About this series:
In this series, we are exploring what are the best practices a web developer must take care of when creating or managing PHP code.
Sanitize, validate and escape
Security and managing passwords
Handling error and exceptions
Introduction
21st October 1879 19:15:13
Menlo Park, New Jersey
A strong breeze is cooling down the evening,
the weather has not been kind lately and the rain has been fallen continuously for the past 2 weeks and it does not seem it wants to stop anytime soon.
inside a factory, several men are working like hell on something that has the potential to change the world as they know it.

The final test will happen in a few minutes and it will be the result of weeks of research, hard work and calculation.
3
2
1
POP!!
A flashlight up the room for a second then dark again, another day has passed, another failed one, another error.
That’s the 9’999th now.
“I have not failed. I’ve just found 10,000 ways that won’t work.”
Thomas Edison
If you have ever heard motivational speaker like Brian Tracy, Tony Robin, Zig Ziglar or Jim Rohn you know that all of them have a problem with the way schools run around the world.
In university and colleges, errors are punished rather than welcomed,
In the real world though, errors are the only way you can become a better one.
This is especially true in web development.
Trial and errors are definitely the best way to become great and to craft your skill.
It is also true that we need to be careful and pay attention to the error we make.
The reason for making errors is that we can manage and learn from them.
PHP make it easy to handle, manage and learn by error that can occur in your code.
How to manage errors in PHP 7
If you ask me what are the features that have improved the most between PHP 5.6 and PHP 7 or PHP 7.1 I will surely put error handling in the top 3 positions.
The seventh version of our beloved programming language brought to us an interface with a defined goal:
it needed to be easily implemented and be useful in lots of cases.
The throwable interface,
in fact, can be implemented by both types of class (Error class and Exception) and supply and a handful of methods that we can use to better understand and analyze our error.
Here you can see the class and how can you use it:
Throwable {
abstract public getMessage ( void ) : string
abstract public getCode ( void ) : int
abstract public getFile ( void ) : string
abstract public getLine ( void ) : int
abstract public getTrace ( void ) : array
abstract public getTraceAsString ( void ) : string
abstract public getPrevious ( void ) : Throwable
abstract public __toString ( void ) : string
}
Try {
// some code
} catch (Throwable $e) {
echo "an instance of class Throwable has been caught";
}
In the snippet above are showed all the methods you can use to debug a PHP error in your script (with lots of type hinting)
and the actual code you can use to try a block of code and throw an error or an exception.
Errors, errors everywhere!
Whoever has dealt with error prior to PHP 5.6 know what type of pain it was and the headache he needed to deal with during the debugging phase.
Previously errors were produced within the engine and you could have handled it as long as they weren’t fatal errors.
You also needed to consider that errors and exception were two completely different things in your code and it added another layer of difficulty to the already complicated situation.
From PHP 7 onwards, fatal errors result in error exception being thrown and you can easily manage not fatal errors with bespoke methods
I can, for instance, run some code and only throw an error in case of a fatal occurs.
try {
echo $thisVariableIsNotSet;
inexistentFunctionInvoked();
} catch (Error $e) {
echo "Error: $e->getMessage()";
}
// Error: Call to undefined function inexistentFunctionInvoked();
If this is the first time you handle errors or you see a try-catch this may seem confusing you may feel you want to step back a bit,
Don’t worry, in Php Basics you will find all you need to know to be ready to read this article.
Bear with me while I explain what is happening:
In our pseudocode we have to element a variable and a funtion, both of them have not been defined , thus are unser or inexistent.
PHP handle an unset variable differently that a undefined function,
the first one is just an invalid variable a notice error, web developes work long hour, it can happen often,
the second error instead is an actual fuction, with maybe some important logic in it.
That is why in PHP an undefined function is a serious problem, a fatal error.
Having these two lines of code within the try block permits the catch to instanciate an instance of the Error class (the variable $e).
$e implements the Throwable interface, which means it can use all the method you saw in the previous paragraph. Hence $e->getMessage();
Creating a bespoke error handler
There may be occasions in which some errors that are not instace of the Error class occur.
If these errors are not fatal PHP allows you, as a developer, to define bespoke function and handle them the way you prefer.
To do so you need to use the set_error_handle() function.
This function accept either a string with the name of the function you want to use or an array that contains an object and the name of the method you are invoking.
The fuction can stop the script,
if you do not want it to continue or return a value and continue when the code invoked the function in the first place.
Let’s have a look at a practical yet easy example below.
set_error_handle() cannot manage fatal error, which means that, in order to test it, we need to simulate a warning (a division by zero will do),
then we’ll define the content of the function and catch the error when it occurs.
function myErrorHandler($errno, $errstr, $errfile, $errline) {
echo "An error occurred in line {$errline} of file {$errfile} with message {$errstr}";
}
set_error_handler("myErrorHandler");
try {
5 / 0;
} catch (Throwable $e) {
echo $e->getMessage();
}
// An error occurred in line 1 of file /index with message Division by zero
Do not forget that you want to hide errors from the production environment when an error occurs it has to be visible only on local or a staging server.
In fact, showing an error in production can give a massive hint about the vulnerability of your website to a hacker or malicious users.
To do this you can edit 3 settings within your php.ini
- display_errors if set to false it will suppress errors;
- log_errors store errors into a log file;
- error_reporting configures which type of errors trigger a report;
Error Handling Functions
PHP has several functions that can make handling errors and easy tasks in this section you will find a brief description for each of them.
- debug_•backtrace() it accepts few parameters like options’ flag and a number that limits the results and generate a summary of how your script got where it is, it does it returning an array variable;
- debug_•print_•backtrace() it works in a similar way as the previous one but instead of creating an array of trace it prints them in an inverted chronological order;
- error_•get_•last() it returns an associative array that contains the info of the last error occurred in the script;
- error_•clear_•last() reset the internal error log of PHP, if used before error_get_last() the latter will return null;
- error_•log() it requires a mandatory message as a parameter and sends it to the defined error handling routines;
- error_•reporting() This function requires either none or error constants as a parameter (you can find the complete list here https://www.php.net/manual/en/errorfunc.constants.php ) and set the level of accuracy the PHP application must have when handling errors;
- set_•error_•handler() and set_•exception_•handler() set bespoke functions that handle errors and exception;
- restore_•error_•handler() and restore_•exception_•handler() it is used after set_•error_•handler() and set_•exception_•handler() it aims to revert the handler to the previous error handler it could be the built-in or a user-defined function;
- trigger_•error() this function triggers an error by accepting a message as a mandatory parameter and an error_type’s flag as a discretionary one;
- user_•error() alias of trigger_•error();
The PHP manual provides the entire list of predefined constant you can use as flag in some of the function above
What are exceptions
Exceptions are relatively new features of PHP, they have been implemented only in PHP 5 but they quickly became a core part of any object-oriented programming script.
Exceptions are states of the scripts the require special treatment because the script is not running as it is supposed to.
Both Errors and Exception are just classes that implement the Throwable interface.
Like any other class in the OOP world, the can be extended,
which allows to create error hierarchies and create tailor the way you handle exceptions.
Something to pay attention to and that can lead to errors and misunderstandings is that you cannot declare your own class and then decide to throw exceptions.
