As I’m trying to import JSON file on PostgreSQL pgadmin, I wrote following script, but it didn’t work with the error shown below, for some reason.
The sql/plpgsql:
DROP TABLE IF EXISTS temp01;
DROP TABLE IF EXISTS temp_json;
create temp table temp01 (
tmp text,
tmp02 text,
tmp03 text,
tmp04 text
)
with (oids = false);
BEGIN;
create temporary table temp_json (values text) on commit drop;
copy temp_json from '/home/yuis/pg/psql/tmp03.json';
insert into temp01
select values->>'id' as tmp,
values->>'created_at' as tmp02,
values->>'username' as tmp03,
values->>'tweet' as tmp04
from (
select replace(values,'','\')::json as values from temp_json
)
COMMIT;
SELECT * from temp01;
The above should have resulted a table something like this:
tmp|tmp02|tmp03|tmp04
1396415271359897603,2021-05-23 19:38:39 JST,themooncarl,@elonmusk is still on our side. t.co/K5DnByjzic
1396414423057711109,2021-05-23 19:35:17 JST,..(and so on)
The error:
ERROR: invalid input syntax for type json
DETAIL: The input string ended unexpectedly.
CONTEXT: JSON data, line 1:
SQL state: 22P02
The JSON file, «tmp03.json»:
{"id": 1396415271359897603, "conversation_id": "1396415271359897603", "created_at": "2021-05-23 19:38:39 JST", "date": "2021-05-23", "time": "19:38:39", "timezone": "+0900", "user_id": 978732571738755072, "username": "themooncarl", "name": "The Moon 🌙", "place": "", "tweet": "@elonmusk is still on our side. t.co/K5DnByjzic", "language": "en", "mentions": [], "urls": [], "photos": ["https://pbs.twimg.com/media/E2EQSZgWQAELw9T.jpg"], "replies_count": 78, "retweets_count": 47, "likes_count": 570, "hashtags": [], "cashtags": [], "link": "https://twitter.com/TheMoonCarl/status/1396415271359897603", "retweet": false, "quote_url": "", "video": 1, "thumbnail": "https://pbs.twimg.com/media/E2EQSZgWQAELw9T.jpg", "near": "", "geo": "", "source": "", "user_rt_id": "", "user_rt": "", "retweet_id": "", "reply_to": [], "retweet_date": "", "translate": "", "trans_src": "", "trans_dest": ""}
{"id": 1396414423057711109, "conversation_id": "1396414423057711109", "created_at": "2021-05-23 19:35:17 JST", "date": "2021-05-23", "time": "19:35:17", "timezone": "+0900", "user_id": 978732571738755072, "username": "themooncarl", "name": "The Moon 🌙", "place": "", "tweet": "Me watching Bitcoin go down but realizing that it’s just a nice opportunity to buy more for cheap. t.co/GkmSEPmJCh", "language": "en", "mentions": [], "urls": [], "photos": ["https://pbs.twimg.com/media/E2EPg4ZXMAMIXjJ.jpg"], "replies_count": 94, "retweets_count": 34, "likes_count": 771, "hashtags": [], "cashtags": [], "link": "https://twitter.com/TheMoonCarl/status/1396414423057711109", "retweet": false, "quote_url": "", "video": 1, "thumbnail": "https://pbs.twimg.com/media/E2EPg4ZXMAMIXjJ.jpg", "near": "", "geo": "", "source": "", "user_rt_id": "", "user_rt": "", "retweet_id": "", "reply_to": [], "retweet_date": "", "translate": "", "trans_src": "", "trans_dest": ""}
{"id": 1396388111840645120, "conversation_id": "1396388111840645120", "created_at": "2021-05-23 17:50:44 JST", "date": "2021-05-23", "time": "17:50:44", "timezone": "+0900", "user_id": 978732571738755072, "username": "themooncarl", "name": "The Moon 🌙", "place": "", "tweet": "HODL!!! 💪", "language": "cs", "mentions": [], "urls": [], "photos": [], "replies_count": 263, "retweets_count": 149, "likes_count": 2299, "hashtags": [], "cashtags": [], "link": "https://twitter.com/TheMoonCarl/status/1396388111840645120", "retweet": false, "quote_url": "", "video": 0, "thumbnail": "", "near": "", "geo": "", "source": "", "user_rt_id": "", "user_rt": "", "retweet_id": "", "reply_to": [], "retweet_date": "", "translate": "", "trans_src": "", "trans_dest": ""}
While the above showing «invalid input syntax for type json» error, the below, with a more simpler sample JSON I found on a SO post, this successes with no syntax error.
DROP TABLE IF EXISTS temp01;
DROP TABLE IF EXISTS temp_json;
create temp table temp01 (
tmp text,
tmp02 text,
tmp03 text,
tmp04 text
)
with (oids = false);
BEGIN;
create temporary table temp_json (values text) on commit drop;
-- copy temp_json from '/home/yuis/pg/psql/tmp03.json';
copy temp_json from '/home/yuis/pg/psql/tmp.json';
insert into temp01
-- select values->>'id' as tmp,
-- values->>'created_at' as tmp02,
-- values->>'username' as tmp03,
-- values->>'tweet' as tmp04
select values->>'id' as tmp,
values->>'name' as tmp02,
values->>'comment' as tmp03
from (
select replace(values,'','\')::json as values from temp_json
)
COMMIT;
SELECT * from temp01;
The JSON, «tmp.json»:
{"id": 23635,"name": "Jerry Green","comment": "Imported from facebook."}
{"id": 23636,"name": "John Wayne","comment": "Imported from facebook."}
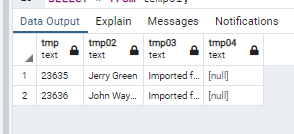
So, apparently the problem here is from the syntax error of the JSON, but as you can see the JSON has no syntax error, apparently the problem is on the SQL side.
I have no idea where in the JSON and/or SQL is wrong.
#sql #json #postgresql
Вопрос:
Когда я пытаюсь импортировать файл JSON в PostgreSQL pgadmin, я написал следующий сценарий, но по какой-то причине он не работал с ошибкой, показанной ниже.
Sql/plpgsql:
DROP TABLE IF EXISTS temp01;
DROP TABLE IF EXISTS temp_json;
create temp table temp01 (
tmp text,
tmp02 text,
tmp03 text,
tmp04 text
)
with (oids = false);
BEGIN;
create temporary table temp_json (values text) on commit drop;
copy temp_json from '/home/yuis/pg/psql/tmp03.json';
insert into temp01
select values->>'id' as tmp,
values->>'created_at' as tmp02,
values->>'username' as tmp03,
values->>'tweet' as tmp04
from (
select replace(values,'','')::json as values from temp_json
)
COMMIT;
SELECT * from temp01;
Вышеизложенное должно было привести к таблице примерно так:
tmp|tmp02|tmp03|tmp04
1396415271359897603,2021-05-23 19:38:39 JST,themooncarl,@elonmusk is still on our side. t.co/K5DnByjzic
1396414423057711109,2021-05-23 19:35:17 JST,..(and so on)
Ошибка:
ERROR: invalid input syntax for type json
DETAIL: The input string ended unexpectedly.
