I want to add a new column like how these tables change below. Where I keep the values ‘member’ and ‘casual’ but change ‘Subscriber’ to ‘member’ and ‘Customer’ to ‘casual’ in a new column. I tried using a conditional mutate but it gives me the error «Error in FUN(left) : invalid argument to unary operator».
If anyone has any ideas on how to get this working, I’d greatly appreciate your input!
| member_casual |
|---|
| member |
| casual |
| Subscriber |
| Customer |
| Subscriber |
| Customer |
Changes to:
| member_casual | membership_type |
|---|---|
| member | member |
| casual | casual |
| Subscriber | member |
| Customer | casual |
| Subscriber | member |
| Customer | casual |
df < - df %>%
mutate(membership_type = case_when(member_casual == "member" ~ "member",
member_casual == "casual" ~ "casual",
member_casual == "Subscriber" ~ "member",
member_casual == "Customer" ~ "casual"))
>>Error in FUN(left) : invalid argument to unary operator
asked Mar 24, 2022 at 1:20
![]()
One possible solution: since you only have two desired categories in your transformation, you could use ifelse().
df <- df %>%
mutate(membership_type = ifelse(member_casual %in% c("member", "Subscriber"), "member", "casual"))
The ifelse() function will check the Boolean condition in the first argument. If the first argument is TRUE, ifelse() will return the second argument; otherwise, it will return the third argument.
answered Mar 24, 2022 at 1:51
![]()
2
- Your last argument needs a default which you set with
TRUE ~ default value
so as it applies to your example, the below should work.
df < - df %>%
mutate(membership_type = case_when(member_casual == "casual" ~ "casual",
member_casual == "Subscriber" ~ "member",
member_casual == "Customer" ~ "casual",
TRUE ~ "member"))
answered Mar 24, 2022 at 2:03
![]()
2
This error commonly occurs when the is an unexpected use of a unary operator (+, -, !)
This error can occur if you provide an extra + when inputting a multiline ggplot2 command, for example,
ggplot(combined.data, aes(x = region, y = expression, fill = species)) +
geom_boxplot() +
+ ggtitle("Title")
You can solve this error by removing the extra + symbols.
The error can also occur if you try to order string columns using the minus sign – with order(). You can solve the error by using the decreasing argument in the order() function call.
This tutorial will go through the error in detail and how to solve it with code examples.
Table of contents
- Example #1: Multiline ggplot2 command
- Solution
- Example #2: Sorting Data Frame String Column Descending Order
- Solution
- Summary
Example #1: Multiline ggplot2 command
Consider the following example, we want to use the gapminder dataset to plot life expectancy across all continents. First, we will install and load gapminder
install.packages("gapminder")
library(gapminder)
head(gapminder)
# A tibble: 6 × 6 country continent year lifeExp pop gdpPercap <fct> <fct> <int> <dbl> <int> <dbl> 1 Afghanistan Asia 1952 28.8 8425333 779. 2 Afghanistan Asia 1957 30.3 9240934 821. 3 Afghanistan Asia 1962 32.0 10267083 853. 4 Afghanistan Asia 1967 34.0 11537966 836. 5 Afghanistan Asia 1972 36.1 13079460 740. 6 Afghanistan Asia 1977 38.4 14880372 786.
Now that we have the dataset, we will attempt to create the life expectancy boxplots.
ggplot(gapminder, aes(x=continent, y=lifeExp, fill=continent)) +
geom_boxplot() +
+ ggtitle("Life Expectancy Across Continents")
Let’s run the code to see what happens:
Error in +ggtitle("Life Expectancy Across Continents") :
invalid argument to unary operator
The error occurs because we have an extra plus-sign + symbol between geom_boxplot() and ggtitle. This typically happens when we copy and paste multiline code. The + sign indicates a new line.
