Содержание
- DNA Replication and Causes of Mutation
- Errors Are a Natural Part of DNA Replication
- Fixing Mistakes in DNA Replication
- When Replication Errors Become Mutations
- Even Low Mutation Rates Can Be Cause for Concern
- Ошибки в репликации ДНК: 13 фактов, о которых не знает большинство новичков
- Является ли репликация ДНК точной?
- Что такое ошибки репликации ДНК?
- Причины ошибок в репликации ДНК
- Частота ошибок репликации ДНК
- Последствия ошибок в репликации ДНК
- Могут ли ошибки в репликации ДНК привести к мутациям?
- Как ошибки в репликации ДНК могут привести к мутациям?
- Какие типы мутаций вызваны случайными ошибками в репликации ДНК?
- Точечная мутация
- Хромосомная мутация
- Мутация сдвига рамки
- Индуцированные мутации инициируются ошибками в репликации ДНК.
- Как исправляются ошибки репликации ДНК?
- Редактирование
- Несоответствие ремонта
- Почему ошибки репликации ДНК более значимы, чем ошибки транскрипции?
- Может ли клетка исправить ошибку репликации ДНК?
- Почему ошибки в репликации ДНК так редки?
- CАКЛЮЧЕНИЕ
- Последние посты
- О НАС
DNA Replication and Causes of Mutation



Errors Are a Natural Part of DNA Replication
After James Watson and Francis Crick published their model of the double-helix structure of DNA in 1953, biologists initially speculated that most replication errors were caused by what are called tautomeric shifts. Both the purine and pyrimidine bases in DNA exist in different chemical forms, or tautomers, in which the protons occupy different positions in the molecule (Figure 1). The Watson-Crick model required that the nucleotide bases be in their more common «keto» form (Watson & Crick, 1953). Scientists believed that if and when a nucleotide base shifted into its rarer tautomeric form (the «imino» or «enol» form), a likely result would be base-pair mismatching. But evidence for these types of tautomeric shifts remains sparse.

Today, scientists suspect that most DNA replication errors are caused by mispairings of a different nature: either between different but nontautomeric chemical forms of bases (e.g., bases with an extra proton, which can still bind but often with a mismatched nucleotide, such as an A with a G instead of a T) or between «normal» bases that nonetheless bond inappropriately (e.g., again, an A with a G instead of a T) because of a slight shift in position of the nucleotides in space (Figure 2). This type of mispairing is known as wobble . It occurs because the DNA double helix is flexible and able to accommodate slightly misshaped pairings (Crick, 1966).

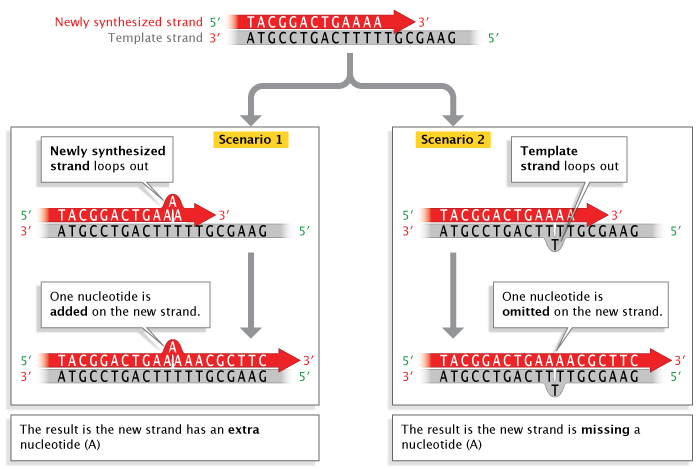
Replication errors can also involve insertions or deletions of nucleotide bases that occur during a process called strand slippage . Sometimes, a newly synthesized strand loops out a bit, resulting in the addition of an extra nucleotide base (Figure 3). Other times, the template strand loops out a bit, resulting in the omission, or deletion, of a nucleotide base in the newly synthesized, or primer , strand. Regions of DNA containing many copies of small repeated sequences are particularly prone to this type of error.
Fixing Mistakes in DNA Replication
DNA polymerase enzymes are amazingly particular with respect to their choice of nucleotides during DNA synthesis, ensuring that the bases added to a growing strand are correctly paired with their complements on the template strand (i.e., A’s with T’s, and C’s with G’s). Nonetheless, these enzymes do make mistakes at a rate of about 1 per every 100,000 nucleotides. That might not seem like much, until you consider how much DNA a cell has. In humans, with our 6 billion base pairs in each diploid cell, that would amount to about 120,000 mistakes every time a cell divides!
Fortunately, cells have evolved highly sophisticated means of fixing most, but not all, of those mistakes. Some of the mistakes are corrected immediately during replication through a process known as proofreading , and some are corrected after replication in a process called mismatch repair . When an incorrect nucleotide is added to the growing strand, replication is stalled by the fact that the nucleotide’s exposed 3′-OH group is in the «wrong» position. (Recall that new nucleotides are added to the growing strand during replication by means of their 5′-phosphate group binding to the 3′-OH group of the previous nucleotide on the strand.) During proofreading, DNA polymerase enzymes recognize this and replace the incorrectly inserted nucleotide so that replication can continue. Proofreading fixes about 99% of these types of errors, but that’s still not good enough for normal cell functioning.
After replication, mismatch repair reduces the final error rate even further. Incorrectly paired nucleotides cause deformities in the secondary structure of the final DNA molecule. During mismatch repair, enzymes recognize and fix these deformities by removing the incorrectly paired nucleotide and replacing it with the correct nucleotide.
When Replication Errors Become Mutations
Incorrectly paired nucleotides that still remain following mismatch repair become permanent mutations after the next cell division . This is because once such mistakes are established, the cell no longer recognizes them as errors. Consider the case of wobble-induced replication errors. When these mistakes are not corrected, the incorrectly sequenced DNA strand serves as a template for future replication events, causing all the base-pairings thereafter to be wrong. For instance, in the lower half of Figure 2, the original strand had a C-G pair; then, during replication, cytosine (C) is incorrectly matched to adenine (A) because of wobble. In this example, wobble occurs because A has an extra hydrogen atom. In the next round of cell division, the double strand with the C-A pairing would separate during replication, each strand serving as a template for synthesis of a new DNA molecule. At that particular spot, C would pair with G, forming a double helix with the same sequence as its original (i.e., before the wobble occurred), but A would pair with T, forming a new DNA molecule with an A-T pair in place of the original C-G pair. This type of mutation is known as a base, or base-pair, substitution. Base substitutions involving replacement of one purine for another or one pyrimidine for another (e.g., a mismatched A-A pair, instead of A-T) are known as transitions; the replacement of a purine by a pyrimidine, or vice versa, is called a transversion .
Likewise, when strand-slippage replication errors are not corrected, they become insertion and deletion mutations. Much of the early research on strand-slippage mutations was conducted by George Streisinger in the 1970s. Streisinger, a professor at the University of Oregon and a fish hobbyist, is known by some as the «founding father of zebrafish research.» However, he is also known for his work with phage T4, a bacterial virus . Streisinger used this virus to show that most nucleotide insertion and deletion mutations occur in areas of DNA that contain many repeated sequences (also called tandem repeats), and he formulated the strand-slippage hypothesis to explain why this was the case (Streisinger et al., 1966). (In Figure 3, notice the series of repeat T’s on the template strand where the slippage has occurred.) When slippage takes place, the presence of nearby duplicate bases stabilizes the slippage so that replication can proceed. During the next round of replication, when the two strands separate, the insertion or deletion on either the template or primer strand, respectively, will be perpetuated as a permanent mutation . Scientists have collected enough evidence to confirm Streisinger’s strand-slippage hypothesis, and this type of mutagenesis remains an active field of scientific research.
Although most mutations are believed to be caused by replication errors, they can also be caused by various environmentally induced and spontaneous changes to DNA that occur prior to replication but are perpetuated in the same way as unfixed replication errors. As with replication errors, most environmentally induced DNA damage is repaired, resulting in fewer than 1 out of every 1,000 chemically induced lesions actually becoming permanent mutations. The same is true of so-called spontaneous mutations. «Spontaneous» refers to the fact that the changes occur in the absence of chemical, radiation , or other environmental damage. Rather, they are usually caused by normal chemical reactions that go on in cells, such as hydrolysis. These types of errors include depurination , which occurs when the bond connecting a purine to its deoxyribose sugar is broken by a molecule of water, resulting in a purine-free nucleotide that can’t act as a template during DNA replication, and deamination , which results in the loss of an amino group from a nucleotide, again by reaction with water. Again, most of these spontaneous errors are corrected by DNA repair processes. But if this does not occur, a nucleotide that is added to the newly synthesized strand can become a permanent mutation.
Even Low Mutation Rates Can Be Cause for Concern
Mutation rates vary substantially among taxa, and even among different parts of the genome in a single organism . Scientists have reported mutation rates as low as 1 mistake per 100 million (10 -8 ) to 1 billion (10 -9 ) nucleotides, mostly in bacteria , and as high as 1 mistake per 100 (10 -2 ) to 1,000 (10 -3 ) nucleotides, the latter in a group of error-prone polymerase genes in humans (Johnson et al., 2000).
Even mutation rates as low as 10 -10 can accumulate quickly over time, particularly in rapidly reproducing organisms like bacteria. This is one reason why antibiotic resistance is such an important public health problem; after all, mutations that accumulate in a population of bacteria provide ample genetic variation with which to adapt (or respond) to the natural selection pressures imposed by antibacterial drugs (Smolinski et al., 2003). Take E. coli, for example. The genome of this common intestinal bacterium has about 4.2 million base pairs, or 8.4 million bases. Assuming a mutation rate of 10 -9 (i.e., midway between reported estimates of 10 -8 and 10 -10 ), every time E. coli divides, each daughter cell will have, on average, 0.0084 new mutations. Or, another way to think about it is like this: Approximately 1% of bacterial cells will contain a new mutation. That may not seem like much. However, because bacteria can divide as rapidly as twice per hour, a single bacterium can grow into a colony of 1 million cells in only about 10 hours (2 20 = 1,048,576). At that point, approximately 10,000 of these bacteria will have accumulated at least one mutation. As the number of bacteria carrying different mutations increases, so too does the likelihood that at least one of them will develop a drug-resistant phenotype .
Likewise, in eukaryotes, cells accumulate mutations as they divide. In humans, if enough somatic mutations (i.e., mutations in body cells rather than sperm or egg cells) accumulate over the course of a person’s lifetime, the end result could be cancer. Or, less frequently, some cancer mutations are inherited from one or both parents; these are often referred to as germ-line mutations. One of the first cancer-associated somatic mutations was discovered in 1982, when researchers found that a mutated HRAS gene was associated with bladder cancer (Reddy et al., 1982). HRAS encodes for a protein that helps regulate cell division. Since then, scientists have identified several hundred additional «cancer genes.» Some of them, like the handful of germ-line mutations associated with a form of colorectal cancer known as hereditary nonpolyposis colorectal cancer (HNPCC), play crucial roles in DNA repair (Wijnen et al., 1998).
Of course, not all mutations are «bad.» But, because so many mutations can cause cancer, DNA repair is obviously a crucially important property of eukaryotic cells. However, too much of a good thing can be dangerous. If DNA repair were perfect and no mutations ever accumulated, there would be no genetic variation—and this variation serves as the raw material for evolution . Successful organisms have thus evolved the means to repair their DNA efficiently but not too efficiently, leaving just enough genetic variability for evolution to continue.
Источник
Ошибки в репликации ДНК: 13 фактов, о которых не знает большинство новичков
Репликация ДНК иногда может быть нарушена из-за добавления или удаления новых нуклеотидных оснований. Давайте посмотрим, как возникают ошибки при репликации ДНК.
Ошибки в Репликация ДНК известны как проскальзывание цепей, когда новые нуклеотидные основания добавляются или удаляются в результате мутации или постоянных изменений последовательности и т. д. ДНК. Свежевыделенные петли прядей немного выходят наружу. Результатом этого изменения является добавление или удаление дополнительного нуклеотидного основания.
Есть в основном три типа ошибок в репликации ДНК. Это базовые замены, удаления и вставки. Если ошибку не исправить, она может вызвать рак. Здесь механизм репарации ДНК исправляет все ошибки.
Давайте обсудим, является ли репликация ДНК точной, каковы все ошибки в репликации ДНК, причины и последствия ошибок в репликации ДНК и многие другие связанные темы в этой статье.
Является ли репликация ДНК точной?
Частота ошибок при репликации ДНК очень мала. Давайте посмотрим, является ли репликация ДНК точной или нет.
Репликация ДНК настолько точна, что частота ошибок в репликации ДНК может быть незначительной. Это формируется таким образом, что геном стабильность зависит от точности репликации ДНК. Но дефектные геномы могут быть фатальными для животного организма из-за мутации всего генофонда.
Точность репликации ДНК хорошо определена благодаря трем факторам. Они есть нуклеотидная избирательность, Редактированиеи Несоответствие ремонта. Эти факторы являются основной причиной меньшего количества ошибок в репликации ДНК.
Что такое ошибки репликации ДНК?
Ошибки репликации ДНК в основном связаны с депуринацией всего геномного пула. Давайте обсудим, каковы все возможные ошибки в репликации ДНК.
Ошибки репликации ДНК делятся на три типа: Ошибки репликации, депуринизация ДНК и повреждение ДНК за счет образования активных форм кислорода.
Давайте посмотрим больше информации об ошибках в репликации ДНК ниже:
- Разрыв вызван молекулой воды, в результате чего образуется нуклеотид, не содержащий пуринов. Это нельзя использовать в репликации.
- Свободные пурины не могут функционировать во время репликации ДНК в качестве матрицы.
- Потеря аминогруппы из нуклеотида также вызвана дезаминированием для того, чтобы не функционировать в качестве матрицы во время ошибок в репликации ДНК по водной реакции.
- Эти непреднамеренные причины снова исправляются в процессе восстановления ДНК.
- Но затем добавляется новый нуклеотид, который становится постоянной мутацией.
- Это происходит во время синтеза новой цепи.
- Накопленные мутации или постоянные изменения последовательности являются причиной такого плохого поведения клеточной ДНК.
Причины ошибок в репликации ДНК
Существует несколько причин возникновения ошибок в репликации ДНК. Давайте посмотрим, что они из себя представляют в деталях.
Ошибки репликации ДНК в основном вызваны разной природой пар оснований. Они могут быть как различной природы, так и не таутомерными по химическим формам.
Три основные причины ошибок в репликации ДНК: подробно обсуждается ниже:
1. Делеция. Делеция — одна из основных ошибок в репликации ДНК. Это вызывает сдвиг структуры всего генофонда. Он изменяет последовательность ДНК, разрушая один (как минимум) или несколько нуклеотидов.
2. Вставка. Вставка — еще одна основная ошибка в репликации ДНК. Это вызывает сдвиг структуры всего генофонда. Он изменяет последовательность ДНК, добавляя одну (как минимум) или более пар нуклеотидных оснований.
3. Замена оснований. Замена оснований также является одной из важных ошибок в репликации ДНК. Он заменяет нужный нуклеотид любым другим нуклеотидом, что меняет весь генофонд. Он также может заменить одну аминокислоту на другую.
Частота ошибок репликации ДНК
Как обсуждалось ранее, существует небольшая вероятность того, что при репликации ДНК могут возникнуть ошибки. Давайте посмотрим на скорость, с которой происходят ошибки в ДНК.
Частота ошибок репликации ДНК составляет один на 10^10 нуклеотидов при синтезе ДНК. Это так меньше, но последствия могут быть фатальными. Это от 10 ^ -9 до 10 ^ -11 ошибок в репликации ДНК на пару оснований. Высокая точность процесса очень важна для поддержания точности генетической идентичности.
Например, E. палочки делает только одну ошибку на миллиард копий нуклеотидов. Он заканчивает свою репликацию в течение 60 минут и может воспроизводить 2000 нуклеотидов в секунду. По сравнению с человеческим телом количество ошибок невелико.
Последствия ошибок в репликации ДНК
Последствия ошибок в репликации ДНК в основном фатальные. Давайте подробно рассмотрим последствия ошибок в репликации ДНК.
Ошибки в репликации ДНК могут привести к опухолям, раку и т. д. Ошибки могут привести к мутациям, которые в дальнейшем приводят к опухолям и, наконец, вызывают рак.
Некоторые последствия ошибок в репликации ДНК:
1. Мутация зародышевой линии
2. Хромосомные изменения
3. Мутация сдвига рамки считывания
4. Точечная мутация
Если ошибки в ДНК не исправляются вовремя корректурным чтением, происходят мутации. Некоторое влияние ошибок в репликации ДНК: серповидноклеточная анемия, одна из форм бета-талассемия, кистозный фиброз, И т.д.
Могут ли ошибки в репликации ДНК привести к мутациям?
Механизм восстановления исправляет все ошибки, возникающие во время репликации ДНК. Давайте обсудим, приводят ли ошибки в репликации ДНК к мутациям.
Ошибки в репликации ДНК могут привести к таким мутациям, как постоянная мутация. В механизме репарации ДНК ферменты репарации находят возникающие ошибки и устраняют их. Впоследствии они рекрутируют нужный нуклеотид на место. Но некоторые ошибки репликации пропускают эти процессы и происходят мутации.
Например, некоторые мутации замещения оснований являются точечными мутациями, такими как мутации молчания, миссенс и нонсенс. Помимо некоторых мутаций, таких как мутация сдвига рамки, зародышевая или соматическая мутация. Основными видами мутаций являются делеция, инверсия, вставка, дупликация, транслокация, амплификация гена и др.
Как ошибки в репликации ДНК могут привести к мутациям?
Ошибки в репликации ДНК могут привести к мутации даже при постоянной мутации. Так что это играет очень важную роль. Формированию некоторых фигур помогает ведение. Давайте объясним это.
В приведенном ниже списке подробно показано, как ошибки в репликации ДНК могут привести к мутациям:
- Ошибки в репликации ДНК могут привести к мутациям, особенно в случае экспансии TNR (тринуклеотидный повтор).
- Этот повтор способствует проскальзыванию ДНК-полимеразы во время репликации.
- Вторичные структуры формируются как шпильки Intra strand.
- Такие вторичные структуры образуются за счет повторяющейся последовательности тринуклеотидных расширений.
- Для этого ферменты возвращаются и копируют прежнюю часть.
- В результате репарация не происходит. Так как репарация ошибок репликации ДНК не происходит, она идет по предыдущему пути.
- Для этого продолжаются ошибки репликации ДНК, и в результате происходит мутация, в частности, постоянная мутация.
Какие типы мутаций вызваны случайными ошибками в репликации ДНК?
Есть три типа мутаций, происходящих во время ошибок в репликации ДНК. Но типов под удаление, вставку, подстановку базы больше. Давайте обсудим их.
Типы мутаций, такие как точковая мутация, хромосомная мутация, зародышевая или соматическая мутация, а также мутация сдвига рамки считывания, вызваны случайными ошибками в репликации ДНК. Под точечной мутацией типов больше. Кроме того, эти мутации могут быть вызваны различными причинами.
Мутация вызывается веществом, называемым мутагеном. Это может быть радиация, химические вещества, токсичные материалы или что-то еще. Они очень спонтанны в окружающей среде.
Точечная мутация
Точечная мутация — это тип мутации, при котором изменяется, сдвигается или заменяется только один нуклеотид. Существует три типа точечных мутаций при ошибках репликации ДНК. Это немые, миссенс и нонсенс-мутации.
Хромосомная мутация
В случае хромосомной мутации структура хромосомы изменяется при ошибках репликации ДНК. Они могут быть изменены или изменены ядром.
Мутация сдвига рамки
При мутации со сдвигом рамки нуклеотиды могут быть добавлены или удалены из-за ошибок в репликации ДНК. Для этого изменяется смещение всего каркаса пула ДНК. Этот сдвиг может выполняться одним или несколькими нуклеотидами.
Индуцированные мутации инициируются ошибками в репликации ДНК.
Мутация изменяет всю последовательность ДНК конкретного организма. Давайте узнаем больше об индуцированных мутациях, которые инициируются ошибками в репликации ДНК.
Индуцированные мутации инициируются ошибками в репликации ДНК, так как при делении клеток в ДНК взрываются мутагены, которые в процессе репликации, привести их к мутации.
Затем индуцированная мутация приводит к постоянной мутации. Генная мутация может быть вызвана многими генами или может быть причиной потери одного или нескольких генов. Он может изменять нуклеотиды ДНК (один или несколько).
Как исправляются ошибки репликации ДНК?
Ошибки в репликации ДНК исправляются с помощью некоторых надежных процессов. Давайте посмотрим, что они из себя представляют в деталях.
Ошибки репликации ДНК исправляются в основном двумя процедурами: корректурой и исправлением несоответствия. Корректура — это то, где ошибки в репликации ДНК исправляются во время репликации ДНК, а исправление несоответствия — это то, где ошибки исправляются после репликации ДНК.
Редактирование
Вычитка создает структуру, которая приглашает другие белки исправить ошибку, потому что белки в ней способны сдерживать ошибки в репликации ДНК.
Когда происходит корректура, полимеразная форма ДНК выявляет ошибки в репликации ДНК. Затем он заменяет неправильно вставленный или удаленный нуклеотид. После исправления репликация продолжается своим потоком.
Несоответствие ремонта
Репарация несоответствия — это когда ошибки исправляются после того, как образование вилки не репарируется во время репликации ДНК. Но он специфичен для отдельных прядей. Ошибки в репликации ДНК исправляются после процесса, поскольку это окончательное исправление.
При репарации несоответствия существуют определенные гены, которые помогают предотвратить ошибки в репликации ДНК после завершения репликации. Гены PMS2, MLH1, MSH2, MSH6.
Почему ошибки репликации ДНК более значимы, чем ошибки транскрипции?
Репликация — более важный процесс, чем транскрипция. Кроме того, ошибки транскрипции РНК не так важны, как ошибки репликации ДНК. Давайте обсудим это.
Ошибки репликации ДНК более серьезны, чем ошибки транскрипции РНК, поскольку они не передаются по наследству, как ошибки репликации ДНК. Кроме того, при транскрипции изменяется очень небольшое количество белков. Изменение не очень вредно, как репликация, и его можно вылечить.
Например, частота ошибок в транскрипции составляет от 2.3*10^-5 в мРНК до 5.2*10^-5 в рРНК на нуклеотид для определенного вида бактерий. Но она не передается следующему поколению, как ошибки в репликации ДНК.
Может ли клетка исправить ошибку репликации ДНК?
Клетка может исправлять некоторые ошибки репликации ДНК. Очень хорошо, что клетки обладают превосходным качеством, позволяющим исправлять ошибки. Давайте исследовать больше.
В некоторых случаях клетка может исправлять ошибки репликации ДНК. Клетки обладают особыми свойствами для борьбы с некоторыми ошибками репликации ДНК. Клетки также могут фиксировать их на определенный процент. В течение клеточного цикла, путем корректурного чтения и устранения несоответствий, клетки могут управлять ими.
Некоторые из механизмов репарации для борьбы и исправления ошибок в репликации ДНК во время клеточного цикла — это прямое обращение повреждения, эксцизионная репарация, пострепликационная репарация, BER (иссечение основания), NER (эксцизионная репарация нуклеотидов), MMR (репарация несоответствия), HR (гомологичная рекомбинация) и NHEJ (негомологичное соединение концов).
Почему ошибки в репликации ДНК так редки?
Ошибки в репликации ДНК настолько редки, что при копировании приходится одна ошибка на миллиарды нуклеотидов. Давайте поймем причину этого.
Ошибки в репликации ДНК настолько редки из-за вычитка и исправление несоответствий механизмы исправления ошибок. Иногда это происходит, когда полимераза ДНК вставляет неправильные нуклеотиды. Если это не так, они могут привести к мутации, которая может привести к раку..
Вычитка устраняет все ошибки перед репликацией, а несоответствие устраняет ошибки после репликации. В результате частота ошибок составляет одну на каждые 10^4-10^5 нуклеотидов в синтезе. Даже если есть какие-то неисправности, скорость составляет менее 0.001%.
CАКЛЮЧЕНИЕ
В конце статьи доказано, что ошибки в репликации ДНК очень редки, и если ошибка остается после механизмов репарации, это может привести к постоянной мутации (хотя и множеству небольших мутаций), которая затем приводит к раку или другим фатальным последствиям. условия здоровья и для следующих поколений. Поскольку репликация ДНК является очень важной и важной процедурой во время клеточного цикла, это высокозащищенная система.
Привет . Я Ахели Дей, я получил степень магистра зоологии. Моя специализация – паразитология и иммунология. Я с большим энтузиазмом изучаю новые вещи. Я предпочитаю тяжелую и умную работу. Подключаемся через LinkedIn-https://www.linkedin.com/in/aheli-dey-793555249
Последние посты
Paramecium — одноклеточные эукариоты, принадлежащие к царству Protista. Обычно они встречаются в водной среде обитания. Сократительные вакуоли в парамециях — это органеллы, участвующие в.
Пищевые вакуоли представляют собой мешкообразные структуры, состоящие из однослойных мембран. Они содержат несколько ферментов для преобразования больших молекул в более мелкие. Пищевые вакуоли у простейших или других.
О НАС
Мы являемся группой профессионалов отрасли из различных областей образования, таких как наука, инженерия, английская литература, и создаем универсальное образовательное решение, основанное на знаниях.
Источник
Problems occur when the molecular machinery responsible for copying the DNA encounters an obstacle. This can cause things to slow down or briefly pause, which creates a narrow window of opportunity for mistakes to be made.
“The pausing of DNA replication leads to the accumulation of fragile, single-stranded DNA that is prone to base damage, slippage and double-strand breaks,” explains Nieduszynski. “Therefore, fork pausing is a major source of replicative errors, including point mutations, expansion/contraction of repeats, deletions and translocations.”
Although several checks and balances mean these obstacles normally get spotted and fixed during replication when things do go wrong the consequences can be catastrophic for the cell.
These rare but serious events are difficult to detect since most DNA replication is regular. Spotting them is something of a ‘needle in a haystack’ problem for researchers.
Nieduszynski’s Group has developed a high-throughput DNA sequencing technology that enables them to study the kinetics of DNA replication ‘in vivo’ on single molecules.
“This technology allows us to rapidly search for the ‘needle in the haystack’ and identify key molecular events, such as the slowing down or pausing of the DNA replication machinery,” he explains.
The Group is now applying this approach to determine what DNA sequences create obstacles to the DNA replication machinery, which protein factors assist in overcoming these hurdles, and how exactly pauses link to errors during the copying process.
“These approaches allow us to identify and characterise rare DNA replication mistakes, prioritising what determines and causes these mistakes and their resulting consequences,” says Nieduszynski.
“This is so important because a single DNA replication error on one chromosome in a single cell division has the potential to be harmless, lead to a subtle effect, or potentially be detrimental to the organism.”
Репликация ДНК иногда может быть нарушена из-за добавления или удаления новых нуклеотидных оснований. Давайте посмотрим, как возникают ошибки при репликации ДНК.
Ошибки в Репликация ДНК известны как проскальзывание цепей, когда новые нуклеотидные основания добавляются или удаляются в результате мутации или постоянных изменений последовательности и т. д. ДНК. Свежевыделенные петли прядей немного выходят наружу. Результатом этого изменения является добавление или удаление дополнительного нуклеотидного основания.
Есть в основном три типа ошибок в репликации ДНК. Это базовые замены, удаления и вставки. Если ошибку не исправить, она может вызвать рак. Здесь механизм репарации ДНК исправляет все ошибки.
Давайте обсудим, является ли репликация ДНК точной, каковы все ошибки в репликации ДНК, причины и последствия ошибок в репликации ДНК и многие другие связанные темы в этой статье.
Является ли репликация ДНК точной?
Частота ошибок при репликации ДНК очень мала. Давайте посмотрим, является ли репликация ДНК точной или нет.
Репликация ДНК настолько точна, что частота ошибок в репликации ДНК может быть незначительной. Это формируется таким образом, что геном стабильность зависит от точности репликации ДНК. Но дефектные геномы могут быть фатальными для животного организма из-за мутации всего генофонда.
Точность репликации ДНК хорошо определена благодаря трем факторам. Они есть нуклеотидная избирательность, Редактированиеи Несоответствие ремонта. Эти факторы являются основной причиной меньшего количества ошибок в репликации ДНК.
Что такое ошибки репликации ДНК?
Ошибки репликации ДНК в основном связаны с депуринацией всего геномного пула. Давайте обсудим, каковы все возможные ошибки в репликации ДНК.
Ошибки репликации ДНК делятся на три типа: Ошибки репликации, депуринизация ДНК и повреждение ДНК за счет образования активных форм кислорода.
Давайте посмотрим больше информации об ошибках в репликации ДНК ниже:
- Разрыв вызван молекулой воды, в результате чего образуется нуклеотид, не содержащий пуринов. Это нельзя использовать в репликации.
- Свободные пурины не могут функционировать во время репликации ДНК в качестве матрицы.
- Потеря аминогруппы из нуклеотида также вызвана дезаминированием для того, чтобы не функционировать в качестве матрицы во время ошибок в репликации ДНК по водной реакции.
- Эти непреднамеренные причины снова исправляются в процессе восстановления ДНК.
- Но затем добавляется новый нуклеотид, который становится постоянной мутацией.
- Это происходит во время синтеза новой цепи.
- Накопленные мутации или постоянные изменения последовательности являются причиной такого плохого поведения клеточной ДНК.
Причины ошибок в репликации ДНК
Существует несколько причин возникновения ошибок в репликации ДНК. Давайте посмотрим, что они из себя представляют в деталях.
Ошибки репликации ДНК в основном вызваны разной природой пар оснований. Они могут быть как различной природы, так и не таутомерными по химическим формам.
Три основные причины ошибок в репликации ДНК: подробно обсуждается ниже:
1. Делеция. Делеция — одна из основных ошибок в репликации ДНК. Это вызывает сдвиг структуры всего генофонда. Он изменяет последовательность ДНК, разрушая один (как минимум) или несколько нуклеотидов.
2. Вставка. Вставка — еще одна основная ошибка в репликации ДНК. Это вызывает сдвиг структуры всего генофонда. Он изменяет последовательность ДНК, добавляя одну (как минимум) или более пар нуклеотидных оснований.
3. Замена оснований. Замена оснований также является одной из важных ошибок в репликации ДНК. Он заменяет нужный нуклеотид любым другим нуклеотидом, что меняет весь генофонд. Он также может заменить одну аминокислоту на другую.
Частота ошибок репликации ДНК
Как обсуждалось ранее, существует небольшая вероятность того, что при репликации ДНК могут возникнуть ошибки. Давайте посмотрим на скорость, с которой происходят ошибки в ДНК.
Частота ошибок репликации ДНК составляет один на 10^10 нуклеотидов при синтезе ДНК. Это так меньше, но последствия могут быть фатальными. Это от 10 ^ -9 до 10 ^ -11 ошибок в репликации ДНК на пару оснований. Высокая точность процесса очень важна для поддержания точности генетической идентичности.
Например, E. палочки делает только одну ошибку на миллиард копий нуклеотидов. Он заканчивает свою репликацию в течение 60 минут и может воспроизводить 2000 нуклеотидов в секунду. По сравнению с человеческим телом количество ошибок невелико.
Последствия ошибок в репликации ДНК
Последствия ошибок в репликации ДНК в основном фатальные. Давайте подробно рассмотрим последствия ошибок в репликации ДНК.
Ошибки в репликации ДНК могут привести к опухолям, раку и т. д. Ошибки могут привести к мутациям, которые в дальнейшем приводят к опухолям и, наконец, вызывают рак.
Некоторые последствия ошибок в репликации ДНК:
1. Мутация зародышевой линии
2. Хромосомные изменения
3. Мутация сдвига рамки считывания
4. Точечная мутация
Если ошибки в ДНК не исправляются вовремя корректурным чтением, происходят мутации. Некоторое влияние ошибок в репликации ДНК: серповидноклеточная анемия, одна из форм бета-талассемия, кистозный фиброз, И т.д.
Могут ли ошибки в репликации ДНК привести к мутациям?
Механизм восстановления исправляет все ошибки, возникающие во время репликации ДНК. Давайте обсудим, приводят ли ошибки в репликации ДНК к мутациям.
Ошибки в репликации ДНК могут привести к таким мутациям, как постоянная мутация. В механизме репарации ДНК ферменты репарации находят возникающие ошибки и устраняют их. Впоследствии они рекрутируют нужный нуклеотид на место. Но некоторые ошибки репликации пропускают эти процессы и происходят мутации.
Например, некоторые мутации замещения оснований являются точечными мутациями, такими как мутации молчания, миссенс и нонсенс. Помимо некоторых мутаций, таких как мутация сдвига рамки, зародышевая или соматическая мутация. Основными видами мутаций являются делеция, инверсия, вставка, дупликация, транслокация, амплификация гена и др.
Как ошибки в репликации ДНК могут привести к мутациям?
Ошибки в репликации ДНК могут привести к мутации даже при постоянной мутации. Так что это играет очень важную роль. Формированию некоторых фигур помогает ведение. Давайте объясним это.
В приведенном ниже списке подробно показано, как ошибки в репликации ДНК могут привести к мутациям:
- Ошибки в репликации ДНК могут привести к мутациям, особенно в случае экспансии TNR (тринуклеотидный повтор).
- Этот повтор способствует проскальзыванию ДНК-полимеразы во время репликации.
- Вторичные структуры формируются как шпильки Intra strand.
- Такие вторичные структуры образуются за счет повторяющейся последовательности тринуклеотидных расширений.
- Для этого ферменты возвращаются и копируют прежнюю часть.
- В результате репарация не происходит. Так как репарация ошибок репликации ДНК не происходит, она идет по предыдущему пути.
- Для этого продолжаются ошибки репликации ДНК, и в результате происходит мутация, в частности, постоянная мутация.
Какие типы мутаций вызваны случайными ошибками в репликации ДНК?
Есть три типа мутаций, происходящих во время ошибок в репликации ДНК. Но типов под удаление, вставку, подстановку базы больше. Давайте обсудим их.
Типы мутаций, такие как точковая мутация, хромосомная мутация, зародышевая или соматическая мутация, а также мутация сдвига рамки считывания, вызваны случайными ошибками в репликации ДНК. Под точечной мутацией типов больше. Кроме того, эти мутации могут быть вызваны различными причинами.
Мутация вызывается веществом, называемым мутагеном. Это может быть радиация, химические вещества, токсичные материалы или что-то еще. Они очень спонтанны в окружающей среде.
Точечная мутация
Точечная мутация — это тип мутации, при котором изменяется, сдвигается или заменяется только один нуклеотид. Существует три типа точечных мутаций при ошибках репликации ДНК. Это немые, миссенс и нонсенс-мутации.
Хромосомная мутация
В случае хромосомной мутации структура хромосомы изменяется при ошибках репликации ДНК. Они могут быть изменены или изменены ядром.
Мутация сдвига рамки
При мутации со сдвигом рамки нуклеотиды могут быть добавлены или удалены из-за ошибок в репликации ДНК. Для этого изменяется смещение всего каркаса пула ДНК. Этот сдвиг может выполняться одним или несколькими нуклеотидами.
Индуцированные мутации инициируются ошибками в репликации ДНК.
Мутация изменяет всю последовательность ДНК конкретного организма. Давайте узнаем больше об индуцированных мутациях, которые инициируются ошибками в репликации ДНК.
Индуцированные мутации инициируются ошибками в репликации ДНК, так как при делении клеток в ДНК взрываются мутагены, которые в процессе репликации, привести их к мутации.
Затем индуцированная мутация приводит к постоянной мутации. Генная мутация может быть вызвана многими генами или может быть причиной потери одного или нескольких генов. Он может изменять нуклеотиды ДНК (один или несколько).
Как исправляются ошибки репликации ДНК?
Ошибки в репликации ДНК исправляются с помощью некоторых надежных процессов. Давайте посмотрим, что они из себя представляют в деталях.
Ошибки репликации ДНК исправляются в основном двумя процедурами: корректурой и исправлением несоответствия. Корректура — это то, где ошибки в репликации ДНК исправляются во время репликации ДНК, а исправление несоответствия — это то, где ошибки исправляются после репликации ДНК.
Редактирование
Вычитка создает структуру, которая приглашает другие белки исправить ошибку, потому что белки в ней способны сдерживать ошибки в репликации ДНК.
Когда происходит корректура, полимеразная форма ДНК выявляет ошибки в репликации ДНК. Затем он заменяет неправильно вставленный или удаленный нуклеотид. После исправления репликация продолжается своим потоком.
Несоответствие ремонта
Репарация несоответствия — это когда ошибки исправляются после того, как образование вилки не репарируется во время репликации ДНК. Но он специфичен для отдельных прядей. Ошибки в репликации ДНК исправляются после процесса, поскольку это окончательное исправление.
При репарации несоответствия существуют определенные гены, которые помогают предотвратить ошибки в репликации ДНК после завершения репликации. Гены PMS2, MLH1, MSH2, MSH6.

