Цель блога описать интересные и полезные примеры программирования в системе 1С:Предприятие 8.
Страницы
вторник, 6 августа 2013 г.
1С:Предприятие 8. Веб-сервисы. Ошибки веб-сервисов и их причины
Хочу рассказать об ошибках, с которыми столкнулся при разработке веб-сервисов на 1С. Статью буду дополнять по мере получения опыта.
1
Это сообщение об ошибке при подключении к веб сервису из PHP.
[31-Mar-2013 05:32:02 UTC] PHP Fatal error: SOAP-ERROR: Parsing WSDL: Couldn’t load from ‘http://test.ru/test/ws/WebServices?wsdl’ : failed to load external entity
Данное сообщение говорит лишь о недоступности веб-сервера, на котором опубликована база. В этом случае попробуйте вручную вызвать http://test.ru/test/ws/WebServices?wsdl и убедиться, что WSDL формируется. Если не формируется, значит либо веб-сервер выключен, либо база опубликована по другому адресу или порту, либо блокирует фаервол. Могут быть и другие причины.
2
02-Apr-2013 13:46:10 UTC] PHP Fatal error: Uncaught SoapFault exception: [HTTP] Error Fetching http headers in /home/users/b/test/domains/ test .ru/ testDIR / test .php:169
Эта ошибка возникает если WSDL возвращается с ошибкой. Есть несколько причин для этой ошибки:
- Несогласованность пространств имен в конфигурации. Например в ws-операции тип возвращаемого значения не соответствует типу из XDTO. Это может возникнуть при сменен URI пространства имен пакета XDTO.
- Возникает если в PHP включить кеш WSDL. Кеш запоминает WSDL и при каждом вызове веб-операции не запрашивает его, но если вы поменяли веб-сервис, то произойдет ошибка. Вообще, при разработке кеш стоит отключить, а если уже все работает то для скорости лучше включить. Ускорение при отключенном кеше заметное. Для примера скажу, что создание объекта SoapClient с выключенным кешем занимает примерно 2 сек, а с включенным — за сотые доли секунды. Отключить можно так:
ini_set ( «soap.wsdl_cache_enabled» , 0);
или
$client = new SoapClient( ‘http://somewhere.com/?wsdl’ , array ( ‘cache_wsdl’ => 0));
12 комментариев :
Не могу разобраться со следующей ошибкой. Разные soap клиенты возвращают ошибку типа «Unable to parse URL» при вызове любого метода после чтения wsdl. Т.е. wsdl читают, а следующий запрос отправить не могут. На причину этой ошибки меня наталкивает отсутствие полного url в wsdl: . 1C 8.2.16.362, apache 2.2.18, 2.2.25. Т.е. обновление апача с 18 до 25 релиза не помогло. В httpd.conf прописан ServerName tst.icc.biz:80. Куда рыть дальше? Пробовать другой релиз 1С?
Я бы проверил пространства имен пакетов XDTO, которые описывают типы возвращаемые в результатах операций.
Я пытаюсь создать соединение с мылом с веб-службами Magento, однако я получаю сообщение об ошибке при попытке создать экземпляр класса клиента soap. Я могу просматривать wsdl-файл в firefox без проблем, и я могу посмотреть, как php делает запрос для wsdl в журналах apaches, но он все еще не работает. Nusoap может подключаться.
Вы пытались добавить
к параметрам создания SoapClient, а затем:
посмотреть, что происходит?
Эта ошибка может появиться на клиенте, если на сервере возникла проблема. Например, если SOAP-сервер является скриптом PHP с ошибкой синтаксического анализа, клиент будет терпеть неудачу с этим сообщением.
Если вы контролируете сервер, запустите свой Apache error_log на компьютере, на котором размещен SOAP-сервер. В CentOS вы найдете это в / var / log / httpd / error_log, поэтому команда:
tail -f / var / log / httpd / error_log
Теперь обновите клиент и посмотрите сообщение об ошибке. Будут показаны любые ошибки PHP с помощью сценария сервера.
Надежда помогает кому-то.
Я столкнулся с такой же проблемой.
Я запускал его как CLI. Поэтому PHP всегда работал, и ему приходилось делать мыльный вызов снова и снова через некоторый интервал.
Ошибка, которую я сделал, это использовать одноэлементный шаблон для этого. Я думал, что использование синглтона приведет к повышению производительности, но я хочу, чтобы
Я исправил его, создав новый объект saop для каждого вызова.
Я не о вашей конфигурации PHP, но до PHP 5.2.6 у PHP есть некоторые проблемы с клиентом SOAP:
Ошибка # 41983 – Ошибка получения заголовков http

Если это проблема, связанная с Magento, вы должны отключить автоматическую повторную индексацию, поскольку это может привести к таймауту сокета (или истечению срока его действия). Вы можете вернуть его обратно, как только скрипт завершит выполнение своих задач. Увеличение времени ожидания по умолчанию в php.ini также является хорошей идеей.
