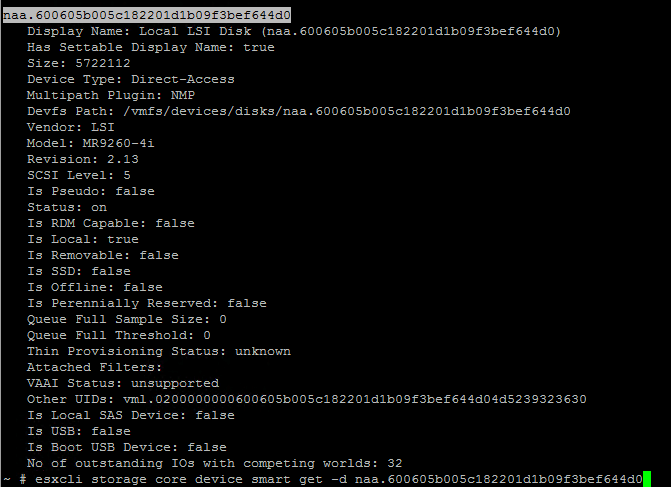
Sure — the devices show up (as they do with esxcli storage core device list) but don’t seem to be able to be accessed:
~ # /usr/lib/vmware/vm-support/bin/smartinfo.sh
SMART Information for disks.
Device: t10.ATA_____OCZ2DVERTEX4_____________________________OCZ2DI8J3EGQ7V45PXF4X
Errors:
Error getting Smart Parameters: CANNOT open device
Device: mpx.vmhba32:C0:T0:L0
Errors:
Error getting Smart Parameters: CANNOT open device
Device: t10.ATA_____M42DCT512M4SSD2__________________________000000001226090E75E5
Errors:
Error getting Smart Parameters: CANNOT open device
Device: t10.ATA_____WDC_WD30EZRX2D00MMMB0_________________________WD2DWCAWZ2097700
Errors:
Error getting Smart Parameters: CANNOT open device
I have used a vendor’s utility (for Crucial M4) in the past to update the disk and IIRC it had the S.M.A.R.T. data visible suggesting it’s coming through the controller/BIOS — that might be the next thing to check though I suppose (when I can power down the host again). I thought I’d check here first to see whether others have had any success though, before wasting too much time on it, as it’s a very new feature.
Hi,
I want to launch a S.M.A.R.T test on my harddrive disk.
I found this code :
esxcli storage core device list | grep ' Display Name:' | cut -d'(' -f2 | cut -d')' -f1 | while read DISK
do
echo "********** $DISK **********"
esxcli storage core device smart get -d $DISK
done
(source : Bitbull Tech Notes — Check SMART Disk Status in ESXi (6.5)
Nevertheless, when I launch this code, I have this error :
[root@localhost:~] esxcli storage core device list | grep ‘ Display Name:’ | cut -d’
(‘ -f2 | cut -d’)’ -f1 | while read DISK
> do echo «********** $DISK **********» ; esxcli storage core device smart get -d $DI
SK
> done
********** naa.600508b1001c413760f7cf004a8de5ab **********
Error getting Smart Parameters: CANNOT open device
********** naa.600508b1001c2b63c3e5216dbe1ba7dc **********
Error getting Smart Parameters: CANNOT open device
********** mpx.vmhba32:C0:T0:L0 **********
Error getting Smart Parameters: CANNOT open device
********** naa.600508b1001c71fc01427153a69ab9c7 **********
Error getting Smart Parameters: CANNOT open device
********** naa.600508b1001cacb17e7e074c24ad122d **********
Error getting Smart Parameters: CANNOT open device
Do you have an idea of problem ?
Thanks !
Обновлено 04.09.2016

Как мониторить SMART дисков, SSD в RAID на ESXI 5.5-01
Всем привет сегодня хочу поделиться своим опытом в мониторинге S.M.A.R.T дисков, SSD в RAID на ESXI 5.5. Немного скучной теории но без нее ни куда. Современные жесткие диски довольно “умные” устройства и, кроме основных присущих им как устройствам хранения и обработки данных свойств, поддерживают технологию самотестирования, анализа состояния, и накопления статистических данных об ухудшении собственных характеристик S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology). Основы S.M.A.R.T. были разработаны в 1995 г. совместными усилиями ведущих производителями жестких дисков (HDD). В последующие годы стандарты S.M.A.R.T дорабатывались в соответствии с изменениями технологий и оборудования ( SMART II и SMART III) и продолжают совершенствоваться в настоящее время.
Жесткий диск, начиная с момента его изготовления, постоянно отслеживает определенные параметры своего состояния и отражает их в специальных характеристиках — атрибутах (Attribute), сохраняющихся в постоянном запоминающем устройстве , как правило, в специально выделенной части дисковой поверхности, доступной только внутренней микропрограмме накопителя — служебной зоне. Данные атрибутов могут быть прочитаны, в соответствии со спецификацией ATA (AT Attachment ) по командам поддержки SMART (SMART READ DATA и еще более десятка команд), которые передаются в накопитель специальным программным обеспечением, как например, утилитами от производителей оборудования или универсальными программами тестирования и мониторинга состояния HDD (udisks, smartctl, GSmartControl, gnome-disks и т.п.). Современные стандарты ATA включают в себя поддержку протокола SCT (SMART Command Transport), обеспечивающего считывание журналов статистики устройства. Журнал статистики устройства — это доступный только для чтения журнал SMART, передаваемый накопителем при получении команд READ LOG EXT, READ LOG DMA EXT или SMART READ LOG.
Атрибут представляет собой характеристику определенного состояния жесткого диска, которая изменяется в процессе эксплуатации, принимая числовое значение от максимального, установленного в момент изготовления данного устройства, до минимального, при достижении которого, работоспособность накопителя не гарантируется. Все атрибуты идентифицируются своим цифровым номером, большинство из которых одинаково интерпретируется жесткими дисками разных моделей. Некоторые из них могут использоваться только конкретным производителем оборудования, и поддерживаться отдельными моделями накопителей. Так, например, атрибут с идентификатором 7, характеризующий количество ошибок установки головок на требуемую дорожку поверхности диска Seek_Error_Rate не имеет смысла для твердотельных дисков ( SSD ) и, соответственно, не поддерживается ими, а атрибут с идентификатором 9,характеризующий суммарное время работы накопителя за весь срок эксплуатации и обозначаемый как Power_On_Hours,поддерживается как SSD, так и традиционными HDD.
Атрибуты состоят из нескольких полей, ( наиболее часто обозначаемых как Val, Worst, Tresh, RAW), каждое из которых является определенным показателем, характеризующим техническое состояние накопителя на данный момент времени. Программы считывания S.M.A.R.T. выводят содержимое атрибутов, как правило, в виде нескольких колонок :
- ID# — числовой идентификатор атрибута
- Attribute — название атрибута
- Flags — флаги атрибутов, задаваемые производителем HDD. Характеризуют тип атрибута ( большинство программ интерпретируют флаги в виде символов k,c,r,s,o,p или аббревиатур, например, EC – Event Count, счетчик событий ).Pre-Failure (PF, 01h) — при достижении порогового значения данного типа атрибутов диск требует замены. Иногда данный бит флагов обозначают какLife Critical (CR) или Pre-Failure warranty (PW)
Online test (OC, 02h)– атрибут обновляет значение при выполнении off-line/on-line встроенных тестов SMART;
Perfomance Related (PE или PR , 04h)– атрибут характеризует производительность ;
Error Rate (ER , 08h )– атрибут отражает счетчики ошибок оборудования;
Event Counts (EC, 10h ) – атрибут представляет собой счетчик событий;
Self Preserving (SP, 20h ) – самосохраняющися атрибут;
Некоторые из программ могут интерпретировать флаги в виде текстовых описаний, близких по смыслу к рассмотренным выше. Один атрибут может иметь несколько установленных в единицу значений флагов, например, атрибут с идентификатором 05 отражающий количество переназначенных из-за сбоев секторов из резервной области, имеет установленные флаги SP+EC+OC – самосохраняющийся, счетчик событий, обновляется при автономном и интерактивном режиме накопителя. - Value — текущее значение атрибута
- Threshold — минимальное пороговое значения атрибута
- Worst — самое худшее значение атрибута за все время работы накопителя
- Raw — абсолютное значение атрибута
- Type — некоторые из программ в данном необязательном поле отображают информацию из флажков атрибутов или признаки их критичности (Criticalили Pre-Fail , отражающих ухудшение характеристик оборудования, и Old-age для атрибутов, отражающих выработку ресурса);Для анализа состояния накопителя, пожалуй самым важным значением атрибута является Value — условное число (обычно от 0 до 100 или до 253), заданное производителем. Значение Value изначально установлено на максимум при производстве накопителя и уменьшается в случае ухудшения его параметров. Для каждого атрибута существует пороговое значение, при достижения которого, производитель не гарантирует его работоспособность — поле Threshold. Если значение Value приближается или становится меньше значения Threshold, — накопитель пора менять.Перечень атрибутов и их значения жестко не стандартизированы и некоторые из них могут определяться изготовителем накопителя, но основная часть интерпретируются одинаково. Например, атрибут с идентификатором 05 (Reallocated sector count) будет характеризовать число забракованных и переназначенных из резервной области секторов диска, как для устройств производства компании Seagate Technology, так и для устройств производства Western Digital . Набор поддерживаемых атрибутов зависит от модели накопителя и может значительно отличаться по составу для разных моделей.