CONTEXT: JSON data, line 1:
SQL state: 22P02
Файл JSON, «tmp03.json»:
{"id": 1396415271359897603, "conversation_id": "1396415271359897603", "created_at": "2021-05-23 19:38:39 JST", "date": "2021-05-23", "time": "19:38:39", "timezone": " 0900", "user_id": 978732571738755072, "username": "themooncarl", "name": "The Moon 🌙", "place": "", "tweet": "@elonmusk is still on our side. t.co/K5DnByjzic", "language": "en", "mentions": [], "urls": [], "photos": ["https://pbs.twimg.com/media/E2EQSZgWQAELw9T.jpg"], "replies_count": 78, "retweets_count": 47, "likes_count": 570, "hashtags": [], "cashtags": [], "link": "https://twitter.com/TheMoonCarl/status/1396415271359897603", "retweet": false, "quote_url": "", "video": 1, "thumbnail": "https://pbs.twimg.com/media/E2EQSZgWQAELw9T.jpg", "near": "", "geo": "", "source": "", "user_rt_id": "", "user_rt": "", "retweet_id": "", "reply_to": [], "retweet_date": "", "translate": "", "trans_src": "", "trans_dest": ""}
{"id": 1396414423057711109, "conversation_id": "1396414423057711109", "created_at": "2021-05-23 19:35:17 JST", "date": "2021-05-23", "time": "19:35:17", "timezone": " 0900", "user_id": 978732571738755072, "username": "themooncarl", "name": "The Moon 🌙", "place": "", "tweet": "Me watching Bitcoin go down but realizing that it’s just a nice opportunity to buy more for cheap. t.co/GkmSEPmJCh", "language": "en", "mentions": [], "urls": [], "photos": ["https://pbs.twimg.com/media/E2EPg4ZXMAMIXjJ.jpg"], "replies_count": 94, "retweets_count": 34, "likes_count": 771, "hashtags": [], "cashtags": [], "link": "https://twitter.com/TheMoonCarl/status/1396414423057711109", "retweet": false, "quote_url": "", "video": 1, "thumbnail": "https://pbs.twimg.com/media/E2EPg4ZXMAMIXjJ.jpg", "near": "", "geo": "", "source": "", "user_rt_id": "", "user_rt": "", "retweet_id": "", "reply_to": [], "retweet_date": "", "translate": "", "trans_src": "", "trans_dest": ""}
{"id": 1396388111840645120, "conversation_id": "1396388111840645120", "created_at": "2021-05-23 17:50:44 JST", "date": "2021-05-23", "time": "17:50:44", "timezone": " 0900", "user_id": 978732571738755072, "username": "themooncarl", "name": "The Moon 🌙", "place": "", "tweet": "HODL!!! 💪", "language": "cs", "mentions": [], "urls": [], "photos": [], "replies_count": 263, "retweets_count": 149, "likes_count": 2299, "hashtags": [], "cashtags": [], "link": "https://twitter.com/TheMoonCarl/status/1396388111840645120", "retweet": false, "quote_url": "", "video": 0, "thumbnail": "", "near": "", "geo": "", "source": "", "user_rt_id": "", "user_rt": "", "retweet_id": "", "reply_to": [], "retweet_date": "", "translate": "", "trans_src": "", "trans_dest": ""}
В то время как выше показана ошибка «недопустимый синтаксис ввода для типа json», приведенная ниже, с более простым образцом JSON, который я нашел в сообщении SO, это успешно без синтаксической ошибки.
DROP TABLE IF EXISTS temp01;
DROP TABLE IF EXISTS temp_json;
create temp table temp01 (
tmp text,
tmp02 text,
tmp03 text,
tmp04 text
)
with (oids = false);
BEGIN;
create temporary table temp_json (values text) on commit drop;
-- copy temp_json from '/home/yuis/pg/psql/tmp03.json';
copy temp_json from '/home/yuis/pg/psql/tmp.json';
insert into temp01
-- select values->>'id' as tmp,
-- values->>'created_at' as tmp02,
-- values->>'username' as tmp03,
-- values->>'tweet' as tmp04
select values->>'id' as tmp,
values->>'name' as tmp02,
values->>'comment' as tmp03
from (
select replace(values,'','')::json as values from temp_json
)
COMMIT;
SELECT * from temp01;
JSON, «tmp.json»:
{"id": 23635,"name": "Jerry Green","comment": "Imported from facebook."}
{"id": 23636,"name": "John Wayne","comment": "Imported from facebook."}
Итак, по-видимому, проблема здесь связана с синтаксической ошибкой JSON, но, как вы можете видеть, в JSON нет синтаксической ошибки, по-видимому, проблема на стороне SQL.
Я понятия не имею, где в JSON и/или SQL что-то не так.
Комментарии:
1. Вырежьте и вставьте свой JSON в валидатор (например, jsonformatter.org ) Убедитесь, что он проверяется перед попыткой загрузки в SQL. Быстрый взгляд говорит мне, что поле идентификатора считается числовым, и это значение слишком велико для числа. Я предлагаю заключить это значение в кавычки и рассматривать как строку. Могут быть и другие ошибки…
2. Ваш код отлично работает для меня с файлом в текстовом формате «tmp03.json», который вы показали. Возможно, процесс копирования и вставки его в текстовое поле html устранил проблему
Ответ №1:
После некоторых попыток, как упоминал @jjanes, я обнаружил причину этой проблемы, это была пустая строка в конце файла json (tmp03.json).
Когда я скопировал и вставил в файл, используя «cat > файл», и я случайно нажал одну ненужную клавишу ввода в конце строк, это привело к созданию пустой строки в конце файла json. Итак, эта строка вызвала ошибку. вздыхать..
Вот несколько дополнительных попыток, которые я предпринял для дальнейшего понимания этой проблемы.
- tmp05.json, строки json с удаленной последней «пустой» новой строкой
работал
- tmp03.json, строки json с пустой строкой в последней (ошибка, упомянутая в вопросе)
ERROR: invalid input syntax for type json
DETAIL: The input string ended unexpectedly.
CONTEXT: JSON data, line 1:
SQL state: 22P02
- tmp05_b.json, строки json, но только одна строка и никаких новых строк
например, так похоже
{"a": "aa"}{"b": "bb"}{"c": "cc"}
скорее, чем
{"a": "aa"}
{"b": "bb"}
{"c": "cc"}
ERROR: invalid input syntax for type json
DETAIL: Expected end of input, but found "{".