В моем журнале ошибок apache я увидел:
Поэтому я удалил все содержимое самого большого файла журнала 2.1GB /var/log/system.log. Теперь все работает.
Существует проблема в версии php менее 5.2.6. Возможно, вам потребуется обновить версию php.
На данный момент мы уже многое знаем про fetch .
Давайте рассмотрим оставшуюся часть API, чтобы охватить все возможности.
Заметим: большинство этих возможностей используются редко. Вы можете пропустить эту главу и, несмотря на это, нормально использовать fetch .
Тем не менее, полезно знать, что вообще может fetch , чтобы, когда появится необходимость, вернуться и прочитать конкретные детали.
Нижеследующий список – это все возможные опции для fetch с соответствующими значениями по умолчанию (в комментариях указаны альтернативные значения):
Довольно-таки внушительный список, не так ли?
В главе Fetch мы разобрали параметры method , headers и body .
Опция signal разъяснена в главе в Fetch: прерывание запроса.
Теперь давайте пройдёмся по оставшимся возможностям.
referrer, referrerPolicy
Данные опции определяют, как fetch устанавливает HTTP-заголовок Referer .
Обычно этот заголовок ставится автоматически и содержит URL-адрес страницы, с которой пришёл запрос. В большинстве случаев он совсем неважен, в некоторых случаях, с целью большей безопасности, имеет смысл убрать или укоротить его.
Опция referrer позволяет установить любой Referer в пределах текущего источника или же убрать его.
Чтобы не отправлять Referer , нужно указать значением пустую строку:
Для того, чтобы установить другой URL-адрес (должен быть с текущего источника):
Опция referrerPolicy устанавливает общие правила для Referer .
Выделяется 3 типа запросов:
- Запрос на тот же источник.
- Запрос на другой источник.
- Запрос с HTTPS to HTTP (с безопасного протокола на небезопасный).
В отличие от настройки referrer , которая позволяет задать точное значение Referer , настройка referrerPolicy сообщает браузеру общие правила, что делать для каждого типа запроса.
- «no-referrer-when-downgrade» – это значение по умолчанию: Referer отправляется всегда, если только мы не отправим запрос из HTTPS в HTTP (из более безопасного протокола в менее безопасный).
- «no-referrer» – никогда не отправлять Referer .
- «origin» – отправлять в Referer только текущий источник, а не полный URL-адрес страницы, например, посылать только http://site.com вместо http://site.com/path .
- «origin-when-cross-origin» – отправлять полный Referer для запросов в пределах текущего источника, но для запросов на другой источник отправлять только сам источник (как выше).
- «same-origin» – отправлять полный Referer для запросов в пределах текущего источника, а для запросов на другой источник не отправлять его вообще.
- «strict-origin» – отправлять только значение источника, не отправлять Referer для HTTPS→HTTP запросов.
- «strict-origin-when-cross-origin» – для запросов в пределах текущего источника отправлять полный Referer, для запросов на другой источник отправлять только значение источника, в случае HTTPS→HTTP запросов не отправлять ничего.
- «unsafe-url» – всегда отправлять полный URL-адрес в Referer , даже при запросах HTTPS→HTTP .
Вот таблица со всеми комбинациями:
| Значение | На тот же источник | На другой источник | HTTPS→HTTP |
|---|---|---|---|
| «no-referrer» | — | — | — |
| «no-referrer-when-downgrade» или «» (по умолчанию) | full | full | — |
| «origin» | origin | origin | origin |
| «origin-when-cross-origin» | full | origin | origin |
| «same-origin» | full | — | — |
| «strict-origin» | origin | origin | — |
| «strict-origin-when-cross-origin» | full | origin | — |
| «unsafe-url» | full | full | full |
Допустим, у нас есть админка со структурой URL, которая не должна стать известной снаружи сайта.
Если мы отправляем запрос fetch , то по умолчанию он всегда отправляет заголовок Referer с полным URL-адресом нашей админки (исключение – это когда мы делаем запрос от HTTPS в HTTP, в таком случае Referer не будет отправляться).
Например, Referer: https://javascript.info/admin/secret/paths .
Если мы хотим, чтобы другие сайты получали только источник, но не URL-путь, это сделает такая настройка:
Мы можем поставить её во все вызовы fetch , возможно, интегрировать в JavaScript-библиотеку нашего проекта, которая делает все запросы и внутри использует fetch .
Единственным отличием в поведении будет то, что для всех запросов на другой источник fetch будет посылать только источник в заголовке Referer (например, https://javascript.info , без пути). А для запросов на наш источник мы продолжим получать полный Referer (это может быть полезно для отладки).
Политика установки Referer, описанная в спецификации Referrer Policy, существует не только для fetch , она более глобальная.
В частности, можно поставить политику по умолчанию для всей страницы, используя HTTP-заголовок Referrer-Policy , или на уровне ссылки .