Если значение Value приближается или становится меньше значения Threshold, — накопитель пора менять
В нашем эксперименте будут 3 производителя контроллеров Adaptec, LSI, HP Smart Array. В ESXI есть отличная команда выводящая SMART дисков и SSD. Сначала посмотрим список ваших дисков и LUN.
esxcli storage core device list
Как мониторить SMART дисков, SSD в RAID на ESXI 5.5-001
Выводим SMART отдельного диска или LUN.
esxcli storage core device smart get -d имя
Если у вас отдельные диски на всех контроллерах Adaptec, LSI, HP Smart Array вы получите такую картину
Как мониторить SMART дисков, SSD в RAID на ESXI 5.5-02
Жирным выделены метрики, которые могут оказаться полезными. Параметр Reallocated Sector Count не должен сильно увеличиваться со временем для исправных дисков. Когда дисковая подсистема получает ошибку read/write/verification для сектора, она перемещает его данные в специально зарезервированную область (spare area), а данный счетчик увеличивается.
Media Wearout Indicator — это уровень «жизни» вашего SSD-диска (для новых дисков он должен отображаться как 100). По мере прохождения циклов перезаписи диск «изнашивается» и данный счетчик уменьшается, соответственно, когда он перейдет в значение 0 — его жизнь формально закончится, исходя из рассчитанного для него ресурса. Кстати, этот счетчик может временно уменьшаться при интенсивных нагрузках диска, а потом восстанавливаться со временем, если средняя нагрузка на диск снизилась.
Если у вас LUN с СХД или RAID LUN то нихера в консоли не получите этой командой.
Как мониторить SMART дисков, SSD в RAID на ESXI 5.5-04
И вопрос как мониторить SMART в RAID ESXI 5.5, очень просто каждый вендор делает свой CIM пакет, вот как его поставить для каждого вендора. (Adaptec, LSI, HP Smart Array). Так же можно мониторить Operation Manager 5.8.
Расшифровка атрибутов S.M.A.R.T
- Идентификаторы атрибутов указаны в десятичной системе счисления, а в скобках они же – в шестнадцатеричной.
- 001 ( 1h ) Raw Read Error Rate — абсолютное значение ошибок считывания. Существует некоторые отличия в формировании значения данного атрибута разными производителями. Из практики могу сказать, что накопители Seagate могут иметь гигантское значение RAW этого атрибута, реально будучи в хорошем состоянии, а накопители Western Digital могут иметь его нулевым, имея критические показатели по другим характеристикам. Некоторые модели вообще не поддерживают данный атрибут.
- 002 ( 02h ) Throughput Performance — усредненная производительность жесткого диска. Редко встречающийся атрибут.
- 003 ( 3h ) Spin Up Time — Среднее время раскрутки шпинделя диска от 0 RPM до рабочей скорости. Для SSD дисков не поддерживается.
- 004 ( 4h ) Start/Stop Count — Количество циклов запуск/останов шпинделя.
- 005 ( 5h ) Reallocated Sector Count — Количество переназначенных ( перераспределенных) секторов . Современные накопители имеют резервную область поверхности для использования ее объема в случае ухудшения характеристик блоков из основной зоны. Если микропрограмма накопителя обнаруживает ошибки с записи/чтения какого-либо блока рабочей поверхности, то запускается механизм, обеспечивающий переадресацию обращений к дефектному блоку ( сектору ), на блок из резервной части. Он автоматически перемещает его данные в резервную область, а данный блок помечается как «переназначенный». Часто этот процесс называют «remapping», или «automatic defect reassignment». Процедура переназначения сбойных секторов на резервные, выполняется автоматически внутренней микропрограммой накопителя, и для пользователя (операционной системы) она невидима. Сам факт переназначения и количество переназначенных секторов доступны только из журналов SMART. Поле абсолютного значения атрибута Raw Valueсодержит общее количество переназначенных секторов. Нормализованное значение Value отражает процент допустимого количества дефектных блоков. При исчерпании резервной области, переназначение становится невозможным и диск подлежит замене. Даже некритическое, но большое значение этого поля, может привести к снижению скорости обмена данными, поскольку накопитель выполняет дополнительные операции установки головок на дорожки резервной области, которая обычно находится в конце рабочей поверхности диска.
- 007 ( 7h ) Seek Error Rate — Частота появления ошибок позиционирования блока магнитных головок (БМГ) . Дисковые накопители контролирует правильность установки головок на требуемую дорожку поверхности. В случае, когда установка выполнилась неверно, фиксируется ошибка и операция повторяется. На практике, большое количество ошибок позиционирования может быть вызвано не только проблемами оборудования, но и влиянием внешних факторов – не соответствующим температурным режимом или вибрацией.
- 008 ( 8h ) Seek Time Performance — средняя скорость позиционирования магнитных головок. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
- 009 (09h) Power-On Hours (POH) Количество рабочих часов — количество часов, когда диск находился во включенном состоянии за весь срок с момента производства, в виде целочисленного значения в часах. Иногда встречаются модели накопителей, в которых внутреннее значение данного атрибута сохраняется в виде количества рабочих минут или секунд, а не часов. Достижение порогового значения данного атрибута означает выработку ресурса, заданного производителем ( MTBF — Mean Time Between Failures
- 010 ( 0Ah ) Spin Retry Count — Количество повторных попыток старта шпинделя. После включения питания, накопитель раскручивает диски и контролирует достижение рабочей скорости вращения, заданной производителем для данной модели . Если за отведенное контрольное время рабочая скорость не достигнута, увеличивается значение данного атрибута и выполняется повторная раскрутка двигателя.
- 011 ( 0B ) Recalibration Retries — атрибут отражает количество повторных рекалибровок, в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью накопителя. Кроме того, увеличение абсолютного значения данного атрибута может быть вызвано тем, что процедура рекалибровки используется внутренней микропрограммой накопителя для коррекции других типов ошибок.
- 012 ( 0Ch ) Device Power Cycle Count — абсолютное значение Raw Value указывает на количество циклов включения/выключения питания накопителя за весь период эксплуатации. Нормализованное значение Value обычно не изменяется и равно 100.
- 013 ( 0Dh ) — Soft Read Error Rate — Количество программных сбоев — совокупное количество программных сбоев. Нормализованное значение: начиная со 100, отображает процент оставшегося допустимого нарастающего количества программных сбоев.
- 100 ( 64h ) Erase/Program Cycles — количество циклов стирания –записи перепрограммируемой памяти (flash) для SSD-дисков. Количество таких циклов ограниченно и зависит от микросхем постоянной перезаписываемой памяти, используемых в данной модели SSD.
- 103 ( 67h ) Translation Table Rebuild — количество событий, связанных с разрушением внутренних таблиц транслятора и его перестроением.
- 170 ( AAh )Reserved Block Count — количество доступных резервных блоков для переназначения сбойных секторов (см. атрибут E8h).
- 171 ( ABh ) Program Fail Count — ошибки записи в перепрограммируемую память SSD
- 172 ( ACh ) Erase Fail Count – ошибки стирания flash-памяти SSD. Процесс записи в перезаписываемую постоянную память состоит из двух частей — стирания и записи. Процедура стирания всегда выполняется перед записью данных.
- 173 ( ADh ) Wear Leveller Worst Case Erase Count — максимально допустимое количество операций стирания для единичного блока SSD-диска.
- 174 ( AEh) Unexpected Power Loss — непредвиденное отключение питания для SSD . Также этот показатель называется «Количество аварийных выключений» в терминологии жестких дисков с магнитными носителями. Абсолютное значение Raw Value: совокупное количество нештатных выключений за весь срок использования устройства.
- 175 ( AFh ) Program Fail Count– данный атрибут используется в SSD-накопителях производства Intel и отображает информацию о сбоях защиты от отключения питания SSD-дисков. Результаты последнего теста в виде количества микросекунд до разряда конденсатора, фиксируется на максимальном значении. Также записывается количество минут после последнего теста и общее количество тестов за весь срок использования устройства. Необработанное значение Raw Value:Байты 0—1: Результаты последнего теста в виде количества микросекунд до разряда конденсатора, фиксируется на максимальном значении. Результат теста должен быть в диапазоне 25 — 5 000 000, более низкое значение указывает на определенный код ошибки. Байты 2—3: количество минут после последнего текста, фиксируется на максимальном значении. Байты 4—5: количество тестов за весь срок использования устройства, не увеличивается при циклах включения и отключения, фиксируется на максимальном значении. Значение Value устанавливается равным 1 при сбое теста, или 11 при тестировании конденсатора в недопустимых температурных условиях; в противном случае устанавливается равным 100.
