-
panos.g.tx
- Lurker
- Posts: 2
- Liked: never
- Joined: Oct 12, 2016 7:48 am
- Full Name: Panagiotis Georgakopoulos
- Contact:
Error: Job was stopped due to backu
Hello to everyone. I get the error below and i am trying to find a solution. I do not understand why this error appears all of a sudden. We are not take windows back up at all and we didn’t make any change to the configuration of veeam or to the server. My server run Windows Server 2012 R2 Standard. Can anyone suggest any solution?
Message: 12/10/2016 9:01:22 πμ :: Error: Job was stopped due to backup window setting
Thank you all.
-
JMora
- Lurker
- Posts: 1
- Liked: never
- Joined: Apr 28, 2020 6:03 pm
- Full Name: Jason Mora
- Contact:
Re: Error: Job was stopped due to backu
Post
by JMora » Apr 28, 2020 6:21 pm
Hello,
I just experience this issue myself this past weekend, but I did not set a backup window set and still got this error. I am running version 9.5. Any recommendation on why this happened?
Thanks,
Jason
-
Dima P.
- Product Manager
- Posts: 13751
- Liked: 1395 times
- Joined: Feb 04, 2013 2:07 pm
- Full Name: Dmitry Popov
- Location: Prague
- Contact:
Re: Error: Job was stopped due to backu
Post
by Dima P. » Apr 28, 2020 7:43 pm
Hello and welcome to the community forums Jason.
This thread is quite old, so I bet that the issue you are facing is different. Please raise a support case and share your case ID with us. Thank you in advance!
Содержание
- Veeam R&D Forums
- Feature Request — Backup Window Error
- Feature Request — Backup Window Error
- Re: Feature Request — Backup Window Error
- Re: Feature Request — Backup Window Error
- Veeam R&D Forums
- Scheduled job no longer runs
- Scheduled job no longer runs
- Veeam R&D Forums
- Replication window exclusion — best practice
- Replication window exclusion — best practice
- Re: Replication window exclusion — best practice
- Re: Replication window exclusion — best practice
- Re: Replication window exclusion — best practice
- Who is online
- Veeam R&D Forums
- Backup Copy — Fail to generate points error
- Backup Copy — Fail to generate points error
- Re: Backup Copy — Fail to generate points error
- Re: Backup Copy — Fail to generate points error
- [MERGED] Feature Request: Active Full Copy of 1 VM
- Re: Feature Request: Active Full Copy of 1 VM
- Re: Feature Request: Active Full Copy of 1 VM
- Re: Feature Request: Active Full Copy of 1 VM
- Error job was stopped due to backup window setting
Veeam R&D Forums
Technical discussions about Veeam products and related data center technologies
Feature Request — Backup Window Error
Feature Request — Backup Window Error
Post by groach » Oct 08, 2015 4:09 pm this post
Processing VMNAME Error: Job was stopped due to backup window setting — Case # 01078050. We do want to be notified of all errors(Failures), but this event is self induced because of the backup window.
Can the status of this notification be changed from an error to a warning?
Re: Feature Request — Backup Window Error
Post by Shestakov » Oct 08, 2015 5:36 pm this post
Re: Feature Request — Backup Window Error
Post by Eugen Fournes » Jan 22, 2021 9:06 pm this post
Looks like this error message was removed from Veeam B&R for a while, then added back again in v10a. Submitted case #04603755.
Just like groach, above, we want to know about actual errors/failures, but would like to suppress this one, or change it to a warning at least, when we *know* a backup copy job is going to be delayed by a restrictive upload window.
Use case: (we’re an MSP) and a number of our clients have slow Internet connections and we have to limit the upload window to only run overnight. The off-site backups sometimes take longer than overnight to complete.
In conjunction with this, we’re also receiving the error:
Job finished with error. Job has failed unexpectedly Details: Error: Data transfer is currently restricted.
This is because we’ve restricted the cloud connection for this client to a single data stream, since that one stream pretty much saturates their Internet connection. Increasing the concurrent connections makes all of the off-site backup jobs take longer.
When we upgraded to Veeam B&R v10a, instead of a single warning, we’re now receiving three errors for a cloud repository backup job that takes more than a day to complete: the above two errors, plus the RPO error because the default is set to one day.
At least the RPO error we could suppress by raising it to three days. Isn’t this what the RPO is supposed to be for—to notify us if the on-site backup isn’t sync’d to the off-site within the specified amount of time? Why would we need three separate errors?
We request that the «backup window» error and the «data transfer is currently restricted» error either be removed altogether, switched to warnings, or given the ability to be suppressed through the Veeam Service Provider Console. Or, another thought, combine all three into the RPO error:
Backup copy job failed to meet RPO (2 days): data transfer restricted to 1 concurrent connections, job stopped due to backup window settings. %jobname% %VMname%, etc. Possible solutions: Check other jobs that may be tying up the connections or allow more concurrent connections; expand the data transfer window; increase network speed.
Источник
Veeam R&D Forums
Technical discussions about Veeam products and related data center technologies
Scheduled job no longer runs
Scheduled job no longer runs
Post by Hajah » Feb 26, 2016 12:40 pm this post
I’ve a scheduled job that runs daily @ 3h30am with Veeam B&R v8 for VMWare.
This scheduled backup job used to work flawlessly since it was created. This last week, it stops because of Backup Window, with nothing done.
Backup window is 3am till 6am. The daily backup job takes
45 minutes. Most of the time it finished before 4h30am.
The thing is that NOTHING is done. Not even 1 VM. Also it doesn’t stop at 6am. It stops at 12h30 (9hours before it started).
The first task reports this:
-Queued for processing at 2/26/2016 3:37:16 AM
-Required backup infrastructure resources have been assigned
-Error: Job was stopped due to backup window setting
-Network traffic verification detected no corrupted blocks
-Processing finished with errors at 2/26/2016 12:37:33 PM
The following tasks (VMs) don’t even start, because of backup window.
Then if I start it manually, all is well. No issues at all.
Where can I look to debug this? I’m assuming something is not «available» at 3h30am when the schedule starts the backup, and when I start it manually @ 2pm, all the resources are there and no errors occur (except for the slowdown on the production VMs).
Источник
Veeam R&D Forums
Technical discussions about Veeam products and related data center technologies
Replication window exclusion — best practice
Replication window exclusion — best practice
Post by Alan_ORiordan » Apr 15, 2015 2:58 pm this post
I have found that if we let our continuous replication jobs run throughout the nightly incremental backup window they can sometimes fail with an error. To prevent this I excluded replication for a couple of hours each night when the backup took place. The only slight nuisance is we get a failure email alert when it stops the replication job:
Processing VMNAME Error: Job was stopped due to backup window setting
Is there a way to exclude this email alert. Or do we just have to accept that this is better than a failing job during the odd backup session running at the same time.
Re: Replication window exclusion — best practice
Post by Vitaliy S. » Apr 15, 2015 3:19 pm this post
There is no way to exclude this type of email, however can you please tell me what error message you have when your backup and replication jobs overlap? Do you manage both types of job through the same backup console?
Re: Replication window exclusion — best practice
Post by Alan_ORiordan » Apr 15, 2015 3:33 pm this post
I believe it is something similar to this:
13/04/2015 21:00:48 :: Processing VMNAME Error: Failed to delete VSS snapshot. It’s in use by job ‘BACKUPJOB NAME — Windows VM — Daily’ (‘a5a40600-5289-42aa-8dd8-7175aa89e4b0’)
We manage the backup jobs by the physical backup server at the Source site and the replication jobs by the DR site’s physical Veeam server so that in a DR event we can control the failover.
Re: Replication window exclusion — best practice
Post by Vitaliy S. » Apr 15, 2015 4:25 pm this post
Who is online
Users browsing this forum: Google [Bot] and 320 guests
- Main
- All times are UTC
- Delete cookies
- Members
- The team
- Contact us
DISCLAIMER: All feature and release plans are subject to change without notice.
Powered by phpBB® Forum Software © phpBB Limited
Источник
Veeam R&D Forums
Technical discussions about Veeam products and related data center technologies
Backup Copy — Fail to generate points error
Backup Copy — Fail to generate points error
Post by shuji » Apr 12, 2016 3:28 pm this post
I found the backup copy job cannot merge full backup file. 
Red lines are:
I have performed a backup file health check in the beginning. Why does this still happen?
More importantly, how can I fix it?
Re: Backup Copy — Fail to generate points error
Post by foggy » Apr 12, 2016 3:45 pm this post
Re: Backup Copy — Fail to generate points error
Post by hyvokar » Apr 13, 2016 8:24 am this post
[MERGED] Feature Request: Active Full Copy of 1 VM
Post by pkelly_sts » Apr 25, 2017 11:05 am this post
Unless I’m missing a way of doing it, I’d like to be able to initiate an active full COPY for a single VM, without having to create a full copy of ALL vms in the job.
In my case it’s because of a (most-likely self-inflicted) issue where a previous pass of the copy job failed for a small number of VMs but I hadn’t noticed it.
Whilst tidying jobs up after some significant changes I was getting the following error at the end of the copy interval:
«Failed to generate points Error: Points group does not contain full point, oldest point date «
The date in question was where the job failed part-way thought (can’t remember why now) so after checking the RPs I found a number of them with a full RP with a status of «Incomplete».
So, rather than have to re-seed the whole lot, I tested deleting the backup copy (ALL rps) of a small minor VM, re-synced & as expected it started a full copy.
I’d like to be able to stage/manage such a full copy in future without having to mess around disabling/re-enabling the copy job (i.e. I had to disable the job to delete the backup but then re-starting the job started the copy immediately whereas I’d like to be able to get it to start later/OOH. This way I had to edit the schedule to block out a time window, then I’ll have to edit the schedule again to block it back in again.
It would be SO much easier if I could somehow right-click a VM & say «perform active full copy of this VM on the next pass».
Hopefully makes sense!
Re: Feature Request: Active Full Copy of 1 VM
Post by PTide » Apr 25, 2017 6:59 pm this post
The Backup Copy job is configured to use a backup job as a source, not VMs, is that correct? Also
Why did it fail, what was the error message?
Re: Feature Request: Active Full Copy of 1 VM
Post by pkelly_sts » Apr 26, 2017 8:09 am this post
Correct, copy job is using backup job as source (I thought that was the only option anyway for a copy job?)
As I mentioned, in fairness to Veeam in this case it was self-inflicted «Job was stopped due to backup window setting». It was around the time that we were moving office/datacenter amongst other things.
My reasoning is, sometimes we have failures for various reasons (network glitch, repo server crash, disk space issues are a few possibilities that spring to mind) and if a few VMs within a larger job have failures in their chain, then other than a full re-seed of the whole job (which is awkward enough, especially if you’re using SoBR repos) this seemed the only way to get a fresh .VBK to the copy site, at the cost of a bunch of RPs (30 days in my case).
Re: Feature Request: Active Full Copy of 1 VM
Post by pkelly_sts » Apr 26, 2017 8:33 am this post
Actually checking status this morning I’m still having issues — I’m going to have to open a ticket (will post case id here when I do).
As mentioned above, one of the things I did this week on a small VM was to:
1) Disable copy job
2) Delete a VM (and all its RPs) from the copy repo
3) Restart the job
This created a .VBK for just that VM as expected.
I then wanted to do the same for more of the VMs, but I wanted to manage bandwidth a little more so, on top of the network bandwidth throttling I already have configured (which is basically no more than around half of the bandwidth of our P2P 100Mb link) I also edited the allowed hours to «stagger» the hours for the job, so from around that time, let’s say 11:00 until 18:00 the «allowed» window within the copy job was disabled for every other hour.
Now I’ve just checked the job, I noticed more than I expected of the error «Failed to generate points Error: Points group does not contain full point, oldest point date 17/03/2017» (which is the oldest full RP on disk) even though I believed I only had two more (larger) servers to repeat the above process on.