CONTEXT: JSON data, line 1: ...anslate": "", "trans_src": "", "trans_dest": ""}{...
SQL state: 22P02
- tmp05_c.json, строки json, но удалите последнюю новую строку
удалена последняя пустая строка, а также рабочий файл tmp05.json, но также удалена последняя новая строка конца строк.
работал
I’m trying to import into postgres a csv file containing the data for a table. One of the column of the table has jsonb type.
One line of my csv file contains something like
1,{"a":"b"}
Suppose the table has a schema
id | smallint |
data | jsonb |
If I try just to insert the data, everything works fine
INSERT INTO table VALUES (1, '{"a":"b"}');
Trying to import directly from the file with
COPY table FROM '/path/to/file.csv' DELIMITER ',' csv;
gives me the following error:
ERROR: invalid input syntax for type json
DETAIL: Token "a" is invalid.
CONTEXT: JSON data, line 1: {a...
COPY availability, line 1, column services: "{a: b}"
I tried to quote the fields with ', with ", with " and ', but nothing works..
Which is the correct syntax do do it?
asked Nov 25, 2016 at 14:09
![]()
1
The PostgreSQL COPY command is seldom ideal, but it often works. For reference there are better methods to figure this out than guessing.
CREATE TEMP TABLE baz AS
SELECT 1::int, '{"a":"b"}'::jsonb;
This is your exact sample data. Now we can test different settings..
# COPY baz TO STDOUT;
1 {"a": "b"}
COPY baz TO STDOUT DELIMITER ',';
1,{"a": "b"}
You’ll see that the above generates the exact data your questioning…
COPY baz TO '/tmp/data.csv' DELIMITER ',';
There is no problem. At least not with PostgreSQL 9.5.
CSV Mode
So where is your problem, it’s with CSV-mode. Observe,
# COPY baz TO STDOUT;
1 {"a": "b"}
# COPY baz TO STDOUT CSV;
1,"{""a"": ""b""}"
You can see these two are different now. Let’s try to load the non-CSV file in CSV mode which assumes the format that CSV mode generated above.
TRUNCATE baz;
COPY baz FROM '/tmp/data.csv' DELIMITER ',' CSV;
ERROR: invalid input syntax for type json
DETAIL: Token "a" is invalid.
CONTEXT: JSON data, line 1: {a...
COPY baz, line 1, column jsonb: "{a: b}"
Now we error. The reason for that comes from RFC 4180
Each field may or may not be enclosed in double quotes (however
some programs, such as Microsoft Excel, do not use double quotes
at all). If fields are not enclosed with double quotes, then
double quotes may not appear inside the fields.
- So JSON RFC 4627 specifies an object’s names in name/value pairs must be strings which require double quotes.
- And CSV RFC 4180 specifies that if any double quotes are inside the field, then the whole field must be quoted.
At this point you have two options..
- Don’t use CSV mode.
- Or, Escape the inner quotes.
So these would be valid inputs under the same options in CSV mode.
#COPY baz TO STDOUT DELIMITER ',' CSV ESCAPE E'\';
1,"{"a": "b"}"
# COPY baz TO STDOUT DELIMITER ',' CSV;
1,"{""a"": ""b""}"
answered Mar 9, 2017 at 6:18
![]()
Evan CarrollEvan Carroll
59k42 gold badges217 silver badges445 bronze badges
Found the solution, postgres uses " as an escaping character, so the correct format should be
{"""a""": """b"""}
answered Nov 25, 2016 at 16:18
![]()
marcoshmarcosh
2311 gold badge2 silver badges6 bronze badges
2
As noted in other answers the CSV and the JSON specs (and probably the postgresql specs) are somewhat incompatible. To get them to stop fighting, at least in their simple forms, you have to escape things until they’re an unreadable mess. Not using CSV mode is even worse as the COPY will die on anything that JSON has an issue with: embedded new lines, back-slashes or quote marks.
I had your exact same problem only with a much more complex input: a bunch of ENUM types, integers and complex JSON fields. To wit:
create table messages( a blab, b integer, c text, d json, e json);
where the typical JSONs would be {"default":"little","sms":"bigger"} and ["name","number"]. Try importing a pile of those with a COPY command: if the commas inside the JSON don’t get you the quote marks will! I spend hours on this until i found this fine blog post which pointed out the causes of the problem and the options you need to get out of it.
Basically you need to change the delimiter and quote fields to something that you can guarantee won’t be in your JSON data. In my case I can guarantee a lot so I can just go
COPY messages( a, b, c, d, e) from stdin csv quote '^' delimiter '|';
malfunction|5|La la la|{"default":"little","sms":"bigger"}|["name","number"]
Nice and readable, easy to get to with some minor character substitution in your favourite text mangler, and no escaping of no nothing! If you can’t guarantee that the characters used above can’t be in your JSON then you can use the rather wacky e'x01' and e'x02' as the JSON spec deems them totally illegal. Not quite as readable and so forth but punctiliously correct.
Note that embedded new-lines, as some JSON generators tend to emit for readability purposes, are still ‘no-no’s so you have to filter them out of your JSON.
answered May 30, 2017 at 8:31
![]()
NadreckNadreck
1451 silver badge8 bronze badges
1
I tried using spyql do to the job and it worked fine. spyql can generate INSERT statements that you can use to import the data into your db. spyql is based on python and the standard csv lib would not work well if your jsons have several keys, since the delimiter is the same. Therefore, the approach I suggest is manually splitting each line into two columns:
$ spyql -Otable=table_name "SELECT col1.split(',',1)[0] AS id, col1.split(',', 1)[1] AS data FROM text TO sql" < sample.csv
INSERT INTO "table_name"("id","data") VALUES ('1','{"a":"b"}'),('2','{"a":"foo", "b": 2}');
This assumes only 2 columns as in the example, and no header row.
Importing the data into postgres could be done by piping the output into psql:
$ spyql -Otable=table_name "SELECT col1.split(',',1)[0] AS id, col1.split(',', 1)[1] AS data FROM text TO sql" < sample.csv | psql -h my_host -U my_user my_db
You would have to create the table in the database beforehand, but that’s it.
Disclosure: I am the author of spyql
![]()
answered Dec 22, 2021 at 1:02
![]()
To address your comments in reverse order. To have this entered in one field you would need to have it as:
'[{"http":"abc","http":"abc"},{"taste":[1,2,3,4]}]'
Per:
select '[{"http":"abc","http":"abc"},{"taste":[1,2,3,4]}]'::json;
json
---------------------------------------------------
[{"http":"abc","http":"abc"},{"taste":[1,2,3,4]}]
As to the quoting issue:
When you pass a dict to csv you will get:
d = {"taste":[1,2,3,4]}
print(d)
{'taste': [1, 2, 3, 4]
What you need is:
import json
json.dumps(d)
'{"test": [1, 2, 3, 4]}'
Using json.dumps will turn the dict into a proper JSON string representation.