The only classes that can throw error are the ones that implement the Throwable class.
Let’s play a game, look at the code and answer the following question.
class MainException extends Exception {}
class SubException extends MainException {}
try {
throw new SubException("SubException thrown");
} catch (MainException $e) {
echo "MainException thrown" . $e->getMessage();
} catch (SubException $e) {
echo "SubException thrown" . $e->getMessage();
} catch (Exception $e) {
echo "Exception thrown" . $e->getMessage();
}
Which exception is thrown?
In the example below the exception thrown is the SubException, it inherits from MainException which extends Exception.
The block is evaluated from the first (the one on top) to the last and when the exception matches the name of the class given it is triggered.
This above can be considered the best practice because we narrow down the message we want to show and eventually.
In case none of our classes matches, we use the PHP class Exception for an overall check.
Catch multiple exceptions at once
Until now we have seen several tries with several catches.
Each block of code echo a message with different errors,
Think at the case we create a dozen of different exceptions,
should we add a dozen of catch blocks? And what if we want to handle several types of error in the same way?
To manage this situation PHP provided the pipe keyword “ | ”;
Here is an example of how to use it:
class MainException extends Exception {}
class SubException extends Exception {}
try {
throw new SubException;
} catch (MainException | SubException $e) {
echo "Exception thrown: " . get_class($e);
}
// Exception thrown: SubException
The finally keyword
I am sure you have already seen a switch-case conditional structure in the past,
if not I got an entire article about conditional statements in PHP.
One of the elements of the switch statement is that if none of the cases is evaluated eventually a “default“ block, if present, is going to run.
The try a catch allows to do something similar to your code by providing the keyword finally
try {
$handle = fopen("c:\folder\resource.txt", "r");
// do some stuff with the file
throw new Exception("Exception thrown");
} catch (Exception $e) {
echo "Exception thrown" . $e->getMessage();
} finally {
fclose ( resource $handle );
}
A common use for this keyword is, as shown in the example above, when we need to close a file that we have previously opened inside the try block.
You must remember that the code inside the finally block is always executed, even if exceptions are thrown earlier in the script.
But you are free to use it whenever you believe this will help your case.
If you think this article was useful and you want to learn more about good practices in PHP click the image below

Conclusion
Thomas Edison came from the humble origin and it is confirmed by historical data that he wasn’t the most brilliant of the individual.
Anyway, his capacity to surround himself by creative and passionate people, plus the ability to deeply analyze and learn from his error made him one of the best inventors ever lived, surely one of the most wealthy and famous of his era.
With no hesitation, I can say that we as web developers can do the same.
Maybe we will never invent a world’s famous application or change the life of billions of people with our website but there is no doubt that by learning from our mistake we will increase our skill way faster.
Managing errors is a fundamental part of this.
Learn how to properly do that and master all the possibility available in PHP and its components such as PHPUnit and Sentry will make this task easy for each of us.
Useful components or website you can use to manage your error right now:
filp/whoops
nette/tracy
vimeo/psalm
sebastianbergmann/phpunit
codeception/codeception
getsentry/sentry
https://phpcodechecker.com
https://www.piliapp.com/php-syntax-check
Overview
Handling Exceptions in Java is one of the most basic and fundamental things a developer should know by heart. Sadly, this is often overlooked and the importance of exception handling is underestimated — it’s as important as the rest of the code.
In this article, let’s go through everything you need to know about exception handling in Java, as well as good and bad practices.
What is Exception Handling?
We are surrounded by exception handling in real-life on an everyday basis.
When ordering a product from an online shop — the product may not be available in stock or there might occur a failure in delivery. Such exceptional conditions can be countered by manufacturing another product or sending a new one after the delivery failed.
When building applications — they might run into all kinds of exceptional conditions. Thankfully, being proficient in exception handling, such conditions can be countered by altering the flow of code.
Why use Exception Handling?
When building applications, we’re usually working in an ideal environment — the file system can provide us with all of the files we request, our internet connection is stable and the JVM can always provide enough memory for our needs.
Sadly, in reality, the environment is far from ideal — the file cannot be found, the internet connection breaks from time to time and the JVM can’t provide enough memory and we’re left with a daunting StackOverflowError.
If we fail to handle such conditions, the whole application will end up in ruins, and all other code becomes obsolete. Therefore, we must be able to write code that can adapt to such situations.
Imagine a company not being able to resolve a simple issue that arose after ordering a product — you don’t want your application to work that way.
Exception Hierarchy
All of this just begs the question — what are these exceptions in the eyes of Java and the JVM?
Exceptions are, after all, simply Java objects that extend the Throwable interface:
---> Throwable <---
| (checked) |
| |
| |
---> Exception Error
| (checked) (unchecked)
|
RuntimeException
(unchecked)
When we talk about exceptional conditions, we are usually referring to one of the three:
- Checked Exceptions
- Unchecked Exceptions / Runtime Exceptions
- Errors
Note: The terms «Runtime» and «Unchecked» are often used interchangeably and refer to the same kind of exceptions.
Checked Exceptions
Checked Exceptions are the exceptions that we can typically foresee and plan ahead in our application. These are also exceptions that the Java Compiler requires us to either handle-or-declare when writing code.
The handle-or-declare rule refers to our responsibility to either declare that a method throws an exception up the call stack — without doing much to prevent it or handle the exception with our own code, which typically leads to the recovery of the program from the exceptional condition.
This is the reason why they’re called checked exceptions. The compiler can detect them before runtime, and you’re aware of their potential existence while writing code.
Unchecked Exceptions
Unchecked Exceptions are the exceptions that typically occur due to human, rather than an environmental error. These exceptions are not checked during compile-time, but at runtime, which is the reason they’re also called Runtime Exceptions.
They can often be countered by implementing simple checks before a segment of code that could potentially be used in a way that forms a runtime exception, but more on that later on.
Errors
Errors are the most serious exceptional conditions that you can run into. They are often irrecoverable from and there’s no real way to handle them. The only thing we, as developers, can do is optimize the code in hopes that the errors never occur.
Errors can occur due to human and environmental errors. Creating an infinitely recurring method can lead to a StackOverflowError, or a memory leak can lead to an OutOfMemoryError.
How to Handle Exceptions
throw and throws
The easiest way to take care of a compiler error when dealing with a checked exception is to simply throw it.
public File getFile(String url) throws FileNotFoundException {
// some code
throw new FileNotFoundException();
}
We are required to mark our method signature with a throws clause. A method can add as many exceptions as needed in its throws clause, and can throw them later on in the code, but doesn’t have to. This method doesn’t require a return statement, even though it defines a return type. This is because it throws an exception by default, which ends the flow of the method abruptly. The return statement, therefore, would be unreachable and cause a compilation error.
Keep in mind that anyone who calls this method also needs to follow the handle-or-declare rule.
When throwing an exception, we can either throw a new exception, like in the preceding example, or a caught exception.
try-catch Blocks
A more common approach would be to use a try—catch block to catch and handle the arising exception:
public String readFirstLine(String url) throws FileNotFoundException {
try {
Scanner scanner = new Scanner(new File(url));
return scanner.nextLine();
} catch(FileNotFoundException ex) {
throw ex;
}
}
In this example, we «marked» a risky segment of code by encasing it within a try block. This tells the compiler that we’re aware of a potential exception and that we’re intending to handle it if it arises.