Solution
We can solve this error by removing the extra + symbol. Let’s look at the revised code:
ggplot(gapminder, aes(x=continent, y=lifeExp, fill=continent)) +
geom_boxplot() +
ggtitle("Life Expectancy Across Continents")
Let’s run the code to see the result:
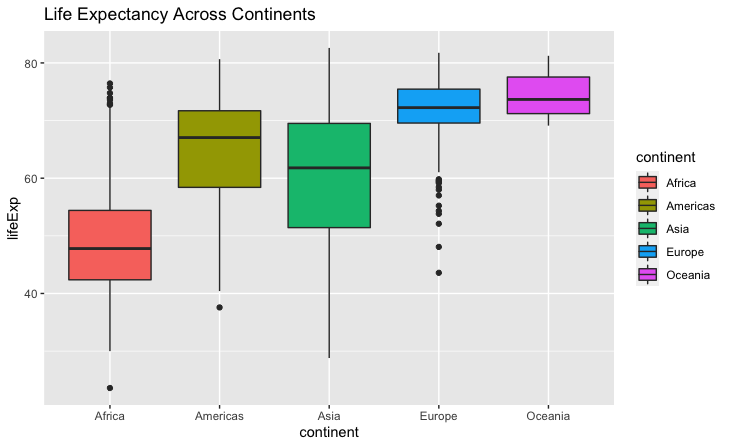
We successfully plotted the box plots for life expectancy across the five continents.
Example #2: Sorting Data Frame String Column Descending Order
Let’s look at an example of a data frame with three variables, gender, age, and degree. The data frame describes a sample of degree holders.
population = 10
gender=sample(c("male","female"),population,replace=TRUE)
age = sample(25:75, population, replace=TRUE)
degree = sample(c("MA","MSci","BA","PhD"), population, replace=TRUE)
(final.data = data.frame(gender=gender, age=age, degree=degree))
gender age degree 1 female 59 MSci 2 female 41 MA 3 female 72 MA 4 female 32 PhD 5 female 43 BA 6 male 55 MSci 7 male 43 BA 8 female 43 BA 9 female 49 PhD 10 male 31 BA
If we want to sort by decreasing age, we can use the minus sign inside the order() function call as follows:
final.data[order(-final.data$age),]
gender age degree 3 female 72 MA 1 female 59 MSci 6 male 55 MSci 9 female 49 PhD 5 female 43 BA 7 male 43 BA 8 female 43 BA 2 female 41 MA 4 female 32 PhD 10 male 31 BA
However, we cannot do this with the degree column because it is type character.
final.data[order(-final.data$degree),]
Error in -final.data$degree : invalid argument to unary operator
In R, we cannot provide a character type object as an argument to the unary operator -.
Solution
We can solve this error by using the decreasing argument in the order function call. Let’s look at the revised code:
final.data[order(final.data$degree, decreasing=TRUE),]
Let’s run the code to see the result:
gender age degree 4 female 32 PhD 9 female 49 PhD 1 female 59 MSci 6 male 55 MSci 2 female 41 MA 3 female 72 MA 5 female 43 BA 7 male 43 BA 8 female 43 BA 10 male 31 BA
We successfully sorted the data frame in descending order of the degree column.
Summary
Congratulations on reading to the end of this tutorial!
For further reading on R related errors, go to the articles:
- How to Solve R Error: mapping should be created with aes() or aes_()
- How to Solve R Error: Could not find function “%”
- How to Solve R Error: Incorrect number of subscripts on matrix
Go to the online courses page on R to learn more about coding in R for data science and machine learning.
Have fun and happy researching!
Lineup optimization for daily fantasy sports
GNU General Public License v3.0
37
9
13

Error in FUN(left) : invalid argument to unary operator
Created at 2 years ago

hi @bluh32, were you able to fix this?
Created at 2 years ago
Yeah, I forget exactly but I needed to shift my dataframe index column one over or something to get it working (or add an index column). This is a really cool app, appreciate you putting it together. Love how you can make a custom contest type.
Created at 2 years ago
Ok awesome. Glad you enjoy it. Feel free to let me know of any other issues you have!
Created at 2 years ago
Я хочу добавить новый столбец, например, как эти таблицы меняются ниже. Где я сохраняю значения «член» и «случайный», но меняю «Подписчик» на «член» и «Клиент» на «случайный» в новом столбце. Я попытался использовать условную мутацию, но это дает мне ошибку «Ошибка в FUN (слева): недопустимый аргумент для унарного оператора».
Если у кого-то есть какие-либо идеи о том, как заставить это работать, я был бы очень признателен за ваш вклад!
| member_casual |
|---|
| член |
| повседневная |
| Подписчик |
| Клиент |
| Подписчик |
| Клиент |
Изменения к:
| member_casual | членство_тип |
|---|---|
| член | член |
| повседневная | повседневная |
| Подписчик | член |
| Клиент | повседневная |
| Подписчик | член |
| Клиент | повседневная |
df < - df %>%
mutate(membership_type = case_when(member_casual == "member" ~ "member",
member_casual == "casual" ~ "casual",
member_casual == "Subscriber" ~ "member",
member_casual == "Customer" ~ "casual"))
>>Error in FUN(left) : invalid argument to unary operator
Я чувствую, что у этого должно быть действительно простое / элегантное решение, но я просто не могу его найти. (Я относительно новичок в r, поэтому неудивительно.)