Putting it all together:
# Create list of dicts
l = [{'http': 'abc', 'http': 'abc'}, {'taste': [1,2,3,4]}]
# Create JSON string representattion
json.dumps(l)
'[{"http": "abc"}, {"taste": [1, 2, 3, 4]}]'
PostgreSQL has quite a lot of features for storing and working with JSON data.
In this guide, you’ll learn:
- What JSON is and why you might want to use it
- Creating a table to store JSON data
- How to add, read, update, and delete JSON data
- Tips for performance, validating and working with JSON
Let’s get into the guide.
If you want to download a PDF version of this guide, enter your email below and you’ll receive it shortly.
What is JSON and Why Should I Use It?
JSON stands for JavaScript Object Notation, and it’s a way to format and store data.
Data can be represented in a JSON format in PostgreSQL so it can be read and understood by other applications or parts of an application.
It’s similar to HTML or XML – it represents your data in a certain format that is readable by people but designed to be readable by applications.
Why Use JSON In Your Database?
So why would you use JSON data in your database?
If you need a structure that’s flexible.
A normalised database structure, one with tables and columns and relationships, works well for most cases. Recent improvements in development practices also mean that altering a table is not as major as it was in the past, so adjusting your database once it’s in production is possible.
However, if your requirements mean that your data structure needs to be flexible, then a JSON field may be good for your database.
One example may be where a user can add custom attributes. If it was done using a normalised database, this may involve altering tables, or creating an Entity Attribute Value design, or some other method.
If a JSON field was used for this, it would be much easier to add and maintain these custom attributes.
The JSON data can also be stored in your database and processed by an ORM (Object Relational Mapper) or your application code, so your database may not need to do any extra work.
What Does JSON Data Look Like?
Here’s a simple example of JSON data:
{
"id": "1",
"username": "jsmith",
"location": "United States"
}
It uses a combination of different brackets, colons, and quotes to represent your data.
Let’s take a look at some more examples.
Name/Value Pair
JSON data is written as name/value pairs. A name/value pair is two values enclosed in quotes.
This is an example of a name/value pair:
"username": "jsmith"
The name is “username” and the value is “jsmith”. They are separated by a colon “:”.
This means for the attribute of username, the value is jsmith. Names in JSON need to be enclosed in double quotes.
Objects
JSON data can be enclosed in curly brackets which indicate it’s an object.
{"username": "jsmith"}
This is the same data as the earlier example, but it’s now an object. This means it can be treated as a single unit by other areas of the application.
How does this help? It’s good for when there are multiple attributes:
{
"username": "jsmith",
"location": "United States"
}
Additional attributes, or name/value pairs, can be added by using a comma to separate them.
You’ll also notice in this example the curly brackets are on their own lines and the data is indented. This is optional: it’s just done to make it more readable.
Arrays
JSON also supports arrays, which is a collection of records within an object. Arrays in JSON are included in square brackets and have a name:
{
"username": "jsmith",
"location": "United States",
"posts": [
{
"id":"1",
"title":"Welcome"
},
{
"id":"4",
"title":"What started it all"
}
]
}
In this example, this object has an attribute called “posts”. The value of posts is an array, which we can see by the opening square bracket “[“.
Inside the square bracket, we have a set of curly brackets, indicating an object, and inside those we have an id of 1 and a title of Welcome. We have another set of curly brackets indicating another object.
These two objects are posts and they are contained in an array.
And that covers the basics of what JSON is.
If JSON is new to you, don’t worry, it gets easier as you work with it more.
If you’re experienced with JSON, you’ll find the rest of the guide more useful as we go into the details of working with JSON in PostgreSQL.
How to Create and Populate a JSON Field in PostgreSQL
So you’ve learned a bit about JSON data and why you might want to use it.
How do we create a field in PostgreSQL?
Two JSON Data Types
There are two data types in PostgreSQL for JSON: JSON and JSONB.
JSON is the “regular” JSON data type and was added in PostgreSQL 9.2. JSONB stands for JSON Binary and was added in PostgreSQL 9.4.
What’s the difference?
There are a few differences, but it’s mainly to do with how the data is stored. JSONB data is stored in a binary format and is easier to process.
PostgreSQL recommends using the JSONB data type in most situations.
Here’s a table describing the differences.
| Feature | JSON | JSONB |
| Storage | Stored exactly as entered | Stored in a decomposed binary format |
| Supports full text indexing | No | Yes |
| Preserve white space | Yes | No, it is removed |
| Preserve order of keys | Yes | No |
| Keep duplicate keys | Yes | No (last value is kept) |
Because of the way the data is stored, JSONB is slightly slower to input (due to the conversion step) but a lot faster to process.
In this guide, we’ll use the JSONB data type. Most of the features will work the same for the JSON data type, but we’ll focus on JSONB.
Creating a JSON Field
We create a new JSONB field to store our JSON data.
Here’s an example using a product table.
CREATE TABLE product (
id INT,
product_name CHARACTER VARYING(200),
attributes JSONB
);We have created a table called product. It has an id and a product name. There’s also an attributes column, which has the data type of JSONB.
Because it’s a JSONB data type, the values inserted into it must be valid JSON. Other databases require a check constraint to be added, but this is not required in PostgreSQL.
Adding a JSON column is as easy as that.
Adding Data to a JSON Field
Now we’ve got our field for storing JSON data, how do we add data to it?
We simply insert a record into our table as though it’s a text value. The value needs to be valid JSON, otherwise, we’ll get an error.
We can add our first product like this:
INSERT INTO product (id, product_name, attributes)
VALUES (1, 'Chair','{"color":"brown", "material":"wood", "height":"60cm"}');We can run this statement and the record is inserted.
If we try to insert an invalid JSON field, we’ll get an error. Here’s the INSERT statement:
INSERT INTO product (id, product_name, attributes)
VALUES (100, 'Bad Chair', '"color":"brown:height}');This is what we’ll see:
ERROR: invalid input syntax for type json LINE 12: VALUES (100, 'Bad Chair', '"color":"brown:height}'); ^ DETAIL: Expected end of input, but found ":". CONTEXT: JSON data, line 1: "color":...
Using the method above, we needed to enter the data in exactly the right format.
Inserting Arrays
If you want to insert JSON data that contains arrays, you can enter it using text in a JSON format.
Here’s how to insert an array by just specifying it in a JSON format.
INSERT INTO product (id, product_name, attributes)
VALUES (
2,
'Desk',
'{"color":"black", "material":"metal", "drawers":[{"side":"left", "height":"30cm"}, {"side":"left", "height":"40cm"}]}'
);This will insert a new product that has an array of drawers. As you can probably see by this statement, reading it (and writing it) is a bit tricky.