Now that I’ve checked the few I’ve caused to re-copy this week, all of the ones that I processed during the «staggered» window have 3 RPs, but the full has a status of «Incomplete». So, the only two that copied successfully are the ones I allowed to fully copy during business hours (i.e. I didn’t interfere with the schedule).
I thought the whole idea of the scheduling window was to allow things to cleanly stop/pause until the available window came back? This doesn’t seem to be the case in my situation for some reason?
Источник
Error job was stopped due to backup window setting

Ошибка Job finished with error at в Veeam Backup & Replication 7-01
Всем привет, сегодня хочу рассказать как решается Ошибка Job finished with error at в Veeam Backup & Replication 7. После того как мы с вами разобрали Как создать задание резервного копирования в Veeam Backup & Replication 7, через какое то время одно из заданий выпало с данной ошибкой, не очень информативной. Данную проблему я решил следующим образом,
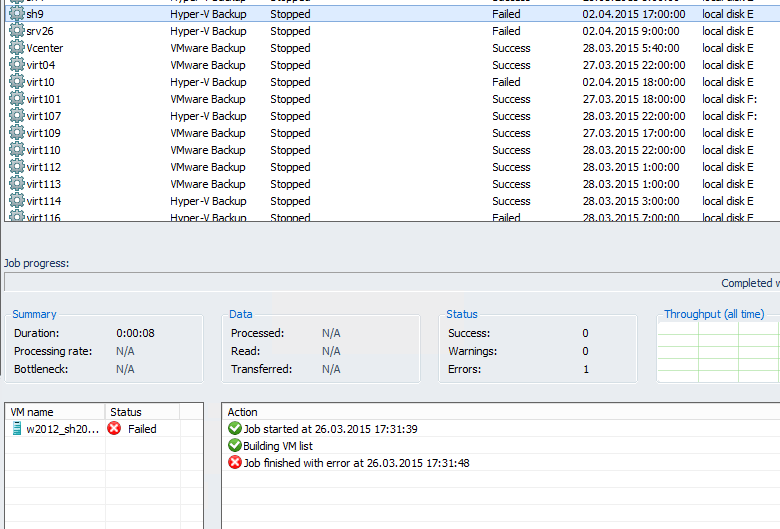
Ошибка Job finished with error at в Veeam Backup & Replication 7-02
Щелкаем правым кликом и удаляем текущее задание, и создаем новое, не самое красивое решение, но работает. Пробовал удалять из задания что нужно копировать и снова добавлять не помогло.
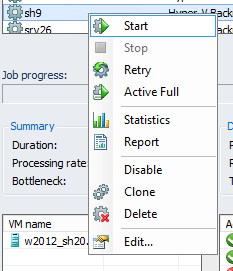
Ошибка Job finished with error at в Veeam Backup & Replication 7-03

Ошибка Job finished with error at в Veeam Backup & Replication 7-04
Вот так вот решается Ошибка Job finished with error at в Veeam Backup & Replication 7.
Источник

Anybody ever see this before? This occurs only with Enterprise vault policies and only after I changed the start windows to be more efficient. There is literally plenty of time to start the jobs yet when the backup window opens and the job kicks off it fails with a status 196 within a matter of seconds. The following is from the job details:
9/29/2013 7:00:06 PM — end Enterprise Vault Resolver, Persist Discovery; elapsed time: 00:00:00
9/29/2013 7:00:06 PM — begin Enterprise Vault Resolver, Policy Execution Manager Preprocessed
Status 196
The backup window opens at 7 PM
I don’t see anything within NBU that would cause this to happen. Can’t see the EV side being an issue. Manual backups run fine. The Master server has been rebooted and the clock is in sync between the Master, Media and client..
Any thoughts?
Labels:
-
7.5
-
Backing Up
-
Backup and Recovery
-
Configuring
-
Error messages
-
Monitoring
-
NetBackup
-
Performance
-
Troubleshooting
-
Windows Server (2003-2008)
-
All forum topics -
Previous Topic -
Next Topic
1 ACCEPTED SOLUTION

Corruption can occur but quite often it is just that the way NetBackup now works is to set timers for when a job is due to kick off
If you edit a job but it does not get picked up to re-set the timers the job can kick in at the wrong time only to find it does not think it has a valid window
It is always good practice to run the nbpemreq -updatepolicies when ever you make any policy or schedule changes
I dont see anything wrong with the schedules so either the timers have not been reset / policy read correctly or corruption has crept in
Hopefully after you re-created the schedules you ran the nbpemreq command, although a deletion and re-add may have forced the re-read anyway
7 REPLIES 7

Please attach Policy attributes
bppllist <policy_name> -U


GV89
Level 4
Partner
Accredited
Certified
Jeff,
Please collet the logs for vxlogview.
And upload them…
Policy Name: Enterprise_vault_closedpartitions_tice
Policy Type: Enterprise-Vault
Active: yes
Effective date: 08/05/2013 10:59:41
Mult. Data Streams: yes
Client Encrypt: no
Checkpoint: no
Policy Priority: 0
Max Jobs/Policy: Unlimited
Disaster Recovery: 0
Collect BMR info: no
Residence: stu_disk_ticsnbapd1
Volume Pool: NetBackup
Server Group: *ANY*
Keyword: (none specified)
Data Classification: —
Residence is Storage Lifecycle Policy: no
Application Discovery: no
Discovery Lifetime: 28800 seconds
ASC Application and attributes: (none defined)
Granular Restore Info: no
Ignore Client Direct: no
Enable Metadata Indexing: no
Index server name: NULL
Use Accelerator: no
HW/OS/Client: Windows-x86 Windows2003 parev01
Include: EV_CLOSED_PARTITIONS=JournalVaultStore
EV_CLOSED_PARTITIONS=MailboxVaultStore
Schedule: EV_ClosedPar_Full
Type: Automatic Backup
Maximum MPX: 1
Synthetic: 0
Checksum Change Detection: 0
PFI Recovery: 0
Retention Level: 9 (infinity)
Number Copies: 1
Fail on Error: 0
Residence: (specific storage unit not required)
Volume Pool: (same as policy volume pool)
Server Group: (same as specified for policy)
Calendar sched: Enabled
Allowed to retry after run day
Day 1 of month
Residence is Storage Lifecycle Policy: 0
Schedule indexing: 0
Daily Windows:
Sunday 19:00:00 —> Sunday 22:00:00
Monday 19:00:00 —> Monday 22:00:00
Tuesday 19:00:00 —> Tuesday 22:00:00
Wednesday 19:00:00 —> Wednesday 22:00:00
Thursday 19:00:00 —> Thursday 22:00:00
Friday 19:00:00 —> Friday 22:00:00
Saturday 19:00:00 —> Saturday 22:00:00
Schedule: EV_ClosedPar_Daily
Type: Automatic Backup
Maximum MPX: 1
Synthetic: 0
Checksum Change Detection: 0
PFI Recovery: 0
Retention Level: 2 (5 weeks)
Number Copies: 1
Fail on Error: 0
Residence: (specific storage unit not required)
Volume Pool: (same as policy volume pool)
Server Group: (same as specified for policy)
Calendar sched: Enabled
Day 2 of month
Day 3 of month
Day 4 of month
Day 5 of month
Day 6 of month
Day 7 of month
Day 8 of month
Day 9 of month
Day 10 of month
Day 11 of month
Day 12 of month
Day 13 of month
Day 14 of month
Day 15 of month
Day 16 of month
Day 17 of month
Day 18 of month
Day 19 of month
Day 20 of month
Day 21 of month
Day 22 of month
Day 23 of month
Day 24 of month
Day 25 of month
Day 26 of month
Day 27 of month
Day 28 of month
Day 29 of month
Day 30 of month
Day 31 of month
Last day of month
Residence is Storage Lifecycle Policy: 0
Schedule indexing: 0
Daily Windows:
Sunday 19:00:00 —> Sunday 22:00:00
Monday 19:00:00 —> Monday 22:00:00
Tuesday 19:00:00 —> Tuesday 22:00:00
Wednesday 19:00:00 —> Wednesday 22:00:00
Thursday 19:00:00 —> Thursday 22:00:00
Friday 19:00:00 —> Friday 22:00:00
Saturday 19:00:00 —> Saturday 22:00:00
Above, backup begins at 7PM and your Schedules show 11AM-1PM.
So your backup is outside the window.
* edit *
I see you changed that to 1900-2200. After modifying the Policy, run
nbpemreq —updatepolicies
Yea, posted the wrong policy output initially. ![]() I do have the same issue with a few different EV policies. I saw a thread from a while back where Mark thought there could be policy corruption and suggested the deletion and re-creation of the policy. Now I don’t know that it needs to be that extreme in this case When I run the backups manually they run fine… Since that bypasses the scheduler I would think if there is an issue at all here its with the schedules, (which btw have been modified often in the last few weeks). I have just deleted the schedules, saved the policy then went back in and added fresh schedules back. I’ll keep you posted on the outcome tomorrow.
I do have the same issue with a few different EV policies. I saw a thread from a while back where Mark thought there could be policy corruption and suggested the deletion and re-creation of the policy. Now I don’t know that it needs to be that extreme in this case When I run the backups manually they run fine… Since that bypasses the scheduler I would think if there is an issue at all here its with the schedules, (which btw have been modified often in the last few weeks). I have just deleted the schedules, saved the policy then went back in and added fresh schedules back. I’ll keep you posted on the outcome tomorrow.
Corruption can occur but quite often it is just that the way NetBackup now works is to set timers for when a job is due to kick off
If you edit a job but it does not get picked up to re-set the timers the job can kick in at the wrong time only to find it does not think it has a valid window
It is always good practice to run the nbpemreq -updatepolicies when ever you make any policy or schedule changes
I dont see anything wrong with the schedules so either the timers have not been reset / policy read correctly or corruption has crept in
Hopefully after you re-created the schedules you ran the nbpemreq command, although a deletion and re-add may have forced the re-read anyway
![]()
![]()
Собственно, возникла следующая проблема. Veeam старой версии, обновить пока нету никакой возможности. При попытке выполнить задания после обновления (vc1 обновил, ресканил, репозитории ресканил, авторизация везде нормальная), возникает ошибка, что на снимке. Пишут, что нужно вроде бы как включить протокол SSLv3. Пытался сделать по этой базе
https://kb.vmware.com/s/article/2121021
при вводе первой же команды esxcli system settings advanced list -o /UserVars/VMAuthdDisabledProtocols
возникает ошибка
Unable to find option VMAuthdDisabledProtocols
Ну что ещё ему надо? До белого каления ведь доводит! Как сделать так, чтобы это проклятие работало? Достал уже этот veeam, честное слово! Столько проблем с ним! То снепшоты нормально удалить не может, то резервные копии сделать!
Вот, я хочу дать дополнительную информацию. В виде лога одной из машин. Прошу извинить меня, если что не так, реально уже выбешивает, по полной. Одни проблемы с этим вимом. Плюс ещё ошибка при добавлении хоста по ip адресу.
Конечно читал. Всё там резолвится, права есть (по логу видно, а также видно, что вход успешен и имена резолвятся). Вот на снимке ещё любопытная вещь. Я их убрал, но хосты теперь требуют перезагрузки. Как их можно так передёрнуть? Если переменная пустая это не вызовет ошибку?
Ну что, передёрнул я без перезагрузки сервисы, одно и то же. Ругаться, конечно, не хочется, но всё же говно этот вим. А за него ещё деньги дерут огромные. Купили лицензию, есть лицензия, новую версию нельзя скачать. Автомобиль продали, ключи не дали. Видимо, придётся идти на крайние меры, но здесь их не опишу, забанят.
Решено было из-за жадности перейти на 9.5 community edition. Только хотелось бы ещё спросить, там есть два каталога, предлагается их при установке выбрать. Так вот, потом после установки можно поменять их и как?