.
Почему ошибки репликации ДНК более значимы, чем ошибки транскрипции?
Репликация — более важный процесс, чем транскрипция. Кроме того, ошибки транскрипции РНК не так важны, как ошибки репликации ДНК. Давайте обсудим это.
Ошибки репликации ДНК более серьезны, чем ошибки транскрипции РНК, поскольку они не передаются по наследству, как ошибки репликации ДНК. Кроме того, при транскрипции изменяется очень небольшое количество белков. Изменение не очень вредно, как репликация, и его можно вылечить.
Например, частота ошибок в транскрипции составляет от 2.3*10^-5 в мРНК до 5.2*10^-5 в рРНК на нуклеотид для определенного вида бактерий. Но она не передается следующему поколению, как ошибки в репликации ДНК.
Может ли клетка исправить ошибку репликации ДНК?
Клетка может исправлять некоторые ошибки репликации ДНК. Очень хорошо, что клетки обладают превосходным качеством, позволяющим исправлять ошибки. Давайте исследовать больше.
В некоторых случаях клетка может исправлять ошибки репликации ДНК. Клетки обладают особыми свойствами для борьбы с некоторыми ошибками репликации ДНК. Клетки также могут фиксировать их на определенный процент. В течение клеточного цикла, путем корректурного чтения и устранения несоответствий, клетки могут управлять ими.
Некоторые из механизмов репарации для борьбы и исправления ошибок в репликации ДНК во время клеточного цикла — это прямое обращение повреждения, эксцизионная репарация, пострепликационная репарация, BER (иссечение основания), NER (эксцизионная репарация нуклеотидов), MMR (репарация несоответствия), HR (гомологичная рекомбинация) и NHEJ (негомологичное соединение концов).
Почему ошибки в репликации ДНК так редки?
Ошибки в репликации ДНК настолько редки, что при копировании приходится одна ошибка на миллиарды нуклеотидов. Давайте поймем причину этого.
Ошибки в репликации ДНК настолько редки из-за вычитка и исправление несоответствий механизмы исправления ошибок. Иногда это происходит, когда полимераза ДНК вставляет неправильные нуклеотиды. Если это не так, они могут привести к мутации, которая может привести к раку..
Вычитка устраняет все ошибки перед репликацией, а несоответствие устраняет ошибки после репликации. В результате частота ошибок составляет одну на каждые 10^4-10^5 нуклеотидов в синтезе. Даже если есть какие-то неисправности, скорость составляет менее 0.001%.
CАКЛЮЧЕНИЕ
В конце статьи доказано, что ошибки в репликации ДНК очень редки, и если ошибка остается после механизмов репарации, это может привести к постоянной мутации (хотя и множеству небольших мутаций), которая затем приводит к раку или другим фатальным последствиям. условия здоровья и для следующих поколений. Поскольку репликация ДНК является очень важной и важной процедурой во время клеточного цикла, это высокозащищенная система.
Mechanisms to correct errors during DNA replication and to repair DNA damage over the cell’s lifetime.
Key points:
-
Cells have a variety of mechanisms to prevent mutations, or permanent changes in DNA sequence.
-
During DNA synthesis, most DNA polymerases «check their work,» fixing the majority of mispaired bases in a process called proofreading.
-
Immediately after DNA synthesis, any remaining mispaired bases can be detected and replaced in a process called mismatch repair.
-
If DNA gets damaged, it can be repaired by various mechanisms, including chemical reversal, excision repair, and double-stranded break repair.
Introduction
What does DNA have to do with cancer? Cancer occurs when cells divide in an uncontrolled way, ignoring normal «stop» signals and producing a tumor. This bad behavior is caused by accumulated mutations, or permanent sequence changes in the cells’ DNA.
Replication errors and DNA damage are actually happening in the cells of our bodies all the time. In most cases, however, they don’t cause cancer, or even mutations. That’s because they are usually detected and fixed by DNA proofreading and repair mechanisms. Or, if the damage cannot be fixed, the cell will undergo programmed cell death (apoptosis) to avoid passing on the faulty DNA.
Mutations happen, and get passed on to daughter cells, only when these mechanisms fail. Cancer, in turn, develops only when multiple mutations in division-related genes accumulate in the same cell.
In this article, we’ll take a closer look at the mechanisms used by cells to correct replication errors and fix DNA damage, including:
-
Proofreading, which corrects errors during DNA replication
-
Mismatch repair, which fixes mispaired bases right after DNA replication
-
DNA damage repair pathways, which detect and correct damage throughout the cell cycle
Proofreading
DNA polymerases are the enzymes that build DNA in cells. During DNA replication (copying), most DNA polymerases can “check their work” with each base that they add. This process is called proofreading. If the polymerase detects that a wrong (incorrectly paired) nucleotide has been added, it will remove and replace the nucleotide right away, before continuing with DNA synthesisstart superscript, 1, end superscript.
Mismatch repair
Many errors are corrected by proofreading, but a few slip through. Mismatch repair happens right after new DNA has been made, and its job is to remove and replace mis-paired bases (ones that were not fixed during proofreading). Mismatch repair can also detect and correct small insertions and deletions that happen when the polymerases «slips,» losing its footing on the templatesquared.
How does mismatch repair work? First, a protein complex (group of proteins) recognizes and binds to the mispaired base. A second complex cuts the DNA near the mismatch, and more enzymes chop out the incorrect nucleotide and a surrounding patch of DNA. A DNA polymerase then replaces the missing section with correct nucleotides, and an enzyme called a DNA ligase seals the gapsquared.
One thing you may wonder is how the proteins involved in DNA repair can tell «who’s right» during mismatch repair. That is, when two bases are mispaired (like the G and T in the drawing above), which of the two should be removed and replaced?
In bacteria, original and newly made strands of DNA can be told apart by a feature called methylation state. An old DNA strand will have methyl (minus, start text, C, H, end text, start subscript, 3, end subscript) groups attached to some of its bases, while a newly made DNA strand will not yet have gotten its methyl groupcubed.
In eukaryotes, the processes that allow the original strand to be identified in mismatch repair involve recognition of nicks (single-stranded breaks) that are found only in the newly synthesized DNAcubed.
DNA damage repair mechanisms
Bad things can happen to DNA at almost any point in a cell’s lifetime, not just during replication. In fact, your DNA is getting damaged all the time by outside factors like UV light, chemicals, and X-rays—not to mention spontaneous chemical reactions that happen even without environmental insults!start superscript, 4, end superscript
Fortunately, your cells have repair mechanisms to detect and correct many types of DNA damage. Repair processes that help fix damaged DNA include:
-
Direct reversal: Some DNA-damaging chemical reactions can be directly «undone» by enzymes in the cell.
-
Excision repair: Damage to one or a few bases of DNA is often fixed by removal (excision) and replacement of the damaged region. In base excision repair, just the damaged base is removed. In nucleotide excision repair, as in the mismatch repair we saw above, a patch of nucleotides is removed.
-
Double-stranded break repair: Two major pathways, non-homologous end joining and homologous recombination, are used to repair double-stranded breaks in DNA (that is, when an entire chromosome splits into two pieces).
Reversal of damage
In some cases, a cell can fix DNA damage simply by reversing the chemical reaction that caused it. To understand this, we need to realize that «DNA damage» often just involves an extra group of atoms getting attached to DNA through a chemical reaction.
For example, guanine (G) can undergo a reaction that attaches a methyl (minus, start text, C, H, end text, start subscript, 3, end subscript) group to an oxygen atom in the base. The methyl-bearing guanine, if not fixed, will pair with thymine (T) rather than cytosine (C) during DNA replication. Luckily, humans and many other organisms have an enzyme that can remove the methyl group, reversing the reaction and returning the base to normalstart superscript, 5, end superscript.
Base excision repair
Base excision repair is a mechanism used to detect and remove certain types of damaged bases. A group of enzymes called glycosylases play a key role in base excision repair. Each glycosylase detects and removes a specific kind of damaged base.
For example, a chemical reaction called deamination can convert a cytosine base into uracil, a base typically found only in RNA. During DNA replication, uracil will pair with adenine rather than guanine (as it would if the base was still cytosine), so an uncorrected cytosine-to-uracil change can lead to a mutationstart superscript, 5, end superscript.
To prevent such mutations, a glycosylase from the base excision repair pathway detects and removes deaminated cytosines. Once the base has been removed, the «empty» piece of DNA backbone is also removed, and the gap is filled and sealed by other enzymesstart superscript, 6, end superscript.
Nucleotide excision repair
Nucleotide excision repair is another pathway used to remove and replace damaged bases. Nucleotide excision repair detects and corrects types of damage that distort the DNA double helix. For instance, this pathway detects bases that have been modified with bulky chemical groups, like the ones that get attached to your DNA when it’s exposed to chemicals in cigarette smokestart superscript, 7, end superscript.
Nucleotide excision repair is also used to fix some types of damage caused by UV radiation, for instance, when you get a sunburn. UV radiation can make cytosine and thymine bases react with neighboring bases that are also Cs or Ts, forming bonds that distort the double helix and cause errors in DNA replication. The most common type of linkage, a thymine dimer, consists of two thymine bases that react with each other and become chemically linkedstart superscript, 8, end superscript.
In nucleotide excision repair, the damaged nucleotide(s) are removed along with a surrounding patch of DNA. In this process, a helicase (DNA-opening enzyme) cranks open the DNA to form a bubble, and DNA-cutting enzymes chop out the damaged part of the bubble. A DNA polymerase replaces the missing DNA, and a DNA ligase seals the gap in the backbone of the strandstart superscript, 9, end superscript.
Double-stranded break repair
Some types of environmental factors, such as high-energy radiation, can cause double-stranded breaks in DNA (splitting a chromosome in two). This is the kind of DNA damage linked with superhero origin stories in comic books, and with disasters like Chernobyl in real life.
Double-stranded breaks are dangerous because large segments of chromosomes, and the hundreds of genes they contain, may be lost if the break is not repaired. Two pathways involved in the repair of double-stranded DNA breaks are the non-homologous end joining and homologous recombination pathways.
In non-homologous end joining, the two broken ends of the chromosome are simply glued back together. This repair mechanism is “messy” and typically involves the loss, or sometimes addition, of a few nucleotides at the cut site. So, non-homologous end joining tends to produce a mutation, but this is better than the alternative (loss of an entire chromosome arm)start superscript, 10, end superscript.
In homologous recombination, information from the homologous chromosome that matches the damaged one (or from a sister chromatid, if the DNA has been copied) is used to repair the break. In this process, the two homologous chromosomes come together, and the undamaged region of the homologue or chromatid is used as a template to replace the damaged region of the broken chromosome. Homologous recombination is “cleaner” than non-homologous end joining and does not usually cause mutationsstart superscript, 11, end superscript.
DNA proofreading and repair in human disease
Evidence for the importance of proofreading and repair mechanisms comes from human genetic disorders. In many cases, mutations in genes that encode proofreading and repair proteins are associated with heredity cancers (cancers that run in families). For example:
-
Hereditary nonpolyposis colorectal cancer (also called Lynch syndrome) is caused by mutations in genes encoding certain mismatch repair proteinsstart superscript, 12, comma, 13, end superscript. Since mismatched bases are not repaired in the cells of people with this syndrome, mutations accumulate much more rapidly than in the cells of an unaffected person. This can lead to the development of tumors in the colon.
-
People with xeroderma pigmentosum are extremely sensitive to UV light. This condition is caused by mutations affecting the nucleotide excision repair pathway. When this pathway doesn’t work, thymine dimers and other forms of UV damage can’t be repaired. People with xeroderma pigmentosum develop severe sunburns from just a few minutes in the sun, and about half will get skin cancer by the age of 10 unless they avoid the sunstart superscript, 14, end superscript.

DNA damage resulting in multiple broken chromosomes
DNA repair is a collection of processes by which a cell identifies and corrects damage to the DNA molecules that encode its genome.[1] In human cells, both normal metabolic activities and environmental factors such as radiation can cause DNA damage, resulting in tens of thousands of individual molecular lesions per cell per day.[2] Many of these lesions cause structural damage to the DNA molecule and can alter or eliminate the cell’s ability to transcribe the gene that the affected DNA encodes. Other lesions induce potentially harmful mutations in the cell’s genome, which affect the survival of its daughter cells after it undergoes mitosis. As a consequence, the DNA repair process is constantly active as it responds to damage in the DNA structure. When normal repair processes fail, and when cellular apoptosis does not occur, irreparable DNA damage may occur, including double-strand breaks and DNA crosslinkages (interstrand crosslinks or ICLs).[3][4] This can eventually lead to malignant tumors, or cancer as per the two hit hypothesis.
The rate of DNA repair is dependent on many factors, including the cell type, the age of the cell, and the extracellular environment. A cell that has accumulated a large amount of DNA damage, or one that no longer effectively repairs damage incurred to its DNA, can enter one of three possible states:
- an irreversible state of dormancy, known as senescence
- cell suicide, also known as apoptosis or programmed cell death
- unregulated cell division, which can lead to the formation of a tumor that is cancerous
The DNA repair ability of a cell is vital to the integrity of its genome and thus to the normal functionality of that organism. Many genes that were initially shown to influence life span have turned out to be involved in DNA damage repair and protection.[5]
Paul Modrich talks about himself and his work in DNA repair.
The 2015 Nobel Prize in Chemistry was awarded to Tomas Lindahl, Paul Modrich, and Aziz Sancar for their work on the molecular mechanisms of DNA repair processes.[6][7]
DNA damage[edit]
DNA damage, due to environmental factors and normal metabolic processes inside the cell, occurs at a rate of 10,000 to 1,000,000 molecular lesions per cell per day.[2] While this constitutes only 0.000165% of the human genome’s approximately 6 billion bases, unrepaired lesions in critical genes (such as tumor suppressor genes) can impede a cell’s ability to carry out its function and appreciably increase the likelihood of tumor formation and contribute to tumour heterogeneity.
The vast majority of DNA damage affects the primary structure of the double helix; that is, the bases themselves are chemically modified. These modifications can in turn disrupt the molecules’ regular helical structure by introducing non-native chemical bonds or bulky adducts that do not fit in the standard double helix. Unlike proteins and RNA, DNA usually lacks tertiary structure and therefore damage or disturbance does not occur at that level. DNA is, however, supercoiled and wound around «packaging» proteins called histones (in eukaryotes), and both superstructures are vulnerable to the effects of DNA damage.
Sources[edit]
DNA damage can be subdivided into two main types:
- endogenous damage such as attack by reactive oxygen species produced from normal metabolic byproducts (spontaneous mutation), especially the process of oxidative deamination
- also includes replication errors
- exogenous damage caused by external agents such as
- ultraviolet [UV 200–400 nm] radiation from the sun or other artificial light sources
- other radiation frequencies, including x-rays and gamma rays
- hydrolysis or thermal disruption
- certain plant toxins
- human-made mutagenic chemicals, especially aromatic compounds that act as DNA intercalating agents
- viruses[8]
The replication of damaged DNA before cell division can lead to the incorporation of wrong bases opposite damaged ones. Daughter cells that inherit these wrong bases carry mutations from which the original DNA sequence is unrecoverable (except in the rare case of a back mutation, for example, through gene conversion).
Types[edit]
There are several types of damage to DNA due to endogenous cellular processes:
- oxidation of bases [e.g. 8-oxo-7,8-dihydroguanine (8-oxoG)] and generation of DNA strand interruptions from reactive oxygen species,
- alkylation of bases (usually methylation), such as formation of 7-methylguanosine, 1-methyladenine, 6-O-Methylguanine
- hydrolysis of bases, such as deamination, depurination, and depyrimidination.
- «bulky adduct formation» (e.g., benzo[a]pyrene diol epoxide-dG adduct, aristolactam I-dA adduct)
- mismatch of bases, due to errors in DNA replication, in which the wrong DNA base is stitched into place in a newly forming DNA strand, or a DNA base is skipped over or mistakenly inserted.
- Monoadduct damage cause by change in single nitrogenous base of DNA
- Diadduct damage
Damage caused by exogenous agents comes in many forms. Some examples are:
- UV-B light causes crosslinking between adjacent cytosine and thymine bases creating pyrimidine dimers. This is called direct DNA damage.
- UV-A light creates mostly free radicals. The damage caused by free radicals is called indirect DNA damage.
- Ionizing radiation such as that created by radioactive decay or in cosmic rays causes breaks in DNA strands. Intermediate-level ionizing radiation may induce irreparable DNA damage (leading to replicational and transcriptional errors needed for neoplasia or may trigger viral interactions) leading to pre-mature aging and cancer.
- Thermal disruption at elevated temperature increases the rate of depurination (loss of purine bases from the DNA backbone) and single-strand breaks. For example, hydrolytic depurination is seen in the thermophilic bacteria, which grow in hot springs at 40–80 °C.[9][10] The rate of depurination (300 purine residues per genome per generation) is too high in these species to be repaired by normal repair machinery, hence a possibility of an adaptive response cannot be ruled out.
- Industrial chemicals such as vinyl chloride and hydrogen peroxide, and environmental chemicals such as polycyclic aromatic hydrocarbons found in smoke, soot and tar create a huge diversity of DNA adducts- ethenobases, oxidized bases, alkylated phosphotriesters and crosslinking of DNA, just to name a few.
UV damage, alkylation/methylation, X-ray damage and oxidative damage are examples of induced damage. Spontaneous damage can include the loss of a base, deamination, sugar ring puckering and tautomeric shift. Constitutive (spontaneous) DNA damage caused by endogenous oxidants can be detected as a low level of histone H2AX phosphorylation in untreated cells.[11]
Nuclear versus mitochondrial[edit]
In human cells, and eukaryotic cells in general, DNA is found in two cellular locations – inside the nucleus and inside the mitochondria. Nuclear DNA (nDNA) exists as chromatin during non-replicative stages of the cell cycle and is condensed into aggregate structures known as chromosomes during cell division. In either state the DNA is highly compacted and wound up around bead-like proteins called histones. Whenever a cell needs to express the genetic information encoded in its nDNA the required chromosomal region is unravelled, genes located therein are expressed, and then the region is condensed back to its resting conformation. Mitochondrial DNA (mtDNA) is located inside mitochondria organelles, exists in multiple copies, and is also tightly associated with a number of proteins to form a complex known as the nucleoid. Inside mitochondria, reactive oxygen species (ROS), or free radicals, byproducts of the constant production of adenosine triphosphate (ATP) via oxidative phosphorylation, create a highly oxidative environment that is known to damage mtDNA. A critical enzyme in counteracting the toxicity of these species is superoxide dismutase, which is present in both the mitochondria and cytoplasm of eukaryotic cells.
Senescence and apoptosis[edit]
Senescence, an irreversible process in which the cell no longer divides, is a protective response to the shortening of the chromosome ends, called telomeres. The telomeres are long regions of repetitive noncoding DNA that cap chromosomes and undergo partial degradation each time a cell undergoes division (see Hayflick limit).[12] In contrast, quiescence is a reversible state of cellular dormancy that is unrelated to genome damage (see cell cycle). Senescence in cells may serve as a functional alternative to apoptosis in cases where the physical presence of a cell for spatial reasons is required by the organism,[13] which serves as a «last resort» mechanism to prevent a cell with damaged DNA from replicating inappropriately in the absence of pro-growth cellular signaling. Unregulated cell division can lead to the formation of a tumor (see cancer), which is potentially lethal to an organism. Therefore, the induction of senescence and apoptosis is considered to be part of a strategy of protection against cancer.[14]
Mutation[edit]
It is important to distinguish between DNA damage and mutation, the two major types of error in DNA. DNA damage and mutation are fundamentally different. Damage results in physical abnormalities in the DNA, such as single- and double-strand breaks, 8-hydroxydeoxyguanosine residues, and polycyclic aromatic hydrocarbon adducts. DNA damage can be recognized by enzymes, and thus can be correctly repaired if redundant information, such as the undamaged sequence in the complementary DNA strand or in a homologous chromosome, is available for copying. If a cell retains DNA damage, transcription of a gene can be prevented, and thus translation into a protein will also be blocked. Replication may also be blocked or the cell may die.
In contrast to DNA damage, a mutation is a change in the base sequence of the DNA. A mutation cannot be recognized by enzymes once the base change is present in both DNA strands, and thus a mutation cannot be repaired. At the cellular level, mutations can cause alterations in protein function and regulation. Mutations are replicated when the cell replicates. In a population of cells, mutant cells will increase or decrease in frequency according to the effects of the mutation on the ability of the cell to survive and reproduce.
Although distinctly different from each other, DNA damage and mutation are related because DNA damage often causes errors of DNA synthesis during replication or repair; these errors are a major source of mutation.
Given these properties of DNA damage and mutation, it can be seen that DNA damage is a special problem in non-dividing or slowly-dividing cells, where unrepaired damage will tend to accumulate over time. On the other hand, in rapidly dividing cells, unrepaired DNA damage that does not kill the cell by blocking replication will tend to cause replication errors and thus mutation. The great majority of mutations that are not neutral in their effect are deleterious to a cell’s survival. Thus, in a population of cells composing a tissue with replicating cells, mutant cells will tend to be lost. However, infrequent mutations that provide a survival advantage will tend to clonally expand at the expense of neighboring cells in the tissue. This advantage to the cell is disadvantageous to the whole organism because such mutant cells can give rise to cancer. Thus, DNA damage in frequently dividing cells, because it gives rise to mutations, is a prominent cause of cancer. In contrast, DNA damage in infrequently-dividing cells is likely a prominent cause of aging.[15]
Mechanisms[edit]
Cells cannot function if DNA damage corrupts the integrity and accessibility of essential information in the genome (but cells remain superficially functional when non-essential genes are missing or damaged). Depending on the type of damage inflicted on the DNA’s double helical structure, a variety of repair strategies have evolved to restore lost information. If possible, cells use the unmodified complementary strand of the DNA or the sister chromatid as a template to recover the original information. Without access to a template, cells use an error-prone recovery mechanism known as translesion synthesis as a last resort.
Damage to DNA alters the spatial configuration of the helix, and such alterations can be detected by the cell. Once damage is localized, specific DNA repair molecules bind at or near the site of damage, inducing other molecules to bind and form a complex that enables the actual repair to take place.
Direct reversal[edit]
Cells are known to eliminate three types of damage to their DNA by chemically reversing it. These mechanisms do not require a template, since the types of damage they counteract can occur in only one of the four bases. Such direct reversal mechanisms are specific to the type of damage incurred and do not involve breakage of the phosphodiester backbone. The formation of pyrimidine dimers upon irradiation with UV light results in an abnormal covalent bond between adjacent pyrimidine bases. The photoreactivation process directly reverses this damage by the action of the enzyme photolyase, whose activation is obligately dependent on energy absorbed from blue/UV light (300–500 nm wavelength) to promote catalysis.[16] Photolyase, an old enzyme present in bacteria, fungi, and most animals no longer functions in humans,[17] who instead use nucleotide excision repair to repair damage from UV irradiation. Another type of damage, methylation of guanine bases, is directly reversed by the enzyme methyl guanine methyl transferase (MGMT), the bacterial equivalent of which is called ogt. This is an expensive process because each MGMT molecule can be used only once; that is, the reaction is stoichiometric rather than catalytic.[18] A generalized response to methylating agents in bacteria is known as the adaptive response and confers a level of resistance to alkylating agents upon sustained exposure by upregulation of alkylation repair enzymes.[19] The third type of DNA damage reversed by cells is certain methylation of the bases cytosine and adenine.
Single-strand damage[edit]