You can insert simpler arrays using this method too.
INSERT INTO product (id, product_name, attributes)
VALUES (
3,
'Side Table',
'{"color":"brown", "material":["metal", "wood"]}'
);The INSERT statements will work.
Using JSON Functions to Insert Data
We just saw how to insert data into a JSONB field by providing text values.
They can be error-prone and hard to type.
Fortunately, PostgreSQL offers a few functions to help us insert data into a JSON field.
The JSONB_BUILD_OBJECT function will take a series of values and create a JSON object in binary format, ready to be inserted into a JSONB field.
We can use the JSONB_BUILD_OBJECT to construct a new record:
JSONB_BUILD_OBJECT('color', 'black', 'material', 'plastic')
This will create a value that looks like this:
{"color": "black", "material": "plastic"}
We can use this in the INSERT statement. We don’t need to worry about putting brackets, commas, colons, and quotes in the right place. As long as the string values are quoted, it should work.
INSERT INTO product (id, product_name, attributes)
VALUES (4, 'Small Table', JSONB_BUILD_OBJECT('color', 'black', 'material', 'plastic'));The new record will be added to the table.
There are several other functions available to help you insert JSON values into a table:
- to_json and to_jsonb
- array_to_json
- row_to_json
- json_build_array and jsonb_build_array
- json_object and jsonb_object
How to Read and Filter JSON Data in PostgreSQL
Once you’ve got some JSON data in a table, the next step is to read it.
How do we do that?
Selecting a JSON field is pretty simple. We can just select it as though it is a column.
SELECT
id,
product_name,
attributes
FROM product;| id | product_name | attributes |
| 1 | Chair | {“color”: “brown”, “height”: “60cm”, “material”: “wood”} |
| 2 | Desk | {“color”: “black”, “drawers”: [{“side”: “left”, “height”: “30cm”}, {“side”: “left”, “height”: “40cm”}], “material”: “metal”} |
| 3 | Side Table | {“color”: “brown”, “material”: [“metal”, “wood”]} |
| 4 | Small Table | {“color”: “black”, “material”: “plastic”} |
This shows us the data in the JSON column, and it looks just like a text value.
The good thing with this is that any application can easily read this field and work with it how they want (display it, filter it, and so on).
What if we wanted to do more in our database?
Selecting Individual Attributes
The JSON data is stored in something that looks like a text field. However, it’s quite easy to get attributes and values out of this text field and display them.
We can extract a value from the JSON field and display it in a separate column. We can do this using a few different symbols or notations.
To view a particular key’s value, we can specify the key as a “child” of the JSONB column.
We do this using the -> notation:
json_column -> key
For example:
SELECT
id,
product_name,
attributes -> 'color' AS color_key
FROM product;We are selecting the color element from the attributes column and giving it an alias of color_key.
Here are the results:
| id | product_name | color_key |
| 1 | Chair | “brown” |
| 2 | Desk | “black” |
| 3 | Side Table | “brown” |
| 4 | Small Table | “black” |
Notice that each value has a quote around it.
Alternatively, we can select only the values, which displays the value without quotes. The symbol for this is ->>.
json_column ->> key
Here’s our updated query. We’ll select both methods so you can see the difference
SELECT
id,
product_name,
attributes -> 'color' AS color_key,
attributes ->> 'color' AS color_value
FROM product;Here are the results.
| id | product_name | color_key | color_value |
| 1 | Chair | “brown” | brown |
| 2 | Desk | “black” | black |
| 3 | Side Table | “brown” | brown |
| 4 | Small Table | “black” | black |
What if the key does not exist?
Not every record has a height key. Let’s see what happens if we select this.
SELECT
id,
product_name,
attributes ->> 'height' AS height
FROM product;| id | product_name | height |
| 1 | Chair | 60cm |
| 2 | Desk | null |
| 3 | Side Table | null |
| 4 | Small Table | null |
Null values are shown where the key does not exist.
Selecting Array Values
We can use a similar concept to select a value that is stored as an array. In our example, the “drawers” attribute is an array.
Our query would look like this:
SELECT
id,
product_name,
attributes ->> 'drawers' AS drawers
FROM product;The results are:
| id | product_name | drawers |
| 1 | Chair | null |
| 2 | Desk | [{“side”: “left”, “height”: “30cm”}, {“side”: “left”, “height”: “40cm”}] |
| 3 | Side Table | null |
| 4 | Small Table | null |
The full value of the drawers attribute is shown. It’s an array with two objects inside, and each object has a side key and a height key.
What if we want to see an attribute that’s inside another attribute? For example, the first of the “drawer” attributes?
We can do this by getting the element of drawers, then selecting the element at a specified number.
attributes -> 'drawers' -> 1
This example will get the attributes column, then the drawers element, then the element at position 1 (which is the 2nd element as arrays start at 0).
Notice how the -> symbol is used, as this symbol retrieves the element and not just the text.
Here’s a sample query.
SELECT
id,
product_name,
attributes -> 'drawers' -> 1 AS drawer_value
FROM product;The results are:
| id | product_name | drawers |
| 1 | Chair | null |
| 2 | Desk | {“side”: “left”, “height”: “40cm”} |
| 3 | Side Table | null |
| 4 | Small Table | null |
We can use a different notation to get an array as either an object or a text. The notation #> will retrieve it as an element and #>> will retrieve it as text.
Let’s see an example.
SELECT
id,
product_name,
attributes #> '{drawers, 1}' AS drawers_element,
attributes #>> '{drawers, 1}' AS drawers_text
FROM product;After the notation, we specify curly brackets, and inside we specify the key name and the element number. In this example, we are looking for the drawers key and element 1, which is the second element.
Here are our results:
| id | product_name | drawers_element | drawers_text |
| 1 | Chair | null | null |
| 2 | Desk | {“side”: “left”, “height”: “40cm”} | {“side”: “left”, “height”: “40cm”} |
| 3 | Side Table | null | null |
| 4 | Small Table | null | null |
In this example, both columns are the same. But we can see how this notation is used and it may be useful for us in our JSON queries.
Filtering on JSON Data in PostgreSQL
Let’s say we wanted to see our Chair product, which has a brown color, wood material, and a height of 60cm. But we want to filter on the JSON attributes for this example.
Let’s try this query.
SELECT
id,
product_name,
attributes
FROM product
WHERE attributes = '{"color":"brown", "material":"wood", "height":"60cm"}';We can run this query. Here’s what we see:
| id | product_name | attributes |
| 1 | Chair | {“color”:”brown”, “material”:”wood”, “height”:”60cm”} |
This works because the text value is stored in the attributes column, and as long as we provide the exact full string, it will work.
Often we need to filter on one of the keys or values. How can we do that?