This code tries to read the contents of the file, and if the file is not found, the FileNotFoundException is caught and rethrown. More on this topic later.
Running this piece of code without a valid URL will result in a thrown exception:
Exception in thread "main" java.io.FileNotFoundException: some_file (The system cannot find the file specified) <-- some_file doesn't exist
at java.io.FileInputStream.open0(Native Method)
at java.io.FileInputStream.open(FileInputStream.java:195)
at java.io.FileInputStream.<init>(FileInputStream.java:138)
at java.util.Scanner.<init>(Scanner.java:611)
at Exceptions.ExceptionHandling.readFirstLine(ExceptionHandling.java:15) <-- Exception arises on the the readFirstLine() method, on line 15
at Exceptions.ExceptionHandling.main(ExceptionHandling.java:10) <-- readFirstLine() is called by main() on line 10
...
Alternatively, we can try to recover from this condition instead of rethrowing:
public static String readFirstLine(String url) {
try {
Scanner scanner = new Scanner(new File(url));
return scanner.nextLine();
} catch(FileNotFoundException ex) {
System.out.println("File not found.");
return null;
}
}
Running this piece of code without a valid URL will result in:
File not found.
finally Blocks
Introducing a new kind of block, the finally block executes regardless of what happens in the try block. Even if it ends abruptly by throwing an exception, the finally block will execute.
This was often used to close the resources that were opened in the try block since an arising exception would skip the code closing them:
public String readFirstLine(String path) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(path));
try {
return br.readLine();
} finally {
if(br != null) br.close();
}
}
However, this approach has been frowned upon after the release of Java 7, which introduced a better and cleaner way to close resources, and is currently seen as bad practice.
try-with-resources Statement
The previously complex and verbose block can be substituted with:
static String readFirstLineFromFile(String path) throws IOException {
try(BufferedReader br = new BufferedReader(new FileReader(path))) {
return br.readLine();
}
}
It’s much cleaner and it’s obviously simplified by including the declaration within the parentheses of the try block.
Additionally, you can include multiple resources in this block, one after another:
static String multipleResources(String path) throws IOException {
try(BufferedReader br = new BufferedReader(new FileReader(path));
BufferedWriter writer = new BufferedWriter(path, charset)) {
// some code
}
}
This way, you don’t have to concern yourself with closing the resources yourself, as the try-with-resources block ensures that the resources will be closed upon the end of the statement.
Multiple catch Blocks
When the code we’re writing can throw more than one exception, we can employ several catch blocks to handle them individually:
public void parseFile(String filePath) {
try {
// some code
} catch (IOException ex) {
// handle
} catch (NumberFormatException ex) {
// handle
}
}
When the try block incurs an exception, the JVM checks whether the first caught exception is an appropriate one, and if not, goes on until it finds one.
Note: Catching a generic exception will catch all of its subclasses so it’s not required to catch them separately.
Catching a FileNotFound exception isn’t necessary in this example, because it extends from IOException, but if the need arises, we can catch it before the IOException:
public void parseFile(String filePath) {
try {
// some code
} catch(FileNotFoundException ex) {
// handle
} catch (IOException ex) {
// handle
} catch (NumberFormatException ex) {
// handle
}
}
This way, we can handle the more specific exception in a different manner than a more generic one.
Note: When catching multiple exceptions, the Java compiler requires us to place the more specific ones before the more general ones, otherwise they would be unreachable and would result in a compiler error.
Union catch Blocks
To reduce boilerplate code, Java 7 also introduced union catch blocks. They allow us to treat multiple exceptions in the same manner and handle their exceptions in a single block:
public void parseFile(String filePath) {
try {
// some code
} catch (IOException | NumberFormatException ex) {
// handle
}
}
How to throw exceptions
Sometimes, we don’t want to handle exceptions. In such cases, we should only concern ourselves with generating them when needed and allowing someone else, calling our method, to handle them appropriately.
Throwing a Checked Exception
When something goes wrong, like the number of users currently connecting to our service exceeding the maximum amount for the server to handle seamlessly, we want to throw an exception to indicate an exceptional situation:
public void countUsers() throws TooManyUsersException {
int numberOfUsers = 0;
while(numberOfUsers < 500) {
// some code
numberOfUsers++;
}
throw new TooManyUsersException("The number of users exceeds our maximum
recommended amount.");
}
}
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
This code will increase numberOfUsers until it exceeds the maximum recommended amount, after which it will throw an exception. Since this is a checked exception, we have to add the throws clause in the method signature.
To define an exception like this is as easy as writing the following:
public class TooManyUsersException extends Exception {
public TooManyUsersException(String message) {
super(message);
}
}
Throwing an Unchecked Exception
Throwing runtime exceptions usually boils down to validation of input, since they most often occur due to faulty input — either in the form of an IllegalArgumentException, NumberFormatException, ArrayIndexOutOfBoundsException, or a NullPointerException:
public void authenticateUser(String username) throws UserNotAuthenticatedException {
if(!isAuthenticated(username)) {
throw new UserNotAuthenticatedException("User is not authenticated!");
}
}
Since we’re throwing a runtime exception, there’s no need to include it in the method signature, like in the example above, but it’s often considered good practice to do so, at least for the sake of documentation.
Again, defining a custom runtime exception like this one is as easy as:
public class UserNotAuthenticatedException extends RuntimeException {
public UserNotAuthenticatedException(String message) {
super(message);
}
}
Rethrowing
Rethrowing an exception was mentioned before so here’s a short section to clarify:
public String readFirstLine(String url) throws FileNotFoundException {
try {
Scanner scanner = new Scanner(new File(url));
return scanner.nextLine();
} catch(FileNotFoundException ex) {
throw ex;
}
}
Rethrowing refers to the process of throwing an already caught exception, rather than throwing a new one.
Wrapping
Wrapping, on the other hand, refers to the process of wrapping an already caught exception, within another exception:
public String readFirstLine(String url) throws FileNotFoundException {
try {
Scanner scanner = new Scanner(new File(url));
return scanner.nextLine();
} catch(FileNotFoundException ex) {
throw new SomeOtherException(ex);
}
}
Rethrowing Throwable or _Exception*?
These top-level classes can be caught and rethrown, but how to do so can vary:
public void parseFile(String filePath) {
try {
throw new NumberFormatException();
} catch (Throwable t) {
throw t;
}
}
In this case, the method is throwing a NumberFormatException which is a runtime exception. Because of this, we don’t have to mark the method signature with either NumberFormatException or Throwable.
However, if we throw a checked exception within the method:
public void parseFile(String filePath) throws Throwable {
try {
throw new IOException();
} catch (Throwable t) {
throw t;
}
}
We now have to declare that the method is throwing a Throwable. Why this can be useful is a broad topic that is out of scope for this blog, but there are usages for this specific case.
Exception Inheritance
Subclasses that inherit a method can only throw fewer checked exceptions than their superclass:
public class SomeClass {
public void doSomething() throws SomeException {
// some code
}
}
With this definition, the following method will cause a compiler error:
public class OtherClass extends SomeClass {
@Override
public void doSomething() throws OtherException {
// some code
}
}
Best and Worst Exception Handling Practices
With all that covered, you should be pretty familiar with how exceptions work and how to use them. Now, let’s cover the best and worst practices when it comes to handling exceptions which we hopefully understand fully now.