У меня есть (большой) вложенный список, содержащий data.frames, которые я пытаюсь объединить. Вот код для создания некоторых образцов данных:
#Create data frames nested in a list
for (i in 1:6) {
for (j in 1:4) {
assign(paste0("v", j), sample.int(100,4))
}
assign(paste0("df", i), list(cbind(v1, v2, v3, v4)))
}
inner1 <- list(data1 = df1, data2 = df2)
inner2 <- list(data1 = df3, data2 = df4)
inner3 <- list(data1 = df5, data2 = df6)
outer <- list(group1 = inner1, group2 = inner2, group3 = inner3)
Мне нужно сложить все фреймы данных с пометкой data1 вместе и все data2 вместе. Если бы они не были в этом формате вложенного списка, я бы сделал следующее:
data1.tot <- df1 + df3 + df5
data2.tot <- df2 + df4 + df6
Поскольку они есть в списке, я подумал, что может быть решение lapply, и попробовал:
grp <- c("group1", "group2", "group3") #vector of groups to sum across
datas <- lapply(outer, "[[", "data1") #select "data1" from all groups
tot.datas <- lapply(datas[grp], "+") #to sum across selected data
#I know these last two steps can be combined into one but it helps me keep everything straight to separate them
Но он возвращает Error in FUN(left): invalid argument to unary operator, потому что я передаю список данных как x.
Я также рассмотрел другие решения, подобные этому: Объединение выбранных фреймов данных из списка фреймов данных
Но вложенная структура моих данных заставляет меня не знать, как применить это решение к моей проблеме.
Следует отметить, что данные, с которыми я работаю, являются данными GCHN Daily, поэтому структура не является моей разработкой. Любая помощь будет принята с благодарностью.
ОБНОВИТЬ: Я частично нашел исправление, используя предложение Reduce от @Parfait, но теперь мне нужно автоматизировать его. Я работаю над решением с использованием цикла for, потому что это дает мне больше контроля над элементами, к которым я обращаюсь, но я открыт для других идей. Вот работающее вручную решение:
get.df <- function(x, y, z) {
# function to pull out the desired data.frame from the list
# x included as argument to make function applicable to my real data
output <- x[[y]][[z]]
output[[1]]
}
output1 <- get.df(x = outer, y = "group1", z = "data1")
output2 <- get.df(x = outer, y = "group2", z = "data1")
data1 <- list(output1, output2)
data1.tot <- Reduce(`+`, data1)
Используя мои образцы данных, я хотел бы перебрать это по 2 типам данных («data1» и «data2») и 3 группам («group1», «group2», «group3»). Я работаю над решением цикла for, но пытаюсь сохранить output1 и output2 в списке. Мой цикл сейчас выглядит так:
dat <- c("data1", "data2")
grp <- c("group1", "group2", "group3")
for(i in 1:length(dat)) {
for(j in 1:length(grp)) {
assign(paste0("out", j), get.df(x = outer, y = grp[j], z = dat[i]))
}
list(??? #clearly this is where I'm stuck!
}
Есть ли предложения по проблеме цикла for или по лучшему методу?
3 ответа
Вот решение, которое отлично работает, если каждый внутренний список содержит только несколько фреймов данных:
sum_df1 <- sum(unlist(lapply(outer, "[[", 1)))
sum_df2 <- sum(unlist(lapply(outer, "[[", 2)))
Если каждый внутренний список содержит e. грамм. 1000 фреймов данных, используйте:
dfs <- seq(1 : 1000)
lapply(dfs, function(x) sum(unlist(lapply(outer, "[[", x))))
Это даст вам список, в котором каждый элемент представляет собой сумму внутренних фреймов данных.
