myrole/tasks/myrole.yaml:54
29952 1559645685.71733: sending task start callback
29952 1559645685.71745: entering _queue_task() for stage/raw
29952 1559645685.72714: worker is 1 (out of 1 available)
29952 1559645685.72762: exiting _queue_task() for stage/raw
29952 1559645685.72783: done queuing things up, now waiting for results queue to drain
29952 1559645685.72794: waiting for pending results...
30001 1559645685.73159: running TaskExecutor() for stage/TASK: myrole : Set Admnistrator SSH key
30001 1559645685.73825: in run() - task 10e7c6f3-602f-cf0b-3453-000000000030
30001 1559645685.74352: calling self._execute()
30001 1559645685.75753: Loading TestModule 'core' from /usr/lib/python3.7/site-packages/ansible/plugins/test/core.py (found_in_cache=True, class_only=False)
30001 1559645685.75836: Loading TestModule 'files' from /usr/lib/python3.7/site-packages/ansible/plugins/test/files.py (found_in_cache=True, class_only=False)
30001 1559645685.75904: Loading TestModule 'mathstuff' from /usr/lib/python3.7/site-packages/ansible/plugins/test/mathstuff.py (found_in_cache=True, class_only=False)
30001 1559645685.76498: Loading FilterModule 'core' from /usr/lib/python3.7/site-packages/ansible/plugins/filter/core.py (found_in_cache=True, class_only=False)
30001 1559645685.76653: Loading FilterModule 'ipaddr' from /usr/lib/python3.7/site-packages/ansible/plugins/filter/ipaddr.py (found_in_cache=True, class_only=False)
30001 1559645685.76768: Loading FilterModule 'json_query' from /usr/lib/python3.7/site-packages/ansible/plugins/filter/json_query.py (found_in_cache=True, class_only=False)
30001 1559645685.76894: Loading FilterModule 'k8s' from /usr/lib/python3.7/site-packages/ansible/plugins/filter/k8s.py (found_in_cache=True, class_only=False)
30001 1559645685.76996: Loading FilterModule 'mathstuff' from /usr/lib/python3.7/site-packages/ansible/plugins/filter/mathstuff.py (found_in_cache=True, class_only=False)
30001 1559645685.77076: Loading FilterModule 'network' from /usr/lib/python3.7/site-packages/ansible/plugins/filter/network.py (found_in_cache=True, class_only=False)
30001 1559645685.77162: Loading FilterModule 'urls' from /usr/lib/python3.7/site-packages/ansible/plugins/filter/urls.py (found_in_cache=True, class_only=False)
30001 1559645685.77279: Loading FilterModule 'urlsplit' from /usr/lib/python3.7/site-packages/ansible/plugins/filter/urlsplit.py (found_in_cache=True, class_only=False)
30001 1559645685.83815: trying /usr/lib/python3.7/site-packages/ansible/plugins/lookup
30001 1559645685.84568: Loaded config def from plugin (lookup/pipe)
30001 1559645685.84578: Loading LookupModule 'pipe' from /usr/lib/python3.7/site-packages/ansible/plugins/lookup/pipe.py
30001 1559645685.86089: Loaded config def from plugin (lookup/file)
30001 1559645685.86108: Loading LookupModule 'file' from /usr/lib/python3.7/site-packages/ansible/plugins/lookup/file.py
30001 1559645685.86125: File lookup term: /home/kvaps/git/myrepo/myproject/environments/stage/secrets/ssh_keys/administrator/id_rsa.pub
30001 1559645685.86928: trying /usr/lib/python3.7/site-packages/ansible/plugins/connection
30001 1559645685.87110: Loading Connection 'ssh' from /usr/lib/python3.7/site-packages/ansible/plugins/connection/ssh.py (found_in_cache=True, class_only=False)
30001 1559645685.87329: trying /usr/lib/python3.7/site-packages/ansible/plugins/shell
30001 1559645685.87513: Loading ShellModule 'sh' from /usr/lib/python3.7/site-packages/ansible/plugins/shell/sh.py (found_in_cache=True, class_only=False)
30001 1559645685.87623: Loading ShellModule 'sh' from /usr/lib/python3.7/site-packages/ansible/plugins/shell/sh.py (found_in_cache=True, class_only=False)
30001 1559645685.88879: Loading ActionModule 'raw' from /usr/lib/python3.7/site-packages/ansible/plugins/action/raw.py (searched paths: /usr/lib/python3.7/site-packages/ansible/plugins/action:/usr/lib/python3.7/site-packages/ansible/plugins/action/__pycache__) (found_in_cache=True, class_only=False)
30001 1559645685.89061: starting attempt loop
30001 1559645685.89151: running the handler
30001 1559645685.89317: _low_level_execute_command(): starting
30001 1559645685.89413: _low_level_execute_command(): executing: set user sshkey Administrator "ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQChKqNqqtE+Va3WCSzf7QGRkackZ0dwX0RYF1r6QoVEqf2sXNa07GNjPyJ9lmUM3d6Az41pI5aJt6JVIxQfihaz4JNuoN5HqiZe/RCZ/ztBEY2UkVJfMH/PnFqNhBc1Y73DYkfA2N2BU3daju9Pah4sTwt4pDlAoZImyxw4gnJ0M7Z5hWtKIV/nK/5/FU5+CB9cMPQQB6BqmHRPk85SuyVOiCOYC1sseC6rafBSwM5/1IbHNVEDL/+scfJnmRnQSlAjytxz0jIXpkPCXC0AXDYpjElYsCPxyM/9JDqjiQ5HZ+WVl3Ou+oXZ67ag7eacIZGxTcAfb3dzw0+FDCZdOMhn [email protected]"
<myhost.example.org> ESTABLISH SSH CONNECTION FOR USER: Administrator
<myhost.example.org> SSH: EXEC ssh -C -o ControlMaster=auto -o ControlPersist=60s -o StrictHostKeyChecking=no -o 'IdentityFile="/home/kvaps/git/myrepo/myproject/environments/stage/secrets/ssh_keys/administrator/id_rsa"' -o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-keyex,hostbased,publickey -o PasswordAuthentication=no -o 'User="Administrator"' -o ConnectTimeout=10 -o Ciphers=+aes128-cbc -o ControlPath=/home/kvaps/.ansible/cp/5dbae0ef82 -tt myhost.example.org 'set user sshkey Administrator "ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQChKqNqqtE+Va3WCSzf7QGRkackZ0dwX0RYF1r6QoVEqf2sXNa07GNjPyJ9lmUM3d6Az41pI5aJt6JVIxQfihaz4JNuoN5HqiZe/RCZ/ztBEY2UkVJfMH/PnFqNhBc1Y73DYkfA2N2BU3daju9Pah4sTwt4pDlAoZImyxw4gnJ0M7Z5hWtKIV/nK/5/FU5+CB9cMPQQB6BqmHRPk85SuyVOiCOYC1sseC6rafBSwM5/1IbHNVEDL/+scfJnmRnQSlAjytxz0jIXpkPCXC0AXDYpjElYsCPxyM/9JDqjiQ5HZ+WVl3Ou+oXZ67ag7eacIZGxTcAfb3dzw0+FDCZdOMhn [email protected]"'
30001 1559645685.96164: stdout chunk (state=2):
>>>set user sshkey Administrator "ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQChsiesjhJ9Vyo9WPxMvaytVkX3TAOCiAqMk1ay8D5UlbC6eKHU4fPbnLIt1dkU87+WMak4NAx8l/QurqrzimvUIVwtc6LLtvCj1ZY1GVDu9z3XFPno6xp63lQHMDGnf1jb0PalNWd86tlpR6uU/48BvzPutpZ86Hgp7cFBf7C94j33dO87/rnVdItUVgCIM+W4VtToEMZfMj8V9qKuOX9KW16z0MYBAqMKcY+jUVI6tpD1R+ltuuG+qG8omHG1RTAR5IpyrWYFDOfSk79N87gbZljaYAsdHfuc1f2mJLTZ5lmqT0ansOpqHwWXXxfieo8xKDplFyy6nb5HfJNE8qFDuuJkHwwnRqtjUTDomHYrS/+OKSXWcrOKYBzmgRZO0sRiZT+OJ6kL3nykzKPXOpzoJA09cUrmszaFSyixJZJlibXHjJ4b6dan0c0rIoBb7dQlzSiJw3G57lr8aj9LcjeqbYXrZDSPG7qy37azIyW65O514ZfosxQbjYaMZojfbAs= [email protected]"
strace:
epoll_wait(10, [], 2, 7976) = 0
wait4(31685, 0x7fff339a4c74, WNOHANG, NULL) = 0
epoll_wait(10, [], 2, 12000) = 0
wait4(31685, 0x7fff339a4c74, WNOHANG, NULL) = 0
epoll_wait(10, [], 2, 12000) = 0
wait4(31685, 0x7fff339a4c74, WNOHANG, NULL) = 0
epoll_wait(10, [], 2, 12000) = 0
wait4(31685, 0x7fff339a4c74, WNOHANG, NULL) = 0
доступный:
ansible 2.8.0
config file = /etc/ansible/ansible.cfg
configured module search path = ['/home/kvaps/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python3.7/site-packages/ansible
executable location = /usr/bin/ansible
python version = 3.7.3 (default, Mar 26 2019, 21:43:19) [GCC 8.2.1 20181127]
Я использую модуль raw
Кстати, я исправил это, добавив в ansible.cfg:
[ssh_connection]
control_path = none
+ ярлык влияет на_2.7
То же самое происходит в # 57780 — ansible-playbook ожидает завершения работы модуля shell на удаленном узле (ах), а затем он зависает навсегда, когда это действие занимает слишком много времени и множество «Невозможно выделить память »появляются незадолго до этого. strace также показывает то же самое, что и другие люди здесь ( WNOHANG ).