Опция mode – это защита от нечаянной отправки запроса на другой источник:
- «cors» – стоит по умолчанию, позволяет делать такие запросы так, как описано в Fetch: запросы на другие сайты,
- «same-origin» – запросы на другой источник запрещены,
- «no-cors» – разрешены только простые запросы на другой источник.
Эта опция может пригодиться, если URL-адрес для fetch приходит от третьей стороны, и нам нужен своего рода «глобальный выключатель» для запросов на другие источники.
credentials
Опция credentials указывает, должен ли fetch отправлять куки и авторизационные заголовки HTTP вместе с запросом.
- «same-origin» – стоит по умолчанию, не отправлять для запросов на другой источник,
- «include» – отправлять всегда, но при этом необходим заголовок Access-Control-Allow-Credentials в ответе от сервера, чтобы JavaScript получил доступ к ответу сервера, об этом говорилось в главе Fetch: запросы на другие сайты,
- «omit» – не отправлять ни при каких обстоятельствах, даже для запросов, сделанных в пределах текущего источника.
cache
По умолчанию fetch делает запросы, используя стандартное HTTP-кеширование. То есть, учитывается заголовки Expires , Cache-Control , отправляется If-Modified-Since и так далее. Так же, как и обычные HTTP-запросы.
Настройка cache позволяет игнорировать HTTP-кеш или же настроить его использование:
- «default» – fetch будет использовать стандартные правила и заголовки HTTP кеширования,
- «no-store» – полностью игнорировать HTTP-кеш, этот режим становится режимом по умолчанию, если присутствуют такие заголовки как If-Modified-Since , If-None-Match , If-Unmodified-Since , If-Match , или If-Range ,
- «reload» – не брать результат из HTTP-кеша (даже при его присутствии), но сохранить ответ в кеше (если это дозволено заголовками ответа);
- «no-cache» – в случае, если существует кешированный ответ – создать условный запрос, в противном же случае – обычный запрос. Сохранить ответ в HTTP-кеше,
- «force-cache» – использовать ответ из HTTP-кеша, даже если он устаревший. Если же ответ в HTTP-кеше отсутствует, сделать обычный HTTP-запрос, действовать как обычно,
- «only-if-cached» – использовать ответ из HTTP-кеша, даже если он устаревший. Если же ответ в HTTP-кеше отсутствует, то выдаётся ошибка. Это работает, только когда mode установлен в «same-origin» .
redirect
Обычно fetch прозрачно следует HTTP-редиректам, таким как 301, 302 и так далее.
Это можно поменять при помощи опции redirect :
- «follow» – стоит по умолчанию, следовать HTTP-редиректам,
- «error» – ошибка в случае HTTP-редиректа,
- «manual» – не следовать HTTP-редиректу, но установить адрес редиректа в response.url , а response.redirected будет иметь значение true , чтобы мы могли сделать перенаправление на новый адрес вручную.
integrity
Опция integrity позволяет проверить, соответствует ли ответ известной заранее контрольной сумме.
Как описано в спецификации, поддерживаемыми хеш-функциями являются SHA-256, SHA-384 и SHA-512. В зависимости от браузера, могут быть и другие.
Например, мы скачиваем файл, и мы точно знаем, что его контрольная сумма по алгоритму SHA-256 равна «abcdef» (разумеется, настоящая контрольная сумма будет длиннее).
Мы можем добавить это в настройку integrity вот так:
Затем fetch самостоятельно вычислит SHA-256 и сравнит его с нашей строкой. В случае несоответствия будет ошибка.
keepalive
Опция keepalive указывает на то, что запрос может «пережить» страницу, которая его отправила.
Например, мы собираем статистические данные о том, как посетитель ведёт себя на нашей странице (на что он кликает, части страницы, которые он просматривает), для анализа и улучшения интерфейса.
Когда посетитель покидает нашу страницу – мы хотим сохранить собранные данные на нашем сервере.
Для этого мы можем использовать событие window.onunload :
Обычно, когда документ выгружается, все связанные с ним сетевые запросы прерываются. Но настройка keepalive указывает браузеру выполнять запрос в фоновом режиме даже после того, как пользователь покидает страницу. Поэтому эта опция обязательна, чтобы такой запрос удался.
У неё есть ряд ограничений:
- Мы не можем посылать мегабайты: лимит тела для запроса с keepalive – 64кб.
- Если мы собираем больше данных, можем отправлять их регулярно, «пакетами», тогда на момент последнего запроса в onunload их останется немного.
- Этот лимит распространяется на все запросы с keepalive . То есть, мы не можем его обойти, послав 100 запросов одновременно – каждый по 64Кбайт.
Содержание
- Ошибка Error 503 Backend fetch failed что делать
- Причины появления проблемы
- Способы решения ошибки Error 503 Backend fetch failed
- Как устранить ошибку «Failed to fetch» в Cydia, вызванную репозиторием repo666.ultrasn0w.com
- Error 503 Backend fetch failed исправляем за минуту
- Причины возникновения проблемы
- Решение ошибки Error 503 Backend fetch failed
- Javascript Fetch — как исправить ошибку Failed to Fetch (возможно, из-за выполнения HTTP-запроса на HTTPS-сайте?)