- 183 ( B7h ) SATA Downshifts — Количество снижений скорости SATA Необработанное значение: количество случаев, когда из-за ошибок для интерфейса SATA была выбрана пониженная скорость передачи данных ( с 6 Гб/с до 3Гб/с или 1,5Гб/с или с 3Гб/с. До 1.5Гб/с. Очень часто данный атрибут характеризует недостаточное качество электропитания, окисление контактов интерфейсного кабеля, или его неисправность.
- 184 ( B8h ) End-to-End error Количество обнаруженных сквозных ошибок кэш-памяти ( disk cache). Абсолютное значение: количество обнаруженных и исправленных оборудованием сквозных ошибок.
- 187 ( BBh ) Reported Uncorrectable Errors Количество невосстановимых ошибок. Необработанное значение Raw Value: количество ошибок, которые не удалось исправить с помощью внутренних подпрограмм накопителя.
- 188 ( BCh ) Command Timeout — количество команд, прерванных по таймауту.
- 189 ( BDh ) High Fly Writes — количество событий, связанных с ошибками, зафиксированными монитором контроля высоты полета Fly Height Monitor, когда головки записи находятся в положении, не гарантирующем нормальное выполнение операции. Если высота полета головки над магнитной поверхностью, даже на короткое время превысит оптимальную, то записанные ею данные, в дальнейшем, могут не прочитаться. Современные накопители используют специально разработанную технологию контроля высоты полета головок, позволяющую не выполнять запись данных при неоптимальной высоте. В счетчик данного атрибута добавляется единица, а запись выполняется после установки нормальной высоты полета. Повышенное значение данного атрибута может быть вызвано внешними ударами или вибрациями, ненормальной температурой, ухудшением характеристик магнитной поверхности или головки.
- 190 ( BEh ) Airflow Temperature температура воздушного потока (корпус). Значение Raw Value: статистические данные по температуре корпуса .Байты 0—1: текущая температура корпуса в градусах по Цельсию; байт 2: недавняя минимальная температура корпуса в градусах по Цельсию; байт 3: недавняя максимальная температура корпуса в градусах по Цельсию; байты 4—5: счетчик превышений температуры. Количество случаев, когда зафиксированная температура превышала максимальную допустимую рабочую температуру накопителя.
- 191 ( BFh ) G-sense error rate — количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера. Обычно довольно точно характеризует условия эксплуатации ноутбуков — большое значение атрибута говорит о резких толчках и падениях при работе устройства.
- 192 ( C0h ) Emergency Retract Cycle Count Количество аварийных выключений (количество нештатных выключений) — совокупное количество событий аварийного (нештатного) отключения питания за весь срок использования устройства. Для SSD дисков под «нештатным выключением» понимается отключение питания устройства без предварительной выдачи команды STANDBY IMMEDIATE.
- 194 ( C2h ) HDA Temperature — температура самого накопителя (HDA — Hard Disk Assembly). В данном атрибуте хранятся показания встроенного температурного датчика, которым обычно служит одна из магнитных головок (как правило — нижняя ). У SSD дисков термодатчик размещается внутри корпуса на печатной плате. Данные, записанные в полях атрибута отображают текущую, минимальную и максимальную температуру. Поле Worst показывает наихудшую, достигнутую за время работы накопителя, температуру (можно установить факт перегрева и его степень), Raw Value — текущую температуру. Некоторые модели накопителей могут поддерживать атрибут 205 ( CDh ) Thermal asperity rate (TAR), фиксирующий количество опасных перепадов температуры.
- 195 ( C3h ) Hardware ECC Recovered — количество ошибок считывания, исправленных оборудованием накопителя с применением кода коррекции ошибок. Подобные ошибки не требуют повторного считывания сектора, и не приводят к потере скорости обмена данными, но большое их количество говорит об ухудшении параметров тракта считывания.
- 196 ( C4h ) Reallocation Event Count — Число событий переназначения сбойных секторов. В поле raw value данного атрибута хранится общее число попыток переноса данных из нестабильных секторов в резервную область. Учитываются как успешные, так и неуспешные попытки.
- 197 ( C5 ) Current Pending Sector Count — Текущее количество нестабильных секторов. Поле raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает кандидатами на переназначение в резервную область . Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка кандидатов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped).
- 198 ( C6 ) Uncorrectable Sector Count — Счетчик некорректируемых ошибок, т.е , счетчик ошибок, которые не были исправлены внутренними средствами коррекции оборудования накопителя. Это означает, что такие ошибки проявляются как классические сбойные блоки файловой системы ( Bad Block ). Причиной подобных сбоев диска, может быть неисправность отдельных элементов или отсутствие свободных секторов в резервной области диска, когда возникла необходимость переназначения.
- 199 ( C7h ) UltraDMA CRC Error Rate — Количество ошибок при передаче данных в режиме прямого доступа к памяти, обнаруженных средствами циклического избыточного кода (англ. Cyclic redundancy check, CRC). Аппаратные средства контроля передачи данных из накопителя в оперативную память обнаружили ошибку контрольной суммы и исправили ее “на лету”, если ошибка исправимая. В данном случае алгоритм обычной работы диска не изменяется. В случае же неисправимой ошибки, процедура ее обработки выполняется системой. Обычно, данный атрибут содержит счетчик любых видов ошибок CRC. Нередко этот тип ошибки связан не столько с оборудованием накопителя, сколько с неисправным интерфейсным кабелем, окислившимися контактами, некачественным электропитанием, разгоном частоты шины PCI, перегревом микросхем чипсета материнской платы и т.п.
- 200 ( C8h ) Write Error Rate (Multi Zone Error Rate) — ошибки записи данных.
- 232 ( E8h ) Total Count of Write Sectors Для SSD-дисков — количество записанных секторов. Значение Raw Value увеличивается на 1 на каждые 65 536 секторов (32 МБ), записываемых системой. Для SSD Intel — Intel SSD Available Reserved Space — процент доступной резервной области, используемой для переназначения дефектных блоков.
- 233 ( E9h ) Power-On Hours — Время работы накопителя. Для SSD-дисков этот атрибут интерпретируется как Remaining Life — указатель износа носителя. Количество циклов работы носителя NAND. Линейно снижается от 100 до 1 по мере увеличения среднего количества циклов стирания от 0 до максимального. Нормализованное значение перестанет уменьшаться после достижения 1, но, по всей вероятности, устройство выдержит значительный дополнительный износ.
- 241 ( F1h) Total LBAs Written — Общее количество записанных секторов LBA. Значение Raw Value : совокупное количество секторов, записанных системой. Значение увеличивается на 1 на каждые 65 536 секторов (32 МБ), записываемых системой.
- 242 ( F2h ) Total LBAs Read — Общее количество прочитанных секторов LBA. Значение Raw Value увеличивается на 1 на каждые 65 536 секторов (32 МБ), прочитываемых системой.
- 254 ( FEh ) Free Fall Event Count — количество событий ускорения свободного падения диска за время эксплуатации ( сколько раз диск падал ).
Оценка технического состояния жесткого диска по данным S.M.A.R.T
Набор атрибутов поддерживаемых конкретной моделью жесткого диска, даже если он минимален, позволяет с высокой достоверностью определить техническое состояние и перспективы эксплуатации устройства. Можно определить время нахождения во включенном состоянии по значению атрибута 9, а в совокупности со значением атрибута 12 — количество включений /выключений электропитания, и следовательно, – круглосуточный или периодический режим эксплуатации. Интенсивность использования, температурный режим, негативные внешние воздействия – все эти факты легко отслеживаются по абсолютным значениям соответствующих атрибутов. Подобным же образом, можно оценить и уровень износа оборудования, качество поверхности и тракта записи/чтения.
Минимально информативный контроль состояния дисков может выполняться даже на уровне BIOS. В случае достижения критического значения любого атрибута, характеризующего работоспособность, при включенном мониторинге состояния S.M.A.R.T в настройках BIOS, загрузка операционной системы приостанавливается и на экран выводится сообщение:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Press F1 to ResumeТаким образом, без установки или запуска дополнительного программного обеспечения, имеется возможность вовремя определить факт критического состояния накопителя средствами Базовой Системы Ввода-Вывода (BIOS) при включении компьютера.
Техническое состояние жесткого диска, не достигшее критического порога, характеризуется абсолютным значением атрибутов, отражающих счетчики сбоев, обнаруженных и исправленных оборудованием накопителя.
- 001 ( 1 ) Raw Read Error Rate — абсолютное значение ошибок считывания. Существует некоторые отличия в формировании значения данного атрибута разными производителями. На практике, накопители Seagate могут иметь гигантское значение RAW этого атрибута, реально будучи в хорошем состоянии, а накопители Western Digital могут иметь его нулевым, имея критические показатели по другим характеристикам. Некоторые модели вообще могут не поддерживать данный атрибут.
- 005 ( 5 ) Reallocated Sector Count — Количество переназначенных секторов. Ненулевое значение данного счетчика говорит о том, что были обнаружены дефектные блоки, данные которых перенесены в резервную область.
- 196 ( C4 ) Reallocation Event Count — Число событий переназначения сбойных секторов. В поле raw value данного атрибута хранится общее число попыток переноса данных из нестабильных секторов в резервную область. Учитываются как успешные, так и неуспешные попытки.