Я не понимаю, почему не срабатывают определенные тайм-ауты? — например:
connect_timeout
command_timeout
accelerate_timeout
accelerate_connect_timeout
accelerate_daemon_timeout
Эта ошибка обнаружена уже более 640 дней и все еще возникает.
Мои два цента:
Для меня Ansible зависает, потому что я настраиваю и включаю UFW где-то в одной из моих включенных книг.
Когда UFW включен, серверы Ubuntu через определенное время ломают открытые сокеты. Таким образом, Ansible мог продолжать выполнение других задач и внезапно зависал позже, примерно через 15 секунд после включения UFW.
Решение состоит в том, чтобы настроить ubuntu так, чтобы соединения оставались активными при включении брандмауэра.
Я нашел решение здесь: https://github.com/ansible/ansible/issues/45446
Это решает проблему для меня:
- name: Configure the kernel to keep connections alive when enabling the firewall
sysctl:
name: net.netfilter.nf_conntrack_tcp_be_liberal
value: 1
state: present
sysctl_set: yes
reload: yes
- name: Enable ufw
ufw: state=enabled
Я исправил это, установив transport = paramiko в ansible.cfg
Я все еще сталкиваюсь с той же проблемой с openstack-ansible
Я пробовал все вышеупомянутые комбинации ansible.cfg, но ничего не помогло
ansible --version
configured module search path = [u'/etc/ansible/roles/config_template/library', u'/etc/ansible/roles/plugins/library', u'/etc/ansible/roles/ceph-ansible/library']
ansible python module location = /opt/ansible-runtime/lib/python2.7/site-packages/ansible
executable location = /opt/ansible-runtime/bin/ansible
python version = 2.7.5 (default, Jun 20 2019, 20:27:34) [GCC 4.8.5 20150623 (Red Hat 4.8.5-36)]
следы:
# ansible -m setup 192.168.56.102 -vvv
Variable files: "-e @/etc/openstack_deploy/user_secrets.yml -e @/etc/openstack_deploy/user_variables.yml "
ansible 2.7.9
config file = None
configured module search path = [u'/etc/ansible/roles/config_template/library', u'/etc/ansible/roles/plugins/library', u'/etc/ansible/roles/ceph-ansible/library']
ansible python module location = /opt/ansible-runtime/lib/python2.7/site-packages/ansible
executable location = /opt/ansible-runtime/bin/ansible
python version = 2.7.5 (default, Jun 20 2019, 20:27:34) [GCC 4.8.5 20150623 (Red Hat 4.8.5-36)]
No config file found; using defaults
/opt/openstack-ansible/inventory/dynamic_inventory.py did not meet host_list requirements, check plugin documentation if this is unexpected
Parsed /opt/openstack-ansible/inventory/dynamic_inventory.py inventory source with script plugin
/opt/openstack-ansible/inventory/inventory.ini did not meet host_list requirements, check plugin documentation if this is unexpected
/opt/openstack-ansible/inventory/inventory.ini did not meet script requirements, check plugin documentation if this is unexpected
/opt/openstack-ansible/inventory/inventory.ini did not meet yaml requirements, check plugin documentation if this is unexpected
Parsed /opt/openstack-ansible/inventory/inventory.ini inventory source with ini plugin
/etc/openstack_deploy/inventory.ini did not meet host_list requirements, check plugin documentation if this is unexpected
/etc/openstack_deploy/inventory.ini did not meet script requirements, check plugin documentation if this is unexpected
/etc/openstack_deploy/inventory.ini did not meet yaml requirements, check plugin documentation if this is unexpected
Parsed /etc/openstack_deploy/inventory.ini inventory source with ini plugin
META: ran handlers
Using module file /opt/ansible-runtime/lib/python2.7/site-packages/ansible/modules/system/setup.py
<192.168.56.102> ESTABLISH SSH CONNECTION FOR USER: None
<192.168.56.102> SSH: EXEC ssh -C -o ControlMaster=auto -o ControlPersist=60s -o StrictHostKeyChecking=no -o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-keyex,hostbased,publickey -o PasswordAuthentication=no -o ConnectTimeout=5 -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no -o ServerAliveInterval=64 -o ServerAliveCountMax=1024 -o Compression=no -o TCPKeepAlive=yes -o VerifyHostKeyDNS=no -o ForwardX11=no -o ForwardAgent=yes -T -o ControlPath=none 192.168.56.102 '/bin/sh -c '"'"'/usr/bin/python && sleep 0'"'"''
ценил любую помощь
благодаря
@ rakeshz11
Здесь та же проблема, что и сегодня утром при запуске ansible через упаковщик. Буквально не знаю, что изменилось, но сегодня утром все сломалось 👍
Одна вещь, которую я заметил с помощью Ubuntu 18.04 (протестированная капля за 5 долларов в Digital Ocean), заключается в том, что если я установлю ansible с помощью pip3 (используя python3 , но, возможно, это произойдет с python2 и pip тоже) ansible в некоторых случаях зависает надолго (иногда это случалось, но не всегда, но если я продолжал выполнять playbook, это происходило время от времени более одного раза).
Странно то, что когда анзибл зависал, даже при нажатии Ctrl^C и повторной попытке выполнить playbook, он немедленно зависал, и анзибл зависал даже при запуске ansible --version . Еще более странно то, что даже запуск python --version завис (но запуски echo "something" и ls работали нормально). Даже если я отключился от SSH и подключился снова, он продолжал зависать в течение нескольких минут (а затем снова работал в течение некоторого времени).
В конце концов, я удалил ansible (2.8) с помощью pip3 и установил с помощью apt , и этого больше не произошло.
Эй, ребята.
В моем случае Ansible зависал в «сборе фактов» из-за двух записей в моем known_hosts. Я узнал, когда пытался использовать ssh вручную:
Warning: the RSA host key for '****' differs from the key for the IP address '****'
Offending key for IP in /****/known_hosts:168
Matching host key in /****/known_hosts:368
Are you sure you want to continue connecting (yes/no)? ^C
После удаления этих двух записей и повторного запуска ssh вручную (чтобы поместить правильную запись в known_hosts) Ansible больше не зависал.
Надеюсь, поможет!
это досадный баг, но этой «компании» все равно плевать
Действительно полезная информация @gophobic … спасибо за ваш вклад. 👍
Наш способ решения этой проблемы — запускать playbooks с использованием -u (имя пользователя) и запускать сценарий bash, который сканирует и уничтожает открытые сеансы ssh, которые существуют по прошествии определенного времени, и уничтожает PID, когда мы можем предположить, что хост заставляя playbook зависать. Я обычно делаю это на этапе сбора фактов или в какой-нибудь другой, не имеющей большого значения, манекен, чтобы проверить связь. Если все проблемные хосты будут уничтожены с помощью этого метода, они просто не будут работать в playbook, и это будет продолжаться до конца воспроизведения, поскольку все хосты, которые могут вызвать зависание, уже вышли из строя.
Я изучил параметр ANSIBLE_SHOW_PER_HOST_START = True, который может помочь определить, какие хосты вызывают проблему, но я все равно предпочел бы иметь возможность запустить playbook и знать, что он завершится, а затем смогу справиться с любыми сбоями, которые могли произойти после факта.