- Обновлению apt-get не удается получить файлы, ошибка «Устранение временного сбоя…»
- обзор
- Временное решение
- вопросы управления пакетами
Ошибка Error 503 Backend fetch failed что делать
Компьютер нужен нам в первую очередь для выхода в Интернет, где на каждом шагу подстерегает большое количество опасностей. Сегодня я поделюсь информацией об одной из таких угроз – ошибке Error 503 Backend fetch failed, и расскажу, что нужно делать, чтобы от нее избавиться. Неприятно то, что данная проблема может возникнуть абсолютно на любом устройстве, использующемся для выхода в Сеть, включая и мобильные гаджеты. Но, как всегда, раз есть ошибка, то есть и решения, созданные умными головами, которыми мы и воспользуемся.

Чтобы подобрать верное решение, необходимо сначала понять причины, из-за которых вылетает ошибка Error 503.
Причины появления проблемы
Данный код ошибки означает, что сервер по каким-то внутренним причинам не в состоянии ответить на обращенный к нему запрос. Чаще всего это связано с:
- кратковременным сбоем при запуске онлайн-приложения;
- неспособностью ресурсов удаленного сервера справиться с огромным количеством запросов, сделанных одновременно;
- нехваткой памяти сервера, необходимой для обработки направленных к нему запросов;
- окончанием срока действия сертификата SSL;
- проведением технических работ на интернет-ресурсе.
Как видим, ошибка вылетает из-за сбоев в техническом состоянии удаленного сервера по не зависящим от пользователя обстоятельствам.
Способы решения ошибки Error 503 Backend fetch failed
Понятно, что от обычного пользователя, сидящего за экраном своего компьютера или держащего в руках мобильный гаджет, почти ничего не зависит – он не сможет при помощи своих средств решить техническую сторону ошибки. Тем не менее стоит предпринять несколько шагов, с помощью которых иногда можно сразу разрешить проблему.
- Первым делом следует попробовать выполнить перезагрузку страницы, нажав F5 (обычно при работе в любом браузере) или на стрелочку, выполняющую функцию обновления ↻.

- Если первый способ не помогает, то вернитесь к проблемному сайту через какое-то время, может быть, специалисты уже успеют отладить со своей стороны техническую составляющую эту проблему.
- Как рекомендация – старайтесь посещать проблемные страницы в моменты, когда другие пользователи наименее активны, это даст возможность серверу нормально справиться с количеством направленных к нему запросов.
- Если ошибка 503 продолжает вылетать, перезагрузите ПК либо мобильное устройство/ ноутбук, а также оборудование, при помощи которого выходите в Сеть.
- В случае, когда сервер все же не отвечает на обращенные к нему запросы, найдите контактные данные проблемного сайта или самого ресурса и отправьте сообщение об ошибке Error 503 Backend fetch failed, приложив скриншот, если в форме обратной связи для него предусмотрено поле.
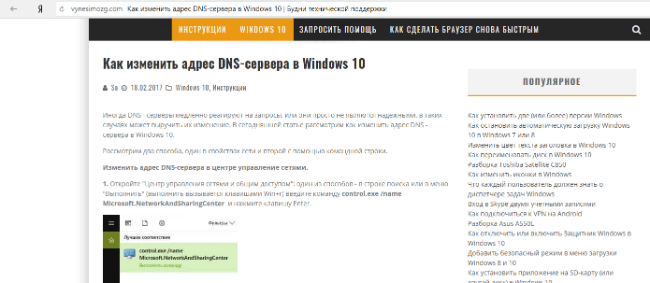
- Если решение долго не находится, а вам обязательно нужно попасть на проблемный сайт, используйте бесплатные DNS-серверы. Для этого введите в строке поиска своего рабочего браузера “как изменить адрес DNS-сервера в (название используемой на устройстве операционной системы)” и поищите решение на предложенных ресурсах. К примеру, если вы используете Windows 10, то на первом же сайте в выдаче Яндекса будет подробная инструкция по изменению DNS-сервера.
- Проблема может быть и в качестве услуг, предоставляемых провайдером. В этом случае решайте все вопросы с ним.

Не забывайте перезагружать компьютер после каждых внесенных в него изменений. Это позволит корректно установить все обновления.
Источник
Как устранить ошибку «Failed to fetch» в Cydia, вызванную репозиторием repo666.ultrasn0w.com
Многие пользователи iPhone, iPad и iPod Touch, получившие джейлбрейк iOS 7 столкнулись с со следующей проблемой — некоторые репозитории, ранее доступные в Cydia, стали недоступны, а в процессе обновления пакетов, появлялись сообщения об ошибках доступа.

