Environment:
- OS (
printf "$(uname -srm)n$(cat /etc/os-release)n"):
Ubuntu 18.04.6 LTS
-
Version of Ansible (
ansible --version): -
ansible 2.9.6
-
Version of Python (
python --version): -
Python 2.7.17
Kubespray version (commit) (git rev-parse --short HEAD):
#2ff7ab8d
Network plugin used:
Calico
Full inventory with variables (ansible -i inventory/sample/inventory.ini all -m debug -a "var=hostvars[inventory_hostname]"):
Command used to invoke ansible:
ansible-playbook -i inventory/mycluster/hosts.yaml --become --become-user=root cluster.yml
Output of ansible run:
TASK [etcd : Configure | Ensure etcd is running] ***************************************************************************************************************
ok: [node2]
ok: [node1]
ok: [node3]
Wednesday 05 January 2022 20:19:00 +0530 (0:00:00.709) 0:09:27.503 *****
Wednesday 05 January 2022 20:19:00 +0530 (0:00:00.108) 0:09:27.612 *****
FAILED — RETRYING: Configure | Wait for etcd cluster to be healthy (4 retries left).
FAILED — RETRYING: Configure | Wait for etcd cluster to be healthy (3 retries left).
FAILED — RETRYING: Configure | Wait for etcd cluster to be healthy (2 retries left).
FAILED — RETRYING: Configure | Wait for etcd cluster to be healthy (1 retries left).
TASK [etcd : Configure | Wait for etcd cluster to be healthy] **************************************************************************************************
fatal: [node1]: FAILED! => {«attempts»: 4, «changed»: false, «cmd»: «set -o pipefail && /usr/local/bin/etcdctl endpoint —cluster status && /usr/local/bin/etcdctl endpoint —cluster health 2>&1 | grep -q -v ‘Error: unhealthy cluster'», «delta»: «0:00:05.024332», «end»: «2022-01-05 20:19:39.020924», «msg»: «non-zero return code», «rc»: 1, «start»: «2022-01-05 20:19:33.996592», «stderr»: «{«level»:»warn»,»ts»:»2022-01-05T20:19:39.018+0530″,»caller»:»clientv3/retry_interceptor.go:61″,»msg»:»retrying of unary invoker failed»,»target»:»endpoint://client-e4dcc9e2-328a-4dcc-a8d6-b45d01e6ae47/192.168.100.155:2379″,»attempt»:0,»error»:»rpc error: code = DeadlineExceeded desc = latest connection error: connection error: desc = «transport: authentication handshake failed: remote error: tls: bad certificate»»}nError: failed to fetch endpoints from etcd cluster member list: context deadline exceeded», «stderr_lines»: [«{«level»:»warn»,»ts»:»2022-01-05T20:19:39.018+0530″,»caller»:»clientv3/retry_interceptor.go:61″,»msg»:»retrying of unary invoker failed»,»target»:»endpoint://client-e4dcc9e2-328a-4dcc-a8d6-b45d01e6ae47/192.168.100.155:2379″,»attempt»:0,»error»:»rpc error: code = DeadlineExceeded desc = latest connection error: connection error: desc = «transport: authentication handshake failed: remote error: tls: bad certificate»»}», «Error: failed to fetch endpoints from etcd cluster member list: context deadline exceeded»], «stdout»: «», «stdout_lines»: []}
We had kubernetes cluster installed using kubespray, and after around a year we ran reset command and reinstallation step we got this error.ansible-playbook -i inventory/mycluster/hosts.yaml reset.yml --become --become-user=root
All nodes have firewall stopped. All nodes were restarted after reset and before starting re installation.
What happened?
I tried to Set up a High Availability etcd Cluster with kubeadm.
I followed the official guide https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/setup-ha-etcd-with-kubeadm/
after all the steps execute when i check cluster health its giving below error message
[root@etcd-01 ~]# docker run —rm -it
—net host
-v /etc/kubernetes:/etc/kubernetes k8s.gcr.io/etcd:3.5.1-0 etcdctl
—cert /etc/kubernetes/pki/etcd/peer.crt
—key /etc/kubernetes/pki/etcd/peer.key
—cacert /etc/kubernetes/pki/etcd/ca.crt
—endpoints https://137.184.157.161:2379 endpoint health —cluster
{«level»:»warn»,»ts»:»2022-02-09T08:12:22.497Z»,»logger»:»etcd-client»,»caller»:»v3/retry_interceptor.go:62″,»msg»:»retrying of unary invoker failed»,»target»:»etcd-endpoints://0xc00045e540/137.184.157.161:2379″,»attempt»:0,»error»:»rpc error: code = DeadlineExceeded desc = latest balancer error: last connection error: connection error: desc = «transport: Error while dialing dial tcp 137.184.157.161:2379: connect: connection refused»»}
Error: failed to fetch endpoints from etcd cluster member list: context deadline exceeded
What you expected to happen?
as per the official guide etcd cluster should be healthy state.
How to reproduce it (as minimally and precisely as possible)?
You can follow the official guide with https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/setup-ha-etcd-with-kubeadm/
Anything else we need to know?