What if we try using the LIKE keyword with a partial match?
SELECT
id,
product_name,
attributes
FROM product
WHERE attributes LIKE '%"color":"brown"%';ERROR: operator does not exist: jsonb ~~ unknown LINE 27: WHERE p.attributes LIKE '%"color":"brown"%'; ^ HINT: No operator matches the given name and argument type(s). You might need to add explicit type casts.
We get an error in PostgreSQL as we can’t use the LIKE attribute on a JSONB column.
There are several features in PostgreSQL that make it possible to filter on JSON data.
Using Notation to Filter Data
Let’s say we want to find all products where the color is brown. The color is a part of the attributes JSON column in our table.
We can use the same notation we used for selecting a column for filtering it.
We can write the notation like this:
attributes -> 'color'
We then add this to our SELECT statement
SELECT
id,
product_name,
attributes
FROM product
WHERE attributes -> 'color' = 'brown';We’ve added this notation to our WHERE clause, and added a condition where the color is equal to “brown”.
Here’s what happens when we run the query.
ERROR: invalid input syntax for type json LINE 27: WHERE attributes -> 'color' = 'brown'; ^ DETAIL: Token "brown" is invalid. CONTEXT: JSON data, line 1: brown
We get this error because the query is expecting a JSON object in the WHERE clause, and we provided the string of “brown”. It’s expecting a JSON object because we used ->.
We can use ->> to be able to provide a string.
SELECT
id,
product_name,
attributes
FROM product
WHERE attributes ->> 'color' = 'brown';The results of this query are shown below.
| id | product_name | attributes |
| 1 | Chair | {“color”:”brown”, “height”:”60cm”, “material”:”wood”} |
| 3 | Side Table | {“color”: “brown”, “material”: [“metal”, “wood”]} |
We can see that the results only show records where the color attribute is brown.
Splitting JSON Data into Rows
So far we’ve seen examples of using different functions to read and filter JSON data.
The result has been that all of the JSON data has been displayed in a single column.
PostgreSQL includes some functions that let you expand the JSON fields and display them in different rows.
The JSONB_EACH function will display each key and value pair as elements. It will split each key into separate rows.
SELECT
id,
product_name,
JSONB_EACH(attributes)
FROM product;Here are the results:
| id | product_name | jsonb_each |
| 1 | Chair | (color,”””brown”””) |
| 1 | Chair | (height,”””60cm”””) |
| 1 | Chair | (material,”””wood”””) |
| 2 | Desk | (color,”””black”””) |
| 2 | Desk | (drawers,”[{“”side””: “”left””, “”height””: “”30cm””}, {“”side””: “”left””, “”height””: “”40cm””}]”) |
| 2 | Desk | (material,”””metal”””) |
| 3 | Side Table | (color,”””brown”””) |
| 3 | Side Table | (material,”[“”metal””, “”wood””]”) |
| 4 | Small Table | (color,”””black”””) |
| 4 | Small Table | (material,”””plastic”””) |
I can’t think of a reason that this function would be useful. Perhaps if you want to filter on attributes and display all of the attribute values as well.
You can also use JSON_OBJECT_KEYS to get a list of all keys in the JSON field:
SELECT
id,
product_name,
JSONB_OBJECT_KEYS(attributes)
FROM product;The results are:
| id | product_name | jsonb_object_keys |
| 1 | Chair | color |
| 1 | Chair | height |
| 1 | Chair | material |
| 2 | Desk | color |
| 2 | Desk | drawers |
| 2 | Desk | material |
| 3 | Side Table | color |
| 3 | Side Table | material |
| 4 | Small Table | color |
| 4 | Small Table | material |
This can be useful to find all rows that have a specific key, or to find the most common keys:
SELECT
JSONB_OBJECT_KEYS(attributes) AS attr_key,
COUNT(*)
FROM product
GROUP BY JSONB_OBJECT_KEYS(attributes)
ORDER BY COUNT(*) DESC;| attr_key | count |
| color | 4 |
| material | 4 |
| drawers | 1 |
| height | 1 |
Check If a Key Exists
PostgreSQL has other operators that let you find records that contain a certain JSON attribute.
One example is the ? operator. This will let you determine if a JSON value contains a specified key.
Let’s see an example. This query finds records that have the key of “drawers”.
SELECT
id,
product_name,
attributes
FROM product
WHERE attributes ? 'drawers' = true;The results are:
| id | product_name | attributes |
| 2 | Desk | {“color”: “black”, “drawers”: [{“side”: “left”, “height”: “30cm”}, {“side”: “left”, “height”: “40cm”}], “material”: “metal”} |
The row with id 2 is shown as it’s the only one with the attribute of drawers.
How to Update JSON Data in PostgreSQL
Reading JSON is one thing. What if you need to update JSON data?
There are several ways to do this. We’ll look at each of them.
Insert a New Key by Concatenating Values
You can update a JSON field using an UPDATE statement. Using this UPDATE statement, you can add a new key and value to the field by concatenating it to the existing value.
Here’s the syntax:
UPDATE table
SET json_field = json_field || new_json_data;If we want to add a new key and value pair to one of our products, we can concatenate a JSON value to the existing value and run it in the UPDATE statement.
Here’s our table before the update:
| id | product_name | attributes |
| 1 | Chair | {“color”: “brown”, “height”: “60cm”, “material”: “wood”} |
Here’s the update statement:
UPDATE product
SET attributes = attributes || '{"width":"100cm"}'
WHERE id = 1;Here’s the table after the update:
| id | product_name | attributes |
| 1 | Chair | {“color”: “brown”, “width”: “100cm”, “height”: “60cm”, “material”: “wood”} |
Notice that the new width key is added to the JSON value. It’s also added in the middle, as the JSONB data type doesn’t preserve the order of the keys. This is OK, our JSON field still works as expected.
Updating an Existing Value Using JSONB_SET
The JSONB_SET function allows you to update an existing key to a new value. This is helpful if you don’t want to read and update the entire field just to change one value.
The syntax looks like this:
JSONB_SET(json_column, key, new_value)
Let’s say we want to update the height for our Chair product from 60cm to 75cm.
Here’s the table before the update:
| id | product_name | attributes |
| 1 | Chair | {“color”: “brown”, “height”: “60cm”, “material”: “wood”} |
Our Update statement would look like this:
UPDATE product
SET attributes = JSONB_SET(attributes, '{height}', '"75cm"')
WHERE id = 1;There are a few things to notice:
- The first parameter of JSONB_SET is the attributes column.
- The second parameter is the height key. This needs to be enclosed in curly brackets to be treated as a JSON key.
- The third parameter is the new value of 75cm. This is enclosed in single quotes as it’s a string, and then double quotes as it’s a JSON value. Without the double quotes, you’ll get an error.