0
Joe
26 Сен 2018 в 03:25
Это то, что вы хотите?
sapply(
X = names(outer[[1]]),
FUN = function(d) {
Reduce(x = unlist(lapply(outer, "[[", d), recursive = F), f = "+")
},
simplify = F,
USE.NAMES = T
)
0
Tino
26 Сен 2018 в 08:08
Рассмотрим Reduce, которые работают вне списков. Эта функция высшего порядка представляет собой компактный способ выполнения вложенных вызовов: ((df1 + df2) + df3) + ....
data1.tot <- Reduce(`+`, lapply(outer, "[[", "data1"))
data2.tot <- Reduce(`+`, lapply(outer, "[[", "data2"))
Чтобы продемонстрировать со случайными данными
Данные
set.seed(9262018)
dfList <- setNames(replicate(6, data.frame(NUM1=runif(50),
NUM2=runif(50),
NUM3=runif(50)), simplify = FALSE),
paste0("df", 1:6))
list2env(dfList, .GlobalEnv)
inner1 <- list(data1 = df1, data2 = df2)
inner2 <- list(data1 = df3, data2 = df4)
inner3 <- list(data1 = df5, data2 = df6)
outer <- list(group1 = inner1, group2 = inner2, group3 = inner3)
Вывод
data1.tot <- Reduce(`+`, lapply(outer, "[[", "data1"))
head(data1.tot, 10)
# NUM1 NUM2 NUM3
# 1 2.0533870 1.3821609 1.0702992
# 2 2.6046584 1.7260646 1.9699774
# 3 2.2510810 1.6690353 1.4495476
# 4 1.7636879 1.2357098 1.9483906
# 5 1.0189969 2.1191041 1.7466040
# 6 1.3933982 0.7541027 1.0971724
# 7 1.8058803 2.4608417 0.7291335
# 8 1.0763517 1.2494739 1.0480818
# 9 0.7069873 1.5496575 1.2264486
# 10 0.9522526 2.1407523 1.2597422
data2.tot <- Reduce(`+`, lapply(outer, "[[", "data2"))
head(data2.tot, 10)
# NUM1 NUM2 NUM3
# 1 1.7568578 0.9322930 1.5579897
# 2 0.9455063 0.9211592 1.7067779
# 3 1.2698614 0.4623059 0.9426310
# 4 1.6791964 1.4304953 1.2435480
# 5 0.8088625 2.6107952 1.2308862
# 6 1.8202400 2.3511104 1.5676112
# 7 0.9765578 0.8870206 0.6725699
# 8 2.6448770 1.8931751 1.8188512
# 9 1.6114870 1.8632245 0.7452924
# 10 0.9710550 1.8367305 2.0994788
Тест на равенство
all.equal(data1.tot, df1 + df3 + df5)
# [1] TRUE
all.equal(data2.tot, df2 + df4 + df6)
# [1] TRUE
identical(data1.tot, df1 + df3 + df5)
# [1] TRUE
identical(data2.tot, df2 + df4 + df6)
# [1] TRUE
0
Parfait
26 Сен 2018 в 19:00
Recommend Projects
-

React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
I’m resorting to R to handling averageif() and maxif() like functions because my data set is too large and Excel keeps crashing.
I’m looking for a way to find the average wind based on status, and between columns Start Date and End Date from df. I’d imagine this would involve the between function in R.
status<-c("tropical depression", "tropical depression", "tropical storm")
Begin_Date <- as.Date(c("1974/06/01","1980/06/05","1990/06/07"))
End_Date <- as.Date(c("1975/06/01","1981/07/05","1991/08/07"))
df<-as.data.frame(cbind(status,Begin_Date,End_Date))
df$Begin_Date<-as.Date(Begin_Date)
df$End_Date<-as.Date(End_Date)
df$status<-as.character(status)
storms$date <- as.Date(with(storms, paste(year, month, day,sep="-")), "%Y-%m-%d")
(Note: my actual problem is billing data, so I would need a solution to gather an average based on IDs, between a start billing date and end billing date).
Take the storms dataset from dplyr as an example.
starting with my df below:
status Begin_Date End_Date
tropical depression 1974-06-01 1975-06-01
tropical depression 1980-06-05 1981-07-05
tropical storm 1990-06-07 1991-08-07
What I’d like:
status Begin_Date End_Date Avg Wind
tropical depression 1974-06-01 1975-06-01 44.3
tropical depression 1980-06-05 1981-07-05 66.7
tropical storm 1990-06-07 1991-08-07 56
I’m trying to get this to be dplyr compliant as well.
My attempt is erroring out:
df$Average_wind < - storms %>% filter (status = df$status, date >= df$Begin_Date,date<df$End_Date) %>% summarise(avg = mean(wind))
Error in FUN(left) : invalid argument to unary operator
The average wind and max wind values in the «I’d like» example are not accurate, simply for formatting purposes.