- 197 ( C5 ) Current Pending Sector Count — Текущее количество нестабильных секторов. Поле raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает кандидатами на переназначение в резервную область (remap). Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка кандидатов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped). Если значение атрибутов 5,196,197 увеличивается за короткий промежуток времени ( дни, или даже часы), то это является настораживающим признаком – либо ухудшаются технические параметры самого накопителя, либо сказывается влияние внешних воздействий.
- 007 ( 07h ) Seek Error Rate — Частота появления ошибок позиционирования блока магнитных головок (БМГ). Большое значение говорит о проблемах механизма позиционирования, хотя может быть вызвано и внешними факторами, такими как перегрев или повышенная вибрация.
- 008 ( 08h ) Seek Time Performance — средняя скорость позиционирования магнитных головок. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
- 199 ( C7 ) UltraDMA CRC Error Count — Счетчик ошибок, возникших при передаче данных в режиме UltraDMA. Рост абсолютного значения указывает на проблемы при передаче данных контроллером диска в оперативную память. Чаще всего, вызвано плохим кабелем и нестабильным электропитание
Обновление 11.12.2015
Недавно на тестирование попал RAID контроллер LSI 9361-8i, моделька свежая со всеми наворотами, но сейчас не об этом. Я так же на него установил Vmware ESXI 5.5 и захотел посмотреть дает ли контроллер S.M.A.R.T. Стандартными командами, он не отдал значения, пришлось установить storcli, после чего введя команду
./storcli /c0/e252/s1 show smart
Я получил smart дисков, но в таком не читабельном виде, что просто ужас 🙂 Как вам оно. Принципе если бы было описание полей или строк, все было бы куда более терпимо. Ну не понимаю я почему столько граблей, чтобы элементарно вытащить smart дисков. Как появится информация, что означает каждое поле отпишусь сюда.

Обновление 12.05.2016
Товарищи, хочу вас обрадовать, что появилась шикарная утилита, способная в Windows показывать smart состояние дисков, находящихся в рейде. Называется она Hard Disk Sentinel
Переходим на сайт производителя hdsentinel.com
Скачиваем либо установщик, либо portble версию. Запускаем HDSentinel.exe
В системном три у вас появятся значки состояния ваших жестких дисков.
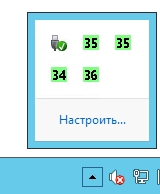
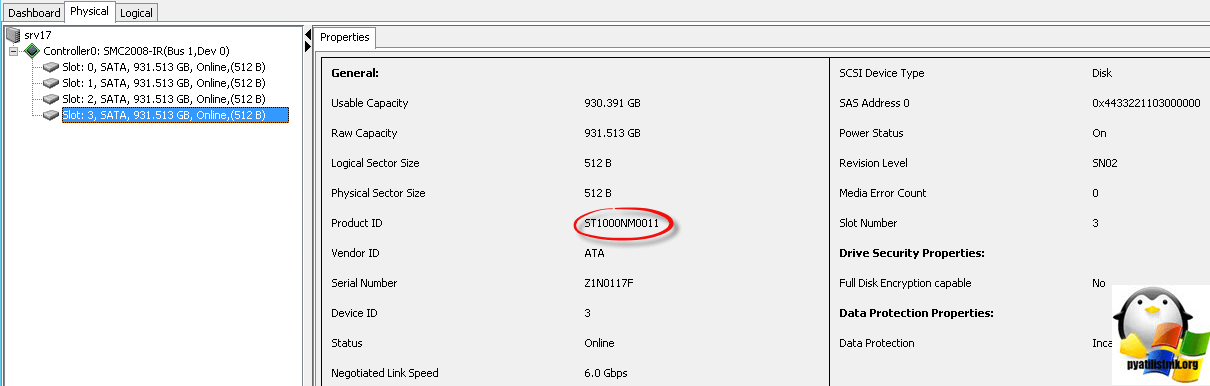
Для примера покажу свой контроллер SMC2008-IR, как видите у меня там 4 диска в 10 рейде.
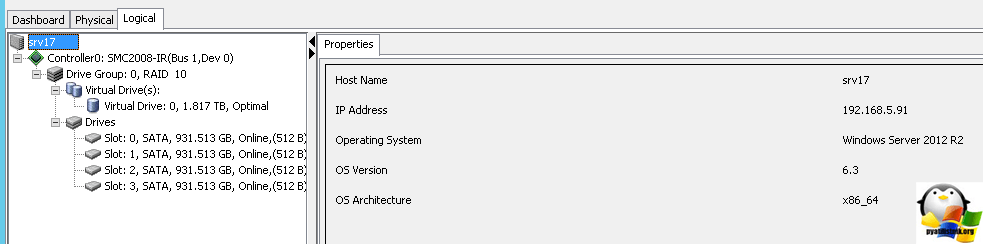
Как видим, у моего 4 диска появились bad sectors
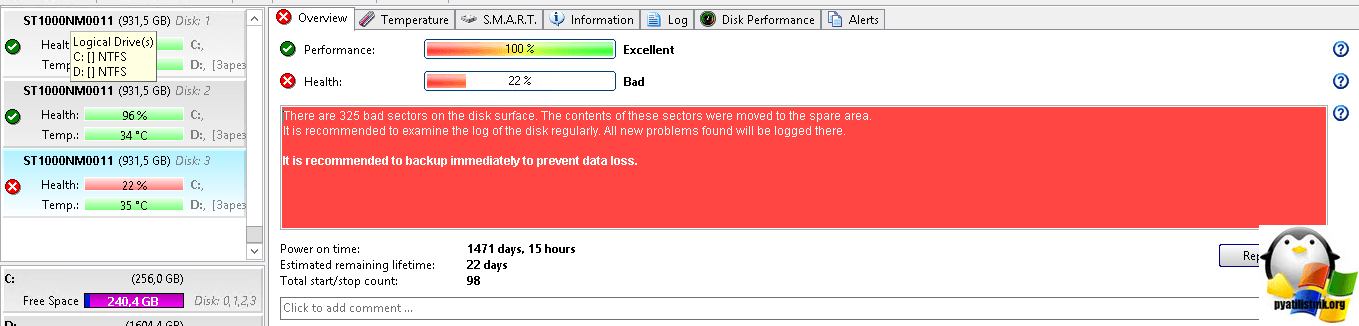
Переходим на вкладку S.M.A.R.T и видим, большинство счетчиков.
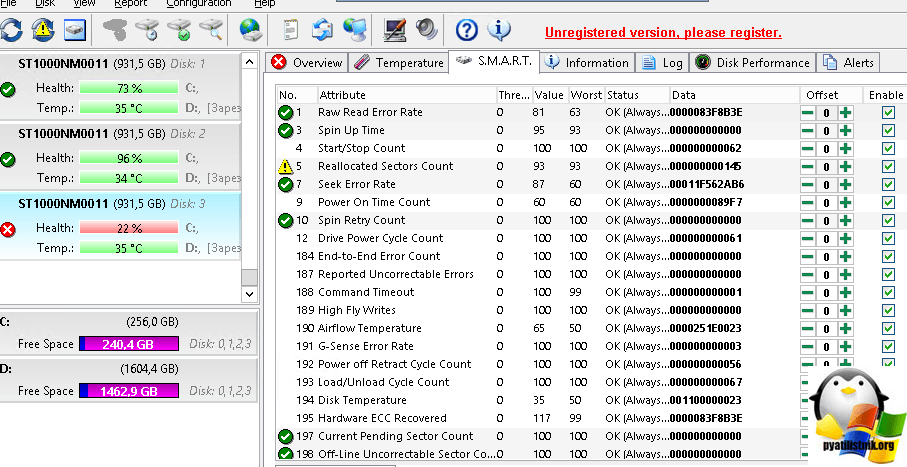
Для примера я в LSI утилите ProductID, так же его видит и HDSentinel
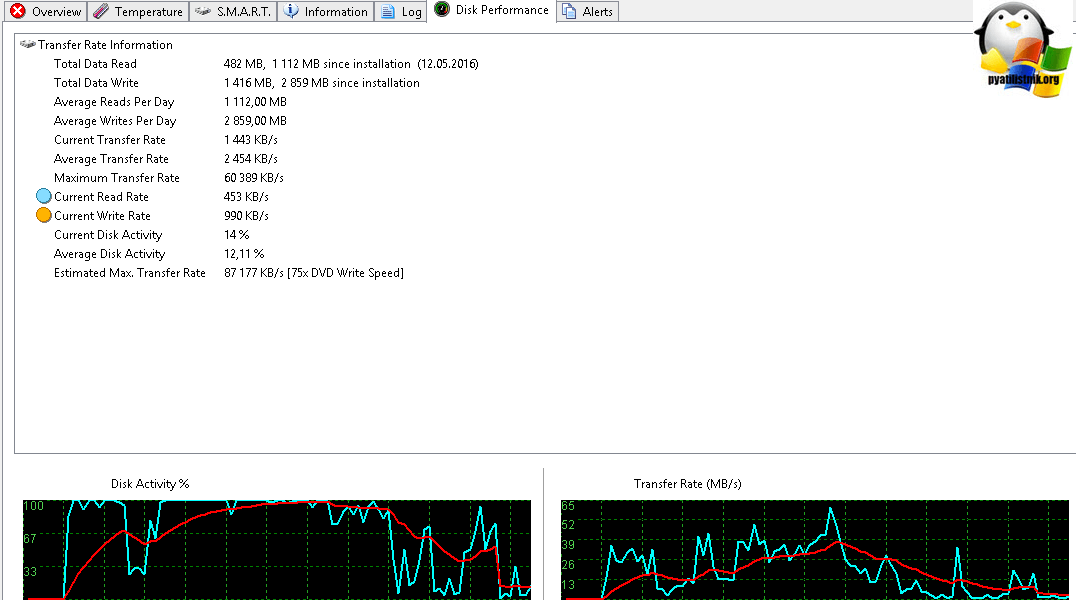
еще HDSentinel удобно отображает загрузку диска в реальном времени.