RTFM, знаю, как всегда. То есть, если мне потребуется перенести вдруг эти каталоги на другой диск, то я этого сделать не смогу. Ну понял.
Политику включил, с требованиями разобрался. Переместить папки тоже знаю как, одну через реестр, уже делал. Очень важный вопрос есть, прямо жизни и смерти. Я могу использовать старые резервные копии, ну которые остались от 7 версии? Если я подключу все диски к машине? Нужно сделать импорт? Было решено использовать Veeam 9.5 community edition.
Почти разобрался, всё поставил. Только почему он «хватает» по несколько машин? Одну копирует, у нескольких создаёт снапшоты. Как только одну копирует, берётся за другую, дальше по цепочке. Это правильно? В 7 версии было по одной машине.
А вот такая ошибка с чем может быть связана?
А вот такая ошибка с чем может быть связана?
Смотрите в сторону хранилища с рк. Из того, что я вижу на скриншоте у Вас утилизация хранилища 70%. Сколько заданий одновременно запускается? График копирования постоянно просаживается , такого не должно быть. Редакция Veeam какая?
Смотрите в сторону хранилища с рк. Из того, что я вижу на скриншоте у Вас утилизация хранилища 70%.
Я давно говорил топикстартеру, еще по другим вопросам, что у него все проблемы, по симптоматике, идут от хранилища. Однако он продолжает их искать в иных местах: в гипервизоре, в Veeam и т.д.
Смотрите в сторону хранилища с рк. Из того, что я вижу на скриншоте у Вас утилизация хранилища 70%. Сколько заданий одновременно запускается? График копирования постоянно просаживается , такого не должно быть. Редакция Veeam какая?
Я уже отмечал, что в хранилище сломался один блок, блок Б, остался работать блок А. Теперь машина скопировалась, но с предупреждением, совершенно справедливым — отвалился, мать его за ногу, третий гипервизор. (предупреждение было насчёт снепшота). Вот сейчас мучаю снова, он почему — то, непонятно, сделал вчера машину эту с предупреждением, сегодня её по новой почему — то, да не копирует, а читает. Я так и не понял, с какой целью veeam это делает, она ведь уже скопировалась. Стоит задание как reversed incremental, редакция veeam 9.5 community edition.
Я давно говорил топикстартеру, еще по другим вопросам, что у него все проблемы, по симптоматике, идут от хранилища. Однако он продолжает их искать в иных местах: в гипервизоре, в Veeam и т.д.
А где же ещё то, товарищ хороший? Кроме хранилища Veeam иногда отваливается консоль, с весёлым сообщением failed to start satellite process, то снапшот машины не создаётся, то гипервизор отваливается, хотя я кабели 100 раз проверял, лазал с тестером, везде смотрел. Единственный бонус, что копируется относительно быстро, а сайт этот, что ошибка снепшота, у меня уже две копии есть, так что зер гут.
И вообще, не понять мне иногда светлого творения богов сей виртуализации — гипервизор not responding, не добавляется, пинги до него идут, машины не съезжают, до машин, которые на нём не достучаться, пробуешь загрузить SSH и рестартануть оттуда, команда вроде бы принимается. но никакой реакции нет, также пробовал рестартовать сервисы, сеть, бесполезно. Пришёл сегодня на работу, он дал ввести пароль и завис, пришлось дёргать питание. Вообще, после отвала гипервизора, даже если пинги до него шли, то мне никогда не удавалось его добавить по нормальному, только рестарт помогал. Как была эта баганутая ситуация в 5.5, так и перешла в 6.5, без изменений.
Все мы когда — то учились, все с чего — то начинали. Опыта по виртуализации у меня мало, я самые азы знаю. Но попробуйте сказать это моему начальству, которое считает, что я должен знать всё.
Короче, придётся эти две машины копировать вручную. Говно этот veeam, уже достал. Ничего адекватного нет, уже несколько дней проблема основная только с этими машинами и есть. Да, чувствую меня опять ждёт бессонная ночь. Надавать бы по морде разработчикам.
И вообще, когда я переносил диски, то я импортировал резервные копии, как мне подсказали, со старого veeam. Они импортировались, восстановить их теоретически можно, но он, один фиг, начал всё по новой. Разработчики, вероятно, думают, что диски у хранилища резиновые и их можно растянуть, по самое не хочу. Вообще ужас. И не понимаю, почему машина не скопировалась с 1С.
Я сейчас напишу часть! У меня только у одного такое ощущение, что Вы как-будто пишите на тп veeam или vmware претензию? Вам назвать цену за ТП годовую обоих продуктом в редакции standard? А теперь я попытаюсь Вам помочь совершенно бесплатно
Что значит сломался блок Б? Как хранилище вм подключено к хостам? Как машина veeam подключена к сети? Я в одной из прошлых тем Вам объяснял что такое обратное инкрементальное копирование и что оно делает, по-моему из того что я писал надо было понять какую нагрузку оно даёт на хранилище резервных копий. У меня ещё потом будет много вопросов наверное… но одно могу сказать Вы не туда пишите с такой агрессией, наверное стоит писать в veeam и VMware
- 1 пользователю нравится это сообщение.
Хорошо, тогда скажу так. Моя не агрессия, но претензия вполне обоснована. Если я, например, попал в аварию на новом автомобиле, в котором заводской брак, значит это я виноват? У меня реально есть заболевание, в котором я не могу разобраться, оно меня мучает, кто тут виноват? Я, по тысяче раз объяснявший врачам симптомы, или врачи, которые не могут разобраться, в силу своей некомпетентности или лени, пиная меня туда и сюда? Ответ, я думаю, очевиден?
Но вернёмся к нашим баранам. Всё по порядку. Хранилище у нас DS3512. Я надеюсь, что вы сталкивались с таким.
https://www.karma-group.ru/catalog/ibm_disk_storage_retired/ibm_system_storage_ds3512/
Там написано, что есть два активных контроллера с горячей заменой. Так вот, один контроллер приказал долго жить. Так что система тянет на одном контроллере. Всё это чудо подключено к трём гипервизорам напрямую. То есть, из первого контроллера выходят три нитки, которые образуют три линка (3 сетевой интерфейс на каждом из гипервизоров), из второго тоже три нитки, которые образуют три линка (4 сетевой интерфейс на каждом гипервизоре). Также каждый из контроллеров имеет по одному линку, каждый идёт в один из свитчей (всего два). От свитчей идёт по две нитки к гипервизорам (по идиотской схеме, то есть получается, что от одного свитча идут три нитки — первые две в первый гипервизор, третья в третий гипервизор, четвёртая в третий гипервизор и пятая шестая в третий гипервизор). То есть, должна была упасть скорость, но никак не надёжность копирования.
Veeam это виртуальная машина, ей выделено достаточно ресурсов.
Кроме того, ещё есть два хранилища.
1. FreeNAS 8.9.3, ставил аутсорсинг. Подключен по iSCSI, к гипервизорам, виртуальные диски выведены в Veeam. Там есть одна особенность — аутсорсинг создал файловый экстент. Во вложении вся информация о проблемах с заданиями.
2. FreeNAS FreeNAS 11.2-U2.1, эту уже ставил я. Так же подключён по iSCSI к гипервизорам, виртуальные диски выведены в Veeam. У меня дисковый экстент. Скорость копирования очень хорошая, проблем нет, только мало места.
Оба FreeNAS созданы на базе старого железа, имеют по 5 дисков — один под систему, остальные под данные. На моём хранилище создан RAID10, на аутсорсинга RAIDZ1, каждая машина по 4 гигабайта памяти. На своей я ещё поставил свежие патчкорды.
Насчёт обратного инкрементального — про обычное я прочитал, что там требуется много места.
Все вопросы прошу писать.
Хочу видеть логи агента Agent.xxxx.Index и Agent.xxxx.Target. Также интересно посмотреть логи Job.xxx.Backup. Для обоих серверов.
По серверу 1С, меня настораживают вот эти сообщения
[b][17.03.2019 03:03:46] <87> Info Stop signal has been received
[17.03.2019 03:03:46] <87> Info Session '3faf4450-554f-4aa9-b423-97fb7384ebc9', state 'Stopping'
[17.03.2019 03:03:55] <120> Info [AP] (db1c) output: --pex:43;60716744704;60596158464;0;60596158464;18700403339;6;15;98;5;15;95;131972474350390000
[17.03.2019 03:03:55] <120> Info Stop signal has been received
[17.03.2019 03:03:55] <120> Info Stop signal has been received
[17.03.2019 03:03:55] <120> Info Stop signal has been received
[17.03.2019 03:03:55] <120> Info Stop signal has been received[/b]
[17.03.2019 03:03:55] <120> Info Terminating CBackupClient [0x3e0b770], reason is Veeam.Backup.Common.Sources.Sessions.CSessionTerminationReason
[b][17.03.2019 03:03:55] <120> Info [AP] (56f6) command: 'breakJobWithReasonnJob aborted due to server terminationn'[/b]
[17.03.2019 03:03:55] <58> Info [AP] (56f6) output: >
[17.03.2019 03:03:56] <46> Info [ReconnectableSocket][StopCondition] Stop confirmation was received on [1051905b-7b9c-4663-9ea0-7ec576af178f].
[17.03.2019 03:03:56] <46> Info [ReconnectableSocket] Stop confirmation was sent on [1051905b-7b9c-4663-9ea0-7ec576af178f].
[17.03.2019 03:03:56] <46> Info [ReconnectableSocket][StopCondition] Stop request was received on [1051905b-7b9c-4663-9ea0-7ec576af178f].
[17.03.2019 03:03:56] <122> Error Job aborted due to server termination (Veeam.Backup.Common.CStopSessionException)
Журнал событий с veeam и c сервера 1с за период с 02:50 по 03:10.
По почтовику. Сразу вопрос почему не обновлены VMTools?
[16.03.2019 19:36:18] <29> Info [VmSnapshotTracker] Closing snapshots for VM: 'server-gw-mail', host: 'vc1'
[16.03.2019 19:36:18] <29> Info Validating guest agent availability for the VM
[16.03.2019 19:36:18] <29> Info VMware Tools are not up to date. Please upgrade VMware Tools to avoid potential issues with VM processing
А теперь самое интересное:
[17.03.2019 03:03:45] <33> Info Stop signal has been received
[17.03.2019 03:03:45] <33> Info Session '3faf4450-554f-4aa9-b423-97fb7384ebc9', state 'Stopping'
[17.03.2019 03:03:51] <59> Info [AP] (9baa) output: --pex:13;58066993152;58066993152;0;58066993152;44729222455;14;14;93;7;15;94;131972474314040000
[17.03.2019 03:03:51] <59> Info Stop signal has been received
[17.03.2019 03:03:51] <59> Info Stop signal has been received
[17.03.2019 03:03:51] <59> Info Stop signal has been received
[17.03.2019 03:03:51] <59> Info Stop signal has been received
[17.03.2019 03:03:51] <59> Info Terminating CBackupClient [0x930ddd], reason is Veeam.Backup.Common.Sources.Sessions.CSessionTerminationReason
[17.03.2019 03:03:51] <59> Info [AP] (f860) command: 'breakJobWithReasonnJob aborted due to server terminationn'
[17.03.2019 03:03:52] <115> Info [AP] (f860) output: >
[17.03.2019 03:03:52] <103> Info [ReconnectableSocket][StopCondition] Stop confirmation was received on [6a6f8a15-83f2-4956-aded-1a3c9b183d42].
Одно и тоже событие в одно и тоже время. Логи журнала событий за это же время. Что-то у меня подозрение что у Вас veeam машина перезагружается ночью когда идет РК.
Насчёт обратного инкрементального — про обычное я прочитал, что там требуется много места.