Можно ли реализовать предварительную проверку, чтобы убедиться, что Ansible может подключиться к каждому хосту и сразу же выйти из строя, если нет?
Наш способ решения этой проблемы — запускать playbooks с использованием -u (имя пользователя) и запускать сценарий bash, который сканирует и уничтожает открытые сеансы ssh, которые существуют по прошествии определенного времени, и уничтожает PID, когда мы можем предположить, что хост заставляя playbook зависать. Я обычно делаю это на этапе сбора фактов или в какой-нибудь другой, не имеющей большого значения, манекен, чтобы проверить связь. Если все проблемные хосты будут уничтожены с помощью этого метода, они просто не будут работать в playbook, и это будет продолжаться до конца воспроизведения, поскольку все хосты, которые могут вызвать зависание, уже вышли из строя.
Делаем то же самое, но очищаем файловую систему / proc, чтобы найти время запуска процесса ssh, а затем убиваем через n секунд. К сожалению, это приводит к срабатыванию SSH_RETRIES, поэтому сценарий уничтожения должен запускаться несколько раз.
Мы работаем с инвентаризацией нескольких тысяч хостов, поэтому нецелесообразно включать дальнейшую отладку, чтобы сузить проблему. Сокращение инвентаря до нескольких сотен хостов по-прежнему вызывает проблему. Как заявляли другие, переключение мультиплексора, изменение параметров ControlMaster, конвейерная обработка, paramiko не помогли.
В нашей среде мы видим, что процессы ssh mux зависли; strace показывает системные вызовы опроса, но процессы, если они не убиты, остаются активными в течение нескольких часов / дней. Процессу ansible supervisor действительно необходимо реализовать жесткую остановку или тайм-аут жесткого отключения.
Я считаю, что это также может быть связано с недосмотром в реализации повторных попыток подключения SSH (и отсутствием / плохой документацией, насколько я мог видеть).
SSH-соединения в ansible также зависят от вашего локального .ssh / config или вашего хоста / etc / ssh / ssh_config в дополнение к стандартным файлам ansible.cfg.
Я обнаружил это при попытке диагностировать зависания из-за модуля wait_for_connection.
Пока выполняется основная команда SSH, в журналах ничего не печатается — даже на уровнях детализации, показанных ниже, — потому что ansible фактически зависает в ожидании, пока SSH вернет управление. Похоже, это синхронный exec ().
Возможные детали:
❯ ansible-playbook --version
ansible-playbook 2.9.0
config file = None
configured module search path = ['~/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/local/Cellar/ansible/2.9.0/libexec/lib/python3.7/site-packages/ansible
executable location = /usr/local/bin/ansible-playbook
python version = 3.7.5 (default, Nov 1 2019, 02:16:23) [Clang 11.0.0 (clang-1100.0.33.8)]
Следующее будет работать в течение 10 м , источники .ssh / config: ConnectionAttempts 10, no / default ansible.cfg:
❯ cat ans-test-conn.yml
- hosts: all
gather_facts: false
tasks:
- name: Wait for 60s
wait_for_connection:
timeout: 60
❯ ansible-playbook -vvvvvvvv -i8.8.8.8, ans-test-conn.yml
[...]
<8.8.8.8> SSH: EXEC ssh -vvv -C -o ControlMaster=auto -o ControlPersist=60s
-o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-keyex,hostbased,publickey
-o PasswordAuthentication=no -o ConnectTimeout=10 -o ControlPath=~/.ansible/cp/28faeff4e9 8.8.8.8 '/bin/sh -c '"'"'echo ~ && sleep 0'"'"''
[...]
>>> elapsed time 11m12s
Следующее будет работать в течение 30 м , исходники .ssh / config: ConnectionAttempts 10, SSH_ANSIBLE_RETRIES = 3:
❯ cat ans-test-conn.yml
- hosts: all
gather_facts: false
tasks:
- name: Wait for 60s
wait_for_connection:
timeout: 60
❯ export SSH_ANSIBLE_RETRIES=3
❯ ansible-playbook -vvvvvvvv -i8.8.8.8, ans-test-conn.yml
[...]
<8.8.8.8> SSH: EXEC ssh -vvv -C -o ControlMaster=auto -o ControlPersist=60s
-o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-keyex,hostbased,publickey
-o PasswordAuthentication=no -o ConnectTimeout=10 -o ControlPath=~/.ansible/cp/28faeff4e9 8.8.8.8 '/bin/sh -c '"'"'echo ~ && sleep 0'"'"''
<8.8.8.8> (255, b'', b'OpenSSH_7.9p1, LibreSSL 2.7.3rndebug1: Reading configuration data ~/.ssh/configrn
[...]
debug1: connect to address 8.8.8.8 port 22: Operation timed outrnssh: connect to host 8.8.8.8 port 22: Operation timed outrn')
<8.8.8.8> ssh_retry: attempt: 1, ssh return code is 255. cmd ([b'ssh', b'-vvv', b'-C', b'-o', b'ControlMaster=auto', b'-o', b'ControlPersist=60s',
b'-o', b'KbdInteractiveAuthentication=no', b'-o', b'PreferredAuthentications=gssapi-with-mic,gssapi-keyex,hostbased,publickey',
b'-o', b'PasswordAuthentication=no', b'-o', b'ConnectTimeout=10', b'-o', b'ControlPath=~/.ansible/cp/28faeff4e9',
b'8.8.8.8', b"/bin/sh -c 'echo ~ && sleep 0'"]...), pausing for 0 seconds
<8.8.8.8> SSH: EXEC ssh -vvv -C -o ControlMaster=auto -o ControlPersist=60s
-o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-keyex,hostbased,publickey
-o PasswordAuthentication=no -o ConnectTimeout=10 -o ControlPath=~/.ansible/cp/28faeff4e9 8.8.8.8 '/bin/sh -c '"'"'echo ~ && sleep 0'"'"''
[...]
>>> elapsed time 30m43s
Следующее будет фактически повторять в течение указанного нами времени, 60 с + 3 60 с, потому что мы перезаписываем * как ConnectTimeout, так и ConnectionAttempts (не уверен, действительно ли требуется ControlMaster = no, но я в основном переопределил wait_for_connection и не хотел конфликтовать с постоянный узел перехода ControlMaster):
❯ cat ans-test-conn-2.yml
- hosts: all
gather_facts: false
tasks:
- name: Wait for 60s
connection: local
shell: "ssh -oConnectTimeout=60s -oControlMaster=no -oConnectionAttempts=1 {{ inventory_hostname }} true"
register: ssh_conn_result
retries: 3
delay: 1
until: ssh_conn_result is not failed
[..]
<8.8.8.8> EXEC /bin/sh -c 'rm -f -r ~/.ansible/tmp/ansible-tmp-1573639556.634926-33012718610740/ > /dev/null 2>&1 && sleep 0'
FAILED - RETRYING: Wait for 60s (2 retries left).Result was: {
"attempts": 2,
"changed": true,
"cmd": "ssh -oConnectTimeout=60s -oControlMaster=no -oConnectionAttempts=1 8.8.8.8 true",
"delta": "0:01:00.052729",
"end": "2019-11-13 11:06:56.841326",
"invocation": {
"module_args": {
"_raw_params": "ssh -oConnectTimeout=60s -oControlMaster=no -oConnectionAttempts=1 8.8.8.8 true",
"_uses_shell": true,
"argv": null,
"chdir": null,
"creates": null,
"executable": null,
"removes": null,
"stdin": null,
"stdin_add_newline": true,
"strip_empty_ends": true,
"warn": true
}
},
"msg": "non-zero return code",
"rc": 255,
"retries": 4,
"start": "2019-11-13 11:05:56.788597",
"stderr": "ssh: connect to host 8.8.8.8 port 22: Operation timed out",
"stderr_lines": [
"ssh: connect to host 8.8.8.8 port 22: Operation timed out"
],
"stdout": "",
"stdout_lines": []
}
[..]
>>> elapsed time 4m5s
1 начальная попытка + 3 попытки => 4 мин.
Последний сценарий будет работать только в том случае, если вы не находитесь за хостом перехода с пользовательской командой (пока SSH обрабатывает соединение самостоятельно).
Если у вас есть узел перехода для подключения к месту назначения и пользовательская команда proxy_command, вам нужно будет увеличить задержку до 59-60 с, чтобы «повторять каждую минуту», в противном случае проксированная команда на узле перехода может немедленно завершиться ошибкой, и delay: 1 заставит ansible запускать все попытки как можно быстрее.
Я, наконец, перешел на доступный метод pull.