Можно в сети установить серверную версию, но она платная. Для linux платформ, так же есть своя сборка.
Материал сайта pyatilistnik.org
Интересуюсь способом следить за здоровьем HDD в гипервизоре или vCenter, покачто нашел один способ:
esxcli storage core device list
Найти девайс:
t10.ATA_____ST1000DM0032D1CH162__________________________________S1D92ZFE Display Name: Local ATA Disk (t10.ATA_____ST1000DM0032D1CH162__________________________________S1D92ZFE) ... t10.ATA_____TOSHIBA_DT01ACA200_________________________________X3F20WMYS Display Name: Local ATA Disk (t10.ATA_____TOSHIBA_DT01ACA200_________________________________X3F20WMYS) ... t10.ATA_____WDC_WD1600AAJS2D00WAA0________________________WD2DWCAS20011233 Display Name: Local ATA Disk (t10.ATA_____WDC_WD1600AAJS2D00WAA0________________________WD2DWCAS20011233) ... mpx.vmhba0:C0:T0:L0 Display Name: Local HL-DT-ST CD-ROM (mpx.vmhba0:C0:T0:L0)
И его имя добавить в стоку, вместо ‘device’:
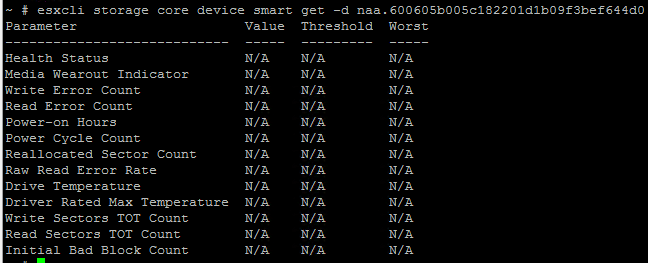
esxcli storage core device smart get -d device
На что получаем ответ ПНХ:
~ # esxcli storage core device smart get -d t10.ATA_____TOSHIBA_DT01ACA200_________________________________X3F20WMYS Error getting Smart Parameters: CANNOT open device
Осталось разобраться почему.
Пробую:
~ # esxcli storage core device smart -d|--device-name=t10.ATA_____TOSHIBA_DT01ACA200_________________________________X3F20WMYS -sh: --device-name=t10.ATA_____TOSHIBA_DT01ACA200_________________________________X3F20WMYS: not found close failed in file object destructor: Error in sys.excepthook: Original exception was:
Вежливо послан…
Последний рубеж:
~ # /usr/lib/vmware/vm-support/bin/smartinfo.sh SMART Information for disks. Device: mpx.vmhba0:C0:T0:L0 Errors: Error getting Smart Parameters: CANNOT open device Device: t10.ATA_____WDC_WD1600AAJS2D00WAA0________________________WD2DWCAS20011233 Errors: Error getting Smart Parameters: CANNOT open device Device: t10.ATA_____TOSHIBA_DT01ACA200_________________________________X3F20WMYS Errors: Error getting Smart Parameters: CANNOT open device Device: t10.ATA_____ST1000DM0032D1CH162__________________________________S1D92ZFE Errors: Error getting Smart Parameters: CANNOT open device
Также безрезультатно. Буду искать способы.

About trianglesis
Александр Брюндтзвельт — гений, филантроп, 100 гривен в кармане.
Этот блог — «сток» моих мыслей и заметок. Достаточно одного взгляда на него, чтобы понять, что такой же бардак творится у меня в голове.
Если вам этот бардак интересен — милости прошу.
Try to do one thing, first of all, let’s filter out the cdrom/s by adding this piece of code (| grep -v cdrom):
esxcli storage core device list | grep «Devfs Path» | grep -v cdrom | awk -F «/» ‘{print $5}’ | sed -e ‘s/^ //g’ -e ‘s/ $//g’
You will get something like this:
naa.60030057023442201e702a961bfeae7d
naa.60030057023442201e702ab61dee11f6
Now if you run this command, for each of the above devices:
esxcli storage core device smart get -d naa.60030057023442201e702a961bfeae7d
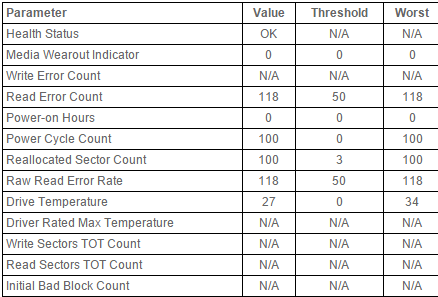
You will get the report that XSIBackup gets and packs with the HTML, something like this (one per disk):
Parameter Value Threshold Worst
Health Status OK N/A N/A
Media Wearout Indicator N/A N/A N/A
Write Error Count N/A N/A N/A
Read Error Count 117 6 99
Power-on Hours 86 0 86
Power Cycle Count 100 20 100
Reallocated Sector Count 100 10 100
Raw Read Error Rate 117 6 99
Drive Temperature 32 0 45
Driver Rated Max Temperature 68 45 55
Write Sectors TOT Count 200 0 200
Read Sectors TOT Count N/A N/A N/A
Initial Bad Block Count 100 99 100
Try to visualize the HTML in the e-mail report and see if this data is there with the HTML. It could be something like a weird character just breaking the HTML compliance.
Error getting smart parameters cannot open device
Как мониторить SMART дисков, SSD в RAID на ESXI 5.5-01
Всем привет сегодня хочу поделиться своим опытом в мониторинге S.M.A.R.T дисков, SSD в RAID на ESXI 5.5. Немного скучной теории но без нее ни куда. Современные жесткие диски довольно “умные” устройства и, кроме основных присущих им как устройствам хранения и обработки данных свойств, поддерживают технологию самотестирования, анализа состояния, и накопления статистических данных об ухудшении собственных характеристик S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology). Основы S.M.A.R.T. были разработаны в 1995 г. совместными усилиями ведущих производителями жестких дисков (HDD). В последующие годы стандарты S.M.A.R.T дорабатывались в соответствии с изменениями технологий и оборудования ( SMART II и SMART III) и продолжают совершенствоваться в настоящее время.
Жесткий диск, начиная с момента его изготовления, постоянно отслеживает определенные параметры своего состояния и отражает их в специальных характеристиках — атрибутах (Attribute), сохраняющихся в постоянном запоминающем устройстве , как правило, в специально выделенной части дисковой поверхности, доступной только внутренней микропрограмме накопителя — служебной зоне. Данные атрибутов могут быть прочитаны, в соответствии со спецификацией ATA (AT Attachment ) по командам поддержки SMART (SMART READ DATA и еще более десятка команд), которые передаются в накопитель специальным программным обеспечением, как например, утилитами от производителей оборудования или универсальными программами тестирования и мониторинга состояния HDD (udisks, smartctl, GSmartControl, gnome-disks и т.п.). Современные стандарты ATA включают в себя поддержку протокола SCT (SMART Command Transport), обеспечивающего считывание журналов статистики устройства. Журнал статистики устройства — это доступный только для чтения журнал SMART, передаваемый накопителем при получении команд READ LOG EXT, READ LOG DMA EXT или SMART READ LOG.
Атрибут представляет собой характеристику определенного состояния жесткого диска, которая изменяется в процессе эксплуатации, принимая числовое значение от максимального, установленного в момент изготовления данного устройства, до минимального, при достижении которого, работоспособность накопителя не гарантируется. Все атрибуты идентифицируются своим цифровым номером, большинство из которых одинаково интерпретируется жесткими дисками разных моделей. Некоторые из них могут использоваться только конкретным производителем оборудования, и поддерживаться отдельными моделями накопителей. Так, например, атрибут с идентификатором 7, характеризующий количество ошибок установки головок на требуемую дорожку поверхности диска Seek_Error_Rate не имеет смысла для твердотельных дисков ( SSD ) и, соответственно, не поддерживается ими, а атрибут с идентификатором 9,характеризующий суммарное время работы накопителя за весь срок эксплуатации и обозначаемый как Power_On_Hours,поддерживается как SSD, так и традиционными HDD.