Одна из них – «Failed to fetch […] HTTP/1.1 404 Not Found». Исправляется эта ошибка довольно просто.
«404 Not Found» — один из стандартных кодов ответа HTTP сервера. Он сигнализирует, что клиентская программа пользователя, к примеру, веб-браузер, не может подсоединиться к серверу. В большинстве случаев, эта ошибка никак не влияет на работу сервиса, однако магазин выдаёт это предупреждение и у некоторых может сложиться впечатление, что Cydia работает нестабильно.
На самом же деле, в данном случае, этот код ошибки говорит лишь о том, что есть проблемы с доступом к репозиторию UltraSn0w. Для того что бы избавиться от назойливого собщения, достаточно в настройках выключить репозиторий Dev Team, в котором находится популярный в прошлом твик для разлочки iPhone — UltraSn0w. Для iPhone 4 и выше этот источник не имеет какой-либо практической ценности. Его можно, без риска для работы всего приложения, удалить. Твик Ultrasn0w, при необходимости, можно найти и в других репозиториях.
Источник
Error 503 Backend fetch failed исправляем за минуту
При работе в сети Интернет, мы можем столкнутся с проблемой обработки страницы серверов и увидеть на экране ошибку Error 503 Backend fetch failed. Особо критического в ней ничего нет, но давайте попробуем разобраться в причинах возникновения и решить данную неисправность.
Как Вы можете знать, все веб-сервера работают на двух базовых серверных утилитах — Apache и Nginx. При неверной настройке сервера может возникнуть проблема с отрисовкой бекэнд части, отвечающей за скрипты.
При работе сайта к примеру на CMS WordPress или Magento, в Apache нужна дополнительная настройка и включение служб для его корректной работы.

Причины возникновения проблемы
Ошибка Error 503 Backend fetch failed может говорить о проблемах с обработкой PHP-скриптов или .htaccess. Опытные пользователи знают, что файл .htaccess отвечает за предварительный инструктажах браузера по обработке запрашиваемой веб-страницы. Давайте выделим основные причины из за которых Вы увидите такое сообщение.
- Неправильная настройка сервера Apache или Nginx.
- Не установлена или выключена служба PHP на сервере.
- Недостаточное количество свободного дискового пространства на хостинге.
- Большое количество циклических SQL-запросов со скрипта.
- Зацикленное включение Apache сервера.
- Сбои при выполнении резервного копирования хостингом.
Как можно видеть, все основные проблемы связаны серверной частью. Вам следует внимательно отнестись к настройках или сбросить их по умолчанию. Файлы конфигурации для обоих типов конфигураций, можно найти в интернете или запросить у хостинг-провайдера.
Решение ошибки Error 503 Backend fetch failed

Для каждой причины есть свойственное простое решение. Если вы обычный пользователь который столкнулся с ошибкой Error 503 Backend fetch failed при заходе на сайт, то попробуйте зайти на него через некоторое время, пока администратор исправит ситуацию. Для владельцев ресурсов, мы составили свои рекомендации по исправлению.
- Убедитесь в приемлемом количестве свободного места на хостинге. Полностью заполненное дисковое пространство, не позволит отображать страницы, т.к. не создаст временные файлы.
- Попробуйте удалить резервные копии или перезапустить службу.
- Включите логирование ошибок если используется ISPPanel. Вы сможете увидеть все проблемы связанные с сайтом.
- Переустановите серверную службу Apache или найдите ошибки в конфигурации.
- Недостаточная мощность VPS сервера (например нехватка CPU), может приводить к такой ошибке.
- Использование устаревшей версии PHP (например 5.3). Обновитесь или установите актуальную 7.2 и выше.
- Оптимизируйте или закешируйте SQL-запросы сайта. Ошибка 503 может является следствием большой выборки из базы данных.
- Замените varnish.vcl в файле конфигурации сервера при использовании Apache
Как можно убедится, что проблема не возникает сама по себе. В частности все заключается в правильной настройке и поддержке сервера. Обратитесь к специалистам или оставьте комментарий под этой записью, мы попробуем помочь вам.
Источник
Javascript Fetch — как исправить ошибку Failed to Fetch (возможно, из-за выполнения HTTP-запроса на HTTPS-сайте?)
Это приложение React (и код). Он генерирует 3 случайных объекта (из списка более 500 объектов, хранящихся локально). Я хочу вызвать API IconFinder при выборе случайных объектов и затем просто отобразить значки (вместо того, чтобы заранее находить 500 значков).
Я запускаю его в Windows 10 с версией Google Chrome 84.0.4147.89 (официальная сборка) (64-разрядная версия). Код размещен на Codesandbox. Вы можете взглянуть на весь код здесь или только на вывод и инструменты разработчика Chrome здесь
Демо-запрос XHR GET, который они показывают в своих документах
My Fetch запрос GET
Вывод: консоль читает Error: Failed to fetch
В инструментах разработчика Chrome на вкладке «Сеть» (снимок экрана 1) я вижу, что в файле типа fetch (снимок экрана 2) и в файле типа json (снимки экрана 3 и 4) что-то не так.