Best Exception Handling Practices
Avoid Exceptional Conditions
Sometimes, by using simple checks, we can avoid an exception forming altogether:
public Employee getEmployee(int i) {
Employee[] employeeArray = {new Employee("David"), new Employee("Rhett"), new
Employee("Scott")};
if(i >= employeeArray.length) {
System.out.println("Index is too high!");
return null;
} else {
System.out.println("Employee found: " + employeeArray[i].name);
return employeeArray[i];
}
}
}
Calling this method with a valid index would result in:
Employee found: Scott
But calling this method with an index that’s out of bounds would result in:
Index is too high!
In any case, even though the index is too high, the offending line of code will not execute and no exception will arise.
Use try-with-resources
As already mentioned above, it’s always better to use the newer, more concise and cleaner approach when working with resources.
Close resources in try-catch-finally
If you’re not utilizing the previous advice for any reason, at least make sure to close the resources manually in the finally block.
I won’t include a code example for this since both have already been provided, for brevity.
Worst Exception Handling Practices
Swallowing Exceptions
If your intention is to simply satisfy the compiler, you can easily do so by swallowing the exception:
public void parseFile(String filePath) {
try {
// some code that forms an exception
} catch (Exception ex) {}
}
Swallowing an exception refers to the act of catching an exception and not fixing the issue.
This way, the compiler is satisfied since the exception is caught, but all the relevant useful information that we could extract from the exception for debugging is lost, and we didn’t do anything to recover from this exceptional condition.
Another very common practice is to simply print out the stack trace of the exception:
public void parseFile(String filePath) {
try {
// some code that forms an exception
} catch(Exception ex) {
ex.printStackTrace();
}
}
This approach forms an illusion of handling. Yes, while it is better than simply ignoring the exception, by printing out the relevant information, this doesn’t handle the exceptional condition any more than ignoring it does.
Return in a finally Block
According to the JLS (Java Language Specification):
If execution of the try block completes abruptly for any other reason R, then the
finallyblock is executed, and then there is a choice.
So, in the terminology of the documentation, if the finally block completes normally, then the try statement completes abruptly for reason R.
If the finally block completes abruptly for reason S, then the try statement completes abruptly for reason S (and reason R is discarded).
In essence, by abruptly returning from a finally block, the JVM will drop the exception from the try block and all valuable data from it will be lost:
public String doSomething() {
String name = "David";
try {
throw new IOException();
} finally {
return name;
}
}
In this case, even though the try block throws a new IOException, we use return in the finally block, ending it abruptly. This causes the try block to end abruptly due to the return statement, and not the IOException, essentially dropping the exception in the process.
Throwing in a finally Block
Very similar to the previous example, using throw in a finally block will drop the exception from the try-catch block:
public static String doSomething() {
try {
// some code that forms an exception
} catch(IOException io) {
throw io;
} finally {
throw new MyException();
}
}
In this example, the MyException thrown inside the finally block will overshadow the exception thrown by the catch block and all valuable information will be dropped.
Simulating a goto statement
Critical thinking and creative ways to find a solution to a problem is a good trait, but some solutions, as creative as they are, are ineffective and redundant.
Java doesn’t have a goto statement like some other languages but rather uses labels to jump around the code:
public void jumpForward() {
label: {
someMethod();
if (condition) break label;
otherMethod();
}
}
Yet still some people use exceptions to simulate them:
public void jumpForward() {
try {
// some code 1
throw new MyException();
// some code 2
} catch(MyException ex) {
// some code 3
}
}
Using exceptions for this purpose is ineffective and slow. Exceptions are designed for exceptional code and should be used for exceptional code.
Logging and Throwing
When trying to debug a piece of code and finding out what’s happening, don’t both log and throw the exception:
public static String readFirstLine(String url) throws FileNotFoundException {
try {
Scanner scanner = new Scanner(new File(url));
return scanner.nextLine();
} catch(FileNotFoundException ex) {
LOGGER.error("FileNotFoundException: ", ex);
throw ex;
}
}
Doing this is redundant and will simply result in a bunch of log messages which aren’t really needed. The amount of text will reduce the visibility of the logs.
Catching Exception or Throwable
Why don’t we simply catch Exception or Throwable, if it catches all subclasses?
Unless there’s a good, specific reason to catch any of these two, it’s generally not advised to do so.
Catching Exception will catch both checked and runtime exceptions. Runtime exceptions represent problems that are a direct result of a programming problem, and as such shouldn’t be caught since it can’t be reasonably expected to recover from them or handle them.
Catching Throwable will catch everything. This includes all errors, which aren’t actually meant to be caught in any way.
Conclusion
In this article, we’ve covered exceptions and exception handling from the ground up. Afterwards, we’ve covered the best and worst exception handling practices in Java.
Hopefully you found this blog informative and educational, happy coding!
Following is a summarization and curation from many different sources on this topic including code example and quotes from selected blog posts. The complete list of best practices can be found here
Best practices of Node.JS error handling
Number1: Use promises for async error handling
TL;DR: Handling async errors in callback style is probably the fastest way to hell (a.k.a the pyramid of doom). The best gift you can give to your code is using instead a reputable promise library which provides much compact and familiar code syntax like try-catch
Otherwise: Node.JS callback style, function(err, response), is a promising way to un-maintainable code due to the mix of error handling with casual code, excessive nesting and awkward coding patterns
Code example — good
doWork()
.then(doWork)
.then(doError)
.then(doWork)
.catch(errorHandler)
.then(verify);
code example anti pattern – callback style error handling
getData(someParameter, function(err, result){
if(err != null)
//do something like calling the given callback function and pass the error
getMoreData(a, function(err, result){
if(err != null)
//do something like calling the given callback function and pass the error
getMoreData(b, function(c){
getMoreData(d, function(e){
...
});
});
});
});
});
Blog quote: «We have a problem with promises»
(From the blog pouchdb, ranked 11 for the keywords «Node Promises»)
«…And in fact, callbacks do something even more sinister: they deprive us of the stack, which is something we usually take for granted in programming languages. Writing code without a stack is a lot like driving a car without a brake pedal: you don’t realize how badly you need it, until you reach for it and it’s not there. The whole point of promises is to give us back the language fundamentals we lost when we went async: return, throw, and the stack. But you have to know how to use promises correctly in order to take advantage of them.«
Number2: Use only the built-in Error object
TL;DR: It pretty common to see code that throws errors as string or as a custom type – this complicates the error handling logic and the interoperability between modules. Whether you reject a promise, throw exception or emit error – using Node.JS built-in Error object increases uniformity and prevents loss of error information
Otherwise: When executing some module, being uncertain which type of errors come in return – makes it much harder to reason about the coming exception and handle it. Even worth, using custom types to describe errors might lead to loss of critical error information like the stack trace!