Versions
kubeadm version (use v1.23.3):
Environment:
- Kubernetes version (use
v1.23.3): - Cloud provider or hardware configuration:
Master Nodes -03
Worker Nodes -03
etcd -03
HA load balancer -01
Digital Ocean cloud
all instance — 4 HB Ram ,2 CPU ,80 GB disk
- OS (e.g. from /etc/os-release):
CentOS 8
[root@etcd-01 ~]# cat /etc/os-release
NAME=»CentOS Stream»
VERSION=»8″
ID=»centos»
ID_LIKE=»rhel fedora»
VERSION_ID=»8″
PLATFORM_ID=»platform:el8″
PRETTY_NAME=»CentOS Stream 8″
ANSI_COLOR=»0;31″
CPE_NAME=»cpe:/o:centos:centos:8″
HOME_URL=»https://centos.org/»
BUG_REPORT_URL=»https://bugzilla.redhat.com/»
REDHAT_SUPPORT_PRODUCT=»Red Hat Enterprise Linux 8″
REDHAT_SUPPORT_PRODUCT_VERSION=»CentOS Stream»
- Kernel (e.g.
uname -a):
[root@etcd-01 ~]# uname -a
Linux etcd-01 4.18.0-277.el8.x86_64 #1 SMP Wed Feb 3 20:35:19 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
-
Container runtime (CRI) (e.g. containerd, cri-o):
Docker -
Container networking plugin (CNI) (e.g. Calico, Cilium):
wavenet -
Others:
Содержание
- Error: failed to fetch endpoints from etcd cluster member list: context deadline exceeded #8374
- Comments
- Unable to check ETCD cluster health
- 1 Answer 1
- Related
- Hot Network Questions
- Subscribe to RSS
- Ломаем и чиним etcd-кластер
- Подготовка
- Проверка состояния кластера
- Удаление неисправной ноды
- Добавление новой ноды
- Создание снапшота etcd
- Восстановление etcd из снапшота
- Потеря кворума
- etcd-v3.4.9: etcdctl command failed and return Error: context deadline exceeded #12006
- Comments
Error: failed to fetch endpoints from etcd cluster member list: context deadline exceeded #8374
Environment:
- OS ( printf «$(uname -srm)n$(cat /etc/os-release)n» ):
Ubuntu 18.04.6 LTS
Version of Ansible ( ansible —version ):
Version of Python ( python —version ):
Kubespray version (commit) ( git rev-parse —short HEAD ):
#2ff7ab8d
Network plugin used:
Calico
Full inventory with variables ( ansible -i inventory/sample/inventory.ini all -m debug -a «var=hostvars[inventory_hostname]» ):
Command used to invoke ansible:
ansible-playbook -i inventory/mycluster/hosts.yaml —become —become-user=root cluster.yml
Output of ansible run:
TASK [etcd : Configure | Ensure etcd is running] ***************************************************************************************************************
ok: [node2]
ok: [node1]
ok: [node3]
Wednesday 05 January 2022 20:19:00 +0530 (0:00:00.709) 0:09:27.503 *****
Wednesday 05 January 2022 20:19:00 +0530 (0:00:00.108) 0:09:27.612 *****
FAILED — RETRYING: Configure | Wait for etcd cluster to be healthy (4 retries left).
FAILED — RETRYING: Configure | Wait for etcd cluster to be healthy (3 retries left).
FAILED — RETRYING: Configure | Wait for etcd cluster to be healthy (2 retries left).
FAILED — RETRYING: Configure | Wait for etcd cluster to be healthy (1 retries left).
We had kubernetes cluster installed using kubespray, and after around a year we ran reset command and reinstallation step we got this error. ansible-playbook -i inventory/mycluster/hosts.yaml reset.yml —become —become-user=root
All nodes have firewall stopped. All nodes were restarted after reset and before starting re installation.
The text was updated successfully, but these errors were encountered:
Источник
Unable to check ETCD cluster health
After following official guidance from (https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/setup-ha-etcd-with-kubeadm/) for HA external ETCD, I was trying to check etcd cluster health status, but, it threw some error which I’m struggling to solve. Please help.
Command used to check etcd cluster health that threw an error:
Three bare-metal hosts, all ufw enabled, 2379 and 2380 ports allowed on entire hosts.
Error:
1 Answer 1
Context deadline exceeded is an unclear error returned by grpc client when it can’t establish the connection. you can set ETCDCTL_API=2 , then you can get the right error message.
Also, you can change some code in etcd to debug this error.
see #10087
You can solve this issue when I applied the right cert/key pair.
Assuming you’re using kubeadm to spin up the cluster, there should be a couple of cert/key pairs under the folder:
You can also try to follow this instruction error-context-deadline-exceeded-accessing.

Hot Network Questions
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
Site design / logo © 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA . rev 2023.1.14.43159
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Источник
Ломаем и чиним etcd-кластер

etcd — это быстрая, надёжная и устойчивая к сбоям key-value база данных. Она лежит в основе Kubernetes и является неотъемлемой частью его control-plane, именно поэтому критически важно уметь бэкапить и восстанавливать работоспособность как отдельных нод, так и всего etcd-кластера.
В предыдущей статье мы подробно рассмотрели перегенерацию SSL-сертификатов и static-манифестов для Kubernetes, а также вопросы связанные c восстановлением работоспособности Kubernetes. Эта статья будет посвящена целиком и полностью восстановлению etcd-кластера.
Для начала я сразу должен сделать оговорку, что рассматривать мы будем лишь определённый кейс, когда etcd задеплоен и используется непосредственно в составе Kubernetes. Приведённые в статье примеры подразумевают что ваш etcd-кластер развёрнут с помощью static-манифестов и запускается внутри контейнеров.