Точно столько же сколько и на обратное. Только на обратное инкрементальное требуется операчий ввода/вывода в 2 раза больше из-за склеивания копии
Всё для вас, уважаемый. С какого — то перепугу сервер решил, что может сам перезагружаться, где это видано? Политика вся чистая, там таких опций нету. Кроме того, есть в главной доменной такой параметр, что не перезагружать автоматически компьютер.
Хорошо, тогда скажу так. Моя не агрессия, но претензия вполне обоснована.
Призрак, Вы не правы! Эмоции — это хорошо на отдыхе или во время развлечений, а в нашей работе — от них лишь вред! Здесь Вам искренне стараются помощь в решении Вашего вопроса. Но ведь здесь пока еще не сообщество экстрасенсов-телепатов, которые читают мысли других!
У меня реально есть заболевание, в котором я не могу разобраться, оно меня мучает, кто тут виноват? Я, по тысяче раз объяснявший врачам симптомы, или врачи, которые не могут разобраться, в силу своей некомпетентности или лени, пиная меня туда и сюда? Ответ, я думаю, очевиден?
Но ведь Вы пишете только о ТЕКУЩИХ симптомах болезни (и догадываюсь, что не все их тут изложили), при этом не предоставив ПОЛНОЙ карты пациента с момента его рождения! Ведь одинаковые на первый взгляд симптомы могут быть в абсолютно разных болезнях и лечение их тоже будет кардинально отличаться! Возьмём к примеру кашель. Это может быть, как обычная простуда или бронхит, а может и вирусный грипп или бактериальное заражение, ну или туберкулёз, лихорадка, аллергия (на пыль, запахи, цветения, другие лекарства, определённые ингредиенты еды) или астма и т.п.
Призываю Вас к конструктиву!
Чтобы в будущем Ваши задачи решались форумчанами более оперативно, излагайте изначально максимально достаточно вводных данных и делайте правильную постановку задачи.
Призрак, в сложившейся сейчас непростой ситуации и с целью таки устранить Вашу проблему максимально быстро, я советую Вам сделать следующее.
1. Приструнить эмоции и извиниться перед форумчанами.
2. Написать в личку понимающим тут людям с просьбой помочь Вам удалённо (например, через тот же TeamViewer). Свои умения не предлагаю, т.к. пока не имею должного уровня.
P.S.: Ваша текущая позиция со стороны мне напоминает ситуацию, когда голодный человек на улице просит что-нибудь покушать и милосердные прохожие дают ему хлеб. А он в ответ бросает этот хлеб обратно дающему с возмущением, что он хочет кушать только лобстера!
Давайте не переходить на личности. Администрация.
Всё для вас, уважаемый. С какого — то перепугу сервер решил, что может сам перезагружаться, где это видано? Политика вся чистая, там таких опций нету. Кроме того, есть в главной доменной такой параметр, что не перезагружать автоматически компьютер.
Обновляйте VMTools, ждите запуска задания. Дальше если ошибки логи сюда. Вопрос с ошибками RPC посмотрим при следующем РК, если полезут ошибки будем смотреть
Пока всё нормально, только вот эта ошибка меня немного смущает, при копировании почты. Спасибо Вам большое за помощь, более менее уже всё сдвинулось.
18.03.2019 21:49:15 :: Transaction logs backup will not be possible due to insufficient permissions to update backupset for SQL instance SQLEXPRESS: Code = 0x80040e09
Code meaning = IDispatch error #3081
Source = Microsoft OLE DB Provider for SQL Server
Description = The UPDATE permission was denied on the object ‘backupset’, database ‘msdb’, schema ‘dbo’.
Говорят, что нужно поставить какой — то патч, но я пока не буду лезть, пока не завершится копирование. Вроде бы пока пошло.
Ещё меня смущает очень низкая скорость копирования. Как вы думаете, из-за железа это вполне может быть? Я имею в виду, не ту самую, разумеется, хранилку DS3512, она пердит ещё и ладно, а про оба FreeNAS. Они организованы на платах P5E, ещё старых, скорость копирования по 5 мегабит в секунду на диск, это очень и очень мало. Две сетевые карты там встроенные, но используется из встроенных только по одной карте, вторые DFE-520TX, они как раз и подключены к гипервизорам по iSCSI. Невозможно тут ничего сделать? Я пробовал openmediavault тестировать, там вообще iSCSI нет, да и то не смог поставить, какой — то глючный там iSCSI. Пробовал Nas4Free, он же xigmanas, там вообще засада — если добавляешь диски, то они тупо не форматируются снова, никак. То есть отформатировал их по другому, удалил, они снова отформатированные. Чудо из чудес. Вот этот товарищ, 2gusia aka mikemac, очень любит почему — то сиё поделие, задаёшь вопрос, молчит, как рыба в пироге. Весьма странно.
Как у FreeNAS организовать подключения? Может быть сделать три сетевые карты — одна пойдёт на веб интерфейс, две другие на iSCSI? Встроенные не использовать вообще? Загадка века, скорость у карт до 1000, копируют они с черепашьей скоростью. Ах да, машины то в хранилке, может из-за этого?
Они организованы на платах P5E
Там же SATA 2 3.0 gB
вторые DFE-520TX
Они 100BASE-TX? Сайт D-link не врет?
а про оба FreeNAS. Они организованы на платах P5E, ещё старых, скорость копирования по 5 мегабит в секунду на диск, это очень и очень мало
Характер доступа случайный или последовательный? При случайном это нормальная скорость для обычных дисков. К примеру широко распространенная «барракуда»: https://interface31.ru/tech_it/2015/04/seagate-desktop-hdd-1-tb-po-prezhnemu-nedorogo-i-serdito.html
На запись блоками 4К дает 1,2 -1,5 МБ/С или 10-12 Мбит/с. Но это одиночный диск, добавьте сюда пенальти RAID на запись и получите что-то близкое к своим цифрам.
Характер доступа случайный или последовательный? При случайном это нормальная скорость для обычных дисков. К примеру широко распространенная «барракуда»: https://interface31.ru/tech_it/2015/04/seagate-desktop-hdd-1-tb-po-prezhnemu-nedorogo-i-serdito.html
На запись блоками 4К дает 1,2 -1,5 МБ/С или 10-12 Мбит/с. Но это одиночный диск, добавьте сюда пенальти RAID на запись и получите что-то близкое к своим цифрам.
Да там все вместе, сначала мы при копировании упираемся в 100 мб сетевуху, потом при склеивании мы упираемся в интерфейс SATA 2. Судя потому, что я видел задания идут одновременно. Представьте вторая машина копируется и тут Veeam начинает дербанить бекап первой машины на этих же дисках. При таких вариантах диски проживут года 1,5.
Да там все вместе, сначала мы при копировании упираемся в 100 мб сетевуху, потом при склеивании мы упираемся в интерфейс SATA 2. Судя потому, что я видел задания идут одновременно. Представьте вторая машина копируется и тут Veeam начинает дербанить бекап первой машины на этих же дисках.
С учетом средних 70 IOPS обычного диска все упрется именно в них. После чего все станет колом с огромной дисковой очередью. Было бы интересно посмотреть iotop в это время.
А 100 Мбит/с сеть только усугубит ситуацию, так как не позволит быстро слить бекап на NAS, в итоге следующий бекап придет как раз в момент, когда хранилище судорожно скрипя винтами пытается сделать обратный инкремент того, что пришло до этого. Эта операция сама по себе носит случайный характер, а с попыткой еще что-то одновременно писать — это просто туши свет.
С учетом средних 70 IOPS обычного диска все упрется именно в них. После чего все станет колом с огромной дисковой очередью. Было бы интересно посмотреть iotop в это время.
А 100 Мбит/с сеть только усугубит ситуацию, так как не позволит быстро слить бекап на NAS, в итоге следующий бекап придет как раз в момент, когда хранилище судорожно скрипя винтами пытается сделать обратный инкремент того, что пришло до этого. Эта операция сама по себе носит случайный характер, а с попыткой еще что-то одновременно писать — это просто туши свет.
Ну собственно поэтому мы на скрине выше и видели загрузку хранилища в 70%
Возможно есть смысл отказаться от инкрементного копирования в пользу полного + дедупликация. Быстро (или не очень быстро) слили бекап — но это последовательная запись, здесь будем упираться только в сеть (ну или в диски). А потом пусть он там оставшееся время скрипит — дедуплицирует.
Одно и тоже событие в одно и тоже время. Логи журнала событий за это же время. Что-то у меня подозрение что у Вас veeam машина перезагружается ночью когда идет РК.
В свете вышеописанного есть подозрения, что она не перезагружается, а просто подвисает из-за большой дисковой очереди.
- Записки IT специалиста — Форум
-
►
Серверные операционные системы -
►
Windows Server 2008/2008R2 -
►
Veeam 7.0 ошибка после обновления инфраструктуры до 6.5
Knowledge Base
-
Home
-
Knowledge Base
-
Windows Agent Backups
-
Agent Job Errors
-
Troubleshooting: Job Errors
-
Home
-
Knowledge Base
-
Virtual Machine Backups
-
VM Job Errors
-
Troubleshooting: Job Errors
-
Home
-
Knowledge Base
-
Troubleshooting
-
Troubleshooting: Job Errors
General Troubleshooting: Veeam Backup Job Errors
Below are common host and backup job error messages you may encounter and what they mean.
This article is organized by Alarm Type:
- Backup Agent Job State Errors
- Job Session State Errors
- Job Status Errors
- Computer/VM Not Backed Up
- Miscellaneous
For Additional Errors Not Listed Below, Consult the Veeam Knowledge Base and/or Forums:
- Veeam Knowledge Base – https://www.veeam.com/kb_search_results.html
- Veeam Community Forums – https://forums.veeam.com/
1. Backup Agent Job State Errors
Error: write: An existing connection was forcibly closed by the remote host Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}.
What This Means
- The last backup job was unsuccessful because the remote host (machine backing up) closed the connection to eSilo while the backup was running.
Possible Causes
- The machine was powered down during the backup. Upon shutdown, the active snapshot taken at the start of the backup is lost.
Troubleshooting Steps
- No user intervention is typically required. When the computer is powered back on, a new snapshot will be taken at the next scheduled backup time, and a new backup job will begin. (Note: If the machine is put to Sleep or Standby during a backup, it should resume when it wakes up. It is only when the machine is completely powered down that this error happens).
Error: Task failed unexpectedly
What This Means
- The job was terminated suddenly, resulting in an incomplete backup and restore point.
Possible Causes
- Host rebooted during the backup, resulting in the loss of the active snapshot.
Troubleshooting Steps
- Check host’s Event Viewer Windows System logs to see if there was a reboot.
- Rerun the backup job.
Error: Root element missing
What This Means
- The VBM file associated with the backup job has become corrupted.
Possible Causes
- This may be caused by a connection issue during the backup job or the Veeam repository had an error.
Troubleshooting Steps
- Locate the VBM file associated with the backup job and rename the file, such as by adding “.old” to end of the file name.
- Start a new backup job to generate a new VBM file.
- After the new VBM file gets created, the old file can be safely deleted without waiting for the running job to complete.
Unable to allocate processing resources. Error: Job session with id [STRING] does not exist
What This Means
- Host requested but was not assigned processing resources by eSilo cloud connect. This happens because the maximum number of concurrent backup jobs was already reached.
Possible Causes
- eSilo limits the number of concurrent backup jobs from a single Company when their bandwidth is lower than recommended thresholds. This max limit ensures hosts queue their backup jobs sequentially (vs. all machines at once) and avoids network slowdowns for the customer.
- When the first few machines’ backup jobs run long, they can cause subsequent hosts’ jobs to time out while waiting for their turn to backup.
Troubleshooting Steps
- Hosts should automatically retry backups at their next scheduled interval. No user intervention is typically required.
- If this is a persistent issue, or if your hosts are connecting from multiple locations (and thus there is little concern that multiple backups may saturate a site’s connection), contact eSilo Support to request the concurrent task limit be increased for your Company.