Code example — doing it right
//throwing an Error from typical function, whether sync or async
if(!productToAdd)
throw new Error("How can I add new product when no value provided?");
//'throwing' an Error from EventEmitter
const myEmitter = new MyEmitter();
myEmitter.emit('error', new Error('whoops!'));
//'throwing' an Error from a Promise
return new promise(function (resolve, reject) {
DAL.getProduct(productToAdd.id).then((existingProduct) =>{
if(existingProduct != null)
return reject(new Error("Why fooling us and trying to add an existing product?"));
code example anti pattern
//throwing a String lacks any stack trace information and other important properties
if(!productToAdd)
throw ("How can I add new product when no value provided?");
Blog quote: «A string is not an error»
(From the blog devthought, ranked 6 for the keywords “Node.JS error object”)
«…passing a string instead of an error results in reduced interoperability between modules. It breaks contracts with APIs that might be performing instanceof Error checks, or that want to know more about the error. Error objects, as we’ll see, have very interesting properties in modern JavaScript engines besides holding the message passed to the constructor..»
Number3: Distinguish operational vs programmer errors
TL;DR: Operations errors (e.g. API received an invalid input) refer to known cases where the error impact is fully understood and can be handled thoughtfully. On the other hand, programmer error (e.g. trying to read undefined variable) refers to unknown code failures that dictate to gracefully restart the application
Otherwise: You may always restart the application when an error appear, but why letting ~5000 online users down because of a minor and predicted error (operational error)? the opposite is also not ideal – keeping the application up when unknown issue (programmer error) occurred might lead unpredicted behavior. Differentiating the two allows acting tactfully and applying a balanced approach based on the given context
Code example — doing it right
//throwing an Error from typical function, whether sync or async
if(!productToAdd)
throw new Error("How can I add new product when no value provided?");
//'throwing' an Error from EventEmitter
const myEmitter = new MyEmitter();
myEmitter.emit('error', new Error('whoops!'));
//'throwing' an Error from a Promise
return new promise(function (resolve, reject) {
DAL.getProduct(productToAdd.id).then((existingProduct) =>{
if(existingProduct != null)
return reject(new Error("Why fooling us and trying to add an existing product?"));
code example — marking an error as operational (trusted)
//marking an error object as operational
var myError = new Error("How can I add new product when no value provided?");
myError.isOperational = true;
//or if you're using some centralized error factory (see other examples at the bullet "Use only the built-in Error object")
function appError(commonType, description, isOperational) {
Error.call(this);
Error.captureStackTrace(this);
this.commonType = commonType;
this.description = description;
this.isOperational = isOperational;
};
throw new appError(errorManagement.commonErrors.InvalidInput, "Describe here what happened", true);
//error handling code within middleware
process.on('uncaughtException', function(error) {
if(!error.isOperational)
process.exit(1);
});
Blog Quote: «Otherwise you risk the state»
(From the blog debugable, ranked 3 for the keywords «Node.JS uncaught exception»)
«…By the very nature of how throw works in JavaScript, there is almost never any way to safely “pick up where you left off”, without leaking references, or creating some other sort of undefined brittle state. The safest way to respond to a thrown error is to shut down the process. Of course, in a normal web server, you might have many connections open, and it is not reasonable to abruptly shut those down because an error was triggered by someone else. The better approach is to send an error response to the request that triggered the error, while letting the others finish in their normal time, and stop listening for new requests in that worker»
Number4: Handle errors centrally, through but not within middleware
TL;DR: Error handling logic such as mail to admin and logging should be encapsulated in a dedicated and centralized object that all end-points (e.g. Express middleware, cron jobs, unit-testing) call when an error comes in.
Otherwise: Not handling errors within a single place will lead to code duplication and probably to errors that are handled improperly
Code example — a typical error flow
//DAL layer, we don't handle errors here
DB.addDocument(newCustomer, (error, result) => {
if (error)
throw new Error("Great error explanation comes here", other useful parameters)
});
//API route code, we catch both sync and async errors and forward to the middleware
try {
customerService.addNew(req.body).then(function (result) {
res.status(200).json(result);
}).catch((error) => {
next(error)
});
}
catch (error) {
next(error);
}
//Error handling middleware, we delegate the handling to the centrzlied error handler
app.use(function (err, req, res, next) {
errorHandler.handleError(err).then((isOperationalError) => {
if (!isOperationalError)
next(err);
});
});
Blog quote: «Sometimes lower levels can’t do anything useful except propagate the error to their caller»
(From the blog Joyent, ranked 1 for the keywords “Node.JS error handling”)
«…You may end up handling the same error at several levels of the stack. This happens when lower levels can’t do anything useful except propagate the error to their caller, which propagates the error to its caller, and so on. Often, only the top-level caller knows what the appropriate response is, whether that’s to retry the operation, report an error to the user, or something else. But that doesn’t mean you should try to report all errors to a single top-level callback, because that callback itself can’t know in what context the error occurred»
Number5: Document API errors using Swagger
TL;DR: Let your API callers know which errors might come in return so they can handle these thoughtfully without crashing. This is usually done with REST API documentation frameworks like Swagger
Otherwise: An API client might decide to crash and restart only because he received back an error he couldn’t understand. Note: the caller of your API might be you (very typical in a microservices environment)
Blog quote: «You have to tell your callers what errors can happen»
(From the blog Joyent, ranked 1 for the keywords “Node.JS logging”)
…We’ve talked about how to handle errors, but when you’re writing a new function, how do you deliver errors to the code that called your function? …If you don’t know what errors can happen or don’t know what they mean, then your program cannot be correct except by accident. So if you’re writing a new function, you have to tell your callers what errors can happen and what they mea
Number6: Shut the process gracefully when a stranger comes to town
TL;DR: When an unknown error occurs (a developer error, see best practice number #3)- there is uncertainty about the application healthiness. A common practice suggests restarting the process carefully using a ‘restarter’ tool like Forever and PM2
Otherwise: When an unfamiliar exception is caught, some object might be in a faulty state (e.g an event emitter which is used globally and not firing events anymore due to some internal failure) and all future requests might fail or behave crazily
Code example — deciding whether to crash
//deciding whether to crash when an uncaught exception arrives
//Assuming developers mark known operational errors with error.isOperational=true, read best practice #3
process.on('uncaughtException', function(error) {
errorManagement.handler.handleError(error);
if(!errorManagement.handler.isTrustedError(error))
process.exit(1)
});
//centralized error handler encapsulates error-handling related logic
function errorHandler(){
this.handleError = function (error) {
return logger.logError(err).then(sendMailToAdminIfCritical).then(saveInOpsQueueIfCritical).then(determineIfOperationalError);
}
this.isTrustedError = function(error)
{
return error.isOperational;
}
Blog quote: «There are three schools of thoughts on error handling»
(From the blog jsrecipes)
…There are primarily three schools of thoughts on error handling: 1. Let the application crash and restart it. 2. Handle all possible errors and never crash. 3. Balanced approach between the two
Number7: Use a mature logger to increase errors visibility
TL;DR: A set of mature logging tools like Winston, Bunyan or Log4J, will speed-up error discovery and understanding. So forget about console.log.
Otherwise: Skimming through console.logs or manually through messy text file without querying tools or a decent log viewer might keep you busy at work until late
Code example — Winston logger in action
//your centralized logger object
var logger = new winston.Logger({
level: 'info',
transports: [
new (winston.transports.Console)(),
new (winston.transports.File)({ filename: 'somefile.log' })
]
});
//custom code somewhere using the logger
logger.log('info', 'Test Log Message with some parameter %s', 'some parameter', { anything: 'This is metadata' });
Blog quote: «Lets identify a few requirements (for a logger):»
(From the blog strongblog)
…Lets identify a few requirements (for a logger):
1. Time stamp each log line. This one is pretty self explanatory – you should be able to tell when each log entry occured.