13 ноября 2019 г., 3:04 Fabio Scaccabarozzi <
[email protected]> написал:
Я считаю, что это также может быть связано с недосмотром при реализации
Повторные попытки подключения SSH (и отсутствие / плохая документация, насколько я мог
видеть).
На SSH-соединения в ansible также влияет ваш локальный .ssh / config
или / etc / ssh / ssh_config вашего хоста в дополнение к стандартному
файлы ansible.cfg.
Я обнаружил это при диагностике зависаний из-за
Модуль wait_for_connection.
Пока выполняется основная команда SSH, ничего не происходит.печатается в журналах — даже на уровнях детализации, показанных ниже — потому что
ansible фактически зависает, ожидая, пока SSH вернет управление. Кажется
быть синхронным exec ().Возможные детали:
❯ ansible-playbook — версия
ansible-playbook 2.9.0
файл конфигурации = Нет
настроенный путь поиска модуля = [‘~ / .ansible / plugins / modules’, ‘/ usr / share / ansible / plugins / modules’]
расположение модуля ansible python = /usr/local/Cellar/ansible/2.9.0/libexec/lib/python3.7/site-packages/ansible
расположение исполняемого файла = / usr / local / bin / ansible-playbook
версия python = 3.7.5 (по умолчанию, 1 ноября 2019 г., 02:16:23) [Clang 11.0.0 (clang-1100.0.33.8)]
Следующее будет работать в течение 10 м , исходники .ssh / config: ConnectionAttempts
10, нет / по умолчанию ansible.cfg:❯ кошка ans-test-conn.yml
хосты: все
gather_facts: false
задания:
имя: Подождите 60 с
wait_for_connection:
timeout: 60❯ ansible-playbook -vvvvvvvv -i8.8.8.8, ans-test-conn.yml
[…]
<8.8.8.8> SSH: EXEC ssh -vvv -C -o ControlMaster = auto -o ControlPersist = 60 с
-o KbdInteractiveAuthentication = no -o PreferredAuthentication = gssapi-with-mic, gssapi-keyex, hostbased, publickey
-o PasswordAuthentication = no -o ConnectTimeout = 10 -o ControlPath = ~ / .ansible / cp / 28faeff4e9 8.8.8.8 ‘/ bin / sh -c’ «‘»‘ echo ~ && sleep 0 ‘»‘» »
[…]
затраченное время 11 мин. 12 сек.
Следующее будет работать в течение 30 минут , исходники .ssh / config: ConnectionAttempts
10, SSH_ANSIBLE_RETRIES = 3:❯ кошка ans-test-conn.yml
хосты: все
gather_facts: false
задания:
имя: Подождите 60 с
wait_for_connection:
timeout: 60❯ экспорт SSH_ANSIBLE_RETRIES = 3
❯ ansible-playbook -vvvvvvvv -i8.8.8.8, ans-test-conn.yml
[…]
<8.8.8.8> SSH: EXEC ssh -vvv -C -o ControlMaster = auto -o ControlPersist = 60 с
-o KbdInteractiveAuthentication = no -o PreferredAuthentication = gssapi-with-mic, gssapi-keyex, hostbased, publickey
-o PasswordAuthentication = no -o ConnectTimeout = 10 -o ControlPath = ~ / .ansible / cp / 28faeff4e9 8.8.8.8 ‘/ bin / sh -c’ «‘»‘ echo ~ && sleep 0 ‘»‘» »
<8.8.8.8> (255, b », b’OpenSSH_7.9p1, LibreSSL 2.7.3 r ndebug1: чтение данных конфигурации ~ / .ssh / config r n
[…]
debug1: подключиться к адресу 8.8.8.8 порт 22: время ожидания истекло r nssh: подключиться к хосту 8.8.8.8 порт 22: время ожидания истекло r n ‘)
<8.8.8.8> ssh_retry: попытка: 1, код возврата ssh — 255. cmd ([b’ssh ‘, b’-vvv’, b’-C ‘, b’-o’, b’ControlMaster = auto ‘, b’-o ‘, b’ControlPersist = 60s’,
b’-o ‘, b’KbdInteractiveAuthentication = no’, b’-o ‘, b’PreferredAuthentication = gssapi-with-mic, gssapi-keyex, hostbased, publickey’,
b’-o ‘, b’PasswordAuthentication = no’, b’-o ‘, b’ConnectTimeout = 10′, b’-o ‘, b’ControlPath = ~ / .ansible / cp / 28faeff4e9’,
b’8.8.8.8 ‘, b «/ bin / sh -c’ echo ~ && sleep 0 ‘»] …), пауза на 0 секунд
<8.8.8.8> SSH: EXEC ssh -vvv -C -o ControlMaster = auto -o ControlPersist = 60 с
-o KbdInteractiveAuthentication = no -o PreferredAuthentication = gssapi-with-mic, gssapi-keyex, hostbased, publickey
-o PasswordAuthentication = no -o ConnectTimeout = 10 -o ControlPath = ~ / .ansible / cp / 28faeff4e9 8.8.8.8 ‘/ bin / sh -c’ «‘»‘ echo ~ && sleep 0 ‘»‘» »
[…]
затраченное время 30 мин. 43 сек.
Следующее будет фактически работать с указанным нами временем, 60 с, потому что мы
перезапись как ConnectTimeout, так и ConnectionAttempts (не уверен, что
ControlMaster = на самом деле не требуется, но я в основном переопределил
wait_for_connection и не хотел конфликтовать с постоянным хостом перехода
ControlMaster):❯ кошка ans-test-conn-2.yml
хосты: все
gather_facts: false
задания:
имя: Подождите 60 с
подключение: местное
оболочка: «ssh -oConnectTimeout = 60s -oControlMaster = no -oConnectionAttempts = 1 {{inventory_hostname}} true»
регистрация: ssh_conn_result
повторных попыток: 3
задержка: 1
пока: ssh_conn_result не завершится ошибкой
[..]
<8.8.8.8> EXEC / bin / sh -c ‘rm -f -r ~ / .ansible / tmp / ansible-tmp-1573639556.634926-33012718610740 /> / dev / null 2> & 1 && sleep 0’
СБОЙ — ПОВТОР: Подождите 60 секунд (осталось 2 попытки). Результат: {
"attempts": 2, "changed": true, "cmd": "ssh -oConnectTimeout=60s -oControlMaster=no -oConnectionAttempts=1 8.8.8.8 true", "delta": "0:01:00.052729", "end": "2019-11-13 11:06:56.841326", "invocation": { "module_args": { "_raw_params": "ssh -oConnectTimeout=60s -oControlMaster=no -oConnectionAttempts=1 8.8.8.8 true", "_uses_shell": true, "argv": null, "chdir": null, "creates": null, "executable": null, "removes": null, "stdin": null, "stdin_add_newline": true, "strip_empty_ends": true, "warn": true } }, "msg": "non-zero return code", "rc": 255, "retries": 4, "start": "2019-11-13 11:05:56.788597", "stderr": "ssh: connect to host 8.8.8.8 port 22: Operation timed out", "stderr_lines": [ "ssh: connect to host 8.8.8.8 port 22: Operation timed out" ], "stdout": "", "stdout_lines": []}
[..]
затраченное время 4 мин. 5 сек.
1 начальная попытка + 3 попытки => 4 мин.
Последний скрипт будет работать только в том случае, если вы не за прыгающим хостом с
настраиваемая команда (пока SSH обрабатывает само соединение).
Если у вас есть узел перехода для подключения к месту назначения и настраиваемый
proxy_command, вам нужно будет увеличить задержку до 59-60 секунд, чтобы «повторить попытку
каждую минуту «, в противном случае прокси-команда на хосте прыжка может завершиться ошибкой
немедленно, а задержка: 1 заставит доступный запускать все попытки так быстро, как
оно может.—
Вы получили это, потому что оставили комментарий.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/ansible/ansible/issues/30411?email_source=notifications&email_token=AFYYS45ZCK46WBT5ZXU32SDQTPNNVA5CNFSM4D3C4LI2YY3PNVWWK3TUL52HS4DFMVREX35
или отписаться
https://github.com/notifications/unsubscribe-auth/AFYYS43GNCJDVKSACEKRSWTQTPNNNVANCNFSM4D3C4LIQ
.
—
Смотрит,
Имам Туфик
213-700-5485
ssh -o "ConnectTimeout 60" [email protected]
или же
echo "ConnectTimeout 60" >> /etc/ssh/ssh_config
Я тоже столкнулся с этой проблемой. В моем случае был файл ~/.ssh/config в котором я объявил что-то вроде этого:
Host *.domain.tld
ForwardAgent yes
User user1
IdentityFile /home/me/id_rsa
После удаления содержимого файла все заработало.