Failed to start a backup job. Failed to perform the operation. Invalid job configuration: Connection over network is blocked by network throttling rules
What This Means
- Backup job was unable to complete due to network restrictions.
Possible Causes
- The host is on a metered connection (ex: hot spot), or on a WiFi connection that has “Set as a metered connection” toggled on in the properties for the currently active WiFi connection. By default, eSilo Backup Jobs are set to “Disable backups over a metered connection”.
- Temporary network congestion may also cause this error.
- Firewall rules that limit or severely restrict certain types of traffic.
Troubleshooting Steps
- To check if the current WiFi connection is flagged as “metered” by Windows, the user can navigate to the Properties of their WiFi Network, and scroll to “Metered Connection” to verify if this is toggled ON. The preferred setting is to turn this OFF. Alternatively, if you don’t have remote access to the machine, uncheck the “Disable backups over metered connection” setting in the backup job and rerun it.

- Wait until the next scheduled backup run to see if the issue persists or was temporary.
- Contact the network or IT administrator for the site to investigate if there were recent firewall rule changes or upgrades that may have introduced new blocking or throttling settings.
Unable to allocate processing resources. Error: Authentication failed because the remote party has closed the transport stream.
What This Means
- The backup job failed due to an authentication error between the client machine backing up and the eSilo infrastructure.
Possible Causes
- Client machine is behind on Windows Updates which include authentication and security enhancements, or they have not checked the box in Windows Update Settings to include updates for other Microsoft Products, such as .NET Framework.
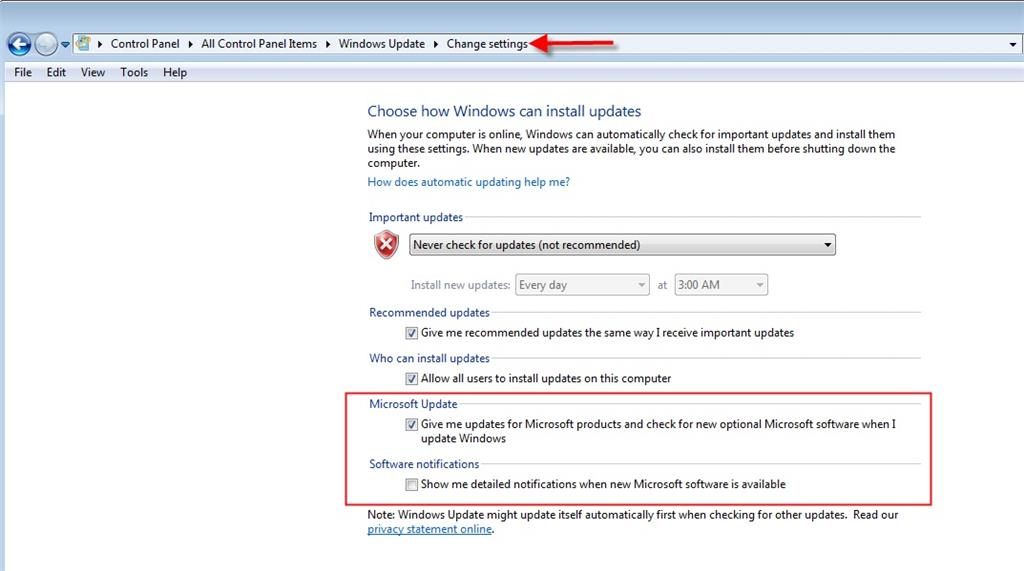
Troubleshooting Steps
- Apply latest Windows Security updates and .NET Framework updates
- Check if at the time of the above error on the tenant side, the eSilo Svc.VeeamCloudConnect.log log file displays the following error: “A call to SSPI failed, see inner exception“. If so, the issue may be related to a Windows Update enforcing a new .Net Framework security check. This check does not allow the client to establish a secure connection between their Veeam backup servers or agents and the eSilo Cloud Connect service, if there is a weak Diffie-Hellman Ephemeral (DHE) key. See this help article from Veeam on the steps needed to confirm and resolve. https://www.veeam.com/kb3208
- Subsequent job reattempts may complete successfully without user intervention, although this error may still sporadically cause jobs to fail.
Error: Failed to connect to the port [DNS_Name:Port].
What This Means
- Host unable to connect to eSilo cloud connect at the specified gateway and port address.
Possible Causes
- If this issue is occurring for only one or two machines (most common), and not all machines connecting to the eSilo cloud connect infrastructure, it may be indicative of a network issue on the client side.
Troubleshooting Steps
- The host should reattempt the job at the next scheduled interval. You can also manually start a backup to reattempt the job. No other user intervention is typically required.
Error: Insufficient quota to complete the requested service. Asynchronous read operation failed Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}. Exception from server: Insufficient quota to complete the requested service. Asynchronous read operation failed Unable to retrieve next block transmission command. Number of already processed blocks: [#]. Failed to download disk ‘[LONG_ID]’.
What This Means
- The error description may be misleading. We’ve observed this error previously, and it was unrelated to the Tenant’s Quota, which was well within limits.
Possible Causes
- When this was observed on an internal testing VM, the cause was that the source VM in the backup job was very low on memory (RAM) resources and was unresponsive. Restarting the VM brought it back online, and the next automatic job try was successful.
Troubleshooting Steps
- Verify the source machine is online and responsive. Ensure resource levels look good.
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: Invalid backup cache synchronization state.
What This Means
- Host is currently saving backups to Local Backup Cache. An attempt to sync cached backups to the eSilo cloud repository failed, due to a mismatch between what the Veeam Agent for Windows had in its local database for expected restore points and what was actually found in the repository and/or local backup cache.
Possible Causes
- If an in-progress backup is abruptly stopped, for example due to power failure, Veeam will discard any partially written restore points. However, if all references to those now discarded restore points are not cleared from the database (which should happen automatically), this can cause a job error on the next run, which highlights a mismatch between restore points expected on disk and what was found.
Troubleshooting Steps
- In most cases where this has been observed, the job will complete successfully the next time it is run, without any user intervention.
- If this error persists more than once, contact eSilo Support for assistance troubleshooting Backup Cache issues.
Job session for “[JOB_NAME]” finished with error. Job [JOB_NAME] cannot be started. SessionId: [ID], Timeout: [XX sec]
What This Means
- The Veeam job could not start due to too many active sessions or jobs running on the host consuming all available memory.
Possible Causes
- Too many running sessions causes Veeam services to be impacted by the host’s Desktop Heap limitation. This is because the Desktop Heap size for services is much smaller than that for applications.
Troubleshooting Steps
- To resolve this issue the Desktop Heap size must be increased via a registry modification.
- See this Veeam Knowledge Base article for detailed resolution steps: KB1909
Error: The system cannot find the file specified. Failed to open I/O device Failed to open emulated disk. Failed to open disk for read. Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}
What This Means
- An expected disk on the client machine (machine to backup) was unable to be opened and read during the backup job.
Possible Causes
- Not known at this time.
Troubleshooting Steps
- The host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: Oib is complete and cannot be continued
What This Means
- The “oib” stands for “objects in backup” and is a unique identifier used by Veeam.
- The error indicates there is a discrepancy; a job is attempting to write to an oib that is already complete or finalized.
Possible Causes
- This may occur on a backup cache sync job that was interrupted right at very end, during the finalization stage. The error indicates that the oib was finalized by the previous job (“oib is complete”), however the current job is trying to modify or append to it, which is not allowed.
Troubleshooting Steps
- This error should resolve itself on next job run. If not, contact eSilo support.
Job session for “[JOB_NAME]” finished with error. Backup cache size has been exceeded
What This Means
- The size of the local backup cache has exceeded the maximum allowed size as configured in the backup job, preventing new restore points from being saved to the cache.
Possible Causes
- Persistent network disruptions may be preventing cached restore points from syncing, or uploading, to the eSilo Backup Cloud and thus they are not rotated out of the local backup cache. Restore points accumulate until the backup cache location is full.
- Service provider resources are busy or unable to be allocated to this host, preventing the syncing of cached restore points.
Troubleshooting Steps
- The Backup Cache Sync should resume in time, once the originating network or resource issues are resolved.
- The maximum Backup Cache size can be increased in the job settings, so long as there is sufficient local space.
- For more detail on advanced resolution steps, see this eSilo KB article: How to Resolve Backup Cache Size Exceeded Error
Error: Failed to create snapshot: Backup job failed. Cannot create a shadow copy of the volumes containing writer’s data. A VSS critical writer has failed. Writer name: [NAME]. Class ID: [ID]. Instance ID: [ID]. Writer’s state: [VSS_WS_FAILED_AT_PREPARE_SNAPSHOT]. Error code: [0x800423f0].
What This Means
- There is an issue with the built-in Windows VSS (Volume Shadow Copy service) on the host machine. Specifically, the VSS writer mentioned was not available at the time of the backup.
- eSilo Backups powered by Veeam use VSS writers to backup files that may be in-use, open or locked at the time of backup. This is particularly useful for databases, allowing backups to complete without downtime. If a writer is not in the proper state and functioning as expected, the backup snapshot will fail. VSS writer issues must be resolved on the host, and can usually be corrected by restarting the associated service.
Possible Causes
- The VSS service and/or the VSS Providers service is disabled
- The VSS writer is not in the Stable state, indicating it is ready and waiting to perform a backup. Below are alternative states:
- Failed or Unstable – the Writer encountered a problem, and must be reset .
- In-Progress or Waiting for Completion – the Writer is currently in use by a backup process. When the backup is finished, the Writer will revert to back to Stable state. However, if you see this state when no backups are running, the Writer needs to be reset.
Troubleshooting Options
- Verify the Volume Shadow Copy and Microsoft Software Shadow Copy Provider services are not disabled in services.msc.
- Check the state of VSS Writers using the following syntax in an admin command prompt. Also check the Windows Event Viewer for additional error information.
vssadmin list writers
-
- For the specified Writer in the error message, verify it is in a Stable state. If not, restart the respective Service related to that writer as mentioned in the table here. Then run the above command a second time to ensure the writer has returned to a stable state.
- Note that Services often have dependencies on one another. When one service is reset it may require others to be reset as well. Restarting a service will momentarily disrupt any application services that rely on it. For example, while resetting the MEIS service (Microsoft Exchange Information Store), MS Exchange will be unable to send and receive emails.
- A system reboot can also resolve most VSS writer problems, although it requires downtime.
- This Veeam KB article can also be useful in troubleshooting VSS issues for servers.
Job Session for [JOB_NAME] finished with error. Job [JOB_NAME] cannot be started. SessionID: [ID], Timeout: [VALUE]
What This Means:
- The job could not start, due to timeout waiting for required Veeam resources
Possible Causes:
- The Concurrent Task limit set at the Company level is too low for the number of hosts and disks schedule to be backup within a defined backup window.
Troubleshooting Options:
- Increase the number of concurrent tasks (e.g. disks that can be processed at once). This setting can be found in the eSilo Backup Portal under Companies >> Edit >> Bandwidth >> Max Concurrent Tasks. The minimum value should be 2, but greater numbers may be needed based on the timing and staggering of host backups.
Job session for “[JOB_NAME]” finished with error.
Error: Service provider side storage commander failed to perform an operation: CreateStorage
What this Means:
- eSilo was not able to allocate repository storage for the backup job.
Possible Causes:
- The assigned repository quota for this Tenant has been exceeded, thus preventing new backups from initiating.
Troubleshooting Options:
- Increase the Company’s repository quota.
- Remove existing backup chains or reduce the retention period to free space.
Job Status Warning: Unable to truncate SQL server transaction logs. Details: Failed to truncate SQL server transaction logs for instances: [MSSQLSERVER].
What this Means:
- Veeam was unable to truncate SQL server logs as specified in the job settings.