2. Logging format should be easily digestible by humans as well as machines.
3. Allows for multiple configurable destination streams. For example, you might be writing trace logs to one file but when an error is encountered, write to the same file, then into error file and send an email at the same time…
Number8: Discover errors and downtime using APM products
TL;DR: Monitoring and performance products (a.k.a APM) proactively gauge your codebase or API so they can auto-magically highlight errors, crashes and slow parts that you were missing
Otherwise: You might spend great effort on measuring API performance and downtimes, probably you’ll never be aware which are your slowest code parts under real world scenario and how these affects the UX
Blog quote: «APM products segments»
(From the blog Yoni Goldberg)
«…APM products constitutes 3 major segments:1. Website or API monitoring – external services that constantly monitor uptime and performance via HTTP requests. Can be setup in few minutes. Following are few selected contenders: Pingdom, Uptime Robot, and New Relic
2. Code instrumentation – products family which require to embed an agent within the application to benefit feature slow code detection, exceptions statistics, performance monitoring and many more. Following are few selected contenders: New Relic, App Dynamics
3. Operational intelligence dashboard – these line of products are focused on facilitating the ops team with metrics and curated content that helps to easily stay on top of application performance. This is usually involves aggregating multiple sources of information (application logs, DB logs, servers log, etc) and upfront dashboard design work. Following are few selected contenders: Datadog, Splunk»
The above is a shortened version — see here more best practices and examples
Editor’s note: This article was updated on September 5, 2022, by our editorial team. It has been modified to include recent sources and to align with our current editorial standards.
The ability to handle errors correctly in APIs while providing meaningful error messages is a desirable feature, as it can help the API client respond to issues. The default behavior returns stack traces that are hard to understand and ultimately useless for the API client. Partitioning the error information into fields enables the API client to parse it and provide better error messages to the user. In this article, we cover how to implement proper Spring Boot exception handling when building a REST API .

Building REST APIs with Spring became the standard approach for Java developers. Using Spring Boot helps substantially, as it removes a lot of boilerplate code and enables auto-configuration of various components. We assume that you’re familiar with the basics of API development with those technologies. If you are unsure about how to develop a basic REST API, you should start with this article about Spring MVC or this article about building a Spring REST Service.
Making Error Responses Clearer
We’ll use the source code hosted on GitHub as an example application that implements a REST API for retrieving objects that represent birds. It has the features described in this article and a few more examples of error handling scenarios. Here’s a summary of endpoints implemented in that application:
GET /birds/{birdId} |
Gets information about a bird and throws an exception if not found. |
GET /birds/noexception/{birdId} |
This call also gets information about a bird, except it doesn’t throw an exception when a bird doesn’t exist with that ID. |
POST /birds |
Creates a bird. |
The Spring framework MVC module has excellent features for error handling. But it is left to the developer to use those features to treat the exceptions and return meaningful responses to the API client.
Let’s look at an example of the default Spring Boot answer when we issue an HTTP POST to the /birds endpoint with the following JSON object that has the string “aaa” on the field “mass,” which should be expecting an integer:
{
"scientificName": "Common blackbird",
"specie": "Turdus merula",
"mass": "aaa",
"length": 4
}
The Spring Boot default answer, without proper error handling, looks like this:
{
"timestamp": 1658551020,
"status": 400,
"error": "Bad Request",
"exception": "org.springframework.http.converter.HttpMessageNotReadableException",
"message": "JSON parse error: Unrecognized token 'three': was expecting ('true', 'false' or 'null'); nested exception is com.fasterxml.jackson.core.JsonParseException: Unrecognized token 'aaa': was expecting ('true', 'false' or 'null')n at [Source: java.io.PushbackInputStream@cba7ebc; line: 4, column: 17]",
"path": "/birds"
}
The Spring Boot DefaultErrorAttributes-generated response has some good fields, but it is too focused on the exception. The timestamp field is an integer that doesn’t carry information about its measurement unit. The exception field is only valuable to Java developers, and the message leaves the API consumer lost in implementation details that are irrelevant to them. What if there were more details we could extract from the exception? Let’s learn how to handle exceptions in Spring Boot properly and wrap them into a better JSON representation to make life easier for our API clients.
As we’ll be using Java date and time classes, we first need to add a Maven dependency for the Jackson JSR310 converters. They convert Java date and time classes to JSON representation using the @JsonFormat annotation:
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
</dependency>
Next, let’s define a class for representing API errors. We’ll create a class called ApiError with enough fields to hold relevant information about errors during REST calls:
class ApiError {
private HttpStatus status;
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "dd-MM-yyyy hh:mm:ss")
private LocalDateTime timestamp;
private String message;
private String debugMessage;
private List<ApiSubError> subErrors;
private ApiError() {
timestamp = LocalDateTime.now();
}
ApiError(HttpStatus status) {
this();
this.status = status;
}
ApiError(HttpStatus status, Throwable ex) {
this();
this.status = status;
this.message = "Unexpected error";
this.debugMessage = ex.getLocalizedMessage();
}
ApiError(HttpStatus status, String message, Throwable ex) {
this();
this.status = status;
this.message = message;
this.debugMessage = ex.getLocalizedMessage();
}
}
-
The
statusproperty holds the operation call status, which will be anything from 4xx to signal client errors or 5xx to signal server errors. A typical scenario is an HTTP code 400: BAD_REQUEST when the client, for example, sends an improperly formatted field, like an invalid email address. -
The
timestampproperty holds the date-time instance when the error happened. -
The
messageproperty holds a user-friendly message about the error. -
The
debugMessageproperty holds a system message describing the error in detail. -
The
subErrorsproperty holds an array of suberrors when there are multiple errors in a single call. An example would be numerous validation errors in which multiple fields have failed. TheApiSubErrorclass encapsulates this information:
abstract class ApiSubError {
}
@Data
@EqualsAndHashCode(callSuper = false)
@AllArgsConstructor
class ApiValidationError extends ApiSubError {
private String object;
private String field;
private Object rejectedValue;
private String message;
ApiValidationError(String object, String message) {
this.object = object;
this.message = message;
}
}
The ApiValidationError is a class that extends ApiSubError and expresses validation problems encountered during the REST call.
Below, you’ll see examples of JSON responses generated after implementing these improvements.
Here is a JSON example returned for a missing entity while calling endpoint GET /birds/2:
{
"apierror": {
"status": "NOT_FOUND",
"timestamp": "22-07-2022 06:20:19",
"message": "Bird was not found for parameters {id=2}"
}
}
Here is another example of JSON returned when issuing a POST /birds call with an invalid value for the bird’s mass:
{
"apierror": {
"status": "BAD_REQUEST",
"timestamp": "22-07-2022 06:49:25",
"message": "Validation errors",
"subErrors": [
{
"object": "bird",
"field": "mass",
"rejectedValue": 999999,
"message": "must be less or equal to 104000"
}
]
}
}
Spring Boot Error Handler
Let’s explore some Spring annotations used to handle exceptions.