Атрибуты состоят из нескольких полей, ( наиболее часто обозначаемых как Val, Worst, Tresh, RAW), каждое из которых является определенным показателем, характеризующим техническое состояние накопителя на данный момент времени. Программы считывания S.M.A.R.T. выводят содержимое атрибутов, как правило, в виде нескольких колонок :
- ID# — числовой идентификатор атрибута
- Attribute — название атрибута
- Flags — флаги атрибутов, задаваемые производителем HDD. Характеризуют тип атрибута ( большинство программ интерпретируют флаги в виде символов k,c,r,s,o,p или аббревиатур, например, EC – Event Count, счетчик событий ).Pre-Failure (PF, 01h) — при достижении порогового значения данного типа атрибутов диск требует замены. Иногда данный бит флагов обозначают какLife Critical (CR) или Pre-Failure warranty (PW)
Online test (OC, 02h)– атрибут обновляет значение при выполнении off-line/on-line встроенных тестов SMART;
Perfomance Related (PE или PR , 04h)– атрибут характеризует производительность ;
Error Rate (ER , 08h )– атрибут отражает счетчики ошибок оборудования;
Event Counts (EC, 10h ) – атрибут представляет собой счетчик событий;
Self Preserving (SP, 20h ) – самосохраняющися атрибут;
Некоторые из программ могут интерпретировать флаги в виде текстовых описаний, близких по смыслу к рассмотренным выше. Один атрибут может иметь несколько установленных в единицу значений флагов, например, атрибут с идентификатором 05 отражающий количество переназначенных из-за сбоев секторов из резервной области, имеет установленные флаги SP+EC+OC – самосохраняющийся, счетчик событий, обновляется при автономном и интерактивном режиме накопителя. - Value — текущее значение атрибута
- Threshold — минимальное пороговое значения атрибута
- Worst — самое худшее значение атрибута за все время работы накопителя
- Raw — абсолютное значение атрибута
- Type — некоторые из программ в данном необязательном поле отображают информацию из флажков атрибутов или признаки их критичности (Criticalили Pre-Fail , отражающих ухудшение характеристик оборудования, и Old-age для атрибутов, отражающих выработку ресурса);Для анализа состояния накопителя, пожалуй самым важным значением атрибута является Value — условное число (обычно от 0 до 100 или до 253), заданное производителем. Значение Value изначально установлено на максимум при производстве накопителя и уменьшается в случае ухудшения его параметров. Для каждого атрибута существует пороговое значение, при достижения которого, производитель не гарантирует его работоспособность — поле Threshold. Если значение Value приближается или становится меньше значения Threshold, — накопитель пора менять.Перечень атрибутов и их значения жестко не стандартизированы и некоторые из них могут определяться изготовителем накопителя, но основная часть интерпретируются одинаково. Например, атрибут с идентификатором 05 (Reallocated sector count) будет характеризовать число забракованных и переназначенных из резервной области секторов диска, как для устройств производства компании Seagate Technology, так и для устройств производства Western Digital . Набор поддерживаемых атрибутов зависит от модели накопителя и может значительно отличаться по составу для разных моделей.
В нашем эксперименте будут 3 производителя контроллеров Adaptec, LSI, HP Smart Array. В ESXI есть отличная команда выводящая SMART дисков и SSD. Сначала посмотрим список ваших дисков и LUN.
Как мониторить SMART дисков, SSD в RAID на ESXI 5.5-001
Выводим SMART отдельного диска или LUN.
Если у вас отдельные диски на всех контроллерах Adaptec, LSI, HP Smart Array вы получите такую картину
Как мониторить SMART дисков, SSD в RAID на ESXI 5.5-02
Жирным выделены метрики, которые могут оказаться полезными. Параметр Reallocated Sector Count не должен сильно увеличиваться со временем для исправных дисков. Когда дисковая подсистема получает ошибку read/write/verification для сектора, она перемещает его данные в специально зарезервированную область (spare area), а данный счетчик увеличивается.
Media Wearout Indicator — это уровень «жизни» вашего SSD-диска (для новых дисков он должен отображаться как 100). По мере прохождения циклов перезаписи диск «изнашивается» и данный счетчик уменьшается, соответственно, когда он перейдет в значение 0 — его жизнь формально закончится, исходя из рассчитанного для него ресурса. Кстати, этот счетчик может временно уменьшаться при интенсивных нагрузках диска, а потом восстанавливаться со временем, если средняя нагрузка на диск снизилась.
Если у вас LUN с СХД или RAID LUN то нихера в консоли не получите этой командой.
Как мониторить SMART дисков, SSD в RAID на ESXI 5.5-04
И вопрос как мониторить SMART в RAID ESXI 5.5, очень просто каждый вендор делает свой CIM пакет, вот как его поставить для каждого вендора. (Adaptec, LSI, HP Smart Array). Так же можно мониторить Operation Manager 5.8.
Расшифровка атрибутов S.M.A.R.T
- Идентификаторы атрибутов указаны в десятичной системе счисления, а в скобках они же – в шестнадцатеричной.
- 001 ( 1h ) Raw Read Error Rate — абсолютное значение ошибок считывания. Существует некоторые отличия в формировании значения данного атрибута разными производителями. Из практики могу сказать, что накопители Seagate могут иметь гигантское значение RAW этого атрибута, реально будучи в хорошем состоянии, а накопители Western Digital могут иметь его нулевым, имея критические показатели по другим характеристикам. Некоторые модели вообще не поддерживают данный атрибут.
- 002 ( 02h ) Throughput Performance — усредненная производительность жесткого диска. Редко встречающийся атрибут.
- 003 ( 3h ) Spin Up Time — Среднее время раскрутки шпинделя диска от 0 RPM до рабочей скорости. Для SSD дисков не поддерживается.
- 004 ( 4h ) Start/Stop Count — Количество циклов запуск/останов шпинделя.
- 005 ( 5h ) Reallocated Sector Count — Количество переназначенных ( перераспределенных) секторов . Современные накопители имеют резервную область поверхности для использования ее объема в случае ухудшения характеристик блоков из основной зоны. Если микропрограмма накопителя обнаруживает ошибки с записи/чтения какого-либо блока рабочей поверхности, то запускается механизм, обеспечивающий переадресацию обращений к дефектному блоку ( сектору ), на блок из резервной части. Он автоматически перемещает его данные в резервную область, а данный блок помечается как «переназначенный». Часто этот процесс называют «remapping», или «automatic defect reassignment». Процедура переназначения сбойных секторов на резервные, выполняется автоматически внутренней микропрограммой накопителя, и для пользователя (операционной системы) она невидима. Сам факт переназначения и количество переназначенных секторов доступны только из журналов SMART. Поле абсолютного значения атрибута Raw Valueсодержит общее количество переназначенных секторов. Нормализованное значение Value отражает процент допустимого количества дефектных блоков. При исчерпании резервной области, переназначение становится невозможным и диск подлежит замене. Даже некритическое, но большое значение этого поля, может привести к снижению скорости обмена данными, поскольку накопитель выполняет дополнительные операции установки головок на дорожки резервной области, которая обычно находится в конце рабочей поверхности диска.
- 007 ( 7h ) Seek Error Rate — Частота появления ошибок позиционирования блока магнитных головок (БМГ) . Дисковые накопители контролирует правильность установки головок на требуемую дорожку поверхности. В случае, когда установка выполнилась неверно, фиксируется ошибка и операция повторяется. На практике, большое количество ошибок позиционирования может быть вызвано не только проблемами оборудования, но и влиянием внешних факторов – не соответствующим температурным режимом или вибрацией.
- 008 ( 8h ) Seek Time Performance — средняя скорость позиционирования магнитных головок. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
- 009 (09h) Power-On Hours (POH) Количество рабочих часов — количество часов, когда диск находился во включенном состоянии за весь срок с момента производства, в виде целочисленного значения в часах. Иногда встречаются модели накопителей, в которых внутреннее значение данного атрибута сохраняется в виде количества рабочих минут или секунд, а не часов. Достижение порогового значения данного атрибута означает выработку ресурса, заданного производителем ( MTBF — Mean Time Between Failures
- 010 ( 0Ah ) Spin Retry Count — Количество повторных попыток старта шпинделя. После включения питания, накопитель раскручивает диски и контролирует достижение рабочей скорости вращения, заданной производителем для данной модели . Если за отведенное контрольное время рабочая скорость не достигнута, увеличивается значение данного атрибута и выполняется повторная раскрутка двигателя.
- 011 ( 0B ) Recalibration Retries — атрибут отражает количество повторных рекалибровок, в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью накопителя. Кроме того, увеличение абсолютного значения данного атрибута может быть вызвано тем, что процедура рекалибровки используется внутренней микропрограммой накопителя для коррекции других типов ошибок.
- 012 ( 0Ch ) Device Power Cycle Count — абсолютное значение Raw Value указывает на количество циклов включения/выключения питания накопителя за весь период эксплуатации. Нормализованное значение Value обычно не изменяется и равно 100.