Для наглядности возьмём схему stacked control plane nodes из предыдущей статьи:
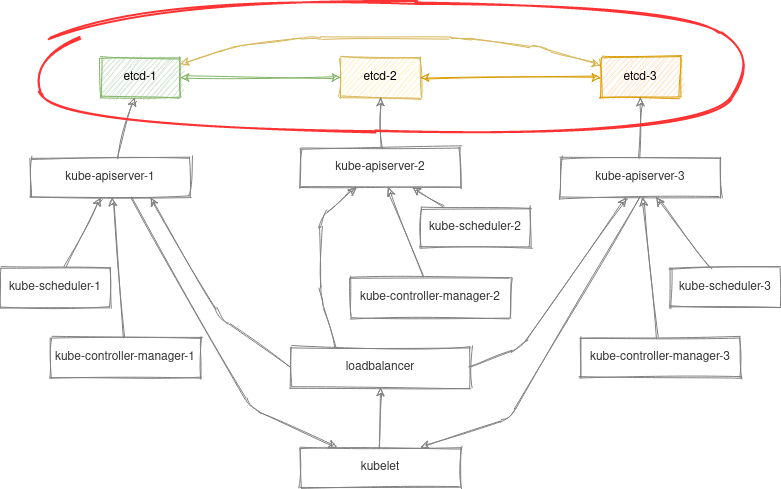 сервер)» title=»(стрелочки указывают на связи клиент —> сервер)» width=»781″ height=»489″ data-src=»https://habrastorage.org/webt/0s/of/k1/0sofk1tnhp6cjs7sw92otrzvsec.png»/> (стрелочки указывают на связи клиент —> сервер)
сервер)» title=»(стрелочки указывают на связи клиент —> сервер)» width=»781″ height=»489″ data-src=»https://habrastorage.org/webt/0s/of/k1/0sofk1tnhp6cjs7sw92otrzvsec.png»/> (стрелочки указывают на связи клиент —> сервер)
Предложенные ниже команды можно выполнить и с помощью kubectl, но в данном случае мы постараемся абстрагироваться от плоскости управления Kubernetes и рассмотрим локальный вариант управления контейнеризированным etcd-кластером с помощью crictl.
Данное умение также поможет вам починить etcd даже в случае неработающего Kubernetes API.
Подготовка
Поэтому, первое что мы сделаем, это зайдём по ssh на одну из master-нод и найдём наш etcd-контейнер:
Так же установим алиас, чтобы каждый раз не перечислять пути к сертификатам в командах:
Приведённые выше команды являются временными, вам потребуется выполнять их каждый раз перед тем как начать работать с etcd. Конечно, для своего удобства вы можете добавить их в .bashrc. Однако это уже выходит за рамки этой статьи.
Если что-то пошло не так и вы не можете сделать exec в запущенный контейнер, посмотрите логи etcd:
crictl logs «$CONTAINER_ID»
А также убедитесь в наличии static-манифеста и всех сертификатов в случае если контейнер даже не создался. Логи kubelet так же бывают весьма полезными.
Проверка состояния кластера
Здесь всё просто:
Каждый инстанс etcd знает всё о каждом. Информация о members хранится внутри самого etcd и поэтому любое изменение в ней будет также обновленно и на остальных инстансах кластера.
Важное замечание, команда member list отображает только статус конфигурации, но не статус конкретного инстанса. Чтобы проверить статусы инстансов есть команда endpoint status , но она требует явного указания всех эндпоинтов кластера для проверки.
в случае если какой-то из эндпоинтов окажется недоступным вы увидите такую ошибку:
Удаление неисправной ноды
Иногда случается так что какая-то из нод вышла из строя. И вам нужно восстановить работоспособность etcd-кластера, как быть?
Первым делом нам нужно удалить failed member:
Прежде чем продолжить, давайте убедимся, что на упавшей ноде под с etcd больше не запущен, а нода больше не содержит никаких данных:
Команды выше удалят static-pod для etcd и дирректорию с данными /var/lib/etcd на ноде.
Разумеется в качестве альтернативы вы также можете воспользоваться командой kubeadm reset , которая удалит все Kubernetes-related ресурсы и сертификаты с вашей ноды.
Добавление новой ноды
Теперь у нас есть два пути:
В первом случае мы можем просто добавить новую control-plane ноду используя стандартный kubeadm join механизм:
Вышеприведённые команды сгенерируют команду для джойна новой control-plane ноды в Kubernetes. Этот кейс довольно подробно описан в официальной документации Kubernetes и не нуждается в разъяснении.
Этот вариант наиболее удобен тогда, когда вы деплоите новую ноду с нуля или после выполнения kubeadm reset
Второй вариант более аккуратный, так как позволяет рассмотреть и выполнить изменения необходимые только для etcd не затрагивая при этом другие контейнеры на ноде.
Для начала убедимся что наша нода имеет валидный CA-сертификат для etcd:
В случае его отсутствия скопируейте его с других нод вашего кластера. Теперь сгенерируем остальные сертификаты для нашей ноды:
и выполним присоединение к кластеру:
Для понимания, вышеописанная команда сделает следующее:
Добавит новый member в существующий etcd-кластер:
Сгенерирует новый static-manifest для etcd /etc/kubernetes/manifests/etcd.yaml с опциями:
эти опции позволят нашей ноде автоматически добавиться в существующий etcd-кластер.
Создание снапшота etcd
Теперь рассмотрим вариант создания и восстановления etcd из резервной копии.
Создать бэкап можно довольно просто, выполнив на любой из нод:
Обратите внимание я намеренно использую /var/lib/etcd так как эта директория уже прокинута в etcd контейнер (смотрим в static-манифест /etc/kubernetes/manifests/etcd.yaml )
После выполнения этой команды по указанному пути вы найдёте снапшот с вашими данными, давайте сохраним его в надёжном месте и рассмотрим процедуру восстановления из бэкапа
Восстановление etcd из снапшота
Здесь мы рассмотрим кейс когда всё пошло не так и нам потребовалось восстановить кластер из резервной копии.
У нас есть снапшот snap1.db сделанный на предыдущем этапе. Теперь давайте полностью удалим static-pod для etcd и данные со всех наших нод:
Теперь у нас снова есть два пути:
Вариант первый создать etcd-кластер из одной ноды и присоединить к нему остальные ноды, по описанной выше процедуре.