Structure of the base-excision repair enzyme uracil-DNA glycosylase excising a hydrolytically-produced uracil residue from DNA. The uracil residue is shown in yellow.
When only one of the two strands of a double helix has a defect, the other strand can be used as a template to guide the correction of the damaged strand. In order to repair damage to one of the two paired molecules of DNA, there exist a number of excision repair mechanisms that remove the damaged nucleotide and replace it with an undamaged nucleotide complementary to that found in the undamaged DNA strand.[18]
- Base excision repair (BER): damaged single bases or nucleotides are most commonly repaired by removing the base or the nucleotide involved and then inserting the correct base or nucleotide. In base excision repair, a glycosylase[20] enzyme removes the damaged base from the DNA by cleaving the bond between the base and the deoxyribose. These enzymes remove a single base to create an apurinic or apyrimidinic site (AP site).[20] Enzymes called AP endonucleases nick the damaged DNA backbone at the AP site. DNA polymerase then removes the damaged region using its 5’ to 3’ exonuclease activity and correctly synthesizes the new strand using the complementary strand as a template.[20] The gap is then sealed by enzyme DNA ligase.[21]
- Nucleotide excision repair (NER): bulky, helix-distorting damage, such as pyrimidine dimerization caused by UV light is usually repaired by a three-step process. First the damage is recognized, then 12-24 nucleotide-long strands of DNA are removed both upstream and downstream of the damage site by endonucleases, and the removed DNA region is then resynthesized.[22] NER is a highly evolutionarily conserved repair mechanism and is used in nearly all eukaryotic and prokaryotic cells.[22] In prokaryotes, NER is mediated by Uvr proteins.[22] In eukaryotes, many more proteins are involved, although the general strategy is the same.[22]
- Mismatch repair systems are present in essentially all cells to correct errors that are not corrected by proofreading. These systems consist of at least two proteins. One detects the mismatch, and the other recruits an endonuclease that cleaves the newly synthesized DNA strand close to the region of damage. In E. coli , the proteins involved are the Mut class proteins: MutS, MutL, and MutH. In most Eukaryotes, the analog for MutS is MSH and the analog for MutL is MLH. MutH is only present in bacteria. This is followed by removal of damaged region by an exonuclease, resynthesis by DNA polymerase, and nick sealing by DNA ligase.[23]
Double-strand breaks[edit]

The main double-strand break repair pathways
Double-strand breaks, in which both strands in the double helix are severed, are particularly hazardous to the cell because they can lead to genome rearrangements. In fact, when a double-strand break is accompanied by a cross-linkage joining the two strands at the same point, neither strand can be used as a template for the repair mechanisms, so that the cell will not be able to complete mitosis when it next divides, and will either die or, in rare cases, undergo a mutation.[3][4] Three mechanisms exist to repair double-strand breaks (DSBs): non-homologous end joining (NHEJ), microhomology-mediated end joining (MMEJ), and homologous recombination (HR):[18][24]

DNA ligase, shown above repairing chromosomal damage, is an enzyme that joins broken nucleotides together by catalyzing the formation of an internucleotide ester bond between the phosphate backbone and the deoxyribose nucleotides.
- In NHEJ, DNA Ligase IV, a specialized DNA ligase that forms a complex with the cofactor XRCC4, directly joins the two ends.[25] To guide accurate repair, NHEJ relies on short homologous sequences called microhomologies present on the single-stranded tails of the DNA ends to be joined. If these overhangs are compatible, repair is usually accurate.[26][27][28][29] NHEJ can also introduce mutations during repair. Loss of damaged nucleotides at the break site can lead to deletions, and joining of nonmatching termini forms insertions or translocations. NHEJ is especially important before the cell has replicated its DNA, since there is no template available for repair by homologous recombination. There are «backup» NHEJ pathways in higher eukaryotes.[30] Besides its role as a genome caretaker, NHEJ is required for joining hairpin-capped double-strand breaks induced during V(D)J recombination, the process that generates diversity in B-cell and T-cell receptors in the vertebrate immune system.[31]
- MMEJ starts with short-range end resection by MRE11 nuclease on either side of a double-strand break to reveal microhomology regions.[32] In further steps,[33] Poly (ADP-ribose) polymerase 1 (PARP1) is required and may be an early step in MMEJ. There is pairing of microhomology regions followed by recruitment of flap structure-specific endonuclease 1 (FEN1) to remove overhanging flaps. This is followed by recruitment of XRCC1–LIG3 to the site for ligating the DNA ends, leading to an intact DNA. MMEJ is always accompanied by a deletion, so that MMEJ is a mutagenic pathway for DNA repair.[34]
- HR requires the presence of an identical or nearly identical sequence to be used as a template for repair of the break. The enzymatic machinery responsible for this repair process is nearly identical to the machinery responsible for chromosomal crossover during meiosis. This pathway allows a damaged chromosome to be repaired using a sister chromatid (available in G2 after DNA replication) or a homologous chromosome as a template. DSBs caused by the replication machinery attempting to synthesize across a single-strand break or unrepaired lesion cause collapse of the replication fork and are typically repaired by recombination.
In an in vitro system, MMEJ occurred in mammalian cells at the levels of 10–20% of HR when both HR and NHEJ mechanisms were also available.[32]
The extremophile Deinococcus radiodurans has a remarkable ability to survive DNA damage from ionizing radiation and other sources. At least two copies of the genome, with random DNA breaks, can form DNA fragments through annealing. Partially overlapping fragments are then used for synthesis of homologous regions through a moving D-loop that can continue extension until complementary partner strands are found. In the final step, there is crossover by means of RecA-dependent homologous recombination.[35]
Topoisomerases introduce both single- and double-strand breaks in the course of changing the DNA’s state of supercoiling, which is especially common in regions near an open replication fork. Such breaks are not considered DNA damage because they are a natural intermediate in the topoisomerase biochemical mechanism and are immediately repaired by the enzymes that created them.
Another type of DNA double-strand breaks originates from the DNA heat-sensitive or heat-labile sites. These DNA sites are not initial DSBs. However, they convert to DSB after treating with elevated temperature. Ionizing irradiation can induces a highly complex form of DNA damage as clustered damage. It consists of different types of DNA lesions in various locations of the DNA helix. Some of these closely located lesions can probably convert to DSB by exposure to high temperatures. But the exact nature of these lesions and their interactions is not yet known[36]
Translesion synthesis[edit]
Translesion synthesis (TLS) is a DNA damage tolerance process that allows the DNA replication machinery to replicate past DNA lesions such as thymine dimers or AP sites.[37] It involves switching out regular DNA polymerases for specialized translesion polymerases (i.e. DNA polymerase IV or V, from the Y Polymerase family), often with larger active sites that can facilitate the insertion of bases opposite damaged nucleotides. The polymerase switching is thought to be mediated by, among other factors, the post-translational modification of the replication processivity factor PCNA. Translesion synthesis polymerases often have low fidelity (high propensity to insert wrong bases) on undamaged templates relative to regular polymerases. However, many are extremely efficient at inserting correct bases opposite specific types of damage. For example, Pol η mediates error-free bypass of lesions induced by UV irradiation, whereas Pol ι introduces mutations at these sites. Pol η is known to add the first adenine across the T^T photodimer using Watson-Crick base pairing and the second adenine will be added in its syn conformation using Hoogsteen base pairing. From a cellular perspective, risking the introduction of point mutations during translesion synthesis may be preferable to resorting to more drastic mechanisms of DNA repair, which may cause gross chromosomal aberrations or cell death. In short, the process involves specialized polymerases either bypassing or repairing lesions at locations of stalled DNA replication. For example, Human DNA polymerase eta can bypass complex DNA lesions like guanine-thymine intra-strand crosslink, G[8,5-Me]T, although it can cause targeted and semi-targeted mutations.[38] Paromita Raychaudhury and Ashis Basu[39] studied the toxicity and mutagenesis of the same lesion in Escherichia coli by replicating a G[8,5-Me]T-modified plasmid in E. coli with specific DNA polymerase knockouts. Viability was very low in a strain lacking pol II, pol IV, and pol V, the three SOS-inducible DNA polymerases, indicating that translesion synthesis is conducted primarily by these specialized DNA polymerases.
A bypass platform is provided to these polymerases by Proliferating cell nuclear antigen (PCNA). Under normal circumstances, PCNA bound to polymerases replicates the DNA. At a site of lesion, PCNA is ubiquitinated, or modified, by the RAD6/RAD18 proteins to provide a platform for the specialized polymerases to bypass the lesion and resume DNA replication.[40][41] After translesion synthesis, extension is required. This extension can be carried out by a replicative polymerase if the TLS is error-free, as in the case of Pol η, yet if TLS results in a mismatch, a specialized polymerase is needed to extend it; Pol ζ. Pol ζ is unique in that it can extend terminal mismatches, whereas more processive polymerases cannot. So when a lesion is encountered, the replication fork will stall, PCNA will switch from a processive polymerase to a TLS polymerase such as Pol ι to fix the lesion, then PCNA may switch to Pol ζ to extend the mismatch, and last PCNA will switch to the processive polymerase to continue replication.
Global response to DNA damage[edit]
Cells exposed to ionizing radiation, ultraviolet light or chemicals are prone to acquire multiple sites of bulky DNA lesions and double-strand breaks. Moreover, DNA damaging agents can damage other biomolecules such as proteins, carbohydrates, lipids, and RNA. The accumulation of damage, to be specific, double-strand breaks or adducts stalling the replication forks, are among known stimulation signals for a global response to DNA damage.[42] The global response to damage is an act directed toward the cells’ own preservation and triggers multiple pathways of macromolecular repair, lesion bypass, tolerance, or apoptosis. The common features of global response are induction of multiple genes, cell cycle arrest, and inhibition of cell division.
Initial steps[edit]
The packaging of eukaryotic DNA into chromatin presents a barrier to all DNA-based processes that require recruitment of enzymes to their sites of action. To allow DNA repair, the chromatin must be remodeled. In eukaryotes, ATP dependent chromatin remodeling complexes and histone-modifying enzymes are two predominant factors employed to accomplish this remodeling process.[43]
Chromatin relaxation occurs rapidly at the site of a DNA damage.[44][45] In one of the earliest steps, the stress-activated protein kinase, c-Jun N-terminal kinase (JNK), phosphorylates SIRT6 on serine 10 in response to double-strand breaks or other DNA damage.[46] This post-translational modification facilitates the mobilization of SIRT6 to DNA damage sites, and is required for efficient recruitment of poly (ADP-ribose) polymerase 1 (PARP1) to DNA break sites and for efficient repair of DSBs.[46] PARP1 protein starts to appear at DNA damage sites in less than a second, with half maximum accumulation within 1.6 seconds after the damage occurs.[47] PARP1 synthesizes polymeric adenosine diphosphate ribose (poly (ADP-ribose) or PAR) chains on itself. Next the chromatin remodeler ALC1 quickly attaches to the product of PARP1 action, a poly-ADP ribose chain, and ALC1 completes arrival at the DNA damage within 10 seconds of the occurrence of the damage.[45] About half of the maximum chromatin relaxation, presumably due to action of ALC1, occurs by 10 seconds.[45] This then allows recruitment of the DNA repair enzyme MRE11, to initiate DNA repair, within 13 seconds.[47]
γH2AX, the phosphorylated form of H2AX is also involved in the early steps leading to chromatin decondensation after DNA double-strand breaks. The histone variant H2AX constitutes about 10% of the H2A histones in human chromatin.[48] γH2AX (H2AX phosphorylated on serine 139) can be detected as soon as 20 seconds after irradiation of cells (with DNA double-strand break formation), and half maximum accumulation of γH2AX occurs in one minute.[48] The extent of chromatin with phosphorylated γH2AX is about two million base pairs at the site of a DNA double-strand break.[48] γH2AX does not, itself, cause chromatin decondensation, but within 30 seconds of irradiation, RNF8 protein can be detected in association with γH2AX.[49] RNF8 mediates extensive chromatin decondensation, through its subsequent interaction with CHD4,[50] a component of the nucleosome remodeling and deacetylase complex NuRD.
DDB2 occurs in a heterodimeric complex with DDB1. This complex further complexes with the ubiquitin ligase protein CUL4A[51] and with PARP1.[52] This larger complex rapidly associates with UV-induced damage within chromatin, with half-maximum association completed in 40 seconds.[51] The PARP1 protein, attached to both DDB1 and DDB2, then PARylates (creates a poly-ADP ribose chain) on DDB2 that attracts the DNA remodeling protein ALC1.[52] Action of ALC1 relaxes the chromatin at the site of UV damage to DNA. This relaxation allows other proteins in the nucleotide excision repair pathway to enter the chromatin and repair UV-induced cyclobutane pyrimidine dimer damages.
After rapid chromatin remodeling, cell cycle checkpoints are activated to allow DNA repair to occur before the cell cycle progresses. First, two kinases, ATM and ATR are activated within 5 or 6 minutes after DNA is damaged. This is followed by phosphorylation of the cell cycle checkpoint protein Chk1, initiating its function, about 10 minutes after DNA is damaged.[53]
DNA damage checkpoints[edit]
After DNA damage, cell cycle checkpoints are activated. Checkpoint activation pauses the cell cycle and gives the cell time to repair the damage before continuing to divide. DNA damage checkpoints occur at the G1/S and G2/M boundaries. An intra-S checkpoint also exists. Checkpoint activation is controlled by two master kinases, ATM and ATR. ATM responds to DNA double-strand breaks and disruptions in chromatin structure,[54] whereas ATR primarily responds to stalled replication forks. These kinases phosphorylate downstream targets in a signal transduction cascade, eventually leading to cell cycle arrest. A class of checkpoint mediator proteins including BRCA1, MDC1, and 53BP1 has also been identified.[55] These proteins seem to be required for transmitting the checkpoint activation signal to downstream proteins.
DNA damage checkpoint is a signal transduction pathway that blocks cell cycle progression in G1, G2 and metaphase and slows down the rate of S phase progression when DNA is damaged. It leads to a pause in cell cycle allowing the cell time to repair the damage before continuing to divide.
Checkpoint Proteins can be separated into four groups: phosphatidylinositol 3-kinase (PI3K)-like protein kinase, proliferating cell nuclear antigen (PCNA)-like group, two serine/threonine(S/T) kinases and their adaptors. Central to all DNA damage induced checkpoints responses is a pair of large protein kinases belonging to the first group of PI3K-like protein kinases-the ATM (Ataxia telangiectasia mutated) and ATR (Ataxia- and Rad-related) kinases, whose sequence and functions have been well conserved in evolution. All DNA damage response requires either ATM or ATR because they have the ability to bind to the chromosomes at the site of DNA damage, together with accessory proteins that are platforms on which DNA damage response components and DNA repair complexes can be assembled.
An important downstream target of ATM and ATR is p53, as it is required for inducing apoptosis following DNA damage.[56] The cyclin-dependent kinase inhibitor p21 is induced by both p53-dependent and p53-independent mechanisms and can arrest the cell cycle at the G1/S and G2/M checkpoints by deactivating cyclin/cyclin-dependent kinase complexes.[57]
The prokaryotic SOS response[edit]
The SOS response is the changes in gene expression in Escherichia coli and other bacteria in response to extensive DNA damage. The prokaryotic SOS system is regulated by two key proteins: LexA and RecA. The LexA homodimer is a transcriptional repressor that binds to operator sequences commonly referred to as SOS boxes. In Escherichia coli it is known that LexA regulates transcription of approximately 48 genes including the lexA and recA genes.[58] The SOS response is known to be widespread in the Bacteria domain, but it is mostly absent in some bacterial phyla, like the Spirochetes.[59]
The most common cellular signals activating the SOS response are regions of single-stranded DNA (ssDNA), arising from stalled replication forks or double-strand breaks, which are processed by DNA helicase to separate the two DNA strands.[42] In the initiation step, RecA protein binds to ssDNA in an ATP hydrolysis driven reaction creating RecA–ssDNA filaments. RecA–ssDNA filaments activate LexA autoprotease activity, which ultimately leads to cleavage of LexA dimer and subsequent LexA degradation. The loss of LexA repressor induces transcription of the SOS genes and allows for further signal induction, inhibition of cell division and an increase in levels of proteins responsible for damage processing.
In Escherichia coli, SOS boxes are 20-nucleotide long sequences near promoters with palindromic structure and a high degree of sequence conservation. In other classes and phyla, the sequence of SOS boxes varies considerably, with different length and composition, but it is always highly conserved and one of the strongest short signals in the genome.[59] The high information content of SOS boxes permits differential binding of LexA to different promoters and allows for timing of the SOS response. The lesion repair genes are induced at the beginning of SOS response. The error-prone translesion polymerases, for example, UmuCD’2 (also called DNA polymerase V), are induced later on as a last resort.[60] Once the DNA damage is repaired or bypassed using polymerases or through recombination, the amount of single-stranded DNA in cells is decreased, lowering the amounts of RecA filaments decreases cleavage activity of LexA homodimer, which then binds to the SOS boxes near promoters and restores normal gene expression.
Eukaryotic transcriptional responses to DNA damage[edit]
Eukaryotic cells exposed to DNA damaging agents also activate important defensive pathways by inducing multiple proteins involved in DNA repair, cell cycle checkpoint control, protein trafficking and degradation. Such genome wide transcriptional response is very complex and tightly regulated, thus allowing coordinated global response to damage. Exposure of yeast Saccharomyces cerevisiae to DNA damaging agents results in overlapping but distinct transcriptional profiles. Similarities to environmental shock response indicates that a general global stress response pathway exist at the level of transcriptional activation. In contrast, different human cell types respond to damage differently indicating an absence of a common global response. The probable explanation for this difference between yeast and human cells may be in the heterogeneity of mammalian cells. In an animal different types of cells are distributed among different organs that have evolved different sensitivities to DNA damage.[61]
In general global response to DNA damage involves expression of multiple genes responsible for postreplication repair, homologous recombination, nucleotide excision repair, DNA damage checkpoint, global transcriptional activation, genes controlling mRNA decay, and many others. A large amount of damage to a cell leaves it with an important decision: undergo apoptosis and die, or survive at the cost of living with a modified genome. An increase in tolerance to damage can lead to an increased rate of survival that will allow a greater accumulation of mutations. Yeast Rev1 and human polymerase η are members of Y family translesion DNA polymerases present during global response to DNA damage and are responsible for enhanced mutagenesis during a global response to DNA damage in eukaryotes.[42]
Aging[edit]
Pathological effects of poor DNA repair[edit]

DNA repair rate is an important determinant of cell pathology.
Experimental animals with genetic deficiencies in DNA repair often show decreased life span and increased cancer incidence.[15] For example, mice deficient in the dominant NHEJ pathway and in telomere maintenance mechanisms get lymphoma and infections more often, and, as a consequence, have shorter lifespans than wild-type mice.[62] In similar manner, mice deficient in a key repair and transcription protein that unwinds DNA helices have premature onset of aging-related diseases and consequent shortening of lifespan.[63] However, not every DNA repair deficiency creates exactly the predicted effects; mice deficient in the NER pathway exhibited shortened life span without correspondingly higher rates of mutation.[64]
If the rate of DNA damage exceeds the capacity of the cell to repair it, the accumulation of errors can overwhelm the cell and result in early senescence, apoptosis, or cancer. Inherited diseases associated with faulty DNA repair functioning result in premature aging,[15] increased sensitivity to carcinogens and correspondingly increased cancer risk (see below). On the other hand, organisms with enhanced DNA repair systems, such as Deinococcus radiodurans, the most radiation-resistant known organism, exhibit remarkable resistance to the double-strand break-inducing effects of radioactivity, likely due to enhanced efficiency of DNA repair and especially NHEJ.[65]
Longevity and caloric restriction[edit]