Here’s the table after the update:
| id | product_name | attributes |
| 1 | Chair | {“color”: “brown”, “height”: “75cm”, “material”: “wood”} |
No new attributes were added. The Update statement simply updated the existing value.
How to Delete from a JSON Field in PostgreSQL
There are two DELETE operations you can do when working with JSON fields:
- delete an attribute from a JSON field
- delete a row from your table
Deleting a Row using JSON_VALUE
Deleting a row from your table is done in the same way as regular SQL. You can write an SQL statement to delete the row that matches your ID, or using the notation.
For example, to delete all rows where the color attribute is brown:
DELETE FROM product
WHERE attributes ->> 'color' = 'brown';This will remove the matching records from the table.
Removing an Attribute from a JSON Field
The other way to delete JSON data is to remove an attribute from a JSON field.
This is different from updating, as you’re removing the attribute entirely rather than just updating its value to something else.
We can remove an attribute from a JSON field using the – operator. We use the UPDATE statement and update the JSON field with the – operator and the key we want to remove.
For example, here’s our Chair product.
| id | product_name | attributes |
| 1 | Chair | {“color”: “brown”, “height”: “60cm”, “material”: “wood”} |
Let’s say we want to remove the “height” attribute. We can do this by writing an update statement and removing it.
UPDATE product
SET attributes = attributes - 'height'
WHERE id = 1;After we run this statement, we can check our table again.
| id | product_name | attributes |
| 1 | Chair | {“color”: “brown”, “material”: “wood”} |
The height attribute has been removed.
Improve the Performance of JSON Queries
The JSON support and features in PostgreSQL are pretty good, and each version includes more features.
So, given that you can add JSON columns to tables, extract fields, and get all the flexibility of JSON fields with validation, wouldn’t it be better to just store all of your data in JSON fields rather than normalised tables?
Well, sometimes that might be a good idea. But then you may be better off using a NoSQL database rather than PostgreSQL.
Another reason why using primarily JSON fields to store your data is not a good idea is that it can struggle with performance.
Select Performance
For example, let’s say we want to select all products where the color is brown. We can use the ->> operator in the WHERE clause that we saw earlier in this guide:
SELECT
id,
product_name,
attributes
FROM product
WHERE attributes ->> 'color' = 'brown';Here is the query plan for this.
| QUERY PLAN |
| Seq Scan on product (cost=0.00..12.40 rows=1 width=454) |
| Filter: ((attributes ->> ‘color’::text) = ‘brown’::text) |
The execution plan shows a Seq Scan, which is short for Sequential Scan and is a slow type of access. This might be OK for our table, which only has a few records, but once you start working with larger tables it can be quite slow.
What can we do?
Full-Text Index with GIN Index
PostgreSQL allows you to create a full-text index on the JSON field. This should improve the performance of any queries on this field.
It uses an index type called GIN, which stands for Generalised Inverted Index. It’s used in several situations, and one of which is for JSONB values.
Let’s see how we can create one.
We create an index based on the JSON_VALUE in the WHERE clause we want to run.
CREATE INDEX idx_prod_json ON product USING GIN(attributes);The name of the index is idx_prod_json. The product table is used, and the attributes column is specified. We add USING GIN to use the GIN feature or index type.
Now let’s run the Select query again and see the explain plan.
| QUERY PLAN |
| Seq Scan on product (cost=0.00..1.06 rows=1 width=454) |
| Filter: ((attributes ->> ‘color’::text) = ‘brown’::text) |
We can see it still uses a Seq Scan, which may be because there are only four rows in the table.
However, we can see the cost is a lot less:
| Before Index | After Index |
| cost=0.00..12.40 | cost=0.00..1.06 |
This may result in a faster query. The difference may be more evident on larger tables.
Tips for Working with JSON in PostgreSQL
In this guide, we’ve looked at what JSON is, seen how to create JSON fields in PostgreSQL, and seen a range of ways we can work with them.
So, what’s the best way to work with JSON fields in PostgreSQL?
Here are some tips I can offer for using JSON in PostgreSQL. They may not apply to your application or database but they are things to consider.
Just because you can, doesn’t mean you should
JSON is flexible and quite powerful, but just because you can store data in a JSON field, doesn’t mean you should. Consider using the advantages of the PostgreSQL relational database and using JSON where appropriate.
Treat the JSON field like a black box
The JSON field can be used to store valid JSON data sent or received by your application. While there are functions for reading from and working with the JSON field, it might be better to just store the JSON data in the field, retrieve it from your application, and process it there.
This is the concept of a black box. The application puts data in and reads data from it, and the database doesn’t care about what’s inside the field.
It may or may not work for your situation, but consider taking this approach.
Search by the Primary Key and other fields
We’ve seen that it can be slow to search by attributes inside the JSON field. Consider filtering by the primary key and other fields in the table, rather than attributes inside the JSON field. This will help with performance.
Conclusion
I hope you found this guide useful. Have you used JSON fields in PostgreSQL? What has your experience been like? Do you have any questions? Feel free to use the comments section on the post.
How does PostgreSQL store data inside jsonb and map them to its data type?
first Postgres has a special data type for JSON it is different from PostgreSQL data types _-like text, numeric and so on …- _and we have different methods to check those types for PostgreSQL type we use pg_typeof, and for jsonb type, we use jsonb_typeof
Remember that in JSON format
- keys should be strings
- values can be strings, numbers, boolean, null, array, or another JSON object
this table from Postgrse documentation
summarize the main JSON data type in Postgres
| JSON type | PostgreSQL type | Notes |
|---|---|---|
| string | text | u0000 is disallowed, as are Unicode escapes representing characters not available in the database encoding |
| number | numeric | NaN and infinity values are disallowed |
| boolean | boolean | Only lowercase true and false spellings are accepted |
| null | (none) | SQL NULL is a different concept |
let’s dive and explain each JSON type in PostgreSQL
jsonb string:
you can store any text value except u0000 — which a Unicode escapes representing characters that represent NULL
to show the meaning of Unicode characters in Postgres use E in front of text like
----------------------- jsonb string ---------------------------
select E'u0001' as value;
-- value
-- -------
-- x01
-- (1 row)
select E'u0000' as value;
-- ERROR: invalid Unicode escape value at or near "E'u0000"
-- LINE 1: select E'u0000' as value;
SELECT '1234u0000';
-- ?column?
-- ------------
-- 1234u0000
-- (1 row)
SELECT E'My star u2B50';
-- ?column?
-- -----------
-- My star ⭐
-- (1 row)
SELECT E'1234u0000';
-- ERROR: invalid Unicode escape value at or near "E'1234u0000"
-- LINE 1: SELECT E'1234u0000';
SELECT '"1234u0000"'::jsonb;
-- ERROR: unsupported Unicode escape sequence
-- LINE 1: SELECT '"1234u0000"'::jsonb;
-- ^
-- DETAIL: u0000 cannot be converted to text.