Что я пробовал
- Запросы Fetch GET работают для Codesandbox с API Звездных войн (аутентификация не требуется), но не для API MovieDB (аутентификация в URL- адресе, а не в заголовках — напр. https://api.themoviedb.org/3/search/movi?api_key=
Это сработало в моей локальной среде разработки. Все еще не совсем уверен, КАК это работает.
Источник
Обновлению apt-get не удается получить файлы, ошибка «Устранение временного сбоя…»
Это то, что я вижу, когда пытаюсь бежать sudo apt-get update . Я сделал обновление на моем экземпляре вчера и сейчас испытываю это.
обзор
Ваш вопрос состоит из двух частей:
- исправление сообщений временного разрешения
- решение проблем управления пакетами
Временное решение
Вполне вероятно, что эта проблема либо:
- временно из-за того, что ваш интернет-провайдер неправильно перенаправляет интернет-имена (DNS) на свои или на внешние DNS-серверы, или
- из-за изменений в вашей сети аналогичным образом заблокировано это наименование — например, новый маршрутизатор / модем, перенастроивший коммутатор с новой конфигурацией.
Давайте посмотрим на возможные проблемы с DNS.
Сначала временно добавьте известный DNS-сервер в вашу систему.
Тогда беги sudo apt-get update .
Если это исправляет ваши временные разрешающие сообщения, то либо подождите 24 часа, чтобы узнать, решит ли ваш провайдер проблему для вас (или просто обратитесь к вашему провайдеру), либо вы можете добавить DNS-сервер в вашу систему:
8.8.8.8 это собственный DNS-сервер Google.
Другим примером DNS-сервера, который вы можете использовать, является OpenDNS — например:
вопросы управления пакетами
В дополнение к временным проблемам разрешения — у вас есть несколько проблем с управлением пакетами, которые необходимо исправить — я предполагаю, что вы недавно пытались обновить одну версию Ubuntu до следующей рекомендуемой версии — в вашем случае с Natty (11.04) до Онейрик (11.10)
Откройте терминал и введите
Найдите в списке строки с другим именем дистрибутива, чем вы ожидали — в вашем случае — вы выполнили обновление, oneiric но у вас есть другое имя выпуска. natty
Например, ищите строки, которые выглядят как deb http:/archive.canonical.com/ natty backports
Добавьте a # в начало строки, чтобы закомментировать — например,
#deb http:/archive.canonical.com/ natty backports
Сохраните и повторно запустите:
Вы не должны иметь больше ошибок именования релизов.
На момент написания этого, возможные общие имена релиза включают в себя lucid , maverick , natty , oneiric , precise , quantal , raring , saucy , trusty , utopic и vivid .
Обратите внимание, что этот ответ был написан для старых версий Ubuntu. В текущих версиях используется локальный сервер имен, управляемый D-Bus, для которого применяется диагностическая часть этого ответа, но не решение. Если /etc/resolv.conf содержит nameserver 127.0.1.1 или в более общем смысле nameserver 127.X.Y.Z , не изменяйте его.
«Устранение временного сбоя…» означает, что ваш DNS , т. Е. Перевод имен хостов в IP-адреса, не работает. Вы недавно что-то перенастроили на своей машине? Если нет, это может быть временная ошибка у вашего интернет-провайдера.
ping -n 8.8.8.8 Показывает ли линии как 64 bytes from 8.8.8.8: … ? (Нажмите Ctrl +, C чтобы остановить ping .)
Источник
Ошибка error 503 backend fetch failed знакома людям, которые постоянно используют свою технику для выхода в Интернет. При этом, важно отметить, что подобная неприятность может проявиться абсолютно на любой операционной системе и на любом устройстве, позволяющим осуществлять подобные операции. То есть, это может быть ноутбук на Линукс, стационарный компьютер с Виндовс, мобильный телефон или планшет с иной системой.

Естественно, для того, чтобы понять, как исправить error 503 backend fetch failed, необходимо изначально понять первопричины, способствующие проявлению подобной ситуации.
Что за ошибка и почему проявляется
К сожалению, но перевод error 503 backend fetch failed совершенно не упрощает поиск оптимального разрешения проблемы, так как даже онлайн-переводчик не способен полностью обработать данную фразу.
Тем не менее, специалисты и обычные пользователи уже выявили основные причины возникновения такой ситуации и почему она проявляется. Ошибка с этим кодом связана с обращением к удаленному серверу, который, вроде бы, обрабатывает запрос, но, по каким-либо причинам, не способен на него ответить.
Чаще всего это связано со следующими нюансами:
- При попытке запуска онлайн-приложения происходят кратковременные сбои.
- Серверу недостаточно собственной памяти для обработки поступающей информации.
- Количество одновременно сделанных запросов слишком высоко и их банально не вытягивают мощности удаленного сервера.