Possible Causes:
- This most commonly due to a permissions issue.
Troubleshooting Options:
- This Veeam Helpcenter article discusses the Log Truncation settings.
- You can confirm if this is a permissions issue by reviewing the Backup Job log for Warning items. Ex: Description = The server principal “[HOST][ACCOUNT]” is not able to access the database “[HOSTNAME]” under the current security context.
- Grant necessary permissions and rerun the job.
- Alternatively, you can modify the Backup Job settings to not truncate SQL Logs.
- Edit the Backup Job
- Under Guest Processing, click to “Customize application handling options for individual applications…”
- On the SQL tab, select the option for “Do not truncate logs”
2. Job Session State Errors (for VMs)
Host [LOCAL_IP] is not available. Error: Cannot complete login due to an incorrect user name or password. Virtual Machine [NAME] is unavailable and will be skipped from processing. Nothing to process. [#] machines were excluded from task list.
What This Means
- Veeam Backup and Replication was unable to access the Virtual Machine (VM) to perform the backup.
Possible Causes
- Incorrect user name or password specified to access the source VM. The password may have expired or the account credentials or permissions may have been changed.
Troubleshooting Steps
- Contact the IT Administrator for the VM to troubleshoot the credentials saved in the Backup Job.
3. Job Status Errors
SQL VSS Writer is missing: databases will be backed up in crash-consistent state and transaction log processing will be skipped
What This Means
- The SQL Writer for the Windows Volume Shadow Copy Service (VSS) is not available on the host machine, or is not configured with adequate permissions. This issue is related to the setup of the SQL database, and not specific to eSilo provided software or the backup itself.
Steps to Confirm the Issue
- Running ‘vssadmin list writers’ in an Administrator Command Prompt shows that SqlServerWriter is not in the list, or is in a State other than ‘Stable’.
Possible Causes
- The SQL instance has at least one database with name starting or ending in a space character
- The account under which SQL VSS Writer service is running doesn’t have sysadmin role on a SQL server – most frequently encountered
- SQL VSS Writer service is stuck in an invalid state, e.g. other than ‘Stable’
Troubleshooting Steps
- Depending on a particular cause:
- Rename the database to a new name (without a space in it). To check if your database has space in the name you can run the following query:
select name from sys.databases where name like '% '
If you notice any spaces in the database names, then you will need to remove the spaces from the database names.
- Grant the SQL VSS Writer service user a sysadmin role (Instructions in KB here: https://www.veeam.com/kb1978)
- Restart SQL VSS Writer service (Instructions in KB here: https://www.veeam.com/kb2041)
- In the case of SBS machines that are also Domain Controllers, ensure that the SQL Writer is running as a domain administrator and not local system.
- Allow the SQL Writer service account access to the Volume Shadow Copy service via the registry:
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesVSSVssAccessControl- If the DWORD value “NT SERVICESQLWriter” is present in this key, it must be set to 1.
- If the Volume Shadow Copy service is running, stop it after changing this registry value. Do not disable it.
For More Information
See this Veeam Knowledgebase article: https://www.veeam.com/kb2095
Microsoft documentation states that the SQL Writer service must run as Local System.
- In SQL Server 2008R2 and earlier, this means that the writer service account appears to SQL Server as “NT AUTHORITYSystem”.
- In SQL Server 2012 and later, the writer service account appears to SQL Server as “NT ServiceSQLWriter”.
4. Computer/VM Not Backed Up Errors
Backup Agent ‘[HOSTNAME]’ has fallen out of the configured RPO interval ([#]days). Last backup: [#] days, [#] hours ago.
What This Means
- The host’s most recent eSilo cloud backup is greater than the specified RPO (Recovery Point Objective) interval.
Possible Causes
- Host has been powered off or offline.
- Backups are being saved to the host’s Local Backup Cache and all restore points in the cache have not yet synced to the eSilo Cloud Repository (e.g. eSilo has not yet received the backups).
- Veeam Backup Agent Service or Veeam Management Agent Service is not running on host.
- The backups and/or backup schedule have been manually disabled (uncommon).
Troubleshooting Steps
- Verify host is online and connected to network.
- Check Backup Job to determine if Backup Cache is enabled. View cache folder on host to see if populated with recent restore points (default location: C:VeeamCache).
- Verify ‘VeeamManagementAgentSvc’ service is running on host. Status should be ‘Running’ and Startup Type should be ‘Automatic (Delayed Start)’. If the service is ‘Stopped’, check the Event Viewer for possible error details. See this article for more troubleshooting steps.
- Verify ‘VeeamEndpointBackupSvc’ service is running on host. Status should be ‘Running’ and Startup Type should be ‘Automatic’. Restart or reinstall if necessary.
- Check Backup Job to verify schedule and ensure not ‘Disabled’
Other Errors – Full Details Coming Soon
Error: Reconnectable protocol device was closed. Agent failed to process method {FileBackup.SyncDirs}. Exception from server: Reconnectable protocol device was closed.
Troubleshooting Steps
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond.
Troubleshooting Steps
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
[In Backup Job Log] Error: [CStorageLinksHelper] Link Id=[LONG_ID] doesn’t exist for storage [JOBNAME_SUBTENANTNAME]yyy-mm-ddTxxxxxx.vib
What This Means
- While the restore point exists on the repository, the Link ID to that restore point in the metadata (.vbm) file is missing.
- Note: If the Backup Job is configured to use Backup Cache, this error does not by itself trigger a Backup Job Failure, since the restore points are successfully written to local cache. You will notice it however, because the eSilo Backup Portal will warn that a new restore point has not been uploaded in X days (according to the RPO alarm thresholds set for this tenant).
Possible Causes
- This can be a symptom of a network drop, where a handshake was missed in the final stages of job completion for the last restore point uploaded to eSilo. The local Veeam Agent database (on the subtenant’s machine) saw the restore point created, but the finalization step didn’t update the metadata file on the repository side with eSilo.
Troubleshooting Steps
- In the repository, we will force the job to recreate the metadata file by editing the existing metadata file to append “.old” at the end. At the next job run, this will force a recheck of all restore points in the backup chain and recreate the metadata file from that chain.
[In Svc.VeeamEndpointBackup.log] Error: Warning [CertificateError] Validation complete with warnings, AND/OR Warning Remote certificate chain errors, AND/OR Warning WarningRevocationStatusUnknown (The revocation function was unable to check revocation for the certificate.
What This Means
- The subtenant was unable to validate the eSilo Cloud Connect server’s certificate.
Possible Causes
- If this is happening for only one tenant, as opposed to all tenants, it suggests an issue with how this specific subtenant is connecting to eSilo.
- If no firewall or other changes have been made recently, you can recheck the credentials used by the subtenant in the backup job.
- This Veeam KB article is also helpful for investigating common causes of certificate errors: https://www.veeam.com/kb2323
Troubleshooting Steps
- Verify the Management Agent status shows as Connected. You can force a reconnect by changing a property in the dialog box, then changing it back and clicking “Apply“.
- Pause and unpause sync of Backup Cache files by right-clicking on the Veeam Backup Agent icon in the taskbar.
- Edit the Backup Job to specify the correct sub-tenant login credentials. Save and rerun the job. Upon the next job run, you should see “Uploading cached restore points” when you hover over the Veeam Backup Agent icon in the taskbar.
Was this article helpful?
Related Articles
Page load link
Go to Top
I installed the free version of Veeam Agent for Windows v3.0.2.1170 on a laptop running Windows 10 Pro x64 with the intention of backing up the device to a mapped drive (an open shared folder on a NAS).
However, the «Veeam Agent for Microsoft Windows» service keeps stopping on its own. The first time it happened was while I was trying to create a backup configuration. After realizing this, I was able to (re)start the service and continue the configuration. Then it happened again while running that backup…and then again while cancelling the backup. Veeam then got stuck cancelling the backup, requiring me to end the processes from the Task Manager.
There is nothing special about this laptop or its use case. It has a ~240GB SSD (with 25GB free) and should have ample resources (16GB RAM). I am re-running the backup now, but do you have any tips or suggestions for having Veeam run as smoothly as possible for this kind of basic use? Thanks!
Edit: the first time, the windows service died when the backup was at 5%. This time, it died when the backup was at 2%. I restarted the service and am hopeful that it will resume from where it left off.
Attempt #1:
(C:) (223.0 GB) 9.1 GB read at 15 MB/s
Task failed unexpectedly
Processing finished with errors at <date & time>
| title | description | ms.topic | ms.date | ms.service | ms.reviewer | author | ms.author |
|---|---|---|---|---|---|---|---|
|
Troubleshoot Agent and extension issues |
Symptoms, causes, and resolutions of Azure Backup failures related to agent, extension, and disks. |
troubleshooting |
05/05/2022 |
backup |
geg |
jyothisuri |
jsuri |
Troubleshoot Azure Backup failure: Issues with the agent or extension
This article provides troubleshooting steps that can help you resolve Azure Backup errors related to communication with the VM agent and extension.
[!INCLUDE support-disclaimer]
Step-by-step guide to troubleshoot backup failures
Most common backup failures can be self-resolved by following the troubleshooting steps listed below:
Step 1: Check Azure VM health
- Ensure Azure VM provisioning state is ‘Running’: If the VM provisioning state is in the Stopped/Deallocated/Updating state, then it will interfere with the backup operation. Open Azure portal > VM > Overview > and check the VM status to ensure it’s Running and retry the backup operation.
- Review pending OS updates or reboots: Ensure there are no pending OS update or pending reboots on the VM.
Step 2: Check Azure VM Guest Agent service health
- Ensure Azure VM Guest Agent service is started and up-to-date:
- On a Windows VM:
- Navigate to services.msc and ensure Windows Azure VM Guest Agent service is up and running. Also, ensure the latest version is installed. To learn more, see Windows VM guest agent issues.
- The Azure VM Agent is installed by default on any Windows VM deployed from an Azure Marketplace image from the portal, PowerShell, Command Line Interface, or an Azure Resource Manager template. A manual installation of the Agent may be necessary when you create a custom VM image that’s deployed to Azure.
- Review the support matrix to check if VM runs on the supported Windows operating system.
- On Linux VM,
- Ensure the Azure VM Guest Agent service is running by executing the command
ps -e. Also, ensure the latest version is installed. To learn more, see Linux VM guest agent issues. - Ensure the Linux VM agent dependencies on system packages have the supported configuration. For example: Supported Python version is 2.6 and above.
- Review the support matrix to check if VM runs on the supported Linux operating system.
- Ensure the Azure VM Guest Agent service is running by executing the command
- On a Windows VM:
Step 3: Check Azure VM Extension health
- Ensure all Azure VM Extensions are in ‘provisioning succeeded’ state:
If any extension is in a failed state, then it can interfere with the backup. - Open Azure portal > VM > Settings > Extensions > Extensions status and check if all the extensions are in provisioning succeeded state.
- Ensure all extension issues are resolved and retry the backup operation.
- Ensure COM+ System Application is up and running. Also, the Distributed Transaction Coordinator service should be running as Network Service account. Follow the steps in this article to troubleshoot COM+ and MSDTC issues.
Step 4: Check Azure Backup Extension health
Azure Backup uses the VM Snapshot Extension to take an application consistent backup of the Azure virtual machine. Azure Backup will install the extension as part of the first scheduled backup triggered after enabling backup.
-
Ensure VMSnapshot extension isn’t in a failed state: Follow the steps listed in this section to verify and ensure the Azure Backup extension is healthy.
-
Check if antivirus is blocking the extension: Certain antivirus software can prevent extensions from executing.
At the time of the backup failure, verify if there are log entries in Event Viewer Application logs with faulting application name: IaaSBcdrExtension.exe. If you see entries, then it could be the antivirus configured in the VM is restricting the execution of the backup extension. Test by excluding the following directories in the antivirus configuration and retry the backup operation.