В одном из наших проектов мы используем команды ad-hoc . Нам потребовалось время, чтобы понять, что это ошибка Ansible. Основная причина в том, что модуль setup работает правильно, когда мы выполняем:
ansible -m setup $IP
но когда мы выполняем это программно:
/bin/sh -c 'ansible -m setup $IP'
На некоторых машинах он висит навсегда.
Для нас это очень важно, потому что мы используем модуль setup для получения информации о системе, а затем используем их для установки правильных пакетов и настройки машины.
Мы бы не стали устанавливать «жесткий» тайм-аут, но попытались бы программно решить некоторые из наиболее распространенных проблем, мешающих работе setup
Поскольку это хорошо известная и устаревшая проблема, я думаю, было бы полезно написать об этом документ. Есть такой документ? Готовы ли мантейнеры написать это? Если оба ответа отрицательные, я напишу его сам и попрошу вас всех внести свой вклад.
Я столкнулся с аналогичной проблемой. Я запускаю команду RAW против маршрутизаторов Cisco и Juniper. Зависает только на некоторых устройствах. Работает 90% устройств. Может кому поможет. Присоединение вывода отладки после выполнения команды
Вот как я запускаю команду
ansible all -i «$ DEVICES» -m raw -a «$ COMMAND» -c paramiko —extra-vars «ansible_user = $ ans_user ansible_password = $ ans_password»
show_hang.txt
Я делаю примерно так:
- name: update system
yum:
name: '*'
state: latest # noqa 403
async: 600
register: yum_sleeper
- name: 'YUM - check on async task'
async_status:
jid: "{{ yum_sleeper.ansible_job_id }}"
register: job_result
until: job_result.finished
retries: 30
Спасибо @tuxick. Похоже, вы делаете повторные попытки.
Но в моем случае просто зависает. Я могу повторить попытку. Та же проблема.
Я добавил таймаут 45 перед командой Ansible. Но это не решает мою проблему.
тайм-аут 45 ansible all -i «$ DEVICES» -m raw -a «$ COMMAND» -c paramiko —extra-vars «ansible_user = $ ans_user ansible_password = $ ans_password»
Зачем это вручать ?? это висит на
<10.121.0.3> SSH: EXEC sshpass -d8 ssh -vvv -C -o ControlPersist = 120s -o StrictHostKeyChecking = no -o ‘User = «user»‘ -o ConnectTimeout = 10 -o ControlPath = / root / .ansible / cp / 5992772463 -tt’показать описания интерфейсов’
может кто-нибудь помочь посмотреть логи или у вас был подобный опыт? Большое спасибо.
У меня была такая же проблема, sftp глохнет.
Вероятно, большинство этих случаев зависит от неправильной конфигурации MTU.
Нередко Ansible работает в какой-то оверлейной сети, такой как VLAN или VxLAN. В последнем случае необходимо правильно настроить значение MTU функции vtep, чтобы разрешить фрагментацию кадров.
Я столкнулся с этой ошибкой в VxLAN со значением MTU функции VTEP 1500, таким же, как значение MTU базовой сети, равным 1500. Поэтому я настроил значение MTU 1450 на VTEP (для инкапсуляции VxLAN требуется 50 байтов).
В моей настройке интерфейс VTEP —
ip link set mtu 1450 eth100
ip link set mtu 1450 eth100p
Это решило мою проблему. Надеюсь поможет.
Ударьте это сейчас с инвентарем ~ 200 хостов. Я попал в это второй раз. Очень болезненный опыт. Зависание всей playbook из-за одного хоста — это очень плохо. Мы должны иметь возможность объявить некоторое max_time. Каждому хосту в моей среде требуется <единицы для сбора фактов. Тайм-аут 30 секунд исправит это для меня.
В этом случае я думаю, что один хост испытывает это: SSH отвечает, но затем зависает при входе в систему из-за отсутствия / home на этом хосте.
@halsafar : Да, я всегда думал, что ansible запускает playbook для каждого хоста независимо и параллельно. Приложение playbook на одном хосте не должно мешать работе другого.
Там, где в этом нет необходимости, НЕ собирайте факты, иначе получите именно то, что вам нужно.
Итак, в playbooks есть что-то вроде:
- hosts: hostgroup
gather_facts: no
tasks:
- name: Collect only network facts
setup:
gather_subset:
- '!all'
- network
и вы собираете именно то, что вам действительно_ нужно, с дополнительным преимуществом ускорения всего процесса.
В специальной команде у вас есть что-то вроде:
ansible -m <MODULE> -a "gather_subset=!all,network"
Вы также можете установить это в файле конфигурации.
Рекомендации
- Документ модуля установки
- См. Этот поток stackoverflow для различных примеров контекста
Запись
Пожалуйста, дважды проверьте синтаксис yml.
Там, где в этом нет необходимости, НЕ собирайте факты, иначе получите именно то, что вам нужно.
Итак, в playbooks есть что-то вроде:
- hosts: hostgroup gather_facts: no tasks: - name: Collect only network facts setup: gather_subset: - '!all' - networkи вы собираете именно то, что вам действительно_ нужно, с дополнительным преимуществом ускорения всего процесса.
В специальной команде у вас есть что-то вроде:
ansible -m <MODULE> -a "gather_subset=!all,network"Вы также можете установить это в файле конфигурации.
Рекомендации
- Документ модуля установки
- См. Этот поток stackoverflow для различных примеров контекста
Запись
Пожалуйста, дважды проверьте синтаксис yml.
Это действительно помогает, но некоторые модули полагаются на уровень FS системы, и если у вас будет зависать NFS, он застрянет
Мы сталкиваемся с этой ошибкой ежедневно на пуле из 40 000 хостов. Это приходит и уходит в зависимости от состояния хостов. Пока что единственный реальный обходной путь — разделить доступные задания на более мелкие партии в нашей оркестровке (мы используем http://screwdriver.cd). Это сводит к минимуму боль, но есть.
Наша инструкция предназначена для аудита, она очень минимальна и оптимизирована для скорости без сбора фактов и т. Д.:
- скопировать файл на хосты
- выполнить этот файл
- копировать результаты с хоста
Существует фундаментальная проблема, заключающаяся в том, что указанные значения тайм-аута не соблюдаются. Если программа на клиенте запущена, но находится в рабочем состоянии сна — потому что, например, она заходит в тупик. Или, возможно, ssh не работает должным образом: (предположительно) ssh-соединение успешно, но удаленная оболочка не завершает открытие из-за проблемы на уровне хоста. Это последнее условие можно наблюдать даже вручную, когда ssh-клиент не соблюдает свой тайм-аут, а также когда кто-то пытается ssh с плохим клиентом.
Это становится довольно серьезным препятствием, поскольку масштаб того, над чем вы работаете, увеличивается. У моей команды есть давление, чтобы заставить эту работу работать. Это означает, что мне нужно взломать или переключиться на другое программное обеспечение для управления заданиями. Прискорбно, что этот баг был открыт так долго
@jgurtz
в таком масштабе вы уже ответили себе, каким будет решение.
но также вернитесь к прошлогодним комментариям к этой заявке. За последние 2 года БЫЛО 1-2 человека с очень полезной информацией. Если бы я был на вашем месте, я бы искал их как временное решение. Но коренная проблема, вероятно, не исчезнет.
Спасибо за ответ. Я ссылался на эту ветку несколько раз за последний год, и AFAIKT, есть меры по устранению последствий, но нет обходных путей для этой проблемы. Если я пропустил что-то революционное, укажите это.
Я вижу, что некоторые люди в этом потоке сталкиваются с этой проблемой с меньшим количеством хостов и, по-видимому, корпоративными коммутаторами / маршрутизаторами. Я действительно хотел бы знать об этой ошибке до того, как начал.