эта команда сгенерирует статик-манифест для etcd c опциями:
таким образом мы получим девственно чистый etcd на одной ноде.
Восстановим бэкап на первой ноде:
На остальных нодах выполним присоединение к кластеру:
Вариант второй: восстановить бэкап сразу на всех нодах кластера. Для этого копируем файл снапшота на остальные ноды, и выполняем восстановление вышеописанным образом. В данном случае в опциях к etcdctl нам потребуется указать сразу все ноды нашего кластера, к примеру
для node1:
для node2:
для node3:
Потеря кворума
Иногда случается так что мы потеряли большинство нод из кластера и etcd перешёл в неработоспособное состояние. Удалить или добавить новых мемберов у вас не получится, как и создать снапшот.
Выход из этой ситуации есть. Нужно отредактировать файл static-манифеста и добавить ключ —force-new-cluster к etcd:
после чего инстанс etcd перезапустится в кластере с единственным экземпляром:
Теперь вам нужно очистить и добавить остальные ноды в кластер по описанной выше процедуре. Только не забудьте удалить ключ —force-new-cluster после всех этих манипуляций 😉
Источник
etcd-v3.4.9: etcdctl command failed and return Error: context deadline exceeded #12006
Hello,
I have installed ecd-v3.4.9 in centos 7.6. I have two node. After I used etcd command to start etcd, the logs seems without errors.But etcdctl command failed and return Error: context deadline exceeded.
the following is installation process.
]# yum -y install python3-psycopg2 python3-pip PyYAML
2.download etcd backage from https://github.com/etcd-io/etcd/releases
[root@pgsrv2 soft]# ll
-rw-r—r—. 1 root root 17364053 Jun 11 17:20 etcd-v3.4.9-linux-amd64.tar.gz
[root@pgsrv2 soft]# tar -zxvf etcd-v3.4.9-linux-amd64.tar.gz -C /usr/local
[root@pgsrv2 soft]# cd /usr/local
[root@pgsrv2 local]# ll
drwxr-xr-x. 3 630384594 600260513 123 May 22 03:54 etcd-v3.4.9-linux-amd64
[root@pgsrv2 local]# mv etcd-v3.4.9-linux-amd64 etcd-v3.4.9
[root@pgsrv2 local]# chown -R postgres:postgres etcd-v3.4.9
[root@pgsrv2 local]# ll
drwxr-xr-x. 3 postgres postgres 123 May 22 03:54 etcd-v3.4.9
[root@pgsrv2 local]# cd etcd-v3.4.9/
[root@pgsrv2 etcd-v3.4.9]# ll
total 40540
drwxr-xr-x. 14 postgres postgres 4096 May 22 03:54 Documentation
-rwxr-xr-x. 1 postgres postgres 23827424 May 22 03:54 etcd
-rwxr-xr-x. 1 postgres postgres 17612384 May 22 03:54 etcdctl
-rw-r—r—. 1 postgres postgres 43094 May 22 03:54 README-etcdctl.md
-rw-r—r—. 1 postgres postgres 8431 May 22 03:54 README.md
-rw-r—r—. 1 postgres postgres 7855 May 22 03:54 READMEv2-etcdctl.md
[root@pgsrv2 etcd-v3.4.9]# mkdir etcd-data
[root@pgsrv2 etcd-v3.4.9]# chown -R postgres:postgres etcd-data
[root@pgsrv2 etcd-v3.4.9]# ll
total 40540
drwxr-xr-x. 14 postgres postgres 4096 May 22 03:54 Documentation
-rwxr-xr-x. 1 postgres postgres 23827424 May 22 03:54 etcd
-rwxr-xr-x. 1 postgres postgres 17612384 May 22 03:54 etcdctl
drwxr-xr-x. 2 postgres postgres 6 Jun 11 19:46 etcd-data
-rw-r—r—. 1 postgres postgres 43094 May 22 03:54 README-etcdctl.md
-rw-r—r—. 1 postgres postgres 8431 May 22 03:54 README.md
-rw-r—r—. 1 postgres postgres 7855 May 22 03:54 READMEv2-etcdctl.md
3.rewrite /etc/hosts.I have two node
[root@pgsrv2 etc]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.163.102 pgsrv2
192.168.163.103 pgsrv3
- wirte etcd.yml in two nodes
[root@pgsrv2 etcd-v3.4.9]# su — postgres
Last login: Thu Jun 11 18:41:15 CST 2020 on pts/0
node1:pgsrv2
[postgres@pgsrv2 etcd-v3.4.9]$ vim etcd.yml
node2:pgsrv3
[postgres@pgsrv3 etcd-v3.4.9]$ vim etcd.yml
5.mkdir log dir in two nodes
[postgres@pgsrv2 etcd-v3.4.9]$ exit
logout
[root@pgsrv2 etcd-v3.4.9]# mkdir /var/log/etcd
[root@pgsrv2 etcd-v3.4.9]# chown -R postgres:postgres /var/log/etcd
6.add «export ETCDCTL_API=3» in /home/postgres/.bashrc
[postgres@pgsrv2
7.excute etcd command in two nodes
[postgres@pgsrv2 etcd-v3.4.9]$ /usr/local/etcd-v3.4.9/etcd —config-file /usr/local/etcd-v3.4.9/etcd.yml &>/var/log/etcd/etcd.log
[postgres@pgsrv3 etcd-v3.4.9]$ /usr/local/etcd-v3.4.9/etcd —config-file /usr/local/etcd-v3.4.9/etcd.yml &>/var/log/etcd/etcd.log
8.excute etcdctl command in any node,it seems normal.