Most life span influencing genes affect the rate of DNA damage.
A number of individual genes have been identified as influencing variations in life span within a population of organisms. The effects of these genes is strongly dependent on the environment, in particular, on the organism’s diet. Caloric restriction reproducibly results in extended lifespan in a variety of organisms, likely via nutrient sensing pathways and decreased metabolic rate. The molecular mechanisms by which such restriction results in lengthened lifespan are as yet unclear (see[66] for some discussion); however, the behavior of many genes known to be involved in DNA repair is altered under conditions of caloric restriction. Several agents reported to have anti-aging properties have been shown to attenuate constitutive level of mTOR signaling, an evidence of reduction of metabolic activity, and concurrently to reduce constitutive level of DNA damage induced by endogenously generated reactive oxygen species.[67]
For example, increasing the gene dosage of the gene SIR-2, which regulates DNA packaging in the nematode worm Caenorhabditis elegans, can significantly extend lifespan.[68] The mammalian homolog of SIR-2 is known to induce downstream DNA repair factors involved in NHEJ, an activity that is especially promoted under conditions of caloric restriction.[69] Caloric restriction has been closely linked to the rate of base excision repair in the nuclear DNA of rodents,[70] although similar effects have not been observed in mitochondrial DNA.[71]
The C. elegans gene AGE-1, an upstream effector of DNA repair pathways, confers dramatically extended life span under free-feeding conditions but leads to a decrease in reproductive fitness under conditions of caloric restriction.[72] This observation supports the pleiotropy theory of the biological origins of aging, which suggests that genes conferring a large survival advantage early in life will be selected for even if they carry a corresponding disadvantage late in life.
Medicine and DNA repair modulation[edit]
Hereditary DNA repair disorders[edit]
Defects in the NER mechanism are responsible for several genetic disorders, including:
- Xeroderma pigmentosum: hypersensitivity to sunlight/UV, resulting in increased skin cancer incidence and premature aging
- Cockayne syndrome: hypersensitivity to UV and chemical agents
- Trichothiodystrophy: sensitive skin, brittle hair and nails
Mental retardation often accompanies the latter two disorders, suggesting increased vulnerability of developmental neurons.
Other DNA repair disorders include:
- Werner’s syndrome: premature aging and retarded growth
- Bloom’s syndrome: sunlight hypersensitivity, high incidence of malignancies (especially leukemias).
- Ataxia telangiectasia: sensitivity to ionizing radiation and some chemical agents
All of the above diseases are often called «segmental progerias» («accelerated aging diseases») because those affected appear elderly and experience aging-related diseases at an abnormally young age, while not manifesting all the symptoms of old age.
Other diseases associated with reduced DNA repair function include Fanconi anemia, hereditary breast cancer and hereditary colon cancer.
Cancer[edit]
Because of inherent limitations in the DNA repair mechanisms, if humans lived long enough, they would all eventually develop cancer.[73][74] There are at least 34 Inherited human DNA repair gene mutations that increase cancer risk. Many of these mutations cause DNA repair to be less effective than normal. In particular, Hereditary nonpolyposis colorectal cancer (HNPCC) is strongly associated with specific mutations in the DNA mismatch repair pathway. BRCA1 and BRCA2, two important genes whose mutations confer a hugely increased risk of breast cancer on carriers,[75] are both associated with a large number of DNA repair pathways, especially NHEJ and homologous recombination.
Cancer therapy procedures such as chemotherapy and radiotherapy work by overwhelming the capacity of the cell to repair DNA damage, resulting in cell death. Cells that are most rapidly dividing – most typically cancer cells – are preferentially affected. The side-effect is that other non-cancerous but rapidly dividing cells such as progenitor cells in the gut, skin, and hematopoietic system are also affected. Modern cancer treatments attempt to localize the DNA damage to cells and tissues only associated with cancer, either by physical means (concentrating the therapeutic agent in the region of the tumor) or by biochemical means (exploiting a feature unique to cancer cells in the body). In the context of therapies targeting DNA damage response genes, the latter approach has been termed ‘synthetic lethality’.[76]
Perhaps the most well-known of these ‘synthetic lethality’ drugs is the poly(ADP-ribose) polymerase 1 (PARP1) inhibitor olaparib, which was approved by the Food and Drug Administration in 2015 for the treatment in women of BRCA-defective ovarian cancer. Tumor cells with partial loss of DNA damage response (specifically, homologous recombination repair) are dependent on another mechanism – single-strand break repair – which is a mechanism consisting, in part, of the PARP1 gene product.[77] Olaparib is combined with chemotherapeutics to inhibit single-strand break repair induced by DNA damage caused by the co-administered chemotherapy. Tumor cells relying on this residual DNA repair mechanism are unable to repair the damage and hence are not able to survive and proliferate, whereas normal cells can repair the damage with the functioning homologous recombination mechanism.
Many other drugs for use against other residual DNA repair mechanisms commonly found in cancer are currently under investigation. However, synthetic lethality therapeutic approaches have been questioned due to emerging evidence of acquired resistance, achieved through rewiring of DNA damage response pathways and reversion of previously inhibited defects.[78]
DNA repair defects in cancer[edit]
It has become apparent over the past several years that the DNA damage response acts as a barrier to the malignant transformation of preneoplastic cells.[79] Previous studies have shown an elevated DNA damage response in cell-culture models with oncogene activation[80] and preneoplastic colon adenomas.[81] DNA damage response mechanisms trigger cell-cycle arrest, and attempt to repair DNA lesions or promote cell death/senescence if repair is not possible. Replication stress is observed in preneoplastic cells due to increased proliferation signals from oncogenic mutations. Replication stress is characterized by: increased replication initiation/origin firing; increased transcription and collisions of transcription-replication complexes; nucleotide deficiency; increase in reactive oxygen species (ROS).[82]
Replication stress, along with the selection for inactivating mutations in DNA damage response genes in the evolution of the tumor,[83] leads to downregulation and/or loss of some DNA damage response mechanisms, and hence loss of DNA repair and/or senescence/programmed cell death. In experimental mouse models, loss of DNA damage response-mediated cell senescence was observed after using a short hairpin RNA (shRNA) to inhibit the double-strand break response kinase ataxia telangiectasia (ATM), leading to increased tumor size and invasiveness.[81] Humans born with inherited defects in DNA repair mechanisms (for example, Li-Fraumeni syndrome) have a higher cancer risk.[84]
The prevalence of DNA damage response mutations differs across cancer types; for example, 30% of breast invasive carcinomas have mutations in genes involved in homologous recombination.[79] In cancer, downregulation is observed across all DNA damage response mechanisms (base excision repair (BER), nucleotide excision repair (NER), DNA mismatch repair (MMR), homologous recombination repair (HR), non-homologous end joining (NHEJ) and translesion DNA synthesis (TLS).[85] As well as mutations to DNA damage repair genes, mutations also arise in the genes responsible for arresting the cell cycle to allow sufficient time for DNA repair to occur, and some genes are involved in both DNA damage repair and cell cycle checkpoint control, for example ATM and checkpoint kinase 2 (CHEK2) – a tumor suppressor that is often absent or downregulated in non-small cell lung cancer.[86]
| HR | NHEJ | SSA | FA | BER | NER | MMR | |
|---|---|---|---|---|---|---|---|
| ATM | |||||||
| ATR | |||||||
| PAXIP | |||||||
| RPA | |||||||
| BRCA1 | |||||||
| BRCA2 | |||||||
| RAD51 | |||||||
| RFC | |||||||
| XRCC1 | |||||||
| PCNA | |||||||
| PARP1 | |||||||
| ERCC1 | |||||||
| MSH3 |
Epigenetic DNA repair defects in cancer[edit]
Classically, cancer has been viewed as a set of diseases that are driven by progressive genetic abnormalities that include mutations in tumour-suppressor genes and oncogenes, and chromosomal aberrations. However, it has become apparent that cancer is also driven by
epigenetic alterations.[87]
Epigenetic alterations refer to functionally relevant modifications to the genome that do not involve a change in the nucleotide sequence. Examples of such modifications are changes in DNA methylation (hypermethylation and hypomethylation) and histone modification,[88] changes in chromosomal architecture (caused by inappropriate expression of proteins such as HMGA2 or HMGA1)[89] and changes caused by microRNAs. Each of these epigenetic alterations serves to regulate gene expression without altering the underlying DNA sequence. These changes usually remain through cell divisions, last for multiple cell generations, and can be considered to be epimutations (equivalent to mutations).
While large numbers of epigenetic alterations are found in cancers, the epigenetic alterations in DNA repair genes, causing reduced expression of DNA repair proteins, appear to be particularly important. Such alterations are thought to occur early in progression to cancer and to be a likely cause of the genetic instability characteristic of cancers.[90][91][92]
Reduced expression of DNA repair genes causes deficient DNA repair. When DNA repair is deficient DNA damages remain in cells at a higher than usual level and these excess damages cause increased frequencies of mutation or epimutation. Mutation rates increase substantially in cells defective in DNA mismatch repair[93][94] or in homologous recombinational repair (HRR).[95] Chromosomal rearrangements and aneuploidy also increase in HRR defective cells.[96]
Higher levels of DNA damage not only cause increased mutation, but also cause increased epimutation. During repair of DNA double strand breaks, or repair of other DNA damages, incompletely cleared sites of repair can cause epigenetic gene silencing.[97][98]
Deficient expression of DNA repair proteins due to an inherited mutation can cause increased risk of cancer. Individuals with an inherited impairment in any of 34 DNA repair genes (see article DNA repair-deficiency disorder) have an increased risk of cancer, with some defects causing up to a 100% lifetime chance of cancer (e.g. p53 mutations).[99] However, such germline mutations (which cause highly penetrant cancer syndromes) are the cause of only about 1 percent of cancers.[100]
Frequencies of epimutations in DNA repair genes[edit]
A chart of common DNA damaging agents, examples of lesions they cause in DNA, and pathways used to repair these lesions. Also shown are many of the genes in these pathways, an indication of which genes are epigenetically regulated to have reduced (or increased) expression in various cancers. It also shows genes in the error-prone microhomology-mediated end joining pathway with increased expression in various cancers.
Deficiencies in DNA repair enzymes are occasionally caused by a newly arising somatic mutation in a DNA repair gene, but are much more frequently caused by epigenetic alterations that reduce or silence expression of DNA repair genes. For example, when 113 colorectal cancers were examined in sequence, only four had a missense mutation in the DNA repair gene MGMT, while the majority had reduced MGMT expression due to methylation of the MGMT promoter region (an epigenetic alteration).[101] Five different studies found that between 40% and 90% of colorectal cancers have reduced MGMT expression due to methylation of the MGMT promoter region.[102][103][104][105][106]
Similarly, out of 119 cases of mismatch repair-deficient colorectal cancers that lacked DNA repair gene PMS2 expression, PMS2 was deficient in 6 due to mutations in the PMS2 gene, while in 103 cases PMS2 expression was deficient because its pairing partner MLH1 was repressed due to promoter methylation (PMS2 protein is unstable in the absence of MLH1).[107] In the other 10 cases, loss of PMS2 expression was likely due to epigenetic overexpression of the microRNA, miR-155, which down-regulates MLH1.[108]
In a further example, epigenetic defects were found in various cancers (e.g. breast, ovarian, colorectal and head and neck). Two or three deficiencies in the expression of ERCC1, XPF or PMS2 occur simultaneously in the majority of 49 colon cancers evaluated by Facista et al.[109]
The chart in this section shows some frequent DNA damaging agents, examples of DNA lesions they cause, and the pathways that deal with these DNA damages. At least 169 enzymes are either directly employed in DNA repair or influence DNA repair processes.[110] Of these, 83 are directly employed in repairing the 5 types of DNA damages illustrated in the chart.
Some of the more well studied genes central to these repair processes are shown in the chart. The gene designations shown in red, gray or cyan indicate genes frequently epigenetically altered in various types of cancers. Wikipedia articles on each of the genes highlighted by red, gray or cyan describe the epigenetic alteration(s) and the cancer(s) in which these epimutations are found. Review articles,[111] and broad experimental survey articles[112][113] also document most of these epigenetic DNA repair deficiencies in cancers.
Red-highlighted genes are frequently reduced or silenced by epigenetic mechanisms in various cancers. When these genes have low or absent expression, DNA damages can accumulate. Replication errors past these damages (see translesion synthesis) can lead to increased mutations and, ultimately, cancer. Epigenetic repression of DNA repair genes in accurate DNA repair pathways appear to be central to carcinogenesis.
The two gray-highlighted genes RAD51 and BRCA2, are required for homologous recombinational repair. They are sometimes epigenetically over-expressed and sometimes under-expressed in certain cancers. As indicated in the Wikipedia articles on RAD51 and BRCA2, such cancers ordinarily have epigenetic deficiencies in other DNA repair genes. These repair deficiencies would likely cause increased unrepaired DNA damages. The over-expression of RAD51 and BRCA2 seen in these cancers may reflect selective pressures for compensatory RAD51 or BRCA2 over-expression and increased homologous recombinational repair to at least partially deal with such excess DNA damages. In those cases where RAD51 or BRCA2 are under-expressed, this would itself lead to increased unrepaired DNA damages. Replication errors past these damages (see translesion synthesis) could cause increased mutations and cancer, so that under-expression of RAD51 or BRCA2 would be carcinogenic in itself.
Cyan-highlighted genes are in the microhomology-mediated end joining (MMEJ) pathway and are up-regulated in cancer. MMEJ is an additional error-prone inaccurate repair pathway for double-strand breaks. In MMEJ repair of a double-strand break, an homology of 5–25 complementary base pairs between both paired strands is sufficient to align the strands, but mismatched ends (flaps) are usually present. MMEJ removes the extra nucleotides (flaps) where strands are joined, and then ligates the strands to create an intact DNA double helix. MMEJ almost always involves at least a small deletion, so that it is a mutagenic pathway.[24] FEN1, the flap endonuclease in MMEJ, is epigenetically increased by promoter hypomethylation and is over-expressed in the majority of cancers of the breast,[114] prostate,[115] stomach,[116][117] neuroblastomas,[118] pancreas,[119] and lung.[120] PARP1 is also over-expressed when its promoter region ETS site is epigenetically hypomethylated, and this contributes to progression to endometrial cancer[121] and BRCA-mutated serous ovarian cancer.[122] Other genes in the MMEJ pathway are also over-expressed in a number of cancers (see MMEJ for summary), and are also shown in cyan.
Genome-wide distribution of DNA repair in human somatic cells[edit]
Differential activity of DNA repair pathways across various regions of the human genome causes mutations to be very unevenly distributed within tumor genomes.[123][124] In particular, the gene-rich, early-replicating regions of the human genome exhibit lower mutation frequencies than the gene-poor, late-replicating heterochromatin. One mechanism underlying this involves the histone modification H3K36me3, which can recruit mismatch repair proteins,[125] thereby lowering mutation rates in H3K36me3-marked regions.[126] Another important mechanism concerns nucleotide excision repair, which can be recruited by the transcription machinery, lowering somatic mutation rates in active genes[124] and other open chromatin regions.[127]
Epigenetic alterations due to DNA repair[edit]
Damage to DNA is very common and is constantly being repaired. Epigenetic alterations can accompany DNA repair of oxidative damage or double-strand breaks. In human cells, oxidative DNA damage occurs about 10,000 times a day and DNA double-strand breaks occur about 10 to 50 times a cell cycle in somatic replicating cells (see DNA damage (naturally occurring)). The selective advantage of DNA repair is to allow the cell to survive in the face of DNA damage. The selective advantage of epigenetic alterations that occur with DNA repair is not clear.
Repair of oxidative DNA damage can alter epigenetic markers[edit]
In the steady state (with endogenous damages occurring and being repaired), there are about 2,400 oxidatively damaged guanines that form 8-oxo-2′-deoxyguanosine (8-OHdG) in the average mamalian cell DNA.[128] 8-OHdG constitutes about 5% of the oxidative damages commonly present in DNA.[129] The oxidized guanines do not occur randomly among all guanines in DNA. There is a sequence preference for the guanine at a methylated CpG site (a cytosine followed by guanine along its 5′ → 3′ direction and where the cytosine is methylated (5-mCpG)).[130] A 5-mCpG site has the lowest ionization potential for guanine oxidation.