Почти во всех моих случаях -vvvv показал достаточно, чтобы определить проблемы ssh, связанные с аутентификацией, паролями, ключами и т. Д. Я бы не стал утверждать, что это подходит другим, но для меня это правда. Было бы хорошо, если бы ansible предоставил более подробную информацию о проблемах аутентификации без повторного запуска с -vvvv, хотя …
Устранение отдельных проблем с подключением — не лучший вариант. Как только у вас будет
получить тысячи систем всегда будут какие-то проблемные. Назад в
’14 У меня просто было 2 preconditionihg playbooks, которые подключались и
тесты и только выжившие, где затем использовались для реальной инвентаризации. Но
это также означает, что мой инвентарь не был динамичным. Не особый смысл 
Но я хотел указать на …:
Для меня самый интересный пост в ветке был от Фабио. Этот
дает детерминированное поведение тайм-аута, если я хорошо понимаю:
Следующее будет фактически работать с указанным нами временем, 60 с, потому что мы
перезапись как ConnectTimeout, так и ConnectionAttempts (не уверен, что
ControlMaster = на самом деле не требуется, но я в основном переопределил
wait_for_connection и не хотел конфликтовать с постоянным хостом перехода
ControlMaster):
Джейсон Гуртц [email protected] schrieb am Do., 30. апр.2020, 22:26:
Спасибо за ответ. Я несколько раз упоминал эту тему
в прошлом году и AFAIKT, есть меры, но нет обходных путей для этого
вопрос. Если я пропустил что-то революционное, укажите это.Я вижу, что некоторые люди в этой теме сталкиваются с этой проблемой с заказами
значительно меньшее количество хостов и, по-видимому, корпоративные коммутаторы / маршрутизаторы
тоже. Я действительно хотел бы знать об этой ошибке до того, как начал.—
Вы получили это, потому что оставили комментарий.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/ansible/ansible/issues/30411#issuecomment-622091204 ,
или отписаться
https://github.com/notifications/unsubscribe-auth/AAVSVG74SBNZY624W3MYL2DRPHNINANCNFSM4D3C4LIQ
.
не устраняет «почему что-то зависает», но может создать способ избежать остановки воспроизведения # 69284
+1, мы сталкиваемся с одной и той же проблемой всякий раз, когда имеем дело с большими запасами, абсолютно не понимаю, почему anisble зависает и застревает на каком хосте … Можем ли мы иметь вариант, который покажет некоторые детали проблемного хоста, по крайней мере, …
@ Sreenadh8, запущенный с -vvv , покажет вам хосты, к которым он пытается подключиться, это не очень хорошо, но вы можете сравнить это с выводом «результатов», чтобы узнать, на каких хостах он застрял.
Я столкнулся с этими проблемами только с горсткой целевых хостов и смог выявить две вероятные первопричины:
- одновременные вызовы Ansible борются за файлы ControlPersist
- Ansible пытается повторно использовать существующее соединение SSH после перезапуска удаленного хоста, а затем истекает время ожидания должным образом
Основное исправление, казалось, заключалось в том, что потенциально одновременные вызовы определяли отдельные местоположения для ControlPath, но мы также начали явное удаление файлов сохраняемости, когда у нас были веские основания полагать, что они больше не будут действовать.
К сожалению, отладка такого рода проблем очень болезненна, так как существует множество потенциальных основных проблем SSH, которые проявляются как «Ansible зависает при вызове SSH без тайм-аута»
@ncoghlan meta: reset_connection должен обрабатывать удаление устаревшего файла сохранения управления, я рекомендую вам использовать это после действия reboot .
Это не только проблемы с ssh, во многих случаях ssh работает нормально, но sshpass или процесс на другом конце зависает / занимает много времени / блокируется. Мы постоянно пытаемся избавиться от возможных способов зависания, но это, вероятно, никогда не будет решено на 100% … просто пытаемся приблизиться к этому, насколько это возможно.
Вы проверяли патч, о котором я упоминал несколько сообщений назад? Мы столкнулись с той же (или похожей) проблемой в нашем продукте, и это оказалось ошибкой sshpass. Вид состояния гонки. И вероятность его попадания, казалось, коррелировала с загрузкой хоста, на котором работал ансибл. В нашем случае у нас было много хостов, которые мы развертывали с помощью ansible, и это вызывало большую нагрузку и более высокую вероятность возникновения проблемы. Но я могу представить, что мы могли бы достичь этого с меньшим количеством хостов, если бы у нашего доступного хоста была более высокая загрузка процессора по какой-либо другой причине.
Пожалуйста, проверьте https://sourceforge.net/p/sshpass/patches/11/, мы поместили более подробное объяснение проблемы. И соберите и попробуйте исправленную версию sshpass.
Причина проблемы может быть связана с некоторыми проблемами с сетью ipv6, отключением ipv6 или предпочтением, чтобы ipv4 работал у меня, см. Форум об этом
Привет,
Я Решма, у меня похожая проблема, так как мой доступный модуль просто зависает и не дает мне сбоев / пропущенного / статуса и ничего не делает на целевом хосте. если бы кто-нибудь мог помочь с этим, было бы здорово. Если это не тот форум, пожалуйста, помогите закрепить форум, на котором я могу обратиться за помощью.
Детали системы:
Целевой хост: SUSE 12 SP5
python-xml-2.7.17-28.51.1.x86_64
rpm-4.11.2-16.21.1.x86_64
zypper 1.13.51
Ответная команда:
ANSIBLE_DEBUG = 1 ansible -i / etc / ansible / hosts веб-серверы -k -m zypper -a ‘name = git-core state = present’ -v
Вывод отладки:
3676 1600772716.28160: _low_level_execute_command (): выполнение: / bin / sh -c ‘echo PLATFORM; uname; эхо НАЙДЕНО; команда -v ‘»‘» ‘/ usr / bin / python’ «‘»‘; команда -v ‘»‘» ‘python3.7’ «‘»‘; команда -v ‘»‘» ‘python3.6’ «‘»‘; команда -v ‘»‘» ‘python3.5’ «‘»‘; команда -v ‘»‘» ‘python2.7’ «‘»‘; команда -v ‘»‘» ‘python2.6’ «‘»‘; команда -v ‘»‘» ‘/ usr / libexec / platform-python’ «‘»‘; команда -v ‘»‘» ‘/ usr / bin / python3’ «‘»‘; command -v ‘»‘» ‘python’ «‘»‘; echo ENDFOUND && sleep 0 ‘
3676 1600772716.37768: блок stdout (состояние = 2):
ПЛАТФОРМА
<<<
3676 1600772716.37947: блок stdout (состояние = 3):
Linux
НАЙДЕННЫЙ
/ usr / bin / питон
<<<
3676 1600772716.37989: блок stdout (состояние = 3):
/usr/bin/python3.6
/usr/bin/python2.7
/ usr / bin / python3
/ usr / bin / питон
ENDFOUND
<<<
3676 1600772716.38378: блок stderr (состояние = 3):
<<<
3676 1600772716.38424: блок stdout (состояние = 3):
<<<
3676 1600772716.38484: _low_level_execute_command () выполнено: rc = 0, stdout = PLATFORM
Linux
НАЙДЕННЫЙ
/ usr / bin / питон
/usr/bin/python3.6
/usr/bin/python2.7
/ usr / bin / python3
/ usr / bin / питон
ENDFOUND
, stderr =
3676 1600772716.38530 [10.237.222.108]: найдены интерпретаторы: [u ‘/ usr / bin / python’, u ‘/ usr / bin / python3.6’, u ‘/ usr / bin / python2.7’, u ‘/ usr / bin / python3 ‘, u’ / usr / bin / python ‘]
3676 1600772716.38609: _low_level_execute_command (): запуск
3676 1600772716.38650: _low_level_execute_command (): выполнение: / bin / sh -c ‘/ usr / bin / python && sleep 0’
3676 1600772716.39569: Отправка исходных данных
3676 1600772716.39658: Отправлены исходные данные (1234 байта)
3676 1600772716.51494: блок stdout (состояние = 3):
{«osrelease_content»: «NAME = » SLES » nVERSION = » 12-SP5 » nVERSION_ID = » 12.5 » nPRETTY_NAME = » SUSE Linux Enterprise Server 12 SP5 » nID = » sles » nANSI_COLOR = » 0; 32 » nCPE_NAME = » cpe: / o: suse: sles : 12: sp5 » n», «platform_dist_result»: [«SuSE», «12», «x86_64 «]}
<<<
3676 1600772716.51914: блок stderr (состояние = 3):
<<<
3676 1600772716.51960: блок stdout (состояние = 3):
<<<
3676 1600772716.52014: _low_level_execute_command () done: rc = 0, stdout = {«osrelease_content»: «NAME = » SLES » nVERSION = » 12-SP5 » nVERSION_ID = » 12.5 » nPRETTY_NAME = » SUSE Linux Enterprise Server 12 SP5 » nID = » sles » nANSI_COLOR = » 0; 32 » nCPE_NAME = » cpe: / o: suse: sles : 12: sp5 » n», » platform_dist_result «: [» SuSE «,» 12 «,» x86_64 «]}
, stderr =
3676 1600772716.52196: ANSIBALLZ: с использованием кэшированного модуля: /root/.ansible/tmp/ansible-local-3668A5bmKd/ansiballz_cache/zypper-ZIP_DEFLATED
3676 1600772716.52622: перенос модуля на удаленный /root/.ansible/tmp/ansible-tmp-1600772715.9-203940692219450/AnsiballZ_zypper.py
3676 1600772716.53785: Отправка исходных данных
3676 1600772716.53856: отправлены исходные данные (138 байт)
3676 1600772716.63011: блок stdout (состояние = 3):
sftp> поместите /root/.ansible/tmp/ansible-local-3668A5bmKd/tmpduCRmY /root/.ansible/tmp/ansible-tmp-1600772715.9-203940692219450/AnsiballZ_zypper.py
<<<
3676 1600772716.65358: блок stderr (состояние = 3):
<<<
3676 1600772716.65404: блок stdout (состояние = 3):
<<<
3676 1600772716.65466: завершена передача модуля на удаленный
3676 1600772716.65532: _low_level_execute_command (): запуск
3676 1600772716.65568: _low_level_execute_command (): выполнение: / bin / sh -c ‘chmod u + x /root/.ansible/tmp/ansible-tmp-1600772715.9-203940692219450/ /root/.ansible/tmp/ansible-tmp-1600772715.9- 203940692219450 / AnsiballZ_zypper.py && sleep 0 ‘
3676 1600772716.75915: блок stderr (состояние = 2):
<<<
3676 1600772716.76007: блок stdout (состояние = 2):
<<<
3676 1600772716.76066: _low_level_execute_command () выполнено: rc = 0, stdout =, stderr =
3676 1600772716.76099: _low_level_execute_command (): запуск
3676 1600772716.76141: _low_level_execute_command (): выполнение: / bin / sh -c ‘/ usr / bin / python /root/.ansible/tmp/ansible-tmp-1600772715.9-203940692219450/AnsiballZ_zypper.py && sleep 0’
Я обнаружил, что простое уничтожение зависшего процесса на пульте дистанционного управления через ssh возвращает стандартный вывод. Я считаю, что это короче, чем писать обходные пути, которые в любом случае не будут использоваться в окончательной версии:
kill -9 PID
попытайся
Это проблема с настройками прокси на целевой машине SUSE, поэтому на целевой машине добавьте прокси, как указано в ссылке ниже https://www.suse.com/support/kb/doc/?id=000017441
Из-за проблемы с прокси-сервером модуль zypper не может быть установлен.