C:PackagesPluginsMicrosoft.Azure.RecoveryServices.VMSnapshotC:WindowsAzureLogsPluginsMicrosoft.Azure.RecoveryServices.VMSnapshot
-
Check if network access is required: Extension packages are downloaded from the Azure Storage extension repository and extension status uploads are posted to Azure Storage. Learn more.
- If you’re on a non-supported version of the agent, you need to allow outbound access to Azure storage in that region from the VM.
- If you’ve blocked access to
168.63.129.16using the guest firewall or with a proxy, extensions will fail regardless of the above. Ports 80, 443, and 32526 are required, Learn more.
-
Ensure DHCP is enabled inside the guest VM: This is required to get the host or fabric address from DHCP for the IaaS VM backup to work. If you need a static private IP, you should configure it through the Azure portal or PowerShell and make sure the DHCP option inside the VM is enabled, Learn more.
-
Ensure the VSS writer service is up and running: Follow these steps To Troubleshoot VSS writer issues.
-
Follow backup best practice guidelines: Review the best practices to enable Azure VM backup.
-
Review guidelines for encrypted disks: If you’re enabling backup for VMs with encrypted disk, ensure you’ve provided all the required permissions. To learn more, see Back up and restore encrypted Azure VM.
UserErrorGuestAgentStatusUnavailable — VM agent unable to communicate with Azure Backup
Error code: UserErrorGuestAgentStatusUnavailable
Error message: VM Agent unable to communicate with Azure Backup
The Azure VM agent might be stopped, outdated, in an inconsistent state, or not installed. These states prevent the Azure Backup service from triggering snapshots.
- Open Azure portal > VM > Settings > Properties pane > ensure VM Status is Running and Agent status is Ready. If the VM agent is stopped or is in an inconsistent state, restart the agent
- For Windows VMs, follow these steps to restart the Guest Agent.
- For Linux VMs, follow these steps to restart the Guest Agent.
- Open Azure portal > VM > Settings > Extensions > Ensure all extensions are in provisioning succeeded state. If not, follow these steps to resolve the issue.
GuestAgentSnapshotTaskStatusError — Could not communicate with the VM agent for snapshot status
Error code: GuestAgentSnapshotTaskStatusError
Error message: Could not communicate with the VM agent for snapshot status
After you register and schedule a VM for the Azure Backup service, Backup starts the job by communicating with the VM backup extension to take a point-in-time snapshot. Any of the following conditions might prevent the snapshot from being triggered. If the snapshot isn’t triggered, a backup failure might occur. Complete the following troubleshooting steps in the order listed, and then retry your operation:
Cause 1: The agent is installed in the VM, but it’s unresponsive (for Windows VMs)
Cause 2: The agent installed in the VM is out of date (for Linux VMs)
Cause 3: The snapshot status can’t be retrieved, or a snapshot can’t be taken
Cause 4: VM-Agent configuration options are not set (for Linux VMs)
Cause 5: Application control solution is blocking IaaSBcdrExtension.exe
UserErrorVmProvisioningStateFailed — The VM is in failed provisioning state
Error code: UserErrorVmProvisioningStateFailed
Error message: The VM is in failed provisioning state
This error occurs when one of the extension failures puts the VM into provisioning failed state.
Open Azure portal > VM > Settings > Extensions > Extensions status and check if all extensions are in provisioning succeeded state. To learn more, see Provisioning states.
- If any extension is in a failed state, then it can interfere with the backup. Ensure those extension issues are resolved and retry the backup operation.
- If the VM provisioning state is in an updating state, it can interfere with the backup. Ensure that it’s healthy and retry the backup operation.
UserErrorRpCollectionLimitReached — The Restore Point collection max limit has reached
Error code: UserErrorRpCollectionLimitReached
Error message: The Restore Point collection max limit has reached.
- This issue could happen if there’s a lock on the recovery point resource group preventing automatic cleanup of recovery points.
- This issue can also happen if multiple backups are triggered per day. Currently we recommend only one backup per day, as the instant restore points are retained for 1-5 days per the configured snapshot retention and only 18 instant RPs can be associated with a VM at any given time.
- The number of restore points across restore point collections and resource groups for a VM can’t exceed 18. To create a new restore point, delete existing restore points.
Recommended Action:
To resolve this issue, remove the lock on the resource group of the VM, and retry the operation to trigger clean-up.
[!NOTE]
Backup service creates a separate resource group than the resource group of the VM to store restore point collection. You’re advised to not lock the resource group created for use by the Backup service. The naming format of the resource group created by Backup service is: AzureBackupRG_<Geo>_<number>. For example: AzureBackupRG_northeurope_1
Step 1: Remove lock from the restore point resource group
Step 2: Clean up restore point collection
UserErrorKeyvaultPermissionsNotConfigured — Backup doesn’t have sufficient permissions to the key vault for backup of encrypted VMs
Error code: UserErrorKeyvaultPermissionsNotConfigured
Error message: Backup doesn’t have sufficient permissions to the key vault for backup of encrypted VMs.
For a backup operation to succeed on encrypted VMs, it must have permissions to access the key vault. Permissions can be set through the Azure portal/ PowerShell/ CLI.
[!Note]
If the required permissions to access the key vault have already been set, retry the operation after a little while.
ExtensionSnapshotFailedNoNetwork — Snapshot operation failed due to no network connectivity on the virtual machine
Error code: ExtensionSnapshotFailedNoNetwork
Error message: Snapshot operation failed due to no network connectivity on the virtual machine
After you register and schedule a VM for the Azure Backup service, Backup starts the job by communicating with the VM backup extension to take a point-in-time snapshot. Any of the following conditions might prevent the snapshot from being triggered. If the snapshot isn’t triggered, a backup failure might occur. Complete the following troubleshooting step, and then retry your operation:
The snapshot status can’t be retrieved, or a snapshot can’t be taken
ExtensionOperationFailedForManagedDisks — VMSnapshot extension operation failed
Error code: ExtensionOperationFailedForManagedDisks
Error message: VMSnapshot extension operation failed
After you register and schedule a VM for the Azure Backup service, Backup starts the job by communicating with the VM backup extension to take a point-in-time snapshot. Any of the following conditions might prevent the snapshot from being triggered. If the snapshot isn’t triggered, a backup failure might occur. Complete the following troubleshooting steps in the order listed, and then retry your operation:
Cause 1: The snapshot status can’t be retrieved, or a snapshot can’t be taken
Cause 2: The agent is installed in the VM, but it’s unresponsive (for Windows VMs)
Cause 3: The agent installed in the VM is out of date (for Linux VMs)
BackUpOperationFailed / BackUpOperationFailedV2 — Backup fails, with an internal error
Error code: BackUpOperationFailed / BackUpOperationFailedV2
Error message: Backup failed with an internal error — Please retry the operation in a few minutes
After you register and schedule a VM for the Azure Backup service, Backup initiates the job by communicating with the VM backup extension to take a point-in-time snapshot. Any of the following conditions might prevent the snapshot from being triggered. If the snapshot isn’t triggered, a backup failure might occur. Complete the following troubleshooting steps in the order listed, and then retry your operation:
-
Cause 1: The agent installed in the VM, but it’s unresponsive (for Windows VMs)
-
Cause 2: The agent installed in the VM is out of date (for Linux VMs)
-
Cause 3: The snapshot status can’t be retrieved, or a snapshot can’t be taken
-
Cause 4: Backup service doesn’t have permission to delete the old restore points because of a resource group lock
-
Cause 5: There’s an extension version/bits mismatch with the Windows version you’re running or the following module is corrupt:
C:PackagesPluginsMicrosoft.Azure.RecoveryServices.VMSnapshot<extension version>iaasvmprovider.dll
To resolve this issue, check if the module is compatible with x86 (32-bit)/x64 (64-bit) version of regsvr32.exe, and then follow these steps:- In the affected VM, go to Control panel -> Program and features.
- Uninstall Visual C++ Redistributable x64 for Visual Studio 2013.
- Reinstall Visual C++ Redistributable for Visual Studio 2013 in the VM. To install, follow these steps:
- Go to the folder: C:PackagesPluginsMicrosoft.Azure.RecoveryServices.VMSnapshot<LatestVersion>
- Search and run the vcredist2013_x64 file to install.
- Retry the backup operation.
UserErrorUnsupportedDiskSize — The configured disk size(s) is currently not supported by Azure Backup
Error code: UserErrorUnsupportedDiskSize
Error message: The configured disk size(s) is currently not supported by Azure Backup.
Your backup operation could fail when backing up a VM with a disk size greater than 32 TB. Also, backup of encrypted disks greater than 4 TB in size isn’t currently supported. Ensure that the disk size(s) is less than or equal to the supported limit by splitting the disk(s).
UserErrorBackupOperationInProgress — Unable to initiate backup as another backup operation is currently in progress
Error code: UserErrorBackupOperationInProgress
Error message: Unable to initiate backup as another backup operation is currently in progress
Your recent backup job failed because there’s an existing backup job in progress. You can’t start a new backup job until the current job finishes. Ensure the backup operation currently in progress is completed before triggering or scheduling another backup operations. To check the backup jobs status, do the following steps:
- Sign in to the Azure portal, select All services. Type Recovery Services and select Recovery Services vaults. The list of Recovery Services vaults appears.
- From the list of Recovery Services vaults, select a vault in which the backup is configured.
- On the vault dashboard menu, select Backup Jobs it displays all the backup jobs.
- If a backup job is in progress, wait for it to complete or cancel the backup job.
- To cancel the backup job, right-click on the backup job and select Cancel or use PowerShell.
- If you’ve reconfigured the backup in a different vault, then ensure there are no backup jobs running in the old vault. If it exists, then cancel the backup job.
- To cancel the backup job, right-click on the backup job and select Cancel or use PowerShell
- If a backup job is in progress, wait for it to complete or cancel the backup job.
- Retry backup operation.
If the scheduled backup operation is taking longer, conflicting with the next backup configuration, then review the Best Practices, Backup Performance, and Restore consideration.
UserErrorCrpReportedUserError — Backup failed due to an error. For details, see Job Error Message Details
Error code: UserErrorCrpReportedUserError
Error message: Backup failed due to an error. For details, see Job Error Message Details.
This error is reported from the IaaS VM. To identify the root cause of the issue, go to the Recovery Services vault settings. Under the Monitoring section, select Backup jobs to filter and view the status. Select Failures to review the underlying error message details. Take further actions according to the recommendations in the error details page.
UserErrorBcmDatasourceNotPresent — Backup failed: This virtual machine is not (actively) protected by Azure Backup
Error code: UserErrorBcmDatasourceNotPresent
Error message: Backup failed: This virtual machine is not (actively) protected by Azure Backup.
Check if the given virtual machine is actively (not in pause state) protected by Azure Backup. To overcome this issue, ensure the virtual machine is active and then retry the operation.
Causes and solutions
The agent is installed in the VM, but it’s unresponsive (for Windows VMs)
Solution for this error
The VM agent might have been corrupted, or the service might have been stopped. Reinstalling the VM agent helps get the latest version. It also helps restart communication with the service.
- Determine whether the Windows Azure Guest Agent service is running in the VM services (services.msc). Try to restart the Windows Azure Guest Agent service and initiate the backup.
- If the Windows Azure Guest Agent service isn’t visible in services, in Control Panel, go to Programs and Features to determine whether the Windows Azure Guest Agent service is installed.
- If the Windows Azure Guest Agent appears in Programs and Features, uninstall the Windows Azure Guest Agent.
- Download and install the latest version of the agent MSI. You must have Administrator rights to complete the installation.
- Verify that the Windows Azure Guest Agent services appear in services.
- Run an on-demand backup:
- In the portal, select Backup Now.
Also, verify that Microsoft .NET 4.5 is installed in the VM. .NET 4.5 is required for the VM agent to communicate with the service.