Initiation of DNA demethylation at a CpG site. In adult somatic cells DNA methylation typically occurs in the context of CpG dinucleotides (CpG sites), forming 5-methylcytosine-pG, or 5mCpG. Reactive oxygen species (ROS) may attack guanine at the dinucleotide site, forming 8-hydroxy-2′-deoxyguanosine (8-OHdG), and resulting in a 5mCp-8-OHdG dinucleotide site. The base excision repair enzyme OGG1 targets 8-OHdG and binds to the lesion without immediate excision. OGG1, present at a 5mCp-8-OHdG site recruits TET1 and TET1 oxidizes the 5mC adjacent to the 8-OHdG. This initiates demethylation of 5mC.[131]
Oxidized guanine has mispairing potential and is mutagenic.[132] Oxoguanine glycosylase (OGG1) is the primary enzyme responsible for the excision of the oxidized guanine during DNA repair. OGG1 finds and binds to an 8-OHdG within a few seconds.[133] However, OGG1 does not immediately excise 8-OHdG. In HeLa cells half maximum removal of 8-OHdG occurs in 30 minutes,[134] and in irradiated mice, the 8-OHdGs induced in the mouse liver are removed with a half-life of 11 minutes.[129]
When OGG1 is present at an oxidized guanine within a methylated CpG site it recruits TET1 to the 8-OHdG lesion (see Figure). This allows TET1 to demethylate an adjacent methylated cytosine. Demethylation of cytosine is an epigenetic alteration.
As an example, when human mammary epithelial cells were treated with H2O2 for six hours, 8-OHdG increased about 3.5-fold in DNA and this caused about 80% demethylation of the 5-methylcytosines in the genome.[131] Demethylation of CpGs in a gene promoter by TET enzyme activity increases transcription of the gene into messenger RNA.[135] In cells treated with H2O2, one particular gene was examined, BACE1.[131] The methylation level of the BACE1 CpG island was reduced (an epigenetic alteration) and this allowed about 6.5 fold increase of expression of BACE1 messenger RNA.
While six-hour incubation with H2O2 causes considerable demethylation of 5-mCpG sites, shorter times of H2O2 incubation appear to promote other epigenetic alterations. Treatment of cells with H2O2 for 30 minutes causes the mismatch repair protein heterodimer MSH2-MSH6 to recruit DNA methyltransferase 1 (DNMT1) to sites of some kinds of oxidative DNA damage.[136] This could cause increased methylation of cytosines (epigenetic alterations) at these locations.
Jiang et al.[137] treated HEK 293 cells with agents causing oxidative DNA damage, (potassium bromate (KBrO3) or potassium chromate (K2CrO4)). Base excision repair (BER) of oxidative damage occurred with the DNA repair enzyme polymerase beta localizing to oxidized guanines. Polymerase beta is the main human polymerase in short-patch BER of oxidative DNA damage. Jiang et al.[137] also found that polymerase beta recruited the DNA methyltransferase protein DNMT3b to BER repair sites. They then evaluated the methylation pattern at the single nucleotide level in a small region of DNA including the promoter region and the early transcription region of the BRCA1 gene. Oxidative DNA damage from bromate modulated the DNA methylation pattern (caused epigenetic alterations) at CpG sites within the region of DNA studied. In untreated cells, CpGs located at −189, −134, −29, −19, +16, and +19 of the BRCA1 gene had methylated cytosines (where numbering is from the messenger RNA transcription start site, and negative numbers indicate nucleotides in the upstream promoter region). Bromate treatment-induced oxidation resulted in the loss of cytosine methylation at −189, −134, +16 and +19 while also leading to the formation of new methylation at the CpGs located at −80, −55, −21 and +8 after DNA repair was allowed.
Homologous recombinational repair alters epigenetic markers[edit]
At least four articles report the recruitment of DNA methyltransferase 1 (DNMT1) to sites of DNA double-strand breaks.[138][139][140][141] During homologous recombinational repair (HR) of the double-strand break, the involvement of DNMT1 causes the two repaired strands of DNA to have different levels of methylated cytosines. One strand becomes frequently methylated at about 21 CpG sites downstream of the repaired double-strand break. The other DNA strand loses methylation at about six CpG sites that were previously methylated downstream of the double-strand break, as well as losing methylation at about five CpG sites that were previously methylated upstream of the double-strand break. When the chromosome is replicated, this gives rise to one daughter chromosome that is heavily methylated downstream of the previous break site and one that is unmethylated in the region both upstream and downstream of the previous break site. With respect to the gene that was broken by the double-strand break, half of the progeny cells express that gene at a high level and in the other half of the progeny cells expression of that gene is repressed. When clones of these cells were maintained for three years, the new methylation patterns were maintained over that time period.[142]
In mice with a CRISPR-mediated homology-directed recombination insertion in their genome there were a large number of increased methylations of CpG sites within the double-strand break-associated insertion.[143]
Non-homologous end joining can cause some epigenetic marker alterations[edit]
Non-homologous end joining (NHEJ) repair of a double-strand break can cause a small number of demethylations of pre-existing cytosine DNA methylations downstream of the repaired double-strand break.[139] Further work by Allen et al.[144] showed that NHEJ of a DNA double-strand break in a cell could give rise to some progeny cells having repressed expression of the gene harboring the initial double-strand break and some progeny having high expression of that gene due to epigenetic alterations associated with NHEJ repair. The frequency of epigenetic alterations causing repression of a gene after an NHEJ repair of a DNA double-strand break in that gene may be about 0.9%.[140]
Evolution[edit]
The basic processes of DNA repair are highly conserved among both prokaryotes and eukaryotes and even among bacteriophages (viruses which infect bacteria); however, more complex organisms with more complex genomes have correspondingly more complex repair mechanisms.[145] The ability of a large number of protein structural motifs to catalyze relevant chemical reactions has played a significant role in the elaboration of repair mechanisms during evolution. For an extremely detailed review of hypotheses relating to the evolution of DNA repair, see.[146]
The fossil record indicates that single-cell life began to proliferate on the planet at some point during the Precambrian period, although exactly when recognizably modern life first emerged is unclear. Nucleic acids became the sole and universal means of encoding genetic information, requiring DNA repair mechanisms that in their basic form have been inherited by all extant life forms from their common ancestor. The emergence of Earth’s oxygen-rich atmosphere (known as the «oxygen catastrophe») due to photosynthetic organisms, as well as the presence of potentially damaging free radicals in the cell due to oxidative phosphorylation, necessitated the evolution of DNA repair mechanisms that act specifically to counter the types of damage induced by oxidative stress.
Rate of evolutionary change[edit]
On some occasions, DNA damage is not repaired or is repaired by an error-prone mechanism that results in a change from the original sequence. When this occurs, mutations may propagate into the genomes of the cell’s progeny. Should such an event occur in a germ line cell that will eventually produce a gamete, the mutation has the potential to be passed on to the organism’s offspring. The rate of evolution in a particular species (or, in a particular gene) is a function of the rate of mutation. As a consequence, the rate and accuracy of DNA repair mechanisms have an influence over the process of evolutionary change.[147] DNA damage protection and repair does not influence the rate of adaptation by gene regulation and by recombination and selection of alleles. On the other hand, DNA damage repair and protection does influence the rate of accumulation of irreparable, advantageous, code expanding, inheritable mutations, and slows down the evolutionary mechanism for expansion of the genome of organisms with new functionalities. The tension between evolvability and mutation repair and protection needs further investigation.
Technology[edit]
A technology named clustered regularly interspaced short palindromic repeat (shortened to CRISPR-Cas9) was discovered in 2012. The new technology allows anyone with molecular biology training to alter the genes of any species with precision, by inducing DNA damage at a specific point and then altering DNA repair mechanisms to insert new genes.[148] It is cheaper, more efficient, and more precise than other technologies. With the help of CRISPR–Cas9, parts of a genome can be edited by scientists by removing, adding, or altering parts in a DNA sequence.
See also[edit]
- Accelerated aging disease
- Aging DNA
- Cell cycle
- DNA damage (naturally occurring)
- DNA damage theory of aging
- DNA replication
- Direct DNA damage
- Gene therapy
- Human mitochondrial genetics
- Indirect DNA damage
- Life extension
- Progeria
- REPAIRtoire
- Senescence
- SiDNA
- The scientific journal DNA Repair under Mutation Research
References[edit]
- ^ «Nature Reviews Series: DNA damage». Nature Reviews Molecular Cell Biology. 5 July 2017. Retrieved 7 November 2018.
- ^ a b Lodish H, Berk A, Matsudaira P, Kaiser CA, Krieger M, Scott MP, Zipursky SL, Darnell J (2004). Molecular Biology of the Cell (5th ed.). New York: WH Freeman. p. 963.
- ^ a b Acharya PV (1971). «The isolation and partial characterization of age-correlated oligo-deoxyribo-ribonucleotides with covalently linked aspartyl-glutamyl polypeptides». Johns Hopkins Medical Journal. Supplement (1): 254–60. PMID 5055816.
- ^ a b Bjorksten J, Acharya PV, Ashman S, Wetlaufer DB (July 1971). «Gerogenic fractions in the tritiated rat». Journal of the American Geriatrics Society. 19 (7): 561–74. doi:10.1111/j.1532-5415.1971.tb02577.x. PMID 5106728. S2CID 33154242.
- ^ Browner WS, Kahn AJ, Ziv E, Reiner AP, Oshima J, Cawthon RM, et al. (December 2004). «The genetics of human longevity». The American Journal of Medicine. 117 (11): 851–60. CiteSeerX 10.1.1.556.6874. doi:10.1016/j.amjmed.2004.06.033. PMID 15589490.
- ^ Broad WJ (7 October 2015). «Nobel Prize in Chemistry Awarded to Tomas Lindahl, Paul Modrich and Aziz Sancar for DNA Studies». The New York Times. Retrieved 7 October 2015.
- ^ Staff (7 October 2015). «The Nobel Prize in Chemistry 2015 – DNA repair – providing chemical stability for life» (PDF). Nobel Prize. Retrieved 7 October 2015.
- ^ Roulston A, Marcellus RC, Branton PE (1999). «Viruses and apoptosis». Annual Review of Microbiology. 53: 577–628. doi:10.1146/annurev.micro.53.1.577. PMID 10547702.
- ^ Madigan MT, Martino JM (2006). Brock Biology of Microorganisms (11th ed.). Pearson. p. 136. ISBN 978-0-13-196893-6.
- ^ Ohta T, Tokishita SI, Mochizuki K, Kawase J, Sakahira M, Yamagata H (2006). «UV Sensitivity and Mutagenesis of the Extremely Thermophilic Eubacterium Thermus thermophilus HB27». Genes and Environment. 28 (2): 56–61. doi:10.3123/jemsge.28.56.
- ^ Tanaka T, Halicka HD, Huang X, Traganos F, Darzynkiewicz Z (September 2006). «Constitutive histone H2AX phosphorylation and ATM activation, the reporters of DNA damage by endogenous oxidants». Cell Cycle. 5 (17): 1940–45. doi:10.4161/cc.5.17.3191. PMC 3488278. PMID 16940754.
- ^ Braig M, Schmitt CA (March 2006). «Oncogene-induced senescence: putting the brakes on tumor development». Cancer Research. 66 (6): 2881–84. doi:10.1158/0008-5472.CAN-05-4006. PMID 16540631.
- ^ Lynch MD (February 2006). «How does cellular senescence prevent cancer?». DNA and Cell Biology. 25 (2): 69–78. doi:10.1089/dna.2006.25.69. PMID 16460230.
- ^ Campisi J, d’Adda di Fagagna F (September 2007). «Cellular senescence: when bad things happen to good cells». Nature Reviews. Molecular Cell Biology. 8 (9): 729–40. doi:10.1038/nrm2233. PMID 17667954. S2CID 15664931.
- ^ a b c Best BP (June 2009). «Nuclear DNA damage as a direct cause of aging» (PDF). Rejuvenation Research. 12 (3): 199–208. CiteSeerX 10.1.1.318.738. doi:10.1089/rej.2009.0847. PMID 19594328. Archived from the original (PDF) on 15 November 2017. Retrieved 29 September 2009.
- ^ Sancar A (June 2003). «Structure and function of DNA photolyase and cryptochrome blue-light photoreceptors». Chemical Reviews. 103 (6): 2203–37. doi:10.1021/cr0204348. PMID 12797829.
- ^ Lucas-Lledó JI, Lynch M (May 2009). «Evolution of mutation rates: phylogenomic analysis of the photolyase/cryptochrome family». Molecular Biology and Evolution. 26 (5): 1143–53. doi:10.1093/molbev/msp029. PMC 2668831. PMID 19228922.
- ^ a b c Watson JD, Baker TA, Bell SP, Gann A, Levine M, Losick R (2004). Molecular Biology of the Gene (5th ed.). Pearson Benjamin Cummings; CSHL Press. Ch. 9, 10. OCLC 936762772.
- ^ Volkert MR (1988). «Adaptive response of Escherichia coli to alkylation damage». Environmental and Molecular Mutagenesis. 11 (2): 241–55. doi:10.1002/em.2850110210. PMID 3278898. S2CID 24722637.
- ^ a b c Willey J, Sherwood L, Woolverton C (2014). Prescott’s Microbiology. New York: McGraw Hill. p. 381. ISBN 978-0-07-3402-40-6.
- ^ Russell P (2018). i Genetics. Chennai: Pearson. p. 186. ISBN 978-93-325-7162-4.
- ^ a b c d Reardon JT, Sancar A (2006). «Purification and characterization of Escherichia coli and human nucleotide excision repair enzyme systems». Methods in Enzymology. 408: 189–213. doi:10.1016/S0076-6879(06)08012-8. ISBN 9780121828134. PMID 16793370.
- ^ Berg M, Tymoczko J, Stryer L (2012). Biochemistry 7th edition. New York: W.H. Freeman and Company. p. 840. ISBN 9781429229364.
- ^ a b Liang L, Deng L, Chen Y, Li GC, Shao C, Tischfield JA (September 2005). «Modulation of DNA end joining by nuclear proteins». The Journal of Biological Chemistry. 280 (36): 31442–49. doi:10.1074/jbc.M503776200. PMID 16012167.
- ^ Wilson TE, Grawunder U, Lieber MR (July 1997). «Yeast DNA ligase IV mediates non-homologous DNA end joining». Nature. 388 (6641): 495–98. Bibcode:1997Natur.388..495W. doi:10.1038/41365. PMID 9242411. S2CID 4422938.
- ^ Moore JK, Haber JE (May 1996). «Cell cycle and genetic requirements of two pathways of nonhomologous end-joining repair of double-strand breaks in Saccharomyces cerevisiae». Molecular and Cellular Biology. 16 (5): 2164–73. doi:10.1128/mcb.16.5.2164. PMC 231204. PMID 8628283.
- ^ Boulton SJ, Jackson SP (September 1996). «Saccharomyces cerevisiae Ku70 potentiates illegitimate DNA double-strand break repair and serves as a barrier to error-prone DNA repair pathways». The EMBO Journal. 15 (18): 5093–103. doi:10.1002/j.1460-2075.1996.tb00890.x. PMC 452249. PMID 8890183.
- ^ Wilson TE, Lieber MR (August 1999). «Efficient processing of DNA ends during yeast nonhomologous end joining. Evidence for a DNA polymerase beta (Pol4)-dependent pathway». The Journal of Biological Chemistry. 274 (33): 23599–609. doi:10.1074/jbc.274.33.23599. PMID 10438542.
- ^ Budman J, Chu G (February 2005). «Processing of DNA for nonhomologous end-joining by cell-free extract». The EMBO Journal. 24 (4): 849–60. doi:10.1038/sj.emboj.7600563. PMC 549622. PMID 15692565.
- ^ Wang H, Perrault AR, Takeda Y, Qin W, Wang H, Iliakis G (September 2003). «Biochemical evidence for Ku-independent backup pathways of NHEJ». Nucleic Acids Research. 31 (18): 5377–88. doi:10.1093/nar/gkg728. PMC 203313. PMID 12954774.
- ^ Jung D, Alt FW (January 2004). «Unraveling V(D)J recombination; insights into gene regulation». Cell. 116 (2): 299–311. doi:10.1016/S0092-8674(04)00039-X. PMID 14744439. S2CID 16890458.
- ^ a b Truong LN, Li Y, Shi LZ, Hwang PY, He J, Wang H, et al. (May 2013). «Microhomology-mediated End Joining and Homologous Recombination share the initial end resection step to repair DNA double-strand breaks in mammalian cells». Proceedings of the National Academy of Sciences of the United States of America. 110 (19): 7720–25. Bibcode:2013PNAS..110.7720T. doi:10.1073/pnas.1213431110. PMC 3651503. PMID 23610439.
- ^ Sharma S, Javadekar SM, Pandey M, Srivastava M, Kumari R, Raghavan SC (March 2015). «Homology and enzymatic requirements of microhomology-dependent alternative end joining». Cell Death & Disease. 6 (3): e1697. doi:10.1038/cddis.2015.58. PMC 4385936. PMID 25789972.
- ^ Decottignies A (2013). «Alternative end-joining mechanisms: a historical perspective». Frontiers in Genetics. 4: 48. doi:10.3389/fgene.2013.00048. PMC 3613618. PMID 23565119.
- ^ Zahradka K, Slade D, Bailone A, Sommer S, Averbeck D, Petranovic M, et al. (October 2006). «Reassembly of shattered chromosomes in Deinococcus radiodurans». Nature. 443 (7111): 569–73. Bibcode:2006Natur.443..569Z. doi:10.1038/nature05160. PMID 17006450. S2CID 4412830.
- ^ Stenerlöw B, Karlsson KH, Cooper B, Rydberg B. «Measurement of prompt DNA double-strand breaks in mammalian cells without including heat-labile sites: results for cells deficient in nonhomologous end joining». Radiat Res. 2003 Apr;159(4):502–10. doi:10.1667/0033-7587(2003)159[0502:mopdds2.0.co;2] PMID 12643795.
- ^ Waters LS, Minesinger BK, Wiltrout ME, D’Souza S, Woodruff RV, Walker GC (March 2009). «Eukaryotic translesion polymerases and their roles and regulation in DNA damage tolerance». Microbiology and Molecular Biology Reviews. 73 (1): 134–54. doi:10.1128/MMBR.00034-08. PMC 2650891. PMID 19258535.
- ^ Colis LC, Raychaudhury P, Basu AK (August 2008). «Mutational specificity of gamma-radiation-induced guanine-thymine and thymine-guanine intrastrand cross-links in mammalian cells and translesion synthesis past the guanine-thymine lesion by human DNA polymerase eta». Biochemistry. 47 (31): 8070–79. doi:10.1021/bi800529f. PMC 2646719. PMID 18616294.
- ^ Raychaudhury P, Basu AK (March 2011). «Genetic requirement for mutagenesis of the G[8,5-Me]T cross-link in Escherichia coli: DNA polymerases IV and V compete for error-prone bypass». Biochemistry. 50 (12): 2330–38. doi:10.1021/bi102064z. PMC 3062377. PMID 21302943.
- ^ «Translesion Synthesis». Research.chem.psu.edu. Archived from the original on 10 March 2012. Retrieved 14 August 2012.
- ^ Wang Z (July 2001). «Translesion synthesis by the UmuC family of DNA polymerases». Mutation Research. 486 (2): 59–70. doi:10.1016/S0921-8777(01)00089-1. PMID 11425512.
- ^ a b c Friedberg EC, Walker GC, Siede W, Wood RD, Schultz RA, Ellenberger T. (2006). DNA Repair and Mutagenesis, part 3. ASM Press. 2nd ed.
- ^ Liu B, Yip RK, Zhou Z (November 2012). «Chromatin remodeling, DNA damage repair and aging». Current Genomics. 13 (7): 533–47. doi:10.2174/138920212803251373. PMC 3468886. PMID 23633913.
- ^ Halicka HD, Zhao H, Podhorecka M, Traganos F, Darzynkiewicz Z (July 2009). «Cytometric detection of chromatin relaxation, an early reporter of DNA damage response». Cell Cycle. 8 (14): 2233–37. doi:10.4161/cc.8.14.8984. PMC 3856216. PMID 19502789.
- ^ a b c Sellou H, Lebeaupin T, Chapuis C, Smith R, Hegele A, Singh HR, et al. (December 2016). «The poly(ADP-ribose)-dependent chromatin remodeler Alc1 induces local chromatin relaxation upon DNA damage». Molecular Biology of the Cell. 27 (24): 3791–99. doi:10.1091/mbc.E16-05-0269. PMC 5170603. PMID 27733626.
- ^ a b Van Meter M, Simon M, Tombline G, May A, Morello TD, Hubbard BP, et al. (September 2016). «JNK Phosphorylates SIRT6 to Stimulate DNA Double-Strand Break Repair in Response to Oxidative Stress by Recruiting PARP1 to DNA Breaks». Cell Reports. 16 (10): 2641–50. doi:10.1016/j.celrep.2016.08.006. PMC 5089070. PMID 27568560.
- ^ a b Haince JF, McDonald D, Rodrigue A, Déry U, Masson JY, Hendzel MJ, Poirier GG (January 2008). «PARP1-dependent kinetics of recruitment of MRE11 and NBS1 proteins to multiple DNA damage sites». The Journal of Biological Chemistry. 283 (2): 1197–208. doi:10.1074/jbc.M706734200. PMID 18025084.
- ^ a b c Rogakou EP, Pilch DR, Orr AH, Ivanova VS, Bonner WM (March 1998). «DNA double-stranded breaks induce histone H2AX phosphorylation on serine 139». The Journal of Biological Chemistry. 273 (10): 5858–68. doi:10.1074/jbc.273.10.5858. PMID 9488723.
- ^ Mailand N, Bekker-Jensen S, Faustrup H, Melander F, Bartek J, Lukas C, Lukas J (November 2007). «RNF8 ubiquitylates histones at DNA double-strand breaks and promotes assembly of repair proteins». Cell. 131 (5): 887–900. doi:10.1016/j.cell.2007.09.040. PMID 18001824. S2CID 14232192.
- ^ Luijsterburg MS, Acs K, Ackermann L, Wiegant WW, Bekker-Jensen S, Larsen DH, et al. (May 2012). «A new non-catalytic role for ubiquitin ligase RNF8 in unfolding higher-order chromatin structure». The EMBO Journal. 31 (11): 2511–27. doi:10.1038/emboj.2012.104. PMC 3365417. PMID 22531782.
- ^ a b Luijsterburg MS, Goedhart J, Moser J, Kool H, Geverts B, Houtsmuller AB, et al. (August 2007). «Dynamic in vivo interaction of DDB2 E3 ubiquitin ligase with UV-damaged DNA is independent of damage-recognition protein XPC». Journal of Cell Science. 120 (Pt 15): 2706–16. doi:10.1242/jcs.008367. PMID 17635991.
- ^ a b Pines A, Vrouwe MG, Marteijn JA, Typas D, Luijsterburg MS, Cansoy M, et al. (October 2012). «PARP1 promotes nucleotide excision repair through DDB2 stabilization and recruitment of ALC1». The Journal of Cell Biology. 199 (2): 235–49. doi:10.1083/jcb.201112132. PMC 3471223. PMID 23045548.
- ^ Jazayeri A, Falck J, Lukas C, Bartek J, Smith GC, Lukas J, Jackson SP (January 2006). «ATM- and cell cycle-dependent regulation of ATR in response to DNA double-strand breaks». Nature Cell Biology. 8 (1): 37–45. doi:10.1038/ncb1337. PMID 16327781. S2CID 9797133.
- ^ Bakkenist CJ, Kastan MB (January 2003). «DNA damage activates ATM through intermolecular autophosphorylation and dimer dissociation». Nature. 421 (6922): 499–506. Bibcode:2003Natur.421..499B. doi:10.1038/nature01368. PMID 12556884. S2CID 4403303.
- ^ Wei Q, Li L, Chen D (2007). DNA Repair, Genetic Instability, and Cancer. World Scientific. ISBN 978-981-270-014-8.[page needed]
- ^ Schonthal AH (2004). Checkpoint Controls and Cancer. Humana Press. ISBN 978-1-58829-500-2.[page needed]
- ^ Gartel AL, Tyner AL (June 2002). «The role of the cyclin-dependent kinase inhibitor p21 in apoptosis». Molecular Cancer Therapeutics. 1 (8): 639–49. PMID 12479224.
- ^ Janion C (2001). «Some aspects of the SOS response system—a critical survey». Acta Biochimica Polonica. 48 (3): 599–610. doi:10.18388/abp.2001_3894. PMID 11833768.
- ^ a b Erill I, Campoy S, Barbé J (November 2007). «Aeons of distress: an evolutionary perspective on the bacterial SOS response». FEMS Microbiology Reviews. 31 (6): 637–56. doi:10.1111/j.1574-6976.2007.00082.x. PMID 17883408.
- ^ Schlacher K, Pham P, Cox MM, Goodman MF (February 2006). «Roles of DNA polymerase V and RecA protein in SOS damage-induced mutation». Chemical Reviews. 106 (2): 406–19. doi:10.1021/cr0404951. PMID 16464012.
- ^ Fry RC, Begley TJ, Samson LD (2004). «Genome-wide responses to DNA-damaging agents». Annual Review of Microbiology. 59: 357–77. doi:10.1146/annurev.micro.59.031805.133658. PMID 16153173.
- ^ Espejel S, Martín M, Klatt P, Martín-Caballero J, Flores JM, Blasco MA (May 2004). «Shorter telomeres, accelerated ageing and increased lymphoma in DNA-PKcs-deficient mice». EMBO Reports. 5 (5): 503–09. doi:10.1038/sj.embor.7400127. PMC 1299048. PMID 15105825.
- ^ de Boer J, Andressoo JO, de Wit J, Huijmans J, Beems RB, van Steeg H, et al. (May 2002). «Premature aging in mice deficient in DNA repair and transcription». Science. 296 (5571): 1276–79. Bibcode:2002Sci…296.1276D. doi:10.1126/science.1070174. PMID 11950998. S2CID 41930529.
- ^ Dollé ME, Busuttil RA, Garcia AM, Wijnhoven S, van Drunen E, Niedernhofer LJ, et al. (April 2006). «Increased genomic instability is not a prerequisite for shortened lifespan in DNA repair deficient mice». Mutation Research. 596 (1–2): 22–35. doi:10.1016/j.mrfmmm.2005.11.008. PMID 16472827.
- ^ Kobayashi Y, Narumi I, Satoh K, Funayama T, Kikuchi M, Kitayama S, Watanabe H (November 2004). «Radiation response mechanisms of the extremely radioresistant bacterium Deinococcus radiodurans». Uchu Seibutsu Kagaku. 18 (3): 134–35. PMID 15858357.
- ^ Spindler SR (September 2005). «Rapid and reversible induction of the longevity, anticancer and genomic effects of caloric restriction». Mechanisms of Ageing and Development. 126 (9): 960–66. doi:10.1016/j.mad.2005.03.016. PMID 15927235. S2CID 7067036.
- ^ Halicka HD, Zhao H, Li J, Lee YS, Hsieh TC, Wu JM, Darzynkiewicz Z (December 2012). «Potential anti-aging agents suppress the level of constitutive mTOR- and DNA damage- signaling». Aging. 4 (12): 952–65. doi:10.18632/aging.100521. PMC 3615161. PMID 23363784.
- ^ Tissenbaum HA, Guarente L (March 2001). «Increased dosage of a sir-2 gene extends lifespan in Caenorhabditis elegans». Nature. 410 (6825): 227–30. Bibcode:2001Natur.410..227T. doi:10.1038/35065638. PMID 11242085. S2CID 4356885.
- ^ Cohen HY, Miller C, Bitterman KJ, Wall NR, Hekking B, Kessler B, et al. (July 2004). «Calorie restriction promotes mammalian cell survival by inducing the SIRT1 deacetylase». Science. 305 (5682): 390–92. Bibcode:2004Sci…305..390C. doi:10.1126/science.1099196. PMID 15205477. S2CID 33503081.
- ^ Cabelof DC, Yanamadala S, Raffoul JJ, Guo Z, Soofi A, Heydari AR (March 2003). «Caloric restriction promotes genomic stability by induction of base excision repair and reversal of its age-related decline». DNA Repair. 2 (3): 295–307. doi:10.1016/S1568-7864(02)00219-7. PMID 12547392.
- ^ Stuart JA, Karahalil B, Hogue BA, Souza-Pinto NC, Bohr VA (March 2004). «Mitochondrial and nuclear DNA base excision repair are affected differently by caloric restriction». FASEB Journal. 18 (3): 595–97. doi:10.1096/fj.03-0890fje. PMID 14734635. S2CID 43118901.
- ^ Walker DW, McColl G, Jenkins NL, Harris J, Lithgow GJ (May 2000). «Evolution of lifespan in C. elegans». Nature. 405 (6784): 296–97. doi:10.1038/35012693. PMID 10830948. S2CID 4402039.
- ^ Johnson G (28 December 2010). «Unearthing Prehistoric Tumors, and Debate». The New York Times.
If we lived long enough, sooner or later we all would get cancer.
- ^ Alberts B, Johnson A, Lewis J, et al. (2002). «The Preventable Causes of Cancer». Molecular biology of the cell (4th ed.). New York: Garland Science. ISBN 978-0-8153-4072-0.
A certain irreducible background incidence of cancer is to be expected regardless of circumstances: mutations can never be absolutely avoided, because they are an inescapable consequence of fundamental limitations on the accuracy of DNA replication, as discussed in Chapter 5. If a human could live long enough, it is inevitable that at least one of his or her cells would eventually accumulate a set of mutations sufficient for cancer to develop.
- ^ Friedenson B (August 2007). «The BRCA1/2 pathway prevents hematologic cancers in addition to breast and ovarian cancers». BMC Cancer. 7: 152. doi:10.1186/1471-2407-7-152. PMC 1959234. PMID 17683622.
- ^ Gavande NS, VanderVere-Carozza PS, Hinshaw HD, Jalal SI, Sears CR, Pawelczak KS, Turchi JJ (April 2016). «DNA repair targeted therapy: The past or future of cancer treatment?». Pharmacology & Therapeutics. 160: 65–83. doi:10.1016/j.pharmthera.2016.02.003. PMC 4811676. PMID 26896565.
- ^ Bryant HE, Schultz N, Thomas HD, Parker KM, Flower D, Lopez E, et al. (April 2005). «Specific killing of BRCA2-deficient tumours with inhibitors of poly(ADP-ribose) polymerase». Nature. 434 (7035): 913–17. Bibcode:2005Natur.434..913B. doi:10.1038/nature03443. PMID 15829966. S2CID 4391043.
- ^ Goldstein M, Kastan MB (2015). «The DNA damage response: implications for tumor responses to radiation and chemotherapy». Annual Review of Medicine. 66: 129–43. doi:10.1146/annurev-med-081313-121208. PMID 25423595.
- ^ a b Jeggo PA, Pearl LH, Carr AM (January 2016). «DNA repair, genome stability and cancer: a historical perspective» (PDF). Nature Reviews. Cancer. 16 (1): 35–42. doi:10.1038/nrc.2015.4. PMID 26667849. S2CID 14941857.
- ^ Bartkova J, Horejsí Z, Koed K, Krämer A, Tort F, Zieger K, et al. (April 2005). «DNA damage response as a candidate anti-cancer barrier in early human tumorigenesis». Nature. 434 (7035): 864–70. Bibcode:2005Natur.434..864B. doi:10.1038/nature03482. PMID 15829956. S2CID 4398393.
- ^ a b Bartkova J, Rezaei N, Liontos M, Karakaidos P, Kletsas D, Issaeva N, et al. (November 2006). «Oncogene-induced senescence is part of the tumorigenesis barrier imposed by DNA damage checkpoints». Nature. 444 (7119): 633–37. Bibcode:2006Natur.444..633B. doi:10.1038/nature05268. PMID 17136093. S2CID 4406956.
- ^ Gaillard H, García-Muse T, Aguilera A (May 2015). «Replication stress and cancer». Nature Reviews. Cancer. 15 (5): 276–89. doi:10.1038/nrc3916. hdl:10261/123721. PMID 25907220. S2CID 11342123.
- ^ Halazonetis TD, Gorgoulis VG, Bartek J (March 2008). «An oncogene-induced DNA damage model for cancer development». Science. 319 (5868): 1352–55. Bibcode:2008Sci…319.1352H. doi:10.1126/science.1140735. PMID 18323444. S2CID 16426080.
- ^ de Boer J, Hoeijmakers JH (March 2000). «Nucleotide excision repair and human syndromes» (PDF). Carcinogenesis. 21 (3): 453–60. doi:10.1093/carcin/21.3.453. PMID 10688865.
- ^ Broustas CG, Lieberman HB (February 2014). «DNA damage response genes and the development of cancer metastasis». Radiation Research. 181 (2): 111–30. Bibcode:2014RadR..181..111B. doi:10.1667/RR13515.1. PMC 4064942. PMID 24397478.
- ^ Zhang P, Wang J, Gao W, Yuan BZ, Rogers J, Reed E (May 2004). «CHK2 kinase expression is down-regulated due to promoter methylation in non-small cell lung cancer». Molecular Cancer. 3 (4): 14. doi:10.1186/1476-4598-3-14. PMC 419366. PMID 15125777.
- ^ Baylin SB, Ohm JE (February 2006). «Epigenetic gene silencing in cancer – a mechanism for early oncogenic pathway addiction?». Nature Reviews. Cancer. 6 (2): 107–16. doi:10.1038/nrc1799. PMID 16491070. S2CID 2514545.
- ^ Kanwal R, Gupta S (April 2012). «Epigenetic modifications in cancer». Clinical Genetics. 81 (4): 303–11. doi:10.1111/j.1399-0004.2011.01809.x. PMC 3590802. PMID 22082348.
- ^ Baldassarre G, Battista S, Belletti B, Thakur S, Pentimalli F, Trapasso F, et al. (April 2003). «Negative regulation of BRCA1 gene expression by HMGA1 proteins accounts for the reduced BRCA1 protein levels in sporadic breast carcinoma». Molecular and Cellular Biology. 23 (7): 2225–38. doi:10.1128/MCB.23.7.2225-2238.2003. PMC 150734. PMID 12640109.
- ^ Jacinto FV, Esteller M (July 2007). «Mutator pathways unleashed by epigenetic silencing in human cancer». Mutagenesis. 22 (4): 247–53. doi:10.1093/mutage/gem009. PMID 17412712.
- ^ Lahtz C, Pfeifer GP (February 2011). «Epigenetic changes of DNA repair genes in cancer». Journal of Molecular Cell Biology. 3 (1): 51–58. doi:10.1093/jmcb/mjq053. PMC 3030973. PMID 21278452. Epigenetic changes of DNA repair genes in cancer
- ^ Bernstein C, Nfonsam V, Prasad AR, Bernstein H (March 2013). «Epigenetic field defects in progression to cancer». World Journal of Gastrointestinal Oncology. 5 (3): 43–49. doi:10.4251/wjgo.v5.i3.43. PMC 3648662. PMID 23671730.
- ^ Narayanan L, Fritzell JA, Baker SM, Liskay RM, Glazer PM (April 1997). «Elevated levels of mutation in multiple tissues of mice deficient in the DNA mismatch repair gene Pms2». Proceedings of the National Academy of Sciences of the United States of America. 94 (7): 3122–27. Bibcode:1997PNAS…94.3122N. doi:10.1073/pnas.94.7.3122. PMC 20332. PMID 9096356.
- ^ Hegan DC, Narayanan L, Jirik FR, Edelmann W, Liskay RM, Glazer PM (December 2006). «Differing patterns of genetic instability in mice deficient in the mismatch repair genes Pms2, Mlh1, Msh2, Msh3 and Msh6». Carcinogenesis. 27 (12): 2402–08. doi:10.1093/carcin/bgl079. PMC 2612936. PMID 16728433.
- ^ Tutt AN, van Oostrom CT, Ross GM, van Steeg H, Ashworth A (March 2002). «Disruption of Brca2 increases the spontaneous mutation rate in vivo: synergism with ionizing radiation». EMBO Reports. 3 (3): 255–60. doi:10.1093/embo-reports/kvf037. PMC 1084010. PMID 11850397.
- ^ German J (March 1969). «Bloom’s syndrome. I. Genetical and clinical observations in the first twenty-seven patients». American Journal of Human Genetics. 21 (2): 196–227. PMC 1706430. PMID 5770175.
- ^ O’Hagan HM, Mohammad HP, Baylin SB (August 2008). «Double strand breaks can initiate gene silencing and SIRT1-dependent onset of DNA methylation in an exogenous promoter CpG island». PLOS Genetics. 4 (8): e1000155. doi:10.1371/journal.pgen.1000155. PMC 2491723. PMID 18704159.
- ^ Cuozzo C, Porcellini A, Angrisano T, Morano A, Lee B, Di Pardo A, et al. (July 2007). «DNA damage, homology-directed repair, and DNA methylation». PLOS Genetics. 3 (7): e110. doi:10.1371/journal.pgen.0030110. PMC 1913100. PMID 17616978.
- ^ Malkin D (April 2011). «Li-fraumeni syndrome». Genes & Cancer. 2 (4): 475–84. doi:10.1177/1947601911413466. PMC 3135649. PMID 21779515.
- ^ Fearon ER (November 1997). «Human cancer syndromes: clues to the origin and nature of cancer». Science. 278 (5340): 1043–50. Bibcode:1997Sci…278.1043F. doi:10.1126/science.278.5340.1043. PMID 9353177.
- ^ Halford S, Rowan A, Sawyer E, Talbot I, Tomlinson I (June 2005). «O(6)-methylguanine methyltransferase in colorectal cancers: detection of mutations, loss of expression, and weak association with G:C>A:T transitions». Gut. 54 (6): 797–802. doi:10.1136/gut.2004.059535. PMC 1774551. PMID 15888787.
- ^ Shen L, Kondo Y, Rosner GL, Xiao L, Hernandez NS, Vilaythong J, et al. (September 2005). «MGMT promoter methylation and field defect in sporadic colorectal cancer». Journal of the National Cancer Institute. 97 (18): 1330–38. doi:10.1093/jnci/dji275. PMID 16174854.
- ^ Psofaki V, Kalogera C, Tzambouras N, Stephanou D, Tsianos E, Seferiadis K, Kolios G (July 2010). «Promoter methylation status of hMLH1, MGMT, and CDKN2A/p16 in colorectal adenomas». World Journal of Gastroenterology. 16 (28): 3553–60. doi:10.3748/wjg.v16.i28.3553. PMC 2909555. PMID 20653064.
- ^ Lee KH, Lee JS, Nam JH, Choi C, Lee MC, Park CS, et al. (October 2011). «Promoter methylation status of hMLH1, hMSH2, and MGMT genes in colorectal cancer associated with adenoma-carcinoma sequence». Langenbeck’s Archives of Surgery. 396 (7): 1017–26. doi:10.1007/s00423-011-0812-9. PMID 21706233. S2CID 8069716.
- ^ Amatu A, Sartore-Bianchi A, Moutinho C, Belotti A, Bencardino K, Chirico G, et al. (April 2013). «Promoter CpG island hypermethylation of the DNA repair enzyme MGMT predicts clinical response to dacarbazine in a phase II study for metastatic colorectal cancer». Clinical Cancer Research. 19 (8): 2265–72. doi:10.1158/1078-0432.CCR-12-3518. PMID 23422094.
- ^ Mokarram P, Zamani M, Kavousipour S, Naghibalhossaini F, Irajie C, Moradi Sarabi M, Hosseini SV (May 2013). «Different patterns of DNA methylation of the two distinct O6-methylguanine-DNA methyltransferase (O6-MGMT) promoter regions in colorectal cancer». Molecular Biology Reports. 40 (5): 3851–57. doi:10.1007/s11033-012-2465-3. PMID 23271133. S2CID 18733871.
- ^ Truninger K, Menigatti M, Luz J, Russell A, Haider R, Gebbers JO, et al. (May 2005). «Immunohistochemical analysis reveals high frequency of PMS2 defects in colorectal cancer». Gastroenterology. 128 (5): 1160–71. doi:10.1053/j.gastro.2005.01.056. PMID 15887099.
- ^ Valeri N, Gasparini P, Fabbri M, Braconi C, Veronese A, Lovat F, et al. (April 2010). «Modulation of mismatch repair and genomic stability by miR-155». Proceedings of the National Academy of Sciences of the United States of America. 107 (15): 6982–87. Bibcode:2010PNAS..107.6982V. doi:10.1073/pnas.1002472107. PMC 2872463. PMID 20351277.
- ^ Facista A, Nguyen H, Lewis C, Prasad AR, Ramsey L, Zaitlin B, et al. (April 2012). «Deficient expression of DNA repair enzymes in early progression to sporadic colon cancer». Genome Integrity. 3 (1): 3. doi:10.1186/2041-9414-3-3. PMC 3351028. PMID 22494821.
- ^ Human DNA Repair Genes, 15 April 2014, MD Anderson Cancer Center, University of Texas
- ^ Jin B, Robertson KD (2013). «DNA methyltransferases, DNA damage repair, and cancer». Advances in Experimental Medicine and Biology. 754: 3–29. doi:10.1007/978-1-4419-9967-2_1. ISBN 978-1-4419-9966-5. PMC 3707278. PMID 22956494.
- ^ Krishnan K, Steptoe AL, Martin HC, Wani S, Nones K, Waddell N, et al. (February 2013). «MicroRNA-182-5p targets a network of genes involved in DNA repair». RNA. 19 (2): 230–42. doi:10.1261/rna.034926.112. PMC 3543090. PMID 23249749.
- ^ Chaisaingmongkol J, Popanda O, Warta R, Dyckhoff G, Herpel E, Geiselhart L, et al. (December 2012). «Epigenetic screen of human DNA repair genes identifies aberrant promoter methylation of NEIL1 in head and neck squamous cell carcinoma». Oncogene. 31 (49): 5108–16. doi:10.1038/onc.2011.660. PMID 22286769.
- ^ Singh P, Yang M, Dai H, Yu D, Huang Q, Tan W, et al. (November 2008). «Overexpression and hypomethylation of flap endonuclease 1 gene in breast and other cancers». Molecular Cancer Research. 6 (11): 1710–17. doi:10.1158/1541-7786.MCR-08-0269. PMC 2948671. PMID 19010819.
- ^ Lam JS, Seligson DB, Yu H, Li A, Eeva M, Pantuck AJ, et al. (August 2006). «Flap endonuclease 1 is overexpressed in prostate cancer and is associated with a high Gleason score». BJU International. 98 (2): 445–51. doi:10.1111/j.1464-410X.2006.06224.x. PMID 16879693. S2CID 22165252.
- ^ Kim JM, Sohn HY, Yoon SY, Oh JH, Yang JO, Kim JH, et al. (January 2005). «Identification of gastric cancer-related genes using a cDNA microarray containing novel expressed sequence tags expressed in gastric cancer cells». Clinical Cancer Research. 11 (2 Pt 1): 473–82. doi:10.1158/1078-0432.473.11.2. PMID 15701830.
- ^ Wang K, Xie C, Chen D (May 2014). «Flap endonuclease 1 is a promising candidate biomarker in gastric cancer and is involved in cell proliferation and apoptosis». International Journal of Molecular Medicine. 33 (5): 1268–74. doi:10.3892/ijmm.2014.1682. PMID 24590400.
- ^ Krause A, Combaret V, Iacono I, Lacroix B, Compagnon C, Bergeron C, et al. (July 2005). «Genome-wide analysis of gene expression in neuroblastomas detected by mass screening» (PDF). Cancer Letters. 225 (1): 111–20. doi:10.1016/j.canlet.2004.10.035. PMID 15922863. S2CID 44644467.
- ^ Iacobuzio-Donahue CA, Maitra A, Olsen M, Lowe AW, van Heek NT, Rosty C, et al. (April 2003). «Exploration of global gene expression patterns in pancreatic adenocarcinoma using cDNA microarrays». The American Journal of Pathology. 162 (4): 1151–62. doi:10.1016/S0002-9440(10)63911-9. PMC 1851213. PMID 12651607.
- ^ Sato M, Girard L, Sekine I, Sunaga N, Ramirez RD, Kamibayashi C, Minna JD (October 2003). «Increased expression and no mutation of the Flap endonuclease (FEN1) gene in human lung cancer». Oncogene. 22 (46): 7243–46. doi:10.1038/sj.onc.1206977. PMID 14562054.
- ^ Bi FF, Li D, Yang Q (2013). «Hypomethylation of ETS transcription factor binding sites and upregulation of PARP1 expression in endometrial cancer». BioMed Research International. 2013: 946268. doi:10.1155/2013/946268. PMC 3666359. PMID 23762867.
- ^ Bi FF, Li D, Yang Q (February 2013). «Promoter hypomethylation, especially around the E26 transformation-specific motif, and increased expression of poly (ADP-ribose) polymerase 1 in BRCA-mutated serous ovarian cancer». BMC Cancer. 13: 90. doi:10.1186/1471-2407-13-90. PMC 3599366. PMID 23442605.
- ^ Supek F, Lehner B (May 2015). «Differential DNA mismatch repair underlies mutation rate variation across the human genome». Nature. 521 (7550): 81–84. Bibcode:2015Natur.521…81S. doi:10.1038/nature14173. PMC 4425546. PMID 25707793.
- ^ a b Zheng CL, Wang NJ, Chung J, Moslehi H, Sanborn JZ, Hur JS, et al. (November 2014). «Transcription restores DNA repair to heterochromatin, determining regional mutation rates in cancer genomes». Cell Reports. 9 (4): 1228–34. doi:10.1016/j.celrep.2014.10.031. PMC 4254608. PMID 25456125.
- ^ Li F, Mao G, Tong D, Huang J, Gu L, Yang W, Li GM (April 2013). «The histone mark H3K36me3 regulates human DNA mismatch repair through its interaction with MutSα». Cell. 153 (3): 590–600. doi:10.1016/j.cell.2013.03.025. PMC 3641580. PMID 23622243.
- ^ Supek F, Lehner B (July 2017). «Clustered Mutation Signatures Reveal that Error-Prone DNA Repair Targets Mutations to Active Genes». Cell. 170 (3): 534–547.e23. doi:10.1016/j.cell.2017.07.003. hdl:10230/35343. PMID 28753428.
- ^ Polak P, Lawrence MS, Haugen E, Stoletzki N, Stojanov P, Thurman RE, et al. (January 2014). «Reduced local mutation density in regulatory DNA of cancer genomes is linked to DNA repair». Nature Biotechnology. 32 (1): 71–75. doi:10.1038/nbt.2778. PMC 4116484. PMID 24336318.
- ^ Swenberg JA, Lu K, Moeller BC, Gao L, Upton PB, Nakamura J, Starr TB (March 2011). «Endogenous versus exogenous DNA adducts: their role in carcinogenesis, epidemiology, and risk assessment». Toxicol Sci. 120 Suppl 1 (Suppl 1): S130–45. doi:10.1093/toxsci/kfq371. PMC 3043087. PMID 21163908.
- ^ a b Hamilton ML, Guo Z, Fuller CD, Van Remmen H, Ward WF, Austad SN, Troyer DA, Thompson I, Richardson A (May 2001). «A reliable assessment of 8-oxo-2-deoxyguanosine levels in nuclear and mitochondrial DNA using the sodium iodide method to isolate DNA». Nucleic Acids Res. 29 (10): 2117–26. doi:10.1093/nar/29.10.2117. PMC 55450. PMID 11353081.
- ^ Ming X, Matter B, Song M, Veliath E, Shanley R, Jones R, Tretyakova N (March 2014). «Mapping structurally defined guanine oxidation products along DNA duplexes: influence of local sequence context and endogenous cytosine methylation». J Am Chem Soc. 136 (11): 4223–35. doi:10.1021/ja411636j. PMC 3985951. PMID 24571128.
- ^ a b c Zhou X, Zhuang Z, Wang W, He L, Wu H, Cao Y, Pan F, Zhao J, Hu Z, Sekhar C, Guo Z (September 2016). «OGG1 is essential in oxidative stress-induced DNA demethylation». Cell Signal. 28 (9): 1163–1171. doi:10.1016/j.cellsig.2016.05.021. PMID 27251462.
- ^ Poetsch AR (2020). «The genomics of oxidative DNA damage, repair, and resulting mutagenesis». Comput Struct Biotechnol J. 18: 207–219. doi:10.1016/j.csbj.2019.12.013. PMC 6974700. PMID 31993111.
- ^ D’Augustin O, Huet S, Campalans A, Radicella JP (November 2020). «Lost in the Crowd: How Does Human 8-Oxoguanine DNA Glycosylase 1 (OGG1) Find 8-Oxoguanine in the Genome?». Int J Mol Sci. 21 (21): 8360. doi:10.3390/ijms21218360. PMC 7664663. PMID 33171795.
- ^ Lan L, Nakajima S, Oohata Y, Takao M, Okano S, Masutani M, Wilson SH, Yasui A (September 2004). «In situ analysis of repair processes for oxidative DNA damage in mammalian cells». Proc Natl Acad Sci U S A. 101 (38): 13738–43. Bibcode:2004PNAS..10113738L. doi:10.1073/pnas.0406048101. PMC 518826. PMID 15365186.
- ^ Maeder ML, Angstman JF, Richardson ME, Linder SJ, Cascio VM, Tsai SQ, Ho QH, Sander JD, Reyon D, Bernstein BE, Costello JF, Wilkinson MF, Joung JK (December 2013). «Targeted DNA demethylation and activation of endogenous genes using programmable TALE-TET1 fusion proteins». Nat. Biotechnol. 31 (12): 1137–42. doi:10.1038/nbt.2726. PMC 3858462. PMID 24108092.
- ^ Ding N, Bonham EM, Hannon BE, Amick TR, Baylin SB, O’Hagan HM (June 2016). «Mismatch repair proteins recruit DNA methyltransferase 1 to sites of oxidative DNA damage». J Mol Cell Biol. 8 (3): 244–54. doi:10.1093/jmcb/mjv050. PMC 4937888. PMID 26186941.
- ^ a b Jiang Z, Lai Y, Beaver JM, Tsegay PS, Zhao ML, Horton JK, Zamora M, Rein HL, Miralles F, Shaver M, Hutcheson JD, Agoulnik I, Wilson SH, Liu Y (January 2020). «Oxidative DNA Damage Modulates DNA Methylation Pattern in Human Breast Cancer 1 (BRCA1) Gene via the Crosstalk between DNA Polymerase β and a de novo DNA Methyltransferase». Cells. 9 (1): 225. doi:10.3390/cells9010225. PMC 7016758. PMID 31963223.
- ^ Mortusewicz O, Schermelleh L, Walter J, Cardoso MC, Leonhardt H (June 2005). «Recruitment of DNA methyltransferase I to DNA repair sites». Proc Natl Acad Sci U S A. 102 (25): 8905–9. Bibcode:2005PNAS..102.8905M. doi:10.1073/pnas.0501034102. PMC 1157029. PMID 15956212.
- ^ a b Cuozzo C, Porcellini A, Angrisano T, Morano A, Lee B, Di Pardo A, Messina S, Iuliano R, Fusco A, Santillo MR, Muller MT, Chiariotti L, Gottesman ME, Avvedimento EV (July 2007). «DNA damage, homology-directed repair, and DNA methylation». PLOS Genet. 3 (7): e110. doi:10.1371/journal.pgen.0030110. PMC 1913100. PMID 17616978.
- ^ a b O’Hagan HM, Mohammad HP, Baylin SB (August 2008). «Double strand breaks can initiate gene silencing and SIRT1-dependent onset of DNA methylation in an exogenous promoter CpG island». PLOS Genet. 4 (8): e1000155. doi:10.1371/journal.pgen.1000155. PMC 2491723. PMID 18704159.
- ^ Ha K, Lee GE, Palii SS, Brown KD, Takeda Y, Liu K, Bhalla KN, Robertson KD (January 2011). «Rapid and transient recruitment of DNMT1 to DNA double-strand breaks is mediated by its interaction with multiple components of the DNA damage response machinery». Hum Mol Genet. 20 (1): 126–40. doi:10.1093/hmg/ddq451. PMC 3000680. PMID 20940144.
- ^ Russo G, Landi R, Pezone A, Morano A, Zuchegna C, Romano A, Muller MT, Gottesman ME, Porcellini A, Avvedimento EV (September 2016). «DNA damage and Repair Modify DNA methylation and Chromatin Domain of the Targeted Locus: Mechanism of allele methylation polymorphism». Sci Rep. 6: 33222. Bibcode:2016NatSR…633222R. doi:10.1038/srep33222. PMC 5024116. PMID 27629060.
- ^ Farris MH, Texter PA, Mora AA, Wiles MV, Mac Garrigle EF, Klaus SA, Rosfjord K (December 2020). «Detection of CRISPR-mediated genome modifications through altered methylation patterns of CpG islands». BMC Genomics. 21 (1): 856. doi:10.1186/s12864-020-07233-2. PMC 7709351. PMID 33267773.
- ^ Allen B, Pezone A, Porcellini A, Muller MT, Masternak MM (June 2017). «Non-homologous end joining induced alterations in DNA methylation: A source of permanent epigenetic change». Oncotarget. 8 (25): 40359–40372. doi:10.18632/oncotarget.16122. PMC 5522286. PMID 28423717.
- ^ Cromie GA, Connelly JC, Leach DR (December 2001). «Recombination at double-strand breaks and DNA ends: conserved mechanisms from phage to humans». Molecular Cell. 8 (6): 1163–74. doi:10.1016/S1097-2765(01)00419-1. PMID 11779493.
- ^ O’Brien PJ (February 2006). «Catalytic promiscuity and the divergent evolution of DNA repair enzymes». Chemical Reviews. 106 (2): 720–52. doi:10.1021/cr040481v. PMID 16464022.
- ^ Maresca B, Schwartz JH (January 2006). «Sudden origins: a general mechanism of evolution based on stress protein concentration and rapid environmental change». The Anatomical Record Part B: The New Anatomist. 289 (1): 38–46. doi:10.1002/ar.b.20089. PMID 16437551.
- ^ «CRISPR gene-editing tool has scientists thrilled – but nervous» CBC news. Author Kelly Crowe. 30 November 2015.
External links[edit]
![]()
This audio file was created from a revision of this article dated 17 June 2005, and does not reflect subsequent edits.
 Media related to DNA repair at Wikimedia Commons
Media related to DNA repair at Wikimedia Commons- Roswell Park Cancer Institute DNA Repair Lectures
- A comprehensive list of Human DNA Repair Genes
- 3D structures of some DNA repair enzymes
- Human DNA repair diseases
- DNA repair special interest group
- DNA Repair Archived 12 February 2018 at the Wayback Machine
- DNA Damage and DNA Repair
- Segmental Progeria
- DNA-damage repair; the good, the bad, and the ugly
DNA replication is an essential part of cell division and the growth of organisms. The process of DNA replication uses strands of DNA as templates to create new strands of DNA.
The replication of DNA is an incredibly fast and accurate process. On average, around one mistake is made for every 10 billion nucleotides that are replicated. The process includes over a dozen different types of enzymes and other proteins to run correctly.
Structure of DNA
A DNA molecule is made from a series of smaller molecules called ‘nucleotides’. Nucleotides link together to form a linear strand of DNA. Each nucleotide consists of a sugar, a base and a phosphate group.
A nucleotide contains one of four different nitrogenous bases – adenine, thymine, guanine or cytosine. The bases of each nucleotide from one strand of DNA bond to the bases of another strand of DNA to form the DNA double helix.
The four different bases each have a complementary base that they bind with. Adenine and thymine only ever bond with each other, while guanine and cytosine will only bond with each other. The two strands of a double helix are therefore the exact opposite to each other in terms of their sequence of bases.
Starting DNA replication
The process of DNA replication begins at a specific site along a strand of DNA called the ‘origins of replication’. The origins of replication are short sections on a DNA molecule that contain a specific set of nucleotides.
Prokaryotic cells will often have only one origin of replication for their ring of DNA. Eukaryotic cells on the other hand can have hundreds to thousands of origins.
The process is started by a set of proteins that recognise the set of nucleotides at the origins of replication. These proteins are able to separate the two strands of the DNA double helix and create a ‘bubble’ between the two strands.
DNA replication moves in both directions along the two strands of DNA. The bubble increases in size as several other proteins continue to unwind, straighten and separate the two strands of DNA.
As the two strands are separated, binding proteins latch on to the single strands of DNA and prevent them from bonding back together. Both strands are then able to be used as templates for building two new strands of DNA.
The new strand of DNA begins with a short segment of a molecule called RNA. The short segment is known as an RNA primer and it is usually around 5-10 nucleotides long. The new DNA strand begins by attaching a DNA nucleotide to the RNA primer.
Building a DNA molecule
An enzyme called ‘DNA polymerase’ drives the process of building a new strand of DNA. DNA polymerase controls the addition of DNA nucleotides to the new strand of DNA. The polymerase is responsible for adding the correct nucleotides with complementary bases to the template DNA strand. For example, a nucleotide with a thymine base needs to be added to a nucleotide with a complementary adenine base.
Eukaryotic cells have a variety of different DNA polymerase enzymes. Currently more than 10 different DNA polymerases have been discovered. There is, however, only one known DNA polymerase in prokaryotic cells.
DNA polymerases are able to add nucleotides at very impressive rates. In the bacteria E. coli, new strands of DNA are built at a rate of around 500 new nucleotides per second. Human cells aren’t quite that quick but can still add around 50 nucleotides per second to a growing DNA strand.
Leading strand and lagging strand
The two ends of the RNA primer are different and nucleotides are only able to be added to one end. A new strand of DNA can therefore only be grown in one direction.
As the bubble in the double helix grows the two new strands of DNA are built in opposite directions. Each new strand is built towards one of the two forks at the edge of the bubble.
From the RNA primer, the DNA polymerase enzyme can build the new strand of DNA continuously towards the fork. This strand of replicated DNA that grows continuously towards the fork is known as the ‘leading strand’.
As the bubble grows however, new nucleotides are exposed behind the RNA primer at the origin of replication which also need to be replicated. As nucleotides can only be added to one end of an RNA primer, new nucleotides can’t be added in the opposite direction from the origin of replication.
DNA polymerase must replicate the template strand behind the origin of replication. This is achieved by adding short segments of nucleotides to the newly exposed sections from the fork towards the origin of replication. The section of the DNA strand behind the origin of replication is known as the ‘lagging strand’.
Lagging strands are split into multiple short segments. These short segments are known as Okazaki fragments, named after the one of the scientists who discovered them. The lagging strand is split into Okazaki fragments because they cannot continue to grow once they reach the origin of replication or the start of the previous Okazaki fragment.
Each Okazaki fragment is started by its own RNA primer. Two enzymes, a polymerase and a DNA ligase, replace the RNA primer at the start of each Okazaki fragment. This converts the lagging strand into a continuous strand of DNA.
Video created by yourgenome – check out their website to learn more about DNA, genes and genomes
Errors in DNA replication
In the initial pairing of bases with the template DNA strand there is around one error for every 100,000 nucleotides paired. Polymerase enzymes proofread the new strand of DNA against the template strand and fix errors. This fixing reduces errors to around one error for every 10 billion nucleotides. An extremely accurate process.
The one in 10 billion errors exist when a polymerase incorrectly replaces the error with the another incorrect nucleotide. These rare errors are the cause of genetic mutations and cancer.
Telomeres
Telomeres are short sections at the end of DNA strands that get shorter and shorter with each replication of a DNA strand. Telomeres don’t contain information for specific genes but are a safety net for a slight problem with DNA replication in eukaryotic cells.
Remember that DNA replication begins with the attachment of an RNA primer and DNA polymerase can only add nucleotides to one end of the RNA primer. Every time a strand of DNA is replicated the section of DNA behind the RNA primer cannot be replicated.
This is an issue only for eukaryotic cells that have linear strands of DNA. Prokaryotic cells have a single ring of DNA so all their DNA is able to be replicated.
Telomeres provide a solution to this problem. They are short sections at the end of a DNA strand that usually contain one repeating sequence of bases. The sequence is repeated between 100-1000 times and contains no genetic information. Having telomeres at the end of strands of DNA prevents the loss of genetic information through imperfect replication of DNA.
A telomere become shorter each time DNA is replicated. The shortening of telomeres is thought to be involved in the process of aging for both cells and whole organisms. As an individual grows older, the DNA of all of their cells will have been through many replications. If a cell has been through too many replications it is possible for the entire telomere to be lost and the cell is likely to be killed.
Mutations
An error in DNA replication is known as a mutation. If an error is not corrected and remains present in the new DNA strand then every time that strand of DNA is replicated the error will be replicated. If an error occurs in sperm or egg cells the mutation can be passed to the next generation.
Most mutations are harmful but some can be beneficial. Many mutations can affect how a cell performs and often mutant cells will die before they can replicate again.
Mutations are the only way new genetic material is produced. Over billions of years the rare beneficial mutations have taken life from simple, single-celled organisms to diverse array of complex and spectacular species. Mutations are a key part of evolution.
Mutation rate in humans
The DNA of humans has a total of six billion base pairs. With an error rate of around one error for every 10 billions bases, around 0.6 errors will occur for every replication of a cell’s DNA.
A fully grown human has around 37 trillion cells in their body. By the time a human is fully grown their cells will have been replicated over 37 trillion times.
With around 0.6 errors per replication, a fully grown human will have had around 22 trillion mutations to their DNA. Fortunately, the vast majority of these are lost and never have an impact on our lives. Very rarely do mutations become a problem. Needless to say however, we are all mutants!
Last edited: 15 March 2016
Abstract
Accurate DNA replication is essential for genomic stability. One mechanism by which high-fidelity DNA polymerases maintain replication accuracy involves stalling of the polymerase in response to covalent incorporation of mismatched base pairs, thereby favoring subsequent mismatch excision. Some polymerases retain a “short-term memory” of replication errors, responding to mismatches up to four base pairs in from the primer terminus. Here we a present a structural characterization of all 12 possible mismatches captured at the growing primer terminus in the active site of a polymerase. Our observations suggest four mechanisms that lead to mismatch-induced stalling of the polymerase. Furthermore, we have observed the effects of extending a mismatch up to six base pairs from the primer terminus and find that long-range distortions in the DNA transmit the presence of the mismatch back to the enzyme active site, suggesting the structural basis for the short-term memory of replication errors.
Introduction
Uncorrected DNA replication errors result in mutations that are essential for evolutionary processes and may lead to human diseases. DNA replication is catalyzed by high-fidelity polymerases that maintain replication accuracy through two major mechanisms. First, prior to covalent incorporation, the polymerases select for correct, Watson-Crick base pairing, while strongly discriminating against each of the 12 possible mismatched bases (
,
). Second, once incorporated, misinserted bases compromise the rate of DNA extension. Such “stalling” alters the balance between extension by the polymerase and excision by mismatch-editing exonucleases located either on the polymerase itself or on separate enzymes (
,
). Analysis of the structural mechanisms by which mismatch incorporation leads to stalling is therefore important for understanding the fidelity of DNA replication.
Extensive kinetic studies of mismatch incorporation and extension have shown that the presence of a newly incorporated mismatch reduces the efficiency of subsequent nucleotide insertions and extensions by a hundred- to a million-fold (
,
,
). The magnitude of this effect depends on the identities of both the mismatch and the polymerase. Mismatch-induced stalling is not limited to the point of incorporation. For instance, mismatches located up to four base pairs away from the primer terminus show a significantly increased partitioning of the growing primer terminus between the polymerase and 3′-5′ exonuclease active sites in E. coli Klenow Fragment (KF) (
). KF polymerase activity is inhibited when DNA mismatches or lesions are placed at the n-1, n-2, or n-3 positions (n is the point of new base pair incorporation; n-1, the double-stranded primer terminus), but full activity is recovered at the n-5 position (
Miller and Grollman 1997
- Miller H.
- Grollman A.P.
Kinetics of DNA polymerase I (Klenow fragment exo-) activity on damaged DNA templates effect of proximal and distal template damage on DNA synthesis.
- Crossref
- PubMed
- Scopus (75)
- Google Scholar
). In HIV-reverse transcriptase, stalling of the polymerase reaction is also observed when mismatches are placed in the n-1 to n-3 positions (
). Inhibition of activity by mismatches and damaged DNA is observed in the n-1 to n-4 positions in pol α (
,
). Extension of mismatches therefore retains a kinetically observable “short-term memory” of the misincorporation event that promotes subsequent error detection and correction. Mismatch-induced stalling is presumably the consequence of disruption of the structural mechanisms by which heteroduplex DNA interacts with the polymerase that has been the subject of much speculation in the absence of structural information (
,
).
Structural studies of DNA polymerase complexes (reviewed in
,
,
,
,
) in combination with extensive enzyme kinetic studies (
,
,
,
,
; reviewed in
) have revealed the dominant mechanistic and structural features that contribute to accurate DNA replication, which are shared in a large part by all polymerases. In the study presented here, we use the thermophilic Bacillus DNA polymerase I fragment (BF) as our model system (
,
,
). Processive DNA replication can take place in crystals of this polymerase. BF is a high-fidelity Family A polymerase with extensive sequence and structural homology to the Klenow Fragments of E. coli (KF) and T. aquaticus (Taq) polymerases. The current understanding of the replication mechanism as it pertains to BF can be summarized as follows. Five important sites have been identified in the BF polymerase (Figures 1A and 1B;
): (1) the “insertion site,” in which the cognate nucleotide pairs with the template base (n position); (2) the “catalytic site” directly adjacent to the insertion site in which the 3′ hydroxyl of the primer strand and the coordination sphere for two Mg2+ ions are located, forming the catalytic center; (3) the “preinsertion site,” which houses the template base in a step prior to incorporation; (4) the “postinsertion site” in which the growing 3′ end of the duplex DNA is located (n-1 position); and (5) the “DNA duplex binding region” in which a four base pair duplex DNA segment is bound (n-2, …, n-5 positions). Replication proceeds by threading DNA through these sites: the template base moves from the preinsertion site to the insertion site and pairs with an incoming base; covalent incorporation takes place; the newly synthesized base moves into the postinsertion site; the DNA in the duplex binding region translocates by one base pair, releasing a base pair from the n-5 position; the next template base moves into the preinsertion site.