[postgres@pgsrv2 etcd]$ /usr/local/etcd-v3.4.9/etcdctl version
8.excute etcdctl command but return Error: context deadline exceeded
[postgres@pgsrv2
]$ /usr/local/etcd-v3.4.9/etcdctl member list
[postgres@pgsrv2 etcd]$ /usr/local/etcd-v3.4.9/etcdctl member list —endpoints=192.168.163.102:2379
[postgres@pgsrv2 etcd]$ /usr/local/etcd-v3.4.9/etcdctl member list
I don’t know what happened. How can I do about it ? The logs don’t have any errors.
If you need more information,please let me know.
Thanks for you help!
The text was updated successfully, but these errors were encountered:
Источник
Время прочтения
7 мин
Просмотры 25K
etcd — это быстрая, надёжная и устойчивая к сбоям key-value база данных. Она лежит в основе Kubernetes и является неотъемлемой частью его control-plane, именно поэтому критически важно уметь бэкапить и восстанавливать работоспособность как отдельных нод, так и всего etcd-кластера.
В предыдущей статье мы подробно рассмотрели перегенерацию SSL-сертификатов и static-манифестов для Kubernetes, а также вопросы связанные c восстановлением работоспособности Kubernetes. Эта статья будет посвящена целиком и полностью восстановлению etcd-кластера.
Для начала я сразу должен сделать оговорку, что рассматривать мы будем лишь определённый кейс, когда etcd задеплоен и используется непосредственно в составе Kubernetes. Приведённые в статье примеры подразумевают что ваш etcd-кластер развёрнут с помощью static-манифестов и запускается внутри контейнеров.
Для наглядности возьмём схему stacked control plane nodes из предыдущей статьи:
Предложенные ниже команды можно выполнить и с помощью kubectl, но в данном случае мы постараемся абстрагироваться от плоскости управления Kubernetes и рассмотрим локальный вариант управления контейнеризированным etcd-кластером с помощью crictl.
Данное умение также поможет вам починить etcd даже в случае неработающего Kubernetes API.
Подготовка
Поэтому, первое что мы сделаем, это зайдём по ssh на одну из master-нод и найдём наш etcd-контейнер:
CONTAINER_ID=$(crictl ps -a --label io.kubernetes.container.name=etcd --label io.kubernetes.pod.namespace=kube-system | awk 'NR>1{r=$1} $0~/Running/{exit} END{print r}')Так же установим алиас, чтобы каждый раз не перечислять пути к сертификатам в командах:
alias etcdctl='crictl exec "$CONTAINER_ID" etcdctl --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key --cacert /etc/kubernetes/pki/etcd/ca.crt'Приведённые выше команды являются временными, вам потребуется выполнять их каждый раз перед тем как начать работать с etcd. Конечно, для своего удобства вы можете добавить их в .bashrc. Однако это уже выходит за рамки этой статьи.
Если что-то пошло не так и вы не можете сделать exec в запущенный контейнер, посмотрите логи etcd:
crictl logs "$CONTAINER_ID"А также убедитесь в наличии static-манифеста и всех сертификатов в случае если контейнер даже не создался. Логи kubelet так же бывают весьма полезными.
Проверка состояния кластера
Здесь всё просто:
# etcdctl member list -w table
+------------------+---------+-------+---------------------------+---------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+-------+---------------------------+---------------------------+------------+
| 409dce3eb8a3c713 | started | node1 | https://10.20.30.101:2380 | https://10.20.30.101:2379 | false |
| 74a6552ccfc541e5 | started | node2 | https://10.20.30.102:2380 | https://10.20.30.102:2379 | false |
| d70c1c10cb4db26c | started | node3 | https://10.20.30.103:2380 | https://10.20.30.103:2379 | false |
+------------------+---------+-------+---------------------------+---------------------------+------------+Каждый инстанс etcd знает всё о каждом. Информация о members хранится внутри самого etcd и поэтому любое изменение в ней будет также обновленно и на остальных инстансах кластера.
Важное замечание, команда member list отображает только статус конфигурации, но не статус конкретного инстанса. Чтобы проверить статусы инстансов есть команда endpoint status, но она требует явного указания всех эндпоинтов кластера для проверки.
ENDPOINTS=$(etcdctl member list | grep -o '[^ ]+:2379' | paste -s -d,)
etcdctl endpoint status --endpoints=$ENDPOINTS -w tableв случае если какой-то из эндпоинтов окажется недоступным вы увидите такую ошибку:
Failed to get the status of endpoint https://10.20.30.103:2379 (context deadline exceeded)Удаление неисправной ноды
Иногда случается так что какая-то из нод вышла из строя. И вам нужно восстановить работоспособность etcd-кластера, как быть?
Первым делом нам нужно удалить failed member:
etcdctl member remove d70c1c10cb4db26cПрежде чем продолжить, давайте убедимся, что на упавшей ноде под с etcd больше не запущен, а нода больше не содержит никаких данных:
rm -rf /etc/kubernetes/manifests/etcd.yaml /var/lib/etcd/
crictl rm "$CONTAINER_ID"Команды выше удалят static-pod для etcd и дирректорию с данными /var/lib/etcd на ноде.
Разумеется в качестве альтернативы вы также можете воспользоваться командой kubeadm reset, которая удалит все Kubernetes-related ресурсы и сертификаты с вашей ноды.
Добавление новой ноды
Теперь у нас есть два пути:
В первом случае мы можем просто добавить новую control-plane ноду используя стандартный kubeadm join механизм:
kubeadm init phase upload-certs --upload-certs
kubeadm token create --print-join-command --certificate-key <certificate_key>Вышеприведённые команды сгенерируют команду для джойна новой control-plane ноды в Kubernetes. Этот кейс довольно подробно описан в официальной документации Kubernetes и не нуждается в разъяснении.