RestController is the base annotation for classes that handle REST operations.
ExceptionHandler is a Spring annotation that provides a mechanism to treat exceptions thrown during execution of handlers (controller operations). This annotation, if used on methods of controller classes, will serve as the entry point for handling exceptions thrown within this controller only.
Altogether, the most common implementation is to use @ExceptionHandler on methods of @ControllerAdvice classes so that the Spring Boot exception handling will be applied globally or to a subset of controllers.
ControllerAdvice is an annotation in Spring and, as the name suggests, is “advice” for multiple controllers. It enables the application of a single ExceptionHandler to multiple controllers. With this annotation, we can define how to treat such an exception in a single place, and the system will call this handler for thrown exceptions on classes covered by this ControllerAdvice.
The subset of controllers affected can be defined by using the following selectors on @ControllerAdvice: annotations(), basePackageClasses(), and basePackages(). ControllerAdvice is applied globally to all controllers if no selectors are provided
By using @ExceptionHandler and @ControllerAdvice, we’ll be able to define a central point for treating exceptions and wrapping them in an ApiError object with better organization than is possible with the default Spring Boot error-handling mechanism.
Handling Exceptions
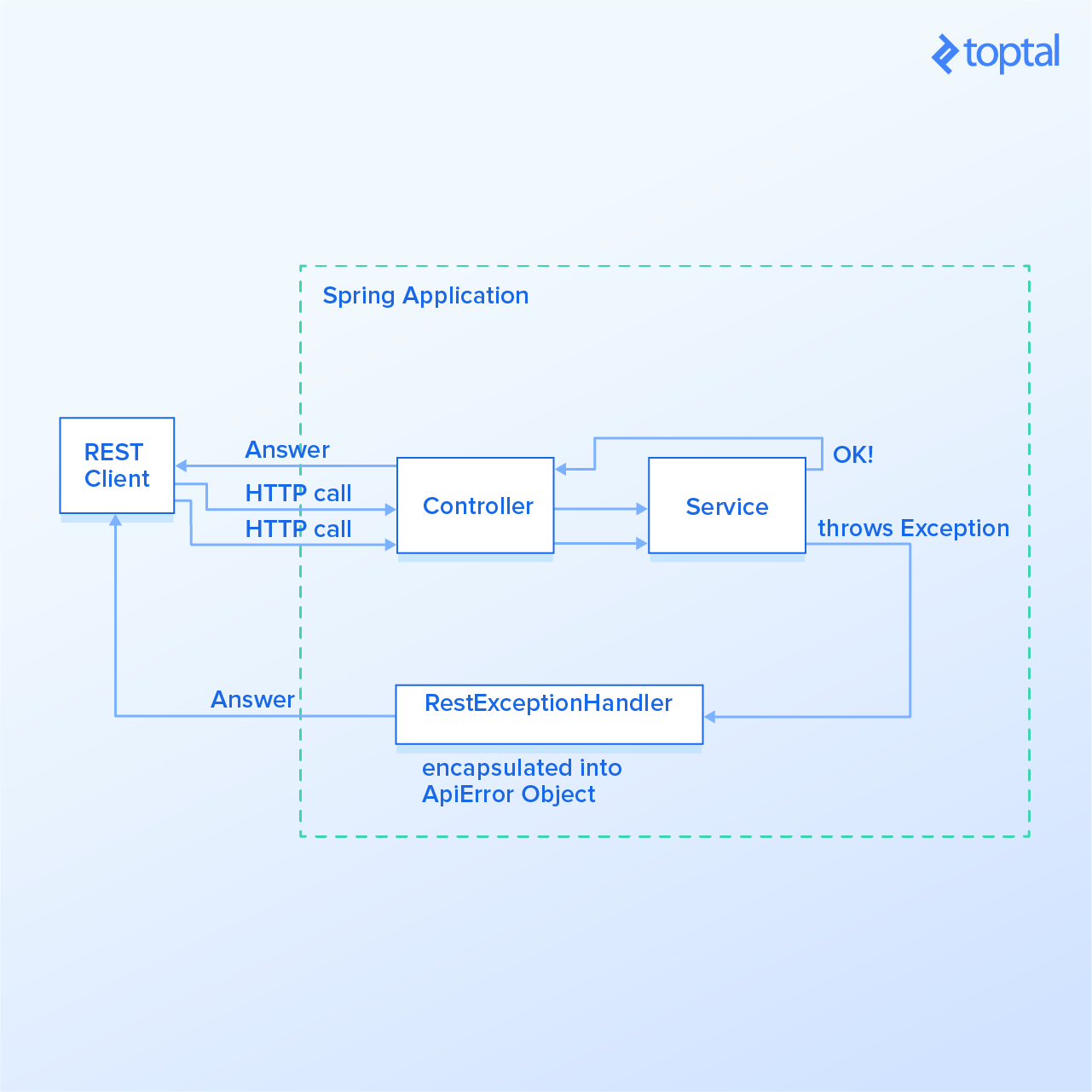
Next, we’ll create the class that will handle the exceptions. For simplicity, we call it RestExceptionHandler, which must extend from Spring Boot’s ResponseEntityExceptionHandler. We’ll be extending ResponseEntityExceptionHandler, as it already provides some basic handling of Spring MVC exceptions. We’ll add handlers for new exceptions while improving the existing ones.
Overriding Exceptions Handled in ResponseEntityExceptionHandler
If you take a look at the source code of ResponseEntityExceptionHandler, you’ll see a lot of methods called handle******(), like handleHttpMessageNotReadable() or handleHttpMessageNotWritable(). Let’s see how can we extend handleHttpMessageNotReadable() to handle HttpMessageNotReadableException exceptions. We just have to override the method handleHttpMessageNotReadable() in our RestExceptionHandler class:
@Order(Ordered.HIGHEST_PRECEDENCE)
@ControllerAdvice
public class RestExceptionHandler extends ResponseEntityExceptionHandler {
@Override
protected ResponseEntity<Object> handleHttpMessageNotReadable(HttpMessageNotReadableException ex, HttpHeaders headers, HttpStatus status, WebRequest request) {
String error = "Malformed JSON request";
return buildResponseEntity(new ApiError(HttpStatus.BAD_REQUEST, error, ex));
}
private ResponseEntity<Object> buildResponseEntity(ApiError apiError) {
return new ResponseEntity<>(apiError, apiError.getStatus());
}
//other exception handlers below
}
We have declared that in case of a thrownHttpMessageNotReadableException, the error message will be “Malformed JSON request” and the error will be encapsulated in the ApiError object. Below, we can see the answer of a REST call with this new method overridden:
{
"apierror": {
"status": "BAD_REQUEST",
"timestamp": "22-07-2022 03:53:39",
"message": "Malformed JSON request",
"debugMessage": "JSON parse error: Unrecognized token 'aaa': was expecting ('true', 'false' or 'null'); nested exception is com.fasterxml.jackson.core.JsonParseException: Unrecognized token 'aaa': was expecting ('true', 'false' or 'null')n at [Source: java.io.PushbackInputStream@7b5e8d8a; line: 4, column: 17]"
}
}
Implementing Custom Exceptions
Next, we’ll create a method that handles an exception not yet declared inside Spring Boot’s ResponseEntityExceptionHandler.