Figure 1DNA Bound at the Polymerase Active Site
Show full caption
(A) Five regions that contribute to high-fidelity DNA replication are shaded: preinsertion (blue), insertion (green), catalytic (orange), and postinsertion sites (yellow), and the DNA duplex binding region (gray). “Fingers,” “palm,” and “thumb” subdomains are indicated. Transfer of the n template base from the template preinsertion site to the insertion site is accompanied by a transition from the open to a closed conformation, mediated by a hinge-bending motion centered around the O and O1 helices. At the insertion site, a complementary dNTP (indicated by PPP−) is selected prior to catalysis. The insertion site is occluded in the open conformation by a conserved tyrosine (Tyr714 in BF) located at the C terminus of the O helix that stacks with the DNA template. In the closed conformation, the tyrosine is displaced, allowing the new base pair to bind. Correct base pairing is detected by interactions at the postinsertion site and along the entire DNA duplex binding region.
(B) Cognate G•C base pair bound at the postinsertion (n-1) site. The molecular van der Waals surface of the base pair is shown in yellow. A hydrogen bond between Asp830 and the 3′ primer terminus is observed in the open conformation. Arg615 and Gln797 interact with hydrogen bond acceptor atom (*) located in the DNA minor groove, providing minor groove readout.
- View Large
Image - Figure Viewer
- Download Hi-res
image - Download (PPT)
Here we present the first high-resolution structures of mismatches captured at the active site of a DNA polymerase, by taking advantage of the catalytic activity of BF crystals (
,
). All 12 possible covalently incorporated mismatches were obtained, positioned at the primer terminus, poised for subsequent extension reactions. Each of these mismatches disrupts the active site of the DNA polymerase in various ways that are the consequence of the specific interactions between the mismatch and the polymerase. Although all 12 DNA heteroduplexes are structurally distinct, we have been able to classify the mismatch-induced disruptions into four broad categories based on the nature of the changes in the active site. Additionally, we have been able to translocate several mismatches through the duplex binding region by using successive rounds of DNA replication in the crystal to extend the heteroduplex, which provide new insight into the mechanism for misincorporation memory. Together, these results provide a firm basis for understanding these early events in polymerase-mediated incorporation or evasion of mutations.
Results
Crystallographic Capture of Mismatches
Crystals with mismatches captured at the BF polymerase active site were obtained either by catalysis in the crystals, using mutagenic reaction conditions, or by cocrystallization of DNA duplexes that contain a mismatch at the primer terminus (Table 1, Table 2, Table 3). In the presence of Mg2+, accurate DNA replication is obtained in BF•DNA crystals, and synthesis stalls in preference to incorporation of DNA mismatches (
). In the presence of Mn2+, the specificity of the enzyme is relaxed, allowing enzymatic incorporation of mismatches. For those mismatches that were captured both by catalytic incorporation and by cocrystallization of preformed duplexes, both structures adopt the same conformation.
Table 1DNA Mismatches Captured at the BF Polymerase Active Site
| Mismatch (primer•template) | Sequence
a The mispair is shown in bold letters. Underlined bases indicate nucleotides that were incorporated into the BF-DNA cocrystals in the presence of Mn2+. |
Method
b Denotes whether the mispair was captured by enzymatic incorporation in the crystal (E), cocrystallization (C), or both methods (E,C). |
Mispair Location | Mispair Conformation | Active Site Regions Disrupted by Mispair Binding
c Active site regions are abbreviated: preinsertion site (Pre-IS); insertion site (IS); catalytic site (CS); postinsertion site (Post-IS); DNA duplex binding region (DBR). |
Extension Products |
|---|---|---|---|---|---|---|
| G•T | 3′- |
E,C | post-insertion site | wobble | Pre-IS, IS, Post-IS, DBR | n-2,n-3,n-4,n-6 |
| T•G | 3′- |
E | post-insertion site | wobble, water-stabilized | Pre-IS, IS, CS, Post-IS, DBR | no extension |
| A•C | 3′- ACGACTAGCG 5′- ACGTCGCTGATCGCA | C | post-insertion site | disordered template | Pre-IS, IS, Post-IS, DBR | n-2 |
| C•A | 3′- CCGTAGTACG 5′- CCCGAGCATCATGCA | C | undetermined | disordered | Pre-IS, IS, Post-IS, DBR | not tested |
| T•T | 3′- |
E,C | post-insertion site | wobble | IS, CS, Post-IS | no extension |
| C•T | 3′- CCGACTAGCG 5′- GTACGTGCTGATCGCA | C | post-insertion site | open, water-stabilized | IS, CS, Post-IS | n-2 |
| T•C | 3′- TCGACTAGCG 5′- ACGTCGCTGATCGCA | C | post-insertion site | disordered template | Pre-IS, IS, Post-IS, DBR | position unclear (disordered) |
| C•C | 3′- CCTAGTACG 5′- GATCGCGATCATGCA | E,C | insertion/pre-insertion sites | frayed | Pre-IS, IS, CS, Post-IS, DBR | no extension |
| A•G | 3′- AACGACTAGCG 5′- GTACGTGCTGATCGC | C | post-insertion site | anti-anti | Pre-IS, IS, CS, Post-IS, DBR | no extension |
| G•G | 3′- GGACTAGCG 5′- GTACGTGCTGATCGCA | C | post-insertion site | syn-anti | Pre-IS, IS, Post-IS, DBR | n-2 |
| A•A | 3′- |
E | insertion/pre-insertion sites | frayed | IS, CS | not tested |
| G•A | 3′- GCGTACTACG 5′- CCCGAGCATGATGCA | C | insertion/pre-insertion sites | frayed | Pre-IS, IS, CS | not tested |
a The mispair is shown in bold letters. Underlined bases indicate nucleotides that were incorporated into the BF-DNA cocrystals in the presence of Mn2+.
b Denotes whether the mispair was captured by enzymatic incorporation in the crystal (E), cocrystallization (C), or both methods (E,C).
c Active site regions are abbreviated: preinsertion site (Pre-IS); insertion site (IS); catalytic site (CS); postinsertion site (Post-IS); DNA duplex binding region (DBR).
- Open table in a new tab
Table 2Data Collection and Refinement Statistics for Mismatch Structures
| G•T | T•G | T•T | C•T | A•G | G•G | A•A | C•C | G•A | |
|---|---|---|---|---|---|---|---|---|---|
| Data Collection (all data) | |||||||||
| Resolution, Å | 50.0–1.9 | 30.0–1.65 | 50.0–2.0 | 50.0–2.0 | 50.0–1.7 | 30.0–1.6 | 35.0–2.1 | 50.0–2.1 | 50.0–1.9 |
| Outer shell, Å | 1.97–1.90 | 1.71–1.65 | 2.07–2.00 | 2.07–2.00 | 1.76–1.70 | 1.66–1.60 | 2.18–2.10 | 2.18–2.10 | 1.97–1.90 |
| No. reflections | |||||||||
| Unique | 63,846 | 100,253 | 58,937 | 59,392 | 94,629 | 113,762 | 50,872 | 51,291 | 63,331 |
| Total | 311,125 | 603,440 | 259,656 | 320,048 | 292,563 | 664,723 | 491,438 | 245,582 | 396,272 |
| Mean I/σI
a Values in parentheses correspond to those in the outer resolution shell. |
23.4 (3.8) | 22.1 (1.7) | 20.6 (3.1) | 16.9 (2.7) | 20.2 (3.3) | 19.3 (1.9) | 17.5 (2.8) | 15.5 (2.6) | 21.9 (3.2) |
| Completeness, % | 92.5 | 95.2 | 99.4 | 99.8 | 98.2 | 98.4 | 99.6 | 99.7 | 91.3 |
| Rsym
a Values in parentheses correspond to those in the outer resolution shell. |
5.9 (36.6) | 7.1 (46.8) | 7.6 (56.4) | 8.9 (41.4) | 4.7 (26.0) | 6.4 (66.7) | 13.6 (55.8) | 10.2 (53.1) | 8.0 (42.6) |
| Refinement | |||||||||
| Completeness, %
a Values in parentheses correspond to those in the outer resolution shell. |
90.9 (56.3) | 90.9 (58.2) | 95.7 (90.0) | 96.7 (88.9) | 96.0 (86.3) | 90.3 (62.4) | 94.6 (79.1) | 95.9 (88.4) | 89.4 (51.4) |
| Rfree, %
a Values in parentheses correspond to those in the outer resolution shell. |
24.3 (33.0) | 23.9 (36.1) | 25.0 (36.1) | 25.4 (32.1) | 21.3 (24.7) | 25.4 (38.2) | 22.8 (27.3) | 25.9 (29.4) | 23.6 (30.4) |
| Rcryst, %
a Values in parentheses correspond to those in the outer resolution shell. |
21.3 (27.1) | 21.8 (33.4) | 21.7 (30.7) | 22.4 (28.9) | 19.3 (24.6) | 22.8 (35.1) | 20.0 (27.3) | 22.1 (27.5) | 20.6 (27.9) |
| Nonhydrogen atoms | |||||||||
| Total | 5610 | 5689 | 5593 | 5530 | 5829 | 5590 | 5758 | 5382 | 5632 |
| Solvent | 423 | 569 | 386 | 368 | 658 | 485 | 500 | 306 | 510 |
| Rmsd from ideal geometry | |||||||||
| Bond lengths, Å | 0.006 | 0.005 | 0.006 | 0.006 | 0.008 | 0.005 | 0.005 | 0.006 | 0.005 |
| Bond angles, ° | 1.2 | 1.2 | 1.2 | 1.1 | 1.2 | 1.2 | 1.1 | 1.2 | 1.1 |
| Average isotropic B value, Å2 | 30.6 | 23.4 | 30.6 | 30.3 | 20.8 | 27.1 | 31.6 | 35.3 | 25.7 |
| PDB accession code | 1NJW | 1NJX | 1NJY | 1NJZ | 1NK0 | 1NK4 | 1NK5 | 1NK6 | 1NK7 |
Rsym= (Σ|(I − <I>)|)/(ΣI), where <I> is the average intensity of multiple measurements. Rcryst and Rfree= (Σ|Fobs − Fcalc|)/(Σ|Fobs|). Rfree was calculated over 5% of the amplitudes not used in refinement. Rms deviations reported include both protein and DNA residues.
a Values in parentheses correspond to those in the outer resolution shell.
- Open table in a new tab
Table 3DNA Base Pair Parameters at the Postinsertion Site of BF
| Base Pair | dC1′-C1′ (Å) | λprimer (°) | λtemplate (°) | Shear (Å) | Stretch (Å) | Stagger (Å) | Buckle (°) | Propeller (°) | Opening (°) |
|---|---|---|---|---|---|---|---|---|---|
| Watson-Crick
a Average values for all four Watson-Crick base pairs observed at the n-1 position of BF polymerase (Johnson et al., 2003). Standard deviations are shown in parenthesis. |
10.3 (0.2) | 57.6 (1.8) | 57.6 (1.1) | 0.04 (0.20) | −0.09 (0.08) | −0.37 (0.26) | 23.0 (5.2) | −6.4 (2.7) | 9.6 (3.0) |
| G•T | 10.4 | 46.2 | 62.2 | −1.59 | −0.38 | −0.06 | 25.1 | 1.5 | 1.7 |
| T•G | 10.8 | 59.7 | 40.9 | 1.67 | −0.31 | −0.66 | 22.9 | 1.8 | −3.6 |
| T•T | 9.1 | 72.1 | 42.0 | 2.60 | −1.64 | 0.21 | 19.9 | −17.2 | −8.4 |
| C•T | 8.7 | 60.8 | 55.4 | 0.46 | −1.55 | −0.28 | 25.4 | −7.3 | −7.7 |
| A•G | 12.3 | 48.6 | 50.5 | 0.09 | 1.58 | −0.18 | 37.9 | −16.2 | 7.7 |
| G•G | 11.0 | 37.0 | 60.2 | −1.10 | −3.72 | 0.11 | 13.5 | −23.0 | 27.6 |
dC1′-C1′ is the distance between the C1′ atoms of the base pair. λ is the angle between the glycosidic bond of the primer or template base and the line drawn between the C1′ atoms. All other parameters are defined in
Dickerson et al. 1989
- Dickerson R.E.
- Bansal M.
- Calladine C.R.
- Diekmann S.
- Hunter W.N.
- Kennard O.
- Lavery R.
- Nelson H.C.M.
- Olson W.K.
- Saenger W.
- et al.
Definitions and nomenclature of nucleic acid structure parameters.
- Crossref
- PubMed
- Scopus (201)
- Google Scholar
. All values were calculated using 3DNA
. The CEHS reference frame was used to calculate the opening parameter.
a Average values for all four Watson-Crick base pairs observed at the n-1 position of BF polymerase . Standard deviations are shown in parenthesis.
- Open table in a new tab
In solution, the efficiency of incorporation varies depending on the identity of the mismatch (
). DNA replication catalyzed in the BF•DNA crystals also exhibits differential mismatch incorporation and extension efficiencies: some mismatches are readily incorporated in the presence of Mn2+, while others were captured only by cocrystallization. Once incorporated, the ease of mismatch extension catalyzed in the crystal parallels that reported for solution studies reported for other, related polymerases. Previous studies have demonstrated that accurate replication of Watson-Crick base pairs is faithfully reproduced in BF crystals (
). The mismatch replication process as observed in the crystal also appears to be a reasonable approximation of that observed in solution.
We have examined all 12 possible covalently incorporated DNA mismatches (Table 1). Six are placed at the postinsertion site and are well ordered (Figure 2) (G•T, T•G, T•T, C•T, A•G, G•G; the first and second letters refer to the primer and template strands, respectively); three mismatches are placed at the postinsertion site but are too disordered for interpretation as a unique molecular structure (T•C, A•C, C•A); and three (A•A, C•C, G•A) are located at the insertion site (primer strand) and preinsertion site (template strand), instead of the postinsertion site, and do not pair (i.e., are frayed).