Этот вариант наиболее удобен тогда, когда вы деплоите новую ноду с нуля или после выполнения kubeadm reset
Второй вариант более аккуратный, так как позволяет рассмотреть и выполнить изменения необходимые только для etcd не затрагивая при этом другие контейнеры на ноде.
Для начала убедимся что наша нода имеет валидный CA-сертификат для etcd:
/etc/kubernetes/pki/etcd/ca.{key,crt}В случае его отсутствия скопируейте его с других нод вашего кластера. Теперь сгенерируем остальные сертификаты для нашей ноды:
kubeadm init phase certs etcd-healthcheck-client
kubeadm init phase certs etcd-peer
kubeadm init phase certs etcd-serverи выполним присоединение к кластеру:
kubeadm join phase control-plane-join etcd --control-planeДля понимания, вышеописанная команда сделает следующее:
-
Добавит новый member в существующий etcd-кластер:
etcdctl member add node3 --endpoints=https://10.20.30.101:2380,https://10.20.30.102:2379 --peer-urls=https://10.20.30.103:2380 -
Сгенерирует новый static-manifest для etcd
/etc/kubernetes/manifests/etcd.yamlс опциями:--initial-cluster-state=existing --initial-cluster=node1=https://10.20.30.101:2380,node2=https://10.20.30.102:2380,node3=https://10.20.30.103:2380эти опции позволят нашей ноде автоматически добавиться в существующий etcd-кластер.
Создание снапшота etcd
Теперь рассмотрим вариант создания и восстановления etcd из резервной копии.
Создать бэкап можно довольно просто, выполнив на любой из нод:
etcdctl snapshot save /var/lib/etcd/snap1.dbОбратите внимание я намеренно использую /var/lib/etcd так как эта директория уже прокинута в etcd контейнер (смотрим в static-манифест /etc/kubernetes/manifests/etcd.yaml)
После выполнения этой команды по указанному пути вы найдёте снапшот с вашими данными, давайте сохраним его в надёжном месте и рассмотрим процедуру восстановления из бэкапа
Восстановление etcd из снапшота
Здесь мы рассмотрим кейс когда всё пошло не так и нам потребовалось восстановить кластер из резервной копии.
У нас есть снапшот snap1.db сделанный на предыдущем этапе. Теперь давайте полностью удалим static-pod для etcd и данные со всех наших нод:
rm -rf /etc/kubernetes/manifests/etcd.yaml /var/lib/etcd/member/
crictl rm "$CONTAINER_ID"Теперь у нас снова есть два пути:
Вариант первый создать etcd-кластер из одной ноды и присоединить к нему остальные ноды, по описанной выше процедуре.
kubeadm init phase etcd localэта команда сгенерирует статик-манифест для etcd c опциями:
--initial-cluster-state=new
--initial-cluster=node1=https://10.20.30.101:2380таким образом мы получим девственно чистый etcd на одной ноде.
# etcdctl member list -w table
+------------------+---------+-------+---------------------------+---------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+-------+---------------------------+---------------------------+------------+
| 1afbe05ae8b5fbbe | started | node1 | https://10.20.30.101:2380 | https://10.20.30.101:2379 | false |
+------------------+---------+-------+---------------------------+---------------------------+------------+Восстановим бэкап на первой ноде:
etcdctl snapshot restore /var/lib/etcd/snap1.db
--data-dir=/var/lib/etcd/new
--name=node1
--initial-advertise-peer-urls=https://10.20.30.101:2380
--initial-cluster=node1=https://10.20.30.101:2380
mv /var/lib/etcd/member /var/lib/etcd/member.old
mv /var/lib/etcd/new/member /var/lib/etcd/member
crictl rm "$CONTAINER_ID"
rm -rf /var/lib/etcd/member.old/ /var/lib/etcd/new/На остальных нодах выполним присоединение к кластеру:
kubeadm join phase control-plane-join etcd --control-planeВариант второй: восстановить бэкап сразу на всех нодах кластера. Для этого копируем файл снапшота на остальные ноды, и выполняем восстановление вышеописанным образом. В данном случае в опциях к etcdctl нам потребуется указать сразу все ноды нашего кластера, к примеру
для node1:
etcdctl snapshot restore /var/lib/etcd/snap1.db
--data-dir=/var/lib/etcd/new
--name=node1
--initial-advertise-peer-urls=https://10.20.30.101:2380
--initial-cluster=node1=https://10.20.30.101:2380,node2=https://10.20.30.102:2380,node3=https://10.20.30.103:2380для node2:
etcdctl snapshot restore /var/lib/etcd/snap1.db
--data-dir=/var/lib/etcd/new
--name=node2
--initial-advertise-peer-urls=https://10.20.30.102:2380
--initial-cluster=node1=https://10.20.30.101:2380,node2=https://10.20.30.102:2380,node3=https://10.20.30.103:2380для node3:
etcdctl snapshot restore /var/lib/etcd/snap1.db
--data-dir=/var/lib/etcd/new
--name=node3
--initial-advertise-peer-urls=https://10.20.30.103:2380
--initial-cluster=node1=https://10.20.30.101:2380,node2=https://10.20.30.102:2380,node3=https://10.20.30.103:2380Потеря кворума
Иногда случается так что мы потеряли большинство нод из кластера и etcd перешёл в неработоспособное состояние. Удалить или добавить новых мемберов у вас не получится, как и создать снапшот.