The agent installed in the VM is out of date (for Linux VMs)
Solution
Most agent-related or extension-related failures for Linux VMs are caused by issues that affect an outdated VM agent. To troubleshoot this issue, follow these general guidelines:
-
Follow the instructions for updating the Linux VM agent.
[!NOTE]
We strongly recommend that you update the agent only through a distribution repository. We don’t recommend downloading the agent code directly from GitHub and updating it. If the latest agent for your distribution is not available, contact distribution support for instructions on how to install it. To check for the most recent agent, go to the Windows Azure Linux agent page in the GitHub repository. -
Ensure that the Azure agent is running on the VM by running the following command:
ps -eIf the process isn’t running, restart it by using the following commands:
- For Ubuntu:
service walinuxagent start - For other distributions:
service waagent start
- For Ubuntu:
-
Configure the auto restart agent.
-
Run a new test backup. If the failure persists, collect the following logs from the VM:
- /var/lib/waagent/*.xml
- /var/log/waagent.log
- /var/log/azure/*
If you require verbose logging for waagent, follow these steps:
- In the /etc/waagent.conf file, locate the following line: Enable verbose logging (y|n)
- Change the Logs.Verbose value from n to y.
- Save the change, and then restart waagent by completing the steps described earlier in this section.
VM-Agent configuration options are not set (for Linux VMs)
A configuration file (/etc/waagent.conf) controls the actions of waagent. Configuration File Options Extensions.Enable should be set to y and Provisioning.Agent should be set to auto for Backup to work.
For full list of VM-Agent Configuration File Options, see https://github.com/Azure/WALinuxAgent#configuration-file-options
Application control solution is blocking IaaSBcdrExtension.exe
If you’re running AppLocker (or another application control solution), and the rules are publisher or path based, they may block the IaaSBcdrExtension.exe executable from running.
Solution to this issue
Exclude the /var/lib path or the IaaSBcdrExtension.exe executable from AppLocker (or other application control software.)
The snapshot status can’t be retrieved, or a snapshot can’t be taken
The VM backup relies on issuing a snapshot command to the underlying storage account. Backup can fail either because it has no access to the storage account, or because the execution of the snapshot task is delayed.
Solution for this issue
The following conditions might cause the snapshot task to fail:
| Cause | Solution |
|---|---|
| The VM status is reported incorrectly because the VM is shut down in Remote Desktop Protocol (RDP). | If you shut down the VM in RDP, check the portal to determine whether the VM status is correct. If it’s not correct, shut down the VM in the portal by using the Shutdown option on the VM dashboard. |
| The VM can’t get the host or fabric address from DHCP. | DHCP must be enabled inside the guest for the IaaS VM backup to work. If the VM can’t get the host or fabric address from DHCP response 245, it can’t download or run any extensions. If you need a static private IP, you should configure it through the Azure portal or PowerShell and make sure the DHCP option inside the VM is enabled. Learn more about setting up a static IP address with PowerShell. |
Remove lock from the recovery point resource group
-
Sign in to the Azure portal.
-
Go to All Resources option, select the restore point collection resource group in the following format AzureBackupRG_
<Geo>_<number>. -
In the Settings section, select Locks to display the locks.
-
To remove the lock, select the ellipsis and select Delete.


Clean up restore point collection
After removing the lock, the restore points have to be cleaned up.
If you delete the Resource Group of the VM, or the VM itself, the instant restore snapshots of managed disks remain active and expire according to the retention set. To delete the instant restore snapshots (if you don’t need them anymore) that are stored in the Restore Point Collection, clean up the restore point collection according to the steps given below.
To clean up the restore points, follow any of the methods:
- Clean up restore point collection by running on-demand backup
- Clean up restore point collection from Azure portal
Clean up restore point collection by running on-demand backup
After removing the lock, trigger an on-demand backup. This action will ensure the restore points are automatically cleaned up. Expect this on-demand operation to fail the first time. However, it will ensure automatic cleanup instead of manual deletion of restore points. After cleanup, your next scheduled backup should succeed.
[!NOTE]
Automatic cleanup will happen after few hours of triggering the on-demand backup. If your scheduled backup still fails, then try manually deleting the restore point collection using the steps listed here.
Clean up restore point collection from Azure portal
To manually clear the restore points collection, which isn’t cleared because of the lock on the resource group, try the following steps:
-
Sign in to the Azure portal.
-
On the Hub menu, select All resources, select the Resource group with the following format AzureBackupRG_
<Geo>_<number>where your VM is located. -
Select Resource group, the Overview pane is displayed.
-
Select Show hidden types option to display all the hidden resources. Select the restore point collections with the following format AzureBackupRG_
<VMName>_<number>. -
Select Delete to clean the restore point collection.
-
Retry the backup operation again.


[!NOTE]
If the resource (RP Collection) has a large number of Restore Points, then deleting them from the portal may timeout and fail. This is a known CRP issue, where all restore points aren’t deleted in the stipulated time and the operation times out. However, the delete operation usually succeeds after two or three retries.
-
#1
Добрый день!
Не могу остановить задачу резервного копирования в Veeam. Пробовал сервер перезагружать с остановкой служб, удалил частичный бекап из хранилища, удалял саму задачу. Кнопка стоп не активна, причем в версии 10.0.01 остановить копирование с рабочей машины windows agent нельзя. При копировании виртуалки кнопка стоп активна. Что это может быть?

Последнее редактирование модератором: 11.09.2020

-
#2
Задание бэкапа завершается успешно или завершается с ошибкой ?
-
#3
Вообще никак не завершается. Более того я сделал задачу с таким же именем и снял бэкап с той же машины, та задача прошла отлично. А этот бэкап уже 19 часов идет и никак ни в какую сторону не завершится.
-
#4
Попробуйте сделать Disable активной задачи, вот например для копирования но вам надо выбрать вкладку Backup. Если это не поможет сделайте рестарт службы Veeam

-
#5
Добрый день!
Не могу остановить задачу резервного копирования в Veeam. Пробовал сервер перезагружать с остановкой служб, удалил частичный бекап из хранилища, удалял саму задачу. Кнопка стоп не активна, причем в версии 10.0.01 остановить копирование с рабочей машины windows agent нельзя. При копировании виртуалки кнопка стоп активна. Что это может быть?Посмотреть вложение 10776
Удалите задание бэкапа вообще и создайте заново.
-
#6
Делал как Disable, так и Delete. После полного перезапуска сервера она висит. Что самое интересно при копирование Windows машин с агентами кнопка STOP в принципе не активна и серая, также как и нельзя остановить задание «Backup copy job»
-
#7
Делал как Disable, так и Delete. После полного перезапуска сервера она висит. Что самое интересно при копирование Windows машин с агентами кнопка STOP в принципе не активна и серая, также как и нельзя остановить задание «Backup copy job»
А если ждать то прогресс копирования хоть сколько нибудь идет ? Посмотрите логи на источнике. Я немного не понял это бэкап виртуалки или физической машины — сервера ?
-
#8
Время во вкладке «Duration» идет. Уже 20 часов натикало . Сами файлы с машины не копируются. Это бэкап обычной физической Windows машины с бэкап агентом в хранилище Veeam.

-
#9
Делал как Disable, так и Delete. После полного перезапуска сервера она висит. Что самое интересно при копирование Windows машин с агентами кнопка STOP в принципе не активна и серая, также как и нельзя остановить задание «Backup copy job»
Вот здесь обсуждали подобное, у человека была такая же проблема, как я понял связана она была с нехваткой свободного места.
Проверьте что в логах C:ProgramDataVeeam
Попробуйте удалить цепочку бэкапов
Попробуйте «отвязать» машину-источник от сервера veeam и привязать заново
-
#10
Можно попробовать на свой страх и риск как предлагали там по аналогии
Вам необходимо полностью стереть существующую историю резервного копирования, чтобы она могла использовать новое имя хоста вместо старого.
Предупреждение: После завершения процедуры, описанной ниже, цепочка резервного копирования должна быть запущена с нуля. Ранее созданные точки восстановления действительны и могут использоваться для восстановления, однако они не будут автоматически удалены логикой хранения, поэтому вам придется очищать их вручную.
1. Перейдите в Панель управления> Администрирование и запустите Службы. Остановите службу Veeam Endpoint Backup.
2. Запустите regedit.exe и найдите ключ HKEY_LOCAL_MACHINE SOFTWARE Veeam Veeam Endpoint Backup. В этом разделе создайте следующее значение:Name = Recreatedatabase
Type = DWORD
Value = 13. Запустите службу Veeam Endpoint Backup
4. Подождите некоторое время для создания нового экземпляра базы данных (5 минут должно быть достаточно).
5. Остановите службу Veeam Endpoint Backup.
6. Запустите regedit.exe и удалите значение Recreatedatabase из ключа HKEY_LOCAL_MACHINE SOFTWARE Veeam Veeam Endpoint Backup.
8. Запустите службу Veeam Endpoint Backup.
-
#11
попробуйте отключить сеть от компа когда задание идет — может оно отрубится когда пинг пропадет
т.е сэмулируйте обрыв сети — данные то у вас через сетку бегут
-
#12
можно посмотреть логи на агенте. Попробуйте удалить все бэкапы этой цепочки, переустановите агента
-
#13
На форуме поддержки veeam сделал схожую тему: https://forums.veeam.com/post384334.html.
В личку пришло сообщение от инженера поддержки: » So you see it’s better to ask for the sql scripts from the Support team — it’s easier than modifying smth in your database on your own. » Из которого следует, что мне сформируют SQL скрипт для удаления повисшего задания.
Также сослались на статью из документации: https://helpcenter.veeam.com/docs/backup/vsphere/job_sessions_termination.html?ver=100, где сказано, что кнопка Stop не работает в следующих сценариях:
You cannot use graceful job stop for the following types of jobs:
File copy jobs
Backup copy jobs
Quick migration job (during quick migration, Veeam Backup & Replication processes all VMs in one task)
Restore operations
попробуйте отключить сеть от компа когда задание идет — может оно отрубится когда пинг пропадет
т.е сэмулируйте обрыв сети — данные то у вас через сетку бегут
Делал полную перезагрузку обоих машин.
как я понял связана она была с нехваткой свободного места.
Свободного места достаточно.
Работник техподдержки дала ссылку на Reddit:
Там рекомендуют:
«
Run this in your SQL
Код:
select * from [Backup.Model.JobSessions] where [state] != '-1'
Thos wil show you all jobs in a running state. I ran the below, after I made sure all my jobs were stopped.
UPDATE [Backup.Model.JobSessions] SET [state] = '-1' WHERE [state] != '-1'This actually ended up removing the job, so be warned it might break something. I didn’t care, as this was an offsite repository that I was replacing.
«
Почитал про SQL не могу разобраться как просто из командной строки выполнить и всё не разрушить. Подскажите
Последнее редактирование модератором: 14.09.2020
-
#14
To run a SQL script from a command line, please perform the following steps:
- Save the script as *.sql file (e.g. script.sql) to local disk
- Make sure that no jobs are running
- Run the following command:sqlcmd -S <SqlServerName><SqlInstanceName> -d <SqlDatabaseName> -i PATHTOSCRIPTscript.sql -o c:resetresult.txt -I
-
Код:
HKLMSoftwareVeeaMVeeam Backup and ReplicationSqlServerName HKLMSoftwareVeeaMVeeam Backup and ReplicationSqlInstanceName HKLMSoftwareVeeaMVeeam Backup and ReplicationSqlDatabaseName If the script needs to be applied to EM database, please use: HKLMSoftwareVeeaMVeeam Backup ReportingSqlServerName HKLMSoftwareVeeaMVeeam Backup ReportingSqlInstanceName HKLMSoftwareVeeaMVeeam Backup ReportingSqlDatabaseName - Restart the Veeam services
-
#15
Большое спасибо. SQL запрос помог.