- 013 ( 0Dh ) — Soft Read Error Rate — Количество программных сбоев — совокупное количество программных сбоев. Нормализованное значение: начиная со 100, отображает процент оставшегося допустимого нарастающего количества программных сбоев.
- 100 ( 64h ) Erase/Program Cycles — количество циклов стирания –записи перепрограммируемой памяти (flash) для SSD-дисков. Количество таких циклов ограниченно и зависит от микросхем постоянной перезаписываемой памяти, используемых в данной модели SSD.
- 103 ( 67h ) Translation Table Rebuild — количество событий, связанных с разрушением внутренних таблиц транслятора и его перестроением.
- 170 ( AAh )Reserved Block Count — количество доступных резервных блоков для переназначения сбойных секторов (см. атрибут E8h).
- 171 ( ABh ) Program Fail Count — ошибки записи в перепрограммируемую память SSD
- 172 ( ACh ) Erase Fail Count – ошибки стирания flash-памяти SSD. Процесс записи в перезаписываемую постоянную память состоит из двух частей — стирания и записи. Процедура стирания всегда выполняется перед записью данных.
- 173 ( ADh ) Wear Leveller Worst Case Erase Count — максимально допустимое количество операций стирания для единичного блока SSD-диска.
- 174 ( AEh) Unexpected Power Loss — непредвиденное отключение питания для SSD . Также этот показатель называется «Количество аварийных выключений» в терминологии жестких дисков с магнитными носителями. Абсолютное значение Raw Value: совокупное количество нештатных выключений за весь срок использования устройства.
- 175 ( AFh ) Program Fail Count– данный атрибут используется в SSD-накопителях производства Intel и отображает информацию о сбоях защиты от отключения питания SSD-дисков. Результаты последнего теста в виде количества микросекунд до разряда конденсатора, фиксируется на максимальном значении. Также записывается количество минут после последнего теста и общее количество тестов за весь срок использования устройства. Необработанное значение Raw Value:Байты 0—1: Результаты последнего теста в виде количества микросекунд до разряда конденсатора, фиксируется на максимальном значении. Результат теста должен быть в диапазоне 25 — 5 000 000, более низкое значение указывает на определенный код ошибки. Байты 2—3: количество минут после последнего текста, фиксируется на максимальном значении. Байты 4—5: количество тестов за весь срок использования устройства, не увеличивается при циклах включения и отключения, фиксируется на максимальном значении. Значение Value устанавливается равным 1 при сбое теста, или 11 при тестировании конденсатора в недопустимых температурных условиях; в противном случае устанавливается равным 100.
- 183 ( B7h ) SATA Downshifts — Количество снижений скорости SATA Необработанное значение: количество случаев, когда из-за ошибок для интерфейса SATA была выбрана пониженная скорость передачи данных ( с 6 Гб/с до 3Гб/с или 1,5Гб/с или с 3Гб/с. До 1.5Гб/с. Очень часто данный атрибут характеризует недостаточное качество электропитания, окисление контактов интерфейсного кабеля, или его неисправность.
- 184 ( B8h ) End-to-End error Количество обнаруженных сквозных ошибок кэш-памяти ( disk cache). Абсолютное значение: количество обнаруженных и исправленных оборудованием сквозных ошибок.
- 187 ( BBh ) Reported Uncorrectable Errors Количество невосстановимых ошибок. Необработанное значение Raw Value: количество ошибок, которые не удалось исправить с помощью внутренних подпрограмм накопителя.
- 188 ( BCh ) Command Timeout — количество команд, прерванных по таймауту.
- 189 ( BDh ) High Fly Writes — количество событий, связанных с ошибками, зафиксированными монитором контроля высоты полета Fly Height Monitor, когда головки записи находятся в положении, не гарантирующем нормальное выполнение операции. Если высота полета головки над магнитной поверхностью, даже на короткое время превысит оптимальную, то записанные ею данные, в дальнейшем, могут не прочитаться. Современные накопители используют специально разработанную технологию контроля высоты полета головок, позволяющую не выполнять запись данных при неоптимальной высоте. В счетчик данного атрибута добавляется единица, а запись выполняется после установки нормальной высоты полета. Повышенное значение данного атрибута может быть вызвано внешними ударами или вибрациями, ненормальной температурой, ухудшением характеристик магнитной поверхности или головки.
- 190 ( BEh ) Airflow Temperature температура воздушного потока (корпус). Значение Raw Value: статистические данные по температуре корпуса .Байты 0—1: текущая температура корпуса в градусах по Цельсию; байт 2: недавняя минимальная температура корпуса в градусах по Цельсию; байт 3: недавняя максимальная температура корпуса в градусах по Цельсию; байты 4—5: счетчик превышений температуры. Количество случаев, когда зафиксированная температура превышала максимальную допустимую рабочую температуру накопителя.
- 191 ( BFh ) G-sense error rate — количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера. Обычно довольно точно характеризует условия эксплуатации ноутбуков — большое значение атрибута говорит о резких толчках и падениях при работе устройства.
- 192 ( C0h ) Emergency Retract Cycle Count Количество аварийных выключений (количество нештатных выключений) — совокупное количество событий аварийного (нештатного) отключения питания за весь срок использования устройства. Для SSD дисков под «нештатным выключением» понимается отключение питания устройства без предварительной выдачи команды STANDBY IMMEDIATE.
- 194 ( C2h ) HDA Temperature — температура самого накопителя (HDA — Hard Disk Assembly). В данном атрибуте хранятся показания встроенного температурного датчика, которым обычно служит одна из магнитных головок (как правило — нижняя ). У SSD дисков термодатчик размещается внутри корпуса на печатной плате. Данные, записанные в полях атрибута отображают текущую, минимальную и максимальную температуру. Поле Worst показывает наихудшую, достигнутую за время работы накопителя, температуру (можно установить факт перегрева и его степень), Raw Value — текущую температуру. Некоторые модели накопителей могут поддерживать атрибут 205 ( CDh ) Thermal asperity rate (TAR), фиксирующий количество опасных перепадов температуры.
- 195 ( C3h ) Hardware ECC Recovered — количество ошибок считывания, исправленных оборудованием накопителя с применением кода коррекции ошибок. Подобные ошибки не требуют повторного считывания сектора, и не приводят к потере скорости обмена данными, но большое их количество говорит об ухудшении параметров тракта считывания.
- 196 ( C4h ) Reallocation Event Count — Число событий переназначения сбойных секторов. В поле raw value данного атрибута хранится общее число попыток переноса данных из нестабильных секторов в резервную область. Учитываются как успешные, так и неуспешные попытки.
- 197 ( C5 ) Current Pending Sector Count — Текущее количество нестабильных секторов. Поле raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает кандидатами на переназначение в резервную область . Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка кандидатов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped).
- 198 ( C6 ) Uncorrectable Sector Count — Счетчик некорректируемых ошибок, т.е , счетчик ошибок, которые не были исправлены внутренними средствами коррекции оборудования накопителя. Это означает, что такие ошибки проявляются как классические сбойные блоки файловой системы ( Bad Block ). Причиной подобных сбоев диска, может быть неисправность отдельных элементов или отсутствие свободных секторов в резервной области диска, когда возникла необходимость переназначения.
- 199 ( C7h ) UltraDMA CRC Error Rate — Количество ошибок при передаче данных в режиме прямого доступа к памяти, обнаруженных средствами циклического избыточного кода (англ. Cyclic redundancy check, CRC). Аппаратные средства контроля передачи данных из накопителя в оперативную память обнаружили ошибку контрольной суммы и исправили ее “на лету”, если ошибка исправимая. В данном случае алгоритм обычной работы диска не изменяется. В случае же неисправимой ошибки, процедура ее обработки выполняется системой. Обычно, данный атрибут содержит счетчик любых видов ошибок CRC. Нередко этот тип ошибки связан не столько с оборудованием накопителя, сколько с неисправным интерфейсным кабелем, окислившимися контактами, некачественным электропитанием, разгоном частоты шины PCI, перегревом микросхем чипсета материнской платы и т.п.
- 200 ( C8h ) Write Error Rate (Multi Zone Error Rate) — ошибки записи данных.
- 232 ( E8h ) Total Count of Write Sectors Для SSD-дисков — количество записанных секторов. Значение Raw Value увеличивается на 1 на каждые 65 536 секторов (32 МБ), записываемых системой. Для SSD Intel — Intel SSD Available Reserved Space — процент доступной резервной области, используемой для переназначения дефектных блоков.
- 233 ( E9h ) Power-On Hours — Время работы накопителя. Для SSD-дисков этот атрибут интерпретируется как Remaining Life — указатель износа носителя. Количество циклов работы носителя NAND. Линейно снижается от 100 до 1 по мере увеличения среднего количества циклов стирания от 0 до максимального. Нормализованное значение перестанет уменьшаться после достижения 1, но, по всей вероятности, устройство выдержит значительный дополнительный износ.
- 241 ( F1h) Total LBAs Written — Общее количество записанных секторов LBA. Значение Raw Value : совокупное количество секторов, записанных системой. Значение увеличивается на 1 на каждые 65 536 секторов (32 МБ), записываемых системой.