Выход из этой ситуации есть. Нужно отредактировать файл static-манифеста и добавить ключ --force-new-cluster к etcd:
/etc/kubernetes/manifests/etcd.yamlпосле чего инстанс etcd перезапустится в кластере с единственным экземпляром:
# etcdctl member list -w table
+------------------+---------+-------+---------------------------+---------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+-------+---------------------------+---------------------------+------------+
| 1afbe05ae8b5fbbe | started | node1 | https://10.20.30.101:2380 | https://10.20.30.101:2379 | false |
+------------------+---------+-------+---------------------------+---------------------------+------------+Теперь вам нужно очистить и добавить остальные ноды в кластер по описанной выше процедуре. Только не забудьте удалить ключ --force-new-cluster после всех этих манипуляций 
Wondering how to resolve Kubernetes error “context deadline exceeded”? We can help you.
As part of our Server Management Services, we assist our customers with several Kubernetes queries.
Today, let us see how our Support techs proceed to resolve it.
How to resolve Kubernetes error “context deadline exceeded”?
The error ‘context deadline exceeded’ means that we ran into a situation where a given action was not completed in an expected timeframe.
Usually, issue occurs if Pods become stuck in Init status.
Typical error will look as shown below:
Warning FailedCreatePodSandBox 93s (x8 over 29m) kubelet, 97011e0a-f47c-4673-ace7-d6f74cde9934 Failed to create pod sandbox: rpc error: code = DeadlineExceeded desc = context deadline exceeded Normal SandboxChanged 92s (x8 over 29m) kubelet, 97011e0a-f47c-4673-ace7-d6f74cde9934 Pod sandbox changed, it will be killed and re-created.You would see errors for containers from kubelet.stderr.log.
Example:
E0114 14:57:13.656196 9838 remote_runtime.go:128] StopPodSandbox "ca05be4d6453ae91f63fd3f240cbdf8b34377b3643883075a6f5e05001d3646b" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
...
E0114 14:57:13.656256 9838 kuberuntime_manager.go:901] Failed to stop sandbox {"docker" "ca05be4d6453ae91f63fd3f240cbdf8b34377b3643883075a6f5e05001d3646b"}
...
W0114 14:57:30.151650 9838 cni.go:331] CNI failed to retrieve network namespace path: cannot find network namespace for the terminated container "ca05be4d6453ae91f63fd3f240cbdf8b34377b3643883075a6f5e05001d3646b"You can also validate the status of the node-agent-hyperbus by running the following nsxcli command from the node (as root):
sudo -i/var/vcap/jobs/nsx-node-agent/bin/nsxcli“at the nsx-cli prompt, enter”: get node-agent-hyperbus status
Expected output:
HyperBus status: HealthyIn this scenario you would see the following error instead:
% An internal error occurred
This causes a loop of DEL (delete) requests to the nsx-node-agent process
Today, let us see the simple steps followed by our Support techs to resolve it.
Restarting the nsx-node-agent process will workaround this issue:
— Use “bosh ssh” command to access the worker node
Then, run the below commands.
sudo -imonit restart nsx-node-agent— Wait for nsx-node-agent to restart: watch monit summary
This must resolve the issue.
[Stuck in between? We’d be glad to assist you]
Conclusion
In short, today we saw steps followed by our Support Techs resolve Kubernetes failed to start in docker desktop error.
PREVENT YOUR SERVER FROM CRASHING!
Never again lose customers to poor server speed! Let us help you.
Our server experts will monitor & maintain your server 24/7 so that it remains lightning fast and secure.
GET STARTED
What happened?
I tried to Set up a High Availability etcd Cluster with kubeadm.
I followed the official guide https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/setup-ha-etcd-with-kubeadm/
after all the steps execute when i check cluster health its giving below error message
[[email protected] ~]# docker run —rm -it
—net host
-v /etc/kubernetes:/etc/kubernetes k8s.gcr.io/etcd:3.5.1-0 etcdctl
—cert /etc/kubernetes/pki/etcd/peer.crt
—key /etc/kubernetes/pki/etcd/peer.key
—cacert /etc/kubernetes/pki/etcd/ca.crt
—endpoints https://137.184.157.161:2379 endpoint health —cluster
{«level»:»warn»,»ts»:»2022-02-09T08:12:22.497Z»,»logger»:»etcd-client»,»caller»:»v3/retry_interceptor.go:62″,»msg»:»retrying of unary invoker failed»,»target»:»etcd-endpoints://0xc00045e540/137.184.157.161:2379″,»attempt»:0,»error»:»rpc error: code = DeadlineExceeded desc = latest balancer error: last connection error: connection error: desc = «transport: Error while dialing dial tcp 137.184.157.161:2379: connect: connection refused»»}
Error: failed to fetch endpoints from etcd cluster member list: context deadline exceeded
What you expected to happen?
as per the official guide etcd cluster should be healthy state.
How to reproduce it (as minimally and precisely as possible)?
You can follow the official guide with https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/setup-ha-etcd-with-kubeadm/
Anything else we need to know?
Versions
kubeadm version (use v1.23.3):
Environment:
- Kubernetes version (use
v1.23.3): - Cloud provider or hardware configuration:
Master Nodes -03
Worker Nodes -03
etcd -03
HA load balancer -01
Digital Ocean cloud
all instance — 4 HB Ram ,2 CPU ,80 GB disk
- OS (e.g. from /etc/os-release):
CentOS 8
[[email protected] ~]# cat /etc/os-release
NAME=»CentOS Stream»
VERSION=»8″
ID=»centos»
ID_LIKE=»rhel fedora»
VERSION_ID=»8″
PLATFORM_ID=»platform:el8″
PRETTY_NAME=»CentOS Stream 8″
ANSI_COLOR=»0;31″
CPE_NAME=»cpe:/o:centos:centos:8″
HOME_URL=»https://centos.org/»
BUG_REPORT_URL=»https://bugzilla.redhat.com/»
REDHAT_SUPPORT_PRODUCT=»Red Hat Enterprise Linux 8″
REDHAT_SUPPORT_PRODUCT_VERSION=»CentOS Stream»
- Kernel (e.g.