Figure 2DNA Mismatches Bound at the Polymerase Postinsertion Site
Show full caption
The bases are shown in the same orientation and location as the G•C base pair in Figure 1B. Left, hydrogen bonding pattern. Right, superimposition of the molecular surface of the mismatch (red) and cognate G•C base pair (yellow, PDB ID 1L3S) bound at the postinsertion site, highlighting differences in shape and location of the primer terminus.
- View Large
Image - Figure Viewer
- Download Hi-res
image - Download (PPT)
The structure of each mismatch is distinct (Table 3). Although some of the mismatch structures adopt conformations that had been previously observed in heteroduplex DNA in the absence of protein (
,
), others do not. The polymerase, therefore, plays a significant role in defining the local and the global conformation of each mismatch structure. The type and degree of disruptions at the polymerase active site vary depending on the identity of the mismatch. We present our observations categorized by the type of base pairing.
Purine-Pyrimidine Mismatch: G•T, T•G
The G•T mismatch was obtained by enzymatic extension in the crystal in the presence of Mn2+ and is bound at the postinsertion site. The protein adopts a distorted open conformation (Figure 3). The newly incorporated, mismatched primer base (G) adopts a conformation similar to that of a cognate base at that position. Consequently, positioning of the 3′ hydroxyl and the assembly of the catalytic site remains essentially intact. In contrast, the positioning of the template base is significantly distorted (Figure 2). The two bases are paired in a wobble conformation (shear, Table 3), in which the thymine is positioned toward the DNA major groove. The minor groove interaction with Gln797 is lost and the template strand is displaced by as much as 3.6 Å from the surface of the protein, relative to the cognate binding site. Additionally, instead of stacking with the template strand, Tyr714 shifts by up to 3 Å and stacks with the primer base of the mismatch. This shift is accomplished by a hinge motion in the O, O1, and O2 helices in the finger domain, which results in a dramatic rearrangement of the loop between the O and O1 helices containing the preinsertion site; the protein backbone at position 716 is displaced by 6 Å, thereby preventing binding of the acceptor template base at the preinsertion site. Placement of a mismatch at the postinsertion site also alters the geometry of the adjacent insertion site, which may alter the base pairing specificity at that site. Distortions extend into the DNA duplex binding region as well, affecting base pairs as far away as the n-3 base position, by changing the conformation of the DNA along the duplex binding region from the normally observed A form to a B form conformation.

Figure 3Mismatch-Induced Disruptions at the Polymerase Active Site
Show full caption
Four categories of active site disruptions are observed in the presence of a replication error. For each category, a representative mismatch structure (bold text) is illustrated. Right, schematic of the polymerase•mismatch active site (color coded as in Figure 1A) indicating the regions (magenta) disrupted by the mismatch (red line). Left, mismatch complex (color) superimposed on a cognate A•T base pair structure (gray, PDB ID 1L3U).
Mechanism 1. A G•T mismatch bound at the postinsertion site results in displacement of the template strand, repositioning of Tyr714, and a rearrangement of the O, O1, and O2 helices that blocks the template preinsertion site, resulting in a distorted open conformation that differs from that seen in the presence of a cognate base pair. The DNA helix adopts a B form conformation at the active site rather than the more A form conformation observed in cognate base pairs. The catalytic site is undisturbed.
Mechanism 2. In the T•T mismatch structure, the primer terminus is displaced, and the interaction between residue Asp830 and the primer 3′ hydroxyl at the catalytic site is disrupted. The template base of the mismatch rotates toward the floor of the polymerase active site, but the DNA backbone of the template strand is undisturbed.
Mechanism 3. The A•G mismatch structure induces displacement of the template strand and blocking of the preinsertion site (similar to mechanism 1) and also displacement of the primer strand, resulting in disruption of the catalytic site (similar to mechanism 2).
Mechanism 4. The A•A mismatch structure is frayed, with the primer base of the mismatch bound at the insertion site and the template base at the preinsertion site.
- View Large
Image - Figure Viewer
- Download Hi-res
image - Download (PPT)
The T•G mismatch was captured in the polymerase crystal by enzymatic extension and also adopts a wobble conformation (shear, Table 3), but an additional water-mediated hydrogen bond is observed between the mismatched bases in DNA minor groove (Figure 2). As with the G•T structure, the DNA template is displaced from its normal binding site and the polymerase adopts a distorted open conformation. However, some differences are observed in binding of the primer strand. In the T•G structure, the minor groove interaction between the primer base and Arg615 in the postinsertion site is lost, and Arg615 drops to the floor of the polymerase into an apo-like conformation. In addition, some disorder is observed in the position of the deoxyribose ring of the thymine nucleotide, suggesting that the primer terminus is predominantly displaced, although the normal interaction between the primer 3′ hydroxyl and Asp830 in the catalytic site may be retained to some degree.
Pyrimidine-Pyrimidine Mismatch: T•T, C•T
The T•T mismatch was obtained by catalysis in the crystal. The mismatch is bound at the postinsertion site. In contrast to the G•T and T•G mismatches, the distortions in the T•T mismatch are confined primarily to the primer strand, and the protein conformation is undisturbed (Figure 2, Figure 3). The T•T mismatch adopts a wobble conformation (shear, Table 3) in which the primer base lifts up into the DNA major groove and the template base rotates slightly toward the minor groove, similar to the wobble conformation reported in an analogous U•U RNA heteroduplex structure obtained in the absence of protein (
). The displacement of the primer base is accompanied by a ∼1.4 Å shift of the 3′ hydroxyl, thereby breaking the hydrogen bond that normally exists between the primer 3′ hydroxyl and Asp830, thus disrupting assembly of the catalytic site (Figure 3).
The C•T mismatch is also bound in the postinsertion site. This mismatch does not adopt a wobble conformation, but rather the bases pair directly opposite each other (Figure 2). The mismatch shows significant opening in the minor groove (Table 3) where the two opposing O2 atoms interact via a bridging water molecule. As with the T•T structure, the primer terminus is displaced, but the DNA template and protein conformation is essentially undisturbed.
Purine-Purine Mismatch: A•G, G•G
The A•G mismatch is bound at the postinsertion site, with the polymerase adopting a distorted open conformation (Figure 3). Both bases in the mismatch maintain an anti conformation about the glycosidic bond (Figure 2), which is one of the three conformations that have been observed in heteroduplex DNA in the absence of protein (
). Consequently, accommodation of the two large purine bases results in a 2.0 Å increase of the helical width (Table 3) and causes extensive disruptions and movement of both template and primer strands (Figure 3). Similar to the G•T mismatch, the template strand lifts away from the surface of the protein, the finger domain rearranges to block the preinsertion site, and the duplex binding region is distorted. At the postinsertion site, the disrupted minor groove contact by Gln797 is replaced with water-mediated interactions to both the N2 and N3 positions of the template guanine base. Along the primer strand, the minor groove interaction between Arg615 and the primer base is retained. However, the widening of the base pair as well as a change in sugar pucker displaces the 3′ hydroxyl by 2.6 Å, thereby significantly altering the interaction with Asp830 at the catalytic site, but without breaking it.
Not all pur•pur mismatches retain an anti-anti conformation in the polymerase active site. In the G•G mismatch, the primer base of the mismatch rotates 180° with respect to the sugar moiety into a syn conformation while the template base remains in an anti conformation (Figure 2). This rearrangement, which also has been observed in heteroduplex DNA in the absence of protein (
Skelly et al. 1993
- Skelly J.V.
- Edwards K.J.
- Jenkins T.C.
- Neidle S.
Crystal structure of an oligonucleotide duplex containing G.G base pairs influence of mispairing on DNA backbone conformation.
- Crossref
- PubMed
- Scopus (98)
- Google Scholar
), allows the mismatch to form two hydrogen bond interactions and results in a helical width that is much closer to a Watson-Crick base pair than is observed in the anti-anti A•G structure (Table 3). Consequently, disruptions to the active site are more limited than in the A•G structure and are confined to the template strand. In this regard, the G•G structure more closely resembles the G•T complex. The template strand is displaced and the preinsertion site is blocked, but the position of the primer terminus is undisturbed. However, rotation of the primer guanine base to a syn conformation removes the N3 hydrogen bond acceptor atom from the minor groove and prevents Arg615 from coordinating the nucleotide. This lost interaction may have particularly disruptive consequences in the closed conformation where Arg615 plays a dual role in anchoring both the primer base at the postinsertion site and the incoming dNTP at the insertion site (
).
Disordered Mismatches: T•C, A•C, C•A
T•C and A•C mismatches were also captured at the postinsertion site, but the mismatches are sufficiently disordered to preclude deduction of a detailed molecular model for the DNA. The disorder is confined primarily to the template strand, extending to the n-3 position of the duplex binding region. A mixture of A and B forms of DNA can be discerned in the duplex binding region. No density for the template strand is observed in either pre- or postinsertion site. In both cases, the protein adopts a distorted open conformation in which the preinsertion site is blocked. Disorder on the primer strand is essentially localized to the primer base. The C•A mismatch structure is too disordered throughout the DNA to permit assignment of the mismatch location.
Frayed Mismatches: A•A, C•C, G•A
In contrast to the other mismatches, these three mismatches do not bind in the postinsertion site. Instead, the primer base of each mismatch is located at the insertion site and the template base is located at the preinsertion site or displaced completely from the active site. The bases, therefore, do not pair with each other, and the 3′ primer terminus has a “frayed” appearance.
In the A•A mismatch, obtained by catalysis in the crystal in the presence of Mn2+, the primer base is located at the insertion site and the template base at the preinsertion site (Figure 3). The two bases cannot pair because Tyr714 blocks access of the template base to the insertion site. Tyr714 also prevents the primer base from stacking adjacent to the DNA helix; the primer base is displaced from the floor of the insertion site and stacks against Phe710. Thus, although the primer base is located at the insertion site, it does not superimpose with the dNTP position observed in a closed BF ternary complex (
). Additionally, since the 3′ primer terminus is located at the insertion site rather than the postinsertion site, the catalytic site is completely disrupted. Density consistent with a single metal ion is observed at the catalytic site (B); the second catalytic metal (A) is not observed.
The G•A and C•C mismatch structures were obtained by cocrystallization with a preformed heteroduplex. Although they differ in detail, the disruption of the catalytic site resembles that observed in the A•A structure.
Mismatch Extensions
Mismatches diminish but do not block the rate of extension. We therefore have been able to probe the mechanism by which processive replication continues upon incorporation of a mismatch by further taking advantage of the catalytic properties of the BF crystals. Extension of a number of mismatches was examined starting with cocrystallized mismatch substrates (Table 1) and directing progression of heteroduplexes through the polymerase in successive extension steps by soaking in different combinations of nucleotides in the presence of Mg2+ to control the final location of the mismatch (one of the n-2, …, n-6 positions of the duplex binding region). Under these conditions, the A•G, T•T, T•G, and C•C mismatches failed to extend, whereas the G•T, C•T, and G•G mismatches were all successfully extended (Table 1, Table 4, Table 5). For the T•C mismatch, the DNA is too disordered to permit interpretation of the product structure. We note that in one case (T•G), we have also successfully extended the mismatch in the crystal under a variety of other reaction conditions (unpublished data).
Table 4Data Collection and Refinement Statistics for G•T and C•T Extension Experiments
| G•T (n-2) | G•T (n-3) | G•T (n-4) | G•T (n-6) | C•T (n-2) | |
|---|---|---|---|---|---|
| Data Collection (All Data) | |||||
| Resolution, Å | 50.0–1.9 | 50.0–1.9 | 50.0–2.0 | 50.0–1.8 | 50.0–1.8 |
| Outer shell, Å | 1.97–1.90 | 1.97–1.90 | 2.07–2.00 | 1.86–1.80 | 1.86–1.80 |
| No. reflections | |||||
| Unique | 64,853 | 60,333 | 52,699 | 62,356 | 80,698 |
| Total | 276,640 | 283,443 | 185,081 | 209,950 | 446,710 |
| Mean I/σI
a Values in parentheses correspond to those in the outer resolution shell. |
18.1 (2.8) | 28.7 (3.5) | 18.9 (2.0) | 31.1 (4.6) | 21.9 (2.5) |
| Completeness, % | 94.2 | 87.1 | 88.3 | 76.7 | 97.8 |
| Rsym* | 6.6 (25.7) | 4.7 (21.7) | 6.9 (32.6) | 4.2 (13.6) | 6.4 (47.4) |
| Refinement | |||||
| Completeness, %
a Values in parentheses correspond to those in the outer resolution shell. |
91.6 (57.8) | 86.3 (42.0) | 86.6 (47.9) | 76.5 (16.8) | 93.8 (81.7) |
| Rfree, %
a Values in parentheses correspond to those in the outer resolution shell. |
21.9 (26.4) | 23.7 (27.7) | 24.3 (25.5) | 21.8 (26.5) | 24.8 (27.2) |
| Rcryst, %
a Values in parentheses correspond to those in the outer resolution shell. |
19.0 (23.6) | 20.4 (24.6) | 20.5 (23.1) | 18.6 (23.0) | 21.6 (25.8) |
| Nonhydrogen atoms | |||||
| Total | 5732 | 5622 | 5595 | 5912 | 5655 |
| Solvent | 532 | 423 | 352 | 613 | 513 |
| Rmsd from ideal geometry | |||||
| Bond lengths, Å | 0.005 | 0.005 | 0.006 | 0.005 | 0.006 |
| Bond angles, ° | 1.2 | 1.2 | 1.2 | 1.1 | 1.2 |
| Average isotropic B value, Å2 | 23.9 | 30.3 | 30.8 | 20.6 | 29.1 |
| PDB accession code | 1NK8 | 1NK9 | 1NKB | 1NKC | 1NKE |
Rsym= (Σ|(I − <I>)|)/(ΣI), where <I> is the average intensity of multiple measurements.
Rcryst and Rfree= (Σ|Fobs − Fcalc|)/(Σ|Fobs|). Rfree was calculated over 5% of the amplitudes not used in refinement.
Rms deviations reported include both protein and DNA residues.
a Values in parentheses correspond to those in the outer resolution shell.
- Open table in a new tab
Table 5Base Pair Parameters for Extended G•T and C•T Mismatches
| Base Pair | dC1′-C1′ (Å) | λprimer (°) | λtemplate (°) | Shear (Å) | Stretch (Å) | Stagger (Å) | Buckle (°) | Propeller (°) | Opening (°) |
|---|---|---|---|---|---|---|---|---|---|
| G•T(n-1) | 10.4 | 46.2 | 62.2 | −1.59 | −0.38 | −0.06 | 25.1 | 1.5 | −4.8 |
| G•T(n-2) | 10.3 | 41.9 | 69.2 | −2.44 | −0.57 | 0.07 | 19.5 | 0.7 | −1.8 |
| G•T(n-3) | 10.9 | 63.7 | 44.9 | 1.91 | 0.00 | −0.70 | −17.7 | −3.6 | −2.7 |
| G•T(n-4) | 11.2 | 62.9 | 41.4 | 2.06 | 0.03 | −0.11 | 2.9 | 7.9 | −6.4 |
| G•T(n-6) | 10.5 | 43.3 | 66.1 | −2.17 | −0.43 | 0.02 | −4.4 | −21.9 | 1.2 |
| G•T (B-DNA)* | 10.4 | 42.5 | 69.9 | −2.49 | 0.64 | −0.04 | 13.4 | −8.3 | −3.0 |
| G•T (B-DNA)
a Two G•T crystal structures observed in heteroduplex DNA (Hunter et al., 1987). |
10.3 | 44.6 | 72.0 | −2.72 | 0.67 | 0.10 | 9.9 | 10.2 | −2.3 |
| C•T (n-1) | 8.7 | 60.8 | 55.4 | 0.46 | −1.55 | −0.28 | 25.4 | −7.3 | 6.0 |
| C•T (n-2) | 10.6 | 60.2 | 58.3 | 0.39 | 0.58 | 0.25 | 26.2 | −16.3 | 10.7 |
dC1′-C1′ is the distance between the C1′ atoms of the base pair. λ is the angle between the glycosidic bond of the primer or template base and the line drawn between the C1′ atoms. All other parameters are defined in
Dickerson et al. 1989
- Dickerson R.E.
- Bansal M.
- Calladine C.R.
- Diekmann S.
- Hunter W.N.
- Kennard O.
- Lavery R.
- Nelson H.C.M.
- Olson W.K.
- Saenger W.
- et al.
Definitions and nomenclature of nucleic acid structure parameters.
- Crossref
- PubMed
- Scopus (201)
- Google Scholar
. All values were calculated using 3DNA
.
a Two G•T crystal structures observed in heteroduplex DNA .
- Open table in a new tab
G•T Extension
The G•T mismatch was captured at the n-2, n-3, n-4, and n-6 positions in separate rounds of replication in the presence of different nucleotide mixtures (Figure 4). As we observed at the n-1 position, the mismatch adopts a wobble conformation at the n-2 position, although water is bound in both the major and minor grooves. At positions n-3 and n-4, the wobble inverts; the thymine base moves into the minor groove and the guanine base moves toward the major groove. This conformation is stabilized by direct contacts between the polymerase and the DNA backbone and solvent-mediated contacts in the minor groove. At position n-6, the G•T mismatch has exited the polymerase and adopts a wobble conformation resembling the crystal structure of a B form G•T heteroduplex obtained in the absence of protein (
).