- Владелец сайта решил заняться техобслуживанием своего интернет-ресурса.
- Срок действия сертификата SSL подошел к концу.
То есть, фактически всегда эта ситуация проявляется из-за каких-либо факторов, непосредственно связанных с функциональным состоянием удаленного ресурса, на который хочет зайти юзер.
Методика лечения
Итак, что делать – error 503 backend fetch failed?
К сожалению, но от обычного человека в таком случае мало чего зависит.
Тем не менее, кое-что можно опробовать:
- Обновить проблемную страничку с помощью кнопки «F5» или заново ввести урл-адрес. Может быть произошел кратковременный сбой.
- Вернуться к попытке осуществить доступ через какой-то промежуток времени. Вполне возможно, что через несколько минут или часов на другом конце соединения неприятность будет устранена.
- Стараться заходить на такие веб-сайты в то время, когда осуществляется минимальное число переходов иных пользователей.
- Выполнить перезапуск оборудование и устройства, отвечающего за доступ к Сети.
- Найти контактные данные проблемного сервера или интернет-ресурса и написать им сообщение о возникающей ситуации, чтобы служба технического ремонта была в курсе таких проблем.
- Временно перейти на использование бесплатных DNS-серверов, информацию о которых можно легко найти в интернет-поиске.
Естественно, такая методика не гарантирует стопроцентного положительного результата. Тем не менее, иногда, она способна оказаться эффективным решением возникшего вопроса. В качестве альтернативного метода можно попробовать поискать требуемую человеку информацию на иных сетевых ресурсах, если проблема на нужном сайте, в течении длительного периода времени, не исчезает.
Содержание
- Решение
- Другие решения
- Страницы
- вторник, 6 августа 2013 г.
- 1С:Предприятие 8. Веб-сервисы. Ошибки веб-сервисов и их причины
- 12 комментариев :
- 14 Answers 14
У меня проблема с SOAP, но я не нашел реального ответа.
Это мой простой SOAP-запрос в блоке try catch.
Я получаю исключение SoapFault:
В чем причина этого?
Решение
Чтобы исправить эту ошибку, мы можем увеличить либо увеличить время ожидания сокета default_socket_time в php.ini или добавить connection_timeout параметр в массиве параметров передается конструктору SoapClient.
Эти параметры находятся в секунд.
Кроме того, вы можете изменить код
Примечание. Время ожидания сокета по умолчанию в php составляет 60 секунд.
- connection_timeout параметр в конструкторе SoapClient
$client = new SoapClient($wsdl, array(‘connection_timeout’ => 120));
Другие решения
Конфигурация, которая работала для меня, определяла в моем php-скрипте следующие параметры:
Самое важное определение параметра, согласно моему опыту с этой проблемой, было ini_set (‘default_socket_timeout’, 5000);
Во время моих тестов я установил default_socket_timeout равным 5 секундам, и ошибка «Ошибка получения заголовков http» возникла мгновенно.
Цель блога описать интересные и полезные примеры программирования в системе 1С:Предприятие 8.
Страницы
вторник, 6 августа 2013 г.
1С:Предприятие 8. Веб-сервисы. Ошибки веб-сервисов и их причины
Хочу рассказать об ошибках, с которыми столкнулся при разработке веб-сервисов на 1С. Статью буду дополнять по мере получения опыта.
1
Это сообщение об ошибке при подключении к веб сервису из PHP.
[31-Mar-2013 05:32:02 UTC] PHP Fatal error: SOAP-ERROR: Parsing WSDL: Couldn’t load from ‘http://test.ru/test/ws/WebServices?wsdl’ : failed to load external entity
Данное сообщение говорит лишь о недоступности веб-сервера, на котором опубликована база. В этом случае попробуйте вручную вызвать http://test.ru/test/ws/WebServices?wsdl и убедиться, что WSDL формируется. Если не формируется, значит либо веб-сервер выключен, либо база опубликована по другому адресу или порту, либо блокирует фаервол. Могут быть и другие причины.
2
02-Apr-2013 13:46:10 UTC] PHP Fatal error: Uncaught SoapFault exception: [HTTP] Error Fetching http headers in /home/users/b/test/domains/ test .ru/ testDIR / test .php:169
Эта ошибка возникает если WSDL возвращается с ошибкой. Есть несколько причин для этой ошибки:
- Несогласованность пространств имен в конфигурации. Например в ws-операции тип возвращаемого значения не соответствует типу из XDTO. Это может возникнуть при сменен URI пространства имен пакета XDTO.