uname -a):
[[email protected] ~]# uname -a
Linux etcd-01 4.18.0-277.el8.x86_64 #1 SMP Wed Feb 3 20:35:19 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
-
Container runtime (CRI) (e.g. containerd, cri-o):
Docker -
Container networking plugin (CNI) (e.g. Calico, Cilium):
wavenet -
Others:
Question:
I’m trying to create a one node etcd cluster on AWS using coreos cloud-config. I have created a Route53 recordset with value etcd.uday.com which has a alias to the ELB which points to the ec2 instance. Etcd is running successfully but when I run the etcd member list command I get below error
|
ETCDCTL_API=3 etcdctl member list —endpoints=https://etcd.udayvishwakarma.com:2379 —cacert=./ca.pem —cert=etcd-client.pem —key=etcd-client-key.pem Error: context deadline exceeded |
However, it lists members when --insecure-skip-tls-verify flag is added to the etcdctl member list command. I have generated certificated using cfssl using below configs
ca.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ «CN»: «Root CA», «key»: { «algo»: «rsa», «size»: 2048 }, «names»: [ { «C»: «UK», «L»: «London», «O»: «Kubernetes», «OU»: «CA» } ], «ca»: { «expiry»: «87658h» } } |
ca.config
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
{ «signing»: { «default»: { «expiry»: «2190h» }, «profiles»: { «client»: { «expiry»: «8760h», «usages»: [ «signing», «key encipherment», «client auth» ] }, «server»: { «expiry»: «8760h», «usages»: [ «signing», «key encipherment», «server auth» ] }, «peer»: { «expiry»: «8760h», «usages»: [ «signing», «key encipherment», «server auth», «client auth» ] }, «ca»: { «usages»: [ «signing», «digital signature», «cert sign», «crl sign» ], «expiry»: «26280h», «is_ca»: true } } } } |
etcd-member.json
|
{ «CN»: «etcd», «key»: { «algo»: «rsa», «size»: 2048 }, «hosts»:[ «etcd.uday.com» ], «names»: [ { «O»: «Kubernetes» } ] } |
etcd-client.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
{ «CN»: «etcd», «key»: { «algo»: «rsa», «size»: 2048 }, «hosts»:[ «etcd.uday.com» ], «names»: [ { «O»: «Kubernetes» } ] } cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -hostname=»etcd.uday.com» -config=ca-config.json -profile=peer etcd-member.json | cfssljson -bare etcd-member cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -hostname=»etcd.uday.com» -config=ca-config.json -profile=client etcd-client.json | cfssljson -bare etcd-client |
My etcd-member.service systemd unit cloudconfig is as below
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
units: — name: etcd-member.service drop-ins: — name: aws-etcd-cluster.conf content: | [Service] Environment=ETCD_USER=etcd Environment=ETCD_NAME=%H Environment=ETCD_IMAGE_TAG=v3.1.12 Environment=ETCD_SSL_DIR=/etc/etcd/ssl Environment=ETCD_CA_FILE=/etc/ssl/certs/ca.pem Environment=ETCD_CERT_FILE=/etc/ssl/certs/etcd-client.pem Environment=ETCD_KEY_FILE=/etc/ssl/certs/etcd-client-key.pem Environment=ETCD_CLIENT_CERT_AUTH=true Environment=ETCD_TRUSTED_CA_FILE=/etc/ssl/certs/ca.pem Environment=ETCD_PEER_CA_FILE=/etc/ssl/certs/ca.pem Environment=ETCD_PEER_CERT_FILE=/etc/ssl/certs/etcd-member.pem Environment=ETCD_PEER_KEY_FILE=/etc/ssl/certs/etcd-member-key.pem Environment=ETCD_PEER_TRUSTED_CA_FILE=/etc/ssl/certs/ca.pem Environment=ETCD_INITIAL_CLUSTER_STATE=new Environment=ETCD_INITIAL_CLUSTER=%H=https://%H:2380 Environment=ETCD_DATA_DIR=/var/lib/etcd3 Environment=ETCD_LISTEN_CLIENT_URLS=https://%H:2379,https://127.0.0.1:2379 Environment=ETCD_ADVERTISE_CLIENT_URLS=https://%H:2379 Environment=ETCD_LISTEN_PEER_URLS=https://%H:2380 Environment=ETCD_INITIAL_ADVERTISE_PEER_URLS=https://%H:2380 PermissionsStartOnly=true Environment=»RKT_RUN_ARGS=—uuid-file-save=/var/lib/coreos/etcd-member-wrapper.uuid» ExecStartPre=-/usr/bin/rkt rm —uuid-file=/var/lib/coreos/etcd-member-wrapper.uuid ExecStartPre=/usr/bin/sed -i ‘s/^ETCDCTL_ENDPOINT.*$/ETCDCTL_ENDPOINT=https://%H:2379/’ /etc/environment ExecStartPre=/usr/bin/mkdir -p /var/lib/etcd3 ExecStartPre=/usr/bin/chown -R etcd:etcd /var/lib/etcd3 ExecStop=-/usr/bin/rkt stop —uuid-file=/var/lib/coreos/etcd-member-wrapper.uuid enable: true command: start |
Is cert generation wrong or something I have missed?
Answer:
The certificates are generated for etcd.uday.com.
You are trying to connect using etcd.udayvishwakarma.com while certificate is valid for etcd.uday.com.
Change endpoint on etcdctl from etcd.udayvishwakarma.com to etcd.uday.com.