Привет,
Я Решма, у меня похожая проблема, так как мой доступный модуль просто зависает и не дает мне сбоев / пропущенного / статуса и ничего не делает на целевом хосте. если бы кто-нибудь мог помочь с этим, было бы здорово. Если это не тот форум, пожалуйста, помогите закрепить форум, на котором я могу обратиться за помощью.
Детали системы:
Целевой хост: SUSE 12 SP5
python-xml-2.7.17-28.51.1.x86_64
rpm-4.11.2-16.21.1.x86_64
zypper 1.13.51Ответная команда:
ANSIBLE_DEBUG = 1 ansible -i / etc / ansible / hosts веб-серверы -k -m zypper -a ‘name = git-core state = present’ -vВывод отладки:
3676 1600772716.28160: _low_level_execute_command (): выполнение: / bin / sh -c ‘echo PLATFORM; uname; эхо НАЙДЕНО; команда -v ‘»‘» ‘/ usr / bin / python’ «‘»‘; команда -v ‘»‘» ‘python3.7’ «‘»‘; команда -v ‘»‘» ‘python3.6’ «‘»‘; команда -v ‘»‘» ‘python3.5’ «‘»‘; команда -v ‘»‘» ‘python2.7’ «‘»‘; команда -v ‘»‘» ‘python2.6’ «‘»‘; команда -v ‘»‘» ‘/ usr / libexec / platform-python’ «‘»‘; команда -v ‘»‘» ‘/ usr / bin / python3’ «‘»‘; command -v ‘»‘» ‘python’ «‘»‘; echo ENDFOUND && sleep 0 ‘
3676 1600772716.37768: блок stdout (состояние = 2):ПЛАТФОРМА
<<<3676 1600772716.37947: блок stdout (состояние = 3):
Linux
НАЙДЕННЫЙ
/ usr / bin / питон
<<<3676 1600772716.37989: блок stdout (состояние = 3):
/usr/bin/python3.6
/usr/bin/python2.7
/ usr / bin / python3
/ usr / bin / питон
ENDFOUND
<<<3676 1600772716.38378: блок stderr (состояние = 3):
<<<
3676 1600772716.38424: блок stdout (состояние = 3):
<<<
3676 1600772716.38484: _low_level_execute_command () выполнено: rc = 0, stdout = PLATFORM
Linux
НАЙДЕННЫЙ
/ usr / bin / питон
/usr/bin/python3.6
/usr/bin/python2.7
/ usr / bin / python3
/ usr / bin / питон
ENDFOUND
, stderr =
3676 1600772716.38530 [10.237.222.108]: найдены интерпретаторы: [u ‘/ usr / bin / python’, u ‘/ usr / bin / python3.6’, u ‘/ usr / bin / python2.7’, u ‘/ usr / bin / python3 ‘, u’ / usr / bin / python ‘]
3676 1600772716.38609: _low_level_execute_command (): запуск
3676 1600772716.38650: _low_level_execute_command (): выполнение: / bin / sh -c ‘/ usr / bin / python && sleep 0’
3676 1600772716.39569: Отправка исходных данных
3676 1600772716.39658: Отправлены исходные данные (1234 байта)
3676 1600772716.51494: блок stdout (состояние = 3):{«osrelease_content»: «NAME =» SLES » nVERSION =» 12-SP5 » nVERSION_ID =» 12.5 » nPRETTY_NAME =» SUSE Linux Enterprise Server 12 SP5 » nID =» sles » nANSI_COLOR =» 0; 32 » nCPE_NAME = «cpe: / o: suse: sles : 12: sp5» n «,» platform_dist_result «: [» SuSE «,» 12 «,» x86_64 «]}
<<<3676 1600772716.51914: блок stderr (состояние = 3):
<<<
3676 1600772716.51960: блок stdout (состояние = 3):
<<<
3676 1600772716.52014: _low_level_execute_command () done: rc = 0, stdout = {«osrelease_content»: «NAME =» SLES » nVERSION =» 12-SP5 » nVERSION_ID =» 12.5 » nPRETTY_NAME =» SUSE Linux Enterprise Server 12 SP5 nID = «sles» nANSI_COLOR = «0; 32» nCPE_NAME = «cpe: / o: suse: sles : 12: sp5» n «,» platform_dist_result «: [» SuSE «,» 12 «,» x86_64 «]}
, stderr =
3676 1600772716.52196: ANSIBALLZ: с использованием кэшированного модуля: /root/.ansible/tmp/ansible-local-3668A5bmKd/ansiballz_cache/zypper-ZIP_DEFLATED
3676 1600772716.52622: перенос модуля на удаленный /root/.ansible/tmp/ansible-tmp-1600772715.9-203940692219450/AnsiballZ_zypper.py
3676 1600772716.53785: Отправка исходных данных
3676 1600772716.53856: отправлены исходные данные (138 байт)
3676 1600772716.63011: блок stdout (состояние = 3):sftp> поместите /root/.ansible/tmp/ansible-local-3668A5bmKd/tmpduCRmY /root/.ansible/tmp/ansible-tmp-1600772715.9-203940692219450/AnsiballZ_zypper.py
<<<3676 1600772716.65358: блок stderr (состояние = 3):
<<<
3676 1600772716.65404: блок stdout (состояние = 3):
<<<
3676 1600772716.65466: завершена передача модуля на удаленный
3676 1600772716.65532: _low_level_execute_command (): запуск
3676 1600772716.65568: _low_level_execute_command (): выполнение: / bin / sh -c ‘chmod u + x /root/.ansible/tmp/ansible-tmp-1600772715.9-203940692219450/ /root/.ansible/tmp/ansible-tmp-1600772715.9- 203940692219450 / AnsiballZ_zypper.py && sleep 0 ‘
3676 1600772716.75915: блок stderr (состояние = 2):<<<
3676 1600772716.76007: блок stdout (состояние = 2):
<<<
3676 1600772716.76066: _low_level_execute_command () выполнено: rc = 0, stdout =, stderr =
3676 1600772716.76099: _low_level_execute_command (): запуск
3676 1600772716.76141: _low_level_execute_command (): выполнение: / bin / sh -c ‘/ usr / bin / python /root/.ansible/tmp/ansible-tmp-1600772715.9-203940692219450/AnsiballZ_zypper.py && sleep 0’
Это проблема с настройками прокси на целевой машине SUSE, поэтому на целевой машине добавьте прокси, как указано в ссылке ниже https://www.suse.com/support/kb/doc/?id=000017441
Из-за проблемы с прокси-сервером модуль zypper не может быть установлен.