-- CONTEXT: JSON data, line 1: ...
SELECT '"My face u2B50"'::jsonb;
-- jsonb
-- -------------
-- "My face ⭐"
-- (1 row)
Enter fullscreen mode
Exit fullscreen mode
jsonb number :
you can store any positive or negative numbers just except NaN and infinity
----------------------- jsonb number ---------------------------
SELECT jsonb_typeof('1'::jsonb);
-- jsonb_typeof
-- --------------
-- number
-- (1 row)
SELECT jsonb_typeof('-1'::jsonb);
-- jsonb_typeof
-- --------------
-- number
-- (1 row)
Enter fullscreen mode
Exit fullscreen mode
infinity: can represent like infinity,- infinity,inf, -inf
SELECT jsonb_typeof('inf'::jsonb);
-- ERROR: invalid input syntax for type json
-- LINE 1: SELECT jsonb_typeof('inf'::jsonb);
-- ^
-- DETAIL: Token "inf" is invalid.
-- CONTEXT: JSON data, line 1: inf
SELECT jsonb_typeof('-inf'::jsonb);
-- ERROR: invalid input syntax for type json
-- LINE 1: SELECT jsonb_typeof('-inf'::jsonb);
-- ^
-- DETAIL: Token "-inf" is invalid.
-- CONTEXT: JSON data, line 1: -inf
Enter fullscreen mode
Exit fullscreen mode
NAN: (not a number) value is used to represent undefined calculational results like
select 'infinity'::float / 'infinity'::float;
-- ?column?
-- ----------
-- NaN
-- (1 row)
SELECT jsonb_typeof('NAN'::jsonb);
-- ERROR: invalid input syntax for type json
-- LINE 1: SELECT jsonb_typeof('NAN'::jsonb);
-- ^
-- DETAIL: Token "NAN" is invalid.
-- CONTEXT: JSON data, line 1: NAN
Enter fullscreen mode
Exit fullscreen mode
jsonb boolean:
Only lowercase true and false are considered as boolean
SELECT 'true'::jsonb;
-- jsonb
-- -------
-- true
-- (1 row)
SELECT jsonb_typeof('true'::jsonb);
-- jsonb_typeof
-- --------------
-- boolean
-- (1 row)
SELECT jsonb_typeof('false'::jsonb);
-- jsonb_typeof
-- --------------
-- boolean
-- (1 row)
SELECT jsonb_typeof('False'::jsonb);
-- ERROR: invalid input syntax for type json
-- LINE 1: SELECT jsonb_typeof('False'::jsonb);
-- ^
-- DETAIL: Token "False" is invalid.
-- CONTEXT: JSON data, line 1: False
SELECT jsonb_typeof('True'::jsonb);
-- ERROR: invalid input syntax for type json
-- LINE 1: SELECT jsonb_typeof('True'::jsonb);
-- ^
-- DETAIL: Token "True" is invalid.
-- CONTEXT: JSON data, line 1: True
SELECT jsonb_typeof('"True"'::jsonb);
-- jsonb_typeof
-- --------------
-- string
-- (1 row)
Enter fullscreen mode
Exit fullscreen mode
null and Null in jsonb and Postgres:
jsonb null is different from NULL in Postgres as SQL’s null means “of unknown value” and JSON’s null means “empty/no value”.
let’s take some examples to explain this:
Note : use -> to return the value of key in jsonb as jsonb type and ->> convert the value of key as text and return text. . By the way I explained this in next post in this series
select '{"a": 1, "b": null}'::jsonb->'c';
-- ?column?
-- ----------
-- (1 row)
Enter fullscreen mode
Exit fullscreen mode
c is not keys in jsonb so if we ask for it is value Postgres will search for it in '{"a": 1, "b": null}' and as it can not find it so Postgres does not know the value of c so it says it is unknown value means it is NULL, as c does not there
Note : in select Null does not shown
select '{"a": 1, "b": null}'::jsonb->'c' IS NULL;
-- ?column?
-- ----------
-- t
-- (1 row)
Enter fullscreen mode
Exit fullscreen mode
but what about b ?! what’s the value of b?
select '{"a": 1, "b": null}'::jsonb->'b';
-- ?column?
-- ----------
-- null
-- (1 row)
Enter fullscreen mode
Exit fullscreen mode
here b is key inside jsonb and it has value but it is null ( empty/no value ) so if Postgres look for b it can find it and return its value as b not NULL because it has value and it does not with unknown value as Postgres really can find it and knows its value
select '{"a": 1, "b": null}'::jsonb->'b' IS NULL;
-- ?column?
-- ----------
-- f
-- (1 row)
Enter fullscreen mode
Exit fullscreen mode
notice that in previous examples we use -> which is used to return the value of key in jsonb as it is but what if we use ->> that will convert it to text … things become tricky here look to these examples
select '{"a": 1, "b": null}'::jsonb->>'b' IS Null;
-- ?column?
-- ----------
-- t
-- (1 row)
select '{"a": 1, "b": null}'::jsonb->>'c' IS Null;
-- ?column?
-- ----------
-- t
-- (1 row)
Enter fullscreen mode
Exit fullscreen mode
now the value of c and b IS NULL why?
Here explain from PostgreSQL
One of the design principles of PostgreSQL, however, is that casting anything to text should give something parsable back to the original value (whenever possible).
So if we will convert null to text it will be NULL as it is the nearest value to it that we can use to re-parse it back …
but why we can not just convert null to be ‘null’ as string with 2 single quotes ??!!
doing something like that will make confused between ‘null’string value that stored as strung in keys like
select '{"a": 1, "b": null}'::jsonb->>'b';
-- ?column?
-- ----------
-- (1 row)
select '{"a": 1, "b": "null"}'::jsonb->>'b';
-- ?column?
-- ----------
-- null
-- (1 row)
select pg_typeof('{"a": 1, "b": "null"}'::jsonb->>'b');
-- pg_typeof
-- -----------
-- text
-- (1 row)
select pg_typeof('{"a": 1, "b": null}'::jsonb->>'b');
-- pg_typeof
-- -----------
-- text
-- (1 row)
Enter fullscreen mode
Exit fullscreen mode
so ‘null’ to text = ‘null’ and if you re-parse ‘null’ to original type it will string ‘null’
but null to text = NULL and if you re-parse null to original type it will null
this lead us to golden point here so if you want to check that if key does not there or its value is null use ->> to get value of that key and check if IS NULL ….
same if you want to say if value is there for keys this means the key is there or its value is not null use ->> to get value of that key and check if IS NOT NULL
Reference : Check this for more details
PostgreSQL_and_null_value
all code examples in jsonb series in my GitHub account 💻jsonb_posts