- Возникает если в PHP включить кеш WSDL. Кеш запоминает WSDL и при каждом вызове веб-операции не запрашивает его, но если вы поменяли веб-сервис, то произойдет ошибка. Вообще, при разработке кеш стоит отключить, а если уже все работает то для скорости лучше включить. Ускорение при отключенном кеше заметное. Для примера скажу, что создание объекта SoapClient с выключенным кешем занимает примерно 2 сек, а с включенным — за сотые доли секунды. Отключить можно так:
ini_set ( «soap.wsdl_cache_enabled» , 0);
или
$client = new SoapClient( ‘http://somewhere.com/?wsdl’ , array ( ‘cache_wsdl’ => 0));
12 комментариев :
Не могу разобраться со следующей ошибкой. Разные soap клиенты возвращают ошибку типа «Unable to parse URL» при вызове любого метода после чтения wsdl. Т.е. wsdl читают, а следующий запрос отправить не могут. На причину этой ошибки меня наталкивает отсутствие полного url в wsdl: . 1C 8.2.16.362, apache 2.2.18, 2.2.25. Т.е. обновление апача с 18 до 25 релиза не помогло. В httpd.conf прописан ServerName tst.icc.biz:80. Куда рыть дальше? Пробовать другой релиз 1С?

Я бы проверил пространства имен пакетов XDTO, которые описывают типы возвращаемые в результатах операций.
I’m trying to invoke a WS over https on a remote host:remote port and I get:
using the PHP5 SoapClient; I can get the list of functions by doing $client->__getFunctions() but when I call $client->myFunction(. ) I always get this error.
I’ve googled and found that increasing default_socket_timeout in php.ini should fix it, but it did not work.
Can anyone suggest me a solution?
EDIT: here is the code:
always ends in the error.
How do I solve the problem?

14 Answers 14
This error is often seen when the default_socket_timeout value is exceeded for the SOAP response. (See this link.)
Note from the SoapClient constructor: the connection_timeout option is used for defining a timeout value for connecting to the service, not for the timeout for its response.
You can increase it like so:
This should tell you if the timeout is the issue, or whether you have a different problem. Bear in mind that you should not use this as a permanent solution, but rather to see if it gets rid of the error before moving on to investigate why the SOAP service is responding so slowly. If the service is consistently this slow, you may have to consider offline/batch processing.
Just wanted to share the solution to this problem in my specific situation (I had identical symptoms). In my scenario it turned out to be that the ssl certificate provided by the web service was no longer trusted. It actually turned out to be due to a new firewall that the client had installed which was interfering with the SOAP request, but the end result was that the certificate was not being correctly served/trusted.
It was a bit difficult to track down because the SoapClient call (even with trace=1) doesn’t give very helpful feedback.
I was able to prove the untrusted certificate by using:
I know this won’t be the answer to everyone’s problem, but hopefully it helps someone. Either way I think it’s important to realise that the cause of this error (faultcode: «HTTP» faultstring: «Error Fetching http headers») is usually going to be a network/socket/protocol/communication issue rather than simply «not allowing enough time for the request». I can’t imagine expanding the default_socket_timeout value is going to resolve this problem very often, and even if it does, surely it would be better to resolve the issue of WHY it is so slow in the first place.
Стандартные коды ошибок:
| Ошибка | Значение |
| unspecified | Тип ошибки не указан. Подробности смотрите в сообщении. |
| invalid_api_key | Указан неправильный ключ доступа к API. Проверьте, совпадает ли значение api_key со значением, указанным в личном кабинете. |
| access_denied | Доступ запрещён. Проверьте, включён ли доступ к API в личном кабинете и не обращаетесь ли вы к методу, прав доступа к которому у вас нет. |
| unknown_method | Указано неправильное имя метода. |
| invalid_arg | Указано неправильное значение одного из аргументов метода. |
| not_enough_money | Не хватает денег на счету для выполнения метода. |
| retry_later | Временный сбой. Попробуйте ещё раз позднее. |
| api_call_limit_exceeded_for_api_key | Сработало ограничение по вызову методов API в единицу времени. На данный момент это 1200 вызовов в минуту. Для метода sendEmail — 60. |
| api_call_limit_exceeded_for_ip | Сработало ограничение по вызову методов API в единицу времени. На данный момент это 1200 вызовов в минуту. Для метода sendEmail — 60. |
Частые ошибки без указания типа:
| Ошибка | Значение |
| «These list ids=»…» has no confirmation letters» | Не создано письмо подтверждение для списка, на который подписывается адресат. Откройте в личном кабинете список контактов на который настроена подписка, внизу слева есть пункт «Инструменты подписки и отписки». Заполните все поля на этой странице и сохраните. Инструкция по созданию письма подтверждения. |
| “Contacts test@example.org and +77777777 already exist but owned by different subscribers” | Вы добавляете email и телефон контакта, который уже есть в вашем кабинете. Укажите email или телефон, который не принадлежит другому адресату. |
| «Call to a member function getMessage() on boolean» | Вызов осуществляется с одновременным использованием методов GET и POST. Выполняйте запрос только одним из данных методов. |
Кроме этих ошибок, могут быть и другие, указанные в описаниях конкретных методов.
Пример ответа с ошибкой:
{"error":"AK100310-02","code":"invalid_api_key"}