Была ли эта страница полезной?
0 / 5 — 0 рейтинги
When Ansible receives a non-zero return code from a command or a failure from a module, by default it stops executing on that host and continues on other hosts. However, in some circumstances you may want different behavior. Sometimes a non-zero return code indicates success. Sometimes you want a failure on one host to stop execution on all hosts. Ansible provides tools and settings to handle these situations and help you get the behavior, output, and reporting you want.
-
Ignoring failed commands
-
Ignoring unreachable host errors
-
Resetting unreachable hosts
-
Handlers and failure
-
Defining failure
-
Defining “changed”
-
Ensuring success for command and shell
-
Aborting a play on all hosts
-
Aborting on the first error: any_errors_fatal
-
Setting a maximum failure percentage
-
-
Controlling errors in blocks
Ignoring failed commands
By default Ansible stops executing tasks on a host when a task fails on that host. You can use ignore_errors to continue on in spite of the failure.
- name: Do not count this as a failure ansible.builtin.command: /bin/false ignore_errors: true
The ignore_errors directive only works when the task is able to run and returns a value of ‘failed’. It does not make Ansible ignore undefined variable errors, connection failures, execution issues (for example, missing packages), or syntax errors.
Ignoring unreachable host errors
New in version 2.7.
You can ignore a task failure due to the host instance being ‘UNREACHABLE’ with the ignore_unreachable keyword. Ansible ignores the task errors, but continues to execute future tasks against the unreachable host. For example, at the task level:
- name: This executes, fails, and the failure is ignored ansible.builtin.command: /bin/true ignore_unreachable: true - name: This executes, fails, and ends the play for this host ansible.builtin.command: /bin/true
And at the playbook level:
- hosts: all ignore_unreachable: true tasks: - name: This executes, fails, and the failure is ignored ansible.builtin.command: /bin/true - name: This executes, fails, and ends the play for this host ansible.builtin.command: /bin/true ignore_unreachable: false
Resetting unreachable hosts
If Ansible cannot connect to a host, it marks that host as ‘UNREACHABLE’ and removes it from the list of active hosts for the run. You can use meta: clear_host_errors to reactivate all hosts, so subsequent tasks can try to reach them again.
Handlers and failure
Ansible runs handlers at the end of each play. If a task notifies a handler but
another task fails later in the play, by default the handler does not run on that host,
which may leave the host in an unexpected state. For example, a task could update
a configuration file and notify a handler to restart some service. If a
task later in the same play fails, the configuration file might be changed but
the service will not be restarted.
You can change this behavior with the --force-handlers command-line option,
by including force_handlers: True in a play, or by adding force_handlers = True
to ansible.cfg. When handlers are forced, Ansible will run all notified handlers on
all hosts, even hosts with failed tasks. (Note that certain errors could still prevent
the handler from running, such as a host becoming unreachable.)
Defining failure
Ansible lets you define what “failure” means in each task using the failed_when conditional. As with all conditionals in Ansible, lists of multiple failed_when conditions are joined with an implicit and, meaning the task only fails when all conditions are met. If you want to trigger a failure when any of the conditions is met, you must define the conditions in a string with an explicit or operator.
You may check for failure by searching for a word or phrase in the output of a command
- name: Fail task when the command error output prints FAILED ansible.builtin.command: /usr/bin/example-command -x -y -z register: command_result failed_when: "'FAILED' in command_result.stderr"
or based on the return code
- name: Fail task when both files are identical ansible.builtin.raw: diff foo/file1 bar/file2 register: diff_cmd failed_when: diff_cmd.rc == 0 or diff_cmd.rc >= 2
You can also combine multiple conditions for failure. This task will fail if both conditions are true:
- name: Check if a file exists in temp and fail task if it does ansible.builtin.command: ls /tmp/this_should_not_be_here register: result failed_when: - result.rc == 0 - '"No such" not in result.stdout'
If you want the task to fail when only one condition is satisfied, change the failed_when definition to
failed_when: result.rc == 0 or "No such" not in result.stdout
If you have too many conditions to fit neatly into one line, you can split it into a multi-line YAML value with >.
- name: example of many failed_when conditions with OR ansible.builtin.shell: "./myBinary" register: ret failed_when: > ("No such file or directory" in ret.stdout) or (ret.stderr != '') or (ret.rc == 10)
Defining “changed”
Ansible lets you define when a particular task has “changed” a remote node using the changed_when conditional. This lets you determine, based on return codes or output, whether a change should be reported in Ansible statistics and whether a handler should be triggered or not. As with all conditionals in Ansible, lists of multiple changed_when conditions are joined with an implicit and, meaning the task only reports a change when all conditions are met. If you want to report a change when any of the conditions is met, you must define the conditions in a string with an explicit or operator. For example:
tasks: - name: Report 'changed' when the return code is not equal to 2 ansible.builtin.shell: /usr/bin/billybass --mode="take me to the river" register: bass_result changed_when: "bass_result.rc != 2" - name: This will never report 'changed' status ansible.builtin.shell: wall 'beep' changed_when: False
You can also combine multiple conditions to override “changed” result.
- name: Combine multiple conditions to override 'changed' result ansible.builtin.command: /bin/fake_command register: result ignore_errors: True changed_when: - '"ERROR" in result.stderr' - result.rc == 2
Note
Just like when these two conditionals do not require templating delimiters ({{ }}) as they are implied.
See Defining failure for more conditional syntax examples.
Ensuring success for command and shell
The command and shell modules care about return codes, so if you have a command whose successful exit code is not zero, you can do this:
tasks: - name: Run this command and ignore the result ansible.builtin.shell: /usr/bin/somecommand || /bin/true
Aborting a play on all hosts
Sometimes you want a failure on a single host, or failures on a certain percentage of hosts, to abort the entire play on all hosts. You can stop play execution after the first failure happens with any_errors_fatal. For finer-grained control, you can use max_fail_percentage to abort the run after a given percentage of hosts has failed.
Aborting on the first error: any_errors_fatal
If you set any_errors_fatal and a task returns an error, Ansible finishes the fatal task on all hosts in the current batch, then stops executing the play on all hosts. Subsequent tasks and plays are not executed. You can recover from fatal errors by adding a rescue section to the block. You can set any_errors_fatal at the play or block level.
- hosts: somehosts any_errors_fatal: true roles: - myrole - hosts: somehosts tasks: - block: - include_tasks: mytasks.yml any_errors_fatal: true
You can use this feature when all tasks must be 100% successful to continue playbook execution. For example, if you run a service on machines in multiple data centers with load balancers to pass traffic from users to the service, you want all load balancers to be disabled before you stop the service for maintenance. To ensure that any failure in the task that disables the load balancers will stop all other tasks:
--- - hosts: load_balancers_dc_a any_errors_fatal: true tasks: - name: Shut down datacenter 'A' ansible.builtin.command: /usr/bin/disable-dc - hosts: frontends_dc_a tasks: - name: Stop service ansible.builtin.command: /usr/bin/stop-software - name: Update software ansible.builtin.command: /usr/bin/upgrade-software - hosts: load_balancers_dc_a tasks: - name: Start datacenter 'A' ansible.builtin.command: /usr/bin/enable-dc
In this example Ansible starts the software upgrade on the front ends only if all of the load balancers are successfully disabled.
Setting a maximum failure percentage
By default, Ansible continues to execute tasks as long as there are hosts that have not yet failed. In some situations, such as when executing a rolling update, you may want to abort the play when a certain threshold of failures has been reached. To achieve this, you can set a maximum failure percentage on a play:
--- - hosts: webservers max_fail_percentage: 30 serial: 10
The max_fail_percentage setting applies to each batch when you use it with serial. In the example above, if more than 3 of the 10 servers in the first (or any) batch of servers failed, the rest of the play would be aborted.
Note
The percentage set must be exceeded, not equaled. For example, if serial were set to 4 and you wanted the task to abort the play when 2 of the systems failed, set the max_fail_percentage at 49 rather than 50.
Controlling errors in blocks
You can also use blocks to define responses to task errors. This approach is similar to exception handling in many programming languages. See Handling errors with blocks for details and examples.