- 242 ( F2h ) Total LBAs Read — Общее количество прочитанных секторов LBA. Значение Raw Value увеличивается на 1 на каждые 65 536 секторов (32 МБ), прочитываемых системой.
- 254 ( FEh ) Free Fall Event Count — количество событий ускорения свободного падения диска за время эксплуатации ( сколько раз диск падал ).
Оценка технического состояния жесткого диска по данным S.M.A.R.T
Набор атрибутов поддерживаемых конкретной моделью жесткого диска, даже если он минимален, позволяет с высокой достоверностью определить техническое состояние и перспективы эксплуатации устройства. Можно определить время нахождения во включенном состоянии по значению атрибута 9, а в совокупности со значением атрибута 12 — количество включений /выключений электропитания, и следовательно, – круглосуточный или периодический режим эксплуатации. Интенсивность использования, температурный режим, негативные внешние воздействия – все эти факты легко отслеживаются по абсолютным значениям соответствующих атрибутов. Подобным же образом, можно оценить и уровень износа оборудования, качество поверхности и тракта записи/чтения.
Минимально информативный контроль состояния дисков может выполняться даже на уровне BIOS. В случае достижения критического значения любого атрибута, характеризующего работоспособность, при включенном мониторинге состояния S.M.A.R.T в настройках BIOS, загрузка операционной системы приостанавливается и на экран выводится сообщение:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Press F1 to Resume
Таким образом, без установки или запуска дополнительного программного обеспечения, имеется возможность вовремя определить факт критического состояния накопителя средствами Базовой Системы Ввода-Вывода (BIOS) при включении компьютера.
Техническое состояние жесткого диска, не достигшее критического порога, характеризуется абсолютным значением атрибутов, отражающих счетчики сбоев, обнаруженных и исправленных оборудованием накопителя.
Обновление 11.12.2015
Недавно на тестирование попал RAID контроллер LSI 9361-8i, моделька свежая со всеми наворотами, но сейчас не об этом. Я так же на него установил Vmware ESXI 5.5 и захотел посмотреть дает ли контроллер S.M.A.R.T. Стандартными командами, он не отдал значения, пришлось установить storcli, после чего введя команду
Я получил smart дисков, но в таком не читабельном виде, что просто ужас 🙂 Как вам оно. Принципе если бы было описание полей или строк, все было бы куда более терпимо. Ну не понимаю я почему столько граблей, чтобы элементарно вытащить smart дисков. Как появится информация, что означает каждое поле отпишусь сюда.
Обновление 12.05.2016
Товарищи, хочу вас обрадовать, что появилась шикарная утилита, способная в Windows показывать smart состояние дисков, находящихся в рейде. Называется она Hard Disk Sentinel
Скачиваем либо установщик, либо portble версию. Запускаем HDSentinel.exe
В системном три у вас появятся значки состояния ваших жестких дисков.
Для примера покажу свой контроллер SMC2008-IR, как видите у меня там 4 диска в 10 рейде.
Как видим, у моего 4 диска появились bad sectors
Переходим на вкладку S.M.A.R.T и видим, большинство счетчиков.
Для примера я в LSI утилите ProductID, так же его видит и HDSentinel
еще HDSentinel удобно отображает загрузку диска в реальном времени.
Можно в сети установить серверную версию, но она платная. Для linux платформ, так же есть своя сборка.
Популярные Похожие записи:
6 Responses to Как мониторить SMART дисков, SSD в RAID на ESXI 5.5
# esxcli storage core device list
mpx.vmhba1:C0:T0:L0
Display Name: Local VMware Disk (mpx.vmhba1:C0:T0:L0)
Has Settable Display Name: false
Size: 476908
Device Type: Direct-Access
Multipath Plugin: NMP
Devfs Path: /vmfs/devices/disks/mpx.vmhba1:C0:T0:L0
Vendor: VMware
Model: Block device
Revision: 1.0
SCSI Level: 2
Is Pseudo: false
Status: on
Is RDM Capable: false
Is Local: true
Is Removable: false
Is SSD: false
Is Offline: false
Is Perennially Reserved: false
Queue Full Sample Size: 0
Queue Full Threshold: 0
Thin Provisioning Status: unknown
Attached Filters:
VAAI Status: unsupported
Other UIDs: vml.0000000000766d686261313a303a30
Is Shared Clusterwide: false
Is Local SAS Device: false
Is SAS: false
Is USB: false
Is Boot USB Device: false
Is Boot Device: true
No of outstanding IOs with competing worlds: 32
# esxcli storage core device smart get -d mpx.vmhba1:C0:T0:L0
Error getting Smart Parameters: CANNOT open device
Сервер HP Proliant ML350 G5 — есть вариант увидеть SMART таким образом или в моем случае лучше юзать тулзу hpssacli?
Добрый день, hpssacli вам тоже покажет только статус ок или нет, выше есть скрин как выдает smart strocli, но это не читабельно. Единственное, это можно либо скрипт запулить который будет вытаскивать значение количества ошибок, либо настроить мониторинг через MSM отправка сообщений, либо отправка сообщений в vcenter по состоянию дисков, vmvare от туда число ошибок дергает и вам показывает. Я честно не понимаю почему до сих пор LSI не реализовало данную вещь. Если у вас что получится, просьба тоже написать поделиться:)
Не появилось ли информации, как рав дату
из ./storcli /cX/eX/sX show smart
привести в человеческий вид.
SSD количество записей нечем мониторить…
У меня такой же контроллер, но в MSM не видно дисков не подскажите как устранить данную проблему?
OS: 2008 R2
Мат. плата: Suermicro X8DA6 ( https://www.supermicro.nl/products/motherboard/QPI/5500/X8DA6.cfm )
MSM: 12.05.03
С большой долей вероятности у вас стоят не те драйвера или не та версия SMIS провайдера
Источник
Posted by NemesisByDesign 2018-12-19T16:23:10Z
Seems overly simple when asked, but for the life of me I can not pull this data. I’ve searched Google, I have searched Spiceworks and I do not see a clear way to pull this data.
Short version of story, I purchased NEW SAS drives on Amazon.
However, I do not think they are new.
These are running on a R720 and R320, both running ESXI 6.5
Thanks in advance
15 Replies
-
If I understand your situation, you need some method of querying the hard drive itself to see if there is such information available. Have you looked through what is available via an iDrac or iLO or similar port/board— it being independent of the installed hypervisor?
I have doubts that powered on time is a value stored on / with the drive but rather kept somewhere in nvram by the firmware of a system it (was) is attached to and really is just a summary of time from the beginning of said system knowing about this drive.
A quick look at a Dell DSET report I just ran suggest to me could be fields «Manufacture Day», «Manufacture Week», «Manufacture Year» on a drive itself. In my case they are not being helpful since the result is «Not Available».
Was this post helpful?
thumb_up
thumb_down
-
What are you trying to do? Are attempting to take them out of your current array?
Was this post helpful?
thumb_up
thumb_down
-
I think this is a feature when you boot into the bios for your hard drive controller. On those model Dell’s it will probably be something like CTRL+J or CTRL+K after the main bios post.
Was this post helpful?
thumb_up
thumb_down
-
@scottbrindley — As the post read, I am trying to pull powered on hours. The array has nothing to do with it.
Was this post helpful?
thumb_up
thumb_down
-
@
Jim Peters, powered on time should be stored in the S.M.A.R.T. on the HDD itself.
Was this post helpful?
thumb_up
thumb_down
-
@
John4120 — I think it is CTRL-R on these, I have been all through there when I created the virtual disk. Can see some S.M.A.R.T. data, but not all like power cycles and powered on hours.
Was this post helpful?
thumb_up
thumb_down
-
Being the host is ESXI, you could use the VMWare utilities for statistics collection from StarWind …
https://www.starwindsoftware.com/blog/setting-statistics-collection-levels-for-the-vmware-vcenter-server-and-the-size-of-database Opens a new window
Also did you try esxtop and vscsiStats?
Was this post helpful?
thumb_up
thumb_down
-
@JCAlexandres — I have not yet, but I will. It is my understanding that VMware will not see past the virtual disk. But I will check it out.
Was this post helpful?
thumb_up
thumb_down
-
I think you can get the data too from powershell/powercli. However, the disk being in an array, that data might not be available unless the drive is temporarily removed to another system and queried directly.
1 found this helpful
thumb_up
thumb_down
-
Thank you @JeffNew1213, I have a spare that I can plug in without pulling one from the array, so I will see if that work. And thank you for the link!
I tried it in esxi, unfortunately it didn’t matter how tightly I crossed my fingers:
Error getting Smart Parameters: CANNOT open device
Was this post helpful?
thumb_up
thumb_down
-
Got a Windows machine you can/have popped one of those drives into? Try… http://www.hdtune.com/ Opens a new window
1 found this helpful
thumb_up
thumb_down
-
Also, probably any off-the-shelf NAS (Synology, etc.) will tell you the parameters for an installed drive.
1 found this helpful
thumb_up
thumb_down
-

-
@darekhamann — Unfortunately, that software is of no use in this environment
Was this post helpful?
thumb_up
thumb_down