A common scenario for a Spring application that handles database calls is to provide a method that returns a record by its ID using a repository class. But if we look into the CrudRepository.findOne() method, we’ll see that it returns null for an unknown object. If our service calls this method and returns directly to the controller, we’ll get an HTTP code 200 (OK) even if the resource isn’t found. In fact, the proper approach is to return a HTTP code 404 (NOT FOUND) as specified in the HTTP/1.1 spec.
We’ll create a custom exception called EntityNotFoundException to handle this case. This one is different from javax.persistence.EntityNotFoundException, as it provides some constructors that ease the object creation, and one may choose to handle the javax.persistence exception differently.
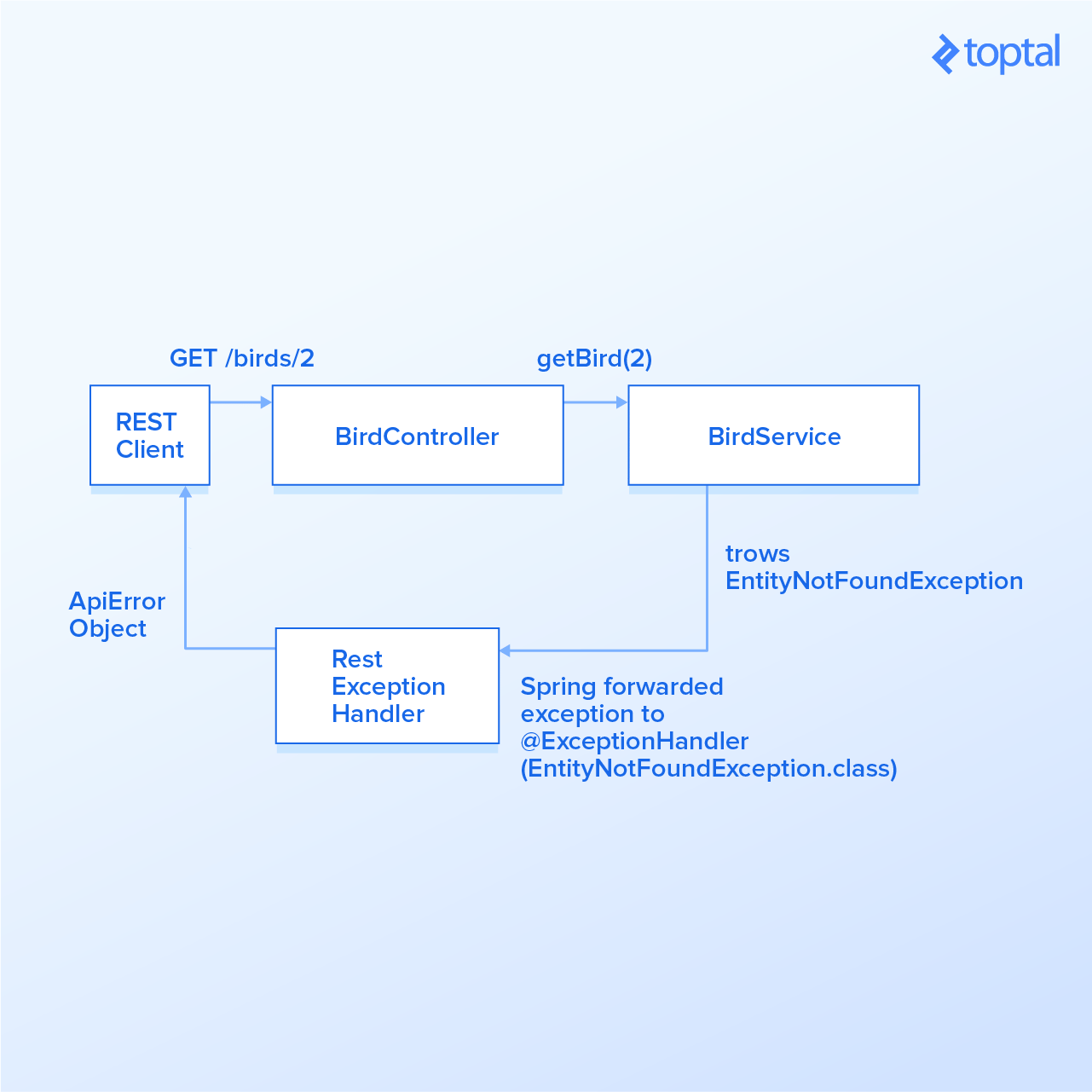
That said, let’s create an ExceptionHandler for this newly created EntityNotFoundException in our RestExceptionHandler class. Create a method called handleEntityNotFound() and annotate it with @ExceptionHandler, passing the class object EntityNotFoundException.class to it. This declaration signalizes Spring that every time EntityNotFoundException is thrown, Spring should call this method to handle it.
When annotating a method with @ExceptionHandler, a wide range of auto-injected parameters like WebRequest, Locale, and others may be specified as described here. We’ll provide the exception EntityNotFoundException as a parameter for this handleEntityNotFound method:
@Order(Ordered.HIGHEST_PRECEDENCE)
@ControllerAdvice
public class RestExceptionHandler extends ResponseEntityExceptionHandler {
//other exception handlers
@ExceptionHandler(EntityNotFoundException.class)
protected ResponseEntity<Object> handleEntityNotFound(
EntityNotFoundException ex) {
ApiError apiError = new ApiError(NOT_FOUND);
apiError.setMessage(ex.getMessage());
return buildResponseEntity(apiError);
}
}
Great! In the handleEntityNotFound() method, we set the HTTP status code to NOT_FOUND and usethe new exception message. Here is what the response for the GET /birds/2 endpoint looks like now:
{
"apierror": {
"status": "NOT_FOUND",
"timestamp": "22-07-2022 04:02:22",
"message": "Bird was not found for parameters {id=2}"
}
}
The Importance of Spring Boot Exception Handling
It is important to control exception handling so we can properly map exceptions to the ApiError object and inform API clients appropriately. Additionally, we would need to create more handler methods (the ones with @ExceptionHandler) for thrown exceptions within the application code. The GitHub code provides more more examples for other common exceptions like MethodArgumentTypeMismatchException, ConstraintViolationException.
Here are some additional resources that helped in the composition of this article:
-
Error Handling for REST With Spring
-
Exception Handling in Spring MVC
Further Reading on the Toptal Engineering Blog:
- Top 10 Most Common Spring Framework Mistakes
- Spring Security with JWT for REST API
- Using Spring Boot for OAuth2 and JWT REST Protection
- Building an MVC Application With Spring Framework: A Beginner’s Tutorial
- Spring Batch Tutorial: Batch Processing Made Easy with Spring
Understanding the basics
-
Why should the API have a uniform error format?
A uniform error format allows an API client to parse error objects. A more complex error could implement the ApiSubError class and provide more details about the problem so the client can know which actions to take.
-
How does Spring know which ExceptionHandler to use?
The Spring MVC class, ExceptionHandlerExceptionResolver, performs most of the work in its doResolveHandlerMethodException() method.
-
What information is important to provide to API consumers?
Usually, it is helpful to include the error origination, the input parameters, and some guidance on how to fix the failing call.