Figure 4Extension of a G•T Mismatch by Successive Rounds of Replication
Show full caption
The conformation of the G•T mismatch is shown at each position (left), including interacting water molecules (red spheres). Dashed lines indicate potential hydrogen bonds. At the n-3 and n-4 positions, hydrogen bonds are shown between groups within the appropriate distance (≤3.2 Å) and correspond to tautomerization or ionization of one of the bases (see text). A schematic representation (right) of the mismatch complex, drawn and color coded as described in Figure 1, Figure 2, Figure 3, indicates regions of the polymerase active site that are disrupted upon binding of the mismatch (red line). Mismatch binding at positions n-1 to n-4 along the DNA duplex binding region (gray) results in a distorted open conformation at the polymerase active site as described by mechanism 1 (Figure 3). The normal open conformation observed with homoduplexes is fully restored when the mismatch is bound at the n-6 position.
- View Large
Image - Figure Viewer
- Download Hi-res
image - Download (PPT)
The G•T base pairing observed at the n-3 and n-4 positions is inconsistent with the interbase hydrogen bonding geometry associated with the major tautomeric form of the nucleotides. This suggests that a tautomeric shift, or ionization of the mismatch, has taken place. It is not possible to deduce the position of the hydrogens in these bases, however, since there are several, structurally similar possibilities, and the 2.0 Å resolution of the X-ray structures does not permit clear distinction between the alternatives.
Mismatches at the n-2 and n-3 locations disrupt the normal A to B form conformational transition in this region. This disruption results in partial release of the DNA template, repositioning of Tyr714, and closing of the template preinsertion site, similar to the disruptions observed when the G•T mismatch is positioned at the primer terminus. Consequently, the presence of this mismatch within the duplex binding region continues to disrupt to the active site. Positioning of the mismatch in the n-4 location partially restores the normal DNA structure in the duplex binding region, and a mixture of both a disrupted and an undisrupted active site is observed. Positioning at n-6 fully restores the DNA conformation at all other sites on the polymerase (the 3′ primer terminus in this complex has a blunt end, so there is no template base to occupy the preinsertion site).
C•T Extension
The C•T mismatch was extended in a single round of replication, placing it in the n-2 location of the duplex binding region. Although positioning of the C•T mismatch at the postinsertion site disrupts the catalytic site, translocation of the C•T mismatch to the n-2 position fully restores the catalytic site. The mismatch at the n-2 position shows a 2 Å increase in the separation between the mismatched bases (stretch) as compared to the original structure (Table 5). Consequently, the DNA adopts a normal helical width, but interbase distance in the mismatch is ∼5 Å, preventing direct contact between the two opposing bases (Figure 5). This conformation is stabilized by a bridging water molecule that forms interbase hydrogen bonds, as well as direct contacts between the DNA phosphate backbone and the protein, stacking with the adjacent base pairs, and a water-mediated minor groove interaction between the protein and the minor groove base—interactions that are all present in normal Watson-Crick structures. No distortion is observed in the DNA helix outside the mismatch or in the conformation of the active site.

Figure 5The C•T Mismatch Extension Product
Show full caption
The C•T mismatch located at the n-2 position provides a dramatic example of DNA conformations that have not been observed in heteroduplex structures determined in the absence of protein. The bases are separated by >5.0 Å and are stabilized by an intervening water molecule, the protein, and DNA stacking interactions.
- View Large
Image - Figure Viewer
- Download Hi-res
image - Download (PPT)
Discussion
The high-resolution structures of covalently incorporated DNA mismatches at the active site of the BF polymerase allow us to suggest mechanisms by which replication errors stall a polymerase, enhancing subsequent dissociation and exonucleolytic excision. Such stalling is the consequence of mismatch-induced disruptions of the polymerase active site. We observe four broad categories of mismatch-induced disruptions at the active site. Furthermore, we find that mismatches need not be positioned at the primer terminus to induce these disruptions. Mismatches positioned up to four base pairs in from the point incorporation can still disrupt the active site, thereby providing a mechanism whereby the polymerase retains a short-term memory of the mismatch incorporation event.
Four Broad Categories of Mismatch-Induced Disruptions at the Active Site
Although each of the 12 mismatches is structurally unique, we find that mismatch-induced disruptions of the polymerization mechanism can be divided into four broad categories (Figure 3): (1), displacement of the template strand and disruption of the preinsertion site; (2), disruption of primer strand and the assembly of the catalytic site; (3), disruption of both the template and primer strands; and (4), fraying of the DNA at the insertion site. A consequence of each of these mechanisms is disruption of the insertion site.
All four mechanisms are observed when a mismatch is positioned at the primer terminus: (1), G•T, G•G, A•C, T•C; (2), T•T, C•T; (3), A•G, T•G; (4), A•A, G•A, C•C. The disruptions induced by the G•T mismatch as it is extended through the duplex binding region (the memory mechanism) are confined to mechanism 1.
Mismatch Extension and the Mechanism of Replication Error Memory
Extension of a number of mismatches through the duplex binding region of a polymerase retains a “memory” of the misincorporation event that results in further stalling, even though the mismatch is located up to four base pairs from the point of incorporation (
,
). Of particular relevance to understanding mismatch extensions, therefore, are the structural contortions that allow a heteroduplex to translocate through the duplex binding region, which is stereochemically complementary to correctly formed base pairs (
,
), and the mechanism by which a heteroduplex disrupts the polymerase active site at a distance to provide a short-term memory of the mismatch incorporation event.
In one case (G•T), we have carried out multiple extension reactions (Figure 4) and captured the progression of this mismatch through the entire duplex binding region (n-1, …, n-6). The structural adaptations to heteroduplex are confined primarily to the DNA, with some local protein side chain motions. There are three striking features of the adaptations in the DNA structure: (1) at each position the conformation of the mismatch is different; (2) at several positions base pair geometry indicates that the tautomeric or ionization state of the bases has changed; and (3) distortions are not localized to the vicinity of the mismatch, but can also affect the DNA and protein conformation at the active site. The long-range distortions are transmitted primarily through the template strand and result in disruption of the single-stranded DNA template and the preinsertion site at the active site (mechanism 1), suggesting a mechanism whereby the polymerase retains a short-term memory of the mismatch after incorporation.
The template-mediated distortions are the result of significant disruptions in the transition from the A form (at the active site) to the B form (at n-6) of the DNA helix. This transition in the DNA conformation is a structural feature that is common to many polymerase families (
,
,
,
,
,
). A notable exception is the “error prone” Y family, in which no distortion of the DNA conformation is observed along the polymerase-DNA interface (
). The absence of a conformational transition in the DNA duplex binding region may contribute to the insensitivity of these polymerases to downstream replication errors or damaged DNA.
Mismatch Extension Efficiencies
It is tempting to speculate that the category of mismatch-induced disruptions can be correlated with differences in mismatch extension efficiencies observed with other Family A DNA polymerases (
,
). However, such correlations are not straightforward, because the inherent flexibility of DNA permits access to many states (see below). Interference with the catalytic site is the most critical, yet even in severely disrupted catalytic sites a catalytically competent conformation can remain accessible by virtue of this flexibility. Conversely, in cases where the catalytic site is undisturbed, observed decreases in the rates of mismatch extension must arise from distortions in one or more of the other sites.
For example, the G•T mismatch, which is one of the easiest mismatches to extend in solution and is associated with a high frequency of mutagenesis (
,
,
), shows no structural disruption of the catalytic site and can be extended readily in the polymerase crystals. In this case, the observed displacement of the template is predicted to interfere with transfer from the preinsertion site to the insertion site. This disruption may account for the reduced extension efficiency of G•T mismatch of ten-fold to a thousand-fold depending on the polymerase (
,
,
). Although the structural disruptions observed in the G•G mismatch are similar to G•T, the additional loss of a hydrogen bond with Arg615, which plays a dual role in anchoring the primer base at the postinsertion site and the incoming dNTP at the insertion site (see Results), may account for the observation that G•G extension efficiencies are more than 100-fold slower than that of G•T (
,
).
In contrast, the C•T mismatch complex has an extensively disrupted active site, but nevertheless can be extended readily both in solution and in the BF crystal. This case illustrates that DNA must be conformationally dynamic and that competent conformers that are not observed in the crystals are kinetically accessible at the n-1 position. Furthermore, a reasonable model for a catalytically competent C•T mismatch conformation is suggested by the structure of the C•T mismatch located at the n-2 position, generated by extension in the crystal (Figure 5). In this structure, the pyrimidine bases are stretched apart in a manner that does not disrupt the DNA helix. If a similar conformation is adopted at the postinsertion site, the primer 3′OH would be appropriately positioned for catalysis. The loss of interbase hydrogen bonds in this conformation is compensated for by hydrogen bonds between protein residues and the minor groove. This model suggests a structural basis for the ease of C•T extension reported in both KF (
) and Taq (
).
Another case is represented by the A•G mismatch, which is among the most difficult to extend in solution (
,
). The A•G mismatch shows significant disruptions both in the catalytic site and template binding regions. Extension efficiencies of the A•G mismatch are reduced by up to a million-fold in related polymerases (
,
). With extension efficiencies between that of the A•G and G•T mismatches (
,
), the T•T mismatch has a significantly disrupted catalytic site but intact template binding region. The T•T and A•G mismatches have yet to be extended in the BF crystal.
Stalling and Dissociation of the Mismatch from the Polymerase
Exonucleolytic excision of mismatches requires dissociation of the heteroduplex from the polymerase active site, followed by cleavage by a proofreading exonuclease located either on the polymerase itself (not in the case of BF) or on a separate enzyme (
,
,
). Furthermore, dissociation of a mismatch from the polymerase per se contributes to replication fidelity, since mismatch extension stops. A number of the structures that we have observed show significantly diminished interactions between the heteroduplex and the polymerase, indicating weakened binding of a heteroduplex by a polymerase. In the cases where the template strand distortions are observed (G•T, T•G, A•G, G•G, extension of G•T), the number of hydrogen bonds between the polymerase and DNA is reduced, and the template has lifted away from the polymerase surface. Additionally, ordered waters can be observed between the DNA and the polymerase, which are absent in homoduplex structure. In several cases (T•G, G•G, extensions of G•T), the amino acid side chains involved in minor groove readout (Arg615, Gln797) adopt a conformation observed in an apo-polymerase structure (
).
Furthermore, in three cases the mismatch is not paired, but frays instead (G•A, A•A, C•C). In the frayed structures, the bases are held apart by interactions with the protein (Figure 3). Factors that stabilize the formation of 3′ single-stranded ends such as observed in these frayed mismatches enhance excision (
). Here we observe that the polymerase itself can stabilize these single-stranded mismatched structures, which is likely to contribute directly to stalling prior to dissociation and subsequent excision editing steps.
Heteroduplex DNA Conformation of the Mismatches
We observe that mismatches form stable complexes with the DNA polymerase by exploiting the large number of conformational degrees of freedom that are thermodynamically and kinetically accessible within the DNA heteroduplex, resulting in noncanonical DNA structures, and heteroduplex-protein interactions that differ from the homoduplex interactions. Relatively small motions and changes are sufficient to avoid steric barriers and hydrogen bonding deficiencies in the interactions between the polymerase and the mismatch. The interactions between the protein and the DNA clearly alter the equilibria between accessible conformations and states. Furthermore, given the wide range of conformational flexibility and the potential stabilization of any of these states by protein-DNA interactions, there is no a priori expectation that the mismatch DNA structures in complex with the polymerase will be similar to those observed in the absence of protein.
Some mismatch conformations that we have observed have not been previously described in a DNA heteroduplex (C•T, T•T, and extensions of C•T and G•T). Binding of mismatches to the polymerase active site stabilizes structures that include stretched pairings (C•T extension, Figure 5), transition in base orientation from anti to syn (G•G), and water-bridged interbase hydrogen bonds (C•T, T•G, and extensions of C•T or G•T). Structural adaptations in mismatches are not confined to simple conformational rearrangements; the noncanonical hydrogen bonds observed in the G•T extension reaction products (Figure 4) involve either a tautomeric rearrangement or ionization of the bases.
Additionally, large-scale disruptions of the DNA helix is a common theme in our polymerase structures (Figure 3, Figure 4), in contrast to heteroduplex structures obtained in the absence of protein, which are dominated by local disruptions (
). Striking examples of such large-scale transitions are the effect of a mismatch on the long-range transition between A and B forms of DNA and distortions in the template strand.
Multiple Base Conformations at the Mismatch Site
Three of the mismatch structures are disordered, with the disorder being confined to the position of the mismatch, retaining a well-ordered structure in the other parts of the DNA and polymerase. As with the frayed A•A and C•C mismatches, the A•C and C•A mismatches are unable to form more than a single hydrogen bond in their dominant tautomeric state, although additional hydrogen bonding could occur upon formation of a different tautomer or ionized state. Indeed, an A•C mismatch formed in the absence of protein adopts a protonated form that forms two hydrogen bonds (
). The observed disorder could therefore indicate the presence of several different species, arising from an equilibrium between several different states of the bases, again illustrating the dynamic nature of the protein-DNA interactions.
Nonequivalence of Mismatch Binding
The binding interactions of equivalent correct base pairs (e.g., A•T, T•A) to the polymerase are identical (
,
), whereas each equivalent mismatch (e.g., G•T, T•G) interacts in a unique manner with the protein. For instance, the T•G mismatch breaks contact with Arg615 in the minor groove and shows some disruption in the catalytic site due to a shifting of the primer thymine into the major groove. On the other hand, the G•T mismatch shows no disruption in either position along the primer strand but has disruptions associated with the template instead. The nonequivalence of interactions continues to be observed at the level of chemical classes. For instance, purine•purine mismatches interact differently. In the case of the A•G mismatch, both bases retain an anti conformation, which results in significant disruption of the catalytic site. Conversely, the primer base of the G•G mismatch switches to the syn conformation, which narrows the width of the base pair and preserves the assembly of the catalytic site.
Outlook
The data presented here are expected to form the basis for future biochemical and structural studies, molecular simulations, and protein engineering experiments for understanding the mechanism of mismatch and lesion incorporation. The structures that we have captured are unlikely to represent all possible interactions between a mismatch and the polymerase. For a given mismatch, different conditions (pH, sequence context, etc.) may lead to other relevant structural changes. However, it is likely that we have delineated some of the major mechanisms by which mismatches can disrupt extension and enhance the fidelity of replication. Many of the mechanisms described here for a Family A polymerase may be generally applicable to other DNA polymerases and may even extend to RNA polymerases (
).
Experimental Procedures
Cocrystallization of BF with DNA Primer Template Substrates
Purification of the thermostable Bacillus stearothermophilus DNA polymerase large fragment (BF) and crystallization with DNA substrates was performed as described previously (
,
). The DNA sequences used for cocrystallization are shown in Table 1.
Data Collection, Structure Determination, and Analysis
Diffraction data were collected at 98 K using an RAXIS-IV detector (Molecular Structure) on a Rigaku rotating anode X-ray generator, at the NSLS X12B and X25 beam lines, and at the APS 14-BMC and 14-BMD beam lines (Table 2, Table 4). Data were processed, phases calculated, and models refined and built as described previously (
). DNA structure analysis was performed with 3DNA (
). A summary of base pair and helical parameters for the mismatch structures is shown in Table 3, Table 5 and Supplemental Table S1 at http://www.cell.com/cgi/content/full/116/6/803/DC1.
Catalysis in the Crystal
The protocol for accurate DNA synthesis in the BF•DNA crystals has been described previously (
). G•T, T•G, T•T, and A•A mismatches were incorporated into BF•DNA complexes by replacing MgSO4 with MnSO4 in the reaction buffer, using the DNA sequence and dNTP indicated in Table 1. Mismatch extension experiments were performed in the presence of MgSO4 by transferring BF•DNA cocrystals containing a mismatch at the 3′ primer terminus into reaction buffers containing nucleotides complementary to the template strand.
Acknowledgements
We thank J.S. Taylor and L.J. Forsberg for assistance with the A•A and C•T extension structures, respectively. We thank H.W. Hellinga for extensive discussions and C.M. Joyce and P. Modrich for critical reading of the manuscript. Research was carried out in part at the National Synchrotron Light Source, Brookhaven National Laboratory, which is supported by the U.S. Department of Energy, Division of Materials Sciences and Division of Chemical Sciences, under Contract No. DE-AC02-98CH10886. Use of the Advanced Photon Source was supported by the U.S. Department of Energy, Basic Energy Sciences, Office of Science, under Contract No. W-31-109-Eng-38. Use of the BioCARS Sector 14 was supported by the National Institutes of Health, National Center for Research Resources, under grant number RR07707. The work was supported by grants to L.S.B. from the Human Frontiers Science Program (RG0351/1998-M) and the National Cancer Institute (P01 CA92584).
Supplementary Material
References
-
- Baeyens K.J.
- De Bondt H.L.
- Holbrook S.R.
Structure of an RNA double helix including uracil-uracil base pairs in an internal loop.
Nat. Struct. Biol. 1995; 2: 56-62
-
- Beckman R.A.
- Loeb L.A.
Multi-stage proofreading in DNA replication.
Q. Rev. Biophys. 1993; 26: 225-331
-
- Brautigam C.A.
- Steitz T.A.
Structural and functional insights provided by crystal structures of DNA polymerases and their substrate complexes.
Curr. Opin. Struct. Biol. 1998; 8: 54-63
-
- Carroll S.S.
- Cowart M.
- Benkovic S.J.
A mutant of DNA polymerase I (Klenow fragment) with reduced fidelity.
Biochemistry. 1991; 30: 804-813
-
- Carver T.J.
- Hochstrasser R.A.
- Millar D.P.
Proofreading DNA.
Proc. Natl. Acad. Sci. USA. 1994; 91: 10670-10674
-
- Dickerson R.E.
- Bansal M.
- Calladine C.R.
- Diekmann S.
- Hunter W.N.
- Kennard O.
- Lavery R.
- Nelson H.C.M.
- Olson W.K.
- Saenger W.
- et al.
Definitions and nomenclature of nucleic acid structure parameters.
J. Mol. Biol. 1989; 205: 787-791
-
- Doublié S.
- Tabor S.
- Long A.M.
- Richardson C.C.
- Ellenberger T.
Crystal structure of a bacteriophage T7 DNA replication complex at 2.2 Å resolution.
Nature. 1998; 391: 251-258
-
- Doublié S.
- Sawaya M.R.
- Ellenberger T.
An open and closed case for all polymerases.
Struct. Fold. Des. 1999; 7: R31-R35
-
- Echols H.
- Goodman M.F.
Fidelity mechanisms in DNA replication.
Annu. Rev. Biochem. 1991; 60: 477-511
-
- Eger B.T.
- Kuchta R.D.
- Carroll S.S.
- Benkovic P.A.
- Dahlberg M.E.
- Joyce C.M.
- Benkovic S.J.
Mechanism of DNA replication fidelity for three mutants of DNA polymerase I.
Biochemistry. 1991; 30: 1441-1448
-
- Friedberg E.C.
- Fischhaber P.L.
- Kisker C.
Error-prone DNA polymerases.
Cell. 2001; 107: 9-12
-
- Goodman M.F.
- Creighton S.
- Bloom L.B.
- Petruska J.
Biochemical basis of DNA replication fidelity.
Crit. Rev. Biochem. Mol. Biol. 1993; 28: 83-126
-
- Huang M.M.
- Arnheim N.
- Goodman M.F.
Extension of base mispairs by Taq DNA polymerase.
Nucleic Acids Res. 1992; 20: 4567-4573
-
- Huang H.
- Chopra R.
- Verdine G.L.
- Harrison S.C.
Structure of a covalently trapped catalytic complex of HIV-1 reverse transcriptase.
Science. 1998; 282: 1669-1675
-
- Hunter W.N.
- Brown T.
- Anand N.N.
- Kennard O.
Structure of an adenine.cytosine base pair in DNA and its implications for mismatch repair.
Nature. 1986; 320: 552-555
-
- Hunter W.N.
- Brown T.
- Kneale G.
- Anand N.N.
- Rabinovich D.
- Kennard O.
The structure of guanosine-thymidine mismatches in B-DNA at 2.5-Å resolution.
J. Biol. Chem. 1987; 262: 9962-9970
-
- Jacobo-Molina A.
- Arnold E.
Crystal structure of Human Immunodeficiency Virus Type I reverse transcriptase complexed with double-stranded DNA at 3.0 Å shows bent DNA.
Proc. Natl. Acad. Sci. USA. 1993; 90: 6320-6324
-
- Johnson K.A.
Conformational coupling in DNA polymerase fidelity.
Annu. Rev. Biochem. 1993; 62: 685-713
-
- Johnson S.J.
- Taylor J.S.
- Beese L.S.
Processive DNA synthesis observed in a polymerase crystal suggests a mechanism for the prevention of frameshift mutations.
Proc. Natl. Acad. Sci. USA. 2003; 100: 3895-3900
-
- Joyce C.M.
How DNA travels between the separate polymerase and 3′-5′ exonuclease sites of DNA polymerase I (Klenow Fragment).
J. Biol. Chem. 1989; 264: 10858-10866
-
- Joyce C.M.
- Steitz T.A.
Function and structure relationships in DNA polymerases.
Annu. Rev. Biochem. 1994; 63: 777-822
-
- Joyce C.M.
- Sun X.C.
- Grindley N.D.F.
Reactions at the polymerase active site that contribute to the fidelity of Escherichia coli DNA polymerase I (Klenow Fragment).
J. Biol. Chem. 1992; 267: 24485-24500
-
- Kennard O.
- Hunter W.N.
Oligonucleotide structure.
Q. Rev. Biophys. 1989; 22: 327-379
-
- Kiefer J.R.
- Mao C.
- Hansen C.J.
- Basehore S.L.
- Hogrefe H.H.
- Braman J.C.
- Beese L.S.
Crystal structure of a thermostable Bacillus DNA polymerase I large fragment at 2.1 Å resolution.
Structure. 1997; 5: 95-108
-
- Kiefer J.R.
- Mao C.
- Braman J.C.
- Beese L.S.
Visualizing DNA replication in a catalytically active Bacillus DNA polymerase crystal.
Nature. 1998; 391: 304-307
-
- Kuchta R.D.
- Benkovic P.
- Benkovic S.J.
Kinetic mechanism whereby DNA polymerase I (Klenow) replicates DNA with high fidelity.
Biochemistry. 1988; 27: 6716-6725
-
- Kunkel T.A.
- Bebenek K.
DNA replication fidelity.
Annu. Rev. Biochem. 2000; 69: 497-529
-
- Li Y.
- Waksman G.
Crystal structures of a ddATP-, ddTTP-, ddCTP, and ddGTP- trapped ternary complex of Klentaq1.
Protein Sci. 2001; 10: 1225-1233
-
- Li Y.
- Korolev S.
- Waksman G.
Crystal structures of open and closed forms of binary and ternary complexes of the large fragment of Thermus aquaticus DNA polymerase I.
EMBO J. 1998; 17: 7514-7525
-
- Ling H.
- Boudsocq F.
- Woodgate R.
- Yang W.
Crystal structure of a Y-family DNA polymerase in action.
Cell. 2001; 107: 91-102
-
- Lu X.J.
- Shakked Z.
- Olson W.K.
A-form conformational motifs in ligand-bound DNA structures.
J. Mol. Biol. 2000; 300: 819-840
-
- Miller H.
- Grollman A.P.
Kinetics of DNA polymerase I (Klenow fragment exo-) activity on damaged DNA templates.
Biochemistry. 1997; 36: 15336-15342
-
- Ng L.
- Weiss S.J.
- Fisher P.A.
Recognition and binding of template-primers containing defined abasic sites by Drosophila DNA polymerase alpha holoenzyme.
J. Biol. Chem. 1989; 264: 13018-13023
- Patel D.J. Shapiro L. Hare D. Conformation of DNA Base Pair Mismatches in Solution. Springer-Verlag,
Berlin1987 -
- Pelletier H.
- Sawaya M.R.
- Kumar A.
- Wilson S.H.
- Kraut J.
Structures of ternary complexes of rat DNA polymerase beta, a DNA template-primer, and ddCTP.
Science. 1994; 264: 1891-1903
-
- Perrino F.W.
- Loeb L.A.
Proofreading by the epsilon subunit of Escherichia coli DNA polymerase III increases the fidelity of calf thymus DNA polymerase alpha.
Proc. Natl. Acad. Sci. USA. 1989; 86: 3085-3088
-
- Skelly J.V.
- Edwards K.J.
- Jenkins T.C.
- Neidle S.
Crystal structure of an oligonucleotide duplex containing G.G base pairs.
Proc. Natl. Acad. Sci. USA. 1993; 90: 804-808
-
- Steitz T.A.
DNA polymerases.
J. Biol. Chem. 1999; 274: 17395-17398
-
- Weiss S.J.
- Fisher P.A.
Interaction of Drosophila DNA polymerase alpha holoenzyme with synthetic template-primers containing mismatched primer bases or propanodeoxyguanosine adducts at various positions in template and primer regions.
J. Biol. Chem. 1992; 267: 18520-18526
-
- Yin Y.W.
- Steitz T.A.
Structural basis for the transition from initiation to elongation transcription in T7 RNA polymerase.
Science. 2002; 298: 1387-1395
Article info
Publication history
Published: March 18, 2004
Accepted:
January 23,
2004
Received in revised form:
January 7,
2004
Received:
February 19,
2003
Identification
DOI: https://doi.org/10.1016/S0092-8674(04)00252-1
Copyright
© 2004 Cell Press. Published by Elsevier Inc.
User license
Elsevier user license |
How you can reuse 
Permitted
For non-commercial purposes:
- Read, print & download
- Text & data mine
- Translate the article
Not Permitted
- Reuse portions or extracts from the article in other works
- Redistribute or republish the final article
- Sell or re-use for commercial purposes
Elsevier’s open access license policy
ScienceDirect
Access this article on ScienceDirect
- View Large Image
- Download Hi-res image
- Download .PPT